- 投稿日:2020-03-28T23:53:21+09:00
SQLとNoSQL(Amazon DynamoDB)
概要
- Amazon DynamoDBの入門として、まずNoSQLとSQLの違いは何か、またDynamoDBでの仕組みはどうなっているかについてまとめました
- 対象読者は、RDBは経験があるけどNoSQLとかはちょっとよくわかっていなくて気になっている方です。
SQLとNoSQL(Amazon DynamoDB)の比較
SQLとNoSQL概要
Oracle、DB2、SQL Server、MySQL、PostgreSQLなどのリレーショナルデータベースで使用するリレーショナルデータモデルへのアクセスにSQLが用いられてきた。2000年代半から後半にかけて他のデータモデルが採用され始め、これらの新しいクラスのデータベースとデータモデルを区別し、分類するためにNoSQL(Not only SQL)ができた。
以下では、SQLデータベース(リレーショナルデータベース)とNoSQLデータベース(とAmazon DynamoDB)の違いを示した。
最適なワークロード
リレーショナルデータベース
トランザクショなるで強固な一貫性をもつオンライントランザクション処理(OLTP)アプリケーション用に設計されている。オンライン分析処理(OLAP)やアドホッククエリやデータウェアハウスに適している。
NoSQLデータベース
低レイテンシーアプリケーションを含む多数のデータアクセスパターン用に設計されている。
Amazon DynamoDB
Amazon DynamoDBでは、ソーシャルネットワーク、ゲーム、メディア共有、IoTなどの、ウェブスケールアプリケーションに適している。
データモデル
リレーショナルデータベース
データを行と列で構成したテーブルに正規化する。テーブル、行、列、インデックス、テーブル間の関係などのデータベース要素は、スキーマによって厳密に定義される。テーブル間の関係によってデータベースの参照整合性が維持されている。
NoSQLデータベース
キー値、ドキュメント、グラフなどの様々なデータモデルを利用できる。これらのデータモデルはパフォーマンスと規模に応じて最適化されている。
Amazon DynamoDB
Amazon DynamoDBでは、全てのテーブルに、各データ項目を一意に識別するプライマリキーが必要だが、他の非キー属性のような制約はなくスキーマレスである。また、JSONドキュメントを含む構造化データまたは半構造化データを管理できる。
ACID特性
リレーショナルデータベース
- 原子性(Atomicity)
- トランザクションは必ず完全に実行されるか、全く実行されないかのどちらかになる
- 一貫性(Consistency)
- 一度トランザクションが実行されると、データが必ずデータベーススキーマに従う
- 分離性(Isolation)
- 同時発生したトランザクションが相互に独立して実行される
- 耐久性(Durability)
- 異常事態発生時に、異常時大発生前の最後の状態まで復旧できる
上記4つのACIDの特性がある。
NoSQLデータベース
ACID特性の一部を緩和することと引き換えに、水平方向に拡張(より多くのマシンを用いて拡張)できる柔軟なデータモデルを実現している。これにより、単一インスタンスの制限を超えて水平方向に拡張する必要のある、高スループット、低レイテンシーユースケースの優れた選択肢になっている
データアクセス
リレーショナルデータベース
データベース駆動型アプリケーションの開発を簡素化するためのツールが豊富だが、これらのツールは全て、データを保存および取得するための基準となるSQLを使用する。
Amazon DynamoDB
DynamoDBでは、AWSマネジメントコンソールやAWS CLIを使用してDynamoDBを操作し、アドホックタスクを実行できる。アプリケーションでは、AWS SDKを活用してDynamoDBを操作できる。
パフォーマンス
リレーショナルデータベース
ストレージに最適化されているので、通常はディスクサブシステムによって異なる。最善のパフォーマンスを実現するには、多くの場合は、クエリ、インデックス、テーブル構造の最適化が必要。
NoSQLデータベース
基盤となるハードウェアクラスターのサイズ、ネットワークレイテンシー、呼び出すアプリケーションに依存する。
Amazon DynamoDB
DynamoDBは、これらの実装の詳細からアプリケーションを隔離し、堅牢で高パフォーマンスなアプリケーションの設計と構築に集中できるようにされている。
拡張性
リレーショナルデータベース
ハードウェアの演算機能を増強してスケールアップするか、読み取り専用ワークロードのレプリカを追加してスケールアウトする。データベーステーブルが分散システムの複数のホストにまたがることは可能だが、この場合は追加の投資が必要になる。スケーラビリティに上限を課すファイル数とサイズが最大サイズになる。
NoSQLデータベース
分散型アーキテクチャを使用したアクセスパターンのスケールアウトに基づくパーティション化が可能で、これにより、ほぼ無限の規模でスループットを高め、一貫したパフォーマンスを維持することができる。
Amazon DynamoDB
DynamoDBでは、レイテンシーの増加なしでスループットの強化ができ、スループット要件を指定すると、その要件に対応するためな十分なリソースが割り当てられる。テーブル単位の項目数、およびそのテーブルの合計サイズに上限はない。
API
リレーショナルデータベース
データの保存および取得のリクエストは構造化クエリ言語(SQL)準拠のクエリを使用して伝えられる。これらのクエリはリレーショナルデータベースによって解析されて実行される。
NoSQLデータベース
アプリケーション開発者は、オブジェクトベースのAPIを使用して、データ構造の保存および取得を簡単に行うことができる。アプリケーションはパーティションキーによって、キーと値のペア、列セット、またはアプリケーションのシリアライズされたオブジェクトや属性を含む半構造化ドキュメントを調べる。
- 投稿日:2020-03-28T22:43:24+09:00
Amazon Aurora MySQL 5.7 互換版で Comprehend 感情分析を試してみる
昨年の JAWS-UG 名古屋 AWS re:Invent2019 大復習(+忘年会)で「RDS / Aurora 関連アップデート」と題して LT 登壇をしたのですが、その中で表題の内容についても触れました。
- RDS / Aurora 関連アップデート [4-1] Aurora Machine Learning(Speaker Deck)
- スライドのページタイトル、Typo してて恥ずかしい
本日、JAWS DAYS 2020 オンラインライブ視聴の裏側で「JAWS DAYS 2020 [オンラインハンズオン] はじめての自然言語処理(NLP) powered by LINE API Expert」が行われていたことで冒頭の LT 登壇を思い出したので、今回は日本語を使って試してみました。
【参考リンク】
- Amazon Aurora の新機能 – データベースから直接機械学習を使用する(Amazon Web Services ブログ)
- Using Machine Learning (ML) with Aurora MySQL(AWS Documentation)
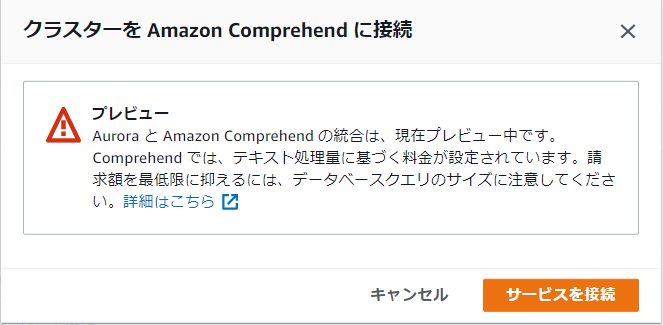
1. 準備
今回は表題のとおり Aurora MySQL 5.7 を使います(現在は PostgreSQL 互換版でも使えるようになっているようです)。
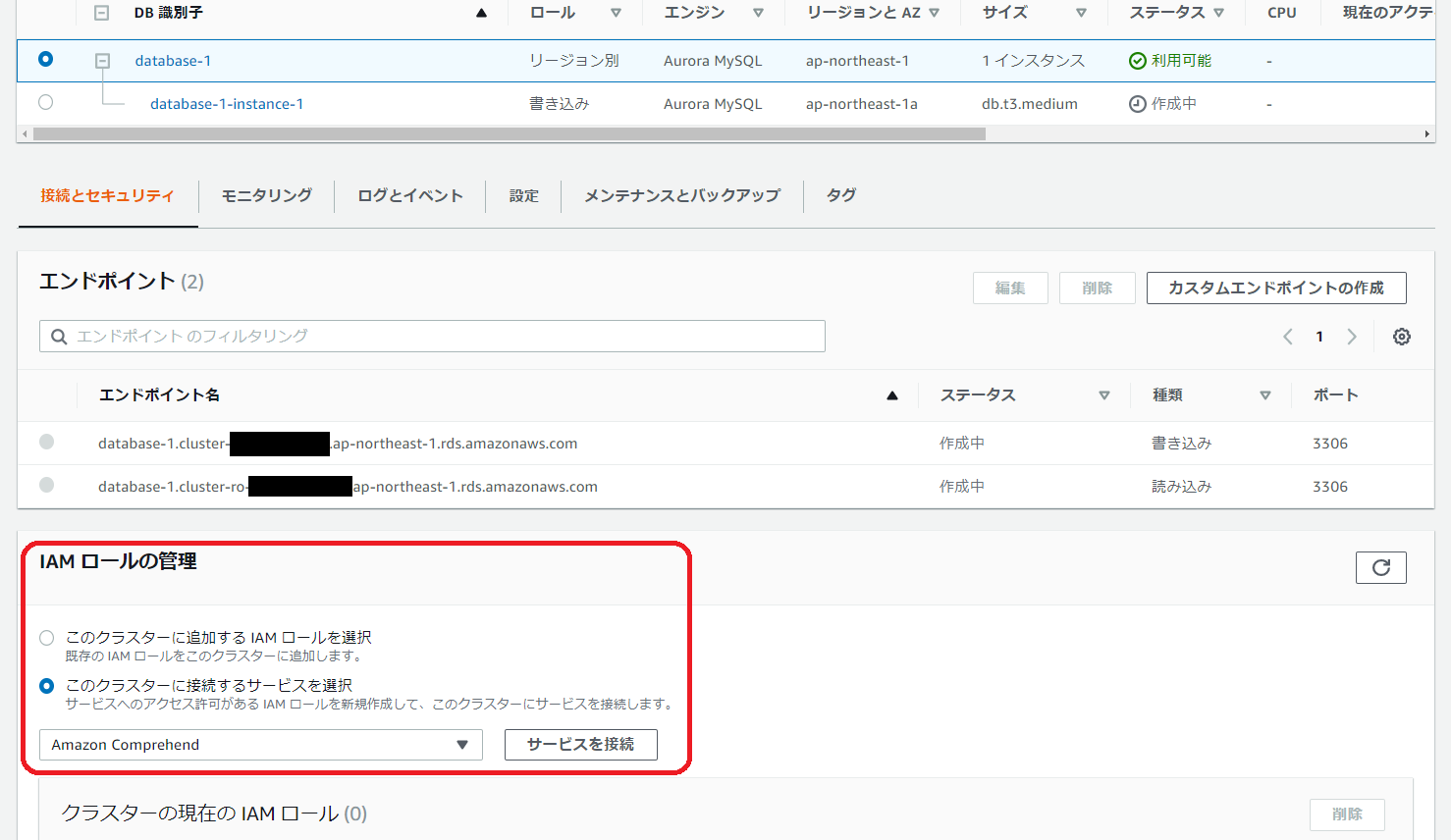
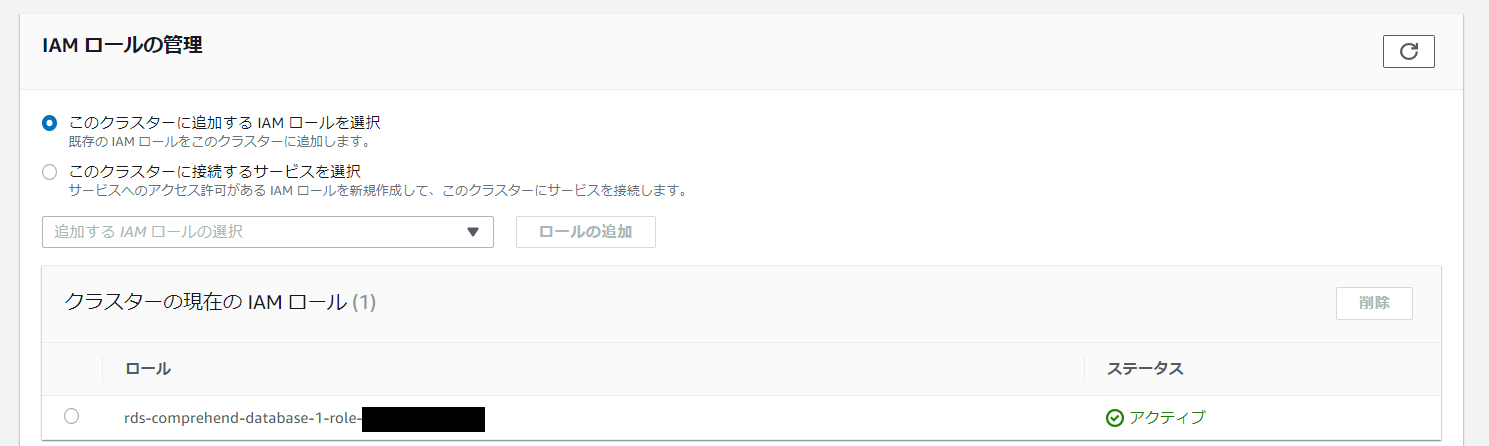
まずは IAM ロールを Aurora クラスターに追加します。
※この記事を書いている時点ではまだプレビュー中です。
追加されました。
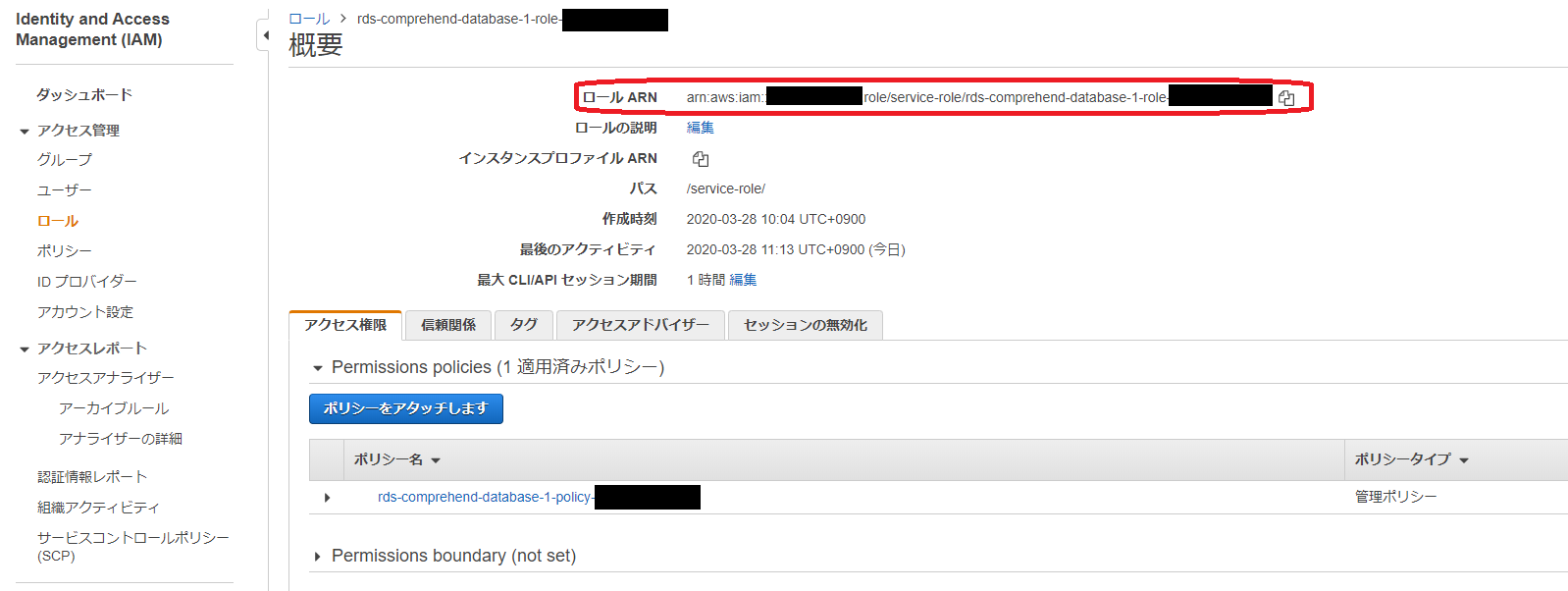
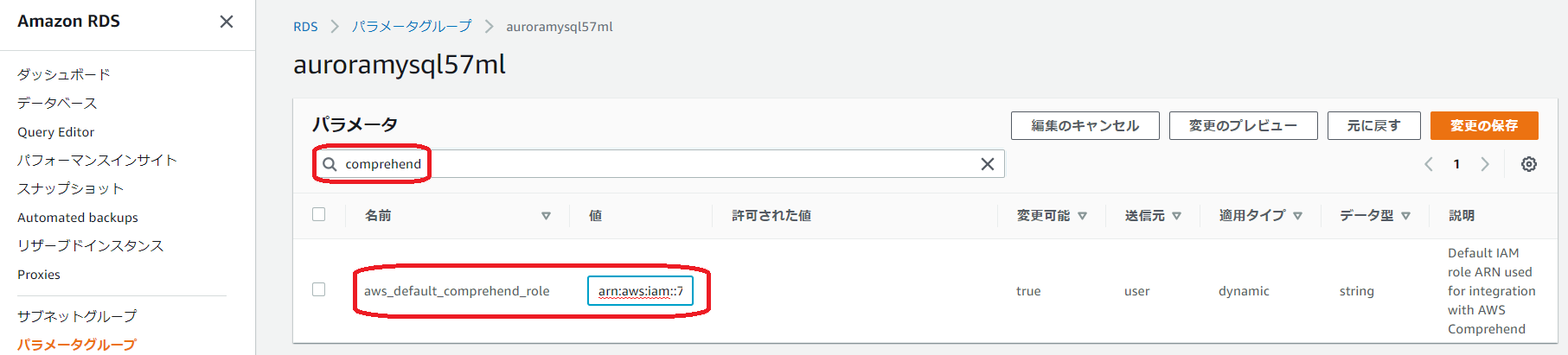
そして、IAM でこのロールの ARN を調べます。
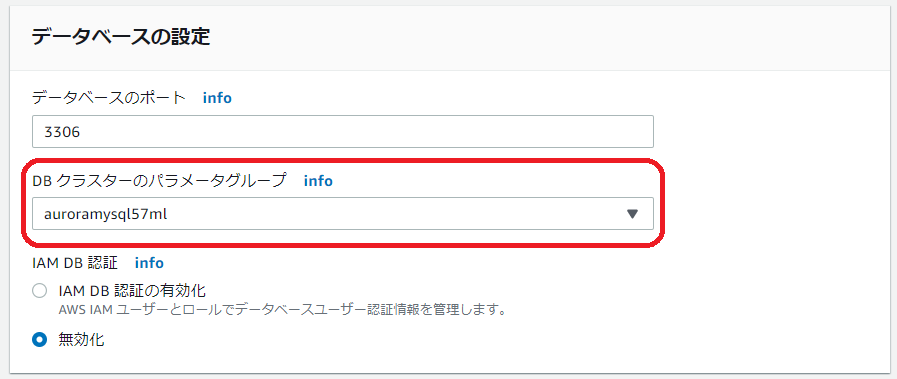
Aurora のクラスターパラメータグループ(なければ新規作成)でaws_default_comprehend_roleにさきほどの ARN を設定します。
このクラスターパラメータグループを対象の Aurora クラスターに適用します。
なお、これらのほかに、以下のいずれかが必要です(Aurora から Comprehend にリクエストを送るため)。
- NAT ゲートウェイの設置+Aurora クラスター(各ノード)からのルーティング
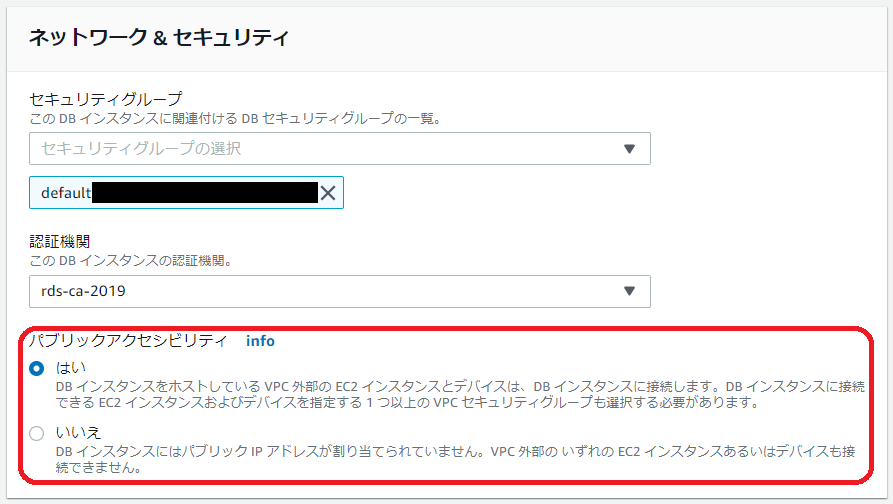
- パブリックアクセス有効化
今回はテストのためパブリックアクセスを有効化しています。
2. 試してみる
わたし自身が年末年始に 2019 年の振り返りと 2020 年の抱負として書いた、以下の Qurnch 記事の文章から、セクションごとの文章について感情分析を行ってみます。
- ちょっと早いけど 2019 年を振り返る(Qrunch)
- 2020 年、今年は何をする?(Qrunch)
まずデータベース・テーブルを用意します。
DB・テーブル定義mysql> CREATE DATABASE mltest CHARACTER SET utf8mb4 COLLATE utf8mb4_bin; Query OK, 1 row affected (0.01 sec) mysql> USE mltest; Database changed mysql> CREATE TABLE sentiment_test ( -> id INT AUTO_INCREMENT PRIMARY KEY, -> heading VARCHAR(100), -> analyze_text VARCHAR(500) -> ); Query OK, 0 rows affected (0.03 sec)まず、2019 年の振り返りについてデータを挿入していきます。
2019年データ挿入mysql> INSERT INTO sentiment_test SET -> heading='引っ越し', -> analyze_text='たぶん驚かれるでしょうが、まだ終わってません(笑)。早い 時期に今年中の旧居撤収は諦めました。なぜか…は続きを読んでいただければ、大体 像 がつくかと。'; Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO sentiment_test SET -> heading='SRE 活動', -> analyze_text='はい、こちらも一旦頓挫しました。やはり「兼業 SRE」は無理 があります。メンバーが落ち着いて勉強する余裕などありませんでした。途中で「再起動」したものの、前途多難であります。'; Query OK, 1 row affected (0.04 sec) (以降省略)分析結果を見てみます。
2019年分析結果mysql> SELECT heading, -> aws_comprehend_detect_sentiment(analyze_text, 'ja') AS sentiment, -> aws_comprehend_detect_sentiment_confidence(analyze_text, 'ja') AS confidence FROM sentiment_test; +-----------------------------------------------------------------+-----------+--------------------+ | heading | sentiment | confidence | +-----------------------------------------------------------------+-----------+--------------------+ | 引っ越し | NEUTRAL | 0.9790685176849365 | | SRE 活動 | NEGATIVE | 0.9979338645935059 | | 登録セキスペ | NEUTRAL | 0.9953206181526184 | | その他の資格・検定関連 | NEGATIVE | 0.9806546568870544 | | IT イベント・カンファレンス・勉強会への参加 | NEUTRAL | 0.9641426801681519 | | 各種アウトプット | NEUTRAL | 0.9664930701255798 | | MySQL(Aurora MySQL 互換含む)に関する技術 | NEUTRAL | 0.9988293051719666 | | MySQL 以外のデータストアに関する技術 | NEGATIVE | 0.968559741973877 | | AWS 環境のアカウント分離 | MIXED | 0.8833306431770325 | | まとめ | NEUTRAL | 0.9767121076583862 | +-----------------------------------------------------------------+-----------+--------------------+ 10 rows in set (0.34 sec)うっ、NEGATIVE が多い…。しかも confidence の値も高いので、自信を持って(?)判定されてるようです。
気を取り直して、今度は 2020 年の抱負で試してみます。
2020データ挿入mysql> TRUNCATE TABLE sentiment_test; Query OK, 0 rows affected (0.03 sec) mysql> INSERT INTO sentiment_test SET -> heading='引っ越し', -> analyze_text='2018 年の 10 月に引っ越しました…引っ越したはず…ですが、まだ旧居の片づけが終わらず。早く片付けねば…とは思うものの、今年もプライベートの時 間が忙しくなりそうなので、無理せず少しずつ進めます。'; Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO sentiment_test SET -> heading='会社の SRE 活動', -> analyze_text='メンバー再構成で再起動はしたものの、相変わらず兼業メンバ ーばかりなので、うまくいくイメージが全く持てません(笑)。ただ、「SRE」という名 称にこだわらず、地道な改善を足掛かりにサイト(サービス)の信頼性を確保する(確保しつつスケールさせていく)意識は一部の参加メンバーのおかげで少しずつ定着しつつあるので、1 年では難しいと思いますが地道にやっていきます。とりあえず、1/25 は SRE NEXT 2020 に参加します。※個人スポンサーのところに紛れ込んでいます。'; Query OK, 1 row affected (0.04 sec) (以降省略)分析結果を見てみます。
2020年分析結果mysql> SELECT heading, -> aws_comprehend_detect_sentiment(analyze_text, 'ja') AS sentiment, -> aws_comprehend_detect_sentiment_confidence(analyze_text, 'ja') AS confidence FROM sentiment_test; +-----------------------------------------------------------------+-----------+--------------------+ | heading | sentiment | confidence | +-----------------------------------------------------------------+-----------+--------------------+ | 引っ越し | NEUTRAL | 0.8793296813964844 | | 会社の SRE 活動 | NEUTRAL | 0.5283552408218384 | | 登録セキスペ | NEUTRAL | 0.9994049072265625 | | その他の資格・検定関連 | NEUTRAL | 0.9416397213935852 | | IT イベント・カンファレンス・勉強会への参加 | NEUTRAL | 0.8604051470756531 | | 各種アウトプット | NEUTRAL | 0.9865009188652039 | | 技術的なものへの取り組み | NEUTRAL | 0.9960585832595825 | | さいごに | NEUTRAL | 0.9857586622238159 | +-----------------------------------------------------------------+-----------+--------------------+ 8 rows in set (0.42 sec)NEGATIVE はなくなりましたが、POSITIVE もまったくない NEUTRAL おじさんと判定されてしまいました。
LT ではネタ的に扱ってしまいましたが、分析基盤から SQL で蓄積データの取り込みと同時に Comprehend を呼び出すことで効率的な分析ができるようになります。
ただし、調子に乗って使っているうちに課金が積み上がる可能性がありますので、ご利用は計画的に…。
- 投稿日:2020-03-28T21:32:24+09:00
CDKでS3バケットポリシーを設定する
CDKでS3のリソースを作成する際にバケットリソースを設定する実装コードのメモ
今回はFirebaseで作成したHostingアプリと特定のIPからのみAWSのS3バケットのオブジェクトを取得できるようにポリシーを設定します。cdk-stack.tsimport cdk = require('@aws-cdk/core') import iam = require('@aws-cdk/aws-iam') import s3 = require('@aws-cdk/aws-s3') export class TestStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props) // S3 const testBucket = new s3.Bucket(this, 'test-bucket-id', { bucketName: 'test-bucket' }) const testBucketPolicy = new iam.PolicyStatement({ effect: iam.Effect.DENY, actions: ['s3:GetObject'], principals: [new iam.ArnPrincipal('*')], resources: [ testBucket.bucketArn + '/*' ], conditions: { // リクエストのヘッダーに含まれるrefererが下記に含まれないものをDENY 'StringNotLike': { 'aws:Referer': [ 'https://app-name.firebaseapp.com/*', ] }, // リクエスト元のIPが下記に含まれないものをDENY 'NotIpAddress': { 'aws:SourceIp': [ '123.456.78.90', ] } } }) testBucket.addToResourcePolicy(testBucketPolicy)この設定で特に注意すべき点としては
Conditionsで設定されているものはAND条件ではなくOR条件であるということ。
上記のような設定でオブジェクトの取得を自宅のIPからのアクセス(検証用)とfirebaseのhostingアプリからのアクセスだけを許可するように設定できました。
- 投稿日:2020-03-28T20:07:03+09:00
JAWS DAYS 2020エンジョイ・オンライン!!~アウトプットしよう!~
今までQiitaは読むだけで記事を書くことはありませんでした。
しかし、初めて投稿してみようと思います。きっかけをくれたのは、本日開催された、
『JAWS DAYS 2020 ~サメの恩返し』というオンラインイベントです。このイベントはJAWS-UG(AWS User Group - Japan)という、
AWSユーザのコミュニティーのメンバによって開催されました。
今年で10回目の開催とのことですが、私は初参加です。■私とAWSの出会い
私とAWSの出会いは2019年10月のことでした。
「顧客がAWSを希望しているので勉強して提案して」
との指示を上司から受けたのです。私はインフラエンジニアでしたが、
AWSどころかパブリッククラウドについて全く知識がなく、
えっAWS?アマゾン?のような状況でした。これは、ヤバイ、と思い勉強をはじめましたが、
私がインフラエンジニアとして問題と感じていた事が、
AWSで大きく改善できることに気付き、ひたすら勉強しまくりました。
顧客の環境をAWSに置き換えるとどうなるか考えるのが楽しくなり、
勝手に構成図を書いて妄想したりしていました。
解らないところはBlackBeltを読み漁りました。結果、今年の3月に「AWS Solution Architect Professional」の
資格を取得できるレベルまで成長できました。そんなこんなで、今ではAWSの資料があれば読み漁り、
イベントがあれば参加する、といった生活となっています。そういうこともあり『JAWS DAYS 2020 ~サメの恩返し』
の視聴も実施した訳です。■『JAWS DAYS 2020』の感想
コロナの影響も跳ね返す初のオンライン開催で、
準備も大変な中、とても有意義な時間を提供して頂きました!!
