- 投稿日:2020-02-22T22:49:46+09:00
LightsailにシングルノードKubernetesクラスターを作る
AWSのLightsailに毎月2000円ぐらいの仮想マシンを建てて、シングルノードKubernetesクラスターを作る話。
OSのコンソールに直接アクセスしてdockerコマンドとかを実行できるので開発環境には都合が良い。今回の個人的な用途はOperator SDKでの開発用。
記事作成時点のKubernetesバージョンは1.17。OSは訳あって、と言うかOperator SDKと相性良さそうというか、でCentOS 7。
Lightsailに仮想マシンを作る
https://lightsail.aws.amazon.com/ls/webapp/home/instances
OSのみ。CentOS 7 1901-01。月額$20の、4GB Memory、2 vCPUのインスタンスを作成。Lightsailコンソールを開く
インスタンスが出来たらコンソールを開き、何はともあれsudo -iを実行。
$ sudo -iDockerとか、前提パッケージのインストール
https://kubernetes.io/docs/setup/production-environment/container-runtimes/
コマンドをコピペするときは、改行文字がCRLFで転送されない様に注意。notepad++の改行モードをUnix(LF)にして、それに貼り付けてから改めてLightsailコンソールに貼るとかね。# yum install -y yum-utils device-mapper-persistent-data lvm2 # yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # yum update -y && yum install -y containerd.io-1.2.10 docker-ce-19.03.4 docker-ce-cli-19.03.4 # mkdir /etc/docker # cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ] } EOF # mkdir -p /etc/systemd/system/docker.service.d # systemctl daemon-reload # systemctl restart docker # systemctl enable dockerkubelet、kubeadmのインストール
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
# cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOF # setenforce 0 # sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config # yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes # systemctl enable --now kubelet # cat <<EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF # sysctl --systemKubernetesのインストール
ネットワーク・ドライバーはcalico。
# kubeadm init --pod-network-cidr=192.168.0.0/16 # mkdir -p $HOME/.kube # sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config # sudo chown $(id -u):$(id -g) $HOME/.kube/config # kubectl apply -f https://docs.projectcalico.org/v3.11/manifests/calico.yamlCoreDNSが起動している事を確認
calicoインストール後、暫くするとCoreDNSが起動する。
[root@ip-172-26-4-124 ~]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-5b644bc49c-wgfzv 1/1 Running 0 44s calico-node-ktkgn 1/1 Running 0 45s coredns-6955765f44-mgpjr 1/1 Running 0 2m52s coredns-6955765f44-xszrk 1/1 Running 0 2m52s etcd-ip-172-26-4-124.ap-northeast-1.compute.internal 1/1 Running 0 3m8s kube-apiserver-ip-172-26-4-124.ap-northeast-1.compute.internal 1/1 Running 0 3m8s kube-controller-manager-ip-172-26-4-124.ap-northeast-1.compute.internal 1/1 Running 0 3m7s kube-proxy-qctwk 1/1 Running 0 2m52s kube-scheduler-ip-172-26-4-124.ap-northeast-1.compute.internal 1/1 Running 0 3m8staint解除
シングルノードクラスターのためMasterノードでアプリが起動する必要があり、taintを解除。
# kubectl taint nodes --all node-role.kubernetes.io/master-動作確認
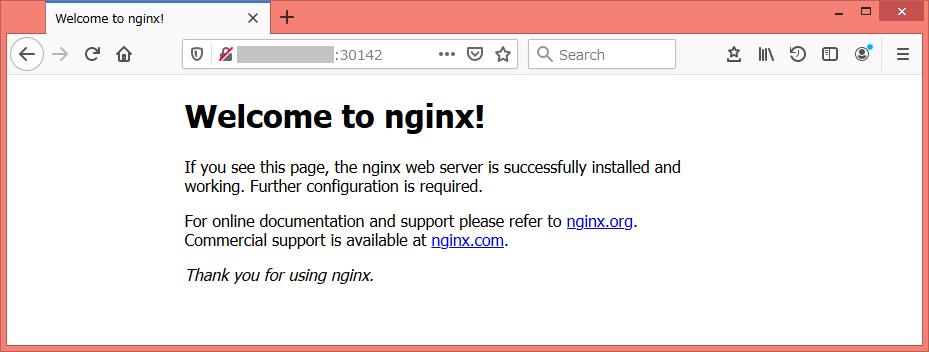
とりあえずnginx動かしてみてアクセスできるか。
# kubectl run nginx --image=nginx # kubectl expose deploy/nginx --type=NodePort --port=80 # kubectl get svc (最後のコマンドの出力結果) [root@ip-172-26-4-124 ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 57m nginx NodePort 10.96.212.196 <none> 80:30142/TCP 17m手元のWebブラウザからアクセスするなら、NodePortで開いているポート番号(上の例なら30142)で仮想マシンにアクセスできるよう、Lightsailファイアウォールに許可するポートを追加。
で、「http://<インスタンスのIPアドレス>:<NodePort>」でWebブラウザからアクセスすれば以下の画面が表示される。
。。まあ、当初の目的がOperator SDK開発環境なので外部webアクセスは必要ないが。
Operator SDKのチュートリアルやってみましたを、気が向いたら日を改めて。
- 投稿日:2020-02-22T22:34:27+09:00
SDK for RubyでAWSの環境作ってみるよハンズオン
概要
コードでAWS環境を構築する、いわゆるInfrastructure as Code(Iac)と言えばCloudFormationやTerraformが主流ですが、主要なプログラミング言語でリソースの構築や操作ができるSDKがAWSからは提供されています。
そのSDKのうち今回はRubyを使って環境(VPC、IGW、Subnet、RouteTable)を構築するハンズオンを紹介したいと思います!
※作業環境はMacOS、SDK for Rubyのバージョン3になりますおしながき
- 事前準備
- SDKのインストールと設定
- コードを書いていく
- どうやってコードを書いているのか?
- 今後
- まとめ
1.事前準備
必要なもの
AWSアカウント
いわずもがなですが、各リソースを起動させるためにAWSのアカウントが必要です。もう持ってるという前提で進めますのでご了承Ruby(バージョン1.9以降)
これもいわずもがな…Rubyでコードを書いていきますので作業端末にインストールしてください。参考サイト
AWS SDK for Ruby Developer Guide
こちらの公式サイトにそってやっていきます。2.SDKのインストールと設定
SDKをインストールする
SDK for Rubyはgemとして配布されています。Rubyの外部ライブラリですね。
- bundlerを使用している場合
Gemfileに下記を追記してbundle installを実行するgem 'aws-sdk'
- bundler使わない場合
下記のコマンドを実行してgemをインストールsudo gem install aws-sdk※けっこう時間がかかります。5分くらいターミナル画面が止まったままになりますが、フリーズではありません。
認証情報の設定
SDK経由でAWSにアクセスするための認証情報をローカルファイルに記述します。場所は
~/.aws/credentialsです。# ディレクトリを作成 mkdir ~/.aws # 移動 cd ~/.aws # vimでcredentialsファイルを編集 sudo vim credentialsvimで下記を記述します
[default] aws_access_key_id = your_access_key_id aws_secret_access_key = your_secret_access_key※上記の
your_access_key_id、your_secret_access_keyにアクセスキー、シークレットアクセスキーを入力するため、一旦おいといて下の作業を進めますアクセスキー、シークレットアクセスキーを作成する
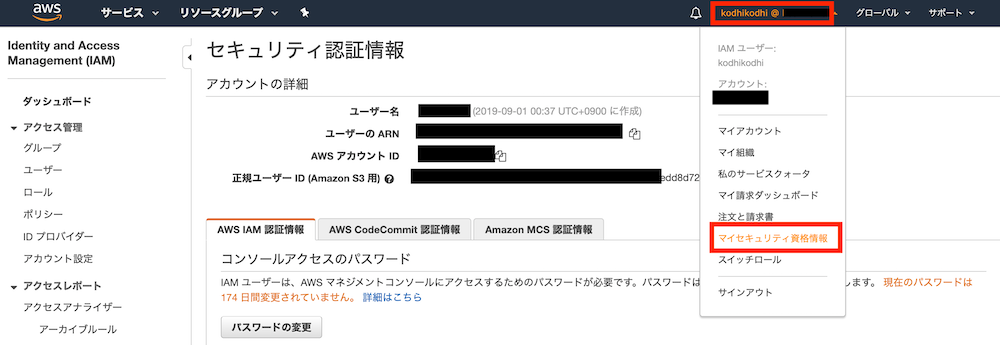
- AWSマネジメントコンソールにログインします
- マネジメントコンソールの右上のアカウント部分をクリック
- ドロップダウンメニューから「マイセキュリティ資格情報」を選択
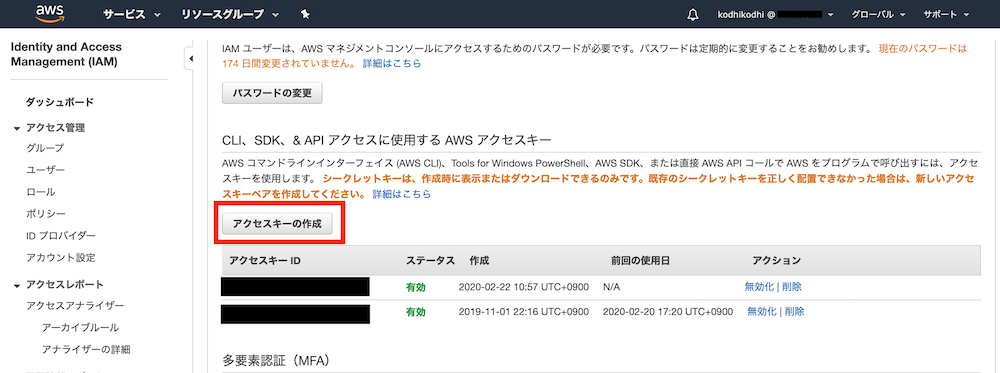
- 「セキュリティ認証情報」画面に移動したら「アクセスキーの作成」ボタンを押す
※アクセスキーは1アカウントにつき2つまでしか作成できません。既に2つある場合は使っていないものを削除するなどしてください
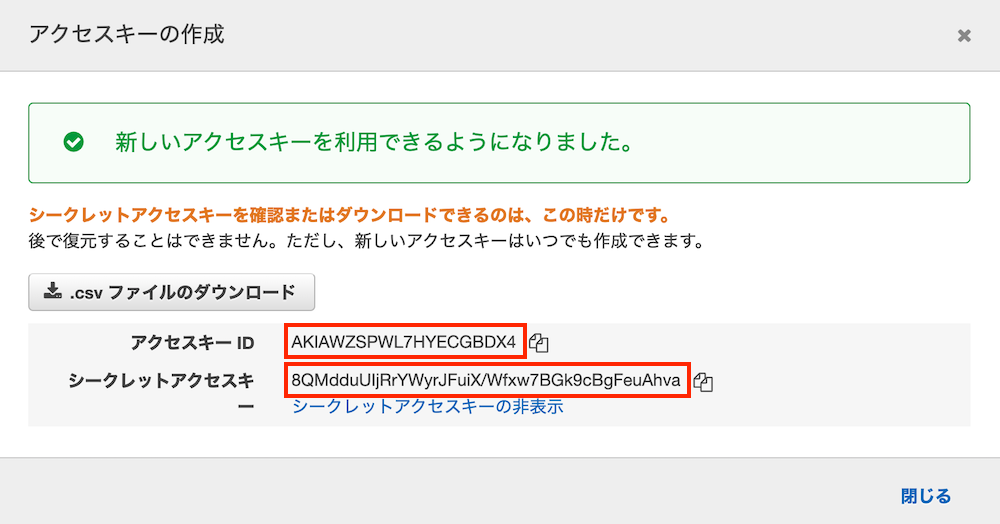
- 「アクセスキーの作成」ボタンを押して出てきたウインドウの情報をメモする
※このウインドウは一旦閉じると2度とシークレットアクセスキーを見られなくなるので注意!もし閉じた場合は、作成したキーを削除してもう一度作成しなおしてください
※画像のアクセスキーは削除してるので使えません あしからず(笑)
- vimに戻ってメモしたアクセスキーとシークレットアクセスキーの情報をそれぞれコピペする
escキー =>:wqで編集内容を保存してvimを閉じる環境変数でリージョンを設定する
東京リージョンを使用するよう設定します
export AWS_REGION=ap-northeast-13.コードを書いていく
今回のゴールはVPC、サブネット、インターネットゲートウェイ、ルートテーブルを作るところまでです。出来上がったrbファイルを実行するだけでAWSリソースが立ち上がる!というハンディさを実感してもらうのが目的なのでひとまずここまでで。
# sdkをrubyファイルに読み込み require 'aws-sdk' # VPCなどはEC2のカテゴリなのでAws::EC2::Clientクラスからインスタンスを作成 client = Aws::EC2::Client.new(region: "ap-northeast-1") # VPC ---------------------------------------------------------------- # VPCを作成 上で作成したclientインスタンスに対してcreate_vpc()メソッドを適用する resp_vpc = client.create_vpc({ cidr_block: "10.0.0.0/16", # 必須項目 IPアドレス範囲を指定する }) # 出来上がったVPCのIDを取得(他のリソース作成時やアタッチする時に使用する) VPC_ID = resp_vpc.vpc.vpc_id puts VPC_ID # IGW ---------------------------------------------------------------- # インターネットゲートウェイ(IGW)を作成 resp_igw = client.create_internet_gateway({ }) # IGWのID IGW_ID = resp_igw.internet_gateway.internet_gateway_id # IGWをVPCにアタッチ client.attach_internet_gateway({ internet_gateway_id: IGW_ID, # 上で作成したIGWのID vpc_id: VPC_ID, # 上で作成したVPCのID }) puts IGW_ID # Subnet ---------------------------------------------------------------- # サブネットを作成(インターネット向けパブリックサブネット) resp_pubsub1 = client.create_subnet({ availability_zone: "ap-northeast-1a", cidr_block: "10.0.0.0/24", # 必須項目 vpc_id: VPC_ID, # 必須項目 }) # サブネットのID SUB_ID1 = resp_pubsub1.subnet.subnet_id puts SUB_ID1 # RouteTable ---------------------------------------------------------------- # ルートテーブルを作成 resp_rt = client.create_route_table({ vpc_id: VPC_ID, # 必須項目 }) # ルートテーブルのID RT_ID = resp_rt.route_table.route_table_id # ルートを作成(IGWに向けたルート) resp_route = client.create_route({ destination_cidr_block: "0.0.0.0/0", # インターネット向けルート gateway_id: IGW_ID, # IGWのID route_table_id: RT_ID, # 必須項目 ルートテーブルのID }) # ルートテーブルをサブネットに紐付け client.associate_route_table({ route_table_id: RT_ID, # 必須項目 ルートテーブルのID subnet_id: SUB_ID1, # 紐付けるサブネットのID }) puts RT_ID # まとめてリソースにタグ(名前)を追加 ---------------------------------------------------------------- client.create_tags({ resources: [VPC_ID, IGW_ID, SUB_ID1, RT_ID], # 必須項目 名前をつけるリソースのID tags: [ { key: 'Name', value: 'HogeTestVPC', # VPCの名前 }, { key: 'Name', value: 'HogeTestIGW', # IGWの名前 }, { key: 'Name', value: 'HogeTestPublicSubnet1a', # Subnetの名前 }, { key: 'Name', value: 'HogeTestPublicRT', # RTの名前 }, ], }) puts "Create environment successfully done!"適当なディレクトリに上記のコードを.rbファイルとして保存して、
cdコマンドで保存したディレクトリに移動。ruby 保存したファイル名.rbで実行するとリソースの作成がAWS上で始まります。4.どうやってコードを書いているのか?
ひたすら下記の公式ドキュメントから該当するコードを引っ張ってきて、必要な要素を記述するだけです。ここが一番のツボというか、どのリソースに対して何をしたいのか?というのを考えてドキュメントから探し出すことさえ出来れば(書き方の良し悪しは置いておいて)リソースを操作するためのコードが書けるようになるはずです。
5.今後
公式ドキュメントの読み方や、EC2やその他のリソースに関する記述方法なども記事にしていけたらと考えています。また、今回はリソースを作成するだけでしたが、SDKの本領はプログラマブルなところで、書き方次第でAWSリソースを思い通りに操作することもできるみたいなので、そのへんも研究して記事にできたらいいなぁ、と思っています。
6.まとめ
ボク自身、ぜんぜんRubyやAWSに関しては初心者をようやく脱したかな?というレベルで、業務でSDK for Rubyを使うことになりました。思いの外、日本語での記事が少なく、四苦八苦しながら英語ドキュメントと戦って書いたので、同じようにSDKを使い始めようかという方の一助になればと思い記事を書きました。
また、SDKが提供されている言語を学習している方であれば、Gitでバージョン管理しつつGitHubに上げてポートフォリオとしてもいいかもな〜とか思いました。(CFnでもTerraformでもなくなぜSDK?ってツッコミには答えられるようにしたほうがいいかもですが笑…個人的にはSDKの方が学習コスト低いし、柔軟なリソース操作ができる可能性を感じます。)最後に、掲載したコードはちゃんと走ることを確認していますが「書き方がなってない、もっとうまい書き方があるぞ」というコメントやご指摘などあれば、お手柔らかにお願いします(>人<;)
- 投稿日:2020-02-22T21:10:30+09:00
【AWS】エラー文make_bucket failed: s3://名前 ~ (BucketAlreadyExists) The requested bucket name is not available. The bucket namespace is shared by all users of the system. Please select a different name and try again.
