- 投稿日:2021-02-13T23:47:40+09:00
ラズパイ4BでSSH接続(Mac、最初からディスプレイなし、無線LANの場合)<後編>
5.起動する(電源に繋ぐ)
Raspberry Pi4にMicroSDカードを挿して、USB-Cで給電し起動を行ってください。
緑のランプが点滅すればSDCardの読み込みが行われています。
6.SSH接続を行う
前回の記事でmicroSDCardにwpa_supplicant.confファイルが書いてあるので(ちなみにwpaはWi-Fi Protected Accessの略です)、ラズパイの電源を起動をしただけでラズパイとWiFiが繋がっている状態になります。その状態でMacからリモートでSSH接続を行います。
リモート接続するためにはラズパイのIPアドレスが必要になります。
調べるためにはターミナルで以下のコマンドを打ってください。
arp -aそうするとこのような画面が出てきます。
ここでは(192.168.3.7)でした。
注意してほしいのはここではraspberrypiと表示されていますが、必ずしもraspberrypiと表示されているとは限りません。表示されてなくてもWiFi接続しているラズパイの場合もあります。それでも次のSSH接続で確認すれば問題ないので、これかな?と思うものがあればSSH接続を試してみてください。
ちなみに192.168.3.1とか192.168.3.255はルータかその辺です。
それでは大変長らくお待たせしました。いよいよSSH接続を行います。
接続のコマンドはターミナルで
ssh pi@各々のIPアドレスになるので今回の場合は以下のようになります。
ssh pi@192.168.0.7このように各自で調べたIPアドレスを書いてください。
そうするとパスワードを求められるのでraspberryと入力してください。(初期設定がユーザ名pi、パスワードraspberryになっています。)
接続できれば一番下に
pi@raspberrypi:~ $と表示されます。
余談ですが、僕が初めて接続できたときは嬉しくて雄叫びを上げたっけなぁ。SDCard買い替えたりしたりして苦労しましたもの。。
それでは最後にVNCに移ります。
7.VNC viewerでGUI接続
VNCとは?
Virtual Network Computingの略
ネットワーク上の離れたコンピュータを遠隔操作ができるソフトウェア。デスクトップ画面を操作できる。
VNC viewerはこちらから無料ダウンロードできます。
ラズパイをSSH接続した状態で、
sudo raspi-configと打ってください。そしたら下のような画面が出ます
設定によって背景の色は違うかもしれませんが、書かれている単語が同じであれば問題ないです。
まずはVNCの設定をONにします。
3→P3→YesVNC接続をデフォルトに設定します(これをしないとエラーがでます。)
1→S5→B4ラズパイのデスクトップのサイズです。
2→D1→好きなサイズ(ちなみに僕はMac Book Proの13.3インチでDMT Mode 35 1280x1024 60Hz 5:4 にしています。ちょうどいい具合に使えています。)
このツールをアップデートします。
8このツールを終了します。
Finishここで一度ラズパイを再起動をします。「~ like to reboot now?」と聞かれたらyesを押します。
もし聞かれなかったら下のコマンドを入力してください。一度SSH接続からログアウトします。
sudo rebootその後、reboot(再起動)するとssh接続が切れるのでまた
ssh pi@各々のIPアドレスでSSH接続を行い、VNC Viewer(こちらからインストールしてください)
を開き、上の方にある入力欄に先ほど入れた確認したIPアドレスを入力してください。VNC Server has not recognizedという画面が出たらcontinueを押します。
以前違うラズパイを、同じIPアドレスに接続していたら場合「VNC Server identity check failed 」という警告が出ますが、continueで大丈夫です。
Authenticate VNC Server という画面が出るのでusernameにpi,passwordにraspberryと入力してOKを押してください。
接続に成功すればデスクトップ画面が表れます。
以上で終了です!お疲れ様でした。(その後の初期設定やセキュリティ等も重要ですが、それは後日気が向いたら書きます。)


- 投稿日:2021-02-13T22:54:38+09:00
Lambdaでメッセージを編集してSNS Publishする一例
Lambdaのコード
ヒアドキュメントと変数、
json.dumpsを利用した一例です。
SecurityHubの通知を例にして作成しています。lambda_functionfrom __future__ import print_function import json import boto3 import os sns = boto3.client("sns") def lambda_handler(event, context): message = event["detail"]["findings"][0] msg = """ Security Hubにより検知した違反内容 セキュリティ基準コントロール:{standards_control_arn} タイトル:{title} 説明:{description} セキュリティステータス:{status} 重要度:{severity} 修復手順:{remediation_text}({remedeation_url}) 対象リソース {resources} 詳細 -- {detail} """.format(standards_control_arn=message["ProductFields"]["StandardsControlArn"], \ title=message["Title"],\ description=message["Description"], \ status=message["Compliance"]["Status"], \ severity=message["Severity"]["Label"],\ remediation_text=message["Remediation"]["Recommendation"]["Text"], \ remedeation_url=message["Remediation"]["Recommendation"]["Url"],\ resources=json.dumps(message["Resources"], indent=4), \ detail=json.dumps(event, indent=4)) response = sns.publish( TopicArn=os.environ.get("sns_arn"), Subject="テスト", Message=msg ) return response
- 投稿日:2021-02-13T21:53:13+09:00
VS Code Remote ContainersとPylanceで快適Python環境を構築する方法
最近、チーム用のPython開発環境を構築する機会があり、VS Codeを使った環境構築がかなり便利だったので記事にしました。
はじめに
本記事では、VS CodeのRemote Containersを利用し、再現性が高く快適なPython環境を構築する方法を紹介します。
すでにあるRemote Containersの記事との違いは、Pythonを使ったチームでの開発を想定し、リンターや便利な拡張機能も環境構築に含めていることです。
今回紹介する内容を使えば、コードの自動フォーマットやコードの補完などが有効になる快適なPython開発が可能です。
Pythonの実装のコツやノウハウについては、同じチームの@sugulu_Ogawa_ISIDさんの記事が参考になります。
便利なこと
本記事で紹介する方法の便利なところは以下の2点です
- Pythonのバージョンや使用packageをチームで一元管理
- VS codeで使用するリンターや拡張機能をチームで統一
一つ目は、ほぼDockerのメリットになりますが、anacondaやpyenvやvenvのようなバージョン管理やpackage管理で悩まなくてすみます。そして、新しくチーム用の開発環境を作る際に、各々のローカル環境に左右されずDockerが使えさえすればOKとなるので、開発初期の環境構築作業が非常に楽になります。
二つ目は、コード規約や拡張機能の知見を共有できることです。私の周囲では、開発用エディタはVS Codeを利用していることが多く、エディタは統一されています。しかし、VS Codeの設定にはかなり個人差があります。VS Codeで提供されている機能を使いこなしているか否かで作業効率がかなり変わるので、できればVS Codeの環境自体も共有したいです。
今回紹介するRemote Containersでは、設定ファイルさえ渡せば上記2点が簡単にチームで共有できます。
Remote Containersを使った環境構築方法
必要なものはざっくり以下の5つです。
- Visual Studio Code
- Docker
- Remote Containers拡張機能
- devcontainer.json
- Dockerfile
VS CodeとDockerのインストール方法はここでは紹介しません。Remote ContainersはVS Codeの拡張機能からインストールできます。
Remote Containers機能を使うには作業フォルダ内に
.devcontainer/devcontainer.jsonが必要です。このdevcontainer.jsonがRemote Containers機能の設定ファイルに該当します。今回はテスト用に以下のようなプロジェクトを使います。
(公式のPythonテンプレートを参考にしています). ├── .devcontainer │ ├── Dockerfile │ └── devcontainer.json ├── .gitattributes ├── .gitignore ├── requirements.txt └── test.pyDockerfileの中身は以下になります。ほぼ公式のDockerfileのままです。
ARG VARIANT="3" FROM mcr.microsoft.com/vscode/devcontainers/python:0-${VARIANT} ENV PIP_TARGET=/usr/local/pip-global ENV PYTHONPATH=${PIP_TARGET}:${PYTHONPATH} ENV PATH=${PIP_TARGET}/bin:${PATH} RUN if ! cat /etc/group | grep -e "^pip-global:" > /dev/null 2>&1; then groupadd -r pip-global; fi \ && usermod -a -G pip-global vscode \ && umask 0002 && mkdir -p ${PIP_TARGET} \ && chown :pip-global ${PIP_TARGET} \ && ( [ ! -f "/etc/profile.d/00-restore-env.sh" ] || sed -i -e "s/export PATH=/export PATH=\/usr\/local\/pip-global:/" /etc/profile.d/00-restore-env.sh ) COPY requirements.txt /tmp/pip-tmp/ RUN pip3 --disable-pip-version-check --no-cache-dir install -r /tmp/pip-tmp/requirements.txt \ && rm -rf /tmp/pip-tmp次は肝心の
devcontainer.jsonの中身です。こちらも基本的に公式のPythonテンプレートに倣ってます。{ "name": "Python 3", "build": { "dockerfile": "Dockerfile", "context": "..", // Update 'VARIANT' to pick a Python version: 3, 3.6, 3.7, 3.8 "args": { "VARIANT": "3" } }, "workspaceMount": "source=${localWorkspaceFolder},target=/workspaces,type=bind,consistency=delegated", "workspaceFolder": "/workspaces", "settings": { "terminal.integrated.shell.linux": "/bin/bash", "python.pythonPath": "/usr/local/bin/python", "python.linting.enabled": true, "python.linting.pylintEnabled": true, "python.formatting.autopep8Path": "/usr/local/py-utils/bin/autopep8", "python.formatting.blackPath": "/usr/local/py-utils/bin/black", "python.formatting.yapfPath": "/usr/local/py-utils/bin/yapf", "python.linting.banditPath": "/usr/local/py-utils/bin/bandit", "python.linting.flake8Path": "/usr/local/py-utils/bin/flake8", "python.linting.mypyPath": "/usr/local/py-utils/bin/mypy", "python.linting.pycodestylePath": "/usr/local/py-utils/bin/pycodestyle", "python.linting.pydocstylePath": "/usr/local/py-utils/bin/pydocstyle", "python.linting.pylintPath": "/usr/local/py-utils/bin/pylint", "python.analysis.typeCheckingMode": "basic", "python.analysis.completeFunctionParens": true }, "extensions": [ "ms-python.python", "ms-python.vscode-pylance", "ms-vsliveshare.vsliveshare", "njpwerner.autodocstring" ], "remoteUser": "vscode" }
workspaceMountでは、マウントしたいローカルフォルダとコンテナ内のマウント先を指定しています。${localWorkspaceFolder}で.devcontainer/devcontainer.jsonを含むフォルダのパスを指定できます。settingsの内容はRemote Containersで開いた時のVS Codeの設定です。
そして、extensionsに拡張機能を追加することで、Remote Containers内で指定した拡張機能がインストールされます。これにより、「2. リンターや拡張機能を簡単にチームで共有できる」を実現できます。
VS codeでPythonを開発するにあたりぜひ入れて欲しい拡張機能は
ms-python.python、ms-python.vscode-pylance、njpwerner.autodocstringです。(ms-python.vscode-pylanceを使うにはms-python.pythonが必須です)
ms-python.vscode-pylance(Pylance)は後述しますが、VS CodeでのPython開発を強力にサポートしてくれる拡張機能です。njpwerner.autodocstring(Python Docstring Generator)はDocstringを生成してくれる拡張機能です。Remote Containersの使い方
ここまでの設定が完了すればあとは起動するだけです。
起動するには、VS Codeの左下の緑のアイコンをクリックします。
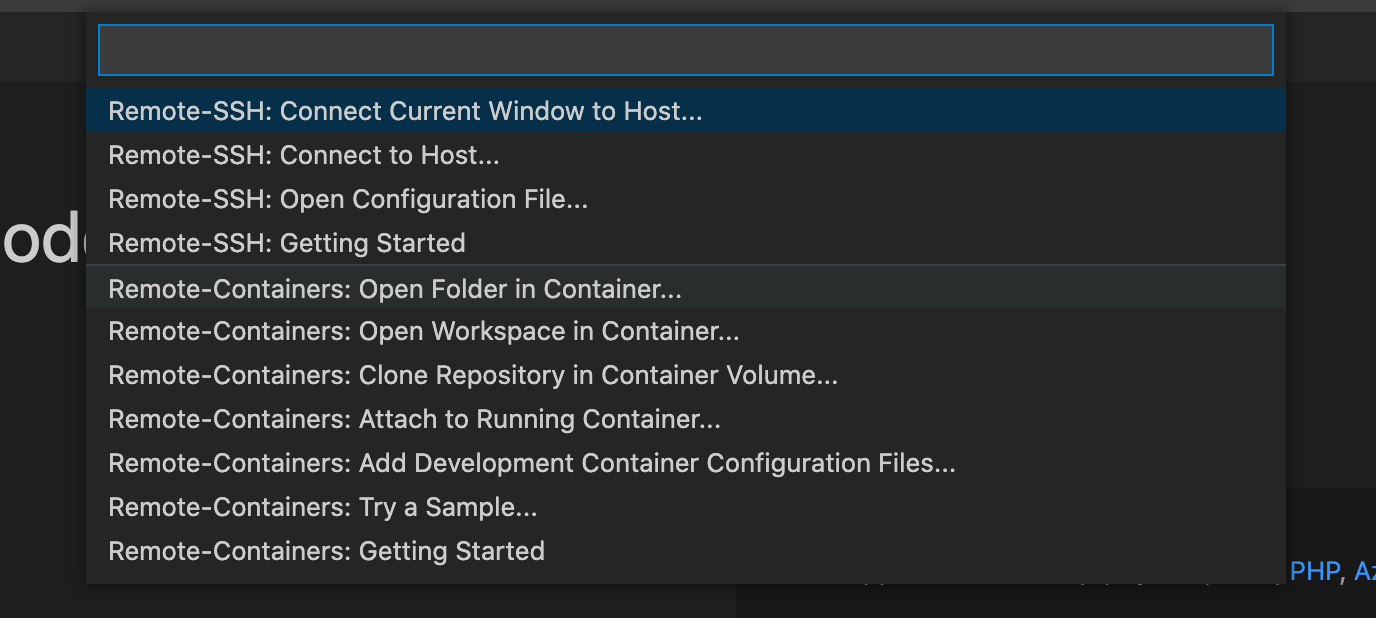
アイコンをクリックすると以下のような選択肢が出るので、
Remote-Containers: Open Folder in Containerを選択し、.devcontainerがあるフォルダを選択します。
これで完了です。あとはローカルで開発するのと同じように作業できます。
Pylanceの使い方
続いて、拡張機能としてインストールしたPylanceについて紹介します。
Pylanceの提供する主な機能は以下になります。
- Docstrings
- Signature help, with type information
- Parameter suggestions
- Code completion
- Auto-imports (as well as add and remove import code actions)
- As-you-type reporting of code errors and warnings (diagnostics)
- Code outline
- Code navigation
- Type checking mode
- Native multi-root workspace support
- IntelliCode compatibility
- Jupyter Notebooks compatibility
- Semantic highlighting
いろいろ便利な機能が提供されていますが、特に便利なのはコードの補完、Docstrings表示と型チェックです。
本記事ではチーム開発で役立つDocstrings表示と型チェックを紹介します。まずはDocstringsについてです。
これはDocstringsで書かれた内容を該当コードにホバーすると以下のように表示される機能です。
(Docstringsとは、関数やクラスの説明を記述したものです。)
この機能があると引数や返り値などについて確認する時間を短縮することが可能です。
Docstringsを書くのはちょっと面倒だったりするのですが、先ほどインストールしたPython Docstring Generatorを使えばDocstringsを書く手間を短縮できます。Macであれば、Docstringを挿入する場所で
cmd + shift + 2とすると、以下のようにテンプレートを作成してくれます。
Docstringのテンプレートは以下から選択できます。
(Python Docstring Generator)Google (default)
docBlockr
Numpy
Sphinx
PEP0257 (coming soon)次に型チェックです。
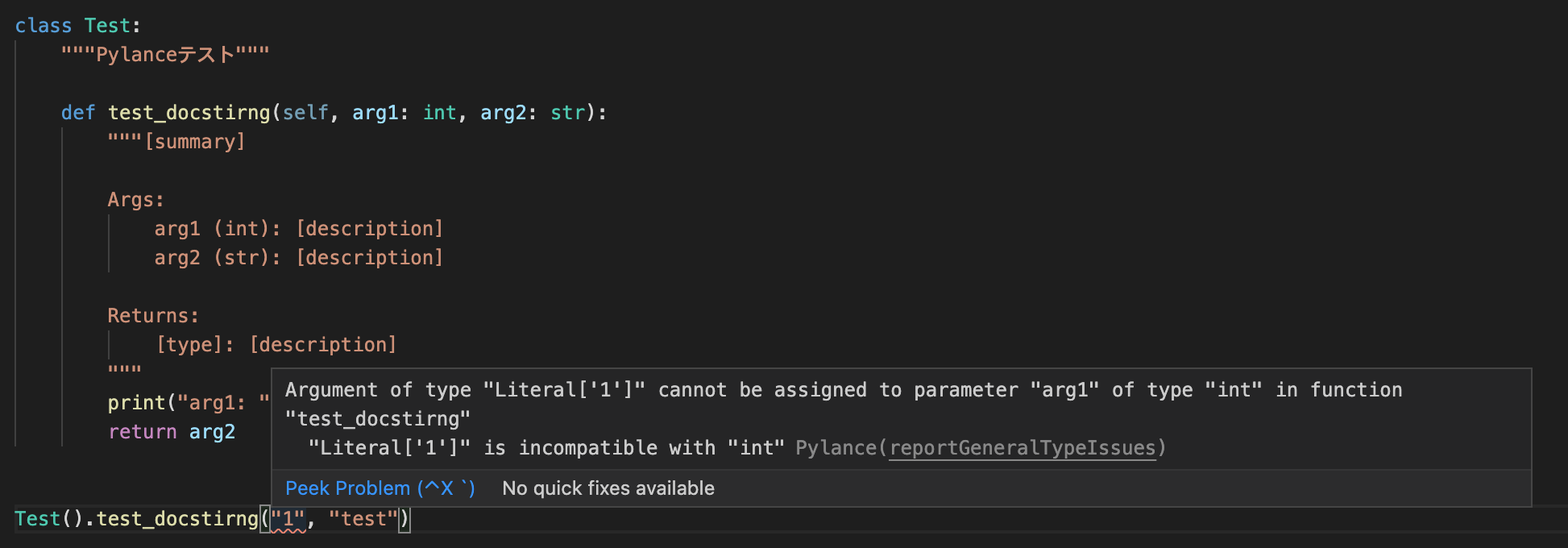
Pythonでは、変数の型が一致しなくても実行できてしまいます。そのため、本来期待していた型と異なる型で実装してしまうことがあります。型指定があるとこのような間違った型の実装を防ぐことができ、特に複数人かつ複雑な構成で開発する場合は便利です。
Pylanceの
Type checking modeを設定すると、以下のようにコードを書いている途中に型の間違いに気づくことができます。
Type checking modeではoff、basic、strictと型チェックの厳しさを選択できます。
strictにすると型の指定がないだけでもエラー判定されます。開発チーム次第ではありますが、基本的には
basicで問題ないと思います。
この設定は、devcontainer.jsonの"python.analysis.typeCheckingMode": "basic"で変更できます。終わりに
本記事では、VS CodeのRemote Containers機能を用いたPythonの開発環境構築方法を紹介しました。
ちなみに、本記事では紹介しませんでしたがJupyter Notebookもインストールするだけで今回の設定で使えます。
他にもsort importやimport文の自動追加や自動削除といった紹介しなかった便利機能もあります。また、拡張機能についても今回は必要最低限しか記載していませんが、他にも便利なものがたくさんありました。
こちらも今後まとまったら記事にしようと思います。参考


- 投稿日:2021-02-13T21:40:10+09:00
Pythonを使ってconnpassイベントをキーワード検索
Pythonを使ってconnpassイベントをキーワード検索
公式ドキュメント ... https://connpass.com/about/api/
リクエストURL
パラメーター
keyword_or ... キーワード (,)区切りで複数選択
ym ... 取得年月(YYYYMM)(,)区切りで複数選択
order ... 表示順(1: 更新日時順, 2: 開催日時順, 3: 新着順)
count ... 取得数Python側
キーワード、取得年月、取得数で検索できるようにした
結果は加工しやすいようにDataFrameに入れたdef get_search(keyword: str, ym: str, count: int = 100): df = pd.DataFrame( columns=[ "id", "title", "catch", "description", "event_url", "hash_tag", "started_at", "ended_at", "limit", "address", "place", "owner_id", "owner_nickname", "owner_display_name", "accepted", "waiting", "updated_at", ], ) url = ( f"https://connpass.com/api/v1/event/?keyword_or={keyword}" f"&ym={ym}&count={count}" ) response = requests.get(url) resources = response.json() for event in resources["events"]: df = df.append( { "id": event["event_id"], "title": event["title"], "catch": event["catch"], "description": event["description"], "event_url": event["event_url"], "hash_tag": event["hash_tag"], "started_at": event["started_at"], "ended_at": event["ended_at"], "limit": event["limit"], "address": event["address"], "place": event["place"], "owner_id": event["owner_id"], "owner_nickname": event["owner_nickname"], "owner_display_name": event["owner_display_name"], "accepted": event["accepted"], "waiting": event["waiting"], "updated_at": event["updated_at"], }, ignore_index=True, ) return df今回はphp,laravel,wordpressを対象に202102,202103のイベントを取得
search = connpass.get_search("php,laravel,wordpress", "202102,202103")結果
id title ... waiting updated_at 0 204563 ヘッドレスWordPress入門 ... 0 2021-02-13T20:30:41+09:00 1 204610 (若手?)エンジニアもくもく会 vol.34 @Slack ... 0 2021-02-13T19:59:55+09:00 2 204076 もくもく会in神戸 #2【三宮&ウェブ開催】 ... 0 2021-02-13T18:15:58+09:00 3 200508 TwilioQuest - 2021 新春チャレンジ ... 0 2021-02-13T17:19:22+09:00 4 204362 【超入門】Webサイトをデプロイしよう! ... 0 2021-02-13T16:54:57+09:00 .. ... ... ... ... ... 72 202607 名古屋駅前 もくもく会 2021.2.7 ... 0 2021-01-25T21:56:44+09:00 73 202576 サーバー構築ハンズオン@オンライン #129 ... 0 2021-01-25T15:14:45+09:00 74 201718 第73回【オンライン開催】PORTもくもく会【学生歓迎!】 ... 0 2021-01-16T14:19:06+09:00 75 201342 錦糸町 朝活・もくもく会 #3 ... 0 2021-01-13T07:26:46+09:00 76 198286 [新宿御苑前]がやがやと勉強する会(テーマ自由、初心者歓迎!) ... 0 2021-01-12T13:50:49+09:00
connpassイベントを取得できました
いいね!と思ったら LGTM お願いします【PR】週末ハッカソンというイベントやってます! → https://weekend-hackathon.toyscreation.jp/about/
- 投稿日:2021-02-13T21:37:38+09:00
共変ベクトル、反変ベクトル生成器を作ってみた(MathJaxがFirebaseで動かなくて中途半端なでき)
共変ベクトルと反変ベクトルの計算を楽にしたい
一般相対性理論を勉強する場合に最大の難関が、「共変ベクトルや反変ベクトルのイメージがつかない」ことだと思います。
共変ベクトルと反変ベクトルを掛け合わせると綺麗にスカラーになる部分が一番面白いと個人的には思うのですが、その手前でイメージがつかないと挫折しそうでした。
そんなとき、「自動でクリストッフェルや共変や反変を計算してくれるサイトがあればなあ」と思っていました。
思っていたので、作りたくなり、作りました。自分のコンピューターでみた場合 vs Firebaseにホスティングした場合
自分のコンピューターでみると、うん!ばっちり!なできです 1次〜100次元まで計算できます!
しかし、Firebaseにホスティングすると、LaTex表示になってしまいます。
なぜこうなったのか
webに数式を表示するには、「MathJax」というjavascriptの手法を使うのが楽で、
MathJaxを使えば、Latex形式で貼り付ければ数式が表示されます。
しかし、FirebaseはMathJaxと相性が悪いらしく、なんらかのおまじないを打たなければ厳しいみたいです。中の仕組み
今回の作品は、全然ダメではありますが、
「LaTex形式では掃き出せている」ので、個人的には満足です(wordとかに貼り付けて変換するなりしていただければ使えるでしょうし)その場で計算式を解いているわけではなく、pythonでn=1~100まで計算させてからその結果を予めhtmlに忍ばせており、
vue.jsでイベントハンドリング(数値が入力されたら、showされるものを変える)しています。結果と考察
・webに数式を表示する技術に技術的限界が現状あり、これは誰かが解決してもいい問題のように感じた
⇨そのため、今回はwebブラウザ上での計算を諦め、予めpythonで計算したものを表示することにした。・クリストッフェルをそのまま計算したりする手法は、pythonやC++では存在するが、web上でだれでも計算できるようには現状なっていない。ここは誰かが解決してもいいような問題に感じた
⇨大学生のレポートが楽になるし、相対性理論で苦しめられる学生が減るのでは?・LaTexにおいて、「\」が多様されるが、pythonはこの記号がエスケープに使われるため、かなりプログラム自体に苦戦した。
⇨pythonにおいては、「\」によって、「\」一個分を表示する(エスケープでエスケープする)という文法であることを学んだ。これに気づくまでがまた長かった。今後
Firebaseがダメなら、HerokuとAWSは試したいところ。
できれば、共変ベクトル、反変ベクトルの経験をいかして、リッチテンソル、クリストッフェルも計算したいところ!(これもブラウザ上計算ではなく、結果を予め出力したものが妥当に思います。)HTMLでLaTex形式で出力するpythonのソースコード
for n in range(1,101): First_1 = " <jigen" First_2 = " v-show=" First_3 = "\"jigen == " First_4 = "\">" First = First_1 + str(n) + First_2+ First_3 + str(n) + First_4 print(First) Second_1 = " ~~~~~~~~~~~~~~" print(Second_1) Third_1 = " <br>共変ベクトル \[q_i^\prime=\]" print(Third_1) Forth_1 = " <p class="+ "\"sample1\"" + ">" print(Forth_1) Fifth_1 = " <!-- 共変ベクトル -->" print(Fifth_1) #共変 res_start = "\[" res1 = "\\"+ " " + "\\"+ " " +"\\"+ "frac{\partial x_" res2 = "}{\partial x_i\ }\ q_" res_end = "\]" res_ans1 = "" for s in reversed(range(1,n+1)): res = res1 + str(s) + res2 + str(s) #print(res) res_ans1 = res + "+" + " " + res_ans1 #print(res_ans1) res_ans1 = res_ans1.rstrip(" +") res_ans2 = " " +res_start + res_ans1 + res_end print(res_ans2) Seventh_1 = " </p>" print(Seventh_1) Eighth_1 = " ~~~~~~~~~~~~~~" print(Eighth_1) Ninth_1 = " <br>反変ベクトル \[q^{\prime i}=\]" print(Ninth_1) Tenth_1 = " <p class="+ "\"sample1\"" + ">" print(Tenth_1) Eleventh_1 = " <!-- 反変ベクトル -->" print(Eleventh_1) #反変 res_start = "\[" res1 = "\\"+ " " + "\\" + "frac{\partial x^{\prime i}}{\partial x^" res2 = "\ }\ q^" res_end = "\]" res_ans1 = "" for s in reversed(range(1,n+1)): res = res1 + str(s) + res2 + str(s) #print(res) res_ans1 = res + "+" + " " + res_ans1 #print(res_ans1) res_ans1 = res_ans1.rstrip(" +") res_ans2 = " " + res_start + res_ans1 + res_end print(res_ans2) Thirteenth_1 = " </p>" print(Thirteenth_1) Forteenth_1 = " </jigen"+str(n)+">" print(Forteenth_1)


- 投稿日:2021-02-13T21:21:17+09:00
Pythonによる四則演算コンパイラの作成
はじめに
こんにちは,keygoroと申します.よろしくお願いします.
