- 投稿日:2019-12-04T23:54:30+09:00
ActiveSupport 無しで beginning_of_day
お題
時刻(日時)を表すデータがあって,その時刻を含む日の開始の瞬間(0 時)をどうやって得るか。
Rails なら ActiveSupport の
beginning_of_dayを使えばよい。たとえば今日の始まりであれば
require "active_support/time" t = Time.now p t.beginning_of_day # => 2019-12-04 00:00:00 +0900といった具合。
この例のように,Rails じゃなくてもactive_support/timeをrequireすれば使える。素の Ruby ではどうする?
答え
require "date" t = Time.now p t.to_date.to_time # => 2019-12-04 00:00:00 +0900Date 化すると時・分・秒の情報が消え,それを Time 化すると,0 時 0 分 0 秒ということになるみたい。
なお,上の例は Time オブジェクトが最初に与えられていたが,「今日の始まり」であれば
Date.todayから出発してもよい:require "date" p Date.today.to_time # => 2019-12-04 00:00:00 +0900感想
小ネタ感がハンパない。
こんなの既出だろうと思ったけど,類似の記事が見つけられなかった。
- 投稿日:2019-12-04T23:43:06+09:00
【Rails】 N+1問題の解消 & tips
Atrae Advent Calendar 2019 5日目を担当する新卒1年目の土屋です。
普段は、ビジネス版マッチングアプリ yenta でサーバサイドエンジニアとしてRailsで開発をしています。アトラエに入社してから半年間、度々立ち向かってきたN+1問題について書きます。
対象読者は、Ruby on Railsを使って開発をしている初級者〜中級者です、ご容赦ください。N+1問題とは
ループ処理(each, mapなど)を用いてデータを取得してくる際に、
必要以上にSQL文(クエリ)が発行され、レスポンスが遅くなる(パフォーマンスが低下する)ことです。例えば、
AさんというUserのPosts(投稿)を5件取得して、Aさんの投稿一覧のページを表示したいといった時には、
- AさんのUserデータを取得するために1回
- 5件のPostsデータを取得するために5回
の合計6回のクエリを発行し、表示したいデータを取得することになります。
5件だったら大した問題にはなりませんが、
これが10000件だったら大変です。
仮に1回のクエリで0.001秒しか時間がかからなかったとしても、
10001回もクエリを叩いたら、10秒もかかります。
普段使うアプリやWebサービスでそんなにローディングで待たされたことがあるでしょうか。このように、ループ処理によって、
N件のデータを取得したい時に、N+1回もクエリを発行してしまうことによって発生するパフォーマンス低下を、N+1問題といいます。この問題はコードの書き方次第で解消でき、
適切に書けば、仮に10000件のPostsであっても、2回のクエリで取得できます。
(あんまり大きいテーブルをjoinしたくないとかindex張ろとかそういう話は今回はなしで、、!)とりあえずpreloadかeager_load書こ
結論としては、ループ処理の前に
preloadかeager_loadを書けばほぼ解決します。無思考でも、この2つのどちらかを書いておけばひとまず解決することが多いです。
また、具体的にどう書いてなぜ解決されるのか?などは、ググるとたくさんの素晴らしい記事が出てきますので、そちらを見て頂ければいいかなと思いますw参考:
【Ruby on Rails】N+1問題ってなんだ?
preloadとeager_loadで1000000億倍早くなったはなしけどincludesはやめとこ
「rails N+1問題」などでググると、
上述のpreloadやeager_load以外に、includesを用いた解決法もいくつか出てくるかと思います。
が、includesを用いるのは個人的にはあまりお勧めしません。
理由は、includesを用いると、Railsがよしなにやろうとしすぎて、自分が予期していない挙動になる可能性があるのと、
preloadとeager_loadの違いは明確に理解して使い分けた方が良いと思うためです。
が、詳しくは下記の素晴らしい参考記事達に譲りますw参考:
ActiveRecordのjoinsとpreloadとincludesとeager_loadの違い
ActiveRecordのincludes, preload, eager_load の個人的な使い分け
[Rails] そのincludesはpreloading?それともeager loading?また、上記の
preload,eager_load,includes,joinsなどの違いを考えるにあたって、
テーブル同士の内部結合、外部結合周りが怪しいと理解しづらいので、怪しい方は先にこっちから整理すると良いと思います。
(僕はそもそもこっちが怪しかったので、最初全然ピンとこなかったです。)参考:
SQL素人でも分かるテーブル結合(inner joinとouter join)
INNER JOINとOUTER JOINとは?tips
上記の通り、基本的にはググればわかりやすい記事がたくさんあるのですが、
その中でも僕が実際にN+1問題と戦った時に、
「知りたいけどあんまり出てこなかった」「先輩のコードを見て / 直接聞いて知った」ことを、少し書きます。孫以下の要素の(多段)joinの仕方
UserのPostについたCommentのデータをpreloadしたい時、
CommentはUserの孫要素にあたりますが、以下のように書きます。User.preload(posts: :comments).each.{~~UserのPostについたCommentについたFavoriteのデータをpreloadしたい時、
FavoriteはUserの曽孫要素にあたりますが、以下のように書きます。User.all.preload(posts: [comments: :favorites]).each.{~~その次や次の次は、、
User.all.preload(posts: [comments: [favorites: :hoge]]).each.{~~ User.all.preload(posts: [comments: [favorites: [hoge: :fuga]]]).each.{~~のようにどんどんネストして行くように書きます。
複数かつ多段のjoinの仕方
前節とほぼ同じですが、地味に書き方迷ったので。
Postの子として、CommentとFavoriteがある場合が以下です。User.all.preload(posts: [comments, favorites]).each.{~~eager_load多すぎたらeager_loadだけまとめてscopeにしちゃう
の方がスッキリすると思います。
scope :eager_load_for_hogehoge, -> { eager_load(hoge: [:fuga, piyo: [abc: :def]]).merge(User.where(id: 111)) }チェーンで書かないと、せっかくeager_loadしても意味ない
「完璧にeager_loadingしたはずなのになぜかクエリが繰り返される、、」という時は、
色々とメソッドを介した結果、せっかくeager_loadingしたのに、
また改めてモデルを呼んでる場合があります。おまけ
先日、検索機能を作っている時に、納期に焦って、このN+1問題の確認と解消をサボって雑に進めたら、
検索した際のクエリが重すぎて見事にstagingのDBが落ちました。
これが本番だったらと思うと、ぞっとします。
自分が発行するクエリには責任を持って開発していきたいですね。また、Railsは全くの未経験で入社して8ヶ月程経ちましたが、流石に慣れてきたと同時に、
サーバサイドはデータを司る神になった気分()になれるので、好きになってきました。次回は、同じく1年目の小倉です。よろしく!
- 投稿日:2019-12-04T23:11:13+09:00
C - Buy an Integer
問題
https://atcoder.jp/contests/abc146/tasks/abc146_c
回答
A,B,X = gets.chomp.split.map(&:to_i) result = 0 max = 1000000000 if A + B > X elsif X >= A * max + B * ( max.to_s.length ) result = max else N = X.to_s.length N.step( 1, -1 ) do |n| p = A * ( 10 ** ( n - 1 ) ) + B * n if p <= X result = ( X - B * n ) / A if result.to_s.length != n result -= 1 end break end end end p result結果
感想
result = ( X - B * ( n + 1 ) ) / Aで割り切れちゃって、桁が1つ多くなってしまった場合がわからなくて一生悩んでしまった・・・


- 投稿日:2019-12-04T21:34:22+09:00
railsのDigest::UUIDを試す
Digest::UUID見てみたのでメモ
公式ドキュメント
https://api.rubyonrails.org/classes/Digest/UUID.html
概要
定義されているメソッドは以下の3つでそれぞれハッシュ関数が違います。
- self.uuid_v3 ->
Digest::MD5を使用- self.uuid_v4 ->
SecureRandom.uuidの簡易メソッド。- self.uuid_v5 ->
Digest::SHA1を使用$ Digest::UUID.uuid_v4 => "4ad2a6a9-0135-4158-94d3-a33e41bbe048" $ Digest::UUID.uuid_v3("name_space", "sample") => "3b0ead59-ca8d-350b-a392-e656db58b0fc" $ Digest::UUID.uuid_v5("name_space", "sample") => "d7a9ae1a-b099-5318-8828-340cc10a1550"rails -v
$ bundle exec rails -v Rails 6.0.2.rc1
- 投稿日:2019-12-04T19:12:10+09:00
rubyのバージョンアップのときのエラー対処
rubyをバージョンアップをして、budnle installを叩いたら、
Fetching: mysql2-0.3.18.gem (100%) Building native extensions. This could take a while... p ERROR: Error installing mysql2: ERROR: Failed to build gem native extension. /Users/my_username/.rvm/rubies/ruby-2.1.2/bin/ruby -r ./siteconf20150614-72129-orqsb7.rb extconf.rb checking for ruby/thread.h... yes checking for rb_thread_call_without_gvl() in ruby/thread.h... yes checking for rb_thread_blocking_region()... yes checking for rb_wait_for_single_fd()... yes checking for rb_hash_dup()... yes checking for rb_intern3()... yes ----- Using mysql_config at /usr/local/bin/mysql_config ----- checking for mysql.h... yes checking for errmsg.h... yes checking for mysqld_error.h... yes ----- Don't know how to set rpath on your system, if MySQL libraries are not in path mysql2 may not load ----- ----- Setting libpath to /usr/local/Cellar/mysql/5.6.25/lib ----- creating Makefile make "DESTDIR=" clean make "DESTDIR=" compiling client.c compiling infile.c compiling mysql2_ext.c compiling result.c linking shared-object mysql2/mysql2.bundle ld: warning: directory not found for option '-L/Users/travis/.sm/pkg/active/lib' ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) make: *** [mysql2.bundle] Error 1 make failed, exit code 2 Gem files will remain installed in /Users/my_username/.rvm/rubies/ruby-2.1.2/lib/ruby/gems/2.1.0/gems/mysql2-0.3.18 for inspection. Results logged to /Users/my_username/.rvm/rubies/ruby-2.1.2/lib/ruby/gems/2.1.0/extensions/x86上記のようにmysqlのエラーが出る。。。。