結論:他ユーザーとかぶらない様なバケット名をつける。
バケットを作るためにaws s3 mb s3:(名前) と入力したところターミナルに次のエラー文が表示されました。
make_bucket failed: s3://potepanec An error occurred (BucketAlreadyExists) when calling the CreateBucket operation: The requested bucket name is not available. The bucket namespace is shared by all users of the system. Please select a different name and try again.原因
重複するバケット名をつけることはできないらしい。
自分のアカウントのみで重複する名前を付けていなくても、別のAWSアカウント(つまり他人)が同じ名前のバケットを所有していればバケット名が重複することになるります。
(出典:AWS公式サイト)解決策
誰も思いつかない様なバケット名をつける。
- 投稿日:2020-02-22T20:51:44+09:00
goofysの設定手順
目的
EC2インスタンスをS3にマウントするソフトウェアであるGoofyの設定手順について解説します。
前提
この手順を実施する前に以下条件が整っていることを確認します。
- EC2: Amazon Linux 2をAMIとしたEC2インスタンスが起動していること。
- S3: EC2にアクセスができるバケットを作成し、権限が設定してあること。
- IAM: アクセスキー&シークレットキーなどの接続情報が払い出されていること。
設定手順(一時利用)
1. 前提ソフトウェアのインストール
前提ソフトウェアである以下パッケージ一覧についてインストールします。
- golang
- goofyがGO実行環境で動作するため
- Filesystem in Userspace (FUSE) :
- Unix系コンピュータオペレーティングシステム用のソフトウェアインタフェース。goofyはこの仕組みを利用している。
- git
- GitHub上のgoofyをインストールする時に必要。
sudo yum install golang fuse git -y各前提ソフトウェアのバージョンは以下の通り。
go version go version go1.13.4 linux/amd64 git --version git version 2.14.5 fusermount -V fusermount version: 2.9.42. GOPATHを設定する
GOPATHを設定します。GOPATHとは Go言語では、環境変数GOPATHに保存されたパス(以降、単にGOPATHと呼びます)を開発時の作業ディレクトリとして扱います
export GOPATH=${HOME}/go3. goofysをGitHubからインストール
Github上からgoofysをインストールします。
go get github.com/kahing/goofys go install github.com/kahing/goofys4. goofysにマウントするディレクトリを作成
goofysにマウントするディレクトリを作成します。他ユーザーからアクセスすることを想定して、root権限でしかアクセスできない階層にはマウントすディレクトリを作成しないように注意してください。 作者の設定手順のページには記載がありませんでしたが、読み書きの権限で怒られることもあるので、chmodで適切に権限を付与します(ここはオプションなので、場合に応じて設定してください)。
mkdir /home/ec2-user/mount-goofyschmod 777 /home/ec2-user/mount-goofys5. awsの認証情報(aws credentials)を設定
aws credentialsを直接編集しても良いですが、aws configureコマンドを使用すれば、簡単に編集できるので、今回はこちらを利用します。AMIによっては、aws cliが入っていない場合もあるので、その場合はaws cliをインストールする必要があります。aws credentialsの詳細な設定手順は、こちらをご参照願います。
なぜ、sudo aws configureも実行する必要があるかと言うと、自動マウントの設定(fstab)を利用する際に利用するためです(fstabはroot権限でしか利用できない)。作者のページにも、To mount an S3 bucket on startup, make sure the credential is configured for rootとの記述があります。sudo aws configureを実行することで、rootユーザーのaws credentialsも設定することが可能です。aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXX Default region name [None]: XXXXXXXXXXXXXXXXX Default output format [None]: XXXXXXXXXXXXXXXXX sudo aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXX Default region name [None]: XXXXXXXXXXXXXXXXX Default output format [None]: XXXXXXXXXXXXXXXXX6. マウントコマンドの実行
以下コマンドを実行して、既に作成済みのbucket(bucket-XXX )に対して、ディレクトリ(/home/ec2-user/mount-goofys)をマウントします。
$GOPATH/bin/goofys bucket-XXX /home/ec2-user/mount-goofys```bash df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 16451592 0 16451592 0% /dev tmpfs 16469640 0 16469640 0% /dev/shm tmpfs 16469640 492 16469148 1% /run tmpfs 16469640 0 16469640 0% /sys/fs/cgroup /dev/xvda1 8376300 3089196 5287104 37% / tmpfs 3293932 0 3293932 0% /run/user/1000 tmpfs 3293932 0 3293932 0% /run/user/0 bucket-XXX 1099511627776 0 1099511627776 0% /home/ec2-user/mount-goofys ←ここです。設定手順(恒久利用)
7. fstabを編集して、再起動後もマウントされるように設定
fstabを編集することで、EC2が再起動した後も、S3にマウントするように設定します。
その前に手順6で設定したマウントをumountコマンドで解除します。sudo umount /home/ec2-user/mount-goofys/ここは一般的なfstabの設定と基本的には同様です。uidとgidを設定する場合は、idコマンドを利用して、それらを確認する必要があります。私の場合、該当ユーザーのuidとgidが共に1000であったため、これらの情報をfstabに設定します。
id uid=1000(ec2-user) gid=1000(ec2-user) groups=1000(ec2-user),4(adm),10(wheel),190(systemd-journal)次に、
/etc/fstabを編集します。Githubのページと上記で確認したコマンドを参考に、設定する必要があります。sudo vim /etc/fstab /home/ec2-user/go/bin/goofys#bucket-XXX /home/ec2-user/mount-goofys fuse _netdev,allow_other,--dir-mode=0777,--file-mode=0777,--uid=1000,--gid=1000 0 0
mount -aすることで設定は完了です。sudo mount -aここで、golangの環境変数も永続化しておきます。Githubには記載がありませんでしたけど、念のためです。
vim /home/ec2-user/.bash_profile export GOPATH=${HOME}/go再起動します。
sudo rebootここで問題が発生します。
dfコマンドでマウントしていることは確認ができたのですが、なぜか書き込みを行うことができません。。Github issueを確認すると、ftabを利用した方法だとRead-onlyとなってしまう事象が発生していることが記載してあります。どうやらレグレッションっぽいですね。8. bash_profileで自動起動を設定
仕方なしにbash_profileに直接書き込むことで、自動起動を設定することに。これで設定完了。
vim /home/ec2-user/.bash_profile $GOPATH/bin/goofys bucket-XXX /home/ec2-user/mount-goofys以上です。
- 投稿日:2020-02-22T20:14:49+09:00
awsのインフラコストを削減する方法をまとめてみた。
コストを削減する時にどのような手段があるのか?ということをまとめました。
※webサービスの種類により色々コスト削減の方法も変わってくると思います。
ここでは一般的なwebサービスを想定してコスト削減方法を書いています。RI(リザーブド・インスタンス)の使用
RIは1年か3年間分のインスタンス使用量を予約して、その分割引料金を受けられるサービスです。
ec2, rds, elsasticacheなど色々なサービスで使えます。例えば、月に100$かかるインスタンスがあるとして、3年間分のRI(60%割引)を購入すると、このインスタンスを月40$で利用できるという感じです。
https://aws.amazon.com/jp/ec2/pricing/reserved-instances/使うタイミングとしては、リソースを最適化(Ec2のインスタンスタイプを適切なものにするとか)した後がいいと思います。
Savings Plans
RIの代わりにSavings Planというのもあります。
