- 投稿日:2019-12-04T19:17:03+09:00
AWS SageMakerでTensorflow2.0のトレーニングジョブを実行する
はじめに
Tensorflow 2.0の正式版が2019/10/1にリリースされましたが、2019/12/04現在SageMakerのTensorflowのlatest versionは1.14です。このエントリでは、SageMakerのトレーニングコンテナを無理やりTensorflow 2.0対応させてトレーニングの実行を行わせることを目的としています。
SageMaker
SageMakerはAWSの提供する機械学習用のマネージド型サービスで、トレーニングジョブをコンテナで行うことで、リソースの最適化をすることができます。
SageMakerは大きく構築、トレーニング、デプロイの3機能に分かれますが、このエントリでは構築機能のノートブックを作成し、そこからTensorflow2.0に対応したトレーニングジョブを実行させます。
モデル
対象となるモデルはTensorflow2.0のチュートリアルにある、MNISTデータセットを対象としたシンプルなCNNです。
学習処理
Tensorflow2.0チュートリアルページにあるMNIST分類のためのシンプルなCNNをSageMakerを使ってトレーニングします。
学習処理は
script.pyという名前のファイルに記述し、実装部分はチュートリアルをそのまま流用します。本来であれば、訓練および評価用のデータセットをS3上に用意して
sagemaker.Tensorflow.estimatorに読み込ませる必要があるのですが、今回はkeras.datasetsにあるMNISTのデータセットをそのまま使っています。script.py# https://www.tensorflow.org/tutorials/images/cnn のほぼコピー import tensorflow as tf from tensorflow.keras import datasets, layers, models if __name__ == '__main__': (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) test_images = test_images.reshape((10000, 28, 28, 1)) train_images, test_images = train_images / 255.0, test_images / 255.0 model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5)このプログラムを使ったトレーニングジョブを実行するためのノートブックを用意します。
まずは
estimator作成などに必要なライブラリを読み込み、role情報をget_execution_role()から読み込みます。notebookimport os import numpy as np import pandas as pd import sagemaker from sagemaker import get_execution_role from sagemaker.tensorflow import TensorFlow sagemaker_session = sagemaker.Session() role = get_execution_role()次に
estimator.Tensorflowを使い、トレーニングジョブに必要な情報を登録するのですが、気を付ける点が2点あり、1つめはTensorflow 2.0のトレーニングをscript modeで実行するため、そのままだとトレーニング終了後にコンテナが破棄されてしまいます。これを防ぐため、トレーニング終了後にS3に学習済みモデルを出力する必要があります。
先ほどの
script.pyの最後にモデルの重みを保存するためのsave_weights()を追加します。script.py... model.fit(train_images, train_labels, epochs=args.epochs) model.save_weights(args.model_dir+'/model')モデルの保存先は
estimator.TensorFlowのhyperparametersで指定でき、script.pyではArgumentParser()を使って引数を受け取ります。script.pyparser = argparse.ArgumentParser() parser.add_argument('--epochs', type=int, default=30) parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR']) args, _ = parser.parse_known_args()2点目はtensorflow 2.0でトレーニングのために
script.py内でtensorflowのバージョンを2.0にアップグレードする必要があることで、そのためにはestimator.Tensorflowを通じて作成するトレーニングジョブ用コンテナのframework_versionを最新のもの(現時点では1.14.0)にする必要があります。notebookmodel_location = "s3://path/to/s3/cnn" estimator = TensorFlow(entry_point='cnn_train.py', role=role, framework_version='1.14.0', # バージョンを最新に hyperparameters={ 'epochs' : 10, 'model-dir' : model_location, # モデルの出力先を指定 }, train_instance_count=1, train_instance_type='ml.m5.xlarge', script_mode=True, py_version='py3')さらに
