- 投稿日:2019-12-04T23:13:07+09:00
[AWS]閉域オンプレ環境からのDirect Connect経由でのS3接続についてちゃんと書く
概要
エンタープライズでは、閉域でオンプレ+AWSのハイブリッド環境を構築することがままあります。
Solution Architect Professional取得にあたってこの辺は勉強したものの、
実際やってみると自分がなにもわかってないことがわかったので皆様にも共有します。まず最初に、単にDirect Connectを繋いだだけでは、閉域環境のオンプレからAWSサービスを利用することはできません。
原因の1つは、VPC外のAWSサービスを利用するためにインターネットが必要なこと。
もう1つは、現状1一部のサービス2はDirect Connect経由でVPC エンドポイントに到達できないこと。これらの問題の解決策としては、VPC エンドポイントと、パブリック接続のDirect Connectの組み合わせがあります。
しかし、パブリック接続は、敷設まで敷居が少々高く利用できないシチュエーションもあると思います。
そこで、AWS内にHTTPプロキシ on EC2を設置し、このプロキシ経由でS3に接続する構成をご紹介します。最終構成イメージ
- オンプレ環境、AWS環境ともに閉域
- オンプレ環境とAWS環境間はDirect Connectによって接続
- オンプレ環境内の端末からCLIやSDKでS3に接続したい
- (アプリケーション自体や冗長化策については割愛)
作業概要
ざっくり次の作業が必要になります。
- AWS内から閉域でS3を使えるようにする
- オンプレから閉域でS3を使えるようにする
具体的な作業
AWS内から閉域でS3を使えるようにする
今回は、閉域オンプレからS3を使う記事ですが、これを実現するためにはまずAWS内からS3にアクセスする必要があります。
実際に閉域環境を構築するまであまり意識していませんでしたが、AWS内(例えばEC2)からAWSサービス(S3等)にアクセスする際は、インターネット接続が必須です。
閉域に限らず、プライベートサブネットにNATゲートウェイを持たせていない場合も、S3やCloudWatchに接続できません。
このようなときに助けになるのが、VPC エンドポイントです。はい。わかります。なんとなくめんどくさいイメージがありますよね。
大丈夫です。できます。素晴らしい記事がクラスメソッドさんにあるのでこちらに従って作ってください。オンプレから閉域でS3を使えるようにする
先のフェーズでAWS内からAWSサービスに、インターネットを介さず接続することはできました。
しかし、S3等の一部のサービスでは、これだけでは閉域オンプレ環境からS3にアクセスすることはできません。
(インターネットに接続可能なオンプレ環境であれば可能です)
そこで、このフェーズでは次の作業を行います。
- AWS側にHTTPプロキシを構築する
- HTTPプロキシサーバをNLBに組み込む(任意)
- オンプレ側がHTTPプロキシを使えるようにする
AWS側にHTTPプロキシを構築する
S3等の一部のサービスに、閉域オンプレから直接接続することはできませんが、CLIやJDKはHTTPプロキシに対応しているため、これを利用することができます。
以下のような手順でササッとHTTPプロキシをインストールしましょう。
ここではSquidを利用しますがなんでも大丈夫です。
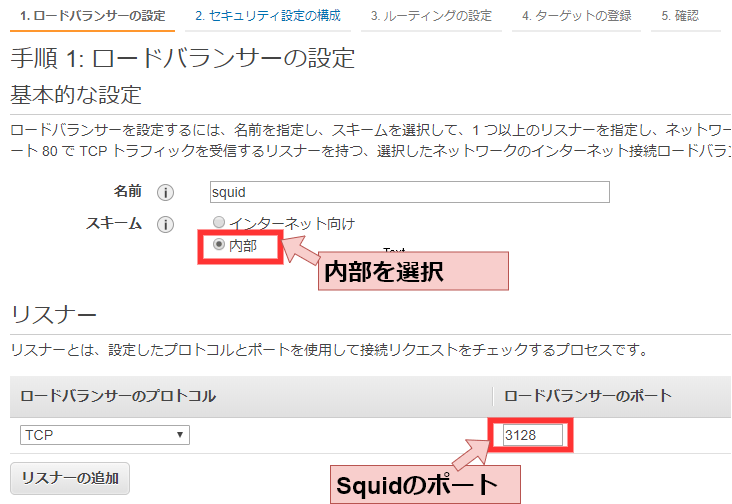
※以下、Amazon Linux2と仮定して進めます# yum install -y squid # systemctl start squid # netstat -anp | grep 3128 # systemctl enable squidSquidの設定についてここでは詳細を記しませんが、以下を設定するものとします。
- 3128ポートでの待受(デフォルト)
- オンプレ環境からのアクセス許可
- キャッシュの無効化
/etc/squid/squid.conf# Example rule allowing access from your local networks. # Adapt to list your (internal) IP networks from where browsing # should be allowed #acl localnet src all # すべての接続を許可する場合はこちら(テスト用) acl localnet src XXX.XXX.XXX.XXX/24 # オンプレ環境の接続元IPアドレスを入力 # Squid normally listens to port 3128 http_port 3128 # デフォルト設定 # Disable cache acl no_cache_acl src all # すべての接続でキャッシュを無効化 cache deny no_cache_aclHTTPプロキシサーバをNLBに組み込む(任意)
後々の冗長性確保とプロキシのホスト名を名前で解決できるようNLBを作成します。
転送する情報はHTTP(S)なので、ALBでもいけそうな気がしますが、必ずNLBで作成する必要があります。
これは、ALBがHTTPリクエストを転送する際に、FQDN部分を握り潰してしまうためです。
ここハマったので2回書きます。ALBは使えません。NLBで作成する必要があります。この作業は必須ではありませんが、実施することをおすすめします。
実施しない場合は、次の作業でNLBのエンドポイントの代わりに、HTTPプロキシサーバのIPアドレスを指定します。
ターゲットの登録は、オートスケーリンググループとの連携による自動登録を想定しているため割愛します。
オンプレ側がHTTPプロキシを使えるようにする
前段でAWS側の準備は整いました。
次は、オンプレ側がHTTPプロキシを使うよう設定する必要があります。
ここでは、例としてCLIでの設定方法を記載します。CLIは環境変数でプロキシを利用してくれるため、以下を設定するだけです。(参考)
Mac/Linux# ホスト名はNLBのエンドポイント。NLB未作成の場合はHTTPプロキシサーバのIPアドレス $ export HTTPS_PROXY=squid-xxxxxx.elb.ap-northeast-1.amazonaws.com:3128 $ export HTTP_PROXY=squid-xxxxxx.elb.ap-northeast-1.amazonaws.com:3128Windows環境の方は、安易に上記「参考」を参考にしてsetxを使うと叱られるのでお気をつけください。
以下のようにPowerShellで書くほうが安全ですね。Windows# 実行ユーザのユーザ環境変数に追加 PS C:\> [System.Environment]::SetEnvironmentVariable('HTTP_PROXY', 'squid-xxxxxx.elb.ap-northeast-1.amazonaws.com:3128',[System.EnvironmentVariableTarget]::User) PS C:\> [System.Environment]::SetEnvironmentVariable('HTTPS_PROXY', 'squid-xxxxxx.elb.ap-northeast-1.amazonaws.com:3128',[System.EnvironmentVariableTarget]::User)もちろんCredentialの設定は必要です。合わせて設定したCredentialにS3バケットのListBucket権限があることを確認してください。
aws configureまた、オンプレ側をEC2で擬似的に再現してみたい方は、インスタンスメタデータへのアクセスはプロキシを使用しないよう除外設定を入れてください。
詳細は上記「参考」のリンクの最後に記載されています。SDKでも同様にプロキシを設定できます。
例えば、Pythonのboto3ですと、botocore.configで設定できるようです。(参考)Pythonimport boto3 from botocore.config import Config boto3.resource('s3', config=Config(proxies={'https': 'squid-xxxxxx.elb.ap-northeast-1.amazonaws.com:3128'}))確認
お疲れ様でした。
CLIでS3に接続できることを確認しましょう。aws s3 ls s3://squid-test-bucket/



- 投稿日:2019-12-04T23:08:10+09:00
AWS Well-Architected 5本の柱を要約する(信頼性)
5本の柱ごとに自分なりの解釈を書いていきたいと思います。
※誤りがあればコメント頂けると嬉しいです。
今回は信頼性についてです。~~~は原文引用
信頼性とは
~~~インフラストラクチャやサービスの中断から復旧し、需要に適したコンピューティングリソースを動的に獲得し、誤設定や⼀時的なネットワークの問題といった中断の影響を緩和する能⼒~~~
信頼性の指標。
・MTBF(Mean Time Between Failure:平均故障間隔)
故障が回復してから次に故障するまでの平均時間。長いほど信頼性が高い。作業ミスがシステムの故障となりえる
・MTTR(Mean Time To Repair:平均復旧時間)
故障が発生したときに復旧に要する平均時間。短いほど信頼性が高い。
・稼働率=MTBF/(MTBF+MTTR)信頼性の柱は壊れにくく、復旧が容易な状態であることが目標となる。
設計の原則
クラウドにおける運用上の優秀性には、5 つの設計の原則があります。
・復旧⼿順をテストする
⇒オートメーションで疑似障害を発生させることができ、
以前の障害のシミュレートができる。
これによりテストしたことがないコンポーネントに対して障害が発生するリスクを低減できる。・障害から⾃動的に復旧する
⇒障害の検知とオートメーションを組み合わせることで自動復旧を実現する。・⽔平⽅向にスケールしてシステム全体の可⽤性を⾼める
⇒1つの大規模なリソースを複数に分割し、障害の影響を軽減。
共通の障害点を共有?・キャパシティーを推測しない
⇒実測値を元にキャパシティを設定・オートメーションで変更を管理する
⇒作業をドキュメント化(⇒手作業を認めない)することでミスがなくなる。ベストプラクティス
~~~⾼い信頼性を達成するため、システムの基盤について⼗分に計画し、モニタリングを実施する必要があります。需要や要件の変更に対応するためのメカニズムも必要です。障害を検出し、⾃動的に修復できるシステムを設計することが必要です。~~~
基盤、変更管理、障害の管理に分けて対応方針を記載している。基盤
~~~お客様はストレージデバイスのサイズといったリソースのサイズ
と割り当てを需要に応じて⾃由に変更できます。~~~オンプレと違い設計不要。基本的には制限がない。(制限の意識が必要なサービスもある)
DDOSなどの攻撃からシステムを守るサービスなども利用可能。・関連するAWSサービス
AWS IAM、Amazon VPC、AWS Trusted Advisor、AWS Shield変更管理
~~~AWS を使⽤すると、システムの動作をモニタリングし、KPI への応答を⾃動化できます。~~~
※KPI(Key Performance Indicator):重要業績評価指標長期的にリソース状況の傾向を見ることが簡単に行える。
リソース状況によって、サーバ台数の増減が自動で行える。
変更作業はCloudFormationなどを利用して、原則は自動化する。・関連するAWSサービス
AWS CloudTrail、AWS Config、Amazon Auto Scaling、Amazon CloudWatch障害の管理
~~~どのようなシステムでも、ある程度複雑になると障害が発⽣することが予想されます。そのため、それらの障害をどのように検出して対応し、再発を防⽌するかが問題です。~~~
問題検知と復旧の自動化。
テストプロセスも自動化する。(どうやって自動テストやるのか調査中)・関連するAWSサービス
Amazon CloudWatch、AWS CloudFormation、Amazon S3、AWS KMSレビューシート実践
信頼性 障害管理 データをどのようにバックアップしていますか?
□ バックアップが必要なデータを特定し、手動でバックアップを実施している
□ バックアップを自動化している(RDSとEBSのスナップショットなど)
□ 定期的なリカバリテストでバックアップがRTO、RPOを満たすことを確認している
□ バックアップはセキュリティ保護され、暗号化されている参考ドキュメント
〇AWS Well-Architected
(日本語 201907)
https://d1.awsstatic.com/whitepapers/ja_JP/architecture/AWS_Well-Architected_Framework.pdf?sc_icampaign=aware_well_architected_jp_wa_framework&sc_ichannel=ha&sc_icontent=awssm-3366&sc_iplace=content&trk=awssm-3366_aware_well_architected_jp_wa_framework〇Well-Architected_review_sheet
https://d1.awsstatic.com/webinars/jp/pdf/services/Well-Architected%E3%83%92%E3%82%A2%E3%83%AA%E3%83%B3%E3%82%B0%E3%82%B7%E3%83%BC%E3%83%88%E6%97%A5%E6%9C%AC%E8%AA%9E%E7%89%88.77c25d2afd0a69894be16b95aae6a423011f5a1f.xlsx
- 投稿日:2019-12-04T23:03:54+09:00
NAT ゲートウェイ設置数の上限に達した
ansible で VPC を作成、削除して実験していたら、以下のエラーとなりました。
"msg": "An error occurred (AddressLimitExceeded) when calling the AllocateAddress operation: The maximum number of addresses has been reached.",どうやら、NAT ゲートウェイの設置数の上限値に達したらしい。
いちいち削除していたんだけど、時間的なものがあるのかなぁ。確認してみると、上限値に達していた。
約 1時間後...
再度確認すると、半減していた。
NAT ゲートウェイを削除しても、その確認には時間がかかるので、上限値に達した場合は、1時間程待ってみるとよいようです。
上限に達しているのは、あるリージョンの問題なので、別のリージョンでは、実験を続けられました(ここでも、上限に達すると同じ事が起きますが)。
(参考)
https://docs.aws.amazon.com/vpc/latest/userguide/amazon-vpc-limits.html
- 投稿日:2019-12-04T23:03:54+09:00
NAT ゲートウェイの上限に達した
ansible で VPC を作成、削除して遊んでいたら、以下のエラーとなりました。
"msg": "An error occurred (AddressLimitExceeded) when calling the AllocateAddress operation: The maximum number of addresses has been reached.",どうやら、NAT ゲートウェイの上限値に達したらしい。
いちいち削除していたんだけど、時間的なものがあるのかなぁ。(参考)
https://docs.aws.amazon.com/vpc/latest/userguide/amazon-vpc-limits.html
- 投稿日:2019-12-04T22:52:14+09:00
Java(Eclipse)でAWSBatchにジョブ送信
Java(Eclipse)でAWSBatchにジョブ送信を試してみたので共有します。
前提
AWSBatchで以下が設定されている。
・ジョブ定義名:sample-job-definition
・キュー名:sample-job-queue
・コンピューティング環境名:sample-compute-environmentEclipseで以下を実施している。
・AWS Toolkit for Eclipseをインストール。
・AWS Toolkit for EclipseにIAMユーザのアクセスキー、シークレットアクセスキーを設定。
・Gradleプロジェクト作成。build.gradleの編集、SDKをインストール
dependenciesにaws-java-sdk-batchを追加して、プロジェクトにインストールします。
(プロジェクトを右クリックして Gradleプロジェクトのリフレッシュなどすると処理が開始されます)dependenciesに追加dependencies { …略 compile('com.amazonaws:aws-java-sdk-batch:1.11.683') // compile group: 'com.amazonaws', name: 'aws-java-sdk-batch', version: '1.11.683' // この書き方でもOK …略 }Javaサンプルコード
ドキュメントを参考に、以下のお試しコードを作成しました。
サンプルコードpackage sample; import java.util.HashMap; import java.util.Map; import com.amazonaws.regions.Regions; import com.amazonaws.services.batch.AWSBatch; import com.amazonaws.services.batch.AWSBatchClientBuilder; import com.amazonaws.services.batch.model.SubmitJobRequest; import com.amazonaws.services.batch.model.SubmitJobResult; public class AwsBatchSample { public static void main(String[] args) { AwsBatchSample awsBatchSample = new AwsBatchSample(); ab.awsBatchJobSend(); } private void awsBatchJobSend() { try { AWSBatch client = AWSBatchClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); Map<String,String> parameters = new HashMap<String, String>(); parameters.put("param1", "JobParam1"); // ジョブ定義でのコマンド:echo sample-batch Ref::param1 // ログでの出力結果 :sample-batch JobParam1 SubmitJobRequest request = new SubmitJobRequest() .withJobName("sample-job-submit") .withJobQueue("sample-job-queue") .withJobDefinition("sample-job-definition") .withParameters(parameters) ; SubmitJobResult response = client.submitJob(request); System.out.println(response); } catch (Exception e) { System.out.println(e); } } }ジョブ送信が成功すると以下が返却される。{JobName: sample-job-submit,JobId: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa}はまりポイント
ドキュメントの例では指定されていませんでしたが、
