- 投稿日:2019-08-30T23:34:48+09:00
AWS Certified Developer - Associate の取得
目的
- エンジニアとしての気持ちを忘れないように、少しずつAWSの勉強をしている。なんとなく勉強した成果というか証がほしいので順番に資格を取得していく。
勉強方法の方針
- Solution Architectは参考書がたくさんあるが、DeveloperやSysOps Administrator等は参考書がなく、どんな問題が出てどれくらいできればよいのか分からない。
- 今回は英語の勉強も兼ねて、英語の有料学習サイトの「Linux Academy」を使ってみる。他にもudemyとかいろいろあるが、たまたま最初に目に留まったため。
Linux Academy での勉強
- 月額課金コースだと、$49/Month。年契約すると割引あり。
- 資格毎にコースが構成されており、取りたい資格のコースを好きなだけ選択可能。今回は「AWS Certified Developer - Associate Level」を受講する。AWSの他、AzureやGCPの資格取得対策コースもある。
- コースの構成としては、サービス毎(IAM, EC2, VPC等)に、1)講義のビデオ、2)ハンズオン、3)テスト の3ステップになっており、これを順番にやっていく。
- 全部講義ビデオを見るとかなり時間がかかるので、EC2とかIAMとか、ある程度理解しているところは、講義ビデオは省略する。
- 通勤でビデオを見て、家でハンズオンやテストを実施。触ったほうが覚えるのでハンズオンはなるべく実施する。ハンズオンはサンドボックスになっているので自分のAWSアカウントを使う必要はない。
受験
- 試験結果: 合格(778点)
- 真面目に勉強したつもりだったがギリギリだった。
所感
- 当然のことだが、実際に触ると、意識せずとも設定項目や手順をなんとなく覚えるので、実際に触ってみるのが大切と改めて実感。Linux Academyだけに頼らず、各サービスの操作を試してみるのが必要。
- Linux Academyの講義ビデオの英語が聞き取れないことがあるが、私のような人向けに字幕が付いた(全部ではない?)のでありがたい。当然ながら講義ビデオ、ハンズオンのテキスト、テスト問題等全て英語なので、ついでに英語の勉強になった。
- Linux Academyはコンテンツ買い切りではなくサブスクリプションモデルなので、休みなくたくさんやらないと損してしまう。次はこの流れでSysOps Administrator - Associate を取得したい。
- 投稿日:2019-08-30T23:12:11+09:00
EC2上でwebpackを実行したらNo space left on deviceと出てバンドリングできなかった
作業メモです。
ディスク容量が足りていないとのことで確認。
$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 488M 56K 488M 1% /dev tmpfs 498M 0 498M 0% /dev/shm /dev/xvda1 7.8G 7.7G 0 100% /この場合ec2のコンソールからボリュームをアタッチすればいいのですが、 そんなにメモリを圧迫するようなことをした覚えがなかったので、インスタンスを再起動して再び確認。
すると使用率が48%となっており、webpackも問題なく動きました。 原因は謎です。
- 投稿日:2019-08-30T22:06:55+09:00
cloud9の環境構築ではまった。
環境:Chrome,Mac
以前、cloud9で開発環境を構築する際につまずいたポイントと解決方法を。
エディタが開かない!!
一つのプロジェクトを作成し作ったエディタを開こうとすると以下のエラーメッセージか。。
「Enable third-party cookies in your web browser, and then try opening the environment again. For more information, see your web browser’s documentation.」
cookieが邪魔してそうなのはわかった。
そこで対処法を調べ、まず以下を実行。対処法
1.ChromeのCookieの許可ボタンに「[*.]amazonaws.com」を追加する
1-1.Chromeの右上にある◯が三つ並んでるボタンをクリック
1-2.[プライパシートセキュリティー]項目の[サイトの設定]項目をクリック
1-3.[Cookie]直下の[許可]項目に[[*.]amazonaws.com」]を追加。通常であればこれで解決。
だがしかし!!!!
僕の場合は解決しなかった。なぜだ。さらに調べている内にどうやらChromeの拡張機能が悪さをしている可能性がわかった。
2.Chromeの拡張機能が悪さをしているかも。
僕の場合、[GHOSTERY]という広告をブロックする拡張機能を導入していた。
その拡張機能OFFにした結果、エラーが解決されました。困ることがほぼないcloud9での環境構築ですが、詰まった人にとって
助けになれば幸いです。
- 投稿日:2019-08-30T21:48:00+09:00
AWS障害復旧後に対応したEC2インスタンス復旧(暫定処置)
前書き
先日発生したAWS Tokyoリージョンの大規模障害。
東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
https://aws.amazon.com/jp/message/56489/私もこの障害により、運用中の一部のEC2インスタンスがダウンしました。
が、幸いにも復旧に無事成功し、ほぼ事なきを得たのは不幸中の幸いでした。こうした事案を踏まえて認識せねばと思ったことは2つ。
- 1.クラウドだって物理のマシンなんだ
