- 投稿日:2019-12-04T23:34:30+09:00
プロキシ祭りだ☆ワッショイ!
プロローグ
デバッグをしていると PKIX path building failed ~
あり~?
昨日まで普通に動いていたのに。
しかし、これは前にも起きたことがあるのでサクっと解決できる。
いま思えば、これが不幸の始まりでした。(所要時間12時間)1.証明書エラーの解決(プロキシなし)
AWS環境では、EC2 with 似非SSLからインターネットに接続しようとして、 PKIX path building failed ~ が発生していたので、javaに似非SSL証明書を登録して解決。
PKIX path building failed:javaにSSL証明書を追加する
2.証明書エラーの解決(プロキシあり)⇒ 失敗!
ローカルPCから繋がらなくなり、PKIX path building failed ~ が出ていたので、何の疑いもなく似非SSL証明書を登録した。
これが不幸の始まり。2.1 証明書を登録、登録&登録
eclipseを使ってウン10年、jdk、jre 以外にeclipseのjreがあるとは知りませんでした。
Eclipseでgradleプロジェクト作成時、証明書エラーで失敗した場合
jdkのcacerts に証明書を登録してもダメ、jreのcacerts に証明書を登録してもダメ。
これを見つけたときは、tomcatでデバッグしていることもあり、手ごたえありでしたが、ダメ。2.2 証明書をexp&imp
コンパネの証明書の管理から、臭そうな証明書をexp&imp、exp&imp、、、泥沼
※このときjavaのcacertsが復旧不能な状態になったと思います。3.不変的なエラーの解決方法
いくつかありますが、ここでは確実に解決する方法を取り上げます。
3.1 事象が再現する最小構成を構築する
今回の件なら、以下の2点を確認できれば泥沼にハマることはなかったでしょう。
インターネットに繋がらないのは特定のサイトか?
java以外で繋がるか?
・インターネットに繋がらないのは特定のサイトか?
最初のアクセスがgoogle apiのため、またセキュリティが強化されたと思い込んだのが間違いでした。yahooでも繋がりませんでした。
spring bootでしたが、URLConnectionで繋ぐところだけ抜き出して素のjavaで確認しました。・java以外で繋がるか?
最初のアクセスがGETなので、ブラウザでアクセスしたら繋がりました。いちおうnodeでも繋がることを確認しました。だいたいプロキシを通してるんだから、「似非SSL証明書」をjavaに登録する事自体が奇妙だったんだ
4.証明書エラーの解決(プロキシあり)⇒ 解決
隣人のjdkのcacertsをもらって上書きしたら直りました(^^;
cacertsに登録されているリストも見ましたが、長いし、どれを直したらいいか分からないし、、、
3.1 事象が再現する最小構成を構築する で、jdkのcacertsがおかしいことは確信したので、迷わず上書きしました。エピローグ
原因が分からないまま解決を優先してしまいました。
javaのcaについては分からないままです。
心残りはありますが、ここはjavaめんどくせー
proxyうざー
で締めたいと思います。
(ちなみに、本来の改修は30分で終わりました)「似非SSL」口に出すと言いづらいですね。エセエスエスエル
もうセッセッセでいいんじゃないでしょうか、ワッショイ!



- 投稿日:2019-12-04T22:52:14+09:00
Java(Eclipse)でAWSBatchにジョブ送信
Java(Eclipse)でAWSBatchにジョブ送信を試してみたので共有します。
前提
AWSBatchで以下が設定されている。
・ジョブ定義名:sample-job-definition
・キュー名:sample-job-queue
・コンピューティング環境名:sample-compute-environmentEclipseで以下を実施している。
・AWS Toolkit for Eclipseをインストール。
・AWS Toolkit for EclipseにIAMユーザのアクセスキー、シークレットアクセスキーを設定。
・Gradleプロジェクト作成。build.gradleの編集、SDKをインストール
dependenciesにaws-java-sdk-batchを追加して、プロジェクトにインストールします。
(プロジェクトを右クリックして Gradleプロジェクトのリフレッシュなどすると処理が開始されます)dependenciesに追加dependencies { …略 compile('com.amazonaws:aws-java-sdk-batch:1.11.683') // compile group: 'com.amazonaws', name: 'aws-java-sdk-batch', version: '1.11.683' // この書き方でもOK …略 }Javaサンプルコード
ドキュメントを参考に、以下のお試しコードを作成しました。
サンプルコードpackage sample; import java.util.HashMap; import java.util.Map; import com.amazonaws.regions.Regions; import com.amazonaws.services.batch.AWSBatch; import com.amazonaws.services.batch.AWSBatchClientBuilder; import com.amazonaws.services.batch.model.SubmitJobRequest; import com.amazonaws.services.batch.model.SubmitJobResult; public class AwsBatchSample { public static void main(String[] args) { AwsBatchSample awsBatchSample = new AwsBatchSample(); ab.awsBatchJobSend(); } private void awsBatchJobSend() { try { AWSBatch client = AWSBatchClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); Map<String,String> parameters = new HashMap<String, String>(); parameters.put("param1", "JobParam1"); // ジョブ定義でのコマンド:echo sample-batch Ref::param1 // ログでの出力結果 :sample-batch JobParam1 SubmitJobRequest request = new SubmitJobRequest() .withJobName("sample-job-submit") .withJobQueue("sample-job-queue") .withJobDefinition("sample-job-definition") .withParameters(parameters) ; SubmitJobResult response = client.submitJob(request); System.out.println(response); } catch (Exception e) { System.out.println(e); } } }ジョブ送信が成功すると以下が返却される。{JobName: sample-job-submit,JobId: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa}はまりポイント
ドキュメントの例では指定されていませんでしたが、
.withRegion(Regions.AP_NORTHEAST_1)を指定しない場合、以下のようなエラーが出力されました。エラーログ20:31:11.636 [main] DEBUG com.amazonaws.AmazonWebServiceClient - Internal logging successfully configured to commons logger: true 20:31:11.998 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.EnvironmentVariableCsmConfigurationProvider@17fc391b: Unable to load Client Side Monitoring configurations from environment variables! 20:31:11.998 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.SystemPropertyCsmConfigurationProvider@2b30a42c: Unable to load Client Side Monitoring configurations from system properties variables! 20:31:11.998 [java-sdk-http-connection-reaper] DEBUG org.apache.http.impl.conn.PoolingHttpClientConnectionManager - Closing connections idle longer than 60000 MILLISECONDS 20:31:11.999 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.ProfileCsmConfigurationProvider@43df23d3: Unable to load config file 20:31:12.025 [main] WARN com.amazonaws.internal.InstanceMetadataServiceResourceFetcher - Fail to retrieve token com.amazonaws.SdkClientException: Failed to connect to service endpoint: at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:100) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.getToken(InstanceMetadataServiceResourceFetcher.java:91) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.readResource(InstanceMetadataServiceResourceFetcher.java:69) at com.amazonaws.internal.EC2ResourceFetcher.readResource(EC2ResourceFetcher.java:62) at com.amazonaws.util.EC2MetadataUtils.getItems(EC2MetadataUtils.java:400) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:369) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:365) at com.amazonaws.util.EC2MetadataUtils.getEC2InstanceRegion(EC2MetadataUtils.java:280) at com.amazonaws.regions.InstanceMetadataRegionProvider.tryDetectRegion(InstanceMetadataRegionProvider.java:59) at com.amazonaws.regions.InstanceMetadataRegionProvider.getRegion(InstanceMetadataRegionProvider.java:50) at com.amazonaws.regions.AwsRegionProviderChain.getRegion(AwsRegionProviderChain.java:46) at com.amazonaws.client.builder.AwsClientBuilder.determineRegionFromRegionProvider(AwsClientBuilder.java:475) at com.amazonaws.client.builder.AwsClientBuilder.setRegion(AwsClientBuilder.java:458) at com.amazonaws.client.builder.AwsClientBuilder.configureMutableProperties(AwsClientBuilder.java:424) at com.amazonaws.client.builder.AwsSyncClientBuilder.build(AwsSyncClientBuilder.java:46) at sample.AwsBatchSample.awsBatchJobSend(AwsBatchSample.java:17) at sample.AwsBatchSample.main(AwsBatchSample.java:12) Caused by: java.net.SocketException: Network is unreachable: connect at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at sun.net.NetworkClient.doConnect(NetworkClient.java:175) at sun.net.www.http.HttpClient.openServer(HttpClient.java:463) at sun.net.www.http.HttpClient.openServer(HttpClient.java:558) at sun.net.www.http.HttpClient.<init>(HttpClient.java:242) at sun.net.www.http.HttpClient.New(HttpClient.java:339) at sun.net.www.http.HttpClient.New(HttpClient.java:357) at sun.net.www.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.java:1202) at sun.net.www.protocol.http.HttpURLConnection.plainConnect0(HttpURLConnection.java:1181) at sun.net.www.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:1032) at sun.net.www.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:966) at com.amazonaws.internal.ConnectionUtils.connectToEndpoint(ConnectionUtils.java:52) at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:80) ... 16 common frames omitted 20:31:12.025 [main] WARN com.amazonaws.util.EC2MetadataUtils - Unable to retrieve the requested metadata (/latest/dynamic/instance-identity/document). Failed to connect to service endpoint: com.amazonaws.SdkClientException: Failed to connect to service endpoint: at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:100) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.getToken(InstanceMetadataServiceResourceFetcher.java:91) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.readResource(InstanceMetadataServiceResourceFetcher.java:69) at com.amazonaws.internal.EC2ResourceFetcher.readResource(EC2ResourceFetcher.java:62) at com.amazonaws.util.EC2MetadataUtils.getItems(EC2MetadataUtils.java:400) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:369) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:365) at com.amazonaws.util.EC2MetadataUtils.getEC2InstanceRegion(EC2MetadataUtils.java:280) at com.amazonaws.regions.InstanceMetadataRegionProvider.tryDetectRegion(InstanceMetadataRegionProvider.java:59) at com.amazonaws.regions.InstanceMetadataRegionProvider.getRegion(InstanceMetadataRegionProvider.java:50) at com.amazonaws.regions.AwsRegionProviderChain.getRegion(AwsRegionProviderChain.java:46) at com.amazonaws.client.builder.AwsClientBuilder.determineRegionFromRegionProvider(AwsClientBuilder.java:475) at com.amazonaws.client.builder.AwsClientBuilder.setRegion(AwsClientBuilder.java:458) at com.amazonaws.client.builder.AwsClientBuilder.configureMutableProperties(AwsClientBuilder.java:424) at com.amazonaws.client.builder.AwsSyncClientBuilder.build(AwsSyncClientBuilder.java:46) at sample.AwsBatchSample.awsBatchJobSend(AwsBatchSample.java:17) at sample.AwsBatchSample.main(AwsBatchSample.java:12) Caused by: java.net.SocketException: Network is unreachable: connect at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at sun.net.NetworkClient.doConnect(NetworkClient.java:175) at sun.net.www.http.HttpClient.openServer(HttpClient.java:463) at sun.net.www.http.HttpClient.openServer(HttpClient.java:558) at sun.net.www.http.HttpClient.<init>(HttpClient.java:242) at sun.net.www.http.HttpClient.New(HttpClient.java:339) at sun.net.www.http.HttpClient.New(HttpClient.java:357) at sun.net.www.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.java:1202) at sun.net.www.protocol.http.HttpURLConnection.plainConnect0(HttpURLConnection.java:1181) at sun.net.www.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:1032) at sun.net.www.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:966) at com.amazonaws.internal.ConnectionUtils.connectToEndpoint(ConnectionUtils.java:52) at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:80) ... 16 common frames omitted com.amazonaws.SdkClientException: Unable to find a region via the region provider chain. Must provide an explicit region in the builder or setup environment to supply a region.ざっくりですが、今回は以上です。
参考
https://docs.amazonaws.cn/AWSJavaSDK/latest/javadoc/com/amazonaws/services/batch/AWSBatchClient.html#submitJob-com.amazonaws.services.batch.model.SubmitJobRequest-
https://docs.amazonaws.cn/AWSJavaSDK/latest/javadoc/com/amazonaws/services/batch/model/SubmitJobRequest.html
https://github.com/aws/aws-sdk-java/issues/2062
https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-batch
- 投稿日:2019-12-04T22:34:06+09:00
Java で DataFrame を使う
DataFrame ご存知ですか?
