- 投稿日:2020-01-12T23:55:20+09:00
AtCoder Beginner Contest 151 参戦記
AtCoder Beginner Contest 151 参戦記
ABC151A - Next Alphabet
1分半で突破. 書くだけ.
C = input() print(chr(ord(C[0]) + 1))ABC151B - Achieve the Goal
4分で突破. 書くだけ.
N, K, M = map(int, input().split()) A = list(map(int, input().split())) t = sum(A) if N * M > t + K: print(-1) else: print(max(N * M - t, 0))ABC151C - Count Order
7分半で突破. AC 後の WA は無視しないといけないところだけを気にすればよい.
N, M = map(int, input().split()) ac = [False] * N wa = [0] * N for _ in range(M): p, S = input().split() p = int(p) - 1 if S == 'AC': ac[p] = True else: if not ac[p]: wa[p] += 1 a = 0 b = 0 for i in range(N): if ac[i]: a += 1 b += wa[i] print(*[a, b])ABC151D - Maze Master
17分で突破. 見た瞬間に AtCoder Typical Contest 002A - 幅優先探索 を思い出したので、全箇所から幅優先探索して、最長をかき集める方向性で解いた.
H, W = map(int, input().split()) S = [input() for _ in range(H)] def f(i, j): t = [[-1] * W for _ in range(H)] t[i][j] = 0 q = [(i, j)] while q: y, x = q.pop(0) if y - 1 >= 0 and S[y - 1][x] != '#' and t[y - 1][x] == -1: t[y - 1][x] = t[y][x] + 1 q.append((y - 1, x)) if y + 1 < H and S[y + 1][x] != '#' and t[y + 1][x] == -1: t[y + 1][x] = t[y][x] + 1 q.append((y + 1, x)) if x - 1 >= 0 and S[y][x - 1] != '#' and t[y][x - 1] == -1: t[y][x - 1] = t[y][x] + 1 q.append((y, x - 1)) if x + 1 < W and S[y][x + 1] != '#' and t[y][x + 1] == -1: t[y][x + 1] = t[y][x] + 1 q.append((y, x + 1)) return max(max(tt) for tt in t) result = 0 for i in range(H): for j in range(W): if S[i][j] != '#': result = max(result, f(i, j)) print(result)ABC151E - Max-Min Sums
糸口すらつかめず敗退. 70分の間、順位が800番台から1300番台までずり落ちるのを眺める羽目になった.
- 投稿日:2020-01-12T23:54:52+09:00
AtCoder 第6回 ドワンゴからの挑戦状 予選 参戦記
- 投稿日:2020-01-12T23:54:01+09:00
AtCoder Beginner Contest 150 参戦記
AtCoder Beginner Contest 150 参戦記
ABC150A - 500 Yen Coins
5分で突破. 書くだけ. 問題文が中々表示されなかったせいで時間がかかった.
K, X = map(int, input().split()) if 500 * K >= X: print('Yes') else: print('No')ABC150B - Count ABC
2分半で突破. 書くだけ.
N = int(input()) S = input() result = 0 for i in range(N): if S[i:i+3] == 'ABC': result += 1 print(result)ABC150C - Count Order
26分で突破. C問題にしては難しいというか、最初は解ける気がしなかった. 素直に積算すればよかったんだなと…….
N = int(input()) P = list(map(int, input().split())) Q = list(map(int, input().split())) fac = [0] * 8 fac[1] = 1 for i in range(2, N): fac[i] = i * fac[i - 1] a = 0 l = list(range(1, N + 1)) for i in range(N): a += l.index(P[i]) * fac[len(l) - 1] l.remove(P[i]) b = 0 l = list(range(1, N + 1)) for i in range(N): b += l.index(Q[i]) * fac[len(l) - 1] l.remove(Q[i]) print(abs(a - b))ABC150D - Semi Common Multiple
敗退.
- 投稿日:2020-01-12T23:42:38+09:00
C# GUIアプリケーションからPythonスクリプトを実行する
はじめに
Pythonには機械学習をはじめとする優れたライブラリがたくさんある。一方C#はGUIアプリケーションの開発に広く利用されている言語である。したがってPythonスクリプトをC#アプリケーションから呼び出すことができれば、C#アプリケーション開発者にとって便利であるし、何よりGUIアプリケーションの幅も広がるはずだ。そこで今回、C#のGUIアプリケーションからPythonスクリプトを呼び出す方法について調べ、プロトタイプを作成してみた。
環境
- Windows10
- C#
- Python
開発したいプロトタイプ
開発したいプロトタイプの要件を以下に洗い出してみた。
- Pythonのパス、実行ディレクトリ(Working Directory)、Pythonスクリプトを指定し、実行することができる。
- 実行に長時間かかる場合を考慮し、途中で処理をキャンセルすることができる。
- 実行に長時間かかる場合に進捗状況が分かるよう、全ての標準出力、標準エラー出力をGUIのTextBoxに表示する。
- 以前に書いた 標準入出力を介してMOLファイルをSMILESに変換する のように、標準入力を受け取るPythonスクリプトの場合、ファイルを介さずにGUI側のデータをPythonスクリプトに渡すことにより、実行結果を手軽に受け取ることができる。このため標準入力も指定できるようにしたい。
- Pythonスクリプトの終了コードにより、正常終了かエラー終了かを判定し、MessageBoxにより表示する。
できたもの
画面
こんな感じ。
画面の説明
- Python Pathには、python.exeの場所をフルパスで指定する。Anacondaの場合は、Anacondaの仮想環境のpython.exeの場所を調べて指定する。
- Working Directoryには、Pythonスクリプトの実行ディレクトリを指定する。引数にファイルパスを指定する場合は、ここを起点とする相対パスで記載することもできる。
- Python Commandには、Pythonスクリプトの場所をフルパスで指定する。また引数があればそれも指定する。
- Standard Input には、Pythonスクリプトの標準入力に渡したいデータを入力する。標準入力を使わないPythonスクリプトの場合、無視される。
- Standard Output and Standard Errorには、Pythonスクリプトの全ての標準出力、標準エラー出力が表示される。
- 「Execute」ボタンにより処理を開始し、「Cancel」ボタンにより処理をキャンセルすることができる。
ソース
ソースは以下の通りだ。とても長くなったが、編集が面倒なためそのまま張り付ける(手抜き)。デザイン側のコードは両略した。GUI部品のオブジェクトの変数名は、コードから読み取ってほしい。ソースの解説は次項で説明する。
using System; using System.Diagnostics; using System.IO; using System.Text; using System.Threading; using System.Windows.Forms; namespace PythonCommandExecutor { public partial class Form1 : Form { private Process currentProcess; private StringBuilder outStringBuilder = new StringBuilder(); private int readCount = 0; private Boolean isCanceled = false; public Form1() { InitializeComponent(); } /// <summary> /// Textboxに文字列追加 /// </summary> public void AppendText(String data, Boolean console) { textBox1.AppendText(data); if (console) { textBox1.AppendText("\r\n"); Console.WriteLine(data); } } /// <summary> /// 実行ボタンクリック時の動作 /// </summary> private void button1_Click(object sender, EventArgs e) { // 前処理 button1.Enabled = false; button2.Enabled = true; isCanceled = false; readCount = 0; outStringBuilder.Clear(); this.Invoke((MethodInvoker)(() => this.textBox1.Clear())); // 実行 RunCommandLineAsync(); } /// <summary> /// コマンド実行処理本体 /// </summary> public void RunCommandLineAsync() { ProcessStartInfo psInfo = new ProcessStartInfo(); psInfo.FileName = this.textBox2.Text.Trim(); psInfo.WorkingDirectory = this.textBox3.Text.Trim(); psInfo.Arguments = this.textBox4.Text.Trim(); psInfo.CreateNoWindow = true; psInfo.UseShellExecute = false; psInfo.RedirectStandardInput = true; psInfo.RedirectStandardOutput = true; psInfo.RedirectStandardError = true; Process p = Process.Start(psInfo); p.EnableRaisingEvents = true; p.Exited += onExited; p.OutputDataReceived += p_OutputDataReceived; p.ErrorDataReceived += p_ErrorDataReceived; p.Start(); // 標準入力への書き込み using (StreamWriter sw = p.StandardInput) { sw.Write(this.textBox5.Text.Trim()); } //非同期で出力とエラーの読み取りを開始 p.BeginOutputReadLine(); p.BeginErrorReadLine(); currentProcess = p; } void onExited(object sender, EventArgs e) { int exitCode; if (currentProcess != null) { currentProcess.WaitForExit(); // 吐き出されずに残っているデータの吐き出し this.Invoke((MethodInvoker)(() => AppendText(outStringBuilder.ToString(), false))); outStringBuilder.Clear(); exitCode = currentProcess.ExitCode; currentProcess.CancelOutputRead(); currentProcess.CancelErrorRead(); currentProcess.Close(); currentProcess.Dispose(); currentProcess = null; this.Invoke((MethodInvoker)(() => this.button1.Enabled = true)); this.Invoke((MethodInvoker)(() => this.button2.Enabled=false)); if (isCanceled) { // 完了メッセージ this.Invoke((MethodInvoker)(() => MessageBox.Show("処理をキャンセルしました"))); } else { if (exitCode == 0) { // 完了メッセージ this.Invoke((MethodInvoker)(() => MessageBox.Show("処理が完了しました"))); } else { // 完了メッセージ this.Invoke((MethodInvoker)(() => MessageBox.Show("エラーが発生しました"))); } } } } /// <summary> /// 標準出力データを受け取った時の処理 /// </summary> void p_OutputDataReceived(object sender, System.Diagnostics.DataReceivedEventArgs e) { processMessage(sender, e); } /// <summary> /// 標準エラーを受け取った時の処理 /// </summary> void p_ErrorDataReceived(object sender, System.Diagnostics.DataReceivedEventArgs e) { processMessage(sender, e); } /// <summary> /// CommandLineプログラムのデータを受け取りTextBoxに吐き出す /// </summary> void processMessage(object sender, System.Diagnostics.DataReceivedEventArgs e) { if (e != null && e.Data != null && e.Data.Length > 0) { outStringBuilder.Append(e.Data + "\r\n"); } readCount++; // まとまったタイミングで吐き出し if (readCount % 5 == 0) { this.Invoke((MethodInvoker)(() => AppendText(outStringBuilder.ToString(), false))); outStringBuilder.Clear(); // スレッドを占有しないようスリープを入れる if (readCount % 1000 == 0) { Thread.Sleep(100); } } } /// <summary> /// キャンセルボタンクリック時の動作 /// </summary> private void button2_Click(object sender, EventArgs e) { if (currentProcess != null) { try { currentProcess.Kill(); isCanceled = true; } catch (Exception e2) { Console.WriteLine(e2); } } } private void button3_Click(object sender, EventArgs e) { // 標準入力エリアのクリア this.textBox5.Clear(); // 標準出力エリアのクリア this.textBox1.Clear(); } } }ソース解説
基本的には参考文献の寄せ集めになるのだが、説明を以下に記載する。
- RunCommandLineAsyncメソッド内でProcessクラスによりPythonスクリプトを実行している。
p.Start()以降は処理が非同期になるため、これ以降UIを操作する場合は、UIスレッドから実行しないと怒られてしまう。this.Invoke((MethodInvoker)(() => AppendText(outStringBuilder.ToString(), false)));のような呼び出しがところどころあるのはこのためである。p.EnableRaisingEvents = true;,p.Exited += onExited;により、プロセス終了時にonExitイベントハンドラが実行されるため、ここに後始末的な処理や、終了コードの判定、完了ダイアログの表示等を記載している。- キャンセルについては、キャンセル時に実行されるイベントハンドラの中でProcessクラスのKillメソッドを呼び出している。するとonExitイベントハンドラが実行され、通常終了時と同じになるため、それ以外に特別なことはしていない。
- 標準入力にデータを食わせるところは、
using (StreamWriter sw = p.StandardInput)から始まるところでやっている。- 標準出力、標準エラー出力の取り出しについては、
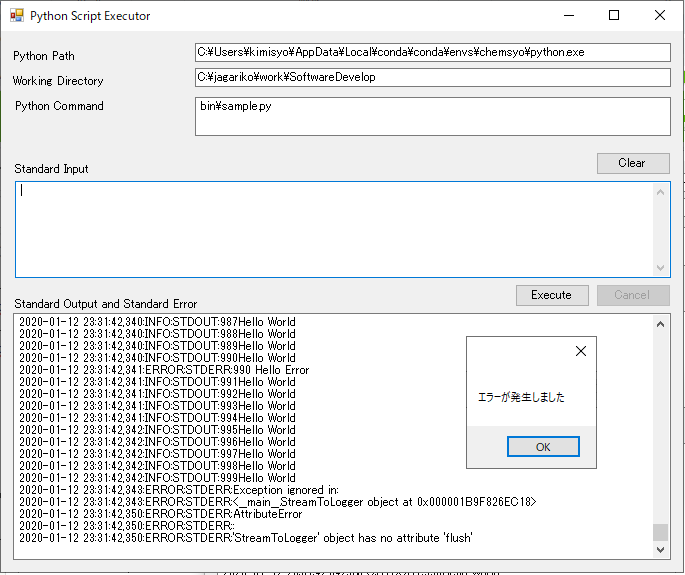
p.OutputDataReceived += p_OutputDataReceived;,ErrorDataReceived += p_ErrorDataReceived;によりそれぞれのイベントハンドラで受け取った標準出力、標準エラー出力を処理するようにしている。p.BeginOutputReadLine();,p.BeginErrorReadLine();により1行出力がある度にそれぞれのイベントハンドラが実行されるため、その中でTextBoxへの出力を行っている。1行毎にTextBoxに書き出すと大量の出力があるアプリの場合にGUIの処理に時間がかかる可能性もあるため、ある程度まとめて出力する等の工夫を行っている。実行例① 出力の多いPythonスクリプト(途中でエラー)を実行する
以下はサンプルとして作成した、ある程度標準出力や標準エラー出力の多いPythonスクリプトを実行した例である。標準エラーに出力されたエラーメッセージもTextBoxに出力され、かつ終了コードによりエラーのMessageBoxが表示されていることが分かる。
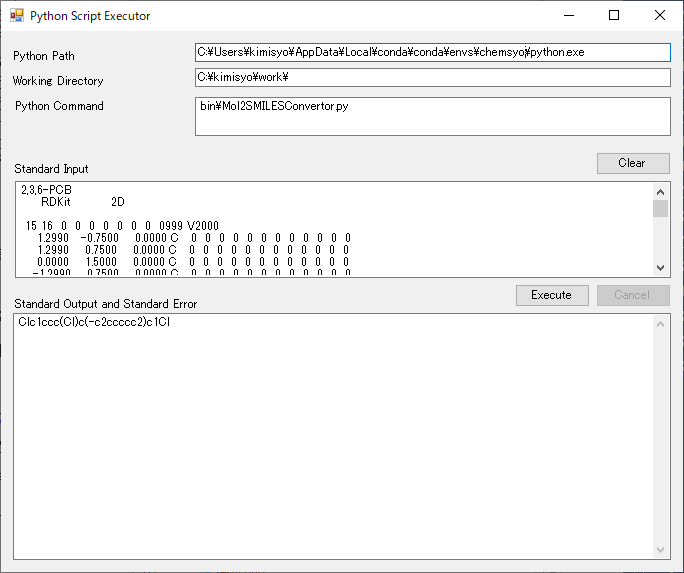
実行例② 標準入力を介してPythonスクリプトを実行する
以下は、「標準入出力を介してMOLファイルをSMILESに変換する 」のスクリプトを本GUIを通して実行した図である。簡単なPythonスクリプトを書くだけでC#とPythonの処理結果の受け渡しができることを実感してもらえると思う。
おわりに
- async/awaitを使った方法で当初進めていたが、UIのデッドロックらしき現象が発生し、丸一日かけても解決できなかったため断念した。
- Pythonスクリプトの標準出力に進捗情報を出力することによって、C#側でプログレスバーによる進捗表示も簡単に行えると思う。
- 動作もまずまず安定しているため、このプロトタイプをベースに今後、C#からPythonの便利な機能をガンガン使い、魅力的なアプリを作ってみたい。
参考文献

- 投稿日:2020-01-12T23:40:03+09:00
AtCoderに参加してみたお話
はじめてAtCoderに参加してみた
Qiitaに記事を書くようになったり、仕事のことでいろいろ調べているうちに
「競技プログラミング」が流行っていることを知りました。
Twitterなんかでもはてブの記事がTLに流れてきたりするので興味本位でアカウントを作成。
いろいろ調べていると、コンテストが金曜日の夜や休日の夜に開催されるらしく、
そこに参加して問題を解いていくそう。年末年始で忙しく、アカウント作成だけで終わっていたのでやっとコンテストに参加することができました。
初めて参加したのがAtCoder Beginner Contest 151。
最近はkintoneをいじることが多く、jsでやってみようと思ったものの
おすすめはされていないみたいなので、数ヶ月前に少しだけ勉強したPythonで参加しました。初回なので何がなんだかパルプンテ
どきどきしながらPCの前で待機し、時間ピッタリにスタート。
画面の右下にカウントダウンが表示されます。
問題はAからFの6題があって、問題ごとに配点が違いました(Aは100点で100点ずつ増える)。問題がズラッと並べられているし、よくわからないけどAが初心者向けだろうということでAの問題を選択。
実行制限時間とか書いてるけどとりあえず無視…。解いた問題 ABC 151 A-Next Alphabet
【問題文】
$z$ でない英小文字 $C$ が与えられます。
アルファベット順で $C$ の次の文字を出力してください。
【制約】
$C$ は $z$ でない英小文字
【入力】
入力は以下の形式で標準入力から与えられる。
$C$
【出力】
アルファベット順で $C$ の次の文字を出力せよ。
【入力例】
a
【出力例】
b参加してみて
・まず標準入力という言葉に詰まる。
・Pythonの知識が抜け落ちている。
・JavaScriptからPythonの配列の考え方にシフトするのが大変だった。とりあえず解けたものの、ダサいコードになったので戒めとして貼っておくことにします。
ライブラリやメソッドを調べればよかったのかなと反省。alpha.pya = input() alpha = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"] for i in range(len(alpha)): alphabet = alpha[i] if a == alphabet: s = i + 1 alphabet = alpha[s] print(alphabet) break実行制限時間が2secと書いているのに対してこのコードは17secかかっていました。
完全にアウト。これはハマるなあ、と終わった瞬間に思いました。終わりに
AtCoderは過去問なども公開されているので休日など時間のある際に
書く練習をしてみようと思います。
まずは毎週何かしらのコンテストに参加して慣れることも大切なんじゃないかなと感じました。
次回は実行時間も気にしながら解けるようにコードを書いてみようと思います!
- 投稿日:2020-01-12T23:16:16+09:00
Andible のパスワード/パスフレーズ自動入力
Ansible で使用するパスワードの指定(利用方法)に関するまとめ。
サマリ
ssh 接続のパスワード
- ssh のパスワードを自動入力するためには、sshpass が必要。
- sshpass は ansible のモジュールではないため、別途インストールが必要。
- sshpass は、"assword" という文字列 (プロンプト) が表示されるのを待って、パスワードを入力。
- ansible から呼び出す sshpass へ引数を渡す方法が用意されていないため、秘密鍵のパスフレーズ入力には(そのままでは)使用不可。
- 秘密鍵のパスフレーズは外さずに ssh-agent/ssh-add を使用。
- やむを得ずパスワード/パスフレーズを設定ファイル等に記載する場合には、ansible-vault で暗号化。
- ログインパスワードは一般的に sudo 権限昇格のパスワードと同じため、公開鍵暗号等に速やかに移行。
become (sudo) パスワード
- パスワードを記載する必要がある場合には、ansible-vault で暗号化。
公開鍵暗号の秘密鍵のファイル名の tips
- sshpass プログラムはデフォルトで "
assword" を含むプロンプトを期待している。- ssh のパスフレーズ入力プロンプトは "
Enter passphrase for key '...id_rsa':" となっており、"assword" を含まない。(そのため、sshpass がプロントを待ち続けて、そのままでは自動化できない)- 秘密鍵のファイル名に "
assword" を含めると、プロンプトに "assword" を含むことになり、sshpass がデフォルトのまま利用可能。ということで、秘密鍵のファイル名に "
assword" を含めれば、ansible でもパスフレーズを自動入力できるようになります。ansible-valut: vault-id の tips
- 暗号化された文字列のヘッダに label がついていても、vault-id-list に設定された ID のパスワードファイルを頭から順に試している模様。
- つまり、現バージョンでは、label は人間が識別するためのもので、ansible-vault プログラムにとっては、ほとんど意味をなしていない。(と思われる)
前提環境
OS 環境
コントロールホスト OS: Ubuntu 18.04
対象ホスト OS: Ubuntu 18.04 (docker) × 2/etc/os-releaseNAME="Ubuntu" VERSION="18.04.3 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.3 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicPython 環境
Python仮想環境(ansible) $ pip freeze ansible==2.9.2 cffi==1.13.2 cryptography==2.8 Jinja2==2.10.3 MarkupSafe==1.1.1 passlib==1.7.2 pkg-resources==0.0.0 pycparser==2.19 PyYAML==5.2 six==1.13.0 (ansible) $接続先とパスフレーズ等接続環境
接続先 IP address ssh 接続 秘密鍵パスフレーズ ユーザ名&sudo 利用 172.17.0.2 公開鍵方式 " privkey_passphrase"pubkeyuser パスワード: " pubkeyuser_password"172.17.0.3 パスワード入力 - pwduser パスワード: " pwduser_password"Ansible 環境
Ansible バージョン
コントロールホストのansibleバージョン(ansible) $ ansible --version ansible 2.9.2 config file = /home/luser/work/ansible.cfg configured module search path = ['/home/luser/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules'] ansible python module location = /home/luser/work/Python.d/envs/ansible/lib/python3.6/site-packages/ansible executable location = /home/luser/work/Python.d/envs/ansible/bin/ansible python version = 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] (ansible) $Ansible hosts ファイル
./hosts[hostgroup] 172.17.0.2 172.17.0.3Ansible の DEPRECATION WARNING の抑制
接続先で python2 ではなく、明示的に python3 を使うようにし、
DEPRECATION WARNINGを抑制するため、以下のような ansible.cfg をカレントディレクトリに置きます。
(deprecation_warnings=Falseを設定してもよいのですが、他の警告まで消えてしまわないように)ansible.cfg ファイル
./ansible.cfg(初期設定)[defaults] interpreter_python = /usr/bin/python3秘密鍵
動作確認用の秘密鍵をカレントディレクトリに置きます。
pubkeyuser_id_rsa ファイル
秘密鍵のパーミッション(ansible) $ ls -l pubkeyuser_id_rsa -rw------- 1 luser luser 1766 Jan 11 02:19 pubkeyuser_id_rsaファイル構成
初期ファイル構成(ansible) $ tree -a ./ ./ |-- ansible.cfg |-- host_vars | |-- 172.17.0.2.yml | `-- 172.17.0.3.yml |-- hosts |-- pubkeyuser_id_rsa `-- pubkeyuser_id_rsa_assword -> pubkeyuser_id_rsa 1 directory, 6 files (ansible) $前提ここまで。
Ansible で使用するパスワード(パスフレーズ)の種類
- ssh 接続時のパスワード/パスフレーズ
- sudo (become) 時のパスワード
ssh 接続のパスワード/パスフレーズ設定
参照: ssh – connect via ssh client binary — Ansible Documentation
ssh 接続は主に以下の2つの方法で行われます。
- 公開鍵暗号を用いた接続
- PAM パスワードによる接続
公開鍵暗号を用いた接続
公開鍵によるssh接続確認(ansible) $ ssh -i ./pubkeyuser_id_rsa pubkeyuser@172.17.0.2 Enter passphrase for key './pubkeyuser_id_rsa': ← ここで秘密鍵のパスフレーズを入力 Last login: Tue Jan 7 08:00:57 2020 from 172.17.0.1 $ id -a uid=1001(pubkeyuser) gid=1001(pubkeyuser) groups=1001(pubkeyuser),27(sudo) $ exit Connection to 172.17.0.2 closed. (ansible) $ansible での接続は以下のようになります。
公開鍵によるansible動作確認(ansible) $ ansible -i hosts -u pubkeyuser --private-key pubkeyuser_id_rsa 172.17.0.2 -m ping Enter passphrase for key 'pubkeyuser_id_rsa': ← ここで秘密鍵のパスフレーズを入力 172.17.0.2 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $ssh-agent/ssh-add の利用
sh-agent/ssh-add を利用して、パスフレーズの入力を避けることができます。
- Ansible does not expose a channel to allow communication between the user and the ssh process to accept a password manually to decrypt an ssh key when using this connection plugin (which is the default). The use of ssh-agent is highly recommended.