- 2.だからダウンする時だってあるんだ
内心どこかで「国内のAWSリージョンは落ちない」みたいな妄想は持っていたと。
それが間違いだと思い知る機会にはなったと思います。その上で「すぐにやったこと」をまとめました。
やったこと
- 1. 復旧したインスタンスをスナップショットで立ちあげ直す
- 2.一部のインスタンスは手動でなく定期でスナップショットを取得する
1. 復旧したインスタンスをスナップショットで立ちあげ直す
今回の障害についてのAWSの公式見解は、以下の通りでした。
日本時間 2019年8月23日 12:36 より、東京リージョン (AP-NORTHEAST-1) の単一のアベイラビリティゾーンで、オーバーヒートにより一定の割合の EC2 サーバの停止が発生しました。この結果、当該アベイラビリティゾーンの EC2 インスタンスへの影響及び EBS ボリュームのパフォーマンスの劣化が発生しました。サーバが熱でやられた、と認識しました。
だから、今割り当てられているサーバにも物理的な故障が生じている可能性がある。
このまま利用する前に、一度安全な環境でインスタンスを立て直した方が良さそうと判断しました。一度インスタンスを止めて、スナップショットから別のインスタンスを立ち上げます。
手順
スクショはいずれも、記事用にテストで立てたものを使っています。
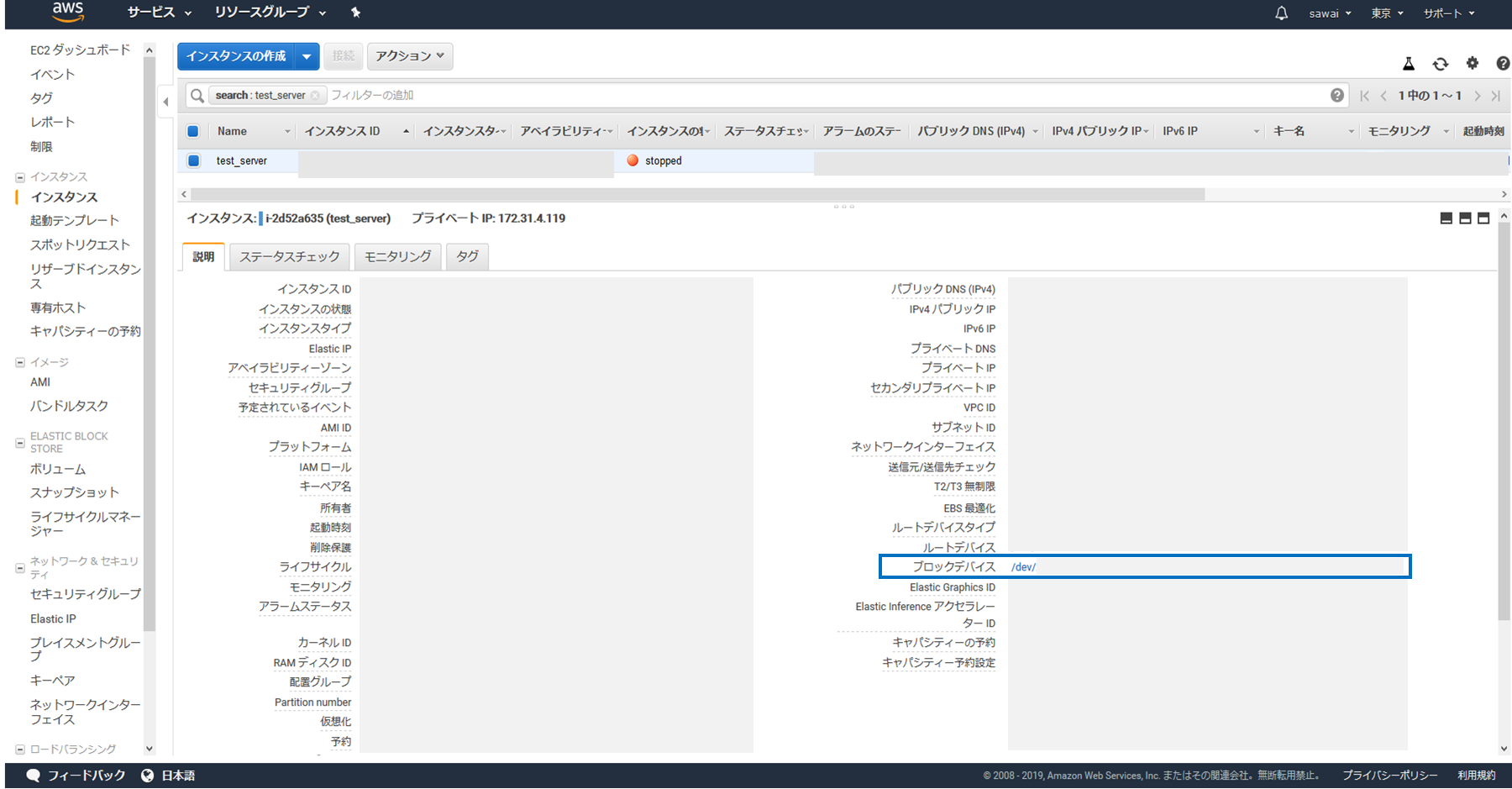
不要な情報は一応マスキングしていますのでご了承ください。(1) 該当インスタンスを「stopped」にしてから「説明タブ」の「ブロックデバイス」を選択します
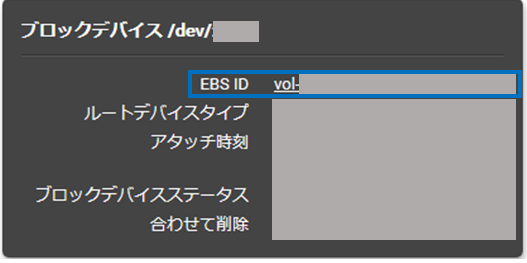
(2) 立ち上がる小ウィンドウ内から「EBS ID」を選択します
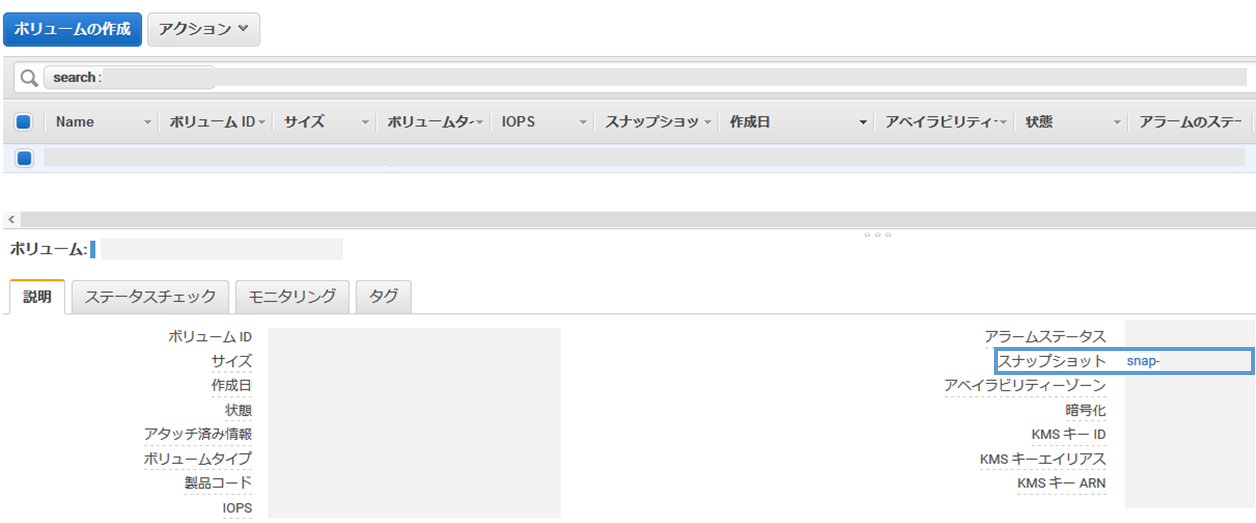
(3) ボリュームの設定が立ち上がるのでここから「スナップショット」を選択します
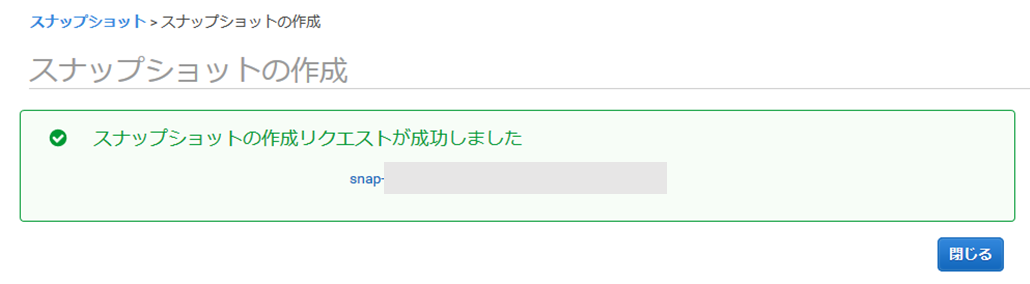
(4) スナップショットの一覧が立ち上がるので「スナップショットの作成」を選択します
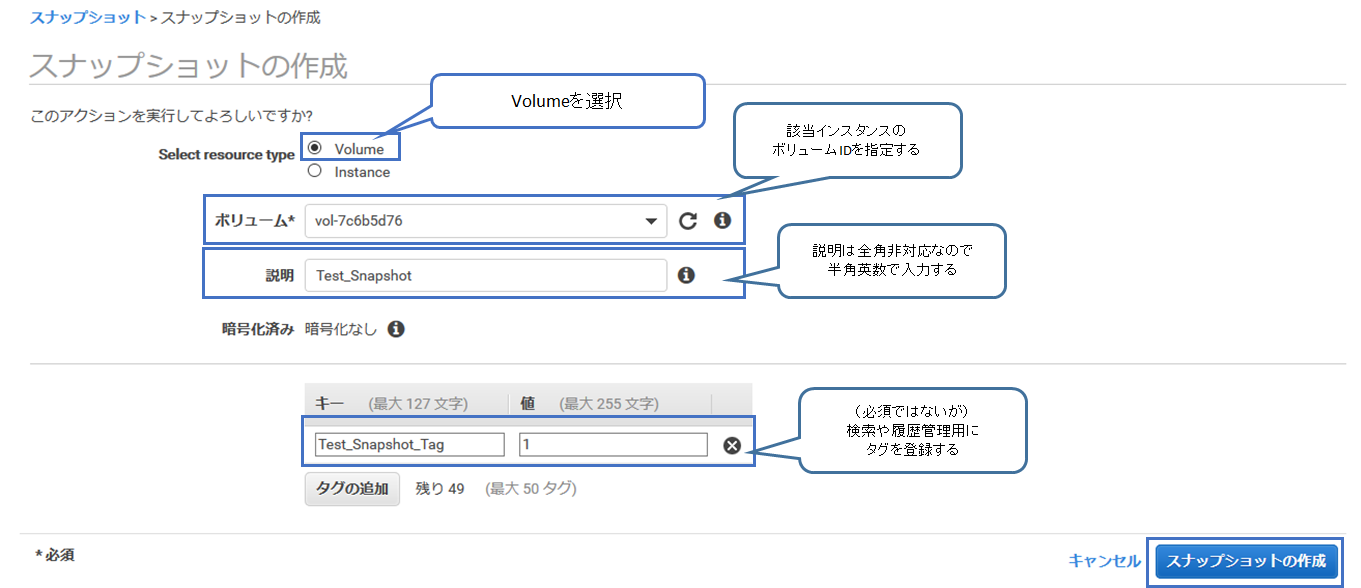
(5) スナップショットを作成します
- Select resource type は「Volume」を選択
- ボリュームは「当該インスタンスのID」を指定
- 説明は「それらしい情報」を入力, 全角非対応なので注意
- タグは検索や履歴管理で役立つので「任意に設定」しておく(6) スナップショットの作成に成功しました
(7) スナップショットの一覧に作成したスナップショットが表示されました
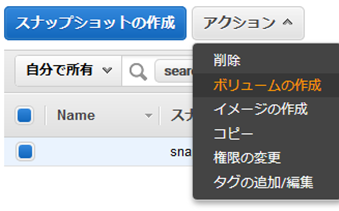
(8) これを選択して「アクション」から「ボリュームの作成」を選べば「EC2インスタンス」を立てていけます
IPやセキュリティグループ、VPC等、現在利用中のインスタンスの設定を加味しながら立ち上げ直しましょう。
(じゃないとあとで変更できないとインスタンスを作り成す羽目にあったりorz)これで復旧がひとまず完了。
動作検証をかけて問題なければ利用できる状態として良さそうです。2.一部のインスタンスは手動でなく定期でスナップショットを取得する
記事の冒頭にも書いた通り、私は、
内心どこかで「国内のAWSリージョンは落ちない」みたいな妄想は持っておりました。そんなわけでスナップショットを定期取得する、といった運用も行えておらず・・・。
これを機に、障害対策の一環で定期でスナップショットを作成するのも良いかと考えました。手順
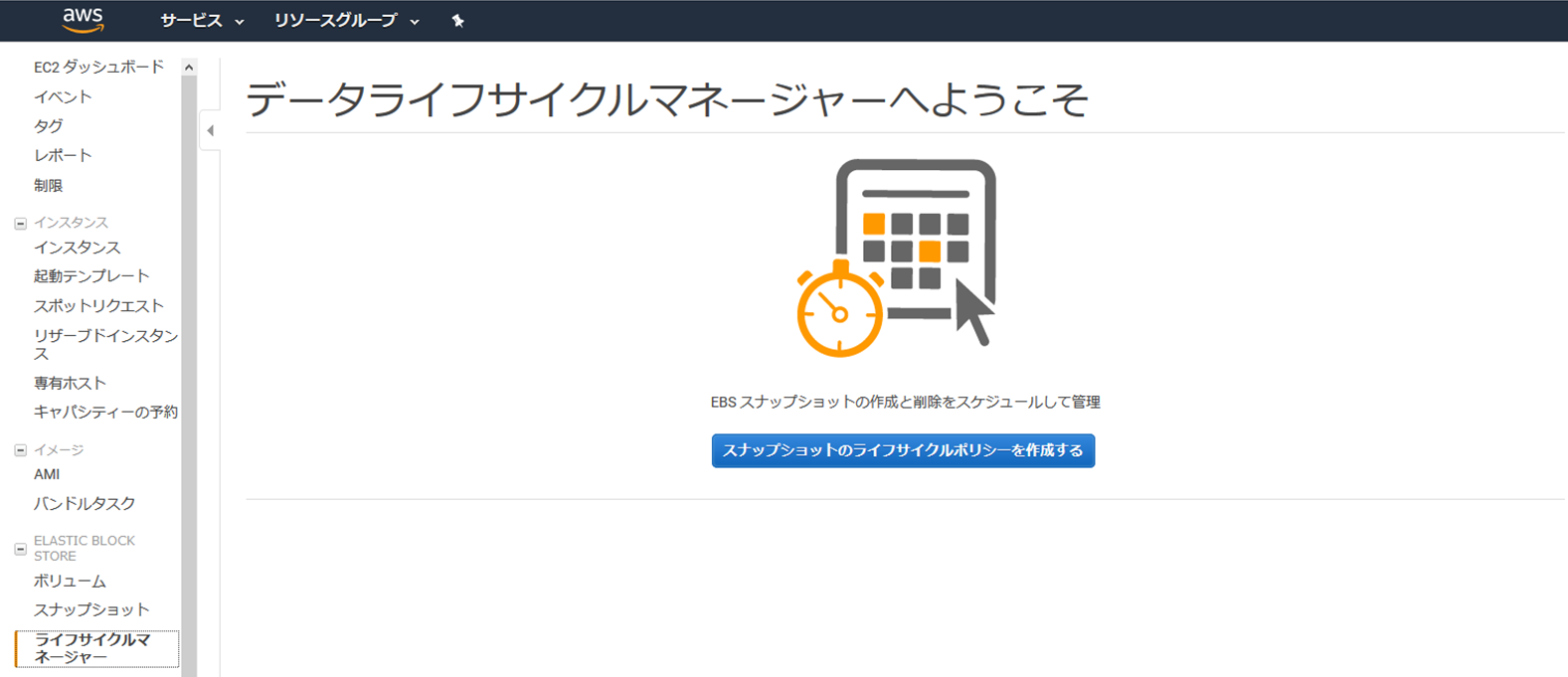
(1) EC2インスタンスの左メニューより「ライフサイクルマネージャー」を選択します
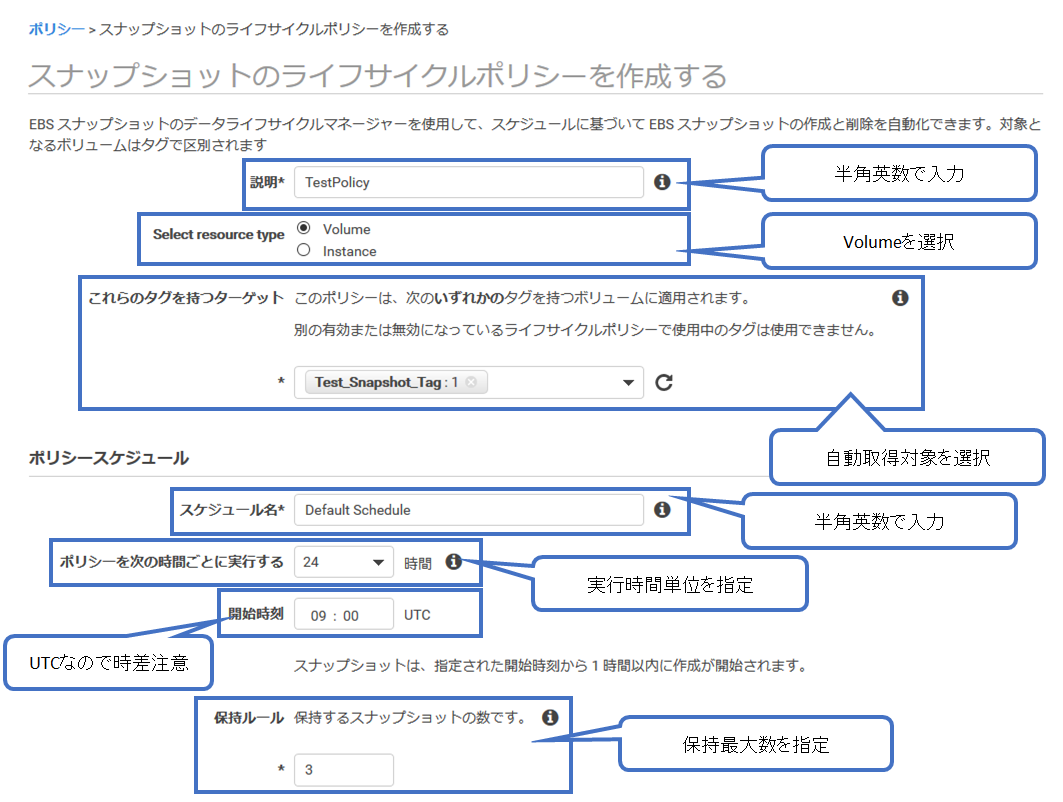
(2) スナップショットのライフサイクルポリシーを作成します
- 説明は「それらしい情報」を入力, 全角非対応なので注意
- Select resource type は「Volume」を選択
- これらのタグを持つターゲットは「該当するターゲットのタグ」などを選択
- スケジュール名は「それらしい情報」を入力, 全角非対応なので注意
- ポリシーを次の時間ごとに実行するは「生成頻度の時間」を入力
- 開始時刻は「該当時刻」を入力, UTC基準なので時差に注意
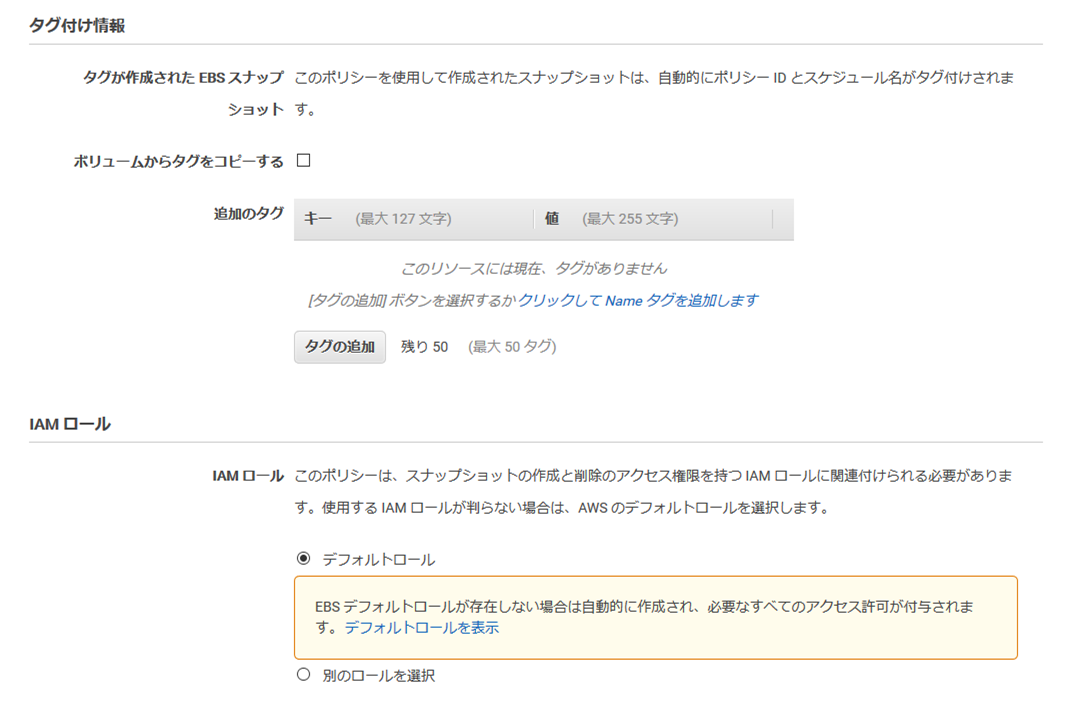
- 保持ルールに「スナップショット生成数の上限数」を入力(3) 追加でスナップショットのタグや権限設定にIAMロールも指定します
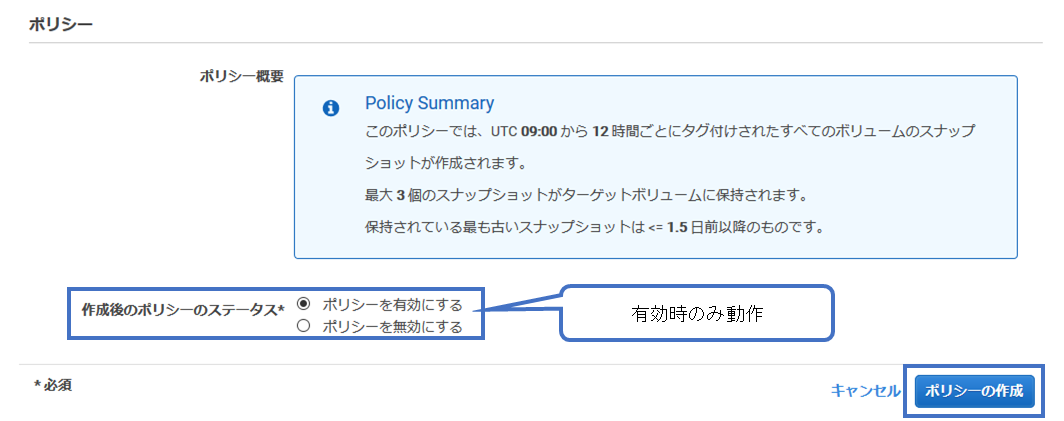
(4) 最後に作成後のポリシーのステータスを選択 スクショは「有効」ですが仮作成時は「無効」にしましょう
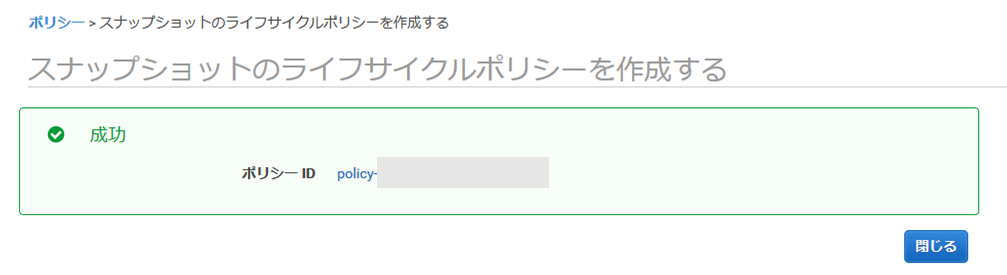
(5) ライフサイクルポリシーの作成に成功しました
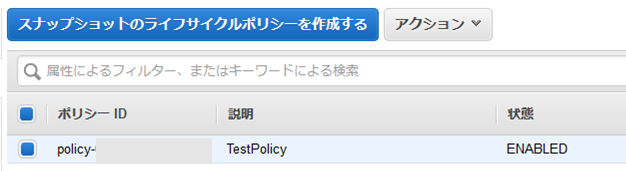
(6) 一覧上では「ENABLED(有効)」になり定期スナップショットの作成が動作するようになりました
まとめ
暫定で即座にやったのはこれくらいです。
でも、やるべきことはもっとたくさんありそうですね。スナップショットだけでは足りない。
AWS Backup の活用、複数のアベイラビリティゾーンでアプリケーションを稼働させる、
サーバレスやコンテナ化でサービスをもっとマイクロ化する、ローカルにもバックアップを落とすなど。考えたらキリがありませんが、
こうした機会をきっかけに自分たちのサービスの守り方を見つめ直す時間は必要だなと感じています。つまり、転んでも泣かない!!!ってことですね!