DataFrame は Python や R言語でデータを扱ったり、機械学習したいときによく使われるとても便利なライブラリ・オブジェクトです。表形式のデータや2次元の配列のデータを扱うための様々な機能が揃っています。
https://amalog.hateblo.jp/entry/kaggle-pandas-tipsどのくらい便利かというと、Excel や CSV から一気にデータを読み込んだり、2次元配列の任意の行列を抽出したり、表同士を SQL 操作のごとく join したりと、とにかく 2次元データを使う際には欠かせないというレベルです。
でも Java だとこれという DataFrame 相当の実装が無くて、ありがたい DataFrame の恩恵を受けられない、データ処理に時間がかかる、なんで Python じゃないんですかと暴言(?)を吐かれるなどの悲しい目に合うわけです。
Morpheus data science framework
しかし、そこに一筋の光が。
Morpheus data science framework が、その DataFrame と(たぶん)同等の機能を提供してくれています。
https://github.com/zavtech/morpheus-coreA Simple Example に沿って試してみましょう。
Consider a dataset of motor vehicle characteristics accessible here. The code below loads this CSV data into a Morpheus DataFrame, filters the rows to only include those vehicles that have a power to weight ratio > 0.1 (where weight is converted into kilograms), then adds a column to record the relative efficiency between highway and city mileage (MPG), sorts the rows by this newly added column in descending order, and finally records this transformed result to a CSV file.
(このサンプルでは)車の特性データを使用します。CSV を Morpheus DataFrame に読み込み、出力(馬力)重量比が 0.1 を超える条件で行をフィルタし、高速道路/都市部のMPG(燃費?)の比率の列を追加します。追加した列でソートして、結果を CSV ファイルに出力します。
サンプルコードと実行結果
import com.zavtech.morpheus.frame.*; public class MorpheusTester { public static void main(String[] args) { DataFrame.read().csv(options -> { options.setResource("http://zavtech.com/data/samples/cars93.csv"); options.setExcludeColumnIndexes(0); }).rows().select(row -> { double weightKG = row.getDouble("Weight") * 0.453592d; double horsepower = row.getDouble("Horsepower"); return horsepower / weightKG > 0.1d; }).cols().add("MPG(Highway/City)", Double.class, v -> { double cityMpg = v.row().getDouble("MPG.city"); double highwayMpg = v.row().getDouble("MPG.highway"); return highwayMpg / cityMpg; }).rows().sort(false, "MPG(Highway/City)").write().csv(options -> { options.setFile("./cars93m.csv"); options.setTitle("DataFrame"); }); } }戻り値の型が DataFrame 型なので、メソッドチェーンで csv(), select(), add(), sort() と続けて実行できます。csv() のあたりはとても DataFrame 感に溢れています。
処理前のデータ
処理後のデータ
DataFrame は機能が豊富で、同等かどうか試すのも容易ではありませんが、行抽出、列追加、ソートといった操作を確認することができました。
Java でデータ処理される際には、利用を検討してみても良いと思います。
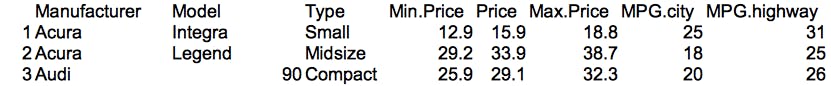

- 投稿日:2019-12-04T22:20:30+09:00
アップキャスト/ダウンキャスト
初学者ですが、個人的な勉強のため書きました
アップキャスト
・サブクラスのインスタンスをスーパークラスのオブジェクトに格納することをアップキャストという
・コンパイラは互換性をチェックできればキャストを自動的に行ってくれるので、継承関係であるサブクラスはスーパークラスのすべてのメンバーを保証できるためアップキャストは暗黙的に行われる
・スーパークラスとサブクラスに、同じ名前のフィールド変数やメソッドがある場合には、フィールド変数はスーパークラス、メソッドはサブクラスが優先されるダウンキャスト
・アップキャストとは逆に、サブクラスのオブジェクトにスーパークラスのオブジェクトを格納することをダウンキャストという
・スーパークラスはサブクラスのすべてのメンバーを保証できないため、スーパークラスからサブクラスにダウンキャストする場合は明示的にダウンキャストを行う必要がある
・アップキャストされていないオブジェクトをダウンキャストすると、ClassCastExceptionの例外が発生するので、一度アップキャストしてからダウンキャストする必要がある
・instanceof演算子でオブジェクトが指定したクラス型もしくは指定したクラスを継承しているか比較することでダウンキャストできるか判定できる
- 投稿日:2019-12-04T22:13:16+09:00
エラーメッセージ出す処理
エラーメッセージ出す処理
なんか便利そうなの思いついたので備忘録に
ErrorMessage.javapackage listTest; import java.util.ArrayList; import java.util.Collection; import java.util.LinkedList; import java.util.List; import java.util.stream.Collectors; public class ErrorMessage { public static void main(String[] args) { // モデルのリストが入力とかされたとする List<Model> models = new ArrayList<>(); // 検知されたエラーメッセージを全種類取得 List<String> eMsgCodes = models.stream() .map(ErrorMessage::validationLogic) .flatMap(Collection::stream) .distinct() .collect(Collectors.toList()); // メッセージコードを設定ファイルとかから変換とかして出力的な eMsgCodes.forEach(ErrorMessage::viewErrorMessage); } /** * 各要素ごとに入力値チェックをする. * <p> * アノテーションなどではじけないような固有判定. * * @param model チェック対象のモデル * @return エラー文言のリスト */ private static List<String> validationLogic(Model model) { List<String> errorMessages = new LinkedList<>(); // idが0でないエラー if (0 != model.getId()) { errorMessages.add("MessageCode.001"); } // 名前が〇〇でないエラー if (!"???".equals(model.getName())) { errorMessages.add("MessageCode.002"); } // アドレスが〇〇でないエラー if (!"???".equals(model.getAddress())) { errorMessages.add("MessageCode.003"); } return errorMessages; } /** * メッセージコードを表示用メッセージに変換して出力. * <p> * 設定ファイルから取得した該当文言を画面に表示する. * * @param msgCode メッセージコード * @see 設定ファイル */ private static void viewErrorMessage(String msgCode) { System.out.println(msgCode); } } class Model { private int id; private String name; private String address; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } }おもにここですね
ここ.java// 検知されたエラーメッセージを全種類取得 List<String> eMsgCodes = models.stream() .map(ErrorMessage::validationLogic) .flatMap(Collection::stream) .distinct() .collect(Collectors.toList());チェック後にエラーメッセージが複数件出るとわかっている場合
ロジック的には引数がmodelで戻り値がListになるわけで
それをすべてstreamにならして、かぶりを排除って処理ですねわりといい感じなのでは
- 投稿日:2019-12-04T21:24:07+09:00
Swift Network.framework Study 20191204「UDP」
Study
Network.framework
Study:Client側環境
Client:Swift、Xcode
Server:Java、NetBeansClient Source Swift
SwiftはNWConnectionに「NWParameters.udp」を設定するだけ。
import Foundation import Network var running = true func startConnection() { let myQueue = DispatchQueue(label: "ExampleNetwork") let connection = NWConnection(host: "localhost", port: 7777, using: NWParameters.udp) connection.stateUpdateHandler = { (newState) in switch(newState) { case .ready: print("ready") sendMessage(connection) case .waiting(let error): print("waiting") print(error) case .failed(let error): print("failed") print(error) default: print("defaults") break } } connection.start(queue: myQueue) } func sendMessage(_ connection: NWConnection) { let data = "Example Send Data".data(using: .utf8) let completion = NWConnection.SendCompletion.contentProcessed { (error: NWError?) in print("送信完了") running = false } connection.send(content: data, completion: completion) } startConnection() //dispatchMain() while running { sleep(1) }Server Source Java
JavaはTCPとUPDで使用するクラスが違う。
package example.java.network; import java.net.DatagramPacket; import java.net.DatagramSocket; public class ExampleServerUDP { private static final int EXHOMAX = 255; public static void main(String[] args) { try { DatagramSocket datagramSocket = new DatagramSocket(7777); DatagramPacket datagramPacket = new DatagramPacket(new byte[EXHOMAX], EXHOMAX); while(true) { datagramSocket.receive(datagramPacket); for(int i = 0; i < datagramPacket.getLength(); i++) { System.out.print(datagramPacket.getData()[i]); System.out.print(" "); } System.out.println(); datagramPacket.setLength(EXHOMAX); } } catch(Exception e) { } } }
- 投稿日:2019-12-04T19:09:44+09:00
インターフェイス/抽象クラス/オーバーライド
初学者ですが、個人的な勉強のために書いたものです
インターフェイス
インターフェイスとはクラスのような具体的な処理を提供するものではなく、決まり事を定めるために明示しとくものであり、実際の処理はインターフェイスを実装したクラスで定義する
これにより、プログラムを複数人で作るような会社の現場では、親の抽象クラスで子クラスに実装してほしいメソッドを抽象メソッドとして定義しておくことで、他の人が作成する子クラスでも、必ずそのメソッドを実装してもらえるという利点がある※抽象メソッド・・・名前/型/引数だけを定義したメソッド
①クラスから「型」だけ取り出したもの
※「型」・・・そのものの「扱い方を決める方法」であり、変数を宣言するときに、型を指定するのは変数の扱い方を決めるためである
