- 投稿日:2020-03-14T23:31:40+09:00
API Gatewayでリクエストして、Lambdaで処理させて、AppSyncで受け取る
API Gatewayでリクエストして、Lambdaで処理させて、AppSyncで受け取る
この記事はサーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事の1つです。
以下を見てからこの記事をみるといい感じです。
はじめに
検出した顔を並べて表示しました。次はいよいよ顔にモザイクをかけてゆきます。
処理をキックするためにAPI GatewayとLambdaを利用します。また、実行結果はAppSyncのSubscriptionで受け取ります。顔の位置情報を渡す
前回の記事(Lambda(Python) + Rekognition で顔検出)では顔を検出して切抜き画像を作って表示するだけでした。この時に顔の位置情報(座標)が分かってます。モザイク処理する時にこの座標が必要になりますのでAppSync経由で渡してあげましょう。
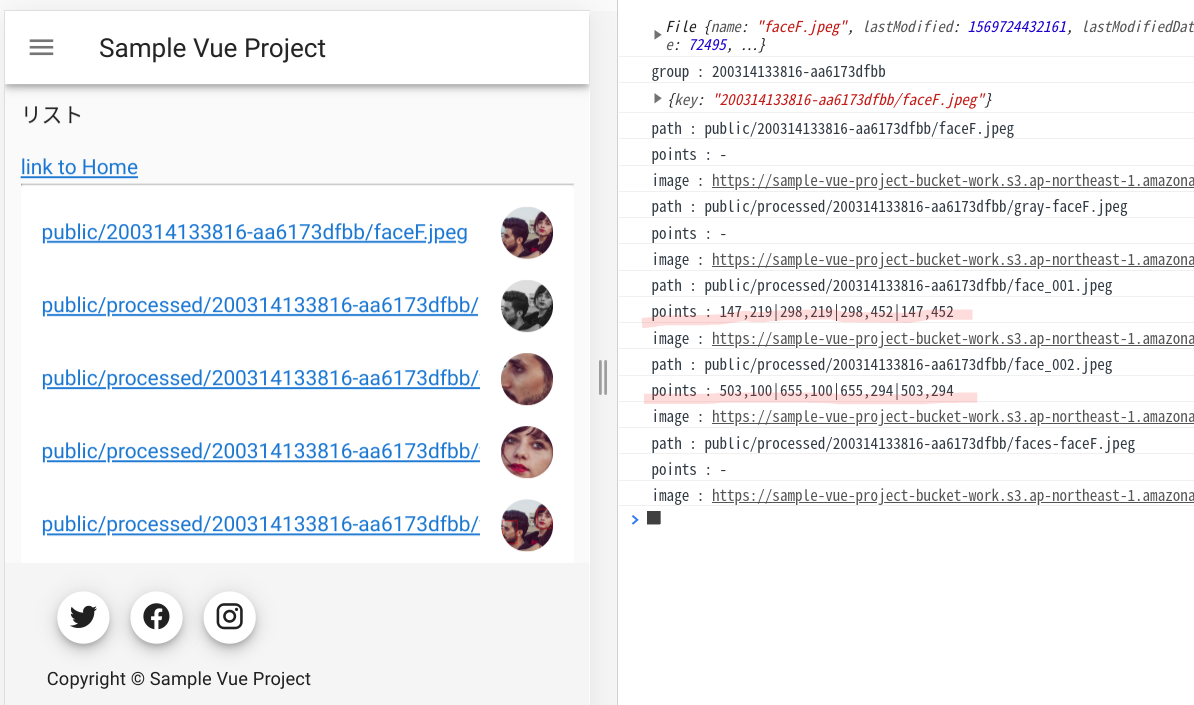
(キックした後にまた検出し直すこともできますが、それだと無駄が多いですよね。)以前書いた顔検出するサンプルコードにpointsという位置情報を入れておくための変数を追加します。
lambda_function.pydef uploadImage(image, localFilePath, bucket, s3Key, group, points): logger.info("start uploadImage({0}, {1}, {2}, {3})".format(localFilePath, bucket, s3Key, group)) try: cv2.imwrite(localFilePath, image) s3.upload_file(Filename=localFilePath, Bucket=bucket, Key=s3Key) apiCreateTable(group, s3Key, points) except Exception as e: logger.exception(e) raise e finally: if os.path.exists(localFilePath): os.remove(localFilePath) def apiCreateTable(group, path, points): logger.info("start apiCreateTable({0}, {1}, {2})".format(group, path, points)) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" points: \"{2}\" }}){{ group path points }} }} """.format(group, path, points)) _client.execute(query) except Exception as e: logger.exception(e) raise e def detectFaces(bucket, key, fileName, image, group, dirPathOut): logger.info("start detectFaces ({0}, {1}, {2}, {3}, {4})".format(bucket, key, fileName, group, dirPathOut)) try: response = rekognition.detect_faces( Image={ "S3Object": { "Bucket": bucket, "Name": key, } }, Attributes=[ "DEFAULT", ] ) name, ext = os.path.splitext(fileName) imgHeight = image.shape[0] imgWidth = image.shape[1] index = 0 for faceDetail in response["FaceDetails"]: index += 1 faceFileName = "face_{0:03d}".format(index) + ext box = faceDetail["BoundingBox"] x = max(int(imgWidth * box["Left"]), 0) y = max(int(imgHeight * box["Top"]), 0) w = int(imgWidth * box["Width"]) h = int(imgHeight * box["Height"]) points = "{0},{1}|{2},{3}|{4},{5}|{6},{7}".format(x, y, x+w, y, x+w, y+h, x, y+h) logger.info("BoundingBox({0},{1},{2},{3})".format(x, y, w, h)) faceImage = image[y:min(y+h, imgHeight-1), x:min(x+w, imgWidth)] localFaceFilePath = os.path.join("/tmp/", faceFileName) uploadImage(faceImage, localFaceFilePath, bucket, os.path.join(dirPathOut, faceFileName), group, points) cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 3) processedFileName = "faces-" + fileName processedFilePath = "/tmp/" + processedFileName uploadImage(image, processedFilePath, bucket, os.path.join(dirPathOut, processedFileName), group, points) except Exception as e: logger.exception(e) raise eAppSyncのスキーマも更新しましょう。
AWSコンソール > AppSync > 目的のAPI > スキーマ
input(引数)とtype(戻り値)のデータに points: String を加えておきます。input CreateSampleAppsyncTableInput { group: String! path: String! points: String } type SampleAppsyncTable { group: String! path: String! points: String }フロントのWebアプリ側も更新します。
getListやsubscriptionでpointsを受け取るため、graphqlファイルを更新します。src/graphql/queries.jsexport const listSampleAppsyncTables = `query listSampleAppsyncTables($group: String) { listSampleAppsyncTables( limit: 1000000 filter: { group: {eq:$group} } ) { items { group path points } } } `;src/graphql/subscriptions.jsexport const onCreateSampleAppsyncTable = `subscription OnCreateSampleAppsyncTable($group: String) { onCreateSampleAppsyncTable(group : $group) { group path points } } `;さぁこれで、検出した顔の座標をクライアント側に渡すことができるようになりました。
受け取ったpointsをメンバ変数にセットしたり、ログに出したりして確認してみましょう。src/components/List.vue: <script> : async getList() { this.group = this.$route.query.group; console.log("group : " + this.group); if(!this.group){ return; } let apiResult = await API.graphql(graphqlOperation(listSampleAppsyncTables, { group : this.group })); let listAll = apiResult.data.listSampleAppsyncTables.items; for(let data of listAll) { let tmp = { path : data.path, image : "", points : data.points }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); console.log("points : " + data.points); Storage.get(data.path.replace('public/', ''), { level: 'public', expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } API.graphql( graphqlOperation(onCreateSampleAppsyncTable, { group : this.group } ) ).subscribe({ next: (eventData) => { let data = eventData.value.data.onCreateSampleAppsyncTable; let tmp = { path : data.path, image : "", points : data.points }; let list = [...this.dataList, tmp]; this.dataList = list; console.log("path : " + data.path); console.log("points : " + data.points); Storage.get(data.path.replace('public/', ''), { level: 'public', expires: dataExpireSeconds }).then(result => { tmp.image = result; console.log("image : " + result); }).catch(err => console.log(err)); } }); }, :
はい、ちゃんと顔の位置情報が受け取れてますね。顔を選択するための実装は今回は割愛し、検出された全ての顔にモザイクをかけるようにしたいと思います。
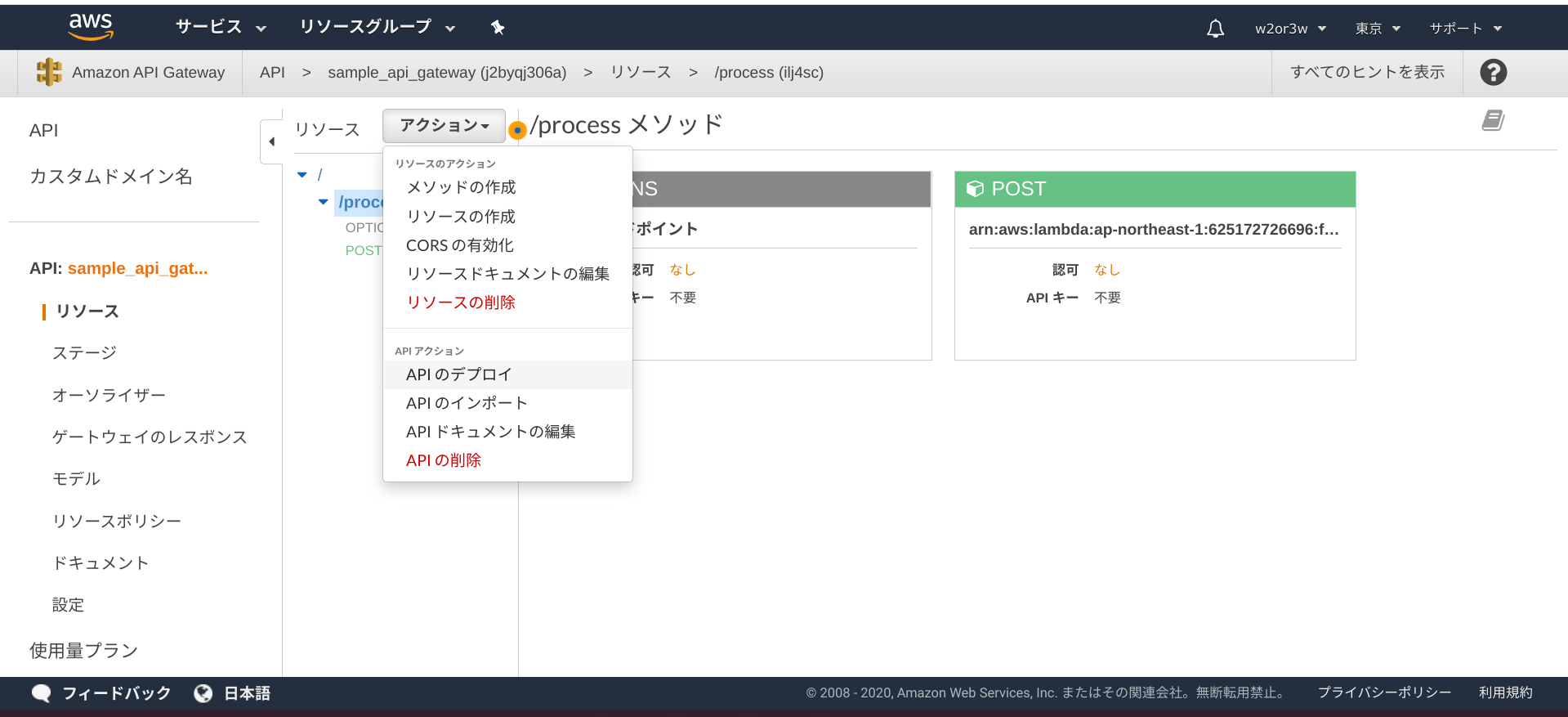
全ての顔にモザイクをかける処理を実行するためのボタンを設置し、押下したらAPI Gatewayに対して処理をリクエストします。モザイク処理された画像は他の画像と同様にS3にアップロードしたらAppSync経由でパスを通知し、クライアント側でそれを受け取るような流れです。API GatewayとLambdaのセットアップ
以下のような流れでAPI GatewayとLambdaをセットアップしてゆきます。
Lambdaの作成
先にLambdaの関数を作成しておきます。
AWSコンソール > Lambda > 関数 > 関数の作成
一から作成, 任意の関数名, ランタイムにはPython3.6, 実行ロールは「基本的な Lambda アクセス権限で新しいロールを作成」を選択して作成します。
関数名は「sample_lambda_apply」としておきました。関数コードはひとまずインラインで以下のようにしておきます。
lambda_function.pyimport json import logging logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info("Hello from lambda! - sample_lambda_apply") return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda! - sample_lambda_apply') }LambdaのIAMロール編集
LambdaがS3操作やAppSyncアクセスできるようにします。
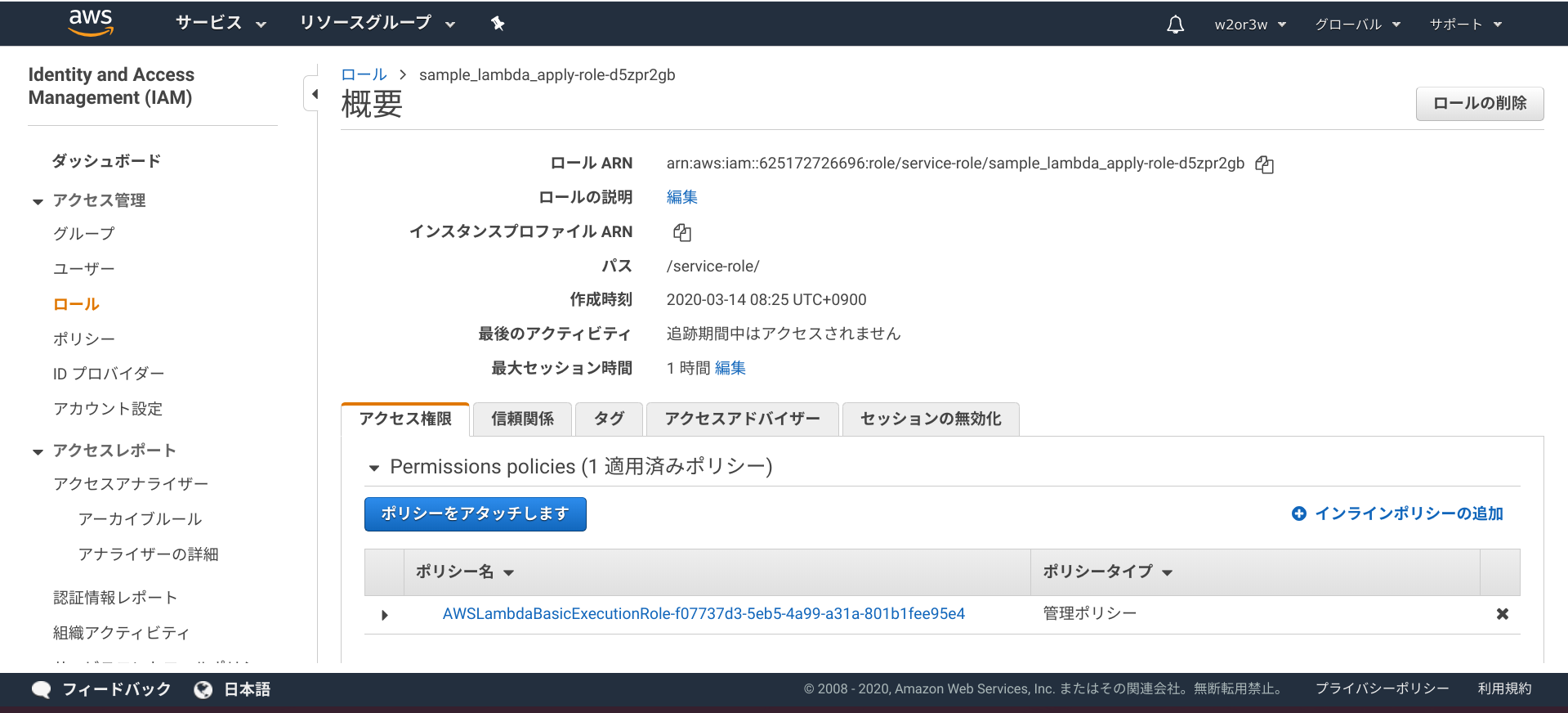
AWSコンソール > IAM > ロール
Lambdaと一緒に作成された sample_lambda_apply-role-xxxxxxxx というロールを表示します。
アクセス権限タブの「+インラインポリシーの追加」から追加してください。
ポリシーのJSONは以下のような感じになります。{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:PutObject", "s3:GetObject", "appsync:GraphQL" ], "Resource": [ "arn:aws:s3:::sample-vue-project-bucket-work/*", "arn:aws:appsync:ap-northeast-1:888888888888:apis/xxxxxxxxxxxxxxxxxxxxxxxxxx/*" ], "Effect": "Allow" } ] }API Gatewayの作成
続いて、API Gatewayを作成します。
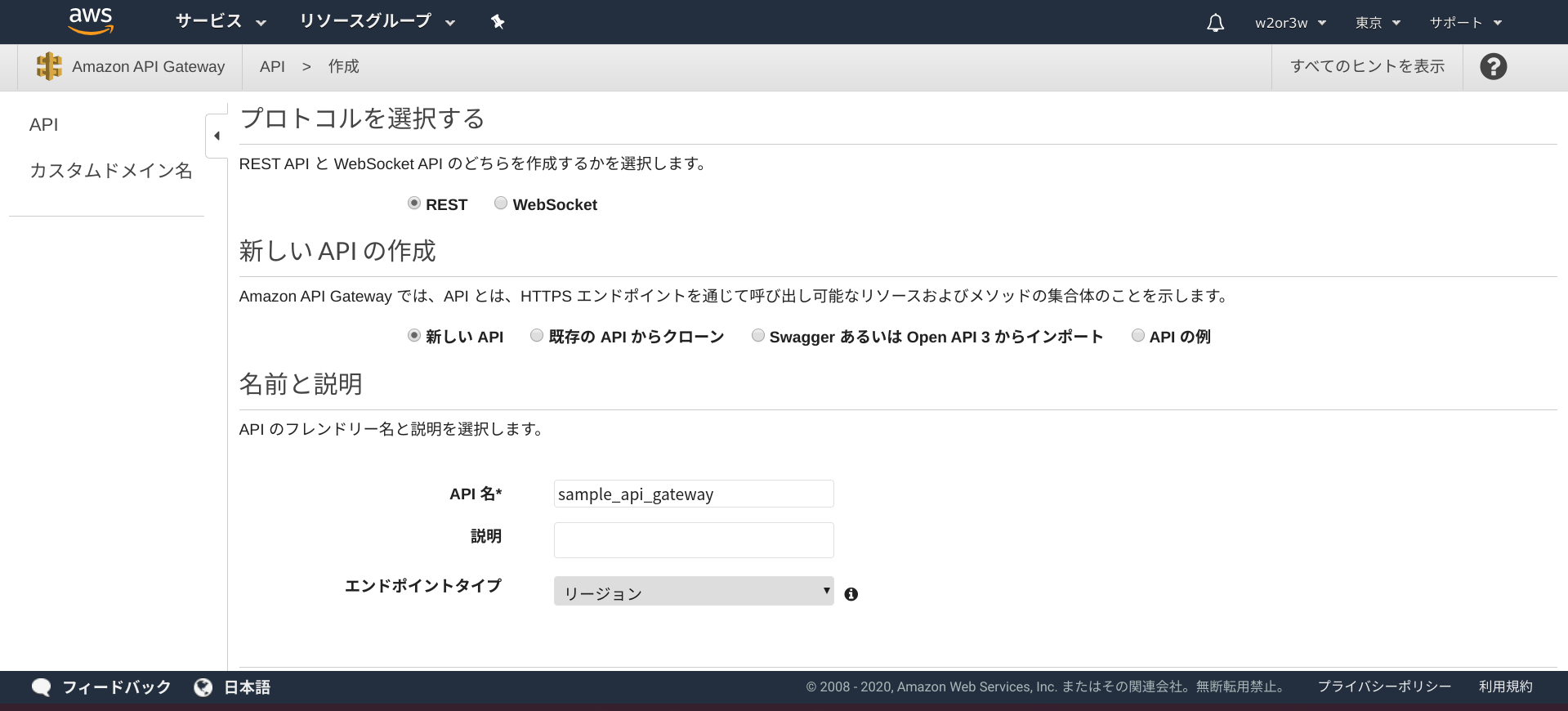
AWSコンソール > API Gateway
APIを作成ボタンを押下し、APIタイプを選択画面でREST APIを選択します。
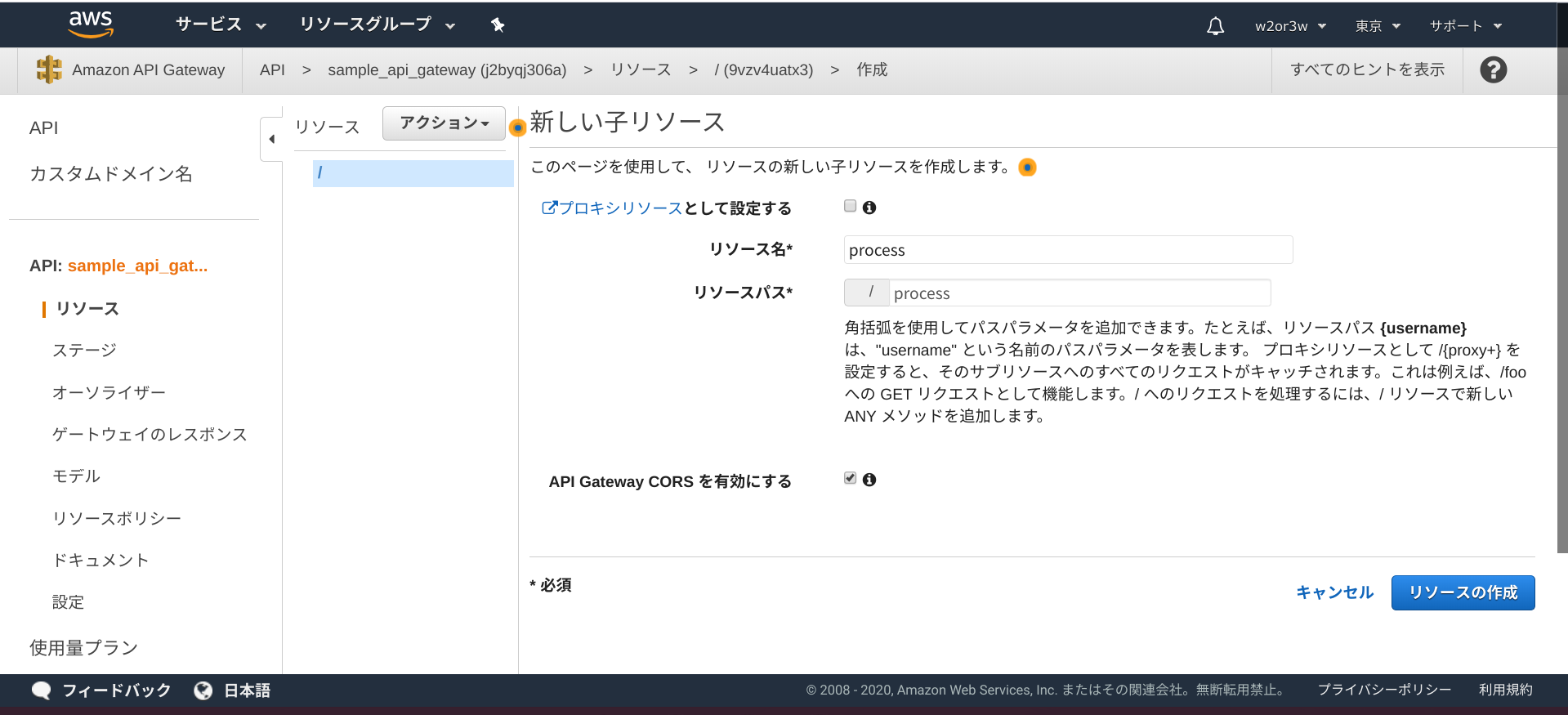
REST, 新しいAPI, 任意の名前を設定し, エンドポイントタイプはリージョンとし、APIの作成ボタンを押下します。
processという名前の子リソースを作成し、そこにPOSTメソッドを作成してゆこうと思います。リソースを作成する際、CORSを有効にするチェックはONにしておきましょう。
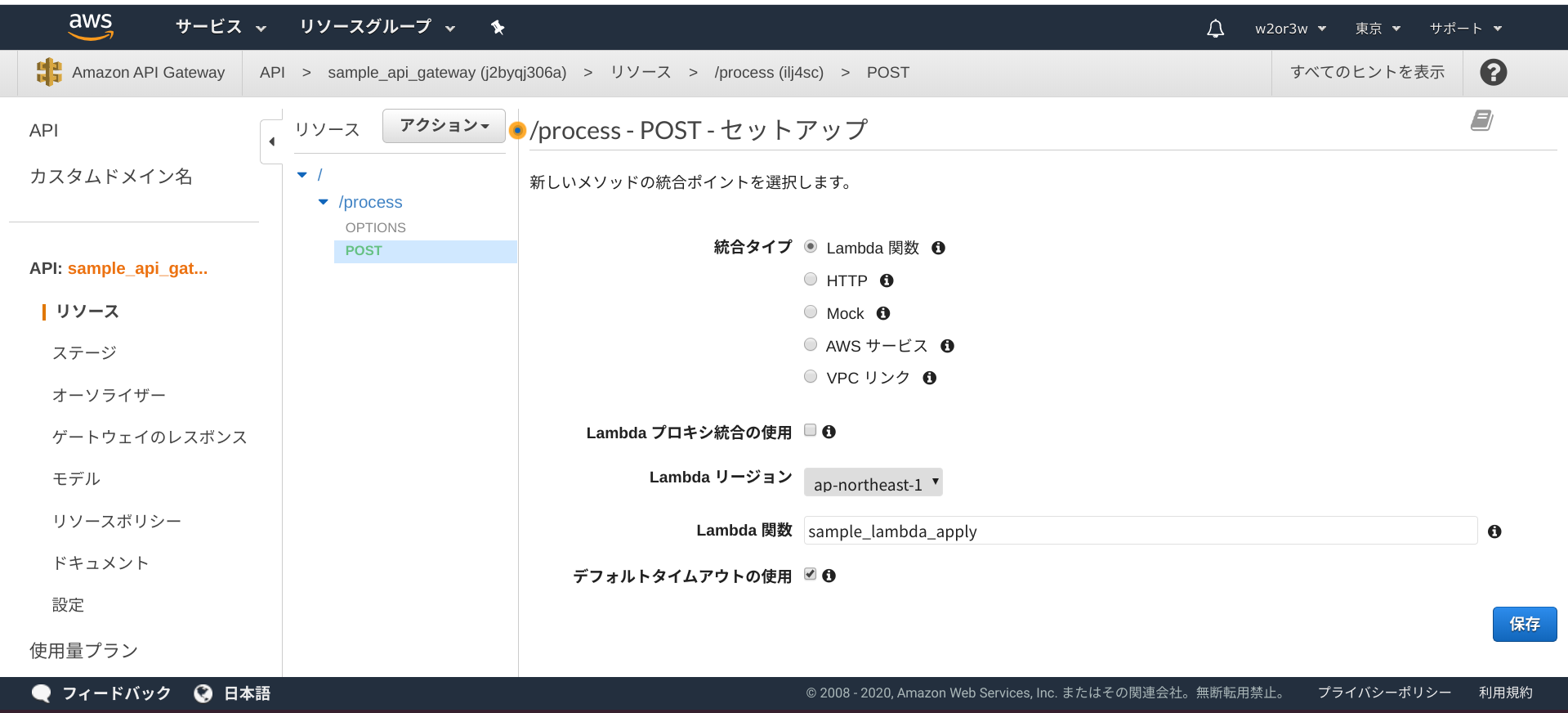
POSTのセットアップでは、統合タイプはLambda関数とし、Lambda関数は先程作成した「sample_lambda_apply」を選択し、保存ボタンを押下します。
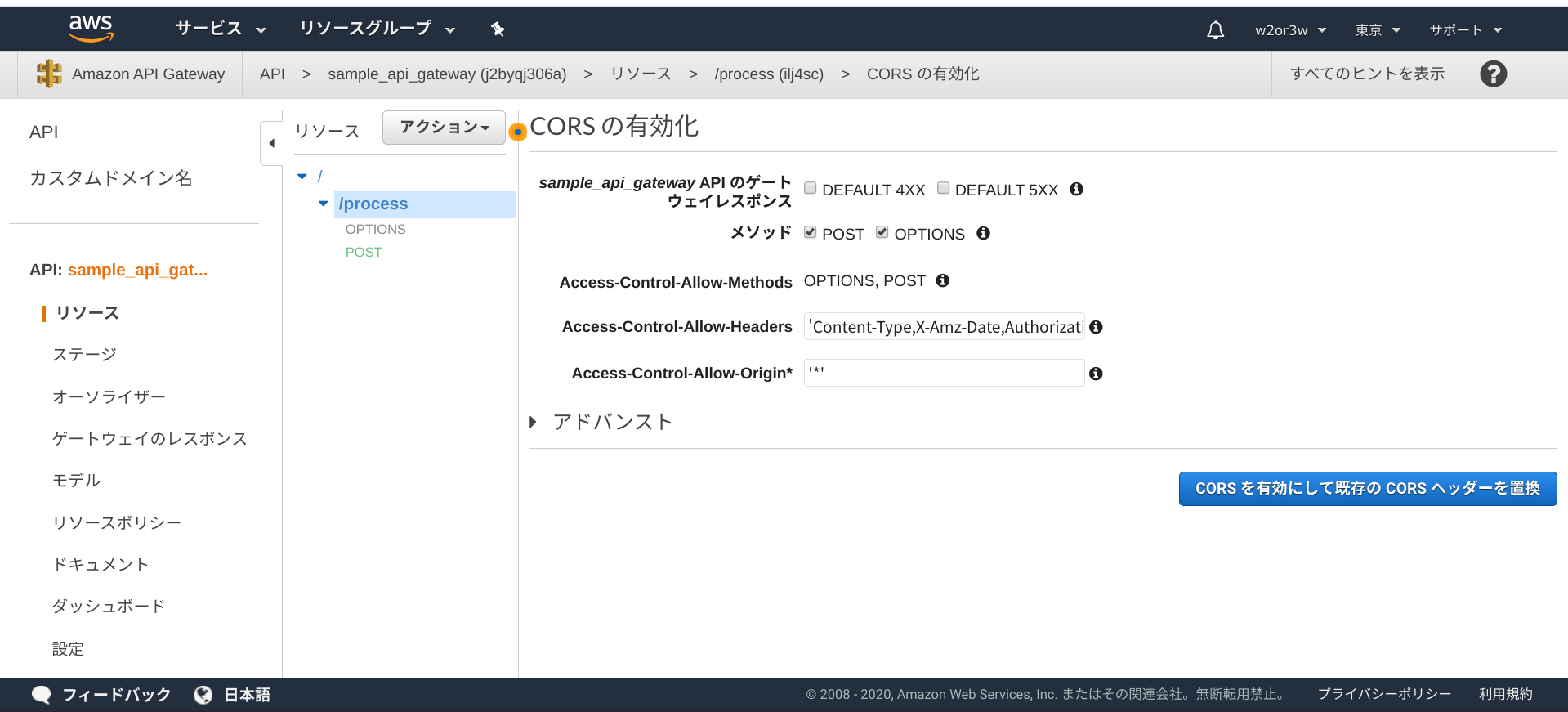
POSTに対してもCORSの有効化を行う必要があります。
CORSの有効化をしないと、クライアント側からリクエストした際に以下のような例外が発生すると思います。
Access to XMLHttpRequest at 'https://j2byqj306a.execute-api.ap-northeast-1.amazonaws.com/work/process' from origin 'https://fed9513d88324171b593944f5acca30f.vfs.cloud9.ap-northeast-1.amazonaws.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Error: Network Error at createError (createError.js?2d83:16) at XMLHttpRequest.handleError (xhr.js?b50d:81)CORSの有効化をしたら、APIのデプロイも再実施しましょう。
