- 投稿日:2019-12-04T23:58:56+09:00
ラズパイとMESHで始めるお手軽IoT
Ubiregi Advent Calendar 2019 4日目はラズパイとMESHを使ったお手軽IoTを紹介します。
作るもの
MESHブロックの「ボタン」を押すと、Slackに決まったメッセージが投稿される、という非常に簡単なものを作ります。
応用としてはラズパイにモニタを付けてドアホンとして使う、見たいのはアリかなとか思っています。一人暮らしだと留守の間、人が訪問してきてるか分からない問題があり、代わりにMESHボタンを配置しておけば人が来たことをスマホに通知する、みたいなことができてよさそうです。用意するもの(今回使ったもの)
- MESHのボタンブロック
- Raspberry Pi Zero WH(以下ラズパイ)
- スマホ
前提条件
- ラズパイでRaspbianが動くようになっていること
- MESHアプリがスマホにインストールされていること
- Slackのアカウントを持っていること
手順
ラズパイを「MESHハブ」にする
これに関しては公式が非常に手厚いので、そちらを参照した方がよいです。
Raspberry Piに「MESH ハブ」アプリをインストールする方法を教えてほしい – MESHサポート | 遊び心を形にできる、アプリとつなげるブロック形状の電子タグ
補足
今回使ったラズパイはZeroなので、ブラウザを立ち上げると大変重たいです。
ということで、上記手順のブラウザでアクセスする部分は通常のPCで行ない、
②Raspberry Piにログインしてダウンロード用のコマンドを実行する方法
のコマンドをコピーしてSSH経由でダウンロードするのが楽だと思います。Incoming WebhookのURLを取得
事前に通知先のチャンネルを決める/作るなどしておきます。
次に、
SlackのIncoming Webhooksを使い倒す - Qiita
を参考にIncoming Webhookを追加してURLをコピーしましょう。
メモ帳でもなんでもいいのでURLを退避させておくことをおすすめします(次で使います)。PythonでServerを書く
Pythonを使っているのは単純に僕がPythonをよく使うので使っている感じなので、同じことができれば言語は何でもいいです。
ちなみにRasbianはデフォルトでPythonがインストールされているため特にPythonそのものをインストールしたりする必要はありません。
なお、今回使用したPythonのバージョンはPython 2.7.13となります。MESHからラズパイのプログラムを叩くための簡単なHTTP Serverを作ります。
今回はbottleという軽量マイクロWebフレームワークを使いました。事前準備
ソースコード内で使用するライブラリを
pipでインストールしておきます。
(requestsはSlackをたたきに行くときに使います)$ pip install bottle requestsソースコード
場所はどこでもいいので適当なところにファイルを作り、下記ソースコードを書きます。
名前は何でもいいですが今回はserver.pyとしました。
(「ラズパイ版MESHを使って、Apple Watchで操作するおしゃべりロボットを作る - Qiita」を参考にしました)server.py# -*- coding: utf-8 -*- from bottle import route, run, template import json import requests slack_settings = { # channel_nameは任意で変えましょう # こうしておくと他のチャンネルにも通知したくなったとき設定を増やしやすいのでこうしてあります 'channel_name': { 'url' : '{「Incoming WebhookのURLを取得」の工程で取得したURL}', 'botname': 'test', 'icon' : ':muscle:', 'message': '<!here>\nMESHからの通知だよ' } } def push(setting): datas = { 'username' : setting['botname'], 'icon_emoji' : setting['icon'], 'text' : setting['message'], 'contentType': 'application/json' } payload = json.dumps(datas) result = requests.post(setting['url'], payload) print(result) @route('/post/slack/<command>') def mesh_button(command): if command == 'channel_name': push(slack_settings['channel_name']) else: raise Errorサーバの起動
以下コマンドでサーバを起動します。特に難しいことは無いと思います。
$ python server.py上手く起動すればこんな表示が出ます。
Bottle v0.12.17 server starting up (using WSGIRefServer())... Listening on http://localhost:8080/ Hit Ctrl-C to quit.試しに
curlで叩いて試してみましょう。python server.pyをしているコンソールを閉じてしまうとサーバが止まってしまうので、別コンソールを開きましょう(SSH接続してる場合も)。$ curl http://localhost:8080/post/slack/channel_nameサーバを起動している側に
<Response [200]> 127.0.0.1 - - [04/Dec/2019 13:46:15] "GET /post/slack/channel_name HTTP/1.1" 200 0というログが出ると思うので、出ていれば成功です。
MESH SDKからカスタムブロックを作成する
MESHではブロックと呼ばれる定型処理を線でつなぐことで処理を作っていきます。
(のちに設定します)
ということで、先ほど作成したserver.pyのURLを叩くブロックを作成しておく必要があるんですね。なので、まずはそれを先に作ります。カスタムブロック作成ページへアクセス
SDK_TOP_JPにアクセスします。
「MESH SDKを使う」からカスタムブロックの管理画面に行けます。
カスタムブロックを作成する
Create New Blockをクリックすると、カスタムブロックの作成画面になるので設定していきます。
設定は下記の通りです。一通り設定できたら左上の「Save」をクリックして保存しましょう。
Codeに設定したソースコードvar localhost = 'http://localhost:8080' + properties.path; ajax({ url : localhost, type : 'get', timeout: 5000, success: function (data) { callbackSuccess({ resultType : 'continue' }); }, error: function(request, errorMessage) { log('ERROR: ' + errorMessage); callbackSuccess({ resultType: 'continue' }); } }); return { resultType: 'pause' }設定の簡単な説明
この辺の設定は「ラズパイ版MESHを使って、Apple Watchで操作するおしゃべりロボットを作る - Qiita」を参考にしました。
Connector
これはInput Connectorのみを設定しました。
あとでMESHアプリを触れば分かるんですが、MESHのブロックにはInputとOutputがあります。
今回はボタンを押したあとこのカスタムブロックの処理を起動して終わりという感じになるので、Output Connectorには設定なしという状態です。
もしもこのカスタムブロックが動いた後に何か他のことをしたいとなったら、Output Connectorの方にも設定が必要です。Property
これはコード内で参照できるプロパティを作れるものになります。カスタムブロック配置時に、プロパティの値をいじれます。なので、例えば別のチャンネルに通知したくなったとかでも、ブロックを新しく作る必要はなく、配置するときにプロパティの値だけいじればOKみたいな風にできるということです。
Code
これはカスタムブロックがキックされたときに実行されるJavaScriptのコードになります。コードがキックされたら、Ajaxで先ほどPythonで書いたサーバを叩きに行ってます。
MESHアプリでレシピを作成する
MESHアプリの簡単な説明
MESHを使って処理を作るには必ずMESHアプリで「レシピ」を作る必要があります。このレシピはMESHアプリからでないと作れません。ラズパイで動作させるレシピもMESHアプリから作ることになります。
MESHハブの登録
事前準備として、スマホとラズパイのBluetoothはオンにしておきましょう。
スマホからMESHアプリを起動します。右上にスマホマークがありますが、これをタップすると以下の「他の端末に変更する」っていうのが出てくると思うのでこれをタップします。
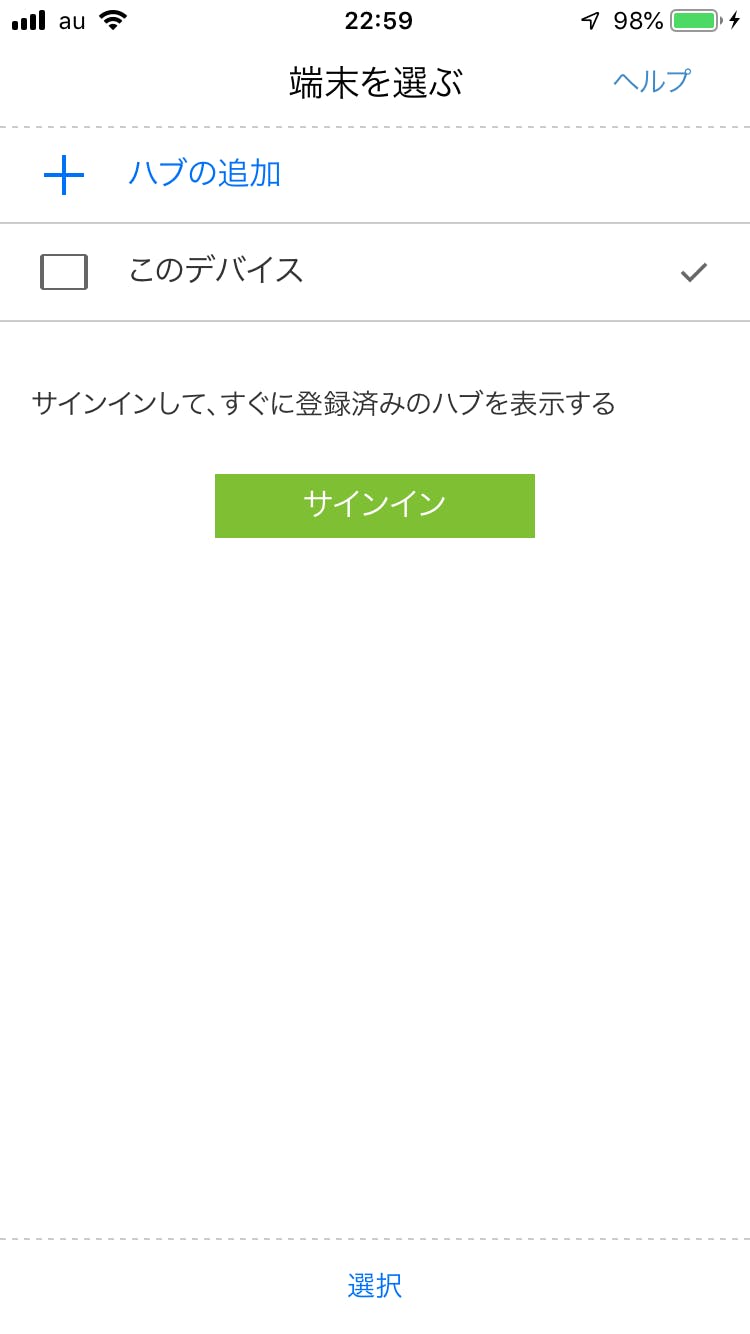
すると「端末を選ぶ」画面になるので、サインインして「ハブの追加」をタップします。
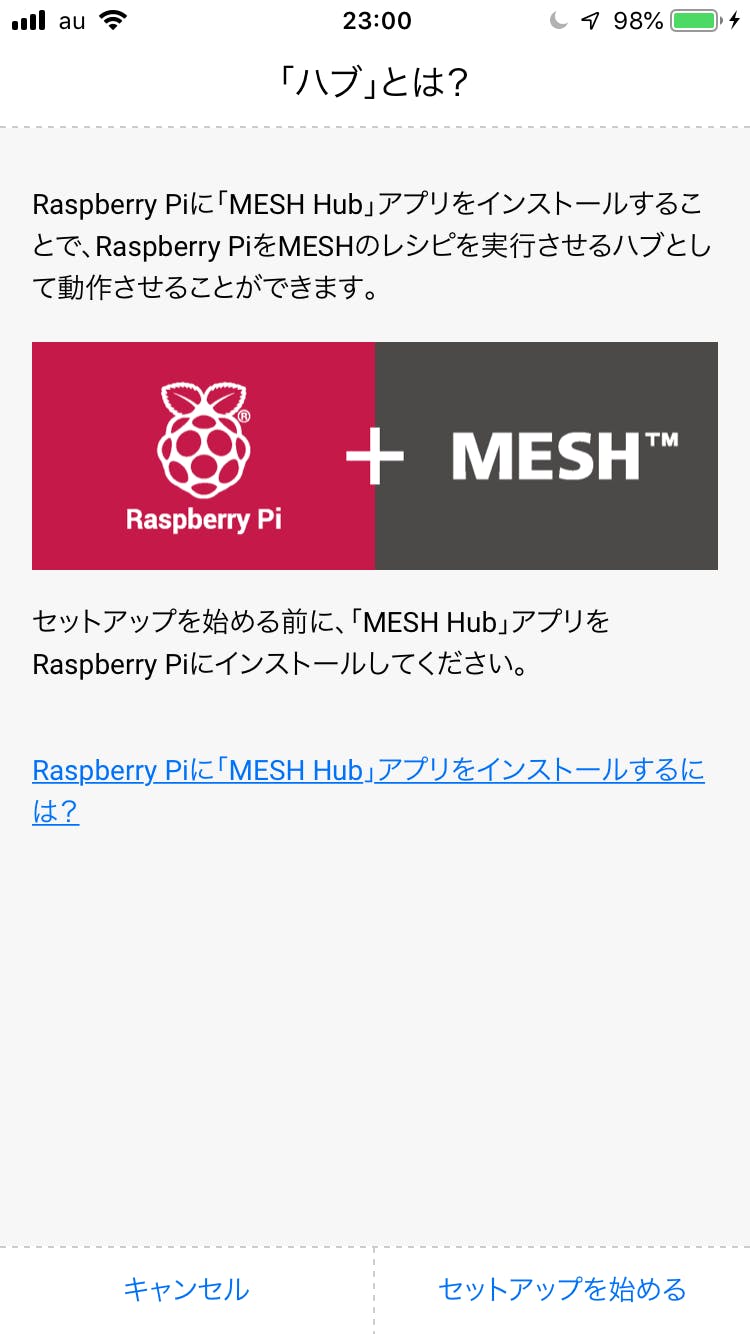
「ハブの追加」をタップすると次の画面になります。「セットアップを始める」をタップして次へ行きましょう。
この画面も「次へ」で進みます。
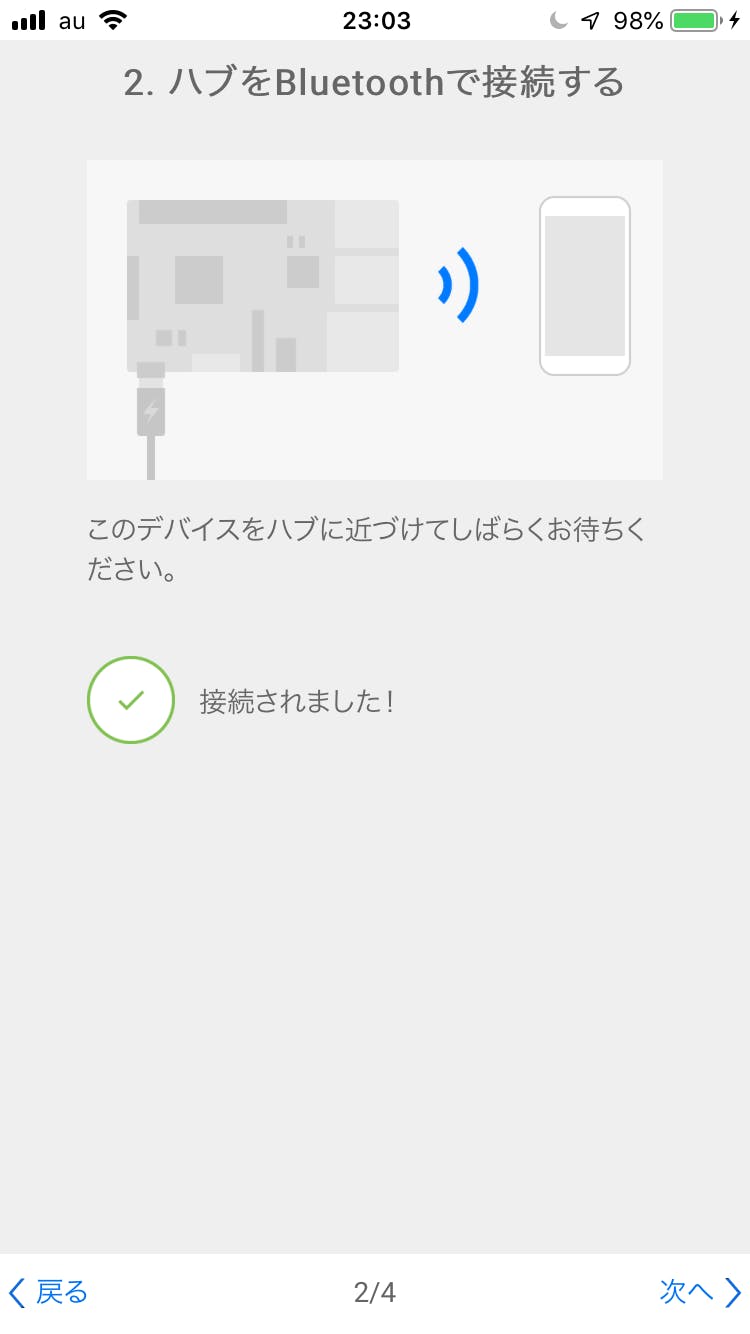
スマホとラズパイの接続に成功すると以下の画面になります。もし何分待ってもつながらないということであれば、Bluetoothを確認するか、ラズパイがセットアップ可能な状態か確認しましょう(画面に表示されているリンクをタップすればやり方が書いてあると思います)。
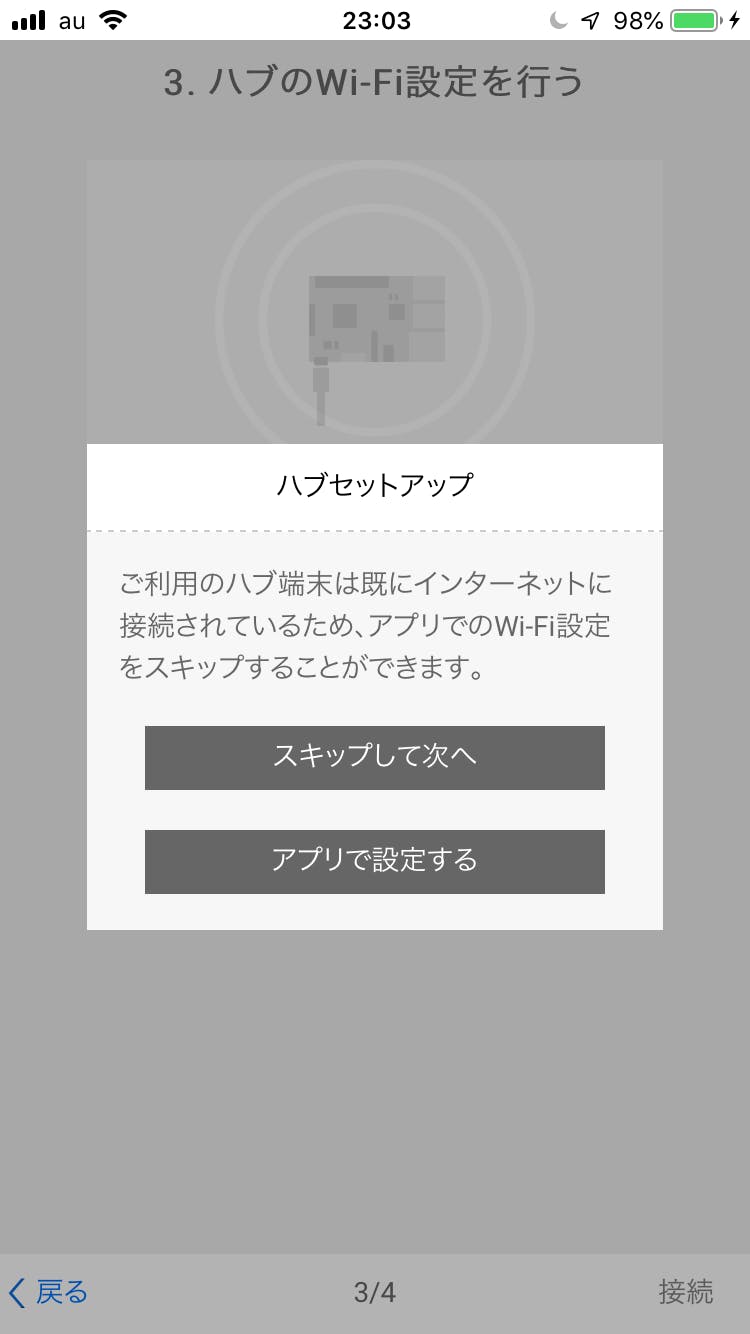
この画面ですが、ラズパイのWi-Fi設定をするかしないかの画面です。有線で接続してしまっている場合は別ですが、基本的にはWi-Fiの接続も終わっているはずなのでスキップします。
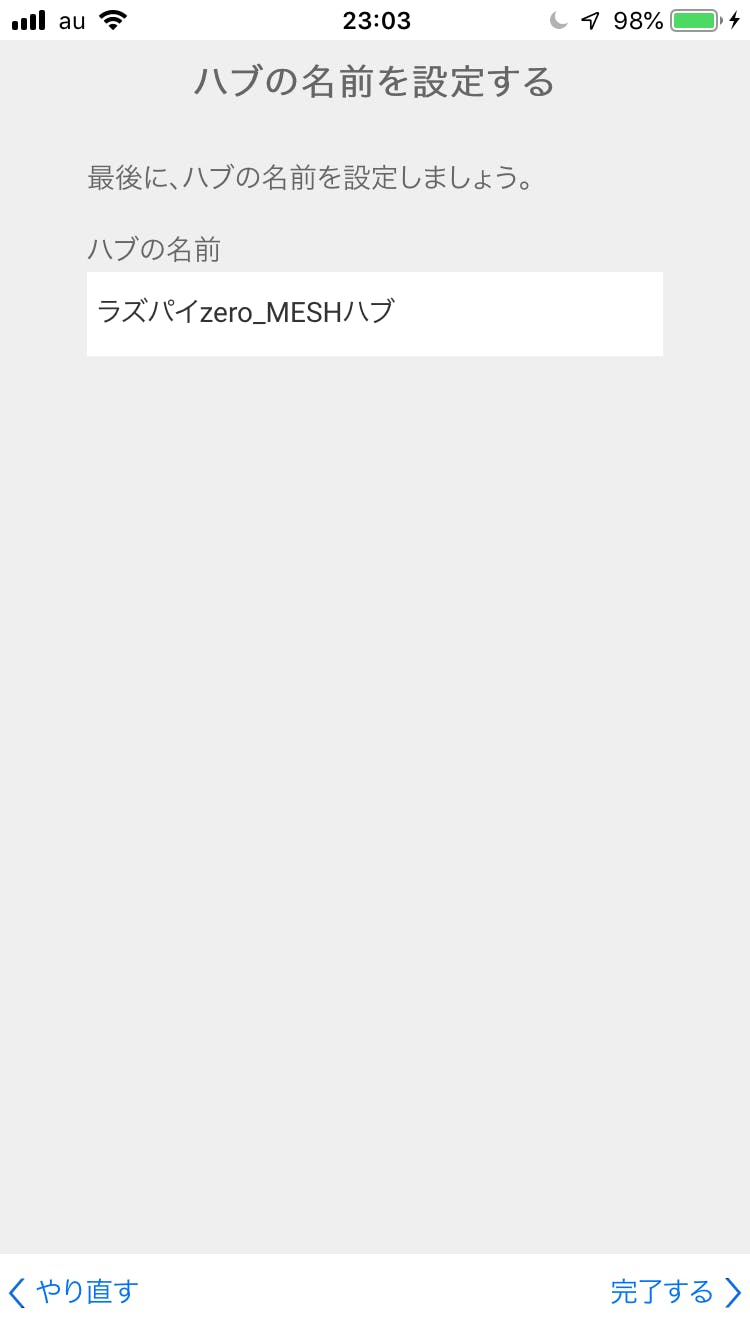
適当にハブの名前を決めて次へ進めます。
上手くいくと最終的にこの画面になるので、先ほど追加したラズパイのMESHハブを選択して、画面下の「選択」をタップしましょう。
ブロック/カスタムブロックの追加・レシピの作成
※この工程を始める前にスマホのBluetoothを切っておくことをおすすめします。MESHブロックの電源を入れると、スマホの方とペアリングしようとしてきますが、ペアリングの相手はラズパイです。スマホのBluetoothを切っておかないと、MESHは永遠にスマホにペアリングしようとしてくるのでラズパイとペアリングしてくれません。
アプリトップの画面で「新しいレシピ」をタップするとこの画面になります。まずはMESHブロックを追加しましょう。MESHブロックの電源を入れ、左下の「ブロック 追加」のプラスマークをタップしましょう。
(電源はMESHブロックのシリコン素材部分を長押しで入ります、もし入らない場合は充電してください)
上手く追加できると左下のブロックのところに「ボタンブロック」が表示されるので、タップしてドラッグして配置しましょう。下記画面のようになるはずです。
次にカスタムブロックを追加します。先ほどWeb画面でJavaScriptのコードを登録したりしたものです。上画面に映っていますが「カスタム 追加」のプラスマークをタップすると追加画面へ行けます。そうすると以下のように先ほど登録したカスタムブロックが表示されるので、タップして、「追加」ボタンをタップします。
無事追加できたと思うので、先ほど「ボタンブロック」を配置したのと同じ要領でカスタムブロックを配置し、ボタンブロックの端とカスタムブロックの端を下記のようにつなげます。配置済みのボタンブロックからカスタムブロックまでをドラッグすれば線でつなぐことができます。
補足
配置したカスタムブロックをタップするとこのような画面になります。ここでプロパティの値をいじれるんですね。Pythonのサーバ側プログラムを変更すれば、同じカスタムブロックでここのPathを変えれば動作を変えられるというわけです。
動作確認
以上で設定は終わったので、MESHのボタンを押してみましょう。Slackに投稿がされれば成功です。
まとめ
以上でMESHのボタンを押したらSlackで通知する(ラズパイ経由で)が完成しました。
手順は結構多いですが、お気づきの通り書いたソースコードは僅かです。そもそもラズパイのインストールができないといけないみたいなハードルはありますが、それさえ超えてしまっていれば割とサクッとできてしまいます。
MESHはボタン以外にもLED、人感センサー、動きセンサー、温度湿度センサー、明るさセンサー、GPIOと様々なブロックがあります。強みとして、(GPIOを除いて)電子工作が全くできなくてもIoTの自作ができてしまうというところにあります。電子工作ってなるとどうしても多少電気電子の知識が必要になってくるので、普通にソフトウェアエンジニアをしてきた人からすると若干ハードルが高かったりするんですよね。しかしMESHタグなら電子工作の知識がほぼ不要で、ソフトウェアでほとんどのことがなぎ倒せるのでオススメです。
ちなみに物理的に何かしたいけど電子工作の知識がない…とかであれば、Ejectコマンドっていう大変便利なものがあるのでそれを使ってみるといいかもしれません(参考:EjectコマンドをRaspberry Piで遊ぼう ~CD-ROMドライブでかんたん工作~)。












