- 投稿日:2020-02-22T23:57:30+09:00
numpyの1次元配列のshapeがややこしかった
概要
numpy初心者向けの記事です。Pythonを使い始めて間もない頃、1行列のshapeの出力について勘違いしてました。割と引っかかりやすいんじゃないかなと思い、実例をもとに共有いたします。
例
まず以下のarrayのshapeを見てみる。
a = np.array([[1, 2, 3], [4, 5, 6]]) print(a.shape)出力は以下のようになります。
(2, 3)左側に行列の行、右側に列が表示される。数学的にも2行3列と表現されるので納得。
\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix}行を一つ減らして、再びshapeを出力してみる。
b = np.array([1, 2, 3]) print(b.shape)出力は以下。
(3, )...? 1行3列で、(1, 3) が出力されると思ったけど違った。。
以下のように行列積を計算してみる
a = np.array([2, 2]) b = np.array([[1, 2], [3, 4]]) print(np.dot(a, b)) print(np.dot(b, a))すると、結果は
[ 8 12] [ 6 14]行列積の計算の際は、もう一つの行列の shape に応じて、柔軟に行ベクトル、列ベクトルとして計算してくれることがわかる。
まとめ
一次元配列のshapeは要素が1個のタプルになり、(要素数, )として表現される。数学的には1つの行のみを持つ行列を行ベクトル、1つの列のみを持つ行列を列ベクトルと呼ぶが、ndarrayの一次元配列では行ベクトルと列ベクトルの区別はない。
- 投稿日:2020-02-22T23:29:45+09:00
SIRモデル計算プログラムをGUI化する
はじめに
前回の記事に、感染症の拡散を説明するSIRモデルについて説明しました。その時に、SIRモデルを解く数値積分のPythonプログラムも掲載しました。今回の記事には、そのPythonプログラムをGUI化してみます。
前回の記事:感染病の数学予測モデル (SIRモデル):事例紹介(1) https://qiita.com/kotai2003/items/d74583b588841e6427a2
GUIの説明
自分が作ったプログラムをGUI化する理由は、「他人に使ってもらいたいから」です。将来的には、GUIのPyコードだけではなくて、setup.exeの形で配布したいと思います。
まず、今回に作成したGUIの画面構成です。SIRモデルの感染率(Beta)と除去率(Gamma)を右側の空欄に入力し、その下のDrawボタンを押すと、SIRモデルの計算結果が中央の画面にプロットされます。
\begin{align} \frac{dS}{dt} &= -\beta SI \\ \frac{dI}{dt} &= \beta SI -\gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align}\begin{align} S &: 感染可能者 \quad \text{(Susceptible)} \\ I &: 感染者 \quad \text{(Infectious)} \\ R &: 感染後死亡者、もしくは免疫を獲得した者 \quad \text{(Removed)} \\ \beta &: 感染率\quad \text{(The infectious rate)} \quad [1/day] \\ \gamma &:除去率\quad \text{(The Recovery rate)} \quad [1/day] \\ \end{align}初期の画面に、Typical Condition~と書いてありますが、これは感染率(Beta)と除去率(Gamma)を入力する際に参考にするためです。
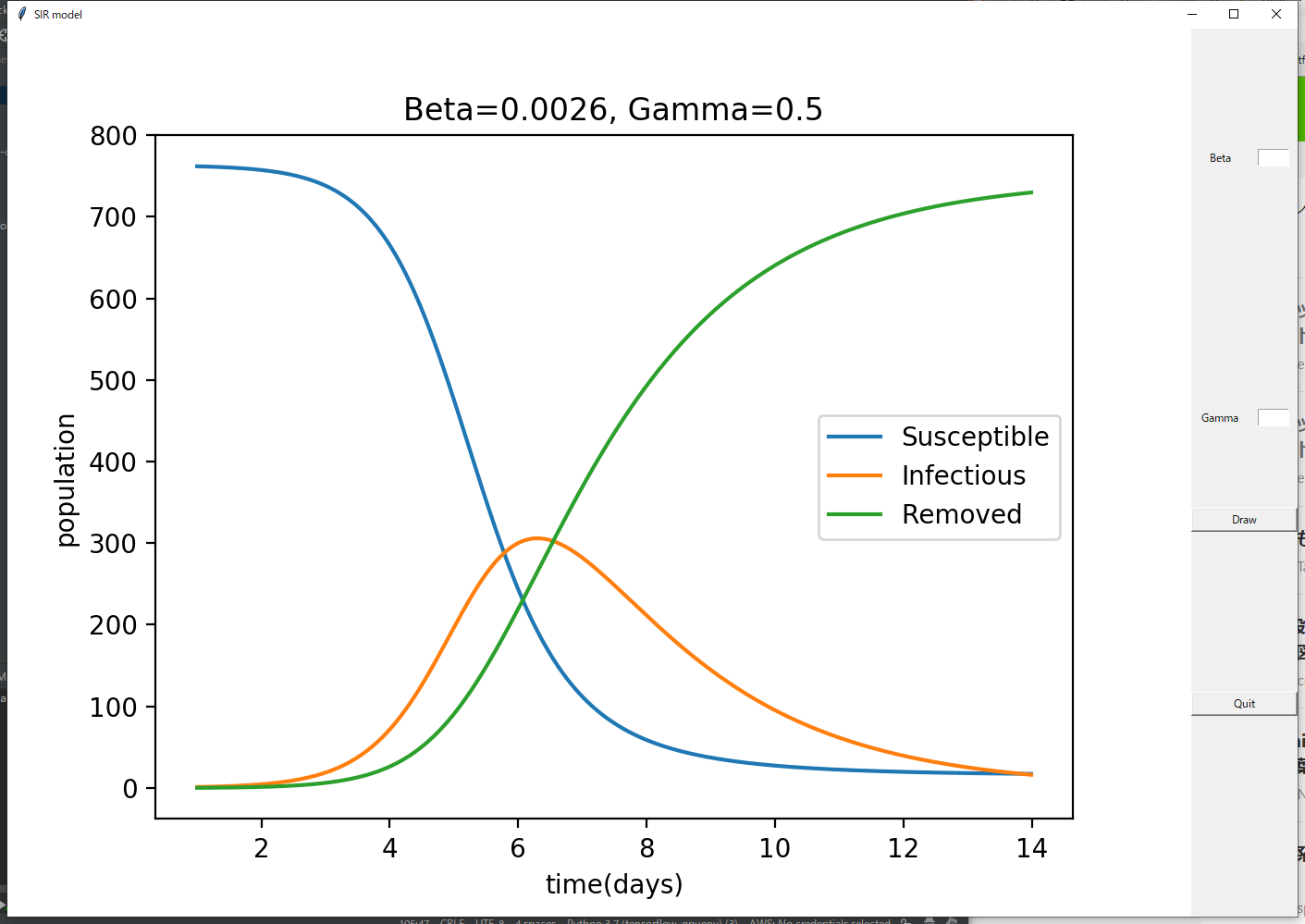
次の画面が計算結果を示します。SIRモデルの数値積分結果がLine Plotで表示されます。新しく入力した感染率(Beta)と除去率(Gamma)の値が、タイトルに更新されます。
GUIの終了は、右下のQuitボタンを押すことで実行されます。
プログラムの説明
GUIのライブラリは、Tkinterを利用しました。
簡単にプログラムの動作を説明します。(1) TkinterでCanvas Widgetを用意する。 TkinterのEntry Widgetで、感染率(Beta)と除去率(Gamma)を入力するテキストボックスを用意する。
(2) scipyでSIRモデルを計算し、その結果をmatplotlibでプロットする。
(3) matplotlibのFigureを Canvas WidgetでDrawする。必要なライブラリをインポートします。
import tkinter import tkinter.messagebox as tkmsg import matplotlib.pyplot as plt from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg from matplotlib.backends.backend_tkagg import NavigationToolbar2Tk import numpy as np from functools import partial from scipy.integrate import odeintSIRモデルの数値積分に必要な関数を用意します。
# SIR Differential Equation def SIR_EQ(v, t, beta, gamma): ''' dS/dt = -beta * S * I dI/dt = beta * S * I - gamma * I dR/dt = gamma * I [v[0], v[1], v[2]]=[S, I, R] dv[0]/dt = -beta * v[0] * v[1] dv[1]/dt = beta * v[0] * v[1] - gamma * v[1] dv[2]/dt = gamma * v[1] ''' return [-beta*v[0]*v[1], beta * v[0] * v[1] - gamma * v[1], gamma * v[1]] # Solving SIR Equation def Calc_SIR(var_b, var_r): # parameters t_max = 14 dt = 0.01 #beta_const = 0.0026 #gamma_const = 0.5 beta_const = var_b gamma_const = var_r # initial_state S_0 = 762 I_0 = 1 R_0 = 0 ini_state = [S_0, I_0, R_0] # [S[0], I[0], R[0]] # numerical integration times = np.arange(1, t_max, dt) args = (beta_const, gamma_const) # Solver SIR model result = odeint(SIR_EQ, ini_state, times, args) return times,resultTkinterのボタンのEventの時に実行される関数を用意します。
DrawCanvas関数に、matplotlibのaxesインスタンス(=ax)を用意し、そのインスタンスをプロットする仕組みです。最後のcanvas.draw()で、matplotlibのaxesインスタンスが、canvas widgetに表示されることになります。def Quit(): tkmsg.showinfo("Tomomi Research Inc.","Thank you for running this program!") root.quit() root.destroy() #Draw Button def DrawCanvas(canvas, ax): value_beta = EditBox_beta.get() value_gamma = EditBox_gamma.get() if value_beta != '': EditBox_beta.delete(0, tkinter.END) EditBox_gamma.delete(0, tkinter.END) ax.cla() beta = float(value_beta) gamma = float(value_gamma) t_r, res_r = Calc_SIR(beta,gamma) ax.plot(t_r, res_r) ax.legend(['Susceptible', 'Infectious', 'Removed']) ax.set_title('Beta='+str(beta)+', Gamma='+str(gamma) ) ax.set_xlabel('time(days)') ax.set_ylabel('population') canvas.draw()この部分はメインのプログラムです。
Tkinterの各Widgetの設定は、この部分に書いてあります。if __name__ == '__main__': try: # GUI generate root = tkinter.Tk() root.title("SIR model") # Graph setting fig, ax1 = plt.subplots() #fig.gca().set_aspect('equal', adjustable='box') # グラフ領域の調整 #get current axes ax1.set_title('Typical Condition: beta=0.0026, gamma=0.5, $S_0$=762, $I_0$=1') # Generate Canvas Canvas = FigureCanvasTkAgg(fig, master=root) Canvas.get_tk_widget().grid(row=0, column=0, rowspan=10) #Beta EditBox_beta = tkinter.Entry(width=5) # テキストボックスの生成 EditBox_beta.grid(row=1, column=2) GridLabel_beta = tkinter.Label(text="Beta") GridLabel_beta.grid(row=1, column=1) # Gamma EditBox_gamma = tkinter.Entry(width=5) # テキストボックスの生成 EditBox_gamma.grid(row=4, column=2) GridLabel_gamma = tkinter.Label(text="Gamma") GridLabel_gamma.grid(row=4, column=1) # ボタンに関する諸々の設定 ReDrawButton = tkinter.Button(text="Draw", width=15, command=partial(DrawCanvas, Canvas, ax1)) # ボタンの生成 ReDrawButton.grid(row=5, column=1, columnspan=2) # 描画位置(テキトー) QuitButton = tkinter.Button(text="Quit", width=15, command=Quit) # ボタンの生成 QuitButton.grid(row=7, column=1, columnspan=2) # 描画位置(テキトー) DrawCanvas(Canvas, ax1) root.mainloop() except: import traceback traceback.print_exc() finally: input(">>") # エラー吐き出したときの表示待ちまとめ
Python GUIのライブラリには、Tkinterと PyQTが有名だそうですが、Tkiknterが初心者にもプログラムしやすいと聞いたため、Tkinterを選んでみました。今だにもPyQTに興味がありますので、両方使ったことがある方は、コメントを残していただければと思います。
PythonのGUIのメリットは、Cross Platformであることだと思います。プログラムを一つ作成すれば、変更なしにWindows, Mac OS, Linuxに使えることが可能です。現在、WindowsでDeep Learningのプログラムを開発し、Nvidia製のJetson系(Linux)に実装することを考えています。その時、Python GUIが大変役に立つと思います。
参考資料
- MatplotlibにGUI(Tkinter)を組み合わせる話 https://www.shtsno24.tokyo/2018/12/matplotlibguitkinter.html
- Matplotlib&Seaborn実装ハンドブック https://amzn.to/2ujQ2CL
- 感染病の数学予測モデルの紹介 (SIRモデル)https://qiita.com/kotai2003/items/3078f4095c3e94e5325c
- 感染病の数学予測モデル (SIRモデル):事例紹介(1) https://qiita.com/kotai2003/items/d74583b588841e6427a2

- 投稿日:2020-02-22T22:49:40+09:00
AtCoder Beginner Contest 156 参戦記
AtCoder Beginner Contest 156 参戦記
ABC156A - Beginner
4分で突破. 書くだけ.
N, R = map(int, input().split()) if N >= 10: print(R) else: print(R - 100 * (10 - N))ABC156B - Digits
2分で突破. 書くだけ. K進数の 10 は K で、100 は K2 だと分かっていれば、K で何回割れるか調べるだけと分かるはず.
N, K = map(int, input().split()) result = 0 while N != 0: result += 1 N //= K print(result)ABC156C - Rally
3分半で突破. 書くだけ……なのは、この計算をしなれてるからなんですが. (Xi−P)2 が最小になる P は重心. 減色の K-means で3次元のこの計算をしてます…….
N = int(input()) X = list(map(int, input().split())) P = int(sum(X) / N + 0.5) print(sum((x - P) * (x - P) for x in X))ABC156D - Bouquet
70分半で突破. まず nC0+nC1+...+nCn = 2n を知っていないといけない. 私は知りませんでした orz. パスカルの三角形の Wikipedia 見てたら書いてあって知りました. これで過去に書いた mpow と mcomb を貼って終わりかと思ったら n! を求める部分があって 2≤n≤109 に殺される. a, b はたかだか 105 であることに気づき、nCk を求める別の式に組み替えてようやく解けた. 良問!
def mpow(x, n): result = 1 while n != 0: if n & 1 == 1: result *= x result %= 1000000007 x *= x x %= 1000000007 n >>= 1 return result def mcomb(n, k): a = 1 b = 1 for i in range(k): a *= n - i a %= 1000000007 b *= i + 1 b %= 1000000007 return a * mpow(b, 1000000005) % 1000000007 n, a, b = map(int, input().split()) result = mpow(2, n) - 1 result -= mcomb(n, a) result + 1000000007 result %= 1000000007 result -= mcomb(n, b) result + 1000000007 result %= 1000000007 print(result)
- 投稿日:2020-02-22T22:30:49+09:00
BigQuery Storage APIを使ってみた
はじめに
基本的な機械学習の手順:②データを準備しようでは、BigQueryで作ったテーブルをPytohn環境にPandas Dataframe形式で取り込む処理をしてきました。
ただ、テーブルのサイズが大きくなると、結構時間がかかってしまいます。
たぶん、そんな悩みを持つ方が多かったのでしょう。そこで出てきたのが、BigQuery Storage APIという新たなサービス。一説には7~8倍も速いと聞きましたが、どうなのでしょう。試してみたいと思います。
分析環境
Google BigQuery
Google Colaboratory参考にしたサイト
BigQuery Storage API を使用して BigQuery データを pandas にダウンロードする
対象とするデータ
用いるテーブルは、
myproject.mydataset.mytableという約100MBのテーブルです。
それを、下記の様に全件取ってくるだけというシンプルな処理で、Pandas Dataframe形式で取り込みます。query="SELECT * FROM `myproject.mydataset.mytable`1.BigQuery 標準API
まずは、これまでも使っているBigQueryの標準APIでやってみます。
import time from google.cloud import bigquery start = time.time() client = bigquery.Client(project="myproject") df = client.query(query).to_dataframe() elapsed_time = time.time() - start約120秒で処理できました。まあ、これくらいなら許容範囲ですが。
2.Pandas read_gbq
BigQueryのAPIを使わなくても、Pandasの機能でできるよね。ということで、そちらも試してみます。
import time import pandas as pd start = time.time() df = pd.io.gbq.read_gbq(query, project_id="myproject", dialect="standard") elapsed_time = time.time() - start約135秒で処理が完了。BigQueryのAPIより少し遅くなっていますね。
BigQueryの標準APIでも、Pandasの機能に比べると、何か工夫がされているようです。3.BigQuery Storage API
そして、今回のテーマであるBigQuery Storage APIの出番です。
Colabでライブラリーをimportしようとしたら、ライブラリーが無いよと言われてしまったので、まずはinstallから。pip install --upgrade google-cloud-bigquery-storageと、インストールするとランタイムの再起動を求めるメッセージが。時々他のライブラリーでも出ますが、ちょっと面倒ですね。
WARNING: The following packages were previously imported in this runtime: [google] You must restart the runtime in order to use newly installed versions.さて、ランタイムを再起動して、改めてライブラリーをimportして実行します。
import time from google.cloud import bigquery from google.cloud import bigquery_storage start = time.time() client = bigquery.Client(project="myproject") bqstorageclient = bigquery_storage.BigQueryStorageClient() df3 = ( client.query(query) .result() .to_dataframe(bqstorage_client=bqstorageclient) ) elapsed_time = time.time() - start実行時間は、なんと驚異の約12秒。標準APIの7~8倍どころか、10倍出てます。
偶然かと思って、何度かやってみましたが、1~2秒程度の誤差はあるものの、ほぼこのスピードで完了しました。おわりに
予想よりもかなり速い結果が返ってきて、ビックリしました。
普段の10倍速ければ、数GBとかのデータも短時間で取り込むことが可能ですね。(その後のPythonでの処理が重そうですが)普通にBigQueryを回すのに加えて、$1.10 per TBと費用が掛かるので、乱発はできませんが、テーブルが大きすぎてデータ取り込みに何十分も待たないといけない、というときには使っていきたいサービスですね。
- 投稿日:2020-02-22T22:07:58+09:00
python→Google Spreadsheet→LINEで、Raspberry Piでの処理状況を定期通知させる
はじめに
これを作ろうと思ったきっかけについて。
Raspberry Piでちょっとしたバッチ処理を動かすことになったのですが、Raspberry Piに限らずサーバーを長期間稼働させていると、知らぬ間にサーバー停止していた。という事象があり得ます。
また、サーバー自体は動いているけど、何かしらの理由でバッチ処理がコケ始めるということも考えられますが、流石に毎日ログインして確認するのは手間になります。
なので、Raspberry Pi上でバッチ処理が正常か異常かの結果をスマホに通知できると嬉しいと思いました。通知がない場合はサーバーで異常が起きたと判断できますし。
それを実装する一つの方法として、
1. cronでGoogle Spreadsheetにデータ更新を行うpythonプログラムを定期実行させる
2. IFTTTでGoogle Spreadsheetの更新をトリガーにLINE通知させる
上記で実現できそうだったのでやってみた。という記事でございます。
※色々手探りでやってみた感じなので、拙い感じとなってますが。。。(1) Google SpreadSheetへの投稿準備
- Python Quickstartにアクセスして、以下を実施
- "Enable the Google Sheets API"ボタンをクリックして、適当なプロジェクト名を入力。「credentials.json」をローカルに保存する
- 下記コマンドで専用のライブラリを導入する。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib投稿準備について、過去の記事で分かりやすくまとまっているのでオススメです。
https://qiita.com/connvoi_tyou/items/7cd7ffd5a98f61855f5c(2) Google SpreadSheetへの投稿用プログラムの作成
あらかじめ、Google Drive上にSpreadsheetを作成しておきます。
ファイルURLの一部をプログラム内に記述する必要があるので、控えておきます。https://docs.google.com/spreadsheets/d/<XXXXXXXXXXXXXXXXXXX>/edit#gid=zzzzzzzz # "<XXXXXXXXXXXXXXXXXXX>"を控えておく下記のような、GoogleSpreadsheetへの
「server_check.py」という名前で作っておきました。server_check.pyfrom __future__ import print_function import pickle import os.path from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request SCOPES = 'https://www.googleapis.com/auth/spreadsheets' creds = None if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open('token.pickle', 'wb') as token: pickle.dump(creds, token) service = build('sheets', 'v4', credentials=creds) # ここまではgoogle提供のガイドに記載されているものとほぼ同じ # 以下、Spreadsheet固有の情報を記入。 spreadsheet_id = '<XXXXXXXXXXXXXXXXXXX>' sheetname='シート1' range_ = sheetname # 日付情報を取得する import datetime _str_dt=datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S") # A列、B列、C列へ書き込むため、データを代入 # A列は日付を、B列、C列には任意の文字列を(今回はテスト的な文字列で代用) values = [ [_str_dt,"Status-1","Status-2"] ] body = { 'values' : values } # Spreadsheetへの書き込みを実施 result=service.spreadsheets().values().append(spreadsheetId=spreadsheet_id,valueInputOption='RAW',range=range_,body=body).execute() print(result)上記プログラムでは"Status-1"のようなテストメッセージにしています。
実際に運用させるときは、ログファイルの出力を抽出したりして、
values配列に追加する形になると思います。(3) プログラムの実行とブラウザでのアクセス許可
必要な箇所が修正できたら、上記pythonプログラムを実行します。
その際、「credentials.json」ファイルが同じディレクトリに存在している必要があります。
また、プログラムの初回実行時はブラウザ認証する必要があるため、GUI環境で実行する必要があります。実行すると、ブラウザが立ち上がりgoogleアカウントの確認ページが表示されます。画面に従ってアクセス権を付与します。
(途中、安全でないページへの警告が表示されますが続けます)
"The authentication flow has completed. You may close this window."みたいな文字がブラウザに出力されると設定完了ぽいです。アクセス権の付与が完了すると、Spreadsheetにエントリーが追加(先頭行に値が入力)されているはずです。
また、プログラムと同じディレクトリに「token.pickle」ファイルが作成されます。
このファイルがあれば、次回以降はブラウザでの認証をSKIPして、行が追加されるようになります。(4) IFTTTでの通知設定
- IFTTTアプリが必要なので、ない場合はインストール&初期セットアップ
- "Make your own Applets from scratch"でアプレットを作る
- This(トリガー)は「Google Sheets」->「New row addedto spreadsheet」
- (2)で作成したシート情報を入力する
- That(アクション)は「LINE」->「Send message」
- Recipientは"1:1でLINE Notifyから通知を受け取る"
- メッセージ本文をカスタマイズする
はまったところ
プログラム実行環境でブラウザが開けない場合
今回の最終的な目標はラズベリーパイから対象プログラムを動かすことでしたが、ラズベリーパイにはGUI環境は導入していませんでした(通常はSSH接続で作業)。
ラズベリーパイ上で"server_check.py"を実行してもブラウザが開けないため、アクセス許可の設定ができません。
*コンソール上に表示されるURLを、PC上のブラウザにコピペすると最後の画面でエラーになってしまいます。そういった場合ですが、別のGUI環境で同じプログラムを実行して、生成された「token.pickle」ファイルを対象のサーバーに配置すれば、CUI上でもプログラムを実行できると思われます。
自分は同じプログラムをMac上で実行して、生成されたtoken.pickleをラズベリーパイに送ることで、ラズベリーパイからも実行できるようになりました。プログラム実行時になんかエラーが出てしまう
たまに、プログラムを実行するとエラーが出てしまうことがありました。
[root@localhost python]# python server_check.py Traceback (most recent call last): File "server_check.py", line 17, in <module> creds.refresh(Request()) File "/usr/local/lib/python3.7/site-packages/google/oauth2/credentials.py", line 182, in refresh self._scopes, File "/usr/local/lib/python3.7/site-packages/google/oauth2/_client.py", line 248, in refresh_grant response_data = _token_endpoint_request(request, token_uri, body) File "/usr/local/lib/python3.7/site-packages/google/oauth2/_client.py", line 124, in _token_endpoint_request _handle_error_response(response_body) File "/usr/local/lib/python3.7/site-packages/google/oauth2/_client.py", line 60, in _handle_error_response raise exceptions.RefreshError(error_details, response_body) google.auth.exceptions.RefreshError: ('invalid_scope: Some requested scopes were invalid. {invalid=[a, c, d, e, g, h, i, l, m, ., /, o, p, r, s, t, u, w, :]}', '{\n "error": "invalid_scope",\n "error_description": "Some requested scopes were invalid. {invalid\\u003d[a, c, d, e, g, h, i, l, m, ., /, o, p, r, s, t, u, w, :]}",\n "error_uri": "http://code.google.com/apis/accounts/docs/OAuth2.html"\n}') [root@localhost python]#どういったエラーなのかはっきりと分からないのですが、自分は「token.pickle」を再作成すると解消しました。
再作成するには、「token.pickle」を削除してプログラムを実行すれば良いです。
ただ、またブラウザからの設定からになるので、ブラウザを開けないCUI環境は注意してください。ちなみに、どういった理由で起きるのかも不明なのですが、個人的な感覚だと下記のタイミングでエラーになった気がします。
- プログラムを大幅に改修した際
- 別のプログラムを実行して認証を行なった際
おわりに
これでバッチ処理の異常時や、サーバー停止時に早めに気づけるようになりましたが、毎日LINEがくるとちょっとうんざりですね。
本当は「便りが無いのは元気な証拠」スタイルで、異常を検知した際(サーバーから異常を検知、もしくは定時連絡がない)に、LINEへ通知させるようにしたかったのですが、それは次の課題ということで。
- 投稿日:2020-02-22T22:05:42+09:00
【Python】GoogleTranslationAPIを叩く
英語の文章を日本語に翻訳するスクリプトです。
以前のコードをクラスにしたものです。配布されているライブラリがうまく動かなかったので作成したものです。GoogleCloudのAPI Keyは取得していただく必要があります。(すぐできます)
google_translate.pyimport requests import json import time class GoogleTranslate: def __init__(self): self.private_key = '<ここにAPIKeyを入れる>' def post_text(self,text): url_items = 'https://www.googleapis.com/language/translate/v2' item_data = { 'target': 'ja', 'source': 'en', 'q':text } response = requests.post('https://www.googleapis.com/language/translate/v2?key={}'.format(self.private_key), data=item_data) return json.loads(response.text)["data"]["translations"][0]["translatedText"] def split_and_send_to_post(self,text): sen_list = text.split('.') to_google_sen = "" translated_text = "" for index, sen in enumerate(sen_list[:-1]): to_google_sen += sen + '. ' if len(to_google_sen)>1000: #1000字を超えてたらgoogleに送信 translated_text += self.post_text(to_google_sen) time.sleep(3) to_google_sen = "" if index == len(sen_list)-2: #最後の文章の翻訳 translated_text += self.post_text(to_google_sen) time.sleep(3) return translated_text def main(self,text): original_text = text if original_text[-1] != '.': original_text+='.' #.で終わっていない場合に分割処理に支障が出るので text_translated = self.split_and_send_to_post(original_text) print(text_translated) return text_translatedtest.pyfrom google_translate import * input_text = input('英語に変換して検索したいワードを日本語で入力してください:') google_tr = GoogleTranslate() translated = google_tr.main(input_text) print(translated)
- 投稿日:2020-02-22T21:58:15+09:00
ゼロから作るDeep Learningで素人がつまずいたことメモ:8章
はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep LearningーーPythonで学ぶディープラーニングの理論と実装」の8章で私がつまずいたことのメモです。
実行環境はmacOS Mojave + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章)
8章 ディープラーニング
この章は、層を深くしたディープなニューラルネットワークの説明です。
8.1 ネットワークをより深く
これまでに学んだことを使って、ディープなネットワークでMNISTの手書き文字認識の実装に挑戦します。残念ながらこの章はソースの解説が全くないので大変です。
前章までで学んだDropoutやAdamは実装をサボっていたのですが、今回使うのでここから片付けます。
(1)Dropoutレイヤーの実装
Dropoutレイヤーは本の「6.4.3 Droput」に実装の解説があるので、それを見ながら実装しました。
dropout.py# coding: utf-8 import numpy as np class Dropout: def __init__(self, dropout_ratio=0.5): """Dropoutレイヤー Args: dropout_ratio (float): 学習時のニューロンの消去割合、デフォルトは0.5。 """ self.dropout_ratio = dropout_ratio # 学習時のニューロンの消去割合 self.valid_ratio = 1.0 - self.dropout_ratio # 学習時に生かしていた割合 self.mask = None # 各ニューロンの消去有無を示すフラグの配列 def forward(self, x, train_flg=True): """順伝播 Args: x (numpy.ndarray): 入力 train_flg (bool, optional): 学習中ならTrue、デフォルトはTrue。 Returns: numpy.ndarray: 出力 """ if train_flg: # 学習時は消去するニューロンを決めるマスクを生成 self.mask = np.random.rand(*x.shape) > self.dropout_ratio # 出力を算出 return x * self.mask else: # 認識時はニューロンは消去しないが、学習時の消去割合を加味した出力に調整する return x * self.valid_ratio def backward(self, dout): """逆伝播 Args: dout (numpy.ndarray): 右の層から伝わってくる微分値 Returns: numpy.ndarray: 微分値(勾配) """ # 消去しなかったニューロンのみ右の層の微分値を逆伝播 assert self.mask is not None, '順伝播なしに逆伝播が呼ばれた' return dout * self.mask(2)Adamの実装