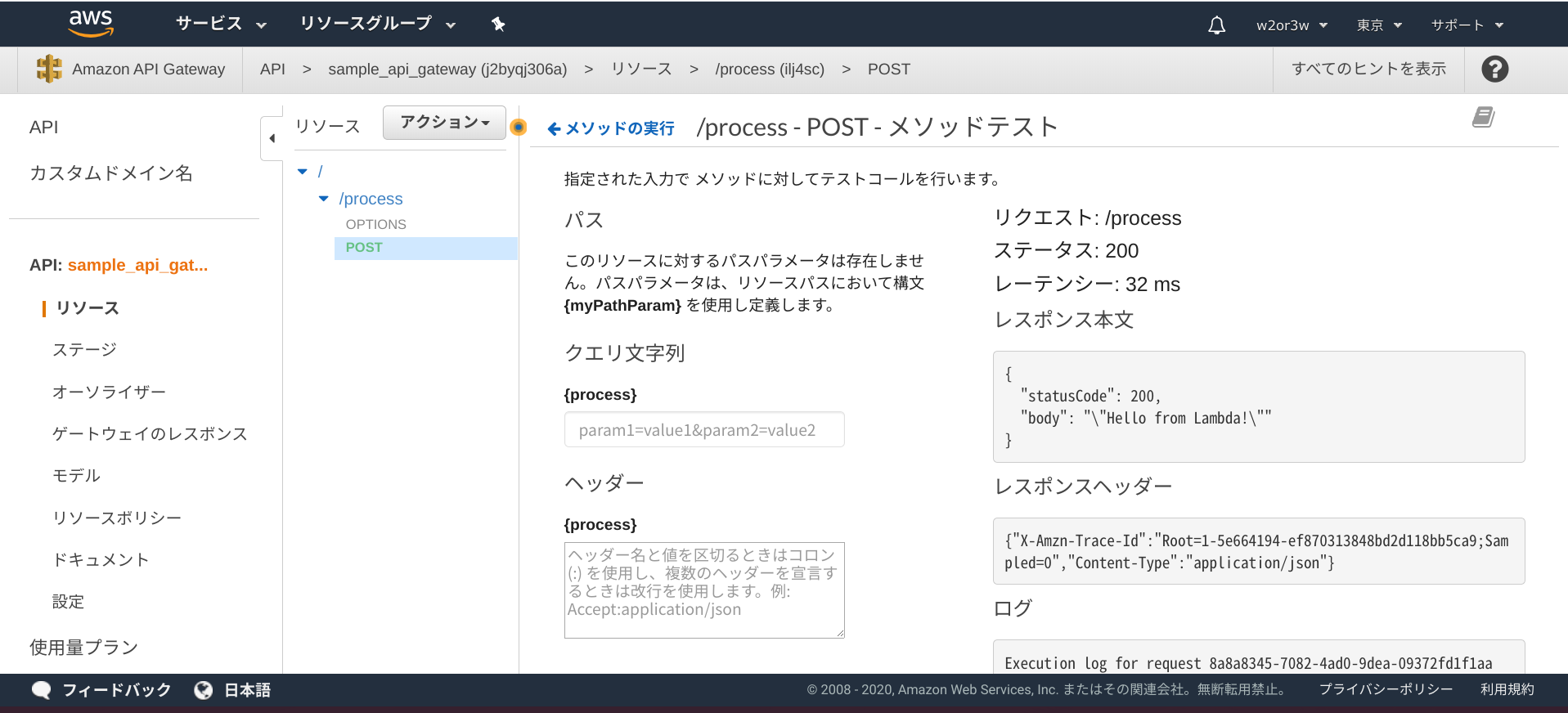
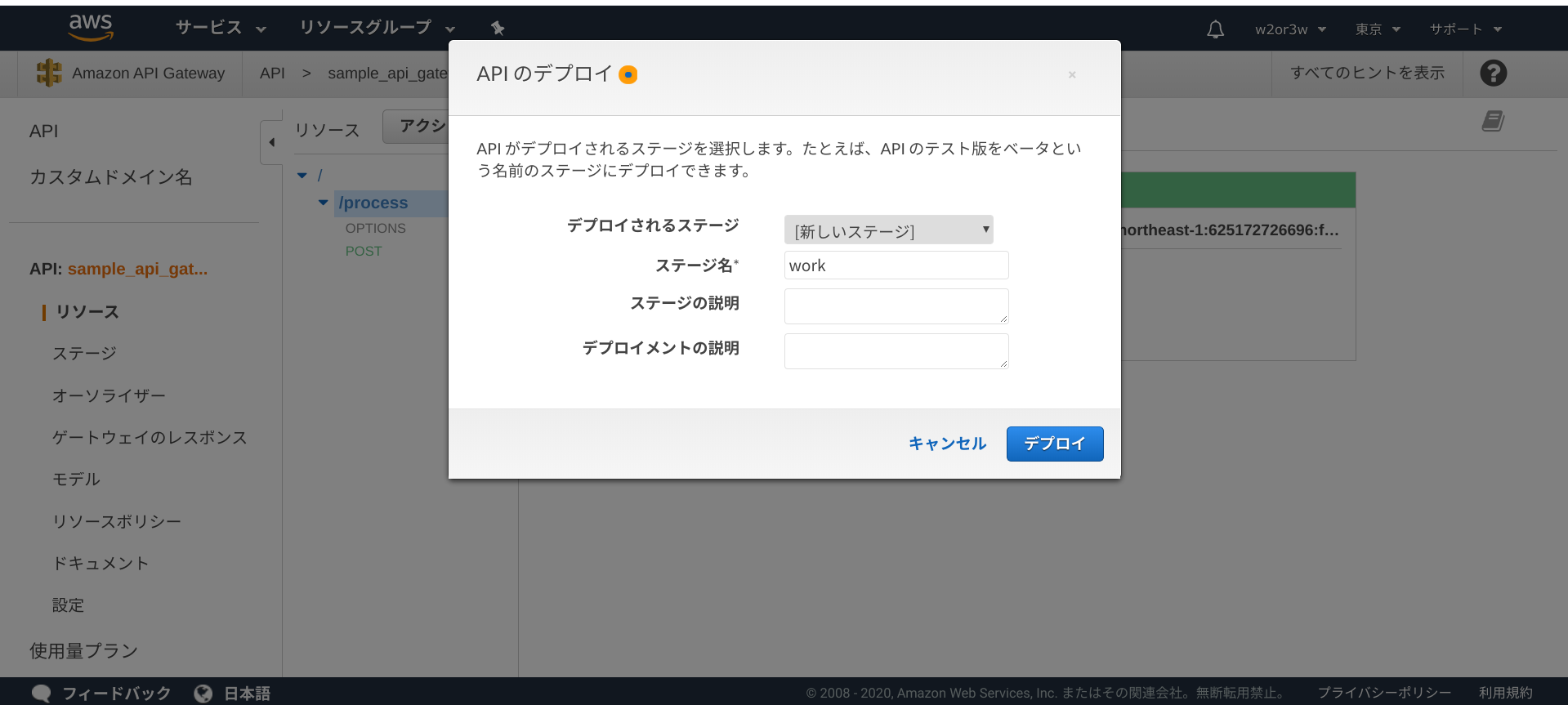
念の為テストを実行してstatusCode=200が返ってくることも確認しておきましょう。
確認できたら、APIのデプロイから任意のステージ名を設定し、デプロイを行っておいてください。
VueのWebアプリからAPI Gatewayに対してリクエストする
WebアプリからAPI Gatewayを呼べるようにします。
src/components/List.vue: <v-list> <v-list-item v-for="data in this.dataList" :key="data.path"> <v-list-item-content> <a :href="data.image" target=”_blank”> <v-list-item-title v-text="data.path"></v-list-item-title> </a> </v-list-item-content> <v-list-item-avatar> <v-img :src="data.image"></v-img> </v-list-item-avatar> </v-list-item> </v-list> <v-btn v-if="dataList.length > 0" @click="processMosaic"> PROCESS MOSAIC </v-btn> : <script> import { API, graphqlOperation, Storage } from 'aws-amplify'; import { listSampleAppsyncTables } from "../graphql/queries"; import { onCreateSampleAppsyncTable } from "../graphql/subscriptions"; import axios from 'axios'; const apiUrl = "https://j2byqj306a.execute-api.ap-northeast-1.amazonaws.com/work/process"; const config = {headers: { 'Content-Type': 'application/json' }} : 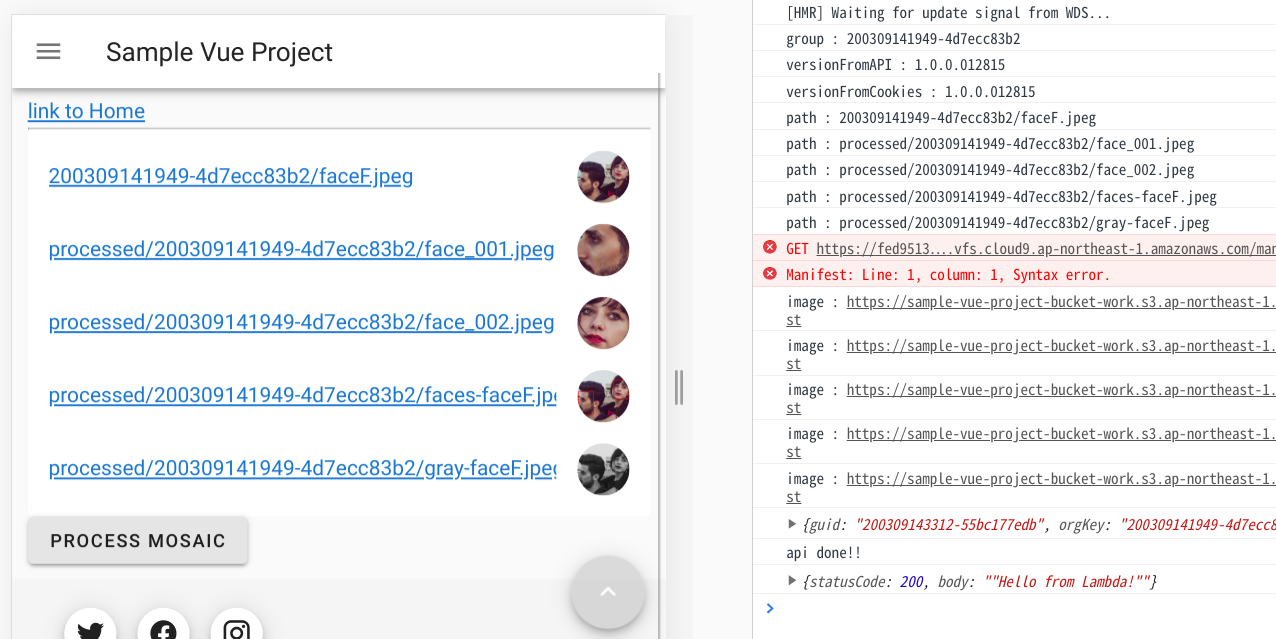 processMosaic() { let pointsList = []; let orgKey = ""; for(let index = 0; index < this.dataList.length; index++) { let data = this.dataList[index]; if(data.points != "-"){ pointsList.push(data.points); }else if(data.path.startsWith("processed") == false){ orgKey = data.path; } } this.myGuid = this.getGUIDString(new Date()); let requestData = { guid: this.myGuid, orgKey: orgKey, pointsList: pointsList }; console.log(requestData); axios .post(apiUrl, requestData, config) .then(response => { let result = response.data console.log(result) }) .catch(error => console.log(error)) }, getGUIDString(date){ let random = date.getTime() + Math.floor(100000 * Math.random()); random = Math.random() * random; random = Math.floor(random).toString(16); return random; }, :PROCESS MOSAICボタンを押したらstatusCode=200が返ってくることを確認しておきましょう。
Lambdaの実装
Lambdaファンクションの実装をしてゆきます。
以前の記事「Lambda + OpenCVで画像処理 (グレー画像作成)」と同じ要領で必要なライブラリをインストールし、lambdafunction.pyを実装し、zip圧縮して、Lambdaにデプロイします。必要なライブラリのインストール
$ pip install opencv-python -t . $ pip install gql -t .実装
lambda_function.py# coding: UTF-8 import json import boto3 import os import datetime import numpy as np import cv2 import logging logger = logging.getLogger() logger.setLevel(logging.INFO) s3 = boto3.client("s3") BUCKET_INPUT = "sample-vue-project-bucket-work" BUCKET_OUTPUT = "sample-vue-project-bucket-work" from gql import gql, Client from gql.transport.requests import RequestsHTTPTransport ENDPOINT = "https://xxxxxxxxxxxxxxxxxxxxxxxxxx.appsync-api.ap-northeast-1.amazonaws.com/graphql" API_KEY = "da2-XXXXXXXXXXXXXXXXXXXXXXXXXX" _headers = { "Content-Type": "application/graphql", "x-api-key": API_KEY, } _transport = RequestsHTTPTransport( headers = _headers, url = ENDPOINT, use_json = True, ) _client = Client( transport = _transport, fetch_schema_from_transport = True, ) def lambda_handler(event, context): try: logger.info(event) guid = event["guid"] orgKey = event["orgKey"] pointsList = event["pointsList"] pathList = orgKey.split("/") name, ext = os.path.splitext(os.path.basename(orgKey)) fileName = "mosaic.w2or3w.com." + guid + ext dirPath = os.path.dirname(orgKey) dirName = os.path.basename(dirPath) rootDirName = pathList[0] localTmpPath = u'/tmp/' + os.path.basename(orgKey) s3.download_file(Bucket = BUCKET_INPUT, Key = orgKey, Filename = localTmpPath) before = cv2.imread(localTmpPath) after = cv2.imread(localTmpPath) after = mosaicFromPointsList(pointsList, before, after) uploadAppliedImage(after, BUCKET_OUTPUT, os.path.join(rootDirName, "processed", dirName), fileName) return { 'statusCode': 200, 'body': json.dumps("completed") } except Exception as e: logger.exception(e) return { "statusCode": 500, "body": json.dumps("failed") } finally: if os.path.exists(localTmpPath): os.remove(localTmpPath) def mosaicFromPointsList(pointsList, before, after): try: height = before.shape[0] width = before.shape[1] mosaicImg = mosaic(before, 0.08) mask = np.tile(np.uint8(0), (height, width, 1)) for points in pointsList: pointList = points.split('|') lt = Point(pointList[0]) rt = Point(pointList[1]) rb = Point(pointList[2]) lb = Point(pointList[3]) contours = np.array( [ [lt.x, lt.y], [rt.x, rt.y], [rb.x, rb.y], [lb.x, lb.y], ] ) cv2.fillConvexPoly(mask, contours, color=(255, 255, 255)) after = np.where(mask != 0, mosaicImg, after) return after except Exception as e: logger.exception(e) raise e def mosaic(src, ratio=0.1): try: small = cv2.resize(src, None, fx=ratio, fy=ratio, interpolation=cv2.INTER_NEAREST) return cv2.resize(small, src.shape[:2][::-1], interpolation=cv2.INTER_NEAREST) except Exception as e: logger.exception(e) raise e def uploadAppliedImage(img, bucket, dirPath, name): tmp = "/tmp/" + name guid = os.path.basename(dirPath) s3key = dirPath + "/" + name try: cv2.imwrite(tmp, img) s3.upload_file(Filename=tmp, Bucket=bucket, Key=s3key) apiCreateMosaicTable(guid, s3key) except Exception as e: logger.exception(e) raise e finally: if os.path.exists(tmp): os.remove(tmp) def apiCreateMosaicTable(guid, s3key): logger.info("apiCreateMosaicTable : guid={0}, s3key={1}".format(guid, s3key)) time = datetime.datetime.now() time = time + datetime.timedelta(minutes=30) epocTime = int(time.timestamp()) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" points: \"-\" deleteTime: {2} }}){{ group path points }} }} """.format(guid, s3key, epocTime)) _client.execute(query) except Exception as e: logger.exception(e) raise e class Point: def __init__(self, text): tmp = text.strip("("")") tmpList = tmp.split(',') self.x = int(tmpList[0]) self.y = int(tmpList[1])モザイク処理の詳細についてはこちらの記事(画像に様々な形のモザイクをかける(Python, OpenCV))も見てみてください。
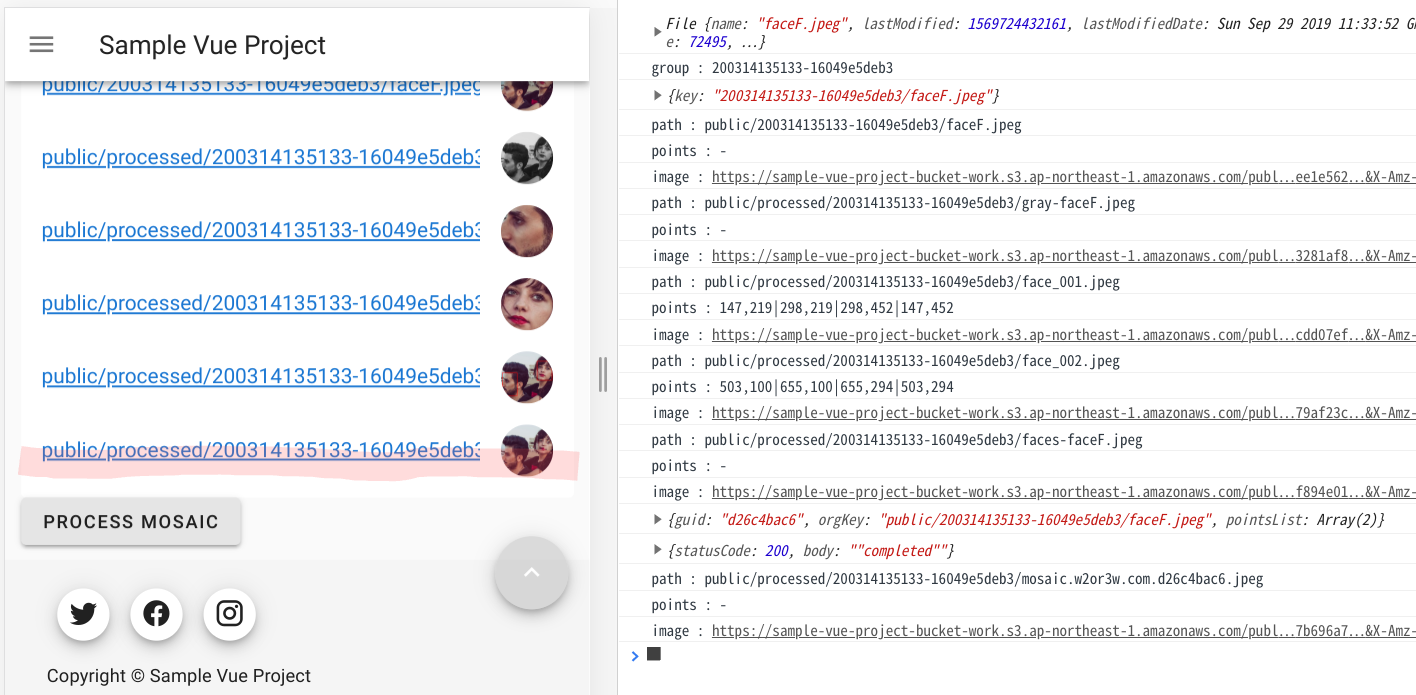
Lambdaにデプロイしたら、Webアプリに追加したPROCESS MOSAICボタンを押下しましょう。顔にモザイク処理された画像が追加されましたね。
API GatewayにCognito認証を設定する
現状、API Gatewayには認証制限を設けてません。呼び放題です。
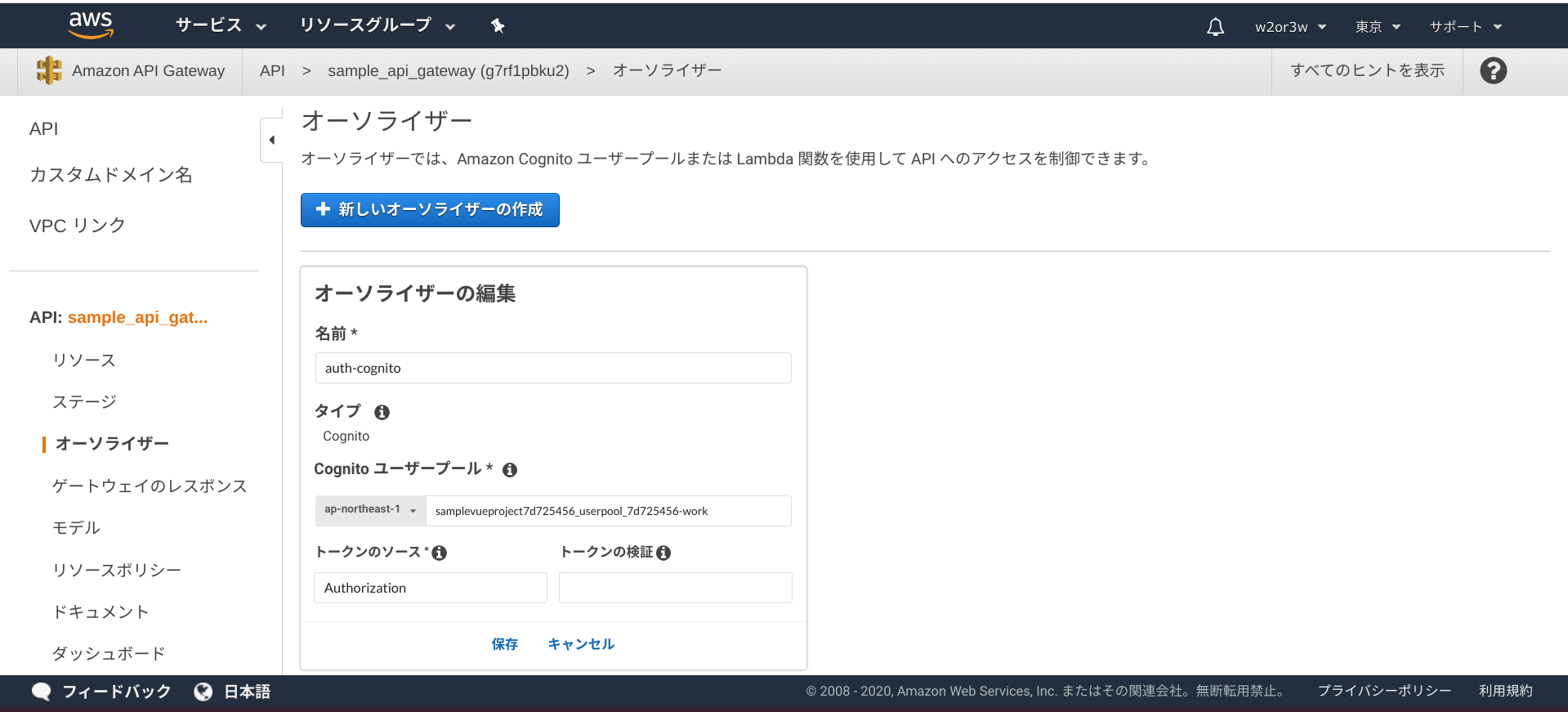
フロント側はCognito認証を利用してますので、このCognito認証をAPI Gatewayにも適用させましょう。AWSコンソール > API Gateway > 作成したAPI > オーソライザー
「+オーソライザーの作成」ボタンを押下。Cognitoユーザープールのオーソライザーを作成します。
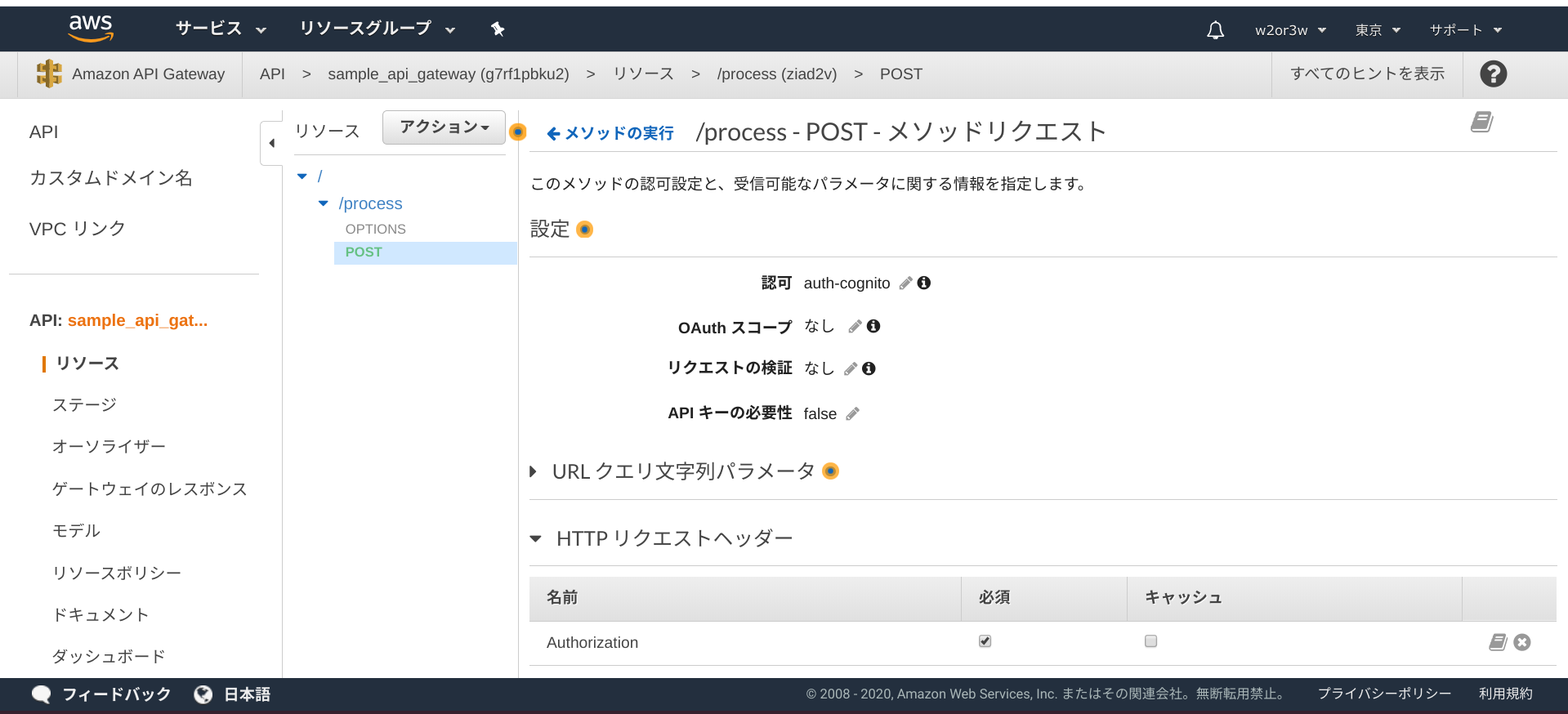
POSTメソッドリクエストを編集します。
認可に対して作成したCognitoユーザープールオーソライザーを指定、HTTPリクエストヘッダに「Authorization」を必須にして追加します。
そして、APIをデプロイしましょう。
WebアプリのPROCESS MOSAICボタンを押すと、以下のような例外が帰ってくるようになりました。Access to XMLHttpRequest at 'https://j2byqj306a.execute-api.ap-northeast-1.amazonaws.com/work/process' from origin 'https://fed9513d88324171b593944f5acca30f.vfs.cloud9.ap-northeast-1.amazonaws.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. List.vue?9185:114 Error: Network Error at createError (createError.js?2d83:16) at XMLHttpRequest.handleError (xhr.js?b50d:81)CORSの有効化をしない時の例外と同じ感じでイマイチ判断つかないですが、とにかく失敗し、Cognito認証が効いてるらしいことが確認できました。
それでは、Webアプリの実装を更新してゆきましょう。
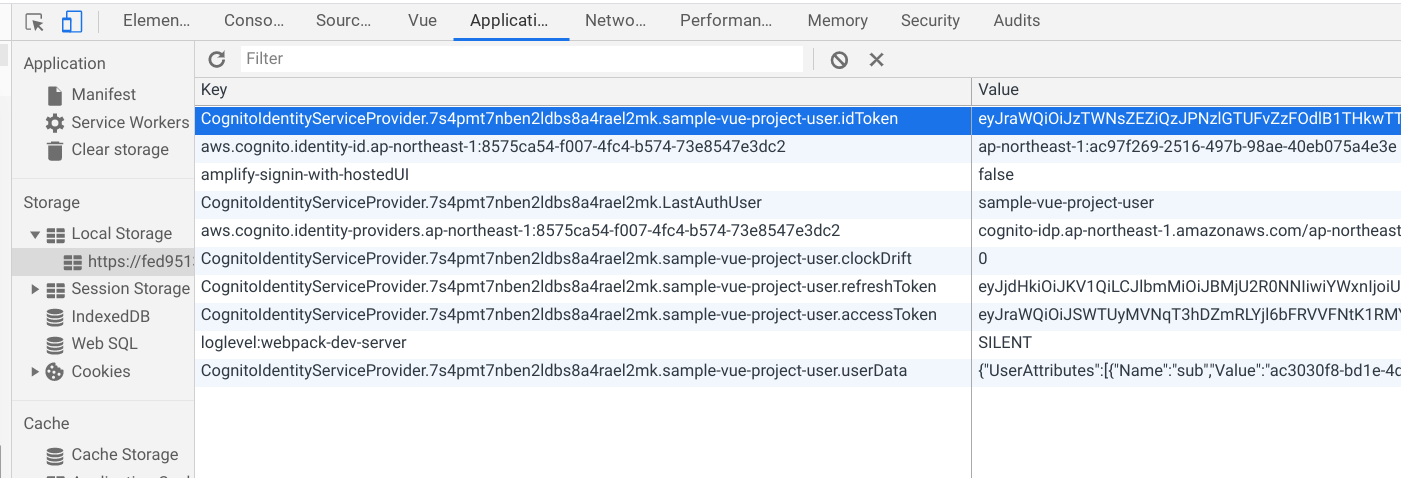
API GatewayにリクエストするHeaderに、Cognito認証でLocal Storageに保存されているidTokenの値を設定してあげます。
<script> : const currSession = await Auth.currentSession(); config.headers["Authorization"] = currSession.getIdToken().getJwtToken(); axios .post(apiUrl, requestData, config) .then(response => { let result = response.data console.log(result) }) .catch(error => console.log(error)) :WebアプリのPROCESS MOSAICボタンを押すと、成功するようになりましたね。