もしもインストールをしていなければ、
bundle config --local build.mysql2 "--with-ldflags=-L/usr/local/opt/openssl/lib --with-cppflags=-I/usr/local/opt/openssl/include"こいつを叩いて、
bundle installしてみて、Library not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib (LoadError)上記のエラーが出るようなら、
$ brew install openssl $ export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/opt/openssl/lib/これでPATHを指定してから、再度
budnle install
これでも無理なら、、、、brew update && brew upgradeこれで行けるケースもあります。
ただ、これでもLibrary not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib (LoadError)こいつが出るようなら、
rbenvをアンインストールする。$ ruby -v ruby 2.3.4p301でrubyのバージョン確認
$ rbenv unistall 2.3.4$ rbenv install --list $ rbenv install 2.3.4インストールするlistの確認をして、rubyのバージョンを指定してinstallする。
$ gem install bundlerその後、
bundle installする。
ただ、念の為にgemfile.rockを消してからやるとよいメモ書きの感じで書いたので、まだ理解不足です。
ご指摘等あればお願いします。
- 投稿日:2019-12-04T17:27:41+09:00
Rails:ajax通信の流れとデバッグの解説[超初心者編]
まずはじめに
ajaxを勉強中に簡易なrailsアプリを作りました。
その時大枠の処理の流れが大切だと感じたので今回復習も兼ねて解説してみようと思います。大枠の流れを理解しているとエラーが起きた際にどこでデバッグしてどの変数の中身を見たら良いか、どこまでは処理がうまく書けているか。という原因特定をする際に非常に便利です。
むしろ流れを理解していないとエラー解決は手探りでの作業となってしまい非効率です。
作ったアプリ内容
検索フォームからDBに保存してあるユーザー情報を表示する
アプリGIF
https://gyazo.com/ac90a773abec869ddb72d59037f62f46[したいこと]
検索フォームにキーワードを入力された毎にユーザー検索して該当するユーザー名を表示する[必要な手段]
検索フォームに入力されたら反応
フォームに入力されたキーワードを取得
コントローラでキーワードを元にユーザーテーブルを検索
検索結果をビューで表示する対象者
この記事では、ajax通信とは、
どのようにして送信先を決めているのか、
送ったデータはどのように処理されているのか、
どのように処理したデータを返すのか
エラーで詰まってしまった際にどう対処するのか
を学びます。よって概ね同じようなajax通信の流れを組む、インクリメンタルサーチや非同期通信、自動更新の実装にもこの記事で紹介する処理の流れやデバッグの方法は応用できます
大まかな処理の流れについて説明できる自信がない方に対してザックリと理解できるようにまとめました。
極力専門的な言い方や記述を省き、イメージしやすいように言い回しも変えています。
開発環境
Rails: 5.0.7.2
ruby: 2.5.1
jquery-rails: 4.3.3
mac: Mojave(10.14.4)まずは登場ファイルの紹介
・ edit.html ----------------- HTMLファイル(ビューファイル)
・ test.js -------------------- JavaScriptファイル
・ users_controller.rb -------- コントローラファイル
・ index.json.jbuilder --------- json.jbuilderファイルajax通信の流れ
ビューファイルが読み込まれる
(コントローラのアクションに紐づくビューファイルが読み込まれるということ)
edit.html<input class="name-form" placeholder="検索したいユーザー名" type="text"> <div class='append-user'>表示されている画面
ブラウザに入力フォームが表示される
ビューと同時にJavaScriptファイルも読み込まれる
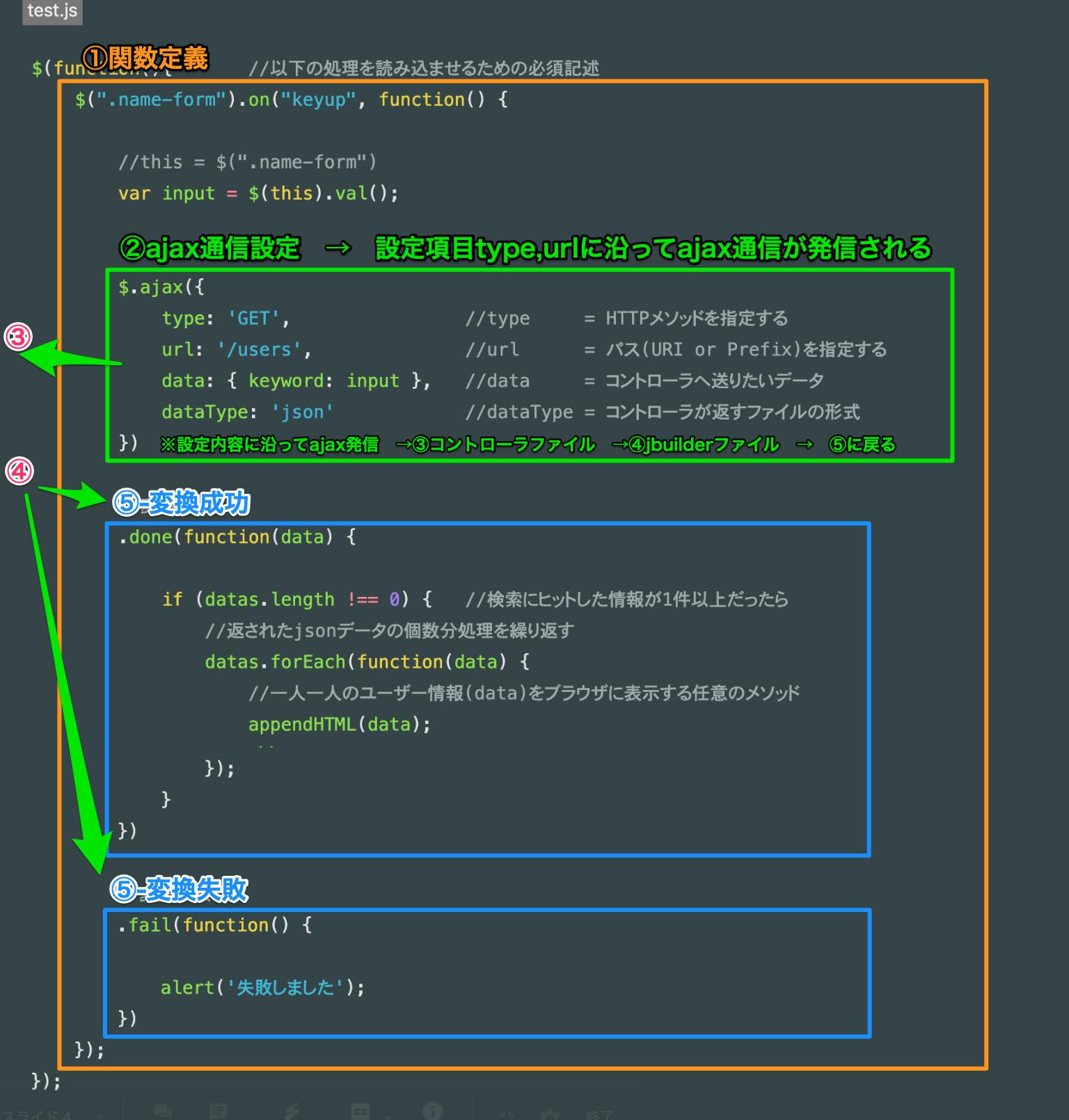
test.js$(function(){ //以下の処理を読み込ませるための必須記述 $(".name-form").on("keyup", function() { //this = $(".name-form") var input = $(this).val(); $.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 }) //変換完了 .done(function(datas) { if (datas.length !== 0) { //検索にヒットした情報が1件以上だったら //返されたjsonデータの個数分処理を繰り返す datas.forEach(function(data) { //一人一人のユーザー情報(data)をブラウザに表示する任意のメソッド appendHTML(data); }); } }) //変換失敗 .fail(function() { alert('失敗しました'); }) }); });ここで一旦test.jsファイルは何をしてくれるファイルなのかを解説
※1行目のfunctionの記述はJSファイルを読み込ませる必要最低限の記述のため解説割愛
JavaScriptファイルは、簡単に言ってしまうと「ビューファイルを監視して処理を実行してくれる」ファイルです。
画像の①関数を定義しておくとオレンジの範囲の処理を行なってくれます。
オレンジの範囲には②処理や②と関係する③・④の処理、⑤の処理が含まれています。② → ③ → ④ → ⑤の順番で処理が進んでいきます
ではどんな時に①関数が動き出すのか?これは①関数の最初に書かれている記述から読み取ることができます。
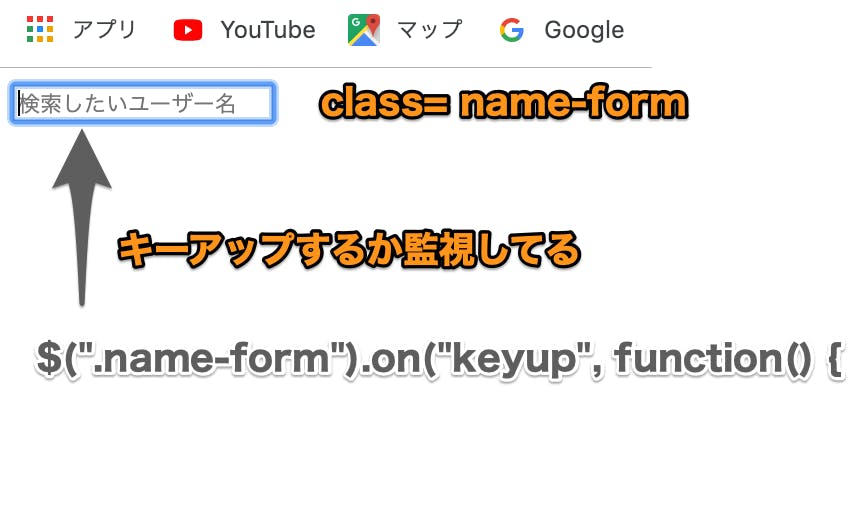
$(".name-form").on("keyup", function() { 直訳 「クラス名「name-form」の入力フォームにキー入力され、そのキーが離された瞬間」に動き出す関数 解説 ①:$(".name-form") → 読み込んだHTMLファイルの中でclass= "name-form"の要素 ②:.on → ①が ③:"keyup" → キーアップされたら(入力時のキーを離したら)
クラス名「name-form」といえば、
edit.html.hamlで生成した入力フォームのことですね。
このフォームに入力がされたら、関数が動くという仕組みです。
つまり、test.jsの
$(".name-form").on("keyup", function() {という記述が、現在読み込まれているビューファイルの特定のクラス名の要素の「動き」を監視しているという言い方もできるわけです。
また、記述の各部分には名称がついているので、人へ伝える時や調べものをするときに下記のワードを用いて理解を深めましょう。$(".name-form").on("keyup", function() { 処理 }名称:セレクタ
$(".name-form")・・・「動き」を監視する対象や要素名称:イベントハンドラ
.on・・・セレクタに対して名称:イベント
"keyup"・・・予め検知したい「動き」を定義する(例:キーアップイベントが発生したら)名称:無名関数
function() { 処理 }・・・セレクタに検知したい「動き」が起こったら{処理}を行う
$(セレクタ).on(イベント名, イベントが発生したときに実行する処理)
ちなみに、JavaScriptファイル内で「$」マークで始まる記述はJavascriptのライブラリの一つである「jQuery」の記述です。
もちろんイベントには「送信されたら」、「クリックされたら」などたくさんの種類があるので
「jQuery イベントハンドラ」でググってみましょうjQueryイベント一覧 わかりやすい記事
http://www.jquerystudy.info/reference/events/index.html
test.jsファイルの解説は一旦終了です。イベントを発火させる
登場するファイルと処理の順番
【edit.html】 → ブラウザで入力操作 → 【test.js】それではいよいよtest.jsに書かれた①関数を動かします。
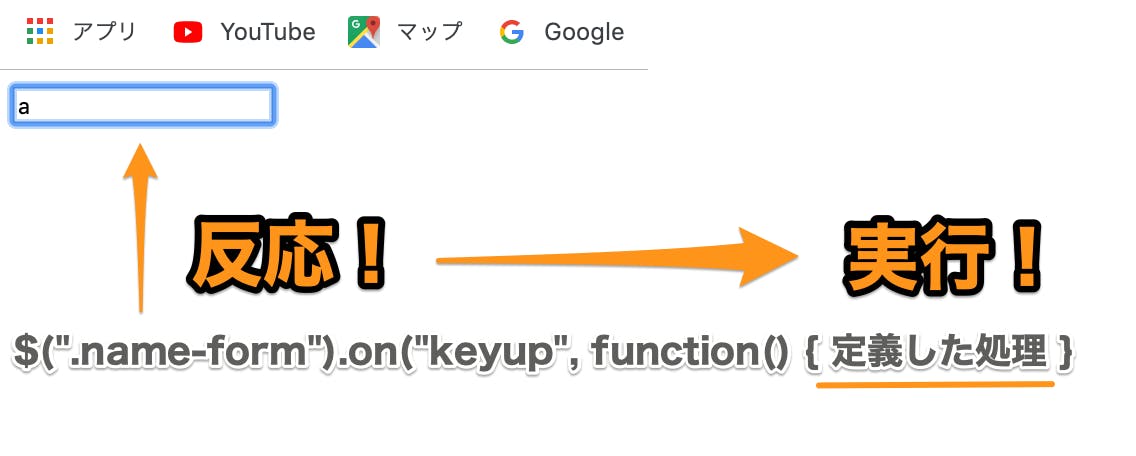
そのために入力フォームへ何か文字を入力するんでしたね
ほい
これで定義していた処理が実行されます
①関数定義が動く
登場するファイルと処理の順番
【test.js①】 → 【test.js②】
入力イベントに反応して上記画像の1番上のfunction{}関数内の処理が実行されていきます
もちろん処理は上から下へ実行されるので②ajax通信の処理ブロックにたどり着くまでに書かれている記述を実行していきます。
途中にある
var input = $(this).val();この記述は、変数
inputに対してjQueryの記述で値を代入しています。$マークのカッコで囲んだものはjQueryオブジェクトとして扱うのでしたね!
ではカッコの中に記述されているthisとは何かというと現在処理されているfunctionのセレクタを指します。
※thisは使う場面によって色々な状態の情報が取得できるので一概に取得できる情報を明言できません。
①関数(function)内でthisと書くとfunctionのセレクタである$(".name-form")が取得できます
よって「this」は書く場所によって結果が違う。ということです
この後解説するdone関数やfail関数のfunction内でthisを記述すると①関数内でthisを書いた時の情報とは違う状態の情報がthisの記述で取得できます
デバッグ作業の心構え
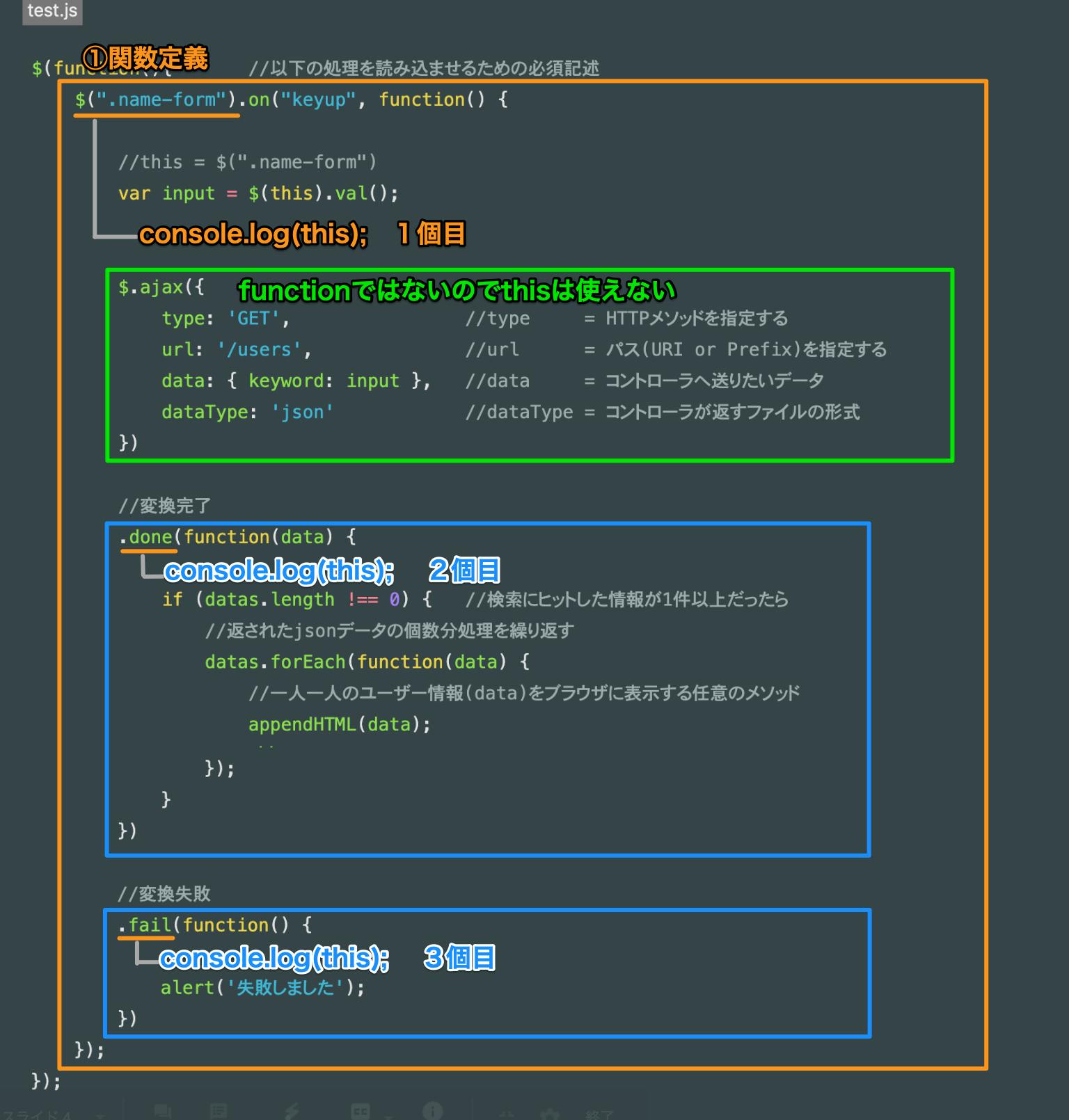
this情報の確認方法について、ここで一旦デバッグ作業の仕方についてサクッと解説です。
this情報の確認は簡単で、確認したい場所でconsole.log(this)を記述するだけです。
例で下の画像のように3箇所にconsole.log(this)を記述します
上記画像のようなconsole.log(this)の配置で様々な状況下のthisの値がコンソール画面で確認できます。
注意:console.log(〇〇)と書いたあとは①関数を動かす必要があるので必ずキーアップイベントを起こす必要あり。
console.log()とはlogカッコ内に記述した変数の中身をブラウザの検証の「console」画面に表示するメソッドです。定義しておいた変数などをlog引数に記述すると変数の中身がコンソール画面に表示することができ、処理に使う変数が期待する値かどうかを確認するときに大活躍します。
var num = 10 + 5; console.log(num); //コンソール画面には「15」と表示されるこの作業こそ、まさに「デバッグ」ですね!!
デバッグ作業の重要なポイントとしては
①変数の中身を確認する(どの変数を確認すべきか)
②変数の中身を予想する(期待する答えを考える)この2点です!
