- 投稿日:2020-01-12T22:25:41+09:00
AWS AmplifyのAuth.signUpでNoUserPoolError: Authentication Error
前提
AWS Amplifyでamplify add authした後に、Auth.signUp呼んだらエラー起きた場合。
エラー内容
ConsoleLogger.js?36de:84 [ERROR] 59:18.392 AuthError - Error: Amplify has not been configured correctly. This error is typically caused by one of the following scenarios: 1. Make sure you're passing the awsconfig object to Amplify.configure() in your app's entry point See https://aws-amplify.github.io/docs/js/authentication#configure-your-app for more information 2. There might be multiple conflicting versions of aws-amplify or amplify packages in your node_modules. Try deleting your node_modules folder and reinstalling the dependencies with `yarn install` ConsoleLogger._log @ ConsoleLogger.js?36de:84 ConsoleLogger.error @ ConsoleLogger.js?36de:150 AuthError @ Errors.js?13ca:41 NoUserPoolError @ Errors.js?13ca:50 AuthClass.rejectNoUserPool @ Auth.js?bf82:1795 AuthClass.signUp @ Auth.js?bf82:202 onclick1 @ App.vue?234e:21 invokeWithErrorHandling @ vue.runtime.esm.js?2b0e:1854 invoker @ vue.runtime.esm.js?2b0e:2179 original._wrapper @ vue.runtime.esm.js?2b0e:6917# 原因と対処 エラーメッセージが親切で、書いてあるURL https://aws-amplify.github.io/docs/js/authentication#configure-your-app を開いてみると、main.jsに下記を追加しろって書いてありました。Errors.js?13ca:34 Uncaught (in promise) NoUserPoolError: Authentication Error at NoUserPoolError.AuthError [as constructor] (webpack-internal:///./node_modules/@aws-amplify/auth/lib-esm/Errors.js:39:24) at new NoUserPoolError (webpack-internal:///./node_modules/@aws-amplify/auth/lib-esm/Errors.js:55:28) at AuthClass.rejectNoUserPool (webpack-internal:///./node_modules/@aws-amplify/auth/lib-esm/Auth.js:1806:31) at AuthClass.signUp (webpack-internal:///./node_modules/@aws-amplify/auth/lib-esm/Auth.js:213:25) at VueComponent.onclick1 (webpack-internal:///./node_modules/cache-loader/dist/cjs.js?!./node_modules/babel-loader/lib/index.js!./node_modules/cache-loader/dist/cjs.js?!./node_modules/vue-loader/lib/index.js?!./src/App.vue?vue&type=script&lang=js&:22:56) at invokeWithErrorHandling (webpack-internal:///./node_modules/vue/dist/vue.runtime.esm.js:1853:26) at HTMLButtonElement.invoker (webpack-internal:///./node_modules/vue/dist/vue.runtime.esm.js:2178:14) at HTMLButtonElement.original._wrapper (webpack-internal:///./node_modules/vue/dist/vue.runtime.esm.js:6907:25)import Amplify, { Auth } from 'aws-amplify'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig);自分のアプリの場合、この未使用変数はエラーでダメだったので、Authを削除して、
import Amplify from 'aws-amplify'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig);で無事通りました。
修正後のmain.jsの全体像は下記の通りです。import Vue from 'vue' import App from './App.vue' import Amplify from 'aws-amplify'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig); Vue.config.productionTip = false new Vue({ render: h => h(App), }).$mount('#app')補足
FRAMEWORK SUPPORT(Vue)のところに詳しく書いてありますね。
https://aws-amplify.github.io/docs/js/vue
- 投稿日:2020-01-12T22:16:19+09:00
AWS AmplifyでVue.jsを使いたいときに読むべきドキュメント
AWS Amplifyとは
mBaaSサービスの一つ。Firebase使ったら負けかなと思ったので手を出してみました。が、しかし、いきなりハマったので早速記事として残しておく。
結論
FRAMEWORK SUPPORTという章があるが、それをいきなり読むのは地雷。
Getting Startedで手を動かしながら理解を深めたのち、次に、FRAMEWORK SUPPORT(Vue)を読むとよい。
(Getting Startedだけ読んでもダメということが分かったので、Getting Started => FRAMEWORK SUPPORTの順に読むべしという内容に変更しました。)Getting Started(Vue)
https://aws-amplify.github.io/docs/js/start?platform=vue
Vue.jsのプロジェクトの作り方から、AWS Amplifyの初期化、APIモジュールの追加、デプロイしてAWS環境上で動作させるところまで一通り学べる。ここから始めるのが良い。ドキュメントのトップ
https://aws-amplify.github.io/docs/
からは、
- iOS
- Android
- Web
- React Native
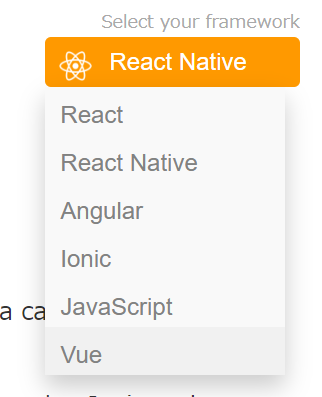
の4種類しか選べない(2020/1/12現在)が、4つのうちどれかを開いた後、右上の「Select your framework」からVueを選ぶとVue対応のドキュメントが表示されます。いや分かんなかったわ・・・
まあ、mBaaSなんでWebよりネイティブってことでしょうし、Vueが英語圏ではマイナーってこともあるんでしょうね、きっと。
FRAMEWORK SUPPORT(Vue)
https://aws-amplify.github.io/docs/js/vue
もろもろ端折られているので、ここから始めるのはよくない。Getting Startedを読んだ後に読む。
- 投稿日:2020-01-12T21:49:41+09:00
不断のDevOps パイプライン: DynatraceとAWSで、シフトライト、シフトレフト、セルフヒーリングを実装する
本記事は、Dynatraceブログ にポストされた ” Unbreakable DevOps Pipeline: Shift-Left, Shift-Right & Self-Healing / Andreas Grabner ” の日本語翻訳(部分編集あり)になります。
本ブログは、チュートリアル ”Dynatrace-AWS-DevOps Tutorial” の技術解説であり、シフトライト、シフトレフト、及びセルフヒーリング(自己修復)を、どのように継続的デリバリとディプロイメントパイプラインに実装するか、その方法について説明するものです。
このチュートリアルでは、フルスタックモニタリングのためにDynatraceを、パイプライン、ディプロイメント、オーケストレーション、コンピューティング、ストレージのためにAWSのサービスを選択していますが、同じことを他のクラウドプラットフォームやCI/CDツールに対しても適用できるはずです。
次のアニメーションは、「プルリクエスト」(左側)から「プロダクション ディプロイメント」(右側)までのデリバリパイプラインのフローを示しています。この中で、Dynatraceは、各ステージ間(クオリティゲート)で監視者の役割と、プロダクション環境でのセルフヒーリングをコントロールする役割を担っています。
【画像】AWSとDynatraceを使用したシフトレフト(クオリティゲート)、シフトライト(モニタリングへのコンテキスト情報提供)、およびセルフヒーリング(自己修復)
このチュートリアルでは、モダンなデリバリパイプラインにおける、フルスタックモニタリングの果たし得る役割を示しています。Dynatraceを使用するか、他のツールを使用するかに関係なく、問題あるコード変更によってエンドユーザーが影響を受けないようにするために、パイプラインは次の要件を満たすべき だと考えます。
自動化されたフルスタックモニタリング:
ホスト、PaaS( CloudFoundry、 OpenShift、 SAP Cloud Platform 等)または関数( Lambda、 Azure Functions 等)のモニタリングを自動でディプロイし有効化できること。使用される技術スタック(言語やフレームワーク等)に関係なく、すべてのプロセス、サービス、およびアプリケーションを自動で検出できること。
シフトライト:
ディプロイメント情報やメタデータをモニタリング環境にプッシュできること。例えば、ブルーとグリーンのディプロイメントを区別したり、ビルドまたはディプロイメントのリビジョン番号をプッシュし構成の変更を通知すること、など。
シフトレフト:
パイプラインを停止するか実行するかを決定するために、APIを介して特定のエンティティ(プロセス、サービス、アプリケーション、テストなど)のデータを取得できること
セルフヒーリング(自己修復):
発生したシステムトラブルの根本原因に対応する様な、インテリジェンスな自動自己修復ができること。例えば、GC設定不良の自動修正
それではこれらの4つの要件を、上述のチュートリアルの中で実際にどう実装したか、解説していきます。
1. 自動化されたフルスタックモニタリングの実装例:
DynatraceのOneエージェントテクノロジーは、それぞれ異なるエージェントで監視するような対象(Java、.NET、Webサーバー、ノード、Lambdaなど)や、それぞれ異なるツールで監視するような対象(ネットワーク、ログ、コンテナ、クラウド)も、1つのエージェントでまとめてフルスタックの自動監視を実現します。
このチュートリアルでは、AWS CloudFormation を利用し、EC2インスタンス定義のUserDataセクションにダウンロードとインストールのスクリプトステップを追加するだけで、Dynatrace Oneエージェントを自動デプロイしています。
以下は、私のCloudFormationテンプレートの抜粋です。任意のDynatraceテナントで機能するように、実際のダウンロードURLがパラメーター化されています。
"UserData": { "Fn::Base64": { "Fn::Join": ["", [ "#!/bin/bash -x\n", "# First: we download and install the Dynatrace OneAgent\n", "yum update -y\n", "yum install ruby wget -y\n", "wget -O Dynatrace-OneAgent-Linux.sh \"", { "Ref": "DynatraceOneAgentURL" }, "\"\n", "sudo /bin/sh Dynatrace-OneAgent-Linux.sh APP_LOG_CONTENT_ACCESS=1\n", "# Second: ...",EC2インスタンスが起動すると、Dynatraceは次のスクリーンショットの様に、自動的にフルスタックの監視(フロントエンド、サーバサイド、インフラ、ログ、クラウド等)を開始します。
【画像】Dynatrace Oneエージェントをインストールすると、ホスト、すべてのプロセス、サービス、およびアプリケーションのフルスタックの可視性が得られます
上のスクリーンショットでは、左側にDynatrace スマートスケープが表示され、右側に各エンティティの一部のデータが自動的にキャプチャされています。このデータはすべて、Dynatrace スマートスケープ APIおよびTimeseries APIからもアクセスできます。
2. シフトライトの実装例:
私にとってシフトライトとは、ディプロイメントまたは変更に関するコンテキスト情報を、監視プロセスにプッシュすることを意味します。獲得するコンテキスト情報が多ければ多いほど、問題の根本原因をより適切に検出することも、セルフヒーリングをより効果的に実装することもできます。
メタデータ(タグ、プロパティなど)をフルスタック監視プロセスに渡す
シフトライトの最初の実装は、自動化されたディプロイメントプロセスのメタデータを取得することです。デフォルトでは、DynatraceはAWS EC2インスタンス、Docker、CloudFoundry、OpenShift、Kubernetes 等のタグなどのメタデータを自動でキャプチャします。これにより監視ツールでエンティティにタグを付け直す必要がなくなります。プラットフォームで既に指定したものを再利用するだけです。
それらプラットフォームからのメタデータの自動キャプチャに加え、Dynatraceは環境変数、Javaプロパティなどからも、メタデータを抽出できます。
私のチュートリアルでは、AWS CodeDeploy を利用し、アプリケーションを実行するシェルスクリプトで、環境変数 DT_TAGS、DT_CUSTOM_PROP および DT_CLUSTER_ID をエクスポートしています。
これらはDynatrace Oneエージェントがプロセスグループのメタデータとして取り扱う特別な環境変数です。ビルド固有の情報を含む独自の環境変数やJavaプロパティがある場合、Dynatraceのカスタムプロセスグループ検出ルールを設定することで、これらを取得できます。次のスクリーンショットは、AWS CodeDeployスクリプトがどのように見えるかを示しています。
【画像】ディプロイメントスクリプトを使用して、メタデータをDynatrace監視対象エンティティに渡します。CodeDeploy、Chef、Puppet、Ansible、Electric Flow、XLRelease 等で動作しますこれは、"Monitoring as Code" または "Monitoring as Configuration" に呼ばれるものに相当します。なぜなら、監視対象に関するデータが、自動ディプロイメント構成スクリプトを介して渡されているためです!これらの重要な情報を2回設定する必要はありません!単に再利用するだけです!
デプロイ情報をフルスタック監視プロセスに渡す
シフトライトの2番目の実装は、Dynatrace API を使って実行できます。APIは、カスタムタグ、時系列、またはカスタムイベントを監視対象エンティティ(ホスト、プロセスグループインスタンス、サービス、またはアプリケーション)にプッシュする機能を提供します。
私のチュートリアルでは、Dynatrace Events API を使用して、AWS CodePipeline と AWS CodeDeploy のビルドおよびデプロイ情報を Dynatraceが監視しているサービスに対してプッシュしました。
【画像】AWS Lambdaを使用し、イベントAPIを介してCodePipelineとCodeDeployの情報をDynatrace に渡す
3. シフトレフトの実装例:
シフトレフトという用語が広まっていますが、恐らくDevOpsと同じくらい頻繁に誤解されているのではないでしょうか? 私見では、シフトレフトとは、次のきわめて重要な質問に答えるために、より多くのデータをライフサイクル初期に獲得することであると考えます。
この変更は、プロダクションにプッシュしても良いようなものなのか、それとも悪いものなのか?
そして、それが悪い変更であった場合は、決してパイプラインの先にプッシュさせてはいけません!
パイプラインで確認すべきデータはパフォーマンス関連の監視データだけではありませんが(コード品質に関するメトリックも確認しましょう)、ビルド検証を自動化するために、多くの人がそれらをパイプラインに自動的に含めることにトライしています。
このチュートリアルでは、Dynatrace Timeseries (時系列) API を使って、パイプラインによってプッシュされるサービスの異なる複数のメトリックを比較することで、ビルド検証プロセスを自動化させています。
プッシュされようとしているカレントビルドを、他のベースラインビルドと比較したり、更にはプロダクションの稼働状況と比較します。
次の図は、このタイプの比較を定義する方法(Monitoring as Code)を示しており、メトリックを取得する先(どの環境か)と、これが良いビルドか悪いビルドかを判断する方法(しきい値の定義)について説明しています。
【画像】ビルドまたは環境毎のメトリックを比較することにより、変更によって、パフォーマンスを改善させているか又は低下させているかどうか確認できます。
従来、ビルド検証はパフォーマンスエンジニアによって手動で行われ、パフォーマンスエンジニアはさまざまな時間枠のさまざまなダッシュボードをプルアップし、親指を上げたり下げたりしていました。多くの場合、これらのレポートの生成は自動化されていますが、最終的なレポートは手動で比較されているのです!
私のチュートリアルでは、このビルド検証プロセスを完全に自動化しました!ビルド検証(=比較)はパイプラインからトリガーされ、AWS Lambda 関数 によって実行されます。AWSLambda 関数は、パイプラインの承認ステージにおいて、次のステージへの移行を許可または拒否します。すべてのビルド検証結果と比較されたすべてのメトリックは、私が作成したHTMLレポートからもアクセスできます。
【画像】すべてのビルドについてのDynatraceによるビルド検証結果。新しいビルドのすべてのメトリックをベースラインと比較表示します!