こちらはRIと違ってFargateにも適用できるのが重要なポイントだと思います。RIと同じく1年間か3年間でリソースの使用料を予約することにより、予約分のリソースについて割引を受けられるサービスです。
予約分のリソースを超える分の料金は割引ではなく、オンデマンド料金になります。
https://aws.amazon.com/jp/savingsplans/pricing/スポットインスタンス
awsクラウド内の使用されていないEc2インスタンスを使えるサービスです。
使われていないインスタンスはオークション形式で価格を設定することができ、変動する価格より入札した価格が高い場合にインスタンスを使うことができます。逆に入札した価格が低い場合にはインスタンスが終了、停止、休止状態になってしまいます。
こちらは途中で停止してしまう可能性があるため扱いが難しいですが、割引率がRIやSavings Plansより大きく最大90%の割引になります。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/using-spot-instances.html途中でインスタンスが止まってしまう可能性があるので、オートスケール、バッチ処理あたりに使ってやるといいです。
オートスケール
BtoB向けのwebサービスなら土日に負荷が下がることもあるかと思います。
そのような時はec2、ecs、fargateでオートスケールをすることでコストの削減ができる場合があります。Data Transfer
意外と見落としがち。気づくとここら辺の請求が増えてることがあります。
Data Transfer(データ転送)についてはここの記事が詳しいです。
要はインスタンスがインターネットや他のインスタンスにデータを送る際にかかる料金のことですね。
https://www.scutum.jp/information/waf_tech_blog/2011/08/waf-blog-004.htmlコストの削減ですが、インスタンス同士でデータの通信が走る場合はできるだけ近いリージョン、AZにインスタンスを配置しましょう。
また、CloudFrontを使用して、Internet Data Transferを減らしていくのがいいのでしょう。気付きにくいですが、下記の記事の一番下の方にCloudFrontも10TB以上はRIのように使用容量を予約することがで割引を受けられると書いてあります。
CloudFrontが10TB超えてる場合はこちらも検討した方がいいです。
https://aws.amazon.com/jp/blogs/news/aws-data-transfer-price-reductions-up-to-34-japan-and-28-australia/その他
直接コストを削減できるわけではないですが、役に立つツールを挙げていきます。
TrustedAdvisor、Cost Explorerの活用
TrustedAdvisor、Cost Explorerではコストを削減できそうなリソースを教えてくれます。
TrustedAdvisorのコスト最適化はビジネスプラン(100$)にしないと使えないですが、コスト削減をしたいなら有効にした方がいいでしょう。
https://aws.amazon.com/jp/about-aws/whats-new/2019/07/introducing-amazon-ec2-resource-optimization-recommendations/
https://dev.classmethod.jp/cloud/aws/cm-advent-calendar-2015-getting-started-again-aws-td/#service-detail1AWS Cost Explorer API
APIを使うことで、slackにbotとして日々の請求を投稿できます。
急に請求が高くなったりとか、ユーザーが少ない日のインフラコスト確認にも使えるので、是非入れてみてはどうでしょうか。
https://dev.classmethod.jp/cloud/aws/notify-slack-aws-billing/Billing アラート
請求アラートを作成することで、請求が予算を超えた場合にアラートを鳴らすことができます。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/monitor_estimated_charges_with_cloudwatch.html最後に
思いつくままに、コスト削減方法を書いてみましたが、他にもこんなの知っているという方がいたら是非教えていただきたいです。
- 投稿日:2020-02-22T20:07:05+09:00
S3で静的コンテンツを公開する
概要
AWSを利用していて、ウェブサイトを公開する簡単な方法は、S3を使うことです。
方法はあちこちにあると思いますが、人に説明するときの資料として作成します。やり方
S3バケットを作る
(1) マネジメントコンソールからS3のメニューへ移行します。
(2) 「バケットを作成する」をクリックします。
(3) バケット名には公開したいドメイン名を入力して、「次へ」をクリックします。
リージョンは、基本はどこでも構いませんが、私は国内向けサイトとして考えているので、「アジアパシフィック(東京)」を選択しました。
尚、ここで入力した名前をDNSに登録する必要があります。
(4) タグなどを必要に応じて設定し、「次へ」をクリックします。
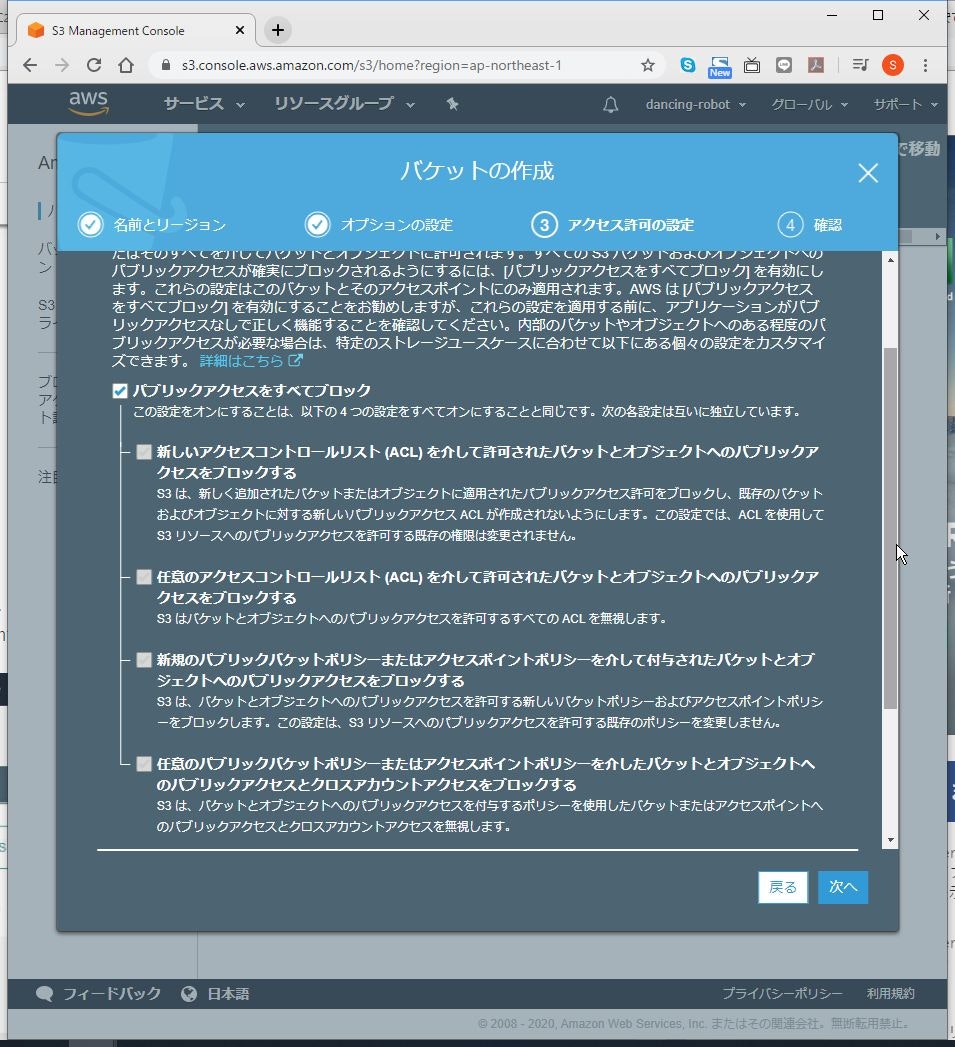
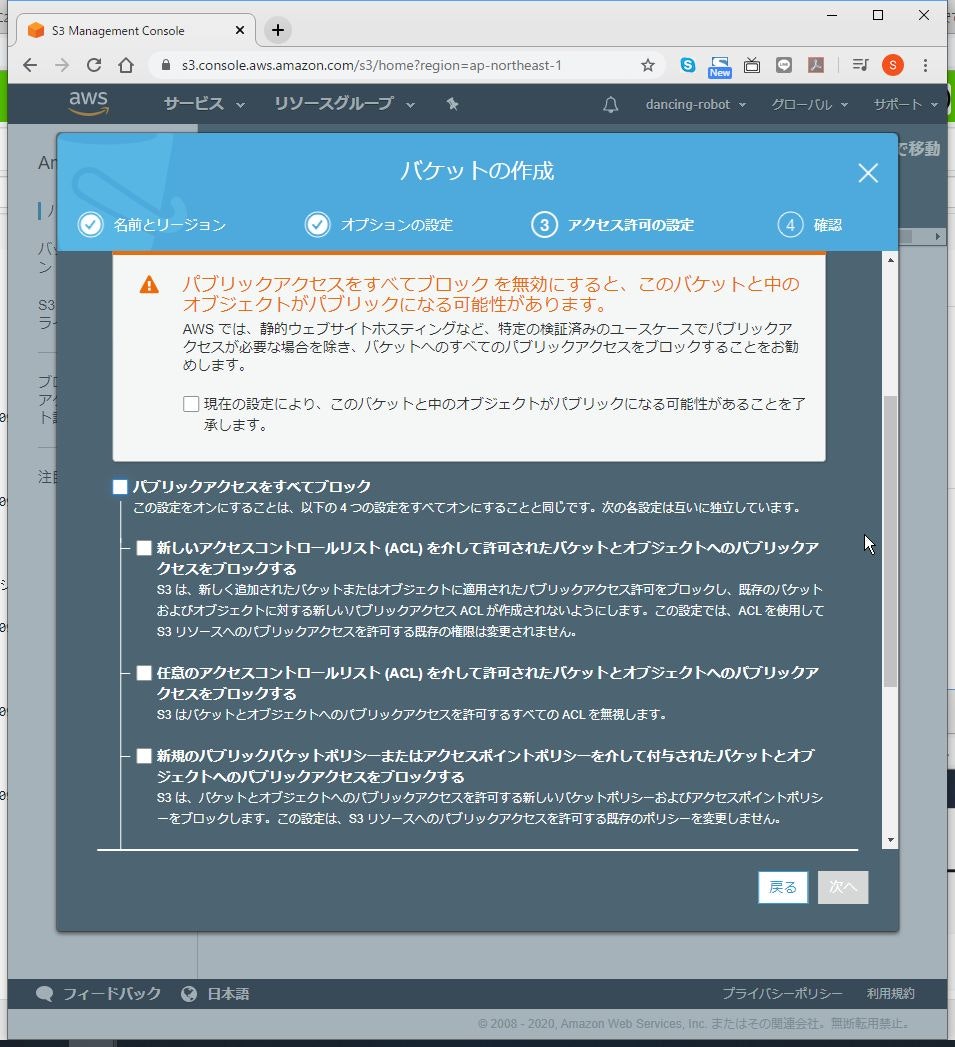
(5) 「パブリックアクセスをすべてブロック」のチェックを外します。
(6) 警告が出ますが、「現在の設定により、このバケットと中のオブジェクトがパブリックになる可能性があることを了承します。」にチェックを入れ、「次へ」をクリックします。
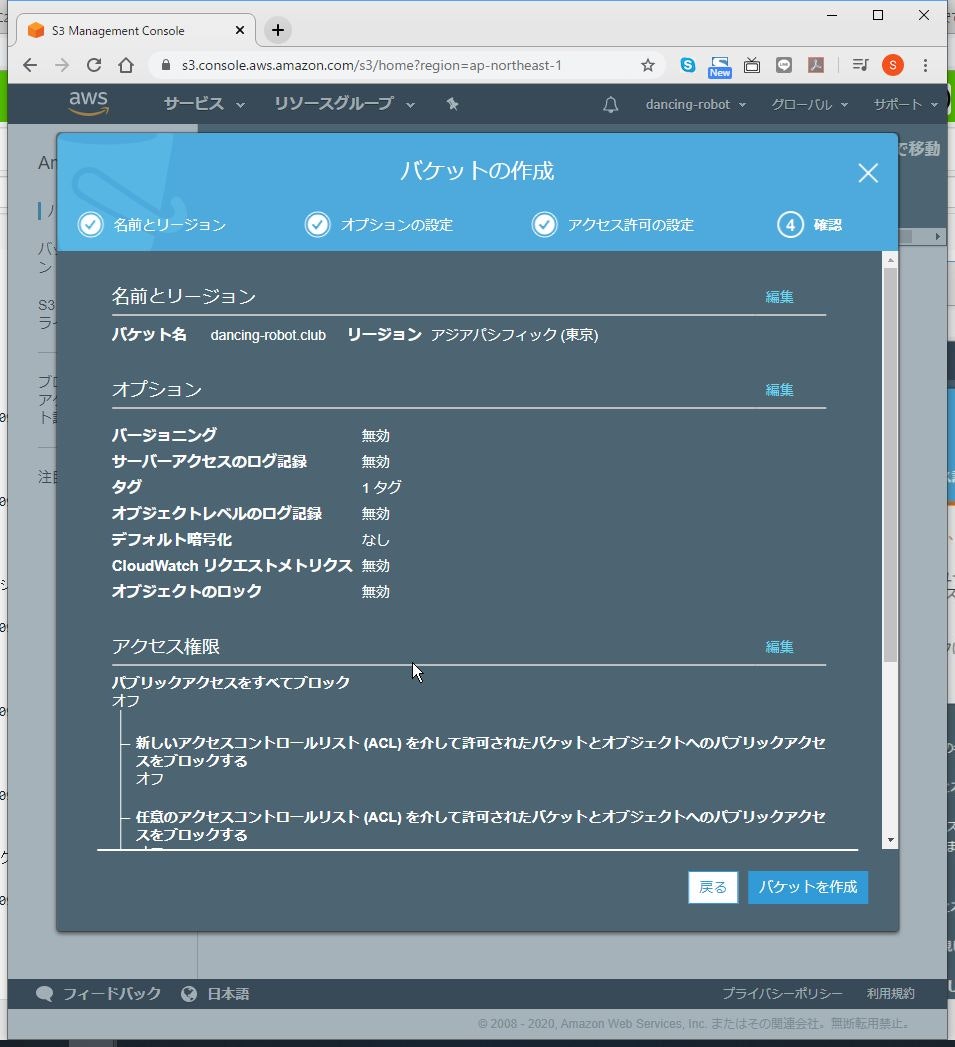
(7) バケット名、リージョンに間違いがないことを確認して、「バケットを作成」をクリックします。
(8) 作成したS3バケットをクリックします。
ウェブサイト公開の設定
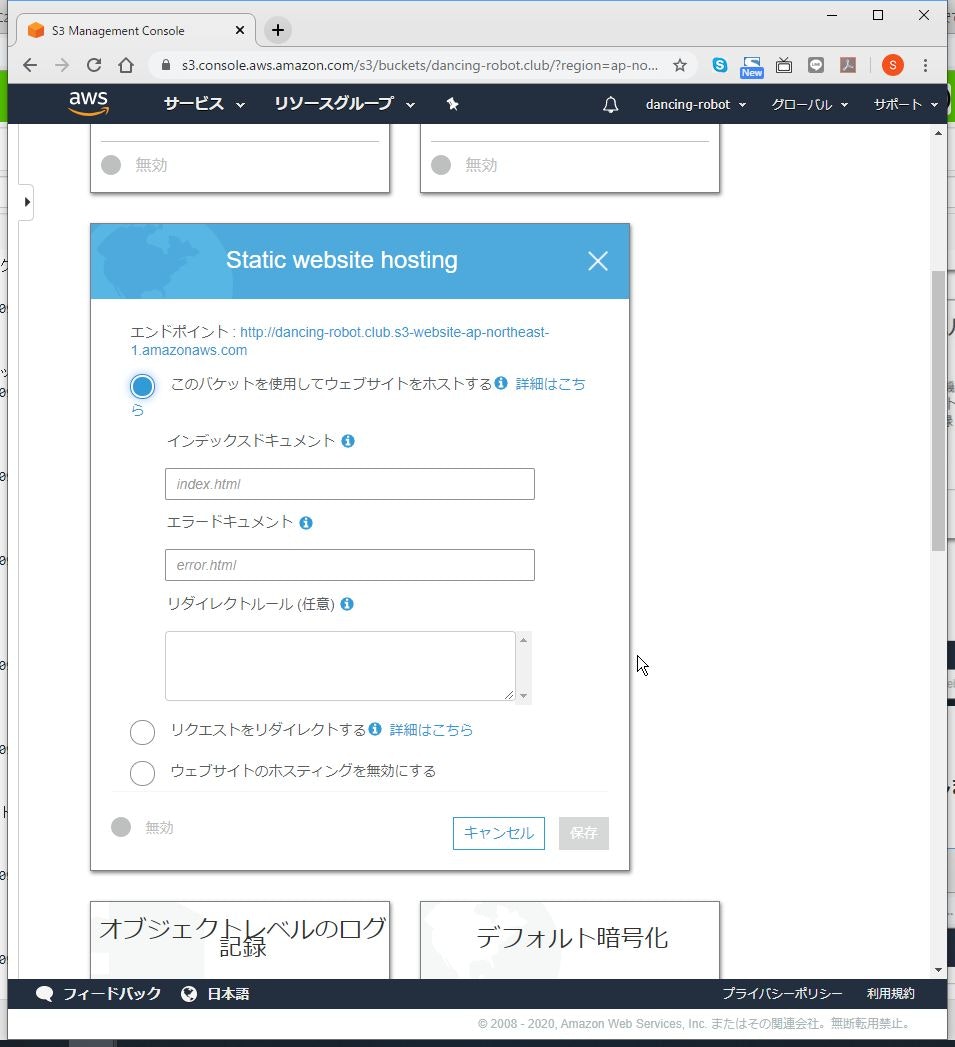
(1) 「プロパティ」をクリックします。
(2) 「Static website hosting」の〇をクリックします。
グレーアウトされていますが、クリックするとメニューが表示されます。
(3) 「このバケットを使用してウェブサイトをホストする」を選択します。
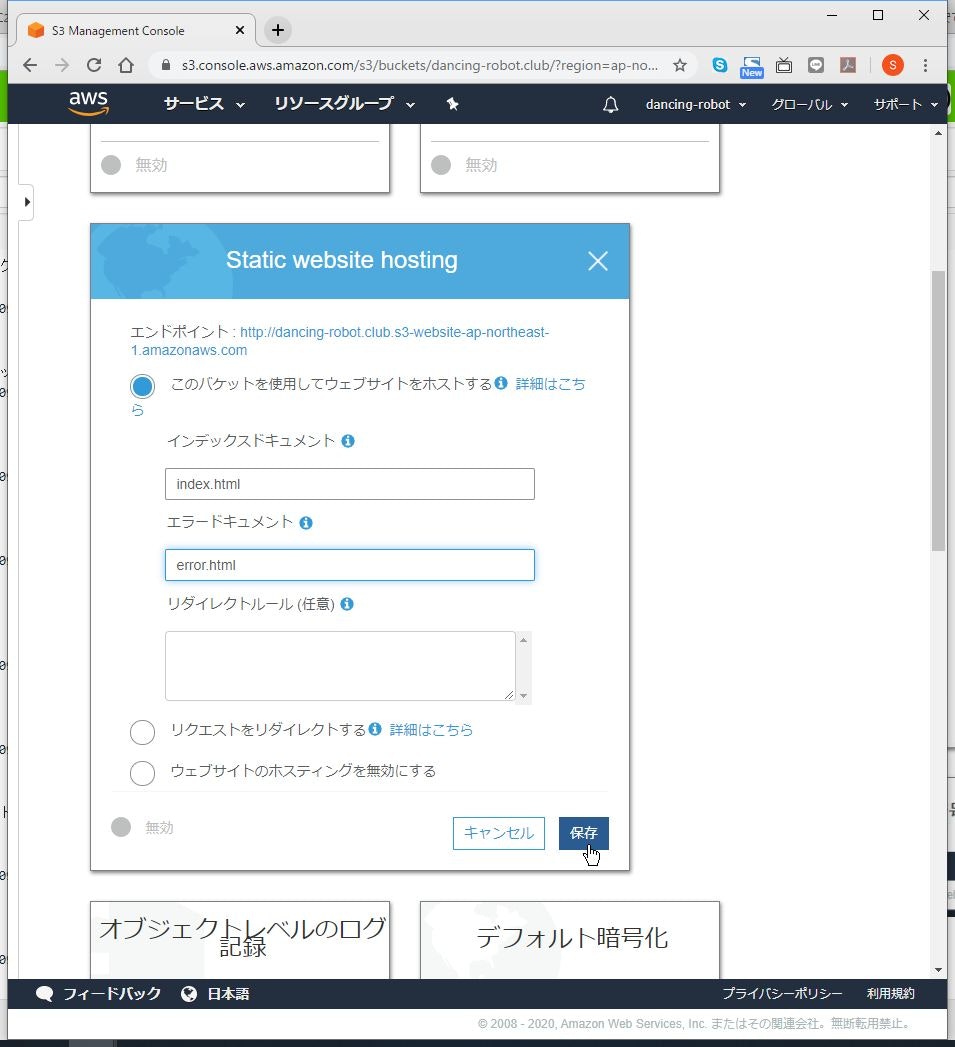
(4) 「インデックスドキュメント」に公開するファイル名を入力し、「エラードキュメント」に存在しないページにアクセスするなどエラー時に表示するファイル名を入力し、「保存」をクリックします。
ここでは、デフォルトの「index.html」、「error.html」を入力しました。
(5) 以下のような表示になればOKです。
インターネットからのアクセス設定
(1) 「アクセス権限」をクリックします。
(2) 「バケットポリシー」をクリックします。
(3) 「ARN:: am::aws:s3:::バケット名」の部分を確認しておきます。
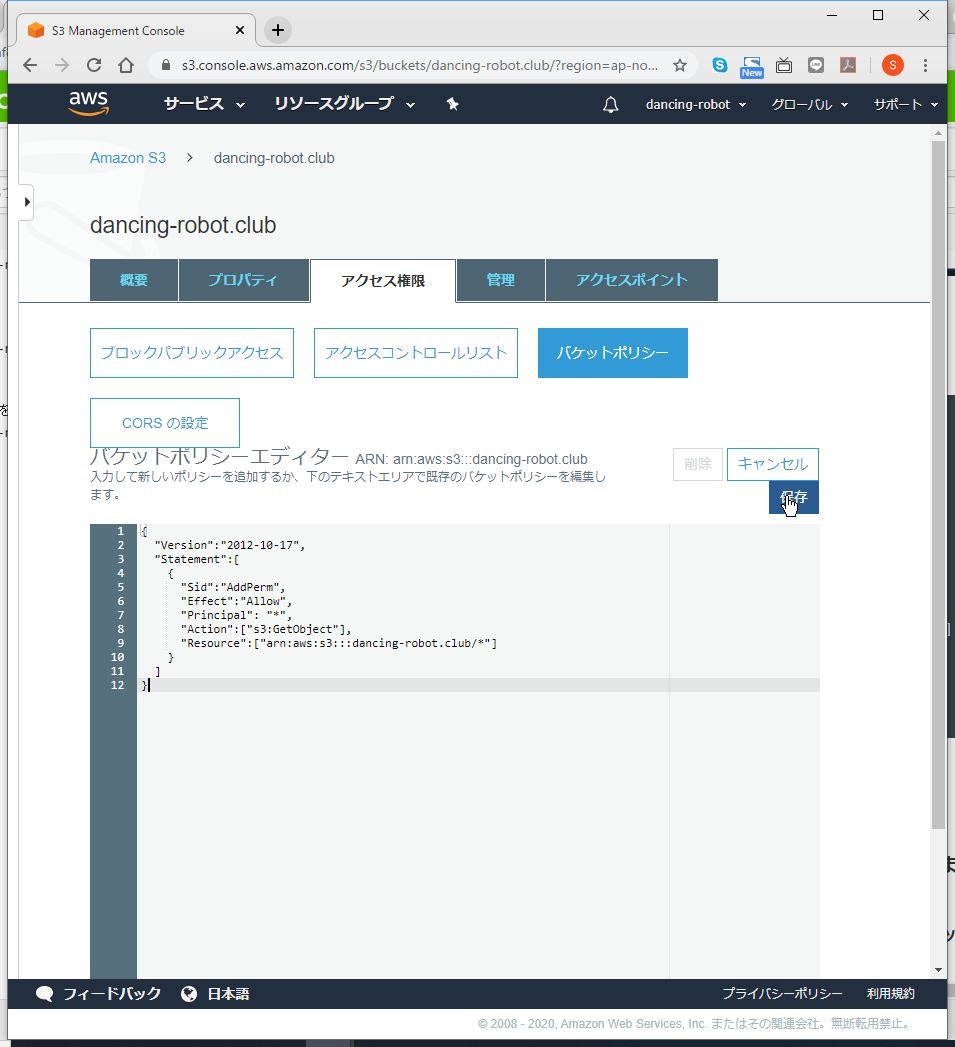
(4) 入力欄に以下のように入力します。
「バケット名」の部分は読み替えて入力してください。{ "Version":"2012-10-17", "Statement":[ { "Sid":"AddPerm", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::バケット名/*"] } ] }(5) 「保存」をクリックします。
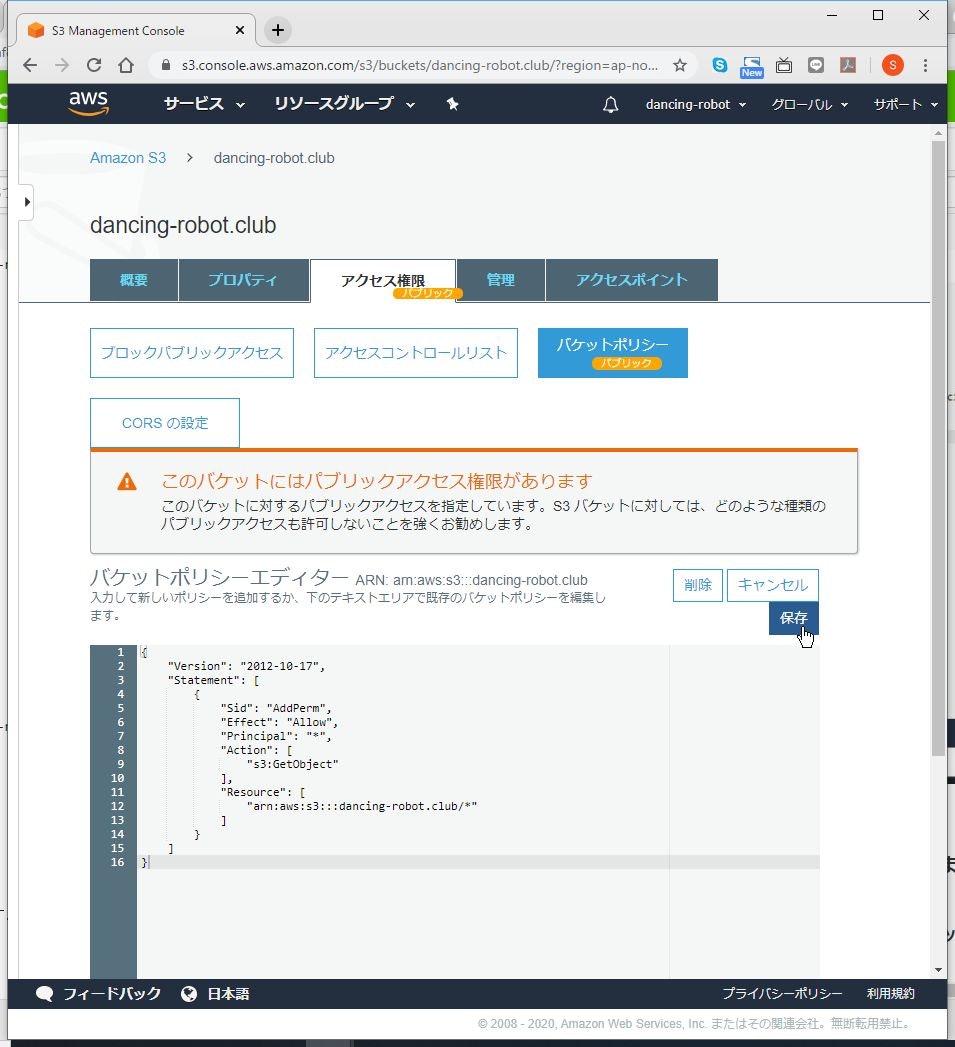
(6) 警告が出ますが、もともとインターネット公開が目的なので、気にしなくても大丈夫です。
コンテンツアップロード
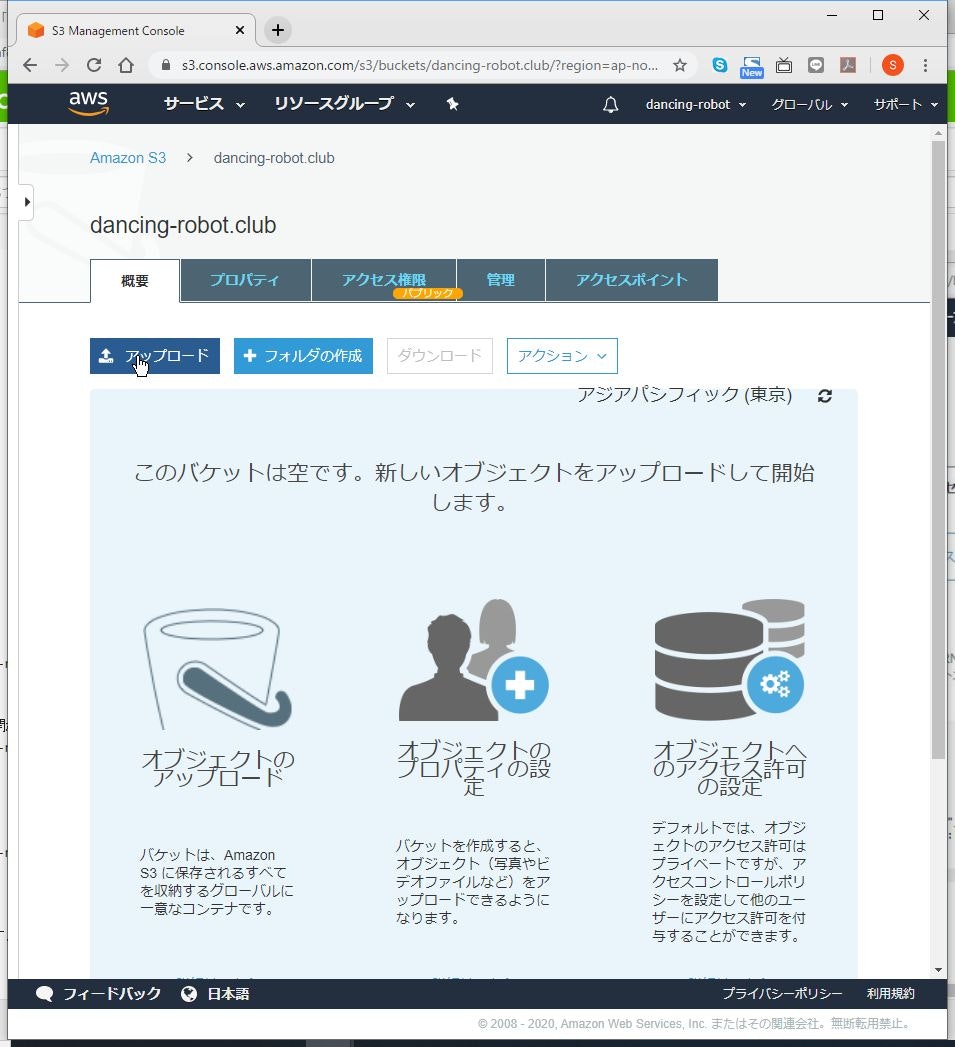
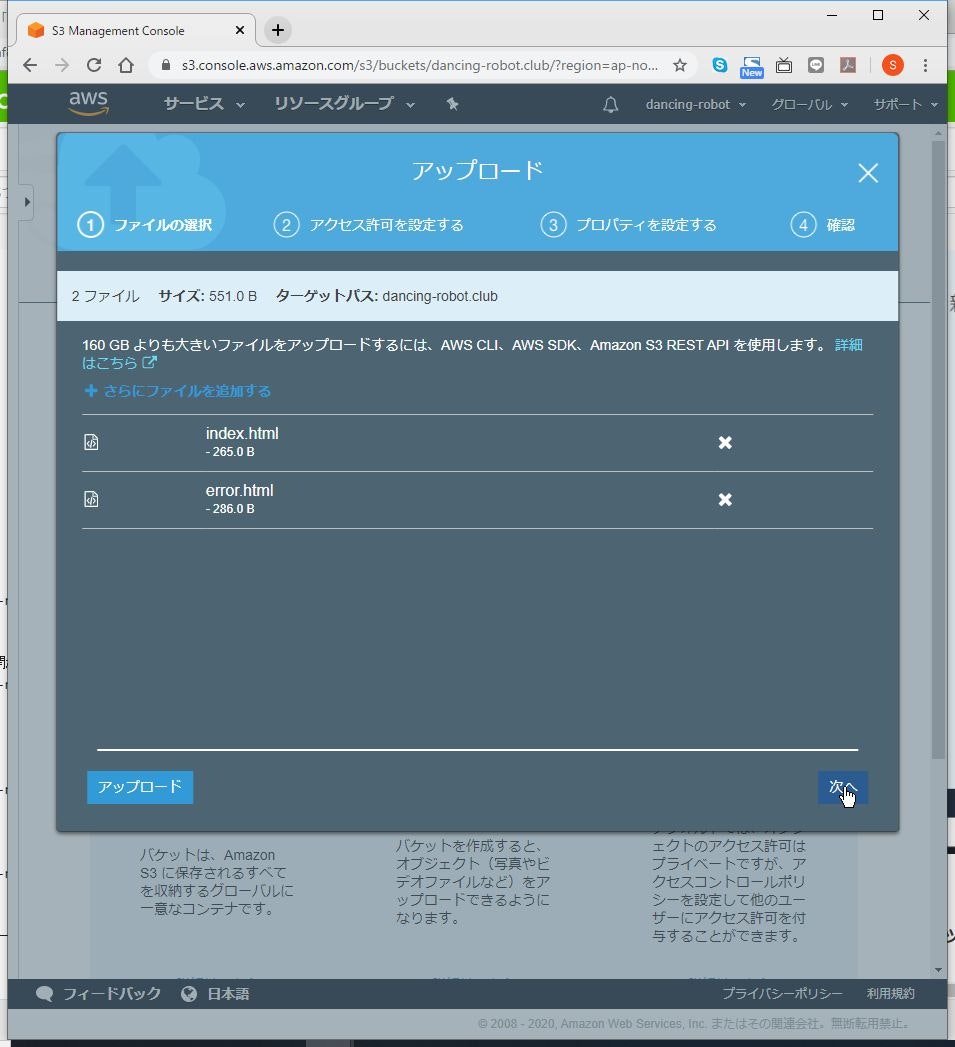
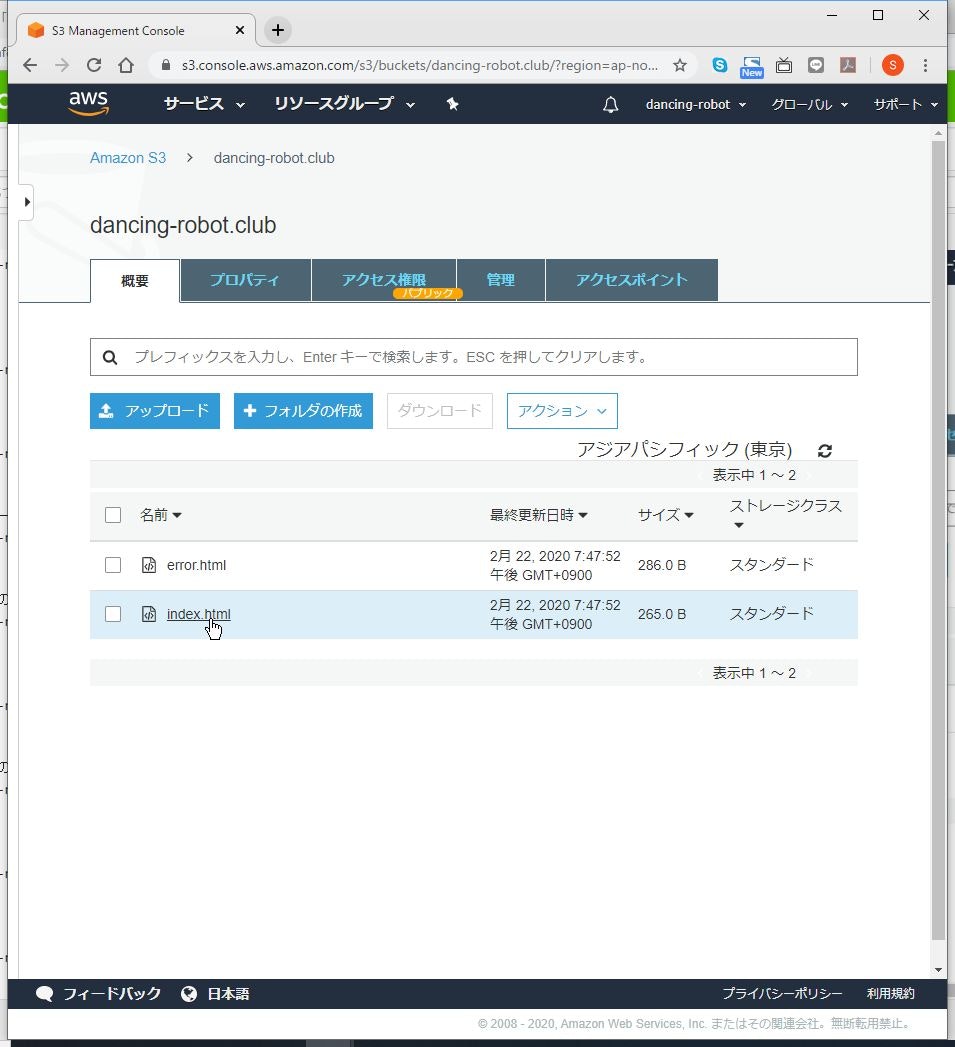
(1) 「概要」をクリックします。
(2) 「アップロード」をクリックします。
(3) 「index.html」と「error.html」をアップロードし、「次へ」をクリックします。
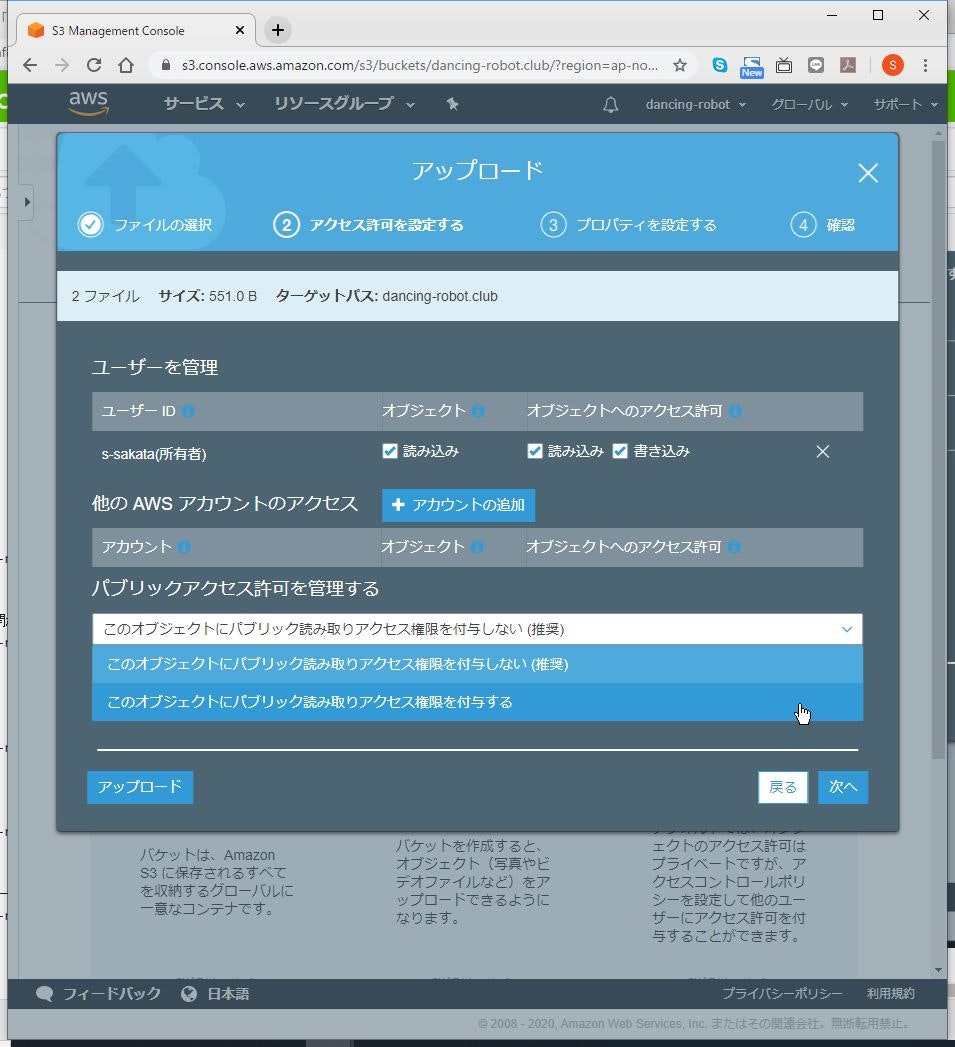
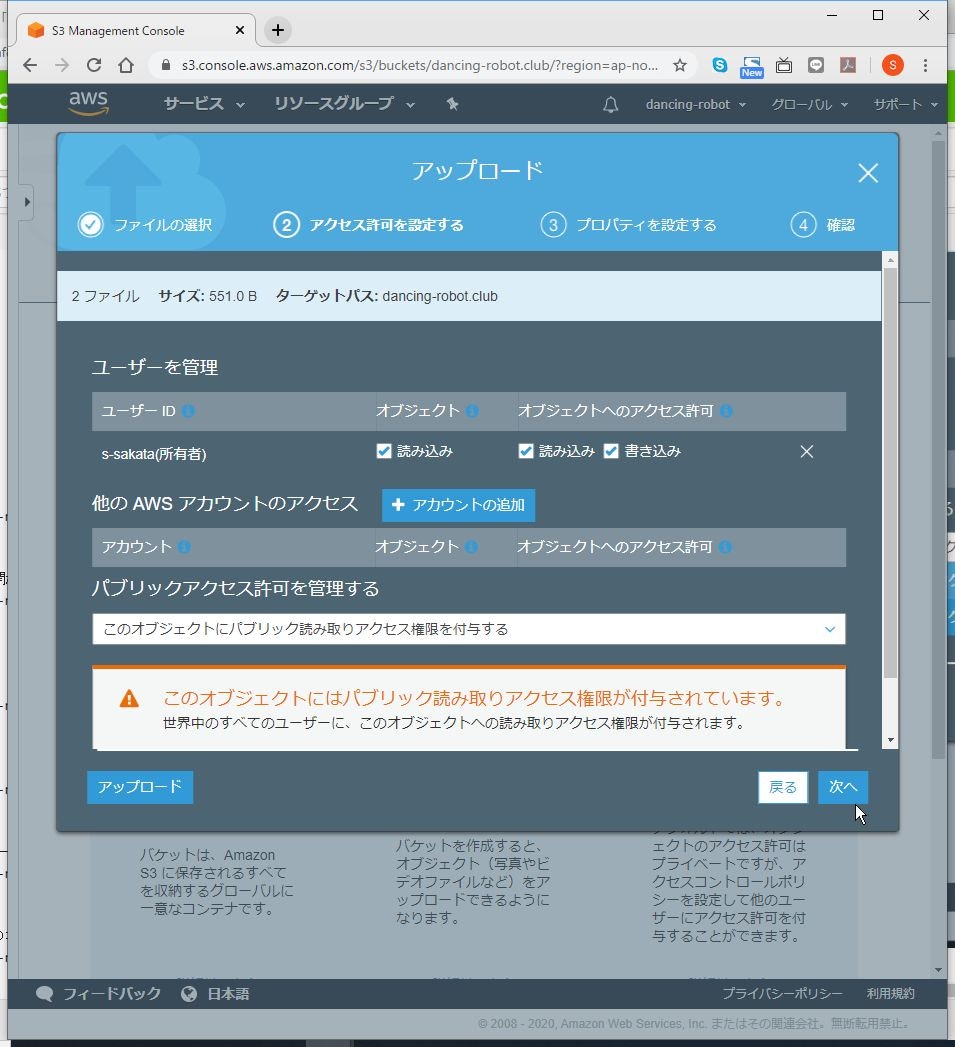
(4) 「パブリックアクセス許可を管理する」で「このオブジェクトにパブリック読み取りアクセス権限を付与する」を選択します。
(5) 「次へ」をクリックします。
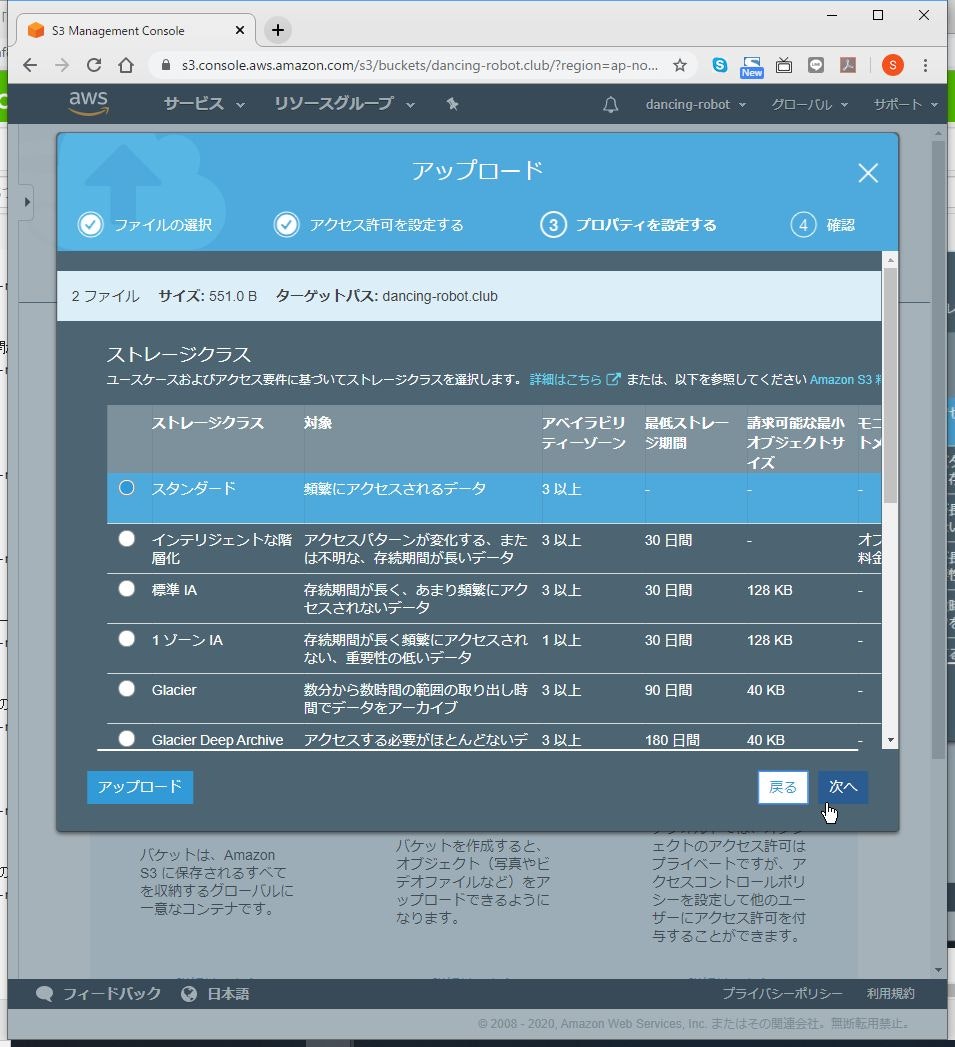
(6) ストレージクラスはデフォルトのまま、暗号化の設定は不要ですので、そのまま「次へ」をクリックします。
(7) 「アップロード」をクリックします。
(8) アップロードされたファイルをクリックします。
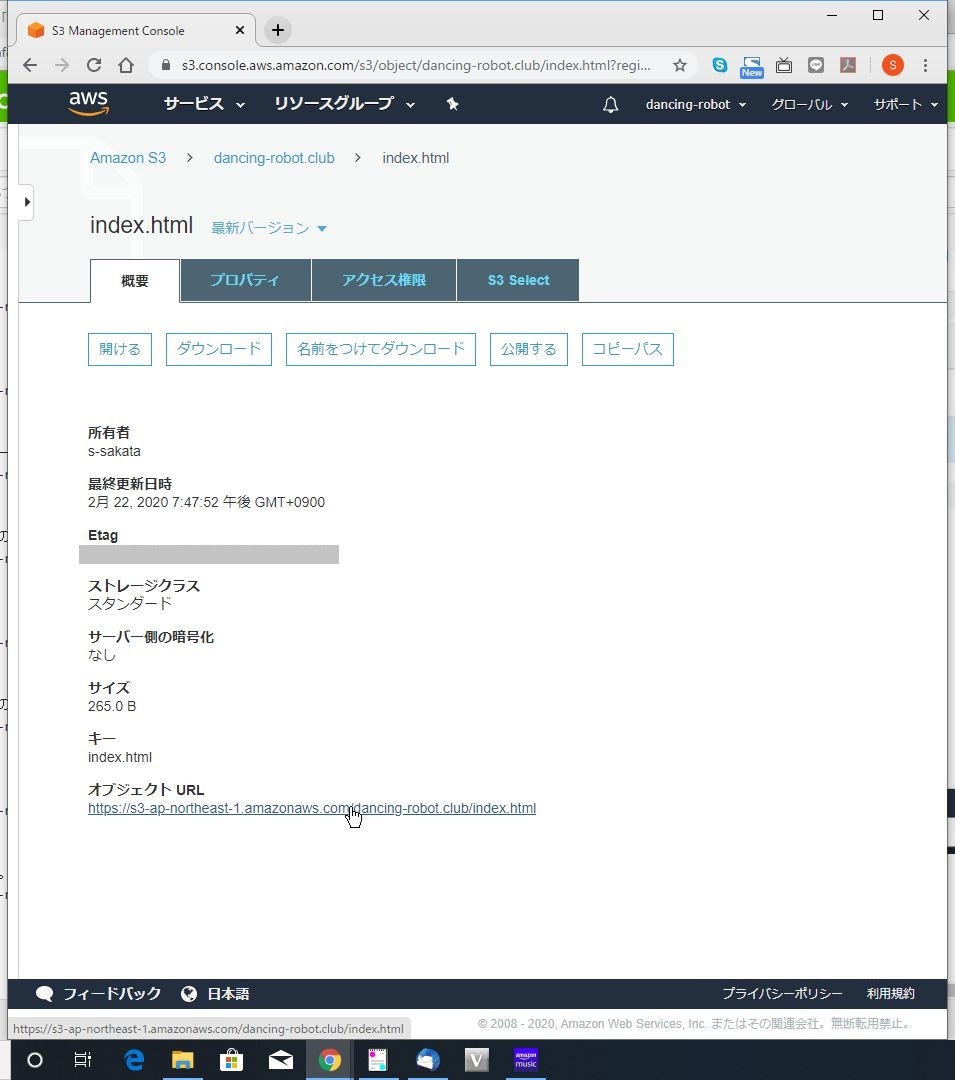
(9) 「オブジェクト URL」をクリックします。
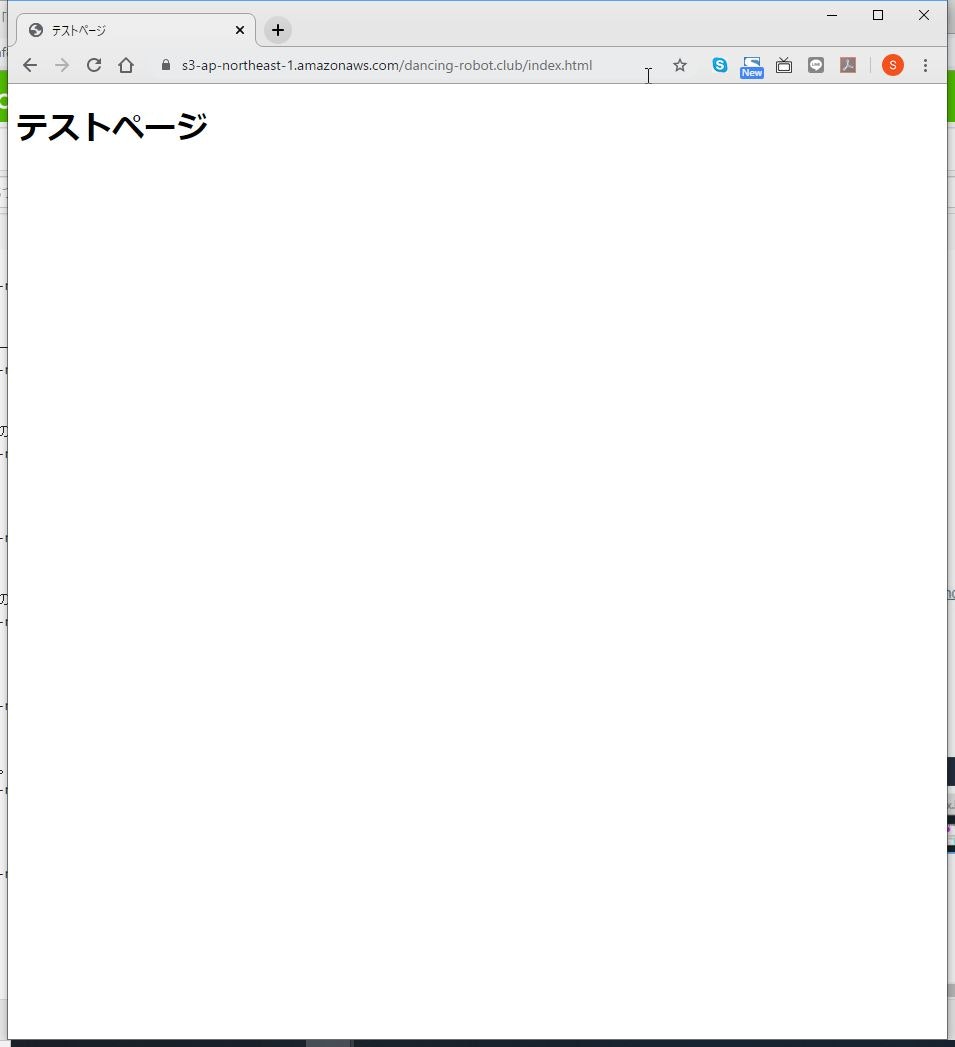
(10) アクセス出来たら成功です。
DNS登録
ここでは、Route53を使って登録します。
本手順を行う場合、前提として、ドメインを持っていて、Route53で管理していることが必要です。(1) DNS登録する「オブジェクト URL」をコピーしておきます。
(2) AWSコンソールのメニューに戻って、Route53メニューに移動します。
(3) ホストゾーンを選択します。
(4) 管理しているホストゾーンの設定画面へ移動します。
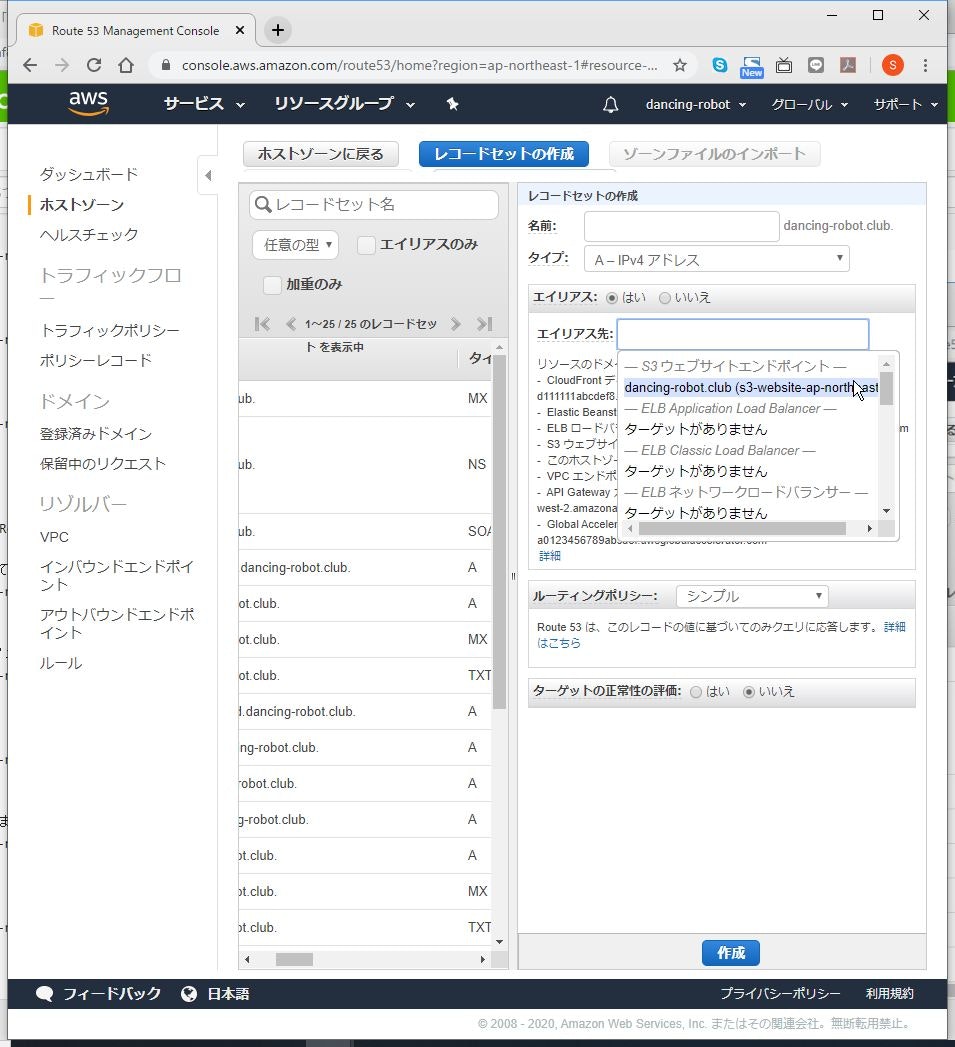
(5) 「レコードセットの作成」をクリックします。
(6) S3のホストをAレコードのエイリアスで登録します。
ここでは、エイリアスを使うのが重要です。
(7) 登録出来たら、実際にURLにアクセスして表示できるか確認します。
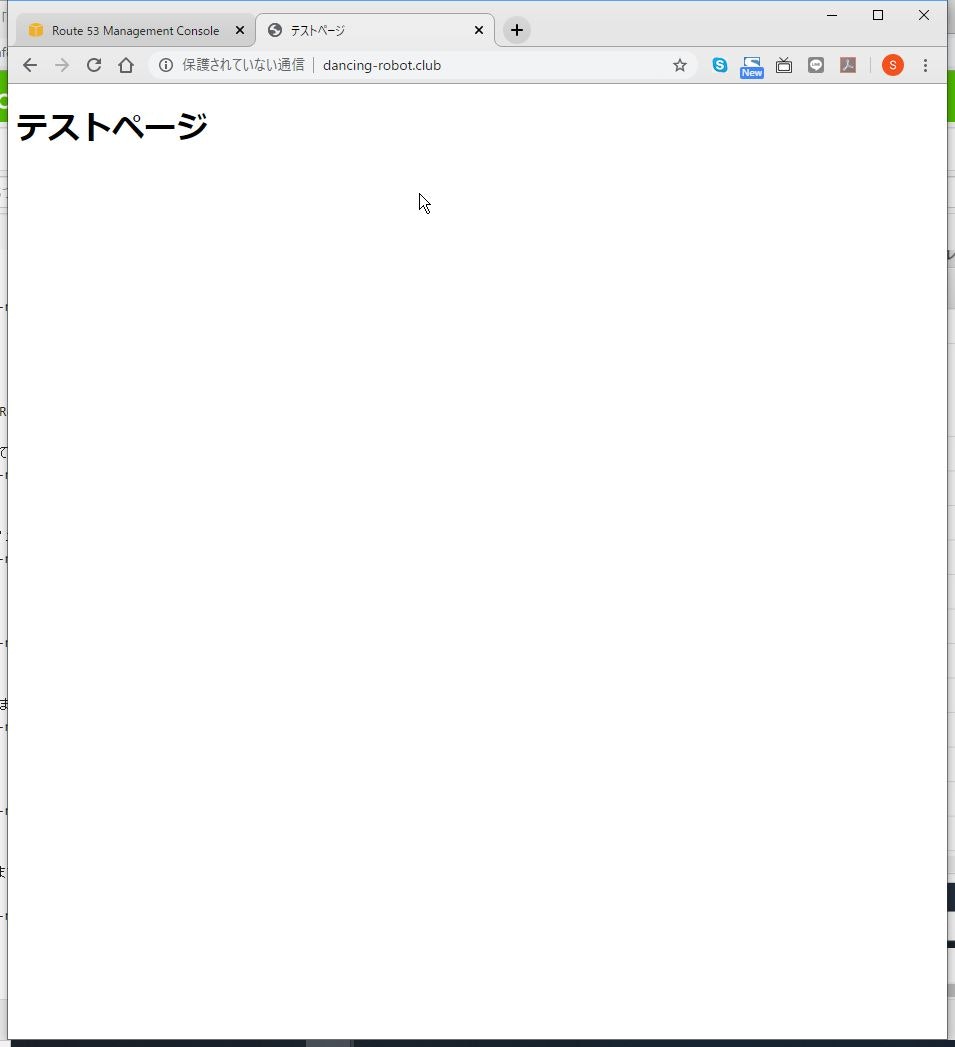
以上です。
備考
このままでは、httpアクセスしかできません。
