- 投稿日:2020-01-12T21:18:13+09:00
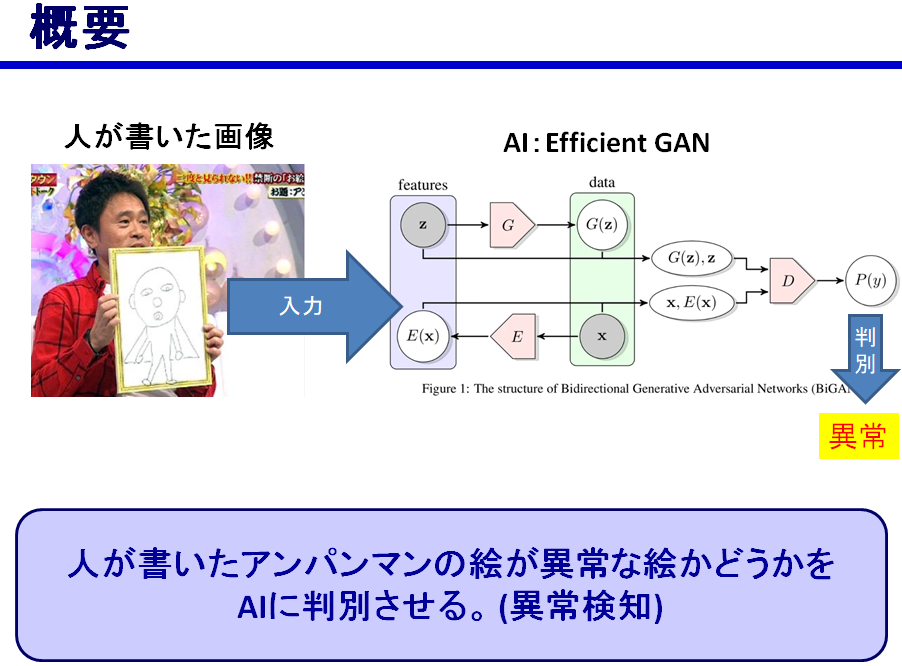
アンパンマン画伯判別機を作ってみた
はじめに
AIを勉強して学んだ技術で簡単なアプリを作ってみようと思い、
以下のようなものを作ってみました。
何故アンパンマンにしたかというと、簡単に書ける漫画キャラという事で選びました。
モデルはGANを扱ってみたかったのと、正常画像のみの学習で異常検知ができるという事で
ANOGANにしようと思いましたが、調べてみるとANOGANの高速版でEfficientGANという
ものがあるらしいので、それにしました。
また、シンプルにするためアンパンマンの顔だけを判別する前提で作成しました。流れ
1. AIにアンパンマンの正常画像を学習させる。
2. 正常画像群と異常画像群をAIに入力し、それぞれのスコアの平均の中間値を
異常画像を判別する閾値に設定。
3. 実際に手書き画像を入力し、AIにその絵が異常かどうか判別させる。やったこと
データセット作成
・学習用画像
ネットからスクレイピングでアンパンマン画像を集め、画像を加工して顔だけ切り取りました。
また後述の通り携帯撮影画像の背景がグレーになっていたので、背景も学習させるため
下記関数を用いて、グレーのグラデーションのデータ拡張を行いました。from PIL import Image, ImageOps import numpy as np def make_gray_gradation(img, gradation_range=(230, 255)): """ 入力画像の背景をランダムな度合いのグレイグラデーションに変換する Input : 画像ファイル(カラーでも可) Output : 画像ファイル(背景がグレイグラデーション変換された画像) Pramater img : 入力画像 gradation_range : グラデーションするRGB値の範囲 """ gra_range = np.random.randint(*gradation_range) gray = ImageOps.grayscale(img) output = ImageOps.colorize(gray, black=(0, 0, 0), white=(gra_range, gra_range, gra_range)) return output・正常画像群と異常画像群
正常画像は、イラスト画像を透かして画用紙に書いたアンパンマンと、
私と学友が書いたアンパンマンを携帯で撮影した画像を用いました。異常画像は、バイキンマンやドキンちゃん等のイラスト画像を上記同様に携帯で撮影した画像と
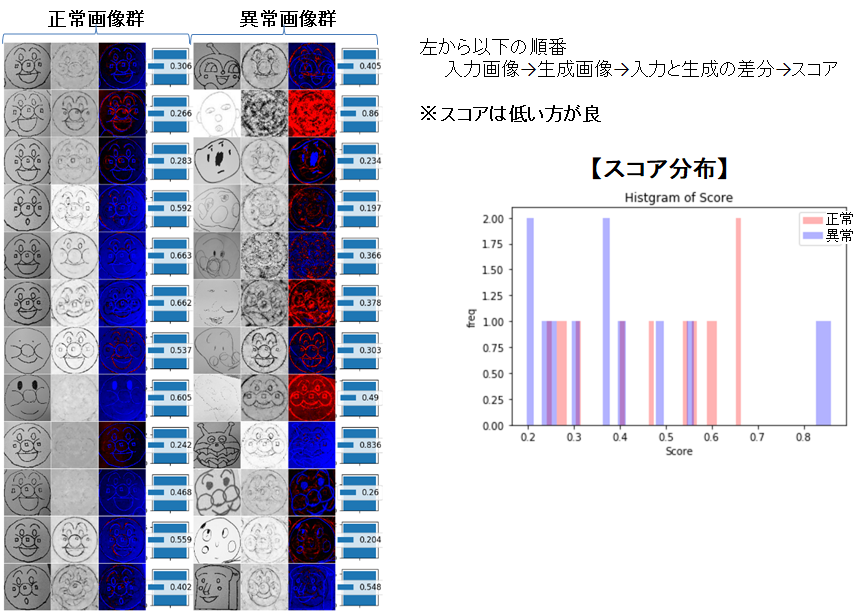
ネットでスクレイピングした下手なアンパンマン画像を用いました。学習後、正常画像群と異常画像群の入力、生成画像比較、スコア分布
携帯で撮影した入力画像の背景がグレーになっていたので、学習用画像にグレーのグラデーションも
入れたのですが、うまく再現できませんでした。
スコアもアンパンマンの絵がうまく書けているかよりも、背景がうまく生成できているかどうかで
決まっているようで、異常画像を判別するための閾値がうまく決まりませんでした。対策 2値化
対策として、すべての画像について背景は全て真っ白にして、絵の輪郭がアンパンマンに似ているかだけで
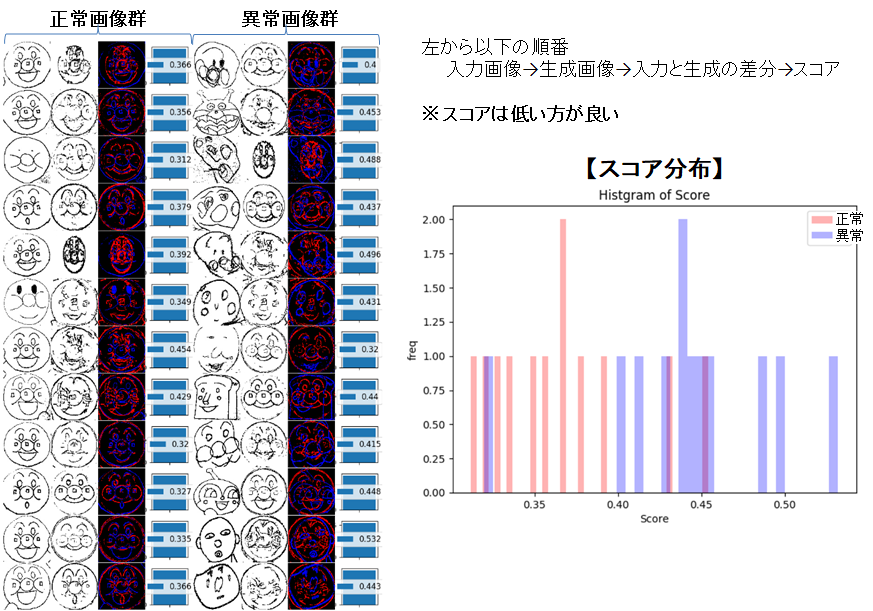
異常な絵かどうか判別できるようにしました。以下は入力画像を2値化する関数です。import os import scipy.stats as stats from PIL import Image def image_binarization(path_in, path_out, th_zero_num=1400, width=100, height=100): """ 入力画像の輪郭を白黒で2値化して出力する。 Input : 画像ファイルが保存されているフォルダパス(終わりは/) (フォルダには画像以外入れない) Output : 2値化後の画像を指定フォルダに保存。 2値化後の0(輪郭線)のドット数を出力。 Pramater path_in : 入力画像群が入ったディレクトリパス path_out : 出力ディレクトリパス th_zero_num : 画像の0(輪郭線)のドット数のMIN値(輪郭が濃過ぎる時は小さくして調整) width : 画像の横幅サイズ height : 画像の縦幅サイズ """ list_in = os.listdir(path_in) im_np_out = np.empty((0, width*height)) for img in list_in: path_name = path_in+img x_img = cv2.imread(path_name) x_img = cv2.resize(x_img, (width, height)) x_img= cv2.cvtColor(x_img, cv2.COLOR_BGR2GRAY) x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1, width, height)) x_img = x_img.reshape(1, width*height) m = stats.mode(x_img) max_hindo = m.mode[0][0] for c in reversed(range(50)): th = (c+1)*0.01 th_0_1 = max_hindo-th x_img_ = np.where(x_img>th_0_1, 1, 0) if (np.count_nonzero(x_img_ == 0))>th_zero_num: break display(np.count_nonzero(x_img_ == 0)) x_img = x_img_.reshape(width, height) x_img = (x_img * 2.0) - 1.0 img_np_255 = (x_img + 1.0) * 127.5 img_np_255_mod1 = np.maximum(img_np_255, 0) img_np_255_mod1 = np.minimum(img_np_255_mod1, 255) img_np_uint8 = img_np_255_mod1.astype(np.uint8) image = Image.fromarray(img_np_uint8) image.save(path_out+img, quality=95)対策後、正常画像群と異常画像群の入力、生成画像比較、スコア分布
正解画像と異常画像で、ある程度スコアの分布が分かれましたので、とりあえずざっくりと
正常、異常を分ける閾値を決められそうです。(閾値は0.40372に決められていました)入力したアンパンマン画像が正常な絵か、異常な絵か判別
入力画像
5枚だけイラスト画像を透かして書いたアンパンマン画像を入力し、
他はネットでスクレイピングした下手なアンパンマンを14枚を入力しました。
(上記の2値化関数を用いて2値化してから入力)判別結果
判別結果はスコア表示枠の背景の色で表されます。背景が青なら正常画像、赤なら異常画像です。
結果は、イラストを透かしたアンパンマンは4/5が正常判定。
他のスクレイピングした下手なアンパンマンは8/14が異常判定で
正解率12/19=63.15%でした。もっと精度上げないといけないですね。学んだこと
・真っ白な画用紙に描いた絵を撮影したにもかかわらず、実際の画像は背景がグレーだったので
光の影響の大きさを感じたとともに、2値化等やり方を工夫して、より学習しやすい条件に限定する事で
精度を向上出来る事を学びました。
・GANの精度を向上させるために、GrobalAvaragePoolingやLeakyReLuやレイヤーにノイズを入れる等
いろいろ精度向上手法を試せたのが良かったと思います。(結果はあまり改善しませんでしたが)今後
GANの精度向上策をもっといろいろ調べて試していきたいですね。
また、GoogleColabやAWSのEC2を使用していたのですが、今後AWSのSageMakerやGCP等いろいろな
クラウドを使用して勉強していきたいと思っています。コード
train_BiGAN.py
train_BiGAN.pyimport numpy as np import os import tensorflow as tf import utility as Utility import argparse import matplotlib.pyplot as plt from model_BiGAN import BiGAN as Model from make_datasets_TRAIN import Make_datasets_TRAIN as Make_datasets def parser(): parser = argparse.ArgumentParser(description='train LSGAN') parser.add_argument('--batch_size', '-b', type=int, default=300, help='Number of images in each mini-batch') parser.add_argument('--log_file_name', '-lf', type=str, default='anpanman', help='log file name') parser.add_argument('--epoch', '-e', type=int, default=1001, help='epoch') parser.add_argument('--file_train_data', '-ftd', type=str, default='../Train_Data/191103/', help='train data') parser.add_argument('--test_true_data', '-ttd', type=str, default='../Valid_True_Data/191103/', help='test of true_data') parser.add_argument('--test_false_data', '-tfd', type=str, default='../Valid_False_Data/191103/', help='test of false_data') parser.add_argument('--valid_span', '-vs', type=int, default=100, help='validation span') return parser.parse_args() args = parser() #global variants BATCH_SIZE = args.batch_size LOGFILE_NAME = args.log_file_name EPOCH = args.epoch FILE_NAME = args.file_train_data TRUE_DATA = args.test_true_data FALSE_DATA = args.test_false_data IMG_WIDTH = 100 IMG_HEIGHT = 100 IMG_CHANNEL = 1 BASE_CHANNEL = 32 NOISE_UNIT_NUM = 200 NOISE_MEAN = 0.0 NOISE_STDDEV = 1.0 TEST_DATA_SAMPLE = 5 * 5 L2_NORM = 0.001 KEEP_PROB_RATE = 0.5 SEED = 1234 SCORE_ALPHA = 0.9 # using for cost function VALID_SPAN = args.valid_span np.random.seed(seed=SEED) BOARD_DIR_NAME = './tensorboard/' + LOGFILE_NAME OUT_IMG_DIR = './out_images_BiGAN' #output image file out_model_dir = './out_models_BiGAN/' #output model_ckpt file #Load_model_dir = '../model_ckpt/' #Load model_ckpt file OUT_HIST_DIR = './out_score_hist_BiGAN' #output histogram file CYCLE_LAMBDA = 1.0 try: os.mkdir('log') os.mkdir('out_graph') os.mkdir(OUT_IMG_DIR) os.mkdir(out_model_dir) os.mkdir(OUT_HIST_DIR) os.mkdir('./out_images_Debug') #for debug except: pass make_datasets = Make_datasets(FILE_NAME, TRUE_DATA, FALSE_DATA, IMG_WIDTH, IMG_HEIGHT, SEED) model = Model(NOISE_UNIT_NUM, IMG_CHANNEL, SEED, BASE_CHANNEL, KEEP_PROB_RATE) z_ = tf.placeholder(tf.float32, [None, NOISE_UNIT_NUM], name='z_') #noise to generator x_ = tf.placeholder(tf.float32, [None, IMG_HEIGHT, IMG_WIDTH, IMG_CHANNEL], name='x_') #image to classifier d_dis_f_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_g_') #target of discriminator related to generator d_dis_r_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_r_') #target of discriminator related to real image is_training_ = tf.placeholder(tf.bool, name = 'is_training') with tf.variable_scope('encoder_model'): z_enc = model.encoder(x_, reuse=False, is_training=is_training_) with tf.variable_scope('decoder_model'): x_dec = model.decoder(z_, reuse=False, is_training=is_training_) x_z_x = model.decoder(z_enc, reuse=True, is_training=is_training_) # for cycle consistency with tf.variable_scope('discriminator_model'): #stream around discriminator drop3_r, logits_r = model.discriminator(x_, z_enc, reuse=False, is_training=is_training_) #real pair drop3_f, logits_f = model.discriminator(x_dec, z_, reuse=True, is_training=is_training_) #real pair drop3_re, logits_re = model.discriminator(x_z_x, z_enc, reuse=True, is_training=is_training_) #fake pair with tf.name_scope("loss"): loss_dis_f = tf.reduce_mean(tf.square(logits_f - d_dis_f_), name='Loss_dis_gen') #loss related to generator loss_dis_r = tf.reduce_mean(tf.square(logits_r - d_dis_r_), name='Loss_dis_rea') #loss related to real image #total loss loss_dis_total = loss_dis_f + loss_dis_r loss_dec_total = loss_dis_f loss_enc_total = loss_dis_r with tf.name_scope("score"): l_g = tf.reduce_mean(tf.abs(x_ - x_z_x), axis=(1,2,3)) l_FM = tf.reduce_mean(tf.abs(drop3_r - drop3_re), axis=1) score_A = SCORE_ALPHA * l_g + (1.0 - SCORE_ALPHA) * l_FM with tf.name_scope("optional_loss"): loss_dec_opt = loss_dec_total + CYCLE_LAMBDA * l_g loss_enc_opt = loss_enc_total + CYCLE_LAMBDA * l_g tf.summary.scalar('loss_dis_total', loss_dis_total) tf.summary.scalar('loss_dec_total', loss_dec_total) tf.summary.scalar('loss_enc_total', loss_enc_total) merged = tf.summary.merge_all() # t_vars = tf.trainable_variables() dec_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="decoder") enc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="encoder") dis_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="discriminator") with tf.name_scope("train"): train_dis = tf.train.AdamOptimizer(learning_rate=0.0001, beta1=0.5).minimize(loss_dis_total, var_list=dis_vars , name='Adam_dis') train_dec = tf.train.AdamOptimizer(learning_rate=0.01, beta1=0.5).minimize(loss_dec_total, var_list=dec_vars , name='Adam_dec') train_enc = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_total, var_list=enc_vars , name='Adam_enc') train_dec_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_opt, var_list=dec_vars , name='Adam_dec') train_enc_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_opt, var_list=enc_vars , name='Adam_enc') sess = tf.Session() ckpt = tf.train.get_checkpoint_state(out_model_dir) saver = tf.train.Saver() if ckpt: # checkpointがある場合 last_model = ckpt.model_checkpoint_path # 最後に保存したmodelへのパス saver.restore(sess, last_model) # 変数データの読み込み print("load " + last_model) else: # 保存データがない場合 #init = tf.initialize_all_variables() sess.run(tf.global_variables_initializer()) summary_writer = tf.summary.FileWriter(BOARD_DIR_NAME, sess.graph) log_list = [] log_list.append(['epoch', 'AUC']) #training loop for epoch in range(0, EPOCH): sum_loss_dis_f = np.float32(0) sum_loss_dis_r = np.float32(0) sum_loss_dis_total = np.float32(0) sum_loss_dec_total = np.float32(0) sum_loss_enc_total = np.float32(0) len_data = make_datasets.make_data_for_1_epoch() for i in range(0, len_data, BATCH_SIZE): img_batch = make_datasets.get_data_for_1_batch(i, BATCH_SIZE) z = make_datasets.make_random_z_with_norm(NOISE_MEAN, NOISE_STDDEV, len(img_batch), NOISE_UNIT_NUM) tar_g_1 = make_datasets.make_target_1_0(1.0, len(img_batch)) #1 -> real tar_g_0 = make_datasets.make_target_1_0(0.0, len(img_batch)) #0 -> fake #train discriminator sess.run(train_dis, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:True}) #train decoder sess.run(train_dec, feed_dict={z_:z, d_dis_f_: tar_g_1, is_training_:True}) # sess.run(train_dec_opt, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_1, is_training_:True}) #train encoder sess.run(train_enc, feed_dict={x_:img_batch, d_dis_r_: tar_g_0, is_training_:True}) # sess.run(train_enc_opt, feed_dict={x_:img_batch, d_dis_r_: tar_g_0, is_training_:True}) # loss for discriminator loss_dis_total_, loss_dis_r_, loss_dis_f_ = sess.run([loss_dis_total, loss_dis_r, loss_dis_f], feed_dict={z_: z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:False}) #loss for decoder loss_dec_total_ = sess.run(loss_dec_total, feed_dict={z_: z, d_dis_f_: tar_g_1, is_training_:False}) #loss for encoder loss_enc_total_ = sess.run(loss_enc_total, feed_dict={x_: img_batch, d_dis_r_: tar_g_0, is_training_:False}) #for tensorboard merged_ = sess.run(merged, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:False}) summary_writer.add_summary(merged_, epoch) sum_loss_dis_f += loss_dis_f_ sum_loss_dis_r += loss_dis_r_ sum_loss_dis_total += loss_dis_total_ sum_loss_dec_total += loss_dec_total_ sum_loss_enc_total += loss_enc_total_ print("----------------------------------------------------------------------") print("epoch = {:}, Encoder Total Loss = {:.4f}, Decoder Total Loss = {:.4f}, Discriminator Total Loss = {:.4f}".format( epoch, sum_loss_enc_total / len_data, sum_loss_dec_total / len_data, sum_loss_dis_total / len_data)) print("Discriminator