- 投稿日:2019-03-02T23:28:07+09:00
Rails5 で geocoder を使って、緯度経度の取得する(Google API の設定)
Rails5 で地図アプリを作成するため、gmap4rails, geocoder を実験しました。緯度経度が取得できず苦労しましたが、APIの設定を見直すことで成功したので記録に残します。
Rails GoogleMap表示 gem gmaps4railsとgeocoder を参照に地図アプリを作成する。
https://qiita.com/yuki_chrono/items/a2638c33eedc3c036d01作成したアプリで地図は表示できたが、緯度経度が取得できない場合があった。「埼玉県」なら取得できるが「埼玉県さいたま市」にすると取得できない...
どうやら geocoder 単体では、細かい緯度経度が取得できないらしい。Google geocoding を利用することで、(Google で調べられる地点なら)すべての場所の緯度経度を取得することができるようになる。
geocoder 設定ファイルを作成
$ bundle exec rails generate geocoder:configconfig/initializers/geocoder.rbGeocoder.configure( # street address geocoding service (default :nominatim) lookup: :google, # IP address geocoding service (default :ipinfo_io) # ip_lookup: :maxmind, # to use an API key: api_key: "AIzaxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # geocoding service request timeout, in seconds (default 3): timeout: 5, # set default units to kilometers: units: :km, )コンソールで動作確認
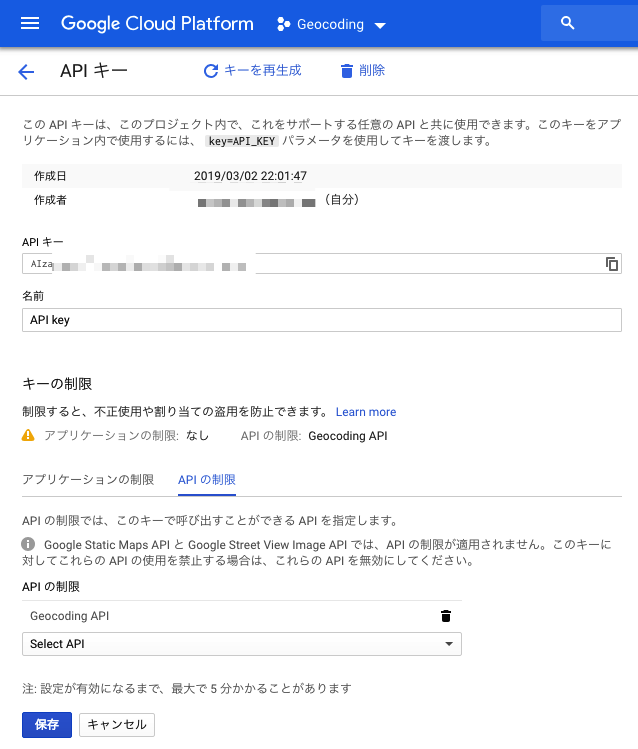
$ bundle exec rails console irb(main):002:0> Geocoder.search("東京タワー") Google API error: request denied (API keys with referer restrictions cannot be used with this API.). => [] irb(main):003:0> Geocoder.coordinates('埼玉県さいたま市') Google API error: request denied (API keys with referer restrictions cannot be used with this API.). => nilエラーメッセージ
Google API error: request denied (API keys with referer restrictions cannot be used with this API.).
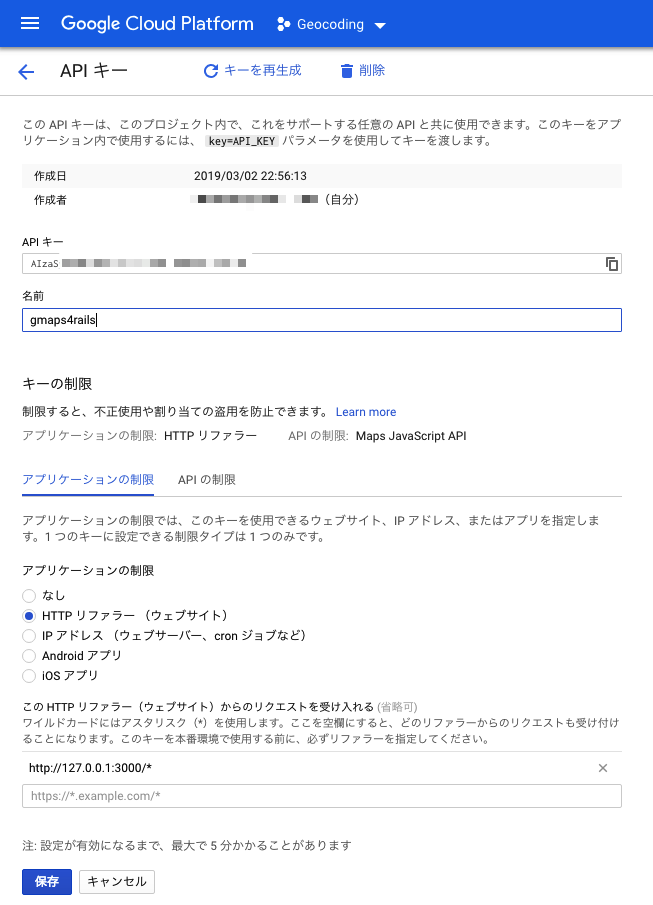
をヒントにAPIの設定を見直すことで緯度経度を取得できるようになった。原因は(gmaps4railsのAPI設定と同じように)「HTTP リファラー」で制限をかけていたためだった。アプリケーションの制限を「なし」に変更する。
irb(main):005:0> Geocoder.search("東京タワー") => [#<Geocoder::Result::Google:0x00007faf8616c7f8 @data={"address_components"=>[{"long_name"=>"8", "short_name"=>"8", "types"=>["premise"]}, {"long_name"=>"2", "short _name"=>"2", "types"=>["political", "sublocality", "sublocality_level_4"]}, {"long_name"=>"4 Chome", "short_name"=>"4 Chome", "types"=>["political", "sublocality", "s ublocality_level_3"]}, {"long_name"=>"Shibakoen", "short_name"=>"Shibakoen", "types"=>["political", "sublocality", "sublocality_level_2"]}, {"long_name"=>"Minato", "s hort_name"=>"Minato", "types"=>["locality", "political"]}, {"long_name"=>"Tokyo", "short_name"=>"Tokyo", "types"=>["administrative_area_level_1", "political"]}, {"lon g_name"=>"Japan", "short_name"=>"JP", "types"=>["country", "political"]}, {"long_name"=>"105-0011", "short_name"=>"105-0011", "types"=>["postal_code"]}], "formatted_a ddress"=>"4 Chome-2-8 Shibakoen, Minato, Tokyo 105-0011, Japan", "geometry"=>{"location"=>{"lat"=>35.6585805, "lng"=>139.7454329}, "location_type"=>"ROOFTOP", "viewpo rt"=>{"northeast"=>{"lat"=>35.6599294802915, "lng"=>139.7467818802915}, "southwest"=>{"lat"=>35.6572315197085, "lng"=>139.7440839197085}}}, "place_id"=>"ChIJCewJkL2LG GAR3Qmk0vCTGkg", "plus_code"=>{"compound_code"=>"MP5W+C5 Tokyo, Japan", "global_code"=>"8Q7XMP5W+C5"}, "types"=>["establishment", "point_of_interest", "premise"]}, @c ache_hit=nil>] irb(main):006:0> Geocoder.coordinates('埼玉県さいたま市') => [35.8617292, 139.6454822](注意)
gmaps4rails のAPI KEY は「HTTP リファラー」で制限をかける必要がある点に注意が必要です。

- 投稿日:2019-03-02T22:08:13+09:00
重複する条件分岐の断片の統合(Consolidate Duplicate Conditional Fragments)
1つずつリファクタリング技法まとめ
個人的に簡単かつ取り入れ易いと思うものから目的
すぐ引き出せるようにする
基本作業サイクル
- システムを動かして仕様を精査
- テストメソッドを作成
- テストの失敗を確認
- テストの成功を確認
- 小さい変更、随時テスト実行(パターン追加失敗確認->成功確認)
- 最後テスト実行
- 最後動作確認
重複する条件分岐の断片の統合(Consolidate Duplicate Conditional Fragments)とは
複数条件文内に共通で入っている処理を外出しすること
ポイント
- 共通処理が入っている位置によって、切り出し先が変わる
- 複数の処理が共通している場合、メソッドの抽出を行う
例
- 共通処理が条件文内の末尾(冒頭)にある場合は末尾(冒頭)に切り出す。
if tax? total = price * 1.08 puts(total) else total = price puts(total) end↓
if tax? total = price * 1.08 else total = price end puts(total)
- 複数の処理が共通している場合、メソッドの抽出を行う
if sunny? greet eat walk else greet eat drive end↓
def routine greet eat end routine if sunny? walk else drive end書籍情報
Jay Fields (著), Shane Harvie (著), Martin Fowler (著), Kent Beck (著),
長尾 高弘(訳), リファクタリング:Rubyエディション
https://amzn.to/2VlyWML雑感
切り分けの意味をしっかり理解する

- 投稿日:2019-03-02T21:35:19+09:00
Ruby 配列、ハッシュ
動作環境はMacです。
puts,print,p,ppメソッドの違い
irb(main):002:0> puts 'kaneko' kaneko => nil #変数の内容に改行を加えてメソッドの戻り値をターミナルに出力 irb(main):003:0> print 'kaneko' kaneko=> nil #改行なしでメソッドの戻り値をターミナルに出力 irb(main):004:0> p 'kaneko' "kaneko" => "kaneko" #pメソッドの戻り値は引数のオブジェクト デバック向け。 #デバックとはプログラムの不具合を見つけて修正すること。 ppメソッドはpメソッドより適切な改行をして出力する。 pメソッドで適切でない場合は、ppメソッドを使う。配列
- 複数のデータを格納できるオブジェクト。
- 配列内のデータは順番に並んでいて、添字(インデックス)を指定することで取り出すことができる。
配列の作成方法
空の配列を作る
[]3つの要素が格納された配列を作る
[要素1,要素2,要素3]実践
irb(main):003:0> a = [1, 2, 3, 'aa', [1, 2, 3]] #変数aに配列を代入 => [1, 2, 3, "aa", [1, 2, 3]] irb(main):004:0> a[0] => 1 irb(main):005:0> a[1] => 2 irb(main):006:0> a[3] => "aa" irb(main):007:0> a[2] => 3 irb(main):008:0> a[4] => [1, 2, 3] irb(main):009:0> puts a 1 2 3 aa 1 2 3 => nil irb(main):010:0> p a [1, 2, 3, "aa", [1, 2, 3]] => [1, 2, 3, "aa", [1, 2, 3]] irb(main):011:0> pp a NoMethodError: undefined method `pp' for main:Object Did you mean? p from (irb):11 from /Users/toripurug884/.rbenv/versions/2.4.1/bin/irb:11:in `<main>' irb(main):012:0> a.empty? #変数aが空か? => false irb(main):013:0> b = [] => [] irb(main):014:0> b.empty? => true irb(main):015:0> a.include?('aa') #変数aに'aa'が含まれるか? => true irb(main):016:0> a.include?('a') => false irb(main):017:0> a.reverse #配列の中身を反転 => [[1, 2, 3], "aa", 3, 2, 1] irb(main):018:0> a => [1, 2, 3, "aa", [1, 2, 3]] irb(main):019:0> a.reverse! #配列の中身を反転させる破壊的メソッド => [[1, 2, 3], "aa", 3, 2, 1] irb(main):020:0> a => [[1, 2, 3], "aa", 3, 2, 1] irb(main):021:0> a.shuffle #配列の中身をランダムに入れ替え => [2, 3, 1, "aa", [1, 2, 3]]配列を使ったメソッド(数値)