次のアニメーションは、これがパイプラインにどのように統合されるかを示しています。重要な点は、有効な比較となるように、十分な長さの負荷テストで十分なデータを取得して初めて、ビルド検証プロセスを実行できることです。このための”待機”は、DynamoDBテーブルに入力された検証リクエストと、十分な時間が経過したときにのみそのリクエストを実行するLambda関数の、それぞれを実行する期間によって実現されます。
【画像】デプロイが成功すると、ビルド検証リクエストが発行されます。ビルド検証ワーカーは、適切なタイミングで検証を行い、承認ステージの承認または拒否を行います4. セルフヒーリングの実装例:
テストをしたからプロダクションで順風満帆だ、という訳では決してありません。したがって、プロダクション環境で何か問題が発生した場合の状況を自動化する方法も検討する必要があります。
ご存じのとおり、Dynatrace AIは自動的に発生した問題を検出し、Oneエージェントが収集したフルスタックすべてのデータの中から、根本原因を自動で検出します。問題が検出されるたびに、Dynatraceは外部ツール(ServiceNow、PagerDuty、xMattersなど)に通知したり、Webhookを呼び出したりできます。
このチュートリアルでは、問題が発生した場合に、DynatraceからAPI Gatewayを経由して呼び出されるAWS Lambda関数を実装しました。Lambda関数は、問題に関するDynatraceからの付加的情報を獲得します。たとえば、最新のディプロイメントが何で、いつ行われたか、などです。もしも最新のディプロイでディプロイ直後に問題が発生した場合、Lambda関数はAWS CodeDeployを呼び出して、プロダクション環境に以前のリビジョンをディプロイます。
【画像】古典的なロールバックシナリオ。AWS Lambdaと、Dynatrace AIで検出された問題とその根本原因のデータを使用して問題を解決する
以前のリビジョンをディプロイすることは、究極のセルフヒーリングプロセスではないことは理解しています。問題の根本原因と環境に応じて、システムを修復するための様々なアクションを実行する必要があります。宜しければ、私の最近のブログである ”デジタルパフォーマンスライフにおけるAIへの適用” をご参照ください。ここでは、実際に私が関わった3つの問題と、Lambda関数などで修復用スクリプトを使って、システムをセルフヒーリングするために何をしなければならなかったについて説明しています。
(了)
参照: 本ブログに連動するコンテンツは以下の通りです
本解説の元となっているチュートリアル ”Dynatrace-AWS-DevOps Tutorial”
著者の紹介:
Andreas Grabner は、ソフトウェア開発者、テスター、アーキテクトとして20年以上の経験があり、high-performing cloud scale applications の提唱者です。 彼はDevOpsコミュニティへの定期的な寄稿者であり、技術カンファレンスでも頻繁に講演を行っており、blog.dynatrace.comで定期的に記事を公開しています。 Twitterで彼をフォローできます:@grabnerandi


- 投稿日:2020-01-12T21:42:14+09:00
[備忘録] AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト(SBクリエイティブ刊)
この記事はAWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト(SBクリエイティブ刊)読了時の備忘録です。
正誤に関する情報が含まれていますが、公式の正誤表に反映されるまでのラグを考慮してQiitaでも公開しています。(出版社にはこのページのURLを送付しています)底本
2019年5月30日 初版第2冊発行のデータを元にした2019年7月1日 電子版第2版を底本としています。
気になった点
ページ 元の記述 訂正やメモ 28 DyanamoDB DynamoDB 55 0.95USD 前述の0.129USDより価格が上がってしまっているので0.095USD? 116 通信の暗号化; 通信の暗号化: (めちゃ細かい) 134 (表の2つ目の)max_execution_time Redshiftのドキュメントによると WLM タイムアウト (max_execution_time) は廃止されました。とあるのでquery_execution_timeが正? Redshiftを使ってないので詳細不明161 拡張認証(EV):OVより厳格な審査で認証する。アドレスバーに組織名が表示される。 刊行時点でも表示されない方向になっているのでそれに触れてもよいのでは、と思ったけれども、2019/09/10リリースのChrome 77、2019/10/22リリースのFirefoxで表示がなくなったので全然刊行後の最近の話だった 282 CloudWatch Log CloudWatch Logs
- 投稿日:2020-01-12T20:55:43+09:00
【AWS完全に理解したへの道】 EC2 基本編
【AWS完全に理解したへの道】 EC2 基本編
IAM 基本編
VPC 基本編
S3 基本編
データベース(RDS/ElastiCache/DynamoDB)基本編EC2(Amazon Elastic Compute Cloud)
ハードウェアに事前投資することなく、必要な数の仮想サーバを起動して、セキュリティやネットワーキングの設定、ストレージの管理を行う。要件変更や需要増に対して、迅速に拡張または縮小できる。
EC2に関連する主要コンポーネント
ここでは深く掘り下げないが、EC2に連携しているサービスは以下の図のような感じ。
AWS Black Belt Online Seminar Amazon Elastic Compute Cloud (Amazon EC2)より画像を引用
EC2インスタンス初回作成手順
- AMI(Amazon Machine Image)の選択
- インスタンスタイプの選択
- インスタンスの詳細設定(ネットワーク/IAMロール/ユーザデータなどの設定)
- ストレージの設定
- タグ付け
- セキュリティグループの設定
- ここまでの設定の確認
- キーペアの選択
1. AMIの選択
EC2インスタンスを初回起動する際に必要となる仮想マシンイメージ。
2. インスタンスタイプの選択
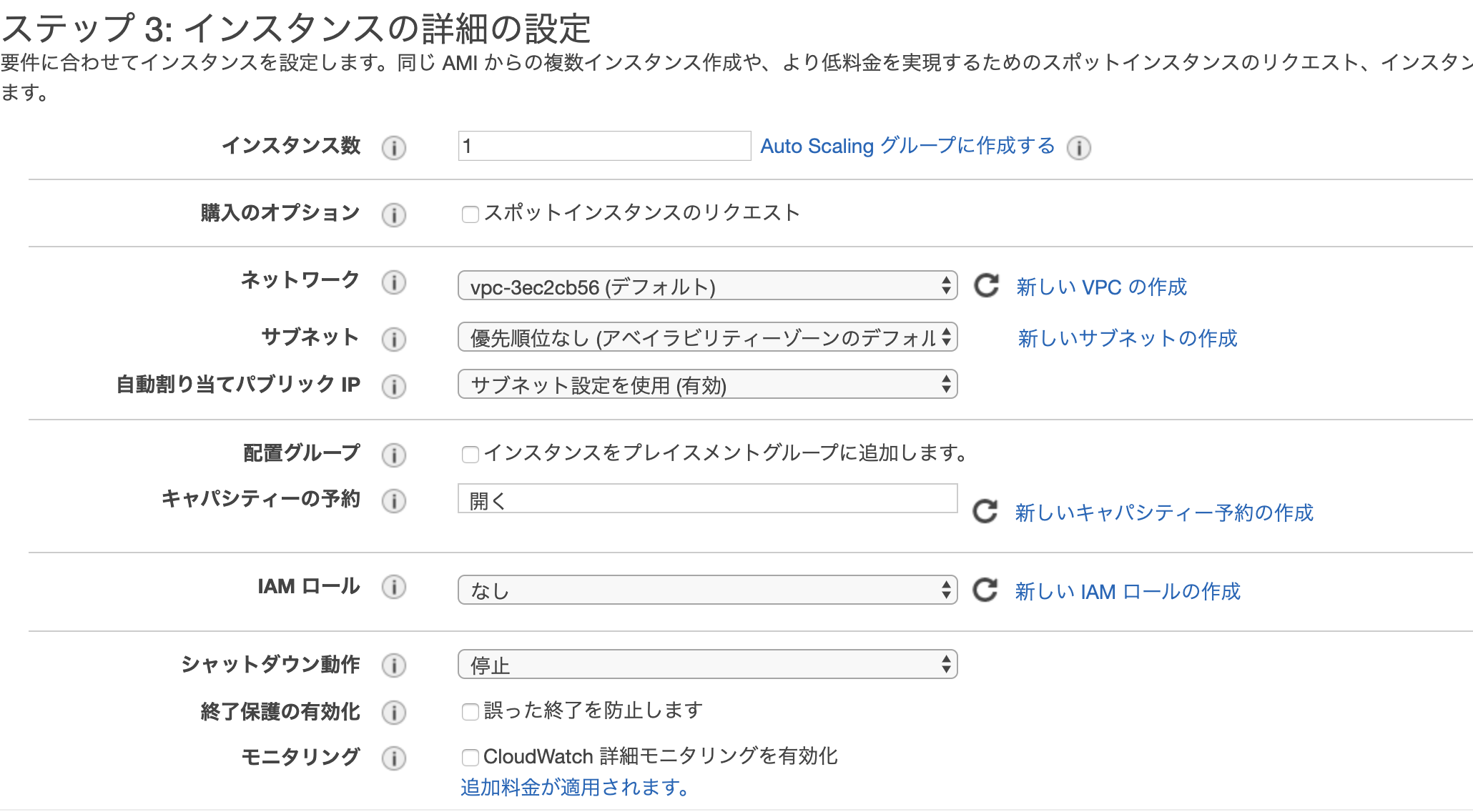
インスタンスファミリー インスタンスタイプ ユースケース 汎用(バランス重視) A1, T3, T3a, T2,M6g, M5, M5a, M5n, M4 ウェブサーバー、コンテナ化されたマイクロサービス、キャッシュサーバー群、分散データストア、開発環境といったスケールアウト型のワークロード コンピューティング最適化 C5, C5n, C4 ハイパフォーマンスのウェブサーバー、科学的モデリング、バッチ処理、分散分析、ハイパフォーマンスコンピューティング (HPC)、機械学習/深層学習推論、広告サービス、拡張性の高いマルチプレイヤーゲーム、動画エンコーディング。 GPU(高速コンピューティング) P3, P2, Inf1, G4, G3, F1 機械学習/深層学習、ハイパフォーマンスコンピューティング (HPC)、計算流体力学、金融工学、耐震解析、音声認識、自律走行車、創薬。 メモリ最適化 R5, R5a, R5n, R4, X1e, X1, ハイメモリ, z1d 高パフォーマンスデータベース、分散型ウェブスケールインメモリキャッシュ、中規模のインメモリデータベース、リアルタイムのビッグデータ分析、およびその他エンタープライズアプリケーションなどのメモリ集約型アプリケーションに最適。 ストレージ最適化 I3, I3en, D2, H1 NoSQL データベース (例:. Cassandra、MongoDB、Redis)、インメモリデータベース (例: Aerospike)、スケールアウトトランザクションデータベース、データウェアハウジング、Elasticsearch、分析ワークロード。 3. インスタンスの詳細設定(ネットワーク/IAMロール/ユーザデータなどの設定)
下記画像のようにネットワークやサブネット、IAMロールなどの設定を行う。
4. ストレージの設定
ストレージデバイスは以下の二種類がある。
- EBS
AZ内に作成されるネットワーク接続型のブロックストレージで不揮発性(永続的なデータボリューム)
- インスタンスストア EC2インスタンス上の物理ホストの内蔵ストレージで、揮発性(一時的なデータボリューム) EC2インスタンスを停止すると保存されていたデータは削除される。
注意点
EBSの追加はEC2インスタンスの初回起動後でも可能だが、インスタンスストアを追加できるのはEC2インスタンスの初回起動時のみ。
5. タグ付け
キーとバリューのペアで構成され、このタグを元に検索をかけたり、操作の際の絞り込み条件として指定することができる。
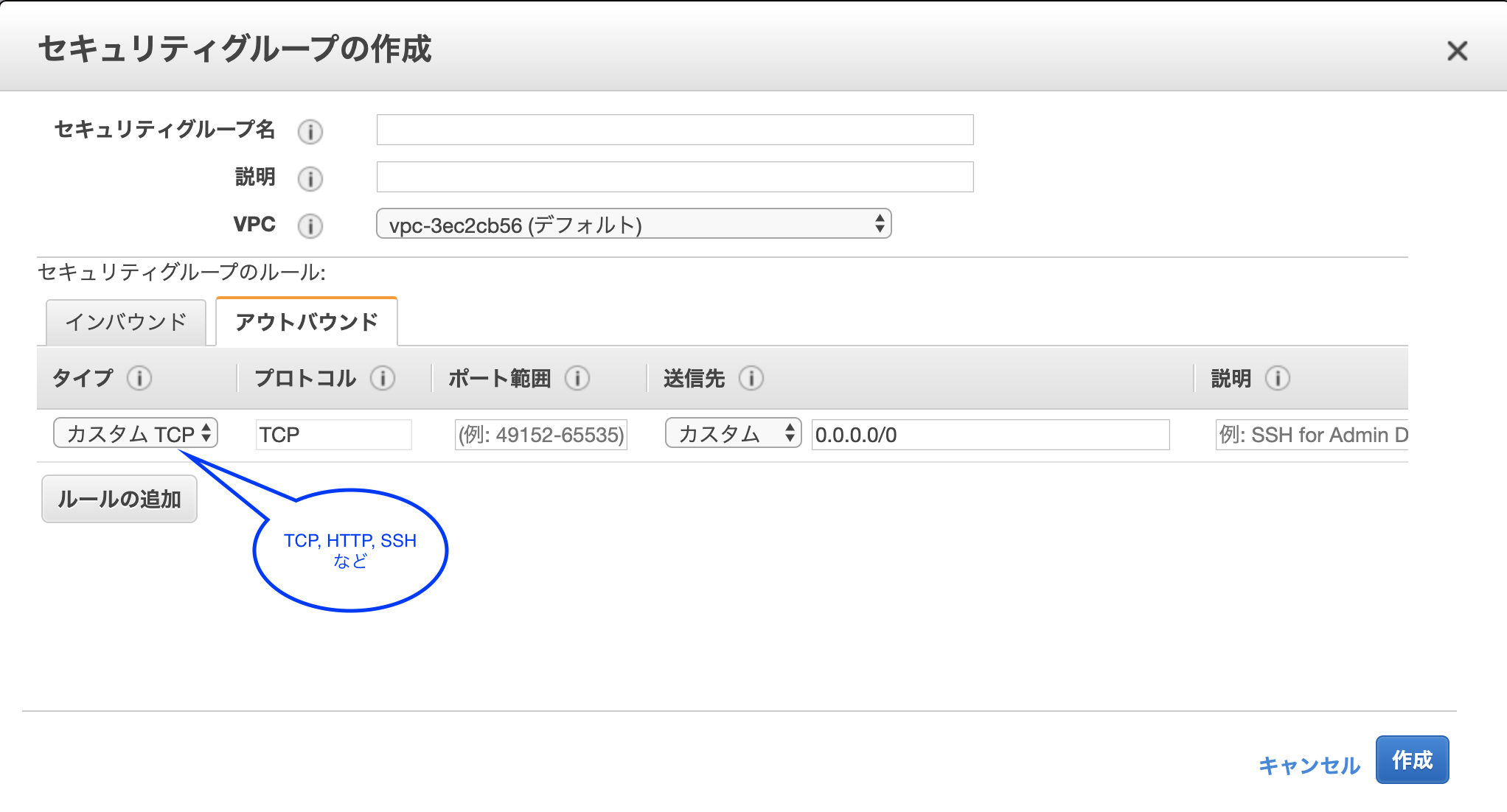
6. セキュリティグループの設定
EC2インスタンスのファイアーウォール
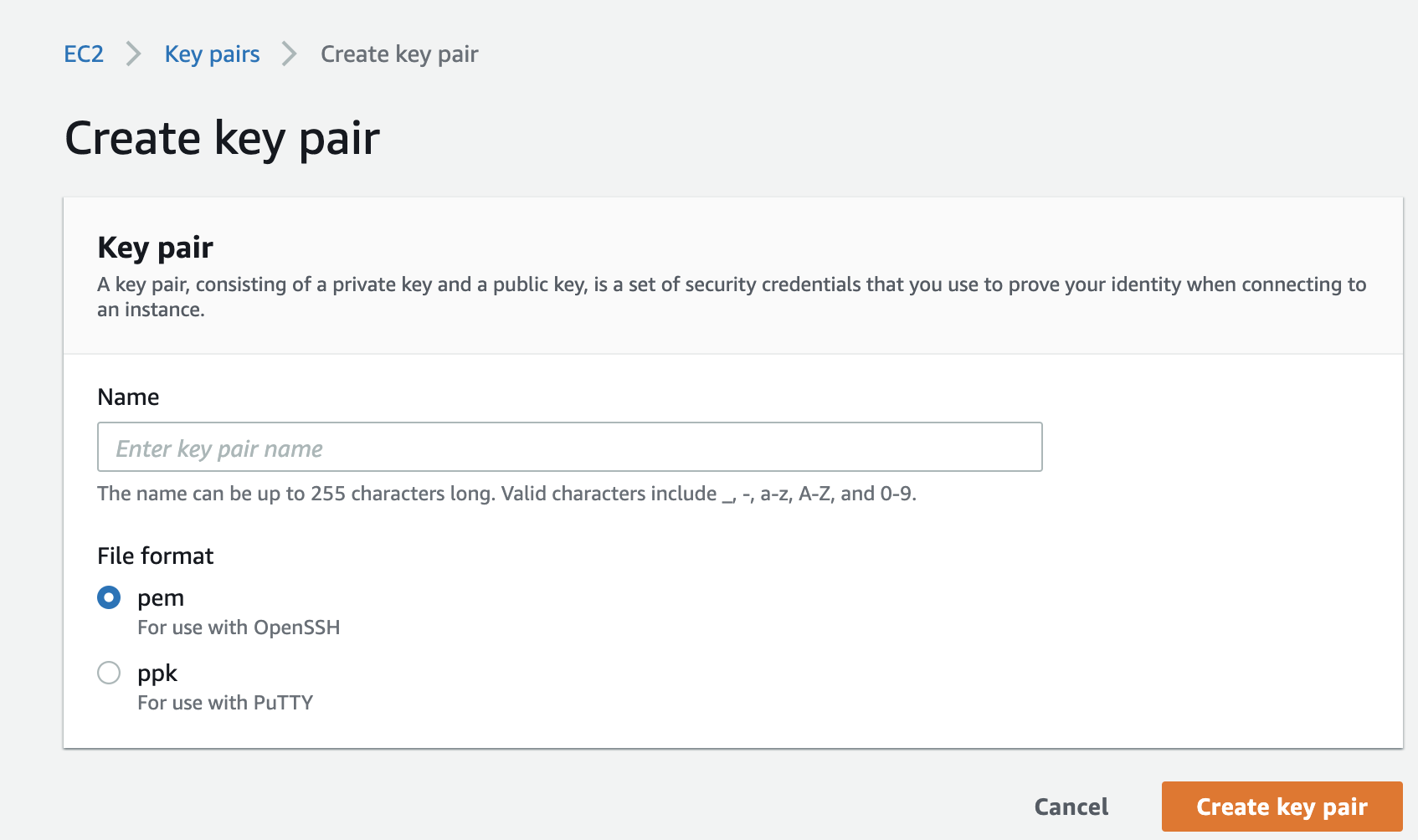
