- 投稿日:2021-02-13T23:03:56+09:00
【AWS】未経験からAWS認定6冠達成までのまとめ
SIer2年目、オンプレインフラ設計(パブクラ未経験)者が、半年でAWS認定6冠できるまでの道のりをつらつらと書いていきます。
過去合格記は以下をご覧ください。
【AWS】クラウドプラクティショナー(CLF)合格記
【AWS】ソリューションアーキテクト-アソシエイト(SAA)合格記
【AWS】SysOpsアドミニストレーター-アソシエイト(SOA)合格記
【AWS】Developer-アソシエイト(DVA)合格記
【AWS】ソリューションアーキテクト – プロフェッショナル(SAP)合格記
【AWS】DevOps エンジニア – プロフェッショナル(DOP)合格記取得資格
まずは、各試験について取得日と点数をまとめます。
こう見るとほとんどギリギリで取ってましたね。。。ほんと、よく取れました(笑)
日付 資格 点数 2020-06-27 AWS Certified Cloud Practitioner(CLF-C01) 755 2020-07-26 AWS Certified Solutions Architect - Associate(SAA-C02) 725 2020-08-10 AWS Certified SysOps Administrator - Associate(SOA-C01) 731 2020-08-29 AWS Certified Developer - Associate(DVA-C01) 829 2020-09-11 AWS Certified Solutions Architect - Professional(SAP-C01) 819 2020-09-26 AWS Certified DevOps Engineer - Professional(DOP-C01) 762 全体的な感想をまず述べておくと、全体を通して同じ範囲が深さが変わって出題されるので、SAPやDOPを目指すのであれば、連続して学習することをおススメします。
あとは、各試験で主に意識するべきポイントが変わるので、その部分を押さえておけば問題ないと思います。
基本的にベストプラクティスがあり、その次にコスト効率なのか耐障害性なのかといった要件が入ってきます。まずは、ベストプラクティスを理解するところから始めましょう。勉強方法
勉強方法については、いろいろな方法があると思います。ご自身に合った方法で続けられるものを選んでください。
基本的には以下の9つの組み合わせかなと思います。
- AWS公式のホワイトペーパーを読み込む。
- AWS公式のBlackBeltを読み込む。
- 模擬問題集を解く。
- Udemyで問題集を解く。
- Web問題集で問題を解く。
- 無料ハンズオンを受講する。(サービスには課金されるので注意)
- 公式研修を受講する。(高額ですので余裕があればぜひ)
- AWS認定公式動画を見る。
- 先人の知恵を授かる。
1と2はAWSが公式に出しているベストプラクティス集のようなものです。これだけで合格したという方もいらっしゃいます。(私には無理でした。。。)
3はAWS公式模擬試験です。問題数は少ないですが、実際の試験のレベル感や内容を把握するのには十分です。回答が表示されませんので、各問題をスクショしてあとから見直しができるようしておきましょう。
4と5は問題を実際に解いて理解していけるので、試験の練習も兼ねてできるので良いです。
4のUdemyは試験1回分通して問題を解く必要があり、私のように一問ずつ確認して進めたい人には合わないかもしれません。
5は過去記事でも紹介している、AWS WEB問題集で学習しようを利用しました。こちらは1問ごとに解説を確認でき、1セット7問なので隙間時間に気軽に勉強できました。(こちらのサイト関係者ではありませんので、ご安心ください笑)あとは実際にサービスに触れるという点で、6と7を活用してみてください。特に6はかなり優秀で受講自体は無料です。ただし、構築したサービスには課金されますので、ご注意ください。受講が終わり次第サービスを止めることを忘れないでください、結構高額になったりします。。。
8の動画もおススメです。各動画に数問ずつ問題もありますので、これだけでも対策としてはかなりのレベルまで上げられると思います。
最後に数多の先人が受験記録をアップしていますので、その方々の記事を読むこともどんな点につまずいたのかなどがわかるので良いです。
様々な方法がありますので、ご自身に合った方法で頑張ってください!
最後に
AWSは頻繁にサービスが新しくなり、試験のベストプラクティスと今のベストプラクティスが異なることがありますので、試験がいつのものなのかを把握しておくことも大事です。
試験自体は問題文から要件を汲み取って、選択肢の中で満たすものを選択するので、今と違うということでパニックならないように注意してください。ためになるようなならないような内容になってしまいました。。。ここまで読んでいただきありがとうございます。
12冠目指して頑張ろうと思います。無事取得出来次第、アップしていきたいと思います。
- 投稿日:2021-02-13T22:36:29+09:00
AWS 認定クラウドプラクティショナーに合格したお話
はじめに
私が試験を受ける際に使用した教材や試験のポイントを簡潔にまとめてみました。
主な対象者
・クラウドプラクティショナーを受験する方
・一度受験したが合格できなかった方使用した教材
・AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
https://www.amazon.co.jp/AWS%E8%AA%8D%E5%AE%9A%E8%B3%87%E6%A0%BC%E8%A9%A6%E9%A8%93%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88-AWS%E8%AA%8D%E5%AE%9A-%E3%82%AF%E3%83%A9%E3%82%A6%E3%83%89%E3%83%97%E3%83%A9%E3%82%AF%E3%83%86%E3%82%A3%E3%82%B7%E3%83%A7%E3%83%8A%E3%83%BC-%E5%B1%B1%E4%B8%8B-%E5%85%89%E6%B4%8B/dp/4797397403/ref=sr_1_1?adgrpid=112883073061&dchild=1&hvadid=492569283323&hvdev=c&hvqmt=b&hvtargid=kwd-574411356434&hydadcr=26606_10279519&jp-ad-ap=0&keywords=aws+%E3%83%97%E3%83%A9%E3%82%AF%E3%83%86%E3%82%A3%E3%82%B7%E3%83%A7%E3%83%8A%E3%83%BC&qid=1613221735&sr=8-1&tag=yahhyd-22
・この問題だけで合格可能!AWS認定クラウドプラクテショナー模擬試験問題集(Udemy)やったこと
・まずは上記の教材を一読して全体の概要を掴み、サービスの名前やアーキテクチャの概要を理解していきました。
・次にUdemyの模擬試験問題集を正答率80%を超えるまで繰り返し解きました。(平均して3回ずつくらい)
・模擬試験を解き終わったあともう一度教材を読み直し試験に望みました。試験で意識するべきポイント!!!
ここからが重要なのですが試験を受ける上で抑えておいたほうが良いポイントを下記に示します。
- AWSの責任範囲とユーザーの責任範囲の違いについて(OSのアップデートは誰がやるのかなど)
- EC2インスタンスの特徴(リザーブド・オンデマンド)
- RDSの利点(→結構でますしっかり抑えましょう!)
- CloudWatchとCloudTrailとCloudFrontは出ると思います。
- ベーシックプラン、開発者、エンタープライズプランの違いを理解する。(ベーシックではできなくて開発者ではできることなど)
- クラウドアーキテクチャの設計原理
- Well-Architectedフレームワーク(信頼性の柱とは何かなど)
- IAMの理解
- クラウドのメリット(迅速に対応できるなど)
- アベイラビリティゾーンとエッジロケーションの違いについて
- コスト見積もりの違いについて
- アジリティとは何かについて
- シングルサインオンのサービスについて
などなどざっとポイントを列挙してみました。
他にも教材に出てくるサービスの概要は理解しておきましょう。
このサービスは〇〇をすると言えるまで覚えましょう。以上、クラウドプラクティショナー試験を受験する上でのポイントをまとめてみました。ご参考までに。
- 投稿日:2021-02-13T22:21:14+09:00
【AWS】DevOps エンジニア – プロフェッショナル(DOP)合格記
はじめに
AWS 認定DevOps エンジニア – プロフェッショナル(DOP)に合格した(2020-09-26)ので、合格までの道のりを残しておこうと思います。
CLF合格記は以下をご覧ください。
【AWS】クラウドプラクティショナー(CLF)合格記
SAA合格記は以下をご覧ください。
【AWS】ソリューションアーキテクト-アソシエイト(SAA)合格記
SOA合格記は以下をご覧ください。
【AWS】SysOpsアドミニストレーター-アソシエイト(SOA)合格記
DVA合格記は以下をご覧ください。
【AWS】Developer-アソシエイト(DVA)合格記
SAP合格記は以下をご覧ください。
【AWS】ソリューションアーキテクト – プロフェッショナル(SAP)合格記DOPはSAPの合格後すぐに勉強を始めました。
AWS認定試験は範囲が被る部分が多いので、複数資格取得を目指すなら、継続して勉強することをおススメします。DOPは試験の名の通りDevOpsがメインになります。
DevOpsとは、「Development」と「Operations」つまり、「開発」と「運用」をより協調性をもって、迅速にビジネスの価値を高めながらエンドユーザーへシステムを提供するという概念です。
なので、開発や運用の自動化や効率化といった部分が多く出題されます。What's SAP?
まずは、DOP試験について
AWS 認定 DevOps エンジニア – プロフェッショナル上記サイトによると、認定によって検証される能力は以下のようです。
- AWS で継続的デリバリーのシステムと手法を実装して管理する
- セキュリティコントロール、ガバナンスプロセス、コンプライアンス検証を実装し、自動化する
- AWS でのモニタリング、メトリクス、ログ記録システムを定義し、デプロイする
- 高可用性、スケーラビリティ、自己修復機能を備えたシステムを AWS プラットフォームで実装する
- 運用プロセスを自動化するためのツールの設計、管理、維持を行う
開発経験やIaC経験などが推奨されていますが、私は何も経験していません。
AWSとして推奨しているDevOpsに関する各サービスのベストプラクティスとパターンに合った選択が理解できるようにしましょう。試験に向けて
基本的にはSAAと同じ手法をとっていきました。(研修への参加はしていません。)
問題⇒解説⇒BlackBelt⇒問題⇒・・・の流れは変わりません。
ただし、今まで以上に開発・運用までの効率化や自動化の手法(構成)を意識して学習しました。公式サンプル問題
これはCLFと変わらず事前に受けて現状のレベルの確認をします。
他の試験を通して勉強してきたので、私は80%ほどの出来でした。ホワイトペーパーを読む
CLFと同じくホワイトペーパーを読みました。
Black Beltを読む
こちらもCLFと同じくBlack Beltを読みました。
問題を解く
こちらのサイトは一問ごとに解説が表示され、都度確認ができ、BlackBeltやホワイトペーパーへのリンクもあるので、勉強しやすかったです。
個人のハンズオンでは実践できる範囲が限られているので、机上での学習がメインになります。
問題文の構成図を素早くイメージして、最適解を導く訓練をしましょう。
DOPはさらに自動化ツールや運用効率化をメインに出題されるので、CodeシリーズやElasticSerchなどをメインに学習することをお勧めします。
というか、ほとんどこのあたりの出題ですので、ここを完璧にすると、安心して試験に向かえます。試験当日
上記対策を計2週間(延べ20時間程度)行い、試験に臨みました。
結果は、762点(720点以上で合格)で合格でした。
感想
SAPを受けた後なので、問題分の長さには困りませんでしたが、インシデントへの対応やセキュリティなどの管理ポリシーが難しかった印象です。
やはり、CodeシリーズやElasticシリーズが多かったです。デプロイ方法の最適解も聞かれたりしましたので、そのあたりは詳しく勉強しておいた方が良いです。(BeanstalkとCodeDeploy、OpsWorksの違いや、All at onceとRolling with an additional batch等々)最後まで読んでいただきありがとうございます。
- 投稿日:2021-02-13T21:44:07+09:00
【AWS】認定ソリューションアーキテクト-アソシエイト-受験記録
前回クラウドプラクティショナーを受験してから、
次なる目標としたのはみんな大好きソリューションアーキテクト-アソシエイト-です。受験の際に同意した受験者行動規範により、試験内容の開示、共有は禁止されていますので、今回もあくまで試験に向けて行った準備とか感想とかを記していこうと思います。
本題
今回の試験も無事に一発合格しております。
スコアは753でしたので、余裕を持っての合格と言う感じではなかったですが。
準備期間はちょうど4週間、学習ペースは土日は3~5時間、平日は仕事が終わった後に1時間くらい。教材も前回と変わらず、安定の問題集をゴリゴリ解きまくるスタイルで。
書籍
・AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版
Udemy
・これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
その他
・AWS WEB問題集で学習しよう書籍はお馴染みAWS認定資格試験テキストですが、改訂第2版がちょうど発売されるタイミングだったので購入しました。SAA-C02に対応した内容も含んでいるようではありますが、これだけで完結と言う事ではなく、概要を掴んで各サービスの理解を深めるのは自分でやってねと言う書き方だったかなと思います。書籍ではあっさり書かれているサービスでも公式資料などを見て、深く理解しておく必要があると思います。
Udemyは模試を1、2周だけ。気になるサービスのハンズオンは少しやりましたが、サービスを起動して試運転する程度の内容なので、効率的に試験対策したいなら全部をやる必要はないかなと思います。動かすなら、実際にサービス組んでみるくらいやらないと意味ないなあと個人的には思います。
一番世話になったのはWEB問題集ですね。
SAAは問題文が長い傾向にあるので、数をこなすにはかなりの忍耐力が必要になりますが、腐らずガンガン解いて、正解も不正解も解説をしっかり読み、サービスの理解を深めるのが重要です。数をこなせば、サービス毎の長所短所が把握出来て、ユースケースのパターンもある程度想像出来るようになりますので、このサービスならこう言う問題が作れるな、みたいな感じで自分で問題を考えられるくらいになると自身がつくかなと。
まあ、出題範囲が広いんで、網羅するのはなかなか難しいんですけどね。
今回あまり点が伸びなかったのは、問題集を過信し過ぎたのが要因かなと思います。新しく試験範囲になった新サービスの理解が明らかに足りなかったです。試験は今回もピアソンVUEですが、近所のテストセンターで予約が取れなかったので、
自宅からはちょっと遠目のテストセンターで受験しました。運営企業は前回とは異なるようでしたが、段取りはほとんど変わりませんでした。まとめ
ビッグデータを扱うようなサービスは実際に使ってみるという事はないかもしれないですが、
ストレージ系やサーバレスなコンピューティング系のサービスは個人アプリとかで使ってみながらこれからも理解を深めて行こうかなと思いました。AWSは奥が深い・・・。一先ず合格出来て一安心ですが、アソシエイト資格は是非網羅したいので、
次に受けるSysOpsアドミニストレーターの勉強を早速始めたいと思います。

- 投稿日:2021-02-13T21:15:43+09:00
CloudWatchEventsからECS on Fargateのタスクを定期的に実行しつつ環境変数を上書きする方法
バージョン情報
$ terraform version Terraform v0.14.6 + provider registry.terraform.io/hashicorp/aws v3.27.0結果はこちら
resource "aws_cloudwatch_event_rule" "cwevent_rule" { name = ${好きな名前} schedule_expression = "cron(%d 21 * * ? *), # JST cron(%d 6 * * ? *)" # schedule_expression = "rate(1 minute)" is_enabled = true } resource "aws_cloudwatch_event_target" "cwevent_target" { arn = ${ECSクラスターのARN} rule = aws_cloudwatch_event_rule.cwevent_rule.name role_arn = aws_iam_role.event_bridge.arn input = <<EOL { "containerOverrides": [ { "name": "${上書きしたいコンテナのname}", "environment": [ { "name": "HOGEFUGE", "value": "hogefuge" } ] } ] } EOL ecs_target { launch_type = "FARGATE" platform_version = "1.4.0" task_count = 1 task_definition_arn = ${起動したいtask_definitionのARN} # リビジョン指定部分をsubstr()とかで削れば常にlatestで動く network_configuration { assign_public_ip = false subnets = ${タスクを動かしたいサブネットID} security_groups = [${タスクにアタッチしたいSGのID}] } } } data "aws_iam_policy_document" "event_bridge" { statement { effect = "Allow" principals { identifiers = ["events.amazonaws.com"] type = "Service" } actions = ["sts:AssumeRole"] } } data "aws_iam_policy_document" "event_bridge" { statement { effect = "Allow" actions = ["ecs:RunTask"] resources = ["*"] } statement { effect = "Allow" actions = ["iam:PassRole"] resources = ["*"] condition { test = "StringLike" variable = "iam:PassedToService" values = ["ecs-tasks.amazonaws.com"] } } } resource "aws_iam_role_policy" "event_bridge" { policy = data.aws_iam_policy_document.event_bridge.json role = aws_iam_role.event_bridge.name } resource "aws_iam_role" "event_bridge" { name = ${好きな名前} assume_role_policy = data.aws_iam_policy_document.event_bridge.json }なんでこんなことをしたか
- embulkをECSを利用し定期的に実行したかった
- ただし、すべてのテーブルを全部同時に動かすと負荷が怖いのでテーブル単位で動かしたかった
- でもテーブルごとにdockerイメージやECSタスクを作るのはめんどくさい
- ECSでコンテナ起動する時に環境変数を注入するがそのときの環境変数をCW Events側で上書きできればECSサービス、ECSタスク、Dockerイメージ、それぞれ1つだけ用意すれば動かせることに気がついた
「CloudWatch Events」?「Amazon EventBridge」?
- CW Eventsは名前が変わるっぽいのでドキュメント探すときは注意が必要かも?
- Terraform側はどう対応するのか気になる
https://aws.amazon.com/jp/eventbridge/faqs/
Q: Amazon EventBridge は CloudWatch Events とどのように関連していますか?
Amazon EventBridge は、CloudWatch Events をベースに構築された、CloudWatch Events を拡張するサービスです。Amazon EventBridge では、CloudWatch Events と同じサービス API とエンドポイント、同じ基盤となるサービスインフラストラクチャを使用します。これまで CloudWatch Events を使用しているお客様にとっては、何も変わることはありません。これまでと同じ API、CloudFormation テンプレート、コンソールを引き続き使用できます。お客様からの報告によれば、CloudWatch Events はイベント駆動型アーキテクチャを構築するための理想的なサービスです。そのため、AWS ではお客様が独自のアプリケーションとサードパーティーの SaaS アプリケーションからデータを接続できるようにする新しい機能を構築しました。AWS は、この機能を CloudWatch サービス内にとどめておくのではなく、Amazon EventBridge という新しい名前でリリースしました。この機能が、CloudWatch Events が開発された目的であるモニタリングユースケースを超えた拡張であることを示すためです。
参考資料
- 投稿日:2021-02-13T21:05:59+09:00
AWS Client VPNをAWS SSOで認証できるようにする途中で詰まったところを書く
各種ログファイルの出力先
MacOS のトラブルシューティング - AWS Client VPN :
https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-user/macos-troubleshooting.html/Users/username/.config/AWSVPNClient/logs アプリケーションログ: アプリケーションに関する情報が含まれます。これらのログには「aws_vpn_client_」が前に付けられます。 OpenVPN ログ: OpenVPN プロセスに関する情報が含まれます。これらのログには「ovpn_aws_vpn_client_」が前に付けられます。 /tmp/AcvcHelperErrLog.txt /tmp/AcvcHelperOutLog.txtTunnelBlickなどのOpenVPNクライアントで読み込めない。もしくは接続エラーになる
現象
- TunnelBlickで出てきたエラー
"Unrecognized option or missing or extra parameter(s)". このエラーは OpenVPN サーバから送られた OpenVPN 設定に以下の問題が含まれていることを示しています: • スペルが間違っている • パラメータが不足している、余計なパラメータが指定されている •このバージョンの OpenVPN では実装されていないオプションです(おそらく新しいオプションでまだサポートされていないか、古いオプションで既に削除されているもの)。"VPN の詳細" ウインドウの "設定" タブにある "OpenVPN バージョン" で、この設定で使用する OpenVPN のバージョンを選択できます。 詳細は "VPN の詳細" ウインドウの "ログ" タブに出力されているログを確認してください。解決策
クライアント VPN エンドポイントが SAML ベースのフェデレーション認証を使用するように設定されている場合は、AWS が提供するクライアントを使用して接続する必要があります。
- ユーザーガイド > AWS Client VPN > MacOS
- https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-user/macos.html発生した環境
Tunnelblick 3.8.3 (build 5520)原因
- SAMLベースのフェデレーション認証を使用するクライアント VPN エンドポイントからクライアント設定をダウンロードしたovpnファイルには以下のようなオプション指定が入っている
〜大体110行目あたり〜 〜前略〜 auth-user-pass auth-federate ←問題の部分 auth-retry interact auth-nocache reneg-sec 0
- OpenVPN2.4時点では「auth-federate」と言うオプションは存在しないのでエラーとなる
ダウンロードしたプロファイルをAWS Client VPNで読み込み接続をしても、ログイン画面が開かず、ぐるぐる回ったまま動かなくなってしまう。
原因
Amazonから提供された クライアントVPN設定ファイルに認証機関 (CA) チェーン情報がないため、検証に失敗します。
- Windows のトラブルシューティング - AWS Client VPN :
- https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-user/windows-troubleshooting.html
- ※Windows向け記事だがMacOSでも当てはまる解決策
- ダウンロードしたプロファイルを開きセクションの3番目の証明書を置き換えて、設定ファイルをインポートしなおしてみる
- 置き換え先の内容は以下URLに記載されている
- Windows のトラブルシューティング - AWS Client VPN :
- ※Windows向け記事だがMacOSでも当てはまる
- https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-user/windows-troubleshooting.html
反省
- 全部ドキュメントに書いてあることでした。。。。
- サポートの人ごめんなさい。。。
- 投稿日:2021-02-13T19:12:49+09:00
laravel6でS3に画像アップロード&削除
前提
参考記事のコード =
PostsController.php
実装コード =exampleController.phpS3に画像をアップロードする方法
LaravelでAWS S3へ画像をアップロードする
こちらの記事を参考にして無事S3に画像を保存できましたS3の画像の削除
削除ボタンを押すと、このコントローラが走るようにルーティング
exampleController.phppublic function delete(Request $request) { $image = $request->image_path; $s3_delete = Storage::disk('s3')->delete($image); $db_delete = Post::where('image',$image)->delete(); return redirect('hogehoge'); }これでDBとS3から画像を削除!