irb(main):022:0> (0..25).to_a #範囲オブジェクトを指定し、配列へ => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25] irb(main):024:0> a = (0..99).to_a.shuffle! #オブジェクトの中身を破壊的メソッドでランダムに入れ替える => [17, 1, 46, 12, 62, 69, 39, 40, 96, 87, 77, 50, 84, 56, 70, 7, 98, 19, 64, 8, 67, 89, 14, 33, 20, 29, 22, 51, 26, 18, 68, 57, 86, 47, 55, 48, 97, 44, 34, 42, 79, 30, 61, 6, 81, 13, 85, 0, 59, 71, 65, 99, 75, 72, 23, 66, 63, 5, 15, 49, 91, 36, 35, 38, 94, 45, 95, 11, 41, 2, 4, 10, 31, 54, 88, 43, 32, 28, 73, 92, 3, 58, 80, 16, 27, 82, 52, 25, 9, 60, 90, 74, 93, 21, 24, 83, 37, 53, 78, 76] irb(main):025:0> a #中身が入れ替わる => [17, 1, 46, 12, 62, 69, 39, 40, 96, 87, 77, 50, 84, 56, 70, 7, 98, 19, 64, 8, 67, 89, 14, 33, 20, 29, 22, 51, 26, 18, 68, 57, 86, 47, 55, 48, 97, 44, 34, 42, 79, 30, 61, 6, 81, 13, 85, 0, 59, 71, 65, 99, 75, 72, 23, 66, 63, 5, 15, 49, 91, 36, 35, 38, 94, 45, 95, 11, 41, 2, 4, 10, 31, 54, 88, 43, 32, 28, 73, 92, 3, 58, 80, 16, 27, 82, 52, 25, 9, 60, 90, 74, 93, 21, 24, 83, 37, 53, 78, 76] irb(main):026:0> z = (0..10).to_a => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] irb(main):027:0> z[0] => 0 irb(main):028:0> z[1] => 1 irb(main):029:0> z => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] irb(main):030:0> z << 20 #末尾に20を追加 pushとイコール => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):031:0> z.push(30) #末尾に30を追加 <<とイコール => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30] irb(main):033:0> z.pop #末尾の数値を削除 => 30 irb(main):034:0> z => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):035:0> z.shift #先頭の数値を削除 => 0 irb(main):036:0> z << 3 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3] irb(main):037:0> z => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3] irb(main):038:0> z << 3 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3] irb(main):039:0> z << 6 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3, 6] irb(main):040:0> z => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3, 6] irb(main):041:0> z.uniq #被っている数値を出力しない => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):042:0> z.uniq! #破壊的メソッド => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):043:0> z #3と6が出力されない => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20]配列を使ったメソッド(文字列)
irb(main):044:0> a = [ "my", "name", "is", "nakamura"] => ["my", "name", "is", "nakamura"] irb(main):045:0> a => ["my", "name", "is", "nakamura"] irb(main):046:0> a.join #配列の中身を結合 => "mynameisnakamura" irb(main):048:0> a.join(' ') #配列の中身を結合し、スペースを開ける スプリット => "my name is nakamura" irb(main):049:0> a.join('_') => "my_name_is_nakamura" irb(main):050:0> a.sort #配列の中身を入れ替える => ["is", "my", "nakamura", "name"] irb(main):051:0> a.sort.reverse #配列の中身を逆にする => ["name", "nakamura", "my", "is"] irb(main):053:0> a => ["my", "name", "is", "nakamura"] irb(main):054:0> a.sort!.reverse! #破壊的メソッド => ["name", "nakamura", "my", "is"] irb(main):055:0> a.size #配列に入っているデータ数の出力 => 4ハッシュ
- キー(key)と値(value)でデータの管理をするオブジェクト
- 連想配列、マップ、ディクショナリと呼ばれる場合もある
作成方法
空のハッシュを作成
{}キーと値の組み合わせを3つ格納するハッシュ
{ キー1 => 値1, キー2 => 値2, キー3 => 値3 }
実践
irb(main):001:0> {} => {} #空のブランケット作成 irb(main):002:0> kaneki = {'name' => 'ken', 'birthplace' => 'saga'} #変数kanekiにハッシュで代入 => {"name"=>"ken", "birthplace"=>"saga"} irb(main):003:0> kaneki => {"name"=>"ken", "birthplace"=>"saga"} irb(main):007:0> puts kaneki['name'] ken => nil #nameキーを出力 irb(main):009:0> puts kaneki['birthplace'] saga #birthplaceキーを出力 => nil irb(main):010:0> kaneki['age'] = 20 => 20 #ageキーを追加 irb(main):011:0> kaneki => {"name"=>"ken", "birthplace"=>"saga", "age"=>20} irb(main):013:0> kaneki['age'] = 21 => 21 #ageキーを書き換え irb(main):014:0> kaneki => {"name"=>"ken", "birthplace"=>"saga", "age"=>21} irb(main):017:0> kaneki.delete('age') #ageキーを削除 => 21 irb(main):019:0> puts kaneki {"name"=>"ken", "birthplace"=>"saga"} => nilシンボル
・ソースコード上は文字列に見えるが、内部では整数として扱われる
・文字列を使う場合よりシンボルを使った方が処理が速い
実践
irb(main):031:0> imawano.keys #変数が持つキーを出力 => [:name, :birthplace] irb(main):032:0> imawano.values #変数が持つ値の出力 => ["kiyosirou", "okinawa"] irb(main):034:0> imawano.has_key?(:name)#変数が引数に渡されるキーを持っているか? => true #持っているのでtrue irb(main):035:0> imawano.has_key?(:id) => false #持っていないのでfalse irb(main):036:0> imawano.size #変数に入っているキーの数 => 2
- 投稿日:2019-03-02T21:30:57+09:00
『オブジェクト指向設計実践ガイド』に学ぶ単一責任のクラス設計
『オブジェクト指向設計実践ガイド』の「第2章:単一責任のクラスを設計する」のまとめです。
ポイント:「クラスに属するものをどのように決めるか」
・クラスを使い、"今すぐに"求められている動作を行い、かつ"あとにも"かんたんに変更できるようにする
・設計とは、アプリケーションの可変性を保つために技巧を凝らすことであり、完璧を目指すものではない
変更がかんたんなようにコードを組成する
「変更がかんたんである」とは1.変更は副作用をもたらさない 2.要件の変更が小さければ、コードの変更も相応して小さい 3.既存のコードはかんたんに再利用できる 4.最もかんたんな変更方法はコードの追加。ただし追加するコードはそれ自体変更が容易なものどんな性質のコードを書けばいいか?
「変更がかんたんなコード」の定義を受けて、実際にコードを書くときには「TRUEなコード」を心がける。
「TRUEなコード」1.見通しが良い(Transparent):変更がもたらす影響が明白 2.合理的(Reasonable):かかるコストは変更がもたらす利益にふさわしい 3.利用性が高い(Usable):新しい環境、予期していなかった環境でも再利用できる 4.模範的(Exemplary):コードに変更を加える人が、上記の品質を自然と保つようなコードになっている・TRUEなコードを書くための最初の第一歩は、「それぞれのクラスが、明確に定義された単一の責任を持つように徹底する」こと
単一の責任を持つクラスをつくる
・クラスはできる限り最小で有用なことをするべき -> 単一の責任を持つべき
・クラスになるにふさわしいもの -> 「データ」と「振る舞い」Q.なぜ単一責任が重要なのか
A.2つ以上の責任を持つクラスは、アプリケーションが予期せず壊れる可能性があるから
->変更が加わるたびに、クラスに依存するクラスを全て破壊する可能性があるクラスが単一責任かどうかを見極める
Q.あるクラスが、別のどこかに属する"振る舞い"を含んでいるかどうかを見極める方法は?
A1.あたかもそれに"知覚"があるかのように仮定して問いただす。
->クラスの持つメソッドを質問に言い換えたときに、意味をなす質問になっているべき
例)「〇〇クラスさん、あなたの××を教えてください」 <-理にかなった質問になっているか?A2.1文でクラスを説明したときに、「それと」「または」が含まれない
・「クラスでできる限り最小で有用なことをすべき」 => 「かんたんに説明できるものであるべき」
・「それと」が含まれる => おそらく2つ以上の責任を負っている
・「または」が含まれる => クラスの責任が2つ以上あるだけでなく、互いにあまり関連しない責任を負っている設計を決定する時を見極める
・「早い段階で設計を決定しなければ」という気持ちに駆られるのはダメ
・何もしないことによる将来的なコストが今と変わらない時、設計の決定は延期する
・決定は必要なときにのみ、その時点で持っている情報を使ってする単一責任の概念はクラス以外のコードでも役立つ
メソッドから余計な責任を抽出する
・単一責任にすることで、メソッドの変更も再利用もかんたんになる
・メソッドに対しても、役割がなんであるか質問をし、また1文で責任を説明できるようにするとわかりやすい
・「単に振る舞いを別のメソッドに分離する」リファクタリングは、最終的な設計がわかっていない段階でも実施すべき単一責任のメソッドがもたらす恩恵
1.隠蔽された性質を明らかにする 2.コメントをする必要がない 3.再利用を促進する 4.他のクラスへの移動がかんたん1.隠蔽された性質を明らかにする
クラス内のメソッドを他のクラスに再編する意図がなくても、それぞれのメソッドが単一の目的を果たすようにすることによって、クラスが行うこと全体がより明確になる
2.コメントをする必要がない
もしメソッド内のコードにコメントが必要な部分があれば、その部分のコードを別のメソッドに抽出する。
別のメソッドに抽出した新しいメソッドの名前が、コメントの目的を果たす。3.再利用を促進する
メソッドを小さくすることで、アプリケーションにとって健康的なコードの書き方を促進する。
4.他のクラスへの移動がかんたん
設計のための情報が増え変更をしようと決めたとき、小さなメソッドならかんたんに動かせる。
移動のためにいくつものリファクタリングやメソッドの抽出もする必要がない。クラス内の余計な責任を隔離する
・いったん全てのメソッドを単一責任にしてしまえば、クラスのスコープはより明白に
・単一責任にこだわり、余計な振る舞いをそのクラスに「あるorない」の二択にするのは短絡的すぎる
⇨設計の目的は、設計に手を加える数を可能な限り最小にしつつ、クラスを単一責任に保つこと
⇨普段から変更可能なコードを書いておくことで、どうしてもしなければならない時まで決断を先延ばしすることができる終わり
単一責任とか、ただ書籍で読んで知った知識はなかなか理解できないのですが、ちょうどこの章を読んでいるときに自分の初めて作ったサービスのコードを思い出しました。
それはメソッド部分だったのですが、コードを読み直すと明らかに単一責任ではない部分があったので実践しました。
明らかにメソッドもシンプルに、かつ読みやすくなったと思います。
書籍から学ぶ場合も、勉強したことをすぐに取り入れるのは効率的な学習をするためにも必須ですね。
- 投稿日:2019-03-02T20:47:20+09:00
サーバのキャッシュ情報を利用してキャッシュする実装(Ruby)
参考URL
Working with HTTP cache
https://www.brianstorti.com/working-with-http-cache/はじめに
httpのレスポンスのヘッダに
last-modifiedやEtag等のキャッシュに関する情報が載っていることがあります.
