- 投稿日:2020-03-14T23:43:14+09:00
[Java]リストをストリームとラムダ式を利用して並び替え
リストをストリームとラムダ式を利用して並び替え
ストリームとラムダ式を利用することで、リストの並び替え処理のコーディングを減らせる
コード例
Main.javapackage sample; import java.util.List; import java.util.stream.Collectors; public class Main { public static void main(String[] args) { // リストの設定(addメソッドを使わない方法) List<String> sampleList = List.of("Ishikari","Sorachi","Shiribeshi","Iburi","Hidaka","Hiyama","Oshima","Rumoi","Kamikawa","Soya","Tokachi","Kushiro","Okhotsk","Nemuro"); // 作成したリスト samples を確認 System.out.println(sampleList); System.out.println(""); // 作成したリスト samples をストリームとラムダ式を使って並び替え // A → Z List<String> sortedSampleList1 = sampleList.stream().sorted((a,b) -> (a.compareTo(b))).collect(Collectors.toList()); System.out.println("A → Z"); System.out.println(sortedSampleList1); System.out.println(""); // Z → A System.out.println("Z → A"); List<String> sortedSampleList2 = sampleList.stream().sorted((a,b) -> (b.compareTo(a))).collect(Collectors.toList()); System.out.println(sortedSampleList2); } }出力結果
[Ishikari, Sorachi, Shiribeshi, Iburi, Hidaka, Hiyama, Oshima, Rumoi, Kamikawa, Soya, Tokachi, Kushiro, Okhotsk, Nemuro] A → Z [Hidaka, Hiyama, Iburi, Ishikari, Kamikawa, Kushiro, Nemuro, Okhotsk, Oshima, Rumoi, Shiribeshi, Sorachi, Soya, Tokachi] Z → A [Tokachi, Soya, Sorachi, Shiribeshi, Rumoi, Oshima, Okhotsk, Nemuro, Kushiro, Kamikawa, Ishikari, Iburi, Hiyama, Hidaka]備考
基本情報技術者試験のプログラミング(Java)にも、時々ストリーム・ラムダ式を利用したコードが題材として出題されることがある。
- 投稿日:2020-03-14T23:28:01+09:00
初心者から始めるJava、オーバーロード・コンストラクタ
追記 2020/3/15
・多態性について、より抽象度の高い考え方であることをコメントで教えていただいたので、オーバーロードとの関係について修正。はじめに
この記事は備忘録である。
参考書レベルの内容だが、本記事に掲載するコードについては、
間違えたものが中心となる。これは実際にコーディング中に間違えた部分を掲載し、自分で反省するために投稿するという目的によるもの。
また、後日にJavaSilver試験問題の勉強を兼ねて復習するため、深い部分の話はここでは触れない。環境
言語:Java11、JDK13.0.2
動作環境:Windows10オーバーロード
クラスの中では、同じ名前のメソッドが同居しても構わないルールがある。
ひとつのメソッドの中で、扱う引数を無制限に増やしてもすべての引数を一度に宣言するのは難しいので、必要な機能に分けて用意した方が、クラスを使う側からしても楽になる。Cat.javagetCatStatus(double weight,double height){ (略) } getCatStatus(int age,int number){ (略) } getCatStatus(String name,String voice){ (略) }このとき、
getCatStatus()を使った場合の引数指定に応じて、同じ名前のメソッドから合致するものを選んで使ってもらえる。
この機能の事をオーバーロードという。
注意点として、同じ名前の各メソッドが持つ引数の型・個数が異なるようにする必要がある。
これには、戻り値の型による違いは含まれてないため、修飾子が違うだけの同じ引数を必要とするメソッドは作れない。コンストラクタ
クラスを用意してメソッドを書く際、クラスのオブジェクトが生成された直後にクラスフィールドの初期値を定めることが出来る。
Cat.javaclass Cat { private double weight; private int age; public Cat() { weight = 1.0; age = 0; } }クラス名と全く同じ名前のメソッドを書くと、クラスを使って
newしてオブジェクトが生成された際自動的に初期値を格納することが出来る。終わりに