とおもいきや、Dbからは削除されるのにS3からは削除できていないS3から削除できない原因
PostsController.php$post->image_path = Storage::disk('s3')->url($path);参考記事ではこのように、パスにURL関数を使いそれをDBに保存しているので、DBにはURLを含んだパスが保存されています。
S3は
vi3kAwK0z0X19XU3LWcz63101t0rYilRHiWG9MmC.jpgDBは
https://example.s3-ap-northeast-1.amazonaws.com/myprefix/vi3kAwK0z0X19XU3LWcz63101t0rYilRHiWG9MmC.jpg
のように保存されているため、
exampleController.phpの$imageはこうなっています。exampleController.php$image = https://example.s3-ap-northeast-1.amazonaws.com/myprefix/vi3kAwK0z0X19XU3LWcz63101t0rYilRHiWG9MmC.jpg;なのでS3に「そんなものないよ!」と言われているので削除ができないということでした。
解決策
参考記事をこのように変更します。
PostsController.phppublic function create(Request $request) { $post = new Post; $form = $request->all(); //s3アップロード開始 $image = $request->file('image'); // バケットの`myprefix`フォルダへアップロード $path = Storage::disk('s3')->putFile('myprefix', $image, 'public'); // アップロードした画像のフルパスを取得 + $post->image_path = $path; //追加 - $post->image_path = Storage::disk('s3')->url($path); //削除 $post->save(); return redirect('posts/create'); }こうすることで、S3とDBに保存される名前を一致できたので
exampleController.phpを内容は変更せず削除ができるようになりました。View
srcに
https://example.s3-ap-northeast-1.amazonaws.com/を追加すると表示することができました!<img src="https://example.s3-ap-northeast-1.amazonaws.com/{{ $my_image['image'] }}" >参考
- 投稿日:2021-02-13T17:49:30+09:00
CloudWatchを仮想マシンに導入してみる
環境
OS:CentOS7
仮想マシン:Virtual Box方法
CloudWatchを利用するには、オンプレの場合はEC2インスタンスの場合と違ってCloudWatchエージェントをインストールする必要があります。
しかし、エージェントをインストールするだけでは不十分で、専用のIAMユーザーを作成し、サーバーに情報を設定しなければなりません。手順
CentOSにrootユーザーでログインする。
CloudWatch エージェントパッケージをダウンロード
CloudWatch エージェントパッケージをダウンロードします。
wget https://s3.amazonaws.com/amazoncloudwatch-agent/centos/amd64/latest/amazon-cloudwatch-agent.rpmパッケージの署名を確認します。
#公開鍵のダウンロード wget https://s3.amazonaws.com/amazoncloudwatch-agent/assets/amazon-cloudwatch-agent.gpg #公開鍵をインポート gpg --import amazon-cloudwatch-agent.gpg #結果 gpg: 鍵3B789C72: 公開鍵"Amazon CloudWatch Agent"をインポートしました gpg: 処理数の合計: 1 gpg: インポート: 1 (RSA: 1) #この場合キー値は3B789C72 #フィンガープリントの確認 #引数にキー値をとる gpg --fingerprint 3B789C72 #結果 pub 2048R/3B789C72 2017-11-14 フィンガー・プリント = 9376 16F3 450B 7D80 6CBD 9725 D581 6730 3B78 9C72 uid Amazon CloudWatch Agent #パッケージ署名ファイルのダウンロード wget https://s3.amazonaws.com/amazoncloudwatch-agent/centos/amd64/latest/amazon-cloudwatch-agent.rpm.sig #署名の確認 gpg --verify amazon-cloudwatch-agent.rpm.sig amazon-cloudwatch-agent.rpm #結果 gpg: 2021年01月14日 07時00分29秒 JSTにRSA鍵ID 3B789C72で施された署名 gpg: "Amazon CloudWatch Agent"からの正しい署名 gpg: *警告*: この鍵は信用できる署名で証明されていません! gpg: この署名が所有者のものかどうかの検証手段がありません。 主鍵のフィンガー・プリント: 9376 16F3 450B 7D80 6CBD 9725 D581 6730 3B78 9C72 #このフィンガープリントと先のフィンガープリントが一致しているのでOKですインストール
rpm -Uvh ./amazon-cloudwatch-agent.rpmIAMユーザーの作成
次にIAMユーザーを作成します。
IAMコンソールを開きます。
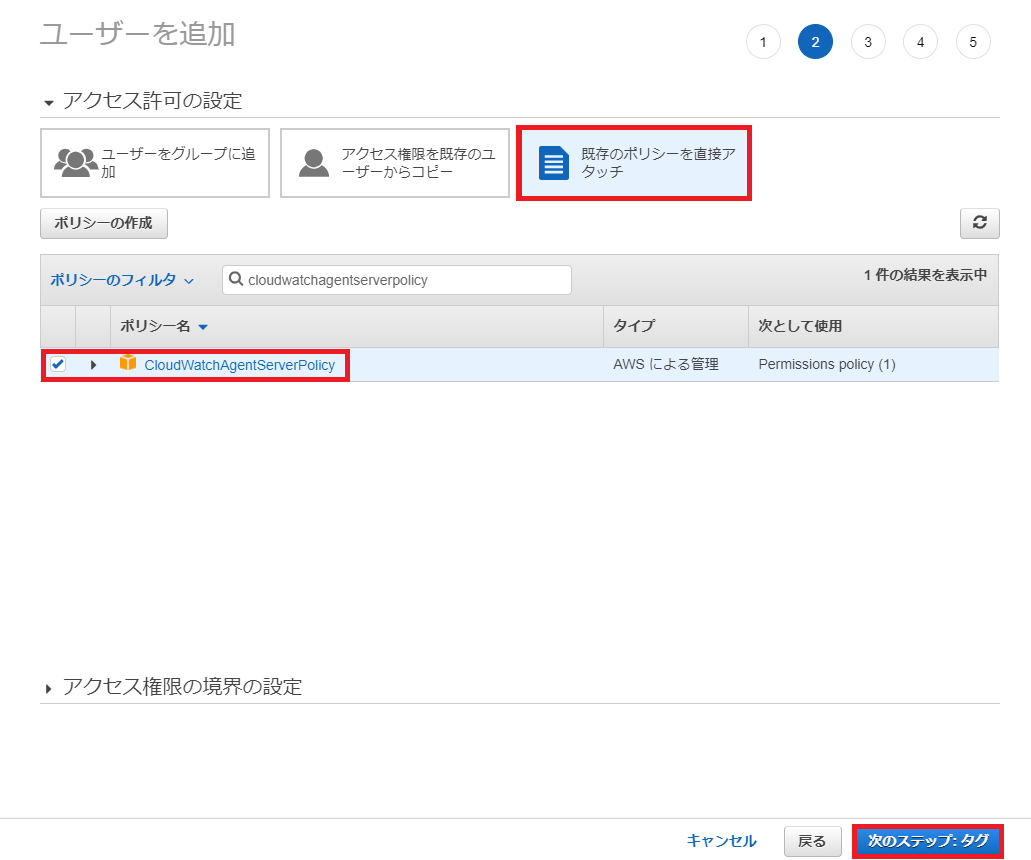
ユーザーを追加をクリックします。
今回ユーザー名は「VBox_CloudWatch」とします。
プログラムによるアクセス、次のステップ:アクセス権限の順に選択します。
既存のポリシーを直接アタッチを選択します。
CloudWatchAgentServerPolicyを選択します。
タグはそのままで次へ
適切なポリシーがリストされていることを確認し、
ユーザーの作成を選択します。
csvファイルをダウンロードし、閉じます。
AWS CLIのインストール
IAM情報をコマンドラインで入力するために、まずはAWS CLIをインストールする必要があります。
#AWS CLIのインストールファイルをダウンロード curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64-2.0.30.zip" -o "awscliv2.zip" #インストーラを解凍 unzip awscliv2.zip #インストールプログラムの実行 ./aws/install #インストールの確認 aws --version #結果 aws-cli/2.0.30 Python/3.7.3 Linux/3.10.0-1160.15.2.el7.x86_64 botocore/2.0.0dev34IAM認証情報とAWSリージョンの指定
#認証情報の設定 aws configure --profile AmazonCloudWatchAgent #対話形式で設定 AWS Access Key ID [None]: #ダウンロードしたcsvファイルを参照し入力 AWS Secret Access Key [None]: # 同上 Default region name [None]: ap-northeast-1 Default output format [None]: jsonCloudWatch エージェントを起動
ウィザードを使用して CloudWatch エージェント設定ファイルを作成します。
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard #対話形式で入力 ============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows 3. darwin default choice: [1]: Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [2]: 2 Please make sure the credentials and region set correctly on your hosts. Refer to http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html Which user are you planning to run the agent? 1. root 2. cwagent 3. others default choice: [1]: 1 Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: 2 Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]: 2 Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: 1 Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: 1 Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: 4 Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: 1 Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "metrics": { "metrics_collected": { "cpu": { "measurement": [ "cpu_usage_idle" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": true }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "net": { "measurement": [ "bytes_sent", "bytes_recv", "packets_sent", "packets_recv" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: 1 Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]: 2 Do you want to monitor any log files? 1. yes 2. no default choice: [1]: 1 Log file path: /var/log/messages Log group name: default choice: [messages] /var/log/messages Log stream name: default choice: [{hostname}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "/var/log/messages", "log_stream_name": "{hostname}" } ] } } }, "metrics": { "metrics_collected": { "cpu": { "measurement": [ "cpu_usage_idle" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": true }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "net": { "measurement": [ "bytes_sent", "bytes_recv", "packets_sent", "packets_recv" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 2 Program exits now./opt/aws/amazon-cloudwatch-agent/bin/config.jsonに設定ファイルが保存されます。
