- 投稿日:2020-03-28T23:52:33+09:00
サーボドライバ PCA9685 を使って複数のサーボモータ MG996R を制御してみた
ハードウェアの準備
用意するもの
動かしたいサーボモータを複数用意します。
ここではMG996Rを12個動かすことを目標としますが、他のサーボモータや個数でも同様だと思います。
Jetson Nano単体では、せいぜい数個程度のサーボモータしか制御できません。
そのため、サーボドライバ PCA9685を使用します。
PCA9685は16チャンネルあるので、サーボモータを最大16個まで制御することができます。
ここでは12個のサーボモータを動かしたいので、1つあれば充分です。
デバイス 個数 説明 Jetson Nano 1 PCA9685 1 サーボドライバ MG996R 12 サーボモータ ACアダプタ 5V-4A 2 Jetson NanoおよびPCA9685用の電源 ジャンパワイヤ メスーメス 4 Jetson NanoとPCA9685を接続 回路図
Jetson NanoのGPIOピンのレイアウトは次のようになっています。
以下のように繋ぎます。
Jetson NanoとPCA9685の外部電源は、ともに5V 4Aを使用します。
Jetson Nano GPIOピン番号 <---> PCA9685 1 <---> VCC 3 <---> SDA 5 <---> SCL 9 <---> GND
ソフトウェアの準備
ライブラリのインストール
こちらのサイトを参考に各種ライブラリをインストールしていきます。
接続確認
インストールが完了すれば、以下のコマンドで接続確認ができます。
$ sudo i2cdetect -y -r 1正しく接続されていれば、次のような表示になるはずです。
0 1 2 3 4 5 6 7 8 9 a b c d e f 00: -- -- -- -- -- -- -- -- -- -- -- -- -- 10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 40: 40 -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 60: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 70: 70 -- -- -- -- -- -- --モータ制御プログラム
joint_control.py#!/usr/bin/python # -*- coding: utf-8 -*- import Adafruit_PCA9685 import time # Initialise the PCA9685 using desired address and/or bus: pwm = Adafruit_PCA9685.PCA9685(address = 0x40, busnum = 1) # Number of servo servo_num = 12 # Configure min and max servo pulse lengths servo_min = 150 # min. pulse length servo_max = 600 # max. pulse length servo_offset = 50 # Set frequency to 60[Hz] pwm.set_pwm_freq(60) while True: # Move servo on each channel for i in range(servo_num): print('Moving servo on channel: ', i) pwm.set_pwm(i, 0, servo_min + servo_offset) time.sleep(1) for i in range(servo_num): print('Moving servo on channel: ', i) pwm.set_pwm(i, 0, servo_max - servo_offset) time.sleep(1) # Move servo on all channel for i in range(servo_num): print('Moving servo on channel: ', i) pwm.set_pwm(i, 0, servo_min + servo_offset) time.sleep(1) for i in range(servo_num): print('Moving servo on channel: ', i) pwm.set_pwm(i, 0, servo_max - servo_offset) time.sleep(1)サーボを動かす
ここまで準備ができたらいざ動かしてみましょう!
実行権限を与えてから実行すればサーボが動くはずです。$ chmod +x joint_control.py $ python3 joint_control.py
おまけ
PCA9685の外部電源として、5V-4Aではなく5V-2Aを供給した場合の動作と外部電源の電圧が以下になります。
単体で動かす分には充分ですが、複数個動かす場合には電流が足りず、電圧が低下してしまうためうまく動いてくれません。
定格電流には注意しましょう。
参考



- 投稿日:2020-03-28T23:41:19+09:00
Pythonで多変量正規分布を使わずに楕円っぽい散布図を作る
はじめに
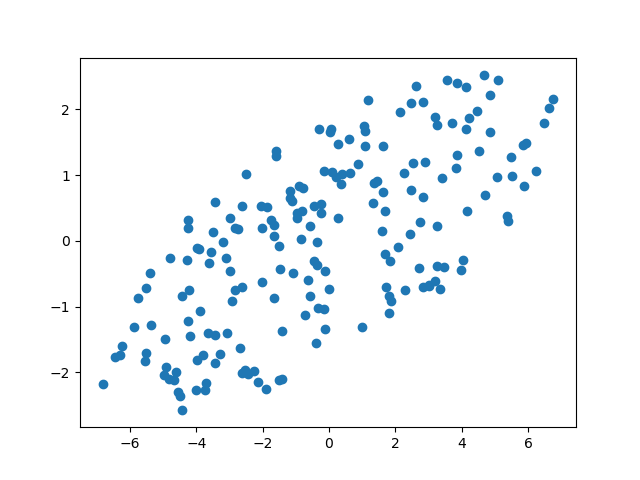
機械学習のサイトでは点を楕円形にプロットした図をよく見かけます。その作り方が分からなかったので、Numpyをいじって作ってみました。
コード
ellipseLike.pyimport numpy as np import matplotlib.pyplot as plt #出力件数 n = 1000 #乱数を発生 x = np.random.uniform(-4, 4, n) y = np.random.uniform(-1, 1, n) #フィルタリング coordinates = np.array([((x[i])**2 + (y[i])**2)**(1/2) < 1 for i in range(n)]) index = np.where(coordinates==True) #座標を操作 x_points = x[index] *4 y_points = y[index] #座標を回転移動(30度) x_points2 = x_points * (3**(1/2)) - y_points * (1/2) y_points2 = x_points * (1/2) + y_points * (3**(1/2)) #プロット plt.scatter(x_points2, y_points2) plt.show()結果
おわりに
作り終わってから多変量正規分布を知りました。勉強不足でした...
ご覧いただきありがとうございました。コメント・ご指摘等ありましたらよろしくお願いいたします。
- 投稿日:2020-03-28T23:40:40+09:00
yukicoder contest 241 参戦記
yukicoder contest 241 参戦記
A 1009 面積の求め方
8分半で突破. ヒント通り区分求積法でスパッと解いてみた. 区間をどれくらいの数で割ればいいのかに悩んだが、適当にえいやで4096でやったら一発目で良さげな精度が出たので、提出してみたら無事 AC.
a, b = map(int, input().split()) x = a result = 0 t = 1 / 4096 while x < b: result += abs((x - a) * (x - b) * t) x += t print(result)B 1010 折って重ねて
41分で突破. 整数で処理するコードを書いて、なんで AC しないんだと延々と悩んでいた. アホすぎる. 縦と横で短い方を限界まで折ってから、長い方を限界まで折ればいい.
x, y, h = map(int, input().split()) if x < y: x, y = y, x x *= 1000 y *= 1000 result = 0 while y > h: y /= 2 h *= 2 result += 1 while x > h: x /= 2 h *= 2 result += 1 print(result)整数で処理することもできる. 相対的に数字が正しく変わればいいのだ.
x, y, h = map(int, input().split()) if x < y: x, y = y, x x *= 1000 y *= 1000 result = 0 while y > h: x *= 2 h *= 4 result += 1 while x > h: y *= 2 h *= 4 result += 1 print(result)C 1011 Infinite Stairs
敗退. 素直に DP すると O(N2d) なので TLE する. よくよく考えると、i 段目にたどり着くのは i-d .. i-1 段目、i + 1 段目にたどり着くのは i - d + 1 .. i 段目と端の2箇所以外は同じである. であれば、O(d) ではなく O(1) で処理できるので O(N2) になり解けた.
package main import ( "bufio" "fmt" "os" "strconv" ) func main() { N := readInt() d := readInt() K := readInt() buf0 := make([]int, d*N+K+1) buf1 := make([]int, d*N+K+1) buf0[0] = 1 for i := 0; i < N; i++ { t := 0 for j := 0; j < d; j++ { t += buf0[j] t %= 1000000007 buf1[j] = t } for j := d; j < (i+1)*d; j++ { t -= buf0[j-d] if t < 0 { t += 1000000007 } t += buf0[j] t %= 1000000007 buf1[j] = t } buf0, buf1 = buf1, buf0 } fmt.Println(buf0[K-N]) } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result }# PyPy なら AC N, d, K = map(int, input().split()) buf0 = [0] * (d * N + K + 1) buf1 = [0] * (d * N + K + 1) buf0[0] = 1 for i in range(N): t = 0 for j in range(d): t += buf0[j] t %= 1000000007 buf1[j] = t for j in range(d, (i + 1) * d): t -= buf0[j - d] t += buf0[j] t %= 1000000007 buf1[j] = t buf0, buf1 = buf1, buf0 print(buf0[K - N])
- 投稿日:2020-03-28T23:01:27+09:00
AtCoder Beginner Contest 160 参戦記
AtCoder Beginner Contest 160 参戦記
ABC160A - Coffee
1分半で突破. 書くだけ.
S = input() if S[2] == S[3] and S[4] == S[5]: print('Yes') else: print('No')ABC160B - Golden Coins
2分半で突破. 500円のほうがコスパがいいので、500円を可能なだけ、余りを5円で.
X = int(input()) result = (X // 500) * 1000 X -= (X // 500) * 500 result += (X // 5) * 5 print(result)ABC160C - Traveling Salesman around Lake
7分で突破. ジャッジが詰まっててコードテストがなかなか実行されなくて参った. N軒全て回るということは、移動開始地点と移動終了地点の間だけ歩かなくていいということなので、それが最大のところを探せばいい.
K, N = map(int, input().split()) A = list(map(int, input().split())) result = A[0] - A[N - 1] + K for i in range(N - 1): result = max(result, A[i + 1] - A[i]) print(K - result)ABC160D - Line++
解かずにEに行ってしまったがこっちを解くべきだったろうか.
ABC160E - Red and Green Apples
敗退. ソートして、累積和して、にぶたんすればいいかと思ったが、WA 5個が消せず. 無念.
- 投稿日:2020-03-28T22:58:43+09:00
PythonでABC160を解きたかった
はじめに
A,Bしか解けませんでした。簡単だったのに。
A問題
考えたこと
index指定してifs = str(input()) if s[2] == s[3]: if s[4] == s[5]: print('Yes') quit() print('No')B問題
考えたこと
500でXを割れるだけ割って余りを5で同様にしています。x = int(input()) a = x // 500 b = (x % 500) // 5 ans = (1000*a+5*b) print(ans)C問題
考えたこと
K - Aの隣の要素の差が最小になるような距離を取ればいいはず。これに気付くのに1時間以上かかりましたし、十分に時間あったのに実装できませんでした。まとめ
色々とおつかれ様でした。疲れている時に無理してコンテストは参加しないほうがいいです。
おやすみなさい。
- 投稿日:2020-03-28T22:54:42+09:00
ラインプロファイルの取得法
自身の研究の都合上、画像データを取り扱うことが多く、ラインプロファイルを取得したくなるときがあります。
画像中の二点を指定し、離散的な画像データを補完しながら二点間でのラインプロファイルを1ピクセルの間隔で取得するプログラム
How to extract an arbitrary line of values from a numpy array?を参考にして、
任意の線幅でラインプロファイルを描けるようにしましたので、サンプルコードとその結果を紹介したいと思います。サンプルコードは、
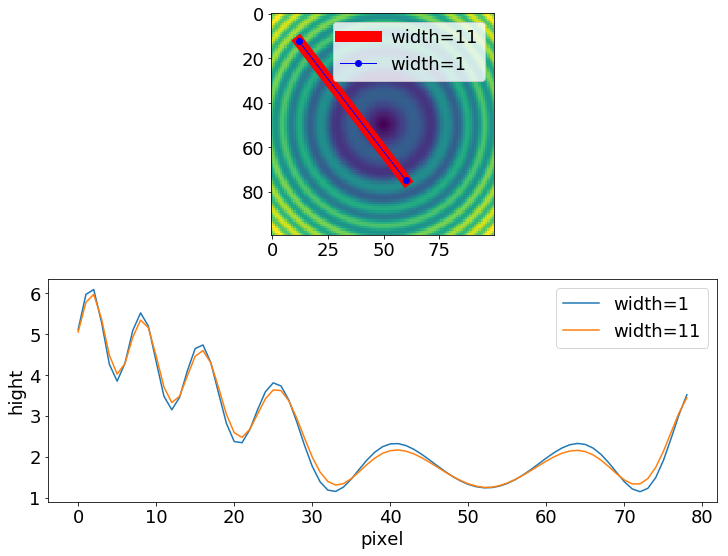
import numpy as np import scipy.ndimage import matplotlib.pyplot as plt #-- Generate some data... x, y = np.mgrid[-5:5:0.1, -5:5:0.1] z = np.sqrt(x**2 + y**2) + np.sin(x**2 + y**2) #-- Extract the line... # Make a line with "num" points... x0, y0 = 12, 12.5 # These are in _pixel_ coordinates!! x1, y1 = 60, 75 a = (y1-y0)/(x1-x0) inv_a = - 1/a print(a,inv_a) num = int(round(np.hypot(x1-x0, y1-y0))) #二点間の距離をピクセル数に変換 num1 = int(round((np.sqrt((y1-y0)**2+(x1-x0)**2)))) # num と 同じ print(num,num1) x, y = np.linspace(x0, x1, num), np.linspace(y0, y1, num) # Extract the values along the line, using cubic interpolation width = 11 SumZ =np.zeros(num) for i in range(0,width): zi = scipy.ndimage.map_coordinates(z, np.vstack((x+i-int(width/2),y+round(inv_a*(i-int(width/2)))))) SumZ = SumZ + zi avZ = SumZ/width z1 = scipy.ndimage.map_coordinates(z, np.vstack((x,y))) #-- Plot... plt.figure(figsize=(12,9)) plt.subplot(2,1,1) plt.imshow(z) plt.plot([x0, x1], [y0, y1], 'ro-',linewidth = width,label='width='+str(width)) plt.plot([x0, x1], [y0, y1], 'bo-',linewidth = 1, label='width=1') plt.legend() plt.subplot(2,1,2) plt.rcParams["font.size"] = 18 plt.tick_params(labelsize=18) plt.plot(z1,label='width=1') plt.plot(avZ,label='width=11') plt.legend() plt.xlabel('pixel') plt.ylabel('hight') plt.show()この通りです。出力結果は、
となります。
私のサンプルコードでは、元のプログラムを参考に、線幅を変えることができるようにしました。そのために、二点間を結ぶ直線をその直線に対して垂直な方向に平行移動させています。平行移動後の位置でプロファイルを平行移動する距離を変えながら取得して、それらの平均を取ることで、線幅を太くしています。
ある直線の傾きとその直線に直交する直線の傾きの積が$-1$になる事実を利用したの中学数学以来かもしれません…(笑)Pythonによるラインプロファイル取得を試してみたい人は、よろしければご参考にしてみてください。
以上
- 投稿日:2020-03-28T22:48:36+09:00
Pythonで毎日AtCoder #19
はじめに
前回
ABC160ができなくてつらかったので諦めてこっち書きます。
疲れているのでとっても雑に書きます。すみません#19
考えたこと
h[i]とh[i-1]の関係を比較したときに単調非減少になるにはh[i]の方が大きいか同じでなければならない。今回はマスの高さを-1することができるのでもし-1した場合にはcheckerの真偽を変更して対応しているn = int(input()) h = list(map(int,input().split())) seed = h[0] checker = True for i in range(1,n): if h[i] == h[i-1]: continue d = h[i] - h[i-1] + 1 if d > 0: checker = True pass elif d == 0: if checker: checker = False else: print('No') quit() else: print('No') quit() print('Yes')まとめ
疲れているときと眠いときは絶対にコンテストにでるな!!。では、また
- 投稿日:2020-03-28T22:26:33+09:00
製薬企業研究者ゆきやのPython記事まとめ
- 投稿日:2020-03-28T22:12:47+09:00
ドキュメント作成ツールSphinxに入門する
はじめに
本エントリで説明すること
- Python製のドキュメント作成ツール「Sphinx」の導入から簡単なドキュメント生成まで
- ホットリロードするモジュール「sphinx-autobuild」のインストールと使い方
- テーマの変更方法
本エントリで説明しないこと
- python3とpipのインストール方法
- reStructuredTextについての細かい説明
- MkDocsのような他のドキュメント作成ツールとの比較
- Sphinxの細かいオプション等
前提
- python3系をインスールしていること
筆者の環境
- macOS Catalina 10.15.3
- Python 3.7.4
venvでSphinx用の仮想環境を作成する
Sphinx用の仮想環境のディレクトリを作成します。
ディレクトリ名は任意です$ mkdir sphinx作成したディレクトリに移動し、仮想環境を作成します
仮想環境名はここではsphinx-venvとしておきます。$ cd sphinx # 「python3 -m venv 仮想環境名」とすることで仮想環境を作成できます。 $ python3 -m venv sphinx-venv仮想環境のディレクトリに移動し、仮想環境を有効にする
$ cd sphinx-venv $ source bin/acitvatepipでsphinxをインストールする
$ pip install sphinxsphinxのプロジェクトを作成する
sphinx-quickstartを打つと、ズラズラとメッセージが流れて、対話的に何個か聞かれます。
ひとまず特にこだわりがなければ、下記のように設定すればよいと思います。$ sphinx-quickstart > ソースディレクトリとビルドディレクトリを分ける(y / n) [n]:y > プロジェクト名: test-project > 著者名(複数可): test-author > プロジェクトのリリース []: 1.0.0 > プロジェクトの言語 [en]: ja私の実行環境では、上記の通りに日本語で聞かれましたが、
環境によっては下記のように英語で聞かれます。$ sphinx-quickstart > Separate source and build directories (y/N) [n]:y > Project name: test-project > Author name(s): test-author > Project version []: 1.0.0 > Project language [en]: jahtmlファイルを生成する
まずはデフォルト状態で、htmlファイルを生成します。
htmlファイルを生成するには、Makefileがある場所で以下のようにコマンドを打ちます$ make htmlこれで、buildディレクトリ以下にindex.htmlというファイルが生成されますので、
任意のブラウザで表示させてください。コンテンツを追加する
Sphinxでは、コンテンツを追加するために、
- 新しくファイルを作成し、
- トップページに登録する
必要があります。
新しくファイルを作成する
「source」配下に適当な名前のファイルを作成します。
ここでは、ファイル名を「test.rst」とします。適当に中身を書きます。
test.rst=================== ここにタイトルを入れる =================== 大見出しを入れる --------------- - 箇条書きです - 箇条書きですトップページに登録する
「source」配下にある「index.rst」がトップページになっています。
このファイルを編集し、先程作成した「test.rst」を登録します。
編集は以下のように、ファイル名と同じ名前を追記してください。index.rst(編集前).. toctree:: :maxdepth: 2 :caption: Contents:index.rst(編集後).. toctree:: :maxdepth: 2 :caption: Contents: testここで、もう一度、「make html」を実行すると、トップページに
「ここにタイトルを入れる」がリンク付きで表示されるようになります。
こちらのリンクをクリックすると、test.rstに記載した内容を見ることができます。【おまけ】ホットリロードできるようにする
Sphinxでは通常、ドキュメントを編集した後、「make html」と打ち、ブラウザをリロードし直す必要があります。これは地味に面倒ですので、ドキュメントを編集したら、自動でhtmlファイルを生成し、自動でリロードが掛かるようにします。
$ pip install sphinx-autobuildインストール後は、「Makefile」があるディレクトリで以下のコマンドを打ちます。
# sphinx-autobuild [xxx.rstがあるディレクトリ] [htmlファイルが生成されるディレクトリ] # 本エントリでは、以下のようになります $ sphinx-autobuild source buildすると、ローカルでサーバが起動しますので、URL(http://localhost:8080)をブラウザで表示すると、作成されたhtmlファイルを閲覧できます。
【おまけ】テーマを変える
「source」ディレクトリ配下にある「conf.py」の下の方に以下の記述があります。
conf.pyhtml_theme = 'alabaster''alabaster'のところを書き換えることで、テーマを変えることができます。
なお、'alabaster'はデフォルトのテーマになっています。Sphixでは標準の以下のテーマが用意されています。
- alabaster
- default
- sphinxdoc
- scrolls
- agogo
- nature
- pyramid
- haiku
- traditional
- bizstyle
サードパーティ製のテーマを設定することも可能です。
例えば、マテリアルデザインのテーマを設定したい場合は以下のようにテーマをインストールします。$ pip install sphinx-theme-materialテーマをインストールしたら、conf.pyを以下のように設定します。
設定後、テーマがマテリアルデザインに変わっています。conf.pyhtml_theme = 'material'
- 投稿日:2020-03-28T22:12:37+09:00
再帰を使ったマージソート
再帰を使ったマージソートのやり方
※備忘録的な感じ (見返す時に忘れている・コードだけでは理解ができない等があると思うので)
配列data = [3, 1, 9, 4, 2, 5, 7, 6, 8, 10]
1. 配列の真ん中でleft(左)・right(右)に分ける => 左[3,1,9,4,2] 右[5,7,6,8,10] 真ん中: 5
2. left・rightでそれぞれでさらに分けていく(再帰を使う) => 左[3,1,9,4,2] -> 左[3,1] 右[9,4,2] 真ん中: 2
右[5,7,6,8,10] -> 左[5,7] 右[6,8,10]....のように分けていく3.最終的に[3],[1],[9],[4],[2],[5],[7],[6],[8],[10] となる(下準備完了!)