ネットワークトラフィックの制限、ユーザに対するアクセス権限の付与を設定できる。8. キーペアの作成
EC2インスタンス上のOSに対する安全な認証を提供する機能。
下記画像のようにpemかppkを選択しキーペアを作成する。

- 投稿日:2020-01-12T19:40:21+09:00
S3ファイルやDynamoDBレコードの自動削除
S3ファイルやDynamoDBレコードの自動削除
この記事はサーバーレスWebアプリ Mosaicを開発して得た知見を振り返り定着させるためのハンズオン記事の1つです。
以下を見てからこの記事をみるといい感じです。
* Lambda(Python) + Rekognition で顔検出はじめに
S3やDynamoDBって、もちろん長期的に保存したい用途に利用することもありますが、一時的なデータ保存場所として利用するケースも多いですよね。ワタシのMosaicなんかも、30分くらいで消えてしまって何ら問題ありません。
そんな時は自動的に削除される仕組みがありますので、それを利用しましょう。コンテンツ
S3ファイルの自動削除
上で「30分くらいで消えてしまって何ら問題ありません」と書きましたが、残念ながらS3からの自動削除は、最小1日からとなります。いやー、残念。
さて設定の仕方ですが、
AWSコンソール > S3 > 管理タブ > ライフサイクル > +ライフサイクルルールの追加 ボタンを押下
ルール名は適当に
delete-a-day-in-publicなどと付けました。
今回はpublicフォルダの中だけを対象にしたいのでpublic/のようなプレフィックスを追加します。
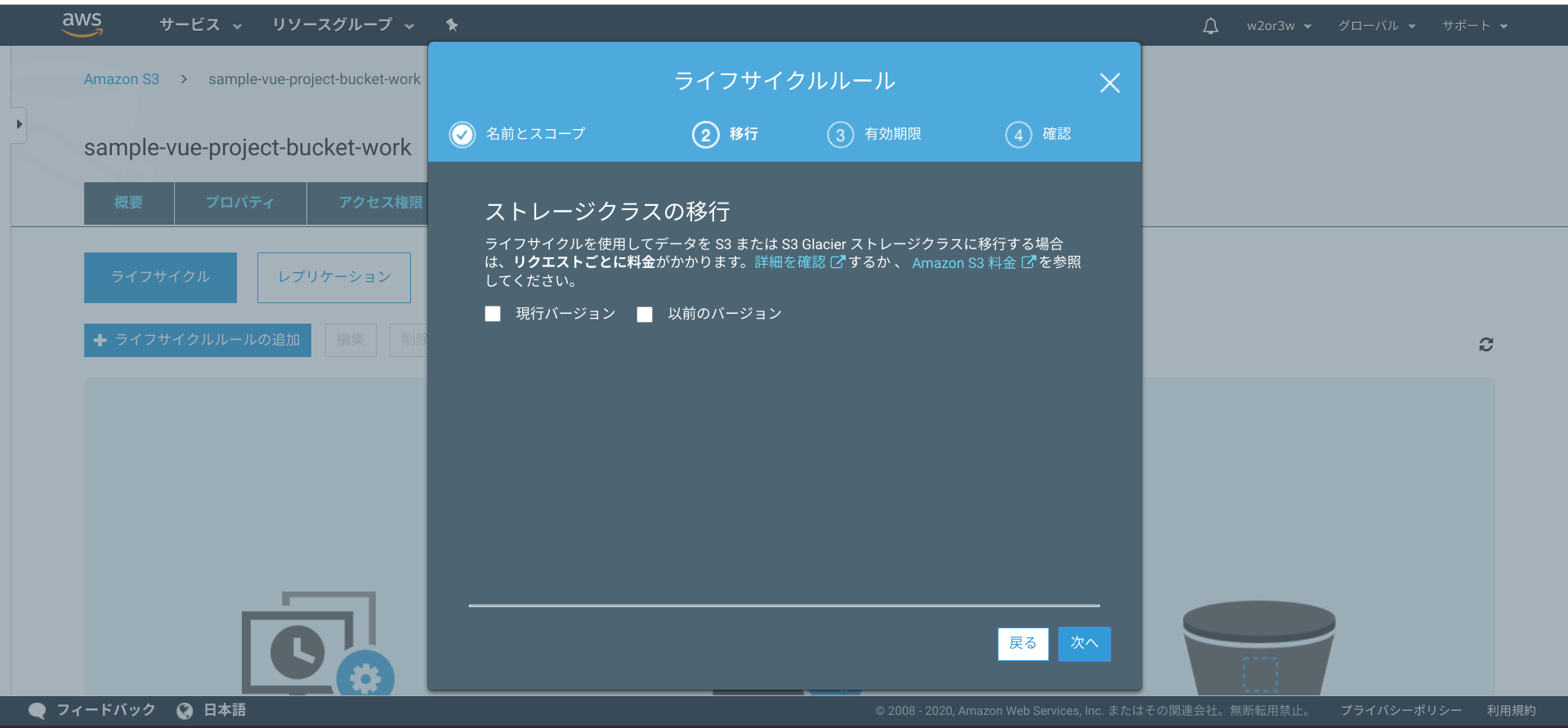
次に進んで、ライフサイクルルールは、削除しますので全てチェックOFFのままとします。
次の「失効の設定」は全てチェックONにして、日数を入力します。ここでは1日で消えるようにしました。
で、最後確認して、保存してください。
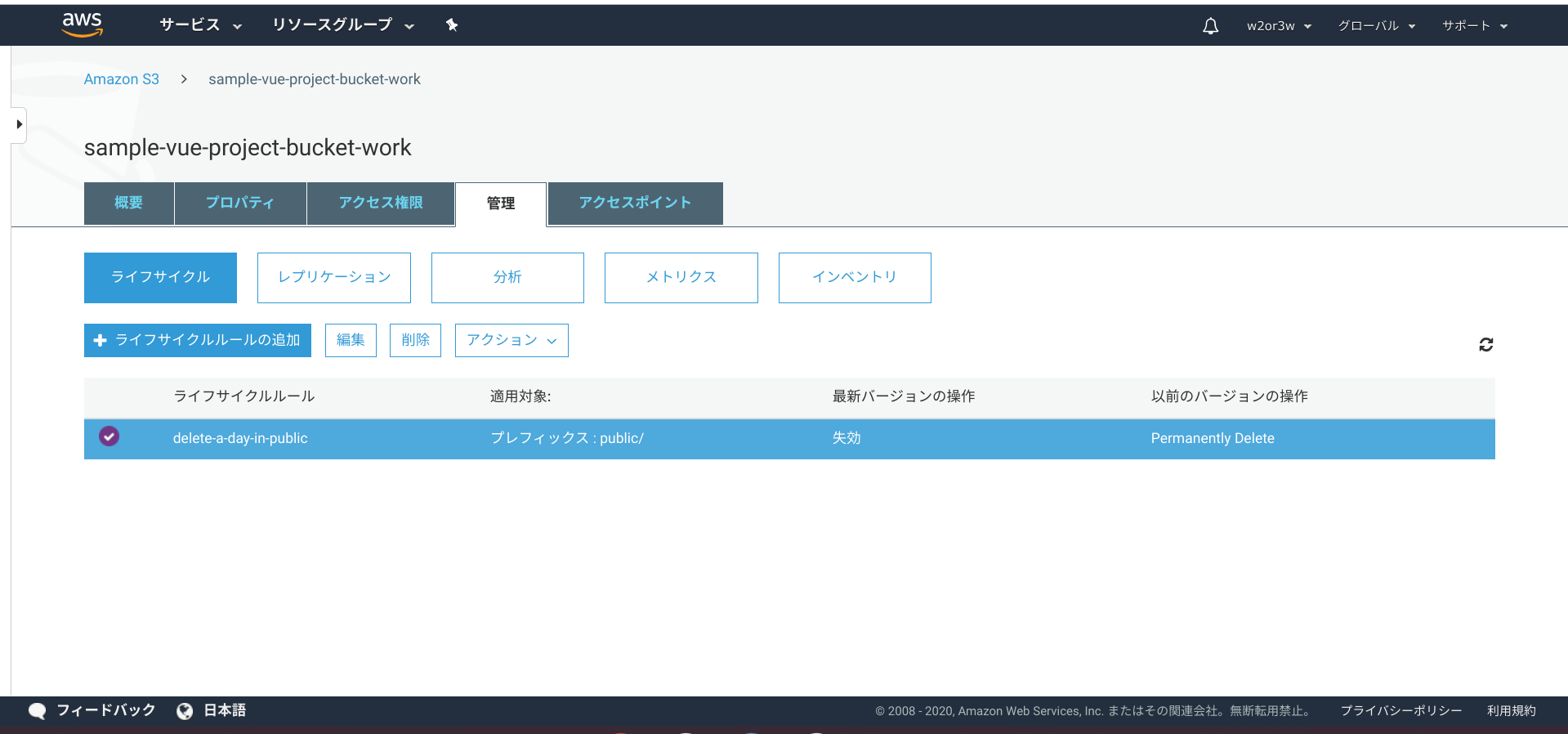
ライフサイクルの一覧に追加されていますね。
S3のファイルを最小1日で自動的に削除するための設定は以上です。
DynamoDBレコードの自動削除
続いてDynamoDBです。
DynamoDBは秒単位で削除される日時を指定できます。これなら「30分くらいで消えてしまって何ら問題ありません」が実現できますね!と思いきやざーんねん。最大48時間のタイムラグがあるとか。なんだそりゃって感じですよね。
運が良ければ30分、運が悪くても最大48時間30分で、自動的にレコードを削除することはできるということです。そしてDynamoDBは、S3のようにコンソールをポチポチやったら設定できるというわけではありません。
自動的に削除される時間を入れるためのフィールド(列)が必要となります。
つまり、その列にレコードを入れる際に、削除される時間を毎回設定する必要があるということです。
ちょっと面倒ですよね。さてサンプルプログラムの方から削除用のフィールドに値をいれてゆきましょう。
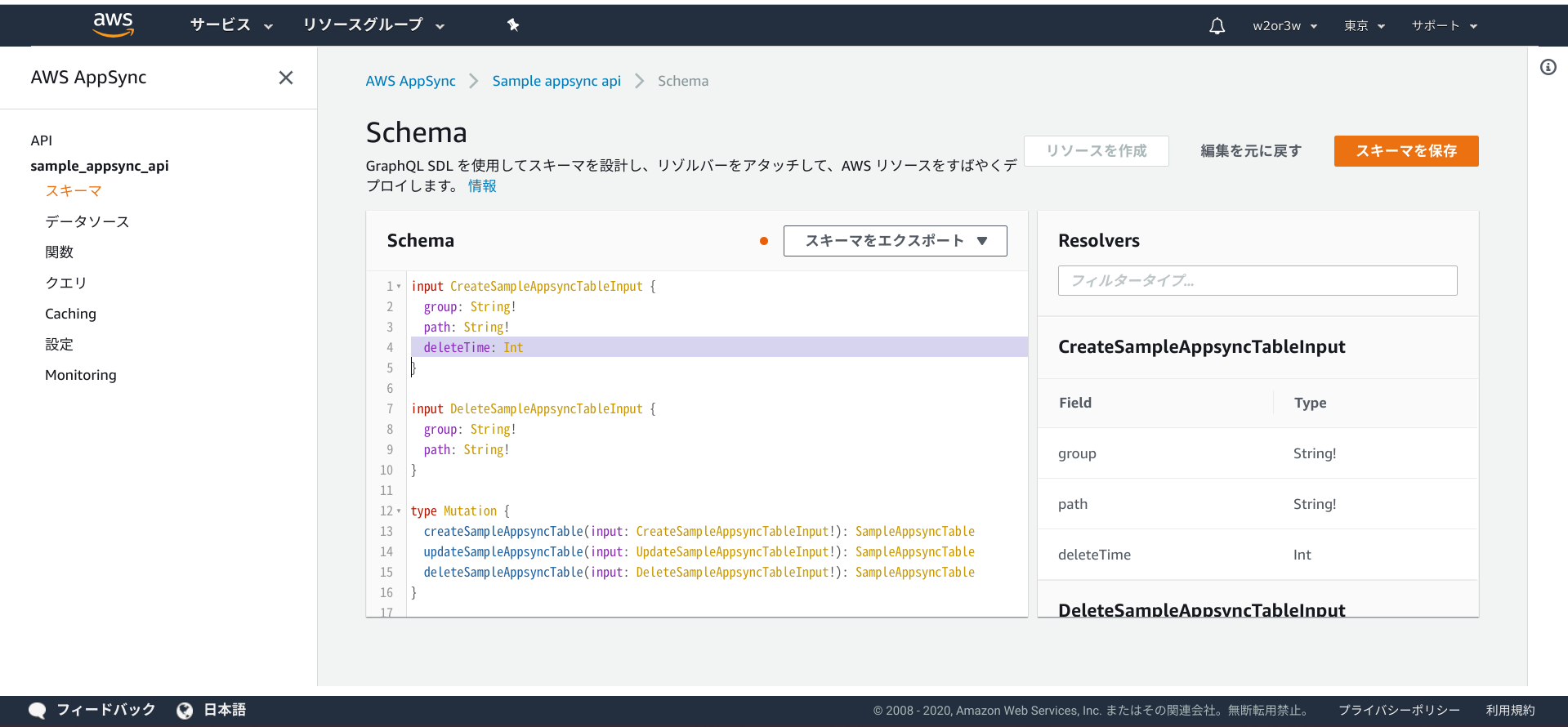
DynamoDBへレコードを挿入するのはAppSync経由ですので、そこにフィールドを追加することになります。AWSコンソール > AppSync > Sample appsync api > スキーマ
SchemaのCreateSampleAppsyncTableInputにInt型のdeleteTimeというフィールドを追加しておきます。
deleteTime: Intを追加したら、「スキーマを保存」ボタンを押下します。今回のサンプルアプリは、DynamoDBへのレコード挿入はバックエンドからのみです。
従いまして、LambdaのPythonのコードを修正してゆくことになります。lambda_function.py: import datetime : def apiCreateTable(group, path): logger.info("start apiCreateTable({0}, {1})".format(group, path)) time = datetime.datetime.now() time = time + datetime.timedelta(minutes=30) epocTime = int(time.timestamp()) try: query = gql(""" mutation create {{ createSampleAppsyncTable(input:{{ group: \"{0}\" path: \"{1}\" deleteTime: {2} }}){{ group path }} }} """.format(group, path, epocTime)) _client.execute(query) except Exception as e: logger.exception(e) raise e :
deleteTimeフィールドへ指定する値ですが、「エポック秒」で指定します。
は?って感じの人も多いと思いますが、「エポック秒」とはつまり「UNIX時間」のことです。
・・・は?(怒)って感じですよね。UNIX時間.wikiUNIX時間(ユニックスじかん)またはUNIX時刻(ユニックスじこく、UNIX time(ユニックスタイム)、POSIX time(ポジックスタイム))とはコンピューターシステム上での時刻表現の一種。UNIXエポック、すなわち協定世界時 (UTC) での1970年1月1日午前0時0分0秒から形式的な経過秒数(すなわち、実質的な経過秒数から、その間に挿入された閏秒を引き、削除された閏秒を加えたもの)として表される。GPS時刻などとは異なり、大多数のシステムでは、本当の経過秒数を表すものではない。さてエポック秒の詳細はほどほどにして、先ほどのプログラムを実行すると、DynamoDBの
deleteTimeフィールドに値が入っているのを確認しましょう。
この状態ではまだレコードは削除されません。DynamoDBのコンソールで、このフィールドに対して「有効期限 (TTL) 属性」の指定をする必要があります。
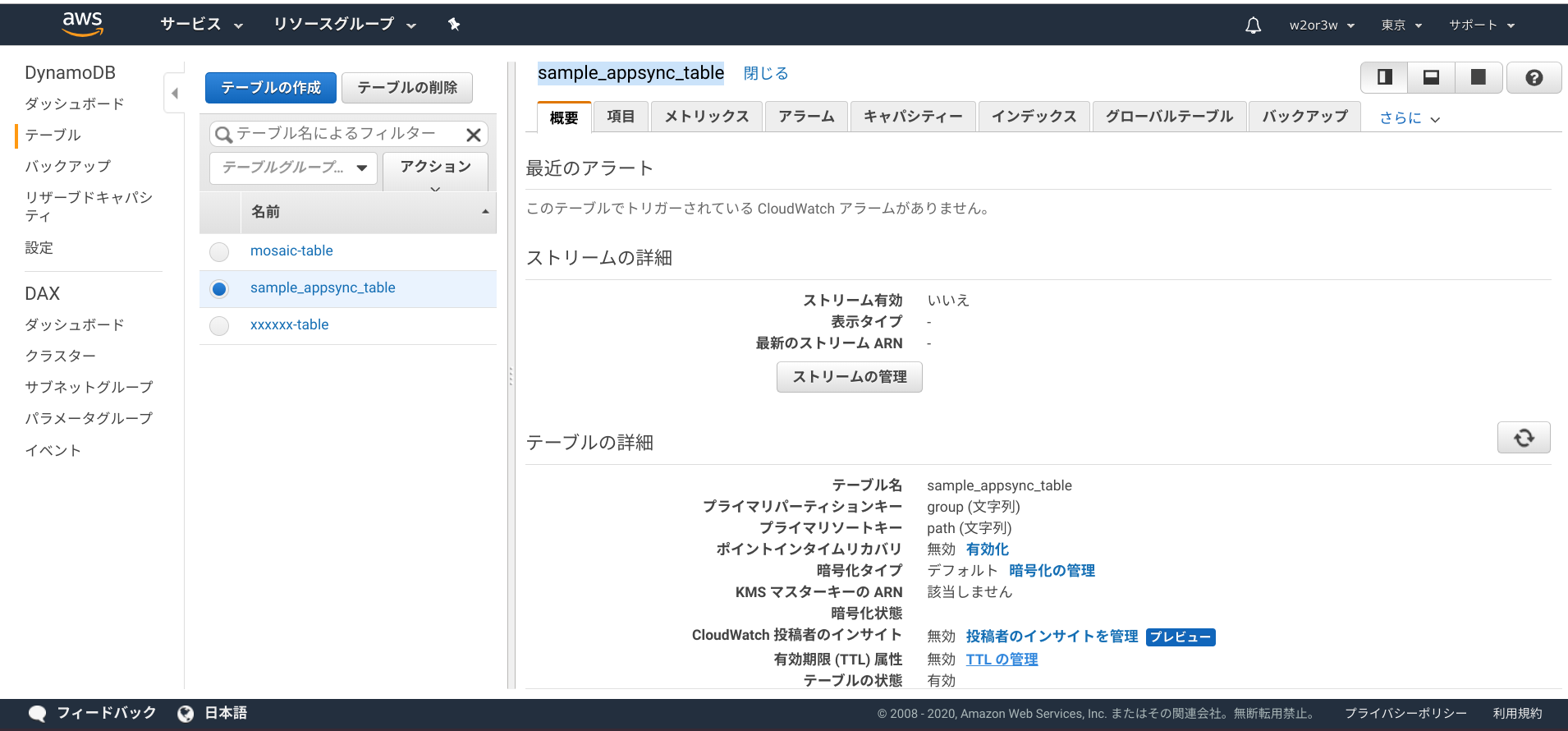
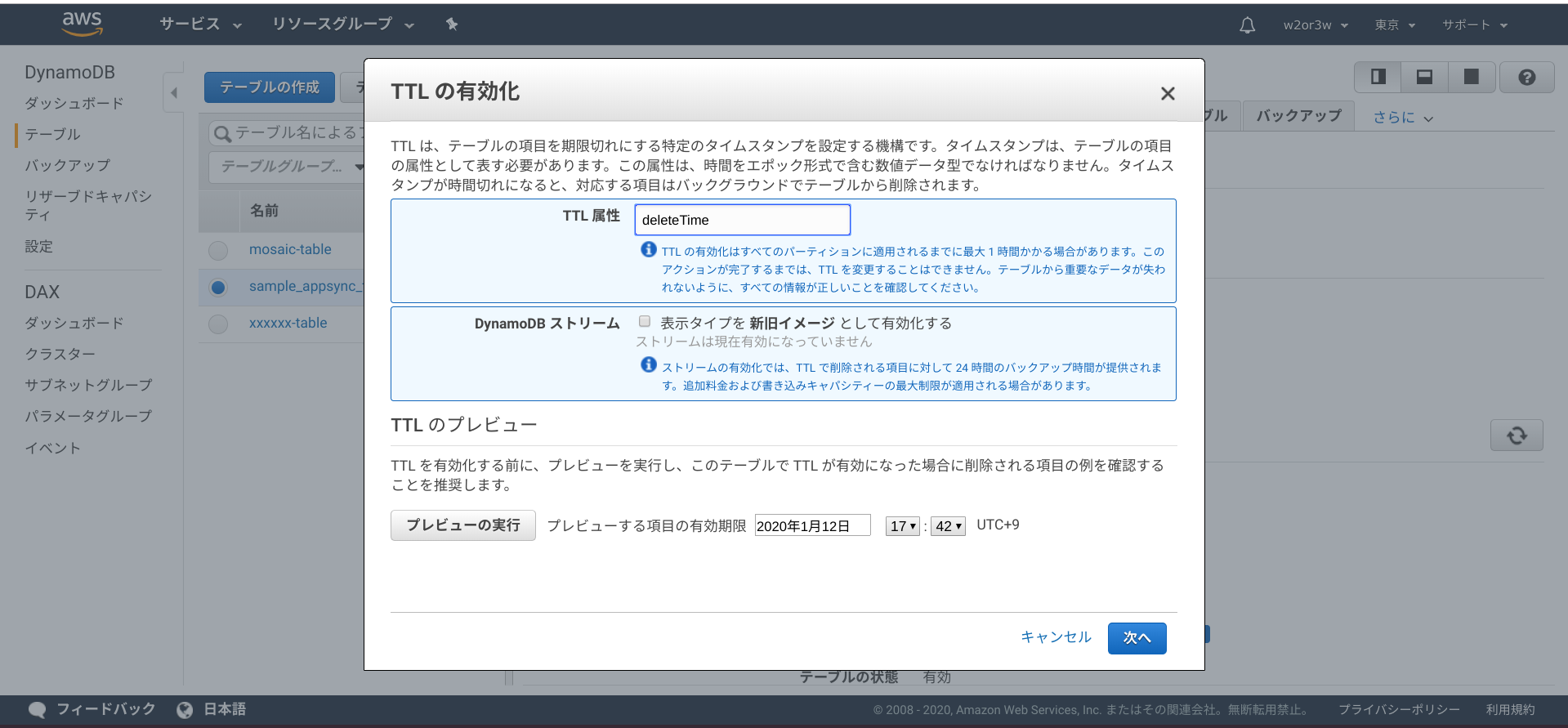
AWSコンソール > DynamoDB > テーブル > sample_appsync_table の概要タブで、「有効期限 (TTL) 属性」という項目が無効になっています。「TTLの管理」を選択してください。
TTL属性にフィールド名
deleteTimeを設定して次へ進みます。
これで設定完了なのですが、設定が反映されるまでに最大1時間かかるようです。
しばらく待ってから、テーブルの項目を見てみましょう。反映されると、指定したdeleteTimeフィールドに(TTL)というマークが付きます。
これで、deleteTimeに指定したエポック時間(から48時間以内)にレコードが自動的に削除されます。
あとがき
不要なものはどんどん削除しましょうというお話でしたが、それが許されるのであればどんどん積極的に削除してゆくべきですね。パフォーマンスや料金的にもメリットありますし、フロントからアクセスされる画像やそのパスなどはさっさと消えてくれたほうがプライバシー保護の観点からも望ましいですよね。
しかしDynamoDBのレコードは、テーブルに対して設定できるようになってくれるともっと使いやすいと思うんですけどねぇ。アプリが気にしなくて済む日を夢見ています。




- 投稿日:2020-01-12T17:40:52+09:00
(Python)AWSの請求金額を取得する
はじめに
AWS アカウントを取得したので、請求を管理したいと思う。
予定外の出費はできる事なら避けたい。
そこで、Python を使用して AWS の Cost Explorer から請求情報を取得する。環境
実行環境は以下
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.1 BuildVersion: 19B88 $ python --version Python 3.7.4API 仕様
- 合計請求額を表示する。
- 各サービスごとの詳細請求額を表示する。
- 請求金額取得対象期間は以下とする。
- START : API 実行日を含む月の1日
- END : API 実行日の前日
- API 実行日が1日だった場合、前月の請求額を表示する。
API 実行日と実行月の1日を取得する
datetimeパッケージを使用して以下のように実行日と実行月の1日を取得するメソッドを作成する。from datetime import datetime, timedelta, date # 実行月の1日を取得 def get_begin_of_month() -> str: return date.today().replace(day=1).isoformat() # 実行日を取得 def get_today() -> str: return date.today().isoformat()請求金額取得対象期間を取得する
前述したメソッドを用いて請求金額取得対象期間を返却するメソッドを作成する。
