- 投稿日:2019-07-28T23:52:21+09:00
pythonで画像収集プログラムを書いてみた 1日目
目標
最終的にはgoogleの画像検索のURLを入力することで自動で画像のサイズを調節してダウンロードしてくれるプログラムを作る。
1日目はURLを入力したらそのページの画像を全て保存するプログラムを書く。PCスペック
プロセッサ 1.6 GHz Intel Core i5
メモリ 8 GB 2133 MHz LPDDR3まずBeautifulSoupの使い方を勉強
pythonでのスクレイピングにはBeautifulSoupを用いるのが良いと聞いたので、その使い方について少しだけ説明します。
bs4.BeautifulSoupクラスの作り方
from bs4 import BeautifulSoup import requests url="https://sample_url" #URLからhtmlファイルを取得 html=requests.get(url).text #htmlファイルからbs4.BeautifulSoupインスタンスを作る soup=BeautifulSoup(html,"html.parser")URLからのhtmlの取得にはrequestsモジュールを使用しました。
BeautifulSoupクラスの使い方
今回はページのタグとタグの要素の取得を主に使います。タグの検索の方法は三種類あり
#aタグの一番初めを取得 a_soup=soup.find("a") #簡単な書き方 a_soup=soup.a #aタグを全て取得 a_soup_all=soup.find_all("a")属性の取得には先ほどのタグに対してgetメソッドを用いる
#aタグのhref要素を取得 href=soup.find("a").get("href") href=soup.a.get("href") href=soup.find_all("a")[0].get("href")完成したコード
""" 入力:url、枚数、保存するディレクトリのパス,ファイルの名前 出力:ファイルへの画像の保存 """ import requests from bs4 import BeautifulSoup as bs from shutil import move from os import getcwd,path,mkdir def image_download(url,size,save_path,filename): #保存するディレクトリを作成する if not path.isdir(path.join(save_path,filename)): mkdir(path.join(save_path,filename)) #URLからHTMLを取得 res=requests.get(url).text #HTMLをBeautifulSoupに変換 soup=bs(res,"html.parser") #ページの中で画像のタグを全て取得 image_soup=soup.find_all("img") for i in range(min(len(image_soup),size)): name=filename+str(i+1)+".jpg" #画像ファイルのURLを取得 img_url=image_soup[i].get("src") image_page=requests.get(img_url) #画像を取得 image=image_page.content #画像を保存したファイルを作り、目的のディレクトリに移動する if image_page.status_code==200: with open(name,"wb") as f: f.write(image) move(path.join(in_path,name),path.join(save_path,filename))感想
少し処理の内容が解りづらいので、もう少し単純にしたいです。次は、画像の整形か、URLではなく検索したいワードなどから画像を収集できるようにしたいです。
- 投稿日:2019-07-28T23:34:02+09:00
connpassイベントのキャンセル傾向を調べてみる
はじめに
connpassイベントのキャンセル率が高いとの発言をたびたび目にします。
実際どの程度キャンセルされているのか、pandas, matplotlibの練習を兼ねて調べてみました。TL;DR
- 全体の平均キャンセル率は27.5%
- 前払い制や参加上限のないイベントではキャンセル率が半減する
- キャンセル処理をせず当日参加しなかったものは集計できていないため、実際のキャンセル率はさらに高い
- 意外な結果はなし
データ収集
コードはこちらです。
hookbook/connpass-analyses取得方法
python collect.py --s 201901 --e 201902connpass API
公式にAPIが用意されているため、これを利用します。
パラメータ詳細はリンク先参照してください。※過度な検索やクローリングに対しては、アクセス制限を施す可能性があります。robots.txt を尊守してください。
User-agent: *
Crawl-delay: 5
Allow: /
Disallow: /series/optout/
Disallow: /account/collect.pydef get_event_data_ym(ym: int, seve_csv: bool = False) -> pd.DataFrame: """指定年月のconnpassイベント情報をDataFrameとして返す。 Parameters ---------- ym : int 取得するイベントの開催年月。 save_csv : bool, default False 取得した情報を保存するか。 Returns ------- df : DataFrame 指定年月のconnpassイベント情報。 """ df = pd.DataFrame(columns=df_columns) # イベント件数 count = get_event_info(ym, 1, 1)['results_available'] for i in range((count // 100) + 1): # イベント情報取得 events = get_event_info(ym, (i * 100) + 1)['events'] time.sleep(SLEEPING_SECONDS) for event in events: # connpassで受け付けているイベントのみを対象とする if event['event_type'] == 'participation': # キャンセル数や決済方法を取得 scraped_dict = get_event_data(event['event_url']) time.sleep(SLEEPING_SECONDS) # api とスクレイピング結果を結合 se = pd.Series({**event, **scraped_dict}, index=df.columns) df = df.append(se, ignore_index=True) if seve_csv: # 途中経過をcsv保存 df.to_csv(DATASET_DIR + 'dataset_temp.csv', mode='a') return dfスクレイピング
APIで取得できない情報は各イベントページをスクレイピングして取得しました。
- キャンセル者数
- 有料イベントかどうか
- 参加費
- 参加者選出方法(先着順・抽選)
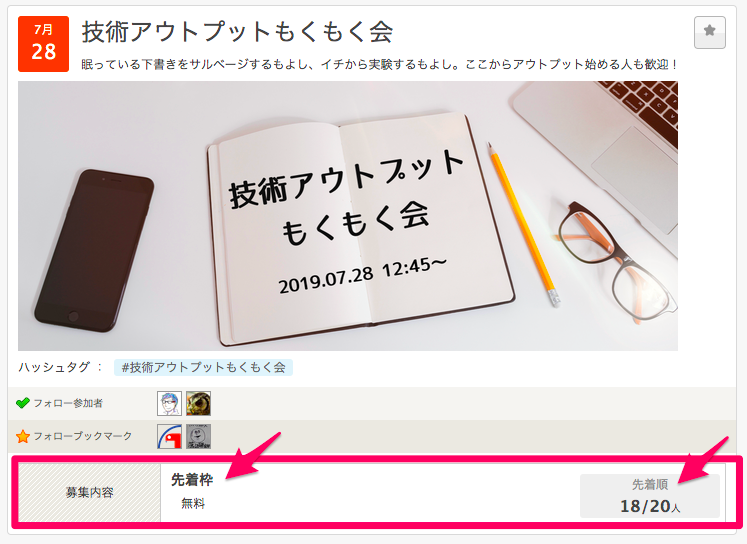
connpassイベントでは一つのイベントに対して複数の募集があるケースがあります。
それぞれ別々に集計するのが望ましいのですが、簡単のために上に表示されている募集を優先して取得しました。
- 有料と無料の募集が混在している場合は、有料と判定
- 先着順・抽選どちらもある場合は、上に表示されている方式と判定
- 複数の参加費設定がある場合は、上に表示されている参加費
collect.pydef get_event_data(url: str) -> dict: """connpassイベントページより追加情報を取得する。 Parameters ---------- url : str connpassイベントのurl。 Returns ------- event_dict : dict[str, Any] イベント情報dict。 """ try: html = urlopen(url) except Exception: # アクセス失敗した場合には全てNoneで返す event_dict = { 'canceled': None, 'lottery': None, 'firstcome': None, 'freedom': None, 'prepaid': None, 'postpaid': None, 'amount': None } return event_dict soup = BeautifulSoup(html, 'html.parser') canceled = 0 cancel = soup.find(href=url + 'participation/#cancelled') if cancel is not None: canceled = cancel.text[9:-2] # 抽選 or 先着順(混在している場合には表示順上位の内容を優先) lottery = False firstcome = False free = False participant_decision_list = soup.find_all('p', class_='participants') for participant_decision in participant_decision_list: if '抽選' in participant_decision.text: lottery = True break elif '先着' in participant_decision.text: firstcome = True break # 抽選でも先着順でもないイベント free = not lottery and not firstcome # 会場払い or 前払い(混在している場合には表示順上位の内容を優先) prepaid = False postpaid = False # 金額(表示順上位・有料を優先) amount = 0 payment_list = soup.find_all('p', class_='join_fee') for payment in payment_list: payment_text = payment.text if '(前払い)' in payment_text: prepaid = True amount = re.sub(r'\D', '', payment_text) break elif '(会場払い)' in payment_text: postpaid = True amount = re.sub(r'\D', '', payment_text) break event_dict = { 'canceled': canceled, 'lottery': lottery, 'firstcome': firstcome, 'free': free, 'prepaid': prepaid, 'postpaid': postpaid, 'amount': amount } return event_dict取得した項目
2011年11月〜2019年6月のイベントデータを対象に、67,557件を取得しました。
フィールド 説明 取得方法 値 event_id イベントID API 139640 title タイトル API 技術アウトプットもくもく会 catch キャッチ API 眠っている下書きをサルベージするもよし、イチから実験するもよし。 event_url connpass.com 上のURL API https://connpass.com/event/139640/ hash_tag Twitterのハッシュタグ API 技術アウトプットもくもく会 address 開催場所 API 東京都港区南青山 1 丁目12-3 (LIFORK MINAMI AOYAMA S209) place 開催会場 API StockMark, Inc. lat 開催会場の緯度 API 35.668502700000 lon 開催会場の経度 API 139.724649300000 started_at イベント開催日時 API 2019-07-28T12:45:00+09:00 ended_at イベント終了日時 API 2019-07-28T19:30:00+09:00 limit 定員 API 20 accepted 参加者数 API 18 waiting 補欠者数 API 0 canceled キャンセル人数 スクレイピング 13 lottery 参加者決定方法(抽選) スクレイピング False firstcome 参加者決定方法(先着順) スクレイピング True freedom 参加者決定方法(無制限) スクレイピング False prepaid 支払い方法(前払い) スクレイピング False postpaid 支払い方法(会場払い) スクレイピング False amount 参加費 スクレイピング 0 データ編集
