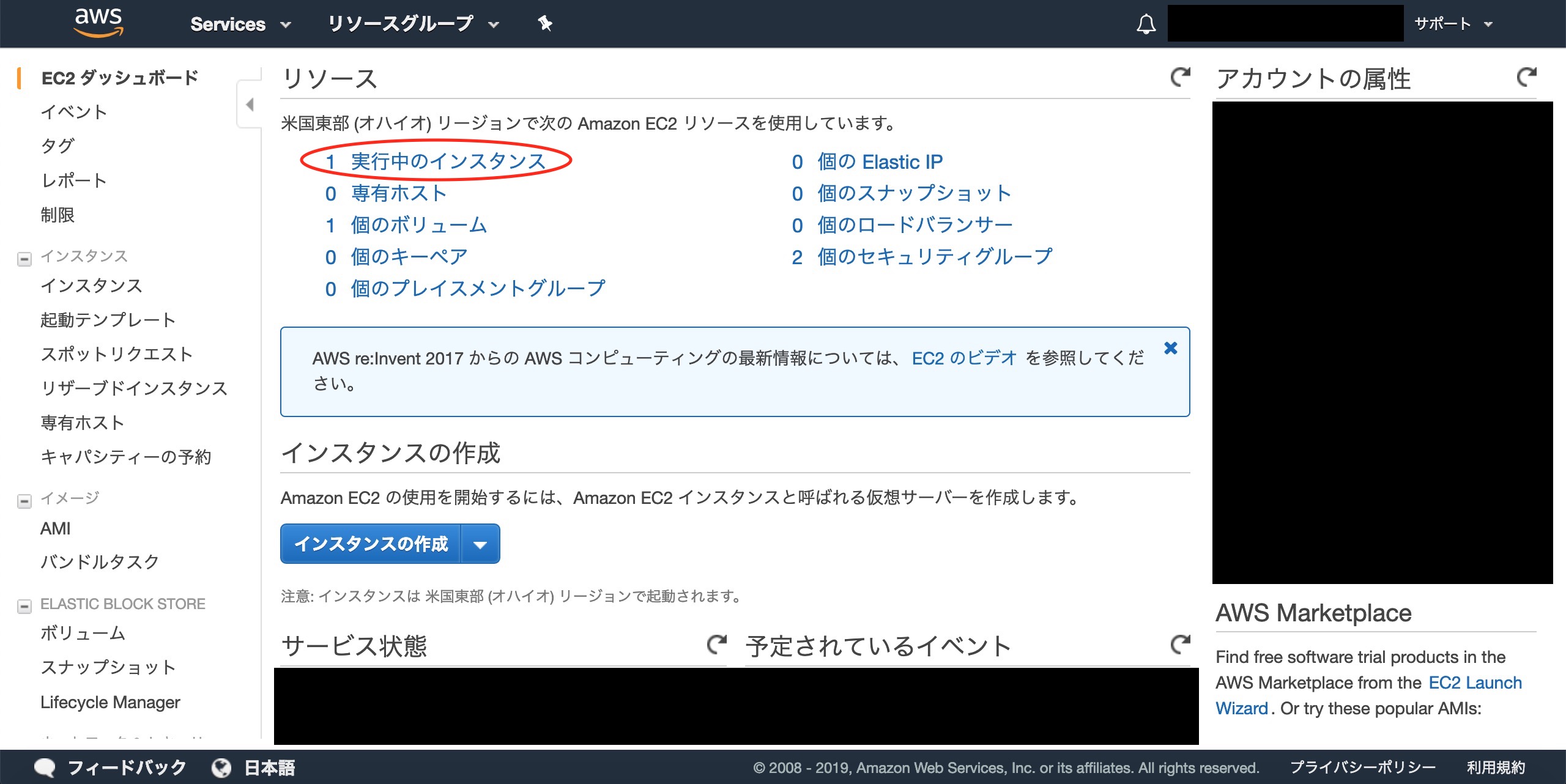
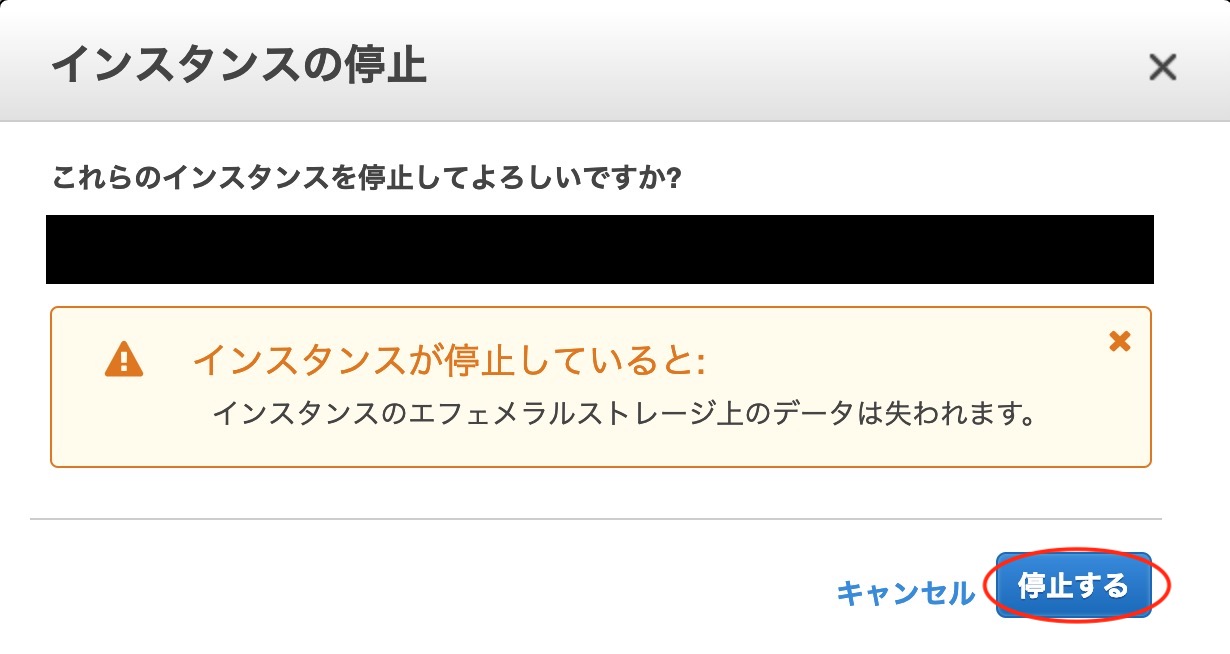
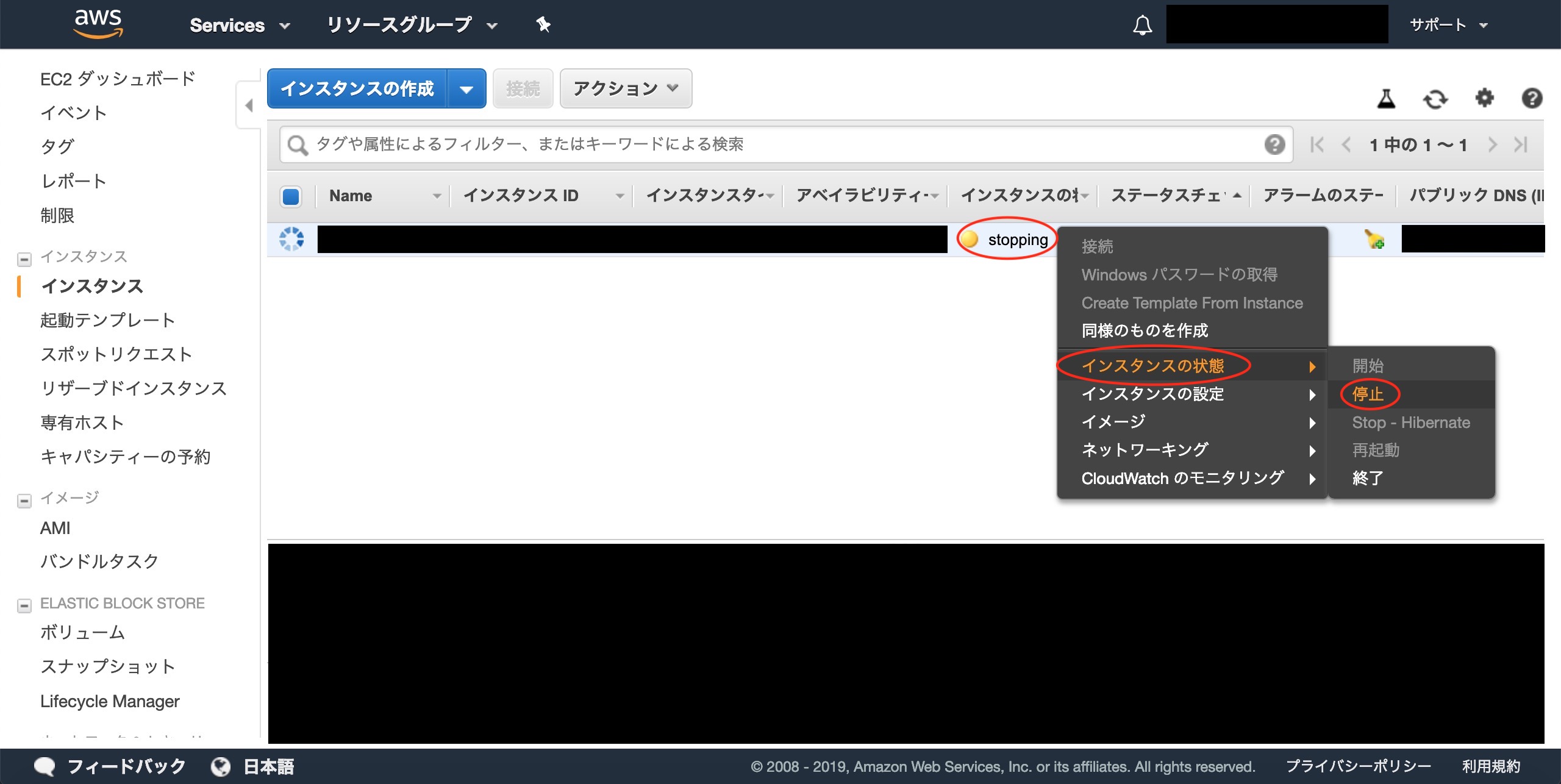
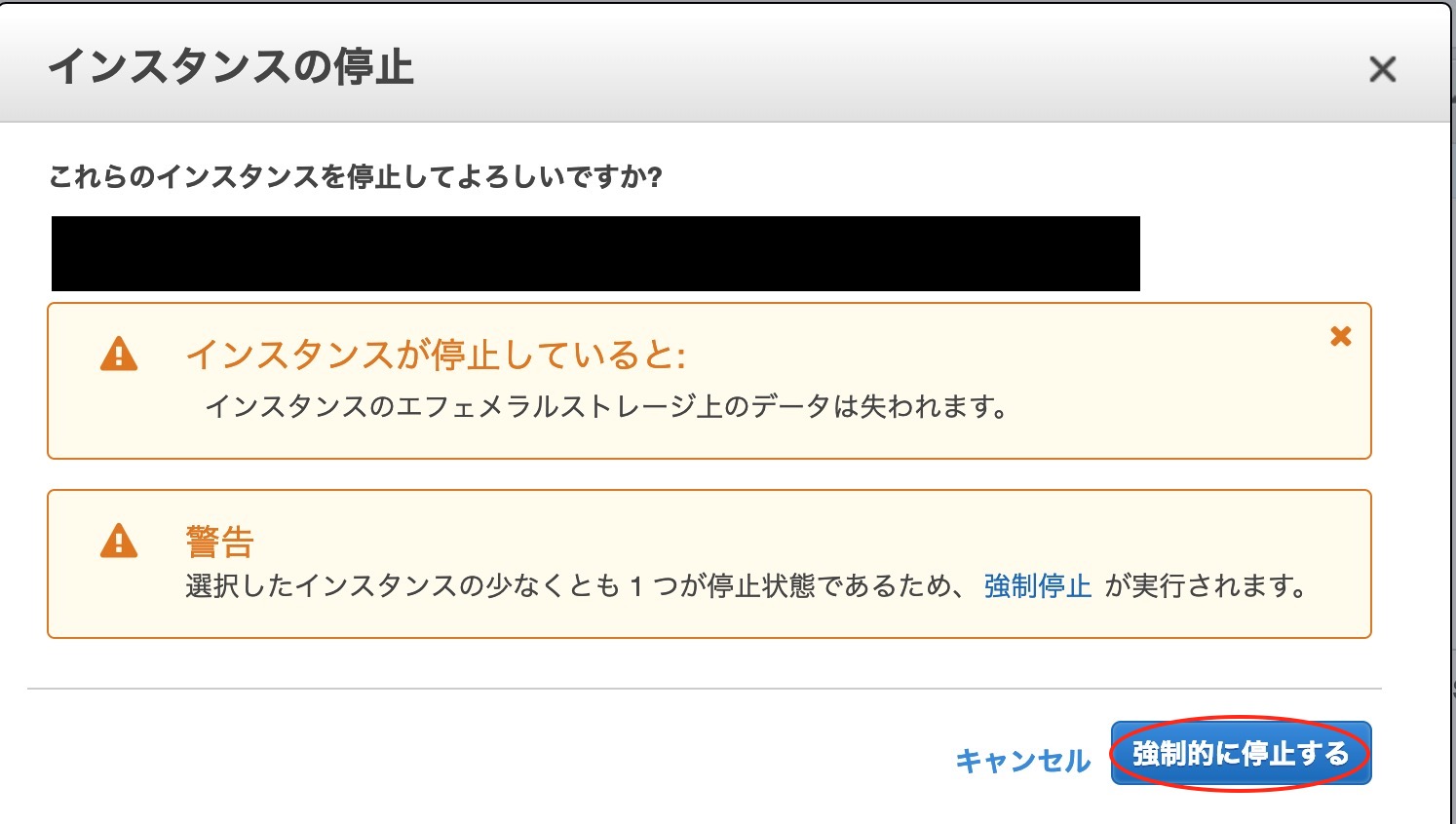
result,_:=svc.ListBuckets(nil)fmt.Println("Buckets:")for_,b:=rangeresult.Buckets{fmt.Printf("* %s created on %s\n",aws.StringValue(b.Name),aws.TimeValue(b.CreationDate))}
in registry with id '******' cannot be deleted because it still contains images (Service: AmazonECR; Status Code: 400; Error Code: RepositoryNotEmptyException; Request ID: cbe340fe-39e6-11e9-90f7-******)