- 投稿日:2019-12-04T23:43:06+09:00
【Rails】 N+1問題の解消 & tips
Atrae Advent Calendar 2019 5日目を担当する新卒1年目の土屋です。
普段は、ビジネス版マッチングアプリ yenta でサーバサイドエンジニアとしてRailsで開発をしています。アトラエに入社してから半年間、度々立ち向かってきたN+1問題について書きます。
対象読者は、Ruby on Railsを使って開発をしている初級者〜中級者です、ご容赦ください。N+1問題とは
ループ処理(each, mapなど)を用いてデータを取得してくる際に、
必要以上にSQL文(クエリ)が発行され、レスポンスが遅くなる(パフォーマンスが低下する)ことです。例えば、
AさんというUserのPosts(投稿)を5件取得して、Aさんの投稿一覧のページを表示したいといった時には、
- AさんのUserデータを取得するために1回
- 5件のPostsデータを取得するために5回
の合計6回のクエリを発行し、表示したいデータを取得することになります。
5件だったら大した問題にはなりませんが、
これが10000件だったら大変です。
仮に1回のクエリで0.001秒しか時間がかからなかったとしても、
10001回もクエリを叩いたら、10秒もかかります。
普段使うアプリやWebサービスでそんなにローディングで待たされたことがあるでしょうか。このように、ループ処理によって、
N件のデータを取得したい時に、N+1回もクエリを発行してしまうことによって発生するパフォーマンス低下を、N+1問題といいます。この問題はコードの書き方次第で解消でき、
適切に書けば、仮に10000件のPostsであっても、2回のクエリで取得できます。
(あんまり大きいテーブルをjoinしたくないとかindex張ろとかそういう話は今回はなしで、、!)とりあえずpreloadかeager_load書こ
結論としては、ループ処理の前に
preloadかeager_loadを書けばほぼ解決します。無思考でも、この2つのどちらかを書いておけばひとまず解決することが多いです。
また、具体的にどう書いてなぜ解決されるのか?などは、ググるとたくさんの素晴らしい記事が出てきますので、そちらを見て頂ければいいかなと思いますw参考:
【Ruby on Rails】N+1問題ってなんだ?
preloadとeager_loadで1000000億倍早くなったはなしけどincludesはやめとこ
「rails N+1問題」などでググると、
上述のpreloadやeager_load以外に、includesを用いた解決法もいくつか出てくるかと思います。
が、includesを用いるのは個人的にはあまりお勧めしません。
理由は、includesを用いると、Railsがよしなにやろうとしすぎて、自分が予期していない挙動になる可能性があるのと、
preloadとeager_loadの違いは明確に理解して使い分けた方が良いと思うためです。
が、詳しくは下記の素晴らしい参考記事達に譲りますw参考:
ActiveRecordのjoinsとpreloadとincludesとeager_loadの違い
ActiveRecordのincludes, preload, eager_load の個人的な使い分け
[Rails] そのincludesはpreloading?それともeager loading?また、上記の
preload,eager_load,includes,joinsなどの違いを考えるにあたって、
テーブル同士の内部結合、外部結合周りが怪しいと理解しづらいので、怪しい方は先にこっちから整理すると良いと思います。
(僕はそもそもこっちが怪しかったので、最初全然ピンとこなかったです。)参考:
SQL素人でも分かるテーブル結合(inner joinとouter join)
INNER JOINとOUTER JOINとは?tips
上記の通り、基本的にはググればわかりやすい記事がたくさんあるのですが、
その中でも僕が実際にN+1問題と戦った時に、
「知りたいけどあんまり出てこなかった」「先輩のコードを見て / 直接聞いて知った」ことを、少し書きます。孫以下の要素の(多段)joinの仕方
UserのPostについたCommentのデータをpreloadしたい時、
CommentはUserの孫要素にあたりますが、以下のように書きます。User.preload(posts: :comments).each.{~~UserのPostについたCommentについたFavoriteのデータをpreloadしたい時、
FavoriteはUserの曽孫要素にあたりますが、以下のように書きます。User.all.preload(posts: [comments: :favorites]).each.{~~その次や次の次は、、
User.all.preload(posts: [comments: [favorites: :hoge]]).each.{~~ User.all.preload(posts: [comments: [favorites: [hoge: :fuga]]]).each.{~~のようにどんどんネストして行くように書きます。
複数かつ多段のjoinの仕方
前節とほぼ同じですが、地味に書き方迷ったので。
Postの子として、CommentとFavoriteがある場合が以下です。User.all.preload(posts: [comments, favorites]).each.{~~eager_load多すぎたらeager_loadだけまとめてscopeにしちゃう
の方がスッキリすると思います。
scope :eager_load_for_hogehoge, -> { eager_load(hoge: [:fuga, piyo: [abc: :def]]).merge(User.where(id: 111)) }チェーンで書かないと、せっかくeager_loadしても意味ない
「完璧にeager_loadingしたはずなのになぜかクエリが繰り返される、、」という時は、
色々とメソッドを介した結果、せっかくeager_loadingしたのに、
また改めてモデルを呼んでる場合があります。おまけ
先日、検索機能を作っている時に、納期に焦って、このN+1問題の確認と解消をサボって雑に進めたら、
検索した際のクエリが重すぎて見事にstagingのDBが落ちました。
これが本番だったらと思うと、ぞっとします。
自分が発行するクエリには責任を持って開発していきたいですね。また、Railsは全くの未経験で入社して8ヶ月程経ちましたが、流石に慣れてきたと同時に、
サーバサイドはデータを司る神になった気分()になれるので、好きになってきました。次回は、同じく1年目の小倉です。よろしく!
- 投稿日:2019-12-04T23:31:40+09:00
[Rails] undefined method `' はself.メソッド名で解決する時がある。
エラー内容
RailsでModelに定義したメソッドがControllerで呼び出すと、"undefined method `メソッド名'"になるエラー。(ControllerとModelで同じメソッド名を定義している場合)
解決方法
モデルのメソッド名の前に "self." を付けたらエラー解消され、
コントローラーで呼び出せた!!models/モデル名.rbdef self.メソッド名 endコード詳細
controllerもmodelも両方、"import_csv"という名前で定義したため、エラーが発生した可能性あり。(追加検証は省略)
modelで定義したメソッドに"self."をつけることでエラー解消。controllers/import.rb#コントローラー class ImportController < ApplicationController def import_csv if Information.import_csv(params[:csv_file]) xxxx end end endmodels/information.rb#モデル class Information < ApplicationRecord def self.import_csv(csv_file) xxxx end endあとがき
self.の効果はplz google!
参考
- 投稿日:2019-12-04T23:04:30+09:00
【Rails】ユーザーのフォロー機能その1 UserモデルとRelationshipモデルの関連付け【Rails Tutorial 14章まとめ】
フォロー機能
特定のユーザーをフォローできるようにし、フォローしたユーザーのマイクロポストをフィードに表示できるようにする。
Relationshipモデル
能動関係と受動関係
ユーザーAがユーザーBをフォローしている場合、AにはBをフォローしている(following, follower)という能動関係がある。
逆に、BにはAにフォローされている(followed)という受動関係がある。この関係を構築するために、Relationshipモデルを作成する。
Relationshipモデルには、フォローしているユーザーのIDを保存するfollower_idと、フォローされているユーザーのIDを保存するfollowed_idカラムがある。$ rails generate model Relationship follower_id:integer followed_id:integerRelationshipモデルからは頻繁にユーザーを検索することになるので、インデックスを追加する。
db/migrate/[timestamp]_create_relationships.rbclass CreateRelationships < ActiveRecord::Migration[5.0] def change create_table :relationships do |t| t.integer :follower_id t.integer :followed_id t.timestamps end add_index :relationships, :follower_id add_index :relationships, :followed_id add_index :relationships, [:follower_id, :followed_id], unique: true end end最後の行は複合キーインデックスと呼ばれ、follower_idとfollowed_idの組み合わせがユニークであり、同じユーザーを2回フォローしたりすることがないようにしている。
$rails db:migrateしておく。UserとRelationshipの関連付け/外部キーと能動関係
UserモデルとMicropostモデルの関連付けはhas_manyとbelongs_toを使って実現していた。
Userモデルではhas_many :micropostsとすることで、Railsは対応するMicropostモデルを見つけることができる。
今回は能動関係を表す関連付けを:active_relationshipとしたいのだが、これだとActiveRelationshipモデルを探してしまうので、これがRelationshipモデルであることを明示する必要がある。また、Micropostモデルではbelongs_to :userとすることで、Railsは対応するUserモデルを見つけることができる。
この時、Micropostモデルにはuser_id属性があるので、これをもとに正確なUserオブジェクトを見つけている。
user_id属性のような、2つのモデルを関連づける属性を外部キー(foreign key)と呼ぶ。
Railsにおける外部キーのデフォルトは<class>_idという形になっており、<class>の部分にはクラス(モデル)名を小文字にしたものが入る。
今回はフォローユーザーを見つけるためにfollower_idを外部キーとして使うのだが、Followerモデルは存在しないので、これが外部キーであることを明示する必要がある。以上により、UserモデルのRelationshipモデルに対する関連付けは以下のようになる(能動関係)。
app/models/user.rbclass User < ApplicationRecord has_many :microposts, dependent: :destroy has_many :active_relationships, class_name: "Relationship", foreign_key: "follower_id", dependent: :destroy . . . endUserモデルは多くの能動関係(active_relationships、ユーザーをフォローしている)を持ち、それはfollower_idによってRelationshipモデルに関連づけられる。
また、ユーザーが削除されたらその関係も削除される(dependent: :destroy)。次に、RelationshipモデルをUserモデルに関連づける。
app/models/relationship.rbclass Relationship < ApplicationRecord belongs_to :follower, class_name: "User" belongs_to :followed, class_name: "User" endこの関連付けにより、以下のようなメソッドが使えるようになる。
Relationshipモデルのバリデーション
Relationshipモデルのfollower_id属性とfollowed_id属性に存在性のバリデーションを追加する。
app/models/relationship.rbclass Relationship < ApplicationRecord belongs_to :follower, class_name: "User" belongs_to :followed, class_name: "User" validates :follower_id, presence: true validates :followed_id, presence: true endテストも書いておく。
test/models/relationship_test.rbrequire 'test_helper' class RelationshipTest < ActiveSupport::TestCase def setup @relationship = Relationship.new(follower_id: users(:michael).id, followed_id: users(:archer).id) end test "should be valid" do assert @relationship.valid? end test "should require a follower_id" do @relationship.follower_id = nil assert_not @relationship.valid? end test "should require a followed_id" do @relationship.followed_id = nil assert_not @relationship.valid? end endここでREDになるのは、自動生成されたRelationshipモデル用のfixtureファイルが原因である。
fixtureファイルを空にすればGREENになる。フォロー/被フォローの関連付け(能動関係)
被フォローユーザー
Userモデルにhas_many throughを使って被フォローユーザー(followed)を関連づけ、被フォローユーザーを取得できるようにする。
フォローユーザー(follower)も被フォローユーザーも共にUserモデルのオブジェクトなので、Userモデル(follower)からRelationshipモデルを経由してUserオブジェクト(followed)を取得するという流れになる。
具体的には以下のコードになる。has_many :followeds, through: :active_relationshipsユーザーは多くの被フォローユーザー(followeds)を持ち、RailsはRelationshipテーブルのfollowed_id(followedsからsを取った単数形)から各被フォローユーザーを取得する。
ここで、followedsというのは文法的に正しくないので、代わりにfollowingを使うことにする。
(過去分詞の代わりに現在分詞を使うことは、誤解を招く原因になると思うが...)app/models/user.rbclass User < ApplicationRecord has_many :microposts, dependent: :destroy has_many :active_relationships, class_name: "Relationship", foreign_key: "follower_id", dependent: :destroy has_many :following, through: :active_relationships, source: :followed . . . endsource:パラメータを使って、following=followedであることを明示する。
これにより、user.followingとすることで、被フォローユーザーを配列で取得できるようになる。フォロー関連のメソッド
ユーザーを簡単にフォローしたりフォロー解除できるように、followやunfollowメソッドを作成する。
また、following?論理値メソッドを作成し、フォロしているかどうかを確認できるようにする。メソッドのテスト
テストから書いていく。
test/models/user_test.rbrequire 'test_helper' class UserTest < ActiveSupport::TestCase . . . test "should follow and unfollow a user" do michael = users(:michael) archer = users(:archer) assert_not michael.following?(archer) michael.follow(archer) assert michael.following?(archer) michael.unfollow(archer) assert_not michael.following?(archer) end end①michaelがarcherをフォローしていないことをfollowing?メソッドで確認する。
②michaelがarcherをフォローする。
③フォローできていることを確認する。
④フォロー解除する。
⑤フォロー解除できていることを確認する。メソッドの実装
各メソッドを実装する。
app/models/user.rbdef feed . . . end # ユーザーをフォローする def follow(other_user) following << other_user end # ユーザーをフォロー解除する def unfollow(other_user) active_relationships.find_by(followed_id: other_user.id).destroy end # 現在のユーザーがフォローしていたらtrueを返す def following?(other_user) following.include?(other_user) end private . . .フォロー/被フォローの関連付け(受動関係)
フォローユーザー
Userモデルとactive_relationshipを関連づけ、被フォローユーザーを取得できるようになったので、逆にフォローユーザーを取得できるようにする。
これは能動関係の関連付けとちょうど逆のことをするだけでよい。app/models/user.rbclass User < ApplicationRecord has_many :microposts, dependent: :destroy has_many :active_relationships, class_name: "Relationship", foreign_key: "follower_id", dependent: :destroy has_many :passive_relationships, class_name: "Relationship", foreign_key: "followed_id", dependent: :destroy has_many :following, through: :active_relationships, source: :followed has_many :followers, through: :passive_relationships, source: :follower . . . endここでsourceパラメータは不要だが、followedとの対称性を強調するために付けている。
メソッドテストの追記
この関連付けによってfollowsメソッドを使えるようになり、フォローユーザーを被フォロワーユーザーから取得できるようになったので、テストに追記する。
test/models/user_test.rbtest "should follow and unfollow a user" do michael = users(:michael) archer = users(:archer) assert_not michael.following?(archer) michael.follow(archer) assert michael.following?(archer) assert archer.followers.include?(michael) michael.unfollow(archer) assert_not michael.following?(archer) endarcherをフォローしているユーザーの中に、michaelがいるかどうかをinclude?メソッドで確認している。

- 投稿日:2019-12-04T21:34:22+09:00
railsのDigest::UUIDを試す
Digest::UUID見てみたのでメモ
公式ドキュメント
https://api.rubyonrails.org/classes/Digest/UUID.html
概要
定義されているメソッドは以下の3つでそれぞれハッシュ関数が違います。
- self.uuid_v3 ->
Digest::MD5を使用- self.uuid_v4 ->
SecureRandom.uuidの簡易メソッド。- self.uuid_v5 ->
Digest::SHA1を使用$ Digest::UUID.uuid_v4 => "4ad2a6a9-0135-4158-94d3-a33e41bbe048" $ Digest::UUID.uuid_v3("name_space", "sample") => "3b0ead59-ca8d-350b-a392-e656db58b0fc" $ Digest::UUID.uuid_v5("name_space", "sample") => "d7a9ae1a-b099-5318-8828-340cc10a1550"rails -v
$ bundle exec rails -v Rails 6.0.2.rc1
- 投稿日:2019-12-04T21:33:18+09:00
【英語】follower/followedの話【Rails】
followうんぬん
Railsチュートリアル14章をやっていて、followという単語の変化形がどのような意味で使われているかが分かりにくいと感じたので、整理しようと思う(僕だけかもしれないけど)。
この分かりにくさは、単に英語の文法的な話だけでなく、(世間一般の)慣習的な話が絡んでくることから生じていると思う。
よって、能動とか受動、分詞といった英文法を理解できていても、頭に?が浮かぶことになる。followerとは何か?
followerはユーザーをフォローしている人である。
AがBをフォローしている場合、Aのことを指す。A follows Bである。
しかし、twitterの話題とかで「フォロワー」という言葉を使った時、AとBどちらのことを言っているのだろう。
「フォロワーに〇〇さんっていう人がいて〜」なんて言った場合に、上の意味を使って主体であるAを指すとしたら、自分のことを「フォロワー」と言っていることになる。
つまり、この文脈ではBを指すことになる。
世間一般的な「フォロワー」の使い方としては、こちらがスタンダードなんじゃないかと思う。しかし、チュートリアルのフォロー機能ではもともとの意味でAを指している。
よって、active_relationship.follower(フォロワーを返す)は、主体としてのAを返す。followedとは何か?
followedとは、followerの逆で、フォローされているBのことである。
B is followed by Aである。
よって、active_relationship.followed(フォローしているユーザーを返す)は、Bを返す。
「フォローしている」って書いてあるんだから、Aを指すんじゃないの?と思うかもしれないが、「Aがフォローしているユーザー」という意味だからBになる。
結論
結局のところ、世間一般的な慣習として使われている「フォロワー」という言葉を無視して、英文法的に考えればいいだけの話である。
現在分詞を使ってfollowing userと書けば、userはAのことであり、"follower"である。
現在分詞は能動関係を表すのだから、当然といえば当然である。過去分詞を使って
followed userと書けば、userはBのことである。
過去分詞は受動関係を表すのだから、やはりこれも当然である。
- 投稿日:2019-12-04T20:58:38+09:00
アセットプリコンパイル時のuninitialized constantのエラー
はじめに
今回のエラーの解決策は至ってシンプルであり、凡ミスでもあったが、
今後忘れないよう、自分への備忘録として記録しておきます。状況
・Herokuへのデプロイ時にアセットプリコンパイルがうまくいかない。
・GemのDeviseの実装テスト中原因から解決まで
アセットプリコンパイルを実施。
rails assets:precompile RAILS_ENV=production以下エラー文が発生。
NameError: uninitialized constant DeviseDeviseの読み込みがうまくいっていないとのこと。
Gemfilegroup :development, :test do gem 'devise' endGemfileのテスト環境位置にgem 'devise'を記入した状態でしかbundle installしていなかったので、本番環境に位置に変更してbundle installでOK。
経験値が少なすぎるからかなかなか気づけませんでした。。。
- 投稿日:2019-12-04T20:03:41+09:00
大丈夫、俺もDocker分かってないから一緒にやろう。
はじめに:挫折しても良い
プログラミング学習って、用語の難しさとか学習コストの高さとかでやっぱ大変なことですよ。
時代が変わって、ハードルは低くなったが未だに「難しそう」という固定概念はあるし、やった事がないことなんて大抵難しいそうなもんです。。
いまだにプログラミングってやつには全然なれなくて、めっちゃ悔しいわけだが、アウトプットをさせて欲しいです。公式の説明文でポルナレフ状態になろう(困惑)
まず最初にみてもらいたいのは、docker社の公式HPでの説明文だ。
え、エンジニアは英語にアレルギー感じちゃダメだって・・?「そうかもしれないが、今じゃない。俺はDockerが触りてえんだよ゛お゛お゛ぉ゛お゛!゛!゛!゛ん゛あ゛あ゛あ゛あ゛あ゛ぁ゛ぁ゛あ゛あ゛!゛!゛!゛!゛。」
ってことで翻訳にかけてみた。
翻訳してみると、こんな感じの解釈になる。
コイツァ...頭が痛い。。まるでセンターの現代文みたいだ。
この時点だと俺もDockerに対する認識はこんな感じだ。
でも、これじゃあ困る。
dockerを使えると嬉しくなるっぽいので、なんとかdockerとは何者なのか、
何ができるのか知っておきたい。Dockerの要点をまとめてみた。
まず、具体的作業を説明する前に一通りやってみた上でDockerについてまとめてみた。
---概要---
・コンテナ型の仮想環境を作成、配布、実行するためのプラットフォーム
・仮想マシン(VirtualBoxなど)と比較されやすい
・Linuxのコンテナ技術を使ったもの
・ホストマシン(PC)のカーネル(OSの中核)を利用し、プロセス(実行状態にあるプログラム?)やユーザなどを隔離することで、あたかも別のマシンが動いているかのように動かすことができる。---メリット---
・コード化されたファイルを共有することで、どこでも誰でも同じ環境が作れる。
・作成した環境を配布しやすい。
・スクラップ&ビルドが容易にできる。
・軽量で高速に起動、停止などが可能---やった作業(復習)---
参考記事:https://qiita.com/wMETAw/items/8cb41425a5d0bdace2df
詳細説明:https://qiita.com/azul915/items/5b7063cbc80192343fc0① dataonlyコンテナを生成
② webserverコンテナ・dbserverコンテナの生成
③ Docker Composeによる複数コンテナの起動
④ データの確認
⑤ MySQL接続今の時点で知っておいて欲しいこと
・自分のパソコンの中に、もう一個パソコンを擬似的に作ることをこれからする。
・イメージ的には「スマホでゲームボーイのゲームを起動する」みたいなことをするっぽい。
・メリットは速さ・手軽さ具体的手順1 "ファイル構成"
$ mkdir dataonly
dataonlyという名前のディレクトリ作成
$ touch Dataonly
Dataonlyファイルの作成
$ touch Gemfile
Gemfileファイルの作成(Railsのgemについては下記リンク参照)
※https://qiita.com/kamohicokamo/items/ded4cad5be1778547640
$ touch Gemfile.lock
Gemfile.lockファイルの作成
$ touch docker-compose.yml
docker-compose.ymlファイルの作成※ディレクトリとファイルの違い
https://webliker.info/60828/ディレクトリやファイル作成に困るようになら、右クリックでファイル作成・フォルダ作成でもいい。
具体的手順2 "各ファイルの中身について"
①ファイルを開く
$ open /dataonly/Dockerfile
②下記テキストをコピペ。
Dockerfileの中身を編集Dockerfile.FROM ruby:2.3.3 # RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN apt-get update -qq RUN apt-get install -y build-essential RUN apt-get install -y libpq-dev RUN apt-get install -y nodejs # ワーキングディレクトリの設定 RUN mkdir /myapp WORKDIR /myapp # gemfileを追加する ADD Gemfile /myapp/Gemfile ADD Gemfile.lock /myapp/Gemfile.lock # gemfileのinstall RUN bundle install ADD . /myapp書き終わったら、内容を保存するためにテキストエディタ上で保存(winならctrl+S/macならcommand+S)
①と②の作業を下記ファイルでも実行(ただし、コピペする内容は下記の内容でやる。)
$ open dataonly/Gemfile
Gemfileの中身を編集Gemfile.source 'https://rubygems.org' gem 'rails', '5.0.0.1'
$ open dataonly/Gemfile
docker-compose.ymlの中身を編集docker-compose.ymldb: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: root web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/myapp ports: - "3000:3000" links: - db具体的手順3 "Railsでプロジェクトを作成"
rails newでプロジェクトを作成
$ docker-compose run web rails new . --force --database=mysql --skip-bundledocker-composeを走らせて、rails newする。
※docker-composeとは、複数のコンテナから成るサービスを構築・実行する手順を自動的にし、管理を容易にする機能。
※rails newについて→https://www.sejuku.net/blog/14144
後で再度ビルドを行う必要がある為、--skip-bundleでビルドをスキップする。具体的手順4 "DBhostの修正を行う"
$ open config/database.yml元の内容を下記内容に書き換える
database.ymladapter: mysql2 encoding: utf8 pool: 5 username: rootpassword: root # docker-compose.ymlのMYSQL_ROOT_PASSWORD
host: db # docker-compose.ymlのサービス名具体的手順5 "Docker上でRailsを起動させる"
コンテナをビルド(https://wa3.i-3-i.info/word12775.html)
$ docker-compose buildコンテナの一斉起動
$ docker-compose up
●なぜ一斉起動が必要か?(https://knowledge.sakura.ad.jp/5736/)・DB作成
$ docker-compose run web rails db:create・通常、RailsでDBを作成しようとするなら、下記のURLを利用。
https://techacademy.jp/magazine/7207確認(きちんとできているか)
http://localhost:3000/具体的手順6 "中身を入れて動作を確認する"
・scaffoldでCRUDを生成してみる
●scaffoldとは何か
https://techacademy.jp/magazine/7204●CRUDについて
CRUD(クラッド)とは、ほとんど全てのコンピュータソフトウェアが持つ永続性の4つの基本機能のイニシャルを並べた用語。その4つとは、Create(生成)、Read(読み取り)、Update(更新)、Delete(削除)である。scaffoldする。
$ docker-compose run web rails g scaffold users name:stringmigrationする
$ docker-compose run web rails db:migrate●migrationとは何か
https://qiita.com/right1121/items/0a54ba76dc4261702d1e・動作確認しよう!
http://localhost:3000/users




- 投稿日:2019-12-04T19:28:44+09:00
railsの今日学んだアクションについてのまとめ
今回学んだアクションはresourcesメソッドの new edit の2つについてです。
newメソッド 新規登録画面
books_controller.rbdef new @book = Book.new endという風に定義する
Book.newを渡してあげることで新しく登録するための設計図をnewが得ることができます。
ビューの方には、このような記述をします。new.html.erb<%= render 'form', book: @book %>renderメソッドでformからテンプレートを引っ張ってきていることがわかります。
このようにするのは登録画面も編集画面も共通のものを使用できるので、外部化することで重複したコードの記述を避けるためです。
bookに@bookを渡すことでform内でも定義を使用できるようになります。editメソッド 編集登録画面
books_controller.rbbefore_action :set_book, only: [:show, :edit, :update, :destroy] def edit end private def set_book @book = Book.find(params[:id]) end endこういう風に記述しており、editには何も渡されていないように見えて、before_actionにてset_bookを渡されているため、@bookがedit内で使用できます。
先ほどと違い、編集なので.find(params[:id])が渡されており対応するidのページが渡されることになっています。
edit.html.erbにはnew.html.erbと同じことが書かれていて、formからテンプレートを引っ張ってくることになります。form内の記述
form内には以下のような記述があります。
_form.html.erb<%= form_with(model: book, local: true) do |form| %>form_withメソッドでモデルのプロパティ名に対応した名前を渡すことで、createまたはupdateアクションに振り分けられるようにしている仕組みになってます。
- 投稿日:2019-12-04T19:20:52+09:00
Elasticsearch 6.8.X に上げるときの注意点
TL; DR
- ヒープサイズのデフォルト値が2GBから1GBに変更になりました。
- itamaeで
jvm.optionsを管理している方は要注意。- デフォルト値の指定で書き換えを行っていると、書き換えされずデフォルト値のままElasticsearchが起動されます。
- like_textからlikeへの変更
- kibanaでの差分
- more_like_this
- elasticsearch-railsのmongoidのimport処理で障害になった
- importo処理を実行する
- countクエリが走る
- メタ情報で帰ってこないから素直にカウントしにいく
はじめに
EOLを向かえた
5.X系から6.X系の最新までバージョンを上げました。
その時の注意点やクラスタの入れ替え方法をまとめました。変更概要
ヒープサイズがデフォルト1GBに変更
Elasticsearch 5系のインストール時のデフォルトサイズは2GBとなっています。
しかし6系からデフォルト値は1GBに変更されています。6系のリファレンスだとこんな感じです。
By default, Elasticsearch tells the JVM to use a heap with a minimum and maximum size of 1 GB. When moving to production, it is important to configure heap size to ensure that Elasticsearch has enough heap available.