script.py内部でpipmainを使ってtensorflow2.0に強制的にアップグレードさせます。script.pyfrom pip._internal import main as pipmain pipmain(['install','tensorflow==2.0'])すべてまとめると
script.pyはこのような形になります。script.pyimport os import argparse from pip._internal import main as pipmain pipmain(['install','tensorflow==2.0']) import tensorflow as tf from tensorflow.keras import datasets, layers, models if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--epochs', type=int, default=30) parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR']) args, _ = parser.parse_known_args() (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) test_images = test_images.reshape((10000, 28, 28, 1)) train_images, test_images = train_images / 255.0, test_images / 255.0 model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=args.epochs) model.save_weights(args.model_dir+'/model')ここまでできたらノートブックから
estimator.fit()を実行します。notebookestimator.fit()しばらくするとトレーニングジョブ用のコンテナが立ち上がります。
2019-12-04 02:23:40 Starting - Starting the training job... 2019-12-04 02:23:42 Starting - Launching requested ML instances......... 2019-12-04 02:25:15 Starting - Preparing the instances for training... 2019-12-04 02:26:05 Downloading - Downloading input data...正常に処理が進むと、tensorflow2.0のアップグレードが始まります。
Collecting tensorflow==2.0 Downloading https://files.pythonhosted.org/packages/46/0f/7bd55361168bb32796b360ad15a25de6966c9c1beb58a8e30c01c8279862/tensorflow-2.0.0-cp36-cp36m-manylinux2010_x86_64.whl (86.3MB)途中でいくつかのライブラリでエラーになりますが、トレーニングジョブでawscliは使わないためそのまま処理を進めます。
ERROR: tensorboard 2.0.2 has requirement grpcio>=1.24.3, but you'll have grpcio 1.22.0 which is incompatible. ERROR: awscli 1.16.196 has requirement botocore==1.12.186, but you'll have botocore 1.12.198 which is incompatible. ERROR: awscli 1.16.196 has requirement PyYAML<=5.1,>=3.10; python_version != "2.6", but you'll have pyyaml 5.1.1 which is incompatible.アップグレードが完了すると、トレーニングが始まります。
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz #015 8192/11490434 [..............................] - ETA: 1s#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#01510838016/11490434 [===========================>..] - ETA: 0s#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#01511493376/11490434 [==============================] - 0s 0us/step Train on 60000 samplesトレーニングの進行具合はAWSコンソールのトレーニングジョブからも確認でき、CloudWatchで進行具合を見ることもできます。
ジョブが正常に完了するとS3にモデルが出力されます。
モデルの評価
作成したモデルをノートブックで復元します。
notebookmodel.load_weights('cnn/model')<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7fcbd658eeb8>精度を確認します。
notebooktest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print(test_acc)0.9906無事学習できているようです。
おわりに
SageMakerのトレーニングジョブ内で無理やりtensorflow 2.0にアップグレードすることで、トレーニングジョブをtensorflow 2.0に対応させることができます。