たったコレだけですが、この2点ができるできないで作業効率は大きく変わります
普段こういったことを考えないで闇雲にデバッグしている人は、めちゃくちゃ損してます。以上、デバッグの心構えでした。
では、話は戻って
var input = $(this).val();この記述は
var input = $(".name-form").val();このように変換※でき、
.val()は対象のvalue属性の値を取得するので
現状入力フォーム(クラス名name-formのHTML要素)には「a」が入力されているので
※ここでの「変換」とはわかりやすいようにイメージするならば。という意味var input = "a";と変換できることになります。
②関数が動く。ajax通信の設定
登場するファイルと流れ
【test.js②】 → ③【users_controller.rb】
変数
inputを定義した状態で次に②関数のajax通信の設定が実行されます。ここでのajax通信は、railsのMVCの流れに割り込んだ形でビュー(HTML)ファイルからコントローラファイルへデータを渡すために記述されています。
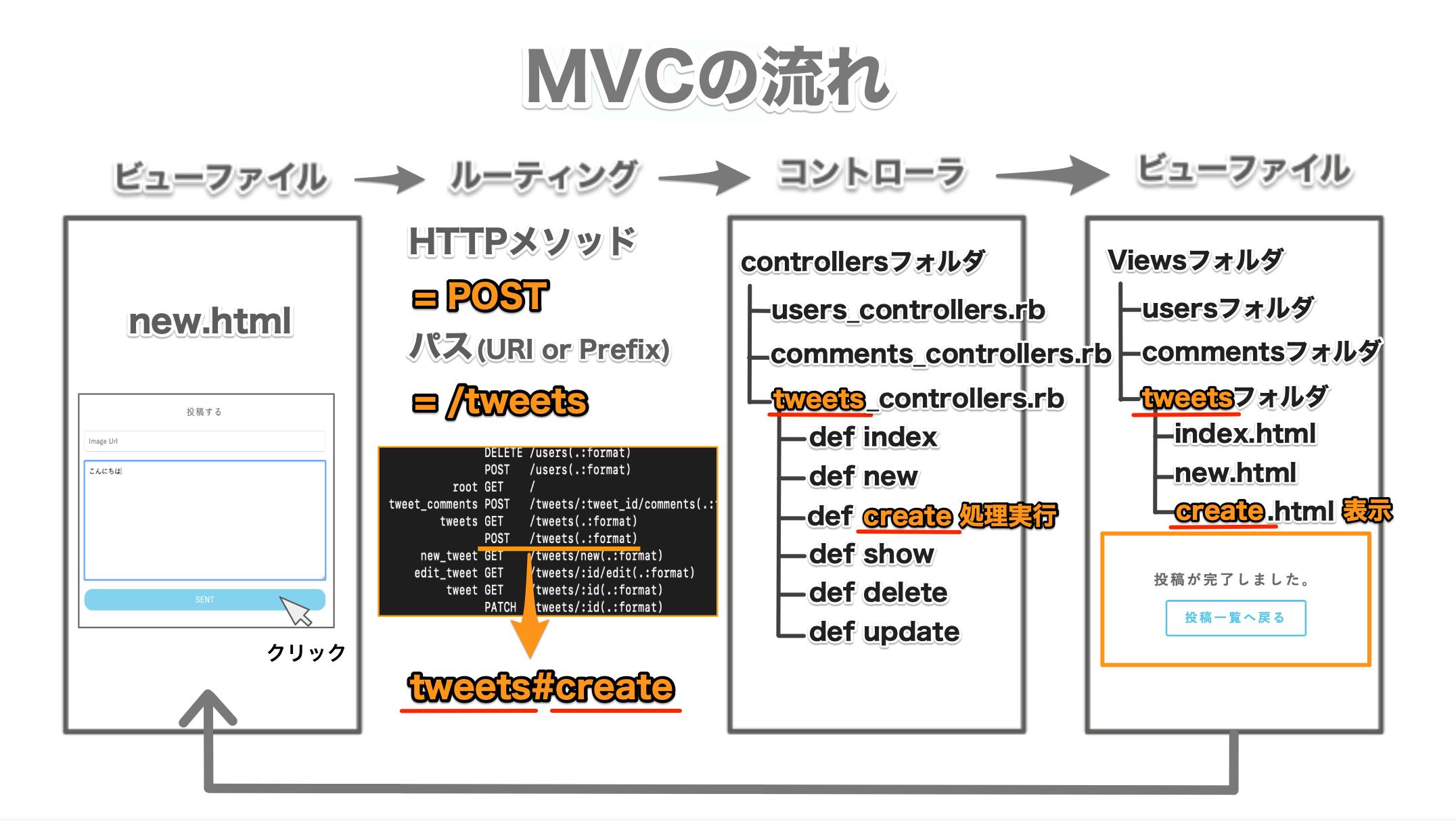
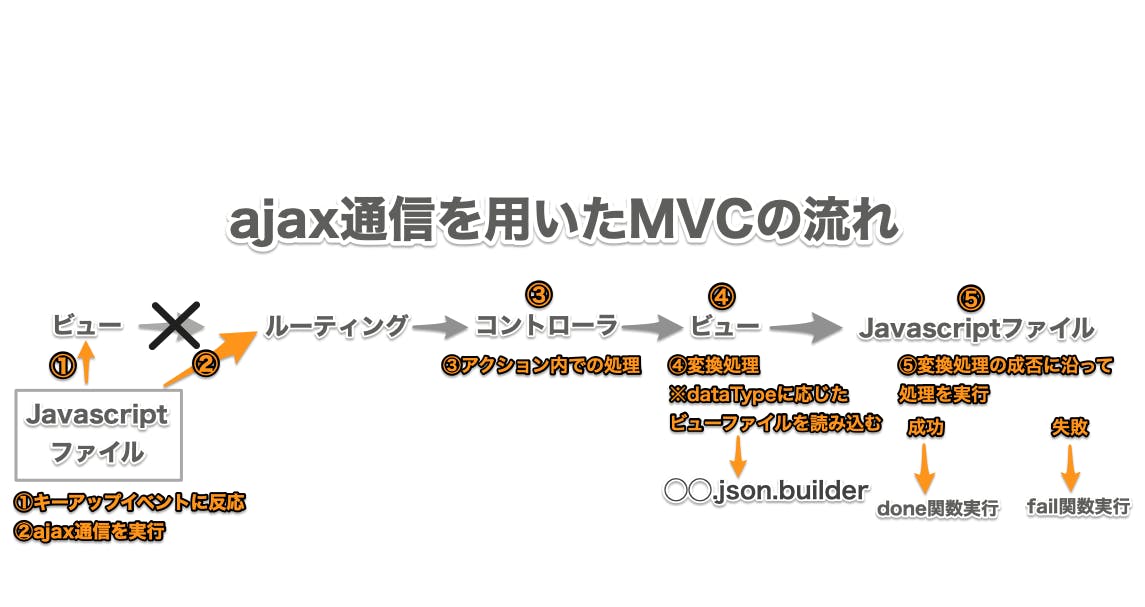
通常のMVCの流れ
ajax通信を用いたMVCの流れ
この流れでファイルを読み込んでいきます。
ajax通信の設定は以下の内容で実行されます
$.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 })ajax通信の項目
・typeとurlはルーティングに渡す情報を指定
・dataはルーティングが判断したコントローラファイルに渡す情報の指定
ここで先ほど定義したinput変数を使っています。
・dataTypeはdata項目を送ったり送り返してもらう際の通信形式を指定(値はjsonやhtmlなどが存在)ここでもajax通信のイメージを掴んでもらうために、たとえを用いると
ajax通信とは、「外国へ荷物を配達してくれる郵便屋さん」みたいな存在です。
ちょっとよく分からないとは思いますが黙って聞いていてください。②関数が動くと郵便屋さんが配達の準備を始めます
$.ajax({ type: 'GET', //type = 目的地情報その1 url: '/users', //url = 目的地情報その2 data: { keyword: input }, //data = 送る荷物 dataType: 'json' //dataType = 発送方法 })上記の情報をもとに目的地の設定や送る荷物の中身を決めます。
実行されたajax通信はまずルーティングに解析され、ルーティングではHTTPメソッドは
GET、パスは/usersとして判断され
users_controller.rbファイルのindexアクションが実行されます。発火させるべきコントローラとアクションの選定方法
ここで大事なのは発火させたいコントローラとアクションは何であるのかイメージしておくことです。
まず、なぜコントローラのアクションを発火させたいのでしょうか?
それは、コントローラではDBの情報を取得・登録・編集・削除などのアクションが実行でき、今まさにDBの情報を取得したいからです。まずは行いたい処理を大枠で思い出しましょう。
・したいこと
DBからキーワードに該当するユーザーを取得する・そのための手段
ajax通信を使う
キーアップされたごとに検索する
入力されたキーワード情報を取得する
キーワード情報をコントローラへ送るでは「したいこと」を実行するために最適なコントローラとは?
答えは簡単です。関係性のあるコントローラを選べば良いのです。例えば
・users_controller.rb
・groups_controller.rb
・messages_controller.rb
と3つのコントローラがあったら、コントローラそれぞれの役割を思い出します。・users_controller.rb:ユーザーに関わることを操作する
・groups_controller.rb:グループに関わることを操作する
・messages_controller.rb:メッセージに関わることを操作する「したいこと」はユーザー情報の取得です。
こう考えると、users_controller.rbの一択ですね。
では次に、users_controller内のどのアクションを発火させるか?
これも7つのアクションからひとつ当てはまるものを選べば良いのです。冷静に考えれば楽勝です
当てはまるものがわからなければ目的とは異なるものを排除していきましょう!・index・・・・・・一覧表示
・new・・・・・・新規作成画面
・create・・・・・DBに新規作成
・show ・・・・・・詳細画面
・edit・・・・・・・編集画面
・update・・・・・DBに編集内容を保存
・delete ・・・・・DBから削除すでに登録されているユーザー情報を取得する。という観点だけでも、
・index
・show
の2つに絞られます。・index・・・・・・一覧表示
・new・・・・・・新規作成画面 → ユーザーを新規作成するわけではない
・create・・・・・・DBに新規作成 → ユーザーを新規作成するわけではない
・show・・・・・・詳細画面
・edit・・・・・・・編集画面 → 既存のユーザー情報を書き換えたいわけではない
・update・・・・・DBに編集内容を保存 → 既存のユーザー情報を書き換えたいわけではない
・delete ・・・・・DBから削除 → ユーザー情報を削除したいわけではないここで重要なのは、キーワード検索して該当したユーザー情報を全て取得するという部分がポイントです。
「a」と検索したら「aaa」さんも「abc」さんの情報も該当する情報一覧を取得したいということです。indexは一覧情報。対して
editは一人のユーザー情報の詳細です。だからindexアクションが適切です。
users_controller#indexアクションです
これで発火させたいコントローラとアクションが選定できました!
ターミナルで「rails routes」コマンドを打って表示される一番右端に書いてあるコントローラとアクションに紐づくパスとHTTPメソッドを確認してみましょう!
railsにてページの遷移を行うには何かしらのコントローラのアクションを発火させなければいけません。
その場合、必ず「したいこと」を言語化し、発火させたいコントローラとアクションを決めてから細かい処理を組み立てていきましょうでは話を戻して、
(以下一部重複)
実行されたajax通信はまずルーティングに解析され、ルーティングではHTTPメソッドは
GET、パスは/usersとして判断され
users_controller.rbファイルのindexアクションが実行されます。その後はjson.jbuilderファイル→ test.jsファイルの⑤処理というふうに処理がされていきます。
郵便屋さんが
dataという荷物をコントローラに渡し、コントローラはもらったdataを使って変数を生成します。最後に郵便屋さんがコントローラで生成された変数をdataの送り主(test.js)に届けるという流れです。通常は荷物を届けた時点で郵便屋さんの仕事は終了ですが、今回はお届け先から送り主に対して送り返す荷物(情報)が発生するというお仕事になります。
一旦はこんなイメージで見ててください
③コントローラでの処理
登場するファイルと流れ
③【users_controller.rb】 → ④【index.json.jbuilder】users_controller.rbファイルのindexアクションではDBのusersテーブルからブラウザの入力フォームに入力された「a」のワードに該当するユーザー情報を
@usersに代入しています。※大枠の処理の流れが重要のため、コントローラ内の処理詳細は割愛します。
users_controller.rbclass UsersController < ApplicationController def index return nil if params[:keyword] == "" @users = User.where(['name LIKE ?', "%#{params[:keyword]}%"] ).where.not(id: current_user.id).limit(10) # ajax通信の記述:dataTypeの種類に応じて参照するファイルを切り替える respond_to do |format| format.html format.json # ajax記述には、dataType: 'json' と書かれているので # index.json.jbuilderファイルが読み込まれる end end end上記で記述されている
params[:keyword]とは
ajax通信の設定で記述したdata項目(送る荷物)のハッシュデータが深く関わってきます。
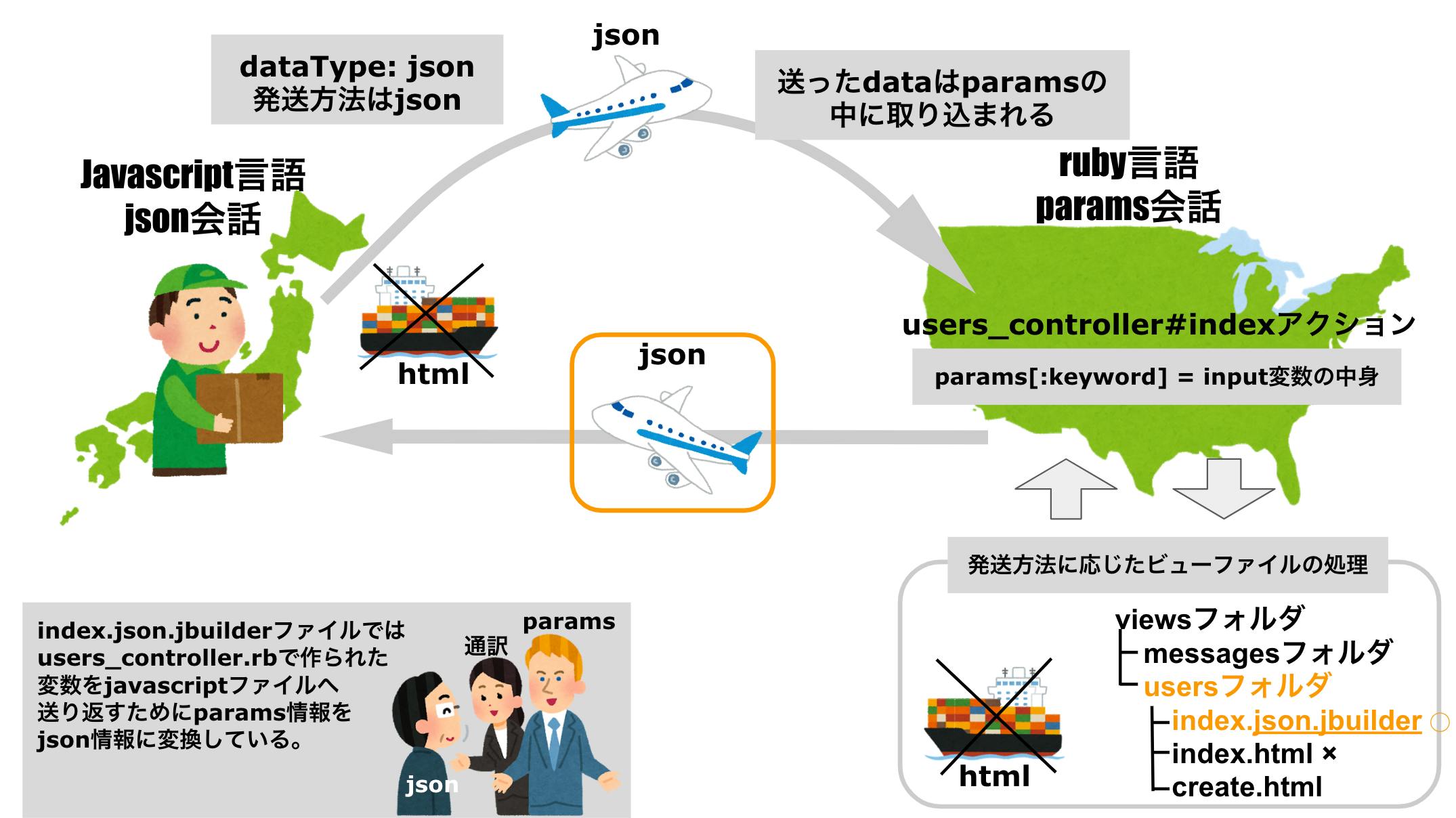
params[:keyword]とは、data項目に定義したハッシュのキー名を指定してバリューとなるinput (入力ワード「a」)を取得する記述です。data: { keyword: input }, //data = コントローラへ送りたいデータなぜ送った
dataがparamsに取り込まれているのかajax郵便屋さんが言語の違う「外国」へ行っていることを思い出してイメージしましょう
日本語がアメリカでは通じないように、javascript語をrubyの言語内では使えないのでjsonという通信方法を使ってruby語の会話であるparamsに情報を混ぜてもらっているのです。
そうすると、javascript語で書いた情報でもruby国に籍を置くusers_controller.rbファイルでも読み取ることができるようになり、
test.jsから受け取った変数
inputの中身を使ってDBからユーザー情報を検索できるのです。また、検索結果を代入した
@users変数はtest.js(javascript)ファイルにてユーザー検索結果を表示する際に使われる重要な変数です。
コントローラでtest.js(javascript)ファイルに送り返す変数@usersを定義できたら、通常のMVCの流れ同様コントローラ → ビューと処理が移るのですが、
ビューファイルの参照前に、ajax通信の設定で記述したdataTypeの値に応じて参照するファイルを選定する記述がコントローラには書かれています。
users_controller.rbrespond_to do |format| format.html format.json end今回はdataType:
jsonでajax通信を行なっていますよねtest.js$.ajax({ type: 'GET', //type = HTTPメソッドを指定する url: '/users', //url = パス(URI or Prefix)を指定する data: { keyword: input }, //data = コントローラへ送りたいデータ dataType: 'json' //dataType = コントローラが返すファイルの形式 })なので「コントローラで処理されたアクション名.jsonファイル」の
views/users/index.json.jbuilderファイルが読み込まれます。※respond_toの記述がなければ、コントローラで処理されたアクション名.htmlファイルが参照されます。
④json.jbuilderファイルでの変換処理
登場するファイルと流れ
④【index.json.jbuilder】 → 【test.js⑤】
index.json.jbuilderファイルではコントローラで生成した変数
@usersの変換処理を行います。
ん?