最適化に使うAdamは、本の「6.1.6 Adam」に簡単な解説があるのですが、簡単すぎてこれだけでは実装できません。また、本のソースを見てもアルゴリズムが良く分かりませんでした。そこでまず、 @omiita さんの 【2020決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法- で大まかな仕組みを理解しました。そして、本で紹介されている 原著論文のPDF (本の参考文献[8]のサイト Adam: A Method for Stochastic Optimization の右上からダウンロードできます)のP.2の「Algorithm 1」の説明を見ながら実装しました。英語ですが擬似コードによる20行程度の説明なので、英語が苦手な私でもなんとかなりました。パラメータの初期値も、この論文の推奨値通りにしてみました。
adam.py# coding: utf-8 import numpy as np class Adam: def __init__(self, alpha=0.001, beta1=0.9, beta2=0.999): """Adamによるパラメーターの最適化 Args: alpha (float, optional): 学習係数、デフォルトは0.001。 beta1 (float, optional): Momentumにおける速度の過去と今の按分の係数、デフォルトは0.9。 beta2 (float, optional): AdaGradにおける学習係数の過去と今の按分の係数、デフォルトは0.999。 """ self.alpha = alpha self.beta1 = beta1 self.beta2 = beta2 self.m = None # Momentumにおける速度 self.v = None # AdaGradにおける学習係数 self.t = 0 # タイムステップ def update(self, params, grads): """パラメーター更新 Args: params (dict): 更新対象のパラメーターの辞書、keyは'W1'、'b1'など。 grads (dict): paramsに対応する勾配の辞書 """ # mとvの初期化 if self.m is None: self.m = {} self.v = {} for key, val in params.items(): self.m[key] = np.zeros_like(val) self.v[key] = np.zeros_like(val) # 更新 self.t += 1 # タイムステップ加算 for key in params.keys(): # mの更新、Momentumにおける速度の更新に相当 # 過去と今の勾配を beta1 : 1 - beta1 で按分する self.m[key] = \ self.beta1 * self.m[key] + (1 - self.beta1) * grads[key] # vの更新、AdaGradにおける学習係数の更新に相当 # 過去と今の勾配を beta2 : 1 - beta2 で按分する self.v[key] = \ self.beta2 * self.v[key] + (1 - self.beta2) * (grads[key] ** 2) # パラメーター更新のためのmとvの補正値算出 hat_m = self.m[key] / (1.0 - self.beta1 ** self.t) hat_v = self.v[key] / (1.0 - self.beta2 ** self.t) # パラメーター更新、最後の1e-7は0除算回避 params[key] -= self.alpha * hat_m / (np.sqrt(hat_v) + 1e-7)(3)畳み込み層とプーリング層の出力サイズの計算
今回は層が多く、畳み込み層とプーリング層の出力サイズの計算が何度も出てきます。そのため、それぞれ
conv_output_sizeとpool_output_sizeという関数としてfunctions.pyに追加しました。他の関数は前章までのままです。functions.py# coding: utf-8 import numpy as np def softmax(x): """ソフトマックス関数 Args: x (numpy.ndarray): 入力 Returns: numpy.ndarray: 出力 """ # バッチ処理の場合xは(バッチの数, 10)の2次元配列になる。 # この場合、ブロードキャストを使ってうまく画像ごとに計算する必要がある。 # ここでは1次元でも2次元でも共通化できるようnp.max()やnp.sum()はaxis=-1で算出し、 # そのままブロードキャストできるようkeepdims=Trueで次元を維持する。 c = np.max(x, axis=-1, keepdims=True) exp_a = np.exp(x - c) # オーバーフロー対策 sum_exp_a = np.sum(exp_a, axis=-1, keepdims=True) y = exp_a / sum_exp_a return y def cross_entropy_error(y, t): """交差エントロピー誤差の算出 Args: y (numpy.ndarray): ニューラルネットワークの出力 t (numpy.ndarray): 正解のラベル Returns: float: 交差エントロピー誤差 """ # データ1つ場合は形状を整形(1データ1行にする) if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size) # 誤差を算出してバッチ数で正規化 batch_size = y.shape[0] return -np.sum(t * np.log(y + 1e-7)) / batch_size def conv_output_size(input_size, filter_size, pad, stride): """畳み込み層の出力サイズ算出 Args: input_size (int): 入力の1辺のサイズ(縦横は同値の前提) filter_size (int): フィルターの1辺のサイズ(縦横は同値の前提) pad (int): パディングのサイズ(縦横は同値の前提) stride (int): ストライド幅(縦横は同値の前提) Returns: int: 出力の1辺のサイズ """ assert (input_size + 2 * pad - filter_size) \ % stride == 0, '畳み込み層の出力サイズが割り切れない!' return int((input_size + 2 * pad - filter_size) / stride + 1) def pool_output_size(input_size, pool_size, stride): """プーリング層の出力サイズ算出 Args: input_size (int): 入力の1辺のサイズ(縦横は同値の前提) pool_size (int): プーリングのウインドウサイズ(縦横は同値の前提) stride (int): ストライド幅(縦横は同値の前提) Returns: int: 出力の1辺のサイズ """ assert (input_size - pool_size) % stride == 0, 'プーリング層の出力サイズが割り切れない!' return int((input_size - pool_size) / stride + 1)(4)ディープなCNNの実装
これで必要なパーツの実装が終わったので、いよいよネットワークの実装です。
まず、今回のネットワークにおける入出力の整理です。
レイヤー 入出力の形状 実装時の形状 $ (バッチサイズN, チャンネル数CH, 画像の高さH, 幅W) $ $ (100, 1, 28, 28) $ [1] Convolution #1 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 16, 28, 28) $ [2] ReLU #1 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 16, 28, 28) $ [3] Convolution #2 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 16, 28, 28) $ [4] ReLU #2 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 16, 28, 28) $ [5] Pooling #1 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 16, 14, 14) $ [6] Convolution #3 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 32, 14, 14) $ [7] ReLU #3 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 32, 14, 14) $ [8] Convolution #4 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 32, 16, 16) $ [9] ReLU #4 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 32, 16, 16) $ [10] Pooling #2 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 32, 8, 8) $ [11] Convolution #5 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 64, 8, 8) $ [12] ReLU #5 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 64, 8, 8) $ [13] Convolution #6 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 64, 8, 8) $ [14] ReLU #6 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 64, 8, 8) $ [15] Pooling #3 ↓ $ (バッチサイズN, フィルター数FN, 出力の高さOH, 幅OW) $ $ (100, 64, 4, 4) $ [16] Affine #1 ↓ $ (バッチサイズN, 隠れ層のサイズ) $ $ (100, 50) $ [17] ReLU #7 ↓ $ (バッチサイズN, 隠れ層のサイズ) $ $ (100, 50) $ [18] Dropout #1 ↓ $ (バッチサイズN, 隠れ層のサイズ) $ $ (100, 50) $ [19] Affine #2 ↓ $ (バッチサイズN, 隠れ層のサイズ) $ $ (100, 10) $ [20] Dropout #2 ↓ $ (バッチサイズN, 隠れ層のサイズ) $ $ (100, 10) $ [21] Softmax ↓ $ (バッチサイズN, 最終出力サイズ) $ $ (100, 10) $ 壮大な表になりましたが、これを1層ずつ実装します。
本のコードはループを使ってシンプルにまとめられていますが、各層の入出力サイズの計算が混乱しそうなので、私は1層ずつパラメーターの初期化とレイヤーの生成を実装しました。かなり泥臭いコードになっています。なお、パラメーターは「Heの初期値」で初期化しています。
deep_conv_net.py# coding: utf-8 import numpy as np from affine import Affine from convolution import Convolution from dropout import Dropout from functions import conv_output_size, pool_output_size from pooling import Pooling from relu import ReLU from softmax_with_loss import SoftmaxWithLoss class DeepConvNet: def __init__( self, input_dim=(1, 28, 28), conv_param_1={ 'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1 }, conv_param_2={ 'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1 }, conv_param_3={ 'filter_num': 32, 'filter_size': 3, 'pad': 1, 'stride': 1 }, conv_param_4={ 'filter_num': 32, 'filter_size': 3, 'pad': 2, 'stride': 1 }, conv_param_5={ 'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1 }, conv_param_6={ 'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1 }, hidden_size=50, output_size=10 ): """ディープな畳み込みニューラルネットワーク Args: input_dim (tuple, optional): 入力データの形状、デフォルトは(1, 28, 28)。 conv_param_1 (dict, optional): 畳み込み層1のハイパーパラメーター、 デフォルトは{'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}。 conv_param_2 (dict, optional): 畳み込み層2のハイパーパラメーター、 デフォルトは{'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1}。 conv_param_3 (dict, optional): 畳み込み層3のハイパーパラメーター、 デフォルトは{'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1}。 conv_param_4 (dict, optional): 畳み込み層4のハイパーパラメーター、 デフォルトは{'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1}。 conv_param_5 (dict, optional): 畳み込み層5のハイパーパラメーター、 デフォルトは{'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}。 conv_param_6 (dict, optional): 畳み込み層6のハイパーパラメーター、 デフォルトは{'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1}。 hidden_size (int, optional): 隠れ層のニューロンの数、デフォルトは50。 output_size (int, optional): 出力層のニューロンの数、デフォルトは10。 """ assert input_dim[1] == input_dim[2], '入力データは高さと幅が同じ前提!' # パラメーターの初期化とレイヤー生成 self.params = {} # パラメーター self.layers = {} # レイヤー(Python 3.7からは辞書の格納順が保持されるので、OrderedDictは不要) # 入力サイズ channel_num = input_dim[0] # 入力のチャンネル数 input_size = input_dim[1] # 入力サイズ # [1] 畳み込み層#1 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_1.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W1', 'b1' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv1'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [2] ReLU層#1 : レイヤー生成 self.layers['ReLU1'] = ReLU() # [3] 畳み込み層#2 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_2.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W2', 'b2' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv2'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [4] ReLU層#2 : レイヤー生成 self.layers['ReLU2'] = ReLU() # [5] プーリング層#1 : レイヤー生成 self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) # 次の層の入力サイズ算出 input_size = pool_output_size(input_size, pool_size=2, stride=2) # [6] 畳み込み層#3 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_3.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W3', 'b3' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv3'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [7] ReLU層#3 : レイヤー生成 self.layers['ReLU3'] = ReLU() # [8] 畳み込み層#4 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_4.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W4', 'b4' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv4'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [9] ReLU層#4 : レイヤー生成 self.layers['ReLU4'] = ReLU() # [10] プーリング層#2 : レイヤー生成 self.layers['Pool2'] = Pooling(pool_h=2, pool_w=2, stride=2) # 次の層の入力サイズ算出 input_size = pool_output_size(input_size, pool_size=2, stride=2) # [11] 畳み込み層#5 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_5.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W5', 'b5' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv5'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [12] ReLU層#5 : レイヤー生成 self.layers['ReLU5'] = ReLU() # [13] 畳み込み層#6 : パラメーター初期化とレイヤー生成 filter_num, filter_size, pad, stride = list(conv_param_6.values()) pre_node_num = channel_num * (filter_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W6', 'b6' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(filter_num, channel_num, filter_size, filter_size) ) self.params[key_b] = np.zeros(filter_num) self.layers['Conv6'] = Convolution( self.params[key_w], self.params[key_b], stride, pad ) # 次の層の入力サイズ算出 channel_num = filter_num input_size = conv_output_size(input_size, filter_size, pad, stride) # [14] ReLU層#6 : レイヤー生成 self.layers['ReLU6'] = ReLU() # [15] プーリング層#3 : レイヤー生成 self.layers['Pool3'] = Pooling(pool_h=2, pool_w=2, stride=2) # 次の層の入力サイズ算出 input_size = pool_output_size(input_size, pool_size=2, stride=2) # [16] Affine層#1 : パラメーター初期化とレイヤー生成 pre_node_num = channel_num * (input_size ** 2) # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W7', 'b7' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(channel_num * (input_size ** 2), hidden_size) ) self.params[key_b] = np.zeros(hidden_size) self.layers['Affine1'] = Affine(self.params[key_w], self.params[key_b]) # 次の層の入力サイズ算出 input_size = hidden_size # [17] ReLU層#7 : レイヤー生成 self.layers['ReLU7'] = ReLU() # [18] Dropout層#1 : レイヤー生成 self.layers['Drop1'] = Dropout(dropout_ratio=0.5) # [19] Affine層#2 : パラメーター初期化とレイヤー生成 pre_node_num = input_size # 1ノードに対する前層の接続ノード数 key_w, key_b = 'W8', 'b8' # 辞書格納時のkey self.params[key_w] = np.random.normal( scale=np.sqrt(2.0 / pre_node_num), # Heの初期値の標準偏差 size=(input_size, output_size) ) self.params[key_b] = np.zeros(output_size) self.layers['Affine2'] = Affine(self.params[key_w], self.params[key_b]) # [20] Dropout層#2 : レイヤー生成 self.layers['Drop2'] = Dropout(dropout_ratio=0.5) # [21] Softmax層 : レイヤー生成 self.lastLayer = SoftmaxWithLoss() def predict(self, x, train_flg=False): """ニューラルネットワークによる推論 Args: x (numpy.ndarray): ニューラルネットワークへの入力 train_flg (Boolean): 学習中ならTrue(Dropout層でニューロンの消去を実施) Returns: numpy.ndarray: ニューラルネットワークの出力 """ # レイヤーを順伝播 for layer in self.layers.values(): if isinstance(layer, Dropout): x = layer.forward(x, train_flg) # Dropout層の場合は、学習中かどうかを伝える else: x = layer.forward(x) return x def loss(self, x, t): """損失関数の値算出 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル Returns: float: 損失関数の値 """ # 推論 y = self.predict(x, True) # 損失は学習中しか算出しないので常にTrue # Softmax-with-Lossレイヤーの順伝播で算出 loss = self.lastLayer.forward(y, t) return loss def accuracy(self, x, t, batch_size=100): """認識精度算出 batch_sizeは算出時のバッチサイズ。一度に大量データを算出しようとすると im2colでメモリを食い過ぎてスラッシングが起きてしまい動かなくなるため、 その回避のためのもの。 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル(one-hot) batch_size (int), optional): 算出時のバッチサイズ、デフォルトは100。 Returns: float: 認識精度 """ # 分割数算出 batch_num = max(int(x.shape[0] / batch_size), 1) # 分割 x_list = np.array_split(x, batch_num, 0) t_list = np.array_split(t, batch_num, 0) # 分割した単位で処理 correct_num = 0 # 正答数の合計 for (sub_x, sub_t) in zip(x_list, t_list): assert sub_x.shape[0] == sub_t.shape[0], '分割境界がずれた?' y = self.predict(sub_x, False) # 認識精度は学習中は算出しないので常にFalse y = np.argmax(y, axis=1) t = np.argmax(sub_t, axis=1) correct_num += np.sum(y == t) # 認識精度の算出 return correct_num / x.shape[0] def gradient(self, x, t): """重みパラメーターに対する勾配を誤差逆伝播法で算出 Args: x (numpy.ndarray): ニューラルネットワークへの入力 t (numpy.ndarray): 正解のラベル Returns: dictionary: 勾配を格納した辞書 """ # 順伝播 self.loss(x, t) # 損失値算出のために順伝播する # 逆伝播 dout = self.lastLayer.backward() for layer in reversed(list(self.layers.values())): dout = layer.backward(dout) # 各レイヤーの微分値を取り出し grads = {} layer = self.layers['Conv1'] grads['W1'], grads['b1'] = layer.dW, layer.db layer = self.layers['Conv2'] grads['W2'], grads['b2'] = layer.dW, layer.db layer = self.layers['Conv3'] grads['W3'], grads['b3'] = layer.dW, layer.db layer = self.layers['Conv4'] grads['W4'], grads['b4'] = layer.dW, layer.db layer = self.layers['Conv5'] grads['W5'], grads['b5'] = layer.dW, layer.db layer = self.layers['Conv6'] grads['W6'], grads['b6'] = layer.dW, layer.db layer = self.layers['Affine1'] grads['W7'], grads['b7'] = layer.dW, layer.db layer = self.layers['Affine2'] grads['W8'], grads['b8'] = layer.dW, layer.db return grads(5)学習の実装
学習は前の章のコードとほとんど変わりません。本のコードに合わせて
Trainerクラスを実装しようかと思っていたのですが、もう最後の章になってしまって今回の実装で終わりなので従来のままにしています。更新回数は
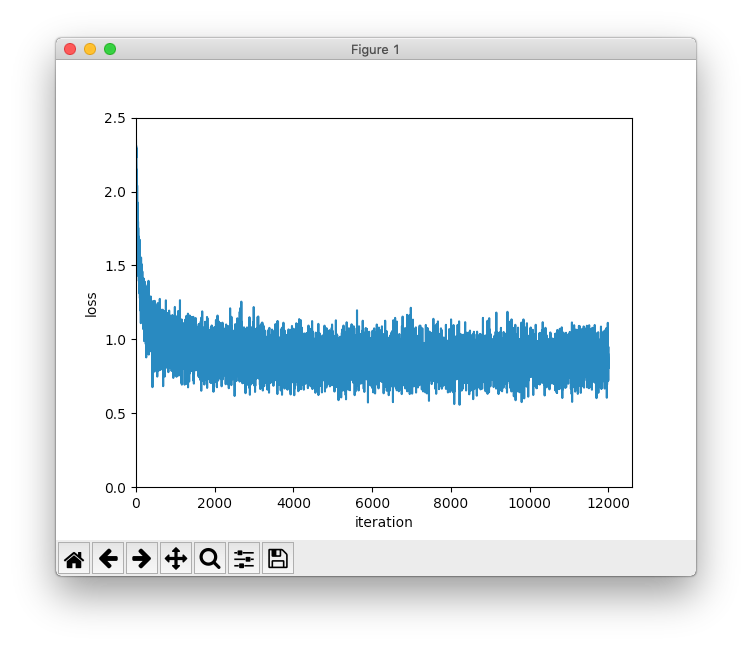
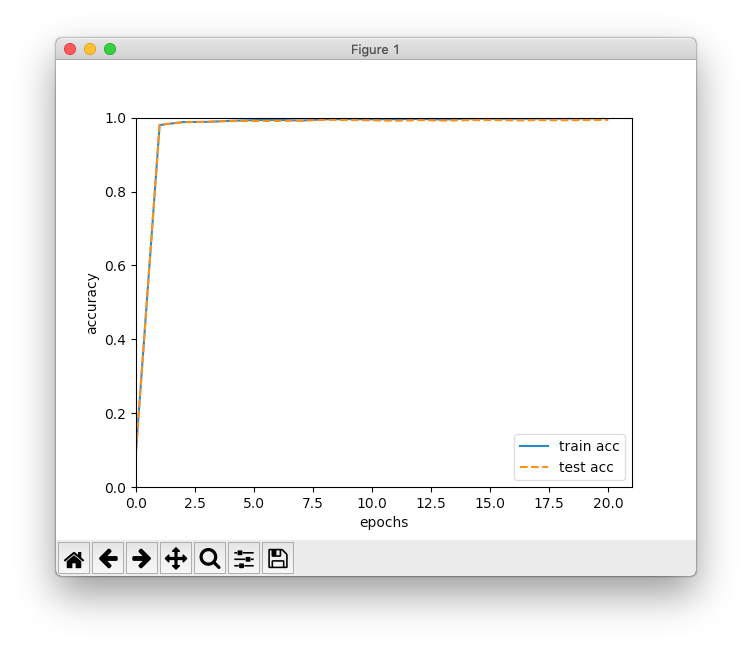
12,000(20エポック)にしてみました。mnist.py# coding: utf-8 import os import sys import matplotlib.pylab as plt import numpy as np from adam import Adam from deep_conv_net import DeepConvNet sys.path.append(os.pardir) # パスに親ディレクトリ追加 from dataset.mnist import load_mnist # MNISTの訓練データとテストデータ読み込み (x_train, t_train), (x_test, t_test) = \ load_mnist(normalize=True, flatten=False, one_hot_label=True) # ハイパーパラメーター設定 iters_num = 12000 # 更新回数 batch_size = 100 # バッチサイズ adam_param_alpha = 0.001 # Adamのパラメーター adam_param_beta1 = 0.9 # Adamのパラメーター adam_param_beta2 = 0.999 # Adamのパラメーター train_size = x_train.shape[0] # 訓練データのサイズ iter_per_epoch = max(int(train_size / batch_size), 1) # 1エポック当たりの繰り返し数 # ディープな畳み込みニューラルネットワーク生成 network = DeepConvNet() # オプティマイザー生成、Adamを使用 optimizer = Adam(adam_param_alpha, adam_param_beta1, adam_param_beta2) # 学習前の認識精度の確認 train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_loss_list = [] # 損失関数の値の推移の格納先 train_acc_list = [train_acc] # 訓練データに対する認識精度の推移の格納先 test_acc_list = [test_acc] # テストデータに対する認識精度の推移の格納先 print(f'学習前 [訓練データの認識精度]{train_acc:.4f} [テストデータの認識精度]{test_acc:.4f}') # 学習開始 for i in range(iters_num): # ミニバッチ生成 batch_mask = np.random.choice(train_size, batch_size, replace=False) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] # 勾配の計算 grads = network.gradient(x_batch, t_batch) # 重みパラメーター更新 optimizer.update(network.params, grads) # 損失関数の値算出 loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) # 1エポックごとに認識精度算出 if (i + 1) % iter_per_epoch == 0: train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) # 経過表示 print( f'[エポック]{(i + 1) // iter_per_epoch:>2} ' f'[更新数]{i + 1:>5} [損失関数の値]{loss:.4f} ' f'[訓練データの認識精度]{train_acc:.4f} [テストデータの認識精度]{test_acc:.4f}' ) # 損失関数の値の推移を描画 x = np.arange(len(train_loss_list)) plt.plot(x, train_loss_list, label='loss') plt.xlabel('iteration') plt.ylabel('loss') plt.xlim(left=0) plt.ylim(0, 2.5) plt.show() # 訓練データとテストデータの認識精度の推移を描画 x2 = np.arange(len(train_acc_list)) plt.plot(x2, train_acc_list, label='train acc') plt.plot(x2, test_acc_list, label='test acc', linestyle='--') plt.xlabel('epochs') plt.ylabel('accuracy') plt.xlim(left=0) plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()(6)実行結果
以下、実行結果です。私の環境では半日くらいかかりました。
学習前 [訓練データの認識精度]0.0975 [テストデータの認識精度]0.0974 [エポック] 1 [更新数] 600 [損失関数の値]1.0798 [訓練データの認識精度]0.9798 [テストデータの認識精度]0.9811 [エポック] 2 [更新数] 1200 [損失関数の値]0.8792 [訓練データの認識精度]0.9881 [テストデータの認識精度]0.9872 [エポック] 3 [更新数] 1800 [損失関数の値]0.9032 [訓練データの認識精度]0.9884 [テストデータの認識精度]0.9890 [エポック] 4 [更新数] 2400 [損失関数の値]0.8012 [訓練データの認識精度]0.9914 [テストデータの認識精度]0.9906 [エポック] 5 [更新数] 3000 [損失関数の値]0.9475 [訓練データの認識精度]0.9932 [テストデータの認識精度]0.9907 [エポック] 6 [更新数] 3600 [損失関数の値]0.8105 [訓練データの認識精度]0.9939 [テストデータの認識精度]0.9910 [エポック] 7 [更新数] 4200 [損失関数の値]0.8369 [訓練データの認識精度]0.9920 [テストデータの認識精度]0.9915 [エポック] 8 [更新数] 4800 [損失関数の値]0.8727 [訓練データの認識精度]0.9954 [テストデータの認識精度]0.9939 [エポック] 9 [更新数] 5400 [損失関数の値]0.9640 [訓練データの認識精度]0.9958 [テストデータの認識精度]0.9935 [エポック]10 [更新数] 6000 [損失関数の値]0.8375 [訓練データの認識精度]0.9953 [テストデータの認識精度]0.9925 [エポック]11 [更新数] 6600 [損失関数の値]0.8500 [訓練データの認識精度]0.9955 [テストデータの認識精度]0.9915 [エポック]12 [更新数] 7200 [損失関数の値]0.7959 [訓練データの認識精度]0.9966 [テストデータの認識精度]0.9932 [エポック]13 [更新数] 7800 [損失関数の値]0.7778 [訓練データの認識精度]0.9946 [テストデータの認識精度]0.9919 [エポック]14 [更新数] 8400 [損失関数の値]0.9212 [訓練データの認識精度]0.9973 [テストデータの認識精度]0.9929 [エポック]15 [更新数] 9000 [損失関数の値]0.9046 [訓練データの認識精度]0.9974 [テストデータの認識精度]0.9934 [エポック]16 [更新数] 9600 [損失関数の値]0.9806 [訓練データの認識精度]0.9970 [テストデータの認識精度]0.9924 [エポック]17 [更新数]10200 [損失関数の値]0.7837 [訓練データの認識精度]0.9975 [テストデータの認識精度]0.9931 [エポック]18 [更新数]10800 [損失関数の値]0.8948 [訓練データの認識精度]0.9976 [テストデータの認識精度]0.9928 [エポック]19 [更新数]11400 [損失関数の値]0.7936 [訓練データの認識精度]0.9980 [テストデータの認識精度]0.9932 [エポック]20 [更新数]12000 [損失関数の値]0.8072 [訓練データの認識精度]0.9984 [テストデータの認識精度]0.9939