しかしながら、途中でERRORが出ていることからもわかるように、この方法がうまくいく保証はどこにもないため、AWSには一日も早くtensorflow 2.0に正式対応していただきたいです。



- 投稿日:2019-12-04T17:19:31+09:00
TensorFlow.jsを用いた画像認識をNode-REDで行う手順
こんにちは、(株)日立製作所 研究開発グループ サービスコンピューティング研究部の横井一仁です。
今回は、Node-REDからTensorFlow.jsを用いて画像認識を行うフローをご紹介します。Node-REDが動くPCのカメラ画像やアップロードした画像に、何が映っているか(例えば、人物、犬、車、瓶など)を判定させてみます。
Node-REDの事前設定
今回は簡単にTensorFlow.jsを利用するため、学習済みモデルが入ったTensorFlow.jsモジュールをNode-REDのfunctionノードから呼び出してみます。functionノードで外部のnpmモジュールを利用する手順は、Node-REDの日本語サイトの「追加モジュールのロード」のページが参考になります。
(1) npmモジュールをインストール
コマンドプロンプトを起動し、Node-REDのホームディレクトリ(Windowsの場合はC:\Users\<ユーザ名>\.node-red)にて外部npmモジュール「max-image-segmenter」をインストールします。
cd cd .node-red npm install @codait/max-image-segmenter@0.1.4執筆時点の最新バージョンであるv0.1.12は仕様が変わり以降の手順で動作しないため、旧バージョンのv0.1.4を指定してください。
(2) Node-REDの設定ファイルを編集
Node-REDのホームディレクトリ(Windowsの場合はC:\Users\<ユーザ名>\.node-red)の中にあるsettings.jsをテキストエディタで開き、216行目辺りのfunctionGlobalContextセクションの中に以下の定義を記載します。
functionGlobalContext: { imageSegmenter: require('@codait/max-image-segmenter') },これによってfunctionノードのグローバルコンテキスト経由で外部npmモジュールを呼び出すことができる様になります。
(3) Node-REDを起動
node-redコマンドでNode-REDを起動します。もし起動中の場合はCtrl+cで終了し、再度Node-REDを起動してください。
node-redNode-REDフローエディタ( http://<Node-REDのIPアドレス>:<ポート番号> )にアクセスすると、functionノード上でTensorFlow.jsモジュールを利用できる様になっています。
画像認識を行うフローを作成
(1) 必要なノードをインストール
Node-REDフローエディタから画像ファイルをアップロードしたり、カメラで撮影をしたりするため、node-red-contrib-browser-utilsモジュールをインストールします。Node-REDフローエディタの右上のメニューから「設定」->「パレット」->「ノードを追加」を選択し、検索窓に「node-red-contrib-browser-utils」と入力してインストールしてください。
(2) フローを作成
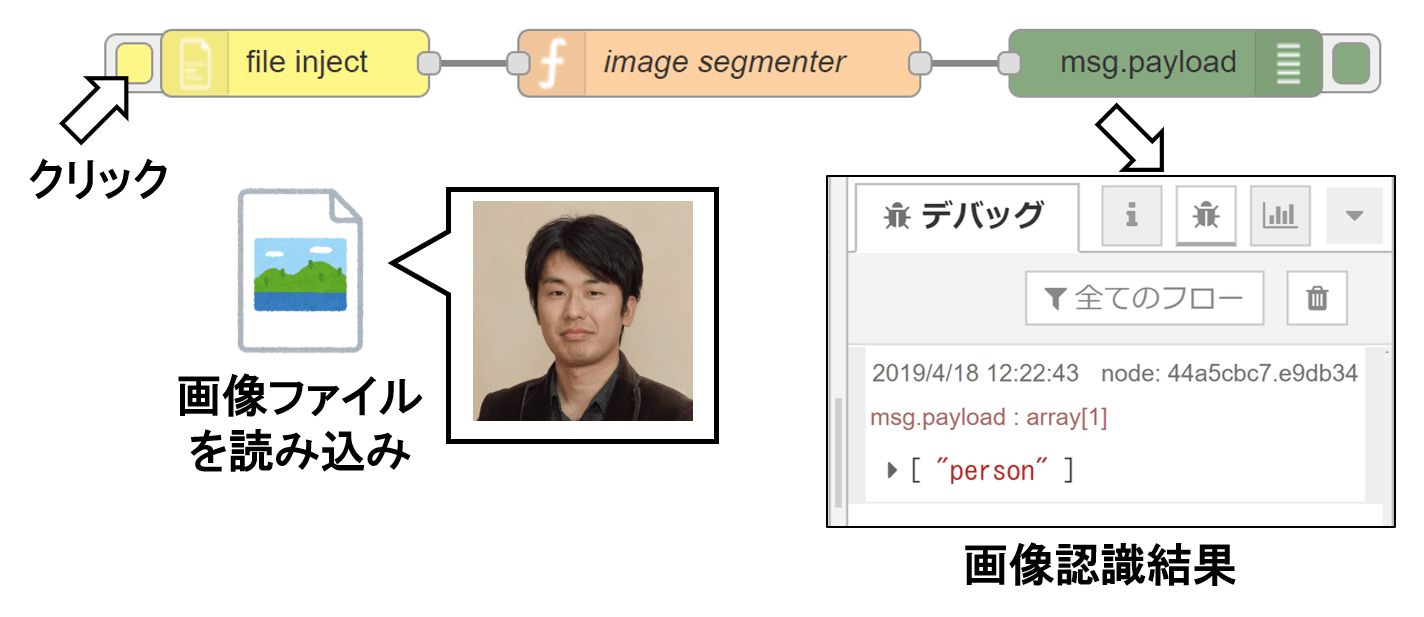
file injectノード、functionノード、debugノードをワークスペース上に配置し、順にワイヤーで接続します。
(3) functionノードにコードを記載
functionノードに下記のJavaScriptコードを記載します。このJavaScriptコードは、前のノードから受け取った画像のバイナリデータを外部npmモジュールに渡し、画像認識結果を後続のノードに渡す処理をしています。
- コード:
var imageSegmenter = global.get('imageSegmenter'); imageSegmenter.predict(msg.payload).then(function (response) { msg.payload = response.objectsDetected; node.send(msg); });
- 名前: image segmenter
functionノードをライブラリに登録する際のトラブルを避けるため、名前は英数字と空白を用いた方が良いです。
デプロイボタンを押した後、file injectノードの左側のボタンをクリックすると、画像ファイルをアップロードできるダイアログが表示されます。試しに、人物が写った画像をアップロードしてみると、デバッグタブに"person"と出力されました。
その他、犬や猫の画像をアップロードすると、正しく区別してデバックタブに"dog"や"cat"を出力してくれます。file injectノードの代わりにcameraノードを用いると、PCのカメラで撮影した画像を用いた画像認識もできますので、試してみてください。
最後に
この様にNode-REDを用いて簡単に画像認識アプリを開発できました。今回ご紹介した手順の様にTensorFlow.jsを用いることで、Node-REDが搭載されているラズパイ等のデバイス上でエッジ分析ができる様になります。TensorFlowコミュニティでは、様々なモデルが公開されていますので、ぜひNode-REDと連携して遊んでみてください。



- 投稿日:2019-12-04T00:19:21+09:00
Tensorflow 2.0で画像分類を試してみた
これまでPytorch/Chainerメインで開発をしていたが、Tensorflow 2.0はデフォルトでDefine-By-Runをサポートしいるため、この機会に試してみた。
Googleトレンドでの比較で見てわかる通り、2018年後半からPytorchの人気がかなり上昇している。
TF2.0がEager Execution Mode(Define-By-Run)をデフォルトでサポートした真意は不明だが、少なからずPytorchの追い上げに関連してそう...
