- 投稿日:2019-03-02T21:35:19+09:00
Ruby 配列、ハッシュ
動作環境はMacです。
puts,print,p,ppメソッドの違い
irb(main):002:0> puts 'kaneko' kaneko => nil #変数の内容に改行を加えてメソッドの戻り値をターミナルに出力 irb(main):003:0> print 'kaneko' kaneko=> nil #改行なしでメソッドの戻り値をターミナルに出力 irb(main):004:0> p 'kaneko' "kaneko" => "kaneko" #pメソッドの戻り値は引数のオブジェクト デバック向け。 #デバックとはプログラムの不具合を見つけて修正すること。 ppメソッドはpメソッドより適切な改行をして出力する。 pメソッドで適切でない場合は、ppメソッドを使う。配列
- 複数のデータを格納できるオブジェクト。
- 配列内のデータは順番に並んでいて、添字(インデックス)を指定することで取り出すことができる。
配列の作成方法
空の配列を作る
[]3つの要素が格納された配列を作る
[要素1,要素2,要素3]実践
irb(main):003:0> a = [1, 2, 3, 'aa', [1, 2, 3]] #変数aに配列を代入 => [1, 2, 3, "aa", [1, 2, 3]] irb(main):004:0> a[0] => 1 irb(main):005:0> a[1] => 2 irb(main):006:0> a[3] => "aa" irb(main):007:0> a[2] => 3 irb(main):008:0> a[4] => [1, 2, 3] irb(main):009:0> puts a 1 2 3 aa 1 2 3 => nil irb(main):010:0> p a [1, 2, 3, "aa", [1, 2, 3]] => [1, 2, 3, "aa", [1, 2, 3]] irb(main):011:0> pp a NoMethodError: undefined method `pp' for main:Object Did you mean? p from (irb):11 from /Users/toripurug884/.rbenv/versions/2.4.1/bin/irb:11:in `<main>' irb(main):012:0> a.empty? #変数aが空か? => false irb(main):013:0> b = [] => [] irb(main):014:0> b.empty? => true irb(main):015:0> a.include?('aa') #変数aに'aa'が含まれるか? => true irb(main):016:0> a.include?('a') => false irb(main):017:0> a.reverse #配列の中身を反転 => [[1, 2, 3], "aa", 3, 2, 1] irb(main):018:0> a => [1, 2, 3, "aa", [1, 2, 3]] irb(main):019:0> a.reverse! #配列の中身を反転させる破壊的メソッド => [[1, 2, 3], "aa", 3, 2, 1] irb(main):020:0> a => [[1, 2, 3], "aa", 3, 2, 1] irb(main):021:0> a.shuffle #配列の中身をランダムに入れ替え => [2, 3, 1, "aa", [1, 2, 3]]配列を使ったメソッド(数値)
irb(main):022:0> (0..25).to_a #範囲オブジェクトを指定し、配列へ => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25] irb(main):024:0> a = (0..99).to_a.shuffle! #オブジェクトの中身を破壊的メソッドでランダムに入れ替える => [17, 1, 46, 12, 62, 69, 39, 40, 96, 87, 77, 50, 84, 56, 70, 7, 98, 19, 64, 8, 67, 89, 14, 33, 20, 29, 22, 51, 26, 18, 68, 57, 86, 47, 55, 48, 97, 44, 34, 42, 79, 30, 61, 6, 81, 13, 85, 0, 59, 71, 65, 99, 75, 72, 23, 66, 63, 5, 15, 49, 91, 36, 35, 38, 94, 45, 95, 11, 41, 2, 4, 10, 31, 54, 88, 43, 32, 28, 73, 92, 3, 58, 80, 16, 27, 82, 52, 25, 9, 60, 90, 74, 93, 21, 24, 83, 37, 53, 78, 76] irb(main):025:0> a #中身が入れ替わる => [17, 1, 46, 12, 62, 69, 39, 40, 96, 87, 77, 50, 84, 56, 70, 7, 98, 19, 64, 8, 67, 89, 14, 33, 20, 29, 22, 51, 26, 18, 68, 57, 86, 47, 55, 48, 97, 44, 34, 42, 79, 30, 61, 6, 81, 13, 85, 0, 59, 71, 65, 99, 75, 72, 23, 66, 63, 5, 15, 49, 91, 36, 35, 38, 94, 45, 95, 11, 41, 2, 4, 10, 31, 54, 88, 43, 32, 28, 73, 92, 3, 58, 80, 16, 27, 82, 52, 25, 9, 60, 90, 74, 93, 21, 24, 83, 37, 53, 78, 76] irb(main):026:0> z = (0..10).to_a => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] irb(main):027:0> z[0] => 0 irb(main):028:0> z[1] => 1 irb(main):029:0> z => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] irb(main):030:0> z << 20 #末尾に20を追加 pushとイコール => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):031:0> z.push(30) #末尾に30を追加 <<とイコール => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 30] irb(main):033:0> z.pop #末尾の数値を削除 => 30 irb(main):034:0> z => [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):035:0> z.shift #先頭の数値を削除 => 0 irb(main):036:0> z << 3 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3] irb(main):037:0> z => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3] irb(main):038:0> z << 3 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3] irb(main):039:0> z << 6 => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3, 6] irb(main):040:0> z => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 3, 3, 6] irb(main):041:0> z.uniq #被っている数値を出力しない => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):042:0> z.uniq! #破壊的メソッド => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20] irb(main):043:0> z #3と6が出力されない => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20]配列を使ったメソッド(文字列)