確認します。ls -l /opt/aws/amazon-cloudwatch-agent/bin/config.json #結果 -rwxr-xr-x. 1 root root 1258 2月 13 16:19 /opt/aws/amazon-cloudwatch-agent/bin/config.jsonエージェントの起動
#エージェントの起動 /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m onPremise -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json #確認 systemctl status amazon-cloudwatch-agent.service -l #結果 ● amazon-cloudwatch-agent.service - Amazon CloudWatch Agent Loaded: loaded (/etc/systemd/system/amazon-cloudwatch-agent.service; enabled; vendor preset: disabled) Active: active (running) since 土 2021-02-13 16:22:47 JST; 3min 25s ago Main PID: 4406 (amazon-cloudwat) Tasks: 7 CGroup: /system.slice/amazon-cloudwatch-agent.service └─4406 /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent -config /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml -envconfig /opt/aws/amazon-cloudwatch-agent/etc/env-config.json -pidfile /opt/aws/amazon-cloudwatch-agent/var/amazon-cloudwatch-agent.pidCloudWatchエージェントが無事に起動されたことが確認されました。
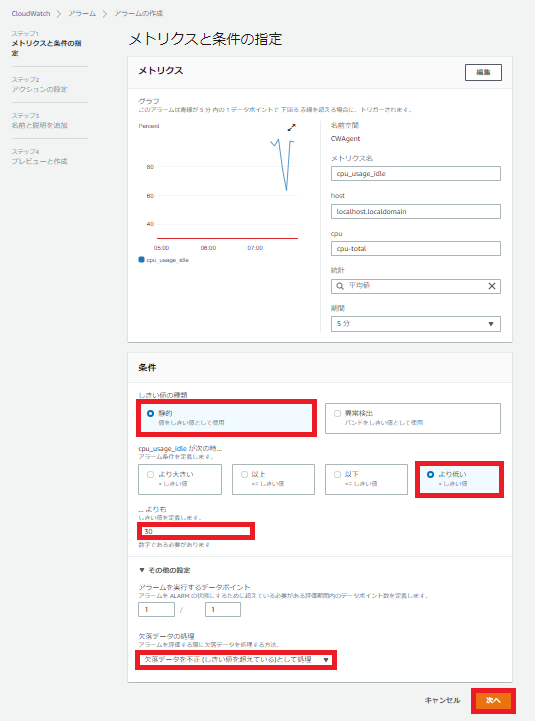
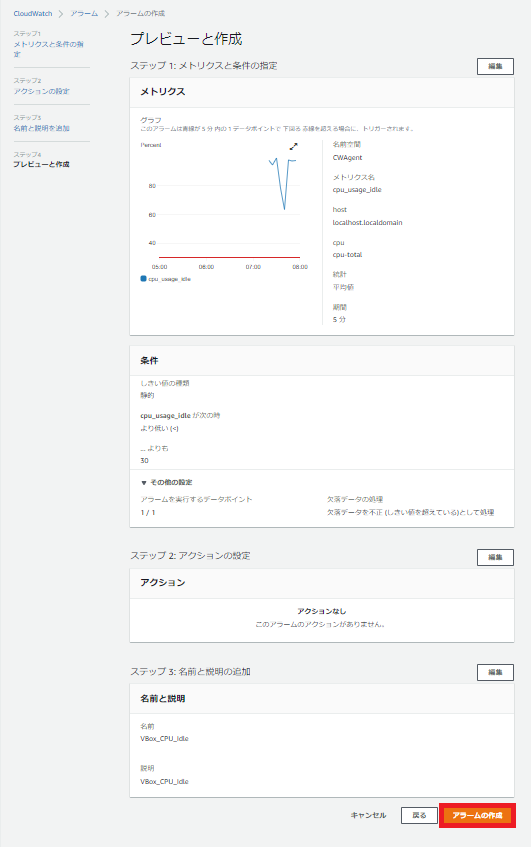
アラームの作成
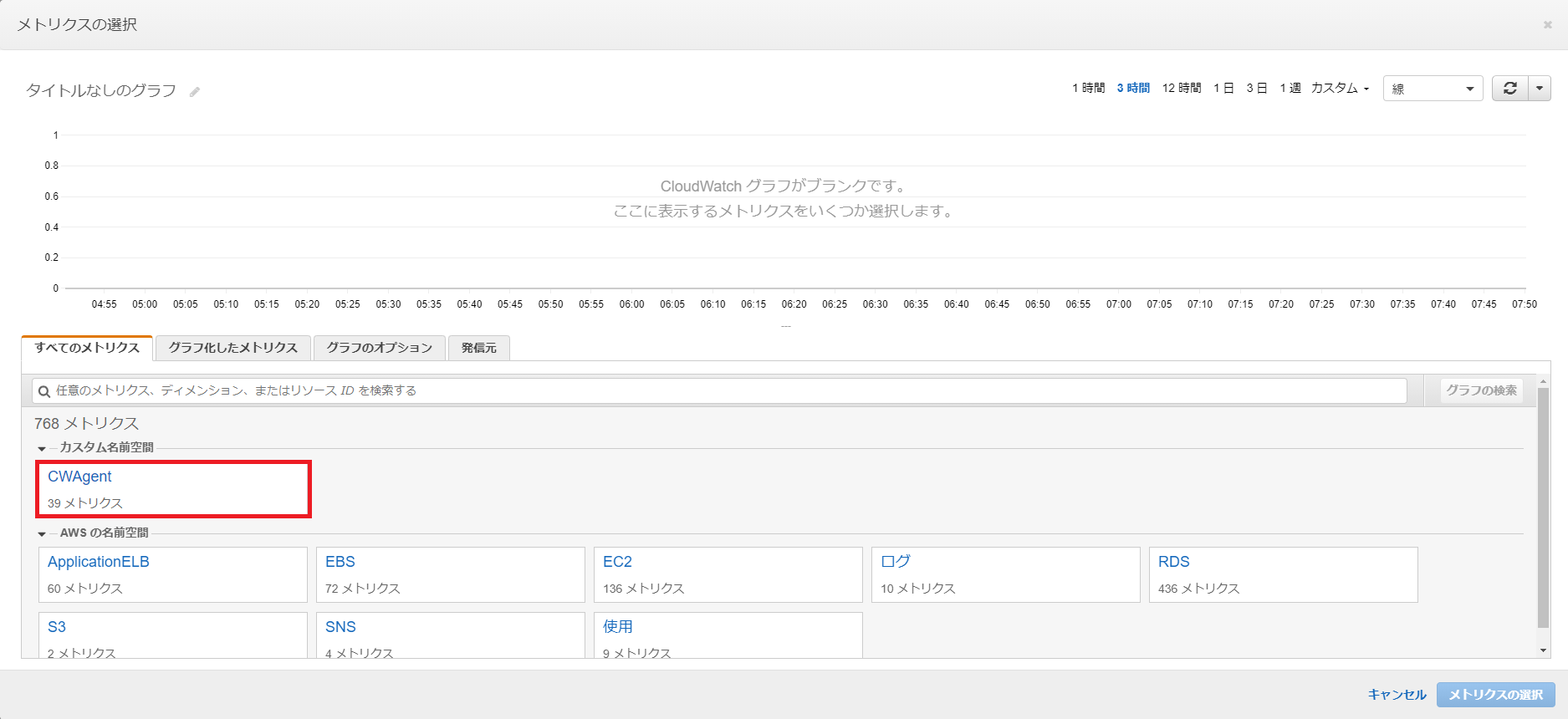
ではCloudWatchコンソールを開いてアラームを作成します。
メトリクスの選択を選択します。
「CWAgent」が今回導入した名前空間です。
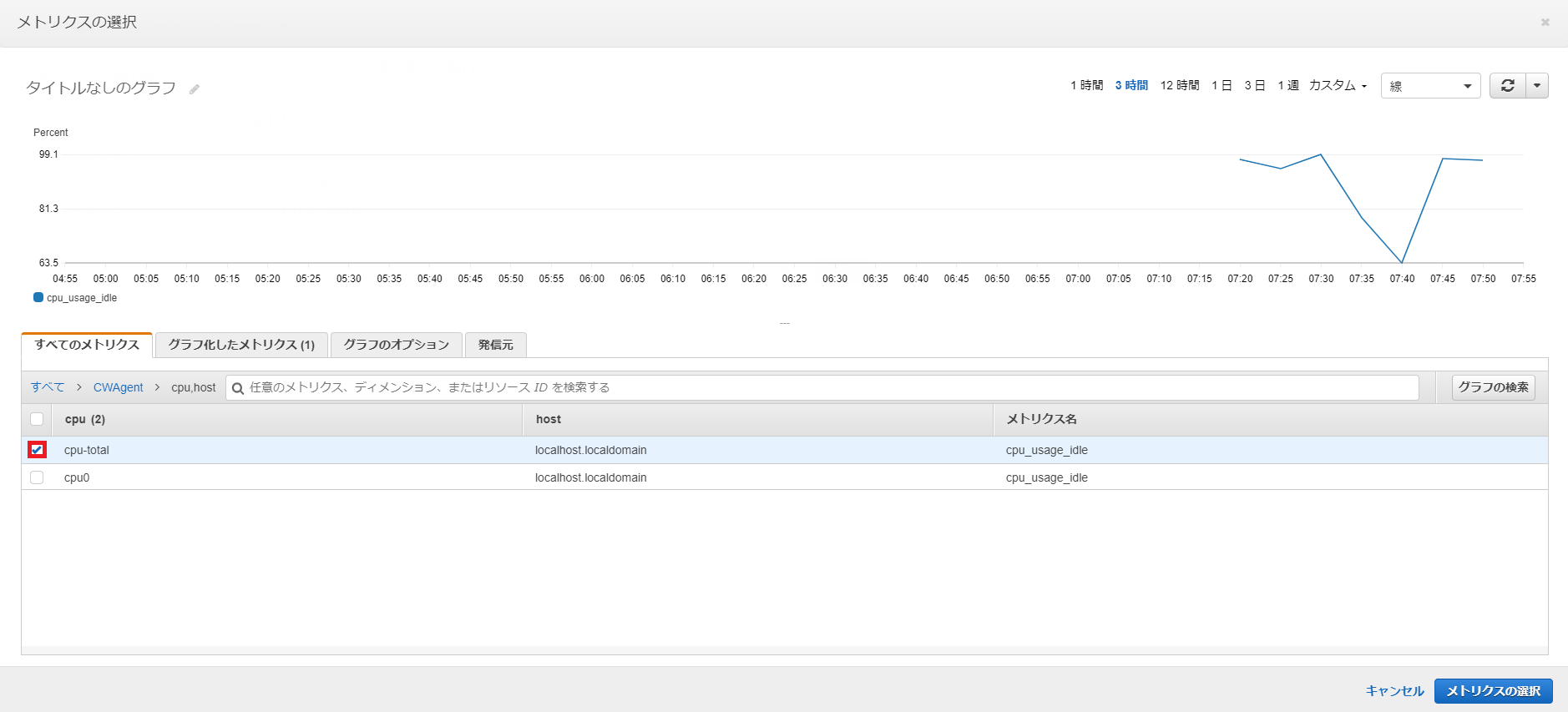
「cpu,host」を選択します。
「cpu-total」を選択します。
CPUのアイドル率の監視をするメトリクスなので、アイドル率があるパーセンテージを下回った時にアラームが発せられるように設定します。
というか、CPU使用率そのものを監視するメトリクスがなかったのですが、どう設定したらできるようになるんですかね?詳しい人教えてください。
今回は通知の設定はしません。
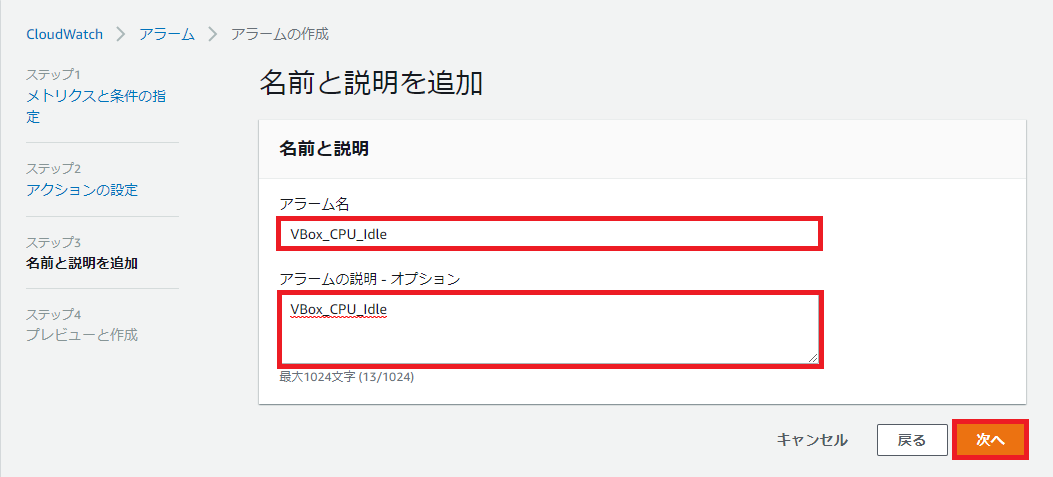
アラーム名は「VBox_CPU_Idle」とします。
問題がなければアラームの作成を選択します。
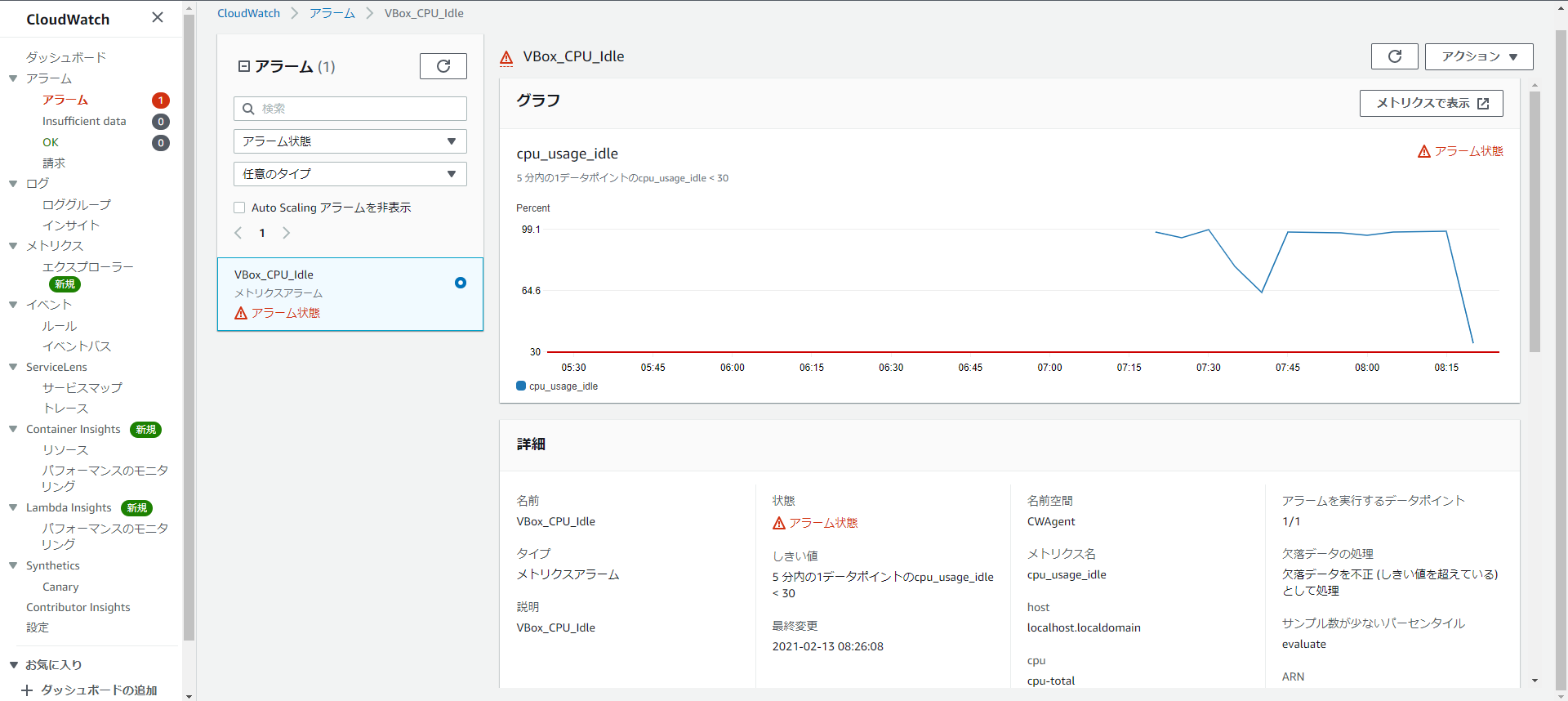
これでアラームが作成されました。CPUに負荷をかける
CPUに負荷をかけてアラームが発生するか確認しましょう。
以下のコマンドを4回くらい打ってCPUに負荷をかけます。yes >> /dev/null &しばらくするとアラーム状態になっていました。
このままだとCPUに負荷がかかったままなのでバックグラウンドで実行されているyesコマンド停止させるのを忘れずに。
killall yes感想
慣れないうちはオンプレ環境にCloudWatchを導入するのは大変ですが、クラウドとオンプレを併用した環境でも一緒にCloudWatchで監視することができるのは便利ですね。
参考
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/installing-cloudwatch-agent-commandline.html
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-on-premise.html
https://dev.classmethod.jp/articles/cloudwatch-agent-on-premise-windows/
https://qiita.com/murata-tomohide/items/3e66d63b21c08d6481a2
https://qiita.com/TK1989/items/0d1903846c6c54956132
この記事はAWS初学者を導く体系的な動画学習サービス
「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com







- 投稿日:2021-02-13T16:38:32+09:00
AWS未経験から1.5ヶ月でSAA-C02に合格する方法 結論:ハンズオンと公式模試は必要ない
はじめに
2020年9月にAWS認定ソリューションアーキテクトアソシエイト(SAA-C02)試験に合格しました。
勉強を開始した時点でAWS知識はゼロ、また、業務関連の知識習得も必要で試験勉強のみに集中するのは難しい状況でしたが、余裕をもって合格することができました。
効率も再現性も高い勉強ができたという自負があるので、みなさまに共有したいと思った次第です。
結論をいうと、試験合格のためだけならハンズオンも公式模試も必要ありません。
学習開始時の私のスペック
- 営業からエンジニアに転職して2週間
- 業務はモバイルアプリ開発(TypeScript, React Native)とバックエンド開発(PHP, Laravel)
- AWS知識はゼロ(いーしーつー?なんやそれ...?レベル)
受験の動機
- 錯覚資産を得るため
- AWS業務に関わる足がかりにするため
- 社内でAWS知ってるキャラのポジションを確立するため
未経験からエンジニアに転職した人ならわかると思うのですが、入社直後は自分だけにできる仕事はなく自己肯定感が下がりがちです。業務をしっかりこなすことでまわりからの信頼を徐々に得ていく、というのが定石なのですが、前職から年収が250万以上下がって生活が苦しかった私には、周りからの信頼を得ることと同時に、エンジニアとしての市場価値を早く上げて給料アップしたいという気持ちがありました。
社内にはAWSをバリバリ使える方よりも勉強中の方のほうが多く、「SAA-C02合格」を目標に掲げている方々も数人いらっしゃったので、この人達よりも先に試験に合格してしまえば、マネージャへのアピールになりインフラ業務に携われるだろうと思いました。
勉強の詳細
使った教材と勉強の流れをまとめました。
教材
勉強の流れ(6週間)
0週目
勉強を開始する前に試験に申込みます。
どんな試験にも言えることですが、試験日が決まっているだけで勉強のモチベーションがめちゃくちゃ変わってきます。
また、仕事しながらの試験勉強は長期戦になるほど辛くなってきます。1-2ヶ月くらいの短期決戦でいきましょう。1週目
まずは知識のインプットから始めます。
インプットには「aws WEB問題集で学習しよう」を活用します。問題集というよりAWSサービスに関するクイズのようなイメージが強く、本番試験のような問題はあまりでません。しかし、問題を解いて解説を読んでいくだけでサービスに関する知識を確実に身につけることができます。約7問で1セットとなっており、これが140セットほど(1000問以上)あります。全問解くためにはゴールドプランに入る必要があります。
最初の1週間で問題集を1周することを目指します。
全く解けなくても問題ありません。とりあえず最後まで解ききって、「1000問解いたぞ!」という自信をつけることが大事です。私の場合は、出社前と昼休みの間(あわせて約2時間)に毎日約20セットの問題をスマホで解いてました。
2週目
問題集2周目を解きます。
2周目に入るとわかる問題が増えて1周目より解くのが楽になっていると思います。
全部解けた問題のセットがあれば番号をメモします。3週目はこれらを解く必要はありません。20~30セット(200問)くらい解けるようになっていれば順調に知識が身についていると思います。
3週目
ここから知識補強フェーズに入ります。
1~2周目は問題を解ききるだけで精一杯だったと思うのですが、3周目はそんなに時間はかからないと思います。
問題の理解に時間をかけるため、わからない問題があったら、解説と合わせて「AWS サービス別資料のPDF」を読みます。こちらはAWSの中の人が公式で出している資料なので、そこらの参考書よりも正確で詳細な内容が書いてあります。
Kinesis, ECS, WAFなどは問題集の解説だけだとよくわからないので、こちらの資料を呼んでおくと理解が深まります。4-5週目
だいぶ知識が身についてきたと思うので、ここからはひたすら実践問題を解きます。
おすすめは【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集というUdemyの問題集です。模擬試験が6回分収録されており、力試しにもってこいの教材です。
本番試験と問題の傾向が非常に近く、ほぼ同じ問題が本番で5問くらい出ました。
ただ、難易度は本番よりも高いので、解けなくても落ち込む必要はありません(試験前日に解いて40%くらいでした...)。1~5回分の試験を1日1回ずつ解き、わからなかった問題があれば、サービス別資料を片手に見直します。2週間で3周を目指してください。
また、問題集は頻繁に行われているUdemyのセール中に買いましょう。だいたい1500円くらいです。
6週目
最後の週は、WEB問題集とUdemy問題集で解けなかった問題をひたすら解き、苦手の穴を潰します。
そして試験前日になったら、Udemy問題集の残りの1回分を受けます。これが40%以上取れていれば、本番試験にはおそらく受かります。
合格してよかったこと
- マネージャだけではなく、その他同僚の方々にも「こいつすげーな」という目でみられるようになった(錯覚資産のゲット)
- インフラ周りの話に混ぜてもらえるようになった
- AWSサービスを苦手意識なくアプリの機能に組み込めるようになった(SQS, Lambda, API Gatewayなど)
錯覚資産を得られただけでなく、様々なAWSサービスの用途を知ったことで、自分が関わっているサービスの問題解決の手段として使えるようになったのが一番大きかったです。
また、業務と両立して試験に合格したことで、「ちゃんと努力ができる奴」という印象が付き、いろんな仕事をまかせてもらえるようになりました。おわりに
資格試験の勉強をすることは短期間で知識を身につけるのに有効な手段だと思います。また、SAA-C02は錯覚資産を得るには非常にコスパがよいので、みなさんにおすすめです。


- 投稿日:2021-02-13T16:38:32+09:00
AWS未経験から6週間でSAA-C02に合格する方法 結論:ハンズオンと公式模試は必要ない
はじめに
2020年9月にAWS認定ソリューションアーキテクトアソシエイト(SAA-C02)試験に合格しました。
勉強を開始した時点でAWS知識はゼロ、また、業務関連の知識習得も必要で試験勉強のみに集中するのは難しい状況でしたが、6週間のスキマ時間の勉强で余裕をもって合格することができました。
効率も再現性も高い勉強ができたので、今後受験される方の参考になればと思い記事にしました。
結論をいうと、試験合格のためだけならハンズオンも公式模試も必要ありません。
学習開始時の私のスペック
- 営業からエンジニアに転職して2週間
