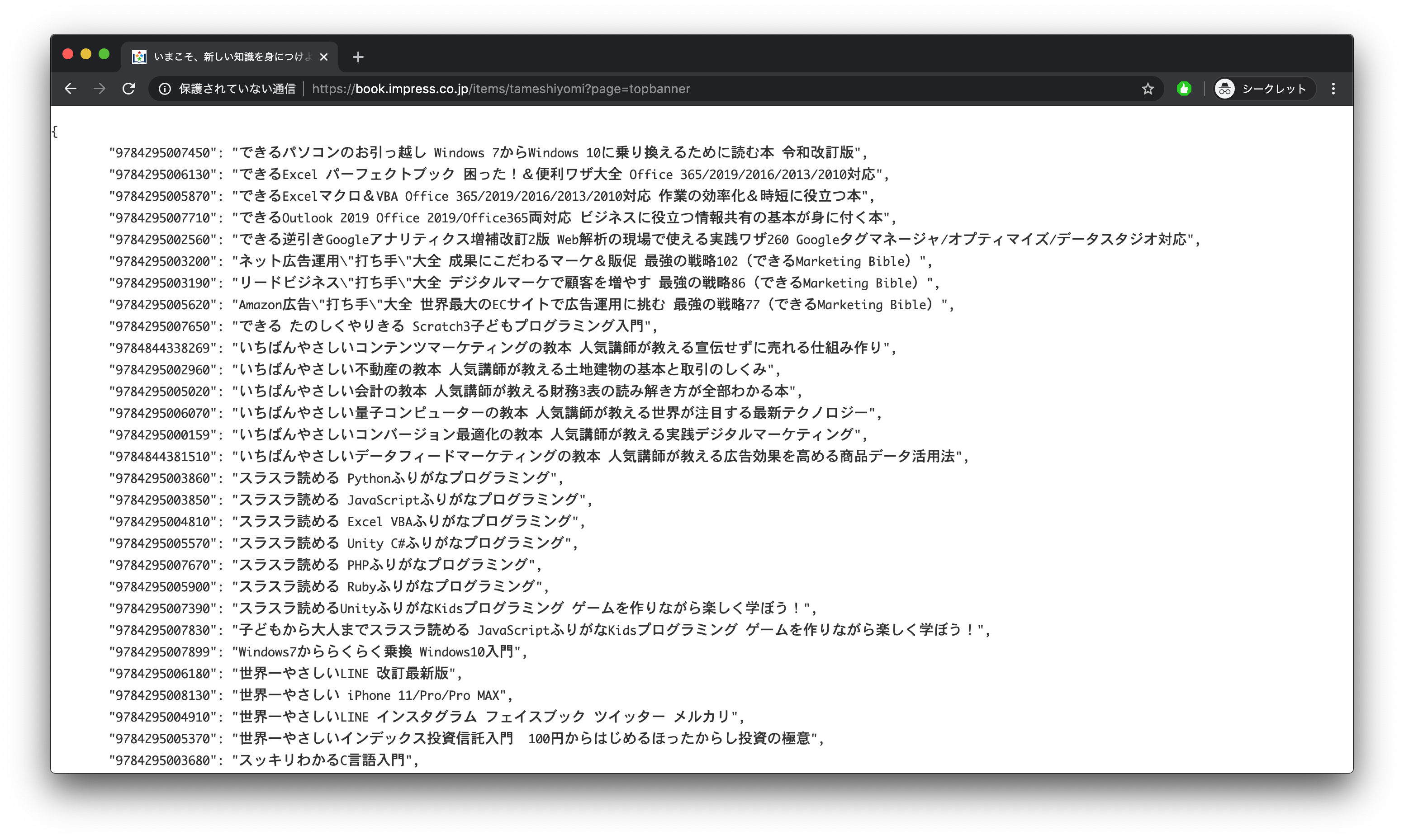
- 投稿日:2020-03-14T23:57:56+09:00
matplotlibで特定のデータにだけマーカーを適用する方法
はじめに
雑誌の掲載順をグラフ化するときに、matplotlibで特定の項目にだけマーカー(グラフに打つ点)をつけたくなった(センターカラーのときにだけわかりやすいように目印をつけたかった)が、探しても全く出てこなかったのでメモ。
↑こんな感じで強調するために特定の値の時だけマーカーを適用したかった。環境
$ uname -a Linux kali 4.18.0-kali2-amd64 #1 SMP Debian 4.18.10-2kali1 (2018-10-09) x86_64 GNU/Linux $ python3 --version Python 3.7.6 $ pip3 show matplotlib Name: matplotlib Version: 3.1.2問題
例えば、以下のようなデータがあったとする。
month 1月 2月 3月 4月 5月 6月 7月 8月 9月 10月 11月 12月 data 13 15 21 5 10 18 21 17 15 16 21 13 これらをグラフにするとこうなる。
このグラフの1,4,7,10月のデータにだけダイヤモンドでマーカーを付けたい(その他には付けたくない)ときどうすればいいだろうか。
解決法
マーカーを付けたい部分だけを配列にしてプロットするときに
markevery=で渡す。
X番目にマーカーを付けたければX-1番目の数を配列に追加する。こんな感じ。
#!/usr/bin/env python import matplotlib.pyplot as plt X_data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] Y_data=[13,15,21,5,10,18,21,17,15,16,21,13] month_name=['Jan.','Feb.','Mar.','Apr.','May','Jun.','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.'] mark_point=[0,3,6,9] plt.xlabel('month') plt.ylabel('data') plt.grid(color='gray') plt.xticks(X_data,month_name) plt.yticks(range(1,max(Y_data)+1)) plt.plot(X_data,Y_data, '.', linestyle='solid', marker="D", markevery=mark_point) plt.show()結果
y軸のデータを基準にしたければ、先にデータを比較して配列に格納すれば良い。
例)データが奇数のときだけマーカーを適応する#!/usr/bin/env python import matplotlib.pyplot as plt X_data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] Y_data=[13,15,21,5,10,18,21,17,15,16,21,13] month_name=['Jan.','Feb.','Mar.','Apr.','May','Jun.','Jul.','Aug.','Sep.','Oct.','Nov.','Dec.'] mark_point=[] for i,data in enumerate(Y_data): if data%2: mark_point.append(i) plt.xlabel('month') plt.ylabel('data') plt.grid(color='gray') plt.xticks(X_data,month_name) plt.yticks(range(1,max(Y_data)+1)) plt.plot(X_data,Y_data, '.', linestyle='solid', marker="D", markevery=mark_point) plt.show()結果
一件落着。
参考文献




- 投稿日:2020-03-14T23:50:17+09:00
Heroku、Flask、SQLAlchemyで掲示板を作る
はじめに
今回、掲示板の作成について、以下の通り6つに分類にして記述した。
(1)環境構築
(2)csvで掲示板
(3)SQLとSQLAlchemyで掲示板
(4)PostgreSQLとSQLAlchemyで掲示板
(5)SQLAlchemyを使ってデータ操作
(6)Postgresqlを使ってデータ操作(1)環境構築
デスクトップにディレクトリtestを作成。
test内に仮想環境を構築して起動。python3 -m venv . source bin/activate必要なフレームワークとwebサーバーをインストール。
pip install flask pip install gunicorn(2)csvで掲示板
まず、ローカル環境でcsvを使って掲示板を作る。
①ディレクトリ構成
test ├app.py ├articles.csv ├Procfile ├requirements.txt └templates ├index.html ├layout.html └index_result.html②csvデータを用意する
articles.csvを作成し、分かりやすさの観点から、あらかじめ以下のデータを入力しておく。
たま,眠いにゃー しろ,腹減ったにゃー クロ,なんだか暖かいにゃー たま,ぽえーぽえーぽえー ぽんたん,トイレットペーパーがない なおちん,チーン③メインとなるapp.pyを作成する
app.py#coding: utf-8 from flask import Flask,request,render_template app = Flask(__name__) @app.route('/') def bbs(): lines = [] #with openしてcsvファイルを読み込む with open('articles.csv',encoding='utf-8') as f: lines = f.readlines() #readlinesはリスト形式でcsvの内容を返す #index.htmlに返す return render_template('index.html',lines=lines) #postメソッドを受け取る @app.route('/result',methods=['POST']) def result(): #requestでarticleとnameの値を取得する article = request.form['article'] name = request.form['name'] #csvファイルに上書きモードで書き込む with open('articles.csv','a',encoding='utf-8') as f: f.write(name + ',' + article + '\n') #index_result.htmlに返す return render_template('index_result.html',article=article,name=name) if __name__ == '__main__': app.run(debug=False)④掲示板本体とその他テンプレ
index.html{% extends 'layout.html' %} {% block content %} <h1> にゃん子掲示板</h1> <form action='/result' method='post'> <label for='name'>にゃん子の名前</label> <input type='text' name='name'> <p></p> <label for='article'>投稿</label> <input type='text' name='article'> <button type='subimit'>書き込む</button> </form> <p></p> <p></p> <table border=1> <tr><th>にゃん子の名前</th><th>投稿内容</th></tr> {% for line in lines: %} <!--columnという変数をセット(jinja2の変数セットにはsetが必要) --> <!--splitを利用して,で分類する。splitはリストを返す --> {% set column = line.rstrip().split(',') %} <tr><td>{{column[0]}}</td><td>{{column[1]}}</td></tr> {% endfor %} </table> {% endblock %}layout.html<!DOCTYPE html> <html lang='ja'> <head> <meta charset='utf-8'> <title>Nyanko BBS</title> <style>body{padding:10px;}</style> </head> <body> {% block content %} {% endblock %} </body> </html>index_result.html{% extends 'layout.html' %} {% block content %} <h1>にゃ-んと掲示板に書き込みました</h1> <p>{{name}}{{article}}</p> <!--formで/に戻る --> <form action='/' method='get'> <button type='submit'>戻る</button> </form> {% endblock %}⑤Herokuへデプロイする
ローカル環境でテストした後に、Herokuへデプロイする。
Herokuへのデプロイ詳細は以下の記事に書いた通りなので、エッセンスのみとし、詳細説明を省く。
Heroku、Flask、Python、Gitでアップロードする方法(その②)
Heroku、Flask、Python、Gitでアップロードする方法(その③)
Herokuにログインし、Heroku上にアプリを作成heroku loginアプリ名はcat-bbsとした。
Heroku create cat-bbsディレクトリappを初期化して、
git initHerokuとローカル環境を紐つけて、
heroku git:remote -a cat-bbsディレクトリappにrequirements.txtを作成して、
pip freeze > requirements.txtディレクトリapp内にProckfileを作成し、以下を入力。
この時、gの前はブランク一つ必要、また、:appの前のappは、app.pyのappという意味なので注意が必要(form.pyなら、form:app)web: gunicorn app:app --log-file -全てをaddして、
git add .今回は、the-firstという名前でcommitして、
git commit -m'the-first'Herokuにpushする。
git push heroku master最後に、
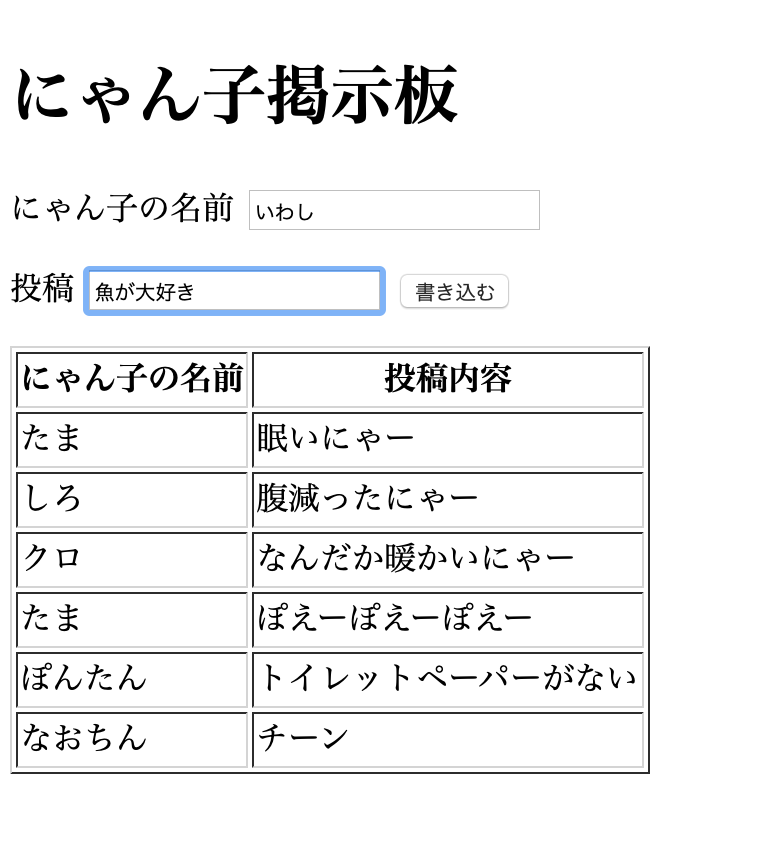
heroku openheroku openのコマンドを入力すると、ブラウザが立ち上がり以下が表示された。
にゃん子の名前を”いわし”とし、投稿内容を”魚が大好き”と投稿すると、
ちゃんと掲示板に書き込みされた。
herokuでは書き込みされたcsvは一定時間(30分)経過すると消えてしまうので、データベースの組み込みに取り掛かる。(3)SQLとSQLAlchemyで掲示板
①ディレクトリ構成等
test ├app.py ├articles.csv ├Procfile ├requirements.txt ├assets │ ├init.py │ ├database.py │ └models.py │ └templates ├index.html ├layout.html └index_result.htmlSQLAlchemyとは、Pythonの中では最もよく利用されているORMの一つ。
最初にsqlite3のバージョン確認(Mac)と、sqlalchemyをインストールする。sqlite3 --version pip install sqlalchemyまた、app.pyから、database.pyやmodels.pyをモジュールとして読み込むために必要なファイルとして、 init.pyをassetsフォルダ内に作成する(アンダーバーがつくので注意)
touch __init__.py②SQLAlchemyの初期設定
以下の2つのファイルをassetsフォルダ内に作成する。
database.py・・・sqliteやmysqlなど、どのデータベースを使うのかを定義するファイル
models.py・・・そのデータベースにどのような情報を入れるかを定義するファイル
まず、database.pyは以下の通り。database.py#coding: utf-8 #database.py/sqliteなど、どのデータベースを使うのか初期設定を扱うファイル from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session,sessionmaker from sqlalchemy.ext.declarative import declarative_base import datetime import os #data_dbという名前で、database.pyのある場所に(os.path.dirname(__file__))、絶対パスで(os.path.abspath)、data_dbを保存する database_file = os.path.join(os.path.abspath(os.path.dirname(__file__)),'data.db') #データベースsqliteを使って(engin)、database_fileに保存されているdata_dbを使う、またechoで実行の際にsqliteを出す(echo=True) engine = create_engine('sqlite:///' + database_file,convert_unicode=True,echo=True) db_session = scoped_session( sessionmaker( autocommit = False, autoflush = False, bind = engine ) ) #declarative_baseのインスタンス生成する Base = declarative_base() Base.query = db_session.query_property() #データベースの初期化をする関数 def init_db(): #assetsフォルダのmodelsをインポート import assets.models Base.metadata.create_all(bind=engine)次に、models.pyは以下の通り。
ここで、投稿日時も掲示板に反映させるようした。models.py#coding: utf-8 from sqlalchemy import Column,Integer,String,Boolean,DateTime,Date,Text from assets.database import Base from datetime import datetime as dt #データベースのテーブル情報 class Data(Base): #テーブルnameの設定,dataというnameに設定 __tablename__ = "data" #Column情報を設定、uniqueはFalseとする(同じ値でも認めるという意味) #主キーは行を検索する時に必要、通常は設定しておく id = Column(Integer,primary_key=True) #nameは投稿者 name = Column(Text,unique=False) #articleは投稿内容 article = Column(Text,unique=False) #timestampは投稿日時 timestamp = Column(DateTime,unique=False) #初期化する def __init__(self,name=None,article=None,timestamp=None): self.name = name self.article = article self.timestamp = timestamp③app.pyを修正する
データベースの作成や削除等には以下2つが必要なためインポートする。
assetsフォルダのdatabaseモジュールから変数de_sessionのインポートと、assetsフォルダのmodelsモジュールから、Dataクラスをインポート。from assets.database import db_session from assets.models import Data③−1データベースへの書き込み
index.htmlからarticle、nameの値を取得する処理が必要。また、それぞれの値をで取得時の(書き込み時の)日時をtoday()で取得し、today変数に代入する処理が必要。具体的には以下の通り。
article = request.form['article'] name = request.form['name'] today = datetime.datetime.today()上記の内容をrowに格納し、db_sessionとde_commitでデータベースに書き込む処理が必要。具体的には以下の通り。
row = Data(name=name,article=article,timestamp=today) db_session.add(row) db_session.commit()③−2データベースからの読み込み
データベースからデータを読み込むには、db_session.query(Data).all()で取得できる。
例えば、データベースの中の値を取り出すために以下のように記述すると、db_session.query(Data.name,Data.article,Data.timestamp).all()以下のようにリスト形式で出力される(分かりやすさの観点から、掲示板で何件か投稿し、データベースに保存された場合を想定)
('ミケ', '本日は晴れ', datetime.datetime(2020, 3, 13, 0, 7, 4, 828409)), ('しろ', '明日は雨だにゃー', datetime.datetime(2020, 3, 13, 0, 7, 4, 828409)), ('クロ', 'ぽかぽか', datetime.datetime(2020, 3, 13, 0, 7, 4, 828409)), ('ぽんたん', 'にゃーにゃーカラスは紙飛行機', datetime.datetime(2020, 3, 13, 0, 7, 4, 828409)), ('しろ', '腰が痛いにゃー', datetime.datetime(2020, 3, 13, 0, 7, 46, 513144)), ('ミケ', 'もんだろにゃ?', datetime.datetime(2020, 3, 13, 0, 8, 57, 193710)), ('クロ', 'ぽかぽか', datetime.datetime(2020, 3, 13, 0, 9, 42, 45228)), ('ミケ', '本日は曇り', datetime.datetime(2020, 3, 13, 0, 17, 13, 709028)), ('ブー太郎', '今日は一日雨かにゃー', datetime.datetime(2020, 3, 14, 13, 26, 29, 438012)),index.htmlに読み込んだデータベースの内容を返す処理が必要。具体的には以下の通り。
data = db_session.query(Data.name,Data.article,Data.timestamp).all() return render_template('index.html',data=data)これまでの修正についてまとめると、app.py全体としては以下の通り。
app.py#coding: utf-8 from flask import Flask,request,render_template import datetime #データベースを使うにあたり追加 from assets.database import db_session from assets.models import Data app = Flask(__name__) @app.route('/') def bbs(): #データベースから読み込む data = db_session.query(Data.name,Data.article,Data.timestamp).all() #index.htmlに返す return render_template('index.html',data=data) #postメソッドを受け取る @app.route('/result',methods=['POST']) def result(): #requestでarticleとnameの値を取得する article = request.form['article'] name = request.form['name'] #today関数でpostメソッドを受け取った日時を変数に代入 today = datetime.datetime.today() #index_resultからの情報をデータベースに書き込む row = Data(name=name,article=article,timestamp=today) db_session.add(row) db_session.commit() #index_result.htmlに返す return render_template('index_result.html',article=article,name=name) if __name__ == '__main__': app.run(debug=False)③−4(参考)データベースからの削除
参考として、読み込んだデータベースからの削除は以下の通り。
db_session.query(Data).allから削除したい項目を指定して(以下のケースは1番目の項目)、de_session.deleteを使う#coding: utf-8 from assets.database import db_session from assets.models import Data def csv_sakujo(): data = db_session.query(Data).all() datum = data[0] db_session.delete(datum) db_session.commit() csv_sakujo()③−5(参考)読み込んだデータベースをcsvに書き出し
参考として、読み込んだデータベースをcsvに書き出すファイルは以下の通り。
to_csv.py#coding: utf-8 from assets.database import db_session from assets.models import Data #データを読み込む def csv_kakikomi(): data = db_session.query(Data.name,Data.article,Data.timestamp).all() print(data) #csvファイルに書き込みモードで書き込む# with open('articles2.csv','w',encoding='utf-8') as f: for i in data: f.write(str(i[0])+',') f.write(str(i[1])+',') f.write(str(i[2])+',' + '\n') csv_kakikomi()④index_html.pyを修正する
app.pyから送られてきたdataの値を表示する。
dataの値のうち、data[2]は現在日時であるが、投稿前はNoneの値があるため、if文でエラーにならないように設定。投稿後はdatatime型をstr型にstrftimeを用いて変換した上で表示。index.html{% extends 'layout.html' %} {% block content %} <h1> にゃん子掲示板</h1> <form action='/result' method='post'> <label for='name'>にゃん子の名前</label> <input type='text' name='name'> <p></p> <label for='article'>投稿</label> <input type='text' name='article'> <button type='subimit'>書き込む</button> </form> <p></p> <p></p> <table border=1> <tr> <th>にゃん子の名前</th> <th>投稿内容</th> <th>投稿日時</th> </tr> {% for datum in data %} <tr> <td>{{datum[0]}}</td> <td>{{datum[1]}}</td> {% if datum[2] == None %} <td>{{datum[2]}}</td> {% else %} <td>{{datum[2].strftime('%Y年%m月%d日/%H時%M分%S秒')}}</td> {% endif %} </tr> {% endfor %} </table> {% endblock %}ここまでを、一度ローカル環境で正常に動くかどうかを試す。
問題なく稼働するのを確認したら、次にHeokuへのデプロイと、HerokuのPostgreSQLを使う。(4)PostgreSQLとSQLAlchemyで掲示板
Herokuへデプロイし、PostgreSQLを使う。
①環境準備
postgresqlをbrewを使ってインストールする。
brew install postgresql次に postgresqlを使うためのpython用のドライバーとして、 psycopg2-binaryをインストールする。psycopg2をそのままインストールすると、なぜかエラーが出るため、psycopg2-binaryをインストール(原因不明)。
pip install psycopg2-binary次にdatabase.pyを修正するが、environというHeroku上の環境変数を見に行ってDATABASE_URLというデータベースを取得する処理を記述する。environには接続先のURLがセットされる。また、orをつけることで、ローカル環境上はsqliteをデータベースとして参照することとした。herokuに接続されている場合はpostgresqlのurlを参照して、接続されていない場合はsqlを参照に行くという格好。具体的には以下の通り。
engine = create_engine(os.environ.get('DATABASE_URL') or 'sqlite:///' + database_file,convert_unicode=True,echo=True)修正後のapp.py全体は以下となる
database.py#coding: utf-8 #database.py/sqliteなど、どのデータベースを使うのか初期設定を扱うファイル from sqlalchemy import create_engine from sqlalchemy.orm import scoped_session,sessionmaker from sqlalchemy.ext.declarative import declarative_base import datetime import os database_file = os.path.join(os.path.abspath(os.path.dirname(__file__)),'data.db') engine = create_engine(os.environ.get('DATABASE_URL') or 'sqlite:///' + database_file,convert_unicode=True,echo=True) db_session = scoped_session( sessionmaker( autocommit = False, autoflush = False, bind = engine ) ) #declarative_baseのインスタンス生成する Base = declarative_base() Base.query = db_session.query_property() #データベースの初期化をする def init_db(): #assetsフォルダのmodelsをインポート import assets.models Base.metadata.create_all(bind=engine)②Herokuへデプロイする
Herokuへデプロイする。
heroku loginHerokuとローカル環境を紐つけて、
heroku git:remote -a cat-bbsあらためて、ディレクトリappにrequirements.txtを作成する。
(psycopg2-binaryをインストールしたため、再度の作成が必要。)pip freeze > requirements.txtProckfileは作成済みのため今回は触らず。
全てをaddして、
git add .今回は、the-secondという名前でcommitして、
git commit -m'the-second'Herokuにpushする。
git push heroku master
最後にheroku openするherokuにデプロイする前に、データベースの初期化を行う。
heroku上でpythonを起動する(pythonモード)。heroku run pythonデータベースを初期化する。
pythonモードで以下を記述。from assets.database import init_db init_db()pythonモードを終了し、herokuをrestartして、openする。
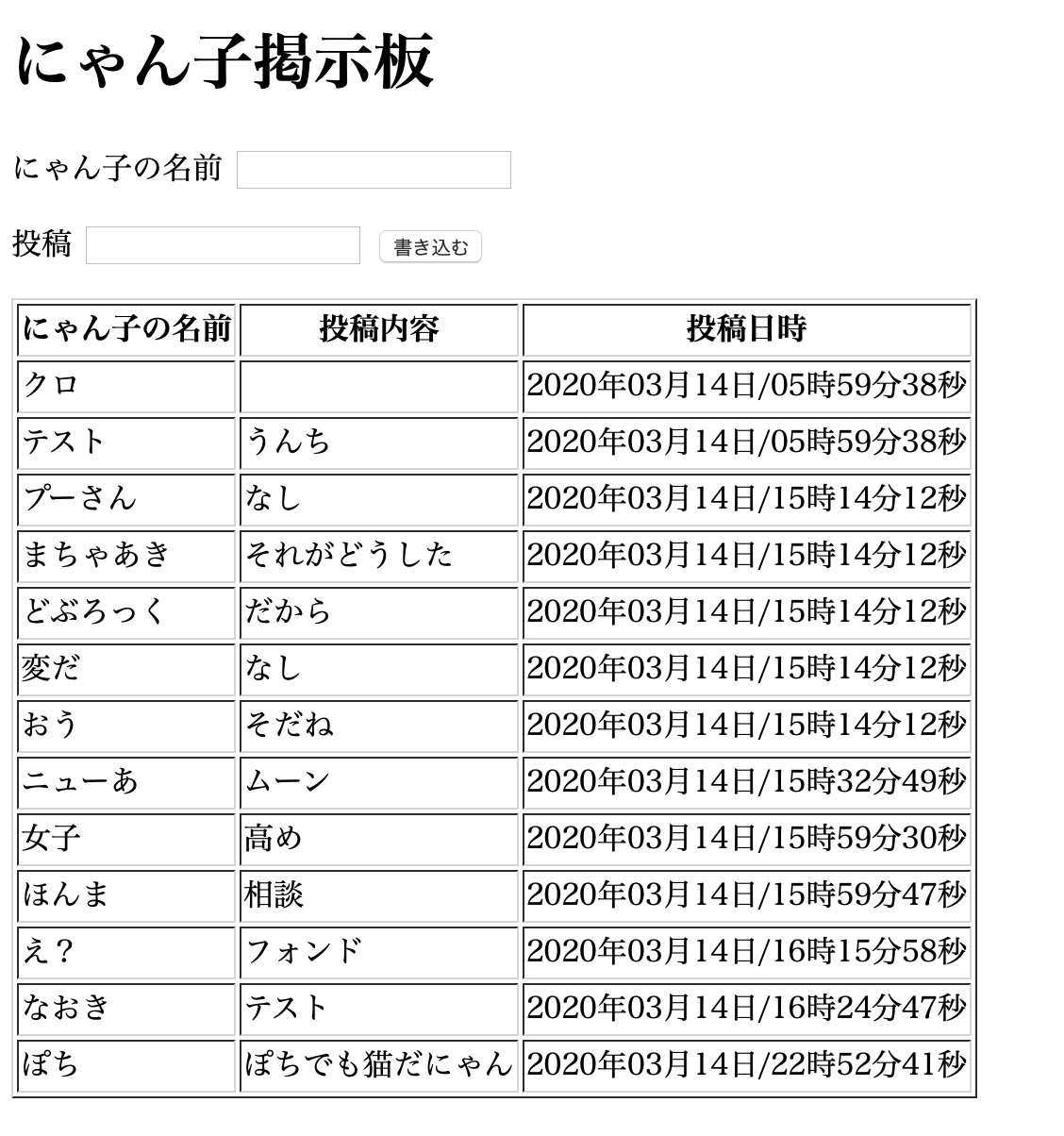
heroku restart heroku openブラウザで以下を確認して成功。
(5)SQLAlchemyを使ってデータ操作
例として、データベースの1番上の項目を削除してみる(”クロ”)。
Heokuのpythonモード起動。heroku run pythonpythonモードで以下を記述
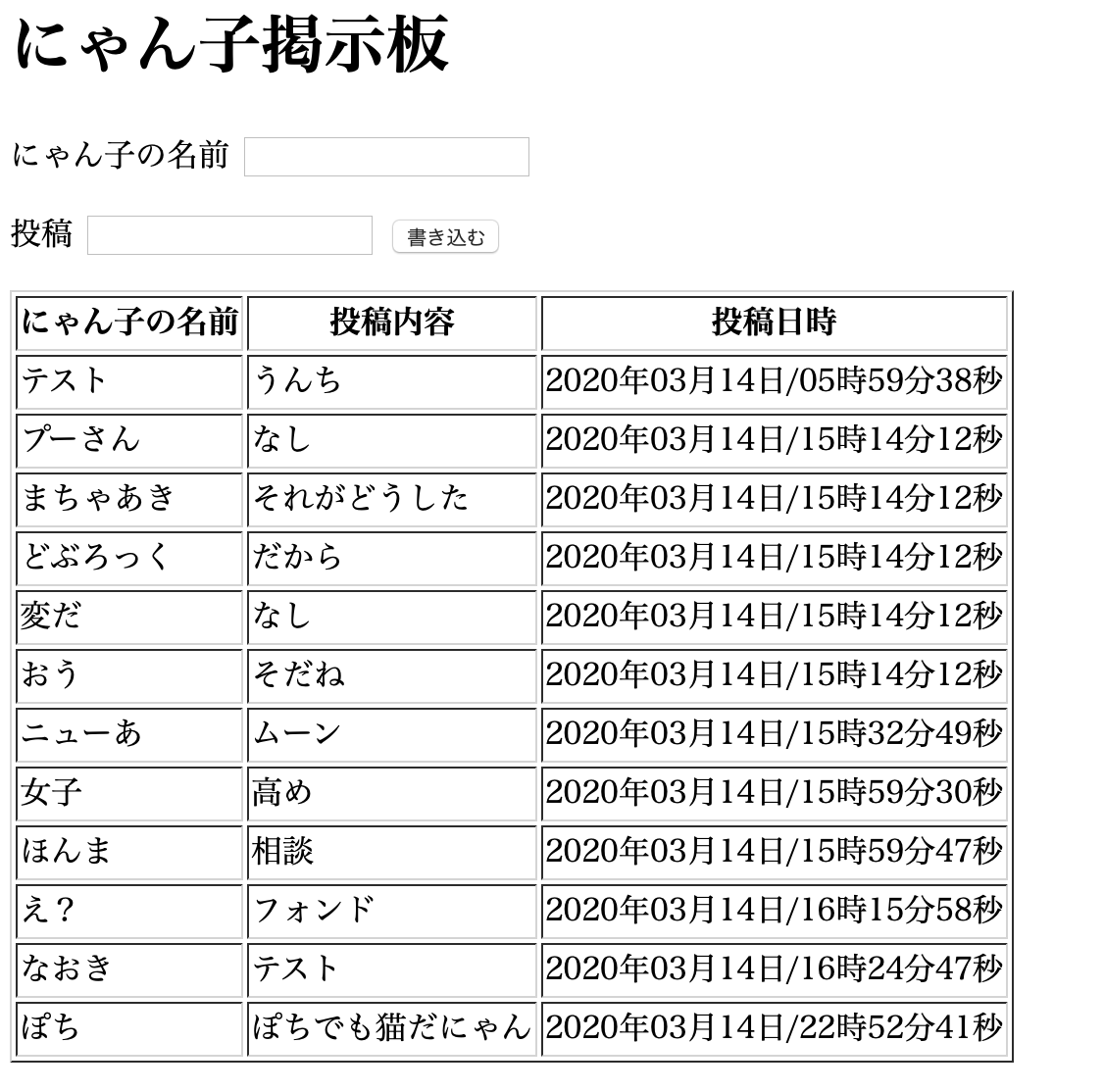
from assets.database import db_session from assets.models import Data data = db_session.query(Data).all() datum = data[0] db_session.delete(datum) db_session.commit()として、heroku openしてブラウザで確認すると、
一番上の”クロ”が削除された。
(pythonモードは忘れずに終了させること)(6)Postgresqlを使ってデータ操作
PostgreSQL をインストールすると、heroku pg コマンドで Heroku Postgres を操作できるようになる。
例えば以下を入力すると、インストールした Heroku Postgresの状況は以下のように確認できる。heroku pg:info=== DATABASE_URL Plan: Hobby-dev Status: Available Connections: 2/20 PG Version: 12.2 Created: 2020-03-14 04:53 UTC Data Size: 8.2 MB Tables: 1 Rows: 3/10000 (In compliance) Fork/Follow: Unsupported Rollback: Unsupported Continuous Protection: Off hobby-dev プラン (無料枠) で、Status は Available (有効) 。以下を入力すると、Heroku Postgresに接続できる。
heroku pg:psql接続後はPostgreSQLのコマンドを使用
例えば、1番上の項目を削除してみる(”テスト”、”うんち”)。テーブル一覧の表示のコマンド \dt;テーブル内のデータを一覧するコマンド select * from data(テーブル名);以下が出力される。