今更ではあるが、、
Caffe/TheanoのようなDefine-and-Runは、モデルをコンパイル(静的グラフ)を構築した後に、データを流し込む。それに対して、Pytorch/Chainerに代表されるDefine-By-Runはデータを流し込むタイミングで動的に計算グラフを構築する。
Define-by-Runのメリットとしては、入力データ構造に対して柔軟に対応が可能であり、コードのデバッグが容易であるが、最適化が困難というデメリットがある。対して、Define-and-Runのメリットは、最適化が容易である反面、データ構造の変化に対応しづらいというデメリットがある。Define-by-Runについて、ある程度理解した上で、以下実際にコードに落とし込んでみる。
開発環境は画像データということもありローカルではさすがに時間が掛かるため、無料でGPU環境を提供しているGoogle Laboratryを使うことにした。
データは、Kaggleの以下データを使用
Chest X-Ray Images (Pneumonia):
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia①Google Driveに配置したデータを取得するために必要なライブラリをインポート
from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials import os②OAuth認証実行
auth.authenticate_user() gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth)③Google Driveデータダウンロード
def download_drive_data(save_folder, drive_folder_id): max_results = 100 if not os.path.exists(save_folder): os.makedirs(save_folder) query = "'{}' in parents and trashed=false".format(drive_folder_id) for file_list in drive.ListFile({'q': query, 'maxResults': max_results}): for file in file_list: if file['mimeType'] == 'application/vnd.google-apps.folder': download_drive_data(os.path.join(save_folder, file['title']), file['id']) else: file.GetContentFile(os.path.join(save_folder, file['title'])) download_drive_data(save_folder='*****', drive_folder_id="*****")③Tensorflow(GPU版)をインストール
!pip install tensorflow-gpu==2.0.0-rc1④必要ライブラリのインポート
import numpy as np %tensorflow_version 2.x import tensorflow as tf import cv2 import os from sklearn.model_selection import train_test_split from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, BatchNormalization, InputLayer from tensorflow.keras import Model from datetime import datetime⑤バージョン確認
print(tf.__version__) print(np.__version__) print(cv2.__version__) 2.0.0 1.17.4 3.4.3⑥GPUの使用するメモリ量を制限
physical_devices = tf.config.experimental.list_physical_devices('GPU') assert len(physical_devices) > 0, "Not enough GPU hardware devices available" tf.config.experimental.set_memory_growth(physical_devices[0], True)⑥前処理用クラス
今回使用する画像は、サイズが統一されていないため、統一したサイズにリサイズする。また、トレーニング用データを増やすため、30度ずつ画像をローテートしAugmentationを実行している。画像サイズに関しては、Google Colabのメモリ上限の都合上少し小さめにしている。
class PreProcess: def __init__(self): self.height = 64 self.width = 64 self.angle = 30 self.scale = 1.0 self.aug_cnt = 5 self.label_name_list = ['NORMAL', 'PNEUMONIA'] #画像リサイズ処理 def p_ps_img(self, file_path): for i, label_name in enumerate(self.label_name_list): if os.path.exists(file_path + str(i)) == False: os.mkdir(file_path + str(i)) print(file_path + str(i) + ' has been created.') files = os.listdir(file_path + label_name) for file in files: img = cv2.imread(file_path + label_name + '/' + file) risize_img = cv2.resize(img, dsize=(self.height, self.width)) rgb_img = cv2.cvtColor(risize_img, cv2.COLOR_BGR2RGB) if 'train' in file_path: int_angle = 0 for rotate_num in range(self.aug_cnt): int_angle += self.angle augmated_img = self.__aug_img(rgb_img, int_angle) cv2.imwrite(file_path + str(i) + '/' + file + '_' + str(rotate_num) + '.jpg', augmated_img) else: cv2.imwrite(file_path + str(i) + '/' + file, rgb_img) #画像データ読み込み def load_data(self, file_path): img_list = [] y_list = [] for label in range(2): files = os.listdir(file_path + str(label)) for file in files: img = cv2.imread(file_path + str(label) + '/' + file) img_list.append(img) y_list.append(label) return img_list, y_list #ローテート処理 def __aug_img(self, img, int_angle): size = (self.height, self.width) center = (int(size[0]/2), int(size[1]/2)) angle = int_angle scale = self.scale rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) rotated = cv2.warpAffine(img, rotation_matrix, size) return rotated⑦前処理実行
train_path = '/content/chest_xray/train/' test_path = '/content/chest_xray/test/' pre_ps = PreProcess() pre_ps.p_ps_img(train_path) pre_ps.p_ps_img(test_path)実際の前処理後の画像は以下のようになる。
⑧学習/テスト用データをロード
X_train_list, y_train_list = pre_ps.load_data(train_path) X_test_list, y_test_list = pre_ps.load_data(test_path)⑨Numpy配列に変換
X_train, y_train, X_test, y_test = np.array(X_train_list), np.array(y_train_list), np.array(X_test_list), np.array(y_test_list)⑩入力データの正規化
X_train, X_test = X_train / 255.0, X_test / 255.0⑪ミニバッチ作成
train_ds = tf.data.Dataset.from_tensor_slices( (X_train, y_train)).shuffle(X_train.shape[0]).batch(64) test_ds = tf.data.Dataset.from_tensor_slices( (X_test, y_test)).shuffle(X_test.shape[0]).batch(64)⑫ネットワーク層(CNN)
オブジェクト指向型な記載方法をサポートしており、Pytorch/Chainerに慣れている人にとってはとっつきやすい。
tensorflow.keras.Modelを継承しており、Pytorchで言えばnn.Moduleに該当する。