あとがき
久しぶりにこのシリーズの記事を追加しました。
薄々分かっていましたが、やっぱりこの記事は内容が盛りだくさんになってしまいました。最近AppSync関係の記事にお熱で、本当はAppSyncのデータソースを複数登録するヤツをやりたいと思っているのです。モザイク処理をキックする手段として、この記事でも書いた通りAPI Gatewayを利用しているのですが、AppSyncだけでイケるんじゃね?って思いまして。
それを実際にやってみて記事を書くにあたり、API Gatewayでやってるこの記事が必要だなと思い、超重たい腰を上げて書いた次第です。
後回しにした上にこんな不純な動機で、ごめんね、API Gateway。
- 投稿日:2020-03-14T21:57:15+09:00
AWS FireLensでfluentbitコンテナをカスタマイズする具体的な方法
ECSのログ事情について
AWSのECSによるコンテナ運用では、ログの出力がデフォルトで
CloudWatchに限定されています。
これはECSのログドライバがawslogsになっているということになりますが、実用面では力不足であることが否めません。
S3やElasticsearchにログを流すには?Datadogなどのサードパーティツールにログを流すには?
解決方法として、AWSの公式でFireLensという方法が紹介されています。FireLensは
fluentbitのコンテナをサイドカーとして起動し、ログの収集をfluentbitの機能で実行するというものです。
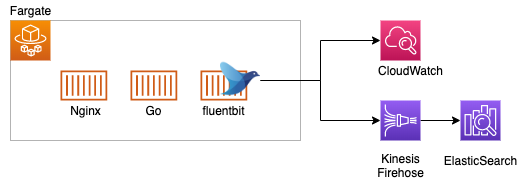
(fluentdも選択できます)例)今回目指すWebアプリケーションの構成
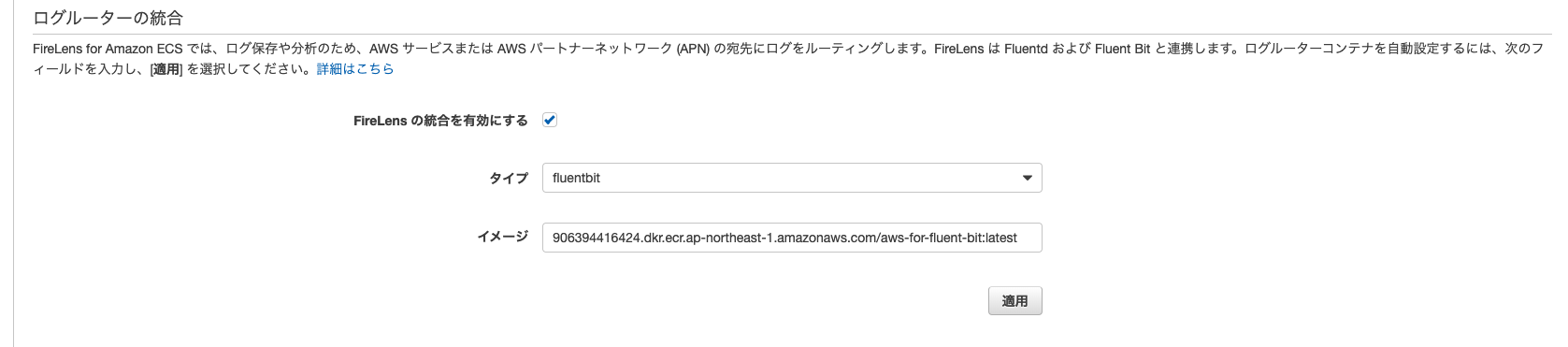
実際に、AWSコンソールのECSのタスク定義を設定する画面には以下のような設定項目があります。
FireLensの統合を有効にするを選択すると、自動で906394416424.dkr.ecr.ap-northeast-1.amazonaws.com/aws-for-fluent-bit:latestのコンテナがサイドカーとして追加されるようになります。
このコンテナはAWSの公式コンテナです。当記事では、このコンテナを自身でカスタマイズしたものを適用する一例を紹介します。
コンテナ定義
それではコンテナ定義がどのようになるかTerraformで見てみましょう。
サンプルコードを以下にまとめていますので合わせてご覧ください。task_definitisons.tfdata "template_file" "default" { template = <<EOF [ { "image": "${var.aws-account-id}.dkr.ecr.ap-northeast-1.amazonaws.com/firelens-sample/go:latest", "name": "go", "essential": false, "logConfiguration": { "logDriver": "awsfirelens" }, "portMappings": [], "cpu": 64, "memoryReservation": 128 }, { "image": "${var.aws-account-id}.dkr.ecr.ap-northeast-1.amazonaws.com/firelens-sample/nginx:latest", "name": "nginx", "essential": true, "logConfiguration": { "logDriver": "awsfirelens" }, "portMappings": [ { "hostPort": 80, "protocol": "tcp", "containerPort": 80 } ], "cpu": 64, "memoryReservation": 128 }, { "image": "${var.aws-account-id}.dkr.ecr.ap-northeast-1.amazonaws.com/firelens-sample/fluentbit:latest", "name": "log_router", "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/firelens-sample", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "firelensConfiguration": { "type": "fluentbit", "options": { "config-file-type": "file", "config-file-value": "/fluent-bit/etc/fluent-bit_custom.conf" } }, "portMappings": [], "cpu": 128, "memoryReservation": 256 } ] EOF }Goのコンテナ、Nginxのコンテナ、fluentbitのコンテナを定義しました。
以下を確認してください。"logConfiguration": { "logDriver": "awsfirelens" }logDriverを
awsfirelensとしています。
なお、fluentbitコンテナ自体のログドライバはawslogsとしてください。そして注目すべき定義はこちらです。
"firelensConfiguration": { "type": "fluentbit", "options": { "config-file-type": "file", "config-file-value": "/fluent-bit/etc/fluent-bit_custom.conf" } }config-file-valueを指定しています。
この/fluent-bit/etc/fluent-bit_custom.confに独自カスタマイズしたfluentbitの設定を記載しましょう。fluentbitの設定
よくある設定
サンプルコードをもとに進めます。
先ほどの/fluent-bit/etc/fluent-bit_custom.confを記載していきましょう。/docker/fluentbit/fluent-bit_custom.conf[SERVICE] Flush 1 Grace 30 Log_Level info [OUTPUT] Name cloudwatch Match * log_key log region ap-northeast-1 log_group_name /ecs/firelens-sample log_stream_name container [OUTPUT] Name firehose Match * delivery_stream my-firehose region ap-northeast-1OUTPUTに
cloudwatchとfirehoseを指定していることに注目してください。
後述しますが、amazon/aws-for-fluent-bitのコンテナをベースに進めますのでデフォルトで上記のプラグインがインストールされた状態になっています。さて、この設定で
cloudwatchとfirehoseにログが出力されるようになりますが、一点、Match *に注目しましょう。
これはFireLensが収集したログを全て出力されるようになっており、
例えばDataLakeのようなログの流し方であれば問題ありませんが、もう少し整形してから流したいというニーズがあるかもしれません。そこで
Parserを使って、ログをコンテナごとのCloudWatchストリームに分けるということをしてみましょう。Parser
先ほどのconfを以下のようにしました。
/docker/fluentbit/fluent-bit_custom.conf[SERVICE] Flush 1 Grace 30 Log_Level info Streams_File stream_processor.conf Parsers_File parser.conf [FILTER] Name parser Match * Key_Name container_name Parser container Reserve_Data true [OUTPUT] Name cloudwatch Match combine.nginx log_key log region ap-northeast-1 log_group_name /ecs/firelens-sample log_stream_name nginx [OUTPUT] Name cloudwatch Match combine.go log_key log region ap-northeast-1 log_group_name /ecs/firelens-sample log_stream_name go [OUTPUT] Name firehose Match container delivery_stream my-firehose region ap-northeast-1以下の箇所でログのパースをおこないます。
[FILTER] Name parser Match * Key_Name container_name Parser container Reserve_Data trueさてここで、そもそも
FireLensからはどのようなログが収集されているのでしょうか。
当然、自身で流したアプリケーション用のログ、Nginxのアクセスログなどをイメージしますが
実はそのほかのメタ情報を付与した状態で収集しています。
以下を確認してください。{ "container_id": "abcde12345", "container_name": "/ecs-firelens-sample-1-nginx-xxxyyyzzz", "ecs_cluster": "arn:aws:ecs:ap-northeast-1:1234567890123:cluster/firelens-sample", "ecs_task_arn": "arn:aws:ecs:ap-northeast-1:1234567890123:task/aaa-bbb-ccc-ddd-eee", "ecs_task_definition": "firelens-sample:1", "log": "10.0.0.0 - - [14/Mar/2020:10:00:00 +0000] \"GET /healthcheck HTTP/1.1\" 200 0 \"-\" \"ELB-HealthChecker/2.0\" \"-\"", "source": "stdout" }firelensが収集するログの例です。
logというキーが出力されるログですが、それ以外にタスク定義の情報やコンテナ名などもあります。
今回はこれらの情報でパースをしてみます。
container_nameをパースしてnginxという部分を抜き出します。
Goコンテナの場合はgoという文字を抜き出します。/docker/fluentbit/parser.conf[PARSER] Name container Format regex Regex ^\/(?<task_name>(ecs-firelens-sample))-(?<task_revision>\d+)-(?<container_name>.+)-(?<target_name>.+)$正規表現で抜き出してみました。以下のようにパースされました。
{ "task_name": "ecs-firelens-sample", "task_revision": 1, "container_name": "nginx", "target_name": "xxxyyyzzz", }
container_nameが「nginx」となっています。
これでコンテナ別にログの出力先を分けるということができそうです。もちろん、ログそのものに対してパースをしてログを振り分けることができれば様々な要件にも対応できるかと思います。
いろいろなパターンを考慮して要件に沿った設計を考えてみてください。Stream Processor
ログの種類別にタグを振り分けることができます。
先ほどのcontainer_name「nginx」「go」をそれぞれ「combine.nginx」「combine.go」というタグを付与してみましょう。/docker/fluentbit/stream_processor.conf[STREAM_TASK] Name nginx Exec CREATE STREAM nginx WITH (tag='combine.nginx') AS SELECT log FROM TAG:'*-firelens-*' WHERE container_name = 'nginx'; [STREAM_TASK] Name go Exec CREATE STREAM go WITH (tag='combine.go') AS SELECT log FROM TAG:'*-firelens-*' WHERE container_name = 'go'; # すべてのログ [STREAM_TASK] Name container Exec CREATE STREAM container WITH (tag='container') AS SELECT * FROM TAG:'*-firelens-*';SQLのような形式で記載します。
FireLensのログは元々*-firelens-*にマッチするタグが付与されています。
それにWHERE container_name = 'nginx'などとすることでnginxの新しいタグを追加できます。追加したタグは、
[OUTPUT]セクションで指定しましょう。[OUTPUT] Name cloudwatch Match combine.nginx log_key log region ap-northeast-1 log_group_name /ecs/firelens-sample log_stream_name nginxDocker定義
続いてDocker定義です。
amazon/aws-for-fluent-bitコンテナをベースに使います。./docker/fluentbit/DockerfileFROM amazon/aws-for-fluent-bit:2.1.1 COPY ./docker/fluentbit/fluent-bit_custom.conf /fluent-bit/etc/fluent-bit_custom.conf COPY ./docker/fluentbit/stream_processor.conf /fluent-bit/etc/stream_processor.conf COPY ./docker/fluentbit/parser.conf /fluent-bit/etc/parser.confこれでECRにプッシュすれば立派なログ収集コンテナとして活躍できるでしょう。
$ aws ecr get-login-password | docker login --username AWS --password-stdin ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com $ docker build -t firelens-sample-fluentbit:latest -f docker/fluentbit/Dockerfile . $ docker tag firelens-sample-fluentbit:latest ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/firelens-sample/fluentbit:latest $ docker push ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/firelens-sample/fluentbit:latestおわり