基本的にクラスタを組んで一括で管理している方が多数だと思います。(itamaeやchefなどで)
そういった方でデフォルト値から書き換えている方は注意してください。
sedで置き換えておりましたが、変更されていることに気づかず1台1GBのクラスタを組んでしまいました。
more_like_thisのlike_textがサポートされなくなったシンプルに
like_textがなくなり、likeになりました。[400] {"error":{"root_cause":[{"type":"parsing_exception","reason":"[mlt] query does not support [like_text]","line":1,"col":96}],"type":"parsing_exception","reason":"[mlt] query does not support [like_text]","line":1,"col":96},"status":400}公式リファレンスでは見つけられず、そのままクラスタの入れ替えをしてしまいました。
後々GitHub上のIssueで発見しました。(ググっても見つけられなかった、というかページが見つからなかった)
resqueで非同期処理を実行していて、そちらで処理がコケていました。
また、残念なことにエラー検知システムの方でアラートが上がらず、発見したのが翌日でした。
幸いなことに致命的な処理ではなかったので、再実行すれば問題ありませんでした。elasticsearch-railsのmongoidのimport処理で障害になった
シンプルにこんな処理を流してElasticsearchクラスタにDBにデータを流し込む処理を実行しました。
Hogehoge.__elasticsearch__.importすると、数分の間にslow queryカウントが急激に増加し、webサーバが処理しきれなくなりサービスが完全ダウンしかけました。
elasticsearch-model/lib/elasticsearch/model/adapters/mongoid.rbscope.no_timeout.each_slice(batch_size) do |items| yield (preprocess ? self.__send__(preprocess, items) : items) endこの
each_sliceってカウントクエリが走ります。
そのため、メタ情報でカウントが帰ってこない数え方だと純粋に数えに行きレスポンスが帰ってこなくなります。
データ量もそこそこあるcollectionだったので、余計遅くなりサービスダウンの障害となりました。monkeypatch.rbitems = [] scope.no_timeout.each do |item| items << item if items.count >= batch_size yield (preprocess ? self.__send__(preprocess, items) : items) items.clear end end yield (preprocess ? self.__send__(preprocess, items) : items) if items.present?最終的にはこんな感じのモンキーパッチを当てて対応しました。
バッチのデフォルトサイズ1000件まで配列に追加して、そのままyieldに投げ込むやり方に変更しました。最後に
Beaking Changeは読みましょう!(読んでいたけど・・)
どこで障害に起こっているかわからないため、エラー検知だけを信じず見れるところは見ましょう。
- 投稿日:2019-12-04T19:12:10+09:00
rubyのバージョンアップのときのエラー対処
rubyをバージョンアップをして、budnle installを叩いたら、
Fetching: mysql2-0.3.18.gem (100%) Building native extensions. This could take a while... p ERROR: Error installing mysql2: ERROR: Failed to build gem native extension. /Users/my_username/.rvm/rubies/ruby-2.1.2/bin/ruby -r ./siteconf20150614-72129-orqsb7.rb extconf.rb checking for ruby/thread.h... yes checking for rb_thread_call_without_gvl() in ruby/thread.h... yes checking for rb_thread_blocking_region()... yes checking for rb_wait_for_single_fd()... yes checking for rb_hash_dup()... yes checking for rb_intern3()... yes ----- Using mysql_config at /usr/local/bin/mysql_config ----- checking for mysql.h... yes checking for errmsg.h... yes checking for mysqld_error.h... yes ----- Don't know how to set rpath on your system, if MySQL libraries are not in path mysql2 may not load ----- ----- Setting libpath to /usr/local/Cellar/mysql/5.6.25/lib ----- creating Makefile make "DESTDIR=" clean make "DESTDIR=" compiling client.c compiling infile.c compiling mysql2_ext.c compiling result.c linking shared-object mysql2/mysql2.bundle ld: warning: directory not found for option '-L/Users/travis/.sm/pkg/active/lib' ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) make: *** [mysql2.bundle] Error 1 make failed, exit code 2 Gem files will remain installed in /Users/my_username/.rvm/rubies/ruby-2.1.2/lib/ruby/gems/2.1.0/gems/mysql2-0.3.18 for inspection. Results logged to /Users/my_username/.rvm/rubies/ruby-2.1.2/lib/ruby/gems/2.1.0/extensions/x86上記のようにmysqlのエラーが出る。。。。
もしもインストールをしていなければ、
bundle config --local build.mysql2 "--with-ldflags=-L/usr/local/opt/openssl/lib --with-cppflags=-I/usr/local/opt/openssl/include"こいつを叩いて、
bundle installしてみて、Library not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib (LoadError)上記のエラーが出るようなら、
$ brew install openssl $ export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/opt/openssl/lib/これでPATHを指定してから、再度
budnle install
これでも無理なら、、、、brew update && brew upgradeこれで行けるケースもあります。
ただ、これでもLibrary not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib (LoadError)こいつが出るようなら、
rbenvをアンインストールする。$ ruby -v ruby 2.3.4p301でrubyのバージョン確認
$ rbenv unistall 2.3.4$ rbenv install --list $ rbenv install 2.3.4インストールするlistの確認をして、rubyのバージョンを指定してinstallする。
$ gem install bundlerその後、
bundle installする。
ただ、念の為にgemfile.rockを消してからやるとよいメモ書きの感じで書いたので、まだ理解不足です。
ご指摘等あればお願いします。
- 投稿日:2019-12-04T17:31:25+09:00
railsで超シンプルなコメント機能を作った時の手順
rails g controller comment
rails g model Comment post_id:integer comment:string
rails db:migrateルート
post "comments/create/:id" => "comment#create" # :idはcommentテーブルのpost_id参照に使うコントローラ
def create
@comment = Comment.new(post_id: params[:id],
comment: params[:comment])
@comment.save
redirect_to "/"
endビュー
formforを取り付けたいビューに張り付け
@comment = Comment.new()をformforに連動するアクションに張り付けposts/showの下部にコメント入力と送信、表示を取り付ける。
最初はコメント入力と送信formtagに変更
<%= form_tag("/comments/create/#{@a.id}") do %> <textarea name="comment"></textarea> <input type="submit" value="コメント投稿" %> <% end %></br>
- 投稿日:2019-12-04T17:30:57+09:00
【gemなし】Railsのseeds.rbでuserのシードデータを500人作る!
- 投稿日:2019-12-04T17:27:41+09:00
Rails:ajax通信の流れとデバッグの解説[超初心者編]
まずはじめに
ajaxを勉強中に簡易なrailsアプリを作りました。
その時大枠の処理の流れが大切だと感じたので今回復習も兼ねて解説してみようと思います。大枠の流れを理解しているとエラーが起きた際にどこでデバッグしてどの変数の中身を見たら良いか、どこまでは処理がうまく書けているか。という原因特定をする際に非常に便利です。
むしろ流れを理解していないとエラー解決は手探りでの作業となってしまい非効率です。
作ったアプリ内容
検索フォームからDBに保存してあるユーザー情報を表示する
アプリGIF
https://gyazo.com/ac90a773abec869ddb72d59037f62f46[したいこと]
検索フォームにキーワードを入力された毎にユーザー検索して該当するユーザー名を表示する[必要な手段]
検索フォームに入力されたら反応
フォームに入力されたキーワードを取得
コントローラでキーワードを元にユーザーテーブルを検索
検索結果をビューで表示する対象者
この記事では、ajax通信とは、
どのようにして送信先を決めているのか、
送ったデータはどのように処理されているのか、
どのように処理したデータを返すのか
エラーで詰まってしまった際にどう対処するのか
を学びます。よって概ね同じようなajax通信の流れを組む、インクリメンタルサーチや非同期通信、自動更新の実装にもこの記事で紹介する処理の流れやデバッグの方法は応用できます
大まかな処理の流れについて説明できる自信がない方に対してザックリと理解できるようにまとめました。
極力専門的な言い方や記述を省き、イメージしやすいように言い回しも変えています。
開発環境
Rails: 5.0.7.2
ruby: 2.5.1
jquery-rails: 4.3.3
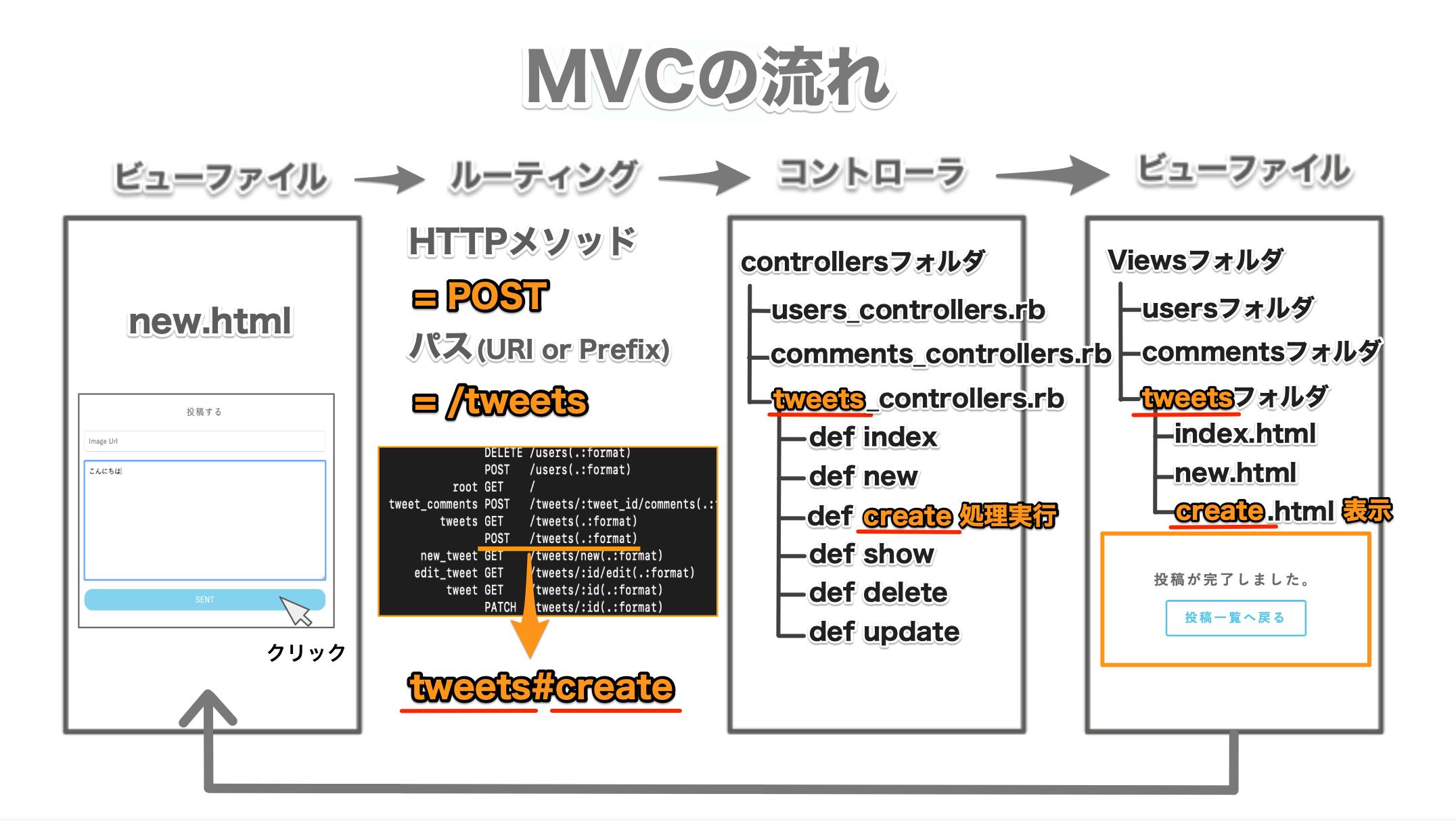
mac: Mojave(10.14.4)まずは登場ファイルの紹介
・ edit.html ----------------- HTMLファイル(ビューファイル)
・ test.js -------------------- JavaScriptファイル
・ users_controller.rb -------- コントローラファイル
・ index.json.jbuilder --------- json.jbuilderファイルajax通信の流れ
ビューファイルが読み込まれる
(コントローラのアクションに紐づくビューファイルが読み込まれるということ)
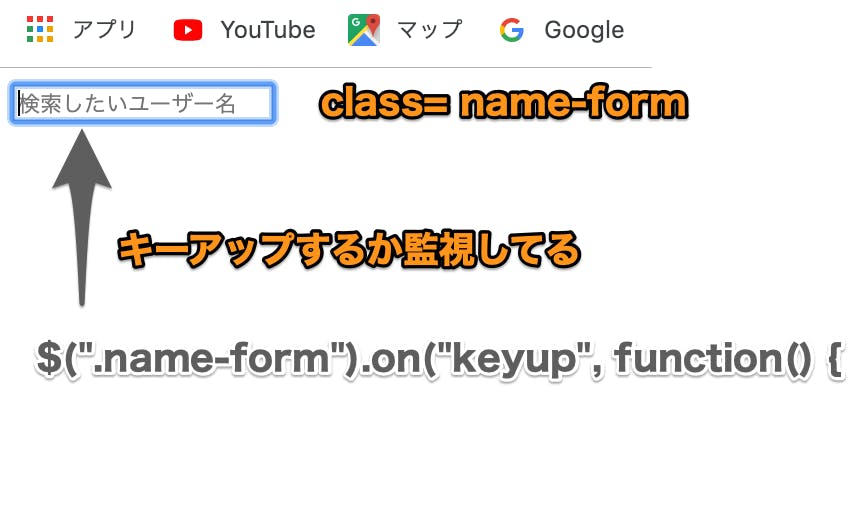
edit.html<input class="name-form" placeholder="検索したいユーザー名" type="text"> <div class='append-user'>表示されている画面
ブラウザに入力フォームが表示される
ビューと同時にJavaScriptファイルも読み込まれる
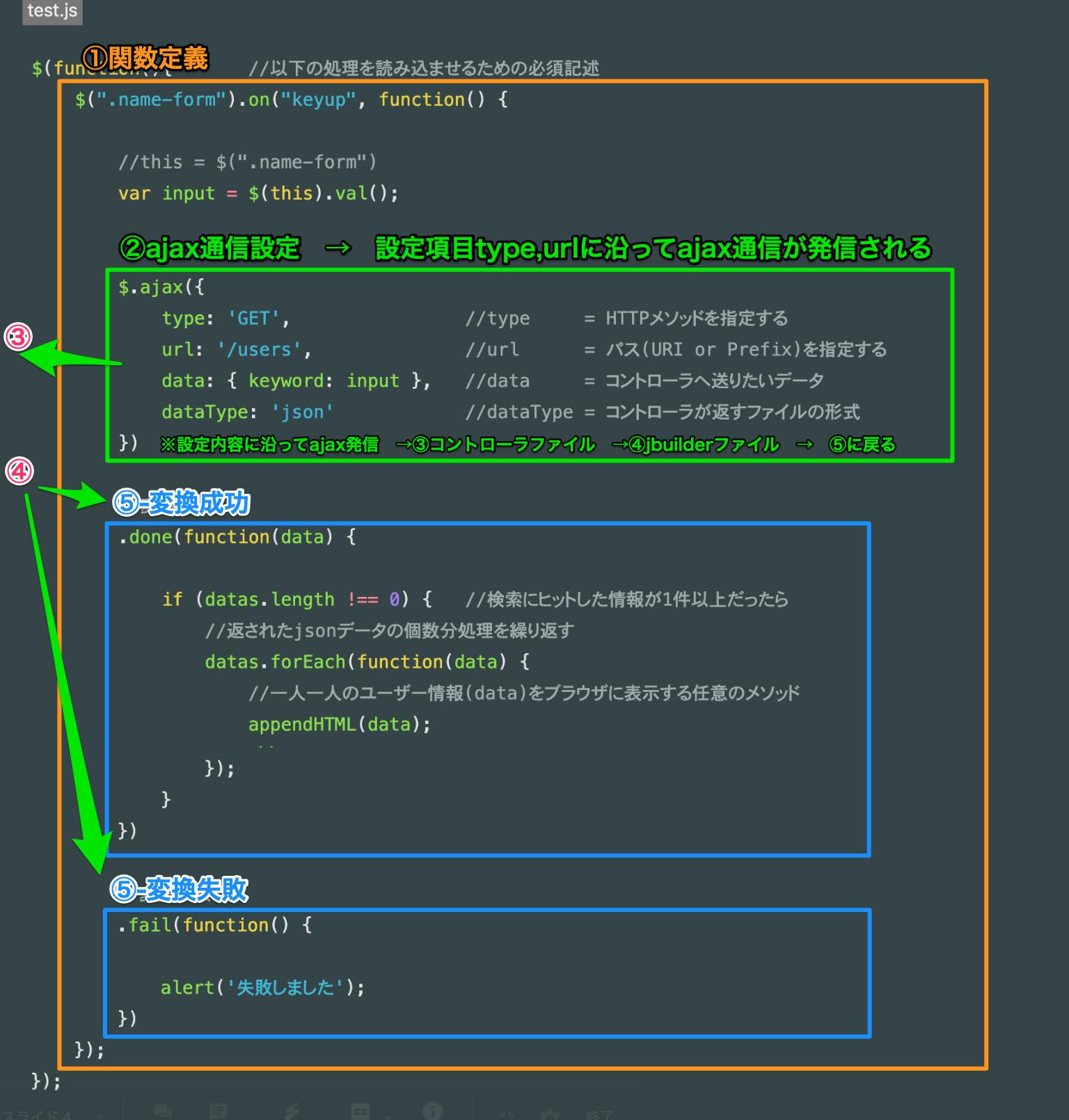
test.js$(function(){ //以下の処理を読み込ませるための必須記述 $(".name-form").on("keyup", function() { //this = $(".name-form") var input = $(this).val(); $.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 }) //変換完了 .done(function(datas) { if (datas.length !== 0) { //検索にヒットした情報が1件以上だったら //返されたjsonデータの個数分処理を繰り返す datas.forEach(function(data) { //一人一人のユーザー情報(data)をブラウザに表示する任意のメソッド appendHTML(data); }); } }) //変換失敗 .fail(function() { alert('失敗しました'); }) }); });ここで一旦test.jsファイルは何をしてくれるファイルなのかを解説
※1行目のfunctionの記述はJSファイルを読み込ませる必要最低限の記述のため解説割愛
JavaScriptファイルは、簡単に言ってしまうと「ビューファイルを監視して処理を実行してくれる」ファイルです。
画像の①関数を定義しておくとオレンジの範囲の処理を行なってくれます。
オレンジの範囲には②処理や②と関係する③・④の処理、⑤の処理が含まれています。② → ③ → ④ → ⑤の順番で処理が進んでいきます
ではどんな時に①関数が動き出すのか?これは①関数の最初に書かれている記述から読み取ることができます。
$(".name-form").on("keyup", function() { 直訳 「クラス名「name-form」の入力フォームにキー入力され、そのキーが離された瞬間」に動き出す関数 解説 ①:$(".name-form") → 読み込んだHTMLファイルの中でclass= "name-form"の要素 ②:.on → ①が ③:"keyup" → キーアップされたら(入力時のキーを離したら)
クラス名「name-form」といえば、
edit.html.hamlで生成した入力フォームのことですね。
このフォームに入力がされたら、関数が動くという仕組みです。
つまり、test.jsの
$(".name-form").on("keyup", function() {という記述が、現在読み込まれているビューファイルの特定のクラス名の要素の「動き」を監視しているという言い方もできるわけです。
また、記述の各部分には名称がついているので、人へ伝える時や調べものをするときに下記のワードを用いて理解を深めましょう。$(".name-form").on("keyup", function() { 処理 }名称:セレクタ
$(".name-form")・・・「動き」を監視する対象や要素名称:イベントハンドラ
.on・・・セレクタに対して名称:イベント
"keyup"・・・予め検知したい「動き」を定義する(例:キーアップイベントが発生したら)名称:無名関数
function() { 処理 }・・・セレクタに検知したい「動き」が起こったら{処理}を行う
$(セレクタ).on(イベント名, イベントが発生したときに実行する処理)
ちなみに、JavaScriptファイル内で「$」マークで始まる記述はJavascriptのライブラリの一つである「jQuery」の記述です。
もちろんイベントには「送信されたら」、「クリックされたら」などたくさんの種類があるので
「jQuery イベントハンドラ」でググってみましょうjQueryイベント一覧 わかりやすい記事
http://www.jquerystudy.info/reference/events/index.html
test.jsファイルの解説は一旦終了です。イベントを発火させる
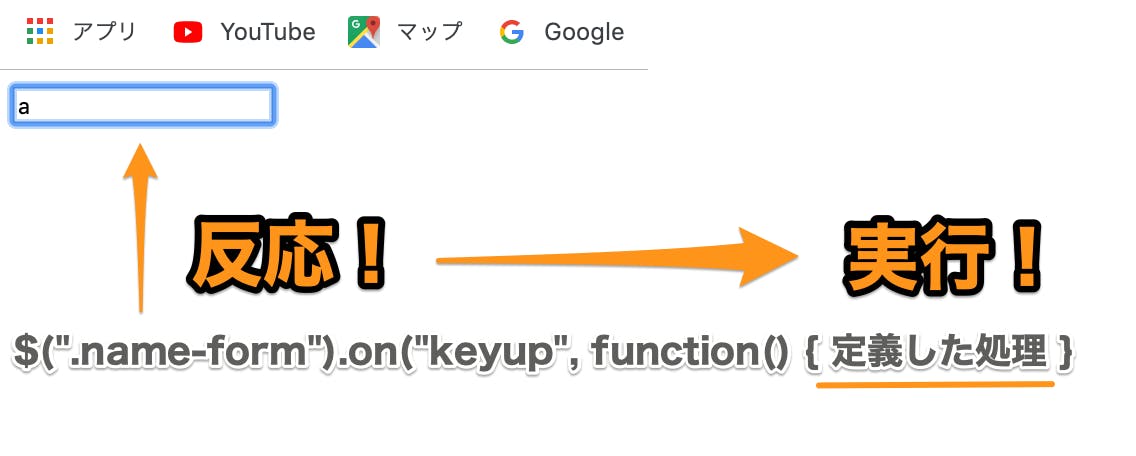
登場するファイルと処理の順番
【edit.html】 → ブラウザで入力操作 → 【test.js】それではいよいよtest.jsに書かれた①関数を動かします。
そのために入力フォームへ何か文字を入力するんでしたね
ほい
これで定義していた処理が実行されます
①関数定義が動く
登場するファイルと処理の順番
【test.js①】 → 【test.js②】
入力イベントに反応して上記画像の1番上のfunction{}関数内の処理が実行されていきます
もちろん処理は上から下へ実行されるので②ajax通信の処理ブロックにたどり着くまでに書かれている記述を実行していきます。
途中にある
var input = $(this).val();この記述は、変数
inputに対してjQueryの記述で値を代入しています。$マークのカッコで囲んだものはjQueryオブジェクトとして扱うのでしたね!