イベントページが404のデータを除外
len(df[df['canceled'].isnull()]) # 3 # canceled が欠損しているデータは404として除外 df.dropna(subset=['canceled'], inplace=True)実施されなかったイベントを除外
len(df.query( "accepted == 0")) # 7566 # 参加者がいなかったイベントは、イベント自体がキャンセルされたとして除外 df = df.query( "accepted != 0")カテゴリ変数追加
# 参加者決定方法 # 抽選:0 # 先着順:1 # 無制限:2 df.loc[df['lottery'] == True, 'decision_type'] = 0 df.loc[df['firstcome'] == True, 'decision_type'] = 1 df.loc[df['freedom'] == True, 'decision_type'] = 2 df['decition_type'] = df['decision_type'].astype(int) df['decision_type'].value_counts() # 1 49821 # 0 5443 # 2 4724 # Name: decision_type, dtype: int64# 支払い方法 # 無料:0 # 前払い:1 # 会場払い:2 df.loc[df['amount'] == 0, 'paid_type'] = 0 df.loc[df['prepaid'] == True, 'paid_type'] = 1 df.loc[df['postpaid'] == True, 'paid_type'] = 2 df['paid_type'] = df['paid_type'].astype(int) df['paid_type'].value_counts() # 0 42372 # 2 15926 # 1 1690 # Name: paid_type, dtype: int64データ確認
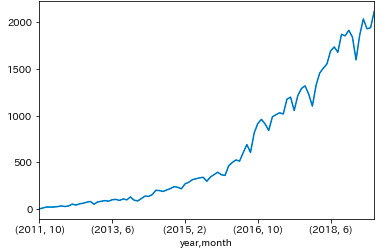
# イベント開始時刻をインデックスに指定 df_ts = df.set_index('started_at') df_ts.index = pd.to_datetime(df_ts.index, utc=True).tz_convert('Asia/Tokyo').tz_localize(None) # 集計用列の追加 df_ts['post_count'] = 1 # 開始時刻順に並び替え df_ts.sort_index(inplace=True) # マルチインデックス指定 df_multi = df_ts.set_index([df_ts.index.year, df_ts.index.month, df_ts.index.weekday, df_ts.index.hour, df_ts.index]) df_multi.index.names = ['year', 'month', 'weekday', 'hour', 'date']年月別のイベント数推移
ym = df_multi.sum(level=['year', 'month']).post_count.sort_index() ym.plot() plt.show()
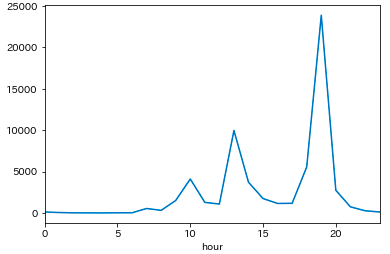
時刻別のイベント数
- 19時開始に集中している
hour = df_multi.sum(level='hour').post_count.sort_index() # hour # 0 115 # 1 47 # 2 9 # 3 6 # 4 1 # 5 15 # 6 18 # 7 535 # 8 310 # 9 1501 # 10 4097 # 11 1275 # 12 1073 # 13 9956 # 14 3708 # 15 1735 # 16 1143 # 17 1162 # 18 5555 # 19 23876 # 20 2736 # 21 737 # 22 265 # 23 113 # Name: post_count, dtype: int64 hour.plot() plt.show()
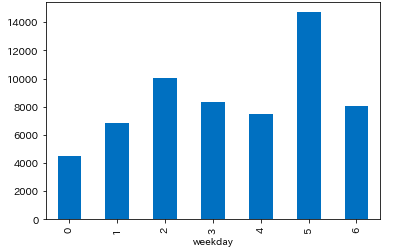
曜日別のイベント数
- 水曜、土曜はイベントが多い
weekday = df_multi['post_count'].sum(level='weekday').sort_index() # weekday # 0 4491 # 1 6840 # 2 10045 # 3 8346 # 4 7499 # 5 14699 # 6 8068 # Name: post_count, dtype: int64 weekday.plot.bar() plt.show()月曜日:0 〜 日曜日:6
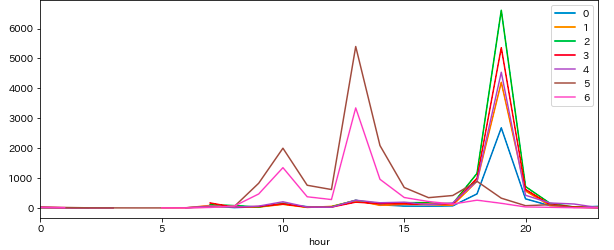
時刻別・曜日別にイベント数
イベント開始時刻をヒートマップ表示してみます。
- 平日の19時と休日の13時(うっすら10時)に偏っている
df_w_h = df_multi['post_count'].sum(level=['weekday', 'hour']).sort_index() plt.figure(figsize=(12, 4)) sns.heatmap(df_w_h.unstack(level='hour'))
折れ線グラフでも。
fig = plt.figure() ax = fig.add_subplot(1, 1, 1) df_w_h.unstack(level='weekday').plot(figsize=(10, 4), ax=ax) plt.legend(loc='upper right', bbox_to_anchor=(1, 1))
キャンセル率の確認
キャンセル率の計算方法
キャンセル率は以下で計算します。
(イベントに申し込んだ人数に対するキャンセルした人数の割合。)キャンセル率 = \frac{キャンセル人数}{参加者数+補欠者数+キャンセル人数}def get_cancel_rate(df): return df['canceled'].sum() / (df['accepted'].sum() + df['waiting'].sum() + df['canceled'].sum())全イベント
- 全データを対象にすると平均で約27.6%
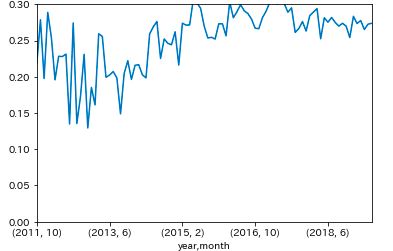
get_cancel_rate(df) # 0.2755642788195028年月別
plt.ylim(0, 0.3) cr_ym = df_multi.groupby(['year', 'month'], as_index=False).apply(lambda d: get_cancel_rate(d)) cr_ym.plot()
曜日別
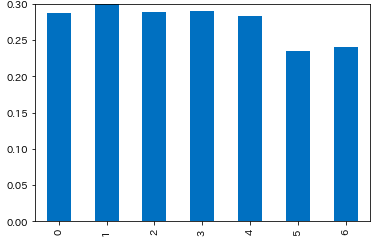
- 土日はキャンセル率が低い
- 祝日は未確認
plt.ylim(0, 0.3) cr_weekday = df_multi.groupby(['weekday'], as_index=False).apply(lambda d: get_cancel_rate(d)) # 0 0.287851 # 1 0.301708 # 2 0.289396 # 3 0.290123 # 4 0.282869 # 5 0.235157 # 6 0.240867 # dtype: float64 cr_weekday.plot.bar()月曜日:0 〜 日曜日:6
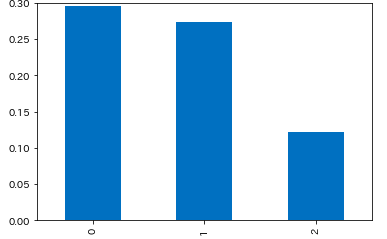
参加者の決定方法別
- 参加者上限がないイベントではキャンセル率が約12.2%
plt.ylim(0, 0.3) cr_decision_type = df.groupby(['decision_type'], as_index=False).apply(lambda d: get_cancel_rate(d)) # 0 0.295299 # 1 0.274411 # 2 0.121591 # dtype: float64 cr_decision_type.plot.bar()抽選:0
先着順:1
無制限:2
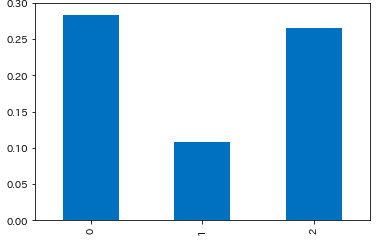
支払い方法別
- 前払いのイベントはキャンセル率が約10.9%
plt.ylim(0, 0.3) cr_paid_type = df.groupby(['paid_type'], as_index=False).apply(lambda d: get_cancel_rate(d)) # 0 0.283863 # 1 0.108790 # 2 0.265070 # dtype: float64 cr_paid_type.plot.bar()無料:0
前払い:1
会場払い:2
まとめ
おおむね調査前の予想通りで、意外性のない結果となりました。
この結果はあくまでconnpassイベントページから取得できる情報による調査のため、キャンセル処理をせず当日参加しなかったものは集計できていません。
そのため、実際のキャンセル率はさらに低くなります。connpassイベントのデータは集まったので、次はイベントキャンセル率の予測モデルを作成してみます。
参考

- 投稿日:2019-07-28T22:57:13+09:00
49日目。pandas経由でCSVをsqlliteにぶっこんだら便利でした。
前回の続きです。
48日目。pandasで10万×1万のCSVをマージしたら簡単・早くて驚きました!
for..loopだと終わらないので、pandasのDFに入れてマージしたら一瞬で片付いてやった!と思ったのですが、データを綺麗に揃えるのが大変でうんざりでした。何万行もあるのに一行ダメだとそこで止まる。止まっては直し、また止まっては直し・・・
そこで、pythonの標準機能で使えるデータベース、sqlliteを試してみました。
まずCSVをテーブルにどんどん入れていきます。
importcsv.pyimport sqlite3 import pandas as pd # pandasでカレントディレクトリにあるcsvファイルを読み込む df = pd.read_csv("test999.csv") # カラム名はAから順番に。Excelで開いたときに探しやすくて便利なので。 df.columns=['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] dbname = 'TEST.db' conn = sqlite3.connect(dbname) cur = conn.cursor() # table名はsample、tableがあったらappendする。 df.to_sql('sample', conn, if_exists='append') cur.close() conn.close()シンプルですね。
データをどかどか入れたら読み出します。
selectdb.pyimport sqlite3 dbname = 'TEST.db' conn = sqlite3.connect(dbname) cur = conn.cursor() def getname(sampleid): cur.execute('SELECT * FROM sample where A=' + str(sampleid)) return cur.fetchall() #IDが一致した列をもってくる。 df = getname(1234567890) print(df) #データは「タプル」にはいっている。 #目的のデータのみ表示する例。 df1 = df[2][4] print(df1) #最後にカーソルを閉じる。 cur.close() conn.close()はやっ!