fluentbitを使ったログ収集用コンテナのカスタマイズについて解説しました。
この記事で使ったECSアプリケーション用のコード(Nginx、Goアプリ)についてはサンプルコードを確認してください。誰かの参考になれば幸いです。
- 投稿日:2020-03-14T21:19:02+09:00
CloudflareをALBの前に配置してAzureAD認証してみた
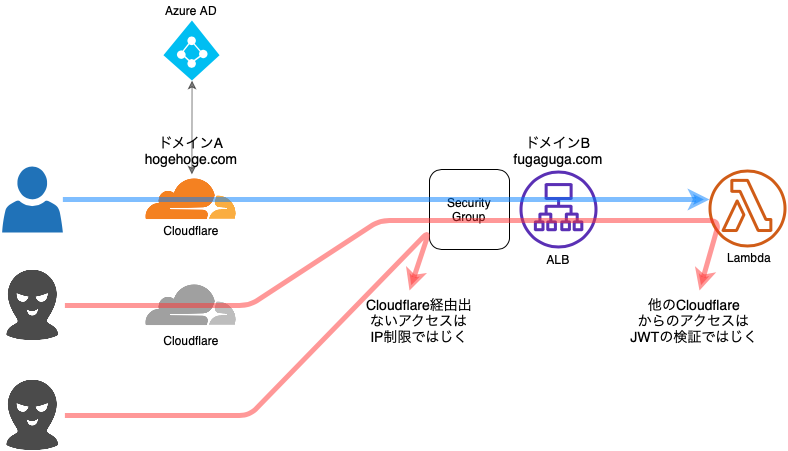
CloudflareをALB(AWS)の前に配置して、CloudflareのAccessでAzureAD認証してみました。
どのクラウドでも実装できるはずなので、ちょっと認証かけたい時などなかなか便利です。構成
- Cloudflare以外からのアクセスは、ALBのセキュリティーグループでブロックします。
- 自分のCloudflare以外のCloudflareからのアクセスは、Lambdaでjwtを検証してブロックします。
必要なもの
- Cloudflareアカウント
- AWSアカウント
- ドメイン2個
- ドメインA
- ドメインB
- ドメインBに対しAWS ACMで取得したワイルドカード証明書1個
設定
- Azure AD認証の対象リソースを作成する
- Cloudflare DNSを設定する
- Cloudflare Accessを設定する
- CloudfraleのIPアドレスをALBのセキュリティグループに設定する
- テストする
1. Azure AD認証の対象リソースを作成する
- AWS側でALBのターゲット用のLambdaを作成する
- ALBを作成する
- HTTPSのリスナーを作成しドメインBの証明書を紐づける
- ターゲットグループを作成して、Lambdaをターゲットに設定する
- Route53に、ALBのエイリアスレコードをドメインBのサブドメインとして設定する
- jwtの検証は以下を参考にしました。
- Lambda作成時のハマりポイント
- Amazon Linux上でpip installしてLambdaのパッケージをzipで固めます。
- Amazon Linuxの現在のyumリポジトリのPythonのバージョンは3.6なので、Lambda側も3.6に合わせます。
- Lambdaのパッケージをzipで固める時、".libs_cffi_backend"配下も忘れずに含めます。
- Cloudflareからのjwtを検証するためALBからのヘルスチェックは失敗するので、ヘルスチェックを外します。
以下Lambda内で指定している値は、Cloudflareの設定後に確認します。
Lambda内で指定している定数 値 CERTS_URL CloudflareのAccessのLogin Page Domain+"/cdn-cgi/access/certs" AUDIENCE_TAG CloudflareのAccessのAccess PoliciesのAudience Tag requirements.txtpyjwt cryptography cffiLambda_function.pyimport jwt import json import urllib.request CERTS_URL = 'https://*******************/cdn-cgi/access/certs' AUDIENCE_TAG = '**************************************' def get_public_keys(): headers = { 'User-Agent': 'curl/7.61.1' } req = urllib.request.Request(CERTS_URL, headers=headers) with urllib.request.urlopen(req) as response: res = response.read() public_keys = [] jwk_set = json.loads(res) for key_dict in jwk_set['keys']: public_key = jwt.algorithms.RSAAlgorithm.from_jwk(json.dumps(key_dict)) public_keys.append(public_key) return public_keys def validate(header): is_valid = False token = '' if 'cf-access-jwt-assertion' in header: token = header['cf-access-jwt-assertion'] else: return is_valid keys = get_public_keys() for key in keys: try: decoded_token = jwt.decode(token, key=key, audience=AUDIENCE_TAG) # print(decoded_token) is_valid = True break except Exception as e: print(e) pass return is_valid def lambda_handler(event, context): is_valid = validate(event['headers']) if is_valid: res = { "isBase64Encoded": False, "statusCode": 200, "statusDescription": "200 OK", "headers": { "Set-cookie": "cookies", "Content-Type": "text/html" } } res['body'] = """<html> <head> <title>hello world</title> </head> <body> <h1>Hello World</h1> </body> </html>""" else: res = { "isBase64Encoded": False, "statusCode": 403, "statusDescription": "403" } return res2. Cloudflare DNSを設定する
Cloudflare側でドメインAを登録します。
プランを選択します。
ドメインAのレジストラで、Cloudfraleのネームサーバを設定します。
設定後、Cloudflareの画面に戻って、下記をクリックします。
Cloudflare側がドメインを認識するまで、数時間かかりました。
CNAMEレコードを登録します。
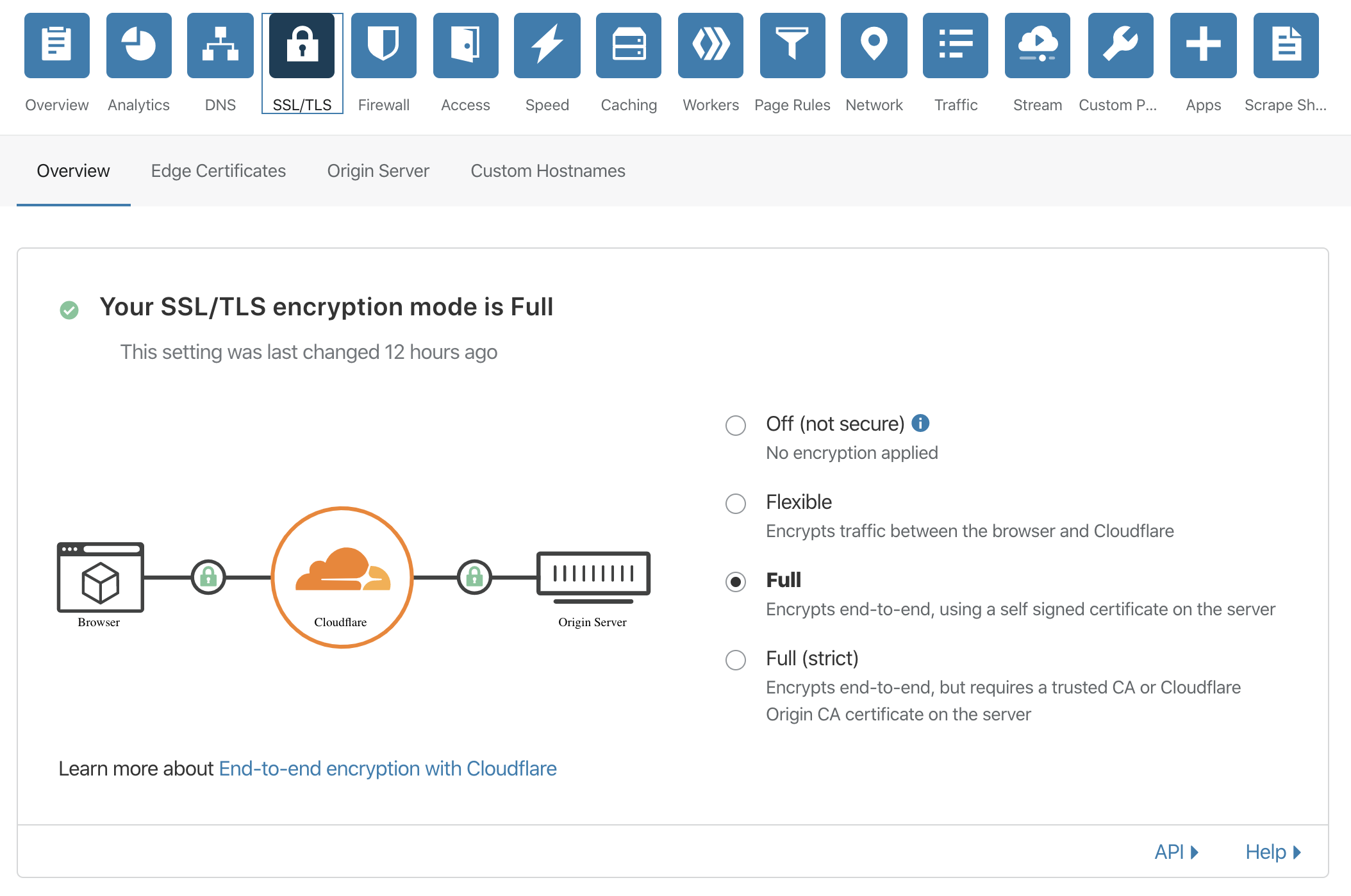
項目 値 Type CNAME Name ドメインA Content ドメインBのサブドメイン(Route53に設定したALBのCNAME) Proxy status Proxied SSL/TLSの画面で、Fullを選択します。
ここまででの設定で、ドメインAにアクセスするとドメインBのサブドメインにproxyされてALBのターゲットのLambdaが呼ばれるようになります。
3. Cloudflare Accessを設定する
Cloudflare Accessを有効化します。
下記以外はデフォルトのまま設定します。
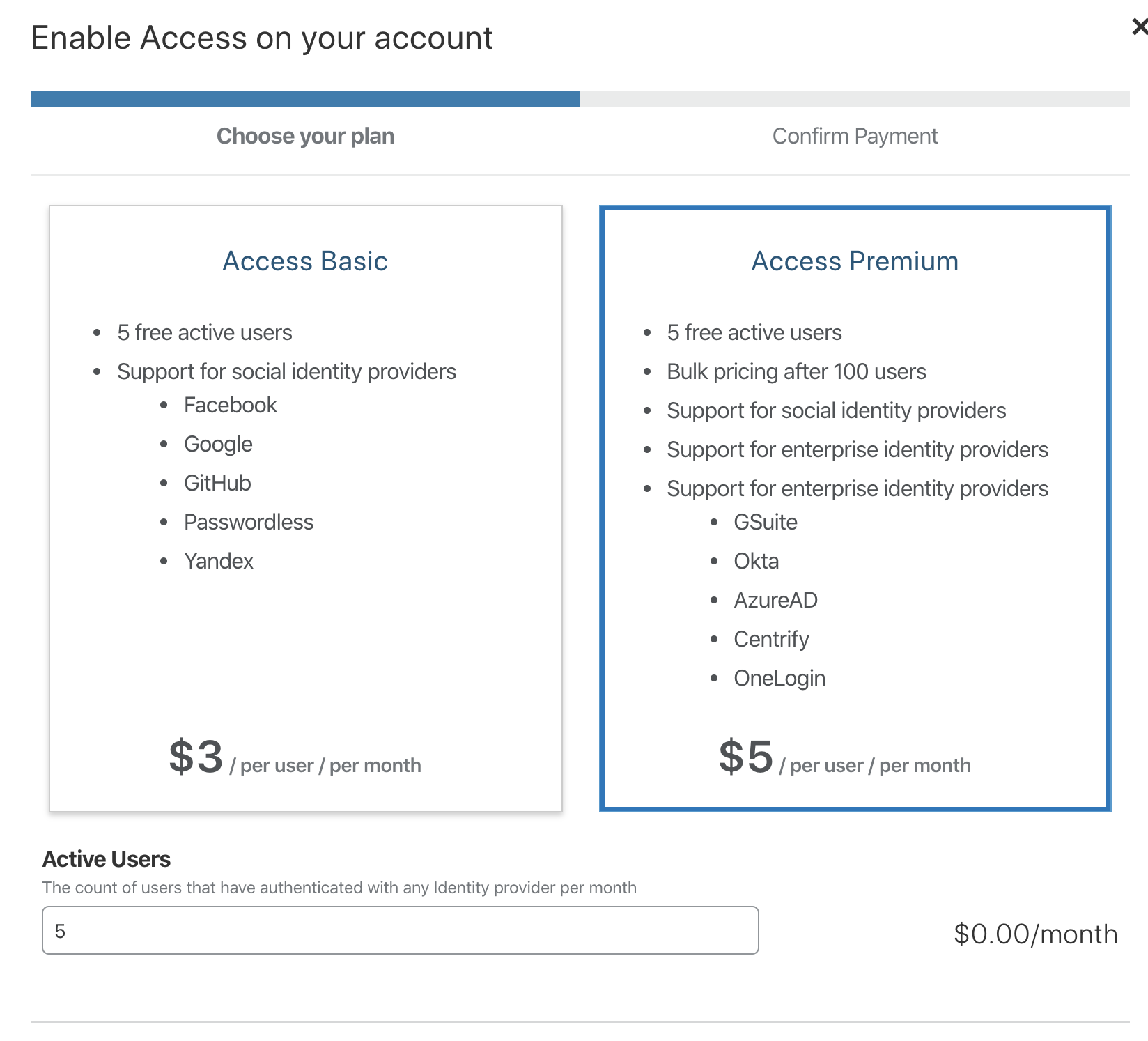
- プランはAzure ADを利用するため、Access Premiumを選択
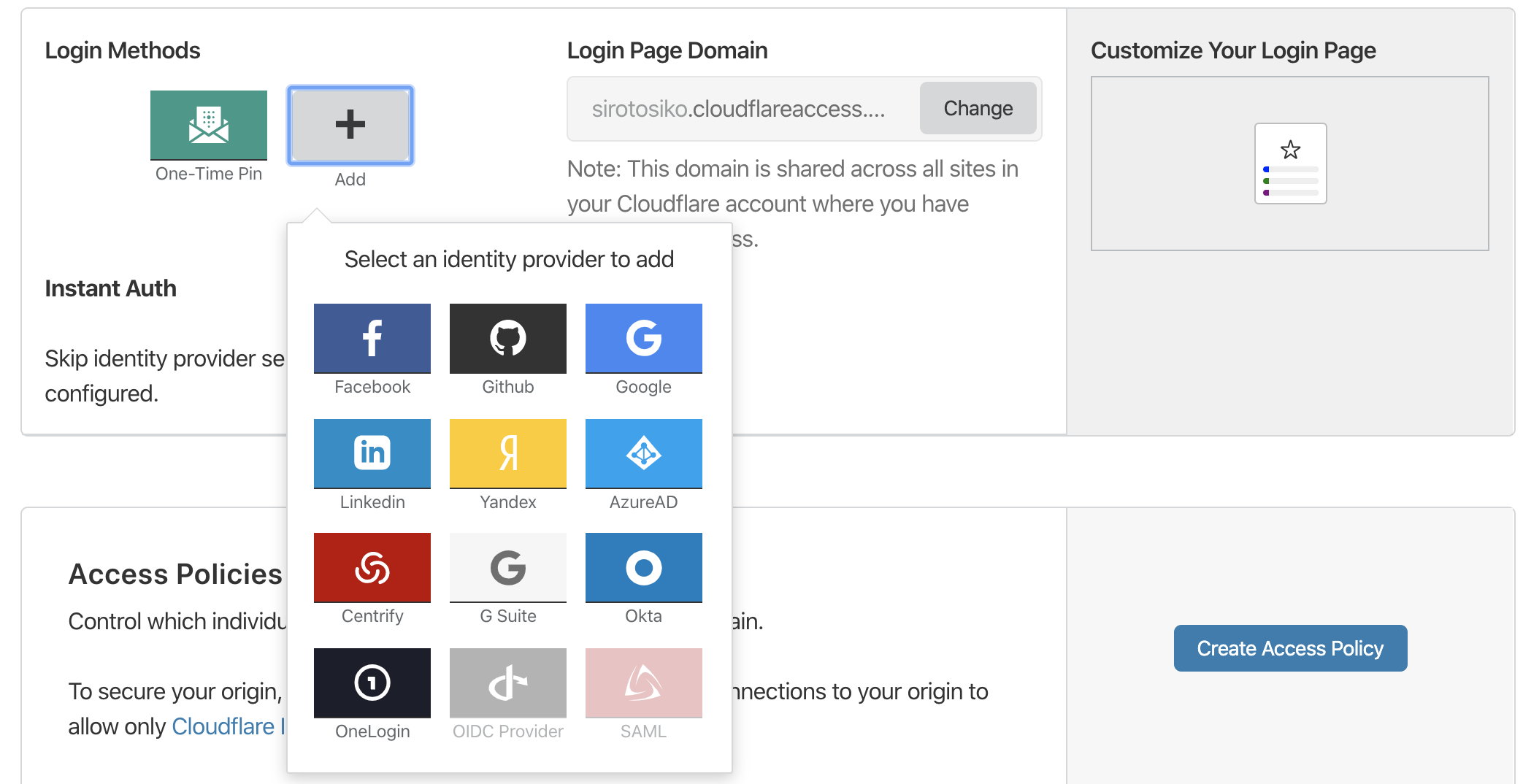
Login methodでAzure ADを選択します
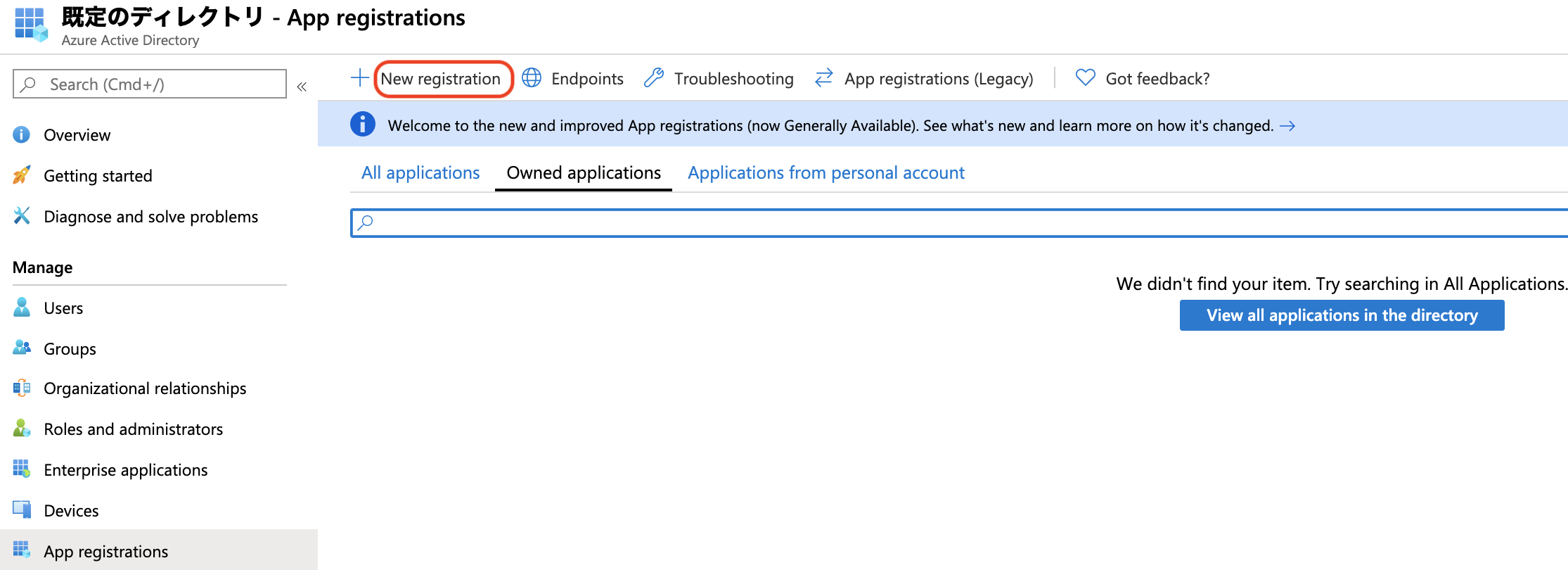
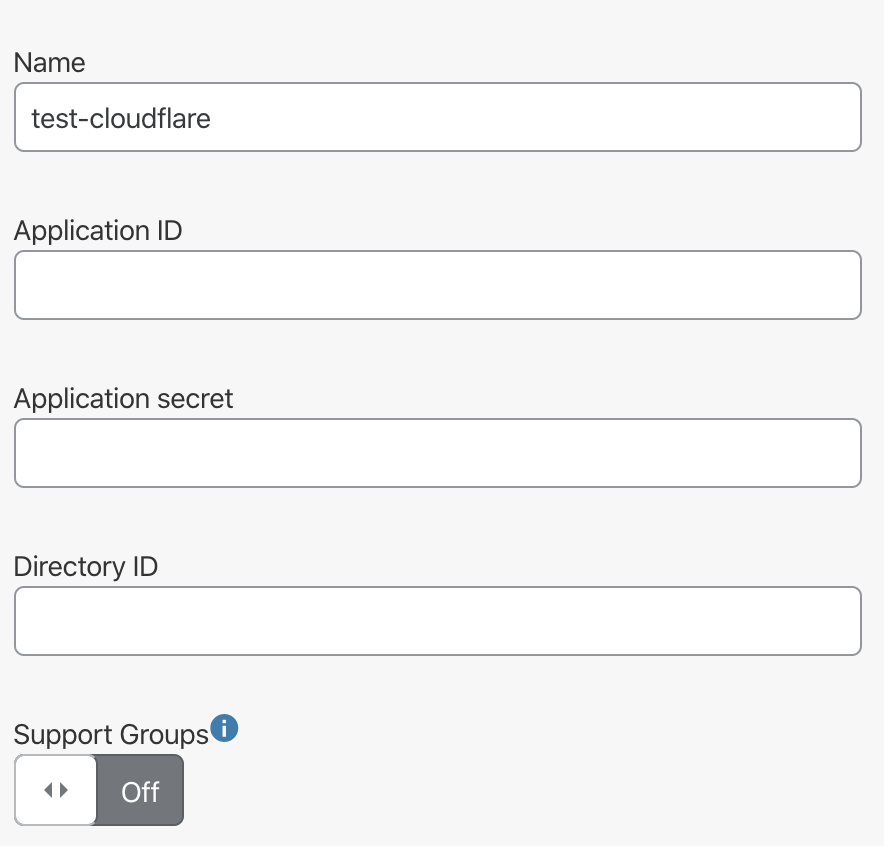
Azure ADでアプリケーションを登録します。
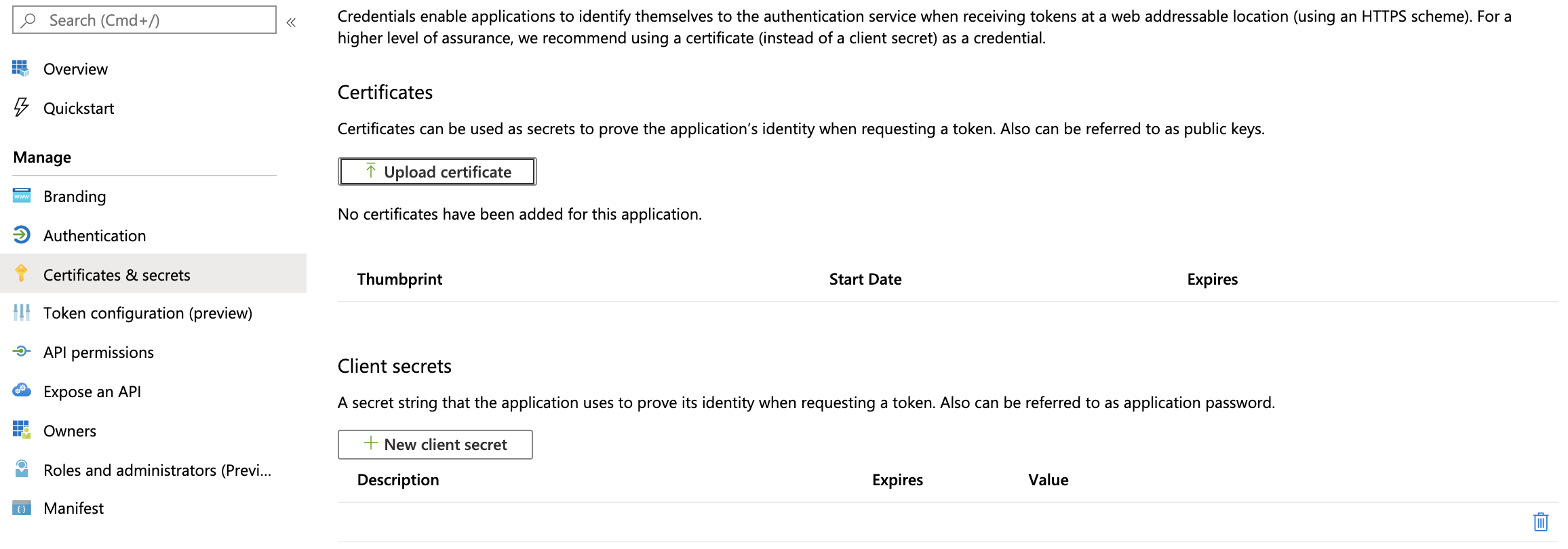
クライアントシークレットを作成します。
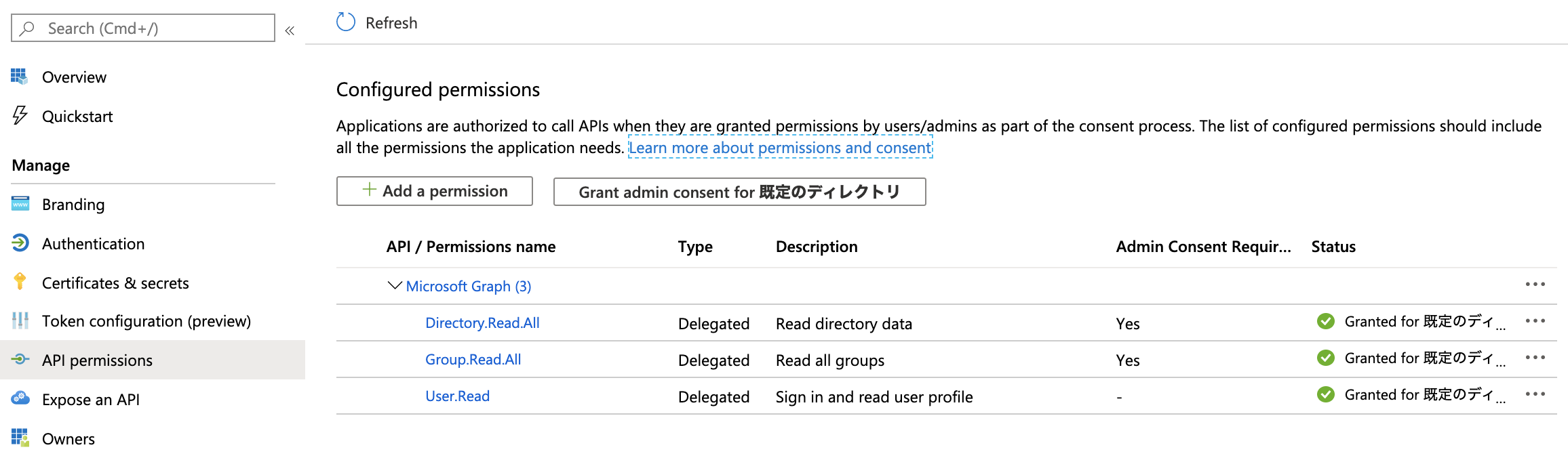
パーミッションを設定します。
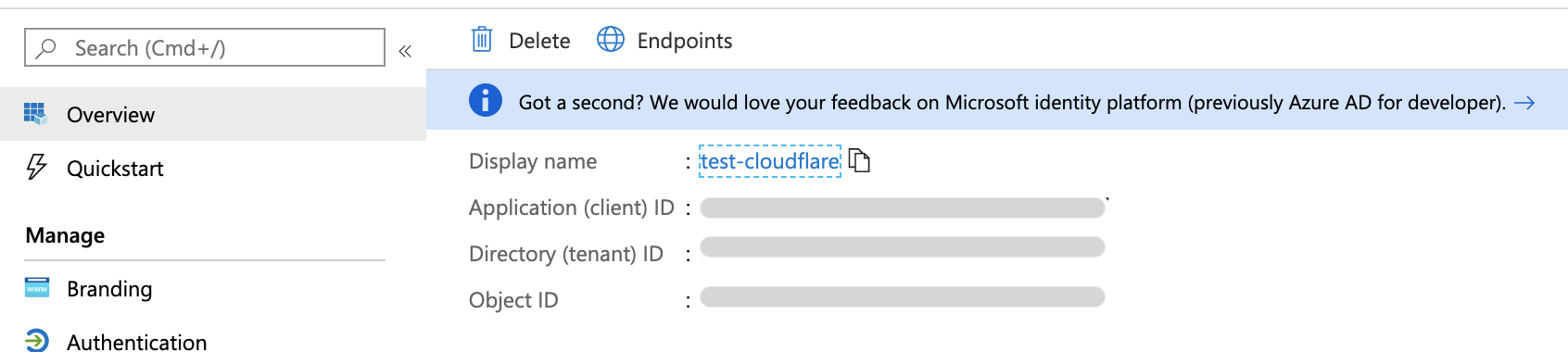
Application IDとDirectory IDを確認します。
Azure ADで設定した値をCloud flare側で設定します。
4. CloudfraleのIPアドレスをALBのセキュリティグループに設定する
下記IPアドレスをALBのセキュリティグループに設定します。
https://www.cloudflare.com/ips/5. テストする
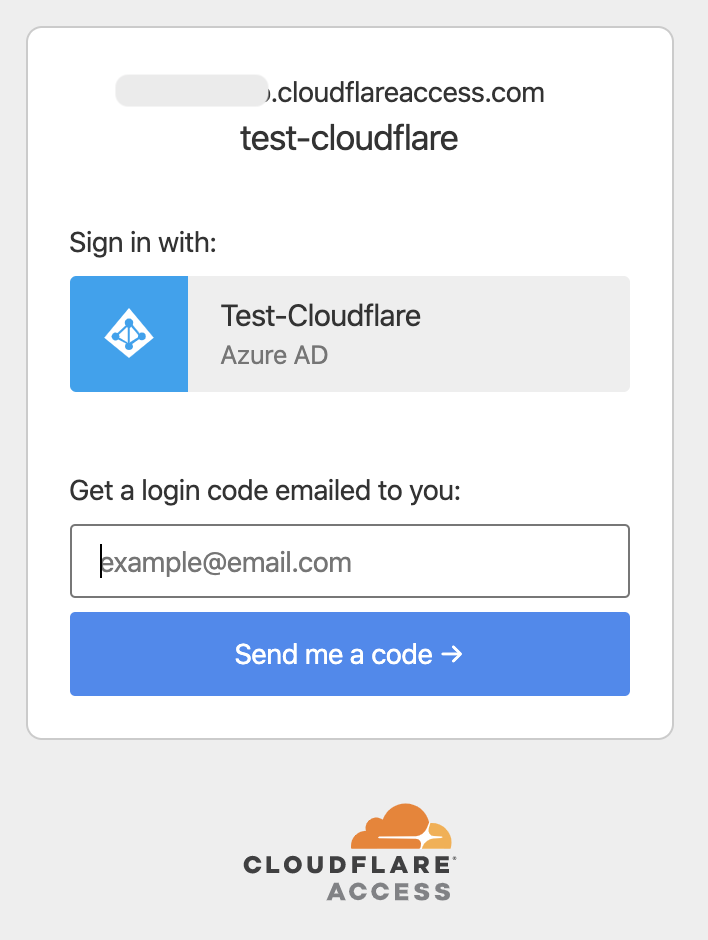
ドメインAに対しアクセスするとCloudflareの認証画面が表示されます。
Azure ADで認証して…
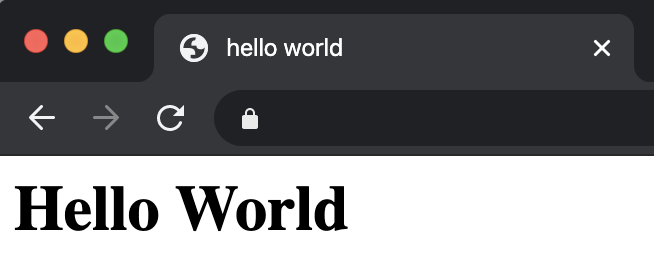
Lambdaで生成したページが表示されれば成功です!




- 投稿日:2020-03-14T20:18:36+09:00
EC2で稼働するAPIサーバのログをCloudWatchに連携してSlackに通知する | Send logs of EC2 based API server to Slack via CloudWatch
ㅤ
₍₍⁽⁽?₎₎⁾⁾見て!APIサーバーが動いているよ
かわいいね?
お前らがログを取らないので、エラーでAPIサーバーは死んでしまいました
お前らのせいです
あ〜あ現状
2台のEC2(Amazon Linux (2ではない))の上で踊るAPIサーバー (Node製)
やりたいことざっくり
これまでログ全然取ってなかった()ので、とりあえずサーバサイドのログを良い感じに残すようにしたい。
かつ、緊急度の高いログはすぐに気づけるようにしておきたい。考えたこと
- ログはどこかにためておきたい
- DBにはためたくない
- 常に使うデータでもないし、無駄にたくさんデータを突っ込みたくない
- まずはEC2にためるか
- しかしEC2上にため続けるのは微妙
- 分析しづらい。いざというときにいちいちSSHログインするの?
- 無計画に貯めるとEC2の容量限界に達して死亡する (してたのを前々職で見た気がする)
- そもそもEC2はログをためるための場所ではない
- CloudWatch Logsにためるのでいかがか
- EC2よりは分析しやすそうだし、そもそもログ見るためのサービスだし、良さげ
- ただしログが多くなればなるほどクエリにかかるMoneyが高くなったりする
- ので、ためておくのは直近のログだけにしておこう
- 一定期間より前のログはS3にぶちこんでしまう
- とりあえず置いといて、必要に応じて参照できるようにすれば良い
- Athenaとかでもクエリできるし、なんならあとでGCPにうつしてBigQuery使うとかでも良い
- エラーを吐いたらすぐに気づきたい
- 正直メールとかそんなに見ない
- 仕事中常に見てるのはSlack
- ログをためる過程でエラーだった場合はWebhookでメッセージ送信できればよさげ
- アプリケーションコード内にSlack呼び出し書きたくない
- 業務ロジックに関係無いし、書き忘れたらエラーに気づかないのはイケてない
- CloudWatch Logsの機能でなにかできないか
- メトリクスフィルタとアラーム、Lambdaを組み合わせる方法
- 調べたらすぐ出てくる方法
- 一見良さげで実装しちゃったが、テストする中で問題点を見つけた
- アラームの設定むずかしい (理解する脳内リソースが足りなかったw)
- アラームの挙動が謎 (メトリクス評価期間を1分に設定しても、1分前のデータがなければそれ以前のデータポイントのデータを評価するっぽい)
- 総じて考えると、今回のように「取りこぼしたくないエラーをもれなく補足する」ためのものではなく、「一度でも起きたらやばいもの」を即座に通知するためのものだと思ったほうが良さそう
- サブスクリプションフィルタ機能とLambdaを組み合わせる方法
- ログそのまま流せるし、こっちのほうが用途にあってそう
- ほぼリアルタイムでエラーログ検知できる
- ただしログが出る度にほぼ毎回Lambdaを呼び出すことになる
- 正直Lambdaはそんなに詳しくないのでなんとも言えないが、料金とか同時実行数とか気にしたほうが良さそう
- ここまで考えるならアプリケーションコード内でSlack呼び出したほうが良いのでは感も正直あるが、とりあえず実装してみる
作業を分解する
- ログをEC2にためる
- EC2からCloudWatch Logsに連携する
- CloudWatch Logs上でのログの寿命を決める
- CloudWatch LogsからサブスクリプションフィルタでLambda -> ログを解析してエラー系ならSlackに流す
- CloudWatch LogsからS3にログ連携する (今回ここまではやらないが方針だけ決める)
ログをEC2にためる
今回Nodeを使っているので、log4js-nodeを使う。
ログのレベリングや出力先やログローテーションをかんたんに設定できる。cf) ログローテーションとは
参照元: IT用語辞典
ログローテーションとは、システムが残す記録(ログ)が際限なく増えることを防ぐために、一定の容量や期間ごとに古いログを削除したり新しいログで上書きすること。また、そのような機能。他にもいくつかライブラリはあるが、既にこいつが入っていたのと昔も使ってたのでそのまま使う。
ちなみにpm2で動かしている場合、log4jsのconfigurationに
pm2: trueを入れてあげないとうまく動かない。こんな感じでLoggerを設定してあげて
logger.tsimport { configure, getLogger } from "log4js" import * as path from 'path' const log4jsConfig = { pm2: process.env.NODE_ENV !== "development" ? true : false, appenders: { application: { category: "application", type: "dateFile", // 日にちでログローテーションする daysToKeep: 7 // ログを保存する日数 filename: `${path.join(__dirname, "../log")}/application.log`, // ここで出力先を決める alwaysIncludePattern: true // .yyyy-MM-dd などのパターン文字列を常にファイル名に含める }, }, categories: { default: { appenders: ["application"], level: "ALL" }, application: { appenders: ["application"], level: "ALL" // 既定値のレベル(FATAL, ERROR, WARN, INFO, DEBUG, TRACE)を全て出力する }, } } configure(log4jsConfig) export const applicationLogger = getLogger("application")使う側では
sample.tsimport { applicationLogger } from "./Logger" applicationLogger.info('This is test log.') applicationLogger.error('This is test log.') applicationLogger.fatal('This is test log.')という感じで使える。