ではカッコの中に記述されているthisとは何かというと現在処理されているfunctionのセレクタを指します。
※thisは使う場面によって色々な状態の情報が取得できるので一概に取得できる情報を明言できません。
①関数(function)内でthisと書くとfunctionのセレクタである$(".name-form")が取得できます
よって「this」は書く場所によって結果が違う。ということです
この後解説するdone関数やfail関数のfunction内でthisを記述すると①関数内でthisを書いた時の情報とは違う状態の情報がthisの記述で取得できます
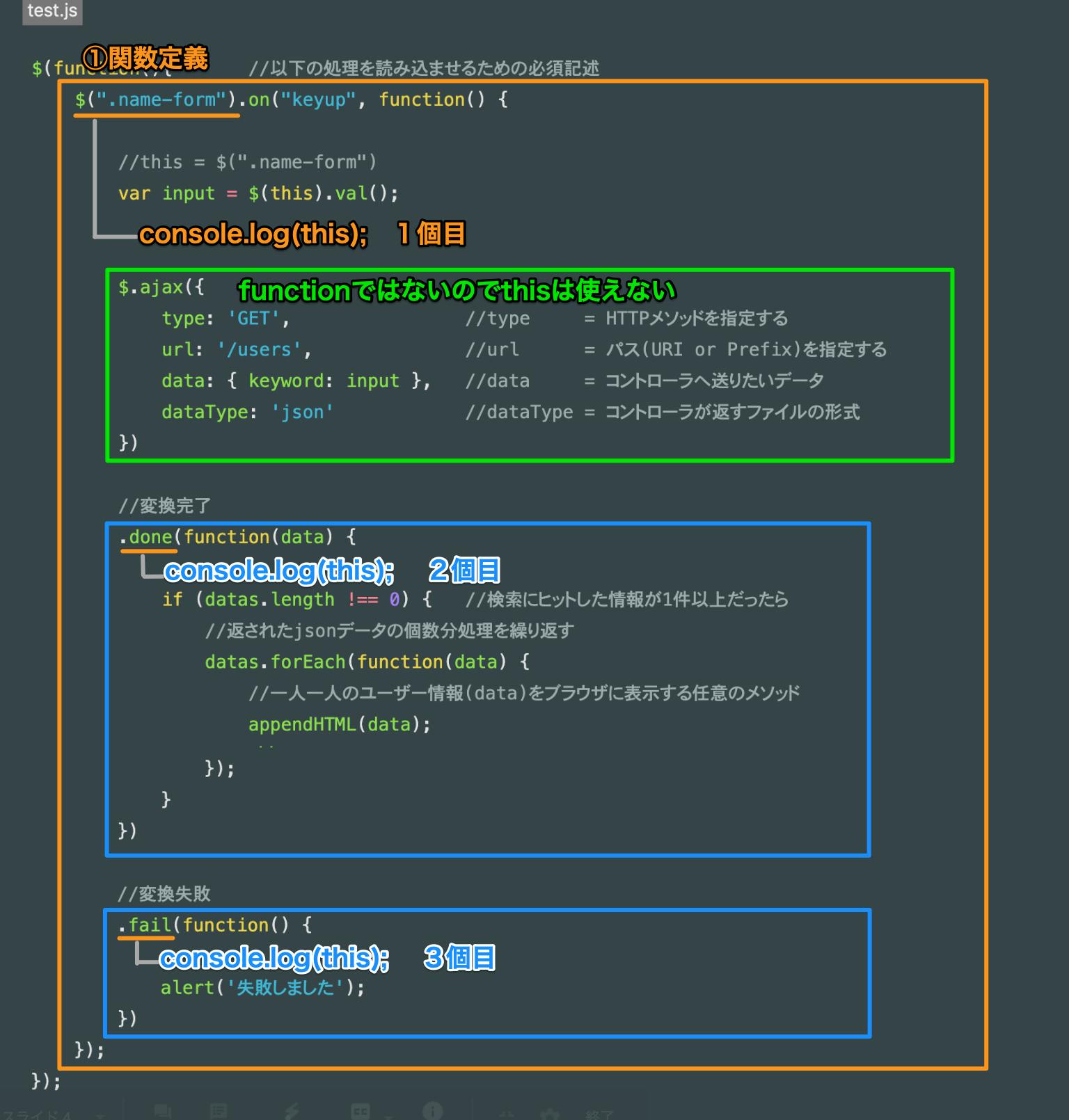
デバッグ作業の心構え
this情報の確認方法について、ここで一旦デバッグ作業の仕方についてサクッと解説です。
this情報の確認は簡単で、確認したい場所でconsole.log(this)を記述するだけです。
例で下の画像のように3箇所にconsole.log(this)を記述します
上記画像のようなconsole.log(this)の配置で様々な状況下のthisの値がコンソール画面で確認できます。
注意:console.log(〇〇)と書いたあとは①関数を動かす必要があるので必ずキーアップイベントを起こす必要あり。
console.log()とはlogカッコ内に記述した変数の中身をブラウザの検証の「console」画面に表示するメソッドです。定義しておいた変数などをlog引数に記述すると変数の中身がコンソール画面に表示することができ、処理に使う変数が期待する値かどうかを確認するときに大活躍します。
var num = 10 + 5; console.log(num); //コンソール画面には「15」と表示されるこの作業こそ、まさに「デバッグ」ですね!!
デバッグ作業の重要なポイントとしては
①変数の中身を確認する(どの変数を確認すべきか)
②変数の中身を予想する(期待する答えを考える)この2点です!
たったコレだけですが、この2点ができるできないで作業効率は大きく変わります
普段こういったことを考えないで闇雲にデバッグしている人は、めちゃくちゃ損してます。以上、デバッグの心構えでした。
では、話は戻って
var input = $(this).val();この記述は
var input = $(".name-form").val();このように変換※でき、
.val()は対象のvalue属性の値を取得するので
現状入力フォーム(クラス名name-formのHTML要素)には「a」が入力されているので
※ここでの「変換」とはわかりやすいようにイメージするならば。という意味var input = "a";と変換できることになります。
②関数が動く。ajax通信の設定
登場するファイルと流れ
【test.js②】 → ③【users_controller.rb】
変数
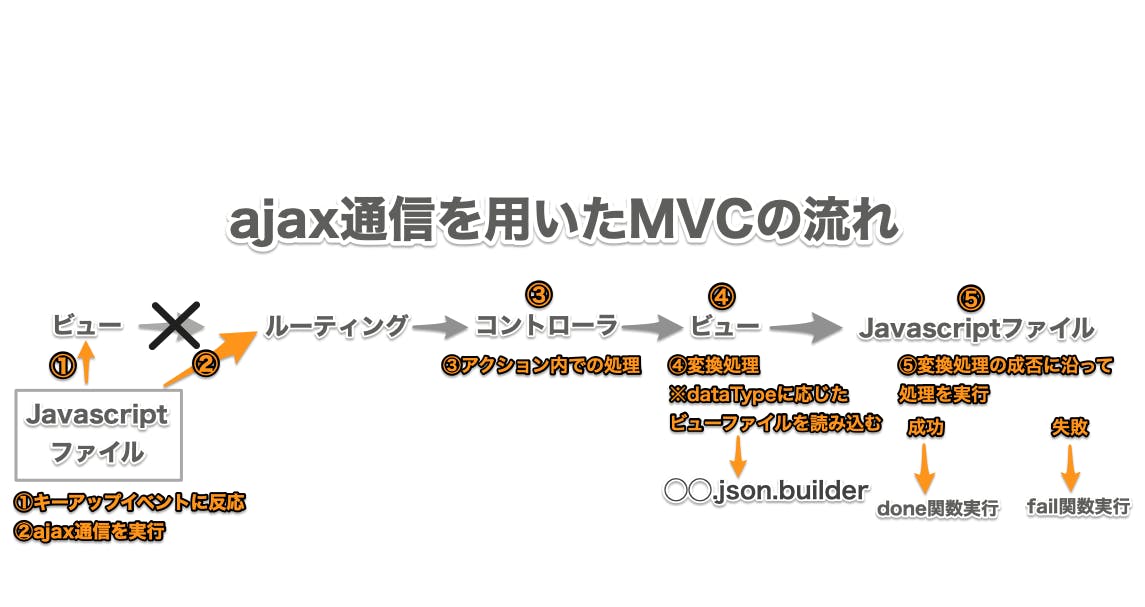
inputを定義した状態で次に②関数のajax通信の設定が実行されます。ここでのajax通信は、railsのMVCの流れに割り込んだ形でビュー(HTML)ファイルからコントローラファイルへデータを渡すために記述されています。
通常のMVCの流れ
ajax通信を用いたMVCの流れ
この流れでファイルを読み込んでいきます。
ajax通信の設定は以下の内容で実行されます
$.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 })ajax通信の項目
・typeとurlはルーティングに渡す情報を指定
・dataはルーティングが判断したコントローラファイルに渡す情報の指定
ここで先ほど定義したinput変数を使っています。
・dataTypeはdata項目を送ったり送り返してもらう際の通信形式を指定(値はjsonやhtmlなどが存在)ここでもajax通信のイメージを掴んでもらうために、たとえを用いると
ajax通信とは、「外国へ荷物を配達してくれる郵便屋さん」みたいな存在です。
ちょっとよく分からないとは思いますが黙って聞いていてください。②関数が動くと郵便屋さんが配達の準備を始めます
$.ajax({ type: 'GET', //type = 目的地情報その1 url: '/users', //url = 目的地情報その2 data: { keyword: input }, //data = 送る荷物 dataType: 'json' //dataType = 発送方法 })上記の情報をもとに目的地の設定や送る荷物の中身を決めます。
実行されたajax通信はまずルーティングに解析され、ルーティングではHTTPメソッドは
GET、パスは/usersとして判断され
users_controller.rbファイルのindexアクションが実行されます。発火させるべきコントローラとアクションの選定方法
ここで大事なのは発火させたいコントローラとアクションは何であるのかイメージしておくことです。
まず、なぜコントローラのアクションを発火させたいのでしょうか?
それは、コントローラではDBの情報を取得・登録・編集・削除などのアクションが実行でき、今まさにDBの情報を取得したいからです。まずは行いたい処理を大枠で思い出しましょう。
・したいこと
DBからキーワードに該当するユーザーを取得する・そのための手段
ajax通信を使う
キーアップされたごとに検索する
入力されたキーワード情報を取得する
キーワード情報をコントローラへ送るでは「したいこと」を実行するために最適なコントローラとは?
答えは簡単です。関係性のあるコントローラを選べば良いのです。例えば
・users_controller.rb
・groups_controller.rb
・messages_controller.rb
と3つのコントローラがあったら、コントローラそれぞれの役割を思い出します。・users_controller.rb:ユーザーに関わることを操作する
・groups_controller.rb:グループに関わることを操作する
・messages_controller.rb:メッセージに関わることを操作する「したいこと」はユーザー情報の取得です。
こう考えると、users_controller.rbの一択ですね。
では次に、users_controller内のどのアクションを発火させるか?
これも7つのアクションからひとつ当てはまるものを選べば良いのです。冷静に考えれば楽勝です
当てはまるものがわからなければ目的とは異なるものを排除していきましょう!・index・・・・・・一覧表示
・new・・・・・・新規作成画面
・create・・・・・DBに新規作成
・show ・・・・・・詳細画面
・edit・・・・・・・編集画面
・update・・・・・DBに編集内容を保存
・delete ・・・・・DBから削除すでに登録されているユーザー情報を取得する。という観点だけでも、
・index
・show
の2つに絞られます。・index・・・・・・一覧表示
・new・・・・・・新規作成画面 → ユーザーを新規作成するわけではない
・create・・・・・・DBに新規作成 → ユーザーを新規作成するわけではない
・show・・・・・・詳細画面
・edit・・・・・・・編集画面 → 既存のユーザー情報を書き換えたいわけではない
・update・・・・・DBに編集内容を保存 → 既存のユーザー情報を書き換えたいわけではない
・delete ・・・・・DBから削除 → ユーザー情報を削除したいわけではないここで重要なのは、キーワード検索して該当したユーザー情報を全て取得するという部分がポイントです。
「a」と検索したら「aaa」さんも「abc」さんの情報も該当する情報一覧を取得したいということです。indexは一覧情報。対して
editは一人のユーザー情報の詳細です。だからindexアクションが適切です。
users_controller#indexアクションです
これで発火させたいコントローラとアクションが選定できました!
ターミナルで「rails routes」コマンドを打って表示される一番右端に書いてあるコントローラとアクションに紐づくパスとHTTPメソッドを確認してみましょう!
railsにてページの遷移を行うには何かしらのコントローラのアクションを発火させなければいけません。
その場合、必ず「したいこと」を言語化し、発火させたいコントローラとアクションを決めてから細かい処理を組み立てていきましょうでは話を戻して、
(以下一部重複)
実行されたajax通信はまずルーティングに解析され、ルーティングではHTTPメソッドは
GET、パスは/usersとして判断され
users_controller.rbファイルのindexアクションが実行されます。その後はjson.jbuilderファイル→ test.jsファイルの⑤処理というふうに処理がされていきます。
郵便屋さんが
dataという荷物をコントローラに渡し、コントローラはもらったdataを使って変数を生成します。最後に郵便屋さんがコントローラで生成された変数をdataの送り主(test.js)に届けるという流れです。通常は荷物を届けた時点で郵便屋さんの仕事は終了ですが、今回はお届け先から送り主に対して送り返す荷物(情報)が発生するというお仕事になります。
一旦はこんなイメージで見ててください
③コントローラでの処理
登場するファイルと流れ
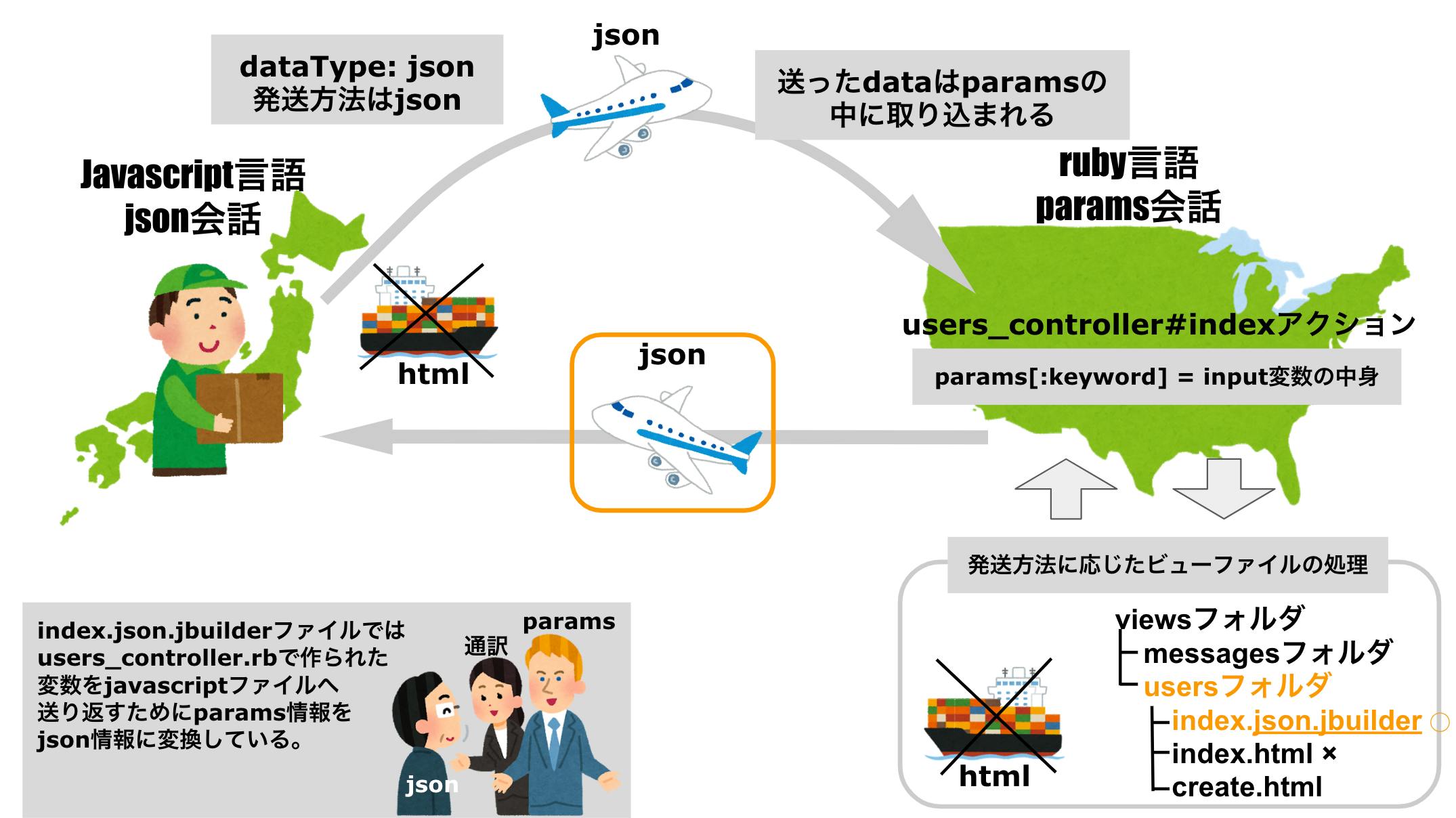
③【users_controller.rb】 → ④【index.json.jbuilder】users_controller.rbファイルのindexアクションではDBのusersテーブルからブラウザの入力フォームに入力された「a」のワードに該当するユーザー情報を
@usersに代入しています。※大枠の処理の流れが重要のため、コントローラ内の処理詳細は割愛します。
users_controller.rbclass UsersController < ApplicationController def index return nil if params[:keyword] == "" @users = User.where(['name LIKE ?', "%#{params[:keyword]}%"] ).where.not(id: current_user.id).limit(10) # ajax通信の記述:dataTypeの種類に応じて参照するファイルを切り替える respond_to do |format| format.html format.json # ajax記述には、dataType: 'json' と書かれているので # index.json.jbuilderファイルが読み込まれる end end end上記で記述されている
params[:keyword]とは
ajax通信の設定で記述したdata項目(送る荷物)のハッシュデータが深く関わってきます。
params[:keyword]とは、data項目に定義したハッシュのキー名を指定してバリューとなるinput (入力ワード「a」)を取得する記述です。data: { keyword: input }, //data = コントローラへ送りたいデータなぜ送った
dataがparamsに取り込まれているのかajax郵便屋さんが言語の違う「外国」へ行っていることを思い出してイメージしましょう
日本語がアメリカでは通じないように、javascript語をrubyの言語内では使えないのでjsonという通信方法を使ってruby語の会話であるparamsに情報を混ぜてもらっているのです。
そうすると、javascript語で書いた情報でもruby国に籍を置くusers_controller.rbファイルでも読み取ることができるようになり、
test.jsから受け取った変数
inputの中身を使ってDBからユーザー情報を検索できるのです。また、検索結果を代入した
@users変数はtest.js(javascript)ファイルにてユーザー検索結果を表示する際に使われる重要な変数です。
コントローラでtest.js(javascript)ファイルに送り返す変数@usersを定義できたら、通常のMVCの流れ同様コントローラ → ビューと処理が移るのですが、
ビューファイルの参照前に、ajax通信の設定で記述したdataTypeの値に応じて参照するファイルを選定する記述がコントローラには書かれています。
users_controller.rbrespond_to do |format| format.html format.json end今回はdataType:
jsonでajax通信を行なっていますよねtest.js$.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 })なので「コントローラで処理されたアクション名.jsonファイル」の
views/users/index.json.jbuilderファイルが読み込まれます。※respond_toの記述がなければ、コントローラで処理されたアクション名.htmlファイルが参照されます。
④json.jbuilderファイルでの変換処理
登場するファイルと流れ
④【index.json.jbuilder】 → 【test.js⑤】
index.json.jbuilderファイルではコントローラで生成した変数
@usersの変換処理を行います。
ん?
なぜ変換するの?と思うかもしれませんが
コントローラで生成した変数ということは、ゴリゴリのruby語で書かれた情報ということになり、
このままの状態で変数をtest.js(javascript)ファイルへ持ち帰っても誰も解読できないよね。ということになります。
そこで荷物を届けに来るときにjson → paramsと変換した時同様に、
送り返す際もparams → jsonと変換をしてあげます。index.json.jbuilderjson.array! @users do |user| json.id user.id json.name user.name end一つ一つ解説すると、まず始めの記述
json.jbuilderjson.array! @users do |user|これは変数
@usersをruby言語でいうeach文で取り出しているような書き方ですね!
いわゆる繰り返し処理です。なぜ繰り返すかというと変数
@usersは複数情報が格納されている配列情報だからです。
配列情報とは1個以上の複数情報から成り立っています。
今回のコントローラでの処理では入力ワード「a」に該当するユーザー情報が変数
@usersに詰められていますが、
DBのusersテーブルにもし「abc」さんと、「aaa」さんの2人ユーザー情報が登録されていたら、どちらのユーザーも「a」という文字列を含むため、コントローラの処理で前述の2人分の情報が変数@usersに詰められてくる可能性があるからです。そうしたら「abc」さんにも「aaa」さんにも変換処理を行なってあげないと、test.js(javascript)ファイルで変数を受け取る際に解読できなくなってしまいます。
では次に、
json.jbuilder#javascript語 ← ruby語 #jsonデータ ← paramsデータ #パン ← bread json.id user.id json.name user.nameこの記述は左辺がjavascript語での呼び方、右辺がruby語での呼び方を定義している記述です。
左辺に定義した名前にどんなrubyの情報を定義するか。といった感じです。試しに、
json.jbuilderjson.n user.nameこう書けば、
javascriptファイルで◯◯.nと記述すると、ruby語でuser.nameの情報が取得できる。といった感じ
※「〇〇」はdone関数の引数名などが入る⑤変換結果に応じた処理(done & fail)
登場するファイルと流れ
【test.js⑤ done】 or 【test.js⑤ fail】
※appendHTML関数はブラウザにユーザー情報を表示する関数です
※この記事では大枠の処理の流れをメインに解説を行うため、doneメソッド内で使われているappendHTML関数の詳細は敢えて記述せず、解説もしません。
④index.json.jbuilderファイルでの変換処理を経て、test.jsファイルに返ってきたjsonデータ。
このjsonデータには入力ワード「a」に該当するユーザー情報が詰められているのですが、
④index.json.jbuilderの変換結果によって実行される関数が分岐します。変換結果
変換成功 → done関数
変換失敗 → fail関数failメソッドが実行される場合
変換失敗の際はfail関数が処理されます。
ではどのような時に変換失敗になるか
これはjson.jbuilderでの処理が以下のような時です。NG.json.jbuilderjson.array! @users do |user| json.id user.user.id #userが重複 json.nickname user.mickname #カラム名の間違い or 存在しないカラム名の指定(mickname) json.nickname @users.nickname #変換する変数名が違う endカラム名の記述ミスや存在しないテーブルの参照など、記述をよく観察すると発見できるミスが多いです。
他にもコントローラファイル → json.jbuilderへと参照させるためにコントローラ内に記述が必要なrespond_toが抜けていたりすると適切な変換ファイルが参照されずfailメソッドが実行されてしまいます。users_controller.rbrespond_to do |format| format.html format.json end予めfailメソッド内に
alert("通信失敗しました");などの記述を配置してfailメソッドが呼ばれてしまったタイミングを見逃さないようにしておきましょう。json.jbuilderファイルの記述に間違いがなさそうであれば処理の流れを遡ってコントローラで定義した変数が怪しいと考えましょう
そうしたらコントローラ内に
binding.pryを記述し、処理を止めて変数名を入力して期待通りの中身か確認しましょう!
このように原因箇所を処理の流れに沿って絞っていくことが大切です。doneメソッド内の処理で不具合が起こった場合
変換処理に問題がなければdoneメソッドが処理されます。
さらにdoneメソッドの引数にはjson.jbuilder内で変換されたjsonデータが入ります。
今回の例でいうとtest.js.done(function(datas) { 処理 })
datasという引数がjsonデータです。引数名は自由に名付けられます!