ただし、取得対象期間の START と END が同じ場合、 Cost Explorer の SDK に引数として設定できない。
そのため、取得対象期間の START と END が同じ場合は前月の1日から月末を返却するようにする。# 請求金額取得対象期間を取得 def get_total_cost_date_range() -> (str, str): start_date = get_begin_of_month() end_date = get_today() # get_cost_and_usage()のstartとendに同じ日付は指定不可のため、 # 「今日が1日」なら、「先月1日から今月1日(今日)」までの範囲にする if start_date == end_date: end_of_month = datetime.strptime(start_date, '%Y-%m-%d') + timedelta(days=-1) begin_of_month = end_of_month.replace(day=1) return begin_of_month.date().isoformat(), end_date return start_date, end_date合計請求額取得を取得する
SDK を用いて取得対象期間の合計請求額取得する。
import boto3 client = boto3.client('ce', region_name='us-east-1') # 合計請求額取得を取得 def get_total_billing(client) -> dict: (start_date, end_date) = get_total_cost_date_range() response = client.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ] ) return { 'start': response['ResultsByTime'][0]['TimePeriod']['Start'], 'end': response['ResultsByTime'][0]['TimePeriod']['End'], 'billing': response['ResultsByTime'][0]['Total']['AmortizedCost']['Amount'], }各サービスの詳細請求金額を取得する
合計請求額と同様に各サービスの詳細請求金額を取得する。
import boto3 client = boto3.client('ce', region_name='us-east-1') # 各サービスの詳細請求金額を取得 def get_service_billings(client) -> list: (start_date, end_date) = get_total_cost_date_range() #CostExplorer.Client.get_cost_and_usage response = client.get_cost_and_usage( TimePeriod={ 'Start': start_date, 'End': end_date }, Granularity='MONTHLY', Metrics=[ 'AmortizedCost' ], GroupBy=[ { 'Type': 'DIMENSION', 'Key': 'SERVICE' } ] ) billings = [] for item in response['ResultsByTime'][0]['Groups']: billings.append({ 'service_name': item['Keys'][0], 'billing': item['Metrics']['AmortizedCost']['Amount'] }) return billings作成した API を実行する。
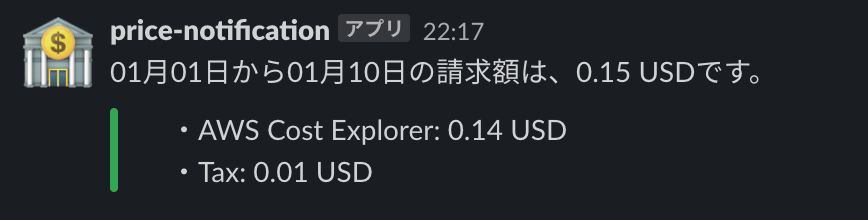
以下、実行結果。
{'start': '2020-01-01', 'end': '2020-01-12', 'billing': '0.44'} [ {'service_name': 'AWS Cost Explorer', 'billing': '0.4'}, {'service_name': 'AWS Key Management Service', 'billing': '0'}, {'service_name': 'AWS Lambda', 'billing': '0'}, {'service_name': 'Amazon API Gateway', 'billing': '0'}, {'service_name': 'Amazon DynamoDB', 'billing': '0'}, {'service_name': 'Amazon Simple Notification Service', 'billing': '0'}, {'service_name': 'Amazon Simple Storage Service', 'billing': '0'}, {'service_name': 'AmazonCloudWatch', 'billing': '0'}, {'service_name': 'Tax', 'billing': '0.04'} ]おわりに
この結果を Slack などに表示したいメッセージに加工し、こちらで作成したbotAPIに組み込む。
こんな感じに表示されるようになる。
- 投稿日:2020-01-12T16:01:54+09:00
AWSのセキュリティ
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
AWSの責任共有モデル
AWSの責任共有モデルとは
・AWSとユーザーが責任を負う部分が明確に分かれ、それぞれがセキュリティを共有して守っていくこと
クラウド本体のセキュリティ
・AWSが担当
クラウド内のセキュリティ
・ユーザが担当
・AWSが用意するセキュリティサービスを適切に活用して、ユーザはクラウド内のセキュリティを管理できるAWSクラウドのセキュリティ
AWSセキュリティの利点
データの保護
・すべてのデータは安全性が非常に高いAWSデータセンターに保存される
コンプライアンスの要件に準拠
・AWSでは、インフラストラクチャ内で多くのコンプライアンスプログラムを管理できる
・コンプライアンスの一部は最初から達成されているコスト削減
・AWSデータセンターを利用することでコストを削減できる
・ユーザが独自の施設を管理する必要がなく、最上位のセキュリティを維持できる迅速なスケーリング
・AWSクラウドの使用量にあわせてセキュリティをスケーリングできる
AWSが責任を持つ範囲の考え方
物理的なセキュリティ
・AWSのデータセンターのセキュリティの範囲はAWSが担当する
・環境レイヤー:
洪水、異常気象、地震といった環境的なリスクを軽減するために、データセンターの設置場所を選択
AWSの各リージョンにおけるデータセンター群は、互いにそれぞれ独立し、物理的に分離されて配置されている⇒自然災害が特定のデータセンター群に影響を与えたとしても、処理中のトラフィックを影響のある地域から自動的に移動できる
物理的な境界防御レイヤー:
保安要員、防御壁、侵入検知テクノロジー、監視カメラ、その他セキュリティ上の装置などインフラストラクチャレイヤー:
データセンターの建物、各種機器、およびそれらの運用にかかわるシステム
発電設備や冷暖房換気空調設備、消火設備などの機器や設備データレイヤー:
データを保持する唯一のエリア ⇒ 防御の観点で最もクリティカルなポイント
アクセスを制御し、各レイヤーにおいて特権を分離するハイパーバイザーのセキュリティの範囲
・AWSが担当する
・各インスタンスは別のインスタンスのメモリを読み取ることも、AWSハイパーバイザーのメモリを読み取ることもできない管理プレーンの保護
・ユーザが担当
・IDとパスワードの管理
・ユーザの責任
・権限の強いアカウントにはMFA(多要素認証)などを設定しアカウントの保護を行う
・ルートアカウント
・AWSサインアップ時に作成したメールアドレスのアカウント
・すべての操作をすることができる、ユーザが利用する最も権限の強いアカウント
・日常の操作には利用せず、適切な権限のみを付与したユーザを作成し、利用する
・キーペアの管理
・EC2などのインスタンスへのログインで利用する
・公開鍵認証方式を用いる
・キーペアの秘密鍵の管理はユーザの責任
・APIキーの管理
・コマンドライン操作をするCLIやプログラム上で利用する際に利用する
・アクセスキーとシークレットアクセスキーのペアで構成される
・権限の強いアカウントからはAPIキーは作成しない
・そのCLIで利用する範囲の権限や、プルグラム内で必要な権限のみを付与する
・環境変数や認証ファイルに書き出し、適切な権限づけを行い、定期的にAPIキーを入れ替えて運用するマネージドでないサービスのセキュリティ
・Amazon EC2やAmazon VPCなどIaaSのカテゴリーに分類されるAWSサービス
・ユーザが必要なセキュリティ設定と管理タスクをすべて実行する
・ユーザがオンプレミスのシステム上でこれまで実行してきたセキュリティタスクと基本的に同じマネージドなサービスのセキュリティ