一瞬でした。
元のデータが穴ぼこだらけでも良いのが助かります。
SQLでマージしてもいいし、DFにもってきてマージしてもいいし。
何かと便利になりそうです。
- 投稿日:2019-07-28T22:43:11+09:00
ラズベリーパイで距離測定センサーを作る
作りたいもの
- 距離計測センサー
使用したもの
- ラズベリーパイ
- HC-SR04
コード
sensor.py#!/usr/bin/env python # -*- coding: utf-8 -*- import RPi.GPIO as GPIO import time # HIGH or LOWの時計測 def pulseIn(PIN): while GPIO.input(PIN) == 0: t_start = time.time() while GPIO.input(PIN) == 1: t_end = time.time() return t_end - t_start # 距離計測 def calc_distance(TRIG_PIN, ECHO_PIN, num, v=34000): for i in range(num): # TRIGピンを0.3[s]だけLOW GPIO.output(TRIG_PIN, GPIO.LOW) time.sleep(0.3) # TRIGピンを0.00001[s]だけ出力(超音波発射) GPIO.output(TRIG_PIN, True) time.sleep(0.00001) GPIO.output(TRIG_PIN, False) # HIGHの時間計測 t = pulseIn(ECHO_PIN) # 距離[cm] = 音速[cm/s] * 時間[s]/2 distance = v * t/2 print(distance, "cm") # ピン設定解除 GPIO.cleanup() # TRIGとECHOのGPIO番号 TRIG_PIN = 14 ECHO_PIN = 15 # 音速[cm/s] v = 34000 # ピン番号をGPIOで指定 GPIO.setmode(GPIO.BCM) # TRIG_PINを出力, ECHO_PINを入力 GPIO.setup(TRIG_PIN,GPIO.OUT) GPIO.setup(ECHO_PIN,GPIO.IN) GPIO.setwarnings(False) # 距離計測(TRIGピン番号, ECHO_PIN番号, 計測回数, 音速[cm/s]) calc_distance(TRIG_PIN, ECHO_PIN, 10, v)参考サイト
【ラズベリーパイ3】Pythonで超音波距離センサ(HC-SR04)の精度向上(気温考慮)
参考サイトから修正した部分
- pulseIn関数の中身
- 音速を34000に固定
疑問
参考サイトにある以下の部分の、start、end、t_start、t_endの役割がわからなかった。
# HIGH or LOWの時計測 def pulseIn(PIN, start=1, end=0): if start==0: end = 1 t_start = 0 t_end = 0 # ECHO_PINがHIGHである時間を計測 while GPIO.input(PIN) == end: t_start = time.time() while GPIO.input(PIN) == start: t_end = time.time() return t_end - t_start
- 投稿日:2019-07-28T22:24:47+09:00
(自分メモ)Selenium + Python でwait制御
ちょっとした自動化ツールでSeleniumとPythonを使ってプチツールを作成した話です。
そもそもはIE9を使っていた頃にExcelシートのデータをWebインターフェースを介して
ちょこちょこと自動反映するものだったのですが
- IE9になってからBusy制御が逝かれた
- もうVBAは・・・いいでしょ
ということでPythonで書き直しました。
はい、環境に入っていないものがたくさんありますので導入から。
- firefox
- firefoxドライバ(geckodriver)
- selenium
で、結局Pythonでもwaitの制御で少々苦労することになるのですが
WebDriverWaitを使うことで期待の制御ができる感じです。ただページの特徴に応じてロード完了条件を書いているので
わかっているページならいい・仕様が固定ならなのですが
もうすこし汎用的にWait制御ができないかなあ。。。というのは自分への宿題です。# ライブラリ from pathlib import Path import time from selenium import webdriver from selenium.webdriver.common.keys import Keys # for headless from selenium.webdriver.firefox.options import Options # wait from selenium.webdriver.support.ui import WebDriverWait from selenium.common.exceptions import TimeoutException from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By # パラメータ DRIVER_PATH = Path('/xxxxxxxx/geckodriver') SLEEP_TIME = 5 # 秒 # 検索パラメータ URL = 'https://www.google.ne.jp' SEARCH_KEYWORD = '今週の天気' def main(): try: # ブラウザ生成 firefox headlessモード options = Options() options.add_argument('-headless') browser = webdriver.Firefox(executable_path=str(DRIVER_PATH), firefox_options=options) # ブラウザロードされるまで待つ browser.implicitly_wait(3) # 試行錯誤の過程として残しておく ## Pageが完全ロードされるまで最大5秒待つように設定 ## browser.set_page_load_timeout(SLEEP_TIME) ## browse_wait = WebDriverWait(browser, 10) try: # URLアクセス browser.get(URL) # 画面ロード完了条件を記載する WebDriverWait(browser, 5).until( EC.presence_of_all_elements_located((By.NAME, 'q')) ) # 取得確認 print(browser.title) # 検索設定 elem = browser.find_element_by_name('q') # search boxに値が入っている可能性ありなので一旦消す elem.clear() # 検索ボックスへキーワード設定 elem.send_keys(SEARCH_KEYWORD) # 検索実行 try: elem.submit() # 画面ロード完了条件を記載する WebDriverWait(browser, 5).until( EC.presence_of_all_elements_located((By.CLASS_NAME, 'pn')) ) print(browser.title) except TimeoutException: print('loading took too much time!') except: print('get timeout!') finally: # browser を終了 browser.quit() if __name__ == '__main__': main()
- 投稿日:2019-07-28T22:05:24+09:00
pipでpyaudioが入らない時の対処法
Overview
pyaudioを入れようとしたらエラーが出た.
やったこと
- Xcodeセットアップツールの更新
- pipセットアップツールの更新
portaudioのインストール(brew)環境
- macOS Mojave 10.14.6
- Python 3.7.3
- pip 19.2.1
実際に出たエラー
pip3 install pyaudiopipだとcondaにぶちこまれる設定のため
pip3を利用しています.Command "/usr/local/opt/python/bin/python3.7 -u -c "import setuptools, tokenize;__file__='/private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-9gsm8qwi/pyaudio/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-record-6t7resky/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-9gsm8qwi/pyaudio/こんな感じのエラーが出ました.
推定される原因
- 最近Xcodeのアプデがあった
- Pythonでの音声処理をまったくやってないため,なんか設定が必要
解決策
解決策というより実際にやったことです
1. Xcodeの再設定
こちらの記事を参考にXcodeのセットアップをしてみました.
1-1. Xcode立ち上げてセットアップ
Xcodeを立ち上げてセットアップツールをインストール
→ ダメ1-2.
xcode-select --installを実施xcode-select: error: command line tools are already installed, use "Software Update" to install updatesと言われダメ
1-3. Apple Developerから手動でインストール
ここから
Command Line Tools(macOS 10.14) for Xcode 10.3をダウンロードし,実行.
→ダメ(変わらなかった)2と3に関しては1で再設定したため変わらなかった可能性があります.
2. pipサイドの問題解決
直接的に関係があるかはわからないですが,こちらを参考に
pipのsetuptoolsの更新をしました.
具体的にはpip3 install --upgrade pip setuptoolsをしました.(pipだとanaconda行きのため一応pip3で)
結果setuptoolsが40.8.0から41.0.1に更新されました.この状態でpyaudioインストールを試みました.
その結果...ERROR: Command errored out with exit status 1: command: /usr/local/opt/python/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-0e82wcyk/pyaudio/setup.py'"'"'; __file__='"'"'/private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-0e82wcyk/pyaudio/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-record-2_i9454h/install-record.txt --single-version-externally-managed --compile cwd: /private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-0e82wcyk/pyaudio/ Complete output (16 lines): running install running build running build_py creating build creating build/lib.macosx-10.14-x86_64-3.7 copying src/pyaudio.py -> build/lib.macosx-10.14-x86_64-3.7 running build_ext building '_portaudio' extension creating build/temp.macosx-10.14-x86_64-3.7 creating build/temp.macosx-10.14-x86_64-3.7/src clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.14.sdk -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.14.sdk/usr/include -I/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.14.sdk/System/Library/Frameworks/Tk.framework/Versions/8.5/Headers -DMACOSX=1 -I/usr/local/include -I/usr/local/opt/openssl/include -I/usr/local/opt/sqlite/include -I/usr/local/Cellar/python/3.7.3/Frameworks/Python.framework/Versions/3.7/include/python3.7m -c src/_portaudiomodule.c -o build/temp.macosx-10.14-x86_64-3.7/src/_portaudiomodule.o src/_portaudiomodule.c:29:10: fatal error: 'portaudio.h' file not found #include "portaudio.h" ^~~~~~~~~~~~~ 1 error generated. error: command 'clang' failed with exit status 1 ---------------------------------------- ERROR: Command errored out with exit status 1: /usr/local/opt/python/bin/python3.7 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-0e82wcyk/pyaudio/setup.py'"'"'; __file__='"'"'/private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-install-0e82wcyk/pyaudio/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/4k/bzsywl69619c1t7dws5_h43w0000gn/T/pip-record-2_i9454h/install-record.txt --single-version-externally-managed --compile Check the logs for full command output.エラーの種類が変わりました.