(いやいや、泣いてたらあかんやろ。泣かんでええようにせなあかんのやでっ・・・!)参考
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-creating-snapshot.html
https://dev.classmethod.jp/cloud/aws/amazon-dlm-ebs-snapshot-lifecycle/


- 投稿日:2019-08-30T21:48:00+09:00
AWS障害復旧後 すぐにやったEC2インスタンスへの暫定処置
前書き
先日発生したAWS Tokyoリージョンの大規模障害。
東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
https://aws.amazon.com/jp/message/56489/私もこの障害により、運用中のEC2インスタンスが一部ダウンしました。
が、幸いにも復旧に無事成功し、ほぼ事なきを得たのは不幸中の幸いでした。こうした事案を踏まえて認識せねばと思ったことは2つ。
- 1.クラウドだって物理のマシンなんだ
- 2.だからダウンする時だってあるんだ
内心どこかで「国内のAWSリージョンは落ちない」みたいな妄想は持っていたと。
それが間違いだと痛感する機会となってしまいました。。。その上で障害復旧後に「すぐにやったこと」をまとめました。
すぐにやったこと
- 1. 復旧したインスタンスをスナップショットで立ちあげ直す
- 2.一部のインスタンスは手動でなく定期でスナップショットを取得する
1. 復旧したインスタンスをスナップショットで立ちあげ直す
今回の障害についてのAWSの公式見解は、以下の通りでした。
日本時間 2019年8月23日 12:36 より、 東京リージョン (AP-NORTHEAST-1) の単一のアベイラビリティゾーンで、 オーバーヒートにより一定の割合の EC2 サーバの停止が発生しました。 この結果、当該アベイラビリティゾーンの EC2 インスタンスへの影響及び EBS ボリュームのパフォーマンスの劣化が発生しました。サーバが熱でやられたんだ、と認識しました。
だから、今割り当てられているサーバにも物理的な故障が生じている可能性がある。
このまま利用する前に、一度安全な環境でインスタンスを立て直した方が良さそうとも判断しました。一度インスタンスを止めて、スナップショットから別のインスタンスを立ち上げます。
手順
スクショはいずれも、記事用にテストで立てたものを使っています。
不要な情報は一応マスキングしていますのでご了承ください。(1) 該当インスタンスを「stopped」にしてから「説明タブ」の「ブロックデバイス」を選択します
(2) 立ち上がる小ウィンドウ内から「EBS ID」を選択します
(3) ボリュームの設定が立ち上がるのでここから「スナップショット」を選択します
(4) スナップショットの一覧が立ち上がるので「スナップショットの作成」を選択します
(5) スナップショットを作成します
- Select resource type は「Volume」を選択
- ボリュームは「当該インスタンスのID」を指定
- 説明は「それらしい情報」を入力, 全角非対応なので注意
- タグは検索や履歴管理で役立つので「任意に設定」しておく(6) スナップショットの作成に成功しました
(7) スナップショットの一覧に作成したスナップショットが表示されました
(8) これを選択して「アクション」から「ボリュームの作成」を選べば「EC2インスタンス」を立てていけます
IPやセキュリティグループ、VPC等、現在利用中のインスタンスの設定を加味しながら立ち上げ直しましょう。
(じゃないとあとで設定変更できないやんとインスタンスを作り成す羽目にあったりorz)これで復旧がひとまず完了。
動作検証をかけて問題なければ利用できる状態として良さそうです。2.一部のインスタンスは手動でなく定期でスナップショットを取得する
記事の冒頭にも書いた通り、私は、
内心どこかで「国内のAWSリージョンは落ちない」みたいな妄想は持っておりました。そんなわけでスナップショットを定期取得する、といった運用も行えておらず・・・。
これを機に、障害対策の一環で定期でスナップショットを作成するのも良いかと考えました。手順
(1) EC2インスタンスの左メニューより「ライフサイクルマネージャー」を選択します
(2) スナップショットのライフサイクルポリシーを作成します
- 説明は「それらしい情報」を入力, 全角非対応なので注意
- Select resource type は「Volume」を選択
- これらのタグを持つターゲットは「該当するターゲットのタグ」などを選択
- スケジュール名は「それらしい情報」を入力, 全角非対応なので注意
- ポリシーを次の時間ごとに実行するは「生成頻度の時間」を入力
- 開始時刻は「該当時刻」を入力, UTC基準なので時差に注意
- 保持ルールに「スナップショット生成数の上限数」を入力(3) 追加でスナップショットのタグや権限設定にIAMロールも指定します
(4) 最後に作成後のポリシーのステータスを選択 スクショは「有効」ですが仮作成時は「無効」にしましょう
(5) ライフサイクルポリシーの作成に成功しました
(6) 一覧上では「ENABLED(有効)」になり定期スナップショットの作成が動作するようになりました
まとめ
暫定で即座にやったのはこれくらいです。
でも、やるべきことはもっとたくさんありそうですね。スナップショットだけでは足りない。
AWS Backup の活用、複数のアベイラビリティゾーンでアプリケーションを稼働させる、
サーバレスやコンテナ化でサービスをもっとマイクロ化する、ローカルにもバックアップを落とすなど。考えたらキリがありませんが、
こうした機会をきっかけに自分たちのサービスの守り方を見つめ直す時間は必要だなと感じています。つまり、転んでも泣かない!!!ってことですね!
(いやいや、泣いてたらあかんやろ。泣かんでええようにせなあかんのやでっ・・・!)参考
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-creating-snapshot.html
https://dev.classmethod.jp/cloud/aws/amazon-dlm-ebs-snapshot-lifecycle/
- 投稿日:2019-08-30T19:51:24+09:00
AWS認定ビッグデータ専門知識(BDS)を、1ヶ月の準備期間で取得した試験準備やったことまとめ
はじめに
AWS認定ビッグデータ専門知識(BDS)について、受験者数の絶対数が少ないのか試験対策に関する参考記事の投稿が少なく情報収集に苦労しました。
今回、2019年のお盆休みを主に利用して短期で取得できた試験準備のコツなどについてまとめてみました。ビッグデータ専門知識に関わるAWS関連サービスのイメージを掴んでいただければ幸いです。
本記事の主な対象者
- AWS認定の他の試験区分は取得済みで、ビッグデータ専門知識の受験を検討している方
- 取得に向けて有効な学習方法などの情報収集したい方
筆者のAWS認定履歴
AWS認定 取得日 ソリューションアーキテクト - アソシエイト 2018-05-13 デベロッパー - アソシエイト 2018-06-03 SysOpsアドミニストレーター - アソシエイト 2018-06-10 ソリューションアーキテクト - プロフェッショナル 2018-07-29 DevOpsエンジニア - プロフェッショナル 2018-08-26 ビッグデータ専門知識 2019-08-26 昨年は、自分自身としての re:Invent2018 エントリー要件として受験し、4ヶ月ほどで5区分を一気に取得しました。
今回の受験モチベーションは、AWS Summit Tokyo 2019に参加して、今年はAWSとして機械学習分野を推している雰囲気があり、そのプリプロセスとしてのビックデータの扱いについて体系立てた学習をしてみたくなったのがきっかけです。今回のスコア(2019-08-26受験)
総合成績: 76% 分野別の成績 : 1.0 収集: 62% 2.0 格納: 77% 3.0 処理: 75% 4.0 分析: 87% 5.0 可視化: 71% 6.0 データセキュリティ: 80%やはり業務で関わっている分野のスコアは高く、そうでない分野は低い傾向でした。
AWS認定ビッグデータ専門知識(BDS)について
ここからが本題となります。
まずは、以下の公式ページから試験概要の把握を行いました。少し困ったこと
公式ページにおいて、ビッグデータ専門知識のみ他の試験区分と以下の点が異なりました。
- サンプル問題が全て英語
- AWS公式のオンライン模擬試験がない
具体的な試験準備で効果があったと思えること
実際に受験をしてみて、試験対策として効果があったと思う内容について、主観的な効果度合いで順に記載します。
AWS サービス別資料 (旧ブラックベルト)
分野毎に、理解したと思えるレベルまで繰り返し読みこみました。
- 収集:Kinesis, IoT, SQS
- 格納:S3, DynamoDB
- 処理:EMR, Glue, Lambda
- 分析:Redshift, Athena, (ML)
- 可視化:QuickSight
- データセキュリティ:IAM, Cognito , KMS, CloudHSM
re:Invent 2017: Big Data Architectural Patterns and Best Practices on AWS
上記のサービス別資料単体では深く表現していない、AWSサービス間の横串連携について詳しく説明されていました。特に意識すべきは以下の点です。
- リアルタイム、インタラクティブ、バッチの各ビックデータ処理プロセスにおいて、選択すべきAWSのサービスは何か
- アンチパターン
- Summaryのスライド上に記載されている、AWS、オープンソース、3rdパーティツールの基本的な知識(結構重要なポイント)
動画学習サイトの活用
英語力は必要となりますが、網羅的な試験対策コースがあります。動画を視聴する時間はそれなりに取られます。AWS公式のオンライン模擬試験が無い試験区分なので、何れかのサイトを利用しておくと試験前の安心感が得られると思います(サイトのみの紹介、コースはお好みで)その他試験TIPS
私見を多分に含むメモです。キーワードの参考に。
- Kinesis
- Kinesis Streams は、ストリームストレージという概念とその構成要素
- Kinesis Streams と、Kinesis Firehose のユースケースの明確な違い
- DynamoDB
- 他のサービスから、メタデータの格納先として内部的に使われているということ
- 毎度毎度のホットパーティション問題とその本質の構成要素
- EMR
- Hadoopクラスタに関する理解
- Hive、Presto、Sparkなど、re:Invent動画内で紹介されているものは要チェック
- Redshift
- パフォーマンスに影響を与える構成要素
- COPY、UNLOADコマンド
- ML
- 教師ありなし、ラベル、モデル(バイナリ、マルチクラス、回帰)に関する基本的な理解
- QuickSight
- ビジュアルタイプ(円グラフ、折れ線グラフ等)毎の可視化要件に対するユースケース
おわりに
スポーツに例えると、「正しい位置で、正しい方向に向かって、正しく素振りする」ことが、短期上達のコツかと思い、試験対策に取り組みました。
今後受験を検討される方の一助になれば幸いです。
- 投稿日:2019-08-30T16:57:24+09:00
PrivateLinkを使ってVPC間でHTTPS通信を実現する方法
はじめに
VPCが異なるアプリケーション間で通信を行う手段として、インターネット経由で行う方法と、PrivateLink、VPCピアリングなどを使った方法があります。企業によって、インターネットに接続させたくないといったセキュリティポリシーがあったりしますが、その場合は後者で挙げた方法を利用することになると思います。
そこで今回は、PivateLinkを使って、VPC間のHTTPS通信を実現してみたいと思います。
PriavteLinkを使うことで、異なるAWSアカウントでも通信が可能です。前提
ACMで証明書を取得するので、ドメインを取得しておいてください。
ちなみに無料で取得したい場合は、Freenomで取得できます。
以降、ドメインは「example.com」で説明していきます。手順
サービスを提供する側、サービスを利用する側で構築していきます。
あと通常、アプリケーションはプライベートサブネットに構築しますが、今回は動作確認のため踏み台なしでSSH接続したいので、パブリックサブネットに構築します。
あと、ElasticIPとインスタンスの関連付けの手順は割愛させていただきます。サービス提供者
1. ElasticIPの取得
- 「EC2」
- 「Elastic IP」
- 「新しいアドレスの割り当て」ボタンクリック
- 「割り当て」ボタンクリック
2. VPCの作成
- 「VPC」
- 「VPCウィザードの起動」ボタンクリック
- 「パブリックサブネットとプライベートサブネットを持つVPC」クリック ※1
- 以下の内容を入力
項目 設定値 IPv4 CIDR ブロック 10.0.0.0/16 VPC 名 vpc-user パブリックサブネットの IPv4 CIDR 10.0.0.0/24 アベイラビリティーゾーン ap-northeast-1a サブネット名 subnet-a-provider プライベートサブネットの IPv4 CIDR 10.0.1.0/24 アベイラビリティーゾーン ap-northeast-1c サブネット名 subnet-c-provider Elastic IP 割り当て ID 1.で発行したElasticIP - 「VPCの作成」クリック
※1 Application Load Balancerを利用するため2つ以上のサブネットが必要
3. セキュリティグループの作成
- 「EC2」
- 「セキュリティグループ」
- 「セキュリティグループの作成」ボタンクリック
- 以下の2つのセキュリティグループを作成
セキュリティグループ名 VPC タイプ プロトコル ポート範囲 ソース security-alb-provider vpc-provider HTTPS TCP 443 0.0.0.0/0 security-app-provider vpc-provider HTTP TCP 80 security-alb-provider SSH TCP 22 PCの接続元IP 4. アプリケーションの作成
- 「EC2」
- 「インスタンスの作成」
- 「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択
- 「t2.micro」にチェック
- 「次の手順:インスタンスの詳細の設定」ボタンクリック
- 以下の項目を入力
項目 設定値 ネットワーク vpc-provider サブネット subnet-a-provider - 「次の手順:ストレージの追加」ボタンクリック
- 「次の手順:タグの追加」ボタンクリック
- 「次の手順:セキュリティグループの設定」ボタンクリック
項目 設定値 セキュリティグループの割り当て 既存のセキュリティグループを選択する セキュリティグループ security-app-provider - 「確認と作成」ボタンクリック
- 「起動」ボタンクリック
※キーペアがない場合は作成しておいてください。
5. nginxのインストール
上記で作成したEC2にSSHで接続して、nginxをインストールします。
# Nginxインストール sudo amazon-linux-extras install nginx1.12 -y # Nginx起動 sudo systemctl start nginx.service # index.htmlページ編集 sudo vi /usr/share/nginx/index.html # "Hello PrivateLink"に書き換える6. 証明書の取得
- 「Certificate Manager」
- 「証明書のリクエスト」クリック
- 「パブリック証明書のリクエスト」を選択し、「証明書のリクエスト」クリック
- ドメイン名に以下を追加
- example.com
- *.example.com
- 「次へ」クリック
- 「DNSの検証」選択
- 「確認」クリック
- 「確定とリクエスト」クリック
※検証時にDNSにレコードを作るようにしてください。
7. Application Load Balancer(ALB)の作成
VPC間でHTTP通信で問題ないならALBは不要ですが、HTTPSが必要な場合は小細工が必要になってきます。PrivateLinkを使う場合、NLBにはSSL/TLS終端(証明書)を設定できません。つまり、NLBだけを使った場合、HTTPS通信ができません。HTTPS通信を行うために、NLBの裏でSSL/TLS終端を設定する必要があります。そこで今回はその役割を担うALBを用意します。