.withRegion(Regions.AP_NORTHEAST_1)を指定しない場合、以下のようなエラーが出力されました。エラーログ20:31:11.636 [main] DEBUG com.amazonaws.AmazonWebServiceClient - Internal logging successfully configured to commons logger: true 20:31:11.998 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.EnvironmentVariableCsmConfigurationProvider@17fc391b: Unable to load Client Side Monitoring configurations from environment variables! 20:31:11.998 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.SystemPropertyCsmConfigurationProvider@2b30a42c: Unable to load Client Side Monitoring configurations from system properties variables! 20:31:11.998 [java-sdk-http-connection-reaper] DEBUG org.apache.http.impl.conn.PoolingHttpClientConnectionManager - Closing connections idle longer than 60000 MILLISECONDS 20:31:11.999 [main] DEBUG com.amazonaws.monitoring.CsmConfigurationProviderChain - Unable to load configuration from com.amazonaws.monitoring.ProfileCsmConfigurationProvider@43df23d3: Unable to load config file 20:31:12.025 [main] WARN com.amazonaws.internal.InstanceMetadataServiceResourceFetcher - Fail to retrieve token com.amazonaws.SdkClientException: Failed to connect to service endpoint: at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:100) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.getToken(InstanceMetadataServiceResourceFetcher.java:91) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.readResource(InstanceMetadataServiceResourceFetcher.java:69) at com.amazonaws.internal.EC2ResourceFetcher.readResource(EC2ResourceFetcher.java:62) at com.amazonaws.util.EC2MetadataUtils.getItems(EC2MetadataUtils.java:400) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:369) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:365) at com.amazonaws.util.EC2MetadataUtils.getEC2InstanceRegion(EC2MetadataUtils.java:280) at com.amazonaws.regions.InstanceMetadataRegionProvider.tryDetectRegion(InstanceMetadataRegionProvider.java:59) at com.amazonaws.regions.InstanceMetadataRegionProvider.getRegion(InstanceMetadataRegionProvider.java:50) at com.amazonaws.regions.AwsRegionProviderChain.getRegion(AwsRegionProviderChain.java:46) at com.amazonaws.client.builder.AwsClientBuilder.determineRegionFromRegionProvider(AwsClientBuilder.java:475) at com.amazonaws.client.builder.AwsClientBuilder.setRegion(AwsClientBuilder.java:458) at com.amazonaws.client.builder.AwsClientBuilder.configureMutableProperties(AwsClientBuilder.java:424) at com.amazonaws.client.builder.AwsSyncClientBuilder.build(AwsSyncClientBuilder.java:46) at sample.AwsBatchSample.awsBatchJobSend(AwsBatchSample.java:17) at sample.AwsBatchSample.main(AwsBatchSample.java:12) Caused by: java.net.SocketException: Network is unreachable: connect at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at sun.net.NetworkClient.doConnect(NetworkClient.java:175) at sun.net.www.http.HttpClient.openServer(HttpClient.java:463) at sun.net.www.http.HttpClient.openServer(HttpClient.java:558) at sun.net.www.http.HttpClient.<init>(HttpClient.java:242) at sun.net.www.http.HttpClient.New(HttpClient.java:339) at sun.net.www.http.HttpClient.New(HttpClient.java:357) at sun.net.www.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.java:1202) at sun.net.www.protocol.http.HttpURLConnection.plainConnect0(HttpURLConnection.java:1181) at sun.net.www.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:1032) at sun.net.www.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:966) at com.amazonaws.internal.ConnectionUtils.connectToEndpoint(ConnectionUtils.java:52) at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:80) ... 16 common frames omitted 20:31:12.025 [main] WARN com.amazonaws.util.EC2MetadataUtils - Unable to retrieve the requested metadata (/latest/dynamic/instance-identity/document). Failed to connect to service endpoint: com.amazonaws.SdkClientException: Failed to connect to service endpoint: at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:100) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.getToken(InstanceMetadataServiceResourceFetcher.java:91) at com.amazonaws.internal.InstanceMetadataServiceResourceFetcher.readResource(InstanceMetadataServiceResourceFetcher.java:69) at com.amazonaws.internal.EC2ResourceFetcher.readResource(EC2ResourceFetcher.java:62) at com.amazonaws.util.EC2MetadataUtils.getItems(EC2MetadataUtils.java:400) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:369) at com.amazonaws.util.EC2MetadataUtils.getData(EC2MetadataUtils.java:365) at com.amazonaws.util.EC2MetadataUtils.getEC2InstanceRegion(EC2MetadataUtils.java:280) at com.amazonaws.regions.InstanceMetadataRegionProvider.tryDetectRegion(InstanceMetadataRegionProvider.java:59) at com.amazonaws.regions.InstanceMetadataRegionProvider.getRegion(InstanceMetadataRegionProvider.java:50) at com.amazonaws.regions.AwsRegionProviderChain.getRegion(AwsRegionProviderChain.java:46) at com.amazonaws.client.builder.AwsClientBuilder.determineRegionFromRegionProvider(AwsClientBuilder.java:475) at com.amazonaws.client.builder.AwsClientBuilder.setRegion(AwsClientBuilder.java:458) at com.amazonaws.client.builder.AwsClientBuilder.configureMutableProperties(AwsClientBuilder.java:424) at com.amazonaws.client.builder.AwsSyncClientBuilder.build(AwsSyncClientBuilder.java:46) at sample.AwsBatchSample.awsBatchJobSend(AwsBatchSample.java:17) at sample.AwsBatchSample.main(AwsBatchSample.java:12) Caused by: java.net.SocketException: Network is unreachable: connect at java.net.DualStackPlainSocketImpl.waitForConnect(Native Method) at java.net.DualStackPlainSocketImpl.socketConnect(DualStackPlainSocketImpl.java:85) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188) at java.net.PlainSocketImpl.connect(PlainSocketImpl.java:172) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:589) at sun.net.NetworkClient.doConnect(NetworkClient.java:175) at sun.net.www.http.HttpClient.openServer(HttpClient.java:463) at sun.net.www.http.HttpClient.openServer(HttpClient.java:558) at sun.net.www.http.HttpClient.<init>(HttpClient.java:242) at sun.net.www.http.HttpClient.New(HttpClient.java:339) at sun.net.www.http.HttpClient.New(HttpClient.java:357) at sun.net.www.protocol.http.HttpURLConnection.getNewHttpClient(HttpURLConnection.java:1202) at sun.net.www.protocol.http.HttpURLConnection.plainConnect0(HttpURLConnection.java:1181) at sun.net.www.protocol.http.HttpURLConnection.plainConnect(HttpURLConnection.java:1032) at sun.net.www.protocol.http.HttpURLConnection.connect(HttpURLConnection.java:966) at com.amazonaws.internal.ConnectionUtils.connectToEndpoint(ConnectionUtils.java:52) at com.amazonaws.internal.EC2ResourceFetcher.doReadResource(EC2ResourceFetcher.java:80) ... 16 common frames omitted com.amazonaws.SdkClientException: Unable to find a region via the region provider chain. Must provide an explicit region in the builder or setup environment to supply a region.ざっくりですが、今回は以上です。
参考
https://docs.amazonaws.cn/AWSJavaSDK/latest/javadoc/com/amazonaws/services/batch/AWSBatchClient.html#submitJob-com.amazonaws.services.batch.model.SubmitJobRequest-
https://docs.amazonaws.cn/AWSJavaSDK/latest/javadoc/com/amazonaws/services/batch/model/SubmitJobRequest.html
https://github.com/aws/aws-sdk-java/issues/2062
https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-batch
- 投稿日:2019-12-04T22:03:46+09:00
AWS CDK と Typescript で EC2 を構築してみる。
前提条件
% node --version v12.13.0% npm --version 6.12.0CDK をインストール
README を参考にして npm からインストールします。
% npm i -g aws-cdkプロジェクトの初期化
適当なディレクトリを作成します。
% mkdir cdk-ec2 % cd cdk-ec2初期化用のテンプレートは次のコマンドから確認できます。
% cdk init --list Available templates: * app: Template for a CDK Application └─ cdk init app --language=[csharp|fsharp|java|javascript|python|typescript] * lib: Template for a CDK Construct Library └─ cdk init lib --language=typescript * sample-app: Example CDK Application with some constructs └─ cdk init sample-app --language=[csharp|fsharp|java|javascript|python|typescript]今回はテンプレートとして sample-app を選択しました。
% cdk init sample-app --language=typescriptコマンドを実行すると次のファイルとディレクトリが作成されます。
% tree -I node_modules -L 2 -a . . ├── .git │ ├── COMMIT_EDITMSG │ ├── HEAD │ ├── config │ ├── description │ ├── hooks │ ├── index │ ├── info │ ├── logs │ ├── objects │ └── refs ├── .gitignore ├── .npmignore ├── README.md ├── bin │ └── cdk-ec2.ts ├── cdk.context.json ├── cdk.json ├── jest.config.js ├── lib │ └── cdk-ec2-stack.ts ├── package-lock.json ├── package.json ├── test │ └── cdk-ec2.test.ts └── tsconfig.jsonインフラ構築用のコード以外にテストが追加されています。
git リポジトリの初期化も行ってくれるようです。CDK の認証
aws-cliと同じように--profileオプションを指定して ~/.aws/config のプロファイルを指定できます。% cdk diff --profile my-profile自分の場合、次のエラーが発生しました。
% cdk diff --profile my-profile Stack CdkEc2Stack AWS region must be configured either when you configure your CDK stack or through the environment~/.aws/config の source_profile のプロファイルから region を引き継がないようです。
[default] region = ap-northeast-1 [profile my-profile] role_arn = arn:aws:iam::123456789012:role/myrole source_profile = default~/.aws/config の my-profile へ region を追加した後、再度コマンドを実行します。
% cdk diff --profile my-profile Stack CdkEc2Stack Unable to resolve AWS account to use. It must be either configured when you define your CDK or through the environmentどうやら JavaScript の AWS SDK では MFA 認証が行えないようです。
aws-mfa を使用して temporary credentials を取得する必要があります。まずは pip から aws-mfa をインストールします。
% pip install aws-mfa~/.aws/credentials の default プロファイルを default-long-term プロファイルへ変更します。
[default-long-term] aws_access_key_id = type_your_id aws_secret_access_key = type_your_key aws_mfa_device = type_your_mfa_arn
aws-mfaコマンドを実行します。aws-mfaデバイスに表示されているコードの入力を求められるため、入力します。
すると ~/.aws/credentials の default プロファイルが追加されます。[default-long-term] aws_access_key_id = type_your_id aws_secret_access_key = type_your_key aws_mfa_device = type_your_mfa_arn [default] aws_access_key_id = xxxxx aws_secret_access_key = yyyyy aws_security_token = zzzzzこの状態で再度、CDK の認証を試みます。
% cdk diff --profile my-profile Stack CdkEc2Stack IAM Statement Changes ...長いので略認証でだいぶハマってしまいました。
今回発生したエラーの詳細は次の issue にまとめられています。
https://github.com/aws/aws-cdk/issues/1656VPC の構築
aws-ec2 モジュールを import した後、 Vpc クラスを new するだけです。
import cdk = require('@aws-cdk/core'); import ec2 = require('@aws-cdk/aws-ec2') export class CdkEc2Stack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props); new ec2.Vpc(this, 'MyVpc'); } }コンストラクタの第三引数から作成する VPC のタイプを選択できます。
new ec2.Vpc(this, 'MyVpc', { subnetConfiguration: [ { cidrMask: 28, subnetType: ec2.SubnetType.PUBLIC, name: 'public' }, ] });インスタンスの構築
Instance クラスを new します。
コンストラクタの第三引数へインスタンスを構築する VPC とイメージ、インスタンスタイプを指定できます。const image = new ec2.AmazonLinuxImage() new ec2.Instance(this, 'MyInstance', { vpc: vpc, instanceType: ec2.InstanceType.of(ec2.InstanceClass.T2, ec2.InstanceSize.MICRO), machineImage: image })デプロイ
次のコマンドからデプロイすることができます。
% cdk deploy --profile my-profile後始末は
destroyコマンドから行うことができます。% cdk destroy --profile my-profile
- 投稿日:2019-12-04T21:35:19+09:00
AWSで業務時間外には使わないリソースを停止しておいてコスト削減するスタックをサーバレスで作った話
以前エンジニア組織のコスト管理おじさん業をやっていて、
その中の一つにインフラコスト管理というテーマがありました。
その時に使ってみてその後色々なプロジェクトに展開して行った手法を紹介します。概要
staging環境など、production環境以外のRDS, EC2を夜間は停止しておいて、
朝方メンバー出社する前に起動しておく事で節約します。コード
https://github.com/soartec-lab/aws_cloudformation_batch
説明
技術スタック
- CloudFormation -> IaCというより不要になった場合に全て消せるように
- CloudWatchEvent -> スケジューラー
- CloudWatchLogs/CloudWatch -> イベントログ取得、監視