cat-bbs::DATABASE=> select * from data; id | name | article | timestamp ----+------------+--------------------+---------------------------- 3 | テスト | うんち | 2020-03-14 05:59:38.062361 4 | プーさん | なし | 2020-03-14 15:14:12.453124 5 | まちゃあき | それがどうした | 2020-03-14 15:14:12.453124 6 | どぶろっく | だから | 2020-03-14 15:14:12.635542 7 | 変だ | なし | 2020-03-14 15:14:12.635542 8 | おう | そだね | 2020-03-14 15:14:12.453124 9 | ニューあ | ムーン | 2020-03-14 15:32:49.082485 10 | 女子 | 高め | 2020-03-14 15:59:30.175208 11 | ほんま | 相談 | 2020-03-14 15:59:47.029891 12 | え? | フォンド | 2020-03-14 16:15:58.35794 13 | なおき | テスト | 2020-03-14 16:24:47.435301 14 | ぽち | ぽちでも猫だにゃん | 2020-03-14 22:52:41.633207 (12 rows)次に、deleteで1番上の項目を削除する(”テスト”、”うんち”)。
delete from data(テーブル名) where id=3;とすると、
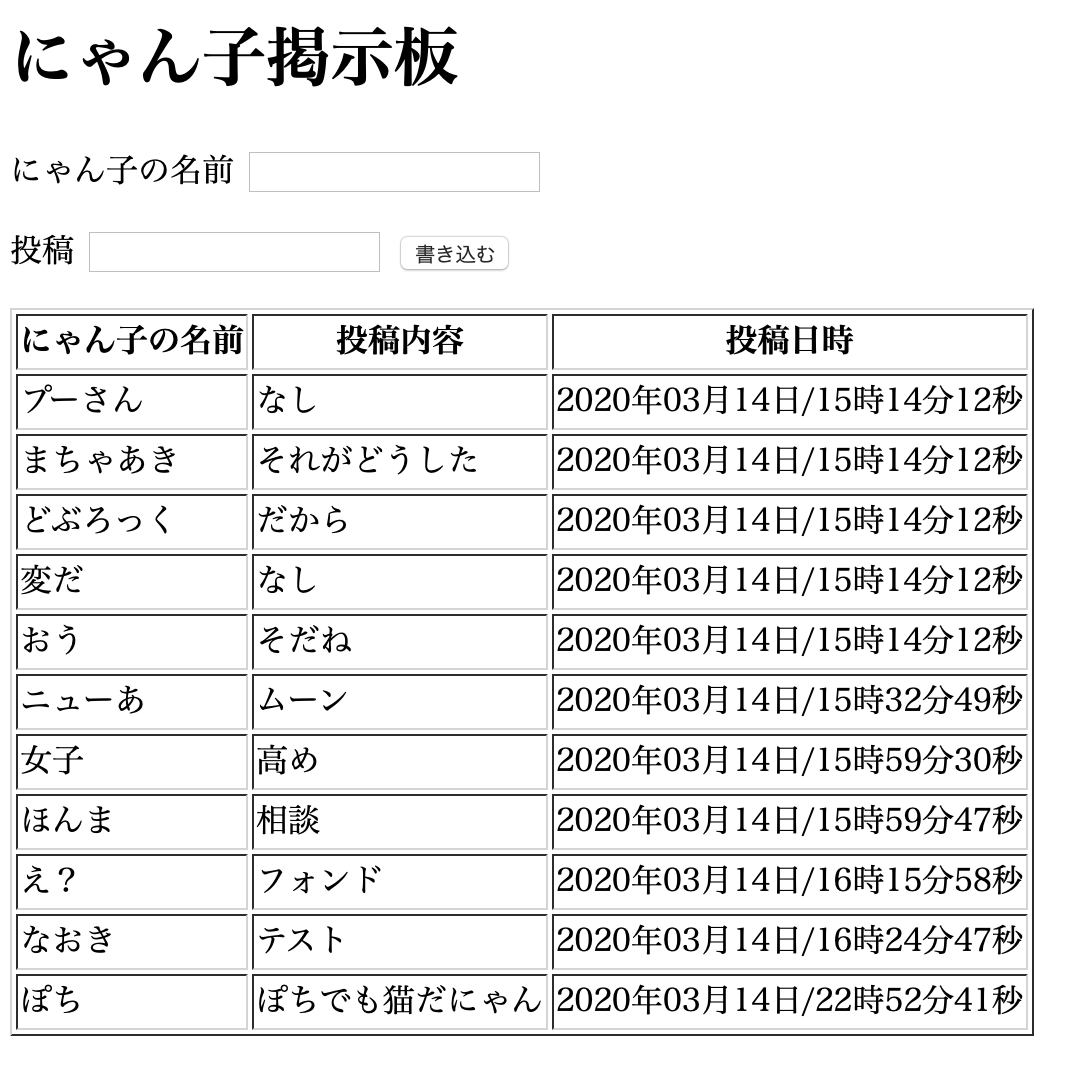
cat-bbs::DATABASE=> select * From data; id | name | article | timestamp ----+------------+--------------------+---------------------------- 4 | プーさん | なし | 2020-03-14 15:14:12.453124 5 | まちゃあき | それがどうした | 2020-03-14 15:14:12.453124 6 | どぶろっく | だから | 2020-03-14 15:14:12.635542 7 | 変だ | なし | 2020-03-14 15:14:12.635542 8 | おう | そだね | 2020-03-14 15:14:12.453124 9 | ニューあ | ムーン | 2020-03-14 15:32:49.082485 10 | 女子 | 高め | 2020-03-14 15:59:30.175208 11 | ほんま | 相談 | 2020-03-14 15:59:47.029891 12 | え? | フォンド | 2020-03-14 16:15:58.35794 13 | なおき | テスト | 2020-03-14 16:24:47.435301 14 | ぽち | ぽちでも猫だにゃん | 2020-03-14 22:52:41.633207 (11 rows)削除した。
ブラウザで確認してもちゃんと削除されている。


- 投稿日:2020-03-14T23:45:55+09:00
説明変数、目的関数の作り方
目的関数の書き方
dfが
- PassengerID (乗客のID)
- Survived (trainデータだけ)
- Pclass (部屋のクラス)
- Name
- Sex
- Age
- SibSp
- Parch
- Ticket
- Fare
- Cabin (客室を持っていたか)
- Embarked (どこの港で乗ったか)
このような項目を持っていた時に
説明変数は
x=df[["項目名1","項目名2","項目名3","項目名4"]]というように、自分選びたい項目を[["項目"]]のように追加します。
目的関数
目的関数は一つしか項目がないので、
t=df["目的関数の項目"]終わり
こんなかんじで、このあとモデルに学習させたりします。
- 投稿日:2020-03-14T23:11:37+09:00
PEP-362 (Function Signature Object) を読んだよメモ
__signature__という属性がどこからやってきたのを理解するために PEP 362 -- Function Signature Object を読むことになったので、自分の理解をメモに残しておく。概要
- これまで関数シグネチャの表現は複雑な形式で表現されていた
- PEP 362 では、関数シグネチャを表現する
Signatureというクラスを使って、関数シグネチャをシンプルに表現できるようにする- また、 inspect.signature() という関数を使って、かんたんに関数オブジェクトから関数シグネチャを取り出せるようにする
感想
あとは細かい使い方なので説明は省きます。PEP 362 を読んでもいいし、Python のドキュメントの inspect のページ を読んでもよいです。
かつてinspect.getargspec()やオブジェクトの属性を駆使して関数シグネチャを読み取っていた過去がありましたが、いまやinspect.signature()ひとつで大抵のことが事足りるようになりました。ビバ、Signature。さて、最初の疑問であった
__signature__についてもこの PEP で言及されていました。Signatureオブジェクトをfunc.__signature__に保存しておくとinspect.signature()はその値を返してくれる、とのことです。つまりキャッシュみたいなものですね。なお、PEP 362 では C拡張については対象外とされていましたが、Argument Clinic How-To を流し読みした限りでは、C ファイルのプリプロセッサである Argument Clinic を使って(従って)C拡張を作ると Signature に対応したモジュールが作れるようです。便利ですね。
なかなか関数シグネチャを必要とする場面は少ないのですが、引数や関数の型について調べたいに活躍するので試してみてはどうでしょうか。
- 投稿日:2020-03-14T23:05:57+09:00
AtCoder パナソニックプログラミングコンテスト2020 参戦記
AtCoder パナソニックプログラミングコンテスト2020 参戦記
panasonic2020A - Kth Term
2分半で突破. まあ、書くだけ.
K = int(input()) t = [1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51] print(t[K - 1])panasonic2020 B - Bishop
6分くらい?で突破. 1WA. H と W が1の場合をすっかり忘れてました.
H, W = map(int, input().split()) if H == 1 or W == 1: print(1) elif W % 2 == 0: print(H * W // 2) else: if H % 2 == 0: print(H * W // 2) else: print((W + 1) // 2 + (H - 1) * W // 2)panasonic2020C - Sqrt Inequality
敗退. 整数で計算しないと駄目なんだろうとは分かっていても、整数の式に落とせなかった. 二回二乗すればいいじゃんと言われればあああーってすぐ分かるやつ. 何故かコンテスト中は分からない orz. 数学問題嫌いだー.
panasonic2020D - String Equivalence
32分半で突破. 1WA. 何回読んでも、何回読んでも定義が頭に入ってこなくて困った. で、完全に定義を誤解して出して WA を食らい、その後に N = 4 くらいまで手で全部書いてようやく分かって AC. 要するに N - 1 までの文字列に、aからそれまでに出ている文字の一番辞書順で大きいやつの次のやつまでを追加したのが答え.
N = int(input()) q = ['a'] for i in range(N - 1): nq = [] for s in q: stop = ord(max(s)) + 2 for i in range(ord('a'), stop): nq.append(s + chr(i)) q = nq for s in q: print(s)
- 投稿日:2020-03-14T23:02:42+09:00
Pythonでパナソニックプログラミングコンテスト2020を解きたかった
はじめに
今回はA,Bしか解けませんでした。ABC相当のコンテストでAとBしか解けないのは良くない。
A問題
考えたこと
問題に書いてある数列をコピーして、kでindexを指定してprintしました。k = int(input()) l = [1, 1, 1, 2, 1, 2, 1, 5, 2, 2, 1, 5, 1, 2, 1, 14, 1, 5, 1, 5, 2, 2, 1, 15, 2, 2, 5, 4, 1, 4, 1, 51] print(l[k-1])B問題
問題
1WA
考えたこと
問題文の図を見ると、i行目とi+1行目を足すとWになると思ったのでhの偶奇で判別して計算しようとしたら1WAしました。WAの理由は、W,Hが1のときを考慮していなかったためです。ですので、どちらかが1のときを場合分けして書きました。import math h, w = map(int,input().split()) if w == 1 or h == 1: print(1) quit() if h % 2 != 0: ans = w * (h-1) / 2 + math.ceil(w / 2) print(int(ans)) else: ans = w * h / 2 print(int(ans))C問題
問題
12WA NoAC考えたこと
やったー、数学の問題じゃんと思っていたら地獄を見ました。まずは、安直に全部sqrtにつっこんで計算して1WA付きたので、計算をうまく減らしてあげないといけないと思いました。ですので、紙とペンを用意して必死にゼロに近い数学力で計算していました。\sqrt(a) + \sqrt(b) < \sqrt(c)は両辺は0以上なので、両辺を二乗して \\ = a + b < c = a + b - c + 2\sqrt(ab)< 0 が成り立てば\sqrt(a) + \sqrt(b) < \sqrt(c)を満たす \\ a + b - cは整数だから計算的にあふれないと思ったので、\\ 2\sqrt(ab)をどうやって処理するかを考えました。\\ 相加相乗平均の関係より、 \\ a + b >= 2 \sqrt(ab) \\ が成り立つ。等号成立条件はa = bなので、そのときはifで分ければいいと考えてました。 \\ 問題は、a != bのときで、自分の力ではどうしても根号を消すことができませんでした。 \\それで、うまく工夫したつもりでしたがWAは消えず...結局ACできませんでした。
コンテスト終了した後に他のACした人のコードを見るとDecimalとかいうモジュールを使って小数をうまく計算していました。こんなに楽に計算できたら、楽勝問題だったのに...<追記>
from decimal import * a, b, c = map(int, input().split()) if Decimal(a).sqrt() + Decimal(b).sqrt() < Decimal(c).sqrt(): print("Yes") else: print("No")でACでました。
まとめ
言語に対しての知識不足を再認識するコンテストでした。色々と悔しいし、悲しい。毎日AtCoderチャレンジをしているので、次回のコンテストこそは結果を残したいです。
では、おやすみなさい。
- 投稿日:2020-03-14T23:00:12+09:00
強化学習における迷路問題の避難経路設計への応用の可能性
前書き
春休みの間を利用して安全工学に関する強化学習による研究を進めていたが、どうにも具体的な形にまで昇華できなさそうであるので、今回できた分までを背景と並べてここに示す。
強化学習と研究背景
迷路問題
強化学習において、迷路問題は良く取り扱われる問題の1例である。
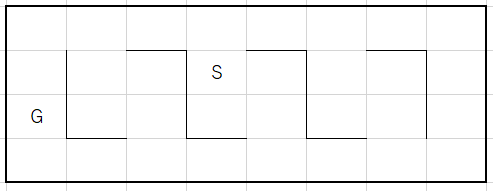
実装の例としてはこちらを参考にした。説明:
図で示したような迷路で、S(start)からG(Goal)までの道筋を学習することが目的となる。今回はQ学習でε‐greedy法を用いて学習を行っていく。Q学習ではそれぞれのマス目に対して取れる移動の選択肢(方策)が定められていて、その方策ごとに行動価値が決まっている。あるマス目である方策をとった場合、その移動先の行動価値の最大値との差をある割合で増加させて、そのマス目におけるその方策の行動価値を更新する。
もう一つ、Goalにおいてはある一定の行動価値が定められていて、Goalに到着する方策はその報酬により行動価値を更新して迷路を解く1セットを終了する。行動価値Qの更新式の基本形は以下のようになる。
$$Q(s,a)\leftarrow Q(s,a) + \alpha[r+\gamma*max_{a'}Q(s',a')-Q(s,a)]$$$Q$:行動価値
$s$:状態(エージェントの位置、マス目)
$a$:行動
$\alpha$:学習率
$\gamma$:時間割引率
$r$:報酬
としてあたえられる。$s', a'$は1つ先の状態(すなわち、決定された行動先の行動価値)であることを表している。上の式を見ればわかる通り、Q学習における更新は1つ先のマス目の行動価値Qとの差を更新の駆動力としているので、もし最初に与えられる各マス目のQの値が一律0であるならば、エージェントはstartから各マスをランダムに動き回り、偶然Goalにたどり着く方策を取得した場合のみそのマスの行動価値が更新される。
これは実際その通りであって、最初にうちはランダムな探索を行い報酬を得て、だんだんとGoalやその近辺のマスからStartへ向かって行動価値が伝播していく。一方で、上式では一旦行動価値がStartからGoalまで決定された場合にその経路のみを絶対に通ってしまう(ほかのマスは0なのでそちらに移動する方策は選択されない)という欠陥がある。そこで、方策決定の際にある確率εでランダムに行動をとるようにして、だんだんとεの値を減らしていく計算方法がとられる。これがε‐greedy法の簡単な説明である。
研究背景
安全工学のの中では火災という災害は1つの大きな研究対象である。火災時の避難について、既往の研究においては実験と計算から様々な報告がなされている。例としては、迷路を用いた火災避難行動の模擬などがある。計算においては
- 人間行動を粒子運動と解釈して運動方程式を解くモデル
- セルオートマトンモデル
などが頻繁に議論の俎上に上がるが、どちらも環境に対する情報や環境依存の顕著なルールが計算に用いられる現状がある。そのため、多くの研究が実際の火災事例の検証とともに論じられており、避難行動の予測に関しては疑問が浮かび上がる。
そこで、ここで考えるのはQ学習による迷路問題を応用して火災発生から避難までの最適経路の計算とその定量的な考察をしてみようというアイデアに基づく研究である。
この手法の一つの利点としては、事前に設定するパラメータの環境依存が少ないという特徴がある。また、報酬や方策の設定如何によりアルゴリズムのルール設定を増やすことなく大きな拡張性を持つことが予想される。Q学習による迷路問題
コードを張り付けることが早いだろう。
Q学習による解法
plain_Q_model.pyimport numpy as np import matplotlib.pyplot as plt #decide the direction to move by Q table and random probability epsilon #and convert it as movement on the map. def decide_action(status, maze_row, q_table, maze_map, epsilon): direction=["up", "right", "down", "left"] if(np.random.rand() < epsilon): #at random choice direction_to=np.random.choice(direction, p=maze_map[status]) else: #direction is selected at max Q value direction direction_to=direction[np.nanargmax(q_table[status])] #convert direction to map information at matrix if(direction_to=="up"): status=status-maze_row action=0 elif(direction_to=="right"): status=status+1 action=1 elif(direction_to=="down"): status=status+maze_row action=2 elif(direction_to=="left"): status=status-1 action=3 return status, action #q_learning function to update the Q_value def q_learning(status, action, next_status, goal, q_table, alfa, gamma, reward): #setting of reward if(next_status==goal): r=reward else: r=0 #update fomula of Q_value q_table[status][action]+=alfa*(r+gamma*(np.nanmax(q_table[next_status])-q_table[status][action])) return q_table #solve and update the maze at once def goal_once(start, goal, maze_row, maze_map, q_table, alfa, gamma, reward, epsilon): flag=True history_move=[] #initialize status=start #solve maze until it gets the goal while(flag): next_status, action=decide_action(status, maze_row, q_table, maze_map, epsilon) q_table=q_learning(status, action, next_status, goal, q_table, alfa, gamma, reward) #record the history of action history_move.append([status, action]) #flag of goal if(next_status==goal):flag=False #status update status=next_status return q_table, history_move move_0=np.array([0, 0, 0, 0]) move_w=np.array([1, 0, 0, 0]) move_d=np.array([0, 1, 0, 0]) move_s=np.array([0, 0, 1, 0]) move_a=np.array([1, 0, 0, 1]) move_wd=np.array([1, 1, 0, 0])/2 move_ws=np.array([1, 0, 1, 0])/2 move_wa=np.array([1, 0, 0, 1])/2 move_ds=np.array([0, 1, 1, 0])/2 move_da=np.array([0, 1, 0, 1])/2 move_sa=np.array([0, 0, 1, 1])/2 move_wds=np.array([1, 1, 1, 0])/3 move_wda=np.array([1, 1, 0, 1])/3 move_wsa=np.array([1, 0, 1, 1])/3 move_dsa=np.array([0, 1, 1, 1])/3 move_wdsa=np.array([1, 1, 1, 1])/4 ###input form### maze_map=np.array([move_ds, move_dsa, move_dsa, move_dsa, move_sa, \ move_wds, move_wdsa, move_wdsa, move_wdsa, move_wsa,\ move_wds, move_wdsa, move_wdsa, move_wdsa, move_wsa,\ move_wd, move_wda, move_wda, move_wda, move_wa]) q_table=np.where(maze_map==0.0, np.nan, 0) maze_row=5 maze_columns=4 start=0 goal=19 reward=1 time_of_episode=100 alfa = 0.10 # 学習率 gamma = 0.92 # 時間割引率 epsilon = 0.99 # ε-greedy法の初期値 probability_reduce_rate=1.04 ###input form end### history_move=[] size_of_epi=[] episode = 1 flag=True while(flag): q_table, history_move=goal_once(start, goal, maze_row, maze_map, q_table, alfa, gamma, reward, epsilon) print("this is episode: {0:5d}, steps to goal are {1:5d}".format(episode, len(history_move))) size_of_epi.append(len(history_move)) if(time_of_episode==episode): flag=False episode=episode-1 episode+=1 epsilon=epsilon/probability_reduce_rate q_table=q_table/np.nanmax(q_table) direcion=["↑", "→", "↓", "←"] for i in range(len(history_move)): print(direcion[history_move[i][1]]) plt.plot(size_of_epi) plt.show() q_table[goal]=1.0 np.set_printoptions(suppress=True, precision=4, floatmode='maxprec') #print(maze_map) print(q_table) q_table_max=np.zeros(goal+1) for i in range(len(q_table)): q_table_max[i]=np.nanmax(q_table[i]) print(q_table_max.reshape(maze_columns, maze_row)) q_table_max=q_table_max.reshape(maze_columns, maze_row) plt.figure(figsize=(10, 5)) plt.imshow(q_table_max, interpolation='nearest', vmin=0 ,cmap='YlOrRd') plt.colorbar() plt.show()下に計算結果を示してあるが、左上から右下にゴールする迷路で極めて明瞭に行動価値が伝播してGoalまでの道筋ができていることがわかる。
火災の模擬
これを拡張して、火災発生時の避難行動の学習を模擬してみる。
ここではGoalに報酬を置いただけのモデルであるが、簡単な拡張として火災に見立てたマスを用意してそこにたどり着いた時に負の報酬を与えるものとする。また、負の報酬を持つマスについた場合もゲームを1セット終了とする。すなわち、エージェントはStartから知識0の状態で出発して、何度も死に戻りをしながらGoalを目指すわけである。結果
上がその計算結果であるが、なかなか面白い結果が得られた。Q学習の更新式をもう一度見てみよう。
$$Q(s,a)\leftarrow Q(s,a) + \alpha[r+\gamma*max_{a'}Q(s',a')-Q(s,a)]$$
以上の式に基づいて各マス各方策の行動価値が更新されるが、上の式ではすべての更新が行動先の最大値を反映させるようになっているので、負の報酬を与えても周辺の1マス以外はMax関数で無視されてしまう。
Q学習の上の更新式は楽観的な行動価値の計算式なので、簡単に言えば隣に大きな負の報酬が存在しても最良の経路をとる。隣で炎が燃え盛っていても、そこが最短経路ならそこを通るように計算してしまうという問題点がある。悲観的な更新式
ここで少し悲観的なエージェントを考えてみる。Pessimismというパラメーターを与えて、
$$Q(s,a)\leftarrow Q(s,a) + \alpha[r+\gamma*max_{a'}Q(s',a')-Q(s,a)]$$
$$Q(s,a)\leftarrow Q(s,a) + \alpha[r+\gamma*(max_{a'}Q(s',a')/(1+pessimism)+min_{a'}Q(s',a')*pessimism/(1+pessimism))-Q(s,a)]$$
上の式を下の式のように改変する。つまり一定の割合で行動先の行動価値の最低値を見積もるように改変する。pessimism=0なら元の更新式と同じに、pessimism→∞なら各マスの行動価値の最低値のみを評価して学習するプログラムになる。
具体的には、q_learning#q_learning function to update the Q_value def q_learning(status, action, next_status, goal, q_table, alfa, gamma, reward, pesimism): r=0 #setting of reward for i in range(len(goal)): if(next_status==goal[i]): r=reward[i] #update fomula of Q_value q_table[status][action]+=alfa*(r+gamma*(np.nanmax(q_table[next_status])-q_table[status][action])) return q_table該当箇所の関数を
q_learning#q_learning function to update the Q_value def q_learning(status, action, next_status, goal, q_table, alfa, gamma, reward, pesimism): r=0 #setting of reward for i in range(len(goal)): if(next_status==goal[i]): r=reward[i] #update fomula of Q_value q_table[status][action]+=alfa*(r+gamma*(np.nanmax(q_table[next_status])/(1+pesimism)\ +np.nanmin(q_table[next_status])*pesimism/(1+pesimism)-q_table[status][action])) return q_tableと書き換える。
これで計算をしてみると。
きちんと火災発生個所を回避するような経路が選択されていることがわかる。
中規模迷路の行動価値マップ(ポテンシャル)
以上の知見を踏まえて、迷路の規模をさらに拡大した状態で、迷路の各マスからGoalまでの道順を学習させ、さらにそこから得られた行動価値を平均化して、迷路全体からGoalまでのヒートマップを作製した。
ヒートマップ自体に本質的な意味はないが、火災の発生時にどの程度のリスクが生じて、どのような経路の選択の変化が起きるのかを分かりやすく示すうえで有用であると考えられる。上部中央をゴールとしている。
火災なし:
火災あり:
フロア右側で火災を発生させた場合、右側のスペースの行動価値が著しく下がることがわかる。一方で中央下部の2本の経路のうち左側の通路がより行動価値が高く選好されることがわかる。
火災を単一の負の報酬マスとみなした場合でもなかなか面白い結果が得られた。問題点
冒頭で自主研究と宣言したが、これがまだ具体的な形にならないのには以下の問題点がある。
マルチエージェント化
火災発生時の人の流動は言うまでもなくマルチエージェントなタスクを解く必要がある。また、実際の避難行動の特徴として
- 避難者はリーダー(知識のある係員)などに従う。(これは行動価値関数の共有とみなせる)
- 案内板や避難誘導などは一定の効果がある。(特定のマスに報酬や方策を設定する必要がある)
- 出口付近では混雑が発生して人の流動性が落ちる。(もちろん、逃げるのが遅れるので、あとから脱出する人ほど報酬を漸減するように設定する必要がある)
このような実際の避難行動の特性を考慮に入れたうえで学習を行う必要がある。それに比べると今回のプログラムはQ学習の改良で終わっている。
火災の特徴の組み込み
火災時の避難行動では火災それ自体が時間とともに大きく変化する。避難行動における一番の大きな要因は煙である。
煙の横方向の移動速度は大体人間の歩行速度程度といわれるが、拡散の特性、移動速度や方向などはさらに吟味する必要がある。ターンごとに負の報酬領域を時間発展させることが有効なアルゴリズムとして考えられるが、実際の火災の避難行動の実験では、火災の煙が人の視界を遮ること、歩行速度を低下させることなどが指摘されており、その効果を負の報酬だけで表現していいものかは不明である。人間の避難行動のジレンマ
先ほど述べたように、人間の避難行動には実験から観測された特徴的な行動がある。影響力のあるリーダーについていくこと、とりあえず人についていく群集行動なども知られている。たとえ出口が狭くほかの出口に向かうほうが効率的でもこのような行動は起こりうる。
問題は強化学習で学習した最適な経路が、人間の非合理性や本能といった部分を鑑みたときに最適とは限らないということである。パニックに陥る人もいる中で果たしてどこまでの非合理的な行動を報酬に落とし込めば、それが人間行動にとって最適といえるのかが最大の問題となってくる。展望
結局計算のほうはサーバー側で高速に処理して、避難者それぞれに最適な避難経路を提示できるようになったら面白いかも程度に考えている。既往のセルオートマトン法などに比べて環境依存のアルゴリズムが少ないというのはこのあたりの拡張性にも効いてきそう。
都市交通や駅の乗り換えなど、この辺りの分野ではすでに実用化されているのだろうか?何か有益な文献があれば教えていただけると幸いです。
結び
※参考文献の数が多いので略させていただきます。参考文献に興味があれば御一報ください





- 投稿日:2020-03-14T22:02:00+09:00
「出品者Amazonのマスク」が出品されたらslack通知するプログラム(BeautifulSoup+Python)
はじめに
新型コロナウイルス感染症 (COVID-19) の影響でマスクが入手しづらい状況が続いています。
私は花粉症ですがマスクの手持ちが少なくなってきてこの春を無事に過ごせるか心配しています。
薬を飲めばいいって話もありますが、薬はあまり好きではないです。そこでAmazonをちょこちょこ見ていたら、出品者がAmazonのマスクが常識的な値段で稀に出品されて、即売り切れになることを発見しました。
もしかして発見が早ければAmazonで常識的な値段でマスクが買えるのでは、、、と思った私が作成した「出品者がAmazonのマスクが出品されたら通知するプログラム」を公開いたします。前提
- ここに記載する「出品者がAmazonのマスク」とは、マスクのカテゴリで出品者がAmazonになっているものを指します
- APIを使ってスマートにやる方法があると思いますが、他の人も簡単に使えるようにWebスクレイピング+slackでやることにします
- マスクを買うことが目的のため、必要最低限の機能にします
方針を決める
どのようなものを作るか以下の流れで方針を検討し、決めました。
- 私は50枚とか入っている使い捨てのマスクが欲しいのですが、余計な検索条件を入れて欲しいマスクが通知されないと悲しい
- 使い捨てのマスクの中にも寝るときに使用する濡れマスクなどが含まれており、機械的に私が欲しいものだけを通知するのは厳しそう
- 3月14日時点でAmazonが出品者のマスクは65件しか無く、出品数に変動が少ない
- 新しく出品されたものを全て通知しても大した件数にならないと思われる
- マスクカテゴリに出品者Amazonの商品が追加されたらslackで通知する!!