オーバーロードで扱った、同じ名前のメソッドではあるが引数に応じて別の働きをもたせることが出来る機能について。
関数の多重定義という仕組みであり、特に引数の型に応じて関数の振る舞いが変わる多相性のことをアドホック多相と呼ぶ。メモ:アドホック多相は多態性(ポリモーフィズム:Polymorphism)のうちのひとつ
参考
出来るだけ自分で変数や式を書いてコンパイルしているので、完全に引用する場合はその旨記述する。
- 投稿日:2020-03-14T23:12:14+09:00
Java try-catch文 お助け下さい!!
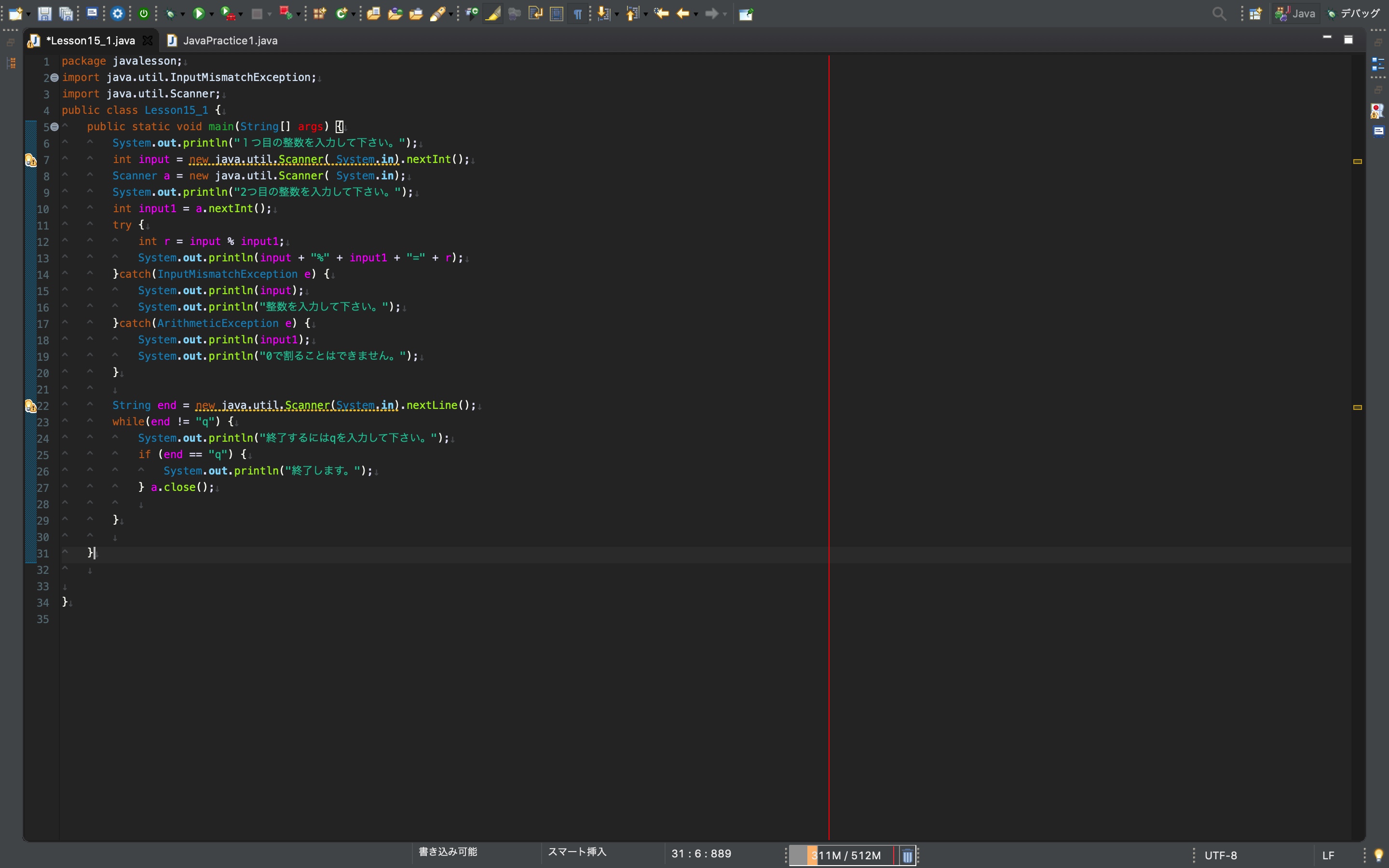
初めまして。今年からエンジニアとして転職し絶賛研修中の者です。javaを学習しているのですが、とあるtry-catch文を絡めたコード作成に詰まってしまい、中々前へ進めません。。。
このコードの期待値としては、
[1]2つの整数を1つずつ入力させ、その剰余を出力する。
[2]もしint型以外の入力があった場合、「整数を入力して下さい。」を出力する。
(その際のエラー文と入力された値も出力する。)
[3]もし2つ目の整数に0が入力されたら、「0では割れません。」を出力する。
(その際のエラー文と入力された値も出力する。)
[4]「終了するにはqを入力して下さい。」を出力し、qと入力があれば、「終了します」の出力と共にプログラムを終了する。q以外の入力があったときはこの処理を繰り返す。です。以下が私の書いたコードになります。
実行すると、catchがどちらも拾われず、while文も無限ループとなってしまいます。。。皆さんからすると常識問題なのかもしれませんが、どれだけ頭を捻っても分かりません。どうかお力をお貸しくださいませ。
- 投稿日:2020-03-14T22:11:00+09:00
【アルゴリズム入門】Javaでバブルソートを実装する
バブルソートを定義すると「隣接する要素の大小を比較して、昇順もしくは降順に整列するアルゴリズム」と言える。
今回は昇順に整列するアルゴリズムをjavaで実装した。
ソースコード
BubbleSort.javapublic class BubbleSort { public static void main(String[] args) { int[] data = {30, 60, 70, 90, 20}; sort(data); for(int element : data) { System.out.println(element); } } public static void sort(int[] data) { for(int i = data.length - 1; i > 0; i --)/*...⒈*/ { for(int j = 0; j < i; j++)/*...⒉*/ { if(data[j] > data[j + 1]) { int temp = data[j + 1]; data[j + 1] = data[j]; data[j] = temp; } } } } }以下、理解するのが難しかったところをピックアップして言語化したい。
⒈ 外側のループの条件
普段は制御変数が1ずつ増やすタイプのループを見ることが多いのでiを減らしていくというのが直観的に理解し辛い印象がある。
iは配列のどの範囲まで探索するかということを意味する変数なので、iがdata.length - 1(この場合は5 - 1 = 4)から1に減少する=探索範囲を1つずつ狭めていく、という理解で良いと思う。
⒉比較ループの条件
前述の通り隣接する要素同士を比較して整列していく。
比較ループのポイントはjの範囲がi未満になっていることじゃないかと思う。if文の分岐条件を見ると分かりやすいが、基準値の右隣の要素と比較するため、j = i - 1の時点でdata[i - 1] とdata[i] を比較できるためこのようになっている。
まとめ
バブルソートのキモはループ探索範囲を1づつ減らすという動作をいかに実装するのか、という点にありそう。
- 投稿日:2020-03-14T21:41:20+09:00
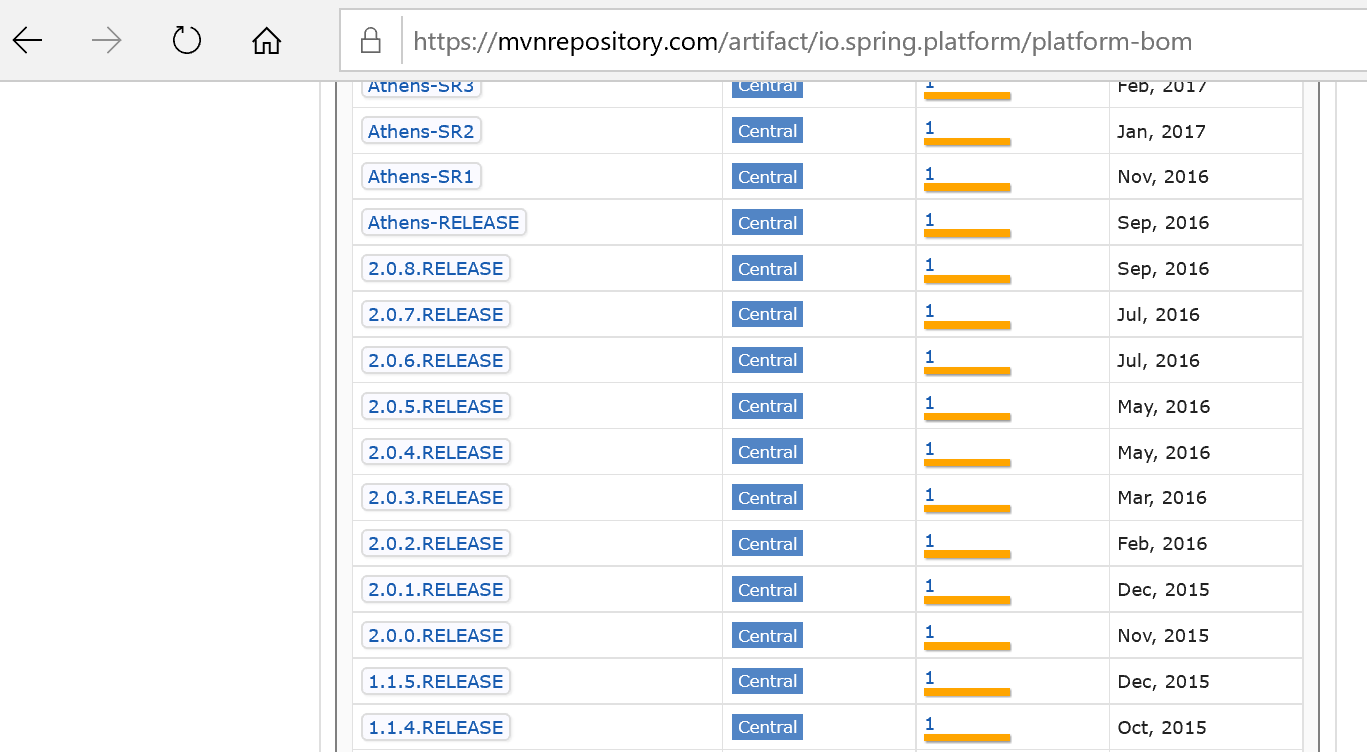
Spring (STS)のpom.xmlに記述するためのio.spring.platformの最新バージョンの確認方法
Spring の環境構築時に使用する依存ライブラリのバージョンを調べる方法
Springの環境を構築するときに、pom.xmlの中に依存ライブラリの指定をする必要がある。その際に使用するio.spring.platformの最新バージョンが何かを調べる方法である。
調べた結果は、下記に示すpom.xmlの
<version>???</version>
のところに記述する。
mvnrepository.comのサイトに行く。
https://mvnrepository.com/検索用のテキストボックスに「io.spring.platform」と入力してSearchボタンを押す。
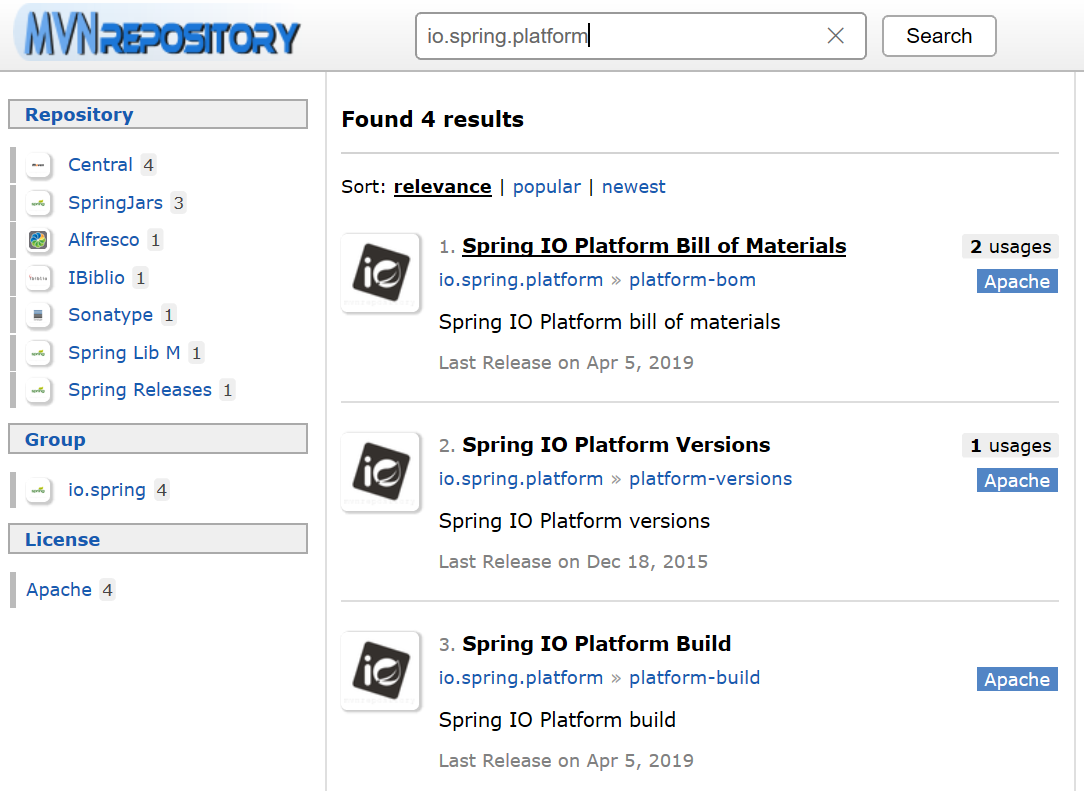
3.検索結果が表示される。
「Spring IO Platform Bill of Materials」をクリックする。
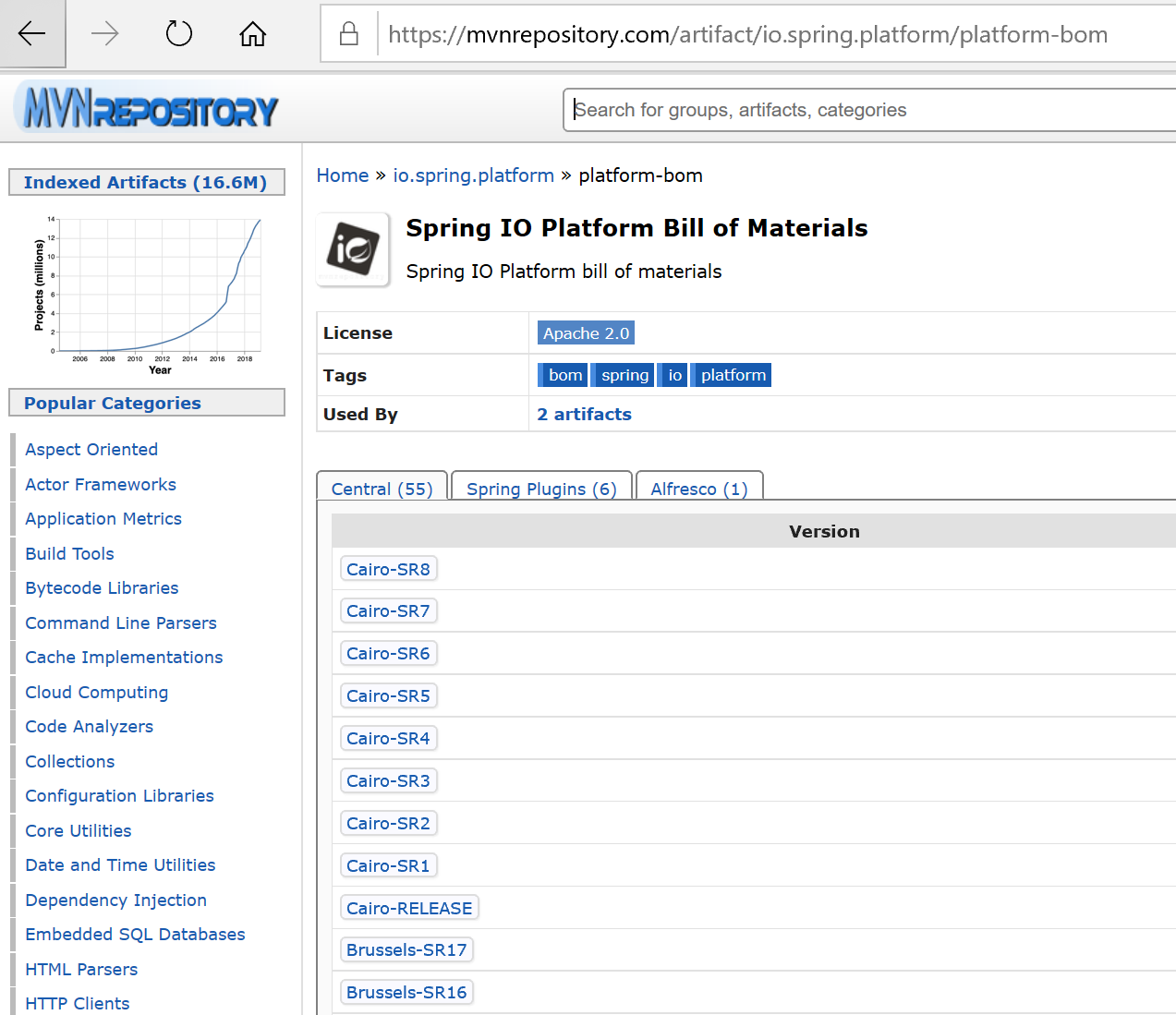
4.詳しい情報が表示される。
- 2.x.x.RELEASEの最新のものを探す。この例では、2.0.8.RELEASEが最新ということが分かる。
以上
補足
特になし
Written by Collab KM

- 投稿日:2020-03-14T20:57:39+09:00
[Mockito] 3.2.4 → 3.3.xにアップデートしたら(イケテナイところが)エラーになった件