- 投稿日:2019-12-04T23:52:04+09:00
pythonで色の変わる時計を作成する
目的
1秒毎に回転し、60秒で1周する秒針(時計)を作成します。
ただ秒針を描くだけではつまらないので、時計の色が0~60[s]の範囲で、青色から赤色へ次第に変化するようにします。最後にgifとして保存して完成です。完成品
コード
second_hand.py%matplotlib nbagg import matplotlib.pyplot as plt import matplotlib.animation as animation import matplotlib.patches as pat fig = plt.figure() ax = plt.subplot() def clock(i): circle = [ax.add_patch(pat.Wedge(center=(0, 0), r=1, color=[0+i/60,0,1-i/60], theta1 = 95-i*(360/60), theta2 = 85-i*(360/60)))] #center:中心のxy座標,r:ウェッジの半径,color:RGBでの色指定(各色0~1),theta:ウェッジの角度を指定 #circleをリストにすることに注意してください。あとでimgsに追加できるようにするためです。 return circle #リストimgsに、各秒ごとのclockを追加していきます。 imgs=[] for i in range(60): imgs.append(clock(i)) ani = animation.ArtistAnimation(fig, imgs, interval=1000, repeat=True) plt.axis("scaled") plt.show() ani.save("second_hand.gif", writer="imagemagick")#gifとして保存環境
macOS Catalina
jupyter-notebook

- 投稿日:2019-12-04T23:30:55+09:00
Pythonらしいコードを書く(辞書編)
はじめに
Pythonを学習するにあたって、せっかくなので、Pythonらしい書き方というものを調べてみました。
Pythonらしさは、Pythonの効率の良いコードと同意だからです。参考にしたスライド
https://speakerdeck.com/pyconslides/transforming-code-into-beautiful-idiomatic-python-by-raymond-hettinger-1
http://kesin.hatenablog.com/entry/2013/05/12/004541辞書の使い方
これぞ
Pythonらしさというもので、辞書の使い方は非常に重要かつ基本的なテクニックです。
何かとお世話になる辞書には、うまいやり方がありそうです。キーでループ
辞書を指定しても、辞書オブジェクトの
keysメソッドを使っても、キーでのループが可能です。d = {'kaijo': 'red', 'shinmei': 'blue', 'ooiwa': 'yellow', 'pegie': 'pink', 'asuka': 'green'} for k in d: print(k) for k in d.keys(): print(k)キー、バリューのループ
キーと値とをループさせる方法としては、上段のキーによるループをして、キーから値を取得する方法が考えられます。
Pythonの辞書にはitemsメソッドがあり、これを利用することで、辞書からキーを用いて値を取得することが必要なくなります。また、値の変数が自由に決められるため、読みやすいコードになります。d = {'kaijo': 'red', 'shinmei': 'blue', 'ooiwa': 'yellow', 'pegie': 'pink', 'asuka': 'green'} for k in d: print(k, '->', d[k]) for k, v in d.items(): print(k, '->', v)辞書を2つのリストから作成する
キーのリストと値のリストが既にあるような場合では、これらを合成することで辞書を作成することができます。
for文を使わずにできます。from itertools import izip keys = ['kaijo', 'shinmei', 'ooiwa', 'pegie', 'asuka'] values = ['red', 'blue', 'yellow', 'pink', 'green'] d = dict(izip(keys, values))インデックス的な連番をつけた辞書にしたい場合は
enumerateを使うと作成できます。values = ['red', 'blue', 'yellow', 'pink', 'green'] d = dict(enumerate(values))辞書を使ったカウント
英語の文章に同じ単語がいくつ出現するか、などの処理をするときには、以下のような処理が想像しやすいです。
colors = ['red', 'green', 'red', 'blue', 'green', 'red'] d = {} for color in colors: if not color in d: d[color] = 0 d[color] += 1辞書の
getメソッドは指定したキーがいくつあるかを返しますが、キーがない場合は、引数で与えた値を返します。
それを利用して以下のように書けます。colors = ['red', 'green', 'red', 'blue', 'green', 'red'] d = {} for color in colors: d[color] = d.get(color, 0) + 1
collectionsモジュールのdefaultdictは、キーがない場合に追加する機能を持っています。
それを利用して以下のようにも書けます。
getを使うより読みやすくなります。from collections import defaultdict colors = ['red', 'green', 'red', 'blue', 'green', 'red'] d = defaultdict(int) for color in colors: d[color] += 1辞書を使ったグルーピング
例えば単語のリストがあったとして、単語の文字数でグルーピングしたいといったような場合には、わかりやすいコードとして、キーがないときにデフォルト値(この場合は名前を格納するリスト)を設定する方法があります。
デフォルト値を格納するところはsetdefaultメソッドが使えます。names = ['raymond', 'rachel', 'matthew', 'ronger', 'betty', 'melissa', 'judith', 'charlie'] d = {} for name in names: key = len(name) if not key in d: d[key] = [] d[key].append(name) d2 = {} for name in names: key = len(name) d2.setdefault(key, []).append(name)これを先程の
defaultdictを使うと以下のように書けます。
if文がなくなってエレガントになりました。from collections import defaultdict names = ['raymond', 'rachel', 'matthew', 'ronger', 'betty', 'melissa', 'judith', 'charlie'] d = defaultdict(list) for name in names: key = len(name) d[key].append(name)
- 投稿日:2019-12-04T23:29:19+09:00
Ansibleのテキストパース用フィルタープラグインを自作してみた
はじめに
以前の記事で、TTP(Template Text Parser)というPythonのパーサーライブラリを使って、L2SWのConfigファイルをパースし、ポート管理表の自動生成を行いました。
L2SWのConfigからポート管理表を自動生成してみた今回は、このパーサーをAnsibleのカスタムフィルターとして取り込み、
xxx_commandモジュールで取得したshowコマンド結果をパースできるようにしてみました。※ フィルタープラグイン自作例は、以前こちらでも紹介しています。
※ 私が知る限り、パース用フィルタープラグインとして、他にもTextFSMを利用したparse_cli_textfsmや、pyATS/Genieを利用したparse_genie(Ansible Galaxyからインストールが必要。詳細はGitHub/parse_genieに記載。)があります。セットアップ
Python3.6.7の仮想環境内にインストールしたAnsibleを使いました。当初、バージョン2.9.0でテストしていたのですが、Logging error(KeyError)メッセージが複数出たため、2.8.4を使っています。
追加でTTPのインストールが必要です。
(venv) [centos@localhost ansible]$ pip install ttpカスタムフィルター
以下のPythonスクリプトを作成しました。
custom_filters_ttp.pyfrom ansible.errors import AnsibleError # ttp、jsonのインポート。インポートに失敗した場合、後続の処理でエラー出力できるようにする。 try: from ttp import ttp HAS_TTP = True except ImportError: HAS_TTP = False try: import json HAS_JSON = True except ImportError: HAS_JSON = False class FilterModule(object): def parse_cli_ttp(self, cli_output, template_file): if not HAS_TTP: raise AnsibleError('parse_cli_ttp filter requires TTP library to be installed') if not HAS_JSON: raise AnsibleError('parse_cli_ttp filter requires JSON library to be installed') with open(template_file, 'rt') as ft: ttp_template = ft.read() # create parser object and parse data using template parser = ttp(data=cli_output, template=ttp_template) parser.parse() # return result in JSON format results = parser.result(format='json')[0] return results def filters(self): return { # 左側がPlaybook内で使用するフィルター名、右側が紐付ける関数名。 'parse_cli_ttp': self.parse_cli_ttp, }ベストプラクティスに従い、Playbookを格納しているディレクトリ配下に、filter_pluginsディレクトリを作成し、その中に本ファイルを格納しました。
また、Ansibleがこのカスタムフィルターを認識できるよう、ansible.cfgの設定を以下の通り書き換えました。
ansible.cfg[defaults] filter_plugins = [Playbook格納ディレクトリのフルパス]/filter_pluginsPlaybook
ios_commandモジュールでRunning Configを取得し、続くdebugモジュール内で、取得したConfigと以前の記事で作成したL2インターフェース設定用テンプレートのファイルパスを指定しました。シンプルですね!playbook_ttp.yml--- - hosts: cisco gather_facts: no connection: network_cli tasks: - name: run show command on remote devices ios_command: commands: show running-config register: result - name: display parsed output debug: msg: "{{ result.stdout[0] | parse_cli_ttp('catalyst2960_template_ttp2.txt') }}"出力結果
前回とConfigが異なるため結果に違いはありますが、パース自体は問題なくできています。
$ ansible-playbook -i inventory_2960.ini playbook_ttp.yml PLAY [cisco] ************************************************************************************************* TASK [run show command on remote devices] ******************************************************************** ok: [hqdist1A] TASK [display parsed output] ********************************************************************************* ok: [hqdist1A] => { "msg": [ { "l2_interfaces": [ { "description": "<< Connect hqdist1 and hqdist2 >>", "duplex": "auto", "mode": "trunk", "port_no": "Port-channel1", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1,101" }, { "description": "<< To hqborder1 Fa1 >>", "duplex": "full", "mode": "access", "port_no": "FastEthernet0/1", "portfast": "x", "speed": "100", "status": "o", "vlan": "200" }, { "description": "<< To hqborder2 Fa1 >>", "duplex": "full", "mode": "access", "port_no": "FastEthernet0/2", "portfast": "x", "speed": "100", "status": "o", "vlan": "202" }, { "description": "<< To hqaccess1 Fa0/23 >>", "duplex": "full", "mode": "access", "port_no": "FastEthernet0/3", "portfast": "x", "speed": "100", "status": "o", "vlan": "100" }, { "duplex": "auto", "mode": "trunk", "port_no": "FastEthernet0/4", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/5", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/6", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/7", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/8", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/9", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/10", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/11", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/12", "portfast": "x", "speed": "auto", "status": "o", "vlan": "203" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/13", "portfast": "x", "speed": "auto", "status": "o", "vlan": "100" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/14", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/15", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/16", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/17", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/18", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/19", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/20", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/21", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "FastEthernet0/22", "portfast": "x", "speed": "auto", "status": "x", "vlan": "1" }, { "description": "<< To hqdist2 Fa0/23 >>", "duplex": "auto", "mode": "trunk", "port_no": "FastEthernet0/23", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1,101" }, { "description": "<< To hqdist2 Fa0/24 >>", "duplex": "auto", "mode": "trunk", "port_no": "FastEthernet0/24", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1,101" }, { "duplex": "auto", "mode": "access", "port_no": "GigabitEthernet0/1", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1" }, { "duplex": "auto", "mode": "access", "port_no": "GigabitEthernet0/2", "portfast": "x", "speed": "auto", "status": "o", "vlan": "1" } ] } ] } PLAY RECAP *************************************************************************************************** hqdist1A : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0最後に
今回作ったプラグインはGitHub/ansible-ttpにアップしています。Configだけでなく、他のshowコマンドの出力結果も比較的簡単にパース出来ますので、ぜひ使ってみて頂ければと思います。
- 投稿日:2019-12-04T23:17:21+09:00
画像処理?のためにPythonを始めた話
Pythonを始めました。目的は、アートのために動画から画像を生成するプログラムを作りたいから。
Pythonは、Anacondaでインストールしました。Anacondaというのは、Pythonとその他もろもろを一発で入れてくれる便利パッケージのようです。
バージョンはPython3です。なんでもPython2は業務上の理由がなければ入れる必要がないとか。要は移行期間であって、2はやがて廃れる運命のようです。
AnacondaでPythonをインストールした後は、処理を楽ちんにするためのサブ武器的なやつを入れていったとおもいます(試行錯誤しまくっていたので、他にも何かしてたかも)。正確には何という名称なのかわかりませんが…
入れる方法は二つ。
- pip
- conda
pipはすべてのPythonで利用可能なサブ武器インストールツール。condaは名前の通りAnaconda専用のようです。pipでしか入れられないサブ武器もあれば、condaでしか入れられないサブ武器もあるようですね。
今回は画像を扱いたいので、opencvを入れました(【Python】Anaconda上にOpenCVをインストールする方法【Windows】)。最後に一つ、Qiita等読むうえで、知らなくて困ったこと。冒頭の
$マークについて。$ pip install opencv-pythonこのような記述があった場合、冒頭の
$はコマンドプロンプトに打ち込むことを示している。Mac等のUnix系では権限の弱い通常ユーザーの場合に、入力待ちであること示すため行頭に$が表示されることから、このような表記をするらしい。今回はここまで。
- 投稿日:2019-12-04T23:04:17+09:00
Qiita API で投稿を自動化する
この記事はtomowarkar ひとりAdvent Calendar 2019の6日目の記事です。
はじめに
今日は軽めにQiita APIを叩いてローカルの
MarkdownファイルをQiitaに投稿したいと思います。完成したファイルツリーはこんな感じ。
. ├── article │ ├── config.json │ └── item.md └── main.py
item.mdに投稿する内容をそのままMarkdown形式で記載。config.jsonにQiitaAPIの諸設定を保存して管理といった感じになります。
Qiitaに投稿する記事をそのままローカルで管理でき、新規投稿、更新をできてしまいます。
それではいってみよう
コード全文
main.py
QiitaAPIを叩くメインプログラムです。
submit_articleに投稿する記事のdirectoryを指定してあげることでdirectory内のconfig.jsonとitem.mdを読み込んで投稿するという感じにしてみました。main.pyimport requests import json import datetime BASE_URL = "https://qiita.com/api/v2/items" TOKEN = "{your_token}" def submit_article(path): with open(f"{path}/config.json") as f: conf = f.read() with open(f"{path}/item.md") as f: body = f.read() headers = {"Authorization": f"Bearer {TOKEN}"} item = json.loads(conf) item["body"] = body if item["id"] == "": res = requests.post(BASE_URL, headers=headers, json=item) with open(f"{path}/config.json", "w") as f: item["id"] = res.json()["id"] item["body"] = "" f.write(json.dumps(item)) return res else: now = datetime.datetime.now() item["title"] += now.strftime("【%Y/%m/%d %H時更新】") item_id = item["id"] res = requests.patch(BASE_URL + f"/{item_id}", headers=headers, json=item) return res if __name__ == "__main__": res = submit_article("article", conf, body).json() print(res["title"], res["url"])config.json
QiitaAPIのための諸設定
config.json{ "title": "Qiita API テスト", "id": "", "tags": [ { "name": "qiita" }, { "name": "test" } ], "private": true, "coediting": false, "tweet": false, "body": "" }item.md
投稿する記事内容をそのままMarkdown形式で書いていきます。
item.md# Qiita Api テスト ### これはテストです Hello world解説
今回使用するアクセストークンの発行はこちらからできます。
アクセストークンの発行
main.py:submit_articleでは該当config.json内のidの有無に応じて
新規投稿と記事更新を分岐させています。また新規投稿の場合はレスポンスとして帰ってきた記事idを
config.json内に上書きするという仕様です。今回は特に問題ないのですが
submit_articleの機能をもりもりにしてしまいました?結果
以下のようになっていれば?♀️です
新規投稿時(id無し)
再投稿時(id有り)
参考サイト
https://qiita.com/api/v2/docs
https://qiita.com/tag1216/items/b0b90e30c7e581aa2b00まとめ
QiitaAPIを叩いてサクッと記事をローカル管理するコードを書いていきました。
もう少し拡張させればconfig.jsonを自動で書き出したり、タグ設定をできるようにしたりということもできそうです。以上明日も頑張ります!!
tomowarkar ひとりAdvent Calendar Advent Calendar 2019


- 投稿日:2019-12-04T22:34:06+09:00
Java で DataFrame を使う
DataFrame ご存知ですか?
DataFrame は Python や R言語でデータを扱ったり、機械学習したいときによく使われるとても便利なライブラリ・オブジェクトです。表形式のデータや2次元の配列のデータを扱うための様々な機能が揃っています。
https://amalog.hateblo.jp/entry/kaggle-pandas-tipsどのくらい便利かというと、Excel や CSV から一気にデータを読み込んだり、2次元配列の任意の行列を抽出したり、表同士を SQL 操作のごとく join したりと、とにかく 2次元データを使う際には欠かせないというレベルです。
でも Java だとこれという DataFrame 相当の実装が無くて、ありがたい DataFrame の恩恵を受けられない、データ処理に時間がかかる、なんで Python じゃないんですかと暴言(?)を吐かれるなどの悲しい目に合うわけです。
Morpheus data science framework
しかし、そこに一筋の光が。
Morpheus data science framework が、その DataFrame と(たぶん)同等の機能を提供してくれています。
https://github.com/zavtech/morpheus-coreA Simple Example に沿って試してみましょう。
Consider a dataset of motor vehicle characteristics accessible here. The code below loads this CSV data into a Morpheus DataFrame, filters the rows to only include those vehicles that have a power to weight ratio > 0.1 (where weight is converted into kilograms), then adds a column to record the relative efficiency between highway and city mileage (MPG), sorts the rows by this newly added column in descending order, and finally records this transformed result to a CSV file.
(このサンプルでは)車の特性データを使用します。CSV を Morpheus DataFrame に読み込み、出力(馬力)重量比が 0.1 を超える条件で行をフィルタし、高速道路/都市部のMPG(燃費?)の比率の列を追加します。追加した列でソートして、結果を CSV ファイルに出力します。
サンプルコードと実行結果
import com.zavtech.morpheus.frame.*; public class MorpheusTester { public static void main(String[] args) { DataFrame.read().csv(options -> { options.setResource("http://zavtech.com/data/samples/cars93.csv"); options.setExcludeColumnIndexes(0); }).rows().select(row -> { double weightKG = row.getDouble("Weight") * 0.453592d; double horsepower = row.getDouble("Horsepower"); return horsepower / weightKG > 0.1d; }).cols().add("MPG(Highway/City)", Double.class, v -> { double cityMpg = v.row().getDouble("MPG.city"); double highwayMpg = v.row().getDouble("MPG.highway"); return highwayMpg / cityMpg; }).rows().sort(false, "MPG(Highway/City)").write().csv(options -> { options.setFile("./cars93m.csv"); options.setTitle("DataFrame"); }); } }戻り値の型が DataFrame 型なので、メソッドチェーンで csv(), select(), add(), sort() と続けて実行できます。csv() のあたりはとても DataFrame 感に溢れています。
処理前のデータ
処理後のデータ
DataFrame は機能が豊富で、同等かどうか試すのも容易ではありませんが、行抽出、列追加、ソートといった操作を確認することができました。
Java でデータ処理される際には、利用を検討してみても良いと思います。
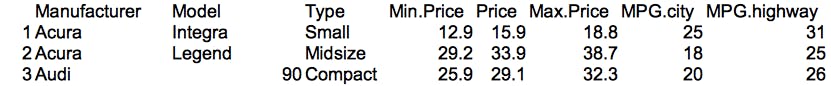