・注意すべき点は、扱う対象そのものの種類と、型で指定する「扱うものの種類」は異なる概念であること。例えると、1という数値をint型で扱うのか、double型で扱うのか変えられるように種類と扱い方は異なるということ
②ほかのクラスからの「扱い方」を規定したもの
・ほかのクラスから扱えるようにするために、規定するメソッドはすべてpublicと解釈されるため、インターフェイスはコンパイラによって自動的にpublicにされる
・インターフェイスで定義するメソッドは、protectdやprivateで修飾することはできない (Java8からdefault修飾子を付けることで中身も定義できるようになった)
・クラスがインターフェイスを継承するときにimplements(実現する)を使うことからわかるように「規定を実現するクラス」があって初めて動作する③インターフェイスは実装を持てない
インターフェイスは扱い方だけを規定しているので、実装を持てないため、インスタンスを生成して動的に動作するもの(動的に値が変わるもの)は記述できない
ただし、以下の二つの条件をどちらか満たしていれば記述可能・finalを使い、動的に値が変更されないこと(定数)
・staticを使い、インスタンスを生成できないこと④インターフェイスの継承
・継承はextends(拡張する)を使うことからわかるようにクラス機能を拡張した新しいクラスを定義することができるが、インターフェイスにおいてもextendsで、あるインターフェイスを拡張した新しいインターフェイスを定義(継承)できる
・クラスの多重継承は禁止だが、インターフェイスの多重実現は認められている抽象クラス
①インターフェイスとクラスの両方の性質をもつ
・実装を持つ具象メソッドと、実装を持たない抽象メソッドの両方を持つことができる
・抽象クラスに定義した具象メソッドは、その抽象クラスを継承したサブクラスが引き継ぐ
・抽象メソッドは、そのサブクラスでオーバーライドして実装しなおさなくてはいけない②インスタンス化はできない
・インターフェイスのの特性(抽象メソッド)を持つ抽象クラスは、インターフェイス同様にインスタンス化できない
・インスタンス化できないことからわかるとおり、継承されて利用されることが前提である
・抽象クラスに定義した抽象メソッドはこれを継承した具象クラスが実装を提供しなければならない
・抽象クラスを継承した抽象クラスは、具象クラスのように必ずしも実装する必要はなく、元の抽象クラスを拡張し、新しい抽象メソッドを追加したり、既存の抽象メソッドをオーバーライドして実装することができる。③フィールド定義
・抽象クラスを継承したサブクラスのインスタンスには、抽象クラスのインスタンスが含まれる。つまり、抽象クラスを継承したサブクラスのインスタンスには抽象クラスのインスタンスが含まれ、型だけを提供するインターフェイスは定数フィールドしかできないが、抽象クラスには動的に値が変更できるフィールドが定義できる
オーバーライド
・オーバーライドは、サブクラスでスーパークラスに定義されたメソッドを再定義すること
・多重定義を表すオーバーロードと間違えないように注意
・メソッドの再定義のため、メソッドのシグニチャは同じでなければならない※シグニチャ・・・メソッド名、引数リストの型、数、順番を組み合わせたもの
・同じ型かそのサブクラスであれば、オーバーライドしたメソッドの戻り値型に指定できるようになった
public Number method{ //any code }public Integer method{ //any code }上記の例はInteger型がNumber型のサブクラスであるのでオーバーライドできる
・オーバーライドは上書き(overwrite)ではなく、追加(再定義)なので、サブクラスのインスタンスには同じ名前のメソッドが複数存在していることになる。この場合、オーバーライドされたメソッドが使われる
・オーバーライドされたメソッドでは、元の定義よりもアクセス制御を緩くすることはできるが、厳しくすることはできない
- 投稿日:2019-12-04T18:19:36+09:00
[Java] すこしふしぎなsplitの挙動
[Java] すこしふしぎなsplitの挙動
環境
Java8 (のはず)
splitクイズ
突然ですが問題です。
以下はJavaのコードです。
実行結果はどうなるでしょうか。第1問!デデン♪
String test = "a-i-u-e-o"; String[] tests = test.split("-"); System.out.println(tests.length); System.out.println(java.util.Arrays.toString(tests));
答え
5 [a, i, u, e, o]
正解しましたか?
次です。 こちらの結果はどうなるでしょうか。
String test = "--o"; String[] tests = test.split("-"); System.out.println(tests.length); System.out.println(java.util.Arrays.toString(tests));
答え
3 [, , o]
正解しましたか?
先頭にデリミタがある場合はこのような挙動になるのですね。次はこちらです。 こちらの結果はどうなるでしょうか。
なんとなく予想がつくのではないでしょうか。String test = "a----o"; String[] tests = test.split("-"); System.out.println(tests.length); System.out.println(java.util.Arrays.toString(tests));
答え
5 [a, , , , o]
正解しましたか?
さて最後です。 こちらの結果はどうなるでしょうか。
ここまで正解したならきっと簡単ですね。 さくさくいきましょう。String test = "a--"; String[] tests = test.split("-"); System.out.println(tests.length); System.out.println(java.util.Arrays.toString(tests));
答え
1 [a]
正解しましたか?
正解した方はおめでとうございます
外れてしまったかたは惜しかったですね...(´・ω・`)ちなみにこれらの挙動を見たときの私の反応はこのような感じでした。
₍₍(ง˘ω˘)ว⁾⁾
??????????????????????????
え、ん...? あ、そう...ふーん( ´_ゝ`)なんでやねん
Javaのsplit
今まで出たものをまとめて俯瞰すると以下のようになります。
/* * Java Playground * https://code.sololearn.com */ class Main { public static void main(String[ ] args) { { String test = "a-i-u-e-o"; String[] tests = test.split("-"); System.out.println(tests.length); // 5 System.out.println(java.util.Arrays.toString(tests)); // [a,i,u,e,o] } { String test = "a-"; String[] tests = test.split("-"); System.out.println(tests.length); // 1 System.out.println(java.util.Arrays.toString(tests)); // [a] } { String test = "-o"; String[] tests = test.split("-"); System.out.println(tests.length); // 2 System.out.println(java.util.Arrays.toString(tests)); // [,o] } { String test = "a--"; String[] tests = test.split("-"); System.out.println(tests.length); // 1 System.out.println(java.util.Arrays.toString(tests)); // [a] } { String test = "--o"; String[] tests = test.split("-"); System.out.println(tests.length); // 3 System.out.println(java.util.Arrays.toString(tests)); // [,,o] } { String test = "a----o"; String[] tests = test.split("-"); System.out.println(tests.length); // 5 System.out.println(java.util.Arrays.toString(tests)); // [a,,,,o] } } }いかがでしょうか。
私は正直気持ち悪いと思ゲフンゲフン
空を無視するのかしないのかはっきりしてほしいと思いました。
しかしながら、このような挙動になっていることにはなにかしらの理由があるのかもしれませんね。1蛇足
Golangのsplit
ちなみに言語ごとにsplitの挙動は異なるようですので、複数言語を扱う場合はご注意ください。
一例として、比較的わかりやすいGolangのサンプルを以下に貼ります。
Golangのsplitサンプル
/* * Golang Playground * https://play.golang.org/ */ package main import ( "fmt" "strings" ) func main() { { test := "a-i-u-e-o" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 5 fmt.Println(tests) // [a i u e o] } { test := "a-" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 2 fmt.Println(tests) // [a ] } { test := "-o" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 2 fmt.Println(tests) // [ o] } { test := "a--" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 3 fmt.Println(tests) // [a ] } { test := "--o" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 3 fmt.Println(tests) // [ o] } { test := "a----o" tests := strings.Split(test, "-") fmt.Println(len(tests)) // 5 fmt.Println(tests) // [a o] } }
Javaの挙動を見たあとだと素直な挙動に感じますね...
付録
Javaのsplitは要するに右端のデリミタを無視すればよさそうなので、
Golangで同様の挙動を模倣する場合は、右端のデリミタを除去してからsplitするといいかもしれません。
需要があるかはわかりませんがサンプルを貼ります。 需要があるかはわかりませんが。
GolangでJavaのsplitのような挙動をさせ隊 (隊員1名)
package main import ( "fmt" "strings" ) func main() { { test := "a-i-u-e-o" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 5 fmt.Println(tests) // [a i u e o] } { test := "a-" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 1 fmt.Println(tests) // [a] } { test := "-o" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 2 fmt.Println(tests) // [ o] } { test := "a--" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 1 fmt.Println(tests) // [a] } { test := "--o" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 3 fmt.Println(tests) // [ o] } { test := "a----o" tests := javaSplit(test, "-") fmt.Println(len(tests)) // 5 fmt.Println(tests) // [a o] } } // Javaの String#split(delimiter) を模倣 func javaSplit(str string, delimiter string) []string { return strings.Split(strings.TrimRight(str, delimiter), delimiter) }
え、JavaでGolangのような挙動にしたい場合...?
あー... .. . がんばってください!【追記】
え、JavaでGolangのような挙動にしたい場合...?
@saka1029 さんに教えていただきました!
第2引数に負の数を指定すればよいのでは?(String.split(String, int))
String[] test = "a--".split("-", -1); System.out.println(test.length); // -> 3 System.out.println(Arrays.toString(test)); // -> [a, , ]
javadocより抜粋
public String[] split(String regex, int limit)
limitパラメータは、このパターンの適用回数を制御するため、結果となる配列の長さに影響を及ぼします。
- 「制限」が正の場合、パターンはほとんどの「制限」に適用されます。-1回は配列の長さが「制限」を超えることはなく、最後に一致したデリミタを超えるすべての入力が配列の最後のエントリに含まれます。
- 「制限」がゼロの場合、パターンは可能なかぎり何度も適用され、配列には任意の長さを指定でき、後続の空の文字列は破棄されます。
- 「制限」が負の場合、パターンは可能なかぎり適用され、配列の長さは任意になります。
まさにこれです!いえーい!
というかjavadoc読んでから執筆しなさいよ
リンクはjava13のdocですが、java8も同様です。さいごに
「ここまずいですよ」や「そいつぁちげーぜ!」などがありましたらコメントいただけますと幸いです₍₍(ง˘ω˘)ว⁾⁾
ゼロは俺に何も言ってはくれない...