なぜ変換するの?と思うかもしれませんが
コントローラで生成した変数ということは、ゴリゴリのruby語で書かれた情報ということになり、
このままの状態で変数をtest.js(javascript)ファイルへ持ち帰っても誰も解読できないよね。ということになります。
そこで荷物を届けに来るときにjson → paramsと変換した時同様に、
送り返す際もparams → jsonと変換をしてあげます。index.json.jbuilderjson.array! @users do |user| json.id user.id json.name user.name end一つ一つ解説すると、まず始めの記述
json.jbuilderjson.array! @users do |user|これは変数
@usersをruby言語でいうeach文で取り出しているような書き方ですね!
いわゆる繰り返し処理です。なぜ繰り返すかというと変数
@usersは複数情報が格納されている配列情報だからです。
配列情報とは1個以上の複数情報から成り立っています。
今回のコントローラでの処理では入力ワード「a」に該当するユーザー情報が変数
@usersに詰められていますが、
DBのusersテーブルにもし「abc」さんと、「aaa」さんの2人ユーザー情報が登録されていたら、どちらのユーザーも「a」という文字列を含むため、コントローラの処理で前述の2人分の情報が変数@usersに詰められてくる可能性があるからです。そうしたら「abc」さんにも「aaa」さんにも変換処理を行なってあげないと、test.js(javascript)ファイルで変数を受け取る際に解読できなくなってしまいます。
では次に、
json.jbuilder#javascript語 ← ruby語 #jsonデータ ← paramsデータ #パン ← bread json.id user.id json.name user.nameこの記述は左辺がjavascript語での呼び方、右辺がruby語での呼び方を定義している記述です。
左辺に定義した名前にどんなrubyの情報を定義するか。といった感じです。試しに、
json.jbuilderjson.n user.nameこう書けば、
javascriptファイルで◯◯.nと記述すると、ruby語でuser.nameの情報が取得できる。といった感じ
※「〇〇」はdone関数の引数名などが入る⑤変換結果に応じた処理(done & fail)
登場するファイルと流れ
【test.js⑤ done】 or 【test.js⑤ fail】
※appendHTML関数はブラウザにユーザー情報を表示する関数です
※この記事では大枠の処理の流れをメインに解説を行うため、doneメソッド内で使われているappendHTML関数の詳細は敢えて記述せず、解説もしません。
④index.json.jbuilderファイルでの変換処理を経て、test.jsファイルに返ってきたjsonデータ。
このjsonデータには入力ワード「a」に該当するユーザー情報が詰められているのですが、
④index.json.jbuilderの変換結果によって実行される関数が分岐します。変換結果
変換成功 → done関数
変換失敗 → fail関数failメソッドが実行される場合
変換失敗の際はfail関数が処理されます。
ではどのような時に変換失敗になるか
これはjson.jbuilderでの処理が以下のような時です。NG.json.jbuilderjson.array! @users do |user| json.id user.user.id #userが重複 json.nickname user.mickname #カラム名の間違い or 存在しないカラム名の指定(mickname) json.nickname @users.nickname #変換する変数名が違う endカラム名の記述ミスや存在しないテーブルの参照など、記述をよく観察すると発見できるミスが多いです。
他にもコントローラファイル → json.jbuilderへと参照させるためにコントローラ内に記述が必要なrespond_toが抜けていたりすると適切な変換ファイルが参照されずfailメソッドが実行されてしまいます。users_controller.rbrespond_to do |format| format.html format.json end予めfailメソッド内に
alert("通信失敗しました");などの記述を配置してfailメソッドが呼ばれてしまったタイミングを見逃さないようにしておきましょう。json.jbuilderファイルの記述に間違いがなさそうであれば処理の流れを遡ってコントローラで定義した変数が怪しいと考えましょう
そうしたらコントローラ内に
binding.pryを記述し、処理を止めて変数名を入力して期待通りの中身か確認しましょう!
このように原因箇所を処理の流れに沿って絞っていくことが大切です。doneメソッド内の処理で不具合が起こった場合
変換処理に問題がなければdoneメソッドが処理されます。
さらにdoneメソッドの引数にはjson.jbuilder内で変換されたjsonデータが入ります。
今回の例でいうとtest.js.done(function(datas) { 処理 })
datasという引数がjsonデータです。引数名は自由に名付けられます!
注:これまでの処理順番画像のdoneメソッドの引数名が全て「data」で記述されています。ミスですsorryこの引数の中に変換されたユーザー情報が代入されています。
このdatas引数の中身を展開してブラウザにユーザー情報を表示していくのですが、ここdoneメソッド内での処理が一番記述を間違いやすい箇所でもあるので、エラーが起こった際は
冷静にこれまでの処理の順番を遡り、確認すべき変数を見極めデバッグしていくことが求められます。よくある間違いの原因としては、
・doneメソッドの引数であるjsonデータを配列情報として扱っていないミス
・json.jbuilderで定義していない名前を展開しようとしている
・そもそもコントローラでの処理の時点で@users変数の中身が正常ではない
・@users変数を作るための材料であるinput変数の中身がすでに正常ではないなどなど、
どの原因もconsole.logやbinding.pryを使えばすぐに割り出せる内容です。デバッグの使い分け
javascriptファイルでの変数確認 = console.log または debugger
使えるファイル例:test.jsファイルrubyファイルでの処理停止 = binding.pry
使えるファイル例:コントローラファイル、ビューファイル、語尾に.rbと付くファイルなら大概使える
よくある間違いへの対処
・doneメソッドの引数であるjsonデータを配列情報として扱っていないミス
このミスへの対処は下記のような
forEachメソッドで配列の各情報を取り出して個別に処理(appendHTMLなど)することを心がけましょうtest.js.done(function(datas) { if (datas.length !== 0) { //検索にヒットした情報が1件以上だったら //返されたjsonデータの個数分処理を繰り返す datas.forEach(function(data) { //一人一人のユーザー情報(data)をブラウザに表示する任意のメソッド appendHTML(data); }); } })コントローラでの処理にもよりますが、コントローラでwhereメソッドを使って配列情報を送ることが決定している以上は該当するユーザー情報が「aaa」さん一人分の情報であろうと配列情報に変わりはありません。
よって配列情報には必ずforEachを使って個別処理を行う必要があります。
そして、ここで取り出した変数(data)に対してようやくjson.jbuilderでの変換内容を展開できます。例:
data.id = ユーザーのid情報を展開
data.nickname = ユーザーの名前情報を展開またキーワード検索で何もヒットしなかった時 = 配列に何も情報が含まれて来ない時
の処理も考えておくとユーザビリティの向上に繋がります。
「該当するユーザーはいませんでした」などなど。。。
・json.jbuilderで定義していない名前を展開しようとしている
appendHTML関数でjsonデータを展開したら「Undefind」だった。
これはもう楽勝ですね。
json.jbuilderファイルをじっくり確認しましょう!!
変換名や変換内容、展開名が食い違っていないか確認しましょう!!
・そもそもコントローラでの処理の時点で@users変数の中身が正常ではないjson.jbuilderファイルの記述にミスが見当たらなければ、もう一つ処理を遡ってコントローラを確認しにいきます
binding.pryを記述してjson.jbuilderファイルで変換する変数@usersの中身を見てみましょう!users_controller.rbclass UsersController < ApplicationController def index return nil if params[:keyword] == "" @users = User.where(['name LIKE ?', "%#{params[:keyword]}%"] ).where.not(id: current_user.id).limit(10) binding.pry # @users変数を定義した直後に処理を止める、ターミナルに「@users」と入力して中身の確認 respond_to do |format| format.html format.json end end endターミナルに「@users」と入力する前に、
最初は間違ってもいいので、「おそらくこんな値が入っているはず」と仮説を立ててから中身を確認することが超重要です。
・@users変数を作るための材料であるinput変数の中身がすでに正常ではないコントローラファイル内で
binding.pryを記述して@users変数の中身を確認してもし値が崩れていたら、
尽かさずparams[:keyword]とターミナルに入力しましょう!
params[:keyword]と入力するとキーワード情報が取得できるはずです。もしキーワード情報が取得できない場合は、test.jsのajax通信のdata項目
test.js$.ajax({ type: 'GET', url: '/users', data: { keyword: input }, dataType: 'json' })ここの記述が原因です
input変数を定義している記述を確認しましょう
ここでもconsole.logが大活躍です。尽かさず変数の中身を確認しましょう!
var input = $(this).val(); console.log(input);これでも値が崩れているのなら
input変数を形成するthisを確認console.log($(this));このように処理の順番を遡って変数の中身を確認する。
もう分かってると思うんですが。。。
最初はとにかくデバッグなんです
繰り返してデバッグをしているとデバッグのポイントでもある
①変数の中身を確認する(どの変数を確認すべきか)
②変数の中身を予想する(期待する答えを考える)これが自然と身についてきます。
まずは手を動かすこと
コツとしては、
変数や引数があったのであれば、直後にconsole.logで確認。これでまずは手を動かしてみましょう
test.js$(function(){ $(".name-form").on("keyup", function() { var input = $(this).val(); console.log(input); //input変数の中身を確認 $.ajax({ type: 'GET', url: '/users', data: { keyword: input }, dataType: 'json' }) .done(function(datas) { console.log(datas); //引数datasの中身を確認 if (datas.length !== 0) { datas.forEach(function(data) { console.log(data); //引数dataの中身を確認 appendHTML(data); }); } }) .fail(function() { alert('失敗しました'); }) }); });中身の値の崩れが発見できたら、これまでの処理の順番を遡って変数の中身を確認していきましょう
以上、ajax通信の流れでした!!







- 投稿日:2019-12-04T16:23:56+09:00
Windows で Textbringer-presentation を使いたい
概要
Ruby で作られたテキストエディタ Textbringer (https://github.com/shugo/textbringer)にはプレゼンテーションモード(https://github.com/shugo/textbringer-presentation)があります。これを Windowsで使いたいと思います。
環境
Windows と言っても Windows10 で WSL を使うのであれば簡単です。以下の環境で行います。
- Windows 10 Home 64bit バージョン 1903
- WSL(Windows Subsystem for Linux)を利用
- Ubuntu 18.04 LTS
- WSLtty
- rbenv
- ruby 2.6.5p114 (2019-10-01 revision 67812) [x86_64-linux]
Textbringer のインストール
https://qiita.com/kurod1492/items/c759c1533ae98d937d95の記事に書いていますのでご覧ください。
Textbringer-presentation のインストール
gem でインストールすることができます。
$ gem install textbringer-presentationtextbringer で markdown ファイルを開き
M-x presentationを実行すればプレゼンテーションを開始することができます。
q を押すとプレゼンテーションを終了します。mlterm のインストール
WSLtty では画像を表示することができませんでした。mlterm を使えば表示できたので、mlterm を使うことにしました。
apt でインストールします。
$ sudo apt install mltermmlterm で使うときの設定が Textbringer の README(https://github.com/shugo/textbringer/blob/master/README.md)に書かれていますのでそのようにします。
libsixel、imagemagick のインストール
画像を表示するために libsixel と imagemagick が必要のようで、以下のようにパッケージでインストールします。
sudo apt install imagemagick libsixel1 libsixel-binこれで画像を表示することができます。
以下の画像は mlterm で Textbringer の README の Screenshot のスライドを表示しているスクリーンショットです。

- 投稿日:2019-12-04T16:17:56+09:00
railsでのテーブルの作り方、カラム追加、カラムの型替えの方法
はじめに
railsでのDBテーブルの作成方法、カラムの追加など一連のデータベース操作についてまとめます。
railsでのテーブルの生成方法
テーブルを生成しましょう。
①テーブルのmigrationファイルを作成します。具体的な作成コマンドとしては以下になります。$ rails g model モデル名 フィールド:型 ※例えばpostモデルでnameカラム(string型)とuser_idカラム(integer型)を作成したい場合は以下になります。 $ rails g model Post name:string user_id:integer②コマンドを打ち込むとmigrationファイルが新規で出来上がっているはずなのでそれを以下のコマンドで実行します。
実行後はdbサーバー上にpostsテーブルが出来上がります。$ rails db:migrateカラム追加方法
既に作成したテーブルにカラムを追加したい場合は下記の手順で追加します。
①追加したい項目を下記のようにコマンド入力する。
rails g migration Addカラム名Toテーブル名 カラム名:データ型 # 例えば既にあるpostテーブルにcategoryカラム(integer型)を作成したい場合は以下になります。 rails g migration AddCategoryToPosts category:integer②db/migrateフォルダにマイグレーションファイルが出来上がっていますので、確認、必要があれば追記してください。
下記ファイルにはhogehogeカラムを追記しています。class AddCategoryToPosts < ActiveRecord::Migration[5.2] def change add_column :posts, :category, :integer add_column :posts, :hogehoge, :text #追記 end end③編集終わりましたら、以下のコマンドで実行します。
これでテーブルにカラムが追加されます。$ rails db:migrateカラムの型の変換
既にあるテーブルのカラムの型を変えたいときは以下の手順で変更を行います。
カラム追加と似た手順となります。①型変更したいカラムを下記のようにコマンド入力しmigrationファイルを作る。
$ rails g migration change_data_カラム名_to_テーブル名 # 例えばpostテーブルのhogehogeカラムを型変更したい場合は以下になります。 rails g migration change_data_hogehoge_to_posts②db/migrateフォルダにマイグレーションファイルが出来上がっていますので、class内に以下のメソッドを追加してください。
def change change_column :posts, :hogehoge, :integer end③編集終わりましたら、以下のコマンドで実行します。
これでテーブルにカラムが追加されます。$ rails db:migrate終わりに
この記事で誤っている箇所や追記したほうが良い点がありましたらコメント欄などでご指摘いただけますとありがたいです!