4.今度は、二分割した値を左(0から始まるため)から順番新しい変数(result_sortに並び替え結果を代入していく(結合)。[3,1],[4,2] => それぞれソートを行う [1,3][2,4]
※ [9],[6]がない!なぜ? => [9,4,2]を分けるとき 真ん中が「1」のため 右:[9] 左: [4,2]となってしまうため先に[4,2]から処理をしてしまう。(再帰は、1->2->3->4->5 と進めた後, 5->4->3->2->1と巻き戻しをしながら処理を戻していく) => より理解を深めるためには、再帰の勉強をする
5.[9]と[4,2]は ->[9]と[4,2]で並び替え -> result_sort => [2,4,9]となる
6.[3,1]と[9,4,2]は -> [3,1]と[9,4,2]で並び替え -> result_sort => [1,2,3,4,9]
7.右が完了。次は左から 4~6 を行う
8 [3,1,9,4,2] と 右[5,7,6,8,10] を比較して行う
9 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] となるコードでの解説(python)
sample.pydata = [3, 1, 9, 4, 2, 5, 7, 6, 8, 10]データを変数に代入
sample.pydef merge_sort(data): if len(data) <= 1: #配列の中身が1以下になったらtrue return data center = len(data) // 2 #配列の中心 left = merge_sort(data[:center])#左側に分断 [3,1,9,4,2] => [3,1] => [3] right = merge_sort(data[center:]) #右側に分断 [5,7,6,8,10] => [9,4,2] => [1] return left, right #=> [3], [1]が渡される1 ~ 3 をこのコードで行う事ができる。
sample.pydef merge_sort(data): if len(data) <= 1: #配列の中身が1以下になったらtrue return data center = len(data) // 2 #配列の中心 left = merge_sort(data[:center])#左側に分断 [3,1,9,4,2] => [3,1] => [3] right = merge_sort(data[center:]) #右側に分断 [5,7,6,8,10] => [9,4,2] => [1] return merge(left, right)
return merge(left, right)を加えただけsample.pydef merge(left, right): result_sort = [] #結合結果 left_i, right_j = 0, 0 print(left + right) #=> 並び替えをしようとする配列がわかる while(left_i < len(left)) and (right_j < len(right)): if left[left_i] <= right[right_j]: result_sort.append(left[left_i]) #ここで結合をしようとしている rightとleftを比較しながらresultに当てていく left_i += 1 else: result_sort.append(right[right_j]) #ここで結合をしようとしている rightとleftを比較しながらresultに当てていく right_j += 1 if len(left[left_i:]) != 0: #=> 並び替えをしたが余ってしまったleftの配列内の数字が0で無ければTrue(left_iで確認) result_sort.extend(left[left_i:]) if len(right[right_j:]) != 0: result_sort.extend(right[right_j:]) #並び替えをしたが余ってしまったrightの配列内の数字が0で無ければTrue(right_jで確認) print(result_sort) #=> 並び替えた配列がわかる return result #最終的な返り値4 ~ 8 を行っている
引用(ありがとうございます)
- 投稿日:2020-03-28T22:05:31+09:00
Ubuntuにpip/pip3をインストールする
はじめに
UbuntuにPythonの実行環境を整える際、同時にpipを入れる人は少なくないだろう。
そして、Googleさんに聞けばaptでインストールができるという回答が得られるだろう。ただ、私の記憶が正しければ、この方法で入れてしまうと後々pip自体のアップデートがうまく行かないなどの不具合が発生する可能性がある。
そこで、不具合が生じない方法を備忘録的に簡潔に残しておくpipの導入
Python2系。もういらない子...
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py sudo python2 get-pip.pypip自体のアップデート
pip install -U pippip3の導入
多分よく使うのがこっち。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py sudo python3 get-pip.pypip3自体のアップデート
pip3 install -U pip
- 投稿日:2020-03-28T21:34:42+09:00
psycopg2 で Pandas DataFrame を Bulk Insert する
Pandas DataFrame を PostgreSQL に Bulk Insert したいときは SQLAlchemy を入れて
.to_sql()を使うとできるのだけど、PostgreSQL クライアントとして psycopg2 を使っている状況だと「そのためだけに SQLAlchemy 入れたくねぇ〜」という気持ちになってしまう。そこで「DataFrame を
.to_csv()してそれを psycopg2 の.copy_from()で読み込めば Bulk Insert できるのではないか」と考えてやってみたらできた。from io import StringIO import pandas as pd import psycopg2 def df2db(conn: psycopg2.extensions.connection, df: pd.DataFrame, table: str): buf = StringIO() df.to_csv(buf, sep='\t', na_rep=r'\N', index=False, header=False) buf.seek(0) with conn.cursor() as cur: cur.copy_from(buf, table, columns=df.columns)こういう関数を作っておいて、
例えばこんな DataFrame を PostgreSQL の
logsというテーブルに Bulk Insert したいときは、with psycopg2.connect('postgresql://...') as conn: df2db(conn, df.reset_index(), 'logs')これでできる。
index は出力しないようにしているので、index もテーブルに入れたい場合は
.reset_index()しておく必要がある。
- 投稿日:2020-03-28T21:34:10+09:00
Jupyter Notebookの基本操作と便利な機能
最近、データ分析のためにJupyter Notebookを使うことが多くなりましたので、基本操作と便利な機能を簡単にまとめました。
基本操作
- コマンドモードに移行:Esc
- ショートカットキー一覧を表示:(コマンドモードで)h
- 編集モードに移行:Enter
- セルの実行:(編集モードで)Shift-Enter
- セルの削除:(コマンドモードで)削除したいセルを選択してdd
- 実行中のコードの中断:Ctrl-C
便利な機能
- タブ補完:変数名・メソッド名などを途中まで入力した状態でタブ
- オブジェクトイントロスペクション(オブジェクトの一般情報やdocstringを見る):変数の前または後に?をつけてセルを実行
- マジックコマンド(IPython専用コマンド):後述
マジックコマンド
- %magic:全マジックコマンドの詳細記述を表示
- %time 命令(メソッドなど):命令実行時間の計測
- %timeit 命令(メソッドなど):命令実行時間の計測(複数回)※実行時間が極短い命令の計測に有効
- %debug:直前に発生した例外に対して、トレースバックの最下部から開始
- %run Pythonファイル名 コマンドライン引数(オプション):Pythonプログラムの起動
- %who, %who_ls, %whos 型名・変数名など:利用中の名前空間内で定義された、その種類の変数リストを返す(%whoは一覧で、%who_lsはリストで、%whosは整形した一覧で返す)
- %reset:名前空間から変数を含めた名前を除去
- %matplotlib inline:Matplotlibをインライン表示する
参考文献
Wes McKinney(2018)「Pythonによるデータ分析入門 第2版 -NumPy, pandasを使ったデータ処理」,オライリー・ジャパン
- 投稿日:2020-03-28T21:27:06+09:00
[python]twitterのフォロー相関図を作成してみた(Gremlin編)
記事の内容
先日Twitterのフォロー相関図を作成する記事を書きました。
[Python]Twitterのフォロー関係を可視化してみた
上記の記事ではTwitterAPIでフォローアカウントの情報を取得しmongoDBに登録する。
その後、mongoDBからデータを取得し、相互フォローしているかを確認しながらグラフに描画するというロジックでした。GraphDBというものを使えばネットワーク分析などに便利だということを知ったので、この仕組みをGraphDBでもやってました。
環境
python:3.7
gremlinpython:3.4.6
gremlin:3.4.6Gremlinのインストール
私はWindowsで環境を構築しました。
Windows用のツールは以下からダウンロードできます。https://downloads.apache.org/tinkerpop/3.4.6/
ダウンロードするのは「server」です。「console」はあると便利ですが、今回の記事では使いません。
ダウンロード後はZIPを解凍し、任意のフォルダに配置し、binフォルダ配下のbatを実行するだけです。
gremlinpython
pipコマンドでインストールできます。
pip install gremlinpython実装
環境が出来たので実装していきます
mongoDBのデータをGremlinに登録する
GremlinはGraph型のデータモデルを扱えるDBです。
mongoDBではデータ間のリレーションは管理出来ませんでしたので、Gremlinにデータを登録しながらデータのリレーションを登録していきます。mongoDBのデータ
mongoDBのデータは以下のとおりです。
Twitterのアカウントと、そのアカウントがフォローしているアカウントのリストが登録されています。
以下のようなデータが多数登録されています。{ "_id" : ObjectId("5e6c52a475646eb49cfbd62b"), "screen_name" : "yurinaNECOPLA", "followers_info" : [ { "screen_name" : "Task_fuuka", "id" : NumberLong("784604847710605312") }, (略) { "screen_name" : "nemui_oyasumi_y", "id" : NumberLong("811491671560974336") } ] }コード
mongo_to_gremlin.pyfrom gremlin_python import statics from gremlin_python.structure.graph import Graph from gremlin_python.process.graph_traversal import __ from gremlin_python.process.traversal import TraversalSideEffects from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection from mongo_dao import MongoDAO mongo = MongoDAO("db", "followers_info") graph = Graph() # Gremlinのコネクション作成 g = graph.traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g')) start_name = 'yurinaNECOPLA' def addValueEdge(parent_name, depth): if depth == 0: return False print(parent_name) result = mongo.find_one(filter={'screen_name': parent_name}) if result == None or len(result) == 0: return False # 頂点の追加 g.addV(parent_name).property('screen_name', parent_name).toSet() p = g.V().has('screen_name', parent_name).toList()[0] for follower in result['followers_info']: if addValueEdge(follower['screen_name'], depth-1): cList = g.V().has('screen_name', follower['screen_name']).toList() if len(cList) != 0: # エッジの追加 g.addE('follow').from_(p).to(cList[0]).toSet() return True addValueEdge(start_name, 3)コード解説
- 頂点となるアカウントを決める
- addValueEdgeにアカウント名を渡す
- MongoDBからデータを取得
- データが取得出来たらGremlinに頂点を追加する
- フォローしているアカウント名を1件ずつ渡す(2. に戻る)
- エッジを追加する
この様に再帰的にデータとエッジを登録していきます。
相関図を作成する
基本的な作りはmongoDBからデータ取得した時と同じです。
create_network_pict.pyimport json import networkx as nx import matplotlib.pyplot as plt from gremlin_python import statics from gremlin_python.structure.graph import Graph from gremlin_python.process.graph_traversal import __ from gremlin_python.process.traversal import TraversalSideEffects from gremlin_python.driver.driver_remote_connection import DriverRemoteConnection start_screen_name = 'yurinaNECOPLA' graph = Graph() # Gremlinのコネクション作成 g = graph.traversal().withRemote(DriverRemoteConnection('ws://localhost:8182/gremlin','g')) #新規グラフを作成 G = nx.Graph() #ノードを追加 G.add_node(start_screen_name) def add_edge(screen_name, depth): if depth == 0: return name = g.V().has('screen_name', screen_name).toList()[0] follows_list = g.V(name).both().valueMap().toList() for follow in follows_list: print(follow['screen_name'][0]) G.add_edge(screen_name, follow['screen_name'][0]) add_edge(follow['screen_name'][0], depth-1) add_edge(start_screen_name, 3) #図の作成。figsizeは図の大きさ plt.figure(figsize=(10, 8)) #図のレイアウトを決める。kの値が小さい程図が密集する pos = nx.spring_layout(G, k=0.8) #ノードとエッジの描画 # _color: 色の指定 # alpha: 透明度の指定 nx.draw_networkx_edges(G, pos, edge_color='y') nx.draw_networkx_nodes(G, pos, node_color='r', alpha=0.5) #ノード名を付加 nx.draw_networkx_labels(G, pos, font_size=10) #X軸Y軸を表示しない設定 plt.axis('off') plt.savefig("mutual_follow.png") #図を描画 plt.show()コード解説
ポイントとなる部分は以下になります。
name = g.V().has('screen_name', screen_name).toList()[0] follows_list = g.V(name).both().valueMap().toList() for follow in follows_list: print(follow['screen_name'][0]) G.add_edge(screen_name, follow['screen_name'][0]) add_edge(follow['screen_name'][0], depth-1)1行目でフォロワーの情報をGremlinから取得します。
2行目で取得した情報のエッジの情報を取得できます。