とりあえず仕様であることだけは間違いありません。 https://docs.oracle.com/javase/jp/8/docs/api/java/lang/String.html#split-java.lang.String- ↩
- 投稿日:2019-12-04T17:04:02+09:00
Javaをはじめよう - 開発環境をつくる②
今回は,前回説明していなかったIDEのダウンロード,インストール方法について説明します。
「なんとなくわかる」などの方はこの回をスルーしても大丈夫です。
※この記事は2019/12/04現在のモノです。表記が古い場合がありますPleiades All in One(Eclipse)の導入
ダウンロードしよう
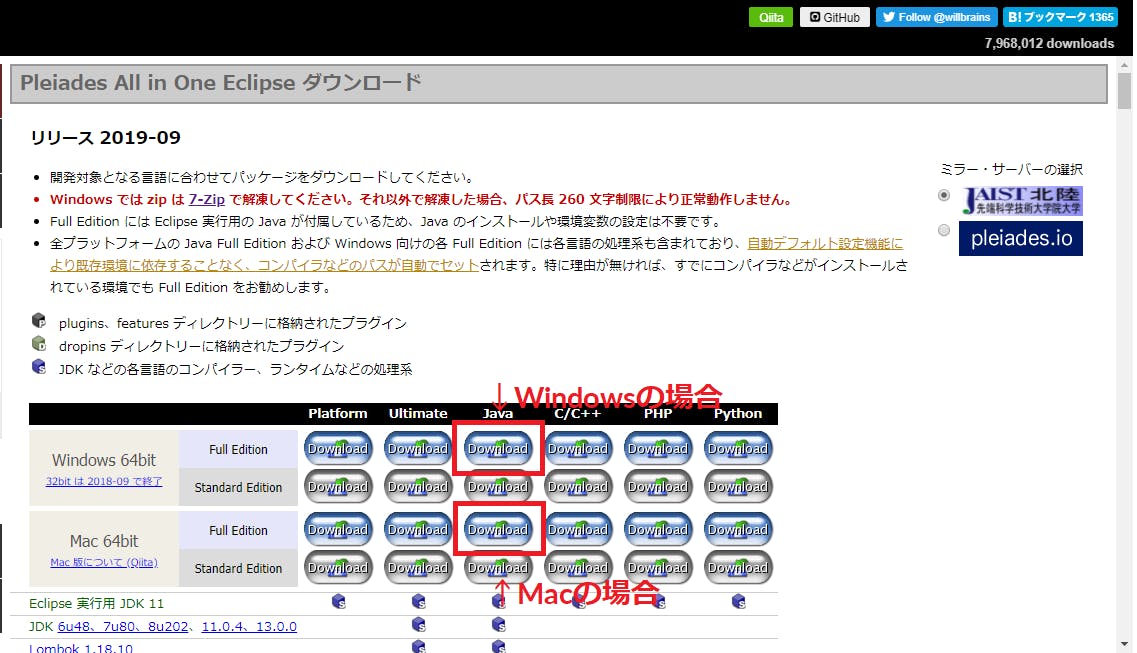
ダウンロードリンク: https://mergedoc.osdn.jp/
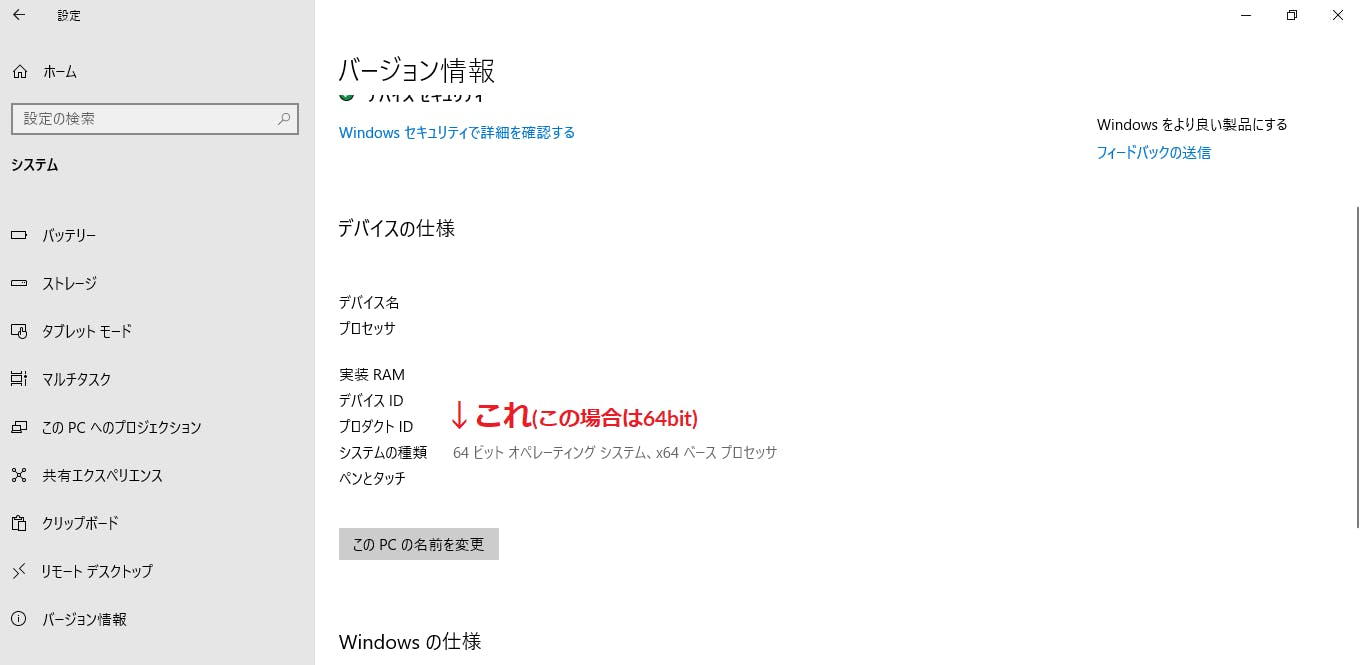
このページに飛んだら,自分のパソコンのbit数に合ったものをダウンロードしてください。bit数の確認方法(Win10)
「設定」を開く→左上の「システム」を選択→左の項目を下までスクロールし,「ⓘバージョン情報」を選択→「デバイスの仕様」項目の「システムの種類」に書いてあります。
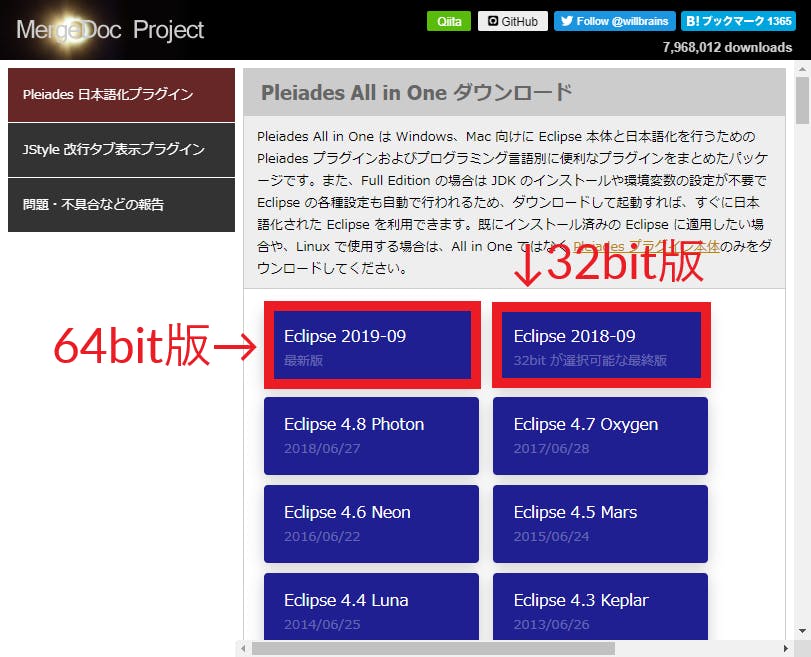
64bitの場合は,最新版の「2019-9」をクリック。32bitの場合は,32bit最終版「2018-9」をクリック。
32,64bit同様で,今回はJavaのIDEを導入するのでWindowsの場合は「Windows」,Macの場合は「Mac」のJavaを選択してください。また,「Full Edition」と「Standard Edition」の2種類がありますが,今回は「Full Edition」を選択してください(コンパイラ,JDKがインストールされているため)。
クリックすると下のようなテキストが現れるのでリンクをクリックします。
するとダウンロードが開始します。
※1.5GBほどあります。気長に待ちましょう...