・データベースサービスであるAmazon RDSやAmazon DynamoDBなど
・ユーザからは直接見えない(触ることのできない)部分のセキュリティ対応に関しては、AWSが行う
オペレーティングシステムやデータベースのパッチ適用、ファイアウォールの設定、災害対策といった基本的なセキュリティタスク
・ほとんどのマネージドサービスの場合、リソースのアクセスコントロールの設定と、アカウント認証情報の保護のみがユーザの責任範囲
・AWSがクラウドのインフラストラクチャの保護とメンテナンスを行うのに対し、ユーザはクラウド上に保存するあらゆるものを保護する責任を負う
・マネージドでないサービスより、ユーザのセキュリティに関する負担は軽減されるセキュリティのベストプラクティス
転送中データの保護
・適切なプロトコルおよび暗号化アルゴリズムを選択する
蓄積データの保護
・データベースへの登録時にアプリケーション上でデータの暗号化を行う
・コンプライアンス要件に従い暗号化を行う
・AWSの提供する暗号化オプションを活用するAWS資格情報の保護
・ユーザごとにIAMユーザを作成し、必要な業務内容や機能を実行するために必要な最小限の権限を付与する
アプリケーションの安全性の確保
・定期的な脆弱性診断と脆弱性情報の確認、青売りケーションの改善を行う
IAM
IAMとは
・「AWS Identify and Access Management」の頭文字をとったもの
・ユーザのAWSクラウドリソースへのアクセス管理サービス
・IAMを使用しることでAWSのユーザ(IAMユーザ)とグループ(IAMグループ)を作成および管理し、アクセス権を使用してAWSリソースへのアクセスを許可および拒否できる
・IAMユーザやIAMグループには、最初は権限が与えられていない ⇒ 必要最低限の権限を割り当てる
・アクセス権限は許可と拒否の設定を行うことができる
・IAMポリシーが相反するときは拒否が優先される
・1人のIAMユーザにつき、APIキーは最大2つまで発行できるIAMロール
・現在APIキーの利用は推奨されておらず、これを解決するためにIAMロールを利用する
・EC2やLambdaなどのAWSリソースに権限を付与することができる
・AWSの内部でIAMロールとEC2を直接紐付けることができるため、キーを管理する必要がないセキュリティグループ
セキュリティグループとは
・1つ以上のインスタンスのトラフィックを制御する仮想ファイアウォール
・各インスタンスごとに個別のファイアウォール設定を行える機能
・グループとして利用でき、同一の目的で利用するサーバ群に対して同一の設定を適用することも可能
・セキュリティグループの設定
・許可ルールの指定が可能
・拒否ルールの指定は不可能
・インバウンドトラフィックとアウトバウンドトラフィックのルールを個別に指定可能
・セキュリティグループを新規作成する際、インバウンドルールはない
⇒インバウンドルールをセキュリティグループに追加するまで、別のホストからインスタンスに送信されるインバウンドトラフィックは許可されない
・デフォルトではセキュリティグループにはすべてのアウトバウンドトラフィックを許可するアウトバウンドルールが含まれるAWS ShieldとAWS WAF
AWS Shieldとは
・マネージド型の分散サービス妨害(DDoS攻撃)に対する保護サービス
・AWSで実行しているWebアプリケーションを保護してくれる
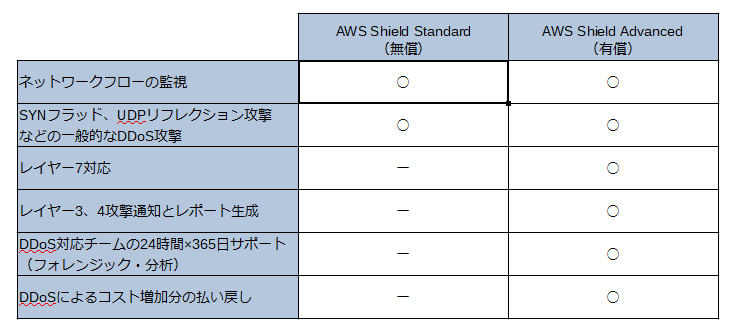
・AWS ShieldのStandardとAdvanced
・すべてのAWSユーザは追加料金なしでAWS Shield Standardの保護の適用を自動的に受けることができる
・AWS Shield Standardは一般的なDDoS攻撃からAWS上のシステムを保護する
・AWS Shield Advancedは、Standardに加えて、DDoS Response Teamによる緩和策を実施し、攻撃を可視化する
・AWS Shield Advancedは、AWS WAFサービスを無償で無制限に利用できる
AWS WAF
・アプリケーションの可用性低下、セキュリティの侵害、リソースの過剰消費などの一般的なWebの脆弱性からWebアプリケーションを保護する、マネージド型のWebアプリケーションファイアウォール
・ユーザからの入力を受け付けたり、リクエストに応じて動的なページを生成したりするタイプのWebサイトを不正な攻撃から守る役割を果たす
・データの中身をアプリケーションレベルで解析できる
・基本利用料は無料
・WAFの定義はユーザ自身で行う必要がある
・課金は、ユーザが作成するカスタマイズ可能なWebセキュリティルールの指定に基づいて行われる
・Webアクセスコントロールリスト(Web ACL)数に基づく課金方法
・Web ACLごとに追加するルール数に基づく課金方法
・受け取るWebリクエスト数に基づく課金方法AWS WAFの適用範囲
・CDNサービスのCloudFront、ロードバランサーのApplication Load Balancer、API GateWayから選択する
Inspector
・AWSのEC2上にデプロイされたアプリケーションのセキュリティとコンプライアンスを向上させるための、脆弱性診断を自動で行うことができるサービス
・自動的にアプリケーションを評価し、脆弱性やベストプラクティスからの逸脱がないかどうかの確認をする
・各種ルールパッケージはAWSが最新のものにアップデート
・スケジューリング設定により完全に自動でチェック可能

- 投稿日:2020-01-12T12:21:32+09:00
AWSに構築したWordPressのエラーページを変更してみた
はじめに
「AWSにWordPressを構築してみた」
「AWSに構築したWordPressに独自ドメインを割り当ててみた」
「AWSに構築したWordPressをhttps対応してみた」
の続き。構築した時に利用したWordPressのAMIがnginxを利用していたのでそれ用の設定。
とりあえずちょっと調べたところによると既にWordPressにはエラーページが用意されているみたい。
https://xxxxxxxxx/?error=404
こんな感じでアクセスするとエラーページが表示される。
でも今、適当なURLでアクセスするとnginx側の404ページが表示される。
なので、nginxで404を検知したらWordPressの404ページにリダイレクトする作戦でいく。サーバー側の設定
設定はすごく簡単。
# error_page....の行を追加 $ sudo vi /etc/nginx/conf.d/wordpres.conf _/_/_/_/_/_/_/_/_/_/_/_/_/_/ server { listen 80; server_name olafblog.org; error_page 403 404 500 503 =404 /?error=404; location / { if ($http_x_forwarded_proto = 'http'){ return 301 https://$host$request_uri; _/_/_/_/_/_/_/_/_/_/_/_/_/_/ # 再起動 $ sudo nginx -s reloadはい、完了。適当なURLでアクセスしてみる。
おk。うまくできた。お疲れ様でした。

- 投稿日:2020-01-12T11:49:22+09:00
はじめてAWSでデプロイする方法⑥(EC2サーバーにAppをクローンしてアップロード)
前回までの記事
はじめてAWSでデプロイする方法①(インスタンスの作成)
はじめてAWSでデプロイする方法②(Elastic IPの作成と紐付け)
はじめてAWSでデプロイする方法③(AWSセキュリティグループの設定)
はじめてAWSでデプロイする方法④(EC2インスンタンスにSSHログイン)
はじめてAWSでデプロイする方法⑤(EC2の環境構築、Ruby, MySQL)EC2インスタンス(サーバー)を作成し、パブリックIPをElastic IPで固定。
一般ユーザーがアクセスできるように、セキュリティグループの設定を追加(入り口を作成)
IDとPWを使って、EC2にログインして、環境構築をしました。ざっくり説明すると、こんなところです。
今回はWEB AppをEC2インスタンスにアップロードしていきます。
WEB AppをEC2にクローンする
現段階
EC2サーバにアプリケーションのコードをクローンしようとしてもpermission deniedとエラーが出てしまいます。
原因
Githubから見てこの許可していないEC2インスタンスを拒否する
対策
EC2インスタンスのSSH公開鍵をGithubに登録する。
SSH鍵をGithubに登録すると、Githubはそれを認証してクローンを許可をだす
作業
EC2サーバのSSH鍵ペアを作成
- EC2にログイン
- キーペア作成のためコマンドを入力
[ec2-user@ip-172-31-23-189 ~]$ ssh-keygen -t rsa -b 40963.下記が表示されるので、エンターを押す
Enter file in which to save the key (/home/ec2-user/.ssh/id_rsa):4.さらにエンターを押す(2回)