このデータはdict型のlistになっていますので、1件ずつ取得しscreen_nameを取得すればアカウント名を得ることが出来ます。結果
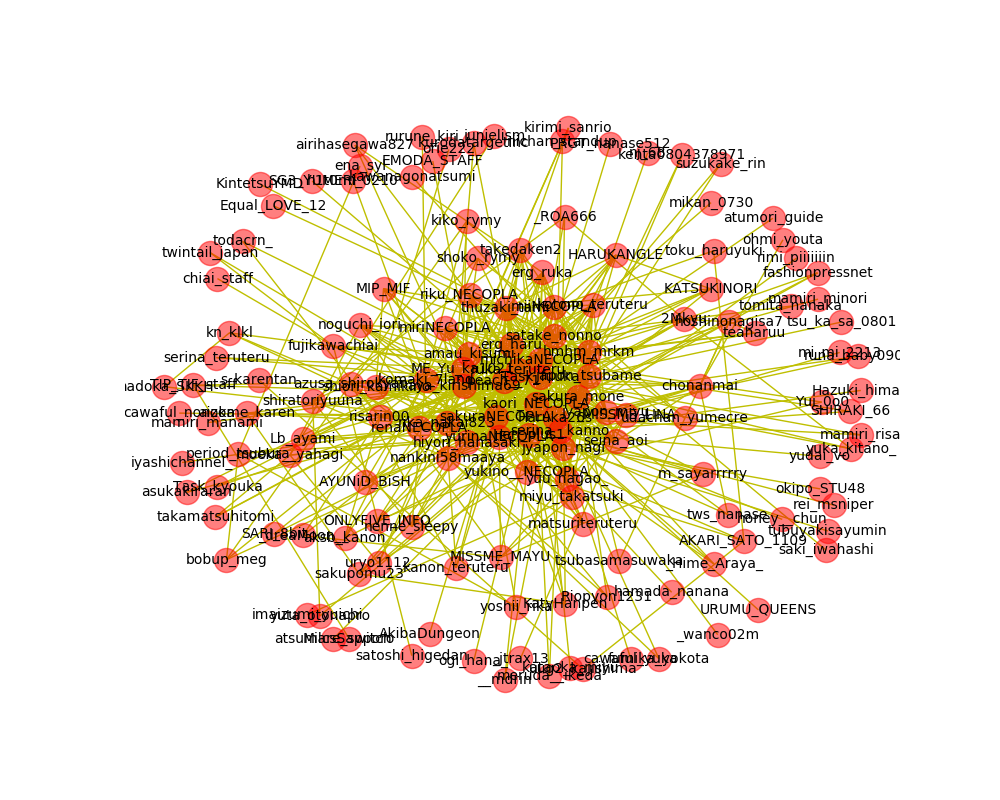
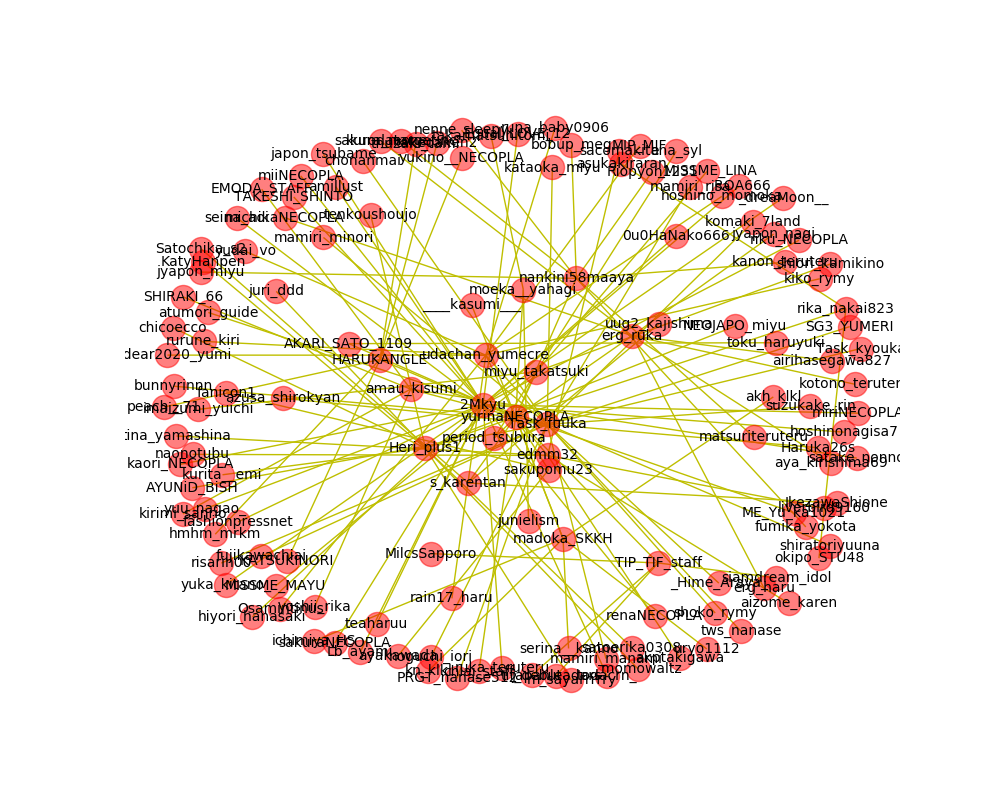
実行結果です
かなり見辛い結果になりましたが、相関図を作成することが出来ました。
別パターンの相関図
上記の相関図はアカウントA→アカウントB、アカウントB→アカウントC、アカウントC→アカウントAといった循環した関係も表現されています。
循環しないようにするのであれば、Gremlinに登録するタイミングで既に登録されているデータは追加対象外という制御を加えることで実現出来ます。
mongoDB_to_gremlin.pydef registCheck(screen_name): check = g.V().has('screen_name', screen_name).toList() if len(check) == 0: return False else: return True def addValueEdge(parent_name, depth): if depth == 0 or registCheck(parent_name): return False print(parent_name) result = mongo.find_one(filter={'screen_name': parent_name}) if result == None or len(result) == 0: return False # 頂点の追加 g.addV(parent_name).property('screen_name', parent_name).toSet() p = g.V().has('screen_name', parent_name).toList()[0] for follower in result['followers_info']: if addValueEdge(follower['screen_name'], depth-1): cList = g.V().has('screen_name', follower['screen_name']).toList() if len(cList) != 0: # エッジの追加 g.addE('follow').from_(p).to(cList[0]).toSet() return TrueGremlinにデータが登録されているか確認するためのregistCheckを追加することで循環する関係は除外出来ました。
結果
まとめ
循環ありの図では相互フォローしあっている関係の深いアカウント同士が纏まって出力されています。
循環なしの図では起点としたアカウントがフォローしているアカウントが近くに出力されていますが、再帰的にロジックを組んでいるため、アカウントAと相互フォローしているアカウントが離れた位置に出力されているものもあります。
エッジの設定方法はまだまだ検討していく必要がありそうです。データの関係を登録するというのはRDBに近いものがありますが、gremlinpythonで扱うには直感的に扱うことは非常に難しい印象を受けました。
ある程度、ドキュメントを読んで仕組みなどを理解することが出来ればネットワーク分析などに活かすことが出来そうです。
- 投稿日:2020-03-28T20:42:08+09:00
第1回 AI実装検定【A級】に合格したので色々まとめてみた
日本ディープラーニング協会主催のE資格対策のJDLA認定プログラムを提供していることで知られるStudy-AI株式会社がAI実装検定実行委員会を立ち上げ、E資格にチャレンジするためのスキルを身に付ける資格として「AI実装検定」を開始しました。受験してみたところ
無事合格
実際に届いた合格通知のメール
Pythonの問題は何かケアレスミスをしてしまった様ですね。。。
この資格は過去記事を取り上げて下さった@kazzy0099 さんの記事【随時更新予定】データサイエンス・機械学習関連資格まとめで見つけて受験に至りました。随時更新とのこと。今後の更新も楽しみにしたいと思います。
受験の動機
以下の様な動機で受験しました。
- 機械学習、Deep Learningに関心が有り、勉強しているため
- 将来的にE資格を受験したいと思っているため
- 実装にスポットライトを当てた資格を受験することで実装力強化に繋がると思ったため
- 資格取得が趣味だからetc...
AI実装検定とは?
詳細は以下のリンクに記載されています。
http://kentei.ai/ に試験の位置付けを略図にした物が掲載されていました。
今後A級以外の級も策定される可能性が有りますが、今回はA級のみの募集でした。また、この試験は自宅のPC上で受験できる試験です。数学、プログラミング、ディープラーニングの各々の分野について20題ずつ計60題出題されます。試験時間は60分であるため、じっくり考える余裕は有りません。合格点については試験回毎に発表される合格点に合計点が達している必要が有る様です。受験料は¥3,500.です。最近は高額な受験料の資格試験が多い中、良心的な価格設定です。(あくまで筆者の見解)
AI実装検定 A級に合格=E資格の受験資格ではありません。別途受験資格要件としてJDLA認定を受けた研修の受講が必要です。
試験範囲
検定問題サンプルが試験の出題範囲も兼ねています。全60問の構成比についての言及も有ります。
試験対策
実際に試験対策に使用した教材を紹介したいと思います。勉強期間としては断続的だったので正確なことは言えませんが、ある程度ニューラルネットワークやDeep Learningに関する知識が有るなら2週間ぐらいで公式教材の動画を2周出来るのではないかと思います。
公式教材
AI実装検定公式教材に掲載されています。今回は期間限定で¥3,000.1でした。講師の解説無し(動画解説+ソース付き)で、受験エントリー者のみ購入が可能な教材です。今後動画解説が付いた正式版がリリースされる様です。価格は¥45,000.となるとのことです。今回の教材の動画は6月30日まで限定で視聴が出来る様です。
公式教材概要
http://kentei.ai/introduction/howto より
★Bambiβ-Taurus(Section1 基礎編)
Pythonの基礎やパソコンの操作から進めたい方はここからスタート。ニューラルネットに必須な関数の描画や数値計算に必要なライブラリ、NumpyやMatplotlib の扱いも学ぼう。★Bambiβ-Gemini(Section2 基礎編)
ニューラルネットワークの順伝播の基礎はここからスタート。★Bambiβ-Cancer1(Section3 応用編)
ニューラルネットワークの逆伝播。ここまで踏み込めば初級者は卒業。★Bambiβ-Cancer2(Section3 応用編)
ニューラルネットワークの連鎖律。ここが理解できていれば中級者。★Bambiβ-Leo(Section4 応用編)
中間層を導入した更新式の実装です。ソースコードも配布するので実際に手を動かして「習得」してください。ここが出来ればかなりの実力者です。★Bambiβ-Virgo1(Section4 応用編)
手書き文字データでディープラーニングを実装します。ここまでできれば中級者は卒業。この先独学でもディープラーニングを学んでいけるレベルに到達することができます。★Bambiβ-Virgo2(Section5 応用編)←Section5の内容は試験範囲外ですが、興味深い内容なのでじっくり取り組む価値有り
手書き文字データでディープラーニングを実装します。ここまでできれば中級者は卒業。この先独学でもディープラーニングを学んでいけるレベルに到達することができます。為替データを例に,5つの言語とフレームワークで実装します。(Chainer,NumPy,PyTorch,TensorFlow ,Keras)為替データはRNNという時系列を扱う概念も登場し、Bambiの世界を超えて上級の域に入ります。サンプル問題
公式サイトの検定問題サンプルの問題も解きました。答えが無かったので、参考までに略解を作成しました。
AI
- 入力層と出力層: (ア) 入力
- 順伝搬の計算: 小問1 カラーコード, 小問2 27
- 行列の掛け算: (ク) 2, 8
- バイアス項の導入: 選択肢1
プログラミング
- Numpy 1問目: 選択肢1(但し、wとxが入れ替わっている誤植有り)
- Numpy 2問目: (ウ)
- Pandas: read_csv
- scikit-learn: trainデータとtestデータに分割している
数学
- 数列と行列 1問目: 問題文ミス?
- 数列と行列 2問目: ア:10 イ:22
- 数列と行列 3問目: ア:6 イ:10 ウ:14
市販の書籍
ニューラルネットワーク自作入門(Tariq Rashid 著, 新納 浩幸 監訳)
Make Your Own Neural Networkという書籍の日本語版です。
公式教材をやってから改めて読み返してみると、この書籍がいかに理論理屈の説明の分かりやすさに腐心し、厳密さを失わない様にしつつ、かみ砕いた説明で読者に分かり易い説明でニューラルネットワークを解説した優れた書籍だと改めて実感しました。この書籍は邦訳版なので原書も読んでみたいと思います。
実際受験しての感想
実際の試験は数学、プログラミング、AIの順に20台ずつ出題されます。最初の数学では主に線形代数学の知識が問われます。最初は面食らってしまうかもしれませんが、60分で60題というあまりじっくり考えて解く時間の無い試験である為、時間が掛かりそうな計算問題などは潔く後回しにするか、捨てるという選択も必要になります。プログラミング問題では範囲にscikit-learnと有ることから結構な割合で出題されていました。AI部分は公式教材と粗同じと言う感じの出題でした。(勾配降下法大好き)E試験対策を意識した資格だからかもしれませんが、試験ページでも言及が有る様に実装や理屈に重きを置いた試験という印象を強く受けました。後、計算問題は手で書いて計算をして解ける様に紙とペンは用意しておく方が良いでしょう。筆者は数多くの資格試験を今まで受験しましたが、自宅で受験する試験は初めて受験しました。今のご時世にはピッタリの形式やもしれません。
@PoppeDwarf さんのAI実装検定の感想と備忘録という記事が投稿さていました。この記事の筆者の方も私とほぼ同じことを感想で述べています。
まとめ
AI実装検定 A級についてまとめました。今回改めてNeural Networkについて再学習してみて自分の理解が甘い点を再確認出来たという点でこの受験は大変意味の有る物だったと思います。今後も機械学習、Deep Learning、そして理論が難しく理解が追いついていない量子コンピュータ、量子機械学習など最新のトピックを継続的に学んでいきたいと思います。昨年8月から始めた記事投稿はこの記事で20報目となりました。今後も積極的な情報発信に努めたいと思います。
今後の目標
- S級が登場したら受験してみたい。
- ゼロから作るDeep Learningの再読
- ゼロから作るDeep Learning2の読了
- 線形代数を再学習(主に機械学習で必要な部分だけ)
- Tensor Flow, PyTorchでモデル実装のマスター
- E資格受験要件を確保
- Make Your Own Neural Network(英語の勉強も兼ねて)
- 量子コンピュータを作る本が出版されたら作ってみるetc...



- 投稿日:2020-03-28T20:34:44+09:00
AtCoder Beginner Contest 157の復習, E問まで(Python)
競プロ初心者の復習用記事です。
ここで書く解は解説や他の人の提出を見ながら書いたものです。自分が実際に提出したものとは限りません。
A - Duplex Printing
ページ数Nを両面印刷すると何枚の紙が必要か答える問題です。
2で割って切り上げればよし。
n = int(input()) print((n+1)//2)B - Bingo
与えられた番号とビンゴカードで列が揃っているか答える問題です。
二次元配列を探索して要素を探すのがめんどくさかったので、
numpyを用いてnp.whereで置き換える操作を利用しました。ついでに縦軸、横軸にそってnp.sum()を利用することでビンゴの有無も調べました。pypy3ではnumpyを読み込めないので注意。
import numpy as np S = np.array([list(map(int, input().split())) for _ in range(3)]) n = int(input()) for _ in range(n): S = np.where(S==int(input()), 0, S) HBingo = min(np.sum(S, axis=0)) == 0 WBingo = min(np.sum(S, axis=1)) == 0 SBingo = S[2][0] == 0 and S[1][1] == 0 and S[0][2] == 0 BSBingo = S[0][0] == 0 and S[1][1] == 0 and S[2][2] == 0 if HBingo or WBingo or SBingo or BSBingo: print('Yes') exit() print('No')ただし、numpyを使わずに素直に配列を探索する方がずっと早いようです。
C - Guess The Number
受け取った桁数と数値の条件を満たす最小の数値を返す問題です。
まずそれぞれの桁を
-1を初期状態として作成します。そこから入力を受け取るごとに「書き換える数値が-1である」もしくは「書き換える数値が矛盾が生じない」どちらかの条件を満たしたとき書き換えます。矛盾が発生したときは-1を出力して終了。最後に書き換えが発生しなかった桁(-1)を最小値取るように変換させれば完成です。左から1桁目なら1(N=1の時0が許されるのに注意)、それ以降なら0に変換。
$N\geq2$の時1桁目を0に変えられないことに注意(一敗)。
N, M = map(int, input().split()) ans = [-1] * N for _ in range(M): i, n = map(int, input().split()) if (ans[i-1] == -1 or ans[i-1] == n) and not(N > 1 and i == 1 and n == 0): ans[i-1] = n else: print(-1) exit() ans = [n if n != -1 else 0 for n in ans] if ans[0] == 0 and N > 1: ans[0] = 1 print(*ans, sep='')D - Friend Suggestions
SNSの状態を与えられて、「友達の友達」であり、「友達でも敵でもない」関係が何人いるかを答える問題です。
繋がり合いっているかを探索する方法がわからず、諦めました。
解説を見ました。友達候補の数は、「自身が含まれるクラスター内の人数」から「自身の友達の数」と「自身の数(1)」と「クラスター内のブロックしている人数」を引いた数が答えになります。
よって配列として「それぞれの要素が所属しているクラスター」を格納する配列
clusterI、「それぞれのクラスターの持つ人数」を格納する配列clusterN、後で引く「友達とブロックしている人数」outの三つの配列を作成します。
clusterIにはそのクラスター内の最も低いインデックスを格納します。ここが問題。インデックスを書き換える処理をforで回して雑に変えたのが以下のコード。n, m, k = map(int, input().split()) clusterN = [1] * n clusterI = list(range(n)) out = [0] * n def unite(x, y): CX = clusterI[x] CY = clusterI[y] if CX != CY: if CX < CY: CX, CY = CY, CX clusterN[CX] += clusterN[CY] for i in range(n): if clusterI[i] == CY: clusterI[i] = CX for _ in range(m): a, b = map(int, input().split()) unite(a-1, b-1) out[a-1] -= 1 out[b-1] -= 1 for _ in range(k): a, b = map(int, input().split()) if clusterI[a-1] == clusterI[b-1]: out[a-1] -= 1 out[b-1] -= 1 out = [out[i] + clusterN[clusterI[i]] - 1 for i in range(n)] print(*out)TLEです。
他の人のコードを参考に、再帰関数による書き換えにしました。これで通りました。探索についての知識を持ってないのが大きな課題ですね。
n, m, k = map(int, input().split()) clusterN = [1] * n clusterI = list(range(n)) out = [0] * n def find(x): if clusterI[x] != x: minI = find(clusterI[x]) clusterI[x] = minI return minI else: return x def unite(x, y): CX = find(x) CY = find(y) if CX != CY: if CX > CY: CX, CY = CY, CX x, y = y, x clusterN[CX] += clusterN[CY] clusterI[CY] = CX for _ in range(m): a, b = map(int, input().split()) unite(a-1, b-1) out[a-1] -= 1 out[b-1] -= 1 for _ in range(k): a, b = map(int, input().split()) if find(a-1) == find(b-1): out[a-1] -= 1 out[b-1] -= 1 out = [out[i] + clusterN[find(i)] - 1 for i in range(n)] print(*out)E - Simple String Queries
入力に従って文字列を変換する操作を繰り返し、文字の種類数を調べる問題です。
いつものように愚直にやったのが以下のコードです。