解凍しよう
※注意 Windowsの場合,この解凍は7-Zip(無料)が必要です。 Windows標準または別の解凍アプリケーションで解凍を行った場合正常に動作しない可能性があります。
7-Zipのダウンロードページ https://sevenzip.osdn.jp/
こちらも自分のbit数に合ったものをダウンロードしてください。
bit数を間違うと使えません。ダウンロードされたzipファイルを右クリックして,「7-Zip」を選択→「展開...」を選択し,解凍先をCドライブに指定して解凍してください。
これで解凍は完了です。起動してみよう
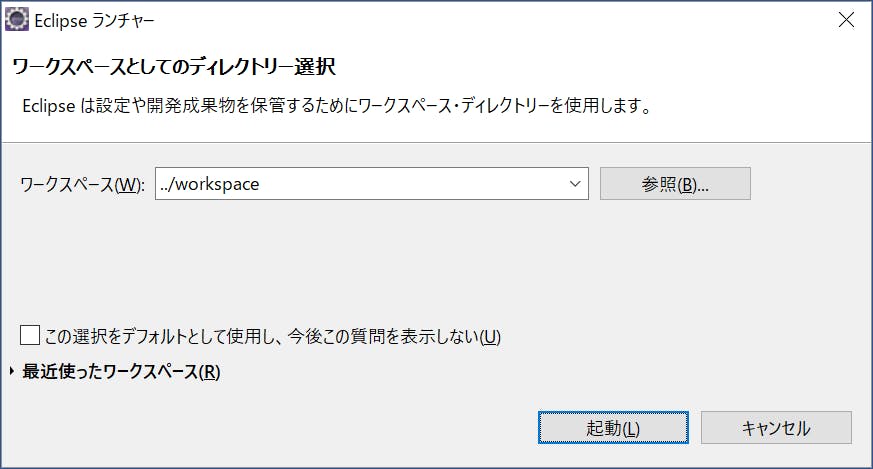
起動後,ワークスペースの指定をします。
特にこだわりがない場合は,そのまま「起動」を押しましょう。
これで日本語化されたEclipseの導入が完了しました。次回化は少しコードに触れていきたいと思います。
前) Javaをはじめよう - 開発環境をつくる①
https://qiita.com/_Hage_K/items/117095082ef3bc1b4ccb次) 後日投稿

- 投稿日:2019-12-04T14:57:16+09:00
Javaをはじめよう
Javaをはじめよう
Javaのプラグラムを組むときは,IDE(統合開発環境)を使いましょう。IDE以外でJavaのプログラムを組むにはメモ帳なども使えますが,こちらは軽めのプログラムを試すときに使いましょう(大規模なプログラムを組むには向いていない)。
IDEを使ってみよう
まず,IDEとは,Javaなどのプログラムを扱うときに効率よくコードを組めるアプリケーションです。
無償で公開されているものもあります。JDKとインストールすれば,すぐに使用することができます。JDKとは,Java SE Development Kit(Java SE開発キット)の略。無料でインストールができます。
今回は詳しい説明は省きます。代表的なIDEとしてEclipseやIntelliJ IDEAがあります。
しかし単体だとすべて英語となっているため,日本語したい場合は,Pleiades All in OneというIDEを使い,EclipseやIntelliJ IDEAなどといったIDEを日本語化することができます。
これらを使うことで,大規模なプログラムを効率よく組むことができます。
- 投稿日:2019-12-04T14:57:16+09:00
Javaをはじめよう - 開発環境の整備
Javaをはじめよう
Javaのプラグラムを組むときは,IDE(統合開発環境)を使いましょう。IDE以外でJavaのプログラムを組むにはメモ帳なども使えますが,こちらは軽めのプログラムを試すときに使いましょう(大規模なプログラムを組むには向いていない)。
IDEをインストールしよう
まず,IDEとは,Javaなどのプログラムを扱うときに効率よくコードを組めるアプリケーションです。
無償で公開されているものもあります。JDKとインストールすれば,すぐに使用することができます。
追記: 今回説明したIDEにはJDKがセットになっているためJDK単体は不要です!!JDKとは,Java SE Development Kit(Java SE開発キット)の略。無料でインストールができます。
今回は詳しい説明は省きます。代表的なIDEとしてEclipseやIntelliJ IDEAがあります。
しかし単体だとすべて英語となっているため,日本語したい場合は,Pleiades All in OneというIDEを使い,EclipseやIntelliJ IDEAなどといったIDEを日本語化することができます。
これらを使うことで,大規模なプログラムを効率よく組むことができます。Eclipse: https://www.eclipse.org/downloads/
IntelliJ IDEA: https://www.jetbrains.com/idea/
Pleiades All in One: https://mergedoc.osdn.jp/私はEclipseを使っていくので,Eclipseの導入方法を別記事で説明します。
記事が完成したらリンクを張っておきます
- 投稿日:2019-12-04T14:57:16+09:00
Javaをはじめよう - 開発環境をつくる①
Javaをはじめよう
Javaのプラグラムを組むときは,IDE(統合開発環境)を使いましょう。IDE以外でJavaのプログラムを組むにはメモ帳なども使えますが,こちらは軽めのプログラムを試すときに使いましょう(大規模なプログラムを組むには向いていない)。
IDEをインストールしよう
まず,IDEとは,Javaなどのプログラムを扱うときに効率よくコードを組めるアプリケーションです。
無償で公開されているものもあります。JDKとインストールすれば,すぐに使用することができます。
追記: 今回説明したIDEにはJDKがセットになっているためJDK単体は不要です!!JDKとは,Java SE Development Kit(Java SE開発キット)の略。無料でインストールができます。
今回は詳しい説明は省きます。代表的なIDEとしてEclipseやIntelliJ IDEAがあります。
しかし単体だとすべて英語となっているため,日本語したい場合は,Pleiades All in OneというIDEを使い,EclipseやIntelliJ IDEAなどといったIDEを日本語化することができます。
これらを使うことで,大規模なプログラムを効率よく組むことができます。Eclipse: https://www.eclipse.org/downloads/
IntelliJ IDEA: https://www.jetbrains.com/idea/
Pleiades All in One: https://mergedoc.osdn.jp/私はEclipseを使っていくので,Eclipseの導入方法を別記事で説明します。
記事が完成したらリンクを張っておきます~次) Javaをはじめよう - 開発環境をつくる②
https://qiita.com/_Hage_K/items/08308ff5abd372155fbc
- 投稿日:2019-12-04T13:40:19+09:00
Azure BlobStorage SDK Java V8 で BlobItemにテキストを書き込む
BlobItem の TYPE が APPEND BLOBとして作成されていないとAppendできないところがポイントでした。
package hello.azure.blobstorage; import java.util.Date; import com.microsoft.azure.storage.CloudStorageAccount; import com.microsoft.azure.storage.StorageException; import com.microsoft.azure.storage.blob.BlobRequestOptions; import com.microsoft.azure.storage.blob.CloudAppendBlob; import com.microsoft.azure.storage.blob.CloudBlobClient; import com.microsoft.azure.storage.blob.CloudBlobContainer; public class WriteData2 { // copy from azure console public static final String storageConnectionString = "{yourString}"; public static void main(String[] args) { CloudStorageAccount storageAccount; CloudBlobClient blobClient = null; CloudBlobContainer container = null; String containerName = "{yourContainerName}"; String blobName = "{yourBlobName}"; try { // Parse the connection string and create a blob client to interact with Blob // storage storageAccount = CloudStorageAccount.parse(storageConnectionString); blobClient = storageAccount.createCloudBlobClient(); container = blobClient.getContainerReference(containerName); { CloudAppendBlob cab = container.getAppendBlobReference(blobName); if (cab.exists() == false) { // BLOB TYPE : Append Blob として作成される cab.createOrReplace(); } BlobRequestOptions options = new BlobRequestOptions(); options.setAbsorbConditionalErrorsOnRetry(true); // BLOB TYPE が Append Blob でないとエラーになる // Error returned from the service. Http code: 306 and error code: // IncorrectBlobType cab.appendText("Hello " + new Date() + "\n", "UTF-8", null, options, null); } System.err.println("finished."); } catch (StorageException ex) { ex.printStackTrace(); System.err.println( String.format("HttpStatusCode=%d,ErrorCode=%d", ex.getHttpStatusCode(), ex.getErrorCode())); } catch (Exception ex) { ex.printStackTrace(); } finally { } } }
- 投稿日:2019-12-04T13:40:19+09:00
Azure BlobStorage SDK Java V8 で BlobItemにテキストを追記(Append)する
BlobItem の TYPE が APPEND BLOBとして作成されていないとAppendできないところがポイントでした。
package hello.azure.blobstorage; import java.util.Date; import com.microsoft.azure.storage.CloudStorageAccount; import com.microsoft.azure.storage.StorageException; import com.microsoft.azure.storage.blob.BlobRequestOptions; import com.microsoft.azure.storage.blob.CloudAppendBlob; import com.microsoft.azure.storage.blob.CloudBlobClient; import com.microsoft.azure.storage.blob.CloudBlobContainer; public class WriteData2 { // copy from azure console public static final String storageConnectionString = "{yourString}"; public static void main(String[] args) { CloudStorageAccount storageAccount; CloudBlobClient blobClient = null; CloudBlobContainer container = null; String containerName = "{yourContainerName}"; String blobName = "{yourBlobName}"; try { // Parse the connection string and create a blob client to interact with Blob // storage storageAccount = CloudStorageAccount.parse(storageConnectionString); blobClient = storageAccount.createCloudBlobClient(); container = blobClient.getContainerReference(containerName); { CloudAppendBlob cab = container.getAppendBlobReference(blobName); if (cab.exists() == false) { // BLOB TYPE : Append Blob として作成される cab.createOrReplace(); } BlobRequestOptions options = new BlobRequestOptions(); options.setAbsorbConditionalErrorsOnRetry(true); // BLOB TYPE が Append Blob でないとエラーになる // Error returned from the service. Http code: 306 and error code: // IncorrectBlobType cab.appendText("Hello " + new Date() + "\n", "UTF-8", null, options, null); } System.err.println("finished."); } catch (StorageException ex) { ex.printStackTrace(); System.err.println( String.format("HttpStatusCode=%d,ErrorCode=%d", ex.getHttpStatusCode(), ex.getErrorCode())); } catch (Exception ex) { ex.printStackTrace(); } finally { } } }
- 投稿日:2019-12-04T12:25:17+09:00
Javaの配列宣言+実体化でnew演算子を省略できるのはなぜですか
- 投稿日:2019-12-04T11:36:57+09:00
MultipartResolverを設定してSpringでファイルアップロードを行えるようにする
Springでファイルアップロードができるようになるまで
Spring MVCでJava Configの続編を少しだけ書いてみました。
前回Java Configで設定した内容に加えて、今回はSpringのファイルアップロード設定を行ってアップロードができるようにしていきます。設定方法
設定クラスにMultipartResolverをBean登録していきます。
登録時にメモリサイズ、アップロードサイズの上限値を同時に設定することができます。
FWのマイグレーションとしてこの設定を行う場合は、元々の設定値を調べて設定することで同様の挙動を再現することができます。private static final int MAX_UPLOAD_SIZE = 1024 * 1024; //1MB private static final int MAX_IN_MEMORY_SIZE = 1024 * 256; //256KB @Bean public MultipartResolver multipartResolver() { CommonsMultipartResolver multipartResolver = new CommonsMultipartResolver(); multipartResolver.setMaxUploadSize(MAX_UPLOAD_SIZE); multipartResolver.setMaxInMemorySize(MAX_IN_MEMORY_SIZE); return multipartResolver; }使用方法
ファイルアップロード対象のプロパティは型をMultipartFileとして定義します。
/** * アップロードするファイル */ private MultipartFile file = null;あとは上記のプロパティにgetter,setterを付与し、Viewと連携してファイルをアップロードすることで実際にファイル操作することが可能となります。
手順としては上記のように簡単に設定して行えるようにできます。
はじめて設定した時は時間がかかった記憶があるので、誰かのお役に立てたら嬉しく思います!