Mockito 3.2.4から3.3.x(3.3.3)にアップデートしたら・・・スタブを設定しているコードが冗長?だったことが原因でエラーになってしまいました。
どんなコードだったの?
こんなコードでした。
when(rs.getInt("column")).thenReturn(100); assertEquals(Integer.valueOf(100), TYPE_HANDLER.getResult(rs, "column")); when(rs.getInt("column")).thenReturn(0); assertEquals(Integer.valueOf(0), TYPE_HANDLER.getResult(rs, "column"));どんなエラーになったの?
こんなエラーです。
org.mockito.exceptions.misusing.UnnecessaryStubbingException: Unnecessary stubbings detected. Clean & maintainable test code requires zero unnecessary code. There are 1 unnecessary stubbing (click to navigate to relevant line of code): 1. -> at org.apache.ibatis.type.YearTypeHandlerTest.shouldGetResultFromResultSetByName(YearTypeHandlerTest.java:44) Please remove unnecessary stubbings or use 'lenient' strictness. More info: javadoc for UnnecessaryStubbingException class.何がイケテナイの?
どうやら・・・
thenReturnのところがイケテナイようで、以下のようにしたらエラーがなくなりました。when(rs.getInt("column")).thenReturn(100, 0); // 一箇所に集約!! assertEquals(Integer.valueOf(100), TYPE_HANDLER.getResult(rs, "column")); assertEquals(Integer.valueOf(0), TYPE_HANDLER.getResult(rs, "column"));まーね・・・という感じです。
コードを直さないとダメなの?
明確な意図がない場合は基本的にはコードを直した方がよいと思いますが、エラーメッセージにも記載があるように「lenient」モードにすることでこのエラーを抑止することができます。以下に、抑止する方法をいくつか紹介します。
NOTE:
ざっと調べた範囲で見つけた抑止方法なので、他にももっとよい方法があるかもしれません!!
@Mockのlenient属性の利用アノテーションを利用してモックオブジェクトを生成している場合、アノテーションの属性指定で抑止可能です。
// @Mock @Mock(lenient = true) protected ResultSet rs;
MockSettings#lenient()の利用
Mockito#mockメソッドを利用してモックオブジェクトを生成している場合は、メソッドのオプション指定で抑止可能です。// ResultSet rs = mock(ResultSet.class); ResultSet rs = mock(ResultSet.class, withSettings().lenient()); when(rs.getInt("column")).thenReturn(INSTANT.getValue()); assertEquals(INSTANT, TYPE_HANDLER.getResult(rs, "column")); when(rs.getInt("column")).thenReturn(0); assertEquals(Year.of(0), TYPE_HANDLER.getResult(rs, "column"));
Mockito.lenient()の利用
Mockito.lenient()を使用して抑止することもできますが、この方法で抑止するくらいなら、ちゃんと直しちゃった方がよいでしょう。// when(rs.getInt("column")).thenReturn(100); lenient().when(rs.getInt("column")).thenReturn(100); // ...JUnit 5編:
@MockitoSettingsのstrictness属性の利用JUnit 5(
MockitoExtension)を利用している場合は、@MockitoSettingsアノテーションの属性指定で抑止可能です。
この設定は、Mockito#mockメソッドを使用している部分にも適用されるみたいです。@MockitoSettings(strictness = Strictness.LENIENT) // これを追加 @ExtendWith(MockitoExtension.class) abstract class BaseTypeHandlerTest { // ... @Mock protected PreparedStatement ps; // ... }NOTE:
本エントリでは触れませんが、JUnit 4でも同様のオプションが用意されているみたいです。
まとめ