Real Loss = {:.4f}, Discriminator Generated Loss = {:.4f}".format( sum_loss_dis_r / len_data, sum_loss_dis_r / len_data)) if epoch % VALID_SPAN == 0: # score_A_list = [] score_A_np = np.zeros((0, 2), dtype=np.float32) val_data_num = len(make_datasets.valid_data) val_true_data_num = len(make_datasets.valid_true_np) val_false_data_num = len(make_datasets.valid_false_np) img_batch_1, _ = make_datasets.get_valid_data_for_1_batch(0, val_true_data_num) img_batch_0, _ = make_datasets.get_valid_data_for_1_batch(val_data_num - val_false_data_num, val_true_data_num) x_z_x_1 = sess.run(x_z_x, feed_dict={x_:img_batch_1, is_training_:False}) x_z_x_0 = sess.run(x_z_x, feed_dict={x_:img_batch_0, is_training_:False}) score_A_1 = sess.run(score_A, feed_dict={x_:img_batch_1, is_training_:False}) score_A_0 = sess.run(score_A, feed_dict={x_:img_batch_0, is_training_:False}) score_A_re_1 = np.reshape(score_A_1, (-1, 1)) score_A_re_0 = np.reshape(score_A_0, (-1, 1)) tars_batch_1 = np.ones(val_true_data_num) tars_batch_0 = np.zeros(val_false_data_num) tars_batch_re_1 = np.reshape(tars_batch_1, (-1, 1)) tars_batch_re_0 = np.reshape(tars_batch_0, (-1, 1)) score_A_np_1_tmp = np.concatenate((score_A_re_1, tars_batch_re_1), axis=1) score_A_np_0_tmp = np.concatenate((score_A_re_0, tars_batch_re_0), axis=1) score_A_np = np.concatenate((score_A_np_1_tmp, score_A_np_0_tmp), axis=0) #print(score_A_np) tp, fp, tn, fn, precision, recall = Utility.compute_precision_recall(score_A_np) auc = Utility.make_ROC_graph(score_A_np, 'out_graph/' + LOGFILE_NAME, epoch) print("tp:{}, fp:{}, tn:{}, fn:{}, precision:{:.4f}, recall:{:.4f}, AUC:{:.4f}".format(tp, fp, tn, fn, precision, recall, auc)) log_list.append([epoch, auc]) Utility.make_score_hist(score_A_1, score_A_0, epoch, LOGFILE_NAME, OUT_HIST_DIR) Utility.make_output_img(img_batch_1, img_batch_0, x_z_x_1, x_z_x_0, score_A_0, score_A_1, epoch, LOGFILE_NAME, OUT_IMG_DIR) #after learning Utility.save_list_to_csv(log_list, 'log/' + LOGFILE_NAME + '_auc.csv') #saver2 = tf.train.Saver() save_path = saver.save(sess, out_model_dir + 'anpanman_weight.ckpt') print("Model saved in file: ", save_path)
model_BiGAN.py
model_BiGAN.pyimport numpy as np # import os import tensorflow as tf # from PIL import Image # import utility as Utility # import argparse class BiGAN(): def __init__(self, noise_unit_num, img_channel, seed, base_channel, keep_prob): self.NOISE_UNIT_NUM = noise_unit_num # 200 self.IMG_CHANNEL = img_channel # 1 self.SEED = seed np.random.seed(seed=self.SEED) self.BASE_CHANNEL = base_channel # 32 self.KEEP_PROB = keep_prob def leaky_relu(self, x, alpha): return tf.nn.relu(x) - alpha * tf.nn.relu(-x) def gaussian_noise(self, input, std): #used at discriminator noise = tf.random_normal(shape=tf.shape(input), mean=0.0, stddev=std, dtype=tf.float32, seed=self.SEED) return input + noise def conv2d(self, input, in_channel, out_channel, k_size, stride, seed): w = tf.get_variable('w', [k_size, k_size, in_channel, out_channel], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_channel], initializer=tf.constant_initializer(0.0)) conv = tf.nn.conv2d(input, w, strides=[1, stride, stride, 1], padding="SAME", name='conv') + b return conv def conv2d_transpose(self, input, in_channel, out_channel, k_size, stride, seed): w = tf.get_variable('w', [k_size, k_size, out_channel, in_channel], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_channel], initializer=tf.constant_initializer(0.0)) out_shape = tf.stack( [tf.shape(input)[0], tf.shape(input)[1] * 2, tf.shape(input)[2] * 2, tf.constant(out_channel)]) deconv = tf.nn.conv2d_transpose(input, w, output_shape=out_shape, strides=[1, stride, stride, 1], padding="SAME") + b return deconv def batch_norm(self, input): shape = input.get_shape().as_list() n_out = shape[-1] scale = tf.get_variable('scale', [n_out], initializer=tf.constant_initializer(1.0)) beta = tf.get_variable('beta', [n_out], initializer=tf.constant_initializer(0.0)) batch_mean, batch_var = tf.nn.moments(input, [0]) bn = tf.nn.batch_normalization(input, batch_mean, batch_var, beta, scale, 0.0001, name='batch_norm') return bn def fully_connect(self, input, in_num, out_num, seed): w = tf.get_variable('w', [in_num, out_num], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_num], initializer=tf.constant_initializer(0.0)) fc = tf.matmul(input, w, name='fc') + b return fc def encoder(self, x, reuse=False, is_training=False): #x is expected [n, 28, 28, 1] with tf.variable_scope('encoder', reuse=reuse): with tf.variable_scope("layer1"): # layer1 conv nx28x28x1 -> nx14x14x32 conv1 = self.conv2d(x, self.IMG_CHANNEL, self.BASE_CHANNEL, 3, 2, self.SEED) with tf.variable_scope("layer2"): # layer2 conv nx14x14x32 -> nx7x7x64 conv2 = self.conv2d(conv1, self.BASE_CHANNEL, self.BASE_CHANNEL*2, 3, 2, self.SEED) bn2 = self.batch_norm(conv2) lr2 = self.leaky_relu(bn2, alpha=0.1) with tf.variable_scope("layer3"): # layer3 conv nx7x7x64 -> nx4x4x128 conv3 = self.conv2d(lr2, self.BASE_CHANNEL*2, self.BASE_CHANNEL*4, 3, 2, self.SEED) bn3 = self.batch_norm(conv3) lr3 = self.leaky_relu(bn3, alpha=0.1) with tf.variable_scope("layer4"): # layer4 fc nx4x4x128 -> nx200 shape = tf.shape(lr3) print(shape[1]) reshape4 = tf.reshape(lr3, [shape[0], shape[1]*shape[2]*shape[3]]) fc4 = self.fully_connect(reshape4, 21632, self.NOISE_UNIT_NUM, self.SEED) return fc4 def decoder(self, z, reuse=False, is_training=False): # z is expected [n, 200] with tf.variable_scope('decoder', reuse=reuse): with tf.variable_scope("layer1"): # layer1 fc nx200 -> nx1024 fc1 = self.fully_connect(z, self.NOISE_UNIT_NUM, 1024, self.SEED) bn1 = self.batch_norm(fc1) rl1 = tf.nn.relu(bn1) with tf.variable_scope("layer2"): # layer2 fc nx1024 -> nx6272 fc2 = self.fully_connect(rl1, 1024, 25*25*self.BASE_CHANNEL*4, self.SEED) bn2 = self.batch_norm(fc2) rl2 = tf.nn.relu(bn2) with tf.variable_scope("layer3"): # layer3 deconv nx6272 -> nx7x7x128 -> nx14x14x64 shape = tf.shape(rl2) reshape3 = tf.reshape(rl2, [shape[0], 25, 25, 128]) deconv3 = self.conv2d_transpose(reshape3, self.BASE_CHANNEL*4, self.BASE_CHANNEL*2, 4, 2, self.SEED) bn3 = self.batch_norm(deconv3) rl3 = tf.nn.relu(bn3) with tf.variable_scope("layer4"): # layer3 deconv nx14x14x64 -> nx28x28x1 deconv4 = self.conv2d_transpose(rl3, self.BASE_CHANNEL*2, self.IMG_CHANNEL, 4, 2, self.SEED) tanh4 = tf.tanh(deconv4) return tanh4 def discriminator(self, x, z, reuse=False, is_training=True): #z[n, 200], x[n, 28, 28, 1] with tf.variable_scope('discriminator', reuse=reuse): with tf.variable_scope("x_layer1"): # layer x1 conv [n, 28, 28, 1] -> [n, 14, 14, 64] convx1 = self.conv2d(x, self.IMG_CHANNEL, self.BASE_CHANNEL*2, 4, 2, self.SEED) lrx1 = self.leaky_relu(convx1, alpha=0.1) dropx1 = tf.layers.dropout(lrx1, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("x_layer2"): # layer x2 conv [n, 14, 14, 64] -> [n, 7, 7, 64] -> [n, 3136] convx2 = self.conv2d(dropx1, self.BASE_CHANNEL*2, self.BASE_CHANNEL*2, 4, 2, self.SEED) bnx2 = self.batch_norm(convx2) lrx2 = self.leaky_relu(bnx2, alpha=0.1) dropx2 = tf.layers.dropout(lrx2, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) shapex2 = tf.shape(dropx2) reshape3 = tf.reshape(dropx2, [shapex2[0], shapex2[1]*shapex2[2]*shapex2[3]]) with tf.variable_scope("z_layer1"): # layer1 fc [n, 200] -> [n, 512] fcz1 = self.fully_connect(z, self.NOISE_UNIT_NUM, 512, self.SEED) lrz1 = self.leaky_relu(fcz1, alpha=0.1) dropz1 = tf.layers.dropout(lrz1, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("y_layer3"): # layer1 fc [n, 6272], [n, 1024] con3 = tf.concat([reshape3, dropz1], axis=1) fc3 = self.fully_connect(con3, 40000+512, 1024, self.SEED) lr3 = self.leaky_relu(fc3, alpha=0.1) self.drop3 = tf.layers.dropout(lr3, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("y_fc_logits"): self.logits = self.fully_connect(self.drop3, 1024, 1, self.SEED) return self.drop3, self.logits
make_datasets_TRAIN.py
make_datasets_TRAIN.pyimport numpy as np import os import glob import re import random #import cv2 from PIL import Image from keras.preprocessing import image class Make_datasets_TRAIN(): def __init__(self, filename, true_data, false_data, img_width, img_height, seed): self.filename = filename self.true_data = true_data self.false_data = false_data self.img_width = img_width self.img_height = img_height self.seed = seed x_train, x_valid_true, x_valid_false, y_train, y_valid_true, y_valid_false = self.read_DATASET(self.filename, self.true_data, self.false_data) self.train_np = np.concatenate((y_train.reshape(-1,1), x_train), axis=1).astype(np.float32) self.valid_true_np = np.concatenate((y_valid_true.reshape(-1,1), x_valid_true), axis=1).astype(np.float32) self.valid_false_np = np.concatenate((y_valid_false.reshape(-1,1), x_valid_false), axis=1).astype(np.float32) print("self.train_np.shape, ", self.train_np.shape) print("self.valid_true_np.shape, ", self.valid_true_np.shape) print("self.valid_false_np.shape, ", self.valid_false_np.shape) print("np.max(x_train), ", np.max(x_train)) print("np.min(x_train), ", np.min(x_train)) self.valid_data = np.concatenate((self.valid_true_np, self.valid_false_np)) random.seed(self.seed) np.random.seed(self.seed) def read_DATASET(self, train_path, true_path, false_path): train_list = os.listdir(train_path) y_train = np.ones(len(train_list)) x_train = np.empty((0, self.img_width*self.img_height)) for img in train_list: path_name = train_path+img x_img = Image.open(path_name) # サイズを揃える x_img = x_img.resize((self.img_width, self.img_height)) # 3chを1chに変換 x_img= x_img.convert('L') # PIL.Image.Imageからnumpy配列へ x_img = np.array(x_img) # 正規化 x_img = x_img / 255.0 # axisの追加 x_img = x_img.reshape((1,self.img_width, self.img_height)) # flatten x_img = x_img.reshape(1, self.img_width*self.img_height) x_train = np.concatenate([x_train, x_img], axis = 0) print("x_train.shape, ", x_train.shape) print("y_train.shape, ", y_train.shape) test_true_list = os.listdir(true_path) y_test_true = np.ones(len(test_true_list)) x_test_true = np.empty((0, self.img_width*self.img_height)) for img in test_true_list: path_name = true_path+img x_img = Image.open(path_name) x_img = x_img.resize((self.img_width, self.img_height)) x_img= x_img.convert('L') x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1,self.img_width, self.img_height)) x_img = x_img.reshape(1, self.img_width*self.img_height) x_test_true = np.concatenate([x_test_true, x_img], axis = 0) print("x_test_true.shape, ", x_test_true.shape) print("y_test_true.shape, ", y_test_true.shape) test_false_list = os.listdir(false_path) y_test_false = np.zeros(len(test_false_list)) x_test_false = np.empty((0, self.img_width*self.img_height)) for img in test_false_list: path_name = false_path+img x_img = Image.open(path_name) x_img = x_img.resize((self.img_width, self.img_height)) x_img= x_img.convert('L') x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1,self.img_width, self.img_height)) x_img = x_img.reshape(1, self.img_width*self.img_height) x_test_false = np.concatenate([x_test_false, x_img], axis = 0) print("x_test_false.shape, ", x_test_false.shape) print("y_test_false.shape, ", y_test_false.shape) return x_train, x_test_true, x_test_false, y_train, y_test_true, y_test_false def get_file_names(self, dir_name): target_files = [] for root, dirs, files in os.walk(dir_name): targets = [os.path.join(root, f) for f in files] target_files.extend(targets) return target_files def