Webサーバ側がせっかくキャッシュ情報を設定しているんだから,クライアント側も実装しよう.基本
以降,Ruby 2.4.3(Windows10 64bit),2.5.1(Windows Subsystem for Linux)で説明します.
次のコードは,httpsで
docs.ruby-lang.orgから/をダウンロードします.
httpのヘッダやステータスコードも出力させています.require 'net/https' https = Net::HTTP.new("docs.ruby-lang.org", 443) https.use_ssl = true https.verify_mode = OpenSSL::SSL::VERIFY_NONE https.start do |http| response = http.get("/") p response.code puts response.each.map{|k,v| k+"\t => "+v }.to_a puts response.body[0..200] if response.body end結果はこんな感じでした.
"200" server => nginx/1.10.3 content-type => text/html last-modified => Thu, 27 Dec 2018 00:19:32 GMT etag => W/"5c241a94-394" cache-control => public, max-age=43200, s-maxage=172800, stale-while-revalidate=86400, stale-if-error=604800 via => 1.1 varnish, 1.1 varnish fastly-debug-digest => 33272ba139e924bc977ca4803fe9bfe699d76ef3818ac8b578bbfe42b3afa6cc content-length => 579 accept-ranges => bytes date => Sat, 02 Mar 2019 01:49:34 GMT age => 102622 connection => keep-alive x-served-by => cache-nrt6147-NRT, cache-itm18822-ITM x-cache => HIT, HIT x-cache-hits => 1, 3 x-timer => S1551491375.978827,VS0,VE5 vary => Accept-Encoding <!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <!-- Global Site Tag (gtag.js) - Google Analytics --> <script async src="https://www.googletagmanager.com/gtag/js?id=UA-620926-3"></scriptキャッシュ
last-modified を使う
ヘッダに含まれている
last-modifiedは,「最後にそのページが更新された時間」です.
last-modifiedの値が前回アクセスした時と同じならば,
更新が無かったとみなすことができるので,bodyを取得する必要はありません.require 'net/https' require 'time' @cache = {} def get(path) https = Net::HTTP.new("docs.ruby-lang.org", 443) https.use_ssl = true https.verify_mode = OpenSSL::SSL::VERIFY_NONE https.start do |http| # ヘッダのみを取得 response = http.head(path) # そのパスのキャッシュが無い OR キャッシュが古いならば if @cache[path].nil? || Time.parse(@cache[path][:last_modified]) < Time.parse(response["last-modified"]) STDERR.puts "get" # bodyも含めて取得 response = http.get(path) # 取得結果を記憶 @cache[path] = { last_modified: response["last-modified"], body: response.body } @cache[path][:body] else STDERR.puts "cached" # 記憶済みの取得結果を返す @cache[path][:body] end end end puts get("/")[0..50] sleep 1 puts get("/")[0..50] sleep 1 puts get("/")[0..50]If-Modified-Sinceを使う
クライアント側で更新時刻を比較するのではなく,サーバ側で比較してもらう方法です.
If-Modified-Sinceヘッダを付けて,クエリを投げます.
更新がなかった場合,304が返ってきます.require 'net/https' require 'time' @cache = {} def get(path) https = Net::HTTP.new("docs.ruby-lang.org", 443) https.use_ssl = true https.verify_mode = OpenSSL::SSL::VERIFY_NONE https.start do |http| # 最後に取得した日付 since = @cache[path] ? @cache[path][:last_modified] : "" # サーバから取得する response = http.get(path, {"If-Modified-Since"=>since}) if (response.code == "200") # OK(変更がある) STDERR.puts "get" # 取得結果を記憶 @cache[path] = { last_modified: response["last-modified"], body: response.body } @cache[path][:body] elsif (response.code == "304") # Not Modified STDERR.puts "cached" # 記憶済みの取得結果を返す @cache[path][:body] else "?" end end end puts get("/")[0..50] sleep 1 puts get("/")[0..50] sleep 1 puts get("/")[0..50]Etag
ヘッダに
Etagが記載されている場合があります.
ウェブページのハッシュ値のような識別子で,前回のクエリとEtag値が同じならば,
ページに変化がない,とみなすことが出来ます.
If-Modified-Since同様に,If-None-Matchヘッダを付けてクエリを投げることで,
サーバ側でEtag値の比較をしてくれるはずです.require 'net/https' require 'time' @cache = {} def get(path) https = Net::HTTP.new("docs.ruby-lang.org", 443) https.use_ssl = true https.verify_mode = OpenSSL::SSL::VERIFY_NONE https.start do |http| # 最後に取得した日付 etag = @cache[path] ? @cache[path][:etag] : "" # サーバから取得する response = http.get(path, {"If-None-Match"=>etag}) if (response.code == "200") # OK(変更がある) STDERR.puts "get" # 取得結果を記憶 @cache[path] = { etag: response["Etag"], body: response.body } @cache[path][:body] elsif (response.code == "304") # Not Modified STDERR.puts "cached" # 記憶済みの取得結果を返す @cache[path][:body] else "?" end end end puts get("/")[0..50] sleep 1 puts get("/")[0..50] sleep 1 puts get("/")[0..50]ETagには「強いETag値」「弱いETag値」の2種類があるようです.
詳細は日本語版Wikipediaに記載されています.
https://ja.wikipedia.org/wiki/HTTP_ETag
- 投稿日:2019-03-02T18:49:54+09:00
Docker + Rails + MySQL + Vue で Todo アプリ作成 〜その2 RSpec 〜
おさらい
最終目標 : trello
前回 : seed データを投入して、ルートページと index ページで seed データの一覧表示できるところまでその2 の目標
1.前回の分のテストを書く
1. なぜテストを書くのか
なぜなんだ
→ 安全だからです。
あー、とっても答えになってないですね
そう言う時は先生に聞きますRails Tutorial が僕の基本的な先生です。(10章までやった)
先生は テスト駆動開発(TDD) を推奨していましたテスト駆動開発とはなんぞや
- テストを先に書く
- もちろん失敗する
- 失敗しないように実装していく
だいたいこんな感じ。
なんでそんなことすんの?
あれ?なんでそんなことするの?
なぜなんだ(本日2回目)
ということで一旦ググる良さげな記事を発見
【初心者向け】テスト駆動開発とRspecについて調べてみた
ありがとうございます。勉強になります。2. インストールする
だいたいわかったので
とりあえず RSpec をインストールする。。。Gemfile# ~~省略~~ group :development, :test do gem 'rspec-rails' end参考:RSpec 公式
Gemfile を更新したらば、web コンテナで gem をインストールしていく
web# bundle install # rspec -v RSpec 3.8 - rspec-core 3.8.0 - rspec-expectations 3.8.2 - rspec-mocks 3.8.0 - rspec-rails 3.8.2 - rspec-support 3.8.0 # rails g rspec:install Running via Spring preloader in process 495 create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb入ってますね。
3. どんなテストを書くか
/(ルートページ) と/indexにアクセスした際に
seed に入れたデータが全て取得できることを確認する。必要なテストは2つ
1./ルートページにアクセスした際に、 期待するデータの全てが取得できること
2./indexにアクセスした際に、期待しt(ryこんなもんかな
まだしなきゃいけないことあるなら思いついた時にやります。
とりあえず今回はこの二つ4. 作業開始(準備)
まずはテストファイルを作成します。
$ touch spec/controllers/index_page_spec.rb今後 Contoroller のテストを行うものは全て
spec/controllers/に入れようと思います。memo
hogehoge_spec.rbの_specこれ
書かなくてもテストは実行できるんです。
じゃあなんで書くのかと言うと
bundle exec rspecでテストを実行した時に_specがついてるファイルを
わざわざ指定しなくても、まとめて実行できるんです。つまり
$ bundle exec rspec spec/hoge/hoge.rb $ bundle exec rspec spec/fuga/fuga.rb $ bundle exec rspec spec/piyo.rb $ bundle exec rspec poyo.rbと、しないといけないところを
お尻に_specとつけるだけで$ bundle exec rspec上記のをまとめて実行できるようになるんですね、すごい!