データを入力したタイミングでcallメソッドが呼び出される。class cnnModel(Model): def __init__(self, width, height, channel, batch_size, output_dim): super(cnnModel, self).__init__() self.inlayer = InputLayer(input_shape=(width, height, channel), batch_size=batch_size) self.conv1 = Conv2D(32, 3, activation='relu') self.conv2 = Conv2D(64, 3, activation='relu') self.pool1 = MaxPool2D(pool_size=(2, 2)) self.btnorm1 = BatchNormalization() self.conv3 = Conv2D(128, 3, activation='relu') self.conv4 = Conv2D(256, 3, activation='relu') self.pool2 = MaxPool2D(pool_size=(2, 2)) self.btnorm2 = BatchNormalization() self.conv5 = Conv2D(512, 3, activation='relu') self.conv6 = Conv2D(512, 3, activation='relu') self.pool3 = MaxPool2D(pool_size=(2, 2)) self.btnorm3 = BatchNormalization() self.flatten = Flatten() self.d1 = Dense(1024, activation='relu') self.do1 = Dropout(0.2) self.d2 = Dense(64, activation='relu') self.do2 = Dropout(0.2) self.d3 = Dense(output_dim, activation='softmax') def call(self, x): x = self.inlayer(x) x = self.conv1(x) x = self.conv2(x) x = self.pool1(x) x = self.btnorm1(x) x = self.conv3(x) x = self.conv4(x) x = self.pool2(x) x = self.btnorm2(x) x = self.conv5(x) x = self.conv6(x) x = self.pool3(x) x = self.btnorm3(x) x = self.flatten(x) x = self.d1(x) x =self.do1(x) x = self.d2(x) x =self.do2(x) return self.d3(x)⑬学習/予測/評価クラス
デフォルトでは、Eager Executionとして実行されるが、バッチごとに計算グラフを構築するため、パフォーマンス観点からは、あまり好ましくない。そのため、学習/予測実行関数に対しては、アノテーションに@tf.functionを付与し、Graph Modeで実行(静的グラフにコンパイル)することでパフォーマンス上の問題を改善できる。
また、エポック毎にチェックポイントを生成し、次回学習時に前回学習終了時点のパラメータを復元できるようにした。
TFのチェックポイントの仕組みとしては、変数をロードされたオブジェクトから始めて、名前付けられたエッジ(オブジェクトの属性)を持つ有向グラフを辿ることによりチェックポイントされた値に合わせる。
tf.train.Checkpoint オブジェクト上の restore() 呼び出しは要求された復元をキューに入れて、Checkpoint オブジェクトから一致するパスがあった場合に変数値を復元する。つまり、定義したモデルから単にカーネルをネットワークと層を通してそれへのパスを再構築することによりパラメータを復元する。
class Trainer: def __init__(self, model): self.model = model #誤差/最適化関数 lr = 1e-4 self.loss_object = tf.keras.losses.SparseCategoricalCrossentropy() self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr) #評価関数 self.train_loss = tf.keras.metrics.Mean(name='train_loss') self.train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy') self.test_loss = tf.keras.metrics.Mean(name='test_loss') self.test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy') max_keep = 10 self.chk_point_path = './tf_ckpts' self.ckpt = tf.train.Checkpoint(step=tf.Variable(1), optimizer=self.optimizer, model=self.model) self.manager = tf.train.CheckpointManager(self.ckpt, self.chk_point_path, max_to_keep=max_keep) #学習実行関数(グラフモード) @tf.function def train_step(self, image, label): with tf.GradientTape() as tape: predictions = self.model(image) loss = self.loss_object(label, predictions) gradients = tape.gradient(loss, self.model.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.model.trainable_variables)) self.train_loss(loss) self.train_accuracy(label, predictions) #検証実行関数(グラフモード) @tf.function def test_step(self, image, label): predictions = self.model(image) t_loss = self.loss_object(label, predictions) self.test_loss(t_loss) self.test_accuracy(label, predictions) #学習/予測/評価実行 def train_test_fn(self, epochs, train_ds, test_ds): #既存チェックポイントからのリストア self.ckpt.restore(self.manager.latest_checkpoint) if self.manager.latest_checkpoint: print("チェックポイント {} をリストア...".format(self.manager.latest_checkpoint)) else: print("チェックポイントが存在しないため、初期状態からの学習...") for epoch in range(epochs): for image, label in train_ds: self.train_step(image, label) for test_image, test_label in test_ds: self.test_step(test_image, test_label) if (epoch + 1) % 1 == 0: template = 'Epoch {}, Loss: {:.5f}, Accuracy: {:.5f}, Test Loss: {:.5f}, Test Accuracy: {:.5f}' print (template.format(epoch+1, self.train_loss.result(), self.train_accuracy.result()*100, self.test_loss.result(), self.test_accuracy.result()*100)) #エポック毎にチェックポイント保存 self.ckpt.step.assign_add(1) if int(self.ckpt.step) % 1 == 0: save_path = self.manager.save() print("チェックポイントを保存: {}".format(int(self.ckpt.step), save_path))⑭モデルの初期化
cnn_model = cnnModel(X_train.shape[1], X_train.shape[2], X_train.shape[3], batch_size=32, output_dim=2)⑮学習/評価
trainer = Trainer(cnn_model) trainer.train_test_fn(epochs=3, train_ds=train_ds, test_ds=test_ds) チェックポイントが存在しないため、初期状態からの学習... Epoch 1, Loss: 0.23452, Accuracy: 89.93098, Test Loss: 0.36582, Test Accuracy: 85.41667 チェックポイントを保存: 2 Epoch 2, Loss: 0.17365, Accuracy: 92.79333, Test Loss: 0.35779, Test Accuracy: 85.09615 チェックポイントを保存: 3 Epoch 3, Loss: 0.14549, Accuracy: 94.07976, Test Loss: 0.35449, Test Accuracy: 85.04273 チェックポイントを保存: 4 Epoch 4, Loss: 0.12709, Accuracy: 94.90222, Test Loss: 0.40183, Test Accuracy: 82.97276 チェックポイントを保存: 5 Epoch 5, Loss: 0.11380, Accuracy: 95.47240, Test Loss: 0.40445, Test Accuracy: 83.30128 チェックポイントを保存: 6



- 投稿日:2019-12-04T00:19:21+09:00
Tensorflow 2.0で画像分類器を実装してみた
これまでPytorch/Chainerメインで開発をしていたが、Tensorflow 2.0はデフォルトでDefine-By-Runをサポートしいるため、この機会に試してみた。
Googleトレンドでの比較で見てわかる通り、2018年後半からPytorchの人気がかなり上昇している。
TF2.0がEager Execution Mode(Define-By-Run)をデフォルトでサポートした真意は不明だが、少なからずPytorchの追い上げに関連してそう...