最後は通信トラブル見舞われましたが、
きちんとバックアップで復旧させたところが、
さすがだ!と感じました。
まさに『Design for Failure』です。登壇者の皆さんも運営の皆さんも、すごいです。
結局、明日が資格試験の受験日だというのに、
最初から最後まで視聴してしまった私です・・・・。その中で、今回の初投稿のきっかけになったのは、
吉田真吾さんの
「アウトプットしよう。これはあなたの成長の物語」
という講演になります。「アウトプットすることで自分に起こる30個のよいことを書き出してください」
という話から始まり、私も一生懸命に書き出していきました。
20個くらいはかけるんですが、最後の10個くらいはなかなか思い浮かばず、
絞り出す感じになりました。でも、これがアウトプットを出し続けるための、
大事な「動機付け」になるんですね。自分の技術力を高めたい!
顧客の信頼を得たい!
収入を増やしたい!
評価されたい!
もてたい!?人には色々な「動機付け」がある訳ですが、
それが明確に意識できていれば、人は行動し続けることができる訳です。
きちんと「動機付け」を事前に考えるってのは大事なステップなんですよね。
これが出来ていないと何事も三日坊主で終わってしまうわけです。私の場合、「動機付け」以前の話で、ROMってるだけで、
いままでアウトプットを出すことがありませんでした。それじゃダメだと感じたので、Qiitaに初投稿することにしたんです。
『JAWS DAYS 2020 ~サメの恩返し』は、
こんな形で私に良い刺激を与えてくれました。
また、技術的にもいろいろな新しい気付きをくれました。顧客にAWSを使った新しい提案をしてみたい!
もっと勉強して、自分も登壇できるようなレベルになりたい!
色々と思いは膨らみます。未視聴の方は、ぜひ来年参加されては如何でしょうか?
あと、JAWS-UG自体の日頃の勉強会の開催をオンラインで実施したら?
との話がライブ中にあったのですが、是非実現してもらえたら嬉しいです!以上、『JAWS DAYS 2020』視聴感想と、私の初投稿でした!
- 投稿日:2020-03-28T19:48:57+09:00
AWS SNS から送られてくる POST リクエストは text/plain なので body パラメーターをパースするときは注意する
概要
AWS SNS から来る POST リクエストの body パラメーターをパースしようとしたときに、上手く行かなくてはまったので、解決策を共有します。
解決策
AWS SNS は HTTPS POST リクエストでアプリケーションにメッセージを送信してくれます。
参考記事: 受信者が HTTP/S エンドポイントの場合のシステム間メッセージングに Amazon SNS を使用するその際に、body パラメーターにメッセージの内容が入っているのですが、Rails の params メソッドを使用してもパラメーターの中身を取得できませんでした。
class SnsController < ApplicationController def message params # メッセージがない end endリクエストの中身を調べたところ、content-type に text/plain が設定されていたことが原因でした。
もし content-type に application/json が設定されていれば、パラメーターを params メソッドで取得できたはずです。なので、下記のようにすることででパラメーターを取得できます。
class SnsController < ApplicationController def message raw_body = request.body.read body_params = JSON.parse(raw_body) end endメッセージの文章はあくまで単純なテキストで、そのテキストが json の形式になっていることもあれば XML かもしれないし、あるいは何の形式にも当てはまらないテキストかもしれない、というのが AWS SNS の考え方なのだと思います。
考えてみれば AWS SNS はメッセージを送信するのが役割で、そのメッセージ文字列の形式を固定するのは責務の対象外なんだなと納得しました。
- 投稿日:2020-03-28T18:59:22+09:00
AWSでネットワーク入門
はじめに
(学習メモです。)
私のように、令和になってから独学でプログラミングを学び始める人間にとって、圧倒的に不足しがち(だと思う)のはいわゆる「インフラ関係」の知識です。そこで、今回の目的は、
- AWSを実際に動かしながら、ネットワークの構築やそれに関わるサーバー、データベースの接続など、一通り全体を把握してみること
です。
謝辞
今回の学習に当たってはudemyの「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得」が非常に参考になりました。
初学者の方に本当におすすめです。価格もボリュームの割に安価ですので、ぜひご覧ください。
加えてAWS公式「AWSome Day」の動画もおすすめです。
目標の成果物
- 「AWS:VPC」を利用し、クラウド上に仮想ネットワークを構築する
- 仮想ネットワーク上に「AWS:EC2」を利用しサーバーを立ち上げる
- 仮想ネットワーク上に「AWS:RDS」を利用しデータベースを立ち上げる
- EC2インスタンスにでWordPressサイトをホストする
AWSマネジメントコンソールにアクセス
====手順=====
- AWSにログイン
- リージョンの確認(今回は「東京」に設定)
====用語=====
- リージョン:AWSのデータセンターがある地域(東京リージョン...など)
- アベイラビリティゾーン(AZ):各リージョン内にある、個別のデータセンターのようなもの
各リージョン内には複数のAZが存在しており、物理的に離れた場所にある。
これによって、仮に1つのAZに障害が起きても、別のAZが稼働していることでサービスの可用性を担保しているVPCの作成
VPCとは、「Amazon Virtual Private Cloud」の略です。
Virtual Private Cloud (VPC) は、AWS アカウント専用の仮想ネットワークで、つまり自分専用のネットワークを作るサービスです。====手順=====
メニューから「VPC」-> 「VPCの作成」
(すでに1つのVPCがデフォルトで作成されているが無視する)====用語=====
- 名前タグ: VPCの名前
IPv4 CIDR ブロック: VPCのIPアドレス (今回は、10.0.0.0/16に設定)プライベートIPアドレスの中から設定する
テナンシー: 「デフォルト」でOK
上記設定で「VPCの作成」する
サブネットの作成
サブネットは、VPC の IP アドレスの範囲です。
VPCはリージョン全体に対して作成され、サブネットはAZに対して作成されます。
つまり、サブネットを作成すると言うことは、
先ほど作成したVPC内の、個別のAZに対してネットワークを構築することになります。「パブリックサブネット」と「プライベートサブネット」を作成する
====用語=====
パブリックサブネット:インターネットからアクセスできる
プライベートサブネット:インターネットからアクセスできないパブリックサブネットの作成
====手順=====
メニューから「サブネット」-> 「サブネットの作成」
====用語=====
名前タグ: サブネットの名前(設置するアベイラビリティゾーンも名前に含めておくとわかりやすい)
VPC: このVPC内にサブネットが作成される(先ほど作成したVPCを選択)
アベイラビリティーゾーン:このAZ内にサブネットが作成される
IPv4 CIDR ブロック:VPC内の任意のIPアドレス(今回は10.0.10.0/24を設定)
上記設定で「VPCの作成」する
プライベートサブネットの作成
====手順=====
メニューから「サブネット」-> 「サブネットの作成」
====用語=====
名前タグ: サブネットの名前(設置するアベイラビリティゾーンも名前に含めておくとわかりやすい)
VPC: このVPC内にサブネットが作成される(先ほど作成したVPCを選択)
アベイラビリティーゾーン:このAZ内にサブネットが作成される(今回はパブリックサブネットと同じAZに設定)
IPv4 CIDR ブロック:VPC内の任意のIPアドレス(今回は10.0.20.0/24を設定)
ルーティングの設定
先ほど「パブリックサブネットを作成する」と手順を踏みましたが、このサブネットはまだインターネットに接続されていません。そのためにルーティングを設定する必要があります。
VPCやサブネットなど、ネットワークには固有のIPアドレスがあり、ルーティングはそのIPアドレスの接続先の設定です。
ルーターはIPアドレスの行き先を管理する仕組みです。
VPCやサブネットは「ルートテーブル」を使用して、IPアドレスの接続先を調べます。今回は、パブリックサブネットがインターネットに接続できるようにします。
つまり、パブリックサブネットに対してルーティングを設定することになります。インターネットゲートウェイの作成
パブリックサブネットのルーティングに「インターネットゲートウェイ」を追加することで、インターネットに接続できるようにしていきます。
インターネットゲートウェイは、あなたのVPCとインターネットの通信を可能にするためのコンポーネント(部品)です。
====手順=====
メニューから「インターネットゲートウェイ」-> 「インターネットゲートウェイの作成」
作成しただけでは、「detached」(どこにも接続されていない)なので、
「アクション」から、VPCにアタッチする
ルートテーブルの作成
VPCでは「ルートテーブル」を使用して、IPアドレスの接続先を設定します。
ここで、各IPアドレスの接続先を設定する必要があります。先ほど作成した「インターネットゲートウェイ」は、いわばあなたのネットワーク(VPC)の玄関になります。
インターネットゲートウェイにアクセスできるよう、ルートテーブルの設定をします。====手順=====
メニューから「ルートテーブル」-> 「ルートテーブルの作成」
====用語=====
名前タグ:ルートテーブルの名前
VPC: ルートテーブルを作成するVPC
作成されたルートテーブルは、指定したVPC内に存在しているだけで、まだどの接続先も設定されていません。
ここにサブネットを関連付けします。ルートテーブルは、サブネットかVPCに関連付けして使います
====手順=====
タブメニュー「サブネットの関連付け」 -> 「サブネットの関連付けの編集」
先ほど作成したパブリックサブネットを関連付ける
さらに、デフォルトルートをインターネットゲートウェイに設定します。
現状、「ルートテーブルに存在しない送信先」へのアクセスは、ターゲットが存在しないため破棄されてしまっています。
これを、インターネットゲートウェイがターゲットになるよう設定します。
====手順=====
タブメニュー「ルート」 -> 「ルートの編集」 -> 「ルートの追加」
デフォルトルートとは
0.0.0.0/0 のこと。
これはネットワーク上のどのルートにも一致しないIPアドレスであり、つまり「あらゆるIPアドレス」ということです。
====用語=====
送信先:0.0.0.0/0
ターゲット:先ほど作成したインターネットゲートウェイ
「ルートの保存」をする
ルートテーブル内の送信先に一致しない、全てのIPアドレスへの通信は、まずインターネットゲートウェイへと向かうようになりました。
これでパブリックサブネットからインターネットに接続できるようになっています。
EC2の作成
EC2(仮想マシン)をパブリックサブネット内に設置します。
その後、OSとしてApacheをインストールし、Webサーバーとして使用します。====用語=====
インスタンス:EC2から立てられたサーバーのこと
AMI: サーバーのテンプレート、OSのイメージ
インスタンスタイプ:サーバーのスペック
ストレージ:EBSと「インスタンスストア」の2種から選べる
EBS:外部ストレージのようにマウントして使うので、他のインスタンスに移動できる、高可用性。
インスタンスストア:付け替えできない。EC2インスタンスにひっついているので、EC2をstop/Tarminateするとクリアされてしまう
====手順=====
メニュー「インスタンス」 -> 「インスタンスの作成」
Amazon Linux 2 AMI (HVM), SSD Volume Type を選択
インスタンスタイプ:t2.micro(無料)を選択
「インスタンス詳細の設定」へ
EC2を設置するネットワークを先ほど作成したVPC内のパブリックサブネットに設定する
====手順=====
自動割り当てパブリック IP:有効にすることで、インターネットから接続するためのパブリックIPアドレスが自動で割り当てられる
キャパシティーの予約:多量のアクセスがあった場合に、追加キャパシティが必要かどうか(今回はなし)
ネットワークインターフェイスの設定
このEC2インスタンスに、パブリックIPアドレスだけでなく、プライベートIPアドレスも設定することができる。
サブネットに、今回作成したサブネットを設定()し、そこでのプライベートIPアドレスを設定する
プライマリIPに「10.0.10.10」を設定する(サブネットのIPの範囲の中にあることを確認!)
ストレージの追加
とりあえずこだわりないので汎用SSDでOK
タグの追加
キーに「Name」、値に任意の名前を設定する
セキュリティグループの設定
セキュリティグループ名:任意の名前
SSHでこのEC2に接続できるIPアドレスを指定する(今回は、どのIPからでも接続できるよう「0.0.0.0/0」デフォルトルートのまま続行する)
最終確認画面 -> 起動
キーペアの設定
SSH接続するための、SSHキーを設定する
「新しいキーペアの作成」する
キーペア(.pemファイル)は必ずダウンロードする
SSHでサーバーにログインする
作成したVPC内のEC2に、SSHでログインする。
SSHはコンピュータを安全に遠隔操作するための仕組みです。
EC2インスタンスを遠隔操作して、最終的にはApache(マシンをWebサーバーとして使用するためのOS)のインストールをします。
====用語=====
- SSHクライアント:自分のローカルのコンピュータ(接続元)
- SSHサーバー:接続先のサーバー
公開鍵認証とは
SSHログインする時の認証は公開鍵認証によって行う。
====用語=====
- 公開鍵:サーバーが持っている暗号鍵?
- 秘密鍵:自分が使用する暗号鍵?
実際にSSHでEC2に接続する
ターミナルから以下のコマンドで、秘密鍵(
.pemファイル)が使用できるよう権限を変更する$ chmod 600 .pemファイルへのパスEC2のダッシュボードから、割り当てられたIPv4パブリックIPを確認し、クリップボードにコピーする
ターミナルから
ssh -iコマンドを実行。以下は例。$ ssh -i ~/Documents/ssh-key/yu-demy-sshkey.pem ec2-user@18.176.57.59無事ログインできると、以下のようにロゴが表示される
__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/EC2にSSH接続した状態で、以下のコマンドを実行すると、ポートの一覧が表示される
$ sudo lsof -i -n -P※
sudo(スードゥ)は「ルート権限で実行する」コマンドです。EC2インスタンスにApacheをインストールする
まずはEC2インスタンスのライブラリをアップデートする
$ sudo yum update -yApacheのインストール
$ sudo yum -y install httpd # ApacheをインストールApache(OS)の起動
インストールしただけでは動いていないので、Apacheを起動させます。
$ sudo systemctl start httpd.serviceちゃんと起動したかどうか、状態の確認
$ sudo systemctl status httpd.serviceプロセスの表示コマンドでも確認できる
$ ps -axu表示結果の中でApache(httpd)だけ検索して表示させる
$ ps -axu | grep httpd真ん中の縦棒は、「パイプ」と呼ばれ、左側のoutputを右側のコマンドに渡す
Apacheが自動起動するように設定する
$ sudo systemctl enable httpd.serviceファイアウォールを設定する
ファイアウォール:セキュリテイのため、アクセスできる通信を限定します。
EC2のセキュリティグループを設定する
EC2ではファイアウォールとして、「セキュリティグループ」を設定します。
デフォルトの設定で、アクセスが制限された状態になっているので、
今回は、アクセスを許可する作業をします。====手順=====
作成したEC2のダッシュボードから「セキュリティグループ(EC2作成時につけた名前)」のリンクにアクセスする
タブから「インバウンドルール」を確認すると、
- ポート22番が開いていること
- さらに「0.0.0.0/0」つまりどのIPアドレスからでもアクセス可能になっていること
がわかる
インバウンドルールを編集する
ブラウザからアクセスできるよう、Httpアクセスを許可するように設定する
====手順=====
「インバウンドルールの編集」 -> 「ルールの追加」
- type: http
- source: Anywhare(任意の場所)
これで「Anywhare」つまりどこからでもHttpアクセスを許可した状態になった。
ブラウザからEC2のパブリックIPにアクセスすると、Apacheのテストページが表示される
ElasticIPでIPアドレスを固定する
EC2のパブリックIPアドレスは起動するたびに新しく割り振られます。
ElasticIPアドレスを使用することで、IPアドレスを固定することができます。
ただし、課金の対象になるのでインスタンスを使用しない時には「ElasticIPアドレスの解放」をしておくようにします。
====手順=====
EC2ダッシュボードから「ElasticIP」 -> 「Elastic IPアドレスの割り当て」
これで、固定アドレスを確保できる
Elastic IPアドレスがダッシュボードに表示されたら、「アクション」から「ElasticIPアドレスの関連付け」を選択肢、作成したEC2インスタンスに関連付ける
これで、発行したElastic IPアドレスがEC2インスタンスに関連づけられ、ブラウザからアクセスするとApacheのテストページが表示される
Elastic IPアドレスの解放
インスタンスを停止した時には、課金されないようにElasticIPの解放をしておく方が良い
インスタンスを停止するなど、使用していない状態から
「アクション」->「Elastic IP アドレスの関連付けの解除」
ElasticIPのダッシュボードから、当該のIPアドレスを「解放」する
RDSの作成
Amazon Relational Database Service (Amazon RDS) はAWSが提供するデータベースサービスの一つです。
1番の特徴はその高可用性で、Multi-AZ(マルチAZ)と呼ばれる、複数AZに設置されるバックアップです。
RDSは複数のAZに設置することができ、それによって1つのAZで仮に障害が起きても、自動で別のAZにあるバックアップに運用を切り替えることができます。
また、メインとバックアップは常に完全に同期されているので、切り替えのタイミングでデータにズレが発生しません。
この高可用性を活かすために、今回は2つのAZにまたがる形でRDSを運用していきます。
もう一つプライベートサブネットを作成
先ほど作成したプライベートサブネットに加えて、今回もう一つ、今度は別のAZにサブネットを作成します。
これで、2つのAZに1つづつ、合計2つのプライベートサブネットを作成することになります。2つのサブネットに1つづつ、メインとバックアップのRDSを設置し、可用性の高い構成にします。
なお、このバックアップのことをSlaveと呼びます。RDSの作成準備
今回はセキュリティのため、インターネットからはデータベースにアクセスできない構成にします。
データベースへのアクセスは、EC2からのみに限定します。まずは、RDS用にEC2でセキュリテイグループを新たに設定します。
セキュリティグループの設定
EC2のダッシュボードから、「セキュリティグループの作成」
====用語=====
- セキュリティグループ名:任意の名前
- 説明:任意の説明文
- VPC:先ほど作成したVPCを選択
セキュリティグループのルールを設定
今回はMySQLでDBへのアクセスを許可したいと思います。
そのため、インバウンド(受け付ける入力)のルールをまずは追加します。
セキュリティグループをインバウンドルールのソースから許可することで、そのセキュリティグループ内のインスタンスからアクセスできるようになります。====用語=====
- タイプ:MySQL/Aurora
- ソース:先ほど作った、接続元のEC2が存在するセキュリティグループ
サブネットグループの作成
マルチAZで、複数のサブネットにまたがってRDSを設置するので、それらのサブネットをまずグルーピングしておきます。