注:これまでの処理順番画像のdoneメソッドの引数名が全て「data」で記述されています。ミスですsorryこの引数の中に変換されたユーザー情報が代入されています。
このdatas引数の中身を展開してブラウザにユーザー情報を表示していくのですが、ここdoneメソッド内での処理が一番記述を間違いやすい箇所でもあるので、エラーが起こった際は
冷静にこれまでの処理の順番を遡り、確認すべき変数を見極めデバッグしていくことが求められます。よくある間違いの原因としては、
・doneメソッドの引数であるjsonデータを配列情報として扱っていないミス
・json.jbuilderで定義していない名前を展開しようとしている
・そもそもコントローラでの処理の時点で@users変数の中身が正常ではない
・@users変数を作るための材料であるinput変数の中身がすでに正常ではないなどなど、
どの原因もconsole.logやbinding.pryを使えばすぐに割り出せる内容です。デバッグの使い分け
javascriptファイルでの変数確認 = console.log または debugger
使えるファイル例:test.jsファイルrubyファイルでの処理停止 = binding.pry
使えるファイル例:コントローラファイル、ビューファイル、語尾に.rbと付くファイルなら大概使える
よくある間違いへの対処
・doneメソッドの引数であるjsonデータを配列情報として扱っていないミス
このミスへの対処は下記のような
forEachメソッドで配列の各情報を取り出して個別に処理(appendHTMLなど)することを心がけましょうtest.js.done(function(datas) { if (datas.length !== 0) { //検索にヒットした情報が1件以上だったら //返されたjsonデータの個数分処理を繰り返す datas.forEach(function(data) { //一人一人のユーザー情報(data)をブラウザに表示する任意のメソッド appendHTML(data); }); } })コントローラでの処理にもよりますが、コントローラでwhereメソッドを使って配列情報を送ることが決定している以上は該当するユーザー情報が「aaa」さん一人分の情報であろうと配列情報に変わりはありません。
よって配列情報には必ずforEachを使って個別処理を行う必要があります。
そして、ここで取り出した変数(data)に対してようやくjson.jbuilderでの変換内容を展開できます。例:
data.id = ユーザーのid情報を展開
data.nickname = ユーザーの名前情報を展開またキーワード検索で何もヒットしなかった時 = 配列に何も情報が含まれて来ない時
の処理も考えておくとユーザビリティの向上に繋がります。
「該当するユーザーはいませんでした」などなど。。。
・json.jbuilderで定義していない名前を展開しようとしている
appendHTML関数でjsonデータを展開したら「Undefind」だった。
これはもう楽勝ですね。
json.jbuilderファイルをじっくり確認しましょう!!
変換名や変換内容、展開名が食い違っていないか確認しましょう!!
・そもそもコントローラでの処理の時点で@users変数の中身が正常ではないjson.jbuilderファイルの記述にミスが見当たらなければ、もう一つ処理を遡ってコントローラを確認しにいきます
binding.pryを記述してjson.jbuilderファイルで変換する変数@usersの中身を見てみましょう!users_controller.rbclass UsersController < ApplicationController def index return nil if params[:keyword] == "" @users = User.where(['name LIKE ?', "%#{params[:keyword]}%"] ).where.not(id: current_user.id).limit(10) binding.pry # @users変数を定義した直後に処理を止める、ターミナルに「@users」と入力して中身の確認 respond_to do |format| format.html format.json end end endターミナルに「@users」と入力する前に、
最初は間違ってもいいので、「おそらくこんな値が入っているはず」と仮説を立ててから中身を確認することが超重要です。
・@users変数を作るための材料であるinput変数の中身がすでに正常ではないコントローラファイル内で
binding.pryを記述して@users変数の中身を確認してもし値が崩れていたら、
尽かさずparams[:keyword]とターミナルに入力しましょう!
params[:keyword]と入力するとキーワード情報が取得できるはずです。もしキーワード情報が取得できない場合は、test.jsのajax通信のdata項目
test.js$.ajax({ type: 'GET', url: '/users', data: { keyword: input }, dataType: 'json' })ここの記述が原因です
input変数を定義している記述を確認しましょう
ここでもconsole.logが大活躍です。尽かさず変数の中身を確認しましょう!
var input = $(this).val(); console.log(input);これでも値が崩れているのなら
input変数を形成するthisを確認console.log($(this));このように処理の順番を遡って変数の中身を確認する。
もう分かってると思うんですが。。。
最初はとにかくデバッグなんです
繰り返してデバッグをしているとデバッグのポイントでもある
①変数の中身を確認する(どの変数を確認すべきか)
②変数の中身を予想する(期待する答えを考える)これが自然と身についてきます。
まずは手を動かすこと
コツとしては、
変数や引数があったのであれば、直後にconsole.logで確認。これでまずは手を動かしてみましょう
test.js$(function(){ $(".name-form").on("keyup", function() { var input = $(this).val(); console.log(input); //input変数の中身を確認 $.ajax({ type: 'GET', url: '/users', data: { keyword: input }, dataType: 'json' }) .done(function(datas) { console.log(datas); //引数datasの中身を確認 if (datas.length !== 0) { datas.forEach(function(data) { console.log(data); //引数dataの中身を確認 appendHTML(data); }); } }) .fail(function() { alert('失敗しました'); }) }); });中身の値の崩れが発見できたら、これまでの処理の順番を遡って変数の中身を確認していきましょう
以上、ajax通信の流れでした!!







- 投稿日:2019-12-04T16:18:25+09:00
form_forのselectタグでRequiredを適用させる
やりたいこと
railsのフォームで
required: trueを記述すると、空の送信を防げる。
selectタグでも同様のことをしたい。やること
erb<div> <label for="category">お問い合わせカテゴリ<br>(リストから選択してください。)</label> <%= f.select :category, [["弊社サービス・お見積りについて", 1], ["採用について", 2], ["その他", 3]], :include_blank => "選択してください ▼", :required => true %> </div>上記のコードだとなぜか
requiredが効かない。erb<div> <label for="category">お問い合わせカテゴリ<br>(リストから選択してください。)</label> <%= f.select :category, [["弊社サービス・お見積りについて", 1], ["採用について", 2], ["その他", 3]], { :include_blank => "選択してください ▼" }, :required => true %> </div>上のコードだと
requiredが効くようになる。
- 投稿日:2019-12-04T16:17:56+09:00
railsでのテーブルの作り方、カラム追加、カラムの型替えの方法
はじめに
railsでのDBテーブルの作成方法、カラムの追加など一連のデータベース操作についてまとめます。
railsでのテーブルの生成方法
テーブルを生成しましょう。
①テーブルのmigrationファイルを作成します。具体的な作成コマンドとしては以下になります。$ rails g model モデル名 フィールド:型 ※例えばpostモデルでnameカラム(string型)とuser_idカラム(integer型)を作成したい場合は以下になります。 $ rails g model Post name:string user_id:integer②コマンドを打ち込むとmigrationファイルが新規で出来上がっているはずなのでそれを以下のコマンドで実行します。
実行後はdbサーバー上にpostsテーブルが出来上がります。$ rails db:migrateカラム追加方法
既に作成したテーブルにカラムを追加したい場合は下記の手順で追加します。
①追加したい項目を下記のようにコマンド入力する。
rails g migration Addカラム名Toテーブル名 カラム名:データ型 # 例えば既にあるpostテーブルにcategoryカラム(integer型)を作成したい場合は以下になります。 rails g migration AddCategoryToPosts category:integer②db/migrateフォルダにマイグレーションファイルが出来上がっていますので、確認、必要があれば追記してください。
下記ファイルにはhogehogeカラムを追記しています。class AddCategoryToPosts < ActiveRecord::Migration[5.2] def change add_column :posts, :category, :integer add_column :posts, :hogehoge, :text #追記 end end③編集終わりましたら、以下のコマンドで実行します。
これでテーブルにカラムが追加されます。$ rails db:migrateカラムの型の変換
既にあるテーブルのカラムの型を変えたいときは以下の手順で変更を行います。
カラム追加と似た手順となります。①型変更したいカラムを下記のようにコマンド入力しmigrationファイルを作る。
$ rails g migration change_data_カラム名_to_テーブル名 # 例えばpostテーブルのhogehogeカラムを型変更したい場合は以下になります。 rails g migration change_data_hogehoge_to_posts②db/migrateフォルダにマイグレーションファイルが出来上がっていますので、class内に以下のメソッドを追加してください。
def change change_column :posts, :hogehoge, :integer end③編集終わりましたら、以下のコマンドで実行します。
これでテーブルにカラムが追加されます。$ rails db:migrate終わりに
この記事で誤っている箇所や追記したほうが良い点がありましたらコメント欄などでご指摘いただけますとありがたいです!
ActiveRecordと通常のsqlコマンドは書き方違うので勉強必要ですね・・
- 投稿日:2019-12-04T15:57:42+09:00
【Rails】コーディング時に気をつけるべきこと
Webエンジニア2年目の@gggkです。
これまで、コードレビューで色々と指摘を受けてきたのですが、コードを書く上で大切なことなので、コーディング時に気をつけるべきことをまとめてみました。
特に、Rails慣れたての人の参考になればいいなと思います!バグを生み出さない
エンジニアやってて怖いのは、リリース後にバグが出ることですね。普段から意識してコーディングすることで、バグを発生させないようにしましょう。
nilチェックをする
大体のバグは、nilが原因となることが多いんじゃないかなと思います。
レシーバーがnilになってしまい、メソッドを呼び出そうとして「NoMethodError」になる。変数に値が入っていないときは、returnして次の処理をしないようにして対応することができます。ifで分岐してもいいですね。
# restaurantがnilになってしまってもエラーにはならない restaurant = Restaurant.find_by(id: 1) return unless restaurant restaurant.nameまたは、ぼっち演算子(&.)を使用してレシーバーに定義されていないメソッドを呼び出した場合は、nilを返すようにすれば対応できます。
restaurant&.name =>nilSQL発行される処理を定数にしない
NG
TOKYO = Area1.find_by(name: "東京")メソッドで呼び出す形にしましょう。
OKdef tokyo Area1.find_by(name: "東京") endprivate_constant
定数を定義した際に、そのクラス内でしか使用しない場合は、private_constantを使用して、他のクラスから呼び出されないようにする。
class Italian PIZZA = "ピザ" PASTA = "パスタ" private_constant :PIZZA, :PASTA endpartialで受け取る変数を初期化
partialで変数を初期化しておけば、変数の受け渡しを忘れた場合にもエラーにはならない。
(デメリットとしては、逆にエラーに気づけないということもあるので注意)_users.html.slim- users ||= [] - users.each do |user| = user.nameパフォーマンス
pluckを使用する
例えば、DBから都道府県の名前データを取得したい場合に、ActiveRecordモデルをすべて読み込むのではなく、pluckを使用して、必要な名前だけを配列で取得するようにします。
そうすることで、メモリを大量に使わずに済み、速度も早くなります。
NGprefs = Prefecture.all prefs.map(&:name) =>["北海道","青森",...]OK
Prefecture.all.pluck(:name) =>["北海道","青森",...]n+1問題
includes,preload,eager_loadを使用することで、SQLの発行回数を削減することができます。n+1問題については、@massaaaaanさんの下記記事で説明しているので、どうぞご覧ください。
【Ruby on Rails】N+1問題ってなんだ?メモ化
複数回呼ばれる場合に下記のようにすることで、2回目以降は1回目で処理した値を返すことができる。
def countries_link @_link ||= build_countries_link endまた、build_countries_linkが、nilになる可能性がある場合は下記のように書くと良い。
この場合は、@_linkが、定義されている場合はその値を返す。def countries_link return @_link if defined?(@_link) @_link = build_countries_link end可読性
読みやすさは大事ですね。次、自分や他の人が見たときに、わかりやすいように記述しましょう。改修がしやすくなり、バグも起こりにくくなります。
早期リターン
処理しない条件で早めにreturnすることで、複雑にならずに見やすくなります。
def food_genre(food_name) return if food_name.blank? return if food_name == "hogehoge" genre = Food.find_by(name: food_name)&.genre endhashのslice,except
hashから、必要な値だけを取り出したいときに使用する。
paramsの値を取得するときに便利。hash = { a: "hoge", b: "foo", c: "bar" } # aとcのみ取り出す hash.slice(:a, :c) => { a: "hoge", c: "bar" } # c以外取り出す hash.except(:c) => { a: "hoge", b: "foo" }index_by
配列を特定のキーのhashにしてくれる。モデルからpluckで値を取得したときになどに、扱いやすくなる。
Food.where(genre: "和食").pluck(:id, :name, :en_name).index_by {|item| item[0] } =>{1=>[1,"寿司","sushi"], 2=>[2,"鍋","nabe"], ...}each_with_object
配列やhashなどのオブジェクトに繰り返し、値を入れていく処理などのときに、初めにオブジェクトを定義する必要がなくなる。
price = { apple: 100, orange: 30, banana: 200, cherry: 10 } # 100以上のものを調べてキーを配列にする fruits = price.each_with_object([]) do |(key, val), arr| arr << key if val >= 100 end =>[:apple, :banana]その他細かい点
- {}の前後にスペースを入れる
- カンマ(,)の後にスペースを入れる
- ロケットハッシュを使用しない
{ a: "hoge", b: "hoge" } # こっちの方が見やすいと思う {:a=>"hoge",:b=>"hoge"}
- %記法を活用する
%w(apple orange banana cherry) =>["apple", "orange", "banana", "cherry"] %i(apple orange banana cherry) =>[:apple, :orange, :banana, :cherry]最後に
今回は、Railsプロダクトのコードチェックで、指摘されがちな点をまとめてみました。
私も、ありがたいことに先輩エンジニア達から多くの指摘をされてきましたが、次コーディングするときには気をつけるようにしています。自分がコードチェックするときにも指摘できるようになっていくので、コードチェック大切ですね。明日は、@ya-manさんの「Ansibleを最大で25倍高速化するMitogenについて調べてみた」です。
お楽しみに!
- 投稿日:2019-12-04T14:39:49+09:00
【サーバーサイド一式】Docker + Rails + Circle CI + Terraformでインフラをコードで環境構築 & ECSへ自動コンテナデプロイ【前半】
流行りの技術を使いたい我々は
おはようございます。今年もアドヴェントな感情が舞い散る季節になってきました。皆さん如何お過ごしでしょうか? 本番環境と仲良くやっていますでしょうか? 自分は非常に犬猿な仲になりつつあります。いいんです、人生はいつだって本番なのですから(?)
さて、巷のエンジニア達によるエンジニアの為のエンジニア論では、もはや
- (主にサーバーサイドの)アプリをDockerを使って環境構築して
- terraformでインフラの構成をコード化して
- (Kubernetesなどのコンテナオーケストレーションツールを用いて)なるべく開発環境との差異が無いままコンテナデプロイをして
- CircleCIでテストからデプロイまで自動化
といった事がサーバーサイドエンジニアとしては求められている、いや最早知らないようではやっていくのは難しい、といったご意見が結構な頻度で見られたりします。
(そういったご意見の是非はまた別の機会に預けるとして)だとしたら初心者のサーバーサイド志望のエンジニアさん達の為には、これらの
- Docker
- CircleCI
- Terraform
- コンテナデプロイ(今回はECS)
といった要素をバーーーーーーーーとチュートリアル形式で学んでいくのが手っ取り早いのでは無いか(そして自分の理解の整理にもなる)と思い立ちました! どうでしょうか?
つまりこの記事で現時点でナウいサーバーサイドの技術が一通り触れちゃう!ということです!
自分はその膨大さに今若干後悔しています。まあ、じゃ、書きます!まーた多分長いよ。。。
※過去の長い記事たち
【初心者向け】丁寧すぎるRails『アソシエーション』チュートリアル【幾ら何でも】【完璧にわかる】
【初心者向け】railsアプリをherokuを使って確実にデプロイする方法【決定版】明日(12/5)ワンマンライブなんでよかったらきてください
MV
予約はこちら目次
目次 全体像を把握しよう Dockerを用いてRailsの環境を構築 CircleCIでCIの設定 Terraformを使うための準備 前半はここで終わり この記事を読むにあたっての前提
- gitとgithubを使った事がある
- Dockerをなんとなく理解している
- Railsも触ったことある(触ったことなくてもできるかも)
- AWSのコンソールでEC2やVPCを立てた事がある
もちろん、それ以外の方も是非是非挑戦してみてください。理解なんて後から帳尻合わせればいいんです。プログラミングは体で覚えるものです(?)
できるようになること
railsアプリをDockerで構築できて、pushしたタイミングでCircleCIが走って、予めterraformで構築しておいたAWS環境(ECS)に自動デプロイする事ができるようになる!
注意してほしい事
- DBはsqliteです。RDSとつないでません。
- Webサーバもpumaで兼用してます。nginxなどのWebサーバーとつないでません =>これらはまた次回やろうと思います!
自分の環境
- ruby 2.6.3
- rails 6.0.1
- Docker 19.03.4
- git 2.14.1
- terraform 0.12.8
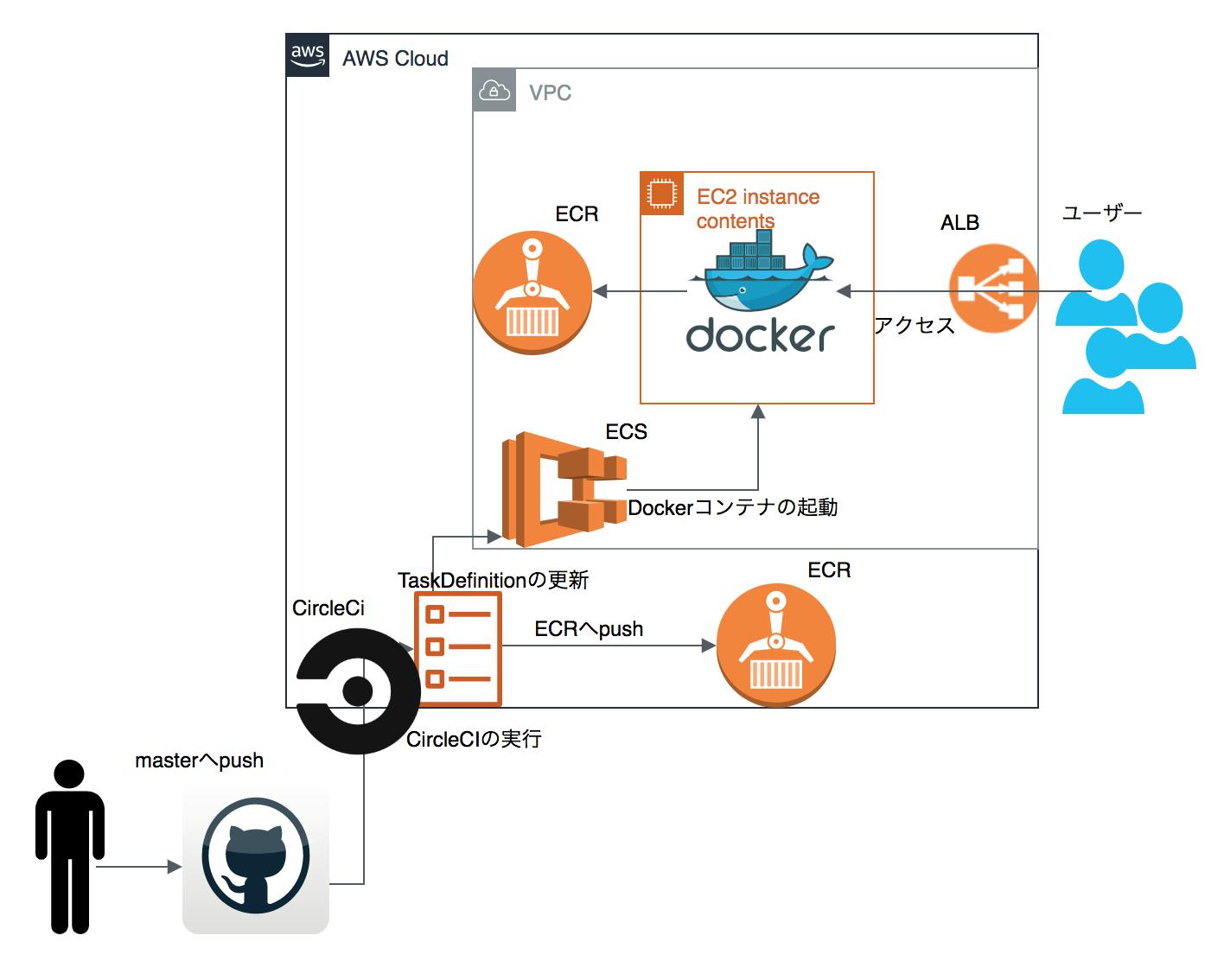
全体像を把握しよう
目次 全体像を把握しよう←今ココ Dockerを用いてRailsの環境を構築 CircleCIでCIの設定 Terraformを使うための準備 前半はここで終わり 様々なツールやサービスを繋げていく事は、全体像の把握がとても大事になってきます。
まず大きい流れを確認しましょう。時系列順に列挙すると以下となります。アプリが自動でコンテナデプロイされるまでの流れ
(0.terraformでAWS上のリソースを定義)
1.railsアプリをgithubにpush
2.CircleCIでCI開始
3.CIでDockerイメージをビルド
4.DockerイメージをECRへpush
5.ECSのTaskDefinitionを更新
6.CIでmigration
7.アプリがデプロイされる!画像に表す以下となります。
画像1ざっくり各ツールの役割も解説すると
terraform
インフラストラクチャ定義ツール。
クラウド上のリソースを定義ファイルの状態になるように生成・操作してくれる。
画面上でポチポチやってたインフラの操作をコードにできる。rails
デプロイしたいアプリそのもの。
github
バージョン管理ツール。
アプリとCircleCIをつなぐ為のハブみたいな役割も担っている。CircleCI
ビルド/テスト/デプロイなどについて自動実行できるサービス。
これを用いて色々面倒くさい事を自動化しよう。Docker
アプリを動かす為の環境が一式詰まった仮想化プラットホーム。
ここでrailsが動く事はだいたい担保されてるので、Railsアプリが入ったDockerコンテナをそのまま本番>環境にのっけたいECR
コンテナイメージをprivateな環境に格納しておけるサービス。
Railsアプリの環境を入れたDockerコンテナイメージをここにぶっ込みたい。ECS
dockerコンテナを通して処理をしたりサービスを立ち上げたりと行った挙動を、EC2上で容易に行うための>AWSのサービス。EC2上での操作は全部AWSでやってくれるので、デプロイが簡単(のはずだがそうでもない)。
となります!非常に盛りだくさんですね。
はい、いつも通り順番に解説していきますのでご安心ください。ではまずはDockerを用いて、Railsアプリを動かせる環境を作っていきましょう!
Dockerを用いてRailsの環境を構築
目次 全体像を把握しよう Dockerを用いてRailsの環境を構築←今ココ CircleCIでCIの設定 Terraformを使うための準備 前半はここで終わり とりあえずローカル環境で一度作ります。
terraformとrailsアプリを一つのディレクトリにまとめちゃいたいので、terraform_ecs_deploy
というディレクトリを作っちゃいましょう(githubのリポジトリは別にするので注意してください!)ターミナル$ mkdir terraform_ecs_deploy $ cd terraform_ecs_deploy $ rails new terraform_ecs_app --skip-javascript # webpackerは今回いらないです $ cd terraform_ecs_app $ rails db:migrateさて、このタイミングでRailsアプリをDocker化します。
Dockerfileを作り、公式のRubyのイメージを取得し、以下のように書きましょう。
(今回簡単なDockerfileしか用意していないのはご了承ください。)Dockerfile# 公式のイメージから取得 FROM ruby:2.6.3 # Dockerfile内部で使える変数として定義 ARG RAILS_ENV ARG RAILS_MASTER_KEY # コンテナ内のルートとする変数を/appと定義 ENV APP_ROOT /app # 環境変数化 ENV RAILS_ENV ${RAILS_ENV} ENV RAILS_MASTER_KEY ${RAILS_MASTER_KEY} # コンテナ内のルートとする。 WORKDIR $APP_ROOT # ローカルのGemfile, Gemfile.lockをコンテナ内のルートへコピー ADD Gemfile $APP_ROOT ADD Gemfile.lock $APP_ROOT # bundle install実行。 # (バージョンのエラーが出る為、一応bundler 2.0.2を指定) RUN \ gem install bundler:2.0.2 && \ bundle install && \ rm -rf ~/.gem # バンドルインストールが終わってから他のファイルもコンテナ内へコピー ADD . $APP_ROOT # 本番環境の場合プロダクション RUN if ["${RAILS_ENV}" = "production"]; then bundle exec rails assets:precompile; else export RAILS_ENV=development; fi # ポート3000番を公開 EXPOSE 3000 CMD ["rails", "server", "-b", "0.0.0.0"]では、この
Dockerfileを元にDockerコンテナをbuildし、railsを立ち上げてみます。ターミナル$ docker build -t terraform_ecs_app:latest . # -tでタグを指定 $ docker run -it -p 3000:3000 terraform_ecs_app:latest # -it
docker run時のオプションは以下の通りです。-i, --interactive・・・コンテナのSTDINにアタッチする
-t, --tty・・・疑似ターミナルを割り当てるこのようになっていたらOKです。
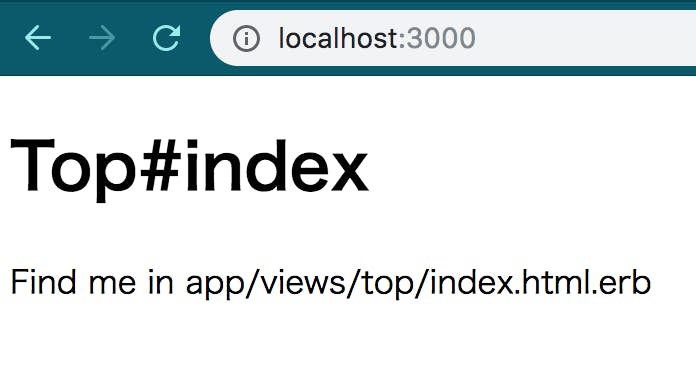
http://localhost:3000にアクセスするとこのようにおなじみの画面になっているはずです。
※注意! docker run -it -p 3000:3000 terraform_ecs_app:latestが通らない場合
もしここで
~~~
docker: you are not authorized to perform this operation: server returned 401.