出品者がAmazonのマスクを表示するURLの確認
GUIでマスクのカテゴリに移動して出品者Amazonを選択した場合、URLは以下のようになると思います。
人により若干異なる場合もあります。上記のURLを使っても良いのですが余計な文字が含まれていそうなため、もう少しシンプルにできないか試してみます。
ドキュメントを探すのが面倒だったのでURLを変えながら試した結果、以下のことがわかりました。
n:160384011,n:!161669011,n:169911011,n:169922011はカテゴリを絞るところのようで、大カテゴリ→中カテゴリ→小カテゴリ、という感じで指定されているようです(たぶん)p_6:AN1VRQENFRJN5は出品者Amazonの意味のようです(たぶん)- 他の
stqidrnidrefは無くてもよいようです(たぶん)ということでマスクカテゴリに出品されている出品者がAmazonのマスクを表示するには、以下のURLでOKでした。
https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5作成
0. 準備
必要に応じて以下のコマンドで必要なものをインストールしてください。
sudo apt install python3-pip sudo pip3 install beautifulsoup4 sudo pip3 install lxml私はMacでAnacondaを使用しているので記事内では省略していますが、Linux上でファイルを作成する場合などは以下のようにプログラムの先頭にpython3の場所を記載してください。
#!/usr/bin/python31. 必要なものをインポート
BeautifulSoupを使用します。
import requests from bs4 import BeautifulSoup import re import urllib.parse2. ページ全体を取得
target_url = 'https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5' headers = {'User-Agent': ''} response = requests.get(target_url, headers=headers) soup = BeautifulSoup(response.text, 'lxml')なお、headersを付けないとHTML内に以下のメッセージが記載されて、商品一覧が取得できませんでした。
To discuss automated access to Amazon data please contact api-services-support@amazon.com.
For information about migrating to our APIs refer to our Marketplace APIs at https://developer.amazonservices.jp/ref=rm_c_sv, or our Product Advertising API at https://affiliate.amazon.co.jp/gp/advertising/api/detail/main.html/ref=rm_c_ac for advertising use cases.3. 商品名と商品URLの要素を確認
商品名と商品URLの2つを取得したいのでソースを確認したところ、
class="a-size-mini a-spacing-none a-color-base s-line-clamp-4"で取得できることがわかりました。※要素名の簡単な取得方法は以下に記載しています。
https://qiita.com/hanzawak/items/58553017e107fce2f34c#3-操作したい要素を確認する
4. 商品名と商品URLの要素を取得
find_allで先ほど得られた要素名の中身を取得します。
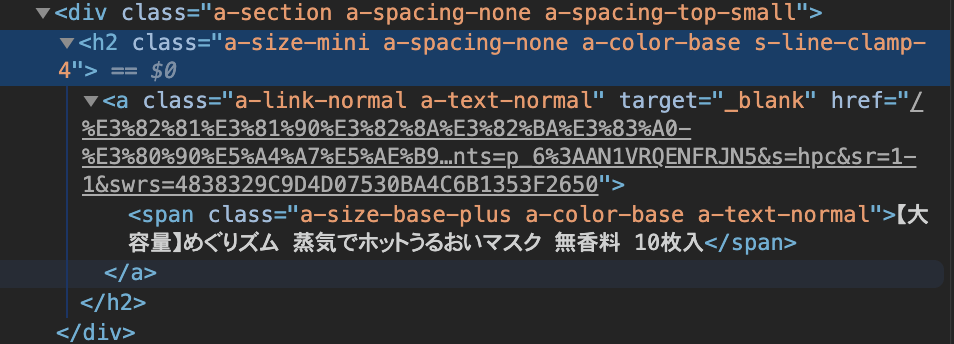
find_allを使うと全要素が取得できます。product_info= soup.find_all(class_='a-size-mini a-spacing-none a-color-base s-line-clamp-4')取得した
product_infoの中身を確認すると以下のようになっています。<h2 class="a-size-mini a-spacing-none a-color-base s-line-clamp-4"> <a class="a-link-normal a-text-normal" href="/%E3%82%81%E3%81%90%E3%82%8A%E3%82%BA%E3%83%A0-%E3%80%90%E5%A4%A7%E5%AE%B9%E9%87%8F%E3%80%91%E3%82%81%E3%81%90%E3%82%8A%E3%82%BA%E3%83%A0-%E8%92%B8%E6%B0%97%E3%81%A7%E3%83%9B%E3%83%83%E3%83%88%E3%81%86%E3%82%8B%E3%81%8A%E3%81%84%E3%83%9E%E3%82%B9%E3%82%AF-%E7%84%A1%E9%A6%99%E6%96%99-10%E6%9E%9A%E5%85%A5/dp/B07ZTDR2Q1/ref=sr_1_1?dchild=1&m=AN1VRQENFRJN5&qid=1584167047&refinements=p_6%3AAN1VRQENFRJN5&s=hpc&sr=1-1" target="_blank"> <span class="a-size-base-plus a-color-base a-text-normal">【大容量】めぐりズム 蒸気でホットうるおいマスク 無香料 10枚入</span> </a> </h2>, <h2 class="a-size-mini a-spacing-none a-color-base s-line-clamp-4"> <a class="a-link-normal a-text-normal" href="/%E3%82%B9%E3%82%BA%E3%83%A9%E3%83%B3-%E3%83%AA%E3%83%AA%E3%83%BC%E3%83%99%E3%83%AB-%E3%81%BE%E3%82%8B%E3%81%94%E3%81%A8%E3%83%89%E3%83%A9%E3%82%A4%E3%83%8F%E3%83%BC%E3%83%96%E3%83%9E%E3%82%B9%E3%82%AF-%E3%83%AD%E3%83%BC%E3%82%BA%E3%83%9E%E3%83%AA%E3%83%BC-%E6%98%BC%E7%94%A8/dp/B0857HY5NC/ref=sr_1_2?dchild=1&m=AN1VRQENFRJN5&qid=1584167047&refinements=p_6%3AAN1VRQENFRJN5&s=pantry&sr=1-2" target="_blank"> <span class="a-size-base-plus a-color-base a-text-normal">リリーベル まるごとドライハーブマスク ローズマリー 昼用</span> </a> </h2>, 略
a-link-normal a-text-normalの後ろが商品URL、a-size-base-plus a-color-base a-text-normalの後ろが商品名となっているようです。
ただよく見ると商品URLの中身にも商品名が含まれていそうなのでデコードしてみたところ、以下のように商品名が含まれていました。
そのためa-link-normal a-text-normalだけを取得すれば商品URLと商品名が取得できるようです。/めぐりズム-【大容量】めぐりズム-蒸気でホットうるおいマスク-無香料-10枚入/dp/B07ZTDR2Q1/ref=sr_1_1?dchild=1&m=AN1VRQENFRJN5&qid=1584167047&refinements=p_6:AN1VRQENFRJN5&s=hpc&sr=1-1また、商品URLは
/めぐりズム-【大容量】めぐりズム-蒸気でホットうるおいマスク-無香料-10枚入/dp/B07ZTDR2Q1/までで機能しますので、その後ろの余計な文字列は後の工程で削除しようと思います。5. 商品URLを抽出
product_infoの中身から商品URLのみ抽出します。
product_infoはリスト型なのですが正規表現でサクッと抽出したいため、strに変換して抽出しています。product_url = [] product_info = str(product_info) for line in product_info.split('\n'): if '<a class="a-link-normal a-text-normal" href="' in line: # URLリンクの含まれている行であれば pattern = '<a class="a-link-normal a-text-normal" href="(.+)/ref=.*' # URLリンクの必要な部分のみ抽出 result = re.match(pattern, line) result_decode = urllib.parse.unquote(result.group(1)) # デコード product_url.append(result_decode) # デコードした結果をproduct_urlに追加product_urlの中身は以下のようになりました。
['/めぐりズム-【大容量】めぐりズム-蒸気でホットうるおいマスク-無香料-10枚入/dp/B07ZTDR2Q1', '/スズラン-リリーベル-まるごとドライハーブマスク-ローズマリー-昼用/dp/B0857HY5NC', '/プロフェッショナルマスク-シールド付-51417-25マイ-ゴムヒモブルー-オオサキメディカル/dp/B0797JWNV4', 略いっそのことリンクの形にしてしまおうと思いますので、
https://www.amazon.co.jp/を先頭につけます。product_url_amazon = ['https://www.amazon.co.jp' + i for i in product_url]product_urlの中身は以下のようになりました。
['https://www.amazon.co.jp/めぐりズム-【大容量】めぐりズム-蒸気でホットうるおいマスク-無香料-10枚入/dp/B07ZTDR2Q1', 'https://www.amazon.co.jp/スズラン-リリーベル-まるごとドライハーブマスク-ローズマリー-昼用/dp/B0857HY5NC', 'https://www.amazon.co.jp/プロフェッショナルマスク-シールド付-51417-25マイ-ゴムヒモブルー-オオサキメディカル/dp/B0797JWNV4', 略ここまでで1ページ目のURLを取得することができました。
6. 2ページ目以降の商品URL取得方法の検討
まず商品ページ下の「次へ」ボタンのソースを確認します。
ソースは以下の通りです。
じーっと見てるとどうやらURLの末尾に&page=2という感じでページ指定ができるような気がします。
試しに以下のようにURLを組み立ててみると想定通り2ページ、3ページと表示できました。
ちなみに1ページ目も表示できました。https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=1
https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=2
https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=3本来であれば「全何ページあるのでそのページ数分ループを繰り返す」方法が良いと思いますが、以下のようにページ数が3ページ以内のものと3ページより多いもので若干リンクの形式が異なるため、全何ページかは取得しないことにします。
代わりにURL末尾をpage=1page=2page=3.... と数字を増やしていき、商品がなくなったら終了という処理にします。
7. 全ページの商品URL取得
今まで作成した部分を結合して、全ての商品URLが取得できるように変更していきます。
全ページをループして確認しても良いのですがとりあえず9ページまでしか見ないようにしておきます。import requests from bs4 import BeautifulSoup import re import urllib.parse product_url = [] for page_num in range(1,10): # 1〜9ページを確認 target_url = 'https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=' + str(page_num) # ページ番号を末尾に追加 headers = {'User-Agent': ''} response = requests.get(target_url, headers=headers) soup = BeautifulSoup(response.text, 'lxml') product_info= soup.find_all(class_='a-size-mini a-spacing-none a-color-base s-line-clamp-4') if len(product_info) == 0: # 商品が0個の場合(商品が存在しないページの場合) break product_info = str(product_info) for line in product_info.split('\n'): if '<a class="a-link-normal a-text-normal" href="' in line: # URLリンクの含まれている行であれば pattern = '<a class="a-link-normal a-text-normal" href="(.+)/ref=.*' # URLリンクの必要な部分のみ抽出 result = re.match(pattern, line) result_decode = urllib.parse.unquote(result.group(1)) # デコード product_url.append(result_decode) # デコードした結果をproduct_urlに追加 product_url_amazon = ['https://www.amazon.co.jp' + i for i in product_url]これで全商品のURLを抽出することができました。
8. 前回抽出時と今回抽出時を比較し、追加分を抽出
比較にはいろいろな方法がありますが、ここではテキストに書き込んだ内容で比較しようと思います。
まず取得した商品URLを改行区切りでファイルに書き込みます。
tmp = "\n".join(product_url_amazon) with open('before_mask_url.txt', 'w') as f: f.write(tmp)以下のように書き込まれます。
https://www.amazon.co.jp/COZEE-CRITTERS-コージークリッター-防寒マスク-フリーサイズ/dp/B000CED4F2 https://www.amazon.co.jp/EXECUTE-エクゼキュート-ストレッチエナメル口開きマスク/dp/B07KYG8FYR https://www.amazon.co.jp/EXECUTE-エクゼキュート-ストレッチエナメル目口開きマスク/dp/B07KYW8XZY 略改行区切りのファイルをリストで読み込むには以下のようにします。
with open('before_mask_url.txt', 'r') as f: before_mask_url = [tmp.strip() for tmp in f.readlines()]リストを比較するには以下のようにします。
before = ['aaa', 'bbb', 'ccc'] after = ['aaa', 'bbb', 'ddd'] diff = set(after) - set(before) print(diff) # {'ddd'}上記を踏まえて、今回は以下の流れで比較しようと思います。
- 1回目のプログラム実行で、商品URLを取得し、ファイルに書き込み
- 2回目のプログラム実行で、商品URLを取得し、ファイルに書き込まれた内容と比較し、追加分を出力
- 以降、2の繰り返し
9. 前回抽出時と今回抽出時を比較し、追加分を出力するプログラム
今までの内容を全て結合します。
import requests from bs4 import BeautifulSoup import re import urllib.parse import os product_url = [] sava_filename = 'before_product_url_amazon.txt' # 商品URL一覧を保存するファイル名を指定 for page_num in range(1,10): # 1〜9ページを確認 target_url = 'https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=' + str(page_num) # ページ番号を末尾に追加 headers = {'User-Agent': ''} response = requests.get(target_url, headers=headers) soup = BeautifulSoup(response.text, 'lxml') product_info= soup.find_all(class_='a-size-mini a-spacing-none a-color-base s-line-clamp-4') if len(product_info) == 0: # 商品が0個の場合(商品が存在しないページの場合) break product_info = str(product_info) for line in product_info.split('\n'): if '<a class="a-link-normal a-text-normal" href="' in line: # URLリンクの含まれている行であれば pattern = '<a class="a-link-normal a-text-normal" href="(.+)/ref=.*' # URLリンクの必要な部分のみ抽出 result = re.match(pattern, line) result_decode = urllib.parse.unquote(result.group(1)) # デコード product_url.append(result_decode) # デコードした結果をproduct_urlに追加 product_url_amazon = ['https://www.amazon.co.jp' + i for i in product_url] if os.path.exists(sava_filename): # 商品URLを記録したファイルがあれば with open(sava_filename, 'r') as f: # 商品URLを読み込み before_product_url_amazon = [tmp.strip() for tmp in f.readlines()] added_product_url_amazon = set(product_url_amazon) - set(before_product_url_amazon) # 差分取得(Python実行時に取得した商品URL - 商品URLを記載したファイル) tmp = "\n".join(product_url_amazon) # Python実行時に取得した商品URLをファイルに保存 with open(sava_filename, 'w') as f: f.write(tmp) if(added_product_url_amazon): print('\n'.join(added_product_url_amazon))今までのプログラムを結合しただけなので可読性に欠けますが、上記のプログラムを実行すると、前回実行時から追加されたURLがあれば出力されます。
10. slackで通知
WebHookで通知するのが簡単なのでその方法を記載します。
WebHookの設定ページにアクセス
https://slack.com/services/new/incoming-webhook
通知先のchannelを選択
通知先のchannelを選択した後、Add Incoming WehHooks integrationをクリックします。
次の画面で表示される
Webhook URLをメモします。slackに通知するプログラム
以下のプログラムを実行するとslackに通知されます。
import json webhook_url = '<Webhook URL>' requests.post(webhook_url, data = json.dumps({ 'text': str('\n'.join(added_product_url_amazon)), # メッセージ内容 'username': 'Amazon Mask', # ユーザー名 }))slackでは以下のように表示されます。
11. 前回実行時から追加されたURLがあればslack通知
以下を実行すると前回実行時から追加されたURLがあればslack通知されます。
import requests from bs4 import BeautifulSoup import re import urllib.parse import os import json product_url = [] sava_filename = 'before_product_url_amazon.txt' # 商品URL一覧を保存するファイル名を指定 webhook_url = '<Webhook URL>' for page_num in range(1,10): # 1〜9ページを確認 target_url = 'https://www.amazon.co.jp/s?rh=n:169922011,p_6:AN1VRQENFRJN5&page=' + str(page_num) # ページ番号を末尾に追加 headers = {'User-Agent': ''} response = requests.get(target_url, headers=headers) soup = BeautifulSoup(response.text, 'lxml') product_info= soup.find_all(class_='a-size-mini a-spacing-none a-color-base s-line-clamp-4') if len(product_info) == 0: # 商品が0個の場合(商品が存在しないページの場合) break product_info = str(product_info) for line in product_info.split('\n'): if '<a class="a-link-normal a-text-normal" href="' in line: # URLリンクの含まれている行であれば pattern = '<a class="a-link-normal a-text-normal" href="(.+)/ref=.*' # URLリンクの必要な部分のみ抽出 result = re.match(pattern, line) result_decode = urllib.parse.unquote(result.group(1)) # デコード product_url.append(result_decode) # デコードした結果をproduct_urlに追加 product_url_amazon = ['https://www.amazon.co.jp' + i for i in product_url] if os.path.exists(sava_filename): # 商品URLを記録したファイルがあれば with open(sava_filename, 'r') as f: # 商品URLを読み込み before_product_url_amazon = [tmp.strip() for tmp in f.readlines()] added_product_url_amazon = set(product_url_amazon) - set(before_product_url_amazon) # 差分取得(Python実行時に取得した商品URL - 商品URLを記載したファイル) tmp = "\n".join(product_url_amazon) # Python実行時に取得した商品URLをファイルに保存 with open(sava_filename, 'w') as f: f.write(tmp) if(added_product_url_amazon): requests.post(webhook_url, data = json.dumps({ 'text': str('\n'.join(added_product_url_amazon)), # メッセージ内容 'username': 'Amazon Mask', # ユーザー名 }))12. プログラムの定期実行
「11. 前回実行時から追加されたURLがあればslack通知」のプログラムをcronなどで定期的に実行します。
これで「出品者がAmazonのマスクが出品されたらslack通知するプログラム」が完成です。その他
変数名、コメント、そもそもの書き方、が雑すぎました。。
後日綺麗に書き換えようと思います。





- 投稿日:2020-03-14T21:30:44+09:00
「アイネクライネナハトムジーク」に出てくる斉藤さんをミスチルの桜井さんとして再現してみた
はじめに
伊坂幸太郎の小説「アイネクライネナハトムジーク」という作品をご存知でしょうか。
小説好きな人なら分かるかもしれませんね。
割と日常っぽい感じの短編集なのですが、
その作品には「斉藤さん」という人物が登場します。
百円を払って「今、こんな気持ちです」「こんな状況です」と話をすると、
斉藤さんがパソコンでその客の気分にマッチする曲の一部を流してくれます。
曲は斉藤さんだけあって斉藤和義の曲の一部が流れるようになっています。そこで感情分析を使って同じようなことができるのではないかと考え、
今回作ってみることにしました。
アーティストは何でも良いですが、私自身がミスチルファンということで
桜井さんというキャラクターにして作りました。今回はCOTOHA APIの感情分析を使います。
ちょうどキャンペーンもやってるみたいですし、参加も兼ねて。どんなものを作ったか
説明するよりまずはものを作ったのかを見たほうが早いということで。
- 入力前
あなた:
- 入力
あなた:毎日が単調でつまらない。何かいいことないかな。
- 出力
あなた:毎日が単調でつまらない。何かいいことないかな。 桜井さん:東京―パリ間を行ったり来たりして 順風満帆の20代後半だね バブリーな世代交代の波押し退けて クライアントに媚び売ったりなんかして [デルモ]なんとでもとれますが、
パリにしょっちゅう行くような仕事をし、順風満帆な人生が来ることがあるよと解釈できそうです。
これはミスチルの楽曲「デルモ」の歌詞の一部となります。システム概要
大きく①データ構築と②フレーズ検索の処理の2つに分かれます。
①データ構築
歌ネットから歌詞をスクレイピングして、
フレーズに分割する。(歌詞全体のうちの1段落を1フレーズとする)
各フレーズを感情分析APIにかけて分析結果をDBに保存。②フレーズ検索
客が状況を説明してその内容を感情分析APIにかけて分析結果を取得。
その後、スコアが近いフレーズをDBから検索する。
検索は、スコアの範囲検索を、範囲を広めながら実施し、
複数のフレーズが取得できた場合はランダムに1つ選択し、客に返信する。実行結果
いくつか実行して面白かったのを載せます。
- 仕事でいいことあったよ
あなた:今日仕事でめっちゃ褒められて嬉しい! 桜井さん:イライラして過ごしてんなら愛を補充 君へと向かう恋の炎が燃ゆる 向かいの家の柴犬にも「ハイ ポンジュール!」 あぁ世界は薔薇色 ここは そう CENTER OF UNIVERSE 僕こそが中心です あぁ世界は素晴らしい [CENTER OF UNIVERSE]前半だけ見ると、あれイライラしてる?ってなったけど、
後半めっちゃ陽気なことを歌ってます。
仕事うまくいってる俺は世界の覇者なり!的な。
- 受験勉強に失敗しちゃった
あなた:受験勉強失敗した。また来年頑張ろうかな。。。 桜井さん:思い切り息を吸い込んで この想いを空に放ちたい 自分の世界に閉じこもった 冴えない気分から抜け出して どんなときだってサンライズ この胸に輝かせていたいんだ [SUNRISE]とりあえず息吸い込んで冴えない気分から抜け出せよ的な。ネガティブな感じでてるけど、結構励ます感じも出てますね。
- とある曲のタイトルをそのまま気持ちにして伝えてみた
あなた:もう恋なんてしないなんて言わないよ絶対 桜井さん:聞こえてくる 流れてくる 君を巡る 抑えようのない想いがここにあんだ 耳を塞いでも鳴り響いてる [365日]好きでたまらない気持ちがマッチしてますね。
- 小説に出てくる日高さんと同じ心境を伝えてみた
あなた:実は付き合っている彼女と別れようと思ってるんだ 桜井さん:もう いいでしょう!? これで終わりにしよう ねぇ どうでしょう!? 君だってそう思うでしょ!? [I]もう終わらせていいよと伝えてるのかもしれません。
コード
興味ある方はみてみてください。
とりあえず動くものを作ったのであまり整理されていないのはご承知の上で。。。
DBスキーマ
MYSQLを使っています。
今回は事前にMr.Childrenをアーティスト情報として登録します。create database sakurai; create table artist (artist_id smallint auto_increment not null primary key, artist_name varchar(100)); insert into artist (artist_name) values('Mr.Children'); create table title (title_id smallint auto_increment not null primary key, title varchar(100), artist_id smallint); create table lyric (title_id smallint, phrase_id int auto_increment not null primary key, phrase varchar(1000), score float, sentiment tinyint);
Pythonコード
sakuraisan.py# -*- coding: utf-8 -*- import random, requests, json, sys, time import urllib.request import mysql.connector as mydb import pandas as pd from bs4 import BeautifulSoup ARTIST_ID = 1 # DBに事前に登録するアーティストのID AGENT_NAME = '桜井さん' # 答えてくるエージェントの名前 # COTOHA APIクラス class CotohaApi(): def __init__(self): self.COTOHA_ACCESS_INFO = { "grantType": "client_credentials", "clientId": "<ご自身のClient ID>", "clientSecret": "<ご自身のClient Secret>" } self.ACCESS_TOKEN_PUBLISH_URL = '<ご自身のAccess Token Publish URL>' self.BASE_URL = '<ご自身のAPI Base URL' self.ACCESS_TOKEN = self.get_access_token() # アクセストークンの取得 def get_access_token(self): headers = { "Content-Type": "application/json;charset=UTF-8" } access_data = json.dumps(self.COTOHA_ACCESS_INFO).encode() request_data = urllib.request.Request(self.ACCESS_TOKEN_PUBLISH_URL, access_data, headers) token_body = urllib.request.urlopen(request_data) token_body = json.loads(token_body.read()) self.access_token = token_body["access_token"] self.headers = { 'Content-Type': 'application/json;charset=UTF-8', 'Authorization': 'Bearer {}'.format(self.access_token) } # 感情分析APIを実施、分析結果を返却 def sentiment_analysis(self, text): request_body = { 'sentence': text } url = self.BASE_URL + 'nlp/v1/sentiment' text_data = json.dumps(request_body).encode() request_data = urllib.request.Request(url, text_data, headers=self.headers, method='POST') sentiment_result = urllib.request.urlopen(request_data) sentiment_result = json.loads(sentiment_result.read()) return sentiment_result # Positive:1, Negative:-1, Neutral:0 に変換 def convert_sentiment(self, sentiment_in_word): if sentiment_in_word == 'Positive': return 1 elif sentiment_in_word == 'Neutral': return 0 elif sentiment_in_word == 'Negative': return -1 # DB操作クラス class DBHandler(): def __init__(self): self.conn = mydb.connect( host = '<DBのホスト名>', port = '<DBのポート番号>', user = '<DBのユーザ名>', password = '<DBのパスワード>', database = '<DB名>', charset='utf8' ) self.conn.ping(reconnect=True) self.cur = self.conn.cursor() # データ構築クラス class Learn(): def __init__(self): self.FILE_NAME = 'list.csv' self.ARTIST_NUMBER = '684' # 歌ネットのアーティストNo.(Mr.Childrenは684) self.MAX_PAGE = 2 # 歌ネットのアーティストの曲数一覧のページ数(Mr.Childrenは2ページ存在) # 歌詞を歌ネットから収集 def gather_lyric(self): #スクレイピングしたデータを入れる表を作成 list_df = pd.DataFrame(columns=['曲名', '歌詞']) for page in range(1, self.MAX_PAGE + 1): #曲ページ先頭アドレス base_url = 'https://www.uta-net.com' #歌詞一覧ページ url = 'https://www.uta-net.com/artist/' + self.ARTIST_NUMBER + '/0/' + str(page) + '/' response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') links = soup.find_all('td', class_='side td1') for link in links: a = base_url + (link.a.get('href')) #歌詞詳細ページ response = requests.get(a) soup = BeautifulSoup(response.text, 'lxml') title = soup.find('h2').text print(title) song_lyrics = soup.find('div', itemprop='text') for lyric in song_lyrics.find_all("br"): lyric.replace_with('\n') song_lyric = song_lyrics.text #サーバーに負荷を与えないため1秒待機 time.sleep(1) #取得した歌詞を表に追加 tmp_se = pd.DataFrame([title, song_lyric], index=list_df.columns).T list_df = list_df.append(tmp_se) #csv保存 list_df.to_csv(self.FILE_NAME, mode = 'a', encoding='utf8') # 歌詞をフレーズに分割し、DBに感情分析結果も含めたデータを登録 def add_lyric(self): db = DBHandler() df_file = pd.read_csv(self.FILE_NAME, encoding='utf8') song_titles = df_file['曲名'].tolist() song_lyrics = df_file['歌詞'].tolist() # 注意:曲数が多いとCOTOHAの1日に実行できるAPIの上限にひっかかかる(1日100曲程度が目安) for i in range(len(song_titles)): # タイトルの追加 title = song_titles[i] print("Info: Saving {}...".format(title), end="") db.cur.execute( """ insert into title (title, artist_id) values (%s, %s); """, (title, ARTIST_ID) ) db.conn.commit() db.cur.execute( """ select title_id from title where title= %s and artist_id = %s; """, (title, ARTIST_ID) ) title_id = db.cur.fetchall()[-1][0] # 歌詞のフレーズの感情分析結果を登録 # 二回改行が出現した場合をフレーズ区切りにする lyric = song_lyrics[i] lyric_phrases = lyric.split('\n\n') lyric_phrases = [lyric.replace('\u3000', ' ').replace('\n', ' ') for lyric in lyric_phrases] # フレーズごとに感情分析APIを利用し、感情分析結果をDBに登録 cotoha_api= CotohaApi() for phrase in lyric_phrases: sentiment_result = cotoha_api.sentiment_analysis(phrase)['result'] sentiment = cotoha_api.convert_sentiment(sentiment_result['sentiment']) score = sentiment_result['score'] db.cur.execute( """ insert into lyric (title_id, score, sentiment, phrase) values (%s, %s, %s, %s); """, (title_id, score, sentiment, phrase) ) db.conn.commit() print("Done") db.conn.close() if db.conn.is_connected() == False: print("Info: DB Disonnected") def execute(self): print("Info: 歌詞を収集中...") self.gather_lyric() print("Info: 歌詞をDBに追加中...") self.add_lyric() # フレーズ検索クラス class Search(): def __init__(self): self.SEARCH_SCOPE = [0.01, 0.1, 0.3] # 検索するスコアの幅 SCORE±SEARCH_SCOPEの範囲でリストの順に検索 def execute(self): print("あなた:", end="") input_data = input() print("{}:".format(AGENT_NAME), end="") cotoha_api= CotohaApi() sentiment_result = cotoha_api.sentiment_analysis(input_data)['result'] sentiment = cotoha_api.convert_sentiment(sentiment_result['sentiment']) score = sentiment_result['score'] db = DBHandler() find_flag = 0 # 検索範囲を徐々に広げながらスコアの近いフレーズを検索 for scope in self.SEARCH_SCOPE: # 最低1件あることを確認 db.cur.execute( """ select count(phrase_id) from lyric join title on lyric.title_id = title.title_id where sentiment = %s and score between %s and %s and artist_id = %s; """, (sentiment, score-scope, score+scope, ARTIST_ID) ) hit_num = db.cur.fetchall()[-1][0] if hit_num > 0: find_flag = 1 break # 検索結果が1件でも存在すれば、検索結果を取得し、客に返信 if find_flag == 1: db.cur.execute( """ select phrase,title from lyric join title on lyric.title_id = title.title_id where sentiment = %s and score between %s and %s and artist_id = %s; """, (sentiment, score-scope, score+scope, ARTIST_ID) ) search_result = db.cur.fetchall() phrase_chosen = random.choice(search_result) print("{} [{}]".format(phrase_chosen[0], phrase_chosen[1])) else: print("いい歌詞が見つからなかった。") db.conn.close() if __name__ == "__main__": args = sys.argv if len(args) == 2: process = args[1] # コマンドライン引数 learn: DBに歌詞情報を登録、search: DBから似た感情のフレーズを抽出 if process == 'search': searcher = Search() searcher.execute() elif process == 'learn': learner = Learn() learner.execute() else: print("Error: コマンドライン引数を1つ指定 [learn/search]") else: print("Error: コマンドライン引数を1つ指定 [learn/search]")実行方法は2通りあります。
- データ構築時
python sakuraisan.py learn
- フレーズ検索時
python sakuraisan.py searchおわりに
今回は感情分析結果のスコアが近い歌詞のフレーズをとってくるというシンプルなアルゴリズムで実装しましたが、
COTOHA APIには単語の感情を取ることもできます。
例えば公式の例にあるように、
「謳歌」という単語には「喜ぶ」「安心」といった感情を付与してくれます。
このあたりの情報もうまく検索に埋め込めたらもっと良い結果が返ってくるのではないかなと思ってます。また、LINE Botとかにしたら面白いのかなと思ったりしてます。
参考
以下の記事を参考にさせていただきました!

