- 投稿日:2019-03-02T15:57:31+09:00
【fast.ai】 Data Block API解説
本記事はfast.aiのwikiのData Blockページの要約となります。
筆者の理解した範囲内で記載します。概要
training, validation, testに用いるデータの読み込みを行うためのDataBunchの設定をわずか数行のコードで行うことができる!
細かく設定できる非常にフレキシブルなAPI
今回は以下の7つの例を用いていきます。
1. Binary Classification
2. Multi Label Classification
3. Mask Segmentation
4. Object Detection
5. Text Language Model
6. Text Classification
7. Tabular1. [Binary Classification] 最初に、MNISTを用いた例を挙げていきます。
from fastai.vision import *path = untar_data(URLs.MNIST_TINY) tfms = get_transforms(do_flip=False) path.ls()(path/'train').ls()肝心のDataBlockは下から!
python
data = (ImageList.from_folder(path) #どこからのデータか? -> pathの中のフォルダとサブフォルダで、ImageList
.split_by_folder() #train/validをどのように分けるか? -> フォルダをそのまま用いる
.label_from_folder() #labelをどのように付けるか? -> フォルダの名前から転用する
.add_test_folder() #testを付け足す
.transform(tfms, size=64) #Data augmentationを用いるか? -> size64のtfmsを用いる
.databunch()) #DataBunchへと変換する
DataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(3, figsize=(6,6), hide_axis=False)
すげええええ、本当にたった数行でtrain/validation/testに分けてdata augmentation用いたdatabunchを作成できた!
2. [Multi Label Classification] 次は、planetを用いた例を挙げていきます。
planet = untar_data(URLs.PLANET_TINY) planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)data = (ImageList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg') #どこからのデータか? -> planet内のtrainフォルダで、ImageList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_df(label_delim=' ') #labelをどのように付けるか? -> csvファイルを用いる .transform(planet_tfms, size=128) #Data augmentationを用いるか?-> size128のtfmsを用いる .databunch()) #DataBunchへと変換する同様にDataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(rows=2, figsize=(9,7))
きちんとmulti-label-classificationが読み込めていますね。
3. [Mask Segmentation] camvidを用いた例を挙げていきます。
camvid = untar_data(URLs.CAMVID_TINY) path_lbl = camvid/'labels' path_img = camvid/'images'codes = np.loadtxt(camvid/'codes.txt', dtype=str); codeslabelを付け足す関数を自作します。
python
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
tfm_y=Trueによって、data_augmentationが元々のmaskにも適用されるそう。
python
data = (SegmentationItemList.from_folder(path_img)
#どこからのデータか? -> path_imgで、SegmentationItemList
.random_split_by_pct()
#train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ
.label_from_func(get_y_fn, classes=codes)
#labelをどのように付けるか? -> get_y_func
.transform(get_transforms(), tfm_y=True, size=128)
#Data augmentationを用いるか?-> Standard transforms で tfm_y=True, size=128を指定
.databunch())
#DataBunchへと変換する
出力します。
data.show_batch(rows=2, figsize=(7,5))
簡単すぎ、、なのにすげええええ
どんどんいきます。4. [Object Detection] cocoを用いた例を挙げます。
coco = untar_data(URLs.COCO_TINY) images, lbl_bbox = get_annotations(coco/'train.json') img2bbox = dict(zip(images, lbl_bbox)) get_y_func = lambda o:img2bbox[o.name]data = (ObjectItemList.from_folder(coco) #どこからのデータか? -> cocoで、ObjectItemList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_func(get_y_func) #labelをどのように付けるか? -> get_y_func .transform(get_transforms(), tfm_y=True) #Data augmentationを用いるか?-> Standard transforms で tfm_y=True .databunch(bs=16, collate_fn=bb_pad_collate)) #DataBunchへと変換する -> bb_pad_collateによって一部のbbを出力data.show_batch(rows=2, ds_type=DatasetType.Valid, figsize=(6,6))
細かい設定をいじって非常にフレキシブルなAPIですね
5. [Text Language Model] IMDBを用いた例を挙げます。
from fastai.text import *imdb = untar_data(URLs.IMDB_SAMPLE)data_lm = (TextList.from_csv(imdb, 'texts.csv', cols='text') #どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_for_lm() #labelをどのように付けるか? -> Language Modelから .databunch()) #DataBunchへと変換するdata_lm.show_batch()
これだけでLanguage Modelを鍛えることができます。
6. [Text Classification] IMDBを用いた例を挙げます。
上のLanguage Modelを延長して、
python
data_clas = (TextList.from_csv(imdb, 'texts.csv', cols='text')
#どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList
.split_from_df(col='is_valid')
#train/validをどのように分けるか? -> 'is_valid' column にて分割
.label_from_df(cols='label')
#labelをどのように付けるか? -> 'label' column dfを参照する
.databunch())
#DataBunchへと変換する
完成!