Ansible のドキュメントでも、ssh-agent の利用を強く推奨しています。
ssh-agentとssh-addを用いた接続確認(ansible) $ eval `ssh-agent` Agent pid 3256 (ansible) $ echo $SSH_AUTH_SOCK /tmp/ssh-dcXxsNEXR7zu/agent.3254 (ansible) $ ssh-add pubkeyuser_id_rsa Enter passphrase for pubkeyuser_id_rsa: Identity added: pubkeyuser_id_rsa (pubkeyuser_id_rsa) (ansible) $ ssh-add -l 2048 SHA256:Skhwkjn4nNRdRzWxNZBRGSPamcZikVkeBVpPhtFzgXw pubkeyuser_id_rsa (RSA) (ansible) $ ansible -i hosts -u pubkeyuser --private-key pubkeyuser_id_rsa 172.17.0.2 -m ping 172.17.0.2 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $csh 系を使用している場合には、
eval `ssh-agent -c`というように、-cオプションを付けます。バッチ処理におけるパスフレーズの設定
インタラクティブ(会話型)ではなく、バッチ処理のように、無人で起動するような場合には、設定が必要になります。
ssh-agent/ssh-add の利用
- ssh-agent は、(通常)ログアウトしてもプロセスが残り、ソケットが利用可能です。
- これを利用すると、非インタラクティブな処理でもパスワードの入力を省略できます。
以下のようなシェルスクリプトを ~/.bashrc から呼び出す (あるいは、.bashrc に直接記述する) と、既存のプロセスを再利用できます。
setup-ssh-agent.sh#!/bin/sh LANG=C SSH_AGENT=ssh-agent SSH_AGENT_SAVED=${SSH_AGENT_SAVED:-"${HOME}/.ssh/.${SSH_AGENT}"} AGENT_ENV="" if [ -f ${SSH_AGENT_SAVED} ] then eval $(tail -1 ${SSH_AGENT_SAVED}) > /dev/null if (ps -fp ${SSH_AGENT_PID} | sed -e 's/ */ /g' | cut -d' ' -f 8 | grep '^ssh-agent$' > /dev/null) then AGENT_ENV=$(tail -1 ${SSH_AGENT_SAVED}) else AGENT_ENV=$(${SSH_AGENT}) fi else AGENT_ENV=$(${SSH_AGENT}) fi echo ${AGENT_ENV} | tee ${SSH_AGENT_SAVED} chmod 0600 ${SSH_AGENT_SAVED}ssh-agent の環境変数設定を読み込んで、ansible コマンドを利用するようにするとよいでしょう。
非インタラクティブな実行でも、前処理として、実行済み ssh-agent/ssh-add に関する環境変数の読み込みなどを行う必要があります。
パスワード自体をファイルなどで保存しておく必要がない、という点で、推奨されます。sshpass の利用
sshpass を利用すると、パスフレーズ記載したファイルを指定して実行できます。
sshpass は ansible の一部ではないので、別途インストールする必要があります。
sshpassのインストールと動作確認(ansible) $ sudo apt install sshpass Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: sshpass 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded. : Processing triggers for man-db (2.8.3-2ubuntu0.1) ... (ansible) $ ls -l ~/.ansible_rings/.pubkeyuser_passphrase -rw------- 1 luser luser 19 Jan 12 21:00 /home/luser/.ansible_rings/.pubkeyuser_passphrase (ansible) $ cat ~/.ansible_rings/.pubkeyuser_passphrase privkey_passphrase (ansible) $ sshpass -P "pubkeyuser_id_rsa':" -f ~/.ansible_rings/.pubkeyuser_passphrase ansible -i hosts -u pubkeyuser --private-key pubkeyuser_id_rsa 172.17.0.2 -m ping 172.17.0.2 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $ cat ~/.ansible_rings/.pubkeyuser_passphrase | sshpass -P "pubkeyuser_id_rsa':" -d 0 ansible -i hosts -u pubkeyuser --private-key pubkeyuser_id_rsa 172.17.0.2 -m ping 172.17.0.2 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $sshpass を非インタラクティブに使用する場合には、どこかに平文でパスフレーズを保存しておく必要があることに注意してください。
sshpass は、パスワード入力のプロンプトとして "assword" を期待しているので、秘密鍵のパスフレーズを入力する際のプロンプトを-Pオプションで指定する必要があります。ところが、ansible から sshpass へ引数を渡す方法が用意されていません。
そこで、"assword" がプロンプトに現れるように、プライベートキーのファイル名に "assword" を含めます。秘密鍵のファイル名設定(ansible) $ ln -s pubkeyuser_id_rsa pubkeyuser_id_rsa_assword (ansible) $ ls -l pubkeyuser_id_rsa pubkeyuser_id_rsa_assword -rw------- 1 luser luser 1766 Jan 11 02:19 pubkeyuser_id_rsa lrwxrwxrwx 1 luser luser 17 Jan 12 21:12 pubkeyuser_id_rsa_assword -> pubkeyuser_id_rsa (ansible) $ssh – connect via ssh client binary — Ansible Documentation の "password" の行を見ると、変数(var)として
var: ansible_password
var: ansible_ssh_pass
var: ansible_ssh_passwordが使えることが記載されています。
そこで、172.17.0.2 のホストにパスワードを設定します。
(tips として後述しますが、"ansible_ssh_password" は使用しないほうが無難です)./host_vars/172.17.0.2.yml--- # Remote User ansible_ssh_user: pubkeyuser # 秘密鍵 ansible_private_key_file: ./pubkeyuser_id_rsa_assword # SSH 共通引数 ansible_ssh_common_args: "-o PubkeyAuthentication=yes -o PasswordAuthentication=no -o StrictHostKeyChecking=no" # SSH 秘密鍵パスフレーズ ansible_ssh_pass: 'privkey_passphrase'動作確認(ansible) $ ansible 172.17.0.2 -m ping 172.17.0.2 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $パスフレーズの入力をせずに実行することができました。
PAM パスワードによる接続
ログインパスワードを用いた接続は避けたいところ1 ですが、何らかの事情でユーザのパスワードで ssh 接続を行わなければならないことがあります。
例えば、初期状態で、public キーがまだコピーできていないようなケースです。(可能であれば、ansible 実行前に公開鍵の登録を行いたいところです)sshの接続確認(ansible) $ ssh -o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no pwduser@172.17.0.3 id -a pwduser@172.17.0.3's password: ← "pwduser" のログインパスワードを入力 uid=1001(pwduser) gid=1001(pwduser) groups=1001(pwduser),27(sudo) (ansible) $このようなケースでは、SSH のパスワードを入力する必要があります。
パスワードでのansibleの試み(ansible) $ ansible --ssh-common-args="-o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no" -i hosts -u pwduser 172.17.0.3 -m ping 172.17.0.3 | UNREACHABLE! => { "changed": false, "msg": "Failed to connect to the host via ssh: Permission denied (publickey,password).", "unreachable": true } (ansible) $ansible では、
-kオプションを指定することで、SSH のパスワードを訊いてきますが、このオプションを付けないと、上のようにエラーになります。-kオプションを指定したansible実行(ansible) $ ansible --ssh-common-args="-o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=" -i hosts -u pwduser 172.17.0.3 -m ping -k SSH password: 172.17.0.3 | FAILED! => { "msg": "to use the 'ssh' connection type with passwords, you must install the sshpass program" } (ansible) $
-kオプションをつけることで、パスワード入力のプロンプトが出ましたが、こんどは、「sshpass プログラムをインストールしろ("to use the 'ssh' connection type with passwords, you must install the sshpass program")」と言ってきます。公開鍵での接続の際にも利用しましたが、sshpass は ansible の一部ではありませんので、別途インストールする必要があります。sshpassのインストール(ansible) $ sudo apt install sshpass Reading package lists... Done Building dependency tree Reading state information... Done The following NEW packages will be installed: sshpass 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded. : Processing triggers for man-db (2.8.3-2ubuntu0.1) ... (ansible) $sshpass をインストールすると、動作するようになります。
sshpassインストール後の接続確認(ansible) $ ansible --ssh-common-args="-o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no" -i hosts -u pwduser 172.17.0.3 -m ping -k SSH password: 172.17.0.3 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $バッチ処理におけるパスフレーズの設定
公開鍵の場合と同様に、172.17.0.3.yml で変数を設定します。
./host_vars/172.17.0.3.yml--- # Remote User ansible_ssh_user: pwduser # パスワード認証の指定 ansible_ssh_common_args: '-o PreferredAuthentications=password -o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no' # 認証パスワード ansible_ssh_pass: 'pwduser_password'(ansible) $ ansible 172.17.0.3 -m ping 172.17.0.3 | SUCCESS => { "changed": false, "ping": "pong" } (ansible) $パスワードの入力をせずに実行することができました。
sudo (become) 時のパスワード
参照: sudo – Substitute User DO — Ansible Documentation
sudo – Substitute User DO — Ansible Documentation を参照すると、パスワードの設定は以下のように記載されています。
ini entries:
[sudo_become_plugin]
password = VALUEenv:ANSIBLE_BECOME_PASS
env:ANSIBLE_SUDO_PASS
var: ansible_become_password
var: ansible_become_pass
var: ansible_sudo_pass変数(var)
ansible_become_passを使って、172.17.0.2.ymlと172.17.0.3.ymlに設定します。./host_vars/172.17.0.2.yml--- # Remote User ansible_ssh_user: pubkeyuser # 秘密鍵 ansible_private_key_file: ./pubkeyuser_id_rsa_assword # SSH 共通引数 ansible_ssh_common_args: "-o PubkeyAuthentication=yes -o PasswordAuthentication=no -o StrictHostKeyChecking=no" # SSH 秘密鍵パスフレーズ ansible_ssh_pass: 'privkey_passphrase' # become (sudo) パスワード ansible_sudo_pass: 'pubkeyuser_password'./host_vars/172.17.0.3.yml--- # Remote User ansible_ssh_user: pwduser # パスワード認証の指定 ansible_ssh_common_args: '-o PreferredAuthentications=password -o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no' # 認証パスワード ansible_ssh_pass: 'pwduser_password' # become (sudo) パスワード ansible_sudo_pass: 'pwduser_password'パスワードを入力せずに(非インタラクティブで) become が実行できるようになります。
非インタラクティブなbecomeの動作確認(ansible) $ ( set -x; for h in 172.17.0.2 172.17.0.3 hostgroup; do ansible $h -m command -a 'id -a'; ansible $h -m command -a 'id -a' -b; done ) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible 172.17.0.2 -m command -a 'id -a' 172.17.0.2 | CHANGED | rc=0 >> uid=1001(pubkeyuser) gid=1001(pubkeyuser) groups=1001(pubkeyuser),27(sudo) + ansible 172.17.0.2 -m command -a 'id -a' -b 172.17.0.2 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible 172.17.0.3 -m command -a 'id -a' 172.17.0.3 | CHANGED | rc=0 >> uid=1001(pwduser) gid=1001(pwduser) groups=1001(pwduser),27(sudo) + ansible 172.17.0.3 -m command -a 'id -a' -b 172.17.0.3 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible hostgroup -m command -a 'id -a' 172.17.0.3 | CHANGED | rc=0 >> uid=1001(pwduser) gid=1001(pwduser) groups=1001(pwduser),27(sudo) 172.17.0.2 | CHANGED | rc=0 >> uid=1001(pubkeyuser) gid=1001(pubkeyuser) groups=1001(pubkeyuser),27(sudo) + ansible hostgroup -m command -a 'id -a' -b 172.17.0.3 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) 172.17.0.2 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) (ansible) $ansible-vault を利用した暗号化
参照: Ansible Vault — Ansible Documentation
パスワード/パスフレーズを各変数に設定することで、入力せずに実行できるようになりましたが、パスワード/パスフレーズが平文で残っているのは好ましくありません。
そこで、ansible-vault を利用して、暗号化します。
ansible-vault で、以下のようなことができます。
- ファイル全体を暗号化する
- key=value を暗号化する
- value 部分を暗号化する
詳しいことは参照先の "Ansible Vault — Ansible Documentation" を見ていただくとして、ここでは、3番目の value 部分を暗号化した実例を示します。
ansible-vault には、vault-id というものがありますが、これがドキュメントではわかりにくくなっています。
--vault-idオプションで、ID リスト (カンマ区切りで複数指定可) を提示し、--encrypt-vault-idオプションで、暗号化時の ID (label) を指定します。- vault-id の形式は、"label@パスワードファイル名" という形で、label とパスワードの記載されたファイル名の組み合わせになります。
ansible-vault の暗号化/復号パスワードを以下のようなファイルに設定することにします。
(ansible) $ tree -a ~/.ansible_rings/ /home/luser/.ansible_rings/ |-- .vault_pass_sample.txt |-- .vault_pass_sample1.txt |-- .vault_pass_sample2.txt |-- .vault_pass_sample3.txt |-- .vault_pass_sample4.txt `-- .vault_pass_sample_default.txt 0 directories, 6 files (ansible) $~/.ansible_rings/.vault_pass_sample.txtsamplepassword~/.ansible_rings/.vault_pass_sample1.txtsample1password~/.ansible_rings/.vault_pass_sample2.txtsample2password~/.ansible_rings/.vault_pass_sample3.txtsample3password~/.ansible_rings/.vault_pass_sample4.txtsample4password~/.ansible_rings/.vault_pass_sample_default.txtdefaultPassword次に、ansible.cfg に ansible-vault の設定を行います。
./ansible.cfg[defaults] interpreter_python = /usr/bin/python3 # インベントリ inventory = hosts # ansible-vault 関連 vault_identity = sample vault_encrypt_identity = sample vault_identity_list = sample@~/.ansible_rings/.vault_pass_sample.txt,sample1@~/.ansible_rings/.vault_pass_sample1.txt,sample2@~/.ansible_rings/.vault_pass_sample2.txt,sample3@~/.ansible_rings/.vault_pass_sample3.txt,sample4@~/.ansible_rings/.vault_pass_sample4.txt,@~/.ansible_rings/.vault_pass_sample_default.txt #[privilege_escalation] ## become (sudo) #become = Trueansible.cfg の設定が終わったら、パスワード/パスフレーズの暗号化を行います。
ansible-vaultによる暗号化(ansible) $ ( set -x; ( while read n p s; do ansible-vault encrypt_string -v --encrypt-vault-id $s -n $n $p; done ) << EOT ansible_ssh_pass privkey_passphrase sample1 ansible_sudo_pass pubkeyuser_password sample2 ansible_ssh_pass pwduser_password sample3 ansible_sudo_pass pwduser_password sample4 EOT ) + cat + read n p s + ansible-vault encrypt_string -v --encrypt-vault-id sample1 -n ansible_ssh_pass privkey_passphrase Using /home/luser/work/Ansible.d/passwordtest.withVault/ansible.cfg as config file ansible_ssh_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample1 31386662393263333631396165646631616139323064346631633931363563323330643035393366 3132633136633734383665373135343833353835396461640a633132663862633130653735633436 61613535333964383162373135383966643438303661326333303337656263626262303232333961 3436656633316232310a636336323737323761346535613761623038623362636565633934656437 30633462363565383035626165393832626465636161313932333866306266666638 Encryption successful + read n p s + ansible-vault encrypt_string -v --encrypt-vault-id sample2 -n ansible_sudo_pass pubkeyuser_password Using /home/luser/work/Ansible.d/passwordtest.withVault/ansible.cfg as config file ansible_sudo_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample2 34646236623634393565333836346238333662313466323762316462636637633735326330393261 6335373233666334386362626661653363373563393763360a633161336663303737376535393638 65333033333330326534643233336466363931336633643464373862653663316665373331616566 3333343232306266350a656464363232376661626135613063333032353037376333323830363538 35333362353534376664613736343765373862333631346338656634383262373935 Encryption successful + read n p s + ansible-vault encrypt_string -v --encrypt-vault-id sample3 -n ansible_ssh_pass pwduser_password Using /home/luser/work/Ansible.d/passwordtest.withVault/ansible.cfg as config file ansible_ssh_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample3 39623031313762626535383264623838613435306233323863363466363231663265363230653666 3739666333396133313332613563626238323665636638300a653433303139373734326562633735 36303536366533323665623436633939393138393064633435383063366531373662343339643631 6263386465663838630a623365383336373536343039343663393662396162613433646132373438 61326165326566373761613831663961363237376563653863666330336330396139 Encryption successful + read n p s + ansible-vault encrypt_string -v --encrypt-vault-id sample4 -n ansible_sudo_pass pwduser_password Using /home/luser/work/Ansible.d/passwordtest.withVault/ansible.cfg as config file ansible_sudo_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample4 62346235306363343334653464653235373632386165383735343038313765633133376462663737 3532323962316536663333363366666432383832323531340a336132376130326430633765333566 66336238653038366233323834383862303262336435623039316135613139303862306133646562 3162393332343931370a366365666564326462396365376434353234353661353763626465383734 65383938383535356137313531613631646366363231393737656266383134353239 Encryption successful + read n p s (ansible) $上では、標準出力に表示させていますが、ファイルに書き込む場合には --output オプションが使用できます。
それぞれの出力を、変数として設定します。
host_vars/172.17.0.2.yml--- # Remote User ansible_ssh_user: pubkeyuser # 秘密鍵 ansible_private_key_file: ./pubkeyuser_id_rsa_assword # SSH 共通引数 ansible_ssh_common_args: "-o PubkeyAuthentication=yes -o PasswordAuthentication=no -o StrictHostKeyChecking=no" # SSH 秘密鍵パスフレーズ #ansible_ssh_pass: 'privkey_passphrase' ansible_ssh_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample1 31386662393263333631396165646631616139323064346631633931363563323330643035393366 3132633136633734383665373135343833353835396461640a633132663862633130653735633436 61613535333964383162373135383966643438303661326333303337656263626262303232333961 3436656633316232310a636336323737323761346535613761623038623362636565633934656437 30633462363565383035626165393832626465636161313932333866306266666638 # become (sudo) パスワード #ansible_sudo_pass: 'pubkeyuser_password' ansible_sudo_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample2 34646236623634393565333836346238333662313466323762316462636637633735326330393261 6335373233666334386362626661653363373563393763360a633161336663303737376535393638 65333033333330326534643233336466363931336633643464373862653663316665373331616566 3333343232306266350a656464363232376661626135613063333032353037376333323830363538 35333362353534376664613736343765373862333631346338656634383262373935host_vars/172.17.0.3.yml--- # Remote User ansible_ssh_user: pwduser # パスワード認証の指定 ansible_ssh_common_args: '-o PreferredAuthentications=password -o PubkeyAuthentication=no -o PasswordAuthentication=yes -o StrictHostKeyChecking=no' # 認証パスワード #ansible_ssh_pass: 'pwduser_password' ansible_ssh_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample3 39623031313762626535383264623838613435306233323863363466363231663265363230653666 3739666333396133313332613563626238323665636638300a653433303139373734326562633735 36303536366533323665623436633939393138393064633435383063366531373662343339643631 6263386465663838630a623365383336373536343039343663393662396162613433646132373438 61326165326566373761613831663961363237376563653863666330336330396139 # become (sudo) パスワード #ansible_sudo_pass: 'pwduser_password' ansible_sudo_pass: !vault | $ANSIBLE_VAULT;1.2;AES256;sample4 62346235306363343334653464653235373632386165383735343038313765633133376462663737 3532323962316536663333363366666432383832323531340a336132376130326430633765333566 66336238653038366233323834383862303262336435623039316135613139303862306133646562 3162393332343931370a366365666564326462396365376434353234353661353763626465383734 65383938383535356137313531613631646366363231393737656266383134353239(ansible) $ ( set -x; for h in 172.17.0.2 172.17.0.3 hostgroup; do ansible $h -m command -a 'id -a'; ansible $h -m command -a 'id -a' -b; done ) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible 172.17.0.2 -m command -a 'id -a' 172.17.0.2 | CHANGED | rc=0 >> uid=1001(pubkeyuser) gid=1001(pubkeyuser) groups=1001(pubkeyuser),27(sudo) + ansible 172.17.0.2 -m command -a 'id -a' -b 172.17.0.2 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible 172.17.0.3 -m command -a 'id -a' 172.17.0.3 | CHANGED | rc=0 >> uid=1001(pwduser) gid=1001(pwduser) groups=1001(pwduser),27(sudo) + ansible 172.17.0.3 -m command -a 'id -a' -b 172.17.0.3 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) + for h in 172.17.0.2 172.17.0.3 hostgroup + ansible hostgroup -m command -a 'id -a' 172.17.0.2 | CHANGED | rc=0 >> uid=1001(pubkeyuser) gid=1001(pubkeyuser) groups=1001(pubkeyuser),27(sudo) 172.17.0.3 | CHANGED | rc=0 >> uid=1001(pwduser) gid=1001(pwduser) groups=1001(pwduser),27(sudo) + ansible hostgroup -m command -a 'id -a' -b 172.17.0.2 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) 172.17.0.3 | CHANGED | rc=0 >> uid=0(root) gid=0(root) groups=0(root) (ansible) $ssh のパスフレーズは、ssh-agent/ssh-add を使うことが推奨されていますし、become(sudo)のパスワードは、ansible-vault で暗号化し、復号パスワードが記載されたファイルは、厳重に管理しましょう。
ssh のパスワード設定の tips
- ssh – connect via ssh client binary — Ansible Documentation の password の説明では、変数名として
ansible_ssh_passwordが使えるように記載されているが、ansible_ssh_passとansible_passwordのみが実装されており、ansible_ssh_passwordは実装されていない。var: ansible_password
var: ansible_ssh_pass
var: ansible_ssh_password
- 以下の修正を加えれば使用できるようになるが、回避策(
ansible_ssh_passかansible_passwordを使用する)があるのと、まとめようという issue もあるで、修正されるかどうかは不明。ansible-constants.py.patch*** constants.py.orig 2019-12-04 23:10:58.000000000 +0000 --- constants.py 2020-01-10 05:16:07.520928899 +0000 *************** *** 140,146 **** # connection common remote_addr=('ansible_ssh_host', 'ansible_host'), remote_user=('ansible_ssh_user', 'ansible_user'), ! password=('ansible_ssh_pass', 'ansible_password'), port=('ansible_ssh_port', 'ansible_port'), pipelining=('ansible_ssh_pipelining', 'ansible_pipelining'), timeout=('ansible_ssh_timeout', 'ansible_timeout'), --- 140,146 ---- # connection common remote_addr=('ansible_ssh_host', 'ansible_host'), remote_user=('ansible_ssh_user', 'ansible_user'), ! password=('ansible_ssh_password', 'ansible_ssh_pass', 'ansible_password'), port=('ansible_ssh_port', 'ansible_port'), pipelining=('ansible_ssh_pipelining', 'ansible_pipelining'), timeout=('ansible_ssh_timeout', 'ansible_timeout'),
一般に、ログインパスワードを用いた接続で入力するパスワードと、sudo によって管理者権限へ昇格する場合のパスワードは同じため、ログインパスワードが漏れると、対象サーバ上の管理者権限が奪われるリスクが高くなります。ログインのためのパスワード/パスフレーズと、権限昇格のための sudo で用いるパスワードは、分けておく(つまり、ログインはできるだけログインパスワード以外で利用する)ことをお勧めします。 ↩
- 投稿日:2020-01-12T23:12:35+09:00
【初心者向け】再帰関数(ハノイの塔を分かりやすく!)