めっちゃ便利なので積極的にお尻にスペックをつけましょう。(この認識に誤りがあったら教えてください。mm)
それでは作業に戻ります。
spec/controllers/index_page_spec.rbRSpec.describe 'TasksController' do context 'show index page' do it 'show task list on root page' do end it 'show task list on index page' do end end endweb# bundle exec rspec .. Finished in 0.00874 seconds (files took 0.13328 seconds to load) 2 examples, 0 failures何も書いてないので、当然グリーンになります。
公式 に書いてあった書き方を真似てみました。
一行目で、君は RSpec の仲間だよ〜って教えてあげてるんだと思います。
んー、ちょっと微妙な理解っぽいので、もう少し調べてみます
公式を読み進めてみると。。
Controller のテストの書き方かな? リンクがありましたね
こちら
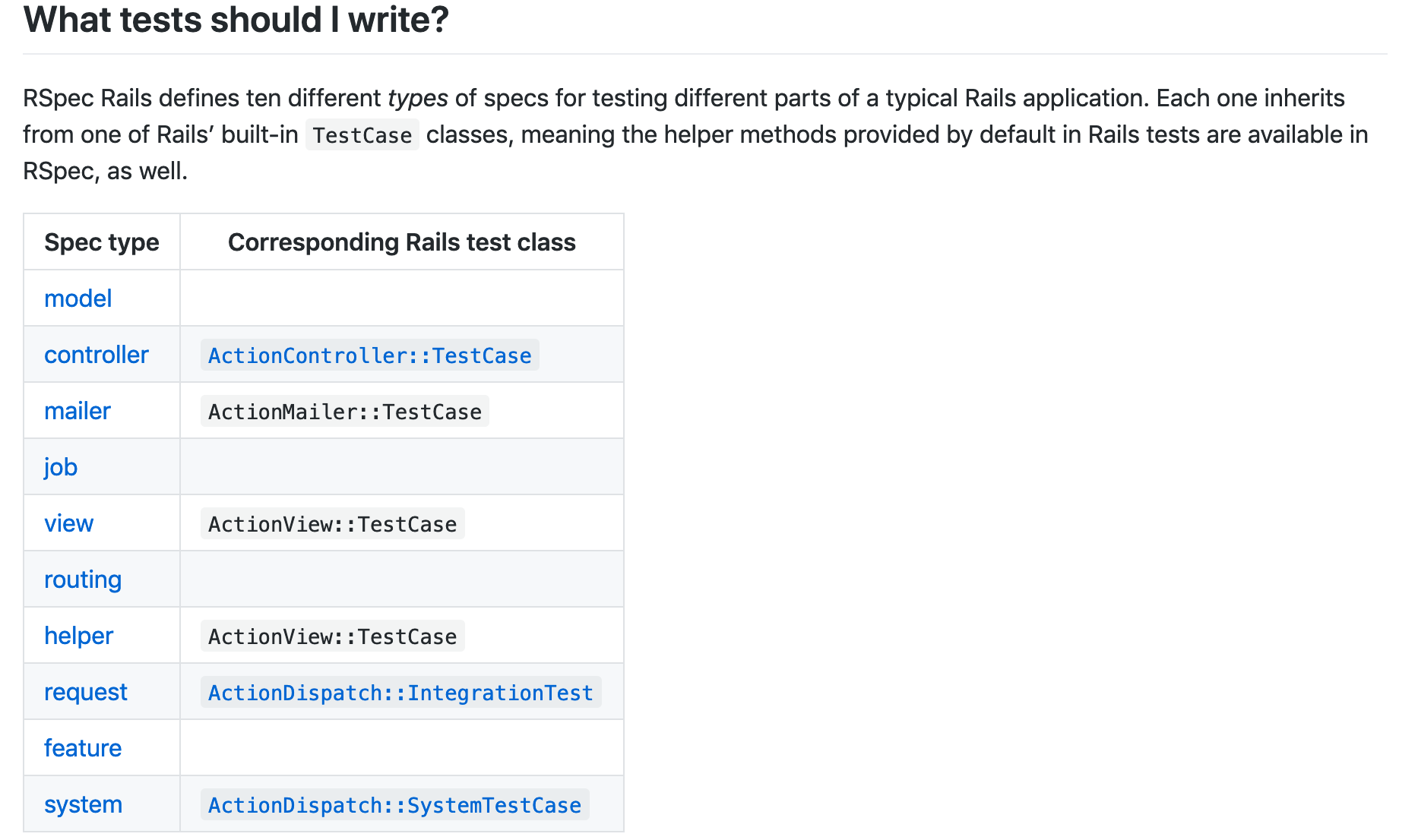
いいぞ、すごいそれっぽいぞController specs are marked by :type => :controller or if you have set
config.infer_spec_type_from_file_location! by placing them in spec/controllers.コントローラーのテストだよーって教えてあげるためには、どこかに
:type => :controllerを書くかspec/controllers/に配置する必要があるみたいです。
コントローラーのテストだよって教えてあげないといけないんですね
render_viewsというものがあるみたい
僕のは こちら に該当したので、書き方を変えます。spec/controllers/index_page_spec.rbrequire 'rails_helper' RSpec.describe TasksController do render_views context 'show index' do it 'show task list on root page' do end it 'show task list on index page' do end end end
type ~~を書くように書いてありましたが、さっきspec/controllers/配下なら書かなくていいよとも書いてあったので書きません。
あと、ここではコントローラーを' 'で囲わなくても大丈夫だったので、こうします
require 'rails-helper'????
...誰ですか???!!!〜回想〜
$ bundle install
$ rails g rspec:install
Running via Spring preloader in process 495
create .rspec
create spec
create spec/spec_helper.rb
create spec/rails_helper.rbいた...。
いた!!
いました。どうやら このヘルパーを require しないと render_views が使えないみたいです。
オマケがありました
おそらく Rails のヘルパーを使う事を明記したので、Rails で作成したコントローラーが文字列でなくても認識してくれたのかなって思います。
書かなくていいことは書きたくないので' '消しましたweb# bundle exec rspec .. Finished in 0.04538 seconds (files took 7.39 seconds to load) 2 examples, 0 failuresは??なんか7秒もかかりました。
ふざけんな、なんでじゃ、なんもテストしとらんのに!ちょっとテストの時間がかかるのはストレスですが、一旦後回しにします。
テストの時間がかかる事を対策することに時間がかかりそうなので5. 作業開始(本当に)
ちょっと予想外に調べるものが多かったので、章分けしました。
それでは気を取り直してやっていきますか
(もう結構しんどい、こんなややこしいの...?)とりあえず、index を開いてほしい。
公式をみるとそれっぽいことが書いてあった。spec/controllers/index_page_spec.rb~~ it 'show task list on index page' do get :index end ~~web# bundle exec rspec .. Finished in 0.48295 seconds (files took 5.18 seconds to load) 2 examples, 0 failuresいい感じ、なぜか時間も短くなってるし、なげえけどな
spec/controllers/index_page_spec.rb~~ it 'show task list on index page' do get :index expect(response).to render_template('index') expect(response.body).to eq 'task 001 : hogehoge' end ~~web# bundle exec rspec .F Failures: 1) TasksController show index show task list on index page Failure/Error: expect(response).to render_template('index') NoMethodError: assert_template has been extracted to a gem. To continue using it, add `gem 'rails-controller-testing'` to your Gemfile. # ./spec/controllers/index_page_spec.rb:12:in `block (3 levels) in <top (required)>' Finished in 0.48037 seconds (files took 5.57 seconds to load) 2 examples, 1 failure Failed examples: rspec ./spec/controllers/index_page_spec.rb:10 # TasksController show index show task list on index pageなんか Gem がないよって怒ってますね
どうやらassert_templateを使うにはrails-controller-testingという Gem が必要みたい
は?なにこいつめっちゃ親切にエラーを出すじゃないか、やさしい5.1 Gem install
インストールは公式を見た方が最新の情報が書いてあったりするので、安全だと思っています。
ので
公式 を見ます。
Gemfile のどこに書いてもいいみたい、けどまあ RSpec を使う環境でしか使わないし、一緒の所に書いておきましょうか。Gemfilegroup :development, :test do gem 'rspec-rails' gem 'rails-controller-testing' endweb# bundleあっ、へ〜、公式の install 方法に書いてあったので真似たのですが
bundle installはbundleと省略できるんですね、便利。
よく使うからきっと用意されたのでしょう、楽チンなので覚えましたweb1) TasksController show index show task list on index page Failure/Error: expect(response.body).to eq 'task 001 : hogehoge' expected: "task 001 : hogehoge" got: "<!DOCTYPE html>\n<html>\n <head>\n <title>Myapp</title>\n \n \n\n <link rel=\"styleshee...\"></script>\n </head>\n\n <body>\n <h1>Your Tasks</h1>\n\n<ul>\n</ul>\n\n </body>\n</html>\n" (compared using ==) Diff: @@ -1,2 +1,20 @@ -task 001 : hogehoge +<!DOCTYPE html> +<html> + <head> + <title>Myapp</title> + + + + <link rel="stylesheet" media="all" href="/assets/application-e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855.css" data-turbolinks-track="reload" /> + <script src="/assets/application-3c2e77f06bf9a01c87fc8ca44294f3d3879d89483d83b66a13a89fc07412dd59.js" data-turbolinks-track="reload"></script> + </head> + + <body> + <h1>Your Tasks</h1> + +<ul> +</ul> + + </body> +</html> # ./spec/controllers/index_page_spec.rb:13:in `block (3 levels) in <top (required)>'なんで..
天才なので閃きました
rails db:seedをしたのは開発環境、 RSpec はテスト環境に対してテストを実行している、つまり、テスト環境には seed データが投入されていない!!!!!!!!
Q.E.D.
俺でなきゃ見逃しちゃうね..え、そうなの??
まあ、よくわかんねーけど、テスト環境でもrails db:seedしてもらえばいいんじゃね?(鼻ほじ)5.2 VS テスト環境
spec/controllers/index_page_spec.rbbefore do `rails db:seed` endダメでした
まあ流石にダメな予感はしてました。
With RSpec, how to seed the database on load?
めっちゃそれっぽい!!!!!!spec/controllers/index_page_spec.rbbefore do `rails db:reset RAILS_ENV=test` endさっきのはニアピンだったんですね。
railsコマンドはENV=developmentに向けてやってる見たい
ここでしっかりと「お前はテスト向きにコマンドやりやがれ」と命令してあげる事で、はいわかりましたテスト向きですね。と聞き分けよくやってくれるみたいそれと、毎回
rails db:seedをやると無限にデータが増えるので、rails db:resetにしましたweb1) TasksController show index show task list on index page Failure/Error: expect(response.body).to eq 'task 001 : hogehoge' expected: "task 001 : hogehoge" got: "<!DOCTYPE html>\n<html>\n <head>\n <title>Myapp</title>\n \n \n\n <link rel=\"styleshee.../li>\n <li>task 002 : fugafuga</li>\n <li>task 003 : piyopiyo</li>\n</ul>\n\n </body>\n</html>\n" (compared using ==) Diff: @@ -1,2 +1,23 @@ -task 001 : hogehoge +<!DOCTYPE html> +<html> + <head> + <title>Myapp</title> + + + + <link rel="stylesheet" media="all" href="/assets/application-e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855.css" data-turbolinks-track="reload" /> + <script src="/assets/application-3c2e77f06bf9a01c87fc8ca44294f3d3879d89483d83b66a13a89fc07412dd59.js" data-turbolinks-track="reload"></script> + </head> + + <body> + <h1>Your Tasks</h1> + +<ul> + <li>task 001 : hogehoge</li> + <li>task 002 : fugafuga</li> + <li>task 003 : piyopiyo</li> +</ul> + + </body> +</html> # ./spec/controllers/index_page_spec.rb:17:in `block (3 levels) in <top (required)>'おおおおおおお!!!入ってるっぽいじゃん!!!
まあただ、全然違う箇所見てるよ、と怒られてしまったので、
expect(response.body).to eq 'task 001 : hogehoge'
この辺をいじる5.3 データの取得方法
spec/controllers/index_page_spec.rbit 'show task list on index page' do get :index expect(response).to render_template('index') expect(response.body.ui.li).to include 'task 001 : hogehoge' endすげー適当
web1) TasksController show index show task list on index page Failure/Error: expect(response.body.ui.li).to include 'task 001 : hogehoge' NoMethodError: undefined method `ui' for #<String:0x0000561683469d40> # ./spec/controllers/index_page_spec.rb:17:in `block (3 levels) in <top (required)>'だよね。
ということは、これまでの経験的に、画面に表示されている要素を取得するため Gem が用意されているのではないだろうか?という仮説が立つ
capybaraのhave_contentなどで、含まれていてほしい単語の数を指定したい。
ほら
で、次はcapybaraを調べる
capybara
ほらぁ!!!!成長を感じている...