- 投稿日:2019-12-04T22:16:52+09:00
pythonでポートスキャン
はじめに
CTFの本でポートスキャンをpythonでできるってことを知り
「え?pythonってそんなのできる?」という好奇心からスタート
その過程でシングルで動かすよりもマルチスレッドのほうが抜群に早いことを知り
せっかくなので比較のために両方残す。気を付ける事
ポートスキャンは外部のサイトにやるのはNGなので
実験にあたっては自前のPCでVirtualboxを使って仮想サーバを立ち上げて
そこに対してポートスキャンをかました。
そんなわけで↓↓のソースコードで書かれている"10.0.0.2"は自前の仮想サーバのIPです。1.シンプルなポートスキャン
参考:https://qiita.com/najayama/items/728682bcae824c902046
一番勉強になったコードはコレ。なんせ無駄が一つもない。
その代わり遅い。逆に遅いからこそ「マルチスレッドの有効性」というもの痛烈に感じることができた。simple-port-scanner.pyimport socket max_port = 6000 min_port = 1 target_host = input("Input target host name or address: ") for port in range(min_port, max_port): #target_host のポート番号portに接続を試行 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) return_code = sock.connect_ex((target_host, port)) sock.close() #socket.connect_ex は成功すると0を返す if return_code == 0: print("Port %d open!" % (port)) print("Complete!")2.マルチスレッドなポートスキャン
参考:https://www.valuestar.work/news/archives/20
こちらも負けず劣らず無駄がない。
threadをうまく使ってるので死ぬほど早い。1.では1ポートあたり1秒くらいかかっていたので
1~1024ポートやるのに結構な時間を要したがこっちのプログラムだと、3秒程度で処理が終了した。
threadやばい。今回は突貫で参考にしたのでコード丸写しなため、比較できる形になっていない。
後々比較できるように整形出来たら…いいなぁmulti-port-scanner.pyimport socket import threading scan_range = [1, 10000]; host = "10.0.0.2"; threads = []; ports = []; isopen = []; def Run(port, i): con = socket.socket(socket.AF_INET, socket.SOCK_STREAM) return_code = con.connect_ex((host, port)) con.close() if return_code == 0: isopen[i] = 1; count = 0; for port in range(scan_range[0], scan_range[1]): ports.append(port); isopen.append(0); thread = threading.Thread(target=Run, args=(port, count)); thread.start(); threads.append(thread); count = count + 1; for i in range(len(threads)): threads[i].join(); if isopen[i] == 1: print("%d open" % ports[i]);おわりに
ポートスキャンの勉強のために調べたけど
予想以上に自分の中ではthreadの破壊力が印象に残ってしまった。
後でゆっくりソースコードを眺めて整理することにしよう~おしまい~
- 投稿日:2019-12-04T21:50:19+09:00
Qiskitで量子テレポーテーション!
はじめに
Qiskitを使った量子テレポーテーションの実験をしてみたいと思います。
理論的な説明を始めると難しいので、今回は実際に回路を作ってシミュレータで動かしてみる、というのを目標にやってみます。
「理解するより、まず先にやってみよう」ということですね。では、始めていきましょう。
環境
Python 3.7.3
Qiskit 0.13.0量子テレポーテーションとは?
手元にある量子状態がはるか彼方に一瞬で転送されるという現象です。
アインシュタインの相対性理論においては、光より速いものは存在しないとされています。
しかし、量子テレポーテーションでは光の速度を超えて相互作用を伝達することができるという嘘みたいなことが起こるのです。量子テレポーテーションで世界が変わる?
手元の量子状態をはるか彼方で再現できることから、何かしらの輸送問題が解決できそうにも思います。
しかし、実際は非常に小さな世界のできごとになるため、物質輸送よりは情報通信への応用が期待されます。でも応用が進んだら本当のテレポーテーションも夢じゃないかも・・・?
量子テレポーテーションの量子実験
説明はそこそにして実験開始です。
Qiskitの準備
Qiskitはpipでインストールできます。
pip install qiskit量子回路を作ってシミュレータで動かしてみる
まずはライブラリ準備から。
# ライブラリのインポート from qiskit import QuantumRegister, ClassicalRegister, BasicAerベースとなる回路を作ります。
# 古典レジスタ(回路図の下3本)を準備 cr0 = ClassicalRegister(1) cr1 = ClassicalRegister(1) cr2 = ClassicalRegister(1) # ベース回路を作る(量子レジスタ3本+古典レジスタ3本) circ = QuantumCircuit(QuantumRegister(3), cr0, cr1, cr2) # 表示確認 circ.draw(output='mpl')
できました。
回路の役割は以下のとおりです。
量子レジスタ3本目、古典レジスタ3本目がはるか彼方の転送先にあるという想定です。
続いて回路にゲートを配置していきます。
作り方は簡単で、回路上にゲートをポチポチと置いていくだけです。# 測定までの回路を作る circ.h(0) circ.h(1) circ.cx(1,2) circ.cx(0,1) circ.h(0) # 表示確認 circ.draw(output='mpl')
とても簡単ですね。
では残りの回路を作っていきます。
barrierで区切りを入れてから、またゲートをポチポチと置いていきます。
古典レジスタ(1本目と2本目)の値によって、量子レジスタ(3本目)のゲート操作が発生するため、c_ifが入ってきますが、要領は同じです。# 残りの回路を作る circ.barrier(range(3)) circ.measure(0, 0) circ.measure(1, 1) circ.z(2).c_if(cr0, 1) circ.x(2).c_if(cr1, 1) circ.measure(2, 2) # 表示確認 circ.draw(output='mpl')
とても簡単にできました、回路はこれで完成です。
量子テレポーテーションというと難しそうですが、回路表現ではたったこれだけです。では、シミュレータで動かしてみましょう。
# シミュレータで実行する backend = BasicAer.get_backend('qasm_simulator') # デフォルトで1024回実行 job = execute(circ, backend) result = job.result()これで実行完了です。
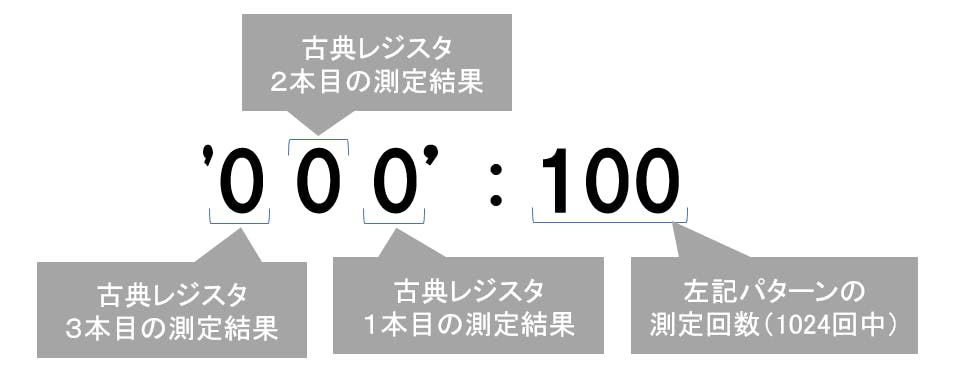
実行結果を見てみます。# 実行結果を表示、8パターンで合計1024回になる result.get_counts(circ)出力結果は以下の通り。
{'0 0 0': 100, '1 1 0': 127, '1 0 1': 147, '1 0 0': 140, '0 0 1': 131, '0 1 0': 128, '0 1 1': 131, '1 1 1': 120}見方は以下のとおりです。
実際にテレポーテーションさせるときは、量子レジスタ3本目は測定せず、そのままの状態で使います。
測定をしなければ、転送元の量子レジスタ1本目と同じ状態が量子レジスタ3本目に再現(テレポーテーション)されます。
測定をすると「重ね合わせ」状態が壊れてしまうのですが、今回は実験なので測定して本当にテレポーテーションしたのかを確認しているわけです。あれ、ちょっと待って
できあがった回路をもう一度よく見てみましょう。
転送元の古典レジスタ1本目、2本目(量子レジスタ1本目、2本目の測定結果)をもとに、転送先の量子レジスタ(3本目)のゲート操作(Z、X)をしていることが分かります。
実は、量子テレポーテーションの実現には「転送元の測定結果を転送先にお知らせする」ということが必要なんです。
どうやって伝えるのかって・・・? LINEかな。ともあれ、これをしないと「転送先の量子ビットは転送元とちょっとだけ違う状態になっていることがある」ということなんです。
量子テレポーテーションに落とし穴あり!!
おわりに
今回は解説そこそこに書いてみました。
量子コンピュータは最初の概念理解が難しいので、「まず触ってみる」というのもありだと思います。
触って学んで、理解を深めていきましょう。参考
https://qiskit.org/documentation/index.html
https://github.com/Qiskit/qiskit-iqx-tutorials/blob/master/qiskit/fundamentals/1_getting_started_with_qiskit.ipynb
https://github.com/maru-labo/ibm-q-handson/blob/master/5_ibm_q.ipynb




- 投稿日:2019-12-04T21:38:00+09:00
Pythonの高速フィボナッチ
こうです(lru_cacheをつかって)
from functools import lru_cache @lru_cache(maxsize=None) def fib(n): if n <= 1: return 1 return fib(n - 2) + fib(n - 1)こうです(自作キャッシュでメモ化して)
def fib(n): cache = {} def impl(ni): nonlocal cache if ni <= 1: return 1 if ni not in cache: cache[ni] = impl(ni - 2) + impl(ni - 1) return cache[ni] return impl(n)@shiracamusさんからのコメントを元に少し変更したもの↓
def fib(n, cache={0:1, 1:1}): if n not in cache: cache[n] = fib(n - 2) + fib(n - 1) return cache[n]⚠️これは遅いです⚠️
def fib(n): if n <= 1: return 1 return fib(n - 2) + fib(n - 1)
- 投稿日:2019-12-04T21:29:45+09:00
おひとり様カレンダーランキング【2019/12/07 01時更新】
この記事はtomowarkar ひとりAdvent Calendar 2019の7日目の記事です。
はじめに
自分と同じようにひとりでアドベントカレンダーを埋めようとしている人ってどれくらいるんだろうといった興味から、おひとり様アドベントカレンダーランキングを作ってみました。
来年はアドベントカレンダのカテゴリ別で"ひとり"みたいなものできませんかね?(需要は知らない)
ランキングの収集、記事生成、投稿は自動で行なっていますが、更新のためのコマンドを打つのは自動化していないので不定期更新となります。
カレンダー期間中は毎日更新と合わせて更新していけたらと思います。参考記事
記事投稿の自動化: Qiita API で投稿を自動化する
ノミネート対象
- Advent Calendar 2019 全体カレンダーランキングの
企業・学校・団体以外のタグ- いいね数が1以上
- 計測時時点での記事数が日数と同じ(12/7の場合7記事の投稿がある)
- カレンダーの参加者が1人
以上を満たすおひとり様アドベントカレンダーがノミネート対象です。
いいね数でのランキングを表示しています。計測、更新のタイミングによっては間違いがあるやもしれませんがその際はお伝えいただけると幸いです。
おひとり様カレンダーランキングTop10
1. ちょうぜつ Advent Calendar 2019
いいね数: 94
購読数: 60
最新の記事: マンガでわかる Adapter
2. gyu-don Advent Calendar 2019
いいね数: 38
購読数: 12
最新の記事: serde-jsonのjson!マクロを読む
3. カレー Advent Calendar 2019
いいね数: 29
購読数: 50
最新の記事: 人参を用意する
4. minato Advent Calendar 2019
いいね数: 27
購読数: 9
最新の記事: Quantum Hedge Fund / 量子ヘッジファンド
5. Minato Advent Calendar その2 Advent Calendar 2019
いいね数: 27
購読数: 9
最新の記事: ブータンで量子コンピュータのyoutubeの動画を作ってもらってる話
6. diffeasyCTO西の24(にし)日連続投稿チャレンジ Advent Calendar 2019
いいね数: 17
購読数: 11
最新の記事: Nuxt.jsとCloudFunctionsでサーバーレスアプリ開発入門編
7. iOS13、Xcode11 私はこうしてつまずいた Advent Calendar 2019
いいね数: 17
購読数: 43
最新の記事: Xcode11.0の画面収録につまずいた
8. とある英国企業におけるマイクロサービス実践例 Advent Calendar 2019
いいね数: 11
購読数: 20
最新の記事: gRPCサーバーの実装
9. Prolog Advent Calendar 2019
いいね数: 9
購読数: 17
最新の記事: Prolog でわかる TAPL 7日目 - 第Ⅲ部 部分型付け
10. tomowarkar ひとり Advent Calendar 2019
いいね数: 9
購読数: 4
最新の記事: Qiita API で投稿を自動化する
まとめ
ひとりで頑張っているカレンダーをウォッチングしていけたらなーって思います。
以上明日も頑張ります!!
tomowarkar ひとりAdvent Calendar Advent Calendar 2019
- 投稿日:2019-12-04T21:18:43+09:00
Kaggle初心者に向けたタイタニックコンペの課題
先日、Kaggleのタイタニックコンペを課題とした社内研修を行いました。
その際の説明資料と参加者にやってもらった演習を共有します。
資料と課題はKaggleのNotebookとなっていますので、興味のある方はそちらも合わせてご確認ください。ちなみにQiita初投稿です。
はじめに
なぜKaggleを選んだか
研修だけで全てを教える(学ぶ)ことはできないため、各個人で継続して取り組んでもらう必要があると考えました。
何かを学ぼうとしたときに環境構築で躓くこともあるため、それが不要となるKaggleを利用することにしました。想定した参加者
- 機械学習に興味を持っている
- Kaggleを利用したことがない
- Python未経験
研修について
研修の目標
- 機械学習の流れを体験する
- 『自分でもプログラムが書けそう』と感じてもらう
説明資料、演習課題
Kaggleを使用するので、説明資料もKaggleのNotebookとして作成しました。
説明資料:Kaggleチュートリアル『Titanic生存者予測』をやってみよう!
https://www.kaggle.com/plasticgrammer/kaggle-titanic演習課題:Titanic: Predict survivors (ΦωΦ)
https://www.kaggle.com/plasticgrammer/titanic-predict-survivors進め方
説明と演習をバランスよく組み合わせようと思い、下記の流れで進めました。
資料を使ってデータ分析まで説明
- Pythonの基本
- Kaggleの使い方、用語説明
- 機械学習の流れを確認(データ読込,データ分析)
データ分析の演習
資料を使って予測まで説明
- 前処理
- モデル作成、学習、予測
予測精度向上の課題
用意した演習
下記内容は演習用のNotebookにも記載していますが、一応こちらの記事にも記載しておきます。
データ分析
step1) データの概要を確認
- トレーニングデータとテストデータの行数、列数を確認しましょう
- トレーニングデータの先頭5件を表示してみましょう
- テストデータの先頭5件を表示してみましょう
- トレーニングデータとテストデータの違いは何でしょうか?
機械学習で生存者を予測するとは、具体的にどのようなことでしょうか?step2) データの詳細を確認
- infoメソッドでトレーニングデータの情報を表示してみましょう
- トレーニングデータの欠損値状況を確認しましょう
- テストデータの欠損値状況を確認しましょう
- ターゲット変数 Survived の値毎の件数を確認してみましょう
- 変数 Pclass にはどんな値が設定されているか確認してみましょう
- 変数 Age の分布をヒストグラムで確認してみましょう
- 変数 Age の最大値、平均値、中央値を確認してみましょう
- 変数 Sex の分布をvalue_counts+棒グラフで確認してみましょう
- pd.crosstabを使って、【Survived毎】の 変数 Sex の件数を確認してみましょう
Step3) 相関関係があるのか可視化
- 【Survived毎】の 変数 Sex の件数を棒グラフで確認してみましょう
相関関係はありそうですか?あるとしたらどのような傾向がありますか?- 【Survived毎】の 変数 Pclass の件数を棒グラフで確認してみましょう
相関関係はありそうですか?あるとしたらどのような傾向がありますか?特徴量作成および予測
前提)Age(欠損値0埋め)、Sexを使用してRandomForestで予測する流れは作成済み
- Age の欠損値を中央値で埋めてみましょう
- Fare を予測に使ってみましょう
- Embarked を予測に使ってみましょう
- SibSp+Parch+1 を FamilySize として追加してみましょう
- FamilySize<=1 を IsAlone として追加してみましょう
- Cabin の1文字目を特徴量として追加してみましょう
振り返っての反省
今回の研修は5時間で行いました。
最後に用意していた予測精度を上げる課題を進めるのに、思った以上に時間かかり、
結果として難しかったという印象を持たれてしまいました。
後日、追加研修という形で再度実施しましたが、演習多めで1つ1つじっくりと進めるのが良いと感じました。おわりに
タイタニックコンペについて書かれた記事は多く、色々と参考にさせて頂きました。
Python初心者向けの研修課題にしようとした時に、資料としてまとめることが多かったので、私も皆さんのお役に立てればと共有しました。
- 投稿日:2019-12-04T21:18:03+09:00
Pythonライブラリ bleakでWindows10/macOS/Linux上でtoioコア キューブを動かしてみる
身近にあるパソコンでtoioコア キューブを動かしてみたい
toioコア キューブはBLE通信で制御できるとてもかわいい二輪ロボットです。
https://toio.github.io/toio-spec/先日、スマホを使ってBLE通信を直につかってtoioコアキューブを動かしてみる話を書いてみましたが今回はパソコンを使ってtoioコアキューブを動かしてみます。
オフィシャルにはjavascriptおよびビジュアルプログラミングの環境が用意されています。
- ビジュアルプログラミング環境(scratch)
- JavaScriptライブラリ(node.js)
が、この記事ではpythonを使います。
ビジュアルプログラミング環境は(2019年12月10日時点で)macOS用しかリリースされていませんし、JavaScriptもnode.js、nobleのインストールが必要です。この記事の趣旨としては、身近に使えるパソコンやRaspberry Piなどをつかってサクッとtoioコアキューブを動かしたい、というものなので、インストールが比較的簡単なpythonを使う方法を紹介してみます。なお、bleakのサンプルコードがasyncioを使っているので、対応するPythonのバージョンはPython3.5以降になります。
bleakって?
Windows10/Linux/macOSで動くBLE通信Python用ライブラリです。
BLE通信用pythonライブラリはいろいろなものがありますが、Windows10、Linux(raspbian、ubuntu)、macOSの3種のOSで(ほぼ)同じように動かせるものとしてbleakを選んでみました。
その他のBLE通信pythonライブラリ
BLE直でというのはちょっとなーという場合は偉大な先人たちが作成されたtoio コアキューブ用ライブラリを使うのが良いでしょう。動作するOSなどはそれぞれの動作要件を確認してください。
- Raspberry Pi で toio コアキューブをコントロールする(2回目)~ Notifyの処理+おまけ
- Toioで遊んでみる (1)
- toio を Mac + Python で制御できるライブラリつくった
bleakのしくみ
bleakは各OSのBLE通信APIをwrapする形で実装されています。
- Windows10だと共通言語ランタイム(CLR)を使ってdllを呼び出しその中でUWP APIを呼び出して呼び出しています。
- Linuxだとbluez スタックを呼び出しています。
- macOSだとpyobjcを使ってObjective-CのCore Bluetooth APIを呼び出しています
それぞれのOSのBLE通信部を隠蔽する形でpythonライブラリ化されているので、どのOS上でも(ほぼ)同じpythonスクリプトでBLE通信をすることができるようになっています。
まー、なにはともあれやってみましょう
Windows10とmacOSにpythonをインストール
Linuxでは(だいたいは)最初からpythonが入っていますが、Windows10には入っていないので、インストールする必要があります。また、macOSはpython2.7は入っていますが、python3は入っていないのでこちらもインストールする必要があります。以下の記事が参考になります。
以下の説明ではプロンプトが「$」になっていますが、Windows10、macOS、Linuxそれぞれの環境でのプロンプトになっているものとします。動作自体はどの環境でも同じです。
bleakをインストール
- コマンドプロンプト(Windows10ならPowerShellかコマンドプロンプト(cmd.exe))、LinuxならLXterminal等、macOSならターミナルを起動)を使える状態にします。
- pipコマンドでbleakをインストールします。
$ pip install bleakしばらく待つとbleakライブラリのインストールが終わり、利用可能になります。
toioコアキューブのBLEデバイスアドレスを調べる
これはbleakのサンプルコードdiscover.pyそのまんまです。
discover.pyimport asyncio from bleak import discover async def run(): devices = await discover() for d in devices: print(d) loop = asyncio.get_event_loop() loop.run_until_complete(run())これを動かすと以下のように出力されます。
$ python3 discover.py D0:8B:7F:12:34:56: toio Core Cube B0:52:22:33:44:5A: Unknown 6E:E4:DA:12:34:55: bluetooth deviceY 63:87:F5:55:22:33: bluetooth deviceXtoio Core Cubeとあるところの6バイト16進数がデバイスアドレスになります。この値をメモしておきます。この値を後のスクリプトの中でセットします。上の実行例だと「D0:8B:7F:12:34:56」。
macOSの場合、6バイト16進数ではなく、243E23AE-4A99-406C-B317-18F1BD7B4CBEのような長いUUID文字列になります。toioコアキューブのバッテリー残量を読み取り、LEDを点灯し、モーターを回す
toioコアキューブのバッテリー残量を読み取るには、oioコアキューブに接続したあと、バッテリー(Battery Information)のキャラクタリスティック(10B20108-5B3B-4571-9508-CF3EFCD7BBAE)を読み取ります。
LEDを点灯するには、ランプ(Light Control)のキャラクタリスティック(10B20103-5B3B-4571-9508-CF3EFCD7BBAE)に書き込みます。
モーターを動かすにはモーター(Motor Control)のキャラクタリスティク(10B20102-5B3B-4571-9508-CF3EFCD7BBAE)に値を書き込みます。toioコアキューブ技術仕様書の通信仕様の「ランプ」「モーター」の例を参考に値を書き込んでみます。
read_write_sample.pyimport asyncio import platform from bleak import BleakClient # バッテリーとLEDとモーターのキャラクタリスティック BATTERY_CHARACTERISTIC_UUID = ("10b20108-5b3b-4571-9508-cf3efcd7bbae") LAMP_CHARACTERISTIC_UUID = ("10b20103-5b3b-4571-9508-cf3efcd7bbae") MOTOR_CHARACTERISTIC_UUID = ("10b20102-5b3b-4571-9508-cf3efcd7bbae") # bleakではキャラクタリスティックのUUIDは小文字で書かないとダメみたい async def run(address, loop): async with BleakClient(address, loop=loop) as client: x = await client.is_connected() #logger.info("Connected: {0}".format(x)) print("Connected: {0}".format(x)) # バッテリー残量読み取り battery = await client.read_gatt_char(BATTERY_CHARACTERISTIC_UUID) print("battery: {0}".format(int(battery[0]))) # LEDを160ミリ秒、赤に点灯 write_value = bytearray(b'\x03\x10\x01\x01\xff\x00\x00') await client.write_gatt_char(LAMP_CHARACTERISTIC_UUID, write_value) # モーター 左を前に100の速度、右を後ろに20の速度 write_value = bytearray(b'\x01\x01\x01\x64\x02\x02\x14') await client.write_gatt_char(MOTOR_CHARACTERISTIC_UUID, write_value) # 5秒後に終了 await asyncio.sleep(5.0, loop=loop) if __name__ == "__main__": address = ( # discovery.pyでみつけたtoio Core Cubeのデバイスアドレスをここにセットする "D0:8B:7F:12:34:56" # Windows か Linux のときは16進6バイトのデバイスアドレスを指定 if platform.system() != "Darwin" else "243E23AE-4A99-406C-B317-18F1BD7B4CBE" # macOSのときはmacOSのつけるUUID ) loop = asyncio.get_event_loop() loop.run_until_complete(run(address, loop))$ python read_write_sample.py Connected: True battery: 100動かすとバッテリー残量を読み取って表示した後、LEDが赤く一瞬点灯します。
その後、toioコアキューブのやや右側を中心に時計回りに回転します。
5秒後に終了します。toioコアキューブのボタン状態や読み取りセンサーの読み取るIDを通知させる
toioコアキューブのボタン状態や読み取りセンサーの読み取るIDを通知(notify)させるにはボタン(Button Information)のキャラクタリスティック(10B20107-5B3B-4571-9508-CF3EFCD7BBAE)と、読み取りセンサー(ID Information)ののキャラクタリスティック(10B20101-5B3B-4571-9508-CF3EFCD7BBAE)の通知をうけるようにします。
これはbleakのサンプルコードenable_notifications.pyを参考に、以下のようなスクリプトを書きます。
enable_button_and_id_info_notification.pyimport asyncio import platform from bleak import BleakClient # ボタンと読み取りセンサーのキャラクタリスティック BUTTON_CHARACTERISTIC_UUID = ("10b20107-5b3b-4571-9508-cf3efcd7bbae") ID_READER_CHARACTERISTIC_UUID = ("10b20101-5b3b-4571-9508-cf3efcd7bbae") # bleakではキャラクタリスティックのUUIDは小文字で書かないとダメみたい # ボタン状態の通知ハンドラ def button_notification_handler(sender, data): print("BUTTON {0}: {1}".format(sender, data)) #読み取りセンサーの通知ハンドラ def id_reader_notification_handler(sender, data): print("toio ID {0}: {1}".format(sender, data)) async def run(address, loop): async with BleakClient(address, loop=loop) as client: x = await client.is_connected() print("Connected: {0}".format(x)) # ボタン状態の通知スタート await client.start_notify(BUTTON_CHARACTERISTIC_UUID, button_notification_handler) # 読み取りセンサーの通知スタート await client.start_notify(ID_READER_CHARACTERISTIC_UUID, id_reader_notification_handler) # 10秒後に終了 await asyncio.sleep(10.0, loop=loop) # ボタン状態、読み取りセンサーの通知終了 await client.stop_notify(BUTTON_CHARACTERISTIC_UUID) await client.stop_notify(ID_READER_CHARACTERISTIC_UUID) if __name__ == "__main__": address = ( # discovery.pyでみつけたtoio Core Cubeのデバイスアドレスをここにセットする "D0:8B:7F:12:34:56" # Windows か Linux のときは16進6バイトのデバイスアドレスを指定 if platform.system() != "Darwin" else "243E23AE-4A99-406C-B317-18F1BD7B4CBE" # macOSのときはmacOSのつけるUUID ) loop = asyncio.get_event_loop() loop.run_until_complete(run(address, loop))動かしたらtoioコアキューブを持ち上げてボタンを押してみたり、トイオコレクションのマットやステッカーの上にのせてみます。
$ python enable_button_and_id_info_notification.py Connected: True toio ID 10b20101-5b3b-4571-9508-cf3efcd7bbae: bytearray(b'\x01\xa4\x01g\x01|\x00\xaf\x01e\x01|\x00') toio ID 10b20101-5b3b-4571-9508-cf3efcd7bbae: bytearray(b'\x01\xa4\x01h\x01|\x00\xaf\x01f\x01|\x00') toio ID 10b20101-5b3b-4571-9508-cf3efcd7bbae: bytearray(b'\x01\xa4\x01g\x01|\x00\xaf\x01e\x01|\x00')逐一変わる値が通知されてくるのがわかります。
実は...
実際に動作を確認できたのはWindows10(1909)とLinux(raspbian busterで、RasPi3Bと4Bで動作確認)だけです。
すみません。自分の環境ではmacOSでbleakを動かすことはできませんでした。discovery.pyは動くのですが、それ以外がさっぱり動かなかったです。(環境はMacBookPro 13inch(early2015) macOS 10.14.6(mojave))
このmacOS環境では、Linux/macOS対応をうたうAdafruitのBLEライブラリだと動くのですが、逆にこちらはraspbian busterでは動きませんでした。(bluezのバージョン違いが原因) bluezのbackendを修正すれば動くような気がしますが、原因がつかめてないのでなんとも。さいごに
小学校や中学校のパソコン部?にもありそうな身近にあるパソコンやRaspberry Piでpythonを使ってtoioコアキューブを動かして見る方法を紹介してみました。ノートPCのようにbluetoothインタフェースが内蔵されていないPCでも、USBドングル型のBluetoothインタフェースをつければ動かすことができると思います。
node.jsとnoble、scratch-linkの導入がちょっとハードルが高いという方、またWindows10は使えるが、インストールできるアプリはストアアプリに制限されているような環境でもストアアプリのpython3はインストールできてbleakが使えるので、ぜひ試してみてください。


