- 投稿日:2019-03-02T23:52:23+09:00
Discord Botを作成するときにハマったこと
唐突にDiscord Botが作りたくなった
とりあえずPythonを公式サイトからダウンロード(最新版 3.7)
パスを通してターミナルで
$python3 -m pip install discord.pyと入力謎のエラー
Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/anaconda3/lib/python3.7/site-packages/websockets-7.0.dist-info/INSTALLER' Consider using the `--user` option or check the permissions.
面倒くせえと思ったが折角なのでもうちょいやる
--userオプションを付けろと書いてあるので付ける
$python3 -m pip install discord.py --user
Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/Users/i23xxaye/.local/lib/python3.7/site-packages/websockets-3.4.dist-info' Check the permissions.
sudoを付けてもう一度
$sudo python3 -m pip install discord.py --user
Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/Users/i23xxaye/.local/lib/python3.7/site-packages/websockets-3.4.dist-info' Check the permissions.なぜか出来ない
ggったところDiscord.pyが3.7非対応だった
PythonをアンインストールしてVer.3.6を再インストール後にもう一度
$python3 -m pip install discord.py成功した!
*すいません成功した時のターミナルコピるの忘れました
結論
・Pythonで使えないモジュールがある時は対応バージョンを確認する<-ココ大事
・Googleの力を沢山借りようその後
めっちゃbot作って遊んでますw
- 投稿日:2019-03-02T23:32:10+09:00
【機械学習】MLflowのQuickstartやってみた(2)
前回の記事
前回の記事の続きです。
環境
- macOS High Sierra
- pyenv 1.2.1
- anaconda3-5.0.1
- Python 3.6.8
- MLflow==0.8.2
MLflow Projectsを実行してみる
MLflow Projectsとは
MLflow Projectsは、機械学習を実行するための情報をMLprojectというファイルにまとめることで実験を再現しやすいようにしたものです。
MLprojectファイルには実行するコマンドやcondaの設定ファイルなどが記述してあります。
condaの設定ファイルには、依存するライブラリの情報などを記載することで、実行時にその環境が再現できるようになっています。サンプル
ここにサンプルがおいてあります。
中身はこんな感じです。mlflow-example ├── LICENSE.txt ├── MLproject ├── README.md ├── conda.yaml ├── train.py └── wine-quality.csv
MLprojectファイルの中身はこんな感じMLprojectname: tutorial conda_env: conda.yaml entry_points: main: parameters: alpha: float l1_ratio: {type: float, default: 0.1} command: "python train.py {alpha} {l1_ratio}"
conda_envにcondaの設定ファイル、entry_pointsに実行するコマンドや引数の情報が記載されています。わかりやすいですね。次は
conda.yamlファイルの中身です。conda.yamlname: tutorial channels: - defaults dependencies: - numpy=1.14.3 - pandas=0.22.0 - scikit-learn=0.19.1 - pip: - mlflow
dependenciesに依存ライブラリの情報が記載されています。
channelsについてはよくわからなかったので調べてみるとこんな情報がありました。
anaconda.orgに登録した独自のパッケージのインストールが必要なときなどに使用するようです。
一般的なライブラリならばchannelsはdefaultsで問題無さそうです。
MLprojectを実行してみるQuickstartには以下の2種類の実行方法が記載されています。
①mlflow run tutorial -P alpha=0.5
②mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=5①はローカルにある
MLprojectを実行する方法で、②はgithub上のMLprojectを実行する方法です。まずはgithub上のリポジトリから直接起動してみます。②の方法ですね。
githubリポジトリ上の
MLprojectを起動するさっそく実行です。
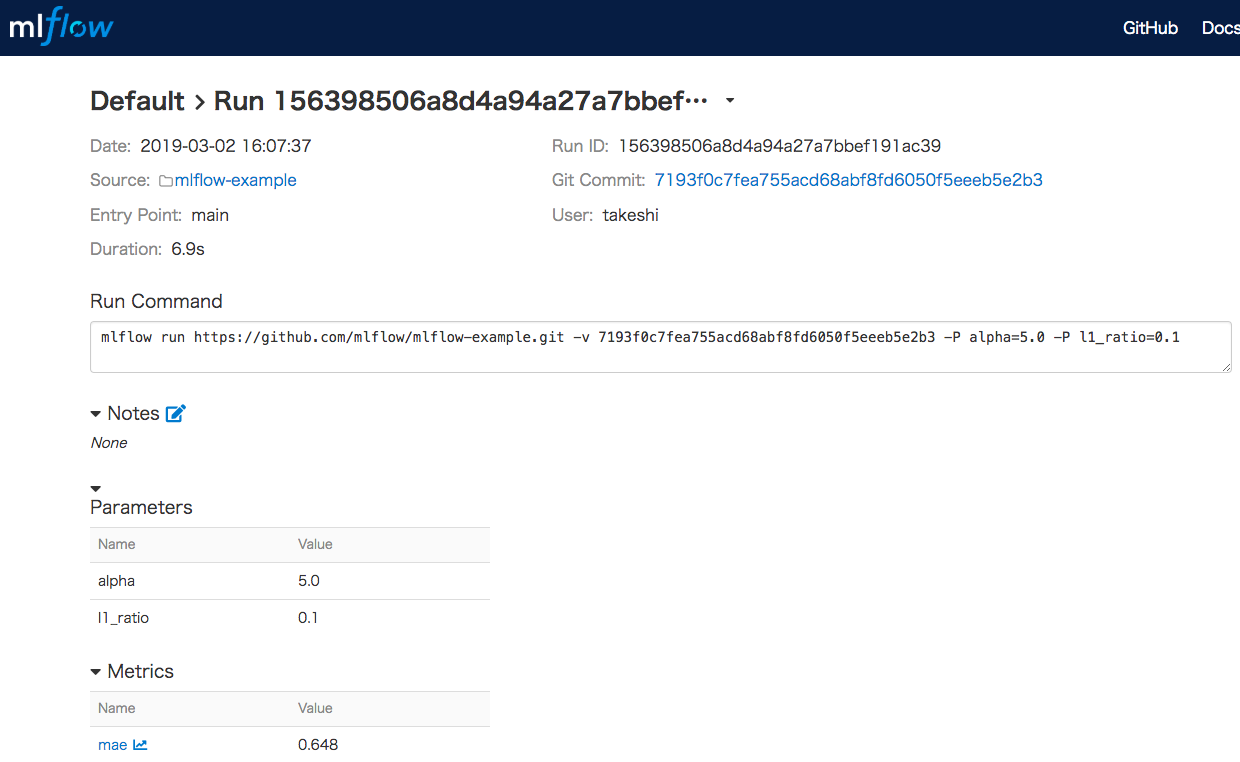
$ mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=5はい。
エラーorz2019/03/02 15:26:35 INFO mlflow.projects: === Fetching project from git@github.com:mlflow/mlflow-example.git into /var/folders/tl/lvx29tf163sbphlr4tqsfp_80000gn/T/tmpl53vj9ne === Traceback (most recent call last): File "/Users/takeshi/.local/bin/mlflow", line 11, in <module> load_entry_point('mlflow==0.8.2', 'console_scripts', 'mlflow')() File "/Users/takeshi/.local/lib/python3.6/site-packages/click/core.py", line 764, in __call__ return self.main(*args, **kwargs) File "/Users/takeshi/.local/lib/python3.6/site-packages/click/core.py", line 717, in main rv = self.invoke(ctx) File "/Users/takeshi/.local/lib/python3.6/site-packages/click/core.py", line 1137, in invoke return _process_result(sub_ctx.command.invoke(sub_ctx)) File "/Users/takeshi/.local/lib/python3.6/site-packages/click/core.py", line 956, in invoke return ctx.invoke(self.callback, **ctx.params) File "/Users/takeshi/.local/lib/python3.6/site-packages/click/core.py", line 555, in invoke return callback(*args, **kwargs) File "/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/cli.py", line 129, in run run_id=run_id, File "/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/projects/__init__.py", line 171, in run storage_dir=storage_dir, block=block, run_id=run_id) File "/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/projects/__init__.py", line 54, in _run git_username=git_username, git_password=git_password) File "/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/projects/__init__.py", line 297, in _fetch_project _fetch_git_repo(parsed_uri, version, dst_dir, git_username, git_password) File "/Users/takeshi/.local/lib/python3.6/site-packages/mlflow/projects/__init__.py", line 347, in _fetch_git_repo origin.fetch() File "/Users/takeshi/.local/lib/python3.6/site-packages/git/remote.py", line 789, in fetch res = self._get_fetch_info_from_stderr(proc, progress) File "/Users/takeshi/.local/lib/python3.6/site-packages/git/remote.py", line 675, in _get_fetch_info_from_stderr proc.wait(stderr=stderr_text) File "/Users/takeshi/.local/lib/python3.6/site-packages/git/cmd.py", line 415, in wait raise GitCommandError(self.args, status, errstr) git.exc.GitCommandError: Cmd('git') failed due to: exit code(128) cmdline: git fetch -v origin stderr: 'fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.'上記のコマンドではダメっぽいので以下のコマンドに変更したらいけました。
$ mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=52019/03/02 16:07:35 INFO mlflow.projects: === Fetching project from https://github.com/mlflow/mlflow-example.git into /var/folders/tl/lvx29tf163sbphlr4tqsfp_80000gn/T/tmp255y1l6j === 2019/03/02 16:07:40 INFO mlflow.projects: === Created directory /var/folders/tl/lvx29tf163sbphlr4tqsfp_80000gn/T/tmp4aockzav for downloading remote URIs passed to arguments of type 'path' === 2019/03/02 16:07:40 INFO mlflow.projects: === Running command 'source activate mlflow-3eee9bd7a0713cf80a17bc0a4d659bc9c549efac && python train.py 5 0.1' in run with ID '156398506a8d4a94a27a7bbef191ac39' === Elasticnet model (alpha=5.000000, l1_ratio=0.100000): RMSE: 0.8594260117338262 MAE: 0.6480675144220316 R2: 0.046025292604596424 2019/03/02 16:07:44 INFO mlflow.projects: === Run (ID '156398506a8d4a94a27a7bbef191ac39') succeeded ===githubからフェッチしてきて実行してその結果が表示されていますね!
指定した引数もきちんと渡っているようです。
※一回目に実行したときにconda.yamlの情報に従って仮想環境が作成されます。私も作成されましたが何度か試行錯誤したのでコマンドログが消えてしまいました。。。
ちなみに私の場合はmlflow-3eee9bd7a0713cf80a17bc0a4d659bc9c549efacという名前の仮想環境が作成されていました
mlflow uiコマンドでサーバーを起動すればもちろんMLprojectの実行結果も確認できます。
Sourceの部分がmlflow-exampleのリンクになっています。
クリックするとgithubのリポジトリに飛びました。
Git Commitのハッシュ値を使っていつのコードなのかを判断しているぽいですね。また、
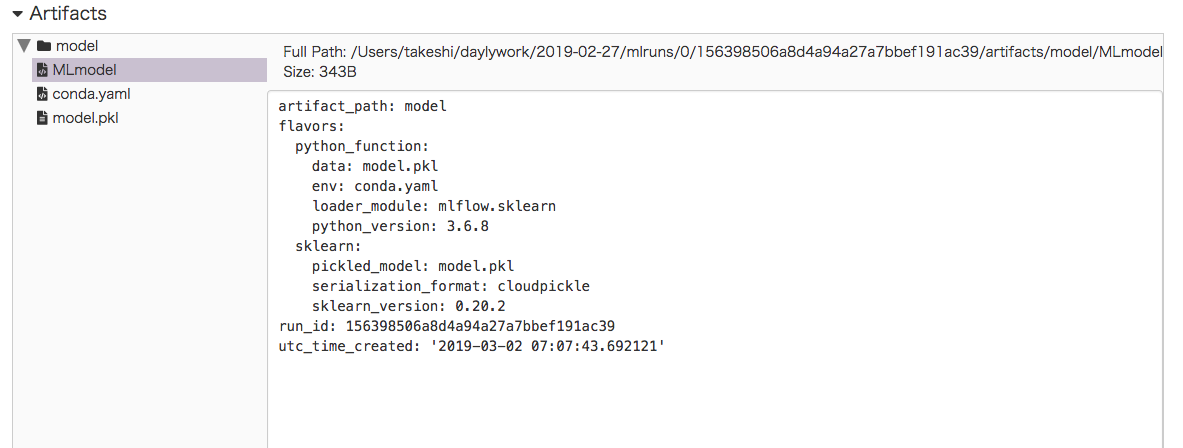
Artifactsに保存されているmodelにはMLmodel、conda.yaml、model.pklが保存されており、次回のSaving and Serving Modelsで使うためのデータになります。
ローカルの
MLprojectを起動するそれでは次はローカルの
MLprojectを起動してみます。
今回は、上記で使ったサンプルリポジトリをクローンして使います。git clone https://github.com/mlflow/mlflow-example.gitこれで以下のコマンドでいける…はず?
$ mlflow run tutorial -P alpha=0.5
tutorialってなんやねん。。。と思いながらもとりあえず実行。2019/03/02 23:10:39 ERROR mlflow.cli: === Could not find subdirectory of tutorial ===ですよねぇー。
ということでコマンドを以下のように変更します。$ mlflow run mlflow-example -P alpha=0.5これで無事に実行できました。
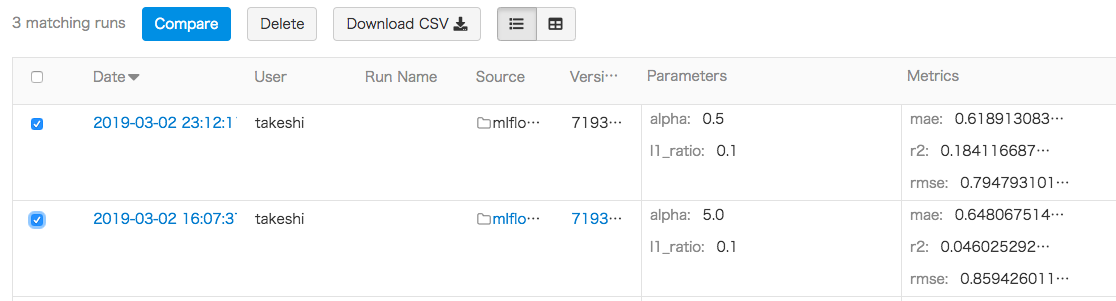
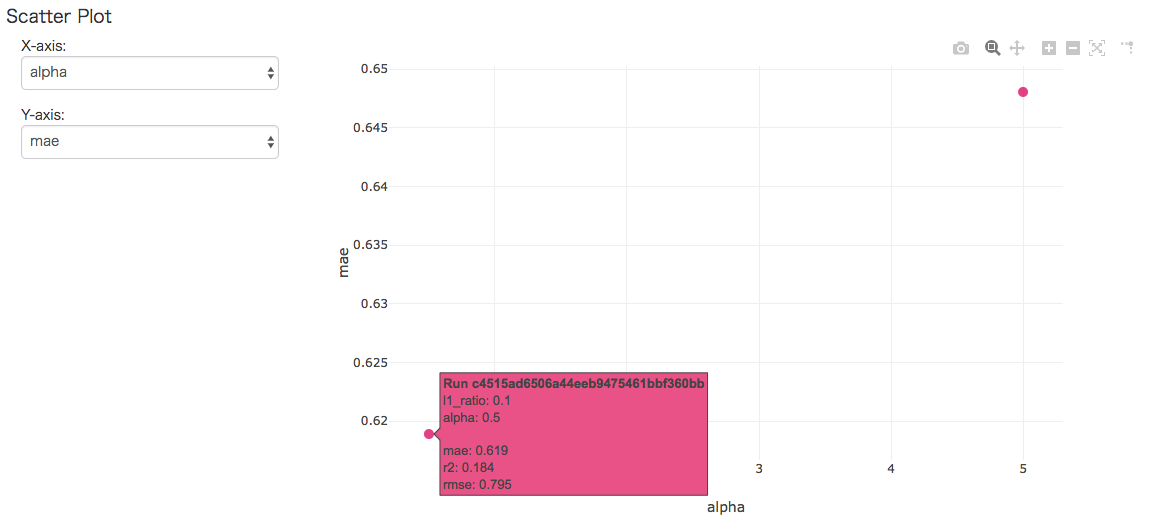
mlflow run xxxxのxxxx部分はMLprojectファイルが含まれるディレクトリ名を指定する必要があるみたいです。2019/03/02 23:12:14 INFO mlflow.projects: === Created directory /var/folders/tl/lvx29tf163sbphlr4tqsfp_80000gn/T/tmpvi_ejt9v for downloading remote URIs passed to arguments of type 'path' === 2019/03/02 23:12:14 INFO mlflow.projects: === Running command 'source activate mlflow-3eee9bd7a0713cf80a17bc0a4d659bc9c549efac && python train.py 0.5 0.1' in run with ID 'c4515ad6506a44eeb9475461bbf360bb' === Elasticnet model (alpha=0.500000, l1_ratio=0.100000): RMSE: 0.7947931019036528 MAE: 0.6189130834228137 R2: 0.1841166871822183 2019/03/02 23:12:17 INFO mlflow.projects: === Run (ID 'c4515ad6506a44eeb9475461bbf360bb') succeeded ===こちらはフェッチしてないですね。
パラメータalphaの値が違うので結果も異なっています。
以下のようにチェックボックスを複数チェックすることで、異なる実験結果をブラウザ上で比較することも出来ます。
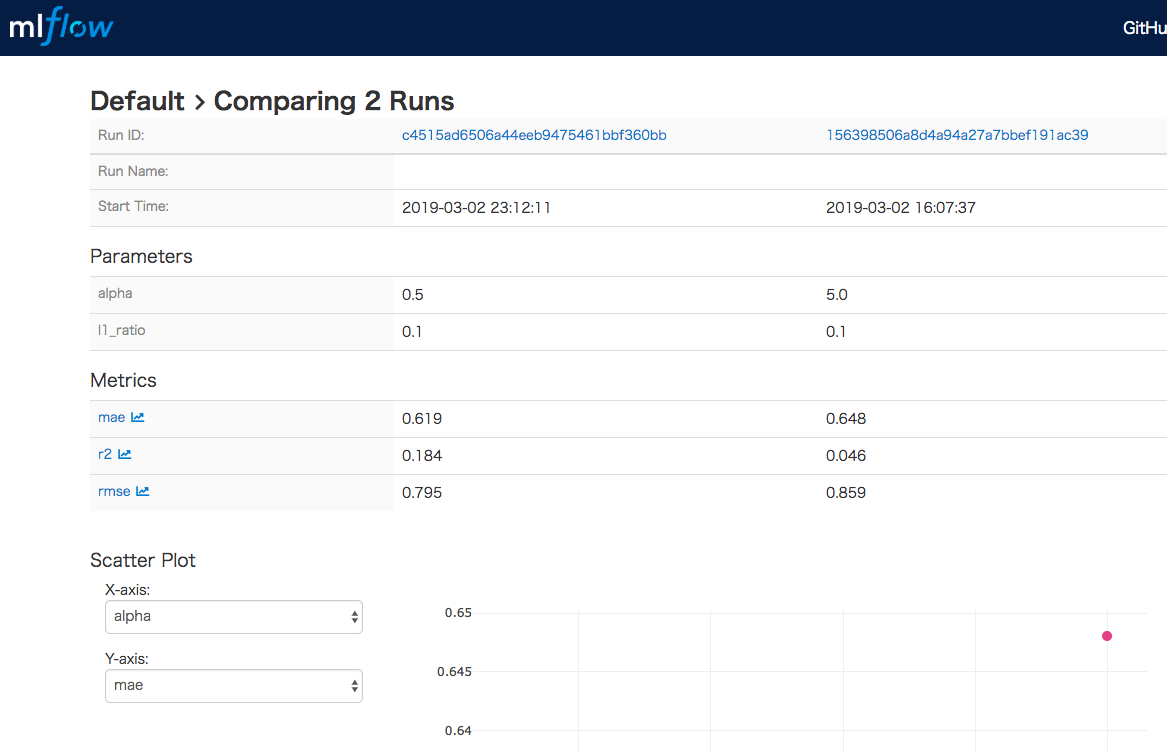
Compareボタンを押すと以下のような画面が表示されます。
実行日時や処理時間、パラメータやMetricsなどの比較ができます。さらに、下図のように、パラメータとMetricsのそれぞれの値についてX軸とY軸に対応する値を選択することでグラフ上で関係を確認できます。
便利ですね。
まとめ
MLprojectについて、githubから直接起動パターンとローカルで起動パターンの2つを試してみました。
またもや長くなってしまったので、Saving and Serving Modelsについては次回にしたいと思います。
- 投稿日:2019-03-02T23:25:52+09:00
ROOTで機会学習してみる〜Multi Layer Perceptron(ANN)
概要
欧州原子核研究機構CERNが開発しているデータ分析ツールROOTを使って簡単に機械学習をしてみる。
ROOTで用意されているチュートリアルのサンプルコードを参考に、
Multi Layer Perceptron(MLP)で回帰曲線を出すところまでやってみる。ROOTのインストール方法や基本的な使い方は過去に書いた記事を参考までに。
https://qiita.com/dyamaguc/items/2f723cbc304c4debd82e
https://qiita.com/dyamaguc/items/397121b303e26f8286cf環境
- Mac Book Air
- Mac OS X 10.13.6
- ROOT 6.14/06
サンプルコードと実行結果
ROOTのサンプルコード(C++)
ROOTが提供しているサンプルコードはこちら
https://root.cern.ch/root/html608/mlpRegression_8C.htmlROOTをすでにインストールしている場合、サンプルコードは
<path to root>/tutorials/mlp/mlpRegression.C
ここにおいてある。
これを動かすには
root <path to root>/tutorials/mlp/mlpRegression.C
とターミナルでコマンドを打てば、いくつかプロットが出てきて、
うまく予測できていることがわかる。
C++のコードだが、コンパイルは不要。自分のサンプルコード(Python)
ROOTが提供しているサンプルコードだとあまり面白くないので、
自分でサンプルコード少し変えて走らせてみた。
まず目的変数zに対し、説明変数x、yが次のような関係を持っているとする。def theUnknownFunction(x, y): return TMath.Sin( (1.7+x)*(x-0.3) - 2.3*(y+0.7))(x、y、z)の組を500個学習させて、得た回帰曲線の予想z_predと、正解z_trueを比較する。
from ROOT import TNtuple, TRandom, TMultiLayerPerceptron, TMLPAnalyzer, TMath, TCanvas, TGraph, TGraph2D, TTree, gROOT from array import array import numpy as np def createData(): N = 1000 r = TRandom() r.SetSeed(0) data_tree = TTree("tree", "tree") x = np.empty((1), dtype="float32") y = np.empty((1), dtype="float32") z = np.empty((1), dtype="float32") data_tree.Branch("x", x, "x/f") data_tree.Branch("y", y, "y/f") data_tree.Branch("z", z, "z/f") # fill data for i in range(0, N): x[0] = r.Rndm() y[0] = r.Rndm() z[0] = theUnknownFunction(x, y) data_tree.Fill() del x,y,z return data_tree if __name__ == '__main__': # fill data data_tree = createData() # create ANN mlp = TMultiLayerPerceptron("x,y:10:8:z", data_tree, "Entry$%2","(Entry$%2)==0") mlp.Train(150, "graph update=10") mlpa = TMLPAnalyzer(mlp) mlpa.GatherInformations() mlpa.CheckNetwork() mlpa.DrawDInputs()
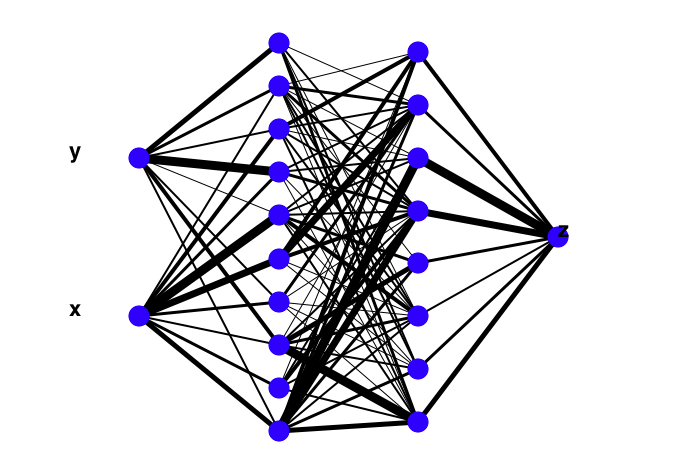
TMultiLayerPerceptronの最初の引数"x,y:10:8:z"はニューラルネットワークのレイヤーを記述している。
今回は、xとyが入力の層、その次の10と8はhidden layerのニューロンの数、zが出力。
今回はもとのサンプルと同じ設定にしている。
ROOTでは、Draw()で設定したニューラルネットワークの構造を可視化できる(下図)。
第2引数はデータ。ROOTのデータ構造である、TTreeで渡している。
第3引数は学習用データの条件。今回はEntry(データのID)が奇数の場合を指定している。
第4引数はテスト(検証用)データの条件。Entryが偶数の場合を指定している。その次に
Train(150, "graph update=10")で学習をしている。
第1引数はイテレーションの回数。
第2引数は学習のオプション。10イテレーション毎にグラフで学習曲線を描くように指定している。
TMLPAnalyzerで学習したMLPの結果を簡単に表示できる。
結果を可視化する。#draw statistics shows the quality of the ANN's approximation canvas = TCanvas("TruthDeviation", "TruthDeviation") canvas.Divide(2,2) canvas.cd(1) mlp.Draw() canvas.cd(2) # draw the difference between the ANN's output for (x,y) and # the true value f(x,y), vs. f(x,y), as TProfiles mlpa.DrawTruthDeviations() canvas.cd(3) # draw the difference between the ANN's output for (x,y) and # the true value f(x,y), vs. x, and vs. y, as TProfiles mlpa.DrawTruthDeviationInsOut() canvas.cd(4) graph_truth_y05 = TGraph() graph_predi_y05 = TGraph() graph_truth_y05.SetMarkerStyle(20) graph_predi_y05.SetMarkerStyle(21) graph_predi_y05.SetMarkerColor(2) for ix in range(0, 15 ): v = array( 'd', [0,0]) v[0] = ix / 10.0 v[1] = 0.5 graph_truth_y05.SetPoint( graph_truth_y05.GetN(), v[0], theUnknownFunction(v[0], v[1])) graph_predi_y05.SetPoint( graph_predi_y05.GetN(), v[0], mlp.Evaluate(0, v)) graph_truth_y05.Draw("AP1") graph_predi_y05.Draw("P1 SAME") graph_truth_y05.SetTitle("y = 0.5;x;z") canvas.SaveAs("output.png") # To avoid error del mlp実行結果は下図の通り。
x,y(右上),z(左下)を横軸にとって、縦軸に正解と予測の差をとると、いい精度で予測できていることがわかる。
右下は、y=0.5のときの正解(黒)と予想(赤)のプロット。横軸がx、縦軸がz。
xが1以上で予想と正解がずれているが、学習データの範囲外なので、まあそんなところかなというところ。
0 <= x <= 1では正解(黒)と予測(赤)がよく一致している。
まとめ
ROOTのフレームワークを使うことで簡単に、ニューラルネットワークの機械学習をしてみた。
チュートリアルのコードを参考にしたので、簡単に(数行で)回帰曲線を求められた。参考
TMultiLayerPerceptron
https://root.cern.ch/doc/master/classTMultiLayerPerceptron.html#a9262eee03feb52487900c31f279691c2TMLPAnalyzer
https://root.cern.ch/doc/master/classTMLPAnalyzer.html実行後に出力されるエラーを消す方法
https://root-forum.cern.ch/t/output-could-be-produced-but-here-is-a-long-list-of-errors/10620/4その他
https://www-he.scphys.kyoto-u.ac.jp/member/n.kamo/wiki/doku.php?id=study:software:root:pyroot

- 投稿日:2019-03-02T22:36:19+09:00
[Learning to Rank] ランク学習で好みの犬画像を推薦させる PyTorch
TL;DR
- ニューラルネットワークを用いたランク学習を勉強した
- RankNetとListNetの説明と実装
- ランク学習で好みの犬画像を教えてもらう実験を行った
ランク学習(Learning to Rank)
ランク学習は検索サイトなどで主に使われ,入力となるクエリに対して,データの並び順を出力する技術です.