そしてググり力も上がってきている...
にっこり。Gemfilegroup :test do # Adds support for Capybara system testing and selenium driver gem 'capybara', '>= 2.15' gem 'selenium-webdriver' # Easy installation and use of chromedriver to run system tests with Chrome gem 'chromedriver-helper' endあれれ??すでにいるんですけど...ドユコト
If the application that you are testing is a Rails app, add this line to your test helper file:
翻訳:
テストしているアプリケーションがRailsアプリケーションの場合は、この行をテストヘルパーファイルに追加します。へ〜、入ってるだけじゃ使えないのね
spec/controllers/index_page_spec.rbrequire 'rails_helper' require 'capybara/rails' ~~ it 'show task list on index page' do get :index expect(response).to render_template('index') expect(page).to have_content('task 001 : hogehoge') endよし、これで使えるわけだ
1) TasksController show index show task list on index page Failure/Error: expect(page).to have_content('task 001 : hogehoge') NameError: undefined local variable or method `page' for #<RSpec::ExampleGroups::TasksController::ShowIndex:0x0000558ab86d98e8> # ./spec/controllers/index_page_spec.rb:19:in `block (3 levels) in <top (required)>'ダメみたい
そもそもpageって何よって感じに思ってたらそこで怒られた、capybaraを理解する必要がありそう5.4 VS capybara
いや、長い。まじで
5.4.1 エラー発見しやすくしてみた
it 'show task list on index page' do visit '/index' get :index expect(response).to render_template('index') expect(page).to have_content('task 001 : hogehoge') endcapybara が使えてんのかダメなのか、確認するために
capybara の method かな?visitを最初に書いておく
ここで落ちれば capybara がちゃんと入ってないことが証明されるだろう1) TasksController show index show task list on index page Failure/Error: visit '/index' NoMethodError: undefined method `visit' for #<RSpec::ExampleGroups::TasksController::ShowIndex:0x00005564b14ad970>ちなみにダメでした。
5.4.2 requore の記載場所を変えてみた
capybara の公式に
Load RSpec 3.5+ support by adding the following line (typically to your spec_helper.rb file):
spec_helper.rbにかけってって書いてありました
せっかくなのでrails_helperも一緒に引っ越ししましょう。spec_helper.rbrequire 'rails_helper' require 'capybara/rails' require 'capybara/rspec'同じエラー
ちょっとまじできつい、わからない
やろうとしてることが難しいのかなとも思ったけど、
画面に表示されているもの取得するだけなんだから難しくないでしょうに助けてください。
- したいこと。
- index ページできちんとモデルが表示されているかのテスト
- seed データを入れて、ローカルホストに接続したら seed データが表示された
- テストでも同じことをしたい
- わからないこと
- そもそも開発環境で使っている seeds をテストでも使うのが普通なのか
- capybara を使う必要があるのか
- 使うとしたら何が間違っていたのか
- 使わないならどうしたらいいのか
すごくざっくりした質問になってしまって申し訳ございません。
また、質問をするなら Qiita じゃなくて、ここの方がいいよ、とかあったら教えてください。
5.4.3 敗退
やめました。
capybara 使うのやめました。it 'show task list on index page' do get :index expect(response).to render_template('index') expect(response.body).to include 'task 001 : hogehoge' endこれで通りました。
この方向でもっとちゃんと探したい。
- 投稿日:2019-03-02T18:45:23+09:00
RubyXLを使ってExcelを編集してクライアントに返す
railsでエクセルを編集してクライアントに返そうとしたときのやり方を残しておきます。
作るもの
- クライアントがエクセルファイルをアップロードする
- サーバが受け取ったエクセルに何かしらの変更を加える
- クライアントが変更されたファイルをダウンロードする
といった動きになる機能をRailsで作ります。
出来上がったソースコードはこちらExcelの編集
RubyXLというgemを使います。
https://github.com/weshatheleopard/rubyXL
他にもエクセルを開けるgemはあるのですが、
- Roo: 読み込みのみ
- AXSLX: 新規作成のみ
という感じで用途が絞られています。
今回は、編集ができるRubyXLを使います。単体だと、以下のような感じで使えます。
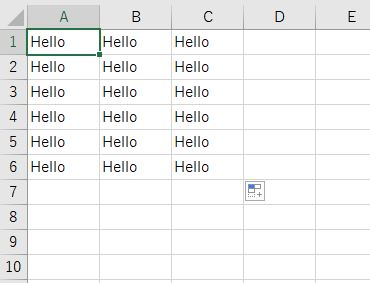
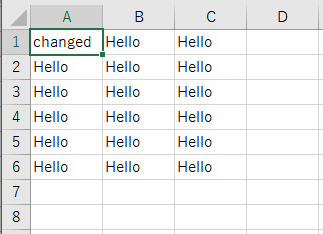
require 'rubyXL' # ファイルを読み込んでRubyXL::Workbookにデシリアライズ workbook = RubyXL::Parser.parse("path/to/Excel/file.xlsx") # ブック→シート→行→セルという構造になっている worksheet1 = workbook[0] row1 = worksheet1[0] cell1 = row1[0] # 書き込むときはWorksheetのメソッドが使える worksheet1.add_cell 0, 0, 'changed' # 保存 workbook.saverails new
railsプロジェクトを作ります。
今回は横着してモデルを作らないので、ActiveRecordなどいらないモジュールを生成しないようオプションを付けます。rails new -MOCJルーティング
excelリソースへのルートを作ります。
加えて、ルートをexcelsにします。下記とおりルーティングされます
- GET / -> ExcelsController#show
- GET /excels -> ExcelsController#show
- POST /excels -> ExcelsController#create
GET /excelsでファイルを受け取るフォームを表示し、POST /excelsでサーバへのファイルアップロードと編集後ファイルの送信を行います。
Rails.application.routes.draw do # For details on the DSL available within this file, see http://guides.rubyonrails.org/routing.html root to: "excels#show" resource :excel, only: [:show, :create] endhttps://github.com/ytnk531/excel-example/blob/master/config/routes.rb
コントローラ
showメソッドでは何もせず、ページを表示するだけです。
createにはエクセルファイルが送られて来るので、ファイルの編集とクライアントへの送信を行います。class ExcelsController < ApplicationController def show end def create file = params[:file] # ファイルを開く workbook = RubyXL::Parser.parse file.path # 編集する workbook[0].add_cell 0, 0, 'changed' # 編集したファイルを送る send_data workbook.stream.string, type: file.content_type, filename: 'modified.xlsx' end endアップロードされたファイルはUploadedFileオブジェクトとして受け取ることができます。
RubyXL::Parser.parseはFileオブジェクトではなくパスを引数に取るので、アップロードされたファイルのパスを指定してRubyXL::Workbookオブジェクトに変換します。
アップロードされたファイルは、tempfileとして保存されていて、
UploadedFile#pathでこのtempfileのパスを取得できます。編集したファイルは、send_dataメソッドを使って送信します。
データとして渡すのは、Workbook#streamで取得できるバイナリのストリームを、Stream#stringで文字列にしたものです。
コンテントタイプを指定する必要がありますが、UploadedFileは受信したときのContent-Typeを記録しているので、同じものを指定しておけばいいでしょう。https://github.com/ytnk531/excel-example/blob/master/app/controllers/excels_controller.rb
ビュー
エクセルファイルをアップロードするためのビューを作ります。
<%= form_tag({action: :create}, multipart: true) do %> <div> <%= file_field_tag :file %> </div> <div> <%= submit_tag "Send" %> </div> <% end %>https://github.com/ytnk531/excel-example/blob/master/app/views/excels/show.html.erb
ファイル選択と送信ができます。
送信したファイルはExcelsController#createで処理します。
試してみる
このようなEXCELファイルを用意し、
送ってみます。
編集されたファイルのダウンロードが始まります。
開いてみます。期待通り編集されたエクセルをダウンロードできました。
まとめ
- RubyXLでエクセルの編集ができる
- アップロードされたファイルはUploadedFileオブジェクトに記録される
- RubyXLで保存したワークブックは、保存しなくてもデータ送信できる
UploadedFileの存在を知らなかったので、うまくいくかわからなかったのですが、うまくrailsと一緒に使うことができました。