- 業務はモバイルアプリ開発(TypeScript, React Native)とバックエンド開発(PHP, Laravel)
- AWS知識はゼロ(いーしーつー?なんやそれ...?レベル)
受験の動機
- 錯覚資産を得るため
- AWS業務に関わる足がかりにするため
- 社内でAWS知ってるキャラのポジションを確立するため
未経験からエンジニアに転職した人ならわかると思うのですが、入社直後は自分だけにできる仕事はなく自己肯定感が下がりがちです。業務をしっかりこなすことでまわりからの信頼を徐々に得ていく、というのが定石なのですが、前職から年収が250万以上下がって生活が苦しかった私には、周りからの信頼を得ることと同時に、エンジニアとしての市場価値を早く上げて給料アップしたいという気持ちがありました。
社内にはAWSをバリバリ使える方よりも勉強中の方のほうが多く、「SAA-C02合格」を目標に掲げている方々も数人いらっしゃったので、この人達よりも先に試験に合格してしまえば、マネージャへのアピールになりインフラ業務に携われるだろうと思いました。
勉強の詳細
使った教材と勉強の流れをまとめました。
教材
勉強の流れ(6週間)
0週目
勉強を開始する前に試験に申込みます。
どんな試験にも言えることですが、試験日が決まっているだけで勉強のモチベーションがめちゃくちゃ変わってきます。
また、仕事しながらの試験勉強は長期戦になるほど辛くなってきます。1-2ヶ月くらいの短期決戦でいきましょう。1週目
まずは知識のインプットから始めます。
インプットには「aws WEB問題集で学習しよう」を活用します。問題集というよりAWSサービスに関するクイズのようなイメージが強く、本番試験のような問題はあまりでません。しかし、問題を解いて解説を読んでいくだけでサービスに関する知識を確実に身につけることができます。約7問で1セットとなっており、これが140セットほど(1000問以上)あります。全問解くためにはゴールドプランに入る必要があります。
最初の1週間で問題集を1周することを目指します。
全く解けなくても問題ありません。とりあえず最後まで解ききって、「1000問解いたぞ!」という自信をつけることが大事です。私の場合は、出社前と昼休みの間(あわせて約2時間)に毎日約20セットの問題をスマホで解いてました。
2週目
問題集2周目を解きます。
2周目に入るとわかる問題が増えて1周目より解くのが楽になっていると思います。
全部解けた問題のセットがあれば番号をメモします。3週目はこれらを解く必要はありません。20~30セット(200問)くらい解けるようになっていれば順調に知識が身についていると思います。
3週目
ここから知識補強フェーズに入ります。
1~2周目は問題を解ききるだけで精一杯だったと思うのですが、3周目はそんなに時間はかからないと思います。
問題の理解に時間をかけるため、わからない問題があったら、解説と合わせて「AWS サービス別資料のPDF」を読みます。こちらはAWSの中の人が公式で出している資料なので、そこらの参考書よりも正確で詳細な内容が書いてあります。
Kinesis, ECS, WAFなどは問題集の解説だけだとよくわからないので、こちらの資料を呼んでおくと理解が深まります。4-5週目
だいぶ知識が身についてきたと思うので、ここからはひたすら実践問題を解きます。
おすすめは【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集というUdemyの問題集です。模擬試験が6回分収録されており、力試しにもってこいの教材です。
本番試験と問題の傾向が非常に近く、ほぼ同じ問題が本番で5問くらい出ました。
ただ、難易度は本番よりも高いので、解けなくても落ち込む必要はありません(試験前日に解いて40%くらいでした...)。1~5回分の試験を1日1回ずつ解き、わからなかった問題があれば、サービス別資料を片手に見直します。2週間で3周を目指してください。
また、問題集は頻繁に行われているUdemyのセール中に買いましょう。だいたい1500円くらいです。
6週目
最後の週は、WEB問題集とUdemy問題集で解けなかった問題をひたすら解き、苦手の穴を潰します。
そして試験前日になったら、Udemy問題集の残りの1回分を受けます。これが40%以上取れていれば、本番試験にはおそらく受かります。
合格してよかったこと
- マネージャだけではなく、その他同僚の方々にも「こいつすげーな」という目でみられるようになった(錯覚資産のゲット)
- インフラ周りの話に混ぜてもらえるようになった
- AWSサービスを苦手意識なくアプリの機能に組み込めるようになった(SQS, Lambda, API Gatewayなど)
錯覚資産を得られただけでなく、様々なAWSサービスの用途を知ったことで、自分が関わっているサービスの問題解決の手段として使えるようになったのが一番大きかったです。
また、業務と両立して試験に合格したことで、「ちゃんと努力ができる奴」という印象が付き、いろんな仕事をまかせてもらえるようになりました。おわりに
資格試験の勉強をすることは短期間で知識を身につけるのに有効な手段だと思います。また、SAA-C02は錯覚資産を得るには非常にコスパがよいので、みなさんにおすすめです。
- 投稿日:2021-02-13T16:31:26+09:00
「S3とは」
S3とは
前回に「EBS、S3、EFS三者の違い」でAWSのストレージサービスを紹介しました。
今回はそのS3について、詳しく紹介させていただきます。
S3:Simple Storage Service (頭文字は三つのSなので、S3を名前にしています。)
ユーザーがデータを容量制限なく保存可能なマネージド型で提供されるオブジェクト型ストレージ。
?特徴:
・耐久性:99.999999999%。(11個9)
・データを暗号化可能?データ保存形式
・バケット
オブジェクトの保存場所。
(命名ルール:全regionで使うため、名前がユニークな必要がある。)・オブジェクト
S3に格納されるファイルはURLが付与される。・データサイズ
OKB~5TBまで保存可能。
S3のデータ構造

S3のストレージタイプとその特徴
参照先:Amazon AWS Document↓
ストレージクラスのパフォーマンスS3の暗号化
S3の暗号化は二つの方法があります。
・サーバーサイト暗号化(暗号化タイプ:SSE-S3,SSE-KMS,SSE-C)
・クライアントサイト暗号化(暗号化タイプ:AWS-KMS)
S3のその他の機能
・ライフサイクル管理
・バージョン管理
・バックアップ&復元


- 投稿日:2021-02-13T12:56:23+09:00
AWS覚書 - boto3を使ってIoT coreのエンドポイントを取得する -
IoT coreを使用するのに、クライアントからカスタムエンドポイントを取得する必要があるので、取得できるようになるまでの手順を覚書しておく。
必要なもののインストール
pythonへboto3と、AWSクライアント
boto3
pip3 install boto3AWSクライアント
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-mac.html
キーセットの取得
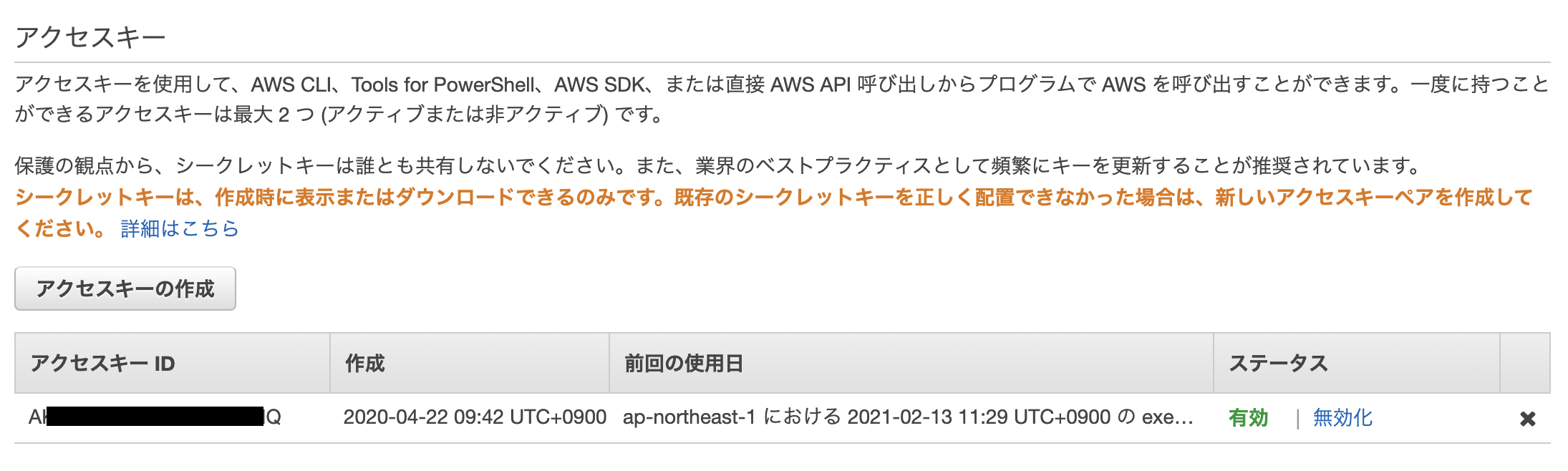
まずはアクセスキーとシークレットーキーが必要
アカウントの IAM → アクセス管理 → ユーザー → アクセスキー と進む。
アクセスキーを作成してシークレットキーを取得する(一度しか取得できないので紛失に注意する)。AWSクライアントへのキーセットの登録
> aws configure --profile <プロファイル名(自由な名前でOK)> AWS Access Key ID [None]: <取得したアクセスキー> AWS Secret Access Key [None]: <取得したシークレットキー> Default region name [None]: <デフォルトで使用したいリージョン、東京ならば「ap-northeast-1」> Default output format [None]: jsonプロファイルを作成したらプロファイルをデフォルト設定する
> set AWS_DEFAULT_PROFILE= <先ほど作成したプロファイル名>ちゃんとキーセットが設定されているか確認する。
> aws configure list Name Value Type Location ---- ----- ---- -------- profile <not set> None None access_key ****************3LHQ shared-credentials-file secret_key ****************vexf shared-credentials-file region us-east-2 config-file ~/.aws/config以下のファイルに、それっぽいのがあるか確認できる。
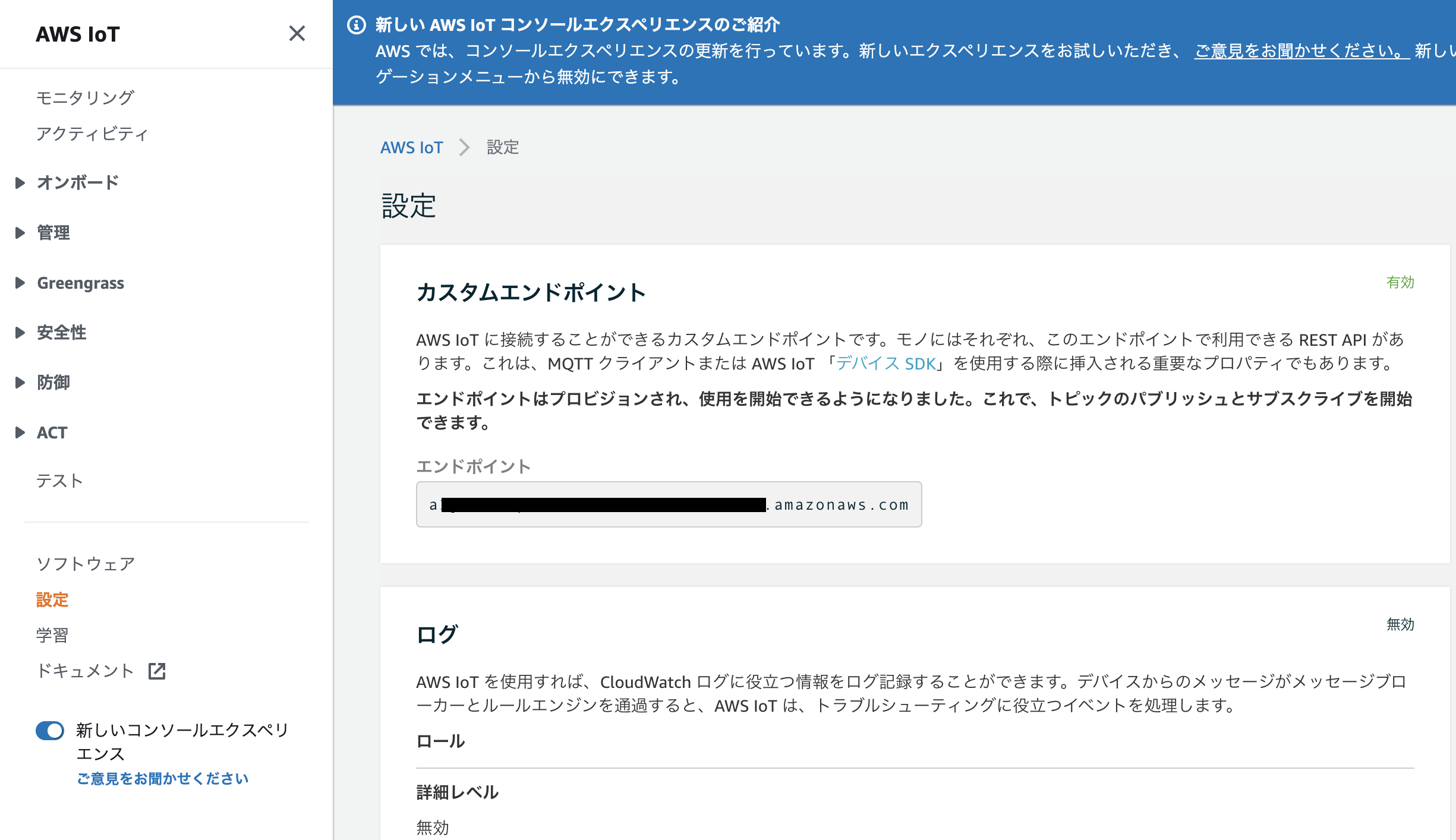
> cat ~/.aws/credentialsIoT coreのエンドポイントを確認
Iot core → 設定 と進むとみれる。
クライアントからエンドポイントの取得
pythonから取得する。
> python Python 3.8.2 (default, Apr 27 2020, 13:03:04) [Clang 10.0.0 (clang-1000.10.44.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import boto3 >>> client = boto3.client('iot', region_name='ap-northeast-1') >>> endpoint_response = client.describe_endpoint(endpointType='iot:Data-ATS') >>> print(endpoint_response) {'ResponseMetadata': {'RequestId': '**************', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Sat, 13 Feb 2021 03:42:30 GMT', 'content-type': 'application/json', 'content-length': '74', 'connection': 'keep-alive', 'x-amzn-requestid': '****************', 'access-control-allow-origin': '*', 'x-amz-apigw-id': '********', 'x-amzn-trace-id': 'Root=****************'}, 'RetryAttempts': 0}, 'endpointAddress': '<ここが実際に取得したいエンドポイントになる>'}整形
{ "ResponseMetadata": { "RequestId": "**************", "HTTPStatusCode": 200, "HTTPHeaders": { "date": "Sat, 13 Feb 2021 03:42:30 GMT", "content-type": "application/json", "content-length": "74", "connection": "keep-alive", "x-amzn-requestid": "****************", "access-control-allow-origin": "*", "x-amz-apigw-id": "********", "x-amzn-trace-id": "Root=****************" }, "RetryAttempts": 0 }, "endpointAddress": "<ここが実際に取得したいエンドポイントになる>" }画面でみたエンドポイントと同じであるか確認する。
boto3.clientの部分は、キーセット直接指定でも問題ない。>>> client = boto3.client('iot', region_name='ap-northeast-1', aws_access_key_id='***', aws_secret_access_key='***')