Mickitoは単体テストの前提を整えるのに非常に便利なライブラリですが、それらのコードをクリーンな状態を保たないと後から見た時に「これ何やってるんだっけ?」みたいな状態になりがちなので・・・こういったチェック機構はありがたいですね(直し方がわからない時がたまにありますが・・・
)。
ただ・・・ライブラリのレポート内容が絶対的に正しいとは限らないので、レポート内容とコードを見極めたうえで、必要に応じて「lenient」モードの利用も検討するとよいと思います。
- 投稿日:2020-03-14T18:44:01+09:00
Firebase Realtime Database を Cocos Creatorで使う。
はじめに
初投稿です。こんにちは。
昨今ではクロスプラットフォームのゲームエンジンといえば Unity 一択で、
次点でどうにかUEが出てくる程度じゃないかと思います。
そんな中 cocos creator に手を出したのはいいものの、情報が少なく割と困ったので、備忘録がてら投稿します。したいこと
cocos creator で開発中のアプリで Firebase の Realtime Databaseにアクセスする。
方法
cocos creator は Node.js を利用しているので基本的には npm を利用する。
ただし、この方法ではAndroid上では動作しなかった。(iOSやWeb上では問題ない)
仕方なくAndroid StudioでFirebase Databaseを導入し、それをJavaを通じて呼び出すという手法をとりました。npm install --save firebase
Cocos creator のプロジェクトフォルダでターミナル等を使って
npm install --save firebaseを実行する。
これについては以下の記事が非常に参考になりました。
Cocos Creator を使って Firebase Authentication を実装する最初はうまくモジュールを読み込めていなかったのですが、Cocos Creator を再起動するとうまく読み込めたようです。
あとは Node.js でFirebase を利用するやり方で問題なく実行できます。
Firebase を JavaScript プロジェクトに追加するAndroid
Androidでは何故かモジュールを利用できません。Node.js の npm を利用しているという都合上、何か問題が起きているのかもしれないです。(把握できてない)
上記の記事では少なくとも Firebase Authentication については問題なく実行できていますが、自分の環境では Firebase Realtime Database は使用できなかったので仕方なく Java を直接利用することにしました。まずはプロジェクトに Firebase を導入する必要があります。
Android プロジェクトに Firebase を追加する
そうして導入した Firebase Realtime Database を Java を通じて利用します。
cocos creator から javascript で Java を利用するにはjsb.reflection.callStaticMethod(className, methodName, methodSignature, parameters...)を使用します。
How to Call Java methods using JavaScript on Android具体的には org.cocos2dx.javascript に使いたい Java のパッケージを置き、それを javascript から呼び出すといった形です。最初は org.cocos2dx.javascript の場所がわからなかったので一応書いておくと、
/Project_Folder/build/jsb-default/frameworks/runtime-src/proj.android-studio/src/org/cocos2dx/javascript/
にあります。そこに、
FirebaseWrapper.javapackage org.cocos2dx.javascript; import android.util.Log; import com.google.firebase.database.FirebaseDatabase; public class FirebaseWrapper { private static FirebaseDatabase database=null; public static void init(){ if(null==database){ database=FirebaseDatabase.getInstance(); Log.d("Firebase Wrapper","Firebase Initialized!"); } } }みたいなものを適当にでっち上げました。
これを実行するには javascript 上でjsb.reflection.callStaticMethod("org/cocos2dx/javascript/FirebaseWrapper","init","()V")を呼びます。
なおresult=jsb.reflection.callStaticMethod()は残念ながら引数、返り値ともに渡せるものが限られています。
具体的には、int, float, boolean, String しか渡せません。なので、配列などを渡すことはできません。一つずつ渡すなど何か工夫が必要です。とはいえ一先ずこれで無事 Firebase Realtime Database にはアクセスできます。
終わりに
今回、cocos creator を使って初めてアプリを作ったのですが、自分の技術不足もあり、正直とてもしんどかったです。