- 投稿日:2020-03-14T21:26:29+09:00
djangoとpostgresqlをDockerで接続しようとしたときに「django.db.utils.OperationalError: could not translate host name "db" to address: Name or service not known」というエラーが出る
エラー
Quickstart: Compose and Djangoを見ながらdockerでDjangoの開発環境を構築しようとして、
docker-compose upしたときに以下のエラーが出た。django.db.utils.OperationalError: could not translate host name "db" to address: Name or service not knownsetting.py
setting.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'postgres', 'USER': 'postgres', 'PASSWORD': 'postgres', 'HOST': 'db', 'PORT': 5432, } }修正前のdokcer-compose.yml
Docker-compose.ymlversion: '3' services: web: build: . command: python manage.py runserver 0.0.0.0:8000 volumes: - .:/code ports: - "8000:8000" depends_on: - db db: image: postgres修正後のdocker-compose.yml
docker-compose.ymlversion: '3' services: web: build: . command: python3 manage.py runserver 0.0.0.0:8000 volumes: - .:/code ports: - "8000:8000" depends_on: - db db: image: postgres ports: - "5432" environment: - POSTGRES_DB=postgres - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgresこれで、エラーが解消しました。
Docker内でpostgresを使用するには、データベースユーザー、パスワード、db-nameなどの情報を構成する必要があります。これは、修正後のdokcer-compose.ymlにあるenvironmentにおいてコンテナの環境変数を設定することにより行うことができる。
- 投稿日:2020-03-14T21:08:11+09:00
For, While Python 入門編
For文
for seireki in range(1989, 2017): print("西暦" + str(seireki) + "年", end="") heisei = seireki - 1988 print("平成" + str(heisei) + "年です。")<出力> 西暦1989年平成1年です。 西暦1990年平成2年です。 西暦1991年平成3年です。 西暦1992年平成4年です。 ....While文
import random hp = 20 while hp > 0: hit = random.randint(1, 10) print("スライムに" + str(hit) + "のダメージを与えた!") hp -= hit print("残りのHPは" + str(hp) + "です!") print("スライムを倒しました")<出力値> スライムに1のダメージを与えた! 残りのHPは19です! スライムに9のダメージを与えた! 残りのHPは10です! スライムに5のダメージを与えた! 残りのHPは5です! スライムに3のダメージを与えた! 残りのHPは2です! スライムに2のダメージを与えた! 残りのHPは0です! スライムを倒しました
- 投稿日:2020-03-14T20:38:35+09:00
「オバケ」は「お前」で韻踏める
はじめに
サンプル
result「オバケ」は「お前」で韻踏める[類似度:0.24651645]本題
ツールを作るにあたり利用させていただいた外部API
ソースコード
作ったもの
- ① 韻を踏める単語検索ツール
- 使用したAPI
- ② 検索用単語プール生成ツール
- 使用したAPI
① 韻を踏める単語検索ツール
役割
- 指定した単語と韻を踏める単語をCSVファイルから抽出するツール
- オプションとしてCOTOHA APIを使い単語間の類似度判定
図
仕組み
- 指定した単語とCSVファイルにある単語を pykakashiを使用してローマ字に変換
converterdef convert_hiragana_to_roma(self, target_word_hiragana): # 促音の場合 # 「つ」と「っ」が同じ「tsu」に変換されるため特殊文字として「x」とする if target_word_hiragana == "っ": return "x" else: kakasi_lib = kakasi() # 平仮名をローマ字に kakasi_lib.setMode('H', 'a') conv = kakasi_lib.getConverter() target_word_roma = conv.do(target_word_hiragana) return target_word_roma
- ローマ字から母音のパターンを抽出し、同じパターンであるかを比較
条件 元の単語 変換前 変換後 母音のみ オバケ obake oae 促音が含まれている いっぱい ippai ixai 「ん」が含まれている 秋刀魚 sanma ana 「ー」が含まれている サンダー sanda- anaa converter# 読み仮名を音韻のパターンに変換 def convert_roma_to_phoneme_pattern(self, target_char_roma_list): pre_phoneme = None hit_list = [] for target_char_roma in target_char_roma_list: # 母音のケース # 「あ、い、う、え、お」のどれか vowel_char = self.__find_vowel_char( target_char_roma ) specific_char = self.__find_specific_char( pre_phoneme, target_char_roma ) if vowel_char: hit_list.append(vowel_char) pre_phoneme = vowel_char elif specific_char: # 母音ではないが、対象とするケース # 「っ」 # 「ん」 # 「ー」 hit_list.append(specific_char) pre_phoneme = specific_char else: continue phoneme_pattern = "".join(hit_list) return phoneme_pattern def __find_vowel_char(self, char_roma): # 母音の場合 vowel_list = ["a", "i", "u", "e", "o"] for vowel in vowel_list: if char_roma.find(vowel) > -1: return vowel else: continue # 母音でない場合 return None def __find_specific_char(self, pre_phoneme, char_roma): # 「ん」の場合 # 「っ」の場合: if char_roma == "n" or char_roma == "x": return char_roma # 「ー」の場合 # 前回の母音と同じとみなす # 例) だー -> a elif pre_phoneme != None and char_roma == "-": return pre_phoneme else: return None実行例
execute$cd src $python main.py オバケresult「オバケ」は「答」で韻を踏める 「オバケ」は「お前」で韻を踏める類似度判定
- 韻が踏める単語の組み合わせを抽出後、指定した単語を
base_wordにCSVから抽出した単語をpool_wordに設定して解析をかけるcotoha_client.pydef check_score(self, base_word, pool_word, access_token): headers = { "Content-Type": COTOHA_CONTENT_TYPE, "charset": COTOHA_CHAR_SET, "Authorization": "Bearer {}".format(access_token) } data = { "s1": base_word, "s2": pool_word, "type": "default" } req = urllib.request.Request( f"{COTOHA_BASE_URL}/{COTOHA_SIMILARITY_API_NAME}", json.dumps(data).encode(), headers ) time.sleep(COTOHA_REQUEST_SLEEP_TIME) with urllib.request.urlopen(req) as res: body = res.read() return json.loads(body.decode())["result"]["score"]実行例
execute$cd src $python main.py オバケresult「オバケ」は「答」で韻踏める[類似度:0.063530244] 「オバケ」は「お前」で韻踏める[類似度:0.24651645]課題
元となるCSVファイルが固定
- 元々開発中はmecabに付属している名詞リストを単語プールとして使わせて頂いていました。
- ただ語彙の数や種類を増やす仕組みを作ることができたら、より面白そうだと思い単語プールを生成するツールを作るに至りました。
② 単語プール生成ツール
役割
- ① 韻を踏める単語検索ツールで使用する単語検索用のCSVを生成するツール
図式
仕組み
- Qiitaの投稿記事取得APIで得た投稿記事のタイトルを取得
qiita_client.pydef list_articles(self): req = urllib.request.Request( f"{QIITA_BASE_URL}/{QIITA_API_NAME}?page={QIITA_PAGE_NUMBERS}&per_page={QIITA_ITEMS_PAR_PAGE}" ) with urllib.request.urlopen(req) as res: body = res.read() return json.loads(body.decode())
- 取得したタイトルをCOTOHAの構文解析APIにかけて品詞に分類
cotoha_client.py# target_sentence にQiitaの記事タイトルを入れる def parse(self, target_sentence, access_token): headers = { "Content-Type": COTOHA_CONTENT_TYPE, "charset": COTOHA_CHAR_SET, "Authorization": "Bearer {}".format(access_token) } data = { "sentence": target_sentence, } req = urllib.request.Request( f"{COTOHA_BASE_URL}/{COTOHA_PARSE_API_NAME}", json.dumps(data).encode(), headers ) time.sleep(COTOHA_REQUEST_SLEEP_TIME) with urllib.request.urlopen(req) as res: body = res.read() return json.loads(body.decode())["result"]
- 品詞から名詞のみを抽出しCSVファイルに出力
finder.py# 構文解析の結果から名詞のみを抽出し、そのリストを返す def find_noun(self, target_sentence_element): noun_list = [] for element_num in range(len(target_sentence_element)): tokens = target_sentence_element[element_num]["tokens"] for tokens_num in range(len(tokens)): target_form = tokens[tokens_num]["form"] target_kana = tokens[tokens_num]["kana"] target_pos = tokens[tokens_num]["pos"] # 名詞であればリストに格納する if target_pos == TARGET_CLASS: # 英語や数字、記号の単語は読み仮名を代わりに格納する # TODO:判定に改善の余地あり。 if re.match(FINDER_REGEX, target_form): noun_list.append(target_kana) else: noun_list.append(target_form) return noun_list実行例
execute$cd tool $python word_pool_generator.pyword_pool.csvバックアップ ツール エービーシー ストリング ビジュアル スタジオ コード ノート 管理 拡張 まとめ 論文 解説課題
正直重いです。投稿記事40本でも5分ほど処理にかかってしまいます。
- 1つの記事タイトルで抽出できる名詞数はおよそ2〜5個です。
- ただCSVファイルへの出力にあたり
pandasを初めてさわっていることもあり、もっとロジックの改善はできると思ってます。- まだとりあえず動くものを作ったというレベルです。
英単語の判定の改善
- 今のロジックでは「Raspberry Pi」は「ラズベリーパイ」ではなく「アールエーエスピービーイーアールアールワイピーアイ」になります。
- 例えば「Raspberry」だけを構文解析APIに渡して「ラズベリー」と判定できるのであれば単語の受け渡し方を工夫すればもう少しいい感じにできそうです。
- ちなみに「Google」は「グーグル」でした。
単語のバリエーションを増やせるようにする
- 他のサイトなどでスクレイピングすると他の分野の単語も集めることができそうです。
終わりに
- 誤字脱字や内容に不備や不適切な部分が、ありましたら遠慮なくコメント・ご指摘ください。
- 万が一、何か問題がありましたら記事の削除、リポジトリの破棄を致します。
参考にさせていただいた記事
- https://note.com/junkawashima/n/n146874f827bc
- https://qiita.com/komorin0521/items/8cd1eb0cdb4a9ede217e
その他
作った動機について
- そもそも何でこんなものを作ったかというと、半年ほど前にこの記事を見て、友人と「自然言語処理を使って韻を踏める単語を探せないか」という会話をしたのがきっかけでした。
- ただ私は、当時(今も)自然言語処理についての分野は全然分かっておらず、たまたま今回の企画を見て、何か近いものが作れるのではないかと思いたち、このツールを作成することにしました。



- 投稿日:2020-03-14T19:28:17+09:00
[Python]Twitterのフォロー関係を可視化してみた
記事の内容
友達の友達の友達と友達・・と辿っていく誰に辿り着くのか?
意外な所でこの人とこの人が繋がってるんだ!みたいなことありますよね。この記事ではTwitterの相互フォローしている人同士を可視化してみました。
やったこと
やったことは大きく分けると2つです。
- フォローしているユーザーの情報を取得する
- 可視化するフォローしているユーザー情報を取得する
get_follower_info.pyimport json import config from requests_oauthlib import OAuth1Session from time import sleep from mongo_dao import MongoDAO import datetime # APIキー設定(別ファイルのconfig.pyで定義しています) CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET # 認証処理 twitter = OAuth1Session(CK, CS, AT, ATS) mongo = MongoDAO("db", "followers_info") get_friends_url = "https://api.twitter.com/1.1/friends/list.json" # フォローしているアカウントを取得 get_user_info_url = "https://api.twitter.com/1.1/users/show.json" # ユーザー情報を取得する count = 200 targets = ['yurinaNECOPLA'] registed_list = [] depth = 2 # 潜る深さ max_friends_count = 1000 # フォローアカウントがめちゃくちゃ多い人が居るので一定数を超えてると除外する # フォローアカウントが一定数を超えていないか判定する def judge_friends_count(screen_name): params = {'screen_name': screen_name} while True: res = twitter.get(get_user_info_url, params=params) result_json = json.loads(res.text) if res.status_code == 200: # フォローしている人数は「friends_count」、フォローされている人数は「followers_count」 if result_json['friends_count'] > max_friends_count: return False else: return True elif res.status_code == 429: # 15分間で15回しかリクエストを送信出来ないので上限に達していたら待つ now = datetime.datetime.now() print(now.strftime("%Y/%m/%d %H:%M:%S") + ' 接続上限のため待機') sleep(15 * 60) # 15分待機 else: return False # 指定したscreen_nameのフォロワーを取得する def get_followers_info(screen_name): followers_info = [] params = {'count': count,'screen_name': screen_name} while True: res = twitter.get(get_friends_url, params=params) result_json = json.loads(res.text) if res.status_code == 200 and len(result_json['users']) != 0: for user in result_json['users']: # APIから取得した情報のうち、必要な情報だけをdict形式で設定 (このPGでidは使ってない・・) followers_info.append({'screen_name': user['screen_name'], 'id': user['id']}) # パラメーターに次の取得位置を設定する params['cursor'] = result_json['next_cursor'] # APIの接続上限を超えた場合の処理 elif res.status_code == 429: now = datetime.datetime.now() print(now.strftime("%Y/%m/%d %H:%M:%S") + ' 接続上限のため待機') sleep(15 * 60) # 1分待機 else: break return followers_info # dictのlistからscreen_nameのみのlistを取得する def followers_list(followers_info): followers_list = [] for follower in followers_info: followers_list.append(follower['screen_name']) return followers_list # 再帰処理 def dive_search(target_list, d): for name in target_list: if name in registed_list or not judge_friends_count(name): continue print(name) followers_info = get_followers_info(name) mongo.insert_one({'screen_name': name, 'followers_info': followers_info}) registed_list.append(name) if depth > d: dive_search(followers_list(followers_info), d + 1) else: return dive_search(targets, 0)このプログラムでは起点となるアカウントを決めておきます。
(//ネコプラ//というアイドルグループの碧島ゆりなさんのアカウントを起点としています)その後、以下の流れで再帰的に処理していきます。
① フォローしているユーザーの情報を取得する
② ①の情報をmongoDBに登録する
③ ①で取得したユーザー情報を1件ずつ取得し、①から実行するdepthの値を変えるとどれだけ再帰的に潜っていくのかを変更出来ます。
2だと友達の友達までを取得するイメージです。
本当はもっとデータを取得したかったのですが、フォロー関係の情報を取得するAPIが15分間で15リクエストしか送れません。
起点としているアカウントは現時点で100アカウントをフォローしていますが、このアカウントから始めても処理が完了するのに3時間ほどかかりました。
しかも、途中で「既存の接続はリモート ホストに強制的に切断されました。」というエラーが発生して処理が落ちてしまいました。この時点でフォローしているユーザー100アカウントのうち、60ほどしか完了していません。
うまく動いたとしても、6時間ほどは掛かっていたと思います。mongoDBへのデータ登録などは以下のコードを使っています。
可視化する
前項で記載した通り、データは全て集まったとは言えない状況ですが、とりあえず集まったデータで可視化してみます。
可視化に使用するライブラリはNetworkXというものを使いました。
インストールは以下のコマンドで出来ます。pip install networkxcreate_network.pyimport json import networkx as nx import matplotlib.pyplot as plt from requests_oauthlib import OAuth1Session from mongo_dao import MongoDAO mongo = MongoDAO("db", "followers_info") start_screen_name = 'yurinaNECOPLA' #新規グラフを作成 G = nx.Graph() #ノードを追加 G.add_node(start_screen_name) depth = 3 processed_list = [] def get_followers_list(screen_name): result = mongo.find(filter={"screen_name": screen_name}) followers_list = [] try: doc = result.next() if doc != None: for user in doc['followers_info']: followers_list.append(user['screen_name']) return followers_list except StopIteration: return followers_list def dive(screen_name, d): if depth > 0: if screen_name in processed_list: return followers_list = get_followers_list(screen_name) for follower in followers_list: f = get_followers_list(follower) if start_screen_name in f: G.add_edge(screen_name, follower) processed_list.append(screen_name) dive(follower, d + 1) else: return dive(start_screen_name, 0) #図の作成。figsizeは図の大きさ plt.figure(figsize=(10, 8)) #図のレイアウトを決める。kの値が小さい程図が密集する pos = nx.spring_layout(G, k=0.8) #ノードとエッジの描画 # _color: 色の指定 # alpha: 透明度の指定 nx.draw_networkx_edges(G, pos, edge_color='y') nx.draw_networkx_nodes(G, pos, node_color='r', alpha=0.5) #ノード名を付加 nx.draw_networkx_labels(G, pos, font_size=10) #X軸Y軸を表示しない設定 plt.axis('off') plt.savefig("mutual_follow.png") #図を描画 plt.show()フォロワーの取得手順とロジックは似ています。
再帰的にフォロワーを取得していき、相互フォローしているアカウントが見つかったらエッジを追加しています。結果
こんな感じになりました。
ライブラリの詳しい仕組みまでは理解出来ていないのですが、繋がりが多いアカウント同士が密集していますね。
この密集しているあたりのアカウントは同じ事務所所属のアイドルなので納得の結果になりました。感想
なかなか面白い結果になりました。
Twitter APIのリクエスト発行上限が15/分となっているため、あまりデータ量を増やせませんでした。
時間を見つけてデータをもっと収集出来れば、友達の友達の友達の・・・という繋がりが見えてくるかもしれません。

- 投稿日:2020-03-14T19:12:08+09:00
【Python】前処理大全 そのまま メモ
以前書いて試したメモです。
※想像以上にそのままです。下記書籍を参考にしています。
前処理大全[データ分析のためのSQL/R/Python実践テクニック]使用するデータ
https://github.com/ghmagazine/awesomebook
抽出
# quety関数を使う pd.query('"2018-01-01" <= checkout_data <= "2018-01-20"')サンプリング(標本抽出)
# dfから50%サンプリングする df.sample(frac=0.5)集合
集合IDに基づくサンプリング
pd.Series(df['customer_id'].unique()).sample(frac=0.5)データ数、種類数の算出
df.groupby('hotel_id').agg({'reserve_id': 'count', 'customer_id': 'nunique'})合計値の算出
df.groupby(['hotel_id', 'people_num'])['total_price'].sum().reset_index()最頻値の算出
# modeが最頻出のメソッド df['total_price'].round(-3).mode()roundについて
正の整数を指定すると小数点以下の桁、負の整数を指定すると整数の桁(位)の指定となる。
-1は10の位に丸め、-2は100の位に丸める。0は整数(1の位)に丸められるが省略した場合と異なりfloat型を返す。順位の算出
df['reserve_datetime'] = pd.to_datetime(df['reserve_datetime'], format='%Y-%m-%d %H:%M:%S') df['log_no'] = df.groupby('customer_id')['reserve_datetime'].rank(ascending=True, method='first') df結合
マスタテーブルの結合
pd.merge(df.query('people_num == 1'), df_hotel.query('is_business'), on='hotel_id', how='inner')過去n件の合計値
df['price_sum'] = pd.Series( df .groupby('customer_id') .apply(lambda x: x.sort_values(by='reserve_datetime', ascending=True)) .loc[:, 'total_price'] .rolling(center=False, window=3, min_periods=3).sum() .reset_index(drop=True) )分割
交差検証とは
- データ分割
- 一部のデータを使い、学習
- そのほかのデータを使って、検証
- 2と3をパターンを繰り返す https://mathwords.net/kousakakunin
k分割交差検証
- データをk個に分ける
- k-1個で学習し、残りの1個で検証
- 1と2を繰り返す https://mathwords.net/kousakakunin
ホールドアウト検証
交差検証ばかりしていると、交差検証の問題に対して過学習している状態に近づく。
これに対しての解決策が、ホールドアウト検証。
交差検証とは別にデータを準備し、最後に精度を検証する際に準備したデータを使用する。生成
不均衡データを調整するときにデータ生成は使用される
パターンは3つ存在し、よく使用されるのは、オーバーサンプリングとアンダーサンプリングの併用。オーバーサンプリングで悪影響が出ないくらいデータ数を増やし、
アンダーサンプリングで悪影響が出ないくらいデータ数を減らす。オーバーサンプリング
データ数を増やす
アンダーサンプリング
データ数を減らす
# オーバーサンプリング from imblearn.over_sampling import SMOTE sm = SMOTE(ratio='auto', k_neighbors=5, random_state=71) balance_data, balance_target = sm.fit_sample(df[['length', 'thickness']], df['fault_flg'])数値型
整数型、浮動小数点型へ変換
# 整数型へ変換 df['value'].astype('int8') # 浮動小数点型へ変換 df['values'].astype('float64')対数化
入力値を対数に変換する。
df['total_price_log'] = df['total_price'].apply(lambda x: np.log(x / 1000 + 1))数値型のカテゴリ化
df = (np.floor(df['age'] / 10) * 10).astype('category')正規化
過学習を防ぐためのしくみ。
from sklearn.preprocessing import StandardScaler df['people_num'] = df['people_num'].astype(float) ss = StandardScaler() result = ss.fit_transform(df[['people_num', 'total_price']]) df['people_num_normalized'] = [x[0] for x in result] df['total_price_normalized'] = [x[1] for x in result]外れ値の除去
# 平均値から標準偏差値の一定倍数以上離れた値を除去 # 3より大きな値を設定している # 正規分布にしたがった値は、平均値から標準偏差値の3倍以内の範囲に約99.73%の値が収まるため、発生する確率が0.27%以下の値を外れ値としてみなす df[(abs(df['total_price'] - np.mean(df['total_price'])) / np.std(df['total_price']) <= 3)].reset_index()主成分分析による次元圧縮
from sklearn.decomposition import PCA pca = PCA(n_components=2) pca_values = pca.fit_transform(df[['length', 'thickness']]) print('累積寄与率: {0}'.format(sum(pca.explained_variance_ratio_))) print('各次元の寄与率: {0}'.format(pca.explained_variance_ratio_)) print('各次元の寄与率: {}'.format(pca.explained_variance_ratio_)) pca_newvalues = pca.transform(df[['length', 'thickness']])PCA 情報損失
主成分分析PCAを用いて手書き数字を分析する。その1 - Qiita
30分でわかる機械学習用語「次元削減(Dimensionality Reduction)」 - Qiita数値の補完
定数補完
# replace関数で、Noneをnanに変換 df.replace('None', np.nan, inplace=True) # fillna関数で、thicknessの欠損値を補完 df['thickness'].fillna(1, inplace=True)カテゴリ型
カテゴリ型への変換
# bool型に変換 df[['sex_is_man']] = (df[['sex']] == 'man').astype('bool') # sexをカテゴリ型に変換 df['sex_c'] = pd.Categorical(df['sex'], categories=['man', 'woman']) # astypeでも変換可能 df['sex_c'] = df['sex_c'].astype('category') df['sex_c'].cat.codes df['sex_c'].cat.categoriesダミー変数化
# カテゴリ型へ変換 df['sex'] = pd.Categorical(df['sex']) # get_dummies関数によってsexをダミー変数化 dummy_vars = pd.get_dummies(df['sex'], drop_first=False)カテゴリ値の集約
# Category型に変換 df['age_rank'] = pd.Categorical(np.floor(df['age']/10)*10) # マスタデータに`60以上`を追加 df['age_rank'].cat.add_categories(['60以上'], inplace=True) # isin関数 # データフレームの列に値が含まれているかどうかをチェックする df.loc[df['age_rank'].isin([60.0, 70.0, 80.0]), 'age_rank'] = '60以上' df['age_rank'].cat.remove_unused_categories(inplace=True)KNNによる補完
from sklearn.neighbors import KNeighborsClassifier df.replace('None', np.nan, inplace=True) # 欠損していないデータの抽出 train = df.dropna(subset=['type'], inplace=False) # 欠損しているデータの抽出 test = df.loc[df.index.difference(train.index), :] # knnモデル生成 kn = KNeighborsClassifier(n_neighbors=3) # knnモデル学習 kn.fit(train[['length', 'thickness']], train['type']) # knnnで、予測値を計算し、typeを補完 test['type'] = kn.predict(test[['length', 'thickness']])
- 投稿日:2020-03-14T19:08:55+09:00
AtomのインストールとPythonを実行できるようにするまでの過程
Atomとは
Atomとは、エディタの名前です。エディタとは名前のまま編集するためのソフトウェアをいうのですが、Windowsでも利用できるため、使用しています。
ubuntu入れたPCは今手元に無いため、もう一つのPCで作業をしています(小声)
2015年からの新しいエディタですが、作業が効率化できる優れものです。拡張機能も数多くありますし、使用者が多く、Web上にも情報が多いので初心者にもおすすめです。今回やること
今回は以下の順で進めていきます。
・Atomのインストール
・Pythonを実行する。想定する環境
Windows10
InternetAtomのインストール
まずは以下のリンクからホームページにいき、Downloadをします。
https://atom.io/次にDownloadしたファイルを実行します。おそらく以下の名前のファイルになっていると思います。
AtomSetup-x64.exe
これでインストールは完了です。あとは自動でAtomが開かれるか、ショートカットからAtomを開いてください。
Pythonを実行する
まずは、Fileタブの中からNew Fileを選択し、新しいファイルを作成します。次にSave As…でファイル名を決めます。フィル名はsample.pyなどファイルの拡張子をpyにしてPythonファイルにしてくだい。
次に、Fileタブの中からSettingsを選択し、設定画面を開いてください。
Fileタブの中身は以下の画像に示した通りです。赤枠に今回使用したものを示します。
次に実行するためのpackageをインストールします。
設定画面から左下にある+Installボタンをクリックします。
検索窓の中にatom-runnerと打ち込み、検索します。
検索して出てきたatom-runnerをInstallします。
これで実行することができます。
以下の画像のなかの赤枠で囲ったものが今回使用したものです。インストールした後の画面なのでこのような画面が出たらインストールできています。
今回は以下のPythonファイルを使用します。
sample.pyprint('Hello World!!')実行は、Alt+Rです。以下のような画面が出たら成功です。




- 投稿日:2020-03-14T18:18:38+09:00
【Scrapy】抜き出したURLを修正・加工する
想定例
ScrapyのCrawlSpiderを使用して、
アイテム一覧ページ->個々のアイテムの概要ページ->個々のアイテムの詳細ページ、とリンクを辿っていけるサイトをクローリングし、
詳細ページの情報をスクレイピングして保存する場合を想定。ページとURLの対応関係は下のような感じで。
ページ URL アイテム一覧 example.com/list アイテムの概要 example.com/item/(ID)/ アイテムの詳細 example.com/item/(ID)/details こういった構造のサイトの場合、一覧ページから抜き出した、概要ページへのリンクの末尾に、/detailsをつけ加えて、それを使って直接詳細ページにリクエストすることができれば、相手先のサイトへのリクエスト数が半減し、こちらのプログラムの実行にかかる時間も減らせて一石二鳥!