しかし,未だ入れられず.
Xcodeが原因ではない気がしたので,pipに絞って調べました.3. Homebrew側の問題
調べているとこの記事を見つけました.ここで
portaudioを入れないといけないみたいなので入れてやってみました.brew install portaudio少し時間はかかりましたが,ここは問題なくできました.
改めてpip3 install pyaudioすると,うまく入りました!(
pyaudioのバージョンは0.2.11)結論
色々やったので断定はできないですが,原因としてはXcode側と
pyaudio側に分けられるのではないかと考えます.Xcode更新 → セットアップツールインストール(1回起動すればOK).
pyaudio入れる →portaudioを入れておく.といった感じです.Winに比べてmacはpythonの設定が楽と言いますが,それでもわからないことだらけです.
- 投稿日:2019-07-28T21:55:06+09:00
Google Cloud Platform(GCP)での機械学習(GPU)
Google Cloud Platform
Googleが提供するクラウドサービスの総称。(https://cloud.google.com)
機械学習データセット
cifar10を使った(ローカルCPUとGPUでの処理速度比べたい)
cifar10:10のクラスにラベル付けされた,50,000枚の32x32訓練用カラー画像,10,000枚のテスト用画像のデータセット.環境
ローカル
OS:Windows10
エディタ: Atom
AnacondaGPUのみこれを追加
GCP OS:ubuntu16.04 LS
GPU:Cuda 9.0
device name:Tesla K80trainingコード
train_cifar10.pyimport numpy as np import matplotlib.pyplot as plt import keras from keras.datasets import cifar10 from keras.models import Sequential from keras.layers import Conv2D,Activation,MaxPooling2D,Dense,Dropout,Flatten from keras.optimizers import Adam from keras.utils import np_utils #下のコードでcifar10のデータ取得 (x_train, y_train), (x_test, y_test) = cifar10.load_data() x_train=np.asarray(x_train).astype("float")/255.0 x_test=np.asarray(x_test).astype("float")/255.0 y_train=np_utils.to_categorical(y_train,10) y_test=np_utils.to_categorical(y_test,10) epoch=30 def train_model(): model=Sequential() model.add(Conv2D(32,(3,3),padding="same",input_shape=x_train.shape[1:])) model.add(Activation("relu")) model.add(Conv2D(64,(3,3),padding="same")) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(128,(3,3),padding="same")) model.add(Activation("relu")) model.add(Conv2D(256,(3,3),padding="same")) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(256,(3,3),padding="same")) model.add(Activation("relu")) model.add(Conv2D(256,(3,3),padding="same")) model.add(Activation("relu")) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(1024)) model.add(Activation("relu")) model.add(Dropout(0.5)) model.add(Dense(y_train.shape[1])) model.add(Activation("softmax")) model.compile(loss="categorical_crossentropy",optimizer="Adam",metrics=["accuracy"]) result=model.fit(x_train,y_train,batch_size=120,epochs=epoch,validation_split=0.2,shuffle=True) #評価 score=model.evaluate(x_test,y_test,verbose=0) print("Test Loss:",score[0]) print("Test Accuracy:",score[1]) #モデルの重み保存(predictやevalusteの時に使う) model.save("./cifar10_train.h5") return model if __name__=="__main__": train_model()Training
・GPU(GCP train) Epoch 1/30 2019-07-28 09:48:47.961033: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10.0 2019-07-28 09:48:51.145668: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7 50000/50000 [==============================] - 43s 863us/step - loss: 1.7028 - acc: 0.3595 - val_loss: 1.3475 - val_acc: 0.4981 Epoch 2/30 50000/50000 [==============================] - 32s 640us/step - loss: 1.1785 - acc: 0.5752 - val_loss: 0.9698 - val_acc: 0.6595 Epoch 3/30 50000/50000 [==============================] - 32s 639us/step - loss: 0.9198 - acc: 0.6775 - val_loss: 0.7873 - val_acc: 0.7246 Epoch 4/30 50000/50000 [==============================] - 32s 635us/step - loss: 0.7709 - acc: 0.7287 - val_loss: 0.7076 - val_acc: 0.7577 Epoch 5/30 50000/50000 [==============================] - 32s 637us/step - loss: 0.6777 - acc: 0.7638 - val_loss: 0.6583 - val_acc: 0.7758 Epoch 6/30 50000/50000 [==============================] - 32s 642us/step - loss: 0.6102 - acc: 0.7859 - val_loss: 0.6247 - val_acc: 0.7891 Epoch 7/30 50000/50000 [==============================] - 32s 644us/step - loss: 0.5575 - acc: 0.8044 - val_loss: 0.6225 - val_acc: 0.7926 Epoch 8/30 50000/50000 [==============================] - 32s 634us/step - loss: 0.5113 - acc: 0.8218 - val_loss: 0.5550 - val_acc: 0.8114 Epoch 9/30 50000/50000 [==============================] - 32s 640us/step - loss: 0.4731 - acc: 0.8329 - val_loss: 0.5555 - val_acc: 0.8117 Epoch 10/30 50000/50000 [==============================] - 32s 632us/step - loss: 0.4471 - acc: 0.8429 - val_loss: 0.5509 - val_acc: 0.8175 Epoch 11/30 50000/50000 [==============================] - 32s 636us/step - loss: 0.4145 - acc: 0.8558 - val_loss: 0.5768 - val_acc: 0.8170 Epoch 12/30 50000/50000 [==============================] - 32s 643us/step - loss: 0.3883 - acc: 0.8638 - val_loss: 0.5925 - val_acc: 0.8089 Epoch 13/30 50000/50000 [==============================] - 32s 639us/step - loss: 0.3715 - acc: 0.8695 - val_loss: 0.5669 - val_acc: 0.8156 Epoch 14/30 50000/50000 [==============================] - 32s 634us/step - loss: 0.3479 - acc: 0.8750 - val_loss: 0.6267 - val_acc: 0.8086 Epoch 15/30 50000/50000 [==============================] - 32s 641us/step - loss: 0.3352 - acc: 0.8806 - val_loss: 0.5758 - val_acc: 0.8277 Epoch 16/30 50000/50000 [==============================] - 31s 628us/step - loss: 0.3191 - acc: 0.8869 - val_loss: 0.5729 - val_acc: 0.8259 Epoch 17/30 50000/50000 [==============================] - 32s 642us/step - loss: 0.3068 - acc: 0.8912 - val_loss: 0.5528 - val_acc: 0.8331 Epoch 18/30 50000/50000 [==============================] - 32s 639us/step - loss: 0.2950 - acc: 0.8951 - val_loss: 0.5619 - val_acc: 0.8330 Epoch 19/30 50000/50000 [==============================] - 32s 640us/step - loss: 0.2897 - acc: 0.8986 - val_loss: 0.5595 - val_acc: 0.8319 Epoch 20/30 50000/50000 [==============================] - 32s 631us/step - loss: 0.2761 - acc: 0.9039 - val_loss: 0.6063 - val_acc: 0.8251 Epoch 21/30 50000/50000 [==============================] - 32s 631us/step - loss: 0.2736 - acc: 0.9039 - val_loss: 0.5647 - val_acc: 0.8375 Epoch 22/30 50000/50000 [==============================] - 31s 630us/step - loss: 0.2587 - acc: 0.9092 - val_loss: 0.5871 - val_acc: 0.8344 Epoch 23/30 50000/50000 [==============================] - 31s 629us/step - loss: 0.2578 - acc: 0.9109 - val_loss: 0.6191 - val_acc: 0.8303 Epoch 24/30 50000/50000 [==============================] - 31s 627us/step - loss: 0.2420 - acc: 0.9166 - val_loss: 0.5932 - val_acc: 0.8346 Epoch 25/30 50000/50000 [==============================] - 31s 628us/step - loss: 0.2473 - acc: 0.9135 - val_loss: 0.5977 - val_acc: 0.8358 Epoch 26/30 50000/50000 [==============================] - 31s 628us/step - loss: 0.2406 - acc: 0.9168 - val_loss: 0.5824 - val_acc: 0.8373 Epoch 27/30 50000/50000 [==============================] - 32s 