read_data(self, d_y_np, width, height): tars = [] images = [] for num, d_y_1 in enumerate(d_y_np): image = d_y_1[1:].reshape(width, height, 1) tar = d_y_1[0] images.append(image) tars.append(tar) return np.asarray(images), np.asarray(tars) def normalize_data(self, data): # data0_2 = data / 127.5 # data_norm = data0_2 - 1.0 data_norm = (data * 2.0) - 1.0 #applied for tanh return data_norm def make_data_for_1_epoch(self): self.filename_1_epoch = np.random.permutation(self.train_np) return len(self.filename_1_epoch) def get_data_for_1_batch(self, i, batchsize): filename_batch = self.filename_1_epoch[i:i + batchsize] images, _ = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n def get_valid_data_for_1_batch(self, i, batchsize): filename_batch = self.valid_data[i:i + batchsize] images, tars = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n, tars def make_random_z_with_norm(self, mean, stddev, data_num, unit_num): norms = np.random.normal(mean, stddev, (data_num, unit_num)) # tars = np.zeros((data_num, 1), dtype=np.float32) return norms def make_target_1_0(self, value, data_num): if value == 0.0: target = np.zeros((data_num, 1), dtype=np.float32) elif value == 1.0: target = np.ones((data_num, 1), dtype=np.float32) else: print("target value error") return target
utility.py
utility.pyimport numpy as np # import os from PIL import Image import matplotlib.pyplot as plt import sklearn.metrics as sm import csv import seaborn as sns def compute_precision_recall(score_A_np, ): array_1 = np.where(score_A_np[:, 1] == 1.0) array_0 = np.where(score_A_np[:, 1] == 0.0) mean_1 = np.mean((score_A_np[array_1])[:, 0]) mean_0 = np.mean((score_A_np[array_0])[:, 0]) medium = (mean_1 + mean_0) / 2.0 print("mean_positive_score, ", mean_1) print("mean_negative_score, ", mean_0) print("score_threshold(pos_neg middle), ", medium) np.save('./score_threshold.npy', medium) array_upper = np.where(score_A_np[:, 0] >= medium)[0] array_lower = np.where(score_A_np[:, 0] < medium)[0] #print(array_upper) print("negative_predict_num, ", array_upper.shape) print("positive_predict_num, ", array_lower.shape) array_1_tf = np.where(score_A_np[:, 1] == 1.0)[0] array_0_tf = np.where(score_A_np[:, 1] == 0.0)[0] #print(array_1_tf) print("negative_fact_num, ", array_0_tf.shape) print("positive_fact_num, ", array_1_tf.shape) tn = len(set(array_lower)&set(array_1_tf)) tp = len(set(array_upper)&set(array_0_tf)) fp = len(set(array_lower)&set(array_0_tf)) fn = len(set(array_upper)&set(array_1_tf)) precision = tp / (tp + fp + 0.00001) recall = tp / (tp + fn + 0.00001) return tp, fp, tn, fn, precision, recall def score_divide(score_A_np): array_1 = np.where(score_A_np[:, 1] == 1.0)[0] array_0 = np.where(score_A_np[:, 1] == 0.0)[0] print("positive_predict_num, ", array_1.shape) print("negative_predict_num, ", array_0.shape) array_1_np = score_A_np[array_1][:, 0] array_0_np = score_A_np[array_0][:, 0] #print(array_1_np) #print(array_0_np) return array_1_np, array_0_np def save_graph(x, y, filename, epoch): plt.figure(figsize=(7, 5)) plt.plot(x, y) plt.title('ROC curve ' + filename + ' epoch:' + str(epoch)) # x axis label plt.xlabel("FP / (FP + TN)") # y axis label plt.ylabel("TP / (TP + FN)") # save plt.savefig(filename + '_ROC_curve_epoch' + str(epoch) +'.png') plt.close() def make_ROC_graph(score_A_np, filename, epoch): argsort = np.argsort(score_A_np, axis=0)[:, 0] value_1_0 = score_A_np[argsort][::-1].astype(np.float32) #value_1_0 = (np.where(score_A_np_sort[:, 1] == 7., 1., 0.)).astype(np.float32) # score_A_np_sort_0_1 = np.concatenate((score_A_np_sort, value_1_0), axis=1) sum_1 = np.sum(value_1_0) len_s = len(score_A_np) sum_0 = len_s - sum_1 tp = np.cumsum(value_1_0[:, 1]).astype(np.float32) index = np.arange(1, len_s + 1, 1).astype(np.float32) fp = index - tp fn = sum_1 - tp tn = sum_0 - fp tp_ratio = tp / (tp + fn + 0.00001) fp_ratio = fp / (fp + tn + 0.00001) save_graph(fp_ratio, tp_ratio, filename, epoch) auc = sm.auc(fp_ratio, tp_ratio) return auc def unnorm_img(img_np): img_np_255 = (img_np + 1.0) * 127.5 img_np_255_mod1 = np.maximum(img_np_255, 0) img_np_255_mod1 = np.minimum(img_np_255_mod1, 255) img_np_uint8 = img_np_255_mod1.astype(np.uint8) return img_np_uint8 def convert_np2pil(images_255): list_images_PIL = [] for num, images_255_1 in enumerate(images_255): # img_255_tile = np.tile(images_255_1, (1, 1, 3)) image_1_PIL = Image.fromarray(images_255_1) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_score_hist(score_a_1, score_a_0, epoch, LOGFILE_NAME, OUT_HIST_DIR): list_1 = score_a_1.tolist() list_0 = score_a_0.tolist() #print(list_1) #print(list_0) plt.figure(figsize=(7, 5)) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(list_1, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(list_0, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='0') plt.legend(loc=1) plt.savefig(OUT_HIST_DIR + "/resultScoreHist_"+ LOGFILE_NAME + '_' + str(epoch) + ".png") plt.show() def make_score_hist_test(score_a_1, score_a_0, score_th, LOGFILE_NAME, OUT_HIST_DIR): list_1 = score_a_1.tolist() list_0 = score_a_0.tolist() #print(list_1) #print(list_0) plt.figure(figsize=(7, 5)) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(list_1, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(list_0, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='0') plt.legend(loc=1) plt.savefig(OUT_HIST_DIR + "/resultScoreHist_"+ LOGFILE_NAME + "_test.png") plt.show() def make_score_bar(score_a): score_a = score_a.tolist() list_images_PIL = [] for score in score_a: x="score" plt.bar(x,score,label=score) fig, ax = plt.subplots(figsize=(1, 1)) ax.bar(x,score,label=round(score,3)) ax.legend(loc='center', fontsize=12) fig.canvas.draw() #im = np.array(fig.canvas.renderer.buffer_rgba()) # matplotlibが3.1より以降の場合 