2010年までのランク学習のサーベイ論文をMS Researchが発表していますので参考にしてください.日本語で学ぶ場合はこちらのブログを参照.
ニューラルネットによるランク学習
2005年 RankNet
ニューラルネットワークで特徴抽出し,ランクに相当するスカラーを返す手法です.
pairwiseというサンプリング手法を用いており,2つのデータ[tex: x_i], [tex: x_j]とそれらのランク[tex: U_i], [tex: U_j]を1セットとして学習を行います.
2つのデータ間のランクの上下関係をうまく学習させることで,全体に対してもうまくランク付けが出来るようになるのではというモチベーションで提案されました.$x_i$が$x_j$よりラベルが上になる確率を以下の式で定義します.
$s_i$と$s_j$はNNによる$x_i$と$x_j$の出力です.P_{ij} \equiv P(U_i > U_j) \equiv sigmoid(\sigma*(s_i - s_j))ここでのσはsigmoid関数をうまく当てはめるために設定するハイパーパラメータで基本は適当に1を入れておけばいいと思います.
そしてRankNetにおける損失関数は以下の式で定義されます.
$P_{ij}$を通常のNNの出力としてみると,CrossEntropyLossと同じです.Loss = -\bar{P_{ij}}\log{P_{ij}} - (1 - \bar{P_{ij}})\log(1 - P_{ij}) \\式中の$\bar{P_{ij}}$の定義は以下.
\bar{P_{ij}} \equiv \frac{1}{2}(1 + S_{ij}) \\ S_{ij} = \left\{ \begin{array}{ll} 1 & (U_i > U_j) \\ -1 & (U_i < U_j) \\ 0 & (U_i = U_j) \end{array} \right.2010年時点ではGradient Boostingを用いたランク学習が広く用いられているようですが,画像によるクエリの場合にはおそらくベストな選択肢はCNNで特徴抽出する方法だと思われるので,考え方としては非常に重要な手法だと思われます.
またこのpairwiseなサンプリング手法を用いた他のアルゴリズムとしてRanking SVM, RankBoostなどもあるようです.2007年 ListNet
著者の解説スライド
RankNetの弱点を改良するべく提案されたのがこのListNetです.
pairwiseな手法の欠点として,損失関数が各データの上下関係のみを学習対象としており,ランク全体でどの位置にいるのか不明(で評価手法のNDCGなどを直接的に最適化できない)という点があります.web検索などでトップn個に表示されるものがより尤もらしくなって欲しいのに対し,1つ1つの上下関係を学習させるのはあまりに間接的すぎるということですね.ListNetではpermutation probability distributionというデータの順列が生じる確率分布を考え,その確率分布を正解ラベルとモデルの予測とで最小化するように学習します.Permutation probability自体は順列の確率そのままですが,以下の式で定義されます.ちょっと実装がダルそう...
P_s(\pi) = \prod_{j=1}^{n} \frac{exp(s_{\pi(j)})}{\sum_{k=j}^{n}exp(s_{\pi(k)})}ListNetの損失関数は以下の式で定義されています.
\begin{align} L(y^{(i)}, z^{(i)}(f_{\omega})) &= -\sum_{j=1}^{n^{(i)}}P_{y^{(i)}}(x_j^{(i)})\log(P_{z^{(i)}(f_{\omega})}(x_j^{(i)})) \\ P_{z^{(i)}(f_\omega)}(x_j^{(i)}) &= \frac{exp(f_\omega(x_j^{(i)}))}{\sum_{k=1}^{n^{(i)}}exp(f_\omega(x_k^{(i)}))} \\ P_y^{(i)}(x_j^{(i)}) &= \frac{exp(y_j^{(i)})}{\sum_{k=1}^{n^{(i)}}exp(y_j^{(i)})} \end{align}$P_y$と$P_z$は正解ラベルと予測値に対するsoftmaxを計算しているだけなので,loss全体も結果的にはCrossEntropyLossとみなせます.
好みの顔を推薦してもらう
実験概要
3つの犬種の画像を学習し,同じ3つの犬種の画像からなるテストデータでランク付けを行いました.
用いた画像はOxford Pet datasetの柴犬(2),チワワ(1),パグ(0)の3種で,カッコ内の数字が正解ラベルとなる優先順位です.
つまり好みの順に,柴犬 > チワワ > バグとなります.また,データ数は訓練データが犬種ごとに約180枚,検証データが各20枚,テストデータが各5枚です.
実装
今回使用したコードはすべてGitHubにまとめています.
学習にはRankNetを用いました.
RankNetのコードがこちら.
RankNetとしては最終的にスカラーを出力できるものであればなんでもよいです.
今回はResNet18のImageNetによるpretrainedモデルをエンコーダとし,その後ろに全結合層を1つつけ,エンコーダの重みは固定し,全結合層1層のみ学習させました.class RankNet(nn.Module): def __init__(self): super(RankNet, self).__init__() resnet = torchvision.models.__dict__['resnet18'](pretrained=True) for params in resnet.parameters(): params.requires_grad = False self.resnet = nn.Sequential( resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1, resnet.layer2, resnet.layer3, resnet.layer4, resnet.avgpool, ) self.fc = nn.Linear(resnet.fc.in_features, 1) def forward(self, x): out = F.relu(self.resnet(x)) out = out.view(out.size(0), -1) return self.fc(out)RankNetでの損失関数をRankNetLossとして定義します.
class RankNetLoss(nn.Module): def __init__(self, sigma=1.0): super(RankNetLoss, self).__init__() self.sigma = sigma def forward(self, s_i, s_j, u_i, u_j): s_ij = torch.zeros_like(u_i) s_ij[u_i > u_j] = 1 s_ij[u_i < u_j] = -1 p_ij_bar = 0.5 * (1 + s_ij) p_ij = torch.sigmoid(self.sigma*(s_i - s_j)).view(-1) loss = - p_ij_bar*torch.log(p_ij) - (1-p_ij_bar)*torch.log(1-p_ij) return loss.mean()また,RankNetはpairwiseなサンプリングを行うので,PyTorchのDatasetクラスを継承し,PairwiseSamplerという形で実装しました.
class PairwiseSampler(Dataset): def __init__(self, X, u): self.X = X self.u = u def __len__(self): return len(self.u) def __getitem__(self, idx_i): x_i = self.X[idx_i] u_i = self.u[idx_i] indices = list(range(len(self.u))) indices.remove(idx_i) idx_j = np.random.choice(indices) x_j = self.X[idx_j] u_j = self.u[idx_j] return x_i, x_j, u_i, u_j実験結果
そして学習の結果テストデータからレコメンドされた順番がこちらです.
左上が最もランクが高く,右下が最もランクの低い画像です.(ランク順のイメージ)
img(1,1) > img(1,2) > ... > img(1,5) >
img(2,1) > img(2,2) > ... > img(2,5) >
img(2,1) > img(2,2) > ... > img(2,5)
完全に望んだランク通り(柴犬>チワワ>パグ)の結果になっています.
まとめ
ランク学習の概要説明と実験を行ってみました.
実際はListNetのほうが一般に学習がうまく行くのでしょうが,ここまで単純なタスクであればRankNetでも十分な精度でランク付けできることがわかりました.
クエリを今回は私の好みのみで実験しましたが,クエリ数が増加するとラベル付けとデータの設定が相当面倒になるので闇を感じています...

- 投稿日:2019-03-02T22:36:00+09:00
Pythonでソケットプログラミング
pythonでsocketプログラミングをしてみたので備忘録として残しておく.
ソケット(socket)について
ソケットは以下の2種類があり,単純にソケットと言うとネットワークソケットを示すことが多い.
- UNIXドメインソケット/IPCソケット
- ネットワークソケット/TCPソケット
UNIXドメインソケット/IPCソケット
IPCはInter-Process Communicationの略.
同じコンピュータ上で実行されている異なるプログラム(プロセス)間でデータを送受信するためのインターフェース.ネットワークソケット/TCPソケット
TCP/IPネットワークを通じて別のコンピュータ上で実行されるプログラム(プロセス)とデータを送受信するためのインターフェース.
socketライブラリ(python)
pythonでソケットプログラミングをする際,よく以下の関数を利用する.
- socket.socket([family[,type[,proto]]])
- socket.bind(address)
- socket.listen(backlog)
- socket.accept()
socket.socket([family[,type[,proto]]])
ソケットを生成するための関数.これがないと始まらない.アドレスファリミ,ソケットタイプ,プロトコル番号を指定する.
よくアドレスファミリとソケットタイプだけ指定して利用する場合が多い.アドレスファミリ
主に使うのは以下の2つ.
- AF_INET(デフォルト値)
- AF_INET6
インターネットを示しており,INETはIPv4,INET6はIPv6である.
ソケットタイプ
TCP/UDPとか.以下の2つをよく利用する
- SOCK_STREAM(TCP/デフォルト値)
- SOCK_DGRAM(UDP)
sock.bind(address)
ソケットをaddressにバインドする.例えば,socket.socketでAF_INETを利用している場合は(host,port)のタプルがaddressになる.
socket.listen(backlog)
ソケットをListenし,接続を行う.backlogは0以上にする必要があるが,通常は5である.
socket.accept()
接続を受け付ける.bindやlistenを既に済ましてあることが前提条件.返り値は(conn,address)であり,connはデータ送受信用の新しいソケットオブジェクト,addressはIPアドレス.
- 投稿日:2019-03-02T22:29:56+09:00
【Python】Pillow ↔ OpenCV 変換
グレースケールやαチャンネル付きの画像でも変換できるように関数化しました。
Pillow → OpenCV
import numpy as np import cv2 def pil2cv(image): ''' PIL型 -> OpenCV型 ''' new_image = np.array(image) if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) elif new_image.shape[2] == 4: # 透過 new_image = cv2.cvtColor(image, cv2.COLOR_RGBA2BGRA) return new_imagecv2を使わずに書くなら,
import numpy as np def pil2cv(image): ''' PIL型 -> OpenCV型 ''' new_image = np.array(image) if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = new_image[:, :, ::-1] elif new_image.shape[2] == 4: # 透過 new_image = new_image[:, :, [2, 1, 0, 3]] return new_imageOpenCV → Pillow
from PIL import Image import cv2 def cv2pil(image): ''' OpenCV型 -> PIL型 ''' new_image = image.copy() if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) elif new_image.shape[2] == 4: # 透過 new_image = cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA) new_image = Image.fromarray(new_image) return new_imagecv2を使わずに書くなら,
from PIL import Image def cv2pil(image): ''' OpenCV型 -> PIL型 ''' new_image = deepcopy(image) if new_image.ndim == 2: # モノクロ pass elif new_image.shape[2] == 3: # カラー new_image = new_image[:, :, ::-1] elif new_image.shape[2] == 4: # 透過 new_image = new_image[:, :, [2, 1, 0, 3]] new_image = Image.fromarray(new_image) return new_image
- 投稿日:2019-03-02T22:29:19+09:00
画像をOCRして仕分けるツールを作る
環境
- Windows 10
- Python 3.7.1 (Anaconda3-2018.12-Windows-x86_64)
- PyOCR
- Tesseract-OCR 4.0.0
導入は以下の記事を参考にした。
PythonでOCR画像整理ツール
個人的に拾い物画像をたくさん保存しているが、数が増えてくると整理が大変。
そこで、画像の中のテキストから、画像整理を支援するツールが作れないかと考えた。
例えば古のFirefoxのスクリーンショット
以下、同画像のOCR結果1 Firefox Start て Goosle ウェブ イッージ ニュニス グルーブ ディレクトリ にミヌゴゴゴゴ ⑤ ウェブ全体から検索 〇日本語のページを検索 天それなりに画像を特徴づける単語は取れている。
ただ、出力される文字列が若干間違っていてゴミ混じりなので、文章などの場合MeCabとかに食わせても全部ちゃんと認識するのか不安な状態
(そもそも自分は自然言語処理自体が専門分野ではないので、MeCab使いこなせそうにないが…)粗削りな方法だが、OCR結果の文章に登録単語が含まれるかどうかを特徴量にして、適当な分類器で画像を整理するツールを作ってみることにした。
つまり、アプローチ的には画像ファイルが相手といっても(OCR後の汚れた)テキストを対象に分類しているという方が正しいかもしれない。機械学習は院生時代に少しかじった程度のニワカなので、色々荒いところは勘弁してほしい。
あらかじめ言っておくと、まだこのツールの精度は低い。
今回は対象が画像なので、シンプルな方法をとる。
手持ちの画像の場合、大抵含まれる文字列は長くないので、含まれているその画像を特徴づける単語を持ってくれれば良い。まず改行区切りの単語ファイルを用意する(これは人力で入れる)
中身は国名、普通名詞、固有名詞などで画像の特徴になりそうなものを手動で適当に選んだものを入れている。
(本当はちゃんとしたコーパスから持ってくるべきかもしれないが、大規模になると色々複合的な問題起きそうで今回は諦めた)単語・文字ファイルは以下のような内容(約400単語)
東京 京都 大阪 ... コンピュータ プログラム データ ファイル フォルダ ... Windows Office Google ... パン うどん そば ソース タレ パスタ ...そして、画像が含んでいるテキストに単語ファイルの単語を含むかどうか表すベクトルを作る。
当然ながら単語ファイルの単語を含まない画像は分類できない
(コードを動かすと分類できるが結果は無意味)そして、既にフォルダ内にある整理済みの画像で学習し、直下を未知画像として仕分ける方針とした。フォルダ名をラベルとする。
フォルダ内の画像ファイル (約2600個) 学習・評価用 直下にある画像ファイル 未整理画像 →実用 具体的には以下のようにしたい。
例)
日本 推移 ラベル(=フォルダ名) 統計の画像 0 1 0 社会 世界情勢の画像 1 0 0 世界 Web関連の画像 0 0 1 ネット 以下、実際のフォルダの一部の抜粋。(画像を直接出すと著作権的にあれかもしれないので、フォルダ名だけ。)
1. 画像のOCR
OCRはそこそこ時間がかかるのでOCRするコードを分けている。
まず学習用・分類対象画像についてOCRして、データをPickleで保存しておく。
並列化がフォルダごとだったり、雑なつくりなのは容赦。gen.pyimport pickle from PIL import Image import sys import pyocr import pyocr.builders import glob import os import numpy as np from multiprocessing import Pool import multiprocessing as multi def ocrimage(file): tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) ocrtext = tool.image_to_string( Image.open(file), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) return ocrtext if __name__ == '__main__': njobs = 1 if multi.cpu_count() > 2: njobs = multi.cpu_count() - 1 ocrdata1 = [] for p in glob.glob('./**', recursive=False): #ディレクトリとファイル取得 if os.path.isdir(p): # ディレクトリの場合 filelist = [] for p2 in glob.glob('./'+p+'/*', recursive=False): #ディレクトリとファイル取得 if os.path.isfile(p2): # ファイルの場合 name, ext = os.path.splitext(p2) if ".jpg" == ext or ".png" == ext or ".gif" == ext: filelist.append(p2) # せめてフォルダー内の画像ごとでの並列化はやる process = Pool( njobs ) ocrtexts = process.map(ocrimage, filelist) process.close() for index, p2 in enumerate(filelist): ocrtxt = ocrtexts[index] label = str(p) filepath = p2 print( filepath ) print( ocrtxt ) ocrdata1.append( [label, filepath, ocrtxt] ) ocrdata2 = [] filelist = [] for p in glob.glob('./**', recursive=False): #直下のディレクトリとファイル取得 if os.path.isfile(p): # 直下のファイルの場合 name,ext = os.path.splitext(p) if ".jpg" == ext or ".png" == ext or ".gif" == ext: filelist.append(p) process = Pool( njobs ) ocrtexts = process.map(ocrimage, filelist) process.close() for index, p in enumerate(filelist): ocrtxt = ocrtexts[index] print( p ) print( ocrtxt ) ocrdata2.append( [p, ocrtxt] ) # テキストを保存する filename = 'ocrdata1.dat' pickle.dump(ocrdata1, open(filename, 'wb')) # テキストを保存する filename = 'ocrdata2.dat' pickle.dump(ocrdata2, open(filename, 'wb'))2. 画像の分類
次に、OCRしたテキストからRandomForestを使ってファイルを分類する。
本当は一筆書きの長いコードになってしまったのだが、目的別に分離しておく。
まず、必ず実行する部分のみ記載しておく。以下のコードで行うことは次の通り。
- 各画像をOCRしたテキストから登録単語が含まれるかをベクトルに変換
- 画像ごとの変換したベクトルを繋げてデータセットを作成。
seiri.pyimport pickle from PIL import Image import sys import pyocr import pyocr.builders import glob import os import shutil from matplotlib import pyplot as plt import numpy as np from sklearn.decomposition import PCA f = open('word.txt', "r", encoding='utf-8') wordlist = f.read() f.close() words = wordlist.split('\n') # 改行で区切る print(words) def text2train(txt): data = np.zeros(len(words)) for index, word in enumerate(words): if word in txt: # 単語が含まれる data[index] = 1 return data ocrdata1 = pickle.load(open('ocrdata1.dat', 'rb')) ocrdata2 = pickle.load(open('ocrdata2.dat', 'rb')) labels = [] train = [] for data in ocrdata1: txt = data[2] labels.append( data[0] ) train.append( text2train(txt) ) labels = np.array(labels) train = np.array(train)データの偏り・OCR失敗対策
OCR失敗したファイルと、分類に使えるファイルがほとんど入ってないフォルダは学習から除外(uncategorized)にした。
また、不均衡データの対策方法として学習時にデータに重みを与えると良いらしい 1 ので、それを採用した。# OCR失敗したものを省く for i,label in enumerate( labels ): if train[i].sum() == 0: labels[i] = ".\\uncategorized" # 散布図の色用 & 不均衡データ対策の計算のため ラベルを数値に変換 labels_unique = np.unique(labels) label2num = {} for i, label in enumerate(labels_unique): label2num[label] = i col = np.zeros(len(labels)) for i,label in enumerate(labels): col[i] = label2num[label] # データ数が10個未満のラベルを省く for i,p in enumerate(labels_unique): if (labels == p).sum() < 10: print("ignore {}".format(p)) labels[labels == p] = ".\\uncategorized" labels_unique = np.unique(labels) #再更新 # 不均衡データ対策 weights = dict() for i,p in enumerate(labels_unique): weights[p] = 1 / ( len(labels[labels == p]) / (len(labels)) ) # 大きさの正規化 for data in train: dist = np.vectorize(lambda x:x**2)(data).sum() if dist > 0: data /= np.sqrt(dist) # 大きさを正規化する targetdata = [] filepathdata = [] for data in ocrdata2: filepath = data[0] filepathdata.append( filepath ) txt = data[1] targetdata.append(text2train(txt))分類
RandomForestを使う。
clf_RF = RandomForestClassifier(n_estimators=1000, random_state=0, class_weight=weights)評価
次に、①学習で使った画像と同じデータセットをそのまま突っ込む場合と、②3分割の交差検証を試行した。
評価用コード
(ちなみに以下のコードだと1個とか2個で画像入れてるフォルダがある場合「データ分割できねえぞ」って怒られる)
model = clf_RF from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import make_scorer from sklearn.metrics import f1_score from sklearn.model_selection import cross_validate def precision_micro(y_true, y_pred): return precision_score(y_true, y_pred, average='micro') def recall_micro(y_true, y_pred): return recall_score(y_true, y_pred, average='micro') def f1_micro(y_true, y_pred): return f1_score(y_true, y_pred, average='micro') cv_results = cross_validate(model.fit(X_train, labels), X_train, labels, scoring = {'accuracy': 'accuracy', 'precision': make_scorer(precision_micro), 'f1': make_scorer(f1_micro), 'recall': make_scorer(recall_micro)}, cv=3) print(cv_results) from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X_train, labels, cv=3) print('Cross-Validation scores: {}'.format(scores)) print('Average score: {}'.format(np.mean(scores)))出力結果