====手順=====
コンソールからRDSダッシュボードへ
メニューから「サブネットグループ」->「DBサブネットグループの作成」====用語=====
- 名前:任意の名前
- 説明:任意の説明文
- VPC:作成したVPC
- サブネットの追加:作成した2つのプライベートサブネットを追加する
パラメータグループの作成
DBの設定は直接編集できず、このパラメータグループで設定を行います。
====手順=====
メニューから「パラメータグループ」->「パラメータグループの作成」
====用語=====
- パラメータグループファミリー:使用したいDBのエンジンを指定する
- グループ名:任意の名前
- 説明:任意の説明文
作成したパラメータグループの「アクション」->「編集」から設定を変更できる
オプショングループの作成
DBの機能部分のオプション設定を行う
====手順=====
メニューから「オプショングループ」->「オプショングループの作成」
====用語=====
- 名前:任意の名前
- 説明:任意の説明文
- エンジン:任意のエンジン
- エンジンのバージョン:エンジンのバーション
RDSを作成
====手順=====
「RDS」のメニューから「データベース」 -> 「データベースの作成」
====用語=====
先ほど作成したDB設定にあわせた内容を選択する。
DBのIDやパスワードは、ワードプレスの初期設定にも必要になる値になる。
DBインスタンスサイズ(「インスタンスサイズ」とはスペックのこと)は練習で作成するなら一番安い「バースト可能クラス」「t2micro」を選択
マルチ AZ 配置:今回は「スタンバイインスタンスを作成しないでください」を選択
接続:VPCとサブネットグループを設定する
パブリックアクセス可能:DBへは同一VPC内のEC2からのみアクセスできるようにしたいので、パブリックアクセスは不可にする
追加設定:先ほど作成した「DB パラメータグループ」と「オプショングループ」を設定する
その他の各項目を設定し、「データベースの作成」
これで、RDSの作成が完了です。
RDSに EC2から接続する
====手順=====
- EC2のダッシュボードからEC2インスタンスのIPアドレスを確認しておく
- ターミナルからEC2インスタンスにSSH接続する
EC2にMySQLをインストールする
$ sudo yum -y install mysqlMySQLでデータベースに接続する
RDSのダッシュボードからエンドポイントを確認しておく
$ mysql -h {エンドポイント} -u {データベースのユーザID} -pRDSにワードプレス用のデータベースを作成する
====手順=====
RDSにMySQLで接続する
データベースを作成する
CREATE DATABASE DBの名前 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;作成されたDBを確認する
SHOW DATABASESワードプレス用のユーザーを作成する
CREATE USER 'ユーザ名ー'@'%' IDENTIFIED BY 'password';作成したユーザーに権限を付与する
GRANT ALL ON DBの名前.* TO 'ユーザー名'@'%';変更した権限の設定を反映させる
FLUSH PRIVILEGESワードプレスをEC2にインストールする
====手順=====
EC2インスタンスにphpをインストールする
$ sudo amazon-linux-extras install -y php7.2関連ライブラリのインストール
$ sudo yum install -y php php-mbstringワードプレスのダウンロード
$ wget https://ja.wordpress.org/latest-ja.tar.gzダウンロードされた圧縮ファイルを解凍する
$ tar xzvf latest-ja.tar.gz解凍した
wordpressディレクトリに移動して
全てのファイルをApacheの参照するルートにコピーする$ cd wordpress $ sudo cp -r * /var/www/html/ファイルの所有権をApacheにする(Apacheがwordpressを参照できるようにする)
$ sudo chown apache:apache /var/www/html/ -Rapacheを再起動して変更を適用する
$ sudo systemctl restart httpd.serviceWordpressの設定をする
EC2のIPアドレスにアクセスし、Wordpressの初期設定画面が表示される
ホスト名は、RDSのエンドポイントを入力する
あとは、通常のWordPressの設定を進める
完成
- VPC(自身のネットワーク)を作成: リージョン
- その中に複数のサブネットを作成: 複数のAZ
- ファイアウォール(セキュリティゾーン)を設定:サブネット
- WebサーバーとなるEC2を作成:パブリックサブネット
- データベースとなるRDSを作成:プライベートサブネット
- 投稿日:2020-03-28T17:54:00+09:00
Capistranoを利用した自動デプロイ
Capistrano
Capistranoは、自動デプロイツールと呼ばれるものの一種です。
自動デプロイツールのメリット
自動デプロイツールを利用することによって、デプロイ時に必要なコマンド操作が1回で済むようになります。これにより、手動でデプロイする場合に起こりがちな下記の問題を解消することができます。
1. コマンドの打ち間違い、手順の間違いが発生する可能性がある
2. 手順が多く、煩わしい
Capistranoを利用すれば、サーバにログインする必要はありません。ローカルのターミナルからのコマンド1つで、これらの作業をいっぺんに完了することができます。
また、一度Capistranoによるデプロイが成功してしまえば、打ち間違いによるデプロイの失敗は起こらなくなります。Capistranoの導入
まずは、必要なGemをインストールします。
Gemfilegroup :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' endターミナル(ローカルPC)
bundle installターミナル(ローカルPC)
bundle exec cap installアプリケーション名
capfile
config
deploy
production.rb
staging.rb
deploy.rb
lib
capistrano
tasks
上記のファイルが生成されます。Capfile
Capistranoの機能を提供するコードはいくつかのライブラリ(Gem)に分かれています。そのため、Capistranoを動かすにはいくつかのライブラリを読み込む必要があります。Capfileは、Capistrano関連のライブラリのうちどれを読み込むかを指定できます。
デプロイについての設定を書くファイル
deploy.rb、production.rb、staging.rb
Githubへの接続に必要なsshキーの指定、デプロイ先のサーバのドメイン、AWSサーバへのログインユーザー名、サーバにログインしてからデプロイのために何をするか、といった設定を記載します。Capfile
Capfileは、capistrano全体の設定ファイルです。
Capfilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }require により引数としておかれた文字列が指すディレクトリが読み込まれ、その中にデプロイに際して必要な動作が一通り記述されています。
次は、デプロイについての設定を記載するファイルを編集します。
cap installコマンドを打つと、config/deploy配下にproduction.rbとstaging.rbの2種類のファイルが生成されます。
これらは、デプロイする環境別の設定を記述するファイルです。今回はproduction、本番環境のものだけ編集します。
編集する内容としては
サーバーホスト名
AWSサーバーへのログインユーザー名
サーバーロール(後述)
SSHの設定
その他サーバーに紐づく任意の設定
を編集していきます。config/deploy/production.rbserver '<用意したElastic IP>', user: 'ec2-user', roles: %w{app db web}<用意したElastic IP>はご自身のElastic IPを入れてください。ちなみにElastic IPを入れるときに<>は不要です。
次に、production環境、staging環境どちらにも当てはまる設定を記述します。
下記のような項目を記述していきます。
アプリケーション名
gitのレポジトリ
利用するSCM
タスク
それぞれのタスクで実行するコマンド
deploy.rbの記述をすべて削除し、以下のコードを貼り付けます。config/deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '<Capistranoのバージョン(ご自身のバージョン)>' # Capistranoのログの表示に利用する set :application, '<自身のアプリケーション名>' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:<Githubのユーザー名>/<レポジトリ名>.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, '<このアプリで使用しているrubyのバージョン>' #2.5.1などです # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス(例:~/.ssh/key_pem.pem)>'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end
<自身のアプリケーション名>
/<レポジトリ名>
<このアプリで使用しているrubyのバージョン>
<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス>
をご自身のに変えてください。変える際には、<>は削除してください。
capistranoのバージョンは、gemfile.lockに記載されています。
例gemfile.lock# 省略 capistrano (3.11.0) # 省略この場合はcapistranoのバージョンは3.11.0になります。
DSL
ある特定の処理における効率をあげるために特化した形の文法を擬似的に用意したプログラムです。
上記のset :名前, 値について、これは言わば変数のようなものです。
例えばset: Name, 'value' と定義した場合、fetch Name とすることで 'Value'が取り出せます。
また、一度setした値はdeploy.rbやproduction.rbなどの全域で取り出すことができます。
また、ファイル内には、desc '◯◯'やtask:XX doといった記述があります。これは、先ほどCapfileでrequireしたものに加えて追加のタスクを記述している形です。ここで記述したものもcap deploy時に実行されます。Capistranoによる自動デプロイ後のディレクトリ構成
一度Capistranoによる自動デプロイを実行すると、本番環境のアプリケーションのディレクトリが変化します。
Capistranoによるアプリのバックアップなど、複数のディレクトリが作成されます。その中でも特に重要なのが、releases、current、sharedディレクトリです。releasesディレクトリ
capistranoを通じてデプロイされたアプリは、releasesフォルダにひとまとめにされます。
ここに過去分のアプリが残っていることにより、デプロイ時に何か問題が発生しても一つ前のバージョンに戻ったりすることができます。
そして、その過去分の保存数を指定しているのがdeploy.rbのset :keep_releasesの記述となります。今回は5つ、過去のバージョンを保存するよう設定してます。currentディレクトリ
releasesフォルダの中で一番新しいものが、自動的にcurrentフォルダ内にコピーされます。
そのため、このcurrent内に入っているアプリの内容が、現在デプロイされている内容ということになります。sharedディレクトリ
バージョンが変わっても共通で参照されるディレクトリが格納されるディレクトリです。具体的には、log、public、tmp、vendorディレクトリが格納されます。
unicorn.rbを編集
capistranoでのデプロイ後は、アプリケーションのディレクトリ直下にあるcurrentディレクトリが動きます。そこで、app_pathのディレクトリ指定も一段階追加します。
また、実際に動くディレクトリであるworking_directoryの指定をcurrentにしたり、ログやpidの指定をshared以下にするなどの変更を加えます。config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen "#{app_path}/tmp/sockets/unicorn.sock" stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" ↓↓↓↓↓↓↓ 以下のように変更 ↓↓↓↓↓↓ # ../が一つ増えている app_path = File.expand_path('../../../', __FILE__) worker_processes 1 # currentを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log"次に、Nginxの設定ファイルの変更をします。
これまでは/var/www/以下のアプリケーションに対して連携を設定していたので、/var/www/アプリケーション以下のcurrent、sharedなどのディレクトリと連携するように設定を変更します。
ターミナル(EC2サーバ)$ sudo vim /etc/nginx/conf.d/rails.confrails.confの既存のコードがある場合、いったん削除したほうが楽だと思うので、新しく変えていきます。
rails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }<アプリケーション名> のなってるところほご自身のに変更してください。変更する際には<>は不要です。
Nginxの設定を変更したら、再読込・再起動をします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx reload [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartMySQLが立ち上がっていないとデプロイが失敗するので。再起動をします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld restart自動デプロイを実行する前にunicornのコマンドをkillしておきます。
まず、プロセスを確認です。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn次に、プロセスをkillします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上記では17877)>ローカルでのコードの変更が、全てmasterにpushされているかを確認してください。
以上までが自動デプロイの準備です。自動デプロイ
これで、ターミナル(ローカル)からコマンド一発でデプロイできるようになりました。実際に、自動デプロイを実行していきます。
ローカルのターミナルで、以下のコマンドで自動デプロイを実行します。
ターミナル(ローカルPC)# アプリケーションのディレクトリで実行する $ bundle exec cap production deployもし、途中でエラーが出て止まってしまった場合は、以下を試してください。
そのままもう一度同じコマンドを実行してみる
特に、bundle installのタスクの際に、初めて自動デプロイを実行する場合は、メモリ不足で落ちることがあります
記述ミスが無いか
手順を飛ばしていないか
bundle installなどのコマンド実行を忘れていないか確認しましょう
エラーがなければ、ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000をつける必要はありません)。IPアドレスにアクセスしてもエラーが出る時
ローカル側(localhost3000)においてエラーが出ていないか
サーバー側で、/var/www/<レポジトリ名>/current/log/unicorn.stderr.logをlessまたはcatコマンドで確認しエラーが出ていないか確認する(下に行くほど最新のログです。時刻表記がUTCであることに注意してください)
ローカルでの編集のpushやpullを忘れていないか
サーバー側のmysqlやnginxの再起動を行ってみる
EC2インスタンスの再起動を行ってみる(※本番環境にてmysqlとnginxの起動も必要です。)
などが考えられます。
以上で自動デプロイの設定は完了です。
あとはローカルのターミナルからコマンド1つでデプロイし、アプリケーションを安全に更新することが可能です。
今後のアプリケーションの更新の流れは以下です。
1.アプリをローカルで更新し、リモートリポジトリにプッシュする
2.ローカルのプロジェクトのディレクトリにいる状態のターミナルでbundle exec cap production deploy を実行する
- 投稿日:2020-03-28T17:53:28+09:00
無料ドメインを使ってAWS上のアプリケーションをHTTPS化(上げ直し)
流れ
freenom(ドメイン取得)
↓
Route53(DNS管理)
↓
ACM(証明書作成)→SES(メールでドメイン認証)
↓
Beanstalk(HTTPS化したアプリケーション)無料ドメイン取得
freenom
下記サイトで無料でドメイン取得できます。
https://www.freenom.com私は.tkを使っています。
太平洋の島?かどこかのドメインらしいです。
詳しくは下記参照。
https://qiita.com/hanbaga324/items/da0c4f6fa8d365db10c9アカウント作成
freenomのアカウントを作成します。
ドメイン取得
メニューバーのServicesからRegister a new domainを選択。
取得したいドメインを入力して、Check。
無料のドメインを選択して、Checkout。
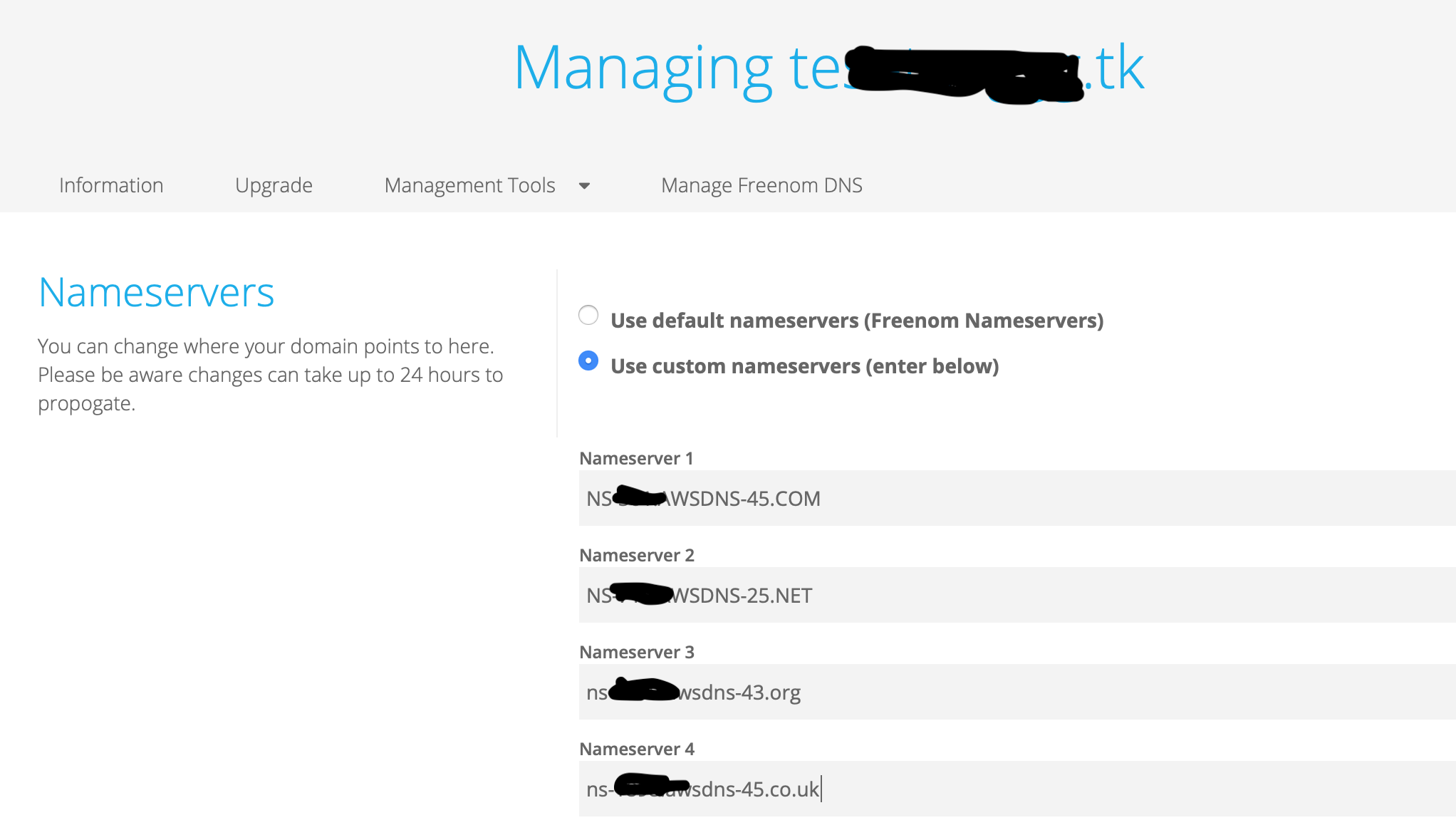
ここでDNSの設定がありますが、今回はRoute53で指定されたNameserverを設定します。
一旦Route53へ
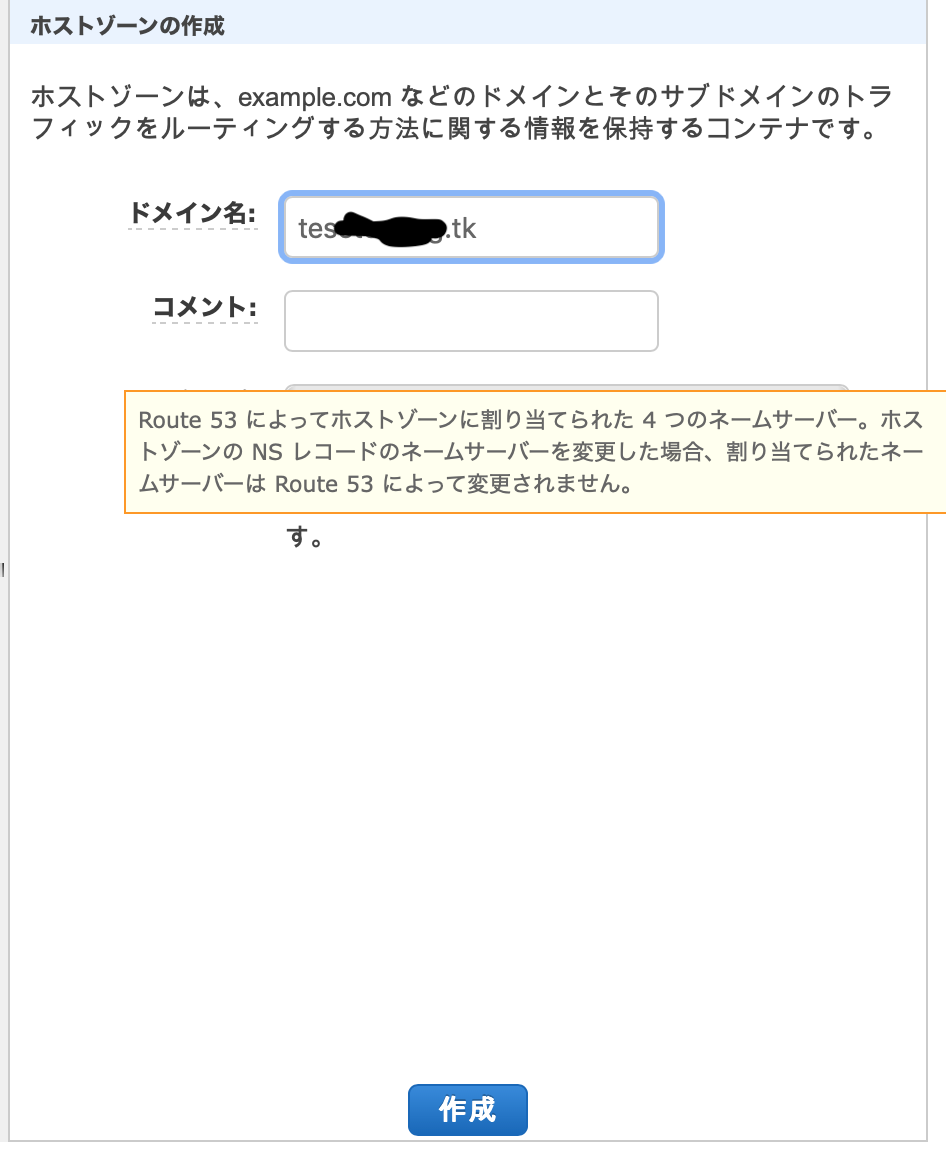
「ホストゾーン」→「ホストゾーンの作成」で作成したいドメインを入力し、作成。
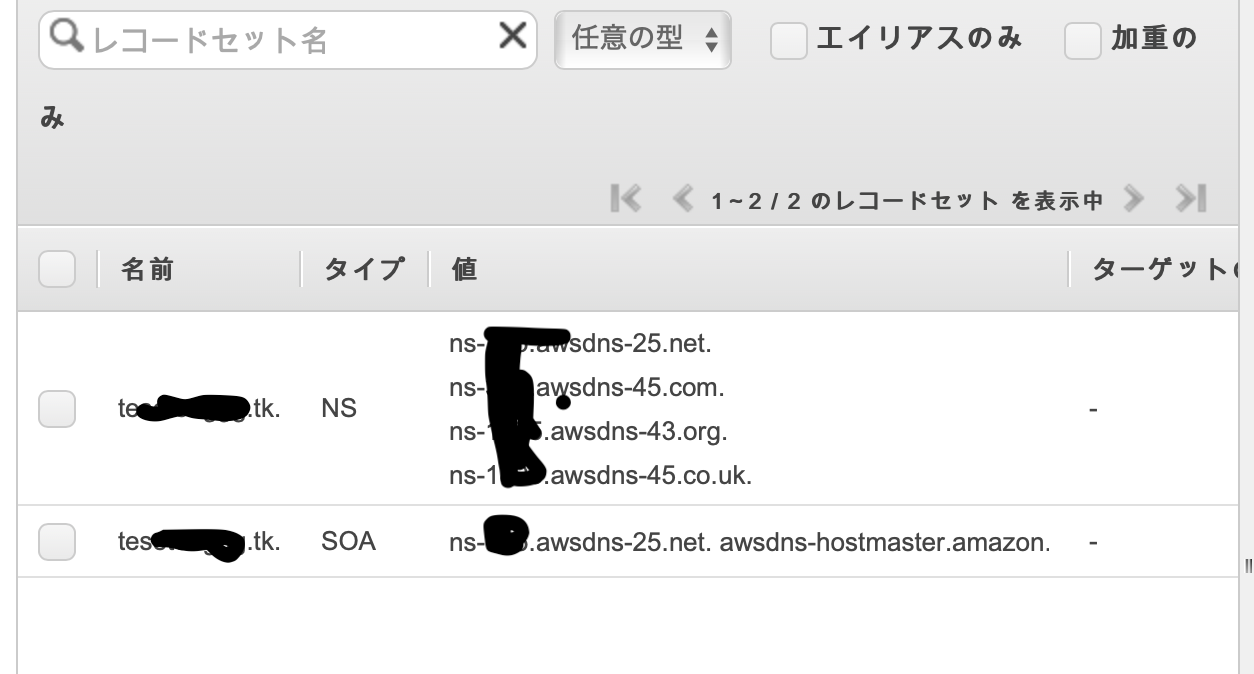
すると、4つのNSレコードができるので、このうち2つを先ほどのfreenomの設定欄に入力します。(最後の.は不要。)
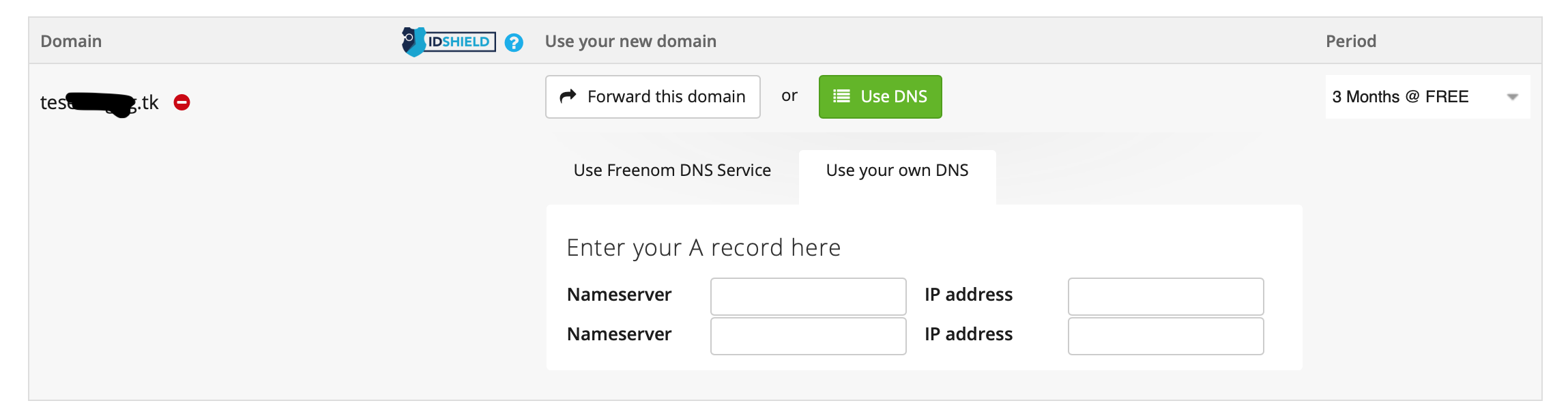
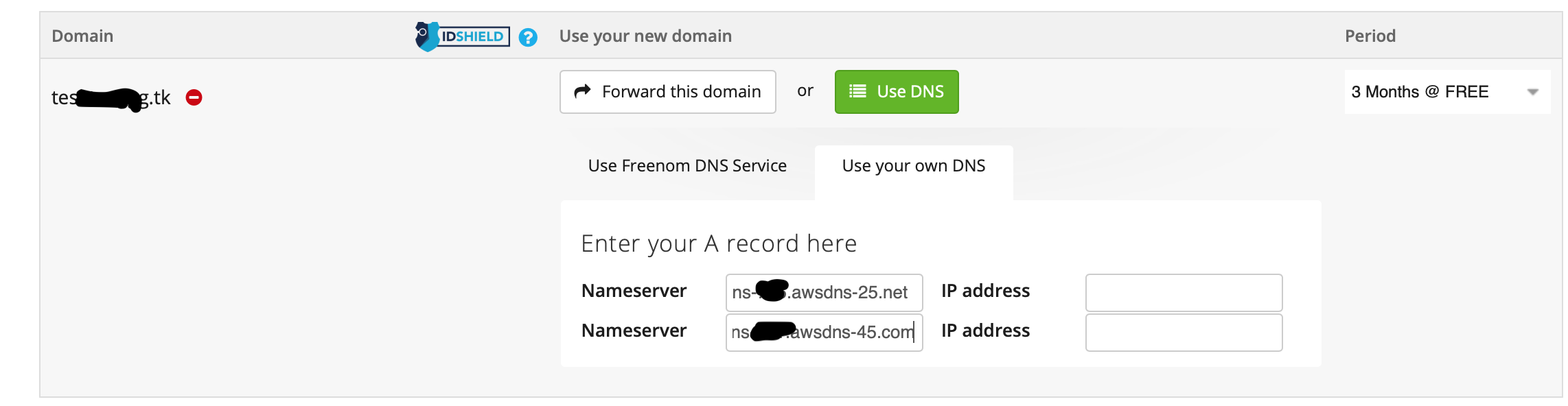
「Use DNS」→「Use Your Own DNS」のNameserverに入力しして、Continue。(IPアドレスは不要)
内容を確認し、同意欄にチェックして、Complete Order。
(Safariでやると、「お前人間か?」とか言われてエラーになりましたが、Chromeでは問題なし。あるいは、少し時間を置けば大丈夫かも)
ドメインの取得が完了したら、「Services」→「My Domains」から先ほど登録しなかった2件のNameserverを登録。
「Manage Domain」から「Management Tools」で「Nameservers」を選択し、Nameserverを追加。
証明書作成
SES設定
ドメイン設定
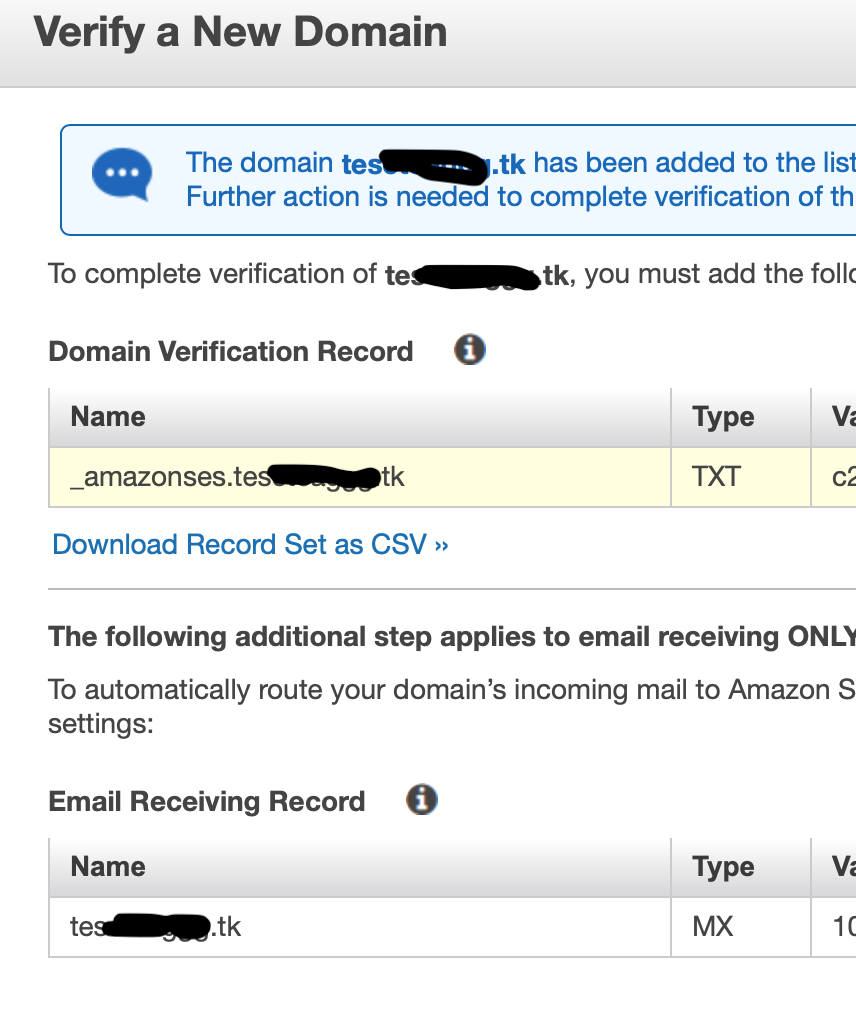
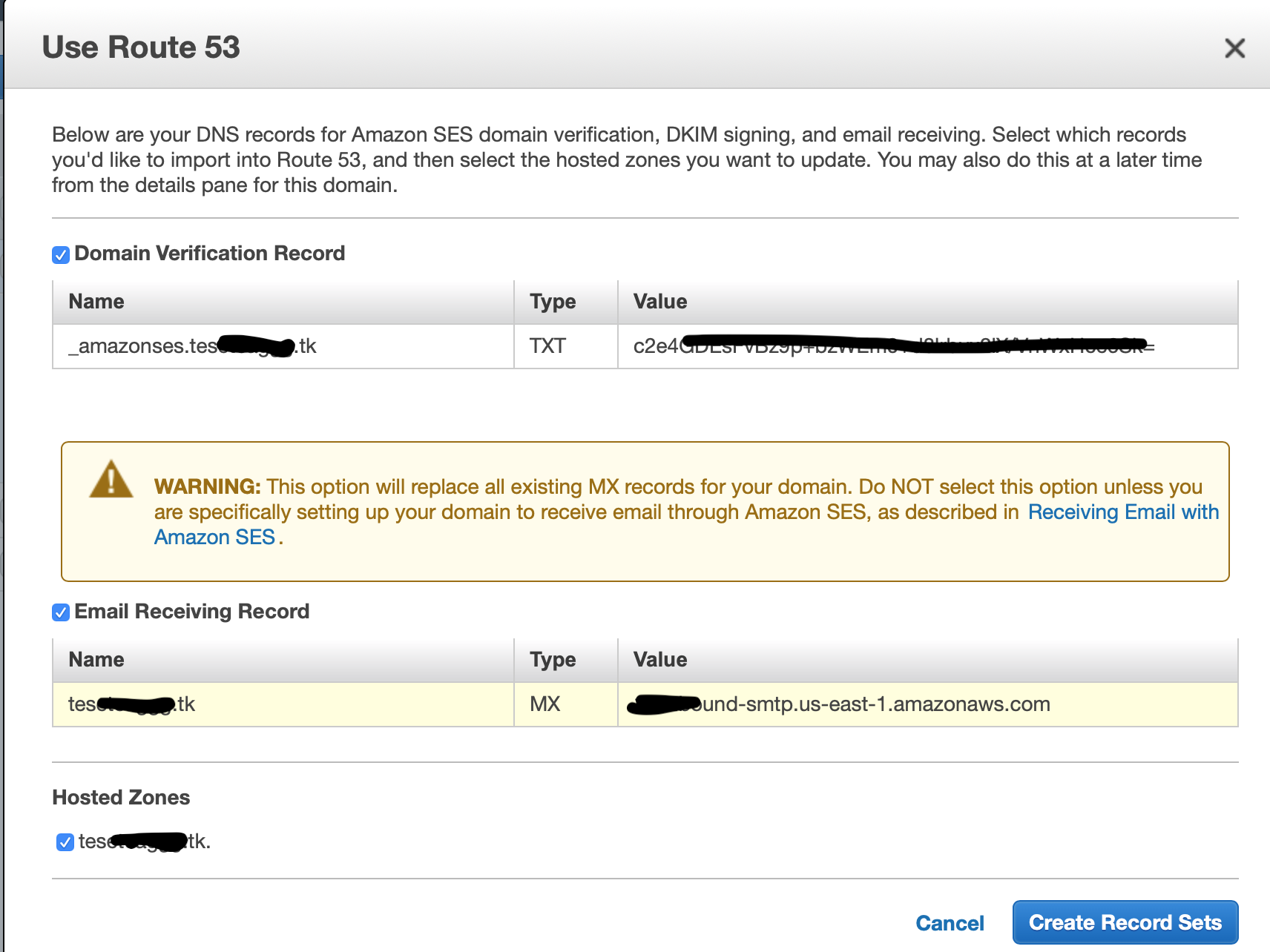
順に「Use Route53」→Email Receiving Recordにチェックして「Create Record Sets」を選択するとTXT、MXレコードが作成されます。
受信設定
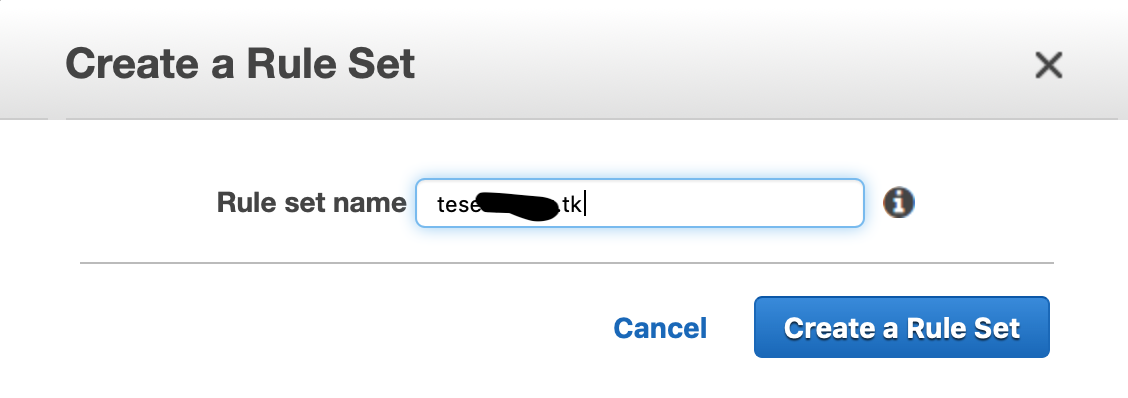
「Email Receiving」→「Rule Sets」から「Create a Rule」でドメインを設定。
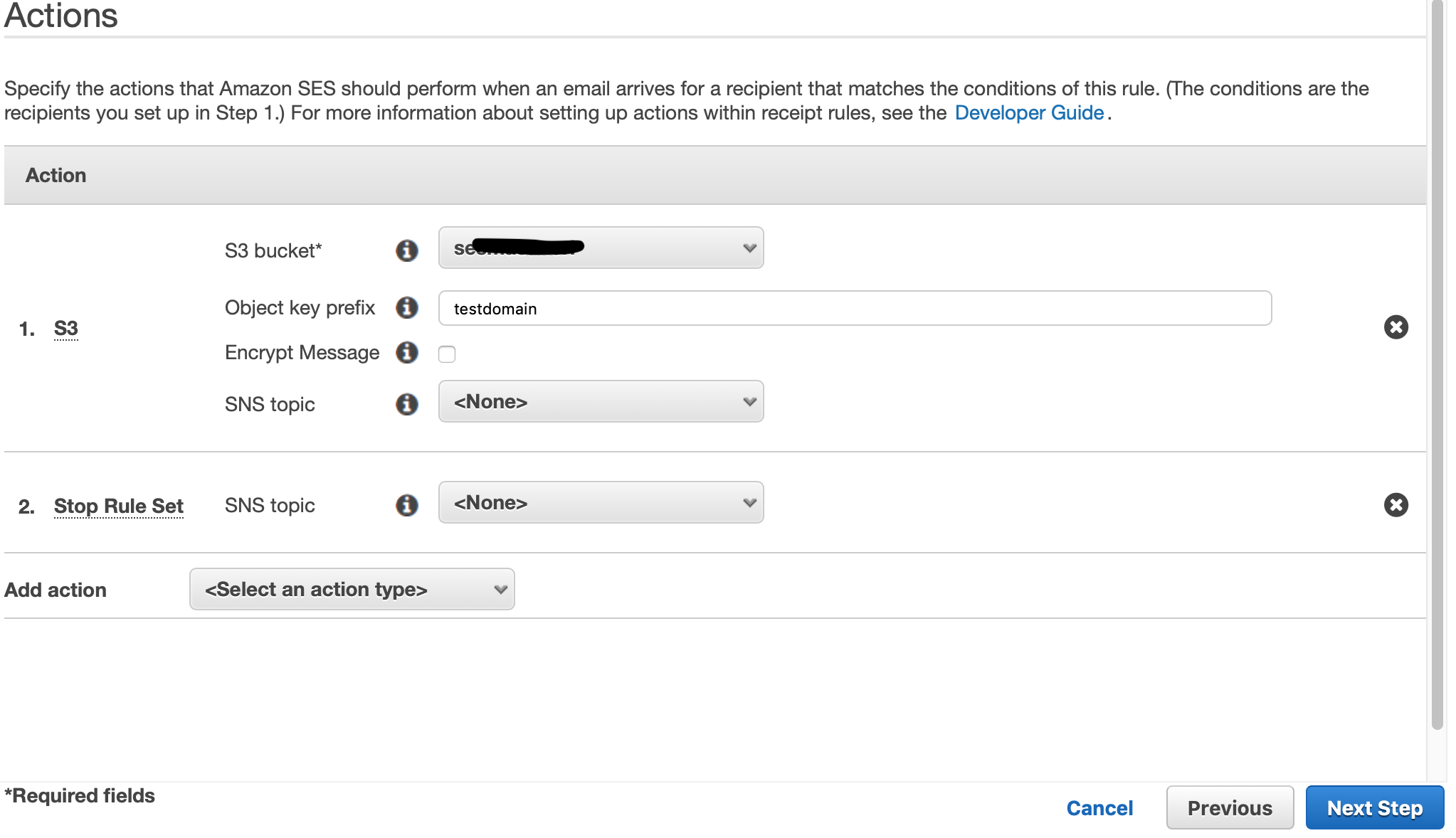
S3での受信を設定。
(受信はアメリカリージョンでしかできない?)