- 投稿日:2019-12-04T21:08:03+09:00
Twitterで特定のユーザから画像を取得する
はじめに
SLP KBIT Advent Calendar 2019の記事です。
前からtwitterでの画像収集などをやってみたいと思っていたので、この機会にやってみました。
今回のプログラムは特定のアカウントのツイートから画像をダウンロードするプログラムです。環境
Python3.7.5
準備
今回twitterに上がっている画像を表示させるので、そのためのキーが必要になります。
キーの取得方法はググれば出てくるので割愛します。
tweepyを使うので、インストールしておきます。pip install tweepy取得したキーを入れるファイルを作ります。
実行ファイルと同じ場所でもいいですが、個人的にこのほうが良かったので・・・config.pyCONFIG1 = { "CONSUMER_KEY":"XXXXXXXXXXX", "CONSUMER_SECRET":"XXXXXXXXXXXX", "ACCESS_TOKEN":"XXXXXXXXXXXXXXXXXXX", "ACCESS_SECRET":"XXXXXXXXXXXXXXXXX", }画像取得
必要なものをインポートし、config.pyからキーを持ってきます。
下から3行はAPIを使うために必要です。twitter.pyimport tweepy from config import CONFIG import urllib.request import re CONSUMER_KEY = CONFIG["CONSUMER_KEY"] CONSUMER_SECRET = CONFIG["CONSUMER_SECRET"] ACCESS_TOKEN = CONFIG["ACCESS_TOKEN"] ACCESS_SECRET = CONFIG["ACCESS_SECRET"] auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET) api = tweepy.API(auth)プログラム全体
ターミナル上で動くプログラムで、IDを与えると、そのIDのアカウントからツイートを取得し、画像ツイートがあった場合、ダウンロードするものである。
twitter.pyimport tweepy from config import CONFIG2 import urllib.request import re CONSUMER_KEY = CONFIG["CONSUMER_KEY"] CONSUMER_SECRET = CONFIG["CONSUMER_SECRET"] ACCESS_TOKEN = CONFIG["ACCESS_TOKEN"] ACCESS_SECRET = CONFIG["ACCESS_SECRET"] auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET) api = tweepy.API(auth) #キーワードで検索 def log(user_name, count, id): result_url = [] for i in range(0, 2): results = api.user_timeline(screen_name=user_name, count=count, max_id=id) id = results[-1].id for result in results: if 'media' in result.entities: judg = 'RT @' in result.text if judg == False: for media in result.extended_entities['media']: result_url.append(media['media_url']) return result_url def extract_pic_file(image_url): m = re.search(r"(([A-Za-z0-9]|_)+\.(png|jpg))", image_url) if m: name = 'img_dl/' + m.group(0) else: name = 'img_dl/None.png' return name def save_image(url, name): count = 1 for image_url in url: file_name = extract_pic_file(image_url) urllib.request.urlretrieve(image_url, file_name) count += 1 def fast(user_name): results = api.user_timeline(screen_name=user_name, count="1") for result in results: id = result.id return id def start(): count = 100 user_name = input("IDを入力>>") id = fast(user_name) url = log(user_name, count, id - 1) save_image(url, user_name) if __name__ == "__main__": start()流れ
log関数によってURLを取得し、save_image関数で指定したフォルダに画像を保存する。
関数の説明
log関数
アカウントID、取得ツイート数、ツイートIDを引数として受け取ります。
resultsをfor文で渡していきます。画像のURLはjsonのような形で格納されているので、それを取り出し、result_urlに格納します。それを返り値にします。
今回リツイートした画像は取得したくないので、if文で除外するようにしています。sava_image
名前の通り、画像を保存する関数になります。その際、URLでは保存するときにエラーが出るので、extract_pic_file関数を呼び出して、ファイル名を変換します。
extract_pic_file関数
正規表現を用いて、画像のファイル名をURLから決めている。こうすることで、同じアカウントから画像を取得する際に、画像が被ることを防ぎます。
fast関数
例外処理のための処理である。
これが必要な理由は、log関数はツイートのIDを引数として受け取り、そのツイートより過去のツイートを取得するようになっている。そのため、初めの例外処理が必要となる。終わりに
人にわかりやすく書くのは苦手ですね。
自分は関数の中で何が行われているかが書いていたほうが、わかりやすいと感じたので、関数ごとの説明を書きました。
- 投稿日:2019-12-04T21:07:45+09:00
djangoでホームページを作成
今まで何度も作ってはまた作り直してを繰り返してその度いろんなところをググったりするので、
さすがに備忘録を残しておこうかなと。ちなみに内容はほぼ、
https://qiita.com/noraricl/items/08937a508a2abecc7179
にかかれてある通りになります。(超簡単なミニマムなページを作りたかったのですごく助かりました・・・)環境設定
pyenvとvirtualenvで3.6.1のバージョンからrate-siteという仮想環境を作っていますが、僕以外の方はここはスルーして大丈夫です。
mkdir rate_site cd rate_site pyenv virtualenv 3.6.1 rate-site pyenv local rate-site以下の、
requirements.txtを作成。dj-database-url==0.5.0 dj-static==0.0.6 Django==2.2.6 django-heroku==0.3.1 gunicorn==20.0.0 mysqlclient==1.4.4 psycopg2==2.8.4 PyMySQL==0.9.3 python-dateutil==2.8.1 pytz==2019.3 six==1.13.0 sqlparse==0.3.0 static3==0.7.0 whitenoise==4.1.4そして、
pip install -r requirements.txtで必要なものをインストール。
※
requirements.txtを作成したディレクトリ(rate_site) がgitで管理する一番トップでディレクトリになる。プロジェクトとアプリケーション作成
mkdir rate_site # 今いるrate_site内でもう一個作る cd rate_site django-admin startproject rate_site . python manage.py startapp rate_hp設定ファイル編集
rate_site/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rate_hp', #追加 ] (省略) LANGUAGE_CODE = 'ja' #変更 TIME_ZONE = 'Asia/Tokyo' #変更 (省略) USE_TZ = False #変更migrateする
python manage.py migrate管理者ユーザ作成
python manage.py createsuperuser起動確認
python manage.py runserverにアクセスするとdjangoでデフォルトのページが表示される。
rate_hp にアクセスできるようにする
rate_site/urls.pyfrom django.urls import path, include #追加 urlpatterns = [ path('admin/', admin.site.urls), path('', include('rate_hp.urls')), #追加 ]HTMLファイル作成
rate_siteやrate_hpがあるディレクトリ内に、
templatesディレクトリを作成し、templates/base.html<html> <head> <title>ホームページ</title> </head> <body> <p>ここがbase.htmlです。</p> {% block main_containts %} {% endblock %} <p>ここがbase.htmlです。</p> </body> </html>templates/index.html{% extends "base.html" %} {% block main_containts %} {% load static %} <main> ここがindex.htmlです。 </main> {% endblock %}rate_hpの中のファイルを編集していく。
rate_hp/views.pyfrom django.shortcuts import render from django.http import HttpResponse from django.template import Context, loader def index(request): template = loader.get_template('index.html') context = {} return HttpResponse(template.render(context, request))
urls.pyは存在しないので、新規作成rate_hp/urls.pyfrom django.urls import path from . import views app_name = 'rate_hp' #django2.0から必要になったnamespace定義 urlpatterns = [ path('', views.index, name='index'), ]先程作ったtemplatesをdjangoが読み込むようにする。
rate_site/settings.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': ['templates'], # 追加 'APP_DIRS': True,ここでもっかい、
python manage.py runserverを実行して、
http://127.0.0.1:8000/
にアクセスする。いったん完了
一応今後は、ここのホームに対して新しく作ったアプリケーションだとかをどんどん追加していって、アクセスできるようにしていく想定。
- 投稿日:2019-12-04T20:17:33+09:00
GitLab CIのRunnerで、手元のDockerイメージを使用してコンテナ内でテストを行う(git push後の自動実行 & git push前にローカルで手動実行)
この記事で行うこと
- PythonコードをDockerコンテナ内でテストします。
- CI(継続的インテグレーション)として、GitLab CIを使用します。
- gitサーバーとして、オンプレのGitLabを使用します。今回はローカルにDockerで導入します。
- git push時にGitLabサーバーが自動で走らせるテストに加えて、git push前にローカルでも手動でテストできるようにします。
- GitLab Runnerは2つ導入します。(1)ローカルでの手動実行用にホストに直接インストール、(2)git push後の自動実行用にDockerコンテナを起動。
- テストに使用するDockerコンテナは、都度イメージをdocker pullするのではなく、手元にある構築済のイメージを使用して起動します。
- GitLab RunnerとテストをDockerコンテナ内で動かす理由は、将来GitLabをローカルでなくリモートサーバーで動かす時に、GitLab Runnerとテストの環境もそのままクラウド等に移行させたいからです。
- コンテナからコンテナを操作する時は、DooD(Docker outside of Docker)を使用します。DooDの使用には注意が必要だそうですが(Dockerコンテナ内からホストマシンのルートを取る具体的な方法(あるいは/var/run/docker.sockを晒すことへの注意喚起))、本記事ではとりあえず使います。
参考ページ(全部読めていませんが、感謝します)
Gitlab CIでDockerベースのサービス開発のCI環境を作る
GitLab CIでテスト・ビルド・デプロイを自動化する
Dockerコンテナ内からホストマシンのルートを取る具体的な方法(あるいは/var/run/docker.sockを晒すことへの注意喚起)
GitLab-CIのRunnerでDockerのローカルイメージを使う
Self-Managed な社内 Gitlab をhttps化 したら Gitlab Runnerがうまく動かなかった件GitLabの導入とプロジェクト作成
では作業を開始します。
gitサーバーとして、オンプレのGitLabを使用します。今回は手っ取り早くDockerでローカルに導入します。
端末で適当なディレクトリに移動後、以下を実行します。git clone https://github.com/sameersbn/docker-gitlab cd docker-gitlab docker-compose up -dMacを使っている場合、以下のようなエラーが出ることがあります。
対処として、docker-compose.ymlを編集し、「/srv/docker」をOSユーザーがアクセスできるディレクトリに変更するのが手っ取り早いでしょう。ERROR: for docker-gitlab_redis_1 Cannot start service redis: b'Mounts denied: \r\nThe path /srv/docker/gitlab/redis\r\nis not shared from OS X and is not known to Docker.\r\nYou can configure shared paths from Docker -> Preferences... -> File Sharing.\r\nSee https://docs.docker.com/docker-for-mac/osxfs/#namespaces for morRecreating docker-gitlab_postgresql_1 ... errorコンテナ立ち上げ後に「docker-compose ps」を実行すると、以下のように表示されました。
Name Command State Ports --------------------------------------------------------------------------------------------------------------------------- docker-gitlab_gitlab_1 /sbin/entrypoint.sh app:start Up 0.0.0.0:10022->22/tcp, 443/tcp, 0.0.0.0:10080->80/tcp docker-gitlab_postgresql_1 /sbin/entrypoint.sh Up 5432/tcp docker-gitlab_redis_1 /sbin/entrypoint.sh --logl ... Up 6379/tcpGitLabコンテナのhttpポートが10080ですので、ブラウザで http://localhost:10080/ にアクセスします。
下の画面が出たら、rootのパスワードを変更します。
下の画面に行き、開発ユーザーを作成します。
開発ユーザーでログインできたら、下の画面からCreate a projectを選択します。
本記事ではPythonソースコードとして、書籍「テスト駆動Python」に記載のサンプルコード のch1を使用します(感謝します)。
それにちなんで、プロジェクト名を「bopytest_ch1」としましたが、名前は何でも良いです。
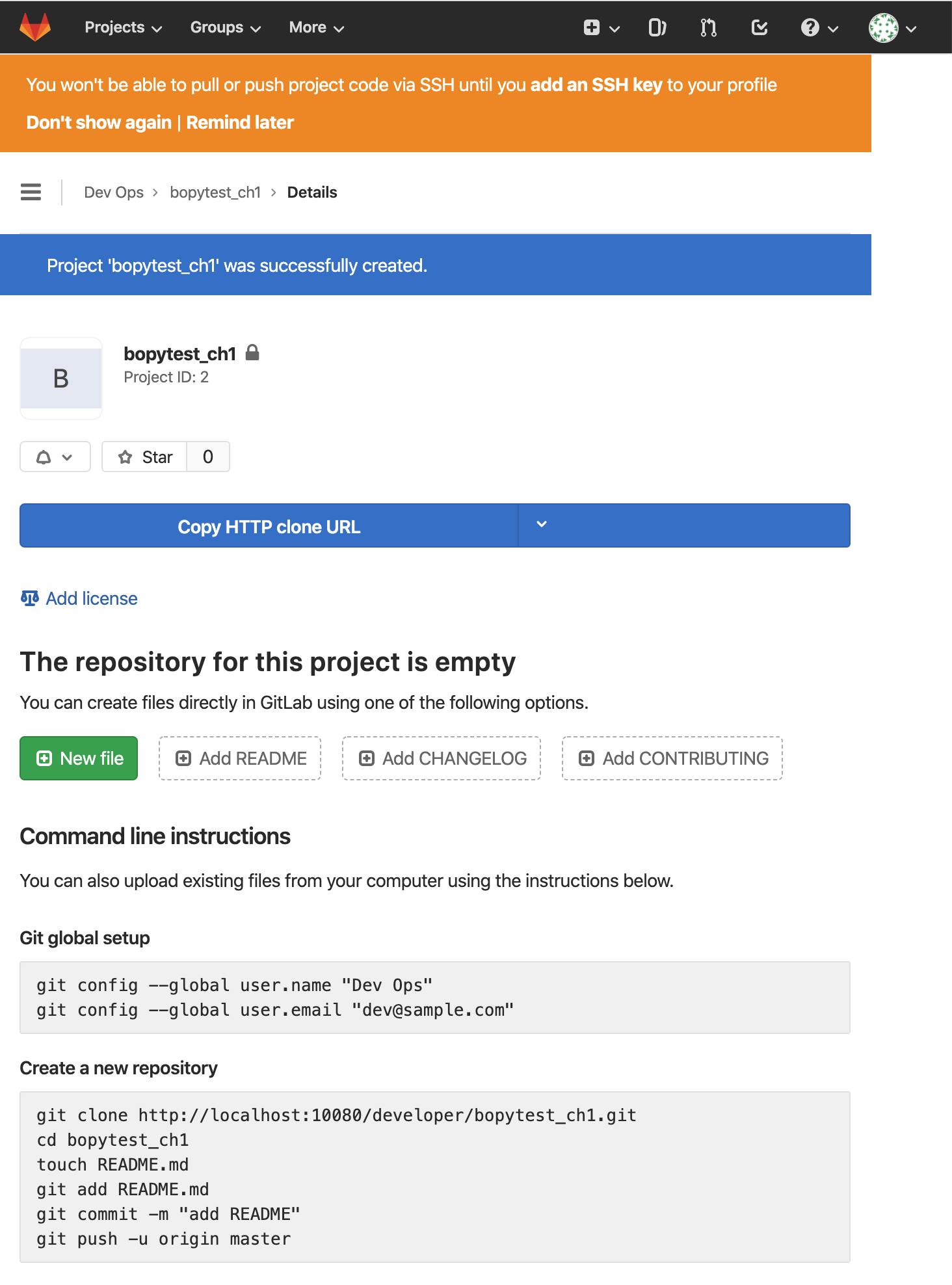
Create projectボタンを押してプロジェクトを作成します。
以下のように、プロジェクトが作成されました。
ローカルでソースコードの準備
端末で適当なディレクトリに移動し、以下を実行して先程作った空のプロジェクトをgit cloneします。
git clone http://localhost:10080/developer/bopytest_ch1.git cd bopytest_ch1ソースファイルの置き場所として行儀が悪いかもしれませんが、bopytest_ch1ディレクトリ(gitリポジトリのルート)の下に、以下の内容でソースファイルを作ってしまいます。
test_one.pydef test_passing(): assert (1, 2, 3) == (1, 2, 3)以下のように、pipenv等でpytestをインストールします。
pipenvでの初回インストールなので、同時にvirtual environmentも作成されました。pipenv install pytest自動生成されたPipfileは以下の通りです。
[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] pytest = "*" [requires] python_version = "3.7"試しにpytestでテストしてみます。
pipenv run pytest -v test_one.py以下のようにテストが通りました。
===================================== test session starts ====================================== platform darwin -- Python 3.7.4, pytest-5.3.1, py-1.8.0, pluggy-0.13.1 -- /Users/username/.local/share/virtualenvs/bopytest_ch1-KFvVvv1C/bin/python3 cachedir: .pytest_cache rootdir: /Users/username/PycharmProjects/bopytest_ch1 collected 1 item test_one.py::test_passing PASSED [100%] ====================================== 1 passed in 0.01s =======================================test_one.pyはもう変更しませんので、git commitしておきます。
git add test_one.py git commit -m "test_one.py 完成"テスト実行用のDockerイメージをローカルで作成
行儀が悪いかもしれませんが、同じディレクトリ(gitリポジトリのルート)の下にDockerfileも作ってしまいます。
ここからリンクされているDockerfile を見ながら、以下の内容で作成しました。FROM python:3-alpine RUN apk update \ && pip install --upgrade pip \ && python3 -m pip install pytest pytest-cov CMD ["python3"]引き続き、Dockerイメージをビルドします。イメージ名を「bopytest_ch1」としましたが、名前は何でも良いです。
docker build -t bopytest_ch1 .以下のように表示されて、Dockerイメージが作成されました。
Sending build context to Docker daemon 52.22kB Step 1/3 : FROM python:3-alpine ---> 59acf2b3028c Step 2/3 : RUN apk update && pip install --upgrade pip && python3 -m pip install pytest pytest-cov ---> Running in 08917176ca6d fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/main/x86_64/APKINDEX.tar.gz fetch http://dl-cdn.alpinelinux.org/alpine/v3.10/community/x86_64/APKINDEX.tar.gz v3.10.3-71-g50e386f088 [http://dl-cdn.alpinelinux.org/alpine/v3.10/main] v3.10.3-68-ge1e42c5d6c [http://dl-cdn.alpinelinux.org/alpine/v3.10/community] OK: 10342 distinct packages available Requirement already up-to-date: pip in /usr/local/lib/python3.8/site-packages (19.3.1) Collecting pytest Downloading https://files.pythonhosted.org/packages/da/ed/d22d7f06eb1107271694ed2171b9d52e8eea38d9757124e75ba13324ac77/pytest-5.3.1-py3-none-any.whl (233kB) Collecting pytest-cov Downloading https://files.pythonhosted.org/packages/b9/54/3673ee8be482f81527678ac894276223b9814bb7262e4f730469bb7bf70e/pytest_cov-2.8.1-py2.py3-none-any.whl Collecting py>=1.5.0 Downloading https://files.pythonhosted.org/packages/76/bc/394ad449851729244a97857ee14d7cba61ddb268dce3db538ba2f2ba1f0f/py-1.8.0-py2.py3-none-any.whl (83kB) Collecting pluggy<1.0,>=0.12 Downloading https://files.pythonhosted.org/packages/a0/28/85c7aa31b80d150b772fbe4a229487bc6644da9ccb7e427dd8cc60cb8a62/pluggy-0.13.1-py2.py3-none-any.whl Collecting wcwidth Downloading https://files.pythonhosted.org/packages/7e/9f/526a6947247599b084ee5232e4f9190a38f398d7300d866af3ab571a5bfe/wcwidth-0.1.7-py2.py3-none-any.whl Collecting packaging Downloading https://files.pythonhosted.org/packages/cf/94/9672c2d4b126e74c4496c6b3c58a8b51d6419267be9e70660ba23374c875/packaging-19.2-py2.py3-none-any.whl Collecting more-itertools>=4.0.0 Downloading https://files.pythonhosted.org/packages/5c/1d/3df99de956abb96305956e09e6a1fa955883295e1f28808f9c97b3d5364d/more_itertools-8.0.0-py3-none-any.whl (40kB) Collecting attrs>=17.4.0 Downloading https://files.pythonhosted.org/packages/a2/db/4313ab3be961f7a763066401fb77f7748373b6094076ae2bda2806988af6/attrs-19.3.0-py2.py3-none-any.whl Collecting coverage>=4.4 Downloading https://files.pythonhosted.org/packages/85/d5/818d0e603685c4a613d56f065a721013e942088047ff1027a632948bdae6/coverage-4.5.4.tar.gz (385kB) Collecting pyparsing>=2.0.2 Downloading https://files.pythonhosted.org/packages/c0/0c/fc2e007d9a992d997f04a80125b0f183da7fb554f1de701bbb70a8e7d479/pyparsing-2.4.5-py2.py3-none-any.whl (67kB) Collecting six Downloading https://files.pythonhosted.org/packages/65/26/32b8464df2a97e6dd1b656ed26b2c194606c16fe163c695a992b36c11cdf/six-1.13.0-py2.py3-none-any.whl Building wheels for collected packages: coverage Building wheel for coverage (setup.py): started Building wheel for coverage (setup.py): finished with status 'done' Created wheel for coverage: filename=coverage-4.5.4-cp38-none-any.whl size=170507 sha256=d3665a3a0effbdc986e7cc706bba755367bf179f9474e808c5a7ea78c2c514fa Stored in directory: /root/.cache/pip/wheels/3d/78/f3/27ada0157c9551bcc19de14154a4a83db09bbe275c6765f283 Successfully built coverage Installing collected packages: py, pluggy, wcwidth, pyparsing, six, packaging, more-itertools, attrs, pytest, coverage, pytest-cov Successfully installed attrs-19.3.0 coverage-4.5.4 more-itertools-8.0.0 packaging-19.2 pluggy-0.13.1 py-1.8.0 pyparsing-2.4.5 pytest-5.3.1 pytest-cov-2.8.1 six-1.13.0 wcwidth-0.1.7 Removing intermediate container 08917176ca6d ---> 4793ce025832 Step 3/3 : CMD ["python3"] ---> Running in d89f321e7c73 Removing intermediate container d89f321e7c73 ---> 8d7b94c4ea9a Successfully built 8d7b94c4ea9a Successfully tagged bopytest_ch1:latestGitLab CIの設定ファイル「.gitlab-ci.yml」の準備
同じディレクトリ(gitリポジトリのルート)の下に、以下の内容で.gitlab-ci.ymlを作成します。
gitlab-ci.ymlimage: bopytest_ch1 test: stage: test tags: - docker script: - pytest -vローカルでテストの手動実行(Mac使用)
GitLab Runnerを使用して、ローカルでテストを手動実行してみます。
本記事ではMacを使用していますので、以下のようにMacに直にGitLab Runnerをインストールしました。
各OSへのインストール方法は こちら。brew install gitlab-runnergit commitされているけど、git pushされていない状態で、GitLab Runnerを起動してみます。
gitlab-runnerコマンドのdocker-pull-policyオプションで「if-not-present」を指定し、先程作成した手元のDockerイメージを使用してテストが行われるようにします。
参考:GitLab-CIのRunnerでDockerのローカルイメージを使うgitlab-runner exec docker test --docker-pull-policy "if-not-present"以下のようにテストが通りました。
手元のDockerイメージ「bopytest_ch1」が使用され、そのコンテナ内でテストが実行されていることがわかります。Runtime platform arch=amd64 os=darwin pid=3583 revision=577f813d version=12.5.0 fatal: ambiguous argument 'HEAD~1': unknown revision or path not in the working tree. Use '--' to separate paths from revisions, like this: 'git <command> [<revision>...] -- [<file>...]' Running with gitlab-runner 12.5.0 (577f813d) Using Docker executor with image bopytest_ch1 ... Using locally found image version due to if-not-present pull policy Using docker image sha256:8d7b94c4ea9a5cf5cf70191cc2f39b21a7f0ea670cc4b6ea66529d4b27e4eeeb for bopytest_ch1 ... Running on runner--project-0-concurrent-0 via Foo.local... Fetching changes... Initialized empty Git repository in /builds/project-0/.git/ Created fresh repository. From /Users/username/PycharmProjects/bopytest_ch1 * [new branch] master -> origin/master Checking out fd44bd91 as master... Skipping Git submodules setup $ pytest -v ============================= test session starts ============================== platform linux -- Python 3.8.0, pytest-5.3.1, py-1.8.0, pluggy-0.13.1 -- /usr/local/bin/python3 cachedir: .pytest_cache rootdir: /builds/project-0 plugins: cov-2.8.1 collecting ... collected 1 item test_one.py::test_passing PASSED [100%] ============================== 1 passed in 0.02s =============================== Job succeededgit push後のテストの自動実行
引き続き、git push時にGitLabサーバーが自動でテストを走らせるようにします。
まず、GitLab Runnerを設定するためにトークンが必要ですので、GitLabから取得します。
以下のように、ブラウザでbopytest_chプロジェクトに入り、Settings → CI/CD を選択します。
RunnersのExpandボタンを押します。
「Set up a specific Runner manually」の部分にトークンが表示されていますので、クリップボードにコピーします。
本記事で使用するGitLab Runnerのトークンは「JkxKzm4sWNzE4KKG_Wgx」です。
先ほど、ローカルでのテスト手動実行用に、Macに直にGitLab Runnerをインストールして実行しました。
それとは別に、GitLabサーバーに自動実行してもらうGitLab RunnerをDockerで起動します。
端末で適当なディレクトリの下に「gitlab_runner/bopytest_ch1」サブディレクトリを作成することにします。mkdir -p gitlab_runner/bopytest_ch1 cd gitlab_runner/bopytest_ch1そのディレクトリ配下に、以下の内容でdocker-compose.ymlを作成します。
volumesの「/var/run/docker.sock:/var/run/docker.sock」の部分は、DooD(Docker outside of Docker)を使用するために必要な設定です。DooD参考:Building Docker images with GitLab CI/CD
docker-compose.ymlversion: '3' services: runner: image: gitlab/gitlab-runner restart: always volumes: - /var/run/docker.sock:/var/run/docker.sock - ./config:/etc/gitlab-runner以下を実行して、GitLab RunnerのDockerコンテナを起動します。
docker-compose up -d以下を実行して、GitLab RunnerをGitLabに登録します。
今回、GitLabサーバーのIPアドレスは「 http://localhost:10080/ 」でした。
また、本記事の環境では、Dockerコンテナ内からホスト(localhost)に「172.17.0.1」でアクセスできています。オプション説明:
- url:GitLabサーバーのアドレス
- clone-url:git cloneする時にアクセスされるgitサーバーのアドレス
- registration-token:GitLabから取得したトークン
- name:任意の名前
- executor:今回はDockerコンテナ内でテストジョブを動かす
- docker-image:テストを動かすDockerイメージ
- tag-list:.gitlab-ci.ymlのtagsに紐付け
- docker-volumes:今回はDooD(Docker outside of Docker)を使用するために必要な設定を入れている
- docker-pull-policy:都度docker pullするのではなく、手元にDockerイメージがあればそれを使用
オプション参考:
Self-Managed な社内 Gitlab をhttps化 したら Gitlab Runnerがうまく動かなかった件
Building Docker images with GitLab CI/CD
GitLab-CIのRunnerでDockerのローカルイメージを使うdocker-compose exec runner gitlab-runner register -n \ --url "http://172.17.0.1:10080/" \ --clone-url "http://172.17.0.1:10080/" \ --registration-token "JkxKzm4sWNzE4KKG_Wgx" \ --name bopytest-ch1-runner \ --executor "docker" \ --docker-image "bopytest_ch1" \ --tag-list docker \ --docker-volumes "/var/run/docker.sock:/var/run/docker.sock" \ --docker-pull-policy "if-not-present"以下のように表示されて、GitLab Runnerの登録が成功しました。
Runtime platform arch=amd64 os=linux pid=14 revision=577f813d version=12.5.0 Running in system-mode. Registering runner... succeeded runner=JkxKzm4s Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!また、configディレクトリ配下にconfig.tomlが以下の内容で生成されました。
config/config.tomlconcurrent = 1 check_interval = 0 [session_server] session_timeout = 1800 [[runners]] name = "bopytest-ch1-runner" url = "http://172.17.0.1:10080/" token = "ypQHT_M7UcY74iHdb9ZQ" executor = "docker" clone_url = "http://172.17.0.1:10080/" [runners.custom_build_dir] [runners.docker] tls_verify = false image = "bopytest_ch1" privileged = false disable_entrypoint_overwrite = false oom_kill_disable = false disable_cache = false volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"] pull_policy = "if-not-present" shm_size = 0 [runners.cache] [runners.cache.s3] [runners.cache.gcs]ブラウザでRunnersを再表示させると、以下のように下方の「Runners activated for this project」の部分に、先程登録したbopytest-ch1-runnerが見つかりました。
それではgit pushしてテストが自動実行されるか確かめてみます。
自動実行のために、ファイル「.gitlab-ci.yml」をリポジトリに追加する必要があります。
以下のようにgit pushまで実行します。git add .gitlab-ci.yml git commit -m ".gitlab-ci.yml 新規" git pushGitLabサーバーが自動でテストを走らせたか確認します。
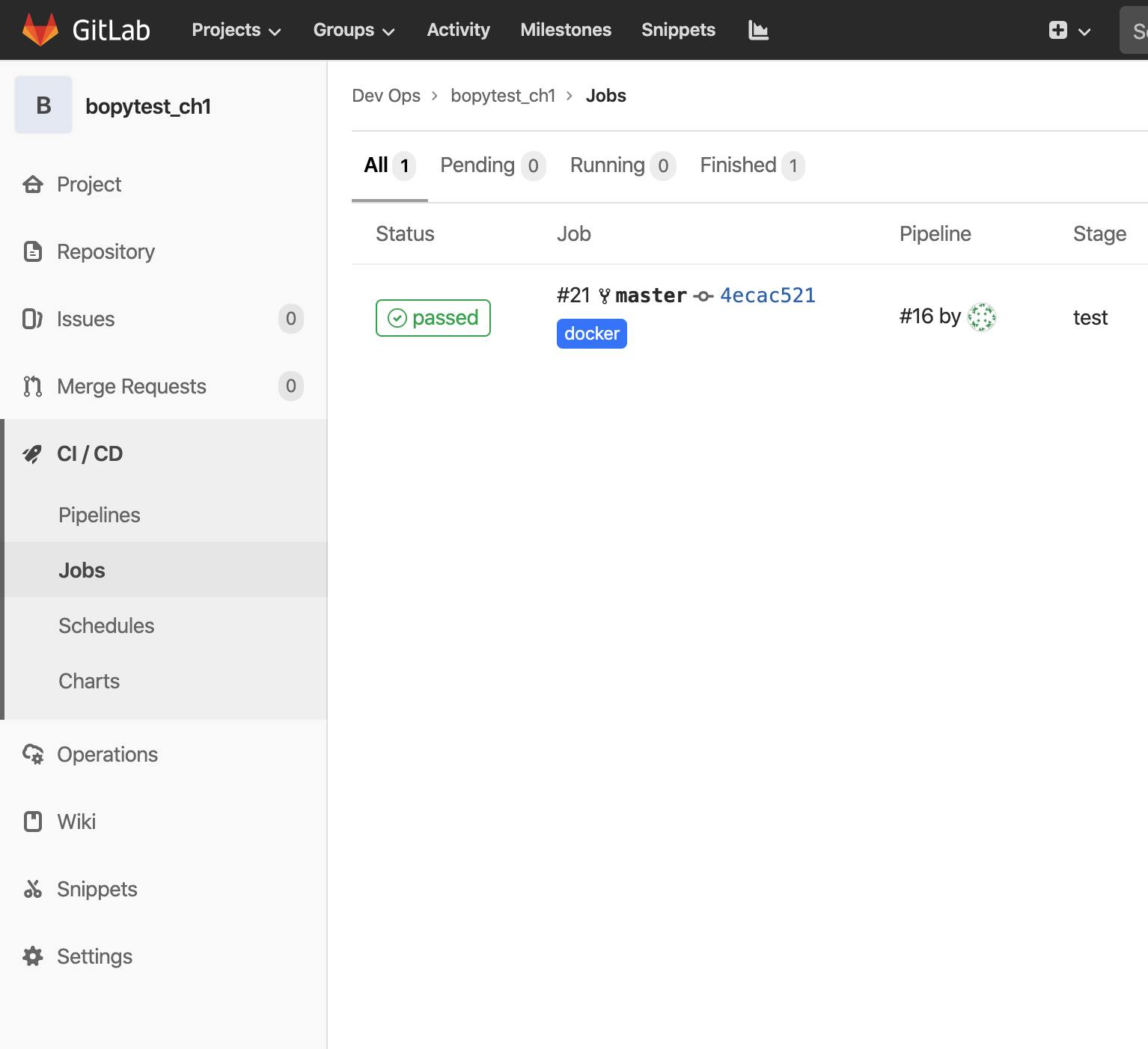
以下のようにbopytest_chプロジェクトに入り、CI/CD → Pipelines を選択します。
以下のように表示されました。テストが自動実行され、Statusはpassedになっていました。
テストジョブがコンソールに出力したメッセージを見るために、CI/CD → Jobs を選択します。
Statusのpassedの部分をクリックすると、以下のようにコンソール出力が見られます。
一度エラーが発生していますが(赤字)、その後リトライしてテストが通っています。
メッセージを読むと、登録したGitLab Runner「bopytest-ch1-runner」が使用され、手元のテスト用Dockerイメージ「bopytest_ch1」も使用され、そのコンテナ内でテストが通ったことが確認できます。
メッセージのコピペは以下の通り。Running with gitlab-runner 12.5.0 (577f813d) on bopytest-ch1-runner ypQHT_M7 Using Docker executor with image bopytest_ch1 ... ERROR: Preparation failed: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? (cache_container.go:111:141s) Will be retried in 3s ... Using Docker executor with image bopytest_ch1 ... Using locally found image version due to if-not-present pull policy Using docker image sha256:8d7b94c4ea9a5cf5cf70191cc2f39b21a7f0ea670cc4b6ea66529d4b27e4eeeb for bopytest_ch1 ... Running on runner-ypQHT_M7-project-2-concurrent-0 via a211f459e198... Fetching changes with git depth set to 50... Initialized empty Git repository in /builds/developer/bopytest_ch1/.git/ Created fresh repository. From http://172.17.0.1:10080/developer/bopytest_ch1 * [new branch] master -> origin/master Checking out 4ecac521 as master... Skipping Git submodules setup $ pytest -v ============================= test session starts ============================== platform linux -- Python 3.8.0, pytest-5.3.1, py-1.8.0, pluggy-0.13.1 -- /usr/local/bin/python3 cachedir: .pytest_cache rootdir: /builds/developer/bopytest_ch1 plugins: cov-2.8.1 collecting ... collected 1 item test_one.py::test_passing PASSED [100%] ============================== 1 passed in 0.04s =============================== Job succeeded以上です。