{'fit_time': array([2.6834538 , 2.62779975, 2.7557683 ]), 'score_time': array([1.08580923, 1.04728389, 1.01936221]), 'test_accuracy': array([0.42834138, 0.45409836, 0.44147157]), 'train_accuracy': array([0.70943709, 0.69729286, 0.71649066]), 'test_precision': array([0.42834138, 0.45409836, 0.44147157]), 'train_precision': array([0.70943709, 0.69729286, 0.71649066]), 'test_f1': array([0.42834138, 0.45409836, 0.44147157]), 'train_f1': array([0.70943709, 0.69729286, 0.71649066]), 'test_recall': array([0.42834138, 0.45409836, 0.44147157]), 'train_recall': array([0.70943709, 0.69729286, 0.71649066])} Cross-Validation scores: [0.42834138 0.45409836 0.44147157] Average score: 0.4413037724750721ここでの結果は44%程度とかなり微妙な感じに。
OCR失敗対策の下処理を終えた後でもOCRに不向きそうな画像が結構あり、もう少しテキストの多いものに絞れば精度上がりそうではある。
実用
数値的な評価だけじゃなくて人間的な納得感の面でも見てみる。
ここで出しても怒られなさそうな無難なやつだけ。
なお、ここで試す画像は当然学習データに含まないものを選ぶ。スクショじゃないものも選びたかったが、ここで出して良さそうなのがなかなか見つからなかったので仕方なし。
Java
OCR結果あなたとJAVA, 今すぐダウンローOCRの時点でサイズの小さい文字が取れていない。
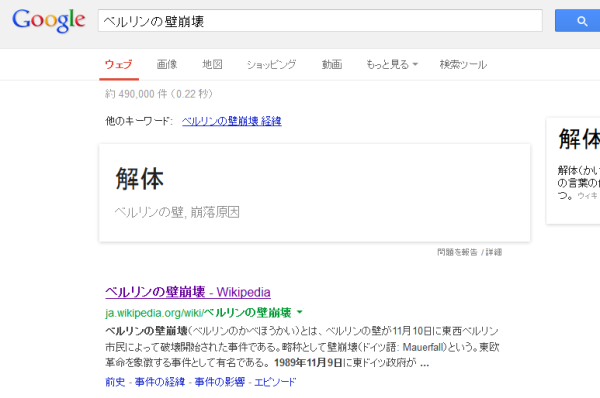
特徴になる単語がなかったのか「uncategorized」に分類されてしまった。Googleの検索結果
OCR結果Google ベルリンの生順 ウェブ 画俺 地図 ショッピング 動画 。 もっと見る< 検索ウール 00000條0のめ 他のキーワード。 ペルリンの明夫 解人 解 体 親はかし の言葉の うう ベルリンの革准還 ame ベルリンの副 - idpeda 評wikipedia_orgwikiベルリンの豆崩壌 ・ ベルリンの加間9りこのかべき2のいをは、べリンの宮が11有OB東大ペリン 市民によって破壊開欠された事件である。時称として壁剛壊ドイッ語- Mauerfal)という。 東欧 人する人として笛でる1969年人月9Hににイ>和が 。 人村人のエピソードこれはなぜか「漫画」に分類された。
学習データの「漫画」のフォルダには「絵柄は漫画だけど様々なジャンルのファイル」を入れていたので、そいつらに影響された可能性がある。昔のFirefoxのホーム画面
記事序盤に出した画像。
OCR結果1 Firefox Start て Goosle ウェブ イッージ ニュニス グルーブ ディレクトリ にミヌゴゴゴゴ ⑤ ウェブ全体から検索 〇日本語のページを検索 天これは「コンピュータ」に分類された。
結果としては悪くはない。
ただし、「コンピュータ・ソフト」や「ネット」というフォルダにもブラウザやWeb関連の単語を含んでいる画像を入れていた。そのため、そっちに分類された方が良かったかもしれない。
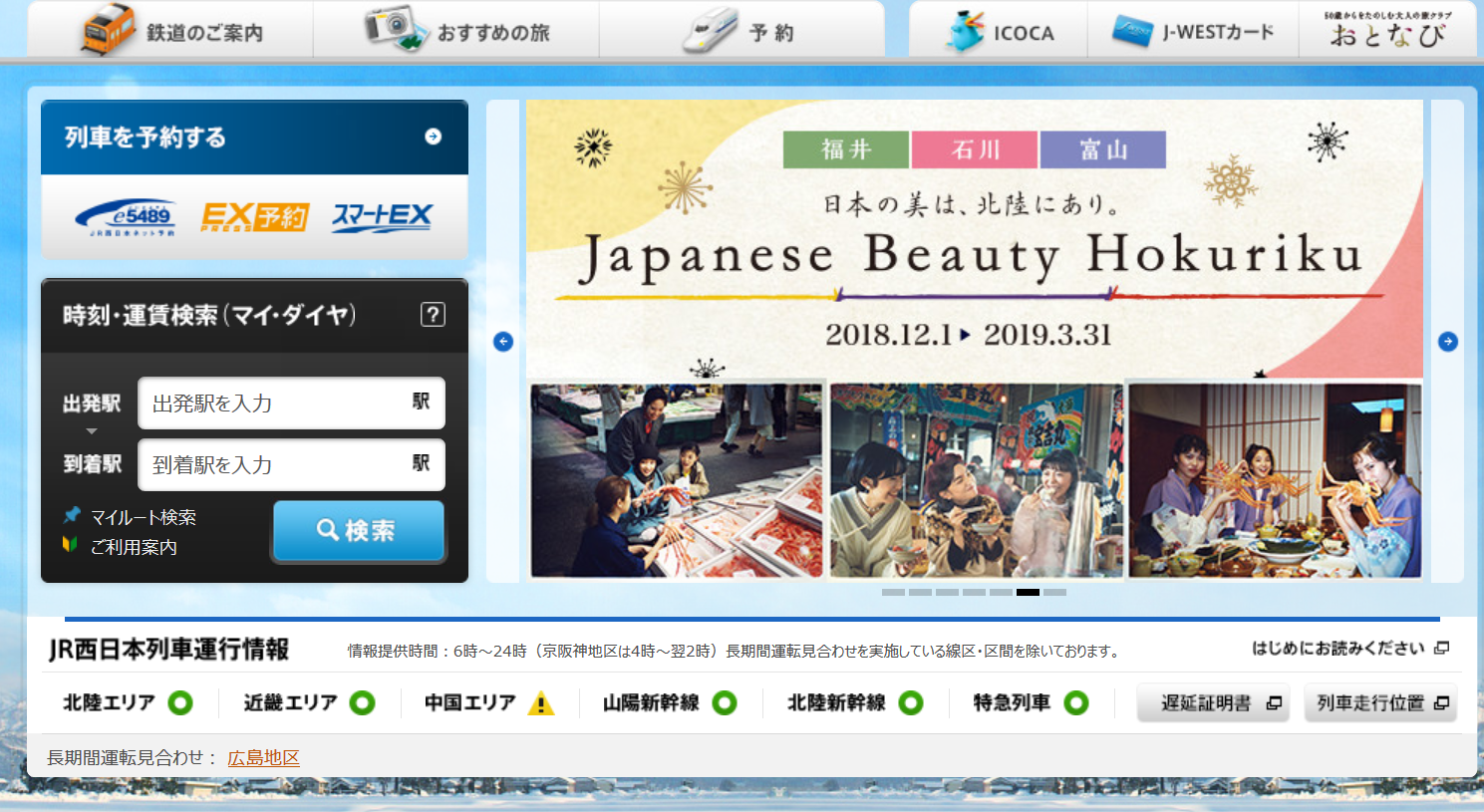
JRおでかけネット(JR西日本のサイト)のスクショ
OCR結果と 鉄道ご案内 1 9 ぉすすゅの放 ーグ oc 編)wesみ-ト おとなび @ っと 層に 「 2を了する 上本還可 。 ンーsiss ズー/丘 日本の身は、北村にあり。 3 Japanese Beauty Hokuriku 購 ー メーーーーーーーーーーーーーーとーーーーーーーーーーーーーデ議 記・ (マイダイヤ) 較 プー拉 RE 間旨 o 2018.12.1> 2019.3.31 胃 o ー 補に ま ー 本 "| czcmREH5n そ細 遇計 中 | 到着 7 M 】 にし 2 ee間 。 の co 電 Nグ3代要 衣 2 ご利用案内 で て 1 人 こまアーミー こす 5 旨遇引 Em SS 還/ や:全WW | 1 革eeデデー、 JR西日本列車運行情報 情報提供時間 : 6時ご24時 (京阪神地区は4時ご伴2時) 長期間運転見合わせを実施している角区・区間を除いております。 はじめにお読みください 避 北陸エリアァ 〇 近畿エリア ① 中国エリア 』m 山陽新幹線 〇 北陸新幹線 〇 特急列車 〇 遅延証明書 品 列車走行位置品 剛 長期間軍転見合わせ : 広島地区 8 mo 人ーーイトー本これは「鉄道」に分類された。
これは真っ当な結果。分類はテキストベースなので、直にテキストを放り込んでどうなるかを見ることもできる。
model.predict([text2train("駅 JR 列車 山陽線")])出力結果array(['.\\鉄道'], dtype='<U16')学習データの質が良くないので単語1つの違いで全然結果が違うこともある。
model.predict([text2train("Windows Linux Mac")])出力結果array(['.\\コンピュータ'], dtype='<U16')Linuxを入れなかったらデザインになった。
model.predict([text2train("Windows Mac")])出力結果array(['.\\デザイン'], dtype='<U16')最後にフォルダ分け用コード片
for index, result_label in enumerate(result): if os.path.isfile( filepathdata[index] ): print( result_label, filepathdata[index] ) os.makedirs("./autoclf/"+result_label, exist_ok=True) print( os.path.basename(filepathdata[index]) ) shutil.move(os.path.basename(filepathdata[index]), "./autoclf/"+result_label)まだまだ微妙だなあと思う点
- 画像内にジャンルに無関係な単語が結構ある(データの問題)
画像が特定のフォルダに偏る
- 不均衡なデータなのが原因?(学習ベクトルの重み付けで対策はしたが、まだ不十分)
- OCRに失敗した場合に滅茶苦茶なテキストが出力されるので、そこに登録単語が含まれていた場合引きずられる
- 1文字の漢字だけで入れてる単語とかが引っかかりやすい
今回の手法だと、分類する際にデータに同じ単語が必ず含まれている必要がある
- 単語の登録数拡大と、類義語、対義語が集約できれば精度が上がると思うのだが…
そもそもフォルダ分けが適当
- 複数の属性を持つ画像がある
- 例えば昔のホビーコンピュータの画像は「ゲーム」に分類すべきか「コンピュータ」に分類すべきか
- Google翻訳の面白い翻訳の画像は「ネット」に分類すべきか「言語」に分類すべきか
- ゲームとアニメのネタがコラボで同一画像の中に混じっている場合は?
- (人間でも悩むのでこれはどうしようもない)
フォルダ名が元々分類を想定していない
- 2018って名前のフォルダに画像を整理せず突っ込んでたりとかするため画像ジャンルとしての意味をなさない
- そもそも、その時その時の感性でフォルダに入れているのでいい加減
漫画の吹き出しに多い縦書きが読めない
- (TesseractOCRのインストール時にjpn-vertを入れようとしたけどなぜか404になるので諦めた)
- script/Japanese_vertが手書き用のモデルっぽい?が、OCR結果があまり良くなかった。
ロゴや手書きの文字、ポップ体など文章で一般的ではない書体はTesseract OCRではほぼ読み取れない
そもそも文字の入ってない画像が結構な割合ある
- 単語ベースで分類したので、ほぼ文字の入ってない未整理画像が大量に残ってしまった…
実用重視で作ったため評価がガバガバ→なんとかしたい
- 再現率は??F値は?
- カジュアルにSVM使いたかっただけなので許してくれ…
まとめ
OCR結果に基づく画像整理支援ツールを作った。
全く分類できてないわけではないのだが、体感でも精度はイマイチ。改良の余地はかなりありそう。
作るのより評価の方が大変だった。研究だったらもう少し詰めないといけない感がある(文章が画像の重要な要素となってる画像群のみで試すとか)けど、個人用ツールなのでまた手作業で色々検証するのはしんどいかな。
何か改良案あれば教えてほしい。
研究とかではないので続くかは…未定。今後やりたいこと
手動で単語リスト作るのは微妙なので、単語リストを自動作成したい。また、ちゃんとしたコーパスから抽出したものを使いたい
- 汎用のコーパスを使うと、今の方法だと雑過ぎて一般的すぎる単語が邪魔してきそうな感もあるが…(TF-IDFが関係する話か?)
学習データに画像だけではなくジャンルごとに分けた文章ファイルも追加するとか
- 画像だけで学習させるのはだいぶ横着
- 別途、文章ファイルの頻出単語みたいなもの抽出した方がデータ量も確保できそうだし、ちゃんと学習しそう
- ジャンルごとに登録単語を入れておいてルールベース的な手法の補完みたいな手法?(単語登録がしんどそうだけど)。
(微妙な点にも書いたが)word2vecを使えば類義語対義語が近くに出てくるはずなので、類似度を使うアプローチというのもありかもしれない
- ある単語に類似度が高い単語を含んでたら、その単語含んでることにするとか
本当は画像って複数の属性を持ちうるものなので、フォルダという1つの属性に縛るのは良くない気もしている
- 階層的クラスタリングなるものが中間処理に使えないか気になっている
前は画像の整理にFenrirFSを使っていたが、データベースから中身のタグを引っ張ってきたりすればもっと良くなりそう?
画像を直接使ってChainerとかTensorFlowとかで分類するアプローチと組み合わせるのも面白そう
- ただ、画像が含んでいる物体ごとの詳細なラベル付けとかはしんどそう
- 深層学習フレームワークの導入なんも分からん…
比較的シンプルな方法で言えば、平均色とかRGBそれぞれについて空間周波数とかの特徴量取ってきて分類に使うことで、画像の質感的なものを頼りにできるかも
- →写真(風景、食べ物など)、ゲーム画面、アニメ、マンガ、スクショぐらいの区別はつきそう?
Google ColaboratoryのOCRの方が精度高いみたいなのでそっち使いたいが大量の画像処理しても良いのか謎
その他
最初はかな、アルファベット、JIS第一水準漢字を1文字ずつ単語帳に含んでいたのだが、無関係な文字にひきずられて過学習してしまったのでやめた。
- これをやることで、単語が未登録だった場合でも、"JAXA"という文字列がある画像なら、「A,J,Xを含んでいる→宇宙関連」という形で学習に影響してくれれば全く分類されないよりはマシになる…と考えていた。
- また、OCRにゴミが混じった場合でも何かしら反映してくれるため対策になるはず。
- 実際、分類精度は高まったのだが、無関係な文字列に機敏に影響される分類器になってしまった(OCR失敗時のゴミ文字を拾うため)。
最初はSVM使ってグリッドサーチとかしてたがRandomForestに書き換えた
- (とある人にその方が良いとアドバイス受けたのと、BoW的な特徴量の場合その方が向いているという記事2 があったため)
最初は主成分分析かけてたけどそんなに意味なかったのでやめた
参考



- 投稿日:2019-03-02T22:19:40+09:00
Pythonで塩基配列を相補鎖に変換[3パターン]
PythonでDNA、RNA配列を相補鎖に変換
状況によって使い分けれる3パターンのまとめ
best_choice.py# 一番お手軽、biopythonを使う # DNAでもRNAでも使える from Bio.Seq import Seq seq='ATGCatgc--Nn' seq_c=str(Seq(seq).reverse_complement()) print(seq_c) # nN--gcatGCATuse_string_module.py# あえてbiopythonを使わない import string # DNA seq='ATGCatgc--Nn' seq_c=seq.translate(str.maketrans('ATGCatgc', 'TACGtagc'))[::-1] # python3 print(seq_c) # nN--gcatGCAT # RNAの場合 seq_c=seq.translate(str.maketrans('AUGCaugc', 'UACGuagc'))[::-1] # python3DIY.py# どうしても自分でやりたい時 # DNA def complement_dna(string): comp='' for char in string: if char == 'A': comp += 'T' elif char == 'T': comp += 'A' elif char == 'G': comp += 'C' elif char == 'C': comp += 'G' elif char == 'a': comp += 't' elif char == 't': comp += 'a' elif char == 'g': comp += 'c' elif char == 'c': comp += 'g' else: comp += char return comp[::-1] seq='ATGCatgc--Nn' seq_c=complement_dna(seq) print(seq_c) # nN--gcatGCAT # RNAの場合 def complement_rna(string): comp='' for char in string: if char == 'A': comp += 'U' elif char == 'U': comp += 'A' elif char == 'G': comp += 'C' elif char == 'C': comp += 'G' elif char == 'a': comp += 'u' elif char == 'u': comp += 'a' elif char == 'g': comp += 'c' elif char == 'c': comp += 'g' else: comp += char return comp[::-1]環境
Python 3.7.1
biopython 1.72
- 投稿日:2019-03-02T22:16:33+09:00
Django CharFieldとTextFieldの使い分け
Djangoでモデルを作っている際に
「CharFieldとTextFieldを分ける必要ないんじゃない?」
と思った方もいると思います。しかし、結論から申し上げますと使い分けるべきです。
その理由としては以下のような理由があげられます。以下ソースより
’’’
端的に申しますとパフォーマンスの問題です。
TextFieldはCharFieldに比べるとデータベースのパフォーマンスが悪いのです。
具体的には、保存にかかるコスト、読み出しに関するコストが若干高いのです。
小規模なデータベースなら大した差にはならないのですが、これが大規模なものになるとかなりの差になります。
なのでもともと入力する文字数がわかっているなら、CharFieldのほうが良いのです。
普段から少し気にしておくことで、いざというときに困らなくなるので気にするようにしましょう。
’’’参照先
https://e-tec-memo.herokuapp.com/article/71/
https://stackoverflow.com/questions/7354588/django-charfield-vs-textfield
- 投稿日:2019-03-02T21:58:11+09:00
selenium自動処理用の基底クラスを作成してみました
selenium自動処理用の基底クラス
概要
seleniumを使って自動テストを作成する際以下のようなコードをたくさん書くことになるかと思います。
self.driver.find_element_by_xpath(webElement).click()操作内容の数だけ記述すると結構な量になったり修正が必要になったら全部の箇所を修正することになりかなり面倒だったので基底クラスを作ってそれを継承させたクラスで制御しました。
今回はChromeとFireFoxで確認は取っています。
言語としてはPythonで要素の指定にはXpathを使っています。画面が動的に変わる場合はXpathの方が指定が楽だからXpathを使っています。
必要なもの
- python 3.7.2
- selenium
- 対応ブラウザのwebdriver
エクセルで作った入力データを登録していくツールを作成した都合上
* numpy
* pandas
* openpyxl
* xlrdも使用していましたが今回の範囲では不要です。
公開場所
githubで公開してみました。
調べながら作ったのでまだまだ甘い部分もあるかと・・・実装説明
インスタンス作成処理
処理の説明
* driverはクラスのインスタンス作成の際引数で渡すことで呼び出し元で制御します。
* waitは画面の要素が待つ時間を設定します。time.sleepで待機させるコードをよく見かけますが、こちらの方法なら指定したものが表示したりクリックできるようになり次第即座に操作を行えるようになります。
* logは独自に作ったlogようのクラスです。loggingを使って作っています。
* screenShotBaseNameはスクリーンショットの接頭辞に使っています。driver=None wait=None log=None # スクリーンショットを格納するディレクトリ screenShotBaseName=None # 初期化処理 def __init__(self,driver,log,screenShotBaseName='screenShot'): self.driver=driver # 画面描画の待ち時間 self.wait=WebDriverWait(self.driver,20) driver.implicitly_wait(30) self.log=log self.screenShotBaseName=screenShotBaseName+'/'+datetime.now().strftime("%Y%m%d%H%M%S")+'/' os.makedirs(self.screenShotBaseName,exist_ok=True)画面操作処理 クリック
画面のクリック処理です。
継承先のクラスでこの処理を呼び出すことで要素がクリックできるまで待ってクリックするようになり、失敗した場合はスクリーンショットを取るようにしています。
指定ミスなどで要素がない場合は20秒ほどでエラーになります。# 画面要素をクリックする 要素が表示されるまで20秒待つ さらに待ち時間が必要な場合は指定を行う def webElementClickWaitDisplay(self,webElement,waitTime=0): try: time.sleep(waitTime) self.wait.until(expected_conditions.element_to_be_clickable((By.XPATH,webElement))) self.driver.find_element_by_xpath(webElement).click() except RuntimeError as err: self.log.error('画面要素押下失敗:'+webElement) self.log.error('例外発生 {}'.format(err)) self.getScreenShot() raise except: self.outputException(webElement) raise画面操作処理 クリック マウス移動
画面によってはクリック後マウスを移動させないとメニューが出ないなどある場合は
以下のようにクリック後マウスを移動させます。# 画面要素をクリックしてマウスを移動させる クリックした後のメニューの操作を行いたいときに使用する # 待ち時間が必要な場合は指定を行う # 画面の要素がクリックできるまでまつ def webElementClickAndMoveWaitDisplay(self,webElement,waitTime=0): try: time.sleep(waitTime) self.wait.until(expected_conditions.element_to_be_clickable((By.XPATH,webElement))) target = self.driver.find_element_by_xpath(webElement) actions = ActionChains(self.driver) actions.click(target).move_by_offset(10,10).perform() except RuntimeError as err: self.log.error('画面要素押下失敗:'+webElement) self.log.error('例外発生 {0}'.format(err)) self.getScreenShot() raise except: self.outputException(webElement) raise画面操作処理 テキスト送信
テキスト送信処理
クリックできるまで待ってから送信しています。# テキストを送る 要素が表示されるまで20秒待つ さらに待ち時間が必要な場合は指定を行う def sendTextWaitDisplay(self,webElement,sendTexts,waitTime=0): try: time.sleep(waitTime) self.wait.until(expected_conditions.element_to_be_clickable((By.XPATH,webElement))) self.driver.find_element_by_xpath(webElement).clear() self.driver.find_element_by_xpath(webElement).send_keys(sendTexts) except RuntimeError as err: self.log.error('テキスト送信失敗:'+webElement) self.log.error('例外発生 {}'.format(err)) self.getScreenShot() raise except: self.outputException(webElement) raise画面操作処理 スクロール
画面でスクロールしたい時用
FireFoxの場合画面の範囲外の要素を操作しようとするとエラーになることがあるので
こちらの処理でスクロールして実施しました。
またスクリーンショットを取る時に微妙に動かしたいときのためスクロール処理も共通化しました。
正の値で上に負の値で下に移動します。FireFoxのみ確認Chromeではまだ未検証
# 指定した位置までスクロールを行う def moveScroll(self,webElement): # スクロール確認の処理 指定した位置までスクロールを行う try: self.wait.until(expected_conditions.visibility_of_element_located((By.XPATH,webElement))) inputLabel=self.driver.find_element_by_xpath(webElement) self.driver.execute_script("arguments[0].scrollIntoView();", inputLabel) except RuntimeError as err: self.log.error('画面スクロール失敗:'+webElement) self.log.error('例外発生 {0}'.format(err)) self.getScreenShot() raise except: self.outputException(webElement) raise # 画面をスクロールさせる def adjustScroll(self,offset): try: self.driver.execute_script("window.scrollTo(0, window.pageYOffset +"+str(offset)+")" ) except RuntimeError as err: self.log.error('画面スクロール失敗:'+str(offset)) self.log.error('例外発生 {0}'.format(err)) self.getScreenShot() raise except: self.log.error(traceback.format_exc()) self.getScreenShot() raise実際例
実装例
以下のように
SeleniumOperationBaseを継承してsuper()で呼び出すことができます。class Login(SeleniumOperationBase): def __init__(self,driver,log,screenShotBaseName='screenShotName'): super().__init__(driver,log,screenShotBaseName) def loginMethod(self,userId,password): self.driver.get(TARGET_URL) useridForm=self.driver.find_element_by_xpath(LOGIN_USER_ID) useridForm.clear() super().sendTextWaitDisplay(LOGIN_USER_ID,userId) passwordForm=self.driver.find_element_by_xpath(LOGIN_PASSWORD) passwordForm.clear() super().sendTextWaitDisplay(LOGIN_PASSWORD,userId) super().webElementClickWaitDisplay(LGOIN_LOGINBUTTON)
- 投稿日:2019-03-02T21:26:22+09:00
Django on_deleteの役割
- 投稿日:2019-03-02T21:09:19+09:00
Python: ラプラス変換(数式通り実装してみた)
はじめに
目標
今回は以下のラプラス変換の数式を眺めながら実装してみた.
${\displaystyle F(s)=\int _{0}^{\infty }f(t)\mathrm {e} ^{-st}\mathrm {d} t}$
また, タイトルの通りpythonコードと数式を対応させながら実装していく.
※注意: 比較できる実装を見つけられず, 正しく実装出来たかの検証はしていない準備
まず最初のおまじない.これで, πやeなどを使ったり, 求めた値をグラフ化できる.
%matplotlib inline import numpy as np import matplotlib.pyplot as plt関数fの定義
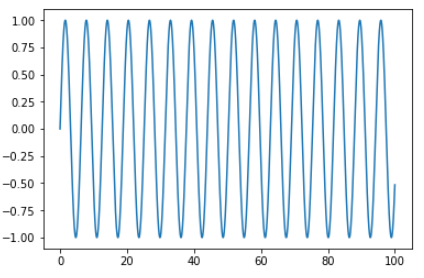
今回は以下の部分はsin波を用いる事にします.
${f(t)}$
ここは以下のように書くとfがsin関数になります.
f = np.sintを与えるとちゃんとsin(t)の値が出力される.
>>> t = np.pi / 2 >>> f(t) 1.0上限とdtの設定
本来はそのまま以下の数式のように0から∞まで扱いたいのですが・・・
${\displaystyle \int _{0}^{\infty }f(t)\mathrm {e} ^{-st}\mathrm {d} t}$
さすがに無限は扱えないので, 上限とdtの値を設定します.(妥協・・・)
今回は上限を100, dt=0.001とします. そして以下で0から100まで0.001間隔で変化する数列Tが作れます.dt = 0.001 max_t = 100 T = np.arange(int(max_t / dt)) * dtこの数列を関数fに与えてsin波を作ってみると以下のような感じ.
plt.plot(T, f(T)) plt.show()結果 ちゃんとできてそうですね.