どこかでhttpsアクセスできるよう、CloudFrontを使ったやり方を説明します。

- 投稿日:2020-02-22T20:07:05+09:00
S3でウェブサイトを公開する
概要
AWSを利用していて、ウェブサイトを公開する簡単な方法は、S3を使うことです。
方法はあちこちにあると思いますが、人に説明するときの資料として作成します。やり方
S3バケットを作る
(1) マネジメントコンソールからS3のメニューへ移行します。
(2) 「バケットを作成する」をクリックします。
(3) バケット名には公開したいドメイン名を入力して、「次へ」をクリックします。
リージョンは、基本はどこでも構いませんが、私は国内向けサイトとして考えているので、「アジアパシフィック(東京)」を選択しました。
尚、ここで入力した名前をDNSに登録する必要があります。
(4) タグなどを必要に応じて設定し、「次へ」をクリックします。
(5) 「パブリックアクセスをすべてブロック」のチェックを外します。
(6) 警告が出ますが、「現在の設定により、このバケットと中のオブジェクトがパブリックになる可能性があることを了承します。」にチェックを入れ、「次へ」をクリックします。
(7) バケット名、リージョンに間違いがないことを確認して、「バケットを作成」をクリックします。
(8) 作成したS3バケットをクリックします。
ウェブサイト公開の設定
(1) 「プロパティ」をクリックします。
(2) 「Static website hosting」の〇をクリックします。
グレーアウトされていますが、クリックするとメニューが表示されます。
(3) 「このバケットを使用してウェブサイトをホストする」を選択します。
(4) 「インデックスドキュメント」に公開するファイル名を入力し、「エラードキュメント」に存在しないページにアクセスするなどエラー時に表示するファイル名を入力し、「保存」をクリックします。
ここでは、デフォルトの「index.html」、「error.html」を入力しました。
(5) 以下のような表示になればOKです。
インターネットからのアクセス設定
(1) 「アクセス権限」をクリックします。
(2) 「バケットポリシー」をクリックします。
(3) 「ARN:: am::aws:s3:::バケット名」の部分を確認しておきます。
(4) 入力欄に以下のように入力します。
「バケット名」の部分は読み替えて入力してください。{ "Version":"2012-10-17", "Statement":[ { "Sid":"AddPerm", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::バケット名/*"] } ] }(5) 「保存」をクリックします。
(6) 警告が出ますが、もともとインターネット公開が目的なので、気にしなくても大丈夫です。
コンテンツアップロード
(1) 「概要」をクリックします。
(2) 「アップロード」をクリックします。
(3) 「index.html」と「error.html」をアップロードし、「次へ」をクリックします。
(4) 「パブリックアクセス許可を管理する」で「このオブジェクトにパブリック読み取りアクセス権限を付与する」を選択します。
(5) 「次へ」をクリックします。
(6) ストレージクラスはデフォルトのまま、暗号化の設定は不要ですので、そのまま「次へ」をクリックします。
(7) 「アップロード」をクリックします。
(8) アップロードされたファイルをクリックします。
(9) 「オブジェクト URL」をクリックします。
(10) アクセス出来たら成功です。
DNS登録
ここでは、Route53を使って登録します。
本手順を行う場合、前提として、ドメインを持っていて、Route53で管理していることが必要です。(1) DNS登録する「オブジェクト URL」をコピーしておきます。
(2) AWSコンソールのメニューに戻って、Route53メニューに移動します。
(3) ホストゾーンを選択します。
(4) 管理しているホストゾーンの設定画面へ移動します。
(5) 「レコードセットの作成」をクリックします。
(6) S3のホストをAレコードのエイリアスで登録します。
ここでは、エイリアスを使うのが重要です。
(7) 登録出来たら、実際にURLにアクセスして表示できるか確認します。
以上です。
備考
このままでは、httpアクセスしかできません。
どこかでhttpsアクセスできるよう、CloudFrontを使ったやり方を説明します。
- 投稿日:2020-02-22T19:37:34+09:00
EC2上にLaravel6の環境を作ってみる
目的
Laravelのデプロイ
EC2とRDSを利用する
RDSはEC2からの通信のみ許可
WEBサーバ nginx
アプリケーションサーバ php-fpm
特に冗長化構成とかにはしないVPCの作成
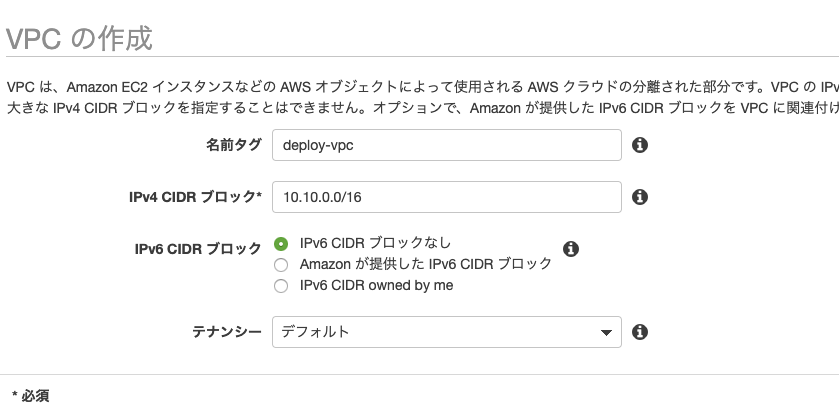
名前を「deploy-vpc」
IPv4 CIDR ブロック*を「10.10.0.0/16」に設定publicサブネットの作成
WEBサービスを公開するためのサブネットを作成したいので、サブネットをpublicで作成します。
こちらのサブネットにWEBサーバ用のEC2を紐付けて外部からアクセスできる状態を作ります。
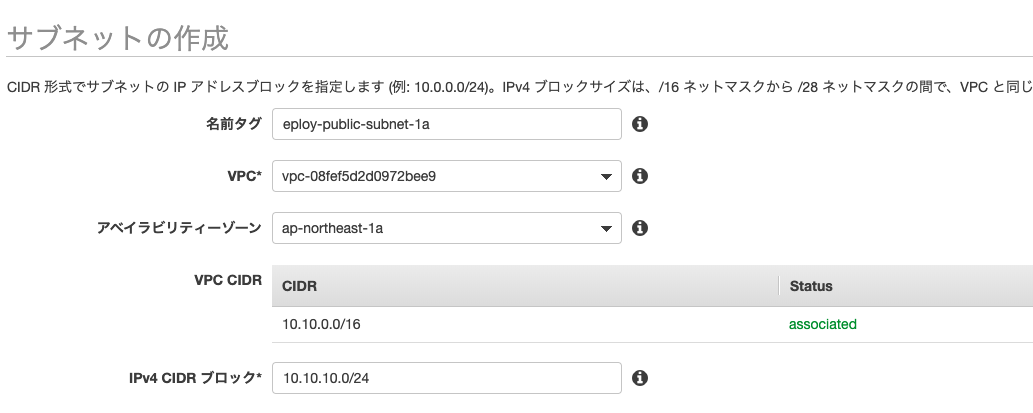
名前を「deploy-public-subnet-1a」
VPCに先ほど作成作成した「deploy-vpc」を選択
アベイラビリティーゾーンを「ap-northeast-1a」
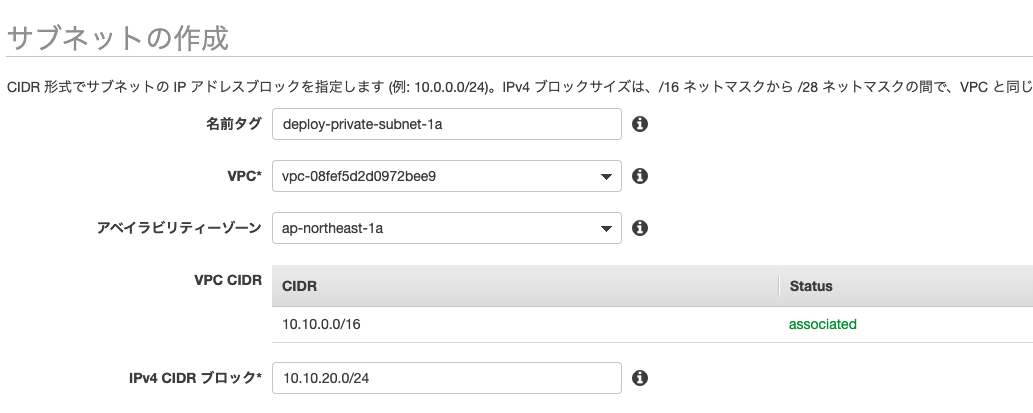
IPv4 CIDR ブロックを「10.10.10.0/24」privateサブネットの作成
こちらはWEBサービス用のRDSを紐づけるためのサブネットです。
外部からアクセスされたくないためプライベート用のサブネットを用意します。
名前を「deploy-private-subnet-1a」
VPCに先ほど作成作成した「deploy-vpc」を選択
アベイラビリティーゾーンを「ap-northeast-1a」
IPv4 CIDR ブロックを「10.10.20.0/24」DB用のsubnetを作成するときに、複数のアベイラビリティーゾーンを指定する必要があるので同様にもう一つprivateサブネットを作成します。
名前を「deploy-private-subnet-1c」
VPCに先ほど作成作成した「deploy-vpc」を選択
アベイラビリティーゾーンを「ap-northeast-1c」
IPv4 CIDR ブロックを「10.10.21.0/24」インターネットゲートウェイの作成
名前を「deploy-igw」で作成
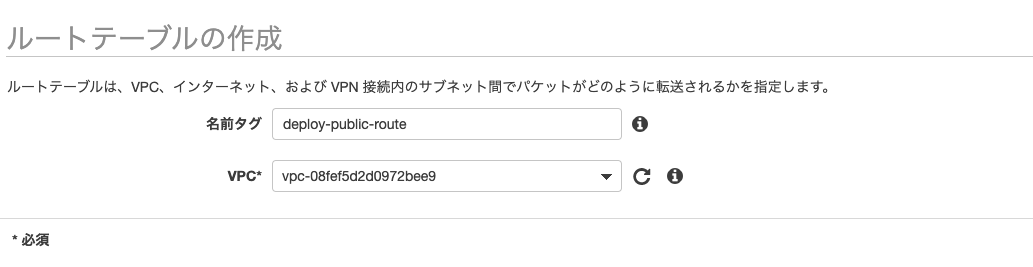
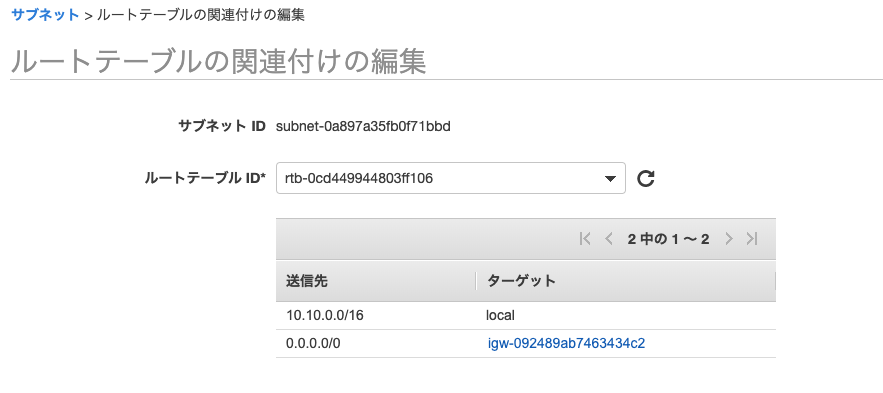
作成後、VPC「deploy-vpc」にアタッチしますルートテーブルの作成
VPCダッシュボードのルートテーブルを選択し、
名前「deploy-public-route」のルートテーブルを作成
サブネット「deploy-public-subnet-1a」のsubnetの関連付けで「deploy-public-subnet」を関連付けます。
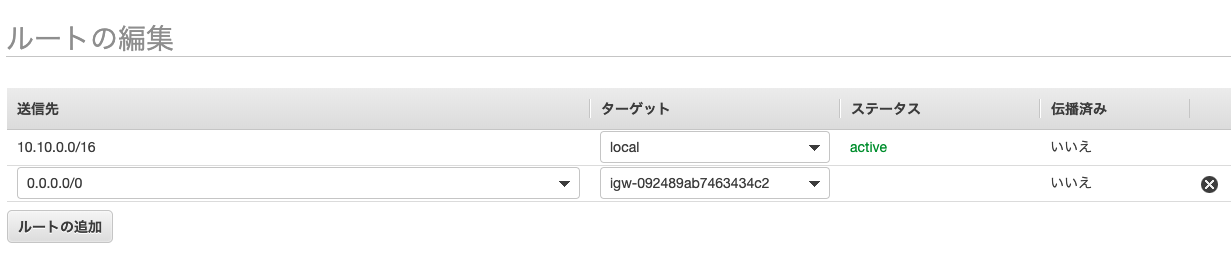
routeの編集で
送信先を「0.0.0.0/0」 ターゲットにインターネットゲートウェイ「deploy-igw」を選択します。WEBサーバ用のEC2を作成
1.AMIの選択
クイックスタートで「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択2.インスタンスタイプの選択
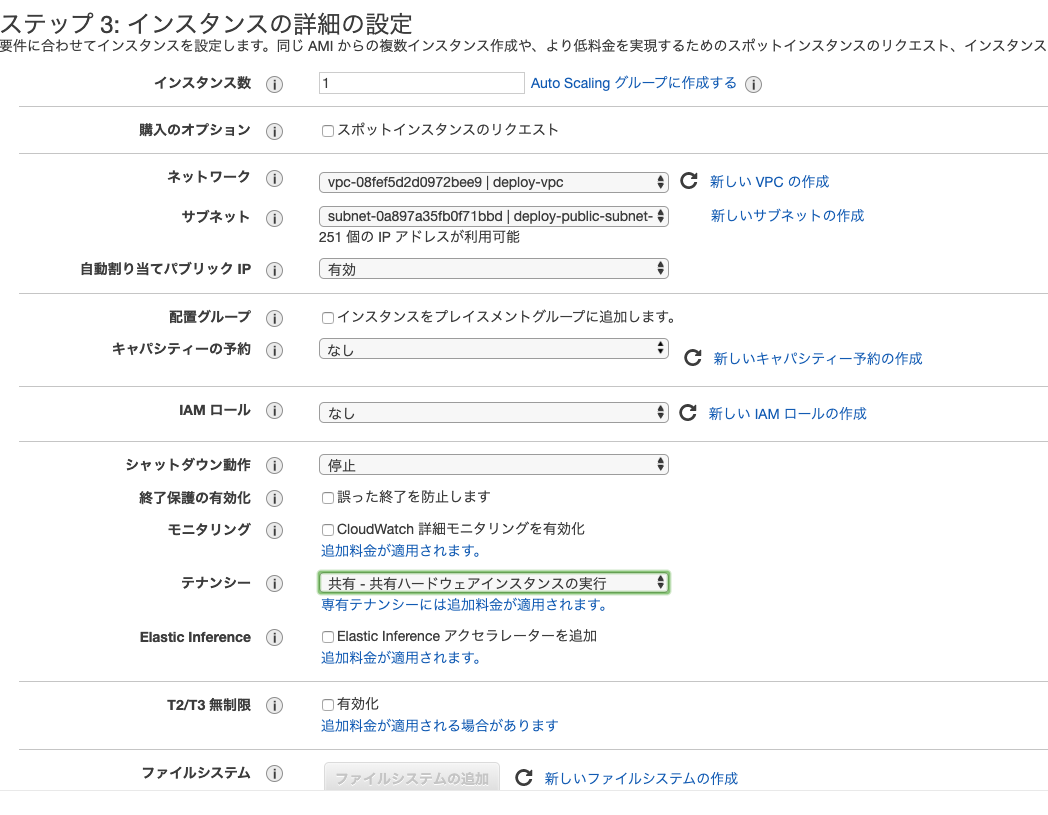
インスタンスタイプに「t2.micro」を選択3.インスタンスの詳細の設定
ネットワークに「deploy-vpc」を選択
サブネットに「deploy-public-subnet-1a」を選択
ネットワークインターフェースのIPに「10.0.10.10」を指定4.ストレージの追加
特に何もしなくてOK5.タグの追加
Nameに「deploy-ec2」を設定6.セキュリティグループの設定
新しいセキュリティーグループを作成する
グループ名を「deploy-ec2」
必要に応じてSSHのIPアドレスを絞ることも可能です。
webとして公開したいので下記の設定を追加してください。
SSH接続もできるようにしたいので以下を追加しましょう(自宅IPなどで絞った方が安全なので推奨です)
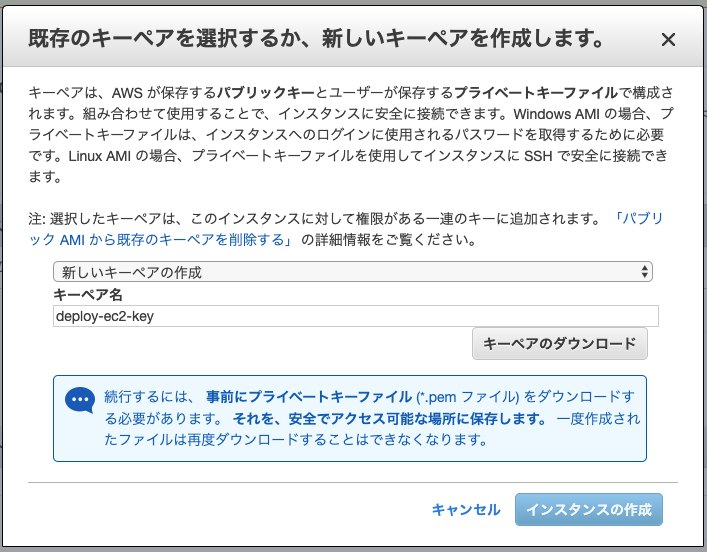
7.EC2に接続するためのキーペアを作成
ssh接続するために必要なkeyを作成し、ダウンロードしておきましょう。
以上の条件でインスタンスを作成します。WEBサーバにアクセスできるように設定
1.EC2のIPアドレスを確認
EC2のインスタンスの説明タブを開くと
IPv4 パブリック IP にEC2のIPが記載されているのでそちらをチェック
今回は「18.182.54.143」でやっていきます。2.sshの設定
$ mv ~/Downloads/deploy-ec2-key.pem ~/.aws/ #keyの移動 $ chmod 600 ~/.aws/deploy-ec2-key.pem # keyの権限を変更.ssh/configを編集する
.ssh/configHost deploy-ec2 HostName 18.182.54.143 User ec2-user IdentityFile ~/.aws/deploy-ec2-key.pem Port 22接続確認
$ ssh deploy-ec2 The authenticity of host '18.182.54.143 (18.182.54.143)' can't be established. ECDSA key fingerprint is SHA256:XUj6MKrad+8tZ4eAOsvNvb3fbaEgtwcgtuia7ZckxFM. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '18.182.54.143' (ECDSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-10-10-10-10 ~]$OK
RDSの設定