上記設定の場合、アウトプットは下記のようになる。log/application.log.2020-03-12[2020-03-12T02:57:22.528] [INFO] application - This is test log. [2020-03-12T02:57:22.528] [ERROR] application - This is test log. [2020-03-12T02:57:22.528] [FATAL] application - This is test log.EC2からCloudWatch Logsに連携する
ログを貯められるようになったら次はCloudWatch Logsに連携する。
CloudWatch Logsエージェントというのが用意されているので、それを使う。
一応公式資料はこちら
だけどやっぱり分かりづらいのでざっくり解説します。
CloudWatch Logs エージェントとは
ログファイルを監視して、更新があった場合には差分をCloudWatchに送信してくれるやつ。
なお、CloudWatchエージェントというやつもいて、こっちの方が新しく、かつLogsの方は廃止予定らしいので、気になる方はLogsついてないほうをインストールしたほうが良いです。
今回必要な機能の部分については大きく変わるものではないはず。
EC2に、CloudWatch Logsの操作権限を追加する
わかりにくいと悪名高いIAMを設定する必要があります。
ちゃんと書くと結構な分量になるので割愛しますが、EC2に下記の権限が割り当てられていればOKです。
ちなみにterraformです。resource "aws_iam_policy" "api_cw_logs" { name = "EC2-CloudWatchLogs" path = "/" description = "Allow sending log to CloudWatch" policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogStreams" ], "Resource": [ "arn:aws:logs:*:*:*" ] } ] } EOF }CloudWatch Logs エージェントのインストール
Amazon Linux前提で書いていきます。
まずはAPIサーバの載ってるEC2にSSHログインしましょう。
その上で、下記コマンドでエージェントをインストールします。sudo yum update -y sudo yum install -y awslogsエージェントの設定
- リージョンの設定
- 出力ログの設定
を行います。
リージョンの設定
これは地味に罠で、CloudWatch Logsエージェントのデフォルトリージョンは
us-east-1になっている。
普段見ているリージョンがap-northeast-1の人は、「ちゃんと設定してるはずなのにログが出ない」問題に悩まされるケースあり。設定ファイルは
/etc/awslogs/awscli.confなので、vimなりで開きましょう。なおec2-userでログインしている場合
sudoで開かないと編集権限が無いため気をつけてください。また、awslogsのインストールの仕方によっては設定ファイルの場所が違うっぽいので、もし上記にデフォルトのファイルが無かったら疑ってください。
sudo vim /etc/awslogs/awscli.conf/etc/awslogs/awscli.conf[plugins] cwlogs = cwlogs [default] - region = us-east-1 # こいつを + region = ap-northeast-1 # こっちに変える出力ログの設定
設定ファイルは
/etc/awslogs/awslogs.confです。また、awslogsのインストールの仕方によっては設定ファイルの場所が違う(ry
sudo vim /etc/awslogs/awslogs.confで、一番下に下記を追記します。
/etc/awslogs/awslogs.conf[/home/ec2-user/log/application.log] file = /home/ec2-user/log/application.log.* # log4jsで設定した出力先を入れる log_group_name = api # CloudWatch Logsのロググループ名。もっとわかりやすい名前を設定するのが吉 log_stream_name = {instance_id}/home/ec2-user/log/application.log # ロググループ内のログストリーム名 datetime_format = %Y-%m-%dT%H:%M:%SZ # タイムスタンプのフォーマットエージェントを起動する
起動コマンド
sudo service awslogs startちゃんとスタートしているかを確認するなら
cat /var/log/awslogs.logで、こんな感じのログが出るようになってれば問題ないはず
2020-03-12 06:22:25,268 - cwlogs.push.stream - INFO - 17305 - Thread-1 - Starting publisher for [811461142fa2f7e3020774f08be5083d, /var/log/messages]これで設定完了なので、CloudWatchを確認しに行きましょう〜
リージョンを間違えないように!CloudWatch Logs上でのログの寿命を決める
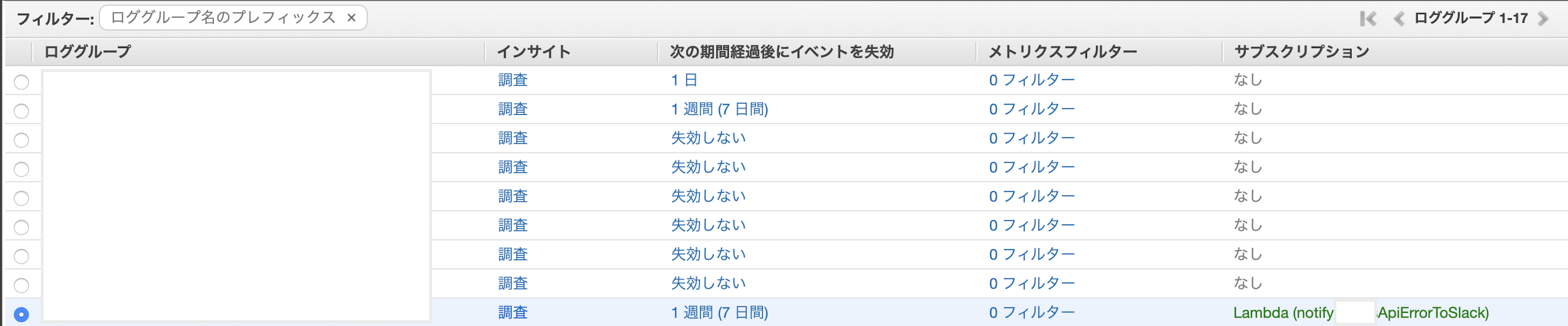
これはかんたんで、AWSのGUIでぱぱっと設定しちゃいましょう。
CloudWatchのロググループ一覧は上記のようになってると思います。
対象ログの「次の期間経過後にイベントを失効」部分をクリックすると、ログの保存期間の設定ダイアログが出るのでそこでお好みの期間に設定しましょう。CloudWatch LogsからサブスクリプションフィルタでLambda -> ログを解析してエラー系ならSlackに流す
めちゃ地味な機能で「AWS、あんまりこの機能使ってほしくないのでは」邪推してしまいそうなんですが、、
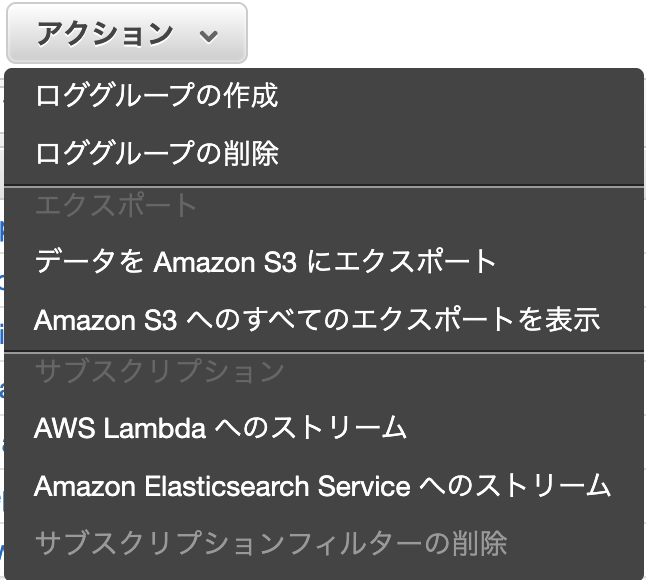
サブスクリプションフィルタという、ログ内容を所定の条件でフィルターした上で、指定した連携先に流す機能が実はあります。前項のロググループの画像の状態で、特定のロググループを選択し、上の方にある「アクション」プルダウンを表示させるとその一番下に「サブスクリプション」があります。
わかりづらすぎて草。
AESにも流せるので試してみたい感あるけど、今回はLambdaに流しましょう。
Lambda functionの実装
さて、いずれにしても流し先のLambdaが存在しないと作れないので、Lambda関数を実装しましょう。
普段TS使ってますが、環境つくるのめんどくさそうだったのでとりあえずJSで書いてしまってます。反省。zlibパッケージは、ぐぐったらみんなそれ使ってたので使ってます。
axiosは、Slack送信した昔のコードそのまま使ったので入れてるだけです。
適宜ご自分の好みに改変してください。notify-api-error-to-slack.jsconst zlib = require('zlib') const axios = require("axios") const awsSDK = require('aws-sdk') const cwLogs = new awsSDK.CloudWatchLogs() const unzip = (buffer) => new Promise(resolve => { const base64Logs = new Buffer(buffer, 'base64') zlib.gunzip(base64Logs, function (err, bin) { if (err != null) throw err; resolve(bin.toString('ascii')) }) }) exports.handler = async function(event, context) { try { const unzippedLog = await unzip(event['awslogs']['data']) const parsedLog = JSON.parse(unzippedLog) const { logEvents } = parsedLog if (!logEvents.length) { return context.succeed() } const warnEvents = [] const errorEvents = [] const fatalEvents = [] logEvents.forEach(event => { switch (true) { case (event.message.includes('WARN')): warnEvents.push(event) break case (event.message.includes('ERROR')): errorEvents.push(event) break case (event.message.includes('FATAL')): fatalEvents.push(event) break default: break } }) const messagePromises = [] if (warnEvents.length) { messagePromises.push( sendSlackMessage( 'notify_api_warn', ['<!channel>\n'].concat(warnEvents.map(event => event.message)).join('\n') ).catch((err) => { console.log(err) }) ) } if (errorEvents.length) { messagePromises.push( sendSlackMessage( 'notify_api_error', ['<!channel>\n'].concat(errorEvents.map(event => event.message)).join('\n') ).catch((err) => { console.log(err) }) ) } if (fatalEvents.length) { messagePromises.push( sendSlackMessage( 'notify_api_fatal', ['<!channel>\n'].concat(fatalEvents.map(event => event.message)).join('\n') ).catch((err) => { console.log(err) }) ) } // 各送信のエラーは握りつぶす await Promise.all(messagePromises).catch((err) => { throw err }) return context.succeed() } catch (err) { return context.fail(err) } } async function sendSlackMessage(channel, message) { return axios({ headers: { "Content-type": "application/json", Accept: "application/json", Authorization: `Bearer API_KEY` // 自分のAPI_KEYいれましょう }, method: "POST", url: "https://slack.com/api/chat.postMessage", data: { channel: `${channel}${genEnvSuffix()}`, text: message, username: "sample-bot" } }) } function genEnvSuffix() { switch (process.env.NODE_ENV) { case "production": return "" case "staging": return "_stg" case "development": default: return "_dev" } }LambdaをCloudWatch Logsから呼び出せるようにする
別サービス -> Lambdaを呼び出す形式の場合、「別サービス側でLambdaへのアクセス権限を付与する」というよりは、「特定のLambda function側で、誰が自分を呼び出せるのかを定義する」形になります。
な、何を言っているのかわからねーと思うが、俺もよくわからねえ。
terraformだと下記のような設定をすることになります。
resource "aws_lambda_permission" "with_api_error_cloudwatch" { statement_id = "AllowExecutionFromCloudWatch" action = "lambda:InvokeFunction" function_name = "${aws_lambda_function.notify_api_error_to_slack.function_name}" principal = "logs.ap-northeast-1.amazonaws.com" source_arn = "${aws_cloudwatch_log_group.api_application.arn}" }api_applicationというロググループから、notify_api_error_to_slack関数を呼び出せる設定をしてます。
Lambdaの定義は省略します。
サブスクリプションフィルタを用意する
GUIなら、上の方で紹介した「アクション」の中から「AWS Lambdaへのストリーム」を選択していけば良いです。
ちなみにterraformだと下記な感じで設定できます。
resource "aws_cloudwatch_log_subscription_filter" "api_application_error_to_lambda" { name = "api_error_slack_notification_lambda_logfilter" log_group_name = "${aws_cloudwatch_log_group.api_application.name}" filter_pattern = "?FATAL ?ERROR ?WARN" destination_arn = "${aws_lambda_function.notify_api_error_to_slack.arn}" }今回は、log4jsで定義されているエラー系のやつを全て補足したいので、
?FATAL ?ERROR ?WARNをフィルターパターンに設定しています。これは、「FATALもしくはERRORもしくはWARNのいずれかがログイベント文字列に含まれていれば」という意味になります。
詳細はこちらで。
動くか試してみる
ここまでできたら動くはず。テストしましょう。
いちいちエラー発生させるのはめんどいので、ログファイルに適当な文字列を突っ込んで検証します。
再度APIサーバにSSHログインして、ログディレクトリに移動して下記コマンド。echo "ERROR: this is test log" >> application.log.2020-03-13
やったぜ。
CloudWatch LogsからS3にログ連携する
さて、ここまででログためて、必要に応じてSlack通知する仕組みはできました。
あとはS3にデータ保存するだけ。
リアルタイムで保存していくならKinesis firehoseを使う手もあるが、よく事例で出てくるのはサブスクリプションフィルタを使ったもの。
実はサブスクリプションフィルタは1ロググループに対して1つしか用意できないため、既にこの手は封じられている?