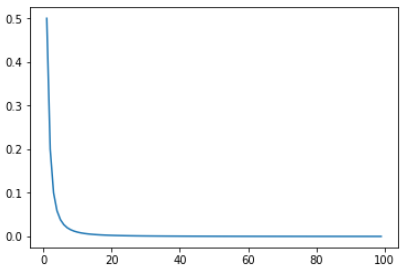
関数Fの定義
ここまで出来たらF(s)はlambda式を使ってさくっと書けます.
(数式まんまなのでわかりやすい・・・かな?)F = lambda s: np.sum(f(T) * np.e**(-s * T) * dt)そして以下の式が完成!ρ(・ω・、)
${\displaystyle F(s)=\int _{0}^{\infty }f(t)\mathrm {e} ^{-st}\mathrm {d} t}$
いぁ・・・∞じゃないからこうかな(´・ω・`)
${\displaystyle F(s)=\int _{0}^{100}f(t)\mathrm {e} ^{-st}\mathrm {d} t}$
最後にsが1~100まで変化した時, F(s)がどのように変化するか見ておきます.
map使ってサクッと作った方が良いのですが・・・F(s)を順番に求めてるのが分かりやすいのであえてfor文で.
ついでにmap使った書き方はコメントで載せておく.S = range(1, 100) N = [] for s in S: N.append(F(s)) plt.plot(S, N) # plt.plot(S, list(map(F, S))) plt.show()
まとめ
今回はラプラス変換の数式を眺めながら実装してみた.
未検証で正しく実装出来たかは分からないため, 今後検証は行いたい.またwikiをみると
ラプラス変換は, 関数 f (t) にいったん e−σtθ(t) を乗じてからフーリエ変換する操作であると考えることができる${\displaystyle F(s):=F(\sigma ,\omega )=\int _{-\infty }^{\infty }\theta (t)f(t)\mathrm {e} ^{-\sigma t}\mathrm {e} ^{-i\omega t}\,\mathrm {d} t{\overset {s=\sigma +i\omega }{=!=}}\int _{0}^{\infty }f(t)\mathrm {e} ^{-st}\,\mathrm {d} t}$
っとあるので, 今後は以前実装したフーリエ変換にかけてみたいρ(・ω・、)
(同時に検証もできるかな?)
- 投稿日:2019-03-02T21:06:18+09:00
PyCharmでDjangoチュートリアル
はじめに
以下のインストールが完了している状態から始めます。
- Python 3.7
- Pycharmの有償版(プロフェッショナル版)
※無償版でもDjangoを扱えるそうですが、そちらには触れません。
- Django 2.1.7
※Pycharmが有償版だからか、自分でインストールした覚えはないけど入ってました。
下記URLのチュートリアルを実施します。
https://docs.djangoproject.com/ja/2.1/intro/tutorial01/プロジェクトを作成する
チュートリアルページの、プロジェクトを作成するに該当する操作をPycharmで実施します。
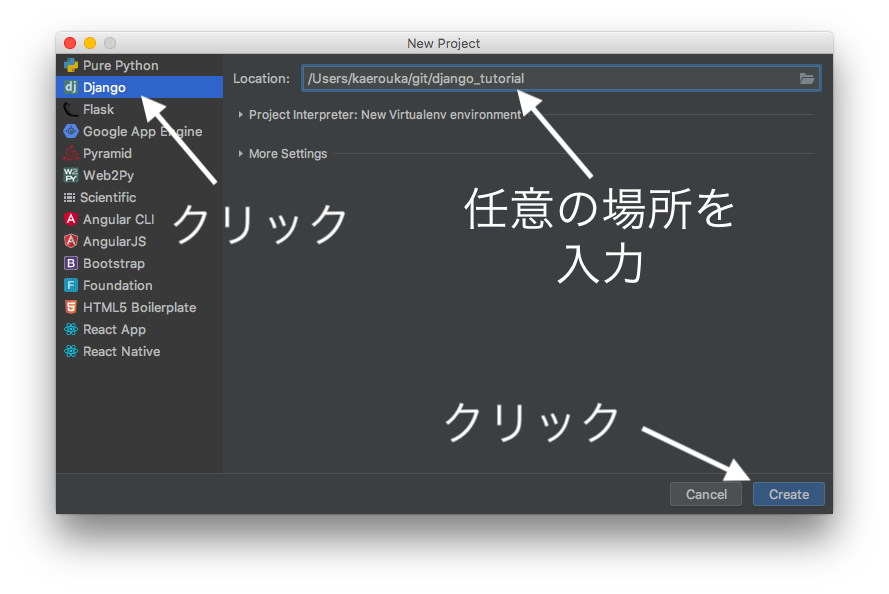
- Create New Project をクリック

プロジェクトの種類などを選択してCreateボタンをクリック
プロジェクトの種類:Django
ロケーション:任意の場所
空っぽじゃないけど、ここでいいの?と聞かれます。
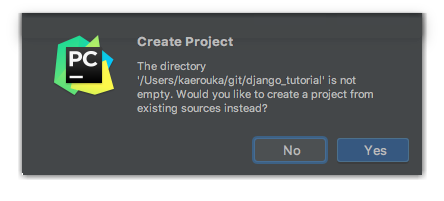
予めgitの関係のファイル(README.md, .git)があるのでこんなウィンドウが出てますが、そのままYesでOK。
開発用サーバー
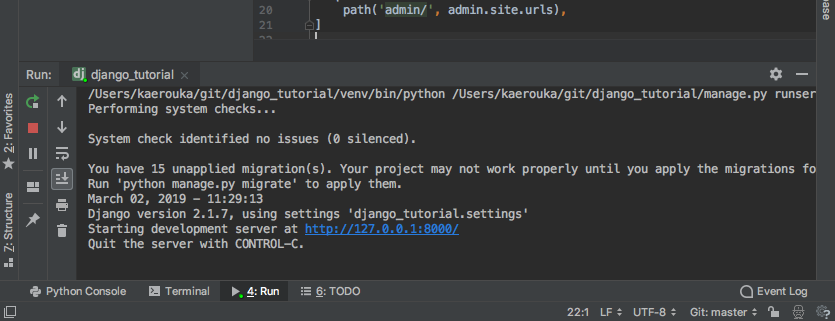
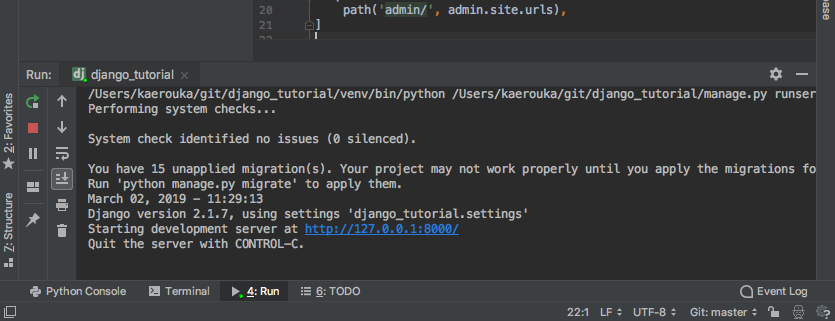
チュートリアルページの、開発用サーバーに該当する操作をPycharmで実施します。
- 画面上部の、Run -> Run 'django_tutorial' をクリック
※ Ctrl + R がショートカットになっています。
- 画面下部に起動した開発用サーバーのログが出てきます。
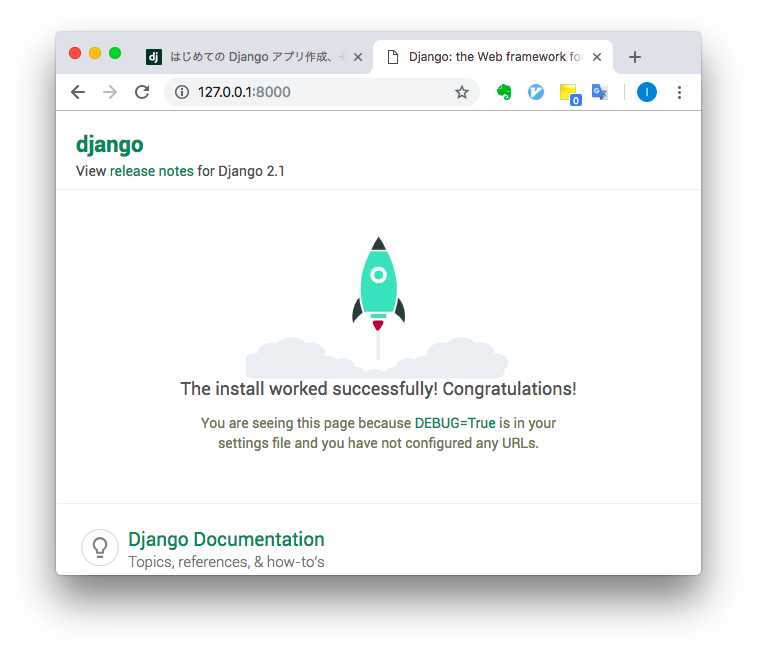
- 先程のログに出てきた、 http://127.0.0.1:8000/ のリンクをクリックすると、起動確認ができます。
Polls アプリケーションをつくる
- 画面上部の、Tools -> Run manage.py Taskをクリック。
※Option + R がショートカットになっています。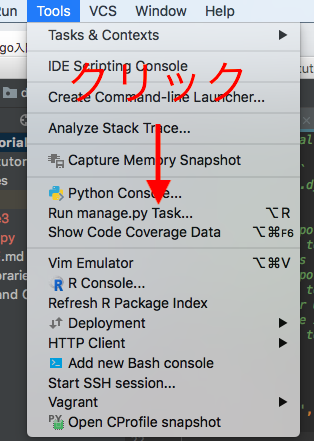
- startapp pollsと入力しますが、入力途中でコマンドの補完が出てくるのが嬉しいところです。

感想
サーバの立ち上げが楽でいいですね。
manage.pyのコマンドなんていちいち覚えてないので、補完が使えるのも良かった。
ただ、ここまでならわざわざIDEを使うほどでもないので、今後の実装やテスト、Gitとの親和性などに期待します。



- 投稿日:2019-03-02T20:02:56+09:00
Anaconda環境にpowerlineをインストール
pythonのパスを確認
$ which python /anaconda3/bin/pythonpipを使ってpowerlineをインストール
pip install powerline-status成功したら
Successfully installed powerline-status-2.7みたいなログが出るpowerlineのインストール先を調べる
自分の環境ではここ
/anaconda3/lib/python3.7/site-packages.bash_profileに追加
最後のパスは各自の環境にあわせて
# powerline powerline-daemon -q POWERLINE_BASH_CONTINUATION=1 POWERLINE_BASH_SELECT=1 . /anaconda3/lib/python3.7/site-packages/powerline/bindings/bash/powerline.sh
source ~/.bash_profileでプロファイルリロード
これでターミナルやハイパーの表示が変わるはずpowerline用のフォントをインストール
上のコマンドは以前やっていたら不要
brew tap homebrew/cask-fonts brew cask install font-source-code-pro font-source-code-pro-for-powerlineフォントインストールできたらターミナルやハイパーのフォント設定を
font-source-code-pro-for-powerlineに変更(e) base という表示を消す
Anaconda環境だとpowerlineの表示に環境変数
CONDA_DEFAULT_ENV=baseが表示される
こんな感じ
user > (e) base > ~ >
これを消すためにはpowerlineパッケージインストール先にある
powerline/segments/common/env.pyの下記の関数にアナコンダ用のロジックがある
CONDA_DEFAULT_ENVがあればpowerlineに表示するようになっているが邪魔なのでこれを消す
関数の第二引数の部分をignore_code=TrueとすればOK@requires_segment_info def virtualenv(pl, segment_info, ignore_venv=False, ignore_conda=False): '''Return the name of the current Python or conda virtualenv. :param bool ignore_venv: Whether to ignore virtual environments. Default is False. :param bool ignore_conda: Whether to ignore conda environments. Default is False. ''' return ( (not ignore_venv and os.path.basename(segment_info['environ'].get('VIRTUAL_ENV', ''))) or (not ignore_conda and segment_info['environ'].get('CONDA_DEFAULT_ENV', '')) or None)本来であれば
config_files配下の設定ファイルにあるvirtualenvの表示部分を優先度を変えるとか修正するべきところだけど、どちらかというとAnaconda固有の処理をしてほしくないから上記ロジックを変更
- 投稿日:2019-03-02T19:50:34+09:00
[百聞は]大数の弱法則,中心極限定理empiricalにやってみた(クソコード有り)[一見に如かず]
1. 雑要約
本記事では大数の弱法則,中心極限定理の様子をpythonで記述し実感することを目的としました.例のごとく稲垣先生の「数理統計学」を参考にしています.
2. 大数の弱法則
2-1.大数の弱法則とは
大数の弱法則とは,$X_1,\cdot,X_n$が独立で同一分布に従い,その平均と分散がが存在し,それぞれ$\mu$,$\sigma$であるとき,任意の正数$\epsilon$に対して$$\lim_{n \to \infty}P[|\bar{X_n}-\mu|\ge\epsilon]=0$$となる法則のことです.日本語で書くと,標本平均と母平均の差($=|\bar{X_n}-\mu|$)がある正数$\epsilon$より大きくなる確率は,サンプル数nが無限大に近くにつれて0になるというものです.ここでポイントとなるのは,分布の具体的な形を決めていない(=母平均,母分散のみ決めいている)という点です.
~証明~
チェビシェフの不等式から,$$P[|\bar{X_n}-\mu|\ge\epsilon]\le\frac{\sigma^2}{\epsilon^2 n}$$であり,\begin{eqnarray} \lim_{n \to \infty}P[|\bar{X_n}-\mu|\ge\epsilon]&\le&\lim_{n\to \infty}\frac{\sigma^2}{\epsilon^2 n}\\ =0 \end{eqnarray}よって$\lim_{n \to \infty}P[|\bar{X_n}-\mu|\ge\epsilon]\le0$となるが,確率は非負なので等号が成立します.(証明終了)
(稲垣「数理統計学」p.101を参考に)2-2. 実際に計算させてみた
とはいっても本当かなぁ?となったので,実際に計算してみることにしました.正規分布$N(0,10^2)$,$N(0,20^2)$,二項分布$Bin(1000,0.2)$($\mu=1000*0.2=200$),指数分布$Exp(6)$($\mu=1/6$)について計算してみました.
こう見てみるとやはりサンプル数nを増やすにつれて,標本平均が母平均にどんどん近づいていく様子が読み取れます(
from Bin(1000,0.2)とfrom Exp(6)のあたりがぐしゃぐしゃですがそこはご愛嬌で).3. 中心極限定理
3-1. 中心極限定理とは
中心極限定理とは,平均,分散がそれぞれ$\mu$,$\sigma^2$である分布からの無作為標本の標本平均$\bar{X_n}$を標準化した構成された確率変数$Z_n$の分布は標準正規分布($N(0,1)$)に分布収束する.つまり,$$\lim_{n\to\infty}P(Z_n\le z)=\Phi(z)=\int_{-\infty}^z\frac{1}{\sqrt{2\pi}}e^{-\frac{u^2}{2}}du$$が成り立つという定理のことです.ここで$\Phi(z)$は$Z_n$の分布関数を表しています.これも日本語で書くと,Z変換(標準化した)した確率変数は標本数が増えると,標準正規分布に従う確率変数の振る舞いに近づくということを表しています.分布収束という確率論の言葉が出ましたが,深くは掘り下げません.この定理のポイントは先ほどの大数の弱法則と同様,Xの具体的な分布の形状にとらわれないという点です.大数の弱法則と中心極限定理めちゃくちゃ大事です.酸素くらい大事.
~証明~
証明はめちゃ長くて書くのが面倒だったので,稲垣「数理統計学」p.102-104を見てください.3次の絶対モーメントの存在を仮定しているので割と簡潔で分かりやすい証明となっています.3-2. 実際にやってみた
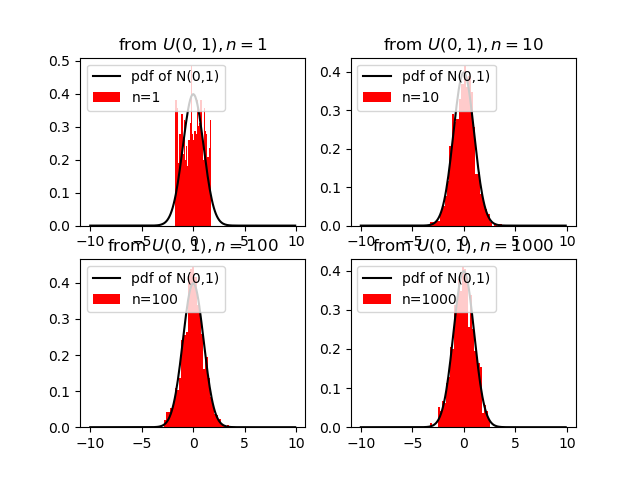
とはいえ,やっぱり本当かなぁ?と納得いかないので実際に可視化してみました.一様分布U(0,1)から標本数nを1,10,100,1000とした場合の度数分布をシミュレーションしています.黒い曲線は標準正規分布の確率密度関数を表しています.
標本数を増やしていくにつれて,標準正規分布N(0,1)の形状に近づいていっていることが体感できました.他の分布(e.g.,二項分布,ポアソン分布,etc.)からの標本でも同様の振る舞いを観測できます.サンプルコードの分布の部分と平均,標準偏差の部分を書き換えればシミュレートできます.4. サンプルコード
2秒で思いついたコード&無駄削減してない(動作確認だけしました)なので汚いコードですが,もしよかったら使ってください.
# -*- coding: utf8 -*- import numpy as np import random import matplotlib.pyplot as plt import scipy.stats as sp ## 大数の法則 ### 1-1. 正規分布 N(0,100) rv_list = []; mean_list = [] for i in range(3000): a = random.gauss(mu=0, sigma=100) rv_list.append(a) mean_list.append(np.mean(rv_list)) plt.subplot(2,2,1) plt.plot(np.arange(len(mean_list)),mean_list) plt.title("from $N(0,10^2)$") ### 1-2. 正規分布 N(0, 20^2) numpy.random.normal()を使って rv_list = []; mean_list = [] for i in range(3000): a = np.random.normal(0, 20, 1) rv_list.append(a) mean_list.append(np.mean(rv_list)) plt.subplot(2,2,2) plt.plot(np.arange(len(mean_list)),mean_list,color="c") plt.title("from $N(0,20^2)$") ### 2. 二項分布 Bin(1000,0.2) mu=1000*0.2=200 rv_list = []; mean_list = [] for i in range(3000): a = np.random.binomial(1000, 0.2, 1) rv_list.append(a) mean_list.append(np.mean(rv_list)) plt.subplot(2,2,3) plt.plot(np.arange(len(mean_list)),mean_list,color="g") plt.title("from $Bin(1000,0.2)$") ### 3. 指数分布 Exp(6), mu=1/6(だいたい0.167) rv_list = []; mean_list = [] for i in range(3000): a = np.random.exponential(1/6, size=1) rv_list.append(a) mean_list.append(np.mean(rv_list)) plt.subplot(2,2,4) plt.plot(np.arange(len(mean_list)),mean_list,color="y") plt.title("from $Exp(6)$") #plt.savefig("適当なディレクトリ") plt.show() ##中心極限定理 x_range = np.arange(-10,10,0.1) gauss = sp.norm.pdf(x_range,0,1) ### 1 一様分布 U(0,1), mu = (0+1)/2 = 1/2, sigma^2 = (1-0)^2/12 = 1/12 mu = 1/2;sigma = np.sqrt(1/12) z1_l = [];z10_l = [];z100_l = [];z1000_l = [] for i in range(1000): a1 = np.random.uniform(size=1) z1_l.append(np.sqrt(1)*(np.mean(a1)-mu)/sigma) a10 = np.random.uniform(size=10) z10_l.append(np.sqrt(10)*(np.mean(a10)-mu)/sigma) a100 = np.random.uniform(size=100) z100_l.append(np.sqrt(100)*(np.mean(a100)-mu)/sigma) a1000 = np.random.uniform(size=1000) z1000_l.append(np.sqrt(1000)*(np.mean(a1000)-mu)/sigma) plt.subplot(2,2,1) plt.hist(z1_l,bins=30,color="r",normed=True,label="n=1") plt.plot(x_range,gauss,color="black",label="pdf of N(0,1)") plt.legend(loc="upper left") plt.title("from $U(0,1),n=1$") plt.subplot(2,2,2) plt.hist(z10_l,bins=30,color="r",normed=True,label="n=10") plt.plot(x_range,gauss,color="black",label="pdf of N(0,1)") plt.legend(loc="upper left") plt.title("from $U(0,1),n=10$") plt.subplot(2,2,3) plt.hist(z100_l,bins=30,color="r",normed=True,label="n=100") plt.plot(x_range,gauss,color="black",label="pdf of N(0,1)") plt.legend(loc="upper left") plt.title("from $U(0,1),n=100$") plt.subplot(2,2,4) plt.hist(z1000_l,bins=30,color="r",normed=True,label="n=1000") plt.plot(x_range,gauss,color="black",label="pdf of N(0,1)") plt.legend(loc="upper left") plt.title("from $U(0,1),n=1000$") #plt.savefig("適当なディレクトリ") plt.show()5. 参考文献

- 投稿日:2019-03-02T18:34:28+09:00
【機械学習】自動車の性能を分類してみる
【大反省】ダミー変数化しろ!!!