- 投稿日:2019-03-02T16:10:56+09:00
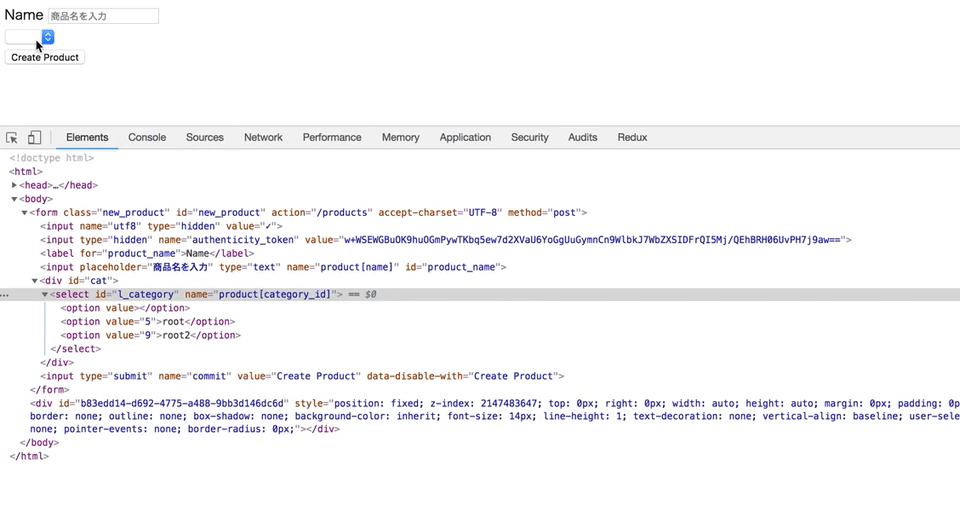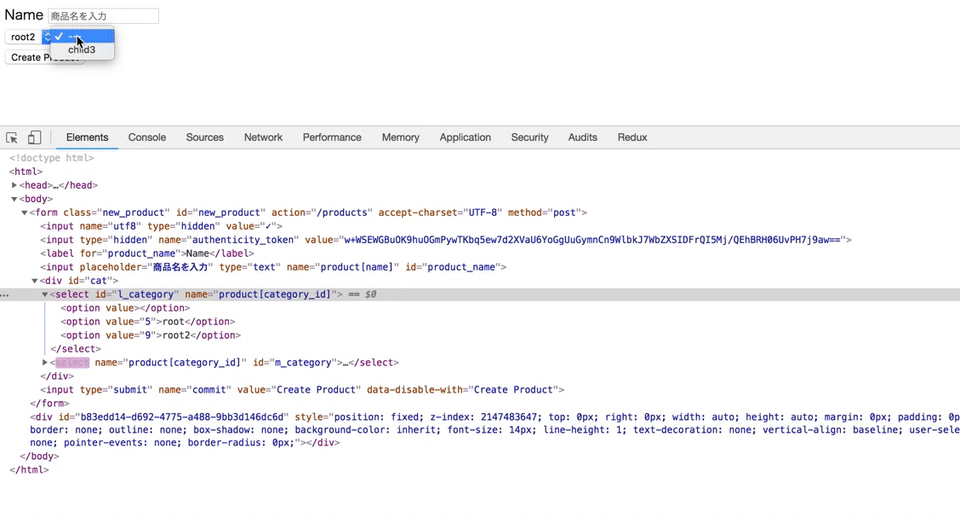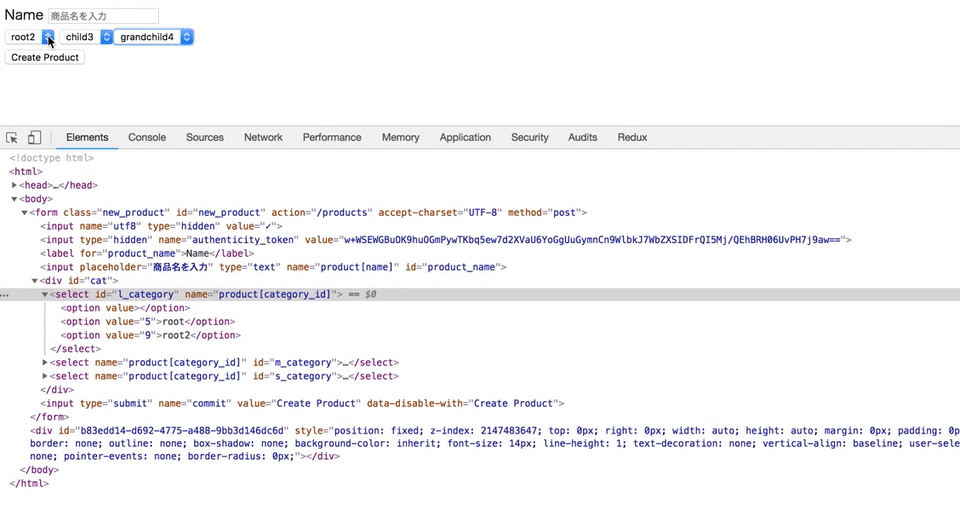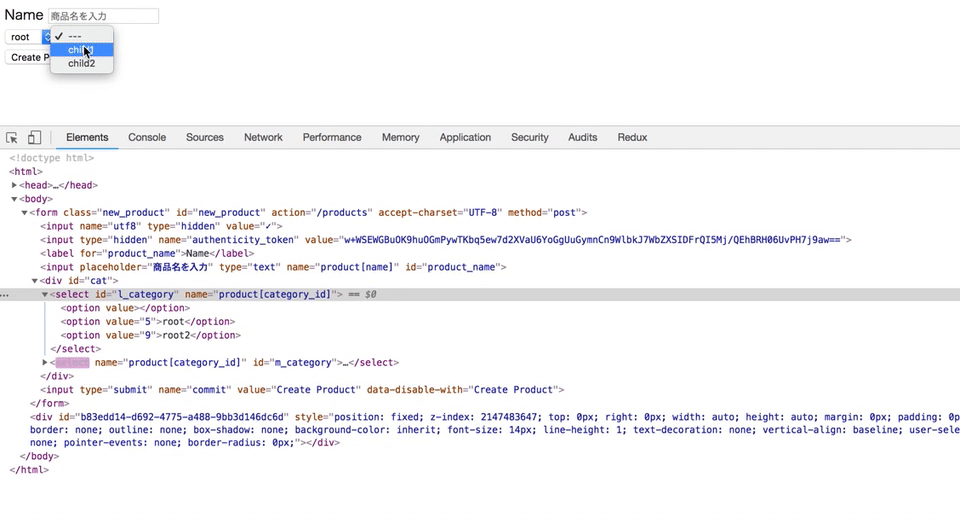
selectとoptionタグをjQueryを使って動的に追加する
デモ(動画)
やりたいこと
上記のGIF通り、
カテゴリーが選択されたと同時に、親カテゴリーに紐づく子カテゴリーが出てくるようにしたい。
入れ子構造については以下を参照
【追記予定】awesome_nested_setを使った入れ子構造のDB設計実装概要
jQueryのajaxメソッドを使って、カテゴリーが選択されたら子カテゴリーがappendされるようにした。
コード
routing
route.rbRails.application.routes.draw do root 'products#new' resources :products, only: [:create] do <!-- 今回はsearchアクションをajaxメソッドで叩きます--> collection do get 'search' end end endview
new.html.haml= form_for @product do |f| = f.label :name = f.text_field :name, placeholder: "商品名を入力" #cat = f.select :category_id, Category.roots.map {|i| ["#{i.name}", i.id]}, { selected: @product.category_id, include_blank: true }, {id: "l_category"}js
category.js$(document).on('turbolinks:load', function() { // Mカテゴリーのselectを追加するHTML var cat_seach = $("#cat"); function appendMselect() { var html = `<select name="product[category_id]" id="m_category"> <option value>---</option> </select>` cat_seach.append(html) } // Sカテゴリーのselectを追加するHTML function appendSselect() { var html = `<select name="product[category_id]" id="s_category"> <option value>---</option> </select>` cat_seach.append(html) } // Mカテゴリーのoptionを追加するHTML function appendMcat(m_cat) { $("#m_category").append( $("<option>") .val($(m_cat).attr('id')) .text($(m_cat).attr('name')) ) } // Sカテゴリーのoptionを追加するHTML function appendScat(s_cat) { $("#s_category").append( $("<option>") .val($(s_cat).attr('id')) .text($(s_cat).attr('name')) ) } // Lカテゴリーが選択された時のアクション $("#l_category").on('change', function() { l_cat = $(this).val() $("#m_category").remove() $("#s_category").remove() // ajaxでリクエストを送信 $.ajax({ type: "GET", url: "/products/search", data: {l_cat: l_cat}, dataType: 'json' }) // doneメソッドでappendする .done(function(m_cat) { appendMselect() m_cat.forEach(function(m_cat) { appendMcat(m_cat) }) }) }) // Mカテゴリーが選択された時のアクション $(document).on('change', "#m_category", function() { m_cat = $(this).val() $("#s_category").remove() $.ajax({ type: "GET", url: "/products/search", data: {m_cat: m_cat}, dataType: 'json' }) .done(function(s_cat) { appendSselect() s_cat.forEach(function(s_cat) { appendScat(s_cat) }) }) }) })controller
categories_controller.rb<!--関係ないアクションは省略しています--> def search if params[:l_cat] @m_cat = Category.find(params[:l_cat]).children else @s_cat = Category.find(params[:m_cat]).children end respond_to do |format| format.html format.json end endjbuilder
search.json.jbuilderjson.array! @m_cat do |m_cat| json.id m_cat.id json.name m_cat.name end json.array! @s_cat do |s_cat| json.id s_cat.id json.name s_cat.name end勉強になったところ
optionタグの追加の方法
optionの追加$("#m_category").append( $("<option>") .val($(m_cat).attr('id')) .text($(m_cat).attr('name')) ) }こういう風に書くことで、selectタグのoptionが追加できることを知りました。
始めはselectを追加すればいいじゃん!と思ってましたが、配列形式で渡ってくるため、配列の中身分selectが増えてしまい、上手な方法が浮かばなかったので、こちらの方法にしました。参考記事
・jQuery でセレクトボックスのプルダウン項目(option 要素)を追加/削除する方法
https://webllica.com/jquery-select-option-add-del/まとめ
なんとか狙った機能は実装できましたが、MカテゴリーとSカテゴリーで二回書いているようなコードになっているので、リファクタリングしたいけどどうしていいのかわからん・・・
- 投稿日:2019-03-02T14:30:55+09:00
Failed to load resource: the server responded with a status of 404 (Not Found)の原因と解決策
問題:画像が表示できない
エラー
Failed to load resource: the server responded with a status of 404 (Not Found)404 (Not Found)は、ファイルが見つからないという意味。
推定原因は、2つあるらしい。①ファイルがデータベースに保存されていない
②画像がDBに保存されているけど、パスがずれてるファイルは保存できていた。なので、原因は、②。
参照記事:https://teratail.com/questions/3951パスの確認
views/user/show.html.erb<img src="<%= "/img/#{@user.id}"%>">解決策
/img/#{@user.id}に、jpgを付け加えてみたら、パスが特定されて、無事画像が表示された。
views/user/show.html.erb<img src="<%= "/img/#{@user.id}.jpg"%>">

- 投稿日:2019-03-02T13:41:35+09:00
ActiveRecordでのレコード数のカウント方法の差(count, length, size)
- 投稿日:2019-03-02T13:41:35+09:00
[WIP]ActiveRecordでのレコード数のカウント方法の差(count, length, size)
- 投稿日:2019-03-02T13:40:35+09:00
`require': cannot load such fileエラーをインタプリタ指定から探る ~ファイル1行目のshebang設定~
結論... shebangで指定すべきインタプリタを誤って設定していた。

※コメントだとおもっていた件前提をお伝えすると、
ソースコードのフローチャートを自動化してくれるGemを、ソースコード可視化ツールを作りたかった。
こんなの↓
関連記事:Rails要らず、CGIとRubyでソースコードをフローチャートにするツール作成
関連リポジトリ:VisualizeSrc詰まったところ
Gemを読み込みのための
require bundle/setupで「該当ファイルないぞ」って怒られる。
エラー内容は↓/usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require': cannot load such file -- bundler/setup (LoadError), referer: http://localhost/index.cgi状況を整理すると
- 特定の実行Rubyファイル(A)にて、
require bundler/setupがロードエラーになっていた.
- rbenvで環境指定はできている。
- 同じ環境下の他のRubyファイル(B)は実行は可能
- かつRubyファイル(B)では
require bundler/setupは成功する- しかし、Rubyファイル(B)をRubyファイル(A)に取り込んで処理させると、やはり上述のロードエラーになる。
- 権限問題も解消
- 全て777に変更してみたが、それでも解決せず。
問題ソースコードはこちら
# 問題ファイル(result.rb)中身 ---- 1 #! usr/bin/ruby 2 require "bundler/setup" ← ここで死んでいた。 3 require 'cgi' 4 cgi = CGI.new 5 print "Content-Type: text/html\n\n" 6 print "<html>\n" 7 print "<head>\n" 8 print "<title>CGI Test</title>\n" 9 print "</head>\n" 10 print "<body>\n" 11 print "<a href=\"/form.cgi\">\"こちらのページから画像が見れます\"</a>" 12 print "</body>\n" 13 print "</html>\n" 14 $src = cgi["sub"] ...エラー内容を詳しくみてみる。
教えてApache先生

apacheのエラーログを見てみると、(再掲になるが↓)# /var/log/httpd/error_logのログ /usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55:in `require': cannot load such file -- bundler/setup (LoadError), referer: http://localhost/index.cgi
- エラーの内容から明らかに、pathに誤りがあることがわかる。
- 失敗箇所は先に触れているが、指定ファイルがrequireできない、というもの...