まだまだ情報不足の面が多く、基本的に英語か中国語の情報を漁るしかないので素人は手を出すべきでなかったと感じました。
ただそれゆえに情報が増えづらいといった面もあるので、未来の誰かか自分の為にもこの記事を投稿しておきます。いろいろ勉強にはなりましたが次はたぶん素直に Unity を使うと思います。笑
- 投稿日:2020-03-14T14:09:53+09:00
61st聖光祭 アプリ局 AndroidJavaの教科書
1. AndroidStudioの操作一覧
英語さえ読めれば大丈夫だと思うが、一応まとめとく。
1.1 プロジェクトのつくり方
- ホーム画面に行く。
Start a new Android Studio projectをクリックEmpty Activityを選択NextをクリックNameを入力 (英語 全単語頭文字大文字 その他小文字 記号特殊文字禁止)Package Nameを入力 (英語 単語間は.全文字小文字 特殊文字禁止)LanguageはJava固定Minimum API levelはお好みで。(23推奨)Finishをクリック- ビルドを待つ
1.2 画面の見方
ファイルツリー
左にはファイルツリーが表示される。
-ボタンで非表示に。非表示後はさらに左の1:Projectをクリックで表示できる。デバッグ関係
下にはデバッグやビルドをしたときのログが表示される。実行時は勝手に表示されるので作業中は必要ないと思われ。ログ以外にも補助ソフトをいれると
CheckStyleやFind-Bugも表示されるが、これらの切り替えはさらに下のタブでできる。TODO機能はぜひ使ってほしい。プロセスステータスバー
デバッグ関係の下の下。右側には左から
行番号:左からの文字数、文字コード、インデントのスペース数、ロック、フィードバック二つ、なんかが表示されている。これらは使わないでくれ(切実)。ロックは押すと編集不可になり、文字を入力するとダイヤログがでる。問題なのは通常では何もないがバーのまんなかと右側である。ビルドすると真ん中には現在何を行っているか表示され、右側にはプロセスバーが現れる。これがあるときはファイルの編集しない方がいい。
ツールバー(OS標準)
ウィンドウの一番うえの左から
File、Edit...と続いているツールバー。ほとんどのソフトに存在するOSが描画した(プログラミング脳)ツールバーである。かなり使うのでツールバーといわれたらここを見てほしい。ショートカットツールバー(AS装備)
ツールバーの下にあるAndroidStudio固有のツールバー。左にいま開いてるファイルの階層が表示される。階層をまたぐ移動はのちほど紹介するファイルタブではなくここからやるといい。右にはユーザーが編集できるショートカットがある。
▶は実行、虫みたいなマークはデバックである。ここで注意なのがデバックを使うことである。実行はエラーの詳細、現状のログを出してくれない。実行はアプリの動画を撮ったりしたり完成品で遊ぶときに使用しよう。他にも上級者にはありがたい機能のショートカットがあるが、割愛する。メイン画面
メインの作業画面。上部にはファイルタブがあり、複数の(開かれている)ファイルを移動できる。xmlのときはそれ用の画面になる。他にも画像を開くと編集画面になったり、音声や動画を開くと再生バーがでてきたりする。
Palette-パレット(xml)
xmlを開くとメイン画面の左上に表示されるView一覧。ここから使うViewをとってくる。
Component Tree-コンポネントツリー(xml)
xmlを開くとメイン画面の左下に表示される配置済みのView一覧。PaletteからViewをここにドラッグしよう。あとは階層と上下関係を意識してレッツ!ドラッグアンドドロップ!(ガヴリ―ルドロップアウトみたいだよね←どこが)
メイン画面(xml)
Android画面が表示されてるところ。ここいじることは少ない。ちなみに右に表示されてる青い画面は領域の境とか大きさとか書かれているので参考にするといい。あとは、Android画面の左下のなぞの
//はドラッグすると画面サイズを変えられる。(結構これすごい)また、上部にはたくさんの項目があるが、端末の向きを変えたり画面を本当に存在する端末(Googleが監修した端末のみ)のプリセットを利用できる。(Nexus5!!!)ほかはあんまりいじんないほうがいいよ(60回の聖光祭でやらかしました)
Attributes-アトリビュート(xml)
Viewの属性(パラメータ)を変更する画面。右側に縦長にあるやーつ。編集したいViewを選択してから変えようね?パラメータはViewによって違うし、多すぎるので覚える必要はない。英語よめ。
1.3 Androidのディレクトリ事情
Pathはファイルツリーでのパス。JavaはJava内での表記方法。xmlはxml内での表記方法。
ちなみにファイル名は拡張子を含みません。Javaファイル
Path:
app/java/パッケージ名/Jファイル名
Java:パッケージ名.Class名
xml :パッケージ名.Class名画面を設計するxmlファイル
Path:
app/res/layout/ファイル名
Java:R.layout.xmlファイル名
xml :なし素材の画像
Path:
app/res/drawable/ファイル名
Java:R.drawable.ファイル名
xml :@drawable/ファイル名その他の素材(動画とか音声とか)
Path:
app/res/row/ファイル名
Java:R.row.ファイル名
xml :@row/ファイル名
rowフォルダは新しく作る。その他のxml(string.xmlとか)
Path:
app/res/values/ファイル名
Java:R.ファイル名.