ActiveRecordと通常のsqlコマンドは書き方違うので勉強必要ですね・・
- 投稿日:2019-12-04T15:57:42+09:00
【Rails】コーディング時に気をつけるべきこと
Webエンジニア2年目の@gggkです。
これまで、コードレビューで色々と指摘を受けてきたのですが、コードを書く上で大切なことなので、コーディング時に気をつけるべきことをまとめてみました。
特に、Rails慣れたての人の参考になればいいなと思います!バグを生み出さない
エンジニアやってて怖いのは、リリース後にバグが出ることですね。普段から意識してコーディングすることで、バグを発生させないようにしましょう。
nilチェックをする
大体のバグは、nilが原因となることが多いんじゃないかなと思います。
レシーバーがnilになってしまい、メソッドを呼び出そうとして「NoMethodError」になる。変数に値が入っていないときは、returnして次の処理をしないようにして対応することができます。ifで分岐してもいいですね。
# restaurantがnilになってしまってもエラーにはならない restaurant = Restaurant.find_by(id: 1) return unless restaurant restaurant.nameまたは、ぼっち演算子(&.)を使用してレシーバーに定義されていないメソッドを呼び出した場合は、nilを返すようにすれば対応できます。
restaurant&.name =>nilSQL発行される処理を定数にしない
NG
TOKYO = Area1.find_by(name: "東京")メソッドで呼び出す形にしましょう。
OKdef tokyo Area1.find_by(name: "東京") endprivate_constant
定数を定義した際に、そのクラス内でしか使用しない場合は、private_constantを使用して、他のクラスから呼び出されないようにする。
class Italian PIZZA = "ピザ" PASTA = "パスタ" private_constant :PIZZA, :PASTA endpartialで受け取る変数を初期化
partialで変数を初期化しておけば、変数の受け渡しを忘れた場合にもエラーにはならない。
(デメリットとしては、逆にエラーに気づけないということもあるので注意)_users.html.slim- users ||= [] - users.each do |user| = user.nameパフォーマンス
pluckを使用する
例えば、DBから都道府県の名前データを取得したい場合に、ActiveRecordモデルをすべて読み込むのではなく、pluckを使用して、必要な名前だけを配列で取得するようにします。
そうすることで、メモリを大量に使わずに済み、速度も早くなります。
NGprefs = Prefecture.all prefs.map(&:name) =>["北海道","青森",...]OK
Prefecture.all.pluck(:name) =>["北海道","青森",...]n+1問題
includes,preload,eager_loadを使用することで、SQLの発行回数を削減することができます。n+1問題については、@massaaaaanさんの下記記事で説明しているので、どうぞご覧ください。
【Ruby on Rails】N+1問題ってなんだ?メモ化
複数回呼ばれる場合に下記のようにすることで、2回目以降は1回目で処理した値を返すことができる。
def countries_link @_link ||= build_countries_link endまた、build_countries_linkが、nilになる可能性がある場合は下記のように書くと良い。
この場合は、@_linkが、定義されている場合はその値を返す。def countries_link return @_link if defined?(@_link) @_link = build_countries_link end可読性
読みやすさは大事ですね。次、自分や他の人が見たときに、わかりやすいように記述しましょう。改修がしやすくなり、バグも起こりにくくなります。
早期リターン
処理しない条件で早めにreturnすることで、複雑にならずに見やすくなります。
def food_genre(food_name) return if food_name.blank? return if food_name == "hogehoge" genre = Food.find_by(name: food_name)&.genre endhashのslice,except
hashから、必要な値だけを取り出したいときに使用する。
paramsの値を取得するときに便利。hash = { a: "hoge", b: "foo", c: "bar" } # aとcのみ取り出す hash.slice(:a, :c) => { a: "hoge", c: "bar" } # c以外取り出す hash.except(:c) => { a: "hoge", b: "foo" }index_by
配列を特定のキーのhashにしてくれる。モデルからpluckで値を取得したときになどに、扱いやすくなる。
Food.where(genre: "和食").pluck(:id, :name, :en_name).index_by {|item| item[0] } =>{1=>[1,"寿司","sushi"], 2=>[2,"鍋","nabe"], ...}each_with_object
配列やhashなどのオブジェクトに繰り返し、値を入れていく処理などのときに、初めにオブジェクトを定義する必要がなくなる。
price = { apple: 100, orange: 30, banana: 200, cherry: 10 } # 100以上のものを調べてキーを配列にする fruits = price.each_with_object([]) do |(key, val), arr| arr << key if val >= 100 end =>[:apple, :banana]その他細かい点
- {}の前後にスペースを入れる
- カンマ(,)の後にスペースを入れる
- ロケットハッシュを使用しない
{ a: "hoge", b: "hoge" } # こっちの方が見やすいと思う {:a=>"hoge",:b=>"hoge"}
- %記法を活用する
%w(apple orange banana cherry) =>["apple", "orange", "banana", "cherry"] %i(apple orange banana cherry) =>[:apple, :orange, :banana, :cherry]最後に
今回は、Railsプロダクトのコードチェックで、指摘されがちな点をまとめてみました。
私も、ありがたいことに先輩エンジニア達から多くの指摘をされてきましたが、次コーディングするときには気をつけるようにしています。自分がコードチェックするときにも指摘できるようになっていくので、コードチェック大切ですね。明日は、@ya-manさんの「Ansibleを最大で25倍高速化するMitogenについて調べてみた」です。
お楽しみに!
- 投稿日:2019-12-04T14:36:12+09:00
Your Ruby version is OOO, but your Gemfile specified OOOと怒られた時の対処法
やろうとしたこと
githubからアプリケーションをpullして、bundle installをしようとした時にエラーが出ました。
すぐ解決したのですが備忘録として残しておきます。
rbenvについて知りたい方はQiitaや公式ドキュメントをお読みください!
今回起きたエラー
bundle installの後に以下エラーが起きました。
Your Ruby version is 2.6.3, but your Gemfile specified 2.5.5rbenvを使ってrubyのバージョンを管理していますが、バージョンが違うと怒られました。
原因
エラーを翻訳すると、「pullしたアプリケーションのGemfileに記述されているRubyは2.5.5だけど、あなたのRubyは2.6.3だよ!!!」
原因はエラーが言ってくれている通りですね。
バージョンを合わせてあげれば即解決です。
解決方法
「rbenv versions」を実行して、rbenvにインストールされているrubyのバージョンを確認します。
$ rbenv versions ↓出力結果 system 2.5.5 * 2.6.3 (set by /Users/poti/Desktop/アプリ名/.ruby-version)2.5.5と2.6.3がインストールされていますが、このディレクトリ内のバージョンは2.6.3になっています。
これを2.5.5に変えてあげれば完了ですね。
rbenv versionsを実行して使用したいバージョンが出てこなければインストールする必要があります。
「2.5.5」がない場合を想定して挙げておきます。
以下のコマンドを実行しましょう。
$ rbenv install -l 2.4.5 2.4.6 2.4.7 2.4.8 2.4.9 2.5.0-dev 2.5.0-preview1 2.5.0-rc1 2.5.0 2.5.1 2.5.2 2.5.3 2.5.4 2.5.5 ←これインストールしたい! 2.5.6 2.5.7 2.6.0-dev 2.6.0-preview1 2.6.0-preview2 $ rbenv install 2.5.5 $ rbenv versions //(インストール出来たか確認)「rbenv install -l」でインストール可能なRubyを確認して、 「rbenv install ooo ←インストールしたいバージョン」でそのRubyをインストールします。
最後に以下のコマンドを実行しましょう。
$ rbenv local 2.5.5 $ source ~/.bash_profile「rbenv local ooo」をするとそのディレクトリ下のバージョンを指定したものに変更することができます。
localの反対でglobalというものもあります。
$ rbenv global 2.5.5とすると、全てのディレクトリのバージョンが2.5.5に変更されます。
ここは場合に応じて使い分けましょう。
最後に「source ~/.bash_profile」で変更を確定させます。
source ~/.bash_profileがよくわからない方は以下の記事がおすすめです。
.bash_profile ? .bashrc ? いろいろあるけどこいつらなにもの?
PATHを通すために環境変数の設定を理解する (Mac OS X)
おわり
- 投稿日:2019-12-04T10:44:27+09:00
Raspberry Piを使ったネットワーク&アプリケーション構築Part1
株式会社LITALICOでエンジニアをやっている @koheiyamaguchi0203 です。
この記事は『LITALICO Engineers Advent Calendar 2019』の12日目の記事になります。目的
- 同一ネットワーク上に存在するRaspberry Pi4台とMac1台とルータ3台でいい感じに通信します。
- いい感じな通信を具体化すると以下になります。
- 2台のRaspberry PiでRubyアプリケーションが動作しています。
- 1台のRaspberry Piでmariadbサーバが動作しています。
- 1台のRaspberry PiでLoad Balancerが動作しています。
- MacからSinatraアプリケーションにリクエストを送ると、リクエストに応じたHTMLを返します。
- ページを返すときにDBからデータを取得し、それをHTMLに反映します。
- これを読んだ人が以下の状態になること。
- クラウドサービスが裏側でどういう風に、どう物理的につながっているのか?を理解できる。また、それをイメージしやすくなる。
- ネットワークを物理的に構築することに興味を持てる。
どうしてこれを書くのか?
インフラ構築の勉強をする中で「EC2って何?」「IGWって何?」「Route Tableって何?」とよく分からないけど、なんか動くぞ??みたいなことが多いです。
クラウドが抽象化していい感じにやっているところをできる限り自前でやることで、クラウドをなんとなーく使いこなしている状態を脱することができるのではなかろうか?という考えがあり、Raspberry Piを使ってソフトウェアを0から入れてみたり、物理的な配線、ルータの設置などをしつつ、簡単なアプリケーションを作ってみることになりました。もう少し補足すると、社内で同じようなことをやっている研修があります。だが、数人(メンター1とメンティー4ぐらい)でやっており、私が何もせずとも進んでいく研修になっていました。一人でその研修をやってみたくなり、メンターに週に一回ぐらい分からんかったことや自分がどう構築したのか?などを壁打ちしよう!と思いました。
そのプロセスが自分の勉強がてら、他に同じような悩みを持っている人に届けば良いなぁと思っています。
対象者
- クラウドを用いたインフラ構築しかやったことがない。それも雰囲気でやっている人。
- アプリケーションを作ったことがある。
- フロントエンドもサーバサイドも一定の経験があると良いと思います。
- LinuxやTCP/IP、mariadb、ルータについて詳しくない人。
- 私も詳しくないので、この辺について詳しくなりたいと思っています。そのプロセスを書くので、そのような人には参考になるかもしれないです。
- 全てを説明していると、大変なので、この辺が分かっていれば、大丈夫だと思う!みたいなテンションで書いています。
やったことの要約
今回は以下の写真のような論理ネットワークを構築しました。
こっちは物理的な結線を表したものです。
実際にできるようにしたこと
- Clientから各Raspberry Piにsshできるようにした。
- ClientからLoadBalancer(以下LB)にHTTP通信をできるようにした。
- ClientからAPサーバにHTTP通信をできるようにした。
本当はClientからはLBにしかHTTP通信できないようにして、LBが二台のAPサーバに通信を振り分けるようにしたかったのですが、時間の都合上、この記事を書いた時点では出来ていないです。できるようにしたあとに追記しようと考えています。
使った物リスト
個数は実行者の環境によりますが、概ねこのくらい必要になります。
- microSD(8GB~16GBあると良いんじゃなかろうか?) × 4
- 有線LAN × 10(以上)
- 有線LAN to USB 2.0 Type A × 4
- USB 2.0 Type A to microUSB × 4
- ルータ * 3
- Raspberry Pi zero * 2
- Raspberry Pi zero w * 2
- Mac × 1
- microUSB × 4
- スイッチングハブ × 1
- 電源タップ(環境に応じて変わる)
Rapberry Piのセットアップ
やることは以下。
- Rasbian Buster Liteをダウンロードする。
- SDカードをフォーマットする。
- SDカードにRasbianを焼く。
- SDカード内の一部を編集する。
- SDカードをRaspberry Piに刺す。
- Raspberry Piにsshする。
Rasbian Buster Liteをダウンロードする
まずはRasbianというOSをダウンロードします。
今回はRasbian Buster Liteをダウンロードします。
このミラーサイトからダウンロードできます。
2019-09-26-raspbian-buster-lite.zipとあり、これをクリックします。そうすれば、Raspbianのimageファイルをzip形式でダウンロードできます。SDカードをフォーマットする
私はこのツールを使ってフォーマットしました。
使い方は分かると思うので、頑張りましょう。SDカードにRasbianを焼く~Raspberry Piにsshする
この記事がわかりやすかったです。私はこの記事の通りにやることで、Raspberry Piのセットアップができました。
APサーバを用意する
- Raspberry Pi × 2にRubyをインストールします。
- RubyのインストールはRaspberry Piの種類によりますが、相当時間がかかります。その上Cライブラリがなくて、コンパイルが失敗します。エラーが出たら、エラー文を読み、どのライブラリをインストールする必要があるのか判断して、インストールしてください。頑張りましょう。
- sinatraの環境を整えます。
- これは適当にググれば誰でもできると思います。
- 外部ホストのDBサーバと通信できるようにします。
- https://qiita.com/NoriIka/items/cccaf60eacee6fb6951b
- ↑の記事が分かりやすいです。ただ、CentOSとはFWの設定コマンドなどが違うので、読み替えると良いと思います。
- ufwなどを使ってFWを設定するときに、22番を開放しないでlogoutすると、sshできなくなるので、本当に気を付けましょう。
- mariadb/mysqlに関連するライブラリをAPサーバが動作するホストにインストールしないと不都合が起きると思います。エラーになったら、エラー文を読み、必要なライブラリをインストールしましょう。頑張りましょう。
DBサーバを用意する
- Raspberry PiにmariaDBをインストールします。
- APサーバと通信できるようにします。
- 「APサーバを用意する」というところにおすすめ記事を書いたので、それを読みましょう。
LBを用意する
- Raspberry PiにNginxをインストールします。
- HTTPリクエストをAPサーバにいい感じに振り分ける設定を書く(これがまだできてないので、後日追記します)。
ネットワーク
再掲となりますが、このようなネットワークを構築しました。
どうしてこのようなネットワークが構築されるのかについて以下の順で説明していきます。
- IPについて
- Routerの機能について
- DHCP
- ルーティングテーブル
- NAPTについて
IP
ISO参照モデルで言うところのL3 ネットワーク層に当たるプロトコルです。
「インターネット」を構成する中でIPはなくてはならない仕組みです。
IPの役割は物理的/論理的なネットワーク間を超えた通信を可能にすることです。図にします。
図の2つの四角は物理的にも論理的にも別のネットワークです。L1(物理層)/L2(データリンク層)だけではネットワークを超えた通信をすることはできないのですが、L3(ネットワーク層)のプロトコルであるIPによってそれは実現されています。
詳しいことはまだ調べきれていないので、ここでは説明できません。後日、L2/L3について調べることがあった場合に、まとめてみたいと思います。よくIP Addressという言葉を聞くと思いますし、上の写真でもIP Addressという単語があります。これが何なのかについて説明します。
IP Addressとはネットワークに接続されているノード(ホストとルータの総称)に割り振られるユニークな32ビットの正整数です。
ノード間で通信を行う際には通信内容とは別に送信元、送信先の情報が必要です。なぜならば、情報をどこに渡すのかがわからないと、情報を送信できないし、情報を送信しても、送信元がないと、受け取った側(送信先)はどこに返事をして良いのかわからないからです。
この送信先と送信元を一意に特定するためにIP Addressが用いられます。
IP Addressは32ビット正整数なので、実際には00001010000000000000000100000001となります。これだと人間が識別しづらいため、8bitずつに分けて、その分けた値を10進数にすることでIP Addressを表現しています。上で書いたIP Addressを8bitずつ10進数に直すと、このような流れで変換されます。
- 00001010000000000000000100000001
- 00001010.00000000.00000001.00000001
- 10.0.2.2
IP Addressはネットワーク部とホスト部に分けることができます。
IP Addressはパケットの送信先、送信元を指定するために使われます。ネットワーク部はホストがどのネットワークに属するかを示す部分であり、ホスト部はそのネットワーク内でユニークな値になります。どう分けているかというと、CIDRという仕組みがあります。詳しくは他の書籍や記事を読んでください。ざっくり言えば、どこまでがネットワーク部で、どこからがホスト部なのかを指定する仕組みです。Routerの機能について
Routerには「接続されているノード(ここではRaspberry PiとMac、Router)にIPアドレスを割り振る」「送られてきたパケットをどこに流すかを決める」機能があります(他にもあります)。
DHCP
ルータにはDHCP(Dynamic Host Configure Protocol)という機能があります。この機能によってルータに接続されているホスト(MacとRaspberry Pi)にIP Addressなどを割り振る設定が行われます。
このDHCPという仕組みのおかげでMacとRaspberry PiにIP Addressを割り振っています。
具体的な仕組みについて以下に書いていきます。
まず、ネットワークに繋がれたDHCPクライアントはそのネットワークに対してBroadcast通信を行います。その通信を受け取ったDHCPサーバはDHCPクライアントに「この設定を使うように」というレスポンスを返します。
そのレスポンスを受け取ったDHCPクライアントは再びBroadcast通信を行い、「レスポンスに書かれていた設定を使って良いですか?」とDHCPサーバに確認を取ります。
どうして確認を取るのかというと、ネットワーク内には複数のDHCPサーバがある場合があります。他のDHCPサーバが同一ネットワーク内のホストに同じ設定を割り振っている場合、ネットワークとしておかしくなってしまう(例えば、同じIP Addressを持っているホストが2つになってしまう)ので、再度確認を取っています。
最後にDHCPサーバがその設定を使うことを許可するレスポンスをDHCPクライアントにすることで、ホストにIP Addressが割り振られます。ルーティングテーブル
ルーティングテーブルとは「ルータに到達したパケットをどこに流すかを判断する対応表」のことです。ネットワーク図をもとに説明します。
まず、ルーティングテーブルにはネットワークアドレスとゲートウェイと呼ばれるカラムがあります。これはルータによって名称は違えど、意味するものは同じです。
ネットワークアドレスはルータに到達したパケットの宛先IP Addressと照らし合わせられます。そこでルーティングテーブルのネットワークアドレスとパケットの宛先IP Addressのネットワーク部がマッチする場合において、ゲートウェイに指定されているIP Addressを持つノードにパケットが送信されます。