今回,Pythonを使用して四則演算に対応するアセンブリ言語プログラムを生成するプログラムを作成しました.完成形ではありませんが,ここにまとめたいと思います.作成するにあたり,植山類さんの低レイヤを知りたい人のためのCコンパイラ作成入門(https://www.sigbus.info/compilerbook) を参考にさせていただきました.目的
今回の目的は,四則演算に対応するアセンブリ言語プログラムを生成するコンパイラをPythonで作成することである.例えば,30 + (4 − 2) × 5などの式がコンパイルできるようにする.
コンパイラで計算を行う際,計算の優先順位を処理する必要がある.入力として与えられる数式はただの文字列であって,構造化されたデータではない.式を正しく評価するためには,文字の並びを解析して,そこに隠れた構造をうまく導き出す必要がある.そのために,今回は構文解析の最も一般的なアルゴリズムの一つである「再帰下降構文解析法」を用いてコンパイラを作成する.以下で,コンパイラを作成するために重要なトークナイザ,構文解析,スタックマシンについて解説する.トークナイザ
四則演算の式の最小単位のことをトークンと呼ぶ.例えば,5 + 20 − 4は,5, + ,20, − ,4という5つのトークンで構成されている.四則演算の式(文字列)をトークンの列に分解することを「トークナイズする」という.トークナイズする際には,四則演算に関係ない空白文字は無視する必要がある. 例えば,”5 + 20 − 4”という式も"5, + ,20, − ,4"という5つのトークンに分解されるようにプログラムする必要がある.
今回作成したPythonのプログラムでは,プログラム1で示すクラスにトークンの情報を格納している.kindはトークンの種類,valはトークンが数字だった場合の値,strはそのときのトークン文字列を表している.
例として, 1 * (2 + 3)のとき先頭のトークンは,kind=num,val=1,str=1*(2+3)となる.#プログラム1 トークンのクラス class Token: def __init__(self, kind, val, str): self.kind = kind self.str = str構文解析
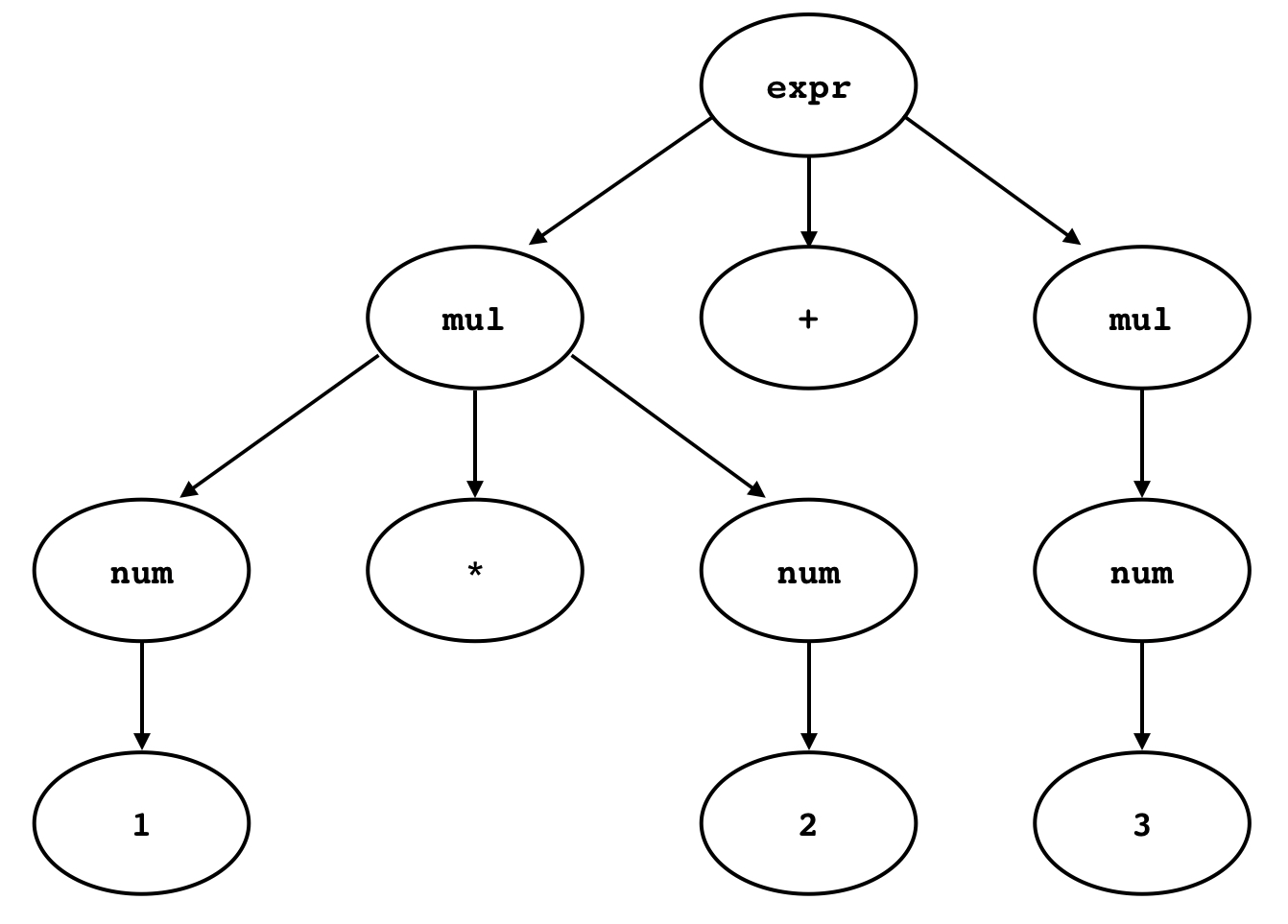
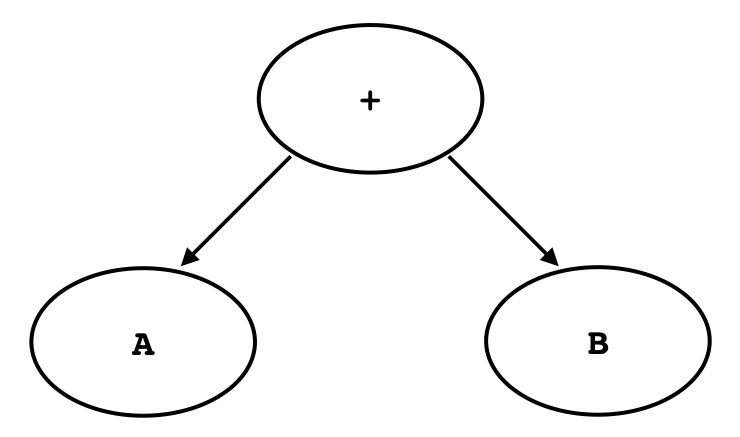
四則演算の演算子の優先順位をうまく処理するためには,トークン列に対して構文解析を行う必要がある.コンパイルの行程で構文解析をする機能のことをパーサーと呼ぶ.パーサーはフラットなトークン列を演算子の優先順位を表現可能な木構造で表すことができる. 例えば,1 * (2 + 3)という式は,図1のような木構造で表すことができる.
図1 1*(2+3)を表す抽象構文木トークン列から構文木を生成するには,四則演算の法則を記述する必要がある.法則を記述するためにここではEBNF(Extended Backus-Naur Form)を用いることにする.
EBNFでは,一つ一つの生成規則を$A=\alpha_1,\alpha_2,\dots$という形式で表す.これは記号$A$を$\alpha_1,\alpha_2,\dots$に展開できるという意味である.
$\alpha_1,\alpha_2,\dots$は0個以上の記号の列で,それ以上展開できない記号と,さらに展開される(いずれかの生成規則で左辺に来ている)記号の両方を含むことができる.以下は,EBNFを使って加減算の式の文法を表したものである.expr = num ("+" num | "-" num)*ここで,
numは数値を表す記号を表している.この式では,まずnumが1つあって,その後に0個以上 の「+とnum,あるいは-とnum」があるものをexprとして定めている.演算子の優先規則もEBNFによって,以下のように記述することができる.
expr = mul ("+" mul | "-" mul)* mul = num ("*" num | "/" num)*この規則では,
exprが直接num(数字)に展開されず,mulを介してnumに展開されている.mulは乗除算の生成規則を表しているが,図2からもわかるように,この規則によって乗除算が先に実行されるという規則を構文木の中で自然に表現できる.
図2 1*2+3を表す具象構文木
ここで,図1のようなシンプルな構文木を抽象構文木,図2のような文法に1対1対応の構文木を具象構文木という.
また,以下のように再帰的に文法記述することにより,カッコの中を優先するという四則演算の規則を記述することができるようになる.expr = mul ("+" mul | "-" mul)* mul = primary ("*" primary | "/" primary)* primary = num | "(" expr ")"以下のプログラム3は,この文法にしたがって,トークン列から構文木を生成するプログラムの主要部分である.
Expr(), Mul(), Primary()という関数が,ENBFにおけるexpr, mul, primaryに対応している.NewNnode()は,構文木の新しいノードを生成する関数である.Consume()は今参照しているトークンが+, -, *, /などの演算子であるかを判定する関数である.#プログラム2 構文木を生成するプログラム def Expr(): node = Mul()#nodeに関数Mul()が入る while True:#Trueの間繰り返す. if Consume("+"):#Consumeでstr_opr="+"だったとき node = New_Node(ND.ADD,node,Mul())#このような新しいノードを作る elif Consume("-"):#Consumeでstr_opr="-"だったとき node = New_Node(ND.SUB,node,Mul())#このような新しいノードを作る else: return node def Mul(): node = Primary()#nodeに関数Primary()が入る while True:#Trueの間繰り返す if Consume("*"):#Consumeでstr_opr="*"だったとき node = New_Node(ND.MUL,node,Primary())#このような新しいノードを作る elif Consume("/"):#Consumeでstr_opr="/"だったとき node = New_Node(ND.DIV,node,Primary())#このような新しいノードを作る else: return node def Primary(): if Consume("("):#Consumeでstr_opr="("だったとき node = Expr()#nodeにExpr()が入る Expect(")")#関数Expectでstr_opr=) return node return New_Node_Num(Expect_Number())スタックマシン
この章では,パーサーが生成した構文木をアセンブリ言語に変換するプログラムについて説明する.説明を簡単にするために,コンピュータとしては,スタックマシンを想定する.スタックマシンに対して変換できれば,それをx86-64用に拡張するのは容易である.スタックマシンは,スタックをデータ保存領域として持っているコンピュータのことである.したがってスタックマシンでは「スタックにプッシュする」と「スタックからポップする」という2つの操作が基本操作となる.プッシュでは,スタックの一番上に新しい要素が積まれ,ポップでは,スタックの一番上から要素が取り除かれる.スタックマシンにおける演算命令は,スタックトップの要素に作用する.例えばスタックマシンのADD命令は,スタックトップから2つ要素をポップしてきて,それらを加算し,その結果をスタックにプッシュする.SUB,MUL,DIV命令は, ADDと同じように,スタックトップの2つの要素を,それらを減算・乗算・除算した1つの要素で置き換える命令ということになる.このように定義したスタックマシンを使うと,次のようなコードで2*3+4*5を計算することができる.
// 2*3を計算 PUSH 2 PUSH 3 MUL // 4*5を計算 PUSH 4 PUSH 5 MUL // 2*3 + 4*5を計算 ADD構文木をスタックマシンのコードに変換する方法について説明するために,図3のような加算を表す構文木を考える.
図3 加算を表す構文木AやBというのは部分木を抽象化して表したもので,実際にはなんらかの型のノードを意味している.この木をコンパイルするときは次のようにすればよい.
- 左の部分木をコンパイルする
- 右の部分木をコンパイルする
- スタックの2つの値を,それらを加算した結果で 置き換えるコードを出力
すなわち,構文木をスタックマシンにコンパイルするときは,再帰的に考えて,木を下りながらアセンブリを出力していくことになる.プログラム3はこの処理を行うPythonのプログラムの主要部である. gen()という関数は再帰処理を行っている.
#プログラム3 スタックマシンへコンパイルするプログラム def gen(node): if node.kind == ND.NUM:#nodeの種類が数字のとき print(" push ",node.val)#nodeの値をpushする return gen(node.lhs)#左辺 gen(node.rhs)#右辺 print(" pop rdi") print(" pop rax") if node.kind == ND.ADD:#nodeの種類がADDだった場合 print(" add rax, rdi") elif node.kind == ND.SUB:#nodeの種類がSUBだった場合 print(" sub rax, rdi") elif node.kind == ND.MUL:#nodeの種類がMULだった場合 print(" imul rax, rdi") elif node.kind == ND.DIV:#nodeの種類がDIVだった場合 print(" cqo") print(" idiv rdi") else: print("error")#どれにも当てはまらなかったらerror print(" push rax")プログラム
以下に,作成した四則演算コンパイラのプログラムをまとめて示す.
新しいトークンを作る関数,入力した数式をトークナイズする関数を定義
#新しいトークンを作る関数,入力した数式をトークナイズする関数を定義 from enum import Enum class TK(Enum): #列挙型 RESERVED = 0#記号なら0 NUM = 1#整数なら1 EOF = 2#入力の終わりなら2を出力 class Token: def __init__(self, kind, val, str):#トークンの種類、数値、トークン文字列の場所 self.kind = kind #アトリビュートを追加 (kind,val,str)に対応 self.val = val self.str = str token = []#apendで追加していくリスト oprlist=["+","-","*","/","(",")"]#演算子のリスト def StrtoL(str): str2="" flg=0 for i in range(len(str)):#strの長さ分繰り返す if oprlist.count(str[i]):#oprlistにある演算子に当てはまったらflg1としてbreak flg=1 break else: str2+=str[i] #演算子ではないとき数字がstr2に加わる if flg==1: return int(str2),str[i:]#flg==1だったらこれを出力.int(str2)でstr2の文字列を数値に変換.str[i+1:]はstr[i]以降の数字を表示する else: return int(str2),0 def NewToken(kind,str):#tokenをつくってtoken[]に追加する a=Token(kind,0,str)#numは「低レイヤ〜」で追加していないので0としている。 token.append(a)#tokenに追加 return a#aを返す def Tokenize(p_str):#入力をトークナイズする関数 while True:#Trueの間繰り返す if p_str[0].isspace():#先頭が空白なのかチェック p_str=p_str[1:]#p_strの1文字目以降としてcontinue continue if p_str[0] in oprlist:#p_strの1文字目がoprlistと一致したら(p_oprの1文字目が記号だったら) NewToken(TK.RESERVED,p_str)#kindをTK.RESERVED、strをp_strとして新しいトークンを作成 if len(p_str) >1:#p_strの長さが1以上として終端を決めている p_str=p_str[1:]#p_strの1文字目以降としてcontinue continue else: break#p_strの長さが1より小さければbreak if p_str[0].isdigit():#p_strの1文字目が数字かどうかチェック b = NewToken(TK.NUM,p_str)#kindをTK.NUM、strをp_strとして新しいトークンを作成 num,p_str=StrtoL(p_str) b.val=num#valにnumを入れている #p_str=n_str if p_str==0:#p_str=0かチェック break#p_str=0だったらbreak else:#p_str=0でなかったら「トークナイズできません」と表示 continue print("トークナイズできません") NewToken(TK.EOF,0) str1=input("数式:") print(str1) #str1 = "1*(2+2)" Tokenize(str1)#入力str1についてトークナイズ for i in token: print("kind:",i.kind,"val:",i.val,"str:",i.str) #1*(2+2)と入力した場合の出力 数式:1+(2*2) 1+(2*2) kind: TK.NUM val: 1 str: 1+(2*2) kind: TK.RESERVED val: 0 str: +(2*2) kind: TK.RESERVED val: 0 str: (2*2) kind: TK.NUM val: 2 str: 2*2) kind: TK.RESERVED val: 0 str: *2) kind: TK.NUM val: 2 str: 2) kind: TK.RESERVED val: 0 str: ) kind: TK.EOF val: 0 str: 0EBNFによる四則演算の記述に対応した構文木を生成するための関数
from enum import Enum cur_pos=0 def Consume(str_opr):#C言語でコンパイラを作成した場合のconsumeに対応 global token global cur_pos if token[cur_pos].kind!=TK.RESERVED or token[cur_pos].str[0]!=str_opr:#トークンの種類が記号ではない、または文字列の1文字目がstr_oprではないとき、falseを返す return False cur_pos+=1 return True#それ以外のときはtrue def Expect(str_opr):#C言語でコンパイラを作成した場合のexpectに対応 global token global cur_pos if token[cur_pos].kind!=TK.RESERVED or token[cur_pos].str[0]!=str_opr:#トークンの種類が記号ではない、または文字列の1文字目が+,-ではないとき print(str_opr,"ではありません")#+ではありません、-ではありません をプリント cur_pos+=1 def Expect_Number():#C言語でコンパイラを作成した場合のexpect_numberに対応 global token global cur_pos if token[cur_pos].kind!=TK.NUM:#トークンの種類が数字ではない時、 print("数ではありません")#数ではありません。をプリント val = token[cur_pos].val cur_pos+=1 return val#数字を出力 def At_EOF():#C言語でコンパイラを作成した場合のat_eofに対応 global token global cur_pos return token[cur_pos].kind==TK.EOF#トークンの種類がEOF class ND(Enum): #列挙型.抽象構文木でのノードの種類 ADD = 0#+ SUB = 1#- MUL = 2#* DIV = 3#/ NUM = 4#整数 class Node:#抽象構文木のノードの型 def __init__(self): self.kind = None#ノードの型.何も入っていない場合はNone self.val = None#ノードの値.kindがND_NUMの場合そのときの値を表示 self.lhs = None#左辺 self.rhs = None#右辺 def New_Node(kind,lhs,rhs):#新しいノードを作る関数 node = Node()#classNodeが入っている node.kind = kind#ノードの型 node.lhs = lhs#左辺 node.rhs = rhs#右辺 return node def New_Node_Num(val): node = Node() node.kind = ND.NUM#nodeの種類が数字 node.val = val#そのときの値 return node def Expr(): node = Mul()#nodeに関数Mul()が入る while True:#Trueの間繰り返す. if Consume("+"):#Consumeでstr_opr="+"だったとき node = New_Node(ND.ADD,node,Mul())#このような新しいノードを作る elif Consume("-"):#Consumeでstr_opr="-"だったとき node = New_Node(ND.SUB,node,Mul())#このような新しいノードを作る else: return node def Mul(): node = Primary()#nodeに関数Primary()が入る while True:#Trueの間繰り返す if Consume("*"):#Consumeでstr_opr="*"だったとき node = New_Node(ND.MUL,node,Primary())#このような新しいノードを作る elif Consume("/"):#Consumeでstr_opr="/"だったとき node = New_Node(ND.DIV,node,Primary())#このような新しいノードを作る else: return node def Primary(): if Consume("("):#Consumeでstr_opr="("だったとき node = Expr()#nodeにExpr()が入る Expect(")")#関数Expectでstr_opr=) return node return New_Node_Num(Expect_Number()) node = Expr()スタックマシンへコンパイルするプログラム
def gen(node): if node.kind == ND.NUM:#nodeの種類が数字のとき print(" push ",node.val)#nodeの値をpushする return gen(node.lhs)#左辺 gen(node.rhs)#右辺 print(" pop rdi") print(" pop rax") if node.kind == ND.ADD:#nodeの種類がADDだった場合 print(" add rax, rdi") elif node.kind == ND.SUB:#nodeの種類がSUBだった場合 print(" sub rax, rdi") elif node.kind == ND.MUL:#nodeの種類がMULだった場合 print(" imul rax, rdi") elif node.kind == ND.DIV:#nodeの種類がDIVだった場合 print(" cqo") print(" idiv rdi") else: print("error")#どれにも当てはまらなかったらerror print(" push rax")アセンブリプログラムを出力
print(".intel_syntax noprefix") print(".globl main") print("main:"); gen(node) print(" pop rax") print(" ret") #出力 .intel_syntax noprefix .globl main main: push 1 push 2 push 2 pop rdi pop rax imul rax, rdi push rax pop rdi pop rax add rax, rdi push rax pop rax retまとめ
四則演算に対応するアセンブリ言語プログラムを生成するコンパイラをPythonで作成した.今後としては,コンパイラを改良し現在扱うことのできない−3などの単項式の演算や,比較演算子を扱えるようにすることを考えている.
参考文献
1] 植山 類:低レイヤを知りたい人のためのCコンパイラ作成入門,https://www.sigbus.info/ compilerbook#,2020.

- 投稿日:2021-02-13T20:39:33+09:00
TensorflowのPreProcessでTensorflow以外の関数を使う
はじめに
tensorflow.data.Datasetを使っていて、preprocess内でnumpyのFFTやopenCVを使ったらエラーが出て困った人向けです。いや自分自身が困ったので、そのTipです。
時間がない人向け
tf.py_functionを使用すると出来る。
細かい説明
tf.data.Datasetの簡単な動き
こちらはtensorflowの公式のドキュメントで書いてある通りに、datasetのloaderを作ります。pytorchでいえばdataloaderですね。
def preprocess_image(image): image = tf.image.decode_jpeg(image, channels=3) image = tf.image.resize(image, [192, 192]) return image def load_and_preprocess_image(path): image = tf.io.read_file(path) return preprocess_image(image) path_ds = tf.data.Dataset.from_tensor_slices(path_list) image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=tf.data.experimental.AUTOTUNE) label_ds = tf.data.Dataset.from_tensor_slices(label) image_label_ds = tf.data.Dataset.zip((image_ds, label_ds))やっていることは簡単で、pathを渡すと、preprocessを終えたデータが読み込まれるというよくあるdataloaderを作っています。事前に画像のPathのリストと、紐づくラベルのリストを作っておけば簡単です。
これを実行してみると、下記のようなサンプルとなります。ちなみに画像はCifar10です。fig = plt.figure(figsize=(10, 10)) for i, (im, l) in enumerate(image_label_ds.take(9)): fig.add_subplot(3, 3, i + 1) plt.imshow(im.numpy().astype(np.uint8)) plt.title(annot[l.numpy()]) # annotはラベル名のdictionary plt.tight_layout()
凝ったPreProcessをしたい
このpreprocess内で少し凝った処理を走らせましょう。今回は例として、openCVを使って、色空間を変換(RGB->YCrCb)しています。別にNumpyのFFT関数でもいいし、まぁtensorflow純正以外の関数を使うなら何でも良いです。これで実行してみます。
def preprocess_image(image): image = tf.image.decode_jpeg(image, channels=3) image = tf.image.resize(image, [192, 192]) image = cv2.cvtColor(image.numpy(), cv2.COLOR_RGB2YCrCb) image = tf.convert_to_tensor(image) return image
なんかものすごいエラーが出ます。エラー内容が見たい人は左の三角をクリック。
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) ~/workspace/project/cifar10/load_cifar10.py in 58 AUTOTUNE = tf.data.experimental.AUTOTUNE 59 path_ds = tf.data.Dataset.from_tensor_slices(path_list) ----> 60 image_ds = path_ds.map(load_and_preprocess_image, num_parallel_calls=AUTOTUNE) 61 62 label_ds = tf.data.Dataset.from_tensor_slices(label) ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py in map(self, map_func, num_parallel_calls, deterministic) 1700 num_parallel_calls, 1701 deterministic, -> 1702 preserve_cardinality=True) 1703 1704 def flat_map(self, map_func): ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py in __init__(self, input_dataset, map_func, num_parallel_calls, deterministic, use_inter_op_parallelism, preserve_cardinality, use_legacy_function) 4082 self._transformation_name(), 4083 dataset=input_dataset, -> 4084 use_legacy_function=use_legacy_function) 4085 if deterministic is None: 4086 self._deterministic = "default" ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py in __init__(self, func, transformation_name, dataset, input_classes, input_shapes, input_types, input_structure, add_to_graph, use_legacy_function, defun_kwargs) 3369 with tracking.resource_tracker_scope(resource_tracker): 3370 # TODO(b/141462134): Switch to using garbage collection. -> 3371 self._function = wrapper_fn.get_concrete_function() 3372 if add_to_graph: 3373 self._function.add_to_graph(ops.get_default_graph()) ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/eager/function.py in get_concrete_function(self, *args, **kwargs) 2937 """ 2938 graph_function = self._get_concrete_function_garbage_collected( -> 2939 *args, **kwargs) 2940 graph_function._garbage_collector.release() # pylint: disable=protected-access 2941 return graph_function ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _get_concrete_function_garbage_collected(self, *args, **kwargs) 2904 args, kwargs = None, None 2905 with self._lock: -> 2906 graph_function, args, kwargs = self._maybe_define_function(args, kwargs) 2907 seen_names = set() 2908 captured = object_identity.ObjectIdentitySet( ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _maybe_define_function(self, args, kwargs) 3211 3212 self._function_cache.missed.add(call_context_key) -> 3213 graph_function = self._create_graph_function(args, kwargs) 3214 self._function_cache.primary[cache_key] = graph_function 3215 return graph_function, args, kwargs ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/eager/function.py in _create_graph_function(self, args, kwargs, override_flat_arg_shapes) 3073 arg_names=arg_names, 3074 override_flat_arg_shapes=override_flat_arg_shapes, -> 3075 capture_by_value=self._capture_by_value), 3076 self._function_attributes, 3077 function_spec=self.function_spec, ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/framework/func_graph.py in func_graph_from_py_func(name, python_func, args, kwargs, signature, func_graph, autograph, autograph_options, add_control_dependencies, arg_names, op_return_value, collections, capture_by_value, override_flat_arg_shapes) 984 _, original_func = tf_decorator.unwrap(python_func) 985 --> 986 func_outputs = python_func(*func_args, **func_kwargs) 987 988 # invariant: `func_outputs` contains only Tensors, CompositeTensors, ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py in wrapper_fn(*args) 3362 attributes=defun_kwargs) 3363 def wrapper_fn(*args): # pylint: disable=missing-docstring -> 3364 ret = _wrapper_helper(*args) 3365 ret = structure.to_tensor_list(self._output_structure, ret) 3366 return [ops.convert_to_tensor(t) for t in ret] ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/data/ops/dataset_ops.py in _wrapper_helper(*args) 3297 nested_args = (nested_args,) 3298 -> 3299 ret = autograph.tf_convert(func, ag_ctx)(*nested_args) 3300 # If `func` returns a list of tensors, `nest.flatten()` and 3301 # `ops.convert_to_tensor()` would conspire to attempt to stack ~/.pyenv/versions/py37_emopy/lib/python3.7/site-packages/tensorflow/python/autograph/impl/api.py in wrapper(*args, **kwargs) 256 except Exception as e: # pylint:disable=broad-except 257 if hasattr(e, 'ag_error_metadata'): --> 258 raise e.ag_error_metadata.to_exception(e) 259 else: 260 raise AttributeError: in user code: <ipython-input-87-550493cbb714>:12 load_and_preprocess_image * return preprocess_image(image) <ipython-input-93-6034e2f0f0fd>:4 preprocess_image * image = cv2.cvtColor(image.numpy(), cv2.COLOR_RGB2YCrCb) AttributeError: 'Tensor' object has no attribute 'numpy'ちなみにこの色変換の関数そのものには異常はありません。TensorflowのDatasetのようなパイプラインを介さずに利用すると、ちゃんと画像が表示できます。
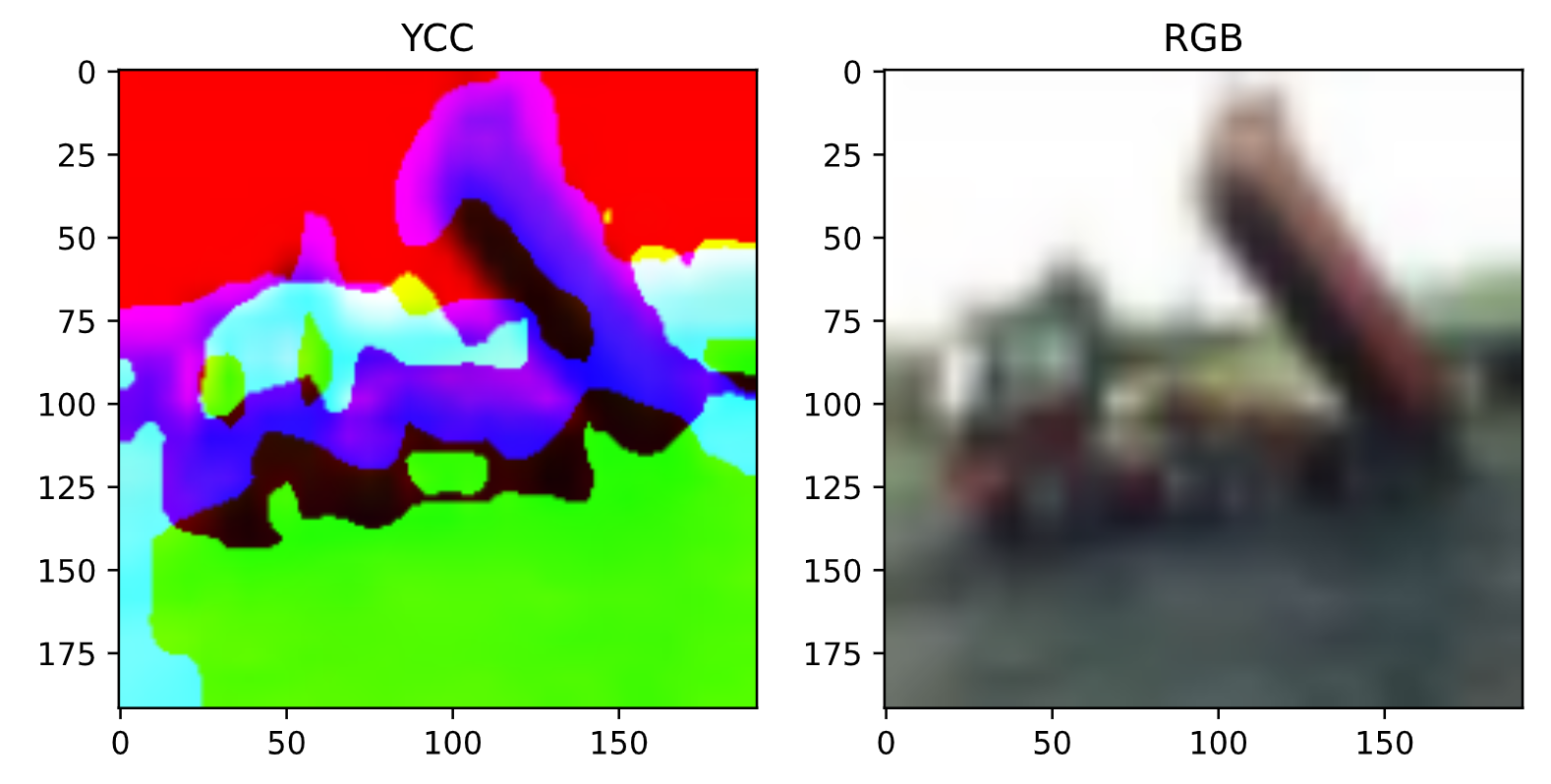
image = tf.io.read_file(image_path) image = preprocess_image(image) fig = plt.figure(figsize=(8, 4)) fig.add_subplot(1, 2, 1) plt.imshow(image.numpy().astype(np.uint8)) plt.title("YCC") fig.add_subplot(1, 2, 2) # 表示用にもう一度YCC→RGBに戻している image = cv2.cvtColor(image.numpy(), cv2.COLOR_YCrCb2RGB) plt.imshow(image.astype(np.uint8)) plt.title("RGB")
tf.py-function降臨
こういう事態を避ける方法があって、tf.py_functionを使用します。下記の例のように、tensorflow純正の関数ではない変換を別の関数にしてやり、それをラッピングする形で使用します。簡単ですね。
def trans_color(image): image = cv2.cvtColor(image.numpy(), cv2.COLOR_RGB2YCrCb) return tf.convert_to_tensor(image) def preprocess_image(image): image = tf.image.decode_jpeg(image, channels=3) image = tf.image.resize(image, [192, 192]) image = tf.py_function(trans_color, [image], tf.float32) return imageこれで実際に動かしてみると、下記画像が得られました。
右上の画像と前項での画像が同じになっているのでうまく動いていそうです。
まとめ
tensorflowの前処理で、自身がよく知っているnumpyのFFTを使いたいとか、画像処理の定番のopenCVを使いたいとか、そういうことのTipsでした。py_functionはもっと奥深い機能だと思いますが、こんなふうにも使えるんですね。

- 投稿日:2021-02-13T20:34:37+09:00
Jupyter Notebook で Ruby が使えるってま!?