- 投稿日:2019-12-04T10:59:22+09:00
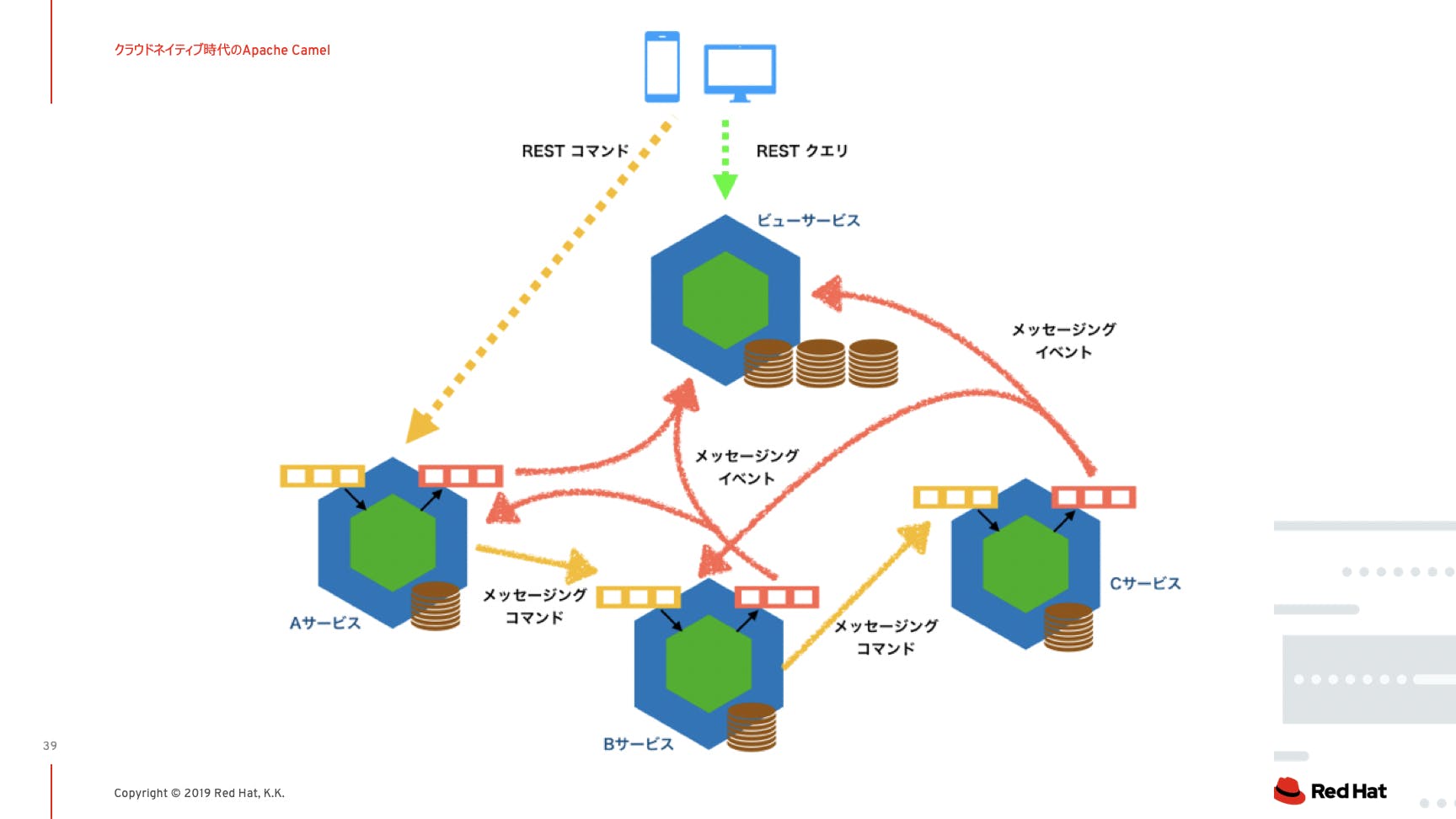
クラウドネイティブ時代のApache Camel
こんにちは、レッドハットの駒澤です。
今年のRed Hat Forumでは、Apache Camelの魅力について紹介しました。
Apache Camel はオープンソースのインテグレーションフレームワークです。2007年に産まれて10年以上、IT環境の変化とともに進化してきました。
クラウドネイティブなアプリケーションが増えてくると、連携の組み合わせもより複雑になっていきます。そのような連携をシンプルに開発する仕組みとして、EIPを実装しています。今回は、最新のサーバーレス技術である、Camel Kもデモを交えて紹介しました。セッション資料:http://redhat.lookbookhq.com/rhft2019-matome/65-25?lx=ChT-oZ
今回私がテーマにしたかったのが、「企業システムにおけるインテグレーションのあり方」です。
長年蓄積されたIT資産は、もはや全体を把握することも難しいくらい複雑になっていますが、少し大きな視点でシステムを見つめ直すと解決策が見えてくるのではないかと思います。
そこで私は、「企業システムをシルクロードのような経済圏として見てみませんか?」という大胆な問いかけをしてみました。
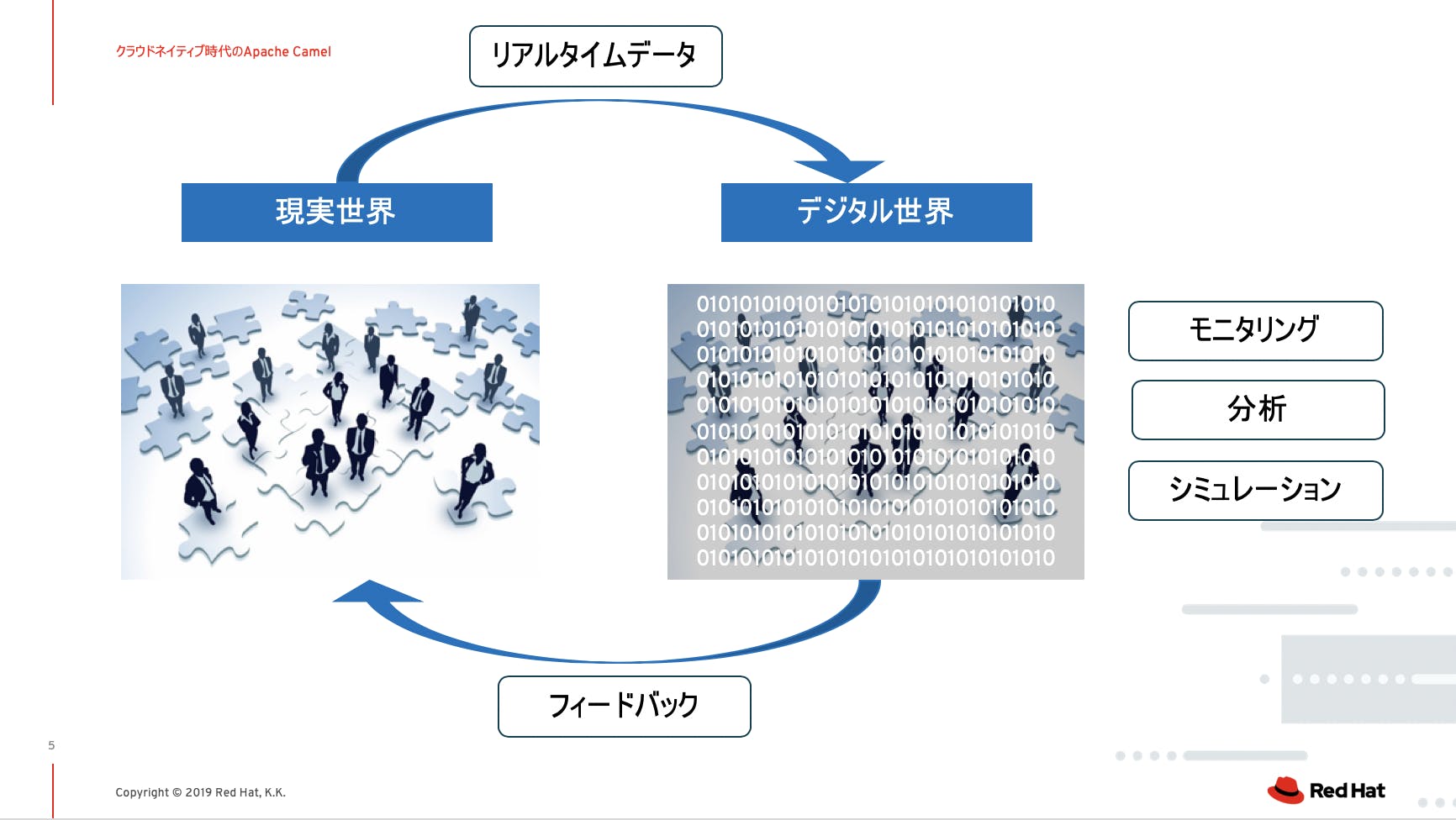
デジタル化が進んだ現代では、ものづくりの業界から「デジタルツイン」という言葉が生まれ、現実世界と仮想世界の融合が進んできました。
その考え方は、組織の活動にも浸透してきており、「組織のデジタルツイン」が次に目指すべきシステム像になると考えています。
それが進むと、組織を変えようと思ったら同時にシステムも変え、またシステムを変えれば組織も柔軟に変えることができる、コンウェイの法則、逆コンウェイの法則が成り立つと思うんですね。これまではシステムがガチガチで組織と一体化していなかったし、ERPのようにむしろシステムに組織を合わせようという、本末転倒な現象も起こっていました。
究極は、まるで業務で人間がコミュニケーションをとるように、システムもコミュニケーションをとれれば良いと思うのです。
コミュニケーションには、同期的なコミュニケーション (対面や電話で1対1に会話する)と、非同期的なコミュニケーション(メールで複数に送ったり、チームでまとめて会議したい場合など)があるので、システムも自然と2つのコミュニケーション方法がとられるはずです。
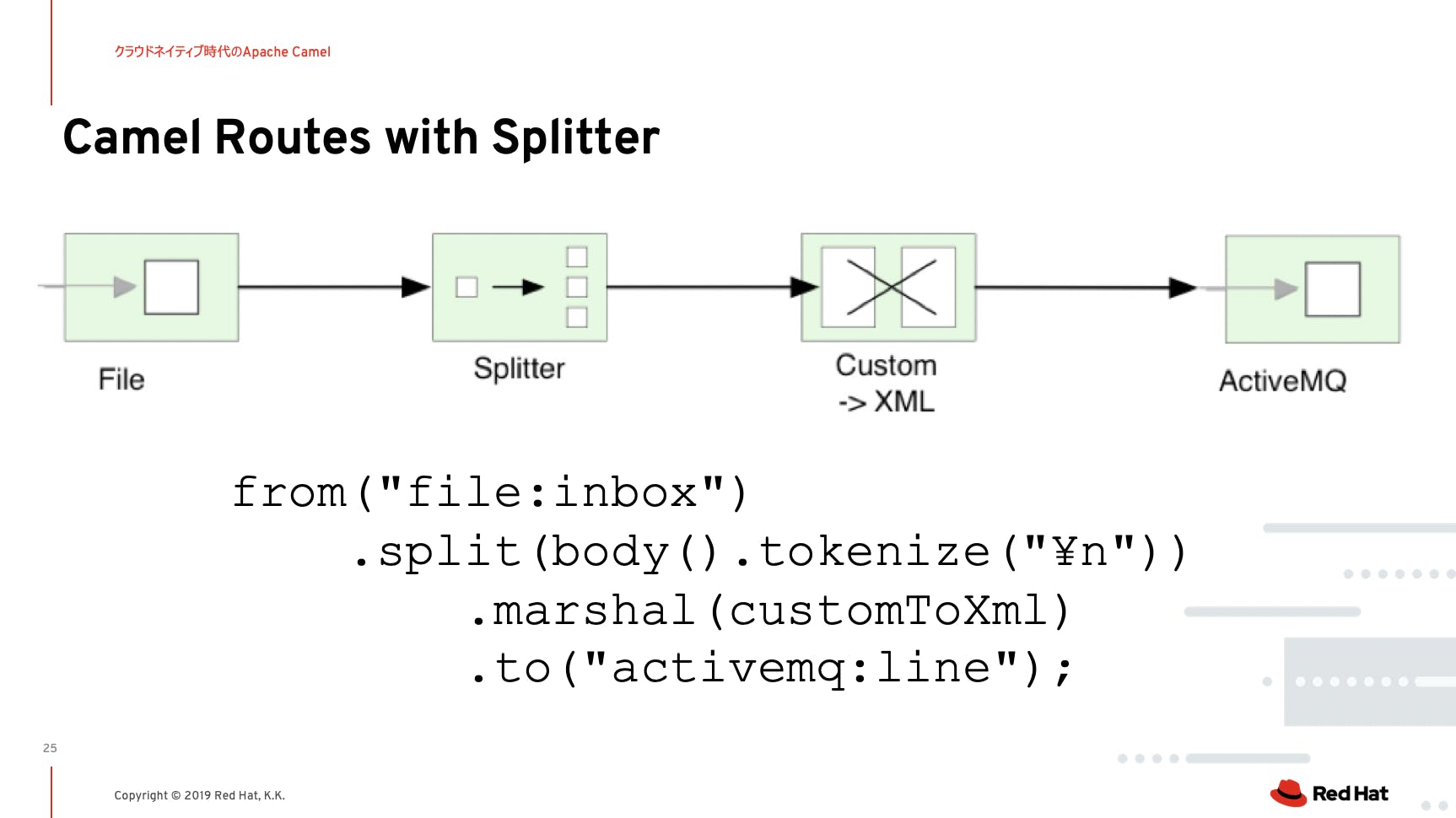
そのコミュニケーション手段がまさにインテグレーションで解決すべき問題領域です。Apache Camelとは?という解説をこのセッションで行いましたが、今回のブログでは技術的な説明は省略します。
ポイントはまさに人間のコミュニケーションに必要な、文法、マナー、言葉づかいが整理されており、システムのコミュニケーションを取りやすくする仕組みだということです。
ドメインに分けられたシステム群は独自の言語と文化を持つ国家のような動きをしていくことで、自律的に進化を遂げていきます。国家間のコミュニケーションは自然と独自性を吸収した標準化が必要となり、そこでApache Camelは活躍します。
またシステムのインテグレーション機能はデータの永続性を求めない(各サブシステムが永続性を担保する)ので、サーバーレスアーキテクチャーにも向いています。
そこでApache Camel のサーバーレス版である、Camel Kが今後大きく期待される技術となっています。
(引用:赤帽エンジニアブログ「マイクロサービスとメッセージングのなぜ(前編)」https://rheb.hatenablog.com/entry/microservices_messaging)Apache Camelは、非常に将来性があるオープンソースソフトウェアであり、コミュニティも活発です。
JCUG (Japan Camel User Group) も毎月読書会をやっていますので、ぜひ皆さん参加してコミュニティを盛り上げていきましょう。

- 投稿日:2019-12-04T09:52:05+09:00
2つのEntityでのやり取りで簡単そうなのに意外と難しかったやつメモ
難しいというか長かった
完全に備忘録です
モデルが2個あって
PKがかぶってるデータを排除して
のこったデータをリストとして保持するpackage test; public class Models { class Model1 { private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } class Model2 { private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } }package test; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.List; import java.util.Objects; import java.util.stream.Collectors; import test.Models.Model1; import test.Models.Model2; /** * test * * @author me * */ public class Test2 { /** * main * @param args */ public static void main(String[] args) { distinct(); } /** * モデルからPKかぶりを排除するやつ */ private static void distinct() { Models models = new Models(); List<Model1> list1 = Collections.synchronizedList(new ArrayList<Model1>()); List<Model2> list2 = Collections.synchronizedList(new ArrayList<Model2>()); Models.Model1 model1 = models.new Model1(); model1.setId("1"); model1.setName("asdasdasdas"); list1.add(model1); Models.Model1 model11 = models.new Model1(); model11.setId("2"); model11.setName("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"); list1.add(model11); Models.Model2 model2 = models.new Model2(); model2.setId("1"); list2.add(model2); Models.Model2 model22 = models.new Model2(); model22.setId("2"); list2.add(model22); Models.Model2 model222 = models.new Model2(); model222.setId("3"); list2.add(model222); /** -----本機能----- */ // list2とPKがかぶっているものを排除したlist1のPKリスト List<String> uniKeyList = list1.stream().map(data1 -> data1.getId()) .filter(key1 -> list2.stream().map(data2 -> data2.getId()).anyMatch(key2 -> key1.equals(key2))) .collect(Collectors.toList()); // list1をuniKeyListで検索 List<Model1> uniData = list1.stream() .filter(data -> uniKeyList.stream().anyMatch(key -> data.getId().equals(key))) .collect(Collectors.toList()); System.out.println(uniData); } }まずかぶりのないPKだけのリストを作り
もとのモデルのリストから、検索して
かぶりPKのデータをなくす、というステップを踏みました
絶対無駄が多い...もっとスマートにできるはずなのでは
- 投稿日:2019-12-04T09:45:32+09:00
Java 7以降でのEnumの差別
1.中黒「.」(U+30FB)が使えなくなったため
例:
Java 7 以前の場合
enum 学校 {
...
保育園・幼児園
}
Java 7 以後の場合
enum 学校 {
...
保育園幼児園
}
- 投稿日:2019-12-04T08:57:21+09:00
jcmdを使ってみよう
みなさん
jstackでスタックトレースを出力したり、jmapでヒープダンプを取得したことがあると思います。でも最近(?)は