import collections N = int(input()) S = list(input()) Q = int(input()) for _ in range(Q): Q1, Q2, Q3 = input().split() if Q1 == '1': S[int(Q2)-1] = ord(Q3) else: print(len(collections.Counter(S[int(Q2)-1: int(Q3)])))TLE出ました。
解説を見てみました。
AからZまでについての情報をもつ要素数26個の配列を作成します。要素内には、その文字が登場する位置を格納。数を数えるときは、26個の文字について指定範囲内にその文字の登場位置が含まれているかを調べます。
というのをそのまま実装したのが以下です。
N = int(input()) S = list(str(input())) def ordN(x): return ord(x) - ord('a') li = [[] for _ in range(26)] for i,s in enumerate(S): li[ordN(s)].append(i) for i in range(int(input())): Q1, Q2, Q3 = input().split() if Q1 == "1": Q2 = int(Q2) - 1 if S[Q2] != Q3: li[ordN(S[Q2])] = [n for n in li[ordN(S[Q2])] if n != Q2] li[ordN(Q3)].append(Q2) S[Q2] = Q3 else: Q2, Q3 = int(Q2)-1, int(Q3)-1 count = 0 for j in range(26): if [True for n in li[j] if Q2 <= n and n <= Q3]: count += 1 print(count)このままだとTLEがやはり出ます。他の人のコードを参考に書き換えます。文字の登場位置をソートした状態で保持。さらに二分探索によって置き換えや位置のチェックを行います。二分探索にはライブラリ
bisectを使用します。使う関数は以下の二つ。
bisect.bisect_left(list, x)a = [1, 2, 4, 6, 10] print(bisect.bisect_left(a, 4)) # 3第一引数のリストに対して第二引数をソート順を崩さず入れられる位置を返します。
bisect.insort(list, x)a = [1, 2, 4, 6, 10] bisect.insort(a, 4) print(a)# [1, 2, 4, 4, 6, 10]第一引数のリストに対してソート順を崩さず挿入を行います。
これを利用して書き換えたのが以下のコード。
import bisect N = int(input()) S = list(str(input())) def ordN(x): return ord(x) - ord('a') li = [[] for _ in range(26)] for i,s in enumerate(S): li[ordN(s)].append(i) for i in range(int(input())): Q1, Q2, Q3 = input().split() if Q1 == "1": Q2 = int(Q2) - 1 if S[Q2] != Q3: I = bisect.bisect_left(li[ordN(S[Q2])], Q2) li[ordN(S[Q2])].pop(I) bisect.insort(li[ordN(Q3)], Q2) S[Q2] = Q3 else: Q2, Q3 = int(Q2)-1, int(Q3)-1 count = 0 for j in range(26): I = bisect.bisect_left(li[j], Q2) if I < len(li[j]) and li[j][I] <= Q3: count += 1 print(count)これで通りました。
この記事はここまでとします。
- 投稿日:2020-03-28T20:13:28+09:00
sys.path.append('..')しても親ディレクトリにあるモジュールをimportできない
問い
- Pythonでmain.pyからmodule1.pyを使いたい。
- projectディレクトリで
python scripts/main.pyを実行。ディレクトリ構成project/ ├ module/ │ └ module1.py └ scripts/ └ main.pymain.pyimport sys sys.path.append('..') from module import module1このままでは
ModuleNotFoundErrorが出る。答え
..が示すのは、作業ディレクトリから見た親ディレクトリ。実行ファイルのあるディレクトリではない。つまり、projectディレクトリに対する親ディレクトリを参照している。
解決策としては、モジュールとして実行することが考えられる。python -m scripts.main
- 投稿日:2020-03-28T20:08:11+09:00
Python3でメール等の返信のための引用符「>」をつける
この記事について
この記事ではメール等で返信を行う際に、相手の文面の文頭に引用符をつけるコードを紹介します。筆者は素人です。色々教えていただけると幸いです。
筆者はPython2のことをよく知りませんが、自分がPython3を使ってるっぽいことだけはわかっています(Python3.6.0かな?)。そのため、記事のタイトルではPython3としました。
やりたいこと
下記のように送られてきたメール(相手の文面)に対して、先頭に「>」をつけた返信用の文面を出力したいです。ただし、空行はそのままにしておきたいです。
送られてきたメール(相手の文面)
佐藤さん
こんにちは
来週の飲み会のお店の候補です。
店A
うまい。少し高い。店B
味はまあまあ。安い。店C
飲み物が沢山ある。雰囲気が良い。鈴木
返信用の文面
>佐藤さん
>こんにちは
>来週の飲み会のお店の候補です。
>店A
>うまい。少し高い。>店B
>味はまあまあ。安い。>店C
>飲み物が沢山ある。雰囲気が良い。>鈴木
実装コードと実行結果
実装したコードと使い方、実行例を以下に示します。
コード
reply_mark.pypath_r = "sent_text.txt" path_w = "reply_text.txt" with open(path_r) as f_r, open(path_w, mode='w') as f_w: for line in f_r: if len(line) > 1: f_w.write(">" + line) else: f_w.write("\n")
with openなんたら〜の書き方でファイルオープンすると、ブロックの終了時にファイルクローズしてくれるらしいです。
(参考: https://note.nkmk.me/python-file-io-open-with/ )if では空行かどうかの判定をしています。
用途に合わせて f_w.write(">" + line) の > を他の記号等に変えるなどもできます。
使い方
- reply_mark.py があるディレクトリに sent_text.txtというファイルを作成し、送られてきたメール(相手の文面)をコピペする。
下記のように、ターミナルで reply_mark.py を実行する。
$ python reply_mark.pyreply_text.txt というファイルが作成され(※)、相手の文面の先頭に「>」をつけた返信用の文面が出力される。使うときはここからコピペする。
※reply_text.txt というファイルが既に存在している場合は上書きされます。
入力例
sent_text.txt佐藤さん こんにちは 来週の飲み会のお店の候補です。 店A うまい。少し高い。 店B 味はまあまあ。安い。 店C 飲み物が沢山ある。雰囲気が良い。 鈴木出力例
reply_text.txt>佐藤さん >こんにちは >来週の飲み会のお店の候補です。 >店A >うまい。少し高い。 >店B >味はまあまあ。安い。 >店C >飲み物が沢山ある。雰囲気が良い。 >鈴木終わりに
もう少し便利にしたいですね。理想で言えば、DeepLのアプリの「command + C」を2回押したら結果出るみたいなの良いなあ。
あと、シェルスクリプトで同じことできる気がしますが、Pythonの勉強を兼ねてるのでまあいっかということで。
気づいた点などあればご指摘、ご質問いただければと思います。特にコードの書き方や仕組みの作り方の改善案などあれば勉強になるなと思います。
- 投稿日:2020-03-28T19:52:26+09:00
Pytorchでsin波予測(回帰)
概要
こんにちは。とあるIT企業の新入社員です。
ここでは、オープンソース機械学習ライブラリであるPytorchを使って、sin波予測の回帰モデル学習プログラムをサンプルとして記載してみました。
(時系列予測ではないです。。。そのうち時系列予測もやりたいです。)chainerがpytorchに移行するということで、
遅れましたが、今回キャッチアップしようということで書きました。
私が違いを感じた点も記載しています。以前に書いた以下の記事のpytorch移行といった感じです。
今更、丁寧にsin波をchainerで学習させてみる何かご指摘・質問等ございましたら、ご遠慮なくコメント欄にお願い致します。
コード全体
コードは以下のGitHubに置いています。
kazu-ojisan/NN-pytorch_PredictSinWave環境
macOS Catalina 10.15.3
conda 4.7.12
python 3.7.6 (condaで仮想環境を作成)
pytorch 1.4.0pytorchのインストールは秒殺。
以下の公式サイトでご自身の環境を選択すると、
インストールコマンドを表示してくれる。
Pytorch -公式サイト-各パラメータ
- Input :0〜2π
- Output :sin(Input)
- 学習回数:200
- バッチサイズ:10 (ミニバッチ法)
- 学習データ数:1000
- テストデータ数:200
モデル構造
- 中間層:2層(ユニット数:10)
- 活性化関数:ReLU
実装
以下、実装のために参考にしたURLです。
- 実践Pytorch
- PyTroch で実装したニューラルネットワークで回帰問題を解く使用モジュール
pytorchのモジュールは最低限以下がimportされていればOK。
test.pyimport numpy as np # 配列 import time # 時間 from matplotlib import pyplot as plt # グラフ import os # フォルダ作成のため # pytorch import torch as T import torch.nn as nn # layer構成 import torch.nn.functional as F # 活性化関数 from torch import optim # 最適化関数データセット
単純なy=sin(x)のデータセット(x,y)です。
# y=sin(x)のデータセットをN個分作成 def get_data(N, Nte): x = np.linspace(0, 2 * np.pi, N+Nte) # 学習データとテストデータに分ける ram = np.random.permutation(N+Nte) x_train = np.sort(x[ram[:N]]) x_test = np.sort(x[ram[N:]]) t_train = np.sin(x_train) t_test = np.sin(x_test) return x_train, t_train, x_test, t_testNeural Network構造・順伝搬等
chainerからの違いは特になしでモジュールを置き換える程度。
強いていうなら、pytorchが扱うデータ型は、"Tensor型"なので変換が必要。
(chainerでいうValiable型).pyclass SIN_NN(nn.Module): def __init__(self, h_units, act): super(SIN_NN, self).__init__() self.l1=nn.Linear(1, h_units[0]) self.l2=nn.Linear(h_units[0], h_units[1]) self.l3=nn.Linear(h_units[1], 1) if act == "relu": self.act = F.relu elif act == "sig": self.act = F.sigmoid def __call__(self, x, t): x = T.from_numpy(x.astype(np.float32).reshape(x.shape[0],1)) t = T.from_numpy(t.astype(np.float32).reshape(t.shape[0],1)) y = self.forward(x) return y, t def forward(self, x): h = self.act(self.l1(x)) h = self.act(self.l2(h)) h = self.l3(h) return h学習
Chainerとの違いを感じた点(後に詳細あり)
①最適化関数の第一引数にmodel.parameter()が必要
②MSEはClassで定義されているため、インスタンスを作成しないと使えない
③"model.train()"と"model.eval()"による学習モード・テストモードの切替
(今回は無くても問題ない。)
④modelの拡張子は".pt"もしくは".pth".pydef training(N, Nte, bs, n_epoch, h_units, act): # データセットの取得 x_train, t_train, x_test, t_test = get_data(N, Nte) x_test_torch = T.from_numpy(x_test.astype(np.float32).reshape(x_test.shape[0],1)) t_test_torch = T.from_numpy(t_test.astype(np.float32).reshape(t_test.shape[0],1)) # モデルセットアップ model = SIN_NN(h_units, act) optimizer = optim.Adam(model.parameters()) MSE = nn.MSELoss() # loss格納配列 tr_loss = [] te_loss = [] # ディレクトリを作成 if os.path.exists("Results/{}/Pred".format(act)) == False: os.makedirs("Results/{}/Pred".format(act)) # 時間を測定 start_time = time.time() print("START") # 学習回数分のループ for epoch in range(1, n_epoch + 1): model.train() perm = np.random.permutation(N) sum_loss = 0 for i in range(0, N, bs): x_batch = x_train[perm[i:i + bs]] t_batch = t_train[perm[i:i + bs]] optimizer.zero_grad() y_batch, t_batch = model(x_batch, t_batch) loss = MSE(y_batch, t_batch) loss.backward() optimizer.step() sum_loss += loss.data * bs # 学習誤差の平均を計算 ave_loss = sum_loss / N tr_loss.append(ave_loss) # テスト誤差 model.eval() y_test_torch = model.forward(x_test_torch) loss = MSE(y_test_torch, t_test_torch) te_loss.append(loss.data) # 学習済みモデルの保存 T.save(model, "Results/model.pt")詳細:Chainerとの違いを感じた点
①最適化関数の第一引数にmodel.parameters()が必要
model.parameters()は、モデル情報である重みやユニット数などが格納されている。
公式ドキュメント:model.parameters()
ドキュメント通りに出力してみると以下のように出力される。$ python exportModelParam.py <class 'torch.Tensor'> torch.Size([10, 1]) <class 'torch.Tensor'> torch.Size([10]) <class 'torch.Tensor'> torch.Size([10, 10]) <class 'torch.Tensor'> torch.Size([10]) <class 'torch.Tensor'> torch.Size([1, 10]) <class 'torch.Tensor'> torch.Size([1])②MSEはClassで定義されているため、インスタンスを作成しないと使えない
Pytorchの"MSELoss"とChainerの"mean_squared_error"の公式ドキュメントを見ると納得する。
Pytorch:Pytorch -SOURCE CODE FOR TORCH.NN.MODULES.LOSS-MSELoss.pyclass MSELoss(_Loss):Chainer:Chainer -mean_squared_error.py-
mean_squared_error.pydef mean_squared_error(x0, x1):③"model.train()"と"model.eval()"による学習モード・テストモードの切替
.evalでテストモードにすると、DropoutやBatch Normalizationが無効になり、テスト仕様になるみたい。本コードでは、DropoutもBatch Normalizationも使っていないため、無くても変わらずに動作する。しかし、今後pytorchを使っていくのであれば、書くクセはつけておいた方が良い気がする。
④modelの拡張子は".pt"もしくは".pth"
以下、参照。
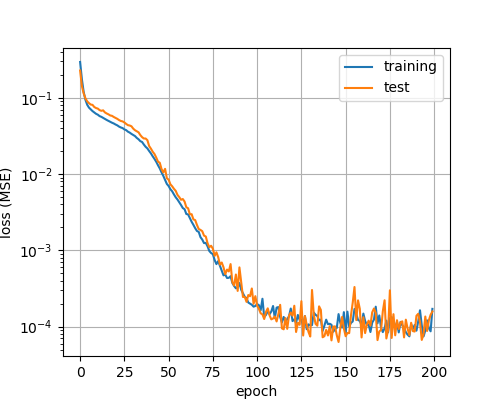
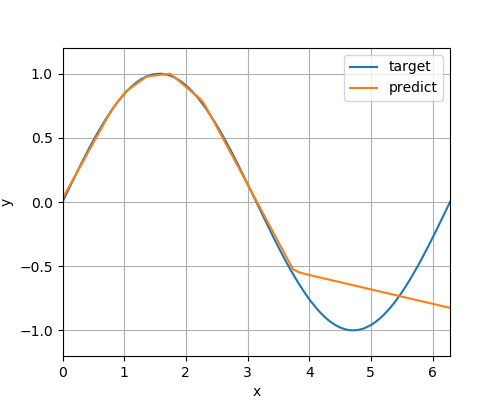
Tutorials > Saving and Loading Models結果
誤差グラフ
テストデータ予測グラフ
epoch:20
epoch:200
Trouble Shooting
- どうやら学習されていない?