1.はじめに
再帰関数はプログラミングの最初の関門かもしれない。Pythonでハノイの塔を解きながら、再帰関数をマスターしよう。
再帰関数は、マトリョーシカのように、プログラムの構造が入れ子になっている。ぜひ、マトリョーシカをイメージしながら、以下の説明を読んでみてください。
2.ハノイの塔
ハノイの塔は、以下を参照してください。ハノイの塔
簡単に説明すると、棒が3本あって、板を刺せるようになっている。右に板が何枚かある。板の大きさは下が一番大きくて、上に行くほど小さくなる。板を一枚ずつ動かして、最終的に全ての板を真ん中の棒に移したい。但し、小さい板の上に大きな板は置けない。
プログラミングの学習では、再帰関数を使って解く問題だ。
3.考え方
1枚は超簡単。右から真ん中に移して、おしまい。
2枚の場合がポイント。いきなり、右の棒の小さい板を真ん中に移してはダメ。
(1)まず、小さい板は、一旦、左のワーク用の棒に移す。
(2)それから、右に残った、大きい板を真ん中に移す。
(3)その後、小さい板を左から真ん中に移せば、OKだ。つまり、n枚の板(この場合、2枚)、すべてを真ん中に移すためには、(1)一番下の一番大きい板を除くn-1枚(この場合、1枚)を、一旦、左のワーク用の棒に移す必要がある。
(2)そして、一番下の一番大きい板を右から真ん中に移した後で、(3)左のワーク用の棒にあるn-1枚の板(この場合、1枚)すべてを、真ん中に移せば、OKだ。以下の説明では、上記の(1)から(3)を繰り返し説明する。以下の説明で出てくる(1)から(3)も上記の(1)から(3)と、基本的には、同じ意味になる。但し、「どこから、どこへ」は、操作の意味により、「右、真ん中、左」の中で、場合によって変化する。
4.再帰関数での解法
以下がハノイの塔の解法プログラムになる。後ほど実行するが、使う際には、板の枚数をNに代入する。
start=list(range(N,0,-1));end=[];tmp=[];i=0 #1 def print_hanoi(): #2 print(start,end,tmp) def hanoi(n,start,end,tmp): #3 if n<=0: return #4 hanoi(n-1,start,tmp,end) #5 end.append(start.pop()) #6 print_hanoi() #7 global i; i+=1 #8 print('上記は',i,'回目の操作後の状態') #9 hanoi(n-1,tmp,end,start) #10 print_hanoi() #11 print('上記は最初の状態') #12 hanoi(N,start,end,tmp) #13簡単に解説する。数字はプログラムで#を付けた部分に該当する。
1.startは最初に右の棒に刺さっている板を表すリスト。初期状態は、下が一番大きく、1ずつ小さくなり、最後は1となるリスト。
endは最終的に板を映したい真ん中の棒に刺さっている板を表すリスト。最初は何も刺さっていないので、空(から)のリスト。
tmpはワーク用の棒に刺さっている板を表すリスト。こちらも最初は何も刺さっていないので空のリスト。
iは、何回目の操作かを表すために設定。
2.状態を表す。順番に「右、真ん中、左」の棒に刺さっている板を、リストで表す。
3.これがハノイの塔を解く関数。但し、再帰関数をとして使うので、マトリョーシカのように、入れ子になる。
引数に注意してもらいたい。最初のnが板の枚数。次がstartが右で、それを次のendに動かしたい。最後のtmpがワーク用。4.これがベースとなる終了条件。動かすべき板が0になれば、終了。
ベースとなる終了条件を忘れると、無限ループに陥るので、注意が必要だ。5.3の関数を再帰的に使っている。但し、3の関数は第一引数のn枚すべてを、第二引数のstartから第三引数のendに移すように定義した。(第四引数はワーク用のtmpとした。)
ここでは、(1)一番下のnを除いた 残りのn-1枚すべて(第一引数)をstart(第二引数)から一旦、tmp(第三引数)に移す。(第四引数は残りの引数であるend。)
こうすることで、上からn-1枚はtmpに移るので、一番下にあるnを動かすことができるようになる。
6.5で上からn-1枚をtmpに移したので、右のstartの棒には、一番下のnだけが残っている。(2)その一番下の板を取り出して
start.pop()、真ん中のendの棒に移すend.append()(リストへの追加)。7.ここで状態をプリント。
8.回数をカウントアップ。
9.分かりやすいように何回目の操作後かをプリント。
10.6で一番大きい板は真ん中に移っている。(3)その一番大きい板の上に、左のワーク用の棒にあるn-1枚の板すべてを移す。引数に注目すると、やっていることが分かると思う。
11.ここで最初の状態をプリント。
12.分かりやすいようにコメントをプリント。
13.実際の実行。Nは実際に使う際に、与える。
5.実際にやってみよう
1.まずは板が1枚の場合。やるまでも無い気がするが何事も念入りに。Nはプログラムの冒頭で指定している。
N=1;start=list(range(N,0,-1));end=[];tmp=[];i=0 #1 def print_hanoi(): #2 print(start,end,tmp) def hanoi(n,start,end,tmp): #3 if n<=0: return #4 hanoi(n-1,start,tmp,end) #5 end.append(start.pop()) #6 print_hanoi() #7 global i; i+=1 #8 print('上記は',i,'回目の操作後の状態') #9 hanoi(n-1,tmp,end,start) #10 print_hanoi() #11 print('上記は最初の状態') #12 hanoi(N,start,end,tmp) #13結果は以下の通り。右から真ん中に移して、おしまい。
ここでは、3の「考え方」で説明した(2)の部分だけが実行される。(1)に相当する#5や(2)に相当する#10を見てもらうと分かるけど、n-1が0になり、#4で何も実行されないことになる。
[1] [] [] 上記は最初の状態 [] [1] [] 上記は 1 回目の操作後の状態2.次は、2枚のケース。1枚のケースと異なり、2枚のケース以降は左のワーク用の棒を使う。
N=2;start=list(range(N,0,-1));end=[];tmp=[];i=0 #1 def print_hanoi(): #2 print(start,end,tmp) def hanoi(n,start,end,tmp): #3 if n<=0: return #4 hanoi(n-1,start,tmp,end) #5 end.append(start.pop()) #6 print_hanoi() #7 global i; i+=1 #8 print('上記は',i,'回目の操作後の状態') #9 hanoi(n-1,tmp,end,start) #10 print_hanoi() #11 print('上記は最初の状態') #12 hanoi(N,start,end,tmp) #13結果は以下の通り。数字は板の大きさを表す。リストの数字は、下にあるものから順番に出力するようにしている。つまり、リストの中の数字が降順に並んでいることがハノイの塔のルール上、必要となる。
2枚のケースでは、
(1)まず、小さい板を右から左のワーク用の棒に移す。(1回目の操作)
(2)そして、そうすることで、右の大きい板を真ん中に移すことが出来る。(2回目の操作)
(3)最後に、左の小さい板を真ん中の大きい板の上に移せば、OKだ。(3回目の操作)[2, 1] [] [] 上記は最初の状態 [2] [] [1] 上記は 1 回目の操作後の状態 [] [2] [1] 上記は 2 回目の操作後の状態 [] [2, 1] [] 上記は 3 回目の操作後の状態3.3枚以降はプログラムは省略。Nに代入する枚数を変えればOKだ。
結果は以下の通り。[3, 2, 1] [] [] 上記は最初の状態 [3, 2] [1] [] 上記は 1 回目の操作後の状態 [3] [1] [2] 上記は 2 回目の操作後の状態 [3] [] [2, 1] 上記は 3 回目の操作後の状態 [] [3] [2, 1] 上記は 4 回目の操作後の状態 [1] [3] [2] 上記は 5 回目の操作後の状態 [1] [3, 2] [] 上記は 6 回目の操作後の状態 [] [3, 2, 1] [] 上記は 7 回目の操作後の状態(1)1回目から3回目までの操作で、2枚(つまり、n-1枚)を左のワーク用の棒に移している。この1回目から3回目の中に、2枚の場合の(1)から(3)が含まれる。もちろん、「どこから、どこへ」の詳細は、ケースバイケース。
(2)そして、4回目の操作で、一番大きい3枚目(つまり、n枚目)を右から真ん中に移す。
(3)その後、5回目から7回目までの操作で、左のワークにある2枚(つまり、n-1枚)を真ん中の一番大きい板の上に移して、おしまい。この5回目から7回目の中にも、2枚の場合の(1)から(3)が含まれる。もちろん、「どこから、どこへ」の詳細は、ケースバイケース。
ここで気をつけてほしいのは、まず(1)で2枚を左のワーク用の棒に移す方法。2でやった2枚を右から真ん中に移すケースでは、左がワークになった。しかし、3枚の(1)で2枚を右から左に移すケースでは、当然のことながら、真ん中がワーク用になる。だから、1回目の操作で一番小さい板を、真ん中に移すことになる。
(3)で2枚を左から真ん中に移す場合も同様。ここでは右がワークになるので、5回目の操作では、一番小さい板を左から右に移している。
4.最後に4枚のケースをやって、おしまいにしよう。
[4, 3, 2, 1] [] [] 上記は最初の状態 [4, 3, 2] [] [1] 上記は 1 回目の操作後の状態 [4, 3] [2] [1] 上記は 2 回目の操作後の状態 [4, 3] [2, 1] [] 上記は 3 回目の操作後の状態 [4] [2, 1] [3] 上記は 4 回目の操作後の状態 [4, 1] [2] [3] 上記は 5 回目の操作後の状態 [4, 1] [] [3, 2] 上記は 6 回目の操作後の状態 [4] [] [3, 2, 1] 上記は 7 回目の操作後の状態 [] [4] [3, 2, 1] 上記は 8 回目の操作後の状態 [] [4, 1] [3, 2] 上記は 9 回目の操作後の状態 [2] [4, 1] [3] 上記は 10 回目の操作後の状態 [2, 1] [4] [3] 上記は 11 回目の操作後の状態 [2, 1] [4, 3] [] 上記は 12 回目の操作後の状態 [2] [4, 3] [1] 上記は 13 回目の操作後の状態 [] [4, 3, 2] [1] 上記は 14 回目の操作後の状態 [] [4, 3, 2, 1] [] 上記は 15 回目の操作後の状態(1)1回目から7回目までの操作で、3枚(つまり、n-1枚)を左のワーク用の棒に移している。この1回目から7回目の中に、3枚の場合の(1)から(3)が含まれる。そして、3枚の場合の(1)の中に、2枚の場合の(1)から(3)が含まれ、3枚の場合の(3)の中にも、2枚の場合の(1)から(3)が含まれる。
(2)そして、8回目の操作で、一番大きい4枚目(つまり、n枚目)を右から真ん中に移す。
(3)その後、9回目から15回目までの操作で、左のワークにある3枚(つまり、n-1枚)を真ん中の一番大きい板の上に移して、おしまい。この9回目から15回目の中に、3枚の場合の(1)から(3)が含まれる。そして、3枚の場合の(1)の中に、2枚の場合の(1)から(3)が含まれ、3枚の場合の(3)の中にも、2枚の場合の(1)から(3)が含まれる。
今回も3枚のときと同様、ワーク用は変化する。
6.まとめ
ハノイの塔におけるワーク用などの役割は、板の枚数などによって、変化する。
しかし、着目してほしいのは、5の2枚、3枚、4枚に記載した(1)(2)(3)の部分だ。
(1)まず、上からn-1枚を、右から左のワーク用に移し、
(2)そうすることで、一番下の大きい板を、右から真ん中に移すことが出来て、
(3)最終的に、上からn-1枚を、左のワークから真ん中に移せば、OKだ。4のプログラムで言えば、(1)が5に、(2)が6に、(3)が10に、対応する。この操作を、マトリョーシカよろしく、繰り返し、行っているのが、ハノイの塔の解法に使われている再帰関数ということになる。(なお、正確に言うと、純粋な再帰の部分は(1)と(3)です。)
7.参考サイト
以下のサイトは、c++で記載されていますが、とても参考になるサイトです。著者の方は、僕が個人的に尊敬している方です。


- 投稿日:2020-01-12T23:08:09+09:00
Jupyter学習ノート_006
データを地図に見る
google colabにデータを地図上で表示するライブラリfoliumを使ってみる。
- サンプル1(東京駅の地図を見る)
- parm1: location[緯度, 経度]
- parm2: zom_start=18 (0から18まで拡大/縮小可能です)
folium_01.pyimport folium map_ = folium.Map(location=[35.681384, 139.766073], zoom_start=18) map_
実行結果
サンプル2(京急線の駅をマックする)
folium_02.pyimport folium #京急線の泉岳寺〜横浜までの緯度と経度を定義する kk_ekis = [ ['泉岳寺',35.638692,139.74002], ['品川',35.630152,139.74044], ['北品川',35.622716,139.739152], ['新馬場',35.61762,139.741366], ['青物横丁',35.609351,139.742905], ['鮫洲',35.605144,139.742547], ['立会川',35.598453,139.738803], ['大森海岸',35.587695,139.735465], ['平和島',35.579074,139.734996], ['大森町',35.572622,139.732169], ['梅屋敷',35.567042,139.728341], ['京急蒲田',35.560685,139.723731], ['雑色',35.549911,139.715199], ['六郷土手',35.540893,139.707789], ['京急川崎',35.532833,139.700896], ['八丁畷',35.523113,139.691488], ['鶴見市場',35.51783,139.686592], ['京急鶴見',35.50729,139.678098], ['花月園前',35.500413,139.67301], ['生麦',35.495297,139.666969], ['京急新子安',35.487106,139.65554], ['子安',35.484959,139.645635], ['神奈川新町',35.481462,139.640158], ['仲木戸',35.477312,139.634489], ['神奈川',35.471399,139.627467], ['横浜',35.466188,139.622715]] #駅ごとのマックを地図につける for kk_eki in kk_ekis: folium.Marker([kk_eki[1], kk_eki[2]], popup=kk_eki[0]).add_to(map_) map_
- 実行結果



- 投稿日:2020-01-12T23:07:33+09:00
ortoolpyによる最適化問題のとってもシンプルな例
やったこと
「Python実践データ分析100本ノック」を読んでいたら、ortoolpyとpulpを使用した最適化問題が出てきました。
使用したことが無いモジュールであったため、自分の理解のために簡単な例を作りました。詳しくはコード中のコメントを参照。
環境
- python 3.7.4
- ortoolpy 0.2.29
- PuLP 2.0
コード
# 必要なモジュールのインポート from pulp import LpVariable, lpSum, value from ortoolpy import model_min # モデルの定義 model = model_min() # 変数の定義 # v_0 と v_1 という2つの変数を定義。具体的な値は入っていない入れ物。 v_0 = LpVariable("V0") v_1 = LpVariable("V1") # 目的関数の設定 # v_0 + v_1 を最小化したい。 model += lpSum([v_0, v_1]) # 制約条件の追加 # v_0 は2以上 model += v_0 >= 2 # v_1 は3以上 model += v_1 >= 3 # v_0 と v_1 は同じ値 model += v_0 == v_1 # 上の条件から、v_0 = v_1 = 3 となることを期待する。 # 問題を解く model.solve() # 結果の表示 # value(変数名)で、計算結果の値を読みだせる。 print("v_0 : ", value(v_0)) print("v_1 : ", value(v_1)) # v_0 : 3.0 # v_1 : 3.0 # 期待通りの値が得られた。
- 投稿日:2020-01-12T23:05:57+09:00
lambda
先頭を大文字に1l = ['Apple', 'banana', 'orange', 'Strawberry', 'cherry'] def change_words(func, words): for word in words: print(func(word)) def capit_func(word): return word.capitalize() change_words(capit_func, l)先頭を大文字に1の実行結果Apple Banana Orange Strawberry Cherrycapi_func関数は、引数wordの先頭を大文字にする関数である。
これをlambdaを使えば、コード量を減らすことができる。先頭を大文字に2l = ['Apple', 'banana', 'orange', 'Strawberry', 'cherry'] def change_words(func, words): for word in words: print(func(word)) capit_func = lambda word: word.capitalize() change_words(capit_func, l)わざわざ、
capit_funcを定義しないで、
change_words関数の引数に直接書く事も可能で、
更にコード量を減らすことが可能である。先頭を大文字に3l = ['Apple', 'banana', 'orange', 'Strawberry', 'cherry'] def change_words(func, words): for word in words: print(func(word)) change_words(lambda word: word.capitalize(), l)このlambdaは、
ファンクションがcapit_func関数だけでなく、
複数ファンクションが必要な場合に威力を発揮する。複数ファンクションl = ['Apple', 'banana', 'orange', 'Strawberry', 'cherry'] def change_words(func, words): for word in words: print(func(word)) change_words(lambda word: word.capitalize(), l) change_words(lambda word: word.lower(), l)複数ファンクションの実行結果Apple Banana Orange Strawberry Cherry apple banana orange strawberry cherryもし、
lambdaを使わなかったら、複数ファンクション2l = ['Apple', 'banana', 'orange', 'Strawberry', 'cherry'] def change_words(func, words): for word in words: print(func(word)) def capit_func(word): return word.capitalize() def low_func(word): return word.lower() change_words(capit_func, l) change_words(low_func, l)と書かねばならない。
capit_func関数とlow_func関数の2つの関数を定義する事が必要となる。
- 投稿日:2020-01-12T22:16:06+09:00
ArcPyでフィーチャにフィールドを追加する
Pythonコード
AddField.pyimport arcpy # 入力パラメータを確認 arcpy.AddMessage("GetArgumentCount() = {0}".format(arcpy.GetArgumentCount())) for i in range(arcpy.GetArgumentCount()): arcpy.AddMessage("type(GetParameter({0})) = {1}".format(i, type(arcpy.GetParameter(i)))) arcpy.AddMessage("GetParameterAsText({0}) = {1}".format(i, arcpy.GetParameterAsText(i))) inFeatureLayer = arcpy.GetParameter(0) outFeatureClass = arcpy.GetParameter(1) # フィーチャレイヤーをコピー arcpy.CopyFeatures_management(inFeatureLayer, outFeatureClass) # フィールドを追加 arcpy.AddField_management(outFeatureClass, "field1", "DOUBLE", field_alias = "フィールド1") arcpy.AddField_management(outFeatureClass, "field2", "DOUBLE", field_alias = "フィールド2") fields = ["OID@", "SHAPE@X", "SHAPE@Y", "field1", "field2"] # フィールドに値を入力 with arcpy.da.UpdateCursor(outFeatureClass, fields) as cursor: arcpy.AddMessage("入力前のフィールド") for row in cursor: arcpy.AddMessage(row) row[3] = row[1] row[4] = row[2] cursor.updateRow(row) del cursor # 入力後の状態を確認 with arcpy.da.SearchCursor(outFeatureClass, fields) as cursor: arcpy.AddMessage("入力後のフィールド") for row in cursor: arcpy.AddMessage(row) del cursor実行結果
ポリゴンが2つ含まれているフィーチャレイヤーを入力として実行した場合。
GetArgumentCount() = 2 type(GetParameter(0)) = <class 'arcpy._mp.Layer'> GetParameterAsText(0) = テストポリゴン type(GetParameter(1)) = <class 'geoprocessing value object'> GetParameterAsText(1) = D:\GIS\ArcGIS_Project\GeometryTest\GeometryTest.gdb\テストポリゴン_AddField 入力前のフィールド [1, 134.32332180386206, 30.338120870687362, None, None] [2, 144.42135929631993, 39.08930527833865, None, None] 入力後のフィールド [1, 134.32332180386206, 30.338120870687362, 134.32332180386206, 30.338120870687362] [2, 144.42135929631993, 39.08930527833865, 144.42135929631993, 39.08930527833865]
リファレンス


- 投稿日:2020-01-12T22:15:57+09:00
pythonで16進数を10進数に変換するプログラムを作成してみた
pythonの学習のため16進数を10進数に変換するプログラムを作成してみました。
下記のようにint関数を使えば一発で変換できるので、あくまでも学習です。
main.pyprint(int('3b',base=16))terminal59実際に作成したコードは下記の感じです。
main.pybase_num = '0123456789ABCDEF' count_num = 3 def hex_to_int(hex_str):# HEX文字列を数値へ変換 i = len(hex_str) value = 0 digits = 0 while i > 0: value += base_num.find(hex_str[i - 1]) * (len(base_num) ** digits) i -= 1 digits += 1 return value if __name__ == "__main__": num_list = [] while len(num_list) < count_num: input_num = input('16進数を入力してください:') input_num = input_num.upper() # HEX文字列チェック is_num_check = True for num in input_num: if not num in base_num: is_num_check = False if is_num_check: input_val = hex_to_int(input_num) num_list.append(input_val) else: print('16進数ではありません') print(*num_list)入力した16進数の値を10進数に変換して返します。
内包表記を使えばもっと短く書けそうです。
- 投稿日:2020-01-12T21:41:43+09:00
デコレーター2
2つのデコレーター1def print_more(func): def wrapper(*args, **kwargs): print('func:', func.__name__) print('args:', args) print('kwargs:', kwargs) result = func(*args, **kwargs) print('result:', result) return result return wrapper def print_info(func): def wrapper(*args, **kwargs): print('start') result = func(*args, **kwargs) print('end') return result return wrapper @print_info @print_more def add_num(a, b): return a + b r = add_num(10, 40) print(r)2つのデコレーター1の実行結果start func: add_num args: (10, 20) kwargs: {} result: 30 end 30@print_info と @print_more の順番を入れ替えると
実行結果は入れ替えた場合の実行結果func: wrapper args: (10, 40) kwargs: {} start end result: 50 50となる
これは、
下記の様に
@を使わない書き方でかくと少しは分かりやすいかも。。。2つのデコレーター2def print_more(func): def wrapper(*args, **kwargs): print('func:', func.__name__) print('args:', args) print('kwargs:', kwargs) result = func(*args, **kwargs) print('result:', result) return result return wrapper def print_info(func): def wrapper(*args, **kwargs): print('start') result = func(*args, **kwargs) print('end') return result return wrapper def add_num(a, b): return a + b f = print_info(print_more(add_num)) r = f(10, 40) print(r)2つのデコレーター2の実行結果start func: add_num args: (10, 20) kwargs: {} result: 30 end 30print_info で print_more を包み込むイメージ。。。
- 投稿日:2020-01-12T21:41:30+09:00
Flask-SQLAlchemy + PostgreSQLでWebサービスを作成する
Flask-SQLAlchemy + PostgreSQLでWebサービスを作成する
はじめに
サンプルアプリ(Feedback)を用いてご紹介します。
Mac環境の記事ですが、Windows環境も同じ手順になります。環境依存の部分は読み替えてお試しください。目的
この記事を最後まで読むと、次のことができるようになります。
No. 概要 キーワード 1 Flask-SQLAlchemyの開発 Flask-SQLAlchemy, psycopg2 2 PostgreSQLの設定 psql, Flask-Migrate 実行環境
環境 Ver. macOS Catalina 10.15.2 Python 3.7.3 Flask-Migrate 2.5.2 Flask-SQLAlchemy 2.4.1 Flask 1.1.1 psycopg2 2.8.4 requests 2.22.0 ソースコード
実際に実装内容やソースコードを追いながら読むとより理解が深まるかと思います。是非ご活用ください。
関連する記事
0. 開発環境の構成
tree.sh/ ├── app │ ├── __init__.py │ ├── config.py │ ├── feedback │ │ ├── __init__.py │ │ ├── common/ │ │ ├── models │ │ │ ├── __init__.py │ │ │ └── feedback.py │ │ ├── static/ │ │ ├── templates/ │ │ └── views/ │ ├── run.py │ └── tests/ └── instance ├── postgresql.py ├── sqlite3.py └── config.py1. Flask-SQLAlchemyの開発
パッケージのインストール
パッケージをインストールする。
procedure.sh~$ pip install Flask-Migrate ~$ pip install Flask-SQLAlchemy ~$ pip install Flask ~$ pip install psycopg2
psycopg2のインストールでエラーが出る場合は、環境変数を指定してコマンドを実行する(macOS + venv環境)。procedure.sh~$ xcode-select --install ~$ env LDFLAGS="-I/usr/local/opt/openssl/include -L/usr/local/opt/openssl/lib" pip install psycopg2SQLAlchemyの設定
開発環境のコンフィグを設定する。
config.py"""instance/config.py """ from instance.postgresql import SQLALCHEMY_DATABASE_URI as DATABASE_URI DEBUG = True # SECRET_KEY is generated by os.urandom(24). SECRET_KEY = '\xf7\xf4\x9bb\xd7\xa8\xdb\xee\x9f\xe3\x98SR\xda\xb0@\xb7\x12\xa4uB\xda\xa3\x1b' STRIPE_API_KEY = '' SQLALCHEMY_DATABASE_URI = DATABASE_URI SQLALCHEMY_TRACK_MODIFICATIONS = True SQLALCHEMY_ECHO = TruePostgreSQLを設定する。
postgresql.py"""instance/postgresql.py """ SQLALCHEMY_DATABASE_URI = 'postgresql+psycopg2://{user}:{password}@{host}/{name}'.format(**{ 'user': 'nsuhara', 'password': 'nsuhara', 'host': '127.0.0.1', 'name': 'db.postgresql' })SQLite3を設定する(おまけ)。
sqlite3.py"""instance/sqlite3.py """ import os SQLALCHEMY_DATABASE_URI = 'sqlite:///{host}/{name}'.format(**{ 'host': os.path.dirname(os.path.abspath(__file__)), 'name': 'db.sqlite3' })Modelの作成
SQLAlchemyのインスタンスを生成する。
__init__.py"""app/feedback/models/__init__.py """ from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy() def init(): """init """ db.create_all()SQLAlchemyのクラス(
db.Model)を継承してModelを作成する。feedback.py"""app/feedback/models/feedback.py """ from datetime import datetime from feedback.models import db class Feedback(db.Model): """Feedback """ __tablename__ = 'feedback' id = db.Column(db.Integer, primary_key=True, autoincrement=True) service = db.Column(db.String(255), nullable=False) title = db.Column(db.String(255), nullable=False) detail = db.Column(db.String(255), nullable=False) created_date = db.Column( db.DateTime, nullable=False, default=datetime.utcnow) def __init__(self, service, title, detail): self.service = service self.title = title self.detail = detail def to_dict(self): """to_dict """ return { 'id': self.id, 'service': self.service, 'title': self.title, 'detail': self.detail, 'created_date': self.created_date }2. PostgreSQLの設定
Homebrewの実行例となります。サービスの確認
サービスを確認する。
procedure.sh~$ brew services listexample.shName Status User Plist postgresql started nsuhara /Users/nsuhara/Library/LaunchAgents/homebrew.mxcl.postgresql.plistサービスの開始/終了
サービスを開始する。
procedure.sh~$ brew services start postgresqlサービスを終了する。
procedure.sh~$ brew services stop postgresqlデータベースの確認
データベースを確認する。
デフォルトで3つのデータベースが作成される。また、Macのユーザ名がOwnerとして設定される。procedure.sh~$ psql -lresult.shList of databases Name | Owner | Encoding | Collate | Ctype | Access privileges --------------+---------+----------+---------+-------+--------------------- postgres | nsuhara | UTF8 | C | C | template0 | nsuhara | UTF8 | C | C | =c/nsuhara + | | | | | nsuhara=CTc/nsuhara template1 | nsuhara | UTF8 | C | C | =c/nsuhara + | | | | | nsuhara=CTc/nsuharaデータベースの接続/切断
データベースに接続する。
procedure.sh~$ psql -h "<host_name>" -p <port_number> -U "<role_name>" -d "<database_name>"example.sh~$ psql -h "127.0.0.1" -p 5432 -U "nsuhara" -d "postgres"データベースの接続を切断する。
procedure.shpostgresql=# \qロール(ユーザ)の作成
データベースに接続する。
ロール(ユーザ)を確認する。
procedure.shpostgresql=# \duresult.shList of roles Role name | Attributes | Member of ----------+------------------------------------------------------------+----------- nsuhara | Superuser, Create role, Create DB, Replication, Bypass RLS | {}ロール(ユーザ)を作成する。
procedure.shpostgresql=# CREATE ROLE "<role_name>" LOGIN PASSWORD "password";example.shpostgresql=# CREATE ROLE "nsuhara" LOGIN PASSWORD "nsuhara";ロール(ユーザ)を削除する。
procedure.shpostgresql=# DROP ROLE "<role_name>";example.shpostgresql=# DROP ROLE "nsuhara";データベースの作成
データベースに接続する。
データベースを確認する。
procedure.shpostgresql=# \lresult.shList of databases Name | Owner | Encoding | Collate | Ctype | Access privileges --------------+---------+----------+---------+-------+--------------------- db.postgresql | nsuhara | UTF8 | C | C | postgres | nsuhara | UTF8 | C | C | template0 | nsuhara | UTF8 | C | C | =c/nsuhara + | | | | | nsuhara=CTc/nsuhara template1 | nsuhara | UTF8 | C | C | =c/nsuhara + | | | | | nsuhara=CTc/nsuharaデータベースを作成する。
procedure.shpostgresql=# CREATE DATABASE "<database_name>" OWNER "<role_ name>";example.shpostgresql=# CREATE DATABASE "db.postgresql" OWNER "nsuhara";データベースを削除する。
procedure.shpostgresql=# DROP DATABASE "<database_name>";example.shpostgresql=# DROP DATABASE "db.postgresql";データベースのマイグレーション
Flaskの環境変数を設定する。
データベースをマイグレートする。
procedure.sh~$ flask db init ~$ flask db migrate ~$ flask db upgrade
- 投稿日:2020-01-12T21:28:13+09:00
日本語を駅名に変換するプログラム
初めに
みなさまは駅名替え歌というものをご存じでしょうか。youtubeなどで探せばすぐに出てくると思います。
歌の歌詞をすべて存在する駅名にするというものです。最初に聴いたときはその再現度の高さに驚きました。
見たところ皆さん自作されているように見受けられたので、「これプログラムできるくない?」と思い、作成にとりかかった次第です。環境
本件はローカルで作成しました。
- Window 10
- Python 3.8.1
画面
機能
一番上のテキストエリアに日本語を入力して変換ボタンを押すと、入力された文字列が駅名に変換され、中段に漢字、下段にひらがなで表示されます。
今後の課題
- Githubの使い方を学習して当プログラムを公開する
- ひらがな・カタカナしか対応していないので漢字も対応できるようにする
- 変換された文字列に「語感の近さ」を与えて、それっぽい駅名を出力するようにする
- 見た目をかっこよくする(優先度低)
- LINEのAPI連携とかAndroidアプリとか...(優先度低)
所感
見た目に時間かけなくていいなと思ったのでhtmlとbootstrapで最小限の実装をしています。
できる人は最小限でもおしゃれなんだろうな...