im = np.array(fig.canvas.renderer._renderer) image_1_PIL = Image.fromarray(im) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_score_bar_predict(score_A_np_tmp): score_a = score_A_np_tmp.tolist() list_images_PIL = [] for score in score_a: x="score" #plt.bar(x,score[0],label=score) fig, ax = plt.subplots(figsize=(1, 1)) if score[1]==0: ax.bar(x,score[0], color='red',label=round(score[0],3)) else: ax.bar(x,score[0], color='blue',label=round(score[0],3)) ax.legend(loc='center', fontsize=12) fig.canvas.draw() #im = np.array(fig.canvas.renderer.buffer_rgba()) # matplotlibが3.1より以降の場合 im = np.array(fig.canvas.renderer._renderer) image_1_PIL = Image.fromarray(im) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_output_img(img_batch_1, img_batch_0, x_z_x_1, x_z_x_0, score_a_0, score_a_1, epoch, log_file_name, out_img_dir): (data_num, img1_h, img1_w, _) = img_batch_1.shape img_batch_1_unn = np.tile(unnorm_img(img_batch_1), (1, 1, 3)) img_batch_0_unn = np.tile(unnorm_img(img_batch_0), (1, 1, 3)) x_z_x_1_unn = np.tile(unnorm_img(x_z_x_1), (1, 1, 3)) x_z_x_0_unn = np.tile(unnorm_img(x_z_x_0), (1, 1, 3)) diff_1 = img_batch_1 - x_z_x_1 diff_1_r = (2.0 * np.maximum(diff_1, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_1_b = (2.0 * np.abs(np.minimum(diff_1, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_1_g = diff_1_b * 0.0 - 1.0 diff_1_r_unnorm = unnorm_img(diff_1_r) diff_1_b_unnorm = unnorm_img(diff_1_b) diff_1_g_unnorm = unnorm_img(diff_1_g) diff_1_np = np.concatenate((diff_1_r_unnorm, diff_1_g_unnorm, diff_1_b_unnorm), axis=3) diff_0 = img_batch_0 - x_z_x_0 diff_0_r = (2.0 * np.maximum(diff_0, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_0_b = (2.0 * np.abs(np.minimum(diff_0, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_0_g = diff_0_b * 0.0 - 1.0 diff_0_r_unnorm = unnorm_img(diff_0_r) diff_0_b_unnorm = unnorm_img(diff_0_b) diff_0_g_unnorm = unnorm_img(diff_0_g) diff_0_np = np.concatenate((diff_0_r_unnorm, diff_0_g_unnorm, diff_0_b_unnorm), axis=3) img_batch_1_PIL = convert_np2pil(img_batch_1_unn) img_batch_0_PIL = convert_np2pil(img_batch_0_unn) x_z_x_1_PIL = convert_np2pil(x_z_x_1_unn) x_z_x_0_PIL = convert_np2pil(x_z_x_0_unn) diff_1_PIL = convert_np2pil(diff_1_np) diff_0_PIL = convert_np2pil(diff_0_np) score_a_1_PIL = make_score_bar(score_a_1) score_a_0_PIL = make_score_bar(score_a_0) wide_image_np = np.ones(((img1_h + 1) * data_num - 1, (img1_w + 1) * 8 - 1, 3), dtype=np.uint8) * 255 wide_image_PIL = Image.fromarray(wide_image_np) for num, (ori_1, ori_0, xzx1, xzx0, diff1, diff0, score_1, score_0) in enumerate(zip(img_batch_1_PIL, img_batch_0_PIL ,x_z_x_1_PIL, x_z_x_0_PIL, diff_1_PIL, diff_0_PIL, score_a_1_PIL, score_a_0_PIL)): wide_image_PIL.paste(ori_1, (0, num * (img1_h + 1))) wide_image_PIL.paste(xzx1, (img1_w + 1, num * (img1_h + 1))) wide_image_PIL.paste(diff1, ((img1_w + 1) * 2, num * (img1_h + 1))) wide_image_PIL.paste(score_1, ((img1_w + 1) * 3, num * (img1_h + 1))) wide_image_PIL.paste(ori_0, ((img1_w + 1) * 4, num * (img1_h + 1))) wide_image_PIL.paste(xzx0, ((img1_w + 1) * 5, num * (img1_h + 1))) wide_image_PIL.paste(diff0, ((img1_w + 1) * 6, num * (img1_h + 1))) wide_image_PIL.paste(score_0, ((img1_w + 1) * 7, num * (img1_h + 1))) wide_image_PIL.save(out_img_dir + "/resultImage_"+ log_file_name + '_' + str(epoch) + ".png") def make_output_img_test(img_batch_test, x_z_x_test, score_A_np_tmp, log_file_name, out_img_dir): (data_num, img1_h, img1_w, _) = img_batch_test.shape img_batch_test_unn = np.tile(unnorm_img(img_batch_test), (1, 1, 3)) x_z_x_test_unn = np.tile(unnorm_img(x_z_x_test), (1, 1, 3)) diff_test = img_batch_test - x_z_x_test diff_test_r = (2.0 * np.maximum(diff_test, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_test_b = (2.0 * np.abs(np.minimum(diff_test, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_test_g = diff_test_b * 0.0 - 1.0 diff_test_r_unnorm = unnorm_img(diff_test_r) diff_test_b_unnorm = unnorm_img(diff_test_b) diff_test_g_unnorm = unnorm_img(diff_test_g) diff_test_np = np.concatenate((diff_test_r_unnorm, diff_test_g_unnorm, diff_test_b_unnorm), axis=3) img_batch_test_PIL = convert_np2pil(img_batch_test_unn) x_z_x_test_PIL = convert_np2pil(x_z_x_test_unn) diff_test_PIL = convert_np2pil(diff_test_np) score_a = score_A_np_tmp[:, 1:] #tars = score_A_np_tmp[:, 0] score_a_PIL = make_score_bar_predict(score_A_np_tmp) wide_image_np = np.ones(((img1_h + 1) * data_num - 1, (img1_w + 1) * 8 - 1, 3), dtype=np.uint8) * 255 wide_image_PIL = Image.fromarray(wide_image_np) for num, (ori_test, xzx_test, diff_test, score_test) in enumerate(zip(img_batch_test_PIL, x_z_x_test_PIL, diff_test_PIL, score_a_PIL)): wide_image_PIL.paste(ori_test, (0, num * (img1_h + 1))) wide_image_PIL.paste(xzx_test, (img1_w + 1, num * (img1_h + 1))) wide_image_PIL.paste(diff_test, ((img1_w + 1) * 2, num * (img1_h + 1))) wide_image_PIL.paste(score_test, ((img1_w + 1) * 3, num * (img1_h + 1))) wide_image_PIL.save(out_img_dir + "/resultImage_"+ log_file_name + "_test.png") def save_list_to_csv(list, filename): f = open(filename, 'w') writer = csv.writer(f, lineterminator='\n') writer.writerows(list) f.close()
predict_BiGAN.py