- Lambda -> インスタンスの起動、停止処理
説明
インスタンスの起動、停止処理をPythonで実装したLambdaを
CloudWatchEventで起動する。
監視をCloudWatchLogs/CloudWatchで行う。
上記の構成をCloudFormationでサクッと構築する
- 投稿日:2019-12-04T19:49:57+09:00
AWSとのClient VPNの張り方(忘備)
AWSとのClient VPNの張り方(忘備)
環境
- デバイス(クライアント)
- OS: iOS 13.1.3
- 認証局、証明書作成環境
- OS: Ubuntu 18.04.2 LTS (Bionic Beaver)
作業イメージ
作業① サーバ証明書、クライアント証明書作成、インポート
- ローカルコンピュータに OpenVPN Easy-RSA レポジトリのクローンを作成します。
miamo@ubuntu:~$ git clone https://github.com/OpenVPN/easy-rsa.git Cloning into 'easy-rsa'... remote: Enumerating objects: 14, done. remote: Counting objects: 100% (14/14), done. remote: Compressing objects: 100% (11/11), done. remote: Total 1568 (delta 4), reused 10 (delta 3), pack-reused 1554 Receiving objects: 100% (1568/1568), 5.63 MiB | 2.15 MiB/s, done. Resolving deltas: 100% (730/730), done. miamo@ubuntu:~$ cd easy-rsa/easyrsa3 miamo@ubuntu::~/easy-rsa/easyrsa3$
- 初期化します。
miamo@ubuntu:~/easy-rsa/easyrsa3$ ./easyrsa init-pki init-pki complete; you may now create a CA or requests. Your newly created PKI dir is: /home/miamo/easy-rsa/easyrsa3/pki miamo@ubuntu:~/easy-rsa/easyrsa3$
- 新しい PKI 環境を初期化し、新しい認証機関 (CA) を構築します。パスフレーズは不要なのでnopassオプションを指定します。
miamo@ubuntu::~/easy-rsa/easyrsa3$ ./easyrsa build-ca nopass Using SSL: openssl OpenSSL 1.1.1 11 Sep 2018 Generating RSA private key, 2048 bit long modulus (2 primes) .....+++++ ................+++++ e is 65537 (0x010001) You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Common Name (eg: your user, host, or server name) [Easy-RSA CA]:openvpn #任意 CA creation complete and you may now import and sign cert requests. Your new CA certificate file for publishing is at: /home/miamo/easy-rsa/easyrsa3/pki/ca.crt miamo@ubuntu::~/easy-rsa/easyrsa3$
- 秘密鍵の作成から証明書の署名までまとめて行うので、build-server-fullを実行して、サーバー証明書とキーを生成します。パスフレーズは不要なのでnopassオプションを指定します。
miamo@ubuntu::~/easy-rsa/easyrsa3$ ./easyrsa build-server-full server nopass Using SSL: openssl OpenSSL 1.1.1 11 Sep 2018 Generating a RSA private key ................................................................................................+++++ ...........+++++ writing new private key to '/home/miamo/easy-rsa/easyrsa3/pki/easy-rsa-313.nNPqog/tmp.KctDJX' ----- Using configuration from /home/miamo/easy-rsa/easyrsa3/pki/easy-rsa-313.nNPqog/tmp.R1SYTG Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'server' Certificate is to be certified until Mar 7 07:50:41 2022 GMT (825 days) Write out database with 1 new entries Data Base Updated miamo@ubuntu::~/easy-rsa/easyrsa3$
- 秘密鍵の作成から証明書の署名までまとめて行うので、build-client-fullを実行して、クライアント証明書とキーを生成します。パスフレーズは不要なのでnopassオプションを指定します。
miamo@ubuntu::~/easy-rsa/easyrsa3$ ./easyrsa build-client-full client nopass Using SSL: openssl OpenSSL 1.1.1 11 Sep 2018 Generating a RSA private key ......................+++++ ..................+++++ writing new private key to '/home/miamo/easy-rsa/easyrsa3/pki/easy-rsa-1249.5x3I8d/tmp.6vgYCl' ----- Using configuration from /home/miamo/easy-rsa/easyrsa3/pki/easy-rsa-1249.5x3I8d/tmp.8e1zDA Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'client' Certificate is to be certified until Mar 8 01:47:32 2022 GMT (825 days) Write out database with 1 new entries Data Base Updated miamo@ubuntu::~/easy-rsa/easyrsa3$
- ルート証明書(pki/ca.crt)、サーバ証明書(pki/issued/server.crt)、サーバ秘密鍵(pki/private/server.key)をACM登録用のフォルダへコピー
miamo@ubuntu:~/easy-rsa/easyrsa3$ mkdir ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ cp pki/ca.crt ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ cp pki/issued/server.crt ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ cp pki/private/server.key ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ cp pki/issued/client.crt ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ cp pki/private/client.key ./acm miamo@ubuntu:~/easy-rsa/easyrsa3$ ls -l ./acm/ total 16 -rw------- 1 miamo miamo 1188 Dec 4 17:12 ca.crt -rw------- 1 miamo miamo 4472 Dec 4 17:13 client.crt -rw------- 1 miamo miamo 1708 Dec 4 17:13 client.key -rw------- 1 miamo miamo 4588 Dec 4 17:12 server.crt -rw------- 1 miamo miamo 1704 Dec 4 17:13 server.key
- ルート証明書(pki/ca.crt)、サーバ証明書(pki/issued/server.crt)、サーバ秘密鍵(pki/private/server.key)を ACM にアップロードして、登録します。
miamo@ubuntu:~/easy-rsa/easyrsa3$ cd acm miamo@ubuntu:~/easy-rsa/easyrsa3/acm$ aws acm import-certificate --certificate file://server.crt --private-key file://server.key --certificate-chain file://ca.crt --region ap-northeast-1 { "CertificateArn": "arn:aws:acm:ap-northeast-1:************:certificate/d9939cb4-b36a-4b9e-87a9-f63981d3ddc0" } miamo@ubuntu:~/easy-rsa/easyrsa3/acm$
- ACM を確認します。

作業② クライアントVPNエンドポイント作成、設定
マネジメントコンソールの場合
- VPC ダッシュボードからクライアント VPN エンドポイントを選択し、クライアントVPNエンドポイントの作成をクリックします。

- Client IPv4 CIDRは、/22以上/16以下で指定し、VPNのCIDRと被らないようにしておく、Server certificate ARNとClient certificate ARNはクライアント側もサーバ証明書を指定する。
- ※CloudwatchLogStreamは事前に作成しておく。

- 作成できたことを確認
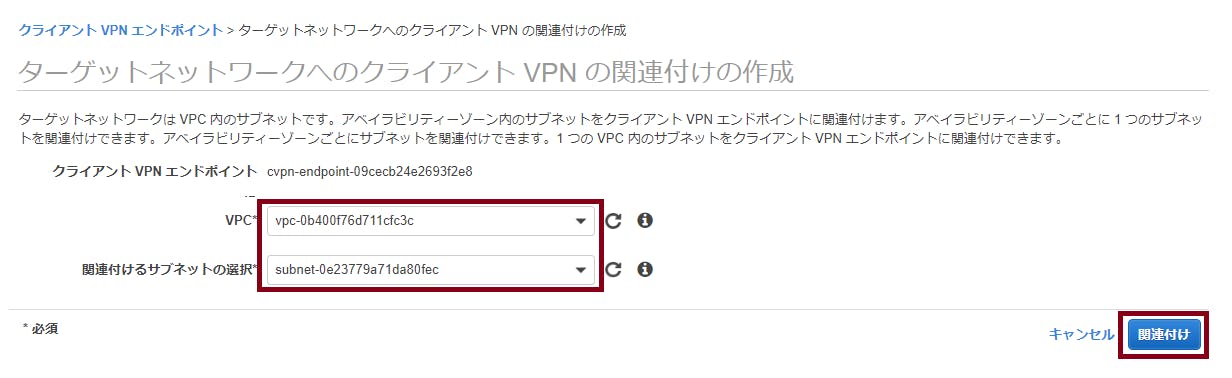
- 関連付けタブを選択し、関連付けを選択

- 作成したクライアントVPNエンドポイントに通信対象のサブネットを関連付ける。※紐づけたサブネット単位で0.15USD/時間(東京リージョンの場合)かかる。
- 紐づいたことを確認します。

- 認証タブを選択肢、受信の承認をクリックします。
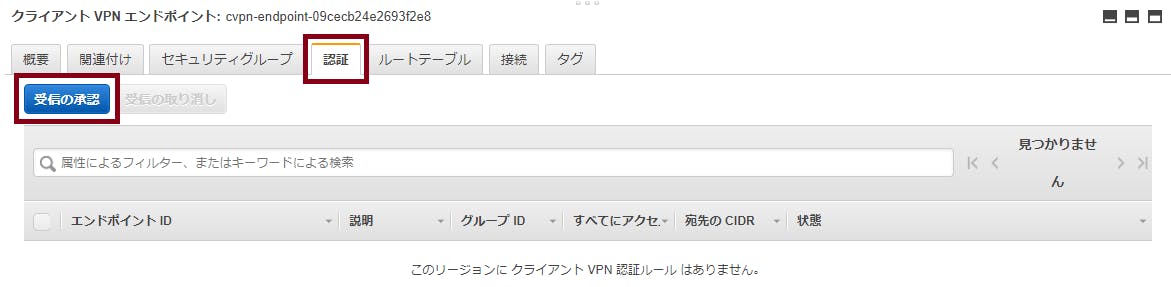
- 通信を許可するCIDRを入力して、承認ルールの追加をクリックします。

- 追加されたことを確認

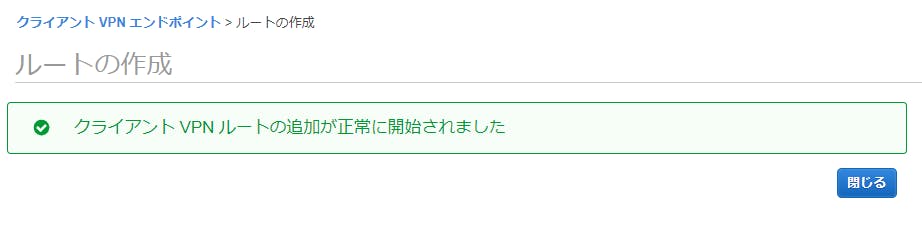
- ルートテーブルタブを選択して、ルート作成をクリックします。

- インターネットへのルーティングテーブルを追加します。

- 作成されたことを確認します。
AWS CLIから設定する場合
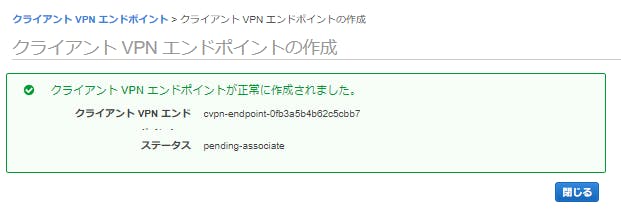
- 『aws ec2 create-client-vpn-endpoint』を実行してクライアントVPNエンドポイントを作成 ※CloudwatchLogStreamは事前に作成しておく。
miamo@ubuntu:~$ aws ec2 create-client-vpn-endpoint \ > --client-cidr-block "172.16.16.0/22" \ > --server-certificate-arn "arn:aws:acm:ap-northeast-1:************:certificate/bfd08d0b-83c0-4b0b-bed1-42b7f17685b2" \ > --authentication-options "[{\"Type\":\"certificate-authentication\",\"MutualAuthentication\":{\"ClientRootCertificateChainArn\":\"arn:aws:acm:ap-northeast-1:************:certificate/bfd08d0b-83c0-4b0b-bed1-42b7f17685b2\"}}]" \ > --connection-log-options "{\"Enabled\":true,\"CloudwatchLogGroup\":\"aws_ansible_conf_flowlogs_role\",\"CloudwatchLogStream\":\"OpenVPN\"}" \ > --description "OpenVPN" \ > --transport-protocol "udp" \ > --no-split-tunnel \ > --tag-specifications "[{\"ResourceType\":\"client-vpn-endpoint\",\"Tags\":[{\"Key\":\"Name\",\"Value\":\"OpenVPN\"}]}]" \ > --region ap-northeast-1 { "ClientVpnEndpointId": "cvpn-endpoint-09cecb24e2693f2e8", "Status": { "Code": "pending-associate" }, "DnsName": "cvpn-endpoint-09cecb24e2693f2e8.prod.clientvpn.ap-northeast-1.amazonaws.com" }
- 『aws ec2 associate-client-vpn-target-network』を実行してクライアントVPNエンドポイントにサブネットを紐づけ。※CloudwatchLogStreamは事前に作成しておく。
miamo@ubuntu:~$ aws ec2 associate-client-vpn-target-network \ > --client-vpn-endpoint-id cvpn-endpoint-09cecb24e2693f2e8 \ > --subnet-id subnet-0e23779a71da80fec { "AssociationId": "cvpn-assoc-00e0542f29d674770", "Status": { "Code": "associating" } }
- 『aws ec2 authorize-client-vpn-ingress』を実行して、許可する通信先を設定します。
miamo@ubuntu:~$ aws ec2 authorize-client-vpn-ingress \ > --client-vpn-endpoint-id cvpn-endpoint-09cecb24e2693f2e8 \ > --target-network-cidr "172.16.0.0/20" \ > --authorize-all-groups { "Status": { "Code": "authorizing" } }
- 『aws ec2 create-client-vpn-route』を実行して、インターネットへのルーティングテーブルを追加します。
miamo@ubuntu:~$ aws ec2 create-client-vpn-route \ > --client-vpn-endpoint-id cvpn-endpoint-09cecb24e2693f2e8 \ > --destination-cidr-block 0.0.0.0/0 \ > --target-vpc-subnet-id subnet-0e23779a71da80fec { "Status": { "Code": "creating" } }作業③ デバイスに証明書登録
OpenVPN設定用ファイル作成
マネジメントコンソールからクライアント設定ファイルを作成する場合
- クライアント設定用のファイルをダウンロードします。

- ダウンロードしたファイルにクライアント証明書とキーを追記するとファイルが完成します。

AWS CLIからのクライアント設定ファイルを作成する場合
- 『export-client-vpn-client-configuration』を実行してクライアント設定用のファイルをダウンロードした後、クライアント証明書と鍵をマージするとファイルが完成します。
miamo@ubuntu:~/easy-rsa/easyrsa3$ aws ec2 export-client-vpn-client-configuration \ > --client-vpn-endpoint-id cvpn-endpoint-003fc8dedffd7e2ec \ > --output text > client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ echo "<cert>" >> client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ cat acm/client.crt | grep -v Certificate: | grep -v " " >> client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ echo "</cert>" >> client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ echo "<key>" >> client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ cat acm/client.key >> client.ovpn miamo@ubuntu:~/easy-rsa/easyrsa3$ echo "</key>" >> client.ovpnOpenVPN設定用ファイルをiphoneへ登録
- 以下の画像通り作成したファイルをメール等で送信して証明書を登録して、設定画面のVPNで接続します。(左から右へ)


- 投稿日:2019-12-04T19:42:42+09:00
Amazon Lightsailで気軽にサーバー構築
Amazon Lightsail とは?
Amazon Lightsailは、AWSが提供しているVPS(仮想プライベートサーバー)です。数クリックでクラウド上にサーバーを構築できるので、EC2よりも手軽に使用できます。
また、LAMPやWordPress、Node.jsといったWebアプリケーションをプリインストールしているインスタンスも作成できます。
料金は月額$3.50〜
AWSでは珍しく、固定費用で使えます。(転送量を超えると課金されるので注意)
サーバースペックを上げると、料金も増えていきます。
$3.50のプランは最初の1ヶ月無料なので、サクッとインスタンスを作って実験し、削除するようなお試し環境として使いやすいです。
Amazon Lightsail を使ってみよう!!
今回の構成
CentOS上にNode.jsをインストールして、Next.jsを動かしてみます。
インスタンスの作成
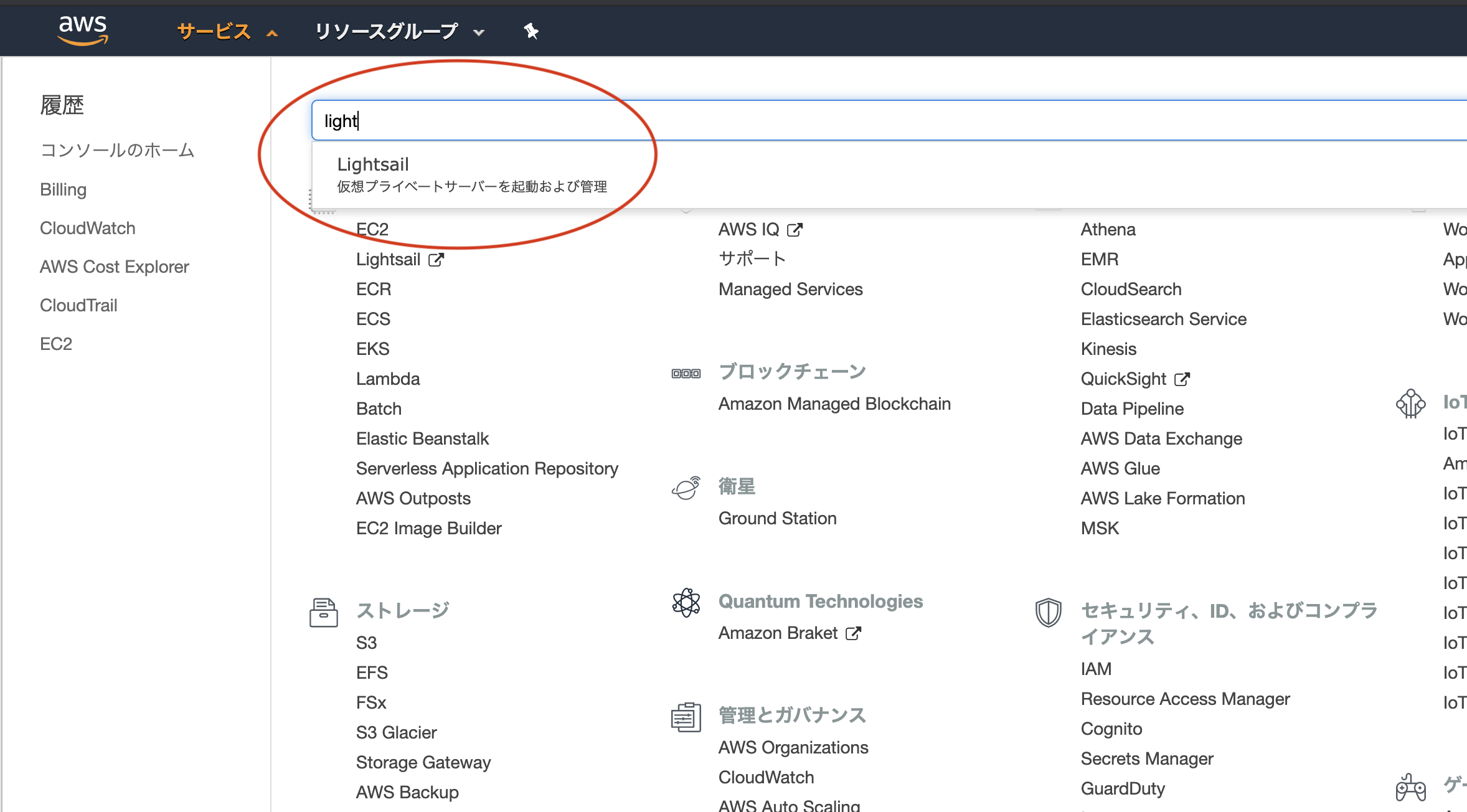
AWS マネジメントコンソールで
lightsailを検索して選択します。
(事前にAWSアカウントを取得している必要があります)
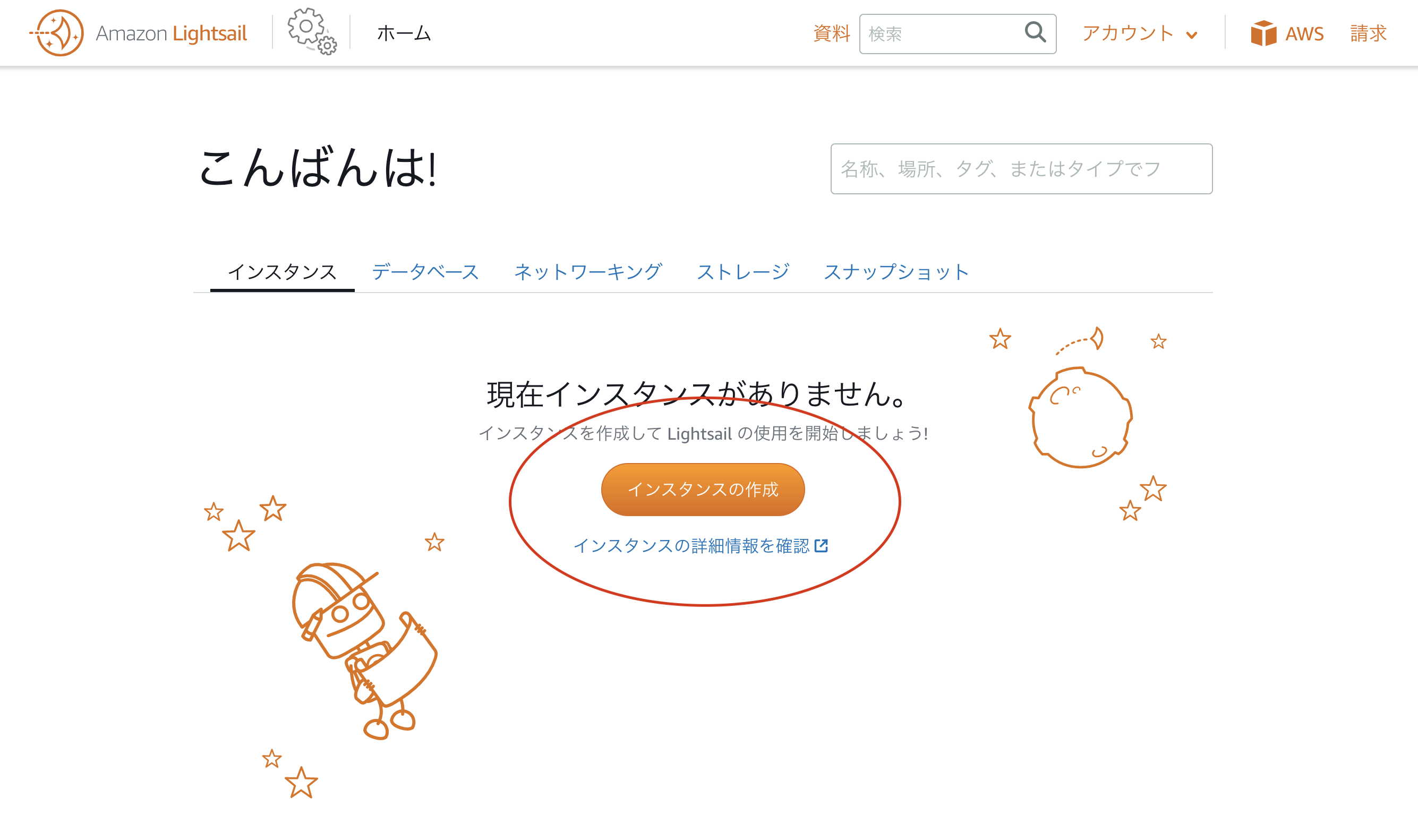
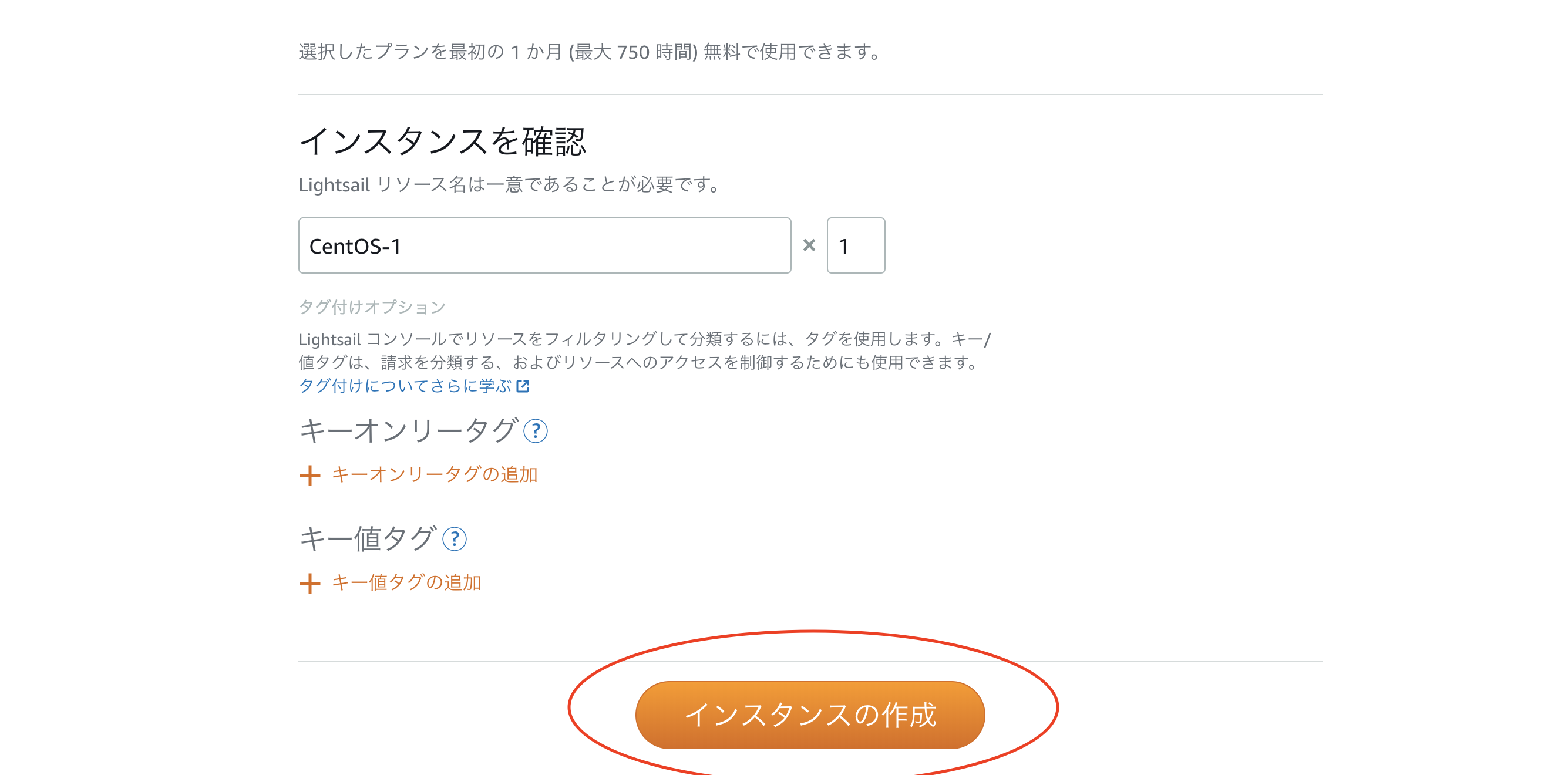
Lightsailの管理画面に移動したら、インスタンスの作成ボタンをクリック。
東京リージョン、Linux/Unix、OSのみのCentOSを選択して、下にスクロールしていきます。
料金は、$3.5のままでOKです。
さらに下までスクロールして、インスタンスの作成をクリック。
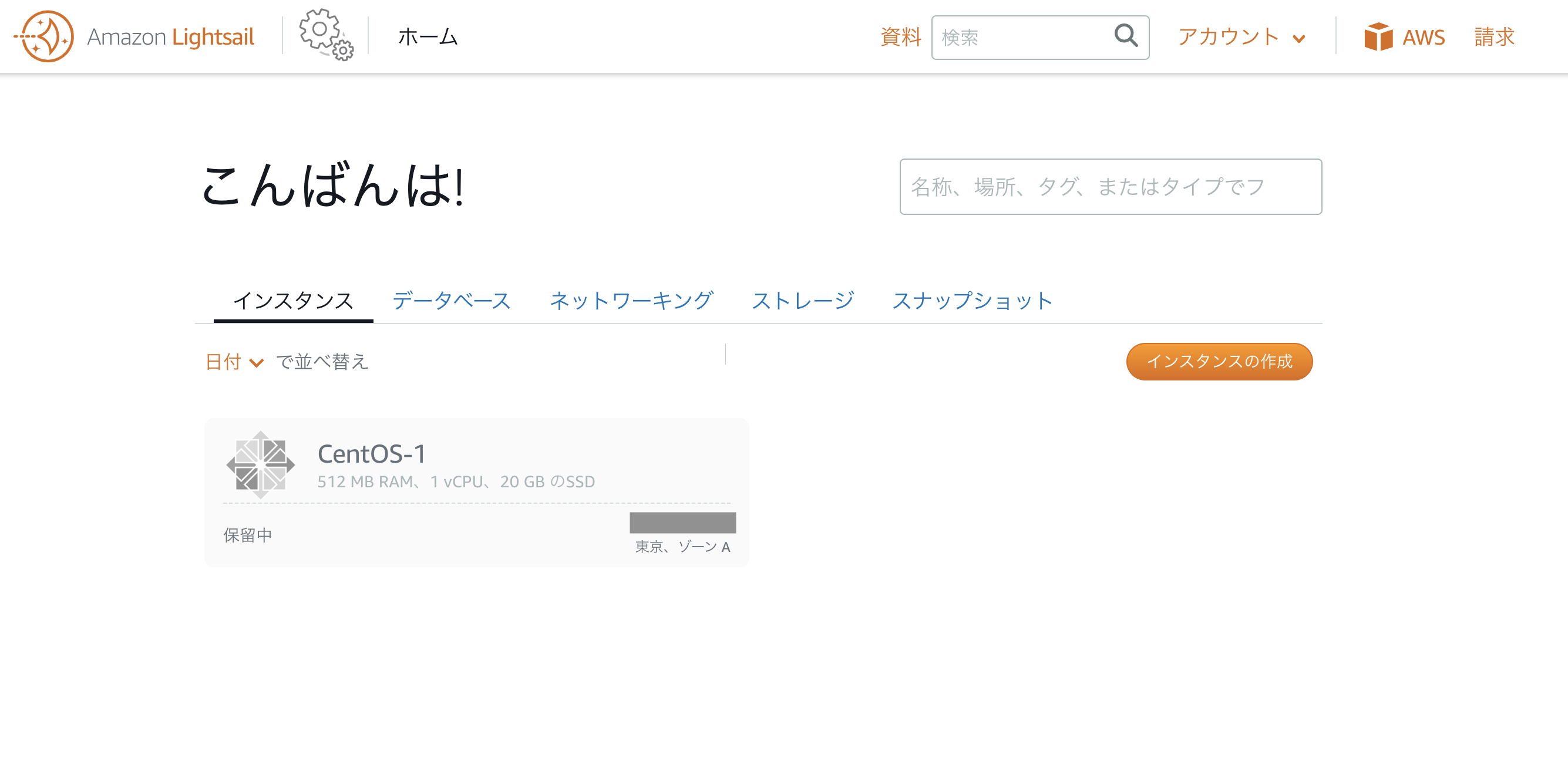
インスタンスが作成されます。数分は保留中となっているので、少し待ちましょう。
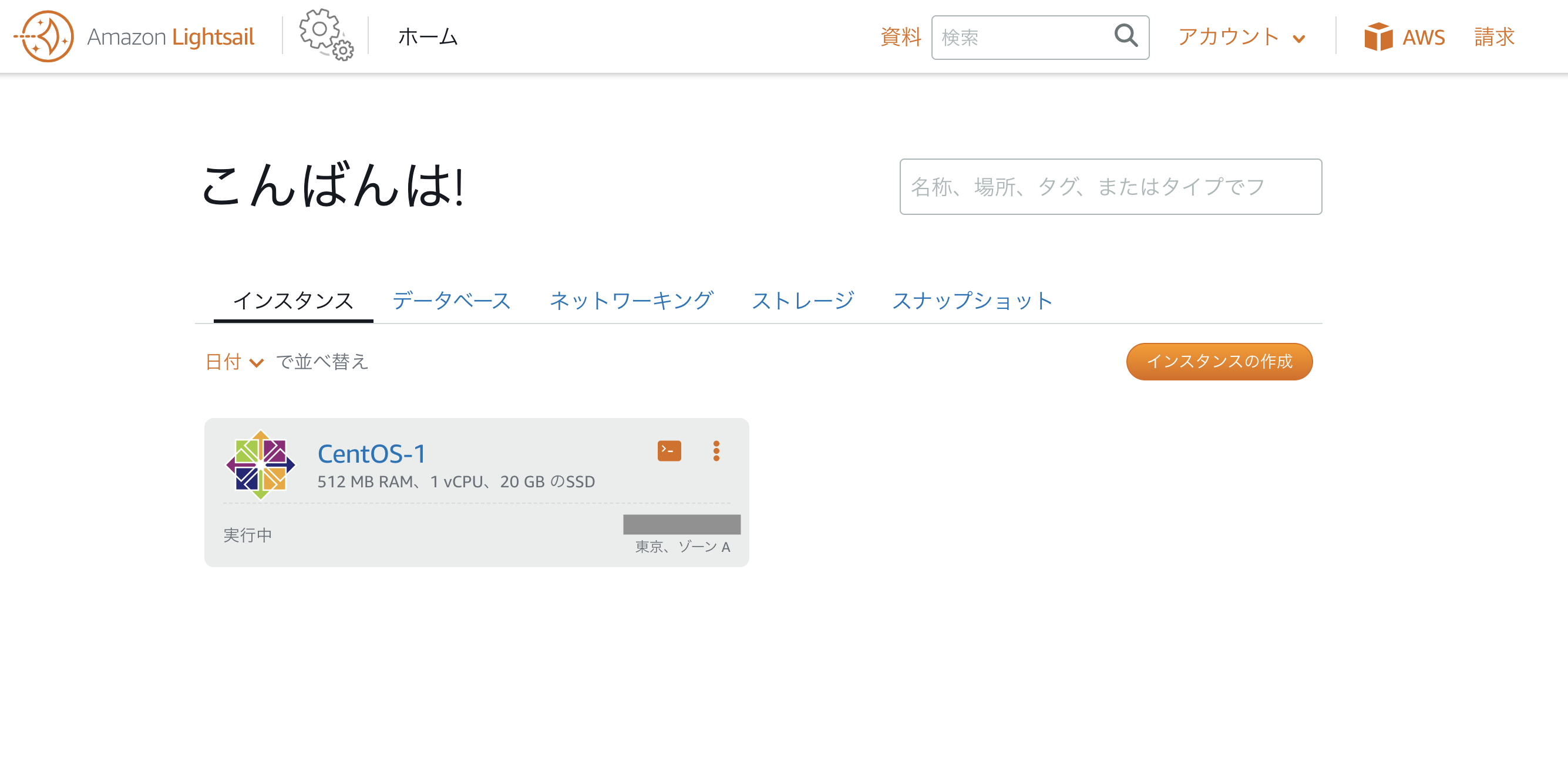
実行中になったら、テキスト部分をクリックします。
インスタンスの詳細ページに移動します。ここでインスタンスの状態や設定を確認できます。
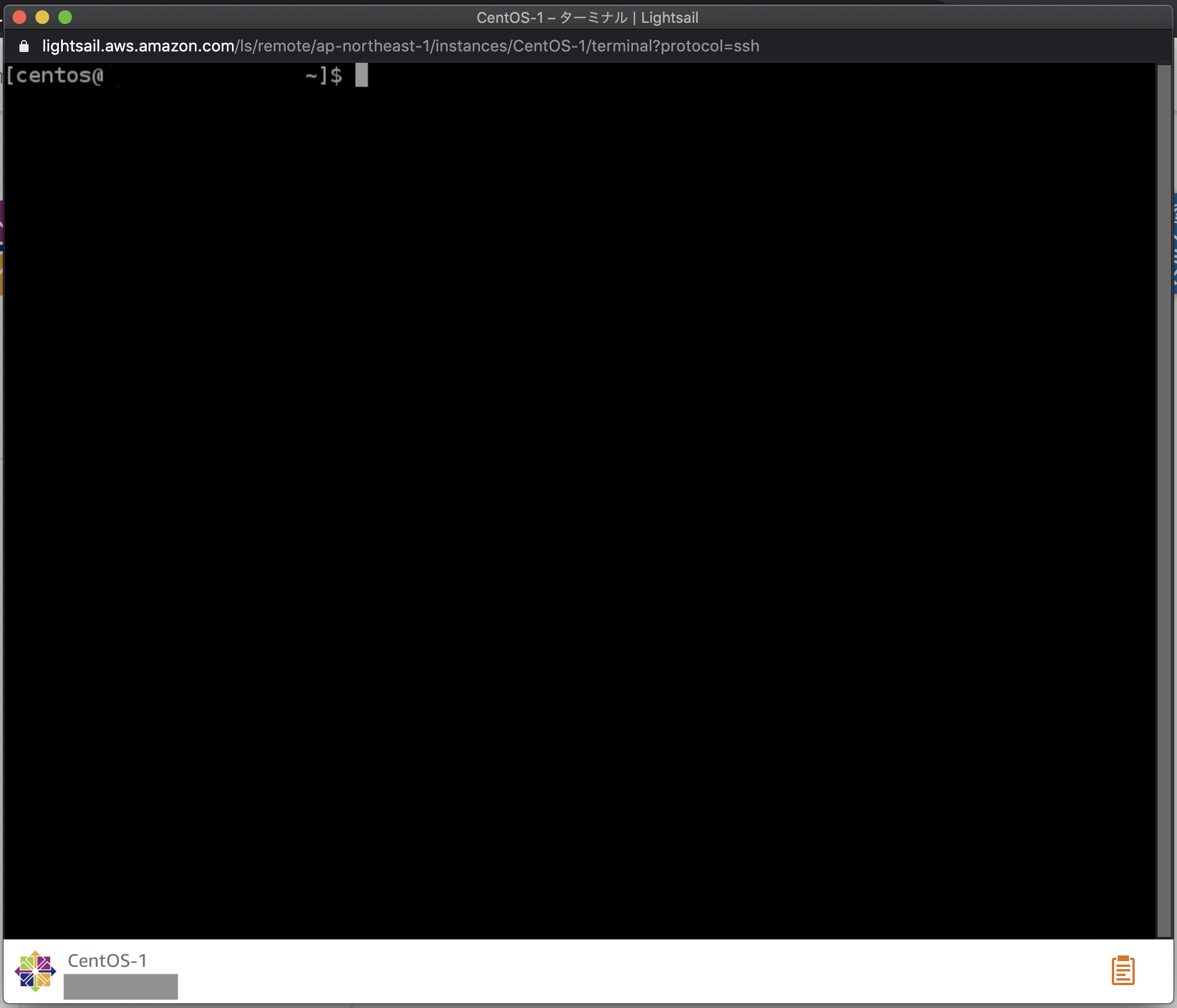
SSHを使用して接続ボタンをクリックすると、ブラウザ上でサーバーに接続できます。
ウインドウが新規で立ち上がり、ターミナルでサーバーを操作することができます。
CentOSにNode.jsをインストール
Node.jsをインストールしてnpmを使えるようにしましょう。
$ curl —sL https://rpm.nodesource.com/setup_12.x | sudo bash - $ sudo yum install -y nodejs $ node -v $ npm -vNode.jsとnpmのバージョンが表示されれば、成功です。
Next.jsとは?
Next.jsとは、Reactでサーバーサイドレンダリングをするためのフレームワークです。Vue.jsで言うところの、Nuxt.jsですね。
簡単にルーティングできて、静的サイトの書き出しもできます。
サーバーサイドレンダリングとは?
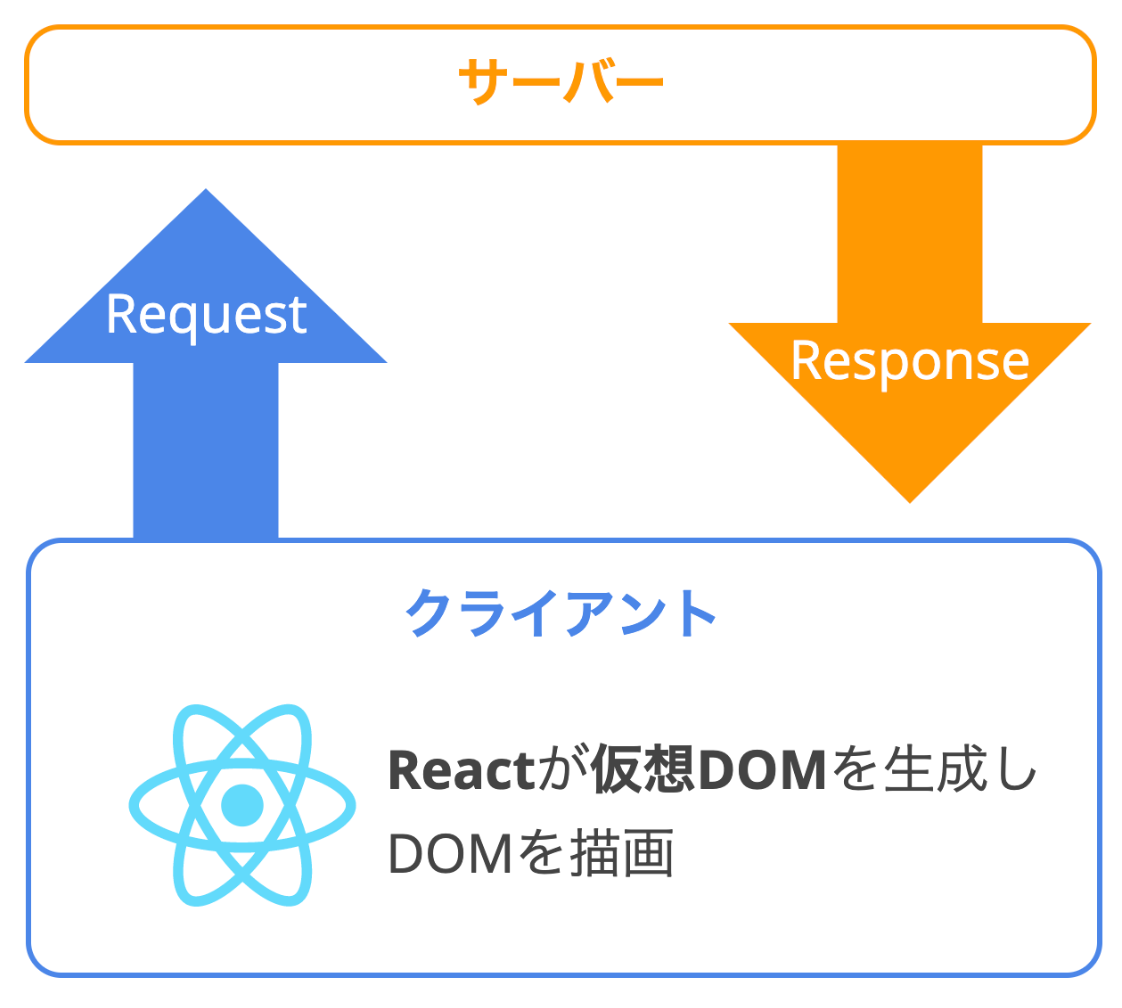
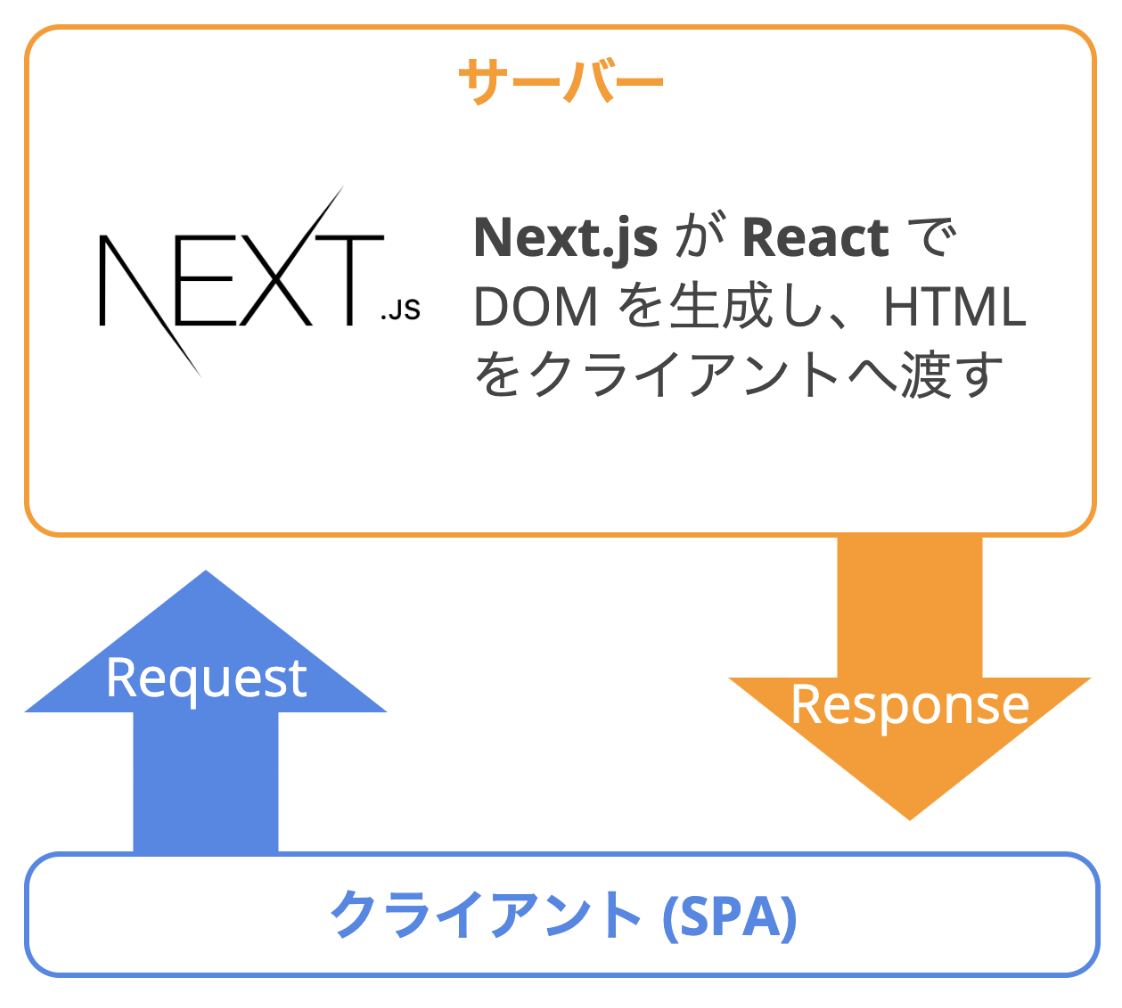
サーバーサイドレンダリング(SSR)とは、PHPやRuby、Java、Node.js等の言語で、動的にサーバーサイドでDOMを生成してクライアントに静的なHTMLとして渡すことです。
Reactは、本来クライアントサイドで仮想DOMを生成し、それを実DOMとしてブラウザに描画します。
Next.jsでSSRすると、サーバー上でReactを実行し、生成したDOMをクライアントへ渡すことができます。また、クライアント上ではSPAになるため、シームレスなページ遷移が可能です。
Next.jsを使ってみよう!!