- 勾配の初期化を忘れていた(optimizer.zero_grad())
- ミニバッチごとに勾配を初期化しないと学習できません。
参考URL
コード全体
コードは以下のGitHubに置いています。
kazu-ojisan/NN-pytorch_PredictSinWave終わりに
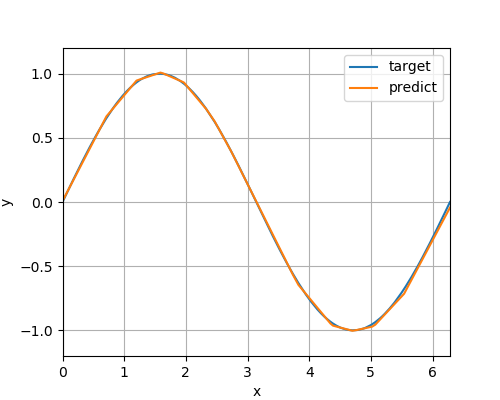
情報通り、chainerとかなり似ていました。Pytorchは機能が整っているなぁと感じました。まだまだ理解不足なので何かご指摘ございましたら、ご遠慮なくコメント欄にお願い致します。
- 投稿日:2020-03-28T19:44:55+09:00
Single GANs(SinGAN)で遊んでみた (+実装しようとして苦労した点(path通し, Linuxコマンド, googlecolab活用等) もまとめた)
はじめに
GANs:敵対的生成ネットワークの技術は日々進歩しています。非IT系の仕事(製造業での技術者)をしている私ですら強く興味が惹かれる技術です。より深く技術を理解するために、実装して遊んでみることが一番です。
従って今回は、Single GANsと呼ばれる2019年に発表されたアルゴリズムを実装してみたいと思います。単一の画像から合成画像を生成するアルゴリズムとなっていますので、実際に動かしてみた記事になります。しかし、この最新の論文を実装すること、それ自体が私にとってはいくつハードルがありましたので、その苦労した点にも着目して記事を作成しています。
今回の論文
今回実装したい論文はこちらです。
SinGAN: Learning a Generative Model from a Single Natural Image
https://arxiv.org/abs/1905.01164単一の画像のみを教師データとして、新しくその教師データに近い画像を生成することができます。さらに、手書きの画像から元画像に近い画像を生成させたり(Paint to image)、別の画像を重ね合わせて同じ作風へ変換させることができます(Harmonization)。
詳しいアルゴリズムの説明については私自身理解しきれないところがあるため、他の方の説明をご覧頂けると幸甚です。
【論文解説】SinGAN: Learning a Generative Model from a Single Natural Image
https://qiita.com/takoroy/items/27f918a2fe54954b29d6SinGANの論文を読んだらテラすごかった
https://qiita.com/yoyoyo_/items/81f0b4ca899152ac8806さて、実装させるためにはまずこちらのgithubからプログラム一式をダウンロードして、zipファイルを解凍しました。
https://github.com/tamarott/SinGAN環境ファイルパスを通す
さて、論文の内容を実装するにあたり、下記画像のようにターミナルからコマンドで指示することがよくあります。
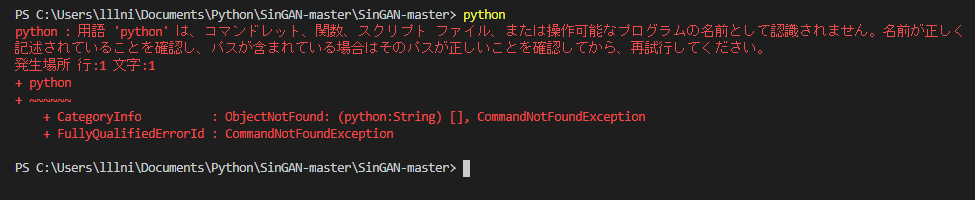
Terminalpython -m pip install -r requirements.txt最初にこれで必要なライブラリをインストールしようとしたら下記エラーメッセージが出ました。
これは、pythonというコマンドによってpython.exeを起動させることができていない=パスが通っていないことを示します。従って、パスを通すための設定を行う必要があります。
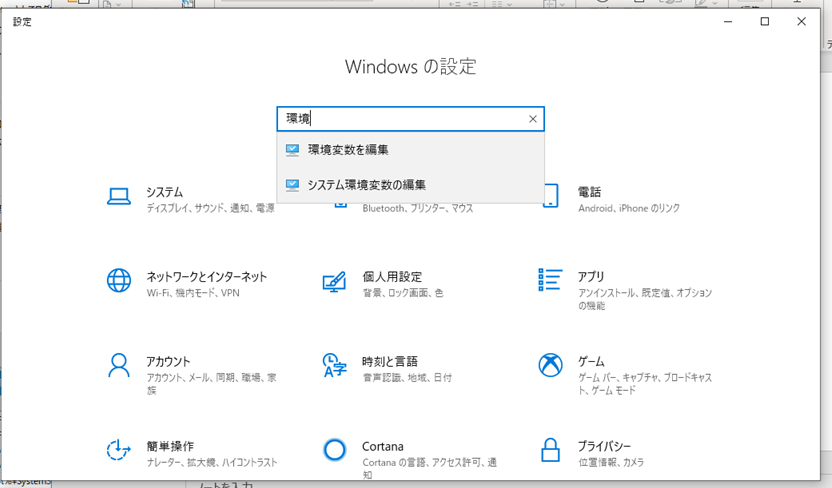
Windowsアイコンを右クリック⇒設定を行います(当方Windows 10 Home)。
そして、検索欄に環境と打つと、システム環境変数の編集欄が現れます。
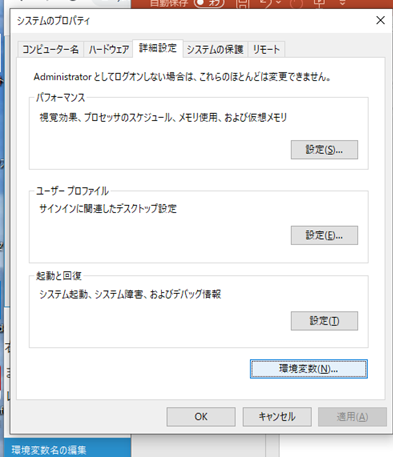
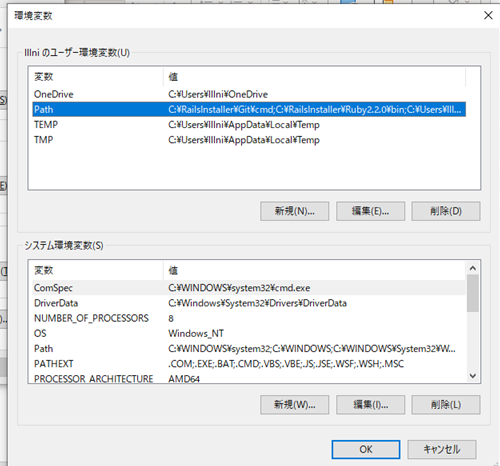
次に、システムのプロパティから環境変数をクリックします。
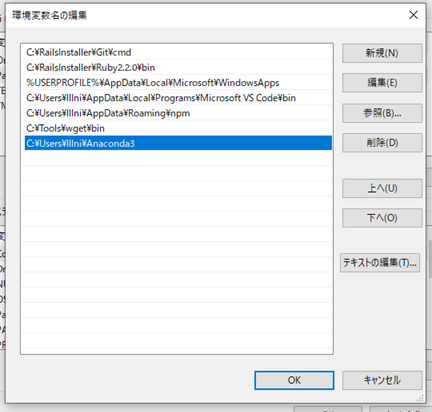
ここのPathの編集を行います。
新規を選択し、python.exeが格納されているフォルダのパスを入れ込みます。これにより、パスが通すことができるようになり先ほどの問題が解決します。
成功するとこのように確認することができます。
Argument Parserを理解する
次に、pythonコマンドが通ったと思い次に進むとこのようなコマンドが現れました。random_samples.pyを実行することは理解しましたがその後の--とハイフンが二つ重なったコマンドになっています。
調べたところ、これはターミナルコマンドから引数を指定することができるArgument Parserというモジュールを利用したものになります。参考URL
https://qiita.com/kzkadc/items/e4fc7bc9c003de1eb6d0Terminalpython random_samples.py --input_name <training_image_file_name> --mode random_samples --gen_start_scale <generation start scale number>コマンドラインから指定できることは便利なのですが、vs codeやjupyter上のカーネルで利用したい場合はどのようにすればよいのでしょうか。
こちらのURLに詳しく載っていました。
http://flat-leon.hatenablog.com/entry/python_argparse# 3.ArgumentParserオブジェクトを使って起動パラメータを解析する args = parser.parse_args()こちらで起動時のパラメータを解析しているようなので、listなどを作ってここに渡してあげることでカーネル上でも起動できるようです。
いざ学習開始
さて、ファイルパスやargumentについても理解できたところで早速実行します。しかし、小職のPCだと非常に学習に時間がかかることが分かりました。
- RAM 8GB
- intel core i7
- 計算用のGPUは無
今回の最初に行う学習では全9回(scale8)のうち6回(scale5中)を実行している断面で3時間程度経過していました。やはりGAN含め画像処理の計算は非常に時間がかかることが分かります。従って、ここは素直にGoogle Colab様のGPUを使用させて頂くことにしました。
Google Drive上に今回のフォルダをまとめてアップロードします。
そして、まずはその格納フォルダへディレクトリを移動します。GoogleColabcd /content/drive/My Drive/SinGAN-masterこれで、あとはLinuxコマンドを用いることで.pyファイルなどを動かすことができます。
ノイズからの画像生成(Train)
ノイズ画像から元の画像へ似せていく学習をさせていきます。学習初期は非常に小さい画像サイズから始まって、徐々に元の画像のサイズへ大きくなっていきます。
GoogleColab!python main_train.py --input_name cows.pngLinuxコマンドを用いる場合は!を最初に入れることで動作します。
いざ動かしてみると、非常に早く進めることができます。凡そ30分くらいで計算が終了しました。
ライブラリのインストールも非常に楽ですので、処理時間を要するものはGoogleColabですね。。
さて、生成した画像と元の画像を比べてみます。scale数が増えていくことは計算回数が増えていった結果です。
うーん本物と区別がつかない笑。画像サイズはscale数が低い時は小さいのですが、分かりやすく比較するために同じサイズにしています。
こうしてみると、徐々に鮮明な元の画像に近い画像に変化していくことが分かります。さらに、画質が上がっていくだけでなく、牛さん達の配置も毎回違うことが分かります。単純に画質を上げる処理ではないことが分かります。
手書き画像から元の画像へ似せる処理(Paint to Image)
次に、手書き画像から教師データ画像に似せるプログラムを実行します。これを行う際は最初に似せたい教師データを上記の訓練を行っておく必要があります。
GoogleColab!python paint2image.py --input_name volacano.png --ref_name volacano3.png --paint_start_scale 1
結果を見てみましょう。上手く再現はできませんでしたね。元の画像が右下です。そして、start_scaleの値は小さいほど訓練数が高いものとなっています。今回は、start_scale3,4あたりが一番近いような気がします。
おそらく、手書きによる元画像の出来具合が似ていないと似せることは難しいようです。
画像サイズを自由に変更してみる(Random samples of arbitrery sizes)
次に、元画像をベースとして画像のサイズを変えた処理をします。
GoogleColab!python random_samples.py --input_name cows.png --mode random_samples_arbitrary_sizes --scale_h 5 --scale_v 4scale_hが横方向(horizonal)の縮尺で1が1倍を示します。また、scale_vが縦方向(vertical)の縮尺です。
試しに、大きな画像を作ってみました。が、気持ち悪いですね。。大草原に密集した牛さんたちがいる画像になってしまいました。失礼致しました。。
元の作風に近づけて合成する(Harmonization)
最後に、元の画像の作風に合わせて修正するという処理です。この処理の場合も最初にtrainで訓練させる必要があります。
今回は、私が撮影した写真とフリー画像の魚を合成させてみました。GoogleColab!python harmonization.py --input_name fish.png --ref_name fish1.png --harmonization_start_scale 1
なんと大きな一匹の魚はスイミー(もしくはポケモンのヨワシ)のように水色の魚群と化しました。元々の朱色の魚群を元に処理されたのでしょう。非常に面白いアルゴリズムですね。
おわりに
GANの最新論文であるSingle GANsを実際に手を動かして遊んでみました。非常に簡便に使用できることが分かりました。実装させるにあたり、環境構築に関してもとても勉強になりました。特に、Google Colabがあることで計算負荷が高いモデルでも簡単に動かせて結果を見れることに感動を覚えました。Googleさんの偉大さを改めて感じました。
今回は実装して遊んでみるところに注力したため、理論的な中身についても理解を深めていこうと思います。派生した論文もいくつかすでに出ているため、それとの関連についても学びたいです。






- 投稿日:2020-03-28T19:44:38+09:00
AtCoder ABC155 問題D Pairs 検討メモ2 NumPyとPython
概要
AtCoder ABC155 問題D Pairsに関してメモ。
PythonとNumPyの速度を「ソート」と「二分法」について測定してみた。実施前はどちらの処理もNumPyの圧勝を予想していた。ソートはNumPyが10倍程度速い。二分法は多数の閾値をリストとして与える場合はNumPyが速いが、一つの閾値について関数を呼び出す場合はNumPyよりもPythonが速いことを示す結果が得られた。結構意外だ。
経緯
AtCoder ABC155 問題D Pairs 検討メモ1の続き。この問題でTLEから抜け出せなかったのはPythonの速度がNumPyに較べて遅いことが理由の様であることが観察された。そこでPythonとNumPyを比較するテスト用プログラムを書いてみて、速度を測定した。
結果
(測定に使用したプログラムは一番下にある)
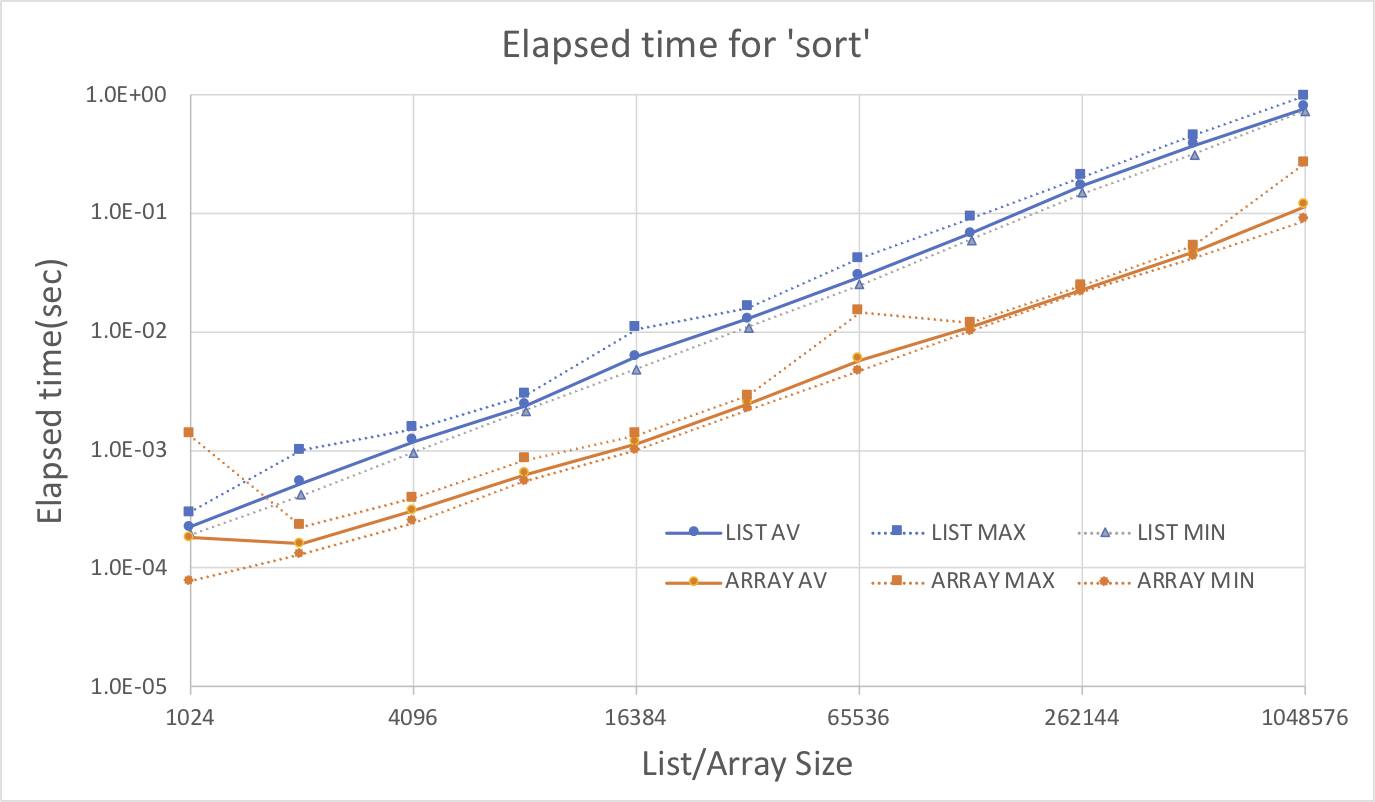
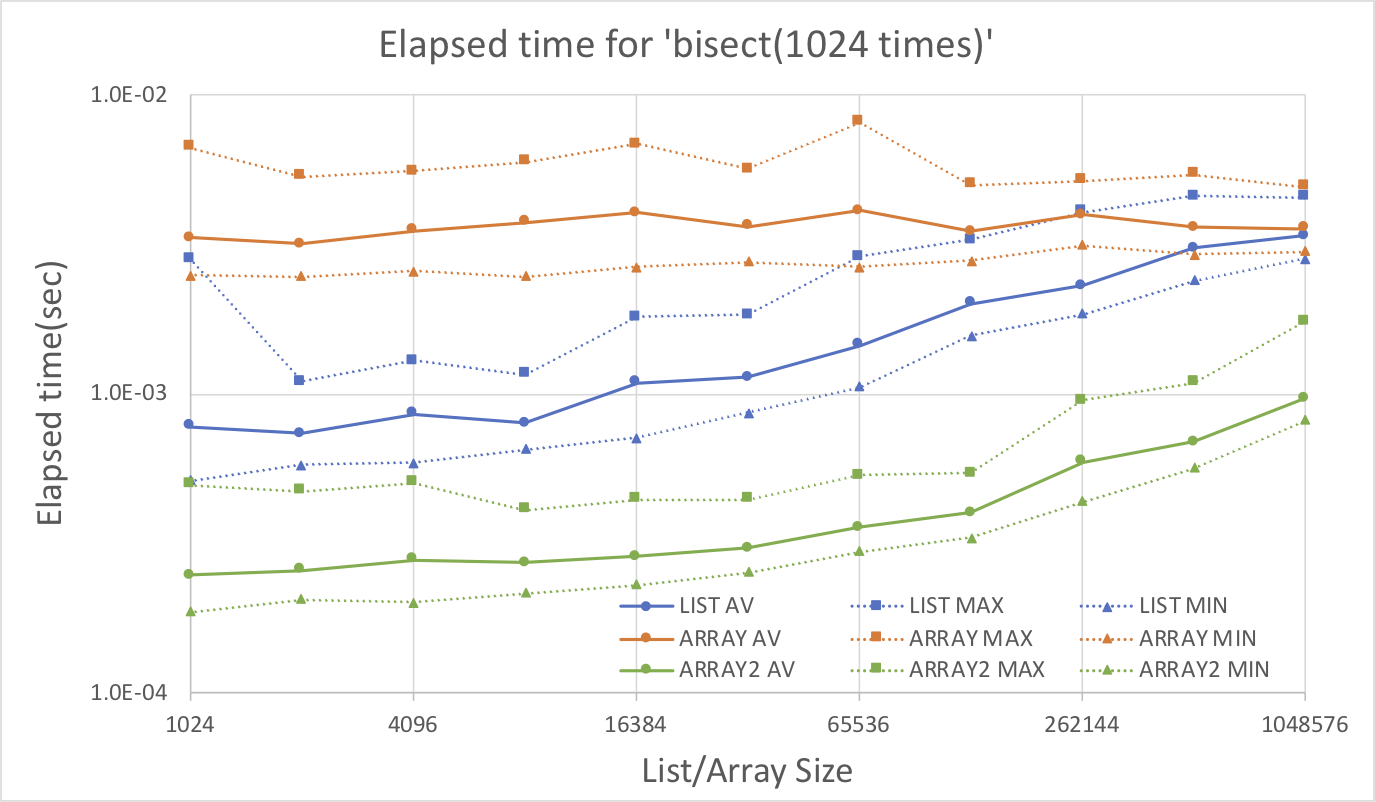
ソート
List(Python)とArray(NumPy)のサイズを1024から1048576まで変えた時にsorted(Python)とnumpy.sort(NumPy)の実行時間を比較してみた。グラフの縦軸は実行時間(秒)、横軸はListもしくはのArrayサイズ。
それぞれの測定は16回試行を実施していて、グラフには平均、最大、最小の経過時間を示している。
LIST:Python sorted()
ARRAY: NumPy numpy.sort()
結果よりArray(NumPy)の処理方がList(Python)の処理にくらべてほぼ10倍速いことが分かる。二分法
List(Python)とArray(NumPy)のサイズを1024から1048576まで変えた時にbisect.bisect_left(Python)とnumpy.searchsorted(NumPy)の実行時間を比較してみた。グラフの縦軸は実行時間(秒)、横軸はListもしくはのArrayサイズ。この関数は同じサイズの問題だと、ソートよりもはるかに短時間で終了して測定制度に問題があるので1.for文で1024回呼び出すかもしくは2.閾値を1024回分LISTで与える事により1試行あたり1024回の二分法を繰り返すかした時の実施時間をプロットしている。
LIST:Python bisect.bisect_left() for文で1024回呼び出し
ARRAY: NumPy numpy.searchsorted() for文で1024回呼び出し
ARRAY2: NumPy numpy.searchsorted() 第二引数にサイズ1024のリストを渡して一回呼出しそれぞれの測定は16回試行を実施していて、グラフには平均、最大、最小の経過時間を示している。Arrayとしているものはfor文を使用して一試行あたりnumpy.searchsorted()を1024回呼び出している。Array2としているものはnumpy.searchsorted()の第二引数にサイズ1024のリストを与えることにより試行一回あたり同じ処理を実施している。
結果よりArray2(NumPy)、List(Python)、Array(NumPy)、の順で性能がよい。サイズが大きくなるに従い性能差は縮む傾向にある。しかしサイズ1048576でもArray2(NumPy)は他のものに較べて性能が数倍よい。第二引数にリストを使用しないときPython bisect.bisect_left()がNumPy numpy.searchsorted()より性能が良い様子であるのは少し意外であった。
感想
この速度差からするとAtCoder ABC155 問題D Pairsで自分のプログラムがTLEできなかったのはNumPyを使用してなかったのが原因と推察される。いろいろ覚えないといけないこと多いな。練習のため同じ問題でC++のテストも機会あればやってみたい。
Appedix
テストに使用したプログラム
random.bisect.pyimport math import sys import numpy as np import random import time import bisect args = sys.argv stdin = sys.stdin rangeMax = 2 ** 60 n_bisect_try = 1024 target = [random.randrange(0,rangeMax) for _ in range(n_bisect_try)] print(rangeMax) N = int(args[1]) def start_time(): global start start = time.time() def end_time(header="Elapsed time: "): global start elapsed_time = time.time() - start print("{0}{1:0.7f}".format(header,elapsed_time)) return elapsed_time start_time() s = [ random.randrange(0,rangeMax) for _ in range(N)] end_time('Time Generate Random List: ') # print(s) start_time() sn = np.array(s) end_time('Time Make Array: ') start_time() s_sort = sorted(s) end_time("Time List Sort: ") #print(s,s_sort) start_time() for t in target: i = bisect.bisect_left(s_sort,t) #print("Result List Bisect:", i) end_time("Time List Bisect: ") start_time() sn_sort = np.sort(sn) end_time("Time Array Sort: ") # print(sn,sn_sort) start_time() for t in target: i = np.searchsorted(sn_sort,t) # print("Result List Bisect:", i) end_time("Time Array Bisect: ") start_time() i_array = np.searchsorted(sn_sort,target) #print("Result List Bisect2:", i_array) end_time("Time Array Bisect2: ")
- 投稿日:2020-03-28T19:04:11+09:00
a, bの最小公倍数と最大公約数の積がabであることを利用した競技プログラミング解法
問題
C - Snack https://atcoder.jp/contests/abc148/tasks/abc148_c
単に最小公倍数を求める問題である。
解答
$a, b$ の最小公倍数を $l$ 、最大公約数を $g$ とおくと $ab = gl$ が成り立つため、 $l = \frac{ab}{g}$ で最小公倍数を求められる。Pythonでの解答は以下の通り。
def GCD(a, b): while a: a, b = b % a, a return b def main(): A, B = map(int, input().split()) print(A // GCD(A, B) * B) main()a, bの最小公倍数と最大公約数の積がabであることの証明
$a, b$共に $g$の倍数であるため
a = ga' \\ b = gb'を満たす互いに素な自然数 $a', b'$が存在する。また、$l$ は$a$ の倍数であるため
l = cga'を満たす自然数 $c$ が存在する。同様にして、
l = dgb'を満たす自然数 $d$ が存在する。これらより、
cga' = dgb' \\ ca' = db' \\ c = d\frac{b'}{a'}が成り立つ。$a', b'$ は互いに素であるため $\frac{b'}{a'}$ は自然数ではない。一方 $c$ は自然数であるため
a' = dを満たす必要がある。よって、
l = ga'b'である。両辺に $g$ をかけると
gl = ga'gb' \\ gl = abである。以上より証明された。
参考文献
【標準】最大公約数と最小公倍数の積 | なかけんの数学ノート https://math.nakaken88.com/textbook/standard-product-of-greatest-common-divisor-and-least-common-multiple/#i
- 投稿日:2020-03-28T18:56:31+09:00