最終的な認識精度は99.39%でした。前の章のCNNは98.60%だったので、0.79ポイント アップです。層を深くすることの可能性を感じさせる結果になりました。
なお、前の章の結果と比べて認識精度に対する損失関数の値が大きいのですが、これはDropoutの影響かと思います。認識精度はすべてのニューロンを使っていますが、損失関数の算出時は半分(Dropoutのレートを0.5で実行したので)のニューロンが削除状態のためです。
この本で実装するのはここまでですが、さらに認識精度を高めるために、アンサンブル学習やData Augmentationなどの手法が紹介されています。また、層を深くすることのメリットについてもまとめられています。
8.2 ディープラーニングの小歴史
ディープラーニングのトレンドの紹介です。いずれも、ここまでに学んだCNNが基本であることが理解できました。
8.3 ディープラーニングの高速化
高速化についての説明です。興味深かったのは、ディープラーニングだと単精度浮動小数点では精度が高すぎてもったいないので、半精度の浮動小数点が注目されているという点です。これまで私が使ってきた開発言語では半精度浮動小数点型というのを聞いたことがなかったのですが、NumPyには
float16という型があることを知りました。8.4 ディープラーニングの実用例
物体検出、セグメンテーション、画像のキャプション生成と、面白そうなことがすでに実現されていることが分かりました。ただ、その仕組みについては、これまでに学んだレベルではまだまだ理解しきれません。
8.5 ディープラーニングの未来
画像の生成や自動運転、強化学習など、研究中の分野の紹介です。ディープラーニングの可能性を感じますね。
8.6 まとめ
なんとか最後の実装も終えました。本の通りの精度が出せて一安心です。ディープラーニングの可能性についても学ぶことができました。
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。
最後に
この本のおかげで、ディープラーニングへの理解が深まりました。著者の斎藤康毅さんに感謝しています。また、みなさんのからのいいね、ストック、はてなブックマークなどに励まされ、途中であきらめずに読破することができました。ありがとうございます。
このメモが、後に続く方の参考になることがあれば幸いです。
- 投稿日:2020-02-22T21:27:08+09:00
ABC153
AtCorder Beginner Contest 153 にバーチャル参加しました。
ABCDの4問ACでした。
Python3を使用しています。A問題
サーバルはモンスターと戦っています。
モンスターの体力は H です。
サーバルが攻撃を 1 回行うとモンスターの体力を A 減らすことができます。攻撃以外の方法でモンスターの体力を減らすことはできません。
モンスターの体力を 0 以下にすればサーバルの勝ちです。
サーバルがモンスターに勝つために必要な攻撃の回数を求めてください。モンスターの体力が何回の攻撃で 0 以下になるかを考えるので、割り算の商を求める必要があると考えます。
しかし、回数は整数でないとおかしいため、割り算の商が小数を取った場合は繰り上げた整数を答える必要があります。H, A = map(int,input().split()) if H % A == 0: print(H // A) else: print(H // A + 1)小数点切り上げだとif文も使わなくて良かった。
import math H, A = map(int,input().split()) print(math.ceil( H // A ))B問題
アライグマはモンスターと戦っています。
モンスターの体力は H です。
アライグマは N 種類の必殺技を使うことができ、i 番目の必殺技を使うとモンスターの体力を Ai 減らすことができます。 必殺技を使う以外の方法でモンスターの体力を減らすことはできません。
モンスターの体力を 0 以下にすればアライグマの勝ちです。
アライグマが同じ必殺技を 2 度以上使うことなくモンスターに勝つことができるなら Yes を、できないなら No を出力してください。
必殺技を 1 回しか使えないという条件から、全ての必殺技を使ったときにモンスターを倒せるのか考えます。全ての必殺技で減らせる体力がモンスターの体力より大きければ勝つことができます。
H, N = map(int,input().split()) A = list(map(int,input().split())) if sum(A) >= H: print("Yes") else: print("No")C問題
フェネックは N 体のモンスターと戦っています。
i 番目のモンスターの体力は Hi です。
フェネックは次の 2 種類の行動を行うことができます。
・攻撃:モンスターを 1 体選んで攻撃することで、そのモンスターの体力を 1 減らす
・必殺技:モンスターを 1 体選んで必殺技を使うことで、そのモンスターの体力を 0 にする
攻撃と必殺技以外の方法でモンスターの体力を減らすことはできません。
全てのモンスターの体力を 0 以下にすればフェネックの勝ちです。
フェネックが K 回まで必殺技を使えるとき、モンスターに勝つまでに行う攻撃の回数 (必殺技は数えません) の最小値を求めてください。モンスターの体力を 0 にする必殺技は、体力の大きいモンスターに使いたいと考えます。
そこでモンスターを体力の大きい順(降順)に並べ、 K 体のモンスターを必殺技で倒します。
残った N - K 体のモンスターは攻撃で倒すため、この N - K 体のモンスターの総合体力の回数だけ攻撃を行う必要があります。N, K = map(int,input().split()) A = list(map(int,input().split())) A.sort(reverse = True) del A[:K] print(sum(A))D問題
カラカルはモンスターと戦っています。
モンスターの体力は H です。
カラカルはモンスターを 1 体選んで攻撃することができます。モンスターを攻撃したとき、攻撃対象のモンスターの体力に応じて、次のどちらかが起こります。
・モンスターの体力が 1 なら、そのモンスターの体力は 0 になる
・モンスターの体力が X > 1 なら、そのモンスターは消滅し、体力が ⌊X/2⌋ のモンスターが新たに 2 体現れる
(⌊r⌋ は r を超えない最大の整数を表す)
全てのモンスターの体力を 0 以下にすればカラカルの勝ちです。
カラカルがモンスターに勝つまでに行う攻撃の回数の最小値を求めてください。最初は体力 H のモンスターが 1 体いる、と問題文から読み取ります。
1 回の攻撃で体力が半分になったモンスターが 2 体になる(小数点以下の値は切り捨て)、という操作を繰り返します。
モンスターの体力 H が 2 の累乗でない場合、 H は約数に奇数を持ちます。
そのため体力を半分にする過程で小数点の切り捨てが起こり、モンスターが分裂するだけで、総合体力が減ります。
そこで、体力 H が 2 の累乗で攻撃回数に変化が起きるのではと考えました。ここからは実際に数値計算し、一般論を導きます。
H 攻撃回数
1 1 回
2 ~ 3 3回
4 ~ 7 7回
8 ~ 15 15回
H が 2n から 2n+1 - 1 のとき、攻撃回数は 20 から 2n までの和で表せるということが分かります。そこで、今度は H が 2 の n 乗と 2 の n + 1 乗 の間にあるかを考えます。
10 進数を 2 進数に変換して文字数を数えることで求めます。H = int(input()) n = len(bin(H)) - 3 N = [2 ** i for i in range(n + 1)] print(sum(N))H が 2n から 2n+1 - 1 のとき、攻撃回数は 2n+1 - 1 で表せた。
さらに、底が 2 の log を取って小数点以下を切り捨てることで n が求められた。import math H = int(input()) n = math.floor(math.log2(H)) print(2 ** (n + 1) -1)E問題
トキはモンスターと戦っています。
モンスターの体力は H です。
トキは N 種類の魔法が使え、i 番目の魔法を使うと、モンスターの体力を Ai 減らすことができますが、トキの魔力を Bi 消耗します。
同じ魔法は何度でも使うことができます。魔法以外の方法でモンスターの体力を減らすことはできません。
モンスターの体力を 0 以下にすればトキの勝ちです。
トキがモンスターに勝つまでに消耗する魔力の合計の最小値を求めてください。どうやら、個数制限ナップサックという有名な問題だったらしい。
DP(動的計画法)もさっぱり分からなかったので、こちらを参考にさせてもらいました。
分かりやすい。https://qiita.com/drken/items/dc53c683d6de8aeacf5a
まずTLEになった結果です。(Pypy3だとAC)
使える N 種類の魔法のうち、 i 番目の魔法について考えます。
i 番目の魔法を使って体力を合計で j 減らせる場合の消耗魔力は
dp[j] = dp[j - a] + b
i 番目の魔法を使わずに体力を合計で j 減らせる場合の消耗魔力は
dp[j] = dp[j]
となります。
これらを比較して、最小値を求めdp[j]とします。
モンスターの体力ぴったりで倒す必要はないため、dp[]の要素数はH + max(減らせる体力)となっています。
初期値はdp[0] = 0
また、0が最小値になってしまうためif文で場合分けしています。H, N= map(int,input().split()) A = [0] * N B = [0] * N for i in range(N): A[i], B[i] = map(int, input().split()) ma = max(A) dp = [0] * (H + ma) dp[0] = 0 for i in range(N): a = A[i] b = B[i] for j in range(1, H + ma): if dp[j] == 0: dp[j] = dp[j - a] + b else: dp[j] = min(dp[j - a] + b, dp[j]) print(min(dp[H:]))二重のforループの中でif文は遅くなりそうだなと反省し改善したのですが、TLEです。(Pypy3だとAC)
dp[]の要素に無限大を入れて作っているので場合分けして判定しなくて良くなった。
見やすくなったけど、1 つ目の解答より時間はかかっている。H, N= map(int,input().split()) A = [0] * N B = [0] * N for i in range(N): A[i], B[i] = map(int, input().split()) ma = max(A) dp = [float("inf")] * (H + ma) dp[0] = 0 for i in range(N): a = A[i] b = B[i] for j in range(1, H + ma): dp[j] = min(dp[j - a] + b, dp[j]) print(min(dp[H:]))PythonでACしたい。
F問題
ギンギツネは N 体のモンスターと戦っています。
モンスターは 1 列に並んでおり、数直線上にいるとみなすことができます。
i 番目のモンスターは座標 Xi にいて、体力は Hi です。
ギンギツネは爆弾を使ってモンスターを攻撃することができます。 座標 x で爆弾を使うと、座標が x−D 以上 x+D 以下の範囲にいる全てのモンスターの体力を A 減らすことができます。 爆弾を使う以外の方法でモンスターの体力を減らすことはできません。
全てのモンスターの体力を 0 以下にすればギンギツネの勝ちです。
ギンギツネがモンスターに勝つまでに爆弾を使う回数の最小値を求めてください。サンプルだと正しい結果が出るんだけど、WAだった。
距離を昇順にならべて、一番小さい値が0になるまで攻撃する。
それで同時に攻撃される範囲のモンスターの体力を減らして、新たにリストを作り直すと考えた。import math N, D, A= map(int,input().split()) X = [0] * N H = [0] * N Y = [] for i in range(N): X[i], H[i] = map(int, input().split()) Y.append([X[i] ,math.ceil(H[i] / A)]) Y.sort() d = 0 while len(Y) > 0: y_min = Y[0][1] c = 0 d += y_min for i in range(len(Y)): if Y[i][0] < Y[0][0] + 2 * D + 1: Y[i][1] = Y[i][1] - y_min if Y[i][1] <= 0: c += 1 del Y[0:c] print(d)
- 投稿日:2020-02-22T21:20:19+09:00
tarfileの圧縮・展開
1import tarfile with tarfile.open('test.tar.gz', 'w:gz') as tr: tr.add('test_dir') #test_dirというディレクトリをtest.tar.gzというファイル名でtarfileに圧縮 with tarfile.open('test.tar.gz', 'r:gz') as tr: tr.extractall(path='test_tar') #test_tarというディレクトリにtest.tar.gzを展開2import tarfile with tarfile.open('test.tar.gz', 'r:gz') as tr: with tr.extractfile('test_dir/sub_dir/sub_test.txt') as f: print(f.read()) #tarfileに圧縮されたtest.tar.gzを展開することなく、sub_test.txtを出力
- 投稿日:2020-02-22T20:45:57+09:00
Pythonのリスト内包表記でいつも混乱するので覚え書き
はじめに
仕事で Python を使っていて、
「あー、ここのリスト作る処理、リスト内包表記にしたら簡潔に書けるのになー。」
と思うことがあります。
でも、私がリスト内包表記を書きたいと思う場面が意外と少ないため、いざ書こうと思ったときに、
「あれ、リスト内包表記って、どうやって書くんだっけ?うーん、時間もないし、いつも通りループにするか。」
と、残念な感じになるので、私自身のための覚え書きの意味も含めて。リスト内包表記とは?
初めてこの言葉を聞いたときは、頭の中が?マークだらけに。。。
すごーく簡単に言うと、リスト内包表記とは、
リストデータを1行で作る方法
です。ただし、何でも1行で書けるわけではなく、(若干語弊がありますが、)ループでリストを作成する処理を1行で書けるものです。
私自身、「仕事で書くコードは複雑なんだよ!」と思っていたのですが、意外と使えます。書き方
通常のループ(これはリスト内包表記ではありません。)
data = [] for i in range(10): data.append(i) print(data) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]リスト内包表記
print([i for i in range(10)]) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]解説
通常のループと、リスト内包表記の結果は同じです。
しかし、リスト内包表記の方が、記述量が少なくてすみます。
そして、コードが簡潔で読みやすくなります。(慣れないと読みにくいですが。)リスト内包表記のコードを見ていきます。
[...]
ご存知の通り、これでリストができるため、通常のループのdata = []が不要になります。
for i in range(10)
これは通常のループでも、リスト内包表記でも同じです。
ただし、リスト内包表記の方には、:は不要です。
i for i in range(10)
最初にでてくるiは、ループで取り出したi(2つめのi)の値が格納されます。
ループのたびに最初にでてくるiの値が書き換わります。
そのiが、ループの回数分、リストに追記(append)されます。もう少し具体的に
もう少し具体的な方が理解しやすいと思うので、次のケースで説明します。
ケース1
リスト内のデータを加工したい場合。
例えば、['aa', 'b', 'ccc']というリストの各データに、@を付加したい場合。items = ['aa', 'b', 'ccc'] print([item + '@' for item in items]) # ['aa@', 'b@', 'ccc@']
itemsのデータに@をつけて、別のリストを作成しています。
リストデータから、別のリストデータを1行で作ったというわけです。ケース2
データ加工処理など、決まったルールで文字列の途中に、別の文字を付加したい場合。
例えば、abcdefghというデータに1文字ごとに、-を付加したい場合。items = 'abcdefgh' print('-'.join([item for item in items])) # a-b-c-d-e-f-g-hこちらは、文字列からリストデータを1行で作っています。
そのリストのデータを-でjoinして文字列に戻しています。ちなみに、2文字ごとに、
-を付加したい場合。items = 'abcdefgh' print('-'.join([items[i*2: i*2+2] for i in range(int(len(items)/2))])) # ab-cd-ef-ghちょっと詰め込みすぎな感じがするので、こんな感じでしょうか。
items = 'abcdefgh' loop_count = int(len(items)/2) print('-'.join([items[i*2: i*2+2] for i in range(loop_count)])) # ab-cd-ef-ghいかがでしょうか?
ケース1では、リストのデータを加工して、別のリストを作る、
ケース2では、文字列を加工して、リストを作る、というサンプルです。どちらのケースも、ループを使って実現できますが、
リスト内包表記を使えば、シンプルかつ簡潔にコードが書けます。
- 投稿日:2020-02-22T20:32:03+09:00
pytestでflaskの単体テストをする
はじめに
開発のテストではライブラリやフレームワークを使用して自動化するのが一般的になっています。そこでpytestを使用してflaskの単体テストを自動化しようとしましたが、シンプルな例が見つけられなかったのでシンプルな例と簡単な説明をまとめました。
環境
- python:3.6.5
- flask:1.0.2
- pytest:5.3.5
インストール
pip install pytestでインストールするだけです。pytestで自動化するのに必要なもの
pytestで単体テストを自動化するために必要なものは、テスト対象のソース(テストされる開発物)とテスト方法を記載したソースが必要になります。テスト方法のソースは、テスト対象の引数と関数の結果を与えてどのように比較するかを記載しています。
簡単な関数の単体テスト自動化
flaskの単体テストの自動化の前に、簡単な関数を通じてpytestの使い方を見ていきます。
テスト対象のソース
テスト対象のソースが無ければテストはできないため、テスト対象のソースを用意します。
例では、引数を加算して返却する関数を用意しましたが、本来の開発であれば開発物が相当します。testing_mod.pydef add_calc(a, b): return a + bテスト方法を書いたソース
テスト対象のソースの呼び方とソースの結果を書いたソースを作ります。このソースはテスト対象のソースの関数を呼び出して、テスト対象の関数が返した結果とこちらが想定した結果を比較して正しければOK、誤っていればNGになります。
例では、テスト対象のtesting_modをimport testing_modでimportしてtesting_mod.add_calc()に1と2を渡して返却される結果が3であればOKとなっています。py_test_main.pyimport pytest import testing_mod def test_ok_sample(): result = testing_mod.add_calc(1, 2) assert 3 == result単体テスト実行
テスト対象とテスト方法のソースができたため、関数ごとに結果を見たいため-vオプションをつけて実行します。
# pytest -v py_test_main.py py_test_main.py . [100%] ====== 1 passed in 0.05s ====== PS C:\Users\xxxx\program\python> pytest -v py_test_main.py ====== test session starts ====== platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 -- c:\users\xxxx\appdata\local\programs\python\python36-32\python.exe cachedir: .pytest_cache rootdir: C:\Users\xxxx\program\python collected 1 item py_test_main.py::test_ok_sample PASSED [100%] ====== 1 passed in 0.02s ======結果を見ると先ほど作成したtest_ok_sampleがPASSEDとなり正常に終わったため、テストOKになります。
関数をたくさん作成すると表示される関数の数が増えていきます。簡単なflaskの単体テスト自動化
flaskの単体テストを自動化します。上の簡単な関数の自動化とは異なり、flaskはクライアントからの通信を必要としますが、単体テストではflaskの機能を使用して単体テストの自動化をします。
テスト対象のソース
flaskのソースを作成します。例では/にアクセスするとroot文字列を返却するものを作成します。本来の開発であれば開発物が相当します。
flaskについては以前のflaskについてまとめたものを参照してください。flask_mod.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route('/') def root(): return "root"テスト方法を書いたソース
flaskのテスト方法を書いたソースは、関数のソースと異なりflaskのクライアントを生成してからそのクライアントを使用してリクエストを発行して結果を確認する必要があります。
テスト用flaskクライアントの生成
まずは、テスト用のクライアントの生成を行います。テスト対象ソースのappをimportしてappのテスト用configをtrueに変更します。その後appの
test_client()を使用してクライアントを生成します。
下の例でいうとテスト対象のソースのimportはfrom flask_mod import appになります。py_test_main.pyimport pytest from flask_mod import app def test_flask_simple(): app.config['TESTING'] = True client = app.test_client()テスト対象の関数の実行
上で生成したクライアントを使用して、テスト対象のURLに向けてget関数やpost関数を使用してリクエストを発行します。その結果がflaskからのレスポンスになるため、期待した答えになるかをpytestの
assertでチェックします。
下の例でいうとresult = client.get('/')で/にgetリクエストを発行してその結果がresultに格納されるのでdata(body)とrootを比較しています。py_test_main.pyimport pytest from flask_mod import app def test_flask_simple(): app.config['TESTING'] = True client = app.test_client() result = client.get('/') assert b'root' == result.data単体テスト実行
テスト対象とテスト方法のソースができたため、実行します。
# pytest -v py_test_main.py ====== 1 passed in 0.22s ======= PS C:\Users\xxxx\program\python\flask> pytest -v .\pytest_flask.py ====== test session starts ====== platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 -- c:\users\xxxx\appdata\local\programs\python\python36-32\python.exe cachedir: .pytest_cache rootdir: C:\Users\xxxx\program\python\flask collected 1 item pytest_flask.py::test_flask_simple PASSED [100%] ====== 1 passed in 0.20s =======結果を見ると先ほど作成したtest_flask_simpleがPASSEDとなり正常に終わったため、テストOKになります。
関数をたくさん作成するとここの関数の数が増えていきます。単体テストがエラーの時の例
試しに、flaskが返却してくる文字列と比較する文字列をsampleにしたときの結果を見てみます。
# pytest -v pytest_flask.py ======= test session starts ======= platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 -- c:\users\xxxx\appdata\local\programs\python\python36-32\python.exe cachedir: .pytest_cache rootdir: C:\Users\xxxx\program\python\flask collected 1 item pytest_flask.py::test_flask_simple FAILED [100%] ============ FAILURES ============= ____________ test_flask_simple ____________ def test_flask_simple(): app.config['TESTING'] = True client = app.test_client() result = client.get('/') > assert b'sample' == result.data E AssertionError: assert b'sample' == b'root' E At index 0 diff: b's' != b'r' E Full diff: E - b'sample' E + b'root' pytest_flask.py:8: AssertionError ======== 1 failed in 0.26s ========ちゃんとsampleとrootが異なるので
AssertionError: assert b'sample' == b'root'と表示されました。おわりに
単体テストの自動化は、自動化スクリプトの作成の労力が少なければとても便利な仕組みになります。
その労力を少なくする方法がフレームワークですが、上記以外にも、テストの前処理と後処理をする、同じテスト方法で複数のパラメータを試すなど便利な機能があります。次はその便利な方法をまとめていきます。
- 投稿日:2020-02-22T20:30:52+09:00
中国語形態素解析エンジンのjiebaを使ってみる
中国語形態素解析エンジンjieba
jiebaのPython版で使ってみました。
他のプログラミング言語のバージョンもあります。インストール
$ pip install jiebaテキストセグメンテーション
>>> import jieba >>> text = "我明天去东京大学上课。早上十点开始。" #"私は明日東京大学の授業に出ます。朝の十時から。"
jieba.cutの戻り値はジェネレータ
jieba.lcutの戻り値はリスト
jieba.cut_for_searchの戻り値はジェネレータ
jieba.lcut_for_searchの戻り値はリストAccurate Mode
>>> segments = jieba.cut(text) >>> list(segments) ['我', '明天', '去', '东京大学', '上课', '。', '早上', '十点', '开始', '。']>>> segments = jieba.lcut(text) >>> segments ['我', '明天', '去', '东京大学', '上课', '。', '早上', '十点', '开始', '。']东京大学がひと単語になっています、いいですね!
Full Mode
cut_all=Trueにする。>>> segments = jieba.cut(text, cut_all=True) >>> list(segments) ['我', '明天', '去', '东京', '东京大学', '大学', '学上', '上课', '。', '早上', '十点', '开始', '。']>>> segments = jieba.lcut(text, cut_all=True) >>> segments ['我', '明天', '去', '东京', '东京大学', '大学', '学上', '上课', '。', '早上', '十点', '开始', '。']Search Engine Mode
>>> segments = jieba.cut_for_search(text) >>> list(segments) ['我', '明天', '去', '东京', '大学', '东京大学', '上课', '。', '早上', '十点', '开始', '。']>>> segments = jieba.lcut_for_search(text) >>> segments ['我', '明天', '去', '东京', '大学', '东京大学', '上课', '。', '早上', '十点', '开始', '。']キーワード抽出
>>> import jieba.analyse >>> text = ''' ... 伴随全球化进程不断加速,人类正面临着日益严峻的挑战,能源危机、环境污染、金融环境不稳定以及贫穷等各种问题不断显现在我们面前。应对这些挑战,各类人才需要通力协作,献力献策,共同攻克这些全球化难题。在这种背景下,作为领导型人才的摇篮,东京大学肩负着义不容辞的责任。我们将会以无限的勇气、智慧与责任感迎面直对这些挑战。 ... 学贵精专,攀登学术巅峰毋庸置疑成为治学的原动力。对于在治学道路上苦苦求索的年轻学者和广大学生而言,他们不断前进、不断成长的动力源自于获取最精尖知识的一种兴奋感与喜悦感。东京大学不负国民所托,为这些学生、学者提供了成长的乐土,使其更好地造福社会。 ... 东京大学创立至今,一直保持着东西方文化相结合的学术观点,不断发展,放眼世界,形成一面独特的旗帜。秉承传统,展望未来,东京大学吸引了各式人才汇聚于此,探索求知,灵变创新,将逐步成为“全球性知识创新与协作的据点”。在东大,国界、文化、年龄的壁垒通通被打破,新领域学术研究超越文理界限,产官学合作在此通力展开。为实现这一目标,首先需要创立卓越性与国际性二者兼备的研究生院,并积极开展跨学科的新学术领域拓展。... 东京大学宪章中规定,东京大学致力于为世界和平与人类福祉作出不朽的贡献。而现代社会正飞速发展,我们需要顺应时代发展的要求,将学术研究赋予新时代的意义。在坚守传统的同时,体制改革亦不可或缺。在深化本科生教育改革的同时,不断推进研究生院的根本变革,使其创造知识价值主体的意义显现出来。此外,亟需推进人事制度的改革创新,大力倡导男女平等,多给年轻人创造学以致用的机会, 并实现兼顾人力资源的流动性与稳定性。 不可忽视的一个问题是,推进上述改革的前提是提升整个社会对科研学术的信赖感,而这种信赖感建立在强化科研道德水准,推动科研成果转化的基础之上。 ... 通过不断推陈出新,我们致力于将东京大学发展成为为日本民众所爱戴,乃至为整个世界所爱戴的东京大学。 ... '''テキストは東京大学総長談論中国語版になります。
tf-idf値による抽出
>>> keywords = jieba.analyse.extract_tags(text, topK=20, withWeight=False, allowPOS=()) >>> keywords ['东京大学', '不断', '信赖感', '学术', '挑战', '人才', '治学', '知识', '研究生院', '爱戴', '学术研究', '创新', '推进', '全球化', '改革', '科研', '这些', '致力于', '喜悦感', '创立']良さそうですね。日本の漢字と少し違いますが、だいたい読めます。
TextRankに基づく抽出
>>> keywords = jieba.analyse.textrank(text, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) >>> keywords ['成为', '知识', '创新', '学术', '发展', '需要', '改革', '人才', '推进', '科研', '挑战', '实现', '领域', '意义', '社会', '学术研究', '人类', '文化', '治学', '勇气']その他
他にもたくさんの機能を持っていて、
辞書をいじったり、品詞タグ付けしたり、などの事ができるので、詳しくは公式をみた方が良さそうです。README.mdの前半は中国語ですが、後半は英語訳になっています。筆者は東京大学と全く関係ありあません。
- 投稿日:2020-02-22T19:03:43+09:00
Django httpステータスコードを指定してreturnさせる。
解決したいこと
・DjangoでHttpステータスコードを指定してreturnさせる。
・jQueryでAjax通信を行なっており、特定条件で強制的にfailを実行させたい。環境
・Windows10 premium
・VScode
・jQuery結果
Ajaxのコードは省略
仮に適当な文字列が送信され、送信された文字列内にテストという文字が含まれていない場合の処理とする。test.pyimport HttpResponse get_post = request.POST["testData"] if not "テスト" in get_post: response = HttpResponse(status=500) # ステータスコードに500を指定 return response参考
- 投稿日:2020-02-22T18:41:22+09:00
Django アップロードファイル読み込み時の権限エラー
解決したいこと
・Djangoでアップロードしたファイルの読み込みを行い、何らかの操作を行うという処理をcronで回そうとした際、ファイルが読めないとパーミッションエラーが発生。
・ファイルアップロード時の権限は「600」試したこと
前提としてchmodを行う際、管理者権限が必要な環境です。
os.pyimport os os.system('sudo shmod 644 path')
python os.py-> 権限切り替わる。
cronで実行 -> 権限切り替わらず。subprocess.pyimport subprocess subprocess.call('sudo shmod 644 path')
python subprocess.py-> 権限切り替わる。
cronで実行 -> 権限切り替わらず。解決策
settings.pyに「FILE_UPLOAD_PERMISSIONS = 0o644」と記載しておくことでアップロードしたファイルの権限が「644」になった。
セキュリティ考慮してデフォルト「600」にしているっぽいですが、時間かかった。。cron回したときにsubprocessやos.systemで切り替わらなかった理由は分かってないです。
- 投稿日:2020-02-22T18:25:32+09:00
ショアのアルゴリズムって何?量子コンピュータだと多項式時間で素因数分解できるってホント?調べてみた!
はじめに
古典的な計算機上で素因数分解をするには愚直には$O(\sqrt{N})$の計算量がかかり、現在開発されている最も効率的なアルゴリズムでも桁数の指数時間程度はかかってしまうようです。でも300桁レベルの素因数分解をしようと思うと、死ぬほど時間がかかってしまいます。え?多項式時間で素因数分解を?できらぁ!というのがショアのアルゴリズムです。この記事ではそのショアのアルゴリズムをqiskitで実装して、実際の量子コンピュータで実行するのがこの記事の目標です。今回は15を因数分解していきます。この記事にはおそらく(というか確実に)間違いや、誤植があると思うので、もし見つけたら優しく教えてください...