See 'docker run --help'.
~~~このようなエラーが出る場合は、ターミナルで以下のコマンドを打ち、環境変数を設定してください。
ターミナルexport DOCKER_CONTENT_TRUST=0これにより、Dockerイメージが改ざんされていないか、という整合性判定をスキップでき、上のコマンドが通るようになるはずです。
Railsの詳細設定
さて、今回Railsの話が本題では無いので、機能的には簡素なもので良いです。なので、
- 表示用のトップ画面
-ALB(Application Load Balancer)のHealthCheck用に、jsonでステータスOKが帰ってくるURLの二つだけ実装できれば良いです。(もちろんALBとヘルスチェックについても後述します。)
ターミナル$ rails g controller top index $ rails g controller health_check
topコントローラはアクションとビューが自動生成されているはずなので、health_checkコントローラだけ変更します。app/controllers/health_check_controller.rbclass HealthCheckController < ApplicationController # ALBにステータスokを返す為のアクション def index render json: '{ "status": "ok" }' end endルーティングも変更します。
config/routes.rbRails.application.routes.draw do root to: 'top#index' resources :health_check, only: [:index] endそれぞれ以下のように表示されればOKです。
http://localhost:3000
http://localhost:3000/health_check
また、本番環境で
tmp/pidsとtmp/socketsが作成されない事がある為、念のため.gitignoreに以下の記述を追加しましょう。.gitignore# See https://help.github.com/articles/ignoring-files for more about ignoring files. # # If you find yourself ignoring temporary files generated by your text editor # or operating system, you probably want to add a global ignore instead: # git config --global core.excludesfile '~/.gitignore_global' # Ignore bundler config. /.bundle # Ignore the default SQLite database. /db/*.sqlite3 /db/*.sqlite3-journal /db/*.sqlite3-* # Ignore all logfiles and tempfiles. /log/* /tmp/* !/log/.keep !/tmp/.keep # ===============追加================ !/tmp/pids !/tmp/sockets # =============ここまで=============== # Ignore uploaded files in development. /storage/* !/storage/.keep /public/assets .byebug_history # Ignore master key for decrypting credentials and more. /config/master.key最低限の機能が実装できたので、githubにpushしましょう。
githubにrailsアプリをpush
今回はgitとgihubの解説は省略します。
カレントディレクトリがrailsアプリなのを確認してから、以下のコマンドを打ってください。
(自分は今回リポジトリ名はterraform_ecs_appとしています。)ターミナル$ git init $ git commit -m "initial commit" $ git remote add origin リポジトリのURL $ git push origin mastergithubのリポジトリが以下のようになっていたらOKです。
それではいよいよCircleCIのCI設定をおこなっていきましょう!
CircleCIでCIの設定
目次 全体像を把握しよう Dockerを用いてRailsの環境を構築 CircleCIでCIの設定←今ココ Terraformを使うための準備 前半はここで終わり CircleCIとは、Saas型のCI/CDサービスであり、CI/CDでやることの基本であるビルドとテストとデプロイの3点が自動化可能なサービスです。
今回はこちらを使ってtestとデプロイ(ECRへのpush)の自動化を行なっていきたいと思います。
以下、CircleCIならではの特徴や料金についてはこちらをご参照ください。
いまさらだけどCircleCIに入門したので分かりやすくまとめてみたCircleCIの導入
↓こちらのURLの右上あたりにある
Loginをクリックし、Log in with Githubを押してログインしましょう。
すると、自動的にgithubと紐づくはずなので、CIの設定画面まで行きましょう。
CircleCI
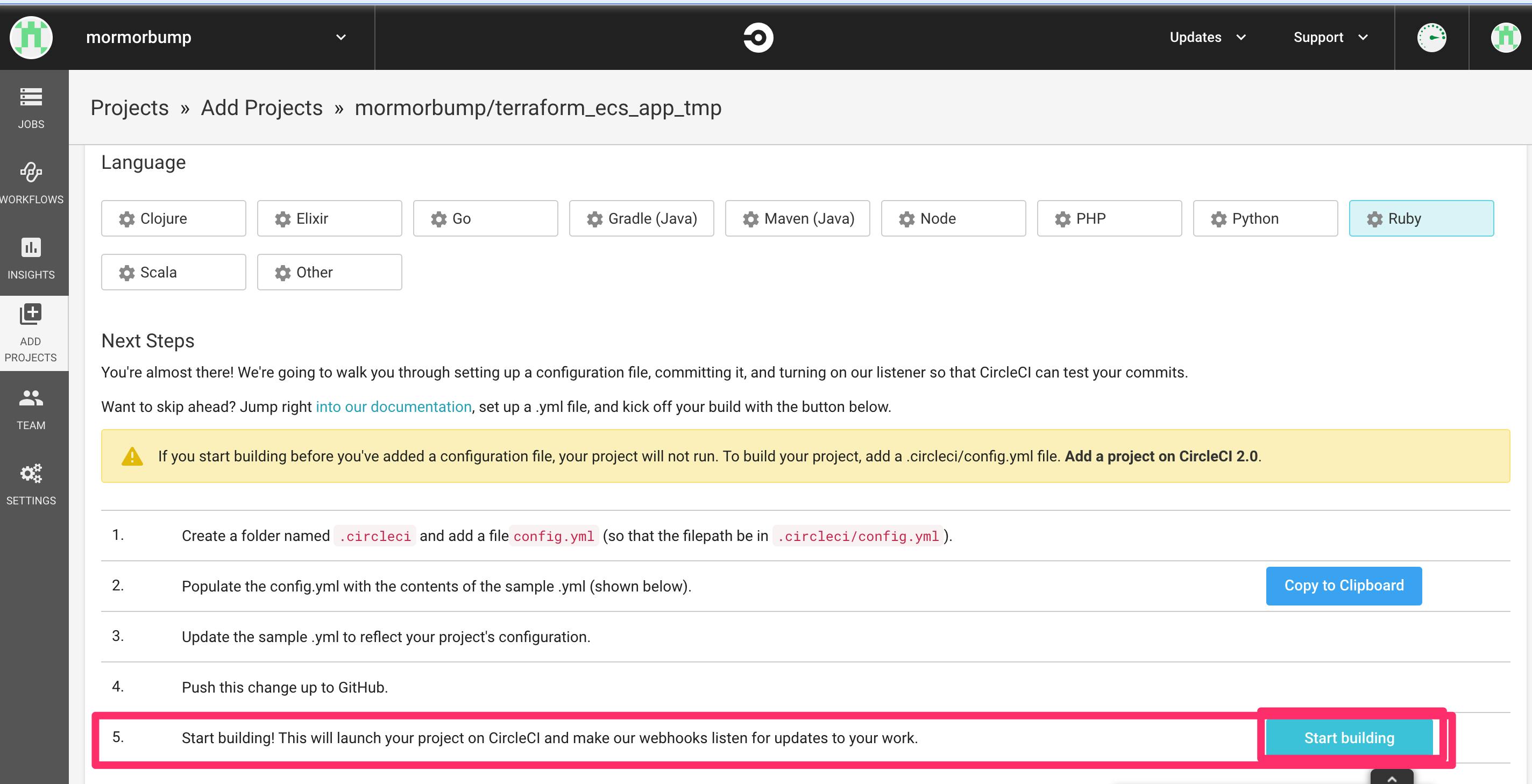
こちらの画像のように、
Add Projectsを押すと、自分のgithubのリポジトリが出てくるので、
その中から先ほど作成したterraform_ecs_appを選択します。Set Up Projectを押しましょう。
すると、プロジェクトの設定画面になると思います。
Operating SystemはLinux
LanguageもRubyのままで大丈夫です。そして、そのすぐ下に英語でチュートリアルが書いてあります。和訳すると
.circleciという名前のフォルダーを作成し、config.ymlファイルを追加します(ファイルパスが.circleci/config.ymlになるように)。config.ymlにsample.ymlの内容を入力します(以下を参照)sample.ymlを更新して、プロジェクトの構成を反映します。- この変更を
GitHubにプッシュします。- 構築を始めましょう!これにより、
CircleCIでプロジェクトが起動し、Webhookが作業の更新をリッスンします。とのことです。実際にそのすぐ下に、あらかじめCircleCIが用意してくれてたrails用の設定ファイル
sample.ymlがあります。
指示通り、これをコピペして、ローカル環境で.circleciというフォルダを作り、その中にconfig.ymlという名前のファイルを作り、そこに貼り付ければOKです。ただし、これだとrubyのバージョンが違うのと、テストフレームワークが
rspecになっているので、今回はrailsデフォルトのテストフレームワークであるminitestに変えた以下のものにしてください。.circleci/config.yml# Ruby CircleCI 2.0 configuration file # # Check https://circleci.com/docs/2.0/language-ruby/ for more details # version: 2 # jobsの中にタスクを定義。一番下のworkflowのjobsのなかで定義したタスクを使う。 jobs: # buildという名前のタスク定義 build: docker: # specify the version you desire here - image: circleci/ruby:2.6.3-node-browsers # Specify service dependencies here if necessary # CircleCI maintains a library of pre-built images # documented at https://circleci.com/docs/2.0/circleci-images/ # - image: circleci/postgres:9.4 working_directory: ~/repo # 実際の処理内容 steps: - checkout # Download and cache dependencies - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} # fallback to using the latest cache if no exact match is found - v1-dependencies- # runのたびに実行 - run: name: install dependencies command: | gem install bundler -v 2.0.2 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # Database setup - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # run tests - run: name: run tests command: | DISABLE_SPRING=true bundle exec rails test # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-resultsここまでできたら、先ほどのCircleCIの設定画面に戻り、5の右側にある
Startbuildingを押してください。CircleCIが動き出します。
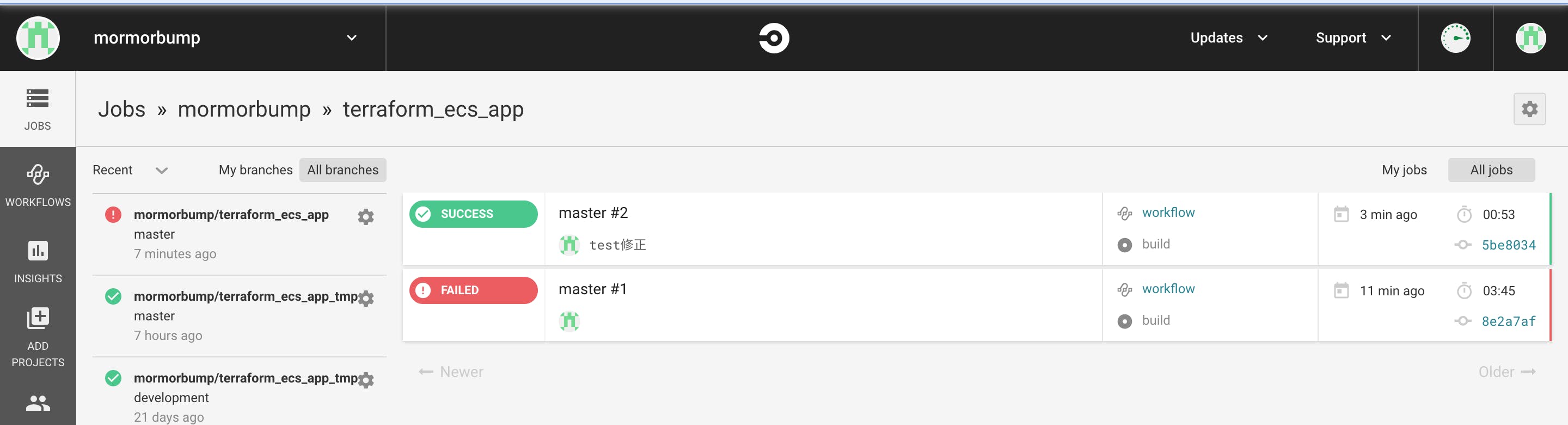
こうすることによって次回以降はpushされたタイミングでCircleCIがJobし始めます!
(ちなみにroutes.rbを変えたせいでtestが失敗してしまうので、該当のtestをコメントアウトするか、正しい記述に直してからpushとbuildをしてください)
成功したらcircleCIのJOBSのタブの表示がこのようになります。(一番上の緑色がそうです。)
さて、ここまできたらようやく
Terraformに入ります!!Terraformを使うための準備
目次 全体像を把握しよう Dockerを用いてRailsの環境を構築 CircleCIでCIの設定 Terraformを使うための準備←今ココ 前半はここで終わり Terraformのインストール
Terraform公式
Terraformを用いることで、今まで手続き的だったインフラの工程をコード化することできます。
homebrewでもインストールできますが、Terraformのバージョンマネージャであるtfenvを使うのがおすすめです。バージョンアップに追従しやすいです。
まずはtfenv自体をインストールしましょう。ターミナル$ brew install tfenv $ tfenv --version tfenv 1.0.1
list-reomteコマンドでインストール可能なTerraformのバージョンを確認できます。
ここでは、0.12.8をインストールしましょう。ターミナル$ tfenv list-remote . . 0.12.8 $ tfenv install 0.12.8 $ terraform -v Terraform v0.12.8TerraformでAWSを扱うためのIAMユーザの設定
terraformでAWSを扱うにはIAMユーザのACCESS KEY、SECRET KEY(とDEFAULT REGION)が必要です。
ここだけはterraformの管理下におけないので、AWSのコンソールでIAMユーザを作成しし、アクセスキーとシークレットキーを発行してください。
発行できたら、ターミナルで以下のようにアクセスキーとシークレットキーを環境変数に設定してください。
ターミナル$ export AWS_ACCESS_KEY_ID=AKIxxxxxxxxx $ export AWS_SECRET_ACCESS_KEY=wJalxxxxxxxxxxxxxxxx $ export AWS_DEFAULT_REGION=ap-northeast-1(PCの電源落としたり、ターミナル落としたりしたら消えてしまうのでもう一度入力し直してください。)
今回自分はAdministratorAccess ポリシーをアタッチしたIAMユーザのアクセスキーを用いていますが、こちら相当に強力な権限なので扱いには注意してください。
(間違ってもGitHubなどで公開してはダメです!)
AdministratorAccessポリシー以外では、権限不足で Terraform の実行が失敗することがあるので、その場合はエラーメッセージを参考に、必要な権限を付与しましょう。これでTerraformを扱う準備ができました!
terraform用のgithubのリポジトリの作成
アプリ開発やCIとインフラ構成は別の話なので、リポジトリを分けるのがセオリーです。
今回はterraform_ecsという名前でgithubのリポジトリを作成します。秘匿情報を扱うので、プライベートリポジトリにすることに注意してください。
さて、terraformのディレクトリ構造に関する考えは色々あるのですが
https://dev.classmethod.jp/devops/directory-layout-bestpractice-in-terraform/
https://qiita.com/anfangd/items/1b84f69fa2a4f8a29fbc
https://future-architect.github.io/articles/20190903/今回は簡単のため環境だけディレクトリを分けて、その中に全てのtfファイルを突っ込む方式でいこうと思います。
terraform_ecs_deploy ├──terraform_ecs_app └──terraform_ecs ├──prod └──stgまた、今回はステージング環境の構築は行いません!ほぼ同じことをやるだけなので、一度productionで構築できたらすぐできちゃうと思います。
では早速、terraform用のディレクトリを作成しましょう。
ターミナル$ cd .. # railsアプリにいた場合 $ pwd /Users/matsumotokazuki/Desktop/terraform_ecs_deploy # terraform_ecs_deployにいることを確認。 $ mkdir terraform_ecs $ mkdir terraform_ecs/prod $ cd terraform_ecs/prodこのようなディレクトリ構成になっていれば大丈夫です。
terraform_ecs_deploy ├──terraform_ecs_app └──terraform_ecs └──prod # カレントディレクトリここで、githubにpushする前に、terraformのインフラ構成ファイルを表すterraform.tfstateや秘匿情報を表すterraform.tfvarsなどをgitの管理下から除外します。(こちらも後述します)
ターミナル$touch .gitignoreterraform_ecs/prod/.gitignore/.terraform/* /terraform.tfvars /terraform.tfstateそれではpushしましょう。
ターミナル$ cd .. # terraform_ecsディレクトリに移動 $ git init $ git add -A $ git commit -m "initial commit" $ git remote add origin リポジトリ名 $ git push origin master
前半はここで終わり
目次 全体像を把握しよう Dockerを用いてRailsの環境を構築 CircleCIでCIの設定 Terraformを使うための準備 前半はここで終わり←今ココ 諸々の大体の準備が終わった時点で一旦区切ります!
後半からいよいよTerraformを使ってインフラを構築していきますので、気長にお待ちください。後半はコチラ(にする予定)










- 投稿日:2019-12-04T08:47:23+09:00
【Rails】scaffoldで作成したpostモデルとrails 6 の ActionText を関連づけの手順
rails6でaction textを使ってみるためscaffodlコマンドでpostモデルを作成しActionTextを利用するための設定をする
$ rails action_text:install $ rails db:migrateこの段階で次のモデルが作成される
rails-6-action-text/db/schema.rb# This file is auto-generated from the current state of the database. Instead # of editing this file, please use the migrations feature of Active Record to # incrementally modify your database, and then regenerate this schema definition. # # This file is the source Rails uses to define your schema when running `rails # db:schema:load`. When creating a new database, `rails db:schema:load` tends to # be faster and is potentially less error prone than running all of your # migrations from scratch. Old migrations may fail to apply correctly if those # migrations use external dependencies or application code. # # It's strongly recommended that you check this file into your version control system. ActiveRecord::Schema.define(version: 2019_12_03_195638) do # These are extensions that must be enabled in order to support this database enable_extension "plpgsql" create_table "action_text_rich_texts", force: :cascade do |t| t.string "name", null: false t.text "body" t.string "record_type", null: false t.bigint "record_id", null: false t.datetime "created_at", precision: 6, null: false t.datetime "updated_at", precision: 6, null: false t.index ["record_type", "record_id", "name"], name: "index_action_text_rich_texts_uniqueness", unique: true end create_table "active_storage_attachments", force: :cascade do |t| t.string "name", null: false t.string "record_type", null: false t.bigint "record_id", null: false t.bigint "blob_id", null: false t.datetime "created_at", null: false t.index ["blob_id"], name: "index_active_storage_attachments_on_blob_id" t.index ["record_type", "record_id", "name", "blob_id"], name: "index_active_storage_attachments_uniqueness", unique: true end create_table "active_storage_blobs", force: :cascade do |t| t.string "key", null: false t.string "filename", null: false t.string "content_type" t.text "metadata" t.bigint "byte_size", null: false t.string "checksum", null: false t.datetime "created_at", null: false t.index ["key"], name: "index_active_storage_blobs_on_key", unique: true end add_foreign_key "active_storage_attachments", "active_storage_blobs", column: "blob_id" endgemファイルを編集する
Gemfile- gem 'rails' - gem 'coffee-rails' + gem 'rails', '~> 6.0.0' + gem 'coffee-rails', '~> 5.0' + gem 'image_processing', '~> 1.9.3' - gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]bundle install する
$bundle installscaffoldコマンドでstring型のtitleカラムのみをもつpostモデルを作成
$rails generate scaffold post title:stringmigrateする
$ rails db:migrateするとpostモデルが作成される
rails-6-action-text/app/models/post.rbclass Post < ApplicationRecord end次のように編集
rails-6-action-text/app/models/post.rbclass Post < ApplicationRecord has_rich_text :content end
has_rich_text :contentとモデルに書き込むことでRichTextモデルへのアクセスができるProvides access to a dependent RichText model that holds the body and attachments for a single named rich text attribute. This dependent attribute is lazily instantiated and will be auto-saved when it's been changed. Example:
class Message < ActiveRecord::Base
has_rich_text :content
endここまでやったら
rails console -sで動作確認する
-sをつけサンドボックスモードで立ち上げると、DBを更新してもロールバックでき、安全$rails console -s Loading development environment in sandbox (Rails 6.0.0) Any modifications you make will be rolled back on exit irb(main):027:0> post = Post.create!(content: "<p>Hello</p>") (0.5ms) BEGIN (0.5ms) SAVEPOINT active_record_1 Post Create (4.6ms) INSERT INTO "posts" ("created_at", "updated_at") VALUES ($1, $2) RETURNING "id" [["created_at", "2019-12-03 23:14:37.768882"], ["updated_at", "2019-12-03 23:14:37.768882"]] ActionText::RichText Create (17.7ms) INSERT INTO "action_text_rich_texts" ("name", "body", "record_type", "record_id", "created_at", "updated_at") VALUES ($1, $2, $3, $4, $5, $6) RETURNING "id" [["name", "content"], ["body", "<p>Hello</p>"], ["record_type", "Post"], ["record_id", 2], ["created_at", "2019-12-03 23:14:38.341012"], ["updated_at", "2019-12-03 23:14:38.341012"]] ActiveStorage::Attachment Load (10.9ms) SELECT "active_storage_attachments".* FROM "active_storage_attachments" WHERE "active_storage_attachments"."record_id" = $1 AND "active_storage_attachments"."record_type" = $2 AND "active_storage_attachments"."name" = $3 [["record_id", 1], ["record_type", "ActionText::RichText"], ["name", "embeds"]] Post Update (4.8ms) UPDATE "posts" SET "updated_at" = $1 WHERE "posts"."id" = $2 [["updated_at", "2019-12-03 23:14:38.364760"], ["id", 2]] (0.5ms) RELEASE SAVEPOINT active_record_1 => #<Post id: 2, title: nil, created_at: "2019-12-03 23:14:37", updated_at: "2019-12-03 23:14:38"> irb(main):028:0> postID2のデータがインサートされているのが確認できた。
has_rich_textメソッドの処理を確認する
# frozen_string_literal: true #ActionTextという名前空間を切り、さらにその下にAttributeという名前空間を切っている module ActionText module Attribute extend ActiveSupport::Concern #クラスメソッドを定義 class_methods do #省略 def has_rich_text(name) #class_evalによって、def #{name}メソッドが動的に定義される class_eval <<-CODE, __FILE__, __LINE__ + 1 #getterメソッド def #{name} rich_text_#{name} build_rich_text_#{name} end #setterメソッド def #{name}=(body) self.#{name}.body = body end CODE has_one :"rich_text_#{name}", -> { where(name: name) }, class_name: "ActionText::RichText", as: :record, inverse_of: :record, autosave: true, dependent: :destroy scope :"with_rich_text_#{name}", -> { includes("rich_text_#{name}") } scope :"with_rich_text_#{name}_and_embeds", -> { includes("rich_text_#{name}": { embeds_attachments: :blob }) } end end end endそのうちgetterとsetterメソッドを抜粋してみると、
has_rich_textの引数によって動的にメソッドが生成されることがわかる。#getterメソッド def #{name} rich_text_#{name} build_rich_text_#{name} end #setterメソッド def #{name}=(body) self.#{name}.body = body endとあるのでしたがってコンソールで
irb(main):030:0> post.content Rendered vendor/bundle/gems/actiontext-6.0.0/app/views/action_text/content/_layout.html.erb (Duration: 10.3ms | Allocations: 488) => #<ActionText::RichText id: 1, name: "content", body: #<ActionText::Content "<div class=\"trix-conte...">, record_type: "Post", record_id: 2, created_at: "2019-12-03 23:14:38", updated_at: "2019-12-03 23:14:38"> irb(main):031:0>とすることもできる。ActionText::RichTextが返ることがわかる。
また
#getterメソッド def #{name} rich_text_#{name} build_rich_text_#{name} endの
rich_text_#{name}メソッドなどは、has_rich_textメソッドの下部にあるhas_one :"rich_text_#{name}", -> { where(name: name) }, class_name: "ActionText::RichText", as: :record, inverse_of: :record, autosave: true, dependent: :destroyで定義されている。
つまりhas_rich_textを利用したモデルはhas_oneで一対一のアソシエーションが定義されている。なおclass_name: "ActionText::RichText",と関連づいている。
- 投稿日:2019-12-04T08:26:47+09:00
検索機能を実装するンゴ
ransackを使わない簡易検索機能です。
ルーティング
routes.rbRails.application.routes.draw do resources :tweets do collection do get 'search' end end end実際生成されるルーティングがこちら。
ターミナルPrefix Verb URI Pattern Controller#Action search_tweets GET /tweets/search(.:format) tweets#searchビュー
検索フォームを好きなところへ配置。
search.html.haml= form_with(url: search_tweets_path, local: true, method: :get) do |form| = form.text_field :keyword = form.submitコントローラー
app/controllers/tweets_controller.rbdef search @tweets = Tweet.where('text LIKE(?)', "%#{params[:keyword]}%").page(params[:page]).per(3) endページネーションで3件ごとに取ってきています。
.limit(3)とかで上から3件取ってきてもいいですね。whereの中身はあいまい検索といいます。
where('カラム名 LIKE(?)', "検索したいワード")
検索ワードに引っかかるものを取ってきます。
%a%とするとaを含むもの
%bとするとbから始まるもの今回はフォームに入力されたワードを含むツイートが表示されます。
ではまた!