ニーズのないサービスに価値はなかったです。

- 投稿日:2020-01-12T21:24:21+09:00
ケンブリッジ大学による機械翻訳アーキテクチャ概論 by Slack翻訳アプリKiara
はじめに
2019年の機械翻訳の進化が非常に良くまとまったケンブリッジ大学の論文があったのでご紹介します。
弊社は自社でSlack向けの翻訳Chatbot Plugin、Kiaraを開発しており、
日本初のSlack Developer Chapter Leaderとしてリードエンジニア原田が頑張っております。
https://kiara-app.com/ (無料お試し版あり)
Slackと働き方革命に対するパッションから、今後も開発者コミュニティを盛り上げてまいります。Abstract
Neural Machine Translation: A Review
(Submitted on 4 Dec 2019)
The field of machine translation (MT), the automatic translation of written text from one natural language into another, has experienced a major paradigm shift in recent years. Statistical MT, which mainly relies on various count-based models and which used to dominate MT research for decades, has largely been superseded by neural machine translation (NMT), which tackles translation with a single neural network. In this work we will trace back the origins of modern NMT architectures to word and sentence embeddings and earlier examples of the encoder-decoder network family. We will conclude with a survey of recent trends in the field.機械翻訳(MT)、ある自然言語から別の自然言語への文章の自動翻訳の分野は、近年大きなパラダイムシフトを経験しています。主にさまざまなカウントベースのモデルに依存し、数十年間MT研究を支配していた統計MTは、単一のニューラルネットワークで翻訳に取り組むニューラル機械翻訳(NMT)にほぼ取って代わられました。この作業では、最新のNMTアーキテクチャの起源を、単語と文の埋め込み、およびエンコーダ/デコーダネットワークファミリの以前の例にまでさかのぼります。最後に、この分野の最近の傾向を調査します。
https://arxiv.org/abs/1912.02047
Conclusion
Neural machine translation (NMT) has become the de facto standard for large-scale machine translation in a very short period of time. This article traced back the origin of NMT to word and sentence embeddings and neural language models. We reviewed the most commonly used building blocks of NMT architectures – recurrence, convolution, and attention – and discussed popular concrete architectures such as RNNsearch, GNMT, ConvS2S, and the Transformer.
We discussed the advantages and disadvantages of several important design choices that have to be made to design a good NMT system with respect to decoding, training, and segmentation. We then explored advanced topics in
NMT research such as explainability and data sparsity.主要箇所 Main Topic
NMT=Neural Machine Translation
Word Embeddings
Phrase Embeddings
Sentence Embeddings
Encoder-Decoder Networks
Attentional Encoder-Decoder Networks
Recurrent NMT
Convolutional NMT
Self attention based NMT
Search problem in NMT
Greedy and beam search
Decoding direction
Generating diverse translation
Simultaneous translation
Open vocabulary NMT
NMT model errors
Reinforcement learning
Adversarial training
Explainable NMT
Multilingual NMT




- 投稿日:2020-01-12T21:18:13+09:00
アンパンマン画伯判別機を作ってみた
はじめに
AIを勉強して学んだ技術で簡単なアプリを作ってみようと思い、
以下のようなものを作ってみました。
何故アンパンマンにしたかというと、簡単に書ける漫画キャラという事で選びました。
モデルはGANを扱ってみたかったのと、正常画像のみの学習で異常検知ができるという事で
ANOGANにしようと思いましたが、調べてみるとANOGANの高速版でEfficientGANという
ものがあるらしいので、それにしました。
また、シンプルにするためアンパンマンの顔だけを判別する前提で作成しました。流れ
1. AIにアンパンマンの正常画像を学習させる。
2. 正常画像群と異常画像群をAIに入力し、それぞれのスコアの平均の中間値を
異常画像を判別する閾値に設定。
3. 実際に手書き画像を入力し、AIにその絵が異常かどうか判別させる。やったこと
データセット作成
・学習用画像
ネットからスクレイピングでアンパンマン画像を集め、画像を加工して顔だけ切り取りました。
また後述の通り携帯撮影画像の背景がグレーになっていたので、背景も学習させるため
下記関数を用いて、グレーのグラデーションのデータ拡張を行いました。from PIL import Image, ImageOps import numpy as np def make_gray_gradation(img, gradation_range=(230, 255)): """ 入力画像の背景をランダムな度合いのグレイグラデーションに変換する Input : 画像ファイル(カラーでも可) Output : 画像ファイル(背景がグレイグラデーション変換された画像) Pramater img : 入力画像 gradation_range : グラデーションするRGB値の範囲 """ gra_range = np.random.randint(*gradation_range) gray = ImageOps.grayscale(img) output = ImageOps.colorize(gray, black=(0, 0, 0), white=(gra_range, gra_range, gra_range)) return output・正常画像群と異常画像群
正常画像は、イラスト画像を透かして画用紙に書いたアンパンマンと、
私と学友が書いたアンパンマンを携帯で撮影した画像を用いました。異常画像は、バイキンマンやドキンちゃん等のイラスト画像を上記同様に携帯で撮影した画像と
ネットでスクレイピングした下手なアンパンマン画像を用いました。学習後、正常画像群と異常画像群の入力、生成画像比較、スコア分布
携帯で撮影した入力画像の背景がグレーになっていたので、学習用画像にグレーのグラデーションも
入れたのですが、うまく再現できませんでした。
スコアもアンパンマンの絵がうまく書けているかよりも、背景がうまく生成できているかどうかで
決まっているようで、異常画像を判別するための閾値がうまく決まりませんでした。対策 2値化
対策として、すべての画像について背景は全て真っ白にして、絵の輪郭がアンパンマンに似ているかだけで
異常な絵かどうか判別できるようにしました。以下は入力画像を2値化する関数です。import os import scipy.stats as stats from PIL import Image def image_binarization(path_in, path_out, th_zero_num=1400, width=100, height=100): """ 入力画像の輪郭を白黒で2値化して出力する。 Input : 画像ファイルが保存されているフォルダパス(終わりは/) (フォルダには画像以外入れない) Output : 2値化後の画像を指定フォルダに保存。 2値化後の0(輪郭線)のドット数を出力。 Pramater path_in : 入力画像群が入ったディレクトリパス path_out : 出力ディレクトリパス th_zero_num : 画像の0(輪郭線)のドット数のMIN値(輪郭が濃過ぎる時は小さくして調整) width : 画像の横幅サイズ height : 画像の縦幅サイズ """ list_in = os.listdir(path_in) im_np_out = np.empty((0, width*height)) for img in list_in: path_name = path_in+img x_img = cv2.imread(path_name) x_img = cv2.resize(x_img, (width, height)) x_img= cv2.cvtColor(x_img, cv2.COLOR_BGR2GRAY) x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1, width, height)) x_img = x_img.reshape(1, width*height) m = stats.mode(x_img) max_hindo = m.mode[0][0] for c in reversed(range(50)): th = (c+1)*0.01 th_0_1 = max_hindo-th x_img_ = np.where(x_img>th_0_1, 1, 0) if (np.count_nonzero(x_img_ == 0))>th_zero_num: break display(np.count_nonzero(x_img_ == 0)) x_img = x_img_.reshape(width, height) x_img = (x_img * 2.0) - 1.0 img_np_255 = (x_img + 1.0) * 127.5 img_np_255_mod1 = np.maximum(img_np_255, 0) img_np_255_mod1 = np.minimum(img_np_255_mod1, 255) img_np_uint8 = img_np_255_mod1.astype(np.uint8) image = Image.fromarray(img_np_uint8) image.save(path_out+img, quality=95)対策後、正常画像群と異常画像群の入力、生成画像比較、スコア分布
正解画像と異常画像で、ある程度スコアの分布が分かれましたので、とりあえずざっくりと
正常、異常を分ける閾値を決められそうです。(閾値は0.40372に決められていました)入力したアンパンマン画像が正常な絵か、異常な絵か判別
入力画像
5枚だけイラスト画像を透かして書いたアンパンマン画像を入力し、
他はネットでスクレイピングした下手なアンパンマンを14枚を入力しました。
(上記の2値化関数を用いて2値化してから入力)判別結果
判別結果はスコア表示枠の背景の色で表されます。背景が青なら正常画像、赤なら異常画像です。
結果は、イラストを透かしたアンパンマンは4/5が正常判定。
他のスクレイピングした下手なアンパンマンは8/14が異常判定で
正解率12/19=63.15%でした。もっと精度上げないといけないですね。学んだこと
・真っ白な画用紙に描いた絵を撮影したにもかかわらず、実際の画像は背景がグレーだったので
光の影響の大きさを感じたとともに、2値化等やり方を工夫して、より学習しやすい条件に限定する事で
精度を向上出来る事を学びました。
・GANの精度を向上させるために、GrobalAvaragePoolingやLeakyReLuやレイヤーにノイズを入れる等
いろいろ精度向上手法を試せたのが良かったと思います。(結果はあまり改善しませんでしたが)今後
GANの精度向上策をもっといろいろ調べて試していきたいですね。
また、GoogleColabやAWSのEC2を使用していたのですが、今後AWSのSageMakerやGCP等いろいろな
クラウドを使用して勉強していきたいと思っています。コード
train_BiGAN.pyimport numpy as np import os import tensorflow as tf import utility as Utility import argparse import matplotlib.pyplot as plt from model_BiGAN import BiGAN as Model from make_datasets_TRAIN import Make_datasets_TRAIN as Make_datasets def parser(): parser = argparse.ArgumentParser(description='train LSGAN') parser.add_argument('--batch_size', '-b', type=int, default=300, help='Number of images in each mini-batch') parser.add_argument('--log_file_name', '-lf', type=str, default='anpanman', help='log file name') parser.add_argument('--epoch', '-e', type=int, default=1001, help='epoch') parser.add_argument('--file_train_data', '-ftd', type=str, default='../Train_Data/191103/', help='train data') parser.add_argument('--test_true_data', '-ttd', type=str, default='../Valid_True_Data/191103/', help='test of true_data') parser.add_argument('--test_false_data', '-tfd', type=str, default='../Valid_False_Data/191103/', help='test of false_data') parser.add_argument('--valid_span', '-vs', type=int, default=100, help='validation span') return parser.parse_args() args = parser() #global variants BATCH_SIZE = args.batch_size LOGFILE_NAME = args.log_file_name EPOCH = args.epoch FILE_NAME = args.file_train_data TRUE_DATA = args.test_true_data FALSE_DATA = args.test_false_data IMG_WIDTH = 100 IMG_HEIGHT = 100 IMG_CHANNEL = 1 BASE_CHANNEL = 32 NOISE_UNIT_NUM = 200 NOISE_MEAN = 0.0 NOISE_STDDEV = 1.0 TEST_DATA_SAMPLE = 5 * 5 L2_NORM = 0.001 KEEP_PROB_RATE = 0.5 SEED = 1234 SCORE_ALPHA = 0.9 # using for cost function VALID_SPAN = args.valid_span np.random.seed(seed=SEED) BOARD_DIR_NAME = './tensorboard/' + LOGFILE_NAME OUT_IMG_DIR = './out_images_BiGAN' #output image file out_model_dir = './out_models_BiGAN/' #output model_ckpt file #Load_model_dir = '../model_ckpt/' #Load model_ckpt file OUT_HIST_DIR = './out_score_hist_BiGAN' #output histogram file CYCLE_LAMBDA = 1.0 try: os.mkdir('log') os.mkdir('out_graph') os.mkdir(OUT_IMG_DIR) os.mkdir(out_model_dir) os.mkdir(OUT_HIST_DIR) os.mkdir('./out_images_Debug') #for debug except: pass make_datasets = Make_datasets(FILE_NAME, TRUE_DATA, FALSE_DATA, IMG_WIDTH, IMG_HEIGHT, SEED) model = Model(NOISE_UNIT_NUM, IMG_CHANNEL, SEED, BASE_CHANNEL, KEEP_PROB_RATE) z_ = tf.placeholder(tf.float32, [None, NOISE_UNIT_NUM], name='z_') #noise to generator x_ = tf.placeholder(tf.float32, [None, IMG_HEIGHT, IMG_WIDTH, IMG_CHANNEL], name='x_') #image to classifier d_dis_f_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_g_') #target of discriminator related to generator d_dis_r_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_r_') #target of discriminator related to real image is_training_ = tf.placeholder(tf.bool, name = 'is_training') with tf.variable_scope('encoder_model'): z_enc = model.encoder(x_, reuse=False, is_training=is_training_) with tf.variable_scope('decoder_model'): x_dec = model.decoder(z_, reuse=False, is_training=is_training_) x_z_x = model.decoder(z_enc, reuse=True, is_training=is_training_) # for cycle consistency with tf.variable_scope('discriminator_model'): #stream around discriminator drop3_r, logits_r = model.discriminator(x_, z_enc, reuse=False, is_training=is_training_) #real pair drop3_f, logits_f = model.discriminator(x_dec, z_, reuse=True, is_training=is_training_) #real pair drop3_re, logits_re = model.discriminator(x_z_x, z_enc, reuse=True, is_training=is_training_) #fake pair with tf.name_scope("loss"): loss_dis_f = tf.reduce_mean(tf.square(logits_f - d_dis_f_), name='Loss_dis_gen') #loss related to generator loss_dis_r = tf.reduce_mean(tf.square(logits_r - d_dis_r_), name='Loss_dis_rea') #loss related to real image #total loss loss_dis_total = loss_dis_f + loss_dis_r loss_dec_total = loss_dis_f loss_enc_total = loss_dis_r with tf.name_scope("score"): l_g = tf.reduce_mean(tf.abs(x_ - x_z_x), axis=(1,2,3)) l_FM = tf.reduce_mean(tf.abs(drop3_r - drop3_re), axis=1) score_A = SCORE_ALPHA * l_g + (1.0 - SCORE_ALPHA) * l_FM with tf.name_scope("optional_loss"): loss_dec_opt = loss_dec_total + CYCLE_LAMBDA * l_g loss_enc_opt = loss_enc_total + CYCLE_LAMBDA * l_g tf.summary.scalar('loss_dis_total', loss_dis_total) tf.summary.scalar('loss_dec_total', loss_dec_total) tf.summary.scalar('loss_enc_total', loss_enc_total) merged = tf.summary.merge_all() # t_vars = tf.trainable_variables() dec_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="decoder") enc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="encoder") dis_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="discriminator") with tf.name_scope("train"): train_dis = tf.train.AdamOptimizer(learning_rate=0.0001, beta1=0.5).minimize(loss_dis_total, var_list=dis_vars , name='Adam_dis') train_dec = tf.train.AdamOptimizer(learning_rate=0.01, beta1=0.5).minimize(loss_dec_total, var_list=dec_vars , name='Adam_dec') train_enc = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_total, var_list=enc_vars , name='Adam_enc') train_dec_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_opt, var_list=dec_vars , name='Adam_dec') train_enc_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_opt, var_list=enc_vars , name='Adam_enc') sess = tf.Session() ckpt = tf.train.get_checkpoint_state(out_model_dir) saver = tf.train.Saver() if ckpt: # checkpointがある場合 last_model = ckpt.model_checkpoint_path # 最後に保存したmodelへのパス saver.restore(sess, last_model) # 変数データの読み込み print("load " + last_model) else: # 保存データがない場合 #init = tf.initialize_all_variables() sess.run(tf.global_variables_initializer()) summary_writer = tf.summary.FileWriter(BOARD_DIR_NAME, sess.graph) log_list = [] log_list.append(['epoch', 'AUC']) #training loop for epoch in range(0, EPOCH): sum_loss_dis_f = np.float32(0) sum_loss_dis_r = np.float32(0) sum_loss_dis_total = np.float32(0) sum_loss_dec_total = np.float32(0) sum_loss_enc_total = np.float32(0) len_data = make_datasets.make_data_for_1_epoch() for i in range(0, len_data, BATCH_SIZE): img_batch = make_datasets.get_data_for_1_batch(i, BATCH_SIZE) z = make_datasets.make_random_z_with_norm(NOISE_MEAN, NOISE_STDDEV, len(img_batch), NOISE_UNIT_NUM) tar_g_1 = make_datasets.make_target_1_0(1.0, len(img_batch)) #1 -> real tar_g_0 = make_datasets.make_target_1_0(0.0, len(img_batch)) #0 -> fake #train discriminator sess.run(train_dis, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:True}) #train decoder sess.run(train_dec, feed_dict={z_:z, d_dis_f_: tar_g_1, is_training_:True}) # sess.run(train_dec_opt, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_1, is_training_:True}) #train encoder sess.run(train_enc, feed_dict={x_:img_batch, d_dis_r_: tar_g_0, is_training_:True}) # sess.run(train_enc_opt, feed_dict={x_:img_batch, d_dis_r_: tar_g_0, is_training_:True}) # loss for discriminator loss_dis_total_, loss_dis_r_, loss_dis_f_ = sess.run([loss_dis_total, loss_dis_r, loss_dis_f], feed_dict={z_: z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:False}) #loss for decoder loss_dec_total_ = sess.run(loss_dec_total, feed_dict={z_: z, d_dis_f_: tar_g_1, is_training_:False}) #loss for encoder loss_enc_total_ = sess.run(loss_enc_total, feed_dict={x_: img_batch, d_dis_r_: tar_g_0, is_training_:False}) #for tensorboard merged_ = sess.run(merged, feed_dict={z_:z, x_: img_batch, d_dis_f_: tar_g_0, d_dis_r_: tar_g_1, is_training_:False}) summary_writer.add_summary(merged_, epoch) sum_loss_dis_f += loss_dis_f_ sum_loss_dis_r += loss_dis_r_ sum_loss_dis_total += loss_dis_total_ sum_loss_dec_total += loss_dec_total_ sum_loss_enc_total += loss_enc_total_ print("----------------------------------------------------------------------") print("epoch = {:}, Encoder Total Loss = {:.4f}, Decoder Total Loss = {:.4f}, Discriminator Total Loss = {:.4f}".format( epoch, sum_loss_enc_total / len_data, sum_loss_dec_total / len_data, sum_loss_dis_total / len_data)) print("Discriminator Real Loss = {:.4f}, Discriminator Generated Loss = {:.4f}".format( sum_loss_dis_r / len_data, sum_loss_dis_r / len_data)) if epoch % VALID_SPAN == 0: # score_A_list = [] score_A_np = np.zeros((0, 2), dtype=np.float32) val_data_num = len(make_datasets.valid_data) val_true_data_num = len(make_datasets.valid_true_np) val_false_data_num = len(make_datasets.valid_false_np) img_batch_1, _ = make_datasets.get_valid_data_for_1_batch(0, val_true_data_num) img_batch_0, _ = make_datasets.get_valid_data_for_1_batch(val_data_num - val_false_data_num, val_true_data_num) x_z_x_1 = sess.run(x_z_x, feed_dict={x_:img_batch_1, is_training_:False}) x_z_x_0 = sess.run(x_z_x, feed_dict={x_:img_batch_0, is_training_:False}) score_A_1 = sess.run(score_A, feed_dict={x_:img_batch_1, is_training_:False}) score_A_0 = sess.run(score_A, feed_dict={x_:img_batch_0, is_training_:False}) score_A_re_1 = np.reshape(score_A_1, (-1, 1)) score_A_re_0 = np.reshape(score_A_0, (-1, 1)) tars_batch_1 = np.ones(val_true_data_num) tars_batch_0 = np.zeros(val_false_data_num) tars_batch_re_1 = np.reshape(tars_batch_1, (-1, 1)) tars_batch_re_0 = np.reshape(tars_batch_0, (-1, 1)) score_A_np_1_tmp = np.concatenate((score_A_re_1, tars_batch_re_1), axis=1) score_A_np_0_tmp = np.concatenate((score_A_re_0, tars_batch_re_0), axis=1) score_A_np = np.concatenate((score_A_np_1_tmp, score_A_np_0_tmp), axis=0) #print(score_A_np) tp, fp, tn, fn, precision, recall = Utility.compute_precision_recall(score_A_np) auc = Utility.make_ROC_graph(score_A_np, 'out_graph/' + LOGFILE_NAME, epoch) print("tp:{}, fp:{}, tn:{}, fn:{}, precision:{:.4f}, recall:{:.4f}, AUC:{:.4f}".format(tp, fp, tn, fn, precision, recall, auc)) log_list.append([epoch, auc]) Utility.make_score_hist(score_A_1, score_A_0, epoch, LOGFILE_NAME, OUT_HIST_DIR) Utility.make_output_img(img_batch_1, img_batch_0, x_z_x_1, x_z_x_0, score_A_0, score_A_1, epoch, LOGFILE_NAME, OUT_IMG_DIR) #after learning Utility.save_list_to_csv(log_list, 'log/' + LOGFILE_NAME + '_auc.csv') #saver2 = tf.train.Saver() save_path = saver.save(sess, out_model_dir + 'anpanman_weight.ckpt') print("Model saved in file: ", save_path)model_BiGAN.pyimport numpy as np # import os import tensorflow as tf # from PIL import Image # import utility