他にはNginxなどでも代用可能ですが、その場合ACMが利用できないので、色々手間かもしれません。
- 「EC2」
- 「ロードバランサー」
- 「Application Load Balancerの作成」クリック
- 以下の内容を入力
- 基本的な設定
※2 スキームを「インターネット向け」にしたのは、外部からの通信もALBを通じて受け付けるためです。 もし不要なら「内部」でも問題ありません。
項目 設定値 名前 alb-provider スキーム インターネット向け ※2 IPアドレスタイプ ipv4 - リスナー
プロトコル ポート HTTPS 443 - アベイラビリティーゾーン
項目 設定値 VPC vpc-provider アベイラビリティーゾーン subnet-a-provider
subnet-c-provider- 「次の手順:セキュリティ設定の構成」クリック
- 以下の内容を入力
- デフォルトの証明書の選択
項目 設定値 証明書タイプ ACMから証明書を選択する 証明書の名前 上記で登録した証明書 - セキュリティポリシーの選択
項目 設定値 セキュリティポリシー ELBSecurityPolicy-2016-08 - 「次の手順:セキュリティグループの設定」クリック
- 以下の内容を入力
項目 設定値 セキュリティグループの割り当て 既存のセキュリティグループを選択する セキュリティグループ security-alb-provider - 「次の手順:ルーティングの設定」クリック
- 以下の内容を入力
- ターゲットグループ
項目 設定値 ターゲットグループ 新しいターゲットグループ 名前 tg-app-provider ターゲットの種類 インスタンス プロトコル HTTP ポート 80 - ヘルスチェック
項目 設定値 プロトコル HTTP パス / - 「次の手順:ターゲットの登録」クリック
- インスタンスの一覧から4.で作成したインスタンスを選択し、「登録済みに追加」クリック
- 「次の手順:確認」クリック
- 「作成」クリック
8. Network Load Balancerの作成
PrivateLinkを利用する際に必要になります。
- 「EC2」
- 「ロードバランサー」
- 「ロードバランサーの作成」クリック
- 「Network Load Balancerの作成」クリック
- 以下の内容を入力
- 基本的な設定
項目 設定値 名前 alb-provider スキーム 内部 - リスナー
プロトコル ポート HTTPS 443 - アベイラビリティーゾーン
項目 設定値 VPC vpc-provider アベイラビリティーゾーン subnet-a-provider - 「次の手順:ルーティングの設定」クリック
- 以下の内容を入力
- ターゲットグループ
項目 設定値 ターゲットグループ 新しいターゲットグループ 名前 tg-alb-provider ターゲットの種類 ip プロトコル TCP ポート 443 - ヘルスチェック
項目 設定値 プロトコル TCP - 「次の手順:ターゲットの登録」クリック
- 以下の内容をIPを入力
項目 設定値 ネットワーク 10.0.0.0/16 IP ALCのプライベートIP ※3 ポート 443 - 「リストに追加」クリック
- 「次の手順:確認」クリック
- 「作成」クリック
※3 ALBのプライベートIPの調べ方
EC2-ネットワークインターフェイスを開きます。
ゾーンが「ap-northeast-1a」で、セキュリティグループが「security-alb-provider」を選択し、
「詳細」を表示し、プライマリプライベートIPv4の値を確認する。9. エンドポイントサービスの作成
- 「VPC」
- 「エンドポイントのサービス」
- 「エンドポイントサービスの作成」クリック
- 以下の内容を入力
項目 設定値 Network Load Balancer の関連付け 「nlb-provider」を選択 エンドポイントの承諾が必要 チェック - 「サービスの作成」クリック
作成後、サービス名をメモしておく。
10. DNSの設定
インターネット経由でHTTPSで接続するために登録します。
ホストゾーンの作成
- 「Route53」
- 「ホストゾーンの作成」クリック
- 以下の内容を入力
項目 設定値 ドメイン名 example.com タイプ パブリックホストゾーン - 「作成」クリック
レコードセットの作成
- 上記で作成したホストゾーン名クリック
- 「レコードセットの作成」クリック
- 以下の内容を入力
項目 設定値 名前 external.example.com タイプ A エイリアス はい エイリアス先 ALB - 「レコードセットの保存」クリック
サービス利用者
11. VPCの作成
- 「VPC」
- 「VPCウィザードの起動」ボタンクリック
- 「パブリックサブネットサブネットを持つVPC」クリック
- 以下の内容を入力
項目 設定値 IPv4 CIDR ブロック 192.168.0.0/16 VPC 名 vpc-user パブリックサブネットの IPv4 CIDR 192.168.0.0/24 アベイラビリティーゾーン ap-northeast-1a サブネット名 subnet-a-user - 「VPCの作成」クリック
12. セキュリティグループの作成
- 「EC2」
- 「セキュリティグループ」
- 「セキュリティグループの作成」ボタンクリック
- 以下の2つのセキュリティグループを作成
セキュリティグループ名 VPC タイプ プロトコル ポート範囲 ソース security-endpoint-user vpc-user HTTPS TCP 443 0.0.0.0/0 security-app-user vpc-user SSH TCP 22 PCの接続元IP 13. アプリケーションの作成
- 「EC2」
- 「インスタンスの作成」
- 「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択
- 「t2.micro」にチェック
- 「次の手順:インスタンスの詳細の設定」ボタンクリック
- 以下の項目を入力
項目 設定値 ネットワーク vpc-user サブネット subnet-a-user - 「次の手順:ストレージの追加」ボタンクリック
- 「次の手順:タグの追加」ボタンクリック
- 「次の手順:セキュリティグループの設定」ボタンクリック
項目 設定値 セキュリティグループの割り当て 既存のセキュリティグループを選択する セキュリティグループ security-app-user - 「確認と作成」ボタンクリック
- 「起動」ボタンクリック
※キーペアがない場合は作成しておいてください。
14. エンドポイントの作成
- 「VPC」
- 「エンドポイント」
- 「エンドポイントの作成」
- サービスカテゴリで「サービスを名前で検索」を選択し、9.でメモしたサービス名を入力
- 「検証」クリック
- 以下の内容を入力
項目 設定値 VPC vpc-user サブネット subnet-a-user セキュリティグループ security-endpoint-user - 「エンドポイントの作成」クリック
作成後、ステータスが「承諾の保留中」になっていることを確認します。
サービス提供者
15. エンドポイント作成の承認
- 「VPC」
- 「エンドポイントのサービス」
- エンドポイントのサービスをチェックし、「エンドポイント接続」タブを選択
- 「承諾の保留中」になっているエンドポイントを選択
- 「アクション」の「エンドポイント接続リクエストの承諾」クリック
サービス利用者
16. DNSの設定
HTTPSで接続するためには、証明書を取得しているドメインを利用する必要があります。
ホストゾーンの作成
- 「Route53」
- 「ホストゾーンの作成」クリック
- 以下の内容を入力
項目 設定値 ドメイン名 example.com タイプ Amazon VPCのプライベートホストゾーン VPC ID vpc-user - 「作成」クリック
レコードセットの作成
- 上記で作成したホストゾーン名クリック
- 「レコードセットの作成」クリック
- 以下の内容を入力
項目 設定値 名前 internal.example.com タイプ A エイリアス はい エイリアス先 VPCエンドポイントのどちらか - 「レコードセットの保存」クリック
動作確認
PrivateLink経由
サービス利用者側のインスタンスにSSH接続し、以下のコマンドを実行します。
curl https://internal.example.com「Hello PrivateLink」が表示されることを確認します。
インターネット経由
ブラウザから「https ://external.example.com」を開きます。
「Hello PrivateLink」が表示されることを確認します。おわりに
今回はPrivateLinkを利用して、VPC間をネットワーク経由せずにHTTPSで通信する方法をご紹介しました。
正直、インターネットを経由しないので、HTTPS通信は不要ではないかと思いますが、セキュリティをより高めるためには必要なのかもしれません。ただ、HTTPSにするためにSSL/TLS終端を設定するものが必要になります。
今回はALBを使いましたが、実はALBのプライベートIPは固定ではないので、NLBのターゲットグループに設定したIPも定期的に監視、更新を行う必要があります。その方法は、参考サイトに載っているので、実際に運用する場合は参考にしてみてください。
参考サイト
- 投稿日:2019-08-30T16:54:22+09:00
AWS lambdaのDynamoDB更新処理で Invalid UpdateExpression: Attribute name is a reserved keywordになった時の対処方法
lambdaからDynamoDBの値を更新しようとした時に
タイトルのエラーで怒られた時の対処方法です。試しにこんな更新処理を書いてみます。
sample.pytable.update_item( Key= {'device_id': device_id}, UpdateExpression='set store = :s, updated_at = :u', ExpressionAttributeValues={ ':s' : store_name, ':u' : updated_at } )これを実行すると…
"An error occurred (ValidationException) when calling the UpdateItem operation: Invalid UpdateExpression: Attribute name is a reserved keyword; reserved keyword: store"どうやらstoreは予約語のようです。
こちらを参照
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/ReservedWords.html対処方法として
ExpressionAttributeNamesを使用して、
属性名をプレースホルダー名で置き換えることで解決出来ました。こんな感じです。
sample.pytable.update_item( Key= {'device_id': device_id}, UpdateExpression='set #st = :s, updated_at = :u', ExpressionAttributeNames= { '#st' : 'store' }, ExpressionAttributeValues={ ':s' : store_name, ':u' : updated_at } )無事更新を行うことが出来ました。
参考
ここにハマった!DynamoDB
https://blog.brains-tech.co.jp/entry/2015/09/30/222148DynamoDB の予約語
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/ReservedWords.html
- 投稿日:2019-08-30T13:53:59+09:00
AWS SystemManagerを使用してCloudWatchを利用する方法(Linux)
こんにちは、kc-dreamです。
今回は、AWSのCloudWatch CustomMetric及びCloudWatch Logsの設定方法についてご紹介していきます。本記事について
AWS SystemManagerを使用し、CloudWatch Agentをインストールし、各種情報を取得するまでの方法をご紹介します。
※CentOS 7を使用した場合となります。1,前提条件
CloudWatch エージェントを使用して Amazon EC2 インスタンスとオンプレミスサーバーからメトリクスとログを収集する
確認方法$ cat etc/os-release OSを確認する $ systemctl list-units --type=service amazon-ssm-agent.serviceが[active]であればOK
- SystemManager(SSM)がインストールされていなければインストールする
Amazon EC2 Linux インスタンスに SSM エージェント を手動でインストールする
2,IAMロールの作成
- IAMロールを作成し、対象のEC2にアタッチ
- 下記2つのPolicyをロールに付与する
 AmazonEC2RoleforSSM
AmazonEC2RoleforSSM{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:DescribeAssociation", "ssm:GetDeployablePatchSnapshotForInstance", "ssm:GetDocument", "ssm:DescribeDocument", "ssm:GetManifest", "ssm:GetParameters", "ssm:ListAssociations", "ssm:ListInstanceAssociations", "ssm:PutInventory", "ssm:PutComplianceItems", "ssm:PutConfigurePackageResult", "ssm:UpdateAssociationStatus", "ssm:UpdateInstanceAssociationStatus", "ssm:UpdateInstanceInformation" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ssmmessages:CreateControlChannel", "ssmmessages:CreateDataChannel", "ssmmessages:OpenControlChannel", "ssmmessages:OpenDataChannel" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2messages:AcknowledgeMessage", "ec2messages:DeleteMessage", "ec2messages:FailMessage", "ec2messages:GetEndpoint", "ec2messages:GetMessages", "ec2messages:SendReply" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:DescribeInstanceStatus" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ds:CreateComputer", "ds:DescribeDirectories" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:PutLogEvents" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:PutObject", "s3:GetObject", "s3:GetEncryptionConfiguration", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts", "s3:ListBucket", "s3:ListBucketMultipartUploads" ], "Resource": "*" } ] }
- AmazonEC2RoleforSSMはSSM Agentを実行するために必要になります。