今更ではあるが、、
Caffe/TheanoのようなDefine-and-Runは、モデルをコンパイル(静的グラフ)を構築した後に、データを流し込む。それに対して、Pytorch/Chainerに代表されるDefine-By-Runはデータを流し込むタイミングで動的に計算グラフを構築する。
Define-by-Runのメリットとしては、入力データ構造に対して柔軟に対応が可能であり、コードのデバッグが容易であるが、最適化が困難というデメリットがある。対して、Define-and-Runのメリットは、最適化が容易である反面、データ構造の変化に対応しづらいというデメリットがある。Define-by-Runについて、ある程度理解した上で、以下実際にコードに落とし込んでみる。
開発環境は画像データということもありローカルではさすがに時間が掛かるため、無料でGPU環境を提供しているGoogle Laboratryを使うことにした。
データは、Kaggleの以下データを使用
Chest X-Ray Images (Pneumonia):
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia①Google Driveに配置したデータを取得するために必要なライブラリをインポート
from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials import os②OAuth認証実行
auth.authenticate_user() gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth)③Google Driveデータダウンロード
def download_drive_data(save_folder, drive_folder_id): max_results = 100 if not os.path.exists(save_folder): os.makedirs(save_folder) query = "'{}' in parents and trashed=false".format(drive_folder_id) for file_list in drive.ListFile({'q': query, 'maxResults': max_results}): for file in file_list: if file['mimeType'] == 'application/vnd.google-apps.folder': download_drive_data(os.path.join(save_folder, file['title']), file['id']) else: file.GetContentFile(os.path.join(save_folder, file['title'])) download_drive_data(save_folder='*****', drive_folder_id="*****")③Tensorflow(GPU版)をインストール
!pip install tensorflow-gpu==2.0.0-rc1④必要ライブラリのインポート
import numpy as np %tensorflow_version 2.x import tensorflow as tf import cv2 import os from sklearn.model_selection import train_test_split from tensorflow.keras.layers import Dense, MaxPool2D, Dropout, BatchNormalization, InputLayer, GlobalAveragePooling2D, SeparableConv2D from tensorflow.keras import Model⑤バージョン確認
print(tf.__version__) print(np.__version__) print(cv2.__version__) 2.0.0 1.17.4 3.4.3⑥GPUの使用するメモリ量を制限
physical_devices = tf.config.experimental.list_physical_devices('GPU') assert len(physical_devices) > 0, "Not enough GPU hardware devices available" tf.config.experimental.set_memory_growth(physical_devices[0], True)⑥前処理用クラス
今回使用する画像は、サイズが統一されていないため、統一したサイズにリサイズする。また、トレーニング用データを増やすため、30度ずつ画像をローテートしAugmentationを実行している。画像サイズに関しては、Google Colabのメモリ上限の都合上少し小さめにしている。
class PreProcess: def __init__(self): self.height = 64 self.width = 64 self.angle = 30 self.scale = 1.0 self.aug_cnt = 5 self.label_name_list = ['NORMAL', 'PNEUMONIA'] #画像リサイズ処理 def p_ps_img(self, file_path): for i, label_name in enumerate(self.label_name_list): if os.path.exists(file_path + str(i)) == False: os.mkdir(file_path + str(i)) print(file_path + str(i) + ' has been created.') files = os.listdir(file_path + label_name) for file in files: img = cv2.imread(file_path + label_name + '/' + file) risize_img = cv2.resize(img, dsize=(self.height, self.width)) rgb_img = cv2.cvtColor(risize_img, cv2.COLOR_BGR2RGB) if 'train' in file_path: int_angle = 0 for rotate_num in range(self.aug_cnt): int_angle += self.angle augmated_img = self.__aug_img(rgb_img, int_angle) cv2.imwrite(file_path + str(i) + '/' + file + '_' + str(rotate_num) + '.jpg', augmated_img) else: cv2.imwrite(file_path + str(i) + '/' + file, rgb_img) #画像データ読み込み def load_data(self, file_path): img_list = [] y_list = [] for label in range(2): files = os.listdir(file_path + str(label)) for file in files: img = cv2.imread(file_path + str(label) + '/' + file) img_list.append(img) y_list.append(label) return img_list, y_list #ローテート処理 def __aug_img(self, img, int_angle): size = (self.height, self.width) center = (int(size[0]/2), int(size[1]/2)) angle = int_angle scale = self.scale rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale) rotated = cv2.warpAffine(img, rotation_matrix, size) return rotated⑦前処理実行