主成分分析を用いた顔認識
はじめに
主成分分析を使った顔認証プログラムを試してみた。プログラムはpythonで主成分分析のライブラリはscikit-learnを使用。顔画像はこの論文だとおっさんの画像で面白くないので橋本環奈の顔画像を使用。
主成分分析とは
詳細な説明のあるサイトや書籍が多数あるので割愛。簡単に言うと多次元の特徴空間を低次元の部分空間に次元削減を行うことで、そのデータの持つ特徴を抽出するデータ分析手法の一種。対象が画像の場合はN×N(ピクセル)の画素値を要素とした2次元の行列だが、$N^2$次元の特徴ベクトルとして表すことに注意する。
顔認証などの画像マッチングに応用する場合は、テンプレートの主成分との相関値(類似度)を算出することにより、最も相関が高いものを正解として出力する。顔認証の実装
理論
この論文をベースとした。
まず、学習用の顔データをn個そろえる。各画像はN×Nにリサイズされているものとする。
X = \{\vec{x}_1,\vec{x}_2,\cdots,\vec{x}_i,\cdots,\vec{x}_n\}ここで、$\vec{x_i}$は、N×N画像を$N^2$次元の特徴ベクトルとして表したものとする。
そこから、平均値
\vec{\mu} = \frac{1}{n}\sum_{i=1}^{n}\vec{x}_iを求め、共分散行列
S = \sum_{i=1}^{n}\sum_{j=1}^{n}(\vec{\mu}-\vec{x}_i)(\vec{\mu}-\vec{x}_j)^Tを得る。そこから固有値問題
S\vec{v}=\lambda\vec{v}を解くことで、固有値$\lambda_j$、固有ベクトル$\vec{v}_j$を得る。固有ベクトルを、対応する固有値の大きい順に並べることで、その固有ベクトルが第一主成分、第二主成分・・・となる。
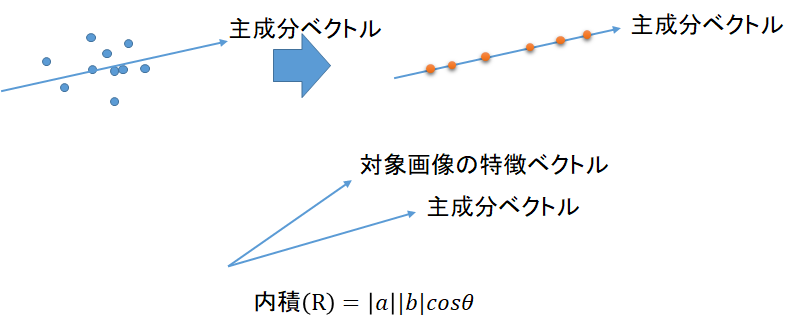
顔認証は、対象画像と、この学習済み主成分との相関値を計算することで行われる。相関値は、固有ベクトル(主成分ベクトル)を横に並べた射影行列
V = \{\vec{v}_1,\vec{v}_2,\cdots,\vec{v}_d\}を用いて、対象画像の特徴ベクトル$X_{obs}$との内積により得られる。ここでは、$d=1$として、第1主成分により相関値を求める。すなわち、相関値$R$は、
R = \vec{v}_1\cdot X_{obs}^Tと計算することができる。
実装
まず、学習用の橋本環奈の顔画像用意。本来はいろいろな画像を登録するが、顔認証の場合はシビアで様々な角度から撮影した画像が多数ないと厳しい。とりあえず、今回はあくまで練習なので下記の画像を5個コピーして登録した。
次に、練習用にいろんな画像を用意。
手書き文字画像、橋本環奈(オリジナルと、ちょっと似てる別の画像の2つ)、出川哲郎、モナ・リザの計5つ
コード
import os from glob import glob import numpy as np import sys from sklearn.decomposition import PCA import cv2 SIZE = 64 # GRAYSCALE def Image_PCA_Analysis(d, X): # 主成分分析 pca = PCA(n_components=d) pca.fit(X) print("主成分") print(pca.components_) print("平均") print(pca.mean_) print("共分散行列") print(pca.get_covariance()) print("共分散行列の固有値") print(pca.explained_variance_) print("共分散行列の固有ベクトル") v = pca.components_ print(v) #主成分分析結果 print("主成分の分散説明率") print(pca.explained_variance_ratio_) print("累積寄与率") c_contribute_ratio = pca.explained_variance_ratio_.sum() print(c_contribute_ratio) # 次元削減と復元 X_trans = pca.transform(X) X_inv = pca.inverse_transform(X_trans) print('X.shape =', X.shape) print('X_trans.shape =', X_trans.shape) print('X_inv.shape =', X_inv.shape) for i in range(X_inv.shape[0]): cv2.imshow("gray", X_inv[i].reshape(SIZE,SIZE)) cv2.waitKey(0) cv2.destroyAllWindows() return v,c_contribute_ratio def img_read(path): x = [] files = glob(path) for file in files: img = cv2.imread(file, cv2.IMREAD_GRAYSCALE) img2 = cv2.resize(img, (SIZE, SIZE)) # N*Nにリサイズ x.append(img2) X = np.array(x) X = X.reshape(X.shape[0],SIZE*SIZE) # 特徴ベクトル×nにする X = X / 255.0 # 0-1にしないといけないのでnormalize print(X.shape) return X def main(): # 主成分分析次元数 d = 5 path = './kanna/*.png' X = img_read(path) # PCA v, c_contribute_ratio = Image_PCA_Analysis(d, X) # マッチング path = './kanna2/*.png' files = glob(path) for file in files: X2 = img_read(file) X2 = X2 / np.linalg.norm(X2) # 相関値(d次元の固有ベクトルを用いて作った射影行列と特徴ベクトルの積) eta = np.dot(v[0],X2.T) print("相関値:", file, np.linalg.norm(eta * 255)) return対象のテスト画像(5つ)は平均輝度がばらばらなので特徴ベクトルのノルムを1に規格化している。
結果
期待通り、橋本環奈の相関値は高く、出川の相関値は低い。出川は手書き文字「3」より低い。
相関値: ./kanna2\3.png 21.292788187030233 相関値: ./kanna2\degawa.png 14.11580341763399 相関値: ./kanna2\kanna_2.png 32.536060418259474 相関値: ./kanna2\kanna_org.png 39.014994579329326 相関値: ./kanna2\MN.png 26.90538714456287```同じ画像を多数登録しているので当たり前だが、第1主成分のみでほぼ説明できており、累積寄与率は100%
主成分の分散説明率 [1.00000000e+00 3.15539405e-32 0.00000000e+00 0.00000000e+00 0.00000000e+00] 累積寄与率 1.0なお、相関値の定性的理解としては以下の図の通り、まず、学習画像のデータは、主成分軸に投影されているとみなす(次元圧縮)。主成分ベクトルと対象画像(の特徴ベクトル)の内積をとることで、主成分ベクトルとの方向に近い画像が、内積の値が大きいことになる。


- 投稿日:2020-03-28T18:51:26+09:00
[Python]リスト内包表記を使おうとして、小一時間ハマった
はじめに
Pythonの勉強中で、リスト内包表記を使ってみようと思ったら、小一時間ハマりました。
Pythonの関数は参照渡しだと思ってしまったのが原因だと思います。
(筆者が「参照渡し」を誤解しているかもしれないですが)実行結果を見比べれば、何が起きたか分かります、きっと。
ハマったコードと実行結果
冒頭の関数
findDiff()を作って、追加要素と削除要素を調べようとしました。
しかし、関数から戻ったら、リストの要素が消え(たように見え)ました。def findDiff(oldList, newList, adds, dels): adds = [x for x in newList if oldList.count(x) < 1] dels = [x for x in oldList if newList.count(x) < 1] oldList = [1,2,3,5,6,7,8,9] newList = [1,2,4,5,6,7,8,10] adds = [] dels = [] print(adds) print(dels) findDiff(oldList, newList, adds, dels) print(adds) print(dels) #>>> [] #>>> [] #>>> [] #>>> []修正したコードと実行結果
冒頭の関数
findDiff()のみ、修正しています。def findDiff(oldList, newList, adds, dels): for x in newList: if oldList.count(x) < 1: adds.append(x) for x in oldList: if newList.count(x) < 1: dels.append(x) oldList = [1,2,3,5,6,7,8,9] newList = [1,2,4,5,6,7,8,10] adds = [] dels = [] print(adds) print(dels) findDiff(oldList, newList, adds, dels) print(adds) print(dels) #>>> [] #>>> [] #>>> [4, 10] #>>> [3, 9]終わりに
記事を書いた後に調べたら、先人の知恵が既にありました。。。
- 投稿日:2020-03-28T18:49:05+09:00
Python で Google Spreadsheets (など)の無人操作
TL; DR
- Google Spreadsheets の表を Python プログラムを使って無人操作する方法を書きました。
- 公式 Quick Start は人間が介在する OAuth2 のやり方だけど、ようはこれの無人版です。
- サービスアカウントというものを作って、それに必要な権限を与え、そのアカウントの秘密鍵を使ってアクセスします。
スプレッドシートの準備
これは何も特別なことはありません。Google Drive に適当なシートを作成して、ファイルの ID だけ控えておいてください。
プロジェクトとサービスアカウント
各種ドキュメントを操作するには当然権限が必要です。プログラムから操作する場合は、大雑把に行って2とおりの権限獲得の手法があります。
- 一時的に人間の許可を得て、その人間のアカウントで操作
- 権限を与えられた 機械ようのアカウント で操作
ざっくり言うと前者はインタラクティヴなソフトで使う方法で、後者は自動化システムで使う方法です。今回は後者の方法を使います。ここで「機械ようのアカウント」を サービスアカウントと言います。つまり、まずはサービスアカウントを作り、必要な権限を与える必要がります。だいたい以下の手順です。
- GCPのコンソール に行って、プロジェクトを作ります。
- GCPの左上のハンバーガーメニュー > IAMと管理 > サービスアカウント > サービスアカウントを作成
- 入力は必須項目だけで良いと思います。
name@project.iam.gserviceaccount.comというアカウントができます。- アカウントを作ると秘密鍵 (private key) をダウンロードできると思います。JSON形式でダウンロードしてください。
- このアカウントに対して、操作したいファイル(スプレッドシート)の操作権限を与えてください(=共有してください)。与え方は通常の人間向けの権限操作といっしょです。
- ハンバーガーメニュー > APIとサービス > ダッシュボード > +APIとサービスを有効化 と進み、
Google Sheets APIを有効化してください。パッケージのインストール
たぶんこれだけでいいはず。
$ pip3 install google-api-python-client google-auth-oauthlib oauth2clientコード
シートの A1 セルに test と書き込むコードです。たったこれだけ!
from googleapiclient.discovery import build from oauth2client.service_account import ServiceAccountCredentials PRIVKEY_FILE = "projectname-*********.json" # ダウンロードした秘密鍵 SPREADSHEET_ID = "********" # シートのファイルのID SCOPE = ["https://www.googleapis.com/auth/spreadsheets"] creds = ServiceAccountCredentials.from_json_keyfile_name(PRIVKEY_FILE, SCOPE) service = build("sheets", "v4", credentials=creds) sheet = service.spreadsheets() result = sheet.values().update( spreadsheetId=SPREADSHEET_ID, range="a1", valueInputOption="RAW", # USER_ENTERED とすると式を式として入力できる(例: "=sum(a1:a100)") body={"values": [["test"]]}).execute()おわりに
Ruby でも同じくらい簡単にできました。
- 投稿日:2020-03-28T17:38:19+09:00
AtCoder ABC 098 C - Attention解答に至るまでの考え方
問題
C - Attention https://atcoder.jp/contests/abc098/tasks/arc098_a
解答に至るまでの考え方
注目すべきポイントは、リーダーを $i$ 番目としたときに向きを変える 人数 が問われていること。すなわち向きを変える人が 何番目 かは問われていない。よって、 $0$ から $i - 1 $ 番目までで西を向いている人数と $i + 1$ から $N - 1$番目までで東を向いている人数を足せば良いと分かる。この操作を $0 \leq i \leq N - 1$ で行い最小値が解答となる。
計算効率を上げるには、西を向いている人数と東を向いている人数の累積和を予め求めておけば、$0 \leq i \leq N - 1$ でリーダーを $i$ 番目としたときに向きを変える人数を $O(1)$ で求められる。
解答
Pythonです。
N = int(input()) S = input() int_s = [0] * N cum_sum_w = [0] * (N + 1) cum_sum_e = [0] * (N + 1) answers = [0] * N for i in range(N): if (S[i] == 'W'): int_s[i] = 1 else: int_s[i] = 0 cum_sum_w[i + 1] = cum_sum_w[i] + int_s[i] for i in range(N): if (S[i] == 'E'): int_s[i] = 1 else: int_s[i] = 0 cum_sum_e[i + 1] = cum_sum_e[i] + int_s[i] for i in range(N): answers[i] = cum_sum_w[i] + (cum_sum_e[N] - cum_sum_e[i + 1]) print(min(answers))
- 投稿日:2020-03-28T17:38:19+09:00
AtCoder ABC 098 C - Attention 解答に至るまでの考え方
問題
C - Attention https://atcoder.jp/contests/abc098/tasks/arc098_a
解答に至るまでの考え方
注目すべきポイントは、リーダーを $i$ 番目としたときに向きを変える 人数 が問われていること。すなわち向きを変える人が 何番目 かは問われていない。よって、 $0$ から $i - 1 $ 番目までで西を向いている人数と $i + 1$ から $N - 1$番目までで東を向いている人数を足せば良いと分かる。この操作を $0 \leq i \leq N - 1$ で行い最小値が解答となる。
計算効率を上げるには、西を向いている人数と東を向いている人数の累積和を予め求めておけば、$0 \leq i \leq N - 1$ でリーダーを $i$ 番目としたときに向きを変える人数を $O(1)$ で求められる。
解答
Pythonです。
N = int(input()) S = input() int_s = [0] * N cum_sum_w = [0] * (N + 1) cum_sum_e = [0] * (N + 1) answers = [0] * N for i in range(N): if (S[i] == 'W'): int_s[i] = 1 else: int_s[i] = 0 cum_sum_w[i + 1] = cum_sum_w[i] + int_s[i] for i in range(N): if (S[i] == 'E'): int_s[i] = 1 else: int_s[i] = 0 cum_sum_e[i + 1] = cum_sum_e[i] + int_s[i] for i in range(N): answers[i] = cum_sum_w[i] + (cum_sum_e[N] - cum_sum_e[i + 1]) print(min(answers))
- 投稿日:2020-03-28T17:37:56+09:00
「-(ハイフン)」の付いたモジュールが削除できない
pip checkでモジュール間の依存関係を確認
pip checkでチェックしたところ以下のエラーが出ました。
$ pip check -iskit 0.13.0 requires qiskit-aer, which is not installed. -iskit 0.13.0 requires qiskit-aqua, which is not installed. -iskit 0.13.0 requires qiskit-ibmq-provider, which is not installed. -iskit 0.13.0 requires qiskit-ignis, which is not installed. -iskit 0.13.0 requires qiskit-terra, which is not installed. tensorflow 2.1.0 has requirement gast==0.2.2, but you have gast 0.3.3. tensorflow 2.1.0 has requirement tensorboard<2.2.0,>=2.1.0, but you have tensorboard 2.2.0. mysql-connector-python 8.0.19 has requirement protobuf==3.6.1, but you have protobuf 3.11.3.