CloudWatchAgentAdminPolicy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "cloudwatch:PutMetricData", "ec2:DescribeTags", "logs:PutLogEvents", "logs:DescribeLogStreams", "logs:DescribeLogGroups", "logs:CreateLogStream", "logs:CreateLogGroup" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ssm:GetParameter", "ssm:PutParameter" ], "Resource": "arn:aws:ssm:*:*:parameter/AmazonCloudWatch-*" } ] }3,SSMのRunCommandを使用してCloudWatch Agentをインストール
- SSM コンソールよりSystem Managerメニューに移動し、左側メニューからランコマンドを選択
- 右側のオレンジボタン「コマンドを実行」
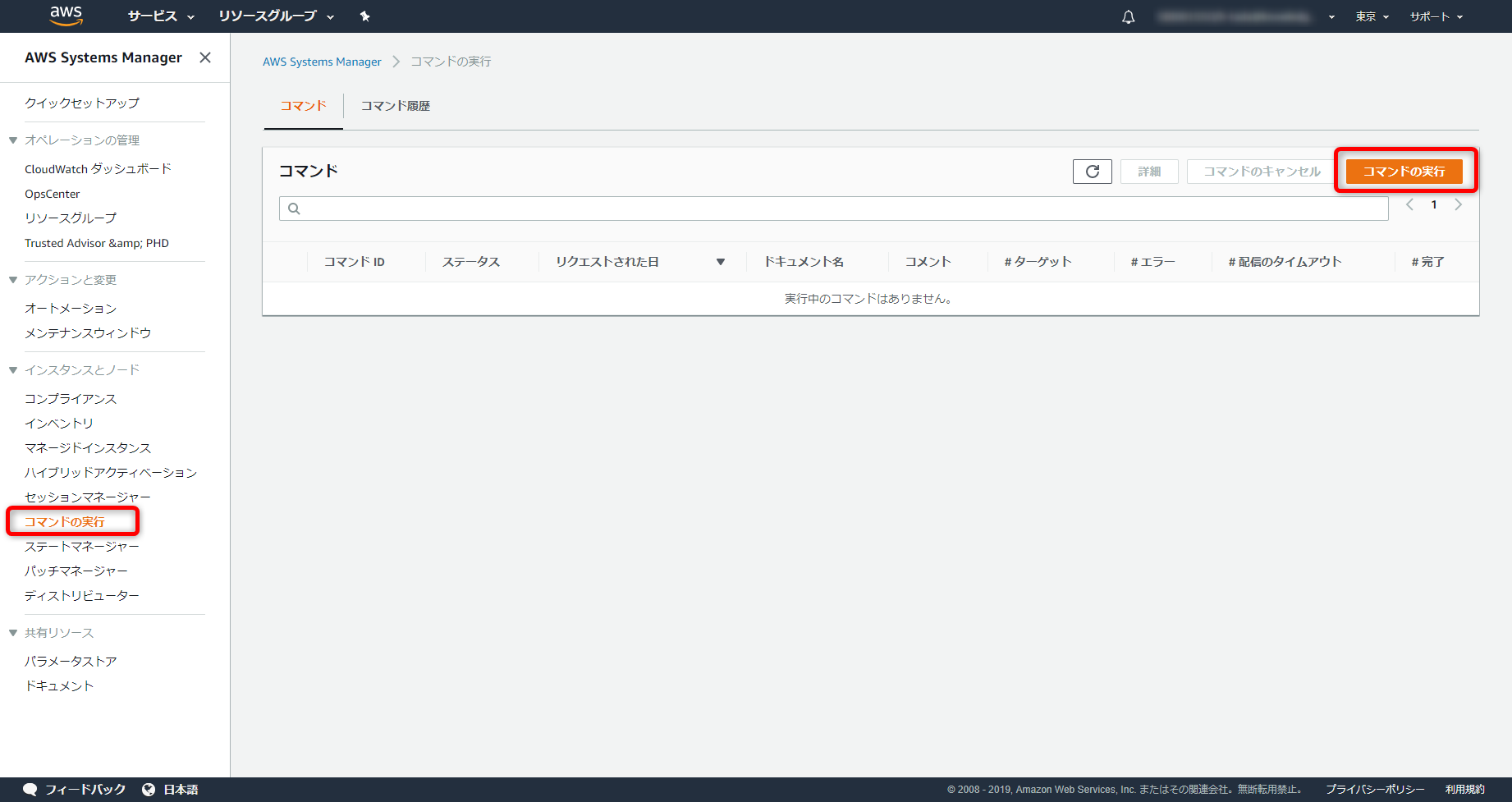
- ターゲットから対象のインスタンスを選択する (IAMロールが正しく割り当てられているインスタンスが表示されます)
- 実行
各種設定情報コマンドのドキュメント AWS-ConfigureAWSPackage コマンドパラメータ Action:Install Name:AmazonCloudWatchAgent Version:latest4,対象のインスタンスにログイン
- 下記コマンドを実行し、設定情報を選択していきます
コマンド$ sudo su # /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard ============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = =============================================================5,CloudWatch Agent設定項目
Agentを使用するOSOn which OS are you planning to use the agent? 1. linux 2. windows default choice: [1]:Agentを使用するサーバはEC2orオンプレTrying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]:Agentを実行するユーザWhich user are you planning to run the agent? 1. root 2. cwagent 3. others default choice: [1]:StatsDデーモンを有効or無効Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]:StatsDデーモンで使用するポートWhich port do you want StatsD daemon to listen to? default choice: [8125]StatsDデーモンのデータ収集間隔What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]:StatsDデーモンのデータ集約間隔What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]:collectDの収集Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]:2メトリクスの収集Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]:CPUコア単位での使用率取得(追加費用発生の可能性有)Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]:ImageId/InstanceId/InstanceType/AutoScalingGroupNameを取得可能であれば取得Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? 1. yes 2. no default choice: [1]:メトリクスの取得間隔Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]:取得するメトリクスの種類Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]:3上記で選択した取得するメトリクスの内容Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } }取得するメトリクスは上記でいいかAre you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]:CloudWatchLogs使用しているかDo you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]:取得したいログファイルはあるかDo you want to monitor any log files? 1. yes 2. no default choice: [1]:取得したいログファイルをフルパスで指定Log file path:/var/log/httpd/access_logロググループ名を指定Log group name: default choice: [access_log]ログストリーム名を指定Log stream name: default choice: [{instance_id}]追加取得したいログファイルはあるかDo you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]:2取得するメトリクスとログファイルの内容(内容を修正する場合はSSMコンソールのパラメータストアを編集)Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/opt/tomcat/logs/access.log", "log_group_name": "access.log", "log_stream_name": "@@@@@" }, { "file_path": "/var/log/httpd/error_log", "log_group_name": "errorlog", "log_stream_name": "@@@@@" }, { "file_path": "/var/log/httpd/access_log", "log_group_name": "access_log", "log_stream_name": "@@@@@" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "cpu": { "measurement": [ "cpu_usage_idle", "cpu_usage_iowait", "cpu_usage_user", "cpu_usage_system" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": false }, "disk": { "measurement": [ "used_percent", "inodes_free" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "io_time", "write_bytes", "read_bytes", "writes", { "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "netstat": { "measurement": [ "tcp_established", "tcp_time_wait" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed.SSMのパラメータストアに設定ファイルを保持しますかDo you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]:パラメータストアの設定ファイル名を指定(先頭に"AmazonCloudWatch-"を必ず使用/ユニークで指定するのがいい)What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] AmazonCloudWatch-@@@@設定ファイルを保持するリージョンを指定Trying to fetch the default region based on ec2 metadata... Which region do you want to store the config in the parameter store? default choice: [ap-northeast-1]SSMパラメータストアにデータを送信するのにアクセスキーを使用するかWhich AWS credential should be used to send json config to parameter store? 1. ASIABBBCCC111222DD33(From SDK) 2. Other default choice: [1]:保存に成功するとSSMコンソールのパラメータストアに保存されているので確認Successfully put config to parameter store AmazonCloudWatch-fi-gridadm. Program exits now.6,CloudWatch Agentの有効化
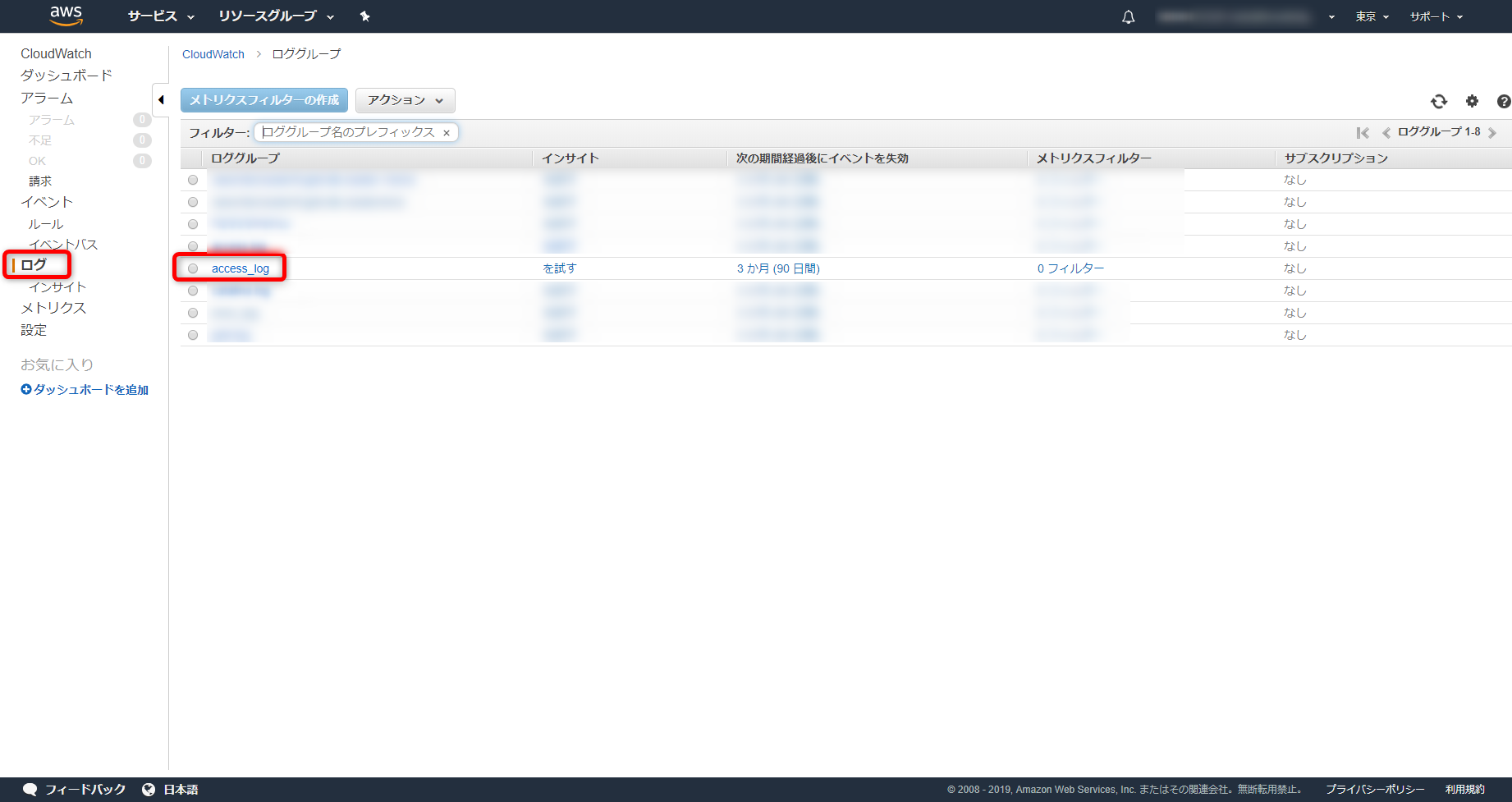
パラメータストアの設定ファイル読み込み# /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c ssm:AmazonCloudWatch-@@@@ -sCloudWatchAgentのステータス確認# systemctl status amazon-cloudwatch-agent.serviceCloudWatchAgentの自動起動有効化# systemctl is-enabled amazon-cloudwatch-agent.service7,AWSコンソールのCloudWatchからCustomMetric及びLogが取得できているかを確認
参考URL
collectDが導入されてるか:collectD設定方法
取得するメトリクスの種類:ウィザードを使用してCloudWatchエージェント設定ファイルを作成する

- 投稿日:2019-08-30T13:29:30+09:00
S3バケットをバブリングにするが、下位フォルダの一部は制限をかけたい
問題
アクセス制限違いでバケットを分けたくない
こうした
アクセス権限→バケットポリシー
- hoge/download
- hoge/content
- hoge/private <- ここはパブリックにしたくない
{ "Version": "2008-10-17", "Statement": [ { "Sid": "PublicReadForGetBucketObjects", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "s3:GetObject", "Resource": [ "arn:aws:s3:::hoge/download/*", "arn:aws:s3:::hoge/content/*" ] } ] }
- hoge/private は"Resource"に記載しないこと
メモ
パブリックにしたバケットがあると、awsから親切にお知らせが来る
We’re writing to notify you that your AWS account xxxxxx has one or more S3 buckets that allow read or write access from any user on the Internet. By default, S3 buckets allow only the account owner to access the contents of a bucket; however, customers can configure S3 buckets to permit public access.
- 投稿日:2019-08-30T12:55:32+09:00
AWS ソリューションアーキテクトプロフェッショナル受けた記録
なんの記事
アソシエイトを7月下旬に取得しましたが、
1ヶ月でプロフェッショナルは難しかった。
敗因も含め受けた感想や、それまでにやった学習を記載します。やった事
まず、どんな学習方法があるのか洗い出し。
情報が少ない感じがしたけれど、取ってる方はいっぱいいるので、検索しまくった。
これはそのまま晒します。以下の通り①ホワイトペーパー(公式)
ホワイトペーパー | AWS②AWSクラウドサービス事例集(公式)
https://aws.amazon.com/jp/aws-jp-introduction/③awskoiwaclub
AWS WEB問題集で学習しよう | 赤本ではなく黒本の問題集から学習する方向け
2周 SAP 34 x 7問 = 238問
1周 SAA 123x 7問 = 861問(既出)
くらい
④whizlabs
Online Certification Training Courses for Professionals⑤Blog
https://blog.mosuke.tech/entry/2018/10/25/sapro-sample-question/⑥qwiklabs(公式)
セルフペースラボ – AWS オンライントレーニング | AWS⑦Amazon Web Services パターン別構築・運用ガイド
Amazon Web Services パターン別構築・運用ガイド 改訂第2版 (Informatics&IDEA) | NRIネットコム株式会社, 佐々木 拓郎, 林 晋一郎, 小西 秀和, 佐藤 瞬 |本 | 通販 | Amazon⑧Udemy
オンラインコース - いろんなことを、あなたのペースで | Udemy⑨AWSSAPサンプル問題、AWSSAP試験ガイド(公式)
AWS 認定ソリューションアーキテクト – プロフェッショナル⑩模擬試験(公式)
アソシエイトの時の不明点解消
EMRなど知識不足だった点を解消。
こちらはサービスのページの確認、ユースケース、メリットをまとめるのみ。学習の選択
もちろん上記全てをやったわけではないです。
今だから言えるがやってたら受かってるはずw上記①〜⑩でもっとも取り組みやすかったのは、
③の日本語の問題集koiwaclub。
SAAでも取り組んでいたので引き続き活用。ここでまず感じた事、問題文の長さ。。
実際の問題も、やたら文章が長いんです。
正直、7問〜14問やったらもう休憩しないと無理って事もありました。そして、実際に有効そうだったのが
④whizlabs や、 ⑤Blog でした。
やはり実践的でそこから調べて学ぶ事も多かった。
英語なので人によって時間はかかります。最後に、実務で役立つしイメージしやすいと感じたのは
⑥qwiklabs(公式) でした。
AWS環境が払い出されて、マニュアルの通りに行うハンズオントレーニングです。
月額6000円以内でやり放題なのでこれからも全部やるまで使おうと思っています。
大変ありがたい。。
英語のものもありますが、そこまで支障はないと感じます。
実は、プロフェッショナルの話ではないですが
以前受けたAWSのDeepLearningトレーニング等もこれを使いました。(内容はここにあるコースではなかったが)実際やった事まとめ
よって、今回は
アソシエイトの不明点解消
③の日本語の問題集koiwaclub
④whizlabs
⑤Blog
⑥qwiklabs(公式)に取り組みました。
ほか、英語サイトを調べながら見つけた記事などで学習しましたがキリがないので。。結果
不合格、パーセンテージにすると55%くらい。
敗因は
①文章問題に体力が持たなかった②コスト周りの問題が不得手すぎる。
コスト効率問題はSAAの時も苦手っぽかったのですが、やはりまだ克服できてませんでした。
理由はサービスを組み合わせたアーキテクトの際、どのパターンが最低限のコストで抑えられるかを答えるような問題で、適切に答えるにはそれぞれのサービスで何が一番最適なオプションなのか、わからなかったこと。③databaseなどの問題、知識が足りない。
こちらは勉強不足。受けた感想
一つ言えるのは、対策できる試験なんだな、という事です。
間違いなく、対策したら勝てるはずの試験。
精進します。
ただ、絶対に今回受けた場所ではもう受けたくない。。辛かった。笑対策ですが
やはり外国圏の方が試験対策のための情報が多いです。
調べたら実感すると思います。まとめ;これからの予定
プロフェッショナルの勉強は続けて行いますが、
来月は先にDevOps系のアソシエイトをとります。
その後、再チャレンジするのでそれらもQiitaに都度まとめます。まだ合格記録ではないですが、
情報など参考になれば幸いです。ありがとうございました!