プログラミングの勉強を始めて3か月、機械学習の勉強を始めて3週間が経ち、一通り広く浅く中身をザッと勉強しました。
今回SIGNATEの練習問題を利用し分類の知識の確認を行ったので、その記録を記したいと思います。
まだまだ勉強不足なので皆さんから色々ご指摘をもらえたら幸いです。1.分析目的
今回の目的は、自動車の属性データから評価値(class)の予測するというものです
【練習問題】自動車の評価データの中身は以下の通りです
ヘッダ名称 データ型 説明 id int インデックスとして使用 class varchar 評価値(unacc, acc, good, vgood) buying varchar 車の売値(vhigh, high, med, low) maint varchar 整備代(vhigh, high, med, low) doors int ドアの数(2, 3, 4, 5, more.) persons int 定員(2, 4, more.) lug_boot varchar トランクの大きさ(small, med, big.) safety varchar 安全性(low, med, high) 2.データの読み込み
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inlinedf=pd.read_table('train.tsv') df.head()
id class buying maint doors persons lug_boot safety 0 0 unacc low med 3 2 small low 1 3 acc low high 3 more small med 2 7 unacc vhigh high 5more 2 small med 3 11 acc high high 3 more big med 4 12 unacc high high 3 2 med high 3.文字列の変換
とりあえず文字列をすべて数値に置換しましたdf['class']=df['class'].apply(lambda x:1 if x=='unacc' else(2 if x=='acc' else(3 if x=='good' else 4))) df['buying']=df['buying'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4))) df['maint']=df['maint'].apply(lambda x:1 if x=='low' else(2 if x=='med' else(3 if x=='high' else 4))) df['doors'][df['doors']=='5more']=5 df['persons'][df['persons']=='more']=5 df['lug_boot']=df['lug_boot'].apply(lambda x:1 if x=='small' else(2 if x=='med' else 3)) df['safety']=df['safety'].apply(lambda x:1 if x=='low' else(2 if x=='med' else 3))特徴量idは不要なので削除してから出力
index class buying maint doors persons lug_boot safety 0 1 1 2 3 2 1 1 1 2 1 3 3 5 1 2 2 1 4 3 5 2 1 2 3 2 3 3 3 5 3 2 4 1 3 3 3 2 2 3 4.データの確認
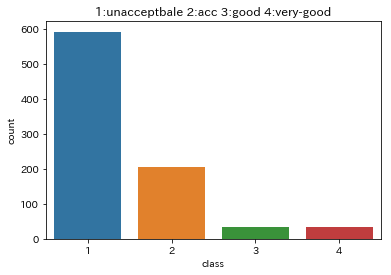
sns.countplot(data=df, x='class') plt.title('1:unacceptbale 2:acc 3:good 4:very-good')
unacc(unacceptable)が大半を占めているようです次に各データ間の相関関係を調べます
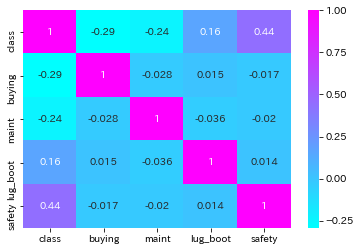
sns.heatmap(df.corr(),annot=True,cmap='cool')
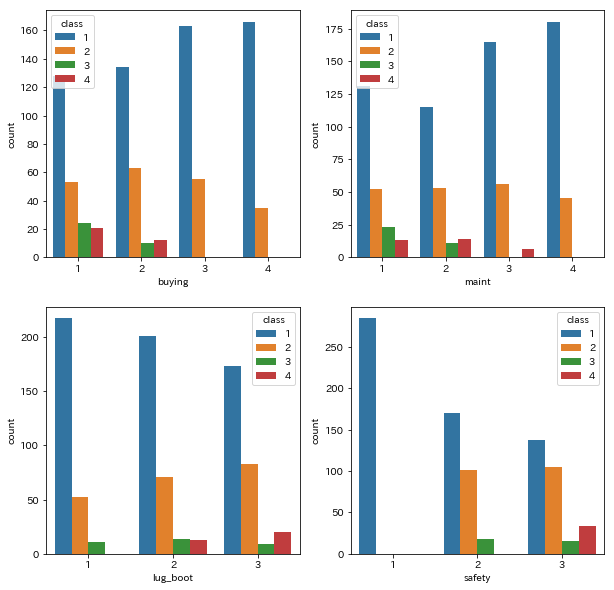
classとsafetyにはやや相関関係があり、lug_boot(トランクの大きさ)とはほとんど相関関係がありません。各項目についても調べます。
figure,axes=plt.subplots(2,2,figsize=(10,10)) sns.countplot(data=df,x='buying',hue='class',ax=axes[0,0]) sns.countplot(data=df,x='maint',hue='class',ax=axes[0,1]) sns.countplot(data=df,x='lug_boot',hue='class',ax=axes[1,0]) sns.countplot(data=df,x='safety',hue='class',ax=axes[1,1])
5.データの分割
X=df.iloc[:,1:] y=df.iloc[:,0] X=np.array(X) y=np.array(y)今回は層化k-Foldで分割しました
from sklearn.model_selection import StratifiedKFold ss=StratifiedKFold(n_splits=10,shuffle=True) train_index, test_index=next(ss.split(X,y)) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index]6-1 ロジスティック回帰
from sklearn.linear_model import LogisticRegression clf=LogisticRegression(C=1000) clf.fit(X_train, y_train) clf.score(X_test, y_test)結果は0.8764044943820225となりました
6-2 線形SVC
from sklearn.svm import SVC clf=SVC(kernel='linear') clf.fit(X_train, y_train) clf.score(X_test, y_test)結果0.9325842696629213
6-3 非線形SVC
from sklearn.svm import SVC clf=SVC(kernel='rbf') clf.fit(X_train, y_train) clf.score(X_test, y_test)結果0.9550561797752809
6-4 k近傍法
from sklearn import neighbors clf=neighbors.KNeighborsClassifier(n_neighbors=5) clf.fit(X_train, y_train) clf.score(X_test, y_test)結果0.9550561797752809
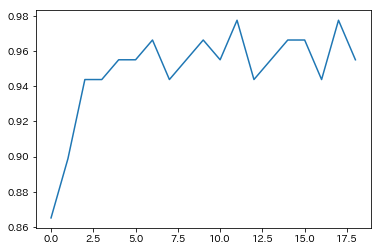
kの値を変えて調べてみます
n_range = range(1,20) scores = [] for n in n_range: clf.n_neighbors = n score = clf.score(X_test, y_test) print(n, score) scores.append(score) scores = np.array(scores) plt.plot(scores)
k=18で98%でしたが、汎用性は低そうです6-5 ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier clf=RandomForestClassifier(n_estimators=100) clf.fit(X_train, y_train) clf.score(X_test, y_test)木の数を増やしてみます
n_range = range(1,100,10) scores = [] for n in n_range: clf.n_estimators = n score = clf.score(X_test, y_test) print(n, score) scores.append(score) scores = np.array(scores)
n_estmatoresを変えても数値に変化はありませんでした
max_depthについてもやりましたが変化なし7 結果の評価
from sklearn.metrics import classification_report y_pred=clf.predict(X_test) print(classification_report(y_test, y_pred, digits=4))
//// precision recall f1-score support 1 0.9833 0.9833 0.9833 60 2 0.8333 0.9524 0.8889 21 3 0.5000 0.2500 0.3333 4 4 1.0000 0.7500 0.8571 4 micro avg 0.9326 0.9326 0.9326 89 macro avg 0.8292 0.7339 0.7657 89 weighted avg 0.9270 0.9326 0.9262 89 クラス3(good)の識別がうまくいっていませんでした。
8 結論
今回の検証ではk近傍法(K=5)で95%得られた
9 わからなかったこと
1.スマートな特徴量変換
ダミー変数ではうまくいかなかった→いろいろやり方を学ぶ必要がある
2.効果的なデータ分析
正直今回のデータ分析結果から何か分類にかけるときに有効な情報を得ることができなかった。
どんなことに着目してデータ整理をすればいいのか?そしてそれをどう分類につなげるか
3.クラス3(good)の識別がうまくいっていなかったが、理由がわからない。
この事実からどう修正すれば識別率を上げられるのかに繋げられないため、これでは結果を評価しても無意味な状態

- 投稿日:2019-03-02T18:10:38+09:00
Kaggle Competition解説:Elo Merchant Category Recommendation その1
この記事について
この記事は2019年2/27まで開催されていたKaggleのコンペElo Merchant Category Recommendationについて備忘録も兼ねて、
データコンペの説明→EDA(データの探索)→特徴量エンジニアリング→RMSEを上げる工夫まで一通り解説します。
最終順位は上位10%で、運良くブロンズメダルを取れました。
拙い所が多いですがよろしくおねがいします。1. コンペの説明
Eloはブラジルのクレジットカード会社の事で、各カード保有者毎にLoyalty_Scoreを予測し、有効なプロモーションを実施する事が今回のコンペの目的のようです。
Loyalty_scoreが何を意味するのか私にはよくわかりません。
以下に用意されているデータの簡単な説明を記載します。
train.csv
card_id及びカード情報に関する変数と、目的変数'target'(Loyalty score)からなるcsvファイルです。データ件数202ktest.csv
同じ様にcard_idとカード情報からなるcsvファイルです。当然ですが、card_idはtrain.csvのものと重複は無く、targetも含まれていません。データ件数124khistorical_transactions.csv
各card_idの購入履歴データです。購入日時や、購入した店のIDを意味する変数merchants_idが含まれています。new_merchant_transactions.csv
historical_transactions.csvに含まれていないmerchant_idに対する購入履歴データです。名前から察するに新しく出来たお店の購入履歴データのようですね。評価指標はRoot Mean Squared Errorです。
2. EDA(探索的データ解析)
一通り行ったデータ探索について記載します。
多くはkernelのコードを参考にしました。実際には更に色々データを弄ってみたり、他の人のEDAをたくさん見てデータの雰囲気を掴みました。2.1 trainについての探索
train.csvのデータ構成は以下となります。
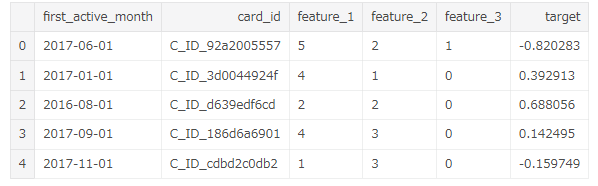
first_active_monthは最初に購入した月、feature_1, 2, 3はそれぞれ匿名化されたカード情報。
targetは目的変数です、
targetの意味と算出方法については議論がされており、ある変数と変数の組み合わせで作る新しい変数がtargetに大きく寄与するという事が判明しています(後述)。データの中身はこんな感じです。
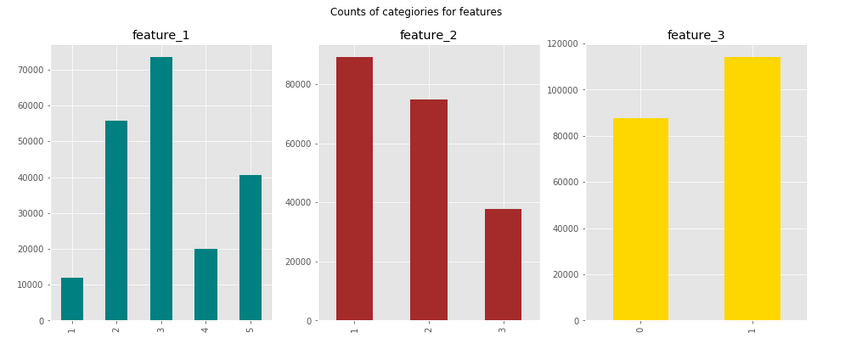
feature_1, 2, 3はそれぞれカテゴリ変数になっています。
それぞれどのような分布になっているか見てみると・・・
どの変数を見てもそこまで大きく偏っているようには見えません。
では次に、各値毎のtargetの分布を見てみます。
どの値もtargetの平均が0で、分布の形が正規分布と同じですね。
分布の違いが特に見られないので、これらのカテゴリ変数はtargetの予測にあまり意味を持たないと考えられます。first_active_monthの推移と、trainとtestの違いを確認します。
2016年あたりから利用者が増えているようです。次に、targetの分布を見てみます。
よく見てみると僅かに-30近辺に値が含まれています。-20未満のtargetの数を見た所、2207個も含まれていました。割合としては約1%です。
kaggleのdiscussionでもこの外れ値について議論が非常に行われ、参加者は外れ値に大いに苦しめられました。
この対処方法については後ほど解説します。2.2 historical_trainsactionsについての探索
各card_id毎の購入履歴データについても調べてみます。
まずはデータ構成について。
trainデータに比べて多くの変数が含まれています。また、データ件数は約3000万でした。
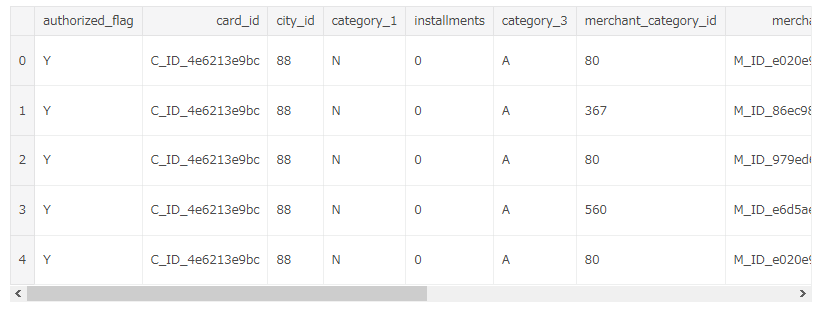
データの中身はこんな感じです。下のスクロールバーを触っても何もありません。ごめんなさい。
card_id毎の購入履歴が、ほぼ匿名化されていますが、お店の街やカテゴリ、購入金額と一緒に記録されています。
installments(分割払い)について各数値をカウントします。
見た限り、0(恐らく一括払い)が一番多く、分割回数が多い購入履歴は少なくなる傾向にあります。
しかし、よく見ると-1と999が含まれており、これは欠損値であると思われます。
欠損値の埋め方も考える必要があります。
999と-1の違いはよく分かりませんが、今回はどちらも0に置換を行いました。次にpurchase_amount(購入金額)について調べます。この変数についてはリスケーリングされています。
購入金額を-1未満、0未満、0以上、10以上、100以上で分割して数をカウントします。
購入金額のほぼ全ては-1と0の間に含まれているようです。ただし、100以上の購入金額を持つデータも僅かに存在し、これを外れ値とするか難しい所です。
最後に、各カテゴリ変数のユニーク値の数を数えます。
ユニーク値の数的に、one_hot_encodingができる変数はstate_idとsubsector_idの2つかなと思います。2.3 new_merchant_transactionsについての探索
こちらも2.2と同様にEDAを行いました。あまり結果が変わらなかったので割愛します。
長くなってしまうので、特徴量エンジニアリング以降についてはまた今度別記事を作成します。








- 投稿日:2019-03-02T17:43:09+09:00
質問させてください。 python selenium スクレイピング
python3の環境でseleniumとfirefoxを使用して日本経済新聞のサイトにログインしようとしています。
ID、PASSまで記入し最後にログインしようとするとPASSがなぜか消えてしまいます。
解決策をご存知であればお教えください。
よろしくお願いいたします。ここから~~~
from selenium import webdriver
from time import sleepbrowser = webdriver.Firefox()
browser.get('https://www.nikkei.com/')
ログイン画面へ
login_elem = browser.find_element_by_link_text('ログイン')
login_elem.click()sleep(5)
ID入力
email_elem = browser.find_element_by_id('LA7010Form01:LA7010Email')
sleep(1)
email_elem.send_keys('ID@xxxx')パスワード入力
password_elem = browser.find_element_by_id('LA7010Form01:LA7010Password')
sleep(1)
password_elem.send_keys('xxxxxx')ボタンをクリック
email_elem1 = browser.find_element_by_id('LA7010Form01:submitBtn')
sleep(1)
email_elem1.submit()ここまで~~~
- 投稿日:2019-03-02T17:03:49+09:00
Custom Visionでフォントを識別してみたかったのでしてみた
Truffleでブロックチェーンアプリを作ろうと思っていたのですが、アイデアがうまく練られず、いろいろと右往左往してしまいました。
結果的にブロックチェーンアプリ案はすべて、別にブロックチェーンで実装しなくても良いようなものばっかりになったので、めんどくさくなって考えるのをやめてしまいました。。。その過程で手書き文字の筆跡をブロックチェーンに記録して、改ざん不可能な筆跡を溜め込むブロックチェーンアプリを作ろうと思ったのですが(その有用性はさておき)、この筆跡認証のためにAzureのCustomVisionを使ったので、せっかくだしその使い方を記録しておくことにしました
Custom Vision Service
CustomVisionServiceとは、Azureが提供している画像識別サービスです。
私はコードを書いて実装しましたが、アカウントを作ればweb上でプロジェクトを作成し、画像分類器を構築することができます。ここに書くのも主にコード側の実装についてです。
プロジェクトの作成
部分的にコードの説明をしていきますが、全体のコードも最後に載せておきます。
プロジェクト名とかは筆跡認識ように作ったものを参考にしているので、Handwriting Projectになっています。あと、実行環境は、
- Python 3.6.4
- macOS Mojave version 10.14
です。
import os import time from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com" # あなたのものを入れてください。 training_key = "your_training_key" prediction_key = "prediction_ley" trainer = CustomVisionTrainingClient(training_key, endpoint=ENDPOINT) # プロジェクトの作成 print ("Creating project...") project = trainer.create_project("Handwriting Project")training_keyとprediction_keyは、プロジェクト画面上部の歯車ボタンを押すと出てきます。
プロジェクト内にタグを作成
プロジェクトに画像分類器のタグを作成します。
作成したタグに学習した内容を紐づけることで、ある画像を与えた時に、その画像がどのタグに属するか(その画像が何なのか)をCustomVisionServiceが返します。bauhaus93_tag = trainer.create_tag(project.id, "bauhaus93") bernardMT_tag = trainer.create_tag(project.id, "bernardMT") century_tag = trainer.create_tag(project.id, "century") engraversMT_tag = trainer.create_tag(project.id, "engraversMT") hadassah_friedlaender_tag = trainer.create_tag(project.id, "hadassah_friedlaender") knewave_tag = trainer.create_tag(project.id, "knewave") typegoshi_tag = trainer.create_tag(project.id, "typegoshi") kurei_tag = trainer.create_tag(project.id, "kurei") bokugoshi_tag = trainer.create_tag(project.id, "bokugoshi") totubangoshi_tag = trainer.create_tag(project.id, "totubanpgoshi") yumin_regu_tag = trainer.create_tag(project.id, "yumin_regu") yumin_36pokana_tag = trainer.create_tag(project.id, "yumin_36pokana")今回私は、筆跡認識プロジェクトを使ったのですが、実際に筆跡を集めたわけではありません。
wordでフォントが異なる同一の内容の文字列を英語と日本語それぞれ6種類を作成し、各タグに5枚画像化したものを学習させました。
なので、ここではそれぞれのタグ名がフォント名になっています。*各フォントに対応するフォントの画像を5枚にしたのは、1枚ではエラーになったからです。どこで読んだかは忘れてしまいましたが、学習時は5枚以上のデータが必要ということだったので、5枚にしています(結果エラーも解消されました)。
CostomVisionServiceに画像をインポート
それでは、上で作成したそれぞれのタグに、対応する画像を追加していきましょう。
ここで使ったプロジェクトのディレクトリは以下の通りです。
---index.py |-prediction.py |-training_img---en---Bauhaus---images... | |-Bernerd MT---images... | |-Century---images... | |-Engravers MT---images... | |-Hadassah FriedLaender---images... | |-knewave---images... |-ja---typegoshi---images...(以下省略)上記のようにtraining_imgディレクトリ配下に画像フォルダが格納されています。
ディレクトリ構成は作る人がそれぞれ好きなようにしてくれれば良いですが、ここでは上記のようになっていることを理解した上で続きを読んでください。# 画像が入っているディレクトリ群が存在するディレクトリ en_base_image_url = "./training_img/en/" ja_base_image_url = "./training_img/ja/" # enの中のディレクトリそれぞれのパスを変数に格納 en_dir = os.listdir(en_base_image_url) # the directory list of "./training_img/en/" bauhaus = os.listdir(en_base_image_url + "Bauhaus") bernard = os.listdir(en_base_image_url + "Bernard MT") century = os.listdir(en_base_image_url + "Century") engravers = os.listdir(en_base_image_url + "Engravers MT") hadassah = os.listdir(en_base_image_url + "Hadassah Friedlaender") knewave = os.listdir(en_base_image_url + "Knewave") # jaの中のディレクトリそれぞれのパスを変数に格納 ja_dir = os.listdir(ja_base_image_url) # the directory list of "./training_img/ja/" typegoshi = os.listdir(ja_base_image_url + "typegoshi") kurei = os.listdir(ja_base_image_url + "kurei") bokugoshi = os.listdir(ja_base_image_url + "bokugoshi") totubangoshi = os.listdir(ja_base_image_url + "totubangoshi") yumin_regu = os.listdir(ja_base_image_url + "yumin_regu") yumin_36pokana = os.listdir(ja_base_image_url + "yumin_36pokana") def createImagesFromFiles(url, tag, dir, label): file_name = url + dir + "/" + label with open(file_name, mode="rb") as image_contents: trainer.create_images_from_files( project.id, images=[ ImageFileCreateEntry(name=file_name, contents=image_contents.read(), tag_ids=[tag.id])]) print ("Adding images...") # en配下のディレクトリ内の特定のフォントのディレクトリに入っている5枚の画像ををそれぞれのタグに追加 for dir in en_dir: print(dir) tag = None if dir == "Bauhaus": tag = bauhaus93_tag for label in bauhaus: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Bernard MT": tag = bernardMT_tag for label in bernard: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Century": tag = century_tag for label in century: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Engravers MT": tag = engraversMT_tag for label in engravers: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Hadassah Friedlaender": tag = hadassah_friedlaender_tag for label in hadassah: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Knewave": tag = knewave_tag for label in knewave: createImagesFromFiles(en_base_image_url, tag, dir, label) # ja配下のディレクトリ内の特定のフォントのディレクトリに入っている5枚の画像ををそれぞれのタグに追加 for dir in ja_dir: print(dir) tag = None if dir == "typegoshi": tag = typegoshi_tag for label in typegoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "kurei": tag = kurei_tag for label in kurei: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "bokugoshi": tag = bokugoshi_tag for label in bokugoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "totubangoshi": tag = totubangoshi_tag for label in totubangoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "yumin_regu": tag = yumin_regu_tag for label in yumin_regu: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "yumin_36pokana": tag = yumin_36pokana_tag for label in yumin_36pokana: createImagesFromFiles(ja_base_image_url, tag, dir, label)それぞれのタグの画像を学習
print ("Training...") iteration = trainer.train_project(project.id) while (iteration.status != "Completed"): iteration = trainer.get_iteration(project.id, iteration.id) print ("Training status: " + iteration.status) time.sleep(1) # 学習完了と学習した内容の適用 trainer.update_iteration(project.id, iteration.id, is_default=True) print ("Done!")学習がCompletedになるまで学習を実施し続けます。
Done! が表示されれば終了です。画像を識別させる
上記のコードたちを記述したindex.pyと同じディレクトリ内に、prediction.pyを作成して、以下のコードを書きます。