ただ、ぶっちゃけリアルタイムで保存する必要はないので、バッチ処理で1日1回、S3に保存するタスクが走れば良いと考えよう。
そもそもCloudWatch LogsにはS3へのエクスポート機能がある。
GUIでも操作できるが、人間バッチはイケてないので、バッチ機構を作って下記APIを叩くようにするのが良いでしょう。https://docs.aws.amazon.com/AmazonCloudWatchLogs/latest/APIReference/API_CreateExportTask.html
以上
さすがに全てを詳細に記述するのはToo muchなので割愛しまくりましたが、大まかな方針として、ロギング周りをこれから実装する方の参考となれば幸いです。
もしもっと詳細が知りたい部分などありましたら、コメントなり編集リクエストなりいただければと思います。
- 投稿日:2020-03-14T18:52:39+09:00
EC2にapache + rails環境を構築する
参考サイト
es2の設定
・(デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
・Linuxグループ作成方法!groupaddで意外とすぐできる
・usermodコマンドについて詳しくまとめました 【Linuxコマンド集】apacheインストール
・Red Hatpassengerインストール
・phusion/passenger - Githubmysqlインストール
・CentOS7.3 に MySQL5.7 をインストールした時のメモ - Qiitaapache,rbenvインストール参考サイト
・EC2にRails5環境を構築する - Qiitagetの設定
・Git
・GitHubでssh接続する手順~公開鍵・秘密鍵の生成から~ - QiitaWARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!エラー
・SSH接続エラー回避方法:.ssh/known_hostsから特定のホストを削除する/削除しないで対処する3つの方法 - Qiitaバージョン
アプリケーション version AMI Amazon Linux 2 Ruby 2.5.3 Rails 5.2.3 Apache 2.4.41 MySQL 5.7 Passenger 6.0.4 インスタンス設定
・ユーザの作成
$ sudo adduser <ユーザ名> $ sudo passwd <ユーザ名> $ sudo visudo ##vim~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ root ALL=(ALL) ALL # の下に追記 <ユーザ名> ALL=(ALL) NOPASSWD:ALL ##~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ $ su - <ユーザ名>・グループの作成、グループにユーザ追加
$ sudo groupadd <グループ名> $ tail /etc/group $ sudo usermod -g <グループ名> <ユーザ名> $ id <ユーザ名>・タイムゾーンを日本時間に設定
$ date $ sudo cp -r /usr/share/zoneinfo/Japan /etc/localtime$ sudo vim /etc/sysconfig/clock ZONE="Asia/Tokyo" UTC=true $ dateapacheインストール
・apacheインストール
$ sudo yum -y update $ sudo yum -y install httpd $ sudo systemctl start httpd $ sudo systemctl status httpd $ sudo systemctl enable httpd.service $ httpd -versionmysqlインストール、設定
・mysqlインストール
$ sudo yum -y install mysql-devel $ sudo yum -y localinstall https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm $ sudo yum info mysql-community-server $ sudo yum -y install mysql-community-server $ mysqld --version・mysqlの設定
$ sudo systemctl start mysqld $ sudo systemctl status mysqld $ sudo systemctl enable mysqld$ sudo cat /var/log/mysqld.log | grep password $ sudo mysql_secure_installation $ mysql -u root -p # ポリシー変更してパスワードの変更 mysql> SHOW VARIABLES LIKE 'validate_password%'; mysql> set global validate_password_length=6; mysql> set global validate_password_policy=LOW; mysql> use mysql mysql> update user set authentication_string=password('パスワード') where user='root'; mysql> flush privileges;Gitのインストール、設定
gitのインストール
$ sudo yum -y install git $ git --version $ cd $ mkdir .ssh $ chmod 700 .ssh $ ll -al $ cd .ssh $ ssh-keygen $ cat <キー名>.pub # 公開鍵をgithubに登録 # キーを命名した場合↓ $ sudo vi config ##vim~~~~~~~~~~~~~~~~~~~~~~~~ Host github github.com HostName github.com IdentityFile ~/.ssh/<キー名> User git ##~~~~~~~~~~~~~~~~~~~~~~~~~~~ $ ssh -T git@github.comrbenvインストール手順
・rbenv install
$ sudo yum install -y git gcc gcc-c++ openssl-devel readline-devel $ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ cat ~/.bash_profile $ source ~/.bash_profile $ rbenv -v $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build $ rbenv install -lRailsアプリをインスタンス上に配置、立ち上げまで
$ sudo mkdir /sample $ chown <ユーザ名>:<グループ名> /sample/ $ cd /sample $ mkdir rails $ cd rails $ git clone <クローンするアプリ>・Rubyのバージョン確認
$ cd <アプリのパス> $ cat .ruby-version・rubyのインストール
$ rbenv install -v 2.5.3 $ rbenv rehash $ rbenv global 2.5.3 $ ruby -v・bundlerのインストール
$ cat Gemfile.lock ##cat~~~~~~~~~~~~~~~~~ BUNDLED WITH 2.0.2 ##~~~~~~~~~~~~~~~~~~~~ $ gem install bundler -v 2.0.2・ railsアプリ立ち上げ
$ bundle install --path vendor/bundle $ bundle exec rails db:create $ bundle exec rails db:migrate $ bundle exec rails s -d $ ps aux | grep puma $ curl http://localhost:3000 $ $ kill -9 <pumaのプロセスid>Passengerのインストール
・passengerのインストール
$ gem install passenger $ passenger-install-apache2-moduleapache設定
$ sudo vim /etc/httpd/conf.d/sample.conf ##vim~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <VirtualHost *:80> ServerName <ip または ドメイン> DocumentRoot /sample/rails/<アプリ名>/public RackEnv production <Directory /sample/rails/<アプリ名>/public> AllowOverride all Require all granted </Directory> </VirtualHost> # passengerのモジュールインストール時に出でくるものを貼る LoadModule passenger_module /home/*****/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/passenger-6.0.4/buildout/apache2/mod_passenger.so <IfModule mod_passenger.c> PassengerRoot /home/*****/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/passenger-6.0.4 PassengerDefaultRuby /home/*****/.rbenv/versions/2.5.3/bin/ruby </IfModule> ##~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ $ sudo systemctl restart httpdでブラウザーからアクセスするとアプリが立ち上がっていると思います。
- 投稿日:2020-03-14T18:15:33+09:00
AWS認定資格_ソリューションアーキテクト-アソシエイト取得への道のり①
はじめに
AWS認定資格_ソリューションアーキテクト-アソシエイト取得を目指すためにQiitaを使って勉強内容を記載していこうと思います。
きっかけ
PLとしてあるシステムの開発に携わる際に、AWSのサービスである下記を用いました。
- EC2
- RDS
- S3
- elasticache
- amazon elasticsearch service
- DMS当初、AWSに触ったことがなかった私としては??が飛び交っており、正直よくわからないまま「よくわからないな~。。」と思いながら使っていました。
しかし、AWSのサービスを利用していくうちに慣れていき、次第にもっと知りたい、様々なサービスを知り顧客に提案できるエンジニアになりたい。という意識を持つようになりました。
上司と面談した際に、「AWSの資格の勉強してみたら?インセンティブももらえるし」という言葉で資格勉強をすることを決意しました(取得できればお金ももらえるし!)資格本
さっそく本屋にいき「ソリューションアーキテクト[アソシエイト]」の本を買いにいきました。
そこで私は「AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト」という書籍を買いました。
詳しくは下記URLを参照
https://bookwalker.jp/de68074883-4cc9-4d5a-bd8e-45f67af85fb9/?adpcnt=7qM_Vsc7&utm_source=google&utm_medium=cpc&utm_term=_&utm_campaign=&utm_content=__cp_1471997507_gr_65566109508_kw_pla-428567606763_cr_281840075652&gclid=CjwKCAjwgbLzBRBsEiwAXVIygPlCk_Stubn-vfVM2S6mRfjiHUM_WtdJrCSwxa1MN-Es8K2icC7toBoCH-AQAvD_BwE
この書籍を1週間で一周しましたが、かなり勉強になりました。
様々なAWSのサービスの概要、資格試験の対策や傾向について細かく記載されているためおすすめです(まだこれしか読んでいないのでなんともいえないですが)サイト(記事)
資格本だけだと具体的な内容について知りたくなります。
Qiitaにはいろんな方がAWSの内容について書かれているのでとても勉強になっています。
私がいままでみて勉強になったリンクを記載していきます。・AWSのルートテーブルについて
https://qiita.com/chro96/items/21863e0960ba4ac72470・【AWS】AWSの勉強
https://qiita.com/s_Pure/items/582673e01ed5218cc62b・AWSで不正利用され80000ドルの請求が来た話
https://qiita.com/koyama9876/items/add70cba3cccdb7fa995あと、実際に手を動かしてみようと思い、下記Qiita記事の手順が非常に参考となったためこの記事通りに「VPC構築→EC2構築→ELB構築」まで構築完了しました。
※RDSは後程構築していこうかと思います。・から始めるAWS入門:概要
https://qiita.com/hiroshik1985/items/6433d5de97ac55fedfdeまた、IAMユーザー作成時に参考にしたURLを下記に記載
https://qiita.com/moiwa/items/ac65481c0b7433aac468最後に
今後AWS関連の記事を記載していこうかと思います。
参考になる資料やURLなどあれば共有いただけるとありがたいと思います。
- 投稿日:2020-03-14T18:09:00+09:00
運用監視の可観測性
AWS Innovate Online Conferenceのセッションより、柳 嘉起氏の「AWS運用監視の実践 システムに問題が発生した時、迅速に対処する方法」のメモ。
監視の目的
「ユーザー体験を損なわないため」です。
・ユーザーが問題なくサービスを使える
・障害が発生したら迅速に復旧する
これを実現するために、システムの監視を行います。可観測性(オブザーバビリティ)
「システムの動作状況を把握できている状態」
「システム運用において、判断に必要な情報がきちんと取得できている状態」
このような状態を可観測性と言います。クラウド環境は変化が激しく情報が多いため、適切な情報を収集し適切な対応を迅速に行うには、運用監視における可観測性が重要となってきます。
可観測性の構成要素
以下の3つの要素が可観測性を実現させます。
・ログ(稼働状況などの記録)
・メトリクス(パフォーマンスデータなどの時系列的に管理される定量的な指標)
・トレース(ある特定の処理の流れ、あるいはその流れをとらえる仕組み)運用監視の課題
以下の2つは運用監視においてよくあることかもしれません。
・エラー通知が出てからユーザー影響を確認している
・エラー通知が出ているが実際はシステムに問題はないこれは可観測性が十分でない状態と言えます。
判断に必要な情報があらかじめ得られるようにするのが理想的です。課題に対する監視方法の提案
①シンセティック監視
ユーザーと同じ経路からアクセスし、ユーザーの視点で監視する方法です。
ユーザーと同じレスポンスを得ることができ、バックエンドでの問題がユーザーに影響があるかがわかります。AWSではAmazon CloudWatchという運用監視サービスがあります。CloudWatchの機能のひとつである「Amazon CloudWatch Synthetics」によって、顧客の視点からのサービス監視を実現します。(2020年1月から東京リージョンで利用可)
②トレース
問題の根本原因を追跡するための方法です。近年よく知られているマイクロサービスは、疎結合になっている小さなサービスを連結させて機能を実現するアーキテクチャです。
この場合、問題発生時には複数のサービスをまたがった処理の追跡を行う必要があり、それをサポートする手法として(分散)トレースが注目されています。トレースは、CloudWatchに統合された「Amazon CloudWatch ServiceLens(W/X-Rey)」というサービスで実現できます。Amazon CloudWatchに既存サービスの「AWS X-Rey」の機能を持たせ、視覚化と分析を1つのサービスで行うことで、問題解決までの時間を短縮します。(東京リージョンで利用可)
- 投稿日:2020-03-14T17:45:41+09:00
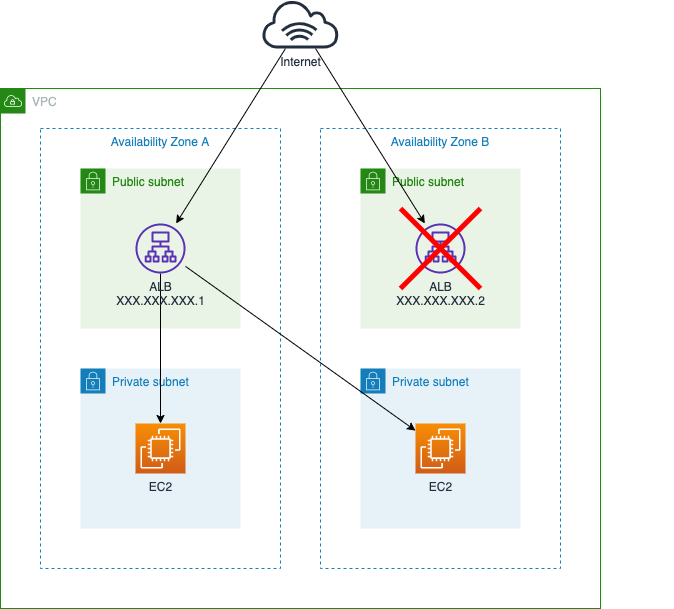
ALBはなぜ3AZにするべきなのか
はじめに
2019年8月に発生したAWSの東京リージョンでの障害は記憶に新しいことかと思います。
東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
マルチAZで構築していても影響があった方も多かったと思います。
その中でALBにおいて、継続してサービスを提供するには2AZより3AZにすべきという意見が見られたので、なぜ3AZにしなければならないのかを調べてみました。なおAWSについて勉強し始めたばかりなので、間違い等あればご指摘ください。
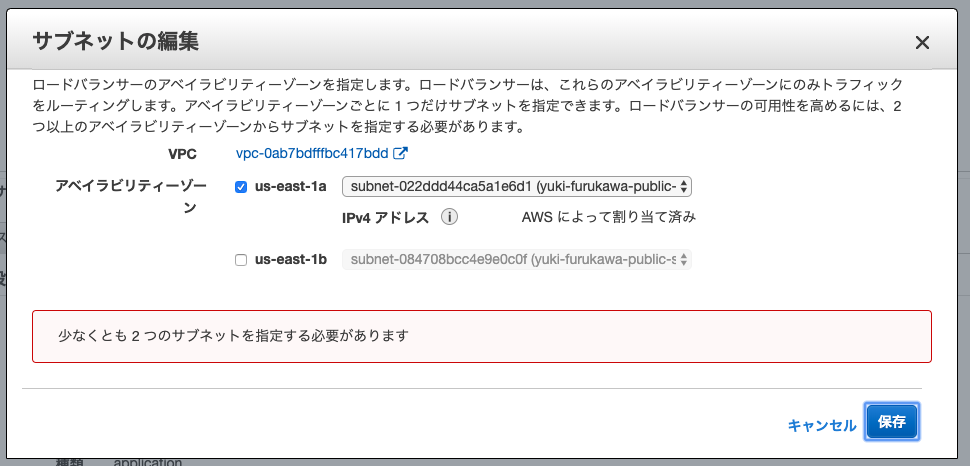
ALBは2AZを指定する必要がある
ALBでは2つ以上のAZのサブネットを設定する必要があります。1AZにすることは出来ません。
そのため、3AZならば2AZに減らすことは出来ます。2AZでもALBがロードバランスしてくれるから、問題ないのではと最初思っていました。
しかし、ALBの仕組みを見ていくと2AZでも障害が起こってしまう可能性があることがわかりました。ALBはどう動いているのか
2AZでALBを試しに作り、
yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.comというDNS名が払い出されたとします。
これをdigコマンドを使って見てみます。
(DNS名やIPアドレスは適当に書き換えています)$ dig yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.com 土 3/14 16:59:20 2020 ; <<>> DiG 9.10.6 <<>> yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26213 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.com. IN A ;; ANSWER SECTION: yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.com. 59 IN A XXX.XXX.XXX.1 yuki-furukawa-alb-hogehoge.us-east-1.elb.amazonaws.com. 59 IN A XXX.XXX.XXX.2 ;; Query time: 41 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Sat Mar 14 17:01:18 JST 2020 ;; MSG SIZE rcvd: 116DNSのAレコードに2つのIPアドレスが割り当てられているため、DNSラウンドロビンによって
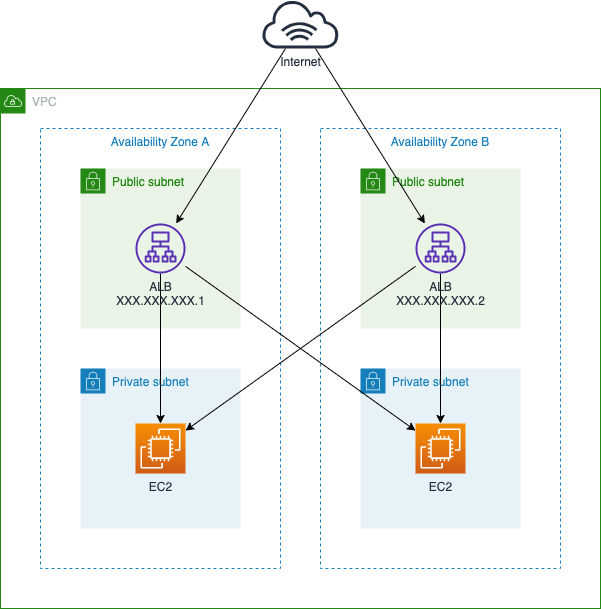
XXX.XXX.XXX.1またはXXX.XXX.XXX.2にアクセスすることになります。ここで今回の構成を図にしてみました。
XXX.XXX.XXX.1とXXX.XXX.XXX.2がALBのIPアドレスになります。
ALBはEC2のインスタンスのようなものが立ち上がって、アクセスを振り分けているということです。EC2のインスタンスが停止した場合
まずはEC2のインスタンスが停止した場合を考えてみます。
ALBはヘルスチェックを行っているので、停止したEC2インスタンスへアクセスは行かず、他のインスタンスにアクセスします。
この場合は2AZでも障害が起きても問題はないです。ALBのインスタンスが停止した場合
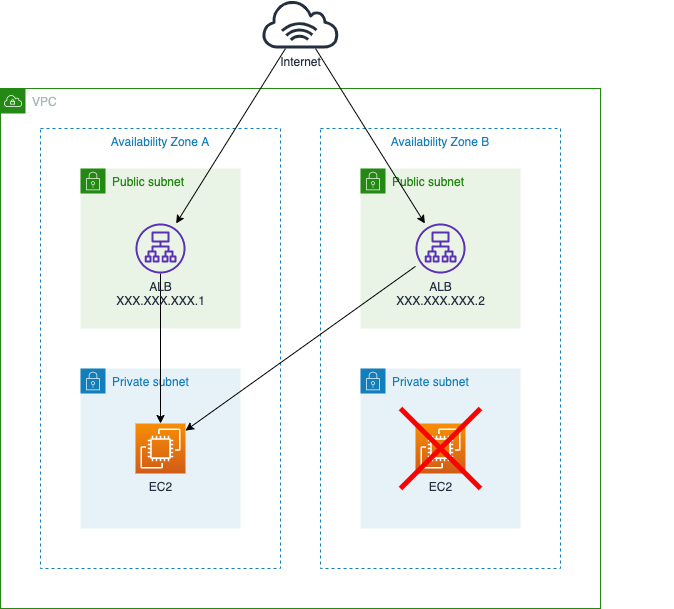
ALBのインスタンスが停止した場合を考えてみます。
ALBはEC2の基盤を使っていると考えれれるので、EC2のサービスが提供できなくなった場合、ALBにも影響が出ると思われます。
DNSラウンドロビンによってALBへのアクセスを振り分けているため、ALBのインスタンスが1つでも停止していると影響を受けることになります。
この例では名前解決の結果XXX.XXX.XXX.2にアクセスした場合、エラーが表示されてしまいます。これが3AZだったらどうでしょうか。
3AZなら2AZに変更することができるので、障害が起きたALBを切り離す事ができます。
つまり、ALBの障害を考慮すると、3AZで構築する必要があるということになります。おわりに
SLAにもよるかと思いますが、ALBでの障害を考慮した場合3AZにしたほうが安心です。
ALBは3AZにした方がいいよって言われたときに、なんでだろうと思った人に参考になれば幸いです。
- 投稿日:2020-03-14T16:57:27+09:00
CloudWatch ダッシュボードを定期的にSlack通知する(ソース付き)
はじめに
最近TypeScriptが楽しいので、実益兼ねて作ったものをご紹介します
どんなものを作るか
AWS上でサーバレスに構築したLPを個人で開発・保守・運用しています?♂️
今まで、メトリクスの異常値(CloudFrontのリクエスト数増加、Lambdaでのエラー発生、請求金額など)については、
CloudWatchアラーム -> SNS -> Chatbot -> Slackという経路で適宜通知を行っていたのですが、
平常時の値についてはダッシュボードを作成したもののあまり見れておらず、Slack上でもう少し手軽&こまめに確認したい...と考えていましたAWS SDKにはGetMetricWidgetImageという、メトリクスを画像出力できるというそのものズバリなやつがありますが、
CloudWatchダッシュボードをそのまま出力する機能は提供されておらず、何かしら工夫が必要となりますということで、TypeScriptとServerless Frameworkを用いて、CloudWatchダッシュボードを日次でSlackに通知する仕組みを開発することとしました?