流れ
ショアのアルゴリズムを説明するには、いろいろ準備が必要なのですがまず全体の流れを書いておきたいと思います。
まず、素因数分解したい自然数$N$と互いに素な自然数$x$を考えます(互いに素かどうかはユークリッドの互除法で判定できます。)。以下modNの世界で考えることにします。$x^r = 1$となるような最小のrを位数と呼びます。この位数を求めることが素因数分解に有効であることが知られています。しかし古典的な計算機ではこの計算にも指数時間がかかってしまいます。これを解決するのが位相推定アルゴリズムです。位相推定アルゴリズムはユニタリ行列の固有値(絶対値は1)の位相を近似的に与えてくれます。$\mod N$の世界で$U^r = I$となるようなUを考えるとその固有値からrを求めることができるようになります。この位相推定アルゴリズムのサブルーチンとしてこのあと説明するアダマールテストと量子フーリエ変換が必要です。
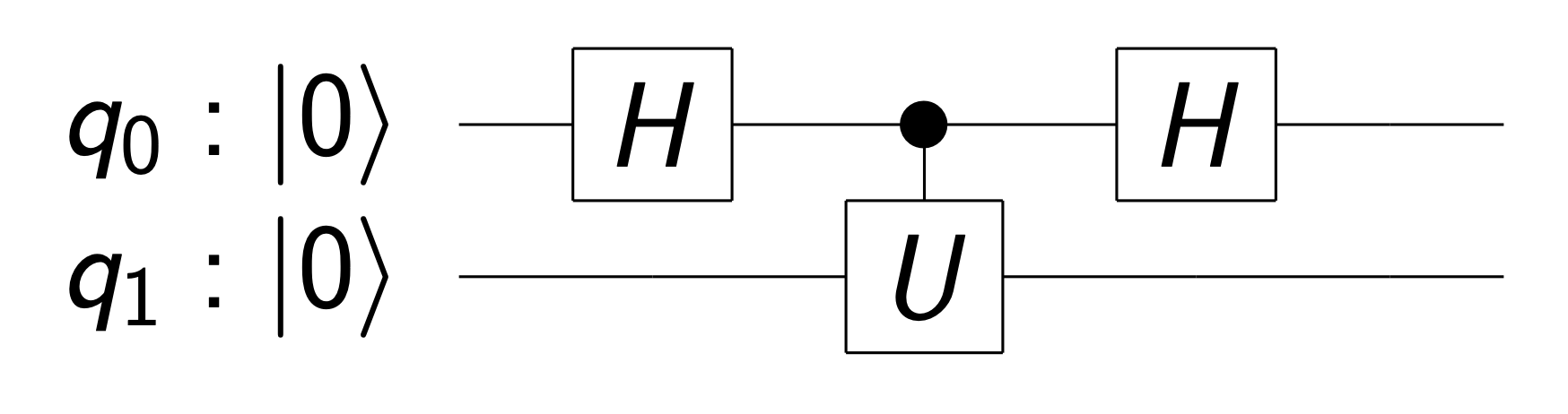
アダマールテスト
まずアダマールテストと呼ばれるアルゴリズムを説明します。
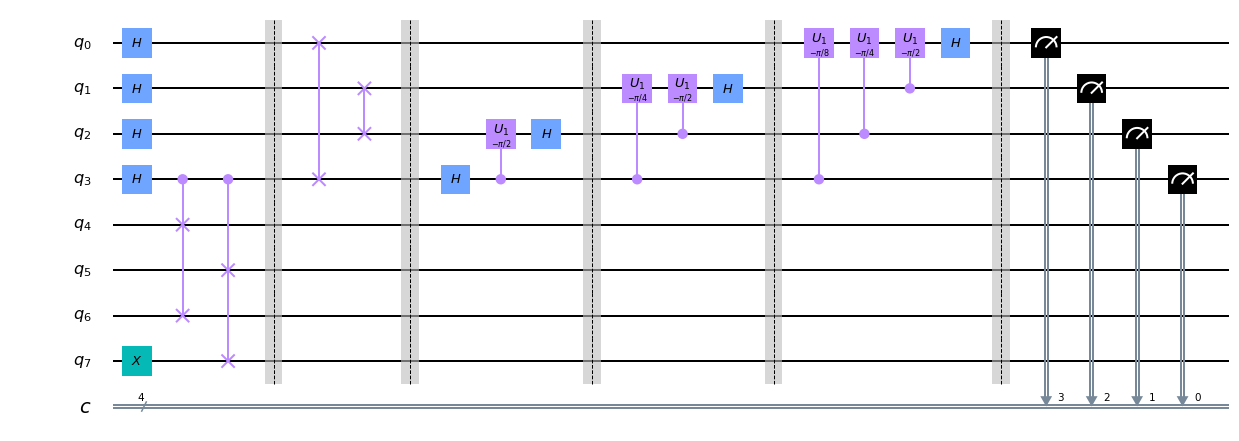
アダマールテストは以下のような回路で実現されます($U$は任意のゲートです)。
この回路に$q_0 = \left|0\right>, q_1 = \left|\varphi\right>$ を通すとどうなるか考えてみましょう。ただし$\left|\varphi\right>$は$U$の固有ベクトルであり、その固有値を$e^{i\lambda}$とします。
$$
\left|0\right>\left|\varphi\right>\rightarrow \frac{1}{\sqrt{2}}(\left|0\right>\left|\varphi\right>+\left|1\right>\left|\varphi\right>)\rightarrow
\frac{1}{\sqrt{2}}(\left|0\right>\left|\varphi\right>+e^{i\lambda}\left|1\right>\left|\varphi\right>)\rightarrow
\left(\frac{1+e^{i\lambda}}{2}\left|0\right>+\frac{1-e^{i\lambda}}{2}\left|1\right>\right)\otimes\left|\varphi\right>
$$control-Uゲートを通過した後の量子ビットは$\frac{1}{\sqrt{2}}(\left|0\right>+e^{i\lambda}\left|1\right>)\otimes \left|\varphi\right>$という状態になります。Uの固有値の位相が前(第一量子ビット)に位相として出てきているのがわかると思います。そこにさらにアダマールゲートを作用させることで、第一量子ビットの観測確率としてUの固有値の位相を得ることができます。コントロールビットにはなんの操作もしていないのに、まるで2番目の量子ビットから位相が乗り移ったかのように観測確率が変化するのは不思議ですね。ただし、この方法で固有値の位相を知ろうとすると何度も測定しなければなりません。この問題点を解決するアルゴリズムとして位相推定アルゴリズムが出てくることになります。
量子フーリエ変換
量子フーリエ変換は離散フーリエ変換を行うアルゴリズムです。数列の長さを$2^n$とすると、古典計算機ではみんな大好き高速フーリエ変換で離散フーリエ変換を$O(n2^n)$で行うことができますが、量子フーリエ変換では$O(n^2)$という$n$の多項式時間で解くことができます!
まず、離散フーリエ変換の定義式を思い出してみましょう。
$$
y_k = \frac{1}{\sqrt{2^n}} \sum_{j=0}^{2^n-1} x_j e^{i\frac{2\pi kj}{2^n}}
$$
これをqubit上で表現すると、
$$
|x\rangle = \sum_{j=0}^{2^n-1} x_j |j\rangle \rightarrow |y\rangle = \sum_{k = 0}^{2^n-1} y_k |k\rangle \\
|j\rangle \rightarrow \frac{1}{\sqrt{2^n}} \sum_{k=0}^{2^n-1} e^{i\frac{2\pi jk}{2^n}}|k\rangle
$$
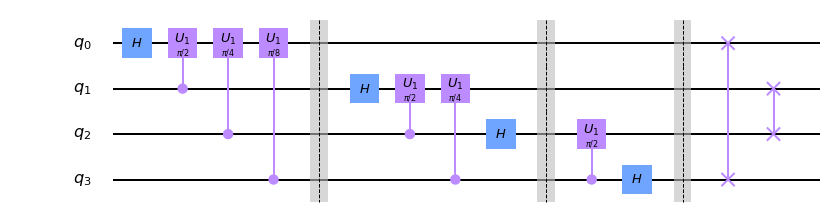
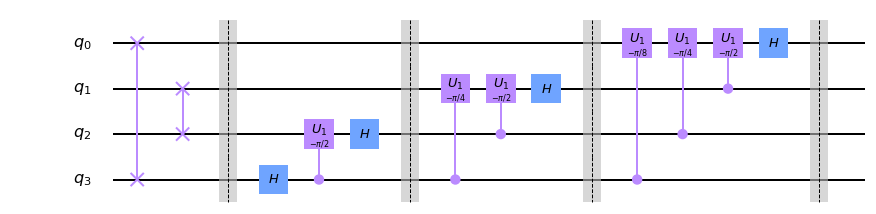
となります。実はこの変換はunitaryであり、量子コンピュータはユニバーサルゲートセットによって任意のユニタリ変換を近似できるので、この変換は量子コンピュータ上で実現可能です。しかし、このままではどのようなゲートを噛ませればいいのかわからないのでもっと使いやすい形に変形したいと思います。kを二進数で展開していろいろ頑張ると以下のようになります。
$$
|j\rangle \rightarrow\otimes_{l = 1}^{2^n} (|0\rangle+e^{\frac{2\pi i}{2^l}}|1\rangle)
$$
この形にすると、それぞれのq-bitのテンソル積としてかけているので、フーリエ変換がアダマールゲートと回転ゲートにより、実現できることがわかると思います(下図)。
実はショアのアルゴリズムではその逆変換である逆量子フーリエ変換を使うのでこれも下に示しておきます。これはただゲートを反対からかけていっただけです(ただし回転は逆回転)。
ところで量子ビットの読む方向には注意が必要です。ここではq0q1q2q3の順に読むことにします。つまり、$q0 = 1, q1 = q2 = q3 = 0$なら$x = 1000(2) = 8$です。
一応ゲートの説明もしておくと、Hはアダマールゲート、U1はRzゲートと同じで、$|1\rangle$にのみ$e^{i\theta}$の位相をつけるゲートです。詳しくはこちら位相推定アルゴリズム
位相アルゴリズムはアダマールテストを改良したようなアルゴリズムとなっています。
サイズ$2^n$のユニタリ行列$U$の固有値を$e^{2\pi i\lambda}$, それに対応する固有ベクトルを$|\varphi\rangle$とします。もし、$\lambda$が二進法で$m$桁の小数で表すことができ、
$$
|y\rangle = \frac{1}{\sqrt{2^n}}\sum_{k = 0}^{2^m-1}e^{2\pi ij\lambda}|j\rangle
$$
という状態を作り出すことができれば、逆離散フーリエ展開で$\lambda$がわかります(前章の定義式と見比べてみてください)。位相推定アルゴリズムにはm+n個の量子ビットを使い、入力には$|0\rangle|\varphi\rangle$を入れることにします。まずアダマールゲートを最初のm個の量子ビットに適用することで$|0\rangle$から$|2^m-1\rangle$までの重ね合わせ状態を作ります。次に$i$の$k$桁目が1ならば後ろの$|\varphi\rangle$に$U^k$をかけます。するとアダマールテストと同じ原理で$|i\rangle\rightarrow e^{2\pi ik\lambda}|i\rangle$になります。これを$k = 1, 2, \cdots m$で繰り返すことで、上位mビットに上の状態を実現することができます!(jを二進数で考えてみてください)回路図は下のようになります。回路図を見た方がわかりやすいかもしれません。
素因数分解への応用
なぜ、位数rが求まると、素因数分解できるのでしょうか?まず、rは偶数であると仮定します(ランダムに取るといい確率で偶数になってくれるらしいです)。すると以下のような変形ができます。
$$
x^r = 1 \mod N\
(x^{r/2}-1)(x^{r/2}+1) = 0\mod N
$$
つまり、$(x^{r/2}-1)$と$(x^{r/2}+1)$のどちらかはNと非自明な公約数を持つことになります。どちらもがN の倍数となってしまう確率は低いです。公約数はユークリッドの互助法によって、古典計算機で高速に計算できます。そこで$U^r = I$なる行列を作りたいのですが、これは簡単で、$U|i\rangle = |i\cdot x \mod N\rangle$となるように定義すれば良いです。ただし$i\geq N$については何もしないことにします。実はこれもユニタリ行列であることが示せます。これに位相推定アルゴリズムを用いれば位数rが十分な確率で求まります。一つ問題があるのは、位相推定アルゴリズムでは、固有ベクトルを利用していましたが、今回はわかりません。しかし、入力としては$\left|1\right>$を用いれば十分です。なぜなら、固有ベクトルで展開すれば、位相推定アルゴリズムで得られる値は固有値のどれかであり、そのどれであっても$s/r (s = 0, 1, \dots r-1)$という形で表せるため、連分数アルゴリズムによってrを高速に求められるからです($s = 0$の場合は無視します)。連分数アルゴリズムは小数を連分数で近似することでもっともらしい分数としての形を推定します。詳しいことはcontinued fraction algorithmでググりましょう。一応実装は後に載せてあります。Qiskitでの実装
さて、ここからが本番です。上で見てきたアルゴリズムをシュミレーターで実行して$N = 15$を$x = 4$で因数分解してみましょう。今回はqiskitという量子計算ライブラリを使います。qiskitについて詳しくは公式ドキュメントを参照してください。実行は全てjupyter notebook上で行なっています。
量子コンピュター部分は以下のようになります。前章で出てきたUの実装ですが、一般の剰余演算を実装するのは困難なので、$N = 15, x = 4$という事実を活用してしまっています(${U}^{2^i}$については位数が2であることも使ってしまってい省略しています...)が、まあ今回は雰囲気を掴むだけなのでいいでしょう。
from qiskit import * from qiskit.providers.ibmq import least_busy from qiskit.visualization import plot_histogram from qiskit.tools.monitor import job_monitor import math q = QuantumRegister(8, "q") c = ClassicalRegister(4, "c") circuit = QuantumCircuit(q, c) circuit.x(7) #Hadamard transform for i in range(4): circuit.h(i) #U4^1 gate circuit.cswap(3, 4, 6) circuit.cswap(3, 5, 7) circuit.barrier() #U4^2 gate #U4^4 gate #U4^8 gate circuit.barrier() #inverse quantum Fourier transform circuit.swap(0, 3) circuit.swap(1, 2) circuit.h(3) circuit.cu1(-np.pi/2, 3, 2) circuit.h(2) circuit.barrier() circuit.cu1(-np.pi/4, 3, 1) circuit.cu1(-np.pi/2, 2, 1) circuit.h(1) circuit.barrier() circuit.cu1(-np.pi/8, 3, 0) circuit.cu1(-np.pi/4, 2, 0) circuit.cu1(-np.pi/2, 1, 0) circuit.h(0) circuit.barrier() #measure for i in range(4): circuit.measure(q[i], c[3-i])#二進法でx = q1q2q3q4になるようにしている circuit.draw(output='mpl')
さて、あとは古典計算の部分です。連分数展開は以下のように実装しました(結構適当に書いてちょっとサンプル試しただけなのでかなり怪しいですが...)。相対誤差がeps以下になったら終了するようにしています。
eps = 0.01 def continued_fractions_algorithm(x): res = [int(x)] x-=int(x) if x/(res[0]+0.1)>eps: a = continued_fractions_algorithm(1/x) res+=a return resさて、ここで(量子計算機としての)計算量を見積もりましょう。素因数分解したい自然数が$n$bitであるとして、離散フーリエ変換パートが $O(n^2)$、位相推定アルゴリズムパートが$O(n^3)$です。古典パートはボトルネックとならないので、全体で$O(n^3)$の多項式時間で解くことができました!
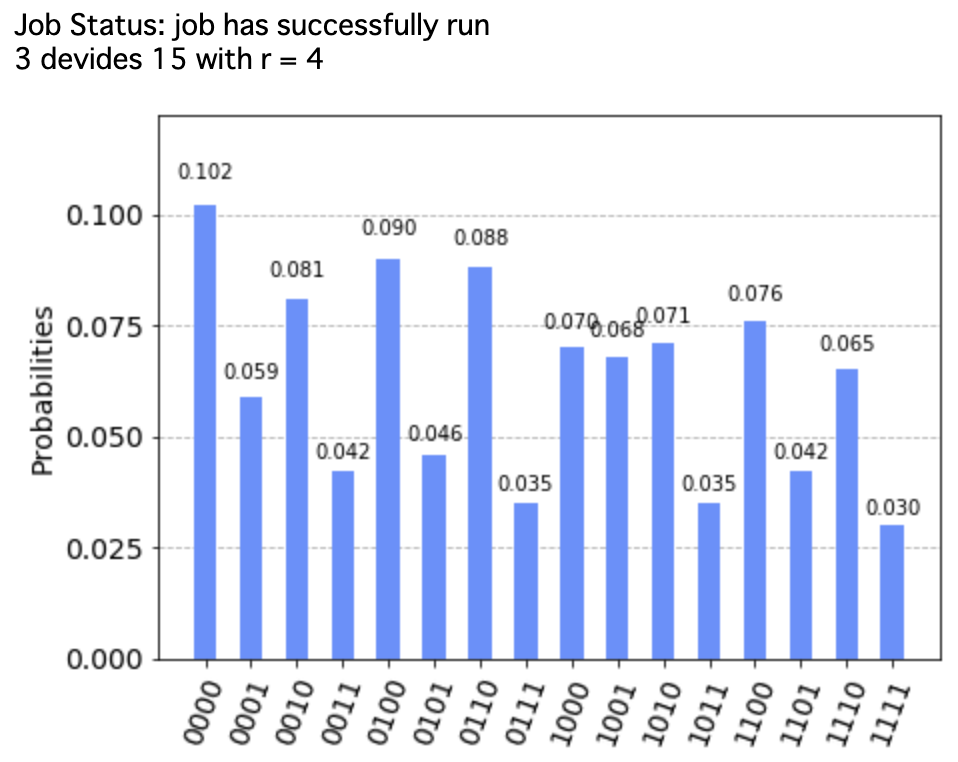
あとは以下のコードを実行すると、def shor_algorithm(use_simulator): if use_simulator: backend = BasicAer.get_backend('qasm_simulator') else: backend = IBMQ.get_provider().get_backend('ibmq_16_melbourne') flag = False job = execute(circuit, backend, shots = N) job_monitor(job) result = job.result() counts = result.get_counts(circuit) measures = np.array(list(map(lambda x:int(x, 2), counts.keys())), dtype = np.int64) probs = np.array(list(counts.values()))/N for i in range(5): output = np.random.choice(measures, p = probs) a = continued_fractions_algorithm(output/2**4) r , s =1, a[-1] for i in range(len(a)-1)[::-1]: r, s = s, a[i]*s+r if r % 15 == 0 or s == 0: continue d = math.gcd(15, 4**(r-1)-1) if d != 1: flag = True break plot_histogram(result.get_counts()) if flag: print('{0} devides 15 with r = {1}'.format(d, r)) else: print('the algorithm failed') return result %matplotlib inline use_simulator = True result = shor_algorithm(use_simulator) plot_histogram(result.get_counts())
となり、因数分解に成功しました!
実機での計算
qiskitから無料で使える量子コンピューターであるIBMQを操作することができます。公式ページはこちら。操作にはアカウント作成が必要です。
まず以下のコードを実行しておきます。
from qiskit import IBMQ my_token = "" IBMQ.save_account(my_token) provider = IBMQ.load_account()my_tokenのところには公式ページのMy Accountのところから取得したトークンを入れてください。
今回は8qubit使っているのでibmq_16_melbourneを使います。少し時間がかかりますが、上のコードでuse_simulator = Falseとして実行すると、
あれっ?
まとめ
いかがでしたか?今回量子コンピュータによる因数分解を試したわけですが、前の章でみてきた通り実機だとかなり誤差があります。もちろん今回は誰でも使えるもの簡易的なもので試しているわけですが、15の因数分解にすら手こずるとなると量子コンピュータが実用化されるには時間がかかりそうですね...。
参考
Quantum Native Dojo https://dojo.qulacs.org/ja/latest/
宮野健二郎,古澤明, 量子コンピュータ入門 日本評論社 2016
Michael A. Nilsen,Isaac L. Chuang Quantum Computation and Quantum Information 10th Anniversary Edition 2010


- 投稿日:2020-02-22T18:11:43+09:00
丁寧な説明付きな python プログラミング自習用ドキュメント
? Kyoto University Research Information Repository: プログラミング演習 Python 2019
好感が持てる説明が丁寧です。
やってみる。
? プログラミング演習 Python 2019 - YouTube
なんだろうな。何となくプログラミングがつまらなく思えてくる基礎ドキュメントつかリファレンスつか。
あれ、Qiita て、YouTube埋め込みできないの?



- 投稿日:2020-02-22T17:36:51+09:00
VBAでPythonを動かす
この記事を読んで出来るようになること
1. Excel VBAでコマンドプロンプトを起動できるようになる
2. Excel VBAからPythonを実行できるようになるExcel VBAでコマンドプロンプトを起動する
下記のコードでコマンドプロンプトを起動し、
Pythonを実行できます。Dim suji1 As String Dim suji2 As String Dim WSH Dim wExec Dim cmd_str As String suji1 = Range("D4").Value ''セルから数字を取得 suji2 = Range("D5").Value Set WSH = CreateObject("WScript.Shell") py_file = ThisWorkbook.Path & "\Python.py" cmd_str = "python " & py_file & " " & suji1 & " " & suji2 cmd_str = Replace(cmd_str, "\", "/") Set wExec = WSH.Exec("%ComSpec% /c " & cmd_str) Do While wExec.Status = 0 DoEvents Loop Range("D6").Value = Val(wExec.StdOut.ReadAll) ''Pythonから結果を受け取る Set wExec = Nothing Set WSH = Nothing解説
''オブジェクトの生成 Set WSH = CreateObject("WScript.Shell") ''実行するPythonのファイルパス py_file = ThisWorkbook.Path & "\Python.py" ''コマンド作成 cmd_str = "python " & py_file & " " & suji1 & " " & suji2 cmd_str = Replace(cmd_str, "\", "/") ''コマンド実行 Set wExec = WSH.Exec("%ComSpec% /c " & cmd_str)これだけで簡単にコマンドプロンプトを起動し、
Pythonを起動できます。''コマンド作成 cmd_str = "python " & py_file & " " & suji1 & " " & suji2suji1とsuji2は引数です。
なのでセルなどから値を取得して渡すことができます。実際に動かす
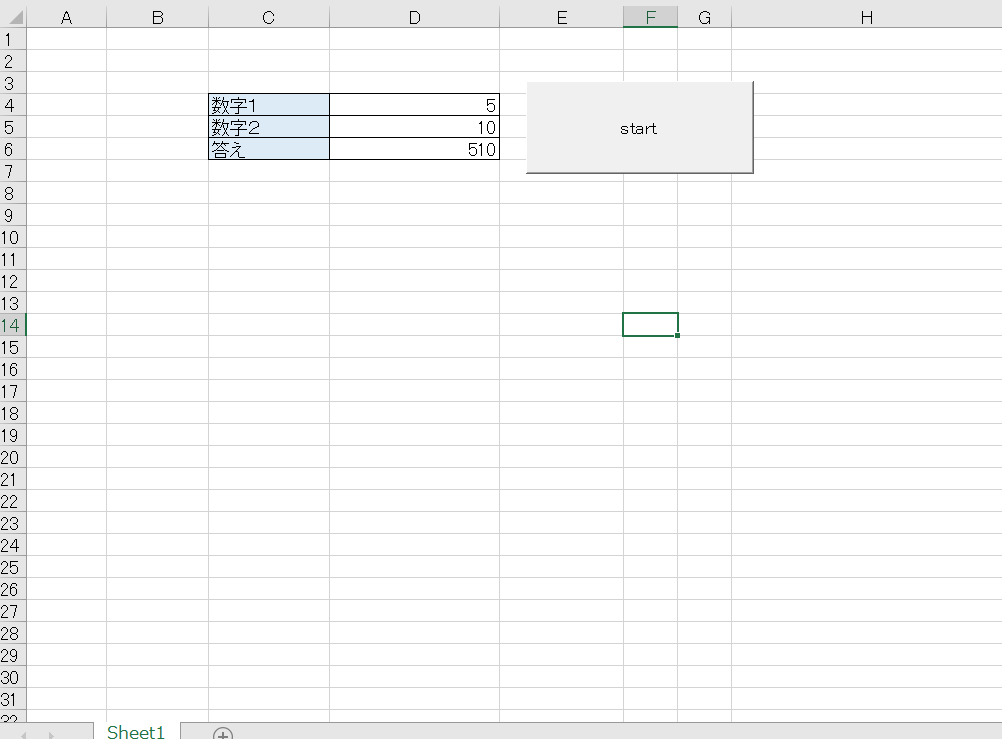
数字1、数字2に任意の値を入れると計算をして、答えに出力します。
ちなみにPythonはこういうコードです。
import sys def sum(suji1, suji2): return suji1 + suji2 if __name__ == "__main__": argv = sys.argv suji1 = str(argv[1]) suji2 = str(argv[2]) total = sum(suji1, suji2) print(total)実行するとこんな感じです。
最後に
今回はVBAでPythonを起動しましたが、実際はコマンドプロンプトを使って実行しているので
応用すればもっといろんなことができる気がします。
また、学びがあれば更新していきます。
- 投稿日:2020-02-22T16:56:00+09:00
機械学習ワークフロー管理ツール Kedroを使ってTitanic生存予測
はじめに
この記事では,Kedroというライブラリを使って,Titanic生存予測のワークフローを構築してみます。
最近機械学習ワークフロー管理ツール,構築支援ツールの類が多く出ています。
自分が聞いたことがあるものだけでも,などがあります。
こうしたツールを,共通の予測プロジェクトを通して性能比較してみよう!というのが今回の記事執筆の発端です。
共通プロジェクトとしては,データ分析を始めたら誰でも必ず通る道,Titanic生存予測を選びました。
ということで,まずはKedroから試してみます。
Kedroを選んだ理由は以下の通りです:
- 使い勝手が良いと一時期twitterで評判になっていた
- Quick StartプロジェクトとTutorialがしっかり書かれていて,着手しやすそうだった
Kedroについて
kedroは,マッキンゼー傘下のデータ分析企業QuantumBlack社が開発しているPython用機械学習ワークフロー管理ツールです。
以下に挙げるように,PoC段階での実験管理に便利なツールですが,一方でプロダクション向けの機能は弱いです。
用途
機械学習モデルの実験開発を円滑に行う
できること
- ディレクトリやPythonコードのテンプレート作成
- フォーマットに沿って記述したpipelineをもとに,データ処理〜モデル構築をコマンドライン実行
- 出力結果や中間データ・オブジェクトの管理
メリット
- ディレクトリ構造やコードフォーマットを統一できる
- データ・中間オブジェクトの管理が楽になる
- catalog.ymlに書いておくだけで,簡単に読み出し・自動保存できる
- テキストベースでのパラメータ指定がしやすい
- parameters.ymlに記述しておけばstringで簡単に読み出せる
できるかわからないこと
- モデルや前処理オブジェクトの再読み込み
- 新たなデータに対する推論をしたい場合,どうすればよい?
- 特に,バージョン指定込みで行えるか?