- おそらく指定しているファイル/ロードパスに誤りがある...
心の声(その1)
ん?でも、同じ環境下に作っているruby fileなのに1つは実行可能で、もう一つは実行不可能ってどういうこと?? Why Ruby!
※ちなみに、
/usr/share/rubygems/rubygems/core_ext/kernel_require.rb:55をggるとたくさん、悩んでいる人がいた印象。軒並み検証してみましたが、解決せず。requireのあとに指定しているパスが間違っているよ、というアドバイスが多かった印象でした。ということで、冷静にみましょう、ロードパス

RubyGems Environment: - RUBYGEMS VERSION: 3.0.2 - RUBY VERSION: 2.3.8 (2018-10-18 patchlevel 459) [x86_64-linux] - INSTALLATION DIRECTORY: /usr/local/rbenv/versions/2.3.8/lib/ruby/gems/2.3.0 - USER INSTALLATION DIRECTORY: /root/.gem/ruby/2.3.0 - RUBY EXECUTABLE: /usr/local/rbenv/versions/2.3.8/bin/ruby - GIT EXECUTABLE: /usr/bin/git - EXECUTABLE DIRECTORY: /usr/local/rbenv/versions/2.3.8/bin - SPEC CACHE DIRECTORY: /root/.gem/specs - SYSTEM CONFIGURATION DIRECTORY: /usr/local/rbenv/versions/2.3.8/etc - RUBYGEMS PLATFORMS: - ruby - x86_64-linux - GEM PATHS: - /usr/local/rbenv/versions/2.3.8/lib/ruby/gems/2.3.0 - /root/.gem/ruby/2.3.0 - GEM CONFIGURATION: - :update_sources => true - :verbose => true - :backtrace => false - :bulk_threshold => 1000 - REMOTE SOURCES: - https://rubygems.org/ - SHELL PATH:心の声(その2)
うん、rbenvで指定できている。。。Why Ruby!
と、もうわからん。頭を抱えているとshebangに出会ったのでした。
天の声(その1)
shebang/シバン(Unix) ってのがあるんだよ??
[引用] シバンまたはシェバン (英: shebang) とはUNIXのスクリプトの #! から始まる1行目のこと。起動してスクリプトを読み込むインタプリタを指定する。ハッシュ・バンまたはシェル・バン、シャープ・バンとも言うが、これらを縮めたシェバンという呼び方が一般的かつ簡素である。*rbenv指定のrubyとgemが正しく指定できてなかった。shebangの指定先が間違っていた...YES, Ruby!!!
本来使いたかったもの(正解) 誤って設定していたもの 設定したshebang #! /usr/local/rbenv/versions/2.3.8/bin/ruby #! usr/bin/ruby 結果 この配下にgemは存在するので成功する gemをinstallしていないので、ロードエラーになる 本来は
#! /usr/local/rbenv/versions/2.3.8/bin/rubyにすべて設定していて、ここを使いたかった。が、問題Rubyファイル(A)では特に関係のない(設定していない)インタプリタを指定してしまっていた。
恥ずかしながら、shebangをずっとコメントだとおもっていたため、原因特定が難しかった。
最終的にはgem envで右記を確認「RUBY EXECUTABLE: /usr/local/rbenv/versions/2.3.8/bin/ruby」して、shebang指定してあげたらOKだった。[補足] 助けてくれた資料達...thanks!!
- #!/bin/sh は ただのコメントじゃないよ! Shebangだよ!
- Perl, Python 及び Ruby スクリプトにおける正しいshebangの書き方
- 「#!/usr/bin/python」と「#!/usr/bin/env python」の違い
- いまさら聞けない、#! で始まる1行目の名前とenv指定時の挙動
[余談] そもそもbundler/setupが何をしているのかは、こちらの記事がわかりやすかった。
- Bundler入門 - setupとrequire を読み解く
- 要はgemファイルを一括で読み込んでいる
- gem同士の互換性を保ちながら各gemの導入、管理を行ってくれるのがBundler
お読み頂きありがとうございました。
以上になります。誰かのお役に立てば...
なにか間違っていたり、ベターな方法がある場合はご教示いただけると幸いです。

- 投稿日:2019-03-02T12:34:15+09:00
Threadクラスを利用した例外処理
Threadクラスを利用した例外処理の方法に苦戦したので、自分用としてアウトプットします。
Threadクラスとは?
スレッドとはメモリ空間を共有して同時に実行される制御の流れです。 Thread を使うことで並行プログラミングが可能になります。
プログラムは通常処理を記述した順に実行されるので、複数の処理を同時に実行することができません。
しかし、AとBという二つに処理を同時に実行した場合ってありますよね?
そんなとき使用できるのがThreadクラスです。
メインスレッドとカレントスレッド
プログラム開始時に生成されるスレッドはメインスレッド、現在実行中のスレッドはカレントスレッドと呼ばれます。
RubyではThread#mainを用いる事でメインスレッドを確認できます。
また、Thread#listでプログラム上に存在するスレッドが配列で表示されます。
joinメソッド
Thread#joinは、 スレッド self の実行が終了するまで、カレントスレッドを停止させるメソッドです。 limit を指定して、limit 秒過ぎても自身が終了しない場合、nil を返します。
要するに、AとBという二つの処理を同時に実行した際に、片方の処理が終わるまでもう片方の処理を停止させることが出来るメソッドです。
Aという処理が終わるまで、Bという処理を停止させるようなイメージ。
使用方法
①Threadのインスタンスを生成(t1,t2)
②それぞれのThreadに対してrescue文を使用し例外処理を行う
(どちらが先に実行されるのかわからないため)
③rescue文で定義した例外処理のeにe1を代入。
④どちらか片方が例外処理によって抜け出した際の、エラー文とクラス(ActiveRecord::RecordInvalid)が一致しているか?のテストを実施。require 'rails_helper' RSpec.describe Ec::ItemImagesRegisterService do context 'with 2 images uploading at the same time' do let(:ec_item) { FactoryBot.create(:ec_item) } let(:ec_item_images_nearest_max) { FactoryBot.create_list(:ec_item_image, 19, ec_item: ec_item) } let(:params){ ActionController::Parameters.new( ec_item_id: ec_item.id, files:[{ file: File.open(Rails.root.join('spec', 'fixtures', 'sample_image_01.jpg')), order: 2}])} before do ec_item_images_nearest_max # ① t1 = Thread.new { ActiveRecord::Base.connection_pool.with_connection { service = described_class.new(params) service.run! } } # ① t2 = Thread.new { ActiveRecord::Base.connection_pool.with_connection { service = described_class.new(params) service.run! } } end it 'returns invalid with the 21st image' do e1 = nil e2 = nil # ② begin t1.join # JoinメソッドはThreadクラスを拡張したクラスのインスタンスから使用できるメソッド。別のスレッドの処理が終了するまで待機させたい処理がある場合に使用 rescue => e # ③ e1 = e end # ② begin t2.join rescue => e # ③ e2 = e end # ④ if e1.nil? expect(e2.class).to eq(ActiveRecord::RecordInvalid) expect(e2.record.errors.messages).to match({:file=>["は20枚までしか登録できません。"]}) expect(ec_item.ec_item_images.count).to eq 20 end # ④ if e2.nil? expect(e1.class).to eq(ActiveRecord::RecordInvalid) expect(e1.record.errors.messages).to match({:file=>["は20枚までしか登録できません。"]}) expect(ec_item.ec_item_images.count).to eq 20 end end end end【参考記事】
https://docs.ruby-lang.org/ja/latest/class/Thread.html
https://qiita.com/k-penguin-sato/items/1326882c400cac8c109b
- 投稿日:2019-03-02T05:15:17+09:00
条件式の統合(Consolidate Conditional Expression)
1つずつリファクタリング技法まとめ
個人的に簡単かつ取り入れ易いと思うものから目的
すぐ引き出せるようにする
基本作業サイクル
- システムを動かして仕様を精査
- テストメソッドを作成
- テストの失敗を確認
- テストの成功を確認
- 小さい変更、随時テスト実行(パターン追加失敗確認->成功確認)
- 最後テスト実行
- 最後動作確認
条件式の統合(Consolidate Conditional Expression)とは
同じ返り値を返す複数の条件式を、メソッドとして抽出してワンライナーにすること
条件式をORやANDでまとめることポイント
- 返り値が同じ
例
- OR系
- 条件式が順に並んでいる
def calorie return 0 if @food == 'donut' return 0 if @food == 'castella' return 0 if @food == 'ice' end↓
def calorie return 0 if @food == 'donut' || @food == 'castella' || @food == 'ice' end ↓ # そうすると条件文の分解ないしメソッドの抽出もできる def calorie return 0 if date? end def date? @food == 'donut' || @food == 'castella' || @food == 'ice' end
- AND系
- 条件式がネストしている
def calorie if @user == 'date' if @food == 'donut' 0 end end end↓
def calorie return 0 if @user == 'date' && @food == 'donut' end書籍情報
Jay Fields (著), Shane Harvie (著), Martin Fowler (著), Kent Beck (著),
長尾 高弘(訳), リファクタリング:Rubyエディション
https://amzn.to/2VlyWML雑感
やってる事は同じなんだけど説明の観点が違う(もしくは包含している)というのがたくさんある
- 投稿日:2019-03-02T02:01:41+09:00
ActiveStorageを使って複数画像管理をしてみる
ActiveStorageについて仕事で利用するかも、となったので、少し調べてみた。
その時の情報を簡単にまとめる。環境
Mac High Sierra
ruby 2.5.1
Rails 5.2.2実装したこと
複数画像をアップして表示する際の手順を記載してみる。
・index画面に画像一覧を表示させる
・new画面を用意する
バリデーションやエラーチェックなどはあまり気にせず作成
最低限の機能ってことで、一覧と新規追加しか搭載しない1.rails new
rails newする
rails new as_sample記事作成時はsqlite3でエラーが出た
Error loading the 'sqlite3' Active Record adapter. Missing a gem it depends on? can't activate sqlite3 (~> 1.3.6), already activated sqlite3-1.4.0. Make sure all dependencies are added to Gemfile.ので、Gemfileの編集をする
Gemfile# Use sqlite3 as the database for Active Record gem 'sqlite3', '~> 1.3.6'2.active_storageインストール、マイグレーション
cd as_sample rails active_storage:install rails db:migrate[マイグレーション結果]