- 投稿日:2019-12-04T08:17:02+09:00
Rails+Vue.jsでバリデーションエラーを各項目の下に表示する
はじめに
Rails側のモデルに定義したバリデーションを使いつつ、
バリデーションエラーを各項目の下に表示するのに苦労したのでまとめておこうと思います。
今回、バリデーション関連以外の説明は省略させていただきます。
ご了承ください。。やりたいこと
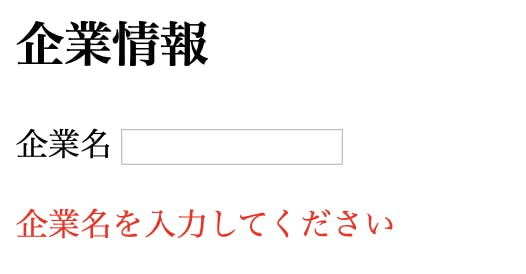
このように項目の下にバリデーションエラーを表示するようにします。(見た目は気にしないでください。。)
実装してみる
バリデーションを設定
ここでは必須のバリデーションだけ設定しておきます。
class Company < ApplicationRecord validates :name, presence: true endAPI側の実装
vue.js側で各項目ごとのエラーメッセージを取り出せるようにします。
具体的には下記のようなハッシュになるように加工します。
{項目名: 日本語化されたエラーメッセージ}今回は下記のように実装しました。
@company = Company.new(create_company_params) if @company.save render json: @company, status: :ok else render json: { errors: @company.errors.keys.map { |key| [key, @company.errors.full_messages_for(key)]}.to_h, render: 'show.json.jbuilder' }, status: :unprocessable_entity endここでerrorsにエラーメッセージを設定しています。
errors: @company.errors.keys.map { |key| [key, @company.errors.full_messages_for(key)]}.to_hAPI側はこれで終わりです。
vue.js側で項目の下にエラーが表示されるようにする
まずはtemplateから実装していきます。
<template> <form @submit.prevent="createCompany"> <h2>企業情報</h2> <div> <label>企業名</label> <input v-model="company.name" type="text"> <!-- これでバリデーションエラーがあるときだけ表示される --> <p v-if="!!errors['name']" class="error" style="color: red;">{{ errors['name'][0]}}</p> </div> </form> </template>errorsのkeyの中に表示する項目名が含まれているかどうかで、
表示/非表示を切り替えています。次にscriptです。
<script> import axios from 'axios' import { csrfToken } from 'rails-ujs' axios.defaults.headers.common['X-CSRF-Token'] = csrfToken() export default { data: function () { return { company:{ name: '' }, // バリデーションエラーがあった場合は、このerrorsにセットされます。 errors: '' } }, methods: { createCompany: function(){ axios .post('api/v1/company.json', this.company) .then(response => { this.$router.push('/'); }) .catch(error => { if (error.response.data && error.response.data.errors) { this.errors = error.response.data.errors; } }); } } </script>これでバリデーションエラーがあるときは各項目の下に表示されるようになるかと思います。
まとめ
今回は各項目の下にエラーメッセージを表示する方法をまとめました。
もっといい感じの方法があれば、是非コメントで教えてください。。
- 投稿日:2019-12-04T07:52:05+09:00
current_page?で場合分け
newとeditで同一の部分テンプレートを利用しているが、それぞれちょっとだけ変えたい時
current_page?(URL)で指定したページにいるか判定してくれます。_form.html.haml- if current_page?(new_tweet_path) 新規作成 - if current_page?("/tweets/#{tweet.id}/edit") 編集 = form_with model: tweet, local: true do |form| ...newページでは
新規作成が、
editページでは編集が表示されるようになりました。
(URL)の部分は以下が可能みたいです。
エラーが出たらいくつか試してみてください。・URL
current_page?(http://hoge.com/hoge)・パス
current_page?(/tweets/new)・prefix
current_page?(new_tweet_path)・アクション指定
current_page?(action: "new")・コントローラー&アクション指定
current_page?(controller: "tweets", action: "new")
参考
ではまた!
- 投稿日:2019-12-04T04:01:47+09:00
【Rails】マイクロポストと画像のアップロード【Rails Tutorial 13章まとめ】
基本的な画像のアップロード
画像付きのマイクロポストを投稿できるようにする。
画像の投稿フォームと、投稿された画像の表示機能を実装する。carrierwaveジェム
画像アップロード機能を追加するcarrierwaveジェムをGemfileに追加する。
加えて、画像をリサイズするmini_magickジェムと、本番環境で画像をアップロードできるfogジェムも追加する。Gemfilesource 'https://rubygems.org' gem 'rails', '5.1.6' gem 'bcrypt', '3.1.12' gem 'faker', '1.7.3' gem 'carrierwave', '1.2.2' gem 'mini_magick', '4.7.0' gem 'will_paginate', '3.1.5' gem 'bootstrap-will_paginate', '1.0.0' . . . group :production do gem 'pg', '0.20.0' gem 'fog', '1.42' end次に、pictureという名前の画像アップローダーを作成する。
$ rails generate uploader Picturepictureカラム
Micropostモデルに、画像を格納するためのpictureカラムを追加する。
$ rails generate migration add_picture_to_microposts picture:string $ rails db:migrateCarrierWaveに画像と関連付けたモデルを伝えるためには、mount_uploaderというメソッドを使う。
このメソッドは、引数に属性名のシンボルと生成されたアップローダーのクラス名を取る。app/models/micropost.rbclass Micropost < ApplicationRecord belongs_to :user default_scope -> { order(created_at: :desc) } mount_uploader :picture, PictureUploader validates :user_id, presence: true validates :content, presence: true, length: { maximum: 140 } endrailsサーバーとGuardを再起動して、テストがGREENになるようにする。
画像投稿フォーム
マイクロポストの投稿フォームにf.file_field :pictureを使って画像の投稿フォームを作成する。
app/views/shared/_micropost_form.html.erb<%= form_for(@micropost) do |f| %> <%= render 'shared/error_messages', object: f.object %> <div class="field"> <%= f.text_area :content, placeholder: "Compose new micropost..." %> </div> <%= f.submit "Post", class: "btn btn-primary" %> <span class="picture"> <%= f.file_field :picture %> </span> <% end %>マイクロポスト投稿のStrong Parametersを修正して、picture属性が送信できるようにしておく。
app/controllers/microposts_controller.rbprivate def micropost_params params.require(:micropost).permit(:content, :picture) end画像の表示
これで画像が投稿できるようになったので、image_tagとurlメソッドを使ってマイクロポストに画像を表示する。
app/views/microposts/_micropost.html.erb<li id="micropost-<%= micropost.id %>"> <%= link_to gravatar_for(micropost.user, size: 50), micropost.user %> <span class="user"><%= link_to micropost.user.name, micropost.user %></span> <span class="content"> <%= micropost.content %> <%= image_tag micropost.picture.url if micropost.picture? %> </span> <span class="timestamp"> Posted <%= time_ago_in_words(micropost.created_at) %> ago. <% if current_user?(micropost.user) %> <%= link_to "delete", micropost, method: :delete, data: { confirm: "You sure?" } %> <% end %> </span> </li>picture?メソッドはCarrierWaveによって生成されるメソッドで、Micropostオブジェクトに画像が入っているかを論理値で返す。
画像アップロードのテスト
画像が投稿できるようになったので、テストを書く。
テスト用画像はtest/fixturesディレクトリに入れる。
マイクロポスト投稿用のテストに追記していく。test/integration/microposts_interface_test.rbtest "micropost interface" do log_in_as(@user) get root_path assert_select 'div.pagination' assert_select 'input[type="file"]' # 無効な送信 post microposts_path, params: { micropost: { content: "" } } assert_select 'div#error_explanation' # 有効な送信 content = "This micropost really ties the room together" picture = fixture_file_upload('test/fixtures/rails.png', 'image/png') assert_difference 'Micropost.count', 1 do post microposts_path, params: { micropost: { content: content, picture: picture } } end assert @user.microposts.paginate(page: 1).first.picture? follow_redirect! assert_match content, response.body # 投稿を削除する . . . endfixture_file_uploadメソッドで、fixture内のファイルをアップロードする。
第一引数に画像へのパス、第二引数に'ファイル形式/拡張子'をとる(多分)。投稿画像のバリデーション
投稿可能な画像ファイルのサイズや種類を制限するために、バリデーションを設定していく。
画像フォーマットとアップローダーファイル
画像ファイルの種類を制限するために、アップローダーファイルを修正する。
app/uploaders/picture_uploader.rbclass PictureUploader < CarrierWave::Uploader::Base storage :file # アップロードファイルの保存先ディレクトリは上書き可能 # 下記はデフォルトの保存先 def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" end # アップロード可能な拡張子のリスト def extension_whitelist %w(jpg jpeg gif png) end end拡張子のリスト部分はデフォルトではコメントアウトされている。
画像サイズとvalidateメソッド
アップロードできる画像のサイズは5MB以下としたいので、Micropostモデルにバリデーションを追加する。
ここで、ファイルサイズを制限するバリデーションがRailsのデフォルトに無いため、自分で定義しなければならない。
定義したバリデーションを適用するには、validateメソッド(単数形)を使って、メソッドをシンボルの形で指定する。app/models/micropost.rbclass Micropost < ApplicationRecord belongs_to :user default_scope -> { order(created_at: :desc) } mount_uploader :picture, PictureUploader validates :user_id, presence: true validates :content, presence: true, length: { maximum: 140 } validate :picture_size private # アップロードされた画像のサイズをバリデーションする def picture_size if picture.size > 5.megabytes errors.add(:picture, "should be less than 5MB") end end end5MBを超えた場合はerrors.addを使って、Micropostオブジェクトのpicture属性にエラーメッセージを追加している。
まずフォーマットのバリデーションを反映するために、投稿フォームのf.file_fieldにacceptパラメータを付ける。
<%= f.file_field :picture, accept: 'image/jpeg,image/gif,image/png' %>また、jQueryを使って警告メッセージを表示しておく。
app/views/shared/_micropost_form.html.erb<%= form_for(@micropost) do |f| %> <%= render 'shared/error_messages', object: f.object %> <div class="field"> <%= f.text_area :content, placeholder: "Compose new micropost..." %> </div> <%= f.submit "Post", class: "btn btn-primary" %> <span class="picture"> <%= f.file_field :picture, accept: 'image/jpeg,image/gif,image/png' %> </span> <% end %> <script type="text/javascript"> $('#micropost_picture').bind('change', function() { var size_in_megabytes = this.files[0].size/1024/1024; if (size_in_megabytes > 5) { alert('Maximum file size is 5MB. Please choose a smaller file.'); } }); </script>画像のリサイズ
ImageMagickとMiniMagickジェム
画像を自動でリサイズするには、ImageMagickというプログラムを使う。
Homebrewでは次のようにインストールする。$ brew install imagemagickImageMagickを使うためには、MiniMagickジェムが必要である。
CarrierWaveの導入時に導入していない場合はしておく。画像を縦400px、横400pxに制限するには、アップローダーファイルに次のように記述する。
app/uploaders/picture_uploader.rbclass PictureUploader < CarrierWave::Uploader::Base include CarrierWave::MiniMagick process resize_to_limit: [400, 400] storage :file # アップロードファイルの保存先ディレクトリは上書き可能 # 下記はデフォルトの保存先 def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" end # アップロード可能な拡張子のリスト def extension_whitelist %w(jpg jpeg gif png) end end画像のリサイズ機能を使いしたことでテストがREDになるので、次のように修正する。
config/initializers/skip_image_resizing.rbif Rails.env.test? CarrierWave.configure do |config| config.enable_processing = false end end本番環境での画像アップロード
AWSを使用するようなので、スキップする。
- 投稿日:2019-12-04T02:59:57+09:00
自動デプロイ実行中にunicornが起動しない(SSHKit::Runner::ExecuteError)
この記事は初学者がエラーになったときの対処法を記載したものになります。
同じ初学者の方は、一度記事を全部読んで同じ症状に当てはまる場合実行してみてください。
現状
現在私は、1つのrailsアプリケーションを作り、AWSのEC2、Mysql、Nginx、Capistrano等を使い自動デプロイを行う際に置きたエラーになります。
また、私は、このアプリケーションで一度自動デプロイを成功させておりますので、初めて自動デプロイを行った際のエラー内容ではありません。エラー内容
ローカル環境bundle exec cap production deploy自動デプロイコマンドを実行後unicornが起動しない
エラーコマンド一部bundle exit status: 1 (SSHKit::Runner::ExecuteError) Caused by: SSHKit::Command::Failed: bundle exit status: 1 Tasks: TOP => unicorn:start (See full trace by running task with --trace)解決策
まず、unicornの環境変数がしっかりと定義されているか確認を行いましょう。
変数の確認するためのコマンドがいくつかあります。printenv env | grep SECRET_KEY_BASE env | grep DATABASE_PASSWORD調べてばもっと出てきます。
上記コマンドを行い定義されているかしっかり確認しましょう。
原因
私の場合一度自動デプロイを行いましたが、違うエラーが起きてしまい、その際に環境変数を変えてしまったと言うことになります。
環境変数の方法が間違っていた。
みなさまも、定義した場合しっかりと定義できているか確認する癖をつけましょう。
- 投稿日:2019-12-04T02:31:39+09:00
We're sorry, but something went wrong.
この記事は初学者がエラーになったときの対処法を記載したものになります。
同じ初学者の方は、一度記事を全部読んで同じ症状に当てはまる場合実行してみてください。
現状
現在私は、1つのrailsアプリケーションを作り、AWSのEC2、Mysql、Nginx、Capistrano等を使い自動デプロイを行う際に置きたエラーになります。
エラー症状
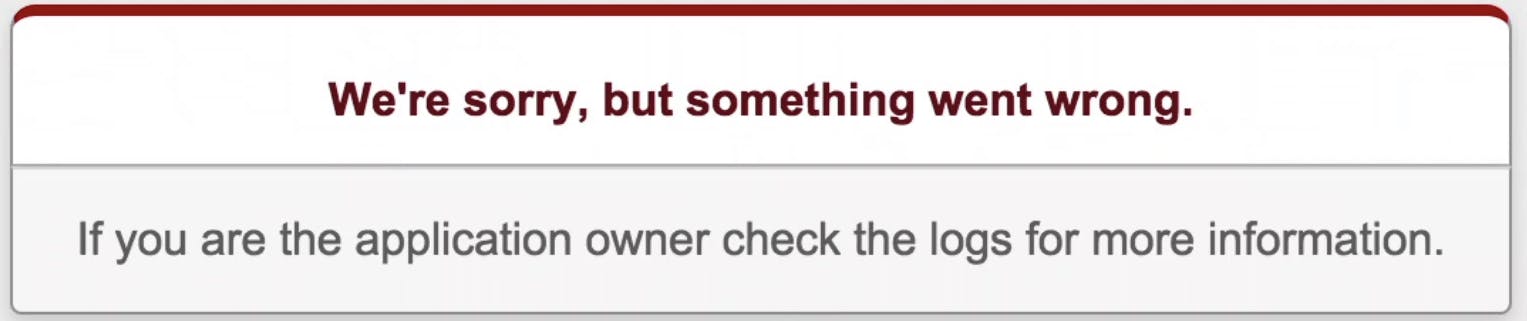
自動デプロイ後 IP で繋いだ所下記の画面が表示される。
原因
私の場合、デプロイ後に
サーバー環境kill -QUIT `cat tmp/pids/unicorn.pid`上記のコマンドを訳もわからずに実行した結果表示されました。
(上記コマンドは、ユニコーンの停止を行うコマンドです。)エラー解説
We're sorry, but something went wrong.
If you are the application owner check the logs for more information.
とは、ローカル環境bundle exec cap production deployを行いましたが、unicornもしくはnginxにエラーが起こっている場合に起こる可能性のあるエラーになります。
私の場合デプロイを行ったのにもかかわらず、unicornサーバーを落とした為エラーになりました。
また、このエラーはlogに残らない場合もあります。解決策
エラーの原因がunicorn,Nginxどちらにあるかわからない為、両方を再起動させましょう。
まず、unicornのサーバーがまだ可動しているか確認を行います。
サーバー環境ps aux | grep unicorn (unicornのサーバー状態を調べるコマンド) 実行後↓ ec2-user 7263 0.0 8.6 335420 87328 ? Sl 16:34 0:02 unicorn master ec2-user 7341 0.0 9.6 349224 97032 ? Sl 16:34 0:00 unicorn worker[0] ec2-user 7763 0.0 0.2 110540 2092 pts/3 S+ 17:14 0:00 grep ※見られたくない部分もある為カットしている部分あります。 サーバーが停止している場合1行しか出てこないです。unicorn masterの行にある左から2番目の番号(7263)を
サーバー環境kill 7263 kill -9 7263 どっちでも良いにて停止してください。
その後Nginxを再起動させます。
サーバー環境sudo service nginx reload (リロードさせるコマンド) 実行後↓ Stopping nginx: [ OK ] Starting nginx: [ OK ]※下記コマンドは行わなくても大丈夫です。
ついでにMysqlも再起動させときます。サーバー環境sudo service mysqld restart (リロードさせるコマンド) 実行後↓ Stopping mysqld: [ OK ] Starting mysqld: [ OK ]その後
ローカル環境bundle exec cap production deploy (自動デプロイさせるコマンド)以上でエラーは解除されると思います。
- 投稿日:2019-12-04T01:26:49+09:00
Railsアプリのデプロイ方法について(基礎)
自身で作成したアプリ(Rails)をデプロイする流れを学習したので、備忘録もかねて纏めます。
*今回まとめた大変なデプロイ作業を Capistrano というライブラリを使うと自動化できるとのこと。
こちらについては、別途学習次第、纏めます。全体の流れ
EC2のサーバに作成したコードをクローンする準備
まずはEC2のサーバに作成したコードを設置します。
そのために、Githubにあるコードのリモートリポジトリからコードをクローンしてくる準備をします。アプリケーションサーバの設定
Railsを動かすためには、アプリケーションサーバと呼ばれる種類のソフトを起動する必要があります。
その後、コードをEC2へクローンします。本番環境でのRailsの設定
最後に、開発環境と本番環境での差異を埋めるための作業を行い、しっかりと公開できているか確認します。1. EC2のサーバに作成したコードをクローンする準備
まず、アプリケーションのコードをGithubからEC2サーバへクローンします。
全世界に公開できるIPアドレスを持ったEC2サーバ上でアプリを動かすためです。
ただし、現状のままEC2サーバにアプリケーションのコードをクローンしようとしても'permission denied'とエラーが出てしまいます。
これはGithubからみた時に、EC2インスタンスが何者なのかわからないため、発生しているエラーです。
このエラーを解消するためにGithubにSSH鍵を登録しましょう。GithubにSSH鍵を登録
EC2インスタンスからGithubにアクセスするためには、作成したEC2インスタンスのSSH公開鍵をGithubに登録する必要があります。
SSH鍵をGithubに登録すると、Githubはそれを認証に利用し、コードのクローンを許可してくれるようになります。
それでは、ターミナルで以下のコードを入力しましょう。
*EC2にしっかりログインしていることを確認してください。
*途中で入力を求められることがありますが、全て何も入力せずにEnterキーで進んでください。terminal(EC2サーバ)$ ssh-keygen -t rsa -b 4096上記コードを入力することでEC2サーバのSSH鍵ペアが作成できます。
続いて、作成したSSH鍵の内容を確認します。
terminal(EC2サーバ)$ cat ~/.ssh/id_rsa.pubここで表示された鍵の内容をコピーし、Github上に登録します。
下記URLから'New SSH Key'ボタンから登録をしてください。
名称は自由で、'key'のスペースに先ほどコピーした鍵の内容を貼り付けて登録します。
https://github.com/settings/keys鍵をしっかりと登録できているかチェックします。
$ ssh -T git@github.com =>ここで、このまま接続していいか質問されますので、yesとすると、以下のコメントが出てきます。 以下のコメントが出てくれば、無事、登録できてます! Hi ユーザー名! You've successfully authenticated, but GitHub does not provide shell access.2. アプリケーションサーバの設定
単語
まず、以下の単語について、確認します。
-アプリケーションサーバ(Appサーバ)
ブラウザからの「リクエスト」を受け付けRailsアプリケーションを実際に動作させるソフトウェアのこと。-Unicorn
全世界に公開されるサーバ上で良く利用されるアプリケーションサーバ。
unicorn_railsコマンドで起動することができます。Unicornに関する設定
それでは、作成したアプリでUnicornを使用できるようにしましょう。
Gemfilegroup :production do gem 'unicorn', '5.4.1' end*group :production do ~ endの間に記述されたgemは本番環境のみで読み込まれます。
bundle installを忘れずに。
terminal$ bundle install続いて、configディレクトリに'unicorn.rb'というファイルを作成し、Unicornの設定を記載していきましょう。
記載に関しては、各々の内容になると思われますので、割愛いたしますが、重要な単語を以下に記載しておきます。
*参照に記述方法の書かれたページを貼り付けておきますので、気になる方は別途参照ください。-worker(ワーカー)
Unicornは、プロセスを分裂させることができ、この分裂したプロセス全てをworkerと呼びます。
プロセスを分裂させることで、リクエストに対してのレスポンスを高速にすることができ、
worker_processesという設定項目で、workerの数を決定します。
設定項目 詳細 worker_processes リクエストを受け付けレスポンスを生成するworker(ワーカー)の数を決めます。 working_directory UnicornがRailsのコードを動かす際、ルーティングなど実際に参照するファイルを探すディレクトリを指定します。 pid Unicornは、起動する際にプロセスidが書かれたファイルを生成します。その場所を指定します。 listen どのポート番号のリクエストを受け付けることにするかを決定します。今回は、3000番ポートを指定しています。 エラー対策
-Uglifier(gem)/JavaScriptでテンプレートリテラル記法を使用している時。
元々このgemはJavaScriptを軽量化するためのものが、テンプレートリテラル記法に対応していません。
そのため、デプロイ時にエラーの原因となるので、この部分をコメントアウトすることで対策します。config/environments/production.rbconfig.assets.js_compressor = :uglifier =>コメントアウトしましょう。変更修正をリモートリポジトリに反映しよう
ローカルのフォルダ内で変更修正を行ったので、こちらをリモートリポジトリへ反映します。
変更修正をGitHub Desktopからコミットしてプッシュしましょう。
この時必ず、masterブランチで行うようにしてください。
別のブランチでコミット&プッシュした場合は、リモートリポジトリでプルリクエストを作成し、ブランチをmasterへマージしてください。Githubからコードをクローンしよう
続いて、Unicornの設定を済ませたコードをEC2インスタンスにクローンしましょう。
まず、以下のコマンドを入力して、ディレクトリを作成します。
*今回は、ここで作成したディレクトリにアプリケーションを設置することにします。terminal(EC2サーバ)#ディレクトリを作成 $ sudo mkdir /var/www/ #作成したwwwディレクトリの権限をec2-userに変更 $ sudo chown ec2-user /var/www/続いて、Githubから「リポジトリURL」を取得します。
リポジトリURLはGithubのページ上、緑色の'clone or download'というボタンを押すと出てきます。terminal(EC2サーバ)#先ほど作成したディレクトリに移動 $ cd /var/www/ $ git clone [コピーしたURL]以上でアプリケーションのコードをEC2サーバにクローンすることができました。
クローンしたアプリを起動するためにGemを使えるようにしましょう。
まずローカルで設計したアプリのbundlerのバージョンをチェックします。
terminal(ローカル)#バージョンチェック $ bundler -v Bundler version 2.0.2バージョンがわかりました。今回は2.0.2ですね。
それでは、本番環境でgemを実装しましょう。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] #ローカルで確認したbundlerのverを導入します。 $ gem install bundler -v 2.0.2 $ bundle install環境変数の設定
環境変数:データベースのパスワードなどセキュリティのためにGithubにアップロードすることができない情報がある時に、環境変数を利用して設定します。
環境変数は、Railsからは ENV['<環境変数名>'] という記述でその値を利用することができます。ローカルで作成したアプリにおける「config/secrets.yml」 と 「config/database.yml」 をチェックしてみましょう。
<%= ENV["SECRET_KEY_BASE"] %> と書かれている部分があります。
これはSECRET_KEY_BASE という環境変数の値になります。secret_key_base
Cookieの暗号化に用いられる文字列です。Railsアプリケーションを動作させる際は必ず用意する必要があります。また、外部に漏らしてはいけない値であるため、こちらも環境変数から参照します。secret_key_baseは以下のコマンドを打つことで生成できます。
terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] #secret_key_baseを生成します。 $ rake secret 69619d9a75b78f2e1c87ec5e07541b42f23efeb6a5........ ↑これがsecret_key_baseです。メモしておきましょう。続いて環境変数の設定をしましょう。
環境変数は '/etc/environment' というファイルに保存することで、サーバ全体に適用されます。
環境変数の書き込みはvimコマンドを使用して行います。terminal(EC2サーバ)$ sudo vim /etc/environment #MySQLのパスワードと先ほどのsecret_key_baseを入力します。(=の前後にスペースは入れないでください。) DATABASE_PASSWORD='MySQLのrootユーザーのパスワード' SECRET_KEY_BASE='先程コピーしたsecret_key_base'書き込みができたら 「esc(エスケープキー)」→「:wq」と入力して内容を保存します。
保存できたら環境変数を適用するために一旦ログアウトします。terminal(EC2サーバ)$ exit logout Connection to 52.xx.xx.xx closed.念のため、しっかり保存できているか確認しましょう。
terminal(EC2サーバ)$ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='secret_key_base' [ec2-user@ip-172-31-23-189 ~]$ env | grep DATABASE_PASSWORD DATABASE_PASSWORD='MySQLのrootユーザーのパスワード''secret_key_base'と'MySQLのrootユーザーのパスワードが先ほど入力したものと同じであれば、OKです!