630us/step - loss: 0.2355 - acc: 0.9179 - val_loss: 0.6245 - val_acc: 0.8322 Epoch 28/30 50000/50000 [==============================] - 31s 628us/step - loss: 0.2381 - acc: 0.9181 - val_loss: 0.5909 - val_acc: 0.8368 Epoch 29/30 50000/50000 [==============================] - 31s 629us/step - loss: 0.2292 - acc: 0.9211 - val_loss: 0.5889 - val_acc: 0.8408 Epoch 30/30 50000/50000 [==============================] - 32s 633us/step - loss: 0.2221 - acc: 0.9239 - val_loss: 0.5917 - val_acc: 0.8368 Test Loss: 0.591716582775116 Test Accuracy: 0.8368 ・CPU Epoch 1/30 50000/50000 [==============================] - 216s 4ms/step - loss: 1.6905 - acc: 0.3657 - val_loss: 1.3237 - val_acc: 0.5209 Epoch 2/30 50000/50000 [==============================] - 215s 4ms/step - loss: 1.1577 - acc: 0.5846 - val_loss: 1.0158 - val_acc: 0.6408 Epoch 3/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.9370 - acc: 0.6677 - val_loss: 0.8442 - val_acc: 0.7018 Epoch 4/30 50000/50000 [==============================] - 216s 4ms/step - loss: 0.8047 - acc: 0.7174 - val_loss: 0.7127 - val_acc: 0.7519 Epoch 5/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.7146 - acc: 0.7494 - val_loss: 0.6724 - val_acc: 0.7659 Epoch 6/30 50000/50000 [==============================] - 217s 4ms/step - loss: 0.6437 - acc: 0.7736 - val_loss: 0.6371 - val_acc: 0.7783 Epoch 7/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.5817 - acc: 0.7962 - val_loss: 0.6174 - val_acc: 0.7872 Epoch 8/30 50000/50000 [==============================] - 216s 4ms/step - loss: 0.5347 - acc: 0.8120 - val_loss: 0.5697 - val_acc: 0.8086 Epoch 9/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.4989 - acc: 0.8255 - val_loss: 0.5885 - val_acc: 0.8058 Epoch 10/30 50000/50000 [==============================] - 216s 4ms/step - loss: 0.4632 - acc: 0.8362 - val_loss: 0.5526 - val_acc: 0.8129 Epoch 11/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.4324 - acc: 0.8483 - val_loss: 0.5568 - val_acc: 0.8198 Epoch 12/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.4154 - acc: 0.8542 - val_loss: 0.5906 - val_acc: 0.8065 Epoch 13/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3894 - acc: 0.8634 - val_loss: 0.5491 - val_acc: 0.8212 Epoch 14/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3727 - acc: 0.8697 - val_loss: 0.5525 - val_acc: 0.8212 Epoch 15/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3477 - acc: 0.8784 - val_loss: 0.5607 - val_acc: 0.8241 Epoch 16/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3404 - acc: 0.8804 - val_loss: 0.5476 - val_acc: 0.8287 Epoch 17/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3208 - acc: 0.8861 - val_loss: 0.5676 - val_acc: 0.8302 Epoch 18/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.3099 - acc: 0.8898 - val_loss: 0.5521 - val_acc: 0.8274 Epoch 19/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2986 - acc: 0.8927 - val_loss: 0.5752 - val_acc: 0.8226 Epoch 20/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2948 - acc: 0.8978 - val_loss: 0.5946 - val_acc: 0.8218 Epoch 21/30 50000/50000 [==============================] - 216s 4ms/step - loss: 0.2755 - acc: 0.9036 - val_loss: 0.6167 - val_acc: 0.8211 Epoch 22/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2726 - acc: 0.9050 - val_loss: 0.5721 - val_acc: 0.8363 Epoch 23/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2623 - acc: 0.9081 - val_loss: 0.5658 - val_acc: 0.8354 Epoch 24/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2633 - acc: 0.9080 - val_loss: 0.5759 - val_acc: 0.8347 Epoch 25/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2575 - acc: 0.9105 - val_loss: 0.6118 - val_acc: 0.8337 Epoch 26/30 50000/50000 [==============================] - 215s 4ms/step - loss: 0.2530 - acc: 0.9121 - val_loss: 0.5677 - val_acc: 0.8370 Epoch 27/30 50000/50000 [==============================] - 222s 4ms/step - loss: 0.2432 - acc: 0.9155 - val_loss: 0.6069 - val_acc: 0.8317 Epoch 28/30 50000/50000 [==============================] - 233s 5ms/step - loss: 0.2387 - acc: 0.9163 - val_loss: 0.5798 - val_acc: 0.8387 Epoch 29/30 50000/50000 [==============================] - 232s 5ms/step - loss: 0.2392 - acc: 0.9163 - val_loss: 0.6137 - val_acc: 0.8265 Epoch 30/30 50000/50000 [==============================] - 230s 5ms/step - loss: 0.2395 - acc: 0.9169 - val_loss: 0.5662 - val_acc: 0.8392 Test Loss: 0.5662494749784469 Test Accuracy: 0.83921epochあたりの時間
GPU:30s前後
CPU:220~230s
大体、6倍くらい変わった。もっといろんなデータを試したい。
- 投稿日:2019-07-28T21:12:13+09:00
Scrapyでformを送信する際にJavaScriptを回避する
問題
- Scpapy は JavaScript で生成されたコンテンツにアクセスできないため、例えば、確認のために表示されるアラートウィンドウの「OK」をクリックして先に進む、などができないことがある。
根本的な解決策
- JavaScriptを制御できるSeleniumなどを併用する。
- (参考記事)StackOverflow
- ScrapyとSeleniumを併用するサンプルコードもある
簡単な解決策(条件付き)
- 場合によっては もっと簡単に解決できる。
- 以下のform送信ボタンのように、
onclick処理でJavaScriptのイベントが発動している場合には、scrapyの機能で回避できる。<input type="submit" onclick="return confirm('確定していいですか?')" name="submit" value="確定" class="button">
- クラスオブジェクト
scrapy.FormRequest.from_responseのパラメータdont_clickをTrueに指定することで、送信ボタンのクリックを省略して form を送信できる。これを利用すれば、onclickによって発動するイベントを回避して form が送信される。def submit_form(self, response): yield scrapy.FormRequest.from_response( response, formcss = 'table#table1 > tr:nth-child(1) > td.value > form', formdata = dict( decision = '1' ), dont_click = True )〜おしまい〜
- 投稿日:2019-07-28T21:09:09+09:00
youtubeにアップロードされた動画や音楽をローカルにダウンロードする
youtube.pyfrom pytube import YouTube url = input("enter youtube movie url >>>") yt = YouTube(url) for lis in yt.streams.all(): print(lis) itag = input("enter itag >>>") yt.streams.get_by_itag(itag).download()
- 投稿日:2019-07-28T21:03:19+09:00
Jupyter にスニペット機能を付加する Chrome 拡張を開発した
結果
Source
https://github.com/harupy/junippets
近いうちに Chrome Store に公開する予定
動機
- 同じコードを毎回書くのが面倒だった(
import pandas as pdとかpd.read_csvとか)- Jupyter notebook snippets menu という Jupyter の拡張機能の存在は認識していたが、メニューまでの移動と、数回のクリックを伴う仕様がどうも気に入らなかった
- ホームポジションから離脱せずに済む方法を探し求めていた
実装
既にご存知の方もいると思うが、Jupyter の各セルの Editor 部には CodeMirror と呼ばれるライブラリが使われている(Kaggle や GoogleColab にも使われている)。この CodeMirror のお力を拝借することで、セルの状態(コード、カーソル位置など)を取得・変更することができる。
- Document: CodeMirror: User Manual
- Github: codemirror/CodeMirror: In-browser code editor
デフォルトの状態ではスニペット機能など備わっていないので、Chrome 拡張を使って、後出しで CodeMirror のキーイベント関連の挙動を上書きして、スニペット機能を付加している。スニペットの展開キーには
Shiftを割り当てた(Tabを割り当てることも検討したが、既に自動補完のトリガーとして使われていたので断念した)。最後に
仕事や趣味で Jupyter を使用している皆様のお力になれれば幸いです!