- 投稿日:2021-02-13T11:44:37+09:00
【SAA試験対策】S3のコストについて
S3のコストについて纏めました。
ポイントは以下の3つだけ。ストレージ容量
・どのくらいの容量を保存しているか。
・データの利用頻度に応じて適切なストレージクラスを選択することでコストを抑えることができる。S3標準とGlacierって5倍も価格が違うようです。。
アクセス頻度が少なくなったデータはライフサイクル管理でストレージクラスを変更するのが良い^^データ転送量
・S3→インターネット外にデータを転送する時のみ有料。
・S3へのデータ転送インは無料。
・AWS同一リージョン内のサービス同士のデータ転送イン・アウトも無料。(※別リージョンの場合は有料)リクエストとデータ取り出し
・GET/PUT/POST/LIST/COPYなどのリクエスト数に応じてコストが発生する。
・GET は安い
・PUT/POST/LIST/COPY はGETよりも高い
・DELETE は無料補足
AWS無料利用枠内であれば、S3 標準で 5 GB の Amazon S3 ストレージ、20,000 GET リクエスト、2,000 PUT、COPY、POST、あるいは LIST リクエスト、データ送信 15 GB を毎月、1 年間利用できるようです。
参考
- 投稿日:2021-02-13T10:28:48+09:00
【初心者】AWS AutoScalingについて(ハンズオン③:オートスケーリングポリシーの作成)
はじめに
AWS AutoScaling・・EC2を処理負荷に合わせて、増やしたり減らしたりすることができる便利なサービス
公式サイトこちらは前回の記事の続きとなっています。
【初心者】AWS AutoScalingについて(ハンズオン①:起動テンプレートの作成)
【初心者】AWS AutoScalingについて(ハンズオン②:オートスケーリンググループの作成)オートスケーリングポリシーの種類
2021/02時点で3つのポリシーがあります。公式サイト
どのようにスケーリングさせたいかでポリシーを選択します。■ターゲットポリシー
特定のメトリクスのターゲット値に基づいて、グループの現在の容量を増減させる
例:「CPU使用率60%と指定」(※数の調整はオートスケーリングが自動で実施)■ステップポリシー
複数段階でのインスタンスの追加、削除を設定し、
例:「平均CPU使用率60%超えたら1台追加、80%超えたらもう1台追加」■シンプルポリシー
1 つのスケーリング調整値に基づいて、グループの現在の容量を増減させる
例:「平均CPU使用率が80%超えたら、2台追加」ハンズオン③:オートスケーリングポリシーの作成
前回作成したオートスケーリンググループにオートスケーリングポリシーを追加します。
今回はオートスケーリンググループで作成されたEC2のCPU使用率が70%超えたらEC2を1台追加、30%より小さくなったらEC2を1台削除するアラームを作成し、それに基づいてインスタンスの数を増減させるシンプルポリシーを実践したいと思います。
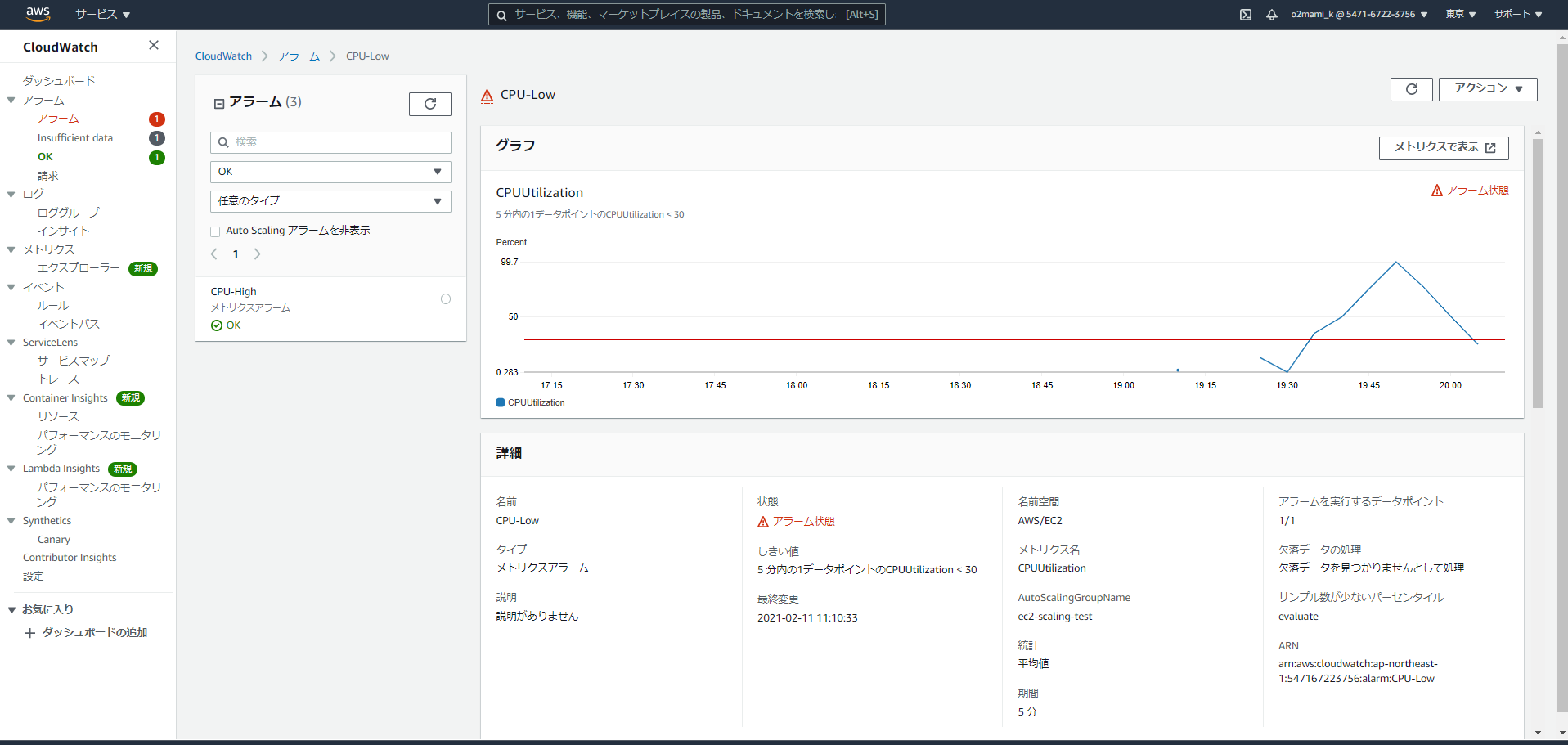
CloudWatchサービスより「アラーム」、「アラームの作成」を選択
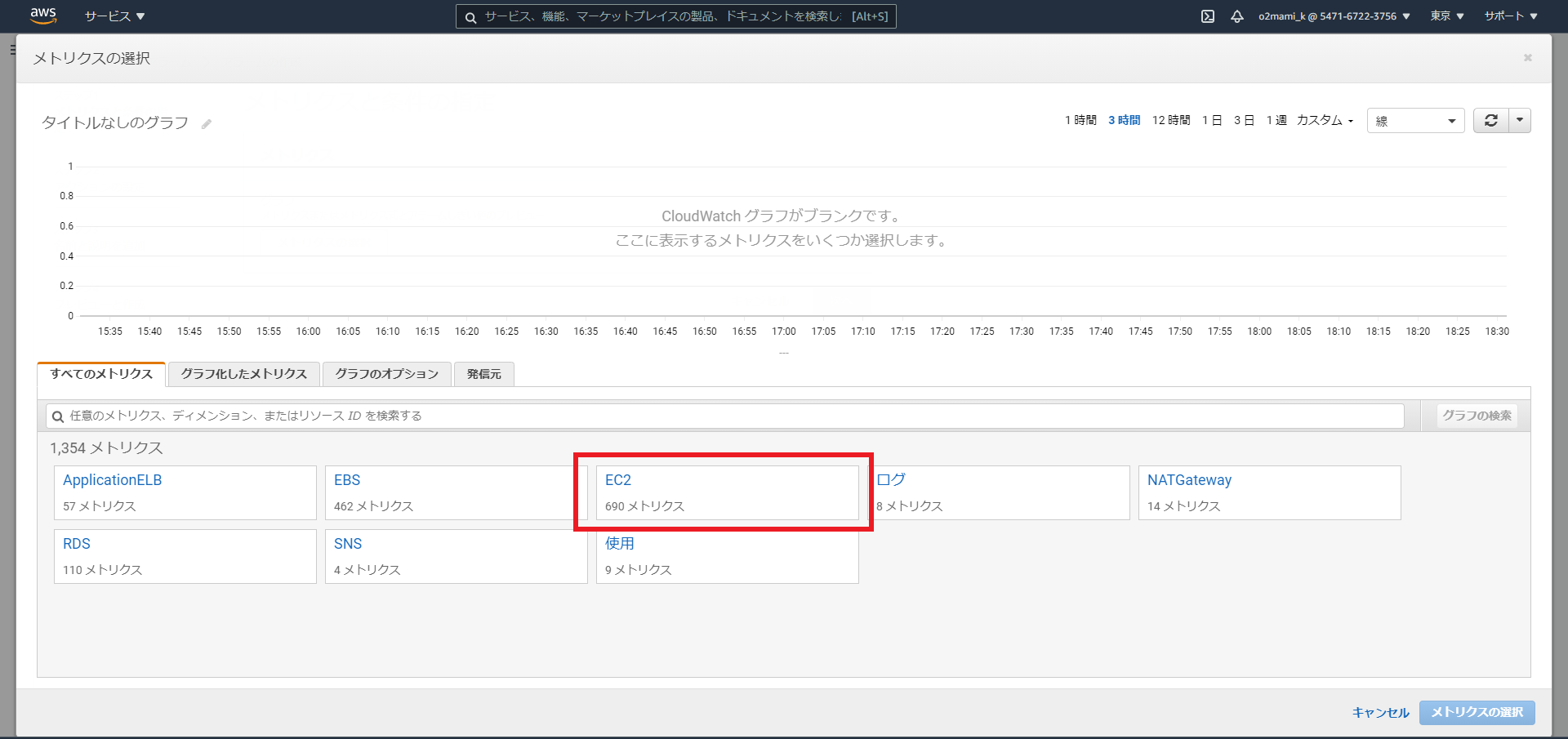
「メトリクスの選択」を選択
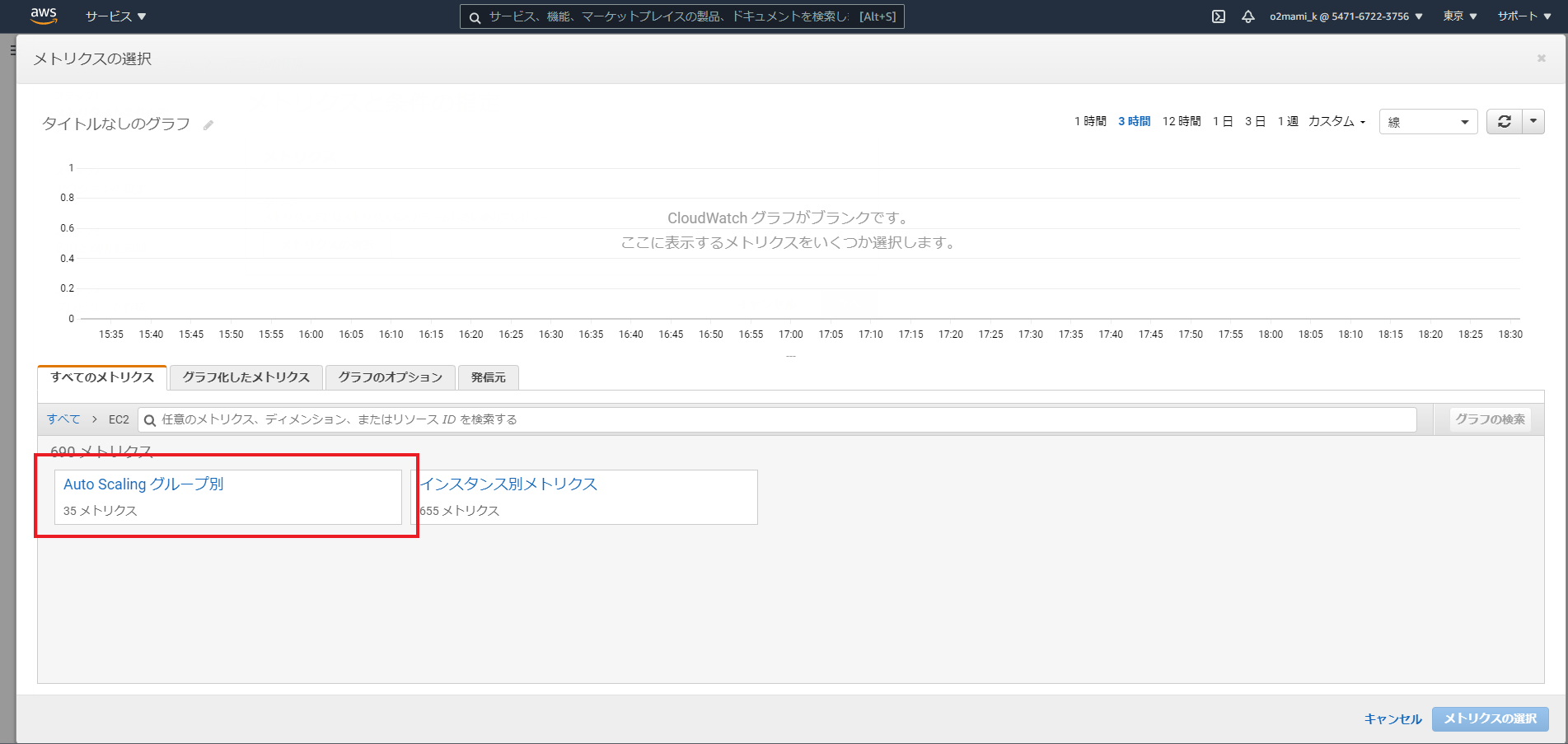
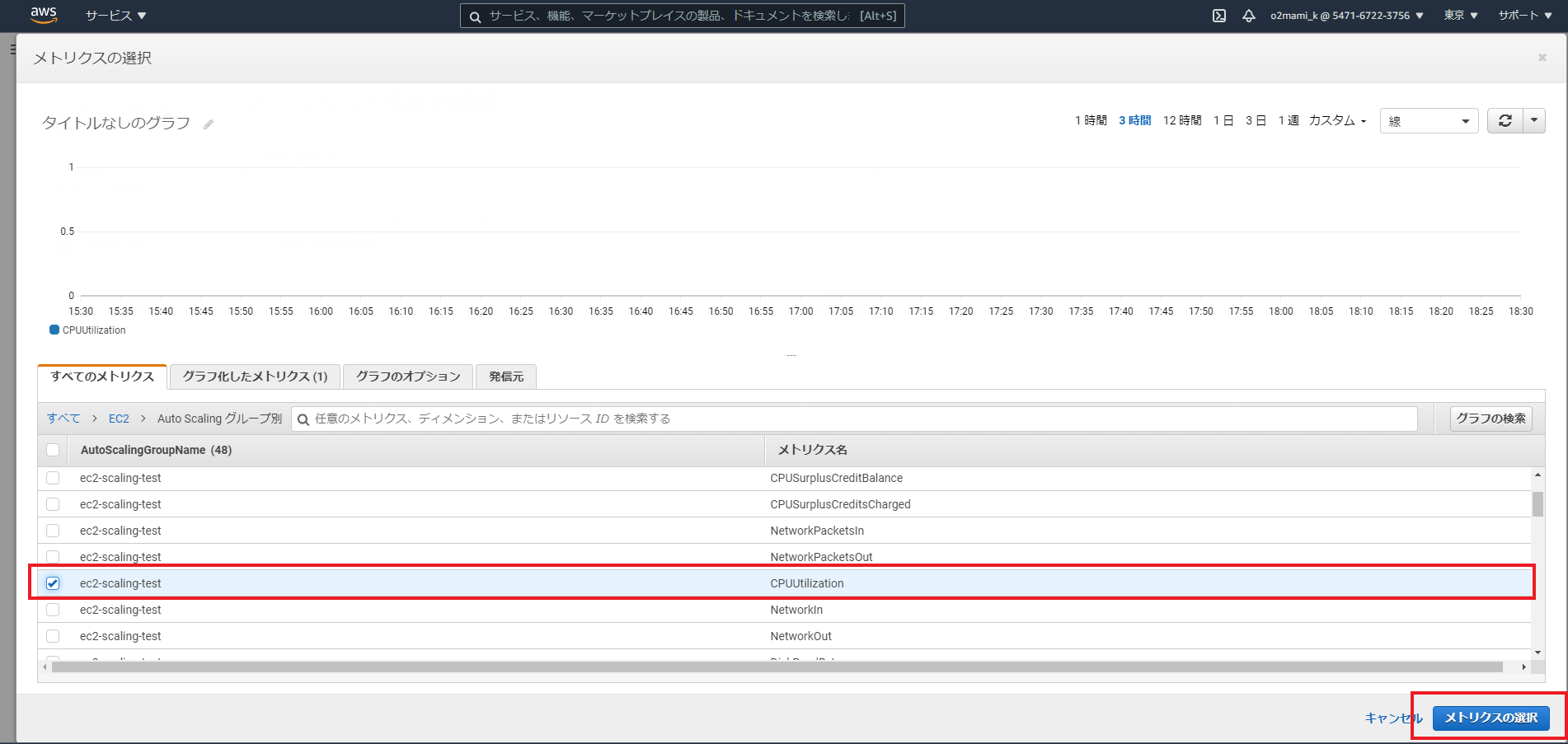
今回対象とするメトリクスをAutoScalingグループのCPU使用率とするため、「EC2」「AutoScalingグループ別」「CPUUtilization」を選択し、「メトリクスの選択」を選択
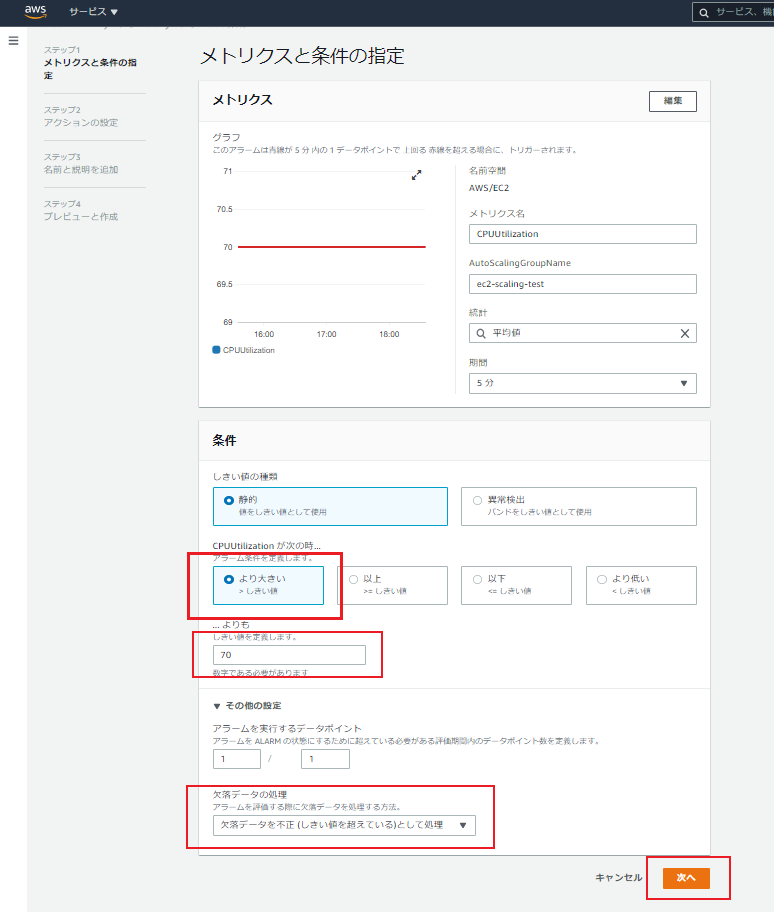
まず、CPU使用率が70%超えた場合のアラームを作成します。・条件:より大きい
・しきい値:70
・欠落データの処理:欠落データを不正(しきい値を超えている)として処理
※CPU使用率がいきなり上昇した場合、データが欠落する可能性があるため上記を選択しています。
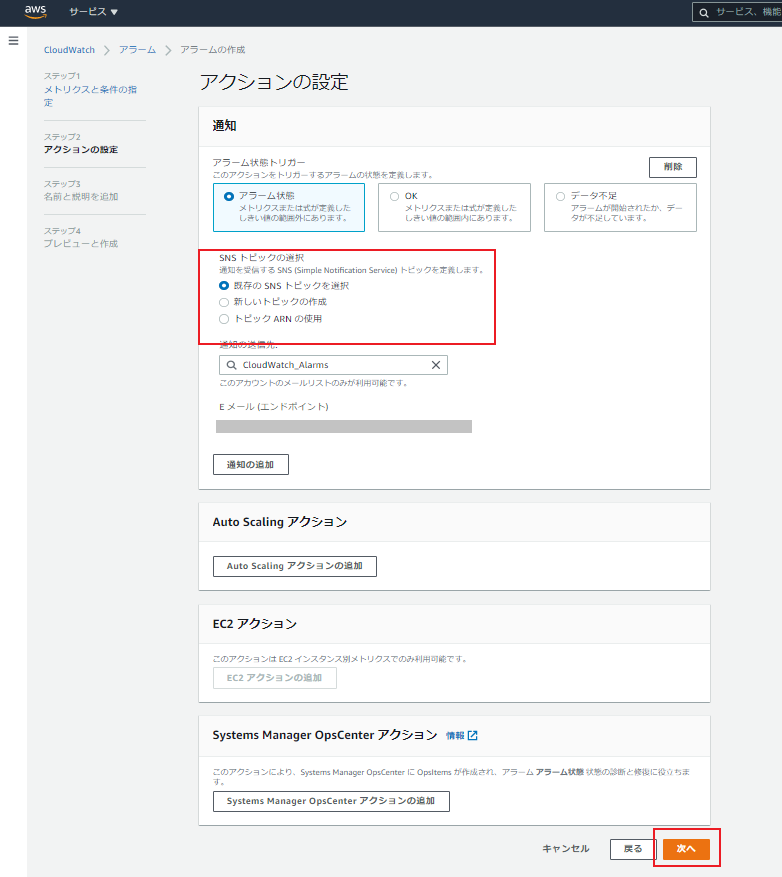
アラーム状態になった場合に通知するSNSトピックの選択
「既存のSNSトピック」もしくは「新しいトピックの作成」を選択し、通知するメールアドレスを決定
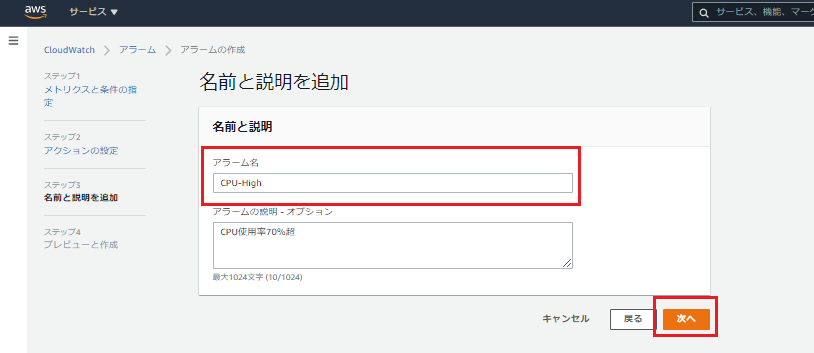
アラーム名と説明(任意)を指定・アラーム名:CPU-High
これでアラームが1つ作成されました。
同様の手順でCPU使用率が30%以下になったときのアラーム「CPU-Low」も作成します。
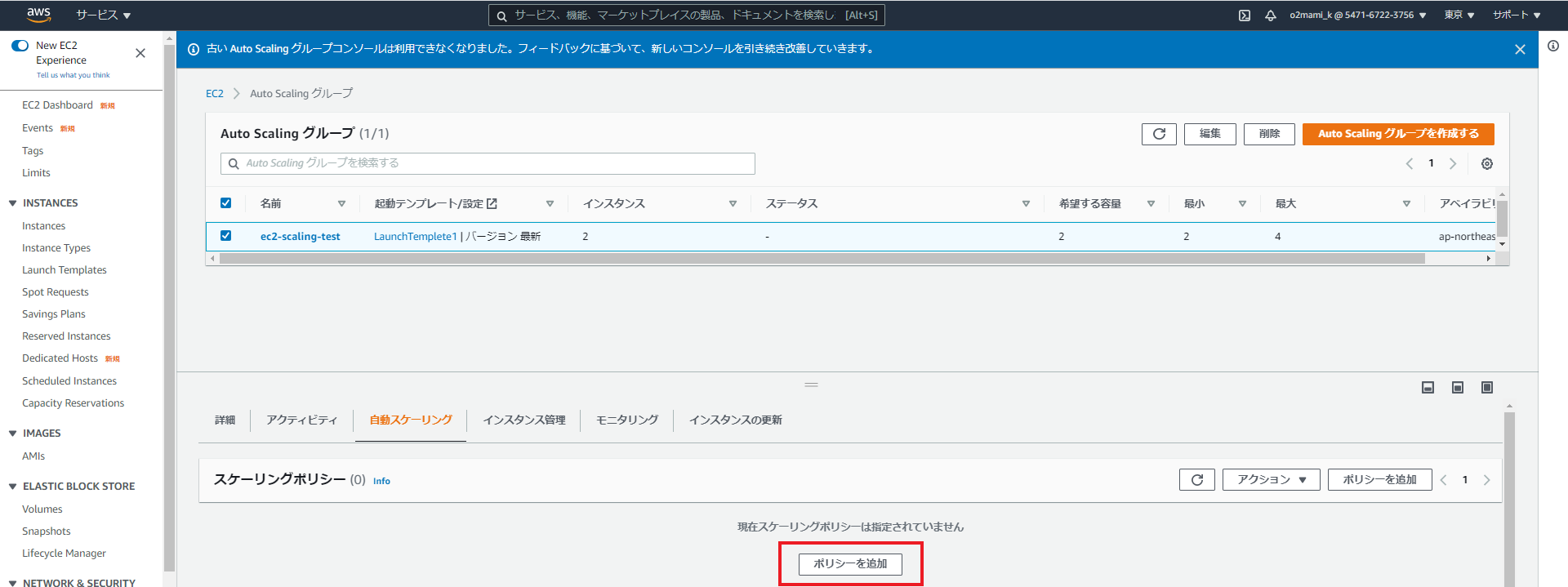
ここから作成したアラームをオートスケーリングポリシーに追加します。事前に作成したAutoScalingグループを選択し、「自動スケーリング」より「ポリシーの追加」を選択
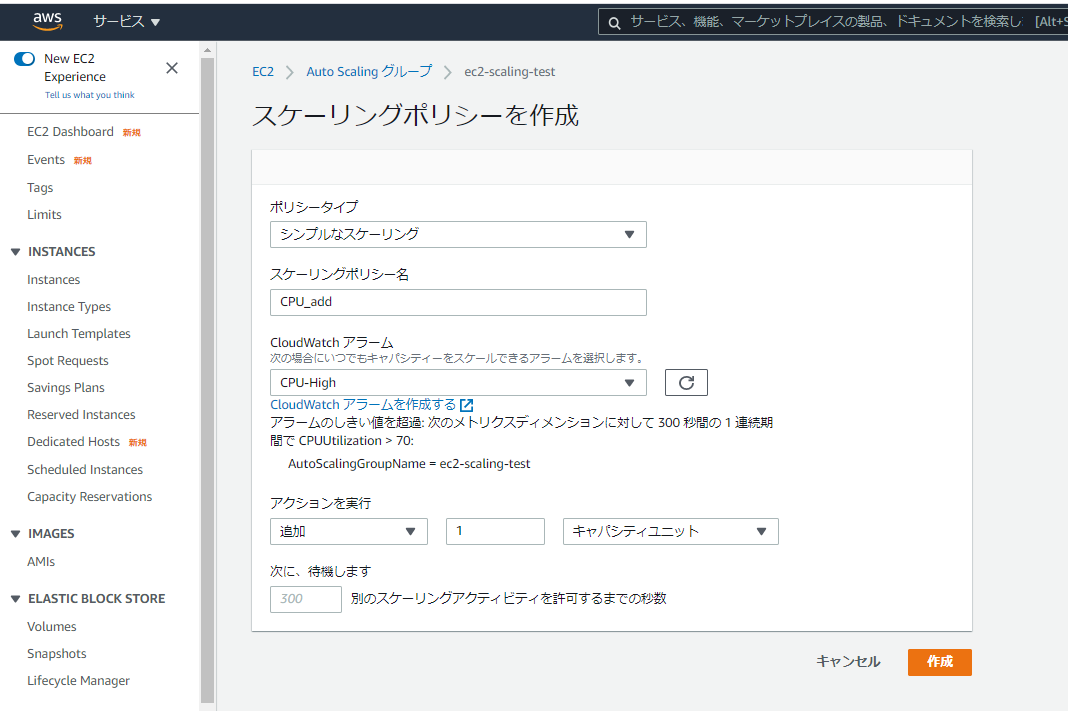
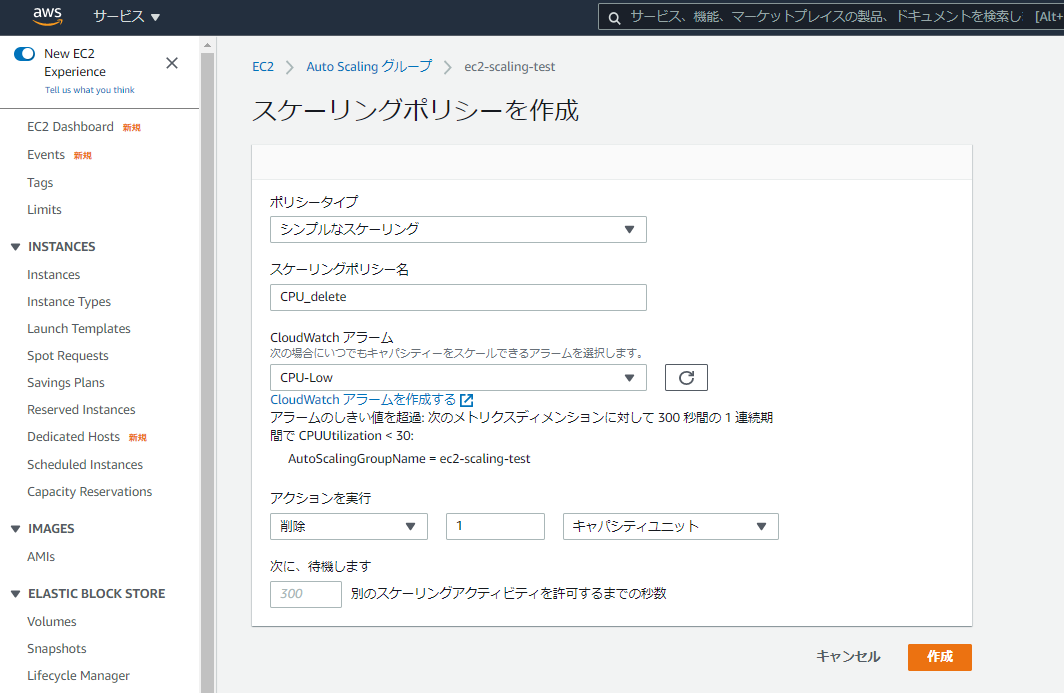
「CPU_high」アラームが発生した場合に、EC2を1台追加したいので、以下のように設定を行います。
・ポリシータイプ:シンプルなスケーリング
・スケーリングポリシー名:CPU_add
・CloudWatchアラーム:CPU_high
・アクションを実行:追加 1 キャパシティユニット
「CPU_Low」アラームが発生した場合に、EC2を1台追削除したいので、以下のように設定を行います。
・ポリシータイプ:シンプルなスケーリング
・スケーリングポリシー名:CPU_delete
・CloudWatchアラーム:CPU_Low
・アクションを実行:削除 1 キャパシティユニット以上で、オートスケーリングポリシーの設定は完了です。
実際に負荷をかけて、EC2の数が増減するのを確認したいと思います。オートスケーリンググループで起動されたEC2に接続し、以下のコマンドでCPUに負荷をかけます。
yes >> /dev/null &そのまま5分ほど待ちます…
※1プロセスだと負荷がかかりにくいので、同じコマンドを実行し、5プロセスぐらい起動させると早く負荷がかかります。
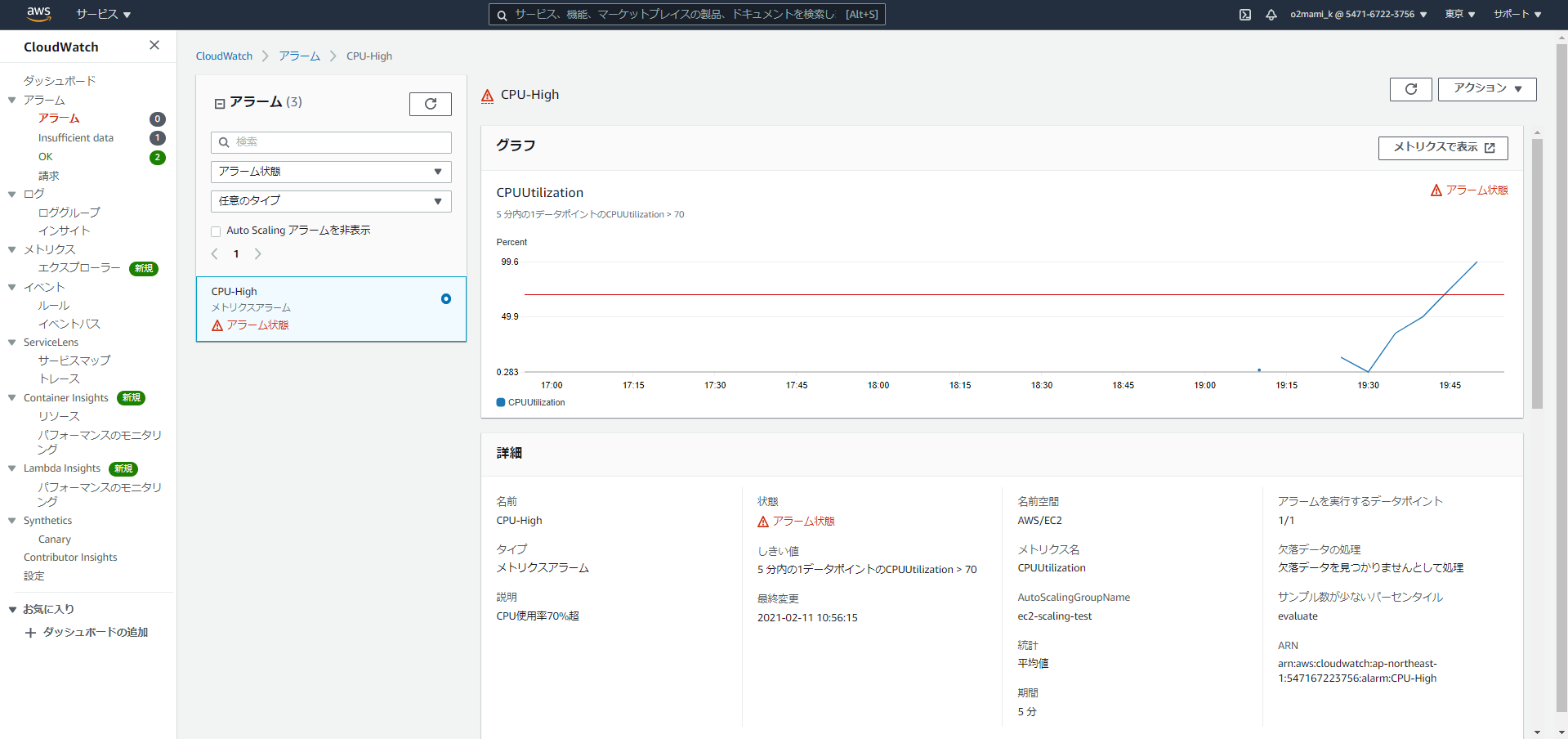
CPU_Highがアラーム状態となりました。
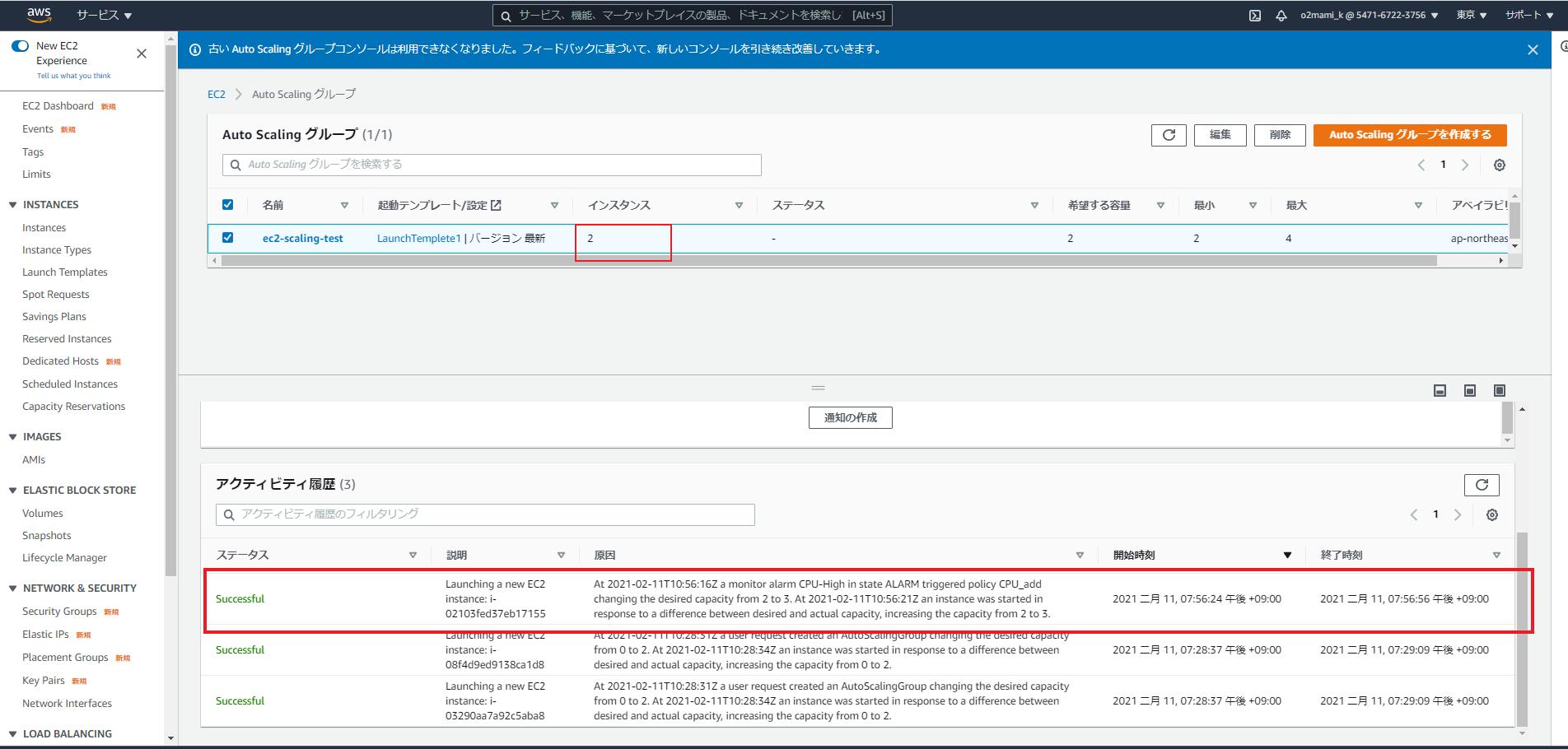
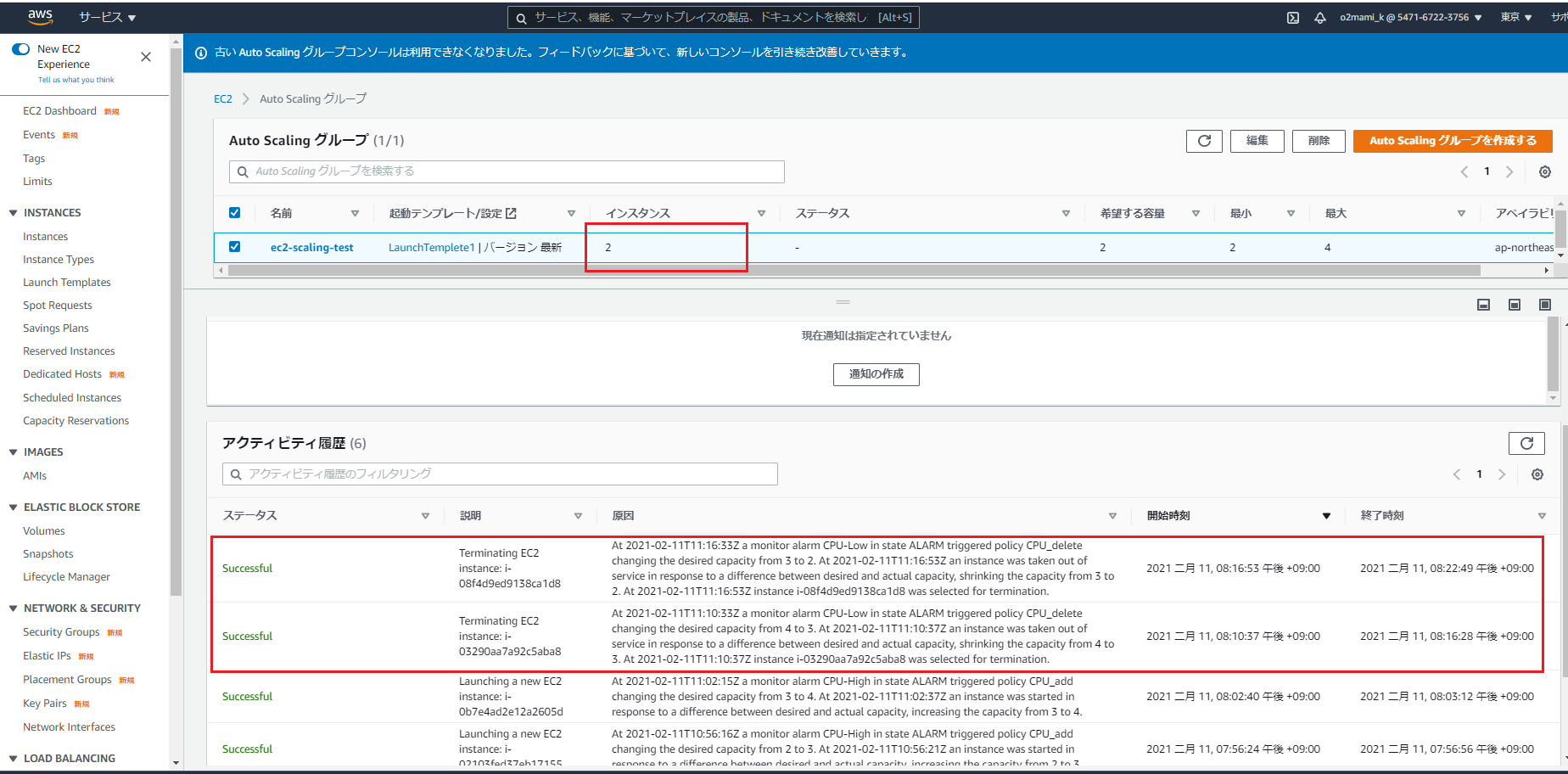
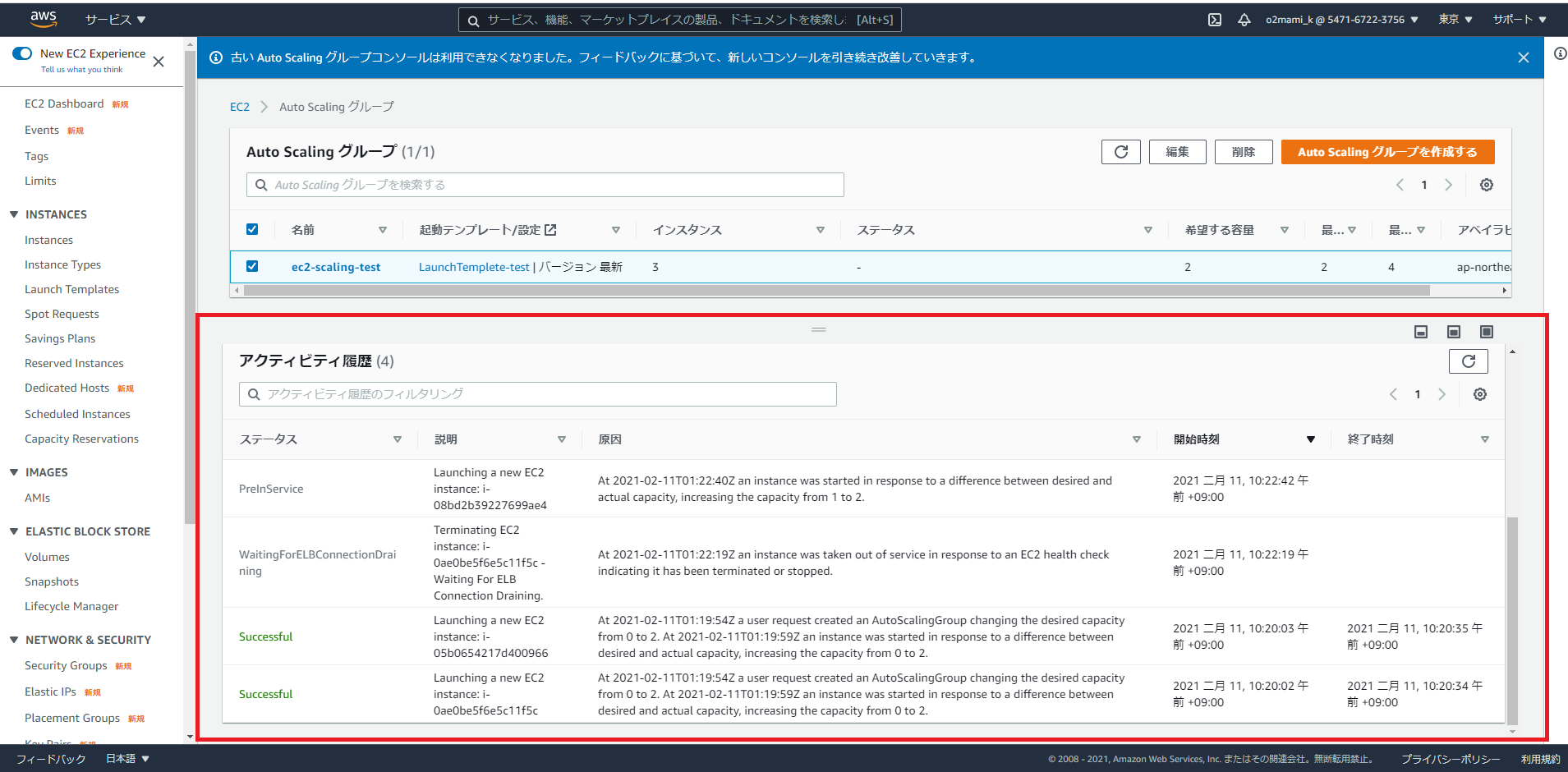
この時AutoScalingグループの「アクティビティ履歴」を確認すると...
EC2インスタンスが2→3台に増加したことが確認できます。
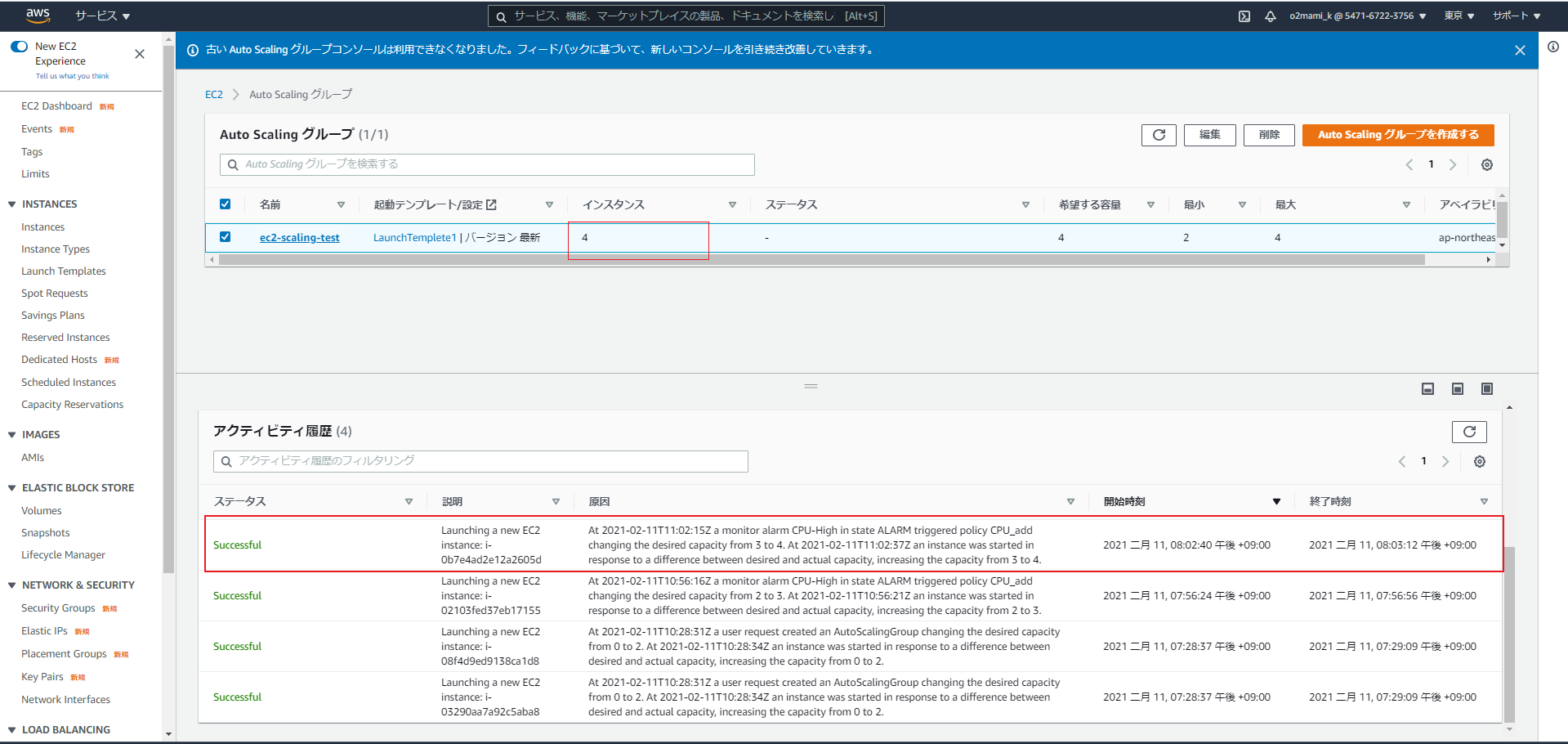
そのまま更に5分ほど待つと…
EC2インスタンスが3→4台に増加したことが確認できます。
そのまま5分ほど待っても上限で決めた4台以上になることはありませんでした。次にEC2インスタンスが削除されるのを確認するために、負荷コマンドを実行したプロセスを停止します。
以下のコマンドでプロセスを停止することができます。top (CPUに負荷をかけているプロセスIDを確認) kill [プロセスID]そのまま5分、10分と待つと…
CPU_Lowがアラーム状態となりました。
この時AutoScalingグループの「アクティビティ履歴」を確認すると...
EC2インスタンスが4→3→2台に減少したことが確認できました。ハンズオンは以上となります。
最後に
今回は3つの記事にわたって、「起動テンプレートの作成」「オートスケーリンググループの作成」「オートスケーリングポリシーの作成」を行いました。
慣れるまで設定するのが大変でしたが、一度作成すれば要領を掴むことができるので、実際に手を動かしてやってみることが大事ですねこの記事はAWS初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com
- 投稿日:2021-02-13T10:27:28+09:00
【AWS】S3ストレージクラスまとめ
AWSのS3にはいくつか種類(クラス)があるので、
・何があるのか
・どんな特徴があるのか
・代表的な用途をまとめてみます。
S3とは
そもそも、S3って何なんでしょうか。
Amazon Simple Storage Service は、インターネット用のストレージです。また、ウェブスケールのコンピューティングを開発者が簡単に利用できるよう設計されています。
Amazon S3 とはAWS上のストレージサービスで、頭文字をとってS3と呼ばれているんですね。
そんなS3の特徴は以下の4つです。
・耐久性:99.999999999%(イレブンナイン)
・安価:月額1GB/約3円
・安定性:データは冗長化されて保存
・安全性:データを暗号化可能ちなみに、アップロード可能な容量は1つのデータにつき5TBまでです。(デカすぎ)
補足
1オブジェクトのサイズが最大5TBで、1回のPUTオペレーションでアップ出来るオブジェクトのサイズが5GBとなります。
5GBを超える場合には、マルチパートアップロード(分割送信)を用いて並列してアップロードを行います。S3のストレージクラス
S3には以下のストレージクラスが存在します。
・Standard(標準)
・Standard-IA(低頻度アクセス)
・One Zone-IA(1ゾーン低頻度アクセス)
・Glacier(アーカイブ)
・Glacier Deep Archive(アーカイブ)それぞれの特徴をみていきます。
Standard
標準的なストレージクラスです。
複数のAZにまたがってデータを複製するため、耐久性が高い(99.999999999%)です。
遅延も少なく、スループットが高いので、幅広い用途に使用できます。代表的な用途
・クラウドアプリケーション
・動的なウェブサイト
・コンテンツ配信
・モバイルやゲームのアプリケーション
・ビッグデータ分析Standard-IA
アクセス頻度は低いけど、必要な時にすぐに取り出したいという用途で使用するストレージクラスです。
Standardとスペックは同様なのに安価です。
しかし、こちらはデータを取り出す際に料金がかかります。代表的な用途
・長期保存
・バックアップ
・災害対策ファイルのデータストアOne Zone-IA
Standard-IAのAZが1つになったバージョンです。
Standard-IAは複数のAZにまたがってデータを保存しますが、
こちらは1つのAZ内にのみデータを保存するため、Standard-IAよりも20%ほど安価になります。冗長性を気にしないようなデータの保存に向いています。
代表的な用途
・セカンダリバックアップのコピーGlacier
セキュア・高耐久性・低価格の三拍子が揃ったストレージクラスです。
オンプレのストレージと同等か、それより低いコストでデータの保存が可能です。しかし、データの読み出しには数分〜数時間かかるため、長期間のデータアーカイブ用途がメインとなります。
代表的な用途
・メディア資産の保存
・ヘルスケア情報のアーカイブ
・規制及びコンプライアンスのアーカイブ
・科学的データのストレージ
・デジタル保存Glacier Deep Archive
S3で最安のストレージクラスです。
1年で1回か2回しかアクセスされないようなデータの長期保存に向いています。
Glacierに保存するものよりも、よりアクセス頻度が低いものを保存するイメージです。
その分、データの読み出しにはより長い時間(12時間以内)がかかります。代表的な用途
・磁気テープの代替
・会計データ
・学籍情報ストレージクラスの比較
それぞれの特徴をざっくり比較してみます。
Standard Standard-IA One Zone-IA Glacier Glacier Deep Archive 冗長性 高 高 低 高 高 読み出し料金 なし あり あり あり あり 読み出し時間 速 速 速 遅 遅 もっと詳しく知りたい方は、公式を参照してくださいな。
Amazon S3 ストレージクラスIntelligent-Tiering
アクセス頻度ごとに自分でストレージクラス変えないといけないの!?めんどくさ!