ポートの解放
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の通信方法では一切つながらないようになっています。
そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。セキュリティグループ
EC2サーバが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものであり、ポートの設定をするためにはEC2の「セキュリティグループ」という設定を変更する必要があります。AWSを使用している場合は、AWSにログインいただき、EC2=>インスタンス=>セキュリティグループから設定できます。
そこで、’インバウンド'=>'編集'=>'ルールの追加'で追加できます!3. 本番環境でのRailsの設定
それでは、いよいよ本番環境でのRailを起動しましょう。
とその前に作成したローカルファイルにおける「database.yml」の本番環境の設定を編集しましょう。config/database.yml(ローカル)#username以下を下記のように変更しましょう。 production: <<: *default database: ~~~(それぞれのアプリケーション名によって異なっているので、こちらは編集しないでください) username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock上記編集が完了次第、ローカルでの編集をコミットして、GitHubにプッシュしましょう。
リモートリポジトリが更新されたため、サーバ上のアプリケーションにも反映させましょう。
先ほどはgit cloneコマンドを利用しましたが、今回はすでにEC2とGithubは接続できているため、git pullコマンドを利用します。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $git pull origin master続いて、データベースを作成しマイグレーションを実行し直しましょう。
terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $ rails db:create RAILS_ENV=production Created database '<データベース名>' $ rails db:migrate RAILS_ENV=production*Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。
sudo service mysqld startというコマンドをターミナルから打ち込み、mysqlの起動を試してみましょう。これでデータベースの準備が整いました。Railsを起動しましょう。
unicorn_railsコマンド
$ unicorn_rails -c config/unicorn.rb -E production -D
-c config/unicorn.rb は設定ファイルの指定。
-E production は環境を「本番モードとして動作させる」。
-Dは「Daemon(デーモン)」の略で、プログラムを起動させつつターミナルで別のコマンドを打てるようにするオプション。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dこれで、移管は完了です。
http://<サーバに紐付けたElastic IP>:3000/でアクセスしてみましょう。
無事Railsが起動できましたが、今のままではレイアウトが崩れてしまっていると思われます。
これは、開発中はアクセス毎にアセットファイル(画像・CSS・JSファイルの総称)を自動的にコンパイル(圧縮)する仕組みが備わっていますが、本番モードのときにはパフォーマンスのためアクセス毎には実行されないようになっているためです。
ということで、アセットコンパイルを実行しましょう。アセットコンパイルを実行
terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] rails assets:precompile RAILS_ENV=productionコンパイルが成功したら反映を確認するため、Railsを再起動します。
そのために、まずは今動いているUnicornをストップします。
Unicornのプロセスを確認し、プロセスを止めましょう。
ターミナルからプロセスを確認するにはpsコマンドを利用します。psコマンド
現在動いているプロセスを確認するためのコマンドです。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] #[aux]と打っているのは、psコマンドのオプションで、表示結果を見やすくしてくれます。 #| grep unicornとしているのはpsコマンドの結果からunicorn関連のプロセスのみを抽出するためです。 $ ps aux | grep unicornここで表示される情報ない、左から2番目の列に表示されるのがプロセスのid、つまりPIDになります。
「unicorn_rails master」と表示されているプロセスがUnicornのプロセス本体です。
早速このプロセスを終了させましょう。
ターミナルからプロセスをストップするにはkillコマンドを利用します。killコマンド
現在動いているプロセスを停止させるためのコマンドです。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $ kill <確認したunicorn rails masterのPID> =>再度、$ ps aux | grep unicornで状態を確認しましょう。 うまくプロセスをストップできていない場合は、下記コマンドで強制終了できます。 $ kill -9 [プロセスID]それでは、再びunicornを起動しましょう。
このとき RAILS_SERVE_STATIC_FILES=1 という指定を先頭に追加してください。
これは、コンパイルされたアセットをRailsが見つけられるような指定になります。terminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上で、設計したアプリがデプロイできているはずです!
長々と説明して参りましたが、以上がデプロイの概要となります。番外編 EC2の能力拡張について
特に何もしていないEC2のインスタンスではコンピューターの能力が足りず、Gemのインストール時などにエラーが発生する可能性があります。具体的には、コンピューターの処理能力に関係するメモリというものが足りません。
そこで、今後の設定を行う前にメモリを増強する処理を行います。
具体的にはSwap領域をうまく使うことで処理落ちを防ぎます。Swap(スワップ)領域とは。。。
メモリが使い切られそうになった時にメモリの容量を一時的に増やすために準備されるファイルのこと。
コンピュータが処理を行う際、メモリと呼ばれる場所に処理内容が一時的に記録されますが、メモリの容量は決まっており、容量を超えてしまうとエラーで処理が止まってしまいます。
そこで、Swap領域を使うことで処理落ちを防ぎます。
*EC2はデフォルトではSwap領域を用意してません。terminal(EC2サーバ)#まず、ホームディレクトリに移動 $cd #コマンドオプションの「of」にファイルのパスを指定して「bs」に基準となる容量の単位を指定して「count」にbsの量を指定します。 #dd if=/dev/zero of=作成するファイル名 bs=ブロックサイズ(byte) count=ブロック数 $ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 # しばらく待って、以下のように表示されれば成功 512+0 レコード入力 512+0 レコード出力 536870912 バイト (537 MB) コピーされました、 7.35077 秒、 73.0 MB/秒 #パーミッションの設定をします。 $ sudo chmod 600 /swapfile1 #mkswapコマンドでスワップ領域を作成します。 $ sudo mkswap /swapfile1 # 以下のように表示されれば成功 スワップ空間バージョン1を設定します、サイズ = 524284 KiB ラベルはありません, UUID=74a961ba-7a33-4c18-b1cd-9779bcda8ab1 #swaponコマンドを使って,スワップ領域を有効にします。 $ sudo swapon /swapfile1 #リダイレクトの設定をします。 $ sudo sh -c 'echo "/swapfile1 none番外編 unicorn操作時のエラーについて
Unicorn関係で発生したエラーはlog/unicorn.stderr.logに記録されます。
そのため、log/unicorn.stderr.logを確認して発生しているエラーを確認しましょうterminal(EC2サーバ)#該当のファイルの場所に移動します。 $ cd /var/www/[リポジトリファイル名] $ less log/unicorn.stderr.log上記コマンドでログが確認できますので、エラーの内容をチェックして対応しましょう。
lessコマンドはq, Q, :q, :Q, ZZのいづれかを入力すれば、とまります。番外編 エラーチェック
-pushのし忘れ、またはEC2サーバ側でのpullのし忘れは無いか
-EC2サーバ側で、/var/www/<リポジトリ名>/log/unicorn.stderr.logをlessまたはcatコマンドで確認し、
エラーが出ていないか確認する(下に行くほど最新のログです。時刻表記がUTCであることに注意してください)
-ローカルでの編集のpushやEC2でのgit pullを忘れていないか
-mysqlの起動は正しく行えているか
-EC2サーバ側のSECRET_KEY_BASE等は正しく設定できているか
-EC2インスタンスの再起動を行ってみる参照
Unicorn設定のまとめ
https://qiita.com/syou007/items/555062cc96dd0b08a610Swap fileの作り方
https://gist.github.com/koudaiii/0ed6a8558aa297af463esudo で書き込みをしたい
https://qiita.com/jiz/items/d4f05ffacedefc11f14dWhat does
sudo sh -cmeans in linux?
https://www.reddit.com/r/learnprogramming/comments/3bsct5/what_does_sudo_sh_c_means_in_linux/lessコマンド(よく使いそうなものだけ版)
https://qiita.com/inokou/items/a73bac8c7e03951d07be
- 投稿日:2019-12-04T01:13:36+09:00
【Rails】ユーザーのマイクロポスト【Rails Tutorial 13章まとめ】
Micropostモデル
ユーザーに紐づいた短いメッセージの投稿機能を実装する。
user:references
user:referencesをつけて、text型のcontentカラムを持つMicropostモデルを作成する。
$ rails generate model Micropost content:text user:referencesこれによりMicropostモデルは自動でbelong_toによってユーザーに関連づけられ、user_idカラムも追加される。
ユーザーごとの投稿を作成時刻の逆順(新しい順)で取り出しやすくするために、user_idカラムとcreated_atカラムにインデックスを追加する。
db/migrate/[timestamp]_create_microposts.rbclass CreateMicroposts < ActiveRecord::Migration[5.0] def change create_table :microposts do |t| t.text :content t.references :user, foreign_key: true t.timestamps end add_index :microposts, [:user_id, :created_at] end endマイグレーションを実行しておく。
Micropostのバリデーション
Micropostモデルの各カラムにバリデーションを設定していく。
先にテストを書く。
一つ目はMicropostモデルが正常かどうか、二つ目はuser_idの存在性のテストである。test/models/micropost_test.rbrequire 'test_helper' class MicropostTest < ActiveSupport::TestCase def setup @user = users(:michael) # このコードは慣習的に正しくない @micropost = Micropost.new(content: "Lorem ipsum", user_id: @user.id) end test "should be valid" do assert @micropost.valid? end test "user id should be present" do @micropost.user_id = nil assert_not @micropost.valid? end endバリデーションを設定してテストが通るようにしておく。
app/models/micropost.rbclass Micropost < ActiveRecord::Base belongs_to :user validates :user_id, presence: true end次に、content属性に関するバリデーションを設定する。
content属性は140文字まで、空白は無効とする。
先にテストを書く。test/models/micropost_test.rbtest "content should be present" do @micropost.content = " " assert_not @micropost.valid? end test "content should be at most 140 characters" do @micropost.content = "a" * 141 assert_not @micropost.valid? endバリデーションを追加する。
app/models/micropost.rbclass Micropost < ApplicationRecord belongs_to :user validates :user_id, presence: true validates :content, presence: true, length: { maximum: 140 } endUser/Micropostの関連付け
belong_toとhas_many
一つのマイクロポストは、一人のユーザーに関連づけられる一対一の関係にある(belong_to)。
また、一人のユーザーは複数のマイクロポストを持つ一対多の関係にある(has_many)。そこで、Userモデルにhas_many :micropostsを追加する。
app/models/user.rbclass User < ApplicationRecord has_many :microposts . . . endこの関連付けによって、Userオブジェクトからマイクロポストを作成したり取得できるようになる。
具体的には、Userオブジェクトにmicropostsというメソッドを使用する。user.microposts.create user.microposts.create! user.microposts.buildこれで先ほどのテストを書き直すと以下のようになる。
test/models/micropost_test.rbdef setup @user = users(:michael) @micropost = @user.microposts.build(content: "Lorem ipsum") endマイクロポストの改良
デフォルトのスコープ
マイクロポストを作成した日時が新しい順に表示できるようにする。
テスト駆動開発で進めるため、まずfixtureファイルにテスト用のマイクロポストを作る。test/fixtures/microposts.ymlorange: content: "I just ate an orange!" created_at: <%= 10.minutes.ago %> tau_manifesto: content: "Check out the @tauday site by @mhartl: http://tauday.com" created_at: <%= 3.years.ago %> cat_video: content: "Sad cats are sad: http://youtu.be/PKffm2uI4dk" created_at: <%= 2.hours.ago %> most_recent: content: "Writing a short test" created_at: <%= Time.zone.now %>fixtureファイルの中では、埋め込みRubyを使って投稿時間を設定できる。
この中で最も新しい投稿であるmonst_recentが最初に取得されるようなテストを書く。test/models/micropost_test.rbrequire 'test_helper' class MicropostTest < ActiveSupport::TestCase . . . test "order should be most recent first" do assert_equal microposts(:most_recent), Micropost.first end endマイクロポストの取得順はdefault_scopeメソッドを使って変更できる。
デフォルトでは昇順(asc)になっているので、これを降順(desc)にする。app/models/micropost.rbclass Micropost < ApplicationRecord belongs_to :user default_scope -> { order(created_at: :desc) } validates :user_id, presence: true validates :content, presence: true, length: { maximum: 140 } endこれでテストがGREENになる。
ユーザーと同時に投稿を削除する
ユーザーが削除された時、そのマイクロポストも削除されるようにする。
そのために、has_manyメソッドにdependent: :destroyオプションを追加する。app/models/user.rbhas_many :microposts, dependent: :destroyテストを書く。
test/models/user_test.rbtest "associated microposts should be destroyed" do @user.save @user.microposts.create!(content: "Lorem ipsum") assert_difference 'Micropost.count', -1 do @user.destroy end end削除するユーザーに関連付くマイクロポストを一つ作成し、ユーザーの削除とともにそれが破棄され、マイクロポストの数が1減ることをassert_differenceで確認する。
マイクロポストの表示
ユーザープロフィールページ
マイクロポストをユーザーのプロフィールページに表示する。
まずMicropostsコントローラを作成する。$ rails generate controller Micropostsマイクロポストの表示部分はパーシャルを使う。
ユーザー一覧ページでは次のようなコードでパーシャルを呼び出していた。<ul class="users"> <%= render @users %> </ul>こうすると、_user.html.erbパーシャルが呼び出されるとともに、@users変数がパーシャルで使えるようになる。
同じことをマイクロポストの表示でも行うことにして、まずパーシャルを作成する。app/views/microposts/_micropost.html.erb<li id="micropost-<%= micropost.id %>"> <%= link_to gravatar_for(micropost.user, size: 50), micropost.user %> <span class="user"><%= link_to micropost.user.name, micropost.user %></span> <span class="content"><%= micropost.content %></span> <span class="timestamp"> Posted <%= time_ago_in_words(micropost.created_at) %> ago. </span> </li>time_ago_in_wordsメソッドを使うと、「3分前に投稿」といった文字列を表示できる。
また、埋め込みRubyを使ってid="micropost-<%= micropost.id %>とすることで、各マイクロポストにそのidごとにcssのidを与えている。マイクロポストの表示にもページネーション機能を使うが、Usersコントローラ内でマイクロポストを使う場合は、以下のようにwill_paginateに@microposts変数を引数として与えねばならない。
<%= will_paginate @microposts %>Usersコントローラ内で@users変数を使う場合は、この引数を省略できる。
@micropostsインスタンス変数を、Usersコントローラのshowアクション内に定義する。
app/controllers/users_controller.rbdef show @user = User.find(params[:id]) @microposts = @user.microposts.paginate(page: params[:page]) end以上をまとめると、ユーザープロフィールページのビューは次のようになる。
app/views/users/show.html.erb<% provide(:title, @user.name) %> <div class="row"> <aside class="col-md-4"> <section class="user_info"> <h1> <%= gravatar_for @user %> <%= @user.name %> </h1> </section> </aside> <div class="col-md-8"> <% if @user.microposts.any? %> <h3>Microposts (<%= @user.microposts.count %>)</h3> <ol class="microposts"> <%= render @microposts %> </ol> <%= will_paginate @microposts %> <% end %> </div> </div>マイクロポストのサンプル
6人のユーザーに、それぞれ50個のマイクロポストを作成する。
db/seeds.rb. . . users = User.order(:created_at).take(6) 50.times do content = Faker::Lorem.sentence(5) users.each { |user| user.microposts.create!(content: content) } endorder(:created_at).take(6)とすることで、最初の6人を取得できる。
content属性には、fakerジェムのLorem.sentenceメソッド使うことでランダムな文章を入れている。データベースをリセットしてseedファイルを実行しておく。
$ rails db:migrate:reset $ rails db:seedプロフィールページのマイクロポストのテスト
プロフィールページ用の統合テストを作成する。
$ rails g integration_test users_profileユーザーに紐付いたテスト用のマイクロポストをfixtureファイルに作成する。
そのためにはuser: michaelを付ける。
また、fakerと埋め込みRubyを使ってテスト用マイクロポストを大量生成する。test/fixtures/microposts.ymlorange: content: "I just ate an orange!" created_at: <%= 10.minutes.ago %> user: michael tau_manifesto: content: "Check out the @tauday site by @mhartl: http://tauday.com" created_at: <%= 3.years.ago %> user: michael cat_video: content: "Sad cats are sad: http://youtu.be/PKffm2uI4dk" created_at: <%= 2.hours.ago %> user: michael most_recent: content: "Writing a short test" created_at: <%= Time.zone.now %> user: michael <% 30.times do |n| %> micropost_<%= n %>: content: <%= Faker::Lorem.sentence(5) %> created_at: <%= 42.days.ago %> user: michael <% end %>テストを書く。
test/integration/users_profile_test.rbrequire 'test_helper' class UsersProfileTest < ActionDispatch::IntegrationTest include ApplicationHelper def setup @user = users(:michael) end test "profile display" do get user_path(@user) assert_template 'users/show' assert_select 'title', full_title(@user.name) assert_select 'h1', text: @user.name assert_select 'h1>img.gravatar' assert_match @user.microposts.count.to_s, response.body assert_select 'div.pagination' @user.microposts.paginate(page: 1).each do |micropost| assert_match micropost.content, response.body end end endto_sメソッドは、文字列以外を文字列に変換する。
また、response.bodyはそのページのhtmlの全文を返す。
assert_matchにより、第一引数の文字列がページのどこかに含まれていることを確認する。Micropostsリソース
ルーティング
Micropostsリソースの表示などはUsersコントローラの中で行うので、Micropostsコントローラに必要なのはcreateとdestroyアクションだけである。
よって、ルーティングは以下のようになる。config/routes.rbRails.application.routes.draw do . . . resources :microposts, only: [:create, :destroy] end名前付きルートなどの関係は以下のよう。
ややこしいことに、createアクションはmicroposts_pathだが、destroyアクションはmicropost_pathである。
Micropostsコントローラのアクセス制御
マイクロポストは関連付けられたユーザーを通して投稿されるので、ログイン済みでなければならない。
非ログイン時にcreateアクションやdestroyアクションにアクセスした場合、ログイン画面にリダレクトされるようテストを書く。
また、assert_no_differenceでマイクロポストが増減していないことも確認しておく。test/controllers/microposts_controller_test.rbrequire 'test_helper' class MicropostsControllerTest < ActionDispatch::IntegrationTest def setup @micropost = microposts(:orange) end test "should redirect create when not logged in" do assert_no_difference 'Micropost.count' do post microposts_path, params: { micropost: { content: "Lorem ipsum" } } end assert_redirected_to login_url end test "should redirect destroy when not logged in" do assert_no_difference 'Micropost.count' do delete micropost_path(@micropost) end assert_redirected_to login_url end endここで、非ログインならばリダイレクトするbeforeフィルターであるlogged_in_userが必要になるが、これはUsersコントローラ内にしかない。
そこで、これを各コントローラが継承するApplicationコントローラに移しておく。app/controllers/application_controller.rbclass ApplicationController < ActionController::Base protect_from_forgery with: :exception include SessionsHelper private # ユーザーのログインを確認する def logged_in_user unless logged_in? store_location flash[:danger] = "Please log in." redirect_to login_url end end endUsersコントローラのほうからは消しておく。
これをMicropostsコントローラのcreateとdestroyアクションに設定する。
app/controllers/microposts_controller.rbclass MicropostsController < ApplicationController before_action :logged_in_user, only: [:create, :destroy] def create end def destroy end endマイクロポストの作成
createアクション
マイクロポストをアプリケーション上で作成するために、createアクションを書いていく。
app/controllers/microposts_controller.rbdef create @micropost = current_user.microposts.build(micropost_params) if @micropost.save flash[:success] = "Micropost created!" redirect_to root_url else render 'static_pages/home' end end private def micropost_params params.require(:micropost).permit(:content) endStrong Parametersを使って属性に値を渡すことも含め、Usersコントローラのcreateアクションとほとんど同じである。
homeビュー
マイクロポストの投稿ページはStaticPagesのhomeビューとする。
ログインしている場合は投稿フォームを表示し、非ログイン時はサインアップページへのリンクを表示する。app/views/static_pages/home.html.erb<% if logged_in? %> <div class="row"> <aside class="col-md-4"> <section class="user_info"> <%= render 'shared/user_info' %> </section> <section class="micropost_form"> <%= render 'shared/micropost_form' %> </section> </aside> </div> <% else %> <div class="center jumbotron"> <h1>Welcome to the Sample App</h1> <h2> This is the home page for the <a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a> sample application. </h2> <%= link_to "Sign up now!", signup_path, class: "btn btn-lg btn-primary" %> </div> <%= link_to image_tag("rails.png", alt: "Rails logo"), 'http://rubyonrails.org/' %> <% end %>homeページに表示するユーザー情報のパーシャルを作成する。
app/views/shared/_user_info.html.erb<%= link_to gravatar_for(current_user, size: 50), current_user %> <h1><%= current_user.name %></h1> <span><%= link_to "view my profile", current_user %></span> <span><%= pluralize(current_user.microposts.count, "micropost") %></span>マイクロポスト投稿フォームのパーシャルを作成する。
app/views/shared/_micropost_form.html.erb<%= form_for(@micropost) do |f| %> <%= render 'shared/error_messages', object: f.object %> <div class="field"> <%= f.text_area :content, placeholder: "Compose new micropost..." %> </div> <%= f.submit "Post", class: "btn btn-primary" %> <% end %>ここで、エラーメッセージ部分のパーシャル呼び出しは次のようになっている。
<%= render 'shared/error_messages', object: f.object %>ユーザー新規登録・ログイン用に作っていたエラーメッセージのパーシャルは@user変数を直接参照していたので、@micropostを使えるように修正する必要がある。
このパーシャル呼び出しにはobject: f.objectというハッシュが渡されている。
これによってエラーメッセージのパーシャル内でobjectという変数が使えるようになり、これで@user変数を置き換えることで、@micropost変数に対応することができる。app/views/shared/_error_messages.html.erb<% if object.errors.any? %> <div id="error_explanation"> <div class="alert alert-danger"> The form contains <%= pluralize(object.errors.count, "error") %>. </div> <ul> <% object.errors.full_messages.each do |msg| %> <li><%= msg %></li> <% end %> </ul> </div> <% end %>エラーメッセージのパーシャルを呼び出していた他のビュー(ユーザー登録、ユーザー編集、パスワード再設定)でもこのobject: f.objectを設定しておく。
次に、StaticPagesコントローラのhomeアクションで、現在のユーザーに関連付いた新しいMicropostオブジェクトを作成する。
app/controllers/static_pages_controller.rbdef home @micropost = current_user.microposts.build if logged_in? endnewではなくbuildを使う点に注意する。
マイクロポスト投稿はログイン時のみの機能なので、if logged_in?を付けてログイン時のみ変数が定義されるようになっている。フィード
投稿がすぐに見れるように、homeビューにマイクロポストのフィードを実装する。
このフィードでは将来的にフォローしたユーザーの投稿も見れるようにする。全てのユーザーがフィードを持つので、Userモデルにfeedメソッドを定義する。
app/models/user.rbclass User < ApplicationRecord . . . # 試作feedの定義 def feed Micropost.where("user_id = ?", id) end private . . . endwhereの検索条件を"user_id = ?", idとしているのは、セキュリティ上の問題を解決するためである。
このfeedメソッドを使って現在のユーザーのマイクロポストを取得し、インスタンス変数@feed_itemsに入れる。
app/controllers/static_pages_controller.rbdef home if logged_in? @micropost = current_user.microposts.build @feed_items = current_user.feed.paginate(page: params[:page]) end endステータスフィードのパーシャルは次のようになる。
app/views/shared/_feed.html.erb<% if @feed_items.any? %> <ol class="microposts"> <%= render @feed_items %> </ol> <%= will_paginate @feed_items %> <% end %>ここで、<%= render @feed_items %>というパーシャル呼び出しが使われている。
@feed_itemsに入っている要素はMicropostクラスを持っているために、Railsは対応する名前のパーシャル(_micropost.html.erb)を、同じディレクトリから探してくれる。これを使って、homeビューにステータスフィードを追加する。
app/views/static_pages/home.html.erb<% if logged_in? %> <div class="row"> <aside class="col-md-4"> <section class="user_info"> <%= render 'shared/user_info' %> </section> <section class="micropost_form"> <%= render 'shared/micropost_form' %> </section> </aside> <div class="col-md-8"> <h3>Micropost Feed</h3> <%= render 'shared/feed' %> </div> </div> <% else %>ここで、マイクロポストの投稿が失敗すると、Homeページは@feed_itemsインスタンス変数を期待しているためエラーになる。
ここの意味がよく分からなかったのだが、次のサイトが参考になった。
「Railsチュートリアル13章 @feed_itemsがnilになる?」
https://teratail.com/questions/194996つまりこういうことになる。
①ステータスフィードのパーシャルは<% if @feed_items.any? %>というif文を使い、@feed_itemsがnilでない時のみマイクロポストのフィードを表示する。
②再レンダリングされるhomeページで使えるインスタンス変数は、Micropostsコントローラのcreateアクション内で定義されたものだけである
③これはリダイレクトではないのでStaticPagesコントローラのhomeアクションは実行されないためである。すなわち、homeアクション内の@feed_itemsが定義されず、nilとなる。
④createアクションで@feed_itemsを定義してやることで、homeビューで@feed_itemsが使えるようになる。そこで、マイクロポストの投稿が失敗した際の処理として、@feed_itemsを定義してやる。
app/controllers/sessions_controller.rbdef create @micropost = current_user.microposts.build(micropost_params) if @micropost.save flash[:success] = "Micropost created!" redirect_to root_url else @feed_items = current_user.feed.paginate(page: params[:page]) render 'static_pages/home' end endマイクロポストの削除
マイクロポストの削除機能を実装する。
ユーザーの削除は管理者のみが行えたが、マイクロポストは投稿したユーザーのみが削除できるようにする。削除リンクと認可フィルター
マイクロポストのパーシャルに削除用リンクを追加する。
app/views/microposts/_micropost.html.erb<li id="micropost-<%= micropost.id %>"> <%= link_to gravatar_for(micropost.user, size: 50), micropost.user %> <span class="user"><%= link_to micropost.user.name, micropost.user %></span> <span class="content"><%= micropost.content %></span> <span class="timestamp"> Posted <%= time_ago_in_words(micropost.created_at) %> ago. <% if current_user?(micropost.user) %> <%= link_to "delete", micropost, method: :delete, data: { confirm: "You sure?" } %> <% end %> </span> </li>ここで、ユーザーとマイクロポストの関連付けを利用して、現在のユーザーがそのマイクロポストを投稿したユーザーの場合のみ削除リンクを表示するようにしている。
<% if current_user?(micropost.user) %>次に、マイクロポストを削除するdestroyアクションを作成する。
app/controllers/microposts_controller.rbclass MicropostsController < ApplicationController before_action :logged_in_user, only: [:create, :destroy] before_action :correct_user, only: :destroy . . . def destroy @micropost.destroy flash[:success] = "Micropost deleted" redirect_to request.referrer || root_url end private def micropost_params params.require(:micropost).permit(:content) end def correct_user @micropost = current_user.microposts.find_by(id: params[:id]) redirect_to root_url if @micropost.nil? end endcorrect_userメソッドは、削除するマイクロポストに関連付けられたユーザーが現在のユーザーと一致するかを確認するフィルターである。
同時に、このメソッドは削除するマイクロポストの取得も行なっている。
つまり、現在のユーザーのマイクロポストの中に、削除するマイクロポストがあるかどうかを確認し、あれば取得して、destroyアクションに繋ぐ。
無ければリダイレクトする。destroyアクション内の、マイクロポスト削除後のリダイレクトは以下のようになっている。
request.referrer || root_urlrequest.referrerは、一つ前のURLを返す。
マイクロポストをhomeページから削除すればhomeページに、プロフィールページから削除すればプロフィールページに戻る。
もし戻り先が見つからなかったとしても、or演算子でルートURLを指定して、そちらに移動するようにしている。フィード画面のマイクロポストのテスト
認可のテスト
他人のマイクロポストを削除できないことのテストを書く。
まず、fixtureファイルに別のユーザーと紐づけられたマイクロポストを追加する。test/fixtures/microposts.yml. . . ants: content: "Oh, is that what you want? Because that's how you get ants!" created_at: <%= 2.years.ago %> user: archer zone: content: "Danger zone!" created_at: <%= 3.days.ago %> user: archer tone: content: "I'm sorry. Your words made sense, but your sarcastic tone did not." created_at: <%= 10.minutes.ago %> user: lana van: content: "Dude, this van's, like, rolling probable cause." created_at: <%= 4.hours.ago %> user: lanaテストは以下のようになる。
test/controllers/microposts_controller_test.rbtest "should redirect destroy for wrong micropost" do log_in_as(users(:michael)) micropost = microposts(:ants) assert_no_difference 'Micropost.count' do delete micropost_path(micropost) end assert_redirected_to root_url end統合テスト
マイクロポスト機能の統合テストを作成する。
$ rails generate integration_test microposts_interfacetest/integration/microposts_interface_test.rbrequire 'test_helper' class MicropostsInterfaceTest < ActionDispatch::IntegrationTest def setup @user = users(:michael) end test "micropost interface" do log_in_as(@user) get root_path assert_select 'div.pagination' # 無効な送信 assert_no_difference 'Micropost.count' do post microposts_path, params: { micropost: { content: "" } } end assert_select 'div#error_explanation' # 有効な送信 content = "This micropost really ties the room together" assert_difference 'Micropost.count', 1 do post microposts_path, params: { micropost: { content: content } } end assert_redirected_to root_url follow_redirect! assert_match content, response.body # 投稿を削除する assert_select 'a', text: 'delete' first_micropost = @user.microposts.paginate(page: 1).first assert_difference 'Micropost.count', -1 do delete micropost_path(first_micropost) end # 違うユーザーのプロフィールにアクセス (削除リンクがないことを確認) get user_path(users(:archer)) assert_select 'a', text: 'delete', count: 0 end end

- 投稿日:2019-12-04T00:45:36+09:00
rails install:webpackerができない件について
環境
- rails 5.2.3
- ruby 2.6.3
- yarn 1.19.2
エラー内容
railsでvue.jsを追加するために、rails install:webpackerをしようとしたところ
rails aborted! Sprockets::Railtie::ManifestNeededError: Expected to find a manifest file in `app/assets/config/manifest.js` But did not, please create this file and use it to link any assets that need to be rendered by your app: Example: //= link_tree ../images //= link_directory ../javascripts .js //= link_directory ../stylesheets .css and restart your server /Users/user/railsProjects/vuejs-on-rails/config/environment.rb:5:in `<main>' /Users/user/railsProjects/vuejs-on-rails/bin/rails:9:in `<top (required)>' /Users/user/railsProjects/vuejs-on-rails/bin/spring:15:in `require' /Users/user/railsProjects/vuejs-on-rails/bin/spring:15:in `<top (required)>' ./bin/rails:3:in `load' ./bin/rails:3:in `<main>' Tasks: TOP => app:template => environment (See full trace by running task with --trace)このようなエラーがでました。
対応
調べたところ、【Rails】rails webpacker:install に失敗する場合の対処法にたどり着き、書いてある通りにconfigにwebpacker.ymlを追加したところ、エラーが変わりませんでした?