- ディレクトリ構造などのカスタマイズ
できないこと
- 異なるモデル間の精度の比較
- MLflowと相補できそう
- プロダクション環境へのdeployとジョブの実行管理・監視
- Airflowやluigiあたりとは方向性が異なりそう
Titanic生存予測による実践例
以下,Kedroの使い方を,データ分析でお馴染みのTitanicを例に紹介していこうと思います。
基本的には公式Tutorialを参考に作成しています。
コードはGitHubにアップしてあります。基本的なワークフロー構築の流れ
- プロジェクト作成
- コマンドラインから
kedro new- 自動的にディレクトリを作成してくれる
- データの準備
- 生データをdata/01_raw/ディレクトリに入れ,catalog.ymlを編集する。
- 以後,stringだけで指定してpandas DataFrameに読み込んでくれる。
- pipelineの構築
- ひとまとまりの処理を関数にまとめ,nodeとして定義しする
- Pipelineクラスにnodeを並べ,処理フローを定義する
- 実行と中間データの保存
- コマンドラインから
kedro run- catalog.ymlで設定しておけば,中間ファイルを保存してくれる。
- モデルのバージョニングも可能。
プロジェクト作成
コマンドラインから
kedro newを実行すると,以下のようにプロジェクト名,レポジトリ名,パッケージ名の入力を促されます。$ kedro new Project Name: ============= Please enter a human readable name for your new project. Spaces and punctuation are allowed. [New Kedro Project]: Titanic with Kedro Repository Name: ================ Please enter a directory name for your new project repository. Alphanumeric characters, hyphens and underscores are allowed. Lowercase is recommended. Python Package Name: ==================== Please enter a valid Python package name for your project package. Alphanumeric characters and underscores are allowed. Lowercase is recommended. Package name must start with a letter or underscore. Generate Example Pipeline: ========================== Do you want to generate an example pipeline in your project? Good for first-time users. (default=N)
Repository Nameで入力した名前でプロジェクト用ディレクトリが作成されます。
中を見てみると,以下のようになっています。titanic-with-kedro ├── README.md ├── conf │ ├── README.md │ ├── base │ │ ├── catalog.yml │ │ ├── credentials.yml │ │ ├── logging.yml │ │ └── parameters.yml │ └── local ├── data │ ├── 01_raw │ ├── 02_intermediate │ ├── 03_primary │ ├── 04_features │ ├── 05_model_input │ ├── 06_models │ ├── 07_model_output │ └── 08_reporting ├── docs │ └── source │ ├── conf.py │ └── index.rst ├── errors.log ├── info.log ├── kedro_cli.py ├── logs ├── notebooks ├── references ├── results ├── setup.cfg └── src ├── requirements.txt ├── setup.py ├── tests │ ├── __init__.py │ └── test_run.py └── titanic_with_kedro ├── __init__.py ├── nodes │ └── __init__.py ├── pipeline.py ├── pipelines │ └── __init__.py └── run.py途中で聞かれる'Python Package Name'は,
src以下に生成されるpipelineコードを置くディレクトリの名前に使われます(今回はtitanic_with_kedro)。最後に'Do you want to generate an example pipeline in your project?'と尋ねられますが,ここでyを押すとチュートリアル用のコードがセットで生成されます。
2回目以降は不要なのでNか入力せずエンターを押しましょう。データの準備
今回はkaggleからAPIを使ってデータを取ってきて,
data/01_raw/におきます。
kaggleへの登録や認証Tokenの取得は別途必要です。$ cd data/01_raw/ $ kaggle competitions download -c titanic $ unzip titanic.zipこれに加えて,データカタログを下記のように編集します。
conf/base/catalog.ymltrain: type: CSVLocalDataSet filepath: data/01_raw/train.csv test: type: CSVLocalDataSet filepath: data/01_raw/test.csvデータ名
train,testは,データを読み込む際にも使います。
type:では,あらかじめkedroで用意されたデータ読み込み形式を選択できます。1試しにデータを読み込めるか確認してみましょう。
以下のkedroコマンドを実行し,Jupyter notebook(もしくはIPython)を立ち上げましょう。データ読み込み用の
catalogが予めimportされた状態でnotebookが立ち上がります2。$ kedro jupyter notebookdf_train = catalog.load("train") df_train.head()pipelineの構築
nodeとpipelineの定義
データ前処理pipelineをkedroのフォーマットに沿って記述します。
src/titanic_with_kedro/pipelines/data_engineering/pipeline.pyfrom kedro.pipeline import node, Pipeline from titanic_with_kedro.nodes import preprocess def create_pipeline(**kwargs): return Pipeline( [ node( func=preprocess.preprocess, inputs="train", outputs="train_prep", name="preprocess", ), ], tags=['de_tag'], )kedroで用意されている
Pipelineクラスに処理単位であるnodeを格納していきます。
node関数には,
- func: 処理を記述した関数
- inputs: 入力データ名
- outputs: 出力データ名
- name: node名
を指定します。
nodeで行う処理は,引数
funcに関数オブジェクトを渡すことで指定します。今回の例では,関数
preprocess()を一つのnodeとし,欠損値の補完やラベルエンコーディングを行なっています。この時,関数
preprocess()の入力には,引数inputsで指定したデータが用いらます。
上記の例ですとtrainが指定されていますが,これは前述のデータカタログconf/base/catalog.ymlで定義したtrainデータのことを指し示しており,カタログに記述したデータフォーマットとpathをもとによしなにファイルを読み込んで入力してくれます。そして出力オブジェクトには
outputsで指定したラベルが付与されます。後続の処理でこのオブジェクトを利用する際は,このラベルで指定し呼び出すことができます。今回nodeで指定した前処理関数は,以下のようになっています。pipelineと違って,特別な記述方法を取る必要はありません。
(関数
_label_encoding()は補助関数です)src/titanic_with_kedro/nodes/preprocess.pyimport pandas as pd from sklearn import preprocessing def _label_encoding(df: pd.DataFrame) -> (pd.DataFrame, dict): df_le = df.copy() # Getting Dummies from all categorical vars list_columns_object = df_le.columns[df_le.dtypes == 'object'] dict_encoders = {} for column in list_columns_object: le = preprocessing.LabelEncoder() mask_nan = df_le[column].isnull() df_le[column] = le.fit_transform(df_le[column].fillna('NaN')) df_le.loc[mask_nan, column] *= -1 # transform minus for missing records dict_encoders[column] = le return df_le, dict_encoders def preprocess(df: pd.DataFrame) -> pd.DataFrame: df_prep = df.copy() drop_cols = ['Name', 'Ticket', 'PassengerId'] df_prep = df_prep.drop(drop_cols, axis=1) df_prep['Age'] = df_prep['Age'].fillna(df_prep['Age'].mean()) # Filling missing Embarked values with most common value df_prep['Embarked'] = df_prep['Embarked'].fillna(df_prep['Embarked'].mode()[0]) df_prep['Pclass'] = df_prep['Pclass'].astype(str) # Take the frist alphabet from Cabin df_prep['Cabin'] = df_prep['Cabin'].str[0] # Label Encoding for str columns df_prep, _ = _label_encoding(df_prep) return df_prep複数pipelineの統合
複数作成したpipelineを組み合わせることもできます。
今回はモデル構築を別のpipeline
src/titanic_with_kedro/pipelines/data_science/pipeline.pyで定義しました。これを先ほどの前処理と組み合わせるには,以下のように行います。
src/titanic_with_kedro/pipeline.pyfrom typing import Dict from kedro.pipeline import Pipeline from titanic_with_kedro.pipelines.data_engineering import pipeline as de from titanic_with_kedro.pipelines.data_science import pipeline as ds def create_pipelines(**kwargs) -> Dict[str, Pipeline]: """Create the project's pipeline. Args: kwargs: Ignore any additional arguments added in the future. Returns: A mapping from a pipeline name to a ``Pipeline`` object. """ de_pipeline = de.create_pipeline() ds_pipeline = ds.create_pipeline() return { "de": de_pipeline, "ds": ds_pipeline, "__default__": de_pipeline + ds_pipeline, }モデル構築のpipelineは以下のように定義しています。
src/titanic_with_kedro/pipelines/data_science/pipeline.pyfrom kedro.pipeline import node, Pipeline from titanic_with_kedro.nodes import modeling def create_pipeline(**kwargs): return Pipeline( [ node( func=modeling.split_data, inputs=["train_prep", "parameters"], outputs=["X_train", "X_test", "y_train", "y_test"], ), node(func=modeling.train_model, inputs=["X_train", "y_train"], outputs="clf"), node( func=modeling.evaluate_model, inputs=["clf", "X_test", "y_test"], outputs=None, ), ], tags=["ds_tag"], )このように,一つのpipelineに複数のノードを配置することもできます。
実行と中間データの保存
pipelineが定義できたら,プロジェクトのrootから実行コマンドを出します。
$ kedro runこうすることで,
src/<project_name>/pipeline.pyが呼び出され,処理が実行されていきます。この時,前処理後の中間データや作成したモデル(今回はランダムフォレスト)を保存しておきたい場合には,データカタログに以下を追記しておきます。
conf/base/catalog.ymltrain_prep: type: CSVLocalDataSet filepath: data/02_intermediate/train_prep.csv clf: type: PickleLocalDataSet filepath: data/06_models/classifier.pickle versioned: true
train_prepとclfはそれぞれ前処理後のデータと学習済みモデルを指しますが,pipeline定義時にnode関数のoutputs引数で指定した名前をそのまま認識し,所定のフォーマット・pathに保存してくれます。また,
versionedをtrueにしておけば実行の都度異なるディレクトリに保存してくれます3。そのほか便利な機能
基本的な機能は以上な感じですが,そのほかにも以下のような機能もあります。
Jupyter notebookから直接nodeを作成
実行コードを作成する際,初めから.pyファイルで書かずにJupyter notebookで逐一実行しながら書き進める人も多いかと思います。
この場合,後からコードをまとめて.pyに書き直すのが面倒ですが,kedroのcliを使えばコードの指定した部分だけ.pyに吐き出してくれます。
それにはまず,kedroのcliからJupyterを立ち上げます。
$ kedro jupyter notebook次に,.pyに書き出したいcellにだけ
nodeタグをつけます。
タグづけには,画面上部メニューのView > Cell Toolbar > Tagsを選択します。各セル上部にタグ入力windowが表示されるので,nodeと打ち込んで付与します。
そのうえでコマンドラインから以下を実行すると,タグづけした部分だけ抜き出して
src/<project name>/nodes/<notebook name>.pyが生成されます。kedro jupyter convert notebooks/<notebook name>.ipynb<参考>
https://kedro.readthedocs.io/en/latest/04_user_guide/11_ipython.htmlパラメータ管理
pipelineを定義する際に,外部ファイルで指定したパラメータを読み込むこともできます。
上記のモデル構築パラメータをもう一度見ると,inputsに
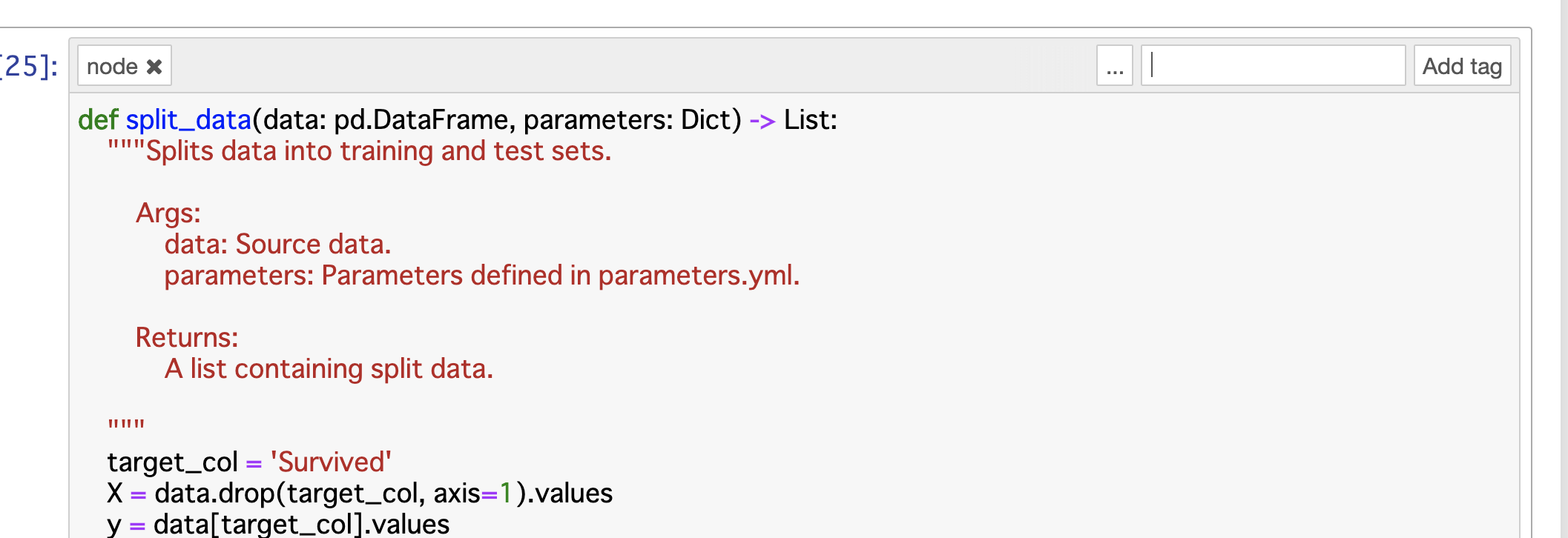
"parameters"が指定されている箇所があります。src/titanic_with_kedro/pipelines/data_science/pipeline.py# 省略 def create_pipeline(**kwargs): return Pipeline( [ node( func=modeling.split_data, inputs=["train_prep", "parameters"], outputs=["X_train", "X_test", "y_train", "y_test"], # 省略上記は,学習データ・テストデータに分割する部分です。
"parameters"は,conf/baseディレクトリ以下のparameters.ymlファイルを参照します。conf/base/parameters.ymltest_size: 0.2 random_state: 17こうしておくことで,以下のように自動で辞書型のオブジェクトとしてnode関数の引数に渡し,参照することができます。
# 省略 def split_data(data: pd.DataFrame, parameters: Dict) -> List: """Splits data into training and test sets. Args: data: Source data. parameters: Parameters defined in parameters.yml. Returns: A list containing split data. """ target_col = 'Survived' X = data.drop(target_col, axis=1).values y = data[target_col].values X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=parameters["test_size"], random_state=parameters["random_state"] ) return [X_train, X_test, y_train, y_test] # 省略まとめ
以上,Kedroの利用方法の紹介がてら,Titanic予測を行ってみました。
課題:前処理オブジェクトの保存とバージョン管理
上記の予測フローは欠陥があります。
データ分析に慣れている方ならお気づきになったかもしれませんが,
- 訓練・テストデータを分ける前に前処理を行なっている
- 新しいデータが与えられた時の推論フローがない
ことが挙げられます。
特に前者については,欠損値の補完とラベルエンコーディングの際にテストデータの情報が訓練データに混ざるので,Leakageの恐れがあります。
いずれの問題点も,前処理部分をクラスで書いておいて,インスタンスをpickleで固めて後から読み出し利用できるようにすれば解決可能です。
解決方法もそこまで難しくなく,nodeの出力に前処理オブジェクトを加えて,catalog.ymlを編集し実行時に保存するようにすれば実現できる見込みです。
ただし,バージョン管理の問題があります。
前処理部分とモデルの両方をバージョン管理ありで保存した場合,各モデルに対応するバージョンの前処理オブジェクトはどのように紐づければよいでしょうか?
例えば前処理部分を書き換えてモデルを作り,後から古いモデルで推論を行いたいとします。
この時,新しい前処理コードが古いモデルと互換性を持たない場合,前処理オブジェクトも古いモデルを作った時のものに置き換える必要があります。これを手間なく行うには,何かしらのタグ付けか実行IDの付与が必要ですが,それをKedroでできるかは未確認です。4
その他思ったこと
そのほか,Kedroを触ってみて「この機能あったらな...」と思った点をいくつか挙げますと,
- テンプレートとして用意されているディレクトリ構造やコードをカスタマイズできないか?
- 出力した予測精度をまとめて記録し,モデルやパラメータごとに比較できないか?
があります。
前者はもしかしたらいじれるかもしれません。
後者については恐らくKedroのカバー範囲外なので,他のツールと併用するしかなさそうです。
具体的にはDatabricksから出ているMLflowがちょうど良さそうです。
実際,Kedroの開発元QuantumBlackの人が書いた記事でもMLflowとの併用が論じられていますし,両者を合わせたPipelineXというライブラリも存在します。参考リンク
- Introducing Kedro: The open source library for production-ready Machine Learning code
- PythonのPipelineパッケージ比較:Airflow, Luigi, Gokart, Metaflow, Kedro, PipelineX
カスタムで作成したデータ読み込み関数を適用することもできます。 ↩
デフォルトでは,モジュール読み込みエラーで実行できないことがあります。その際は,
src/<project-name>/pipeline.pyを開き,Tutorial用のモジュールimportを削除しておきます。 ↩今回の場合,
data/06_models/classifier.pickle/以下に実行時の時刻で新しい時刻が作成され,data/06_models/classifier.pickle/2020-02-22T06.26.54.486Z/classifier.pickleのように保存されます。 ↩MLflowやMetaflowでは実行IDを指定してモデルや中間オブジェクトの読み出しが可能です。これらとうまく組み合わせれば,もしかしたら可能かも... ↩
- 投稿日:2020-02-22T15:23:26+09:00
headless-chrome を Debian ベースのイメージ上で動かす
スクレイピングで js を読み込みたい
Mac os でローカルの中だけでやる分には、いまだに phantom.js が快適に動いてくれるので、ヘッドレスブラウザの利用が簡単なんだけれども
Cloud Run で使用したかったので、公式のpythonイメージで動作確認しようと思ったら、意外とややこしかったのでメモしておく訳わからん情報が溢れてる
どうやら phantom.js は更新をやめてしまうということだったので、大人しく headless-chrome を使用することにしたけど
工数を使用したくなかったので、他の人達の記事を漁った
でも僕はアホなので、記事を見てもとにかくわからんかった、もう自分でなんとかすることにした結論
特に難しいことはなく、以下の条件を満たせば簡単に動く
chrome 本体をダウンロード chrome 本体に合ったバージョンのドライバをダウンロード 起動時のオプションを適切に設定Dockerfile
使用したベースイメージ
# Use the official Python image. # https://hub.docker.com/_/python FROM python:3.7Chrome 本体のダウンロードをする、インストール時のバージョンは必ず見ておくこと
RUN sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - RUN apt update RUN apt install google-chrome-stable -yDriver のダウンロードする、先にChromeのバージョンに一番近いやつを探す
https://chromedriver.storage.googleapis.com/
そんで、本体のバージョンに一番近い最新版を探す、今回は80台だったからこう
https://chromedriver.storage.googleapis.com/LATEST_RELEASE_80見つけた番号でダウンロード&解凍するよ
RUN wget https://chromedriver.storage.googleapis.com/80.0.3987.106/chromedriver_linux64.zip RUN unzip chromedriver_linux64.zip -d /usr/bin/もちろんだけど、この段階で両方ともPATHが見える様にしておくこと
which chromedriver witch google-chromeこんだけでOK
あとは使用するだけ、一応使用例も書いとくapp.pyfrom selenium import webdriver from selenium.webdriver.chrome.options import Options from bs4 import BeautifulSoup URL = "https://example.jp" def get_trends(): try: options = Options() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome(options=options) driver.get(URL) html = driver.page_source.encode('utf-8') # more sophisticated methods may be available soup = BeautifulSoup(html, "lxml")終わり
ぶっちゃけメモ
- 投稿日:2020-02-22T15:22:05+09:00
[python]関数をリストに入れて管理する
はじめに
moduleに複数のロジックがあって、それらをある関数から呼び出したいということはあると思います。
やり方
構成
├── modules │ └──logic.py │ └─ main.pyコード
modules/logic.pydef func1(word): print('こちらfunc1' + word) def func2(word): print('こちらfunc2' + word) def func3(word): print('こちらfunc3' + word) def func4(word): print('こちらfunc4' + word) def func5(word): print('こちらfunc5' + word)main.pyimport modules.logic as logic def func(func_num, word): a = [_, logic.test1, logic.test2, logic.test3, logic.test4, logic.test5] return a[func_num](word if __name__ == '__main__' func(1,'です') func(2,'やで') func(3,'だよ') func(4,'にょろ') func(5,'だじぇ')実行と結果
$ python main.py こちらfunc1です こちらfunc2やで こちらfunc3だよ こちらfunc4にょろ こちらfunc5だじぇひとこと
もっと良い書き方ありましたら教えてください。
- 投稿日:2020-02-22T15:14:58+09:00
Titanic生存者を予測する(ランダムフォレストのパラメータチューニング) ver1.1
1 はじめに
機械学習を学ぶ上でのチュートリアルとして皆さん必ず通る道であろうタイタニック号生存者の予測について、私が行った方法を備忘として記録します。
前回、Titanicの生存者予測をランダムフォレストによって行いました。その際に使用したパラメータを変えたことによる正解率への影響を評価しました。
プログラム全体については下記をご覧下さい。
https://qiita.com/Fumio-eisan/items/77339fc737a3d8cfe1792 ランダムフォレストのパラメータ影響評価
ランダムフォレストは決定木を複数用意して、多数決を取ることで決定木の過学習を平準化するアルゴリズムのことです。
その特徴として、
1.多数決によるアンサンブル学習のため過学習が起こりにくい
2.特徴量の標準化や正規化の処理が必要ない
3.ハイパーパラメータが少ない(サンプリング数と決定木の特徴量数くらい)
4.どの特徴量が重要かを知ることができるといったことが挙げられます。
ニューラルネットワークなどのディープランニングのようなキラキラした技術に対して、堅牢な枯れた技術といわれることもあるようです。
機械学習初心者である私がまずは実際に手を動かして感触を確かめてみたいと思います。参考にさせて頂いたページ
http://aiweeklynews.com/archives/50653819.html2-1 n_estimatorsの影響について
x=[] y=[] for i in [1,2,3,4,5,6,7,8,9,10,15,20,25,30,40,50]: clf = RandomForestClassifier( n_estimators = i , max_depth=5, random_state = 0) clf = clf.fit(train_X , train_y) pred = clf.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred,pos_label = 1) auc(fpr,tpr) accuracy_score(pred,test_y) y.append(accuracy_score(pred,test_y)) x.append(i) plt.scatter(x, y) plt.xlabel('n_estimators') plt.ylabel('accuracy') plt.show()
n_estimatorsとは、決定木の数のことになります。
n_estimatorsについては10程度でサチレートしていることが分かります。さらに50まで上げると過学習になるのか値が下がってきました。
https://amalog.hateblo.jp/entry/hyper-parameter-search2-2 criterionの影響について
x=[] y=[] z=[] for i in [1,2,3,4,5,6,7,8,9,10,15,20,25,30,40,50,100]: clf = RandomForestClassifier( criterion='gini', n_estimators = i , max_depth=5, random_state = 0) clf = clf.fit(train_X , train_y) pred = clf.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred,pos_label = 1) auc(fpr,tpr) accuracy_score(pred,test_y) y.append(accuracy_score(pred,test_y)) clf_e = RandomForestClassifier( criterion='entropy', n_estimators = i , max_depth=5, random_state = 0) clf_e = clf_e.fit(train_X , train_y) pred_e = clf_e.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred_e,pos_label = 1) auc(fpr,tpr) accuracy_score(pred_e,test_y) z.append(accuracy_score(pred_e,test_y)) x.append(i) plt.xlabel('n_estimators') plt.ylabel('accuracy') plt.plot(x,y,label="gini") plt.plot(x,z,label="entropy") plt.legend(bbox_to_anchor=(1, 1), loc='center right', borderaxespad=0, fontsize=18)
ジニ関数と情報エントロピーの取り扱いの差による影響を評価しました。
前回でも紹介させていただきましたが、ジニ関数は回帰を得意としており情報エントロピーはカテゴリーデータを得意としているようです。
決定木数が10未満の時はほとんど変わらない値をとっており、その後10~40まではジニ関数が高くなります。しかし、その後は情報エントロピーのほうが優位になることが分かりました。
この要因については私の理解に及ばないところがあり、宿題とします。。。2-3 ramdom_stateの影響について
from sklearn.ensemble import RandomForestClassifier x=[] y=[] z=[] for i in [1,2,3,4,5,6,7,8,9,10,15,20,25,30,40,50,60,70,80,90,100]: clf = RandomForestClassifier( criterion='gini', n_estimators = 10 , max_depth=5, random_state = i) clf = clf.fit(train_X , train_y) pred = clf.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred,pos_label = 1) auc(fpr,tpr) accuracy_score(pred,test_y) y.append(accuracy_score(pred,test_y)) clf_e = RandomForestClassifier( criterion='entropy', n_estimators = 10 , max_depth=5, random_state = i) clf_e = clf_e.fit(train_X , train_y) pred_e = clf_e.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred_e,pos_label = 1) auc(fpr,tpr) accuracy_score(pred_e,test_y) z.append(accuracy_score(pred_e,test_y)) x.append(i) plt.xlabel('ramdom_state') plt.ylabel('accuracy') plt.plot(x,y,label="gini") plt.plot(x,z,label="entropy") plt.legend(bbox_to_anchor=(1, 1), loc='center right', borderaxespad=0, fontsize=18)
次にrandom_stateを変更させてみました。こちらはかなり安定していないことが分かります。凡そこちらも10回程度でサチレートしているように見えます。
そもそもこの値の意味は、再現性を担保させるためとのことです。https://teratail.com/questions/99054
random_stateを指定すると、同じ乱数を発生させることができる。目的は再現性を担保するため。
乱数が必要な理由は、弱予測器(たち)の作成にデータの一部をランダムに選ぶ必要があるから。3 まとめ
今回の確認により、大きく正解率に影響するのはn_estimators:決定木数であることが分かりました。ある程度大きい値を入れることでサチレートしていくことが確認できました。
仮に計算時間が多量にかかる場合は、自動的にサチレートしたら止まるような細工を入れることが必要になります。
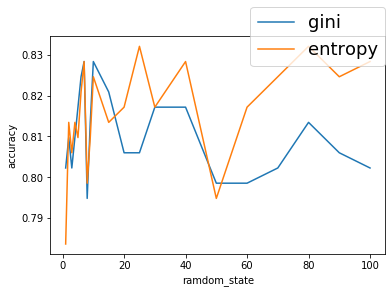
- 投稿日:2020-02-22T13:49:05+09:00
COTOHAを使って大量の有価証券報告書を読む
はじめに
有価証券報告書ってイマイチ何が書いてあるか分からないし、知りたい1社の特定の年度の内容を読んでも他社/他の年度と比較しないとよく分からないですよね
そこでCOTOHAを使って大量の有価証券報告書を読む方法を探ってみようと思います※COTOHAの基本的な使い方は@gossy5454さんの記事が詳しいです
この記事の執筆モチベーション
- COTOHAを使ってお手軽に自然言語処理を行いたい
- あまり知られていない?CoARiJを使ってみたい
- 有価証券報告書を効率よくで読んで投資に活かしたい
ソースコード
今回検証に使用したコードは下記にあります
https://github.com/ice-github/CoARiJAndCOTOHA
※main.pyを参照COTOHAについて
NTTグループの自然言語処理プラットフォームです
https://api.ce-cotoha.com/contents/index.html面白そうなAPI
- 類似度判定
- 過去の報告書と比較できそうです
- 要約(β)
- 既に簡潔に書かれている報告書が要約されるとどうなるか気になるところです
- 固有表現抽出
- 報告書内でどんな話題があるのかざっくり知れそうです
- 感情分析
- 利益が上がっているのにネガティブな表現になっているといった齟齬が分かりそうです
※(β)はベータ版の機能
CoARiJについて
TISが公開した企業分析を行うためのデータセットです
https://www.tis.co.jp/news/2019/tis_news/20191114_1.htmlデータアクセス方法
coarijをインストールしてExtractデータとして2014年~2018年のデータをダウンロード
以下にdataディレクトリが作成され、data/interim/以下に年毎のディレクトリが作成されます$ cd <WorkspacePath> $ pip install coarij $ coarij download --kind E --year 2014 $ coarij download --kind E --year 2015 $ coarij download --kind E --year 2016 $ coarij download --kind E --year 2017 $ coarij download --kind E --year 2018下記のようにPandasでdata/interim/<year>/documents.csvを開き中身を読むことで、data/interim/<year>/docs/ディレクトリ以下にあるテキスト情報にアクセスできるようになります
CompanyInformation.py... csv_path = os.path.join(data_directory_path, 'interim', str(year), 'documents.csv') self.csv_document = pd.read_csv(filepath_or_buffer=csv_path, encoding='UTF-8', sep='\t', index_col='sec_code') # use sec_code as index ...CoARiJの問題点
大きく分けて3点の問題点があります
データには欠損があり、ある年にあった企業がある年に消えていていることがあります。
2017年以降に2.事業の状況の項目が変更されており、ファイルの中身が空になっていることがあります
※これはCoARiJというよりはEDINETの問題です => 参考data/interim/<year>/documents.csvに記述されているはずの総売上高や営業利益の数字が欠損していることがあります
※TOPIX Core 30で確認したところ30社のうち10社が2014年~2018年のデータのいずれかを欠損していました今回は気にせずに存在するデータのみを扱っていきたいと思います

有価証券報告書の【事業の状況】をCOTOHAを使って分析する
有価証券報告書は色々な項目が並んでいるのですが、皆さんはどのように読んでいますか?