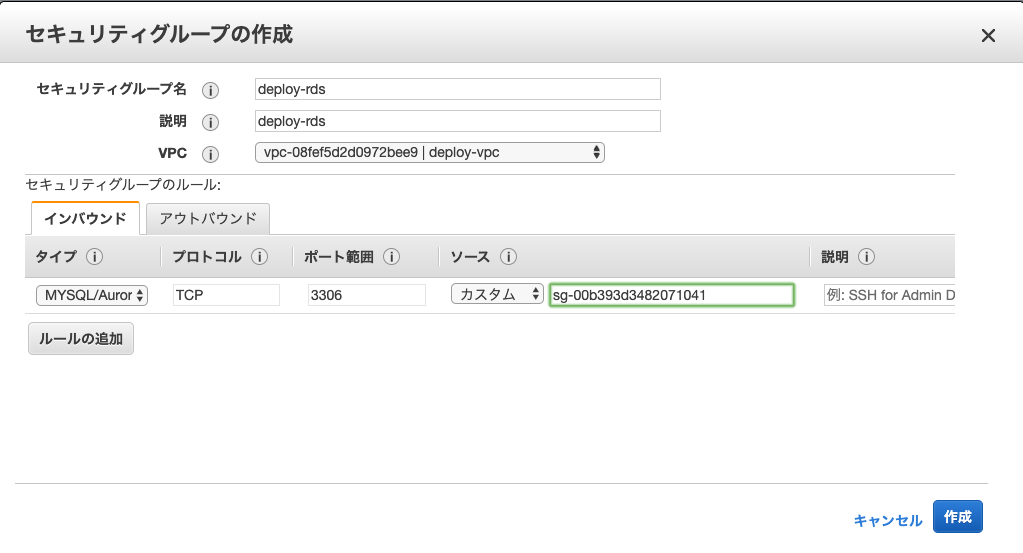
セキュリティーグループを作成
まず最初に、EC2からのみのアクセスを許可するようセキュリティーグループを作成します。
EC2ダッシュボードのセキュリティーグループから作成していきます。
セキュリティーグループ「deploy-rds」
インバウンドルールを
タイプ「MYSQL/Aurora」
プロトコル「TCP」
ポート「3306」
ソースで「deploy-ec2」のセキュリティーグループを選択
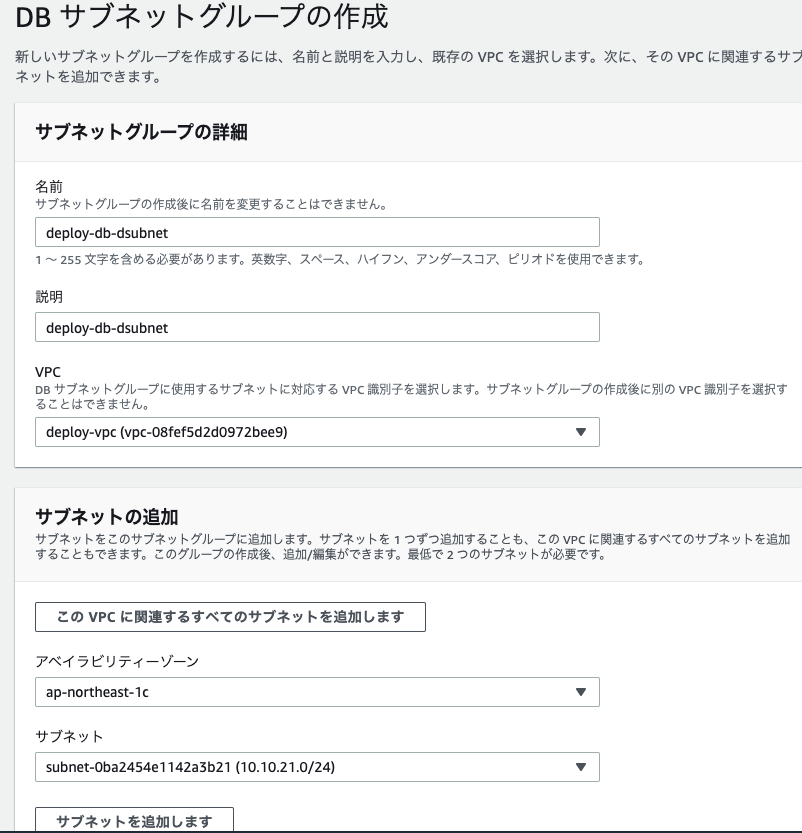
そのまま作成します。DBサブネットの作成
サブネットの追加で先ほど追加したprivateなsubnetを2つ追加し、作成します。
RDSの作成
標準作成でMySQLの最新バージョンを選択し、テンプレートを選択
特に今回は冗長化とかはしないので
ストレージの自動スケーリングは無効に
スタンバイインスタンスも作成しません。VPCに「deploy-vpc」を選択
サブネットグループに先ほど作成したdb-subnetを選択
VPC セキュリティグループに「deploy-rds」を選択上記設定でRDSを作成します。
これでいったんAWS側の設定は完了です。
Laravel 環境構築
nginxとphpをインストール
$ sudo amazon-linux-extras install nginx1.12 $ sudo amazon-linux-extras install php7.3 $ sudo service nginx start #nginxの起動 $ sudo service php-fpm start # php-fpmの起動ここまで問題なくできると自身のEC2インスタンスのIPにアクセスするとnginxのページが表示されると思います!
composerインストール
Composerをインストールしたいのですが、t2.microだとメモリが足りないことがあるので、swapファイルを作成します。
sudo dd if=/dev/zero of=/swapfile1 bs=1M count=1024 sudo chmod 600 /swapfile1 mkswap /swapfile1 swapon /swapfile1 curl -sS https://getcomposer.org/installer | php mv composer.phar /usr/bin/composer sudo yum install --enablerepo=remi,remi-php73 php-pecl-zip php-devel php-mbstring php-pdo php-gd php-xml mkdir /var/www/ cd /var/www/ composer create-project --prefer-dist laravel/laravel site sudo chmod 777 /var/www/site sudo chmod 777 /var/www/site/logs sudo chmod 777 /var/www/site/logs/laravel.log sudo chmod 777 /var/www/site/bootstrap/cache sudo chmod 777 /var/www/site/storage/framework/sessions sudo chmod 777 /var/www/site/storage/framework/views composer update sudo php artisan key:generate途中権限がない箇所でプロジェクトを生成してしまったせいか、やたら権限なくて怒られてしまったので
横着してchmod 777で権限を付けています。
本来ならnginxかphp-fpmを実行するuserに権限を持たせるのが良いかと思います。nginx.confの設定をLaravel用に書き換える
/etc/nginx/nginx.conf# For more information on configuration, see: # * Official English Documentation: http://nginx.org/en/docs/ # * Official Russian Documentation: http://nginx.org/ru/docs/ user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; # Load dynamic modules. See /usr/share/nginx/README.dynamic. include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; # Load modular configuration files from the /etc/nginx/conf.d directory. # See http://nginx.org/en/docs/ngx_core_module.html#include # for more information. include /etc/nginx/conf.d/*.conf; server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /var/www/site/public; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf; location / { #index index.php index.html index.htm; try_files $uri $uri/ /index.php?$query_string; } location ~ \.php$ { fastcgi_pass unix:/run/php-fpm/www.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } } # Settings for a TLS enabled server. # # server { # listen 443 ssl http2 default_server; # listen [::]:443 ssl http2 default_server; # server_name _; # root /usr/share/nginx/html; # # ssl_certificate "/etc/pki/nginx/server.crt"; # ssl_certificate_key "/etc/pki/nginx/private/server.key"; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 10m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # # # Load configuration files for the default server block. # include /etc/nginx/default.d/*.conf; # # location / { # } # # error_page 404 /404.html; # location = /40x.html { # } # # error_page 500 502 503 504 /50x.html; # location = /50x.html { # } # } }php-fpmの設定を編集
/etc/php-fpm.d/www.conf@@ -21,9 +21,9 @@ ; Note: The user is mandatory. If the group is not set, the default user's group ; will be used. ; RPM: apache user chosen to provide access to the same directories as httpd +user = nginx -user = apache ; RPM: Keep a group allowed to write in log dir. +group = nginx -group = apache ; The address on which to accept FastCGI requests. ; Valid syntaxes are: @@ -35,8 +35,6 @@ group = nginx ; (IPv6 and IPv4-mapped) on a specific port; ; '/path/to/unix/socket' - to listen on a unix socket. ; Note: This value is mandatory. +listen.owner = nginx +listen.group = nginx listen = /run/php-fpm/www.sockphp-fpmとnginxの再起動
sudo service php-fpm restart sudo service nginx restartEC2のIPアドレスを確認
動作成功!?
RDSに接続できるよう.envの編集
.envDB_CONNECTION=mysql DB_HOST={RDSのエンドポイント} DB_PORT=3306 DB_DATABASE=hoge DB_USERNAME=root DB_PASSWORD=rootroot動作チェック
$ php artisan migrate Migration table created successfully. Migrating: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_000000_create_users_table (0.03 seconds) Migrating: 2014_10_12_100000_create_password_resets_table Migrated: 2014_10_12_100000_create_password_resets_table (0.03 seconds) Migrating: 2019_08_19_000000_create_failed_jobs_table Migrated: 2019_08_19_000000_create_failed_jobs_table (0.01 seconds)こちらも動作成功!?
記載漏れやおかしい所ありましたら指摘お願いします!