predict_BiGAN.pyimport numpy as np import os import tensorflow as tf import utility as Utility import argparse import matplotlib.pyplot as plt from model_BiGAN import BiGAN as Model from make_datasets_predict import Make_datasets_predict as Make_datasets def parser(): parser = argparse.ArgumentParser(description='train LSGAN') parser.add_argument('--batch_size', '-b', type=int, default=300, help='Number of images in each mini-batch') parser.add_argument('--log_file_name', '-lf', type=str, default='anpanman', help='log file name') parser.add_argument('--epoch', '-e', type=int, default=1, help='epoch') #parser.add_argument('--file_train_data', '-ftd', type=str, default='./mnist.npz', help='train data') #parser.add_argument('--test_true_data', '-ttd', type=str, default='./mnist.npz', help='test of true_data') #parser.add_argument('--test_false_data', '-tfd', type=str, default='./mnist.npz', help='test of false_data') parser.add_argument('--test_data', '-td', type=str, default='../Test_Data/200112/', help='test of false_data') parser.add_argument('--valid_span', '-vs', type=int, default=1, help='validation span') parser.add_argument('--score_th', '-st', type=float, default=np.load('./score_threshold.npy'), help='validation span') return parser.parse_args() args = parser() #global variants BATCH_SIZE = args.batch_size LOGFILE_NAME = args.log_file_name EPOCH = args.epoch #FILE_NAME = args.file_train_data #TRUE_DATA = args.test_true_data #FALSE_DATA = args.test_false_data TEST_DATA = args.test_data IMG_WIDTH = 100 IMG_HEIGHT = 100 IMG_CHANNEL = 1 BASE_CHANNEL = 32 NOISE_UNIT_NUM = 200 NOISE_MEAN = 0.0 NOISE_STDDEV = 1.0 TEST_DATA_SAMPLE = 5 * 5 L2_NORM = 0.001 KEEP_PROB_RATE = 0.5 SEED = 1234 SCORE_ALPHA = 0.9 # using for cost function VALID_SPAN = args.valid_span np.random.seed(seed=SEED) BOARD_DIR_NAME = './tensorboard/' + LOGFILE_NAME OUT_IMG_DIR = './out_images_BiGAN' #output image file out_model_dir = './out_models_BiGAN/' #output model_ckpt file #Load_model_dir = '../model_ckpt/' #Load model_ckpt file OUT_HIST_DIR = './out_score_hist_BiGAN' #output histogram file CYCLE_LAMBDA = 1.0 SCORE_TH = args.score_th make_datasets = Make_datasets(TEST_DATA, IMG_WIDTH, IMG_HEIGHT, SEED) model = Model(NOISE_UNIT_NUM, IMG_CHANNEL, SEED, BASE_CHANNEL, KEEP_PROB_RATE) z_ = tf.placeholder(tf.float32, [None, NOISE_UNIT_NUM], name='z_') #noise to generator x_ = tf.placeholder(tf.float32, [None, IMG_HEIGHT, IMG_WIDTH, IMG_CHANNEL], name='x_') #image to classifier d_dis_f_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_g_') #target of discriminator related to generator d_dis_r_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_r_') #target of discriminator related to real image is_training_ = tf.placeholder(tf.bool, name = 'is_training') with tf.variable_scope('encoder_model'): z_enc = model.encoder(x_, reuse=False, is_training=is_training_) with tf.variable_scope('decoder_model'): x_dec = model.decoder(z_, reuse=False, is_training=is_training_) x_z_x = model.decoder(z_enc, reuse=True, is_training=is_training_) # for cycle consistency with tf.variable_scope('discriminator_model'): #stream around discriminator drop3_r, logits_r = model.discriminator(x_, z_enc, reuse=False, is_training=is_training_) #real pair drop3_f, logits_f = model.discriminator(x_dec, z_, reuse=True, is_training=is_training_) #real pair drop3_re, logits_re = model.discriminator(x_z_x, z_enc, reuse=True, is_training=is_training_) #fake pair with tf.name_scope("loss"): loss_dis_f = tf.reduce_mean(tf.square(logits_f - d_dis_f_), name='Loss_dis_gen') #loss related to generator loss_dis_r = tf.reduce_mean(tf.square(logits_r - d_dis_r_), name='Loss_dis_rea') #loss related to real image #total loss loss_dis_total = loss_dis_f + loss_dis_r loss_dec_total = loss_dis_f loss_enc_total = loss_dis_r with tf.name_scope("score"): l_g = tf.reduce_mean(tf.abs(x_ - x_z_x), axis=(1,2,3)) l_FM = tf.reduce_mean(tf.abs(drop3_r - drop3_re), axis=1) score_A = SCORE_ALPHA * l_g + (1.0 - SCORE_ALPHA) * l_FM with tf.name_scope("optional_loss"): loss_dec_opt = loss_dec_total + CYCLE_LAMBDA * l_g loss_enc_opt = loss_enc_total + CYCLE_LAMBDA * l_g tf.summary.scalar('loss_dis_total', loss_dis_total) tf.summary.scalar('loss_dec_total', loss_dec_total) tf.summary.scalar('loss_enc_total', loss_enc_total) merged = tf.summary.merge_all() # t_vars = tf.trainable_variables() dec_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="decoder") enc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="encoder") dis_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="discriminator") with tf.name_scope("train"): train_dis = tf.train.AdamOptimizer(learning_rate=0.00005, beta1=0.5).minimize(loss_dis_total, var_list=dis_vars , name='Adam_dis') train_dec = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_total, var_list=dec_vars , name='Adam_dec') train_enc = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_total, var_list=enc_vars , name='Adam_enc') train_dec_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_opt, var_list=dec_vars , name='Adam_dec') train_enc_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_opt, var_list=enc_vars , name='Adam_enc') sess = tf.Session() ckpt = tf.train.get_checkpoint_state(out_model_dir) saver = tf.train.Saver() if ckpt: # checkpointがある場合 last_model = ckpt.model_checkpoint_path # 最後に保存したmodelへのパス saver.restore(sess, last_model) # 変数データの読み込み print("load " + last_model) else: # 保存データがない場合 #init = tf.initialize_all_variables() sess.run(tf.global_variables_initializer()) summary_writer = tf.summary.FileWriter(BOARD_DIR_NAME, sess.graph) log_list = [] log_list.append(['epoch', 'AUC']) #training loop for epoch in range(1): if epoch % VALID_SPAN == 0: score_A_np = np.zeros((0, 2), dtype=np.float32) val_data_num = len(make_datasets.valid_data) img_batch_test = make_datasets.get_valid_data_for_1_batch(0, val_data_num) score_A_ = sess.run(score_A, feed_dict={x_:img_batch_test, is_training_:False}) score_A_re = np.reshape(score_A_, (-1, 1)) tars_batch_re = np.where(score_A_re < SCORE_TH, 1, 0) #np.reshape(tars_batch, (-1, 1)) score_A_np_tmp = np.concatenate((score_A_re, tars_batch_re), axis=1) x_z_x_test = sess.run(x_z_x, feed_dict={x_:img_batch_test, is_training_:False}) #print(score_A_np_tmp) array_1_np, array_0_np = Utility.score_divide(score_A_np_tmp) Utility.make_score_hist_test(array_1_np, array_0_np, SCORE_TH, LOGFILE_NAME, OUT_HIST_DIR) Utility.make_output_img_test(img_batch_test, x_z_x_test, score_A_np_tmp, LOGFILE_NAME, OUT_IMG_DIR)