ちなみに…
ホワイトペーパー たくさんありますが、
この辺りを読もうかと思っています。
ホワイトペーパー を英語で読むのはまだちょっと時間がかかる(笑)⑴AWS による優れたアーキテクチャ の設計の枠組み
https://d1.awsstatic.com/whitepapers/ja_JP/architecture/AWS_Well-Architected_Framework.pdf
⑵AWS Well-Architectedフレームワーク
https://d1.awsstatic.com/International/ja_JP/Whitepapers/AWS_Well-Architected_Framework_2018_JA_final.pdf
⑶AWS Cloud Adoption Framework の概要
https://d1.awsstatic.com/International/ja_JP/Whitepapers/aws_cloud_adoption_framework.pdf
⑷AWS における マイクロサービス
https://d1.awsstatic.com/International/ja_JP/Whitepapers/MicroservicesOnAWS-V2_NT0829_SMO_MJ_EditSM_ProofSM_ProofNT.pdf
⑸AWS Lambda を使用した サーバーレスアーキテクチャ
https://d1.awsstatic.com/International/ja_JP/Whitepapers/serverless-architectures-with-aws-lambda_JA.pdf
⑹サーバーレスストリーミングアーキテクチャとベストプラクティス
https://d1.awsstatic.com/International/ja_JP/Whitepapers/Serverless_Streaming_Architecture_Best_Practices_JA.pdf
⑺AWS サーバーレス 多層アーキテクチャ
https://d1.awsstatic.com/International/ja_JP/Whitepapers/AWS-Serverless-Multi-Tier-Architectures_JA.pdf
⑻AWS を使用した バックアップと復元の手法 https://d1.awsstatic.com/whitepapers/jp/Backup%20and%20recovery%20approaches%20using%20AWS.pdf
- 投稿日:2019-08-30T12:34:54+09:00
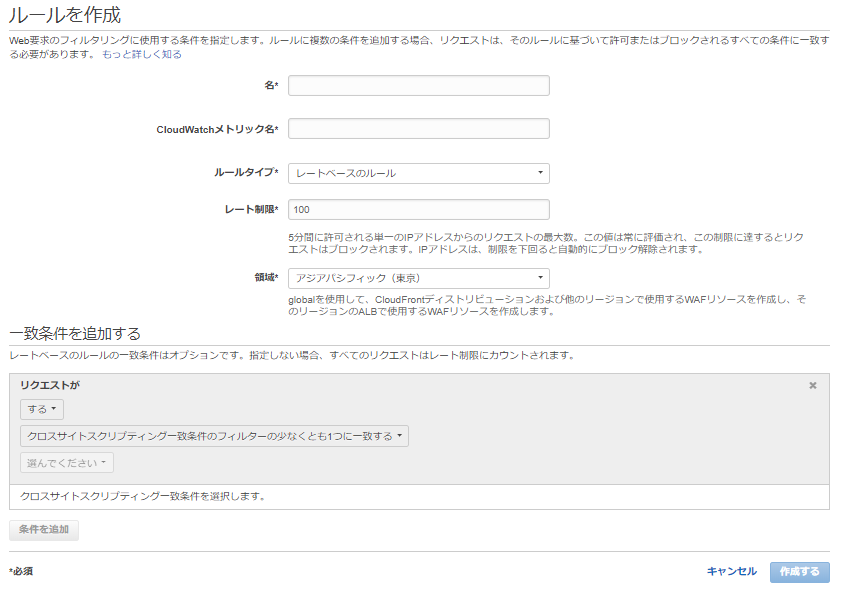
AWS WAF の Rate-based ルールが100リクエストからになったのでいろいろやってみた。
5 分間で単一の IP アドレスから行われるリクエストの最大数、レート制限 2000 → 100 になったようなのでちょっとだけ確認してみた。
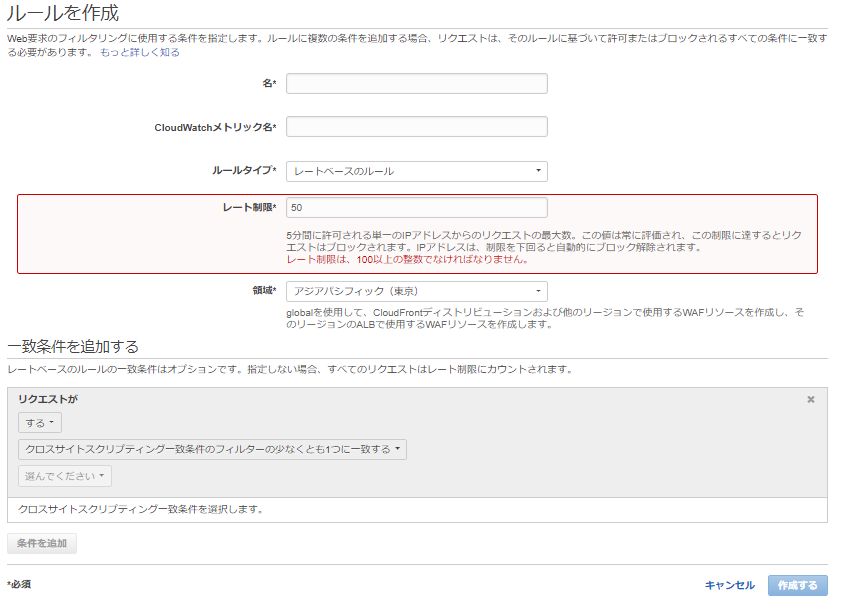
Update:AWS WAFレートベースのルールの下限しきい値100にしてみる。
ちなみに100以下にすると↓のとおり。
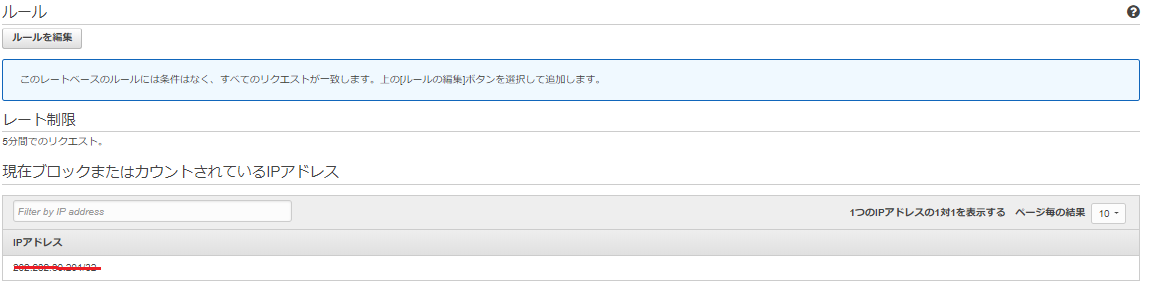
とりあえず、連続で100回アクセスすると表示されなくなる。(アクセス先はALBにしました。)
ルールを確認してみるとアクセスしたIPからの接続がブロックされていることがわかる。
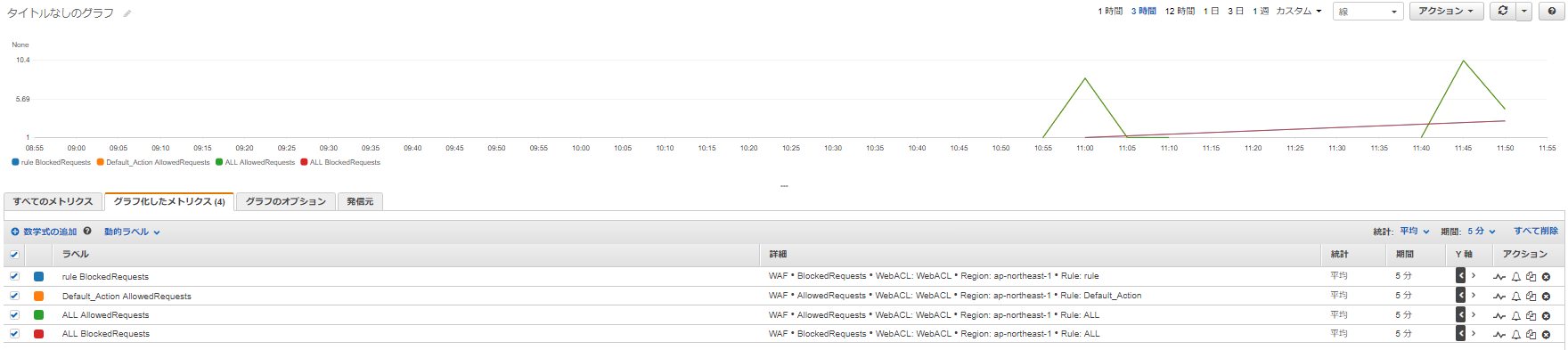
cloudwatchも確認してみると、ALL BlockedRequestsされていることもわかる。
ついでに「ロギング」も有効化して確認してみた。「ロギング」の基本的な設定方法は↓のページどおりなので省略します。
AWS WAFのログをFirehoseでS3に出力しブロックログをS3Selectで確認してみたKinesisのグラフをまず確認してみる。
今回はKinesis→S3に保存するようにした。ALLOW と BLOCK になっていることがわかる。
{"timestamp":1567134912907,"formatVersion":1,"webaclId":"ff22a72d-d373-431b-82b0-8841f8adbd58","terminatingRuleId":"Default_Action","terminatingRuleType":"REGULAR","action":"ALLOW","httpSourceName":"ALB","httpSourceId":"44-app/alb/5a0b887f7f6f65b1","ruleGroupList":[],"rateBasedRuleList":[{"rateBasedRuleId":"88ecdb26-dd5e-47aa-a76f-0a6986c92e72","limitKey":"IP","maxRateAllowed":100}],"nonTerminatingMatchingRules":[],"httpRequest":{"clientIp":"202.232.30.201","country":"JP","headers":[{"name":"Host","value":"alb-1396868620.ap-northeast-1.elb.amazonaws.com"},{"name":"Upgrade-Insecure-Requests","value":"1"},{"name":"User-Agent","value":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"},{"name":"Accept","value":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3"},{"name":"Accept-Encoding","value":"gzip, deflate"},{"name":"Accept-Language","value":"ja,en-US;q=0.9,en;q=0.8"}],"uri":"/","args":"","httpVersion":"HTTP/1.1","httpMethod":"GET","requestId":null}} {"timestamp":1567134936574,"formatVersion":1,"webaclId":"ff22a72d-d373-431b-82b0-8841f8adbd58","terminatingRuleId":"88ecdb26-dd5e-47aa-a76f-0a6986c92e72","terminatingRuleType":"RATE_BASED","action":"BLOCK","httpSourceName":"ALB","httpSourceId":"44-app/alb/5a0b887f7f6f65b1","ruleGroupList":[],"rateBasedRuleList":[{"rateBasedRuleId":"88ecdb26-dd5e-47aa-a76f-0a6986c92e72","limitKey":"IP","maxRateAllowed":100}],"nonTerminatingMatchingRules":[],"httpRequest":{"clientIp":"202.232.30.201","country":"JP","headers":[{"name":"Host","value":"alb-1396868620.ap-northeast-1.elb.amazonaws.com"},{"name":"Upgrade-Insecure-Requests","value":"1"},{"name":"User-Agent","value":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"},{"name":"Accept","value":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3"},{"name":"Accept-Encoding","value":"gzip, deflate"},{"name":"Accept-Language","value":"ja,en-US;q=0.9,en;q=0.8"}],"uri":"/","args":"","httpVersion":"HTTP/1.1","httpMethod":"GET","requestId":null}}

- 投稿日:2019-08-30T12:05:39+09:00
CloudWatch LogsでAWSコンソールでfilterできない量のログをCLIでなんとかする
こんな課題を解決したい
- CloudWatch Logsでログを調査したい
- 特にログ周りの整備や連携は進んでいないので、現状CloudWatch Logsだけでなんとかしている
- 探したいおおまかな時間とキーワードはわかっている
- AWS Console上でイベントのフィルターで時間とキーワードを指定して検索しようとする
- ログが多すぎて、いつまで経っても結果が帰ってこない
- 基本Lambdaのログを想定(他でも使えると思います)
これを、CLIとコマンドを組み合わせて、なんとか周辺のログを取得するお話です
モデルケース
- 今回は、例えば以下のようなLambdaのログを仮定してみます
- Lambda関数名:
TestLambda- 取得したい時間:
2019/08/20 10:00 - 10:10- 検索したいキーワード:
Errorその他条件
- 1日分の該当LogGroupのログがDLできる規模であること
AWS CLI,jqが使えること結論
先に利用したコマンドだけ記載するとこんな感じです。
aws logs describe-log-streams --log-group-name '/aws/lambda/TestLambda' --log-stream-name-prefix '2019/08/20/[1234]' | jq '.logStreams | sort_by(.lastEventTimestamp)' | jq '.[] | select(.lastEventTimestamp > 1566262800)' | grep -e logStreamName | cut -d '"' -f 4 > log-stream-list.txt while read line; do aws logs get-log-events --log-group-name '/aws/lambda/TestLambda' --log-stream-name $line >> all.log; done < log-stream-list.txt cat all.log | jq '.events[]| select(.timestamp>1566262800) | select(.timestamp<1566263400)' > log_between_timestamp.log上記コマンドの解説のようなもの
どういう経緯で上記コマンドになったのか、一応記載しておきます
CLIでDLしてみよう
- AWSコンソールでうまくいかないなら、CLIを使おう
- AWSコンソールでやろうとしたことをコマンドにするとこんな感じ?