つまり、Clientから宛先アドレス10.0.2.2を持つパケットを送ったときには以下のようにパケットは流れます。
- Client→RouterB
- RouterB→RouterA
- RouterA→RouterC
- RouterC→LB
- LB→RouterC
- RouterC→RouterA
- RouterA→RouterB
- RouterB→Client
ただし、BroadStationを使っている場合は上手くいきません。理由としてはBroadStationのWAN側ポートの挙動がおかしいのでは?という推測がありますが、BroadStationの仕様を把握していないので、推測の域をでません。もし、ちゃんと通したいのであれば、中古で安い業務用ルータを買うべきです。会社で使われていなかったRTX 1200というルータを使って同じ構成を試したところ、上手くできたので、この理論が正しいことは証明済みです。
ちなみに、Client(Mac)やRaspberry Pi、RouterB、RouterCにもルーティングテーブルは設定されています。
ClientとRaspberry Piでルーティングテーブルを確認するには以下のコマンドを叩く。$ netstat -rn Routing tables Internet: Destination Gateway Flags Refs Use Netif Expire default 10.0.2.2 UGSc 118 0 en0 ...略 127.0.0.1 127.0.0.1 UH 10 49670 lo0ClientやRaspberry Piから送信されるパケットはこのルーティングテーブルを見て、どこに送信されるのか決まります。Destinationは宛先であり、テーブルの一行目はDestinationがdefaultとなっています。このルーティングテーブルに当てはまらない場合にdefaultで設定されているGatewayにパケットが送信されることを意味します。
AWSでもDefault Gatewayを設定するなどと書かれているが、それはこれのことです。
要するに、ルーティングテーブルに当てはまらないパケットが到達した場合はdefault gatewayにパケットを送信しています。RouterBのルーティングテーブルは以下のようになっています。確認はルータの管理画面orコンソール(BroadStationはコンソールに入れないので、管理画面から確認してください)からできます。
RouterCはこうなります。
上の箇条書きに付け加えて、具体的にパケットの流れを説明すると、以下のようになります。
- Client→RouterB
- Clientで宛先IP Address10.0.2.2がルーティングテーブルに指定されているか確認します。
- マッチしないので、default gatewayにパケットが送信されます。要するにRouterBにパケットが送信されます。
- RouterB→RouterA
- RouterBのルーティングテーブルに10.0.2.2がマッチするか確認します。
- マッチしないので、default gatewayとして指定されているRouterAにパケットが送信されます。
- RouterA→RouterC
- RouterAのルーティングテーブルに10.0.2.2がマッチするか確認します。
- 10.0.2.2はRouterAのルーティングテーブル(10.0.2.0/24のところ)にマッチします。なので、192.168.11.3にパケットを流す処理を行います。
- RouterC→LB
- RouterCのルーティングテーブルに10.0.2.2がマッチするか確認します。
- 10.0.2.2はRouterCのルーティングテーブル(10.0.2.0/24のところ)にマッチします。なので、local、要するに10.0.2.0/24ネットワークに属するホストにパケットを流します。ルータはどのポートにパケットを流せば、宛先IP Addressを持つホストに到達するのか知っているので、特定のホストにパケットを流すことができます。
- LB→RouterC
- 送信元IP Addressが宛先パケットになり、LB→Clientへパケットを返します。やっていることは上述した内容と同じなので、詳しくは書きません。
- RouterC→RouterA
- RouterA→RouterB
- RouterB→Client
ここまではClient→APサーバにパケットを送信することができるみたいに書いていますが、途中で書いたようにルータにBroadStationを使うとできません。もし、Client→APサーバにパケットを送信したいなら、良いルータを買いましょう。
*パケットを送信したいというより、pingを通したいが正しいです。別にNAPTの設定を行い、Portを指定した通信を行えば、APサーバにパケットを送信はできます。NAPTについて
NAPTとは「Network Address And Port Translation」の略です。1つのIP Addressで複数のホストを外部に公開するときに使われる仕組みです。
IP AddressとPortを変換して、ネットワークに属するホストに1つのIP Addressを共有する仕組みのことです。
上は実際に私が構築したネットワークに存在するNAPTの設定です。この設定はRouterCにされています。具体的にどういう処理になるかを以下に書きます。
- Clientが192.168.11.3:80にHTTP通信を行う。
- RouterCはこの通信を10.0.2.2:80に流す。
こうすると、1つのIP Address(192.168.11.3)を使って複数のホストを外部に公開することができます。
どうしてこれを使ったのか?というと、BroadStationの仕様によってClientからAPサーバにpingを通せずにいたからです。しかし、ClientからRouterCのWAN側IPまではpingが通せることが分かっていました。
であれば、NAPTを使えば、TCPによる通信ができだろうと目処を付けました。案の定出来たので、良かったです。感想
- 本当に多くのL3~L7の知識と実践ができて、得られたものが多かったです。さらにマシンにOSをインストールし、bootするという経験もなかったので、これも楽しかったです。普段であれば、AWSが勝手にやってくれていることが何なのか?をある程度理解できている実感があります。この記事には書けていないこともたくさん得るものはありました。それはちゃんと学べたもの、これから学ぶ必要があるという気付きも含めて、得たものです。
- sshについての仕組み
- TCPについての仕組み/詳細
- IPについての仕組み/詳細
- L2の仕組み
- 本来であれば、L7についての研修だったのですが、思いがけずに低いレイヤについて学習してしまいました。これからはL7の話を中心にしていきます。特にHTTP周りの話が多くなると思います。それもいつか記事に出来たらと思います。
- ただ、お金と場所が必要になるので、普通の人はVMやコンテナ技術、あるいはAWSなどのクラウドサービスを使ってやればいいと思いますし、L2/L3の話ならば、cisco packet tracerとか使えばいいと思います。物理でしか得られないのは「楽しさ」「イメージのしやすさ」ぐらいだと思います。これが重要な人は物理で触ってみると良さそうです。私はこれがとても重要な人間なので、良い勉強になっています。
- ちなみに、総額で2万以上は掛かっています。これからルータをこういうやつに買い替えていこうと考えているので、更にお金は掛かりますし、なんなら、Raspberry Piもこれから増えるかもしれないので、まだまだお金がかかるかもしれないです。お金欲しいです。
次回
- 以下のことを実現したいと思っています。
- Cacheやらなんやらを試す。
- Webサーバを追加する。
- DNSを導入する。
- 静的ファイル配信サーバを導入する。
- Reverse Proxyを導入する。
- もっと先の話としてはクラスタ構成とかコンテナ技術の実験、Elixirの分散処理の話とかを実験してみたいと思っています。
明日は明日は、@yoshikitanaka0707 さんの「『障害のない社会を作る』ためにアクセシビリティに向かい合う」です。お楽しみにです。






- 投稿日:2019-12-04T09:37:29+09:00
【Ruby】特異メソッドの定義
特異メソッド
rubyではクラス単位でなくオブジェクト単位で挙動を変えることができる
alice ="i am alice" bob = "i am bob" #aliceのオブジェクトにだけshuffleメソッドを適用する def alice.shuffle chars.shuffle.join end #aliceはshuffleメソッドをもつがbobは持たない p alice.shuffle p bob.shuffle #=> "la eiacmi " Traceback (most recent call last): test2.rb:10:in `<main>': undefined method `shuffle' for "i am bob":String (NoMethodError)上記はdef alice.shuffleのように“オブジェクト.メソッド名”という形でメソッドを定義している。
これは「aliceというオブジェクトにshuffleメソッドを定義する」という意味。
故にaliceオブジェクトにだけshuffleメソッドが定義されbobオブジェクトには適用されていない。ただし、数値やシンボルだけはRubyの実装上の制約により、特異メソッドを定義できない
(IntegerクラスやSymbolクラスのインスタンスは「即値」になっているため)。]
特異メソッドは次のような方法でも定義することができるalice ="i am alice" class << alice def shuffle chars.shuffle.join end end p alice.shuffle #=>"ai ile acm"クラスメソッドは特異メソッドの一種
クラスメソッドの定義方法と特異メソッドの定義方法を一度見比べる。
class User def self.hello 'hello' end class << self def hi 'hi' end end end #特異メソッドを定義するコード例 alice = "i am alice" def alice.hello "alice hello" end class << alice def hi 'hi' end endRubyで便宜上クラスメソッドと呼んでいるものは、
実際は特定のクラスの特異メソッドである。クラスメソッドは以下のようなコードで定義することもできる。このほうが変数に特異メソッドを定義する構文により近い
class User end #クラス構文の外部でクラスメソッドを定義する方法1 def User.hello 'Hello' end #クラス構文の外部でクラスメソッドを定義する方法2 class << User def hi 'hi' end end p User.hello p User.hi #=> "Hello" "hi"
- 投稿日:2019-12-04T09:35:49+09:00
Ruby on Railsで時間が溶けた凡ミス集
はじめに
「Ruby on Rails 速習実践ガイド」をひととおり終え、自分でToDoアプリを作ってみたいと思い、下記の記事を参考に「Ruby on Rails 速習実践ガイド」で作成した Taskleafに機能を追加してみた。
https://qiita.com/sasasoni/items/fb0bc1644ece888ae1d4上手くいかなかった点
①イベントがカレンダーに表示されない
今回参考にしていたWebサイトのようにEventという名前でモデル・コントローラーを作成したのではなく、Taskをそのまま使っていたので、JSON形式で情報をカレンダーに渡す際、変数名に気をつけなければいけなかった。
②Datetimepickerを使ってカレンダーで選んだ日時が表示されない
slimの書き方が分かっておらず、Datetimepickerの実装の仕方に苦労した。
slim形式でHTMLを書く際、動的クラスの書き方には注意すべき。③週表示・1日表示の際に時間が軸に表示されない
こちらはcssに書いていた.fc-time { display: none; }が原因だった。
感想
改めて見返してみると「エラーの原因これ?」と拍子抜けするようなミスでたくさん悩んでいた…。今後はもっと気をつけていきたい。
参考Webサイト
ユーザーの新規登録をログイン画面からも可能にする
https://blog.kansolink.com/develop/ruby/how-to-build-user-signup/jbuilderを使ったJSONの返し方
https://ruby-rails.hatenadiary.com/entry/20150108/1420675366日付選択をカレンダー形式でやる方法
https://qiita.com/nozomi53motomachi/items/fef1b90e69b4a3b52bf7
https://qiita.com/akishin/items/ef197a312a3cb245c0b3
https://blog.hello-world.jp.net/javascript/1762/
https://eonasdan.github.io/bootstrap-datetimepicker/
https://github.com/pingcheng/bootstrap4-datetimepickerTempus Dominusの使い方
https://tempusdominus.github.io/bootstrap-4/Usage/
- 投稿日:2019-12-04T09:01:01+09:00
Rubyで書いたバックアップツールの紹介
目的
社内で色々なバックアップをしていましたが、個別にbashを書いていてメンテナンスしにくいと思ったので、Rubyでまとめてみました。
仕様
- バックアップしたい対象はそれぞれのサーバーで事前に準備(pg_dump等)
- バックアップを集約するサーバーで今回のプログラムを実行
- scpかrsyncのコピーコマンドとバックアップサーバー内の古いバックアップの削除コマンドをサポート
- コマンドの実行に失敗した場合はslackに通知
- バックアップの設定はyamlファイルで管理
- yamlファイルはERBを通して実行する
プログラム
Gemfile# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } gem 'slack-ruby-client' gem 'systemu' gem 'hashie'backup.rbrequire 'systemu' require 'slack-ruby-client' require 'hashie' require 'erb' require 'yaml' require 'fileutils' def notification(config, content) Slack.configure do |cfg| cfg.token = config.slack.token end client = Slack::Web::Client.new client.auth_test text = "#{config.name}\n#{content}" client.chat_postMessage(channel: config.slack.channel, text: text, as_user: true) end def read_config(path) Hashie::Mash.new(YAML.load(ERB.new(File.read(path)).result)) end def scp(command) status, stdout, stderr = systemu "/usr/bin/scp #{command.from} #{command.to}" raise "fail scp" unless status.success? end def rsync(command) status, stdout, stderr = systemu "/usr/bin/rsync -azq --delete #{command.from} #{command.to}" raise "fail rsync" unless status.success? end def clean(command) ymd = (Date.today - command.days ).strftime("%Y%m%d") re = Regexp.new(command.name_match) Dir::entries(command.dir).each do |it| if re =~ it FileUtils.rm_rf(File.join(command.dir, it)) if $1 < ymd end end end config = read_config(ARGV[0]) begin config.commands.each do |command| case command.type when 'scp' then scp(command) when 'rsync' then rsync(command) when 'clean' then clean(command) end end rescue Exception => e # エラーのfull_messageにtermcapが入るのを防いでいる $stderr = $stdout notification(config, e.full_message) #puts e.full_message endwebserver.yamlname: webserver slack: token: <%= ENV['SLACK_API_TOKEN'] %> channel: "#backup" commands: - type: scp from: vps01:/home/me/backup/<%= Date.today.strftime("%Y%m%d") %>.tar.bz2 to: /home/me/backup/webserver - type: clean name_match: ^(\d\d\d\d\d\d\d\d)\. dir: /home/me/backup/webserver days: 5git.yamlname: git backup slack: token: <%= ENV['SLACK_API_TOKEN'] %> channel: "#backup" commands: - type: rsync from: vps01:/var/git/ to: /home/me/backup/git/<%= Date.today.strftime("%Y%m%d") %> - type: clean name_match: ^(\d\d\d\d\d\d\d\d)$ dir: /home/me/backup/git days: 40SLACK_API_TOKEN=xxxx bundle exec ruby backup.sh webserver.yaml
- 投稿日:2019-12-04T05:35:48+09:00
SeleniumでSortableJS系ライブラリのDrag&Dropをテストする
前置き
前回の記事で、Vue.Draggableを使ったコンポーネントのドラッグ&ドロップを実行するCypressのテストコードについて書きました。
これをSeleniumで書いたらどうなるだろうと思い試してみたところCypress以上にハマったので、解決方法を記録しておきます。1本記事内のドラッグ&ドロップのテストコードは、Vue.Draggableに限らずSortableJSベースのライブラリなら概ね動くものになります。
以下の公式サイトのデモにて検証しています。(2019/12/3時点)※react-sortablejsと他の3種類とでは若干テストコードが変わります。
本文内ではSortableJSとreact-sortablejsのデモページに対するテストコードを掲載しています。使用言語はNode.jsとRubyです。環境
- OS: Mac OS X 10.14.6 Mojave
- Node.js
- Node.js: v12.13.1
- selenium-webdriver: 4.0.0-alpha.5
- Mocha: 6.2.2
- Ruby
- Ruby: 2.6.5
- selenium-webdriver: 3.142.6
- minitest: 5.13.0
- Browser
- Google Chrome: 78.0.3904.108(Official Build)
- chromedriver: 78.0.3904.105(Homebrewにてインストール)
- Firefox: 70.0.1 (64 ビット)
- geckodriver: 0.26.0(Homebrewにてインストール)
- Safari: 13.0.3
- safaridriver: 1.0
- Library(公式のデモで使用されていると思われるバージョン)
- SortableJS: 1.10.0-rc3
- Vue.Draggable: 2.23.2
- react-sortablejs: 1.5.1
- ngx-sortablejs: 3.1.3
ドラッグ&ドロップが動作するテストコード(Node.js版)
SortableJSの公式のデモページにアクセスし、Simple list example の Item 1 を Item 2 にドラッグ&ドロップして、テキストが入れ替わることを確認するテストコードです。
テストフレームワークはMochaを、アサーションはNode.jsのassertモジュールを使用しています。
マニュアル操作では以下のGIFアニメのようになります。