概要
会社でRailsを使って開発をしている関係でRubyのコードを試したいことが多々ありました。
Paizaとかブラウザで実行できるものもあるがPythonみたくJupyter notebookでできないかなと思っていました。そこで調べるとRubyをJupyter notebookに入れることが出来ることが判明(゚∀゚) 実際に導入する手順がわかったので今後PCが壊れたときのためにインストール方法をメモします。
条件
言語 ver Ruby 2.10 以上 Jupyter Notebook -- ※Ruby と jupyter notebookの道入がまだの人は以下の記事よりそれぞれのインストールを済ませて下さい。
・Rubyのインストール
【完全版】MacでRails環境構築する手順の全て・Jupyter Noteboookのインストール
① anacondaのインストール
Anaconda(Python3)インストール手順<macOS用>② anacondaのPATHの通し方
AnacondaのPATHの設定③ Jupyter notebook のインストール
Installing the Jupyter Software方法
iRubyのgithubをもとにインストールを進めていきます。
まず、依存関係にあるライブラリのインストールをします。
cmzp の versionによっては動かない可能性あり↓
* Jupyter NotebookにRuby Kernelを追加する方法terminalbrew install automake gmp libtool wget brew install zeromq --HEAD # 1.30以上で動かないとの記事あり brew install czmq --HEAD gem install ffi-rzmq gem install rbczmqirubyのインストールとjupyterへの登録をします。
terminal# irubyのインストール gem install iruby # irubyの登録 iruby register --force最後にjupyter notebookの起動をします。
terminaljupyter notebook以下のように Ruby が New の中に入っているのを確認して下さい。
- 投稿日:2021-02-13T20:07:40+09:00
Streamlit による売上データの分析例
目的
本項では Kaggle に登録されている売上原価の集計・可視化に取り組む。このデータセットにはある会社の支店 A、B、C の売上原価(三ヶ月分)が含まれている。需要予測等のデータ分析実務に近づけるため、支店間の売上原価を比較するダッシュボードの作成を目的とする。今回は streamlit を用いて、集計時のパラメータを GUI で操作できる interactive な図を作成する。
データの形式
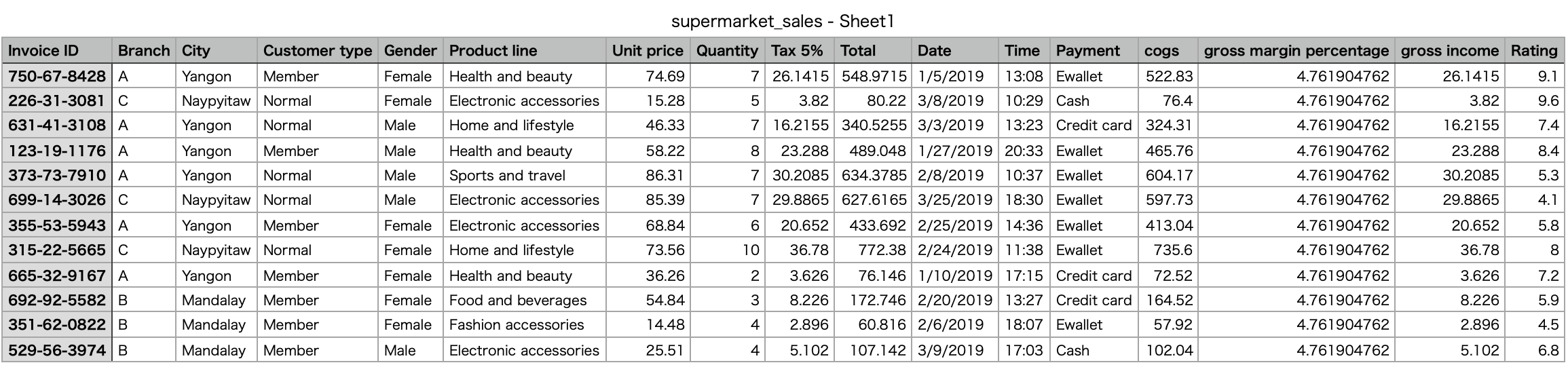
以下のように請求書単位で売上原価(cost of goods sold)の履歴が記録されている。
ちなみに売上原価は次のように計算される。
(cogs)=(Unit Price)×(Quantity)データの前処理
売上原価の時系列変化を調べるために購入時期を表す列
weekを追加し、売上の周期性を調べるために曜日列day時間帯列timeを追加する。Visualization.pyimport re import streamlit as st import pandas as pd import altair as alt df = pd.read_csv('supermarket_sales - Sheet1.csv') date = [] week = [] for c in df['Date']: c = re.findall(r'\d+', c) m,d = int(c[0]),int(c[1]) if m == 3: d += (31+28) # 三月某日には一月と二月の日数を加える。 elif m == 2: d += 31 # 二月某日には一月の日数を加える。 d += -1 # 2019年1月1日は火曜日 if d%7 == 6: tmp = 'Mon' elif d%7 == 0: tmp = 'Tue' elif d%7 == 1: tmp = 'Wed' elif d%7 == 2: tmp = 'Thr' elif d%7 == 3: tmp = 'Fri' elif d%7 == 4: tmp = 'Sat' elif d%7 == 5: tmp = 'Sun' date.append(tmp) if d//14 == 0: tmp = '1/1~1/14' elif d//14 == 1: tmp = '1/15~1/28' elif d//14 == 2: tmp = '1/29~2/11' elif d//14 == 3: tmp = '2/12~2/25' elif d//14 == 4: tmp = '2/26~3/11' elif d//14 == 5: tmp = '3/12~3/25' elif d//14 == 6: tmp = '3/26~3/31' # 最終期は他より短いことに注意 week.append(tmp) df['day'] = date df['week'] = week time = [] for c in df['Time']: c = re.findall(r'\d+', c) t = c[0] + ':00~' + c[0] +':59' time.append(t) df['time'] = time st.table(df.head(10))
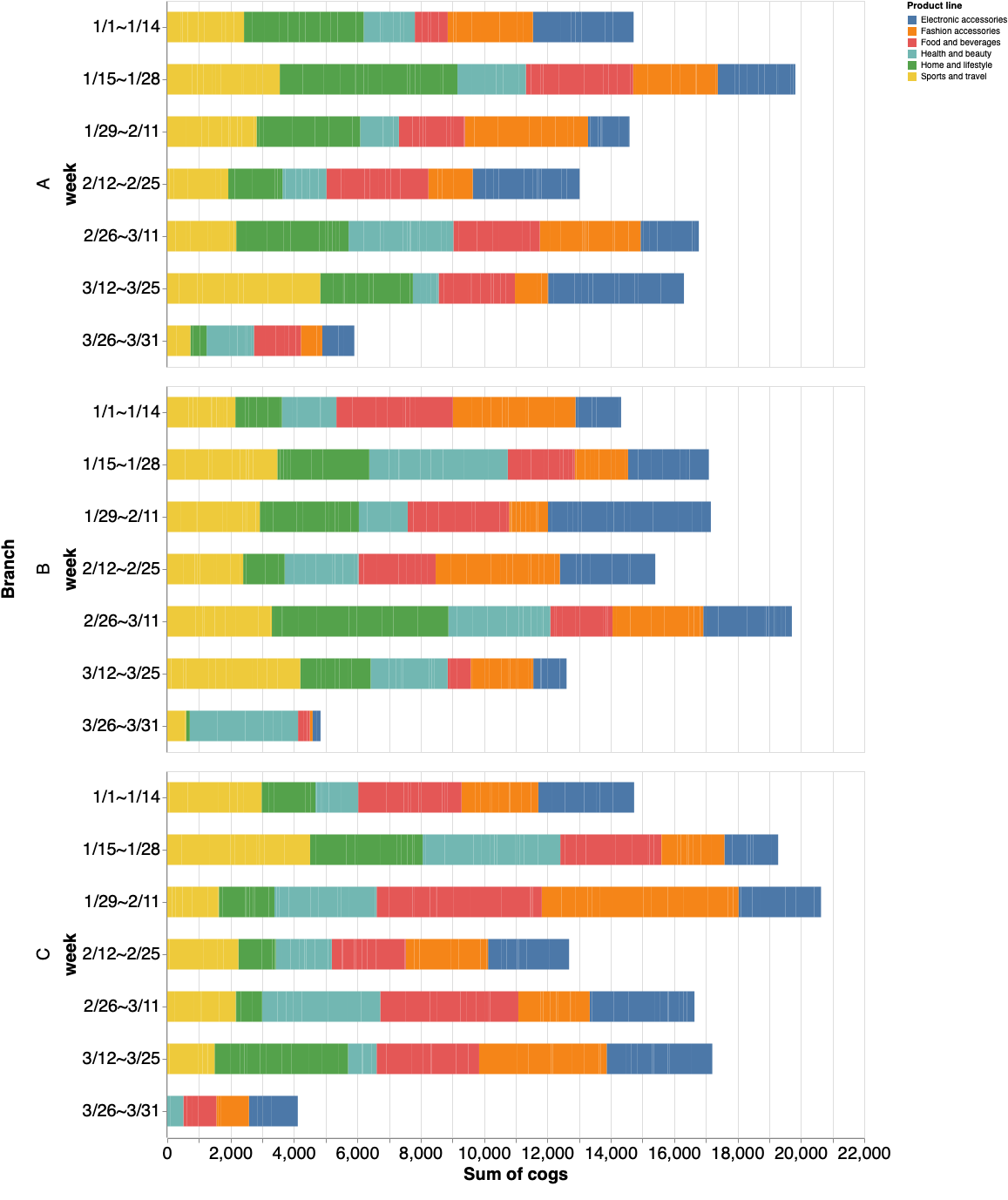
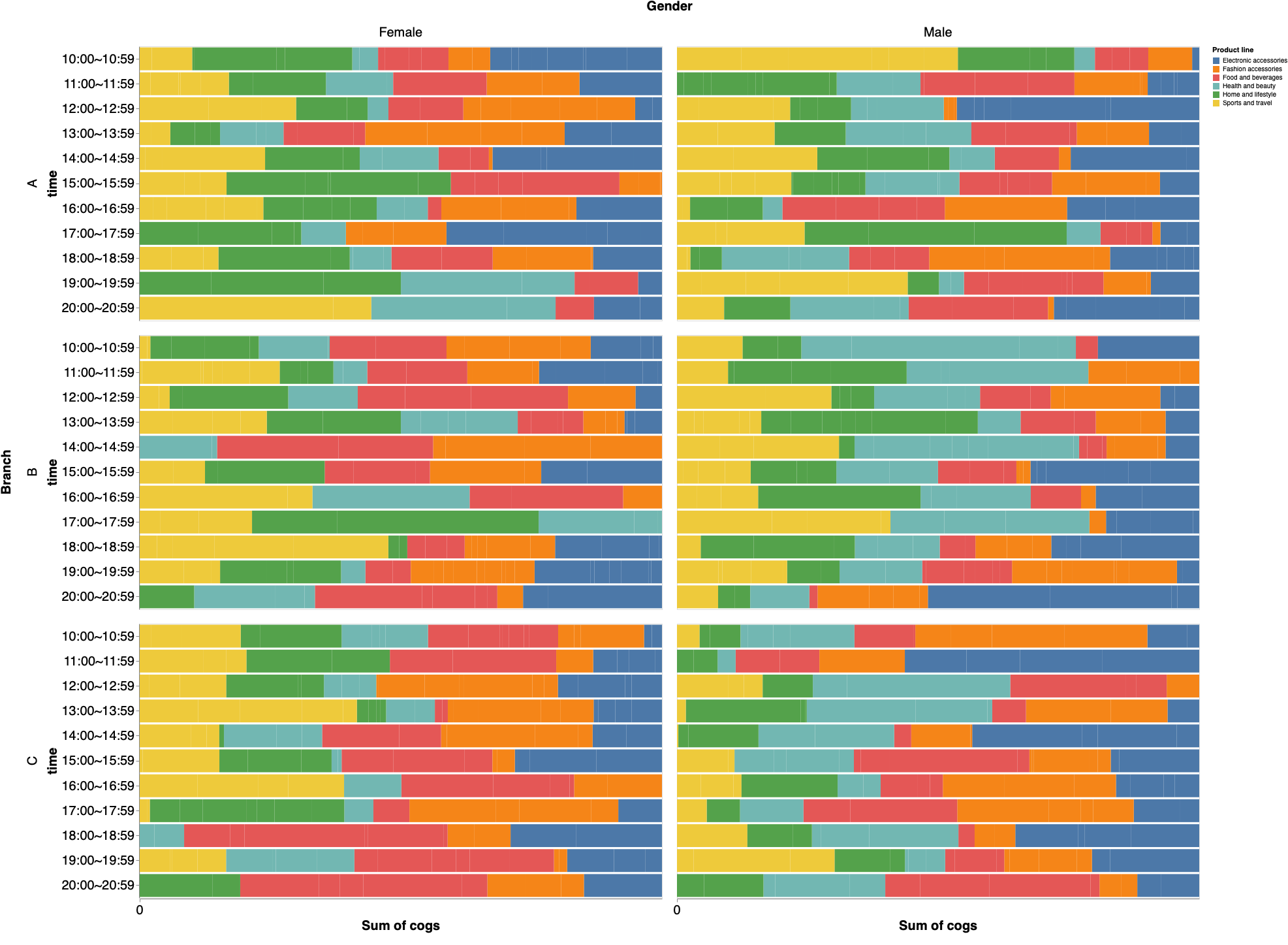
支店間推移
まずは直近の動向を調べてみる。
Visualization.pyst.markdown('# 支店別売上推移') stacked_bar = alt.Chart(df).mark_bar(size=35).encode( x=alt.X('sum(cogs)',axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0)), y=alt.Y('week', axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0),sort=['1/1~1/14','1/15~1/28','1/29~2/11','2/12~2/25','2/26~3/11','3/12~3/25','3/26~3/31']), color='Product line', row = alt.Row('Branch', header=alt.Header(labelFontSize=20, titleFontSize=20)), tooltip=['week','Total'] ).properties( width=800, height=420, ) st.write(stacked_bar)
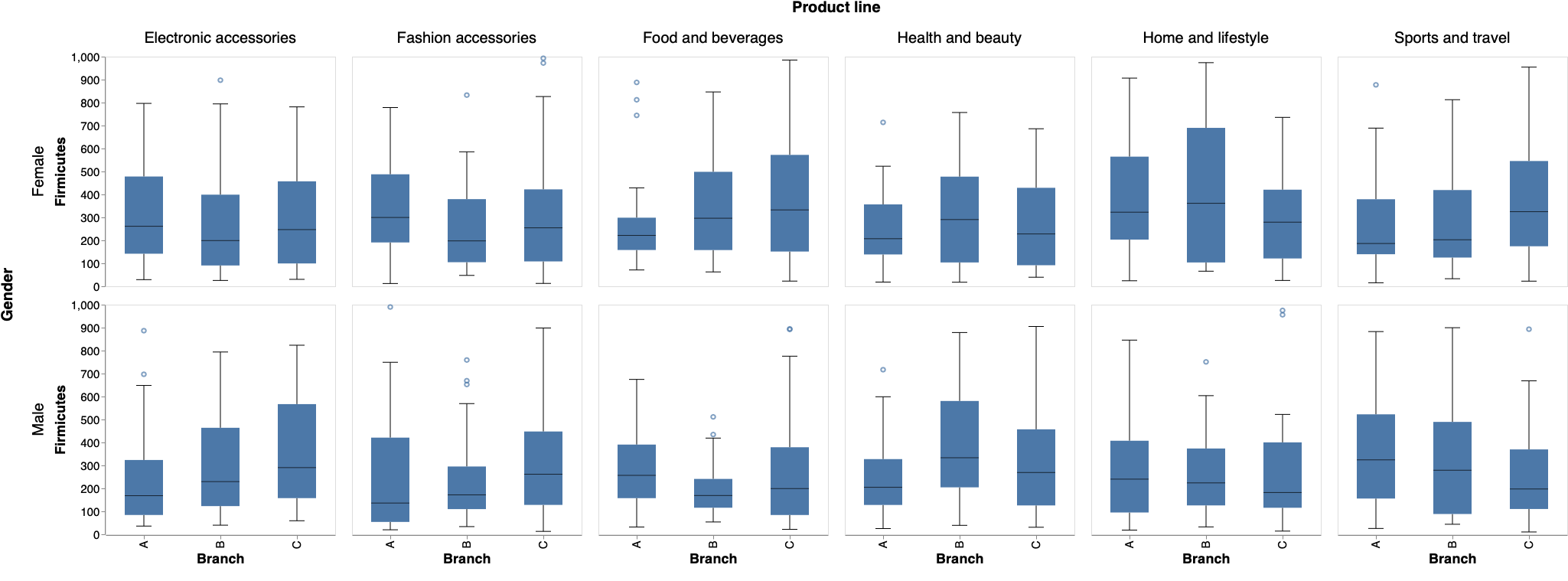
売上原価分布の比較
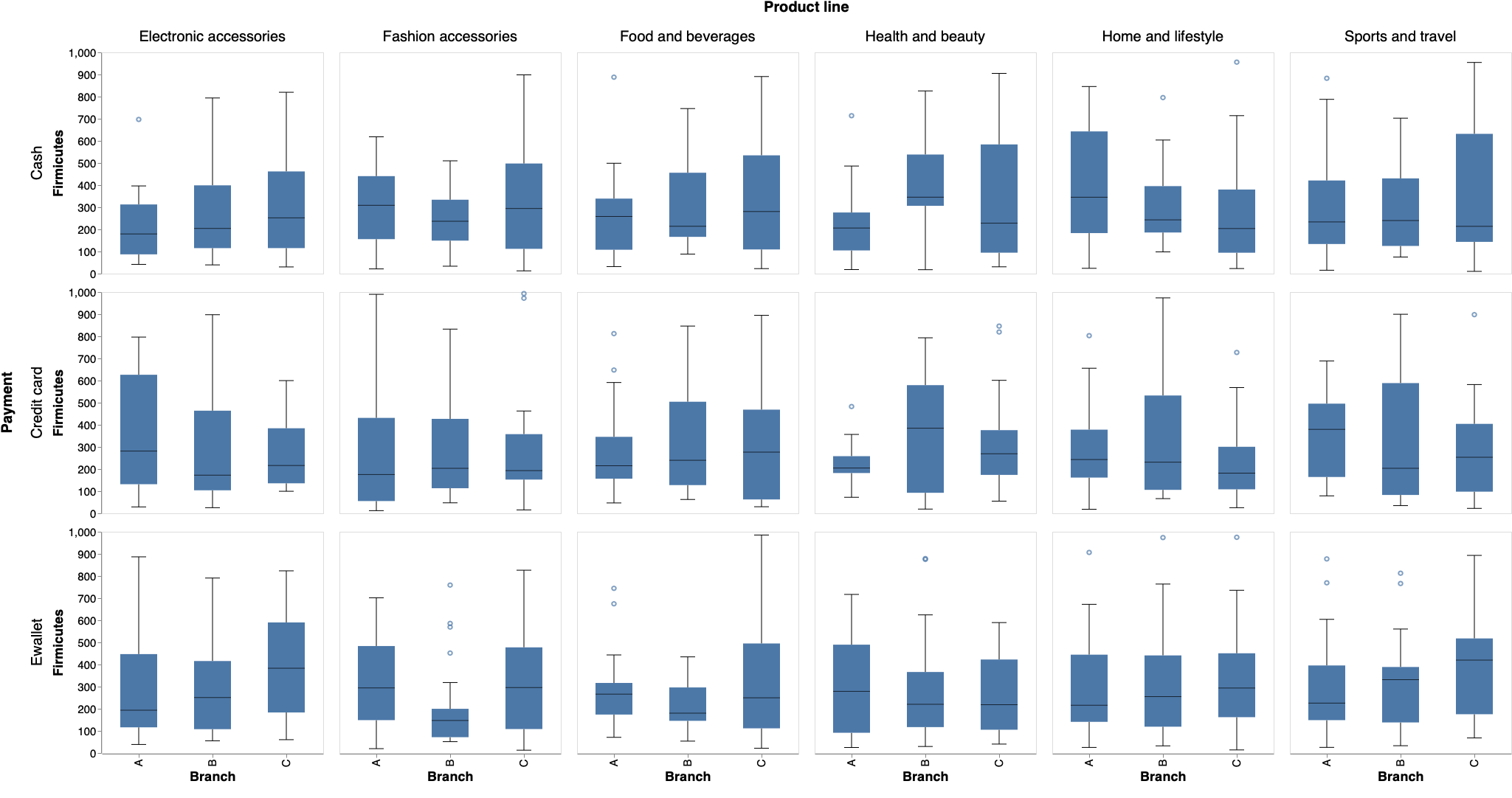
品目別に支店間で売上原価分布を比較する。どのような層に高額商品の需要があるのかを調べたい場合、属性条件をドロップダウンから1つ選択できるようにする。
Visualization.py!st.markdown('# 売上原価分布の比較') cond = st.selectbox( '層別条件を選ぶ', ('Gender', 'Customer type', 'Payment')) boxplot = alt.Chart(df).mark_boxplot(size=50,ticks=alt.MarkConfig(width=20), median=alt.MarkConfig(color='black',size=50)).encode( x = alt.X('Branch',sort = alt.Sort(['A','B','C']), axis=alt.Axis(labelFontSize=15, ticks=True, titleFontSize=18)), y = alt.Y('cogs', axis=alt.Axis(labelFontSize=15, ticks=True, titleFontSize=18, grid=False,domain=True, title='Firmicutes')), column = alt.Column('Product line', header=alt.Header(labelFontSize=20, titleFontSize=20)), row = alt.Row(cond, header=alt.Header(labelFontSize=20, titleFontSize=20)), ).properties( width=300, height=300, ) st.write(boxplot)ドロップダウンで
Genderを選んだ場合は以下のとおり。
ドロップダウンでPaymentを選んだ場合は以下のとおり。
売上原価の詳細な比較
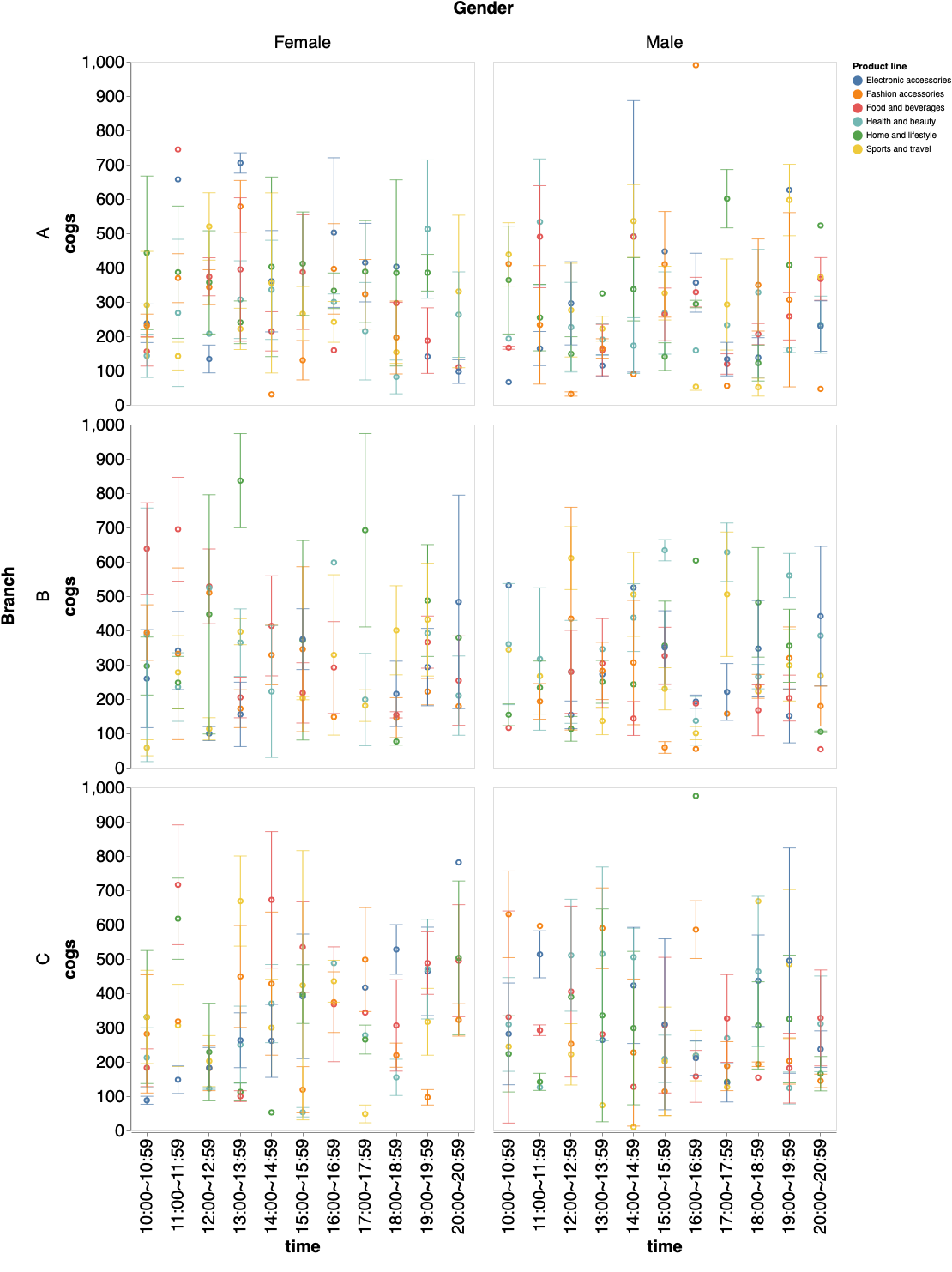
上記の内容を踏まえて支店間で詳細に比較する。多角的に比較できるように次のパラメータを設ける。
- 製造ラインを選択する。特定の製造ラインに着目したい場合は他を除外できる。
- 集計する
cogsの最小値と最大値を決める。スライドバーの範囲外の売上原価は集計しない。外れ値を除外できる。- 標準化するかどうかを決める。
- 集計方法を選ぶ。
weekは二週間毎、dayは曜日毎、timeは時間帯毎に集計する。Visualization.pyst.markdown('# 詳細な売上原価の比較') options = st.multiselect( '製造ラインを選択してください', list(set(df['Product line'])), list(set(df['Product line']))) df = df[df['Product line'].isin(options)] values = st.slider( '集計する cogs の最小値と最大値を決める', min(df['cogs']), max(df['cogs']), (min(df['cogs']), max(df['cogs']))) df = df[(values[0] <= df['cogs']) & (values[1] >= df['cogs'])] norm = st.radio("標準化するか?", ('Yes','No')) axis = st.radio("集計方法を選ぶ", ('week','day','time')) if axis == 'week': sort =['1/1~1/14','1/15~1/28','1/29~2/11','2/12~2/25','2/26~3/11','3/12~3/25','3/26~3/31'] elif axis == 'day': sort =['Mon','Tue','Wed','Thr','Fri','Sat','Sun'] elif axis == 'time': sort =['10:00~10:59','11:00~11:59','12:00~12:59','13:00~13:59','14:00~14:59','14:00~14:59','15:00~15:59','16:00~16:59','17:00~17:59','18:00~18:59','19:00~19:59','20:00~20:59'] st.markdown('## 組成の可視化') if norm == 'Yes': stacked_bar = alt.Chart(df).mark_bar(size=35).encode( x=alt.X('sum(cogs)',axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0),stack="normalize"), y=alt.Y(axis, axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0),sort=sort), color='Product line', column = alt.Column(cond, header=alt.Header(labelFontSize=20, titleFontSize=20)), row = alt.Row('Branch', header=alt.Header(labelFontSize=20, titleFontSize=20)), tooltip=[axis,'cogs'] ).properties( width=800, height=420, ) else: stacked_bar = alt.Chart(df).mark_bar(size=35).encode( x=alt.X('sum(cogs)',axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0)), y=alt.Y(axis, axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, labelAngle=0),sort=sort), color='Product line', column = alt.Column(cond, header=alt.Header(labelFontSize=20, titleFontSize=20)), row = alt.Row('Branch', header=alt.Header(labelFontSize=20, titleFontSize=20)), tooltip=[axis,'cogs'] ).properties( width=800, height=420, ) st.write(stacked_bar) st.markdown('## 分布の可視化') point = alt.Chart().mark_point().encode( x=alt.X(axis, axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, grid=False),sort=sort), y=alt.Y('cogs:Q', aggregate='mean', axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, grid=False,domain=True)), color=alt.Color('Product line'), ).properties( width=400, height=400 ) bar = alt.Chart().mark_errorbar(extent='stderr',ticks=True,orient='vertical').encode( x=alt.X(axis, axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, grid=False),sort=sort), y=alt.Y('cogs', type='quantitative', axis=alt.Axis(labelFontSize=20, ticks=True, titleFontSize=20, grid=False,domain=True)), color=alt.Color('Product line'), ).properties( width=400, height=400 ) chart = alt.layer(point, bar, data=df ).facet( column=alt.Column(cond, header=alt.Header(labelFontSize=20, titleFontSize=20)), row = alt.Row('Branch', header=alt.Header(labelFontSize=20, titleFontSize=20)) ) st.write(chart)今回は次のパラメータで可視化してみる。
組成の可視化
分布の可視化
点は平均値、バーは標準誤差を表す。
Streamlit の利点
平均値、中央値、四分位数、標準誤差といった単純な統計量を用いたデータの吟味は、課題の設定や検証に非常に有効である。Streamlit ではこのような統計量を GUI で操作しながら可視化することができる。
Visualization.py のダウンロード
Githubからダウンロードできる。
参考
本稿は NTT Communications 第七回 TechWorkshop 「データサイエンティストによるデータ分析Workshop」で取り組んだワークの内容を参考に作成しました。

- 投稿日:2021-02-13T19:56:42+09:00
MySQLdbで文字コードエラー
こんなエラー
Traceback (most recent call last): .... cursor.execute(sql) File "/home/user/.local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 188, in execute query = query.encode(db.encoding) File "/usr/lib/python3.6/encodings/cp1252.py", line 12, in encode return codecs.charmap_encode(input,errors,encoding_table) UnicodeEncodeError: 'charmap' codec can't encode characters in position 486-487: character maps to <undefined>対策
デフォルトでlatin-1を使うらしいので、接続時に明示的にエンコードコード方法を指定conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password, use_unicode=True, ★これ charset="utf8mb4" )
- 投稿日:2021-02-13T19:48:51+09:00
Pythonで学ぶ制御工学 第2弾:制御モデルの例
#Pythonで学ぶ制御工学< 制御モデルの例 >
はじめに
基本的な制御工学をPythonで実装し,復習も兼ねて制御工学への理解をより深めることが目的である.