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient import time import os ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com" training_key = "your_training_key" prediction_key = "your_prediction_key" project_id = "your_project_id" predictor = CustomVisionPredictionClient(prediction_key, endpoint=ENDPOINT) # 識別させたい画像のURL test_img_url = "http://www.jiyu-kobo.co.jp/wp@test/wp-content/uploads/2016/02/ym_l_Pr6N_y.gif" results = predictor.predict_image_url(project_id, url=test_img_url) # 結果を表示 for prediction in results.predictions: print ("\t" + prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100))project_idは、プロジェクト画面からプロジェクトを選択して入ったページの上部にある歯車ボタンからみることができます(ページの左側に出てくると思います)。
これを実行すると、
yumin_regu: 9.26% typegoshi: 6.53% century: 3.89% kurei: 2.94% totubangoshi: 1.96% bauhaus93: 1.55% engraversMT: 1.44% hadassah_friedlaender: 0.91% yumin_36pokana: 0.80% bokugoshi: 0.32% knewave: 0.05% bernardMT: 0.01%こんな感じで結果が表示されます。
あんまり精度はよろしくない様子です。。。もっと画像を学習させればうまくなるのかもしれませんが、私はもうこの辺でやめておきます〜
web上でもこれらのプロジェクト作成から予測までを行うことができます。
qiitaで使い方を書いている人もいるのでそちらを参考にどうぞ
Custom Vision Serviceを使ってみたこれも参考になりました。
クイック スタート:Custom Vision Python SDK を使用して画像分類プロジェクトを作成するすべてのコード
改めてディレクトリ構造を載せておきます。
---index.py |-prediction.py |-training_img---en---Bauhaus---images... | |-Bernerd MT---images... | |-Century---images... | |-Engravers MT---images... | |-Hadassah FriedLaender---images... | |-knewave---images... |-ja---typegoshi---images...(以下省略)# index.py import os import time from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com" training_key = "your_training_key" prediction_key = "your_prediction_key" trainer = CustomVisionTrainingClient(training_key, endpoint=ENDPOINT) print ("Creating project...") project = trainer.create_project("Handwriting Project") bauhaus93_tag = trainer.create_tag(project.id, "bauhaus93") bernardMT_tag = trainer.create_tag(project.id, "bernardMT") century_tag = trainer.create_tag(project.id, "century") engraversMT_tag = trainer.create_tag(project.id, "engraversMT") hadassah_friedlaender_tag = trainer.create_tag(project.id, "hadassah_friedlaender") knewave_tag = trainer.create_tag(project.id, "knewave") typegoshi_tag = trainer.create_tag(project.id, "typegoshi") kurei_tag = trainer.create_tag(project.id, "kurei") bokugoshi_tag = trainer.create_tag(project.id, "bokugoshi") totubangoshi_tag = trainer.create_tag(project.id, "totubangoshi") yumin_regu_tag = trainer.create_tag(project.id, "yumin_regu") yumin_36pokana_tag = trainer.create_tag(project.id, "yumin_36pokana") en_base_image_url = "./training_img/en/" ja_base_image_url = "./training_img/ja/" # en en_dir = os.listdir(en_base_image_url) # the directory list of "./training_img/en/" bauhaus = os.listdir(en_base_image_url + "Bauhaus") bernard = os.listdir(en_base_image_url + "Bernard MT") century = os.listdir(en_base_image_url + "Century") engravers = os.listdir(en_base_image_url + "Engravers MT") hadassah = os.listdir(en_base_image_url + "Hadassah Friedlaender") knewave = os.listdir(en_base_image_url + "Knewave") # ja ja_dir = os.listdir(ja_base_image_url) # the directory list of "./training_img/ja/" typegoshi = os.listdir(ja_base_image_url + "typegoshi") kurei = os.listdir(ja_base_image_url + "kurei") bokugoshi = os.listdir(ja_base_image_url + "bokugoshi") totubangoshi = os.listdir(ja_base_image_url + "totubangoshi") yumin_regu = os.listdir(ja_base_image_url + "yumin_regu") yumin_36pokana = os.listdir(ja_base_image_url + "yumin_36pokana") def createImagesFromFiles(url, tag, dir, label): file_name = url + dir + "/" + label with open(file_name, mode="rb") as image_contents: trainer.create_images_from_files( project.id, images=[ ImageFileCreateEntry(name=file_name, contents=image_contents.read(), tag_ids=[tag.id])]) print ("Adding images...") for dir in en_dir: print(dir) tag = None if dir == "Bauhaus": tag = bauhaus93_tag for label in bauhaus: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Bernard MT": tag = bernardMT_tag for label in bernard: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Century": tag = century_tag for label in century: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Engravers MT": tag = engraversMT_tag for label in engravers: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Hadassah Friedlaender": tag = hadassah_friedlaender_tag for label in hadassah: createImagesFromFiles(en_base_image_url, tag, dir, label) elif dir == "Knewave": tag = knewave_tag for label in knewave: createImagesFromFiles(en_base_image_url, tag, dir, label) for dir in ja_dir: print(dir) tag = None if dir == "typegoshi": tag = typegoshi_tag for label in typegoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "kurei": tag = kurei_tag for label in kurei: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "bokugoshi": tag = bokugoshi_tag for label in bokugoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "totubangoshi": tag = totubangoshi_tag for label in totubangoshi: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "yumin_regu": tag = yumin_regu_tag for label in yumin_regu: createImagesFromFiles(ja_base_image_url, tag, dir, label) elif dir == "yumin_36pokana": tag = yumin_36pokana_tag for label in yumin_36pokana: createImagesFromFiles(ja_base_image_url, tag, dir, label) print ("Training...") iteration = trainer.train_project(project.id) while (iteration.status != "Completed"): iteration = trainer.get_iteration(project.id, iteration.id) print ("Training status: " + iteration.status) time.sleep(1) trainer.update_iteration(project.id, iteration.id, is_default=True) print ("Done!")# prediction.py from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient import time import os ENDPOINT = "https://southcentralus.api.cognitive.microsoft.com" training_key = "your_training_key" prediction_key = "your_prediction_key" project_id = "your_project_id" predictor = CustomVisionPredictionClient(prediction_key, endpoint=ENDPOINT) test_img_url = "image_url" results = predictor.predict_image_url(project_id, url=test_img_url) for prediction in results.predictions: print ("\t" + prediction.tag_name + ": {0:.2f}%".format(prediction.probability * 100))興味があったら使ってみてください、簡単なので
- 投稿日:2019-03-02T16:35:57+09:00
コードを1行も書かずにpytestを実行する
pytest-playとは
コードを書かずにテストできる
テストコードは必要だけど作るのは大変ですよね。まるで確定申告のようです。
pytest-playはYAMLファイルを書くだけでテストを実行できるライブラリです。
コードを書く必要がないため、プログラマじゃない人にテストの委託もできそうです。機能
下記のような機能があります。
- 実行時間の計測
- JUnit XML report
- StatsD/graphiteを用いたテストメトリクスの監視
- プラグイン
- play_selenium
- play_requests
- play_sql
- play_cassandra
- play_dynamodb
- play_websocket
- play_mqtt
play_requestsやplay_seleniumを使うと、DjangoやFlaskなどのWebサーバのテストが行なえます。WebサーバはPython製である必要もなく、Railsなどで作られたWebサーバでも構いません。
インストール
pipでインストールします。
pip install pytest-playPythonがインストールされていない環境でも、Dockerから実行できます。
docker run -i --rm -v $(pwd):/src davidemoro/pytest-play使ってみる
簡単なテストをしてみます。pytestと同様に
testで始まるファイル名のYAMLファイルがテスト対象となります。test_add.yml- comment: 足し算のテスト provider: python type: assert expression: "1 + 1 == 2"上記の
test_add.ymlを作成してテストを実行します。pytestコマンドがそのまま使えます。$ pytest ======================================== test session starts ========================================= platform linux -- Python 3.6.7, pytest-4.3.0, py-1.8.0, pluggy-0.9.0 rootdir: /home/driller/work/pytest-play, inifile: plugins: variables-1.7.1, play-2.2.0 collected 1 item test_add.yml . [100%] ====================================== 1 passed in 0.05 seconds ======================================YAMLの設定項目を大雑把に説明するとこんな感じです。
- provider: 実行するコマンドを指定します、
pythonやseleniumなどがあります- type: providerのサブカテゴリのようなものです(うまく説明できない)
- expression: 評価式を渡します
- comment: コメントです
変数
typeにstore_variable、nameに変数名、expressionに値を指定します。
expressionはクォートで囲む必要があります。test_var.yml- comment: 変数を代入 provider: python type: store_variable name: spam expression: "'ham'" - comment: 変数をテスト provider: python type: assert expression: "'$spam' * 2 == 'hamham'"$ pytest ======================================== test session starts ========================================= platform linux -- Python 3.6.7, pytest-4.3.0, py-1.8.0, pluggy-0.9.0 rootdir: /home/driller/work/pytest-play, inifile: plugins: variables-1.7.1, play-2.2.0 collected 2 items test_add.yml . [ 50%] test_var.yml . [100%] ====================================== 2 passed in 0.06 seconds ======================================requestsを使ったテスト
requestを使ってWebサイトのテストをする場合にはplay_requestsをインストールします。
pip install play_requests例として、Weather HacksのAPIをテストしてみます。
インストールしたplay_requestsをproviderに指定します。
city=040020は宮城県白石市のIDです。pinpointLocationの最初には仙台市西部が入っていることをテストします。test_weather_hacks.yml- comment: 白石市の天気 provider: play_requests type: GET url: http://weather.livedoor.com/forecast/webservice/json/v1?city=040020 assert: response.status_code == 200 variable: json variable_expression: response.json() - comment: "json" type: assert provider: python expression: "variables['json']['pinpointLocations'][0]['name'] == '仙台市西部'"$ pytest ======================================== test session starts ========================================= platform linux -- Python 3.6.7, pytest-4.3.0, py-1.8.0, pluggy-0.9.0 rootdir: /home/driller/work/pytest-play, inifile: plugins: variables-1.7.1, play-2.2.0 collected 3 items test_add.yml . [ 33%] test_var.yml . [ 66%] test_weather_hacks.yml . [100%] ====================================== 3 passed in 0.20 seconds ======================================seleniumを使ったテスト
play_seleniumを使います。
インストール方法は同じですが、別途Webdriverが必要になります。pip install play_selenium例としてgoogle.comに検索ワードを入力してみます。
test_google.yml- comment: Google.comにアクセス provider: selenium type: get url: https://google.com - comment: 検索ワードを入力 type: setElementText provider: selenium locator: type: name value: q text: "cp932撲滅" - type: sendKeysToElement provider: selenium locator: type: name value: q text: ENTER - comment: 画面をじっくり眺める時間 type: pause provider: selenium waitTime: 10000$ pytest ======================================== test session starts ========================================= platform linux -- Python 3.6.7, pytest-4.3.0, py-1.8.0, pluggy-0.9.0 rootdir: /home/driller/work/pytest-play, inifile: plugins: variables-1.7.1, splinter-2.0.1, pypom-navigation-2.0.3, play-2.2.0 collected 4 items test_add.yml . [ 25%] test_google.yml . [ 50%] test_var.yml . [ 75%] test_weather_hacks.yml . [100%] ===================================== 4 passed in 14.53 seconds ======================================実行するとブラウザが起動して検索結果の画面が表示されます。
雑感
ざっと使ってみた感想としては、コードを書く手間が省けることよりも、YAMLにすることで見た目がすっきりするというのが利点のように感じました。
紹介していない機能がたくさんありますが、機会があれば紹介したいと思います。
- 投稿日:2019-03-02T16:15:03+09:00
【機械学習入門】K-meansでクラスタリング出来ない><;spectral-clustering♬
K-meansクラスタリングは、簡単に云うと「適当な乱数で生成された初期値から円(その次元を持つ境界が等距離な多様体)を描いてその中に入る点をその中心(重心)に属する」という考え方でクラスタリングしている。
つまり、以下の式の最適化問題である。given\left \{ \begin{array}{l} cluster\ No.:\ k\\ data\ No.:\ n\\ \end{array} \right.\\ {arg\,min} _{V_{1},\dotsc ,V_{k}}\sum _{i=1}^{n}\min _{j}\left\|x_{i}-V_{j}\right\|^{2}実際のアルゴリズムは参考によれば、以下のとおりである。
(以下、Wikipediaから引用)
「k-平均法は、一般には以下のような流れで実装される[5][6]。データの数を $n$、クラスタの数を $k$ としておく。
1. 各データ $x_i$ $(i=1,...,n)$ に対してランダムにクラスタを割り振る。
2. 割り振ったデータをもとに各クラスタの中心 $V_j$ $(j=1,...,k)$ を計算する。計算は通常割り当てられたデータの各要素の算術平均が使用されるが、必須ではない。
3. 各 $x_i$ と各 $V_j$ との距離を求め、 $x_i$ を最も近い中心のクラスタに割り当て直す。
4. 上記の処理で全ての $x_i$ のクラスタの割り当てが変化しなかった場合、あるいは変化量が事前に設定した一定の閾値を下回った場合に、収束したと判断して処理を終了する。そうでない場合は新しく割り振られたクラスタから $V_j$ を再計算して上記の処理を繰り返す。」【参考】
・k平均法@wikipedia
今回は、このアルゴリズムだとクラスタリング出来ないケースがあるということで、それをどうするというところまで書きたいと思う。やったこと
・moonsやドーナツ型はだめらしい
・moonsやcirclesを分類できるspectral clustering・moonsやドーナツ型はだめらしいが、。。
とにかくやってみる
import matplotlib.pyplot as plt from sklearn.cluster import KMeans # K-means クラスタリングをおこなう from sklearn.decomposition import PCA #主成分分析器 import numpy as np from sklearn.datasets import make_moonsまず、moonsを生成する。
N =300 noise=0.05 X, y = make_moons(N, noise=noise, random_state=0) plt.scatter(X[:,0],X[:,1]) plt.pause(1) plt.close()
まず、Kを変えてDistorsionの変化を見る。distortions = [] distortions1 = [] for i in range(1,21): # 1~20クラスタまで一気に計算 km = KMeans(n_clusters=i, init='k-means++', # k-means++法によりクラスタ中心を選択 n_init=10, max_iter=300, random_state=0) km.fit(X) # クラスタリングの計算を実行 #df.iloc[:, 1:] distortions.append(km.inertia_) # km.fitするとkm.inertia_が得られる UF = km.inertia_ + i*np.log(20)*5e2 # km.inertia_ + kln(size) distortions1.append(UF) fig=plt.figure(figsize=(12, 10)) ax1 = fig.add_subplot(311) ax2 = fig.add_subplot(312) ax3 = fig.add_subplot(313) ax1.plot(range(1,21),distortions,marker='o') ax1.set_xlabel('Number of clusters') ax1.set_ylabel('Distortion') #ax1.yscale('log') ax2.plot(range(1,21),distortions,marker='o') ax2.set_xlabel('Number of clusters') ax2.set_ylabel('Distortion') ax2.set_yscale('log') ax3.plot(range(1,21),distortions1,marker='o') ax3.set_xlabel('Number of clusters') ax3.set_ylabel('Distortion+klog') ax3.set_yscale('log') plt.pause(1) plt.savefig('k-means/moons/moons'+str(noise)+'_Distortion.jpg') plt.close()moonsではDistorsionの図はだらだらしていて最適なkは見つからない。
以下でK-meansクラスタリングする。ここでは初期値をinit='k-means++'として工夫している。s=2 km = KMeans(n_clusters=s, init='k-means++', # k-means++法によりクラスタ中心を選択 n_init=10, max_iter=300, random_state=0) y_km=km.fit_predict(X) #df.iloc[:, 1:] # この例では s個のグループに分割 (メルセンヌツイスターの乱数の種を 10 とする) kmeans_model = KMeans(n_clusters=s, random_state=10).fit(X) #df.iloc[:, 1:] # 分類結果のラベルを取得する labels = kmeans_model.labels_ print(labels) ################## print(labels) ################### # それぞれに与える色を決める。 color_codes = { 0:'#00FF00', 1:'#FF0000', 2:'#0000FF', 3:'#00FFFF' , 4:'#00FF77', 5:'#f0FF00', 6:'#FF06F0', 7:'#0070FF', 8:'#FFF444' , 9:'#077777', 10:'#111111',11:'#222222',12:'#333333', 13:'#444444',14:'#555555',15:'#66FF00', 16:'#FF7777', 17:'#0000FF', 18:'#00FFFF',19:'#007777'} # サンプル毎に色を与える。 colors = [color_codes[x] for x in labels]以下でPCA主成分分析を実施する。