test.jsconst { Builder, By } = require('selenium-webdriver') const assert = require('assert') describe('Drag and Drop test', function () { // ブラウザの起動を待つあいだにMochaがタイムアウトしてしまうのを防止 this.timeout(20 * 1000) let driver beforeEach(async () => { driver = await new Builder() .forBrowser('chrome') // Chromeを使う場合 // .forBrowser('firefox') // Firefoxを使う場合 // .forBrowser('safari') // Safariを使う場合 .build() }) afterEach(async () => { await driver.quit() }) it('SortableJS', async () => { // SortableJSの公式デモページにアクセス await driver.get('https://sortablejs.github.io/Sortable/#simple-list') // ドラッグ&ドロップの対象を含むdiv要素のリストを取得 let elements elements = await driver.findElements(By.css('div#example1 > div.list-group-item')) // ドラッグ元(Item 1)とドロップ先(Item 2)のdiv要素を取得 const sourceElement = await elements[0] const targetElement = await elements[1] // ドラッグ&ドロップを実行する関数の呼び出し await simulateDragAndDrop(sourceElement, targetElement) // Item 1 と Item 2 が入れ替わったことを確認 elements = await driver.findElements(By.css('div#example1 > div.list-group-item')) assert.strictEqual(await elements[0].getText(), 'Item 2') assert.strictEqual(await elements[1].getText(), 'Item 1') }) /** * ドラッグ&ドロップを実行する関数 */ async function simulateDragAndDrop(sourceElement, targetElement) { await driver.executeScript( async args => { // dragoverイベントの発火位置を計算 const targetRect = args.targetElement.getBoundingClientRect() const targetPositionX = (targetRect.left + targetRect.right) / 2 const targetPositionY = (targetRect.top + targetRect.bottom) / 2 // ドラッグ&ドロップに必要な各イベントのインスタンスオブジェクトを作成 const pointerDownEvent = new PointerEvent('pointerdown', { bubbles: true, cancelable: true, }) const dragStartEvent = new MouseEvent('dragstart', { bubbles: true, }) const dragOverEvent = new MouseEvent('dragover', { bubbles: true, clientX: targetPositionX, clientY: targetPositionY, }) const dropEvent = new MouseEvent('drop', { bubbles: true, }) // sleep処理用の関数を定義 const sleep = msec => new Promise(resolve => setTimeout(resolve, msec)) // イベントの発火 args.sourceElement.dispatchEvent(pointerDownEvent) args.sourceElement.dispatchEvent(dragStartEvent) await sleep(1) args.targetElement.dispatchEvent(dragOverEvent) args.targetElement.dispatchEvent(dropEvent) }, { sourceElement, targetElement } ) } })テストコードの解説
SortableJSを使用した要素のドラッグ&ドロップを実行するには、以下の4つのイベントの発火が必要になります。
- pointerdown
- dragstart
- dragover
- drop
selenium-webdriver本体にもドラッグ&ドロップ機能は実装されていますし(公式ドキュメント)、ドラッグ&ドロップ操作のための外部ライブラリもいくつか公開されています。
しかし試してみた範囲では、いずれも何かしらのイベントの発火が足りずドラッグ&ドロップは期待通りに動作しませんでした。Cypressのように必要なイベントを個別に発火させることができればよさそうなのですが、selenium-webdriverにはそういった機能はないようです。
そのため、素のJavaScriptでイベントを発火させる処理を書き、それをselenium-webdriverのexecuteScript()を使って実行するという方法をとることになりました。JavaScriptを書く際のポイントが何点かありましたので説明します。
ポイント1
dragover イベントのインスタンス作成時のコンストラクタで、イベントを発火させる位置を指定しておく必要があります。
getBoundingClientRect()でドロップ対象要素の viewport に対する位置を取得し、それをもとに対象要素の中央にあたる位置を計算して、その値をコンストラクタのclientX、clientYに設定しました。test.js// dragoverイベントの発火位置を計算 const targetRect = args.targetElement.getBoundingClientRect() const targetPositionX = (targetRect.left + targetRect.right) / 2 const targetPositionY = (targetRect.top + targetRect.bottom) / 2 // 中略 // dragoverイベントのコンストラクタでイベントの発火位置を指定 const dragOverEvent = new MouseEvent('dragover', { bubbles: true, clientX: targetPositionX, clientY: targetPositionY, })ポイント2
dragstart と dragover を順に dispatchEvent する際、あいだに sleep を挟む必要があります。
sleep が必要になる根本的な理由がまだ突き止められていないのですが、ひとまず動いたのでよしとしています。test.js// sleep処理用の関数を定義 const sleep = msec => new Promise(resolve => setTimeout(resolve, msec)) // イベントの発火 args.sourceElement.dispatchEvent(pointerDownEvent) args.sourceElement.dispatchEvent(dragStartEvent) // ここでsleepが必要 await sleep(1) args.targetElement.dispatchEvent(dragOverEvent) args.targetElement.dispatchEvent(dropEvent)ポイント3
MacのSafariをテスト対象とする場合ですが、SafariではDragEventをnewできません。(Chrome、Firefoxではできます)
そのためドラッグ系のイベントでもMouseEventを使っています。
MDN にも Can I use... にもSafariはDragEventをサポートしていると書かれているのですが、Safariのコンソールで直接コードを叩いてみてもReferenceError: Can't find variable: DragEventと返ってきてしまいました。test.js// Safariでは new DragEvent と書くと動作しない const dragStartEvent = new MouseEvent('dragstart', { bubbles: true, }) const dragOverEvent = new MouseEvent('dragover', { bubbles: true, clientX: targetPositionX, clientY: targetPositionY, }) const dropEvent = new MouseEvent('drop', { bubbles: true, })ポイント4
前置きにも書きましたがreact-sortablejsのデモの場合、前出のテストコードではドラッグ&ドロップが動作しません。react-sortablejsでは、dragstart イベントが発火した際に、イベントターゲットとなった要素が2つに増えるという挙動をします。
この要素の増加により、リスト内でのドロップ先要素の index がずれてしまい、目的のドロップ先に dragover できなくなるケースが発生します。それに対応するため処理に手を加えなければなりません。要素数の増加に対応したテストコードの例が以下になります。
ドラッグ&ドロップが動作するテストコード(Node.js + react-sortablejs版)
react-sortablejsの公式のデモページにアクセスし、Simple List の List Item 1 を List Item 2 にドラッグ&ドロップしてテキストが入れ替わることを確認するテストコードです。
記事が長くなるので折りたたみます。
react-sortablejsのテストコード例
test.js// requireやbefore/after部分は前出のテストコードと共通 it('react-sortable', async () => { // react-sortablejsの公式デモページにアクセス await driver.get('http://sortablejs.github.io/react-sortablejs/#container') let elements, sourceElementIndex, targetElementIndex // ドラッグ&ドロップの対象を含むli要素のリストを取得 elements = await driver.findElements(By.css('ul.block-list > li')) // ドラッグ元(List Item 1)とドロップ先(List Item 2)のli要素の、リスト内でのindexを定義 sourceElementIndex = 0 targetElementIndex = 1 // ドラッグ&ドロップを実行する関数の呼び出し await simulateDragAndDropForReact(elements, sourceElementIndex, targetElementIndex) // List Item 1 と List Item 2 が入れ替わったことを確認 elements = await driver.findElements(By.css('ul.block-list > li')) assert.strictEqual(await elements[0].getText(), 'List Item 2') assert.strictEqual(await elements[1].getText(), 'List Item 1') }) /** * ドラッグ&ドロップを実行する関数 */ async function simulateDragAndDropForReact(elements, sourceElementIndex, targetElementIndex) { await driver.executeScript( async args => { // dragoverイベントの発火位置を計算 const targetRect = args.elements[args.targetElementIndex].getBoundingClientRect() const targetPositionX = (targetRect.left + targetRect.right) / 2 const targetPositionY = (targetRect.top + targetRect.bottom) / 2 // ドラッグ&ドロップに必要な各イベントのインスタンスオブジェクトを作成 const pointerDownEvent = new PointerEvent('pointerdown', { bubbles: true, cancelable: true, }) const dragStartEvent = new MouseEvent('dragstart', { bubbles: true, }) const dragOverEvent = new MouseEvent('dragover', { bubbles: true, clientX: targetPositionX, clientY: targetPositionY, }) const dropEvent = new MouseEvent('drop', { bubbles: true, }) // sleep処理用の関数を定義 const sleep = msec => new Promise(resolve => setTimeout(resolve, msec)) // ドラッグ元の要素よりもドロップ先の要素が要素リストの後ろにある場合、 // dragover発火時にイベントターゲットとなるドロップ先要素のindexを+1する const adjustIndex = args.sourceElementIndex < args.targetElementIndex ? 1 : 0 // イベントの発火 args.elements[args.sourceElementIndex].dispatchEvent(pointerDownEvent) args.elements[args.sourceElementIndex].dispatchEvent(dragStartEvent) await sleep(1) args.elements[args.targetElementIndex + adjustIndex].dispatchEvent(dragOverEvent) args.elements[args.targetElementIndex].dispatchEvent(dropEvent) }, { elements, sourceElementIndex, targetElementIndex } ) }ドラッグ&ドロップが動作するテストコード(Ruby版)
Rubyでは以下のように書くことができます。2
テストフレームワークはminitestを使用しています。記事が長くなるので折りたたみます。
Rubyのテストコード例
test.rbrequire 'selenium-webdriver' require 'minitest/autorun' describe 'Drag and Drop test' do driver = nil before do driver = Selenium::WebDriver.for :chrome # Chromeを使う場合 # driver = Selenium::WebDriver.for :firefox # Firefoxを使う場合 # driver = Selenium::WebDriver.for :safari # Safariを使う場合 end after do driver.quit end it 'SortableJS' do # SortableJSの公式デモページにアクセス driver.get 'https://sortablejs.github.io/Sortable/#simple-list' # ドラッグ&ドロップの対象を含むdiv要素のリストを取得 elements = driver.find_elements(:css, 'div#example1 > div.list-group-item') # ドラッグ元(Item 1)とドロップ先(Item 2)のdiv要素を取得 sourceElement = elements[0] targetElement = elements[1] # ドラッグ&ドロップを実行するメソッドの呼び出し simulateDragAndDrop(sourceElement, targetElement, driver) # Item 1 と Item 2 が入れ替わったことを確認 elements = driver.find_elements(:css, 'div#example1 > div.list-group-item') assert_equal(elements[0].text, 'Item 2') assert_equal(elements[1].text, 'Item 1') end end # # ドラッグ&ドロップを実行するメソッド # def simulateDragAndDrop(sourceElement, targetElement, driver) driver.execute_script(<<-EOL, sourceElement, targetElement) (async (sourceElement, targetElement) => { // dragoverイベントの発火位置を計算 const targetRect = targetElement.getBoundingClientRect() const targetPositionX = (targetRect.left + targetRect.right) / 2 const targetPositionY = (targetRect.top + targetRect.bottom) / 2 // ドラッグ&ドロップに必要な各イベントのインスタンスオブジェクトを作成 const pointerDownEvent = new PointerEvent('pointerdown', { bubbles: true, cancelable: true, }) const dragStartEvent = new MouseEvent('dragstart', { bubbles: true, }) const dragOverEvent = new MouseEvent('dragover', { bubbles: true, clientX: targetPositionX, clientY: targetPositionY, }) const dropEvent = new MouseEvent('drop', { bubbles: true, }) // sleep処理用の関数を定義 const sleep = msec => new Promise(resolve => setTimeout(resolve, msec)) // イベントの発火 sourceElement.dispatchEvent(pointerDownEvent) sourceElement.dispatchEvent(dragStartEvent) await sleep(1) targetElement.dispatchEvent(dragOverEvent) targetElement.dispatchEvent(dropEvent) })(arguments[0], arguments[1]) EOL endテスト対象がreact-sortablejsの場合は、Node.js版と同じように手を加える必要があります。(テストコード例は割愛)
後書き
個人的にはドラッグ&ドロップの挙動自体はUI観点も含めてマニュアルテストで見ておくのがよいだろうという考えでいます。
しかし、ドラッグ&ドロップ実行後の画面のテストを自動でまわしたいというケースは、もしかしたら出てくるかもしれません。そのようなときに今回調べた方法が役に立てばと思います。3
参考サイト
- Selenium公式 4
- Seleniumソースコード(Node.js) - GitHub
- Seleniumソースコード(Ruby) - GitHub
- SortableJS公式
- SortableJSソースコード - GitHub
- java - How to fire JS event in selenium? - Stack Overflow
- HTML Standard - Drag and drop
- HTML Standard - Drag and drop(非公式日本語訳)
- MouseEvent - Web API | MDN
- カスタムイベントのディスパッチ - 現代の JavaScript チュートリアル
- ES2017 async/await で sleep 処理を書く - Qiita


- 投稿日:2019-12-04T03:44:15+09:00
フロントエンドエンジニアの限界をこえて
CBcloud Advent Calendar2019 一日目の記事の続編となります。
前職との相違点
前職はフロントエンドに完全に集中して実装することが許される環境でした。
相違点を簡単にまとめてみます。前職
※所属していた会社そのものではなく、常駐先の環境となります。
- 大企業
- 客先常駐
- 応答率90%以上の完璧なレベルのヘルプセンターで、エンジニアがユーザーの問い合わせに直接対応することがない。
- 完全な役割分担がなされ、フロントエンド実装のみが我々のチームに依頼されてくる。
- フロントエンド系のバグ修正。
- 新機能のフロントエンド実装。
- 障害が起きた場合、専門のチームが対応。
- マーケティング部門で入念に検討・分析・企画された上で具体的な案件としてチケットが作られ、エンジニアが対応する体制が確立されており、スケジュールも余裕を持った期間が取られている。
- エンジニアがたくさんいる
CBcloud
- ベンチャー企業(スタートアップ)
- 本社勤務
- 問い合わせについて一次対応者が返答できない場合に、その問い合わせが直接エンジニアに回ってくる。1
- 役割分担がなく、インフラ・バックエンド・フロントエンドをできる人がメインでやり、興味があればいくらでも手を出せる。
- 依頼内容・実装の要望がフロントエンドに収まらず多岐にわたる。
- 障害が起きた場合、自分たちが直接対応する。
- 差し込み対応が多く、短い期間で可能な限りを実装することが多い。
- エンジニアには機能開発全体を任されている
- エンジニアは少数
フロントエンドだけでは、できることに限界があった
新機能実装をする場合、前職だとフロントエンドだけを担当し、他は任せきりで何の問題もありませんでした。
現職の場合、機能開発全体をやり切る必要があり、UIだけでなくサービスの仕組みづくりそのものが求められています。おのずとフロントエンド実装のみで対応する場合、できる範囲に限界が見えてきました。
実は入社した時から「フロントエンドは教えるので、バックエンドを教えてください」と言っており、
それもあって少しずつScala、そしてRubyを書いていくことになります。ログイン処理の変更
急にScalaの案件を任されたと思ったらこれだよ!