xml :@ファイル名/ちょっとした例
string.xml<resources> <string name="hayaku_tugi_coi">Auribus oculi fideliores sunt.</string> </resources>このとき、
@string/hayaku_tugi_coiとなる。1.4 Github関連(Githubにつながっている場合)
リモートレポジトリを作らないとGithubは利用できないので、新規のプロジェクトには使えません。
Commit
こまめに結果にコミット!
1. ツールバーのVCSをクリック
2.Commitをクリックまた、ショートカットのチェックマークでもできます。
Push
- ツールバーの
VCSをクリックGitにホバーするPushをクリック
- 投稿日:2020-03-14T12:42:07+09:00
java JAR 基礎
java初心者。
javaでjarファイルを作り、実行するまで。<概要>
①適当なディレクトリ作成
②適当なjavaファイル作成
③JARファイルの作成
④マニフェストファイルをいじる
⑤実行<詳細>
①適当なディレクトリ作成
~/sample/
②適当なjavaファイル作成
作業ディレクトリ:~/sample/Sample.java
package sample; public class Sample{ public static void main(String[]args){ System.out.println("実行できた"); } }一回、コンパイルと実行してみる。
作業ディレクトリ:~> javac sample/Sample.java > java sample.Sample 実行できた③JARファイルの作成
作業ディレクトリ:~
>jar -cvf Sample.jar sample/ マニフェストが追加されました sample/を追加中です(入=0)(出=0)(0%格納されました) sample/Sample.classを追加中です(入=428)(出=305)(28%収縮されました) sample/Sample.javaを追加中です(入=137)(出=120)(12%収縮されました)JARファイルの中身確認
> jar -tvf Sample.jar Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 0 Sat Mar 14 12:19:02 JST 2020 META-INF/ 66 Sat Mar 14 12:19:02 JST 2020 META-INF/MANIFEST.MF 0 Sat Mar 14 12:15:34 JST 2020 sample/ 428 Sat Mar 14 12:15:34 JST 2020 sample/Sample.class 137 Sat Mar 14 12:09:48 JST 2020 sample/Sample.java④マニフェストファイルをいじる
作業ディレクトリ:~
META-INF/MANIFEST.MFの中身META-INF/MANIFEST.MFManifest-Version: 1.0 Created-By: 13.0.2 (Oracle Corporation)マニフェストファイルの作成
Sample.maniMain-Class: sample.Sampleメイン・マニフェスト属性の追加
>jar -uvfm Sample.jar Sample.mani マニフェストが更新されました⑤実行
作業ディレクトリ:~
```java -jar Sample.jar
Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8
実行できた
```他の実行方法
> java -cp Sample.jar sample.Sample Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 実行できた
- 投稿日:2020-03-14T12:42:07+09:00
Java JAR 基礎
java初心者。
javaでjarファイルを作り、実行するまで。<概要>
①適当なディレクトリ作成
②適当なjavaファイル作成
③JARファイルの作成
④マニフェストファイルをいじる
⑤実行<詳細>
①適当なディレクトリ作成
~/sample/
②適当なjavaファイル作成
作業ディレクトリ:~/sample/Sample.java
package sample; public class Sample{ public static void main(String[]args){ System.out.println("実行できた"); } }一回、コンパイルと実行してみる。
作業ディレクトリ:~> javac sample/Sample.java > java sample.Sample 実行できた③JARファイルの作成
作業ディレクトリ:~
>jar -cvf Sample.jar sample/ マニフェストが追加されました sample/を追加中です(入=0)(出=0)(0%格納されました) sample/Sample.classを追加中です(入=428)(出=305)(28%収縮されました) sample/Sample.javaを追加中です(入=137)(出=120)(12%収縮されました)JARファイルの中身確認
> jar -tvf Sample.jar Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 0 Sat Mar 14 12:19:02 JST 2020 META-INF/ 66 Sat Mar 14 12:19:02 JST 2020 META-INF/MANIFEST.MF 0 Sat Mar 14 12:15:34 JST 2020 sample/ 428 Sat Mar 14 12:15:34 JST 2020 sample/Sample.class 137 Sat Mar 14 12:09:48 JST 2020 sample/Sample.java④マニフェストファイルをいじる
作業ディレクトリ:~
META-INF/MANIFEST.MFの中身META-INF/MANIFEST.MFManifest-Version: 1.0 Created-By: 13.0.2 (Oracle Corporation)マニフェストファイルの作成
Sample.maniMain-Class: sample.Sampleメイン・マニフェスト属性の追加
>jar -uvfm Sample.jar Sample.mani マニフェストが更新されました実行後のMETA-INF/MANIFEST.MFの中身
META-INF/MANIFEST.MFManifest-Version: 1.0 Created-By: 13.0.2 (Oracle Corporation) Main-Class: sample.Sample直接MANIFEST.MFにMain-Classを書き込んだが、それでは実行できなかった。
⑤実行
作業ディレクトリ:~
> java -jar Sample.jar 実行できた他の実行方法
> java -cp Sample.jar sample.Sample Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 実行できた
- 投稿日:2020-03-14T11:55:18+09:00
Scala カスタムExecutionContextの作成
カスタムExecuitonContextを作っていきます。
背景
普段Futureを使う時に、なんとなくExecutionContextをDIして、implicitでFutureに渡しています。
これまでは 一つのExecutionContextをFutureに渡してElasticsearchに対して非同期処理を行っていました。
ところが、諸事情で一つのアプリケーションがElastisearchだけではなくDocumentDB(MongoDBのAWSマネージドサービス)にも、ドキュメントを参照・保存するような処理にするような修正をしなければいけなくなりました。これまで、一つのデフォルトのExecutionContextでElasticsearchに対して非同期処理を行っていたところを、DocumentDBとの接続に対しても利用するようになりました。
共通のExecutionContextを使えれば使いたかったのですが、今回DocumentDBに関して、むやみやたらにコネクションを貼ってしまうと、待機中のスレッドが多すぎて処理しきれなくなります。(デフォルトで最大で500スレッド待機できる)
実際に以下のようなエラーが出てしまいます。
エラー内容
com.mongodb.MongoWaitQueueFullException: Too many threads are already waiting for a connection. Max number of threads (maxWaitQueueSize) of 500 has been exceeded.なので、DocumentDB側で最大でコネクションを貼れる数(プールできるコネクション数)と、アプリケーション側で接続するスレッドの数をチューニングしてあげる必要があります。
アプリケーション側で並列で動かすスレッド数を、DocumentDB側で設定したコネクションプール数を超えなければ、正常に処理できるはず。
そこで、普段何気なく使っているExecutionContextをカスタマイズする必要が出てきました。
ExecutionContextとは