aws logs filter-log-events --log-group-name '/aws/lambda/TestLambda' --start-time 1566262800 --end-time 1566263400 --filter-pattern 'Error'- 当たり前だがコンソールと同様のことをさせているので返ってこない・・・
- LogStreamがわかれば、Stream名を指定すればすぐに落とせるんだけど・・・
- e.g.)
aws logs get-log-events --log-group-name '/aws/lambda/TestLambda' --log-stream-name '2019/08/20/[1234]dae4553dv12349gosjgoe2342qwahwks'- [version]まではわかっても、そのあとはわからないと思います
該当しそうなLogStream全部とる
今回の主題です。
大抵Streamがどれかはわからないので、当てはまりそうなStreamは全部取ってこようと思います。Stream名の一覧を取得する
当てはまりそうなStream名がわからないと、結局
get-log-eventsで取得できません。
Stream名の一覧を取得してみます。
この時、lastEventTimestampつまり、Streamの最後のログだけはわかるので、開始時刻である1566262800より前に終わっているStreamは取得する必要がありません。
jqのsort_byとselectを使って絞ります。
aws logs describe-log-streams --log-group-name '/aws/lambda/TestLambda' --log-stream-name-prefix '2019/08/20/[1234]' | jq '.logStreams | sort_by(.lastEventTimestamp)' | jq '.[] | select(.lastEventTimestamp > 1566262800)' | grep -e logStreamName | cut -d '"' -f 4 > log-stream-list.txtリストを元に実際にログを取得する
以下のような感じで、対象のStreamからログ取得するコマンドをぐるぐる回して1つのログファイルを作ります。
1つにするのが大きそうなら、shellなどにして適宜ファイル分けるなり、整形したりしてください。
while read line; do aws logs get-log-events --log-group-name '/aws/lambda/TestLambda' --log-stream-name $line >> all.log; done < log-stream-list.txtログ内のメッセージを欲しい timestamp で絞る
基本的に、1つのLogStreamには、
lastEventTimestampまでのログが入っており、開始時刻はわかりません。
目的の時刻よりはかなり多いはずなので、絞り込みます。
cat all.log | jq '.events[]| select(.timestamp>1566262800) | select(.timestamp<1566263400)' > log_between_timestamp.log解析を行う
以上で目的の時刻間のログのみが取れたはずです。
あとは普通にgrep 'Error'などで探して、Hitした部分と同じRequestIDで処理を抽出して、同様にjqなどを駆使して解析できるはずです。
- 投稿日:2019-08-30T11:55:39+09:00
【AWS】 EC2インスタンスのstop状態中でのEBSの扱いに注意 [クラウド破産注意][やらかし画像あり]
【AWS】 EC2インスタンスのstop状態中のEBSの扱いに注意 [クラウド破産注意] 【画像あり】
内容は表題の通りなんですが、はじめに、下記はテスト環境です。
料金体系
EC2は従量課金なので、この状態であればt3.smallのインスタンスのみの料金だけ課金される思いますよね!?
実際、AWSの公式でもこのような記載があります。
EC2 は EBS とセット と考えて!!
でも... 違うんですよ。EC2はEBSとセットなんです(当たり前と言ったらそうですが、、、)!
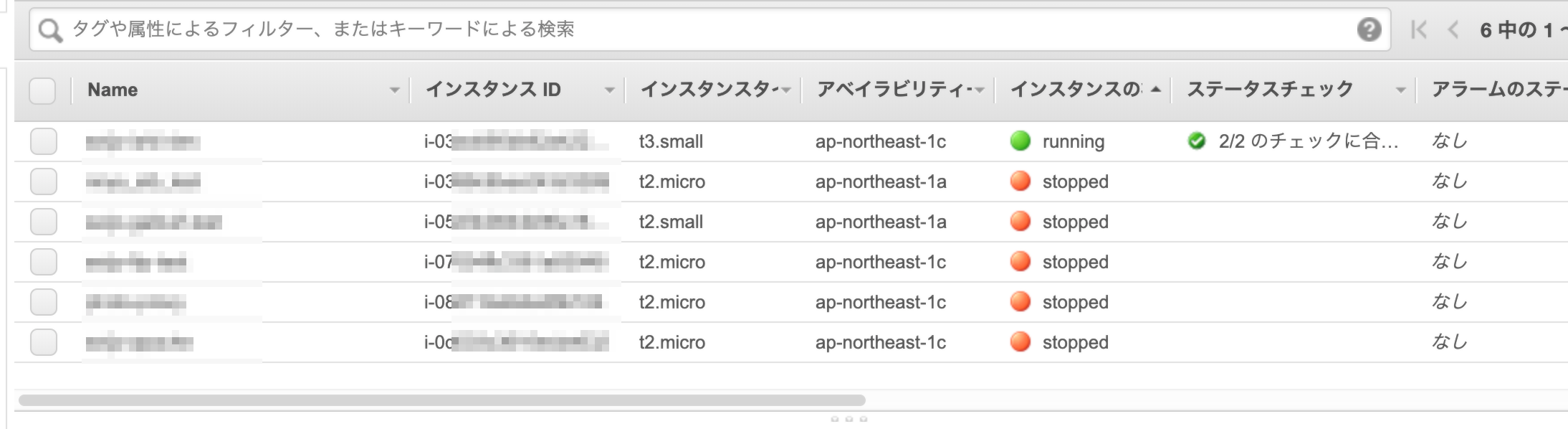
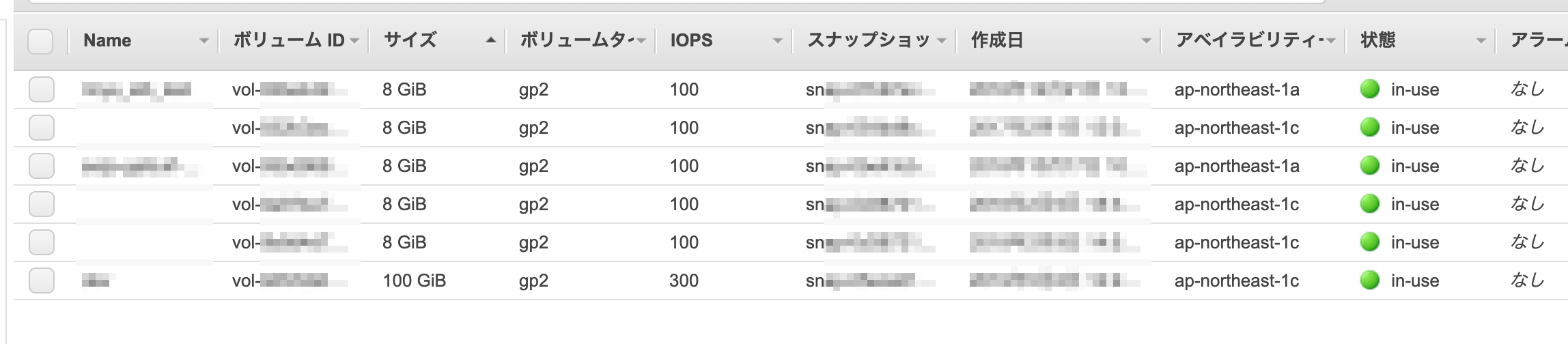
1番上のEC2の状態でのこの状態のときのEBSの画面はこちら
EC2インスタンスがstop状態でもEBSはアタッチしている状態になっています。
要は使っている状態と同じです。EBSはそこまで高額ではないので多少はいいかと思うところもありますが、
油断していると同じ失敗をしますよ。失敗あるある事例がこちら
実際にやらかして、経理の人に怒られかけた事案です... w
(実際は心の中では怒っていたと思いますが) とても理解のある会社なので素直に謝ったら怒られませんでしたw
ごめんなさい m(_ _)m
これは実際のその時の画像です。
本番環境を構築テストしている時に同様の設定で試していたんですが、
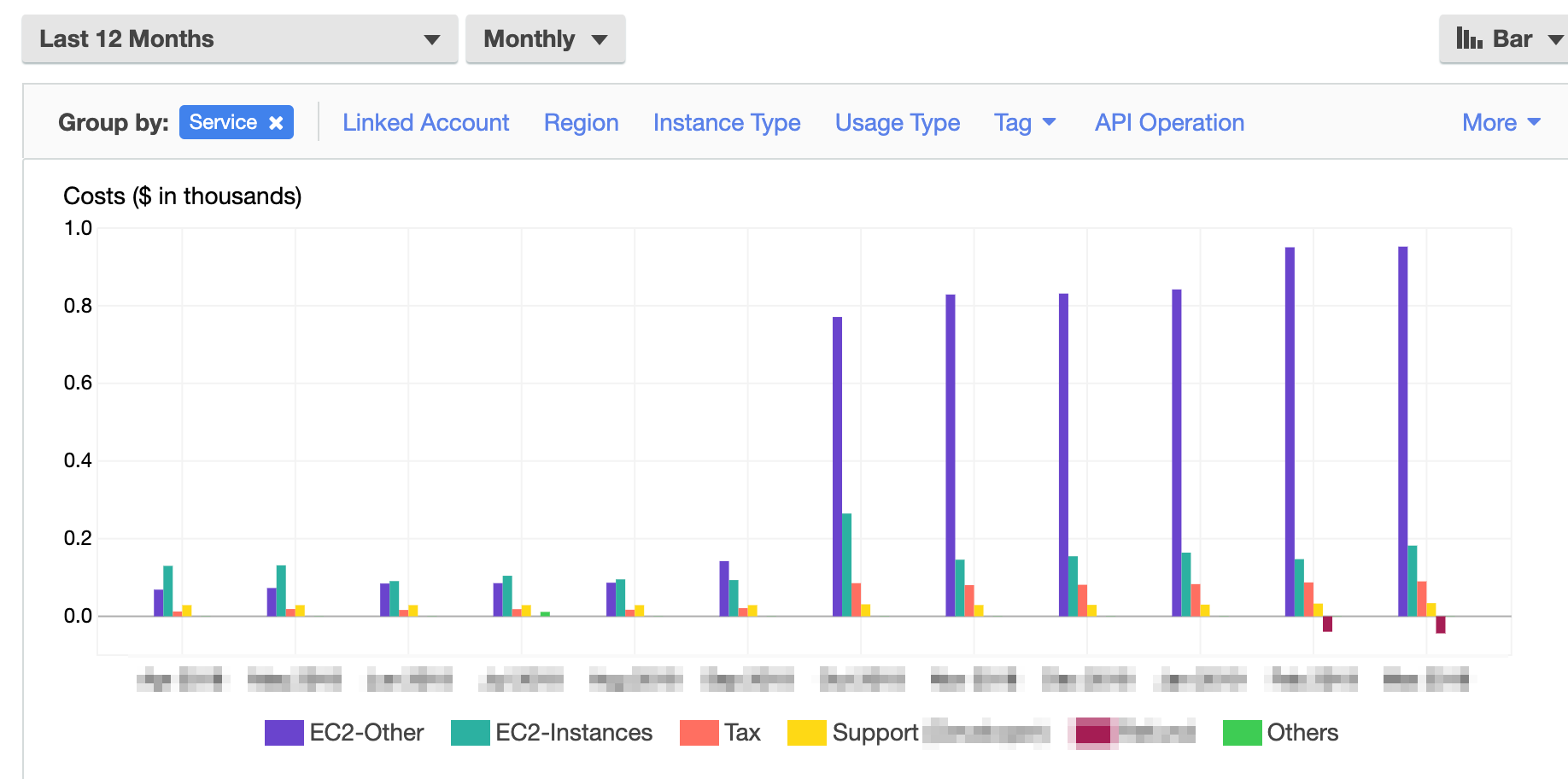
終わったあとにEC2をstop状態にして、数ヶ月放置してしまったんですね...実際は9TBのEBSを5ヶ月放置してしましました...
(普通はこんなにつかわねーよっているツッコミはしないでくださいw)そしたら↓のようになりました。
AWs Billing内のコストCost Explorerの画像です。
ある時点からEC2-Otherが爆発的にあがっていますよね...
ちなみに請求は毎月10万円くらい来ました Σ(゚д゚;) ヌオォ!?
全部で60万円位やらかしました。個人アカウントだったらお小遣いが半年剥奪されるレベルだと思います。便利な世の中になり、クラウドを活用する企業が増えてきたのはいいことですが、
このような危険を潜んでいるということを心に留めておきいていただきたく記事にしました。ちゃんと使えばこれ以上便利なものはないので、ご利用は計画的に!ってことですね。
では、よいAWSライクを!


- 投稿日:2019-08-30T11:17:51+09:00
社内環境からEC2のSSH(備忘録)
きっかけ
社内環境からAWSを利用しようとしたのですが、自分の社内環境がどうも、SSH(22ポート)を許してないみたいだったため、何かやる方法がないかと調べてみた内容(昔調べて忘れてたの忘れていたので)を備忘録として残してます。
参考サイト
https://blue21neo.blogspot.com/2015/08/aws-443-ssh.html
やり方
「手順 3: インスタンスの詳細の設定」のところにある「高度な詳細」で、EC2インスタンスを起動するときにコマンド実行を設定できるそうなので、以下の設定をいれておく。
sshd_config#!/bin/bash echo >> /etc/ssh/sshd_config # https(443)に設定 echo "Port 443" >> /etc/ssh/sshd_config感想
社内からの踏み台サーバになって便利でした!!