というわけで下記が実装例。実装
LinkExtractorの引数process_valueに、URLを加工する処理をラムダ式で記述する。
example.pyclass ExampleSpider(CrawlSpider): name = 'example' allowed_domains = ['example.com'] start_urls = ['http://example.com/list'] #アイテムの一覧ページ rules = [ Rule(LinkExtractor( #/item/を含むURLを抜き出す allow=r'.*/item/.*', #抜き出したURLに'details/'を付け加える process_value= lambda x:x + 'details/' ),callback='parse_details'), ] # def parse_details(self, response): #(省略)以上!
- 投稿日:2020-03-14T17:45:28+09:00
COTOHA APIを使ってダジャレと戯れる
はじめに
【Qiita x COTOHA APIプレゼント企画】COTOHA APIで、テキスト解析をしてみよう!
というプレゼント企画の噂につられてCOTOHA APIを触ってみようと思いました。ダジャレ好きの僕としましては、このAPIを使ってダジャレをパースできたりしないかなあと思い、なんとなーく触ってみた記事です。プレゼントが貰えるとは全く思っておりません。
準備
まずはCOTOHA APIのページにてfor Developer登録します。すぐAPIが叩けます。
ダジャレを相手にする以上、間違いなく試行錯誤すると思います。しかし、for Developerプランは 各API1000コール/1日 という制限があります。んであれば、同じインプットだったらキャッシュして無駄にAPIをコールしないクラスを作ってみます。
COTOHA.py (なんか冗長かも)
import os import sys import pathlib import time import requests import json import hashlib class COTOHA: __BASE_URL = 'https://api.ce-cotoha.com/api/dev/' def __init__(self, id, secret, cache_dir='./COTOHA_cache'): self.id = id self.secret = secret self.cache_dir = cache_dir self._get_token() def _create_cache_path(self, func, key): hash = hashlib.md5(key.encode()).hexdigest() hashpath = "{}/{}/{}".format(hash[:2], hash[2:4], hash[4:]) return self.cache_dir + '/' + func + '/' + hashpath def _save_cache(self, path, content): pathlib.Path(os.path.dirname(path)).mkdir(exist_ok=True, parents=True) with open(path, mode="w") as c: c.write(content) return def _load_cache(self, path): content = None if os.path.exists(path): with open(path, mode="r") as c: content = c.read() return content def _get_token(self): token_cache = self.cache_dir + '/token' # format: token expired_time cache = self._load_cache(token_cache) if cache: token, expired_time = cache.split() if int(expired_time) > int(time.time()): self.token = token return # get new token token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' headers = {'content-type': 'application/json'} payload = {"grantType": "client_credentials", "clientId": self.id, "clientSecret": self.secret} res = requests.post(token_url, headers=headers, data=json.dumps(payload)) res.raise_for_status() res_json = json.loads(res.text) self.token = res_json['access_token'] expired_time = int(time.time()) + int(res_json['expires_in']) self._save_cache(token_cache, self.token + ' ' + str(expired_time)) return # 音声認識誤り検知(β) def detect_misrecognition(self, data): func = sys._getframe().f_code.co_name cache_path = self._create_cache_path(func, data) cache = self._load_cache(cache_path) if cache: print("[INFO] use '"+func+"' api cache", file=sys.stderr) return cache api_url = self.__BASE_URL + 'nlp/beta/detect_misrecognition' payload = {'sentence': data} headers = {'content-type': 'application/json;charset=UTF8', 'Authorization': 'Bearer ' + self.token} res = requests.post(api_url, headers=headers, data=json.dumps(payload)) res.raise_for_status() self._save_cache(cache_path, res.text) return res.text # 要約(β) def summary(self, data, sent_len=1): func = sys._getframe().f_code.co_name cache_path = self._create_cache_path(func, data+str(sent_len)) cache = self._load_cache(cache_path) if cache: print("[INFO] use '"+func+"' api cache", file=sys.stderr) return cache api_url = self.__BASE_URL + 'nlp/beta/summary' payload = {'document': data, 'sent_len': sent_len} headers = {'content-type': 'application/json;charset=UTF8', 'Authorization': 'Bearer ' + self.token} res = requests.post(api_url, headers=headers, data=json.dumps(payload)) res.raise_for_status() self._save_cache(cache_path, res.text) return res.text def keyword(self, data, type='default', max_keyword_num=5): func = sys._getframe().f_code.co_name cache_path = self._create_cache_path(func, data+type+str(max_keyword_num)) cache = self._load_cache(cache_path) if cache: print("[INFO] use '"+func+"' api cache", file=sys.stderr) return cache if type != 'kuzure' and type != 'default': print("[ERROR] type must be default or kuzure! :" + type) return api_url = self.__BASE_URL + 'nlp/v1/keyword' payload = {'document': data, 'type': type, 'max_keyword_num': max_keyword_num} headers = {'content-type': 'application/json;charset=UTF8', 'Authorization': 'Bearer ' + self.token} res = requests.post(api_url, headers=headers, data=json.dumps(payload)) res.raise_for_status() self._save_cache(cache_path, res.text) return res.text def parse(self, data, type='default'): func = sys._getframe().f_code.co_name cache_path = self._create_cache_path(func, data+type) cache = self._load_cache(cache_path) if cache: print("[INFO] use '"+func+"' api cache", file=sys.stderr) return cache if type != 'kuzure' and type != 'default': print("[ERROR] type must be default or kuzure! :" + type) return api_url = self.__BASE_URL + 'nlp/v1/parse' payload = {'sentence': data, 'type': type} headers = {'content-type': 'application/json;charset=UTF8', 'Authorization': 'Bearer ' + self.token} res = requests.post(api_url, headers=headers, data=json.dumps(payload)) res.raise_for_status() self._save_cache(cache_path, res.text) return res.text : (以下略)
で、好きに呼べるようにコマンドにしてみます。python初心者なのでargparseがいいのかよくわからないけど、とりあえずサッと。オプションは付けてない。
coto.py
!/usr/bin/env python import sys import argparse from COTOHA import COTOHA parser = argparse.ArgumentParser() parser.add_argument('api', choices=['summary', 'keyword', 'parse', 'detect_misrecognition']) parser.add_argument('infile', nargs='?', type=argparse.FileType('r'), default=sys.stdin) args = parser.parse_args() id = '' # IDを入れてね! secret = '' # secretを入れてね! coto = COTOHA(id, secret) data = args.infile.read() if args.api == "summary": sent_len = 1 res = coto.summary(data, sent_len) elif args.api == "keyword": type = 'default' max_keyword_num = 5 res = coto.keyword(data, type, max_keyword_num) elif args.api == "parse": type = 'default' res = coto.parse(data, type) elif args.api == "detect_misrecognition": res = coto.detect_misrecognition(data) elif args.api == "sentiment": res = coto.sentiment(data) else: print("unexpected api:" + args.api, file=sys.stderr) sys.exit(1) print(res)なんとなく手始めに枕草子(爆)でもぶつけてみます。
$ cat makurano.txt 春はあけぼの。やうやう白くなりゆく山ぎは、すこしあかりて、紫だちたる雲のほそくたなびきたる。 夏は夜。... (以下略、冬まで。) $ [hoshino@localhost py_scrape]$ ./coto.py summary makurano.txt {"result":"昼になりて、ぬるくゆるびもていけば、火桶の火も白き灰がちになりてわろし。","status":0} $ ./coto.py keyword makurano.txt { "result" : [ { "form" : "見ゆる", "score" : 21.3012 }, { "form" : "いとつきづき", "score" : 20.0 }, { "form" : "火", "score" : 17.12786 }, { "form" : "寝どころ", "score" : 11.7492 }, { "form" : "夕日", "score" : 11.4835 } ], "status" : 0, "message" : "" }うん、いきなり古文を投げるなんて性格の悪さが出てますね。結果の妥当性が分からんw もうちょっと分かりやすく叩いてみよう。
$ echo "今日はすき焼きだ、楽しみだな。" | ./coto.py sentiment {"result":{"sentiment":"Positive","score":0.6113335958534332,"emotional_phrase":[{"form":"楽しみだな","emotion":"P"}]},"status":0,"message":"OK"} $ echo "今日はすき焼きだ、食べたくねえ。" | ./coto.py sentiment {"result":{"sentiment":"Neutral","score":0.2837920794741674,"emotional_phrase":[]},"status":0,"message":"OK"} $ echo "今日はすき焼きだ、食べたくねえ辛い。" | ./coto.py sentiment {"result":{"sentiment":"Negative","score":0.7608419653662558,"emotional_phrase":[{"form":"辛い","emotion":"N"}]},"status":0,"message":"OK"} $ echo "今日はすき焼きだ。なんであんなもの食うかね。" | ./coto.py sentiment {"result":{"sentiment":"Neutral","score":0.3482213983910368,"emotional_phrase":[]},"status":0,"message":"OK"} $ echo "今日はすき焼きだ。よっしゃ。" | ./coto.py sentiment {"result":{"sentiment":"Positive","score":0.0976613052132079,"emotional_phrase":[{"form":"よっしゃ","emotion":"喜ぶ"}]},"status":0,"message":"OK"}うーむ、感情分析は分かりやすい表現が無いと引っかからないみたいですね。とか、色々思うところはありますが。
といった感じで、それなりに自由にAPIが呼び出せるようになりました。作ってから思ったけど、1000コールあればキャッシュなんかいらねーな(おい
ダジャレを持ってくるために、スクレイピングする
さて、では戯れるダジャレを、僕が昔せっせと書いてたクソブログから持ってこようと思います。スクレイピングは『退屈なことはPythonにやらせよう』でもお馴染み(?)のBeautiful Soupを使います。こちらの記事様なら10分で理解できます。
貧乏性なので、これもキャッシュします。好きだなキャッシュ。頑張ってhtmlソース見て、記事部分を抽出します。get_textでパースした記事内容を一つ表示してみます。
scrape.pyif not os.path.exists("hijili/top"): res = requests.get("https://ameblo.jp/hijili/") res.raise_for_status() os.makedirs("./hijili/") with open("./hijili/top", mode="w") as f: f.write(res.text) with open("hijili/top", mode="r") as f: top_soup = bs4.BeautifulSoup(f, 'html.parser') top_soup.find('entryBody') bodies = [n.get_text() for n in top_soup.select('div#entryBody')] print(bodies[1])$ python scrape.py カタナの話をしていたときに「昔買ったなー」(1スベリ)と咄嗟に返せたのは良かったと思いました。勝ったな、と思いました、口には出さなかったけど。(2スベリ)買ったなーと言っても、真剣ではありません。(真剣に訴える3スベリ)こういう、クソみたいなダジャレが沢山書いてあるので、パースし放題です!比較的分かりやすそうなものを選択しています("真剣"の部分が何とどうかかってるのかよく分からんけど…)。ただ、このブログのお約束である"(Nスベリ)"って部分は解析に邪魔そうなので、削ります。
# bodies = [n.get_text() for n in top_soup.select('div#entryBody')] bodies = [re.sub('([^)]*スベリ)', '', n.get_text()) for n in top_soup.select('div#entryBody')]$ python scrape.py カタナの話をしていたときに「昔買ったなー」と咄嗟に返せたのは良かったと思いました。勝ったな、と思いました、口には出さなかったけど。買ったなーと言っても、真剣ではありません。よし、これならCOTOHAくんも読みやすいはずだ。
COTOHA APIでダジャレと戯れる
とりあえずさっきのCOTOHAクラスでガシガシAPIに通してみる。期待としてはダジャレをダジャレであると判定してくれる糸口を掴みたいわけですが…
# 要約 {"result":"カタナの話をしていたときに「昔買ったなー」と咄嗟に返せたのは良かったと思いました。","status":0} # キーワード抽出 { "result" : [ { "form" : "真剣", "score" : 22.027 }, { "form" : "口", "score" : 8.07787 }, { "form" : "話", "score" : 7.23882 } ], "status" : 0, "message" : "" } # 感情分析 {"result":{"sentiment":"Positive","score":0.06420815417815495,"emotional_phrase":[{"form":"良かった","emotion":"P"},{"form":"勝ったな","emotion":"P"},{"form":"真剣ではありません","emotion":"PN"}]},"status":0,"message":"OK"} # ユーザ属性推定(β) { "result" : { "age" : "20-29歳", "civilstatus" : "既婚", "hobby" : [ "CAMERA", "COOKING", "INTERNET", "MUSIC", "SHOPPING" ], "location" : "関東", "moving" : [ "WALKING" ], "occupation" : "会社員" }, "status" : 0, "message" : "OK" }むう、整形されて返ってくるものとそうでないものの違いはどこにあるのだろうか… まあpythonで処理するからいいけど。
要約APIは要約してくれるわけじゃなくて、長い文章の中で重要そうなものを返してくれるってだけなのか。
キーワード抽出、この文ならカタナを抽出して欲しかったが… やはりダジャレキーワードは見つけてくれないらしい…
感情分析しても役に立たん!本人はノリノリでダジャレ書いてるだけだからそりゃ常時ポジティブやで。
ユーザー属性推定、うーん、ダジャレ言いそうなスペックが出てきてる気もするけど、スマン、もっとおっさんでかつ独身やねん。
という感じで、いまいちダジャレへの有効性が確認できませんでした…(あたりめーだ)。
だがしかし、音声認識誤り検知には少し望みが!「真剣」に対して似た響きのワードが出てくる!
# 音声認識誤り検知(β) {"result":{"score":0.7298996038673021,"candidates":[{"begin_pos":76,"end_pos":78,"form":"真剣","detect_score":0.7298996038673021,"correction":[{"form":"試験","correct_score":0.7367702251579388},{"form":"文献","correct_score":0.7148903980845676},{"form":"神経","correct_score":0.6831886720211694},{"form":"進賢","correct_score":0.6443806737641236},{"form":"任県","correct_score":0.6403453079473043}]}]},"status":0,"message":"OK"}真剣に試ん験を受ける!(1スベリ)
神経を試ん験に集中させる!!(2スベリ)
任県がなにか真剣に調べた(いや本当に任県ってなんだよ!?)!!!(3スベリ)など、COTOHAくんがダジャレ候補を考えてくれてるみたいになった!なるほど、こういう風に使えばいいのか!(違う
まっとうにダジャレを発見していく
ということで、一部ダジャレっぽい結果を得られたわけですが、やはりダジャレを発見するのは難しいようです。ただ、構文解析APIの結果をうまく使えばなんかいけるんじゃね、感が出てきました。
構文解析APIの結果は長いから省略… デモページでパッと試せます。
なんとなーく考えたのは、この構文解析で区切られた文節間で、母音が同じ最長部分を見つけたらダジャレなんじゃね?ということです。
とりあえずやってみようと思ったんですけど、「母音が同じ最長部分見つける」ってどうやんの?ローマ字に変換して[aiueo]抜き出してグチャグチャやればなんとかなるかな… 検索… なるほど、KAKASIのpython実装でpykakashiってあるんすね。じゃあとりあえずそれでかな変換までやってみよう!
pykakashi使ってみる
kakasi = kakasi() # Generate kakasi instance kakasi.setMode("H", "a") # Hiragana to ascii kakasi.setMode("K", "a") # Katakana to ascii kakasi.setMode("J", "a") # Japanese(kanji) to ascii kakasi.setMode("r", "Kunrei") # 訓令式 conv = kakasi.getConverter() res = coto.parse(data, 'default') j = json.loads(res) org_sentence = [] ascii_sentence = [] tmp_org_sentence = [] tmp_ascii_sentence = [] org_chunk = "" kana_chunk = "" for chunk_info in j['result']: for token in chunk_info['tokens']: is_end = False if token['form'] == '。' or token['form'] == '.' or token['form'] == '!': is_end = True break else: # chunk += conv.do(token['kana']) org_chunk += token['form'] kana_chunk += token['kana'] tmp_org_sentence.append(org_chunk) tmp_ascii_sentence.append(conv.do(kana_chunk)) org_chunk = "" kana_chunk = "" if is_end: org_sentence.append(tmp_org_sentence) ascii_sentence.append(tmp_ascii_sentence) tmp_org_sentence = [] tmp_ascii_sentence = [] print("org") print(*org_sentence, sep='\n') print("ascii") print(*ascii_sentence, sep='\n')結果。
org ['カタナの', '話を', 'していた', 'ときに', '「昔', '買ったなー」と', '咄嗟に', '返せたのは', '良かったと', '思いました'] ['勝ったな、と', '思いました、', '口には', '出さなかったけど'] ['買ったなーと', '言っても、', '真剣ではありません'] ascii ['katanano', 'hanasio', 'siteita', 'tokini', 'mukasi', 'kattanaato', 'tossani', 'kaesetanoha', 'yokattato', 'omoimasita'] ['kattanato', 'omoimasita', 'kutiniha', 'dasanakattakedo'] ['kattanaato', 'ittemo', 'sinkendehaarimasen']おお、なんかいい感じに分解できましたね。じゃあこれをゴニョゴニョやってみる。
for i, osen in enumerate(org_sentence): c = find_dajare_candidate(ascii_sentence[i], osen) # とても見せられないので今後いい感じになったら… if not c: continue dump_candidate(c) print('----')find_dajare_candidateでは、とりあえず一文の中にダジャレが含まれるはずだろうと仮定し、その一文の中の各文節の母音を比較して、一致数が一番高いパートをcandidate(候補)データとして返してます。
カタナの 買ったなー」と vowel: aaao score:4 ---- 勝ったな、と 出さなかったけど vowel: aaao score:4 ---- 買ったなーと 真剣ではありません vowel: aaa score:3 ----うーん、一個目は正しいけど、あとは微妙ですね。というか、
['勝ったな、と', '思いました、', '口には', '出さなかったけど']
という2つめの文中単独ではダジャレが含まれておらず、最初の文の「カタナ」にかかってるだけなんですよね。じゃあちょっと比較キーワードをぶっこめるようにして、"katana"指定で検索できるようにしてみれば…
c = find_dajare_candidate(ascii_sentence[1], org_sentence[1], "katana") dump_candidate(c) print('----') c = find_dajare_candidate(ascii_sentence[2], org_sentence[2], "katana") dump_candidate(c)勝ったな、と vowel: aaa score:3 ---- 買ったなーと vowel: aaa score:3ある程度導けてる!これでちゃんと子音の類似度まで比較できれば精度上げられそうだ、よーし、頑張るぞ!!!!
あれ…?
もうCOTOHA全然関係なくなっちゃった!
けっこう肝の部分で全然関係なくなっちゃってるから!!(ハライチ風味)
終
制作・著作
━━━━━
ⓃⒽⓀおわりに
ということで、『COTOHA APIを
使ってきっかけにダジャレと戯れる』記事、いかがだったでしょうか。COTOHAくんにダジャレを発見してもらうのは無理そうでしたが、ダジャレのヒントをもらったり、解析の足がかりになってもらうことはできそうでした。誰かがCOTOHAを使うコトハジメになれば幸いです。(1スベリ)
というようなダジャレが大好きな僕のこだわりは、クソみたいなマッハ新書 にて述べられております。超絶暇すぎて死にそうな方は御覧ください。
ってか、プレゼント企画で興味持って、それキッカケでわりと楽しくなってきたのでそれ自体に感謝でございます。もう少しこのダジャレ解析続けてみます(飽きそうだけど)。
- 投稿日:2020-03-14T16:33:54+09:00
ベイズの定理で理解する新型コロナウイルスへのPCR検査の検査対象を絞る意義
はじめに
新型コロナウイルス感染症(COVID-19)の感染者数は、中国から世界中に広がり、2020年3月14日現在、感染者145,637名、死者5,436名と大変な数に上っています。しかし、日本の状況をみると、感染者数は734名と、韓国の8086名の9.1%、イタリアの17,660名の4.2%に留まっています。
この明らかな差の理由として指摘されているのが、日本はPCR検査数を絞っているのではないか?という説です。そのため、実際にどれくらい絞っているのか?絞ることの意義は何か?他国は検査しすぎて医療崩壊しているではないか?、など議論を巻き起こしています。
しかし、あまり定量的な議論がなされていないために、テレビやネット等を通じたアバウトな感情論が展開され、正しい理解の妨げになっているように思われます。そこで、本記事では、ベイズの定理に基づいて、PCR検査を絞る意義に焦点を当てて検討してみました。PCR検査とは?