その第2弾として制御モデルの例を扱う.システム
システムには大きく分けて2つある.
動的システム
過去の状態に影響を受けるようなシステム静的システム
過去の状態に依存しないようなシステム制御対象は多くの場合,動的システムであり,ここで扱うのも動的システムである.
制御モデル
制御を考えるためには,制御モデルを構築できなければならない.以下では,4つの例を示して,制御モデルとはどのようにして求められるのかということへの理解を深める.なお,図において,緑の背景で示したものが制御モデルである.
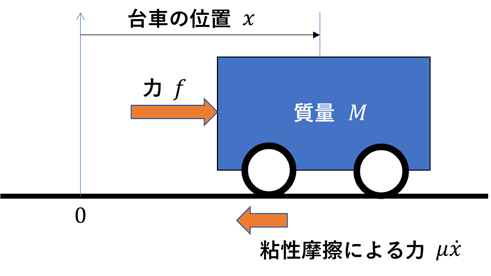
制御モデル①:台車のモデル
次に台車と条件を示した図を示す.
以下にモデルの導出過程を示す.
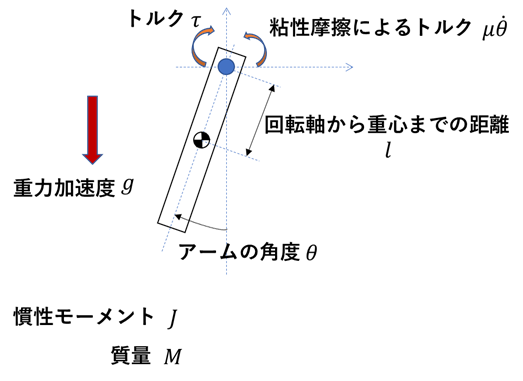
制御モデル②:垂直駆動アームのモデル
次に垂直駆動アームと条件を示した図を示す.
以下にモデルの導出過程を示す.
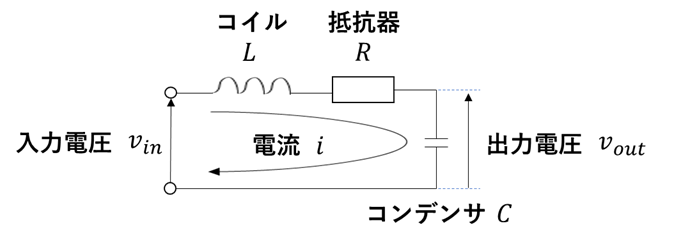
制御モデル③:RLC回路のモデル
次にRLC回路と条件を示した図を示す.
以下にモデルの導出過程を示す.
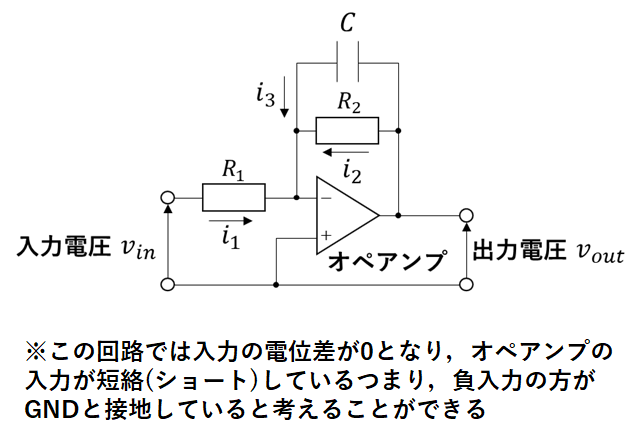
制御モデル④:増幅回路のモデル
次に増幅回路と条件を示した図を示す.
以下にモデルの導出過程を示す.
感想
久しぶりに制御モデルを求める手順をおさらいできた.次回からはようやく,これらの制御モデルに対して伝達関数などを扱うことができる.これについても学んできてはいるが,今回同様,良い復習になり,また新たな鬼月が得られるかもしれない.楽しみである.
参考文献
Pyhtonによる制御工学入門 南 祐樹 著 オーム社






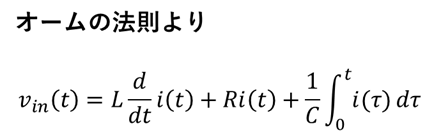





- 投稿日:2021-02-13T19:47:20+09:00
A - Repeat ACL, B - Balance, C - Exam and Wizard
2021/2/12
くじかつ精進A - Repeat ACL
O(1)
pythonN = int(input()) S = "" for i in range(0, N): S += "ACL" print(S)B - Balance
O(N)
pythonimport math import itertools N = int(input()) W = list(map(int, input().split())) S1 = 0 S2 = sum(W) res = 10000 for i in range(0, N): S1 += W[i] S2 -= W[i] res = min(res, abs(S2-S1)) print(res)C - Exam and Wizard
O(N)
pythonN = int(input()) A = list(map(int, input().split())) B = list(map(int, input().split())) total = 0 total_BtoA = 0 total_AtoB = 0 total_AtoB_0 = 0 C = [] for i in range(0, N): if B[i] > A[i]: total_BtoA+=1 total += B[i] - A[i] elif B[i] < A[i]: C.append(A[i] - B[i]) else: total_AtoB_0 += 1 C.sort(reverse=True) for i in range(0, len(C)): if total >=0: total -= C[i] total_AtoB+=1 if total>0: print(-1) elif (len(C) + total_AtoB_0 == N): print(0) else: print(total_AtoB + total_BtoA)
- 投稿日:2021-02-13T19:15:16+09:00
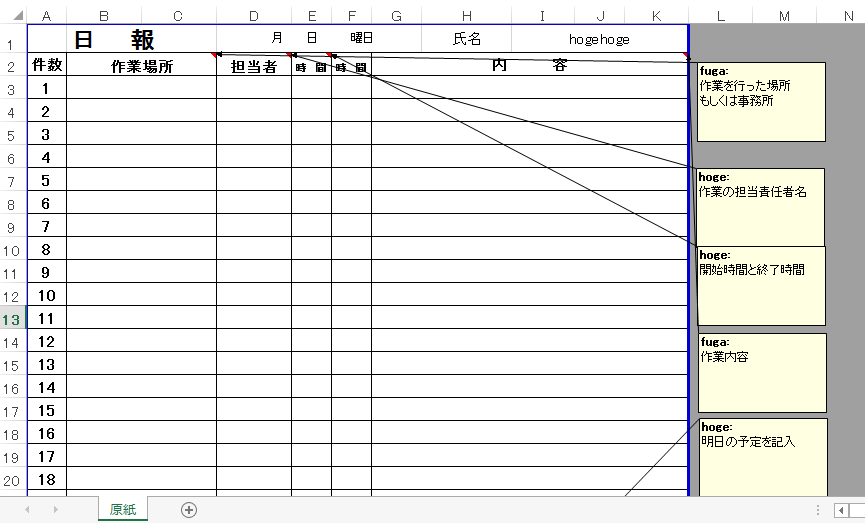
【Python】comment属性でセルのコメントを取得する
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、セルのコメントに関してです。
pythonでExcelを操作するため、openpyxlというパッケージを使用しています。
上記のような各コメントを一覧で残しておきたいとします。
セルのコメントを取得する方法
先ずはセルにコメントがあるかどうかの判定をします
# セルにコメントがあるかどうかを判定 cell.comment # コメントがない場合 --> Noneコメントがあったら、下記のように取得します。
# コメントのテキストを取得 cell.comment.text # コメントの作成者を取得 cell.comment.aoutherコメントを挿入することもできます。
# コメントのテキストを取得 cell.comment = Comment(コメントのテキスト,コメントの作成者)コメントが挿入されている番地を取得する事も出来ます。
# コメントが挿入されているセル番地を取得 cell.coordinateWorksheet.iter_rowsメソッド
今回はセルの1行目から順にコメントの有無を調べたいので、
Worksheet.iter_rowsメソッドを使用しました。ws.iter_rows(min_row=最小の行番号,max_row=最大の行番号, min_col=最小の列番号,max_col=最大の列番号)max_rowなどの引数を省略するとデータが入っている最大の位置まで取得してくれます。
ちなみに、rowsがあったら、colsもやっぱりあって
ws.iter_cols(min_col=最小の列番号,max_col=最大の列番号, min_row=最小の行番号,max_row=最大の行番号)こちらで、列単位で順に取得してくれます。
これらをふまえてread_comment.pyfrom openpyxl import load_workbook, Workbook from openpyxl.comments import Comment wb_new = Workbook() ws_new = wb_new.active ws_new.title = '説明一覧' wb = load_workbook('日報.xlsx') ws = wb.active ws_new['B2'] = '説明内容' ws_new['C2'] = '記入者' ws_new['D2'] = 'セル番地' ws_new.column_dimensions['B'].width = 40 row_count = ws_new.max_row print(f'新規作成したシートの行数は{row_count}です。') for row in ws.iter_rows(min_row=1): for cell in row: if cell.comment is None: continue row_count = row_count + 1 ws_new[f'B{row_count}'] = cell.comment.text ws_new[f'C{row_count}'] = cell.comment.author ws_new[f'D{row_count}'] = cell.coordinate ws_new['D2'].comment = Comment('説明があったセル番号', 'hogehoge') wb_new.save('説明一覧.xlsx')こんな感じで記述してみました。
個人的にはコメント取得よりも、Worksheet.iter_rowsメソッドの方が勉強になりました。
- 投稿日:2021-02-13T18:43:02+09:00
【Python】Google SpreadSheetsから手元のCSVファイルをインポートする
概要
タイトルそのまま。
Google SpreadSheetsから手元のCSVファイルの内容を取り込みます。
環境
- Docker
- Python3系
- Google Cloud Platform
下準備
まず、外部からGoogle SpreadSeetsにアクセスするために「Google Cloud Platform」の設定を行います。
https://console.cloud.google.com/
まだGoogle Cloud Platformのアカウントを持っていない方は下記記事などを参考に作成しておいてください。
参照記事: これから始めるGCP(GCE) 安全に無料枠を使い倒せ
Google Sheets APIを有効化
左サイドバーから「APIとサービス→ライブラリ」を選択。各種Google APIが出てくるので、その中から「Google Sheets API」を見つけて有効化します。
サービスアカウントを作成
次に左サイドバーから「APIとサービス→認証情報」を選択。「サービスアカウント」の作成を行います。
参照記事: GCP Service Accountを理解する
- サービスアカウント名
- 適当
- サービスアカウントの説明
- わかりやすければ何でもOK
サービスアカウント名以外は基本的に任意入力項目なので、特にこだわりが無ければ空欄で大丈夫です。
秘密鍵を取得
サービスアカウント詳細ページの下部にいくと「鍵を追加」という項目があるので、JSON形式で秘密鍵を作成。すると手元のデバイスにJSONファイルがダウンロードされるので、「client_secret.json」にリネームして保管しておいてください。(後ほど使用します。)
Google SpreadSheetsを作成
今回操作するための適当なGoogle SpreadSheetsを作成しておきます。
あと、右の方にある「共有」ボタンから先ほど作成したサービスアカウントのメールアドレスを「編集者」として追加しておくのも忘れずに。
コード
API経由でGoogle SpreadSheetsにアクセスするための下準備が済んだので、いよいよコードを書いていきます。
環境構築
まず、Pythonを実行できる環境をDockerで準備します。
ディレクトリを作成
$ mkdir csv-to-google-spread-sheets $ cd csv-to-google-spread-sheets $ mkdir opt各種ファイルを作成
touch Dockerfile touch docker-compose.yml touch requirements.txt./DockerfileFROM python:3 USER root RUN apt-get update RUN apt-get -y install locales && \ localedef -f UTF-8 -i ja_JP ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9 ENV TERM xterm ADD . /code WORKDIR /code RUN apt-get install -y vim less RUN pip install --upgrade pip RUN pip install --upgrade setuptools RUN pip install -r requirements.txt./docker-compose.ymlversion: '3' services: python3: restart: always build: . container_name: 'python3' working_dir: '/root/' tty: true volumes: - ./opt:/root/opt./requirements.txtgspread oauth2clientclient_secret.jsonを配置
サービスアカウント作成の際にダウンロードした秘密鍵「client_secret.json」をoptフォルダ以下に配置します。
最終的に次のような構成になっていればOK。
csv-to-google-spread-sheets ├─ opt ├─ client_secret.json ├─ docker-compose.yml ├─ Dockerfile ├─ requirements.txtコンテナを起動
$ docker-compose up -d $ docker exec -it python3 /bin/bash $ cd opt root@*********:~/opt#テスト実行
touch test.py./opt/test.pyprint('test')$ python test.py testちゃんと「test」と出力されていたら成功です。
実装
環境構築ができたので、本格的なコードを書いていきます。
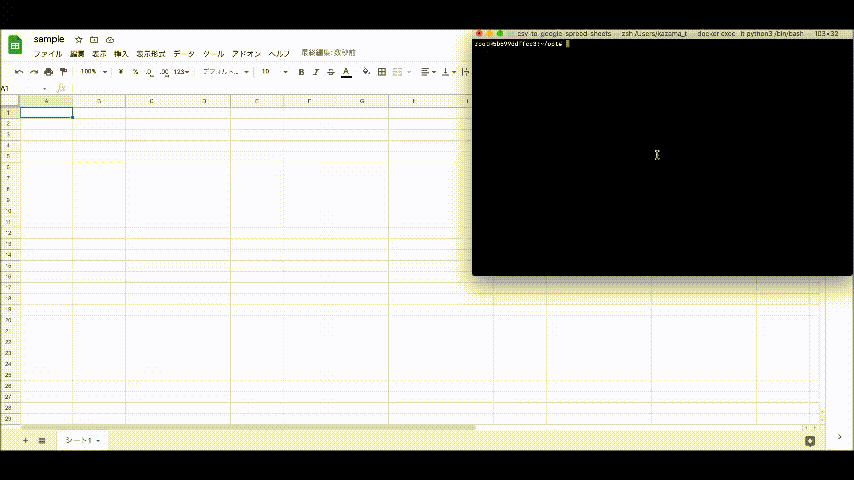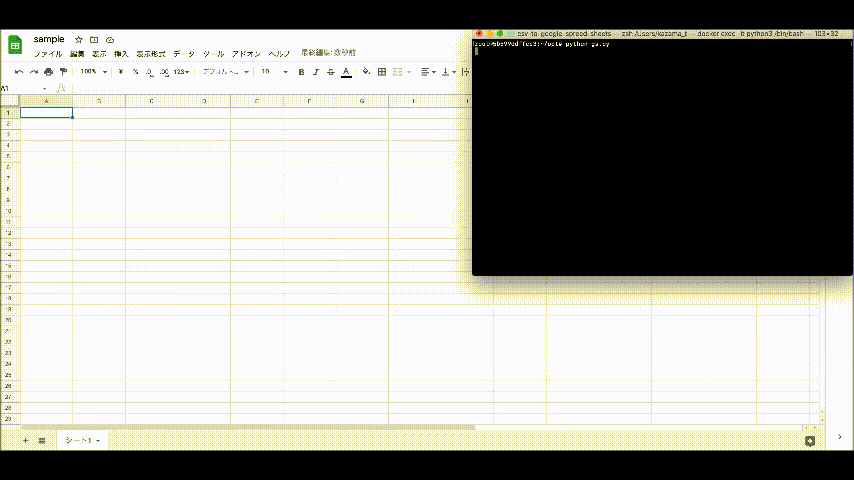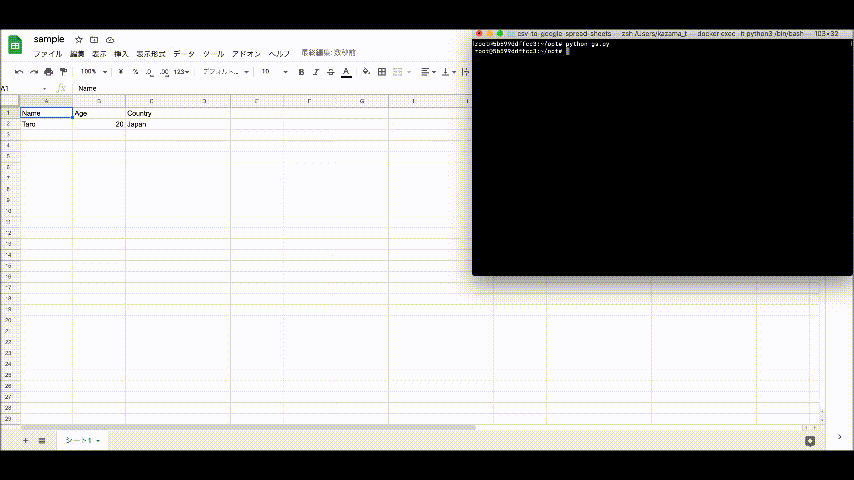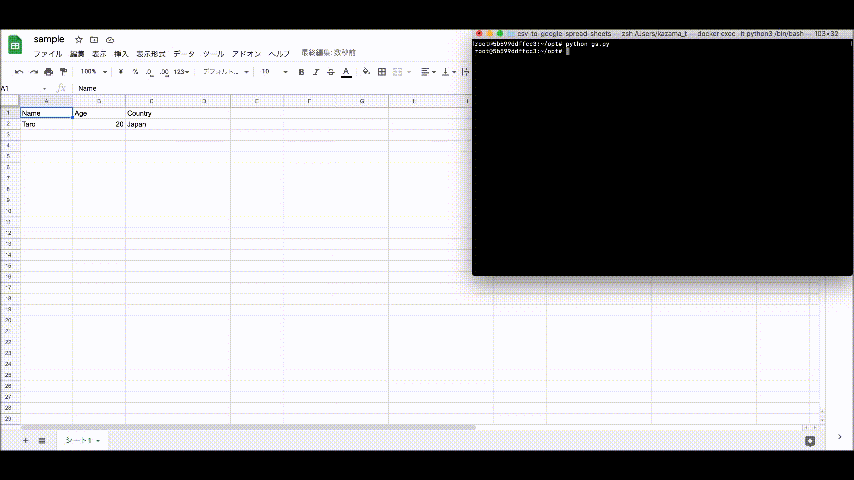
$ touch gs.py./opt/gs.pyimport gspread from oauth2client.service_account import ServiceAccountCredentials import csv SPREADSHEET_KEY = 'それぞれの値を入力' # 「docs.google.com/spreadsheets/d/xxxxxxxxxxxxx/edit#gid=0」の「xxxxxxxxxxxxx」部分 scope = 'https://spreadsheets.google.com/feeds' credentials_file_path = './client_secret.json' credentials = ServiceAccountCredentials.from_json_keyfile_name(credentials_file_path, scope) gc = gspread.authorize(credentials) workbook = gc.open_by_key(SPREADSHEET_KEY) workbook.values_update( 'シート1', # どのシートに書き込むのかを指定 params={'valueInputOption': 'USER_ENTERED'}, body={'values': list(csv.reader(open('./test.csv', encoding='utf_8_sig')))} )最後に、Google Spread Sheetsに取り込むようのCSVファイルを準備します。
$ touch test.csv/opt/test.csvName,Age,Country Taro,20,Japan次のコマンドを実行し、該当のGoogle SpreadSheetsに↑の内容が書き込まれていれば成功です。
$ python gs.py
あとがき
お疲れ様でした。基本的な流れは以上です。あとは各自の目的に合わせてカスタマイズしてみてください。Lambdaとかでも上手く使えそうな気がします。



- 投稿日:2021-02-13T18:36:37+09:00
tensorflow-gpuをRTX3070で動かすのは大変だった
概略
TensorFlow公式ページ(https://www.tensorflow.org/install/gpu) に従ってGPU版を導入するもうまく動作しなかった。
↓
ファイル名の書き換えで動作することを確認。RTX30シリーズで頻発している様子。
今回の対応はかなり応急処置的なので改善待ちですね・・・。環境
OS
Windows 10 Home(64bit)
バージョン : 20H2CPU
Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz 2.90 GHzGPU
GeForce RTX 3070
Driver version : 461.40
CUDA Version : 11.2言語とライブラリ
conda : 4.9.2
Python : 3.8.5
tensorflow-gpu : 2.4.1解決までの経緯
指定の要件で動かない
公式のソフトウェア要件(https://www.tensorflow.org/install/gpu#software_requirements) の通りにセットアップして学習を始めると以下のメッセージが
2021-02-13 17:10:23.436049: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudart64_110.dll 2021-02-13 17:10:24.817916: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-02-13 17:10:24.818847: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library nvcuda.dll 2021-02-13 17:10:24.850803: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties: pciBusID: 0000:01:00.0 name: GeForce RTX 3070 computeCapability: 8.6 coreClock: 1.725GHz coreCount: 46 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 417.29GiB/s ~~ 中略 ~~ 2021-02-13 17:10:24.892311: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'cusolver64_10.dll'; dlerror: cusolver64_10.dll not found 2021-02-13 17:10:24.895383: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusparse64_11.dll 2021-02-13 17:10:24.895962: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cudnn64_8.dll 2021-02-13 17:10:24.908415: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1757] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform. Skipping registering GPU devices... 2021-02-13 17:10:24.909790: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-02-13 17:10:24.910559: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix: 2021-02-13 17:10:24.910934: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 2021-02-13 17:10:24.911055: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set 2021-02-13 17:10:25.019189: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2) Epoch 1/100 15/15 [==============================] - 2s 80ms/step - loss: 1.1186 - accuracy: 0.3416 Epoch 2/100 15/15 [==============================] - 1s 80ms/step - loss: 1.0781 - accuracy: 0.3804 ~~ 以下略 ~~最終的に学習は始まってるし一見できている風なんですが、
ここ
Skipping registering GPU devices...「GPUでやるの飛ばすね。。。」とおっしゃっています。
なので、CPUで動いています。なぜ?'cusolver64_10.dll'が読み込めない
さっきのメッセージをよく読むと
Could not load dynamic library 'cusolver64_10.dll'; dlerror: cusolver64_10.dll not found「'cusolver64_10.dll'がないよ」とのこと。
実際CUDAの入っているフォルダを確認してもそんなものはない。調べてみると公式のGitHubリポジトリでもissueが上がっていました。
(https://github.com/tensorflow/tensorflow/issues/44291)
そこで見つけた解決策がこちら
訳「'cusolver64_11.dll'を'cusolver64_10.dll'に名前変更したら解決しましたよ」それありなの?(笑)
ありでした
2021-02-13 18:02:35.671492: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library cusolver64_10.dllはい、読み込めてますね。
(かなり胡散臭い対応ですが)これでとりあえずは動くみたいです。ちなみにGPUだとさっきのCPUで動かした場合の約10倍の速度で学習しています。早い!