自分の場合は
1.【企業の概況】から総売上、営業利益、経常利益、自己資本比率あたりの推移をざっと読む
2.【事業の状況】をしっかり読んでいく
3. 以降は流し読みというスタイルを取っています
なので今回は1.【企業の概況】と2.【事業の状況】に注目していこうと思いますCoARiJでは1.【企業の概況】は.csvファイルにまとまっているため、2.【事業の状況】の.txtファイルをCOTOHAへの入力にしていきます
※.csvファイルには単独の結果が記載されているため、持株会社(ホールディングス)の場合は異常に高い利益率(コナミやNTTは80%以上)になることがあります
毎年あまり変わらなそうな項目
- 【経営方針、経営環境及び対処すべき課題等】
- business_policy_environment_issue_etc.txt
- 【事業等のリスク】
- business_risks.txt
こちらの項目は大幅に変わらないことが多いため、類似度判定をして前年と変わっているかどうかをチェックし、異なっていれば要約(β)を使って文章を短くします
可能ならばそのままの文章を扱いたかったのですが、3000文字(too long url?)を超えるテキストをリクエストすると500(Internal Server Error)が出ることがあったため文章を分割します
main.py... def GetDividedSubstring(text: str, max_length: int) -> List[str]: if len(text) < max_length: return [text] index = text.rfind('。', 0, max_length) if index < 0: index = text.rfind('\n\n', 0, max_length) # try to find double newlines if index < 0: if len(text) < max_length: return [text] else: index = max_length head = text[: index + 1] tail = text[index + 1:] result: List[str] = [head] for text in GetDividedSubstring(tail, max_length): result.append(text) return result ...分割した文字列同士で類似度を比較するのですが分割数が異なる場合があるためその場合は比較せずに0が返ってきたとします
※この文字列分割は下記の感情分析、固有表現抽出と要約でも使用しています毎年変わっていく項目
- 【財政状態、経営成績及びキャッシュ・フローの状況の分析】 (2017以前)
- business_analysis_of_finance.txt
- 【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】 (2018以降)
- business_management_analysis.txt
- 【研究開発活動】
- business_research_and_development.txt
キャッシュフローに関しては感情分析でポジティブかどうかをチェックし、営業利益もしくは経常利益が増えているにも関わらずネガティブと判定された場合には原文を使い、それ以外の場合は要約(β)を使って文章を短くします
研究開発活動に関しては見慣れない単語が並んでいるため固有表現抽出をしてざっくりとどんな内容が含まれるかをチェックした後、要約(β)を使います固有表現抽出では様々な固有表現クラスがありますが、下記のように固有物名(ART)と人名(PSN)、場所(LOC)にフィルタすることで個別に抽出しても意味の分からない金額などの数値が含まれないようにしています
※sentence(1文)とdocument(複数文)を区別せずに使用していますが、APIの設計上は分けられているようです
main.py... for dict_index in range(len(ne['result'])): word_class = ne['result'][dict_index]['class'] if word_class == 'ART' or word_class == 'PSN' or word_class == 'LOC': if word not in words: # Unique words.append(ne['result'][dict_index]['form']) ...結果
結果が分かりやすそうな数社をピックアップします
企業一覧
[株式会社ニチレイ]
総売上 : 5680.32億円(2017) => 5801.41億円(2018)
営業利益: 298.97億円(2017) => 295.11億円(2018), 営業利益率5.26%(2017) => 5.09%(2018)
経常利益: 306.50億円(2017) => 298.64億円(2018), 経常利益率5.40%(2017) => 5.15%(2018)事業等のリスク
## 要約
品質問題が発生した場合はその危害性と拡散性などから総合的に判断し適切な対応を行いますが、想定を超える大規模な商品回収等が発生した場合には、当社グループの業績に重大な影響を与える可能性があります。そのため、働き方改革の推進、労働環境の整備、業務の自動化や省力化・省人化などに取り組んでおります。 (5) 情報システムについて当社グループでは、適切なシステム管理体制を構築しておりますが、システム運用上のトラブルの発生により、業務運営に支障をきたす可能性があります。 (7) 原油価格等の変動について加工食品事業では、原油価格の変動が商品・原材料や重油等燃料の調達コストに影響を及ぼします。また、海外事業を展開していくうえでも、当該国における法的規制等の適用を受けております。今後環境に関する法改正等に対応するための費用負担等が大幅に増加した場合には、当社グループの業績に重大な影響を与える可能性があります。 (13) 固定資産の保有について当社グループは、多額の設備投資を必要とする物流センターや生産工場を多数保有しております。これらの政策保有株式については個別の銘柄ごとに中長期的な経済合理性等を検証し、保有意義が薄いと判断する株式は売却しております。
財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
(1) 経営成績等の状況の概要及び経営者の視点による経営成績等の状況に関する分析・検討内容① 経営成績の状況及び分析等当期のわが国経済は、企業業績や雇用所得環境が改善するなか、緩やかな回復基調が続きましたが、年度末にかけて輸出や生産の一部に弱さが見られました。また、食品物流業界では、旺盛な保管需要による取扱い拡大を背景に設備増強の動きが顕著となる一方、作業費や車両調達コスト、電力料金などが上昇しました。(単位:百万円) 売上高営業利益(セグメント)当期前期比増減率(%)当期前期比増減率(%) 加工食品226,5885,9012.714,596230.2 水産71,245△266△0.4182△122△40.3 畜産91,0766830.81,45215011.6 低温物流201,0495,9553.111,3981421.3 不動産4,794△74△1.52,096△55△2.6 その他5,7904458.3338△473△58.3 調整額△20,402△535-△553△51-合 計580,14112,1092.129,511△386△1.3 (イ) 加工食品事業《業界のトピックス》加工食品業界では、単身世帯の増加や人手不足などを背景とした簡便調理食品への需要や惣菜などの中食需要が引き続き堅調に推移しました。 《業績のポイント》家庭用・業務用ともにチキン加工品や米飯類などの主力カテゴリーを中心とした商品開発や販売活動に注力した結果、家庭用調理品などの販売が拡大し増収となりました。 業務用調理品需要が堅調に推移する中食に向け、業態別ニーズに合わせた商品開発や販売活動に注力し、主力のチキン加工品や有名シェフ監修による「シェフズ・スペシャリテ」シリーズなどの取扱いが伸長しました。 《業績のポイント》収益性に配慮した慎重な買付や販売に徹したことにより減収となりました。 (ハ) 畜産事業《業界のトピックス》堅調な食肉消費に支えられ国内需要は拡大しました。また、利益面では荷役作業コストなどが上昇したものの、業務改善及び運送効率化などの施策を引き続き推進したことで増益となりました。 海外欧州地域はブラジル食肉不正問題によるチキン搬入量の減少や輸配送コストの上昇がありましたが、小売店向け輸送業務などの運送需要の着実な取り込みや輸入果汁の取扱拡大などにより増収・増益となりました。 (ホ) 不動産事業《業績のポイント》賃貸オフィスビルの競争力強化のため、リニューアル工事を実施し稼働率の維持・向上に努めたものの、茨城県牛久市の宅地分譲の終了や一部賃貸オフィスビルにおける耐震マーク取得費用の発生などにより減収・減益となりました。 (ヘ) その他の事業《業績のポイント》その他の事業のうち、バイオサイエンス事業は,バイオ医薬品原料や迅速診断薬の販売が順調に推移し増収となったものの、生産・研究開発拠点の新設(埼玉県狭山市)や米国での医療機器会社買収による一時的なコスト負担が生じたことにより減益となりました。 ② 財政状態及びキャッシュ・フローの状況及び分析等(イ) 財政状態の状況及び分析等(単位:百万円) 前期当期前期比 〔資産の部〕 流動資産153,564160,5546,989 固定資産213,703216,7032,999(ⅰ)資産合計367,268377,2579,988 〔負債・純資産の部〕 流動負債110,48999,561△10,927 固定負債87,09893,8906,791(ⅱ)負債合計197,587193,451△4,135 うち、有利子負債(リース債務を除く)97,745(79,844)95,951(78,923)△1,794(△920)(ⅲ)純資産合計169,680183,80514,124 (うち自己資本)(162,729)(176,820)(14,090) D/Eレシオ(倍)(リース債務を除く)0.6(0.5)0.5(0.4)△0.1(△0.0)(注)D/Eレシオの算出方法:有利子負債÷純資産 (ⅰ) 総資産のポイント 3,772億円(99億円の増加)販売が好調に推移し売上債権が増加したことなどにより流動資産が69億円増加、主力事業の収益基盤拡大に向けた設備投資などにより有形固定資産は26億円増加しました。 (ⅲ) 財務活動によるキャッシュ・フローのポイント配当金の支払い41億円や有利子負債の返済などにより、財務活動によるキャッシュ・フローは90億円の支出となりました。なお、見積り及び判断・評価については、過去実績や状況に応じて合理的と考えられる要因等に基づき行っておりますが、見積り特有の不確実性があるために実際の結果は異なる場合があります。当社グループは国内連結子会社を含めたキャッシュマネジメントシステム(CMS)を導入しており、運転資金及び設備投資資金の調達は、主に当社の借入れ及び社債の発行やグループ各社の事業活動から生じるキャッシュ・フローを資金集中することによる内部資金によっております。詳細につきましては、「1 経営方針、経営環境及び対処すべき課題等 (2) 中期的な経営戦略、目標とする経営指標、経営環境及び対処すべき課題」をご参照ください。2 上記の金額には、消費税等は含まれておりません。 ② 仕入実績(単位:百万円)セグメントの名称前連結会計年度(自 2017年4月1日至 2018年3月31日)当連結会計年度(自 2018年4月1日至 2019年3月31日)増減率(%)加工食品61,59264,0264.0水産55,47353,843△2.9畜産76,99976,882△0.2低温物流382212△44.4不動産151717.4その他985323△67.2合計195,448195,306△0.1(注)1 セグメント間取引については、相殺消去しております。3 「不動産」の仕入実績は、商品の仕入代金等であります。 ③ 受注実績低温物流セグメント(㈱ニチレイ・ロジスティクスエンジニアリング)の受注実績は次のとおりであります。相手先前連結会計年度(自 2017年4月1日至 2018年3月31日)当連結会計年度(自 2018年4月1日至 2019年3月31日)金額(百万円)割合(%)金額(百万円)割合(%)三菱食品株式会社73,09712.976,66613.23 本表の金額には、消費税等は含まれておりません。
研究開発活動
キーワード
['おいしさ研究', 'ms nose®', '第19回アロマ・サイエンス・フォーラム', '研究開発', '低温物流事業', '環境', '人工知能', '鶏肉加工品製造', '鶏肉加工品', '製造ライン', 'x線検査機', '良品〟〝硬骨混入品', '鶏肉加工品廃棄', 'ピッキングシステム', 'バイオサイエンス事業', '分子診断薬', '迅速診断薬', '自動染色', 'インフルエンザウイルスキット「イムノファインtmfluii', 'ms nose®を', '食と健康', '深層心理', '研究機関', '不凍糖タンパク質(ii型', '不凍糖タンパク(ii型', '第18回基準油脂分析法セミナーとフレグランスジャーナル社', 'ms nose®の', 'mental representation of domestic cooking operations among japanese consumers', 'international journal of gastronomy and food ']
要約
セグメント別の内訳は、加工食品事業では1,547百万円、低温物流事業は296百万円、その他の事業は364百万円、全社(共通)は150百万円となりました。当連結会計年度においては、自社の鶏肉加工品製造ラインにおいて、包装前段階の鶏肉加工品に残存する可能性がある〝硬骨〟を人工知能で選別する技術を機器メーカーと共同で開発しました。 (2) 低温物流事業物流事業における労働力不足の対策として、作業の省人化、簡易化に資する技術検証、システム開発に取り組んでおります。当連結会計年度は、分子診断薬では自動染色装置「ヒストステイナーAT」、迅速診断薬ではインフルエンザウイルスキット「イムノファイン™FLUⅡ」など、数種類の商品の販売を開始しました。[東レ株式会社]
総売上 : 5916.64億円(2017) => 6218.08億円(2018)
営業利益: 267.12億円(2017) => 179.18億円(2018), 営業利益率4.51%(2017) => 2.88%(2018)
経常利益: 921.86億円(2017) => 693.26億円(2018), 経常利益率15.58%(2017) => 11.15%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
3 【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】当連結会計年度における当社グループの財政状態、経営成績及びキャッシュ・フロー(以下「経営成績等」という。連結財務諸表の作成において採用する重要な会計方針は、「第5 経理の状況 1 連結財務諸表等 (1) 連結財務諸表 注記事項」の(連結財務諸表作成のための基本となる重要な事項)に記載している。 (業績指標)(単位:億円) 2017年度実績2018年度実績2019年度見通し “プロジェクト AP-G2019”2019年度目標売上高22,049 23,888 25,300 27,000 営業利益1,565 1,415 1,600 2,500 営業利益率7.1% 5.9% 6.3% 9% ROA6.3% 5.3% 約6% 約9% ROE9.1% 7.1% 約8% 約12% 当連結会計年度の売上高は、ライフサイエンス事業を除くすべてのセグメントで増収となり、前連結会計年度比1,840億円(8.3%)増収の2兆3,888億円で過去最高となった。 営業外損益は、休止設備関連費用が増加したことなどにより、前連結会計年度比28億円の減益となり、経常利益は同178億円(11.7%)減益の1,345億円となった。 (繊維事業)国内では、自動車関連など産業用途は総じて需要が堅調なものの、衣料用途は天候不順の影響もあり荷動きは低調に推移する中、各用途での拡販に加え、糸綿/テキスタイル/製品一貫型ビジネスの拡大を進めるとともに、事業体質強化に注力した。主要な製品の生産規模は、ナイロン糸が前連結会計年度比1.3%減の約468億円(販売価格ベース)、ポリエステル糸が同0.6%増の約598億円(販売価格ベース)、ポリエステルステープルが同7.0%増の約630億円(販売価格ベース)となった。 (機能化成品事業)樹脂事業は、自動車用途向けに拡販するとともに、原料価格上昇に対する価格転嫁を推進したが、中国経済減速の影響を受けた。以上の結果、環境・エンジニアリング事業全体では、売上高は前連結会計年度比8.1%増の2,577億円、営業利益は同7.9%減の122億円となった。 (生産、受注及び販売の状況)当社グループ(当社及び連結子会社)の生産・販売品目は広範囲かつ多種多様であり、同種の製品であっても、その形態、単位等は必ずしも一様ではなく、また受注生産形態をとらない製品も多いため、セグメントごとに生産規模及び受注規模を金額あるいは数量で示すことはしていない。 負債の部は、有利子負債が増加したことを主因に前連結会計年度末比1,677億円増加の1兆5,744億円となった。当連結会計年度末の自己資本比率は、前連結会計年度末比1.8ポイント低下し40.6%、D/Eレシオは同0.11ポイント悪化し0.86ポイントとなった。 (財務活動によるキャッシュ・フロー)当連結会計年度において財務活動による資金の増加は、前連結会計年度比571億円(92.5%)増の1,189億円となった。このうち、設備投資の概要及び重要な設備の新設の計画については、「第3 設備の状況」に記載している。 ③財務政策当社グループは、資金需要の見通しや金融市場の動向などを総合的に勘案した上で、最適なタイミング、規模、手段を判断して資金調達を実施している。また、事業拡大と財務体質強化の両立という基本方針の下、運転資金の圧縮、固定資産の稼働率向上、キャッシュマネジメントシステムによるグループ内余剰資金の有効活用等、資産効率の改善にも取り組んでいる。また、緊急に資金が必要となる場合や金融市場の混乱に備え、国内外の金融機関とコミットメントライン契約、当座貸越契約等を締結し、資金流動性を確保している。
研究開発活動
キーワード
['ap-g 2019', 'グリーンイノベーション', 'ライフイノベーション', 'nanodesign®(ナノデザイン', '深発色tmナイロン', 'ultrasuede® bx', 'ウルトラスエード ビーエックス', '米州', 'トレカ®mxシリーズ', ' 5', '研究開発', '有機合成化学', '高分子化学', 'バイオテクノロジー', '製糸、繊維高次加工', '有機合成', '炭素繊維複合材料', '医療機器', '水処理', '中期経営課題', '新素材', '知的財産', '最細繊度', 'スエード調人工皮革', 'ポリフェニレンサルファイド樹脂', 'pps樹脂」', '透明性', 'オフセット印刷機', '省電力led-uv', 'アジア・新興国', 'トレードオフ', '弾性率', '炭素繊維', 'オートクレーブ', '環境・エンジニアリング事業 機能化成品', '炭素繊維複合', '逆浸透膜(ro膜)エレメント', '流れる', 'ポリフッ化ビニリデン)製限外ろ過(uf)膜', 'uf膜創出', 'ライフサイエンス事業 重点', 'trk-250', '米国', 'trk-950', '複合繊維', '化学構造', 'バイオ', '血液浄化用', 'チップ', '認知症の検出用マーカー', '体外診断薬承認取得', '第i相臨床試験', 'オーファンドラッグ', '希少疾病用医薬品', '既存抗がん剤', '治療薬', '再生医療', '環境', 'ライフサイエンス']
要約
(2) 機能化成品事業 基幹事業として安定収益基盤の強化、戦略的拡大事業として中長期での収益拡大に向け、新製品開発、高付加価値化を目指し、研究・技術開発に取り組んでいる。また、独自のナノ積層技術をさらに深化させ、革新的な層配列デザインにより、ガラス並みの透明性を維持しつつ、温度上昇の原因となる太陽からの赤外線に対する世界最高レベルの遮熱性を備えた革新的な遮熱フィルムを開発した。さらに、食品や生活用品など身近な商品の軟包装材向け印刷用に世界初となる水なしオフセット印刷機を開発した。また、様々な分野の水処理用途に展開しているPVDF(ポリフッ化ビニリデン)製限外ろ過(UF)膜について、孔径制御技術を深化させ、微少な物質を効果的に分離し、かつ高透水性を兼ね備えたUF膜創出に成功した。さらに、㈱ボナックと共同開発を進めてきた核酸医薬品「TRK-250」について、米国での第Ⅰ相臨床試験を開始した。引き続き、関係機関と連携して開発を加速し、がん治療薬として早期の承認取得を目指す。 上記セグメントに属さない基礎研究、基盤技術開発として、独自の機能性高分子設計技術を駆使し、初期長に対して10倍に引き伸ばしても破断せずに復元する、皮膚のような柔軟性を有する新規の生体吸収性ポリマーを創出した。 当連結会計年度の当社グループの研究開発費総額は、664億円(このうち東レ㈱の研究開発費総額は488億円)である。[旭化成株式会社]
総売上 : 6218.75億円(2017) => 6658.39億円(2018)
営業利益: 441.92億円(2017) => 510.72億円(2018), 営業利益率7.11%(2017) => 7.67%(2018)
経常利益: 941.63億円(2017) => 1066.79億円(2018), 経常利益率15.14%(2017) => 16.02%(2018)経営方針、経営環境及び対処すべき課題等
要約
(3) 経営環境を踏まえた当社グループの対処すべき課題当社グループでは、2016年度より3カ年の中期経営計画「Cs for Tomorrow 2018」(以下、「CT2018」)を実行してきました。持続的成長に向けた事業基盤づくりでは、耐震化や更新による製造設備などの強化、高度専門職制度の改定などによる人財育成の強化、リスク管理、コンプライアンスの徹底、品質保証体制の強化、デジタルトランスフォーメーションへの対応などを行いました。計数面では、利益目標(営業利益1,800億円、親会社株主に帰属する当期純利益1,100億円)を上回る業績を達成しました。そして事業や製品の付加価値を創造し、生産性を向上させることで、企業価値の持続的向上を図るとともに、その成果を世の中に還元することで持続可能な社会の実現に貢献していきます。「現場」「現物」「現実」を重視して行動する三現主義を徹底することで、社会から常に信頼される企業となることを目指します。 当社グループは、これらの課題に真摯に向き合い、「誠実」に行動し、果敢に「挑戦」し、新たな価値を「創造」していきます。そのうえで、サステナビリティの実現を目指すとともに、さらなる企業価値の向上と持続的成長を図っていきます。 (4) 会社の支配に関する基本方針当社は、当社の支配権の取得を目的とした当社株式の大量取得行為を受け入れるか否かの判断は、最終的には当社の株主の皆様全体の意思に基づいて行われるべきものと考えており、当社株式の大量取得であっても、当社の企業価値ひいては株主共同の利益に資するものであれば、これを否定するものではありません。
財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
なお、2018年4月4日付で買収を完了したスウェーデンSenseair AB及びその連結子会社の業績、並びに2018年9月27日付(米国東部時間)で買収を完了したSage Automotive Interiors,Inc.の業績については「マテリアル」セグメントに含めて開示しています。 「マテリアル」セグメント売上高は1兆1,762億円で前期比885億円の増収となり、営業利益は1,296億円で前期比76億円の増益となりました。高機能マテリアルズ事業・消費財事業では、イオン交換膜や「サランラップ™」などの販売が堅調に推移しましたが、電子材料製品の販売数量が減少したことなどから、前期比増収、減益となりました。ケミカル事業では、2018年9月に宮崎県延岡市における第3石炭火力発電所について、天然ガス火力発電所への更新を決定しました。建材事業では、各製品の販売数量が増加したことなどにより、前期比増収、増益となりました。 「ヘルスケア」セグメント売上高は3,162億円で前期比199億円の増収となり、営業利益は418億円で前期比24億円の増益となりました。なお、医薬事業では、2018年10月に、骨粗鬆症治療剤「テリボン™皮下注28.2μgオートインジェクター」について、日本における製造販売承認申請を行いました。 (生産、受注及び販売の状況)(1) 生産実績当社グループ(当社及び連結子会社、以下同じ)の生産品目は広範囲かつ多種多様であり、同種の製品であっても、その容量、構造、形式等は必ずしも一様ではないため、セグメントごとに生産規模を金額あるいは数量で示すことはしていません。 (1) 重要な会計方針及び見積り当社グループの連結財務諸表は、我が国において一般に公正妥当と認められている会計基準に基づき作成されています。 (固定資産)固定資産は、無形固定資産が1,154億円増加したことなどから、前期比1,556億円増加し、1兆5,238億円となりました。当期の売上原価率は68.3%と前期比0.1ポイントの悪化となりました。 (親会社株主に帰属する当期純利益)経常利益の2,200億円に特別損益96億円を控除した結果、税金等調整前当期純利益は2,104億円となりました。 (4) キャッシュ・フローの分析当期のフリー・キャッシュ・フロー(営業活動によるキャッシュ・フローと投資活動によるキャッシュ・フローの合計額)は、税金等調整前当期純利益などを源泉とした収入が、固定資産の取得や連結範囲の変動を伴う子会社株式の取得による支出などによる支出を上回り、131億円の収入となりました。 以上の結果、現金及び現金同等物の期末残高は、前期末に比べて319億円増加し、1,805億円となりました。 (財務活動によるキャッシュ・フロー)当期の財務活動によるキャッシュ・フローは、長期借入金の返済による支出538億円、配当金の支払額517億円などがあったものの、長期借入れによる収入855億円、コマーシャル・ペーパーの増加570億円などがあったことから、174億円の収入(前期比1,518億円の収入の増加)となりました。これらの資金を次期中期経営計画では、事業基盤の強化を継続しつつ、持続可能な社会の実現と企業価値の継続的な向上のための戦略投資資金及び株主の皆様への配当原資等に活用していきます。
研究開発活動
キーワード
['ロイカtm', 'ベンベルグtm', 'レオナtm', 'computer aided engineering', '省資源・省エネルギー', '可視外光', 'ロングライフ住宅の実現', 'qol', ' 5', '研究開発', '成果及び研究開発費', 'ポリウレタン', 'ナイロン66繊維', '快適な生活', '高機能テキスタイル', '新基軸不織布', '水島製造所内', 'ジフェニルカーボネート', '易成形性', 'フッ素系イオン', '電子デバイス', '環境負荷軽減', 'リチウムイオン二次電池', 'セパレータ', '蓄電池用セパレータ', '電子部品', '高周波', 'エンドユーザー', '当セグメントに係る研究開発費', '耐震', '温熱・空気', '環境技術', '環境対応性', '炭素化技術', '軽量気泡コンクリート', '高機能基礎システム', '鉄骨造', 'セグメントに係る研究開発費', 'ヘルスケア」セグメント', '整形外科', 'マーケットチャネルの活用', '欧州', 'ドイツデザインアワードspecial mention category 2019', '人工腎臓', '血液浄化技術', 'クリティカルケア事業', '臨床医', '高付加価値化の追求', '新事業開発', '専門職', 'ai', 'デジタル技術', '知的財産領域', '世界', '赤外線小型受発光素子', '空気質', 'アルコール', '環境エネルギー', 'akxytm(アクシー)', 'akxytm」', '全社に係る研究開発費']
要約
「マテリアル」セグメント (繊維事業)繊維事業では、グループ内外との連携により、研究開発機能を充実・高度化させるとともに、成果実現のスピードアップを図っています。高機能マテリアルズ事業・消費財事業では、環境に配慮した食塩電解プロセス用のフッ素系イオン交換膜の開発を強化すると共に、電子材料関連では、次世代電子デバイスの要求に対応できる感光性樹脂材料の開発を加速しています。 当セグメントに係る研究開発費の金額は33,919百万円です。また、住宅における生活エネルギー消費量削減とともに、人の生理・心理から捉えた快適性を研究し、健康・快適性と省エネルギーを両立させる環境共生的住まいを実現する技術開発に注力しています。 当セグメントに係る研究開発費の金額は37,183百万円です。当期は、事業基盤を担う各事業部門の固有領域や事務系職種に同制度を拡大展開し、それらの領域を牽引する人財も新たに高度専門職に任命し、新規事業・事業強化への参画・貢献を図っています。「高付加価値化の追求」の具体例としては、「液体を高度に濃縮できる新規の膜システムの開発」や「世界最小の高精度・低消費電力CO2センサの開発」などが挙げられます。「マーケットチャネルの活用」の取り組みについては、コンセプトカー「AKXY™(アクシー)」を通して、お客様に対し、自動車の安全性や快適性の向上、環境への貢献に資する多様なキーアイテムを提案しています。[アステラス製薬株式会社]
総売上 : 6136.57億円(2017) => 6073.21億円(2018)
営業利益: -134.90億円(2017) => 726.85億円(2018), 営業利益率-2.20%(2017) => 11.97%(2018)
経常利益: 2856.90億円(2017) => 2097.21億円(2018), 経常利益率46.56%(2017) => 34.53%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】(1)経営成績等の状況の概要当連結会計年度における当社グループの財政状態、経営成績及びキャッシュ・フローの状況の概要は次のとおりとなりました。流動負債は4,977億円(同760億円増)となりました。当該コアベースの業績は、フルベースの業績から当社が定める非経常的な項目を調整項目として除外したものです。 コア営業利益/コア当期利益・売上総利益は、1兆143億円(同0.8%増)となりました。売上収益、営業利益、税引前利益、当期利益はいずれも増加しました。フルベースの業績には、コアベースの業績で除外される「その他の収益」、「その他の費用」(減損損失、為替差損等)等が含まれます。日本、米州、EMEA及びアジア・オセアニアの全ての地域で売上が増加しました。◇プログラフ・売上は1,957億円(同1.4%減)となりました。◇その他の新製品・主要製品の状況・日本では、2型糖尿病治療剤スーグラが2018年5月に発売したスージャヌ配合錠と合わせて売上が増加したことに加え、高コレステロール血症治療剤レパーサ、慢性便秘症治療剤リンゼス等が引き続き伸長しました。 ② キャッシュ・フローの状況[営業活動によるキャッシュ・フロー]当連結会計年度の営業活動によるキャッシュ・フローは、2,586億円(前連結会計年度比540億円減)となりました。・配当金の支払額は721億円(同4億円増)となりました。c. 販売実績当連結会計年度における販売実績をセグメントごとに示すと、以下のとおりです。 ① 重要な会計方針及び見積り当社グループは、IFRSに準拠して連結財務諸表を作成しています。 ② 当連結会計年度の経営成績等の状況に関する認識及び分析・検討内容経営成績等の状況に関する認識及び分析・検討内容については、「第2 事業の状況 3 経営者による財政状態、経営成績及びキャッシュ・フロー状況の分析 (1)経営成績等の状況の概要 ①財政状態及び経営成績の状況」に記載しています。 [財務政策]これらの資金基盤を背景に、当社グループは、企業価値の持続的向上に努めるとともに株主還元にも積極的に取り組んでいます。この結果、IFRSでは日本基準に比べて、契約一時金及びマイルストン支払に係る研究開発費が前連結会計年度2,256百万円、当連結会計年度9,128百万円減少しています。
研究開発活動
キーワード