train_path = '/content/chest_xray/train/' test_path = '/content/chest_xray/test/' pre_ps = PreProcess() pre_ps.p_ps_img(train_path) pre_ps.p_ps_img(test_path)実際の前処理後の画像は以下のようになる。
⑧学習/テスト用データをロード
X_train_list, y_train_list = pre_ps.load_data(train_path) X_test_list, y_test_list = pre_ps.load_data(test_path)⑨Numpy配列に変換
X_train, y_train, X_test, y_test = np.array(X_train_list), np.array(y_train_list), np.array(X_test_list), np.array(y_test_list)⑩入力データの正規化
X_train, X_test = X_train / 255.0, X_test / 255.0⑪ミニバッチ作成
train_ds = tf.data.Dataset.from_tensor_slices( (X_train, y_train)).shuffle(X_train.shape[0]).batch(64) test_ds = tf.data.Dataset.from_tensor_slices( (X_test, y_test)).shuffle(X_test.shape[0]).batch(64)⑫ネットワーク層(CNN)
オブジェクト指向型な記載方法をサポートしており、Pytorch/Chainerに慣れている人にとってはとっつきやすい。
tensorflow.keras.Modelを継承しており、Pytorchで言えばnn.Moduleに該当する。
データを入力したタイミングでcallメソッドが呼び出される。class cnnModel(Model): def __init__(self, width, height, channel, batch_size, output_dim): super(cnnModel, self).__init__() self.inlayer = InputLayer(input_shape=(width, height, channel), batch_size=batch_size) self.sconv1 = SeparableConv2D(32, 3, activation='relu') self.sconv2 = SeparableConv2D(64, 3, activation='relu') self.pool1 = MaxPool2D(pool_size=(2, 2)) self.btnorm1 = BatchNormalization() self.do1 = Dropout(0.5) self.sconv3 = SeparableConv2D(128, 3, activation='relu') self.sconv4 = SeparableConv2D(256, 3, activation='relu') self.pool2 = MaxPool2D(pool_size=(2, 2)) self.btnorm2 = BatchNormalization() self.do2 = Dropout(0.5) self.sconv5 = SeparableConv2D(512, 3, activation='relu') self.sconv6 = SeparableConv2D(512, 3, activation='relu') self.pool3 = MaxPool2D(pool_size=(2, 2)) self.btnorm3 = BatchNormalization() self.do3 = Dropout(0.5) self.gapool1 = GlobalAveragePooling2D() self.d1 = Dense(1024, activation='relu') self.do4 = Dropout(0.5) self.d2 = Dense(64, activation='relu') self.do5 = Dropout(0.5) self.d3 = Dense(output_dim, activation='softmax') def call(self, x): x = self.inlayer(x) x = self.sconv1(x) x = self.sconv2(x) x = self.pool1(x) x = self.btnorm1(x) x = self.do1(x) x = self.sconv3(x) x = self.sconv4(x) x = self.pool2(x) x = self.btnorm2(x) x = self.do2(x) x = self.sconv5(x) x = self.sconv6(x) x = self.pool3(x) x = self.btnorm3(x) x = self.do3(x) x = self.gapool1(x) x = self.d1(x) x = self.do4(x) x = self.d2(x) x = self.do5(x) return self.d3(x)⑬学習/予測/評価クラス
デフォルトでは、Eager Executionとして実行されるが、バッチごとに計算グラフを構築するため、パフォーマンス観点からは、あまり好ましくない。そのため、学習/予測実行関数に対しては、アノテーションに@tf.functionを付与し、Graph Modeで実行(静的グラフにコンパイル)することでパフォーマンス上の問題を改善できる。
また、エポック毎にチェックポイントを生成し、次回学習時に前回学習終了時点のパラメータを復元できるようにした。
TFのチェックポイントの仕組みとしては、変数をロードされたオブジェクトから始めて、名前付けられたエッジ(オブジェクトの属性)を持つ有向グラフを辿ることによりチェックポイントされた値に合わせる。
tf.train.Checkpoint オブジェクト上の restore() 呼び出しは要求された復元をキューに入れて、Checkpoint オブジェクトから一致するパスがあった場合に変数値を復元する。つまり、定義したモデルから単にカーネルをネットワークと層を通してそれへのパスを再構築することによりパラメータを復元する。