-iskitって以前インストールしていたqiskitだと当たりは付いたのですが、既にアンインストール済みのはず。
check結果に出て欲しくないので、アンインストールしてみたらエラー。$ pip show ~iskit zsh: no such user or named directory: iskit $ pip uninstall ~iskit zsh: no such user or named directory: iskit $ pip uninstall "~iskit" ERROR: Invalid requirement: '~iskit'色々確認
$ pip list Package Version --------------------------------- -------------------- - xopt -.bsockets 7.0 -.fi 1.13.2 -.re-itertools 8.0.2 -.scf 1.6.5 -.st-asyncio 1.2.1 -.xopt 1.2.3 (以下省略)ゴミが一杯!
実体はあるのか?
/usr/local/lib/python3.7/site-packages $ ls -l|grep -e "~" drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%bsockets-7.0.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%re_itertools-5.0.0.dist-info drwxrwxr-x - nandymak admin 2020-01-02 22:07 ~%re_itertools-8.0.2.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%scf-1.6.5.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%st_asyncio-1.0.0.dist-info drwxrwxr-x - nandymak admin 2020-01-02 22:07 ~%st_asyncio-1.2.1.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%xopt-1.2.3.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~iskit-0.13.0.dist-info (以下省略)「~(チルダ)」の付いたフォルダーが一杯ありますね。
ざっと見る限り現在インストールされているモジュールでは無さそうです。
ググってみましたが、それらしい情報は見つけられませんでした。と言うことで、削除する
/usr/local/lib/python3.7/site-packages $ ls |grep -e "~" ~%bsockets-7.0.dist-info ~%re_itertools-5.0.0.dist-info ~%re_itertools-8.0.2.dist-info ~%scf-1.6.5.dist-info (以下省略)もう一度確認して、
/usr/local/lib/python3.7/site-packages $ for item in `ls |grep -e "~"` ; do rm -rf ./$item donepip list Package Version --------------------------------- -------------------- absl-py 0.7.1 alabaster 0.7.12 annofabapi 0.29.5 appdirs 1.4.3 appnope 0.1.0 (以下省略)綺麗になりました。
実行の際は自己責任でお願いします
私の場合は、おかしくなったら一から入れ直すつもりでしたので(^_^;)おまけ
tensorflowで以下のエラーが出ていました。
tensorflow 2.1.0 has requirement gast==0.2.2, but you have gast 0.3.3. tensorflow 2.1.0 has requirement tensorboard<2.2.0,>=2.1.0, but you have tensorboard 2.2.0.Google Colaboratoryで確認してみたところ、
!pip list|grep tensorflow tensorflow 2.2.0rc1 tensorflow-addons 0.8.3 tensorflow-datasets 2.1.0 tensorflow-estimator 2.2.0rc0 tensorflow-gcs-config 2.1.8 tensorflow-hub 0.7.0 tensorflow-metadata 0.21.1 tensorflow-privacy 0.2.2 tensorflow-probability 0.9.0本体が
2.2.0rc1に上がっていますね。
Google Colaboratoryのデフォルトが2.2.0rc1なら合わせておきましょう。!pip list|grep tensorflow|awk '{print "pip install "$1"=="$2}' pip install tensorflow==2.2.0rc1 pip install tensorflow-addons==0.8.3 pip install tensorflow-datasets==2.1.0 pip install tensorflow-estimator==2.2.0rc0 pip install tensorflow-gcs-config==2.1.8 pip install tensorflow-hub==0.7.0 pip install tensorflow-metadata==0.21.1 pip install tensorflow-privacy==0.2.2 pip install tensorflow-probability==0.9.0
pip install tensorflow〜〜の行をコピーして、Local側のTerminalに貼り付けてインストール、エラーが出なくなりました。実行の際は自己責任でお願いします
- 投稿日:2020-03-28T17:37:56+09:00
「-(ハイフン)」の付いたPythonモジュールが削除できない
pip checkでモジュール間の依存関係を確認
pip checkでチェックしたところ以下のエラーが出ました。
$ pip check -iskit 0.13.0 requires qiskit-aer, which is not installed. -iskit 0.13.0 requires qiskit-aqua, which is not installed. -iskit 0.13.0 requires qiskit-ibmq-provider, which is not installed. -iskit 0.13.0 requires qiskit-ignis, which is not installed. -iskit 0.13.0 requires qiskit-terra, which is not installed. tensorflow 2.1.0 has requirement gast==0.2.2, but you have gast 0.3.3. tensorflow 2.1.0 has requirement tensorboard<2.2.0,>=2.1.0, but you have tensorboard 2.2.0. mysql-connector-python 8.0.19 has requirement protobuf==3.6.1, but you have protobuf 3.11.3.
-iskitって以前インストールしていたqiskitだと当たりは付いたのですが、既にアンインストール済みのはず。
check結果に出て欲しくないので、アンインストールしてみたらエラー。$ pip show ~iskit zsh: no such user or named directory: iskit $ pip uninstall ~iskit zsh: no such user or named directory: iskit $ pip uninstall "~iskit" ERROR: Invalid requirement: '~iskit'色々確認
$ pip list Package Version --------------------------------- -------------------- - xopt -.bsockets 7.0 -.fi 1.13.2 -.re-itertools 8.0.2 -.scf 1.6.5 -.st-asyncio 1.2.1 -.xopt 1.2.3 (以下省略)ゴミが一杯!
実体はあるのか?
/usr/local/lib/python3.7/site-packages $ ls -l|grep -e "~" drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%bsockets-7.0.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%re_itertools-5.0.0.dist-info drwxrwxr-x - nandymak admin 2020-01-02 22:07 ~%re_itertools-8.0.2.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%scf-1.6.5.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%st_asyncio-1.0.0.dist-info drwxrwxr-x - nandymak admin 2020-01-02 22:07 ~%st_asyncio-1.2.1.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~%xopt-1.2.3.dist-info drwxrwxr-x - nandymak admin 2019-11-29 23:33 ~iskit-0.13.0.dist-info (以下省略)「~(チルダ)」の付いたフォルダーが一杯ありますね。
ざっと見る限り現在インストールされているモジュールでは無さそうです。
ググってみましたが、それらしい情報は見つけられませんでした。と言うことで、削除する
/usr/local/lib/python3.7/site-packages $ ls |grep -e "~" ~%bsockets-7.0.dist-info ~%re_itertools-5.0.0.dist-info ~%re_itertools-8.0.2.dist-info ~%scf-1.6.5.dist-info (以下省略)もう一度確認して、
/usr/local/lib/python3.7/site-packages $ for item in `ls |grep -e "~"` ; do rm -rf ./$item donepip list Package Version --------------------------------- -------------------- absl-py 0.7.1 alabaster 0.7.12 annofabapi 0.29.5 appdirs 1.4.3 appnope 0.1.0 (以下省略)綺麗になりました。
実行の際は自己責任でお願いします
私の場合は、おかしくなったら一から入れ直すつもりでしたので(^_^;)おまけ
tensorflowで以下のエラーが出ていました。
tensorflow 2.1.0 has requirement gast==0.2.2, but you have gast 0.3.3. tensorflow 2.1.0 has requirement tensorboard<2.2.0,>=2.1.0, but you have tensorboard 2.2.0.Google Colaboratoryで確認してみたところ、
!pip list|grep tensorflow tensorflow 2.2.0rc1 tensorflow-addons 0.8.3 tensorflow-datasets 2.1.0 tensorflow-estimator 2.2.0rc0 tensorflow-gcs-config 2.1.8 tensorflow-hub 0.7.0 tensorflow-metadata 0.21.1 tensorflow-privacy 0.2.2 tensorflow-probability 0.9.0本体が
2.2.0rc1に上がっていますね。
Google Colaboratoryのデフォルトが2.2.0rc1なら合わせておきましょう。!pip list|grep tensorflow|awk '{print "pip install "$1"=="$2}' pip install tensorflow==2.2.0rc1 pip install tensorflow-addons==0.8.3 pip install tensorflow-datasets==2.1.0 pip install tensorflow-estimator==2.2.0rc0 pip install tensorflow-gcs-config==2.1.8 pip install tensorflow-hub==0.7.0 pip install tensorflow-metadata==0.21.1 pip install tensorflow-privacy==0.2.2 pip install tensorflow-probability==0.9.0