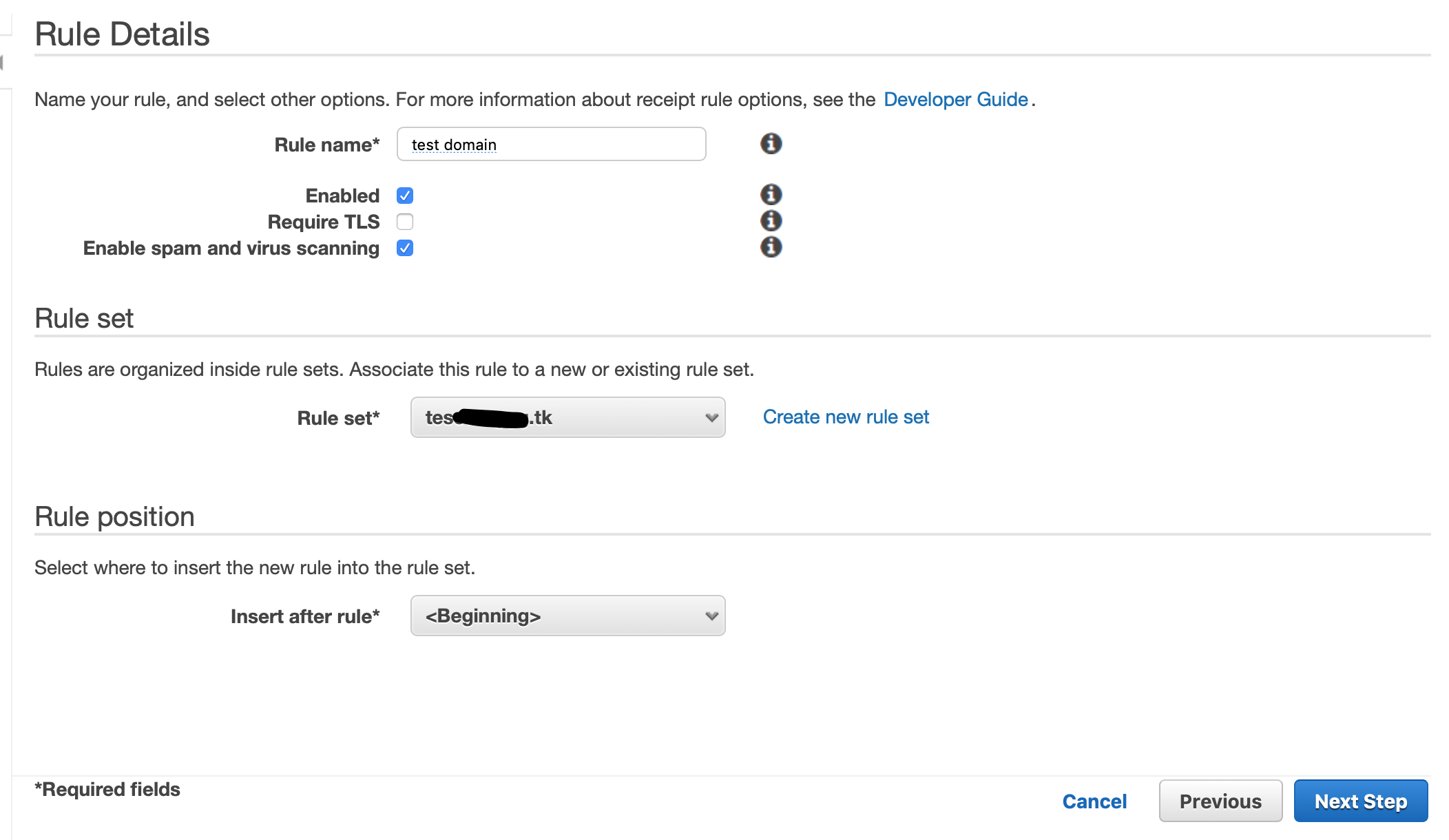
作成したRule SetがActiveになっていない場合は、ActiveにSetします。
ACMで証明書発行
証明書リクエスト
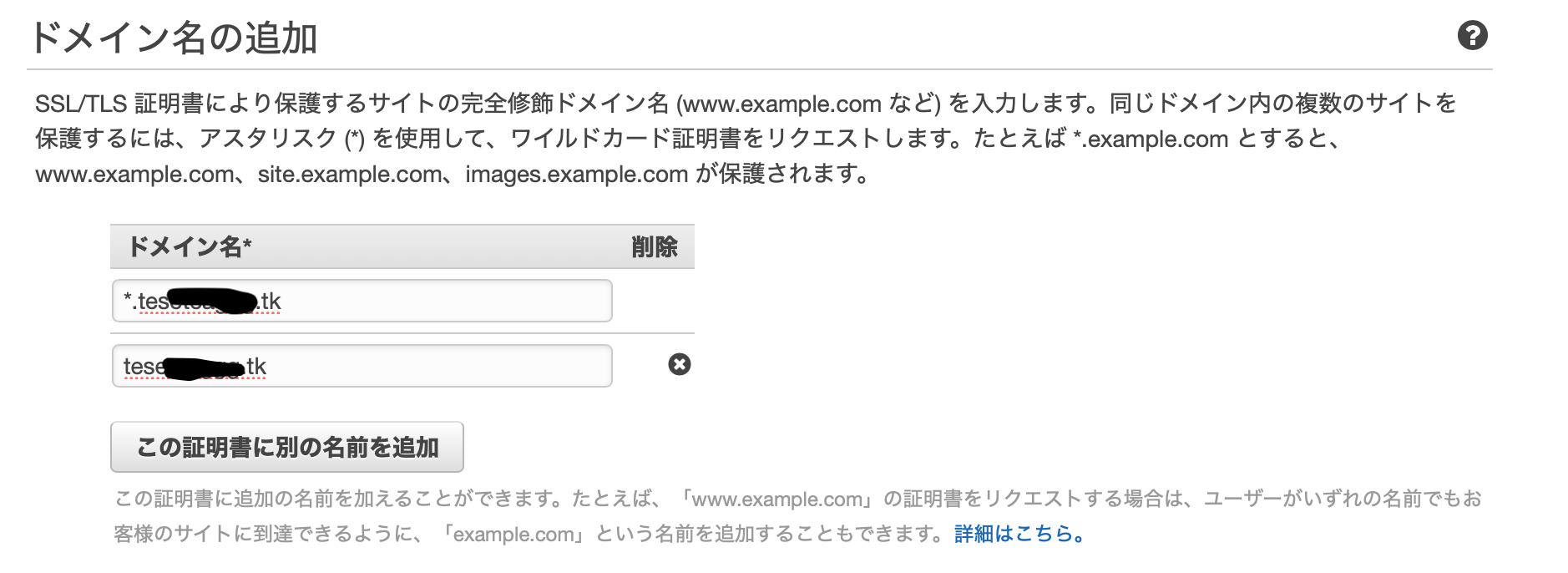
ワイルドカードでドメイン名を指定し、追加の名前でドメイン名のみを指定。
メール検証を指定
私は先にACMの設定をしていたので、改めてACMからメール送信しました。
S3に認証ページのリンク入りのテキストが届くので、リンクを探して開き、Approveをクリック。
証明書を適用
Beanstalkでサンプルアプリ起動
アプリケーション作成、環境作成を行います。
今回はTomcatのサンプルアプリを使います。
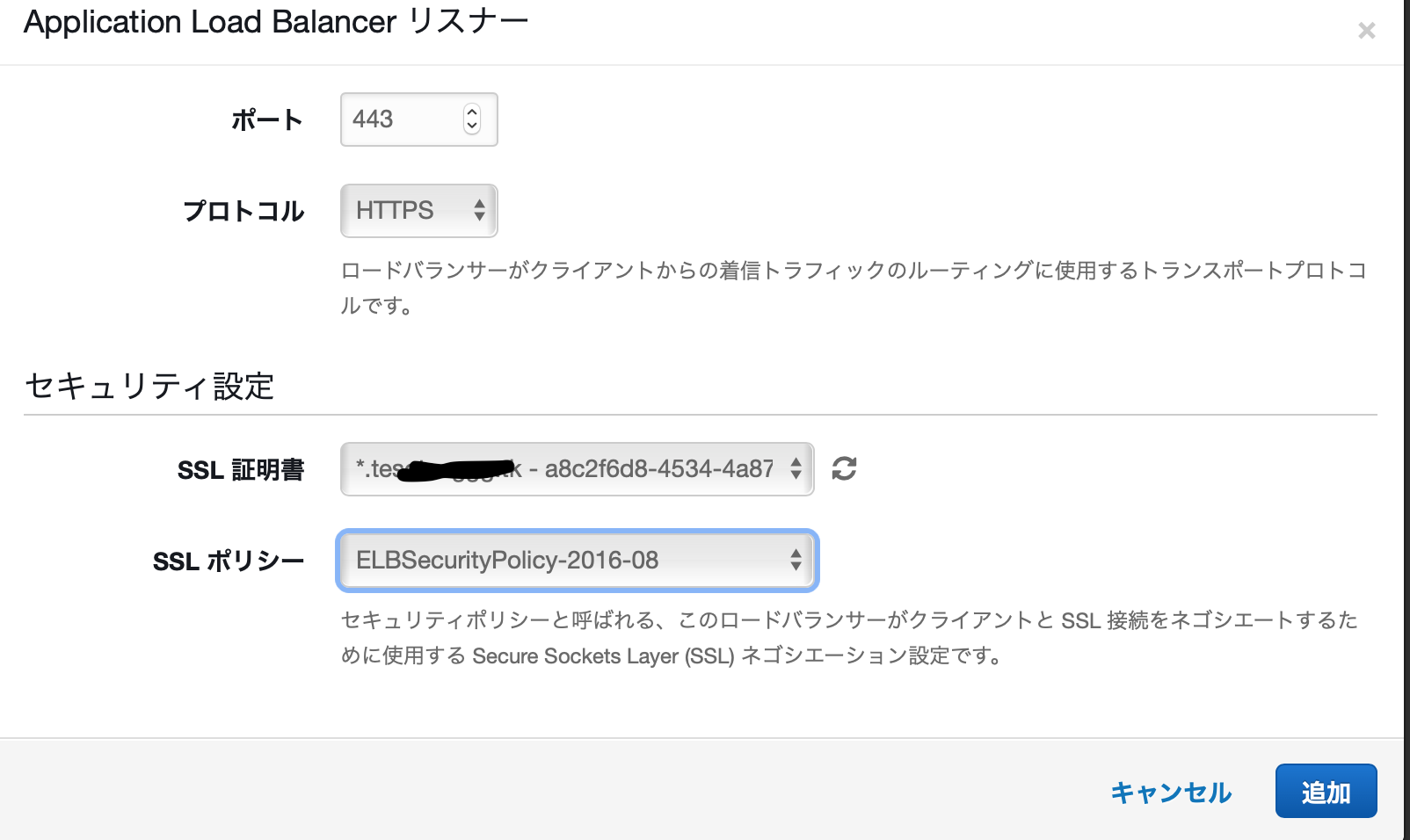
「より多くの設定を追加」でカスタム設定を選び、LBにHTTPSリスナーを追加、先ほど作った証明書を選びます。
Route53でLB向けのAliasを設定
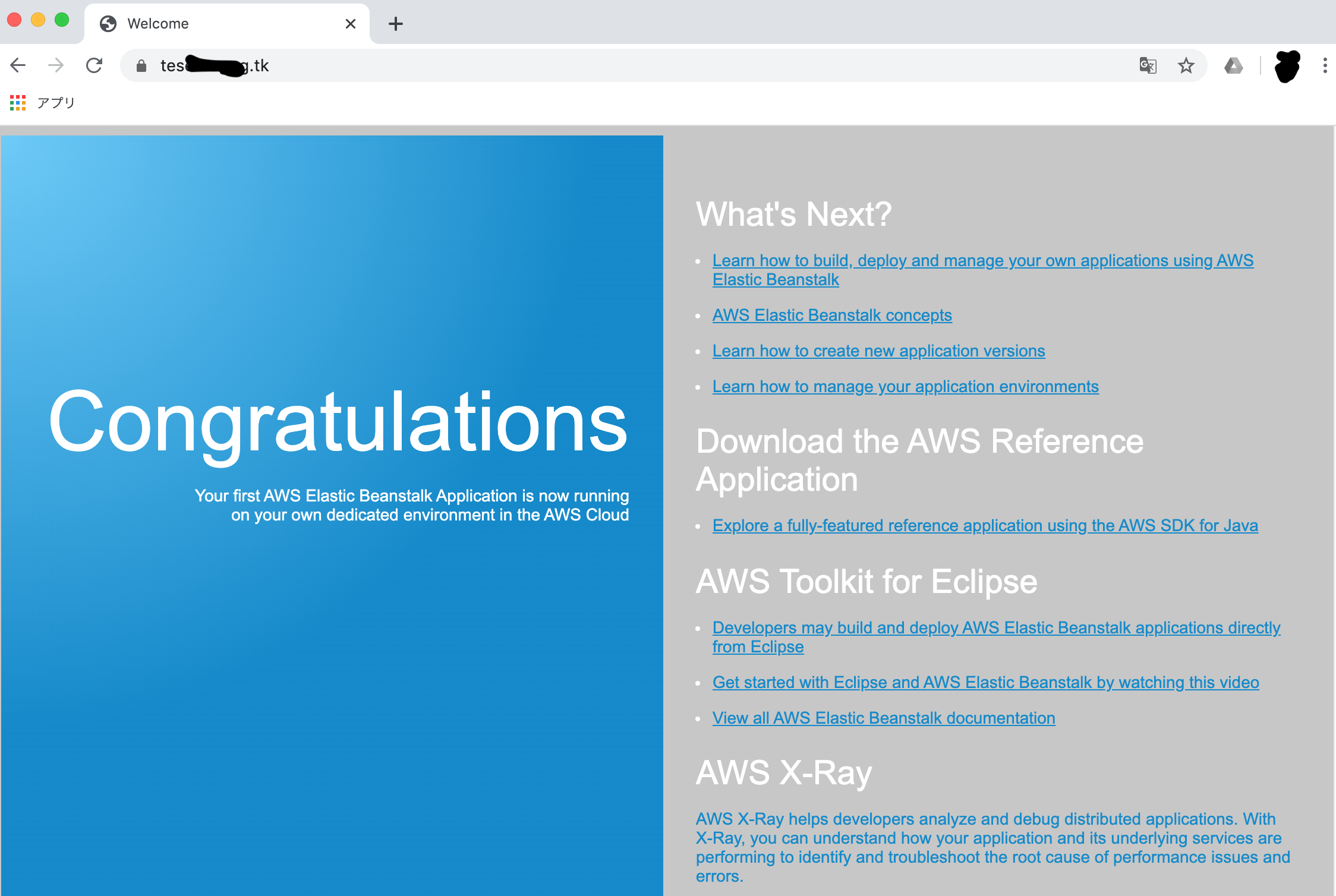
検証
HTTPSで開けました。







- 投稿日:2020-03-28T17:53:07+09:00
AWS上にRedmineを構築してSESで通知メールを送信(上げ直し)
前提
SESにドメイン、アドレスを設定済み。
SESでメールの送信制限を緩和済み。メール送信設定
サーバ作成
MarketplaceのAMIを使って、EC2インスタンスを起動。
インスタンスの設定はよしなにやってください。動かすだけならデフォルトで問題ないです。
SMTPサーバの設定
作成したインスタンスにSSHでログインして、設定ファイルを編集。
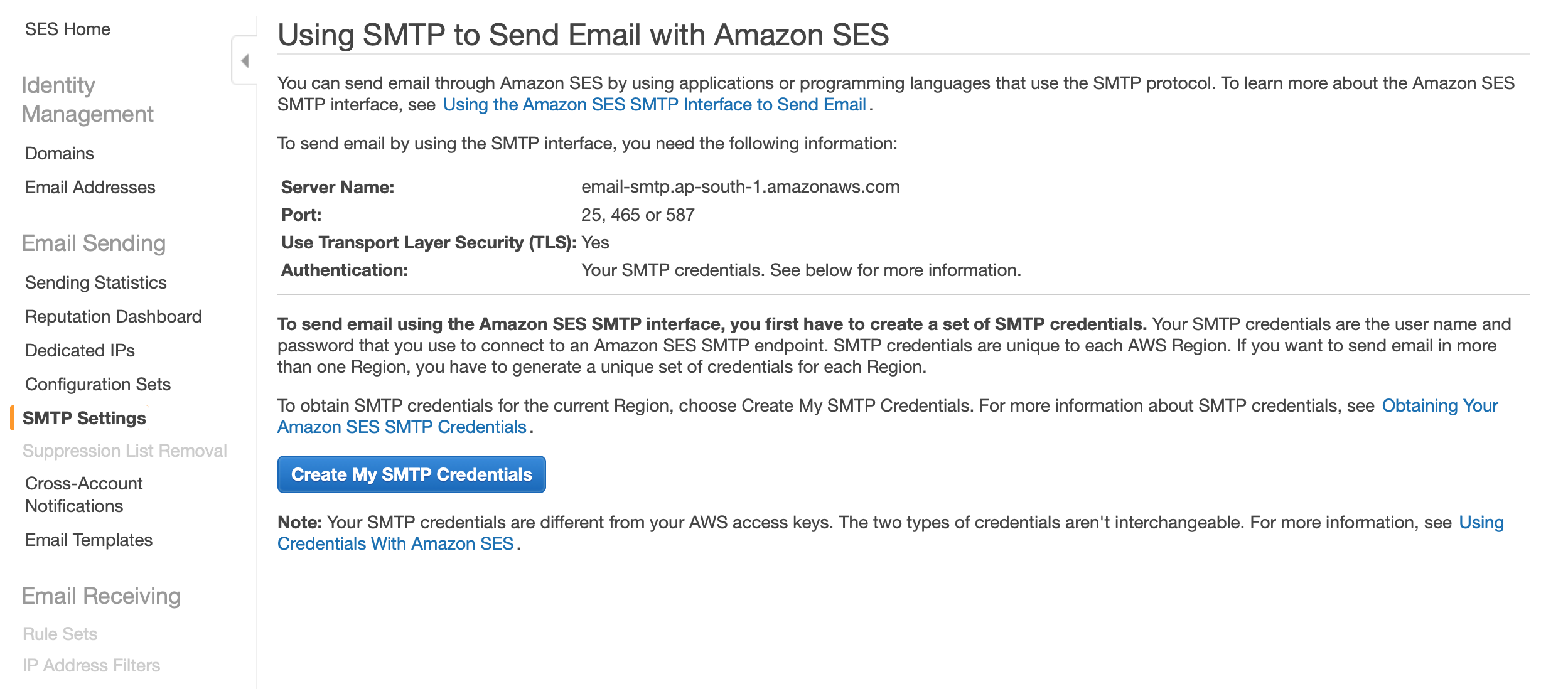
vi /opt/bitnami/apps/redmine/htdocs/config/configuration.ymlemail_delivery: delivery_method: :smtp smtp_settings: address: "SESで確認" port: 587 domain: "あなたのドメイン" authentication: :login user_name: "SESで作成されたユーザー" password: "SESで作成されたパスワード"入力項目はSESで確認。SMTP SettingsのServer Nameが上記のaddressです。
続いて、「Create My SMTP Credentials」をクリック。
続けて「作成」をクリックして、ユーザー、パスワードを作成し、上記のユーザー、パスワードに記載します。
ドメインはSESで設定しているドメインを記載してください。
(""も必要です)メール送信テスト
設定の反映には再起動が必要ですが、その前にadminユーザーのパスワードを確認しておきます。
/home/bitnami配下のbitnami_credentialsに書かれています。
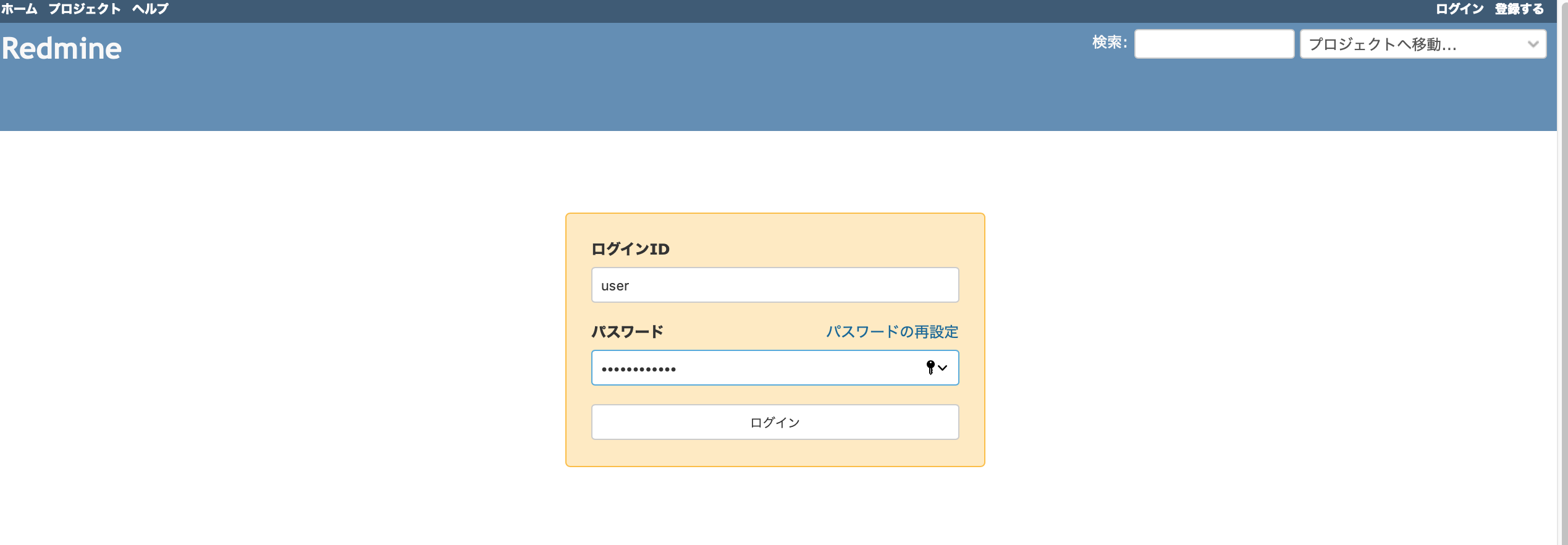
パスワードをメモしたら、インスタンスを再起動します。再起動できたら、インスタンスのDNSまたはIPをブラウザで入力。Redmineのログイン画面が開きます。
IDにuser、パスワードに先ほど確認したパスワードを入力してログイン。
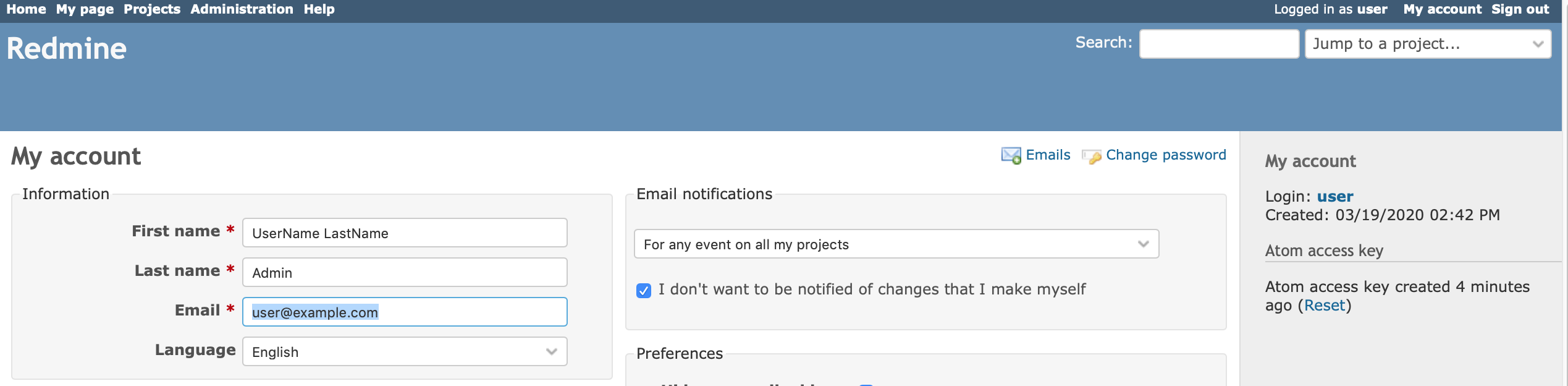
メール送信テスト用に、先に右上のMy Accountから自分のアドレスを修正します。
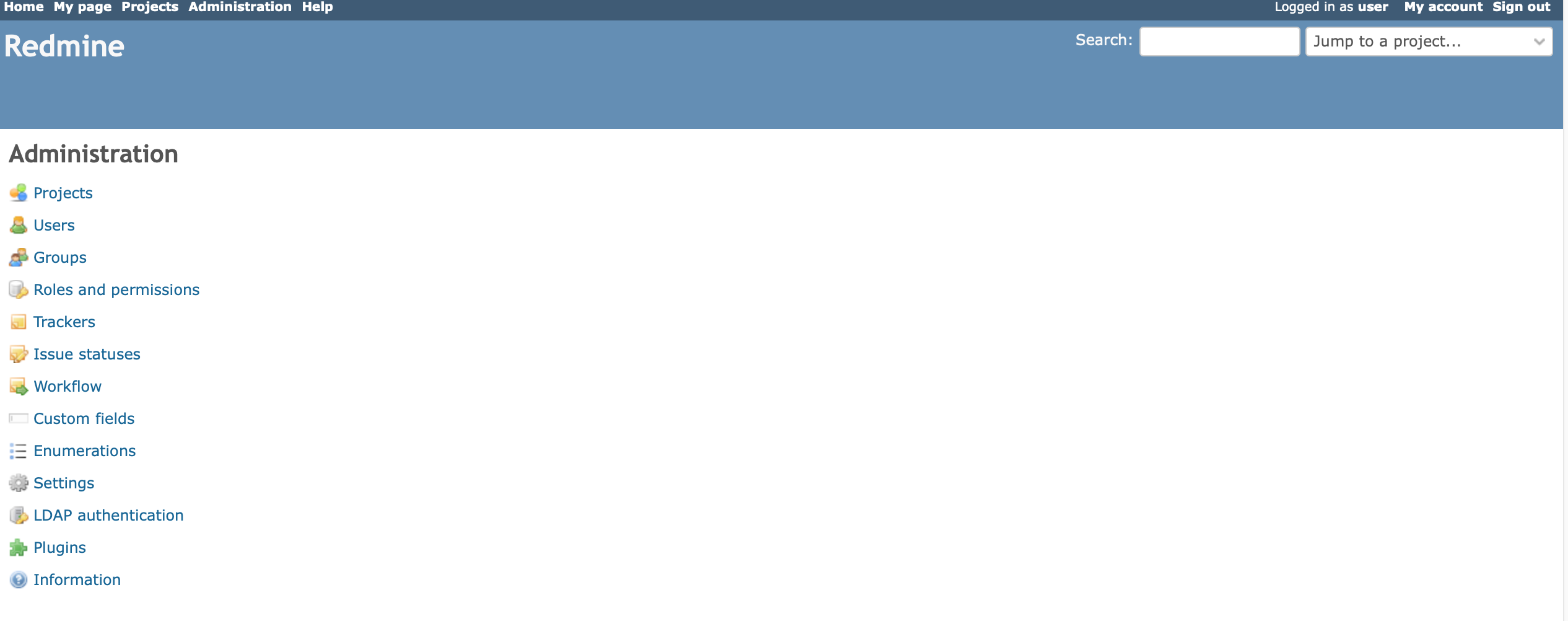
続けて、画面左上のAdministrationから、Settings。
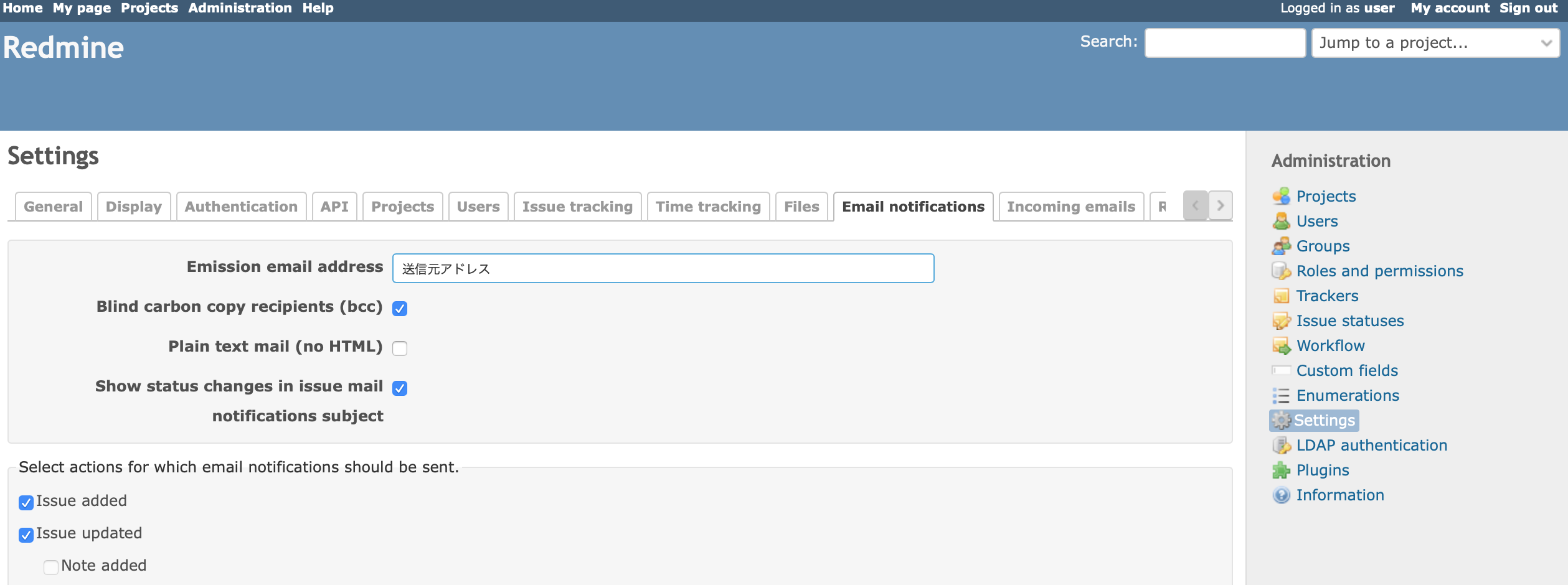
Email Notificationへ。送信元メールアドレスを設定します。
ページ下までスクロールして保存ボタンをクリック。
続いて、ページ下部右にあるSend a test emailでテストメールを送信します。
問題なくメールが届けば、設定完了です。

- 投稿日:2020-03-28T17:53:02+09:00
aws-shell を dockerでクリーンに動かす
TL;DR
https://github.com/hiroga-cc/docker-images/blob/master/aws-shell/Dockerfile
詳細
aws-shellの調子が良くないので、dockerでクリーンに実行します。aliasでdockerを動かし、かつ
~/.awsをボリュームとしてマウントする、という構成です。# alias aws-shell='docker run --rm -it -v "$HOME/.aws:/root/.aws" hiroga/aws-shell:latest' FROM python:3.7.7-alpine3.11 RUN pip install --upgrade pip;\ pip install --upgrade aws-shell ENTRYPOINT [ "aws-shell" ]今後の改善点
- できれば毎度イメージを作るのを避けたいので
startを利用したいのだが、 startにprofileオプションを渡す方法が思いつかないです...- Creating doc index が毎回走るのもなんとかしたい。コンテナビルド時にindexを作るという手もあるが...うーん。
- 投稿日:2020-03-28T17:39:51+09:00
AWS上にRedmineを構築してSESで通知メールを送信
前提
SESにドメイン、アドレスを設定済み。
SESでメールの送信制限を緩和済み。メール送信設定
サーバ作成
MarketplaceのAMIを使って、EC2インスタンスを起動。
インスタンスの設定はよしなにやってください。動かすだけならデフォルトで問題ないです。
SMTPサーバの設定
作成したインスタンスにSSHでログインして、設定ファイルを編集。
vi /opt/bitnami/apps/redmine/htdocs/config/configuration.ymlemail_delivery: delivery_method: :smtp smtp_settings: address: "SESで確認" port: 587 domain: "あなたのドメイン" authentication: :login user_name: "SESで作成されたユーザー" password: "SESで作成されたパスワード"入力項目はSESで確認。SMTP SettingsのServer Nameが上記のaddressです。
続いて、「Create My SMTP Credentials」をクリック。
続けて「作成」をクリックして、ユーザー、パスワードを作成し、上記のユーザー、パスワードに記載します。
ドメインはSESで設定しているドメインを記載してください。
(""も必要です)メール送信テスト
設定の反映には再起動が必要ですが、その前にadminユーザーのパスワードを確認しておきます。
/home/bitnami配下のbitnami_credentialsに書かれています。
パスワードをメモしたら、インスタンスを再起動します。再起動できたら、インスタンスのDNSまたはIPをブラウザで入力。Redmineのログイン画面が開きます。
IDにuser、パスワードに先ほど確認したパスワードを入力してログイン。
メール送信テスト用に、先に右上のMy Accountから自分のアドレスを修正します。
続けて、画面左上のAdministrationから、Settings。
Email Notificationへ。送信元メールアドレスを設定します。
ページ下までスクロールして保存ボタンをクリック。
続いて、ページ下部右にあるSend a test emailでテストメールを送信します。
問題なくメールが届けば、設定完了です。
- 投稿日:2020-03-28T17:01:47+09:00
Lambda Layersを作成する時はdocker-lambdaやyumdaが便利
はじめに
docker-lambda のビルドイメージで各ラインタイムバージョンに対応した Layer が作れる!