class Trainer: def __init__(self, model): self.model = model #誤差/最適化関数 lr = 1e-4 self.loss_object = tf.keras.losses.SparseCategoricalCrossentropy() self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr) #評価関数 self.train_loss = tf.keras.metrics.Mean(name='train_loss') self.train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy') self.test_loss = tf.keras.metrics.Mean(name='test_loss') self.test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy') max_keep = 10 self.chk_point_path = './tf_ckpts' self.ckpt = tf.train.Checkpoint(step=tf.Variable(1), optimizer=self.optimizer, model=self.model) self.manager = tf.train.CheckpointManager(self.ckpt, self.chk_point_path, max_to_keep=max_keep) #学習実行関数(グラフモード) @tf.function def train_step(self, image, label): with tf.GradientTape() as tape: predictions = self.model(image) loss = self.loss_object(label, predictions) gradients = tape.gradient(loss, self.model.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.model.trainable_variables)) self.train_loss(loss) self.train_accuracy(label, predictions) #検証実行関数(グラフモード) @tf.function def test_step(self, image, label): predictions = self.model(image) t_loss = self.loss_object(label, predictions) self.test_loss(t_loss) self.test_accuracy(label, predictions) #学習/予測/評価実行 def train_test_fn(self, epochs, train_ds, test_ds): #既存チェックポイントからのリストア self.ckpt.restore(self.manager.latest_checkpoint) if self.manager.latest_checkpoint: print("チェックポイント {} をリストア...".format(self.manager.latest_checkpoint)) else: print("チェックポイントが存在しないため、初期状態からの学習...") for epoch in range(epochs): for image, label in train_ds: with tf.device("/gpu:0"): self.train_step(image, label) for test_image, test_label in test_ds: with tf.device("/gpu:0"): self.test_step(test_image, test_label) if (epoch + 1) % 1 == 0: template = 'Epoch {}, Loss: {:.5f}, Accuracy: {:.5f}, Test Loss: {:.5f}, Test Accuracy: {:.5f}' print (template.format(epoch+1, self.train_loss.result(), self.train_accuracy.result()*100, self.test_loss.result(), self.test_accuracy.result()*100)) #エポック毎にチェックポイント保存 self.ckpt.step.assign_add(1) if int(self.ckpt.step) % 1 == 0: save_path = self.manager.save() print("チェックポイントを保存: {}".format(int(self.ckpt.step), save_path))⑭モデルの初期化
cnn_model = cnnModel(X_train.shape[1], X_train.shape[2], X_train.shape[3], batch_size=32, output_dim=2)⑮学習/評価
trainer = Trainer(cnn_model) trainer.train_test_fn(epochs=50, train_ds=train_ds, test_ds=test_ds) チェックポイントが存在しないため、初期状態からの学習... Epoch 1, Loss: 0.57603, Accuracy: 74.23697, Test Loss: 0.68871, Test Accuracy: 62.50000 チェックポイントを保存: 2 Epoch 2, Loss: 0.56901, Accuracy: 74.33090, Test Loss: 0.58955, Test Accuracy: 71.07372 チェックポイントを保存: 3 Epoch 3, Loss: 0.49160, Accuracy: 77.48338, Test Loss: 0.52456, Test Accuracy: 74.89317 チェックポイントを保存: 4 Epoch 4, Loss: 0.44060, Accuracy: 79.77665, Test Loss: 0.50206, Test Accuracy: 75.88141 チェックポイントを保存: 5 Epoch 5, Loss: 0.40814, Accuracy: 81.32285, Test Loss: 0.48017, Test Accuracy: 77.11539 チェックポイントを保存: 6 Epoch 6, Loss: 0.38605, Accuracy: 82.38369, Test Loss: 0.46281, Test Accuracy: 78.15171 チェックポイントを保存: 7 Epoch 7, Loss: 0.36836, Accuracy: 83.27782, Test Loss: 0.45715, Test Accuracy: 78.22802 チェックポイントを保存: 8⑯学習再開
チェックポイント ./tf_ckpts/ckpt-8 をリストア... Epoch 1, Loss: 0.34058, Accuracy: 84.69032, Test Loss: 0.44556, Test Accuracy: 78.82835 ・ ・ Epoch 19, Loss: 0.22930, Accuracy: 90.27736, Test Loss: 0.41090, Test Accuracy: 82.16999 チェックポイントを保存: 28 Epoch 20, Loss: 0.22587, Accuracy: 90.44373, Test Loss: 0.41324, Test Accuracy: 82.21153 チェックポイントを保存: 29 Epoch 21, Loss: 0.22260, Accuracy: 90.60131, Test Loss: 0.41246, Test Accuracy: 82.33311 チェックポイントを保存: 30 Epoch 22, Loss: 0.21943, Accuracy: 90.75378, Test Loss: 0.41382, Test Accuracy: 82.39851 チェックポイントを保存: 31 Epoch 23, Loss: 0.21633, Accuracy: 90.90470, Test Loss: 0.41248, Test Accuracy: 82.48553 チェックポイントを保存: 32 Epoch 24, Loss: 0.21344, Accuracy: 91.04456, Test Loss: 0.41313, Test Accuracy: 82.50200 チェックポイントを保存: 33 Epoch 25, Loss: 0.21065, Accuracy: 91.17853, Test Loss: 0.41447, Test Accuracy: 82.52720