- 投稿日:2019-07-28T19:30:33+09:00
Pythonの集合型setの基本
はじめに
Pythonのsetについて最近学習したので基本をまとめる。
set型とは
set型もシーケンスと似たデータ型で、リストのように複数の要素を保存できる。
(シーケンスとは、複数の要素を持つデータ型のこと。(例:リスト・タプルなど))
ではリストと何が違うのか。setはリストと違い、中の要素が重複されないように管理される。
既にsetの中に存在する値を登録しようと思っても、新しい要素が追加されない。
また、インデックスを使って値を取り出すこともできない。つまり、set型とは重複しない要素のグループを集合として扱うためのデータ型。
set型を使うことで複数の集合の集合演算ができる。
要素を集合として扱うため、setに要素の順番はない。setの定義
setは要素に数値や文字列を追加できる。
setの定義は、{}を使用する。ここで、集合numberに1〜6の整数を要素として定義してみる。
例number = {1,2,3,4,5,6} print(number) {1, 2, 3, 4, 5, 6} #結果ただし、リストや辞書は変更できてしまうため、setの要素にはできない。
例list_num = [1,2,3] set_num = {list_num,4,5,6} TypeError: unhashable type: 'list' #結果同様の理由からsetを別のsetの要素にすることもできない。
例A_num = {1,2,3} B_num = {A_num,4,5,6} TypeError: unhashable type: 'set' #結果ちなみに、重複した値を要素に指定して結果をみてみる。
number = {1,2,3,4,5,6,6} pirnt(number) {1, 2, 3, 4, 5, 6} #結果setの和集合
複数の集合の和集合を考える。
setの和集合を得る場合、|演算子を使用する。
和集合→+演算子を使いそうなところだが、
和集合の場合は重複した要素は足されないため論理和(OR)に近いため、この演算子を用いる。実際に和集合を計算してみる。
例prime = {2,3,5,7,11,13} number = {1,2,3,4,5} prime_number = prime | number print(prime_num) {1, 2, 3, 4, 5, 7, 11, 13} #結果setの差集合
複数の集合の差集合を考える。
2つの集合A,Bを与えた時、集合Aから集合Bの要素を取り除く。
setの差集合を得る場合、-演算子を使用する。
実際に差集合を計算してみる。例number = {1,2,3,4,5,6} even = {2,4,6,8,10} odd_number = number - even print(odd_number) {1,3,5} #結果setの交わり
複数の集合の交わりを考える。
setの交わりを得る場合、&演算子を使用する。
実際に交わりを計算してみる。例number = {1,2,3,4,5,6} even = {2,4,6,8,10} even_number = number & even print(even_number) {2, 4, 6} #結果setの対象差
複数の集合の対象差を考える。
2つの集合の対象差をとると、両方のsetに共通して含まれている要素だけを取り除いた要素の集合を得ることができる。
setの対象差を得る場合、^演算子を使用する。
実際に対象差を計算してみる。例dice = {1,2,3,4,5,6} even = {2,4,6,8,10} not_even_dice = dice ^ even print(not_even_dice) {1, 3, 5, 8, 10} #結果リストからsetへの変換
組み込み関数set()を使うとリストをsetに変換することができる。
以下の結果から、setは「重複しない要素の集合」であること、「要素の順番はない」ということも確認できる。例list_alpha = ["A","B","C","D","E","E"] set_alpha = set(list_alpha) print(set_alpha) {'E', 'C', 'A', 'D', 'B'} #結果以上です。

- 投稿日:2019-07-28T19:14:56+09:00
Flask+Python+Herokuで環境構築してから何かをデプロイするまで
0. はじめに
タイトルの通りです。
HerokuのPythonチュートリアル(https://devcenter.heroku.com/articles/getting-started-with-python)はDjangoで作成したデモアプリのデプロイ方法を解説しています。
しかし, 学習コストの高いDjangoよりももっと手軽なFlaskでアプリを作りたかったので実際に試してみました。
参考記事:
https://tanuhack.com/python/deploy-flask-heroku/
https://qiita.com/ymgn_ll/items/96cac1dcf388bc7a8e4e開発環境:
- MacOS ver 10.14.5
- Safari ver 12.1.1
- Homebrew ver 2.1.8
- Python ver 3.6.4
- Flask ver 1.1.1
- Werkzurg ver 0.15.5
1. Herokuのインストール, アカウント作成, ログイン
HomebrewでHerokuをインストールします。
$ brew install heroku/brew/herokuHerokuでアカウントを作成しましょう。
(詳細はhttps://tanuhack.com/python/deploy-flask-heroku/などを参照してください)作成が無事に終わったらHerokuにログインします。
$ heroku loginすると,
> heroku: Press any key to open up the browser to login or q to exit:と指示されるので,
q以外の任意のキーを押しましょう。
ブラウザが開いてHerokuのログイン画面に遷移します。ログインが成功すると以下のように表示されるはずです:
> Opening browser to <URL_FOR_AUTHENTIFICATION> > Logging in... done > Logged in as <USERNAME>2. 仮想環境の作成と立ち上げ
プロジェクト用のディレクトリを作成し, そこに移動しましょう:
$ mkdir myproject $ cd myproject # myproject <- いまこここの直下に
myenvという別のディレクトリを作成し, そこに移動します:$ mkdir myenv $ cd myenv # myproject # └ myenv <- いまここ当然, いまの時点で
myenvの中身は空っぽです:$ ls # 何も表示されないここで
python3 -m venv .と打つと,myenv内部に仮想環境を立ち上げるための種々のファイルが自動的に作成されます:$ python3 -m venv . $ ls > bin include lib pyvenv.cfg # myproject # └ myenv <- いまここ # ├ bin # | ├ activate # | ... # | # ├ include # | ├ ... # | # ├ lib # | └ python3.6 # | └ ... # | # └ pyvenv.cfgさっそくこのファイルを使って仮想環境内に入りましょう:
$ source bin/activateターミナルの左端が
(仮想環境ファイルディレクトリ名)となったら成功です:# myenv以下のファイルで構成された仮想環境内に入っている (myenv) $仮想環境から抜けるには
deactivateと入力します:(myenv) $ deactivate $ # 仮想環境から抜けた3. パッケージの準備
ふたたび仮想環境に入ります:
$ source bin/activate仮想環境には最低限のパッケージしかインストールされていません。
そこでflaskとgunicornをインストールしておきましょう:(myenv) $ pip install flask gunicorn4. ファイルの準備
次にFlaskアプリを動かすために必要なファイルを作成していきましょう。
作成するファイルは以下の3つです:
- hello.py
- requirements.txt
- Procfile
完成予想図myproject ├ hello.py (Flaskアプリ本体) ├ requirements.txt (Herokuでの起動に必要) ├ Procfile (Herokuでの起動に必要) └ myenv <- いまここ ├ bin ├ include ├ lib └ pyvenv.cfg4-1. hello.pyの作成 〜Flaskをローカルで動かそう〜
ローカルで動かないFlaskアプリはHerokuにデプロイしても動きません。
画面に Hello World! と表示するだけの簡単なアプリを作っていきましょう。(myenv) $ cd .. # myproject内に移動 (myenv) $ touch hello.pyhello.pyには次のように記述します:
hello.py# -*- coding: utf-8 -*- from flask import Flask # 自分自身の名前をappという変数でインスタンス化 app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' # コマンドラインで本ファイルを起動させたときの動作 if __name__ == '__main__': # 安全のため debug=False とする # 特に本番稼働するファイルでは debug=True としてはいけない! app.run(debug=False)保存できたら, コマンドラインから
hello.pyを起動してみましょう:(myenv) $ python3 hello.py次のように表示されるはずです:
> * Serving Flask app "hello" (lazy loading) > * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. > * Debug mode: off > * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)最後の行の
http://127.0.0.1:XXXXのXXXXはポート番号を示しています。ポート番号が5000番なら, ブラウザのURL欄に
localhost:5000と入力しましょう。
画面に Hello World! と表示されたら成功です!コマンドラインで
Control+Cを入力すると, Flaskアプリを終了できます。4-2. Procfileの作成 〜Flaskをgunicornで動かそう〜
次のコマンドを打ってみてください:
(myenv)$ gunicorn hello:appこのように表示されるはずです:
[2019-07-28 15:07:00 +0900] [30377] [INFO] Starting gunicorn 19.9.0 [2019-07-28 15:07:00 +0900] [30377] [INFO] Listening at: http://127.0.0.1:8000 (30377) [2019-07-28 15:07:00 +0900] [30377] [INFO] Using worker: sync [2019-07-28 15:07:00 +0900] [30380] [INFO] Booting worker with pid: 303802行目に
http://127.0.0.1:8000とありますね。
ここでブラウザのURL欄にlocalhost:8000と入力してみましょう。
やはり画面に Hello World! と表示されるはずです。つまり, pythonファイルを直接起動するかわりに, gunicornコマンドを通じてFlaskアプリを起動させることもできるということです。
Herokuもアプリを起動させる際にはgunicornコマンドを使います。
そこで, Herokuに実行してほしいgunicornコマンドをあらかじめ指定しておきましょう。
myprojectディレクトリ直下にProcfileを作成し,(myenv)$ touch Procfile次のように編集します:
Procfileweb:gunicorn hello:appこれで, Herokuにアプリ起動指示を与えたときに
gunicorn hello:appコマンドを通じてFlaskアプリを起動してくれるようになります。4-3. requirements.txt
ローカル環境で動いたアプリがきちんと他の環境でも動作するように, 必要なライブラリの種類やバージョンを列挙しておくファイルがrequirements.txtです。
これはコマンド一発で簡単に作成できます:
(myenv)$ pip freeze > requirements.txtこうするとHerokuはrequirements.txtの内容を読み取り, アプリ起動時に必要なライブラリを自動的にHeroku内部にインストールしてくれます。
5. Herokuにデプロイ
Herokuへのアプリのデプロイは, gitリポジトリをpushする形で行います。
つまり, Heroku上で編集作業を加えたり, Herokuに個々のファイルをアップロードしたりする作業は必要ないということです(便利!!)GitHubに日頃から使い慣れている人ならとても簡単にアプリを公開することができます。
まずはアプリを格納したローカルリポジトリを作成しましょう。
(myenv) $ git init (myenv) $ git add hello.py requirements.txt Procfile (myenv) $ git commit -m 'My First Commit!'ローカルリポジトリにはhello.py, requirements.txt, Procfileの3つのファイルが含まれていればOKです。
次に
heroku createと入力しましょう:(myenv) $ heroku createすると, Heroku上に空のリポジトリが作成されます。
Creating app... done, ⬢ XXXX-YYYY-ZZZZ https://XXXX-YYYY-ZZZZ.herokuapp.com/ | https://git.heroku.com/XXXX-YYYY-ZZZZ.git
.herokuapp.comの直前を自分の好きな名前に指定することもできます。その場合はheroku create <好きなプロジェクト名>と入力しましょう。このHeroku上のリポジトリは, GitHub上のリモートと似ています。
PC上のローカルリポジトリをHeroku上にpushしたり, 逆にHerokuからローカル環境にpullしたりすることができるというわけです。早速, ローカルリポジトリをHeroku上にpushしましょう。
(myenv) $ git push heroku masterこれでHerokuへのアプリのデプロイ完了です!