$ docker run --rm -v $(pwd):/var/task lambci/lambda:build-python3.8 \ > pip install -r requirements.txt -t python/lib/python3.8/site-packages/AWS Lambdaで 実行したいソフトウエアパッケージは yumda で Layer 化できる!
$ docker run --rm -v $(pwd)/git-layer:/lambda/opt lambci/yumda:2 yum install -y <package>一からやると環境準備は結構大変
AWS Lambda や Lambda Layers のよくある注意点としてネイティブバイナリの扱いがあります。
Lambda 実行環境は、特定の Amazon Linux 環境とカーネルバージョンに基づいているため、
Lambda 内で使用されるネイティブバイナリも該当の環境でコンパイルされている必要があります。また現在は Amazon Linux のサポート終了の過渡期でもあり、使用するランタイムのバージョンにより
Amazon Linux ベースなのか Amazon Linux 2 ベースな異なるところもやっかいな点です。
例えば Python の場合は 2020/3/28 時点で以下のようになっています。
Version OS Python 3.8 Amazon Linux 2 Python 3.7 Amazon Linux Python 3.6 Amazon Linux Python 2.7 Amazon Linux AWS Lambda Runtimes
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.htmlパッケージ作成の度にEC2を起動するのもさすがに面倒です。
また Docker Hub で公開されている Amazon Linuxのコンテナイメージ を使ってもよいのですが、
このイメージには最小限のパッケージセットしか含まれていないため、
これをベースイメージとして対象のランタイム環境を追加でインストールする必要があります。
複数のランタイムやバージョンを対象に開発する場合、環境毎に Dockerfile やイメージを管理
するのもちょっと大変かなと思います。前置きが長くなりましたが、そんな時は docker-lambda や yumda が便利です。
docker-lambda
docker-lambda とは
docker-lambda は Dockerコンテナ内で AWS Lambda の実行環境を限りなく近く再現します。
(が、完全なコピーではありません)
Docker Hub の lambci/lambda でコンテナイメージが公開されています。
AWS Severless Hero の Michael Hart 氏を中心に OSS として開発されています。docker-lambda
https://github.com/lambci/docker-lambdaAWS SAM CLI の中でもLambda関数の実行環境として採用されています。
SAM CLI で Lambda 関数を ローカルで Invoke する際には内部的には docker-lambda が動いています。docker-lambda のビルドイメージ
docker-lambda には Lambda 関数の ビルドとパッケージを行うためのビルドイメージも提供されています。
ビルドイメージは build-python3.x といったイメージタグでランタイムバージョンごとに用意されています。
ビルドイメージに追加でインストールされているパッケージは
https://hub.docker.com/r/lambci/lambda/#build-environment を参照してください。
AWS CLI や AWS SAM CLI も含まれているので、やろうと思えばコンテナ内でもろもろできちゃいます。python3.8 互換の layer を作成する例
lambci/lambda:build-python3.8を使用します。
requirements.txt に 追加したいライブラリを記載しておきます。
ここではシンプルに pandas のみを追加しています。requirements.txtpandasビルドイメージ内で pip install して、ライブラリを Layer に含めます。
$ docker run --rm -v $(pwd):/var/task lambci/lambda:build-python3.8 \ > pip install -r requirements.txt -t python/lib/python3.8/site-packages/ $ zip -r pandas-1.0.3.zip ./python > /dev/null複数バージョンに互換性を持たせた Layer としたい場合は 各バージョン毎にビルドイメージと
site-packages を指定して docker run してから zip します。
以下のようなディレクトリ構造になります。
展開後のパッケージサイズの制限(250MB)には注意する必要があります。. `-- python `-- lib |-- python3.6 | `-- site-packages |-- python3.7 | `-- site-packages `-- python3.8 `-- site-packages先ほどの Layer を使用して 以下のような超簡易コードで動作確認してみると、、、
lambda_function.pyimport pandas as pd; def lambda_handler(event, context): pd.show_versions()実行できました!
START RequestId: 813889ca-958c-4b60-ae1d-442870679429 Version: $LATEST INSTALLED VERSIONS ------------------ commit : None python : 3.8.2.final.0 python-bits : 64 OS : Linux OS-release : 4.14.165-102.205.amzn2.x86_64 machine : x86_64 processor : x86_64 byteorder : little LC_ALL : None LANG : en_US.UTF-8 LOCALE : en_US.UTF-8 pandas : 1.0.3 numpy : 1.18.2 ~~以下省略~~yumda
yumda を使用すると AWS Lambda 環境で実行可能なソフトウェアパッケージを
yum コマンドで用意することができます。docker-lambda と同様 OSS として開発されています。yumda – yum for Lambda
https://github.com/lambci/yumdaコンテナイメージは lambci/yumda で公開されています。
Amazon Linux 2 環境向けのイメージとAmazon Linux 環境用のイメージが用意されていますので
nodejs10.x、nodejs12.x、python3.8、java11、ruby2.7 はlambci/yumbda:2を、
それ以外のランタイムバージョンではlambci/yumbda:1を使用します。Amazon Linux 2 環境向けに利用可能なパッケージを確認するには以下のようなコマンドを実行します。
$ docker run --rm lambci/yumda:2 yum list available Loaded plugins: ovl, priorities Available Packages GraphicsMagick.x86_64 1.3.34-1.lambda2 lambda2 GraphicsMagick-c++.x86_64 1.3.34-1.lambda2 lambda2 ImageMagick.x86_64 6.7.8.9-18.lambda2 lambda2 OpenEXR.x86_64 1.7.1-7.lambda2.0.2 lambda2 OpenEXR-libs.x86_64 1.7.1-7.lambda2.0.2 lambda2 ~~以下省略~~もしくは 以下からも確認できます。
https://github.com/lambci/yumda/blob/master/amazon-linux-2/packages.txtパッケージは独自のリポジトリで管理されており、GitHub Issues で追加のリクエストを提出できますが、
Amazon Linux core リポジトリおよび amazon-linux-extras リポジトリに既に存在するものを
追加する方針であるようです。Please file a GitHub Issue with your request and add the package suggestion label. For now we'll only be considering additions that already exist in the Amazon Linux core repositories, or the amazon-linux-extras repositories (including epel).
yumda で Layer を作成する例
ここでは 試しに python3.8 の Lmabda 関数で git コマンドを実行してみます。
lambda_function.pyimport subprocess def lambda_handler(event, context): return subprocess.check_output( "git --version;exit 0", stderr=subprocess.STDOUT, shell=True )当然ながら Lambda Layers を使わない場合、実行結果は commnad not found になります。
$ aws lambda invoke --function-name git-layer-test outfile ExecutedVersion: $LATEST StatusCode: 200 $ cat outfile /bin/sh: git: command not foundyumda で Layer を作成します。
$ docker run --rm -v $(pwd)/git-layer:/lambda/opt lambci/yumda:2 yum install -y git $ cd git-layer $ zip -yr ../git-2.25.0-1.zip . > /dev/null以下のようなディレクトリ構成で git とその依存関係がインストールされていることを確認できます。
. |-- bin |-- etc | |-- alternatives | |-- pki | |-- prelink.conf.d | `-- ssh |-- lib | |-- fipscheck | `-- nss |-- libexec | |-- git-core | `-- openssh `-- share |-- git-core `-- licensesLayer を publish して先ほどの Lambda 関数に設定します。
$ aws lambda publish-layer-version \ > --layer-name git-2-25-0-1 --zip-file fileb://git-2.25.0-1.zip $ aws lambda update-function-configuration \ > --function-name git-layer-test \ > --layers arn:aws:lambda:ap-northeast-1:123456789012:layer:git-2-25-0-1:1実行してみると git の version が返ってきました!
$ aws lambda invoke --function-name git-layer-test outfile ExecutedVersion: $LATEST StatusCode: 200 $ cat outfile git version 2.25.0参考: 公開済みの Lambda Layers を使う
ここまで書いておいてなんですが、Sevelress Application Repository でも Lambda Layers が
多数登録されていますし、λ AWSome Lambda Layers というGitHubリポジトリにも
様々な Layer のリストがまとめられています。
これらに必要なものが公開されていれば、それを使わせていただくのが楽ですね!以上です。
参考になれば幸いです。
- 投稿日:2020-03-28T16:49:40+09:00
AWS SSOプロファイルでもTerraformやSAM-CLIを実行する方法
AWS SSOとAWS CLI V2
AWS CLI V2ではAWS SSOのプロファイルを書くことができます。
これにより秘匿情報(secret key)を
~/.aws/credentialsへ書く必要がなくなりました。
それだけではなく複数のAWSアカウントをAWS SSOで集中管理している場合は個別のAWSアカウントでIAMユーザーを作る必要もありません。
AWS SSOでAWSマネージメントコンソールとaws cliの実行権限を一貫した方法で一挙に管理することができます。バンザイ!AWS SSOの問題
ところが、この新しいプロファイルの方式はaws cli v2以外のツールではほとんどサポートされていません。
ツール issue terraform Support AWS CLI v2 AWS Single Sign-On · Issue #10851 · terraform-providers/terraform-provider-aws sam cli Should sam local support named profiles created by aws cli v2 sso commands? · Issue #1843 · awslabs/aws-sam-cli serverless framework Issues · serverless/serverless
(Issueすらない。サポートする方針がない?)各Issueを見てもらえばわかりますがなかなか難航しているようです。単純にAWS SSOをフル活用しているところが少なく需要が少ないということもありますが、aws-sdkのメジャーバージョンが変わったりで大きな変更をする必要があることも背景のようです。2,3ヶ月以上経ってもことが前に進んでいる気配がないことからすぐの対応は期待できそうにないことが伺えます。
解決策: aws2-wrapツールを使う
linaro-its/aws2-wrap: Simple script to export current AWS SSO credentials or run a sub-process with them
このツールを使ってterraformやsamの実行をラップしてやると、それらコマンドの実行直前にaws ssoプロファイルから一時的な認証トークンを生成してくれます。いわば新しい認証方式から古い認証方式への翻訳機の役割を果たしてくれるわけですね。おまけ
aws2-wrapをちょっとだけ使いやすくしたforkバージョンを作りました。本家にもPRを送っているので取り込まれたら不要になるものですが、それまではこちらを使うと便利かもしれません。
bigwheel/aws2-wrap: aws2-wrap2 - fork of https://github.com/linaro-its/aws2-wrap
- 投稿日:2020-03-28T16:34:46+09:00
本番環境でDjangoサーバーの静的ファイルをAWS S3に配置するまで
Djangoサーバーを開発環境から本番環境に移行した時の話。
本番用のサーバーインスタンスをEBSで起ち上げ、CircleCIの構成をちょこちょこっといじってハイ終わり!と思っているとCSSが全く読み込まれない自体に。
理由を探してみるとDjangoのドキュメントで以下の内容を発見
Serving the files In addition to these configuration steps, you’ll also need to actually serve the static files. During development, if you use django.contrib.staticfiles, this will be done automatically by runserver when DEBUG is set to True (see django.contrib.staticfiles.views.serve()). This method is grossly inefficient and probably insecure, so it is unsuitable for production. See Deploying static files for proper strategies to serve static files in production environments.(引用: https://docs.djangoproject.com/en/3.0/howto/static-files/)
つまり、本番用にサーバー設定のDebugをオフにすると今まで自動で行われていた静的ファイルの配置が行われなくなるとのこと。
EC2インスタンスから直接ファイルを送信するのは効率悪いし、せっかくなのでここでデプロイ毎に静的ファイルをS3に配置してCloudFrontから配信することに。静的ファイルとsettings.pyの変更
上のドキュメントにもあるように、まずそもそもテンプレートファイルの中でStatic変数を埋め込んでいなかったので変更
変更前
templates/login.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <meta http-equiv="x-ua-compatible" content="ie=edge"> <link rel="icon" href="/static/favicon.ico"> <title>Login</title> <link href="/static/css/style.css" rel="stylesheet" type="text/css"/> </head>開発用setting.pyは以下の通り
settings/develop.pySTATIC_URL = '/static/' STATICFILES_DIR = "[os.path.join(BASE_DIR, 'static')]"なので、開発サーバーではDjangoが自動でapp下のstaticフォルダー内のファイルにアクセスしてくれていたっぽい。
続いて、本番用の変更。Static変数を入れ、静的ファイルのURLを動的に変更できるように。
templates/login.html{% load static %}<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <meta http-equiv="x-ua-compatible" content="ie=edge"> <link rel="icon" href="{% static 'favicon.ico' %}"> <title>Login</title> <link href="{% static 'css/style.css' %}" rel="stylesheet" type="text/css"/> </head>*{% load static %}を冒頭に入れないと、staticが定義されていないと怒られるので注意。
settings/production.py# For static files AWS_LOCATION = 'static' AWS_ACCESS_KEY_ID = ****************** AWS_SECRET_ACCESS_KEY = ***************** STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' AWS_STORAGE_BUCKET_NAME = 'production-bucket' AWS_S3_CUSTOM_DOMAIN = '%s.s3.amazonaws.com' % AWS_STORAGE_BUCKET_NAME AWS_AUTO_CREATE_BUCKET = True AWS_S3_REGION_NAME = 'ap-northeast-1' AWS_DEFAULT_ACL = 'public-read' STATIC_URL = f'https://{AWS_S3_CUSTOM_DOMAIN}/{AWS_LOCATION}/' STATICFILES_DIR = "[os.path.join(BASE_DIR, 'static')]"django-storagesのライブラリをインストールして静的ファイルの格納場所にS3Boto3Storageを指定。
デプロイ時に静的ファイルの配置
デプロイ実行後(migrateやloaddataをやっているところ)に以下のコマンドを実行するよう追加
python manage.py collectstatic --no-inputこれでAWS_STORAGE_BUCKET_NAMEに指定したバケットのStaticフォルダー内に静的ファイルが配置される。
(EC2インスタンスへのIAM設定などが別途必要ですがここでは割愛)本番サーバーへブラウザからアクセスすると先のlogin.htmlが以下のようになることを確認
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width,initial-scale=1.0"> <meta http-equiv="x-ua-compatible" content="ie=edge"> <link rel="icon" href="https://***-production-bucket.s3.amazonaws.com/static/css/style.css"> <title>Login</title> <link href="https://***-production-bucket.s3.amazonaws.com/static/css/style.css" rel="stylesheet" type="text/css"/> </head>テンプレートファイルはEC2インスタンスから出力、それ以外はS3から読み込まれるように変更されていました。
S3-> CloudFrontへ
このままでもいいのですが、S3から毎回ダウンロードされるのもお財布に優しくないので、出力をCloudFrontへ以降。(CloudFrontの設定方法は割愛)
CloudFrontからバケットとディレクトリを指定してやり、最後に先程のSTATIC_URLをCloudFrontのドメインへ変更。settings/production.py# For static files AWS_LOCATION = 'static' AWS_ACCESS_KEY_ID = ****************** AWS_SECRET_ACCESS_KEY = ***************** STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' AWS_STORAGE_BUCKET_NAME = 'production-bucket' AWS_S3_CUSTOM_DOMAIN = '%s.s3.amazonaws.com' % AWS_STORAGE_BUCKET_NAME AWS_AUTO_CREATE_BUCKET = True AWS_S3_REGION_NAME = 'ap-northeast-1' AWS_DEFAULT_ACL = 'public-read' STATIC_URL = 'https://********.cloudfront.net/static/' STATICFILES_DIR = "[os.path.join(BASE_DIR, 'static')]"これでデプロイされた際にCloudFrontからファイルが配信されるように。
注意点
CloudFrontなどのCDNは配信コンテンツをキャッシュするので、静的ファイルを変更してデプロイしても即座に反映されません(体感30分ぐらいで更新される?)。CSSなんかはそこまで問題にならなかったのですが、フロントで使っているVueJSでハマったので、次回はそちらについて記事を書こうと思います。
- 投稿日:2020-03-28T15:28:22+09:00
AWS DevOps Engineer Professional 合格記録
この記事
AWS Certified DevOps Engineer Professional を取得したので
どんな勉強をしたのかを記録します。また、今回漸くAWS認定5冠を達成したので、全体の感想なども載せます。
about me
インフラエンジニアで、AWS関連のインフラ構築は2年くらい経験しています。
現在もCloudFormationなどをベースに日々AWS環境の構築や運用をしています。
AWS資格は、
Solution Architect Associate (7月)
SysOps Administrator Associate (9月)
Solution Architect Professional (11月)
Developer Associate (12月)
DevOps Engineer Professional (3月)
という順で取得しました。about DOP試験
AWS 認定 DevOps エンジニア – プロフェッショナル
https://aws.amazon.com/jp/certification/certified-devops-engineer-professional/認定により検証される能力に以下の文言があります。
・AWS で継続的デリバリーのシステムと手法を実装して管理する
・セキュリティコントロール、ガバナンスプロセス、コンプライアンス検証を実装し、自動化する
・AWS でのモニタリング、メトリクス、ログ記録システムを定義し、デプロイする
・高可用性、スケーラビリティ、自己修復機能を備えたシステムを AWS プラットフォームで実装する
・運用プロセスを自動化するためのツールの設計、管理、維持を行う正直に書きますが、私はこれらの能力を有すると自負できるレベルではないと思います。
(確かに検証はされたが)なぜなら、知識ベースでは得たものは多いものの、実践した範囲がまだ狭い。
ただし、この認定の学習により
DevOpsという分野に対して向き合い、具体的に学習する大きなきっかけとなリました。試験対策としては、何をやったのか
試験ガイドとサンプル問題
いつもどおり、必須です。
「試験ガイドとサンプル問題」は、はじめに確認
https://aws.amazon.com/jp/certification/certification-prep/また、こちらのサンプル問題解説を拝見しましたがとっても参考になりました。ありがとうございます。
https://blog.nijot.com/aws/explanation-aws-devops-sample-questions/模擬試験(公式)
できればはじめのうちに解いたほうがいいです。
尚、当時の模擬試験結果は40%代で、無事死亡
問題集
DOPの問題は少ないですが、定番のAWS問題集サイトです。
日本語なので解くのが早いという点と、レベル感がつかみやすかったです。
https://aws.koiwaclub.com/問題数も少ないので知識的な意味でも完璧にしてしまいます。
udemy
こちらが今回のメインの手段となりました。
活用したのはこちら。AWS Certified DevOps Engineer Professional [Practice Exam]
https://www.udemy.com/course/aws-certified-devops-engineer-professional-practice-exam-dop/いきなり全部解きました。解説があるのでそこから学習ができるのがとても良い点です。
以前までのUdemyの感想としては、実際の試験問題よりもレベルが高かったので少し悩みましたが
DevOpsの試験では範囲が広いというのと、ここまでの対策で不安が大きかったので、あえて挑戦しました。
これが大正解でした...!全体的に学んだ分野
主に、以下のAWSサービスの知識が必要ということがわかりました。
・CodePipeline(ほかのCode系も)
・CloudFormation
・Elastic Beanstalk (前回までの反省で、奥が深いことを実感)
・AWS Config (超有能)
・ECS EC2(詳しい知識というよりも運用の観点)
・CloudWatch(Logs, Eventなど)
・AWS StepFunction確かにCI/CDの観点でこれらのサービスは必須となるが多い。
SAP試験の時の、ネットワーク構築や移行問題との大きな違いです。↓例えばセキュリティ、運用系のサービスがそれぞれ曖昧なままだと一瞬で落とすと思います。
・Systems Manager
・Opsworks
・GuardDuty
・Macie
・Inspector
それぞれ何ができる?いつ使う?違いは?他のサービスとの統合は?
という点でAWSドキュメントやUdemy等を活用して、はっきりさせておきましょう。
ここが合格の決め手となりました。結果&まとめ
無事合格しました。
終わるとき、これは勉強し直しかな。。と思ってたほどギリギリだったのでびっくりしました。詳細結果は週明けに来ますが、合格の文字を3度見したので間違いないはずです...!
ここまでのAWS試験の感想としては、以下のようになります。
・試験なので対策すれば取れる
・まずは情報収集からしっかり行う。
・構築などの実践は、「ここまで」と決めてやらないとキリがない
・ベストプラクティスを常に意識する(費用、時間、高可用性など)
・問題演習をして、集中力を鍛える
・日本語の問題にするならば、少々特殊な日本語に事前に慣れておく
・様々なところで既出ですが、選択肢は大体半分に切り捨てられるので、とにかく問題に慣れる次はLinuxの学習などをしつつ、Specialityの資格を年内に1つは取得しようと思います。
あとはアウトプット祭りですね。この記事が何かのお役に立てられれば幸いです。
ありがとうございました!