as Utility # import argparse class BiGAN(): def __init__(self, noise_unit_num, img_channel, seed, base_channel, keep_prob): self.NOISE_UNIT_NUM = noise_unit_num # 200 self.IMG_CHANNEL = img_channel # 1 self.SEED = seed np.random.seed(seed=self.SEED) self.BASE_CHANNEL = base_channel # 32 self.KEEP_PROB = keep_prob def leaky_relu(self, x, alpha): return tf.nn.relu(x) - alpha * tf.nn.relu(-x) def gaussian_noise(self, input, std): #used at discriminator noise = tf.random_normal(shape=tf.shape(input), mean=0.0, stddev=std, dtype=tf.float32, seed=self.SEED) return input + noise def conv2d(self, input, in_channel, out_channel, k_size, stride, seed): w = tf.get_variable('w', [k_size, k_size, in_channel, out_channel], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_channel], initializer=tf.constant_initializer(0.0)) conv = tf.nn.conv2d(input, w, strides=[1, stride, stride, 1], padding="SAME", name='conv') + b return conv def conv2d_transpose(self, input, in_channel, out_channel, k_size, stride, seed): w = tf.get_variable('w', [k_size, k_size, out_channel, in_channel], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_channel], initializer=tf.constant_initializer(0.0)) out_shape = tf.stack( [tf.shape(input)[0], tf.shape(input)[1] * 2, tf.shape(input)[2] * 2, tf.constant(out_channel)]) deconv = tf.nn.conv2d_transpose(input, w, output_shape=out_shape, strides=[1, stride, stride, 1], padding="SAME") + b return deconv def batch_norm(self, input): shape = input.get_shape().as_list() n_out = shape[-1] scale = tf.get_variable('scale', [n_out], initializer=tf.constant_initializer(1.0)) beta = tf.get_variable('beta', [n_out], initializer=tf.constant_initializer(0.0)) batch_mean, batch_var = tf.nn.moments(input, [0]) bn = tf.nn.batch_normalization(input, batch_mean, batch_var, beta, scale, 0.0001, name='batch_norm') return bn def fully_connect(self, input, in_num, out_num, seed): w = tf.get_variable('w', [in_num, out_num], initializer=tf.random_normal_initializer (mean=0.0, stddev=0.02, seed=seed), dtype=tf.float32) b = tf.get_variable('b', [out_num], initializer=tf.constant_initializer(0.0)) fc = tf.matmul(input, w, name='fc') + b return fc def encoder(self, x, reuse=False, is_training=False): #x is expected [n, 28, 28, 1] with tf.variable_scope('encoder', reuse=reuse): with tf.variable_scope("layer1"): # layer1 conv nx28x28x1 -> nx14x14x32 conv1 = self.conv2d(x, self.IMG_CHANNEL, self.BASE_CHANNEL, 3, 2, self.SEED) with tf.variable_scope("layer2"): # layer2 conv nx14x14x32 -> nx7x7x64 conv2 = self.conv2d(conv1, self.BASE_CHANNEL, self.BASE_CHANNEL*2, 3, 2, self.SEED) bn2 = self.batch_norm(conv2) lr2 = self.leaky_relu(bn2, alpha=0.1) with tf.variable_scope("layer3"): # layer3 conv nx7x7x64 -> nx4x4x128 conv3 = self.conv2d(lr2, self.BASE_CHANNEL*2, self.BASE_CHANNEL*4, 3, 2, self.SEED) bn3 = self.batch_norm(conv3) lr3 = self.leaky_relu(bn3, alpha=0.1) with tf.variable_scope("layer4"): # layer4 fc nx4x4x128 -> nx200 shape = tf.shape(lr3) print(shape[1]) reshape4 = tf.reshape(lr3, [shape[0], shape[1]*shape[2]*shape[3]]) fc4 = self.fully_connect(reshape4, 21632, self.NOISE_UNIT_NUM, self.SEED) return fc4 def decoder(self, z, reuse=False, is_training=False): # z is expected [n, 200] with tf.variable_scope('decoder', reuse=reuse): with tf.variable_scope("layer1"): # layer1 fc nx200 -> nx1024 fc1 = self.fully_connect(z, self.NOISE_UNIT_NUM, 1024, self.SEED) bn1 = self.batch_norm(fc1) rl1 = tf.nn.relu(bn1) with tf.variable_scope("layer2"): # layer2 fc nx1024 -> nx6272 fc2 = self.fully_connect(rl1, 1024, 25*25*self.BASE_CHANNEL*4, self.SEED) bn2 = self.batch_norm(fc2) rl2 = tf.nn.relu(bn2) with tf.variable_scope("layer3"): # layer3 deconv nx6272 -> nx7x7x128 -> nx14x14x64 shape = tf.shape(rl2) reshape3 = tf.reshape(rl2, [shape[0], 25, 25, 128]) deconv3 = self.conv2d_transpose(reshape3, self.BASE_CHANNEL*4, self.BASE_CHANNEL*2, 4, 2, self.SEED) bn3 = self.batch_norm(deconv3) rl3 = tf.nn.relu(bn3) with tf.variable_scope("layer4"): # layer3 deconv nx14x14x64 -> nx28x28x1 deconv4 = self.conv2d_transpose(rl3, self.BASE_CHANNEL*2, self.IMG_CHANNEL, 4, 2, self.SEED) tanh4 = tf.tanh(deconv4) return tanh4 def discriminator(self, x, z, reuse=False, is_training=True): #z[n, 200], x[n, 28, 28, 1] with tf.variable_scope('discriminator', reuse=reuse): with tf.variable_scope("x_layer1"): # layer x1 conv [n, 28, 28, 1] -> [n, 14, 14, 64] convx1 = self.conv2d(x, self.IMG_CHANNEL, self.BASE_CHANNEL*2, 4, 2, self.SEED) lrx1 = self.leaky_relu(convx1, alpha=0.1) dropx1 = tf.layers.dropout(lrx1, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("x_layer2"): # layer x2 conv [n, 14, 14, 64] -> [n, 7, 7, 64] -> [n, 3136] convx2 = self.conv2d(dropx1, self.BASE_CHANNEL*2, self.BASE_CHANNEL*2, 4, 2, self.SEED) bnx2 = self.batch_norm(convx2) lrx2 = self.leaky_relu(bnx2, alpha=0.1) dropx2 = tf.layers.dropout(lrx2, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) shapex2 = tf.shape(dropx2) reshape3 = tf.reshape(dropx2, [shapex2[0], shapex2[1]*shapex2[2]*shapex2[3]]) with tf.variable_scope("z_layer1"): # layer1 fc [n, 200] -> [n, 512] fcz1 = self.fully_connect(z, self.NOISE_UNIT_NUM, 512, self.SEED) lrz1 = self.leaky_relu(fcz1, alpha=0.1) dropz1 = tf.layers.dropout(lrz1, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("y_layer3"): # layer1 fc [n, 6272], [n, 1024] con3 = tf.concat([reshape3, dropz1], axis=1) fc3 = self.fully_connect(con3, 40000+512, 1024, self.SEED) lr3 = self.leaky_relu(fc3, alpha=0.1) self.drop3 = tf.layers.dropout(lr3, rate=1.0 - self.KEEP_PROB, name='dropout', training=is_training) with tf.variable_scope("y_fc_logits"): self.logits = self.fully_connect(self.drop3, 1024, 1, self.SEED) return self.drop3, self.logitsmake_datasets_TRAIN.pyimport numpy as np import os import glob import re import random #import cv2 from PIL import Image from keras.preprocessing import image class Make_datasets_TRAIN(): def __init__(self, filename, true_data, false_data, img_width, img_height, seed): self.filename = filename self.true_data = true_data self.false_data = false_data self.img_width = img_width self.img_height = img_height self.seed = seed x_train, x_valid_true, x_valid_false, y_train, y_valid_true, y_valid_false = self.read_DATASET(self.filename, self.true_data, self.false_data) self.train_np = np.concatenate((y_train.reshape(-1,1), x_train), axis=1).astype(np.float32) self.valid_true_np = np.concatenate((y_valid_true.reshape(-1,1), x_valid_true), axis=1).astype(np.float32) self.valid_false_np = np.concatenate((y_valid_false.reshape(-1,1), x_valid_false), axis=1).astype(np.float32) print("self.train_np.shape, ", self.train_np.shape) print("self.valid_true_np.shape, ", self.valid_true_np.shape) print("self.valid_false_np.shape, ", self.valid_false_np.shape) print("np.max(x_train), ", np.max(x_train)) print("np.min(x_train), ", np.min(x_train)) self.valid_data = np.concatenate((self.valid_true_np, self.valid_false_np)) random.seed(self.seed) np.random.seed(self.seed) def read_DATASET(self, train_path, true_path, false_path): train_list = os.listdir(train_path) y_train = np.ones(len(train_list)) x_train = np.empty((0, self.img_width*self.img_height)) for img in train_list: path_name = train_path+img x_img = Image.open(path_name) # サイズを揃える x_img = x_img.resize((self.img_width, self.img_height)) # 3chを1chに変換 x_img= x_img.convert('L') # PIL.Image.Imageからnumpy配列へ x_img = np.array(x_img) # 正規化 x_img = x_img / 255.0 # axisの追加 x_img = x_img.reshape((1,self.img_width, self.img_height)) # flatten x_img = x_img.reshape(1, self.img_width*self.img_height) x_train = np.concatenate([x_train, x_img], axis = 0) print("x_train.shape, ", x_train.shape) print("y_train.shape, ", y_train.shape) test_true_list = os.listdir(true_path) y_test_true = np.ones(len(test_true_list)) x_test_true = np.empty((0, self.img_width*self.img_height)) for img in test_true_list: path_name = true_path+img x_img = Image.open(path_name) x_img = x_img.resize((self.img_width, self.img_height)) x_img= x_img.convert('L') x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1,self.img_width, self.img_height)) x_img = x_img.reshape(1, self.img_width*self.img_height) x_test_true = np.concatenate([x_test_true, x_img], axis = 0) print("x_test_true.shape, ", x_test_true.shape) print("y_test_true.shape, ", y_test_true.shape) test_false_list = os.listdir(false_path) y_test_false = np.zeros(len(test_false_list)) x_test_false = np.empty((0, self.img_width*self.img_height)) for img in test_false_list: path_name = false_path+img x_img = Image.open(path_name) x_img = x_img.resize((self.img_width, self.img_height)) x_img= x_img.convert('L') x_img = np.array(x_img) x_img = x_img / 255.0 x_img = x_img.reshape((1,self.img_width, self.img_height)) x_img = x_img.reshape(1, self.img_width*self.img_height) x_test_false = np.concatenate([x_test_false, x_img], axis = 0) print("x_test_false.shape, ", x_test_false.shape) print("y_test_false.shape, ", y_test_false.shape) return x_train, x_test_true, x_test_false, y_train, y_test_true, y_test_false def get_file_names(self, dir_name): target_files = [] for root, dirs, files in os.walk(dir_name): targets = [os.path.join(root, f) for f in files] target_files.extend(targets) return target_files def read_data(self, d_y_np, width, height): tars = [] images = [] for num, d_y_1 in enumerate(d_y_np): image = d_y_1[1:].reshape(width, height, 1) tar = d_y_1[0] images.append(image) tars.append(tar) return np.asarray(images), np.asarray(tars) def normalize_data(self, data): # data0_2 = data / 127.5 # data_norm = data0_2 - 1.0 data_norm = (data * 2.0) - 1.0 #applied for tanh return data_norm def make_data_for_1_epoch(self): self.filename_1_epoch = np.random.permutation(self.train_np) return len(self.filename_1_epoch) def get_data_for_1_batch(self, i, batchsize): filename_batch = self.filename_1_epoch[i:i + batchsize] images, _ = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n def get_valid_data_for_1_batch(self, i, batchsize): filename_batch = self.valid_data[i:i + batchsize] images, tars = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n, tars def make_random_z_with_norm(self, mean, stddev, data_num, unit_num): norms = np.random.normal(mean, stddev, (data_num, unit_num)) # tars = np.zeros((data_num, 1), dtype=np.float32) return norms def make_target_1_0(self, value, data_num): if value == 0.0: target = np.zeros((data_num, 1), dtype=np.float32) elif value == 1.0: target = np.ones((data_num, 1), dtype=np.float32) else: print("target value error") return targetutility.pyimport numpy as np # import os from PIL import Image import matplotlib.pyplot as plt import sklearn.metrics as sm import csv import seaborn as sns def compute_precision_recall(score_A_np, ): array_1 = np.where(score_A_np[:, 1] == 1.0) array_0 = np.where(score_A_np[:, 1] == 0.0) mean_1 = np.mean((score_A_np[array_1])[:, 0]) mean_0 = np.mean((score_A_np[array_0])[:, 0]) medium = (mean_1 + mean_0) / 2.0 print("mean_positive_score, ", mean_1) print("mean_negative_score, ", mean_0) print("score_threshold(pos_neg middle), ", medium) np.save('./score_threshold.npy', medium) array_upper = np.where(score_A_np[:, 0] >= medium)[0] array_lower = np.where(score_A_np[:, 0] < medium)[0] #print(array_upper) print("negative_predict_num, ", array_upper.shape) print("positive_predict_num, ", array_lower.shape) array_1_tf = np.where(score_A_np[:, 1] == 1.0)[0] array_0_tf = np.where(score_A_np[:, 1] == 0.0)[0] #print(array_1_tf) print("negative_fact_num, ", array_0_tf.shape) print("positive_fact_num, ", array_1_tf.shape) tn = len(set(array_lower)&set(array_1_tf)) tp = len(set(array_upper)&set(array_0_tf)) fp = len(set(array_lower)&set(array_0_tf)) fn = len(set(array_upper)&set(array_1_tf)) precision = tp / (tp + fp + 0.00001) recall = tp / (tp + fn + 0.00001) return tp, fp, tn, fn, precision, recall def score_divide(score_A_np): array_1 = np.where(score_A_np[:, 1] == 1.0)[0] array_0 = np.where(score_A_np[:, 1] == 0.0)[0] print("positive_predict_num, ", array_1.shape) print("negative_predict_num, ", array_0.shape) array_1_np = score_A_np[array_1][:, 0] array_0_np = score_A_np[array_0][:, 0] #print(array_1_np) #print(array_0_np) return array_1_np, array_0_np def save_graph(x, y, filename, epoch): plt.figure(figsize=(7, 5)) plt.plot(x, y) plt.title('ROC curve ' + filename + ' epoch:' + str(epoch)) # x axis label plt.xlabel("FP / (FP + TN)") # y axis label plt.ylabel("TP / (TP + FN)") # save plt.savefig(filename + '_ROC_curve_epoch' + str(epoch) +'.png') plt.close() def make_ROC_graph(score_A_np, filename, epoch): argsort = np.argsort(score_A_np, axis=0)[:, 0] value_1_0 = score_A_np[argsort][::-1].astype(np.float32) #value_1_0 = (np.where(score_A_np_sort[:, 1] == 7., 1., 0.)).astype(np.float32) # score_A_np_sort_0_1 = np.concatenate((score_A_np_sort, value_1_0), axis=1) sum_1 = np.sum(value_1_0) len_s = len(score_A_np) sum_0 = len_s - sum_1 tp = np.cumsum(value_1_0[:, 1]).astype(np.float32) index = np.arange(1, len_s + 1, 1).astype(np.float32) fp = index - tp fn = sum_1 - tp tn = sum_0 - fp tp_ratio = tp / (tp + fn + 0.00001) fp_ratio = fp / (fp + tn + 0.00001) save_graph(fp_ratio, tp_ratio, filename, epoch) auc = sm.auc(fp_ratio, tp_ratio) return auc def unnorm_img(img_np): img_np_255 = (img_np + 1.0) * 127.5 img_np_255_mod1 = np.maximum(img_np_255, 0) img_np_255_mod1 = np.minimum(img_np_255_mod1, 255) img_np_uint8 = img_np_255_mod1.astype(np.uint8) return img_np_uint8 def convert_np2pil(images_255): list_images_PIL = [] for num, images_255_1 in enumerate(images_255): # img_255_tile = np.tile(images_255_1, (1, 1, 3)) image_1_PIL = Image.fromarray(images_255_1) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_score_hist(score_a_1, score_a_0, epoch, LOGFILE_NAME, OUT_HIST_DIR): list_1 = score_a_1.tolist() list_0 = score_a_0.tolist() #print(list_1) #print(list_0) plt.figure(figsize=(7, 5)) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(list_1, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(list_0, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='0') plt.legend(loc=1) plt.savefig(OUT_HIST_DIR + "/resultScoreHist_"+ LOGFILE_NAME + '_' + str(epoch) + ".png") plt.show() def make_score_hist_test(score_a_1, score_a_0, score_th, LOGFILE_NAME, OUT_HIST_DIR): list_1 = score_a_1.tolist() list_0 = score_a_0.tolist() #print(list_1) #print(list_0) plt.figure(figsize=(7, 5)) plt.title("Histgram of Score") plt.xlabel("Score") plt.ylabel("freq") plt.hist(list_1, bins=40, alpha=0.3, histtype='stepfilled', color='r', label="1") plt.hist(list_0, bins=40, alpha=0.3, histtype='stepfilled', color='b', label='0') plt.legend(loc=1) plt.savefig(OUT_HIST_DIR + "/resultScoreHist_"+ LOGFILE_NAME + "_test.png") plt.show() def make_score_bar(score_a): score_a = score_a.tolist() list_images_PIL = [] for score in score_a: x="score" plt.bar(x,score,label=score) fig, ax = plt.subplots(figsize=(1, 1)) ax.bar(x,score,label=round(score,3)) ax.legend(loc='center', fontsize=12) fig.canvas.draw() #im = np.array(fig.canvas.renderer.buffer_rgba()) # matplotlibが3.1より以降の場合 im = np.array(fig.canvas.renderer._renderer) image_1_PIL = Image.fromarray(im) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_score_bar_predict(score_A_np_tmp): score_a = score_A_np_tmp.tolist() list_images_PIL = [] for score in score_a: x="score" #plt.bar(x,score[0],label=score) fig, ax = plt.subplots(figsize=(1, 1)) if score[1]==0: ax.bar(x,score[0], color='red',label=round(score[0],3)) else: ax.bar(x,score[0], color='blue',label=round(score[0],3)) ax.legend(loc='center', fontsize=12) fig.canvas.draw() #im = np.array(fig.canvas.renderer.buffer_rgba()) # matplotlibが3.1より以降の場合 im = np.array(fig.canvas.renderer._renderer) image_1_PIL = Image.fromarray(im) list_images_PIL.append(image_1_PIL) return list_images_PIL def make_output_img(img_batch_1, img_batch_0, x_z_x_1, x_z_x_0, score_a_0, score_a_1, epoch, log_file_name, out_img_dir): (data_num, img1_h, img1_w, _) = img_batch_1.shape img_batch_1_unn = np.tile(unnorm_img(img_batch_1), (1, 1, 3)) img_batch_0_unn = np.tile(unnorm_img(img_batch_0), (1, 1, 3)) x_z_x_1_unn = np.tile(unnorm_img(x_z_x_1), (1, 1, 