あとは(myenv) $ heroku openと打てば, Flaskアプリが起動し, 画面にHello World!と表示されるはずです。
- 投稿日:2019-07-28T19:11:59+09:00
Neural NetworkによるTopic Modelingとその実装
この記事では、Neural Topic Modelingについて調べたことをまとめます。
個人的解釈が多少含まれる記事となっていますので、気になる点がありましたら記事へのコメントやTwitterでリプライをいただければと思います。
Twitter : @m3yrin
TL;DR
- 従来の確率生成モデルとしてのトピックモデルに対して、Neural Topic Modeling(NTM)の強みを説明します。
- PyTorchによってNTMの簡易な実装を行い、コードを公開します。
- 従来手法としてLDAでTopic Modelingを行い、NTMとの比較を行います。
トピックモデルとは
トピックモデルは、文書集合で話題となっているトピックを、同じ文書で現れやすい語彙として抽出する手法です。
文書のメタ情報の抽出や、トピックを使って文書の分類に使用できます。
(岩田具治, トピックモデル 機械学習プロフェッショナルシリーズ)トピックモデルでは、文書は構造化されている必要はないため、構造化させる手間がなく、使用しやすい分析手法と言えます。
(Amazon SageMaker ニューラルトピックモデルのご紹介, https://aws.amazon.com/jp/blogs/news/introduction-to-the-amazon-sagemaker-neural-topic-model/)Latent Dirichlet Allocation(LDA)
トピックモデルのモデル化の手法として有名なのは、潜在ディリクレ配分法(Latent Dirichlet Allocation; LDA)です。LDAでは一つの文書に複数のトピックを持つと仮定し、文章が生成される過程をモデル化します。
具体的には、下記のように表されます。\begin{aligned} \theta_{d} & \sim \operatorname{Dir}\left(\alpha_{0}\right), \quad \text { for } d \in D \\ z_{n} & \sim \operatorname{Multi}\left(\theta_{d}\right), \quad \text { for } n \in\left[1, N_{d}\right] \\ w_{n} & \sim \operatorname{Multi}\left(\beta_{z_{n}}\right), \quad \text { for } n \in\left[1, N_{d}\right] \end{aligned}$\theta_d$ : 文書 $d$ に対するTopic分布
$z_n$ : 文書中の単語 $w_n$に対するトピック割当
$\alpha_0, \beta_{z_{n}}$ : Dirichlet分布のhyper-parameterLDAでは、文書集合が与えられたときの各パラメータの事後分布を変分推論やギブスサンプリングによって推論することが学習の目標となります。
memo(上式の解釈)
解釈をあえて書くと以下のような流れで確率分布から文章を生成します。
1. 文書dに対して、ディリクレ分布からトピックの分布$\theta_d$をサンプル
2. 文書d中の単語数$N_d$だけトピック$z_n$を割り当て
3. $z_n$に対応するパラメータ$\beta_{z_n}$で、単語$w_{n}$を生成
確率生成モデルの拡張の難しさ
LDAのようなシンプルなトピックモデルに対して、様々な拡張が考えられますが、モデルの表現力が強化されるほど、推論もより複雑になります。
相関トピックモデル等、Non-conjugate modelsではこれが顕著となるようです。1また、モデルの変更を行なった場合、それがたとえ小さな変更であったとしても、推論方法の再導出が必要となり、使用の障害になります。2
Neural Networkによるモデル構築
Neural Networkの高い表現力で、複雑な分布も近似できると予想できます。
事後分布を直接マップさせる推論モデルをNeural Networkで構築することができれば、確率生成モデルの困難さを回避できます。2Neural Topic Model
Neural Topic Modelは、有り体に言えばVariational Autoencoder(VAE)であり、VAEをトピックモデルのコンテキストで使用します。
Wangらによる論文3をもとに、最もシンプルなGaussian Softmaxモデル(GSM)を説明します。GSMは有限のトピック数を仮定するモデルです。
(NTMの評価を行ったMiaoらによる論文1よりもWangらによる論文のモデルのほうが簡潔で著者実装も提供されているので、こちらを参考にします)
Bag of Wordsの生成
文書集合$C$
C = \left\{ \mathbf { x } _ { 1 },\mathbf { x } _ { 2 }, ... , \mathbf { x } _ { | C | } \right\}のそれぞれの文章$\mathbf{x}$から、BoWベクトル
$$
\mathbf { x } _ { b o w } \in \mathbb{R}^{V}
$$を作成します。$V$は語彙数です。
Encoder
$$
\mu = f _ { \mu } \left( f _ { e } \left( \mathbf { x } _ { b o w } \right) \right),
\log \sigma = f _ { \sigma } \left( f _ { e } \left( \mathrm { x } _ { b o w } \right) \right)
$$
$f _ { * } ( \cdot )$ はReLUを活性化関数とする全結合層です。Decoder
以下のステップで$\mathbf { x } _ { b o w }$を再構成します。
- 潜在トピック変数zをサンプル$\mathbf{z} \sim \mathcal{N}\left(\mu, \sigma^{2}\right)$
- 混合トピックを計算 $\theta={softmax}\left(f_{\theta}(\mathbf{z})\right)$
- それぞれの単語$w \in \mathbf{x}$に対して
- $w \sim {softmax}\left(f_{\phi}(\theta)\right)$
特に$f_{\phi}$のWeight Matrixは、トピックに対する単語の分布$\left(\phi_{1}, \phi_{2}, \ldots, \phi_{K}\right)$とみなすことができます。これについては、後述します。
目的関数
目的関数は以下のように作ります。
\mathcal{L}_{N T M}=D_{K L}(p(\mathbf{z}) \| q(\mathbf{z} | \mathbf{x}))-\mathbb{E}_{q(\mathbf{z} | \mathbf{x})}[p(\mathbf{x} | \mathbf{z})]$p(z)$は標準正規分布、$q(z | x)$はデータに対する$z$の事後分布の近似であり、Encoder出力に対応します。
$p(x|z)$は、トピック変数から文章を生成するネットワークで、Decoderの出力に対応します。目的関数も基本的にVAEと同じで、第一項はEncoderの出力と事前分布$p(z)$とのKLダイバージェンス損失、第二項は再構成損失になります。
実験と評価
Miaoらによる論文1では、三つのデータセット(MXM song lyrics, 20NewsGroups, Reuters RCV1-v2 news)にて、NTMの性能を評価しています。
NTMのモデルとして、今回紹介したGSMと、Gaussian Stick Breaking(GSB), Recurrent Stick Breaking(RSB)、ベースラインとしてOnlineLDA, NVLDAというモデルでパープレキシティを評価し、NTMのモデルがベースラインを上回ったと報告しています。
実装
Wang論文3の著者実装( https://github.com/yuewang-cuhk/TAKG )にNTMの実装が含まれていたため、これを参考に簡易なNTMをPyTorchで実装してみました。
また、日本語のデータセットでNTMとGensimのLDAモデルで性能の比較を行ってみたいと思います。
データセット
データセットとして、livedoorニュースコーパスを使用します。
https://www.rondhuit.com/download.html
前処理のコードについてはtdualdir氏によるブログ記事「LDAとそれでニュース記事レコメンドを作った。」を参考にしました。
http://tdual.hatenablog.com/entry/2018/04/09/133000
上の記事ではTokenizerとしてMecabを使用していますが、MecabをGoogle Colaboratoryで使用するのが手間だったため、TokenizerとしてJanomeを使用しています。
https://mocobeta.github.io/janome/
Janomeに合わせて、ドキュメントのtokenizerクラスを変更しています。
NTMの実装
NTMの実装は下記に公開しています。
工夫した部分について、下記でコメントしたいと思います。
Tokenizer
データのTokenizerでは、URL・ストップワードの除去、特定の品詞の抽出などをしています。
JanomeにAnalyzerという前処理用のAPIがあるようだったので、それを使用してみました。class docTokenizer: def __init__(self, stopwords, parser=None, include_pos=None, exclude_posdetail=None, exclude_reg=None): self.stopwords = stopwords self.include_pos = include_pos if include_pos else ["名詞", "動詞", "形容詞"] self.exclude_posdetail = exclude_posdetail if exclude_posdetail else ["接尾", "数"] self.exclude_reg = exclude_reg if exclude_reg else r"$^" # no matching reg self.char_filters = [ UnicodeNormalizeCharFilter(), RegexReplaceCharFilter(r"https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+", u''), #url RegexReplaceCharFilter(r"\"?([-a-zA-Z0-9.`?{}]+\.jp)\"?", u''), #*.jp RegexReplaceCharFilter(self.exclude_reg, u'') ] self.token_filters = [ NumericReplaceFilter(), POSKeepFilter(self.include_pos), POSStopFilter(self.exclude_posdetail), LowerCaseFilter() ] self.analyzer = analyzer.Analyzer(self.char_filters, Tokenizer(), self.token_filters)Dataloader
Dataloaderはインスタンス生成時にまとめてデータをBow形式に変換します。
self.bow_data = np.array([bow_vocab.doc2bow(s) for s in data])nextで呼ばれた際には、batch_sizeで指定されたサイズでバッチを返します。