Qiitaへの記録
SAA
https://qiita.com/shinon_uk/items/5525178bf98034676b2fSOP
https://qiita.com/shinon_uk/items/e60bcb946b49bf5cabdaSAP
https://qiita.com/shinon_uk/items/c6b599d1cd3000e84d59
https://qiita.com/shinon_uk/items/ba839ba048ba439cc3ffDVA
https://qiita.com/shinon_uk/items/8015953c792ef4bc7223追記
もう合格証と詳細結果来ました。
点数はやはり合格点ギリギリでしたが、分野はまんべんなく取れてました。
また、今回のDevOps取得によって、下位互換のAdministrator, SysOps認定が更新されました。
- 投稿日:2020-03-28T13:49:57+09:00
AWS LambdaでCloudWatchLogsをS3に出力する (Pythyon ver)
AWS Lambda (ランタイムはPython)を使って、CloudWatchLogsをS3に出力するソースコードを書いてみました。
ちなみに、Lambdaの実行は、手動でするなり、CloudWatchEventで定期的に実行するなり考えられると思います。ポイント
1. ログ出力のAPIは非同期で動く
boto3の場合、
logs = boto3.client("logs")
response = logs.create_export_task(**kwargs)でログ出力が動きますが、create_export_taskが非同期で実行されるので、処理の終了を確認しないで、次のログ出力を行った場合、エラーになる可能性があります。
なので、複数ログ出力をするときは、必ずログ出力が終了したかを確認するために、logs.describe_export_tasks(taskId = response["taskId"])
の処理を挟みましょう。
2. 環境変数
環境変数の値は以下の通りです。
変数 値 BUCKET_NAME ログ出力先S3バケット名 WAITING_TIME 10 LOG_GROUPS CloudWatchLogGroupを , 区切りでつなげる ソースコード
# -*- coding: utf-8 -*- from datetime import datetime,timezone,timedelta import os import boto3 import time import logging import traceback #ログの設定 logger = logging.getLogger() logger.setLevel(os.getenv('LOG_LEVEL', logging.DEBUG)) logs = boto3.client("logs") BUCKET_NAME = os.environ["BUCKET_NAME"] WAITING_TIME = int(os.environ["WAITING_TIME"]) #timezoneを日本時間(JST)に設定 JST = timezone(timedelta(hours=9),"JST") #S3にログ出力するときの日付型 DATE_FORMAT = "%Y-%m-%d" def lambda_handler(event, context): """ 1日分のCloudWatchLogsをS3に出力します。 対象時間は以下とします。 AM 00:00:00.000000 ~ PM 23:59:59.999999 """ try: #昨日のPM23:59:59.999999 tmp_today = datetime.now(JST).replace(hour=0,minute=0,second=0,microsecond=0) - timedelta(microseconds=1) #昨日のAM00:00:00.000000 tmp_yesterday = (tmp_today - timedelta(days=1)) + timedelta(microseconds=1) #S3のログ出力時のprefixとして使用 target_date = tmp_yesterday.strftime(DATE_FORMAT) #ログ出力のため、タイムスタンプ型に変換(microsecondsまで取る) today = int(tmp_today.timestamp() * 1000) yesterday = int(tmp_yesterday.timestamp() * 1000) #環境変数からCloudWatchLogGroupを取得する logGroups = os.environ["LOG_GROUPS"].split(",") for logGroupName in logGroups: try: keys = ["logGroupName","yesterday","today","target_date"] values = [logGroupName,yesterday,today,target_date] payload = dict(zip(keys,values)) #ログ出力を実行 response = logs.create_export_task( logGroupName = payload["logGroupName"], fromTime = payload["yesterday"], to = payload["today"], destination = BUCKET_NAME, destinationPrefix = "Logs" + payload["logGroupName"] + "/" + payload["target_date"] ) #ログ出力の実行が終了するまで待つ。 taskId = response["taskId"] while True: response = logs.describe_export_tasks( taskId = taskId ) status = response["exportTasks"][0]["status"]["code"] #タスクの実行が終了している場合breakする if status != "PENDING" and status != "PENDING_CANCEL" and status != "RUNNING": logger.info(f"taskId {taskId} has finished exporting") break else: logger.info(f"taskId {taskId} is now exporting") time.sleep(WAITING_TIME) continue except Exception as e: traceback.print_exc() logger.warning(f"type = {type(e)} , message = {e}",exc_info=True) except Exception as e: traceback.print_exc() logger.error(f"type = {type(e)} , message = {e}",exc_info=True) raise
- 投稿日:2020-03-28T12:59:29+09:00
無料ドメインを使ってAWS上のアプリをHTTPS化
無料ドメイン取得
freenom
下記サイトで無料でドメイン取得できます。
https://www.freenom.com私は.tkを使っています。
太平洋の島?かどこかのドメインらしいです。
詳しくは下記参照。
https://qiita.com/hanbaga324/items/da0c4f6fa8d365db10c9アカウント作成
freenomのアカウントを作成します。
ドメイン取得
メニューバーのServicesからRegister a new domainを選択。
取得したいドメインを入力して、Check。
無料のドメインを選択して、Checkout。
ここでDNSの設定がありますが、今回はRoute53で指定されたNameserverを設定します。
一旦Route53へ
「ホストゾーン」→「ホストゾーンの作成」で作成したいドメインを入力し、作成。
すると、4つのNSレコードができるので、このうち2つを先ほどのfreenomの設定欄に入力します。(最後の.は不要。)
「Use DNS」→「Use Your Own DNS」のNameserverに入力しして、Continue。(IPアドレスは不要)
内容を確認し、同意欄にチェックして、Complete Order。
(Safariでやると、「お前人間か?」とか言われてエラーになりましたが、Chromeでは問題なし。あるいは、少し時間を置けば大丈夫かも)
ドメインの取得が完了したら、「Services」→「My Domains」から先ほど登録しなかった2件のNameserverを登録。
「Manage Domain」から「Management Tools」で「Nameservers」を選択し、Nameserverを追加。
ACMで証明書発行
証明書リクエスト
ワイルドカードでドメイン名を指定し、追加の名前でドメイン名のみを指定。
メール検証を指定
SES設定
ドメイン設定
順に「Use Route53」→Email Receiving Recordにチェックして「Create Record Sets」を選択するとTXT、MXレコードが作成されます。
受信設定
「Email Receiving」→「Rule Sets」から「Create a Rule」でドメインを設定。
S3での受信を設定。
(受信はアメリカリージョンでしかできない?)
作成したRule SetがActiveになっていない場合は、ActiveにSetします。
改めてACMからメール送信。
S3に認証ページのリンク入りのテキストが届くので、リンクを探して開き、Approveをクリック。
証明書を使ってみる
Beanstalkでサンプルアプリ起動
アプリケーション作成、環境作成を行います。
今回はTomcatのサンプルアプリを使います。
「より多くの設定を追加」でカスタム設定を選び、LBにHTTPSリスナーを追加、先ほど作った証明書を選びます。
Route53でLB向けのAliasを設定。
検証
HTTPSで開けました。
- 投稿日:2020-03-28T12:59:29+09:00
無料ドメインを使ってAWS上のアプリケーションをHTTPS化
流れ
freenom(ドメイン取得)
↓
Route53(DNS管理)
↓
ACM(証明書作成)→SES(メールでドメイン認証)
↓
Beanstalk(HTTPS化したアプリケーション)無料ドメイン取得
freenom
下記サイトで無料でドメイン取得できます。
https://www.freenom.com私は.tkを使っています。
太平洋の島?かどこかのドメインらしいです。
詳しくは下記参照。
https://qiita.com/hanbaga324/items/da0c4f6fa8d365db10c9アカウント作成
freenomのアカウントを作成します。
ドメイン取得
メニューバーのServicesからRegister a new domainを選択。
取得したいドメインを入力して、Check。
無料のドメインを選択して、Checkout。
ここでDNSの設定がありますが、今回はRoute53で指定されたNameserverを設定します。
一旦Route53へ
「ホストゾーン」→「ホストゾーンの作成」で作成したいドメインを入力し、作成。
すると、4つのNSレコードができるので、このうち2つを先ほどのfreenomの設定欄に入力します。(最後の.は不要。)
「Use DNS」→「Use Your Own DNS」のNameserverに入力しして、Continue。(IPアドレスは不要)
内容を確認し、同意欄にチェックして、Complete Order。
(Safariでやると、「お前人間か?」とか言われてエラーになりましたが、Chromeでは問題なし。あるいは、少し時間を置けば大丈夫かも)
ドメインの取得が完了したら、「Services」→「My Domains」から先ほど登録しなかった2件のNameserverを登録。
「Manage Domain」から「Management Tools」で「Nameservers」を選択し、Nameserverを追加。
証明書作成
SES設定
ドメイン設定
順に「Use Route53」→Email Receiving Recordにチェックして「Create Record Sets」を選択するとTXT、MXレコードが作成されます。
受信設定
「Email Receiving」→「Rule Sets」から「Create a Rule」でドメインを設定。
S3での受信を設定。
(受信はアメリカリージョンでしかできない?)
作成したRule SetがActiveになっていない場合は、ActiveにSetします。
ACMで証明書発行
証明書リクエスト
ワイルドカードでドメイン名を指定し、追加の名前でドメイン名のみを指定。
メール検証を指定
私は先にACMの設定をしていたので、改めてACMからメール送信しました。
S3に認証ページのリンク入りのテキストが届くので、リンクを探して開き、Approveをクリック。
証明書を適用
Beanstalkでサンプルアプリ起動
アプリケーション作成、環境作成を行います。
今回はTomcatのサンプルアプリを使います。
「より多くの設定を追加」でカスタム設定を選び、LBにHTTPSリスナーを追加、先ほど作った証明書を選びます。
Route53でLB向けのAliasを設定
検証
HTTPSで開けました。
- 投稿日:2020-03-28T11:55:50+09:00
Nginxの導入と設定
Nginx
Nginx(エンジン・エックス)とは、Webサーバの一種です。ユーザーのリクエストに対して静的コンテンツの取り出し処理を行い、動的コンテンツの生成をアプリケーションサーバに依頼します。
まずはターミナル(ローカル)からターミナル(EC2サーバ)に入ります。
次に、Nginxをインストールしていきます。
ターミナル(ローカル)$ ssh -i [ダウンロードした鍵の名前].pem ec2-user@[作成したEC2インスタンスと紐付けたElastic IP] (ダウンロードした鍵を用いて、ec2-userとしてログイン)ターミナル(サーバ)
[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nginxターミナル(EC2サーバ)
[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confでターミナル上でファイルを開き、以下のように編集します。
rails.confupstream app_server { # Unicornと連携させるための設定。アプリケーション名を自身のアプリ名に書き換えることに注意。今回であればおそらくchat-space server unix:/var/www/<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name <Elastic IP>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; } ``` <アプリケーション名>と<Elastic IP>はご自身のを入力してください。 ちなみに、<>は記入不要です。 次に、POSTメソッドでもエラーが出ないようにします。 なぜエラーが出ないようにするかというと、POSTメソッドは、HTTP通信でクライアントからWebサーバへ送るリクエストの種類の一つで、URLで指定したプログラムなどに対してクライアントからデータを送信するためのものです。大きなデータやファイルをサーバに送るために使われます。 ターミナル(EC2サーバ)[ec2-user@ip-172-31-25-189 ~]$ cd /var/lib
[ec2-user@ip-172-31-25-189 lib]$ sudo chmod -R 775 nginx
```
これで、Nginxの設定が完了しました。
次に、Nginxを再起動して設定ファイルを再読み込みします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-25-189 lib]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restart次に、Nginxを介した処理を行うためにunicornの設定を修正します。
ローカルでunicorn.rb修正します。unicorn.rblisten 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"修正をしたら、commitとpushをし、サーバ側で以下のコマンドを実行して修正点を反映させます。
次に、ローカルの変更点を本番環境へ反映させます。
ターミナル(EC2サーバ)# まず、ご自身のレポジトリ名のディレクトリに移動 [ec2-user@ip-172-31-25-189 ~]$ cd /var/www/リポジトリ名 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ git pull origin master次に、Unicornのプロセス(左から2番目の数字)をkillして、再起動をします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn次は、プロセスをkillします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上のコードでは17877)>次は、Unicornを起動します。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上が正しくできていれば、ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000をつける必要はありません)。なお、この時もunicornが起動している必要があります。
IPアドレスにアクセスしてもエラーが出る時
502 but gatewayとエラーが出る場合は、nginxのlogの確認が必要になります。/var/log/nginx/error.logをlessまたはcatコマンドで確認する。
サーバ側で、/var/www/<レポジトリ名>/log/unicorn.stderr.logをlessまたはcatコマンドで確認し、エラーが出ていないか確認する(下に行くほど最新のログです。時刻表記がUTCであることに注意してください)
Railsを起動しているか
EC2インスタンスの再起動を行ってみる(※本番環境にてmysqlとnginxの起動が必要です。)
などが考えられます。
- 投稿日:2020-03-28T11:45:44+09:00
【SRE/AWS Aurora】特定の時点に DB クラスターを復元
手順
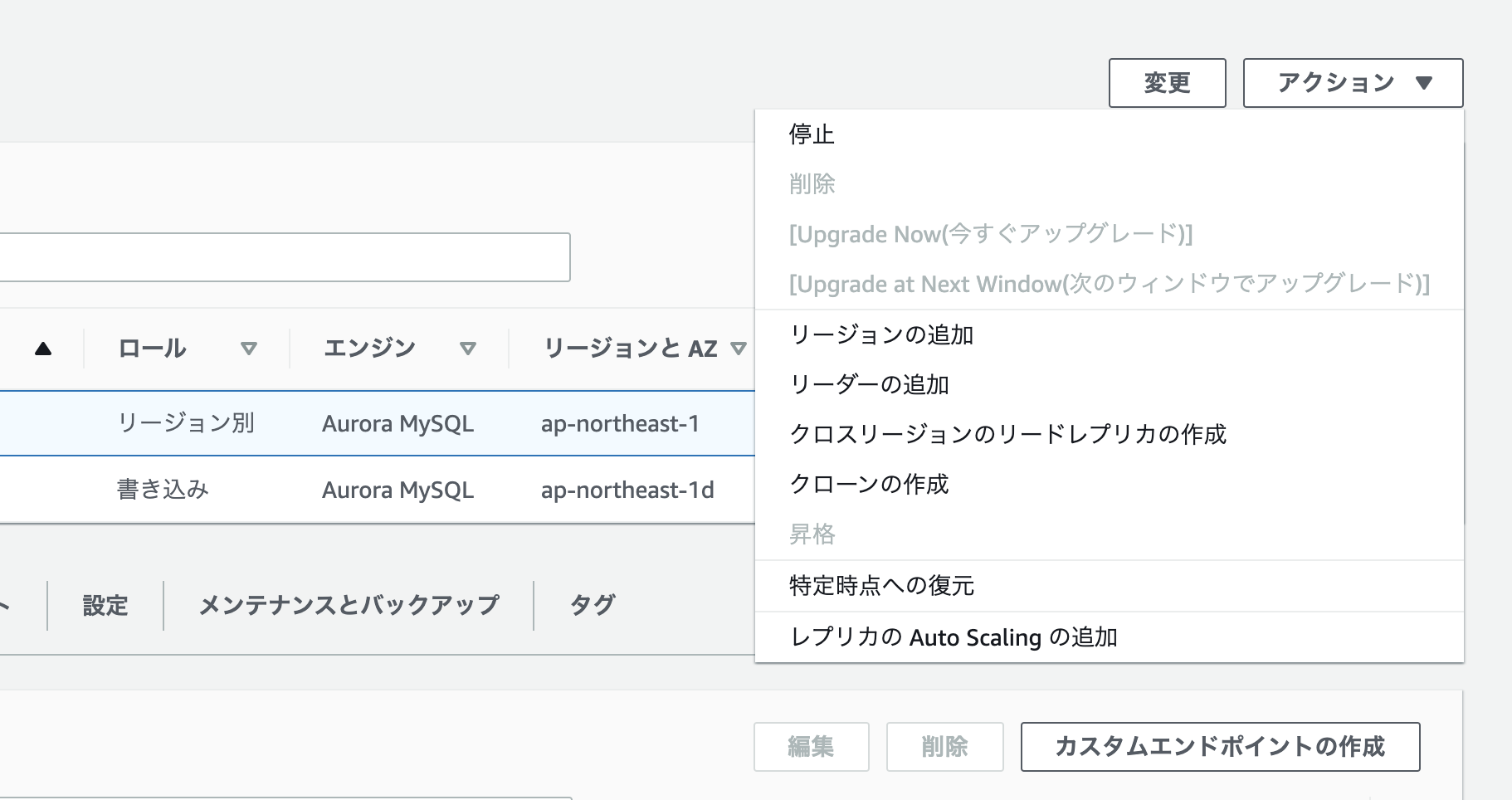
- 復元したいクラスターを選択
- 特定の時点へ復元
主に参考にした記事
特定の時点への DB クラスターの復元
Amazon Aurora(Postgres)におけるデータ復元方法について検討してみた - Qiitaまたスナップショットからの復元は下記でまとめています。
【SRE/AWS Aurora】スナップショットでDBを復元する - Qiita特定の時点への復元
今回の復元手順の最終アウトプットは、新しいDBクラスターが1つになります。
なので、本番用データベースとは別で DB クラスターが1つ作成されます。復元したいクラスターの選択
復元したいクラスター選択し、特定の時点への復元をクリックします。
復元
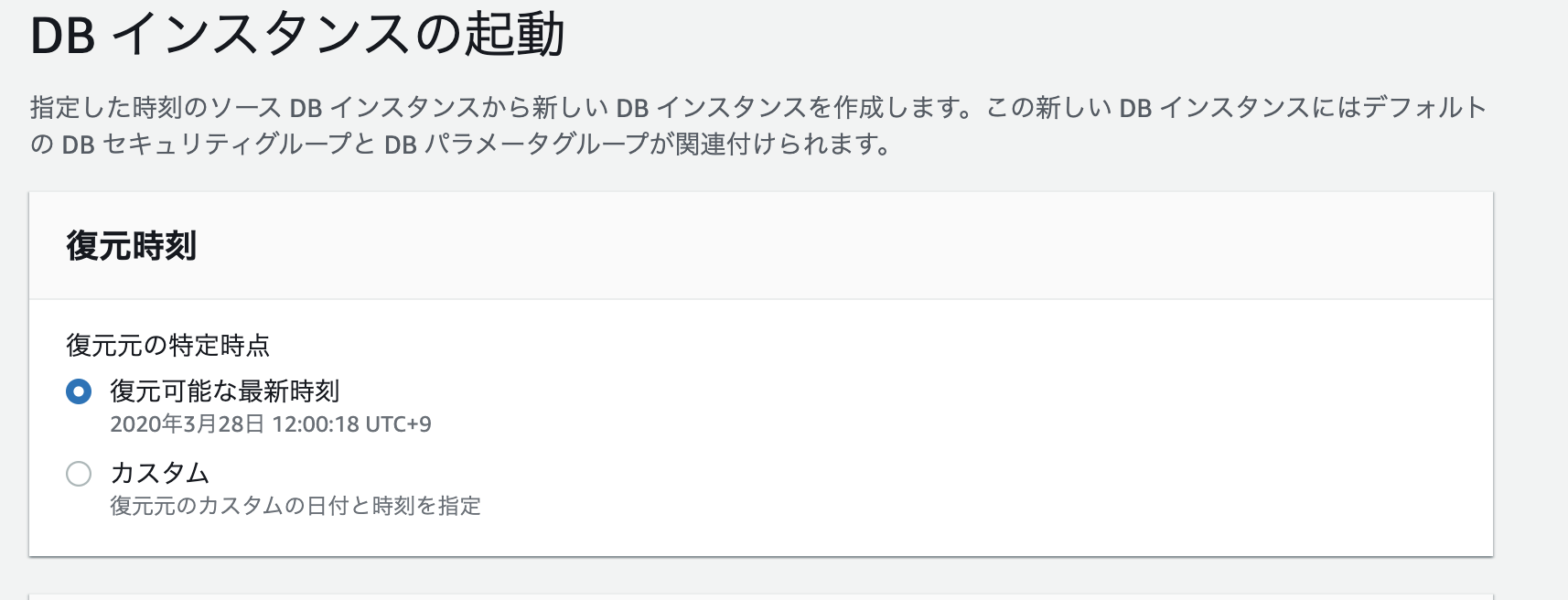
下記のページに遷移します。
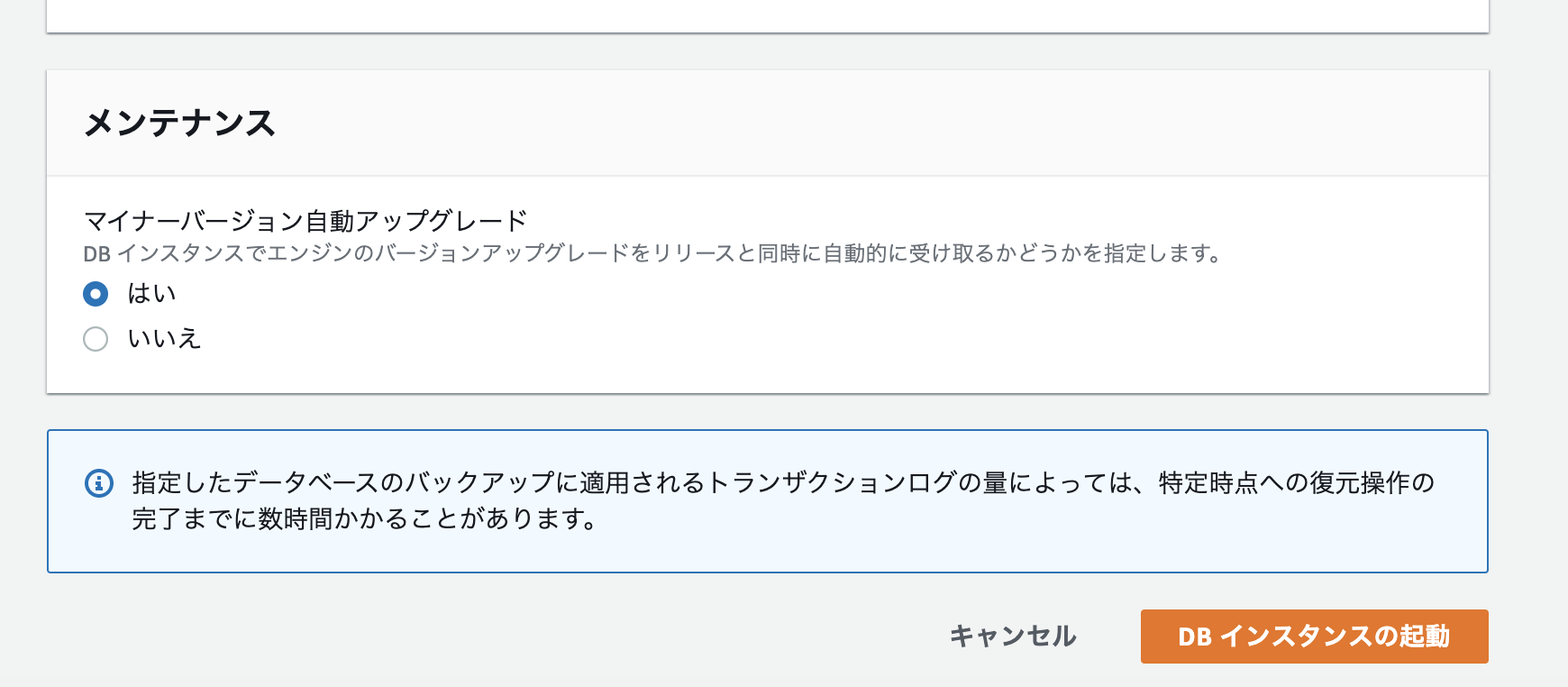
設定が終われば、DBインスタンスの起動を狙います。
確認
サイドバーのデータベースを選択し、データベースが作成されていることを確認します。
少し作成に時間がかかります。
- 投稿日:2020-03-28T11:18:07+09:00
【SRE/AWS Aurora】スナップショットでDBを復元する
復元の手法
Aurora が保持するバックアップデータから、または保存した DB クラスターのスナップショットから、新しい Aurora DB クラスターを作成することで、データを回復できます。
Aurora DB クラスターのバックアップと復元の概要より引用つまり、バックアップデータから復元する手法と スナップショットから復元する手法の2つがあると言えます。
今回は、スナップショットを使って DB を復元していきます。RDSでDBをスナップショットから復元する - Qiita
AWS RDS Auroraのデータを復元する方法 - Qiita手順
- スナップショットの確認
- スナップショットからDBを復元
スナップショットからDBを復元する
今回の復元手順の最終アウトプットは、新しいDBクラスターが1つになります。
なので、本番用データベースとは別で DB クラスターが1つ作成されます。スナップショット一覧
AWSにログインし、RDSを選択します。
次に下記のように左サイドバーのスナップショットを選択します。
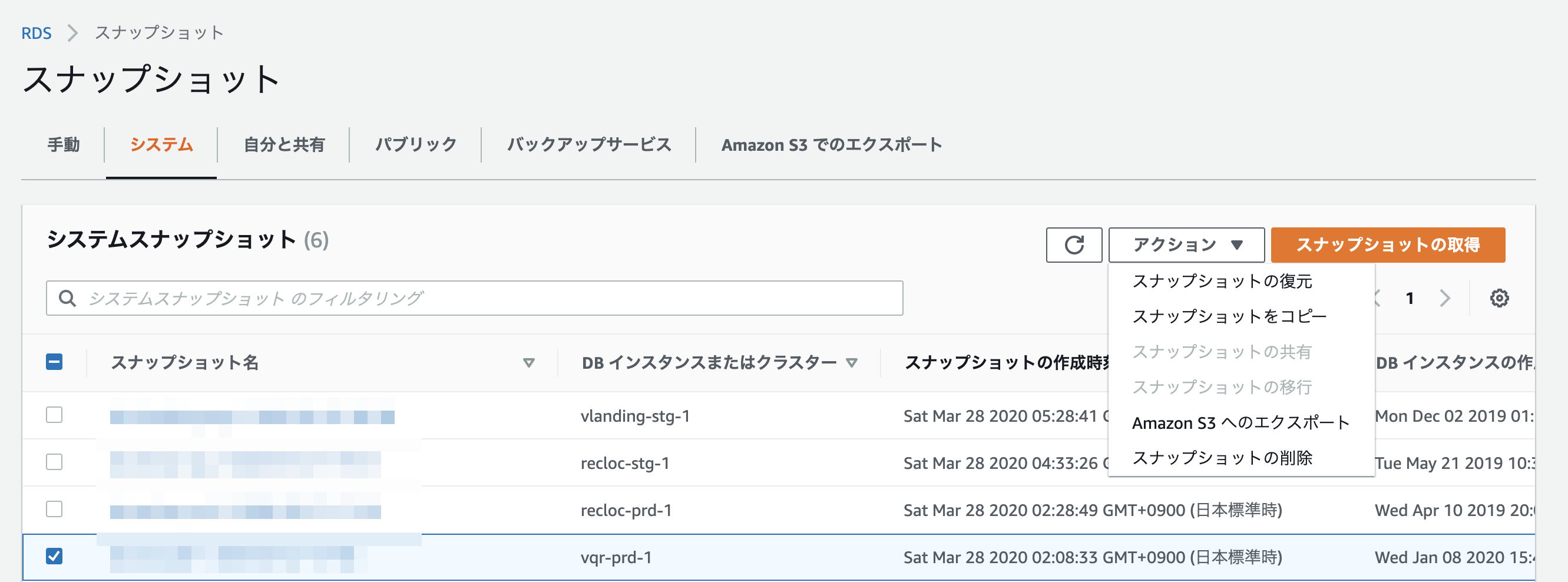
スナップショットの復元
復元したいDBのスナップショットを選択して、アクションをクリックし、スナップショットの復元を選択します
DBインスタンスの復元
データベースが作成されたことを確認
サイドバーのデータベースを選択し、データベースが作成されていることを確認します。
少し時間がかかります。
- 投稿日:2020-03-28T10:58:08+09:00
AWS RDSに作成したMySQLに対して外部から接続可能にする
概要
今回は初心者向けにAWSのRDSに作成したMySQLのDBに対して外部から接続する方法まで説明します。
外部から接続するにあたり、A5Mk2を使用します。では、さっそく捌いていくっ!