['経営計画2018', 'operational excellenceの更なる追求', 'rx+tmプログラムへの挑戦', '日本', '第iii相prosper試験', '米国', '欧州', '第iii相arches試験', '後期第ii相試験', '第ii相試験', '第iii相試験', 'イプラグリフロジン', 'l-プロリン', 'エボロクマブ', '大環状抗菌剤ダフクリア', 'ブリナツモマブ', '研究開発', 'focus', 'area', '重点後期開発品', '治療剤xtandi/イクスタンジ', '一般名', 'イクスタンジ錠', '画像診断', '生存期間', 'flt3', 'ゾスパタ', 'flt3遺伝子変異陽性', '経口投与', '低酸素誘導因子プロリン水酸化酵素阻害薬', 'asp1517/fg-4592', '受容体拮抗薬', 'esn364', '抗体-薬物複合体エンホルツマブ ベドチン', 'asg-22me', '白金製剤', '化学療法及び免疫チェックポイント阻害剤', '抗claudin18.2モノクローナル抗体', 'imab362', '承認取得', 'dpp-4阻害剤', 'ジャヌビア', 'シタグリプチンリン酸塩水和物', 'スーグラ', '2型糖尿病治療剤', '高コレステロール血症治療剤レパーサ', '遺伝子組換え', 'スタチン', '抗悪性腫瘍剤', '二重特異性抗体製剤ビーリンサイト', 'セルトリズマブ ペゴル', 'シムジア', '皮下注200mgオートクリックス', 'ロモソズマブ', 'ペフィシチニブ', 'gt0001x', '中国', 'jvs-100', '追加適応症及び用法', 'デガレリクス酢酸塩', '用量', 'ゴナックス', '皮下注用', '追加適応症及び追加剤', 'ビソノテープ2mg', '経口jak(ヤヌスキナーゼ)阻害剤', 'スマイラフ', '臭化水素酸塩', '遺伝子治療', '設備投資', '臨床初期治験薬', '再生医療', '(英国', '孤発性筋萎縮性側索硬化症', '遺伝子治療プログラム', 'イセンス契約', '独占的共同研究開発契約', '独占的オプション権', 'がん免疫療法プログラム', '売上収益研究開発費']
要約
製品価値の最大化に向けた取り組みの一環として、2020年度以降の成長を支える6つの重点後期開発品に優先的に経営資源を振り向け、着実に開発を進めました。また、欧州での申請に向けた6つの第Ⅲ相試験の全てにおいて、主要評価項目を達成しました。 ・MSD株式会社が製造販売する選択的DPP-4阻害剤ジャヌビア(一般名:シタグリプチンリン酸塩水和物)と当社が製造販売する選択的SGLT2阻害剤スーグラ(一般名:イプラグリフロジン L-プロリン)の配合剤である2型糖尿病治療剤スージャヌ配合錠を2018年5月に発売しました。・抗悪性腫瘍剤/二重特異性抗体製剤ビーリンサイト(一般名:ブリナツモマブ(遺伝子組換え))に関し、「再発又は難治性のB細胞性急性リンパ性白血病」の適応症について、共同開発会社であるアステラス・アムジェン・バイオファーマ株式会社が2018年9月に承認を取得したことを受け、同年11月に発売しました。・前立腺がん治療剤ゴナックス(一般名:デガレリクス酢酸塩)に関し、維持用量を12週間間隔で投与する用法・用量追加の一部変更承認及びその用法・用量で用いるゴナックス皮下注用240mgの承認(剤形追加)を2019年1月に取得しました。米国においては、再生医療・細胞医療分野での研究開発の加速と製造設備の増強に向けた設備投資を行っています。当連結会計年度における主な取り組みは以下のとおりです。・2018年12月、がん免疫関連バイオテクノロジー企業であるポテンザ社(米国)について、2015年に締結した独占的共同研究開発契約に基づく同社を買収する独占的オプション権の行使により、同社を当社の完全子会社としました。[TOTO株式会社]
総売上 : 5923.01億円(2017) => 5860.86億円(2018)
営業利益: 526.02億円(2017) => 401.67億円(2018), 営業利益率8.88%(2017) => 6.85%(2018)
経常利益: 543.76億円(2017) => 431.19億円(2018), 経常利益率9.18%(2017) => 7.36%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
なお、セグメントごとの売上高については、外部顧客への売上高を記載しています。 b.中国・アジア住設事業<中国> 当連結会計年度の業績は、売上高が635億3千9百万円(前期比11.7%減)、営業利益が123億9千5百万円(前期比31.7%減)となりました。 当社グループにおいては、一線から二・三線都市の都市部を中心に、市場環境や消費者の購買行動の変化などに注視しつつ、高級ブランドとしての強みを活用し、事業活動を推進しています。加えて、「ウォシュレット」のプロモーション強化を通じて普及拡大に努めています。2019年1月、ラスベガスで開催された最新家電の展示会「CES2019 (Consumer Electronics Show 2019)」並びに、2019年2月に開催の米国最大規模の水まわり設備の展示会「KBIS2019(Kitchen & Bath Industry Show 2019)」に出展しました。 <欧州> 当連結会計年度の業績は、売上高が37億7千8百万円(前期比5.3%増)、営業損失が11億4千万円(前連結会計年度は営業損失10億3千2百万円)となりました。 欧州のお客様の嗜好に沿う高いデザイン性の新商品を発売し、展示会やセミナー、ショールーム展示を通じてお客様への価値訴求を強化しています。新工場は「ウォシュレット」の量産工場と位置付け、2018年5月より着工し、2020年4月からの本格稼働を目指します。 ・ESG投資指標「Dow Jones Sustainability World Index」の構成銘柄に選定世界の代表的なESG投資指標である「Dow Jones Sustainability Indices」 の「World Index」の構成銘柄に選定されました。同銘柄への選定は7回目です。 ・国際的に権威のあるデザイン賞を受賞国際的に権威のあるデザイン賞である「iFデザイン賞2019」にて、ウォシュレット一体形便器「ネオレストAH/RH」「壁掛RP便器+ウォシュレットRX」「台付シングル混合水栓GMシリーズ」が受賞しました。 (投資活動によるキャッシュ・フロー)投資活動により269億2千8百万円の支出となりました。これは、コマーシャル・ペーパーの発行による収入621億円等の収入と、コマーシャル・ペーパーの償還による支出335億円、配当金の支払額137億1千2百万円等の支出によるものです。 生産、受注及び販売の実績(1)生産実績当連結会計年度における生産実績をセグメントごとに示すと、次のとおりです。セグメントの名称金額(百万円)前期比(%)日本362,7560.8中国90,654△4.3アジア・オセアニア55,4554.7米州29,2762.9欧州2,819△5.6グローバル住設事業計540,9630.3セラミック事業20,21231.9環境建材事業7,015△2.4新領域事業計27,22820.9報告セグメント計568,1921.2その他--合計568,1921.2(注)1.金額は、売価換算値で表示しています。2.上記の金額には、消費税等は含まれていません。
研究開発活動
キーワード
['ハイドロテクト', '研究開発', 'セグメントに係る研究開発費']
要約
5【研究開発活動】研究開発部門では、デザインと機能を融合させ、きれいで快適な空間を実現するために、当社にしかできない「オンリーワン技術」を進化させ、TOTOならではの価値をお客様に提供しています。人間工学、感性工学といった、人の動きや感覚を数値化し、論理的に使いやすさや快適性を実現する「人を見る」技術。 当セグメントに係る研究開発費は14,627百万円です。 b.中国・アジア住設事業、米州・欧州住設事業中国・アジア住設事業、米州・欧州住設事業においては、日本で開発したコアテクノロジーをもとに、高機能・高品質を維持しながら、各国の規制や基準を満たした環境配慮商品の開発を行い、それぞれの地域に合ったデザイン設計を進めています。「ハイドロテクト」は、自社製品への応用にとどまらず、パートナー企業と共に多様な建材を通じて更なる普及を目指しており、国内外で広く環境保全に貢献しています。 新領域事業に係る研究開発費は、合計で2,856百万円であり、各セグメントに係る研究開発費は、それぞれセラミック事業が2,271百万円、環境建材事業が585百万円です。[ダイキン工業株式会社]
総売上 : 5278.47億円(2017) => 5701.80億円(2018)
営業利益: 489.69億円(2017) => 487.52億円(2018), 営業利益率9.28%(2017) => 8.55%(2018)
経常利益: 1356.37億円(2017) => 1416.34億円(2018), 経常利益率25.70%(2017) => 24.84%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
3 【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】(経営成績等の状況の概要)「『税効果会計に係る会計基準』の一部改正」(企業会計基準第28号 2018年2月16日)等を当連結会計年度の期首から適用しており、財政状態の状況については、当該会計基準等を遡って適用した後の数値で前連結会計年度との比較・分析を行っております。わが国経済は個人消費と設備投資は堅調に推移したものの、輸出が鈍化し、成長ペースは緩やかでした。利益面では、営業利益は2,762億54百万円(前期比8.9%増)、経常利益は2,770億74百万円(前期比8.6%増)となりました。国内業務用空調機器の業界需要は、設備投資の拡大により堅調に推移しました。インドの住宅用空調機器では、販売店網の拡充や地方都市での拡販により販売が伸び、また、業務用空調機器も販売が堅調に推移し、売上高は前期を上回りました。営業利益は、前期比27.5%増の325億33百万円となりました。フッ素ゴムについても、国内・米国市場において、自動車関連・半導体関連分野での需要が堅調に推移したことにより、売上高は前期を上回りました。これらの結果、化成品全体では売上高は前期を上回りました。建機・車両用油圧機器は、国内および米国主要顧客向け販売が堅調に推移し、売上高は前期を上回りました。負債は、短期借入金の増加等により、前連結会計年度末に比べて1,026億54百万円増加し、1兆2,540億40百万円となりました。 (生産、受注及び販売の状況)(1) 生産実績当連結会計年度における生産実績をセグメントごとに示すと、次のとおりであります。2 上記の金額には、消費税等は含まれておりません。純資産は、親会社株主に帰属する当期純利益の計上による増加等により、前連結会計年度末に比べて1,225億28百万円増加し、1兆4,468億49百万円となりました。なお、セグメントの営業損益については、空調・冷凍機事業では、前連結会計年度比6.3%増の2,376億45百万円の営業利益となり、化学事業では、前連結会計年度比27.5%増の325億33百万円の営業利益となり、その他事業は前連結会計年度比27.5%増の60億65百万円の営業利益となりました。投資活動では、連結子会社買収による支出の増加等により、前連結会計年度に比べて383億14百万円支出が増加し、1,657億73百万円の支出となりました。資金の調達は、内部留保の蓄積を基本とし、自己資金中心に行うことを原則としておりますが、必要に応じ、金融機関からの借入や社債等で調達しております。 2015年3月期2016年3月期2017年3月期2018年3月期2019年3月期自己資本比率(%)45.346.347.252.452.4時価ベースの自己資本比率(%)103.7112.1138.8138.6140.5キャッシュ・フロー対有利子負債比率 (年)4.12.72.32.52.3インタレスト・カバレッジ・レシオ(倍)16.825.926.820.921.2 (注) 自己資本比率:自己資本/総資産時価ベースの自己資本比率:株式時価総額/総資産キャッシュ・フロー対有利子負債比率:有利子負債/営業キャッシュ・フローインタレスト・カバレッジ・レシオ:営業キャッシュ・フロー/利払い ※各指標は、いずれも連結ベースの財務数値により算出しております。※株式時価総額は、期末株価終値×期末発行済株式数(自己株式控除後)により算出しております。※営業キャッシュ・フローは連結キャッシュ・フロー計算書の営業活動によるキャッシュ・フローを使用しております。※有利子負債は、連結貸借対照表に計上されている負債のうち利子を支払っている全ての負債を対象としております。
研究開発活動
キーワード
['産学協創協定', '中国', 'cresnect', '壁掛形エアコン『うるさら7', 'カライエ', 'うるさら7', 'スカイエア', 'five star zeas(ファイブスタージアス)』シリーズ', 'eco-zeas(エコジアス)', 'ストリーマ内部クリーン', 'vrv x', 'vrv a', 'マイクロチャネル熱交換器', 'greenマルチ', 'hfc-32', 'r-410a', '北米', 'rebel', '研究開発', '地球温暖化', 'エネルギー問題', '地球環境問題', '未来のオフィス空間', '協創型プラットホーム', '空調機器', 'エアコン', '無給水加湿', 'ストリーマ', 'led', '夜間みまもり', '室外機', 'アルミ製', 'アルミ', '熱交換器', '大容量圧縮機', '熱交換', '低温暖化冷媒hfc-32', '地球温暖化係数', 'エネルギー効率', '温暖化', 'キガリ改正', 'エアハン', '全熱交機能付き中小型', '欧州', 'ヒートポンプモジュールチラー', 'tic', 'スーパーユニット', 'アジア', 'fガス規制', '低gwp冷媒', '冷媒r32', 'フリークリング', 'gb規格', 'フッ素樹脂', 'テキスタイル処理剤', 'カーペット処理剤', '人工知能', '複合材料', 'フッ素化学グローバル', 'パワー半導体', 'ポリプロピレン', '誘電率', '新素材', 'インバータ', 'ハイブリッド油圧システム', '異電圧電源', '油圧ハイブリッドシステム', '砲弾']
要約
既に提携している京都大学や中国の精華大学、北京大学等の産学連携や様々な産産連携を推進し、協創することで、イノベーションを生み出し、複雑な社会課題を解決し、新たなビジネスを創出してまいります。当社のルームエアコン『うるさら7』が搭載する「無給水加湿」の技術を応用し、室内の空気中に含まれる水分を吸着素材(デシカントエレメント)に吸収させ、高湿度の空気として気体のまま屋外へ排出することで、水捨て作業が不要な除湿を可能にしております。業務用空調機器において、店舗・オフィス用エアコン『スカイエア』の新機種として、業界で唯一、温度と除湿レベルを同時に設定することで、これまで以上の快適性を実現する『FIVE STAR ZEAS(ファイブスタージアス)』シリーズと『Eco-ZEAS(エコジアス)』シリーズを2018年4月に発売しました。HFC-32は従来のR-410Aに比べて地球温暖化係数(GWP)が低く、エネルギー効率に優れ、冷媒充填量が削減できるため、本製品の冷媒による温暖化影響は、従来機に比べて76%の削減を実現します。欧州では、Fガス規制、省エネ規制により、低GWP冷媒への需要が高まる中、冷媒R32を採用したノンインバータスクロールチラーを業界に先駆けて2018年7月に発売し、また、フリークリング仕様機も2018年11月に発売しました。フッ素樹脂、ゴムではフッ素材料の得意とする耐熱性や耐薬品性、誘電特性などを活かし、自動車・半導体・ワイヤー&ケーブル(IT分野)などでの差別化新商品研究を行っております。 ③ その他事業油機関連では、油圧技術とインバータ技術を融合させた商品であるハイブリッド油圧システムの特徴を活かし、従来の油圧システムではなし得ない省エネ性と高機能を実現しております。 その他事業に係る研究開発費は、1,898百万円であります。[ミネベアミツミ株式会社]
総売上 : 8791.39億円(2017) => 8847.23億円(2018)
営業利益: 791.62億円(2017) => 720.33億円(2018), 営業利益率9.00%(2017) => 8.14%(2018)
経常利益: 780.38億円(2017) => 713.21億円(2018), 経常利益率8.88%(2017) => 8.06%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
)の状況の概要は次のとおりであります。 ① 財政状態及び経営成績の状況 当連結会計年度のわが国の経済は、上期では個人消費及び企業収益が堅調に推移し緩やかな回復がみられましたが、期後半にかけて米中貿易摩擦を発端とした景況感の悪化、世界経済の減速による輸出の減少等、先行きへの不透明感が高まりました。 この結果、当連結会計年度の売上高は188,324百万円と前連結会計年度に比べ11,897百万円(6.7%)の増収となり、営業利益は47,750百万円と前連結会計年度に比べ6,743百万円(16.4%)の増益となりました。 電子機器事業 電子機器事業は、電子デバイス(液晶用バックライト等のエレクトロデバイス、センシングデバイス(計測機器)等)、HDD用スピンドルモーター、ステッピングモーター、DCモーター、エアームーバー(ファンモーター)、精密モーター及び特殊機器が主な製品であります。 財務活動によるキャッシュ・フローは、13,334百万円の支出(前連結会計年度は27,026百万円の支出)となりました。2.上記の金額は、セグメント間取引の相殺消去後の金額であります。 (ⅲ) 販売実績当連結会計年度における販売実績をセグメントごとに示すと、次のとおりであります。 セグメントの名称 当連結会計年度(自 2018年4月1日 至 2019年3月31日) 前年同期比(%)機械加工品(百万円)188,324106.7電子機器(百万円)387,29385.7ミツミ事業(百万円)308,423122.2その他(百万円)68398.7合計(百万円)884,723100.4(注)1.上記の金額は、消費税等は含まれておりません。連結財務諸表を作成するにあたり重要な会計方針につきましては、「第5 経理の状況 1 連結財務諸表等 連結財務諸表注記 3.重要な会計方針 4.重要な会計上の判断、見積り及び仮定」に記載しております。 当連結会計年度末における負債は334,867百万円となり、前連結会計年度末に比べ5,470百万円の減少となりました。セグメント別の売上高及び営業利益については、「第2 事業の状況 3 経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析 (1) 経営成績等の状況の概要 ① 財政状態及び経営成績の状況」に記載しております。 当社グループの運転資金需要のうち主なものは、製造費用、販売費及び一般管理費等の営業費用であります。また、当連結会計年度末における現金及び現金同等物の残高は122,432百万円となっております。 2019年3月期(実績)2020年3月期(計画)2021年3月期(計画)2022年3月期(計画)売上高(億円)8,84710,30011,00012,000営業利益(億円)7207701,0001,100 機械加工品事業では、2022年3月期には、売上高2,150億円、営業利益600億円を目指します。ステッピングモーターをはじめとするモーターでは、引き続き品質の向上と原価低減をはかり、自動車、情報通信機器、家電向け等の高付加価値製品の拡販を進め、さらなる業績の向上をはかります。 (3)経営成績等の状況の概要に係る主要な項目における差異に関する情報 IFRSにより作成した連結財務諸表における主要な項目と連結財務諸表規則(第7章及び第8章を除く。 (のれんの償却) 日本基準ではのれんを一定期間にわたり償却しておりましたが、IFRSではのれんの償却を行わず、毎期減損テストを実施しております。 (資本性金融商品) 日本基準では資本性金融商品の売却損益及び減損損失を純損益としておりましたが、IFRSにおいて、その他の包括利益を通じて公正価値で測定することを選択した資本性金融商品については、公正価値の変動額をその他の包括利益として認識し、認識を中止した場合に利益剰余金に振り替えております。
研究開発活動
キーワード
['スイス', 'カンボジア', 'saliot', 'minegetm', ' ミツミ事業 ミツミ', '小型化', '静粛性', '信頼性', '磁気応用技術', '研究開発', 'hdd', '流体軸受け', 'モバイル用超薄型液晶用', 'バックライト導光板', '射出成形', 'スマートフォン用超薄型導光板', 'バックライト自動組立機', 'led照明', '薄型レンズ', 'led', 'paradox engineering sa', '無線', 'スマートビル', 'スマートシティ', '温室効果', '二国間クレジット制度', '高効率無線制御付きled街路', '配光角', '計測機器', '高感度', 'ミネージュtm)', '抵抗体', 'モバイル', 'ロボティクス', 'アクチュエータ', '手ぶれ補正機構', '薄型化', '微小電気機械システム', 'レゾナントデバイス']
要約
当連結会計年度における当社グループの研究開発費は25,453百万円であり、この中にはマテリアルサイエンス・ラボで行っている各種材料の分析等、各セグメントに配分できない基礎研究費用1,997百万円が含まれております。航空宇宙規格であるAS81934の認定を取得しております)。 また、IT産業、家電産業、自動車産業、航空機産業及び医療機器産業等の新しい分野への用途の要求に応えるべく、低発塵、高耐熱、長寿命及び導電性等の信頼性設計と応用設計に重点を置いた開発を行っております。 電子機器事業 電子機器事業の主力のひとつであるモーターには、HDD用スピンドルモーター、ステッピングモーター、DCモーター、エアームーバー(ファンモーター)及び精密モーター等があります。 磁気応用技術については、材料技術及び製造技術の研究開発を行っており、その結果、高性能の各種モーター用希土類ボンドマグネット、高耐熱タイプのマグネット等の高性能製品が生まれております。また、バックライトで培った光学技術を応用し、LED照明用の薄型レンズとLED点灯回路とを組み合わせたLED照明製品を開発しております。このような事業を足掛かりに、スマートシティ実現に貢献できる技術の開発を推進しております。 当事業における研究開発費は9,624百万円であります。[TDK株式会社]
総売上 : 2921.47億円(2017) => 3093.27億円(2018)
営業利益: -370.43億円(2017) => -358.98億円(2018), 営業利益率-12.68%(2017) => -11.61%(2018)
経常利益: 34.55億円(2017) => -152.69億円(2018), 経常利益率1.18%(2017) => -4.94%(2018)財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
3【経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析】(1)経営成績等の状況の概要当連結会計年度における当社グループの財政状態、経営成績及びキャッシュ・フローの状況の概要は次のとおりであります。ICT(情報通信技術)市場では、スマートフォンの買い替えサイクル長期化の影響等により、生産台数が前連結会計年度の水準を若干下回りました。当社グループの事業セグメントは、「受動部品」、「センサ応用製品」、「磁気応用製品」及び「エナジー応用製品」の4つの報告セグメント及びそれらに属さない「その他」に分類されます。磁気応用製品セグメントの連結業績は、売上高は272,807百万円(同277,548百万円、同比1.7%減)、セグメント利益は17,022百万円(同16,128百万円、同比5.5%増)となりました。②キャッシュ・フローの状況(営業活動によるキャッシュ・フロー)営業活動によって得たキャッシュ・フローは、140,274百万円となり、前連結会計年度比48,964百万円増加しました。これは主に、子会社の取得の減少によるものです。事業の種類別セグメントの名称生産実績(百万円)前連結会計年度比増減(%)受動部品430,631△ 4.4センサ応用製品81,1501.8磁気応用製品268,227△ 20.7エナジー応用製品558,91646.3その他60,89711.4合計1,399,8217.2(注)1.金額は販売価格により算出しております。b.受注実績当連結会計年度における受注実績を事業の種類別セグメントごとに示すと、下表のとおりであります。当社グループは、過去の需要や将来の予測に基づき、たな卸資産の過剰及び陳腐化の可能性を考慮し簿価の見直しを行っております。企業結合の会計当社グループは、取得法を用いて企業結合の会計処理を行っております。のれん及びその他の無形固定資産のれん及び耐用年数を特定できないその他の無形固定資産は償却することなく、年に一度、もしくは公正価値が簿価を下回る兆候や状況の変化が生じた都度、減損テストが実施されます。経営者は、将来キャッシュ・フロー及び公正価値の見積もりは合理的であると判断しておりますが、事業遂行上予測不能の変化に起因して将来キャッシュ・フロー及び公正価値が当初の見積もりを下回った場合、当該資産の評価に不利な影響が生じる可能性があります。当社グループは、投資対象の様々な資産カテゴリーの長期期待運用収益見込みに基づき、長期期待収益率を設定しております。割引率の減少は、年金給付債務を増加させ、数理計算上の差異の償却により年金費用の増加をもたらす可能性があります。過去の課税所得の水準及び繰延税金資産が減算できる期間における将来の課税所得の見通しを考えますと、当社グループは、評価性引当金控除後の繰延税金資産は、実現する見込が実現しない見込より大きいと考えております。 ②当連結会計年度の経営成績等の状況に関する認識及び分析・検討内容経営成績及び経営成績に重要な影響を与えた要因当連結会計年度の業績は、連結売上高が前連結会計年度比8.7%増の1,381,806百万円、営業利益が同比20.2%増の107,823百万円となりました。当社グループは、事業運営上必要な流動性と資金の源泉を安定的に確保することを基本方針としており、現預金、短期投資、有価証券等を含む流動性資金は、月次連結売上高の2.0ヶ月以上を維持するよう努めております。当連結会計年度におけるROEは、9.7%でした。セグメントごとの財政状態及び経営成績の状況に関する認識及び分析・検討内容(受動部品セグメント)受動部品セグメントは、①コンデンサ ②インダクティブデバイス ③その他受動部品 で構成され、当セグメントの連結業績は、売上高は433,406百万円(前連結会計年度417,757百万円、前連結会計年度比3.7%増)、セグメント利益は58,438百万円(同50,246百万円、同比16.3%増)、セグメント資産は651,154百万円(同643,605百万円、同比1.2%増)となりました。自動車市場及びICT市場向けの販売は増加したものの、産業機器市場向けの販売は減少しました。HDD用ヘッド及びHDD用サスペンションは、ICT市場向けが減少しました。マグネットは産業機器市場向けの販売が減少しました。(エナジー応用製品セグメント)エナジー応用製品セグメントは、エナジーデバイス(二次電池)、電源で構成され、当セグメントの連結業績は、売上高は537,502百万円(同442,822百万円、同比21.4%増)、セグメント利益は91,036百万円(同72,351百万円、同比25.8%増)、セグメント資産は661,595百万円(同571,066百万円、同比15.9%増)となりました。エナジーデバイスの販売は、ICT市場向けが大幅に増加しました。
研究開発活動
キーワード
['センサ・アクチュエータ', 'mems', 'sesub', '日本', '北米', '欧州', '中国', '研究開発', 'モノづくり', '電子デバイス', '小型化', '省エネルギー化', '技術戦略', '電子部品', 'モータ', 'ic内蔵基板', '技術者', 'チップ', 'インダクタ製品', 'センサ応用製品事業', 'センサエレメント', '磁気応用製品事業', '電気自動車用デバイス', 'エナジー応用製品事業', '次世代リチウム', '研究機関', '産官学', '組織的連携協定']
要約
5【研究開発活動】当社グループの研究開発活動は、多様化するエレクトロニクス分野へ対応するため、継続的に新製品開発の強化拡大を進めております。これらの注力する3分野の市場の変化を捉えた技術戦略を基に、今後の成長が大いに期待されるセンサ・アクチュエータ、エネルギーユニット、次世代電子部品を成長戦略製品と位置づけて、IoT市場における事業機会獲得を目指して強化に注力しております。センサ・アクチュエータはMEMSやソフトウェア技術なども繋げていくことで、お客様に幅広いセンサソリューションを提供することを目指しており、エネルギーユニットについては電池や電源、非接触給電などを組み合わせた製品の開発、またモータ向けに拡大している磁石の開発にも注力しております。受動部品事業分野では、コア技術を活かした次世代積層セラミックチップコンデンサやインダクタ製品ならびにEMC対策部品などの小型化、高性能化を進めております。[日産自動車株式会社]
総売上 : 119511.69億円(2017) => 115742.47億円(2018)
営業利益: 5747.60億円(2017) => 3182.24億円(2018), 営業利益率4.81%(2017) => 2.75%(2018)
経常利益: 7503.02億円(2017) => 5464.98億円(2018), 経常利益率6.28%(2017) => 4.72%(2018)経営方針、経営環境及び対処すべき課題等
要約
当社とルノー及び三菱自動車工業は、平成31年3月にアライアンス オペレーティング ボード(以下、アライアンス ボード)を新たに設立する意向を表明した。当社グループは、これから先10年から15年の間に本格的に訪れるであろう大きな技術革新、そしてそれに伴う市場やお客様の変化を見据え、「Nissan M.O.V.E. to 2022」に取り組むことによりそのミッションを果たしていく。これを受けて、当社の業務改善状況等につき令和元年5月17日に国土交通省に報告した。 当社の元代表取締役が金融商品取引法違反(虚偽有価証券報告書提出罪)で起訴されるとともに、元代表取締役会長においては会社法違反(特別背任罪)でも起訴された。これは、当社において入手可能となった情報に基づいて最善の見積りを行い、過年度の財務情報において処理されていない金額、具体的には、(a)支払いが繰り延べられて支払われていない、未計上であったゴーン氏の報酬費用の計上、(b)法的根拠なく増額がなされたゴーン氏の役員退職慰労金にかかる計上費用の取崩、(c)株価連動型インセンティブ報酬のうち法的に無効なプログラム分にかかる計上費用の取崩等を一括処理したものである。なお、調査は現在も進行中であり、今後、最終金額は当該見積り計上額と異なる可能性がある。 年度毎の金額 (百万円)平成18年3月期59平成19年3月期134平成20年3月期397平成21年3月期―平成22年3月期228平成23年3月期795平成24年3月期907平成25年3月期1,038平成26年3月期△1,660平成27年3月期△106平成28年3月期1,127平成29年3月期498平成30年3月期994合計4,411 なお、当社による調査の結果、当社の連結子会社と当社元取締役カルロス ゴーンの近親者が経営に関与している会社DEXTAR WORLD TRADE LIMITED, L.L.C.との間に取引が存在することが判明した。判明した取引の詳細は、以下のとおりである。
事業等のリスク
## 要約
なお、文中の将来に関する事項は、有価証券報告書提出日(令和元年6月27日)現在において当社グループが判断したものである。 1.世界経済や景気の急激な変動(1) 経済状況当社グループの製品・サービスの需要は、それらを提供している国又は地域の経済状況の影響を強く受けている。予測を超えた急激な変動がある時は業績の悪化や機会損失の発生等、当社グループの業績及び財務状況に影響を及ぼす可能性がある。 また、付加価値の中心がハードウエアとしてのクルマの性能から、クルマに関連したサービスも含め、お客様にどのような体験を提供できるのかといったソフトウエアの方に移っていくことも想定される。また、当社グループは外貨建債権債務の為替変動のリスク回避、変動金利で調達した有利子負債の金利変動リスク回避及び、コモディティの価格変動リスク回避を目的として、デリバティブ取引を行うことがある。しかしながら市場環境に予期せぬ大規模な変化が発生した場合には、当初計画通りの資金調達に支障をきたす可能性があり、当社グループの業績及び財務状況に負の影響を及ぼす可能性がある。 (5) 販売金融事業のリスク販売金融事業は当社グループにとって重要なビジネスのひとつである。実際の結果が前提条件と異なる場合、又は前提条件が変更された場合、その影響は累積され、将来にわたって規則的に認識されるため、一般的には将来期間において認識される費用及び債務に影響を与える可能性がある。しかし、予測を超えた環境の変化や世の中のニーズの変化、相対的な開発競争力の低下により、最終的にお客様にその新技術が受け入れられない可能性もあり、その結果当社グループの業績に大きな影響を及ぼす可能性がある。しかしながら、より高い付加価値を提案するための新技術の採用は、それが十分に吟味されたものであっても、後に製造物責任や製品リコールなど予期せぬ品質に係る問題を惹起することがある。特にクルマの使用時に排出されるCO2量は、企業活動に伴う排出量に比較して著しく多く、全体の80%以上を占めることから、気候変動による規制等のリスクが生じる可能性がある(バリューチェーン全体のCO2排出量216,351kton-CO2のうち、販売したクルマの使用時の排出量が190,261kton-CO2、いずれも平成29年度実績)。この様な取り組みにより「ニッサン・グリーンプログラム2022」 では新車1台あたりのCO2排出量を令和4年に40%削減とする事を目標としている。 (8) 知的資産保護の限界当社グループは、他社製品と差異化できる技術とノウハウを保持している。 (9) 優秀な人材の確保当社グループでは人材は最も重要な財産と考え、グローバルで優秀な人材を採用するとともに、十分に能力を発揮してもらうため人材育成の充実や公平で透明性の高い評価制度の実現にも力を入れている。一方、平成30年から平成31年にかけて、当社の元代表取締役が金融商品取引法違反(虚偽有価証券報告書提出罪)で起訴されるとともに、元代表取締役会長においては会社法違反(特別背任罪)でも起訴された。仮に、企業の社会的責任に照らして不適切な行為を行ったのが2次3次以降のサプライヤーや販売者であったり、あるいは当社グループが想定した販売ルート以外で流通した製品に関連するものであっても、当社グループ自身が社会的責任を追及され、対応の内容や迅速性が不十分な場合には当社グループの社会的信用や評判に悪い影響を及ぼし、売上の減少等、当社グループの業績に影響を与える可能性がある。しかし、想定を超えた大規模な地震により大きな損害が発生し、操業を中断せざるを得ないような場合は、当社グループの業績と財務状況に大きな影響を及ぼす可能性がある。東日本大震災や熊本地震等の災害を契機として、下記のような従来想定していなかった様々なリスクも顕在化した。 (3) 特定サプライヤーへの依存より高い品質や技術をより競争力ある価格で調達しようとすると、発注が特定のサプライヤーに集中せざるを得ないことがある。 (4) 情報システムに係るリスク当社グループの殆ど全ての業務は情報システムに依存しており、システムやネットワークも年々複雑化高度化している。