irb(main):044:0> a = [ "my", "name", "is", "nakamura"] => ["my", "name", "is", "nakamura"] irb(main):045:0> a => ["my", "name", "is", "nakamura"] irb(main):046:0> a.join #配列の中身を結合 => "mynameisnakamura" irb(main):048:0> a.join(' ') #配列の中身を結合し、スペースを開ける スプリット => "my name is nakamura" irb(main):049:0> a.join('_') => "my_name_is_nakamura" irb(main):050:0> a.sort #配列の中身を入れ替える => ["is", "my", "nakamura", "name"] irb(main):051:0> a.sort.reverse #配列の中身を逆にする => ["name", "nakamura", "my", "is"] irb(main):053:0> a => ["my", "name", "is", "nakamura"] irb(main):054:0> a.sort!.reverse! #破壊的メソッド => ["name", "nakamura", "my", "is"] irb(main):055:0> a.size #配列に入っているデータ数の出力 => 4ハッシュ
- キー(key)と値(value)でデータの管理をするオブジェクト
- 連想配列、マップ、ディクショナリと呼ばれる場合もある
作成方法
空のハッシュを作成
{}キーと値の組み合わせを3つ格納するハッシュ
{ キー1 => 値1, キー2 => 値2, キー3 => 値3 }
実践
irb(main):001:0> {} => {} #空のブランケット作成 irb(main):002:0> kaneki = {'name' => 'ken', 'birthplace' => 'saga'} #変数kanekiにハッシュで代入 => {"name"=>"ken", "birthplace"=>"saga"} irb(main):003:0> kaneki => {"name"=>"ken", "birthplace"=>"saga"} irb(main):007:0> puts kaneki['name'] ken => nil #nameキーを出力 irb(main):009:0> puts kaneki['birthplace'] saga #birthplaceキーを出力 => nil irb(main):010:0> kaneki['age'] = 20 => 20 #ageキーを追加 irb(main):011:0> kaneki => {"name"=>"ken", "birthplace"=>"saga", "age"=>20} irb(main):013:0> kaneki['age'] = 21 => 21 #ageキーを書き換え irb(main):014:0> kaneki => {"name"=>"ken", "birthplace"=>"saga", "age"=>21} irb(main):017:0> kaneki.delete('age') #ageキーを削除 => 21 irb(main):019:0> puts kaneki {"name"=>"ken", "birthplace"=>"saga"} => nilシンボル
・ソースコード上は文字列に見えるが、内部では整数として扱われる
・文字列を使う場合よりシンボルを使った方が処理が速い
実践
irb(main):031:0> imawano.keys #変数が持つキーを出力 => [:name, :birthplace] irb(main):032:0> imawano.values #変数が持つ値の出力 => ["kiyosirou", "okinawa"] irb(main):034:0> imawano.has_key?(:name)#変数が引数に渡されるキーを持っているか? => true #持っているのでtrue irb(main):035:0> imawano.has_key?(:id) => false #持っていないのでfalse irb(main):036:0> imawano.size #変数に入っているキーの数 => 2
- 投稿日:2019-03-02T21:30:57+09:00
『オブジェクト指向設計実践ガイド』に学ぶ単一責任のクラス設計
『オブジェクト指向設計実践ガイド』の「第2章:単一責任のクラスを設計する」のまとめです。
ポイント:「クラスに属するものをどのように決めるか」
・クラスを使い、"今すぐに"求められている動作を行い、かつ"あとにも"かんたんに変更できるようにする
・設計とは、アプリケーションの可変性を保つために技巧を凝らすことであり、完璧を目指すものではない
変更がかんたんなようにコードを組成する
「変更がかんたんである」とは1.変更は副作用をもたらさない 2.要件の変更が小さければ、コードの変更も相応して小さい 3.既存のコードはかんたんに再利用できる 4.最もかんたんな変更方法はコードの追加。ただし追加するコードはそれ自体変更が容易なものどんな性質のコードを書けばいいか?
「変更がかんたんなコード」の定義を受けて、実際にコードを書くときには「TRUEなコード」を心がける。
「TRUEなコード」1.見通しが良い(Transparent):変更がもたらす影響が明白 2.合理的(Reasonable):かかるコストは変更がもたらす利益にふさわしい 3.利用性が高い(Usable):新しい環境、予期していなかった環境でも再利用できる 4.模範的(Exemplary):コードに変更を加える人が、上記の品質を自然と保つようなコードになっている・TRUEなコードを書くための最初の第一歩は、「それぞれのクラスが、明確に定義された単一の責任を持つように徹底する」こと
単一の責任を持つクラスをつくる
・クラスはできる限り最小で有用なことをするべき -> 単一の責任を持つべき
・クラスになるにふさわしいもの -> 「データ」と「振る舞い」Q.なぜ単一責任が重要なのか
A.2つ以上の責任を持つクラスは、アプリケーションが予期せず壊れる可能性があるから
->変更が加わるたびに、クラスに依存するクラスを全て破壊する可能性があるクラスが単一責任かどうかを見極める
Q.あるクラスが、別のどこかに属する"振る舞い"を含んでいるかどうかを見極める方法は?
A1.あたかもそれに"知覚"があるかのように仮定して問いただす。
->クラスの持つメソッドを質問に言い換えたときに、意味をなす質問になっているべき
例)「〇〇クラスさん、あなたの××を教えてください」 <-理にかなった質問になっているか?A2.1文でクラスを説明したときに、「それと」「または」が含まれない
・「クラスでできる限り最小で有用なことをすべき」 => 「かんたんに説明できるものであるべき」
・「それと」が含まれる => おそらく2つ以上の責任を負っている
・「または」が含まれる => クラスの責任が2つ以上あるだけでなく、互いにあまり関連しない責任を負っている設計を決定する時を見極める
・「早い段階で設計を決定しなければ」という気持ちに駆られるのはダメ
・何もしないことによる将来的なコストが今と変わらない時、設計の決定は延期する
・決定は必要なときにのみ、その時点で持っている情報を使ってする単一責任の概念はクラス以外のコードでも役立つ
メソッドから余計な責任を抽出する
・単一責任にすることで、メソッドの変更も再利用もかんたんになる
・メソッドに対しても、役割がなんであるか質問をし、また1文で責任を説明できるようにするとわかりやすい
・「単に振る舞いを別のメソッドに分離する」リファクタリングは、最終的な設計がわかっていない段階でも実施すべき単一責任のメソッドがもたらす恩恵
1.隠蔽された性質を明らかにする 2.コメントをする必要がない 3.再利用を促進する 4.他のクラスへの移動がかんたん1.隠蔽された性質を明らかにする
クラス内のメソッドを他のクラスに再編する意図がなくても、それぞれのメソッドが単一の目的を果たすようにすることによって、クラスが行うこと全体がより明確になる
2.コメントをする必要がない
もしメソッド内のコードにコメントが必要な部分があれば、その部分のコードを別のメソッドに抽出する。
別のメソッドに抽出した新しいメソッドの名前が、コメントの目的を果たす。3.再利用を促進する
メソッドを小さくすることで、アプリケーションにとって健康的なコードの書き方を促進する。
4.他のクラスへの移動がかんたん
設計のための情報が増え変更をしようと決めたとき、小さなメソッドならかんたんに動かせる。
移動のためにいくつものリファクタリングやメソッドの抽出もする必要がない。クラス内の余計な責任を隔離する
・いったん全てのメソッドを単一責任にしてしまえば、クラスのスコープはより明白に
・単一責任にこだわり、余計な振る舞いをそのクラスに「あるorない」の二択にするのは短絡的すぎる
⇨設計の目的は、設計に手を加える数を可能な限り最小にしつつ、クラスを単一責任に保つこと
⇨普段から変更可能なコードを書いておくことで、どうしてもしなければならない時まで決断を先延ばしすることができる終わり
単一責任とか、ただ書籍で読んで知った知識はなかなか理解できないのですが、ちょうどこの章を読んでいるときに自分の初めて作ったサービスのコードを思い出しました。
それはメソッド部分だったのですが、コードを読み直すと明らかに単一責任ではない部分があったので実践しました。
明らかにメソッドもシンプルに、かつ読みやすくなったと思います。
書籍から学ぶ場合も、勉強したことをすぐに取り入れるのは効率的な学習をするためにも必須ですね。
- 投稿日:2019-03-02T20:22:09+09:00
「find_by」の所「find」じゃダメなの?