- 投稿日:2019-12-04T20:12:19+09:00
googletransを使ってDiscordで動く翻訳BOTを作ってみた
まえがき
なんか唐突に英文を翻訳したくなったんですが、PCでchromeをつけてgoogle翻訳ひらいて文字打つのが面倒くさく感じました。
しかしDiscordはなぜか常についているので、じゃあDiscordの翻訳BOTを使おうと思ったんですが、そのままダウンロードするのはなんか違う気がしたので、じゃあ作ろうと思い立ちここに至りました。
人生二作目のBOTです。やりたいこと
- 日本語を英語に翻訳してくれる
- 英語を日本語に翻訳してくれる
- 日本語以外の言語を指定なしに日本語に翻訳してくれる
- 言語の指定をすれば任意語から任意語に翻訳してくれる
できたもの
!trans [日本語以外の文字列]で日本語に翻訳する!trans [日本語の文字列]で日本語を英語に翻訳する!trans [言語名A]-[言語名B]-[A語の文字列]でA語をB語に翻訳する!detect [任意の文字列]でその文字列の言語コードを取得する環境
- Windows10
- Discord.py 1.2.3
- Python 3.7.3
- googletrans 2.4.0
事前準備
- Pythonを使える環境
- Pythonの基礎的な知識
- botの簡単な作り方
ここがわかりやすいです。
Pythonで簡単なDiscord Botの作り方
Discord Bot 最速チュートリアル【Python&Heroku&GitHub】googletransとは
Google翻訳のAPIを利用して翻訳したり言語の検出をしたりできる無料のライブラリです。
しかし安定性があまり良くなく、Googleにいつブロックされてもおかしくないので、安定性が欲しいのであればGoogle Cloudの正式なAPIを使用することをお勧めします。インストール
pip install googletrans
でインストールできます。
Successfully installed googletrans-(任意のバージョン)
が出たら完了です。コード例
例として日本語を英語に変換するプログラムを作ってみます。
trans_test.pyfrom googletrans import Translator translator = Translator() japanese = translator.translate('おはようございます。') print(japanese.text) #>> Good morning.またtranslete()で返される値はtext以外にも変換元の言語や変換後の言語などがあります。
trans_test.pyfrom googletrans import Translator translator = Translator() japanese = translator.translate('おはようございます。') print(japanese) #>> Translated(src=ja, dest=en, text=Good morning., pronunciation=None, extra_data="{'translat...")言語検出をするにはdetect()のカッコの中に検出したい文章や単語を入れます。
trans_test.pyfrom googletrans import Translator translator = Translator() detect = translator.detect('おはようございます。') print(detect) #>> Detected(lang=ja, confidence=1.0)langの後の英語二文字で表されてるのが言語名、confidenceは確度を表しています。
なんて便利なライブラリ!!
今回はこのライブラリを使って翻訳BOTを作ります。BOTの作成
まずできたものを下に置きます。
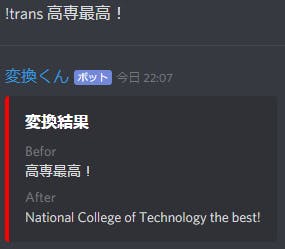
main.pyimport discord from googletrans import Translator TOKEN = 'トークンは伏せます' client = discord.Client() translator = Translator() @client.event async def on_ready(): print('--------------') print('ログインしました') print(client.user.name) print(client.user.id) print('--------------') @client.event async def on_message(message): if message.author.bot: return if message.content.startswith('!trans'): say = message.content say = say[7:] if say.find('-') == -1: str = say detact = translator.detect(str) befor_lang = detact.lang if befor_lang == 'ja': convert_string = translator.translate(str, src=befor_lang, dest='en') embed = discord.Embed(title='変換結果', color=0xff0000) embed.add_field(name='Befor', value=str) embed.add_field(name='After', value=convert_string.text, inline=False) await message.channel.send(embed=embed) else: convert_string = translator.translate(str, src=befor_lang, dest='ja') embed = discord.Embed(title='変換結果', color=0xff0000) embed.add_field(name='Befor', value=str) embed.add_field(name='After', value=convert_string.text, inline=False) await message.channel.send(embed=embed) else: trans, str = list(say.split('=')) befor_lang, after_lang = list(trans.split('-')) convert_string = translator.translate(str, src=befor_lang, dest=after_lang) embed = discord.Embed(title='変換結果', color=0xff0000) embed.add_field(name='Befor', value=str) embed.add_field(name='After', value=convert_string.text, inline=False) await message.channel.send(embed=embed) if message.content.startswith('!detect'): say = message.content s = say[8:] detect = translator.detect(s) m = 'この文字列の言語はたぶん ' + detect.lang + ' です。' await message.channel.send(m) client.run(TOKEN)複雑に見えるかどうかはわかりませんが、やっていることはとても単純です。
①
!trans ~
から始まる命令の時、命令の!transと半角一文字分を命令から取り除く。
↓
detect()でその文章の言語を検出。
↓
その言語が日本語なら英語に、それ以外なら日本語に翻訳する。②(すでに!trans は取り除かれているとして)
!trans [A]-[B]-[C]
の命令の時、Aを変換前の言語名、Bを変換後の言語名、Cを文字列とする。
↓
A、B、CからCをBの言語に翻訳する。③
!detect ~
ではじまる命令の時、命令の!detectと半角一文字分を命令から取り除く。
↓
detect()でその文章の言語を検出して出力全体的な動きは以上です。
いろんなところでembed~と書いてあるところがありますが、これはDiscordで発言させるときに埋め込みで発言させるために必要なところです。埋め込みの方が見やすそう。結果
翻訳する内容に他意はないです。適当に選んでます。
日本語から英語へ
英語から日本語へ
ドイツ語から日本語へ
日本語からドイツ語へ
言語検出
日本語
フランス語
やろうとしてたことは全部実装できました!
おわりに・感想
翻訳の出来はgoogle翻訳には劣ると思いますが、やろうとしてたことはできたので満足です。
まだまだやっていることは初歩なので、これからボイスチャット関係であったり、メンバーの取得、Webスクレイピングと組み合わせたりとやりたいことは山積みです。みんなもBOTつくるのたのしいからつくろう!!
なにか間違いだったり改善点があれば気軽にTwitterでもなんでも言ってくれればなと思います。





- 投稿日:2019-12-04T18:52:00+09:00
[最適化問題]Optuna vs Hyperopt
はじめに
最適化フレームワークとして、OptunaとHyperoptがあります。一体どちらが優れているのか気になったので、関数最適化問題を使って比較してみようと思います。
2つのフレームワークに関しては別記事で紹介しているので、そちらを参考にしてください。
Optunaを使って関数最適化をしてみる
Hyperoptを使って関数最適化をしてみる比較実験
今回は
x^2+y^2+z^2の最小化問題を最適化していきます。
試行ごとに結果が異なるため, 3回試行してみようと思います。コード
今回、実験するために使用したコードは以下になります。
# -*- coding: utf-8 -*- import optuna import hyperopt from hyperopt import hp from hyperopt import fmin from hyperopt import tpe from hyperopt import Trials import matplotlib.pyplot as plt # optuna用の目的関数を設定(今回はx^2+y^2+z^2) def objective_optuna(trial): # 最適化するパラメータを設定 param = { 'x': trial.suggest_uniform('x', -100, 100), 'y': trial.suggest_uniform('y', -100, 100), 'z': trial.suggest_uniform('z', -100, 100) } # 評価値を返す(デフォルトで最小化するようになっている) return param['x'] ** 2 + param['y'] ** 2 + param['z'] ** 2 # optunaで最適化実行 def optuna_exe(): # studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective_optuna, n_trials=500) # ベストパラメータ表示 print(study.best_params) # ベスト目的関数値を表示 print(study.best_value) epoches = [] # 試行回数格納用 values = [] # ベストvalue格納用 best = 100000 # best更新 for i in study.trials: if best > i.value: best = i.value epoches.append(i.number + 1) values.append(best) return epoches, values # hyperopt用の目的関数を設定 def objective_hyperopt(args): x, y, z = args return x ** 2 + y ** 2 + z ** 2 # hyperoptで最適化実行 def hyperopt_exe(): # 探索空間の設定 space = [ hp.uniform('x', -100, 100), hp.uniform('y', -100, 100), hp.uniform('z', -100, 100) ] # 探索の様子を記録するためのオブジェクト trials = Trials() # 探索開始 best = fmin(objective_hyperopt, space, algo=tpe.suggest, max_evals=500, trials=trials) # 結果を出力する print(best) epoches = [] # 試行回数格納用 values = [] # ベストvalue格納用 best = 100000 # best更新 for i, n in zip(trials.trials, range(500)): if best > i['result']['loss']: best = i['result']['loss'] epoches.append(n+1) values.append(best) return epoches, values def plot_graph(): result_optuna = optuna_exe() result_hyperopt = hyperopt_exe() epoch_optuna = result_optuna[0] value_optuna = result_optuna[1] epoch_hyperopt = result_hyperopt[0] value_hyperopt = result_hyperopt[1] # グラフの描画 fig, ax = plt.subplots() ax.set_xlabel("trial") ax.set_ylabel("value") ax.set_title("Optuna vs Hyperopt") ax.grid() # グリッド線を入れる ax.plot(epoch_optuna, value_optuna, color="red", label="Optuna") ax.plot(epoch_hyperopt, value_hyperopt, color="blue", label="Hyperopt") ax.legend(loc=0) # 凡例 plt.show() # グラフ表示 if __name__ == '__main__': plot_graph()実験結果1回目
Optuna:
'x': 0.2690396239515218,
'y': -1.75236444646743,
'z': 0.3724308175904496,
best_value:3.2818681863901693Hyperopt:
'x': -2.9497423868903834,
'y': 0.13662455602710644,
'z': -3.844496541052724,
best_value:23.499800072493738
最終的なbest_valueはOptunaが優れていますね。
グラフより収束速度もOptunaが優れているかなといった感じですかね。実験結果2回目
Optuna:
'x': 0.7811129871251672,
'y': 0.4130867942356189,
'z': 0.6953642534092288,
best_value:1.2643096431468364Hyperopt:
'x': -3.7838067947126675,
'y': -2.595648793357423,
'z': -2.683504623035553,
best_value:28.255783580024783
2回目も1回目と同様、最終的なbest_valueと収束速度の面でOptunaが優れていますかね。
実験結果3回目
Optuna:
'x': -0.19339325990518663,
'y': -0.0030977352573082623,
'z': 0.4961595538587318,
best_value:0.2835848518257752Hyperopt:
'x': 2.810074634010315,
'y': -1.2603362587820195,
'z': -0.7356174272489406,
best_value:10.026099933181214
3回目も最終的なbest_valueの値はOptunaが優れていました。収束速度はあまり変わらない気がしますね。
結論
最終的な最良目的関数値、収束速度の面でOptunaが優れている、との結論に至りました。
最適化問題をもう少し難しくしたら、差も大きく出るのだろうか...



- 投稿日:2019-12-04T18:43:33+09:00
matplotlibのcolormapにブランドイメージカラーを適応してみよう!
はじめに
matplotlibでグラフを描画する際、皆さんはどんなカラーを利用していますか?
matplotlibにはデフォルトで綺麗なcolormapが用意されていますが、
プレゼンのために異なるカラーバリエーションを使いたいとか資料とグラフの
カラーイメージを統一したいとか思ったことはないでしょうか。本記事では、matplotlibのcolormapへのブランドカラーイメージの
適応にチャレンジしてみます!利用するクラス
matplotlibには独自でcolormapを作成するためのクラスが2種類用意されています。
1. matplotlib.colors.ListedColormap
colormapを構成するカラーコードをlistまたはarrayで設定して作成します。
作成されるcolormapの構成色は離散的に変化します。【利用例】
import matplotlib as mpl color_list = ['red', 'green', 'blue'] cmap = mpl.colors.ListedColormap(color_list)【作成されるcolormap】
2. matplotlib.colors.LinearSegmentedColormap
colormapを構成するRGB情報を規定のデータ形式で設定して作成します。
作成されるcolormapの構成色は連続的に変化します。【利用例】
import matplotlib as mpl ######################################################################### # # 【構成色の設定】 # # 構成色のデータは, # [ # (x_0, y_0, z_0) # ... # (x_i, y_i, z_i) # ] # の構造をとり、RGB値を0~1の値で設定する。 # colormapの構成色は z_0 -> y_1, z_1 -> y_2, ... の順で連続的に変化する。 # 下記の設定だと red -> green, green -> blue の変化を意味する。 # ######################################################################### segment_data = { 'red': [ (0.0, 0/255, 255/255), (0.5, 0/255, 0/255), (1.0, 0/255, 0/255), ], 'green': [ (0.0, 0/255, 0/255), (0.5, 128/255, 128/255), (1.0, 0/255, 0/255), ], 'blue': [ (0.0, 0/255, 0/255), (0.5, 0/255, 0/255), (1.0, 255/255, 0/255), ], } cmap = mpl.colors.LinearSegmentedColormap('colormap_name', segment_data)上記の実装だと構成色の設定が直観的でなくちょっと大変ですが、
matplotlib.colors.LinearSegmentedColormap.from_listを利用すると
カラーコードのlistで作成できます。# listで作成する場合 import matplotlib as mpl color_list = ['red', 'green', 'blue'] cmap = mpl.colors.LinearSegmentedColormap.from_list('colormap_name', color_list)【作成されるcolormap】
実装
実際に自作colormapを作成する際は、matplotlib.cm.register_cmapで作成したcolormapを
登録しておくと便利です。import matplotlib.pyplot as plt import matplotlib as mpl def set_custom_colormap(name: str, color_list: list): """ color_listをcolormap化し、nameでmatplotlibに登録する。 colormapは離散型と連続型の2パターン及び逆順で4パターン登録される。 """ cmap_dis = mpl.colors.ListedColormap(color_list) cmap_seq = mpl.colors.LinearSegmentedColormap.from_list(name, color_list) plt.register_cmap(name + '_dis', cmap_dis) plt.register_cmap(name + '_dis_r', cmap_dis.reversed()) plt.register_cmap(name + '_seq', cmap_seq) plt.register_cmap(name + '_seq_r', cmap_seq.reversed()) return後は自分の設定したい色のカラーコードを調べればOKです。
SENSY colormap
COLORMAP_SOURCE_DICT = { # 単色グラデーション 'sensy_single_1': ['#FFFFFF', '#F4458C'], 'sensy_single_2': ['#FFFFFF', '#FF6B9A'], 'sensy_single_3': ['#FFFFFF', '#FA8EB5'], 'sensy_single_4': ['#FFFFFF', '#A7C0FD'], 'sensy_single_5': ['#FFFFFF', '#5073ED'], 'sensy_single_6': ['#FFFFFF', '#4E6FF0'], 'sensy_single_7': ['#FFFFFF', '#4B4C80'], 'sensy_single_8': ['#FFFFFF', '#2B2C4B'], # 多色グラデーション 'sensy': ['#FF6B9A', '#4E6FF0'], 'sensy_diverge': ['#FF6B9A', '#FFFFFF', '#4E6FF0'], 'sensy_accent': ['#5073ED', '#FA8EB5', '#A7C0FD', '#2B2C4B', '#F4458C', '#4B4C80'], } # colormap作成&登録 for name, color_list in COLORMAP_SOURCE_DICT.items(): set_custom_colormap(name, color_list) # 初期設定 ################### # 初期colormap DEFAULT_COLORMAP = 'sensy_accent_dis' # matplotlibを利用する場合 mpl.rcParams['image.cmap'] = DEFAULT_COLORMAP # seabornを利用する場合 import seaborn as sns sns.set() sns.set_palette(DEFAULT_COLORMAP)【colormapイメージ】
※ colormap名のsuffixが'seq'は連続型、'dis'は離散型になります。
また末尾に'_r'をつけると色の順序が逆転します。【適応イメージ】
グラフの種類 イメージ 棒グラフ 散布図 等高線 ヒートマップ ※ グラフ描画に利用したデータとコードは Official seaborn tutorial を参考にしています。
おわりに
利用したいカラーコードが分かるのであれば、簡単に自作のcolormapを作成することができました。
普段利用しているグラフのカラーバリエーションに物足りなさや統一感のなさを感じてきたら、
自分で綺麗なcolormapを作ってみるのも楽しいかもしれませんね。参考