と思った方もいるかと思います。そんなことはありません。ちゃんといい感じのものが用意されています。
Intelligent Tieringは、それぞれのファイルへのアクセス頻度を計測して
OneZone-IAを除く上記4つのストレージクラスへ自動的にデータを振り分けてくれます。
(手動で振り分けを設定するライフサイクルポリシーというものもありますが、今回は割愛します。)こちらを使用することで、コスト効率を最低化することができます。
デフォルトでは、以下のようにデータを振り分けます。(アーカイブアクセス有効化時)
・データをStandardへ保存
・30日連続でアクセスされなかったものはStandard-IAへ移動
・90日連続でアクセスされなかったものはGlacierへ移動
・上記+180日連続でアクセスされなかったものはGlacier Deep Archiveへ移動また、下層のストレージクラスへ振り分けられたデータに再度アクセスがあった際には、
自動的に高頻度のアクセス階層へ移動してくれます。例えば、Glacierに保存されているデータにアクセスがあった場合、
GlacierからStandardへ移動してくれるなど。データをどのぐらいの頻度で使用するかわからない場合、Intelligent-Tieringを使用するのが良いでしょう。
代表的な用途
・ストレージアクセスパターンが不明なデータセットの保存
・データレイクのように予測できないアクセスパターンを持つデータセットの保存まとめ
S3を使用する際は、データの使用頻度に応じて適切なストレージクラスを選択しましょう。
参考
Amazon S3 とは
Amazon S3 ストレージクラスこの記事はAWS初学者を導く体系的な動画学習サービス
「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com
- 投稿日:2021-02-13T10:11:41+09:00
【初心者】AWS AutoScalingについて(ハンズオン②:オートスケーリンググループの作成)
はじめに
AWS AutoScaling・・EC2を処理負荷に合わせて、増やしたり減らしたりすることができる便利なサービス
公式サイトこちらは前回の記事の続きとなっています。
【初心者】AWS AutoScalingについて(ハンズオン①:起動テンプレートの作成)ハンズオン②:オートスケーリンググループの作成
前回作成した起動テンプレートをもとにオートスケーリンググループを作成します。
EC2より「オートスケーリンググループ」を選択し、「AutoScalingグループの作成」を選択。
・Auto Scaling グループ名:任意のグループ名
・起動テンプレート:前回作成したテンプレート
・バージョン:バージョン管理している場合はここでバージョンを指定
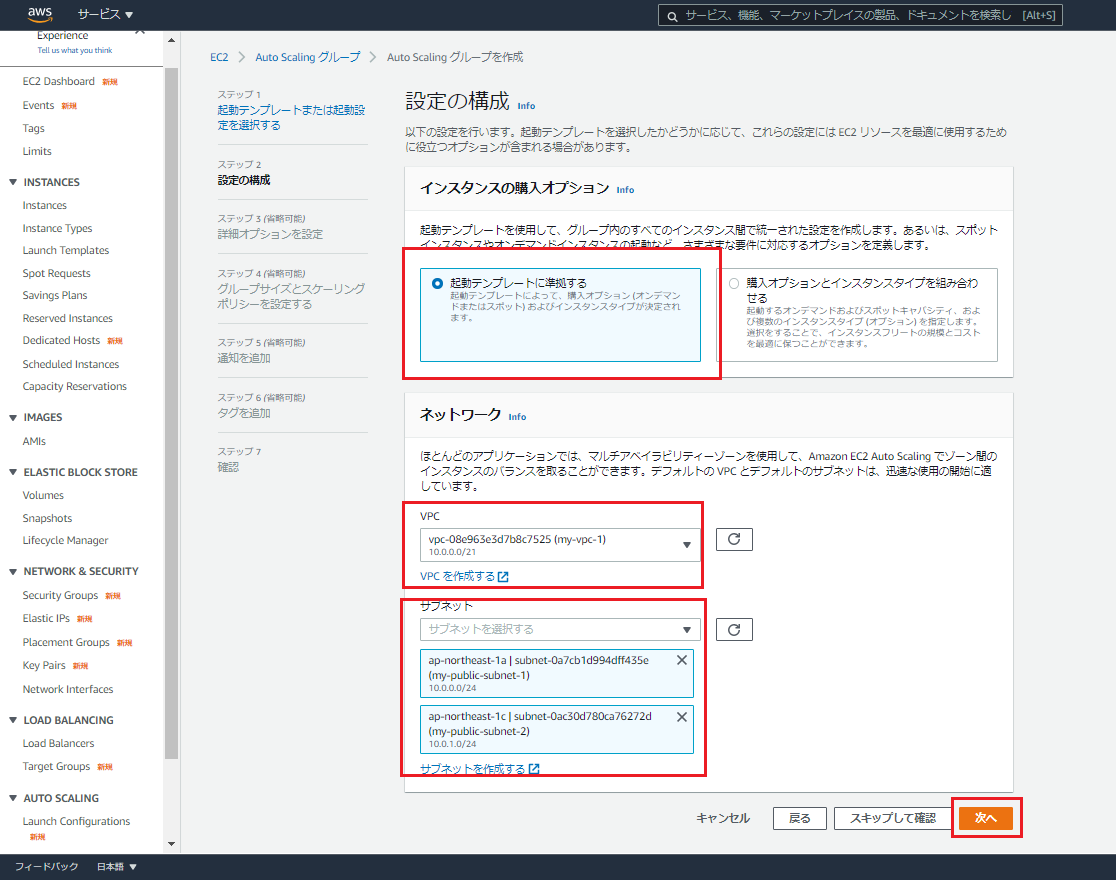
・インスタンスの購入オプション:費用を抑えたい場合はここでスポットインスタンスを選択することもできますが、今回は「起動テンプレートに準拠する」を選択
・ネットワーク VPC:インスタンスを起動するVPC
・ネットワーク サブネット:インスタンスを起動するサブネット
・ロードバランシング:アタッチするロードバランサを選択
・ヘルスチェック:EC2もしくはELBが使用可能な状態になっていることチェックするかどうかを選択※実際ユーザはEC2ではなく、ELBに接続をしに行きます。そのため、ここではELBを選択
・その他の設定:AutoScalingのメトリクスを有効にしたい場合は選択
・グループサイズ:インスタンスをどのくらい増やすか減らすかを決める
・スケーリンググポリシー:グループサイズの変更に合わせて、ルールを決める(例:インスタンスのCPU使用率が80%になったら、EC2 1台増加する)
ここがスケーリングをするうえで、1番重要!ポリシーは後から追加することができるため、ここではなしを選択
・インスタンスのスケールイン保護:追加で作成されたインスタンスを削除したくない場合はチェック
・通知を追加:インスタンスの増減があった場合に、SNSトピックを使用してメール通知が必要な場合は追加
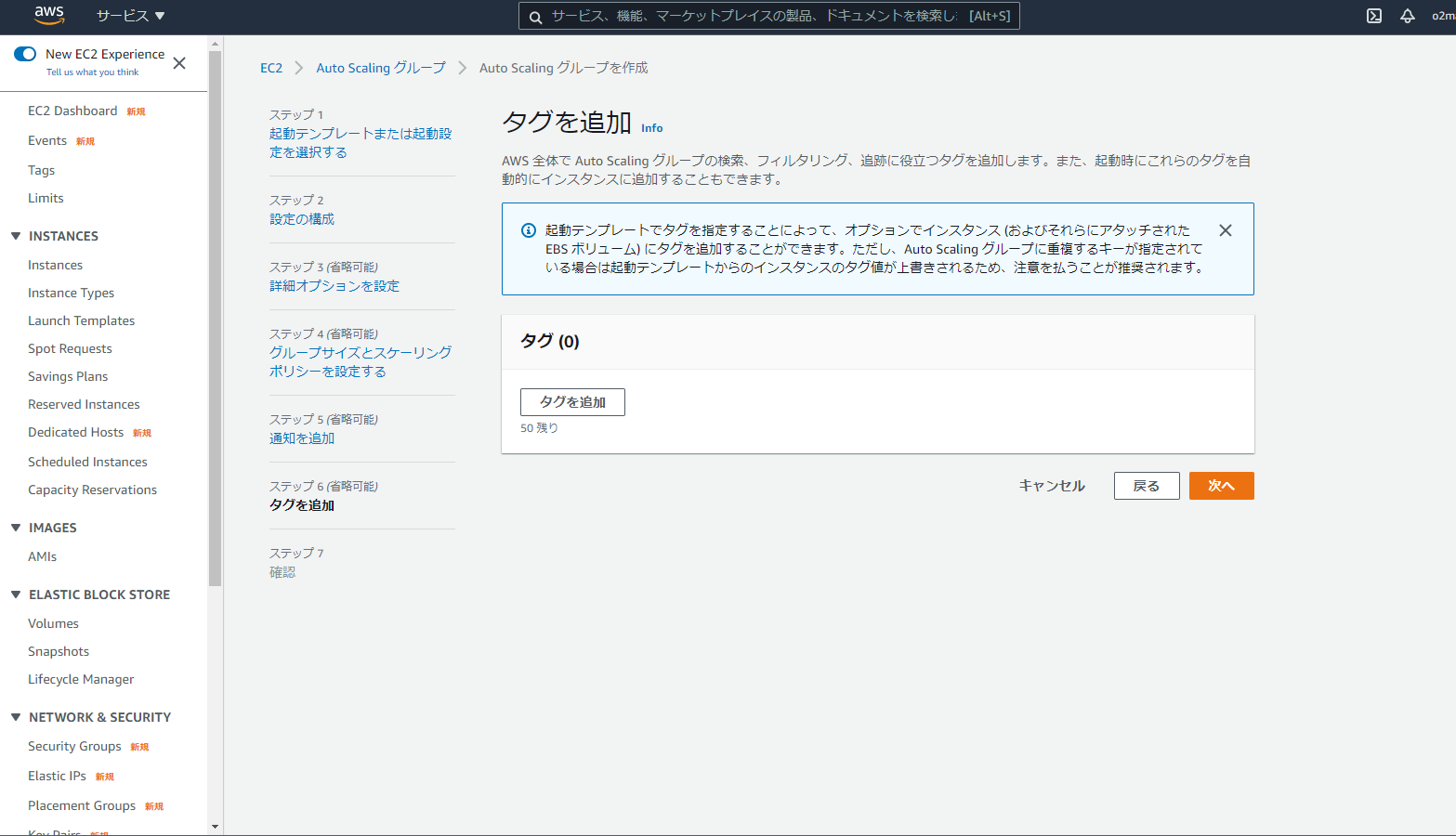
・タグを追加:必要に応じて、タグを追加最後に確認画面で値の設定を確認し、「AutoScalingグループを作成」を選択
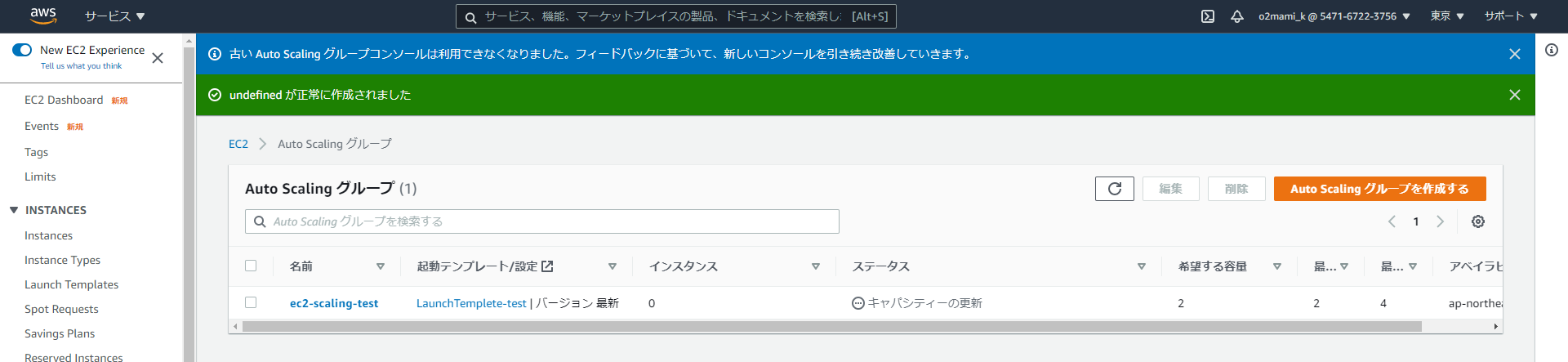
新しくAutoScalingグループが作成。
と同時に...
新しいEC2インスタンスが起動されたことも確認できます。
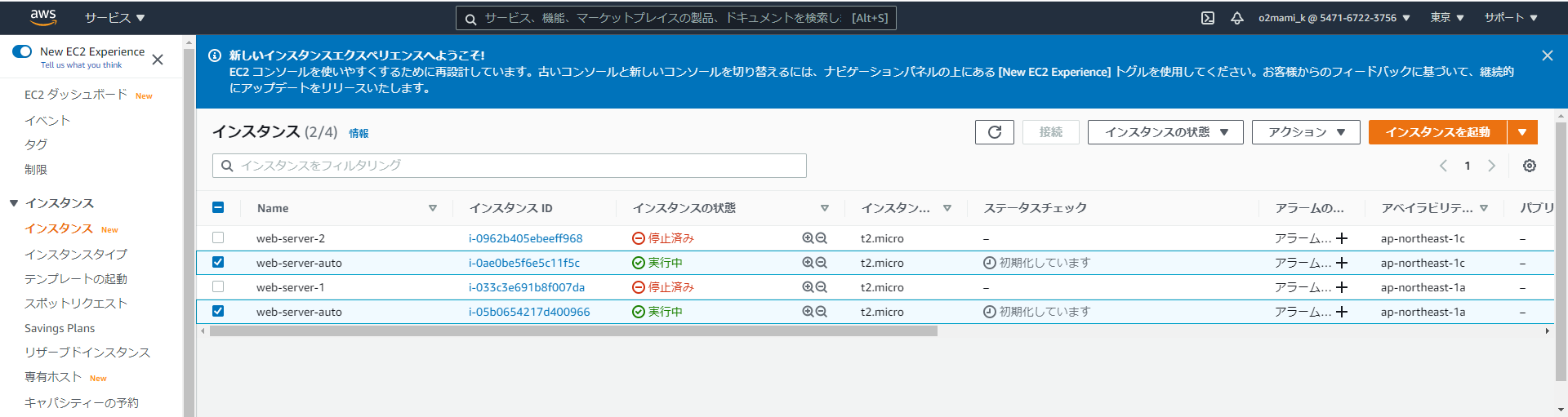
ここで1台インスタンスを停止してみると...
AutoScalingグループの「アクティビティ履歴」より1台インスタンスが停止されたこと、新しく1台インスタンスを立ち上げたことが確認できます。
実際にインスタンスを確認すると...
また新しいインスタンスが起動されていることを確認できます。
このように事前に設定したインスタンスの数をAutoScalingが検知し、自動で調整を行ってくれます。オートスケーリンググループの作成はここまでになります。
最後に
次回の記事では、ハンズオン③:オートスケーリングポリシーの作成を行いたいと思います。
この記事はAWS初学者を導く体系的な動画学習サービス「AWS CloudTech」の課題カリキュラムで作成しました。
https://aws-cloud-tech.com




- 投稿日:2021-02-13T09:50:48+09:00
【Laravel初心者】一覧表示の実装
Laravel初学者です。
オリジナルアプリを作成しているのでその過程を記事にしています。理解が曖昧なところも多いため、ご指摘等ありましたらご連絡いただければ幸いです。
今回は一覧表示の実装について備忘録のため記録として残します。
環境
Version PHP 7.4.14 Laravel 8.24.0 mysql 8.0.23 docker 20.10.2 docker-compose 1.27.4 ルーティング
routes/web.phpRoute::get('/', [GameController::class, 'index']);私の場合は/(ルート)を一覧表示として実装したかったので上記のようなルーティングになります。
/(ルート)にアクセスがあった時にGameControllerのindexアクションが動きますという意味です。モデル
Models/Game.php<?php namespace App\Models; use Illuminate\Database\Eloquent\Factories\HasFactory; use Illuminate\Database\Eloquent\Model; class Game extends Model { use HasFactory; protected $table = "games"; protected $fillable = [ "id", "user_id", "name", "describe", "play_time", "players_minimum", "players_max", "image_path", "updated_at", "created_at", ]; public function user() { return $this->belongsTo(User::class); } }こちらは今回の一覧表示機能にだけ必要というものではないですが。
$fillableで指定して保存を許可します。
$fillableについてはこちらの記事が分かりやすかったです。
ありがとうございます。コントローラー
app/Http/Controllers/GameController.php<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use App\Models\Game; use Illuminate\Support\Facades\Auth; use Storage; class GameController extends Controller { /** * Display a listing of the resource. * * @return \Illuminate\Http\Response */ //下記がindexアクション public function index() { $games = Game::all(); return view('game.index', compact('games')); } }
$gamesにGame::all();でGameモデルから全てのデータを取ってきて代入しています。全てとるので複数形の$gamesになってます。プログラミング学び始めのとき、複数形なのか単数形なのか分からなかったんですよね。
allで全てとる=複数のデータ=つまり複数形なので普通に考えれば簡単ですよね。その後
return viewでindexのviewを返す動きになってます。
compact('games')と記述することでview側で$gamesという変数が使えます。
逆にcompact書かないとエラーになりますので注意です。compactについてはこちらの記事が分かりやすかったです。
ありがとうございます。ビュー
resources/views/game/index.blade.php<section class="page-section bg-light" id="portfolio"> <div class="container"> <div class="text-center"> <h2 class="section-heading text-uppercase">新着ボードゲーム</h2> <h3 class="section-subheading text-muted">Lorem ipsum dolor sit amet consectetur.</h3> </div> <div class="row"> @foreach($games as $game) @if($game->image_path) <div class="col-lg-4 col-sm-6 mb-4"> <div class="portfolio-item" style="text-align:center"> <a class="portfolio-link" href="{{ route('game.show', $game->id) }}"> <img src="{{ $game->image_path }}" height="200" width="200"> </a> <div class="portfolio-caption" style="margin-top:10px"> <div class="portfolio-caption-heading">{{ $game->name }}</div> <div class="portfolio-caption-subheading text-muted">プレイ時間:{{ $game->play_time }}分</div> <div class="portfolio-caption-subheading text-muted">人数:{{ $game->players_minimum }}~{{ $game->players_max }}人</div> </div> </div> </div> @endif @endforeach </div> </div> </section>resources/views/game/index.blade.php@foreach($games as $game) //この中に処理を書く @endforeach上記のように
foreachで繰り返し処理をしています。
コントローラーがデータを$gamesに入れてviewに渡してくれているのでそれをforeachの中では$gameとして一つずつ取り出します。つまり一つずつ呼び出すためには
resources/views/game/index.blade.php{{ $game->name }}上記のように
$gameのnameというように記述します。こちらで一覧表示の実装は完了です。
- 投稿日:2021-02-13T04:13:26+09:00
MacでM5stack Core2 for AWS
0. はじめに
なんとなーく、スイッチサイエンスを徘徊していたら、
M5Stack Core2 for AWS - ESP32 IoT開発キットとかいう面白そうなデバイスを発見!
AWSを使ってIoTのお勉強ができるっぽい。
〜ポチ!〜2日後に着〜そこそこハマりどころがあるので、メモがてら投稿
例によって初心者なので間違っていたらゴメンナサイ?
環境はMacOS Catalina 10.15.71. はじめはサラサラと
スイッチサイエンスの商品ページには詳細が英語しかないように書かれていますが、
日本語ページもあります! やったねというわけで、上のページを見ながら進めていきました。
※ドキュメントはよくできているので、以降ハマったところを書いています1-1. ドライバのインストール
macOS 10.9+を開くとMavericks以降はすでに組み込み済みとのこと。
念のために確認!% kextstat | grep usb.serial 186 1 0xffffff7f8470d000 0x6000 0x6000 com.apple.driver.usb.serial (6.0.0) 8D86815D-64E8-39C5-A879-263C5052B11B <61 21 6 5 3 1>なんか出たから大丈夫っぽい。
1-2. Visual Studio Codeのインストール
ここから
1-3. PlatformIO のインストール
1.Visual Studio Codeを起動したら、Extensionsを開く
(左側の□が4つあるアイコンをクリックするかcommand+shift+x)
2.platformio ideを検索
3.青いinstallをクリック
1-4. あとは
あとはドキュメント通り、
・スマホにESP RainMakerをインストール
・Githubからソースを持ってくる
・MacとM5StackをUSB接続
ここまでは迷うとこはないですな2. ESP RainMaker Agent の実行
2-1. 第1のつまずき
ドキュメント通りに進めていって、
RainMaker Agent ファームウェアのビルドとアップロードの
buildまでは普通に進みましたが、Upload & Monitorでエラー発生!
スクショ取り忘れましたが
/dev/cu.SLAB_USBtoUARTなんてないよ
みたいなエラーだったと。。。
というわけでterminalで% ls /dev/cu.SLAB_USBtoUART ls: /dev/cu.SLAB_USBtoUART: No such file or directoryたしかにない。。。
じゃあコレは?% ls /dev/cu.* /dev/cu.Bluetooth-Incoming-Port /dev/cu.usbserial-0225F023どうも/dev/cu.usbserial-0225F023が正解っぽい
というわけで、platformio.iniファイルのupload_portを変更platformio.ini; PlatformIO Project Configuration File ; ; Build options: build flags, source filter, extra scripting ; Upload options: custom port, speed and extra flags ; Library options: dependencies, extra library storages ; ; Please visit documentation for the other options and examples ; http://docs.platformio.org/page/projectconf.html [env:core2foraws] platform = espressif32@2.1.0 framework = espidf board = esp32dev ;upload_port = /dev/cu.SLAB_USBtoUART upload_port = /dev/cu.usbserial-0225F023 monitor_speed = 115200 board_build.partitions = partitions_4MB_sec.csv board_build.embed_txtfiles = components/esp_rainmaker/server_certs/mqtt_server.crt components/esp_rainmaker/server_certs/claim_service_server.crt components/esp_rainmaker/server_certs/ota_server.crtもう一回buildしてからUpload & Monitor!