find_by→findにしたら
@current_user ||= User.find_by(id: session[:user_id])
↓
@current_user ||= User.find(session[:user_id])
↓
エラーになった。理由
どちらもnil→
その後の処理の仕方が違う。

- 投稿日:2019-03-02T19:52:36+09:00
RESTアーキテクチャとMVCアーキテクチャとscaffoldとresource
RESTアーキテクチャ
REpresentational State Transfer(代表的な状態移動)の略。
簡単に言ってしまえば、Webサイトでよく使うデータの加工方法という感じ。
例えばFacebookだと、投稿の新規作成、読み込み、更新、削除ができますよね。
こういうよく使う操作をRESTと呼びます。ちなみに、RESTfulというのは、後述するresourceコマンドで生成される7つのアクションのことをさします。
しかしこれはあくまでRuby on Railsというフレームワークが考えるRESTfulであって、全フレームワーク共通の設計思想ではないようです。
MVCアーキテクチャ
Model-View-Controller
のこと。Ruby on Railsというフレームワークではこの設計思想がもとになっている。
scaffold
scaffoldは"土台"という意味。
Railsの考えるWebサイトのデータの土台を構築するコマンドがscaffold。
例えばユーザのデータをscaffoldで作りたいときは、
rails generate scaffold User name:string email:string
のように使う。これによりUserのModel, View, Controllerなどを生成する。
デザインは最低限しか整っておらず、あくまでロジックのみ生成される。
resource
routesに書くコマンド。
resources :users
のように使う。この一行のみで様々なアクションが定義される。
具体的には、
index, show, new, create, edit, update, destroy
の7つのアクションが定義される。
- 投稿日:2019-03-02T19:30:11+09:00
railsのデフォルト
このindexアクションの後は、何か実行されるか?
def index
@users = User.all
endRailsでは、デフォルト値として、
app/views/users/index.html.erb
が実行されるようになっている。
- 投稿日:2019-03-02T19:26:48+09:00
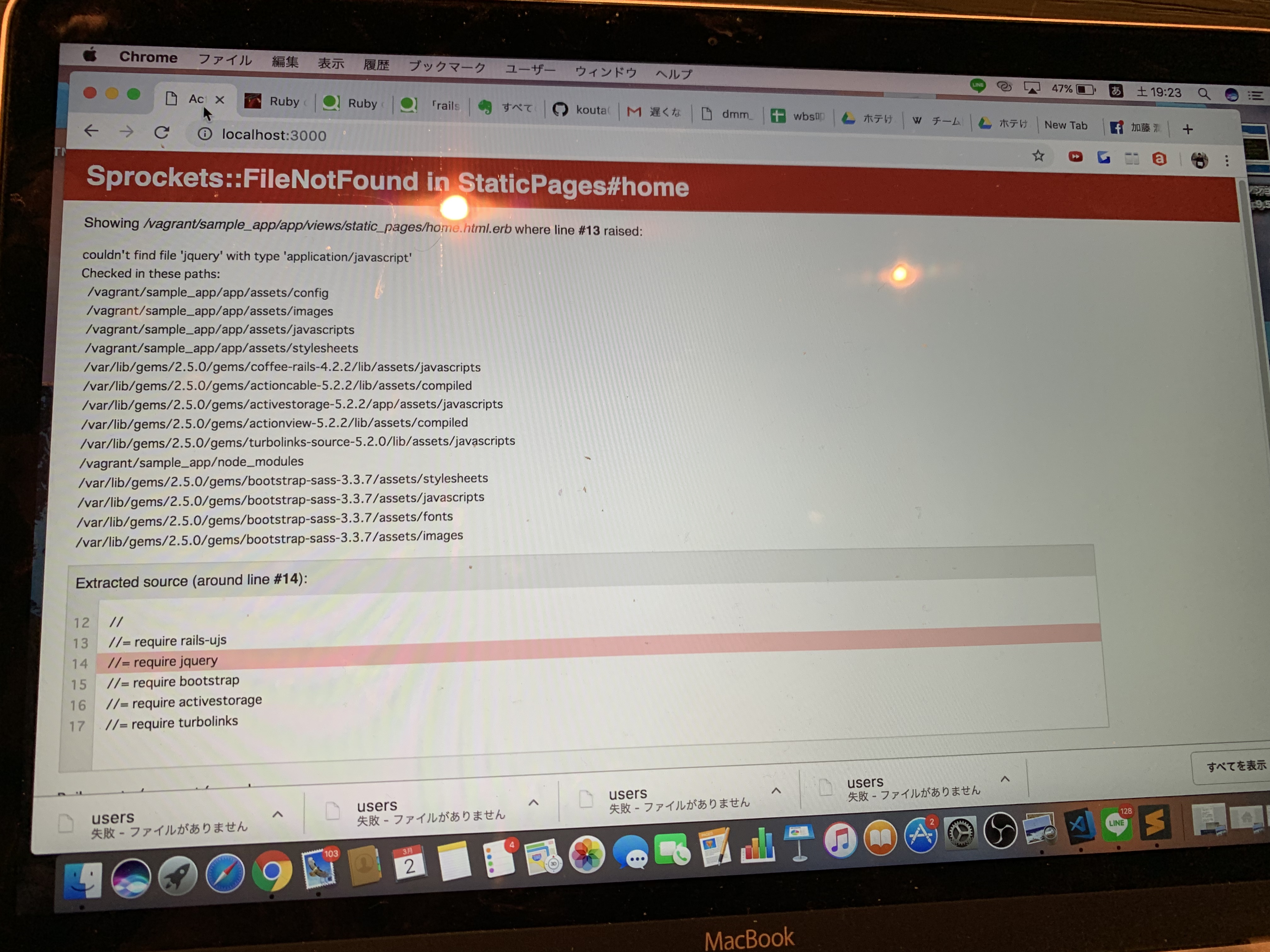
rails require jqueryが反映されない
こんにちは。Railsの八章のところで、application.jsにBootstrapのJavaScriptライブラリを追加するところで反映させようとしたところこのようなエラーが出ました。
すでにRailsは再起動してます。
- 投稿日:2019-03-02T18:45:23+09:00
RubyXLを使ってExcelを編集してクライアントに返す
railsでエクセルを編集してクライアントに返そうとしたときのやり方を残しておきます。
作るもの
- クライアントがエクセルファイルをアップロードする
- サーバが受け取ったエクセルに何かしらの変更を加える
- クライアントが変更されたファイルをダウンロードする
といった動きになる機能をRailsで作ります。
出来上がったソースコードはこちらExcelの編集
RubyXLというgemを使います。
https://github.com/weshatheleopard/rubyXL
他にもエクセルを開けるgemはあるのですが、
- Roo: 読み込みのみ
- AXSLX: 新規作成のみ
という感じで用途が絞られています。
今回は、編集ができるRubyXLを使います。単体だと、以下のような感じで使えます。
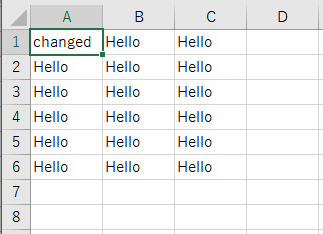
require 'rubyXL' # ファイルを読み込んでRubyXL::Workbookにデシリアライズ workbook = RubyXL::Parser.parse("path/to/Excel/file.xlsx") # ブック→シート→行→セルという構造になっている worksheet1 = workbook[0] row1 = worksheet1[0] cell1 = row1[0] # 書き込むときはWorksheetのメソッドが使える worksheet1.add_cell 0, 0, 'changed' # 保存 workbook.saverails new
railsプロジェクトを作ります。
今回は横着してモデルを作らないので、ActiveRecordなどいらないモジュールを生成しないようオプションを付けます。rails new -MOCJルーティング
excelリソースへのルートを作ります。
加えて、ルートをexcelsにします。下記とおりルーティングされます
- GET / -> ExcelsController#show
- GET /excels -> ExcelsController#show
- POST /excels -> ExcelsController#create
GET /excelsでファイルを受け取るフォームを表示し、POST /excelsでサーバへのファイルアップロードと編集後ファイルの送信を行います。
Rails.application.routes.draw do # For details on the DSL available within this file, see http://guides.rubyonrails.org/routing.html root to: "excels#show" resource :excel, only: [:show, :create] endhttps://github.com/ytnk531/excel-example/blob/master/config/routes.rb
コントローラ
showメソッドでは何もせず、ページを表示するだけです。
createにはエクセルファイルが送られて来るので、ファイルの編集とクライアントへの送信を行います。class ExcelsController < ApplicationController def show end def create file = params[:file] # ファイルを開く workbook = RubyXL::Parser.parse file.path # 編集する workbook[0].add_cell 0, 0, 'changed' # 編集したファイルを送る send_data workbook.stream.string, type: file.content_type, filename: 'modified.xlsx' end endアップロードされたファイルはUploadedFileオブジェクトとして受け取ることができます。
RubyXL::Parser.parseはFileオブジェクトではなくパスを引数に取るので、アップロードされたファイルのパスを指定してRubyXL::Workbookオブジェクトに変換します。