jcmdだけでどちらも賄えます。まず
jcmdを引数なしで実行してみましょう。$ jcmd 62818 com.example.demo.DemoApplication 62819 jdk.jcmd/sun.tools.jcmd.JCmd 62810 org.apache.maven.wrapper.MavenWrapperMain spring-boot:runこのようにマシン上で動いているJavaアプリケーションのPIDとメインクラスが一覧されます。
次に
jcmdにPIDを渡してみましょう。ここではDemoApplicationのPIDを渡してみます。$ jcmd 62818 62818: The following commands are available: Compiler.CodeHeap_Analytics Compiler.codecache Compiler.codelist Compiler.directives_add Compiler.directives_clear Compiler.directives_print Compiler.directives_remove Compiler.queue GC.class_histogram GC.class_stats GC.finalizer_info GC.heap_dump GC.heap_info GC.run GC.run_finalization JFR.check JFR.configure JFR.dump JFR.start JFR.stop JVMTI.agent_load JVMTI.data_dump ManagementAgent.start ManagementAgent.start_local ManagementAgent.status ManagementAgent.stop Thread.print VM.class_hierarchy VM.classloader_stats VM.classloaders VM.command_line VM.dynlibs VM.flags VM.info VM.log VM.metaspace VM.native_memory VM.print_touched_methods VM.set_flag VM.stringtable VM.symboltable VM.system_properties VM.systemdictionary VM.uptime VM.version help For more information about a specific command use 'help <command>'.このように、このプロセスに対して使用できるコマンドが一覧されます。
スタックトレースを出力してみましょう。
$ jcmd 62818 Thread.print 62818: 2019-12-04 08:49:43 Full thread dump OpenJDK 64-Bit Server VM (11.0.2+9 mixed mode): (中略) "Common-Cleaner" #11 daemon prio=8 os_prio=31 cpu=1.60ms elapsed=263.23s tid=0x00007f8650010800 nid=0x5c03 in Object.wait() [0x000070000b852000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(java.base@11.0.2/Native Method) - waiting on <0x000000060003bee0> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(java.base@11.0.2/ReferenceQueue.java:155) - waiting to re-lock in wait() <0x000000060003bee0> (a java.lang.ref.ReferenceQueue$Lock) at jdk.internal.ref.CleanerImpl.run(java.base@11.0.2/CleanerImpl.java:148) at java.lang.Thread.run(java.base@11.0.2/Thread.java:834) at jdk.internal.misc.InnocuousThread.run(java.base@11.0.2/InnocuousThread.java:134) "Catalina-utility-1" #15 prio=1 os_prio=31 cpu=36.80ms elapsed=257.29s tid=0x00007f864802a800 nid=0x7003 waiting on condition [0x000070000c77f000] java.lang.Thread.State: WAITING (parking) at jdk.internal.misc.Unsafe.park(java.base@11.0.2/Native Method) - parking to wait for <0x000000061c615798> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(java.base@11.0.2/LockSupport.java:194) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(java.base@11.0.2/AbstractQueuedSynchronizer.java:2081) at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(java.base@11.0.2/ScheduledThreadPoolExecutor.java:1177) at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(java.base@11.0.2/ScheduledThreadPoolExecutor.java:899) at java.util.concurrent.ThreadPoolExecutor.getTask(java.base@11.0.2/ThreadPoolExecutor.java:1054) at java.util.concurrent.ThreadPoolExecutor.runWorker(java.base@11.0.2/ThreadPoolExecutor.java:1114) at java.util.concurrent.ThreadPoolExecutor$Worker.run(java.base@11.0.2/ThreadPoolExecutor.java:628) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(java.base@11.0.2/Thread.java:834) (以下略)ヒープダンプを取得してみましょう。
$ ls $ jcmd 62818 GC.heap_dump `pwd`/demo.hprof 62818: Heap dump file created $ ls demo.hprofこんな感じで
jstackやjmapといった複数のコマンドを覚えておかなくてもjcmdだけ覚えておけば良いので楽ですね。
- 投稿日:2019-12-04T08:18:00+09:00
メソッドをオーバーライドする時にOverrideアノテーションをつけるべき理由
Overrideアノテーション
Java1.5で追加されたアノテーションです。メソッド宣言だけに使えて、親クラスのメソッドをオーバーライドしていることを表現します。Overrideアノテーションをつけなくてもオーバーライドは可能です。では、なぜOverrideアノテーションをつけるべきなのか?というのが本記事になります。
Overrideアノテーションをつけた方が良い理由
以下のような親クラスがあるとします。
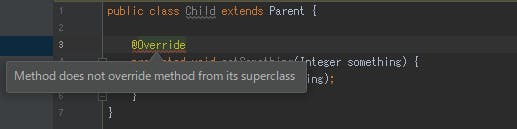
Parent.javapublic class Parent { private String something; protected void setSomething(String something) { this.something = something; } }このクラスを継承しsetSomethingメソッドをオーバーライドする必要があったため以下のコードを書きました。
Child.javapublic class Child extends Parent { protected void setSomething(Integer something) { System.out.println(something); } }引数の型を間違えていますが、正常にコンパイルが通るためそのミスに気付くことができません。このまま気付かずにリリースを迎える、ということはさすがにないと思いますが、思わぬバグとして必ずテストでハマる可能性があります。そして、Overrideアノテーションをつける理由はココにあります。Overrideアノテーションをつけておけば、以下のようにIDEが検知してくれるためそのミスに気付くことができ、事前に問題解決に繋がります(もちろんjavacコマンドでのコンパイルもコンパイラが検知してくれます)