まず、PCR(Polymerase Chain Reaction)検査とは何なのかをざっくり見てみましょう。国立感染研究所のマニュアルやタカラバイオのPCR検査の手引きなどを参考にしながら、概要を図示すると次のような検査のイメージです。
要するに、DNAの2本鎖を分解し、特定部位を増幅し、を繰り返しながら、ウイルスの特徴的な領域を増やして、その部分が電気泳動で目視できれば、陽性ということのようです。本当にウイルスに特徴的な部分だけを十分に増幅(2^N倍)できれば、高い精度(精度については後で議論)で検出できるようですね。
ただし、以下のような要因で検出精度が落ちることがあるようです。
- 熱変性の段階で、DNAが十分に分離しない。
- アニーリングの段階で、プライマーが誤って結合する。
- 伸長の段階で、DNAポリメラーゼの働きが悪くなる。
- 副産物が生成する。
検査の感度・特異度
検査に関連してよく耳にする言葉として、感度や特異度がありますが、関連する用語を整理しておきましょう。こちらのWikiがよくまとまっています。
- 感度(sensitivity または再現率 recall): 罹患している場合に陽性となる割合
- 特異度(specificity): 罹患していない場合に陰性となる割合
- 適合率(precision): 陽性の中で罹患している割合
- 正解率(accuracy): 全体の中で罹患して陽性、罹患していなくて陰性の割合
COVID-19(SARS-CoV-2)のPCR検査に関しては、諸説ありますが、感度は70%程度、特異度は90%以上との報告があるようです。ただし、感度は検体の取り方(咽頭などを綿棒で拭う)や輸送環境などの影響を受けたり、特異度はPCR検査のプロセスに影響を受ける可能性があり、確固とした数値にはならないでしょう。実際には、人体の全てにウイルスが1個もいないのか検査することなど物理的に不可能なので、感度・特異度の真値なるものはないのでしょう。
さて、上記の感度・特異度の定義を見ると、事後確率や同時確率のことを言っているのと思われた方も多いと思います。なので、改めて数式で定義してみましょう。
\begin{eqnarray} 感 度:RC &=& P(検査=T|罹患=T) \\ 特異度:SP &=& P(検査=F|罹患=F) \\ 適合率:PC &=& P(罹患=T|検査=T) \\ 正解率:AC &=& P(検査=T,罹患=T) + P(検査=F,罹患=F)\\ \end{eqnarray}また、よく耳にする言葉として、偽陽性、偽陰性がありますが、これらは以下のように定義されます。
\begin{eqnarray} 偽陽性率:FP &=& P(検査=T|罹患=F) = 1 - 特異度 \\ 偽陰性率:FN &=& P(検査=F|罹患=T) = 1 - 感度 \end{eqnarray}ベイズの定理
ベイズの定理は事前確率と事後確率の関係を表す公式です。機械学習界隈でも、ベイズ推定などでよく出てきますね。
P(B|A)=\frac{P(A|B)P(B)}{P(A)}さて、ベイズの定理に基づくと、適合率は感度と特異度から計算できることが分かります。ここで、検査陽性の適合率をPC(T)、検査陰性の適合率をPC(F)としましょう。
\begin{eqnarray} PC(T) &=& P(罹患=T|検査=T) \\ &=& \frac{P(検査=T|罹患=T) P(罹患=T)}{P(検査=T)} \\ &=& \frac{P(検査=T|罹患=T) P(罹患=T)} { P(検査=T|罹患=T) P(罹患=T) + P(検査=T|罹患=F) P(罹患=F)} \\ &=& \frac{RC \times P(罹患=T)} { RC \times P(罹患=T) + (1 - SP) \times P(罹患=F)} \\ \\ PC(F) &=& P(罹患=F|検査=F)\\ &=& \frac{P(検査=F|罹患=F) P(罹患=F)}{P(検査=F)} \\ &=& \frac{P(検査=F|罹患=F) P(罹患=F)} { P(検査=F|罹患=T) P(罹患=T) + P(検査=F|罹患=F) P(罹患=F)} \\ &=& \frac{SP \times P(罹患=T)} { (1-RC) \times P(罹患=T) + SP \times P(罹患=F)} \\ \end{eqnarray}また、正解率も同様にして、
\begin{eqnarray} AC &=& P(検査=T,罹患=T) + P(検査=F,罹患=F) \\ &=& P(検査=T|罹患=T)P(罹患=T) + P(検査=F|罹患=F)P(罹患=F) \\ &=& RC \times P(罹患=T) + SP \times P(罹患=F) \end{eqnarray}と書けます。
Pythonで計算してみる
では、Pythonを使って、検査陽性の適合率PC(T)、検査陰性の適合率PC(F)、正解率(AC)を計算してみましょう。
前提条件
前提条件として、以下の仮定を使います。
- 再現率(=感度)RCは0.7
- 特異度SPは0.95
- 事前確率P(罹患=T)およびP(罹患=F)をパラメータとする。
上で述べたようにこれらの真値は分からないので、色々と変更してシミュレーションしてみるのもいいかもしれません。
ライブラリをインポートします。
import numpy as np import matplotlib.pyplot as plt検査陽性の適合率PC(T)、検査陰性の適合率PC(F)、正解率(AC)を計算する関数を定義します。引数として、事前確率P(罹患=T)とパラメータを与えます。
def PCT(p, key): rc = key['rc'] fp = 1. - key['sp'] return rc * p / ( rc * p + fp * (1. - p)) def PCF(p, key): sp = key['sp'] fn = 1. - key['rc'] return sp * (1. - p) / ( fn * p + sp * (1. - p)) def AC(p, key): rc = key['rc'] sp = key['sp'] return rc*p + sp*(1. - p)事前確率P(罹患=T)を変えて計算する部分です。0に近い部分でメッシュを細かくするようにしています。
key = {'rc' : 0.7, 'sp' : 0.95 } pp = [ np.exp( - 0.1 * i) for i in range(0,100)] pct = [ PCT( p, key) for p in pp] pcf = [ PCF( p, key) for p in pp] ac = [ AC( p, key) for p in pp]グラフを表示する部分です。
plt.rcParams["font.size"] = 12 fig, ax = plt.subplots(figsize=(10,5)) ax.plot(pp, pct) ax.plot(pp, pcf) ax.plot(pp, ac) ax.legend(['precision (infected)','precision (non-infected)','accuracy']) xw = 0.1; xn = int(1./xw)+1 ax.set_xticks(np.linspace(0,xw*(xn-1), xn)) yw = 0.1; yn = int(1./yw)+1 ax.set_yticks(np.linspace(0,yw*(yn-1), yn)) ax.grid(which='both') ax.set_xlabel('positive ratio (prior probability)') plt.show()シミュレーション結果
それでは、計算結果を見てみましょう。
このグラフから以下の傾向が読み取れます。
- 検査陽性の適合率PC(T)に関しては、事前確率P(罹患=T)が低いとかなり悪化し、P(罹患=T)=0.1のとき、検査陽性でも罹患している確率は60%程度である。
- 検査陽性の適合率PC(F)に関しては、事前確率P(罹患=T)が高いとかなり悪化し、P(罹患=T)=0.9のとき、検査陰性でも罹患していない確率は25%程度である。
- 正解率(AC)は、特異度と感度を線形補完する形状であり、両方とも値が高いに越したことはない。
さらに、もう一歩考察
検査を実施する意義を考えると、検査陽性の適合率も、検査陰性の適合率も隔離を判断する上で重要ですが、それ以外にも、以下の指標が重要であると考えられます。
- 嘘陽性率:検査陽性でも罹患していない確率、P(罹患=F|検査=T):何故なら、検査陽性なら隔離しなければならない法律になっているので、その分無駄に病院のベッドを埋めてしまうからです。
- 嘘陰性率:検査陰性でも罹患している確率、P(罹患=T|検査=F):何故なら、検査陰性だと安心してマスクなどの対策をせずに周囲に感染を広めてしまう可能性があるからです。
※偽陽性率はP(検査=T|罹患=F)、偽陰性率はP(検査=F|罹患=T)と定義されるため、敢えて、P(罹患=F|検査=T)を嘘陽性率、P(罹患=T|検査=F)を嘘陰性率という言葉にしました。造語です。
上記の指標は以下で計算できます。\begin{eqnarray} 嘘陽性率:FP &=& P(罹患=F|検査=T) = 1 - P(罹患=T|検査=T) = 1 - PC(T) \\ 嘘陰性率:FN &=& P(罹患=T|検査=F) = 1 - P(罹患=F|検査=F) = 1 - PC(F) \\ \end{eqnarray}これらの値を計算して表示してみましょう。
fp = [1. - p for p in pct] fn = [1. - p for p in pcf] plt.rcParams["font.size"] = 12 fig, ax = plt.subplots(figsize=(10,5)) ax.plot(pp, fp) ax.plot(pp, fn) ax.legend([ 'fake positive', 'fake negative' ]) xw = 0.1; xn = int(1./xw)+1 ax.set_xticks(np.linspace(0,xw*(xn-1), xn)) yw = 0.1; yn = int(1./yw)+1 ax.set_yticks(np.linspace(0,yw*(yn-1), yn)) ax.grid(which='both') ax.set_xlabel('positive ratio (prior probability)') plt.show()結果がこちらです。
当たり前ですが、嘘陽性率は検査陽性の適合率PC(T)と、嘘陰性率は検査陰性の適合率PC(F)と逆の関係になっています。
このグラフから以下の傾向が読み取れます。
- 嘘陽性率に関しては、事前確率P(罹患=T)が低いとかなり悪化し、P(罹患=T)=0.1のとき、検査陽性でも罹患していない確率は40%程度である。
- 嘘陰性率に関しては、事前確率P(罹患=T)が高いとかなり悪化し、P(罹患=T)=0.9のとき、検査陰性でも罹患している確率は75%程度である。
考察
以上から、COVID-19感染症へのPCR検査に関して、次の傾向がシミュレーションから導けます。なお、数値に関しては、感度・特異度の真値があくまで推定値であることに注意が必要です。
- 事前確率P(罹患=T)が低いと、検査陽性の適合率も嘘陽性率も悪化し、概ね$P(罹患=T) \leq 0.1$では害が多く、$P(罹患=T) \geq 0.2$なら陽性の適合率が8割程度期待できる。
- 事前確率P(罹患=T)が高いと、検査陰性の適合率も嘘陰性率も悪化し、概ね$P(罹患=T) \geq 0.9$では害が多く、$P(罹患=T) \leq 0.45$なら陰性の適合率が8割程度期待できる。
さらに言えば・・・
- 厚生労働省が、濃厚接触者や、発熱などの症状があり、インフルエンザ等の検査が陰性で、医者が必要と認めた場合のみPCR検査を推奨しているのは、事前確率P(罹患=T)を高めているという意味で極めて合理的です。
- 希望する100万人に対して、事前のスクリーニングもなく誰でもPCR検査を受けられるようにするということは、事前確率を極めて低くする行為であり、仮に本当に罹患している人数が1万人以下、$P(罹患=T) \leq 0.01$とすると、嘘陽性率は87.5%以上となり、医療のリソースを過剰に無駄に浪費するものと思われます。
- 韓国、ドイツだけでなく、アメリカもドライブスルー検査を導入しようとしているようですが、とても心配ですね。
参考リンク
下記のページを参考にさせて頂きました。



- 投稿日:2020-03-14T16:01:42+09:00
リモートワーク用にエアリプ探知&自動応答BOTを作ってみた
コロナの影響で万年n次請けな私にもリモートワークがやってきました。
家の静かな環境で仕事ができるとはかどりますね。
通勤電車も乗らないで済み、「今まで相当無駄なことをしていたな」と思い知っているところです。さて、そんなリモートワークで私が困っていることは「チャット」です。
私は、自社や客先部署などかなりたくさんのチャンネルに入っているのですが、
そこで「自分の名前がメンション抜きで出てくる」というエアリプ事象がしばしば起こります。
リモートワークの人員の増加に伴いチャットの流量も増え、拾い出すだけでも一苦労です。これ自体は「用があるならメンションをちゃんとつけさせる」「キーワード通知を設定する」
という運用側カバーでなんとかすべき話ではありますが、せっかくなので今回は
「エアリプの内容を解析して、内容次第でBOTの応答を出しわける」を実装してみます。イメージとしてはこんな感じです。
チャットBOTの作成
何を使っても構いません。
Pythonなら、どのチャットのプラットフォーム向けでも何かしらあるはずですし、
Qiitaにも良い記事がたくさんあります。自社Slackでの運用を考えてみましたが、その前に動作の確認をちゃんとしたいので、
今回はまず私のネットの知り合いがいっぱいいるTelegramで運用しようと思います。また、今回使うCOTOHAは、開発者向け機能だけですと、利用規約の通り、
https://www.ntt.com/content/dam/nttcom/hq/jp/about-us/disclosure/tariff/pdf/c256.pdf
業務用に使うとライセンスの問題となるため、ご利用の際はご注意ください。以前私が作ったこちらのBOTを使います。
https://qiita.com/Ovismeme/items/cc59a2de1cf537c977cf
https://github.com/ovismeme/telegram_autoreply_botこれを作った当時「Pythonなんもわからん」でサンプルコードを見よう見まねに書いたのですが、
一年ぶりに見返したところ「なんだこのゴミは。誰が書いたんだ!」ってなったので、大幅に直しました。
可読性も多少上がったのですが、本記事のメインはそこではないので、割愛します。作り方などは元記事をご参照いただければと思いますが、
BOTの要件としては、「発話されたものの拾い出し」「発話」の機能がついていればなんでも大丈夫です。
moduleも提供されているはずですが、発話を拾う仕組みが物によって違うのでドキュメントはよく読むようにしましょう。COTOHA APIを使う
アカウント登録
「文章がネガティブなものかポジティブなものか」を判別するのに、
NTTコミュニケーションズ株式会社様が開発者向けに提供してくださっているCOTOHAを使います。
ごく簡単に登録方法を説明
ここをクリックしてメールアドレスを入力し、帰ってきたメールのリンクを踏んで本登録したら登録完了です。
登録が終ると、アカウントポータルが見れるようになり、そこでClientIDとClientSecretが払い出されます。
API呼び出し
アクセストークンの取得方法
感情分析API
こちらに方法は書いてあります。APIを叩くだけといえば叩くだけですが、実際に動かしているコードを一応貼っておきます。
アクセス情報やURLなどはconfigに突っ込んであるので、ご自分でお使いになるときは、
ハードコードするなりコンフィグを呼び出すなりして動かしてください。
API呼び出し
cotoha.pyimport requests import configparser import pprint class CotohaController: def __init__(self): config_file = './settings/config.ini' self.config = configparser.ConfigParser() self.config.read(config_file, 'utf-8') self.base_url = str(self.config.get('cotoha_auth', 'base_url')) self.headers = { 'Content-Type' : 'application/json;charset=UTF-8' } self.get_accesstoken() def get_accesstoken(self): request_body = { "grantType": "client_credentials", "clientId": str(self.config.get('cotoha_auth', 'client_id')), "clientSecret": str(self.config.get('cotoha_auth', 'client_secret')) } auth_url = str(self.config.get('cotoha_auth', 'auth_url')) responce = requests.post(auth_url, headers=self.headers, json=request_body) self.headers.update(Authorization = 'Bearer ' + responce.json()['access_token']) def emotion_analysis(self, text): request_body = { "sentence": str(text) } url = self.base_url + '/nlp/v1/sentiment' responce = requests.post(url, headers=self.headers, json=request_body) return responce.json()['result']['sentiment'] if __name__ == '__main__': cotoha = CotohaController() print(cotoha.emotion_analysis('今日も一日がんばるぞい!'))
emotion_analysis()にテキストを渡すと、APIが感情を分析して、PositiveNegativeNeutralが返ってきます。PS D:\src\telegram_autoreply_bot> python .\cotoha.py Positiveサンプルコードでいうとこんな感じです。
BOT側設定
try: cth = cotoha.CotohaController() emote = cth.emotion_analysis(rcv_text) reply_list = self.replyLists['cotoha'][emote] return_text = reply_list[random.randrange(len(reply_list))] except Exception: return_text = "・・・"トリガー発話があった場合、先ほど作ったAPI呼び出しモジュールを叩き、APIの感情分析に合わせて、定義ファイルからランダムに応答を返却します。
[ "regex:.*めめたん.*", "regex:.*(羊|ひつじ|ヒツジ).*" ]私の実装では、この正規表現にマッチすると発火するようになっています。
参考までに、応答の定義部分は、こんな感じになっています。
定義json
"cotoha" : { "Positive" : [ "もっと褒めて!!", "そうだ!そうだ!!", "褒めると伸びます(鼻の下が)" ], "Negative" : [ "聞こえてるぞ!", "何をかいわんや!!", "何をこそこそと!!", "悪口禁止!!" ], "Neutral" : [ "エアリプ禁止!!", "呼んだ?呼んだよね!?呼んだよね!?", "御用の際は要件をお伝えの上、一万円をください", "何かいいましたか?" ] }ちなみに「応答する」という実装ではなく
「ネガティブワードが入ったら自分にチクりメンションをこっそり送る」のような邪悪な実装は色々できます。
今回は色々と自粛していますが、各自面白い実装があったら教えてくださいませ。動作
ご好評をいただき何よりです。
気を付けることやよもやま話
呼び出しトリガーについて
https://api.ce-cotoha.com/contents/reference/apireference.html#parsing
この形態素解析をかけて、自分の名前を形態素から拾いだすほうがクールな実装です。しかし日本語の自然言語処理は固有名詞に弱いです。
特にひらがなの意味の分からない名前はあんまり拾えませんし、何かと誤動作する原因にになります。
COTOHA APIというかNTT系のプロダクトは精度が高いほうだと私は思っていますが、
それでもあだ名のようなものについては正確に拾うのは難しいです。
私の「めめたん」というスクリーンネームも文脈によっては「め/めたん」のように分解される恐れがあります。
よって、トリガーについては形態素解析を使わず、正規表現で発火させる形のほうが間違いがないです。感情分析について
ここまで読んでいただいて申し訳ないのですが、申し上げづらいことがあります。
正直悪口のバリエーションが少ないといいますか、口語の悪口を想定しないで作られているのか、
はたまた「悪口」と「Negative」は違うのか、ちょっとわからないのですが、
現状「Negative」のフラグがあまりたちません。
心を痛めながら自分への悪口を書きまくって実験をしていたのですが、ちょっとそこは残念でした。
その辺は今後に大きく期待するとして、
運用側のカバーとして、私のBOT側では「Neutral」でもそれっぽい回答を返すという実装にしています。
チクりBOTなどを作りたい方も、「Positive」以外で動作するようにしたほうがいいかもしれません。商用で使えないじゃない!リモートワーク用ってなんだよ!
月13万円で音声入力なども含めてガンガン使えますよ!!安いじゃん!!(払うとは言ってない)
もちろんこの機能だけで入れるわけにもいかないと思いますが、他の機能などとセットで提案すると会社で通るかもしれません。
ご利用は自己責任でお願いします。終わりに
チャットBOTは既成のものを使いましたが、今日の午前だけでAPI呼び出しを仕込めたので、
おそらくQiitaをご覧の皆さまでしたらそこまで苦労せずに使いこなせると思います。
自然言語処理は、くだらない使い道が色々あり、遊びで作るのにはとても楽しいので、皆様のアイディアも是非見せてください。ご覧いただきありがとうございました。





- 投稿日:2020-03-14T14:39:38+09:00
AtCoder 第一回 アルゴリズム実技検定 バーチャル参戦記
AtCoder 第一回 アルゴリズム実技検定 バーチャル参戦記
ようやく時間が取れたので PAST をバーチャル参加してみました. 結果は64点だったので中級(60-79点)となりました. 普段の AtCoder の数学的、ひらめき勝負とは違い、なんか実装が微妙に面倒くさい感じの問題が多く、ちょっと毛色が違うように感じました.
past201912A - 2 倍チェック
3分半で突破. 数字だけかをチェックして、OK だったら int に変換して2倍で出力するだけ.
S = input() for i in range(3): if S[i] not in '0123456789': print('error') exit() print(int(S) * 2)past201912B - 増減管理
7分で突破. 一つ前の値と比較して出力するだけ.
N = int(input()) A = [int(input()) for _ in range(N)] prev = A[0] for i in range(1, N): if A[i] == prev: print('stay') elif A[i] < prev: print('down %d' % (prev - A[i])) elif A[i] > prev: print('up %d' % (A[i] - prev)) prev = A[i]past201912C - 3 番目
2分で突破. 降順ソートして、前から3番目の値を出力するだけ.
ABCDEF = list(map(int, input().split())) ABCDEF.sort(reverse=True) print(ABCDEF[2])past201912D - 重複検査
11分で突破. 辞書で出現数を数えて、0個のものと2個の物を特定して出力するだけ.
N = int(input()) A = [int(input()) for _ in range(N)] t = set(A) if len(t) == N: print('Correct') exit() d = {} for i in range(N): if A[i] in d: d[A[i]] += 1 else: d[A[i]] = 1 for i in range(1, N + 1): if i not in d: x = i elif d[i] == 2: y = i print(y, x)past201912E - SNS のログ
24分で突破. フォローフォローの実装が、処理中に増えたフォローのフォローしているユーザも追加してしまっていて、入力例1が通らずに時間がかかった. 入力例1がそこを引っ掛けてくれなければもっと時間がかかったと思う.
N, Q = map(int, input().split()) t = [['N'] * N for _ in range(N)] for _ in range(Q): S = input() if S[0] == '1': _, a, b = map(int, S.split()) t[a - 1][b - 1] = 'Y' elif S[0] == '2': _, a = map(int, S.split()) for i in range(N): if t[i][a - 1] == 'Y': t[a - 1][i] = 'Y' elif S[0] == '3': _, a = map(int, S.split()) for i in [i for i in range(N) if t[a - 1][i] == 'Y']: for j in range(N): if t[i][j] == 'Y' and j != a - 1: t[a - 1][j] = 'Y' for i in range(N): print(''.join(t[i]))past201912F - DoubleCamelCase Sort
7分で突破. 特に難しいところはなく、単語に切り出して、大文字小文字無視ソートをして、結合するだけ.
S = input() t = [] start = -1 for i in range(len(S)): if S[i].isupper(): if start == -1: start = i else: t.append(S[start:i+1]) start = -1 t.sort(key=str.lower) print(''.join(t))past201912G - 組分け
20分で突破. 最初分からないと思ったが、よく見ると N≦10 だったので総当りで行けた. グループが3つあるので bit 全探索できず、int 配列で繰り上げも実装だったけど、特に難しくはなかった.
N = int(input()) a = [list(map(int, input().split())) for _ in range(N - 1)] result = -float('inf') t = [0] * N for _ in range(3 ** N): s = 0 for i in range(N): for j in range(i + 1, N): if t[i] == t[j]: s += a[i][j - i - 1] result = max(result, s) for i in range(N): if t[i] < 2: t[i] += 1 break t[i] = 0 print(result)past201912H - まとめ売り
44分半で突破. 制約を見るからにセット販売も全種類販売も素直に配列に反映すると TLE 必至なので、それぞれ用の累積変数を作って、辻褄合わせをする方針で通した. 全種類販売のときの
odd_min -= aが漏れて気づくまでに結構時間がかかってしまった.N = int(input()) C = list(map(int, input().split())) Q = int(input()) all_min = min(C) odd_min = min(C[::2]) all_sale = 0 odd_sale = 0 ind_sale = 0 for _ in range(Q): S = input() if S[0] == '1': _, x, a = map(int, S.split()) t = C[x - 1] - all_sale - a if x % 2 == 1: t -= odd_sale if t >= 0: ind_sale += a C[x - 1] -= a all_min = min(all_min, t) if x % 2 == 1: odd_min = min(odd_min, t) elif S[0] == '2': _, a = map(int, S.split()) if odd_min >= a: odd_sale += a odd_min -= a all_min = min(odd_min, all_min) elif S[0] == '3': _, a = map(int, S.split()) if all_min >= a: all_sale += a all_min -= a odd_min -= a print(all_sale * N + odd_sale * ((N + 1) // 2) + ind_sale)past201912I - 部品調達
14分で突破. 見るからに DP なので特に難しいことはなく. Yを1、Nを0と各桁のビットにみなした整数に変換して、DP するだけ.
N, M = map(int, input().split()) def conv(S): result = 0 for c in S: result *= 2 if c == 'Y': result += 1 return result dp = [-1] * 2001 dp[0] = 0 for _ in range(M): S, C = input().split() S = conv(S) C = int(C) for i in range(2000, -1, -1): if dp[i] == -1: continue if dp[i | S] == -1 or dp[i | S] > dp[i] + C: dp[i | S] = dp[i] + C print(dp[(1 << N) - 1])past201912J - 地ならし
突破できず. 左下から右下への最安ルートを DP で求め、バックトラックして通ったところを費用0に書き換えて、右下から右上への最安ルートを DP で求め、それぞれでかかった費用を合計するという実装を組んでみたが、半分くらい WA.
past201912K - 巨大企業
突破できず. 当然ナイーブな実装は書けるわけだけど、計算量を減らす手段が全く思いつかず.
- 投稿日:2020-03-14T14:32:56+09:00
ITHACA-FV(OpenFOAMで使えるPODライブラリ)を試す
はじめに
OpenFOAMで次元削減モデルを扱えるようにするライブラリITHACA-FVを試してみました.
https://github.com/mathLab/ITHACA-FV
POD(固有直交分解)などを簡単に行えるようです.
ライセンスはLGPLv3とのこと.インストール
公式通りにやれば問題なくインストールできるはずですが,念のためメモとして書いておきます.
前提としてOpenFOAMの6.0,5.0,v1812がインストールされている必要があります.ITHACA-FVはOpenFOAMの${FOAM_APP}/utilitiesにインストールします.
${FOAM_APP}は具体的には,OpenFOAM/OpenFOAM-*/applications/utilitiesというディレクトリになりますこのディレクトリに移動して,公式通りに操作するとインストールが始まります.
$ git clone https://github.com/mathLab/ITHACA-FV $ cd ITHACA-FV $ source etc/bashrc $ ./Allwmakeインストールに長時間かかるので,コーヒーブレイクが必要です(5杯ぶんくらい).
チュートリアルを試す
一番ベーシックなチュートリアルを動かしてみます.
https://mathlab.github.io/ITHACA-FV/01POD_8C-example.htmlcd tutorials/01POD ./Allrunチュートリアルの計算対象はよくあるcavity流れでした.
ちなみに初期のファイル構成はこんな感じ
01POD.Cをいかに書くかが問題ですね.0 01POD.C Allclean Allrun constant systemAllrunの中を見てみましょう
Allrun#!/bin/sh cd ${0%/*} || exit 1 # Run from this directory # Source tutorial run functions . $WM_PROJECT_DIR/bin/tools/RunFunctions runApplication icoFoam runApplication perform_PODperform_PODと打つだけで簡単に実行できるようです.
計算結果のファイル構成はこうなりました.
0 0.0095 0.019 0.0285 0.038 0.0475 0.057 0.0665 0.076 0.0855 0.095 0.0005 0.01 0.0195 0.029 0.0385 0.048 0.0575 0.067 0.0765 0.086 0.0955 0.001 0.0105 0.02 0.0295 0.039 0.0485 0.058 0.0675 0.077 0.0865 0.096 0.0015 0.011 0.0205 0.03 0.0395 0.049 0.0585 0.068 0.0775 0.087 0.0965 0.002 0.0115 0.021 0.0305 0.04 0.0495 0.059 0.0685 0.078 0.0875 0.097 0.0025 0.012 0.0215 0.031 0.0405 0.05 0.0595 0.069 0.0785 0.088 0.0975 0.003 0.0125 0.022 0.0315 0.041 0.0505 0.06 0.0695 0.079 0.0885 0.098 0.0035 0.013 0.0225 0.032 0.0415 0.051 0.0605 0.07 0.0795 0.089 0.0985 0.004 0.0135 0.023 0.0325 0.042 0.0515 0.061 0.0705 0.08 0.0895 0.099 0.0045 0.014 0.0235 0.033 0.0425 0.052 0.0615 0.071 0.0805 0.09 0.0995 0.005 0.0145 0.024 0.0335 0.043 0.0525 0.062 0.0715 0.081 0.0905 0.1 0.0055 0.015 0.0245 0.034 0.0435 0.053 0.0625 0.072 0.0815 0.091 01POD.C 0.006 0.0155 0.025 0.0345 0.044 0.0535 0.063 0.0725 0.082 0.0915 Allclean 0.0065 0.016 0.0255 0.035 0.0445 0.054 0.0635 0.073 0.0825 0.092 Allrun 0.007 0.0165 0.026 0.0355 0.045 0.0545 0.064 0.0735 0.083 0.0925 constant 0.0075 0.017 0.0265 0.036 0.0455 0.055 0.0645 0.074 0.0835 0.093 ITHACAoutput 0.008 0.0175 0.027 0.0365 0.046 0.0555 0.065 0.0745 0.084 0.0935 log.icoFoam 0.0085 0.018 0.0275 0.037 0.0465 0.056 0.0655 0.075 0.0845 0.094 log.perform_POD 0.009 0.0185 0.028 0.0375 0.047 0.0565 0.066 0.0755 0.085 0.0945 system0.03などの時間のフォルダは通常のOpenFOAMの結果で中身は特に変化なさそうです.時間方向に大量のデータを保存する必要のある非定常計算は闇が深いですね..
THACAoutput/POD/の中を見ると以下の構成でした.
0 10 3 5 7 9 CumEigenvalues_p Eigenvalues_p system 1 2 4 6 8 constant CumEigenvalues_U Eigenvalues_U例えば,Eigenvalues_pの中身はこんな感じで固有値が入っている模様
Eigenvalues_pMatrixMarket matrix array real general 10 1 0.98598269642487645914 0.01333412670236625193 0.00041428833177079141 0.00022875185314061281 0.00002708055184500610 0.00000964132052745271 0.00000296734318563279 0.00000035202349614126 0.00000007256768979182 0.00000002288110189711他はOpenFOAMと同じファイル構成なのでParaviewで可視化をためすと,こんな感じで可視化できました.
さいごに
典型的なやってみた記事になってしまいましたが,まあ,無いよりはいい派なので,許してください.

- 投稿日:2020-03-14T13:43:55+09:00
hello,worldsのみで覚えるpython
はじめに
職場柄、アウトプットがしにくい環境にいる中、技術力を高めるのと理解の再確認のために記事を書くことにしてみた。
とはいえpythonの記事などありふれているわけで、特異性を見出すための手段として誰しも通る道であるhello,worldsのみでpythonを理解していこうではないかと思う。
馬鹿げてるくらいが読み物として丁度いいことだろう。本記事の対象者
・pythonの勉強を始めた人
・pythonの経験値が足りないと感じる人
・物好き注意点
・本記事はpython3系を前提として記載していく。当人が3.7を使用しているので3.8に対する知識が現時点で浅い
本題
1.文字列出力
hello,worldsを語る上では避けては通れない文字列出力である。
ここでは様々なアプローチでhello,worldsをしていく。print('hello,worlds) print('hello,' + 'worlds') print({}.format('hello,worlds')) hoge = 'hello,worlds' print('%s' % hoge)これら全てはhello,worldsである。
作者のやる気次第でこのノリかずっと続くことだろう
- 投稿日:2020-03-14T13:13:08+09:00
Pythonで毎日AtCoder #5
はじめに
前回
5日目です。今日はコンテストがあります。今日のコンテスト#5
考えたこと
1WAしました。
与えられる文字列に'ict'が含まれているかを判断する問題です。いくつかの文字を除いて'ict'になればいいというのが大事で、'ict'のどれかを除いてもいいのです。
最初は、この条件を見落していたのでWAしました。それを改善して順番通りに変換していくようにしました。import re s = str(input()) s = s.lower() l = 'ict' step = 0 for i in range(len(s)): if s[i] == l[step]: step += 1 if step == 3: print('YES') quit() print('NO')stepでindexを指定することで、順番通りに探してくれます。
s.lower()は、sを全て小文字にします。まとめ
A問題なのにWAしてしまったのが悔しいです。今日のコンテストがんばりましょう!