スレッドプールを必要とせず、非同期でプログラムを実行するscalaの標準ライブラリです。
概要は、ExecutionContextライブラリにコメントアウトで、長々と書いてあります。
ExecutionContext.scala/** * An `ExecutionContext` can execute program logic asynchronously, * typically but not necessarily on a thread pool. * * A general purpose `ExecutionContext` must be asynchronous in executing * any `Runnable` that is passed into its `execute`-method. A special purpose * `ExecutionContext` may be synchronous but must only be passed * ............続く自前のExecutionContextを作る
ExecutionContextライブラリに、カスタムする際の良い方法をちょこっと書いています。
* A custom `ExecutionContext` may be appropriate to execute code * which blocks on IO or performs long-running computations. * `ExecutionContext.fromExecutorService` and `ExecutionContext.fromExecutor` * are good ways to create a custom `ExecutionContext`.ExecutionContext.fromExecutorのように、自前のExecutionContextを作成するインターフェースが存在するみたいです。
実際に作ってみる
二通りのやり方でカスタムしていきたいと思います。
1. 一つ目
ExecutionContextTest1.scalaclass MongoRepository1 { implicit val service: ExecutionContextExecutorService = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(1)) def find = { Future { for (i <- 1 to 50) { println(i * 2) } } } }fromExecutorServicenの引数に、Executorsインスタンスを渡しています。
newFixedThreadPool()で、プールできるスレッド数を固定値で指定できます。implicitでFutureに渡してあげることで、カスタマイズしたExecutionContextで非同期処理を実行できます。
2. 二つ目
play framework上で、ExecutionContextをカスタマイズする方法です。
DIで、きれいに実装するためにこのような実装になっています。ExecutionContextTest.scalapackage study.executionContextTest import java.util.concurrent.{ExecutorService, Executors} import com.google.inject.name.{Named, Names} import com.google.inject.{AbstractModule, Inject, Singleton} import scala.concurrent.{ExecutionContext, Future} // 自前のExecutionContextを作る class Execution @Inject()(mongoRepository: MongoRepository) { mongoRepository.find } // DIするモジュールを作っている // ここで、自前のExecutionContextを作成するので、いろいろ自前の設定を定義できる class MongoExecutionContext(threadCount: Int) extends ExecutionContext { // JavaのExecutorServiceを使うことで、スレッドプールを作成できる // newFixedThreadPoolで固定値で、プールするスレッド数を定義している。 private val executorService: ExecutorService = Executors.newFixedThreadPool(threadCount) // Futureは、内部的に引数のブロックをRannableでラップして、ExecutionContextのexecuteメソッドを実行している。 override def execute(runnable: Runnable): Unit = executorService.execute(runnable) override def reportFailure(cause: Throwable): Unit = throw cause } // 自前のモジュールを作成 // google guiceの仕様 // application.confのmoduleに定義することで、google guiceでDIできるようになる class MongoExecutionModule extends AbstractModule { override def configure(): Unit = { bind(classOf[ExecutionContext]) .annotatedWith(Names.named("MongoExecutionContext")) .toInstance(new MongoExecutionContext(50)) } } // このインスタンスは、一個しか作られないようにする。 // 複数のExecutionContextが作成されると、チューニングがバグる @Singleton class MongoRepository @Inject()( implicit @Named("MongoExecutionContext") ec: ExecutionContext ) { // このfindなどで、implicitのexecutionContextを利用するので、 // ここでデフォルトのExecutionContextを使うのではなく、mongoとの接続に適したExecutionContextを使ってあげる。 // このように、ミドルウェア毎に利用するExecutionContextを変更することができる。 // この例では、Futureのapplyに渡された処理が、非同期で処理される。 // その際に、上記でinjectしているExecutionContextが使われるので、thread数が最大50まで並行処理する。 def find = { Future { for (i <- 1 to 50) { println(i * 2) } } } }詳細はコメントアウトに書いていますが、さっくりした流れは、以下のようになっています。
最終的にはカスタムしたExecutionContextをDIしたい。
- 1. ExecutionContextを継承したMongoExecutionContextを作成する。
- 1-1. その中で、スレッドプールを指定したExecutionServiceを作成する
- 2. AbstractModuleを継承したMongoExecutionModuleを作成する
- 2-1. @NameでDIできるように、実装する
- 3. MongoRepositoryで、2で作成したMongoExecutionModuleをDIする
まとめ
先述したように、これまでおまじないのようにExecutionContextを使っていたのですが、自分で作ってみることで理解がグッと深まりました。
参考
実装するにあたり、非常に助けになりました。
- http://tototoshi.hatenablog.com/entry/2015/12/23/154104
- https://qiita.com/sugiyasu-qr/items/d48c04c81ff9a561b5e5
- https://qiita.com/sugiyasu-qr/items/391b2f0523c9974b011d
- 投稿日:2020-03-14T11:55:18+09:00
自前のExecutionContext作成
カスタムExecuitonContextを作っていきます。
背景
普段Futureを使う時に、なんとなくExecutionContextをDIして、implicitでFutureに渡しています。
これまでは 一つのExecutionContextをFutureに渡してElasticsearchに対して非同期処理を行っていました。
ところが、諸事情で一つのアプリケーションがElastisearchだけではなくDocumentDB(MongoDBのAWSマネージドサービス)にも、ドキュメントを参照・保存するような処理にするような修正をしなければいけなくなりました。これまで、一つのデフォルトのExecutionContextでElasticsearchに対して非同期処理を行っていたところを、DocumentDBとの接続に対しても利用するようになりました。
共通のExecutionContextを使えれば使いたかったのですが、今回DocumentDBに関して、むやみやたらにコネクションを貼ってしまうと、待機中のスレッドが多すぎて処理しきれなくなります。(デフォルトで最大で500スレッド待機できる)