data_clas.show_batch()
7. [Text Classification] IMDBを用いた例を挙げます。
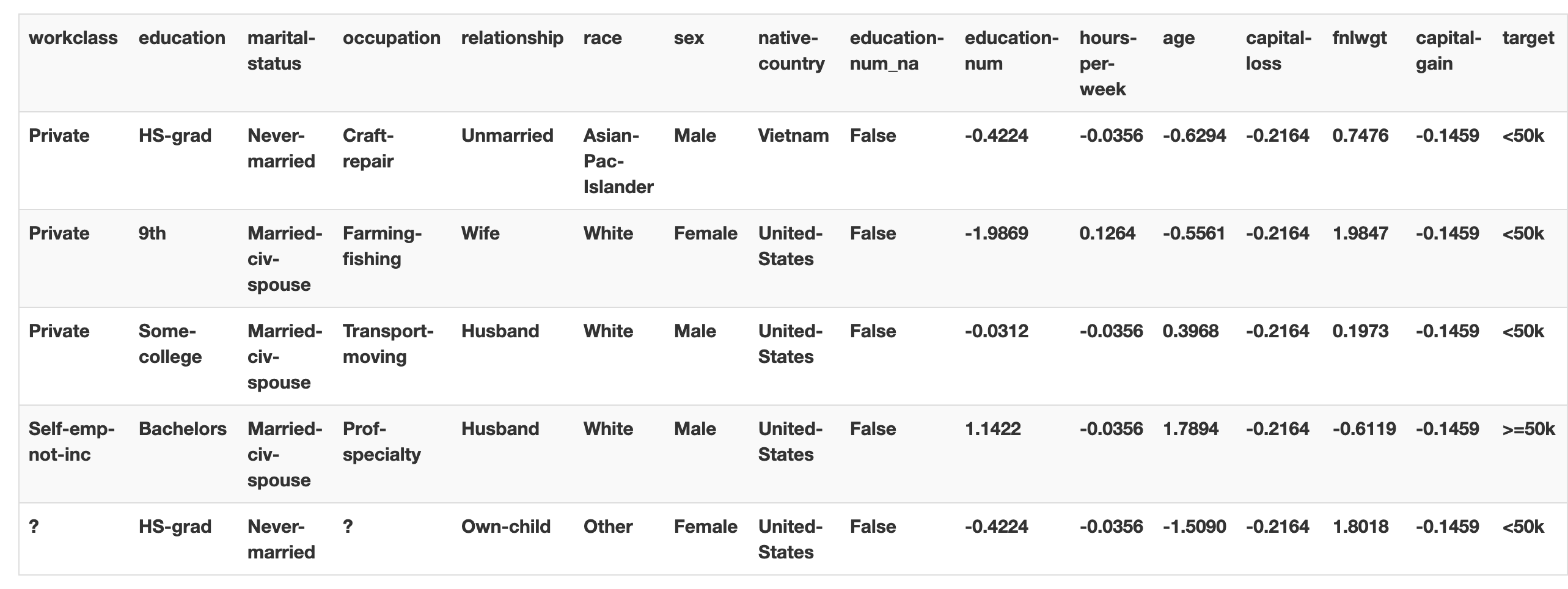
from fastai.tabular import *adult = untar_data(URLs.ADULT_SAMPLE) df = pd.read_csv(adult/'adult.csv') dep_var = 'salary' cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country'] cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain'] procs = [FillMissing, Categorify, Normalize]data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs) #どこからのデータか? -> dfからのTabular List .split_by_idx(valid_idx=range(800,1000)) #train/validをどのように分けるか? -> val_idxの800から1000 .label_from_df(cols=dep_var) #labelをどのように付けるか? -> dep var=ターゲットを用いる .databunch()) #DataBunchへと変換するdata.show_batch()
以上となります。
個人的な振り返り
- 継続的にアウトプットすることでfast.aiの理解度を深め, fast.ai の掲げているdemocratizationへ寄与する。
- より深い部分のコードを解説していく。
- 次回、DataBlockのより細かい設定のAPIを解説していこうと思います。
最後に
間違いやご指摘などが御座いましたらご教示願います!!