#主成分分析の実行 pca = PCA() pca.fit(X) #df.iloc[:, 1:] PCA(copy=True, n_components=None, whiten=False) # データを主成分空間に写像 = 次元圧縮 feature = pca.transform(X) #df.iloc[:, 1:] x,y = feature[:, 0], feature[:, 1] print(x,y) X=np.c_[x,y] plt.figure(figsize=(6, 6)) plt.title("Principal Component Analysis") plt.xlabel("The first principal component score") plt.ylabel("The second principal component score") plt.savefig('k-means/moons/pca/moons'+str(noise)+'_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()結果は予想通り、右と左に色分けしている。
from sklearn.metrics import silhouette_samples from matplotlib import cm cluster_labels = np.unique(y_km) # y_kmの要素の中で重複を無くす s=6 ⇒ [0 1 2 3 4 5] n_clusters=cluster_labels.shape[0] # 配列の長さを返す。つまりここでは n_clustersで指定したsとなる # シルエット係数を計算 silhouette_vals = silhouette_samples(X,y_km,metric='euclidean') # サンプルデータ, クラスター番号、ユークリッド距離でシルエット係数計算 df.iloc[:, 1:] y_ax_lower, y_ax_upper= 0,0 yticks = [] for i,c in enumerate(cluster_labels): c_silhouette_vals = silhouette_vals[y_km==c] c_silhouette_vals.sort() y_ax_upper += len(c_silhouette_vals) color = cm.jet(float(i)/n_clusters) plt.barh(range(y_ax_lower,y_ax_upper), c_silhouette_vals, height=1.0, edgecolor='none', color=color) yticks.append((y_ax_lower+y_ax_upper)/2) y_ax_lower += len(c_silhouette_vals) silhouette_avg = np.mean(silhouette_vals) # シルエット係数の平均値 plt.axvline(silhouette_avg,color="red",linestyle="--") # 係数の平均値に破線を引く plt.yticks(yticks,cluster_labels + 1) # クラスタレベルを表示 plt.ylabel('Cluster') plt.xlabel('silhouette coefficient') plt.savefig('k-means/moons/moons'+str(noise)+'_silhouette_avg'+str(s)+'.jpg') plt.pause(1) plt.close()シルエット係数は以下のようになる。クラス数を増やしてもmoonsの場合はある意味バランスはいい
。。。
# この例では s つのグループに分割 (メルセンヌツイスターの乱数の種を 10 とする) kmeans_model = KMeans(n_clusters=s, random_state=10).fit(X) # 分類結果のラベルを取得する labels = np.unique(kmeans_model.labels_) #kmeans_model.labels_ cluster_labels # 分類結果を確認 print(labels) ################# print(labels) ############ # サンプル毎に色を与える。 colors = [color_codes[x] for x in kmeans_model.labels_] # 第一主成分と第二主成分でプロットする plt.figure(figsize=(6, 6)) for kx, ky, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], labels): plt.text(kx, ky, name, alpha=0.8, size=20) plt.scatter(x, y, alpha=0.8, color=colors) plt.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], c = "b", marker = "*", s = 100) plt.title("Principal Component Analysis") plt.xlabel("The first principal component score") plt.ylabel("The second principal component score") plt.savefig('k-means/moons/pca/moons'+str(noise)+'_PCA12_plotn'+str(s)+'.jpg') plt.pause(1) plt.close()
。。。
11クラスだと8の上辺のところが4に属していてまずいような気がする。
12クラス使うと、一応クラスタリング出来たことになるが、人の目だと2クラスで分類できるので、結果は大きく異なっている。
一方、同じようにドーナツ型の場合も以下のような結果となる。
コードは以下の変更をするだけである。from sklearn.datasets import make_moons, make_circles N =300 noise=0.05 X, z = make_circles(n_samples=N, factor=.5, noise=noise) #X, y = make_moons(N, noise=noise, random_state=0)結果はmoonsとほぼ同じく、クラスタ間の距離が同心円の内外の距離より小さくなるとクラスタリングが成功するが、やはり人間の目の感覚とは異なる分類となっている。
・moonsやcirclesを分類できるspectral clustering
spectral clusteringだとmoonsもcirclesも簡単にクラスタリングしてくれる。。。
【参考】
・sklearn.cluster.SpectralClustering
実際コードで動かしてみると以下のとおり、選べるパラメーターは以下のとおりですが、初心者が簡単に選べるのは、。assign_labels : {‘kmeans’, ‘discretize’}と affinity : {‘rbf’, ‘nearest_neighbors’}あたりかなと思います。assign_labels : {‘kmeans’, ‘discretize’}, default: ‘kmeans’ affinity : string, array-like or callable, default ‘rbf’ If a string, this may be one of ‘nearest_neighbors’, ‘precomputed’, ‘rbf’ or one of the kernels supported by sklearn.metrics.pairwise_kernels.使うものは以下のとおり
from sklearn.cluster import SpectralClustering import numpy as np import matplotlib.pyplot as plt #プロット用のライブラリを利用 from sklearn.datasets import make_moons, make_circlesデータは上と同じものを選びます。
N =300 noise=0.05 #X, z = make_circles(n_samples=N, factor=.5, noise=noise) X, z = make_moons(N, noise=noise, random_state=0) plt.scatter(X[:,0],X[:,1]) plt.title("original") plt.pause(1) plt.close()4種類の組み合わせを以下のように明示的に実施します。
s=2 lists_Alabel={"discretize","kmeans"} lists_Affinity={"nearest_neighbors","rbf"} for l in lists_Alabel: for af in lists_Affinity: clustering = SpectralClustering(n_clusters=s, assign_labels=l, random_state=0,affinity=af).fit(X) print(clustering.labels_) plt.scatter(X[:,0],X[:,1], c=clustering.labels_) plt.title("assign_label={},affinity={}".format(l,af)) plt.pause(1) plt.savefig('k-means/spectral/moons'+str(l)+str(af)+'_PCA'+str(s)+'.jpg') plt.close()実際動かしてみると、いつもクラスタリング出来るわけではなく、affinity : {‘nearest_neighbors’}のときに人の目で見たようにクラスタリングしてくれることが分かります。
まとめ
・K-meansのちょっと理論にて、クラスター重心でクラスタリングしていることを見た
・その結果、moonsやcirclesのような距離が複雑な分布を持つ場合のクラスタリングは苦手であることが分かった
・spectral clusteringでは、属性としてaffinity="nearestneighbers"を選ぶことにより、単純な距離よりもつながりでクラスターを見ることにより、上記の複雑な場合もクラスタリングできることが分かった・spectral-clusteringの理論や多変量への応用については次回記載したいと思う
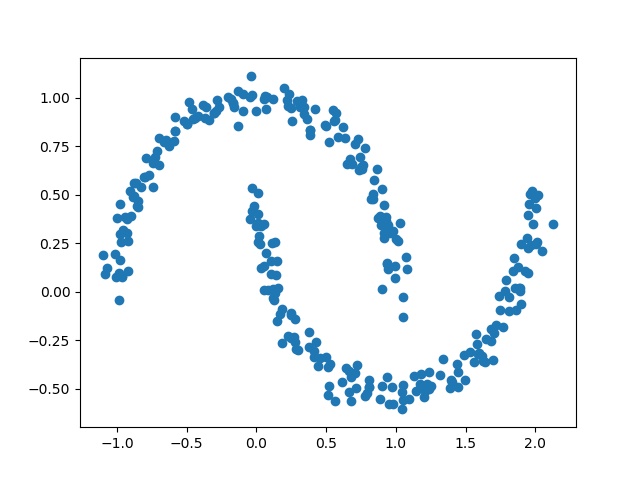
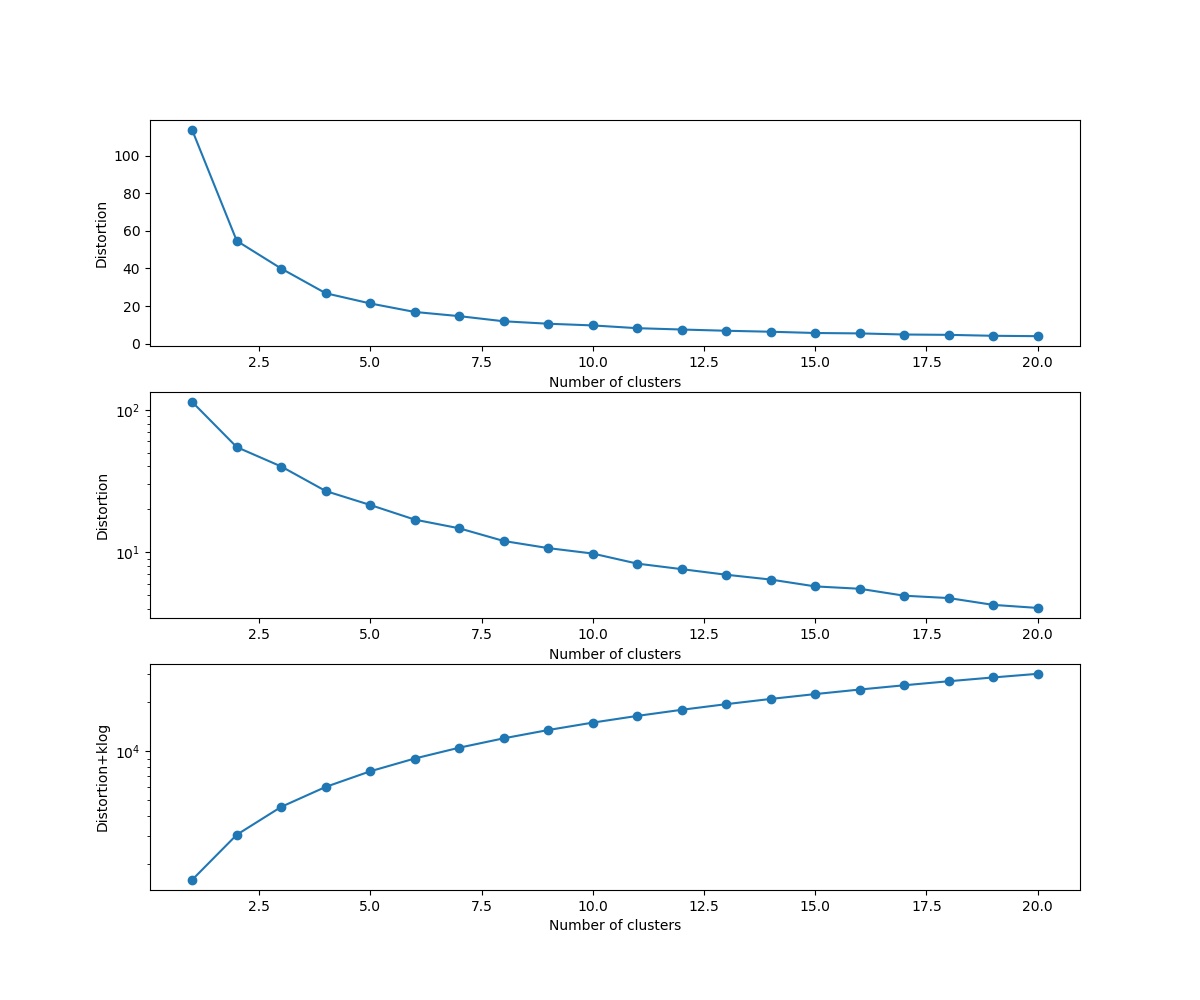
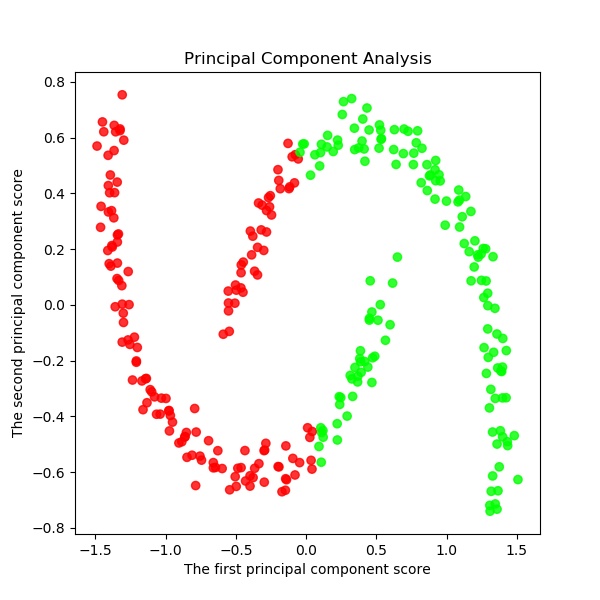

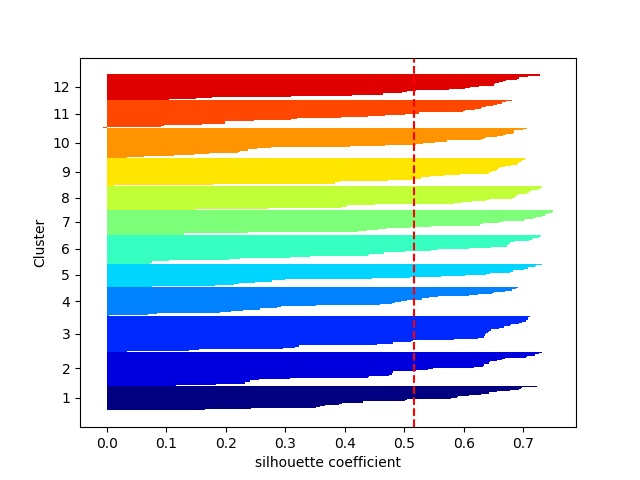
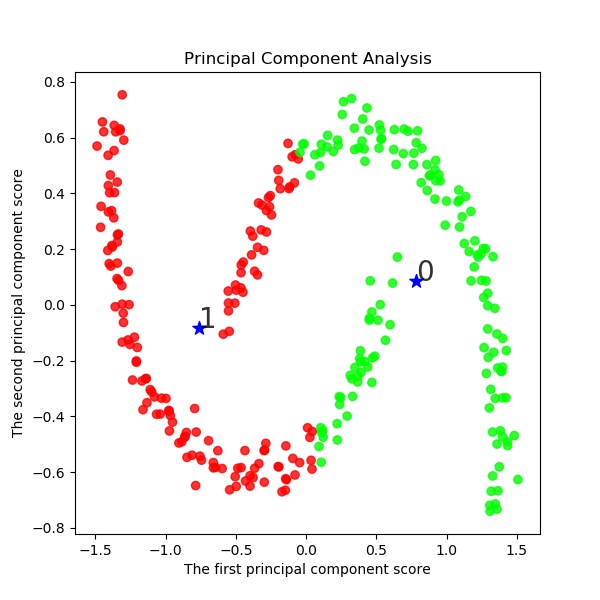
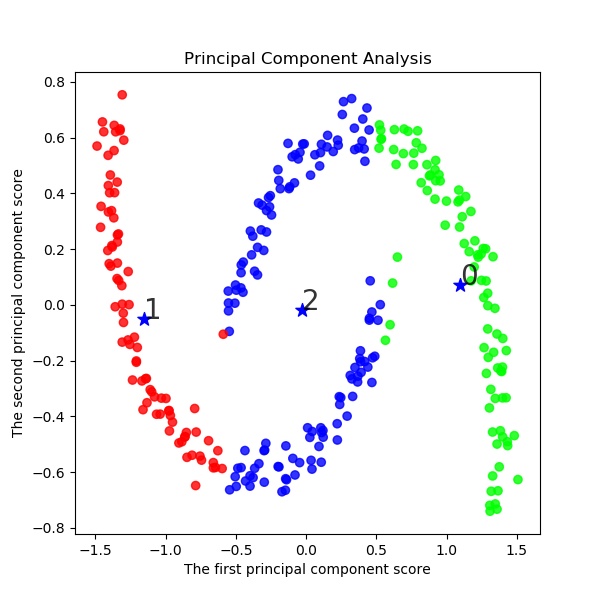


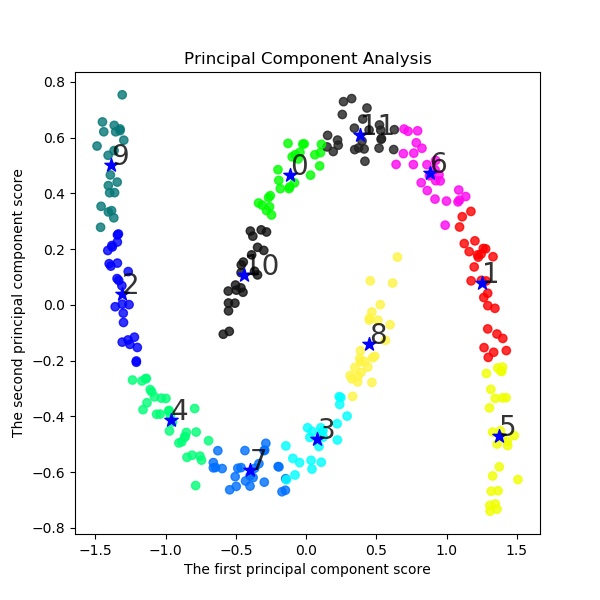
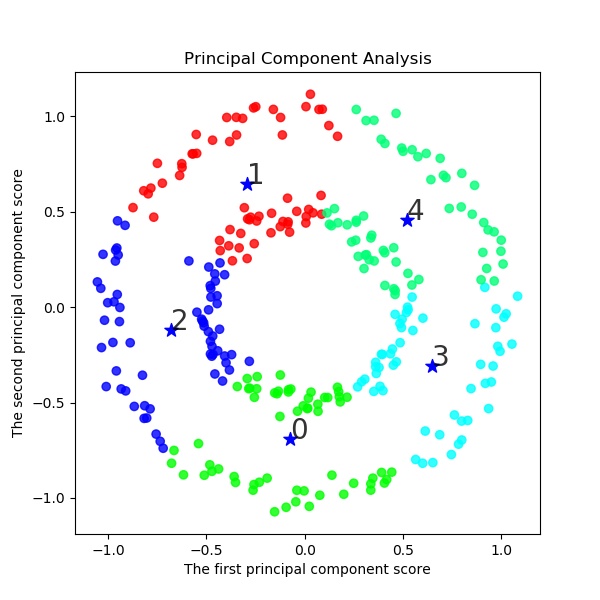
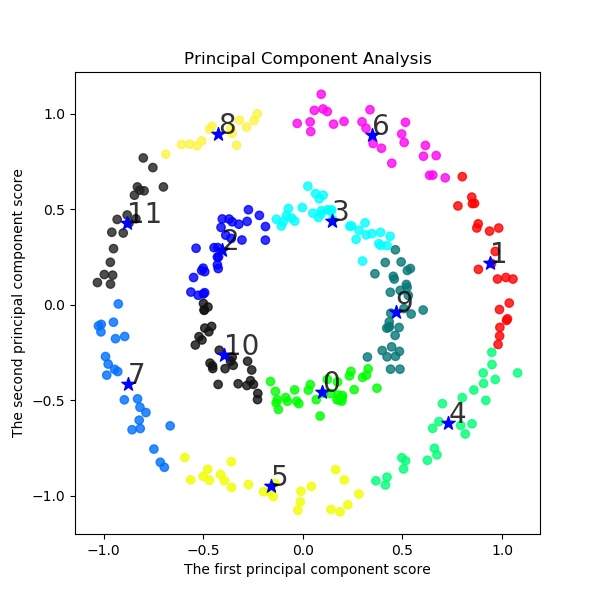
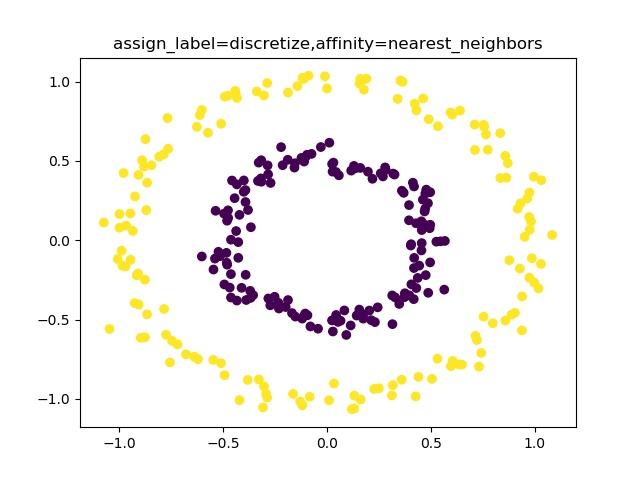
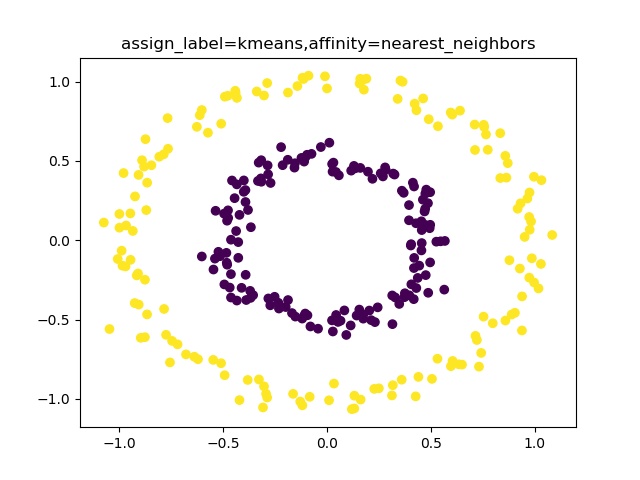
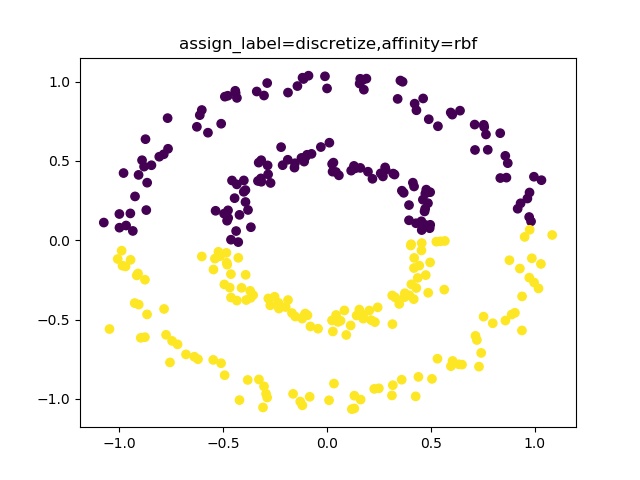
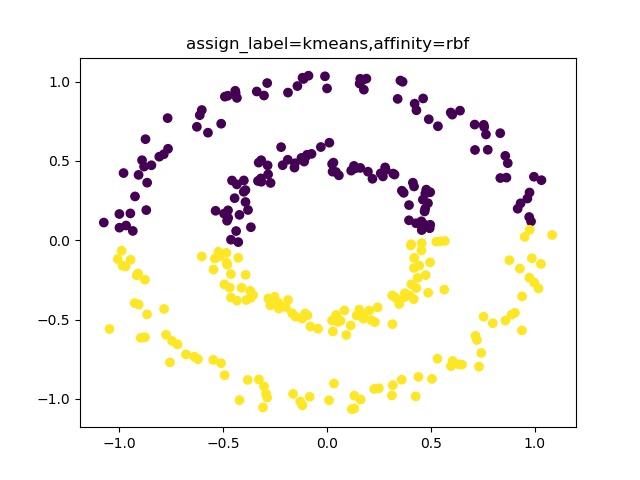
- 投稿日:2019-03-02T15:57:31+09:00
【日本語版】fast.ai Data Block API解説
本記事はfast.aiのwikiのData Blockページの要約となります。
筆者の理解した範囲内で記載します。概要
training, validation, testに用いるデータの読み込みを行うためのDataBunchの設定をわずか数行のコードで行うことができる!
細かく設定できる非常にフレキシブルなAPI
今回は以下の7つの例を用いていきます。
1. Binary Classification
2. Multi Label Classification
3. Mask Segmentation
4. Object Detection
5. Text Language Model
6. Text Classification
7. Tabular1. [Binary Classification] 最初に、MNISTを用いた例を挙げていきます。
from fastai.vision import *path = untar_data(URLs.MNIST_TINY) tfms = get_transforms(do_flip=False) path.ls()(path/'train').ls()肝心のDataBlockは下から!
data = (ImageList.from_folder(path) #どこからのデータか? -> pathの中のフォルダとサブフォルダで、ImageList .split_by_folder() #train/validをどのように分けるか? -> フォルダをそのまま用いる .label_from_folder() #labelをどのように付けるか? -> フォルダの名前から転用する .add_test_folder() #testを付け足す .transform(tfms, size=64) #Data augmentationを用いるか? -> size64のtfmsを用いる .databunch()) #DataBunchへと変換するDataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(3, figsize=(6,6), hide_axis=False)
すげええええ、本当にたった数行でtrain/validation/testに分けてdata augmentation用いたdatabunchを作成できた!
2. [Multi Label Classification] 次は、planetを用いた例を挙げていきます。
planet = untar_data(URLs.PLANET_TINY) planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)data = (ImageList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg') #どこからのデータか? -> planet内のtrainフォルダで、ImageList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_df(label_delim=' ') #labelをどのように付けるか? -> csvファイルを用いる .transform(planet_tfms, size=128) #Data augmentationを用いるか?-> size128のtfmsを用いる .databunch()) #DataBunchへと変換する同様にDataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(rows=2, figsize=(9,7))
きちんとmulti-label-classificationが読み込めていますね。
3. [Mask Segmentation] camvidを用いた例を挙げていきます。
camvid = untar_data(URLs.CAMVID_TINY) path_lbl = camvid/'labels' path_img = camvid/'images'codes = np.loadtxt(camvid/'codes.txt', dtype=str); codeslabelを付け足す関数を自作します。
python
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
tfm_y=Trueによって、data_augmentationが元々のmaskにも適用されるそう。
python
data = (SegmentationItemList.from_folder(path_img)
#どこからのデータか? -> path_imgで、SegmentationItemList
.random_split_by_pct()
#train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ
.label_from_func(get_y_fn, classes=codes)
#labelをどのように付けるか? -> get_y_func
.transform(get_transforms(), tfm_y=True, size=128)
#Data augmentationを用いるか?-> Standard transforms で tfm_y=True, size=128を指定
.databunch())
#DataBunchへと変換する
出力します。
data.show_batch(rows=2, figsize=(7,5))
簡単すぎ、、なのにすげええええ
どんどんいきます。4. [Object Detection] cocoを用いた例を挙げます。
coco = untar_data(URLs.COCO_TINY) images, lbl_bbox = get_annotations(coco/'train.json') img2bbox = dict(zip(images, lbl_bbox)) get_y_func = lambda o:img2bbox[o.name]data = (ObjectItemList.from_folder(coco) #どこからのデータか? -> cocoで、ObjectItemList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_func(get_y_func) #labelをどのように付けるか? -> get_y_func .transform(get_transforms(), tfm_y=True) #Data augmentationを用いるか?-> Standard transforms で tfm_y=True .databunch(bs=16, collate_fn=bb_pad_collate)) #DataBunchへと変換する -> bb_pad_collateによって一部のbbを出力data.show_batch(rows=2, ds_type=DatasetType.Valid, figsize=(6,6))
細かい設定をいじって非常にフレキシブルなAPIですね
5. [Text Language Model] IMDBを用いた例を挙げます。
from fastai.text import *imdb = untar_data(URLs.IMDB_SAMPLE)data_lm = (TextList.from_csv(imdb, 'texts.csv', cols='text') #どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_for_lm() #labelをどのように付けるか? -> Language Modelから .databunch()) #DataBunchへと変換するdata_lm.show_batch()
これだけでLanguage Modelを鍛えることができます。
6. [Text Classification] IMDBを用いた例を挙げます。
上のLanguage Modelを延長して、
python
data_clas = (TextList.from_csv(imdb, 'texts.csv', cols='text')
#どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList
.split_from_df(col='is_valid')
#train/validをどのように分けるか? -> 'is_valid' column にて分割
.label_from_df(cols='label')
#labelをどのように付けるか? -> 'label' column dfを参照する
.databunch())
#DataBunchへと変換する
完成!
data_clas.show_batch()
7. [Text Classification] IMDBを用いた例を挙げます。
from fastai.tabular import *adult = untar_data(URLs.ADULT_SAMPLE) df = pd.read_csv(adult/'adult.csv') dep_var = 'salary' cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country'] cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain'] procs = [FillMissing, Categorify, Normalize]data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs) #どこからのデータか? -> dfからのTabular List .split_by_idx(valid_idx=range(800,1000)) #train/validをどのように分けるか? -> val_idxの800から1000 .label_from_df(cols=dep_var) #labelをどのように付けるか? -> dep var=ターゲットを用いる .databunch()) #DataBunchへと変換するdata.show_batch()
以上となります。
個人的な振り返り
- 継続的にアウトプットすることでfast.aiの理解度を深め, fast.ai の掲げているdemocratizationへ寄与する。
- より深い部分のコードを解説していく。
- 次回、DataBlockのより細かい設定のAPIを解説していこうと思います。
最後に
間違いやご指摘などが御座いましたらご教示願います!!






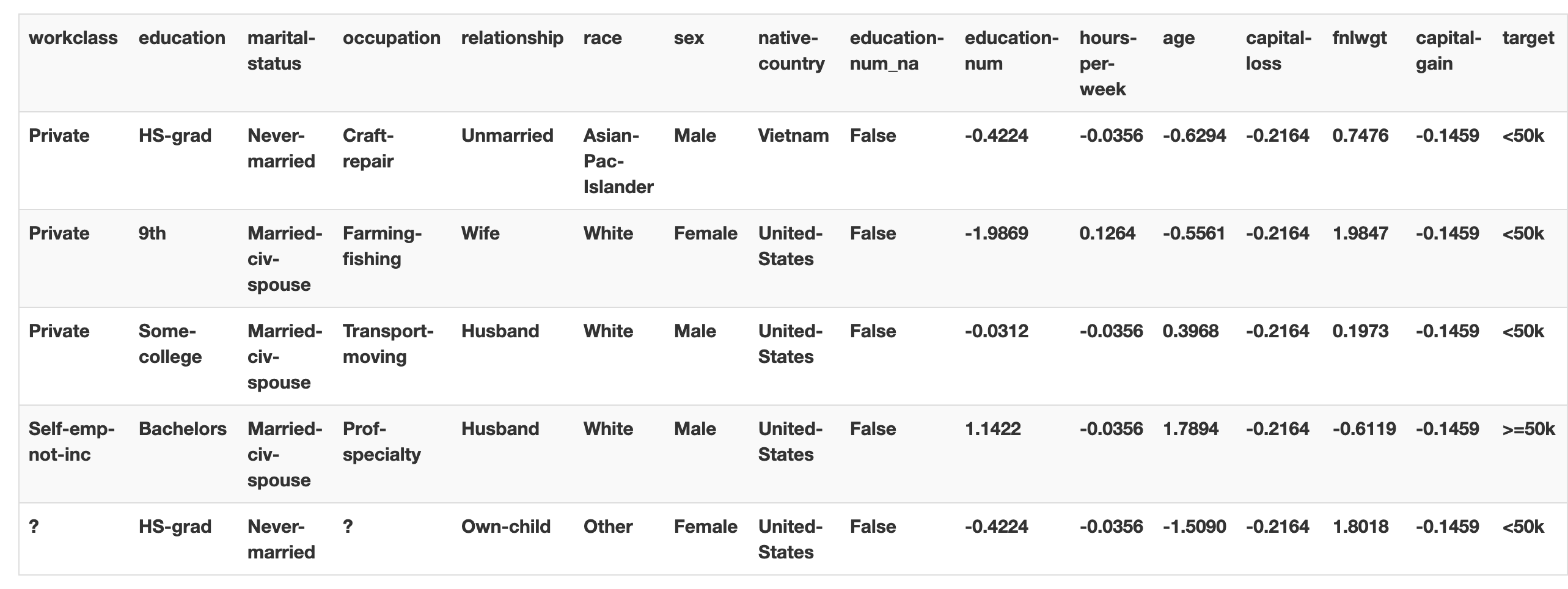
- 投稿日:2019-03-02T15:45:53+09:00
matplotlibのcolormapのRGB情報取得と関連操作
はじめに
自作カラーマップ操作についていろいろなサイトを検索するのが面倒だと感じたので,解析と整理を行うことにした.
下記のコマンドはJupyterでそのまま実行可能(冒頭に%matplotlib inlineを忘れずに).colormap情報の取得【plt.get_cmap()とColormapクラス】
デフォルトのcolormapに関する情報は,plt.get_cmap()から取得する.
import numpy as np import matplotlib.pyplot as plt cm_name = 'jet' # B->G->R cm = plt.get_cmap(cm_name) print(type(cm)) # matplotlib.colors.LinearSegmentedColormapデフォルトのカラーマップは256段階で色が変化する.
この段階の数字および各段階のRGB情報は以下のように取得できる.print(cm.N) # 256 cm(0) # (R,G,B,alpha) = (0.0, 0.0, 0.5, 1.0)たとえば,各色ごとの値を段階的に取得しようとすれば,下記のようになる.
Rs = [] Gs = [] Bs = [] As = [] for n in range(cm.N): Rs.append(cm(n)[0]) Gs.append(cm(n)[1]) Bs.append(cm(n)[2]) As.append(cm(n)[3])これを用いて,グラフを描画してみる.
0から1までの値をとる1次元配列と,それを2段重ねただけの2次元配列を作成する,後者はカラーバーっぽい画像をimshow()で表示するために用いる.# 1d array gradient = np.linspace(0, 1, cm.N) # 2d array (for imshow) gradient_array = np.vstack((gradient, gradient))色段階ステップを横軸にとったRGB値のグラフと,その下にカラーバーを描画するコード.
fig = plt.figure() ax = fig.add_axes((0.1,0.3,0.8,0.6)) ax.plot(As,'k',label='A') ax.plot(Rs,'r',label='R') ax.plot(Gs,'g',label='G') ax.plot(Bs,'b',label='B') ax.set_xlabel('step') ax.set_xlim(0,cm.N) ax.set_title(cm_name) ax.legend() ax2 = fig.add_axes((0.1,0.1,0.8,0.05)) ax2.imshow(gradient_array, aspect='auto', cmap=cm) ax2.set_axis_off()
他のカラーバーについても同様にRGB情報を抽出すると結構面白い.
色段階の変更【plt.get_cmap(cm_name, N)】
デフォルトで256段階とされている色分け段階を,例えば10段階に変更すると,下記のようになる.
cm10 = plt.get_cmap(cm_name,10) print(cm10.N) # 10先ほどと同様にRGB情報を取得するとそのふるまいが分かる.
R10s = [] G10s = [] B10s = [] A10s = [] for n in range(cm10.N): R10s.append(cm10(n)[0]) G10s.append(cm10(n)[1]) B10s.append(cm10(n)[2]) A10s.append(cm10(n)[3]) gradient10 = np.linspace(0, 1, cm10.N) gradient10_array = np.vstack((gradient10, gradient10)) fig = plt.figure() ax = fig.add_axes((0.1,0.3,0.8,0.6)) ax.plot(A10s,'k',label='A') ax.plot(R10s,'r',label='R') ax.plot(G10s,'g',label='G') ax.plot(B10s,'b',label='B') ax.set_xlabel('step') ax.set_xlim(0,cm10.N) ax.set_title(cm_name) ax.legend() ax2 = fig.add_axes((0.1,0.1,0.8,0.05)) ax2.imshow(gradient10_array, aspect='auto', cmap=cm10) ax2.set_axis_off()
なお,256段階以上の数字を入力してもちゃんとなめらかにRGB値を計算してくれる(下はviridisに対してN=5000を入力した結果).
離散値を指定した離散カラーマップの定義【BoundaryNorm()】
ここでは,描画に用いる値と色段階とを対応させることにより,色段階スケールを変更したいと思う.これを,「ノルム(norm)を変化させる」と呼ぶ.
valuesに対応させたノルムを定義するには,BoundaryNorm()を用いる.from matplotlib.colors import BoundaryNorm values = [0, 0.05, 0.10, 0.20, 0.50, 0.80, 0.90, 0.95, 1.00] norm = BoundaryNorm(values, ncolors=cm.N)ここでは,valuesの中にある要素で隔てられた値の間隔(”0-0.05,0.05-0.10,...”)の数だけ,0~(ncolors-1)までのncolors個の数字をを等間隔に区切る.
下記では,normに数字を代入して色段階のint値を取り出している.valuesの端の数字に対して0と255が割り当てられているほか,0.5を境に色段階が変化していることが分かる.print(norm.N) # 9 print(norm.boundaries) # array([0., 0.05, 0.1,...,1.]) print(norm(0)) # 0 print(norm(1)) # 255 print(norm(0.48)) # 109 print(norm(0.49)) # 109 print(norm(0.50)) # 145 print(norm(0.51)) # 145注意すべきなのは,valuesで指定しているのは値の間隔の端の数字(植木算で言う植木の位置座標)であり,色段階はそれより一つ小さい数だけ作成される点である.
cm_constでこの「一つ小さい数」を指定して作成したカラーマップと比較してほしい.cm_const = plt.get_cmap(cm_name,len(values)-1) fig = plt.figure() # real value (0-1) vs norm value (0-255) ax = fig.add_axes((0.1,0.5,0.8,0.4)) ax.plot(gradient, norm(gradient),'b') ax.set_xlabel('step value (0-1)') ax.set_xlim(0,1) ax.set_title('jet') # Colormap with norm ax2 = fig.add_axes((0.1,0.3,0.8,0.05)) ax2.imshow(gradient_array, aspect='auto', cmap=cm, norm=norm) ax2.set_axis_off() # Linear step colormap ax3 = fig.add_axes((0.1,0.2,0.8,0.05)) ax3.imshow(gradient_array, aspect='auto', cmap=cm_const) ax3.set_axis_off() # Default (256 step) colormap ax4 = fig.add_axes((0.1,0.1,0.8,0.05)) ax4.imshow(gradient_array, aspect='auto', cmap=cm) ax4.set_axis_off()
外れ値の色指定とカラーバーの拡張【set_over,set_under】
ノルムで定義されたの最大値と最小値の外側の値を代入した際のふるまいは,norm.clipがTrueであるかFalseであるかで異なる.Trueであれば端の色が延長され,False (default)であれば新規に定義されるその外側の色が指定される.