以下のコマンドを実行し、Next.jsをインストールしましょう。
$ cd ~ $ mkdir nextjs_demo $ cd nextjs_demo $ npm init -y $ npm i react react-dom nextNext.jsは
/pagesディレクトリ内をルーティングの対象としています。/pagesディレクトリにindex.jsを作成し、Hello, Next.js!!テキストをブラウザで表示してみましょう。$ mkdir pages $ touch pages/index.js $ vi pages/index.js
iキーを押し、入力モードに切り替えます。export default () => <div>Hello, Lightsail!!</div>
escキーで入力モードを終了し、:wqで保存してviを終了します。以下のコマンドを実行し、Amazon Lightsailの画面にあるパブリック IPをブラウザでみています。
$ sudo npx next build $ sudo npx next start -p 80ブラウザ上に
Hello, Next.jsが表示されていたら成功です。Queryパラメーターを取得
サーバーサイドレンダリングを体験するために
pages/index.jsを以下のように変更し、URLパラメーターによってHTMLが変化することを確認してみましょう。import React from 'react' import Head from 'next/head' function Index({ query }) { const {text} = query return ( <> <Head> <title>{text}</title> </Head> <div>{text}</div> </> ) } Index.getInitialProps = ({ query }) => { return { query } }さきほどのパブリック IPの後ろに
?text=hogehogeを入れてみましょう。title要素と本文がhogehogeになっているかと思います。また、hogehoge部分を好きな文字列に変更すると、title要素と本文が変更されます。インスタンスを削除する
不要なインスタンスを削除することにより、課金を防ぐことができます。
管理画面の
削除タブを選択肢、インスタンスの削除をクリックします。
このインスタンスを削除?というモーダルが表示されるので、はい、削除しますをクリックしましょう。
これで、インスタンスが削除されました。さいごに
ぼくのようなデザイン側のフロントエンド開発者は、サーバーやインフラの知識が乏しいことがあるかと思います。Amazon Lightsailは、手軽にサーバーを構築できるので学習にぴったりですので、ぜひ触ってみてください。
それでは、よきコーディングライフを。



- 投稿日:2019-12-04T19:01:29+09:00
Athenaに思いのほかいろんな関数が実装されていた
自己紹介
ブログ初投稿の新卒です。
普段はサーバーサイドのプログラムを書いたりしています。はじめに
DBに格納されたデータに対しては、クエリを投げることで効率よく検索したり集計したりできます。しかし、サービスを運営し続けることで溜まっていく膨大なログについては全てDBに入れたりするわけにはいかず、適宜圧縮ファイルにして蓄え続けることになります。
このようにファイルとして書き出してしまうと今度は過去ログを漁りたい時に不便なのですが、Amazon Athenaのようなサービスを使うことで、ファイル群に対してあたかもDBを扱う時のようにクエリを投げることができます。
このサービスについて、S3上のファイルをクエリ実行の度に都度読み込む形式だと聞いて、簡単なSELECT文を投げることができる程度だと勝手に思っていました。
実際にはそんな低機能なサービスではなく、一見すると手元でスクリプトを組んで集計する必要がありそうなデータ形式でも関数の力でなんとかできるケースが多かったので、そういったケースの例をいくつか挙げます。ケース1 : JSONのパース
とあるところに以下のような形式の行がたくさん格納されたログがありました。
日付時刻|json形式のデータ|その他このような行データからjson部分のデータを取り出して検索・集計するとき、地道に作業するなら "|" 区切りで2番目の文字列をjsonデコードするスクリプトを書くのですが、このような形式でもAthenaでクエリを投げることが可能です。
そのためには、以下のような方法でjsonデータの値をカラムとして読み込ませます。
- "|" 区切りのcsvとしてテーブルを作成する
- json部分を
VARCHAR型とし、jsonデコードして特定のキーを取り出すjson部分のカラム名を
json_strとすると、テーブル作成後に投げるクエリはざっくり以下のような感じになります。WITH tmp_table_name AS ( SELECT CAST(JSON_EXTRACT(JSON_PARSE(json_str), '$.id') AS INTEGER) AS id, CAST(JSON_EXTRACT(JSON_PARSE(json_str), '$.str') AS VARCHAR) AS str FROM table_name ) SELECT * FROM tmp_table_name WHERE id = 125
JSON_PARSEでパースしてjson型の値を得たあと、JSON_EXTRACTでjqのような記法で中の値を取り出します。
取り出した値を好きな型に変換して別名をつけたテーブルを用意し、以降のクエリでは名前と型のついたテーブルとして扱います。WITH句を使わなくても同じことはできますが、カラムの情報が必要になる度に
CAST(...)を書くことになるのと、別名でGROUP_BY等が使えないので、素直に一度WITHでテーブル変換を噛ませるのが良いと思います。
補足1
MySQL5.7以降でも同様の関数が使えるようです。知らなかった...。
補足2
データ全体がjson形式になっているときは
STRUCT型を用いてネストしたデータを取得できるようにする例がいくつも見つかったのですが、この例のようにcsvの中にjsonが含まれる場合はうまくSTRUCT型として認識させられませんでした。
(STRUCT<col1:str,col2:int,...>のように定義したところ、json文字列全体がcol1に入って他のカラムがNULLになった)
ケース2 : コンマ区切りのカラムの行展開
とあるところに以下のように複数の値がコンマ区切りで入っているログがありました。
{..., "ids": "1,2,5"}このような行データからコンマ区切り部分を取り出して検索・集計するとき、地道に作業するならjsonデコードしてidsの中身をsplitするスクリプトを書くのですが、この形式でもAthenaでクエリを投げることが可能です。
以下のようなクエリを書くことで行データとして展開できます。
SELECT * FROM table_name CROSS JOIN UNNEST ( SPLIT(ids, ',') ) AS tmp_table_name (id)区切り文字による分割は
SPLITというそのまんまな関数があります。返り値は配列です。
分割によってできた配列をCROSS JOIN UNNESTで結合することで、元の行に分割した配列の値 n 個がそれぞれJOINされた n 行の結果が得られます。
CROSS JOINといえばレコード数が膨れ上がるイメージがありますが、このクエリではUNNESTの効果で長さ n の配列に対応する 1 行ごとに結合しています。ケース3: コンマ区切りの複数カラムの行展開
ケース2と似た内容ですが、以下のようにコンマ区切りの同じ長さの配列が複数個所にあるログがありました。
{..., "item_ids": "1,2,5", "item_amounts": "12,25,125"}このような場合も、配列の結合部分を以下のようなクエリにすることで、複数配列の対応するインデックスを同じ行に展開できます。
CROSS JOIN UNNEST ( MAP( TRANSFORM(SPLIT(item_ids, ","), v -> CAST(v AS INTEGER)), TRANSFORM(SPLIT(item_amounts, ","), v -> CAST(v AS INTEGER)) ) ) AS tmp_table_name (item_id, item_amount)元の行にcsvの値 n 個がそれぞれJOINされた n 行の結果が得られます。
このクエリで出てきた
MAPやTRANSFORM関数は、Pythonでいうところのzipmapにあたる関数です。
ケース2では触れませんでしたが、SPLITの結果は文字列の配列なので、数字として扱いたい場合などはTRANSFORM関数とラムダ関数の組み合わせで各値をCASTさせることができます。まとめ・感想
思いのほか普通のプログラミング言語のような関数が使えることにびっくりしました。
記事の後ろのほうに関数の一覧ページへのリンクを貼っていますが、数値,文字列,配列などに関する基本的な関数は実装されているようです。普段からデータ分析などをやっている人は知っているようなのですが、自分のようにアプリのサーバーロジックで MySQL を使って生きている普通のサーバーマンだとあまり知らない内容なのではないかと思います。
調査のタスクなどをやる際には簡単にスクリプトを書いたりして作業を進めていたのですが、こういった関数を使えばクエリを投げるだけで完結するタスクが増えそうです。
今後、自分に集計などのタスクが振られたときは「それってクエリ投げるだけで完結できないかな?」と考えるようにするつもりです。補足
Athena に焦点を当てた記事になっていますが、同様の関数が実装されているDBやサービスでもできるはずなので、ログの保存先がS3ではない場合でも同じようなことができるサービスがあるか調べるのが良さそうです。
参考
Amazon Athena の Presto 関数
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/functions-operators-reference-section.htmlおまけ
「集計処理をクエリだけで終わらせたいけど、大きなテーブルどうしのJOINみたいな重そうなのを投げるのは無理かな?」と思っていましたが、そういった重いクエリが投げられるのもこういったサービスの利点だという話をちらっと聞いたので、やってみました。
→ Athenaで億単位のレコード数のテーブル同士をJOINしてみる
- 投稿日:2019-12-04T18:53:44+09:00
Google AnalyticsのデータをAWSのs3に保存しQuickSightに可視化
概要
Google AnalyticsのデータをS3に保存して、athenaに取り込んみQuickSightで可視化してみました
構成
Lambda
LambdaでBigQueryからデータの取得しS3にアップロードする。
実際にはBigQueryから直接ダウンロードできないので、一旦Google StorageにBigQueryのダンプファイルを落とす感じになりますBigQueryのデータをダンプしてストレージ保存する
client = bigquery.Client( credentials=credentials, project=credentials.project_id, ) project = credentials.project_id dataset_ref = client.dataset(dataset_id, project=project) table_ref = dataset_ref.table(table_id) ext_job_config = bigquery.job.ExtractJobConfig() ext_job_config.destination_format = bigquery.job.DestinationFormat.NEWLINE_DELIMITED_JSON ext_job_config.compression = bigquery.Compression.GZIP extract_job = client.extract_table( table_ref, destination_uri.format(gcp_bucket_name, target_day, file_name), location='US', job_config=ext_job_config ) extract_job.result()Glue
クローラーを設定する
設定内容はほぼデフォルトのですが「クローラの出力を設定する」の項目以下を設定
- 「設定オプション」で「新規列のみ追加します。」を選択
- 「全ての新規および既存のパーティション〜」にチェックをつける
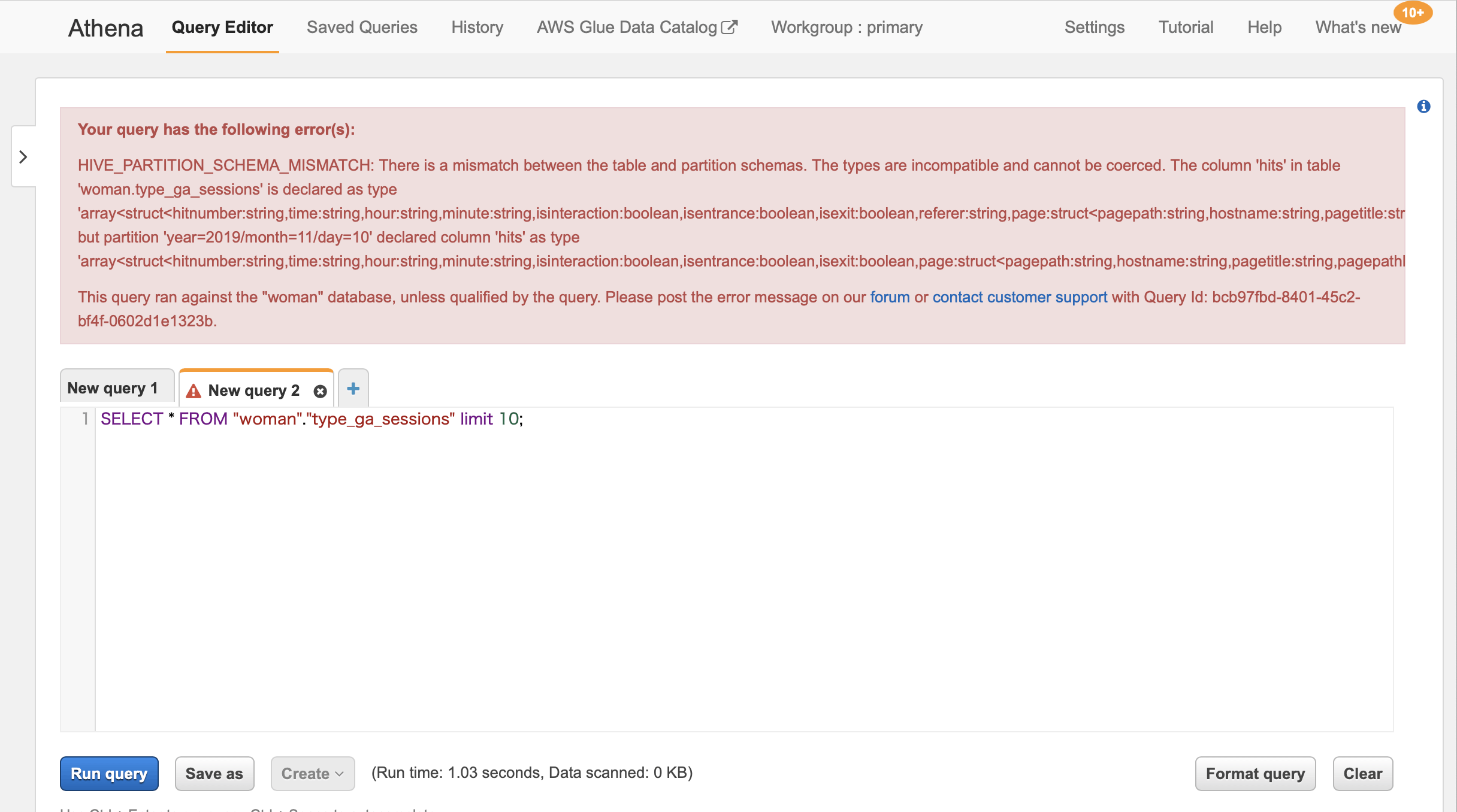
この設定をしないとAthenaでSQLを実行した際に下記の様なエラーメッセージができる
Your query has the following error(s):
HIVE_PARTITION_SCHEMA_MISMATCH: There is a mismatch between the table and partition schemas.
Athena
Glueでクロールが完了するとAthena側でSQLを実行してみる、以下の様に結果が表示されればOK
ちょっと一手間、Athenaに取り込んだデータのカラムが複合型なので、Viewを作りQuickSightで取り出しやすい形にしておきますAthena sqlCREATE OR REPLACE VIEW ga_pageviews AS SELECT "date" , "count"("totals"."pageviews") "pageviews" FROM woman.type_ga_sessions CROSS JOIN UNNEST("hits") t (hit) WHERE ("hit"."type" = 'PAGE') GROUP BY "date"QuickSight
可視化のためQuickSightを使って可視化を行います
注意点
analyticsは360が対象です、360出ない場合はAPIで取得してS3にアップします(制限あり)
Athenaに取り込んだデータの型がstringなので、Glueのジョブで前処理をするか、QuickSigthの方でcastする必要がありますまとめ
開発工数は1〜2人日、すごく手軽にできます。
費用面もbigqueryよりathenaの方が安いように感じます
サービス内で持っているコンテンツの情報も取り込んで、analyticsの情報とかけ合わせると面白い分析が出来ると思いました。



- 投稿日:2019-12-04T18:42:56+09:00
AWS Labs製のPlantUMLライブラリ『AWS Icons for PlantUML』の使い方
はじめに
株式会社オークファンでインフラを担当している近江です。
オークファングループ Advent Calendar 2019 16日目 はじめます!弊社はインフラ環境として AWS を使用しています。
構成図のツールでは PlantUML を採用しており、
インフラチーム全体が構成図をコードで管理出来るようにしております。今回は AWS の構成図を PlantUML で描く際に使用している『AWS Icons for PlantUML』について
ご紹介したいと思います。なお PlantUML そのものについては色々記事が出ていると思いますので割愛させていただきます。
『AWS Icons for PlantUML』って?
PlantUML で AWS の構成図を作成するツールといえば標準ライブラリとして提供されている
AWS-PlantUMLが有名かと思います。
- PlantUML Standard Library
- milo-minderbinder/AWS-PlantUML: PlantUML sprites, macros, and other includes for AWS components.
こちらのツールもアイコンが見やすくていいのですが、今回ご紹介するのは
AWS が提供しているAWS Labs製ツールの『AWS Icons for PlantUML』になります。2019年5月に公開されたようですね。
AWS-PlantUMLやAzure-PlantUMLを元に作られたようです。使い方(コンポーネント図)
1. github の URL を
AWSPumlとして定義する@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist @enduml公式ドキュメント通りに
AWSPumlとして定義しました。2.
commonを読み込む@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml @endumldist以下 の
AWSCommon.pumlを読み込みました。
common は必ず include する必要があるので注意が必要です。3. 使いたいアイコンを読み込む
使いたいAWSのアイコンを
includeurlで指定していきます。
例としてS3のアイコンを include してみます。サービスを個別で include する場合
@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !incude AWSPuml/Storage/AmazonSimpleStorageServiceS3.puml @endumldist以下 に定義されている
.pumlファイルを includeします。
!incude AWSPuml/Storage/AmazonSimpleStorageServiceS3.pumlこれでストレージ系サービスの
AmazonSimpleStorageServiceS3が使えるようになります。サービスをまとめて include する場合
@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !incude AWSPuml/Storage/all.puml @endumldist以下 に定義されている
all.pumlファイルを includeします。
!incude AWSPuml/Storage/all.pumlこれでストレージ系サービス全てが使えるようになり、
AmazonSimpleStorageServiceS3も同時に include されているため使えるようになります。4. コンポーネントを定義する
実際にアイコンを使ってみます。
サービスを個別で include する場合
@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !includeurl AWSPuml/Storage/SimpleStorageServiceS3.puml SimpleStorageServiceS3(storageAlias, "Label", "Technology", "Optional Description") @enduml
"Optional Description"は省略可能です。サービスをまとめて include する場合
@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !includeurl AWSPuml/Storage/all.puml SimpleStorageServiceS3(storageAlias, "Label", "Technology", "Optional Description") @enduml結果
S3 のバケットを出すことが出来ました。
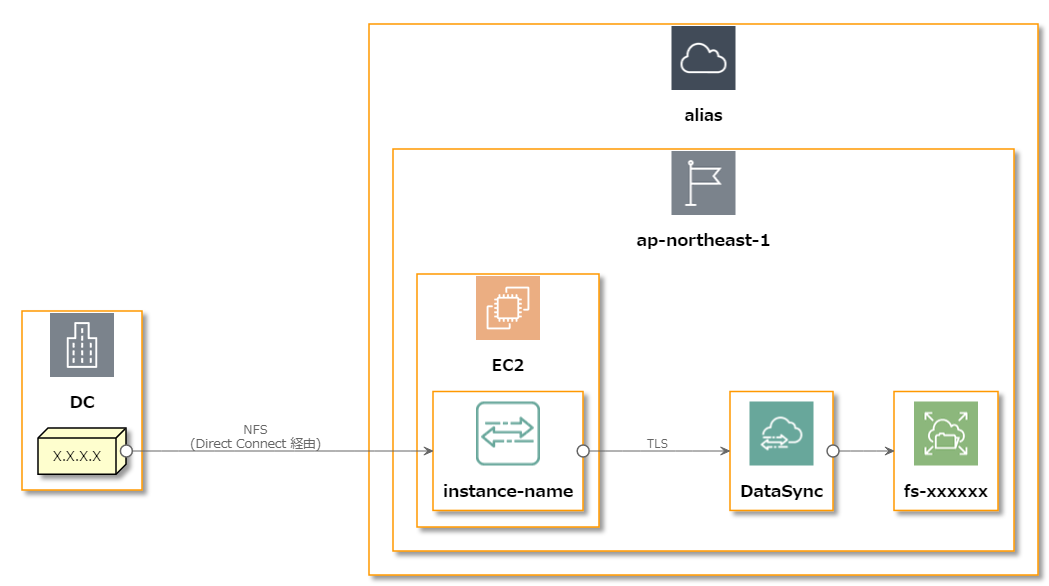
以前、DataSyncを使った際に書いた図だと以下のようになります。
@startuml left to right direction !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !includeurl AWSPuml/GroupIcons/Cloud.puml !includeurl AWSPuml/GroupIcons/CorporateDataCenter.puml !includeurl AWSPuml/Compute/EC2.puml !includeurl AWSPuml/Storage/EFSFilesystem.puml !includeurl AWSPuml/Storage/ElasticFileSystemEFS.puml !includeurl AWSPuml/MigrationAndTransfer/DataSync.puml !includeurl AWSPuml/MigrationAndTransfer/DataSyncAgent.puml !includeurl AWSPuml/GroupIcons/Region.puml CorporateDataCenter(dc,DC,"データセンター") { node "X.X.X.X" <<サーバー>> as server } Cloud(aws,alias,AWSアカウント) { Region(region,ap-northeast-1,"東京リージョン") { EC2(ec2,EC2,インスタンス) { DataSyncAgent(dsa,instance-name,データ転送インスタンス,m5.2xlarge) } DataSync(ds,DataSync,データのSyncを行う) ElasticFileSystemEFS(efs,"fs-xxxxxx","EFSファイルシステム") } } server 0---> dsa : NFS\n(Direct Connect 経由) dsa 0---> ds : TLS ds 0--> efs @enduml
left to right directionと組み合わせると左から右へ生成されるため、
このような図の場合は見やすくなることが多いです。5. 簡略化した出力にする
!includeurl AWSPuml/AWSSimplified.pumlを書くことで説明と枠が簡略化され、
シンプルな見た目にすることが可能です。@startuml !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml ' ↓追加 !includeurl AWSPuml/AWSSimplified.puml !includeurl AWSPuml/Storage/all.puml SimpleStorageServiceS3(storageAlias, "Label", "Technology", "Optional Description") @enduml
!includeurl AWSPuml/AWSSimplified.puml書く位置によって見た目が変わるので注意が必要です。
公式のREADMEでは!includeurl AWSPuml/AWSCommon.pumlの下に書いているようです。
先程の DataSync の図にそのまま適用させてみました。
@startuml left to right direction !define AWSPuml https://raw.githubusercontent.com/awslabs/aws-icons-for-plantuml/master/dist !includeurl AWSPuml/AWSCommon.puml !includeurl AWSPuml/AWSSimplified.puml !includeurl AWSPuml/GroupIcons/Cloud.puml !includeurl AWSPuml/GroupIcons/CorporateDataCenter.puml !includeurl AWSPuml/Compute/EC2.puml !includeurl AWSPuml/Storage/EFSFilesystem.puml !includeurl AWSPuml/Storage/ElasticFileSystemEFS.puml !includeurl AWSPuml/MigrationAndTransfer/DataSync.puml !includeurl AWSPuml/MigrationAndTransfer/DataSyncAgent.puml !includeurl AWSPuml/GroupIcons/Region.puml CorporateDataCenter(dc,DC,"データセンター") { node "X.X.X.X" <<サーバー>> as server } Cloud(aws,alias,AWSアカウント) { Region(region,ap-northeast-1,"東京リージョン") { EC2(ec2,EC2,インスタンス) { DataSyncAgent(dsa,instance-name,データ転送インスタンス,m5.2xlarge) } DataSync(ds,DataSync,データのSyncを行う) ElasticFileSystemEFS(efs,"fs-xxxxxx","EFSファイルシステム") } } server 0---> dsa : NFS\n(Direct Connect 経由) dsa 0---> ds : TLS ds 0--> efs @enduml
AWS-PlantUMLに比べてAWS Icons for PlantUMLは書く箇所が多くなるのが
デメリットだったのですが、この!includeurl AWSPuml/AWSSimplified.pumlを
追加することで省略出来るので便利ですね。まとめ
今回紹介したコンポーネント図以外にもシーケンス図にも対応したようなので、
どんどん使えるツールになってきています。
AWS-PlantUMLを使っている方は乗り換えを検討してみてはいかがでしょうか?(おまけ) include 出来るものまとめ
リポジトリから引っこ抜きました。2019/12/04 時点のものです。
最新は github から探してください。
また全てincludeするとサーバーにすごい負荷がかかるようなので
注意してください。サービスを個別で include する場合
!includeurl AWSPuml/Analytics/Analytics.puml !includeurl AWSPuml/Analytics/Athena.puml !includeurl AWSPuml/Analytics/CloudSearch.puml !includeurl AWSPuml/Analytics/CloudSearchSearchDocuments.puml !includeurl AWSPuml/Analytics/DatalakeResourceIcon.puml !includeurl AWSPuml/Analytics/DataPipeline.puml !includeurl AWSPuml/Analytics/DenseComputeNodeResource.puml !includeurl AWSPuml/Analytics/DenseStorageNodeResource.puml !includeurl AWSPuml/Analytics/ElasticsearchService.puml !includeurl AWSPuml/Analytics/EMR.puml !includeurl AWSPuml/Analytics/EMRCluster.puml !includeurl AWSPuml/Analytics/EMREngine.puml !includeurl AWSPuml/Analytics/EMREngineMapRM3.puml !includeurl AWSPuml/Analytics/EMREngineMapRM5.puml !includeurl AWSPuml/Analytics/EMREngineMapRM7.puml !includeurl AWSPuml/Analytics/EMRHDFSCluster.puml !includeurl AWSPuml/Analytics/Glue.puml !includeurl AWSPuml/Analytics/GlueCrawlers.puml !includeurl AWSPuml/Analytics/GlueDataCatalog.puml !includeurl AWSPuml/Analytics/Kinesis.puml !includeurl AWSPuml/Analytics/KinesisDataAnalytics.puml !includeurl AWSPuml/Analytics/KinesisDataFirehose.puml !includeurl AWSPuml/Analytics/KinesisDataStreams.puml !includeurl AWSPuml/Analytics/KinesisVideoStreams.puml !includeurl AWSPuml/Analytics/LakeFormation.puml !includeurl AWSPuml/Analytics/ManagedStreamingforKafka.puml !includeurl AWSPuml/Analytics/QuickSight.puml !includeurl AWSPuml/Analytics/Redshift.puml !includeurl AWSPuml/ApplicationIntegration/ApplicationIntegration.puml !includeurl AWSPuml/ApplicationIntegration/AppSync.puml !includeurl AWSPuml/ApplicationIntegration/EventBridge.puml !includeurl AWSPuml/ApplicationIntegration/MQ.puml !includeurl AWSPuml/ApplicationIntegration/SNS.puml !includeurl AWSPuml/ApplicationIntegration/SNSEmailNotification.puml !includeurl AWSPuml/ApplicationIntegration/SNSHTTPNotification.puml !includeurl AWSPuml/ApplicationIntegration/SNSTopic.puml !includeurl AWSPuml/ApplicationIntegration/SQS.puml !includeurl AWSPuml/ApplicationIntegration/SQSMessage.puml !includeurl AWSPuml/ApplicationIntegration/SQSQueue.puml !includeurl AWSPuml/ApplicationIntegration/StepFunctions.puml !includeurl AWSPuml/ARVR/ARVR.puml !includeurl AWSPuml/ARVR/Sumerian.puml !includeurl AWSPuml/AWSC4Integration.puml !includeurl AWSPuml/AWSCommon.puml !includeurl AWSPuml/AWSCostManagement/Budgets.puml !includeurl AWSPuml/AWSCostManagement/CostandUsageReport.puml !includeurl AWSPuml/AWSCostManagement/CostExplorer.puml !includeurl AWSPuml/AWSCostManagement/CostManagement.puml !includeurl AWSPuml/AWSCostManagement/ReservedInstanceReporting.puml !includeurl AWSPuml/AWSRaw.puml !includeurl AWSPuml/AWSSimplified.puml !includeurl AWSPuml/Blockchain/Blockchain.puml !includeurl AWSPuml/Blockchain/ManagedBlockchain.puml !includeurl AWSPuml/Blockchain/QuantumLedgerDatabaseQLDB.puml !includeurl AWSPuml/BusinessApplications/AlexaForBusiness.puml !includeurl AWSPuml/BusinessApplications/BusinessApplications.puml !includeurl AWSPuml/BusinessApplications/Chime.puml !includeurl AWSPuml/BusinessApplications/WorkMail.puml !includeurl AWSPuml/Compute/Batch.puml !includeurl AWSPuml/Compute/Compute.puml !includeurl AWSPuml/Compute/EC2.puml !includeurl AWSPuml/Compute/EC2A1Instance.puml !includeurl AWSPuml/Compute/EC2AMI.puml !includeurl AWSPuml/Compute/EC2AutoScaling.puml !includeurl AWSPuml/Compute/EC2AutoScalingResource.puml !includeurl AWSPuml/Compute/EC2C4Instance.puml !includeurl AWSPuml/Compute/EC2C5Instance.puml !includeurl AWSPuml/Compute/EC2C5nInstance.puml !includeurl AWSPuml/Compute/EC2ContainerRegistry.puml !includeurl AWSPuml/Compute/EC2ContainerRegistryImage.puml !includeurl AWSPuml/Compute/EC2ContainerRegistryResource.puml !includeurl AWSPuml/Compute/EC2D2Instance.puml !includeurl AWSPuml/Compute/EC2DBonInstance.puml !includeurl AWSPuml/Compute/EC2ElasticIPAddress.puml !includeurl AWSPuml/Compute/EC2F1Instance.puml !includeurl AWSPuml/Compute/EC2G3Instance.puml !includeurl AWSPuml/Compute/EC2H1Instance.puml !includeurl AWSPuml/Compute/EC2HighMemoryInstance.puml !includeurl AWSPuml/Compute/EC2I3Instance.puml !includeurl AWSPuml/Compute/EC2Instance.puml !includeurl AWSPuml/Compute/EC2Instances.puml !includeurl AWSPuml/Compute/EC2InstancewithCloudWatch.puml !includeurl AWSPuml/Compute/EC2M4Instance.puml !includeurl AWSPuml/Compute/EC2M5aInstance.puml !includeurl AWSPuml/Compute/EC2M5Instance.puml !includeurl AWSPuml/Compute/EC2OptimizedInstance.puml !includeurl AWSPuml/Compute/EC2P2Instance.puml !includeurl AWSPuml/Compute/EC2P3Instance.puml !includeurl AWSPuml/Compute/EC2R4Instance.puml !includeurl AWSPuml/Compute/EC2R5aInstance.puml !includeurl AWSPuml/Compute/EC2R5Instance.puml !includeurl AWSPuml/Compute/EC2Rescue.puml !includeurl AWSPuml/Compute/EC2SpotInstance.puml !includeurl AWSPuml/Compute/EC2T2Instance.puml !includeurl AWSPuml/Compute/EC2T3aInstance.puml !includeurl AWSPuml/Compute/EC2T3Instance.puml !includeurl AWSPuml/Compute/EC2X1eInstance.puml !includeurl AWSPuml/Compute/EC2X1Instance.puml !includeurl AWSPuml/Compute/EC2z1dInstance.puml !includeurl AWSPuml/Compute/ECSContainer1.puml !includeurl AWSPuml/Compute/ECSContainer2.puml !includeurl AWSPuml/Compute/ECSContainer3.puml !includeurl AWSPuml/Compute/ECSService.puml !includeurl AWSPuml/Compute/ElasticBeanstalk.puml !includeurl AWSPuml/Compute/ElasticBeanstalkApplication.puml !includeurl AWSPuml/Compute/ElasticBeanstalkDeployment.puml !includeurl AWSPuml/Compute/ElasticContainerService.puml !includeurl AWSPuml/Compute/ElasticKubernetesService.puml !includeurl AWSPuml/Compute/Fargate.puml !includeurl AWSPuml/Compute/Lambda.puml !includeurl AWSPuml/Compute/LambdaLambdaFunction.puml !includeurl AWSPuml/Compute/Lightsail.puml !includeurl AWSPuml/Compute/Outposts.puml !includeurl AWSPuml/Compute/ServerlessApplicationRepository.puml !includeurl AWSPuml/Compute/ThinkboxDeadline.puml !includeurl AWSPuml/Compute/ThinkboxDraft.puml !includeurl AWSPuml/Compute/ThinkboxFrost.puml !includeurl AWSPuml/Compute/ThinkboxKrakatoa.puml !includeurl AWSPuml/Compute/ThinkboxSequoia.puml !includeurl AWSPuml/Compute/ThinkboxStoke.puml !includeurl AWSPuml/Compute/ThinkboxXMesh.puml !includeurl AWSPuml/Compute/VMwareCloudOnAWS.puml !includeurl AWSPuml/CustomerEngagement/Connect.puml !includeurl AWSPuml/CustomerEngagement/CustomerEngagement.puml !includeurl AWSPuml/CustomerEngagement/Pinpoint.puml !includeurl AWSPuml/CustomerEngagement/SESEmail.puml !includeurl AWSPuml/CustomerEngagement/SimpleEmailServiceSES.puml !includeurl AWSPuml/Database/Aurora.puml !includeurl AWSPuml/Database/Database.puml !includeurl AWSPuml/Database/DatabaseMigrationService.puml !includeurl AWSPuml/Database/DenseComputeNodeResource2.puml !includeurl AWSPuml/Database/DenseStorageNodeResource2.puml !includeurl AWSPuml/Database/DMSDatabaseMigrationWorkflow.puml !includeurl AWSPuml/Database/DocumentDBwithMongoDBcompatibility.puml !includeurl AWSPuml/Database/DynamoDB.puml !includeurl AWSPuml/Database/DynamoDBAttribute.puml !includeurl AWSPuml/Database/DynamoDBAttributes.puml !includeurl AWSPuml/Database/DynamoDBGSI.puml !includeurl AWSPuml/Database/DynamoDBItem.puml !includeurl AWSPuml/Database/DynamoDBItems.puml !includeurl AWSPuml/Database/DynamoDBTable.puml !includeurl AWSPuml/Database/ElastiCache.puml !includeurl AWSPuml/Database/ElastiCacheCacheNode.puml !includeurl AWSPuml/Database/ElastiCacheForMemcached.puml !includeurl AWSPuml/Database/ElastiCacheForRedis.puml !includeurl AWSPuml/Database/Neptune.puml !includeurl AWSPuml/Database/QLDB.puml !includeurl AWSPuml/Database/RDS.puml !includeurl AWSPuml/Database/RDSAmazonAurorainstance.puml !includeurl AWSPuml/Database/RDSAmazonAurorainstancealt.puml !includeurl AWSPuml/Database/RDSAmazonRDSinstance.puml !includeurl AWSPuml/Database/RDSAmazonRDSinstancealt.puml !includeurl AWSPuml/Database/RDSMariaDBinstance.puml !includeurl AWSPuml/Database/RDSMariaDBinstancealt.puml !includeurl AWSPuml/Database/RDSMySQLinstance.puml !includeurl AWSPuml/Database/RDSMySQLinstancealt.puml !includeurl AWSPuml/Database/RDSonVMware.puml !includeurl AWSPuml/Database/RDSOracleinstance.puml !includeurl AWSPuml/Database/RDSOracleinstancealt.puml !includeurl AWSPuml/Database/RDSPIOP.puml !includeurl AWSPuml/Database/RDSPostgreSQLinstance.puml !includeurl AWSPuml/Database/RDSPostgreSQLinstancealt.puml !includeurl AWSPuml/Database/RDSSQLServerinstance.puml !includeurl AWSPuml/Database/RDSSQLServerinstancealt.puml !includeurl AWSPuml/Database/Timestream.puml !includeurl AWSPuml/DeveloperTools/Cloud9.puml !includeurl AWSPuml/DeveloperTools/CloudDevelopmentKit.puml !includeurl AWSPuml/DeveloperTools/CodeBuild.puml !includeurl AWSPuml/DeveloperTools/CodeCommit.puml !includeurl AWSPuml/DeveloperTools/CodeDeploy.puml !includeurl AWSPuml/DeveloperTools/CodePipeline.puml !includeurl AWSPuml/DeveloperTools/CodeStar.puml !includeurl AWSPuml/DeveloperTools/CommandLineInterface.puml !includeurl AWSPuml/DeveloperTools/DeveloperTools.puml !includeurl AWSPuml/DeveloperTools/ToolsAndSDKs.puml !includeurl AWSPuml/DeveloperTools/XRay.puml !includeurl AWSPuml/EndUserComputing/Appstream2.0.puml !includeurl AWSPuml/EndUserComputing/EndUserComputing.puml !includeurl AWSPuml/EndUserComputing/WorkDocs.puml !includeurl AWSPuml/EndUserComputing/WorkLink.puml !includeurl AWSPuml/EndUserComputing/Workspaces.puml !includeurl AWSPuml/GameTech/GameLift.puml !includeurl AWSPuml/GameTech/GameTech.puml !includeurl AWSPuml/General/Client.puml !includeurl AWSPuml/General/Disk.puml !includeurl AWSPuml/General/Forums.puml !includeurl AWSPuml/General/General.puml !includeurl AWSPuml/General/GenericDatabase.puml !includeurl AWSPuml/General/InternetAlt1.puml !includeurl AWSPuml/General/InternetAlt2.puml !includeurl AWSPuml/General/InternetGateway.puml !includeurl AWSPuml/General/Marketplace.puml !includeurl AWSPuml/General/MobileClient.puml !includeurl AWSPuml/General/Multimedia.puml !includeurl AWSPuml/General/OfficeBuilding.puml !includeurl AWSPuml/General/SAMLToken.puml !includeurl AWSPuml/General/SDK.puml !includeurl AWSPuml/General/SSLPadlock.puml !includeurl AWSPuml/General/TapeStorage.puml !includeurl AWSPuml/General/Toolkit.puml !includeurl AWSPuml/General/TraditionalServer.puml !includeurl AWSPuml/General/User.puml !includeurl AWSPuml/General/Users.puml !includeurl AWSPuml/GroupIcons/AutoScalingGroup.puml !includeurl AWSPuml/GroupIcons/Cloud.puml !includeurl AWSPuml/GroupIcons/Cloudalt.puml !includeurl AWSPuml/GroupIcons/CorporateDataCenter.puml !includeurl AWSPuml/GroupIcons/ElasticBeanstalkContainer.puml !includeurl AWSPuml/GroupIcons/Region.puml !includeurl AWSPuml/GroupIcons/ServerContents.puml !includeurl AWSPuml/GroupIcons/SpotFleet.puml !includeurl AWSPuml/GroupIcons/StepFunction.puml !includeurl AWSPuml/GroupIcons/VirtualPrivateCloudVPC.puml !includeurl AWSPuml/GroupIcons/VPCSubnetPrivate.puml !includeurl AWSPuml/GroupIcons/VPCSubnetPublic.puml !includeurl AWSPuml/InternetOfThings/FreeRTOS.puml !includeurl AWSPuml/InternetOfThings/InternetofThings.puml !includeurl AWSPuml/InternetOfThings/IoT1Click.puml !includeurl AWSPuml/InternetOfThings/IoTAction.puml !includeurl AWSPuml/InternetOfThings/IoTActuator.puml !includeurl AWSPuml/InternetOfThings/IoTAlexaEnabledDevice.puml !includeurl AWSPuml/InternetOfThings/IoTAlexaSkill.puml !includeurl AWSPuml/InternetOfThings/IoTAlexaVoiceService.puml !includeurl AWSPuml/InternetOfThings/IoTAnalytics.puml !includeurl AWSPuml/InternetOfThings/IoTAnalyticsChannel.puml !includeurl AWSPuml/InternetOfThings/IoTAnalyticsDataSet.puml !includeurl AWSPuml/InternetOfThings/IoTAnalyticsDataStore.puml !includeurl AWSPuml/InternetOfThings/IoTAnalyticsNotebook.puml !includeurl AWSPuml/InternetOfThings/IoTAnalyticsPipeline.puml !includeurl AWSPuml/InternetOfThings/IoTBank.puml !includeurl AWSPuml/InternetOfThings/IoTBicycle.puml !includeurl AWSPuml/InternetOfThings/IoTButton.puml !includeurl AWSPuml/InternetOfThings/IoTCamera.puml !includeurl AWSPuml/InternetOfThings/IoTCar.puml !includeurl AWSPuml/InternetOfThings/IoTCart.puml !includeurl AWSPuml/InternetOfThings/IoTCertificateManager.puml !includeurl AWSPuml/InternetOfThings/IoTCoffeePot.puml !includeurl AWSPuml/InternetOfThings/IoTCore.puml !includeurl AWSPuml/InternetOfThings/IoTDesiredState.puml !includeurl AWSPuml/InternetOfThings/IoTDeviceDefender.puml !includeurl AWSPuml/InternetOfThings/IoTDeviceGateway.puml !includeurl AWSPuml/InternetOfThings/IoTDeviceManagement.puml !includeurl AWSPuml/InternetOfThings/IoTDoorLock.puml !includeurl AWSPuml/InternetOfThings/IoTEcho.puml !includeurl AWSPuml/InternetOfThings/IoTEvents.puml !includeurl AWSPuml/InternetOfThings/IoTFactory.puml !includeurl AWSPuml/InternetOfThings/IoTFireTV.puml !includeurl AWSPuml/InternetOfThings/IoTFireTVStick.puml !includeurl AWSPuml/InternetOfThings/IoTGeneric.puml !includeurl AWSPuml/InternetOfThings/IoTGreengrass.puml !includeurl AWSPuml/InternetOfThings/IoTGreengrassConnector.puml !includeurl AWSPuml/InternetOfThings/IoTHardwareBoard.puml !includeurl AWSPuml/InternetOfThings/IoTHouse.puml !includeurl AWSPuml/InternetOfThings/IoTHTTP2Protocol.puml !includeurl AWSPuml/InternetOfThings/IoTHTTPProtocol.puml !includeurl AWSPuml/InternetOfThings/IoTLambdaFunction.puml !includeurl AWSPuml/InternetOfThings/IoTLightbulb.puml !includeurl AWSPuml/InternetOfThings/IoTMedicalEmergency.puml !includeurl AWSPuml/InternetOfThings/IoTMQTTProtocol.puml !includeurl AWSPuml/InternetOfThings/IoTOverTheAirUpdate.puml !includeurl AWSPuml/InternetOfThings/IoTPoliceEmergency.puml !includeurl AWSPuml/InternetOfThings/IoTPolicy.puml !includeurl AWSPuml/InternetOfThings/IoTReportedState.puml !includeurl AWSPuml/InternetOfThings/IoTRule.puml !includeurl AWSPuml/InternetOfThings/IoTSensor.puml !includeurl AWSPuml/InternetOfThings/IoTServo.puml !includeurl AWSPuml/InternetOfThings/IoTShadow.puml !includeurl AWSPuml/InternetOfThings/IoTSimulator.puml !includeurl AWSPuml/InternetOfThings/IoTSiteWise.puml !includeurl AWSPuml/InternetOfThings/IoTThermostat.puml !includeurl AWSPuml/InternetOfThings/IoTThingsGraph.puml !includeurl AWSPuml/InternetOfThings/IoTTopic.puml !includeurl AWSPuml/InternetOfThings/IoTTravel.puml !includeurl AWSPuml/InternetOfThings/IoTUtility.puml !includeurl AWSPuml/InternetOfThings/IoTWindfarm.puml !includeurl AWSPuml/MachineLearning/ApacheMXNetonAWS.puml !includeurl AWSPuml/MachineLearning/Comprehend.puml !includeurl AWSPuml/MachineLearning/DeepLearningAMIs.puml !includeurl AWSPuml/MachineLearning/DeepLearningContainers.puml !includeurl AWSPuml/MachineLearning/DeepLens.puml !includeurl AWSPuml/MachineLearning/DeepRacer.puml !includeurl AWSPuml/MachineLearning/ElasticInference.puml !includeurl AWSPuml/MachineLearning/Forecast.puml !includeurl AWSPuml/MachineLearning/Lex.puml !includeurl AWSPuml/MachineLearning/MachineLearning.puml !includeurl AWSPuml/MachineLearning/Personalize.puml !includeurl AWSPuml/MachineLearning/Polly.puml !includeurl AWSPuml/MachineLearning/Rekognition.puml !includeurl AWSPuml/MachineLearning/RekognitionImage.puml !includeurl AWSPuml/MachineLearning/RekognitionVideo.puml !includeurl AWSPuml/MachineLearning/SageMaker.puml !includeurl AWSPuml/MachineLearning/SageMakerGroundTruth.puml !includeurl AWSPuml/MachineLearning/SageMakerModel.puml !includeurl AWSPuml/MachineLearning/SageMakerNotebook.puml !includeurl AWSPuml/MachineLearning/SageMakerTrain.puml !includeurl AWSPuml/MachineLearning/TensorFlowonAWS.puml !includeurl AWSPuml/MachineLearning/Textract.puml !includeurl AWSPuml/MachineLearning/Transcribe.puml !includeurl AWSPuml/MachineLearning/Translate.puml !includeurl AWSPuml/ManagementAndGovernance/AutoScaling.puml !includeurl AWSPuml/ManagementAndGovernance/CloudFormation.puml !includeurl AWSPuml/ManagementAndGovernance/CloudFormationChangeSet.puml !includeurl AWSPuml/ManagementAndGovernance/CloudFormationStack.puml !includeurl AWSPuml/ManagementAndGovernance/CloudFormationTemplate.puml !includeurl AWSPuml/ManagementAndGovernance/CloudTrail.puml !includeurl AWSPuml/ManagementAndGovernance/CloudWatch.puml !includeurl AWSPuml/ManagementAndGovernance/CloudWatchAlarm.puml !includeurl AWSPuml/ManagementAndGovernance/CloudWatchEventEventBased.puml !includeurl AWSPuml/ManagementAndGovernance/CloudWatchEventTimeBased.puml !includeurl AWSPuml/ManagementAndGovernance/CloudWatchRule.puml !includeurl AWSPuml/ManagementAndGovernance/Config.puml !includeurl AWSPuml/ManagementAndGovernance/ControlTower.puml !includeurl AWSPuml/ManagementAndGovernance/LicenseManager.puml !includeurl AWSPuml/ManagementAndGovernance/ManagedServices.puml !includeurl AWSPuml/ManagementAndGovernance/ManagementandGovernance.puml !includeurl AWSPuml/ManagementAndGovernance/ManagementConsole.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorks.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksApps.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksDeployments.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksInstances.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksLayers.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksMonitoring.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksPermissions.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksResources.puml !includeurl AWSPuml/ManagementAndGovernance/OpsWorksStack2.puml !includeurl AWSPuml/ManagementAndGovernance/Organizations.puml !includeurl AWSPuml/ManagementAndGovernance/OrganizationsAccount.puml !includeurl AWSPuml/ManagementAndGovernance/OrganizationsOrganizationalunit.puml !includeurl AWSPuml/ManagementAndGovernance/PersonalHealthDashboard.puml !includeurl AWSPuml/ManagementAndGovernance/ServiceCatalog.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManager.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerAutomation.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerDocuments.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerInventory.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerMaintWindows.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerOpsCenter.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerParameterStore.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerPatchManager.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerRunCommand.puml !includeurl AWSPuml/ManagementAndGovernance/SystemsManagerStateManager.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisor.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisorCheckCost.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisorCheckFaultTolerant.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisorChecklist.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisorCheckPerformance.puml !includeurl AWSPuml/ManagementAndGovernance/TrustedAdvisorCheckSecurity.puml !includeurl AWSPuml/ManagementAndGovernance/WellArchitectedTool.puml !includeurl AWSPuml/MediaServices/ElasticTranscoder.puml !includeurl AWSPuml/MediaServices/ElementalMediaConnect.puml !includeurl AWSPuml/MediaServices/ElementalMediaConvert.puml !includeurl AWSPuml/MediaServices/ElementalMediaLive.puml !includeurl AWSPuml/MediaServices/ElementalMediaPackage.puml !includeurl AWSPuml/MediaServices/ElementalMediaStore.puml !includeurl AWSPuml/MediaServices/ElementalMediaTailor.puml !includeurl AWSPuml/MediaServices/MediaServices.puml !includeurl AWSPuml/MigrationAndTransfer/ApplicationDiscoveryService.puml !includeurl AWSPuml/MigrationAndTransfer/DataSync.puml !includeurl AWSPuml/MigrationAndTransfer/DataSyncAgent.puml !includeurl AWSPuml/MigrationAndTransfer/MigrationandTransfer.puml !includeurl AWSPuml/MigrationAndTransfer/MigrationHub.puml !includeurl AWSPuml/MigrationAndTransfer/ServerMigrationService.puml !includeurl AWSPuml/MigrationAndTransfer/Snowmobile.puml !includeurl AWSPuml/MigrationAndTransfer/TransferforSFTP.puml !includeurl AWSPuml/Mobile/Amplify.puml !includeurl AWSPuml/Mobile/APIGateway.puml !includeurl AWSPuml/Mobile/APIGatewayEndpoint.puml !includeurl AWSPuml/Mobile/AppSync2.puml !includeurl AWSPuml/Mobile/DeviceFarm.puml !includeurl AWSPuml/Mobile/Mobile.puml !includeurl AWSPuml/NetworkingAndContentDelivery/AppMesh.puml !includeurl AWSPuml/NetworkingAndContentDelivery/ClassicLoadBalancer.puml !includeurl AWSPuml/NetworkingAndContentDelivery/ClientVPN.puml !includeurl AWSPuml/NetworkingAndContentDelivery/CloudFront.puml !includeurl AWSPuml/NetworkingAndContentDelivery/CloudFrontDownloadDistribution.puml !includeurl AWSPuml/NetworkingAndContentDelivery/CloudFrontEdgeLocation.puml !includeurl AWSPuml/NetworkingAndContentDelivery/CloudFrontStreamingDistribution.puml !includeurl AWSPuml/NetworkingAndContentDelivery/CloudMap.puml !includeurl AWSPuml/NetworkingAndContentDelivery/DirectConnect.puml !includeurl AWSPuml/NetworkingAndContentDelivery/ElasticLoadBalancing.puml !includeurl AWSPuml/NetworkingAndContentDelivery/ELBApplicationLoadBalancer.puml !includeurl AWSPuml/NetworkingAndContentDelivery/ELBNetworkLoadBalancer.puml !includeurl AWSPuml/NetworkingAndContentDelivery/GlobalAccelerator.puml !includeurl AWSPuml/NetworkingAndContentDelivery/NetworkingandContentDelivery.puml !includeurl AWSPuml/NetworkingAndContentDelivery/PrivateLink.puml !includeurl AWSPuml/NetworkingAndContentDelivery/Route53.puml !includeurl AWSPuml/NetworkingAndContentDelivery/Route53HostedZone.puml !includeurl AWSPuml/NetworkingAndContentDelivery/Route53RouteTable.puml !includeurl AWSPuml/NetworkingAndContentDelivery/SitetoSiteVPN.puml !includeurl AWSPuml/NetworkingAndContentDelivery/TransitGateway.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPC.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCCustomerGateway.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCElasticNetworkAdapter.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCElasticNetworkInterface.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCEndpoints.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCFlowLogs.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCInternetGateway.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCNATGateway.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCNetworkAccessControlList.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCPeering.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCRouter.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCVPNConnection.puml !includeurl AWSPuml/NetworkingAndContentDelivery/VPCVPNGateway.puml !includeurl AWSPuml/Robotics/RoboMaker.puml !includeurl AWSPuml/Robotics/RoboMakerCloudExtensionROS.puml !includeurl AWSPuml/Robotics/RoboMakerDevEnvironment.puml !includeurl AWSPuml/Robotics/RoboMakerFleetManagement.puml !includeurl AWSPuml/Robotics/RoboMakerSimulation.puml !includeurl AWSPuml/Robotics/Robotics.puml !includeurl AWSPuml/Satellite/GroundStation.puml !includeurl AWSPuml/Satellite/Satellite.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/ADConnector.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/Artifact.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/CertificateAuthority.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/CertificateManager.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/CloudDirectory.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/CloudHSM.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/Cognito.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/DirectoryService.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/GuardDuty.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMAddon.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMAWSSTS.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMAWSSTSAlternate.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMDataEncryptionKey.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMEncryptedData.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMLongtermSecurityCredential.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMMFAToken.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMPermissions.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMResource.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMRole.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/IAMTemporarySecurityCredential.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/Inspector.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/InspectorAgent.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/KeyManagementService.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/Macie.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/ManagedMicrosoftAD.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/ResourceAccessManager.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/SecIdentityAndCompliance.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/SecretsManager.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/SecurityHub.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/Shield.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/ShieldShieldAdvanced.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/SimpleAD.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/SingleSignOn.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/WAF.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/WAFFilteringrule.puml !includeurl AWSPuml/Storage/Backup.puml !includeurl AWSPuml/Storage/EBSSnapshot.puml !includeurl AWSPuml/Storage/EBSVolume.puml !includeurl AWSPuml/Storage/EFSFilesystem.puml !includeurl AWSPuml/Storage/EFSInfrequentAccess.puml !includeurl AWSPuml/Storage/EFSStandard.puml !includeurl AWSPuml/Storage/ElasticBlockStoreEBS.puml !includeurl AWSPuml/Storage/ElasticFileSystemEFS.puml !includeurl AWSPuml/Storage/FSx.puml !includeurl AWSPuml/Storage/FSxforLustre.puml !includeurl AWSPuml/Storage/FSxforWindowsFileServer.puml !includeurl AWSPuml/Storage/S3Bucket.puml !includeurl AWSPuml/Storage/S3BucketwithObjects.puml !includeurl AWSPuml/Storage/S3Glacier.puml !includeurl AWSPuml/Storage/S3GlacierArchive.puml !includeurl AWSPuml/Storage/S3GlacierVault.puml !includeurl AWSPuml/Storage/S3Object.puml !includeurl AWSPuml/Storage/SimpleStorageServiceS3.puml !includeurl AWSPuml/Storage/SnowFamilyImportExport.puml !includeurl AWSPuml/Storage/Storage.puml !includeurl AWSPuml/Storage/StorageGateway.puml !includeurl AWSPuml/Storage/StorageGatewayCachedVolume.puml !includeurl AWSPuml/Storage/StorageGatewayNonCachedVolume.puml !includeurl AWSPuml/Storage/StorageGatewayVirtualTapeLibrary.pumlサービスをまとめて include する場合
!includeurl AWSPuml/Analytics/all.puml !includeurl AWSPuml/ApplicationIntegration/all.puml !includeurl AWSPuml/ARVR/all.puml !includeurl AWSPuml/AWSCostManagement/all.puml !includeurl AWSPuml/Blockchain/all.puml !includeurl AWSPuml/BusinessApplications/all.puml !includeurl AWSPuml/Compute/all.puml !includeurl AWSPuml/CustomerEngagement/all.puml !includeurl AWSPuml/Database/all.puml !includeurl AWSPuml/DeveloperTools/all.puml !includeurl AWSPuml/EndUserComputing/all.puml !includeurl AWSPuml/GameTech/all.puml !includeurl AWSPuml/General/all.puml !includeurl AWSPuml/GroupIcons/all.puml !includeurl AWSPuml/InternetOfThings/all.puml !includeurl AWSPuml/MachineLearning/all.puml !includeurl AWSPuml/ManagementAndGovernance/all.puml !includeurl AWSPuml/MediaServices/all.puml !includeurl AWSPuml/MigrationAndTransfer/all.puml !includeurl AWSPuml/MigrationAndTransfer/Snowball.puml !includeurl AWSPuml/MigrationAndTransfer/SnowballEdge.puml !includeurl AWSPuml/Mobile/all.puml !includeurl AWSPuml/NetworkingAndContentDelivery/all.puml !includeurl AWSPuml/Robotics/all.puml !includeurl AWSPuml/Satellite/all.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/all.puml !includeurl AWSPuml/SecurityIdentityAndCompliance/FirewallManager.puml !includeurl AWSPuml/Storage/all.puml(余談)
弊社では情報共有ツールとして kibela というサービスを使っていますが、
標準で PlantUML に対応しているので使いやすいですよ。



- 投稿日:2019-12-04T18:42:31+09:00
NLB配下でgRPC通信するときに考えるALPN対応状況
この記事を書いている背景
ステージング環境上でgRPCサーバの動作確認をしている中で、踏み台サーバからgrpcurlを実行するとリクエスト成功するのですが、システム間のgRPCリクエストが通らなくて困りました。
その原因自体は大したものではないのですが、もう少し突き詰めていくと面白い内容だったので、その時調べたことなどを残しておきます。
主にインフラ寄りの話になります。インフラ前提
ECS/FargateでgRPCクラインととgRPCサーバは別クラスタです。
システム(クラスタ)間の負荷分散はNLBを使用しています。
なぜ、NLBかというと、ALBはリスナーしかHTTP2対応しておらず、ターゲットはHTTP1.1のため、負荷分散できません。
NLBならL4なので負荷分散できます。下はインフラ構成概要図となります。
System1はRESTの受け口を持ち、System2のgRPCクライアントでもあります。
踏み台サーバからNLB経由でgrpcurlなどのクライアントツールを利用し、System2のgRPCサーバのAPIを実行することもできます。
システム間連携の失敗原因
単なるチーム間のコミュニケーションミスです。
バックエンドチームは、平文通信を想定して実装していました。
以下の通り、WithInsecure関数を利用。言語はGoです。grpc.Dial(fmt.Sprintf("%s:%s", os.Getenv(gRPCHostEnvKey), os.Getenv(gRPCPortEnvKey)), grpc.WithInsecure())一方SREチームは、暗号化通信を想定し、NLBのリスナーをssl/tlsのみに絞っていました。
平文用のリスナーに変更したところ、システム間でgRPCリクエストが成功しました。
内部通信なので平文でもセーフです。本題(ALPNを巡る)
ここからが面白いところです。
上記の原因を発見するまでに、色々寄り道をして、「ALPN」というワードが言葉を知りました。
今回は上述の通り、ALPNは直接的な問題になり得なかったのですが、今後のことも考えて色々調べました。ALPNとは
ALPN(Application-Layer Protocol Negotiation)とは、プロトコルネゴシエーションを行うためのTLS拡張です。
クライアントは自身が使用可能なプロトコル一覧をサーバに渡し(ClientHello)、サーバ側はその中から選択し(ServerHello)、TLSハンドシェイクが完了。あとはその上で、通信します。
TLS上でのプロトコルネゴシエーションの仕組み、NPNとALPNHTTP2でSSL/TLSを使う場合は、NPNかALPNのいずれかを使用します。
HTTP/2 プロトコルネゴシエーション方法と ATS での実装ただ、NPNよりもALPNの方が本命のようです。
理由はこちらです。NPNではクライアントがプロトコルを選択するが、ALPNではサーバがプロトコルを選択する。サーバ側が選択権を持つのは他のセキュリティ技術(暗号種類の決定等)で行われているやり方なので、そのポリシーに従う。
NPMは3回クライアント、サーバ間でやり取りが発生するのに対し、ALPNは2回で済むので効率的である。HTTP/2.0のALPN利用に伴うSSL負荷分散装置の不具合にご注意下さい
NLBはALPNに対応していない?