- 投稿日:2019-03-02T15:57:31+09:00
【日本語版】fast.ai Data Block API解説
本記事はfast.aiのwikiのData Blockページの要約となります。
筆者の理解した範囲内で記載します。概要
training, validation, testに用いるデータの読み込みを行うためのDataBunchの設定をわずか数行のコードで行うことができる!
細かく設定できる非常にフレキシブルなAPI
今回は以下の7つの例を用いていきます。
1. Binary Classification
2. Multi Label Classification
3. Mask Segmentation
4. Object Detection
5. Text Language Model
6. Text Classification
7. Tabular1. [Binary Classification] 最初に、MNISTを用いた例を挙げていきます。
from fastai.vision import *path = untar_data(URLs.MNIST_TINY) tfms = get_transforms(do_flip=False) path.ls()(path/'train').ls()肝心のDataBlockは下から!
python
data = (ImageList.from_folder(path) #どこからのデータか? -> pathの中のフォルダとサブフォルダで、ImageList
.split_by_folder() #train/validをどのように分けるか? -> フォルダをそのまま用いる
.label_from_folder() #labelをどのように付けるか? -> フォルダの名前から転用する
.add_test_folder() #testを付け足す
.transform(tfms, size=64) #Data augmentationを用いるか? -> size64のtfmsを用いる
.databunch()) #DataBunchへと変換する
DataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(3, figsize=(6,6), hide_axis=False)
すげええええ、本当にたった数行でtrain/validation/testに分けてdata augmentation用いたdatabunchを作成できた!
2. [Multi Label Classification] 次は、planetを用いた例を挙げていきます。
planet = untar_data(URLs.PLANET_TINY) planet_tfms = get_transforms(flip_vert=True, max_lighting=0.1, max_zoom=1.05, max_warp=0.)data = (ImageList.from_csv(planet, 'labels.csv', folder='train', suffix='.jpg') #どこからのデータか? -> planet内のtrainフォルダで、ImageList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_df(label_delim=' ') #labelをどのように付けるか? -> csvファイルを用いる .transform(planet_tfms, size=128) #Data augmentationを用いるか?-> size128のtfmsを用いる .databunch()) #DataBunchへと変換する同様にDataBlockを実際に読み込んで出力してみましょう
python
data.show_batch(rows=2, figsize=(9,7))
きちんとmulti-label-classificationが読み込めていますね。
3. [Mask Segmentation] camvidを用いた例を挙げていきます。
camvid = untar_data(URLs.CAMVID_TINY) path_lbl = camvid/'labels' path_img = camvid/'images'codes = np.loadtxt(camvid/'codes.txt', dtype=str); codeslabelを付け足す関数を自作します。
python
get_y_fn = lambda x: path_lbl/f'{x.stem}_P{x.suffix}'
tfm_y=Trueによって、data_augmentationが元々のmaskにも適用されるそう。
python
data = (SegmentationItemList.from_folder(path_img)
#どこからのデータか? -> path_imgで、SegmentationItemList
.random_split_by_pct()
#train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ
.label_from_func(get_y_fn, classes=codes)
#labelをどのように付けるか? -> get_y_func
.transform(get_transforms(), tfm_y=True, size=128)
#Data augmentationを用いるか?-> Standard transforms で tfm_y=True, size=128を指定
.databunch())
#DataBunchへと変換する
出力します。
data.show_batch(rows=2, figsize=(7,5))
簡単すぎ、、なのにすげええええ
どんどんいきます。4. [Object Detection] cocoを用いた例を挙げます。
coco = untar_data(URLs.COCO_TINY) images, lbl_bbox = get_annotations(coco/'train.json') img2bbox = dict(zip(images, lbl_bbox)) get_y_func = lambda o:img2bbox[o.name]data = (ObjectItemList.from_folder(coco) #どこからのデータか? -> cocoで、ObjectItemList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_from_func(get_y_func) #labelをどのように付けるか? -> get_y_func .transform(get_transforms(), tfm_y=True) #Data augmentationを用いるか?-> Standard transforms で tfm_y=True .databunch(bs=16, collate_fn=bb_pad_collate)) #DataBunchへと変換する -> bb_pad_collateによって一部のbbを出力data.show_batch(rows=2, ds_type=DatasetType.Valid, figsize=(6,6))
細かい設定をいじって非常にフレキシブルなAPIですね
5. [Text Language Model] IMDBを用いた例を挙げます。
from fastai.text import *imdb = untar_data(URLs.IMDB_SAMPLE)data_lm = (TextList.from_csv(imdb, 'texts.csv', cols='text') #どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList .random_split_by_pct() #train/validをどのように分けるか? -> ランダムでdefaultの20%の割合でvalidへ .label_for_lm() #labelをどのように付けるか? -> Language Modelから .databunch()) #DataBunchへと変換するdata_lm.show_batch()
これだけでLanguage Modelを鍛えることができます。
6. [Text Classification] IMDBを用いた例を挙げます。
上のLanguage Modelを延長して、
python
data_clas = (TextList.from_csv(imdb, 'texts.csv', cols='text')
#どこからのデータか? -> imdb の'texts.csv'のなかの'text'column で、TextList
.split_from_df(col='is_valid')
#train/validをどのように分けるか? -> 'is_valid' column にて分割
.label_from_df(cols='label')
#labelをどのように付けるか? -> 'label' column dfを参照する
.databunch())
#DataBunchへと変換する
完成!