その後、yarnのupgradeをしても変わりませんでした?
下記のエラーを確認
Expected to find a manifest file in `app/assets/config/manifest.js`app/assets/config/manifest.jsに
app/assets/config/manifest.js//= link_tree ../images //= link_directory ../javascripts .js //= link_directory ../stylesheets .cssを追加
無事にrails install:webpackerが通りました。
参考
- 投稿日:2019-12-04T00:29:15+09:00
【超基本】railsで部分テンプレートを使ってみる(haml)
経緯
ずっと苦手意識のあった部分テンプレートと向き合った結果、「なにこれ、便利!!」となったため、備忘録のために記事にします。
hamlで書いた記事があまりなかったり、localオプションの変数の意味や、collection、asの詳しい説明をなかなか見つけられなかったので、同じことで悩んでいる誰かのお役に立てたらすごく嬉しいです。もくじ
- 部分テンプレートとは
- ファイル名
- hamlへの記載方法
- オプション
- partial
- locals
- collection
- as
- まとめ
部分テンプレートとは
部分テンプレート(=パーシャル)とは、繰り返し使用される要素をまとめてテンプレート化するもの。何度も同じコードを書くことを防ぐことができる。また、投稿一覧画面を作成する際、collectionオプションを使用すると、each分を使わずに繰り返しができ、読み込み速度もeach文を使用する時より速い(らしい)。
ファイル名
部分テンプレートのファイル名は、必ずファイル名の最初に「_(アンダーバー)」をつける。アンダーバーをつけることで、当該のファイルが部分テンプレートであることを明示的に表せる。
hamlへの記載方法
部分テンプレートを呼び出す際、呼び出す側のファイルに以下の通りに記載し、呼び出される部分テンプレートを指定する。
例:
呼び出す側のファイル index.html.haml
呼び出される部分テンプレートファイル _post_index.html.hamlindex.html.haml.post__index = render partial: 'post_index'' '内に記載するファイル名は、「_」を省いて記載。
オプション
部分テンプレートには、様々な便利なオプションがあるため、紹介。
partialオプション
前項の通り、呼び出される部分テンプレートを指定するオプション。
尚、呼び出す側のファイルと部分テンプレートが異なるディレクトリにある場合は、ディレクトリ名も含めて指定する必要がある。例:
呼び出す側のファイル view/posts/index.html.haml
呼び出される部分テンプレートファイル view/shared/_post_index.html.hamlindex.html.haml.post__index = render partial: 'shared/post_index'localオプション
部分テンプレート内で使う変数(ローカル変数)を定義するオプション。
index.html.haml.post__index = render partial: 'post_index', local: { posts: @posts } -省略形は = render 'post_index', posts: @posts{ posts: @posts } の
postsは部分テンプレート内で使用する変数(=ローカル変数)。
@postsは、postsコントローラのindexアクションで定義した変数。
=呼び出した側のファイル(postディレクトリのindex.html.haml)で使えるよう、コントローラで定義した変数。つまり、部分テンプレート内でpostsを使用した場合、その変数の中身は、postsコントローラのindexアクションで定義された@postを同義となる。
each文を使用し、一つの投稿を繰り返し表示さのせレバ、投稿一覧ベージの完成。
_post_index.html.haml- posts.each do |post| .post__index__content .post__index__header .post__index__header--user-name = post.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post.textcollectionオプション
このオプション、めちゃ便利! 今回のような投稿一覧を作成する際、普通はビューでeach文を使用して、@postsの中にあるデータを取り出す。しかし、collestionオプションを使用すると、each文を書かずとも、繰り返してくれる。
index.html.haml.post__index = render partial: 'post_index', collection: @postsこのように定義することで、部分テンプレートでは、以下の記述のみでOK。
_post_index.html.haml.post__index__content .post__index__header .post__index__header--user-name = post_index.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post_index.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post_index.textlocalオプションを使用した際に、一番上に記述があったeach文は不要。@posts(postsコントローラのindexアクションで定義した変数)を、一つずつ取り出して表示してくれる。
ちなみに、このように記述した場合、ローカル変数名は、「post_index(部分テンプレートのファイル名)」になることに注意。asオプション
前項で説明したcollectionオプションを使用した場合、ローカル変数名は部分テンプレートのファイル名になる。変数名を自分で指定したい場合に、asオプションを使用する。
index.html.haml.post__index = render partial: 'post_index', collection: @posts, as: postこのように記述することで、前項でpost_indexと記述した箇所をpostに書き換えることができます。
_post_index.html.haml.post__index__content .post__index__header .post__index__header--user-name = post.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post.textまとめ
この他にも、便利なオプションがたくさんあるようだけど、今理解できているのはここまで。
新しいことを学んだら、追記します。
何か誤りがあれば、ご指摘いただけると嬉しいです。
- 投稿日:2019-12-04T00:00:08+09:00
Rails6でProtocol Buffersを使用する
こんにちは。
SmartHR アドベントカレンダーの4日目を担当しますエンジニアの@kurobaraです。
SmartHRでは、プラットフォーム化を促進するプラスアプリの開発をしています。
プラスアプリについては、弊社社長によるSmartHR Next 2018やCTO 芹澤の中長期戦略などに詳しく書かれています。ところで、前日が社長だと次に渡されるバトンを担当する側としても緊張しますね><
前置き
皆さん、型は大好きですか?
僕も好きです。特にサーバサイドになんらかの言語でAPIをフロントエンドにTypeScriptで・・・
そして、サーバサイドとフロントエンドのI/Fとして、JSONを使用する割とよくあるパターンかつ比較的デファクトだと思います
比較的、最近だとサーバサイドにGraphQLを使用しているという話もチラホラ聞くことが多くなってきましたが、今回の話とはちょっと異なるので割愛しますしかしながら、JSONを使っているとフロントエンドにTypeScriptを使用しているにも関わらず、以下の内容で恩恵を受けづらいこともあるのでは?と個人的に感じています
- (現場によりますが)型情報だけでなく、JSONのKeyそのものが存在しないことも多くある
- 同じキーで、
型が違うとか、なんなら逆にある特定のエッジケースだけでキーが増えるとかも...- 注意しないと、バリューに合わせてNullableにしなければならないケースも出てくる
- TypeScriptの型システムの恩恵を受けられない
- 異なる型として認識されてしまうこともある
- 例えば、数値をダブルクォートで括ってAPIが返してしまい、JSON.parseで文字列型として認識されてしまうことなど
- 双方の都合によるパターンではっきりしないJSONになっていることもある
- フロントエンドのライブラリとか...
- サーバ側だと、勢いでさっと作ったJSONとか...
- etc...
挙げればキリが無さそうですが、これに対してのアプローチとして色々あるかと思います。
- テストで担保&テストからドキュメント生成
- OpenAPIを使用する
- 定義ファイルを書いたり...
- 実装から定義ファイル作ったり...
- JSON Schemaを頑張って書く
- etc...(なんか色々やってたような気がしますが忘れました)
どれもこれもですが、(忘れたくなるぐらいなので)結構面倒なのでは(?)と感じています
- テストで担保は現実的に難しい
- ケースを網羅するのは、ちょっと大変でしょう
- ましてや、そこからドキュメント生成だとテストが書けてれば・・・
- OpenAPI / JSON Schema
- 巨大になるとYAMLやJSONは管理不可能でツールを使わざるを得ない
- どこかしらで自動生成したものから定義ファイルを起こし直すなど、なんらかの形での対応が必要そう
- (開発において)フロー整備するなり、うまく仕組み化する必要もある
- etc...
というわけで、自分はものぐさな訳ですが下記をやってくれるといいなと思っています
- 型定義はほしい
- I/Fとしてのスキーマは普遍でいてほしい
- JSONでもいいけど、キーの欠落は極力勘弁してほしいし、APIの定義は決してズレないでほしい
- 定義ファイルから、エンティティとなるコード生成もしてもらいたい
- 定義ファイルの作成や変更を行う場合の変更コストは、仕方ないけど飲む
そんな皆様にProtocol Buffersの使用をオススメしたいかと思います
個人的にオススメしたいところは概ねこのあたりです
- JSON SchemaやOpenAPIの領域を必要最低限カバーできている
- スキーマ言語の仕様として、覚えることがそんなに多くない
- 簡素かつ可読可能
- 特定の言語に依存していない
- データの表現が必要十分で適用範囲が広い
- 必要異常にスキーマ言語として多機能では無い
- 複数言語間でやり取りできるようにするためのシリアライズ/デシリアライズ用のクラスや構造体を自動生成できる
- 一貫性を保つことが十分可能
- 複数言語間でやり取りできるJSONを生成できる
- スキーマに合わせて実装を揃えていくことができる
- APIの定義として、決してブレることが起きない
こんなところでしょうか。。。
例えば、SmartHR APIの従業員取得 のうち一部のデータを表現してみるとこんな感じでしょうか。
普通に見ても、可読性高く、型定義、データ構造も初見で見たとしても意味が分かりそうですよね!syntax = "proto3"; package smarthr.crews; import "smarthr/department.proto"; message Crew { enum Gender { MALE = 0; FEMALE = 1; } string id = 1; string emp_code = 2; string last_name = 3; string first_name = 4; string last_name_yomi = 5; string first_name_yomi = 6; string business_last_name = 7; string business_first_name = 8; string business_last_name_yomi = 9; string business_first_name_yomi = 10; string birth_at = 11; Gender gender = 12; string tel_number = 13; string email = 14; Address address = 15; repeated Department departments = 16; ... } message Address { string id = 1; string pref = 2; }# このスキーマ定義は解説用に書いていますので、公式的な内容ではございません><
本題
さて、そんなProtocol Buffersですが、Railsに組み込みたい場合のことを今回は話そうと思います
組み込み方法
基本は、以下の流れで組み込んで行きます
google-protobuf,grpc-toolsのgemをGemfileに組み込む
- 後者に関しては、Timestampなどの拡張機能もあるのであれば良さそうという感じでしょうか
*.protoのような定義ファイルを記述
- ここで型定義などスキーマを書きます
- キーが欠落するとか、型が曖昧とかそういう問題はここで解消可能です
- スキーマ定義からRubyで処理可能なファイルを生成する
- protocコマンドを使って、スキーマファイルから
*_pb.rbファイルを生成します
- シリアライズ/デシリアライズとなるクラスが生成されます
- Ruby以外の異なる言語とやり取りしたい場合、同じスキーマを使って他言語用のファイルも合わせて生成します
- Railsから生成したクラスを読めるようにする
*_pb.rbを読み込むRails5系までは、何も考えずにこの流れで問題は起きないです
ファイル生成
一つずつ
*.protoファイルから*.rbに変換する処理は面倒です。
従って、下記のようなものを実行できるコマンド、Railsの場合だとRakeタスクを用意しておくとよいかと思いますRUBY_OUT_DIR = "app/pb" Dir["#{Rails.root}/proto/**/*.proto"].each do |file_path| proto_file = file_path.gsub(Rails.root.to_s, '.') system("grpc_tools_ruby_protoc --ruby_out=#{Rails.root}/#{RUBY_OUT_DIR} --proto_path=./proto #{proto_file}") endMIMEの指定
一応Draftとしては、application/protobufのようです
が、観測している限りであれば、application/vnd.google.protobufやapplication/x-protobufなどがあるようです下記のような形で規定しておけば、Railsで使用する際でも便利に扱えるかと思います
# config/initializers/mime_types.rb Mime::Type.register "application/protobuf", :protobufRails6の場合
話が長くなりましたが、あえてRails6と記載したのは嵌る箇所が存在するためです
Rails6から定数やクラスの自動読み込みの仕組みが変更(zeitwerkの導入)となりました
これにより、スキーマから生成されるファイルは影響を受ける形となっていますzeitwerkを有効にしている場合、下記の制約が発生しています
- Rails内で使うファイル名は、定義されている定数名と一致しなければならない
- ファイル名はディレクトリ名と合わせて名前空間として扱わなければならない
この制約により、生成したファイル(_pb.rb)をそのまま扱うと、eager_load*でエラーとなります
また、development/testでは、config.eager_load = falseと設定されています
従って、テストがグリーンだったり、開発環境で動作確認とし実行した場合だと気づかないことが多いです# 余談ですが、個人的に開発協力をしているアプリケーションでは前述の問題に見事に嵌りrevertを行いました><
一番簡単な解決方法
一時凌ぎで根本解決では無いものの、Rails6のデフォルトのオートローダーを従来のオートローダーを使うようにすれば良いです。
これはオートローダーがzeitwerkでは無く従来の物になるため、問題無く動きます# config/application.rb config.load_defaults "6.0" config.autoloader = :classicいつまでも使えるものでは無いため、できれば根本解決を目指したほうが良さそうです
# 先程の余談は、revert後にこちらで一旦対処していました...
根本解決する方法
この記事を執筆している以上ですが、根本的な解決は可能ですので、protoファイル、Railsの双方で以下で実施する手順を行います
protoファイルで対応すること
- protoファイルに定義したpackageのパスとディレクトリをきちんと合わせる
- 生成された
*_pb.rbのファイルパスが、zeitwerkではそのまま名前空間となるため- protoファイルでimportしたファイルパスディレクトリ構造に合わせて調整する
- 生成された
*_pb.rbのrequireが影響を受けるため- messageの名前をファイル名と一致させる
- messageが、生成された
*_pb.rb内で設定されるクラス名となるため- protoファイルに複数のmessageを記載せず、1つのファイルに1つmessageとする
- zeitwerkによって、ファイル名は、定義されている定数名と一致させておく必要があるため
つまり前述のprotoファイルではどうなるかというと、下記のような形になります
# proto/smarthr/crews/crew.proto #<- packageとパスをあわせてファイルを用意 syntax = "proto3"; package smarthr.crews; import "smarthr/department.proto"; import "smarthr/crews/address.proto"; #<- ファイルのimportを追加 message Crew { enum Gender { MALE = 0; FEMALE = 1; } string id = 1; string emp_code = 2; string last_name = 3; string first_name = 4; string last_name_yomi = 5; string first_name_yomi = 6; string business_last_name = 7; string business_first_name = 8; string business_last_name_yomi = 9; string business_first_name_yomi = 10; string birth_at = 11; Gender gender = 12; string tel_number = 13; string email = 14; Address address = 15; repeated Department departments = 16; ... }addressは1つの定義がファイルから分離して、別のファイルにします
# proto/smarthr/crews/address.proto syntax = "proto3"; package smarthr.crews; message Address { string id = 1; string pref = 2; }Rails側で対応すること
自前でカスタムしたInflectionを用意し、Railsに設定します
カスタムzeitwerkの実装方法については、こちらを参照します前述のprotoファイルの手順で挙げた内容が行えていれば、下記のコードで生成したファイルをRails内で問題無くzeitwerkでオートロードすることが可能です
zeitwerkは、ファイル名をString#camelizeで活用するということから、下記の形でInflectionを実装します
- ファイル名をチェック
- パスは関係ないので見ない
_pbで終わるものがあれば、Protocol Buffersで生成したファイルと見なす
- そうじゃない場合、親クラスの処理を実行する(ファイル名のString#camelize)
- 一致する場合、
_pbを除去し、除去したものをcamelizeしたものを返す最後にRailsのautolodersに自前実装したzeitwerkのInflectorを適用しています
class WithProtocolBufferInflector < Zeitwerk::Inflector def camelize(basename, abspath) if basename =~ /\A.*_pb$/ basename.gsub("_pb", '').camelize #<- `_pb` をここで除去した形でRails側でロードするように対応 else super end end end Rails.autoloaders.each do |autoloader| autoloader.inflector = WithProtocolBufferInflector.new end# 余談ですが、この処理を行わないとここでエラーになります(普通に見てもまぁ読めそうって感じのコードですね)
おそらく、今回のケースに限らずですが、他のものでもzeitwerkが想定している規約に合わないファイル類もきっと同じところでエラーになるかと思います。
特にRails5->Rails6にアップデートしたらエラー祭りになるとかはこういうところであったりするのでは(?)と個人的に思いますJSON作れるの?(おまけ1)
そういえば、前述の内容の中で、
複数言語間でやり取りできるJSONを生成できると述べてましたがこちらも下記のようなコードで可能です
(前提として、Crewは、crew_pb.rbの内容と仮定します)crew = Crew.new(id: "id", emp_code: "001", ) Crew.encode(crew) #<- Protocol Buffersでシリアライズしたデータ crew.to_proto #<- Protocol Buffersでシリアライズしたデータ crew.encode_json #<- Protocol Buffersの定義に合うJSONデータ因みに、
encode_jsonメソッドは下記の2つのオプションが存在します
- preserve_proto_fieldnames: trueを設定するとオリジナルのフィールド名(つまりProtocol Buffersに規定した名)を使用する(デフォルトはcamelCase)
- emit_defaults: trueを設定すると0 / false値(blankにあたるもの)を出力する(デフォルトは省略します)
TypeScriptでもProtocol Buffersを使いたい(おまけ2)
TypeScriptでもProtocol Buffersが使用できるか?というところですが、実はできます
ts-protoc-genを使えば可能です。
まずはインストール
$ npm install ts-protoc-gen次に定義ファイルから、
_pb.jsと*_pb.d.tsを生成します$ export TYPE_SCRIPT_OUT_DIR=public/js $ protoc --plugin='protoc-gen-ts=./node_modules/.bin/protoc-gen-ts' --js_out='import_style=commonjs,binary:#{TYPE_SCRIPT_OUT_DIR}' --ts_out='#{TYPE_SCRIPT_OUT_DIR}' --proto_path=./proto #{proto_file}最後に型定義ファイルを使って、axiosなどでサーバと疎通させれば良さそうでしょう
雰囲気、こんな感じでバイナリデータで疎通する形になるかと思います
(ContentTypeは前述したDraftを使用)const data = new Address() data.setId("1") data.setPref("東京都") axios.post(url, data, { responseType: 'arraybuffer', headers: { 'Content-Type': 'application/protobuf', }, })