- 投稿日:2020-02-22T16:59:59+09:00
Amazon S3 バケットへのアクセスを許可する VPC や IP アドレスを指定する方法を教えてください。をやってみる。
はじめに
某金融業界にもようやくAWSの波が来つつあるこの頃、とりあえずデータセンターとAWSをDirect Connectでつないでセキュリティを確保しつつ、AWSのElasticなコンピューティングパワーを活用するというやり方が今後スタンダードになりそうな予感です。
今回のゴール
そうすると問題なのがインターネット禁止という制約。今回は、S3のStatic Web Hostingで作るWebサイトを、インターネットアクセス禁止、特定のVPC経由のみ可能とする。というのをやります。
AWS Developer Forum最高
ググったけど全然わからなかったので、AWS Developer Forumに聞いてみたところ、一瞬で解決したので、みなさんもググってQiita読んでも解決しなかったら、Forumに投稿してみるとよいと思います。
・Discussion Forums > Category: Japanese Forums
https://forums.aws.amazon.com/category.jspa?categoryID=9参考URL
Amazon S3 バケットへのアクセスを許可する VPC や IP アドレスを指定する方法を教えてください。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/block-s3-traffic-vpc-ip/手順
設定手順
VPC
- 「1 個のパブリックサブネットを持つ VPC」を作成する
- サービスエンドポイントに「com.amazonaws.us-east-1.s3」を追加する
- こいつがVPCからS3にインターネット経由しないでアクセスするためのもの
- エンドポイントのメニューで、作成したVPCのエンドポイントIDをメモしておく(vpce-xxxxxxxxxxxxxxxxx)
S3
- バケットを作る
- 作ったバケットのルートフォルダにindex.htmlをアップロードする
- index.htmlを公開する
- 作ったバケットのプロパティ>「Static website hosting」
- 「このバケットを使用してウェブサイトをホストする」にチェック
- インデックスドキュメントに「index.html」を入力
- 保存ボタンをクリック
- エンドポイントURLをメモしておく
- 作ったバケットのアクセス権限>ブロックパブリックアクセス
- 「パブリックアクセスをすべてブロック」をオフにして保存(つまり全部公開)
- 作ったバケットのアクセス権限>バケットポリシー
- 下記を入力して保存する
- [bucketname]と[VPC Endpoint ID]は適宜置き換える
{ "Version": "2012-10-17", "Id": "VPCe and SourceIP", "Statement": [{ "Sid": "VPCe and SourceIP", "Effect": "Deny", "Principal": "*", "Action": "s3:*", "Resource": [ "arn:aws:s3:::[bucketname]", "arn:aws:s3:::[bucketname]/*" ], "Condition": { "StringNotLike": { "aws:sourceVpce": [ "[VPC Endpoint ID]" ] } } }] }テスト手順
- 作成したVPC内にEC2インスタンスを起動する
- sshでログインして、curlコマンド等でS3のエンドポイントURLにアクセス可能であることを確認する。
- 端末のブラウザ等からS3のエンドポイントURLにアクセス不可であることを確認する。(403 Forbidden)
たぶん
API Gateway回りも同様にハマりそうな予感。
- 投稿日:2020-02-22T16:31:28+09:00
Amazon TranscribeとSwiftから連携してみた
Amazon Transcribeとは
音声ファイルから自動的に文字を起こしてくれるAmazonのサービスです。
https://aws.amazon.com/jp/transcribe/
類似のものに、Google CloudのSpeech-to-Textがあります。
https://cloud.google.com/speech-to-text?hl=ja今回説明しないもの
・AWSの設定の詳細
・S3へのアップロード、ダウンロードの詳細
・動画や音声の詳細準備
AWS
・Cognito
iOSアプリからAWSにアクセスするためのやつ。
・S3
Transcribeに使う音声ファイルやjobファイルを置くストレージ。
・Transcribe
本丸。Create Jobから特に困ることなく設定可能です。iOS
・AWS SDK for iOS
AWSS3とAWSTranscribeだけあれば大丈夫です。(AWSCoreもついてくるので。)おおまかな流れ
iOSから音声(動画)ファイルをS3にアップロード
-> iOSからTranscribeのjobを実行命令
-> AWSのTranscribeがjobを実行し、先ほどアップロードしたS3のファイルを文字化
-> Transcribeの結果取得
-> 変換結果のjsonファイルをS3からダウンロード実装
初期設定
SceneDelegate.swiftfunc scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) { // AWS Cognito & S3 & Transcribe registration let credentialProvider = AWSCognitoCredentialsProvider(regionType: .APNortheast1, identityPoolId: "ap-northeast-1:*******************") if let configuration = AWSServiceConfiguration(region:.APNortheast1, credentialsProvider:credentialProvider) { AWSS3TransferUtility.register(with:configuration!, forKey: "MY_S3") AWSTranscribe.register(with:configuration!, forKey: "MY_Transcribe") } }SceneDelegate(AppDelegate)のおなじみの起動ファンクションでAWS初期設定します。
Cognitoでregionと設定の際に発行されたIdentity Pool IDを設定します。
設定後、Transcribe、 AWSS3TransferUtilityへの登録も行っておきます。S3へ該当ファイルをアップロード
let bucketName = "mybucket" let mp4URL = URL(fileURLWithPath: "your/video.mp4") if let awss3 = AWSS3TransferUtility.s3TransferUtility(forKey: "MY_S3") { do { let videoData = try Data(contentsOf: mp4URL) let videoName = "s3video.mp4" awss3.uploadData( videoData, bucket: bucketName, key: videoName, contentType: "mp4", expression: nil, // 途中経過task nullable completionHandler: { task, error in if let error = error { print("s3 upload error \(error)") } else { print("success upload") } } catch let error { print("data convert error \(error)") } }今回はmp4ファイルで行います。Transcribeがフォローしているファイルタイプは、flac, mp3, mp4, wavの4タイプです。(2020/2/20現在)
録画なりして端末に入ってるmp4ファイルをData型で取得し、AWSS3TransferUtility.uploadDataでアップロードします。
ここでのbucketはCognitoで設定したものと同じでなくてはなりません。
expressionはアップロードの途中経過を取得できるtaskですが今回は省きます。
また、uploadData自体もTaskとして登録できるものもあるので使い分けてください。TranscribeのJobを実行
let awstrans = AWSTranscribe(forKey: "MY_Transcribe") let jobName = "MY_JOB" if let startRequest = AWSTranscribeStartTranscriptionJobRequest() { startRequest.languageCode = .jaJP // language code結構いっぱいある let media = AWSTranscribeMedia() media?.mediaFileUri = "https://s3-ap-northeast-1.amazonaws.com/\(bucketName)/\(videoName)" startRequest.media = media // 先ほどアップロードしたs3のファイルのurlを指定する startRequest.mediaFormat = .mp4 // flac, mp3, mp4, wav startRequest.mediaSampleRateHertz = 44100 // いらないかも startRequest.transcriptionJobName = jobName startRequest.outputBucketName = bucketName // Job実行 awstrans.startTranscriptionJob(startRequest, completionHandler: {response, error in if let error = error { print("start job error \(error)") } else { print("success start job") } } }AWSTranscribeStartTranscriptionJobRequestでJobのステータスを設定します。
ここで勘違いしていたのが、startTranscriptionJobのcompletionがJob完了時に呼ばれるものだと思ってましたが、これはあくまでJobがスタートした時に呼ばれるものでした。TranscribeのJobが完了するまで待って取得
// timer使うので DispatchQueue.main.async { self.timer = Timer.scheduledTimer(withTimeInterval: 10, repeats: true, block: { timer in if let getJobRequest = AWSTranscribeGetTranscriptionJobRequest() { getJobRequest.transcriptionJobName = projectId awstrans.getTranscriptionJob(getJobRequest, completionHandler: {response, error in if let error = error { print("get job error \(error)") self.timer.invalidate() } if let reason = response?.transcriptionJob?.failureReason { print("job failed \(reason)") } if response?.transcriptionJob?.transcriptionJobStatus == .completed { // 完了後、awsにアップロードされた、結果の記載されたjsonのuriが取得できる print(response?.transcriptionJob?.transcript?.transcriptFileUri) self.timer.invalidate() } }) } }) }探してみたところ、Jobの完了通知をしてくれるものは見当たらなかったので、取り急ぎTimerで完了するまでgetし続けるという原始的なことをしました。しかも、mp4ファイルだと3MBぐらいのサイズでも40秒とかかかったので、interval=10としました。
JobStatus=completeとなった段階で、transcriptionJobにいろいろな値がセットされて返却されるので、結果の記載されたjsonのURIを取得する。
余談ですが、ハンドラ内でTimerを実行する際は実行スレッドに注意。S3からTranscribeの結果jsonを取得
awss3.downloadData( fromBucket: bucketName, key: projectId + ".json", expression: nil, completionHandler:{task, location, data, error in if let error = error { print("s3 download error \(error)") } else { if let data = data { do { let jsonDecoder = JSONDecoder() let transcribeData = try jsonDecoder.decode(AmazonTranscribe.self, from: data) print(transcribeData.results.transcripts) } catch let error { print("decode error \(error)") } } } } )AmazonTranscribe.swiftstruct AmazonTranscribe: Decodable { let jobName:String let accountId:String let results: AmazonTranscribeResults let status: String } struct AmazonTranscribeResults: Decodable { let transcripts: [AmazonTranscribeTranscripts] let items: [AmazonTranscribeItem] } struct AmazonTranscribeTranscripts: Decodable { let transcript: String // 全文 } struct AmazonTranscribeItem: Decodable { let startTime: Double let endTime: Double let alternatives: [AmazonTranscribeAlternatives] let type: String private enum CodingKeys: String, CodingKey { case startTime = "start_time" case endTime = "end_time" case alternatives, type } init(from decoder: Decoder) throws { let values = try decoder.container(keyedBy: CodingKeys.self) guard let startTimeDouble = Double(try values.decode(String.self, forKey: .startTime)) else { fatalError("The start time is not an Double") } guard let endTimeDouble = Double(try values.decode(String.self, forKey: .endTime)) else { fatalError("The end time is not an Double") } startTime = startTimeDouble endTime = endTimeDouble alternatives = try values.decode([AmazonTranscribeAlternatives].self, forKey: .alternatives) type = try values.decode(String.self, forKey: .type) } } struct AmazonTranscribeAlternatives: Decodable { let confidence: Double let content: String private enum CodingKeys: String, CodingKey { case confidence, content } init(from decoder: Decoder) throws { let values = try decoder.container(keyedBy: CodingKeys.self) guard let confidenceDouble = Double(try values.decode(String.self, forKey: .confidence)) else { fatalError("The confidence is not an Double") } confidence = confidenceDouble content = try values.decode(String.self, forKey: .content) } }おまけでjsonをDecodeするのにつかったDecodableも載せておきます。返却値はこんな(AmazonTranscribe.swift)感じです。
各値の意味は深く調べてませんが、全文(なぜリスト?)と代替候補っぽいのはありました。感想
正直なところ、日本語の文字起こし精度はさほど高くないように感じられました。
ファイルの形式等を調整したらもうちょい精度あがりそうですが、
試しにGoogleHomeとの、「ねぇGoogle、明日の天気は?」「明日の新宿は最高気温15度、最低気温7度で晴れるでしょう」というやりとり動画を送信してみたら、
「めぐる 明日 の 天気 は 明日 の 新宿 は 最高 気温 十 五 度 再 激 音 など で 買える でしょ」
というアウトプットがきました。この場合の使える情報は、明日の新宿が最高気温15度ってことだけでしょう。
英語はしゃべれないし、発音も悪いので試してません。
- 投稿日:2020-02-22T16:31:28+09:00
Amazon TranscribeにSwiftアプリから連携してみた
Amazon Transcribeとは
音声ファイルから自動的に文字を起こしてくれるAmazonのサービスです。
https://aws.amazon.com/jp/transcribe/
類似のものに、Google CloudのSpeech-to-Textがあります。
https://cloud.google.com/speech-to-text?hl=ja今回説明しないもの
・AWSの設定の詳細
・S3へのアップロード、ダウンロードの詳細
・動画や音声の詳細準備
AWS
・Cognito
iOSアプリからAWSにアクセスするためのやつ。
・S3
Transcribeに使う音声ファイルやjobファイルを置くストレージ。
・Transcribe
本丸。Create Jobから特に困ることなく設定可能です。iOS
・AWS SDK for iOS
AWSS3とAWSTranscribeだけあれば大丈夫です。(AWSCoreもついてくるので。)おおまかな流れ
iOSから音声(動画)ファイルをS3にアップロード
-> iOSからTranscribeのjobを実行命令
-> AWSのTranscribeがjobを実行し、先ほどアップロードしたS3のファイルを文字化
-> Transcribeの結果取得
-> 変換結果のjsonファイルをS3からダウンロード実装
初期設定
SceneDelegate.swiftfunc scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) { // AWS Cognito & S3 & Transcribe registration let credentialProvider = AWSCognitoCredentialsProvider(regionType: .APNortheast1, identityPoolId: "ap-northeast-1:*******************") if let configuration = AWSServiceConfiguration(region:.APNortheast1, credentialsProvider:credentialProvider) { AWSS3TransferUtility.register(with:configuration!, forKey: "MY_S3") AWSTranscribe.register(with:configuration!, forKey: "MY_Transcribe") } }SceneDelegate(AppDelegate)のおなじみの起動ファンクションでAWS初期設定します。
Cognitoでregionと設定の際に発行されたIdentity Pool IDを設定します。
設定後、Transcribe、 AWSS3TransferUtilityへの登録も行っておきます。S3へ該当ファイルをアップロード
let bucketName = "mybucket" let mp4URL = URL(fileURLWithPath: "your/video.mp4") if let awss3 = AWSS3TransferUtility.s3TransferUtility(forKey: "MY_S3") { do { let videoData = try Data(contentsOf: mp4URL) let videoName = "s3video.mp4" awss3.uploadData( videoData, bucket: bucketName, key: videoName, contentType: "mp4", expression: nil, // 途中経過task nullable completionHandler: { task, error in if let error = error { print("s3 upload error \(error)") } else { print("success upload") } } catch let error { print("data convert error \(error)") } }今回はmp4ファイルで行います。Transcribeがフォローしているファイルタイプは、flac, mp3, mp4, wavの4タイプです。(2020/2/20現在)
録画なりして端末に入ってるmp4ファイルをData型で取得し、AWSS3TransferUtility.uploadDataでアップロードします。
ここでのbucketはCognitoで設定したものと同じでなくてはなりません。
expressionはアップロードの途中経過を取得できるtaskですが今回は省きます。
また、uploadData自体もTaskとして登録できるものもあるので使い分けてください。TranscribeのJobを実行
let awstrans = AWSTranscribe(forKey: "MY_Transcribe") let jobName = "MY_JOB" if let startRequest = AWSTranscribeStartTranscriptionJobRequest() { startRequest.languageCode = .jaJP // language code結構いっぱいある let media = AWSTranscribeMedia() media?.mediaFileUri = "https://s3-ap-northeast-1.amazonaws.com/\(bucketName)/\(videoName)" startRequest.media = media // 先ほどアップロードしたs3のファイルのurlを指定する startRequest.mediaFormat = .mp4 // flac, mp3, mp4, wav startRequest.mediaSampleRateHertz = 44100 // いらないかも startRequest.transcriptionJobName = jobName startRequest.outputBucketName = bucketName // Job実行 awstrans.startTranscriptionJob(startRequest, completionHandler: {response, error in if let error = error { print("start job error \(error)") } else { print("success start job") } } }AWSTranscribeStartTranscriptionJobRequestでJobのステータスを設定します。
ここで勘違いしていたのが、startTranscriptionJobのcompletionがJob完了時に呼ばれるものだと思ってましたが、これはあくまでJobがスタートした時に呼ばれるものでした。TranscribeのJobが完了するまで待って取得
// timer使うので DispatchQueue.main.async { self.timer = Timer.scheduledTimer(withTimeInterval: 10, repeats: true, block: { timer in if let getJobRequest = AWSTranscribeGetTranscriptionJobRequest() { getJobRequest.transcriptionJobName = projectId awstrans.getTranscriptionJob(getJobRequest, completionHandler: {response, error in if let error = error { print("get job error \(error)") self.timer.invalidate() } if let reason = response?.transcriptionJob?.failureReason { print("job failed \(reason)") } if response?.transcriptionJob?.transcriptionJobStatus == .completed { // 完了後、awsにアップロードされた、結果の記載されたjsonのuriが取得できる print(response?.transcriptionJob?.transcript?.transcriptFileUri) self.timer.invalidate() } }) } }) }探してみたところ、Jobの完了通知をしてくれるものは見当たらなかったので、取り急ぎTimerで完了するまでgetし続けるという原始的なことをしました。しかも、mp4ファイルだと3MBぐらいのサイズでも40秒とかかかったので、interval=10としました。
JobStatus=completeとなった段階で、transcriptionJobにいろいろな値がセットされて返却されるので、結果の記載されたjsonのURIを取得する。
余談ですが、ハンドラ内でTimerを実行する際は実行スレッドに注意。S3からTranscribeの結果jsonを取得
awss3.downloadData( fromBucket: bucketName, key: projectId + ".json", expression: nil, completionHandler:{task, location, data, error in if let error = error { print("s3 download error \(error)") } else { if let data = data { do { let jsonDecoder = JSONDecoder() let transcribeData = try jsonDecoder.decode(AmazonTranscribe.self, from: data) print(transcribeData.results.transcripts) } catch let error { print("decode error \(error)") } } } } )AmazonTranscribe.swiftstruct AmazonTranscribe: Decodable { let jobName:String let accountId:String let results: AmazonTranscribeResults let status: String } struct AmazonTranscribeResults: Decodable { let transcripts: [AmazonTranscribeTranscripts] let items: [AmazonTranscribeItem] } struct AmazonTranscribeTranscripts: Decodable { let transcript: String // 全文 } struct AmazonTranscribeItem: Decodable { let startTime: Double let endTime: Double let alternatives: [AmazonTranscribeAlternatives] let type: String private enum CodingKeys: String, CodingKey { case startTime = "start_time" case endTime = "end_time" case alternatives, type } init(from decoder: Decoder) throws { let values = try decoder.container(keyedBy: CodingKeys.self) guard let startTimeDouble = Double(try values.decode(String.self, forKey: .startTime)) else { fatalError("The start time is not an Double") } guard let endTimeDouble = Double(try values.decode(String.self, forKey: .endTime)) else { fatalError("The end time is not an Double") } startTime = startTimeDouble endTime = endTimeDouble alternatives = try values.decode([AmazonTranscribeAlternatives].self, forKey: .alternatives) type = try values.decode(String.self, forKey: .type) } } struct AmazonTranscribeAlternatives: Decodable { let confidence: Double let content: String private enum CodingKeys: String, CodingKey { case confidence, content } init(from decoder: Decoder) throws { let values = try decoder.container(keyedBy: CodingKeys.self) guard let confidenceDouble = Double(try values.decode(String.self, forKey: .confidence)) else { fatalError("The confidence is not an Double") } confidence = confidenceDouble content = try values.decode(String.self, forKey: .content) } }おまけでjsonをDecodeするのにつかったDecodableも載せておきます。返却値はこんな(AmazonTranscribe.swift)感じです。
各値の意味は深く調べてませんが、全文(なぜリスト?)と代替候補っぽいのはありました。感想
正直なところ、日本語の文字起こし精度はさほど高くないように感じられました。
ファイルの形式等を調整したらもうちょい精度あがりそうですが、
試しにGoogleHomeとの、「ねぇGoogle、明日の天気は?」「明日の新宿は最高気温15度、最低気温7度で晴れるでしょう」というやりとり動画を送信してみたら、
「めぐる 明日 の 天気 は 明日 の 新宿 は 最高 気温 十 五 度 再 激 音 など で 買える でしょ」
というアウトプットがきました。この場合の使える情報は、明日の新宿が最高気温15度ってことだけでしょう。
英語はしゃべれないし、発音も悪いので試してません。
- 投稿日:2020-02-22T16:08:45+09:00
AlicloudにKubernetesクラスタをTerraformで構築する
Alicloud上にマスターnodeをマルチゾーン化したKubernetesクラスタを構築する
イメージ図
マスターnodeをマルチゾーン化し、LBで束ねて高可用性なKubernetesクラスタを構築するのを、Terraformで自動化する。
Kubernetesのnodeは、あらかじめイメージを作成しておく。こちらの記事を参考に。作業場所
Teraformを実行する端末は何でもよく、手元のMacやLinux PCでも構わない。今回はAWSのUbuntuインスタンスから実行している。Terraformのバージョンは次の通り。
root@ip-172-31-27-178:~/terraform/alibaba# terraform version Terraform v0.12.18 + provider.alicloud v1.71.0 Your version of Terraform is out of date! The latest version is 0.12.21. You can update by downloading from https://www.terraform.io/downloads.html嗚呼、バージョンが古い。。
各種tfファイル
main.tf# Alicloud Providerの設定 provider "alicloud" { region = var.alicloud_region } # 有効なゾーンを問い合わせ、local.all_zonesで参照する data "alicloud_zones" "available" { } # local変数の設定 locals { all_vswitchs = alicloud_vswitch.vsw.*.id all_zones = data.alicloud_zones.available.ids } # sshキーペアの登録 resource "alicloud_key_pair" "deployer" { key_name = "${var.cluster_name}-deployer-key" public_key = file(var.ssh_public_key_file) } # セキュリティグループの作成(common) resource "alicloud_security_group" "common" { name = "${var.cluster_name}-common" vpc_id = alicloud_vpc.vpc.id } # セキュリティグループのルール設定(common) resource "alicloud_security_group_rule" "common" { type = "ingress" ip_protocol = "tcp" nic_type = "intranet" policy = "accept" port_range = "${var.ssh_port}/${var.ssh_port}" priority = 1 security_group_id = alicloud_security_group.common.id cidr_ip = "0.0.0.0/0" } # セキュリティグループの作成(master) resource "alicloud_security_group" "master" { name = "${var.cluster_name}-master" vpc_id = alicloud_vpc.vpc.id } # セキュリティグループのルール設定(master) resource "alicloud_security_group_rule" "master" { type = "ingress" ip_protocol = "tcp" nic_type = "intranet" policy = "accept" port_range = "6443/6443" priority = 1 security_group_id = alicloud_security_group.master.id cidr_ip = "0.0.0.0/0" } # VPCの作成 resource "alicloud_vpc" "vpc" { name = "${var.cluster_name}-vpc" cidr_block = var.vpc_cidr } # vswitch(subnet)の作成 resource "alicloud_vswitch" "vsw" { count = length(local.all_zones) name = "${var.cluster_name}-${local.all_zones[count.index]}" vpc_id = alicloud_vpc.vpc.id cidr_block = cidrsubnet(var.vpc_cidr, var.subnet_netmask_bits, var.subnet_offset + count.index) availability_zone = local.all_zones[count.index] } # ロードバランサーの作成 resource "alicloud_slb" "master" { name = "${var.cluster_name}-api-slb" address_type = "internet" } # リスナーの作成 resource "alicloud_slb_listener" "master_api" { load_balancer_id = alicloud_slb.master.id frontend_port = 6443 backend_port = 6443 bandwidth = 5 protocol = "tcp" health_check_type = "tcp" } # インスタンスのアタッチ resource "alicloud_slb_attachment" "master_api" { load_balancer_id = alicloud_slb.master.id instance_ids = alicloud_instance.master.*.id } # Kubernetesマスターノードの作成(ゾーン数分) resource "alicloud_instance" "master" { count = length(local.all_zones) instance_name = "${var.cluster_name}-master-${count.index + 1}" host_name = "${var.cluster_name}-master-${count.index + 1}" availability_zone = local.all_zones[count.index % length(local.all_zones)] image_id = var.node_image key_name = alicloud_key_pair.deployer.key_name instance_type = "ecs.t5-lc1m2.large" system_disk_category = "cloud_efficiency" security_groups = [alicloud_security_group.common.id, alicloud_security_group.master.id] vswitch_id = local.all_vswitchs[count.index % length(local.all_zones)] internet_charge_type = "PayByTraffic" internet_max_bandwidth_out = 5 } # outputデータ用に情報取得 data "alicloud_instances" "masters" { ids = alicloud_instance.master.*.id } # Kubernetesワーカーノードの作成(6つ) resource "alicloud_instance" "worker" { count = 6 instance_name = "${var.cluster_name}-worker-${count.index + 1}" host_name = "${var.cluster_name}-worker-${count.index + 1}" availability_zone = local.all_zones[count.index % length(local.all_zones)] image_id = var.node_image key_name = alicloud_key_pair.deployer.key_name instance_type = "ecs.t5-lc1m2.large" system_disk_category = "cloud_efficiency" security_groups = [alicloud_security_group.common.id] vswitch_id = local.all_vswitchs[count.index % length(local.all_zones)] internet_charge_type = "PayByTraffic" internet_max_bandwidth_out = 5 } # outputデータ用に情報取得 data "alicloud_instances" "workers" { ids = alicloud_instance.worker.*.id } # 踏み台サーバの作成 resource "alicloud_instance" "bastion" { instance_name = "${var.cluster_name}-bastion" host_name = "${var.cluster_name}-bastion" availability_zone = local.all_zones[0] image_id = var.bastion_image key_name = alicloud_key_pair.deployer.key_name instance_type = "ecs.t5-lc2m1.nano" system_disk_category = "cloud_efficiency" security_groups = [alicloud_security_group.common.id, alicloud_security_group.master.id] vswitch_id = local.all_vswitchs[0] internet_charge_type = "PayByTraffic" internet_max_bandwidth_out = 5 } # outputデータ用に情報取得 data "alicloud_instances" "bastion" { ids = alicloud_instance.bastion.*.id }variables.tf# 共通設定 variable "cluster_name" { default = "fabric" } variable "ssh_public_key_file" { default = "~/.ssh/id_rsa.pub" } variable "ssh_port" { default = 22 } variable "vpc_cidr" { default = "10.10.0.0/16" } variable "subnet_offset" { default = 0 } variable "subnet_netmask_bits" { default = 8 } # クラウドベンダー依存部分 variable "alicloud_region" { default = "ap-northeast-1" } variable "node_image" { default = "m-6we7k89y7wwevump3joc" } variable "bastion_image" { default = "ubuntu_18_04_x64_20G_alibase_20191225.vhd" }output.tfoutput "kubeadm_api" { value = { endpoint = alicloud_slb.master.address } } output "kubernetes_bastion" { value = { public_ip = data.alicloud_instances.bastion.instances.0.public_ip } } output "kubernetes_masters" { value = { private_ip = data.alicloud_instances.masters.instances.*.private_ip } } output "kubernetes_workers" { value = { private_ip = data.alicloud_instances.workers.instances.*.private_ip } }terraform applyを実行