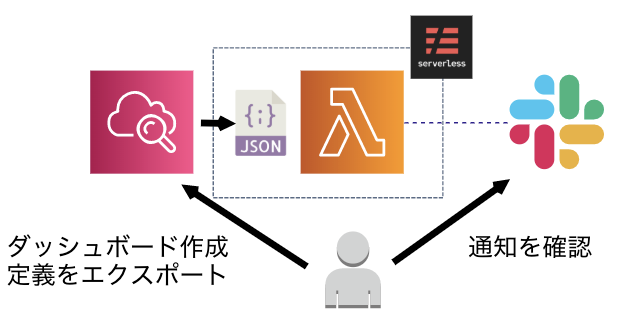
どうやって作るか
この上なく簡単な構成図がこちらです
ダッシュボードはコンソールで手ポチで作成した上で、JSONエクスポートしたものをソースコードから読み込み利用します
Lambda上でダッシュボードの定義ファイルを読み込み、メトリクス毎に画像出力しますそのまま画像毎にSlackに投稿しても悪くはないですが、好みとしてはその時のメトリクスの断面を残しておきたかったので、merge-imagesというライブラリを用いて各メトリクス画像を1枚の画像にまとめることとします
本ライブラリの動作にはnode-canvasが必要になりますが、例によってLambda上では動かず困っていたところ、
渡りに船⛴とばかりにnode-canvas-lambdaなるLambda Layerを作っている方がいたので、こちらをありがたく読み込んで使います作ったもの
コードは以下になります
https://github.com/yktakaha4/cw-metrics-notifier
構築方法
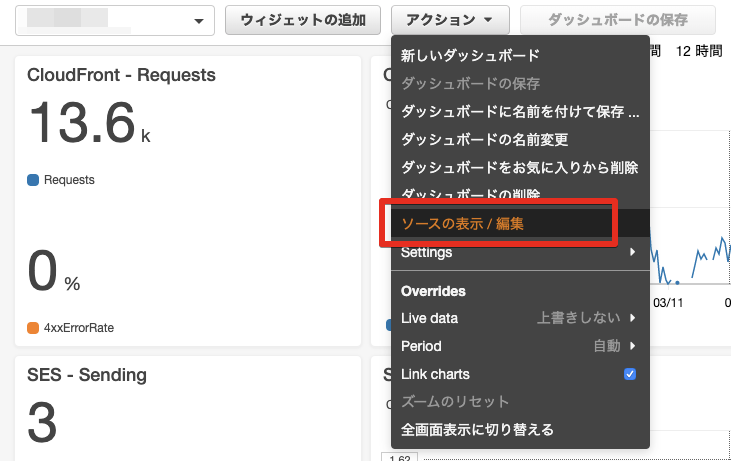
ダッシュボードを作成した上で、
アクション -> ソースの表示/編集で表示されるJSON定義をコピーし、widgets/sample.jsonを上書きしてください
widgets/sample.json{ "comment": "replace me!" }
serverless.ymlのdeploymentBucketやschedule、関数のenvironmentなどを適宜変更してくださいserverless.ymlservice:service: name: cw-metrics-notifier provider: name: aws runtime: nodejs12.x region: ap-northeast-1 stage: prod deploymentBucket: xxxxxxx memorySize: 256 timeout: 60 environment: SLACK_TOKEN: ${env:SLACK_TOKEN} SLACK_METRICS_CHANNEL_ID: ${env:SLACK_METRICS_CHANNEL_ID} iamRoleStatements: - Effect: Allow Action: - cloudwatch:GetMetricWidgetImage Resource: "*" functions: widgets: handler: src/widgets.scheduledHandler environment: # widgets/ 配下のファイル名(カンマ区切り可) WIDGETS_NAMES: sample # マージ画像でx方向にいくつまでメトリクスを並べるか METRICS_X_COUNT: 2 # 何日前までを表示対象にするか METRICS_DAYS_AGO: 7 events: - schedule: rate: cron(0 0 * * ? *) enabled: true layers: - { Ref: NodeCanvasLambdaLayer } - { Ref: CanvasLib64LambdaLayer } layers: nodeCanvas: package: artifact: vendor/node-canvas-lambda/node12_canvas_layer.zip canvasLib64: package: artifact: vendor/node-canvas-lambda/canvas-lib64-layer.zip package: include: - widgets/ plugins: - serverless-plugin-typescript - serverless-plugin-optimize custom: optimize: exclude: - canvas includePaths: - widgets/node-canvas-lambdaの取得については、npm scriptsに書いてあるので気にしなくてもokです
package.json(抜粋){ "scripts": { "predeploy": "rm -rf .build; [[ -d vendor/node-canvas-lambda ]] || (cd vendor && git clone https://github.com/jwerre/node-canvas-lambda.git)", "deploy": "dotenv -- sls deploy -v" } }直してみてよさそうだったらデプロイ
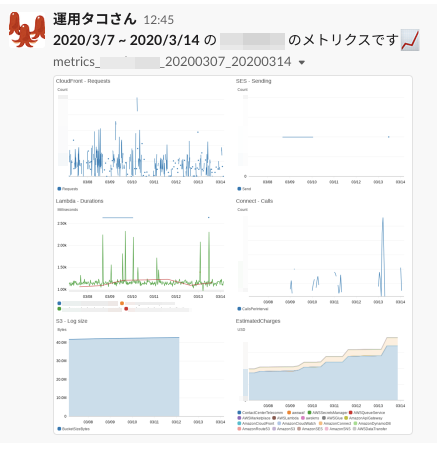
ターミナル# インストール $ npm ci # 環境変数情報を追加 $ cp -p .env.sample .env $ cat .env AWS_ACCESS_KEY_ID=xxxxx AWS_SECRET_ACCESS_KEY=xxxxx SLACK_TOKEN=xoxp-xxxxx SLACK_METRICS_CHANNEL_ID=Cxxxxx # デプロイ $ npm run deployスケジュールした時間が来ると、Slackの所定のチャンネルにダッシュボードっぽい画像が投稿されます?
実際のコードはGitHubを見て頂くのがよいですが、肝となるメトリクスの画像出力とマージのコードを貼っておきます
MetricWidgetに何が渡せるかはこちらを見るといい感じに書いてありますあと、これはちゃんと調査できてないのですが、
timeSeriesタイプ以外のメトリクスはいい感じに描画されない感じがしたので、取得対象外としています
そしてグラフのキャプションに日本語などマルチバイト文字を入れると文字化けします...widgets.ts(抜粋)// ウィジェット毎にpng画像を生成し、マージ用元データを作成する const imageSources = await Promise.all( widgets .filter(widgetPart => widgetPart?.properties?.view === 'timeSeries') .map(async (widgetPart, index) => { const properties = widgetPart.properties; const imagePath = path.join(imagesDir, `${index}.png`); // +0000 形式 const timezone = moment() .format('Z') .replace(':', ''); const cw = new CloudWatch({ region: properties.region, }); // AWSにリクエストし、結果をファイル保存 const output = await cw .getMetricWidgetImage({ MetricWidget: JSON.stringify({ ...properties, start: `-PT${metricsDaysAgo * 24}H`, end: 'PT0H', timezone, width: imageWidth, height: imageHeight, }), }) .promise(); await fs.writeFile(imagePath, output.MetricWidgetImage); // マージ用元データを作成し返却 // 描画位置の指定をおこない、画像を metricsXCount ずつ横に並べる const source: ImageSource = { src: imagePath, x: imageWidth * (index % metricsXCount), y: imageHeight * Math.floor(index / metricsXCount), }; return source; }), ); // 画像のマージ // ライブラリ都合で Canvas.Image が存在しないとエラーとなったため以下指定 const canvas: any = Canvas; canvas.Image = Image; const mergedImageBase64 = await mergeImages(imageSources, { Canvas: canvas, width: imageWidth * metricsXCount, height: imageHeight * Math.ceil(imageSources.length / metricsXCount), }); // Base64形式からファイルに変換 const metricsData = mergedImageBase64.replace(/^data:image\/png;base64,/, ''); const metricsPath = path.join(imagesDir, `${widgetsName}.png`); await fs.writeFile(metricsPath, metricsData, 'base64');今回は主旨から逸れるので触れませんが、
.github/workflows/配下にGitHub Actionsでデプロイする用のワークフローも入れていますので、必要あらばご利用くださいまとめ
TypeScriptは、静的型付けのメリットを手軽に享受しつつ、Node製の各種ライブラリを活用できつつ、Lambdaはじめサーバレスとの親和性も高く、フロントも書けるんだからだいぶ最高感ありますね...!
どんどん使っていきたいと思います?
- 投稿日:2020-03-14T16:52:24+09:00
Amazon Kinesis Video Streams を使ってみた
Amazon Kinesis Video Streams は、AWS のビデオ配信サービスです。
料金
参考) 料金
東京リージョンの場合は以下のような感じです。1GB は 2Mbps の動画で 1 時間ぶんくらいです。意外と安い。
項目 単価 配信 (→Kinesis) 0.01097 USD/GB 閲覧 (Kinesis→) 0.01536 USD/GB × セッション数 データ保存 0.02500 USD/GB•月 このほかにインターネットへのデータ転送料金(0.084~0.114 USD/GB)がかかります。インターネットからの受信、及び同一リージョン内のデータ転送料金はかかりません。データの保存期間は 0 から設定可能なので、ライブ配信なら不要。
小規模な配信なら十分安いのではないかと。
ユーザーの作成 (OPTIONAL)
必要な権限だけを持ったテストユーザーを作成しておきます。
配信用
$ aws iam create-user --user-name kinenes-video-producer-test $ aws iam attach-user-policy --user-name kinenes-video-producer-test \ --policy-arn arn:aws:iam::aws:policy/AmazonKinesisVideoStreamsFullAccess $ aws iam create-access-key --user-name kinenes-video-producer-test閲覧用
$ aws iam create-user --user-name kinenes-video-consumer-test $ aws iam attach-user-policy --user-name kinenes-video-consumer-test \ --policy-arn arn:aws:iam::aws:policy/AmazonKinesisVideoStreamsReadOnlyAccess $ aws iam create-access-key --user-name kinenes-video-consumer-testストリームの作成
配信するためのストリームを作成します。必要な AWS リソースは以上です。(!)
$ aws kinesisvideo create-stream --stream-name test --data-retention-in-hours 1 { "StreamARN": "arn:aws:kinesisvideo:ap-northeast-1:(AccountNumber):stream/test/XXXXXXXXXXXXX" }動画配信 (Producer)
Kinesis Video Streams Producer Library という C++/Java の SDK を使って開発するか、GStreamer の Kinesis Video Streams プラグイン を使って H.264 ファイルを配信することができます。
GStreamer による配信 (Docker)
参考) 開発者ガイド - はじめに - Kinesis ビデオストリームにデータを送信する
SDK がインストールされたコンテナイメージが用意されているので、それに入っている GStreamer を使ってまずは動画ファイルを配信してみます。
$ $(aws ecr get-login --no-include-email --region us-west-2 --registry-ids 546150905175) $ docker pull 546150905175.dkr.ecr.us-west-2.amazonaws.com/kinesis-video-producer-sdk-cpp-amazon-linux:latest $ docker run -it -v $(pwd):/work --network="host" \ 546150905175.dkr.ecr.us-west-2.amazonaws.com/kinesis-video-producer-sdk-cpp-amazon-linux \ /bin/bash動画ファイルをループさせて配信するため、以下のようなスクリプトを書きます。動画ファイルは NHK クリエイティブライブラリー等から適当にダウンロードしました。
// play.sh #!/bin/sh export LD_LIBRARY_PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/lib:$LD_LIBRARY_PATH export PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/bin:$PATH export GST_PLUGIN_PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/lib:$GST_PLUGIN_PATH # kinenes-video-producer-test のアクセスキー AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX AWS_REGION=ap-northeast-1 STREAM_NAME=test MOVIE_FILE=/work/sample.mp4 while [ 1 ] do gst-launch-1.0 \ filesrc location="${MOVIE_FILE}" \ ! qtdemux name=demux \ ! queue \ ! h264parse \ ! video/x-h264,format=avc,alignment=au \ ! kvssink stream-name="${STREAM_NAME}" storage-size=512 \ access-key="${AWS_ACCESS_KEY_ID}" \ secret-key="${AWS_SECRET_ACCESS_KEY}" \ aws-region="${AWS_REGION}" donegst-launch-1.0 は「!」でつないでパイプラインを構成し、順番にプラグインを処理していきます。動画の形式などによってうまく変換してあげる必要があります。最後の「kvssink」が Kinesis Video Streams に流す部分です。各プラグインの説明やオプションはこちらが参考になります。
正しく配信されているかどうかは、マネジメントコンソールから動画を再生することで確認できます。
- Kinesis Video Streams > Vidoe streams > test > Media playback
GStreamer による配信 (Raspberry Pi)
参考) Kinesis Video Streams Producer SDK GStreamer Plugin
公式ドキュメントに書いてあるとおりにインストールします。min-install-script の直前の行は自分の環境では足りなかったので追加でインストールしました(実行すると入れとけって出る)。
$ sudo apt-get update $ sudo apt-get install -y libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev gstreamer1.0-plugins-base-apps $ sudo apt-get install -y gstreamer1.0-plugins-bad gstreamer1.0-plugins-good gstreamer1.0-plugins-ugly gstreamer1.0-tools $ sudo apt-get install -y gstreamer1.0-omx $ mkdir /opt/awssdk && cd /opt/awssdk $ git clone https://github.com/awslabs/amazon-kinesis-video-streams-producer-sdk-cpp $ cd amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build $ sudo apt-get install -y pkg-config libssl-dev cmake libcurl4-openssl-dev liblog4cplus-1.1-9 liblog4cplus-dev $ ./min-install-script $ ./gstreamer-plugin-install-scriptRaspberry Pi のカメラモジュールを動画で配信します。
export LD_LIBRARY_PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/lib:$LD_LIBRARY_PATH export PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/bin:$PATH export GST_PLUGIN_PATH=/opt/awssdk/amazon-kinesis-video-streams-producer-sdk-cpp/kinesis-video-native-build/downloads/local/lib:$GST_PLUGIN_PATH AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX AWS_REGION=ap-northeast-1 STREAM_NAME=test gst-launch-1.0 v4l2src device=/dev/video0 \ ! videoconvert ! video/x-raw,format=I420,width=640,height=480 \ ! omxh264enc control-rate=2 target-bitrate=512000 periodicity-idr=45 inline-header=FALSE \ ! h264parse \ ! video/x-h264,stream-format=avc,alignment=au,profile=baseline \ ! kvssink stream-name="${STREAM_NAME}" \ access-key="${AWS_ACCESS_KEY_ID}" \ secret-key="${AWS_SECRET_ACCESS_KEY}" \ aws-region="${AWS_REGION}"動画再生 (Consumer)
参考) ビデオストリーム再生
Kinesis Video Streams Parser Library という C++/Java の SDK を使って開発するか、HLS または MPEG-DASH プレイヤーで再生できます。
HLS
プレイヤーとして、Video.js または Google Shaka Player が使えます。hls.js もたぶん大丈夫。Safari, Edge はネイティブ対応しているので URL 直接入力でも再生できるようです。
手順としては以下のようになります。
- GetDataEndpoint API で、ストリーム用の API エンドポイントを取得する。
- 上で取得したエンドポイントに対して GetHLSStreamingSessionURL API を呼び、再生用の URL を取得する。これは有効期限を持ったセッショントークンが埋め込まれた一時的なものになります。 例)
https://b-87178fb5.kinesisvideo.ap-northeast-1.amazonaws.com/hls/v1/getHLSMasterPlaylist.m3u8?SessionToken=XXXXXXXVideo.js の例。とりあえず HTML にアクセスキーを埋め込んでいますが、アクセス制御する場合はバックエンド側で URL を発行したほうが良いです。
<!DOCTYPE html> <html> <head> <link href="https://vjs.zencdn.net/7.6.6/video-js.css" rel="stylesheet" /> <script src="https://sdk.amazonaws.com/js/aws-sdk-2.408.0.min.js"></script> <title>HLS Player</title> </head> <body> <video id="videojs" class="player video-js vjs-default-skin" controls autoplay></video> <script src="https://vjs.zencdn.net/7.6.6/video.js"></script> <script> async function getHLSStreamingSessionURL() { // kinenes-video-consumer-test のアクセスキー const accessKeyId = 'XXXXXXXXXXXXXXXXXXXX'; const secretAccessKey = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'; const region = 'ap-northeast-1'; const streamName = 'test'; var options = { accessKeyId: accessKeyId, secretAccessKey: secretAccessKey, region: region, } const kinesisVideoClient = new AWS.KinesisVideo(options); const kinesisVideoArchivedMediaClient = new AWS.KinesisVideoArchivedMedia(options); // GetDataEndpoint // https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_GetDataEndpoint.html const e = await kinesisVideoClient.getDataEndpoint({ APIName: "GET_HLS_STREAMING_SESSION_URL", StreamName: streamName }).promise(); kinesisVideoArchivedMediaClient.endpoint = new AWS.Endpoint(e.DataEndpoint); // GetHLSStreamingSessionURL API // https://docs.aws.amazon.com/kinesisvideostreams/latest/dg/API_reader_GetHLSStreamingSessionURL.html var params = { StreamName: streamName }; const d = await kinesisVideoArchivedMediaClient.getHLSStreamingSessionURL(params).promise(); return d.HLSStreamingSessionURL; } document.addEventListener("DOMContentLoaded", async () => { const url = await getHLSStreamingSessionURL(); const player = videojs('videojs'); player.src({ src: url, type: 'application/x-mpegURL' }); }); </script> </body> </html>MPEG-DASH
- 投稿日:2020-03-14T15:52:18+09:00
AWS Cloud9上でPostgreSQLをソースからインストール
概要
AWS Cloud9 上でpostgreqlとdeviseを使ってRailsアプリを開発をしようとした際に、
postgresqlのバージョンが古いと怒られたのでやってみたことをメモ。
- 環境
- AWS Cloud9
- Amazon Linux AMI release 2018.03
- postgre
- postgres (PostgreSQL) 9.2.24
ソースからコンパイル
下記を順に実行
一応コンパイラからインストール$ sudo yum install -y gcc readline-devel zlib-devel $ wget https://ftp.postgresql.org/pub/source/v10.4/postgresql-10.4.tar.gz $ tar -xf postgresql-10.4.tar.gz $ cd postgresql-10.4 $ ./configure $ make -C src/binここでエラーが出るので
Makefile内を下記のように修正する。$ make -C src/bin make: Entering directory `/home/ec2-user/postgresql-10.4/src/bin' Makefile:14: ../../src/Makefile.global: No such file or directory make: *** No rule to make target `../../src/Makefile.global'. Stop. make: Leaving directory `/home/ec2-user/postgresql-10.4/src/bin'
Makefileの14行目の'Makefile.global'のところが間違いで
'Makefile.global.in'に訂正すると無事にmakeできます。そのまま続きへ、$ sudo make -C src/bin install $ make -C src/include $ sudo make -C src/include install $ make -C src/interfaces $ sudo make -C src/interfaces install $ make -C doc $ sudo make -C doc install以上でエラーが出なければインストールは完了。
今回インストールされた場所は/usr/local/pgsql/bin/psqlなのでそこにパスを通します。$ vi ~/.bash_profileとして最後の行に
export PATH="/usr/local/pgsql/bin:$PATH"を追加して保存。
$ source ~/.bash_profileこれで完了。
バージョンを確認する
$ psql --version psql (PostgreSQL) 10.410.4になってます。
因みに、これをアンインストールするには
makeした場所で、$ make uninstallとすると消える。
参照
How To Completely Uninstall PostgreSQL
Installing PostgreSQL Client v10 on AWS Amazon Linux (EC2) AMI
make installしたソフトウェアをアンインストールする
- 投稿日:2020-03-14T13:03:49+09:00
Lambdaのデフォルトログを出力させずに意図したログのみを出力する
Lambda実行時にデフォルトで表示されるログを非表示にしつつ、アプリケーションで意図したログだけをCloudWatch Logsに出力する方法です。
CloudWatch Logsの料金は高いので、なるべく保存するログを減らしたいという目的で対応しました。