アップロードされたファイルは、tempfileとして保存されていて、
UploadedFile#pathでこのtempfileのパスを取得できます。編集したファイルは、send_dataメソッドを使って送信します。
データとして渡すのは、Workbook#streamで取得できるバイナリのストリームを、Stream#stringで文字列にしたものです。
コンテントタイプを指定する必要がありますが、UploadedFileは受信したときのContent-Typeを記録しているので、同じものを指定しておけばいいでしょう。https://github.com/ytnk531/excel-example/blob/master/app/controllers/excels_controller.rb
ビュー
エクセルファイルをアップロードするためのビューを作ります。
<%= form_tag({action: :create}, multipart: true) do %> <div> <%= file_field_tag :file %> </div> <div> <%= submit_tag "Send" %> </div> <% end %>https://github.com/ytnk531/excel-example/blob/master/app/views/excels/show.html.erb
ファイル選択と送信ができます。
送信したファイルはExcelsController#createで処理します。
試してみる
このようなEXCELファイルを用意し、
送ってみます。
編集されたファイルのダウンロードが始まります。
開いてみます。期待通り編集されたエクセルをダウンロードできました。
まとめ
- RubyXLでエクセルの編集ができる
- アップロードされたファイルはUploadedFileオブジェクトに記録される
- RubyXLで保存したワークブックは、保存しなくてもデータ送信できる
UploadedFileの存在を知らなかったので、うまくいくかわからなかったのですが、うまくrailsと一緒に使うことができました。

- 投稿日:2019-03-02T16:10:56+09:00
selectとoptionタグをjQueryを使って動的に追加する
デモ(動画)
やりたいこと
上記のGIF通り、
カテゴリーが選択されたと同時に、親カテゴリーに紐づく子カテゴリーが出てくるようにしたい。
入れ子構造については以下を参照
【追記予定】awesome_nested_setを使った入れ子構造のDB設計実装概要
jQueryのajaxメソッドを使って、カテゴリーが選択されたら子カテゴリーがappendされるようにした。
コード
routing
route.rbRails.application.routes.draw do root 'products#new' resources :products, only: [:create] do <!-- 今回はsearchアクションをajaxメソッドで叩きます--> collection do get 'search' end end endview
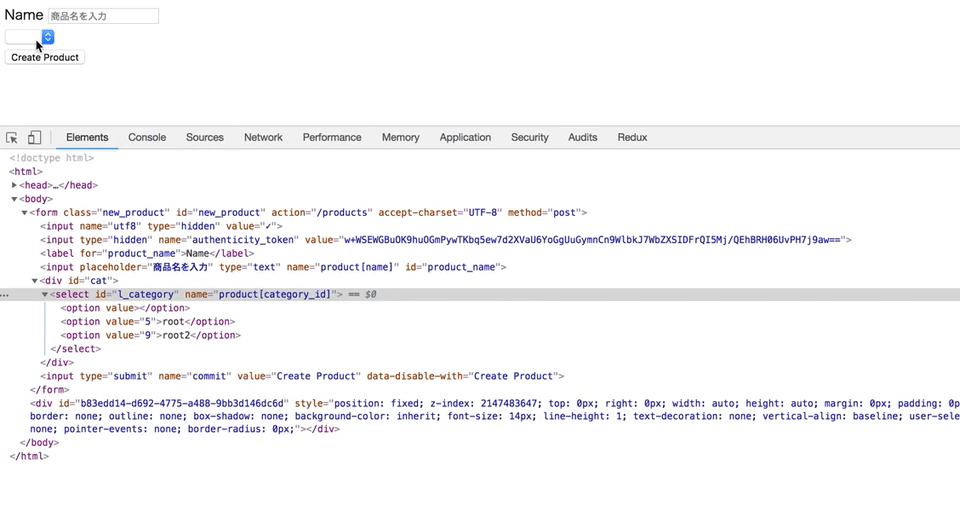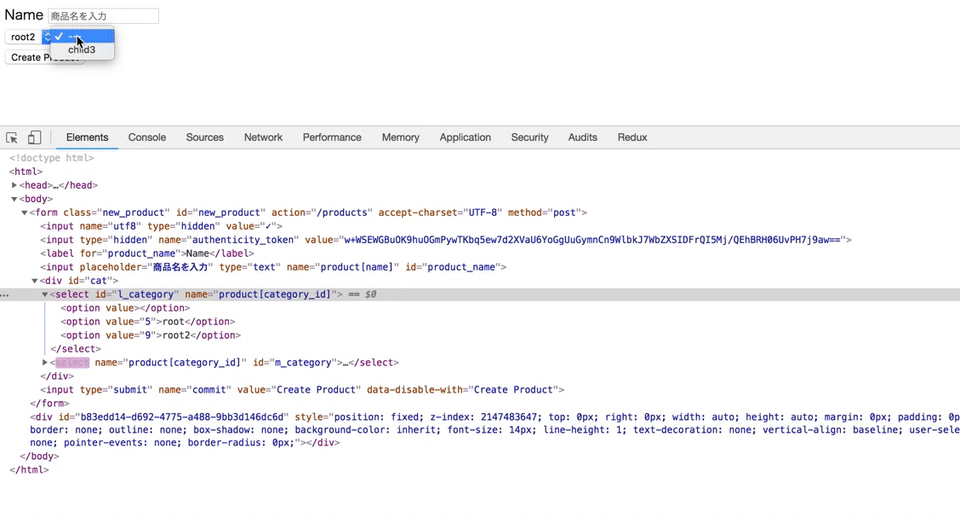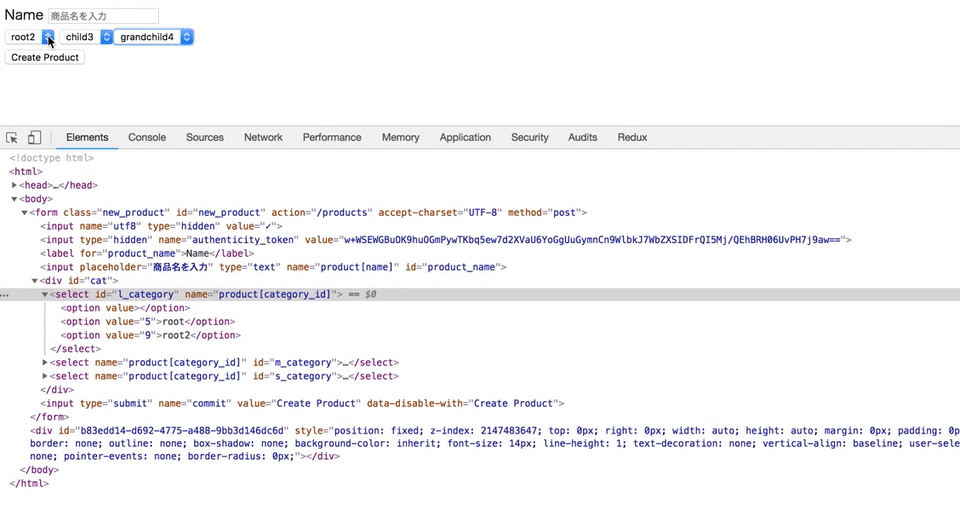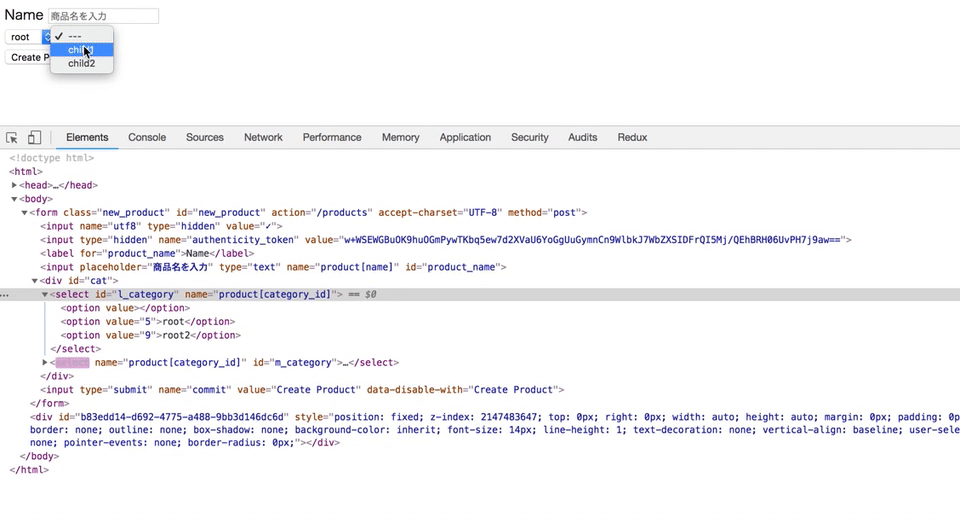
new.html.haml= form_for @product do |f| = f.label :name = f.text_field :name, placeholder: "商品名を入力" #cat = f.select :category_id, Category.roots.map {|i| ["#{i.name}", i.id]}, { selected: @product.category_id, include_blank: true }, {id: "l_category"}js
category.js$(document).on('turbolinks:load', function() { // Mカテゴリーのselectを追加するHTML var cat_seach = $("#cat"); function appendMselect() { var html = `<select name="product[category_id]" id="m_category"> <option value>---</option> </select>` cat_seach.append(html) } // Sカテゴリーのselectを追加するHTML function appendSselect() { var html = `<select name="product[category_id]" id="s_category"> <option value>---</option> </select>` cat_seach.append(html) } // Mカテゴリーのoptionを追加するHTML function appendMcat(m_cat) { $("#m_category").append( $("<option>") .val($(m_cat).attr('id')) .text($(m_cat).attr('name')) ) } // Sカテゴリーのoptionを追加するHTML function appendScat(s_cat) { $("#s_category").append( $("<option>") .val($(s_cat).attr('id')) .text($(s_cat).attr('name')) ) } // Lカテゴリーが選択された時のアクション $("#l_category").on('change', function() { l_cat = $(this).val() $("#m_category").remove() $("#s_category").remove() // ajaxでリクエストを送信 $.ajax({ type: "GET", url: "/products/search", data: {l_cat: l_cat}, dataType: 'json' }) // doneメソッドでappendする .done(function(m_cat) { appendMselect() m_cat.forEach(function(m_cat) { appendMcat(m_cat) }) }) }) // Mカテゴリーが選択された時のアクション $(document).on('change', "#m_category", function() { m_cat = $(this).val() $("#s_category").remove() $.ajax({ type: "GET", url: "/products/search", data: {m_cat: m_cat}, dataType: 'json' }) .done(function(s_cat) { appendSselect() s_cat.forEach(function(s_cat) { appendScat(s_cat) }) }) }) })controller