Enter passphrase (empty for no passphrase): Enter same passphrase again:これで下記の表示ができれば、成功してます。
Your identification has been saved in /home/ec2-user/.ssh/id_rsa. Your public key has been saved in /home/ec2-user/.ssh/id_rsa.pub. The key fingerprint is: 3a:8c:1d:d1:a9:22:c7:6e:6b:43:22:31:0f:ca:63:fa ec2-user@ip-172-31-23-189 The key's randomart image is: +--[ RSA 4096]----+ | + | | . . = | | = . o . | | * o . o | |= * S | |.* + . | | * + | | .E+ . | | .o | +-----------------+5.SSH公開鍵を表示し、値をコピーするため、下記コマンドを実装
[ec2-user@ip-172-31-23-189 ~]$ cat ~/.ssh/id_rsa.pub6.catで表示させた公開鍵(長いテキスト)をコピー
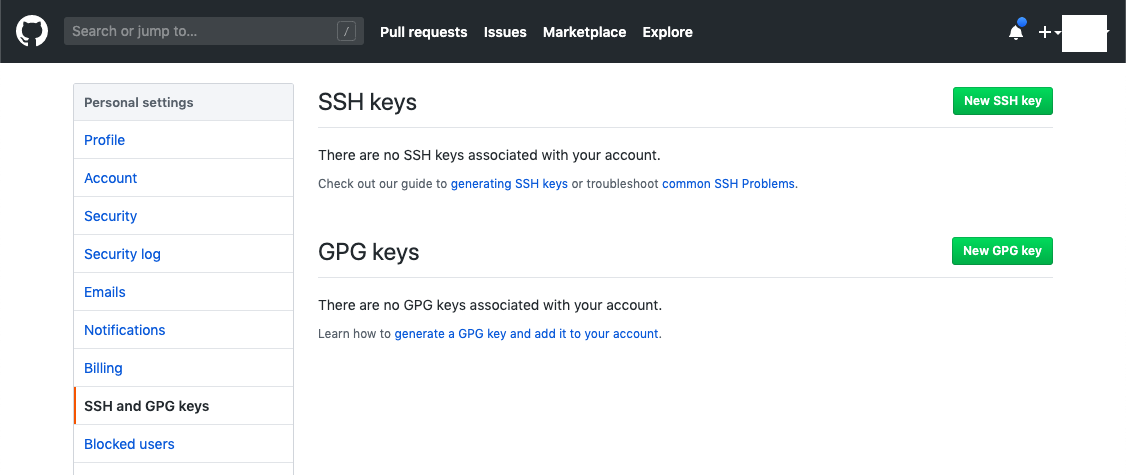
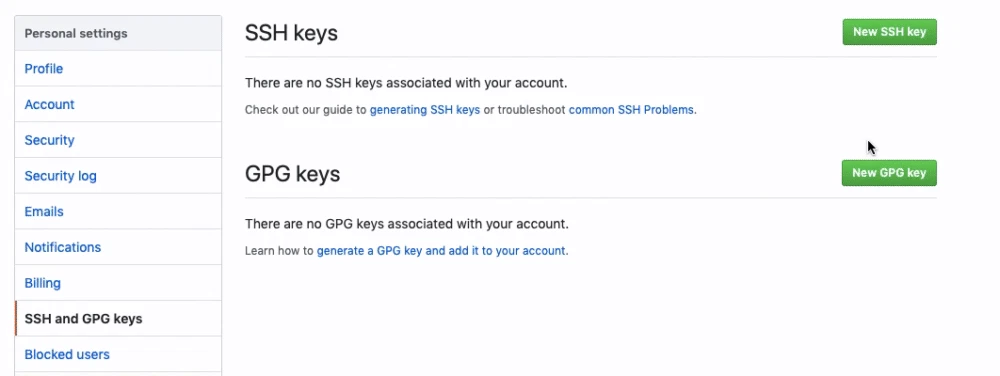
コピーした公開鍵をGithubにアクセスして登録する
2. 画面右上の緑色の『 NEW SSH KEY 』をクリック
3. タイトルを記入する(なんでも可能)
4. 公開鍵(ssh-rsaから)を貼り付け
エラー「Key is invalid. You must supply a key in OpenSSH public key format」が表示された場合、
貼り付けたコードに『 ssh-rsa 』が含まれているかご確認ください
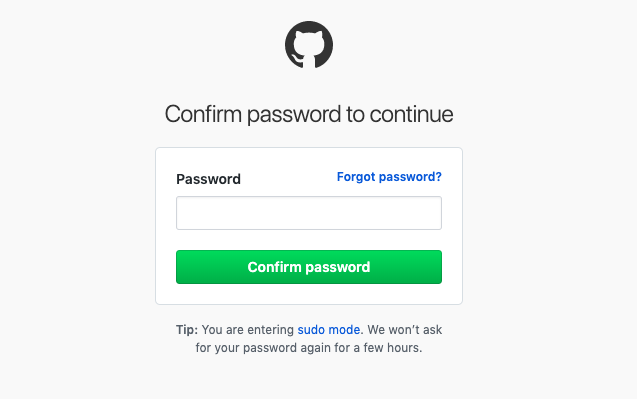
5. 『 Add SSH KEY 』をクリックして保存。
6. GithubのPWを入力
7. 完了
8. 登録できているか確認[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com下記の表示が出た場合: 『 yes 』を選択
The authenticity of host 'github.com (IP ADDRESS)' can't be established. RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48. Are you sure you want to continue connecting (yes/no)?この際に
Warning: Permanently added the RSA host key for IP address '52.111.11.11' to the list of known hosts.と表示された場合は, EC2に入り直しましょう。更新されたのでエラーなく入れます。
成功すると、下記の表示になるはずです。または、下記が表示された場合: 『 yes 』を選択
The authenticity of host 'github.com (IP ADDRESS)' can't be established. RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8. Are you sure you want to continue connecting (yes/no)?成功すると下記の表示が出る
[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com Hi <Githubユーザー名>! You've successfully authenticated, but GitHub does not provide shell access.App側でUnicornのインストール
EC2にGit クローンする前に、準備としてUnicornをインストールさせましょう
Gemfileにgem'unicorn'を追加Gemfile.group :production do gem 'unicorn', '5.4.1' endbundle installでインストール
$ bundle installconfig/unicorn.rbを作成
追加したunicorn.rbに下記を記述unicorn.rbapp_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endproduction.rbを開き、下記の記述をコメントアウトする
config/environments/production.rbconfig.assets.js_compressor = :uglifierconfig/environments/production.rb#config.assets.js_compressor = :uglifierアプリケーションの保存先となるディレクトリを作成
ディレクトリの作成
#/var/wwwディレクトリを作成(後述するCapistranoの初期値がwwwなので、ディレクトリをwwwに設定しています) [ec2-user@ip-172-31-23-189 ~]$ sudo mkdir /var/www/作成したディレクトリをchownコマンドで権限設定
#作成したwwwディレクトリの権限をec2-userに変更 [ec2-user@ip-172-31-23-189 ~]$ sudo chown ec2-user /var/www/作成したディレクトリに移行
[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/git clone でAppをEC2にダウンロード
GithubからGit cloneするためのリポジトリURLを取得
git clone で作成したディレクトリにappをクローン
[ec2-user@ip-172-31-23-189 www]$ git clone リポジトリURLGithubのアカウント名とPWを入力し、
ダウロードが開始されるremote: Enumerating objects: 298, done. remote: Counting objects: 100% (298/298), done. remote: Compressing objects: 100% (190/190), done. remote: Total 298 (delta 109), reused 274 (delta 86), pack-reused 0 Receiving objects: 100% (298/298), 58.53 KiB | 365.00 KiB/s, done. Resolving deltas: 100% (109/109), done.完了
これで、EC2にAppがクローンされています。
次回はEC2にgemをインストールと設定の変更





- 投稿日:2020-01-12T11:39:39+09:00
WordPressにGoogleAnalyticsを導入してみた
はじめに
「AWSにWordPressを構築してみた」
「AWSに構築したWordPressに独自ドメインを割り当ててみた」
「AWSに構築したWordPressをhttps対応してみた」
の続き。WordPressの準備は終わったので次はPVを確認するためにGoogleAnalyticsを導入していく。
設定
Googleアカウント作成
まずはじめにGoogleアカウントを作成する。
作り方は割愛。GoogleAnalyticsの設定
次にGoogleAnalyticsを設定する。
https://analytics.google.com/analytics/web/provision/?authuser=3#/provision
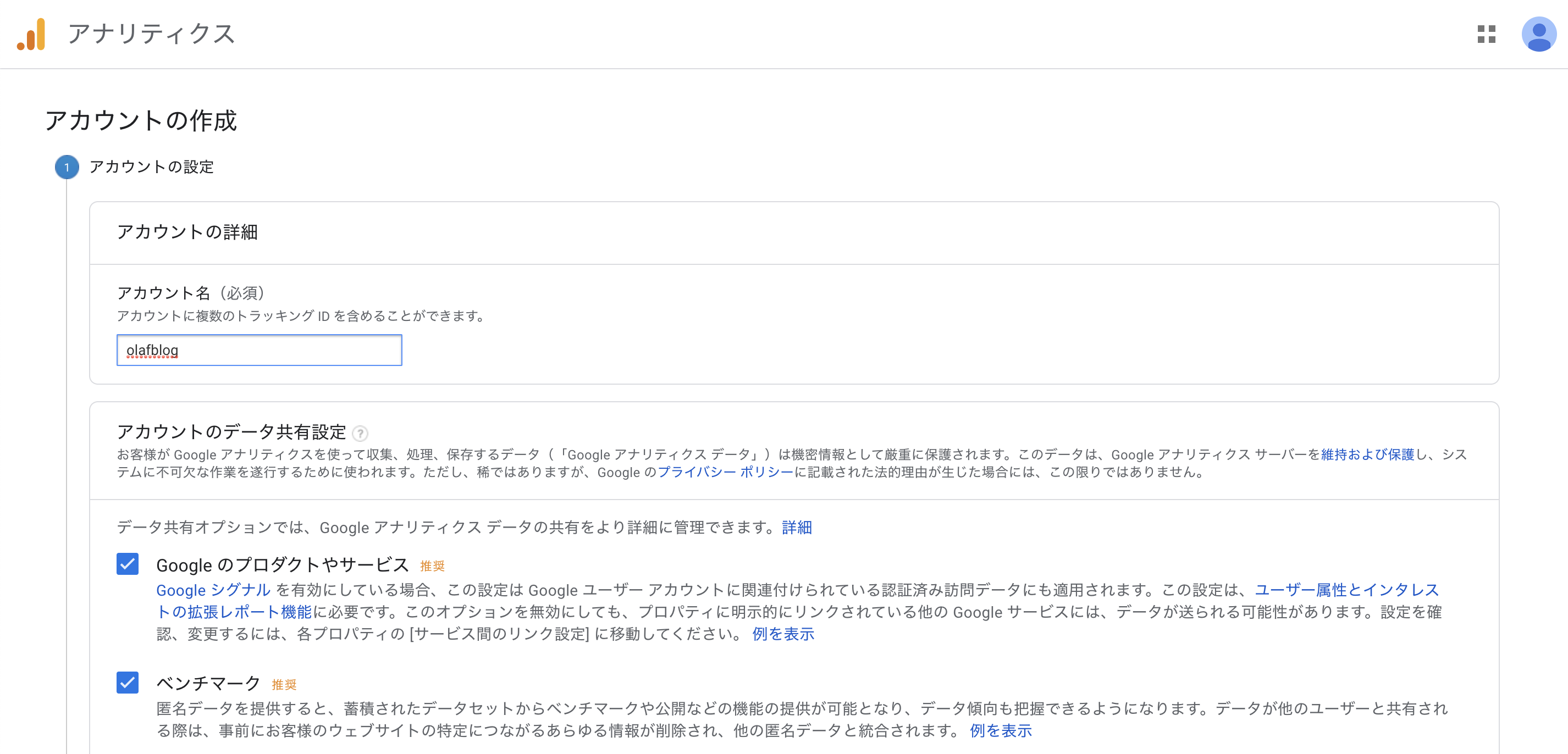
こちらにアクセスからの「無料で設定」をポチッ。
アカウント名を入力して「次へ」。
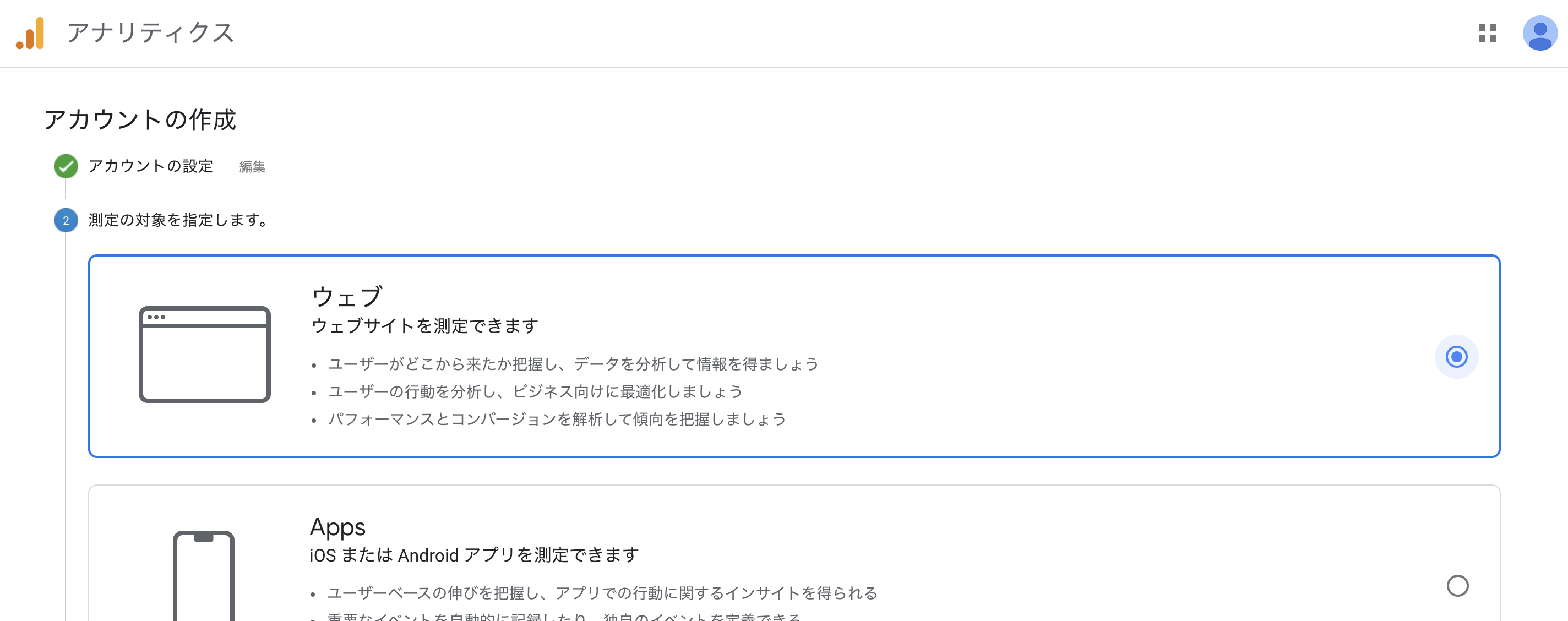
ウェブを選択して「次へ」。
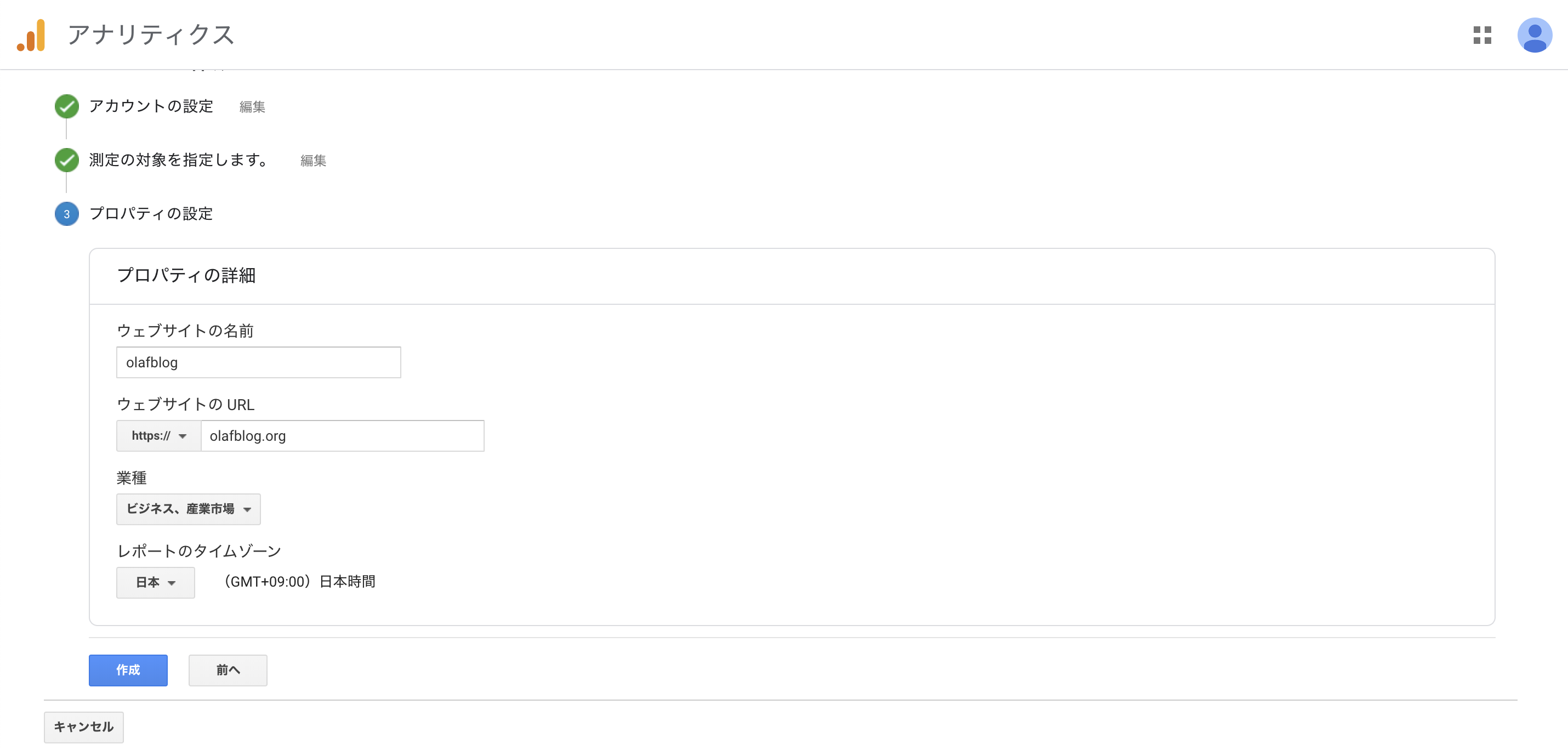
プロパティをそれぞれ入力して「作成」。
はい、終了。
「UA-」から始まるトラッキングIDが発行されるので一旦メモ。WordPressの設定
WordPressに便利なプラグインがあるらしいのでそれに頼る。
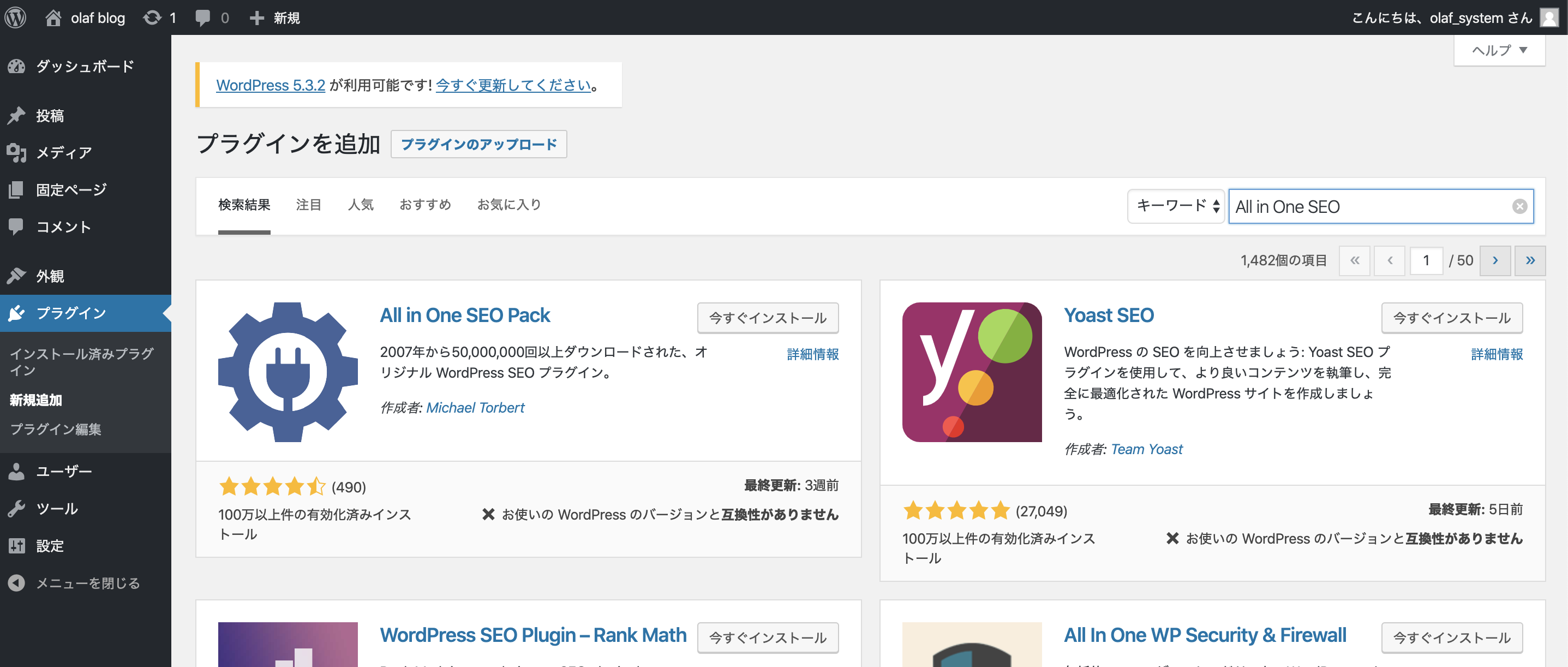
管理画面の「プラグイン」から「新規追加」。
「All in One SEO」
を検索して「いますぐインストール」からの「有効化」。
「お使いのWordPressのバージョンと互換性がありません」・・・。
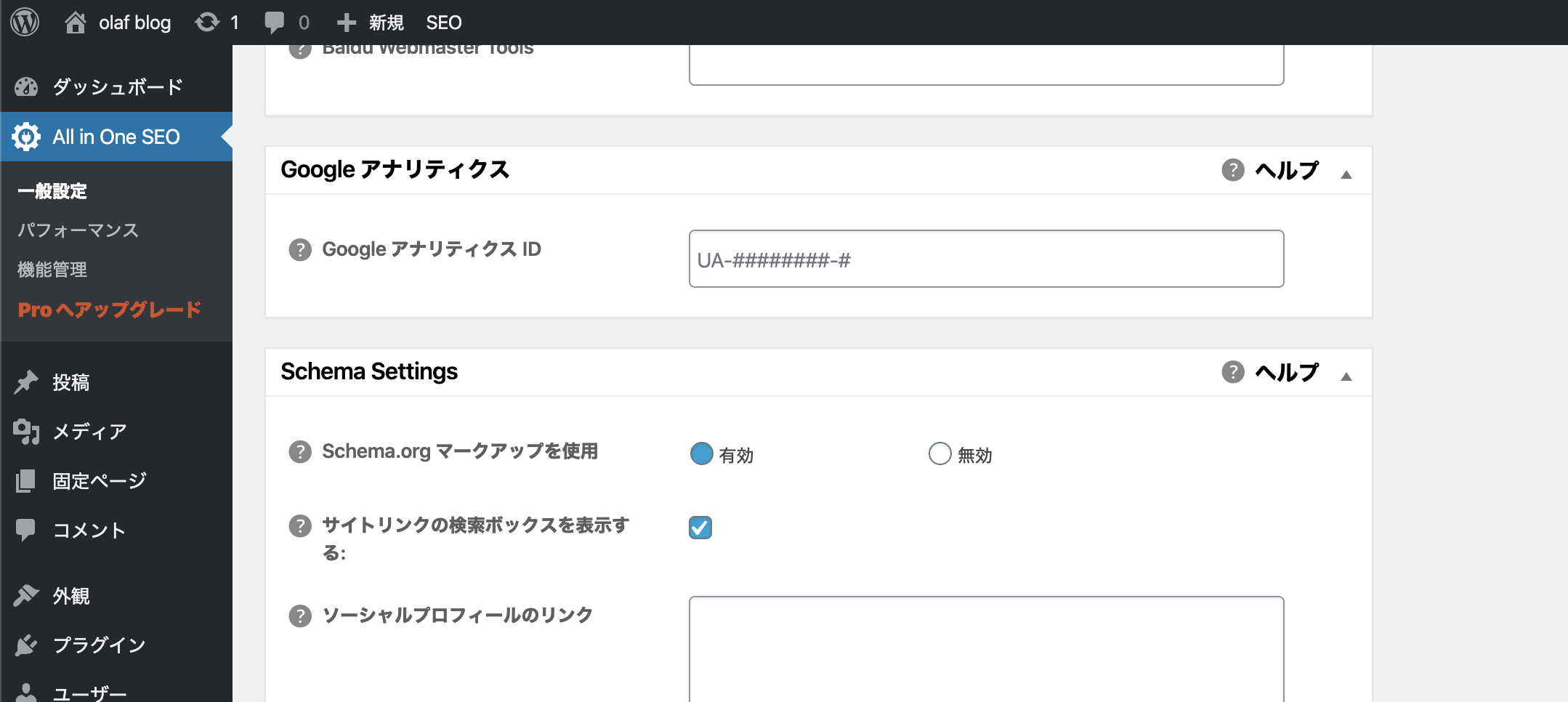
と、とりあえず有効化して見て様子みよか。Googleアナリティクスに先ほどのIDを入力して「更新」。
はい、完了!