pip install tensorflow〜〜の行をコピーして、Local側のTerminalに貼り付けてインストール、エラーが出なくなりました。実行の際は自己責任でお願いします
- 投稿日:2020-03-28T17:27:54+09:00
【Azure】Azure Functionsを使ってみる
はじめに
サーバーレスコンピューティングの代表格、FaaS(Function as a Service)をAzureでやってみたときのメモです。
Azureには"Azure Functions"(関数アプリ)という関数をデプロイするための機能があります。
AWSだと"AWS Lambda"に対応する機能です。とりあえずローカルで作った何かしらの関数をデプロイするやり方を忘れないようにと思って書き残しておきます。
(やり方はほかにもいくつかあります)
用意するもの
- Visual Studio Code
- Azure functions拡張機能
- Azure Account拡張機能
- python拡張機能
- Azure subscription
pythonは3.7.3で作ってます。AzureはMicrosoftのサービスなので(??)、VScodeを使って作ります。
※Azure Functionsの拡張機能はまだプレビュー版みたいです(2020/3/26現在)。以後仕様が変わるかもしれません。手順
作るのは「年/月/日を入力したら曜日を返す関数」です。
デスクトップに"sample functions"という材料を入れておく用の空のフォルダを作って、その中で作業していきます。
①前作業:azure-functions-core-toolsをインストール
Azure Functions Core Toolsはローカルでターミナルやコマンドプロンプトから関数の開発・テストを行うためのモジュールらしいです。とりあえず最初に入れておきます。
VScodeのターミナルを開いてコマンド打つだけです。
npm install -g azure-functions-core-tools②関数を作る
続いてターミナルで
func initと打ちます。
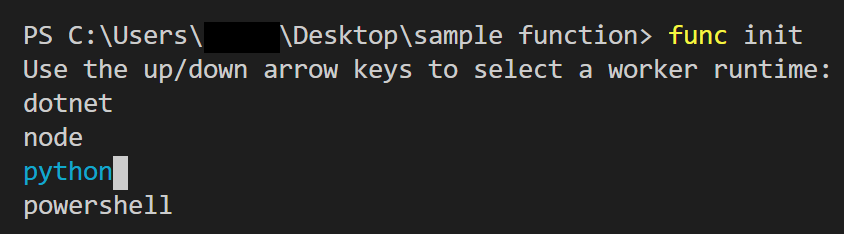
「使用する言語を選んでください」的な画面が出てくるので、'python'を選択します。
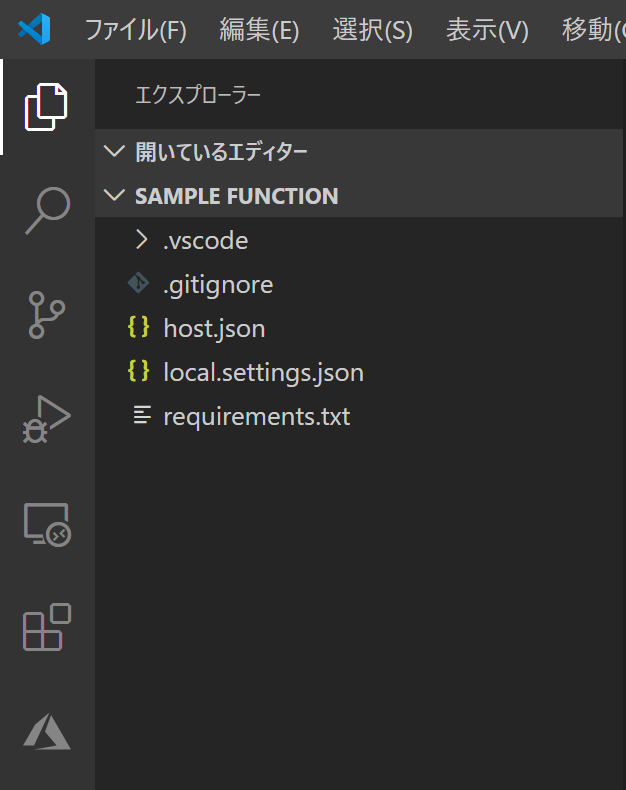
すると、フォルダの中にいくつかファイルが生成されます。
これらはデプロイに必要なファイルです。追加のライブラリが必要であればrequirements.txtに追加したりします。続いて、ターミナルで
func newと打ちます。
そうすると、「使うテンプレートを選んでください」的な画面が出てきます。
今回はクエリを投げたら何かの値を返してくれる関数を作りたいので、Http triggerを選択します。
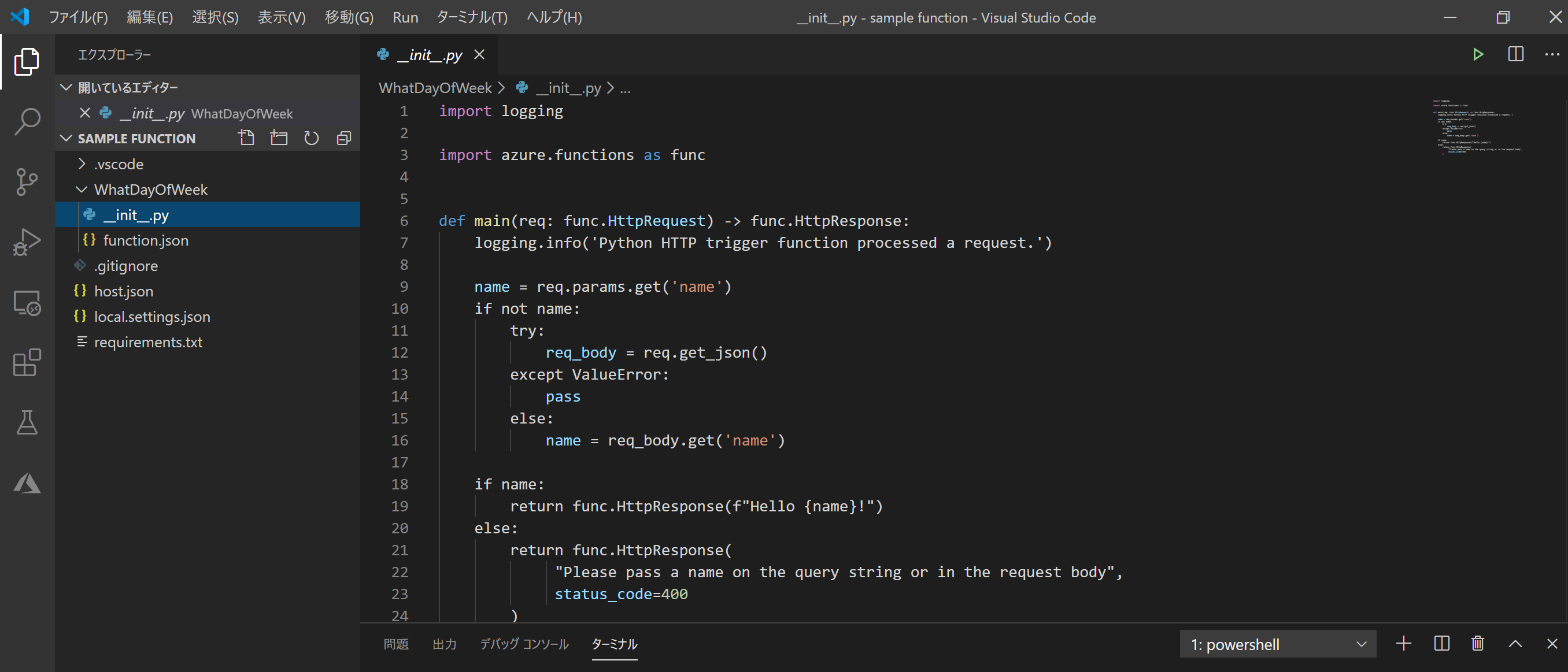
「関数の名前を教えて」と言われるので、今回は"WhatDayOfWeek"としておきます。"sample function"フォルダの中に"WhatDayOfWeek"という名前のフォルダが作られ、中にテンプレートが入っています。
この
__init__.pyがクラウド側で行う処理を記述したものです。
テンプレートでは、HTTPリクエストで文字列を投げたら、『Hello 【入力した名前】!』と返ってくる関数になっています。
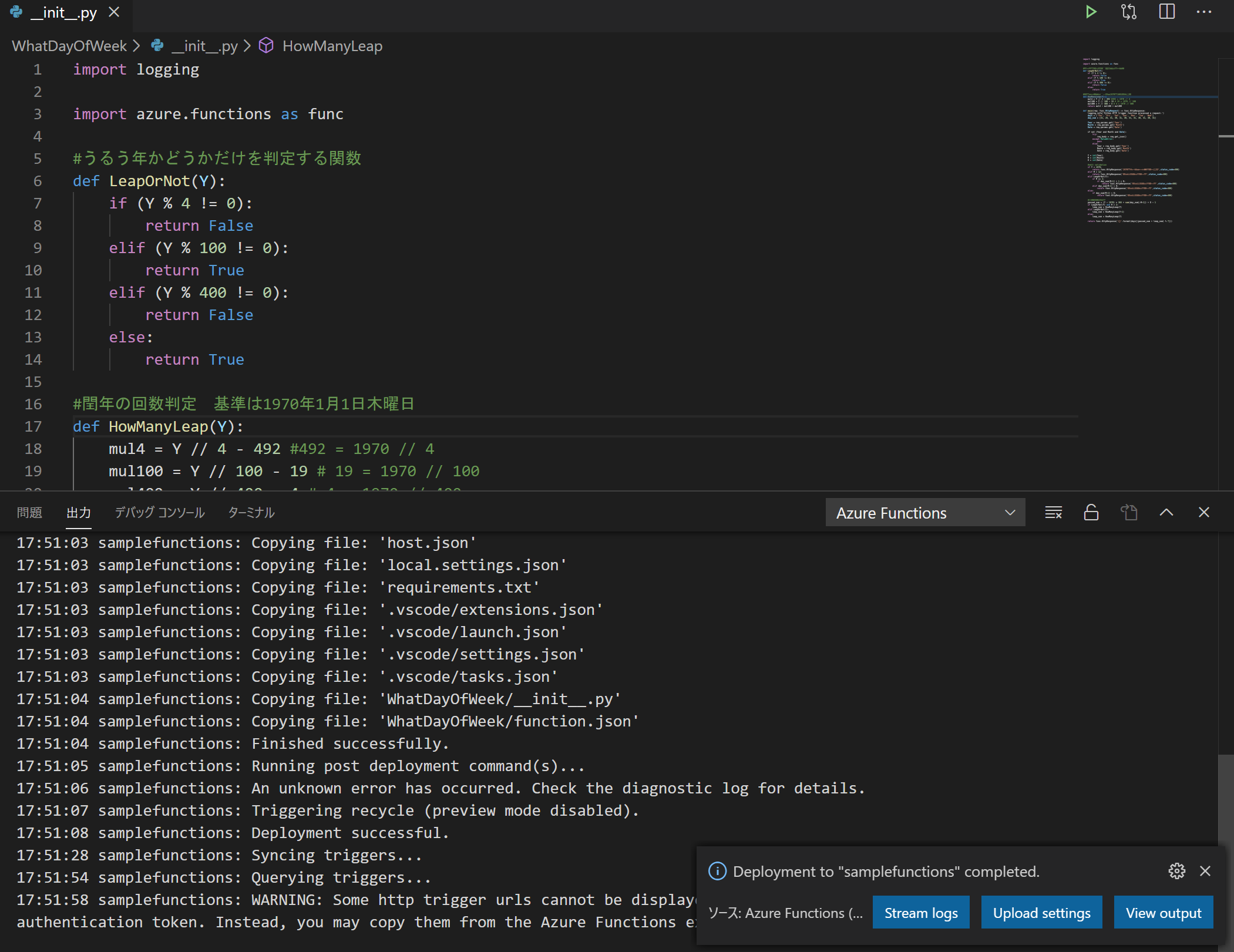
loggingはログを扱うためのpythonの標準モジュールです。requirements.txtに書いてませんが使えます。(逆に下手に追加するとデプロイできなくなりました。)加工するのはこの
__init__.pyだけでOKです。__init__.pyimport logging import azure.functions as func #うるう年かどうかだけを判定する関数 def LeapOrNot(Y): if (Y % 4 != 0): return False elif (Y % 100 != 0): return True elif (Y % 400 != 0): return False else: return True #閏年の回数判定 基準は1970年1月1日木曜日 def HowManyLeap(Y): mul4 = Y // 4 - 492 #492 = 1970 // 4 mul100 = Y // 100 - 19 # 19 = 1970 // 100 mul400 = Y // 400 - 4 # 4 = 1970 // 400 return mul4 - mul100 + mul400 def main(req: func.HttpRequest) -> func.HttpResponse: logging.info('Python HTTP trigger function processed a request.') days = ['Thu', 'Fri', 'Sat', 'Sun', 'Mon', 'Tue', 'Wed'] day_num = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31] Year = req.params.get('Year') Month = req.params.get('Month') Date = req.params.get('Date') if not (Year and Month and Date): try: req_body = req.get_json() except ValueError: pass else: Year = req_body.get('Year') Month = req_body.get('Month') Date = req_body.get('Date') Y = int(Year) M = int(Month) D = int(Date) #edit validation if Y < 1970: return func.HttpResponse('1970年以前には対応していません',status_code=400) elif M > 12: return func.HttpResponse('日付が間違っています',status_code=400) elif LeapOrNot(Y): if M == 2: if day_num[M-1] + 1 < D: return func.HttpResponse('日付が間違っています',status_code=400) elif day_num[M-1] < D: return func.HttpResponse('日付が間違っています',status_code=400) else: if day_num[M-1] < D: return func.HttpResponse('日付が間違っています',status_code=400) #経過日数を計算 passed_num = (Y - 1970) * 365 + sum(day_num[:M-1]) + D - 1 if LeapOrNot(Y) and M > 2: leap_num = HowManyLeap(Y) elif LeapOrNot(Y): leap_num = HowManyLeap(Y-1) else: leap_num = HowManyLeap(Y) return func.HttpResponse('{}'.format(days[(passed_num + leap_num) % 7]))これで関数自体はできました。
"sample function"フォルダ内でfunc newを打てば、また別の関数を作ることもできます。(③)ローカルでテスト
ちゃんと期待した動作ができているかテストしたい場合は
func startとやれば、フォルダ内のすべての関数に対して
WhatDayOfWeek: [GET,POST] http://localhost:7071/api/WhatDayOfWeek
といったようなURLが得られます。
これを使えば、
http://localhost:7071/api/WhatDayOfWeek?Year=2020&Month=3&Day=26
とパラメータを投げてThuと返ってくるといったテストが行えます。④クラウドにデプロイ
ローカルで関数を完成させたらデプロイです。
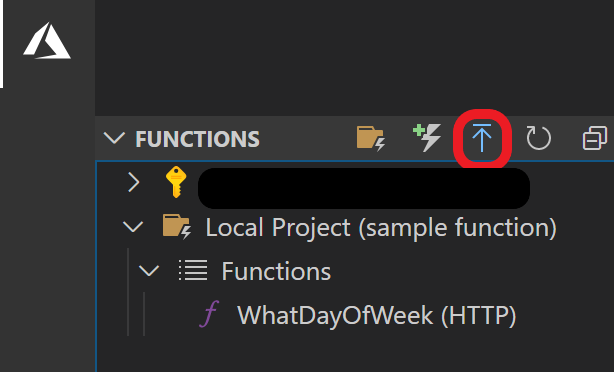
Azure系の拡張機能を入れると、VScodeのアクティビティバーからAzure系の機能を使えるようになります。サイドバーに"FUNCTIONS"が出てくるので、そこから"Local Project"->"Functions"でローカルで作られた関数が表示されるはずです。ここで赤枠で示した部分からデプロイできます。(Azureアカウントにloginしてなければここでログインが必要です。)
このボタンだけで、"Local Project"内に入っている関数がまとめてデプロイできます。ここからはAzure上でのデプロイ作業をVScodeから操作します。
(Azure portalでリソースを一通り作っておけば元々あるAzure Functionsのリソースにそのままデプロイするだけなのですぐです。)一から作っていきます。
<1> +Create new Function App in Azure (Advanced)
新しい関数アプリを作るかどうか聞かれます。ログインしているサブスクリプションで作った関数アプリが表示されるので、あらかじめ作っておけば、ここでそれを選ぶだけです。
"Advanced"と書いてない方もありますが、そちらの方が設定事項が少ないです。<2> 関数アプリの名前を入力
Azure上で作る関数アプリの名前を聞かれるので、入力します。ここでは"samplefunctions"としておきます。
この名前は'globally unique'でなければいけないらしいですが、この名前で作れるということはあまり利用者がいない説??<3> 言語選択
関数アプリで使う言語を選択します。node.jsやjavaなどが選択できますが、ここではpythonにします。
ローカルで作ったときにも聞かれたのにここでも聞かれるの?とは思う<4> 課金プラン選択
"Select a hosting plan"と出てきます。これは課金プランのことで、Azureの公式ドキュメントに詳しく書いてあります。
ざっくり言うと、
- 関数の実行ごとに課金(従量課金,「Consumption」)
- 立てたインスタンスごとに課金(「Premium」)
- ほかのwebサービスと同一の課金制度にする(「App Service Plan」)
の3択です。
従量課金が一番FaaSっぽい?という所感。今回はPremiumにしておきます(特に意味はない)。<5> App Service Planを作る
"Select a Linux App Service Plan"と言われます。結局App Service Plan作るんかいという感じですが、"+Create new App Service Plan"から、新しいプランを作ります。
<6> インスタンスサイズの選択
Premiumだと、インスタンスのサイズが3つから選べます。
インスタンス コア メモリ ストレージ EP1 1 3.5GB 250GB EP2 2 7GB 250GB EP3 4 14GB 250GB とりあえずEP1にしておきます。
<7> App Service Planの名前を入力
なんでもいいと思います。
<8> リソースグループを選択
関数アプリが所属するリソースグループを選びます。新しく作ると、おそらく作るリージョンとか聞かれるかと思いますが、ここでは元々あるものを使います。
<9> ストレージアカウントを選択
データを入れるストレージです。これも元々あるやつを使います。
<10> Application Insightsを選択
Application Insightsは関数の監視モニター的なものです。ログやパフォーマンス状況が見れるみたいです。(公式ドキュメント)
元々他のApp Serviceで作ってあれば、それを選択して統合することもできるみたいです。
これはSkipできるので、とりあえず関数を作りたいだけならいらないかもしれないです。ここまでやると、デプロイが開始されます。
デプロイ中のログはVScodeの"出力"から見ることもできます。
⑤作った関数を使ってみる
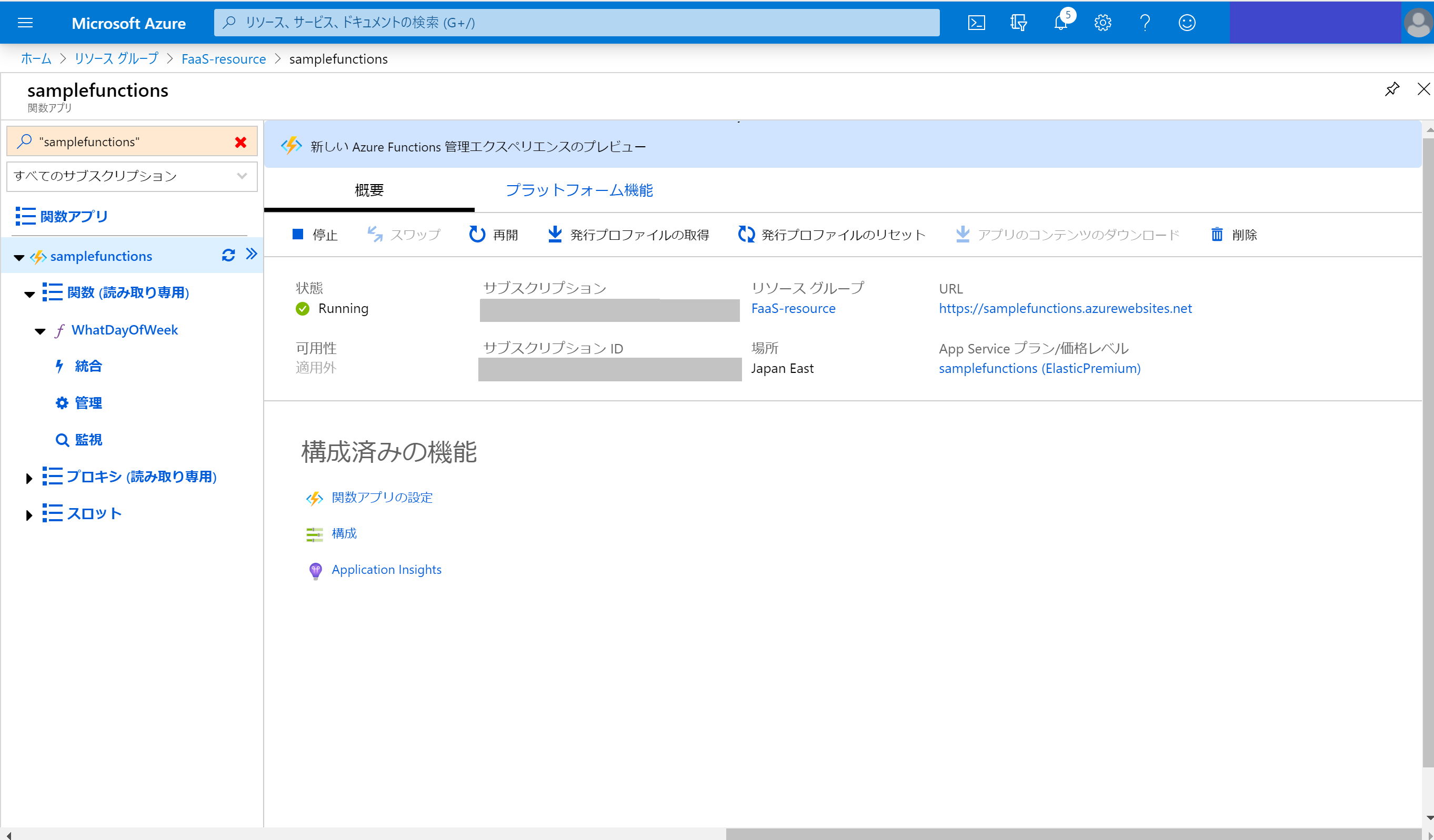
"Deployment to ~~ completed"と出ればデプロイ終了です。
この時点でAzure portalから関数のページを見ることもできます。
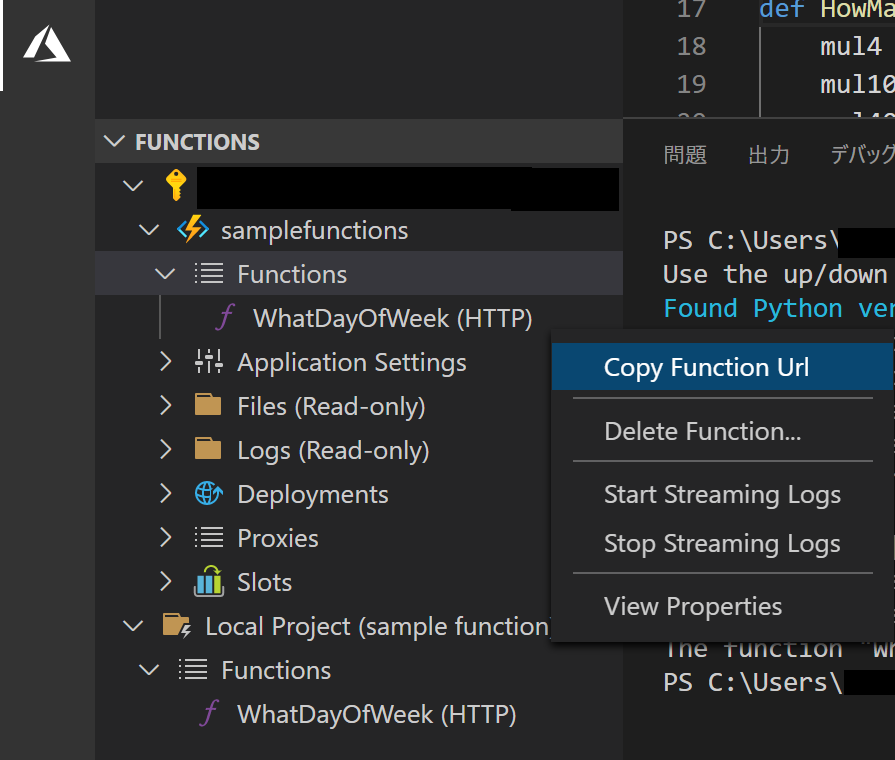
この画面で"URL"をクリックすれば、「あなたの関数は動いてますよ!」的な画面が出てくるはずです。関数のURLは、VScodeの方から、【サブスクリプション名】->【作った関数名】->"Functions"->【関数名】を右クリックから、"Copy Function Url"で取得できます。
ローカルで適当にpythonコードを作って実験してみます。
pythonimport requests url = "【取得したURL】" param = {'Year':2020,'Month':3,'Date':26} res = requests.get(url, params = param) print(res.text)☟結果
Thuさいごに
AzureでFaaSを使う際、すべてCLIでやるやり方もあるらしいです。
自分も結構理解はあやふやです。公式ドキュメントを見ながら試行錯誤してましたが苦労しました。
「とりあえず関数作ってデプロイ」がやりたいだけならこんなもんかな、と思います。