データベースの作成
後にも先にもまずは、データベースを作成しましょう。
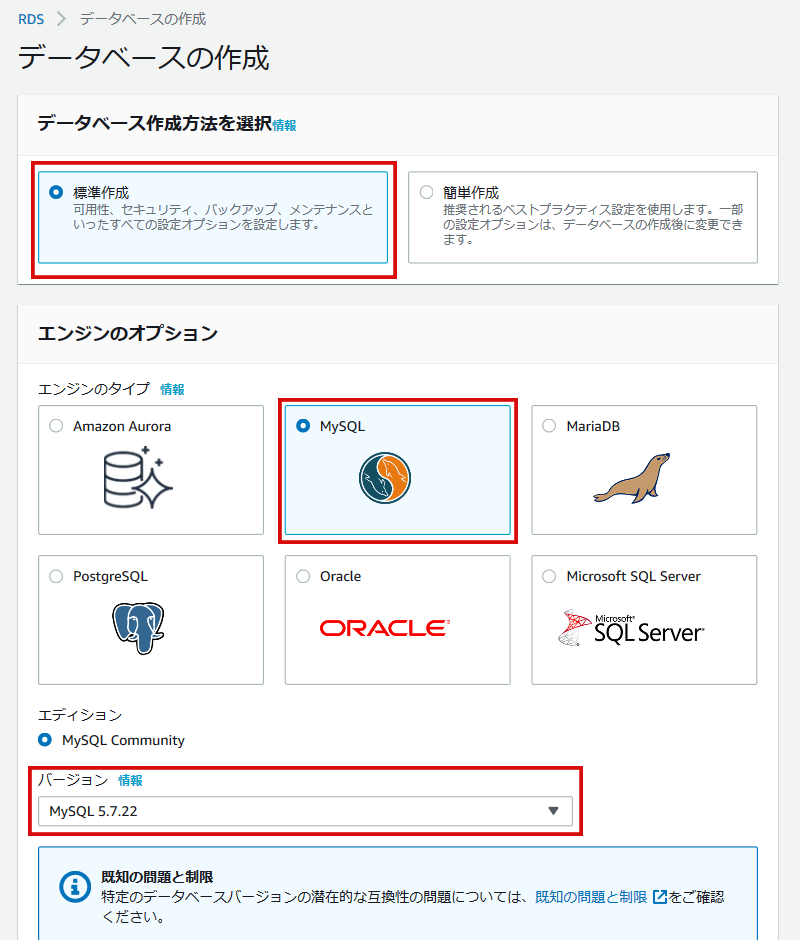
画像を例に進めてみましょう。
まずは、「データベースの作成方法を選択」から「標準作成」を選択します。
「エンジンのオプション」として、今回はMySQLを使用します。
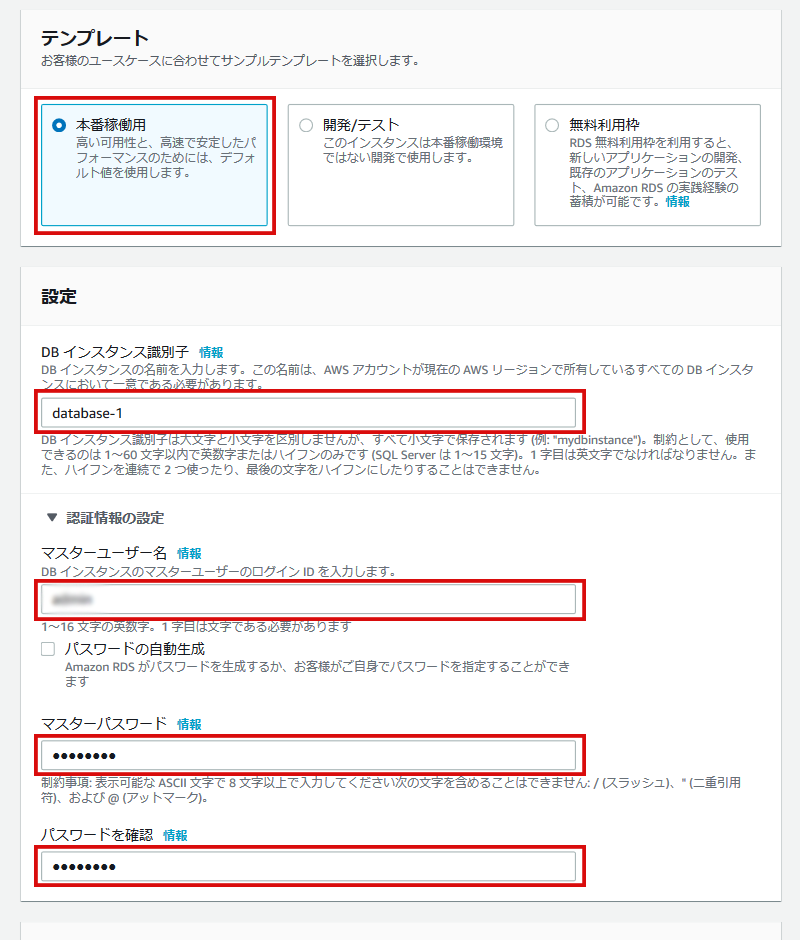
「バージョン」は任意で構いません。特に理由がない場合は、最新バージョンを選びましょう。テンプレート選択と接続情報設定
「テンプレート」は用途によって選択してください。
筆者は「テンプレート」を「本番稼働用」を選択しました。
※ 欲張ったスペックにすると課金料金が大変な事になるので、しっかり料金を下調べすることを強く推奨します。「DBインスタンス識別子」は何でもいいので、自身がわかる名前を適当につけてください。
「マスターユーザー名」は、DB接続時に利用するよくある「root」や「administrator」的なやつです。
ありきたりな名前は、個人的にセキュリティよろしくないと思うので、マニアックな名前にしておきましょう。「マスターパスワード」は、「マスターユーザー」のパスワードです。
忘れないでね!ここで設定してた「マスターユーザー名」と「マスターパスワード」を後に外からDBに接続するときに利用します。
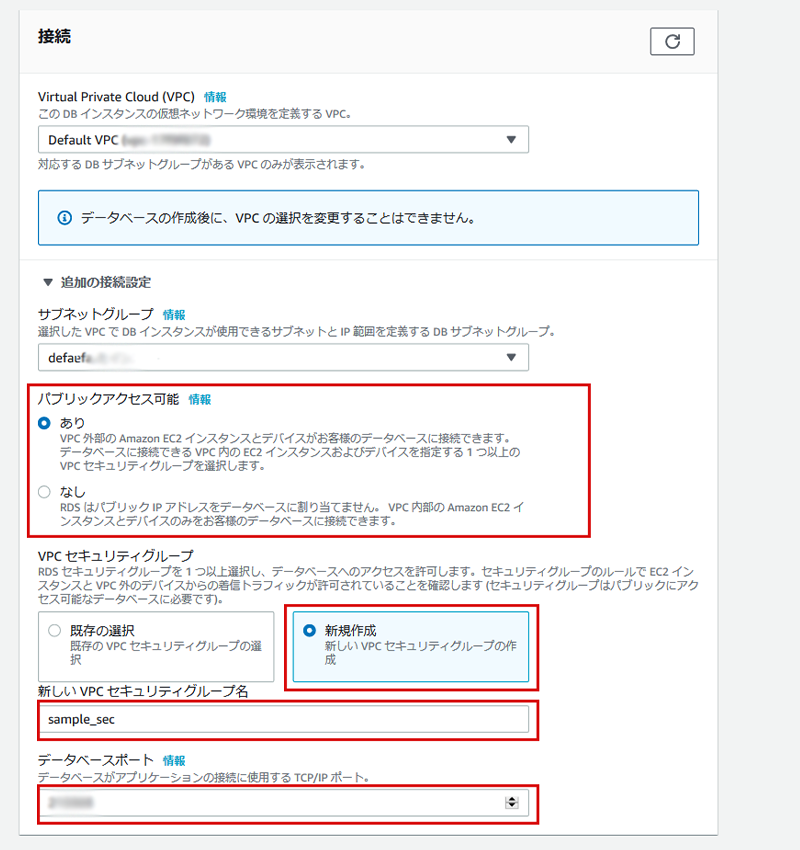
接続関連の設定
AWSのVPCでEC2などに接続するならいいけど、外部のEC2や、自分のPCなどからDBに接続したい場合、よく初心者が設定を忘れる箇所があります。
それは、「パブリックアクセス可能」を「あり」にすること。
大抵、「つながらないな、ポートも開けているのにな」って言うときの原因はここです。あとは、「VPCセキュリティグループ」を画像を参考に設定します。
「VPCセキュリティグループ名」は、適当に付けてください。はい。
ここでまた重要なところがあります。
それは、「データベースポート」です。
デフォルトのままでも利用は可能ですが、セキュリティを意識するなら最低限ポート番号は変えておきましょう。
ここのポート番号は、後にセキュリティグループで使用します。
セキュリティグループはEC2の時のように自身のグローバルIPアドレスや、EC2のStaticIPアドレスのようなグローバルアクセスだけピンポイントで許可しましょう。
間違っても「0.0.0.0」に許可しないように。
「0.0.0.0」のままにすると、全世界からアクセス可能になります。ホント、セキュリティはシビアになりましょう。
「動けばいいや」は後で命取りになります。
後でGRANTなどでさらにセキュリティを強固にしましょう。
何重にもセキュリティ対策を。固有名詞は出しませんが、セキュリティ意識を疎かにすると理由は様々ですが
大手コンビニ「6の次のペイ」の事件や、炊飯器やポットで有名な「エレファントマークのショッピングサイトの個人情報流出」事件になりかねません。余談ですが、筆者は「エレファントマーク個人情報流出事件」の被害者です。
たまに詐欺まがいなメールや、不審なDM郵便が来て困ったもんです。
僕、炊飯器のフタ買っただけなのに、個人情報悪用されるなんて。。。。『僕は嫌だ!』
はい、話はズレましたが次!
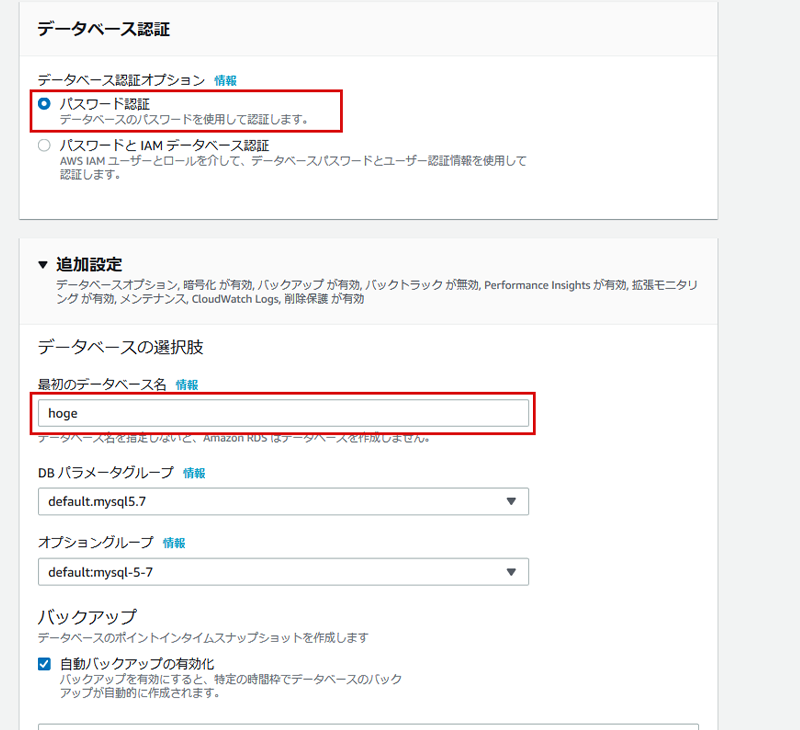
データベース認証と追加設定
「データベース認証」は、簡単に「パスワード認証」としています。
本当は、IAMを利用した方がいいと思いますが手順が長くなるので割愛。そして「最初のデータベース名」を任意のデータベース名にしましょう。
これは、「CREATE DATABASE XXXXXX」のXXXXXXの部分にあたります。先ほどのマスターユーザ、パスワード、ここでのデータベース名で後に外から接続します。
他はデフォルトのままです。
セキュリティグループは、各々の環境に合わせて設定しておいてください。以上、これでDBのインスタンスを作成して起動されるまでしばし待ちましょう。。。
テンテケテケテン♪
外部ツールからDBに接続してみる
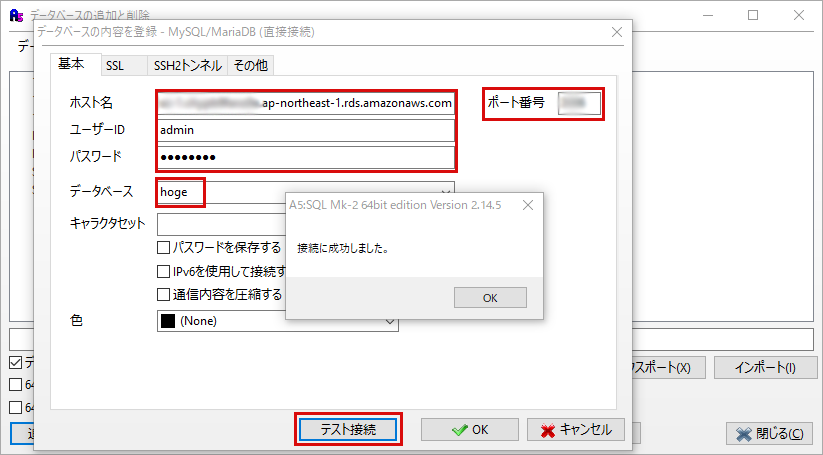
作成したデータベースの起動がAWS RDS上で確認できた場合、接続先の情報(ホスト名)をコピーしましょう。
東京リージョンの場合は、下記の画像のように「ap-northest-1.rds.amazonaws.com」で終わっている長ったらしい文字列の部分です。そして、さっき設定しておいた「マスターユーザー名」「パスワード」「データベース名」「ポート番号」をツールに入力します。
フレームワークをお使いの方は、設定ファイル的なものに記述しましょう。
スクラッチで開発されているかたは、ソースにぶち込んでください。あとは「テスト接続」を押下して「接続に成功しました」って出れば完了です。
この後は、各々CREATE TABLE を実行したり、マイグレーションを実行したり、イジイジしてみてください。
おまけ
クラウドは便利でどこからでも使えていいのですが、ガチでセキュリティは意識しないと大変なことになります。
最低限今回のサービスに限らず、接続元のIPは絞っておきましょう。と、言っても個人だと固定グローバルIP持っている人は少ないでしょう。
個人でも固定IPアドレスが持てる方法を一部お知らせします。
固定IP持ってても、ルーターの設定などしっかりやらないと大変な事になります。プロバイダ:アサヒネットを利用
オプションで800円~1000円くらい払えば、個人でも固定グローバルIPが付与されます。
YAMADA SIM
これはモバイルルーターの話ですが、オプションで月80円から100円くらいで固定のグローバルIPが付与されます。
以上!
- 投稿日:2020-03-28T03:12:13+09:00
AWS CodePipeline勉強メモ① ハローワールド
はじめに
AWS CodePipeline 全然わからないので調査
参考
- 【AWS】CodePipelineから呼び出したLambdaがずっと進行中になっている問題と対応
- CodePipeline で パイプラインに AWS Lambda 関数を呼び出す
- CodePipelineからAWS Lambdaを呼び出してCloudFrontのキャッシュを削除(Invalidation)してみた
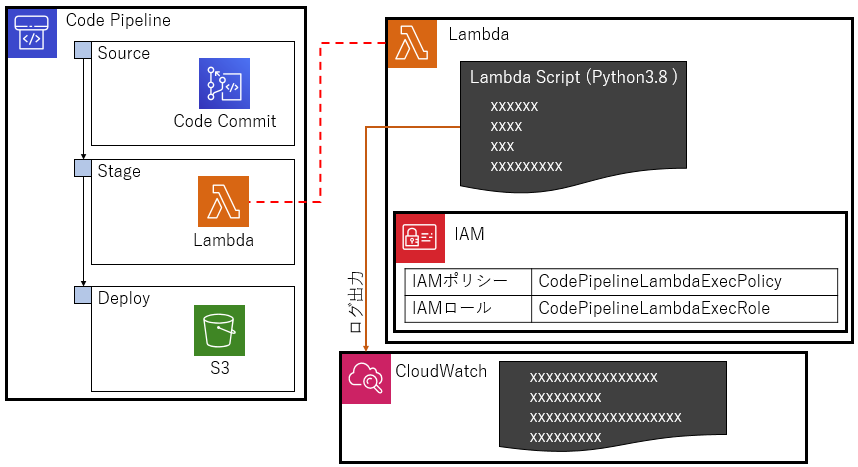
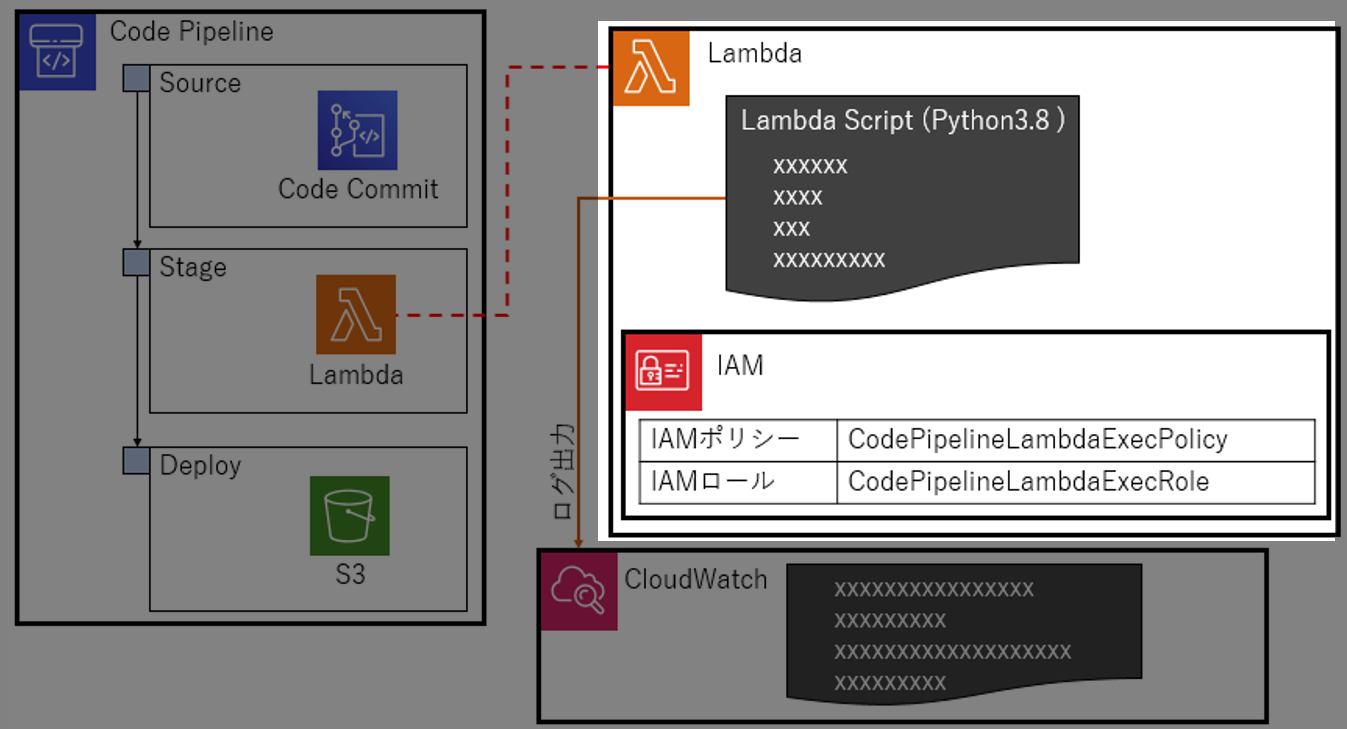
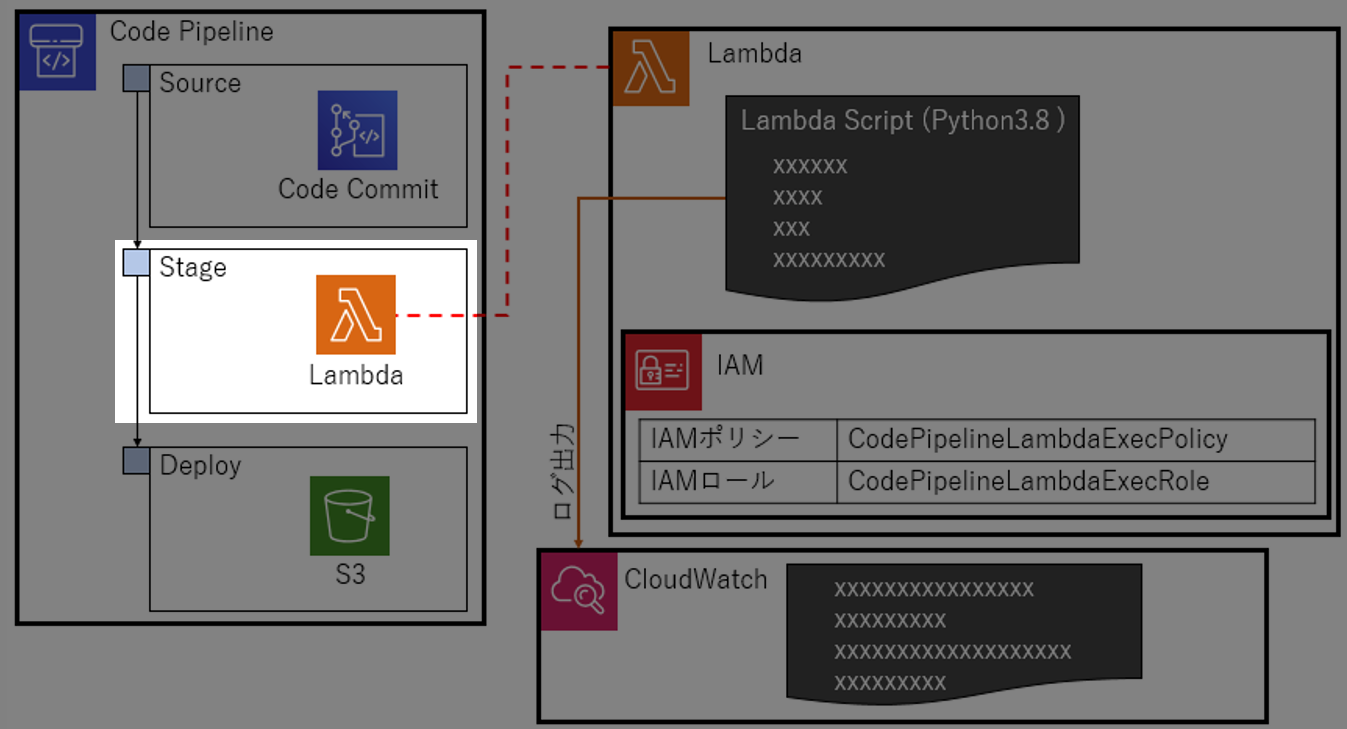
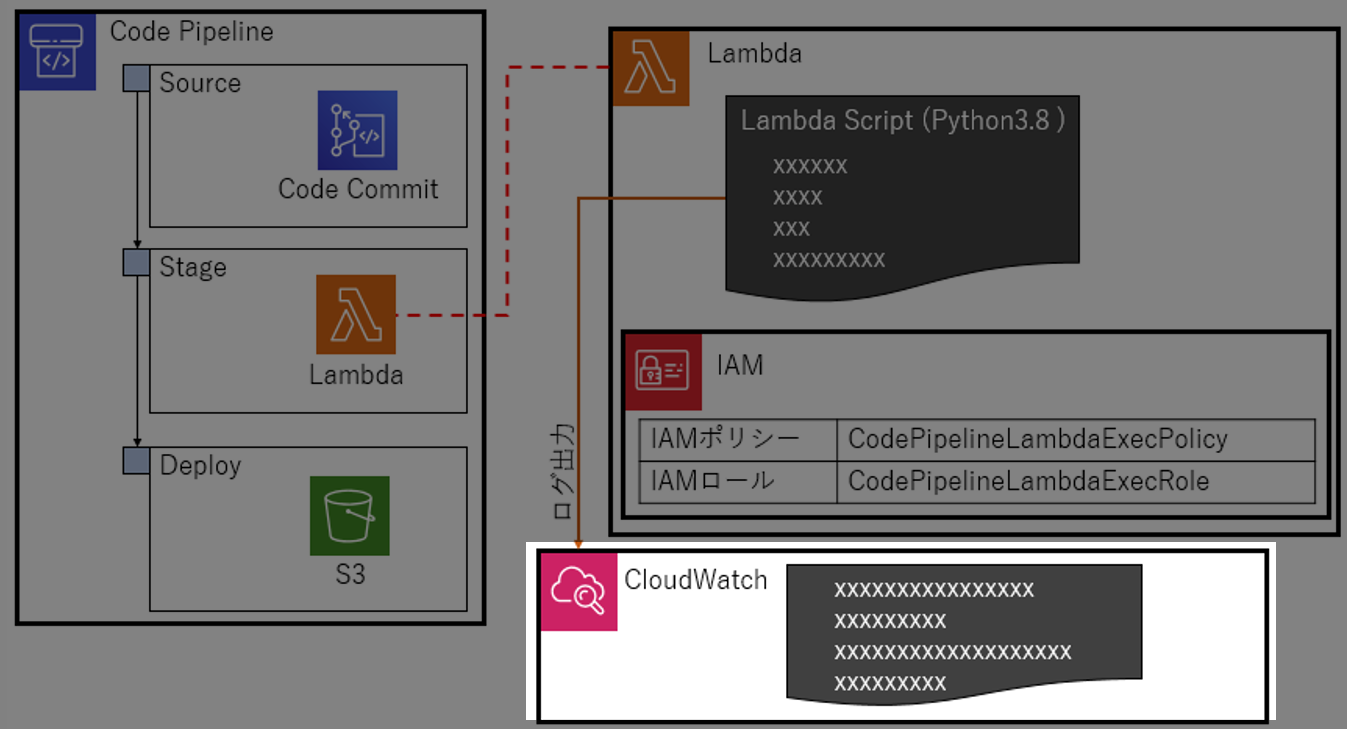
構成図
こんなの作る。
やること
Code Pipelineの
StageにLambdaを登録してみる。ハローワールド的な動作確認までやる。SourceとDeployは適当に設定。
Stageで思った通りに(しょぼい)Lambdaが動くことを確認する1.検証の準備
検証に必要な準備をする。いわゆる環境構築
1-1.IAMポリシーを作る
作成するLambdaに与える権限
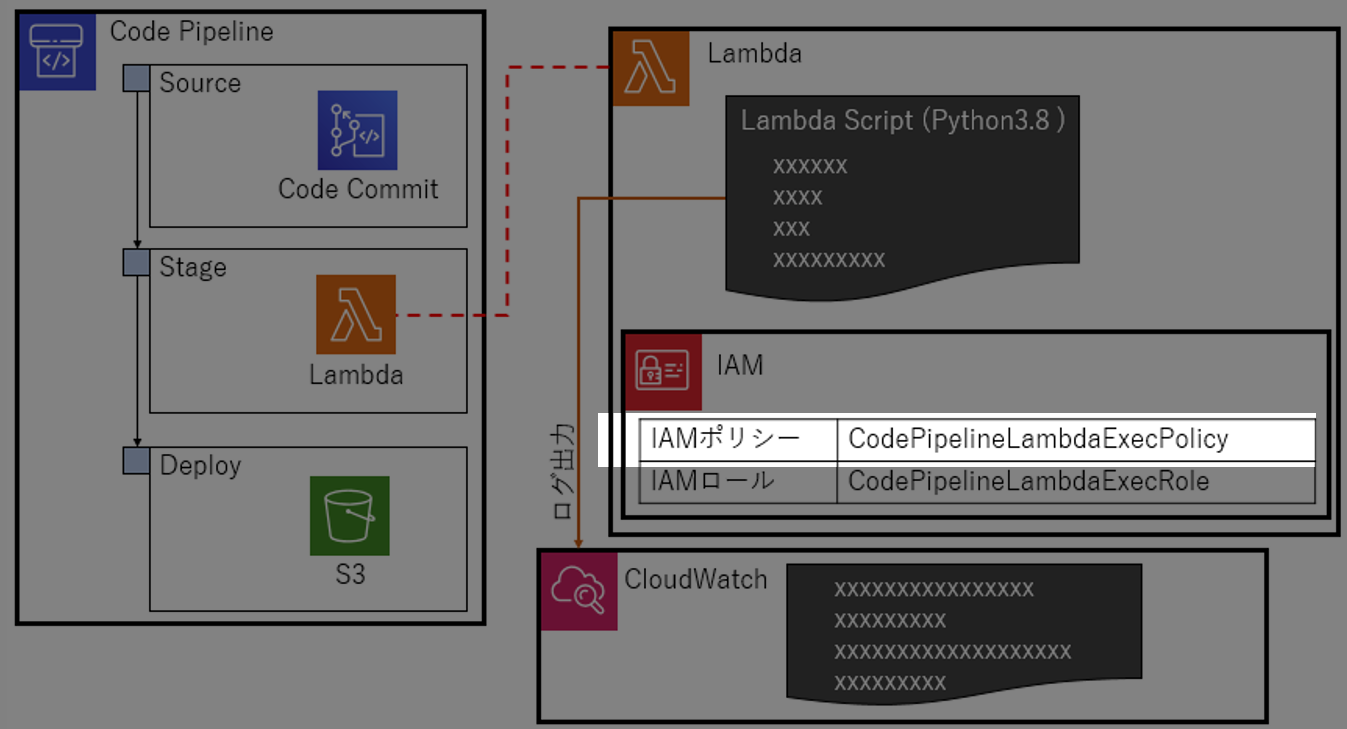
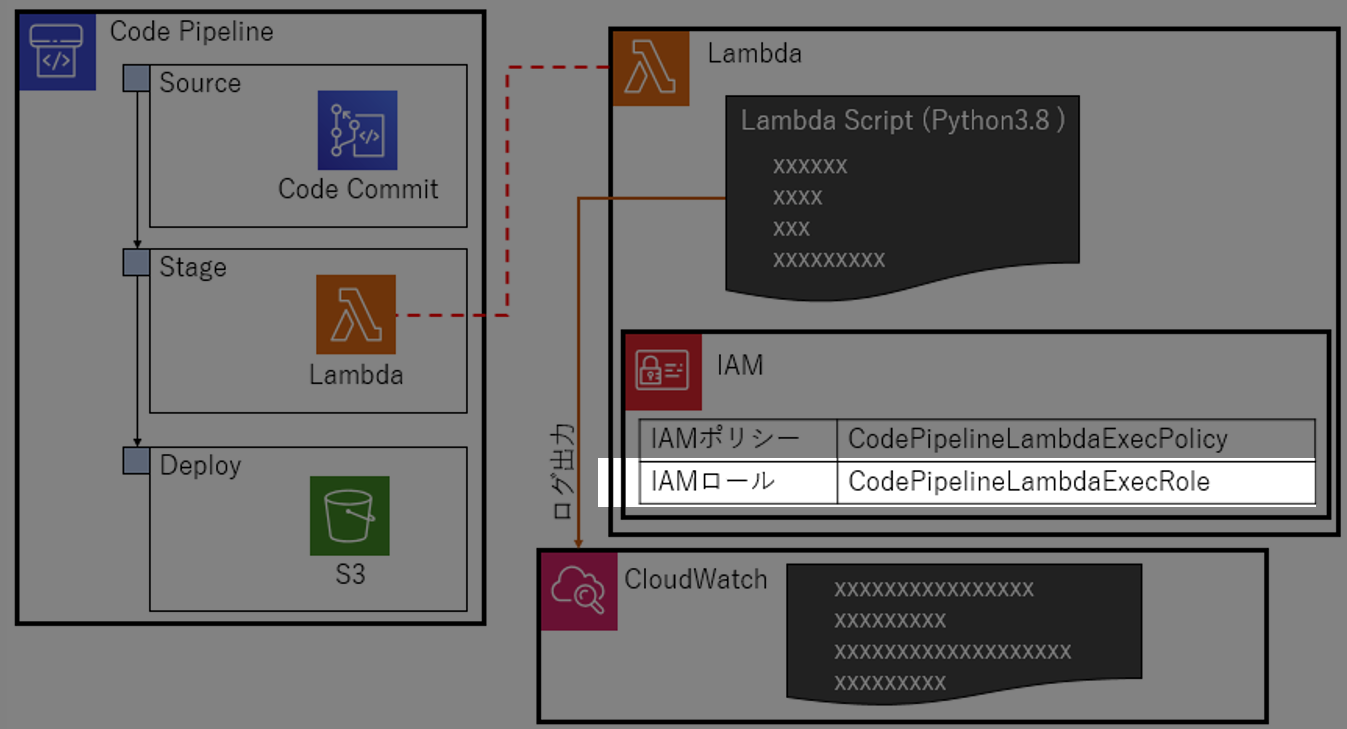
CodePipelineLambdaExecPolicyを作る。
CodePipelineLambdaExecPolicy{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:*" ], "Effect": "Allow", "Resource": "arn:aws:logs:*:*:*" }, { "Action": [ "codepipeline:PutJobSuccessResult", "codepipeline:PutJobFailureResult" ], "Effect": "Allow", "Resource": "*" } ] }以下ができるポリシー
- codepipelineに、SuccessとFailureを返せるようにする
- CloudWatchにログ出力できるようにする
1-2.IAMロールを作る
先ほど作成したIAMポリシー
CodePipelineLambdaExecPolicyをLambdaに適用できるようIAMロールCodePipelineLambdaExecPolicyを作る。IAMポリシー作成時、AWSサービスlambdaを選択する。
1-3.Lambdaを作る
Python3.8を選択し、Lambdaを作る。IAMロールは、
CodePipelineLambdaExecPolicyを選択する ←重要。
1-4.CodePipelineを作る
StageにLambdaを設定する以外は、適当に設定。今回は、CodeCommitのリポジトリ内のデータをS3にpushするように設定したけど、動くならなんでもいい。
2.検証(1) スクリプトの成功/失敗やってみる
Lambdaスクリプトの成功と失敗の動きをやってみる。
2-1.成功を返すスクリプト
今回のメイン、Lambdaスクリプトを書いていく。
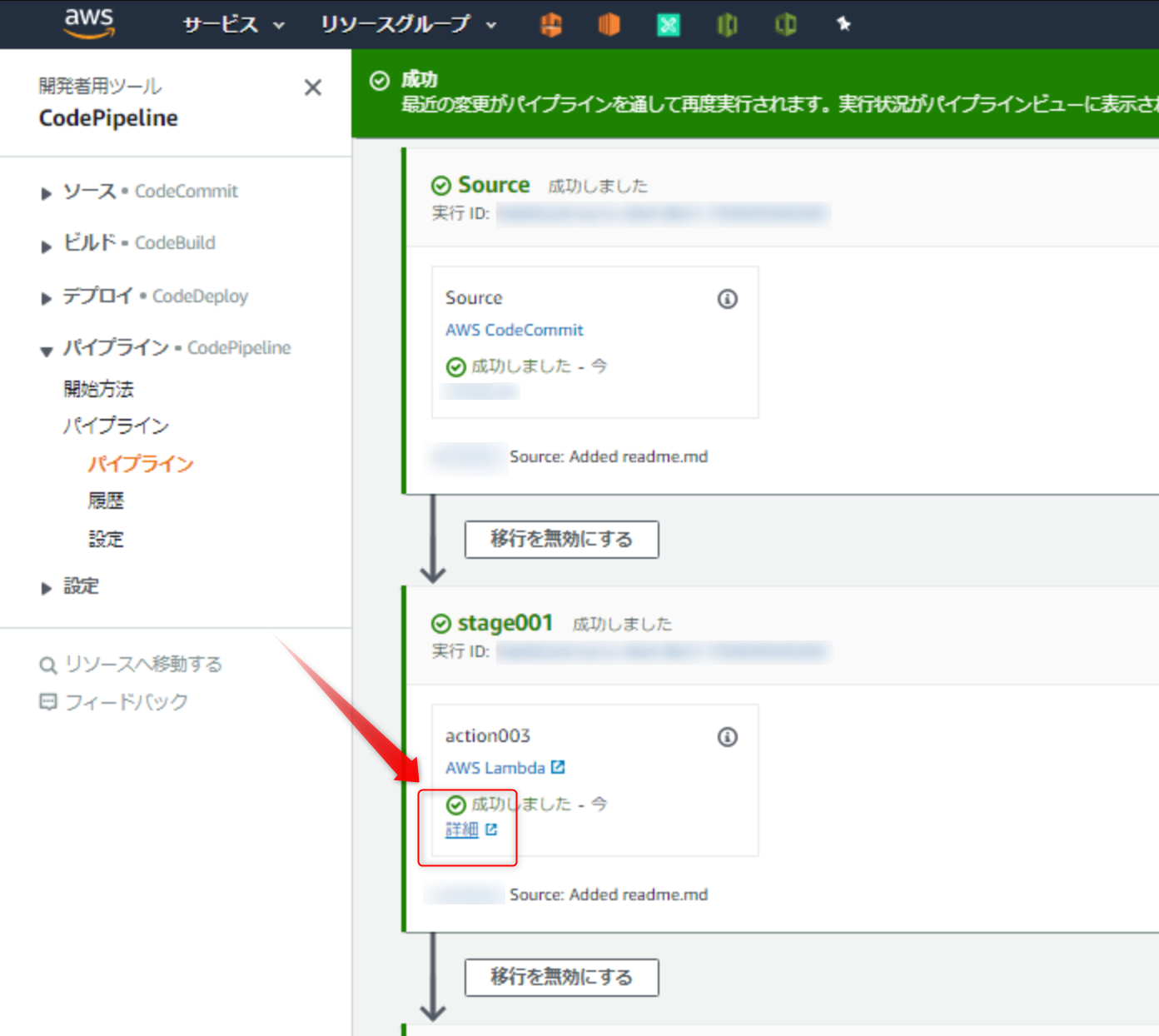
成功を返すimport json import boto3 def lambda_handler(event, context): codepipeline = boto3.client('codepipeline') # CodePipelineに結果(成功)を返す codepipeline.put_job_success_result(jobId = event['CodePipeline.job']['id']) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda! Error') }CodePipelineの
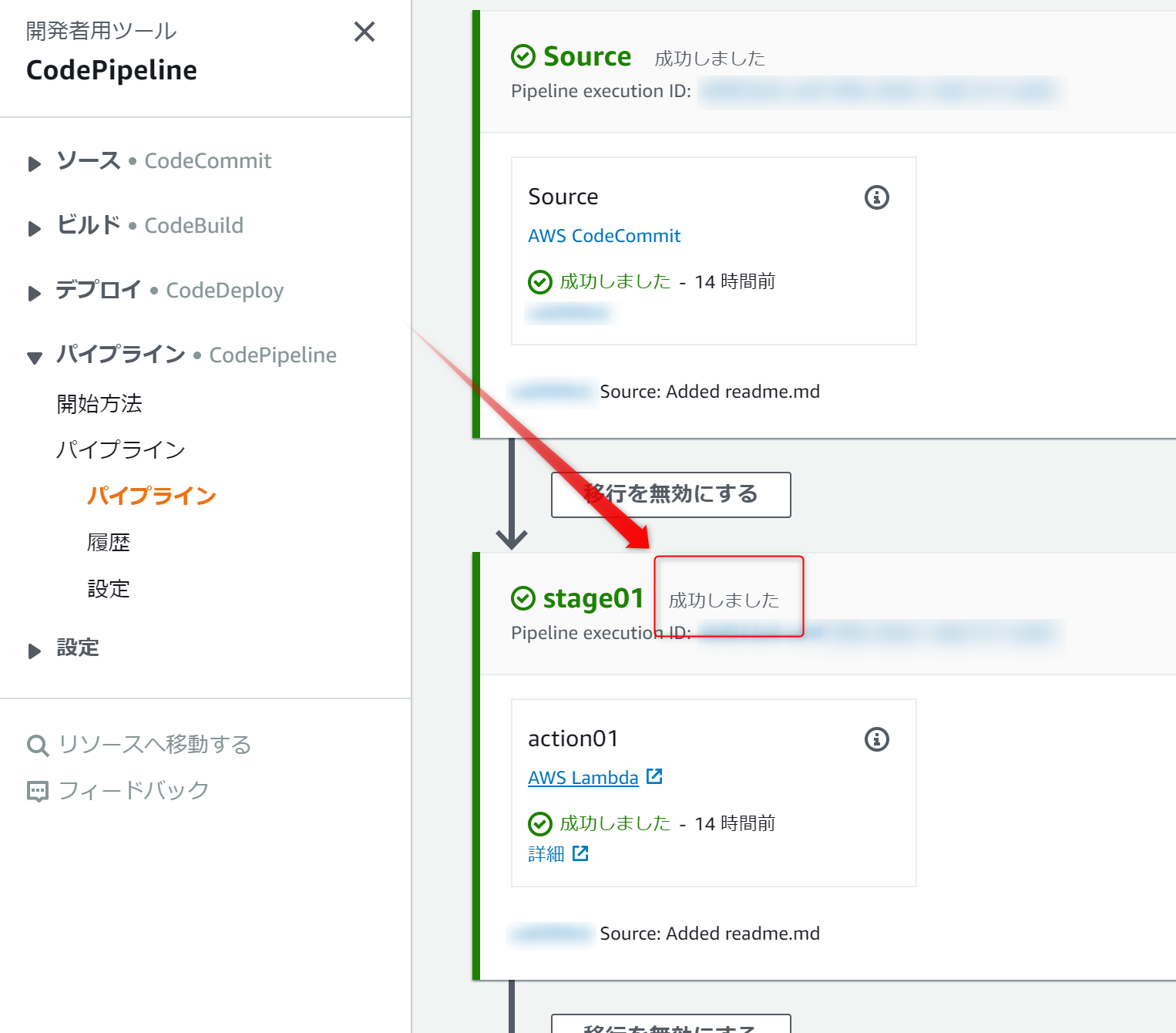
変更をリリースするを実行し、成功しましたと表示されたら成功
2-2.失敗を返すスクリプト