data_clas.show_batch()
7. [Text Classification] IMDBを用いた例を挙げます。
from fastai.tabular import *adult = untar_data(URLs.ADULT_SAMPLE) df = pd.read_csv(adult/'adult.csv') dep_var = 'salary' cat_names = ['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country'] cont_names = ['education-num', 'hours-per-week', 'age', 'capital-loss', 'fnlwgt', 'capital-gain'] procs = [FillMissing, Categorify, Normalize]data = (TabularList.from_df(df, path=adult, cat_names=cat_names, cont_names=cont_names, procs=procs) #どこからのデータか? -> dfからのTabular List .split_by_idx(valid_idx=range(800,1000)) #train/validをどのように分けるか? -> val_idxの800から1000 .label_from_df(cols=dep_var) #labelをどのように付けるか? -> dep var=ターゲットを用いる .databunch()) #DataBunchへと変換するdata.show_batch()
以上となります。
個人的な振り返り
- 継続的にアウトプットすることでfast.aiの理解度を深め, fast.ai の掲げているdemocratizationへ寄与する。
- より深い部分のコードを解説していく。
- 次回、DataBlockのより細かい設定のAPIを解説していこうと思います。
最後に
間違いやご指摘などが御座いましたらご教示願います!!
- 投稿日:2019-03-02T15:27:55+09:00
Ubuntu Server 19.04 disco をGPU深層学習計算サーバーにするための最小限の設定
Ubuntu 19.04 Disco Dingo はUbuntu標準のレポジトリにNVIDIAの新しいドライバとCUDA 10.0が入っているから、tensorflow 1.13.1を使うために必要な作業が少なくて済む。
GPUと関係ない作業
- http://cdimage.ubuntu.com/ubuntu-server/daily/current/ からダウンロードする。
- インストーラーの一番最初の言語選択肢では「English」を選ぶ。そのあと「F6」を押して「Other Options」を選び、「Expert mode」にチェックを入れるとともに、ブートローダーのオプションの
ubuntu-server.seedをubuntu-server-minimal.seedに変更する(これは好みなのでそうしなくてもよい)
- なぜか上記の画面が出なくて通常のgrubの画面が出ることがあるので、その場合カーソルを「Install Ubuntu Server」に合わせてから
eを押して起動オプションを編集する。ubuntu-server.seedをubuntu-server-minimal.seedに変更するとともにpriority=lowを追加してexpert modeにする。編集を終えたらF10を押してインストーラーを起動する。- インストーラーのLinuxが起動するともう一度言語を聞かれるが今度は「日本語」を選んで問題ない。そのあと適切にインストールする。入れるパッケージを最小化したい場合インストーラーが追加のコンポーネントを入れないようにする。
- インストールしたUbuntuが起動したら最初に
/etc/apt/apt.conf.d/01norecommendsにAPT::Install-Recommends 0;を書いて余計なパッケージが入らないようにする(これも好み)dpkg-reconfigure debconfを実行し、パッケージインストール時にどの程度細かい質問を無視するか再設定する- 追加パッケージを入れる
intel-microcodeまたはamd-microcodebuild-essentiallanguage-pack-ja-baseでja_JP.UTF-8ロケールが入り、一部のメッセージの日本語版も入る。mdns(ドメイン名が.localで終わるもの) を使いたい場合はavahi-daemonをインストールするexim4-daemon-lightなどのメール配送ソフトを使いたい場合は入れておく/etc/aliasesを書き換えてnewaliasesを実行するpam-auth-updateを実行して必要なモジュールを入れる(例えばログイン時のホームディレクトリ作成など)/etc/update-motd.d/に必要なメッセージを置く。詳細はman update-motdsmartmontoolsをインストールし/etc/update-motd.d/のスクリプトにif ! smartctl -l xselftest,selftest -l xerror,error -T conservative -q silent /dev/sda; then echo "smartctlが異常なので大至急管理者を読んで下さい"; fiを追加する。/etc/smartd.confを適切に設定する、例えば/dev/sda -a -o on -S on -s (S/../.././02|L/../../6/03) -m rootなどemacs-nox(必要なら)nis(必要なら),/etc/nsswitch.conf,/etc/yp.confの設定をする。わからなければmanを見る。nisを入れてNISクライアントとして用いるときはunscdもインストールしないとログイン時に25秒固まるようになる。systemd-run --userを使うならdbus-user-sessionを入れる必要がある。crontab -u root -eで実行すること