NLBはALPN未対応のようです。
gRPC と HTTP/2 と ALPN別プロジェクトで実際に検証した結果からも、NLBがALPN未対応であることが分かりました。
grpc-goはALPNに対応していない?
仮にNLBのリスナーがssl/tlsのみだとして、grpc-goのWithTransportCredentials関数を利用してtls有効でgRPCリクエストを実行するとどうなるのでしょうか?
// WithTransportCredentials returns a DialOption which configures a connection // level security credentials (e.g., TLS/SSL). This should not be used together // with WithCredentialsBundle. func WithTransportCredentials(creds credentials.TransportCredentials) DialOption { return newFuncDialOption(func(o *dialOptions) { o.copts.TransportCredentials = creds }) }時間が足らず、試せていなくて恐縮なのですが、おそらく成功します。
理由は、grpc-goがALPNに未対応だからです。
issueはこちら。
https://github.com/grpc/grpc-go/issuesjava-grpcの開発者がissueを立てているあたり、JavaはALPN対応済みなのでしょう。
また、Node.jsもALPN対応済みのようですね。grpcurlはALPNに対応していない?
grpcurlのオプション
grpcurlにはtls関連で3つ選択肢があります。
- plaintext(tls無効方式)
- insecure(形式としてはtls有効だけど、証明書の中身は検証しない方式)
- オプション無し(tls有効方式)
-plaintext
Use plain-text HTTP/2 when connecting to server (no TLS).-insecure
Skip server certificate and domain verification. (NOT SECURE!) Not
valid with -plaintext option.蛇足ですが、grpcurlの「insecure」はtls有効だけど、go-grpcの「grpc.WithInsecure」はtls無効で、同じ「Insecure」でも意味がことなるため、少し混乱します。
開発団体が全然違うからしょうがないけど。実行結果
insecureオプションあるいはオプション無しのどちらも(つまりtls有効)リクエスト成功しました。
NLBがALPN未対応で、grpcurlがALPN対応ならば、これらは成功しないはずです。
つまり、grpcurlはALPN未対応なのかと考えました。ところが、issueあげてみたところ、grpcurlはALPN対応とのことでした。
grpcurl(クライアント)はALPNを使うように要求するが、grpc-go(サーバ)がALPN未対応のため、ALPN自体は成功しない。
ただし、grpc-goの仕様によりTLSハンドシェイクは成功するため、tlsでお話ができるようになるようです。
https://github.com/fullstorydev/grpcurl/issues/125振り返り
今回、内部通信なのでssl/tlsでなくても良いし、たとえssl/tls有効必要な外部通信だとしても、grpc-goならALPN未対応だからNLBでも問題なさそうだということがわかりました。
しかしながら、ALPN対応のgrpcライブラリが用意されているJavaやNode.jsなどの言語で、かつ外部通信用にgRPCのAPIを公開(NLB使う)する方式だと苦しいなと思いました。
この場合は、EnvoyやNginxにTLS終端させて、ACMは諦めるという方向になるでしょうか。。。通信通ったからいいやではなく、気になったところをどんどん調べていくことで勉強になりました。
最後に、この問題に付き合って色々調べてくれた弊社SREメンバのいっちーさんに感謝です。

- 投稿日:2019-12-04T18:32:48+09:00
AWS Certified Machine Learning – Specialty 合格しました
先月、AWS認定の機械学習の試験を受験し、合格しました!
その記録を残しておきます。(私のバックグラウンドを書きますと、AWSを勉強し始めたのは8月後半からで、9月終わりごろにソリューションアーキテクトアソシエイト、10月終わりごろにビッグデータ専門知識を取り、11月の今回が3つ目の試験です。機械学習に関してはだいぶ昔に機械学習の勉強会を聴講していましたが、実務経験は多くはないです。)
前回の受験の記録
AWS Certified Big Data - Specialty 合格しました勉強方法
以下のリンクは、2013年~2014年ごろに聴講していた勉強会の資料です。今回の試験のために勉強会に出ていたわけではありませんが、私の機械学習に関する知識はこれがベースだった気がします。
(検索すればYouTubeに講義の動画がたぶん全部あります。1回2時間ぐらいなので、全部見るのは大変です。一時期は私も運営側で動画の編集とかしていました)
今回の試験のための勉強に関しては、どう勉強したらいいのかわからず、行き当たりばったりでサイト上のいろんな記事を読むぐらいでした。機械学習についての一般的な内容の記事や、AWSのSageMakerを中心とする機械学習関係のドキュメントです。最初に書籍も読んだのですが、書籍が試験に生きたかと言えばそうでもない気がします。
以下は、参考にした先輩の方々の記事です。
- AWS Certified Machine Learning – Specialty に合格してきました - YOMON8.NET
- AWSの機械学習エンジニア認定試験を受けてきた - Qiita
- AWS Certified Machine Learning – Specialty合格までにやったこと | Developers.IO
機械学習の用語はいままであいまいだったものをできるだけ正確に覚えるようにしました。この記事後半の勉強ノートに書いた用語です。
AWSについては、サービスごとの公式ドキュメントや以下のリンクの資料は読みました。ドキュメントは全部読んだわけではないです。パラパラと読んでたぐらいです。
SageMakerにどんな機械学習のアルゴリズムがあるのかはある程度は把握しておきました。全部覚えるまではしなかったのですが、ちゃんと全部把握しておいたほうがよかったです。
Amazon SageMaker 組み込みアルゴリズムを使用する - Amazon SageMaker
以下の私の記事は、今回の受験にあたって手を動かそうと思ってやった内容です。しかし、手を動かしたことが試験に役立ったかといえば、正直あまり実感はないです。
- 機械学習を試すための前準備
- 機械学習を試してみる
- AWSのサービスを試してみる
ということで、結局どう勉強したら効率よく試験に臨めるのかはよくわからないままです。
試験当日
65問180分。前回のビッグデータの試験と違って今回は時間が余りました。簡単だから余ったのではなく、考えても無駄と判断して、余りました。90分ぐらいで一巡して、60分ぐらいで見直しフラグを付けた問題を見直すのを2巡ぐらいして、残り時間はもう意味がないと思い、終了させました。見直しフラグを付けたのは全体の6割ぐらい。
前回のビッグデータの試験よりも、時間は余ったし見直しフラグを付けた数も少なかったのは、ビッグデータに比べて問題文が短かったのかもしれません。が、簡単だったわけではなく、わからない問題はぜんぜんわからないし、ビッグデータのときと同じくらいには、もうダメだっていう気持ちでした。もうダメだと思いながらも前回は合格したので、今回もひょっとしたら意外といけるのかもという油断もありつつ。
ビッグデータの試験と同様、問題文は日本語と英語とで都度切り替えられますが、基本は日本語で解きました。日本語の問題文の意味がわからなくて、英語にしてみたらわかったというのが1問か2問ぐらいありました。
わからないサービス仕様や用語があったとしても、後のほうの別の問題を解くときにその問題の整合性のためにこういうことなんだろうって想像つくことがあり、そしたら前の問題に戻って新しく得た知識をもとに問題が解けたというケースもありました。2つぐらいそれで助かりました。(正解がわからないので、本当に助かったのかは不明ですが)
AWS関係なく機械学習の一般的な知識を問うものと、機械学習関係のAWSのサービス知識を問うものがあります。ビッグデータの試験に比べてAWS関係ない問題の割合が高かったと思います。
リモート監視での試験について
AWSでリモート監視でない試験を受けたことがまだないので、どこまでがリモート監視特有の事情なのかはわかりませんが、
前回はリモート監視の会場で試験マシンのスキャナーの調子が悪く、身分確認に非常に時間がかかってしまいましたので、試験予約の段階で別のマシンにしました。今回がAWSの試験3回目で、予約時に記載されている4桁のコードが個別のマシンを識別することがわかってましたので、よさそうなマシン、かつ端の席を選びました。
が、なんとまたスキャナーの調子が悪かったです。調子悪くて時間がかかるとセッションが切れて、初めからやりなおしになって、6桁のコードをもらいなおさないといけないのです。が、セッション切れを想定して、6桁のコードを最初に記憶しておく、というぐらいには慣れてきました。
さらなる不具合として、ネットワークの調子が悪く、2回も一時中断になりました。2回合わせて30分ぐらい。時間を正確には見ていないのですが、残り時間が減ってる感じはしなかったので、中断中は時計も止めてくれるっぽい。
さらにさらなる不具合として、キーボードでの日本語入力ができず、リモート監視員とのチャットに日本語が使えなかったです。しかたなくカタコトの英単語で書いていたのですが、しばらくしたら監視員も英語で書くようになってしまいました。いや、日本語でやりとりしたいんだけど・・・ってなりました。
ちなみにリモート監視員の書く日本語は、たぶん英語からの機械翻訳です。何度か受験すると機械翻訳の日本語でのチャットにも慣れてきます。最後に「部屋を残すことができます」と言われます。よくわからない日本語だったら脳内でいったん英語に翻訳してからもう一度日本語に翻訳するとわかります。「部屋を残すことができます」の意味はわかりますでしょうか?退室していいよってことですね。
結果
スコア807で合格した。
勉強ノート
自分のノートの一部です。このあたりのキーワードは事前に調べていた、というものです。
機械学習に関する用語
- AUCとROC曲線
- TF-IDF
- TF
- Term Frequency
- 文章ごとに単語の占める割合
- 文書と単語ごとの数値で、全体としては行列(2次元配列)
- IDF
- Inverse Document Frequency
- 単語ごとの数値で、全体としては1次元配列
- 頻出単語ほど小さい値
- unigramとbigram
- 深層学習
- learning rate
- batch size
- epoch
- dropout
混同行列と指標
混同行列、confusion matrix
予測値 正解 TP True Positive 正しく正と判断 正 正 FP False Positive 誤って正と判断 正 負 FN False Negative 誤って負と判断 負 正 TN True Negative 正しく負と判断 負 負
がん検診での例 TP がんだと正しく判定 FP がんでないにも関わらずがんであると判定される誤検知 FN がんであるにも関わらずがんではないと判定される見逃し TN がんではないと正しく判定 正解率、精度、accuracy
Accuracy = \frac{TP + TN}{TP + FP + FN + TN}再現率、感度、検出率、真陽性率、recall
Recall = \frac{TP}{TP + FN}
- 0.0はダメ、1.0に近いほどよい
- 検索の場合:マッチしてほしいアイテムの中で、実際にマッチした割合
- 反対は偽陰性率、False negative rate
適合率、precision
Precision = \frac{TP}{TP + FP}
- 見つけ出したもののうち正解の割合
- 0.0はダメ、1.0に近いほどよい
- 検索の場合:マッチしたアイテムの中で、本当にマッチしてほしいアイテムの割合
F値
F = \frac{2 Recall \,Precision}{Recall + Precision}
- 0.0はダメ、1.0に近いほどよい
偽陽性率、False positive rate
\frac{FP}{TN + FP}
- 本当はnegativeなものの中で、検出してしまった割合
- 1.0はダメ、0.0に近いほどよい
偽陰性率、False negative rate
\frac{FN}{TP + FN}
- 本当はpositiveなものの中で、検出できなかった割合
- 1.0はダメ、0.0に近いほどよい
- 再現率、recallの反対
これら指標の名前は英語もわかっておいたほうがいいです。問題文の日本語訳がよくわからないことがあるためです。
AWSのサービスの概要
- SageMaker
- どちらかというとデータサイエンティスト・機械学習エンジニア向けのサービス
- 利点はインフラの管理をAWSに任せられること
- Rekognition
- 画像や動画から顔/テキストの検出、安全でないコンテンツなどの検出が出来るサービス
- 動画はKinesis Video Streamsと組み合わせ可能
- Comprehend
- テキストからエンティティ分析/キーフレーズ分析/言語の分析(何語か?を分析)/感情分析/構文分析ができるサービス
- Kinesis Analytics
- ストリーミングデータからリアルタイムにSQLみたいなことができるサービス
- 一部機械学習の機能がある
- EMR
- Hadoop、Sparkなどのマネジメントサービス
※AWSのre:Inventで機械学習関係のサービスが最近いっぱい発表されていますが、新しいサービスは試験にはなかなか出ないと思います。
- 投稿日:2019-12-04T18:28:03+09:00
ドローンをAWS上で操作するシステムの構築
はじめに
この記事は
ドローンを活用した避難勧告システム
の1ページです.
製作背景などはそれを参照してください.概要
TelloドローンをAWS上で操作可能なシステムの構築します.AWS上で操作できれば,いろんなサービスと連携することができるので夢を広げておきましょう.
使用するドローンについて
中国のスタートアップ企業Ryze Techが開発するTello eduを使用します.IntelとDJIが技術開発していて公式のSDKが公開されていて,edu版だとv2が使用可能でドローンを子機とした編隊飛行が可能なのでedu版の購入がお勧めです.
ドローン制御にはこのSDKを使用するので,事前にgit clone します.環境構築やSDKを用いたPythonでの基本的な飛行や画像ストリーミング方法については適宜SDKのユーザーガイドやTelloに関する別の記事を参照してください.飛行コマンド
Telloクラスのsend_commandメソッドの引数に文字列でコマンドを与えるだけで飛行します.参考までに基本飛行コマンドは以下のようになります.これら以外に回転コマンドや速度を指定して円弧を描き飛行させるコマンドもあるので使い方に合わせて適宜確認しましょう.
Command 説明 command SDKモードを開始 takeoff 離陸 land 着陸 emergency 即座にモーター停止 up x 20~500cmの間で上昇 down x 20~500cmの間で下降 left x 20~500cmの間で左へ飛行 right x 20~500cmの間で右へ飛行 forward x 20~500cmの間で前へ飛行 back x 20~500cmの間で後ろへ飛行 Tello <-> PC <-> AWS 間の通信
そもそもTelloドローンは4G通信などの移動通信サービスに対応しているわけではなく,実運用において遠隔操作をさせることは考えにくいですが,インターネット上のサービスをトリガにして制御することは今後有用的だと考えられます.本システムではクラウドサービスとしてAWSを使用しクラウドからのtelloの飛行操作を試みることにします.
接続方法
wifi親機としてTelloを使用しPCとwifi接続する場合,AWSとの接続でwifi接続を使用することが不可能です.そのため,今回はPCとスマホを有線接続しスマホのテザリングを介してPCとAWSが通信できるようにしました.この時,インターネット接続に使用するテザリングサービスの優先度をWifiより高くしなければなりません.
ドローンとの通信プロトコル
今回AWSとドローン間の通信にはHTTP通信ではなくMQTT通信を採用しました.HTTP通信より軽量なメッセージプロトコルとされ,文字列コマンドを送る用途であればMQTT通信が適していると考えたからです(MQTTやってみたかったというのもあります笑).MQTTブローカーにchannelを設定し,そのchannel上にpublishされたデータをsubscribeすることでMQTT通信が行われます.簡単に多対多の通信が行えるのが大きな特徴です.(たぶん)
AWSIoTCoreはMQTTブローカーを提供していて,本システムではドローンが飛行コマンドのsubscribe側で,IoTCore上で飛行コマンドのpublishを行いひとまず飛行を確認します.
AWS IoT Core
次にAWSにログインしてIoT Coreを開き,モノとしてDroneを登録します.
証明書を作り,ポリシーをアタッチし,証明書をアクティブにします.細かい手順は圧倒的にわかりやすいこの記事が参考になります.(参考URL)
証明書は後で使うので絶対にダウンロードします.Tello制御用プログラム
TelloSDKがpython2系に準拠しているようなのでライブラリ等は2系に合わせるようにすべきだと思います.(python3で動くか未検証)
pip install AWSIoTPythonSDK
をしてPythonからIoT Core用のライブラリを入れておく.
証明書やTello.pyがあるディレクトリ(例.Single_Tello_Testなど)に以下のようなmainの制御プログラムを書けばOK.main.py# -*- coding:utf8 -*- from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient from datetime import datetime from tello import Tello import ast import time import json import sys # For certificate based connection myMQTTClient = AWSIoTMQTTClient('device001') # 適当な値 myMQTTClient.configureEndpoint('xxxxxxxxxxxx.ap-northeast-1.amazonaws.com', 8883) # 管理画面で確認 myMQTTClient.configureCredentials('rootCA.pem', 'xxxxx-private.pem.key', 'xxxxx-certificate.pem.crt') #各種証明書 myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 sec myMQTTClient.connect() tello = Tello() # Telloインスタンスを作成 tello.send_command('command') # SDKモードを開始 def customCallback(client, userdata, message): payload = message.payload print('Received a new message: ') print(payload) print('from topic: ') print(message.topic) print('--------------\n\n') # command = payload[0] dic = ast.literal_eval(payload) tello.send_command(dic['message']) myMQTTClient.subscribe("test/pub", 1, customCallback) # test/pub チャネルをサブスクライブ while True: time.sleep(1)テスト
はい,テストします.まず上記のPythonコードを実行して,Telloとの接続を確認しておきます.次にIoT Core上のテストタブを開きチャンネルを指定した後,飛行コマンドを"message"の値に文字列で指定しトピックに発行するだけです.
分かり易く,動作を動画でまとめました.
https://youtu.be/MKF2P_rrS9U
まとめ
AWS IoT Core上からコマンドを入力してTelloの飛行に成功しました.次は外部サービスと連携してみましょう.
人の発声を自然言語処理,意図解釈し,ドローンを制御するシステムの構築




- 投稿日:2019-12-04T17:49:21+09:00
Amazon Lightsailで構築したRedmineに別で立てたDBを使わせる
Amazon Lightsailで構築したRedmineはデフォルトではインスタンス内に入っているMySQLを使用しています。
これを、Amazon Lightsailで別に構築したMySQLを使わせてみようと言うのが今回の趣旨です。大まかな流れとしては以下のようになります。
1. Redmine側DBのダンプを取得
2. 新しく立てたDBにスキーマを作成してリストア
3. Redmineの設定ファイルを編集し、新しく立てたDBを使うようにする1. Redmine側DBのダンプを取得
Lightsailで立てたインスタンスにsshで入ったらまず、mysqlのrootユーザーのパスワードを確認します。
rootのパスワードは~/bitnami_application_passwordに書かれています。
また、このパスワードはRedmineの管理者ユーザーのパスワードにもなっています。 (ログインIDはuser)パスワードを確認できたら以下のコマンドを実行します。
bitnami_redmine_dump.sqlという名前でダンプファイルが作成されます。
mysqldump -u root -p bitnami_redmine > bitnami_redmine_dump.sqlこのタイミングで何か適当なプロジェクトでも作っておくとRedmineのDBを切り替えた時に確認しやすいかもしれません。
切り替えが上手くいけばこのプロジェクトは表示されなくなるはずですから。前
後 (新しいDBには"前"の時点でのダンプを使うので、切り替えが上手くいけばPJ_2は表示されなくなるはず)
2. 新しく立てたDBにスキーマを作成してリストア
新しく立てた方のmysqlにログイン
mysql -u dbmasteruser -p -h (エンドポイント)
(ユーザー名、パスワード、ホスト(エンドポイント)はコンソールから確認できます。)
ダンプのリストア先となるスキーマを作る
create database bitnami_redminemysqlからログアウト
exit作ったスキーマにダンプをリストア
mysql -u dbmasteruser -p -h (エンドポイント) bitnami_redmine < bitnami_redmine_dump.sqlテーブルを確認するとPJ_1のレコードを確認できる。
mysql> select id, name from bitnami_redmine.projects; +----+------+ | id | name | +----+------+ | 1 | PJ_1 | +----+------+ 1 row in set (0.00 sec)3. Redmineの設定ファイルを編集し、新しく立てたDBを使うようにする
このファイルは
/home/bitnami/apps/redmine/htdocs/config/database.ymlにあります。production: adapter: mysql2 database: bitnami_redmine host: localhost username: bitnami password: xxxxxxxxxx encoding: utf8 socket: /opt/bitnami/mysql/tmp/mysql.sockproduction の database, host, username, password をそれぞれ新しく立てたDBに合わせて書き換えます。
書き換え終わったら保存してRedmineのインスタンスを再起動しましょう。プロジェクト一覧を見てみるとPJ_2が表示されていないので、これでうまく切り替えできたことが分かりました。




- 投稿日:2019-12-04T17:38:47+09:00
Railsチュートリアル 1.5.2 Herokuへのデプロイで発生したエラーへの対処
はじめに
Railsチュートリアル1.5.1~1.5.3をそのまま実行していく中で発生したエラーです。
エラー時の状況
- herokuへのデプロイを実施
- $ git push heroku master には成功しているようだがネット上で表示されない
- rails server 上では問題なく表示される
- もう一度push herokuをすると「Everything up-to-date」と表示される
上記以外の状況の場合は最後に追記してあるのでそちらも見てみてください。
内容
- 情報
- 実行内容と発生したエラー
- 解決方法
- その他の問題の場合
情報
PC
- MacBook Pro(15-inch,2019)
- プロセッサ 2.6GHz 6コアIntel Corei7
- メモリ 16GB 2400MHz DDR4
- グラフィックス Intel UHD Graphics 630 1536 MB
開発環境
- AWS Cloud9
- Ruby 2.6.3
- Ruby on Rails 5.1.7
- Git 2.14.5
- heroku/7.35.0 linux-x64 node-v12.13.0
- Bitbucket
実行内容と発生したエラー
Railsチュートリアル1.5.1の手順に従いHerokuのセットアップ
1.5.2で下記を実行qiita.rb$ git push heroku master問題なく終了したように見えたので帰ってきたURL(.gitと.comがある)を開く。
https://damp-fortress-5769.herokuapp.com https://git.heroku.com/damp-fortress-5769.git.gitは「Method Not Allowed」と表示されるだけなので注意。
.comの方を開くと「Application error」ログの詳細を確認しろとの表示。
だが、初心者なためログを見ても何が何だか分からず、とりあえずpush後の情報を確認。
一度目の物が消えてしまったのでこれと少し内容は違うがほぼ同内容が返ってきていた。
いくつかWARNIGが出ているがあまり重要ではないと判断。(ちなみに一度目は2つ目のWARNIGがGemにrailsのバージョンを記載しろというものだったのでその通りにしたが結果は変わらなかった)解決方法
いくつか試したが多くのエラーパターンがあるように思われたので端的に解決に至ったもののみを記しておく。
この質問の通りにしたら解決した。
手順としては、・ /hello_app/config/database.yml を開く
・ 内容を*1に書き換え
・ 変更を保存(⌘ + S)
・ $ git add .
・ $ git commit -m "change_database.yml"
・ $ git push
・ $ git push heroku masterこれで無事デプロイに成功。
*1default: &default
# adapter: sqlite3 を削除
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000development:
<<: *default
adapter: sqlite3 # 追加
database: db/development.sqlite3production:
<<: *default
adapter: postgresql
database: db/production.pgその他の問題の場合
初心者だからこそのエラーパターンがいくつかあったので追記しておく。
SSH認証に失敗している
メッセージが表示されているはずなのでもう一度手順通りに公開鍵を追加する。.gitと.comのうち、.gitのURLを開いている
.comのURLがデプロイされた物なのでそちらを開く
あまりないと思うが質問サイトの投稿者の中にいた。変更内容を保存せずにaddやcommitをしている
ほぼ無い状況だろうが自分が何回もやらかしているので一応

- 投稿日:2019-12-04T17:36:51+09:00
Aurora Serverless DB を作って Node.js(TS) から使う
概要
Aurora Serverless DB を作成して、
Node.js (TypeScript) からアクセスしてみます。実行時の環境 2019/12/04
- MacOS 10.14.4
- node v10.15.0
- npm 6.6.0
- ts-node v8.5.4
- aws-sdk 2.584.0
DB の作成
Data API 公式ドキュメントを見ると、
現在、Data API が有効なリージョンは限られているらしいので注意
東京リージョンでつくる。
- DB 作成方法
項目 値 テータベース作成方法 標準作成
- エンジンのオプション
項目 値 エンジンのタイプ Amazon Aurora エディション MySQL 互換 バージョン 現行最新: Aurora (MySQL)-5.6.10a データベースロケーション リージョン別
- データベースの機能
項目 値 データベースの機能 サーバーレス
設定
- マスターパスワード はあとでテストに出るのでノートにとること
キャパシティーの設定
ACU=Aurora キャパシティーユニット
- 使用する ACU x 時間に応じて課金が発生する。デフォルト最大値 128 とかいってて怖いから 8 に下げて様子見る。
- コールドスタート
- 使ってない時間帯は勝手に止まってくれる
- 使い始めは 1 分かけてゆるく起動するらしい
- 開発環境とか社内向けサービスなのでゆるくていい
項目 値 最小 ACU 1 最大 ACU 8 追加設定 アイドルの場合、コンピューティングを一時停止: 15 分
- 接続
Data APIを有効にする- そのほかはてきとう
項目 値 ウェブサービスデータ API Data API
- 追加設定
- 基本的にデフォルトのままにした。
最初のデータベース名…DB 名とは違うのか?