active_storage_blobs,active_storage_attachmentsテーブルが作られる== 20190301155320 CreateActiveStorageTables: migrating ======================== -- create_table(:active_storage_blobs) -> 0.0027s -- create_table(:active_storage_attachments) -> 0.0124s == 20190301155320 CreateActiveStorageTables: migrated (0.0153s) ===============3.モデル作成、画像関連づけ
rails g model item name:string rake db:migrateapp/models/item.rbclass Item < ApplicationRecord has_many_attached :images end4.コントローラー作成
rails g controller items5.ルーティング設定
config/routes.rbRails.application.routes.draw do resources :items end6.コントローラー設定
app/controller/items_controller.rbclass ItemsController < ApplicationController # item一覧 def index @items = Item.all end # item新規作成 def new @item = Item.new end # item作成 def create @item = Item.new(item_params) if @item.save redirect_to items_path else render :new end end # item削除 def destroy @item = Item.find(params[:id]) @item.destroy redirect_to items_path end private def item_params params.require(:item).permit(:name, images: []) end end7.ビューの設定
一覧と新規作成画面を用意する。
一覧画面
app/views/items/index.html.erb<h1>Items Index</h1> <%= link_to 'Add item', new_item_path %> <ul> <% @items.each do |item| %> <li> <p><%= item.name %></p> <%= link_to 'Destroy', item, method: :delete, data: { confirm: 'Are you sure?' } %> <% item.images.each do |image| %> <%= image_tag(image, width:100) %> <% end %> </li> <% end %> </ul>画像のサイズは一旦width:100で設定
新規作成画面
app/views/items/new.html.erb<h1>Add Item</h1> <%= form_with model: @item do |form| %> <div> <%= form.label :name %> <%= form.text_field :name %> </div> <div> <%= form.label :images %> <%= form.file_field :images, multiple: true %> </div> <div> <%= form.submit %> </div> <% end %>8.ローカルサーバー起動
rails s8-1. http://localhost:3000/items にアクセス
8-2.item新規作成で画像を選択
ファイル選択から画像ファイル2つを選択した状態
8-3.Create_itemして一覧に遷移した後
とりあえず、想定した動作を作ることができた。
images: []に入るパラメータ
viewで選択したimagesはcontroller側にどんな値で渡されているかを確認してみる。
個人的に見やすくするために改行する。# ActionDispatch::Http::UploadedFile クラスのインスタンス "images"=> [ #<ActionDispatch::Http::UploadedFile:0x00007fa524251a18 @tempfile=#<Tempfile:/var/folders/nf/0ssmnnv545d65f2xd8fcmz2cnr376k/T/RackMultipart2019xxxx-51778-hpwm2k.jpg>, @original_filename="hogehoge.jpg", @content_type="image/jpeg", @headers="Content-Disposition: form-data; name=\"image[images][]\"; filename=\"hogehoge.jpg\"\r\nContent-Type: image/jpeg\r\n"> , #<ActionDispatch::Http::UploadedFile:0x00007fa5242519c8 @tempfile=#<Tempfile:/var/folders/nf/0ssmnnv545d65f2xd8fcmz2cnr376k/T/RackMultipart2019xxxx-51778-6nsna7.jpg>, @original_filename="fugafuga.jpg", @content_type="image/jpeg", @headers="Content-Disposition: form-data; name=\"image[images][]\"; filename=\"fugafuga.jpg\"\r\nContent-Type: image/jpeg\r\n"> ]それぞれの情報は以下のようになる
@tempfile : 画像データ情報(パス情報?)
@content_type: 画像の形式 (jpg,pngとか)
@original_filename : ファイル名情報
@headers: ヘッダーに関する情報 (データ形式など)簡単な動きと渡されるパラメータについて少し知れたので、
次はVueを使って画像登録処理を実装してみようと思う。



- 投稿日:2019-03-02T00:02:30+09:00
Rails要らず、CGIとRubyでソースコードをフローチャートにするツール作成
きっかけは怠惰なお気持ちでした。ということで、こんなの作ってみました。よかったら、ご覧ください。
要は、フォームに入力されたRubyのソースコードを、フローチャートにしてくれる、というもの。
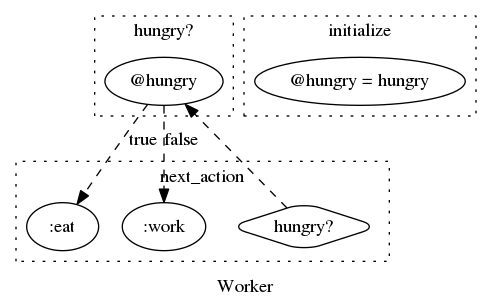
具体的には、以下のソースコードが
class Worker def initialize(hungry:) @hungry = hungry end def next_action if hungry? :eat else :work end end def hungry? @hungry end endこんな画像になって出てくる。
ソースコードのフローチャート化のために、RubyのGemvisualize_rubyとグラフ描画してくれるGraphvizを使っています。きっかけは怠惰なお気持ちでした(T_T)
- 業務の中で仕様書になっていないソースコードを読んで、読んで、理解して、フローチャートにして、要件詰めて、また読んでが面倒に思えた。
- 読むだけなら、まだいいんですが、他の人と共有とかを考えると可視化していく必要があった
- 1回ならいいんだけれど、いろんなところでそれが発生していた
- どんどん変化していく類のものだったときに、仕様書にしてもメンテされない
あと普段Railsを使うことが多いのですが、乳離というか、Rails離れもしたいというお気持ちでした
- Railsにはいつもお世話になっており、細かいことを気にしなくても、ワタシが気持ちよく働ける環境を作ってくれています
- が、いっぽうで、それゆえに根本的なRubyという言語やWebサービスがどう動いているのかの理解が浅いままになっちゃているな、とも思うようになった。
- ミニマムでやりたいことだけをやるとしたときに、なにがあればいいんだろうかっていうのも知りたかった。恥ずかしながら、たぶんRailsなしでは飛べない小鳥ですので。
フローチャートに自動でしてくれるやついないかなって探していたら、街角でばったり出くわしたのがvisualize_rubyでした。
- 有り難いと思いながら、卑屈な人間なので
- 簡単に自分の環境で実装ができたのですが、環境依存とかで設定が面倒だなって思い
- コンソールからイジルの、絶対みんなできないよ〜って思い
そうだ!環境に依存しないDockerでRailsを使わない(CGIとRuby)でブラウザからフォーム入力ができて、描画してくれるツールを作ってみようと決心したのでした。
こちらが該当のリポジトリ、名付けてVisualizeSrc!!
ざっくり取り上げると、以下のような構成で作ってみました。詳細な中身はリポジトリをご覧ください。基本的には、リポジトリを各人のローカル開発環境にpullしてもらって、ビルドしてもらえればlocalhostのport80で動くような設定をしています。ファイル構成
/var配下の処理スクリプト達 ├── www │ ├── cgi-bin │ │ ├── Gemfile │ │ ├── Gemfile.lock │ │ ├── result.rb ...フォームから値を受け取ってモジュールに渡す │ │ ├── source_code.png ...作成される画像データ │ │ └── visualize_mod.rb ...画像を作るモジュール │ └── html │ └── form.cgi ...フォームから入力値を受け取る /etc配下の設定ファイル達 ├── conf │ ├── httpd.conf ... PortやAliasの設定 ├── conf.d │ ├── cgi-enabled.conf ... CIGでRubyファイルが処理できるように設定 ちなみにrbenvを使って管理しており、Gemは以下のパスへ /usr/local/rbenv/versions/2.3.8/lib/ruby/gems/2.3.0/gems/環境
- Dockerfile - CENTOS:7 - Apache - 変更した設定(Dockerでイメージビルドするときに差し替えました) - httpd.conf - cgi-enabled.conf - Ruby:2.3.8 - 使ったライブラリ - parser - visualize_ruby - 詳細はDockerfileを!使い方はこんな感じ。
1. 該当リポジトリを各環境へpull
git pull https://github.com/taishinagasaki/visualize_src.git2. Docker imageの作成
docker build -t repository_name/image_name:tag_name . --no-cache=true3. できたイメージを確認
docker images4. dockerのイメージは以下の特権モードで起動する。ポートは80と80を繋げる。
docker run --privileged -d -p 80:80 --name container_name repository_name/image_name:tag_name /sbin/init5. containerが立ち上がっていることを確認する。statusがUPになればOK。
docker start <container_id>6. 立ち上がっていればcontainer idを指定して起動
docker exec -it <container_id> /bin/bash7. apacheの起動
systemctl start httpd8. apacheの起動を確認
systemctl start httpd9. ブラウザから
localhost/form.cgiへアクセス
使い方は該当リポジトリのREADME.mdに記載しております。各工程と、助けてくれた資料達
作業内容 資料名 ApacheのインストールからCGI設定まで Apache httpd : インストール設定 RubyをCGIで動かす設定まで Apache httpd : Ruby を利用する フォーム入力値をRubyファイルで受け取る [Linux][Ruby]ApacheでRubyのCGIを動かす方法 Dockerでsystemctlを使えるようにする CentOS 7のDockerコンテナ内でsystemdを使ってサービスを起動する Dockerでイメージ作ってコンテナを立ち上げる Dockerコマンドメモ
ハマったこと
Shebangという、インタプリタの指定にハマってしまいました。
シバンまたはシェバン (英: shebang) とはUNIXのスクリプトの #! から始まる1行目のこと。起動してスクリプトを読み込むインタプリタを指定する。
恥ずかしながらShebagの存在すら知らず、インストールしたgemを一括で取り込むためにrequire 'bundler/setup'を実行しても延々とエラーが出続ける、というもので、これに関してはデバッグ方法もわからずでした。ググってもなかなかなく、根本的な理解がなってないな〜ということを改めて知りました。
また後日、投稿したいと思います。
[追記: 2019/03/02] `require': cannot load such fileエラーをインタプリタ指定から探る ~ファイル1行目のshebang設定~...shebang設定について言及まだできてないこと/TODO
- Web化してもいいかなっておもったんですがセキュリティ周りの設定が間に合わず(怖かったので)、またの機会に持ち越しとしました。
- DockerfileのCMD複数指定を実現する。
- CMDでshell scriptを指定してあげるとできるとおもっていたが、できず。
- どうにかやってみたい。
- VIMで環境を整えたい。
学び
- Railsから離れたり、いつも使っている高機能エディタから離れることでより根本理解が深まった印象。
- MW(Apache)やOS層も普段は殆ど触らないので勉強することが多かった。
- 実はQiita投稿も初めてなので、その他「初めて」が多くてよかった。
次にやりたいこと
- TODOを潰す
- Dappに触ってみる
お読み頂きありがとうございました。
なにか間違っていたり、ベターな方法がある場合はご教示いただけると幸いです。