- renice -n 19 -p `pgrep '^python3|^caffe'` (ディープラーニングのプロセスの優先度を下げる)
systemctl --state=running list-unitsを実行して不要なパッケージ見つけて、削除する。例えばapt-get --purge remove open-iscsi lvm2 lxcfs snapdそのあとにapt-get --purge autoremoveする(上記でインストーラーでubuntu-server-minimal.seedを選ぶとこういう要らないアプリが入らない)/etc/fstabについてネットワーク経由でアクセスするNFSやCIFSにはfstabのオプションとして_netdevを付ける。起動時にマウントしない場合はnoautoを付け、一般ユーザーのマウントを許可するときはuserを付ける。マウント出来なくても問題なく起動出来るマウントポイントにはnofailを付ける。マウントにタイムアウトを設定したいときはx-systemd.mount-timeout=何秒を付ける。GPUそのものを使うための作業
- (
add-apt-repository ppa:graphics-drivers/ppaはUbuntu 19.04 Disco Dingoの標準レポジトリに新しいGPUドライバが入っているから不要(2019年3月現在))apt-get updateapt-get install ubuntu-drivers-commonubuntu-drivers devicesを実行してインストールドライバ候補が妥当ならubuntu-drivers autoinstallでインストールする。余計なものをなるべく入れたくない場合はapt-get --no-install-recommends installを用いるnvidia-smi --ecc-config=1を用いてGPUメモリー誤り訂正機能を有効にする(QuadoroとTeslaのみ)深層学習フレームワークのインストール
Python関係共通
apt-get install jupyter-notebook python3-pip python3-ipywidgets python3-setuptools python3-wheel; pip3 install -U setuptools wheel pipCUDAバージョンについて
Ubuntu 19.04に付属するCUDAは10.0である。
Caffe
apt-get install caffe-cudaこれで依存関係によりCUDA10.0の一部もインストールされるTensorflow 1.13.1
Ubuntu 19.04レポジトリに標準で入っているCUDAは10.0でtensorflow 1.13バイナリが期待するバージョンであるから、普通にCUDAライブラリをインストールすればよい。
1.apt-get install libaccinj64-10.0 libcublas10.0 libcudart10.0 libcufft10.0 libcufftw10.0 libcuinj64-10.0 libcupti10.0 libcurand10.0 libcusolver10.0 libcusparse10.0 libnppc10.0 libnppial10.0 libnppicc10.0 libnppicom10.0 libnppidei10.0 libnppif10.0 libnppig10.0 libnppim10.0 libnppist10.0 libnppisu10.0 libnppitc10.0 libnpps10.0 libnvblas10.0 libnvgraph10.0 libnvjpeg10.0 libnvrtc10.0 libnvtoolsext1 libnvvm3
2. http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/ からCUDA10.0で使えるlibcudnn7とlibnccl2の一番新しいバージョンを持ってきて、.debファイルをdpkg -Xで展開し、その中に入っている.soファイルを/usr/lib/x86_64-linux-gnu/にmvする
3.ldconfigを実行する。
4.pip3 install -U matplotlib tensorflow-gpu; apt-get install libgomp1
5.python3 -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"で動作確認するChainer
- 上記のtensorflowのための共有ライブラリの用意を行う(ただしlibncclとlibcudnn7はcupyに含まれているから不要)
pip3 install -U cupy-cuda100 chainerKeras 2.2以降
apt-get install graphviz libgts-bin python3-pil python3-h5pypip3 install -U pydot graphviz keraspytorch
https://pytorch.org/get-started/locally/ に行くとインストールするためのコマンドを教えてくれる