実際に以下のようなエラーが出てしまいます。
エラー内容
com.mongodb.MongoWaitQueueFullException: Too many threads are already waiting for a connection. Max number of threads (maxWaitQueueSize) of 500 has been exceeded.なので、DocumentDB側で最大でコネクションを貼れる数(プールできるコネクション数)と、アプリケーション側で接続するスレッドの数をチューニングしてあげる必要があります。
アプリケーション側で並列で動かすスレッド数を、DocumentDB側で設定したコネクションプール数を超えなければ、正常に処理できるはず。
そこで、普段何気なく使っているExecutionContextをカスタマイズする必要が出てきました。
ExecutionContextとは
スレッドプールを必要とせず、非同期でプログラムを実行するscalaの標準ライブラリです。
概要は、ExecutionContextライブラリにコメントアウトで、長々と書いてあります。
ExecutionContext.scala/** * An `ExecutionContext` can execute program logic asynchronously, * typically but not necessarily on a thread pool. * * A general purpose `ExecutionContext` must be asynchronous in executing * any `Runnable` that is passed into its `execute`-method. A special purpose * `ExecutionContext` may be synchronous but must only be passed * ............続く自前のExecutionContextを作る
ExecutionContextライブラリに、カスタムする際の良い方法をちょこっと書いています。
* A custom `ExecutionContext` may be appropriate to execute code * which blocks on IO or performs long-running computations. * `ExecutionContext.fromExecutorService` and `ExecutionContext.fromExecutor` * are good ways to create a custom `ExecutionContext`.ExecutionContext.fromExecutorのように、自前のExecutionContextを作成するインターフェースが存在するみたいです。
実際に作ってみる
二通りのやり方でカスタムしていきたいと思います。
1. 一つ目
ExecutionContextTest1.scalaclass MongoRepository1 { implicit val service: ExecutionContextExecutorService = ExecutionContext.fromExecutorService(Executors.newFixedThreadPool(1)) def find = { Future { for (i <- 1 to 50) { println(i * 2) } } } }fromExecutorServicenの引数に、Executorsインスタンスを渡しています。
newFixedThreadPool()で、プールできるスレッド数を固定値で指定できます。implicitでFutureに渡してあげることで、カスタマイズしたExecutionContextで非同期処理を実行できます。
2. 二つ目
play framework上で、ExecutionContextをカスタマイズする方法です。
DIで、きれいに実装するためにこのような実装になっています。ExecutionContextTest.scalapackage study.executionContextTest import java.util.concurrent.{ExecutorService, Executors} import com.google.inject.name.{Named, Names} import com.google.inject.{AbstractModule, Inject, Singleton} import scala.concurrent.{ExecutionContext, Future} // 自前のExecutionContextを作る class Execution @Inject()(mongoRepository: MongoRepository) { mongoRepository.find } // DIするモジュールを作っている // ここで、自前のExecutionContextを作成するので、いろいろ自前の設定を定義できる class MongoExecutionContext(threadCount: Int) extends ExecutionContext { // JavaのExecutorServiceを使うことで、スレッドプールを作成できる // newFixedThreadPoolで固定値で、プールするスレッド数を定義している。 private val executorService: ExecutorService = Executors.newFixedThreadPool(threadCount) // Futureは、内部的に引数のブロックをRannableでラップして、ExecutionContextのexecuteメソッドを実行している。 override def execute(runnable: Runnable): Unit = executorService.execute(runnable) override def reportFailure(cause: Throwable): Unit = throw cause } // 自前のモジュールを作成 // google guiceの仕様 // application.confのmoduleに定義することで、google guiceでDIできるようになる class MongoExecutionModule extends AbstractModule { override def configure(): Unit = { bind(classOf[ExecutionContext]) .annotatedWith(Names.named("MongoExecutionContext")) .toInstance(new MongoExecutionContext(50)) } } // このインスタンスは、一個しか作られないようにする。 // 複数のExecutionContextが作成されると、チューニングがバグる @Singleton class MongoRepository @Inject()( implicit @Named("MongoExecutionContext") ec: ExecutionContext ) { // このfindなどで、implicitのexecutionContextを利用するので、 // ここでデフォルトのExecutionContextを使うのではなく、mongoとの接続に適したExecutionContextを使ってあげる。 // このように、ミドルウェア毎に利用するExecutionContextを変更することができる。 // この例では、Futureのapplyに渡された処理が、非同期で処理される。 // その際に、上記でinjectしているExecutionContextが使われるので、thread数が最大50まで並行処理する。 def find = { Future { for (i <- 1 to 50) { println(i * 2) } } } }詳細はコメントアウトに書いていますが、さっくりした流れは、以下のようになっています。
最終的にはカスタムしたExecutionContextをDIしたい。
- 1. ExecutionContextを継承したMongoExecutionContextを作成する。
- 1-1. その中で、スレッドプールを指定したExecutionServiceを作成する
- 2. AbstractModuleを継承したMongoExecutionModuleを作成する
- 2-1. @NameでDIできるように、実装する
- 3. MongoRepositoryで、2で作成したMongoExecutionModuleをDIする
まとめ
先述したように、これまでおまじないのようにExecutionContextを使っていたのですが、自分で作ってみることで理解がグッと深まりました。
参考
実装するにあたり、非常に助けになりました。
- http://tototoshi.hatenablog.com/entry/2015/12/23/154104
- https://qiita.com/sugiyasu-qr/items/d48c04c81ff9a561b5e5
- https://qiita.com/sugiyasu-qr/items/391b2f0523c9974b011d