2週間ほど苦しんだ覚えしかありません。ここがとっかかりで、他にもScalaコードの修正対応を続けていくことで経験を重ね、
データの変更などの処理がある程度書けるようになり、リファクタリングもできるようになりました。パスワード再発行画面+API
こちらはいろいろあってRuby on Railsです。
Grape環境を入れる所から始めました。
やはり環境作りと実装で2週間ほど苦しみました。
Rubyのif文の書き方やmapなどの構文も最初はおぼつきませんでしたが、リファレンスを読んだり、他の詳しいエンジニアに都度聞きながら覚えていきました。2
とはいえ、Rubyの実装自体はScalaに比べると素直に書けるので、一番の鬼門は環境構築だったと思います。
今ではデータを変更するだけなら難なくできるようになりました。クエリのチューニング
入社当時からサーバーが不安定になることが度々あり、
フロントエンドだけ行っているときは手出しできない領域でした。
- 少なくとも結合用のキーにはindexを貼ること
- スローログが出ている怪しいクエリはexplainで計測すること
- クエリを見直し、不要なサブクエリが発行されている箇所を改善すること
しかし、他のエンジニアと一緒に解決していったことで、クエリのチューニングができるようになりました。
データ分析・統計・可視化
前職だとSQLを全く触る必要がなかったのですが、
SQLツールを当たり前に使い、データ出しや分析のためにクエリを書くことが増えたため、
必然的にMySQLクエリを書くスキルが磨かれました。Metabase
毎回生のクエリを書いて出すのは大変+データ出し用のページを実装するのも手間ということで、
Metabaseを使うようになりました。
変数も使えるので可変になる部分は変数で定義しておけます。Metabase環境構築自体はつよつよエンジニアに任せてノータッチだったりしますが、
出来上がった環境で現在までに50個ほどクエリを書いています。GoogleDataPortal
他のエンジニアからすると「使いにくい、わかりにくい」との評価でした。
ただ、実際使ってみるとGoogleスライド+データの可視化ツールといった感じで、
GoogleスライドとMySQLが使えれば使えるという感じで、
今までDBに持っているだけだったデータの可視化に大きく貢献してくれています。これらのサービスを使うまでは独自のページを実装したり、依頼の都度SQLツールでクエリを叩いてCSV出力する泥臭いことが多かったです。
metabaseやGoogleDataPortalを使うと、クエリを書くことに集中できる+URL共有できる=Slackで簡単に伝えられるので便利です。また、事業会社で重要な「日々の数字を意識すること」がグラフ化・可視化されたことで行いやすくなりました。
個人向けサービスの改善企画
MySQLのクエリを本格的に書かざるを得なかったのがこの案件でした。
当時Excelは使えたのですが、Select文とwhere句を覚え立ての段階でやりました。
CSV化したデータをExcelに張り付け、どこの数字を上げると、最終的な売上に一番貢献するのかを算出し、
それを基にやるべき施策を導き出しました。感覚ではなく、データを基に企画し、施策を決めるという初めての経験でした。
作ったExcelデータについては予想以上の分析を提示できていたらしく、CEOから好評だったようです。やれることをいろいろやったら、身についた
いろいろやったら、スキルが身についてきました。
今の自分にできないことを簡単にできる凄い人を見ると「神だ!」と思ったり、
「自分にはとてもできない!すごい!」と感じて終わったりすることが度々あると思います。しかしながら、「神」と崇めているだけでは何も技術は身につかないですし、
最初は何もできない所から始めて当然なので、無暗に崇め奉らないこと、
「自分もやってみよう」と考えてみることが大事なのかな、と今では思っています。contributions
参考までに2016年〜現在までのGitHub contributionsの数を載せておきます。
扱う領域が増えた分、自分が編集する箇所も増え、contributionsが年々増えていっているのが分かります。
年 contributions 2016 133 2017 1064 2018 1601 2019 2230 まとめ
- フロントエンドだけだと機能開発が1から10まで出来ない
- 教えてもらったり調べたりして、ScalaとRubyを覚えた
- SQL文が書けるとどこに行っても役に立つ
- データ可視化ツールを活用して、本質部分に集中する
- 「神」で思考を止めないこと
- 投稿日:2019-12-04T01:17:48+09:00
RubyでDBMSを実装 構文解析(3日目)
この記事は RubyでDBMS Advent Calendar 2019 の3日目の記事です。
本日の概要
2日目はサーバに渡ってきた文字列をSQLとして解析するに当たって、
意味のある最小単位であるトークンに分解するところまで実装しました。(字句解析)
本日は後半のフェーズである構文解析を実装します。実装はこちらのGitHubリポジトリに置いてあります。
構文解析とは
構文解析では、字句解析で分割したトークンの配列を、
予め定義した構文規則に照らし合わせていきます。
(広義には字句解析、構文解析を二つまとめて構文解析と呼ぶこともあるそうです)BNF
BNFというプログラミング言語の構文を定義するのによく用いられる記法を用いて、
今回のオレオレSQLの構文定義をしていきます。
BNFについての解説は省略します。SQL92のBNFを見つけたので、こちらを参考に定義してみます。
<select statement> ::= SELECT <select list> FROM <string literal> [ WHERE <search condition> ] <select list> ::= <asterisk> | <string literal> [ { <comma> <string literal> }... ] <search condition> ::= <string literal> <comp operator> <row value> <comp operator> ::= <equal> | <not equal> | <greater than> | <greater than equal> | <less than> | <less than equal> <row value> ::= <numeric_literal> | <quote> <string literal> <quote> <create statement> ::= CREATE TABLE <string literal> <table element list> <table element list> ::= <left paren> <table element> [ { <comma> <table element> }... ] <right paren> <table element> ::= <string literal> <data type> <data type> ::= INT | VARCHAR <insert_statement> ::= INSERT INTO <string literal> VALUES <left paren> <row value> [ { <comma> <row value> }... ] <right paren>記法の差異は多々あるようですが、
[]で囲まれた部分は省略可能
{}...で0回以上の繰り返し
|はOR
となっています。また、2日目で述べた通り、初期段階ではサポートするクエリは最小限に留めるため、SQL92のBNFとは異なる部分も多々あります。
例えばFROM <string literal>の部分など、今後JOINを実装する際には、変更しなければなりませんね。解析処理
定義したBNFの各要素ごとにメソッドに切り出し、
トークンを頭から一つずつ走査していくことで解析していきます。
再帰下降構文解析というらしいですが、詳細調べようとしたら沼にはまりそうだったのでご興味持たれた方は各自調べてみてください。SELECT文に関する部分だけ抜き出してあります。
詳しくはGitHubをご覧いただければと思います。rbdb/query/parser.rb# frozen_string_literal: true require 'rbdb/query/ast/select_statement' require 'rbdb/query/ast/search_condition' module Rbdb module Query class Parser def initialize(tokens) @tokens = tokens @cur = 0 end def parse case @tokens[0].kind when :select_keyword select_statement when :create_keyword create_statement when :insert_keyword insert_statement else raise 'parse error' end end private def peek(n = 1) @cur += n end # 現在のトークンが期待する種別かを判定する # 期待するものの場合は、イテレータを一つ進め、トークンを返す # 期待しないものの場合は、イテレータは進めず、nilを返す def expect(kind) current_token = @tokens[@cur] return nil unless current_token.kind == kind peek current_token end # トークンが期待しないものの場合は、例外を発生させる # それ以外は#expectと同じ挙動 def expect!(kind) current_token = expect(kind) raise 'parse error' unless current_token current_token end def select_statement expect!(:select_keyword) sl = select_list expect!(:from_keyword) table_name = expect!(:string_literal).value sc = search_condition if expect(:where_keyword) Rbdb::Query::Ast::SelectStatement.new( table_name: table_name, select_list: sl, search_condition: sc, ) end def select_list return :asterisk if expect(:asterisk) columns = [] columns << expect!(:string_literal).value while expect(:comma) do columns << expect!(:string_literal).value end columns end def search_condition lo = expect!(:string_literal).value co = comp_operator ro = row_value Rbdb::Query::Ast::SearchCondition.new( left_operand: lo, comp_operator: co, right_operand: ro, ) end def comp_operator if expect(:equal) then :equal elsif expect(:not_equal) then :not_equal elsif expect(:greater_than) then :greater_than elsif expect(:greater_than_equal) then :greater_than_equal elsif expect(:less_than) then :less_than elsif expect(:less_than_equal) then :less_than_equal else raise 'parse error' end end def row_value nl = expect(:numeric_literal) return nl.value if nl expect!(:quote) sl = expect!(:string_literal) expect!(:quote) sl.value end end end end概ね各メソッドがBNFの定義と対応してるのが分かると思います。
どのように実装していくか少し悩んだのですが、
各々上記コメントの通り動作をするexpectとexpect!という2つのメソッドを用意しました。
次に来るべきトークン種別が必ず決まっている場合はexpect!を用い、
OR条件のような部分ではexpectを用いるようにしています。また、AST(抽象構文木)というNamespaceを切って、結果をこちらのクラスのインスタンスに保持しています。
rbdb/query/ast/select_statement.rb# frozen_string_literal: true module Rbdb module Query module Ast class SelectStatement def initialize(table_name:, select_list:, search_condition: nil) @table_name = table_name @select_list = select_list @search_condition = search_condition end end end end endrbdb/query/ast/search_condition.rb# frozen_string_literal: true module Rbdb module Query module Ast class SearchCondition def initialize(left_operand:, comp_operator:, right_operand:) @left_operand = left_operand @comp_operator = comp_operator @right_operand = right_operand end end end end end動作確認
デバッグ用に各ASTクラスに
to_strメソッドをoverrideしたので、
このようにレスポンスで返してみます。rbdb/server.rbtokens = Rbdb::Query::Lexer.new(query).scan ast = Rbdb::Query::Parser.new(tokens).parse # TODO: res.body += astクライアントからクエリを叩いてみます。
>> CREATE TABLE users (id int, name varchar); --CREATE STATEMENT-- table: users columns: name: id, data_type: int name: name, data_type: varchar >> INSERT INTO users VALUES (1, 'hoge'); --INSERT STATEMENT-- table: users values: 1, hoge, >> SELECT id, name FROM users WHERE id = 1; --SELECT STATEMENT-- table: users columns: id, name, condition: id equal 1大丈夫そうですね!
まとめ
構文解析全般に関する筆者の知識不足な点もあり、詳細を省略したまま駆け足となってしまいましたが、
今回で一通り単なる文字列を意味のあるクエリとして解釈できるところまで到達できました。
明日は一旦はこちらを元に、揮発性のDB(rbdbコマンドを終了するとデータは消えてしまう)をとりあえず作ってみたいと思います。
- 投稿日:2019-12-04T00:29:15+09:00
【超基本】railsで部分テンプレートを使ってみる(haml)
経緯
ずっと苦手意識のあった部分テンプレートと向き合った結果、「なにこれ、便利!!」となったため、備忘録のために記事にします。
hamlで書いた記事があまりなかったり、localオプションの変数の意味や、collection、asの詳しい説明をなかなか見つけられなかったので、同じことで悩んでいる誰かのお役に立てたらすごく嬉しいです。もくじ
- 部分テンプレートとは
- ファイル名
- hamlへの記載方法
- オプション
- partial
- locals
- collection
- as
- まとめ
部分テンプレートとは
部分テンプレート(=パーシャル)とは、繰り返し使用される要素をまとめてテンプレート化するもの。何度も同じコードを書くことを防ぐことができる。また、投稿一覧画面を作成する際、collectionオプションを使用すると、each分を使わずに繰り返しができ、読み込み速度もeach文を使用する時より速い(らしい)。
ファイル名
部分テンプレートのファイル名は、必ずファイル名の最初に「_(アンダーバー)」をつける。アンダーバーをつけることで、当該のファイルが部分テンプレートであることを明示的に表せる。
hamlへの記載方法
部分テンプレートを呼び出す際、呼び出す側のファイルに以下の通りに記載し、呼び出される部分テンプレートを指定する。
例:
呼び出す側のファイル index.html.haml
呼び出される部分テンプレートファイル _post_index.html.hamlindex.html.haml.post__index = render partial: 'post_index'' '内に記載するファイル名は、「_」を省いて記載。
オプション
部分テンプレートには、様々な便利なオプションがあるため、紹介。
partialオプション
前項の通り、呼び出される部分テンプレートを指定するオプション。
尚、呼び出す側のファイルと部分テンプレートが異なるディレクトリにある場合は、ディレクトリ名も含めて指定する必要がある。例:
呼び出す側のファイル view/posts/index.html.haml
呼び出される部分テンプレートファイル view/shared/_post_index.html.hamlindex.html.haml.post__index = render partial: 'shared/post_index'localオプション
部分テンプレート内で使う変数(ローカル変数)を定義するオプション。
index.html.haml.post__index = render partial: 'post_index', local: { posts: @posts } -省略形は = render 'post_index', posts: @posts{ posts: @posts } の
postsは部分テンプレート内で使用する変数(=ローカル変数)。
@postsは、postsコントローラのindexアクションで定義した変数。
=呼び出した側のファイル(postディレクトリのindex.html.haml)で使えるよう、コントローラで定義した変数。つまり、部分テンプレート内でpostsを使用した場合、その変数の中身は、postsコントローラのindexアクションで定義された@postを同義となる。
each文を使用し、一つの投稿を繰り返し表示さのせレバ、投稿一覧ベージの完成。
_post_index.html.haml- posts.each do |post| .post__index__content .post__index__header .post__index__header--user-name = post.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post.textcollectionオプション
このオプション、めちゃ便利! 今回のような投稿一覧を作成する際、普通はビューでeach文を使用して、@postsの中にあるデータを取り出す。しかし、collestionオプションを使用すると、each文を書かずとも、繰り返してくれる。
index.html.haml.post__index = render partial: 'post_index', collection: @postsこのように定義することで、部分テンプレートでは、以下の記述のみでOK。
_post_index.html.haml.post__index__content .post__index__header .post__index__header--user-name = post_index.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post_index.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post_index.textlocalオプションを使用した際に、一番上に記述があったeach文は不要。@posts(postsコントローラのindexアクションで定義した変数)を、一つずつ取り出して表示してくれる。
ちなみに、このように記述した場合、ローカル変数名は、「post_index(部分テンプレートのファイル名)」になることに注意。asオプション
前項で説明したcollectionオプションを使用した場合、ローカル変数名は部分テンプレートのファイル名になる。変数名を自分で指定したい場合に、asオプションを使用する。
index.html.haml.post__index = render partial: 'post_index', collection: @posts, as: postこのように記述することで、前項でpost_indexと記述した箇所をpostに書き換えることができます。
_post_index.html.haml.post__index__content .post__index__header .post__index__header--user-name = post.user.name .post__index__header--btn = link_to edit_post_path(post.id) do %i.fa.fa-edit<> = link_to post_path(post.id), method: :delete do %i.fa.fa-trash .post__index__content--image - if post.image.present? = image_tag post.image.to_s, size: "400x400" .post__index__content--text = post.textまとめ
この他にも、便利なオプションがたくさんあるようだけど、今理解できているのはここまで。
新しいことを学んだら、追記します。
何か誤りがあれば、ご指摘いただけると嬉しいです。