categories_controller.rb<!--関係ないアクションは省略しています--> def search if params[:l_cat] @m_cat = Category.find(params[:l_cat]).children else @s_cat = Category.find(params[:m_cat]).children end respond_to do |format| format.html format.json end endjbuilder
search.json.jbuilderjson.array! @m_cat do |m_cat| json.id m_cat.id json.name m_cat.name end json.array! @s_cat do |s_cat| json.id s_cat.id json.name s_cat.name end勉強になったところ
optionタグの追加の方法
optionの追加$("#m_category").append( $("<option>") .val($(m_cat).attr('id')) .text($(m_cat).attr('name')) ) }こういう風に書くことで、selectタグのoptionが追加できることを知りました。
始めはselectを追加すればいいじゃん!と思ってましたが、配列形式で渡ってくるため、配列の中身分selectが増えてしまい、上手な方法が浮かばなかったので、こちらの方法にしました。参考記事
・jQuery でセレクトボックスのプルダウン項目(option 要素)を追加/削除する方法
https://webllica.com/jquery-select-option-add-del/まとめ
なんとか狙った機能は実装できましたが、MカテゴリーとSカテゴリーで二回書いているようなコードになっているので、リファクタリングしたいけどどうしていいのかわからん・・・
- 投稿日:2019-03-02T16:01:21+09:00
RailsとElasticsearchで検索機能をつくり色々試してみる - Rspec
はじめに
RspecでElasticsearchを使ったテストを書く方法を紹介していきます。
elasticsearch-railsを使うことが前提の記事になります。また、本記事で出てくるサンプルや環境は、RailsとElasticsearchで検索機能をつくり色々試してみる - その1:サンプルアプリケーションの作成をもとにしています。
環境
- Ruby 2.5.3
- Rails 5.2.2
- Elasticsearch 6.5.4
gem
- rspec-rails 3.8.2
- elasticsearch-model 6.0.0
- elasticsearch-rails 6.0.0
テストで使用するElasticsearchのクラスターについて
調査する中で
elasticsearch-extensionsgemを使ってテスト用のclusterを立てる記事が多く見つかりましたが、ローカルの環境で開発用のclusterが起動している状態であれば別に起動する必要はないかと思い使用しませんでした。テスト対象のコード
タイトルと説明カラムを持つ漫画モデルを検索する処理を以下のようにconcernsに実装していた場合のテストを考えます。
app/models/manga.rbclass Manga < ApplicationRecord include MangaSearchable endapp/models/concerns/manga_searchable.rbmodule MangaSearchable extend ActiveSupport::Concern included do include Elasticsearch::Model # index名 # 環境名を入れることで開発用とは別にrspec用のindexを作成する index_name "es_manga_#{Rails.env}" # マッピング情報 settings do mappings dynamic: 'false' do indexes :id, type: 'integer' indexes :title, type: 'text', analyzer: 'kuromoji' indexes :description, type: 'text', analyzer: 'kuromoji' end end def as_indexed_json(*) attributes .symbolize_keys .slice(:id, :title, :description) end end class_methods do def create_index! client = __elasticsearch__.client # すでにindexを作成済みの場合は削除する client.indices.delete index: self.index_name rescue nil client.indices.create(index: self.index_name, body: { settings: self.settings.to_hash, mappings: self.mappings.to_hash }) end # 今回テストする検索処理 def es_search(query) __elasticsearch__.search({ query: { multi_match: { fields: %w(title description), type: 'cross_fields', query: query, operator: 'and' } } }) end end endRspec
index作成について
それぞれのテストを独立して行うため、ケース毎にindexを作成するようにします。また、elasticsearchに関わるテストでのみindex作成を行えばよいのでmeta情報でindex作成を制御できるようにするのがよいと思います。
以下はその例です。spec/rails_helper.rbRSpec.configure do |config| config.before :each do |example| if example.metadata[:elasticsearch] Manga.create_index! end endテストケース
spec/models/concerns/manga_searchable_spec.rbrequire 'rails_helper' # elasticsearch: true を追加しindexをテストケース毎に再作成する RSpec.describe MangaSearchable, elasticsearch: true do describe '.es_search' do describe '検索ワードにマッチする漫画の検索' do let!(:manga_1) do create(:manga, title: 'キングダム', description: '時は紀元前―。いまだ一度も統一...') end let!(:manga_2) do create(:manga, title: '僕のヒーローアカデミア', description: '多くの人間が“個性という力を持つ...') end let!