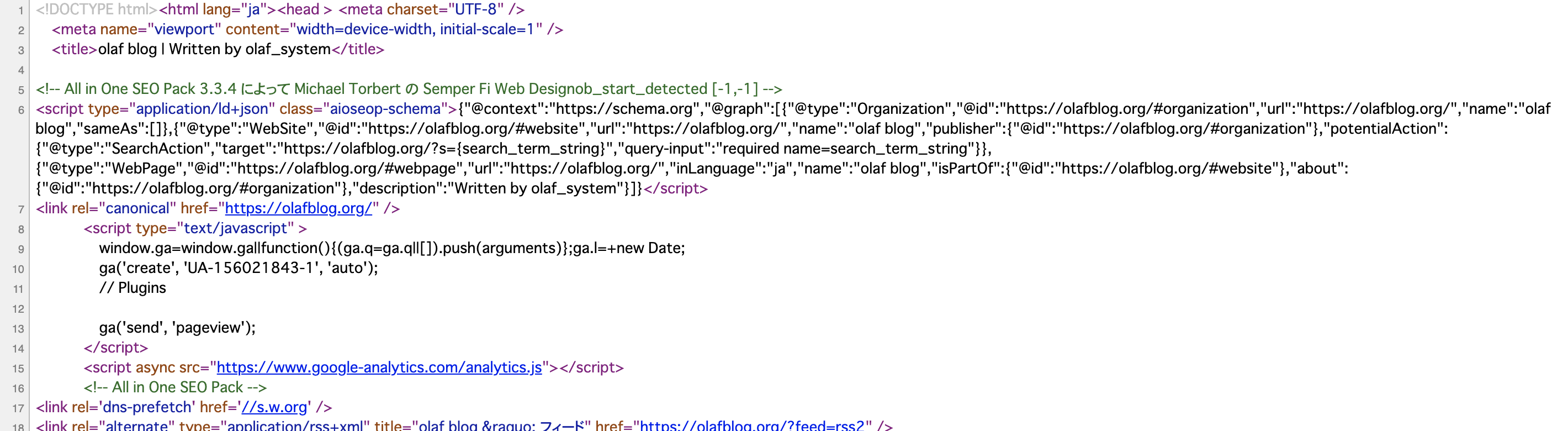
最後にトップページに戻って「ページのソースを表示」でコードが入っていることを確認。
うん、問題なさそう。お疲れ様でした。
- 投稿日:2020-01-12T09:08:40+09:00
APIGatewayにCognitoオーソライザーをSwaggerで設定する(CloudFrontも少し)
背景
AWS使ってサーバーレスで自分用の家計簿的なwebサービスを勉強も兼ねて開発中。メイン機能は大分出来てきて、あとは残課題の対応という形。前の記事でCognitoは対応していたが、フロント部分のみ。APIGateway部分にはCognito制御をしていない。せっかくCognito使ってるので、APIGateway側でも制御を入れたい。
まずAWS側設定
手法検討
色々ページを見ていると、CloudFormationでやっているケースあればSwaggerでやってるケースもあり。今回、API部分はSwaggerでやっているのでSwaggerで出来る部分はSwaggerでやりたい。
やってみた。
色々なページを参考にさせてもらうと、lambdaで認証しているケースが多い。世の中はlambdaで認証チェックするのが主流らしい。Cognitoでやろうという所はあまりないらしい。色々試してみたが、swagger書式でないとか言われたり、エラーは出なかったが、APIGatewayのオーソライザーのタブ見ても新規生成されていなかったり。階層やその表現を色々変えてやったが上手く行かず、手動でやってしまおうかとも考えた。が、結果的に以下の設定でAWSへの反映は出来た。
swaggerのオーソライザー定義部分# トップ階層(componentsセクション配下の方が良いのか?その場合はsecuritySchemes?) securityDefinitions: # このapi_keyは既存部分(Cognito使ったらもう要らないか?) api_key: type: "apiKey" name: "x-api-key" in: "header" # この名前を各メソッド設定で使用 myhomeAccountAuthorizer: type: "apiKey" # 認証に使うトークンを格納するヘッダーのキー name: "Authorization" # ここを変えたらヘッダー以外でも可能? in: "header" x-amazon-apigateway-authtype: "cognito_user_pools" x-amazon-apigateway-authorizer: type: cognito_user_pools # 999999999999はアカウントID、ap-northeast-1_hogehogeはCognitoユーザープールID providerARNs: - "arn:aws:cognito-idp:ap-northeast-1:999999999999:userpool/ap-northeast-1_hogehoge" identityValidationExpression: ".*"swaggerで各メソッドへオーソライザーを指定する部分例paths: /api/download: get: produces: - "application/json" parameters: # ・・中略・・ responses: # ・・中略・・ security: - api_key: [] # で使用したオーソライザーの名前を指定 - myhomeAccountAuthorizer: []AWSコンソール側でのオーソライザーテスト
成功すると、AWSコンソール側で、APIGateway => API => オーソライザーで、作成したオーソライザーが表示される。そこでオーソライザーのトークンテストが出来る。
今回、クライアント側ではVue.jsを使用している。javaScriptのawsライブラリ使用中。
session.getAccessToken().getJwtToken() で取得した値を入れてみたが、Unauthorized requestになってしまった。
session.getIdToken().getJwtToken()で取得した値を入れてみたら、AWSコンソール上でのテストは成功。
参考そしてクライアント側設定
もちろんAPIGateway側で認証設定をしたので何もしないとAPI実行で403エラーが返ってくる様になる。ヘッダにAuthorizerキーで、上記IDトークンを指定すればいいはず。開発環境で普通に成功した。
こんなヘッダ// key, idtokenは変数名 headers: { 'Content-Type': 'application/json', 'x-api-key': key, 'Authorization': idtoken }これで今まで通りに使える、と思っていたら、CloudFront経由のアクセス(本番)でうまく行かない。
ブラウザのResponseHeaderに出てたエラーx-amzn-errortype: UnauthorizedException x-amzn-requestid: ************ x-cache: Error from cloudfrontあ、CloudFrontからAPIGatewayに、ヘッダのAuthorizer情報渡ってない・・・
↓ですね。
【小ネタ】カスタム認証を使うAPI GatewayをCloudFrontの後ろに置いたらAPIを叩けなくなった
こちらの神ページを参考に、ヘッダキャッシュ制御の種別をwhitelist指定にして、Authorizerヘッダをwhitelistに追加する事により解消。CloudFrontまわりはCloudFormationでの構築しているのだが、該当部分は以下の形になった。
※この時、ついでに後で使うかもしれないヘッダーを幾つか追加してみたらアクセスエラーになった。使ってもないヘッダーは指定しない方がよさそう。CloudFrontのCloudFormationテンプレート該当部分CacheBehaviors: - TargetOriginId: ApiGatewayOrigin AllowedMethods: - GET - HEAD - OPTIONS - PUT - PATCH - POST - DELETE ForwardedValues: Cookies: Forward: all # ここを指定する事でwhitelist指定となる。 Headers: - Authorization QueryString: True ViewerProtocolPolicy: redirect-to-https SmoothStreaming: False Compress: True PathPattern: api/* MinTTL: 0 MaxTTL: 0 DefaultTTL: 0参考にさせてもらったページ
- AWS::ApiGateway::Authorizer
- AWS::CloudFront::Distribution Cookies
- AWS::CloudFront::Distribution ForwardedValues
- x-amazon-apigateway-authorizer オブジェクト
- ユーザープールのトークンの使用
- Cognitoから払い出されたIdTokenをAPI Gateway カスタムオーソライザーのLambda(Python3.6)で検証する方法
- AWS Cognitoにサインインしないと見れないLambdaを作る
- Amazon API Gateway の Custom Authorizer を使い、OAuth アクセストークンで API を保護する
- AWS APIGateway with Cognito Authorizer defined in OpenAPI Spec
- 【小ネタ】カスタム認証を使うAPI GatewayをCloudFrontの後ろに置いたらAPIを叩けなくなった
- Cognitoのサインイン時に取得できる、IDトークン・アクセストークン・更新トークンを理解する
- 投稿日:2020-01-12T05:52:47+09:00
EC2 拡張ネットワーキングとプレイスメントグループ
https://dev.classmethod.jp/cloud/aws/ec2-placement-group/
プレイスメントグループは、単一のアベイラビリティーゾーン内のインスタンスを論理的にグループ化したものです。サポートされているインスタンスタイプとともにプレイスメントグループを使用すると、アプリケーションが低レイテンシーの 10 Gbps (ギガビット/秒) ネットワークに参加できるようになります。
- 投稿日:2020-01-12T00:17:51+09:00
code-server オンライン環境篇 (7) git 上のcompose を EC2上に展開する
目次
ローカル環境篇 1日目
オンライン環境篇 1日目 作業環境を整備するオンライン環境篇 3日目 Boto3 で EC2 インスタンスを立ち上げる
オンライン環境篇 4日目 Code-Serverをクラウドで動かしてみる
オンライン環境篇 5日目 Docker 上で、code-server を立ち上げる
オンライン環境篇 7日目 git 上のcompose を EC2上に展開する
...