# GPU Epoch 1/100 15/15 [==============================] - 0s 10ms/step - loss: 1.1017 - accuracy: 0.3842 Epoch 2/100 15/15 [==============================] - 0s 8ms/step - loss: 1.0474 - accuracy: 0.4595 #CPU Epoch 1/100 15/15 [==============================] - 2s 80ms/step - loss: 1.1186 - accuracy: 0.3416 Epoch 2/100 15/15 [==============================] - 1s 80ms/step - loss: 1.0781 - accuracy: 0.3804参考
GPU サポート | TensorFlow
https://www.tensorflow.org/install/gpucuda - tensorflow-gpu の導入がうまくいきません [RTX 3070] - スタック・オーバーフロー
https://ja.stackoverflow.com/questions/72013/tensorflow-gpu-%E3%81%AE%E5%B0%8E%E5%85%A5%E3%81%8C%E3%81%86%E3%81%BE%E3%81%8F%E3%81%84%E3%81%8D%E3%81%BE%E3%81%9B%E3%82%93-rtx-3070nvidia cudaセットアップ - Qiita
https://qiita.com/mailstop/items/a84ac6b4eac8d12ba488tensorflow-nightly-gpu looking for cusolver64_10.dll on a cuDNN 11.1 installation · Issue #44291 · tensorflow/tensorflow
https://github.com/tensorflow/tensorflow/issues/44291RTX 3090 and Tensorflow for Windows 10 - step by step : tensorflow
https://www.reddit.com/r/tensorflow/comments/jsalkw/rtx_3090_and_tensorflow_for_windows_10_step_by/

- 投稿日:2021-02-13T18:20:52+09:00
張り出しばりの断面力を python と API を用いてサクッと算出
構造力学 の教科書に記載されている問題を python で解いてみました
構造力学は人によっては難解だと感じる学問、python の勉強は楽しいけど 構造力学は苦手という人向けに
python を用いて構造力学の問題を解いてみたいと思います。今回取り上げる 例題は、
構造力学[第2版]上-静定編
から
4章 演習問題4.3 より図 4.20 に示す張り出しばりのQ図, M図を描け
を python と api でサクッと解いてみたいと思います。
全ソースコードはこちら
https://colab.research.google.com/drive/11cMEEUSFgu3hVw0vLOo1PZhvwSiM-5Ys?usp=sharing解説
今回用いた環境 Google colaboratory
Google colaboratory という Google が無償で提供する python をインストールしなくても使える環境で
問題を解きます。計算の流れ
- 入力データを生成
- API に断面力の計算をさせる
- 計算結果を表示する
1.入力データを生成する
この変数body に 入力データを記録していきます。
body = dict()格点 を定義する
トラスなどの骨組構造における部材と部材の交点の座標と番号を定義する
n1 = {"x":0, "y":0, "z":0} n2 = {"x":2, "y":0, "z":0} n3 = {"x":6, "y":0, "z":0} body["node"] = { "1": n1, "2": n2, "3": n3 }部材 を定義する
骨組構造における部材の番号と下記の情報を定義する
- ni: 部材の左端の点
- nj: 部材の右端の点
- e: 後述する材料番号
body["member"] = { "1": {"ni":"1", "nj":"2", "e":"1"}, "2": {"ni":"2", "nj":"3", "e":"1"} }材料の番号と下記の情報を定義する
今回の問題では、材料は一様で、特に指定がないので、適当な数値を入力している
- E: 弾性係数
- G: せん断弾性係数
- Xp: 膨張係数
- A: 断面積
- J: ねじり定数
- Iy: y軸周りの断面二次モーメント
- Iz: z軸周りの断面二次モーメント
body["element"] = { "1":{ "1":{ "E":20000000, "G":770000, "Xp":0.00001, "A":1.0, "J":1.0, "Iy":1.0, "Iz":1.0 } } }支点の情報を定義する
- n: 固定する格点番号
- tx: x方向の変位を固定する場合は1, 固定しない場合は0
- ty: y方向の変位を固定する場合は1, 固定しない場合は0
- tz: z方向の変位を固定する場合は1, 固定しない場合は0
- rx: x軸周りの回転を固定する場合は1, 固定しない場合は0
- ry: y軸周りの回転を固定する場合は1, 固定しない場合は0
- rz: z軸周りの回転を固定する場合は1, 固定しない場合は0
body["fix_node"] = { "1":[ {"n":"2","tx":1,"ty":1,"tz":1,"rx":0,"ry":0,"rz":0}, {"n":"3","tx":0,"ty":1,"tz":1,"rx":0,"ry":0,"rz":0} ] }荷重の情報を定義する
- fix_node: 支点の情報の番号
- element: 材料情報の番号
- load_node
- n: 荷重を載荷する格点番号
- tx: x方向に作用する荷重
- ty: y方向に作用する荷重
- tz: z方向に作用する荷重
- rx: x軸周りに作用するモーメント
- ry: y軸周りに作用するモーメント
- rz: z軸周りに作用するモーメント
body["load"] = { "1":{ "fix_node": "1", "element": "1", "load_node":[ { "n":"1","tx":0,"ty":0,"tz":2,"rx":0,"ry":0,"rz":0 } ] } }2. API に断面力の計算をさせる
断面力の計算は、StructuralEngineという API を使います。
上記のデータを ここに POST すると断面力を計算してくれますresponse = requests.post( 'https://asia-northeast1-the-structural-engine.cloudfunctions.net/frameWeb-2', json.dumps(body), headers={'Content-Type': 'application/json'}) result = response.json() # レスポンスのHTMLを文字列で取得 print('解析結果', result)解析結果{'1': {'disg': {'1': {'dx': 0.0, 'dy': 0.0, 'dz': 8e-07, 'rx': 0.0, 'ry': 4.666666666666666e-07, 'rz': 0.0}, '2': {'dx': 0.0, 'dy': 0.0, 'dz': 0.0, 'rx': 0.0, 'ry': 2.6666666666666667e-07, 'rz': 0.0}, '3': {'dx': 0.0, 'dy': 0.0, 'dz': 0.0, 'rx': 0.0, 'ry': -1.333333333333333e-07, 'rz': 0.0}}, 'reac': {'2': {'tx': 0.0, 'ty': 0.0, 'tz': -1.0000000000000016, 'mx': 0.0, 'my': 0.0, 'mz': 0.0}, '3': {'tx': 0.0, 'ty': 0.0, 'tz': 1.0000000000000002, 'mx': 0.0, 'my': 0.0, 'mz': 0.0}}, 'fsec': {'1': {'P1': {'fxi': -0.0, 'fyi': -0.0, 'fzi': -2.0000000000000018, 'mxi': 0.0, 'myi': -3.552713678800501e-15, 'mzi': 0.0, 'fxj': 0.0, 'fyj': 0.0, 'fzj': -2.0000000000000018, 'mxj': -0.0, 'myj': 4.000000000000002, 'mzj': -0.0, 'L': 2.0}}, '2': {'P1': {'fxi': -0.0, 'fyi': -0.0, 'fzi': 1.0000000000000002, 'mxi': 0.0, 'myi': 4.0, 'mzi': 0.0, 'fxj': 0.0, 'fyj': 0.0, 'fzj': 1.0000000000000002, 'mxj': -0.0, 'myj': -4.440892098500626e-16, 'mzj': -0.0, 'L': 4.0}}}}}3. 計算結果を表示する
API で得られた解析結果から Q図と M図を作図します。
断面力の情報を取り出す
情報は、以下の階層で格納されているため 取り出して作図します。
- "1": ケース番号
- "1","2": 部材番号
- fsec: 断面力
- P1:着目点
- fzi:z軸方向 左側のせん断力
- fzj:z軸方向 右側のせん断力
- myi:y軸周り 左側の曲げモーメント
- myj:y軸周り 右側の曲げモーメント
# ケース1の情報を取り出す case1 = result['1'] # 断面力情報を取り出す fsec = case1['fsec'] # 部材番号1の情報を取り出す member1 = fsec['1']['P1'] # 部材番号2の情報を取り出す member2 = fsec['2']['P1']Q図、M図を作図する
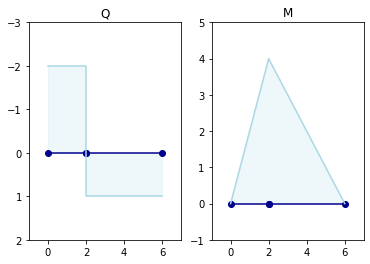
# 部材のx座標 x = [ n1['x'], n2['x'], n2['x'], n3['x'] ] # 部材のy座標 y = [ n1['y'], n2['y'], n2['y'], n3['y'] ] # せん断力 yQ = [ member1['fzi'], member1['fzj'], member2['fzi'], member2['fzj']] # 曲げモーメント yM = [ member1['myi'], member1['myj'], member2['myi'], member2['myj']]以上の情報から図を描きます。
fig = plt.figure() ax1 = fig.add_subplot(1, 2, 1) ax1.set_ylim([2, -3]) ax1.set_xlim([-1, 7]) ax1.plot(x, y, marker ='o', color = "darkblue") ax1.plot(x, yQ, color = "lightblue") ax1.fill_between( x, yQ, color="lightblue", alpha=0.2) ax1.set_title("Q") ax2 = fig.add_subplot(1, 2, 2) ax2.set_ylim([-1, 5]) ax2.set_xlim([-1, 7]) ax2.plot(x, y, marker ='o', color = "darkblue") ax2.plot(x, yM, color = "lightblue") ax2.fill_between( x, yM, color="lightblue", alpha=0.2) ax2.set_title("M")
答えが一致しました
まとめ
構造力学 の教科書に記載されている問題を python で解いてみました
構造力学が苦手でも、python があれば理解せずに先に進めます
いろいろ遊んでるうちに 構造力学の理解が深まれば幸いです






- 投稿日:2021-02-13T17:25:38+09:00
scikit-learnを使ってみる
scikit-learnを使ってみたので、そのメモです。
scikit-learnはPythonから使える機械学習ライブラリです。
https://scikit-learn.org/stable/index.html線形回帰
一次関数
一次関数 y = 2x + 3 を求めます。
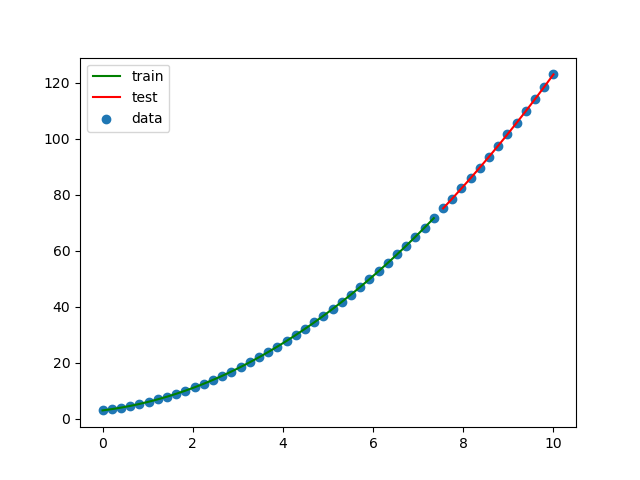
xの値を0〜10の範囲で50個準備します。
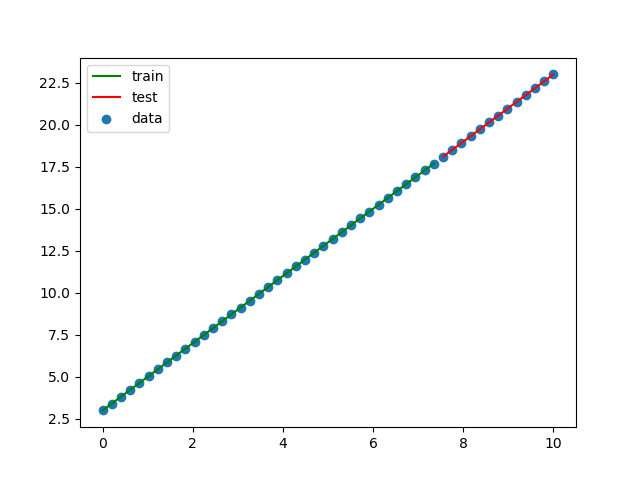
最初の75%をトレーニングデータ、残り25%をテストデータとして使用します。import numpy as np from sklearn import linear_model from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # Y = 2X + 3を求める関数とする。 X = np.linspace(0, 10, num=50) Y = 2 * X + 3 train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) clf = linear_model.LinearRegression() train_X2 = train_X.reshape(-1, 1) clf.fit(train_X2, train_Y) print(f'回帰係数={clf.coef_}') print(f'切片={clf.intercept_}') print(f'決定係数={clf.score(train_X2, train_Y)}') plt.scatter(X, Y, label='data') plt.plot(train_X, clf.predict(train_X2), color='green', label='train') plt.plot(test_X, clf.predict(test_X2), color='red', label='test') plt.legend() plt.savefig('linear_regression1.png') plt.show()結果をグラフにしてみます。
完璧です!
二次関数
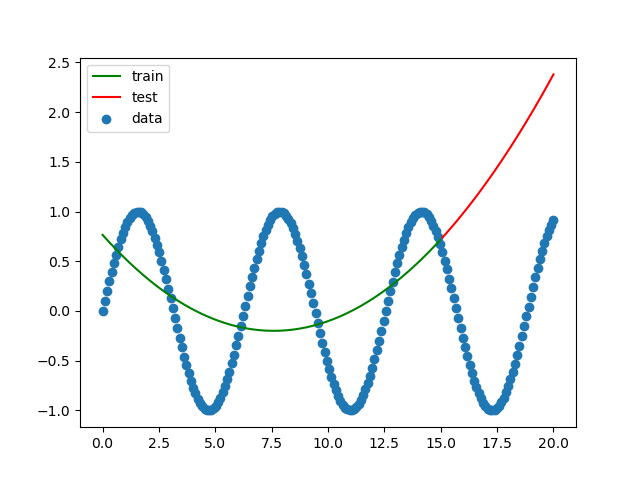
同じような感じで二次関数を求めます。
求める式は、y = x^2 + 2x + 3 です。import numpy as np from sklearn import linear_model from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # Y = X^2 + 2X + 3を求める関数とする。 X = np.linspace(0, 10, num=50) Y = X**2 + 2 * X + 3 train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) clf = linear_model.LinearRegression() train_X2 = train_X.reshape(-1, 1) clf.fit(train_X2, train_Y) print(f'回帰係数={clf.coef_}') print(f'切片={clf.intercept_}') print(f'決定係数={clf.score(train_X2, train_Y)}') plt.scatter(X, Y, label='data') plt.plot(train_X, clf.predict(train_X2), color='green', label='train') plt.plot(test_X, clf.predict(test_X2), color='red', label='test') plt.legend() plt.savefig('linear_regression2.png') plt.show()結果をグラフにしてみます。
一次関数を求めようとしているので、結果は予想通りフィットしていません。
二次関数 - 多項式を使う
前の例をPolynomialFeaturesを使って二次関数として求めてみます。
import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures import matplotlib.pyplot as plt # Y = X^2 + 2X + 3を求める関数とする。 X = np.linspace(0, 10, num=50) Y = X**2 + 2 * X + 3 train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) pf = PolynomialFeatures(degree=2, include_bias=False) train_X2 = pf.fit_transform(train_X2) lr = LinearRegression() lr.fit(train_X2, train_Y) test_X2 = pf.fit_transform(test_X2) print(f'回帰係数={lr.coef_}') print(f'切片={lr.intercept_}') print(f'決定係数={lr.score(train_X2, train_Y)}') plt.scatter(X, Y, label='data') plt.plot(train_X, lr.predict(train_X2), color='green', label='train') plt.plot(test_X, lr.predict(test_X2), color='red', label='test') plt.legend() plt.savefig('linear_regression3.png') plt.show()結果をグラフにしてみます。
フィットしました!
三角関数
次に三角関数で同じことをやってみます。
求める関数はsin関数です。
やる前から結果は見えているような気もしますが...import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures import matplotlib.pyplot as plt # 三角関数 Y = sin(X)を求める。 X = np.linspace(0, 20, num=200) Y = np.sin(X) train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) pf = PolynomialFeatures(degree=2, include_bias=False) train_X2 = pf.fit_transform(train_X2) lr = LinearRegression() lr.fit(train_X2, train_Y) test_X2 = pf.fit_transform(test_X2) print(f'回帰係数={lr.coef_}') print(f'切片={lr.intercept_}') print(f'決定係数={lr.score(train_X2, train_Y)}') plt.scatter(X, Y, label='data') plt.plot(train_X, lr.predict(train_X2), color='green', label='train') plt.plot(test_X, lr.predict(test_X2), color='red', label='test') plt.legend() plt.savefig('linear_regression4.png') plt.show()結果をグラフにしてみます。
三角関数を二次関数として求めているので予想通りの結果です。
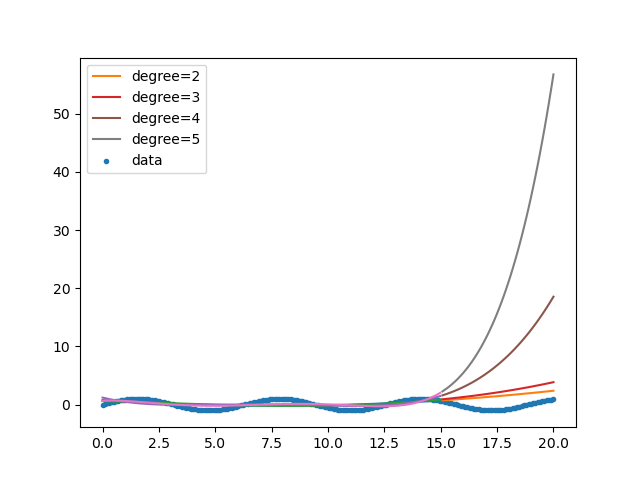
では何次関数ならフィットするのでしょうか?