下記ではclipをTrueとしたnormT,FalseとしたnormFを作成し,外れ値を代入したときの色段階を確認している.from copy import copy print(norm(0)) # 0 print(norm(1)),'\n' # 255 # clip=False normF = copy(norm) normF.clip = False print(normF(-1)) # -1 print(normF(2)),'\n' # 256 # clip=True normT = copy(norm) normT.clip=True print(normT(-1)) # 0 print(normT(2)) # 255外れ値に対する色は,set_over(),set_under()で指定する.
cm.set_over('purple') cm.set_under('gray')外れ値も含めたカラーマップを描画する.同時に,imshowで表示したカラーマップに対するカラーバーもfig.colorbar()で表示する.こちらは,デフォルトでは長方形の形をしているが,extendオプションを'both'に設定すると,三角形の外れ値色を表示させることができる.
# new gradient including out-of-range values new_gradient = np.linspace(-0.2, 1.2, 300) new_gradient_array = np.vstack((new_gradient, new_gradient)) fig = plt.figure() # upper-side outputs of normF & normT ax = fig.add_axes((0.1,0.7,0.8,0.2)) ax.plot(new_gradient, normF(new_gradient),'b',label='clip=F') ax.plot(new_gradient, normT(new_gradient),'r',label='clip=T') ax.set_ylim(254,257) ax.set_title(cm_name) ax.legend() # lower-side outputs of normF & normT ax1 = fig.add_axes((0.1,0.5,0.8,0.2)) ax1.plot(new_gradient, normF(new_gradient),'b',label='clip=F') ax1.plot(new_gradient, normT(new_gradient),'r',label='clip=T') ax1.set_ylim(-2,1) ax1.set_xlabel('gradient (0-1)') ax1.set_xlim(-0.2,1.2) # colormap with normF ax2 = fig.add_axes((0.1,0.3,0.8,0.05)) im = ax2.imshow(new_gradient_array, aspect='auto', cmap=cm, norm=normF) ax2.set_axis_off() # colormap with normT ax3 = fig.add_axes((0.1,0.2,0.8,0.05)) ax3.imshow(new_gradient_array, aspect='auto', cmap=cm, norm=normT) ax3.set_axis_off() # colorbar (extended) cax = fig.add_axes((0.1,0.1,0.8,0.05)) fig.colorbar(im,cax=cax, orientation='horizontal', extend='both')
終わりに
- 描画に用いる値→(norm)→色段階→(colormap)→RGB値
- カラーマップは,デフォルトで256段階のRGB情報をもつ
- 256段階はそれより小さい数にも大きい数にも変更可能(Nを指定)
- normの作成にはBoundaryNorm()などを用いる(他には対数用のLogNormなど)
- 外れ値の色を扱うためには,cm.set_under()とcm.set_over().
- このときカラーバーはextend='both'とする

- 投稿日:2019-03-02T15:26:31+09:00
LinuxマシンのサービスをDockerに移行するスクリプトを書いた
実行中のLinuxマシンからDockerのベースイメージを生成するスクリプトを書いてみました。
https://github.com/hidakanoko/vm2container
このスクリプトは指定されたパッケージの依存性を解決して、パッケージに含まれるコマンドを実行する(プロセスを起動する)のに必要なファイルを集めてDockerのベースイメージを作ります。
RPMを使ったシステムなら動くはずですが、今のところCentOS7でしかテストしていません...
実用性は低いような気がしますが、古いマシンをDockerに乗せ換えてとりあえず延命したいようなケースでは役に立つかも?
使い方
スクリプトのダウンロード
# git clone https://github.com/hidakanoko/vm2container.git Cloning into 'vm2container'... remote: Enumerating objects: 131, done. remote: Counting objects: 100% (131/131), done. remote: Compressing objects: 100% (79/79), done. remote: Total 131 (delta 68), reused 99 (delta 44), pack-reused 0 Receiving objects: 100% (131/131), 34.22 KiB | 0 bytes/s, done. Resolving deltas: 100% (68/68), done.Helpの表示
# cd vm2container/ # bin/v2c -h usage: vm2container [-h] [-p PACKAGE] [-s] [-l] [-a] [-d DIRECTORY] [-v VERBOSE] Create docker image from running full Linux environment. optional arguments: -h, --help show this help message and exit -p PACKAGE, --package PACKAGE -s, --showDeps -l, --listFiles -a, --createArchive -d DIRECTORY, --directory DIRECTORY -v VERBOSE, --verbose VERBOSE ERROR, WARN, INFO, DEBUGパッケージの依存関係をツリー表示する
-p <PACKAGE>で起動したいコマンドを含むパッケージを指定します。下記サンプルでは/usr/sbin/httpdを起動するためhttpdパッケージを指定しています。
-sで指定されたパッケージの依存関係を表示します。# bin/v2c -p httpd -s * Resolving dependency for httpd... done! INFO: Total 115 package(s) found httpd shadow-utils audit-libs libcap-ng glibc glibc-common libselinux pcre glibc [*] libstdc++ libgcc glibc [*] libgcc [*] glibc [*] libsepol glibc [*] bash ncurses-libs libstdc++ [*] libgcc [*] ncurses-base glibc [*] glibc [*] bash [*] tzdata glibc [*] nss-softokn-freebl (...omit) INFO: [*]=Child dependencies are omitted as already described above.依存性ツリーの中で同じパッケージが繰り返し現れるため、表示済のパッケージの依存関係は省略されます。(末尾に"[*]"がついているパッケージ)
プロセスの起動に必要なファイルを一覧表示する
-lで指定されたパッケージと、その依存パッケージに含まれるすべてのファイルを一覧表示します。(rpm -qlで得られるもの)# bin/v2c -p httpd -l * Resolving dependency for bash... done! INFO: Total 41 package(s) found * Creating file list of 1 package(s) and its dependent packages... done! / /bin /bin/egrep /bin/fgrep /bin/grep /bin/sed /etc /etc/DIR_COLORS /etc/DIR_COLORS.256color /etc/DIR_COLORS.lightbgcolor /etc/GREP_COLORS /etc/X11 (...omit) /usr/share/man/ay/man7 (not found) /usr/share/man/ay/man7x (not found) /usr/share/man/ay/man8 (not found) (...omit) /var/run /var/run/setrans /var/spool /var/spool/lpd /var/spool/mail /var/tmp /var/yp INFO: Total 18684 file(s) found, however 13176 file(s) are not present in the file systemパッケージのファイルリストに含まれているものの、ファイルシステム内に存在しないファイルは末尾に"(not found)"がついています。
ユーザーが削除したファイルや、ghostファイルはすでにファイルシステムに存在しないためこのように表示しています。Dockerのイメージを作成する
-aでDockerイメージを作成します。Webコンテンツとhttpdのユーザー設定ファイルを含めるため
-d <DIRECTORY>オプションで/var/www/htmlと/etc/httpd/conf.dをアーカイブに含めるよう指定しています。# ./bin/v2c -p httpd -d /var/www/html -d /etc/httpd/conf.d -a * Resolving dependency for httpd... done! INFO: Total 115 package(s) found * Creating file list of 1 package(s) and its dependent packages... done! INFO: Total 23237 file(s) found, however 13193 file(s) are not present in the file system * Creating archive... done! INFO: Archive created in /tmp/archive.tgzDockerイメージとしてインポートする
生成したアーカイブはそのままDockerにインポートして、ベースイメージとして利用できます。
コンテナ起動時にパラメータを省略できるよう、エントリーポイントとコマンドパラメーターを含めています。
# docker image import /tmp/archive.tgz v2c-httpd:20190302 -c "ENTRYPOINT [\"/usr/sbin/httpd\"]" -c "CMD [\"-DFOREGROUND\"]" sha256:7908fb6eb6f50618c688a51556b0348de5948fe0a855aa32b515a74182ca1bbeコンテナを起動する
# docker run -d --rm -p 8080:80 v2c-httpd:20190302 32409c65c9c5ed96103333461eda513fe1d7c9b842dfc4ad17e22258e155e9e6ブラウザで http://DOCKERHOST:8080/ にアクセスするとApacheのTest Pageが表示されます。
/var/www/htmlに何かコンテンツを置いているのであればそれにアクセスすることもできます。ざっくりとした仕組み
Dockerはnamespaceやcgroupなどの技術を使って作成したサンドボックス内でプロセスを起動する技術です。そのためイメージの中に必要なファイルがそろっていればプロセスを起動できるはずです。
Dockerのドキュメントにベースイメージの作り方がありますが、これはdebootstrapでパッケージを展開してアーカイブで固めているだけです。
https://docs.docker.com/develop/develop-images/baseimages/
つまり逆に考えれば、実行中の環境でパッケージの依存性を解決して必要なファイルをすべて集めればDockerイメージを作ることが出来るはずです。(という思いつきからこのスクリプトを組んでみました)
v2cコマンドはパッケージの依存ツリーを解決して(rpm -q --requires,rpm -q --whatprovidesなど)、依存パッケージのファイルをすべて集めて(rpm -ql)、tgzに固めています。前述のとおりDockerのベースイメージは基本的に必要なライブラリやコマンド、設定ファイルをtarで固めただけなので、このイメージはそのままベースイメージとしてインポート可能です。
TODO
- パッケージに含まれるドキュメントファイルを除外できるようにする
- DEBパッケージ対応
- ベースイメージ + レイヤーイメージを作れるようにする。例えばベースイメージにはコアパッケージを含めておいて、レイヤーイメージにWebサーバーやMariaDBを起動するためのファイルを含めるような感じ。
- 投稿日:2019-03-02T15:18:52+09:00
【Python】文字列から数字だけを取り出したい場合
"2019年"→"2019"、という感じでpythonで文字列から数字を取り出したかった。
ググると下の記事が。pythonで文字列から数字だけ取り出す
https://qiita.com/sakamossan/items/161db7418ade037f6f3dおお、簡単。
記事を参考するとこんな感じ。# 正規表現操作のライブラリ import re # re.sub(正規表現パターン, 置換後文字列, 置換したい文字列) # \D : 10進数でない任意の文字。(全角数字等を含む) num = re.sub("\\D", "", "2019年") print(num) # "2019"re.sub()が何となく正規表現で文字列を""に置換して消しているんだろうな。
と、ふわっとした理解だったのでドキュメントを読んだメモ。re.subの第一引数を記事では、r"\D"と書いていますが、これはraw文字列記法というらしい。
クォーテーションの前にrを書くことで、エスケープシーケンスである\を省略できるようです。
いつも"\\\\192.hogehoge\\C\\hogehoge"みたいなパスの書き方をしていたので今後はraw文字列記法とやらを使います。pythonは現場での独学なので、どんなに短くても人のコードを読むのは非常に勉強になります。
- 投稿日:2019-03-02T15:06:10+09:00
Simon Prince風のヒートマップをPythonで出したい
モチベーション
Simon J. D. Prince
"Computer Vision: Models, Learning, and Inference"
(http://www.computervisionmodels.com/)の中に出てくるヒートマップを、自分でも出してみたい!
実装
コード全体はこちら。(※補足参照)
実装といっても、高級なことは何もしてません。まずはインポートから。import numpy as np import matplotlib.pyplot as plt import matplotlib.mlab as mlab import seaborn as sns
seabornのインポートは必須ではありません。個人的な好みです。
続いてメッシュグリッドを作ります。# メッシュグリッドの作成 X, Y = np.mgrid[-5:5:200j, -5:5:200j]そしてこれらの格子点$(X, Y)$に対して、ガウス分布の値を求めます。
# 2次元ガウス分布 Z = mlab.bivariate_normal(X, Y, 2., 1., 0., 0.)なお、
bivariate_normalのI/Fは↓です。matplotlib.mlab.bivariate_normal(X, Y, sigmax=1.0, sigmay=1.0, mux=0.0, muy=0.0, sigmaxy=0.0)
そして可視化。
# ヒートマップを描画 plt.figure(figsize=(8, 6)) plt.pcolor(X, Y, Z, cmap=plt.cm.hot) plt.colorbar() plt.title('2次元ガウス分布') plt.xlabel('$x$', size=12) plt.ylabel('$y$', size=12) plt.xlim((-5, 5)) plt.ylim((-5, 5)) plt.show()するとこんな感じで表示されます。
よしよし。
※ちなみに
plt.contourを使うと、等高線を出すこともできます。(詳細はコード参照)
補足
- 2019/3/2現在、
bivariate_normalについては以下のワーニングが出ています。何に置き換えればよいのか?は不明。Deprecated since version 2.2: The bivariate_normal function was deprecated in Matplotlib 2.2 and will be removed in 3.1.
- 投稿日:2019-03-02T15:01:44+09:00
環境構築不要で機械学習hello worldする
概要
会社の開発合宿が毎年行われるのですが今年のテーマが機械学習なのでそのハンズオンを作りました.
目的としては「機械学習ライブラリをとりあえず触ってみる」に設定したので環境構築は不要でできるだけ敷居低くしました.
内容は,
- sklearnを使ったボストン
- lightgbmを使ったボストン
- kerasを使ったmnist
です.必要なもの
- googleアカウント 以上!
やり方
↓こちらのレポジトリのREADMEのリンクからcolaboratoryを開くだけ↓
https://github.com/tenajima/hello_machine_learningセルを実行するときに「本当に実行します?」みたいなのでます.githubのjupyterを開いてるためです.
チェックを外して実行するともう聞かれなくなります.以上!
まとめ
colaboratoryすごい.
githubのjuypyterも参照できるんですね.
しかも必要なライブラリはだいたい入ってる.便利.
さらっと機械学習するならcolaboratoryで十分.参考にさせてもらいました
- 投稿日:2019-03-02T12:47:55+09:00
Golangで簡単なweb backendを書いた
経緯
僕、普段はPythonとDjangoを使って
引きこもりしつつ飛び上がり自殺を考えながら独自にwebアプリを書いているのですが、最近ではRailsでもSinatraでもFlaskでもDjangoでもPyramidでもなく、Goとそのフレームワークを使ってバックエンドコードを書いている(ように見える)ウェブアプリが見られます。Goは並列処理がお得意な言語ということでよく知られていますが、今回、実際にGoでコードを書いてみて分かった事をまとめてみました。
書いたコード
使ったフレームワーク
分かったこと
Go言語そのものについて
Go言語それ自体は並列処理が言語機能の一つとして実装されているという点を除けば、非同期処理を得意とする他の言語(NodeJSなど)とほぼ同じような感じ?の印象を受けました。しかし、コンパイル型かつ並列・非同期処理が得意な言語という事で、Pythonなどと比べてウェブアプリを実装する時に飛躍的なスループットの向上が見込めるように思えます。(小並感
フレームワークについて
- 標準ライブラリ(
net/httpなど)はやっぱりWeb開発用途を意識されているようです。でも、DjangoのMiddleware的な概念はchiなど他のライブラリを使わないと面倒でした(小並感- GinはRESTful APIを書く時には使えると思いました。が、Restful APIを書くんだったらOpenAPI Generatorを使うよね、うん。
- GormはPythonで言うところのSQLAlchemy、Djangoで言うところのModel的な存在です。そして、ORMとしてのGormは至極普通でした。が、AutoMigration機能がDjangoのそれとは劣ります。(GormのAutoMigrationとDjangoのMigrationの比較参照)
- GQLGenでResolverを書く時に
ResponseWriterを参照できない。つまり、Backendとして認証機能を実装する場合はフロントエンド側でひと手間掛ける必要がある?(例: セッションのJWTをフロントエンドへペイロードとして渡してフロントエンド側でこいつをCookieなりヘッダなりにぶちこむ)- 認証機能はモノリシックに作るのではなく、別にライブラリとして提供したほうが良さそう。
GormのAutoMigrationとDjangoのMigrationの比較
機能 Gorm Django Tableの自動追加 ✔ ✔ Tableの自動削除 ❌ ✔ Tableの自動リネーム ❌ ✔ カラム自動追加 ✔ ✔ カラム自動削除 ❌ ✔ カラム自動変更 ❌ ✔ マイグレーションのバージョニング ❌(但しサードパーティー製ライブラリで対処可能?) ✔ マイグレーションの自動生成 ❌(その概念がない?) ✔ マイグレーションの手動記述 ✔ ✔ ...GormのAutoMigrationは実用に値しない?ORMの機能だけ頂いてMigration Manager的な代物を書いたほうが良さそう。
まとめ
GolangはAPIの開発には良さげだと思われますが、現状ではWebアプリのバックエンドとしての利用は難しい?ように思えました。また、Djangoではモデルデータの管理の為の画面(
django.contrib.admin)があり、Golangも同様の機能が提供されている(QOR)ようですが筆者がこれを利用しようとしたところ、GQLGenの仕様?によってうまく使えませんでした。と、いうわけで、Golangはセッション、SQLのスキーママイグレーション、モデル管理を解決できればメインで使える言語に出来るんじゃないかと思いました まる
- 投稿日:2019-03-02T11:01:19+09:00
[Tensorflow] Tensorflow 2.0がくる
Tensorflowに公式による2.0からの変化点。
Upgrade code to TensorFlow 2.0
TensorFlow 2.0 includes many API changes, such as reordering arguments, renaming symbols, and changing default values for parameters. Manually performing all of these modifications would be tedious and prone to error. To streamline the changes, and to make your transition to TF 2.0 as seamless as possible, the TensorFlow team has created the
tf_upgrade_v2utility to help transition legacy code to the new API.The
tf_upgrade_v2utility is included automatically with apip installof TF 2.0. It will accelerate your upgrade process by converting existing TensorFlow 1.x Python scripts to TensorFlow 2.0.The conversion script automates as much as possible, but there are still syntactical and stylistic changes that cannot be performed by the script.
Compatibility module
Certain API symbols can not be upgraded simply by using a string replacement. To ensure your code is still supported in TensorFlow 2.0, the upgrade script includes a
compat.v1module. This module replaces TF 1.x symbols liketf.foowith the equivalenttf.compat.v1.fooreference. While the compatibility module is nice, we recommend that you manually proofread replacements and migrate them to new APIs in thetf.*namespace instead oftf.compat.v1.*namespace as quickly as possible.Because of TensorFlow 2.x module deprecations (for example,
tf.flagsandtf.contrib), some changes can not be worked around by switching tocompat.v1. Upgrading this code may require using an additional library (for example,absl.flags) or switching to a package in tensorflow/addons.Upgrade script
To convert your code from TensorFlow 1.x to TensorFlow 2.x, follow these instructions:
Run the script from the pip package
First,
pip installthetf-nightly-2.0-previewortf-nightly-gpu-2.0-previewpackage.Note:
tf_upgrade_v2is installed automatically for TensorFlow 1.13 and later (including the nightly TF 2.0 builds).The upgrade script can be run on a single Python file:
tf_upgrade_v2 --infile tensorfoo.py --outfile tensorfoo-upgraded.pyThe script will print errors if it can not find a fix for the code. You can also run it on a directory tree:
# upgrade the .py files and copy all the other files to the outtree tf_upgrade_v2 --intree coolcode --outtree coolcode-upgraded # just upgrade the .py files tf_upgrade_v2 --intree coolcode --outtree coolcode-upgraded --copyotherfiles FalseDetailed report
The script also reports a list of detailed changes, for example:
'tensorflow/tools/compatibility/testdata/test_file_v1_12.py' Line 65 -------------------------------------------------------------------------------- Added keyword 'input' to reordered function 'tf.argmax' Renamed keyword argument from 'dimension' to 'axis' Old: tf.argmax([[1, 3, 2]], dimension=0)) ~~~~~~~~~~ New: tf.argmax(input=[[1, 3, 2]], axis=0))All of this information is included in the
report.txtfile that will be exported to your current directory. Oncetf_upgrade_v2has run and exported your upgraded script, you can run your model and check to ensure your outputs are similar to TF 1.x.Caveats
Do not update parts of your code manually before running this script. In particular, functions that have had reordered arguments like
tf.argmaxortf.batch_to_spacecause the script to incorrectly add keyword arguments that mismap your existing code.This script does not reorder arguments. Instead, the script adds keyword arguments to functions that have their arguments reordered.
To report upgrade script bugs or make feature requests, please file an issue on GitHub. And if you’re testing TensorFlow 2.0, we want to hear about it! Join the TF 2.0 Testing community and send questions and discussion to testing@tensorflow.org.
+
Upgrade your existing code for TensorFlow 2.0 (Coding TensorFlow)
- 投稿日:2019-03-02T10:02:20+09:00
ロボット初心者のためのROS入門
概要
これからロボットをいじってみたい!
ロボットのソフトウェアってどんなのか気になる!という人向けの記事になります。ROS
Robot Operation System、略してROSと呼ばれるフレームワークを使ってロボットを動かしていきます。
Pepper君も実はROSで動いています、こう聞くと一気に身近に感じるのではないでしょうか。
ロボットは通常、止まるか動く、伸ばすか縮むなどと言った
単純な動きをすることしかできませんが
ROSというフレームワークを使うことで
Pepper君のような知的なロボットを動かすことができるようになるのです!
RobotのOS、略してROSと謳っていますが安心してください、中身はPythonとC++で動きます。
それではまず、環境構築から行いましょう。環境構築
- Windows10:自前で用意しましょう
- VMWare:https://my.vmware.com/jp/web/vmware/downloads
- Ubuntu16.04:https://www.ubuntulinux.jp/News/ubuntu1604-ja-remix
- ROS:Kinetic(コマンドラインでインストールしていきます。)
通常、ROSはwindowsやmacの上で動きません。Ubuntuの上でのみ動くので注意してください。なので環境としてはWindowsの上にVMでUbuntuを起動させ、その上でROSが走るといった具合になります。
もちろん、Ubuntu専用PCを作ってその上で走らせても構いません。
本記事では前者を取ります。Ubuntu16.04のダウンロード
適当に、どれか一つをダウンロードしましょう。わかんないけどKDDI研究所のやつが一番強そう。
WindowsにVMWareのインストール
windows環境にまずはVMWareをインストールしていきます。
VMWareとは1つのOSの上に、擬似的にもう1つのOSを立ち上げるためのツールです。VirtualBoxを使うこともできますが、ROSと物凄く相性が悪いので、特にこだわりがなければVMWareを使いましょう。
インストールが終わり、初回起動を行うとこのような画面が立ち上がると思います。VMWare Workstationsは個人で使う分には無料なので非営利目的をチェックしてすすめてください。
新規仮想マシンを追加し
インストラーディスクにはさっきインストールしてきたubuntuのOSを選択してください。
ここの画面は適当に各自入力してください。
Ubuntu上でROSのインストール
ターミナルで以下のコマンドをコピペして実行
sources.listを設定する
どこからパッケージをとってくるかの準備
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'鍵の設定
鍵を設定します。
sudo apt-key adv --keyserver hkp://ha.pool.sks-keyservers.net:80 --recv-key 421C365BD9FF1F717815A3895523BAEEB01FA116一度全部update
sudo apt-get updateいろいろカスタマイズしてインストールできるが、初心者はとりあえず全部入れておこう。
ROS Kineticのインストール
sudo apt-get install ros-kinetic-desktop-full
インストールするときはros-kinetic-desktop-fullで、rosのkineticバージョンを指定しているので間違えないように気をつけましょう。上記のインストールが終わったあと、一度だけ実行
sudo rosdep init
rosdep update
間違えてもう1回実行しても大丈夫、一回以上実行してればおk。パスの追加
新しいターミナルが立ち上がるたびに一々パスを通すのは面倒なので
bashrcにROSの環境変数を追加しておく。
echo "source /opt/ros/kinetic/setup.bash" >> ~/.bashrc
ワーキングディレクトリであるcatkin_wsもついでに環境変数に追加しておくと便利なのでbashrcに追加します。
$ mkdir -p ~/catkin_ws/src
$ cd ~/catkin_ws/src
$ catkin_init_workspace
$ cd..
catkin_wsの中で
$ catkin_make
を実行したあと、develのなかのsetup.bashをsourceします。
source devel/setup.bash
devel/setup.bashを毎回bashrcで読み込みたいので
bashrcに以下のように書き込みましょう。
source /PATH/catkin_ws/devel/setup.bash
PATHの部分は自分が作ったcatkin_wsの上の部分にあたるので各自書いてください。ROSのPython系のツールのインストール
sudo apt-get install python-rosinstall
を実行する。チュートリアルページにはいくつか選択肢があるけど
初心者はとりあえずフルパックでインストールしておけばおk。おめでとうございます!
ここまででエラーがなければ完全にインストールすることができました。
次回からは初心者のためのチュートリアルを行います。