オンライン篇 .. Coomposeファイルで構築オンライン篇 .. K8Sを試してみる
...
魔改造篇
はじめに
前回までで、Docker を利用して、EC Instance 上に Code-Serverを立ち上げることができるようになりました。
今回は、github 上に、compose file から、EC2 Instance に立ち上げるまでをやってみます。
- 作成
- 停止
- 再開
- 削除
- 情報取得
新規の知識はないので、茶々っと作ってみてください。
汚くて良いと思います。成果物例
https://github.com/kyorohiro/advent-2019-code-server/tree/master/app/docker_image_uploader_for_ec2
$ git clone https://github.com/kyorohiro/advent-2019-code-server.git $ cd advent-2019-code-server/remote_cs04/ $ docker-compose build $ docker-compose up -dブラウザで、
http://127.0.0.1:8443/を開く。
Terminal 上で
Terminal$ pip install -r requirements.txt $ aws configure .. ..EC2Instance を 作成
$ python main.py --createEC2 情報を取得
$ python main.py --get >>>> i-0d1e7775a07bbb326 >>>> >>>> 3.112.18.33 >>>> ip-10-1-0-228.ap-northeast-1.compute.internal >>>> 10.1.0.228 >>>> {'Code': 16, 'Name': 'running'}ブラウザー でアクセス
できました!!
一時停止してみよう
$ python main_command.py --stopEC2 Insntace を止めてます。
利用料金を安く抑えることができます。
EBS の Storage の使用量などはかかります。再開してみよう
python main_command.py --start停止したものを再開できます。
IPアドレスが変わるので注意削除しよう
# ec2 instance から logout $ exit # local の code-server 上で $ python main.py --delete次回
EC2ベースにする場合、あとは、解説するようなものはなく、作り込むだけだと思います。
ここまで出来れば、
クラウド上に、VSCode(Code-Server) を配置することは、もう出来ると思います。VSCode に関係なく、 Docker Image 、 Composefile かした物なら何でも
クラウド上に置けますね。次回は K8S編 or Fargate編 に入ります。
今までは自作してきましたが、
ありものを利用して、アレコレしていきます。コード
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs06


- 投稿日:2020-01-12T00:00:46+09:00
golang で aws s3v4 の署名キーを作成する方法
aws s3v4 署名バージョン
aws s3 は version4 より署名プロセスが変わっています
https://docs.aws.amazon.com/ja_jp/general/latest/gr/signature-version-4.html署名作成の流れ
- 署名に必要なキーを作成する(本記事はここ)
- 1.で作成したキーを使って署名を作成する
各言語での署名キー作成方法
各言語の署名キー作成フローは以下の文書にまとまっています。しかしながら、
Java,.NET (C#),Python,Ruby,Javascriptのサンプルコードはあっても、Golangのサンプルコードは存在しません
https://docs.aws.amazon.com/ja_jp/general/latest/gr/signature-v4-examples.htmlそのため、本記事ではGolangで version4 用の署名取得処理のサンプルコードを載せることとします
ちなみにですが、本記事では署名キーを作成する部分の説明であり、署名作成のために前もって準備しておかなければならない処理が存在します。それについては、後日記事を執筆しようと思います。公式のサンプルを乗せて比較できるようにしていますが、さっさとGolangでの実装方法を知りたい人は、こちらから
署名に必要なキーを作成する(Java-公式サンプルコード)
公式のサンプルコードにならって説明します
言語は何でも良いのですが、Java を載せておきます
HmacSHA256はある文字列を、あるキー(byte配列)を使ってhash化する関数です
getSignatureKeyは特定の文字列をhash化して署名を得る処理です
ある文字列をハッシュ化した[]byteをキーとして、ハッシュを重ねていくことで、最終生成物の署名を得ることができます。
version4では、
- date
- region
- service
- s3のsecretキー
を使って署名を作成しますstatic byte[] HmacSHA256(String data, byte[] key) throws Exception { String algorithm="HmacSHA256"; Mac mac = Mac.getInstance(algorithm); mac.init(new SecretKeySpec(key, algorithm)); return mac.doFinal(data.getBytes("UTF-8")); } static byte[] getSignatureKey(String key, String dateStamp, String regionName, String serviceName) throws Exception { byte[] kSecret = ("AWS4" + key).getBytes("UTF-8"); byte[] kDate = HmacSHA256(dateStamp, kSecret); byte[] kRegion = HmacSHA256(regionName, kDate); byte[] kService = HmacSHA256(serviceName, kRegion); byte[] kSigning = HmacSHA256("aws4_request", kService); return kSigning; }署名に必要なキーを作成する(Golang)
package main import ( "crypto/hmac" "crypto/sha256" "encoding/hex" "fmt" ) func main() { s3Secretkey := "wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY" dateStamp := "20120215" regionName := "us-east-1" serviceName := "iam" signatureKey := getSignature(s3Secretkey, dateStamp, regionName, serviceName) fmt.Println(signatureKey) // f4780e2d9f65fa895f9c67b32ce1baf0b0d8a43505a000a1a9e090d414db404d } func getBinaryByMakeHMAC(msg string, key []byte) ([]byte, error) { mac := hmac.New(sha256.New, key) _, err := mac.Write([]byte(msg)) return mac.Sum(nil), err } func getSignature(s3SecretKey, dateStamp, regionName, serviceName string) string { kSecret := []byte("AWS4" + s3SecretKey) kDate, _ := getBinaryByMakeHMAC(dateStamp, kSecret) kRegion, _ := getBinaryByMakeHMAC(regionName, kDate) kService, _ := getBinaryByMakeHMAC(serviceName, kRegion) kSigning, _ := getBinaryByMakeHMAC("aws4_request", kService) return hex.EncodeToString(kSigning) }サンプルコード
https://play.golang.org/p/91EMyZsbvsx公式が用意している以下のサンプルデータの場合に、出力される値を確認しながら進めるとデバッグしやすいです
key = 'wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY' dateStamp = '20120215' regionName = 'us-east-1' serviceName = 'iam'署名キーを得るまでの中間値
kSecret = '41575334774a616c725855746e46454d492f4b374d44454e472b62507852666943594558414d504c454b4559' kDate = '969fbb94feb542b71ede6f87fe4d5fa29c789342b0f407474670f0c2489e0a0d' kRegion = '69daa0209cd9c5ff5c8ced464a696fd4252e981430b10e3d3fd8e2f197d7a70c' kService = 'f72cfd46f26bc4643f06a11eabb6c0ba18780c19a8da0c31ace671265e3c87fa' kSigning = 'f4780e2d9f65fa895f9c67b32ce1baf0b0d8a43505a000a1a9e090d414db404d'サンプルコードでこの中間値を得るためには、ハッシュ化した後の[]byteを
hex.EncodeToString([]byte)にて[]byteをhex(16進数)へと変換する必要があることに注意してください
- 投稿日:2020-01-12T00:00:46+09:00
golang で aws s3v4 の署名を作成する方法(署名キーを作成する方法)
aws s3v4 署名バージョン
aws s3 は version4 より署名プロセスが変わっています
https://docs.aws.amazon.com/ja_jp/general/latest/gr/signature-version-4.html署名作成の流れ
- 署名に必要なキーを作成する(本記事はここ)
- 1.で作成したキーを使って署名を作成する
各言語での署名キー作成方法
各言語の署名キー作成フローは以下の文書にまとまっています。しかしながら、
Java,.NET (C#),Python,Ruby,Javascriptのサンプルコードはあっても、Golangのサンプルコードは存在しません
https://docs.aws.amazon.com/ja_jp/general/latest/gr/signature-v4-examples.htmlそのため、本記事ではGolangで version4 用の署名取得処理のサンプルコードを載せることとします
ちなみにですが、本記事では署名キーを作成する部分の説明であり、署名作成のために前もって準備しておかなければならない処理が存在します。それについては、後日記事を執筆しようと思います。公式のサンプルを乗せて比較できるようにしていますが、さっさとGolangでの実装方法を知りたい人は、こちらから
署名に必要なキーを作成する(Java-公式サンプルコード)
公式のサンプルコードにならって説明します
言語は何でも良いのですが、Java を載せておきます
HmacSHA256はある文字列を、あるキー(byte配列)を使ってhash化する関数です
getSignatureKeyは特定の文字列をhash化して署名を得る処理です
ある文字列をハッシュ化した[]byteをキーとして、ハッシュを重ねていくことで、最終生成物の署名を得ることができます。
version4では、
- date
- region
- service
- s3のsecretキー
を使って署名を作成しますstatic byte[] HmacSHA256(String data, byte[] key) throws Exception { String algorithm="HmacSHA256"; Mac mac = Mac.getInstance(algorithm); mac.init(new SecretKeySpec(key, algorithm)); return mac.doFinal(data.getBytes("UTF-8")); } static byte[] getSignatureKey(String key, String dateStamp, String regionName, String serviceName) throws Exception { byte[] kSecret = ("AWS4" + key).getBytes("UTF-8"); byte[] kDate = HmacSHA256(dateStamp, kSecret); byte[] kRegion = HmacSHA256(regionName, kDate); byte[] kService = HmacSHA256(serviceName, kRegion); byte[] kSigning = HmacSHA256("aws4_request", kService); return kSigning; }署名に必要なキーを作成する(Golang)
package main import ( "crypto/hmac" "crypto/sha256" "encoding/hex" "fmt" ) func main() { s3Secretkey := "wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY" dateStamp := "20120215" regionName := "us-east-1" serviceName := "iam" signatureKey := getSignature(s3Secretkey, dateStamp, regionName, serviceName) fmt.Println(signatureKey) // f4780e2d9f65fa895f9c67b32ce1baf0b0d8a43505a000a1a9e090d414db404d } func getBinaryByMakeHMAC(msg string, key []byte) ([]byte, error) { mac := hmac.New(sha256.New, key) _, err := mac.Write([]byte(msg)) return mac.Sum(nil), err } func getSignature(s3SecretKey, dateStamp, regionName, serviceName string) string { kSecret := []byte("AWS4" + s3SecretKey) kDate, _ := getBinaryByMakeHMAC(dateStamp, kSecret) kRegion, _ := getBinaryByMakeHMAC(regionName, kDate) kService, _ := getBinaryByMakeHMAC(serviceName, kRegion) kSigning, _ := getBinaryByMakeHMAC("aws4_request", kService) return hex.EncodeToString(kSigning) }サンプルコード
https://play.golang.org/p/91EMyZsbvsx公式が用意している以下のサンプルデータの場合に、出力される値を確認しながら進めるとデバッグしやすいです
key = 'wJalrXUtnFEMI/K7MDENG+bPxRfiCYEXAMPLEKEY' dateStamp = '20120215' regionName = 'us-east-1' serviceName = 'iam'署名キーを得るまでの中間値
kSecret = '41575334774a616c725855746e46454d492f4b374d44454e472b62507852666943594558414d504c454b4559' kDate = '969fbb94feb542b71ede6f87fe4d5fa29c789342b0f407474670f0c2489e0a0d' kRegion = '69daa0209cd9c5ff5c8ced464a696fd4252e981430b10e3d3fd8e2f197d7a70c' kService = 'f72cfd46f26bc4643f06a11eabb6c0ba18780c19a8da0c31ace671265e3c87fa' kSigning = 'f4780e2d9f65fa895f9c67b32ce1baf0b0d8a43505a000a1a9e090d414db404d'サンプルコードでこの中間値を得るためには、ハッシュ化した後の[]byteを
hex.EncodeToString([]byte)にて[]byteをhex(16進数)へと変換する必要があることに注意してください