(:manga_3) do create(:manga, title: 'はたらく細胞', description: '人間1人あたりの細胞の数、およそ60兆個...') end before :each do # 作成したデータをelasticsearchに登録する # refresh: true を追加することで登録したデータをすぐに検索できるようにする Manga.__elasticsearch__.import(refresh: true) end def search_manga_ids Manga.es_search(query).records.pluck(:id) end context '検索ワードがタイトルにマッチする場合' do let(:query) { 'キングダム' } it '検索ワードにマッチする漫画を取得する' do expect(search_manga_ids).to eq [manga_1.id] end end context '検索ワードが本文にマッチする場合' do let(:query) { '60兆個' } it '検索ワードにマッチする漫画を取得する' do expect(search_manga_ids).to eq [manga_3.id] end end context '検索ワードが複数ある場合' do let(:query) { '人間 個性' } it '両方の検索ワードにマッチする漫画を取得する' do expect(search_manga_ids).to eq [manga_2.id] end end end end endrefresh: true オプション
ポイントは、import時にrefresh: true オプションを追加する点です。
ドキュメントより
Elasticsearch is a near-realtime search platform. What this means is there is a slight latency (normally one second) from the time you index a document until the time it becomes searchable.
documentを登録してから、検索ができるようになるまで通常は1秒かかります。(1秒間隔で更新を反映しているようですが、この間隔は変更することもできます。)
そのため、データをimportしてすぐに検索を行うと、更新が反映されていないためテストに失敗してしまいます。refresh: trueオプションを渡すことで、importするタイミングでリフレッシュされ検索できるようになります。参考
Rails から Elasticsearch を使っているときのテストの書き方(elasticsearch-rails, RSpec)
Elasticsearchを使ったテストを書くときにsleep 1するのはやめましょう
ElasticSearchのインデクシングを高速化する
- 投稿日:2019-03-02T15:45:43+09:00
Rails5.2+Vue.jsのセットアップ手順 on Ubuntu 18.04
Keiです。
自分はこれまでデータ分析・数値シミュレーションや、Web開発でもサーバーサイドを中心に学んできたためフロントエンドの最新技術事情に疎い事を引け目に感じていました。とは言えしょぼくれていても何も始まらない。とりあえず動こう、ということで最近人気のJSフレームワークの中でも記述が直感的で比較的分かりやすいと評判のVue.jsを学んでみることにしました。
せっかくなので普段インターン先でも使っているRailsをバックエンドにVueを使いたいと思い少し調べていた所、今の自分にドンピシャハマる神記事に出くわしました↓
Vue.jsとRailsでTODOアプリのチュートリアルみたいなものを作ってみた
@naoki85 さん、ありがとうございます早速こちらの記事を参考にプロジェクトのセットアップを進めていったのですが、ちょいちょい謎のエラーに遭遇しましたのでその一部始終を共有したいと思います。なお開発環境は以下を前提としています。
- OS: Ubuntu 18.04LTS
- Ruby 2.5.1
- Rails 5.2
- gemの管理はbundler (Rails環境構築の詳細はこちら参照)
Railsプロジェクト作成
まずは上の記事にもあるようにRailsプロジェクトを--webpack=vueオプション付きで作成します。
$ bundle exec rails new vue_app --webpack=vueするとモダンJS開発環境構築初心者の自分の場合まず"yarn入ってねーぞ"系のエラーを食らいました。Installation | Yarn のDebian/Ubuntuの部分を参考にまずyarnを入れます。
$ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add - $ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list $ sudo apt-get update && sudo apt-get install yarnはい、Yarn入りましたので今度こそrails newします。
$ bundle exec rails new vue_app --webpack=vue今度は成功しました。
Railsサーバーの起動を確認
次にRailsサーバーの起動を確認します。Yay! You’re on Rails! されたいのですが、、、
$ bundle exec rails s (鬼のようなエラー) (鬼のようなエラー) (鬼のようなエラー) ... vue_app/vendor/bundle/ruby/2.5.0/gems/webpacker-3.5.5/lib/webpacker/configuration.rb:79:in `rescue in load': Webpacker configuration file not found /home/user/Desktop/vue_app/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /home/user/Desktop/vue_app/config/webpacker.yml (RuntimeError)で怒られます。webpackerの設定ファイルがないということなので、言われるがままに
$ bundle exec rails webpacker:installします。inotifyからちょいちょいエラーが出ていましたが一応入りました。
Webpacker successfully installed ? ?プロジェクト内を見直すとconfig/webpack以下に4つのJSファイルが生成され、app/javascript/packs/application.jsという見慣れないファイルも作成されています。
Rails側のSQlite3のバージョン指定でエラー
さあいい加減準備できただろということで。
$ bundle exec rails s #<LoadError: Error loading the 'sqlite3' Active Record adapter. Missing a gem it depends on? can't activate sqlite3 (~> 1.3.6), already activated sqlite3-1.4.0. Make sure all dependencies are added to Gemfile.>またか...しかもSQLiteからのエラーだと?