2〜5次で試してみます。import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures import matplotlib.pyplot as plt # 三角関数 Y = sin(X)を求める。 X = np.linspace(0, 20, num=200) Y = np.sin(X) train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) for degree in np.arange(2, 6): train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) pf = PolynomialFeatures(degree=degree, include_bias=False) train_X2 = pf.fit_transform(train_X2) lr = LinearRegression() lr.fit(train_X2, train_Y) test_X2 = pf.fit_transform(test_X2) print(f'degree={degree}') print(f' 回帰係数={lr.coef_}') print(f' 切片={lr.intercept_}') print(f' 決定係数={lr.score(train_X2, train_Y)}') plt.plot(train_X, lr.predict(train_X2)) plt.plot(test_X, lr.predict(test_X2), label=f'degree={degree}') plt.scatter(X, Y, label='data', marker='.') plt.legend() plt.savefig('linear_regression5.png') plt.show()結果をグラフにしてみます。
次数が多くなると発散していく感じがします。
サポートベクターマシン
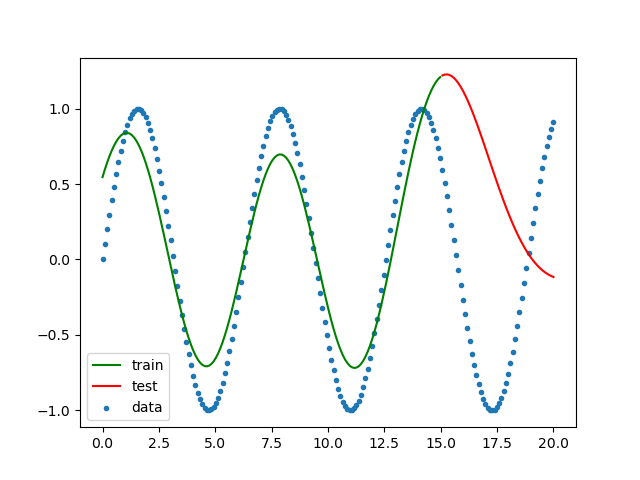
サポートベクターマシンを使って学習させてみます。
import numpy as np from sklearn import svm from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # 三角関数 Y = sin(X)を求める。 X = np.linspace(0, 20, num=200) Y = np.sin(X) train_X, test_X, train_Y, test_Y = train_test_split(X, Y, shuffle=False) train_X2 = train_X.reshape(-1, 1) test_X2 = test_X.reshape(-1, 1) regr = svm.SVR() regr.fit(train_X2, train_Y) plt.scatter(X, Y, label='data', marker='.') plt.plot(train_X, regr.predict(train_X2), color='green', label='train') plt.plot(test_X, regr.predict(test_X2), color='red', label='test') plt.legend() plt.savefig('svm_regression1.png') plt.show()結果をグラフにします。
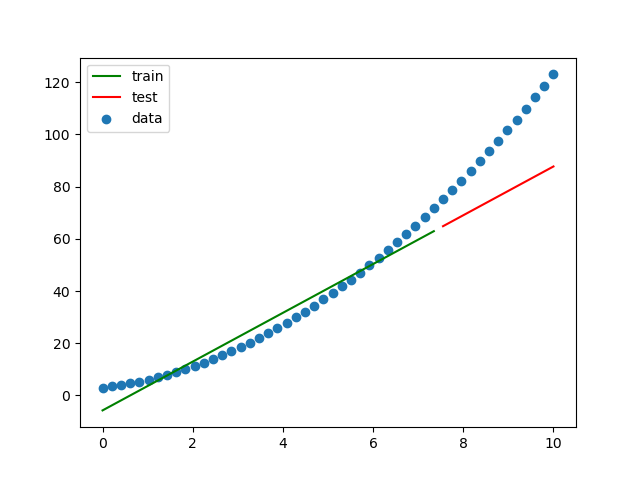
n次関数の予想よりはだいぶ良くなりました。
トレーニングデータはいい感じですが、テストデータに関しては今ひとつです。
- 投稿日:2021-02-13T16:34:17+09:00
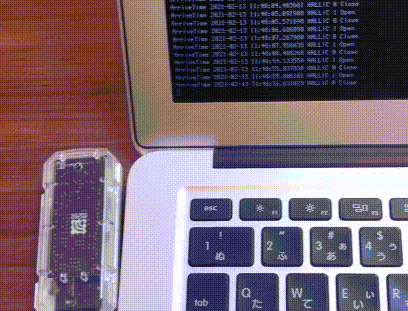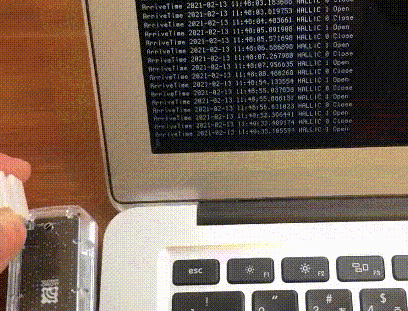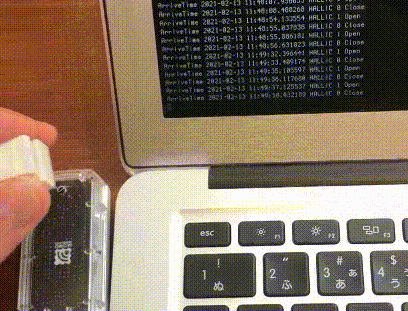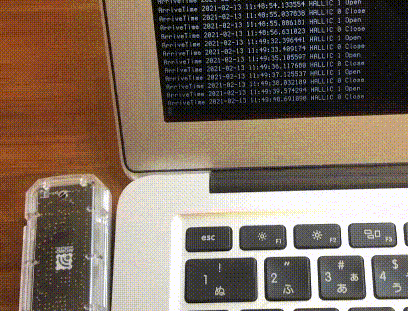
TWELITE OPEN-CLOSE SENSE PALを使って窓の鍵開閉を検知してみた
前から出かけるときに窓の鍵が閉まってるか確認するのが面倒だなと思ってて、IoT機器で簡単に確認できるようにしたいと思っていて、製品が出てるのは知ってるのですが、結構値段が高いので自分で作れないかと思っていました。
そんなある日、たまたま郵便がポストに届いたらLINEで通知がくるようにしたという記事を見てTWELITEを知って、これ使えばやりたいことができると思いました。これ誰かやってるんじゃないか?と思ったら、案の定すでにやってる人がいました。
TWELITE PALを使って窓の施錠確認システムを電子工作なしで作る基本はこれの通りにやったのですが、最初にセットアップする部分がTWELITEのバージョン?によって違ったりWindows向けの情報はすぐ見つかるけどMac向けが見当たらなかったり、親機子機の設定方法がもっと簡単な方法があったので備忘録として残しておきます。ここではPythonでセンサーの変化を読み取るところをゴールとします。
結果
こんな感じで動きます。
手に磁石を持っていて、近づけるとセンサーが感知します。
見づらいですがターミナル上で出力が変わっていて、手を近づけたときにOpen、離すとCloseと出てます。磁石を窓の鍵に付ければ開いてるか閉まってるかわかりますね。動作環境
macOS Catalina 10.15.7
MacBook Air
Python 3.8.6セットアップ
親機をMacにUSB接続して認識されているかlsコマンドで確認する。
ls -l /dev/tty.*
正常に認識されてると
/dev/tty.usbserial-XXXXXX
みたいな結果があるはずです。あとでPythonのスクリプトからセンサー読み取るときに使います。必要なライブラリをインストールする。(公式を参考に)
brew install libusb
pip install pyserial
pip install pyftdiTWELITE STAGE APPのバイナリで親機の設定を行う。
githubに販売元が公開しているバイナリを使う。(ここがソースコードからインストールしている説明がたくさんあって迷ってしまったところ。バイナリを使うのが一番簡単)
https://github.com/monowireless/TWELITE_Stage_BIN_macOS
ダウンロードして解凍したら、解凍したディレクトリ直下にある「TWELITE_Stage.command」がアプリです。これに実行権限をつけます。ターミナルで以下を実行。
chmod +x TWELITE_Stage.commandあとは、公式ページにある通りに以下の設定していく。
https://www.mono-wireless.com/jp/products/twelite-pal/sense/pal-usage.html
- 親機・中継機アプリ(App_Wings)に書換える。
- アプリケーションIDを子機と同じにする。
- 周波数チャネルを子機と同じにする。
- 親機か中継機を選択する(親機モード0に設定する)
- [ビューア]>[PALビューア]で動作確認する。最後に、Pythonからセンサーの状態を読み取るプログラムについて。
公式ページにある下記のスクリプトでできます。TWELITE PALシリーズのデータを受信したときに出力されたシリアルデータを解釈するためのPythonのサンプルスクリプトです。
https://mono-wireless.com/jp/products/TWE-APPS/App_pal/palscript.html引数にUSBが認識されて出力されたIDを指定して実行
python PAL_Script.py -t /dev/tty.usbserial-XXXXXXこれで最初に紹介した動画のようにセンサーの変化を検知して出力できます。
TWELITEは電子工作なしでもセンサーでいろいろ遊べそうです。参考にした記事たち
郵便がポストに届いたら LINE で通知がくるようにした
https://qiita.com/task_jp/items/85ccc04a00982569f6c5TWELITEの無線タグアプリを試す
https://qiita.com/miminashi/items/453f7f3e31c8c009e486無線通信機能付き磁力センサ「OPEN-CLOSE SENSE PAL」を使ってみた
https://qiita.com/RyoOkaya/items/660ceb91d2b4e0378a8dTWELITE STAGE を試す
https://qiita.com/nanbuwks/items/bb07970d5339177aa7a0TWELITE PALを使って窓の施錠確認システムを電子工作なしで作る
https://zlog.hateblo.jp/entry/2019/08/18/Twelite-pal-window-monitorTWELITE STAGE APP macOS向けのバイナリ
https://github.com/monowireless/TWELITE_Stage_BIN_macOS
- 投稿日:2021-02-13T16:32:16+09:00
Windowsでvenv
はじめに
Windowsにおける、venvのメモ
venv単位で仮想環境が作れるので便利
1週間で忘れてしまっていたので、メモ残し(特にポリシーのやつ)構築&実行プロセス
venvの環境を構築
python -m venv envsample※envsampleは好きな名前を
※上記で、envsampleのフォルダができるポリシーの設定
Set-ExecutionPolicy RemoteSigned -Scope Process※このコマンドは毎回実行する必要がある(その代わり管理権限が不要)
※永続設定もある環境下に入る
.\envsample\Scripts\activate※Script以下のactivateを実行すればよい(確かbatファイル)
※docker exec ~ bash みたいなやつ(envsample) PS C:\sample\python※上みたいに先頭にカッコ書きになったら、仮想環境下にいる
環境外に出る
deactivate※多分カッコが外れる
- 投稿日:2021-02-13T14:17:57+09:00
Level別 Pythonリスト内包表記 8選
リストの内包表記はとても便利な書き方ですが、他の言語からやってくる人にとって
少し理解しづらいものだと感じました。なのでこれさえ押さえとけば、簡単な内包表記は書けちゃうよって物をまとめました。
環境
Python 3.7.8
そもそもリストの内包表記とは
リストを生成する簡潔な手段です。【公式:リストの内包表記】
具体的にはこんな感じ。
sample = [1, 2, 3, 4] new_sample = [ x * 2 for x in sample] print(new_sample) # [2, 4, 6, 8]level 1 : 基本をおさえよう
リスト内包表記の基本はこれだ。
式[ expression for item in iterable (if condition) ]実にシンプル。
- iterableオブジェクトをfor文でループ
- expressionでitemデータを加工
- オプションでifによる条件の絞り込み
level 2 : まずはfor文を置き替えて
full_name = "Yamada Taro" name_list = [] for c in full_name: name_list.append(c) print(full_name) print(name_list) # Yamada Taro # ['Y', 'a', 'm', 'a', 'd', 'a', ' ', 'T', 'a', 'r', 'o']上のfor文を内包表記で書き換えてみましょう。
full_name = "Yamada Taro" characters = [char for char in full_name] print(full_name) print(characters) # Yamada Taro # ['Y', 'a', 'm', 'a', 'd', 'a', ' ', 'T', 'a', 'r', 'o']2次元リストもitelableとして利用可能。
Matrix = [[7, 1, 5], [22, 99, 0], [33, 2, 57]] row_min = [min(row) for row in Matrix] # [1, 0, 2]level 3 : optionのifでデータを絞ろう
if文を使えば、データを絞る事ができます。
SQLのWHERE句に該当するものです。4文字より少なく、小文字のものだけに絞ります。
People = ["Taro", "Jiro", 'Wan', "Elepahnt", "Tomas", "ken", "sae"] target = [name for name in People if len(name) < 4 and name.islower()] print(target) # ['ken', 'sae']level 4 : expression でデータを加工しよう
expressionの所は、pythonの構文であれば何を書いても構いません。
nameを加工する例。Genius = ["taro", "jiro", "yamada", "ito"] target = [name.capitalize() for name in Genius] print(target) # ['Taro', 'Jiro', 'Yamada', 'Ito']もちろん、expressionに
if..else..をいれる事も可能です。People = ["Taro", "Hiroyuki", "ken", "youu"] >>> answer = [name if name.startswith('y') else 'Not Genius' for name in People] >>> print(answer) # ['Not Genius', 'Not Genius', 'Not Genius', 'youu']ここでの注意は、
if...else...は三項演算子であり、Level 1 で紹介した式の最後のifとは異なるという事です。[ expression for item in iterable (if condition) ]
この式でのifは抽出条件で、SQLのwhere句と同じものです。
elseは入れられません。もしexpressionに
ifを入れるなら、elseを必ずいれないといけません。
それは、三項演算子だからです。a = 1 b = 2 if a >0 # SyntaxError: invalid syntax b = 2 if a > 0 else -1 print(b) # 2level 5 : ネストされたfor文もリストに入れよう
ネストされたループはどうでしょう。
Genius = ["taro", "jiro", "yamada"] L = [] for name in Genius: for char in name: L.append(char) print(L) # ['t', 'a', 'r', 'o', 'j', 'i', 'r', 'o', 'y', 'a', 'm', 'a', 'd', 'a']内包表記にすると、こんな感じになります。
Genius = ["taro", "jiro", "yamada"] L = [char for name in Genius for char in name] print(L) # ['t', 'a', 'r', 'o', 'j', 'i', 'r', 'o', 'y', 'a', 'm', 'a', 'd', 'a']ループは2つより多くなると分かりづらくなるので、2つまでが良いと思います。
level 6 : map, filterを置き換えよう
mapやfilterはfunctionを引数にする事ができますが、
内包表記で書いたほうが分かりやすくなります。mapは次のように置き換えられます。
mapL = list(map(func, iterable)) # 置き換え可能 L = [func(a) for a in iterable]filterは次のように置き換えられます。
filterL = list(filter(condition_func, iterable)) # 置き換え可能 L = [a for a in iterable if condition]実際に例を見てみましょう。
mapの例People = ["Kenny", "Tomas", "tom", "young"] L = map(lambda a: a.lower(), People) print(list(L)) # ['kenny', 'tomas', 'tom', 'young'] L = [a.lower() for a in People] print(L) # ['kenny', 'tomas', 'tom', 'young']filterの例People = ["Kenny", "Tomas", "tom", "young"] L1 = filter(lambda a: len(a) < 4, People) print(list(L1)) # ['tom'] L2 = [a for a in People if len(a) < 4] print(L2) # ['tom']level 7 : サイズが大きくなる場合は、generator式を使おう
大量の要素を含むものはジェネレーター式を検討しよう。
ジェネレーター式は実際必要になった時に生成されるので、メモリのコストを大幅に削減できます。
(でも、任意の要素にはアクセスできない。先頭から順番のアクセスのみ。)# 100万の要素を生成 >>> large_list = [x for x in range(1_000_000)] >>> large_list_g = (x for x in range(1_000_000)) >>> print(large_list.__sizeof__()) 8697440 >>> print(large_list_g.__sizeof__()) 96 >>>level 8 : 複雑と感じるなら無理して使わない。
下記2つは同じリストを生成しますが、どちらが直感的に分かりやすいでしょうか。
内包表記list_2d = [ [0, 0, 0], [1, 1, 1], [2, 2, 2], ] flat = [num ** 2 if num % 2 == 0 else num for row in list_2d for num in row] print(flat) # [0, 0, 0, 1, 1, 1, 4, 4, 4]forループlist_2d = [ [0, 0, 0], [1, 1, 1], [2, 2, 2], ] flat = [] for row in list_2d: for num in row: flat.append(num ** 2 if num % 2 == 0 else num) print(flat) # [0, 0, 0, 1, 1, 1, 4, 4, 4]私は
forループの方が直感的で分かりやすいと思いますが、人によって違うと思います。
この例では単純な2重ループでしたが、条件文がついたり、expressionでデータを加工したり、forループが増えたりして、複雑だと感じたら内包表記を使わない方が良いのではないでしょうか。さいごに
内包表記は簡潔にリストの記述をできますが、他者が逆に理解しづらくなってしまっては本末転倒なので、チーム内の様子を見ながら利用するのが良いのではないでしょうか。
level1 の式を押さえておくのはお勧めです。
以上
- 投稿日:2021-02-13T13:59:12+09:00
flaskにwebアプリをデプロイして躓いたこと
概要
いくつものエラーを解決して、ようやくflaskフレームワークによるWebアプリが完成しました。
内容はかなりシンプルかつジュニアレベルなもので
言ってしまえば単なるメモ帳のようなものです。
或いは自分しか存在しないtwitterのタイムラインといえば伝わりやすいでしょうか。
https://young-mesa-87008.herokuapp.com/できること
・ユーザ登録
・メモの記録
・過去の記録を閲覧実装してみた主な機能
パスワードはsalt・sha256関数によるパスワードのハッシュ化&認証
ログイン・ログアウトはsessionライブラリによるセッション管理を実装
herokuのDBアドオンによるClearDBサーバに対し、PyMysqlをドライバとして使用開発で躓いたところ

その1:ログイン後、逐一セッションが切れる
ログインに成功して、ひとまず機能動作確認の為
ぐるぐるページ遷移したりガチャガチャ操作していると
突然 500 error が返されることがありました。原因の究明
まず、
heroku logs --tailでErrorの内容を見ると
デコレータによってsessionを確認した際、KeyErrorを起こしているようでした。ERROR in app: Exception on /user/home [GET] return super(SecureCookieSession, self).__getitem__(key) KeyError: 'login'
そもそもの処理内容としましては
アプリ内で登録したユーザでログインを行った後、
メモを記載するページや過去の記録を閲覧するページに遷移できるのですが
その際、login_requiredデコレータで現在ログインしているユーザの情報をsessionから取得させるようにしていました。app.py# ログイン時に呼ばれる関数 @app.route('/login/try', methods=['POST']) def login_try(): name = request.form.get('name') pwd = request.form.get('pwd') result = check_user(name, str(pwd)) if result: # ↓ ココで辞書型配列であるsessionに # 'login'をKey値としてnameを格納 session['login'] = name def login_required(func): @wraps(func) def wrapper(*args, **kwargs): # ↓ ココで問い合わせ if not is_login(): return redirect('/login') return func(*args, **kwargs) return wrapper # セッション管理 def is_login(): # 辞書型配列のsessionから loginをキーに持つ値を返す。 return 'login' in session調査として、flaskのsession絡みのコード記事や
app.secret_keyに関する質問記事を読むと、
sessionの確立にはapp.secret_keyをsetする必要があり
またkey値はアプリケーション内で同一のものを使用する必要がありました。そこで自身のコードを見直してみると..
app.py# ランダム文字列生成 def randomname(n): randlst = [random.choice(string.ascii_letters + string.digits) for i in range(n)] return ''.join(randlst) # Flaskインスタンスと暗号化キーの指定 app = Flask(__name__) app.secret_key = randomname(16)上記のようにapp.secret_keyの値を関数によって算出し、
使用していることが原因のようでした。
アプリケーションを再起動するたびに、新しいキーが与えられるため、以前のキーは無効になります。
つまり、最初に定義したキーが無効になり、新しいsecret key の下でsessionが定義されるので、当然参照したsessionのKeyは空となり、KeyErrorが発生していたようです。修正対応としては、
①iniファイルに機密情報(16文字のstring)を記載しておく
②iniファイルを読み込むインタラクティブなモジュール(ini.py)を用意
③ini.pyをメインモジュール(app.py)にimportして流用する
といった対応にしました。app.pyimport secret app.secret_key = secret.ini_keyini.pyimport configparser ini = configparser.ConfigParser() ini.read('config.ini', encoding='UTF-8') ini_key = ini['secret_key']['sec_key']config.ini[secret_key] sec_key = XXXXXXXXXXXXXXXX
その2:複数のクエリを実行したい時、Pymysqlのconnentionが確立しない
これはselectやinsertのクエリをウォーターフォールで実行するテストを行った時に出会いました。以下のpyを呼び出すと、ins_queryの実行タイミングで
raise err.Error("Already closed")が返されてしまいます。mysql.py# select def query(stmt, *args): try: with conn.cursor() as cursor: cursor.execute(stmt, (args)) data = cursor.fetchall() finally: conn.close() cursor.close() return data # insert def ins_query(stmt, *args): try: with conn.cursor() as cursor: cursor.execute(stmt, (args)) data = cursor.fetchall() finally: conn.commit() conn.close() cursor.close() return True原因の究明
こちらの記事を参考にしました。
1つ目のquery()実行後、conn.close()を行い、
2つ目のins_query()実行時には、cursorを定義して接続しようとしていますが
一度閉じた接続を再接続するにはself.connnection.ping()を投げてやる必要があるようです。
以下のように、cursorによるDB接続試行前に、conn.ping()を書くことで
修正に至りました。class MySQL: # select def query(stmt, *args): try: # ↓ここ conn.ping() with conn.cursor() as cursor: cursor.execute(stmt, (args)) data = cursor.fetchall() finally: conn.close() cursor.close() return data # insert def ins_query(stmt, *args): try: # ↓ここ conn.ping() with conn.cursor() as cursor: cursor.execute(stmt, (args)) data = cursor.fetchall() finally: conn.commit() conn.close() cursor.close() return True
その3:記録を投稿した時刻と、閲覧した時に返される時刻が9時間ずれている
例えば
投稿した時間→ 2/13 0:50の場合
表示される時間→2/12 15:50
9時間前に投稿したことになっていました。現在時刻は以下のように取得しています。
app.py# 今日日付取得 def get_today(): d = datetime.datetime.now() today = (d.strftime('%Y-%m-%d')) return today # 現在時刻取得 def get_time(): t = datetime.datetime.now() time = (t.strftime('%H:%M:%S')) return time原因の究明
恐らくタイムゾーンの設定ではないかと、ClearDBの設定値を疑いましたが
DBの設定値を直接変えることはできず、heroku上で変更が可能だそうです。
herokuのタイムゾーン設定変更
heroku config:add TZ=Asia/Tokyo --app [app-name]終わりに
現在の業務が忙しく(言い訳)、なかなか勉強する時間が取れず(言い訳)
昨年6月頃から始めた学習を滞らせていましたが
ようやくサーバに自作アプリをアップロードさせることが出来、
一つ達成感を得ることが出来ました。ただ、実装した機能は初歩中の初歩ですし、
まだまだ改善の余地があると思います。
それに今後商用アプリを作成するならばもっとセキュアにする必要もありますね。
今後もpythonやフロントサイドのoutputとして開発を積み上げていきたいです。次回はAPI連携や機械学習を取り入れたサービスを創ろうと思います。
また、PHPやvue.jsといった言語も取り入れて、より動的なアプリを作ってみたいです。
それと、他のRuby on Rails, Django, Lavarelといったフレームワークも挑戦してみたいと思います。
- 投稿日:2021-02-13T13:41:53+09:00
EmoPy Challenge
machine
- 64bit ubuntu 18.04LTS
- VMWare Workstation 15 Player
installing pyenv(2021/2/11)
refer the steps of https://github.com/thoughtworksarts/EmoPy/blob/master/README.md#environment-setup
update and upgrade apt before starting
sudo apt update sudo apt upgrade
- installing required libs and then you must reboot your machine.
sudo apt install -y build-essential libffi-dev libssl-dev zlib1g-dev liblzma-dev libbz2-dev libreadline-dev libsqlite3-dev git
- install package of pyenv
git clone https://github.com/pyenv/pyenv.git ~/.pyenv` echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc` echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc` echo 'eval "$(pyenv init -)"' >> ~/.bashrc` source ~/.bashrc`
- check the version of installed pyenv.
pyenv -v
- install python into virtual environment.
pyenv install 3.6.10set up for EmoPy
- install required lib.
sudo apt-get install graphviz` sudo pip3 install virtualenv` sudo apt-get install python3-venv`
- Create and activate the virtual environment. Run:
pyenv exec python3.6 -m venv venv
- activate virtual environment.
source venv/bin/activateinstalling EmoPy
- install via pip or from git
# in case of pip sudo pip3 install -U pip sudo pip3 install EmoPy # in case of git git clone https://github.com/thoughtworksarts/EmoPy.git cd EmoPy/ sudo pip3 install -r requirements.txtrun programs
- run
run_all.pyas a testsudo python3 EmoPy/tests/run_all.pyprog for webcam.
cd EmoPy/EmoPy/examples/ sudo python3 fermodel_example_webcam.py
- you may need to unintall h5py and install other-version
sudo pip3 uninstall h5py sudo pip3 install h5py==2.10.0
- output is shown.
Capturing image ... Image written to: image_data/image.jpg Initializing FER model parameters for target emotions: ['calm', 'anger', 'happiness'] WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. 2021-02-12 20:40:55.266811: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 2021-02-12 20:40:55.330783: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2111995000 Hz 2021-02-12 20:40:55.335114: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x1f22ed0 executing computations on platform Host. Devices: 2021-02-12 20:40:55.335376: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined> WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. anger: 62.6% calm: 28.7% happiness: 8.8%
- 投稿日:2021-02-13T13:31:31+09:00
畳み込みニューラルネットワーク(CNN)の実装
はじめに
今回は、「畳み込みニューラルネットワーク」を実装していきます。
ディープラーニングや畳み込みニューラルネットワークの基本については、下記の記事を参照してください。
?基本となるディープラーニングについて
https://qiita.com/hara_tatsu/items/c0e59b388823769f9704?ディープラーニングの実装及び過学習対策
https://qiita.com/hara_tatsu/items/b7423e90574cf7730978?「畳み込みニューラルネットワーク(CNN)まとめ」
https://qiita.com/hara_tatsu/items/8dcd0a339ad2f67932e7畳み込みニューラルネットワークを実装する
今回は題材として、「【SIGNATE】画像ラベリング(10種類)」を使います。
https://signate.jp/competitions/133画像データに映っているものを10種類のラベルから分類するものです。
データの前処理
必要なライブラリーをインポート
python.pyimport numpy as np import pandas as pd from PIL import Image import glob目的変数と説明変数の処理
目的変数を読み込んでカテゴリー変数へ変換
python.pytrain_Y = pd.read_csv('train_master.tsv', delimiter='\t') train_Y = train_Y.drop('file_name', axis=1) # カテゴリー変数へ変換 from tensorflow.keras.utils import to_categorical Y = to_categorical(train_Y) print(Y.shape) print(Y[:5]) (5000, 10) array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]], dtype=float32)説明変数(画像データ)は、「glob」を使って読み込めるが画像データの並びがバラバラに読み込まれてしまう。そのため、読み込み後に小さい数字の順番に並び替える。
python.pytrain_file = glob.glob('train_images/t*') # 0埋めでない数値を小さい順に並び替える関数 import re from collections import OrderedDict def sortedStringList(array=[]): sortDict=OrderedDict() for splitList in array: sortDict.update({splitList:[int(x) for x in re.split("(\d+)",splitList)if bool(re.match("\d*",x).group())]}) return [sortObjKey for sortObjKey,sortObjValue in sorted(sortDict.items(), key=lambda x:x[1])] # 小さい順に並び替え sort_file = sortedStringList(train_file) print(sort_file[:5]) ['train_images/train_0.jpg', 'train_images/train_1.jpg', 'train_images/train_2.jpg', 'train_images/train_3.jpg', 'train_images/train_4.jpg']説明変数(画像データ)の前処理
現在は、「glob」で画像データのファイル名を取得している状態。
PIL形式で読み込み後にnumpy化及び正規化をする。※画像データは「0〜255」までの数値の集まり。そのため、全体を「255.0」で割ることで、「0〜1」までの数値の集まりに変換する。
(✅ディープラーニングは、データの数値の幅が大きいと学習がうまくいかない)python.pyfrom tensorflow.keras.preprocessing.image import load_img, img_to_array, array_to_img # まずは、1枚で試してみる train = sort_file[0] # 画像ファイルからPIL形式で読み込み train = load_img(train) # PIL形式からnumpy形式へ + 正規化 train = img_to_array(train) / 255.0 print(train.shape) (96, 96, 3) # 画像表示 plt.imshow(train)
全ての画像を一括で処理。
※※CPU環境では学習に時間がかかる場合があるため、「image = load_img(image, target_size = (32, 32)) 」とすれば画像サイズを小さくできるので計算時間が減る。(予測精度は悪くなる可能性あり)
python.pyX = [] for image in sort_file: # 画像ファイルのPIL形式で読み込み image = load_img(image) #image = load_img(image, target_size = (32, 32)) 学習時間を短縮したい場合 # PIL形式からnumpy形式へ + 正規化 image = img_to_array(image) / 255.0 # データをリストへ格納 X.append(image) #Xはリスト型のためnumpy型へ変換 X_np = np.array(X) print(X_np.shape) print(X_np.dtype) print(X_np[0]) (5000, 96, 96, 3) float32 [[[0.57254905 0.5529412 0.42745098] [0.5764706 0.5568628 0.43137255] [0.5803922 0.56078434 0.43529412] [0.6509804 0.627451 0.49411765] [0.64705884 0.62352943 0.49019608] ... [0.6431373 0.61960787 0.4862745 ]] [[0.57254905 0.5529412 0.42745098] [0.57254905 0.5529412 0.42745098] [0.5764706 0.5568628 0.43137255] ... [0.5568628 0.4862745 0.43137255]]]学習用データ、検証用データ、テストデータへ分割
python.py# データの分割 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X_np, Y, test_size=0.2, random_state=0) X_train, X_valid, Y_train, Y_valid = train_test_split(X_train, Y_train, test_size=0.2, random_state=0) # 形状を確認 print("Y_train=", Y_train.shape, ", X_train=", X_train.shape) print("Y_valid=", Y_valid.shape, ", X_valid=", X_valid.shape) print("Y_test=", Y_test.shape, ", X_test=", X_test.shape) Y_train= (3200, 10) , X_train= (3200, 96, 96, 3) Y_valid= (800, 10) , X_valid= (800, 96, 96, 3) Y_test= (1000, 10) , X_test= (1000, 96, 96, 3)畳み込みニューラルネットワークモデルの構築
最初は単純なモデルで精度を確認する。
python.pyfrom tensorflow import keras from tensorflow.keras.layers import Dense, Activation, Conv2D, Flatten, MaxPooling2D # モデルの初期化 model = keras.Sequential() # 入力層and畳み込み層 model.add(Conv2D(32, # フィルター数 kernel_size= 3, # フィルターのサイズ(3×3) input_shape=(96, 96, 3,), # 入力データ(画像)のサイズ padding="same", #ゼロパディング(画像サイズを小さくしない) activation="relu" #活性化関数 )) # プーリング層 model.add(MaxPooling2D()) # 1次元に変換 model.add(Flatten()) # 全結合層 model.add(Dense(128, activation="relu")) # 出力層 model.add(Dense(10, activation='softmax')) # モデルの構築 model.compile(optimizer = "rmsprop", #誤差逆伝播 loss='categorical_crossentropy', #損失関数 metrics=['accuracy'] #訓練時に監視する指標 ) # モデルの表示 model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_12 (Conv2D) (None, 96, 96, 32) 896 _________________________________________________________________ max_pooling2d_12 (MaxPooling (None, 48, 48, 32) 0 _________________________________________________________________ flatten_8 (Flatten) (None, 73728) 0 _________________________________________________________________ dense_17 (Dense) (None, 128) 9437312 _________________________________________________________________ dense_18 (Dense) (None, 10) 1290 ================================================================= Total params: 9,439,498 Trainable params: 9,439,498 Non-trainable params: 0 _________________________________________________________________python.py# EarlyStopping用 from tensorflow.keras import regularizers %%time # 学習の実施 log = model.fit(X_train, Y_train, #学習用データ epochs=5000, #繰り返し計算する回数 batch_size=64, #ミニバッチ勾配降下法で分割するデータのかたまり verbose=True, #計算過程を表示 #過学習していると判断したら学習を止める callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値 min_delta=0, #改善とみなされる最小の量 patience=30, #設定したエポック数改善がないと終了 verbose=1, mode='auto' #監視する値が増減どうなったら終了か自動で推定 )], validation_data=(X_valid, Y_valid) #検証用データ )結果の確認①
python.py# テスト用データ(Y_test)をカテゴリー変数から通常の数値へ復元 Y_test_ = np.argmax(Y_test, axis=1) # モデルでの予測 Y_pred = model.predict_classes(X_test) # モデルの評価 from sklearn.metrics import classification_report print(classification_report(Y_test_, Y_pred)) precision recall f1-score support 0 0.63 0.80 0.70 93 1 0.47 0.44 0.45 100 2 0.72 0.66 0.69 99 3 0.32 0.34 0.33 103 4 0.46 0.50 0.48 117 5 0.23 0.20 0.22 93 6 0.46 0.52 0.49 101 7 0.56 0.36 0.44 110 8 0.62 0.68 0.65 88 9 0.55 0.54 0.55 96 accuracy 0.50 1000 macro avg 0.50 0.50 0.50 1000 weighted avg 0.50 0.50 0.50 1000正解率50%!!
python.pyacc = log.history['accuracy'] val_acc = log.history['val_accuracy'] loss = log.history['loss'] val_loss = log.history['val_loss'] epochs_range = range(37) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Loss') plt.show()
予測精度は低く、早い段階で過学習をしている。
原因として考えられるのは、
✅学習用データが少ないこと。
そこで学習用データの拡張と水増しをしてみる。
学習用データの拡張と水増し
✅学習用データの拡張と水増しが必要な理由
・対象の物体が逆さまや斜めになったデータも学習させることで、応用力をつけさせるため(データの拡張)
・必要な量の学習データが準備できていない(データの水増し)python.pyfrom tensorflow.keras.preprocessing.image import ImageDataGenerator # 学習用データの拡張設定 image_gen = ImageDataGenerator(rotation_range=45, #45°回転 horizontal_flip = True, #左右反転 ) # 拡張データの生成 train_data_gen = image_gen.flow(X_train, Y_train, batch_size = 32, shuffle = False) # 拡張データを表示する関数 def plotImages(images_arr): fig, axes = plt.subplots(1, 5, figsize=(20,20)) axes = axes.flatten() for img, ax in zip( images_arr, axes): ax.imshow(img) ax.axis('off') plt.tight_layout() plt.show() augmented_images = [train_data_gen[0][0][0] for i in range(5)] plotImages(augmented_images)
python.py#学習用データの状態確認 #3200 / 32 print(len(train_data_gen)) 100 print(type(train_data_gen)) tensorflow.python.keras.preprocessing.image.NumpyArrayIterator検証用データを学習用データの状態に合わせる
python.pyvalid_gen = ImageDataGenerator() valid_data_gen = valid_gen.flow(X_valid, Y_valid, batch_size = 32) #800 / 32 print(len(valid_data_gen)) 25 print(type(valid_data_gen)) tensorflow.python.keras.preprocessing.image.NumpyArrayIterator学習用データを拡張して学習
python.py%%time # 学習の実施 log = model.fit_generator(train_data_gen, #学習用データ steps_per_epoch = 100, epochs = 5000, #繰り返し計算する回数 callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値 min_delta=0, #改善とみなされる最小の量 patience=30, #設定したエポック数改善がないと終了 verbose=1, mode='auto' #監視する値が増減どうなったら終了か自動で推定 )], validation_data = valid_data_gen, #検証用データ validation_steps = 25)結果の確認②
python.py# 予測 Y_pred = model.predict_classes(X_test) # モデルの評価 print(classification_report(Y_test_, Y_pred)) precision recall f1-score support 0 0.62 0.86 0.72 93 1 0.38 0.70 0.49 100 2 0.70 0.79 0.74 99 3 0.47 0.19 0.27 103 4 0.74 0.37 0.49 117 5 0.39 0.39 0.39 93 6 0.51 0.56 0.54 101 7 0.49 0.54 0.51 110 8 0.72 0.66 0.69 88 9 0.61 0.43 0.50 96 accuracy 0.54 1000 macro avg 0.56 0.55 0.53 1000 weighted avg 0.56 0.54 0.53 1000正解率54%!!