- 投稿日:2019-12-04T18:28:03+09:00
ドローンをAWS上で操作するシステムの構築
はじめに
この記事は
ドローンを活用した避難勧告システム
の1ページです.
製作背景などはそれを参照してください.概要
TelloドローンをAWS上で操作可能なシステムの構築します.AWS上で操作できれば,いろんなサービスと連携することができるので夢を広げておきましょう.
使用するドローンについて
中国のスタートアップ企業Ryze Techが開発するTello eduを使用します.IntelとDJIが技術開発していて公式のSDKが公開されていて,edu版だとv2が使用可能でドローンを子機とした編隊飛行が可能なのでedu版の購入がお勧めです.
ドローン制御にはこのSDKを使用するので,事前にgit clone します.環境構築やSDKを用いたPythonでの基本的な飛行や画像ストリーミング方法については適宜SDKのユーザーガイドやTelloに関する別の記事を参照してください.飛行コマンド
Telloクラスのsend_commandメソッドの引数に文字列でコマンドを与えるだけで飛行します.参考までに基本飛行コマンドは以下のようになります.これら以外に回転コマンドや速度を指定して円弧を描き飛行させるコマンドもあるので使い方に合わせて適宜確認しましょう.
Command 説明 command SDKモードを開始 takeoff 離陸 land 着陸 emergency 即座にモーター停止 up x 20~500cmの間で上昇 down x 20~500cmの間で下降 left x 20~500cmの間で左へ飛行 right x 20~500cmの間で右へ飛行 forward x 20~500cmの間で前へ飛行 back x 20~500cmの間で後ろへ飛行 Tello <-> PC <-> AWS 間の通信
そもそもTelloドローンは4G通信などの移動通信サービスに対応しているわけではなく,実運用において遠隔操作をさせることは考えにくいですが,インターネット上のサービスをトリガにして制御することは今後有用的だと考えられます.本システムではクラウドサービスとしてAWSを使用しクラウドからのtelloの飛行操作を試みることにします.
接続方法
wifi親機としてTelloを使用しPCとwifi接続する場合,AWSとの接続でwifi接続を使用することが不可能です.そのため,今回はPCとスマホを有線接続しスマホのテザリングを介してPCとAWSが通信できるようにしました.この時,インターネット接続に使用するテザリングサービスの優先度をWifiより高くしなければなりません.
ドローンとの通信プロトコル
今回AWSとドローン間の通信にはHTTP通信ではなくMQTT通信を採用しました.HTTP通信より軽量なメッセージプロトコルとされ,文字列コマンドを送る用途であればMQTT通信が適していると考えたからです(MQTTやってみたかったというのもあります笑).MQTTブローカーにchannelを設定し,そのchannel上にpublishされたデータをsubscribeすることでMQTT通信が行われます.簡単に多対多の通信が行えるのが大きな特徴です.(たぶん)
AWSIoTCoreはMQTTブローカーを提供していて,本システムではドローンが飛行コマンドのsubscribe側で,IoTCore上で飛行コマンドのpublishを行いひとまず飛行を確認します.
AWS IoT Core
次にAWSにログインしてIoT Coreを開き,モノとしてDroneを登録します.
証明書を作り,ポリシーをアタッチし,証明書をアクティブにします.細かい手順は圧倒的にわかりやすいこの記事が参考になります.(参考URL)
証明書は後で使うので絶対にダウンロードします.Tello制御用プログラム
TelloSDKがpython2系に準拠しているようなのでライブラリ等は2系に合わせるようにすべきだと思います.(python3で動くか未検証)
pip install AWSIoTPythonSDK
をしてPythonからIoT Core用のライブラリを入れておく.
証明書やTello.pyがあるディレクトリ(例.Single_Tello_Testなど)に以下のようなmainの制御プログラムを書けばOK.main.py# -*- coding:utf8 -*- from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient from datetime import datetime from tello import Tello import ast import time import json import sys # For certificate based connection myMQTTClient = AWSIoTMQTTClient('device001') # 適当な値 myMQTTClient.configureEndpoint('xxxxxxxxxxxx.ap-northeast-1.amazonaws.com', 8883) # 管理画面で確認 myMQTTClient.configureCredentials('rootCA.pem', 'xxxxx-private.pem.key', 'xxxxx-certificate.pem.crt') #各種証明書 myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 sec myMQTTClient.connect() tello = Tello() # Telloインスタンスを作成 tello.send_command('command') # SDKモードを開始 def customCallback(client, userdata, message): payload = message.payload print('Received a new message: ') print(payload) print('from topic: ') print(message.topic) print('--------------\n\n') # command = payload[0] dic = ast.literal_eval(payload) tello.send_command(dic['message']) myMQTTClient.subscribe("test/pub", 1, customCallback) # test/pub チャネルをサブスクライブ while True: time.sleep(1)テスト
はい,テストします.まず上記のPythonコードを実行して,Telloとの接続を確認しておきます.次にIoT Core上のテストタブを開きチャンネルを指定した後,飛行コマンドを"message"の値に文字列で指定しトピックに発行するだけです.
分かり易く,動作を動画でまとめました.
https://youtu.be/MKF2P_rrS9U
まとめ
AWS IoT Core上からコマンドを入力してTelloの飛行に成功しました.次は外部サービスと連携してみましょう.
人の発声を自然言語処理,意図解釈し,ドローンを制御するシステムの構築




- 投稿日:2019-12-04T18:24:45+09:00
Jupyterで全てを完結させる 〜nbdevの紹介〜
この記事はバカン Advent Calendar 2019の4日目の投稿です。
Jupyterer向けの記事となります。
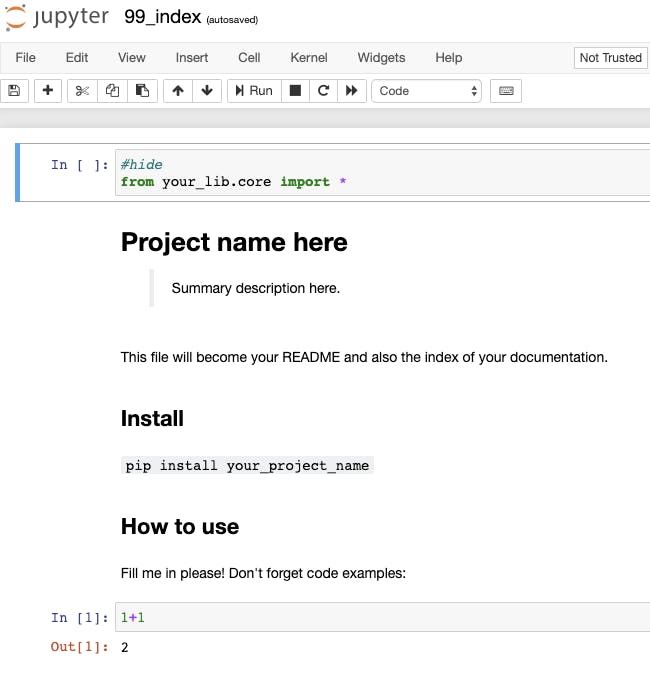
理解不十分な部分もあるため、詳細は公式を確認してください。nbdevとは
おそらく簡潔にいうと、IDEの役割を含めることで、Jupyter Notebook1つで作業を完結させるPythonのプログラム環境のことです。
fast.aiが作成しており、現在開発中のfastai v2もnbdevを用いているとのことです。現状、EDAやモデル構築などの試行錯誤はJupyter Notebookを用いて行われることが多く、"exploring"の役割として存在しています。ですが、それ以降のフェーズではIDEを使うのが一般的とされています。
nbdevでは以下のような機能を提供することで、jupyter上で完結することを試みています。
・pyファイルの作成
・READMEの作成
・Visual diff
・merge conflictの確認、修正(以下公式から拝借)
チュートリアル・使い方
以下はMacで行なっていますが、Winでも手順は変わらないです。
インストール 〜 Jupyter開くまで
1- ターミナルから以下コマンドでインストールします。
pip install nbdev2- 公式がテンプレートを作成しているので、それをもとにRepositoryを作成します。
3- 作成したRepositoryをCloneします。
git clone [以下URL]
4- 連携するRepositoryの情報を加えるため、
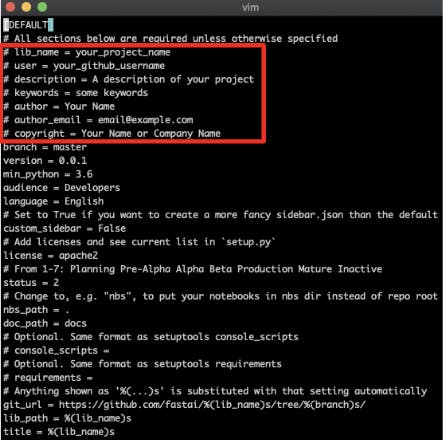
settings.iniを編集します。
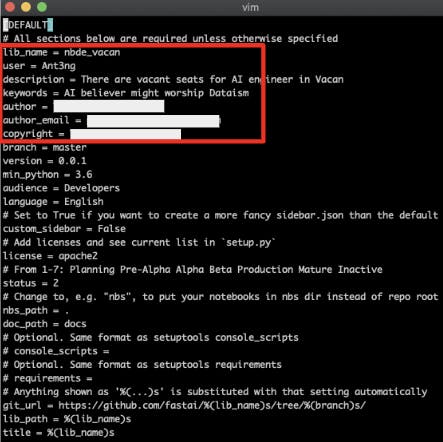
settings.iniの以下項目のコメントアウトを外し、記入例のように編集します。<編集前>
<記入例>
lib_name, user, descriptionは作成したrepositoryに対応させます。
keywordsは何を指しているか不明ですが、適当な文字列を入れてください。
※ copyrightまで記載しないと、次の手順でコケます。5- ターミナルから以下コマンドを打ちこみ、lib_nameのディレクトリを作成します。
nbdev_build_lib
(上の画像ではPipfileとPipfile.lockが表示されてますが、関係ないので無視してください)
6-
jupyter notebookでJupyter Notebookを開きます。pyファイルの作成
00_core.ipynbを開き、以下手順でモジュール作成を行います。
1. python moduleに変換するものに関して、該当セルの先頭に#exportを加えます。
2. 以下2行をセルに打ち込み実行します。(もしくはterminal上でnbdev_build_libを実行します。)
from nbdev.export import *
notebook2script()<以下例>
これによって、
#exportで指定したものが、lib_nameディレクトリ配下のcore.pyに記載されます。
手順2を実行するたびにcore.pyが更新されるため、追加に加え、既存セルを消去すれば削除も可能です。
READMEの編集
99_index.ipynbを開くと以下テンプレートが表示されます。
#hideが記載されたセルは非表示となるため、ここで#exportしたもの含めモジュールをimportしていきます。<テンプレート>
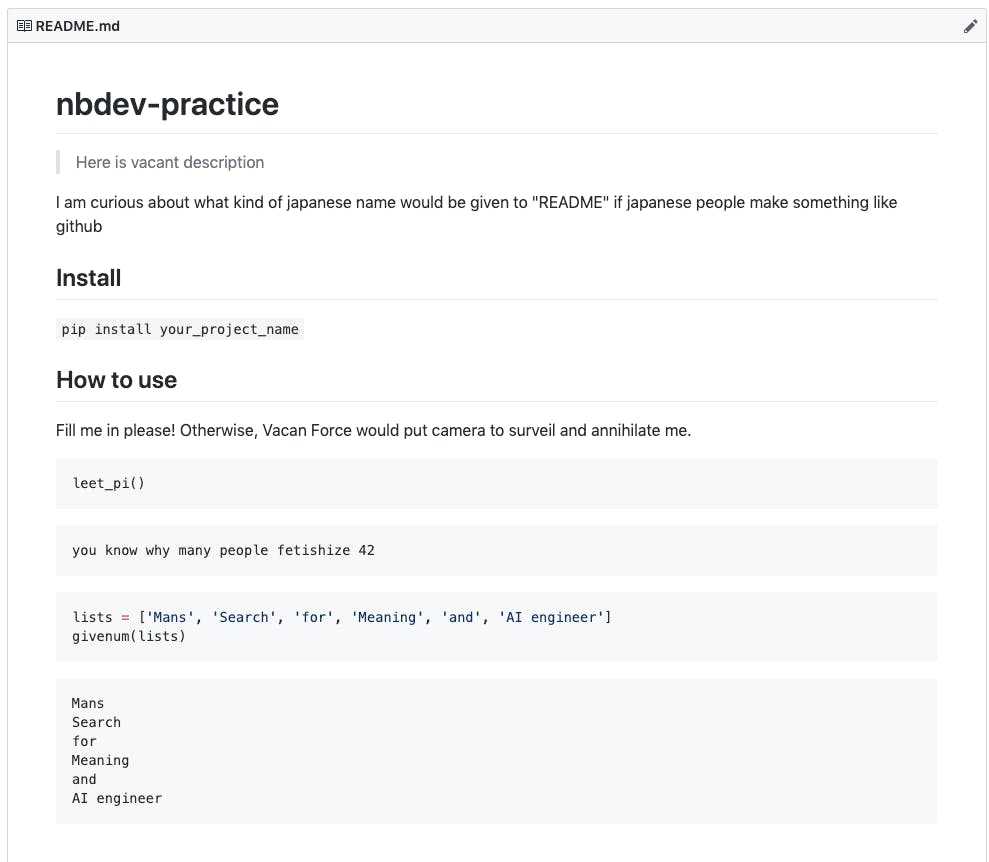
<以下例>
編集完了後、terminal上で
nbdev_build_docsを実行することで、ディレクトリにあるREADME.mdが更新されます。その後、remote repositoryにpushするとgithub上のREADMEでは以下のよう表示されます。
おわりに
いかがでしたか?
nbdevの概要、使い方の一部を紹介してみました。
本記事を通して、nbdevを使ってみるきっかけになれば幸いです。
カバーできていない部分もあるため、以下の参考文献を確認してみてください。参考文献
・nbdev: use Jupyter Notebooks for everything
・Welcome to nbdev
・Nbdev discussion
・A Step-by-Step Introduction to Starting nbdev — Exploratory Programming
・今度こそ挫折しない git 入門 第1回参考リンク
・株式会社バカン(Vacan, Inc.)
・バカン (Vacan) Advent Calendar 2019参考情報
弊社代表取締役はKaggle推しです。






- 投稿日:2019-12-04T18:05:25+09:00
Python-Sounddevice ASIOで使える音響信号処理モジュール[基本編]
PythonモジュールのSounddeviceってなあに?
Pythonで使える音響信号処理モジュールといえばPyaudioがあると思いますが、個人的になんか使いにくい!また一度Windowsで開発中に使えなくなったことでPyaudioには軽いトラウマがあり、ASIOベースでオーディオインターフェースの制御ができるSounddeviceを紹介したいと思います。
sounddeviceのいいところ
・ASIOデバイスをコントロールできる
・入出力のチャンネルマッピング(マイク、スピーカの振り分け)も簡単
・WASAPI、core audioの制御も簡単
・とにかく書きやすい使いやすい
・同時録音再生が超簡単にできる(音響工学やってる人的にはインパルス応答の計測とかめっちゃ簡単にできて嬉しい)この記事で扱う項目
この記事ではsounddeviceを使う前の準備から使う上での初期設定の方法、そしてsounddeviceでの基本的な再生方法、録音方法、同時録音再生方法、ストリーミングの方法までを書いていきます。
チャンネルマッピングの方法(マルチチャンネル環境で好きなマイクから入力、好きなスピーカから出力する方法)やASIO、WASAPI、Core Audioの細かい設定方法などについては後編の[Python Sounddevice ASIOで使える音響信号処理モジュール[応用編]]で書いていきたいと思います。
インストール
①Linux、macOS、Anaconda環境ではconda-forgeからインストールできます。
conda install -c conda-forge python-sounddevice
②pipを使ってPyPlからインストールできます。
python3 -m pip install sounddevice
macOSあるいはWindowsにpipを使ってSounddeviceをインストールした場合、自動的にPortAudioライブラリーがダウンロードされます。他のプラットフォームでインストールする場合には各々ライブラリーをインストールしてください。使い方
インポート
import sounddevice as sd import numpy as np #NumPyは基本必須です。インポートしてください。 import wave #オーディオファイルを扱いたい場合インポートしますsounddeviceでは基本NumPy配列でデータを扱うのでNumPyのインポートが必要です。
しかしNumPyを使わずにデータを扱う方法もあるのでそれについては後述します。初期設定
sounddeviceではデフォルトで使えるサンプルレートやチャンネル数、使用するオーディオインターフェースをあらかじめ設定しておくこともできます。もちろん設定を行わずその都度設定することもできます。今回の記事ではデフォルトの設定を行う場合と行わない場合について両方記述していきますが、とりあえずはじめにデフォルトの設定の仕方を書いておきます。
サンプルレートの設定
default_fs.pyfs = 44100 #普通41000Hzか48000Hz sd.default.samplerate = fsチャンネル数の設定
出力する際のチャンネル数は関数に入力されたデータから自動で設定されますが、入力チャンネル数については自分で指定する必要があります。
default_ch.pychannels = 2 sd.default.channels = channels #sd.default.channels = (in, out)としてチャンネル数をそれぞれ設定することもできます使用機材の設定
まず自分の環境に搭載あるいは接続されているオーディオシステムのデバイスIDを取得します。
default_system.pysd.query_devices()コマンドプロンプトに入力してみると私の環境では次のように出力されました。
> 0 Built-in Microphone, Core Audio (2 in, 0 out) < 1 Built-in Output, Core Audio (0 in, 2 out) 2 Pro Tools 機器セット, Core Audio (2 in, 2 out)現在入力はIDの0、出力はIDの1に設定されています。ASIOデバイスにマシンを接続している場合
3 〇〇Audio system, ASIO (24 in, 24 out)のように出力されます。使いたいデバイスIDを確認できたら次のように設定してください。
default_system.pysd.default.device = 3 # sd.default.device = [in, out]として入出力をそれぞれ設定することもできます。記録するデータ型の設定
録音する際、デフォルトでは'float32'で記録されますが、異なるデータ型で記録したい場合には次のように設定してください。
default_dtype.pysd.default.dtype = 'float64'再生(Playback)
実行すると関数はすぐに戻りますがバックグラウンドで再生をし続けます。
playback.pysd.play(myarray,fs) # myarray : オーディオデータを保持するNumPy配列 # fs : サンプルレートサンプルレートの初期設定を行った場合引数を削減できます。
playback.pysd.play(myarray)その他オプションについてはこのようになっています。
playback.pysd.play(data, samplerate=None, mapping=None, #チャンネルマッピングの設定(後編で説明します) blocking=False, #Trueで関数が戻らないようにします(再生中は待機します) loop=False, #Trueでループ再生します **kwargs)再生停止(stop)
音の再生を停止する。
stop.pysd.stop()録音(Recording)
取得したオーディオデータをNumPy配列で記録します。デフォルトでは配列データは'float32'で記録されます。実行すると関数はすぐに戻りますが、バックグラウンドで録音を続けます。
rec.pyduration = 10.5 #再生時間[秒] recdata = sd.rec(int(duration * fs), samplerate = fs,channels = 2) #タップ数、サンプルレート、チャンネル数初期設定を行った場合引数を削減できます。
rec.pyrecdata = sd.rec(int(duration * fs))録音が完了したか知りたい場合次の関数を使います。
この関数では録音が完了している場合はすぐに戻り、未完了の場合には録音が終了してから戻ります。録音が終了してから次のフェーズに進みたい時にも使えます。rec.pysd.wait()その他オプションについては次のようになっています
rec.pyrecdata = sd.rec(frames=None,#オプション 録音されているフレーム数 outが指定されている場合は必要無し samplerate=None, channels=None,#チャンネル数 mappingまたはoutが指定されている場合必要無し dtype=None,#データ型の設定 out=None,#任意の配列に録音データを書き込みます mapping=None,#チャンネルマッピングの設定(後編で説明します) blocking=False,#Trueで録音中は待機します **kwargs)同時録音再生(Simultaneous Playback and Recording)
Arrayの再生と録音を同時に実行できます。
出力チャンネル数については与えられたデータから自動で設定が行われますが、入力チャンネル数については自分で設定することができます。playrec.pyrecdata = sd.playrec(myarray,fs,channels = 2)初期設定でデフォルトのサンプルレート、チャンネル数を決めている場合は例によって記述を省略できます。
playrec.pyrecdata = sd.playrec(myarray)その他オプションについてはこちら
playrec.pyrecdata = sd.playrec(data, samplerate=None, channels=None,#出力チャンネル数の設定 無ければ自動的にデータから決定 dtype=None,#データ型の設定 out=None,#任意の配列に録音データを書き込みます input_mapping=None,#入力のチャンネルマッピングの設定 output_mapping=None,#出力のチャンネルマッピングの設定 blocking=False,#Trueで録音中は待機 **kwargs)ストリーミング(Callback stream)
マイクで取ってきた音をそのままスピーカに流します
stream.pyduration = 5.5 # seconds def callback(indata, outdata, frames, time, status): if status: print(status) outdata[:] = indata with sd.Stream(channels=2, callback=callback): sd.sleep(int(duration * 1000))またここでのsd.sleepは任意の時間次の呼び出しを凍結できますが、あんまり正確じゃないので注意
sleep.pysd.sleep(msec)とりあえずここまで
簡単な使い方についてはこのあたりで十分だと思います。
チャンネルマッピングの方法(マルチチャンネル環境で好きなマイクから入力、好きなスピーカから出力する方法)やASIO、WASAPI、Core Audioの細かい設定方法などについては後編の[Python Sounddevice ASIOで使える音響信号処理モジュール[応用編]]で書いていきたいと思います。リファレンス
- 投稿日:2019-12-04T17:53:49+09:00
Pythonを用いた火球の電磁波音の解析
はじめに
火球(Bolide)というのは、非常に大きくて明るい流れ星のことです。
火球はまれに音を伴って流れたり、爆発することがあると言われています。
しかし、火球の高度は100~200 km程度1であり、音が聞こえるまでは少なくとも5分以上はかかるはずです。そのため、この音の原因は火球の発する電磁波であると考えられており、”電磁波音(Electrophonic sound)”と呼ばれています。音の発生メカニズムとして様々なモデルが考案されていますが、いまだ統一的な説明はなされていないようです2。そもそも火球自体が珍しい上、目撃者のうち10%ぐらいしか音を感じない3という現象なので、科学的な検証が非常に難しいという問題があります。
しかし最近、ツイッター上でこの音を観測した人がいらっしゃいました。
しかも動画付き。この火球では、流星が光ると同時に音が鳴る電磁波音も捉えることができました。どうして同時に音が鳴るか、詳しい理由はまだわかっていません。 pic.twitter.com/nJeSOr8h3h
— 藤井大地 (@dfuji1) November 14, 2019というわけで、この動画の画像と音声を解析してみたいと思います。
プログラミング言語にはPythonを用います。動画解析
動画解析にはOpenCVを使います。
まずは適当な方法でTwitterから動画をダウンロードします。
今回はmp4形式でダウンロードしました。インポート
import cv2 import numpy as np import matplotlib.pyplot as plt動画の読み込み
まずは、動画ファイルを読み込んでフレームレートを見ます。
cap = cv2.VideoCapture('movie.mp4') #ファイル名を入力 framerate = cap.get(cv2.CAP_PROP_FPS) #フレームレート print(framerate) >> 29.97002997002997よくある29.97 fpsですね。
では、1フレームずつ画像をグレースケールで読み込みます。print(framerate) images = [] while(cap.isOpened()): ret, frame = cap.read() try: gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) except: break images.append(gray) cap.release()120フレーム目、だいたい t = 4 s の時点でのスナップショットを表示してみます。
plt.imshow(images[120]) plt.gray()
ちょうど火球が光ってるあたりですね。
では画像解析をしていきましょう。画像解析
画像解析といっても、正式な計測方法は知らないので、単純に2値化して面積を計る方法で行きます。
とりあえず火球の大きさが分かればいいので大丈夫でしょう。まずは火球だけが画像に写るようにトリミングします。
images_trim = [i[0:250,130:290] for i in images] plt.imshow(images_trim[120])
トリミングした画像に二値化を掛けます。閾値は適当に設定しましょう。
__,th = cv2.threshold(images_trim[120],245,255,cv2.THRESH_BINARY) plt.imshow(th)
二値化後の画像は上のような感じになります。この画像の中で白色の部分の面積を求めます。
では、すべての画像に同様の処理を行いましょう。
ついでに、元画像と2値化画像を重ね合わせた画像も作りました。areas = [] #火球の面積 for n,i in enumerate(images_trim): #火球面積の計測 __,th = cv2.threshold(i,245,255,cv2.THRESH_BINARY) idx = np.where(th == 255) areas.append(idx[0].shape[0]) #合成画像の作成 th = cv2.cvtColor(th, cv2.COLOR_GRAY2RGB) th[idx] = [0,0,255] img = cv2.cvtColor(i,cv2.COLOR_GRAY2RGB) blended = cv2.addWeighted(img,0.7,th,0.3,1) #合成画像の保存 cv2.imwrite('./bolides/'+str(n)+'.png',blended) areas = np.array(areas)合成画像をまとめてGif動画にするとこんな感じ。
二値化で得られた火球の領域を赤色で重ね合わせています。
では、この火球面積の時間変化をプロットします。xrange= np.arange(0,len(areas)/framerate,1/framerate) fig = plt.figure(figsize=(7,4)) plt.plot(xrange,areas,'o-',ms=3) plt.xlabel('time /s',fontsize=12) plt.ylabel('area',fontsize=12)
だいたい3.8秒ぐらいで立ち上がり、4秒あたりで極大に至っていることがわかります。
動画解析はこれくらいでいいでしょう。音声解析
音声の読み込みにはpydubを、解析にlibrosaを使います。
便利なライブラリが多くて助かりますね。インポート
import librosa import librosa.display from pydub import AudioSegment音声読み込み
以下のコードで動画ファイルから音声データを読み込み、numpyのarray形式に変換します。
#動画からの音声の読み込み sound = AudioSegment.from_file('movie.mp4') data = np.array(sound.get_array_of_samples())また、サンプルレート、総時間、チャンネル数は以下のように表示できます。
#サンプルレート, 総時間, rate = sound.frame_rate time = sound.duration_seconds channel = sound.channels print('rate: '+str(rate)+' Hz') print('time: '+str(time)+' s') print('channel: '+str(channel))結果は以下のようになります。
- rate: 44100 Hz
- time: 5.921088435374149 s
- channel: 2
チャンネル数が2のステレオ音声なので、左右のデータを分ける必要があります。
pydubでは、ステレオ音声のarrayとしての出力は偶数番目と奇数番目の要素に分割されているので、以下のようにして別々に取り出します。left = data[::2] #左の音声 right = data[1::2] #右の音声今回の解析には左の音声を使います。とりあえずプロットしてみましょう。
火球が極大に達する辺りの3.8s~4.2sのデータを表示します。fig = plt.figure(figsize=(12,4)) plt.plot(np.linspace(0,left.shape[0]/rate-1,left.shape[0]),left) plt.xlim(3.8,4.2) plt.xlabel('time /s',fontsize=12)
ちゃんとデータが取れていることが分かりますが、何が何だかわかんないですね。
頭の中でフーリエ変換できる人ならあるいは・・・。まあ素直にスペクトログラムを書きましょう。
音声の周波数解析-スペクトログラム
(From wikimedia commons, Aquegg [Public domain])スペクトログラム(英: Spectrogram)とは、複合信号を窓関数に通して、周波数スペクトルを計算した結果を指す。3次元のグラフ(時間、周波数、信号成分の強さ)で表される。(wikipedia)
刑事ドラマの声紋分析とかでたまに出てくるあれです。横軸が実時間(s)、縦軸が音の周波数(Hz)、色が音の強度(dB)で表されるグラフです。
実際に、火球の電磁波音の研究としてスペクトログラムを解析されている方もいます4。
周波数ごとの強度を求めるのはもちろんフーリエ変換ですが、音声信号の処理では、狭い領域でフーリエ変換を行ったものを重ねあわせる短時間フーリエ変換(STFT: Short-time fourier transform)が使われます。
このような音声解析をPythonで行うには、librosaというライブラリが便利です。スペクトログラムの作成には以下のサイトを参考にしました。
Pythonで音声解析 – 音声データの周波数特性を調べる方法
スペクトログラムの作成
以下のコードで短時間フーリエ変換を行います。
フレーム長(フーリエ変換をする領域)とフレームシフト長(フレームごとの間隔)はいい感じに変えましょう。#音声ファイルのデータを-1~1の範囲で正規化 left = left / np.max(left) # フレーム長 fft_size = 1024 # フレームシフト長 hop_length = int(fft_size / 4) # 短時間フーリエ変換実行 amplitude = np.abs(librosa.core.stft(left, n_fft=fft_size, hop_length=hop_length)) # 振幅をデシベル単位に変換 log_power = librosa.core.amplitude_to_db(amplitude)結果をグラフで表示してみましょう。
fig = plt.figure(figsize=(7,4)) librosa.display.specshow(log_power, sr=rate, hop_length=hop_length, x_axis='time', y_axis='hz', cmap='magma') plt.colorbar(format='%+2.0f dB') plt.ylim(0,8000)
ノイズが多くてはっきりしないですが、4秒当たりの部分で変化があるように見えますね。
とりあえずはこれで良しとします。動画と音声データの比較
せっかく動画と音声が一緒にあるのだから、2つを比較してみたいですね。
先ほどの画像解析の結果(火球のサイズ変化)を、スペクトログラム上にプロットしてみます。fig,ax1 = plt.subplots() librosa.display.specshow(log_power, sr=rate, hop_length=hop_length, x_axis='time', y_axis='hz', cmap='magma') plt.colorbar(format='%+2.0f dB') ax1.set_ylim(0,8000) ax2 = ax1.twinx() ax2.plot(xrange,np.array(areas),c='cyan',lw=2,marker='o',ms=4,label='Bolide brightness',alpha=0.7) ax2.set_ylim(0,4000) ax2.tick_params(labelright=False) ax2.tick_params(right=False) plt.xlim(3,5) plt.legend() plt.show()
確かに、火球の立ち上がりと同時に高い音が鳴っていることが分かります。
また、火球が最大となる時点よりも前から音は鳴り始めているようです。音声のノイズ除去
なんか音声がはっきりしないし、デノイズできたらいいなあ、と思っていたら、すでにツイッター上に上げている人がいました。
ノイズを除去してみました。 pic.twitter.com/imr8yJ9HN6
— ナッパ教信徒 (@nappasan) November 18, 2019す、すばらしい・・・!
ということでこのデノイズ済みの動画を解析した結果がこちらです。
スペクトログラムがものすごい明確になりました。
やはり、電磁波音は火球の極大よりも少しだけ早く聞こえているみたいです。
ふしぎですね。最後に
実はこの解析、1月ぐらい前に動画+音声処理の練習としてやったものです。
スペクトログラム作ってみた。4秒付近に高い音のピークがあって、火球が最大となるタイミングと一致している。ふしぎだなあ。 https://t.co/Zpgc6r0pqd pic.twitter.com/Q73ZVNGYGE
— konkon (@konkon28983820) November 21, 2019特に出すほどのものでもないし結果を1つ2つツイートして満足していたんですが、天文学 Advent Calendar 2019なんて面白いものができていたので、ここで出さなきゃいつ出すの! と思い、改めてまとめました。
拙い解析ですが、何か皆さんのお役に立てるようであれば幸いです。