(社内だと使えるツールの制限があるから便利でした)
- 投稿日:2019-08-30T09:02:10+09:00
JAWS コンテナ支部 #15 レポート #jawsug_ct
まえがき
JAWS コンテナ支部 #15 にブログ枠で参加したので、レポートを書きます。
懐かしのツイートと振り返るAWSコンテナサービスアップデート - 2019年上半期編 -
資料
https://speakerdeck.com/toricls/how-memorable-those-aws-container-services-updates-and-tweets-are
本日の資料をアップしました! #jawsug_ct
— ポジティブな Tori (@toricls) 2019年8月29日
/ "懐かしのツイートと振り返るAWSコンテナサービスアップデート - 2019年上半期編 - Speaker" Deck https://t.co/RakN4D30N1
発表者
Yasuhiro Tori Hara @toricls from AWS Japan
感想
このところAWSのニュースはあらかたチェックしていたので、いい再確認になりました。
個人的にはスライドに出てきたニュースの中では
- AWSコンテナサービス ロードマップ
- AWSコンテナ系サービスに関しての要望をissueで挙げられたり、対応予定を確認したりできる。
- Amazon ECS サービスで複数のロードバランサーターゲットグループのサポートを開始
- このアップデートが出来る前は違うLBに紐付けるためだけに同じ内容のサービス作ったりしてましたが、このアップデートによって不要になりました。超便利。
- Amazon ECR でイミュータブルなイメージタグのサポートを開始
- これチェックしてなかったけど地味に便利ですね。多くの場合タグは一意になるもの(ブランチとかコミットハッシュとか日時とか)を自動で生成して付与するようなデプロイ設計になると思いますが、一度タグつけた内容があとから改変されることがなくなるのは安心ですね。
Amazon ECSの開発環境を動的に管理するツールを作ってみました by prog893
資料
https://www.slideshare.net/TamerlanTorgayev/jawsug-15-amazon-ecs/TamerlanTorgayev/jawsug-15-amazon-ecs発表者
Tamirlan Torgayev @prog893 from CyberAgent
内容の要約
- 課題:開発中にECS上での確認作業を行う際、開発者が多いほど開発環境を構築せねばならず、その際リソースの費用や利用タイミングの調整に面倒が発生していた
- 解決のため、CIの一環としてECS Taskを起動できるツールEDENを開発した
- 雑にまとめると、指定した正環境のECS Taskをコピーして同じ構成のECSサービスを起動するツール
- もともとOSS化する予定だったが、この発表あったのでサクッとOSS化した
感想
- ECSの開発環境として、開発者が多くなるにつれてAWSでの挙動を確認するための開発環境が増えていき、「DevXX環境がほしいです」「DevXX環境はこのPRの確認のために使わせてください」のような前時代的なやりとりが発生してしまうのは大変あるあるでした。
- そして下記の点はとても良いと思いました?
- ソリューションを考えて実装して、実際開発現場で利用されてるところ
- 実装への割り切り(ALBは新規作成しない、ECS以外のリソースへの破壊的変更はスコープ外とする)
- Mobile/Webアプリ両方で隠しコマンドで接続先を切り替えられるような協力体制を作ったところ
- OSS化への速度
Fargate運用物語 ~ 本当にコンテナで幸せになりますか? ~
資料
https://speakerdeck.com/soudai/fargate-story
発表者
曽根壮大 @soudai1025 from オミカレ
内容要約
- 経緯
- EC2をやめてコンテナ化したい
- 構成管理が辛い
- クリーンなEC2とAnsibleで構築すると起動が遅くなる
- かといってゴールデンAMI方式だと、AMI作り直しが頻発して辛い
- Ansibleは良いツールだが、スピード感を保ちながら冪等を守るのは難しい
- 構成管理をシンプルにするためにDockerが使いたい
- 開発環境が辛い
- シンプルな構成のサーバならVMで十分
- 開発環境の肥大化・多ロール化に伴いサービスに必要なVMが増えてきた
- 起動が遅い
- 構成差分の発生
- デプロイが辛い
- 8年前の自作デプロイツール
- 出戻りしたら不思議なコードが追加されていた
- 誰もメンテできず属人化
- Fargate導入での知見
- 辛かった点
- AWS/コンテナ/Docker/コンテナオーケストレーションどれも詳しくなかった
- Fargate用のVPC切ったせいでネットワーク設計から苦労
- パフォーマンス計測が甘かった
- ピーク時オートスケーリングでコンテナの起動が間に合わずコンテナがどんどん減っていく
- デバッグで、何のどこをみてもわからず苦戦
- 死んだコンテナが消えていてデバッグできない
- 費用が高い、特にCPU
- ロギングが不自由
- 結果サイドカーが増えていく
- 良かった点
- 課題点
- 構成管理改善
- 開発環境改善
- デプロイ改善
- それ以外の利点
- セキュリティ観点
- ホストEC2のセキュリティの面倒を見なくて良い
- コンテナを直に外に晒していないので守りやすい
- ミドルウェアのアップグレードもしやすい
- デプロイの切り戻し
- アプリケーションに手を入れず過去のイメージを再デプロイするだけでよい
- 取り組みによる学び
- 一足飛びに導入したせいで混乱が発生した
- 開発環境からなど段階的にやってもよかった
- 困っている問題を解決する技術を採用しよう
- EC2で困ってなければEC2でいいじゃん、PaaS,SaaSなども検討しましたか?
- コンテナ化でテスト楽になるけどそもそもテスト書いてますか?
感想
インフラの成長はビジネスの成長と両輪なのでまずはビジネスの成長です。そのために必要なことはこの先5年分くらいはやったと思ってます(例えばDBリファクタリングとかもそう
— そーだい@初代ALF (@soudai1025) 2019年8月29日
- インフラの技術的負債って後回しになりがち、ちゃんと返すタイミングを見極めて返し切ったのがすごいと思いました
- タップルとオミカレの事例並ぶの面白かった
- オミカレ全体の構成もしりたかった、構成図ググってもパッと出てこず……
- これからECSに切り替えていくのも簡単にできそうですね
How Fast can your Fargate Scale?
資料
オラオラスケールアウトするマンの図 #jawsug_ct pic.twitter.com/rSf2SX9FAw
— ポジティブな Tori (@toricls) 2019年8月29日本人のサンプルコードここにあった https://t.co/2dXFkkwFZO #jawsug_ct https://t.co/wrYbcaPmCl
— Ryo Nakamaru (@pottava) 2019年8月29日発表者
Pahud Hsieh from AWS Taiwan
内容要約
- FargateのAutoScaleを10秒程度で行うには?
- FargateにビルトインされているAutoScaleだとCloudWatchがトリガーするまでに1〜3分かかってしまう
- nginxのstub_status出力をLambda StepFunctionsでポーリングしておき、アクセスが増えたらFargateのサービスのタスク数を増加させるAPIを叩くような仕組みを実現
- 実際に10秒程度でAutoScalingした
感想
- 身も蓋もないんですが、AWSのAutoScalingの仕組みがもっと良くなれば自作しなくていいのではないかと思うんですよね。
- この実装が今の最適解であることや、改善される可能性が低そうなのもわかります。
- StepFunctions
- 見たことなかったけどVisual workflowとかも見られてめっちゃいいですね
- CDK面白そう
new ClusterするだけでFargate用のCluster作れるの偉い- アプリエンジニアがインフラ面倒をみるパターンは良さそうだと1思いました。
- やったことないですが、Step FunctionをTerraformで書くのかなりつらそう……
たったこれだけで Fargate タスクが起動して ALB まで用意されるの楽ですよね #jawsug_ct pic.twitter.com/rTz4JL7gaH
— ポジティブな Tori (@toricls) 2019年8月29日イベント全体の感想
- コンテナサービス系の事例紹介、大きなイベントだと詳しく喋ってくれなかったりするので、深く聞けて楽しかったです。また行きたい。
- Chimeで遠方からも参加できるようになってとってもいいですね。
- 投稿日:2019-08-30T09:02:10+09:00
JAWS-UG コンテナ支部 #15 レポート #jawsug_ct
まえがき
JAWS-UG コンテナ支部 #15 にブログ枠で参加したので、レポートを書きます。
懐かしのツイートと振り返るAWSコンテナサービスアップデート - 2019年上半期編 -
資料
https://speakerdeck.com/toricls/how-memorable-those-aws-container-services-updates-and-tweets-are
本日の資料をアップしました! #jawsug_ct
— ポジティブな Tori (@toricls) 2019年8月29日
/ "懐かしのツイートと振り返るAWSコンテナサービスアップデート - 2019年上半期編 - Speaker" Deck https://t.co/RakN4D30N1
発表者
Yasuhiro Tori Hara @toricls from AWS Japan
感想
このところAWSのニュースはあらかたチェックしていたので、いい再確認になりました。
個人的にはスライドに出てきたニュースの中では
- AWSコンテナサービス ロードマップ
- AWSコンテナ系サービスに関しての要望をissueで挙げられたり、対応予定を確認したりできる。
- Amazon ECS サービスで複数のロードバランサーターゲットグループのサポートを開始
- このアップデートが出来る前は違うLBに紐付けるためだけに同じ内容のサービス作ったりしてましたが、このアップデートによって不要になりました。超便利。
- Amazon ECR でイミュータブルなイメージタグのサポートを開始
- これチェックしてなかったけど地味に便利ですね。多くの場合タグは一意になるもの(ブランチとかコミットハッシュとか日時とか)を自動で生成して付与するようなデプロイ設計になると思いますが、一度タグつけた内容があとから改変されることがなくなるのは安心ですね。
Amazon ECSの開発環境を動的に管理するツールを作ってみました by prog893
資料
https://www.slideshare.net/TamerlanTorgayev/jawsug-15-amazon-ecs/TamerlanTorgayev/jawsug-15-amazon-ecs発表者
Tamirlan Torgayev @prog893 from CyberAgent
内容の要約
- 課題:開発中にECS上での確認作業を行う際、開発者が多いほど開発環境を構築せねばならず、その際リソースの費用や利用タイミングの調整に面倒が発生していた
- 解決のため、CIの一環としてECS Taskを起動できるツールEDENを開発した
- 雑にまとめると、指定した正環境のECS Taskをコピーして同じ構成のECSサービスを起動するツール
- もともとOSS化する予定だったが、この発表あったのでサクッとOSS化した
感想
- ECSの開発環境として、開発者が多くなるにつれてAWSでの挙動を確認するための開発環境が増えていき、「DevXX環境がほしいです」「DevXX環境はこのPRの確認のために使わせてください」のような前時代的なやりとりが発生してしまうのは大変あるあるでした。
- そして下記の点はとても良いと思いました?
- ソリューションを考えて実装して、実際開発現場で利用されてるところ
- 実装への割り切り(ALBは新規作成しない、ECS以外のリソースへの破壊的変更はスコープ外とする)
- Mobile/Webアプリ両方で隠しコマンドで接続先を切り替えられるような協力体制を作ったところ
- OSS化への速度
Fargate運用物語 ~ 本当にコンテナで幸せになりますか? ~
資料
https://speakerdeck.com/soudai/fargate-story
発表者
曽根壮大 @soudai1025 from オミカレ
内容要約
- 経緯
- EC2をやめてコンテナ化したい
- 構成管理が辛い
- クリーンなEC2とAnsibleで構築すると起動が遅くなる
- かといってゴールデンAMI方式だと、AMI作り直しが頻発して辛い
- Ansibleは良いツールだが、スピード感を保ちながら冪等を守るのは難しい
- 構成管理をシンプルにするためにDockerが使いたい
- 開発環境が辛い
- シンプルな構成のサーバならVMで十分
- 開発環境の肥大化・多ロール化に伴いサービスに必要なVMが増えてきた
- 起動が遅い
- 構成差分の発生
- デプロイが辛い
- 8年前の自作デプロイツール
- 出戻りしたら不思議なコードが追加されていた
- 誰もメンテできず属人化
- Fargate導入での知見
- 辛かった点
- AWS/コンテナ/Docker/コンテナオーケストレーションどれも詳しくなかった
- Fargate用のVPC切ったせいでネットワーク設計から苦労
- パフォーマンス計測が甘かった
- ピーク時オートスケーリングでコンテナの起動が間に合わずコンテナがどんどん減っていく
- デバッグで、何のどこをみてもわからず苦戦
- 死んだコンテナが消えていてデバッグできない
- 費用が高い、特にCPU
- ロギングが不自由
- 結果サイドカーが増えていく
- 良かった点
- 課題点
- 構成管理改善
- 開発環境改善
- デプロイ改善
- それ以外の利点
- セキュリティ観点
- ホストEC2のセキュリティの面倒を見なくて良い
- コンテナを直に外に晒していないので守りやすい
- ミドルウェアのアップグレードもしやすい
- デプロイの切り戻し
- アプリケーションに手を入れず過去のイメージを再デプロイするだけでよい
- 取り組みによる学び
- 一足飛びに導入したせいで混乱が発生した
- 開発環境からなど段階的にやってもよかった
- 困っている問題を解決する技術を採用しよう
- EC2で困ってなければEC2でいいじゃん、PaaS,SaaSなども検討しましたか?
- コンテナ化でテスト楽になるけどそもそもテスト書いてますか?
感想
インフラの成長はビジネスの成長と両輪なのでまずはビジネスの成長です。そのために必要なことはこの先5年分くらいはやったと思ってます(例えばDBリファクタリングとかもそう
— そーだい@初代ALF (@soudai1025) 2019年8月29日
- インフラの技術的負債って後回しになりがち、ちゃんと返すタイミングを見極めて返し切ったのがすごいと思いました
- タップルとオミカレの事例並ぶの面白かった
- オミカレ全体の構成もしりたかった、構成図ググってもパッと出てこず……
- これからECSに切り替えていくのも簡単にできそうですね
How Fast can your Fargate Scale?
資料
オラオラスケールアウトするマンの図 #jawsug_ct pic.twitter.com/rSf2SX9FAw
— ポジティブな Tori (@toricls) 2019年8月29日本人のサンプルコードここにあった https://t.co/2dXFkkwFZO #jawsug_ct https://t.co/wrYbcaPmCl
— Ryo Nakamaru (@pottava) 2019年8月29日発表者
Pahud Hsieh from AWS Taiwan
内容要約
- FargateのAutoScaleを10秒程度で行うには?
- FargateにビルトインされているAutoScaleだとCloudWatchがトリガーするまでに1〜3分かかってしまう
- nginxのstub_status出力をLambda StepFunctionsでポーリングしておき、アクセスが増えたらFargateのサービスのタスク数を増加させるAPIを叩くような仕組みを実現
- 実際に10秒程度でAutoScalingした
感想
- 身も蓋もないんですが、AWSのAutoScalingの仕組みがもっと良くなれば自作しなくていいのではないかと思うんですよね。
- この実装が今の最適解であることや、改善される可能性が低そうなのもわかります。
- StepFunctions
- 見たことなかったけどVisual workflowとかも見られてめっちゃいいですね
- CDK面白そう
new ClusterするだけでFargate用のCluster作れるの偉い- アプリエンジニアがインフラ面倒をみるパターンは良さそうだと1思いました。
- やったことないですが、Step FunctionをTerraformで書くのかなりつらそう……
たったこれだけで Fargate タスクが起動して ALB まで用意されるの楽ですよね #jawsug_ct pic.twitter.com/rTz4JL7gaH
— ポジティブな Tori (@toricls) 2019年8月29日イベント全体の感想
- コンテナサービス系の事例紹介、大きなイベントだと詳しく喋ってくれなかったりするので、深く聞けて楽しかったです。また行きたい。
- Chimeで遠方からも参加できるようになってとってもいいですね。