通常のログ出力(何もしない場合)
まずは何もしない場合です。
今回のテストで利用するLambdaです。
Node.js 12.X です。Lambdaexports.handler = async (event) => { console.log('log test'); const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), }; return response; };出力されるログは以下のようになります。
START RequestId: XXXXXX Version: $LATEST 2020-03-13T13:33:26.678Z XXXXXX INFO log test END RequestId: XXXXXX REPORT RequestId: XXXXXX Duration: 17.18 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 70 MB Init Duration: 108.39 msこのようにLambda上で出力するように書いたのは、
log testだけなのですが、START~END~REPORT~というLambdaがデフォルトで出力するログが一緒に出力されています。
今回の記事は、これらのデフォルトのログは出力しないようにしつつ、Lambdaで書いたメッセージだけを出力したいという内容です。デフォルトのログを出力しないようにする
IAMの権限修正
Lambdaのデフォルトログを出力しないようにするには、IAMを修正します。
Lambdaを作成した時にロールも同時に作成した場合、そのロールには
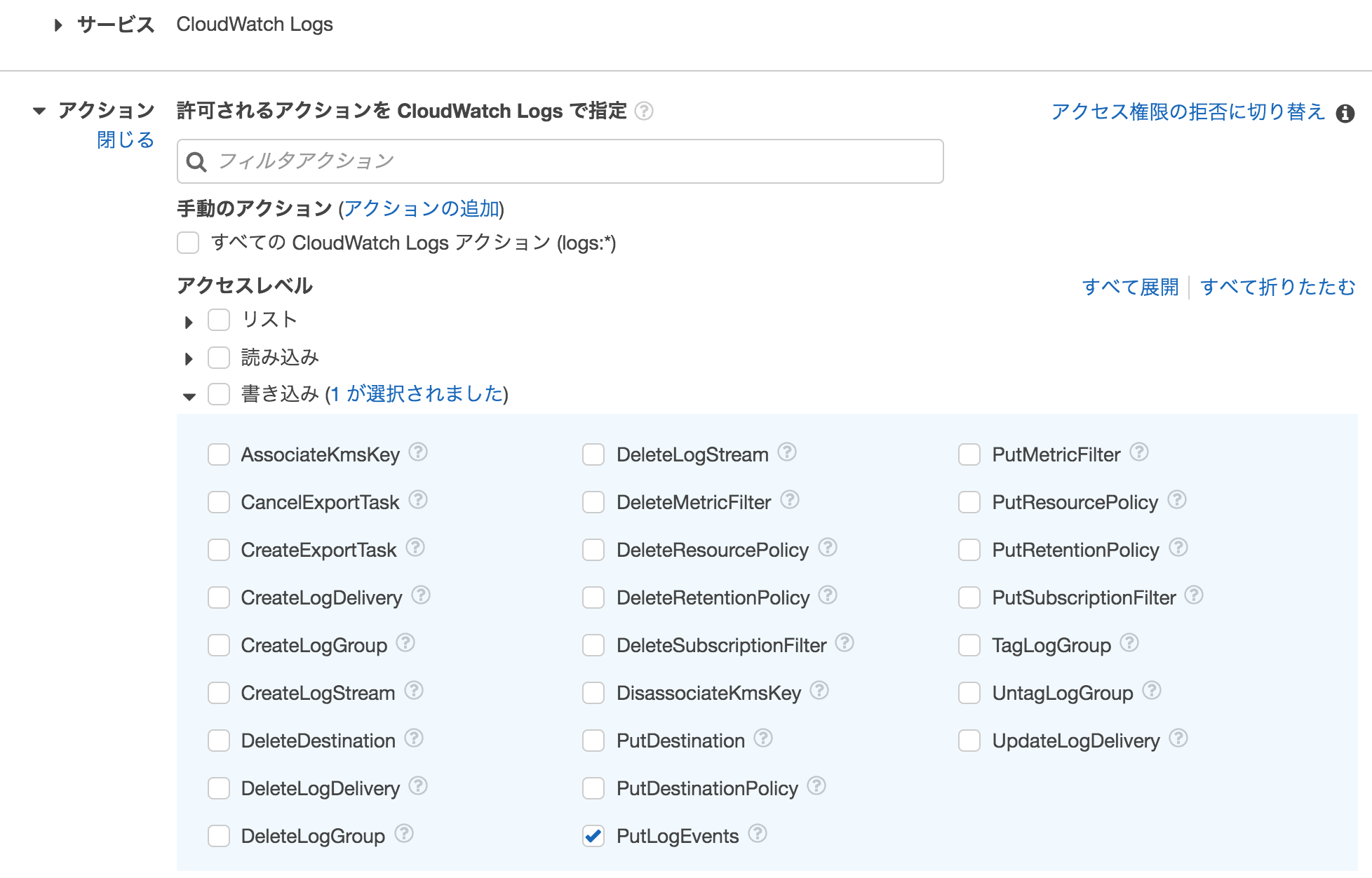
CloudWatch logサービスへの書き込み許可が設定されています。また、CloudWatch logsの
CreateLogStream,PutLogEventsアクションに対して書き込み許可が設定されています。このうち
CreateLogStreamの書き込み許可を外すことで、自動でログストリームが作成されないため、結果としてログを出力しないように設定可能です。
上記は
CreateLogStreamの許可を外して、PutLogEventsだけが残っている状態です。ただしこの対応を行うと
console.logも出力されなくなります。Streamの作成
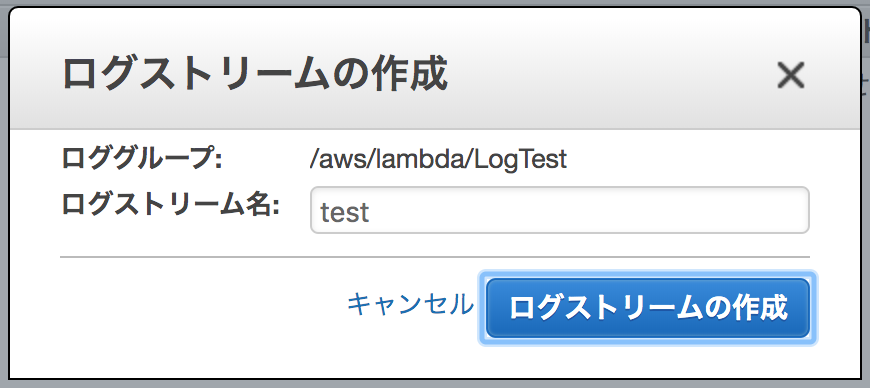
CreateLogStreamの許可を外したことで、ログストリームが自動で作成されなくなりました。
そのため、ログストリームを手動で作成します。CloudWatchのロググループでログストリームの作成を行ってください。
手動でログ出力
では残りはログを出力する処理を書いていきます。
ログの出力は
aws-sdkを利用します。
では全体的なコードをお見せします。ログ出力Lambdaconst LOG_GROUP_NAME = '/aws/lambda/loglog'; const LOG_STREAM_NAME = 'test'; const AWS = require('aws-sdk'); const cloudwatchlogs = new AWS.CloudWatchLogs({region: 'ap-northeast-1'}); const outLog = async (msg) => { const describeParams = { logGroupName: LOG_GROUP_NAME, logStreamNamePrefix: LOG_STREAM_NAME, }; const data = await cloudwatchlogs.describeLogStreams(describeParams).promise(); console.log(data); let sequenceToken = null; if (data.logStreams[0]) { sequenceToken = data.logStreams[0].uploadSequenceToken; } console.log('sequenceToken:' + sequenceToken); const params = { logEvents: [{ message: msg, timestamp: Date.now() }], logGroupName: LOG_GROUP_NAME, logStreamName: LOG_STREAM_NAME, sequenceToken: sequenceToken, }; console.log('put start'); await cloudwatchlogs.putLogEvents(params).promise(); console.log('put end'); }; exports.handler = async (event) => { await outLog('log test'); const response = { statusCode: 200, body: JSON.stringify('Hello from Lambda!'), }; return response; };解説
ログの出力は
putLogEventsメソッドを利用します。putLogEvents AWSドキュメント入力パラメータには、ログを出力するためのロググループやログストリーム、出力するメッセージなどを指定してください。
PutLogEventsを2回以上呼び出すとsequenceTokenを付与しないと拒否されてしまいます。
そのため、describeLogStreamsメソッドを利用して、uploadSequenceTokenを取得し、その値をPutLogEventsに渡してあげています。
describeLogStreams AWSドキュメント今回
outLogというfunctionを作成しましたが、どのLambdaでも使うということであれば、Lambda-Layerにしてしまうのも良いと思います。その他
今回の対応では
CreateLogStreamを拒否にしましたが、CreateLogStreamは許可としつつ、
PutLogEventsで許可するリソースを一部に限定(例えば固定値+日付など)にすることで、Lambdaでログストリームの作成+作成したログストリームにログ出力などの対応でも問題ありません。
その方がログが整理されて出力可能なのでより良いと思います。

- 投稿日:2020-03-14T09:34:10+09:00
kubernetesとEKS早わかりまとめ
概要
- 自分のkubernetesの理解促進のために、kubernetes(とAWS EKS)に関することをざっとまとめています
kubernetesとは
- ものすごく雑にいうと、複数コンテナのオーケストレーションを管理するためのシステムであり、リモート環境上で複数コンテナに対してdocker-composeみたいに管理できる代物
- wiki曰く、
- コンテナ化したアプリケーションのデプロイ、スケーリング、および管理を行うための、オープンソースのコンテナオーケストレーションシステム
- Kubernetesの目的は、「ホストのクラスターを横断してアプリケーションコンテナを自動デプロイ、スケーリング、操作するためのプラットフォーム」を提供することとされている
- Docker単体では、複数のDockerコンテナ群(マイクロサービスの集まり)を管理するのが難しいという欠点があるので、個々のDockerコンテナをオーケストレーションするために使われてる
- 元々はGoogleが作ってたけど、今ではCNCF(Cloud Native Computing Foundation)がメンテしてる
- CNCF基準では
Graduatedレベルであり、品質や安定性はかなりあるっぽい- CNCFによるメンテや、GoogleがkubernetesをGKEとして取り入れたりしてるので、コンテナオーケストレーションエンジンの中ではデファクトに近い存在
特徴
- コードでインフラが管理でき、コンテナのスケーリングやコンテナ間通信とかが楽にできるのがメリット
Infrastracture as Code
- YAML/JSON形式(マニフェストという)でデプロイするコンテナや周辺リソースの管理をできる
スケーリング/オートスケーリング
- 同一コンテナイメージを元に、複数のkubernetes Nodeにレプリカをデプロイできる
スケジューリング
- どのkubernetes Nodeにどんなコンテナをどのように配置するかのスケジューリングが可能
- 例えばAWSのアベイラビリティゾーンやインスタンスタイプなどを指定できる
リソース管理
- 特別な設定をしていない場合には、kubernetesがkubernetes NodeのCPUやメモリの空きリソースを見てコンテナ配置のスケジューリングを自動で行う
セルフヒーリング
- kubernetesはコンテナのプロセス監視を行なっており、コンテナのプロセスが停止した場合には、自動的に再デプロイできる
サービスディスカバリとロードバランシング
- kubernetesはロードバランシング機能を持っており、設定したコンテナ間のルーティングが可能
- スケール時の自動追加/削除はもちろん、障害時における切り離しや、ローリングアップデート時における事前の切り離しなども自動で行える
- 個々のコンテナ同士がお互いに参照できるようにサービスディスカバリ機能を有する
全体的な構成
- kubernetesのアーキテクチャ図がわかりやすいかもです(概念的に押さえといたほうが良さそうなところは赤枠で囲ってます)
- 開発者はkubectlというコマンドを介して、kubernetesのマスターノード(図の左のでかい箱)にいろんな命令を送り、マスターノードが各ノード(図の右側の2つの箱)を管理しています
- NodeはPodというアプリケーション単位の集まりを管理しています
Master Node
- すべてクラスター内の単一ノードで実行される状態を管理するプロセスの集合であり、クラスターの望ましい状態を維持する責務を持つ
Node
- Kubernetesにおけるワーカーマシンで、1つのVMまたは物理的なマシン
- 各ノードにはPodを動かすために必要なサービスが含まれており、マスターコンポーネントによって管理されています
- アプリケーションとクラウドワークフローを実行するマシン(VM、物理サーバーなど)
- Kubernetesマスターが各ノードを制御するが、運用者自身がノードと直接対話することはほとんどない
Pod
- Node上で管理されており、1つ追上のコンテナからなるコンテナの集合体である
- デプロイされたアプリケーションがPodの中にあるイメージ
- 密接に関わるアプリケーション同士を1つのPodにまとめて管理する
- Podの中ではコンテナは同一のstorageやnetworkを共有している
- Nodeの中に複数のPodが存在するイメージ
- 以下はPodとノードについてより拝借


AWS EKSについて
Amazon Elastic Kubernetes Service (EKS) は、AWS で Kubernetes を簡単に実行できるマネージド型の Kubernetes サービスです。お客様独自の Kubernetes コントロールプレーンをインストール、運用、保守管理する必要はありません。Amazon EKS は Kubernetes 準拠を認定されているため、アップストリームの Kubernetes で実行されている既存のアプリケーションは Amazon EKS と互換性があります。
Amazon EKS は、コンテナの起動と停止、仮想マシン上のコンテナのスケジューリング、クラスターデータの保存などのタスクを担当する Kubernetes コントロールプレーンノードの可用性とスケーラビリティを自動的に管理します。Amazon EKS では、各クラスターのコントロールプレーンの異常なノードを自動的に検出し、置換を行います。
Amazon Elastic Container Service for Kubernetes (EKS)の所感によると、
Kubernetesマスタ(Etcd + Controller Node)のマネージドサービスです。
とまぁ、コントロールプレーン(いわゆる、Master Node)をマネージドでやってくれるようで、雰囲気としては、以下の図の感じだそうです(出典:10分くらいでわかる、KubernetesとEKSの何が便利なのか)
コントロールプレーンの運用(冗長化やバックアップなど)はかなり大変らしく、それがマネージドになるのはありがたいそうな。
特徴
Workerノードのデプロイはスコープ外
- デプロイメントツールやCloudFormationを利用して、EKS + Workerノードをセットでつくる必要あり。または、EKSをポチポチしてMasterノードをつくり、EC2インスタンスをポチポチして AnsibleやkubeadmでプロビジョニングすることでWorkerをつくる必要がある
AWSユーザとKubernetesユーザの一元管理サポート
- AWS IAMユーザ、IAMロールとKubernetesユーザの変換をサポート
Kubernetesのネットワークレベルアクセス制御サポート
- CalicoというKubernetes界隈で標準的に使われているOSSを利用するようです
ECSとの違い
- プラットフォームの上でものを作るということが割と参考になるかもしれません
ECSについて
1つ1つのサービスにはそれぞれの責務の範囲が明確にあり、ユーザーはそれらをビルディング・ブロックとして組み合わせることでシステムを作っていく. 各 AWS サービスはそれぞれの API を呼ぶ形で疎結合に組み合わせることができ、一部のブロックを他のブロックに、例えば ECS から Lambda に置き換えられる. この思想と哲学が、AWS が幅広いユースケースをカバーすることを可能にし、ユーザーが AWS 上で持続可能なシステム構築と運用を行うことを可能にしていると言えます.
AWS そのものがプラットフォームであり、ECS はそんなプラットフォームの機能の一部として、ユーザーがコンテナを使って解決したい課題を解くためのサービスという関係性です.
EKSについて
かたや、Kubernetes というソフトウェアは、ユーザー自身が独自の哲学に基づいてそんなプラットフォームを作り上げることを可能にするものです1. つまり、Kubernetes を AWS 上で実行するということは、Platform on Platform の状態を作り上げていることになり、そこには2つの思想と2つの哲学が親子関係を持っていることになります.
要は
- AWSの思想に則ってやる場合にはECSで、kubernetesの思想に則ってやる場合にはEKS
- 優劣というかは、どのプラットフォームでやる必要があるかなどを考える必要がありそう
そのほか
- AWS re:Invent 2019でKES向けのFargateも登場した
- [AWS re:Invent 2019] Amazon Fargate for Amazon EKSが発表されました
- ECSのFargate同様、めちゃくちゃ凝ったEC2を自前で作り込む必要がない場合には、Fargateにしたほうが運用管理は楽っぽい
参考
kubernetes
- Wiki Kubernetes
- kubernetes(本家サイト)
- 特にKubernetesの基本を学ぶとコンセプトが結構全体に関する説明載ってます
- Kubernetes完全ガイド
- 今さら人に聞けない Kubernetes とは?
- 【レポート】Kubernetes on AWS(Amazon EKS実践入門) #AWSSummit(classmethod)
- Amazon EKSとECSの最新事例を聞いてきた( JAWS-UG コンテナ支部 #14 #jawsug_ct )
- Kubernetesの基礎
ECS - EKSの使い分けとか
そのほか




- 投稿日:2020-03-14T09:02:48+09:00
AWS DynamoDB(NoSQL)のテーブル定義書について
アトリビュートがアイテムごとに違うので自由度が高い。
その分、テーブル定義書が書きにくいなーと思いました。サンプルのテーブル定義書をみても、
内容が全然頭に入ってこないし(笑)自分で考えてみました。
記入する項目は以下
テーブル名
モード(オンデマンド or ・・・)
ポイントインタイムリカバリの有無
暗号化
アトリビュート(日本語)
アトリビュート
アトリビュートを登録するプログラム一覧
型
プライマリキーの印(パーティションキー、ソートキー)
グローバルインデックスの印(パーティションキー、ソートキー)
ローカルインデックスの印(パーティションキー、ソートキー)
登録値サンプル
備考
TTLの項目に印
インデックスの射影項目の記載さ、これでファイル作ってみろって話ですが、一旦ここまでです。
- 投稿日:2020-03-14T08:58:56+09:00
EC2インスタンスを立ち上げた時に真っ先にやること + nginxのインストール
railsアプリをEC2を使って立てていて、その途中のメモ書きです。
インスタンス立ち上げ後に実行するコマンドを書きなぐりました。アップデート
とりあえずアップデート
$ sudo yum -y update作業用ユーザーの作成
railsアプリ用のユーザーを作成します。
$ sudo useradd -m hoge_user $ sudo passwd hoge_userパッケージのインストール
使いそうなやつを適当にインストールします。
$ sudo yum install -y git gcc-c++ glibc-headers openssl openssl-devel readline readline-devel zlib zlib-devel bzip2 tar make wgetタイムゾーン設定
$ sudo vi /etc/sysconfig/clockタイムゾーンを"UTC"から"Japan"に変更します。
clock# ZONE="UTC" ZONE="Japan" UTC=trueシンボリックリンクを貼って再起動
$ sudo ln -sf /usr/share/zoneinfo/Japan /etc/localtime $ sudo rebootおまけ:Nginxのインストール
ec2では
yum install nginxと実行すると以下の出力がされます。[hoge_user@ip-xxx-xxx-xxx-xxx ~]$ sudo yum install nginx Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 2.4 kB 00:00:00 No package nginx available. Error: Nothing to do nginx is available in Amazon Linux Extra topics "nginx1.12" and "nginx1" To use, run # sudo amazon-linux-extras install :topic: Learn more at https://aws.amazon.com/amazon-linux-2/faqs/#Amazon_Linux_Extrasec2の場合は専用のやり方があります。
$ sudo amazon-linux-extras install -y nginx1.12sudo systemctl enable nginx ## 自動起動設定 sudo systemctl start nginx ## 起動 sudo systemctl status nginx ## ステータス確認 sudo systemctl stop nginx ## 停止 sudo systemctl reload nginx ## 再ロード参考
Amazon EC2のタイムゾーンを日本時間に変更する方法
EC2にyumでNginxをインストールしようとしたらできなかった話
- 投稿日:2020-03-14T08:35:04+09:00
AWS EC2 にローカルのキーペアを登録する
マネジメントコンソールや CLI でキーペアが作成できますが、初回のみとはいえ秘密鍵を転送するのはあまり気持ちが良くないので、ローカルで作成した SSH 鍵を登録する。
KEY_NAME=$(whoami)@$(hostname -s) aws ec2 import-key-pair --key-name ${KEY_NAME} --public-key-material file://~/.ssh/id_rsa.pub
- 投稿日:2020-03-14T08:19:12+09:00
Rails アプリで S3 の権限制御を外さずに署名付きURLの署名を省いてファイルアクセスする方法を調べた
はじめに
Rails アプリを用いて、S3 の権限制御を外さずに署名付きURLを省いてアクセスする方法について調べたので、その方法をまとめておきます。
背景
S3 バケット内のファイルに権限制御を入れ、そのファイルに対してアクセスするとき、署名付きURLを用いることがあると思います。こんなURLですね。(クレデンシャルはマスクしています)
https://example.s3-ap-northeast-1.amazonaws.com/foo/bar/piyo.txt/?X-Amz-Expires=-0000000000&X-Amz-Date=0000000000000000&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AAAAAAAAAAAAAAAAAAAA/00000000/ap-northeast-1/s3/aws4_request&X-Amz-SignedHeaders=host&X-Amz-Signature=0000000000000000000000000000000000000000000000000000000000000000しかしURLについた署名が、外部ライブラリを使っているときにノイズになることがあります。
例えば本のビューアーや写真のアルバムのようなライブラリを Rails アプリ上で扱っていると、ライブラリでは画像のファイル群をファイル指定で逐一アクセスするというような処理が走ることがあります。
おおよそそのような外部ライブラリは、アプリの同サーバ上のパブリックにアクセスできるディレクトリに画像ファイル群がおかれ、そこに対してアクセスするというケースを想定して作られていることが多いと思います。外部ライブラリ側では画像ファイルについた署名を考慮せずアクセスし、想定通り動かない、ということが起きがちです。
そのため、権限制御を入れたままで、署名付きURLを省いた URL で S3 バケット内のファイルにアクセスできるようにできないかを調べていました。
どうやったか
Rails アプリのルーティングで、S3 バケットのファイルパスをある種プロキシし、実際の S3 バケットの署名付きURLにリダイレクトするみたいな仕組みにしてみました。
以下、やりかたを簡単にまとめます。
ユースケース
以下のファイルに、署名付きURLなしでリクエストしたいとします。
- バケットURL:
https://example.s3-ap-northeast-1.amazonaws.com- ファイルパス:
foo/bar/piyo.txtイメージとしては、Rails の URL を
https://rails-sample.comとしたら、以下URLで S3 ファイルにアクセスできるようにしたいです。
https://rails-sample.com/remote_storages/proxy/foo/bar/piyo.txtワイルドカードセグメントを使った Rails のルーティングを作る
まず、ルーティング用のコントローラーを作りますが、その時のルーティング設定では、ワイルドカードセグメントを使います。
ワイルドカードセグメントとは、最初にアスタリスク(
*) がついた部分のパラメータのことで、ルーティングのある位置から下のすべての部分にパラメータを展開させるために利用できます。例えば
RemoteStoragesControllerというコントローラーで#proxyという get メソッドを作るとしたら、以下のようになります。resources :remote_storages, only: [] do collection do get 'proxy/*path', to: 'remote_storages#proxy', as: 'proxy' end end上記により、
pathにはfoo/bar/piyo.txtというようなスラッシュ有りのパラメータを渡すことができるようになります。コントローラー作成
次にコントローラーを作ります。以下では S3 へのアクセスは fog を使っていますが、AWS SDK を使っても良いと思います。
以下では
proxyメソッドに渡ってきたpathと拡張子formatに応じて、署名付きURLにリダイレクトするという処理を作っています。
検証してみてわかったのですが、ワイルドカードセグメントには.txtのような拡張子は渡ってきませんでした。代わりに、formatというパラメータにtxtという文字列が入ってくるため、メソッド内で再度ファイルパスを作り直しています。また、アクセスキーやバケットは
Rails.application.secretsで秘匿化すると良さそうです。class RemoteStoragesController < ApplicationController def proxy s3_bucket = Fog::Storage.new( provider: 'AWS', aws_access_key_id: 'xxx', aws_secret_access_key: 'xxx', region: 'ap-northeast-1' ).directories.get('example') # 拡張子は *path に入らず :format に入るためここで調整している path = "#{params[:path]}.#{params[:format]}" redirect_to s3_bucket.files.get_https_url(path, 1.minutes.since.to_i) end endこれによって、以下にアクセスすると、
https://rails-sample.com/remote_storages/proxy/foo/bar/piyo.txt以下ファイルパスの署名付きURLにリダイレクトするということができます。
https://example.s3-ap-northeast-1.amazonaws.com/foo/bar/piyo.txtおわりに
今回 Rails ルーティングにワイルドカードセグメントというものがあることを初めて知りました。
ただ、ワイルドカードで渡すとどんな文字列も渡せるようになるため、セキュリティを考慮してある程度のパラメータチェックは入れたほうが良いのかなと思います。
参考
- 投稿日:2020-03-14T02:15:13+09:00
【EC2】本番環境で反映されない!?本番環境エラー時log確認系コマンド【リリース前】
こんばんみ
おささです
さ、前置きはダラダラ書かず
log確認行きまっしょい!
EC2関係のエラーで役立つlog確認コマンド
まずはEC2サーバーにログインしてね!
その後
[ec2-user@ip-アドレス〜]$ cd /var/www/確認したいリポジトリ名/current/log
↓
[ec2-user@ip-アドレス log]$ ls
↓
[ec2-user@ip-アドレス log]$ ls
production.log unicorn.stderr.log unicorn.stdout.log
↑ ↑ ↑上記、3つのlogが出てきたら準備OK!
(これらがなければ、本番環境構築時のミスがあるかも?)あとは、確認したいlogの前に less をつけて、これらを確認!
【例】→ [ec2-user@ip-アドレス log]$ less production.log
ちなみにproduction.logを見れば、
・syntax errorなのか
・method errorなのか
・unknown errorなのか 等ざーっくりとしたerror箇所は確認できます。
もっと詳しくエラー内容を知りたい!
[ec2-user@ip-アドレス log]$ tailf production.log
これで、もっと詳しいエラー内容を見ることができます?
※「この引数がおかしいよ!」みたいに。その他
ⅰnginxの再読込&再起動
[ec2-user@ip-アドレス リポジトリ名]$ sudo service nginx reload
[ec2-user@ip-アドレス リポジトリ名]$ sudo service nginx restartMySQL(お使いの方は)の再起動
[ec2-user@ip-アドレス リポジトリ名]$ sudo service mysqld restartunicornのmasterをkill
[ec2-user@ip-アドレス リポジトリ名]$ ps aux | grep unicorn
[ec2-user@ip-アドレス リポジトリ名]$ kill マスターの番号gitを最新にpull
[ec2-user@ip-アドレス リポジトリ名]$ git pull
[ec2-user@ip-アドレス リポジトリ名]$ git log ←一番上のlogが最新になっているか確認をしてね!なども有効ですので、参考までに♪