では、また
- 投稿日:2020-03-14T12:39:53+09:00
中間層2層, 中間ニューロン数a1, a2個のReLUニューラルネットワークで任意のa1*a2個のデータが誤差0で表現できる話
はじめに
この記事は私の論文"Expressive Number of Two or More Hidden Layer ReLU Neural Networks"の実装記事です。
概略
活性化関数がReLU関数であり、入力がn次元、出力が1次元の中間層2層のニューラルネットワークを考える。中間ニューロン数が入力側から順にa1個、a2個であったとき、任意のa1*a2個の入出力データに対し、それらのデータを誤差0で表現するようなニューラルネットワークのパラメータが存在する。ここでいう「入出力データを誤差0で表現する」とは、ニューラルネットワークに各入力データを与えると、それぞれ対応した出力データと等しい値を返すことを表している。
まとめると、機械学習における訓練データがa1*a2個以下のとき、学習の収束先が必ず存在するということです。(ただし収束先の存在性が言えるだけで、実際に学習が収束するとは限らない。)
証明は元論文にあるので省略しますが、本記事では、実際にその収束先であるパラメータ1組を表示するプログラムを紹介します。まずは実行例をご覧ください。実行例
$python3 NNH2.py ( 5 , 3 , 3 , 1 ) ReLU neural network the number of data = 9 input = [[93 59 58 20 80 57 35 21 38] [ 4 91 47 69 98 85 68 2 15] [14 60 31 86 37 12 23 69 42] [ 4 14 52 98 72 60 67 51 90] [27 12 6 32 76 63 49 41 28]] output = [ 1 81 17 65 25 33 45 77 10] parameters 1st layer W1 = [[Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)]] b1 = [[Fraction(-16778681974, 1)] [Fraction(-60502822101, 2)] [Fraction(-48495714637, 1)]] 2nd layer W2 = [[Fraction(148, 1) Fraction(-9237952317912, 35473138591) Fraction(4049615396998340012232, 18010928872046123981)] [Fraction(15800556778618364518367199397870934943209115691793, 1077111270972508432064314372084032376028236629) Fraction(-11216317162890245084133171070123933902029519034081603343913003835232890, 434989745706342223538442515057047029191074444247675999926788518821) Fraction(2686834406446276617746833568279126654074919365089537293846487174104542, 224870468718735937295513181927691380500164378143178284849730556247)] [Fraction(843610077776665412761527367413211990104912799146270139270113712675305808525969059554219936165800, 154068217051841137536218687813904006692418581384372306328955832146429671252437697) Fraction(-57625119985396507975392986118005960657818304694554844951150042194684795633743261029837087833785575305876950, 5262027877233168541064334417747189692030849998640803800770876843784630220816492104662661549) Fraction(100319159657643248312549073786161213853603634088990731217920689495343417295177190966187025547162361565044553868359914, 11390289225651438251169009216834446835092039706616191741035899343815780751119047453235035761689895223)]] b2 = [[Fraction(-99, 1)] [Fraction(-31282288621675736677206673372946695670689268182842, 4042938352270697695885621047346217759)] [Fraction(-912723226773529956403403228639959057460803178243124784475781762180477870767754518136094, 13495462068042154164632946308945540668991317744154109409049607)]] 3rd layer W3 = [[ 1 -1 1]] b3 = [[16]] check MP(x) = [Fraction(1, 1), Fraction(81, 1), Fraction(17, 1), Fraction(65, 1), Fraction(25, 1), Fraction(33, 1), Fraction(45, 1), Fraction(77, 1), Fraction(10, 1)] output= [ 1 81 17 65 25 33 45 77 10] MP(x) - output = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]これは入力が5次元、中間ニューロン数が順に3個、3個のときの例です。
任意の3*3=9個の入出力データが表現できるので、データを以下のように与えます。input = [[93 59 58 20 80 57 35 21 38] [ 4 91 47 69 98 85 68 2 15] [14 60 31 86 37 12 23 69 42] [ 4 14 52 98 72 60 67 51 90] [27 12 6 32 76 63 49 41 28]] output = [ 1 81 17 65 25 33 45 77 10]これは入力
[[93] [4] [14] [4] [27]]に対応する出力が[1]であるようなデータを意味しており、そのような入出力データが9個並んでいます。この例では乱数でデータを与えましたが、具体的なデータを与えることもできます。
与えられたデータに対し、それらを表現するニューラルネットワークのパラメータである各層の重み値とバイアス値は、それぞれ1層目W1、b1、2層目W2、b2、3層目W3、b3として出力されます。(Fraction(n,m)とは有理数$\frac{n}{m}$を表す。)1st layer W1 = [[Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)]] b1 = [[Fraction(-16778681974, 1)] [Fraction(-60502822101, 2)] [Fraction(-48495714637, 1)]] ...パラメータの分母分子は非常に大きい値が計算されますが、9個の各入力に対するニューラルネットワークの出力はキレイに割り切れて、それぞれ
MP(x) = [Fraction(1, 1), Fraction(81, 1), Fraction(17, 1), Fraction(65, 1), Fraction(25, 1), Fraction(33, 1), Fraction(45, 1), Fraction(77, 1), Fraction(10, 1)]となります。実際に元データの出力との誤差を比較すると、
MP(x) - output = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]となり、誤差0となることがわかります。(見やすさのため
float型に変換しています。)
この結果は入出力データや入力次元、中間ニューロン数に依存せず、任意の値で誤差が0になるはずです。実装
アルゴリズムは元論文のTeorem 3の証明と"表現可能なデータ数に基づいたニューラルネットワークの表現能力"の定理3の証明を参考にしました。具体的には連立方程式の1つの解を求めればいいのですが、相互再帰な二変数漸化式が出てきたりと複雑なので、詳細が知りたい方は元論文をどうぞ。
Pythonによる実装コードはこちら変更可能なパラメータ
ニューロン数
# constants idim = 5 # the number of input neurons a1 = 3 # the number of 1st hidden neurons a2 = 3 # the number of 2nd hidden neurons N = a1 * a2 # the number of data (do not change)
idimが入力次元、a1、a2がそれぞれ1層目、2層目の中間ニューロン数です。
N = a1 * a2がデータ数であり、これは変更しないでください。与えるデータ
idata = randomidata(idim,idataRange) # input data must be unique odata = randomodata(odataRange)
idataは入力データであり、idim×N行列でかつ等しい列ベクトルが存在しない状態、odataは出力データであり、N次元ベクトルである必要があります。
この例では乱数取得のためデータ範囲を制限していますが、実際にはどちらも制限する必要なく、任意の値でパラメータを計算できます。商演算
# select division operator ('Fraction' or '/') divop = fractions.Fraction # divop = lambda x,y: x / yパラメータを計算するのに四則演算しか使わないので、商演算
divopは有理数演算Fractionで定義していますが、不動小数点数の演算/に変更することが可能です。しかし非常に大きい数で割ることがあり、/だと誤差が大きくなる可能性があるため注意が必要です。出力がm次元の場合
元論文のTheorem 4より、出力がm次元の場合は$a_1(a_2 \operatorname{div} m) + a_2 \operatorname{mod} m$個のデータが表現できます。(実装はしていませんが出力が1次元の時のパラメータを流用すれば同じように作れます。)
まとめ
中間ニューロン数がa1、a2個である中間層2層のReLUニューラルネットワークにおいて、与えられたa1*a2個のデータを表現するようなパラメータ1組を出力するようなプログラムを解説しました。
このプログラムで出力されるパラメータは絶対値が非常に大きいように思えますが、一般に与えられたデータを表現するパラメータには一意性が成り立たたないため、もっと絶対値の小さいパラメータで表現できる可能性があることに注意してください。
- 投稿日:2020-03-14T12:39:53+09:00
中間層2層, 中間ニューロン数a1, a2個のReLUニューラルネットワークで任意のa1*a2個のデータが誤差0で表現できてしまう話とその実装
はじめに
この記事は私の論文"Expressive Number of Two or More Hidden Layer ReLU Neural Networks"の実装記事です。
概略
活性化関数がReLU関数であり、入力がn次元、出力が1次元の中間層2層のニューラルネットワークを考える。中間ニューロン数が入力側から順にa1個、a2個であったとき、任意のa1*a2個の入出力データに対し、それらのデータを誤差0で表現するようなニューラルネットワークのパラメータが存在する。ここでいう「入出力データを誤差0で表現する」とは、ニューラルネットワークに各入力データを与えると、それぞれ対応した出力データと等しい値を返すことを表している。
まとめると、機械学習における訓練データがa1*a2個以下のとき、学習の収束先が必ず存在するということです。(ただし収束先の存在性が言えるだけで、実際に学習が収束するとは限らない。)
例えば、出力1次元の訓練データが10,000個あったとき、中間ニューロン数が100個、100個の中間層2層のReLUニューラルネットワークで全てのデータが表現できます。
この事実はデータの入力次元に依存しないので、入力次元はいくら大きくても大丈夫です。(出力が1次元でない場合は後述します。)
証明は元論文にあるので省略しますが、本記事では、実際にその収束先であるパラメータ1組を表示するプログラムを紹介します。まずは実行例をご覧ください。実行例
入力が5次元、中間ニューロン数が入力側から順に3個、3個、出力が1次元のニューラルネットワークで、3*3=9個のデータを表現するパラメータを出力する例です。
$python3 NNH2.py ( 5 , 3 , 3 , 1 ) ReLU neural network the number of data = 9 input = [[93 59 58 20 80 57 35 21 38] [ 4 91 47 69 98 85 68 2 15] [14 60 31 86 37 12 23 69 42] [ 4 14 52 98 72 60 67 51 90] [27 12 6 32 76 63 49 41 28]] output = [ 1 81 17 65 25 33 45 77 10] parameters 1st layer W1 = [[Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)]] b1 = [[Fraction(-16778681974, 1)] [Fraction(-60502822101, 2)] [Fraction(-48495714637, 1)]] 2nd layer W2 = [[Fraction(148, 1) Fraction(-9237952317912, 35473138591) Fraction(4049615396998340012232, 18010928872046123981)] [Fraction(15800556778618364518367199397870934943209115691793, 1077111270972508432064314372084032376028236629) Fraction(-11216317162890245084133171070123933902029519034081603343913003835232890, 434989745706342223538442515057047029191074444247675999926788518821) Fraction(2686834406446276617746833568279126654074919365089537293846487174104542, 224870468718735937295513181927691380500164378143178284849730556247)] [Fraction(843610077776665412761527367413211990104912799146270139270113712675305808525969059554219936165800, 154068217051841137536218687813904006692418581384372306328955832146429671252437697) Fraction(-57625119985396507975392986118005960657818304694554844951150042194684795633743261029837087833785575305876950, 5262027877233168541064334417747189692030849998640803800770876843784630220816492104662661549) Fraction(100319159657643248312549073786161213853603634088990731217920689495343417295177190966187025547162361565044553868359914, 11390289225651438251169009216834446835092039706616191741035899343815780751119047453235035761689895223)]] b2 = [[Fraction(-99, 1)] [Fraction(-31282288621675736677206673372946695670689268182842, 4042938352270697695885621047346217759)] [Fraction(-912723226773529956403403228639959057460803178243124784475781762180477870767754518136094, 13495462068042154164632946308945540668991317744154109409049607)]] 3rd layer W3 = [[ 1 -1 1]] b3 = [[16]] check MP(x) = [Fraction(1, 1), Fraction(81, 1), Fraction(17, 1), Fraction(65, 1), Fraction(25, 1), Fraction(33, 1), Fraction(45, 1), Fraction(77, 1), Fraction(10, 1)] output= [ 1 81 17 65 25 33 45 77 10] MP(x) - output = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]順に解説していくと、
まず任意の3*3=9個の入出力データが表現できるので、データを以下のように与えます。input = [[93 59 58 20 80 57 35 21 38] [ 4 91 47 69 98 85 68 2 15] [14 60 31 86 37 12 23 69 42] [ 4 14 52 98 72 60 67 51 90] [27 12 6 32 76 63 49 41 28]] output = [ 1 81 17 65 25 33 45 77 10]これは入力
[[93] [4] [14] [4] [27]]に対応する出力が[1]であるようなデータを意味しており、そのような入出力データが9個並んでいます。この例では乱数でデータを与えましたが、具体的なデータを与えることもできます。
与えられたデータに対し、それらを表現するニューラルネットワークのパラメータである各層の重み値とバイアス値は、それぞれ1層目W1、b1、2層目W2、b2、3層目W3、b3として出力されます。(Fraction(n,m)とは有理数$\frac{n}{m}$を表す。)1st layer W1 = [[Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)] [Fraction(823849691, 1) Fraction(4336051, 1) Fraction(28907, 1) Fraction(149, 1) Fraction(1, 1)]] b1 = [[Fraction(-16778681974, 1)] [Fraction(-60502822101, 2)] [Fraction(-48495714637, 1)]] ...パラメータの分母分子は非常に大きい値が計算されますが、9個の各入力に対するニューラルネットワークの出力はキレイに割り切れて、それぞれ
MP(x) = [Fraction(1, 1), Fraction(81, 1), Fraction(17, 1), Fraction(65, 1), Fraction(25, 1), Fraction(33, 1), Fraction(45, 1), Fraction(77, 1), Fraction(10, 1)]となります。実際に元データの出力との誤差を比較すると、
MP(x) - output = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]となり、誤差0となることがわかります。(見やすさのため
float型に変換しています。)
この結果は入出力データや入力次元、中間ニューロン数に依存せず、任意の値で誤差が0になるはずです。実装
アルゴリズムは元論文のTeorem 3の証明と"表現可能なデータ数に基づいたニューラルネットワークの表現能力"の定理3の証明を参考にしました。具体的には、証明中に求めた連立方程式の1つの解を計算するようなプログラムなのですが、相互再帰な二変数漸化式が出てきたりとけっこう複雑なので、詳細が知りたい方は元論文をどうぞ。
Pythonによる実装コードはこちら変更可能なパラメータ
ニューロン数
# constants idim = 5 # the number of input neurons a1 = 3 # the number of 1st hidden neurons a2 = 3 # the number of 2nd hidden neurons N = a1 * a2 # the number of data (do not change)
idimが入力次元、a1、a2がそれぞれ1層目、2層目の中間ニューロン数です。
N = a1 * a2がデータ数であり、これは変更しないでください。与えるデータ
idata = randomidata(idim,idataRange) # input data must be unique odata = randomodata(odataRange)
idataは入力データであり、idim×N行列でかつ同じ列ベクトルが存在しない状態、odataは出力データであり、N次元ベクトルである必要があります。
この例では乱数取得のためデータ範囲を制限していますが、実際にはどちらも制限する必要なく、任意の値でパラメータを計算できます。商演算
# select division operator ('Fraction' or '/') divop = fractions.Fraction # divop = lambda x,y: x / yパラメータを計算するのに四則演算しか使わないので、商演算
divopは有理数演算Fractionで定義していますが、不動小数点数の演算/に変更することが可能です。しかし非常に大きい数で割ることがあり、/だと誤差が大きくなる可能性があるため注意が必要です。出力がm次元の場合
元論文のTheorem 4より、出力がm次元の場合は$a_1(a_2 \operatorname{div} m) + a_2 \operatorname{mod} m$個のデータが表現できます。(実装はしていませんが出力が1次元の時のパラメータを流用すれば同じように作れます。)
すなわち2層目の中間ニューロンを出力次元の倍数にすれば
[訓練データ数]×[出力次元] ≦ [1層目の中間ニューロン数]×[2層目の中間ニューロン数]
を満たしていれば表現できるので、例えば訓練データ10,000個、出力が10次元であれば、中間ニューロン数400個、250個のニューラルネットワークで全てのデータが表現できます。まとめ
中間ニューロン数がa1、a2個である中間層2層のReLUニューラルネットワークにおいて、与えられたa1*a2個のデータを表現するようなパラメータ1組を出力するようなプログラムを解説しました。
このプログラムで出力されるパラメータは絶対値が非常に大きいように思えますが、どんな歪なデータに対しても表現するようなパラメータ計算式のため、このような結果になったと考えられます。しかし幸いなことに、与えられたデータを表現するパラメータには一般には一意性が成り立たたないため、データによっては、もっと絶対値の小さいパラメータで表現できる可能性があります。
- 投稿日:2020-03-14T12:14:24+09:00
AtCoder ABC156 問題D Bouquet modの計算と順列等
概要
AtCoder ABC156 問題D Bouquetやってみた。modの逆元とかmodの順列組み合わせ計算の整理。
経緯
暫く仕事で忙殺されていて、コンテストにすら参画できなくて残念な状態だったのだが、一段落したのでコンテスト参加再開。これからは参加するだけでなく多少精進して色を上げていきたい。
私の実力ではABCのD問題の正解率上げていく戦略が良さげなのでとりあえず過去問含めといていくことを考えている。そんな中、AtCoder ABC156 問題D Bouquetやってみた。
結果
問題よんだら計算自体「あー大きな数の順列組み合わせのmod計算しないとダメなのね」という事はすぐ理解したのが、「でどうやってやるんだっけ?」となってしまった。むかしやってた数値計算だとmodとか整数の計算とか出てこない。
自分で一所懸命考えるのはもう少しレベルが上がってからすることにして、優秀そうな人の解法を参照してみる。参考にした提出はこちらAtCoder提出#10273434。
転記10273434.py1 import sys 2 3 stdin = sys.stdin 4 5 ns = lambda: stdin.readline().rstrip() 6 ni = lambda: int(stdin.readline().rstrip()) 7 nm = lambda: map(int, stdin.readline().split()) 8 nl = lambda: list(map(int, stdin.readline().split())) 9 10 n,a,b = nm() 11 mod = 10**9 + 7 12 s = pow(2,n,mod) - 1 13 14 def fur(n,r): 15 p,q = 1,1 16 for i in range(r): 17 p = p*(n-i)%mod 18 q = q*(i+1)%mod 19 return p * pow(q,mod-2,mod) % mod 20 21 print((s - fur(n,a) - fur(n,b)) % mod) 222020/03時点で黄色にせまろうとしている青色の方。提出時間21:09:30か。。。速いなぁ。
コードもシンプル。。pow(a,b,c)という便利な関数があると知る。Python pow
これみていると逆元まで計算できる。
AtCoder提出#10273434の提出者のかたは
a,pが互いに素のとき a ^ (p-2) = a ^ -1 (mod p)
の原理を使用されている様子(参考:フェルマーの小定理)。
リンクにもあるように
バージョン 3.8 で変更: For int operands, the three-argument form of pow now allows the second argument to be negative, permitting computation of modular inverses.
3引数のpowの第二引数に負の数字が許されるようになったのはPython 3.8以降。AtCoderのPythonは2020/03/12現在3.4なのでこっちの方法をつかっているのたど思われる。14行目から関数で
p = n * (n-1) * ... * (n-r+1) (mod)
q = 1 * 2 * ... * r (mod)
return p / q (mod)
として C(n,r) = n! / (r! * (n-r)!)を計算している。あとは
n本種類の花から任意の本数選ぶ組み合わせ 2^n
n本種類の花からa本数選ぶ組み合わせ C(n,a)
n本種類の花からa本数選ぶ組み合わせ C(n,b)
n本種類の花から一本も選ばない組み合わせ 1
で
2^n - C(n,a) - C(n,a) -1
で終了か。。答え見ちゃうとかんたんだが、さっと自分で書けるようにならないと意味ない。
furは何かの略かはわからなかった。C++ではどうしてるのかなともう一つ提出をみてみた
AtCoder提出#10266780。
提出者のかたは2020/03/14時点で黄色の方。提出時間21:03:23。Dを最初に提出している様子ですがそれにしても速いなぁ。
転記10266780.cpp1 #include <bits/stdc++.h> 2 using namespace std; 3 typedef long long ll; 4 #define all(x) (x).begin(),(x).end() 5 const ll mod=1000000007,MAX=200005,INF=1<<30; 6 7 ll inv[MAX],fac[MAX],finv[MAX]; 8 9 ll rui(ll a,ll b){ 10 ll ans=1; 11 while(b>0){ 12 if(b&1) ans=ans*a%mod; 13 a=a*a%mod; 14 b/=2; 15 } 16 return ans; 17 } 18 19 20 21 ll comb(ll a,ll b){ 22 ll ans=1; 23 for(ll i=a;i>a-b;i--){ 24 ans=ans*i%mod; 25 } 26 for(ll i=1;i<=b;i++){ 27 ans=(ans*rui(i,mod-2))%mod; 28 } 29 return ans; 30 } 31 32 int main(){ 33 34 std::ifstream in("text.txt"); 35 std::cin.rdbuf(in.rdbuf()); 36 cin.tie(0); 37 ios::sync_with_stdio(false); 38 39 //make(); 40 41 int N,A,B;cin>>N>>A>>B; 42 43 cout<<(mod+mod+rui(2,N)-comb(N,A)-comb(N,B)-1)%mod<<endl; 44 45 } 46run(a,b) : a ^ b (mod)を計算する関数
comb(a,b) : C(a,b) (mod)を計算する関数
を自分で定義されていて、処理の全体は提出#10273434と同じに見える。
自作しているところをみるとPythonのPOWみたいな関数はC++ではシステム側に用意されてないのかな。今回は結局自分ではコード書いてない。
- 投稿日:2020-03-14T12:14:08+09:00
Pythonの標準ライブラリ3つだけでぷよぷよもどきを作ってみた
以下の動画内で高速でパズルゲームを作り上げていることに触発されて、
私もPython3の標準ライブラリのみを使ってぷよぷよもどきを作ってみました。
パズドラを小一時間で作ってみた【プログラミング実況】Programming Match-Three Game - YouTubeロジックをとてもとてもとても参考にさせてもらっています。(一部まんま同じ箇所があります)
動画内ではC++でコーディングしていたのですが、
私が好きなPythonならもっと簡単に書けるのではないかと思い作ってみました。記事の後半でコードを全て公開しています。
どんなゲーム作ったの??
とりあえず動いているところを見てもらいましょう。

このゲームの特徴は以下です。
- ボード内の二箇所を選択すると選択された箇所のブロックが交換される
- 交換された結果、3つ以上同じ色でつながっているブロックは削除する
- 削除されたブロックの箇所には上のブロックが落ちてくる。
- たくさんコンボをしたら高得点(私の最高は64、雑魚)
どんな環境で動くの??
私はMacOS上で実行していますが、利用しているライブラリが標準ライブラリのみで、1ファイルで完結するものなので、
WindowsでもLinuxでもPython3が動く環境であれば動作するはずです。
(動作確認はMacでしかしていないのでご注意を。)Pythonのバージョンは3.8.2で試してます。
使っているライブラリは??
このアプリケーションは3つの標準ライブラリしかimportしていません。
import tkinter as tk from random import randint from time import sleep
random.randintは乱数を出力してくれる関数。色をランダムに決める時に使います。
sleepは時を止める関数です。パズルの動きに間を作るために使います。
tkinterはGUIインターフェースを提供してくれる標準ライブラリで、このアプリの肝です。
そのため少し詳しく使い方をお話しします。tkinterの簡単な解説
tkinterはGUI画面を提供してくれるツールです。
今回紹介するゲームを作る上で重要なtkinterの特徴は以下になります。
- ウィンドウという名称のGUIの枠を作ることが出来る
- windowにはタイトルを付けられる
- ウィンドウ上に置けるラベルやボタンを作れる
- オブジェクトは背景色や文字色を設定することが出来る
- ボタンはクリックされた時の挙動を指定できる
- 関数の実行など
今回作成したぷよぷよもどきの例の場合以下のようにtkinterを使っています。
- パズル画面全体がウィンドウ
- ウィンドウの上に書いてあるpunyopunyoがタイトル
- 右下の
now comboなどの文字列がラベル- カラフルな一個一個のブロックがボタン
- ボタンはクリックされたときにある関数が実行されるようにしている
簡単に使えそうでしょう。
実際簡単です。とても扱いやすい良いライブラリだと思います。
tkinterについてもっと詳しく知りたい方は以下のサイトを参考にすると良いです。
tkinter — Python interface to Tcl/Tk — Python 3.8.2 documentation
PythonのTkinterを使ってみる - Qiitaコード全文
それではどんなコードを書いたのか紹介します。
punyopunyo.pyimport tkinter as tk from random import randint from time import sleep # パズルの形状 HEIGHT = 10 WIDTH = 10 # ボタン(ブロック)の色の種類 BUTTON_COLLORS = [ "#ffffff", # white "#ff0000", # red "#0000ff", # blue "#ffff00", # yellow "#00ff00", # lime "#ffc0cb", # pink "#00ffff", # aqua # "#000000", # black ] # 色の数 COLOR_NUM = len(BUTTON_COLLORS) # ボタンに設定できる背景色のタイプ3つ COLOR_CHANGEABLE_BACKGROUNDS = [ "background", "highlightbackground", "activebackground", ] # ボタンを選択した時に、選択されたボタン上に表示されるもの SELECTED_BUTTON_TEXT = "⛄" class Punyopunyo(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master.geometry() # ボタンの位置を柔軟に設定出来るwindowに設定 self.master.title('punyopunyo') # タイトルを付与 # 各種インスタンス変数を初期化 self.exists_selected_button = False self.init_board() # ボタン(パズル用ブロック)を作成 self.lock_buttons() # ボタンを押せないようにする self.init_checked_buttons() # あとで使うボタンのチェックフラグ群を初期化 sleep(0.5) # ボタンが作成されたタイミングで一休み self.create_now_combo_label() # 最初に作成されたパズルの時点で、 # すでに3つ以上連結しているブロックをすべて消し、 # 上から詰める、を繰り返す self.erased = True while self.erased: self.init_checked_buttons() self.erase_all_connected_buttons() self.drop_buttons() self.now_combo = 0 # ユーザー操作ではない部分でのコンボが計算されているため、0で初期化 self.create_max_combo_label() self.unlock_buttons() # もろもろの設定が終わった段階でパズルをクリック可能にする def create_now_combo_label(self): """現在のコンボ数を示すためのlabelを作成する """ self.now_combo = 0 self.now_combo_txt = tk.StringVar() self.now_combo_txt.set(f"Now Combo is {self.now_combo}") self.now_combo_label = tk.Label( self.master, textvariable=self.now_combo_txt) self.now_combo_label.grid(row=HEIGHT, column=WIDTH+1) def create_max_combo_label(self): """最大コンボ数を示すためのlabelを作成する """ self.max_combo = 0 self.max_combo_txt = tk.StringVar() self.max_combo_txt.set(f"Now max Combo is {self.max_combo}") self.label = tk.Label(self.master, textvariable=self.max_combo_txt) self.label.grid(row=HEIGHT+1, column=WIDTH+1) def button_action(self, btn): """ボタンが押された時に実行される関数 """ # チェック if not self.exists_selected_button: # すでにセレクトされたセルがなければ選択してボタンアクション終了 self.select_button(btn) return self.select_button(btn) self.master.update() self.lock_buttons() # 2つのボタンが選択されて、パズルの処理が終わるまでユーザー操作をロック sleep(0.4) # ちょっと一息 self.exists_selected_button = False # 選択されたボタンを見つける change_target_buttons = [] for button in self.flatten_buttons: if button["text"] == SELECTED_BUTTON_TEXT: change_target_buttons.append(button) # 選択されたボタン同士の色を入れ替える tmp_color = change_target_buttons[0]["background"] self.change_button_color(change_target_buttons[0], change_target_buttons[1]["background"]) self.change_button_color(change_target_buttons[1], tmp_color) # 色の交換が終わったので、選択されたことを表すボタン上のテキストを消す for target in change_target_buttons: target["text"] = "" self.master.update() self.erased = True self.now_combo = 0 while self.erased: self.drop_buttons() self.init_checked_buttons() self.erase_all_connected_buttons() if self.max_combo < self.now_combo: self.max_combo = self.now_combo self.max_combo_txt.set(f"Your Max Combo is {self.max_combo}") self.unlock_buttons() def erase_all_connected_buttons(self): """3つ以上結合しているボタンを全て消す """ self.erased = False for row in range(HEIGHT-1, -1, -1): for column in range(WIDTH): connected_count = self.count_connected_buttons( x=column, y=row, color=self.buttons[row][column]["background"], connected_count=0 ) if connected_count > 2: self.erase_connected_buttons( x=column, y=row, color=self.buttons[row][column]["background"]) self.erased = True self.now_combo += 1 self.now_combo_txt.set(f"Now Combo is {self.now_combo}") sleep(0.2) self.master.update() # 一箇所消したら都度画面の再描画 def drop_buttons(self): """空白箇所を詰める """ exist_white = True while exist_white: exist_white = False for y in range(HEIGHT-2, -1, -1): for x in range(WIDTH): if (self.buttons[y][x]["background"] != BUTTON_COLLORS[0] and self.buttons[y+1][x]["background"] == BUTTON_COLLORS[0]): self.change_button_color( self.buttons[y+1][x], self.buttons[y][x]["background"]) self.change_button_color( self.buttons[y][x], BUTTON_COLLORS[0]) for x in range(WIDTH): if self.buttons[0][x]["background"] == BUTTON_COLLORS[0]: self.change_button_color( self.buttons[0][x], BUTTON_COLLORS[randint(1, COLOR_NUM-1)]) exist_white = True sleep(0.3) self.master.update() def count_connected_buttons(self, x, y, color, connected_count): """隣接する同じ色のセルを数える(再起メソッド) """ if (x < 0 or WIDTH <= x or y < 0 or HEIGHT <= y or self.checked_buttons[y][x] or self.buttons[y][x]["background"] != color): return connected_count connected_count += 1 self.checked_buttons[y][x] = True connected_count = self.count_connected_buttons(x-1, y, color, connected_count) connected_count = self.count_connected_buttons(x+1, y, color, connected_count) connected_count = self.count_connected_buttons(x, y-1, color, connected_count) connected_count = self.count_connected_buttons(x, y+1, color, connected_count) return connected_count def erase_connected_buttons(self, x, y, color): """隣接する同じ色のセルを消す """ if (x < 0 or WIDTH <= x or y < 0 or HEIGHT <= y or self.buttons[y][x]["background"] == BUTTON_COLLORS[0] or self.buttons[y][x]["background"] != color): return self.change_button_color(self.buttons[y][x], BUTTON_COLLORS[0]) self.erase_connected_buttons(x-1, y, color) self.erase_connected_buttons(x+1, y, color) self.erase_connected_buttons(x, y-1, color) self.erase_connected_buttons(x, y+1, color) def change_button_color(self, button, color): """ボタンを指定された色に変える (なんかOSによって適用される背景が異なるから、三種類の背景を全て変える) """ for background in COLOR_CHANGEABLE_BACKGROUNDS: button[background] = color def init_checked_buttons(self): """ボタンに対する処理が完了したか判断する配列を作成 配列の位置はself.buttonsと対応している チェック済み状態を全てリセットすることにも利用 """ self.checked_buttons = [] for i in range(HEIGHT): checked_rows = [] for j in range(WIDTH): checked_rows.append(False) self.checked_buttons.append(checked_rows) def select_button(self, button): """セルを選択状態にする """ button["text"] = SELECTED_BUTTON_TEXT button["state"] = tk.DISABLED self.exists_selected_button = True def create_button(self, row, column): """ボタンオブジェクトを作成して引数で指定された位置に置く """ btn_color = BUTTON_COLLORS[randint(1, COLOR_NUM-1)] btn = tk.Button(self.master, height=2, width=4) self.change_button_color(btn, btn_color) btn["command"] = lambda: self.button_action(btn) btn.grid(row=row, column=column) return btn def init_board(self): """全ボタンを作成(最初の盤面準備) """ self.buttons = [] for i in range(HEIGHT): button_rows = [] for j in range(WIDTH): btn = self.create_button(row=i, column=j) button_rows.append(btn) self.buttons.append(button_rows) # のちのち扱いやすいようにボタンの一次元配列も作成しておく self.flatten_buttons = \ [button for a_row_buttons in self.buttons for button in a_row_buttons] def lock_buttons(self): """全ボタンを選択不可にする """ for row_buttons in self.buttons: for button in row_buttons: button["state"] = tk.DISABLED def unlock_buttons(self): """全ボタンを選択可にする """ for row_buttons in self.buttons: for button in row_buttons: button["state"] = tk.NORMAL root = tk.Tk() # TKinterのウィンドウを作成 app = Punyopunyo(master=root) app.mainloop() # ウィンドウを起動させるコピペしてpunyopunyo.pyファイルを作成し、
python punyopunyo.pyと実行すればパズル画面が立ち上がり、遊ぶことができます。重要な部分解説
- self.masterはウィンドウ全体を表しています。
- ボタンの色を変えたり、外見を変えるコーディングをしてもウィンドウの再描画をしないと反映されません
- そのため反映させたいタイミングで
self.master.update()をしています。- ボタンを処理しやすいようにするためボードの形と同じ二次元配列に格納しています。
- gridメソッドでボタンの配置を決められます。
- 同じ色のボタンがつながっている個数を数える
count_connected_buttonsメソッドでは、再起処理を使っています。
- パズルをするより、この箇所のコードの動きを理解することの方がよっぽどパズルです
app.mainloop()はウィンドウ内でイベントの発生を待ち、イベントを発生させることを繰り返し行うためのメソッドです。
- mainloopについては右の記事が分かりやすいです。Python 3.x - Python3.0のtkinterのmainloop() について|teratail
コード内にコメントをたくさん書いておいたので、時間をかけてコードを読み進めればどんな実装か理解できるはずです。
ぜひ頑張って読み解いていただき、改善できる箇所があればご指摘ください。ちなみにコード内のHIGHTとWIDTHの値を変えればパズルの形を変えることができます。
BUTTON_COLLORSのコメントアウトされているblackの行を有効にすれば、
ブロックの色に黒が増え難易度をあげることができます。WIDTHを20に変えて、黒色のブロックを追加するとこんな感じの盤面になります。
自分でゲーム作るといろいろカスタマイズできて楽しいです。
まとめ
一番はじめに紹介した動画の主は、
早い段階で一通り動作するものを作って、後は機能を足しながら都度デバッグをしており、さくさく開発を進めていたのが印象的でした。コードだけでなく開発の仕方でも大いに参考になります。まだ見たことがない方は是非。
パズドラを小一時間で作ってみた【プログラミング実況】Programming Match-Three Game - YouTubetkinterを使うと簡単にGUIアプリが作れます。楽しいアプリたくさん作りましょう!