make_datasets_predict.py
make_datasets_predict.pyimport numpy as np import os import glob import re import random #import cv2 from PIL import Image from keras.preprocessing import image class Make_datasets_predict(): def __init__(self, test_data, img_width, img_height, seed): self.filename = test_data self.img_width = img_width self.img_height = img_height self.seed = seed x_test = self.read_DATASET(self.filename) self.valid_data = x_test random.seed(self.seed) np.random.seed(self.seed) def read_DATASET(self, test_path): test_list = os.listdir(test_path) x_test = np.empty((0, self.img_width*self.img_height)) for img in test_list: path_name = test_path+img x_img = Image.open(path_name) # サイズを揃える x_img = x_img.resize((self.img_width, self.img_height)) # 3chを1chに変換 x_img= x_img.convert('L') # PIL.Image.Imageからnumpy配列へ x_img = np.array(x_img) # 正規化 x_img = x_img / 255.0 # axisの追加 x_img = x_img.reshape((1,self.img_width, self.img_height)) # flatten x_img = x_img.reshape(1, self.img_width*self.img_height) x_test = np.concatenate([x_test, x_img], axis = 0) print("x_test.shape, ", x_test.shape) return x_test def get_file_names(self, dir_name): target_files = [] for root, dirs, files in os.walk(dir_name): targets = [os.path.join(root, f) for f in files] target_files.extend(targets) return target_files def divide_MNIST_by_digit(self, train_np, data1_num, data2_num): data_1 = train_np[train_np[:,0] == data1_num] data_2 = train_np[train_np[:,0] == data2_num] return data_1, data_2 def read_data(self, d_y_np, width, height): #tars = [] images = [] for num, d_y_1 in enumerate(d_y_np): image = d_y_1.reshape(width, height, 1) #tar = d_y_1[0] images.append(image) #tars.append(tar) return np.asarray(images)#, np.asarray(tars) def normalize_data(self, data): # data0_2 = data / 127.5 # data_norm = data0_2 - 1.0 data_norm = (data * 2.0) - 1.0 #applied for tanh return data_norm def make_data_for_1_epoch(self): self.filename_1_epoch = np.random.permutation(self.train_np) return len(self.filename_1_epoch) def get_data_for_1_batch(self, i, batchsize): filename_batch = self.filename_1_epoch[i:i + batchsize] images, _ = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n def get_valid_data_for_1_batch(self, i, batchsize): filename_batch = self.valid_data[i:i + batchsize] images = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n#, tars def make_random_z_with_norm(self, mean, stddev, data_num, unit_num): norms = np.random.normal(mean, stddev, (data_num, unit_num)) # tars = np.zeros((data_num, 1), dtype=np.float32) return norms def make_target_1_0(self, value, data_num): if value == 0.0: target = np.zeros((data_num, 1), dtype=np.float32) elif value == 1.0: target = np.ones((data_num, 1), dtype=np.float32) else: print("target value error") return targetGitHubのリンク
https://github.com/YousukeAnai/Dic_Graduation_Assignment
参考にした記事
https://qiita.com/masataka46/items/49dba2790fa59c29126b
https://qiita.com/underfitting/items/a0cbb035568dea33b2d7

- 投稿日:2020-01-12T19:56:26+09:00
TensorFlow2 + Keras で画像分類に挑戦 CNN編1 ~とりあえず動かす~
はじめに
TensorFlow2 + Keras による画像分類の勉強メモ(CNN編の第1弾)です。MLP編(多層パーセプトロンモデル編)については、こちらをご覧ください。
なお、題材はド定番である手書き数字画像(MNIST)の分類です。
今回は、ブラックボックスのまま、とりあえずCNNモデルを学習させて、それを使って予測(分類)をしてみます。
MLP版のプログラム
多層パーセプトロンモデルによる手書き数字画像(MNIST)分類は、TensorFlow2 + Keras を利用して、次のように書くことができました(詳細)。
TensorFlow2に切り替え(GoogleColab.環境のみ)%tensorflow_version 2.xMLPによる画像分類import tensorflow as tf # (1) 手書き数字画像のデータセットをダウンロード・正規化 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # (2) MLPモデルを構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) ) model.add( tf.keras.layers.Dense(128, activation='relu') ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation='softmax') ) # (3) モデルのコンパイル・トレーニング model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) # (4) モデルの評価 model.evaluate(x_test, y_test, verbose=2)これを実行すると、正解率 $97.7\%$ 前後の分類器をつくることができました。
CNN版のプログラム
畳み込みニューラルネットワークモデル(CNN)による手書き数字画像(MNIST)分類は、次のように書くことができます。多層パーセプトロンのモデルに、なんと3行追加するだけで畳み込みニューラルネットワークモデルに変えることができます。
CNNによる画像分類# (1) 手書き数字画像のデータセットをダウンロード・正規化 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # (2) CNNモデルを構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)) ) # 追加 model.add( tf.keras.layers.Conv2D(32, (5, 5), activation='relu') ) # 追加 model.add( tf.keras.layers.MaxPooling2D(pool_size=(2,2)) ) # 追加 model.add( tf.keras.layers.Flatten() ) # 改変 model.add( tf.keras.layers.Dense(128, activation='relu') ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation='softmax') ) # (3) モデルのコンパイル・トレーニング model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) # (4) モデルの評価 model.evaluate(x_test, y_test, verbose=2)これを実行すると、正解率 $98.7\%$ 前後の分類器をつくることができます(上記のMLPよりも正解率が約$1\%$ほど高いモデルをつくることができます)。ただし、学習にかかる時間は長くなっています。
正しく予測できなかった事例
分類(予測)に失敗している具体的なケースを見てみます(これを出力するためのプログラムは「~分類に失敗する画像を観察してみる~」を参照)。
各図の左上に表示している赤文字は、誤って何の数字と予測したかという情報です(括弧内数値は、誤った予測に対するsoftmax出力)。例えば 5(0.9) は、「約 $90\%$ の確信をもって $5$ と予測した」ということです。また、青色の数値は、テストデータ
test_xのインデックス番号です。正解値「0」について正しく予測(分類)できなかったケース 4/980件
正解値「1」について正しく予測(分類)できなかったケース 4/1135件
正解値「2」について正しく予測(分類)できなかったケース 8/1032件
正解値「3」について正しく予測(分類)できなかったケース 12/1010件
正解値「4」について正しく予測(分類)できなかったケース 15/982件
正解値「5」について正しく予測(分類)できなかったケース 6/892件
正解値「6」について正しく予測(分類)できなかったケース 13/958件
正解値「7」について正しく予測(分類)できなかったケース 15/1028件
正解値「8」について正しく予測(分類)できなかったケース 27/974件
正解値「9」について正しく予測(分類)できなかったケース 26/1009件
次回
畳み込みニューラルネットワークモデル(CNN)は、なんで画像分類・画像認識に適しているのか、そもそも畳み込み(フィルタ)とは?といった内容を取り上げていきたいと思います。