原因を調べてみたところRails側の指定しているsqlite3のversionが1.3.x代なのに対し
sqlite3の最新versionは1.4.x代ということで、 Gemfile中でgem 'sqlite3', '~> 1.3.6'とsqliteのバージョンをきちんと指定してあげないとダメな模様。
ついでにまだGemfile全体を載せていなかったので全部載せておきます。Gemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.5.1' gem 'rails', '~> 5.2.0' gem 'sqlite3', '~> 1.3.6' gem 'puma', '~> 3.11' gem 'sass-rails', '~> 5.0' gem 'uglifier', '>= 1.3.0' gem 'webpacker' gem 'turbolinks', '~> 5' gem 'jbuilder', '~> 2.5' gem 'jquery-rails' gem 'materialize-sass' gem 'material_icons' gem 'bootsnap', '>= 1.1.0', require: false group :development, :test do gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] end group :development do gem 'foreman' gem 'web-console', '>= 3.3.0' gem 'listen', '>= 3.0.5', '< 3.2' gem 'spring' gem 'spring-watcher-listen', '~> 2.0.0' end group :test do gem 'capybara', '>= 2.15', '< 4.0' gem 'selenium-webdriver' gem 'chromedriver-helper' end gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]これで
$ bundle install --path vendor/bundleして解決。
inotifyで監視できるファイル数上限に到達しエラー
...と思うじゃないですか。実はもうひと踏ん張りあるんです(白目)。
$ bundle exec rails s FATAL: Listen error: unable to monitor directories for changes. Visit https://github.com/guard/listen/wiki/Increasing-the-amount-of-inotify-watchers for info on how to fix this. Exitingなんだこれ(n回目)。とりあえずエラーメッセージにGithubへのリンクが貼ってあるので飛んで確認します。
どうやらプロジェクト内のファイル数が増えすぎてLinuxのデフォルト設定ではこれ以上ファイルの変更を監視できないということだそうで(詳しくはこちら)。これはLinux系ではよくあるエラーらしく、ちゃんと解決策が用意されていました。自分のようにDebian/RedHat系を使用している方はターミナルで
$ echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -pを実行。ArchLinuxの場合は
$ echo fs.inotify.max_user_watches=524288 | sudo tee /etc/sysctl.d/40-max-user-watches.conf && sudo sysctl --systemで直ります。今度こそ。
$ bundle exec rails s
やれやれやっと全部直ったか...
さあこれで快適なRails+Vueライフを楽しむぞ!!

- 投稿日:2019-03-02T14:30:55+09:00
Failed to load resource: the server responded with a status of 404 (Not Found)の原因と解決策
問題:画像が表示できない
エラー
Failed to load resource: the server responded with a status of 404 (Not Found)404 (Not Found)は、ファイルが見つからないという意味。
推定原因は、2つあるらしい。①ファイルがデータベースに保存されていない
②画像がDBに保存されているけど、パスがずれてるファイルは保存できていた。なので、原因は、②。
参照記事:https://teratail.com/questions/3951パスの確認
views/user/show.html.erb<img src="<%= "/img/#{@user.id}"%>">解決策
/img/#{@user.id}に、jpgを付け加えてみたら、パスが特定されて、無事画像が表示された。
views/user/show.html.erb<img src="<%= "/img/#{@user.id}.jpg"%>">

- 投稿日:2019-03-02T13:41:35+09:00
ActiveRecordでのレコード数のカウント方法の差(count, length, size)
- 投稿日:2019-03-02T13:41:35+09:00
[WIP]ActiveRecordでのレコード数のカウント方法の差(count, length, size)
- 投稿日:2019-03-02T12:34:15+09:00
Threadクラスを利用した例外処理
Threadクラスを利用した例外処理の方法に苦戦したので、自分用としてアウトプットします。
Threadクラスとは?
スレッドとはメモリ空間を共有して同時に実行される制御の流れです。 Thread を使うことで並行プログラミングが可能になります。
プログラムは通常処理を記述した順に実行されるので、複数の処理を同時に実行することができません。
しかし、AとBという二つに処理を同時に実行した場合ってありますよね?
そんなとき使用できるのがThreadクラスです。
メインスレッドとカレントスレッド
プログラム開始時に生成されるスレッドはメインスレッド、現在実行中のスレッドはカレントスレッドと呼ばれます。
RubyではThread#mainを用いる事でメインスレッドを確認できます。
また、Thread#listでプログラム上に存在するスレッドが配列で表示されます。
joinメソッド
Thread#joinは、 スレッド self の実行が終了するまで、カレントスレッドを停止させるメソッドです。 limit を指定して、limit 秒過ぎても自身が終了しない場合、nil を返します。
要するに、AとBという二つの処理を同時に実行した際に、片方の処理が終わるまでもう片方の処理を停止させることが出来るメソッドです。
Aという処理が終わるまで、Bという処理を停止させるようなイメージ。
使用方法
①Threadのインスタンスを生成(t1,t2)
②それぞれのThreadに対してrescue文を使用し例外処理を行う
(どちらが先に実行されるのかわからないため)
③rescue文で定義した例外処理のeにe1を代入。
④どちらか片方が例外処理によって抜け出した際の、エラー文とクラス(ActiveRecord::RecordInvalid)が一致しているか?のテストを実施。require 'rails_helper' RSpec.describe Ec::ItemImagesRegisterService do context 'with 2 images uploading at the same time' do let(:ec_item) { FactoryBot.create(:ec_item) } let(:ec_item_images_nearest_max) { FactoryBot.create_list(:ec_item_image, 19, ec_item: ec_item) } let(:params){ ActionController::Parameters.new( ec_item_id: ec_item.id, files:[{ file: File.open(Rails.root.join('spec', 'fixtures', 'sample_image_01.jpg')), order: 2}])} before do ec_item_images_nearest_max # ① t1 = Thread.new { ActiveRecord::Base.connection_pool.with_connection { service = described_class.new(params) service.run! } } # ① t2 = Thread.new { ActiveRecord::Base.connection_pool.with_connection { service = described_class.new(params) service.run! } } end it 'returns invalid with the 21st image' do e1 = nil e2 = nil # ② begin t1.join # JoinメソッドはThreadクラスを拡張したクラスのインスタンスから使用できるメソッド。別のスレッドの処理が終了するまで待機させたい処理がある場合に使用 rescue => e # ③ e1 = e end # ② begin t2.join rescue => e # ③ e2 = e end # ④ if e1.nil? expect(e2.class).to eq(ActiveRecord::RecordInvalid) expect(e2.record.errors.messages).to match({:file=>["は20枚までしか登録できません。"]}) expect(ec_item.ec_item_images.count).to eq 20 end # ④ if e2.nil? expect(e1.class).to eq(ActiveRecord::RecordInvalid) expect(e1.record.errors.messages).to match({:file=>["は20枚までしか登録できません。"]}) expect(ec_item.ec_item_images.count).to eq 20 end end end end【参考記事】
https://docs.ruby-lang.org/ja/latest/class/Thread.html
https://qiita.com/k-penguin-sato/items/1326882c400cac8c109b
- 投稿日:2019-03-02T01:22:39+09:00
【Rails 5】ドラッグ&ドロップで並び替えて順番を保存できるリストを作る
Introduction
例えばTodoリストアプリなどを作ろうとすると、リストのアイテムを順番通りに整列させて、ドラッグ&ドロップで並び替えて、その順番を保存したい場面があると思います。
jQuery UIのsortableを利用している記事が多かったのですが、モバイルでも利用する前提だと他のjsも使わなくてはいけなかったりと面倒だったのですが、Sortable.jsというライブラリを利用すればモバイルにも対応してくれていたので「Sortable.js」+「acts_as_list」を使ってドラッグ&ドロップで並び替えできるリストを実装してみました。Goal Image
準備中...