失敗を返すimport json import boto3 def lambda_handler(event, context): codepipeline = boto3.client('codepipeline') # CodePipelineに結果(失敗)を返す codepipeline.put_job_failure_result( jobId = event['CodePipeline.job']['id'], failureDetails={ 'type': 'JobFailed', 'message': 'Failed test.' } ) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda! Error') }
失敗しましたと表示されれば成功
3.検証(2) CodePipelineアクションデータからの情報をLambdaで受け取ってログ出力
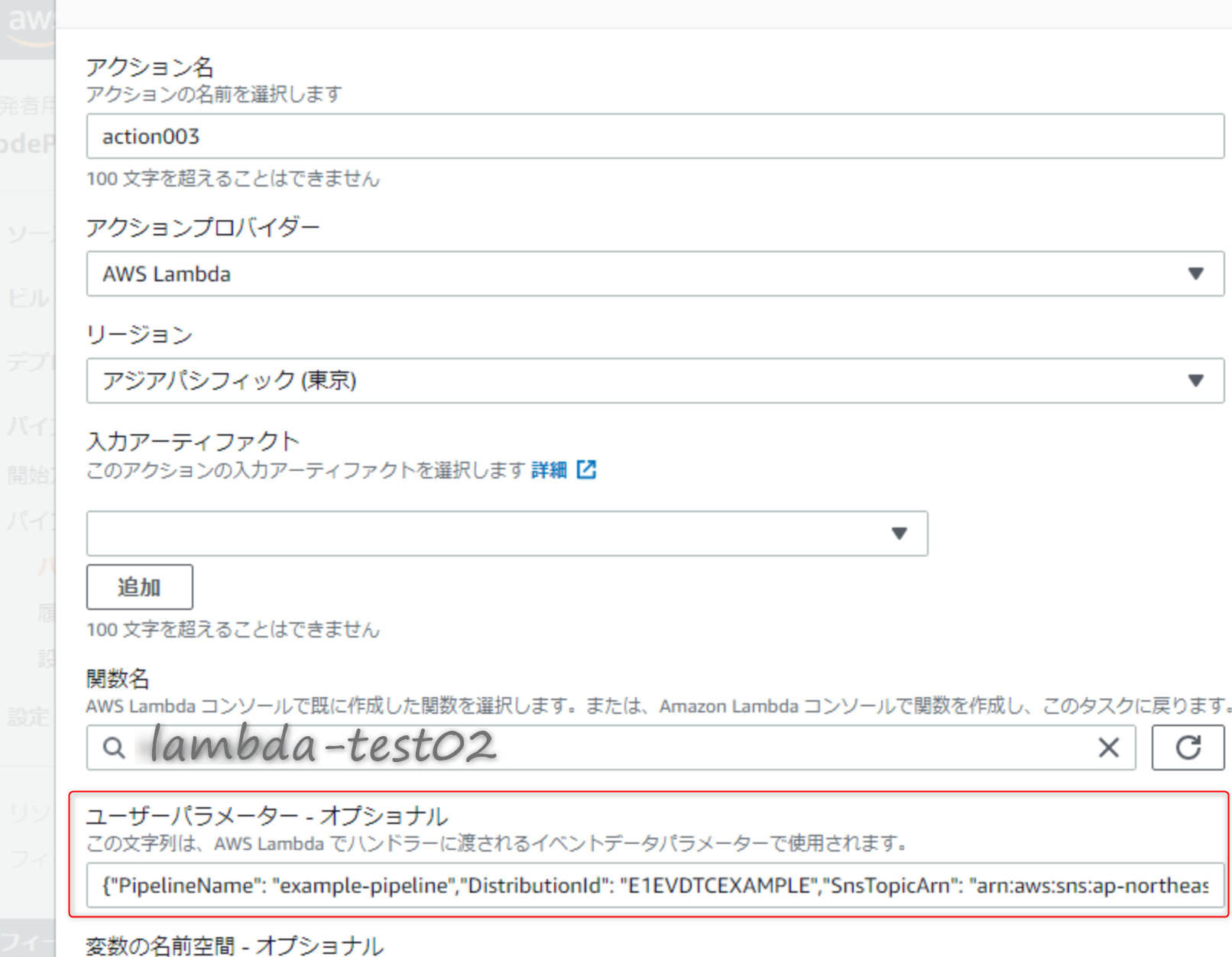
CodePipelineアクションデータからの情報をLambdaで受け取ってログ出力してみる
↑のユーザーパラメータに登録した内容がこれ↓ (ホントは改行してない)
{ "PipelineName": "example-pipeline", "DistributionId": "E1EVDTCEXAMPLE", "SnsTopicArn": "arn:aws:sns:ap-northeast-1:XXXXXXXXXXXX:example-topic" }Lambdaスクリプト(Python3.8)はこれ
lambda-test02import boto3 import json import logging import time import traceback logger = logging.getLogger() logger.setLevel(logging.INFO) cp = boto3.client('codepipeline') cf = boto3.client('cloudfront') sns = boto3.client('sns') def lambda_handler(event, context): codepipeline = boto3.client('codepipeline') job_id = event['CodePipeline.job']['id'] job_data = event['CodePipeline.job']['data'] user_parameters = json.loads( job_data['actionConfiguration']['configuration']['UserParameters'] ) pipeline_name = user_parameters['PipelineName'] distribution_id = user_parameters['DistributionId'] sns_topic_arn = user_parameters['SnsTopicArn'] logger.info('[TEST] job_id = %s', job_id) logger.info('[TEST] job_data = %s', job_data) logger.info('[TEST] pipeline_name = %s', pipeline_name) logger.info('[TEST] distribution_id = %s', distribution_id) logger.info('[TEST] sns_topic_arn = %s', sns_topic_arn) # CodePipelineに結果(成功)を返す codepipeline.put_job_success_result(jobId = event['CodePipeline.job']['id']) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda! Error') }実行結果
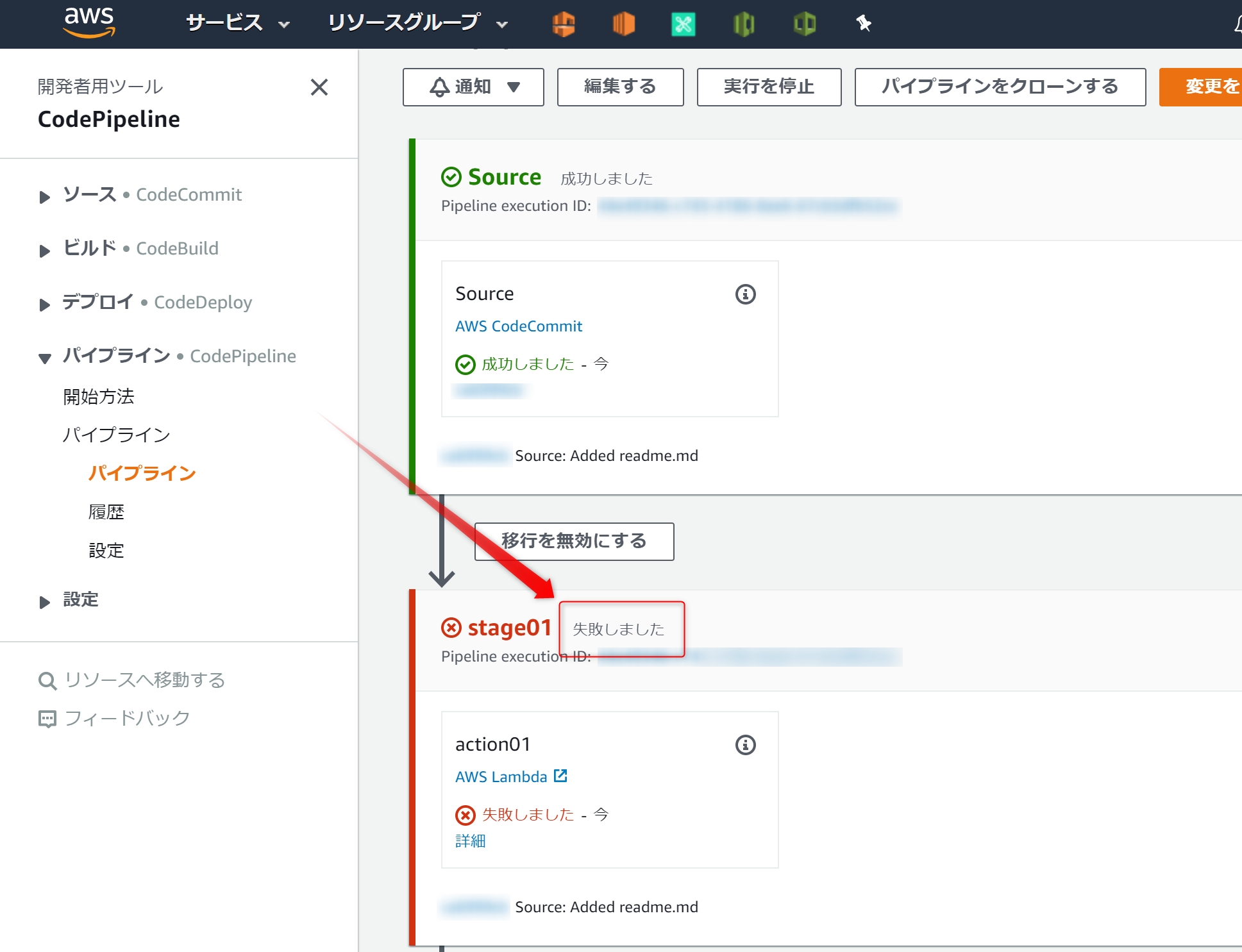
↑の
詳細をクリックしてCloudWatchログを確認する
ログに記録されてたら成功
今回は、ここまででおわり。
ホントにハローワールドしかできなかった、調査はつづく
次は、Souceの情報をStageでチェックするスクリプトを作りたい

- 投稿日:2020-03-28T00:14:10+09:00
AWSの自社認証局への移行に備える方法
タイトルは思いつかなかったのでパクりました。
[Action Required] Amazon S3 and Amazon CloudFront migrating default certificates to Amazon Trust Services in March 2021というメールが飛んできており、何をしたらよいか?と聞かれたので調べました。TLS接続ができなくなるなんて考えてもなかったので漠然と大丈夫だろうとは思ってましたが、いざ聞かれると不安だったので。結論としては利用しているアプリケーションによるとしか言えません。アプリによってルート証明書の管理の仕方が違うからです。
詳しくはAWSのBlogで「AWSの自社認証局への移行に備える方法」という記事があるので読みましょう。概要
メール中にあったAWSのBlogの「AWSの自社認証局への移行に備える方法」に書いてある通り、AWSのサービスは徐々にAWSの自社認証局から証明書を発行する方向になっているようです。
自社認証局の証明書が扱えないと2021/03以降にS3やCloudFrontの利用に影響があるから確認してね、というのがこのメールの内容でした(と機械翻訳から解釈)。動きを見てみる
以下で確認してみます。手元の環境はWindows 10でアップデートはちゃんとしている環境です。
- "eu-north-1" にS3バケットを作成する(AWSの自社認証局を使っているリージョンを選ぶ)
- S3バケットにアクセスできることを確認する(SSLエラーでなければよい。なので、Access Deniedでもよい。)
- ルート証明書を失効させる
- S3バケットにアクセスできなくなることを確認する
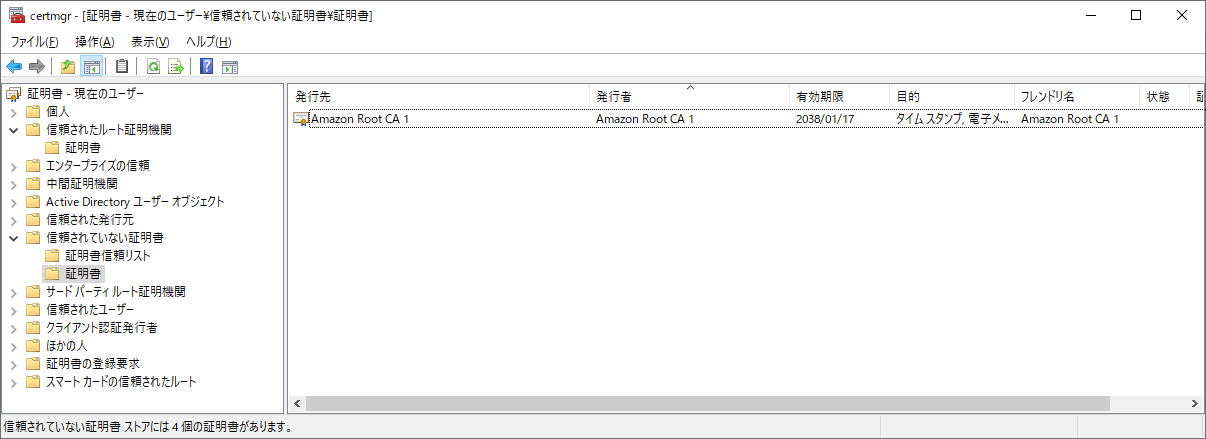
まずはChromeで試しました。
Chromeはルート証明書は内部で持ってると思っていたんですが、Windowsの場合はOSの証明書ストアを見ているようです。Windowsではcertmgrにある「信頼されたルート証明機関」にある証明書を「信頼されていない証明書」にドラッグ&ドロップすると失効にできます。(他の環境では最初はなかったりしたので、1度アクセスしないと出てこないかもしれません。)
失効後に再度アクセスしてみます。しかし、問題なくアクセスできたので困惑します。
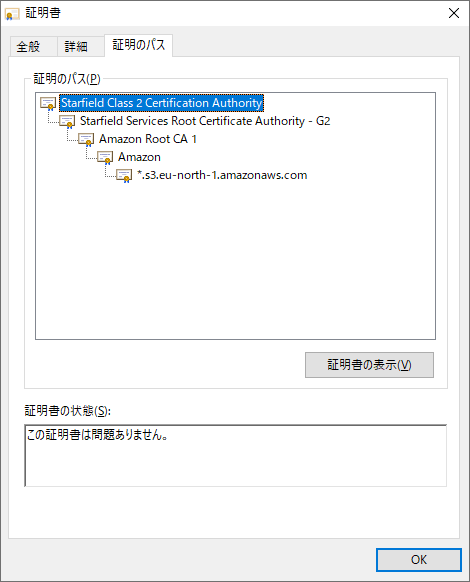
調べてみると別のルート証明書を使って検証がパスされていました。クロスルートな証明書になっているようです。
上記のAWSのBlogにある Starfield Class 2 Certification Authority 等の関係なさそうな証明書が書かれていたのは、このために必要だったようです。
この証明書も含めて
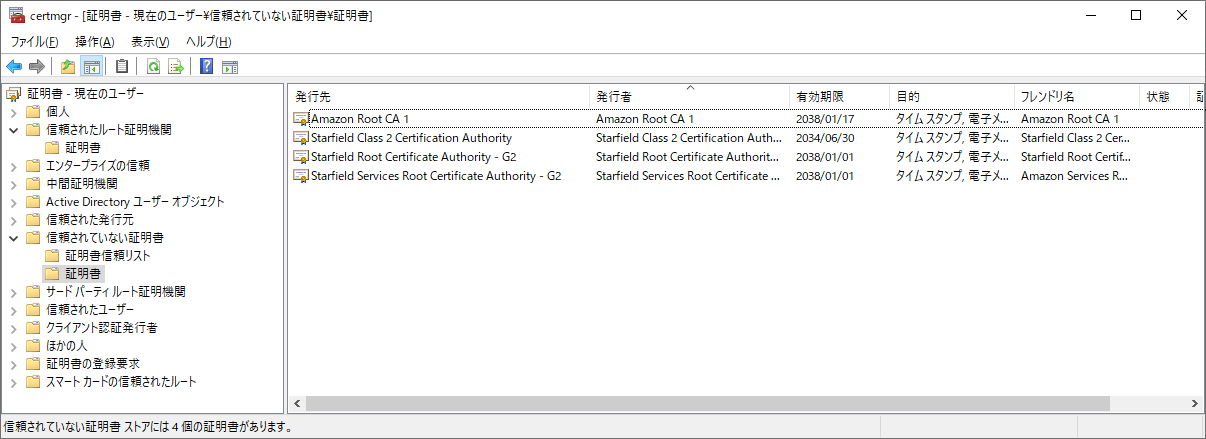
手あたり次第失効させてみると、確かにアクセスできなくなりました。
余談ですがqiita.comもAmazon Root CA 1(おそらくAWS Certificate Manager)から証明書を発行しているのでアクセスできなくなります。
対応は?
様々としか言えません。「対応方法がないとかこの記事は無価値!」という感じですが、そもそもアプリがルート証明書を自前で管理している可能性もあるためです。
例えば、現在のAWS CLIは内部のbotocore(Python用のAWS SDK)がcacert.pemを持っています。インストーラで入れた場合は以下です。
- AWS CLI v1:
C:\Program Files\Amazon\AWSCLI\runtime\Lib\site-packages\botocore\cacert.pem- AWS CLI v2:
C:\Program Files\Amazon\AWSCLIV2\botocore\cacert.pemつまり、OSが持つ証明書ストアを使っていないのでcertmgrで失効させても aws s3コマンドは通ります。逆を言えば、cacert.pemから当該の証明書を削除すると認証ストアが正しい状態だろうがアクセスできなくなります。
実際にAWS CLI v1で証明書を削除して試したところ以下のようなエラーになります。
SSL validation failed for https://バケット名.s3.eu-north-1.amazonaws.com/?list-type=2&prefix=&delimiter=%2F&encoding-type=url [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:749)他にもJavaならJAVA_HOMEの
jre\lib\security\cacertsで持っており、keytoolで確認できます。aliasは違うかもしれません。keytool -list -keystore "%JAVA_HOME%\jre\lib\security\cacerts" -v -alias "amazonrootca1 [jdk]"このようにルート証明書の管理はアプリケーションによるので対応方法は何とも言えない、という感じです。
といっても、blogに書かれている通りで、Amazon側もかなり配慮しています。
AWS は Amazon Trust Services 認証局 があらゆるところで確実に使えるようにするために、2005年以降のほとんどのブラウザで信頼されているルート認証局である Starfield Services の認証局の一つを購入しました。これは Amazon Trust Services で発行された証明書を使うために何もする必要が無いことを意味しています。
2006年ごろからアップデートを一切行っていないような環境や、ルート証明書を自前で管理しているようなことをしていなければ問題はまずないと思います。
もし心配なら軽くチェックしてみましょう。httpsリクエストを投げて通るか試すだけでよいのでそう難しくはないはずです。