> Executing task: pio run --target upload --target monitor --environment core2foraws < Processing core2foraws (platform: espressif32@2.1.0; framework: espidf; board: esp32dev) ----------------------------------------------------------------------------------------------------------------------------- Verbose mode can be enabled via `-v, --verbose` option CONFIGURATION: https://docs.platformio.org/page/boards/espressif32/esp32dev.html PLATFORM: Espressif 32 (2.1.0) > Espressif ESP32 Dev Module HARDWARE: ESP32 240MHz, 320KB RAM, 4MB Flash DEBUG: Current (esp-prog) External (esp-prog, iot-bus-jtag, jlink, minimodule, olimex-arm-usb-ocd, olimex-arm-usb-ocd-h, olimex-arm-usb-tiny-h, olimex-jtag-tiny, tumpa) PACKAGES: - framework-espidf 3.40100.200827 (4.1.0) - tool-cmake 3.16.4 - tool-esptoolpy 1.30000.201119 (3.0.0) - tool-mkspiffs 2.230.0 (2.30) - tool-ninja 1.9.0 - toolchain-esp32ulp 1.22851.191205 (2.28.51) - toolchain-xtensa32 2.80200.200827 (8.2.0) Reading CMake configuration... LDF: Library Dependency Finder -> http://bit.ly/configure-pio-ldf LDF Modes: Finder ~ chain, Compatibility ~ soft Found 0 compatible libraries Scanning dependencies... No dependencies Building in release mode Retrieving maximum program size .pio/build/core2foraws/firmware.elf Checking size .pio/build/core2foraws/firmware.elf Advanced Memory Usage is available via "PlatformIO Home > Project Inspect" RAM: [=== ] 26.8% (used 87864 bytes from 327680 bytes) Flash: [========= ] 95.0% (used 1555753 bytes from 1638400 bytes) Configuring upload protocol... AVAILABLE: esp-prog, espota, esptool, iot-bus-jtag, jlink, minimodule, olimex-arm-usb-ocd, olimex-arm-usb-ocd-h, olimex-arm-usb-tiny-h, olimex-jtag-tiny, tumpa CURRENT: upload_protocol = esptool Looking for upload port... Use manually specified: /dev/cu.usbserial-0225F023 Uploading .pio/build/core2foraws/firmware.bin esptool.py v3.0 Serial port /dev/cu.usbserial-0225F023 Connecting..... Chip is ESP32-D0WDQ6-V3 (revision 3) Features: WiFi, BT, Dual Core, 240MHz, VRef calibration in efuse, Coding Scheme None Crystal is 40MHz MAC: 24:0a:c4:f9:9f:ac Uploading stub... Running stub... Stub running... Changing baud rate to 460800 Changed. Configuring flash size... Auto-detected Flash size: 16MB Flash params set to 0x0240 Compressed 26912 bytes to 16214... Writing at 0x00001000... (100 %) Wrote 26912 bytes (16214 compressed) at 0x00001000 in 0.4 seconds (effective 538.6 kbit/s)... Hash of data verified. Compressed 3072 bytes to 159... Writing at 0x00008000... (100 %) Wrote 3072 bytes (159 compressed) at 0x00008000 in 0.0 seconds (effective 1370.5 kbit/s)... Hash of data verified. Compressed 8192 bytes to 31... Writing at 0x00016000... (100 %) Wrote 8192 bytes (31 compressed) at 0x00016000 in 0.0 seconds (effective 4094.4 kbit/s)... Hash of data verified. Compressed 1555872 bytes to 889938... Writing at 0x00020000... (1 %) Writing at 0x00024000... (3 %) Writing at 0x00028000... (5 %) Writing at 0x0002c000... (7 %) Writing at 0x00030000... (9 %) Writing at 0x00034000... (10 %) Writing at 0x00038000... (12 %) Writing at 0x0003c000... (14 %) Writing at 0x00040000... (16 %) Writing at 0x00044000... (18 %) Writing at 0x00048000... (20 %) Writing at 0x0004c000... (21 %) Writing at 0x00050000... (23 %) Writing at 0x00054000... (25 %) Writing at 0x00058000... (27 %) Writing at 0x0005c000... (29 %) Writing at 0x00060000... (30 %) Writing at 0x00064000... (32 %) Writing at 0x00068000... (34 %) Writing at 0x0006c000... (36 %) Writing at 0x00070000... (38 %) Writing at 0x00074000... (40 %) Writing at 0x00078000... (41 %) Writing at 0x0007c000... (43 %) Writing at 0x00080000... (45 %) Writing at 0x00084000... (47 %) Writing at 0x00088000... (49 %) Writing at 0x0008c000... (50 %) Writing at 0x00090000... (52 %) Writing at 0x00094000... (54 %) Writing at 0x00098000... (56 %) Writing at 0x0009c000... (58 %) Writing at 0x000a0000... (60 %) Writing at 0x000a4000... (61 %) Writing at 0x000a8000... (63 %) Writing at 0x000ac000... (65 %) Writing at 0x000b0000... (67 %) Writing at 0x000b4000... (69 %) Writing at 0x000b8000... (70 %) Writing at 0x000bc000... (72 %) Writing at 0x000c0000... (74 %) Writing at 0x000c4000... (76 %) Writing at 0x000c8000... (78 %) Writing at 0x000cc000... (80 %) Writing at 0x000d0000... (81 %) Writing at 0x000d4000... (83 %) Writing at 0x000d8000... (85 %) Writing at 0x000dc000... (87 %) Writing at 0x000e0000... (89 %) Writing at 0x000e4000... (90 %) Writing at 0x000e8000... (92 %) Writing at 0x000ec000... (94 %) Writing at 0x000f0000... (96 %) Writing at 0x000f4000... (98 %) Writing at 0x000f8000... (100 %) Wrote 1555872 bytes (889938 compressed) at 0x00020000 in 22.2 seconds (effective 561.3 kbit/s)... Hash of data verified. Leaving... Hard resetting via RTS pin... =============================================== [SUCCESS] Took 40.56 seconds =============================================== --- Available filters and text transformations: colorize, debug, default, direct, esp32_exception_decoder, hexlify, log2file, nocontrol, printable, send_on_enter, time --- More details at http://bit.ly/pio-monitor-filters --- Miniterm on /dev/cu.usbserial-0225F023 115200,8,N,1 --- --- Quit: Ctrl+C | Menu: Ctrl+T | Help: Ctrl+T followed by Ctrl+H --- ␛[0;32mI (719) esp_image: segment 5: paddr=0x00185710 vaddr=0x40087fa4 size=0x16664 ( 91748) load␛[0m ␛[0;32mI (777) boot: Loaded app from partition at offset 0x20000␛[0m ␛[0;32mI (832) boot: Set actual ota_seq=1 in otadata[0]␛[0m ␛[0;32mI (832) boot: Disabling RNG early entropy source...␛[0m ␛[0;32mI (833) psram: This chip is ESP32-D0WD␛[0m ␛[0;32mI (837) spiram: Found 64MBit SPI RAM device␛[0m ␛[0;32mI (841) spiram: SPI RAM mode: flash 80m sram 80m␛[0m ␛[0;32mI (846) spiram: PSRAM initialized, cache is in low/high (2-core) mode.␛[0m ␛[0;32mI (854) cpu_start: Pro cpu up.␛[0m ␛[0;32mI (857) cpu_start: Application information:␛[0m ␛[0;32mI (862) cpu_start: Project name: AWS_IoT_EduKit-Getting_Started␛[0m ␛[0;32mI (869) cpu_start: App version: 3c5aa62-dirty␛[0m ␛[0;32mI (875) cpu_start: Compile time: Feb 12 2021 23:41:21␛[0m ␛[0;32mI (881) cpu_start: ELF file SHA256: 9747349fbca1eb77...␛[0m ␛[0;32mI (887) cpu_start: ESP-IDF: 3.40100.200827␛[0m ␛[0;32mI (892) cpu_start: Starting app cpu, entry point is 0x400830b0␛[0m ␛[0;32mI (0) cpu_start: App cpu up.␛[0m ␛[0;32mI (1396) spiram: SPI SRAM memory test OK␛[0m ␛[0;32mI (1396) heap_init: Initializing. RAM available for dynamic allocation:␛[0m ␛[0;32mI (1396) heap_init: At 3FFAFF10 len 000000F0 (0 KiB): DRAM␛[0m ␛[0;32mI (1402) heap_init: At 3FFB6388 len 00001C78 (7 KiB): DRAM␛[0m ␛[0;32mI (1408) heap_init: At 3FFB9A20 len 00004108 (16 KiB): DRAM␛[0m ␛[0;32mI (1415) heap_init: At 3FFBDB5C len 00000004 (0 KiB): DRAM␛[0m ␛[0;32mI (1421) heap_init: At 3FFD3298 len 0000CD68 (51 KiB): DRAM␛[0m ␛[0;32mI (1427) heap_init: At 3FFE0440 len 00003AE0 (14 KiB): D/IRAM␛[0m ␛[0;32mI (1434) heap_init: At 3FFE4350 len 0001BCB0 (111 KiB): D/IRAM␛[0m ␛[0;32mI (1440) heap_init: At 4009E608 len 000019F8 (6 KiB): IRAM␛[0m ␛[0;32mI (1446) cpu_start: Pro cpu start user code␛[0m ␛[0;32mI (1451) spiram: Adding pool of 4096K of external SPI memory to heap allocator␛[0m ␛[0;32mI (1471) spi_flash: detected chip: generic␛[0m ␛[0;32mI (1472) spi_flash: flash io: qio␛[0m ␛[0;32mI (1472) cpu_start: Starting scheduler on PRO CPU.␛[0m ␛[0;32mI (0) cpu_start: Starting scheduler on APP CPU.␛[0m ␛[0;32mI (1481) spiram: Reserving pool of 32K of internal memory for DMA/internal allocations␛[0m ␛[0;32mI (1511) gpio: GPIO[39]| InputEn: 1| OutputEn: 0| OpenDrain: 0| Pullup: 1| Pulldown: 1| Intr:3 ␛[0m ␛[0;32mI (1711) ILI9341: Initialization.␛[0m ␛[0;32mI (1911) ILI9341: Display orientation: LANDSCAPE␛[0m ␛[0;32mI (1911) ILI9341: 0x36 command value: 0x08␛[0m I (2011) wifi:wifi driver task: 3ffd6044, prio:23, stack:6656, core=0 ␛[0;32mI (2011) system_api: Base MAC address is not set, read default base MAC address from BLK0 of EFUSE␛[0m ␛[0;32mI (2011) system_api: Base MAC address is not set, read default base MAC address from BLK0 of EFUSE␛[0m I (2211) wifi:wifi firmware version: 3ea4c76 I (2211) wifi:config NVS flash: enabled I (2211) wifi:config nano formating: disabled I (2211) wifi:Init dynamic tx buffer num: 32 I (2211) wifi:Init data frame dynamic rx buffer num: 16 I (2221) wifi:Init management frame dynamic rx buffer num: 16 I (2221) wifi:Init management short buffer num: 32 I (2231) wifi:Init static tx buffer num: 8 I (2231) wifi:Init static rx buffer size: 1600 I (2231) wifi:Init static rx buffer num: 4 I (2241) wifi:Init dynamic rx buffer num: 16 ␛[0;32mI (2251) esp_claim: Initialising Assisted Claiming. This may take time.␛[0m ␛[0;33mW (2251) esp_claim: Generating the private key. This may take time.␛[0m ␛[0;32mI (67941) esp_rmaker_node: Node ID ----- 240AC4F99FAC␛[0m ␛[0;32mI (67941) display: configuring the house␛[0m ␛[0;32mI (67941) display: house configured␛[0m ␛[0;32mI (67951) display: lights off␛[0m ␛[0;32mI (69361) display: configuring the temperature␛[0m ␛[0;32mI (69361) display: temperature configured␛[0m ␛[0;32mI (69451) display: configuring the fan␛[0m ␛[0;32mI (69451) display: configured fan_object␛[0m ␛[0;32mI (69451) display: configured fan_strength_slider␛[0m ␛[0;32mI (69451) display: configured fan_sw1␛[0m ␛[0;32mI (69451) display: fan configured␛[0m ␛[0;32mI (69461) esp_rmaker_time_sync: Initializing SNTP. Using the SNTP server: pool.ntp.org␛[0m ␛[0;32mI (69471) esp_rmaker_core: Starting RainMaker Core Task␛[0m ␛[0;32mI (69481) esp_claim: Waiting for assisted claim to finish.␛[0m ␛[0;32mI (69481) wifi_prov_scheme_ble: BT memory released␛[0m ␛[0;32mI (69481) app_wifi: Starting provisioning␛[0m ␛[0;33mW (69501) phy_init: failed to load RF calibration data (0x1102), falling back to full calibration␛[0m ␛[0;32mI (69631) phy: phy_version: 4180, cb3948e, Sep 12 2019, 16:39:13, 0, 2␛[0m I (69691) wifi:mode : sta (24:0a:c4:f9:9f:ac) ␛[0;32mI (69701) BTDM_INIT: BT controller compile version [219866f]␛[0m ␛[0;32mI (69701) system_api: Base MAC address is not set, read default base MAC address from BLK0 of EFUSE␛[0m ␛[0;32mI (69881) protocomm_nimble: BLE Host Task Started␛[0m ␛[0;32mI (69891) wifi_prov_mgr: Provisioning started with service name : PROV_02167d ␛[0m ␛[0;32mI (69891) app_wifi: Provisioning started␛[0m ␛[0;32mI (69891) app_wifi: Scan this QR code from the phone app for Provisioning.␛[0m GAP procedure initiated: advertise; disc_mode=2 adv_channel_map=0 own_addr_type=0 adv_filter_policy=0 adv_itvl_min=256 adv_itvl_max=256 █▀▀▀▀▀█ ▄█ ▄▄ █▄▀ ▀▀██▀▀█ █▀▀▀▀▀█ █ ███ █ ▄█▀█ ▄ ▄▄▄▀ ▄▀▀▀▀ █ ███ █ █ ▀▀▀ █ ▄ █ ▀▄ ▄█ █▀ ▀█▀█ █ ▀▀▀ █ █▀████▀▄▀█▄█▀▀ █ ▀█▄▄▄█▄ █▀▄ ▄█ ▀█▀ ▀█▀█▄▀▄▀ ▀██▀▄▀▄▀▀ ▀▄▀▀ ▄▀▄ ▀ ▀▀ ▄▀▀▄▄▄█▀▀ ▀▄ ▀▄ ▄ ▄ ▄█▀ ▄▀▄ ▄▀▀█▄█▀▄ ▄▀▄█▀ ▄▀██▀ ▀▀▄▄█▀ ▄ ▄ ▀ ██▀▄▄▄▀ ▀▀▀▀█▀▄▄ ▄ ▄▀▀▀ █▄ █ ▀▄█▀▄▄ ▄ ▀█▀▀█▄ █▀▄█ █▀▄▄▄▄▄ ▀ ▀ ▀▀▀█▀█ ▀▀▀▀▄██▄ ▄ ▄█▀▀▀██▄▄█ █▀▀▀▀▀█ ▀███▀ █▀ ▄ ▄ ▄█ ▀ █ ▄▀ █ ███ █ █▀█▀█▀ ▀█▀█▄█▄█ █▀▀██▀▄▀ █ ▀▀▀ █ █ ▀ ▀ █▄▀█▄██ ▄█ ▀█▄▀█▀ ▀▀▀▀▀▀▀ ▀ ▀ ▀▀▀▀▀ ▀ ▀▀▀ ▀▀ ▀なんとかQRコード表示までうまくいったようです
アスキーアートでQRコードが出るとは思わなかったw
ターミナルでの表示なので確かに絵はでないか。。。
ちなみに上のQRコードは加工しています。おそらくM5Stackの画面はこんな感じになっていると思います。
ファンのアイコンの下のスライドスイッチあたり触ると
「ぶーーん」とファンが回りますw
2-2. あとは
あとはドキュメント通り、ESP RainMakerにデバイス登録すれば、
スマホ側からFanのOn/Offとか明るさ変えたりとかできると思います^^3. ESP-IDF v4.2 のインストール
3-1. やっぱりココでもつまづく
ドキュメントにある下のコマンドを実行!!!
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" brew install cmake ninja dfu-util mkdir $HOME/esp cd $HOME/esp git clone -b release/v4.2 --recursive https://github.com/espressif/esp-idf.git cd $HOME/esp/esp-idf . $HOME/esp/esp-idf/install.sh . $HOME/esp/esp-idf/export.shそしてエラー
〜〜〜いろいろ省略〜〜〜 Installing Python environment and packages Creating a new Python environment in /Users/オレ/.espressif/python_env/idf4.2_py2.7_env Installing virtualenv /System/Library/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python: No module named pip Traceback (most recent call last): File "/Users/オレ/esp/esp-idf/tools/idf_tools.py", line 1492, in <module> main(sys.argv[1:]) File "/Users/オレ/esp/esp-idf/tools/idf_tools.py", line 1488, in main action_func(args) File "/Users/オレ/esp/esp-idf/tools/idf_tools.py", line 1205, in action_install_python_env stdout=sys.stdout, stderr=sys.stderr) File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/subprocess.py", line 190, in check_call raise CalledProcessError(retcode, cmd) subprocess.CalledProcessError: Command '['/System/Library/Frameworks/Python.framework/Versions/2.7/Resources/Python.app/Contents/MacOS/Python', '-m', 'pip', 'install', '--user', 'virtualenv']' returned non-zero exit status 1 [プロセスが完了しました]う〜ん、どうするかな。。。
。。。とりあえずpython3にしちゃおうw
コケているのは、
. $HOME/esp/esp-idf/install.sh
brewはインストールされている
ということで、、、pyenvをインストール
% brew install pyenv Updating Homebrew... ==> Auto-updated Homebrew! Updated 1 tap (homebrew/core). ==> Updated Formulae Updated 11 formulae. ==> Downloading https://homebrew.bintray.com/bottles/autoconf-2.69.catalina.bottle.4.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/ca510b350e941fb9395522a03f9d2fb5df276085d806ceead763acb95889a368?response-content- ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/pkg-config-0.29.2_3.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/80f141e695f73bd058fd82e9f539dc67471666ff6800c5e280b5af7d3050f435?response-content- ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/pyenv-1.2.22.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/b4f3038e29acde1d99579104ae100777621b9716fe797e7917dad1e9795d3473?response-content- ######################################################################## 100.0% ==> Installing dependencies for pyenv: autoconf and pkg-config ==> Installing pyenv dependency: autoconf ==> Pouring autoconf-2.69.catalina.bottle.4.tar.gz ? /usr/local/Cellar/autoconf/2.69: 67 files, 3.0MB ==> Installing pyenv dependency: pkg-config ==> Pouring pkg-config-0.29.2_3.catalina.bottle.tar.gz ? /usr/local/Cellar/pkg-config/0.29.2_3: 11 files, 623.8KB ==> Installing pyenv ==> Pouring pyenv-1.2.22.catalina.bottle.tar.gz ? /usr/local/Cellar/pyenv/1.2.22: 721 files, 2.6MBで、python3は何をいれようかなー
最新はいくつかな〜% pyenv install --list Available versions: 2.1.3 2.2.3 2.3.7 〜〜〜中略〜〜〜 3.9.0 3.9-dev 3.9.1 3.10-dev activepython-2.7.14 activepython-3.5.4 〜〜〜以下略〜〜〜ということで3.9.1に決定!
早速インストール% pyenv install 3.9.1 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.9.1.tar.xz... -> https://www.python.org/ftp/python/3.9.1/Python-3.9.1.tar.xz Installing Python-3.9.1... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.9.1 to /Users/オレ/.pyenv/versions/3.9.1無事インストール完了
ちゃんとpyenvでみられるか確認して、3.9.1を使うように。。。% pyenv versions * system (set by /Users/オレ/.pyenv/version) 3.9.1 % pyenv global 3.9.1 % pyenv rehash % pyenv versions system * 3.9.1 (set by /Users/オレ/.pyenv/version)で、.bash_profileに
.bash_profilePYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"shellがzshなので
% bash The default interactive shell is now zsh. To update your account to use zsh, please run `chsh -s /bin/zsh`. For more details, please visit https://support.apple.com/kb/HT208050. bash-3.2$ cd bash-3.2$ source .bash_profile bash-3.2$ python --version Python 3.9.1ということでpythonを実行すると3.9.1が起動するように〜
とりあえずpipも最新にしておこbash-3.2$ pip install --upgrade pip Collecting pip Using cached pip-21.0.1-py3-none-any.whl (1.5 MB) Installing collected packages: pip Attempting uninstall: pip Found existing installation: pip 20.2.3 Uninstalling pip-20.2.3: Successfully uninstalled pip-20.2.3 Successfully installed pip-21.0.1やっとこさ環境がそろったので
コケていたinstall.shを〜bash-3.2$ cd $HOME/esp/esp-idf bash-3.2$ . $HOME/esp/esp-idf/install.sh Installing ESP-IDF tools Installing tools: xtensa-esp32-elf, xtensa-esp32s2-elf, esp32ulp-elf, esp32s2ulp-elf, openocd-esp32 Skipping xtensa-esp32-elf@esp-2020r3-8.4.0 (already installed) Skipping xtensa-esp32s2-elf@esp-2020r3-8.4.0 (already installed) Skipping esp32ulp-elf@2.28.51-esp-20191205 (already installed) Skipping esp32s2ulp-elf@2.28.51-esp-20191205 (already installed) Skipping openocd-esp32@v0.10.0-esp32-20200709 (already installed) Installing Python environment and packages Creating a new Python environment in /Users/オレ/.espressif/python_env/idf4.2_py3.9_env Installing virtualenv Collecting virtualenv Downloading virtualenv-20.4.2-py2.py3-none-any.whl (7.2 MB) |████████████████████████████████| 7.2 MB 6.7 MB/s Collecting distlib<1,>=0.3.1 Downloading distlib-0.3.1-py2.py3-none-any.whl (335 kB) |████████████████████████████████| 335 kB 30.1 MB/s Collecting six<2,>=1.9.0 Downloading six-1.15.0-py2.py3-none-any.whl (10 kB) 〜〜〜省略〜〜〜 Successfully installed Flask-0.12.5 Flask-Compress-1.8.0 Flask-SocketIO-2.9.6 Jinja2-2.11.3 MarkupSafe-1.1.1 Pygments-2.7.4 Werkzeug-0.16.1 bidict-0.21.2 bitstring-3.1.7 brotli-1.0.9 cffi-1.14.5 click-7.1.2 cryptography-3.4.4 ecdsa-0.16.1 future-0.18.2 gdbgui-0.13.2.0 gevent-1.5.0 greenlet-1.0.0 itsdangerous-1.1.0 pycparser-2.20 pyelftools-0.27 pygdbmi-0.9.0.2 pyparsing-2.3.1 pyserial-3.5 python-engineio-4.0.0 python-socketio-5.0.4 reedsolo-1.5.4 six-1.15.0 All done! You can now run: . ./export.shインストールできた模様?
あとはexport.shbash-3.2$ . $HOME/esp/esp-idf/export.sh Adding ESP-IDF tools to PATH... Using Python interpreter in /Users/オレ/.espressif/python_env/idf4.2_py3.9_env/bin/python Checking if Python packages are up to date... Python requirements from /Users/オレ/esp/esp-idf/requirements.txt are satisfied. Added the following directories to PATH: /Users/オレ/esp/esp-idf/components/esptool_py/esptool /Users/オレ/esp/esp-idf/components/espcoredump /Users/オレ/esp/esp-idf/components/partition_table /Users/オレ/esp/esp-idf/components/app_update /Users/オレ/.espressif/tools/xtensa-esp32-elf/esp-2020r3-8.4.0/xtensa-esp32-elf/bin /Users/オレ/.espressif/tools/xtensa-esp32s2-elf/esp-2020r3-8.4.0/xtensa-esp32s2-elf/bin /Users/オレ/.espressif/tools/esp32ulp-elf/2.28.51-esp-20191205/esp32ulp-elf-binutils/bin /Users/オレ/.espressif/tools/esp32s2ulp-elf/2.28.51-esp-20191205/esp32s2ulp-elf-binutils/bin /Users/オレ/.espressif/tools/openocd-esp32/v0.10.0-esp32-20200709/openocd-esp32/bin /Users/オレ/.espressif/python_env/idf4.2_py3.9_env/bin /Users/オレ/esp/esp-idf/tools Done! You can now compile ESP-IDF projects. Go to the project directory and run: idf.py build bash-3.2$ idf idf.py idf_monitor.py idf_size.py idf_tools.py bash-3.2$というわけで、idf.pyできるようになった!(っぽい)?
Qiita書くのに疲れたので次回につづく。。。?