0. Sample Model
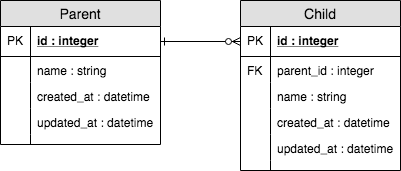
とても単純なrelationshipを持ったParentとChildモデルがあるとします。
Parentは0個以上のChildを持ち(has_many)、Childは1つのParentを持ちます(belongs_to)。1.
Childモデルに順番の概念を与えるまずは、モデルに順番の概念を与えるために
acts_as_listを使っていきます。
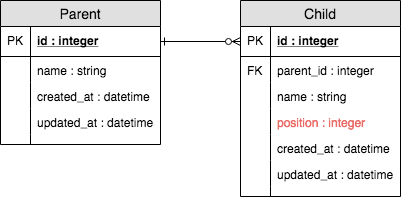
GitHub - swanandp/acts_as_listGemfilegem 'acts_as_list'$ bundle install
acts_as_listがインストールできたら、Childにposition:integerのカラムを追加してください。$ rails g migration AddPositionToTodoItem position:integer $ rake db:migrateこれでER図はこんな感じに変わってます。
Childの順番はParentごとに管理をしたいので、モデルの定義を次のように書き換えます。app/models/parent.rbclass Parent < ApplicationRecord has_many :children, -> { order(position: :asc) } endapp/models/child.rbclass Child belongs_to :parent acts_as_list scope: :parentこれで
Childモデルに順番の概念を与えることができました。
Childがcreateされるごとにpositionカラムにシーケンシャルな数字が自動で追加してくれます。
また、用意されているメソッドを使うことで順番を変更することができます。@child.insert_at(2) #position=2に移動 @child.move_lower #position++ @child.move_higher #position-- @child.move_to_top #position=1 @child.move_to_bottom #position=last2. ドラッグ&ドロップで並び替え可能なリストを作る
これには
Sortable.jsを使います。
GitHub - SortableJS/Sortable
GitHubからSortable.min.jsをダウンロードしてapp/assets/javascripts/に配置します。Sortable.jsでは
getElementByIdでHTMLObjectを取得することでリストを並び替え可能にします。
例として、/parents/:idでParentに紐づくChildを一覧で表示しているページを使います。app/controllers/parents_controller.rbdef show @parent = Parent.find(params[:id]) @children = @parent.children endapp/views/parents/show.html.erb<ul id="sortable_list"> <% @children.each do |child| %> <li><%= child %></li> <% end %> </ul>app/assets/javascripts/parents.coffee$ -> el = document.getElementById("sortable_list") if el != null sortable = Sortable.create(el, delay: 200)これで
<li>要素をドラッグ&ドロップで並び替えできるようになります。
Sortable.jsのdelayオプションは200msの長押しをしないと並び替え可能な状態にならないことを定義しています。デフォルトでは0msなのですが、スマホだとページのスクロールができなくなってしまうので適切な値を設定するといいと思います。3. 並び替えをしたらDBを更新する
Sortable.jsでは並び替えが行われたときに
onUpdateが呼び出されます。
これをトリガーにajaxでドラッグ&ドロップされた要素の「ドラッグ前の位置」と「ドラッグ後(ドロップ)の位置」をバックエンドに連携して並び順をDB更新するようにします。まずは「ドラッグ前後の位置」を受け取れるようにコントローラー側に
sortアクションを追加します。
urlはparent/:id/sort、from(ドラッグ前の位置)とto(ドラッグ後の位置)を受け取る前提とします。app/controllers/parents_controller.rbdef sort @parent = Parent.find(params[:id]) child = @parent.children[params[:from].to_i) child.insert_at(params[:to].to_i + 1) head :ok end
@parent.children[params[:from].to_i]で対象のモデルを取得しています。
そして、child.insert_at(params[:to].to_i + 1)で対象のpositionを更新しています。
Sortable.jsで取得するリストの位置は0から始まるのに対して、insert_atは1から始まるところに注意して、insert_at向けの要素の順番には+1をしています。Rails4では
render nothing: trueなどが有効だったようですがRails5では使えなくなっているのでhead :okでフロント側に200OKを返却。ルーティングも追加しておきます。
config/routes.rbpatch 'parent/:id/sort', to: 'parent#sort'ajax通信をする際に
Parentのidが必要になるのでhiddenフィールドに隠しておいてajaxの前に取得できるようにしておきます。app/views/parents/show.html.erb<ul id="sortable_list"> <% @children.each do |child| %> <li><%= child %></li> <% end %> </ul> <%= hidden_field_tag :parent_id, @parent.id %>あとはajaxを実装すれば完成です。
Sortable.jsではonUpdateイベントでoldIndexとnewIndexを取得できるようになっています。それぞれ「ドラッグ前の位置」と「ドラッグ後の位置」です。これを取得してバックエンドにpatchします。app/assets/javascripts/parents.coffee$ -> el = document.getElementById("sortable_list") if el != null sortable = Sortable.create(el, delay: 200, onUpdate: (evt) -> $.ajax url: 'parent/' + $("#parent_id").val() + '/sort' type: 'patch' data: { from: evt.oldIndex, to: evt.newIndex } )
$("#parent_id").val()でhiddenフィールドに格納しているParentのidを取得してurlを指定してます。typeはroutes.rbで定義したものに合わせて、dataにはバックエンドに連携する情報を記載してます。以上で完成!!
Conclusion
割とシンプルにドラッグ&ドロップでの並び替えができたと思います。しかもモバイル対応!
ただし、acts_as_listの仕様上、並び替えの度にけっこうなDB更新がかかっていそう(from〜toの間の全てのレコードを更新しているっぽい)。リストが大きくなることが想定されている場合は順番をつける方式は検討した方が良いかも。ranked_modelの方がいいのかな?Reference