3)) x_z_x_0_unn = np.tile(unnorm_img(x_z_x_0), (1, 1, 3)) diff_1 = img_batch_1 - x_z_x_1 diff_1_r = (2.0 * np.maximum(diff_1, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_1_b = (2.0 * np.abs(np.minimum(diff_1, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_1_g = diff_1_b * 0.0 - 1.0 diff_1_r_unnorm = unnorm_img(diff_1_r) diff_1_b_unnorm = unnorm_img(diff_1_b) diff_1_g_unnorm = unnorm_img(diff_1_g) diff_1_np = np.concatenate((diff_1_r_unnorm, diff_1_g_unnorm, diff_1_b_unnorm), axis=3) diff_0 = img_batch_0 - x_z_x_0 diff_0_r = (2.0 * np.maximum(diff_0, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_0_b = (2.0 * np.abs(np.minimum(diff_0, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_0_g = diff_0_b * 0.0 - 1.0 diff_0_r_unnorm = unnorm_img(diff_0_r) diff_0_b_unnorm = unnorm_img(diff_0_b) diff_0_g_unnorm = unnorm_img(diff_0_g) diff_0_np = np.concatenate((diff_0_r_unnorm, diff_0_g_unnorm, diff_0_b_unnorm), axis=3) img_batch_1_PIL = convert_np2pil(img_batch_1_unn) img_batch_0_PIL = convert_np2pil(img_batch_0_unn) x_z_x_1_PIL = convert_np2pil(x_z_x_1_unn) x_z_x_0_PIL = convert_np2pil(x_z_x_0_unn) diff_1_PIL = convert_np2pil(diff_1_np) diff_0_PIL = convert_np2pil(diff_0_np) score_a_1_PIL = make_score_bar(score_a_1) score_a_0_PIL = make_score_bar(score_a_0) wide_image_np = np.ones(((img1_h + 1) * data_num - 1, (img1_w + 1) * 8 - 1, 3), dtype=np.uint8) * 255 wide_image_PIL = Image.fromarray(wide_image_np) for num, (ori_1, ori_0, xzx1, xzx0, diff1, diff0, score_1, score_0) in enumerate(zip(img_batch_1_PIL, img_batch_0_PIL ,x_z_x_1_PIL, x_z_x_0_PIL, diff_1_PIL, diff_0_PIL, score_a_1_PIL, score_a_0_PIL)): wide_image_PIL.paste(ori_1, (0, num * (img1_h + 1))) wide_image_PIL.paste(xzx1, (img1_w + 1, num * (img1_h + 1))) wide_image_PIL.paste(diff1, ((img1_w + 1) * 2, num * (img1_h + 1))) wide_image_PIL.paste(score_1, ((img1_w + 1) * 3, num * (img1_h + 1))) wide_image_PIL.paste(ori_0, ((img1_w + 1) * 4, num * (img1_h + 1))) wide_image_PIL.paste(xzx0, ((img1_w + 1) * 5, num * (img1_h + 1))) wide_image_PIL.paste(diff0, ((img1_w + 1) * 6, num * (img1_h + 1))) wide_image_PIL.paste(score_0, ((img1_w + 1) * 7, num * (img1_h + 1))) wide_image_PIL.save(out_img_dir + "/resultImage_"+ log_file_name + '_' + str(epoch) + ".png") def make_output_img_test(img_batch_test, x_z_x_test, score_A_np_tmp, log_file_name, out_img_dir): (data_num, img1_h, img1_w, _) = img_batch_test.shape img_batch_test_unn = np.tile(unnorm_img(img_batch_test), (1, 1, 3)) x_z_x_test_unn = np.tile(unnorm_img(x_z_x_test), (1, 1, 3)) diff_test = img_batch_test - x_z_x_test diff_test_r = (2.0 * np.maximum(diff_test, 0.0)) - 1.0 #(0.0, 1.0) -> (-1.0, 1.0) diff_test_b = (2.0 * np.abs(np.minimum(diff_test, 0.0))) - 1.0 #(-1.0, 0.0) -> (1.0, 0.0) -> (1.0, -1.0) diff_test_g = diff_test_b * 0.0 - 1.0 diff_test_r_unnorm = unnorm_img(diff_test_r) diff_test_b_unnorm = unnorm_img(diff_test_b) diff_test_g_unnorm = unnorm_img(diff_test_g) diff_test_np = np.concatenate((diff_test_r_unnorm, diff_test_g_unnorm, diff_test_b_unnorm), axis=3) img_batch_test_PIL = convert_np2pil(img_batch_test_unn) x_z_x_test_PIL = convert_np2pil(x_z_x_test_unn) diff_test_PIL = convert_np2pil(diff_test_np) score_a = score_A_np_tmp[:, 1:] #tars = score_A_np_tmp[:, 0] score_a_PIL = make_score_bar_predict(score_A_np_tmp) wide_image_np = np.ones(((img1_h + 1) * data_num - 1, (img1_w + 1) * 8 - 1, 3), dtype=np.uint8) * 255 wide_image_PIL = Image.fromarray(wide_image_np) for num, (ori_test, xzx_test, diff_test, score_test) in enumerate(zip(img_batch_test_PIL, x_z_x_test_PIL, diff_test_PIL, score_a_PIL)): wide_image_PIL.paste(ori_test, (0, num * (img1_h + 1))) wide_image_PIL.paste(xzx_test, (img1_w + 1, num * (img1_h + 1))) wide_image_PIL.paste(diff_test, ((img1_w + 1) * 2, num * (img1_h + 1))) wide_image_PIL.paste(score_test, ((img1_w + 1) * 3, num * (img1_h + 1))) wide_image_PIL.save(out_img_dir + "/resultImage_"+ log_file_name + "_test.png") def save_list_to_csv(list, filename): f = open(filename, 'w') writer = csv.writer(f, lineterminator='\n') writer.writerows(list) f.close()predict_BiGAN.pyimport numpy as np import os import tensorflow as tf import utility as Utility import argparse import matplotlib.pyplot as plt from model_BiGAN import BiGAN as Model from make_datasets_predict import Make_datasets_predict as Make_datasets def parser(): parser = argparse.ArgumentParser(description='train LSGAN') parser.add_argument('--batch_size', '-b', type=int, default=300, help='Number of images in each mini-batch') parser.add_argument('--log_file_name', '-lf', type=str, default='anpanman', help='log file name') parser.add_argument('--epoch', '-e', type=int, default=1, help='epoch') #parser.add_argument('--file_train_data', '-ftd', type=str, default='./mnist.npz', help='train data') #parser.add_argument('--test_true_data', '-ttd', type=str, default='./mnist.npz', help='test of true_data') #parser.add_argument('--test_false_data', '-tfd', type=str, default='./mnist.npz', help='test of false_data') parser.add_argument('--test_data', '-td', type=str, default='../Test_Data/200112/', help='test of false_data') parser.add_argument('--valid_span', '-vs', type=int, default=1, help='validation span') parser.add_argument('--score_th', '-st', type=float, default=np.load('./score_threshold.npy'), help='validation span') return parser.parse_args() args = parser() #global variants BATCH_SIZE = args.batch_size LOGFILE_NAME = args.log_file_name EPOCH = args.epoch #FILE_NAME = args.file_train_data #TRUE_DATA = args.test_true_data #FALSE_DATA = args.test_false_data TEST_DATA = args.test_data IMG_WIDTH = 100 IMG_HEIGHT = 100 IMG_CHANNEL = 1 BASE_CHANNEL = 32 NOISE_UNIT_NUM = 200 NOISE_MEAN = 0.0 NOISE_STDDEV = 1.0 TEST_DATA_SAMPLE = 5 * 5 L2_NORM = 0.001 KEEP_PROB_RATE = 0.5 SEED = 1234 SCORE_ALPHA = 0.9 # using for cost function VALID_SPAN = args.valid_span np.random.seed(seed=SEED) BOARD_DIR_NAME = './tensorboard/' + LOGFILE_NAME OUT_IMG_DIR = './out_images_BiGAN' #output image file out_model_dir = './out_models_BiGAN/' #output model_ckpt file #Load_model_dir = '../model_ckpt/' #Load model_ckpt file OUT_HIST_DIR = './out_score_hist_BiGAN' #output histogram file CYCLE_LAMBDA = 1.0 SCORE_TH = args.score_th make_datasets = Make_datasets(TEST_DATA, IMG_WIDTH, IMG_HEIGHT, SEED) model = Model(NOISE_UNIT_NUM, IMG_CHANNEL, SEED, BASE_CHANNEL, KEEP_PROB_RATE) z_ = tf.placeholder(tf.float32, [None, NOISE_UNIT_NUM], name='z_') #noise to generator x_ = tf.placeholder(tf.float32, [None, IMG_HEIGHT, IMG_WIDTH, IMG_CHANNEL], name='x_') #image to classifier d_dis_f_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_g_') #target of discriminator related to generator d_dis_r_ = tf.placeholder(tf.float32, [None, 1], name='d_dis_r_') #target of discriminator related to real image is_training_ = tf.placeholder(tf.bool, name = 'is_training') with tf.variable_scope('encoder_model'): z_enc = model.encoder(x_, reuse=False, is_training=is_training_) with tf.variable_scope('decoder_model'): x_dec = model.decoder(z_, reuse=False, is_training=is_training_) x_z_x = model.decoder(z_enc, reuse=True, is_training=is_training_) # for cycle consistency with tf.variable_scope('discriminator_model'): #stream around discriminator drop3_r, logits_r = model.discriminator(x_, z_enc, reuse=False, is_training=is_training_) #real pair drop3_f, logits_f = model.discriminator(x_dec, z_, reuse=True, is_training=is_training_) #real pair drop3_re, logits_re = model.discriminator(x_z_x, z_enc, reuse=True, is_training=is_training_) #fake pair with tf.name_scope("loss"): loss_dis_f = tf.reduce_mean(tf.square(logits_f - d_dis_f_), name='Loss_dis_gen') #loss related to generator loss_dis_r = tf.reduce_mean(tf.square(logits_r - d_dis_r_), name='Loss_dis_rea') #loss related to real image #total loss loss_dis_total = loss_dis_f + loss_dis_r loss_dec_total = loss_dis_f loss_enc_total = loss_dis_r with tf.name_scope("score"): l_g = tf.reduce_mean(tf.abs(x_ - x_z_x), axis=(1,2,3)) l_FM = tf.reduce_mean(tf.abs(drop3_r - drop3_re), axis=1) score_A = SCORE_ALPHA * l_g + (1.0 - SCORE_ALPHA) * l_FM with tf.name_scope("optional_loss"): loss_dec_opt = loss_dec_total + CYCLE_LAMBDA * l_g loss_enc_opt = loss_enc_total + CYCLE_LAMBDA * l_g tf.summary.scalar('loss_dis_total', loss_dis_total) tf.summary.scalar('loss_dec_total', loss_dec_total) tf.summary.scalar('loss_enc_total', loss_enc_total) merged = tf.summary.merge_all() # t_vars = tf.trainable_variables() dec_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="decoder") enc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="encoder") dis_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="discriminator") with tf.name_scope("train"): train_dis = tf.train.AdamOptimizer(learning_rate=0.00005, beta1=0.5).minimize(loss_dis_total, var_list=dis_vars , name='Adam_dis') train_dec = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_total, var_list=dec_vars , name='Adam_dec') train_enc = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_total, var_list=enc_vars , name='Adam_enc') train_dec_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_dec_opt, var_list=dec_vars , name='Adam_dec') train_enc_opt = tf.train.AdamOptimizer(learning_rate=0.005, beta1=0.5).minimize(loss_enc_opt, var_list=enc_vars , name='Adam_enc') sess = tf.Session() ckpt = tf.train.get_checkpoint_state(out_model_dir) saver = tf.train.Saver() if ckpt: # checkpointがある場合 last_model = ckpt.model_checkpoint_path # 最後に保存したmodelへのパス saver.restore(sess, last_model) # 変数データの読み込み print("load " + last_model) else: # 保存データがない場合 #init = tf.initialize_all_variables() sess.run(tf.global_variables_initializer()) summary_writer = tf.summary.FileWriter(BOARD_DIR_NAME, sess.graph) log_list = [] log_list.append(['epoch', 'AUC']) #training loop for epoch in range(1): if epoch % VALID_SPAN == 0: score_A_np = np.zeros((0, 2), dtype=np.float32) val_data_num = len(make_datasets.valid_data) img_batch_test = make_datasets.get_valid_data_for_1_batch(0, val_data_num) score_A_ = sess.run(score_A, feed_dict={x_:img_batch_test, is_training_:False}) score_A_re = np.reshape(score_A_, (-1, 1)) tars_batch_re = np.where(score_A_re < SCORE_TH, 1, 0) #np.reshape(tars_batch, (-1, 1)) score_A_np_tmp = np.concatenate((score_A_re, tars_batch_re), axis=1) x_z_x_test = sess.run(x_z_x, feed_dict={x_:img_batch_test, is_training_:False}) #print(score_A_np_tmp) array_1_np, array_0_np = Utility.score_divide(score_A_np_tmp) Utility.make_score_hist_test(array_1_np, array_0_np, SCORE_TH, LOGFILE_NAME, OUT_HIST_DIR) Utility.make_output_img_test(img_batch_test, x_z_x_test, score_A_np_tmp, LOGFILE_NAME, OUT_IMG_DIR)make_datasets_predict.pyimport numpy as np import os import glob import re import random #import cv2 from PIL import Image from keras.preprocessing import image class Make_datasets_predict(): def __init__(self, test_data, img_width, img_height, seed): self.filename = test_data self.img_width = img_width self.img_height = img_height self.seed = seed x_test = self.read_DATASET(self.filename) self.valid_data = x_test random.seed(self.seed) np.random.seed(self.seed) def read_DATASET(self, test_path): test_list = os.listdir(test_path) x_test = np.empty((0, self.img_width*self.img_height)) for img in test_list: path_name = test_path+img x_img = Image.open(path_name) # サイズを揃える x_img = x_img.resize((self.img_width, self.img_height)) # 3chを1chに変換 x_img= x_img.convert('L') # PIL.Image.Imageからnumpy配列へ x_img = np.array(x_img) # 正規化 x_img = x_img / 255.0 # axisの追加 x_img = x_img.reshape((1,self.img_width, self.img_height)) # flatten x_img = x_img.reshape(1, self.img_width*self.img_height) x_test = np.concatenate([x_test, x_img], axis = 0) print("x_test.shape, ", x_test.shape) return x_test def get_file_names(self, dir_name): target_files = [] for root, dirs, files in os.walk(dir_name): targets = [os.path.join(root, f) for f in files] target_files.extend(targets) return target_files def divide_MNIST_by_digit(self, train_np, data1_num, data2_num): data_1 = train_np[train_np[:,0] == data1_num] data_2 = train_np[train_np[:,0] == data2_num] return data_1, data_2 def read_data(self, d_y_np, width, height): #tars = [] images = [] for num, d_y_1 in enumerate(d_y_np): image = d_y_1.reshape(width, height, 1) #tar = d_y_1[0] images.append(image) #tars.append(tar) return np.asarray(images)#, np.asarray(tars) def normalize_data(self, data): # data0_2 = data / 127.5 # data_norm = data0_2 - 1.0 data_norm = (data * 2.0) - 1.0 #applied for tanh return data_norm def make_data_for_1_epoch(self): self.filename_1_epoch = np.random.permutation(self.train_np) return len(self.filename_1_epoch) def get_data_for_1_batch(self, i, batchsize): filename_batch = self.filename_1_epoch[i:i + batchsize] images, _ = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n def get_valid_data_for_1_batch(self, i, batchsize): filename_batch = self.valid_data[i:i + batchsize] images = self.read_data(filename_batch, self.img_width, self.img_height) images_n = self.normalize_data(images) return images_n#, tars def make_random_z_with_norm(self, mean, stddev, data_num, unit_num): norms = np.random.normal(mean, stddev, (data_num, unit_num)) # tars = np.zeros((data_num, 1), dtype=np.float32) return norms def make_target_1_0(self, value, data_num): if value == 0.0: target = np.zeros((data_num, 1), dtype=np.float32) elif value == 1.0: target = np.ones((data_num, 1), dtype=np.float32) else: print("target value error") return targetGitHubのリンク
https://github.com/YousukeAnai/Dic_Graduation_Assignment
参考にした記事
https://qiita.com/masataka46/items/49dba2790fa59c29126b
https://qiita.com/underfitting/items/a0cbb035568dea33b2d7




- 投稿日:2020-01-12T20:25:46+09:00
Pythonの環境構築がしたい
この記事は、Pythonの動作環境もないけど、とりあえず動く状態にしたい。
というための記事です。環境構築です。同じような記事は星の数ほどある気がしますが、自分メモと理解するのも兼ねて書かせていただきます。
前提
- Windows10
- エディタはVSCodeを使います
VSCodeのインストール
Microsoftが提供している無料のエディタです。
公式サイトからダウンロードできます。VSCode採用の理由ですが、
- 無料
- Python以外にも用途がある
- 社内で使ってる
です。ここは好みのエディタあれば、VSCodeじゃなくてもよいです。
exeファイルがダウンロードされたら、ダブルクリック。
あとはダイアログにしたがってぽちぽちするとあっという間にインストールが完了します。
(特にこだわりがない場合はデフォルトでよいかと思いますが、Codeで開くは追加しておくと便利かと思います)Anacondaのインストール
Anacondaはpython含めて、便利なライブラリがたくさん詰まっているものらしいです。
色々入ってた方が便利かと思うので、今回はpython単品ではなくこちらのAnacondaをいれていきたいと思います。公式サイトからダウンロードします。
こちらもセットアップ用のexeファイルがダウンロードされるので、ダブルクリックして手順通りやっていけばOKです。
しばらくするといろいろダウンロードがはじまります。結構時間がかかるので休憩しましょう。
Nextが押せるようになったら終わり!ぽちぽちと押していればFinishします。
VS CodeにpythonのExtensionをいれる
- VSCodeを開き、「Ctrl+Shift+x」でExtensionの検索画面を開きます。
- 検索にPythonと入力し、PythonのExtensionを検索し、「Install」をクリックします。
ためしに書いてみる
- 「Ctrl+N」で新しいファイルを開く
print("Hello World!")と書く- 「Ctrl+S」で
hello.pyという名前で適当な場所に保存します。- 右クリック>Run Python File in Terminalで実行できます。
Hello World!が出力されれば無事完了です!お疲れ様でした!以上で実行できました。
無事環境も整ったので、ちょくちょくpythonのコードも書いていこうと思います^^
では、お読みいただきありがとうございました

- 投稿日:2020-01-12T20:05:34+09:00
【学習メモ】Djangoコマンドまとめ
はじめに
DjangoチュートリアルとDjango Girlsチュートリアルを進めつつ、メモしたコマンドです。
学習中のため解釈が間違っている可能性があります。
もし間違いを見つけたらコメント等で教えてくださると嬉しいです。環境確認
# Djangoのバージョン確認 $ python -m django --version作成関連
カウントディレクトリにファイル等作成するコマンド
# プロジェクト作成 $ django-admin startproject [プロジェクト名] # アプリケーション作成 $ python manage.py startapp [アプリケーション名]サーバー関連
#開発用サーバー立ち上げ $ python manage.py runserver $ python manage.py runserver [ポート番号]DB関連
#マイグレーションファイルを作成する $ python manage.py makemigrations polls #マイグレーションの名前を引数にとってSQLを返却 $ python manage.py sqlmigrate polls 0001 #モデルをデータベースに反映 $ python manage.py migrate #Django adminのsuperuserを登録する $ python manage.py createsuperuser
- 投稿日:2020-01-12T19:58:04+09:00
pandas の to_csv -> read_csv で "Unnamed: 0" が追加された場合の対処法
事の発端
事件は Python の pandas で、 以下の様にCSV書き込み→読み込み をシンプルに行った時に起こった。
import pandas as pd # 変数data を定義してCSVファイルに書き込む data = pd.DataFrame({'name': ['太郎', '花子', '二郎', '由紀'], '数学': [80, 15, 90, 50], '英語': [80, 70, 50, 65], '国語': [ 90, 60, 60, 60]}) print(data) data.to_csv('a.csv') # 書き出したCSV ファイルを読みだして出力 data = pd.read_csv('a.csv') print(data)上記を実行した際に、それぞれに出力に差分が生じた。
# 1回目の出力結果 name 数学 英語 国語 0 太郎 80 80 90 1 花子 15 70 60 2 二郎 90 50 60 3 由紀 50 65 60 # 2回目の出力結果 Unnamed: 0 name 数学 英語 国語 0 0 太郎 80 80 90 1 1 花子 15 70 60 2 2 二郎 90 50 60 3 3 由紀 50 65 60
Unnamed: 0という謎カラムが追加されてしまった。これを解消する。何が起きているのか?