- 投稿日:2020-03-14T12:07:29+09:00
PCR検査を全員にしたらいいのか?そんな馬鹿な。
はじめに
「コロナウイルスに対してなぜ希望者全員にPCR検査をしないのか?」ということが話題になっています。
大学院に進学したときにはじめて聞いた講演がまさにこの内容だった気がします。
理系なら医療系でなくても知っている話とおもっていて退屈でしたが、
世間の今の反応を見ると常識じゃないんですね。
関連する記事は随所に出ていますが、ここでも検証してみます。検査の精度
どのようなものでも100%のものはない。
病気なのに病気でないと検査結果が出たり、病気でないのに病気と検査結果が出たり。
ウイルス\検査結果 陽性 陰性 ウイルスあり a 人 b 人 ウイルスなし c 人 d 人 感度
ウイルスありを正しく陽性と検査できる確率
P(感度) = a / (a+b)特異度
ウイルスなしを正しく陰性と検査できる確率
P(特異度) = d / (c+d)感染率
母集団の中の感染率。
P(感染率) = (a+b) / (a+b+c+d)http://canscreen.ncc.go.jp/yougo/11.html
https://www.cresco.co.jp/blog/entry/5987/特異度の違いによる陽性的中率の変化
感度を95%
特異度を99% ~ 95% とするとsample.pyimport numpy as np import matplotlib.pyplot as plt import itertools p_kando_list = [0.95] p_tokuido_list = [0.99,0.98,0.95,0.9] p_kansen = 10.**np.arange(-3,0,0.01) for p_kando, p_tokuido in itertools.product(p_kando_list,p_tokuido_list): p_yousei_tekityu = p_kando * p_kansen / ( p_kando * p_kansen + (1-p_tokuido) * (1-p_kansen) ) plt.plot(p_kansen*100,p_yousei_tekityu*100,"-",label=str(p_tokuido)) plt.grid() plt.xscale("log") plt.title("tokuido dependence") plt.xlabel("Kansen Rate[%]") plt.ylabel("tekityu Rate[%]") plt.legend()
母集団の感染率が1%のとき、99%の特異度でも50%の陽性的中率。
陽性と判断されたとき二人に一人は濡れ布を着せられている。
これは陽性者にたいする風評被害がひどいらしい今、大変なこと。感度の違いによる陽性的中率の変化
感度を70% ~ 99%
特異度を98% とするとsample.pyp_kando_list = [0.7,0.8,0.9,0.95,0.99] p_tokuido_list = [0.98] p_kansen = 10.**np.arange(-3,0,0.01) for p_kando, p_tokuido in itertools.product(p_kando_list,p_tokuido_list): p_yousei_tekityu = p_kando * p_kansen / ( p_kando * p_kansen + (1-p_tokuido) * (1-p_kansen) ) plt.plot(p_kansen*100,p_yousei_tekityu*100,"-",label=str(p_kando)) plt.grid() plt.xscale("log") plt.title("kando dependence") plt.xlabel("Kansen Rate[%]") plt.ylabel("tekityu Rate[%]") plt.legend()
感度が高くなってもあまり陽性的中率は変わらない。
特異度が大切ですね。現在(3/13)の状況からの考察
データは厚労省のサイトから。
https://www.mhlw.go.jp/stf/newpage_10187.html
検査対象者 11,231人
検査陽性者 659人
つまり感染率は 6%弱先ほどのグラフを見ると、感度を95%,特異度を98%だとして、
陽性的中率は80~90%ぐらいでしょう。
10人に1人ぐらいは健康なのに、入院しているのかもしれない。
無症状者が68人ってことは陽性の10%ですが、偶然の一致でしょうか。現在濃厚接触者や有症状者など、感染が疑われる人が検査対象との話ですので、
感染率が6%ですが、気楽に無症状の人が検査を受けられるようになったら
(検査を受けた母集団の)感染率は下がるので、
偽陽性の割合がみるみる増えていきます。無症状や濃厚接触者でもない人が、
検査を受ければ、偽陽性になる確率的には(1-特異度)×(1-陽性的中率)ですから、
特異度を98%, 陽性的中率90%として、
(1-0.98)*(1-0.9) = 0.2% で濡れ衣。
(0.2%のSSRガチャか、ドロップか。余裕だな)不思議なことに母集団の感染率が下がると濡れ衣率が高まります。
デマでも陽性と疑われたら会社が傾きかねないこの世の中よく考えた方がいいです。また陰性的中率は0.06/(1-0.06)*(1-0.95)/0.98 = 0.3%。
陰性がでたとしても、
自分が6%の可能性でウイルス持っているかもしれないという状況から、
0.3%の可能性でウイルス持っているかもしれないという状況に変わることが出来ます。個人的には不安な状況には変わりなさそうですが、どうでしょうか。
感想
社会問題として医療崩壊の危険が言われている中、個人の視点で考えてみました。
簡易キッドが開発中とのこと。特異度に注意してニュースを見ましょう。
簡易検査受けることで不幸になる人が増えないか心配です。おわりに
陰性的中率の方が、話としては深刻だと思いますが、ここまでにします。
医学は全くの素人ですので、数字上の話です。なにか間違っていたら教えてください。
- 投稿日:2020-03-14T11:45:37+09:00
pythonのifはどうやってTrue/Falseを判定する?
はじめに
プログラミング初心者です。
前回の記事を書いたときに、pythonのifはどのようにTrueとFalseを判定しているか気になったので調べてみました。
対象
Python初心者から中級者の少し手前ぐらいの方向けの記事だと思っています。
かなり回りくどい説明になってしまっている箇所もありますが、ご容赦ください。
前提
・Python 3.8.0
__bool__()と__len__()
まず、公式ドキュメントの真理値判定を参照してみます。
オブジェクトは、デフォルトでは真と判定されます。ただしそのクラスが __bool__() メソッドを定義していて、それが False を返す場合、または __len__() メソッドを定義していて、それが 0 を返す場合は偽と判定されます。
文中に2つのメソッドが登場しましたが、まずは__bool__()に着目します。
上記によると、__bool__()がFalseを返すようなクラスを定義したら、ifを実行すると常にFalseが返ってくるとのことです。
以下のクラスを作って確認してみます。
>>> class Class1: ... def __bool__(self): ... return False ... >>> if Class1(): #Class1()はClass1のインスタンス ... print('Trueが返ります') ... else: ... print('Falseが返ります') ... Falseが返ります
実際にFalseが返ってきました。
ここで気になるのは、ifの結果になぜ__bool__()の返り値が関係しているかということです。__bool__()に処理を追加してみます。
>>> class Class1: ... def __bool__(self): ... print('__bool__()メソッド') # print関数を追加 ... return False ... >>> if Class1(): ... print('Trueが返ります') ... else: ... print('Falseが返ります') ... __bool__()メソッド # 追加した処理が実行されている Falseが返ります
上記から、ifを実行したときに、__bool__()が呼ばれていることがわかります。
続いて、公式ドキュメントの真理値判定に登場したもう一つのメソッドである、__len__()に着目します。こちらも同じく、Falseが返る__len__()を持ったクラスを定義してみます。
>>> class Class2: ... def __len__(self): ... print('__len__()メソッド') ... return False ... >>> if Class2(): ... print('Trueが返ります') ... else: ... print('Falseが返ります') ... __len__()メソッド # __len__()が実行されている Falseが返ります同じく、ifを実行を実行したときに__len__()が呼ばれています。
では、両方のメソッドを実装したクラスを定義してみます。
>>> class Class3: ... def __bool__(self): ... print('__bool__()メソッド') ... return False ... def __len__(self): ... print('__len__()メソッド') ... return False ... >>> if Class3(): ... print('Trueが返ります') ... else: ... print('Falseが返ります') ... __bool__()メソッド # __bool__()が実行されている Falseが返ります
両方のメソッドが実装されている場合、ifを実行すると__bool__()が呼ばれることがわかります。
実は、上記は公式の__bool__() に記述されています。
真理値テストや組み込み演算
bool()を実装するために呼び出されます;FalseまたはTrueを返さなければなりません。このメソッドが定義されていないとき、 __len__() が定義されていれば呼び出され、その結果が非 0 であれば真とみなされます。クラスが __len__()も __bool__() も定義していないければ、そのクラスのインスタンスはすべて真とみなされます。
つまり、ifが実行されると、
そのクラスが__bool__()を持っていれば呼び出す
→ 持っていなければ、そのクラスが__len__()を持っていれば呼び出す
→ どちらも持っていなければ、Trueを返す
という流れです。
基本的にユーザーが定義したクラスは、あえて実装しない限り(または実装しているクラスを継承していない限り)__bool()__も__len()__も持っていないので、ifの結果はTrueとなります。(念のため、以下でhasattrを使ってチェックしています)>>> class Class4: ... pass ... >>> hasattr(Class4, '__bool__') # __bool__()を持っていない False >>> hasattr(Class4, '__len__') # __len__()を持っていない False >>> >>> if Class4(): ... print('Trueが返ります') ... Trueが返ります
ちなみに公式によると、__bool__()の返り値は必ずbool型(TrueかFalseか)である必要があるとのことです。
>>> class Class5: ... def __bool__(self): ... return 1 # int型の1を返す ... >>> if Class5(): ... print('1が返ります') ... Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: __bool__ should return bool, returned int # bool型じゃないのでエラー
では、__len()__の返り値には制限がないか確認してみます。公式を参照すると、0以上の整数で返さなければいけないとされています。
オブジェクトの長さを 0 以上の整数で返さなければなりません。
実は、先ほど定義したクラスに実装していた__len__()が返していたFalseは、int型の0とみなされていたため、エラーにはなりませんでした。なぜbool型のFalseがint型の0とみなされるのかは前回の記事に書いています。
以下では__len()__がbool型のTrueとstr型の'True'を返すとどうなるか確認しています。>>> class Class6: ... def __len__(self): ... return True # bool型のTrueを返す ... >>> if Class6(): ... print('1が返っています') ... 1が返っています # Trueがint型の1とみなされるためエラーにならない >>> >>> >>> class Class7: ... def __len__(self): ... return 'True' ... >>> if Class7(): ... print("'True'が返っています") # str型の'True'を返す ... Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object cannot be interpreted as an integer # int型じゃないのでエラー
bool()とlen()
ではここで、もう一度__bool__()の公式を参照してみます。
組み込み演算
bool()を実装するために呼び出されます
bool()との記述があります。このbool()とは何かを見てみます。class
bool([x])
ブール値、即ちTrueまたはFalseのどちらかを返します。x は標準の 真理値判定手続き を用いて変換されます。x が偽または省略されている場合、この関数はFalseを返します。それ以外の場合、Trueを返します。
bool()は、TrueかFalseかを判定して返します。つまり、
if x:
は、実はif bool(x):
を行っています。
クラスを定義して確認してみます。>>> class Class8: ... pass ... >>> if Class8(): ... print('Trueが返っています') ... Trueが返っています >>> >>> if bool(Class8()): #bool()に変換 ... print('Trueが返っています') ... Trueが返っています全く同じ結果となっています。
では前節で登場した__bool__() と__len()__を実装したクラスから生成したインスタンスに、bool()を適用してみます。>>> class Class9: ... def __bool__(self): ... print('__bool__メソッド') ... return False ... >>> bool(Class9()) __bool__メソッド # __bool__()が呼び出されている False >>> >>> >>> class Class10: ... def __len__(self): ... print('__len__メソッド') ... return 0 ... >>> bool(Class10()) __len__メソッド # __len()__が呼び出されている False
前節では、ifが実行される際に__bool__()または__len__()が呼び出されていると記述しましたが、実はifが実行される際ではなく、bool()が実行される際(bool()クラスがインスタンスを返す際)にこれらのメソッドが呼び出されていることがわかりました。
では、今度は__len__()の公式を参照してみます。呼び出して組み込み関数 len()を実装します。
このlen()とは、オブジェクトの長さをint型で返してくれる組み込み関数です。
実際に確認してみます。
>>> class Class11: ... def __len__(self): ... print('__len__') ... return 0 ... >>> len(Class11()) __len__ #__len__()が呼ばれている 0
len()を実行すると、__len__()が呼ばれていることがわかりました。
先ほどまでの結果から、bool()を実行したときに、__bool__()がなければ__len()__が呼ばれることが確認できていました。そして、len()を実行したときにも__len__()が呼び出されています。これらの関係について、どうすれば整理できるでしょう。
ここで、bool(x)を実行したとき、もしそのクラスに__bool__()がなく__len__()がある場合、 bool(len(x))が実行されている、と仮説を立てます。
以下のようなクラスを定義して確認してみます。
>>> class Class12: ... def __len__(self): ... print('__len__メソッド') ... return 1 # 戻り値が0ではない ... >>> bool(Class12()) __len__メソッド True # 戻り値が0ではないのでTrue >>> bool(len(Class12())) __len__メソッド True # 戻り値が0ではないのでTrue >>> >>> >>> class Class13: ... def __len__(self): ... print('__len__メソッド') ... return 0 # 戻り値が0 ... >>> bool(Class13()) __len__メソッド False # 戻り値が0なのでFalse >>> bool(len(Class13())) __len__メソッド False # 戻り値が0なのでFalse
bool()とbool(len())の結果が全く同じになりました。
結果から、この仮説は正しそうです。
ちなみに忘れ去られがちですが、bool()はクラスです。
class
bool([x])
ブール値、即ちTrueまたはFalseのどちらかを返します。
TrueとFalseはboolクラスのインスタンスです。
ifでbool()が実行されるたびに、boolクラスのインスタンスが生成されています。
以下ではisinstanceで確認しています。>>> isinstance(True, bool) True >>> isinstance(False, bool) True >>> isinstance(bool(Class13()), bool) __len__ True
対して、len()は関数です。。
組み込みクラスとbool()
結論として、ifが実行された時の流れは以下になります。
ifが実行される
→ bool()が実行される
→ そのクラスが__bool__()を持っていれば呼び出す
→ 持っていなければ、そのクラスが__len__()を持っていれば呼び出す
→ どちらも持っていなければ、Trueを返す
また、公式の真理値判定を参照すると、bool()がFalseを返すオブジェクトが紹介されています。
以下に型と、その型が持つメソッドと共に記述しています。型 __bool__() or __len__() None NoneType なし False bool __bool__() 0 int __bool__() 0.0 float __bool__() 0j complex __bool__() Decimal(0) decimal __bool__() 注:組み込みではない Fraction(0, 1) Fraction __bool__() 注:組み込みではない '' str __len__() () tuple __len__() [] list __len__() {} dict __len__() set() set __len__() range(0) range 両方
ちなみにですが、intは__bool__()を持ち、listは__len__()を持っています。
これらのdocstringを読んでみると、以下のように書いてあります。>>> int.__bool__.__doc__ 'self != 0' # 0の時にFalseを返す(それ以外はTrue) >>> list.__len__.__doc__ 'Return len(self).' # len(self)の値を返す
これを踏まえ、代表的な組み込みクラスで確認してみます。
int型
>>> hasattr(int, '__bool__') # intは__bool__()メソッドのみ持つ True >>> hasattr(int, '__len__') False >>> bool(1) True >>> bool(0) False # 0以外Trueを返す >>> bool(-1) True
str型
>>> hasattr(str, '__bool__') False >>> hasattr(str, '__len__') # strは__len__()メソッドのみ持つ True >>> bool('str') True >>> bool('') False # 空のstrではFalseを返す
list型
>>> hasattr(list, '__bool__') False >>> hasattr(list, '__len__') # listは__len__()メソッドのみ持つ True >>> bool([1, 2, 3]) True >>> bool([0]) True >>> bool([]) False # 空のlistではFalseを返す
dict型
>>> hasattr(dict, '__bool__') False >>> hasattr(dict, '__len__') # dictは__len__()メソッドのみ持つ True >>> bool({1: 'one', 2: 'two', 3: 'three'}) True >>> bool({}) False # 空のdictではFalseを返す
bool型
>>> hasattr(bool, '__bool__') True >>> hasattr(bool, '__len__') # boolは__bool__()メソッドのみ持つ False True >>> bool(True) True >>> bool(False) False
type型
>>> hasattr(type, '__bool__') False >>> hasattr(type, '__len__') False # typeはどちらも持たない >>> bool(type) True # どちらも持たないのでTrueを返す
注:typeはtypeクラスのインスタンスです(前回の記事参照)>>> isinstance(type, type) True
ここで、__len__()のみしか持っていないクラス(上記だとstr、list、dict)は bool(len(obj))が実行されています。
ちなみに__bool__()と__len__()の両方を持つ組み込みクラスはrangeだけでした。
組み込みクラスのカスタマイズ
最後にクラスのカスタマイズについてです。
以下のように、組み込みクラスを継承したクラスで__bool__()と__len__()の返り値をカスタマイズすることで、bool()の結果を操作することができます。>>> class AcceptOnlyTakoyaki(str): ... def __bool__(self): ... return self == 'たこ焼き' or self == 'Takoyaki' ... >>> # strは元々__len__()を持つが、__bool__()を実装することでこちらが呼ばれる >>> >>> bool(AcceptOnlyTakoyaki('たこ焼き')) True >>> bool(AcceptOnlyTakoyaki('たい焼き')) False >>> bool(AcceptOnlyTakoyaki('Takoyaki')) True >>> bool(AcceptOnlyTakoyaki('Okonomiyaki')) False
>>> class RefuseOnlyCoriander(str): ... def __len__(self): ... return self != 'パクチー' and self != 'Coriander' ... >>> # TrueかFalse(1か0)を返すようにすれば__len__()でも可能 >>> >>> bool(RefuseOnlyCoriander('パクチー')) False >>> bool(RefuseOnlyCoriander('セロリ')) True >>> bool(RefuseOnlyCoriander('Coriander')) False >>> bool(RefuseOnlyCoriander('Carrot')) True >>> bool(RefuseOnlyCoriander('')) # ''でもTrueが返る True
>>> class ZeroInt(int): ... def __len__(self): ... return self == 0 # 0の時Trueを返したい ... >>> bool(ZeroInt(0)) # 0でもFalseになる False >>> hasattr(ZeroInt, '__bool__') # intは__bool__()を持つため、こちらが優先されている True
>>> class ZeroInt(int): ... def __bool__(self): # __bool__()をオーバーライド ... return self == 0 ... >>> bool(ZeroInt(0)) # 0の時Trueが返る True >>> bool(ZeroInt(1)) # 0以外の時Falseが返る False
結論
・if x: を実行すると if bool(x): が実行される・bool(x) が実行される時、クラスが__bool__()を持っていたら呼ばれ、持っていなかったら__len__()が呼ばれる。どちらも持っていなかったらTrueを返す
・クラスが__len__()のみを持つ時、if x: が実行されると if bool(len(x)): が実行される
・組み込みクラスでも、__bool__()、__len__()を持つクラス、持たないクラスがある
最後に
記事を書いたことで、ifが実行されたときに内部で何が起きているのかの理解が深まりました。
このように、pythonの仕組みを紐解くような記事もちょくちょくアウトプットしていきたいと思います。
- 投稿日:2020-03-14T11:20:13+09:00
【 2020/03/31まで ! 】インプレスで無料公開中の書籍をPDF化して読む!
概要
コロナウイルス対策で増えた在宅時間を生かすために、インプレスさんが「できる」シリーズなど44冊を2020/03/31まで無料公開してるよ!
どの書籍も面白そうで全部読みたいけど、本気を出してもあと2週間では読みきれないし、保存してゆっくり読もうと思う
警告
- ダウンロードした画像、作成したPDFは私的利用に限定してください。他人への販売や譲渡は犯罪です。
- この記事は、著作権法とimpressの利用規約を確認した上で、問題ないと判断して書いています。
- 自己責任でお願いします。
分かりやすく書きすぎてリテラシーがない人に悪用されると困るので、環境構築やパッケージのインストールは省略した上で、ステップごとに分散して書いてます。
STEP 1. 無料公開されてる本とそのリンクを取得してみる!
まずは、無料公開されてる本と、無料公開のリンクをオブジェクトにして取得するよ。無料公開の特設ページ(https://book.impress.co.jp/items/tameshiyomi)にアクセスしてから、デベロッパーツールのConsoleを開いて、以下のコードを実行しよう。
const title = [...document.querySelectorAll('h4 a')].map(i => i.innerHTML); const num = [...document.querySelectorAll('.module-book-list-item-img div a')].map(i => i.href.split('/')[3]); if (title.length !== num.length) { throw new Error('タイトルの数とリンクの数が違います。'); } const title_and_num = {}; for (const i in title) { title_and_num[num[i]] = title[i]; } document.body.innerHTML = '<pre>' + JSON.stringify(title_and_num, null, '\t') + '</pre>';すると、画面が書き換えられて、オブジェクトが表示されるよ。
キーになっている数字はそれぞれのページの末尾を表してるから、
url = 'https://impress.tameshiyo.me/' + '9784295003850'みたいにしてURLを求めるよ。
コピペして
impress_title_num.jsonっていうファイルに保存しておいてね。STEP 2. 画像のURLを取得する!
PythonでSeleniumを使用して全ての画像のURLを取得して、jsonファイルを作成するよ。URLを取得するコードは、サーバへの負荷も考慮し、1リクエストごとに5秒以上待つようにしてあります。
from selenium import webdriver from selenium.webdriver.chrome.options import Options import chromedriver_binary from time import sleep import json url_num = input('url_num: ') url = 'https://impress.tameshiyo.me/' + url_num urls_image = [] options = Options() options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary' options.add_argument('--headless') driver = webdriver.Chrome(options=options) driver.get(url + '?page=1') sleep(5) # 表示されている総見開き数 count_of_view = int(driver.find_element_by_id('page_indicator').text.split(' ')[2]) # 総ページ数は、count_of_view * 2 - 1 または、count_of_view * 2 - 2 になる。 count_of_page = count_of_view * 2 for i in range(count_of_page): page = i + 1 # 1, 3, 5の偶数ページ(左側のページ)のとき、新しいページを取得。 if page % 2 == 0: # URLのページ数は実際のページ数より1つ多い(表紙の前の存在しないページを1ページ目としている) driver.get(url + '?page=' + str(page+1)) sleep(3) # ページ数が偶数の時は最初の要素、奇数の時は2つめの要素にURLが含まれる。 number_of_image_url_place = page % 2 try: img_url = '' try_counter = 0 while img_url == '': try_counter += 1 sleep(0.5) img_url = driver.find_elements_by_class_name('page_img')[number_of_image_url_place].get_attribute('src') # 10回試行してsrc無し、かつ、ページ数が最後の2ページなら、ページがないと判断 if try_counter > 10 and page >= count_of_view * 2 - 2: break # 代理画像URLが取得されている場合は警告を出す if img_url == 'https://impress.tameshiyo.me/img/bookfilter.png': print('[warning] img_url is bookfilter in page ' + page) elif img_url == '': break else: urls_image.append(img_url) print('finished page ' + str(page)) except: print('can\'t get url on page ' + str(page)) pass driver.close() driver.quit() title_and_num = json.load(open('impress_title_num.json', 'r', encoding='utf-8')) with open('impress_urllist_' + title_and_num[url_num] + '.json', 'w', encoding='utf-8') as f: f.write(json.dumps(urls_image, indent=4))確認
画像にはCORSの設定がされていないようなので、URLが正しく取得されているか、下のようなHTMLファイルを使って確認してみよう!
注意 : このHTMLファイルを不特定多数の人がアクセスできるサーバーに配置しないでください。著作権侵害となる可能性があります。
<!DOCTYPE html> <html> <body> <input type="text" placeholder="数字を入力してね"> <button type="button">決定</button> <script> fetch('impress_title_num.json') .then(a => a.json()) .then(titleAndNum => { document.querySelector('button').addEventListener('click', () => { const title = titleAndNum[document.querySelector('input').value]; console.log(title) const fileName = `impress_urllist_${title}.json`; fetch(fileName) .then(b => b.json()) .then(json => { for (const i in json) { const img = document.createElement('img'); img.src = json[i]; document.body.appendChild(img); } }); }) }); </script> </body> </html>Macの場合は、PHPでローカルサーバを立てて確認するのが楽だよ。
$ php -S localhost:8080
STEP 3. 画像を保存する!
画像を保存っていうと著作権大丈夫?って感じがするけど、普段ブラウザでみている画像も一時的にローカルに保存されているので、保存している場所が違うだけだよ。
ここでも、1枚保存するごとに3秒間隔をおいてます。import urllib.request, urllib.error import json, os from time import sleep title_and_num = json.load(open('impress_title_num.json', 'r', encoding='utf-8')) num = input('input num : ') title = title_and_num[num] url_list = json.load(open('impress_urllist_' + title + '.json', 'r', encoding='utf-8')) os.makedirs('impress_' + title) for i, url in enumerate(url_list): urllib.request.urlretrieve(url, './impress_{0}/impress_{1}_{2}.jpg'.format(title, num, ('00' + str(i+1))[-3:])) print('[done] impress_{0}_{1}.jpg'.format(num, ('00' + str(i+1))[-3:]))
STEP 4. PDF化する!
ダウンロードした画像をくっつけてPDFにするよ。
import img2pdf from pathlib import Path import json num = input('input num : ') title_and_num = json.load(open('impress_title_num.json', 'r', encoding='utf-8')) title = title_and_num[num] path_import = Path('impress_' + title) path_output = Path('impress_' + title + '/' + title + '.pdf') lists = list(path_import.glob('**/*')) with open(path_output, 'wb') as f: f.write(img2pdf.convert([str(i) for i in sorted(lists) if i.match('*.jpg')]))
いつもの見慣れたPDFビューアだ!これで時間を気にせず引きこもれるぞ!
インプレスさんありがとう!