- MySQL でいう
データベースはスキーマと同じと考えていいらしい- ややこしいわ
- 複数のサービスで DB を利用する予定なので、はじめにのせるサービス名にした
DB ができた
作成中ステータスで表示された- しばらくまつと
利用可能になったQuery Editor を使って DB にユーザーを作る
Query Editor への接続
- RDS メニューから
Query Editorへアクセス
- 作成した DB を選択
- user: admin
- password: さっきメモっといたマスターパスワード
- メモっとかなかったおバカさん(俺)は、DB の設定変更から再設定
- データベースに接続
- コンソールが開き、デフォルトのクエリが実行できたら OK
- せっかくなので、
SHOW DATABASES;してみる
- DB 作成時に
最初のデータベース名に入力していたデータベース(スキーマ)が表示されるはず開発用ユーザーを作り、データベースへのアクセス権を与える
in-QueryEditorCREATE USER 'devuser'@'%' IDENTIFIED BY 'YOUR_PASSWORD'; GRANT ALL ON (最初のデータベース名).* TO devuser;成功を確認したら、作ったユーザーでアクセスしてみる
- 「データベースを変更する」
- user:
devuser- password:
YOUR_PASSWORD- データベースまたはスキーマ:
(最初のデータベース名)- 接続してクエリが実行できたら OK
Node.js から DB に接続する
これがやりたかった
Data API 公式ドキュメント から必要な部分を実行していく
Data API にアクセスするためのシークレットを作る
- Secret Managerから、MySQL ユーザーに対応する Secret を発行する必要がある。
- しかし、なんと Query Editor からアクセスした時点で Secret が勝手に作られている。便利。
アクセスするサンプルコードを書いて実行してみる (TypeScript)
src/aurora-test.tsimport { RDSDataService } from "aws-sdk"; import { ExecuteStatementRequest } from "aws-sdk/clients/rdsdataservice"; (function testQuery() { const rds = new RDSDataService({ region: "ap-northeast-1", accessKeyId: "***", secretAccessKey: "***" }); const params: ExecuteStatementRequest = { resourceArn: "***", // RDS > データベース > 設定 から参照 secretArn: "***", // SecretManager > 追加したユーザーのSecret > シークレットのARN database: "(最初のデータベース名)", sql: "select * from information_schema.tables", includeResultMetadata: true }; rds.executeStatement(params, (err, data) => { if (err) { console.error(err, err.stack); } else { console.log(`Fetch ${data.records!.length} rows!`); console.log(data.columnMetadata!.map(col => col.name).join(",")); for (const record of data.records!) { console.log(record.map(col => Object.values(col)[0]).join(",")); } } }); })();
ts-nodeで実行ts-node src/aurora-test.ts > Fetch 69 rows! > TABLE_CATALOG,TABLE_SCHEMA,TABLE_NAME,TABLE_TYPE,ENGINE,VERSION,ROW_FORMAT,TABLE_ROWS,AVG_ROW_LENGTH,DATA_LENGTH,MAX_DATA_LENGTH,INDEX_LENGTH,DATA_FREE,AUTO_INCREMENT,CREATE_TIME,UPDATE_TIME,CHECK_TIME,TABLE_COLLATION,CHECKSUM,CREATE_OPTIONS,TABLE_COMMENT > def,information_schema,CHARACTER_SETS,SYSTEM VIEW,MEMORY,10,Fixed,true,384,0,16434816,0,0,true,2019-12-04 07:35:09,true,true,utf8_general_ci,true,max_rows=43690, > def,information_schema,COLLATIONS,SYSTEM VIEW,MEMORY,10,Fixed,true,231,0,16704765,0,0,true,2019-12-04 07:35:09,true,true,utf8_general_ci,true,max_rows=72628, > ...UTF-8 を指定してUnicodeを扱えるようにする
デフォルトの character set が
latinとかいうやつで、
日本語が全部???になって困ったので設定を変える。
別記事に切り出したSSH Tunnel (ec2踏み台) を使って直接接続する
Aurora Serverless はpublic ipを持てない。
ふつーに自由にクエリ書きたいときに困るよねってことで、
@hhrrwwttrr さんにおねがいして、踏み台EC2を作ってもらった。
踏み台を準備してもらうと、Sequel Pro などのクライアントからも直接SSH経由で接続できて便利。作る手順とかは @hhrrwwttrr さんがわかりやすく書いてくれるって言ってた。
できあがり
認証情報の扱いにはきをつけてつかおうね
- 投稿日:2019-12-04T17:09:42+09:00
安心して Python2 の EOL を迎えるためにやったこと
自己紹介
SRE/QA チームで SRE をしている @yukin01 です。
半年ほど前までは iOS や Firebase/GCP を用いたアプリケーション開発を主にしていましたが、インフラ周りを強化したいと思い今はグロービスで SRE として AWS や GCP を触っています。Python2 の EOL
ご存知の通り Python2 は2020年1月1日でサポート終了することが発表されていますが、もし Python2 にまだ依存しているプロダクトやツールがあるなら EOL までに何としてでも駆逐したいですよね。
(EOL までのカウントダウンを確認できるサイト を見ると多少臨場感を味わえるかもしれません)https://www.python.org/doc/sunset-python-2/
What will happen if I do not upgrade by January 1st, 2020?
If people find catastrophic security problems in Python 2, or in software written in Python 2, then most volunteers will not help fix them. If you need help with Python 2 software, then many volunteers will not help you, and over time fewer and fewer volunteers will be able to help you. You will lose chances to use good tools because they will only run on Python 3, and you will slow down people who depend on you and work with you.
改めて EOL を迎えるとどうなるのか確認しましたが、2020年1月1日以降は Python2 に脆弱性が見つかっても基本的には放置されるとのことなので、当然ですがそのまま使い続けるリスクはとても高いです。
もちろん各種ベンダーが個別でサポートを続けることはあると思いますが、順次打ち切っていくはずなので結局何かしらの対応は必要です。
弊社のインフラ環境でもいくつか Python2 の存在が確認できたので、脱 Python2 のために対応したことをお伝えできればと思います。AWS Lambda
AWS Lambda は Python 2.7 ランタイムをサポートしています。
ランタイムサポートポリシーによると、今後60日以内に廃止予定のランタイムで Lambda を実行している場合はメールでお知らせしてくれるらしいのですが、今のところ(12/6現在)確認できていないので EOL 後も使用すること自体はできそうです。弊チームでは各種 CloudWatch Events の Slack 通知やスクリプトの定期実行などで Lambda の Python/Go/Node.js ランタイムを利用していますが、Python に関してはほとんどが Python3 でした。
ただ、S3にアップロードされたファイルに対するアンチウイルスソフトとして ClamAV を Lambda 上で実行しているのですが、それだけは Python2.7 で動いています。
これは Lambda 用の zip ファイル作成に利用している bucket-antivirus-function というツールがまだ Python2.7 用のファイルしか吐き出せないことが理由なのですが、すでに Python3 移行の PR が立っているようなので少し様子を見ることにしています。自前 Python スクリプト
サーバ上でのちょっとした作業を Python スクリプト化しておくと非常に便利ですよね。
私自身は元々 Python の経験はありませんでしたが、今は AWS CLI を呼ぶシェルスクリプトを書くのも boto3 を使って Python で書くのもそんなに変わらないので学習コストの低さを実感しています。
これらのスクリプト群はすべて shebang で Python3 が指定されていたので基本的には対応不要でした。Ubuntu AMI
グロービスのプロダクトは基本的に Ubuntu ベースの AMI 上で動いていて、Ansible と Packer を用いてプロビジョニングしています。また Ubuntu のバージョンは 16.04 or 18.04 を使っていて、どちらもデフォルトでは Python2 はインストールされていません。
しかし、稼働中のすべてのインスタンス(AMI)には Python2 が入っていました。$ which python2.7 /usr/bin/python2.7いくつかの原因があったので1つずつ潰していきました。
Ansible を実行している Python
Packer で AMI を作成するときの Provisioner として
ansible-localを使っているので、あらかじめ shell provisioner で Ansible を入れているのですがその方法に問題がありました。packer.json(簡略)"provisioners": [ { "type": "shell", "inline": [ "sudo apt-add-repository -y ppa:ansible/ansible", "sudo apt-get update", "sudo apt-get -y install ansible" ] } ]apt が提供する Ansible パッケージがそもそも Python2 に依存しているので、apt-get 経由でインストールすると Python2.7 で実行されるようになってしまいます。
$ apt-cache depends ansible ansible Depends: python-crypto Depends: python-jinja2 Depends: python-paramiko Depends: python-pkg-resources Depends: python-yaml Depends: <python:any> python Depends: <python:any> python Depends: python-httplib2 Depends: python-netaddr Recommends: python-selinux Suggests: sshpass$ ansible --version ansible 2.9.1 config file = /etc/ansible/ansible.cfg configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules'] ansible python module location = /usr/lib/python2.7/dist-packages/ansible executable location = /usr/bin/ansible python version = 2.7.12 (default, Oct 8 2019, 14:14:10) [GCC 5.4.0 20160609]対応としては、以下のページを参考に pip3 経由でインストールするように修正しました。
https://docs.ansible.com/ansible/latest/reference_appendices/python_3_support.html
packer.json(簡略)"provisioners": [ { "type": "shell", "inline": [ "sudo apt-get update", "sudo apt-get -y install python3-pip", "sudo pip3 install ansible" ] } ]$ ansible --version ansible 2.9.1 config file = /etc/ansible/ansible.cfg configured module search path = ['/root/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules'] ansible python module location = /usr/local/lib/python3.5/dist-packages/ansible executable location = /usr/local/bin/ansible python version = 3.5.2 (default, Oct 8 2019, 13:06:37) [GCC 5.4.0 20160609]Python のパスやバージョンが変わっているのが確認できたので OK です。
Ansible Playbook 内のタスク
数年運用されていることもあり、pip2 経由のパッケージが残っていたので確認して pip3 に移行しました。
加えて apt モジュールでインストールしているパッケージの中に Python2 依存のものがないかチェックしました。tasks/main.yml(例)- name: Install packages from apt apt: name: - python3-pip # OK - software-properties-common # OK - htop # OK - python-pip # NG - python-properties-common # NG - dstat # NG - name: Install packages from pip2 pip: name: - boto - awscli executable: pip2 # NG各タスクを実行するときの Python
これまでの変更箇所を踏まえて Packer を走らせましたが、
/usr/bin/python: not foundというエラーでコケてしまうタスクがありました。
Ansible にはタスクの実行に使用する Python インタプリタを指定できるという機能がありますが、デフォルトで/usr/bin/pythonを探してしまっていたのが原因と考えられたので以下の変数を明示的に指定することで解決しました。ansible_python_interpreter=/usr/bin/python3↑によると ansible.cfg やインベントリファイル、コマンド実行時のオプションとして指定できるようです。
以上の対応で AMI から Python2 を取り除くことが出来ました
$ which python2.7 $ which pythonUbuntu 自体の Python2 サポート
余談ですが Ubuntu 自体も Python2 の依存を切り離すのに苦労しています。
Ubuntu には以下の4つのリポジトリがありますが、16.04 と 18.04 については Python2 自体が main に入っているので EOL 後も公式のリポジトリからインストール可能です。
(もちろんユーザー側が積極的に使っていいという話ではないと思いますが…)The four main repositories are:
- Main - Canonical-supported free and open-source software.
- Universe - Community-maintained free and open-source software.
- Restricted - Proprietary drivers for devices.
- Multiverse - Software restricted by copyright or legal issues.
次期 LTS の Ubuntu 20.04(コードネーム "Focal Fossa")では本格的に Python2 が除去されるらしいのですが、実際のところどうなるのか気になりますね…!
- 投稿日:2019-12-04T17:06:33+09:00
【AWS】既存のECS ClusterにFargate Spotを適用させる
概要
今年のre:inventでFargateにもspot Instanceみたいなものを使えるようになりました。
お値段とかどんなサービスかはクラメソさんのブログを見てください。
【最大70%引きで使用可能、東京でも利用可能】AWS Fargate Spotがリリースされました。今回は既存のClusterに適用にするにはマネジメントコンソールでのやり方がわからなかったためCLIでやりました。
そのための手順のみ記載していきます。手順
AWS CLIのアップデート
CapacityProviders用のコマンドがいるのでバージョンを最新にします。
consolepip install --upgrade awscli今回の手順は以下のバージョンで行いました。
console$ aws --version aws-cli/1.16.296 Python/3.7.4 Darwin/18.7.0 botocore/1.13.32CLIコマンド
aws ecs put-cluster-capacity-providers \ --cluster [クラスター名] \ --capacity-providers FARGATE FARGATE_SPOT \ --default-capacity-provider-strategy capacityProvider=FARGATE,weight=1,base=1\ \ --profile [プロファイル名]参照記事には、
--capacity-providersには既に設定されているCapacityProvidersも全部書きましょうとありますが、ないのでFARGATE,FARGATE_SPOTの2つでOKです。
--default-capacity-provider-strategyに関しては、デフォルトでのCapacityProvidersと割合(weight)及び最低必要数(base)を記載します。Update Cluster
コマンド実行後にCapacityProvidersタブにこのように表示されます。
あとは、右上の
Update Clusterを押すと以下のように割合設定できます。
注意点
2019/12/04時点ではCapacityProvidersタブにあるCapacityProviderを選択して
Deactivateを押すと消えます。
消えたあとにUpdate Cluster画面に戻っても、もとに戻せないのでまたCLIからです。検証中ですが、設定だけしても次回タスクが
FARGATE_SPOTで上がってこない可能性あります。
その場合、CLIでサービスを強制deployしたら行けました。
こちらは、検証後に再度アップします参照記事


- 投稿日:2019-12-04T16:50:42+09:00
OneLoginとSwitchロールでAWSにログインできるようにした
本記事は「Opt Technologies Advent Calendar 2019」4日目の記事である。
1. 概要および制限事項
本記事では
AWS対してOneLoginで認証する手順については記載しない。OneLoginを利用してあるAWSアカウントにログインしたユーザがSwitch Roleで別のAWSアカウントに切り替えられる設定
およびOneLoginの認証情報をもとにSwitchRole可能なアカウントを制限する設定について記載する。
またAWSコンソールの利用のみ対象とし、IAMロールに紐づく一時アクセスキーの取得は対象外とする。今回の手順では一部にAWS CLIを使用する。
$ aws --version aws-cli/1.16.195 Python/2.7.16 Darwin/19.0.0 botocore/1.12.1852. 手順内容
手順はおおよそ以下となる。
- マスターアカウントにSAMLとIAMロールを設定
- OneLoginにAWS用のコネクタを作成
- メンバーアカウントにSwitchRoleのためのIAMロールを作成
- ユーザにURLを共有
2-1. 構成
上図のようにユーザはOneLoginでマスターアカウントにログインする。
各プロダクトが稼働するメンバーアカウントはSwitchRoleして利用することを考えた。2-2. OneLoginでマスターアカウントにログインする
参考資料をもとに設定をおこなう。
参考資料に加えて必要な手順として、今回の構成においてユーザにはメンバーアカウントへのSwitchRoleをさせるため
マスターアカウントに作成するIAMロールにはその権限を付与する。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "*" } ] }2-3. メンバーアカウントにSwitch Role用のIAMロールを作成
メンバーアカウントにてIAMロール作成する。以下はCloudFormationで作成するさいのサンプル。
sample.yamlAWSTemplateFormatVersion: 2010-09-09 Parameters: MasterAccountId: Type: String Resources: IAMRole: Type: 'AWS::IAM::Role' Properties: RoleName: 'PowerUserRole' AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Action: 'sts:AssumeRole' Effect: 'Allow' Principal: AWS: !Sub 'arn:aws:iam::${MasterAccountId}:root' Sid: '' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/PowerUserAccess'AssumeRolePolicyDocumentに
arn:aws:iam::(マスターアカウントのID):rootを設定することで、マスターアカウントからのSwitchRoleだけ許可する。AWS CLIでは以下のようにデプロイする。
注意:メンバーアカウントに対してデプロイするよう注意することmasterAccountId=hoge productAccountProfile=huga aws cloudformation deploy \ --template-file sample.yaml \ --stack-name switchrole-from-onelogin \ --parameter-overrides MasterAccountId=${masterAccountId} \ --capabilities CAPABILITY_NAMED_IAM \ --profile ${productAccountProfile}2-4. 限られたユーザのSwitchRole
上記のIAMロールの設定ではマスターアカウントにログインしたユーザは全員SwitchRole可能となっている。
Administratorなど限られたユーザにのみSwitchRoleを許可したい場合、以下のように設定する。sample.yamlAWSTemplateFormatVersion: 2010-09-09 Parameters: MasterAccountId: Type: String MasterAccountRoleName: Type: String Resources: IAMRole: Type: 'AWS::IAM::Role' Properties: RoleName: 'PowerUserRole' AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Action: 'sts:AssumeRole' Effect: Allow Principal: AWS: - !Sub 'arn:aws:sts::${MasterAccountId}:assumed-role/${MasterAccountRoleName}/erai@example.com' - !Sub 'arn:aws:sts::${MasterAccountId}:assumed-role/${MasterAccountRoleName}/kanrisha@example.com' Sid: '' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/PowerUserAccess'OneLogin経由でマスターアカウントにログインした状態では
<IAMロール名>/<メールアドレス>で認証されているため
AssumeRolePolicyDocumentにarn:aws:sts::(マスターアカウントID):assumed-role/(IAMロール)/(メールアドレス)となる。デプロイは手順2-3と共通。
2-5. SwitchRole用のURLを共有
作成したIAMロールをAWSコンソールから確認すると、赤枠の
コンソールでロールを切り替えることができるユーザーに、このリンクを知らせますが表示される。
このURLをユーザに共有する。
ユーザがOneLogin経由でマスターアカウントにログインしている状態で上記リンクを踏むと以下の画面に遷移する。
上記項目を設定するとSwitchRole設定が完了する。
3. 参考
OneLoginを利用してAWSにSAMLでログインする: Serverworks ENGINEER BLOG
http://blog.serverworks.co.jp/tech/2018/06/22/onelogin-aws-saml/


- 投稿日:2019-12-04T15:31:26+09:00
システム運用をChatOpsからNoOpsでさらに効率化した話
ChatOpsとNoOpsとは

ChatOpsとは?
- 「Chat」と「Ops」という2つのワードを掛け合わせて作られた造語
- チャットサービス(Chat)をベースとして、システム運用(Ops)を行うという意味がある
- みなさんご存知の
Slack、ChatworkなどがチャットサービスにあたりますNoOpsとは?
- 運用のうれしくないことをなくす「No "Uncomfortable" Ops」のこと
- システム運用そのものをなくしてしまう“No Ops” という意味で発言されることもある?
システム運用、監視について私が思うこと

監視ツール、サービスって結構いっぱいある
Zabbix, NewRelic, Mackerel, Prometheus, Nagios, Sensu...etc.
CloudWatch, Datadog, Stackdriver...etc.
なんだこれ、どれ使ったらいいの
この時に私が考えたこと

どれも基本的にやってくれることってこんなことですよね
- モニタリング(Monitoring)

- ロギング(Logging)
- リソース(CPU負荷、メモリ使用率)レポート

- アラート(Notification)

・・・ん

アプリの設計にも同じこと言える
バッチ開発時、エラーはメール or Slackで通知後して終了ってなりがち

え?じゃあアラート来たら家のパソコン開くの
気持ちよく飲んでる時
とかすごい嫌じゃない
可能なら自動 or リモートで簡単に対応したいですよね

そこで ChatOps と NoOps

まずはChatOpsからお話

Chatサービスをベースとして、システム運用(Ops)を行うことを実践してみました
以前に別の場所で話している資料があるので、こちらをご参照お願いします

- ※引用:ChatOpsでシステムの運用が改善された話続いてNoOpsのお話
NoOps = 運用のうれしくないことをなくす(自動化)するってことと解釈し、実践してみました
アプリの現在の設計が影響して、「定期的に○○しないといけない」とか、「エラー(もしくはアラート)が起きた時に何かしらのOpsをしないといけない」とかってことよくありますよね
監視ツールからアラートがきた時に何かアクションできればいいはず
通知後にアクションできるやついた
それできるよ、そうCloudWatchさんならね(ちょっと古いですが・・・

実は皆さんも既に NoOps してるはず
- CPU負荷監視のアラートからのAutoScaling
- SQS監視にて処理速度低下検知アラートからのAutoScaling
- アラート時にLambda動かしてWEBサーバのプロセス再起動など
これだ
今回のNoOps化したい課題
- アプリケーションにて、S3からファイルのDL(download)を繰り返し、削除されないことでEC2のフルディスクによる障害が発生
- Slackへアラートがきたら手動対応を繰り返してた

- AWS Lambda で CloudWatch アラームからの障害対応自動化 - Qiita
- 先駆者というのはいるもんなんだなと感動しました
- 今回対応したのはまさに↓これw
- 毎朝、アラートが来てないか Slackを確認する手間もなくなり、ChatOpsでコマンド打つこともなくなったので、ChatOps -> NoOps化できた
- アラートが発生しても自動で解決する状態ができた
これで心置きなくお酒が飲めますね


開発時、エラーが起きたらメール等での通知っていう設計もありですが
アラートのたびに会社行きたくないので自動復旧させるなら CloudWatch & Lambda でNoOpsかなーと思いました
アプリちゃんと直すまで手動対応なやつは自動化しちゃおう
それでこそエンジニア・・・ですよね

その仕組みが他のPJでも役にたつはず
まとめ
- 導入する監視ツールと運用(Ops)はセットで考えよう
- アプリの設計も同じ
- 運用時の手動対応をChatOpsで自動化すると会社行かなくていいしスマホ(Slack or Chatwork)で対応できるよ
- さらに、NoOps化すると会社行かなくていいし、自動障害対応できるよ
皆さんの
Opsが少しでもハッピーになりますように


- 投稿日:2019-12-04T15:17:35+09:00
Provisioned Concurrency for Lambda Functions ちょっと試してみた。
AWSの一番好きなサービスはAWS Lambda な人です。
re:invnet 2019真っ最中で、量子コンピューティングサービス出てきたり、EKS for Fargateとか出ている中で、Lambdaのアップデートがいくつかありました。
その中で、過去の経緯上、個人にちょっと熱かった
Provisioned Concurrency for Lambda Functions
についてやってみたので、所感のメモです。
※リンクは日本語でたら変えるかも例によって、クラスメソッドさんが速報を上げてくれているので、こちらも
[速報]コールドスタート対策のLambda定期実行とサヨナラ!! LambdaにProvisioned concurrencyの設定が追加されました #reinvent | Developers.IO
リンクとかは随時更新します。
Lambdaをポーリング
AWS Lambda、非常に便利なんですが、VPC内で使うと、実行時にENI作成が起きて、場合によっては、1分ぐらいかかることがあって、
API Gatewayから呼び出したりすると、API Gatewayが先にタイムアウトする(最大29秒なので)ってことが起きていました。今年、ENIをLambda関数デプロイ時に作成し、起動を高速化する改善がありましたが、それでも、リクエストが増えたときには、Lambdaの起動が発生し、コールドスタートは発生するっていう状況でした。
コールドスタートをなるべく少なくするために、Lambdaを起動し続けるように、ポーリングするという手段が取られていたわけですが、
今日発表されたProvisioned Concurrency for Lambda Functionsで、自前でポーリングをしなくても良いようになったようです。あ、コールドスタートについては、Lambda関数のモジュールの大きさとかも絡んでくるので、一概に遅いわけではないです。悪しからず。
試してみた
すでに、東京リージョンにもできているので、新規作成してやってみます。
新規作成して、VPC指定(別に指定する必要はないみたいですけど、まあ)、バージョンを作成します。
同時実行数という項目の中に、プロビジョニングされた同時実行とい項目が追加されています。
追加ボタンを押すとこんな感じのダイアログが出てきます。
ちなみに、バージョン/エイリアス指定だと、当たり前ですが、選択肢が減ります。
なお、#latestは指定できないみたいです。
で設定してみます。とりあえず プロビジョニングされた同時実行 は10にしてみました
実行数は、予約済み実行数と一緒で、「アカウントで指定されているLambdaの同時実行数から、一定数を割り当てる」ので、
あまり割り当てすぎると、割り当てしてないLambdaに大量アクセスがあった場合にスロットリングエラーが起きるかもしないですね。
今回は適当に10割り当てましたが、ちゃんとアクセス数の検討、負荷試験を実施して、適切な数値をセットしたいですね。保存を押すと、設定が始まります。
なお。この状態では、該当Lambdaのロググループ内は空ですが、
設定が進むと、ログストリームができてきます。(つまりLambdaのコンテナが起動した状態)
完了すると、、、なぜか20個のログストリームができていました。謎です。 この事象については何か分かったら追記します。。。
ちなみに、ログストリームには何も書かれてないです。テンプレートそのままなので、起動時に実行される処理があって、ログに吐き出すようにしていれば、そちらの記載されるのではないかと。
で、試しに、設定したバージョンでアクセス(テスト実行してます)すると、
起動したうちの1つにイベントに記載されました。
なお、#latestでテスト実行すると、
対象外なので、別のログストリームが作成されます。
とりあえずは今日のところは以上です。
公式のブログにある通り、Apache Benchなどで、負荷かけてみないとダメかなーというところは、ちょっと今後の課題ということで。価格
課金に関しては、以下になっているようです。
Price Provisioned Concurrency $0.000005384 for every GB-second Requests $0.20 per 1M requests Duration $0.000012562 for every GB-second 以下めっちゃGoogle翻訳ですがw、
プロビジョニングされた同時実行性(Provisioned Concurrency)は、機能で有効化してから無効化するまでの時間から計算され、最も近い5分に切り上げられます。価格は、関数に割り当てるメモリの量と、それに設定する同時実行の量によって異なります。期間(Duration)は、コードが実行を開始してから戻るか終了するまでの時間から計算され、最も近い100ミリ秒に切り上げられます。価格は、関数に割り当てるメモリの量によって異なります。
Lambdaの無料利用枠は、Provisioned Concurrencyが有効になっている機能には適用されません。関数のプロビジョニングされた同時実行を有効にして実行すると、以下の価格に基づいてリクエストと期間に対して課金されます。
無料利用枠対象外になるんですねー。これは注意が必要かも。
ポーリングを自前で設定しなくてもよくなったのは、大きいかもしれません。
数が多くなると、設定も面倒ですからねぇ。。。(遠い目)
こっちも一緒か。。。ちなみに、同時に、Using Amazon RDS Proxy with AWS Lambda | Amazon Web Services
というアップデートも発表されており、
今年あったLambdaのアップデートで、今まで結構アンチパターンだと言われていた、Lambda + RDSの組み合わせが使いやすくなったのではないでしょうか?