python.pyacc = log.history['accuracy'] val_acc = log.history['val_accuracy'] loss = log.history['loss'] val_loss = log.history['val_loss'] epochs_range = range(69) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Loss') plt.show()
正解率は上昇したもの、まだまだ過学習しています。
最後に、過学習対策を施したモデルを構築します。過学習対策をしたモデルを構築
python.pyfrom tensorflow.keras.layers import Dropout # モデルの初期化 model = keras.Sequential() # 入力層 model.add(Conv2D( 32, kernel_size=3, input_shape=(96, 96, 3,), padding="same", activation="relu", )) # プーリング層 model.add(MaxPooling2D()) model.add(Dropout(0.25)) # 層のユニットの繰り返し model.add(Conv2D(64, kernel_size=3, padding="same", activation="relu")) model.add(MaxPooling2D()) model.add(Dropout(0.25)) # 1次元に変換 model.add(Flatten()) model.add(Dense(128, activation="relu")) model.add(Dense(64, activation="relu")) model.add(Dropout(0.5)) # 出力層 model.add(Dense(10, activation='softmax')) # モデルの構築 model.compile(optimizer = "rmsprop", loss='categorical_crossentropy', metrics=['accuracy']) model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_4 (Conv2D) (None, 96, 96, 32) 896 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 48, 48, 32) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 48, 48, 32) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 48, 48, 64) 18496 _________________________________________________________________ max_pooling2d_5 (MaxPooling2 (None, 24, 24, 64) 0 _________________________________________________________________ dropout_4 (Dropout) (None, 24, 24, 64) 0 _________________________________________________________________ flatten_3 (Flatten) (None, 36864) 0 _________________________________________________________________ dense_7 (Dense) (None, 128) 4718720 _________________________________________________________________ dense_8 (Dense) (None, 64) 8256 _________________________________________________________________ dropout_5 (Dropout) (None, 64) 0 _________________________________________________________________ dense_9 (Dense) (None, 10) 650 ================================================================= Total params: 4,747,018 Trainable params: 4,747,018 Non-trainable params: 0 _________________________________________________________________python.py%%time # 学習の実施 log = model.fit_generator(train_data_gen, #学習用データ steps_per_epoch = 100, epochs = 5000, #繰り返し計算する回数 callbacks = [keras.callbacks.EarlyStopping(monitor='val_loss',#監視する値 min_delta=0, #改善とみなされる最小の量 patience=30, #設定したエポック数改善がないと終了 verbose=1, mode='auto' #監視する値が増減どうなったら終了か自動で推定 )], validation_data = valid_data_gen, #検証用データ validation_steps = 25)結果の確認③
python.py# 予測 Y_pred = model.predict_classes(X_test) # モデルの評価 print(classification_report(Y_test_, Y_pred)) precision recall f1-score support 0 0.73 0.77 0.75 93 1 0.45 0.59 0.51 100 2 0.87 0.63 0.73 99 3 0.49 0.42 0.45 103 4 0.57 0.59 0.58 117 5 0.38 0.23 0.28 93 6 0.54 0.75 0.63 101 7 0.64 0.42 0.51 110 8 0.69 0.76 0.72 88 9 0.56 0.73 0.63 96 accuracy 0.58 1000 macro avg 0.59 0.59 0.58 1000 weighted avg 0.59 0.58 0.58 1000正解率58%!!
python.pyacc = log.history['accuracy'] val_acc = log.history['val_accuracy'] loss = log.history['loss'] val_loss = log.history['val_loss'] epochs_range = range(69) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Loss') plt.show()
おわりに
正解率はあまり向上しなかったが、いい感じに学習が進んでいるグラフになっている。
さらなる精度向上を目指すなら、
・モデルの構築をより複雑にする
・転移学習
・学習用データをもっと集める

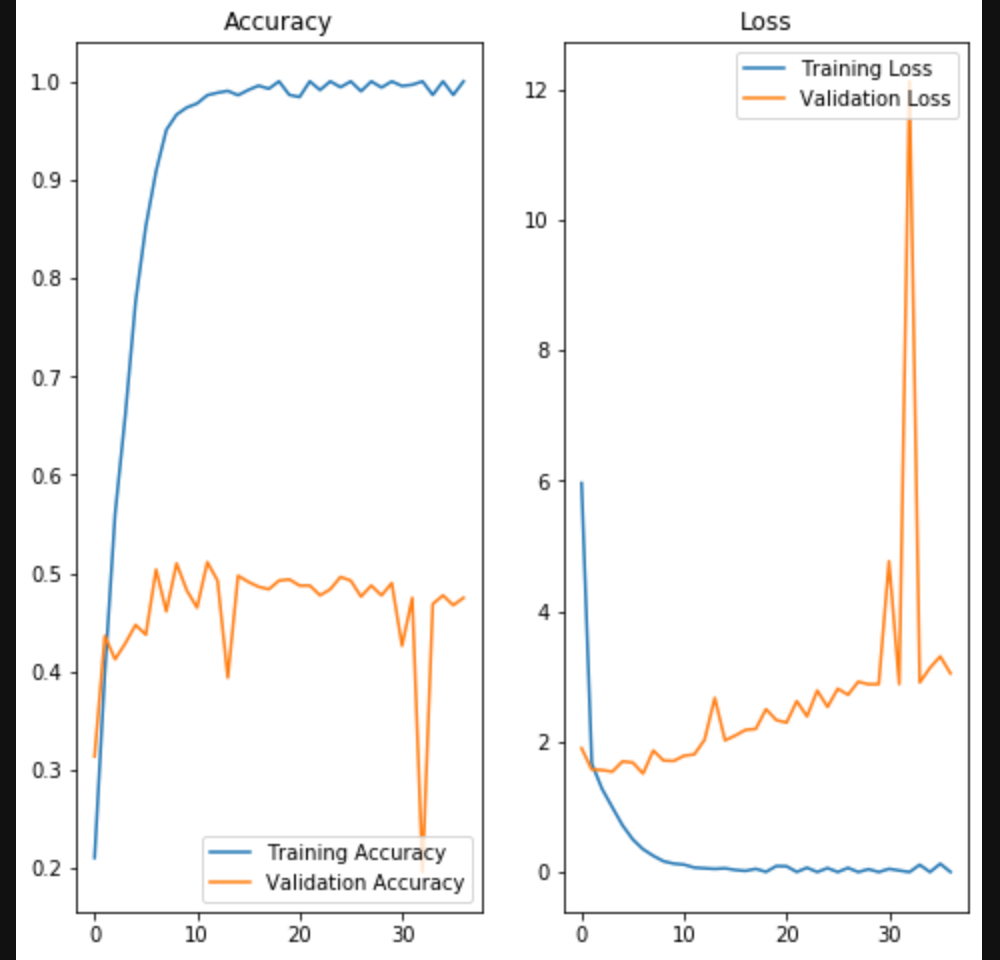

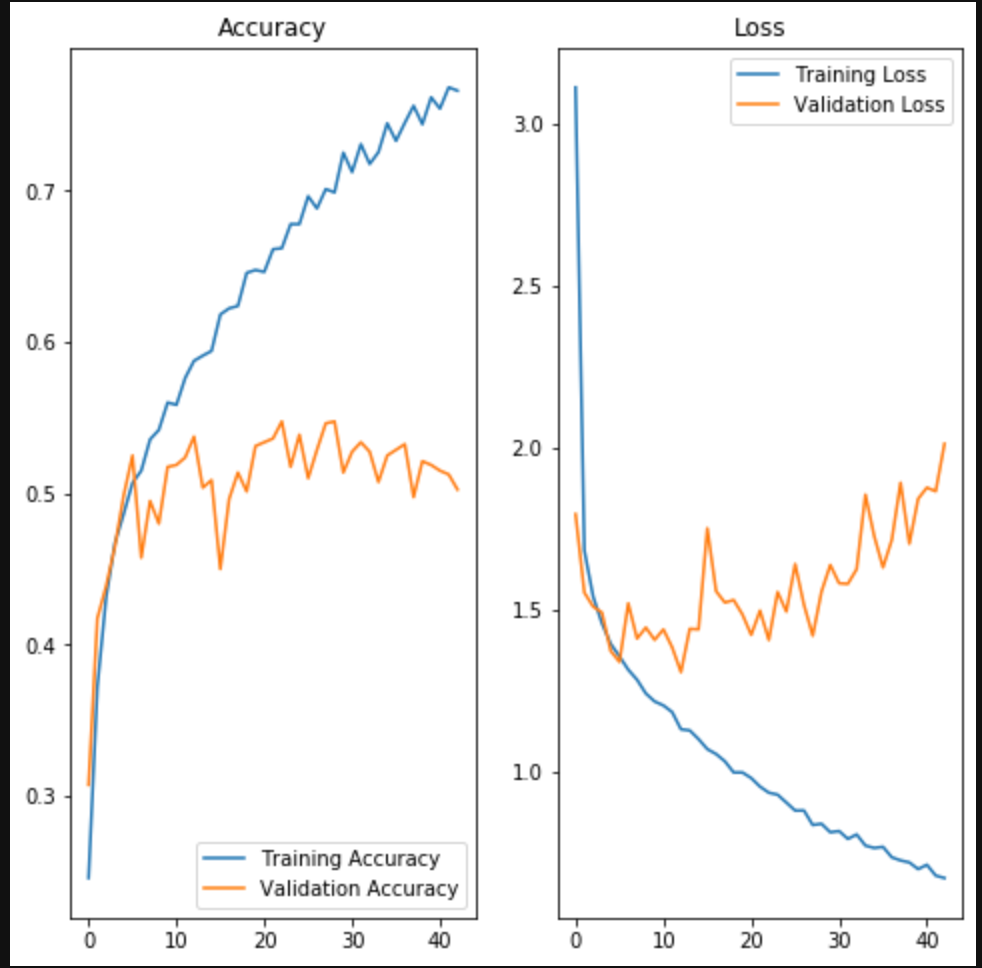
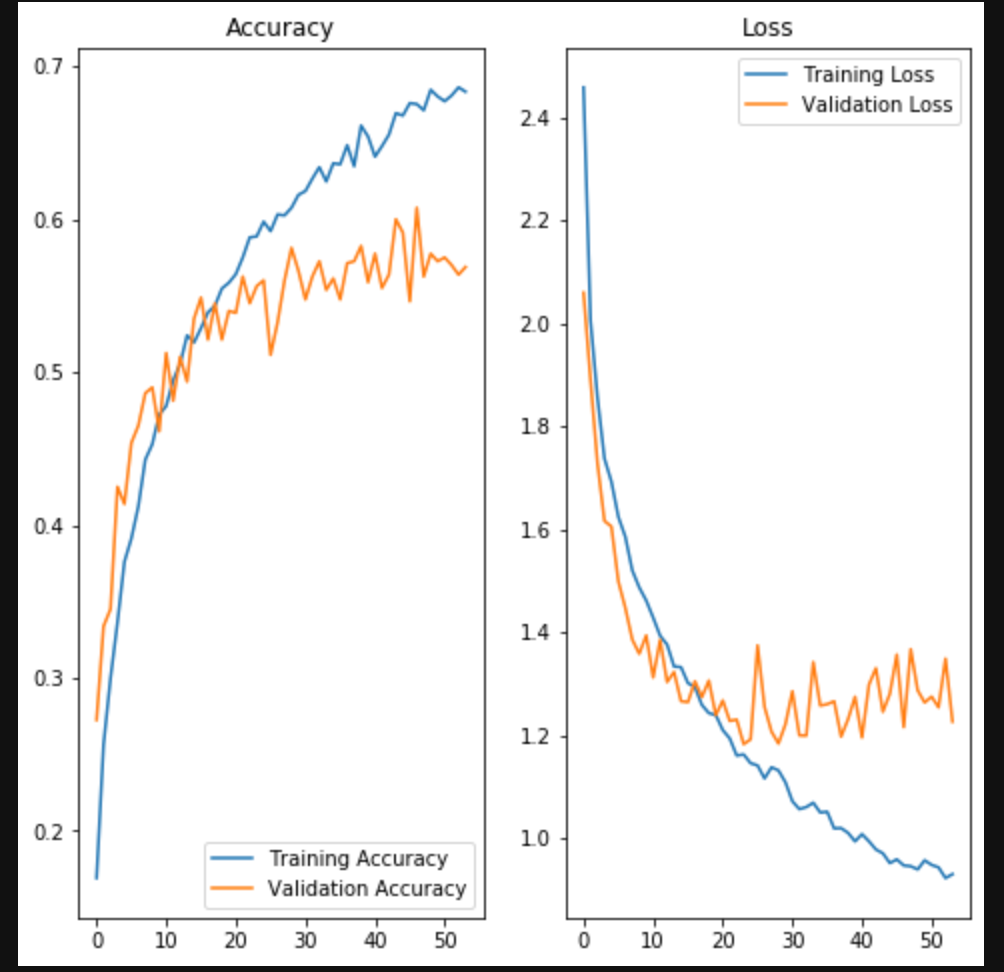
- 投稿日:2021-02-13T13:02:06+09:00
三菱UFJ銀行サイトにPythonとSeleniumを使ってログインする
三菱UFJ銀行のサイトにPythonとSelenium使ってログインするサンプルコードを書いてみました。
※2021/02/13時点の情報です。
ポイントは以下の通りです。
- ログイン情報を、設定ファイルから取得
- SeleniumuでID、パスワードを入力
- 三菱UFJ銀行の場合、formはsubmitではないのでbutton.click()でログインする
環境
- Windows 10
- Python 3.8
- Selenium 3.141.0
サンプルコード
bank_ufj.py# # 三菱UFJ銀行サイトへログイン # import json from selenium.webdriver import Firefox, FirefoxOptions from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait # 設定ファイルからログイン情報を取得 login_info = json.load(open("login_info.json", "r", encoding="utf-8")) # ログインサイト名 site_name = "bank_ufj" # ログイン画面URL url_login = login_info[site_name]["url"] # ユーザー名とパスワードの指定 USER = login_info[site_name]["id"] PASS = login_info[site_name]["pass"] # Firefoxのヘッドレスモードを有効にする options = FirefoxOptions() options.add_argument('--headless') # Firefoxを起動する browser = Firefox(options=options) # ログイン画面取得 browser.get(url_login) # 入力 e = browser.find_element_by_id("tx-contract-number") e.clear() e.send_keys(USER) e = browser.find_element_by_id("tx-ib-password") e.clear() e.send_keys(PASS) # ログイン実行 button = browser.find_element_by_class_name("gonext") button.click() # ページロード完了まで待機 WebDriverWait(browser, 10).until( EC.presence_of_element_located((By.ID, "md-allmenu")) ) # ログインできたか確認(画面キャプチャ取る) browser.save_screenshot("home.png") browser.quit()ログイン情報設定ファイル
サイトURLやログイン情報(IDやパスワード)は、JSON形式のファイルに保持するようにしています。以下のサンプルでは三菱UFJ銀行と楽天証券の2サイトの情報と設定しています。
"id"と"pass"の値を書き換えればそのまま使えるはずです。
なお、このファイルだけは絶対に漏洩しないよう、管理方法に注意しましょう!
login_info.json{ "bank_ufj": { "id": "1234567890", "pass": "password", "url": "https://entry11.bk.mufg.jp/ibg/dfw/APLIN/loginib/login?_TRANID=AA000_001" }, "sec_rakuten": { "id": "1234567890", "pass": "password", "url": "https://www.rakuten-sec.co.jp/ITS/V_ACT_Login.html" } }実行後
Seleniumで動かしていると実際にログインできているのか、画面遷移できているのかが視覚的にわかりにくいですよね。
そこで動作確認のために画面キャプチャを保存しておくとよいでしょう。
# ログインできたか確認(画面キャプチャ取る) browser.save_screenshot("home.png")一部ぼかしを入れていますが実際に保存された画像がこちらです。
- 投稿日:2021-02-13T12:56:23+09:00
AWS覚書 - boto3を使ってIoT coreのエンドポイントを取得する -
IoT coreを使用するのに、クライアントからカスタムエンドポイントを取得する必要があるので、取得できるようになるまでの手順を覚書しておく。
必要なもののインストール
pythonへboto3と、AWSクライアント
boto3
pip3 install boto3AWSクライアント
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-mac.html
キーセットの取得
まずはアクセスキーとシークレットーキーが必要
アカウントの IAM → アクセス管理 → ユーザー → アクセスキー と進む。
アクセスキーを作成してシークレットキーを取得する(一度しか取得できないので紛失に注意する)。AWSクライアントへのキーセットの登録
> aws configure --profile <プロファイル名(自由な名前でOK)> AWS Access Key ID [None]: <取得したアクセスキー> AWS Secret Access Key [None]: <取得したシークレットキー> Default region name [None]: <デフォルトで使用したいリージョン、東京ならば「ap-northeast-1」> Default output format [None]: jsonプロファイルを作成したらプロファイルをデフォルト設定する
> set AWS_DEFAULT_PROFILE= <先ほど作成したプロファイル名>ちゃんとキーセットが設定されているか確認する。
> aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ****************3LHQ shared-credentials-file secret_key ****************vexf shared-credentials-file region us-east-2 config-file ~/.aws/config以下のファイルに、それっぽいのがあるか確認できる。
> cat ~/.aws/credentialsIoT coreのエンドポイントを確認
Iot core → 設定 と進むとみれる。
クライアントからエンドポイントの取得
pythonから取得する。
> python Python 3.8.2 (default, Apr 27 2020, 13:03:04) [Clang 10.0.0 (clang-1000.10.44.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iot', region_name='ap-northeast-1') >>> endpoint_response = client.describe_endpoint(endpointType='iot:Data-ATS') >>> print(endpoint_response) {'ResponseMetadata': {'RequestId': '**************', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Sat, 13 Feb 2021 03:42:30 GMT', 'content-type': 'application/json', 'content-length': '74', 'connection': 'keep-alive', 'x-amzn-requestid': '****************', 'access-control-allow-origin': '*', 'x-amz-apigw-id': '********', 'x-amzn-trace-id': 'Root=****************'}, 'RetryAttempts': 0}, 'endpointAddress': '<ここが実際に取得したいエンドポイントになる>'}整形
{ "ResponseMetadata": { "RequestId": "**************", "HTTPStatusCode": 200, "HTTPHeaders": { "date": "Sat, 13 Feb 2021 03:42:30 GMT", "content-type": "application/json", "content-length": "74", "connection": "keep-alive", "x-amzn-requestid": "****************", "access-control-allow-origin": "*", "x-amz-apigw-id": "********", "x-amzn-trace-id": "Root=****************" }, "RetryAttempts": 0 }, "endpointAddress": "<ここが実際に取得したいエンドポイントになる>" }画面でみたエンドポイントと同じであるか確認する。
boto3.clientの部分は、キーセット直接指定でも問題ない。>>> client = boto3.client('iot', region_name='ap-northeast-1', aws_access_key_id='***', aws_secret_access_key='***')
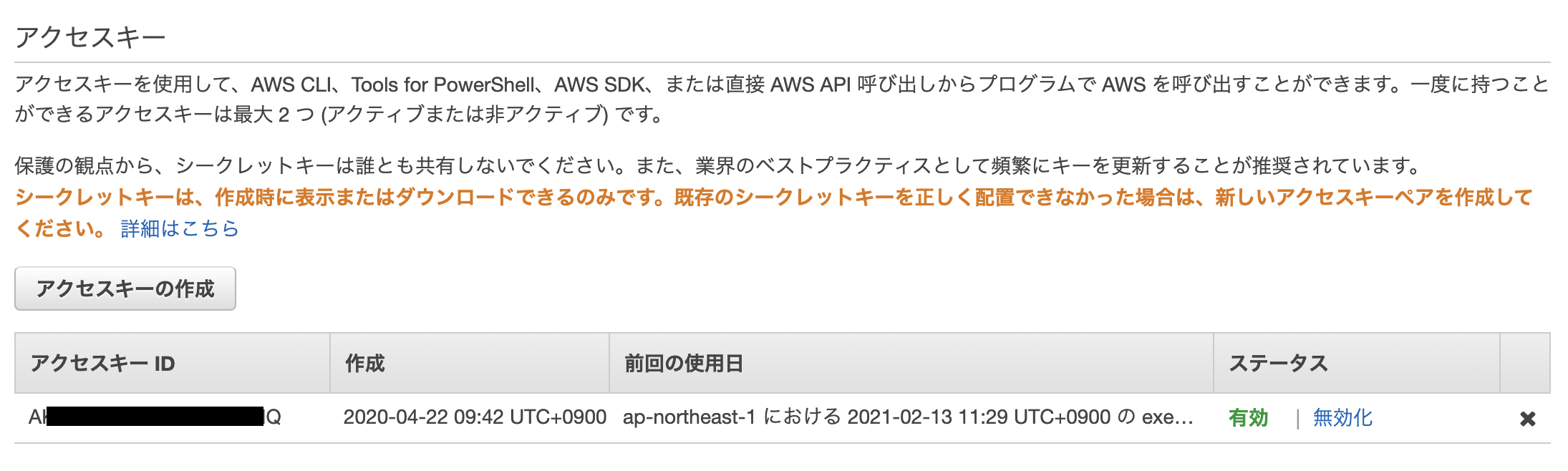
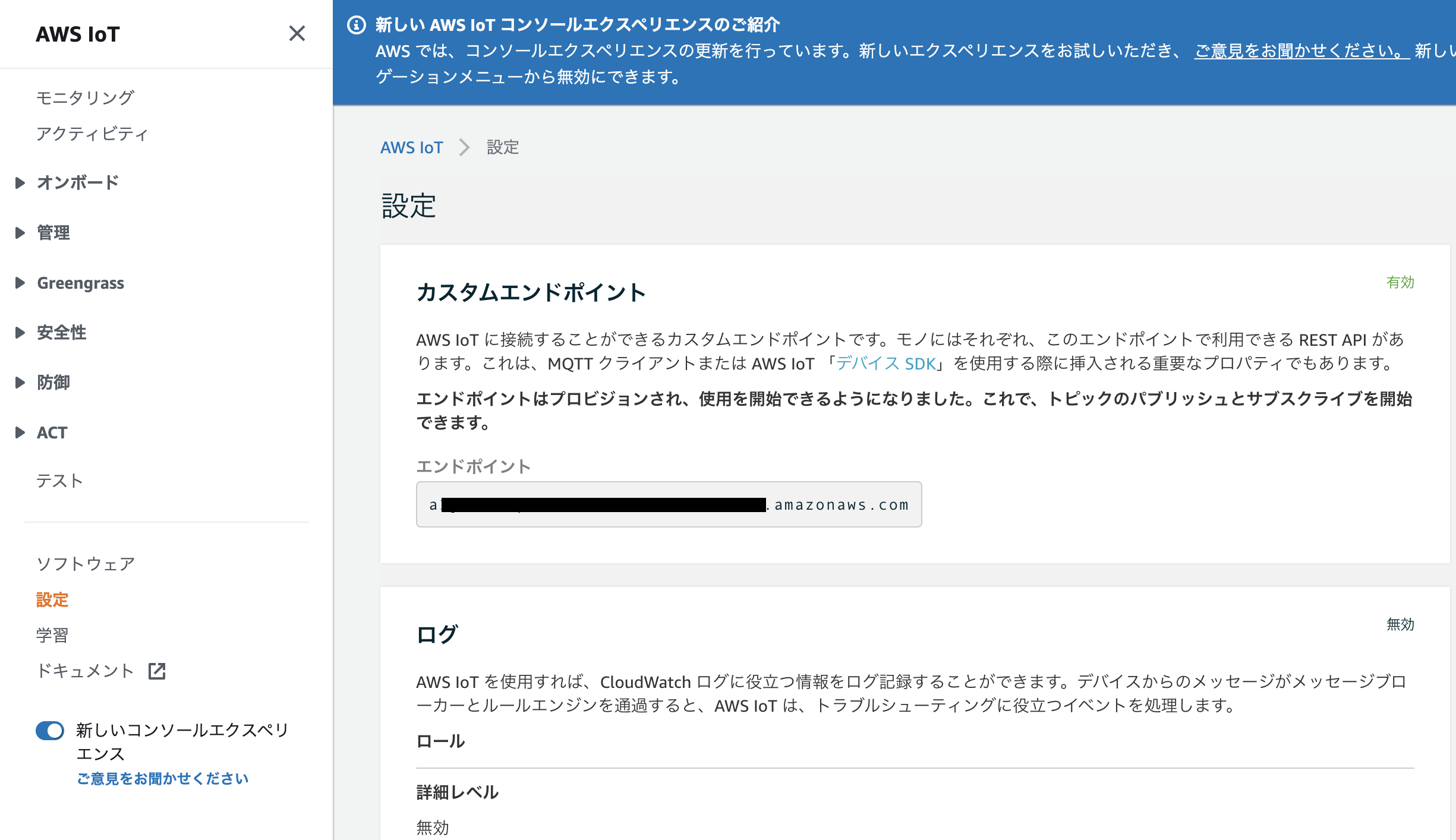
- 投稿日:2021-02-13T12:30:20+09:00
Pythonを複数バージョン管理してみる
概要
Pythonを使ったプログラミングをする際、Pythonの何バージョンを使うかで揉めることがある。毎回使用するバージョンに合わせて環境を入れ替えるのが面倒なので、Python仮想環境を使用して必要がバージョンに切り替えられる快活環境を作る。
実行環境
- OS: Ubuntu 18.04 LTS
- Python: 3.6.9
Python仮想環境ツール
conda Anacondaに同封されているツール pyenv オープンソースで開発しているバージョン管理ツール condaセットアップ
condaはAnacondaに同封されたツールなのでAnacondaをインストールします
参考:Anaconda Installing on LinuxAnacondaインストーラをダウンロード
Anaconda Individual Editionからインストーラをダウンロードする
インストーラを実行する
# ダウンロードしたインストーラに実行権限を与える $ chmod +x Anaconda3-2020.11-Linux-x86_64.sh # インストールを実行する $ ./Anaconda3-2020.11-Linux-x86_64.shインストーラ実行時の操作は以下
Welcome to Anaconda3 2020.11 In order to continue the installation process, please review the license agreement. Please, press ENTER to continue >>> Enterを入力 . . Do you accept the license terms? [yes|no] [no] >>> Please answer 'yes' or 'no': >>> yes . . Anaconda3 will now be installed into this location: /home/$USER/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below [/home/$USER/anaconda3] >>> Enterを入力 . . Do you wish the installer to initialize Anaconda3 by running conda init? [yes|no] [no] >>> yescondaチートシート
# 名前とPythonバージョンを指定して仮想環境を作る # ex) conda create --name py36 python=3.6 $ conda create --name <name> python=<verson> # 準備されている仮想環境リストを表示する $ conda info --envs # conda environments: # base * /home/dai_guard/anaconda3 py36 /home/dai_guard/anaconda3/envs/py36 # 仮想環境を有効にする ※デフォルトのbase環境になる $ conda activate # 名前を指定して仮想環境を有効にする $ conda activate <name> # 仮想環境を無効にする $ conda diactivate
pyenvセットアップ
GitHubで公開されているオープンソースなツール
pyenvをクローン&ビルドする
# リポジトリからクローンする $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv # ビルドする $ cd ~/.pyenv $ src/configure $ make -C src環境変数を設定する
# pyenvのフォルダを設定する echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc # PATHにpyenvフォルダを追加する echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc # 自動でpyenvの仮想環境を起動する設定 echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bashrcpyenvチートシート
# 現在インストールされているPythonバージョン $ pyenv versions * system (set by PYENV_VERSION environment variable) 3.8.7 # イントールできるPythonバージョン $ pyenv install --list # バージョンを指定してPythonをインストールする # ex) pyenv install 3.8.7 $ pyenv install <version> # Pythonバージョンを切り替える # ex) pyenv shell 3.8.7 $ pyenv shell <version>使ってみて
conda
メリット
- インストールが簡単
- Anacondaでメンテナンスしてるので信頼できる
デメリット
- Anacondaに同封なのでライセンス対応のため会社などでは使えない可能性がある
- 力補完が効かないのでコマンドを覚えないといけない
pyenv
メリット
- 入力補完が使えるので簡単
- venvと連動してフォルダごとに個別の環境を作れる
デメリット
- デフォルトだと現在使用中の仮想環境が表示されない
- 投稿日:2021-02-13T11:59:05+09:00
EmoPy Challenge
machine
- 64bit Ubuntu18.04 LTS
- VMWare Workstation 15 Player
installing pyenv(2021/2/11)
refer the steps of https://github.com/thoughtworksarts/EmoPy/blob/master/README.md#environment-setup
update and upgrade apt before starting.
sudo apt update sudo apt upgrade
- installing required libs. then you must reboot your machine.
sudo apt install -y build-essential libffi-dev libssl-dev zlib1g-dev liblzma-dev libbz2-dev libreadline-dev libsqlite3-dev git
- install package of the pyenv
git clone https://github.com/pyenv/pyenv.git ~/.pyenv echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc echo 'eval "$(pyenv init -)"' >> ~/.bashrc source ~/.bashrc
check the version of the installed pyenv.
pyenv -vinstall python into virtual environment.
pyenv install <version> (example) pyenv install 3.6.10set up for EmoPy
install required lib.
sudo apt-get install graphviz sudo pip3 install virtualenv sudo apt-get install python3-venvCreate and activate the virtual environment. Run:
pyenv exec python3.6 -m venv venvactivate virtual environment.
source venv/bin/activateinstalling EmoPy
- update pip and install EmoPy from PyPi or git.