- 投稿日:2021-02-13T02:58:22+09:00
AWSのコストが急に増加したので調査したらNATゲートウェイのデータ転送料金だった
ECS FargateでWebクローラーのバッチ処理を開発しているのですが、新規バッチのデプロイ後にAWSのコストが予想以上に上がったときのことを書きます。
結論としては、ネットワーク設定ミスによって、本来かける必要のないコストがかかってしまっていました。
個人的に気づきにくかったので、AWSのコスト見直しの一つの項目として、確認の手順を書きたいと思います。
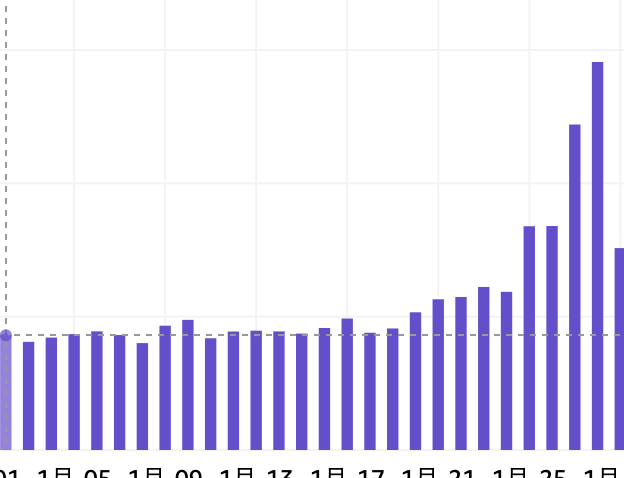
気付いたきっかけ
AWS Cost Explorer のホーム画面で日別コストが見れるのですが、ある日から急にコストが高まっていることに気づきました。
サービス別のコストを見ると、「EC2 その他」の項目が増加していることが分かりました。
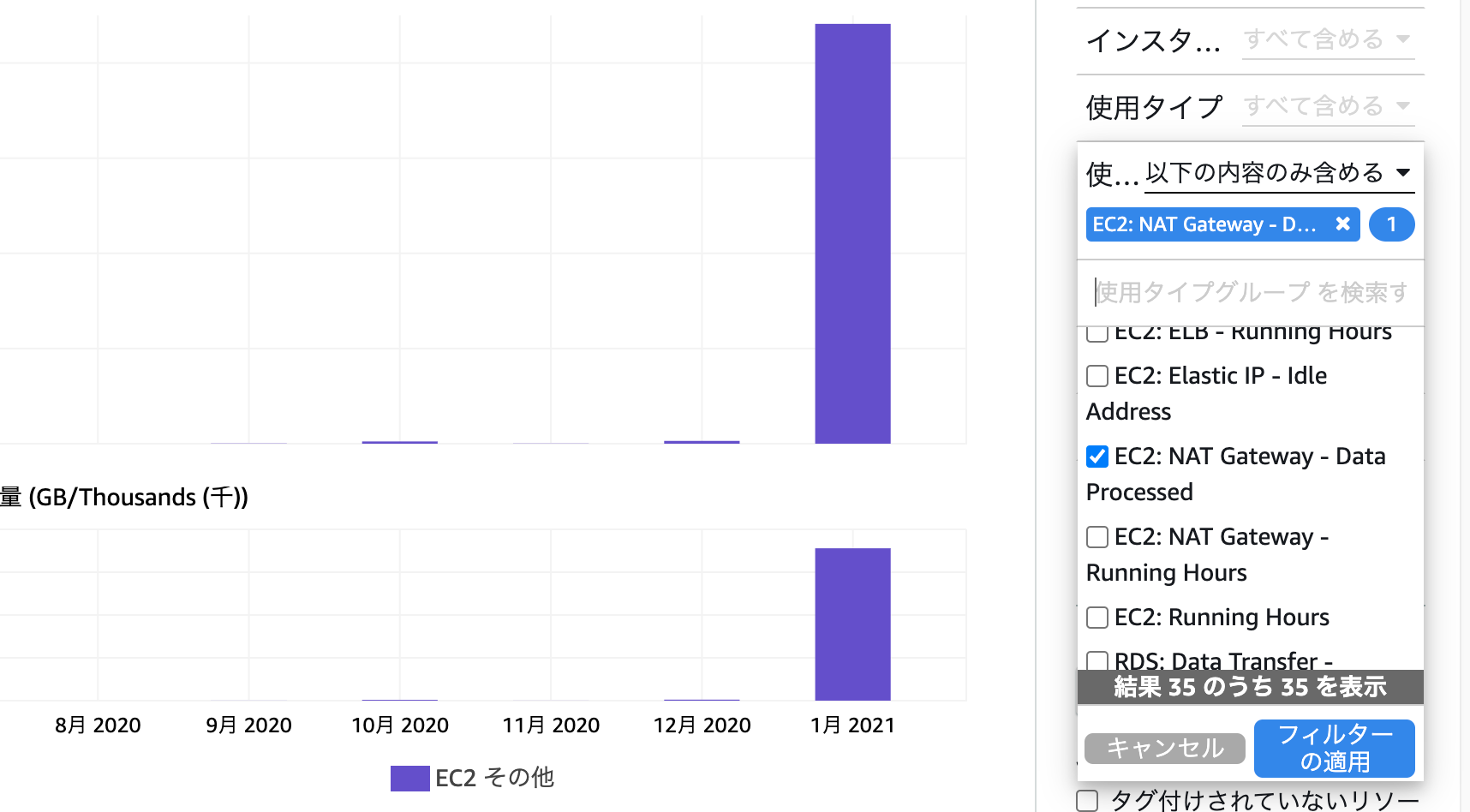
これだけだと原因が分かりにくかったのですが、
「使用タイプグループ」のフィルターでEC2関連を絞り込んでいくことで、原因となっているのが「EC2: NAT Gateway - Data Processed」であることが分かります。
AWSのメニューから、VPC > NATゲートウェイ > モニタリング と遷移した画面でも、NATゲートウェイの通信量が増えていることが確認できます。
NATゲートウェイ通信量増加の原因
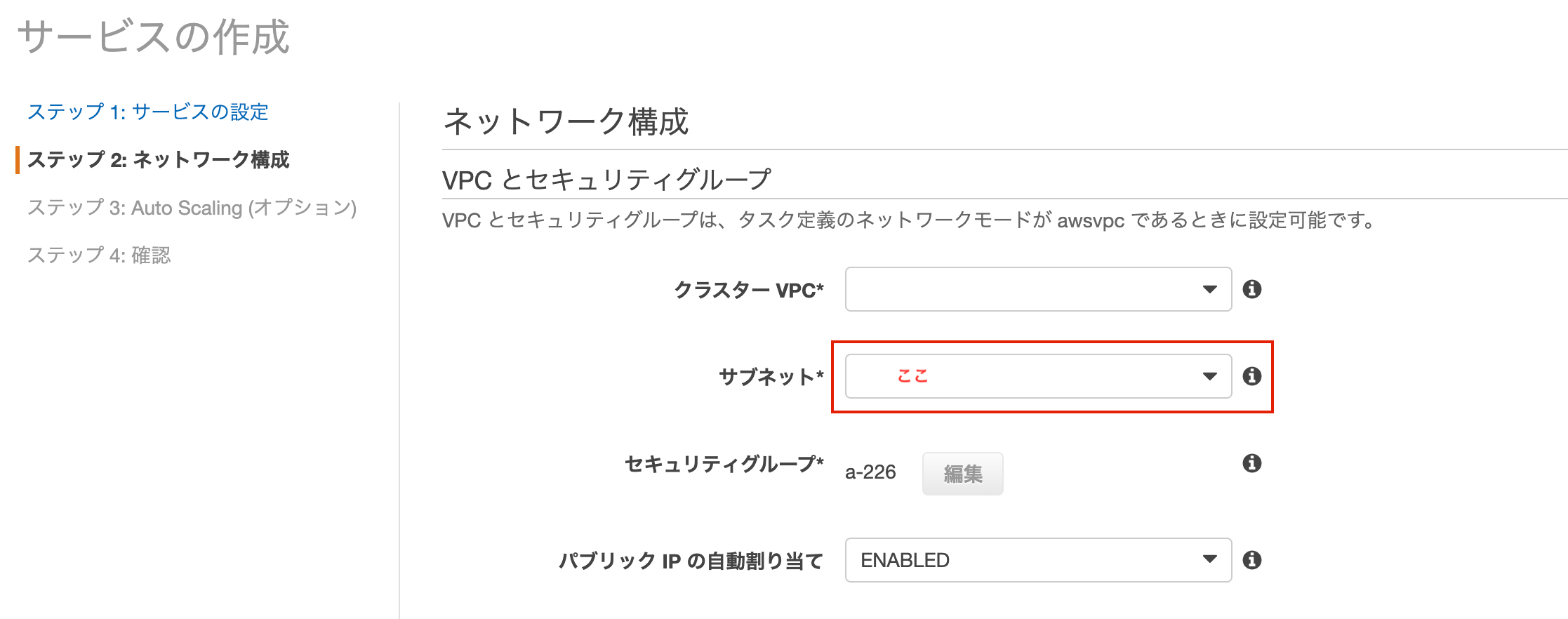
ECS Fargate でサービスを作成したとき、ネットワーク設定のサブネットの項目にパブリックサブネットではなくプライベートサブネットが指定されていたことが原因でした。
そもそも プライベートサブネット ・ パブリックサブネット ・ NATゲートウェイ とは何か
プライベートサブネットはインターネットから接続できないセキュリティ性の高いネットワークで、
パブリックサブネットはインターネットから接続可能なネットワークです。NATゲートウェイは、プライベートサブネットの内側から外部のインターネットに接続する際に、プライベートIPアドレスをグローバルIPアドレスに変換するためのものです。
※ NATは Network Address Translation の略です。
※ グローバルIPアドレスがないとインターネットに接続できません。プライベートサブネットには、外部からのアクセスを遮断したいDBサーバなどを配置することが多いです。
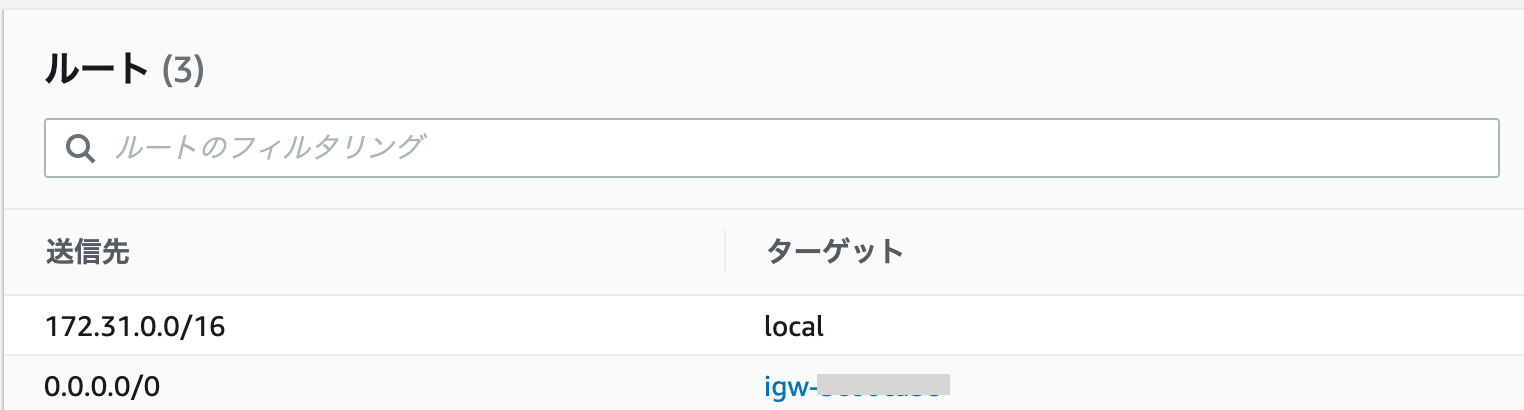
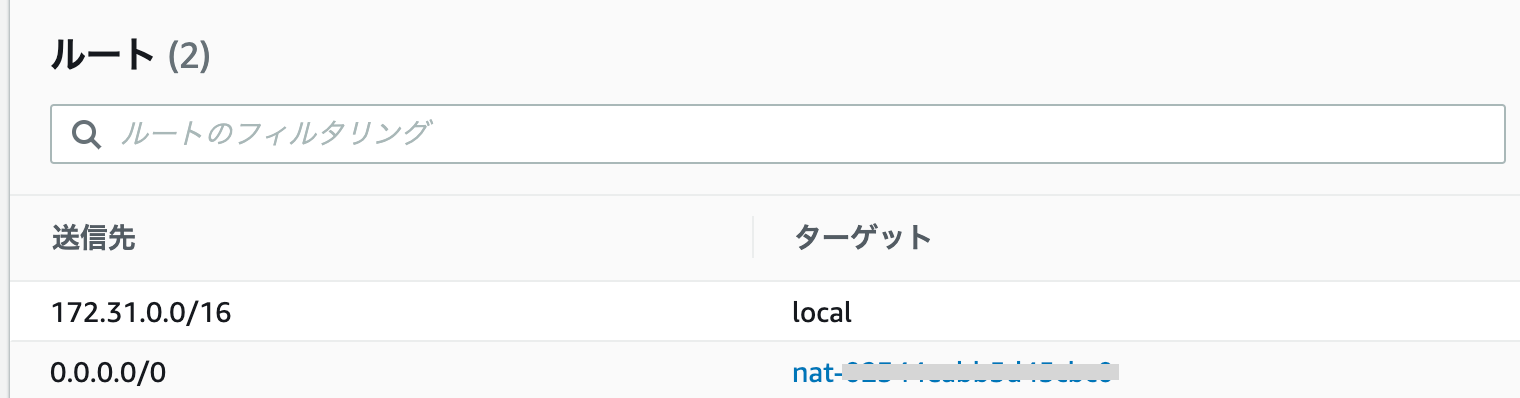
今回問題となったバッチ処理のサーバは別に機密情報を持っているわけではないのでプライベートなネットワークに配置する必要はありませんでした。パブリックサブネットに配置することで、NATゲートウェイを通さなくなるので通信コストの増加をなくすことができました。プライベートサブネットとパブリックサブネットの見分け方は、ルートテーブルの送信先「0.0.0.0/0」がインターネットゲートウェイにつながっているかでどうかで見分けます。
ターゲットが「igw-」から始まるのがインターネットゲートウェイなので、この場合はパブリックサブネットです。
「nat-」や「eni-」から始まる文字の場合は、プライベートサブネットとなります。解決方法
ECS Fargateのサービスのネットワーク構成に設定していたサブネットの項目を、プライベートサブネットからパブリックサブネットに設定し直すことで解決しました。
※ ECSクラスターのサービスで実行している場合、ネットワーク構成がサービス作成時にしか設定できないため、サービスを新たに作り直す必要があります。
ちょっとした設定の違いでコストが大きく変わることがあるので、びっくりして心臓に悪いですが今後もエンジニアとして頑張りたいと思います。


- 投稿日:2021-02-13T01:19:13+09:00
「VPCとは」
VPCとは
VPC:Virtual Private Cloud
日本語で直訳すると、仮想プライベートクラウド。
AWSクラウド内に論理的に分離されたセクションを作り、ユーザーが定義した仮想ネットワークを構築するサービスです。VPCの特徴
・VPC内で多くのサブネットを構築可能。
・サブネットないでEC2インスタンスを使える。
・サブネットのルーティングテーブルを設定できる。
・VPCにInternet Gatewayを設定し、EC2はそれを利用してインターネットに繋げる。
・一つのVPCは複数のAZに跨がれる。
・一つのサブネットは一つのAZにしか使えない。
・Security Groupはステートフル。
(ステートフル:行きの通信が許可されれば、戻りの通信も許可される。)
・Network Access Control Listはステートレス。
(ステートレス:行き通信と戻り通信は別々で配置し、お互いに影響しない。)
・サブネットの設定可能範囲:/16~/28。
VPCの設定手順
- 投稿日:2021-02-13T01:09:13+09:00
RDS for Oracle にEC2から接続する
はじめに
RDS for Oracleのデータベースに接続を試みました。
すっと接続できなかったので備忘のためのメモと役に立ったリンクを記載。背景
社内の踏み台サーバ(Windows Server)からパブリックサブネットに配置したRDS for Oracleに接続を試みたが、なぜか接続できないので色々実施。
とりあえず接続できればよかったので、踏み台→EC2→RDSと間にEC2をはさんで接続を試行。
EC2には問題なくログインできたので、踏み台→AWSのネットワーク的には問題なかったはず。
EC2とRDSは同じVPCのパブリックサブネットに配置。EC2にSSH接続し、以下のリンクを参照し順番に実行。
必要な部分を置き換えて最終的に無事接続できた。
EC2にOracle ClientをインストールしてRDS(Oracle)に接続する
https://zatoima.github.io/oracle-ec2-oracleclient-install.html上記リンク良いところ
他の「RDS sqlplus 接続」系の記事もたくさん見たが、「圧縮ファイルをEC2にアップする」などの手順があったり手間が多かった。
この記事だと、curlとyumで解決するので、怠惰な私にはありがたかった。
→EC2がインターネット出られる状態になっていれば問題なく実施できる。
自分が記事を書く時も、なるべくストレスなく完了できる手順書けるよう意識したい。参考
EC2からSQLPLUSでRDSを接続する設定
https://www.flyenginer.com/low/low_db/ec2%E3%81%8B%E3%82%89sqlplus%E3%81%A7rds%E3%82%92%E6%8E%A5%E7%B6%9A%E3%81%99%E3%82%8B%E8%A8%AD%E5%AE%9A.html#toc7Oracle DB インスタンスへの接続
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_ConnectToOracleInstance.html
- 投稿日:2021-02-13T01:00:41+09:00
AWS S3 CSSが反映されないとき
初めに
s3にboto3を使ってindex.html, main.js, style.cssをアップロードした。URLを開くとJavascriptが動いていることがわかった。しかしstyle.cssが反映されていなかった。
メタデータ編集
手順1
style.cssをクリックし、オブジェクトアクションをクリック
手順2
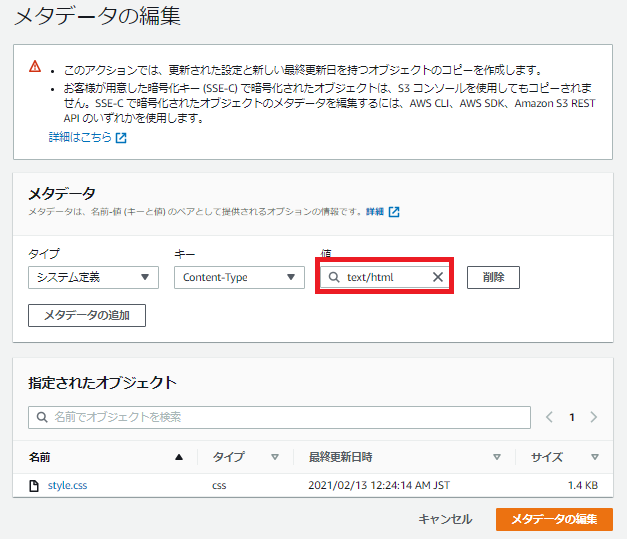
メタデータの編集をクリック
手順3
以下の"値"が"text/html"になっているので、"text/css"に編集する
編集後
手順4
オレンジ色のメタデータの編集ボタンを押す
これで反映される!!!
と思いきや反映されませんでした。
なぜ!!!キャッシュの削除
キャッシュを削除すると反映された・・・
(・∀・)ウン!!
設定しなおした後は必ずキャッシュ削除
以下の記事を参考にしたhttps://hodalog.com/httpd-enablesendfile-off/
boto3
upload.pyimport boto3 def get_content_type_dict(): content_dict = {'html': 'text/html', 'css': 'text/css', 'js': 'text/javascript', 'jpeg': 'image/jpeg', 'png': 'image/png', 'csv': 'text/csv', 'json': 'application/json', 'pdf': 'application/pdf'} return content_dict def upload(up_file, bucket, object_name, credentials): session = boto3.Session(aws_access_key_id=credentials[0], aws_secret_access_key=credentials[1], aws_session_token=credentials[2]) s3_client = session.client('s3') type_dict = get_content_type_dict() content_type = type_dict[os.path.splitext(object_name)[1].strip('.')] try: s3_client.upload_file(up_file, bucket, object_name, ExtraArgs={'ContentType': content_type, 'ACL': 'public-read'})こんな感じで拡張子に応じてアップするときメタデータを設定すると楽かも
Content-Typeは以下の記事を参考にした
https://qiita.com/AkihiroTakamura/items/b93fbe511465f52bffaaExtraArgsなるものの存在は以下の記事が参考になった
https://qiita.com/jansnap/items/ecad5f20659cf138419b疑問
main.jsはメタデータがtext/htmlでも動くこと
参考文献
ローカル環境でCSSが反映されない時に見直すべきhttpdの設定
https://hodalog.com/httpd-enablesendfile-off/Content-Typeの一覧
https://qiita.com/AkihiroTakamura/items/b93fbe511465f52bffaaboto3でS3にアップロードした画像が、ブラウザで表示するとダウンロードされてしまう時
https://hack-le.com/boto3-s3-browser/Python+boto3でS3に画像をアップロードして公開する
https://qiita.com/jansnap/items/ecad5f20659cf138419b




- 投稿日:2021-02-13T00:27:39+09:00
【初心者】AWS Key Management Service (AWS KMS) を使ってみる
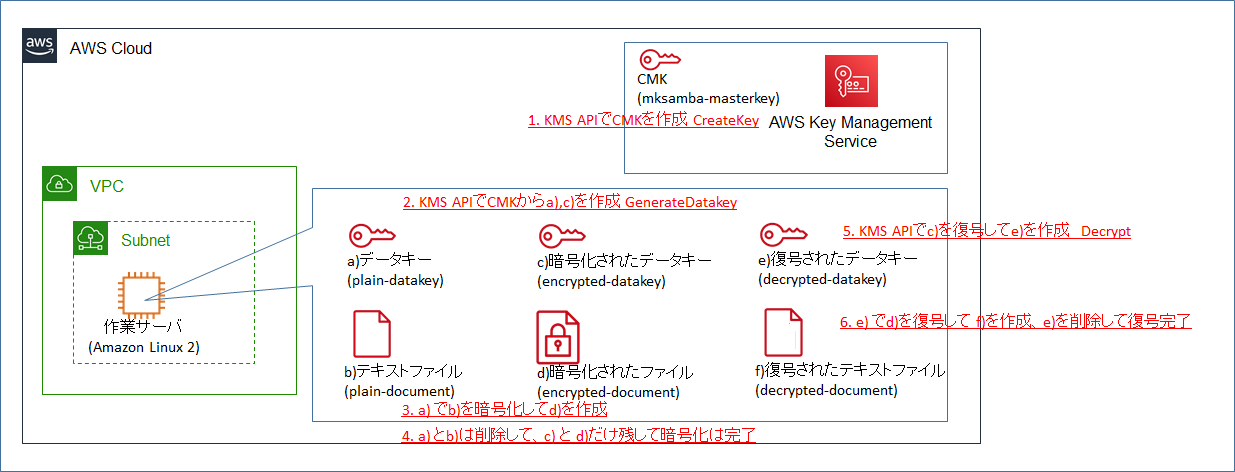
1. 目的
- AWSのセキュリティ関連サービスの復習をしている。AWS KMSについて、暗号鍵の登録や、ファイルの暗号化・復号といった基本的な処理を行い、動作イメージを把握する。
2. AWS KMSとは(自分の理解)
- データを暗号化するための鍵の管理を行ってくれるサービス。暗号鍵をAWSの責任範囲において保管したり、更新したりしてくれる。
3. やったこと
- CMK(カスタマーマスターキー) を作成する。
- CMKに紐づくデータキーを作成する。
- データキーで自分のファイルを暗号化する。
- (暗号化されたデータキー及び暗号化されたファイルを残し、元のファイルを削除する。)
- 暗号化されたデータキーを復号し、復号したデータキーを用いて暗号化されたファイルも復号する。
4. 予習
先人のまとめを読んで勉強する。
- 「10分でわかる!Key Management Serviceの仕組み」
- 2014年の古い記事だが、マスターキーやデータキーなどの概念の説明が非常に分かりやすい。
- 「AWS KMSを使って秘密鍵を管理する」
- こちらも2017年の記事で新しくはないが、暗号化・復号の手順が分かりやすく、この記事に記載されている手順をなぞっていくことで動作を確認する。
5. 実施手順
5.1 CMK(カスタマーマスターキー)の作成
- まずはマネージメントコンソールにて、KMSでの暗号化処理を行う際のベースとなる、CMK(カスタマーマスターキー)を作成する。
- KMSのメニューから「カスタマー管理型のキー」を開き、「キーの作成」を選択する。
- キーのタイプを「対称」、キーマテリアルオリジンを「KMS」とする。※タイプを「対称」とすることでCMKがAES 265bitのものになる。また、オリジンを「KMS」とすることで、KMSのサービス用の領域の中に、AWSが生成し管理するCMKが作成される。
- エイリアス(名前) を 「mksamba-masterkey」とする。
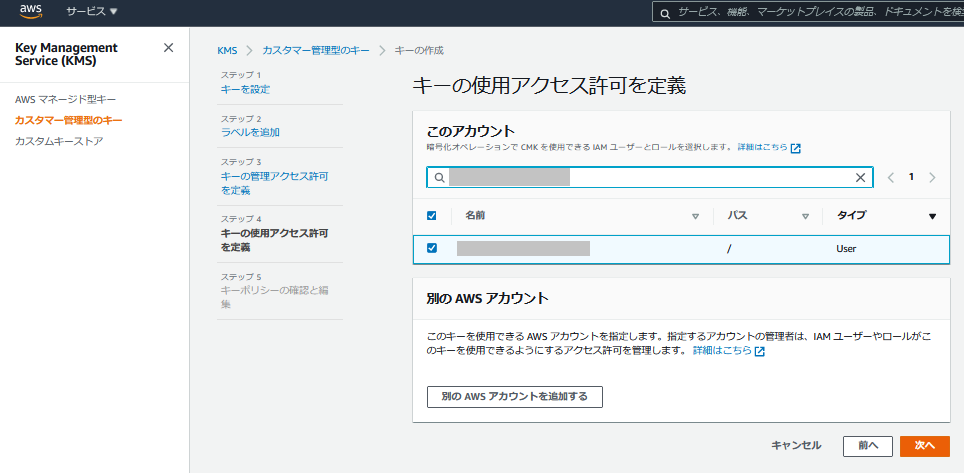
- キー管理者を追加する。今回はIAMユーザ(自分)を指定。キー管理者はキーの有効・無効化、更新、削除が可能。
- キーの使用許可者を追加する。今回はIAMユーザ(自分)を指定。キーの使用許可者は、キーを用いた暗号化、復号の処理を行うことが可能。
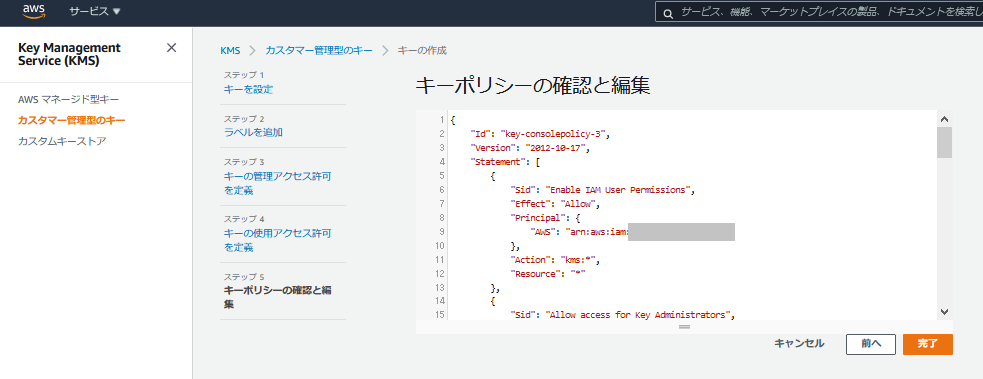
- キーポリシーの内容を確認する。前の手順で追加したキー管理者、キー使用許可者とは別に、初期設定値として、自AWSアカウントのIAMユーザでKMSへのアクセス権があるユーザに対しては全ての操作が許可されている。
- 作成したCMK(mksamba-masterkey)が表示されていることを確認する。メニューから有効化、無効化、削除のスケジューリングが可能。作成したCMKの中身は見ることができない。
5.2 データキーの作成
- CMKに紐づくデータキーを作成する。CMK自体を用いてデータを直接暗号化することもできるが、通常は実際に実データの暗号化処理を行うためのデータキーを発行して、それを用いて暗号化を行う。
- ここからはCLIを用いて操作を行う。
# AWS CLIバージョンの確認 [ec2-user@ip-10-0-0-126 ~]$ aws --version aws-cli/2.1.24 Python/3.7.3 Linux/4.14.214-160.339.amzn2.x86_64 exe/x86_64.amzn.2 prompt/off # KMSのAPI(GenerateDatakey)を用いて、CMKに紐づくデータキーを作成 [ec2-user@ip-10-0-0-126 ~]$ aws kms generate-data-key --key-id arn:[mksamba-masterkeyのARN] --key-spec AES_256 { "CiphertextBlob": "[encrypted-datakey-string]", "Plaintext": "[plain-datakey-string]", "KeyId": "arn:aws:kms:ap-northeast-1:xxxxxxxxxxxx:key/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }
- "Plaintext"がデータキーそのもの、"CiphertextBlob"がCMKにより暗号化されて、かつbase64エンコードされたデータキーとなる。
- "Plaintext"は、文字列をそのままコピペして、ファイル"plain-datakey"として保存する。
- "CiphertextBlob"は、文字列をコピペして、base64デコードして、ファイル"encrypted-datakey"として保存する。
[ec2-user@ip-10-0-0-126 ~]$ echo [plain-datakey-string] > plain-datakey [ec2-user@ip-10-0-0-126 ~]$ echo [encrypted-datakey-string] | base64 --decode > encrypted-datakey5.3 ファイルの暗号化
- 作成したデータキーを用いてファイルの暗号化を行う。
# 暗号化したいファイルの確認 [ec2-user@ip-10-0-0-126 ~]$ cat plain-document 休みがほしい。温泉に行きたい。 # データキーを用いて暗号化する。 # 元ファイル"plain-document"を、暗号鍵"plain-datakey"を用いてaes-256-cbcモードで暗号化して、ファイル"encrypted-document"として保存する。 [ec2-user@ip-10-0-0-126 ~]$ openssl aes-256-cbc -e -in plain-document -out encrypted-document -pass file:plain-datakey # 暗号化されていることの確認 [ec2-user@ip-10-0-0-126 ~]$ cat encrypted-document 縒唳9楳H??合й偉(碁Ra@?肄?;X・^
- 暗号化処理が終わった後、本来は安全のため、元ファイル"plain-document"、及び暗号化されていないデータキー"plain-datakey"を削除する必要がある。今回は復号後の動作確認のためそのままにしておくが、復号時はこれらのファイルが存在しない前提で復号処理を行う。
- データキーを用いて暗号化する仕組みが「Envelope Encryption」と呼ばれている。今回のケースだと、暗号化されたデータキー"encrypted-datakey" が封筒(Envelope)で、暗号化されたファイル"encrypted-document"が便箋で、便箋に書かれた内容が封筒に入っていて外からは読めないイメージととらえた。
5.4 ファイルの復号
- 先の手順で暗号化したファイルを復号する。
# KMSのAPI(Decrypt)を用いて、まず暗号化されたデータキーを復号する。 [ec2-user@ip-10-0-0-126 ~]$ aws kms decrypt --ciphertext-blob fileb://encrypted-datakey --output text --query Plaintext > decrypted-datakey # データキーを作成した時に入手した、暗号化前のデータキーと比較し、データが一致することを確認する。 [ec2-user@ip-10-0-0-126 ~]$ diff plain-datakey decrypted-datakey [ec2-user@ip-10-0-0-126 ~]$ # 復号後のデータキーを用いて、暗号化したファイルを復号する。元通りになっていることを確認する。 [ec2-user@ip-10-0-0-126 ~]$ openssl aes-256-cbc -d -in encrypted-document -pass file:decrypted-datakey 休みがほしい。温泉に行きたい。
- この後、復号後のデータキーを削除して復号処理全体が完了となる。
- decryptの際に、CMKのKeyIDを指定しなくても大丈夫なのか疑問に思ったが、aws kms cli の help 内の記載によると、CMKがsymmetricの場合にはCMKのKeyIDを指定することは必須ではなく、metadataを用いて適切なCMKが自動的に選択されるとのこと。
6. 所感
- 一応、原理としてはどのような仕組みになっているのかを確認することができた。S3やRDSなどのデータを暗号化する際にどのように応用されているのかなどはまた確認してみたい。