財政状態、経営成績及びキャッシュ・フローの状況の分析
要約
① 財政状態及び経営成績の状況当連結会計年度のグローバル全体需要は前年度比1.5%減の9,209万台となった。営業利益は3,182億円と前連結会計年度に比べ2,566億円(44.6%)の減益となった。また、現金及び現金同等物に係る換算差額により383億円減少し、連結範囲の変更に伴い11億円増加した結果、現金及び現金同等物の当連結会計年度末残高は、前連結会計年度末残高に対し1,531億円(12.7%)増加の1兆3,591億円となった。 b.受注状況当社グループの受注生産は僅少なので受注状況の記載を省略する。 (2) 経営者の視点による経営成績の状況に関する分析・検討内容経営者の視点による当社グループの経営成績等の状況に関する分析・検討内容は次のとおりであり、原則として連結財務諸表に基づいて分析したものである。当社グループの連結財務諸表で採用する重要な会計方針は、第5[経理の状況]の連結財務諸表の「連結財務諸表作成のための基本となる事項」に記載しているが、特に次の重要な会計方針が連結財務諸表における重要な見積りの判断に大きな影響を及ぼすと考えている。将来、顧客の財務状況が悪化し、支払能力が低下した場合、引当金の追加計上又は貸倒損失が発生する可能性がある。前連結会計年度の営業利益に対し2,566億円(44.6%)の減益となった。自動車事業の業績は、売上高(セグメント間の内部売上高を含む)は、10兆5,841億円と前連結会計年度に比べ4,438億円(4.0%)の減収となった。主な減益要因は、購買コスト削減による増益はあったものの、販売台数の減少及び開発費の増加によるものである。営業利益は721億円となり、前連結会計年度に比べ1,280億円(64.0%)の減益となった。c.欧州欧州市場の全体需要は前年度比0.3%増の2,003万台となったが、ロシアを除く欧州市場の当社グループの販売台数は、環境規制対応の影響により前年度比17.8%減の53万6千台となり、市場占有率は前年度比0.6ポイント減の3.0%となった。中南米市場の販売台数は好調で前年度比8.1%増の22万5千台となり、南アフリカ等のアフリカ市場の販売台数は前年度比6.1%増の10万1千台となった。投資活動投資活動による支出は1兆1,335億円となり、前連結会計年度の1兆1,477億円に比べて142億円減少した。これは主として、社債の発行による収入が減少したことによるものである。当社グループは、研究開発活動、設備投資及び金融事業に投資するために、適切な資金確保を行い、最適な流動性を保持し、健全なバランスシートを維持することを財務方針としている。
研究開発活動
キーワード
['vcターボ', 'qx50', '米国', 'アルティマ', 'q50', '日本', 'ムラーノ', 'q60', '日産デイズ', 'evエコシステム', 'ニッサン エナジー', '福島県浪江町', '日産リーフ', '欧州', '英国', 'jncap', 'us-ncap', 'パスファインダー', 'qx60', 'キックス', 'tsp', 'ユーロncap', 'セレナ', '圧縮比エンジン', 'インフィニティ新型', 'vcターボ」エンジン', '10ベストエンジン', 'wards 10 best engines)', '可変圧縮比', 'マルチリンク', '圧縮比', '成形性超ハイテン材', 'スカイライン」', '超ハイテン材', '電力系統', '充', '世界初量産型', '(英国)', 'トップセーフティピック', 'ledヘッドライト', '欧州新車アセスメントプログラム', '自動運転', 'プロパイロット', 'エクストレイル', 'ローグ', '神奈川県横浜市', 'セレナ e-power', 'キャシュカイ」', 'easy ride(イージーライド)', 'みなとみらい地区', 'nissan m.o.v.e.', '先端技術等のための研究']
要約
当社グループの研究開発体制及び活動成果は次のとおりである。米欧地域においては、米国の北米日産会社、メキシコのメキシコ日産自動車会社、英国の英国日産自動車製造会社、スペインの日産モトール・イベリカ会社において、一部車種のデザイン及び設計開発業務を行っている。ルノー、三菱自動車工業(株)及び当社は平成29年9月に発表した中期計画アライアンス2022により、さらなる経営資源の効率化を目指し、次世代技術、プラットフォーム、パワートレインの開発を分担し共用化を加速させている。平成31年3月時点で、「日産リーフ」のグローバル累計販売台数は40万台を突破、「e-NV200」、「シルフィ ゼロ・エミッション」、ヴェヌーシア「e30」、東風ブランドを含めた電気自動車全体のグローバル累計販売台数では51万台を超えた。平成25年には高強度と高成形性を両立できる世界初1.2GPa級高成形性超ハイテン材をインフィニティ「Q50」(日本では「スカイライン」)に採用し、「ムラーノ」、インフィニティ「Q60」などに採用を拡大した。・ニッサン エナジー サプライ:安心・便利なEVライフのための各種充電ソリューションを提供・ニッサン エナジー シェア:電気自動車のバッテリーに貯めた電力を、住宅と「シェア」することで、新たな価値を提供。安全面においては、日産車がかかわる死者数を平成27年までに平成7年比で半減させることを目指し、日本、米国、欧州(英国)で達成。米国では、米国新車アセスメントプログラム(US-NCAP)にて「パスファインダー」、インフィニティ「QX60」が最高評価となる5つ星を獲得した。また、当社は令和4年までに「プロパイロット」を20車種に搭載し、20の市場に投入する計画を発表しており、令和4年までに「プロパイロット」搭載車の販売台数が年間100万台になると見込んでいる。同時に将来に向け、モビリティサービスにも取り組んでいる。*1: 発売時点。「セレナ e-POWER」は、26.2km/L(日本基準)*2: 平成30年8月以降の生産車 。
おわりに
CoARiJのデータをCOTOHAで分析/要約を行うことで大量の有価証券報告書を読みやすい形に変換する試みを行いました
その結果、「有価証券報告書の原文を読むか読まないかの判断」ができる程度にはなったかと思います
※事業規模がめちゃくちゃ大きくて何書いてあるかよく分からないことも判断できそうですねCOTOHAに投げるリクエストに文字数制限があるため文章を分割して複数回API呼び出す必要があるので大規模なデータを扱う際には気を付けましょう
※本記事はで429(Too Many Requests)が出てしまい検証が進まないことがありました・・・
- 投稿日:2020-02-22T12:54:55+09:00
[Django] コマンド備忘録
Django作成したwebアプリケーションをUbuntu EC2上で動かすときに良く使うコマンドを載せておきます。(ど初心者です。笑)
・EC2へSSH接続やつ(AWSマネジメントコンソールでEC2が起動していることを確認)
bash
$ ssh -i "秘密鍵名.pem" ubuntu@EC2のパブリックIP
※秘密鍵が置いてあるディレクトリで実行。・サーバ起動やつ
bash
$ python3 manage.py runserver 0.0.0.0:8000[例]・サーバを殺すやつ
bash
$ kill `lsof -ti tcp:8000`↓お世話になってるやつ。
[Django]https://www.udemy.com/course/django-beginner/
- 投稿日:2020-02-22T11:49:06+09:00
pythonで二分探索を実装してみた
pythonとアルゴリズムの勉強かねがね、挿入ソートを実装してみました。
1.ランダムなリストを作成してソートを行う
例:[1,2,4,5,6,9]2.探索する値を決める
(コードでは、最下部のforループで取りうる範囲の値全てを探索しに行ってます)
例:23.リストからド真ん中付近の値を取り出す
リストの長さが偶数の場合→ド真ん中の右側
リストの長さが奇数の場合→ド真ん中
例:[1,2,4,5,6,9]→54.リストを3.で取り出した値を境にして二つに分割する
例:[1,2,4,5,6,9]→[1,2,4],[5,6,9]5.3.で取り出した値を探索する値を比較
一致したら探索終了、不一致なら次へ
例:2 != 56.4.で作った2つのリストに対して、左の最大値、右の最小値と探索する値の比較を行う
探索値が左の最大値より小さければ、探索範囲は左に限定できる
探索値が右の最小値より大きければ、探索範囲は右に限定できる
探索値が左の最大値より大きく右の最小値より小さい場合、探索値は存在しないので探索終了
例:左[1,2,4],右[5,6,9]、探索値2
2<4なので探索範囲は左に限定7.新しく探索範囲とするリストに対して、3.から6.処理を繰り返しを行う
例:[1,2,4]→2
一致したので処理終了…とこんな感じの探索を二分探索法と呼ぶらしいです。
途中で左側のリストを除外した際、及び正解が導出された時点で左側のリストが存在した場合に、その要素数を加算して「何番目に探索値が存在したか」をチェックできるようにしました。
n個の数列に対して総当たりで探索を行うとnステップの処理が必要になります。
これに対し、二分探索法では1ステップ毎に半分の値を探索対象から除外できるので、n個のデータに対しての処理回数は(log n)回になります。binary_search.pyimport copy import random # 準備する値の数を入力 numbers = 100 def binary_search(num_list, target): # 「値が何番目にあるか」を確認するための変数 ans_counter = 0 while True: # 配列の中心にある値を取り出す middle = num_list[len(num_list) // 2] # 配列の左側 left = num_list[:len(num_list) // 2] # 配列の右側 right = num_list[len(num_list) // 2:] # 中心の値が探索値と一致したら探索終了(探索値発見) if middle == target: ans_counter += len(left) + 1 print("{}は{}番目にありました。".format(target, ans_counter)) break # 値が最後の1個になっても一致しなかったら探索終了(探索値不存在1) # 左の最大値 < 探索値 < 右の最小値となった場合探索終了(探索値不存在2) elif len(num_list) == 1 and num_list[0] != target\ or left[-1] < target < right[0]: print("{}はありませんでした。".format(target)) break # 左の最大値より探索値が小さい場合、探索範囲を左側に絞る elif target <= left[-1]: num_list = left # 右の最小値より探索値が大きい場合、探索範囲を右側に絞る elif right[0] < target: ans_counter += len(left) num_list = right # num_list = list(range(1,numbers+1)) # 重複のない(num_list)個分のデータを作ってソートする num_list = [] while len(num_list) < numbers: n = random.randint(1, numbers * 2) if n not in num_list: num_list.append(n) num_list.sort() print(num_list) # 乱数の生成される範囲を探索範囲とする for i in range(1, numbers * 2 + 1): binary_search(num_list, i)
- 投稿日:2020-02-22T11:12:20+09:00
python で pip を使おうとしたら XML_SetHashSalt が見つからないって言われてはまった話
Linux の python で pip を使おうとしたら下記のエラーではまったのでメモ。
# python3 -m pip install numpy (中略) ImportError: /usr/lib64/python3.6/lib-dynload/pyexpat.cpython-36m-x86_64-linux-gnu.so: undefined symbol: XML_SetHashSaltなんてことはない、ライブラリのコンフリクトが原因だったので下記を実行してから再実行で解決。
# export LD_LIBRARY_PATH=
- 投稿日:2020-02-22T10:58:24+09:00
python を使った firefox の画像キャプチャ
python と selenium を使って、ホームページの画像をキャプチャするプログラムを書いてみました。
# -*- coding: utf-8 -*- import sys from selenium import webdriver from selenium.webdriver import FirefoxOptions ''' Firefox を起動して、画像キャプチャする ''' if( len( sys.argv ) < 3 ): print "Usage: firefox.py [uri] [png]" sys.exit( 1 ) opts = FirefoxOptions() opts.add_argument( "--headless" ) driver = webdriver.Firefox( firefox_options = opts ) driver.set_window_size( 1024,768 ) driver.get( sys.argv[1] ) driver.save_screenshot( sys.argv[2] ) driver.quit()
- 投稿日:2020-02-22T10:01:23+09:00
conda vs. pip
始めに
Anaconda Navigatorでは、仮想環境の構築と管理、外部ライブラリのインストールや管理が行えます。Jupyter Notebookを含めた開発環境一式を管理できるのですが、ライブラリのインストールにはcondaというコマンドが使われています。
その反面、Pythonには、外部ライブラリを管理するpipというコマンドがあります。Anaconda Navigatorで任意の仮想環境からターミナルを起動すれば、pipコマンドを入力してインストールが行えます。しかしpipでインストールしたライブラリは、pipで管理しなけれえばならないため、Anacondaのcondaでは管理されません。
場合によっては、condaとpipで同じライブラリをインストールし、競合してしまうことにもなります。
結論
したがって、Anaconda Navigatorを使う場合は、pipコマンドを使わず、condaコマンドを使うことにしましょう。
参考資料
- conda installとpip installの違い。機能の比較など【Python】 https://insilico-notebook.com/conda-pip-install/
- AnacondaのNumPyとpipによるNumPyの速度の違い https://orizuru.io/blog/machine-learning/anaconda_pip_difference/
- Stop Installing Tensorflow using pip for performance sake! https://towardsdatascience.com/stop-installing-tensorflow-using-pip-for-performance-sake-5854f9d9eb0c?gi=677958f0038e
- 投稿日:2020-02-22T08:42:59+09:00
Titanic生存者を予測する ver1.0
1 はじめに
機械学習を学ぶ上でのチュートリアルとして皆さん必ず通る道であろうタイタニック号生存者の予測について、私が行った方法を備忘として記録します。
使用したバージョンについて
・Python 3.7.6
・numpy 1.18.1
・pandas 1.0.1
・matplotlib 3.1.3
・seaborn 0.10.0使用したデータはKaggle登録後、こちらからダウンロードしました。
https://www.kaggle.com/c/titanic2 プログラムについて
Importしたライブラリ等
import pandas as pd import numpy as np df = pd.read_csv('train.csv') import matplotlib.pyplot as plt import seaborn as sns %matplotlib inlineデータフレームdfとして定義しました。
ここで、読み込んだデータのうち最初の5行を見てみます。df.head()
Survivedが1で生存、0で死亡を表します。その他の要因が何を指しているかは公式サイトをご覧ください。
ヒストグラム
次にヒストグラムを見てみます。
df.hist(figsize=(12,12)) plt.show()
歳は20~30代が多く、Pclass(等級)は3(一番安い)が多いことが分かります。
相関係数を確認
plt.figure(figsize = (15,15)) sns.heatmap(df.corr(),annot = True)
Survivedに対して相関係数が高い指標は0.26:Fare、-0.34:Pclassとなります。Pclass等級が決まればFare:運賃も自ずと決まると思いますが、二つは違う指標なんですね。。
欠損値の取り扱い
df.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64Age:年齢とCabin:乗り組み番号が入っていない量が多いことが分かります。欠損値の取り扱いについては、下記を参考にしました。
https://qiita.com/0NE_shoT_/items/8db6d909e8b48adcb203今回は、年齢に関しては中央値を代入することとしました。また、Embarked:乗船地は最も多いSを代入しています。
その他の欠損している値は削除しました。from sklearn.model_selection import train_test_split #欠損値処理 df['Fare'] = df['Fare'].fillna(df['Fare'].median()) df['Age'] = df['Age'].fillna(df['Age'].median()) df['Embarked'] = df['Embarked'].fillna('S') #カテゴリ変数の変換 df['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0) df['Embarked'] = df['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int) #不要なcolumnを削除 df = df.drop(['Cabin','Name','PassengerId','Ticket'],axis =1)学習データとテストデータの分類
train_X = df.drop('Survived',axis = 1) train_y = df.Survived (train_X , test_X , train_y , test_y) = train_test_split(train_X, train_y , test_size = 0.3 , random_state = 0)今回は、テストデータを3割(test_size=0.3)としています。
機械学習による予測(決定木)
from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier(criterion='gini', random_state = 0) clf = clf.fit(train_X , train_y) pred = clf.predict(test_X) #正解率の算出 from sklearn.metrics import (roc_curve , auc ,accuracy_score) pred = clf.predict(test_X) fpr, tpr, thresholds = roc_curve(test_y , pred,pos_label = 1) auc(fpr,tpr) accuracy_score(pred,test_y)決定木パラメータの取り扱いについてはこちらを参考にしました。
http://data-analysis-stats.jp/2019/01/14/%E6%B1%BA%E5%AE%9A%E6%9C%A8%E5%88%86%E6%9E%90%E3%81%AE%E3%83%91%E3%83%A9%E3%83%A1%E3%83%BC%E3%82%BF%E8%A7%A3%E8%AA%AC/criterion='gini', 0.7798507462686567
criterion='entropy', 0.7910447761194029若干entropyの方が正解率が上がりました。参考urlによると、
使い分けのポイントとしては、ジニ係数の方が、連続データを得意としており、エントロピーはカテゴリーデータを得意としていると言われています。ジニ係数は、誤分類を最小化するのに対して、エントロピーは探索的に基準値を探していきます。
とのことです。今回は性別、乗船地等カテゴリーデータが多かったことからエントロピーが適切なのでしょう。
こちらも決定木に関して詳しく載っており参考になりました。
https://qiita.com/3000manJPY/items/ef7495960f472ec14377機械学習による予測(ランダムフォレスト)
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(n_estimators = 10,max_depth=5,random_state = 0) #ランダムフォレストのインスタンスを生成する。 clf = clf.fit(train_X , train_y) #教師ラベルと教師データを用いてfitメソッドでモデルを学習 pred = clf.predict(test_X) fpr, tpr , thresholds = roc_curve(test_y,pred,pos_label = 1) auc(fpr,tpr) accuracy_score(pred,test_y)0.8283582089552238
ランダムフォレストには、分類用(Classifier)と回帰分析用(Regressor)があります。今回は、生存か死亡かを分類することが目的なため分類用を用いて実行します。
RandomForestClassifierクラスの学習パラメータ、引数はこちらを見ながら動かしてみました。
https://data-science.gr.jp/implementation/iml_sklearn_random_forest.htmln_estimatorsを上げていくと正解率がサチレートしていきました。n_estimatorsやニューラルネットワークで使用するepochsは大きな値で計算しても取り越し苦労に終わることが多いと言われています。その内容、対策については下記をご覧ください。
https://amalog.hateblo.jp/entry/hyper-parameter-search予測結果の出力
先ほどの結果から決定木よりランダムフォレストのほうがより正解率が高いことが分かりました。
従って、今回はランダムフォレストにより予測することとしました。fin = pd.read_csv('test.csv') fin.head() passsengerid = fin['PassengerId'] fin.isnull().sum() fin['Fare'] = fin['Fare'].fillna(fin['Fare'].median()) fin['Age'] = fin['Age'].fillna(fin['Age'].median()) fin['Embarked'] = fin['Embarked'].fillna('S') #カテゴリ変数の変換 fin['Sex'] = fin['Sex'].apply(lambda x: 1 if x == 'male' else 0) fin['Embarked'] = fin['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int) #不要なcolumnを削除 fin= fin.drop(['Cabin','Name','Ticket','PassengerId'],axis =1) #ランダムフォレストで予測 predictions = clf.predict(fin) submission = pd.DataFrame({'PassengerId':passsengerid, 'Survived':predictions}) submission.to_csv('submission.csv' , index = False)
4900位/16000位となりました。
もっと精進したいと思います。
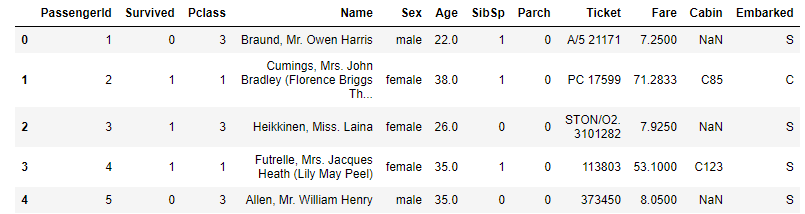
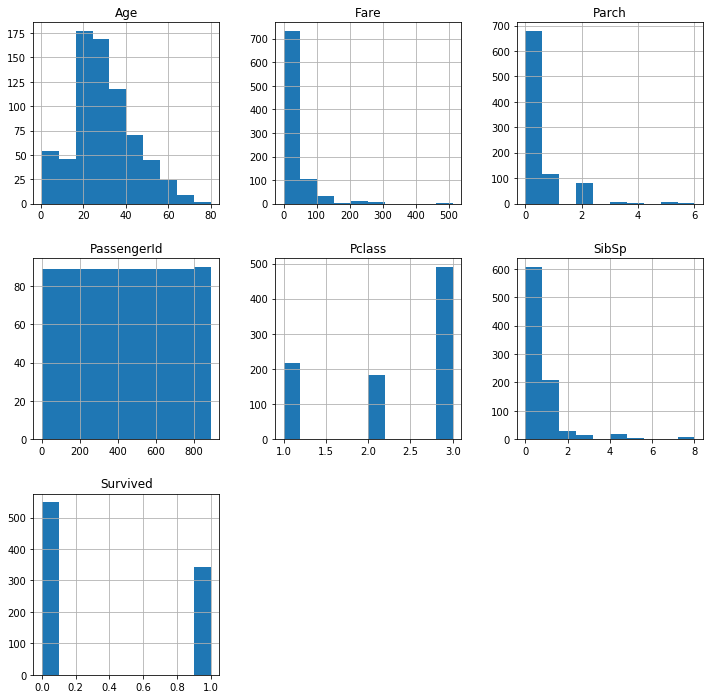

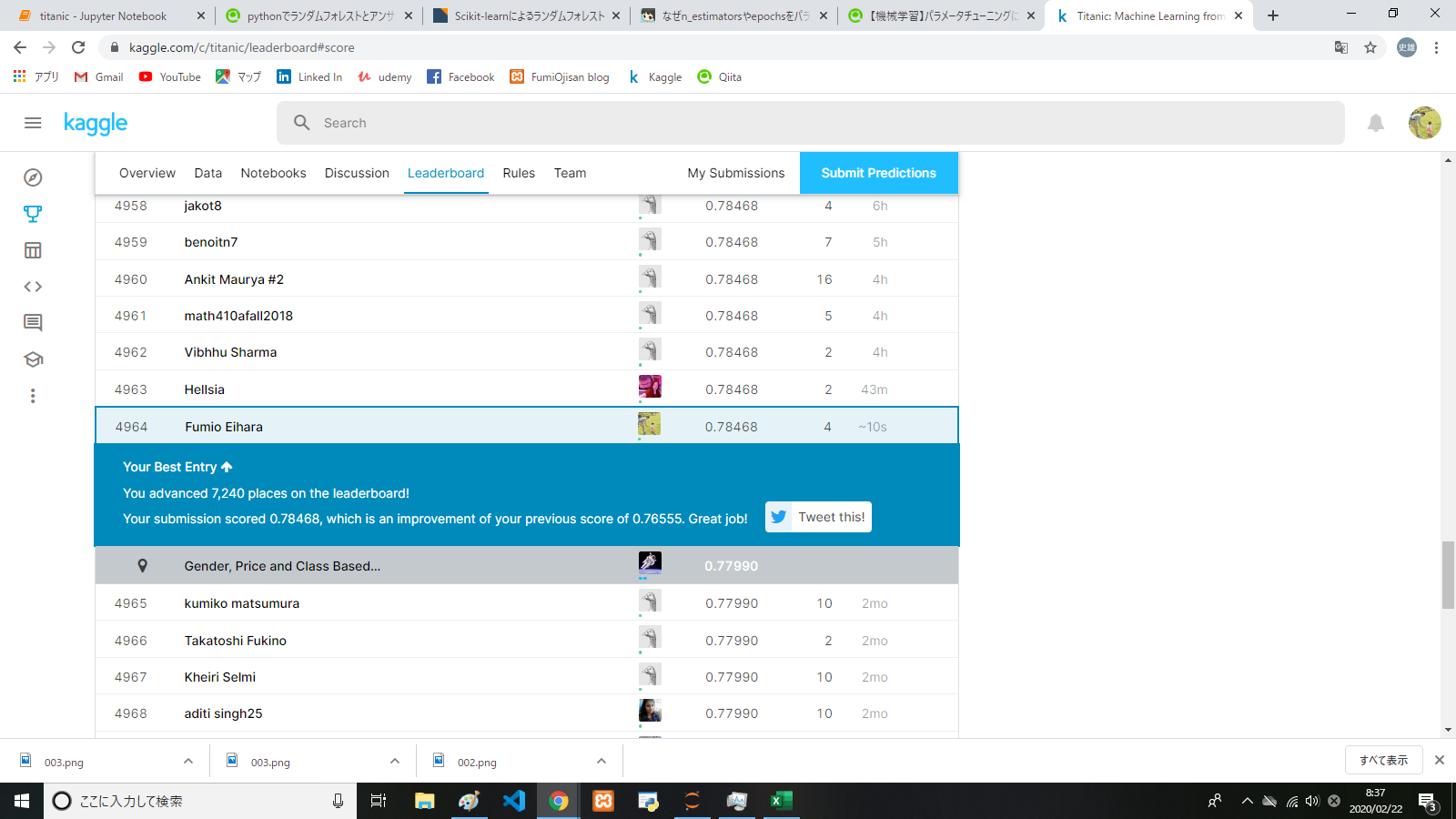
- 投稿日:2020-02-22T08:35:25+09:00
setterとgetter
class Car(object): def __init__(self,model=None): self.model=model def run(self): print('run') class ToyotaCar(Car): def __init__(self, model,enable_auto_run = False): #self.model = modelとも書けるが、superを使って親メソッドを読み出せる super().__init__(model) #getterやsetterを使って変数にアクセスさせたい場合は、変数名の前に_をつける self._enable_auto_run = enable_auto_run #外から完全に遮蔽するには変数名の前に_を2つ付ける #self.__enable_auto_run = enable_auto_run @property def enable_auto_run(self): return self._enable_auto_run @enable_auto_run.setter def enable_auto_run(self,is_enable): self._enable_auto_run = is_enable #メソッドのオーバーライド def run(self): print('fast fun') car = Car() car.run() toyotar_car = ToyotaCar('Lexus') toyotar_car.enable_auto_run = True print(toyotar_car.enable_auto_run)run True
- 投稿日:2020-02-22T01:41:19+09:00
社会性フィルターでSNS時代を生き抜く
はじめに
社会人は日々つらいことが多く、twitterをはじめとするSNSで嘆きたくなることも多いと思います。
ただ、ネガティブな発言は周りの人を不快にさせてしまうことがあるため、代わりに「にゃーん」と呟いて周りを和ませたりします。
これを社会性フィルターといいます。
今回はこの社会性フィルターを実装していきたいと思います。
— 4869 (@sh4869sh) 2016年8月21日実装方針
COTOHA APIの感情分析APIを使っていきます。
感情分析APIは、文章のPositive/Negative/Neutralを返し、感情語が含まれれば感情語と感情を返します。文章がNegativeである場合には、文章を「にゃーん」にします。
また、Negativeであろう単語が含まれる場合には、文章全体がPositiveであろうと「にゃーん」にする厳しいモードも作成します。
ソースコード
すぐ動かせるcolaboratoryのコードはこちらから。
ソースコードはこちら
必要なものをインポート
social_filter.pyimport sys import requeststokenを取得する関数
social_filter.pydef auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"]感情分析する
social_filter.pydef sentiment(access_token, sentence): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "sentence": sentence, "type": "kuzure" } r = requests.post(base_url + "v1/sentiment", headers=headers, data=json.dumps(data)) return r社会性フィルター
social_filter.pydef social_filter(sentence, response, filter_level="low"): result = response.json()["result"] negative_list = ["悲しい", "不安", "恥ずかしい", "嫌", "切ない", "N"] if result["sentiment"] == "Negative": return "にゃーん" else: if filter_level == "high": if len([line for line in result["emotional_phrase"] if line["emotion"] in negative_list]) == 0: return sentence else: return "にゃーん" else: return sentence社会性フィルターにかける
social_filter.pyargs = sys.argv sentence = args[1] response = sentiment(access_token, sentence) social_filter(sentence, response, args[2])実行結果
python social_filter.py "毎日会社と家の往復でしんどい・・・" low 'にゃーん'フィルターのレベルが低いと、ポジティブな表現が多いときに取りこぼしてしまう
python social_filter.py "学生の頃は毎日がバラ色で、何もなくても最高に楽しかった。でも今はつらい" low '学生の頃は毎日がバラ色で、何もなくても最高に楽しかった。でも今はつらい'フィルターのレベルをあげることで対処できる。
python social_filter.py "学生の頃は毎日がバラ色で、何もなくても最高に楽しかった。でも今はつらい" high 'にゃーん'まとめ
今回はCOTOHA APIを使うことで、簡単に社会性フィルターの実装を行いました。
普段のツイートがネガティブなのか、「にゃーん」と呟いたほうがいいのか迷ったときにお使いください。