随時更新します。

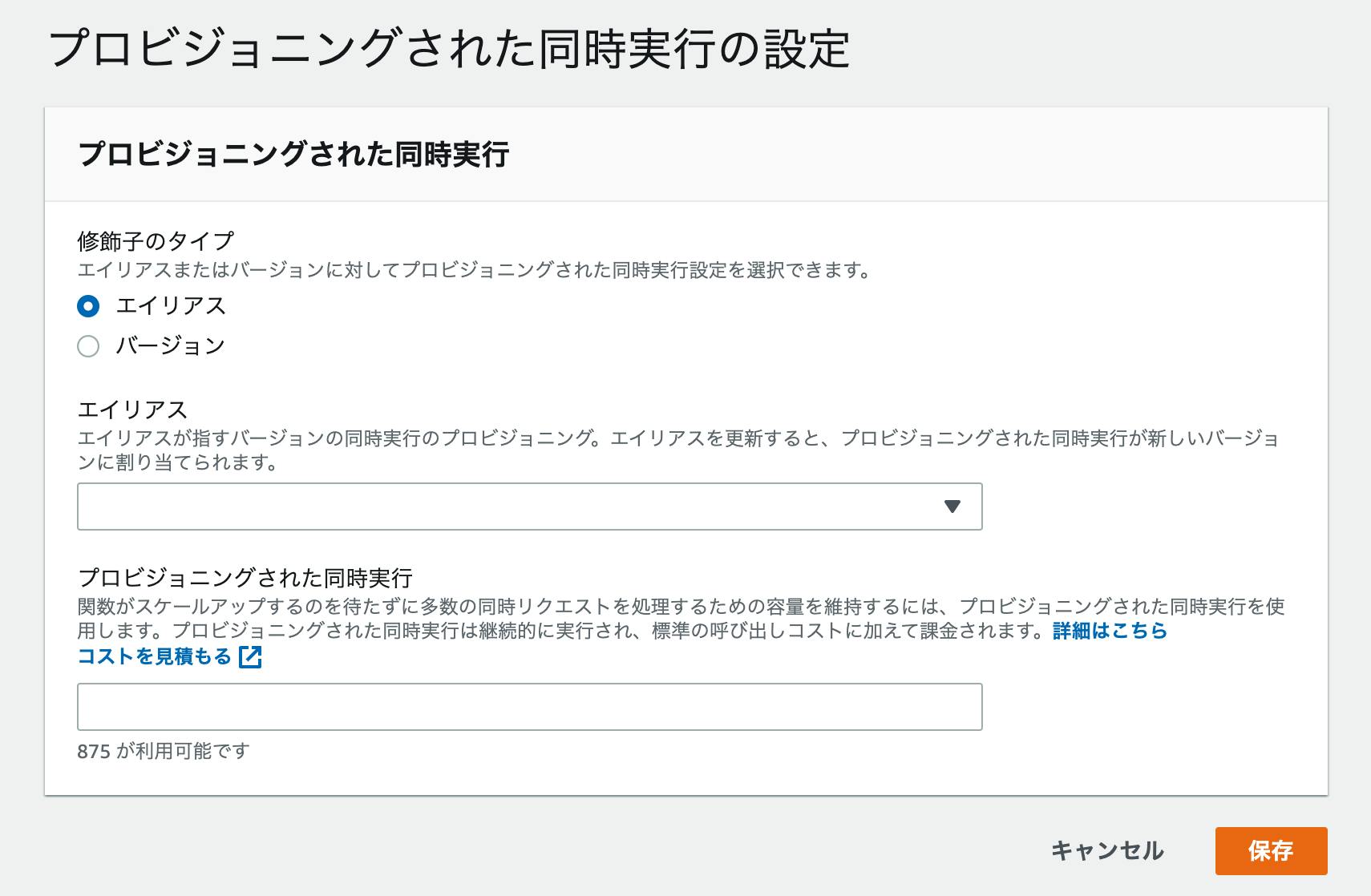










- 投稿日:2019-12-04T15:14:23+09:00
【AWS】AWS Organizations 設定ハンズオン
AWS Organizations
IAMのアクセス管理を大きな組織でも楽に管理できるマネージド型サービス
「組織」という単位をつくりマスターアカウントが管理者ルートから管理するという仕組み
次のようなことができる
- 複数アカウントの一元管理
- AWSアカウンをグループ化してポリシーを適用して一元的に管理する
- 新規アカウントの自動化 - コンソール/SDK/CLIでAWSアカウントを新規作成して作成内容をログとして保存できる
- 一括請求
- 複数AWSアカウントの請求を一元化できる
機能セットの選択
Consolidated Billing Only
支払い一括代行をする場合に選択する
ALL Feature
支払一括代行も含めて企業内の複数アカウントを統制したい場合に選択
マスターアカウントの設定
複数のAWSアカウントがある中で、1アカウントのみをマスターアカウントとして、その他をメンバーアカウントとして運用する
AWS Organizationsの設定 ハンズオン
- 組織を作成する
- 管理者ルートにマスターアカウントを設定する
- 既存のAWSアカウントをメンバーアカウントとして組織内に追加する
- 組織単位(OU)を設定する
- サービスコントロールポリシー(SCP)を設定する
1. 組織をつくる
マネージメントコンソールからAWS Organizationsのページへ。
組織の作成をクリック
確認メールが届くVerify your email address をクリック
アカウントの招待 をクリックして任意のAWSアカウントを登録する
登録後、「アカウントの整理」タブから組織をつくる
こんな感じで追加していく
追加したら「ポリシー」タブからポリシーを追加する
EC2にアクセスできないポリシーを作成する
ポリシー名は適当に
development_groupとする
Jsonはデフォルトで表示されているもので問題ない
画面下部の「2.リソースの追加」をクリックし、次のスナップショット通りに記入
画面下部の「3.条件を追加する」をクリックし、次のスナップショット通りに記入
ポリシーの作成 をクリックする
その後「アカウントの管理」タブからサービスコントロールポリシーを有効化する
以上。













- 投稿日:2019-12-04T14:37:58+09:00
VDI環境を使ってみた
概要
VDI環境のAWS workspacesを業務で利用してみました。
ローカル端末と比較して、なかなか利点を感じましたので、その内容を共有します。VDIとは
VDIとは
wikipedia wrote:
仮想デスクトップインフラストラクチャー (VDI:virtual desktop infrastructure もしくは virtual desktop interface) とは、仮想環境のためのハードウェアとソフトウェアを含むデスクトップ仮想化のためのサーバーシステムを指すです。AWS workspacesに特化した書き方をすると、クラウド上であがってるOSにリモートデスクトップしてる環境になります。
ここが良き
- 複数端末から同じ環境を利用できる(業務上、4か所から使用しておりておても便利)
- 作業中の状態のまま切断、再開できる
- キッティング済みの状態でテンプレートを作成し配布できる
- ID,PWを伝えれば環境を他者と共有できる(物理的に離れている開発メンバーの環境のメンテナンスがしやすい)
- 開発環境構築に邪魔なプロキシがいない
- 端末に情報を残さない
- マルチディスプレイに対応
- ディスク、CPU、メモリの変更が可能
- 料金が月額固定と変動(基本+時間単価)と柔軟
ここはわろし
- AWSに障害が起きると何もできなくなる
- FW内からの利用時には、TCPとUDPのポートをあける必要あり(参考)
- ずっと(何日も)つなげてると入力が遅延しまくる
- 接続ソフトのアップデートがうまくいかない
他
- 社内のサーバーとの接続も可らしい
- 専用ソフトから接続する
- ブラウザアプリからの接続も可能
- クライアント証明書認証も可
妄想そう
- 開発メンバーが数か月で増減するような現場では非常に有効そう
- ローカル側をゼロクライアントにすればコストも圧縮できそう
- 個人の環境をクラウド化したらPCの買い替えから解放されるのだろうか
- 投稿日:2019-12-04T14:34:24+09:00
S3オブジェクトレベルのログ記録+監視方法
こんにちは。みやがわです。
こちらは Fusic Advent Calendar 2019 - Qiita 4日目の記事です。
昨日の記事は、@gorogoroyasu による リアルタイムで顔にモザイクをかける - Fusic Tech Blog でした。
機械学習に興味アリの方、是非ごらんあれ。さて、本日はタイトルの通り
「AWS S3に対するログ記録+監視方法」について書いてみました。(自分のような
AWS触りたてホヤホヤな方向けです。)本記事で出来るようになること
S3の操作ログを、オブジェクト単位で記録することができます。
どのIAMユーザーがどのオブジェクトをどう操作したのかを記録して、一覧画面で確認できます。使うサービス
- IAM (アカウント管理)
- S3 (ストレージ)
- CloudTrail (リソースのモニタリング)
- Amazon Athena (ログ分析)
ログ記録
まずは、S3への操作イベントに対してログファイルが自動生成されるよう設定していきましょう。
S3
- ログファイル用バケット
今回の監視対象バケットを
miyagawa-testとします。
このバケットのログを保存するための新しくバケットをmiyagawa-test-logとして用意しています。
- オブジェクトレベルログ記録
監視したいバケット(miyagawa-test)の
プロパティを開きます。ここに
オブジェクトレベルログ記録という設定があるので、有効化されてない場合は有効化します。
CloudTrail
[証跡の作成] より「証跡」と呼ばれる監視機構を一つ作ってみましょう。
- 設定箇所
「証跡情報の作成」画面では、大きく分けて以下のような設定項目があります。
- 証跡名・リージョン - ○○イベント - 管理イベント (リソースに対する、もしくはリソース内でのイベント。(例)マネジメントコンソールへのログインイベント) - Insightsイベント (異常なレベルの 書き込みAPI) - データイベント (データに対するイベント) - ストレージの場所
今回の目的では、データイベントのみ関係があるので、その他のイベントは全てオフに設定します。
以下が私が行った設定です。- 証跡名・リージョン - 証跡名:「miyagawa-test-trail」 - 証跡情報を全てのリージョンに適用:「いいえ」 - ○○イベント - データイベント: - S3:バケット追加より「miyagawa-test」を追加、「書き込み」のみチェック - その他:全て「いいえ」 - ストレージの場所 - S3バケット:「miyagawa-test-log」 - その他:全て「いいえ」[作成]より証跡が出来ます。
「証跡情報」一覧画面より、ステータスが緑色になっていることを確認してください。
オン時に対象S3のオブジェクトに操作があれば、ログ用バケット記録されます。やりましたね!
※ログ記録のオン/オフは、証跡の設定画面右上にあるトグルスイッチより切り替え可能です。
- ログファイル用バケット
初回ログ生成時に、ログ用バケット内に「AWSLogs」フォルダが自動生成されます。
ログファイルはJSON形式です。
試しにmiyagawa-testというIAMユーザで、hoge.pngというファイルをバケットに追加したときのログファイルを見てみましょう。数分待つと、ファイルが生成されます。
- 出来上がったものがこちら
短時間に複数の操作を行った場合は、1ログファイルにこんなのがつらつら記述されます。
ログ監視
ログは確認できてこそのものです。
ファイル一つ一つを開いて見るわけにはいかないので、ここでAmazon Athenaというサービスをご紹介します。こちらは、
SQLを用いてログファイルの分析・一覧表示を行う優れものです。ログデータのテーブルを作ろう
[CloudTrail] > [イベント情報] の画面を開き、下記リンクをクリックします。
表示されるSQLを横目に、無心でログ用バケットを選択し、[テーブル作成]をクリックして完了です。
Athenaの画面を開くと、こちらで作成したテーブルがサイドバーに表示されます。
SQLでデータを見よう
SQLを流してデータを見てみましょう。
SELECT * FROM cloudtrail_logs_miyagawa_test_log
JSON形式で見たデータがそのまま一覧で出ていますね。
これを
どのIAMユーザーがどのオブジェクトをどう操作したのか
が分かる形式に変換しましょう。SELECT from_iso8601_timestamp(eventtime) AT TIME ZONE 'Asia/Tokyo' AS eventtime, eventname, useridentity.username, resources[1].arn AS object FROM cloudtrail_logs_miyagawa_test_log ORDER BY eventtime DESC;
やりましたね!
料金
おわりに
もっと楽にログが見れるものかと思っていたのですが、
SQLを叩かないといけないようですね。ちなみに、AthenaのSQLはPrestoに準拠しているのですが、完全にPrestoをサポートしているわけではないようです。
(上記のクエリでAthenaのViewを作ろうとしたらtimezone周りでエラーが出ました。)解決策が分かり次第追記します。。!!
それでは、明日のアドベントカレンダーは @tsukabo です!
お楽しみに!









- 投稿日:2019-12-04T13:41:13+09:00
[AWS][CFn]GuardDutyの設定
はじめに
初めまして。なじむです。
クラスメソッドさんのブログ記事、AWSアカウントを作ったら最初にやるべきこと ~令和元年版~を参考にさせていただき、AWSでの初期設定をCloudFormationで実施していこうという記事をしばらく書いていこうと思います。
今回は「GuardDutyの有効化」をCloudFormationで実施していきます。GuardDuty自体に関してはどこかで記事を書いていこうと思います。
※CloudFormationとは何かをある程度理解している人向けになってしまうと思うのでその点はご了承ください。前提
サンプルコードで実行しているのは以下です。
- GuardDutyを有効にする
- SNSを作成する(今回はメール通知)
- GuardDutyでイベントを検知した時にCloudwatchイベントを使用してSNSに通知する
サンプルコード
--- AWSTemplateFormatVersion: 2010-09-09 Description: GuardDuty #------------------------------ # Parameters: Your resource list #------------------------------ Parameters: EMailAddress: # スタック作成時に任意のメールアドレスを指定してください。 Type: String Description: Specifies your E-Mail for notify GuardDutyAlert. #------------------------------ # Resources: Your resource list #------------------------------ Resources: # GuardDutyを有効にする GuardDuty: Type: AWS::GuardDuty::Detector Properties: Enable: true # SNSを作成する(今回はメール通知) ## Topic SNSTopic: Type: AWS::SNS::Topic Properties: TopicName: GuardDutyTopic #任意の名前に変更してください Subscription: - Endpoint: !Ref EMailAddress Protocol: email ## Topic Policy SNSTopicPolicy: Type: AWS::SNS::TopicPolicy Properties: PolicyDocument: Id: default_policy_ID Version: 2012-10-17 Statement: - Sid: default_statement_ID Effect: Allow Principal: AWS: "*" Action: - SNS:GetTopicAttributes - SNS:SetTopicAttributes - SNS:AddPermission - SNS:RemovePermission - SNS:DeleteTopic - SNS:Subscribe - SNS:ListSubscriptionsByTopic - SNS:Publish - SNS:Receive Resource: !Ref SNSTopic Condition: StringEquals: AWS:SourceOwner: !Ref AWS::AccountId - Sid: AWSEvents_AlertGuardDutyFindings_Id123 Effect: Allow Principal: Service: - events.amazonaws.com Action: sns:Publish Resource: !Ref SNSTopic Topics: - !Ref SNSTopic # GuardDutyでイベントを検知した時にCloudwatchイベントを使用してSNSに通知する ## Cloudwatch Rule for GuardDuty GuardDutyCWEventRule: Type: AWS::Events::Rule Properties: Name: AlertGuardDutyFindings Description: Alert to SNS topic when find threats by GuardDuty EventPattern: { "source": [ "aws.guardduty" ], "detail-type": [ "GuardDuty Finding" ] } Targets: - Arn: !Ref SNSTopic Id: Id123実行結果
上記テンプレートを用いてスタックを作成した結果です。
初めての場合はGUIから確認した方が分かりやすいので、結果はGUIで確認します。
GuardDuty
SNSTopic
GuardDutyCWEventRule
まとめ
今回はCloudFormationでGuardDutyを有効にしようお届けしました。
GuardDutyは1クリックでできるので正直CloudFormationで作らなくても良いかもしれませんが、通知の設定をしないと何かあっても通知が来ないので、そこまでをまとめて実施するようテンプレートにしました。
何かのお役に立てれば幸いですノシ


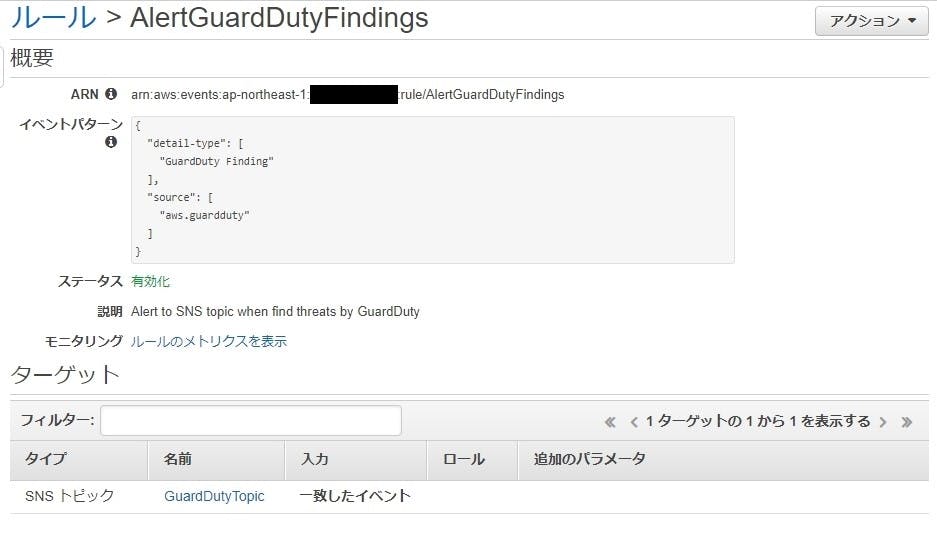
- 投稿日:2019-12-04T13:11:23+09:00
Classic Load BalancerからApplication Load Balancerへの移行
Classic Load BalancerからApplication Load Balancerへ移行したのでその時の手順を記録しておきます。
移行のメリット
移行には基本的にメリットしかないと思うのですが以下の点に魅力を感じて移行しました
ホストベース・パスベースのルーティングのサポート
これまで1サービス1ロードバランサの構成だったのですが、ALBに移行することで、一つのロードバランサで済みます。
あまり多くのサービスとつなぐと設定が複雑になるので避けるべきかもしれませんが、費用が削減できます。ヘルスチェックの高機能化
これまでは単一のヘルスチェックしか動かせなかったのですが、複数のターゲットグループが存在する場合、それぞれにヘルスチェックを設定することが可能となります。
WAFの設定が可能
ALBであればWAFが設定可能です。
リダイレクト設定
これまでEC2インスタンスで設定していたものがロードバランサでの設定で対応可能となります。
いくつか上げましたが、こちらを参照すると詳細なメリットがわかります。
移行手順
- 移行ウィザードを使って新ALBを作成
- Route53でELBのDNS設定の重み付けを95にする
- Route53で新規ALBのDNS設定を重み付け5で作成する
- 動作確認、新規ALBのアクセスが問題ないことを確認して、ELBのDNS設定の重み付けを0にする
- 問題なければELBのDNS設定の削除、ELBの削除
それぞれ簡単に解説すると…
移行ウィザードを使って新ALBを作成
クラシックロードバランサを選択すると移行ウィザードが表示されるのでそこから新しいALBを作成します。
この時ロードバランサの名称やターゲットグループの名称も決定します。デフォルトでは同じ名称となっていますが、変更する場合はここで変更します。後からでは名称の変更ができない(はず)です。Route53でELBのDNS設定の重み付けを95にする
Route53でこれまで設定していたELBのAレコードの設定を変更する。
上記画像のように重み付けを加えて95としておく。
このとき95というのは適当な数字で自分がわかりやすいものとした。一旦は5%をALBに飛ばすつもりにしたので次にALB側で重みを5とすると95%と5%とわかりやすく分かれる。
任意ではあるが、重みは0~255の間で設定できるのでその点だけ注意。
セットIDは一意であれば任意のものでOKRoute53で新規ALBのDNS設定を重み付け5で作成する
2番と同じ様に重み付けを変更します。
動作確認、新規ALBのアクセスが問題ないことを確認して、ELBのDNS設定の重み付けを0にする
動作確認します。ALBを通してEC2インスタンスにアクセスしていることを確認するために、ALB・EC2共にモニタリングします。
動作・モニタリング結果共に良好であれば、CLBの重み付けを0とします。問題なければELBのDNS設定の削除、ELBの削除
すべてALB経由でアクセスすることを確認したのち、CLBを削除します。Route53にした重み付けはそのままでもOKです。
以上で移行が完了しました。移行ウィザードとRoute53の重み付けの設定をいじるだけで簡単に移行ができました。
高機能かつ費用が抑えられるので早めの移行をおすすめします。


- 投稿日:2019-12-04T12:17:23+09:00
ec2-userをパスワード認証にする
公式に書いてある通りではうまくいかず
一味加える必要があったゾ…(keyAuthentication no)# #ec2-userにパスワードを設定する # sudo passwd ec2-user # #sshd_configをちょっといじる必要がある # sudo vim /etc/ssh/sshd_config ----------------------------------------------------------- PasswordAuthentication yes #パスワード認証を有効化 keyAuthentication no #鍵認証を無効化 ----------------------------------------------------------- # #sshdを再起動しないと有効にならない # sudo service sshd restart # #リログして確かめるゾ~ # exit
- 投稿日:2019-12-04T11:59:30+09:00
AWS DeepComposer ワークショップに参加し実機を触ってきた話
AWS re:Invent 2019で新たに発表された「DeepComposer」のワークショップに参加し、実機を触ってきました。
現地でAWS様に「書きます!」と宣言し、記事内容見ていただきOK貰いましたので、その模様を紹介したいと思います。
はじめに: サービスはPreviewなので触り倒した話は書けない
サービス自体がPreviewということもあり、規約上、サービスの評価に関する内容は載せられませんので、公式に出ている資料をベースにして、DeepComposerとはこんな感じだよという、ワークショップの報告のような形になりますので、予めご了承いただければと思います。
ちなみに、Previewは以下から申し込めます。
https://pages.awscloud.com/AWSDeepComposerPreview.htmlDeepComposerとは?
AWSが提供する、人々がAIを学ぶための新しいガジェットで、Generative AI algorithmsを学ぶことに特化し、機械学習による自動編曲にテーマを置いています。
Generative Adversarial Networks (GAN) というモデルに基づく生成物は、実在しないものでありながら、現実との区別がつかないほどの精度になるそうです。
つまりDeepComposerで作曲した楽曲も、少し聴いただけではAIによるものか人手によるものかどうかが分からない、ということでしょうか。
何ともすごい時代がやってきたものです。
詳しくは、以下のサイトにも紹介されています。
AWS DeepComposer – Compose Music with Generative Machine Learning ModelDeepComposer Workshop
今回のワークショップは、そのDeepComposerの実機を触って、試すことができるものです。
アジェンダは以下の内容でした。
- ML on AWS (10 miniutes)
- Introdution to ML and Generative AI (20 minutes)
- Lab 1- Music composition with AWS DeepComposer models (35 minutes)
- Lab 2- Training models with AWS DeepComposer (55 minutes)
ここでは、3.と4.のLabの模様に絞って紹介していきます。
Lab 1: Music composition with AWS DeepComposer models
DeepComposerの使い方、目指すところを理解するための導入ワークショップでした。
最初に、DeepComposerとPCを接続します。
次に、AWSのDeepComposerのマネジメントコンソールを開きます。
ここで「Compose music」を押すと、サンプルの音楽(きらきら星)の音源が表示されます。
ここで再生ボタンを押すと、ピアノの音源が流れます。
この音源に対して編曲していきます。
標準で用意されているモデルの中から「Pop」を選び、「Generate Composition」を押します。
すると、なんと一瞬でPop風のきらきら星が生成されます。
次に、PCに接続したDeepComposerで、AWSが用意した『メリーさんのひつじ』の楽譜に基づいて打ち込みます。
手順の通り、モデルを「Jazz」に変えてみます。
最後に「Generate Composition」を押すと、ジャズ風の『メリーさんのひつじ』が出来上がります。
このように、既存のサンプル音源に加え、DeepComposerで打ち込んだ音源に対して、アレンジすることができます。
マネジメントコンソールでサンプルを扱うことで、DeepComposerが何を学ぶことを目指したサービスでありガジェットなのかということは理解できると思います。Lab 1の資料や手順は、以下に上がっています。
Lab 1: Compose music with DeepComposer models
Lab 2: Training models with AWS DeepComposer
Generative Adversarial Networks(GAN)を使用して音楽を生成する方法を学ぶLabでした。
私がこの分野にあまり精通しておらず恐縮ですが、理解できた範囲でまとめてみます。SageMakerのコンソールにアクセスして、ワークショップ用のノートブックインスタンスで、Jupyterを開くと、カスタムのGANモデルをゼロから作成するための手順とコードが含まれたノートブックが開き、このノートブックを使って学習を進めていきます。
このノートブックで、バッハをインスパイアした機械学習モデルをトレーニングし、トレーニングしたモデルがメロディに伴奏を追加するまでを学びました。
例えば、ユーザーが『きらきら星』などの曲のピアノ音源を1つ作ったとしたら、GANモデルはその音源に3つの他のピアノ音源を追加して、音楽をよりバッハにインスパイアさせるというものです。
トレーニングが進めば進むほど、よりバッハらしくなる (本人と区別がつかないほどに) ということのようです。ワークショップではサンプル音源が用意され、音源をピアノロールとして扱い、x軸に時間、y軸にピッチを持つ、2次元表現として扱いました。
解説によれば、これは画像を機械学習で扱う時の考え方と同じであり、音楽にも応用できるのだと言います。このようにデータを扱った後、ワークショップで予め用意されたモデル(GAN)に基づいて学習していきます。
GANはGeneraterとCitricという2つの要素で構成され、それぞれの損失関数に基づいてトレーニングをしていきます。
損失関数については、AWSにより公開された資料を参照してください。
Loss Functions for GAN architecture
ワークショップの内容はGitHubで公開されていますので、こちらを参考にしてみると良さそうです。
Lab 2- Train a custom GAN modelまた、このLab 2を理解するにあたっては、基礎知識としてGANをちゃんと理解する必要性を感じました。
英語はそこそこ聞き取れましたが、難しかったです。感想
DeepComposer自体の利用は、サンプルモデルを使う範囲であれば非常に簡単ですが、本格的にやるにはLab 2の内容を理解して独自にモデルを作り込むことになります。
そのためには、Lab 2の内容とGANを復唱できるくらいに頭に叩き込まないといけないと感じました。また、ワークショップに取り組んで、この成果物は人が作ったのか、それとも機械的に作られたのか? と問われた時には、もはや問われた側は区別ができない、つまり人間の成果物とAIの成果物の区別ができない時代が来るということが、いよいよ現実に迫ってきたと感じました。
DeepComposerの題材で言えば、過去の作曲家を再現するモデルが共有されて、誰でも簡単に使えるようになる時代がやってくるのではと感じました。
そこには倫理的な問題もある気がしますが、ますます人間とAIの差を縮まっていることを感じました。余談
今回の研修内での理解度確認のため、講師が「kahoot!」というサービスを使われていました。
こちらも面白かったので共有します。「Kahoot!」
https://kahoot.com/参加者全員に同時に4択クイズを出して、結果を集計して、正誤と回答速度でランキング付けするサービスのようです。
UIが面白く、社内研修でどんどん使っていきたいサービスに感じました。以上となります。