上記書き込みにおいて、以下のCSVファイルが出力されていた。
,name,数学,英語,国語 0,太郎,80,80,90 1,花子,15,70,60 2,二郎,90,50,60 3,由紀,50,65,601行目のname の左に想定外の
,が追加されてしまっている。
これによって、最初のカラムが無記名とみなされている模様。対処法
以下のどちらかで対応可能。両方やる必要はない。
to_csv で対応
以下の様にindex をfalse で指定することで解消できる。
data.to_csv('a.csv', index=False)上記により、以下のCSVファイルを出力することができた。
name,数学,英語,国語 0,太郎,80,80,90 1,花子,15,70,60 2,二郎,90,50,60 3,由紀,50,65,60read_csv
以下の様にインデックスカラムを指定する。
data = pd.read_csv('a.csv', index_col=0)
- 投稿日:2020-01-12T19:56:26+09:00
TensorFlow2 + Keras で画像分類に挑戦 CNN編1 ~とりあえず動かす~
はじめに
TensorFlow2 + Keras による画像分類の勉強メモ(CNN編の第1弾)です。MLP編(多層パーセプトロンモデル編)については、こちらをご覧ください。
なお、題材はド定番である手書き数字画像(MNIST)の分類です。
今回は、ブラックボックスのまま、とりあえずCNNモデルを学習させて、それを使って予測(分類)をしてみます。
MLP版のプログラム
多層パーセプトロンモデルによる手書き数字画像(MNIST)分類は、TensorFlow2 + Keras を利用して、次のように書くことができました(詳細)。
TensorFlow2に切り替え(GoogleColab.環境のみ)%tensorflow_version 2.xMLPによる画像分類import tensorflow as tf # (1) 手書き数字画像のデータセットをダウンロード・正規化 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # (2) MLPモデルを構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) ) model.add( tf.keras.layers.Dense(128, activation='relu') ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation='softmax') ) # (3) モデルのコンパイル・トレーニング model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) # (4) モデルの評価 model.evaluate(x_test, y_test, verbose=2)これを実行すると、正解率 $97.7\%$ 前後の分類器をつくることができました。
CNN版のプログラム
畳み込みニューラルネットワークモデル(CNN)による手書き数字画像(MNIST)分類は、次のように書くことができます。多層パーセプトロンのモデルに、なんと3行追加するだけで畳み込みニューラルネットワークモデルに変えることができます。
CNNによる画像分類# (1) 手書き数字画像のデータセットをダウンロード・正規化 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # (2) CNNモデルを構築 model = tf.keras.models.Sequential() model.add( tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)) ) # 追加 model.add( tf.keras.layers.Conv2D(32, (5, 5), activation='relu') ) # 追加 model.add( tf.keras.layers.MaxPooling2D(pool_size=(2,2)) ) # 追加 model.add( tf.keras.layers.Flatten() ) # 改変 model.add( tf.keras.layers.Dense(128, activation='relu') ) model.add( tf.keras.layers.Dropout(0.2) ) model.add( tf.keras.layers.Dense(10, activation='softmax') ) # (3) モデルのコンパイル・トレーニング model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) # (4) モデルの評価 model.evaluate(x_test, y_test, verbose=2)これを実行すると、正解率 $98.7\%$ 前後の分類器をつくることができます(上記のMLPよりも正解率が約$1\%$ほど高いモデルをつくることができます)。ただし、学習にかかる時間は長くなっています。
正しく予測できなかった事例
分類(予測)に失敗している具体的なケースを見てみます(これを出力するためのプログラムは「~分類に失敗する画像を観察してみる~」を参照)。
各図の左上に表示している赤文字は、誤って何の数字と予測したかという情報です(括弧内数値は、誤った予測に対するsoftmax出力)。例えば 5(0.9) は、「約 $90\%$ の確信をもって $5$ と予測した」ということです。また、青色の数値は、テストデータ
test_xのインデックス番号です。正解値「0」について正しく予測(分類)できなかったケース 4/980件
正解値「1」について正しく予測(分類)できなかったケース 4/1135件
正解値「2」について正しく予測(分類)できなかったケース 8/1032件
正解値「3」について正しく予測(分類)できなかったケース 12/1010件
正解値「4」について正しく予測(分類)できなかったケース 15/982件
正解値「5」について正しく予測(分類)できなかったケース 6/892件
正解値「6」について正しく予測(分類)できなかったケース 13/958件
正解値「7」について正しく予測(分類)できなかったケース 15/1028件
正解値「8」について正しく予測(分類)できなかったケース 27/974件
正解値「9」について正しく予測(分類)できなかったケース 26/1009件
次回
畳み込みニューラルネットワークモデル(CNN)は、なんで画像分類・画像認識に適しているのか、そもそも畳み込み(フィルタ)とは?といった内容を取り上げていきたいと思います。










- 投稿日:2020-01-12T19:40:21+09:00
S3ファイルやDynamoDBレコードの自動削除
S3ファイルやDynamoDBレコードの自動削除
この記事はサーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事の1つです。
以下を見てからこの記事をみるといい感じです。
* Lambda(Python) + Rekognition で顔検出はじめに
S3やDynamoDBって、もちろん長期的に保存したい用途に利用することもありますが、一時的なデータ保存場所として利用するケースも多いですよね。ワタシのMosaicなんかも、30分くらいで消えてしまって何ら問題ありません。
そんな時は自動的に削除される仕組みがありますので、それを利用しましょう。コンテンツ
S3ファイルの自動削除
上で「30分くらいで消えてしまって何ら問題ありません」と書きましたが、残念ながらS3からの自動削除は、最小1日からとなります。いやー、残念。
さて設定の仕方ですが、
AWSコンソール > S3 > 管理タブ > ライフサイクル > +ライフサイクルルールの追加 ボタンを押下
ルール名は適当に
delete-a-day-in-publicなどと付けました。
今回はpublicフォルダの中だけを対象にしたいのでpublic/のようなプレフィックスを追加します。
次に進んで、ライフサイクルルールは、削除しますので全てチェックOFFのままとします。
次の「失効の設定」は全てチェックONにして、日数を入力します。ここでは1日で消えるようにしました。
で、最後確認して、保存してください。
ライフサイクルの一覧に追加されていますね。
S3のファイルを最小1日で自動的に削除するための設定は以上です。
DynamoDBレコードの自動削除
続いてDynamoDBです。
DynamoDBは秒単位で削除される日時を指定できます。これなら「30分くらいで消えてしまって何ら問題ありません」が実現できますね!と思いきやざーんねん。最大48時間のタイムラグがあるとか。なんだそりゃって感じですよね。
運が良ければ30分、運が悪くても最大48時間30分で、自動的にレコードを削除することはできるということです。そしてDynamoDBは、S3のようにコンソールをポチポチやったら設定できるというわけではありません。
自動的に削除される時間を入れるためのフィールド(列)が必要となります。
つまり、その列にレコードを入れる際に、削除される時間を毎回設定する必要があるということです。
ちょっと面倒ですよね。さてサンプルプログラムの方から削除用のフィールドに値をいれてゆきましょう。
DynamoDBへレコードを挿入するのはAppSync経由ですので、そこにフィールドを追加することになります。AWSコンソール > AppSync > Sample appsync api > スキーマ
SchemaのCreateSampleAppsyncTableInputにInt型のdeleteTimeというフィールドを追加しておきます。
deleteTime: Intを追加したら、「スキーマを保存」ボタンを押下します。今回のサンプルアプリは、DynamoDBへのレコード挿入はバックエンドからのみです。
従いまして、LambdaのPythonのコードを修正してゆくことになります。lambda_function.py: import datetime : def apiCreateTable(group, path): logger.info("start apiCreateTable({0}, {1})".format(group, path)) time = datetime.datetime.now() time = time + datetime.timedelta(minutes=30) epocTime = int(time.timestamp()) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" deleteTime: {2} }}){{ group path }} }} """.format(group, path, epocTime)) _client.execute(query) except Exception as e: logger.exception(e) raise e :
deleteTimeフィールドへ指定する値ですが、「エポック秒」で指定します。
は?って感じの人も多いと思いますが、「エポック秒」とはつまり「UNIX時間」のことです。
・・・は?(怒)って感じですよね。UNIX時間.wikiUNIX時間(ユニックスじかん)またはUNIX時刻(ユニックスじこく、UNIX time(ユニックスタイム)、POSIX time(ポジックスタイム))とはコンピューターシステム上での時刻表現の一種。UNIXエポック、すなわち協定世界時 (UTC) での1970年1月1日午前0時0分0秒から形式的な経過秒数(すなわち、実質的な経過秒数から、その間に挿入された閏秒を引き、削除された閏秒を加えたもの)として表される。GPS時刻などとは異なり、大多数のシステムでは、本当の経過秒数を表すものではない。さてエポック秒の詳細はほどほどにして、先ほどのプログラムを実行すると、DynamoDBの
deleteTimeフィールドに値が入っているのを確認しましょう。
この状態ではまだレコードは削除されません。DynamoDBのコンソールで、このフィールドに対して「有効期限 (TTL) 属性」の指定をする必要があります。
AWSコンソール > DynamoDB > テーブル > sample_appsync_table の概要タブで、「有効期限 (TTL) 属性」という項目が無効になっています。「TTLの管理」を選択してください。
TTL属性にフィールド名
deleteTimeを設定して次へ進みます。
これで設定完了なのですが、設定が反映されるまでに最大1時間かかるようです。
しばらく待ってから、テーブルの項目を見てみましょう。反映されると、指定したdeleteTimeフィールドに(TTL)というマークが付きます。
これで、deleteTimeに指定したエポック時間(から48時間以内)にレコードが自動的に削除されます。
あとがき
不要なものはどんどん削除しましょうというお話でしたが、それが許されるのであればどんどん積極的に削除してゆくべきですね。パフォーマンスや料金的にもメリットありますし、フロントからアクセスされる画像やそのパスなどはさっさと消えてくれたほうがプライバシー保護の観点からも望ましいですよね。
しかしDynamoDBのレコードは、テーブルに対して設定できるようになってくれるともっと使いやすいと思うんですけどねぇ。アプリが気にしなくて済む日を夢見ています。










- 投稿日:2020-01-12T19:29:08+09:00
MOLファイルを標準入出力でSMILESに変換する
はじめに
MOLファイルをSMILESに変換するpythonスクリプトを作成した。これだとどこにでもある話だが、標準入力からMOLファイルを読み込んで、標準出力にSMILESを吐き出すようにした。これによって、ファイルを経由せずとも結果を得ることができ、より手軽に利用できる。
環境
- Python3.6
- RDKIT 2019.03.3.0
ソース
ソースは以下の通りだ。
Mol2SMILESConvertor.pyimport sys from rdkit import Chem def main(): f = sys.stdin mol_block = "" for line in f: mol_block += line mol = Chem.MolFromMolBlock(mol_block) smiles = Chem.MolToSmiles(mol) print(smiles) if __name__ == "__main__": main()使い方
以下のMOLファイルを例に使い方を説明する。
test.mol2,3,6-PCB RDKit 2D 15 16 0 0 0 0 0 0 0 0999 V2000 1.2990 -0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.2990 0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 1.5000 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2990 0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2990 -0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 -1.5000 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 -3.0008 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2978 -3.7529 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -2.3380 -3.1546 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 -1.2955 -5.2529 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -2.3337 -5.8546 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 0.0048 -6.0009 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.3026 -5.2488 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.3002 -3.7488 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 2.3385 -3.1472 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 1 2 2 0 2 3 1 0 3 4 2 0 4 5 1 0 5 6 2 0 6 1 1 0 6 7 1 0 7 8 2 0 8 9 1 0 8 10 1 0 10 11 1 0 10 12 2 0 12 13 1 0 13 14 2 0 14 7 1 0 14 15 1 0 M END $$$$上のMOLファイルをcatしてこのスクリプトに食わせると、以下のようにSMILESが得られる。お手軽だ。
$ cat test.mol |python bin/Mol2SMILESConvertor.py Clc1ccc(Cl)c(-c2ccccc2)c1Clその他
- 複数の化合物が格納されたSDFファイルを読み込んで、複数のSMILESをまとめて出力するとさらに便利だろう。
- 投稿日:2020-01-12T19:29:08+09:00
標準入出力を介してMOLファイルをSMILESに変換する
はじめに
MOLファイルをSMILESに変換するpythonスクリプトを作成した。これだとどこにでもある話だが、標準入力からMOLファイルを読み込んで、標準出力にSMILESを吐き出すようにした。これによって、ファイルを経由せずとも結果を得ることができ、より手軽に利用できる。
環境
- Python3.6
- RDKit 2019.03.3.0
ソース
ソースは以下の通りだ。
Mol2SMILESConvertor.pyimport sys from rdkit import Chem def main(): f = sys.stdin mol_block = "" for line in f: mol_block += line mol = Chem.MolFromMolBlock(mol_block) smiles = Chem.MolToSmiles(mol) print(smiles) if __name__ == "__main__": main()使い方
以下のMOLファイルを例に使い方を説明する。
test.mol2,3,6-PCB RDKit 2D 15 16 0 0 0 0 0 0 0 0999 V2000 1.2990 -0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.2990 0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 1.5000 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2990 0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2990 -0.7500 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 -1.5000 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 0.0000 -3.0008 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -1.2978 -3.7529 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -2.3380 -3.1546 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 -1.2955 -5.2529 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 -2.3337 -5.8546 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 0.0048 -6.0009 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.3026 -5.2488 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 1.3002 -3.7488 0.0000 C 0 0 0 0 0 0 0 0 0 0 0 0 2.3385 -3.1472 0.0000 Cl 0 0 0 0 0 0 0 0 0 0 0 0 1 2 2 0 2 3 1 0 3 4 2 0 4 5 1 0 5 6 2 0 6 1 1 0 6 7 1 0 7 8 2 0 8 9 1 0 8 10 1 0 10 11 1 0 10 12 2 0 12 13 1 0 13 14 2 0 14 7 1 0 14 15 1 0 M END $$$$上のMOLファイルをcatしてこのスクリプトに食わせると、以下のようにSMILESが得られる。お手軽だ。
$ cat test.mol |python bin/Mol2SMILESConvertor.py Clc1ccc(Cl)c(-c2ccccc2)c1Clその他
- 複数の化合物が格納されたSDFファイルを読み込んで、複数のSMILESをまとめて出力するとさらに便利だろう。
- 投稿日:2020-01-12T19:26:07+09:00
Python Deep Learing
- 投稿日:2020-01-12T19:16:03+09:00
[Python3 入門 7日目] 3章 Pyの具:リスト、タプル、辞書、集合(3.3〜3.8)
3.3 タプル
タプルはリストと異なり、イミュータブルである。
そのためタプルを定義した後での要素の追加、削除、変更は不可である。3.3.1 ()を使ったタプルの作成
タプルを定義するのは値をくぎるカンマ。()を使ってもエラーにならないので、値全体を()で囲むことが慣習となっている。
#タプルを使えば一度に複数の変数を代入できる。 >>> marx_tuple = ("Groucho","Choico","Harpo") >>> marx_tuple ('Groucho', 'Choico', 'Harpo') >>> a,b,c=marx_tuple >>> a 'Groucho' >>> b 'Choico' >>> c 'Harpo' >>> password = "aaaa" >>> icecream = "bbbb" >>> password,icecream =icecream,password >>> password 'bbbb' >>> icecream 'aaaa' #変数関数のtuple()を使うと他のものからタプルを作成できる。 >>> marx_list=["Groucho","Choico", 'Haapo'] >>> tuple(marx_list) ('Groucho', 'Choico', 'Haapo')3.3.2 タプルとリストの比較
タプルの特徴
- タプルは消費スペースが少ない
- タプルは辞書のキーとして使える
- タプルの要素は誤って書き換える危険がない
- 名前付きタプルはオブジェクトの単純な代用品として使える
- 関数の引数はタプルとして渡される。3.4 辞書
辞書はリストに似ているが要素の順序が管理されていないので要素を選択する時に0や1などのオフセットを使用しない。その代わりに個々の値に一意なキーを与える。キーはイミュータブル型ならなんでも良い。
3.4.1 {}による作成
辞書を作るにはkey:valueのペアをカンマで区切って、{}で囲む。
>>> empty_dict ={} >>> empty_dict {} >>> bierce ={ ... "day":"A period of twenty-four hours,mostly misspent", ... "positive":"Mistaken at the top of one's voice", ... "misfortune":"The kind of fortune tha never misses", ... } >>> bierce {'day': 'A period of twenty-four hours,mostly misspent', 'positive': "Mistaken at the top of one's voice", 'misfortune': 'The kind of fortune tha never misses'}3.4.2 dict()を使った変換
dict()関数を使えば二つの値のシーケンスを辞書に変換できる。
シーケンスの先頭要素がキー、第二要素が値になる。#二要素のタプルのリスト >>> lol = [["a","b"],["c","d"],["e","f"]] >>> dict(lol) {'a': 'b', 'c': 'd', 'e': 'f'} >>> lol = [("a","b"),("c","d"),("e","f")] #二要素のリストのタプル >>> dict(lol) {'a': 'b', 'c': 'd', 'e': 'f'} >>> lol = (["a","b"],["c","d"],["e","f"]) >>> dict(lol) {'a': 'b', 'c': 'd', 'e': 'f'} #二字の文字列のリスト >>> los = ["ab","cd","ef"] >>> dict(los) {'a': 'b', 'c': 'd', 'e': 'f'} #二文字の文字列のタプル >>> los = ("ab","cd","ef") >>> dict(los) {'a': 'b', 'c': 'd', 'e': 'f'}3.4.3 [key]による要素の追加、変更
キーを使って要素を参照し、値を代入する。辞書にそのキーが既にある場合は既存の値が新しい値に置き換えられる。
キーがまだない場合は値と共に辞書に追加される。#キーが存在していないためキーと値のセットで辞書に追加される #キーが既に存在しているため値の置き換えを行う >>> pythons {'Chapman': 'Graham', 'Takada': 'Takashi', 'Atushi': 'Kataoka', 'Palin': 'Michael'} >>> pythons["Gilliam"] = "Gerry" >>> pythons {'Chapman': 'Graham', 'Takada': 'Takashi', 'Atushi': 'Kataoka', 'Palin': 'Michael', 'Gilliam': 'Gerry'} #キーを複数使った場合は最後の値が残る。 >>> pythons["Gilliam"] = "Terry" >>> pythons {'Chapman': 'Graham', 'Takada': 'Takashi', 'Atushi': 'Kataoka', 'Palin': 'Michael', 'Gilliam': 'Terry'} #"Chapman"というキーに"Graham"を代入してから、"Tatuo"に置き換えている。 >>> some_pythons = { ... "Chapman":"Graham", ... "Takada":"Takashi", ... "Palin":"Michael", ... "Chapman":"Tatuo", ... } >>> some_pythons {'Chapman': 'Tatuo', 'Takada': 'Takashi', 'Palin': 'Michael'}3.4.4 update()による辞書の結合
update()関数を使えば辞書のキーと値を別の辞書にコピーすることができる。
>>> pythons = { ... "Chapman":"Graham", ... "Takada":"Takashi", ... "Palin":"Michael", ... "Atushi":"Kataoka", ... } >>> pythons {'Chapman': 'Graham', 'Takada': 'Takashi', 'Palin': 'Michael', 'Atushi': 'Kataoka'} #第二の辞書が第一の辞書に含まれているのと同じキーを持っていた場合、第二の辞書の値が残る。 >>> others = {"Marx":"Gerge",'Takada': 'Takakakakakkakka'} >>> pythons.update(others) >>> pythons {'Chapman': 'Graham', 'Takada': 'Takakakakakkakka', 'Palin': 'Michael', 'Atushi': 'Kataoka', 'Marx': 'Gerge', 'Howard': 'Moe'}3.4.5 delによる指定したキーを持つ要素の削除
>>> del pythons["Marx"] >>> pythons {'Chapman': 'Graham', 'Takada': 'Takakakakakkakka', 'Palin': 'Michael', 'Atushi': 'Kataoka', 'Howard': 'Moe'}3.4.6 clear()による全ての要素の削除
辞書から全てのキーと値を削除するにはclear()を使うか、空辞書{}を辞書名に代入すれば良い。
>>> pythons.clear() >>> pythons {} >>> pythons = {} >>> pythons {}3.4.7 inを使ったことキーの有無のテスト
>>> pythons = {'Chapman': 'Graham', 'Takada': 'Takashi', 'Palin': 'Michael', 'Atushi': 'Kataoka', 'Marx': 'Gerge', 'Howard': 'Moe'} #"key" in "辞書名" の文法 >>> "Chapman" in pythons True >>> "Chaaaaan" in pythons False3.4.8 [key]による要素の取得
辞書とキーを指定して、対応する値をとりだす。
>>> pythons = {'Chapman': 'Graham', 'Takada': 'Takashi', 'Palin': 'Michael', 'Atushi': 'Kataoka', 'Marx': 'Gerge', 'Howard': 'Moe'} >>> pythons["Howard"] 'Moe' #キーが辞書になければ例外発生 >>> pythons["Howaaa"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'Howaaa' #例外を避けるためにあらかじめキーが存在しているか確認する方法3選 #in を使う >>> "Howaaa" in pythons False #辞書専用のget()関数を使う 辞書、キー、オプション値を渡す #キーがあればその値を返す >>> pythons.get("Marx") 'Gerge' #キーがなければ指定したオプション値が返される。(第二引数) >>> pythons.get("Howaaa","Not a Python") 'Not a Python' #オプションをしてしなければNoneになる >>> pythons.get("Howaaa")3.4.9 keys()による全てのキー取得
keys()を使えば辞書の全てのキーを取得できる。
Python3ではvalues()やitems()の戻り値を通常のPythonリストにしたい時にもlist()関数を使う必要あり。>>> signals = {"green":"go","yellow":"go faster","red":"smile for the camera"} #辞書の全てのキーを取得する >>> signals.keys() dict_keys(['green', 'yellow', 'red'])3.4.10 values()による全ての値の取得
#辞書の全ての値を取得するにはvalues()を使う >>> list(signals.values()) ['go', 'go faster', 'smile for the camera']3.4.11 items()による全てのキー/値ペアの取得
#辞書から全てのキー/値ペアを取り出したい場合、items()関数を使う >>> list(signals.items()) [('green', 'go'), ('yellow', 'go faster'), ('red', 'smile for the camera')]3.4.12 =による代入とcopy()によるコピー
リストの場合と同様に辞書に変更を加えるとその辞書を参照している全ての名前に影響が及ぶ。
#save_signalsも同じオブジェクトを参照しているため影響を受ける >>> signals = {"green":"go","yellow":"go faster","red":"smile for the camera"} >>> save_signals = signals >>> signals["blue"]="confuse everyone" >>> save_signals {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera', 'blue': 'confuse everyone'} >>> signals {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera', 'blue': 'confuse everyone'} #別の辞書にキー/値をコピーしたい場合copy()を使う。 >>> signals = {"green":"go","yellow":"go faster","red":"smile for the camera"} >>> original_signals = signals.copy() >>> signals["blue"]="confuse everyone" >>> signals {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera', 'blue': 'confuse everyone'} #影響を受けていない >>> original_signals {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera'}3.5 集合
集合は値を放り出してキーだけを残した辞書のようなもの。
キーに値をとして追加したい場合は辞書を使う。3.5.1 set()による作成
集合を作るときはset()関数を使うか、1個以上のカンマ区切りの値を{}で囲んで代入する。
#空集合をは要素がない集合 >>> empty_set = set() >>> empty_set set() >>> even_numbers = {0,2,4,6,8} >>> even_numbers {0, 2, 4, 6, 8}3.5.2 set()による他のデータ型から集合への変換
リスト、文字列、タプル、辞書から重複する値を取り除けば集合を作れる。
#"t","e"が重複しているが集合には一つずつしか含まれていない。 >>> set("letters") {'l', 's', 't', 'r', 'e'} #リストから集合を作成 >>> set(["Danger","Dancer","Prancer","Mason-Dixon"]) {'Mason-Dixon', 'Danger', 'Prancer', 'Dancer'} #タプルから集合を作成 >>> set(("Ummaguma","Echoes","Atom Heart Mother")) {'Echoes', 'Ummaguma', 'Atom Heart Mother'} #set()に辞書を渡すとキーだけが使われる。 >>> set({'apple':"red", 'orange':"orange", 'cherry':"red"}) {'apple', 'orange', 'cherry'}3.5.3 inを使った値の有無のテスト
#集合と辞書はどちらも{}で囲まれているが集合はただのシーケンスになっているのに対し、辞書はkey:valueペアのシーケンスになっている。 >>> drinks = { ... "martini":{"vodka","vermouth"}, ... "black russian":{"vodka","kahlua"}, ... "manhattan":{"cream","kahlua","vodka"}, ... "white russian":{"rye","vermouth","bitters"}, ... "screwdriver":{"orange juice","vodka"} ... } #辞書drinksからkey/valueのペアを順に取り出し、それぞれname/contentsに代入し、contentsに"vodka"を含むキーの値を出力している。 >>> for name,contents in drinks.items(): ... if "vodka" in contents: ... print(name) ... martini black russian manhattan screwdriver #辞書drinksからkey/valueのペアを順に取り出し、それぞれname/contentsに代入し、contentsに"vodka"を含んでいて"vermouth"もしくは"cream"を含まないキーの値を出力している。 >>> for name,contents in drinks.items(): ... if "vodka" in contents and not ("vermouth" in contents or ... "cream" in contents): ... print(name) ... black russian screwdriver3.5.4 組み合わせを演算
&演算子の結果は両方の集合に含まれている全ての要素を格納する集合。
#contentsに"vermouth"、"orange juice"の両方含まれていなければ&演算子は空集合{}を返す。 >>> for name,contents in drinks.items(): ... if contents & {"vermouth","orange juice"}: ... print(name) ... martini white russian screwdriver#3.5.3一番下のコード書き換え >>> for name,contents in drinks.items(): ... if "vodka" in contents and not contents & {"vermouth","cream"}: ... print(name) ... black russian screwdriver#全ての集合演算子を見ていく >>> bruss = drinks["black russian"] >>> wruss = drinks["white russian"] >>> a={1,2} >>> b={2,3} #積集合:&もしくはintersection()関数を使う >>> a & b {2} >>> a.intersection(b) {2} >>> bruss & wruss set() #和集合:|もしくはunion()関数を使う >>> a | b {1, 2, 3} >>> a.union(b) {1, 2, 3} >>> bruss | wruss {'cream', 'kahlua', 'vodka'} #差集合:-もしくはdifference()関数を使う。(第一集合には含まれているものの第二集合には含まれていない要素の集合) >>> a-b {1} >>> a.difference(b) {1} >>> bruss-wruss set() >>> wruss-bruss {'cream'} #排他的OR:^もしくはsymmetric_difference()関数を使う(どちらか一方に含まれている要素) >>> a ^ b {1, 3} >>> a.symmetric_difference(b) {1, 3} >>> bruss^wruss {'cream'} #部分集合(サブセット):<=かissubset()を使う。 >>> a <=b False >>> a.issubset(b) False >>> bruss<=wruss True #どの集合でも自分自身の部分集合になっている。 >>> a<=a True >>> a.issubset(a) True #第一の集合が第二の集合の真部分集合になっているかどうか。 #第二の集合が第一の集合の全ての要素に加えて別の要素のを持っていなければならない。<で計算できる。 >>> a < b False >>> a<a False >>> bruss<wruss True #上位集合:部分集合の逆で第二の集合の全ての要素が第一の集合の要素にもなっている関係。 # >=もしくはis superset()関数で調べる。 >>> a>=b False >>> a.issubset(b) False >>> wruss >= bruss True #全ての集合は自分自身の上位集合である。 >>> a>=a True >>> a.issuperset(a) True #真上位集合:第一の集合に第二の集合の全ての要素とその他の要素が含まれているかどうか >>> a > b False >>> wruss > bruss True #集合は自分自身の真上位集合ではない >>> a>a False3.6 データ構造の比較
- リストは角括弧[]
- タプルはカンマ
- 辞書と集合は{}
でそれぞれ表す
また参照の仕方は以下の通り。
- リストとタプルの場合、角括弧の中に入れる数値はオフセット
- 辞書の場合、キー>>> marx_list=["akagi","Takasuka","Syuda"] >>> marx_tuple="akagi","Takasuka","Syuda" >>> marx_dict={"akagi","Takasuka","Syuda"} >>> marx_list=[2] >>> marx_list=["akagi","Takasuka","Syuda"] >>> marx_list[2] 'Syuda' >>> marx_tuple[2] 'Syuda' >>> marx_dict={"akagi":"banjo","Takasuka":"help","Syuda":"harp"} >>> marx_dict["Syuda"] 'harp'3.7 もっと大きいデータ構造
>>> marxs=["akagi","Takasuka","Syuda"] >>> pythons=["Gilliam","Cleese","Gilliam"] >>> stooges=["Moe","Curly","Larry"] #個々のリストからタプル作成 >>> tuple_of_lists=marxs,pythons,stooges >>> tuple_of_lists (['akagi', 'Takasuka', 'Syuda'], ['Gilliam', 'Cleese', 'Gilliam'], ['Moe', 'Curly', 'Larry']) #リストを含むリスト作成 >>> list_of_lists=[marxs,pythons,stooges] >>> list_of_lists [['akagi', 'Takasuka', 'Syuda'], ['Gilliam', 'Cleese', 'Gilliam'], ['Moe', 'Curly', 'Larry']] #リストの辞書を作成 #辞書のキーはイミュータブルでなければならないためリスト、辞書、集合は他の辞書のキーになれない。 >>> dict_of_lists ={"Marxes":marxes,"Pythons":pythons,"Stooges":stooges} >>> dict_of_lists {'Marxes': ['Groucho', 'Choico', 'Haapo'], 'Pythons': ['Gilliam', 'Cleese', 'Gilliam'], 'Stooges': ['Moe', 'Curly', 'Larry']} #辞書のキーはイミュータブルでなければならないためリスト、辞書、集合は他の辞書のキーになれないが、タプルはキーになれる。 >>> houses={ ... (44.79,-43.55,373):"My House"}復習課題
演習 3-1 誕生年から5歳の誕生日を迎えるまでの各年を順に並べてyears_listというリストを作ろう。
>>> years_list=[1994,1995,1996,1997,1998,1999]演習 3-2 years_listの要素で3歳の誕生日を迎えた年はどれか。
#オフセットは0から始まることに注意 >>> years_list[4] 1998演習 3-3 years_listに含まれている年の中で最も年長だったのはどれ?