また、IDEを使っていれば、設定次第でOverrideアノテーションがついていなくても親クラスのメソッドをオーバーライドしているメソッドがあれば警告を出すことが可能です。つまり、常にOverrideアノテーションを使えば、意図しないオーバーライドを検知することが可能となります。
Overrideアノテーションをつけるべき理由まとめ
- オーバーライドしたつもりができていなかった、といったうっかりミスを事前に防ぐことができ予期せぬバグの防止になります。
- オーバーライドするつもりじゃなかったけどよく見たらオーバーライドしていた、ということに気付き予期せぬバグの防止になります。
以上です。
参考
- 投稿日:2019-12-04T07:56:46+09:00
Javaでコンソールでのキー入力を1文字ずつハンドルしたいときにJLineを使う
概要
このエントリでは、Javaでコンソール入出力で動作するプログラムを書くときに、1文字ずつ入力をハンドリングしたい場合の方法について扱います。
背景
Javaでは、標準入出力を扱うStreamがありますが、1文字ずつ入力を「読み込む」ことはできますが、キー入力のイベントを直接ハンドルすることはできません。
このため、例えば「電卓」プログラムを作るときに「+」を押したらすぐに何かの処理を行う、といったことは標準のライブラリだけでは実現できません。
JLineを使う
JLineとは
JLine3は、CUIアプリケーションを開発するときに使えるライブラリです。いくつかの有名どころのOSSでも利用されています。
JLine3は、Windows環境などでのプラットフォーム独自のターミナルの制御にも対応します。ここではプラットフォームネイティブのライブラリが必要となるため、JNAもしくはJANSIを使用する方式が提供されています。このエントリでは、JNAを使用しています。
コードサンプル
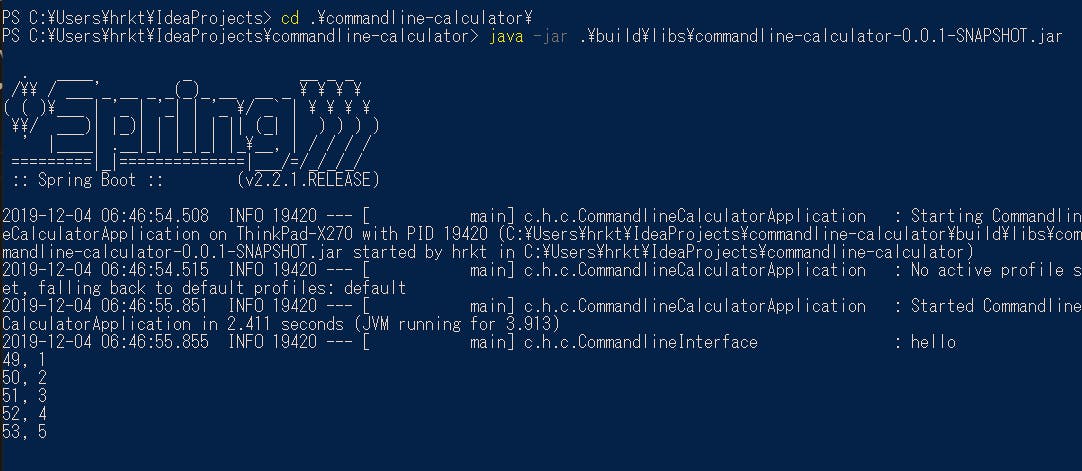
下記のコードを使うと、1文字ずつターミナルから入力し、即時に標準出力に表示しています。
package com.hrkt.commandlinecalculator; import lombok.extern.slf4j.Slf4j; import org.jline.terminal.Terminal; import org.jline.terminal.TerminalBuilder; import org.springframework.stereotype.Component; import java.io.IOException; @Component @Slf4j public class CommandlineInterface { public void run(String... args) { log.info("hello"); try(Terminal terminal = TerminalBuilder.terminal()) { int ch = 0; while ((ch = terminal.reader().read()) != 0x09){ // TAB(0x09)で抜ける char c = (char)ch; System.out.println(String.format("%d, %c", ch, ch)); } } catch(IOException e) { log.error(e.getMessage(), e); } } }下図のような動きとなります。
おわりに
このエントリでは、Javaでコンソールからのキー入力をハンドルする方法について紹介しました。
JLine2を利用した記事も見かけますが、開発が終わっているものであり、JLine3を使うことが推奨されています。コードのサンプル
動作するサンプルは、下記に置いてあります。
https://github.com/hrkt/commandline-calculator/releases/tag/0.0.2
- 投稿日:2019-12-04T02:41:44+09:00
Outsystemsで非同期処理を実装する方法
はじめに
転職して入った会社のITメンバーでアドベントカレンダーに参加するということで、
初めてQiitaに記事を投稿します!
転職してからOutsystemsでアプリ開発をしており、
開発を進める中で調べてもなかなか答えにたどり着けなかったことをシェア出来ればと思います。今回は、Outsystemsで非同期処理を実装する方法について紹介します。
自己紹介
初めて投稿するので、自己紹介しておきます。
以前は30名程度のSIerで様々なプロジェクトに常駐するSEとして7年ほど働いていました。
その頃はJavaやC#で開発をしたり、要件定義や設計などの上流工程もやったりしていました。
そこから外資系の人材会社に転職し社内SEとなりました。
現在は社内の業務効率化のためのアプリなどを主にOutsystemsで開発しています。目次
- 非同期処理とは
- クライアント処理での実装方法
- サーバ処理での実装方法
非同期処理とは
そもそも非同期処理とは? という方のために説明します。
と思ったのですが、説明してくれてる記事があったのでこちらを参考にしてください。
https://qiita.com/kiyodori/items/da434d169755cbb20447例えば、Webページでボタン押したときに画面ぐるぐるの時間が長いと
ユーザビリティが低くてよろしくないので、
処理結果を待つ必要がない処理は非同期で動かそうよってことですね!JavaだとThreadを継承したクラスやRunnableを実装したクラスをnewして
startメソッド呼び出せば実現する感じですが、
Outsystemsだとどう実現するかがなかなか見つからなかったので、シェアしたいなと思いました。では、本題行きます!
クライアント処理での実装方法
クライアント処理では、Javascript の setTimeout が使えます。
例えばこんな感じ。
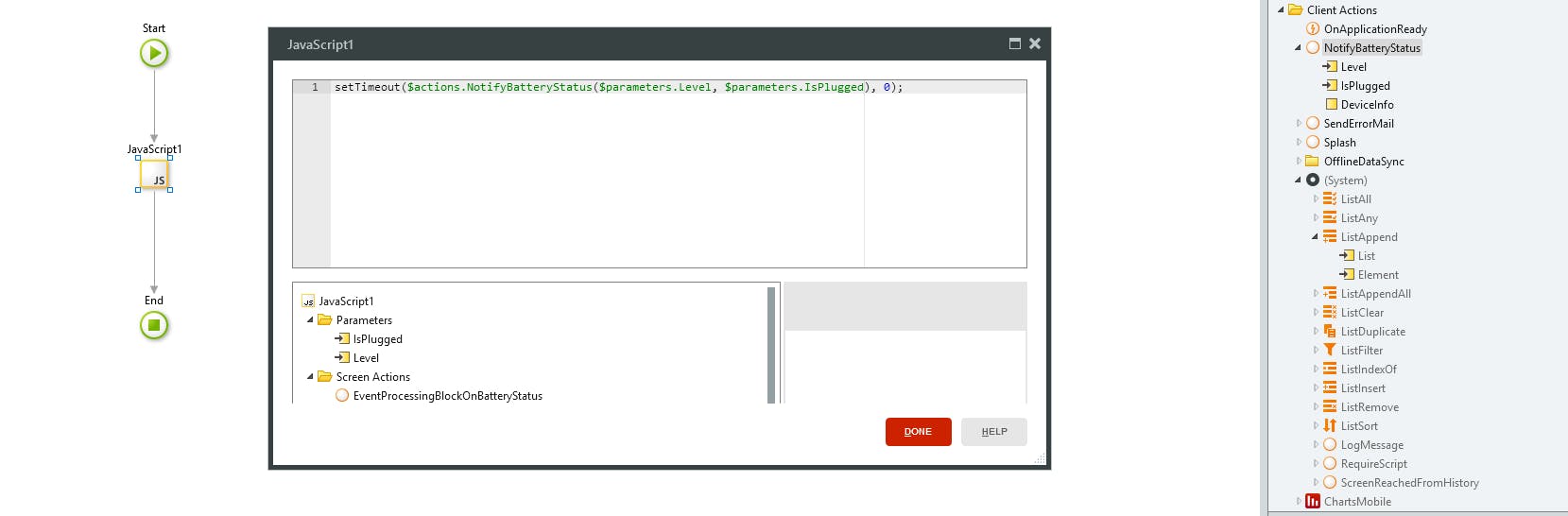
上の画像はなにをしているかというと、
スマホやタブレットのバッテリーの状態をみて、残りが少ないとアラートメールを送信する
NotifyBatteryStatusというクライアントアクションを作っており、
それをsetTimeoutで呼び出しています。
setTimeout($actions.NotifyBatteryStatus($parameters.Level, $parameters.IsPlugged), 0);
setTimeoutの第1引数が非同期で処理させたいアクション(引数付き)で、
第2引数が何ミリ秒後に実行するかです。今回は即実行させたいので0にしてます。メール送信はサーバアクションを呼ぶしかないので、ネットワークを介する分処理に時間がかかりますが
その処理結果を見る必要がなかったので、
メールを送るか判定する部分も含めて非同期で実行するようにしています。というわけでクライアント処理で非同期させたかったら、setTimeout使えます!
これはJavascript経験者ならすぐ出てきそうですね。サーバ処理での実装方法
さて、クライアント処理はJavascript使えば行けるっていうのはすぐたどり着けるのですが、
サーバ処理での実現方法はOutsystems特有で、調査に時間かかりました。
で、結論から言うと2つのやり方があります!
- Timer
- Process
Timerを使った非同期処理(引数指定不可)
Timerってスケジュール起動か手動実行するバッチ処理だよね?って感じですよね。
そのTimerをサーバアクションから呼べるんです。
こんな感じで、
Timerの下にあるWake~をサーバアクション内にドラッグ&ドロップすればTimer処理が呼べちゃいます。
で、それは実行しているサーバアクションとは非同期で動いてくれるんです。
Wake~を呼んだら即実行されるわけではなくて、数秒たってから実行されます。ただ、Timerでの非同期処理の難点としては、パラメータが渡せないところです。
それを解決してくれるのが次です。Processを使った非同期処理(引数指定可能)
Processって使ったことありますか?私はなかったです。。
こんな使い方ができるんだなって感じでした。
ProcessのLaunch~をサーバアクションから呼び出せて、引数も指定できます。
Entityは無理ですが、TextやIntegerなどのBasicTypeと、EntityIdentifierが引数として使えます。
なのでEntityIdentifierを引数に渡して、
Process内でEntityからデータを取得して処理するっていうのはできますね。最後に
というわけで、Outsystemsでの非同期処理の実装方法を紹介しました。
昨今SaasがいろんなAPIを公開してたりしますが、それをRESTやSOAPで呼び出すときに時間がかかるので、
そういった処理を非同期で呼ぶようにするなんてこともよくあるかなと思いますので、
ぜひ参考にしていただけると嬉しいです!