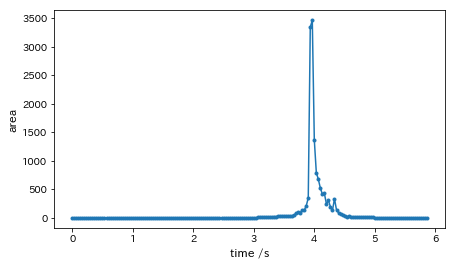




- 投稿日:2019-12-04T17:53:49+09:00
Pythonを用いて流れ星の音(electrophonic sound)を解析する
はじめに
非常に大きくて明るい流れ星は、まるで火の玉のように見えるため、火球(Bolide)と呼ばれます。
火球はまれに音を伴って流れることが知られています。
しかし、火球の高度は100~200 km程度1であり、音が聞こえるまでは少なくとも5分以上はかかるはずです。そのため、この音の原因は火球の発する電磁波であると考えられており、”電磁波音(Electrophonic sound)”と呼ばれています。音の発生メカニズムとして様々なモデルが考案されていますが、いまだ統一的な説明はないようです2。そもそも火球自体が珍しい上、目撃者のうち10%ぐらいしか音を感じない3という現象なので、科学的な検証が非常に難しいという問題があります。
しかし最近、ツイッター上でこの音を観測した人がいらっしゃいました。
しかも動画付き。この火球では、流星が光ると同時に音が鳴る電磁波音も捉えることができました。どうして同時に音が鳴るか、詳しい理由はまだわかっていません。 pic.twitter.com/nJeSOr8h3h
— 藤井大地 (@dfuji1) November 14, 2019というわけで、この動画の画像と音声を解析してみたいと思います。
プログラミング言語にはPythonを用います。動画解析
動画解析にはOpenCVを使います。
まずは適当な方法でTwitterから動画をダウンロードします。
今回はmp4形式でダウンロードしました。インポート
import cv2 import numpy as np import matplotlib.pyplot as plt動画の読み込み
まずは、動画ファイルを読み込んでフレームレートを見ます。
cap = cv2.VideoCapture('movie.mp4') #ファイル名を入力 framerate = cap.get(cv2.CAP_PROP_FPS) #フレームレート print(framerate) >> 29.97002997002997よくある29.97 fpsですね。
では、1フレームずつ画像をグレースケールで読み込みます。print(framerate) images = [] while(cap.isOpened()): ret, frame = cap.read() try: gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) except: break images.append(gray) cap.release()120フレーム目、だいたい t = 4 s の時点でのスナップショットを表示してみます。
plt.imshow(images[120]) plt.gray()
ちょうど火球が光ってるあたりですね。
では画像解析をしていきましょう。画像解析
画像解析といっても、正式な計測方法は知らないので、単純に2値化して面積を計る方法で行きます。
とりあえず火球の大きさが分かればいいので大丈夫でしょう。まずは火球だけが画像に写るようにトリミングします。
images_trim = [i[0:250,130:290] for i in images] plt.imshow(images_trim[120])
トリミングした画像に二値化を掛けます。閾値は適当に設定しましょう。
__,th = cv2.threshold(images_trim[120],245,255,cv2.THRESH_BINARY) plt.imshow(th)
二値化後の画像は上のような感じになります。この画像の中で白色の部分の面積を求めます。
では、すべての画像に同様の処理を行いましょう。
ついでに、元画像と2値化画像を重ね合わせた画像も作りました。areas = [] #火球の面積 for n,i in enumerate(images_trim): #火球面積の計測 __,th = cv2.threshold(i,245,255,cv2.THRESH_BINARY) idx = np.where(th == 255) areas.append(idx[0].shape[0]) #合成画像の作成 th = cv2.cvtColor(th, cv2.COLOR_GRAY2RGB) th[idx] = [0,0,255] img = cv2.cvtColor(i,cv2.COLOR_GRAY2RGB) blended = cv2.addWeighted(img,0.7,th,0.3,1) #合成画像の保存 cv2.imwrite('./bolides/'+str(n)+'.png',blended) areas = np.array(areas)合成画像をまとめてGif動画にするとこんな感じ。
二値化で得られた火球の領域を赤色で重ね合わせています。
では、この火球面積の時間変化をプロットします。xrange= np.arange(0,len(areas)/framerate,1/framerate) fig = plt.figure(figsize=(7,4)) plt.plot(xrange,areas,'o-',ms=3) plt.xlabel('time /s',fontsize=12) plt.ylabel('area',fontsize=12)
だいたい3.8秒ぐらいで立ち上がり、4秒あたりで極大に至っていることがわかります。
動画解析はこれくらいでいいでしょう。音声解析
音声の読み込みにはpydubを、解析にlibrosaを使います。
便利なライブラリが多くて助かりますね。インポート
import librosa import librosa.display from pydub import AudioSegment音声読み込み
以下のコードで動画ファイルから音声データを読み込み、numpyのarray形式に変換します。
#動画からの音声の読み込み sound = AudioSegment.from_file('movie.mp4') data = np.array(sound.get_array_of_samples())また、サンプルレート、総時間、チャンネル数は以下のように表示できます。
#サンプルレート, 総時間, rate = sound.frame_rate time = sound.duration_seconds channel = sound.channels print('rate: '+str(rate)+' Hz') print('time: '+str(time)+' s') print('channel: '+str(channel))結果は以下のようになります。
- rate: 44100 Hz
- time: 5.921088435374149 s
- channel: 2
チャンネル数が2のステレオ音声なので、左右のデータを分ける必要があります。
pydubでは、ステレオ音声のarrayとしての出力は偶数番目と奇数番目の要素に分割されているので、以下のようにして別々に取り出します。left = data[::2] #左の音声 right = data[1::2] #右の音声今回の解析には左の音声を使います。とりあえずプロットしてみましょう。
火球が極大に達する辺りの3.8s~4.2sのデータを表示します。fig = plt.figure(figsize=(12,4)) plt.plot(np.linspace(0,left.shape[0]/rate-1,left.shape[0]),left) plt.xlim(3.8,4.2) plt.xlabel('time /s',fontsize=12)
ちゃんとデータが取れていることが分かりますが、何が何だかわかんないですね。
頭の中でフーリエ変換できる人ならあるいは・・・。まあ素直にスペクトログラムを書きましょう。
音声の周波数解析-スペクトログラム
(From wikimedia commons, Aquegg [Public domain])スペクトログラム(英: Spectrogram)とは、複合信号を窓関数に通して、周波数スペクトルを計算した結果を指す。3次元のグラフ(時間、周波数、信号成分の強さ)で表される。(wikipedia)
刑事ドラマの声紋分析とかでたまに出てくるあれです。横軸が実時間(s)、縦軸が音の周波数(Hz)、色が音の強度(dB)で表されるグラフです。
実際に、火球の電磁波音の研究としてスペクトログラムを解析されている方もいます4。
周波数ごとの強度を求めるのはもちろんフーリエ変換ですが、音声信号の処理では、狭い領域でフーリエ変換を行ったものを重ねあわせる短時間フーリエ変換(STFT: Short-time fourier transform)が使われます。
このような音声解析をPythonで行うには、librosaというライブラリが便利です。スペクトログラムの作成には以下のサイトを参考にしました。
Pythonで音声解析 – 音声データの周波数特性を調べる方法
スペクトログラムの作成
以下のコードで短時間フーリエ変換を行います。
フレーム長(フーリエ変換をする領域)とフレームシフト長(フレームごとの間隔)はいい感じに変えましょう。#音声ファイルのデータを-1~1の範囲で正規化 left = left / np.max(left) # フレーム長 fft_size = 1024 # フレームシフト長 hop_length = int(fft_size / 4) # 短時間フーリエ変換実行 amplitude = np.abs(librosa.core.stft(left, n_fft=fft_size, hop_length=hop_length)) # 振幅をデシベル単位に変換 log_power = librosa.core.amplitude_to_db(amplitude)結果をグラフで表示してみましょう。
fig = plt.figure(figsize=(7,4)) librosa.display.specshow(log_power, sr=rate, hop_length=hop_length, x_axis='time', y_axis='hz', cmap='magma') plt.colorbar(format='%+2.0f dB') plt.ylim(0,8000)
ノイズが多くてはっきりしないですが、4秒あたりで変化があるように見えますね。
とりあえずはこれで良しとします。動画と音声データの比較
せっかく動画と音声が一緒にあるのだから、2つを比較してみたいですね。
先ほどの画像解析の結果(火球のサイズ変化)を、スペクトログラム上にプロットしてみます。fig,ax1 = plt.subplots() librosa.display.specshow(log_power, sr=rate, hop_length=hop_length, x_axis='time', y_axis='hz', cmap='magma') plt.colorbar(format='%+2.0f dB') ax1.set_ylim(0,8000) ax2 = ax1.twinx() ax2.plot(xrange,np.array(areas),c='cyan',lw=2,marker='o',ms=4,label='Bolide brightness',alpha=0.7) ax2.set_ylim(0,4000) ax2.tick_params(labelright=False) ax2.tick_params(right=False) plt.xlim(3,5) plt.legend() plt.show()
確かに、火球の立ち上がりと同時に高い音が鳴っていることが分かります。
また、火球が最大となる時点よりも前から音は鳴り始めているようです。音声のノイズ除去
なんか音声がはっきりしないし、デノイズできたらいいなあ、と思っていたら、すでにツイッター上に上げている人がいました。
ノイズを除去してみました。 pic.twitter.com/imr8yJ9HN6
— ナッパ教信徒 (@nappasan) November 18, 2019す、すばらしい・・・!
ということでこのデノイズ済みの動画を解析した結果がこちらです。
スペクトログラムがものすごい明確になりました。
やはり、電磁波音は火球の極大よりも少しだけ早く聞こえているみたいです。
ふしぎですね。最後に
実はこの解析、1月ぐらい前に動画+音声処理の練習としてやったものです。
スペクトログラム作ってみた。4秒付近に高い音のピークがあって、火球が最大となるタイミングと一致している。ふしぎだなあ。 https://t.co/Zpgc6r0pqd pic.twitter.com/Q73ZVNGYGE
— konkon (@konkon28983820) November 21, 2019大した内容でもないし結果を1つ2つツイートして満足していたんですが、天文学 Advent Calendar 2019なんて面白いものができていたので、ここで出さなきゃいつ出すの! と思い、改めてまとめました。
これって天文学か・・・? 地球物理学とか惑星科学では? と一瞬思いましたが、もう完成したからまあいいや。
拙い解析ですが、何か皆さんのお役に立てるようであれば幸いです。
- 投稿日:2019-12-04T17:48:42+09:00
PythonでSearch Tweets: Full Archive / Sandboxを使う
前の記事で卒論のためにPythonを始め、Twitter APIでいろいろやろうとしました。
Python歴ももう10日ではありません。まあそれほどスキルは上がっていませんが……。今回の前提:Twitter公式ウェブサイト上での検索は全件表示されているのか?
結局卒論のデータ集めは、過去のツイートまで全アクセス権を持つTwitter公式ウェブサイト上での検索となりました。原始的~。
さて、そうやってデータの数を取っていっていたのですが、過去にさかのぼるほど当該キーワードでの検索結果の件数が予想以上に減っていきます。そこで頭をよぎる嫌な予感。
「もしかして、Twitter公式ウェブサイト上の検索って全件表示されていないの……?」
確かに、「過去のツイートになればなるほど、閲覧ニーズが下がるため、検索結果が間引かれる」といったことも考えられなくはないです。
これでは定量的分析もクソもありません。卒論の危機です。(;・∀・)Twitter公式ウェブサイト上での検索の仕様
Twitter公式ウェブサイト上での検索(以下、Twitter検索)には、いくつかの検索結果の表示形式があります。
よく焦点となるのは、「話題のツイート」と「最新」の違いです。
(以前に、「話題のツイート」は「話題」、「最新」は「すべてのツイート」という名称だった時期がありました。)Twitter公式のアナウンス(「検索結果についてのよくある質問」)によると、
私の好きなツイートが話題のツイートに表示されないのはどうしてですか?
話題のツイートは、検索内容との関連性が最も高いものです。Twitterでは、ツイートの人気(多くの人がリツイートや返信などを通じて反応したり共有したりしているなど)、含まれているキーワードをはじめ、数多くの要素に基づいて関連性を判断しています。自分の好きなツイートが話題のツイートに表示されない場合、そのツイートは検索内容との関連性があまり高くないということです。検索キーワードにマッチする最近のツイートを表示するには、[すべてのツイート]([最新])をクリックまたはタップしてください。もちろん、今回のデータ取得も「最新」のタブを使っていました。
以前まで「すべてのツイート」という名前だったのだから、全件表示されとるやろ……というのも思ったのですが、現時点では「最新」という名前であり、かつ公式アナウンスに「全件表示されています」という明確なアナウンスもなかったので、確証が取れない状況です。今回やったこと
そこで、Twitter APIの全件検索の無償試用版(Search Tweets: Full Archive / Sandbox)使って、Twitter検索の結果は全件表示されているのかを検証することにしました。
リクエスト数の制限(Sandboxは50リクエスト/月)により、量的な検索はできませんが、検証のために数回検索出来ればいいや、というノリです。
あと、Search Tweets: Full Archive / Sandboxに関するまとまった日本語の記事が管見で見当たらなかったので、(きわめて僭越ながら)いったんまとめてみようと思います。
Twitter developerアカウントの取得などはすでに終わっている状況です。①Dashboardでの開発環境設定
まず、developerアカウントでログインし、DashboardからSearch Tweets: Full Archive / Sandboxの開発環境を設定しないといけないっぽいです。
上図はすでに設定が終わっているので何も表示されていませんが、最初の状態では「You must first set up a dev environment before accessing an endpoint and viewing usage.」というのが下の方に表示されています。「set up a dev environment」をクリックし、「Dev environment label」と、どのAppでSearch Tweets: Full Archive / Sandboxを使うのかを設定します。
Dev environment label(今回ではdevelopment)は後で使いますし、App Nameは認証に使うコンシューマキー云々のものとそろえる必要があります。②コード中で躓いた点
以前の無償版の検索で使ったコードがそのまま使えるかと思っていたのですが、まずエンドポイントのURLを書き換える必要がありました(それはそう)。
無償版でうまく行っていたのは
https://api.twitter.com/1.1/search/tweets.json
だったのですが、今回は
https://api.twitter.com/1.1/tweets/search/fullarchive/development.json
となりました。(もちろんSearch Tweets: Premium search APIsレファレンスに記述があります。)
上に触れていますが、設定したDev environment labelがこのURLにも含まれます。この場合ではdevelopmentの部分です。適宜自分のに合わせて書き換えてください。また、無学なのでなぜかわからないのですが、Standard search APIでの検索と、Premium search APIsでの検索で、使うパラメータの名前が違います。なので、無償版で使っていたコードから、その点を書き換えないと動きませんでした。
(↑ Search Tweets: Standard search APIレファレンスより)
(↑ Search Tweets: Premium search APIsレファレンスより)検索クエリが入るパラメータの名前が、無償版では「
q」であるのに対し、Premium search APIsでは「query」です。
それ以外のパラメータも、レファレンスを見ながら書き換えました。あと地味ですが、吐き出されるjsonの内部構造の名前もちょっと違いましたので書き換えてます。
③コード
以前のコードがベースとなっているので、以前のコードのベースとなっているこちらを再度引用させていただきます。ありがとうございます。
test.py#! python3 # -*- coding: utf-8 -*- import json from requests_oauthlib import OAuth1Session # OAuth認証部分 CK = '取得したConsumer key' CS = '取得したConsumer secret' AT = '取得したAccess token' ATS = '取得したAccess token secret' twitter = OAuth1Session(CK, CS, AT, ATS) # Twitter Endpoint(検索結果を取得する) url = 'https://api.twitter.com/1.1/tweets/search/fullarchive/development.json' # Enedpointへ渡すパラメーター keyword = '"ピクミン"' params ={ 'query' : keyword , # 検索キーワード 'maxResults': 20 , # 取得するtweet数 'fromDate' : 201301311500 , 'toDate' : 201302011500 } req = twitter.get(url, params = params) if req.status_code == 200: res = json.loads(req.text) for line in res['results']: print(line['text']) print('*******************************************') else: print("Failed: %d" % req.status_code)
'fromDate','toDate'は任意のパラメータですが、これらはUTCで指定します。日本時間ではないです。④結果
このコードを回した結果と、Twitter検索で「"ピクミン" since:2013-02-01_00:00:00_JST until:2013-02-02_00:00:00_JST」と検索した結果を比較してみました。
どちらか一方にのみ表示されているツイートを赤枠で囲んでみました。
APIによる検索結果でのみ表示されるのは、「RT @ XXXX :」から始まるツイートです。当時の公式RTなのでしょうか……?
一方で、APIによる検索では表示されなかったツイートもありました。こちらについてはもうわけわからんです。なんでや。
何かご存知の方、ご教授いただければ幸いです。
(コードが悪いのか、APIでの検索結果で一番最後がダブって表示されているのはいったん置いておいてます)多分卒論は書ける
さて、「APIでの検索結果に表示されないがTwitter検索の結果に表示される」ツイートがあるのはなぜかはわかりませんが、Twitter検索での「最新」に表示される検索結果は、リツイート以外すべて表示されているようです(両方に表示されないツイートがある可能性は否定されませんが……)。
ので、Twitter検索をベースとした定量的分析に一定の妥当性はあると考えている次第です。
何とか首の皮がつながったので、この調子で頑張って卒論を書きたいと思います。(=゚ω゚)ノ何か情報があれば、教えていただけますと幸いです。
まだまだ初心者ですので、至らない点がありましたらご指摘ください。