#オフセット-1でとして指定することで右端を選択可能 >>> years_list[-1] 1999演習 3-4 "mozzarella","cinderella","salmonella"の3つの文字列を要素としてthingsというリストを作ろう。
>>> things=["mozzarella","cinderella","salmonella"] >>> things ['mozzarella', 'cinderella', 'salmonella']演習 3-5 thingsの要素で人間を参照している文字列の先頭文字を大文字にしてリスト表示する。
#capitalize()関数で文字列の先頭文字を大文字にする。 >>> things[1]=things[1].capitalize() >>> things ['mozzarella', 'Cinderella', 'salmonella']演習 3-6 thingsの中で病気に関する要素を全て大文字にしよう。
#upper()関数で要素の文字列を全て大文字にする。 >>> things[2]=things[2].upper() >>> things ['mozzarella', 'Cinderella', 'SALMONELLA']演習 3-7 病気に関する要素を削除し、表示しよう。
#del で要素を削除できる >>> del things[2] >>> things ['mozzarella', 'Cinderella']演習 3-8 "Groucho","Chico","Harpo"を要素としてsurpriseというリストを作成しよう。
>>> surprize=["Groucho","Chico","Harpo"] >>> surprize ['Groucho', 'Chico', 'Harpo']演習 3-9 surpriseリストの最後の要素を小文字にして逆順にしてから、先頭文字を大文字に戻そう。
#最後の文字列を全て小文字にする。 >>> surprize[2]=surprize[2].lower() #最後の要素を逆順にして代入 >>> surprize[2]=surprize[-1][::-1] #最後の要素の先頭文字を大文字にする。 >>> surprize[2]=surprize[2].capitalize() >>> surprize[2] 'Oprah'演習 3-10 e2fという英仏辞書を作り、表示しよう。
>>> e2f={"dog":"chien","cat":"chat","walrus":"morse"} >>> e2f {'dog': 'chien', 'cat': 'chat', 'walrus': 'morse'}演習 3-11 e2fを使ってwalrusという単語に対するフランス語を表示しよう。
#キーである"walrus"を指定して値を表示させる >>> e2f["walrus"] 'morse'演習 3-12 e2fからf2eという仏英辞書を作ろう。items()を使うこと。
#f2eの初期化を忘れない >>> f2e={} #items()を使ってキーと値をそれぞれenglish,frenchに格納 >>> for english,french in e2f.items(): ... f2e[french] = english ... >>> f2e {'chien': 'dog', 'chat': 'cat', 'morse': 'walrus'}演習 3-13 f2eを使ってフランス語のchienに対する英語を表示しよう。
#キーである"chien"を指定して値を表示させる >>> f2e["chien"] 'dog'演習 3-14 e2fのキーから英単語の集合を作って表示しよう。
#集合作成はset()を使用する。 >>> set(e2f.keys()) {'walrus', 'dog', 'cat'}演習 3-15 lifeという多重レベルの辞書を作ろう。最上位のキーとしては"animals","other","plants"という文字列を使う。animalsキーは、"cats","octpi","emus"というキーを持つ他の辞書を参照するようにする。"cats"キーは、"Henry","Grumpy","Lucy"という文字列のリストを参照するようにする。他のキーは全て空辞書を参照するようにする。
>>> life={"animals":{"cats":["Henry","Grumpy","Lucy"],"octpi":{},"emus":{}},"plants":{},"other":{}}演習 3-16 lifeの最上位キーを表示しよう。
#key()を使い多重辞書lifeのキーを表示させている >>> print(life.keys()) dict_keys(['animals', 'plants', 'other'])演習 3-17 life["animals"]のキーを表示しよう。
#key()を使い多重辞書llife["animals"]のキーを表示させている >>> print(life["animals"].keys()) dict_keys(['cats', 'octpi', 'emus'])演習 3-18 life["animals"]["cats"]の値を表示しよう。
#多重辞書life["animals"]["cats"]の値を表示させている >>> print(life["animals"]["cats"]) ['Henry', 'Grumpy', 'Lucy']感想
今まで実行文の横にコメント分を記載していたが振り返る時にとても見にくいことが判明した。実行文の上に記載することで見やすくなったので今までのやつも修正しよう。
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-12T18:50:40+09:00
rdkit 簡単インストール
アナコンダにRDKitをインストールして
ケモインフォマティクスを始めましょう。
1、アナコンダを起動して、
仮想環境を作り、
ターミナルを開く。
2、rdkitをインストール
conda install -c rdkit rdkit
3、必要なライブラリも入れましょう。
Jupyter、scikit-learn など
さあ、ケモインフォマティクスを始めましょう。--以上--


- 投稿日:2020-01-12T18:50:40+09:00
RDKit 簡単インストール
アナコンダにRDKitをインストールして
ケモインフォマティクスを始めましょう。
1、アナコンダを起動して、
仮想環境を作り、
ターミナルを開く。
2、rdkitをインストール
conda install -c rdkit rdkit
3、必要なライブラリも入れましょう。
Jupyter、scikit-learn など
さあ、ケモインフォマティクスを始めましょう。--以上--
- 投稿日:2020-01-12T18:33:25+09:00
Herokuへのデプロイ時に発生したエラーの解決策
django-herokuをインストール
[Python] プログラム初心者のためのWebアプリ簡単作成法
https://qiita.com/okoppe8/items/4cc0f87ea933749f5a49上記を参考にHerokuへのデプロイを試していたところ、
django-herokuインストール時にハマりました。pip install gunicorn django-herokuエラー
Could not fetch URL https://pypi.org/simple/django-heroku/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/django-heroku/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping ERROR: Could not find a version that satisfies the requirement django-heroku (from versions: none) ERROR: No matching distribution found for django-heroku解決策
以下で解決しました。
brew reinstall python参考
SSL module in Python is not available (on OSX)
https://stackoverflow.com/questions/58280484/ssl-module-in-python-is-not-available-on-osx
- 投稿日:2020-01-12T17:58:26+09:00
【Python】俺の株価予測 【HFT】
1. モチベーション
- Qiitaの記事を見ていてもいろいろな株価予測についての記事がありますが、本稿では僕も自分なりに本気で株価の予測をしてみようと思いました。
- ここでの株価予測は数分程度先の短期の予測です。
- 取引所の板を見ていて、買いが強いなーとか、売りが多いなーっていう印象を受けることがありますが、それを元に株価を予測しようというのが今回のアプローチです。
- 参考にしたのは、"Deep Convolutional Neural Networks for Limit Order Books"という論文です。Limit Order Book (LOB)は板情報という意味です。
- また、データセットはFI-2010というフィンランドのヘルシンキ証券取引所のデータを使用しています。
2. 板情報について
- 板情報についてはザイ・オンラインの記事が分かりやすく解説してくれています。簡単に説明すると、以下のような売りと買いのニーズを集約したものが板になります。取引所には様々な人の売買注文が集まってきます。●●円で○○株買いたい(売りたい)というような注文をその値段ごとに集約し、その株数合計を表示してくれています。
売数量(ASK) 株価 買数量(BID) 500 670 400 669 600 668 667 300 666 1,200 665 400
- 株価がなぜどうやって変動するのかについてはいろいろな考え方がありますが、売りたい人たちの売り数量よりも買いたい人たちの売り数量が多い場合、株価が上がっていくというふうにここでは考えます。
- 上の板の例で、ここに100株買いたい人が現れて新たに注文を出す場合を考えてみます。注文の方法はだいたい2パターンに分かれます。
- ひとつめは、668円に600株の売り注文が出ているのに自分の買い注文をぶつける方法です。この時、板は下のように変化します。
ASK 株価 BID 500 670 400 669 500 668 667 300 666 1,200 665 400
- もうひとつは例えば667円に買い注文を出す方法です。必ず約定するとは限りませんが、667円に売りの注文が出てきた時に買いが成立します。このとき、板は下のように変化します。
ASK 株価 BID 500 670 400 669 600 668 667 400 666 1,200 665 400
- ここで言いたいことは以下の通りです。
- 買いたい人が増えた時板情報は、ASKの数量が減るかBIDの数量が増えるという反応になる。
- 売りたい人が増えた時板情報は、ASKの数量が増えるかBIDの数量が減るという反応になる。
- 板情報を丁寧に追っていけば、その後の株価推移について何かしらの示唆が得られるような気がしてきませんか??
3. FI-2010データセット
FI-2010データセットとは
- Benchmark Dataset for Mid-Price Forecasting of Limit Order Book Data with Machine Learning Methodsという論文に詳しく説明があり、以下そこからの抜粋です。
- フィンランドのヘルシンキ取引所から取った板情報のデータです。
- 2010年6月の1日から14日までの期間のデータです。
- 対象の銘柄は5銘柄です。ケスコ(KESBV)、オウトクンプ(OUT1V)、サンポコンツェルン(SAMPO)、ロータールーキー(RTRKS)、バルチラ(WET1V)になります。僕は見事に全銘柄知らない銘柄でした。
- 板に変化があったごとにデータをサンプルしているようです。(それにしてはデータ数が少ない気がするのでここは僕の理解が違うかも。ただ、2010年のことなので分かりません。)
- ダウンロードできるのは正規化された後のデータです。以下の3種類の正規化が用意されています。
- Z-score
$\quad x_i^{Zscore} = \frac{x_i - x_{mean}}{x_{std}}$
$\quad \rm where \quad x_{mean} = \frac{1}{N} \sum_{j=1}^{N} x_j, \quad x_{std} = \sqrt{\frac{1}{N} \sum_{j=1}^{N} (x_j - x_{mean})^2}$- Min-Max Scaling
$\quad x_i^{(MM)} = \frac{x_i - x_{min}}{x_{max} - x_{min}}$- Decimal Precision
$\quad x_i^{DP} = \frac{x_i}{10^k}$
$\quad$where k is the integer that will give the maximum value for $|x_i^{(DP)}|<1$- ここのリンクのData AvailabilityのAccess this dataset freely.をクリックするとダウンロードできます。
データの概観
- 以下ではDecimal Precisionで正規化されたデータを見て行きます。これが一番データの数字を直感的に理解しやすいと思うためです。まずは全データ10日分のうち、初日のデータを読み込んできます。
data = pd.read_csv('Train_Dst_Auction_DecPre_CF_1.txt', header=None, delim_whitespace=True) print(data.shape) #=> (149, 47342)
- 全部で47,342件のデータがあり、それぞれ149の要素で構成されていることが分かります。
- 全体像が掴みにくいのでヒートマップで見てみます。
plt.figure(figsize=(20,10)) plt.imshow(data, interpolation='nearest', vmin=0, vmax=0.75, cmap='jet', aspect=data.shape[1]/data.shape[0]) plt.colorbar() plt.grid(False) plt.show()
- こう見ると、確かに5銘柄のデータが横につながって入っている様子が分かります。上から144個の行は特徴量、最後の5行はラベルを表しています。また、具体的な特徴量については論文に以下のような記述があります。

- 基本的な板情報は$u_1$の40行に入っています。それ以降は板情報を加工して作成した特徴量となっています。板情報についてどのようにデータが入っているか詳細に見てみます。試しに最初の1列目を使います。
lob = data.iloc[:40,0].values lob_df = pd.DataFrame(lob.reshape(10,4), columns=['ask','ask_vol','bid','bid_vol']) print(lob_df)
ask ask_vol bid bid_vol 0 0.2631 0.00392 0.2616 0.00663 1 0.2643 0.00028 0.2615 0.00500 2 0.2663 0.00165 0.2614 0.00500 3 0.2664 0.00500 0.2613 0.00043 4 0.2667 0.00039 0.2612 0.00646 5 0.2710 0.00700 0.2611 0.00200 6 0.2745 0.00200 0.2609 0.00199 7 0.2749 0.00487 0.2602 0.00081 8 0.2750 0.00300 0.2600 0.00197 9 0.2769 0.01000 0.2581 0.01321
- ここまでくると理解しやすいです。1番上に最良ASK、BIDがあって、次第に最良気配から遠いところの板情報になっていってます。
$\quad u_1 = \{P_i^{ask},V_i^{ask},P_i^{bid},V_i^{bid}\}_{i=1}^{10}$
という記述の通り、40行のデータは『1番目(最良)ASK価格、ASK数量、BID価格、BID数量、2番目のASK価格、ASK数量、BID価格、BID数量、、、、』という形で格納されています。4. モデル
学習データとラベル
- ここからは実際に使う機械学習モデルの説明をしていきます。学習するにあたって学習データ$\mathbb X$と対応するラベル$\mathbb y$が必要になりますが、これを構成する$(\mathbb x_t, y_t)$についてです。
- 学習に用いるデータですが、ある時点$t$の板データを
$\quad v_t = \{P_{t,i}^{ask},V_{t,i}^{ask},P_{t,i}^{bid},V_{t,i}^{bid}\}_{i=1}^{10}$
とし、これを直近の$p$個集めたものを1つの学習データ($\mathbb x_t$)とします。具体的には、
$\quad \mathbb x_t = \begin{pmatrix} v_{t-p+1} \\v_{t-p+2} \\ \vdots \\ v_t\end{pmatrix} = \begin{pmatrix} P_{t-p+1,1}^{ask} & V_{t-p+1,1}^{ask} & P_{t-p+1,1}^{bid} & V_{t-p+1,1}^{bid} & P_{t-p+1,2}^{ask} & \cdots & P_{t-p+1,10}^{bid} & V_{t-p+1,10}^{bid} \\ P_{t-p+2,1}^{ask} & V_{t-p+2,1}^{ask} & P_{t-p+2,1}^{bid} & V_{t-p+2,1}^{bid} & P_{t-p+2,2}^{ask} & \cdots & P_{t-p+2,10}^{bid} & V_{t-p+2,10}^{bid} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ P_{t,1}^{ask} & V_{t,1}^{ask} & P_{t,1}^{bid} & V_{t,1}^{bid} & P_{t,2}^{ask} & \cdots & P_{t,10}^{bid} & V_{t,10}^{bid}\end{pmatrix}$
という$p×40$の行列になります。これをCNNで畳み込みしたのち、LSTMに通すので、最も古いデータが1行目、$t$時点のデータは1番下の行に入っています。- ラベル($y_t$)は$t$時点以降の$k$期間の仲値の平均が閾値$\alpha$を基準に上昇しているか、下落しているか、横ばいかをもとに割り振ります。まず、仲値($p_t$)とはそれぞれの時点での最良ASKとBIDの平均を指すので、
$\quad p_t = \frac{P_{t,1}^{ask} + P_{t,1}^{bid}}{2}$
となります。さらに、期間$k$における仲値の平均値($m_{+}(t)$)とその騰落率($l_t$)は、
$\quad m_{+}(t) = \frac{1}{k} \sum_{i=1}^{k} p_{t+i}, \quad l_t = \frac{m_{+}(t) - p_t}{p_t}$
と表すことができます。最後に閾値($\alpha$)を基準にして、
$\quad y_t =\left\{ \begin{array}{}1, & l_t>\alpha \\ -1, & l_t<-\alpha \\ 0, & \rm otherwise\end{array}\right.$
という形にラベリングします。モデルアーキテクチャ
- 先にモデルの例をあげておくと以下の様になります。まず各時点での板情報をCNNで畳み込み、最後にLSTMで時系列の関係を処理するという流れになります。

- input_1レイヤから順に見ていきます。Output Shapeは(バッチサイズ、参照する板情報数($p$)、ひとつの板情報に含まれるデータ数(40)、1)という意味です。ここでは$p=50$としています。
- conv2d_1レイヤは最初の畳み込み層です。カーネルのサイズは$1×2$、ストライドも$1×2$としています。$\mathbb x_t$には板情報の価格と数量のペアが羅列されていますが、ここではこのひとつひとつのペアに対して畳み込みを行なっています。カーネル数は8を指定しています。ここでは行方向の畳み込みをしているのみなので、Output Shapeの参照している板情報数は$p(=50)$のままで変わらず、ひとつの板情報に含まれるデータ数が半減しています。
- conv2d_2レイヤもカーネルのサイズが$1×2$、ストライドが$1×2$の畳み込み層です。カーネル数は8を指定しています。ここの畳み込みは板情報の「ASKサイドの価格・数量をconv2d_1で畳み込んだもの」と「BIDサイドの価格・数量をconv2d_1で畳み込んだもの」に対して畳み込みをしており、最良気配なら最良気配についてASK、BIDの価格・数量という4つの数字をひとまとめにする役割を果たしています。conv2d_1とconv2d_2のウエイト次第では対応するASK、BIDの加重平均仲値を計算するような振る舞いをすることを考えると少しイメージが掴めます。なお、この加重平均仲値はマイクロプライス($p_t^{(micro)}$)とも呼ばれ、以下の様に定義されます。
$\quad p_{t,i}^{(micro)} = \frac{P_{t,i}^{ask} V_{t,i}^{ask} + P_{t,i}^{bid} V_{t,i}^{bid}}{V_{t,i}^{ask} + V_{t,i}^{bid}}$- conv2d_3レイヤはカーネルのサイズが$1×10$、ストライドが$1$の畳み込み層です。カーネル数は8を指定しています。そもそもASK、BID両サイドとも10本の板を参照しているため、conv2d_2のアウトプットはひとつの板情報ごとに10個の数字からなっています。この10の数字をひとまとめに畳み込むのがこのレイヤです。これである時点での板情報がひとつの数字に畳み込まれました。
- reshape_1レイヤはconv2d_3のアウトプットを次のlstm_1にフィードしてやるためにあります。
- ltsm_1レイヤではここまで畳み込まれてきた板情報についてその時系列での関係をキャプチャしようとしています。ユニット数は8を指定しています。
- dense_1レイヤはLSTMのアウトプットを受けるシンプルな隠れ層です。
- dense_2レイヤはこのネットワークの出力層となります。ラベルの種類数に合わせて出力は3つ、activationにはsoftmaxを使っています。
5. 実装
データの前処理
- ここでは先ほど読み込んだデータのうち、最もサンプル数が多い5つ目の銘柄のデータを用いてモデルを動かしていきます。
# 板情報は最初の40行に入っている。5つめの銘柄のデータとして29738~47294を指定。 lob = data.iloc[:40, 29738:47294].T.values # ここで価格・数量ごとに標準化する。 lob = lob.reshape(-1,2) lob = (lob - lob.mean(axis=0)) / lob.std(axis=0) lob = lob.reshape(-1,40) lob_df = pd.DataFrame(lob) # 標準化されていない仲値を計算する。 lob_df['mid'] = (data.iloc[0,29738:47294].T.values + data.iloc[2,29738:47294].T.values) / 2
- 仲値をプロットしてみると以下のようになりました。まあよくある株価チャートです。現値に近い全ての呼値に指値が出ていないこともあり細かい振動が多くなっている印象があります。株価が一方向に動き続けているデータではない点はモデルを作成する上でよさそうです。

- 次にラベルを作成していきます。
# パラメータを指定する。 p = 50 k = 50 alpha = 0.0003 # パラメータをもとに仲値からラベルを作成する。 lob_df['lt'] = (lob_df['mid'].rolling(window=k).mean().shift(-k)-lob_df['mid'])/lob_df['mid'] lob_df = lob_df.dropna() lob_df['label'] = 0 lob_df.loc[lob_df['lt']>alpha, 'label'] = 1 lob_df.loc[lob_df['lt']<-alpha, 'label'] = -1
今回のパラメータによるラベリングは以下のようなイメージになります。それなりに株価が上昇する際には上昇シグナルを、下落するときには下落シグナルを発しています。
必要なライブラリを読み込みます。
from sklearn.model_selection import train_test_split from keras.utils import to_categorical from keras.layers import Conv2D, Dense, Reshape, Input, LSTM from keras import Model, backend import tensorflow as tf
- 学習データを作成していきます。
# 学習データを作成します。 X = np.zeros((len(lob_df)-p+1, p, 40, 1)) lob = lob_df.iloc[:,:40].values for i in range(len(lob_df)-p+1): X[i] = lob[i:i+p,:].reshape(p,-1,1) y = to_categorical(lob_df['label'].iloc[p-1:], 3) print(X.shape, y.shape) #=> (17457, 50, 40, 1) (17457, 3)
- 最後に学習データとテストデータに分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- これで前処理は完了です!
モデル構築
- ここからはkerasを使ってニューラルネットワークのモデルを作成していきます。SequentialよりもFunctional APIに慣れているのでこっちで記述します。
tf.reset_default_graph() backend.clear_session() inputs = Input(shape=(p,40,1)) x = Conv2D(8, kernel_size=(1,2), strides=(1,2), activation='relu')(inputs) x = Conv2D(8, kernel_size=(1,2), strides=(1,2), activation='relu')(x) x = Conv2D(8, kernel_size=(1,10), strides=1, activation='relu')(x) x = Reshape((p, 8))(x) x = LSTM(8, activation='relu')(x) x = Dense(16, activation='relu')(x) outputs = Dense(3, activation='softmax')(x) model = Model(inputs=inputs, outputs=outputs) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])いざ学習!
- 後は学習させるのみです。
epochs = 50 batch_size = 256 history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=1, validation_data=(X_test, y_test))Epoch 100/100
13965/13965 [==============================] - 5s 326us/step - loss: 0.6526 - acc: 0.6808 - val_loss: 0.6984 - val_acc: 0.6595
- エポックごとのlossとaccuracyは以下のようになりました。そこそこうまく学習が進んでいる様子が分かります。
6. 考察
- 学習データに対してはAccuracyが0.6808、テストデータに対しては0.6595という思いのほか良好な結果が得られました。
テストデータの結果をヒートマップで可視化してみまる。正しく分類できていることもいいことですが、実用化を考えると「株価が上昇するときに下落シグナルを出してしまうこと」、「下落するときに上昇シグナルを出してしまうこと」が損失につながるので最も問題となります。この点に関して、まったく逆のシグナルを出してしまっているケースはかなり少なく、ポジティブな結果となりました。
今後の課題
- ハイパーパラメータチューニング。
- 他の銘柄のデータも合わせて学習をする。
- 他の取引日のデータも利用して学習をする。(一般に、ある1日のデータをもとにモデルを作ってもそれを別日に使うとパフォーマンスが落ちることが分かっている。)
- 最近の日本の株式市場でも同様のパフォーマンスを出せるか検証する。