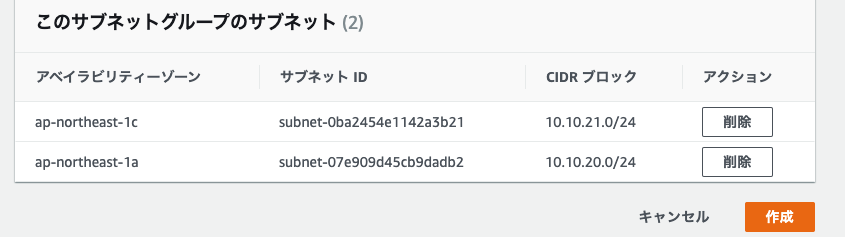
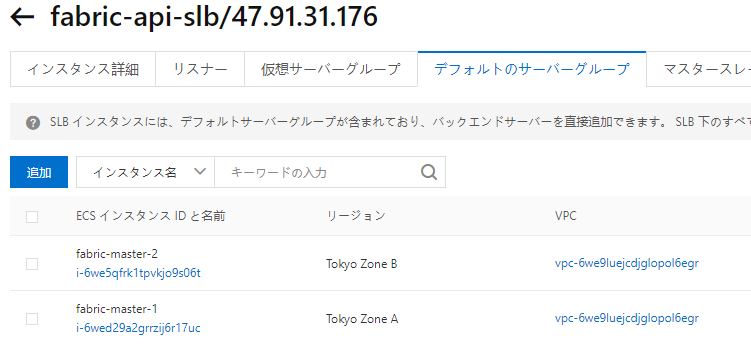
Apply complete! Resources: 20 added, 0 changed, 0 destroyed. Outputs: kubeadm_api = { "endpoint" = "47.91.31.176" } kubernetes_bastion = { "public_ip" = "47.74.3.221" } kubernetes_masters = { "private_ip" = [ "10.10.1.163", "10.10.0.133", ] } kubernetes_workers = { "private_ip" = [ "10.10.1.164", "10.10.0.134", "10.10.0.132", "10.10.0.131", "10.10.1.162", "10.10.1.161", ] }Alicloudのコンソールでインスタンスを確認。ちゃんとマスターnodeがゾーンで分かれている。
LB(SLB)にマスターnodeが2つぶら下がっているのがわかる。
Kubernetesの設定
これでインフラが構築できたので、ここからKubernetes環境を設定していく。基本的にはこのページのMaster nodes:以下を実行すれば良い。
あとすべてのnodeであらかじめ、
swapoff -a export KUBECONFIG=/etc/kubernetes/admin.confしてある。というかマシンイメージの.bashrcに書いてある。
1つのマスターnodeへ入って
/etc/kubernetes/kubeadm/kubeadm-config.yamlを次の通り記述。kubeadm-config.yamlapiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: "47.91.31.176:6443"controlPlaneEndpointには、Outputs:のkubeadm_api.endpointを設定する。
kubeadm initを実行。
root@fabric-master-2:~# kubeadm init --config=/etc/kubernetes/kubeadm/kubeadm-config.yaml --upload-certs - 途中のkubeadmのメッセージは省略 - Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 47.91.31.176:6443 --token 35gsx8.3ea2u1u2dd4dttc7 \ --discovery-token-ca-cert-hash sha256:7b3ca182885585ec33e31d92caff81586acaf60553df2dc9387b5d4590d4289d \ --control-plane --certificate-key 83a57824d8a6eab1370a9d6c510a3a6dfd3c1c2154da713cf5cf73fdaf46e563 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 47.91.31.176:6443 --token 35gsx8.3ea2u1u2dd4dttc7 \ --discovery-token-ca-cert-hash sha256:7b3ca182885585ec33e31d92caff81586acaf60553df2dc9387b5d4590d4289dもう1つのマスターnodeでは、kubeadm initの出力にあるcontrol-plane node用のjoinコマンドを実行する。
6つのワーカーnodeでは、worker node用のjoinコマンドをひたすら実行する。できた環境を確認する
terraformを実行したAWSのインスタンスへ、Kubernetes環境を一式(たぶんkubectlだけで良いと思う)インストール。
最初にkubeadm initしたマスターnodeから/etc/kubernetes/admin.confをコピーする。
これでkubectlが利用できるようになる。export KUBECONFIG=/etc/kubernetes/admin.confを忘れずに。
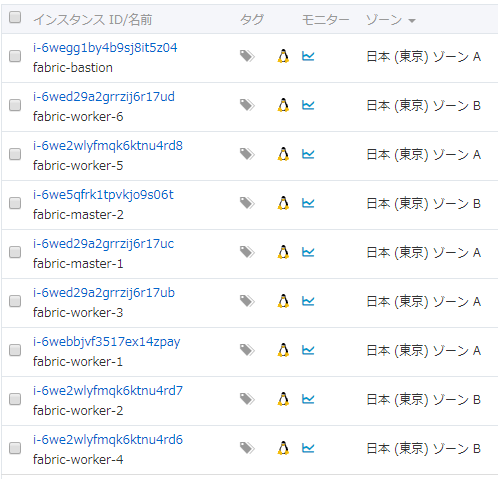
root@ip-172-31-27-178:~/fabric-dev# kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME fabric-master-1 Ready master 20m v1.17.0 10.10.0.133 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-master-2 Ready master 44m v1.17.0 10.10.1.163 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-1 Ready <none> 11m v1.17.0 10.10.0.131 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-2 Ready <none> 10m v1.17.0 10.10.1.162 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-3 Ready <none> 12m v1.17.0 10.10.0.132 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-4 Ready <none> 9m52s v1.17.0 10.10.1.161 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-5 Ready <none> 13m v1.17.0 10.10.0.134 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9 fabric-worker-6 Ready <none> 13m v1.17.0 10.10.1.164 <none> Ubuntu 18.04.3 LTS 4.15.0-74-generic docker://18.9.9マスターnodeが2台、ワーカーnodeが6台確認でき、すべてReadyになっている。
root@ip-172-31-27-178:~/fabric-dev# kubectl get pod -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system calico-kube-controllers-5c45f5bd9f-6xwsl 1/1 Running 0 2m33s 192.168.91.129 fabric-worker-4 <none> <none> kube-system calico-node-4hfbj 1/1 Running 0 2m33s 10.10.1.161 fabric-worker-4 <none> <none> kube-system calico-node-52c69 1/1 Running 0 2m33s 10.10.0.132 fabric-worker-3 <none> <none> kube-system calico-node-7k2q6 1/1 Running 0 2m33s 10.10.1.164 fabric-worker-6 <none> <none> kube-system calico-node-fpmx6 1/1 Running 0 2m33s 10.10.0.133 fabric-master-1 <none> <none> kube-system calico-node-ncjw9 1/1 Running 0 2m33s 10.10.0.131 fabric-worker-1 <none> <none> kube-system calico-node-ptjhm 1/1 Running 0 2m33s 10.10.0.134 fabric-worker-5 <none> <none> kube-system calico-node-x9zsg 1/1 Running 0 2m33s 10.10.1.163 fabric-master-2 <none> <none> kube-system calico-node-ztfdn 1/1 Running 0 2m33s 10.10.1.162 fabric-worker-2 <none> <none> kube-system coredns-6955765f44-8qtjq 1/1 Running 0 46m 192.168.124.129 fabric-worker-2 <none> <none> kube-system coredns-6955765f44-jxkxc 1/1 Running 0 46m 192.168.91.130 fabric-worker-4 <none> <none> kube-system etcd-fabric-master-1 1/1 Running 0 22m 10.10.0.133 fabric-master-1 <none> <none> kube-system etcd-fabric-master-2 1/1 Running 0 45m 10.10.1.163 fabric-master-2 <none> <none> kube-system kube-apiserver-fabric-master-1 1/1 Running 0 22m 10.10.0.133 fabric-master-1 <none> <none> kube-system kube-apiserver-fabric-master-2 1/1 Running 0 45m 10.10.1.163 fabric-master-2 <none> <none> kube-system kube-controller-manager-fabric-master-1 1/1 Running 0 22m 10.10.0.133 fabric-master-1 <none> <none> kube-system kube-controller-manager-fabric-master-2 1/1 Running 1 45m 10.10.1.163 fabric-master-2 <none> <none> kube-system kube-proxy-4lndk 1/1 Running 0 22m 10.10.0.133 fabric-master-1 <none> <none> kube-system kube-proxy-bclfq 1/1 Running 0 14m 10.10.0.132 fabric-worker-3 <none> <none> kube-system kube-proxy-ghjf4 1/1 Running 0 15m 10.10.1.164 fabric-worker-6 <none> <none> kube-system kube-proxy-jlpvp 1/1 Running 0 14m 10.10.0.134 fabric-worker-5 <none> <none> kube-system kube-proxy-k8275 1/1 Running 0 46m 10.10.1.163 fabric-master-2 <none> <none> kube-system kube-proxy-phrzl 1/1 Running 0 13m 10.10.0.131 fabric-worker-1 <none> <none> kube-system kube-proxy-pw9xk 1/1 Running 0 12m 10.10.1.162 fabric-worker-2 <none> <none> kube-system kube-proxy-zt95z 1/1 Running 0 11m 10.10.1.161 fabric-worker-4 <none> <none> kube-system kube-scheduler-fabric-master-1 1/1 Running 0 22m 10.10.0.133 fabric-master-1 <none> <none> kube-system kube-scheduler-fabric-master-2 1/1 Running 1 45m 10.10.1.163 fabric-master-2 <none> <none>kube-system podも問題なく動作している。
AWSのインスタンスからAlicloud上のKubernetesクラスタを操作するのは、なんだか妙な気分である。
node名から分かる通り、このクラスタはHyperledger Fabricのために構築したものである。Fabric Appをデプロイして遊んでみよう。

- 投稿日:2020-02-22T14:10:47+09:00
独学でエンジニアを目指してからの3か月間の学習の振り返り
はじめに
初めまして YKと申します
自己紹介
現在25歳でIT機器関連のテクニカルサポートの仕事をしております。
2019年11月頃に、PG関連に興味を持ち最初はHTMLから入り最終的にはRubyやrailsなどのサーバーサイドの方まで学習しました。
今回は振り返りで、どのように何を学習してきたかまとめます。なにを学習してきたか?(時系列順)
11月5日~12月5日
・Progate 「HTML & CSS」「Javasript」 全コース
最初は王道のProgateさんにて学習を開始しました。
意識した事:このころはWEBコーダーを目指していたので基本的なWEBサイトの構造をおおまかに理解して先にどんどん進めることを意識して学習しました。
・ドットインストールにて「Bootstarap入門」
フレームワークの存在をしりメジャーなBootstarapを学習しようと開始
意識した事:やはりとりあえず手を動かして先に進めることを意識
・youtebeにて「Bootstarap tutorial」の模写
youtubeにアップされている外人さんの解説付きのチュートリアルを2つ模写
LPの基本的な書き方やページ内での移動のさせ方などを理解できた。
参考:https://www.youtube.com/watch?v=gqOEoUR5RHgここまでで大体一ヶ月かかりました。
学習手順は有名な良サイト東京フリーランスさんのデイトラ1stを参考にしました。
https://tokyofreelance.jp/30daystrial-coding-2nd/WEBコーディングに関しては模写できるレベルになるまでとりあえず先に進めてしまうのが効率いいと感じました。
12月6日
・自分はどのようなエンジニアになりたいか考える
東京フリーランスさんのデイトラ1stが終わり、今後の自分について1日思考しました。(デイトラ2nd以降はフロントエンドエンジニアになるための学習になっていく為)
この時自分はサーバーサイドの言語を使って便利なアプリを作ってみたいとも思っており、難易度は上がってしまうが挑戦してみようと方向転換しバックエンドエンジニアになるための学習をはじめることにしました。12月7日~12月18日
・Progate「Ruby」「rails」全コース
まずはProgateにて学習開始、railsコースは2周しました。
本格的なプログラミングに初めて触れ難しさに驚愕意識した事:railsコースの2周目は自分のローカル環境にて実装しました。
Progate上の用意されエディターとは違いエラーなども多く苦戦しましたが良い学習になりました。・Udemyにて「railsコース」
動画教材にてRuby,railsの基礎的な部分、基本的なCRUDなどを学習
dockerやcloud9などを利用する環境構築の手引きがありがたかった印象意識した事:dockerなどを使用しての環境構築の部分を記事にしてアウトプットして残しておくなど工夫しました。初学者には難易度高い環境構築の部分は動画教材を参考にしたほうが効率が良いと思います。
参考:フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座
https://www.udemy.com/course/rails-kj/
はじめての Ruby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう
https://www.udemy.com/course/the-ultimate-ruby-on-rails-bootcamp/・rails tutorial開始
railsの学習といえばコレ!というほど有名な教材
意識した事:文字の教材ということもあり難易度が急激に上がった為、1周目は雰囲気を掴むため通しで読みきり2周目に自分のローカルにて学習しました。結果的にわからなくて先にどんどん進めていくのが完走目指すには最適と感じました。
12月19日~1月19日
・ポートフォリオ製作
いろんな方の動画や記事にてある程度学習したらすぐにポートフォリオ製作に移ったほうが良いと発言されいます。自分もそれに習い早めに作成を開始しました。
結果から言うと早めに初めて本当に良かった思います自分で考えてコードを書く、わからないことを調べて実装する これが思った以上に頭に残りますしどんな学習よりも効率よいと実感しました。
僕が作成したポートフォリオアプリは自動コーディネートアプリというものでその日の気温から最適な洋服を選んで表示してくれるアプリです。
昔から欲しかったものを自分で作り上げられたことに素直にうれしいです。意識した事:学習してきた機能に関しては問題なく実装できたのですがそれ以外の部分に関しては実装方法調べて自分のアプリ用にカスタマイズして作成していきました。
具体的に
・多対多の関係を利用したタグ機能の実装
・外部APIを利用して気象情報を取得し反映させる
・条件分岐を使用して多数のコーディネートを反映させる
・洋服のカテゴリー別ユーザーページの実装 などなど
別の記事にてポートフォリオについては詳しく書こうと思っています。参考までにポートフォリオサイトのgithubとURLを載せておきます
「ポートフォリオサイト Ocean」
https://oceanmorningggg.herokuapp.com/
github
https://github.com/MKprojects39/Ocean1月20日~1月31日
・Git Githubの復習 CicleCiの実装
一人で開発していましたが作業用ブランチを使用してやってみたりはしていたが、理解が足りないと感じたので新しいtestappを作成し疑似的に共同開発の練習をしたりして学習。
CicleCiも試験的に導入してみました。とりあえず自動テストが走るように組み込むことを目標にしました。・Udemy 「Vue.jsコース」
自分のプロフィールサイトがあると便利なのでVue.jsを使用して作成したいと思い学習開始しました。
最近javascriptに力を入れてる企業さんも多いそうなのでどんなものか知りたかったのもあります。意識した事:17時間のコースでボリュームがかなりあったので手を動かすとこ、見て理解に徹するとこのメリハリを意識し効率よく最後まで完走させました。
参考:超Vue JS 2 入門 完全パック - もう他の教材は買わなくてOK! (Vue Router, Vuex含む) https://www.udemy.com/course/vue-js-complete-guide/
この方の動画は声がハキハキしており眠くならずに完走できました。話も分かりやすいのでおすすめですよ!(長時間の動画学習は眠くなるものが多いのでw)
2月1日~2月20日
・Vue.jsを使用してのプロフィールサイトの製作
Udemyにての学習が終わりすぐにプロフィールサイトの作成を開始しました。
意識した事:今回はシンプルに見やすいサイトにしたかったので凝った細工はあまりしてません。
Vue.jsとfirebaseを利用して最速でSPAを作ることを意識して実装。
今後はfirebaseも深堀してVueXの恩恵を受けれるアプリを作成したいです参考:My profile
https://my-profile-yk.firebaseapp.com/2月21日~
・転職活動を開始
現在、転職活動をしております
都内でコードレビュー文化のあるWEB系企業に入りたいので頑張ります!読んでいただきありがとうございました。
- 投稿日:2020-02-22T14:10:47+09:00
独学でエンジニアを目指してからの三ヶ月間の学習振り返り
はじめに
初めまして YKと申します
自己紹介
現在25歳でIT機器関連のテクニカルサポートの仕事をしております。
2019年11月頃に、PG関連に興味を持ち最初はHTMLから入り最終的にはRubyやrailsなどのサーバーサイドの方まで学習しました。
今回は振り返りで、どのように何を学習してきたかまとめます。なにを学習してきたか?(時系列順)
11月5日~12月5日
・Progate 「HTML & CSS」「Javasript」 全コース
最初は王道のProgateさんにて学習を開始しました。
意識した事:このころはWEBコーダーを目指していたので基本的なWEBサイトの構造をおおまかに理解して先にどんどん進めることを意識して学習しました。
・ドットインストールにて「Bootstarap入門」
フレームワークの存在をしりメジャーなBootstarapを学習しようと開始
意識した事:やはりとりあえず手を動かして先に進めることを意識
・youtebeにて「Bootstarap tutorial」の模写
youtubeにアップされている外人さんの解説付きのチュートリアルを2つ模写
LPの基本的な書き方やページ内での移動のさせ方などを理解できた。
参考:https://www.youtube.com/watch?v=gqOEoUR5RHgここまでで大体一ヶ月かかりました。
学習手順は有名な良サイト東京フリーランスさんのデイトラ1stを参考にしました。
https://tokyofreelance.jp/30daystrial-coding-2nd/WEBコーディングに関しては模写できるレベルになるまでとりあえず先に進めてしまうのが効率いいと感じました。
12月6日
・自分はどのようなエンジニアになりたいか考える
東京フリーランスさんのデイトラ1stが終わり、今後の自分について1日思考しました。(デイトラ2nd以降はフロントエンドエンジニアになるための学習になっていく為)
この時自分はサーバーサイドの言語を使って便利なアプリを作ってみたいとも思っており、難易度は上がってしまうが挑戦してみようと方向転換しバックエンドエンジニアになるための学習をはじめることにしました。12月7日~12月18日
・Progate「Ruby」「rails」全コース
まずはProgateにて学習開始、railsコースは2周しました。
本格的なプログラミングに初めて触れ難しさに驚愕意識した事:railsコースの2周目は自分のローカル環境にて実装しました。
Progate上の用意されエディターとは違いエラーなども多く苦戦しましたが良い学習になりました。・Udemyにて「railsコース」
動画教材にてRuby,railsの基礎的な部分、基本的なCRUDなどを学習
dockerやcloud9などを利用する環境構築の手引きがありがたかった印象意識した事:dockerなどを使用しての環境構築の部分を記事にしてアウトプットして残しておくなど工夫しました。初学者には難易度高い環境構築の部分は動画教材を参考にしたほうが効率が良いと思います。
参考:フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座
https://www.udemy.com/course/rails-kj/
はじめての Ruby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう
https://www.udemy.com/course/the-ultimate-ruby-on-rails-bootcamp/・rails tutorial開始
railsの学習といえばコレ!というほど有名な教材
意識した事:文字の教材ということもあり難易度が急激に上がった為、1周目は雰囲気を掴むため通しで読みきり2周目に自分のローカルにて学習しました。結果的にわからなくて先にどんどん進めていくのが完走目指すには最適と感じました。
12月19日~1月19日
・ポートフォリオ製作
いろんな方の動画や記事にてある程度学習したらすぐにポートフォリオ製作に移ったほうが良いと発言されいます。自分もそれに習い早めに作成を開始しました。
結果から言うと早めに初めて本当に良かった思います自分で考えてコードを書く、わからないことを調べて実装する これが思った以上に頭に残りますしどんな学習よりも効率よいと実感しました。
僕が作成したポートフォリオアプリは自動コーディネートアプリというものでその日の気温から最適な洋服を選んで表示してくれるアプリです。
昔から欲しかったものを自分で作り上げられたことに素直にうれしいです。意識した事:学習してきた機能に関しては問題なく実装できたのですがそれ以外の部分に関しては実装方法調べて自分のアプリ用にカスタマイズして作成していきました。
具体的に
・多対多の関係を利用したタグ機能の実装
・外部APIを利用して気象情報を取得し反映させる
・条件分岐を使用して多数のコーディネートを反映させる
・洋服のカテゴリー別ユーザーページの実装 などなど
別の記事にてポートフォリオについては詳しく書こうと思っています。参考までにポートフォリオサイトのgithubとURLを載せておきます
「ポートフォリオサイト Ocean」
https://oceanmorningggg.herokuapp.com/
github
https://github.com/MKprojects39/Ocean1月20日~1月31日
・Git Githubの復習 CicleCiの実装
一人で開発していましたが作業用ブランチを使用してやってみたりはしていたが、理解が足りないと感じたので新しいtestappを作成し疑似的に共同開発の練習をしたりして学習。
CicleCiも試験的に導入してみました。とりあえず自動テストが走るように組み込むことを目標にしました。・Udemy 「Vue.jsコース」
自分のプロフィールサイトがあると便利なのでVue.jsを使用して作成したいと思い学習開始しました。
最近javascriptに力を入れてる企業さんも多いそうなのでどんなものか知りたかったのもあります。意識した事:17時間のコースでボリュームがかなりあったので手を動かすとこ、見て理解に徹するとこのメリハリを意識し効率よく最後まで完走させました。
参考:超Vue JS 2 入門 完全パック - もう他の教材は買わなくてOK! (Vue Router, Vuex含む) https://www.udemy.com/course/vue-js-complete-guide/
この方の動画は声がハキハキしており眠くならずに完走できました。話も分かりやすいのでおすすめですよ!(長時間の動画学習は眠くなるものが多いのでw)
2月1日~2月20日
・Vue.jsを使用してのプロフィールサイトの製作
Udemyにての学習が終わりすぐにプロフィールサイトの作成を開始しました。
意識した事:今回はシンプルに見やすいサイトにしたかったので凝った細工はあまりしてません。
Vue.jsとfirebaseを利用して最速でSPAを作ることを意識して実装。
今後はfirebaseも深堀してVueXの恩恵を受けれるアプリを作成したいです参考:My profile
https://my-profile-yk.firebaseapp.com/2月21日~
・転職活動を開始
現在、転職活動をしております
都内でコードレビュー文化のあるWEB系企業に入りたいので頑張ります!読んでいただきありがとうございました。
- 投稿日:2020-02-22T14:10:47+09:00
エ
はじめに
初めまして YKと申します
自己紹介
現在25歳でIT機器関連のテクニカルサポートの仕事をしております。
2019年11月頃に、PG関連に興味を持ち最初はHTMLから入り最終的にはRubyやrailsなどのサーバーサイドの方まで学習しました。
今回は振り返りで、どのように何を学習してきたかまとめます。なにを学習してきたか?(時系列順)
11月5日~12月5日
・Progate 「HTML & CSS」「Javasript」 全コース
最初は王道のProgateさんにて学習を開始しました。
意識した事:このころはWEBコーダーを目指していたので基本的なWEBサイトの構造をおおまかに理解して先にどんどん進めることを意識して学習しました。
・ドットインストールにて「Bootstarap入門」
フレームワークの存在をしりメジャーなBootstarapを学習しようと開始
意識した事:やはりとりあえず手を動かして先に進めることを意識
・youtebeにて「Bootstarap tutorial」の模写
youtubeにアップされている外人さんの解説付きのチュートリアルを2つ模写
LPの基本的な書き方やページ内での移動のさせ方などを理解できた。
参考:https://www.youtube.com/watch?v=gqOEoUR5RHgここまでで大体一ヶ月かかりました。
学習手順は有名な良サイト東京フリーランスさんのデイトラ1stを参考にしました。
https://tokyofreelance.jp/30daystrial-coding-2nd/WEBコーディングに関しては模写できるレベルになるまでとりあえず先に進めてしまうのが効率いいと感じました。
12月6日
・自分はどのようなエンジニアになりたいか考える
東京フリーランスさんのデイトラ1stが終わり、今後の自分について1日思考しました。(デイトラ2nd以降はフロントエンドエンジニアになるための学習になっていく為)
この時自分はサーバーサイドの言語を使って便利なアプリを作ってみたいとも思っており、難易度は上がってしまうが挑戦してみようと方向転換しバックエンドエンジニアになるための学習をはじめることにしました。12月7日~12月18日
・Progate「Ruby」「rails」全コース
まずはProgateにて学習開始、railsコースは2周しました。
本格的なプログラミングに初めて触れ難しさに驚愕意識した事:railsコースの2周目は自分のローカル環境にて実装しました。
Progate上の用意されエディターとは違いエラーなども多く苦戦しましたが良い学習になりました。・Udemyにて「railsコース」
動画教材にてRuby,railsの基礎的な部分、基本的なCRUDなどを学習
dockerやcloud9などを利用する環境構築の手引きがありがたかった印象意識した事:dockerなどを使用しての環境構築の部分を記事にしてアウトプットして残しておくなど工夫しました。初学者には難易度高い環境構築の部分は動画教材を参考にしたほうが効率が良いと思います。
参考:フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座
https://www.udemy.com/course/rails-kj/
はじめての Ruby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう
https://www.udemy.com/course/the-ultimate-ruby-on-rails-bootcamp/・rails tutorial開始
railsの学習といえばコレ!というほど有名な教材
意識した事:文字の教材ということもあり難易度が急激に上がった為、1周目は雰囲気を掴むため通しで読みきり2周目に自分のローカルにて学習しました。結果的にわからなくて先にどんどん進めていくのが完走目指すには最適と感じました。
12月19日~1月19日
・ポートフォリオ製作
いろんな方の動画や記事にてある程度学習したらすぐにポートフォリオ製作に移ったほうが良いと発言されいます。自分もそれに習い早めに作成を開始しました。
結果から言うと早めに初めて本当に良かった思います。自分で考えてコードを書く、わからないことを調べて実装する これが思った以上に頭に残りますしどんな学習よりも効率よいと実感しました。
- 投稿日:2020-02-22T12:54:55+09:00
[Django] コマンド備忘録
Django作成したwebアプリケーションをUbuntu EC2上で動かすときに良く使うコマンドを載せておきます。(ど初心者です。笑)
・EC2へSSH接続やつ(AWSマネジメントコンソールでEC2が起動していることを確認)
bash
$ ssh -i "秘密鍵名.pem" ubuntu@EC2のパブリックIP
※秘密鍵が置いてあるディレクトリで実行。・サーバ起動やつ
bash
$ python3 manage.py runserver 0.0.0.0:8000[例]・サーバを殺すやつ
bash
$ kill `lsof -ti tcp:8000`↓お世話になってるやつ。
[Django]https://www.udemy.com/course/django-beginner/
- 投稿日:2020-02-22T11:56:37+09:00
EC2でvolumeアタッチしたはずなのに、possibly out of free disk space とかでる時は、パーテーションの拡張を確認してみる
概要
急に
possibly out of free disk spaceといったエラーがでた時の原因のひとつ。
EC2のinstanceを生成する時には、十分な容量のEBSボリュームをアタッチしたはずなのになあ、おかしいなと思っていたところ、割り当てたボリュームが認識されていないという問題がありました。動作環境
AWS CentOS Linux release 7.7.1908 (Core)
解決策
まず、パーテーションの確認を行います。
xvdaには最初にアタッチした160GBのストレージを確認できますが、実際に使われているのは、そのうちのxvda2のパーテーションの34GBしかないです。$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 160G 0 disk ├─xvda1 202:1 0 1G 0 part /boot └─xvda2 202:2 0 34G 0 part /この時のdisk容量を確認すると、見事100%になっています。
$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 225M 7.6G 3% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 34G 34G 0 100% / /dev/xvda1 1014M 192M 823M 19% /boot tmpfs 1.6G 0 1.6G 0% /run/user/1000したがって、この状況を解決するには、
まず、xvda2のパーテーションを拡張する必要があります。
その時にgrowpartというツールを使うので、インストールします。
growpartをinstallできない場合は、空き容量がないということなので、いらないファイルを削除して、再試行するするとうまくいくと思います。$ sudo yum install cloud-utils-growpart $ sudo growpart /dev/xvda 2 # xvdaの2番目のパーテーション(xvda2)を拡張$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 160G 0 disk ├─xvda1 202:1 0 1G 0 part /boot └─xvda2 202:2 0 159G 0 part /パーテーションを拡張できました!