- 投稿日:2019-12-04T17:09:42+09:00
安心して Python2 の EOL を迎えるためにやったこと
自己紹介
SRE/QA チームで SRE をしている @yukin01 です。
半年ほど前までは iOS や Firebase/GCP を用いたアプリケーション開発を主にしていましたが、インフラ周りを強化したいと思い今はグロービスで SRE として AWS や GCP を触っています。Python2 の EOL
ご存知の通り Python2 は2020年1月1日でサポート終了することが発表されていますが、もし Python2 にまだ依存しているプロダクトやツールがあるなら EOL までに何としてでも駆逐したいですよね。
(EOL までのカウントダウンを確認できるサイト を見ると多少臨場感を味わえるかもしれません)https://www.python.org/doc/sunset-python-2/
What will happen if I do not upgrade by January 1st, 2020?
If people find catastrophic security problems in Python 2, or in software written in Python 2, then most volunteers will not help fix them. If you need help with Python 2 software, then many volunteers will not help you, and over time fewer and fewer volunteers will be able to help you. You will lose chances to use good tools because they will only run on Python 3, and you will slow down people who depend on you and work with you.
改めて EOL を迎えるとどうなるのか確認しましたが、2020年1月1日以降は Python2 に脆弱性が見つかっても基本的には放置されるとのことなので、当然ですがそのまま使い続けるリスクはとても高いです。
もちろん各種ベンダーが個別でサポートを続けることはあると思いますが、順次打ち切っていくはずなので結局何かしらの対応は必要です。
弊社のインフラ環境でもいくつか Python2 の存在が確認できたので、脱 Python2 のために対応したことをお伝えできればと思います。AWS Lambda
AWS Lambda は Python 2.7 ランタイムをサポートしています。
ランタイムサポートポリシーによると、今後60日以内に廃止予定のランタイムで Lambda を実行している場合はメールでお知らせしてくれるらしいのですが、今のところ(12/6現在)確認できていないので EOL 後も使用すること自体はできそうです。弊チームでは各種 CloudWatch Events の Slack 通知やスクリプトの定期実行などで Lambda の Python/Go/Node.js ランタイムを利用していますが、Python に関してはほとんどが Python3 でした。
ただ、S3にアップロードされたファイルに対するアンチウイルスソフトとして ClamAV を Lambda 上で実行しているのですが、それだけは Python2.7 で動いています。
これは Lambda 用の zip ファイル作成に利用している bucket-antivirus-function というツールがまだ Python2.7 用のファイルしか吐き出せないことが理由なのですが、すでに Python3 移行の PR が立っているようなので少し様子を見ることにしています。自前 Python スクリプト
サーバ上でのちょっとした作業を Python スクリプト化しておくと非常に便利ですよね。
私自身は元々 Python の経験はありませんでしたが、今は AWS CLI を呼ぶシェルスクリプトを書くのも boto3 を使って Python で書くのもそんなに変わらないので学習コストの低さを実感しています。
これらのスクリプト群はすべて shebang で Python3 が指定されていたので基本的には対応不要でした。Ubuntu AMI
グロービスのプロダクトは基本的に Ubuntu ベースの AMI 上で動いていて、Ansible と Packer を用いてプロビジョニングしています。また Ubuntu のバージョンは 16.04 or 18.04 を使っていて、どちらもデフォルトでは Python2 はインストールされていません。
しかし、稼働中のすべてのインスタンス(AMI)には Python2 が入っていました。$ which python2.7 /usr/bin/python2.7いくつかの原因があったので1つずつ潰していきました。
Ansible を実行している Python
Packer で AMI を作成するときの Provisioner として
ansible-localを使っているので、あらかじめ shell provisioner で Ansible を入れているのですがその方法に問題がありました。packer.json(簡略)"provisioners": [ { "type": "shell", "inline": [ "sudo apt-add-repository -y ppa:ansible/ansible", "sudo apt-get update", "sudo apt-get -y install ansible" ] } ]apt が提供する Ansible パッケージがそもそも Python2 に依存しているので、apt-get 経由でインストールすると Python2.7 で実行されるようになってしまいます。
$ apt-cache depends ansible ansible Depends: python-crypto Depends: python-jinja2 Depends: python-paramiko Depends: python-pkg-resources Depends: python-yaml Depends: <python:any> python Depends: <python:any> python Depends: python-httplib2 Depends: python-netaddr Recommends: python-selinux Suggests: sshpass$ ansible --version ansible 2.9.1 config file = /etc/ansible/ansible.cfg configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] ansible python module location = /usr/lib/python2.7/dist-packages/ansible executable location = /usr/bin/ansible python version = 2.7.12 (default, Oct 8 2019, 14:14:10) [GCC 5.4.0 20160609]対応としては、以下のページを参考に pip3 経由でインストールするように修正しました。
https://docs.ansible.com/ansible/latest/reference_appendices/python_3_support.html
packer.json(簡略)"provisioners": [ { "type": "shell", "inline": [ "sudo apt-get update", "sudo apt-get -y install python3-pip", "sudo pip3 install ansible" ] } ]$ ansible --version ansible 2.9.1 config file = /etc/ansible/ansible.cfg configured module search path = ['/root/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules'] ansible python module location = /usr/local/lib/python3.5/dist-packages/ansible executable location = /usr/local/bin/ansible python version = 3.5.2 (default, Oct 8 2019, 13:06:37) [GCC 5.4.0 20160609]Python のパスやバージョンが変わっているのが確認できたので OK です。
Ansible Playbook 内のタスク
数年運用されていることもあり、pip2 経由のパッケージが残っていたので確認して pip3 に移行しました。
加えて apt モジュールでインストールしているパッケージの中に Python2 依存のものがないかチェックしました。tasks/main.yml(例)- name: Install packages from apt apt: name: - python3-pip # OK - software-properties-common # OK - htop # OK - python-pip # NG - python-properties-common # NG - dstat # NG - name: Install packages from pip2 pip: name: - boto - awscli executable: pip2 # NG各タスクを実行するときの Python
これまでの変更箇所を踏まえて Packer を走らせましたが、
/usr/bin/python: not foundというエラーでコケてしまうタスクがありました。
Ansible にはタスクの実行に使用する Python インタプリタを指定できるという機能がありますが、デフォルトで/usr/bin/pythonを探してしまっていたのが原因と考えられたので以下の変数を明示的に指定することで解決しました。ansible_python_interpreter=/usr/bin/python3↑によると ansible.cfg やインベントリファイル、コマンド実行時のオプションとして指定できるようです。
以上の対応で AMI から Python2 を取り除くことが出来ました
$ which python2.7 $ which pythonUbuntu 自体の Python2 サポート
余談ですが Ubuntu 自体も Python2 の依存を切り離すのに苦労しています。
Ubuntu には以下の4つのリポジトリがありますが、16.04 と 18.04 については Python2 自体が main に入っているので EOL 後も公式のリポジトリからインストール可能です。
(もちろんユーザー側が積極的に使っていいという話ではないと思いますが…)The four main repositories are:
- Main - Canonical-supported free and open-source software.
- Universe - Community-maintained free and open-source software.
- Restricted - Proprietary drivers for devices.
- Multiverse - Software restricted by copyright or legal issues.
次期 LTS の Ubuntu 20.04(コードネーム "Focal Fossa")では本格的に Python2 が除去されるらしいのですが、実際のところどうなるのか気になりますね…!
- 投稿日:2019-12-04T17:09:23+09:00
Windows10 + Pipenv で Pytorch(GPU)を導入する
はじめに
周りの方々がどんどんPyTorchいいぞ~って言いながら乗り換えていくなかで,Tensorflowが公式でTensorboardを使えるようにしてくれたの自分もでそろそろ乗り換えようと思いこの記事を書きました.
対象者
公式の
pip3 install torch===1.3.1 torchvision===0.4.2 -f https://download.pytorch.org/whl/torch_stable.htmlで導入はできるけどこれ
pipenv install hogehogeでやりたくねって人向け
なのでPythonの導入やCUDAの導入は特に書きませんのでそこを期待されている方はブラウザバックで!!
CUDAとか言ってるので今回はGPUに着目してやります.CPUのバージョンはやりません.導入環境
- Windows 10 Pro for Workstations
- Nvidia Driver Version : 430.86
- CUDA : 10.0, V10.0.130
- cudnn : 7.6.2
Pipenvの導入
Pipenvってどんなのと思った方はこのあたり(1)を見てもらえるとよろしいかと.個人的な解釈ではSwiftで使われているCocoaPods(2)と管理の仕方が近いと思っています.
では,インストールの前にpipを最新のバージョンに上げておきます.pip install --upgrade pipそしてPipenvのインストールですね
pip install pipenvこれでOKです.簡単ですね
(1) Pipenv: 人間のためのPython開発ワーク
(2) CocoaPodsPyTorchの導入
さてここからが問題なのですがWindowsだと
pipenv install torch torchvisionだけだと
'ERROR: Could not find a version that satisfies the requirement torch==1.3.1こんな感じのエラーが返ってきちゃってうまくいかなんですよね・・・
なので
pipenv install [URL]の形で導入していきます!
ちなみにPipのオプションで
--find-linksがあるんですがPipenvにはないそうです(3)(3) --find-links (or similar) in PipEnv #2231
URLを探しに行く
PyTorchの公式サイト(4)に行くと
こんな感じでダウンロードできるとこありますよね
今回注目するのはhttps://download.pytorch.org/whl/nightly/cu101/torch_nightly.htmlここの部分です.実際にアクセスすると
PyTorchのライブラリがたくさん置いてあるのでこの中から選んでいきます.一応なんですが欲しいのはURLなので欲しいバージョンがあったら右クリックして[リンクのアドレスをコピー]とかしてもらえればURLが取得できるかと.
あと古いバージョン欲しいんじゃい!!って方は
https://download.pytorch.org/whl/torch_stable.htmlこっちのURL踏んで探してもらったほうが幸せになれるかと
今回自分は
torch: "https://download.pytorch.org/whl/nightly/cu101/torch-1.4.0.dev20191202-cp37-cp37m-win_amd64.whl" torchvision: "https://download.pytorch.org/whl/nightly/cu101/torchvision-0.5.0.dev20191203-cp37-cp37m-win_amd64.whl"をとってきてます.
さて,あとは
```
pipenv install https://download.pytorch.org/whl/nightly/cu101/torch-1.4.0.dev20191202-cp37-cp37m-win_amd64.whlpipenv install https://download.pytorch.org/whl/nightly/cu101/torchvision-0.5.0.dev20191203-cp37-cp37m-win_amd64.whl
```
すれば良しなにPipenv君が頑張ってくれます.(4) PyTorch
導入できたかの確認
Pipenvはできた!!!でも動作確認もしないとですね!
pipenv run python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name())"魔法の一行です気にしないでください.(普通に他のもので確認していただいてもOKです)
返ってくる値としてはTrue TITAN RTX [搭載されているGPUによって変わる]と返してくれればここで一安心です.
あとはpipenv shellでやろうがpipenv runでやろうがお好きなままに・・・最後に
今回はWindows10 + PipenvでPytorch(GPU)の導入方法について記事を書きました.
正直自分がはまってpipで入れたくない一心で探してたので正確かどうかはわかりません.
設定したPipfileはGitHubに置いておくので,おとしてpipenv installして動かしてみてください.リファレンス
(1) Pipenv: 人間のためのPython開発ワーク
(2) CocoaPods
(3) --find-links (or similar) in PipEnv #2231
(4) PyTorch


- 投稿日:2019-12-04T17:09:23+09:00
Windows10 + Pipenv で PyTorch(GPU)を導入する
はじめに
周りの方々がどんどんPyTorchいいぞ~って言いながら乗り換えていくなかで,Tensorflowが公式でTensorboardを使えるようにしてくれたの自分もでそろそろ乗り換えようと思いこの記事を書きました.
対象者
公式の
pip3 install torch===1.3.1 torchvision===0.4.2 -f https://download.pytorch.org/whl/torch_stable.htmlで導入はできるけどこれ
pipenv install hogehogeでやりたくねって人向け
なのでPythonの導入やCUDAの導入は特に書きませんのでそこを期待されている方はブラウザバックで!!
CUDAとか言ってるので今回はGPUに着目してやります.CPUのバージョンはやりません.導入環境
- Windows 10 Pro for Workstations
- Nvidia Driver Version : 430.86
- CUDA : 10.0, V10.0.130
- cudnn : 7.6.2
Pipenvの導入
Pipenvってどんなのと思った方はこのあたり(1)を見てもらえるとよろしいかと.個人的な解釈ではSwiftで使われているCocoaPods(2)と管理の仕方が近いと思っています.
では,インストールの前にpipを最新のバージョンに上げておきます.pip install --upgrade pipそしてPipenvのインストールですね
pip install pipenvこれでOKです.簡単ですね
(1) Pipenv: 人間のためのPython開発ワーク
(2) CocoaPodsPyTorchの導入
さてここからが問題なのですがWindowsだと
pipenv install torch torchvisionだけだと
'ERROR: Could not find a version that satisfies the requirement torch==1.3.1こんな感じのエラーが返ってきちゃってうまくいかなんですよね・・・
なので
pipenv install [URL]の形で導入していきます!
ちなみにPipのオプションで
--find-linksがあるんですがPipenvにはないそうです(3)(3) --find-links (or similar) in PipEnv #2231
URLを探しに行く
PyTorchの公式サイト(4)に行くと
こんな感じでダウンロードできるとこありますよね
今回注目するのはhttps://download.pytorch.org/whl/nightly/cu101/torch_nightly.htmlここの部分です.実際にアクセスすると
PyTorchのライブラリがたくさん置いてあるのでこの中から選んでいきます.一応なんですが欲しいのはURLなので欲しいバージョンがあったら右クリックして[リンクのアドレスをコピー]とかしてもらえればURLが取得できるかと.
あと古いバージョン欲しいんじゃい!!って方は
https://download.pytorch.org/whl/torch_stable.htmlこっちのURL踏んで探してもらったほうが幸せになれるかと
今回自分は
torch: "https://download.pytorch.org/whl/nightly/cu101/torch-1.4.0.dev20191202-cp37-cp37m-win_amd64.whl" torchvision: "https://download.pytorch.org/whl/nightly/cu101/torchvision-0.5.0.dev20191203-cp37-cp37m-win_amd64.whl"をとってきてます.
さて,あとは
```
pipenv install https://download.pytorch.org/whl/nightly/cu101/torch-1.4.0.dev20191202-cp37-cp37m-win_amd64.whlpipenv install https://download.pytorch.org/whl/nightly/cu101/torchvision-0.5.0.dev20191203-cp37-cp37m-win_amd64.whl
```
すれば良しなにPipenv君が頑張ってくれます.(4) PyTorch
導入できたかの確認
Pipenvはできた!!!でも動作確認もしないとですね!
pipenv run python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name())"魔法の一行です気にしないでください.(普通に他のもので確認していただいてもOKです)
返ってくる値としてはTrue TITAN RTX [搭載されているGPUによって変わる]と返してくれればここで一安心です.
あとはpipenv shellでやろうがpipenv runでやろうがお好きなままに・・・最後に
今回はWindows10 + PipenvでPytorch(GPU)の導入方法について記事を書きました.
正直自分がはまってpipで入れたくない一心で探してたので正確かどうかはわかりません.
設定したPipfileはGitHubに置いておくので,おとしてpipenv installして動かしてみてください.リファレンス
(1) Pipenv: 人間のためのPython開発ワーク
(2) CocoaPods
(3) --find-links (or similar) in PipEnv #2231
(4) PyTorch
- 投稿日:2019-12-04T16:51:11+09:00
俺はお前が作業していないのを見たぞ
はじめに
某部活で作業せずにスマブラをする輩がいるので, いつでも部室の様子を見れるようにした話です.
OpenCVとWebSocketで, リアルタイムで様子が見れるものがあっさり作れたので
置いときます.動作環境
CentOS Linux release 7.5.1804
Python 3.6.8
ロジクール ウェブカメラ C270実装
以下をインストール
pip install opencv-python pip install flask pip install gevent pip install gevent-websocketディレクトリ構成
├ main.py ├ templates/ ├ index.htmlサーバー : main.py
カメラとの接続は, これでいけます.
引数で繋いでるカメラを指定するみたいです. 1台しか繋いでないなら0で大丈夫なはずです.# usbbカメラと接続 capture = cv2.VideoCapture(0)カメラからフレームを読み込みます. frameが画像データです.
et, frame = capture.read() # カメラからフレーム読みこみ画像jpgに変換. encimgが画像データです.
90は圧縮率です. 1-100で指定します. 低いほど高圧縮.# jpgにエンコードするときのパラメーター encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 90] result, encimg = cv2.imencode('.jpg', frame, encode_param) #jpgに変換プログラム全体
import cv2 import base64 from flask import Flask, request, render_template from gevent import pywsgi from geventwebsocket.handler import WebSocketHandler app = Flask(__name__) # usbカメラと接続 capture = cv2.VideoCapture(0) # jpgにエンコードするときのパラメーター encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 90] @app.route('/') def index(): return render_template('index.html') @app.route('/live') def live(): if request.environ.get('wsgi.websocket'): ws = request.environ['wsgi.websocket'] while True: ret, frame = capture.read() # カメラから画像読みこみ result, encimg = cv2.imencode('.jpg', frame, encode_param) #jpgに変換 ws.send(base64.b64encode(encimg).decode('ascii')) # webbsocketでbase64に変換したjpg画像を送信 def main(): app.debug = True server = pywsgi.WSGIServer(("", 8080), app, handler_class=WebSocketHandler) server.serve_forever() if __name__ == '__main__': main()フロント : index.html
受け取ったら画像を更新するようにするだけです.
<html> <head> <title>●REC</title> </head> <body> <img id="player" src=""/> <script> const ws = new WebSocket("wss://localhost/live"); const player = document.getElementById("player"); # 受取時の処理 ws.onmessage = function(e) { player.setAttribute("src", "data:image/jpg;base64,"+e.data) } </script> </body> </html>ここまでできればlocalhost:8080にアクセスすれば画像が表示されるはずです.
Nginx
nginxのconfです.
server{ listen 80; server_name hostname; return 301 https://$host$request_uri; } server{ listen 443 ssl; client_max_body_size 500M; server_name hostname; ssl_certificate cert.pem; ssl_certificate_key privkey.pem; location / { proxy_pass http://localhost:8080/; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forward-For $proxy_add_x_forwarded_for; proxy_set_header X-Forward-Proto http; proxy_set_header X-Nginx-Proxy true; proxy_redirect off; } }おわりに
対策された、、、
参考
FlaskとWebSocketを使用してリアルタイム通信を行う
OpenCV3をPython3で動かす。画像データ分析入門の為の下準備。


- 投稿日:2019-12-04T16:18:20+09:00
QGISから3Dデータをエクスポートする
はじめに
QGISに組み込まれた、Pythonコンソールを使って、GISデータをOBJファイルに書き出してみます。
※OBJファイルについては、Wikipediaのリンクを提示しておきます。テキストで書き出せる非常に単純なフォーマットなので、独自にエクスポートする場合に扱いやすいです。
切り抜き
まず、対象範囲を切り抜きます。前回のデータをそのまま使うと、さすがに巨大になりすぎて、リアルタイムレンダリングでは対応できなくなるので、適当な範囲に切り抜いてみます。
今回は、六本木ヒルズ周辺を切り取ってみます。
まず、メニューから「レイヤ」-「レイヤの作成」-「新しい一時スクラッチレイヤ」を選び、ダイアログで、適当な名前とジオメトリタイプにポリゴンを選択します。
追加した新しいレイヤが編集モードになっていることを確認して、メニューから「編集」-「長方形の追加」-「領域範囲の長方形の追加」を行います。頂点と対角の頂点を左クリックで選択し、右クリックで追加終了になります。
図は分かりやすいように矩形の描画を半透明にしてあります。
次に、「ベクタ」-「空間演算ツール」-「切り抜き」を選び、入力に建物データのレイヤ、オーバーレイに今作成した矩形領域を持つレイヤを選択して、実行します。
これで、エクスポートしたい領域が切り抜かれました。
ついでに、この矩形領域の重心を求めておきます。
「ベクタ」-「ジオメトリツール」-「重心」です。
できたポイントを地物情報表示ツールでクリックすれば、重心の緯度経度が分かります。QGISのマクロ?Pythonコンソール
さて、Pythonコンソールを使って、このデータを3DのOBJファイルに書き出してみます。
Pythonコンソールはメニューから「プラグイン」-「Pythonコンソール」で呼び出すことができます。座標変換
現在座標系はWGS84で(何も変えていなければたぶん)作業しています。座標系について細かいところを説明し始めると、ものすごい量になるので、ここでは割愛します。
WGS84では、座標は緯度経度で表されています。ここから、XYZの三次元直交座標系に変換します。以下のメソッドは、世界測地系と座標変換という本のプログラムを参考にして作成した座標変換のメソッドです。WGS84での地球の表し方に沿った極力正確な直交座標変換になっています。
なお、この計算では、少なくともdoubleの精度で行う必要があります。Pythonの浮動小数点はdoubleのはずなので、あまり気にしなくてもいいかと思いますが、UnityのVector3クラスなどはfloatで数値を持っているので、このプログラムを移植する場合は注意が必要です。
往々にして地理座標を扱うときは、doubleで扱うようにしておいた方が余計な失敗をしないで済みます。def BLH2XYZ(b,l,h): # WGS84 a = 6378137.0 f = 1.0 / 298.257223563 b = math.radians(b) l = math.radians(l) e2 = f * (2.0 - f) N = a / math.sqrt(1.0 - e2 * math.pow(math.sin(b), 2.0)) X = (N + h) * math.cos(b) * math.cos(l); Y = (N + h) * math.cos(b) * math.sin(l); Z = (N * (1 - e2) + h) * math.sin(b); return (X,Y,Z)OBJ書き出し
そして、上の座標変換メソッドを組み込んだ形で、OBJ書き出しのプログラムを作成します。
def BLH2XYZ(b,l,h): # WGS84 a = 6378137.0 f = 1.0 / 298.257223563 b = math.radians(b) l = math.radians(l) e2 = f * (2.0 - f) N = a / math.sqrt(1.0 - e2 * math.pow(math.sin(b), 2.0)) X = (N + h) * math.cos(b) * math.cos(l); Y = (N + h) * math.cos(b) * math.sin(l); Z = (N * (1 - e2) + h) * math.sin(b); return (X,Y,Z) layer = iface.activeLayer() features = layer.getFeatures() i = 0 j = 0 fp = open("test.obj",mode='w') fp.write("g "+str(i)+"\n") # ※前に取得しておいた矩形領域の重心に変える cx = 139.72957 cy = 35.66021 ox,oy,oz = BLH2XYZ(cy,cx,0) for feature in features: # print(feature.id()) mp = feature.geometry().asMultiPolygon() try: height = int(feature['height'])*2 if height < 1: height = 2 except: height = 5 for polygon in mp: for polyline in polygon: i=i+1 prev_p_index = j for point in polyline: x,y,z = BLH2XYZ(point.y(),point.x(),0) x2,y2,z2 = BLH2XYZ(point.y(),point.x(),height) x = x - ox y = y - oy z = z - oz x2 = x2 - ox y2 = y2 - oy z2 = z2 - oz s = math.radians(-cx) rx = x * math.cos(s) - y * math.sin(s) ry = x * math.sin(s) + y * math.cos(s) s = math.radians(-cy) rxx = rx * math.cos(s) - z * math.sin(s) rz = rx * math.sin(s) + z * math.cos(s) s = math.radians(-cx) rx2 = x2 * math.cos(s) - y2 * math.sin(s) ry2 = x2 * math.sin(s) + y2 * math.cos(s) s = math.radians(-cy) rxx2 = rx2 * math.cos(s) - z2 * math.sin(s) rz2 = rx2 * math.sin(s) + z2 * math.cos(s) fp.write("v "+str(ry)+" "+str(rxx)+" "+str(rz)+"\n") fp.write("v "+str(ry2)+" "+str(rxx2)+" "+str(rz2)+"\n") j=j+1 current = j - prev_p_index for num in range(current): p1 = (2*num+1) p2 = (2*num+2) p3 = (2*num+3) p4 = (2*num+4) if p3 > current*2: p3 = p3 - current*2 if p4 > current*2: p4 = p4 - current*2 p1 = p1 + prev_p_index*2 p2 = p2 + prev_p_index*2 p3 = p3 + prev_p_index*2 p4 = p4 + prev_p_index*2 fp.write("f "+str(p1)+" "+str(p2)+" "+str(p3)+" "+str(p1)+"\n") fp.write("f "+str(p4)+" "+str(p3)+" "+str(p2)+" "+str(p4)+"\n") fp.close() print("Done")このプログラム内で、処理としては先ほどの地理座標から直交座標への座標変換と、原点の移動と全体の回転、OBJへの書き出しを行っています。
結果