- it takes a long time...
sudo pip3 install -U pip # PyPi sudo pip3 install EmoPy # git git clone https://github.com/thoughtworksarts/EmoPy.git cd EmoPy sudo pip3 install -r requirements.txtrun programs.
run
run_all.pyas a testpython3 EmoPy/tests/run_all.pyprog for webcam(under constructing).
cd examples/ python3 fermodel_example_webcam.py
- 投稿日:2021-02-13T11:57:22+09:00
pythonを組み込み関数でデバッグする方法(超個人的メモ)
- 投稿日:2021-02-13T10:51:43+09:00
量子コンピュータによる機械学習に載っている機械学習手法を実装してみました
目次
- はじめに
- ベイジアンネットワーク
- 隠れマルコフモデル
- カーネル密度推定
- k近傍法
- サポートベクターマシーン
- まとめ
はじめに
機械学習の勉強を始めようと参考書を開くと様々な手法が次々と紹介されていて,少々困惑してしまいました.そこでそれぞれの手法を実際に実装しながら調べたりすることで理解を深めようと思いました.正直pythonのライブラリを使った実装なので細かい理論までは追えていませんがそこは追々ということにしておきます.
ベイジアンネットワーク
ベイジアンネットワークとは条件つき独立性を仮定した確率モデルであり,$p(s)$の扱いを平易にする.
細かい理論については置いておいて,この記事では実装することを目標にpgmpyを用いて実装していきます.
問題設定
上記のような問題を考えます.
緑の表での$R=0$は雨が降らない確率を,$R=1$は雨が降る確率を表しています.
青の表ではスプリンクラーが作動しない確率$S=0$と作動する確率$S=1$を$R=0$の時,$R=1$の時で別々で与えたいます.黄色の表に関しても同様です.ベイジアンネットワークの実装
では実際に上記の図をベイジアンネットワークで作成していきます.
Bayesian.py# ライブラリのimport from pgmpy.factors.discrete import TabularCPD from pgmpy.models import BayesianModel from pgmpy.inference import VariableElimination ## ベイジアンネットワークの構造 model = BayesianModel([ # ('親ノード', '子ノード') ('rain', 'sprinkler'), ('rain', 'grass'), ('sprinkler', 'grass'), ]) rain_cpd = TabularCPD( variable='rain', variable_card=2, values=[[.8], [.2]]) sprinkler_cpd = TabularCPD( variable='sprinkler', variable_card=2, values=[[.6, 0.99], [.4, 0.01]], evidence=['rain'], evidence_card=[2]) grass_cpd = TabularCPD( variable='grass', variable_card=2, values=[[1.0, 0.1, 0.2, 0.01], [0.0, 0.9, 0.8, 0.99]], evidence=['rain', 'sprinkler'], evidence_card=[2, 2]) model.add_cpds(rain_cpd, sprinkler_cpd, grass_cpd)ベイジアンネットワークで推論
実装したベイジアンネットワークを使って推論を行ってみます.
ここでは芝生が濡れていないときの雨が降っていない確率と降っている確率を求めます.model_infer = VariableElimination(model) rain0_given_grass1 = model_infer.query(variables=['rain'], evidence={'grass': 0}) print(rain0_sprinkler1_given_grass1)結果は
+---------+-------------+ | rain | phi(rain) | +=========+=============+ | rain(0) | 0.9282 | +---------+-------------+ | rain(1) | 0.0718 | +---------+-------------+となりました.
ここではベイジアンネットワークを作成し,推論を行いましたが,
実際にベイジアンネットワークを推定することは,一般的に難しい問題とされている.
隠れマルコフモデル
隠れマルコフモデルは,「連鎖したイベント」のシーケンスを表すという点でベイジアンネットワークと性質が多少異なるグラフィカルモデルである.
こちらも細かい理論については置いておいて,この記事では実装することを目標にhmmlearnを用いて実装していきます.
モデルの構築
隠れマルコフモデルには三つのパラメータがあります.
- 初期状態確率$\pi$
- 遷移確率$A$
- 出力確率$B$
これらのパラメータは学習で推定することができるが,明示的に指定してモデルを構築することもできる.
hmm1.pyfrom hmmlearn import hmm import numpy as np model = hmm.GaussianHMM(n_components=5, covariance_type='full') # 初期状態確率π(q_iが初期状態である確率) model.startprob_ = np.array([0.1, 0.1, 0.7, 0.0, 0.1]) # 状態遷移確率 model.transmat_ = np.array([[0.9, 0.1, 0.0, 0.0, 0.0], [0.4, 0.3, 0.3, 0.0, 0.0], [0.1, 0.2, 0.4, 0.3, 0.0], [0.0, 0.1, 0.3, 0.3, 0.3], [0.0, 0.0, 0.3, 0.1, 0.6]]) # 出力確率の平均と共分散(正規分布に従うと仮定している) model.means_ = np.array([[1.0, 1.0], [2.0, 2.0], [3.0, 3.0], [4.0, 4.0], [5.0, 5.0]]) model.covars_ = 0.1 * np.tile(np.identity(2), (5, 1, 1))観測系列のサンプルを得ます.
X, Z = model.sample(10) # (観測系列,状態系列) print(X) print(Z)[[2.71618377 2.78799886] [0.68544061 0.98482839] [1.00413618 0.67011749] [1.48194136 0.40049633] [0.99204692 0.56744503] [1.22996837 1.54221408] [0.96063165 0.7236326 ] [1.09050931 1.02022522] [0.62496655 1.79905732] [2.16068752 2.01486085]] [2 0 0 0 0 0 0 0 0 1]モデルの推定
未知のモデルから観測結果$X$が得られたときのモデルのパラメータ推定を行います.
今回は先ほど得られたXを用いてモデルを推定するので先ほど設定したパラメータと近い結果が出ればよしとなります.# 未知のモデルから観測結果xが得られたときのモデルのパラメータ推定 remodel = hmm.GaussianHMM(n_components=5, covariance_type='full', n_iter=100) # 10個じゃ足りないので X, Z = model.sample(100000) remodel.fit(X) print(remodel.transmat_) print(remodel.means_)[[8.62112104e-001 1.40414272e-043 4.53692486e-002 9.25186472e-002 4.32192981e-210] [9.47989464e-002 3.86113456e-001 1.21180890e-002 2.01738550e-001 3.05230958e-001] [7.35799070e-001 1.74156909e-023 6.10442576e-002 2.03156672e-001 5.34486884e-141] [3.78574551e-001 2.95087807e-001 2.57058086e-002 3.00631833e-001 3.48102550e-037] [4.78719535e-072 2.59776988e-001 6.40756512e-040 5.38660770e-002 6.86356935e-001]] [[0.99491185 0.99964309] [2.98617434 2.99500088] [1.08849405 1.04527434] [2.00120936 2.00125902] [4.37461666 4.36637911]]正解に近いパラメータが推定できていることが確認できる.パラメータ内のベクトルの並び順はランダムなので注意.
カーネル密度推定
カーネル密度推定(kernel density estimation)は,統計学において,確率変数の確率密度関数を推定する.
データの作成
今回は使用するデータとして2020年横浜市の最高気温のデータを使用します.
kde.pyimport numpy as np from scipy.stats import gaussian_kde import matplotlib.pyplot as plt # データの読み込み(今回は2020年横浜市の最高気温のデータを使用) f = open('data/Yokohama_tmp.txt', 'r') lines = f.readlines() data = [] for line in lines: data.append(float(line)) # ヒストグラムで表してみます. plt.hist(data, bins=30, range=(6, 37), color='orange') plt.xlabel('temperature') plt.ylabel('days') plt.show()
推定
このデータを用いて推定を行っていきます.
# gaussian_kdeのインスタンスを作成 kde = gaussian_kde(data) # 6〜37で密度推定 estimate = kde(np.linspace(6, 37, num=32), bw_method=0.2![kde.png] # グラフで表示 plt.plot([x for x in range(6, 38)], estimate) plt.xlabel('temperature') plt.ylabel('kde') plt.show()
k近傍法
k近傍法(K-Nearest Neighbor)は,k個の近傍点を囲むある半径を持った一定値のカーネルによるカーネル密度推定として捉えることができる.
つまりは特徴空間において近くにあるk個のオブジェクトのうち最も一般的なクラスに分類します.
kの値が小さいとノイズの影響を受けやすくなり,kの値が大きいと精度が落ちる.実装
分類するデータとしてアヤメの花を使用します.
kを変えながら精度を確認していきます.knn.pyimport matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # アヤメデータセット読み込み from sklearn.datasets import load_iris iris = load_iris() # 特徴量 X = iris.data # 目的変数 Y = iris.target # データ分割 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0) list_knn = [] scores = [] for k in range(1, 31): # K-NN knc = KNeighborsClassifier(n_neighbors=k) knc.fit(X_train, Y_train) # 予測 Y_pred = knc.predict(X_test) score = knc.score(X_test, Y_test) print("[%d] score: {:.2f}".format(score) % k) list_knn.append(k) scores.append(score) # プロット plt.ylim(0.9, 1.0) plt.xlabel("n_neighbors") plt.ylabel("score") plt.plot(list_knn, scores) plt.show()
kが20を超えたあたりから精度が落ちているのがわかります.
サポートベクターマシーン
サポートベクターマシンは,教師あり学習を用いるパターン認識モデルの一つであり,分類や回帰へ適用できる.現在知られている手法の中でも認識性能が優れた学習モデルの一つである.
ここでもsklearnを使用して実装を行っていきます.
実装
今回使用するデータもアヤメの花です.
svm.pyfrom sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.svm import SVC iris = load_iris() # 説明変数 X = iris.data # 目的変数 Y = iris.target # データの分割 X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=0) # モデルを構築 model = SVC(gamma='scale') model.fit(X_train, Y_train) # 予測 print(model.score(X_test, Y_test)) "0.9466666666666667"sklearnを用いて実装するとさっぱりしすぎな気もしますね...
まとめ
それぞれのアルゴリズムが何に用いられるのか.何が難点なのかをまとめてみました.
ベイジアンネットワーク
- 複数の事象間の因果関係をグラフ構造で表現することができる.
- 既知の情報を元に未知の情報を確率的に知ることができる.
- ベイジアンネットワークの推定は一般的に難しい.
隠れマルコフモデル
- 時系列のパターン認識に用いられる.(株価変動の予測,音声認識など)
- 観測された記号系列の背後に存在する状態の遷移系列を推測する.
- ニューラルネットワークに隠れマルコフモデルの役割が奪われつつあるが,出力結果の導出過程がわかるという利点もある.
カーネル密度推定
- いくつかの標本から全体の分布を推定することができる.
k近傍法
- クラス判別用の手法.
- パラメータkに結果が左右される.
サポートベクターマシーン
- パターン認識に用いられる.
- 分類や回帰に用いられる.
- 2つのグループに分けるのには優れているが3つ以上のグループに分けるものにはそのまま適用できず計算量が多くなってしまう.
軽くまとめてみました.それぞれの手法がどのような手法であるかに加えてどのような場面に適用できて,どのような利点があるのかを知っておくのは良いことだと思います.
コードはこちらに掲載しています.Github
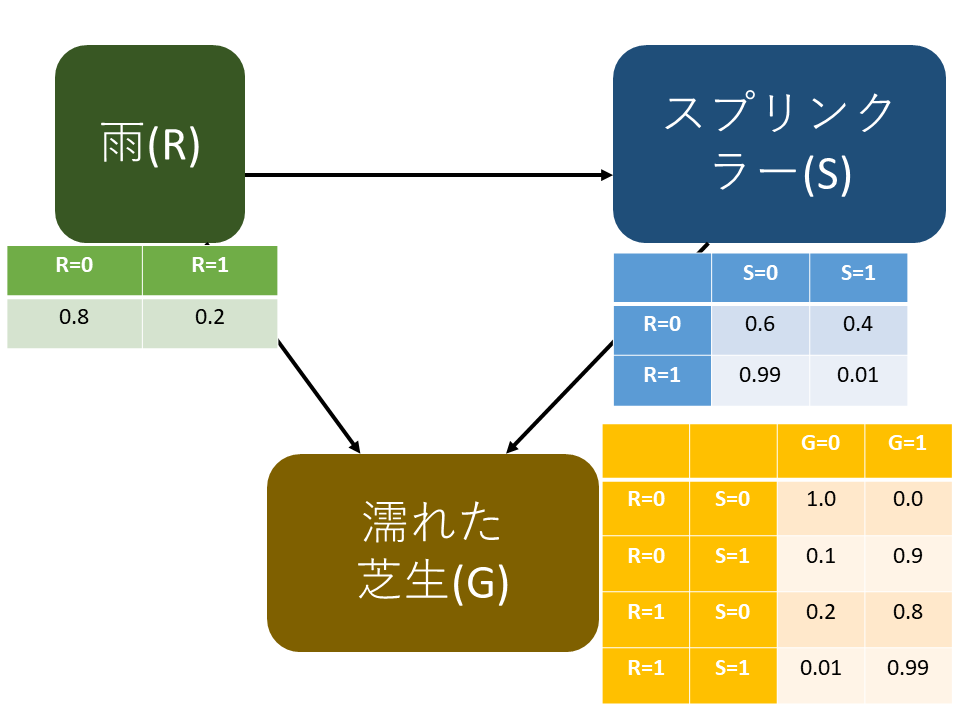
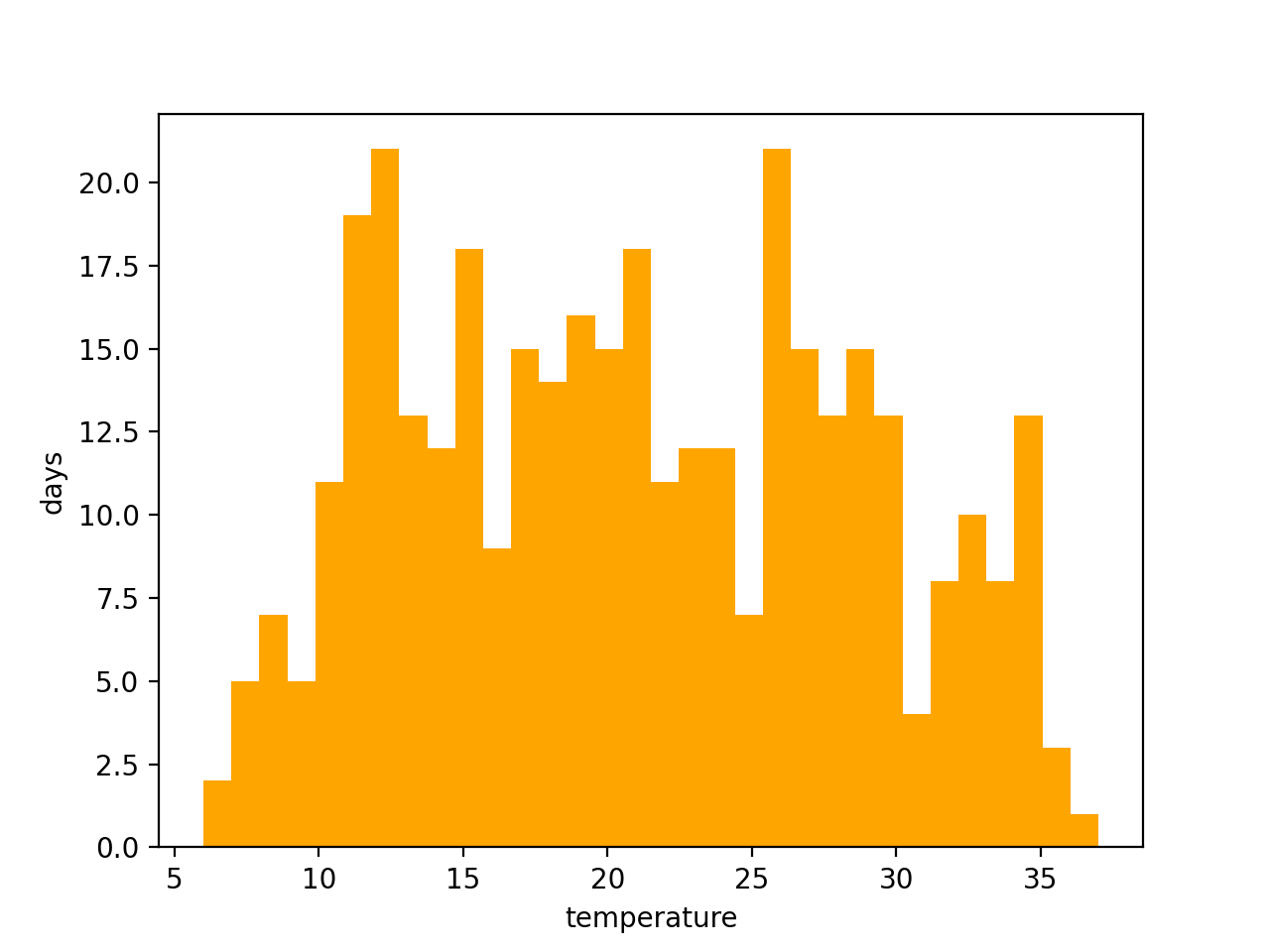
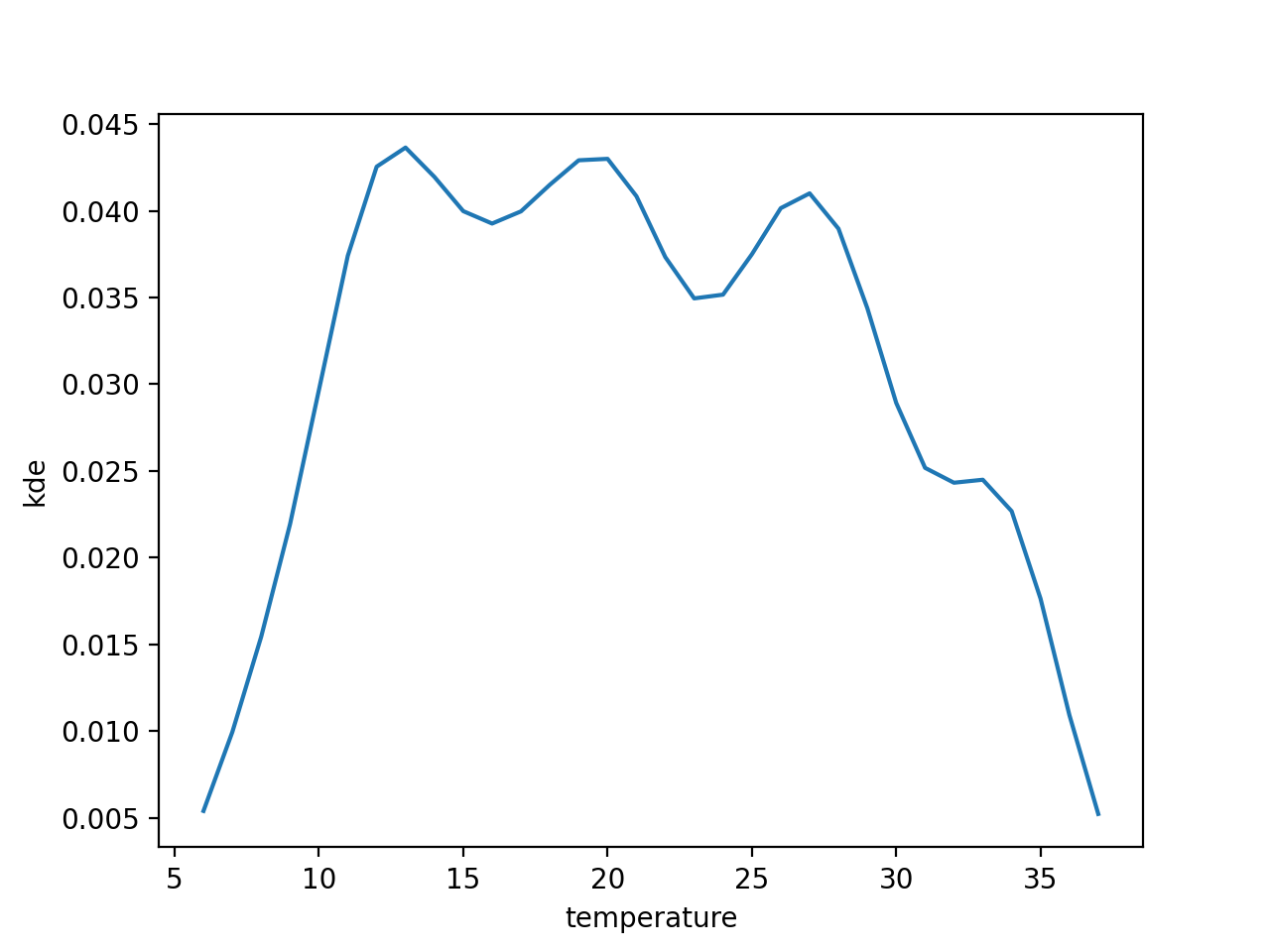
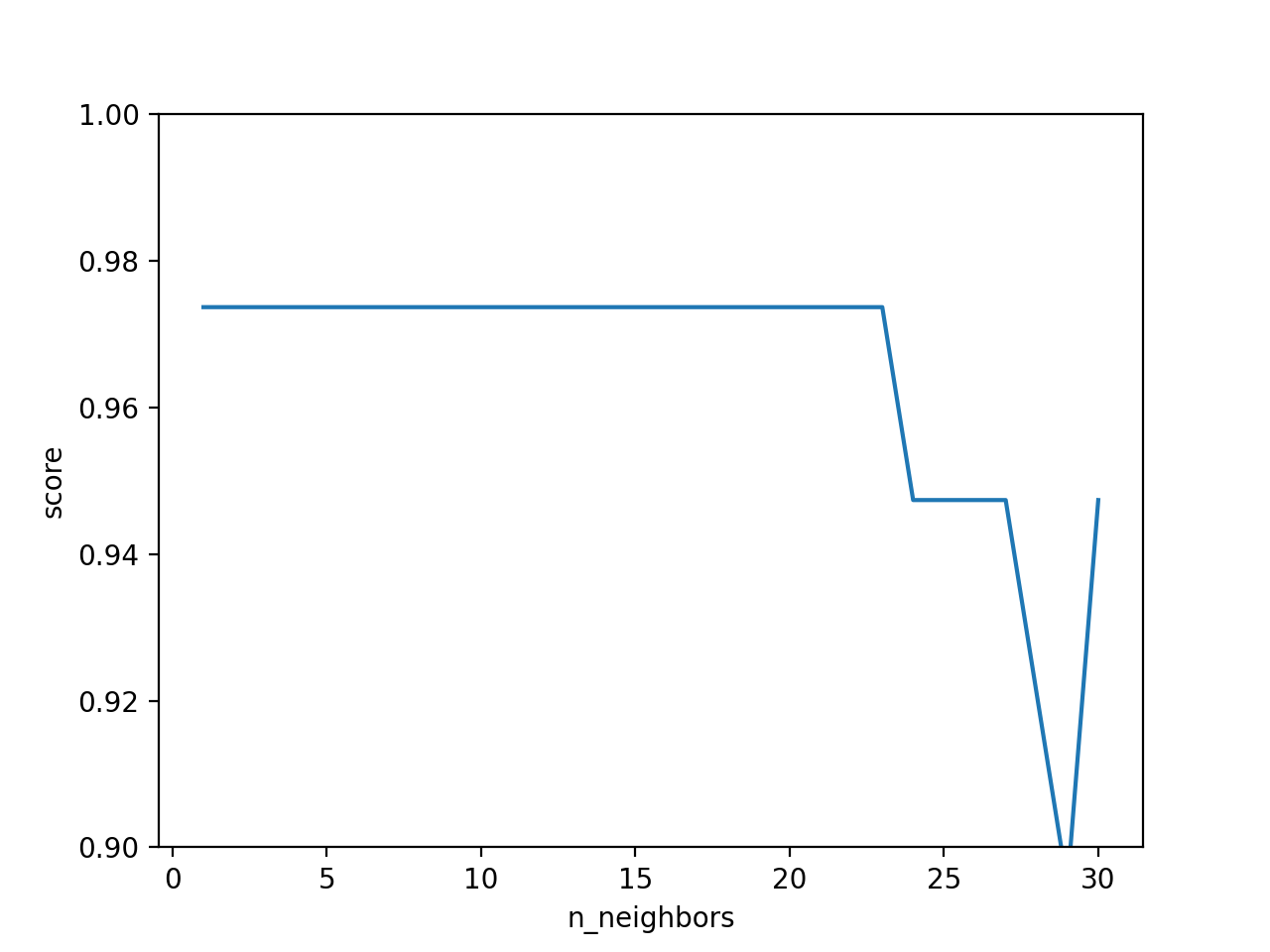
- 投稿日:2021-02-13T09:27:43+09:00
【VSCode】black : pythonのfomatterを導入
背景
fomatterで有名なのがC++ならc-lang, pythonであればblack
いつも使ってるblackのインストール方法をメモinstall
blackをインストール
pip install blackpythonのextensionをinstall
gedit ~/.config/Code/User/settings.jsonで以下の2行を追加する
"python.formatting.provider": "black", "editor.formatOnSave": true,結論
・formatterあると便利!
参考文献
VSCode: Using Black to automatically format Python
https://dev.to/adamlombard/how-to-use-the-black-python-code-formatter-in-vscode-3lo0