念の為、ファイルサイズを確認すると、、、
$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 225M 7.6G 3% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 34G 34G 249M 100% / /dev/xvda1 1014M 192M 823M 19% /boot tmpfs 1.6G 0 1.6G 0% /run/user/1000あれれ。。。まだ使用率が100%になっています。
このままだと、xvda2のファイルサイズが、元の34GBのままなので、今度はファイルシステムを拡張する必要があります。その前に、ext2、ext3、ext4、XFSといったどのファイルシステムでxvdaが管理されているのかを確認します。$ df -T ファイルシス タイプ 1K-ブロック 使用 使用可 使用% マウント位置 devtmpfs devtmpfs 8110620 0 8110620 0% /dev tmpfs tmpfs 8132940 0 8132940 0% /dev/shm tmpfs tmpfs 8132940 229880 7903060 3% /run tmpfs tmpfs 8132940 0 8132940 0% /sys/fs/cgroup /dev/xvda2 xfs 35640300 35386356 253944 100% / /dev/xvda1 xfs 1038336 195928 842408 19% /boot tmpfs tmpfs 1626592 0 1626592 0% /run/user/1000xvda2はxfs形式であることが確認できました。
それでは、xvda2のmount pointである/からファイルシステムを拡張します。$ sudo xfs_growfs -d / meta-data=/dev/xvda2 isize=512 agcount=31, agsize=288256 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=0 spinodes=0 data = bsize=4096 blocks=8912635, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 data blocks changed from 8912635 to 41680635無事ファイルシステムを拡張することができました!
$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 225M 7.6G 3% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 159G 34G 126G 22% / /dev/xvda1 1014M 192M 823M 19% /boot tmpfs 1.6G 0 1.6G 0% /run/user/1000volumeの確認→パーテーションの拡張→ファイルシステムの拡張の順番で処理していけば大丈夫そうですね。
参考
- 投稿日:2020-02-22T09:55:37+09:00
AWS Athena を使い始める前の基礎理解
はじめに
Amazon Athena を利用する前に理解すべき基礎について、【AWS Black Belt Online Seminar】Amazon Athena - YouTube を参考にまとめました。
Amazon Athena とは
S3 上のデータに対して、標準SQL によるインタラクティブなクエリを投げてデータ分析をできるサービス。特徴については下記参照。
- サーバレスでインフラ管理必要無し
- 大規模データに対しても高速なクエリ
- 事前のデータロードなしに S3 に直接クエリ
- スキャンしたデータに対しての従量課金
- JDBC / ODBC / API 経由で BIツールやシステムと連携
- ODBC : RDBMS にアクセスするための共通インタフェース
- JDBC : Java と関係データベースの接続のためのAPI
ユースケース
- 新しく取得したデータに対して、データウェアハウスに入れる価値があるか探索的に検証
- データウェアハウス(ex. Redshift)は管理コストがかかる
- 利用頻度の低い過去のデータに対する BI ツール経由のアドホックな分析
- データウェアハウスだとストレージコストがかかるため
- Webサーバのログを S3 に保存しておくことで、障害発生時に SQL で原因追求できる
- UNIX コマンドで調査が不要になる
- 程頻度実施のETLツール
Amazon Athena のアーキテクチャ
クエリエンジン
- Presto を利用
- データをディスクに書き出さず、全てメモリ上で処理
- ノード故障やメモリ溢れが起きたらクエリ自体が失敗する
- バッチ処理ではなく、インタラクティブクエリ向け
メタデータの管理
- AWS Glue
- Data Catalog でメタデータを管理する
- メタデータとは、DB / Table / View / Partition
Amazon Athena 基本
テーブル定義
- 標準のテーブル定義の後に、データ形式、圧縮形式、データの場所などを指定
- Glue で S3 データに対して Crawler を投げてテーブル登録することも可能
- スキーマオンリードなので、同一のデータに複数のスキーマを定義可能
- スキーマとはデータベースの設計図のようなもの
利用できるデータ型
データ形式
データの圧縮形式
GZIP はあまり効率的ではない。
対応クエリ
- Presto と同様、標準 ANSI (米国規格協会) SQL に準拠したクエリ
- WITH, Window関数, JOIN などに対応
SQLの標準規格は、ANSI(米国規格協会)やISO(国際標準化機構)といった標準化団体により、数年に一度改訂されます。
改訂ごとに決められた規格は、制定された年ごとに「SQL:1999」「SQL:2003:「SQL:2003」「SQL:2008」「SQL:2011」「SQL:2016」などと呼ばれます。こうした標準規格に準拠したSQLが標準SQLです
ただし、SQLの標準規格に「すべてのRDBMSは標準SQLを使わなければならない」という強制力はありません。標準SQLをサポートしたRDBMSは増えましたが、それでも標準SQLで書いたSQL文を実行できないことがあります。
DDL / クエリの注意点
- DDL(Data Definition Language) とはデータ定義言語のこと
- SQL でいうと
CREATE、DROP、ALTER、TRUNCATE- DDLでは、EXTERNAL TABLE のみ利用可能
- データは常に S3 にあり、Athena サービス外のため
- VIEW、CTAS にも対応
- 以下の処理には未対応
- トランザクション処理
- UDF / UDAF
- ストアドプロシージャ
Athena API
- Athena はSQL クライアントからだけでなく、プログラムから API を呼び出すことができる
- API は大きく2種類
- Query Execution API
- クエリを実行することに関する API
- Named Query API
- クエリの保存機能に対する API
Amazon Athena の特性
- OLTP(Online Transactional Processiong) ではなく、OLAP(Online Analytical Processing)向け
- そもそもトランザクションは未サポート
- ETL ではなく分析向け
- データをフルスキャン&変換するのは高コストな設計
- リトライ機構がないので、安定的なバッチ処理には向かない
- いかにして読み込むデータ量を減らすかが重要
- パーティション
- 列指向フォーマット
- 圧縮
スキャン量の減らし方
Athena の特性において、コスト削減のためにはいかにしてS3から読み込むデータ量を減らすかが重要。減らし方については下記。
パーティション
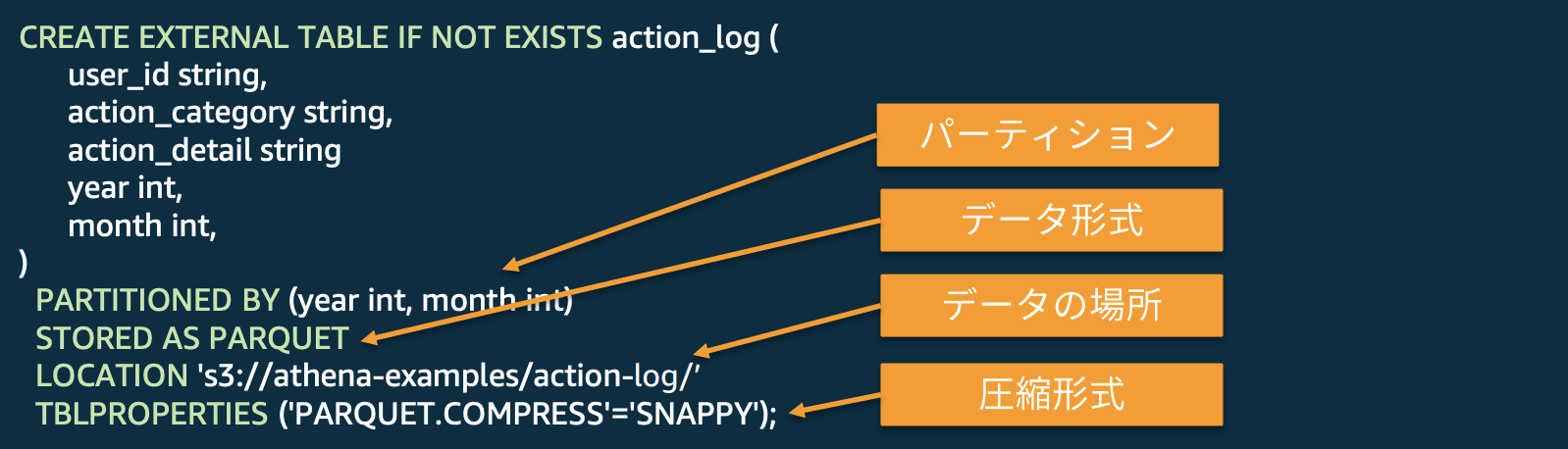
S3 のオブジェクトキーの構成を CREATE TABLE に反映
- 例:
S3://athena-examples/action-logs/year=2020/month=02/day=21/data_01.gzのように保存されている場合、下記のように DDL を発行し、クエリを実行するとWHERE句で絞ったS3 パスのみ読み込まれるためスキャン量が減る。CREATE EXTERNAL TABLE IF NOT EXISTS action_log ( user_id string, action_category string, year int, month int, day int ) PARTITIONED BY (year int, month int, day int) STORED AS PARQUET LOCATION 's3://athena-examples/action-log/’ TBLPROPERTIES ('PARQUET.COMPRESS'='SNAPPY');
WHERE句で 2016年の4月~7月のデータを指定SELECT month , action_category , action_detail , COUNT(user_id) FROM action_log WHERE year = 2016 AND month >= 4 AND month < 7 GROUP BY month , action_category , action_detail以下のS3パスのみ読み込まれるのでスキャン量を削減できる
パーティションの分け方
s3://athena-examples/action-logs/year=2020/month=02/day=21/data_01.gzのように、col=val1/col2=val2のような Hive 標準の方が推奨
- MSCK REPAIR TABLE` は、パーティションを Athena で認識されるためのコマンド
s3://athena-examples/action-logs/2020/02/21/data_01.gzのようにval1/val2のような形式もありだが少し面倒





- 投稿日:2020-02-22T07:02:24+09:00
AWS試験対策(⑨データベース)
データベース編です。正直苦手分野だけど頑張って覚えていきたいと思う。
まず、こんなような違いがある
表をここに作る…
トランザクション処理は、一連の処理ってこと。(〇〇をして△△をしてワンセット的な)
RDS
Amazon Relational Database Serviceのこと。よーするにメジャーなmySQLとかMariaDBとか使える。
異なるAZでデータを複製する、multi-AZ構成な可能。よーするにデータの複製をほかのAZに置ける。稼働系をプライマリ、待機系をスタンバイという。
プライマリが障害などで死んだら、待機系に自動フェイルオーバーしてくれる。
OSのパッチ適用の場合、待機系からやってくれる。リードレプリカ
書き込み用ロードワーク(DBに変更が起こるもの)はプライマリDBへ。読み取り用ロードワーク(DBに変更が起こらないもの)はリードレプリカを参照することによって、負荷が軽減できて効率がいい。
最大5台つくれる。Auroraなら15台。ストレージタイプ
汎用、プロビジョンドIOPS、マグネティックの3種類がある。どっかで聞いたなこれ。
EBSと同じで汎用が普通の、プロビジョンドIOPSが優秀の、マグネティックはちょっと古いのだ。
というかログやデータベースの保存先はEBSなのでまんまEBSやんこれ。
ストレージ容量は稼働中に増やすことができるが、減らすことはできない。新しく作ってそっちに移行しなきゃだめ。
ちなみにプロビジョンドIOPSだけキャパシティ課金がある。早いから代償か。
マグネティックは取り出すときにもお金かかるよってやつ。バックアップ
自動でバックアップ作成、保存してくれる。バックアップの時間を指定すれば、事前に設定したバックアップ保持期間の期間だけ保持してくれる。7日間保持に設定すれば7日前のバックアップまでは戻れる。
手動でもバックアップ可能。
DBを削除するとき、自動バックアップは消えるが手動バックアップは消えない。
multi-AZにしていない場合、プライマリDBで障害が発生した場合、自動のバックアップからリストアしてくれる。そして、アプリとかの接続先をリストアされた新しい方に向けてくれる。有能。メンテナンスウィンドウ
RDSのメンテをするには、オフラインにする必要がある。
セキュリティパッチやインスタンスの信頼性に関するパッチだけは必須として自動的にスケジュールされる。
また、すべてのDBインスタンスには週次のメンテナンスウィンドウがある。変更やソフトウェアのパッチ適用が来た際に、タイミングを指定できる。
例えば、来週の何時から何時って指定したらその間にやってくれる。スケジューリング。
DBがmulti-AZの場合、まずはスタンバイDBから。(前述)
そのあと、スタンバイがプライマリになって(切り替え)、スタンバイになったDBにメンテナンス実行される。(自動切り戻しされない)Aurora
名前が好き。
AWSが提供してるDBエンジン。
特徴は、高度なmulti-AZ、自動復旧、大容量ストレージのサポート、高いスループット。
普通のRDSなら2つのAZに一台ずつのレプリケーションだが、Auroraなら3つのAZに2台ずつ。つまり最低6台。
ストレージも通常32TiBのところ、64TiB。
リードレプリカも前述のとおり3倍の15台。
データ損失がないうえ、自動フェイルオーバーもしてくれる。
しかしレプリケーションは非同期的。ミリ秒単位。Auroraのデータはクラスターボリュームというとこに保存される。
3つのAZにそれぞれ2つずつクラスターボリュームが作られる。要するに、上記レプリケーションとは別に、6つのクラスターボリュームがある。データコピー。
インスタンスが6この、データコピーが6こって感じ。フェイルオーバーの際は、使用可能なリードレプリカに自動的にフェイルオーバーしてくれる。
クラスターエンドポイントというものがあるため、フェイルオーバーが発生しても参照先を変える必要はない。クラスターエンドポイントが自動的に参照先切り替えしてくれる。
まあこのへんはRDS使ってるから同じって考えれば。DynamoDB
マルチリージョンの高速なNoSQL。
リクエストされた大量の連続したデータを高速にデータベースに蓄積できる。
たとえばログとか。SNSアクセス情報とか。IoTとか。
テーブルを自動的にスケールアップ、スケールダウンして、容量を調整して、パフォーマンスを維持してくれる。
データ容量の制限はない。テーブル内の各項目が400KBという制限はあるが。
3つのAZで書き込みをしている。しかし、2つ書き込まれたら書き込み完了の判定になる。残り一個は時間が経ったら同期される。
つまり、S3と同じ。結果整合性モデル。読み込みタイミング悪いと更新前のデータが帰ってくる場合がある。
これがいやなら、強力な整合性のある読み込みオプションを指定すれば最新のデータを受け取れる。しかし、読み取り速度は遅くなるしコストもかかる。ElastiCache
セッション情報やアプリケーションの一時データに高速アクセスできる。
しかし利用できるデータ量に制限がある。パフォーマンス重視の場合は、ElastiCacheに一時的にデータ格納して処理すると早い。
エンジンは2種類ある。
- Memcached用ElastiCache
扱うデータ型、暗号化、高可用性構成、コンプライアンスなどの対応が不要なシンプルなやつ。マルチスレッド対応。並行処理できる。
- Redis用elastiCache 複雑なデータ型、暗号化、高可用性、コンプライアンスへの対応ができる。しかしマルチスレッドはなし。
要するに細かい書き込みめっちゃ早くてでかいのがDynamoDB。容量制限あるが取り出しめちゃくちゃ早いのがElastiCache。
Redshift
データウェアハウス。たくさんの量のデータを入れておいて集計とかできる。
アプリケーションからのリクエストを1つ以上のノードで分散処理することで、高速なデータ処理ができる。
また、列指向型(普通行で横に処理していくが、列なら縦に処理する。)で大容量データへのI/Oを削減してる。
同じ分類のデータの集計や分析が早い。適したワークロードは、ペタバイト級のデータを扱う時や、一つのSQLが複雑で同時実行が少ないときや、データを一括で更新するとき。
同じ大容量のDynamoDBは細かいデータを処理するのが得意だったけど、Redshiftは大きいデータを一括でやりたいタイプ。
適したシナリオはBIツールによるデータ分析、データウェアハウス、データ集計など。Redshiftのアーキテクチャ
クラスターで構成され、1つのリーダーノードと複数のコンピューティングノードで構成。
リーダーノードはリーダーなのでコンピューティングノードに指示を出す役割。
コンピューティングノードはリーダーからもらった指示の実行や、実行後の中間結果を返送したりする。
アプリケーションはリーダーとやり取りなので、コンピューティングノードを気にしない形になってる。
コンピューティングノードではメモリ、CPU、ディスクストレージが分割され、データも分散して格納される。その分割(スライス)毎にデータの並列処理ができるため、高速なデータ処理ができる。
メモリなどはノードタイプによって決まる。ノードタイプ
Dense Compute
DC。SSDで高パフォーマンス。500GBまではこっちがコスパいい。Dense Storage
DS。HDD。コスト削減やスケール拡大がありそうならこっち。バックアップ
S3へ自動バックアップ。最大35日まで保持できる。任意のタイミングの手動バックアップもできる。手動は自分で消すまで消されない。
クラスター削除するときに、スナップショットとっておくか聞かれる。復元したいならそれを使えばいい。ノード障害
クラスター内で障害発生した場合、障害ノードを自動的に検知して障害ノードを新しいノードに交換してくれる。
交換完了するまで更新不可。交換完了したらよく使うデータをS3から持ってきて速やかな更新が行えるようにする。
ノードが一つしかない場合、ノード障害が起きてしまったらスナップショットから復元しなきゃいけなくなるので、最低2つ以上のノードを使っておくと安心。Redshift Spectrum
データウェアハウスとして使ってると、容量大きくなり、ロードに時間がかかったりする。
そのためこいつの出番。S3にあるファイルを外部テーブルとして定義し、アクセス可能になる。普通ならコピーしなきゃいけなかったものが、こいつを間に噛ませることによって直接参照できるようになる。以上!表は後で追加する!