gensimのデータ形式は下記のような単語のindexと出現頻度のタプルの形式では、Neural Netの入力としては使いにくいので
[(13, 1), (25, 1), (26, 1), (28, 2), (34, 4), (56, 13), (69, 1), (71, 3), ...self._pad(batch)でbowデータを(batch_size, bow_vocab)のsizeに変更します。bowデータで現れないindexは0で埋めるような処理をします。
def _pad(self, batch): bow_vocab = len(self.bow_vocab) res_src_bow = np.zeros((len(batch), bow_vocab)) for idx, bow in enumerate(batch): bow_k = [k for k, v in bow] bow_v = [v for k, v in bow] res_src_bow[idx, bow_k] = bow_v return res_src_bowNTM.print_topic_words()
トピックを表す単語群はdecoderの$f_{\phi}$の重みから知ることができます。
もう少し具体的に書くと、トピック数が3の時のトピック変数$\theta$が
$$\theta = (1, 0, 0)$$だったとすると、再構成される単語群dは
d = {softmax}\left(f_{\phi}(\theta)\right) = {softmax}\left(W_{{\phi}}^{T}\theta\right) \\= {softmax}\left((\phi_{1}, \phi_{2}, \phi_{3})^{T}(1, 0, 0)\right) = {softmax}\left(\phi_{1}\right)となります。$\theta$のそれぞれの要素番号に対応する$W_{{\phi}}$の要素を見ることで、トピックを表す単語を知ることができます。
実装では、$f_{\phi}$は
self.fcd1 = nn.Linear(topic_num, self.input_dim)なので、NTM.print_topic_words()では
beta_exp = self.fcd1.weight.data.cpu().numpy().Tとして、fcd1の重みを取得し、
for k, beta_k in enumerate(beta_exp): topic_words = [vocab_dic[w_id] for w_id in np.argsort(beta_k)[:-n_top_words - 1:-1]]のように、重みの大きい順に単語のindexを取得しています。
論文に書いていない実装
このセクションでは、論文には明記されていない内容を他の論文や実装を参考にして実装した内容です。個人的解釈のもとに実装していますが、間違っている場合には指摘していただけると嬉しいです。。
Perplexityの計算
Perplexityは下記で計算される指標で、トピックモデルや言語モデルの性能の指標とされます。Perplexityが小さいほど良い性能となります。
モデルがランダムな単語を返すモデルでは文書の語彙数、最小では1となります。perplexity\left(D_{\text { test }}\right)=\exp \left\{-\frac{\sum_{d=1}^{M} \log p\left(\mathbf{w}_{d}\right)}{\sum_{d=1}^{M} N_{d}}\right\}指数部の分子は負の対数尤度なので、Cross Entropy lossを全文書の単語数で割って計算する形で通常は計算されるようです。
https://github.com/keras-team/keras/issues/2317
今回の実装でも、Cross Entropy lossを全単語数で割ることでPerplexityを計算しています。
def compute_perplexity(model, dataloader): model.eval() loss = 0 with torch.no_grad(): for i, data_bow in enumerate(dataloader): data_bow = data_bow.to(device) data_bow_norm = F.normalize(data_bow) z, g, recon_batch, mu, logvar = model(data_bow_norm) #loss += loss_function(recon_batch, data_bow, mu, logvar).detach() loss += F.binary_cross_entropy(recon_batch, data_bow, size_average=False) loss = loss / dataloader.word_count perplexity = np.exp(loss.cpu().numpy()) return perplexity他の計算方法として、NVDM(Miao+, ICML 2016, Neural Variational Inference for Text Processing)の著者実装ではKL項を含むLossを全単語数で割る方法もあるようです。
https://github.com/ysmiao/nvdm/blob/19bc3d630bc0bace13555e2515de082771827a76/nvdm.py#L140
Perplexityの定義的にはKL項は含まれない方が良いと考えていますが、論文によってPerplexityを直接比較できない可能性があることは認識しておく必要があると思っています。
fϕのWeightのスパース率へのペナルティ
Wang論文3の著者実装では、先に述べた目的関数に、$f_{\phi}$のWeightに対するL1ペナルティを加えた上でbackwordを行っています。
def l1_penalty(para): return nn.L1Loss()(para, torch.zeros_like(para)) def update_l1(cur_l1, cur_sparsity, sparsity_target): diff = sparsity_target - cur_sparsity cur_l1.mul_(2.0 ** diff) def check_sparsity(para, sparsity_threshold=1e-3): num_weights = para.shape[0] * para.shape[1] num_zero = (para.abs() < sparsity_threshold).sum().float() return num_zero / float(num_weights)loss = loss + model.l1_strength * l1_penalty(model.fcd1.weight)L1ペナルティに対する係数
model.l1_strengthは、$f_{\phi}$のスパース率と目標のスパース率(sparsity_target)の差が大きいほど、大きな値に設定されます。(update_l1())
sparsity_targetは0.85など、比較的大きな値に設定され、$f_{\phi}$のWeightがスパースになるように働きます。$f_{\phi}$のWeightをスパースにすることについて、論文ではその解釈を述べていません。
個人的解釈としては、複数のトピックに同じ単語が含まれないように$f_{\phi}$のWeightをある程度スパースにしているのだと考えています。妥当な実装だと思われますので、そのまま使用しました。
結果
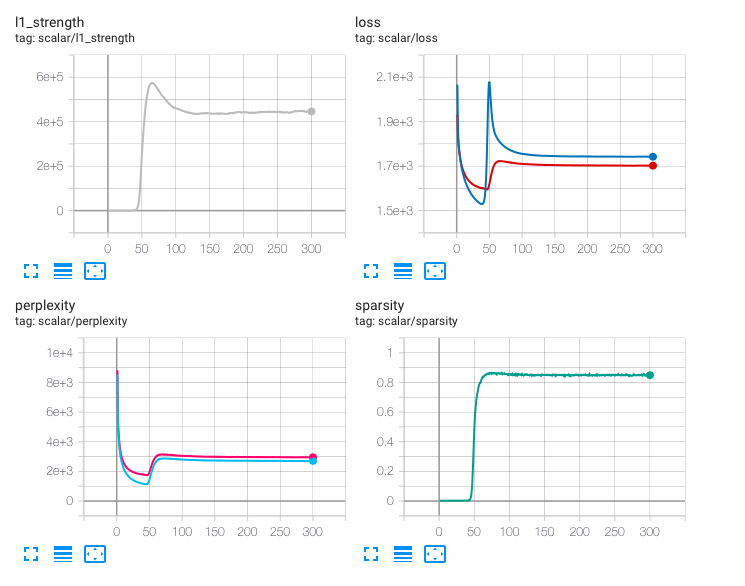
はじめにNTMのloss等の変化について書きます。
パラメータは下記の通りです。# set random seeds random.seed(123) torch.manual_seed(123) num_articles = -1 # data size limitation max_src_len = 150 max_trg_len = 10 max_bow_vocab_size=100000 # Model parameter hidden_dim = 1000 topic_num = 20 target_sparsity=0.85 # Training parameter batch_size = 32 learning_rate = 0.001 n_epoch = 300
LossとPerplexityは~50 Epochでは単調に減少しますが、50 EpochからはL1ペナルティによる効果によりLoss、Perplexity共に増加します。Sparsityが
target_sparsityで指定した0.85に到達し、100 Epoch程度で安定し始めます。実験的にはSparsityが高くなるかわりに、Perplexity多少悪化するようです。
L1ペナルティの係数
model.l1_strengthの初期値は1e-7と小さい値に指定していますが、この値を大きすると、L1ペナルティの効果は50 epochより早く現れます。
model.l1_strengthの初期値は小さくし、L1ペナルティの効果が現れるのをある程度遅らせた方が、最終的なPerplexityは小さくなるようです。Perplexity
PerplexityではLDAの方が安定して良いスコアを出しました。
LDA @ 10 passes 1654.3 NTM @ 300 Epoch 2994.5 トピック単語
NTMもLDAも概ねトピックごとにトピック単語をグループ化できています。
NTMの方が記号等(⇒, :@, ---, ◯)が含まれてしまっていますが、これは実装である程度改善できると思われます。
また、NTMに比べLDAでは単語の重複("映画"等)が多いように見受けられます。NTM
Topic 0: ねこ store apps details タップ htc play :/ 要件 アプリ Topic 1: ソフトウェア 更新 pin 書換え ⇒「 ケータイアップデート ローミング 当社 sms 手順 Topic 2: ビューアー ubuntu ultrabook windows インテル linux ssd usb dropbox mac Topic 3: 占い nifty 鑑定 電力 歯 占い師 節電 消費 先生 測定 Topic 4: 転職 求人 年収 type :@ 辛口 説教 瞬時 お答え 入社 Topic 5: 撮影 シャッター 撮る 写真 カメラ 撮れる 露出 合成 作品 画像 Topic 6: 本田 ブータン ニキビ 中国 販売 市場 肌 購入 契約 価格 Topic 7: note galaxy sc siii サムスン ペン ロゴ samsung iii google Topic 8: チョコレート ケーキ チーズ ショコラ 飴 クリスマス スイーツ チョコ 味わい 神社 Topic 9: 笑 テレコムスクエア ルータ レンタル --- 食べる レビュー 空港 medias 僕 Topic 10: 試合 野村 選手 sports 佑 なでしこ 戦 長友 野球 サッカー Topic 11: 妄想 出産 バッテリー イケショップ 子ども 自転車 歯 ホラー ペット mah Topic 12: xperia sx ダイエット gx 恋愛 体重 恋 レッツ acro セキュリティ Topic 13: ケータイアップデート 河本 サッチャー ドバイ 鉄 受給 マーガレット ヘルプ 賞 グローブ Topic 14: 小沢 クルマ smith 金子 スミス paul 栄子 自動車 吉田 ポール Topic 15: ◯ msm gsm ghz lte mah medias qualcomm xi ワンセグ Topic 16: 沢尻 神社 エリカ ライブ beetv line 曲 料理 歌う 会議 Topic 17: wimax キャプテン isw au アベンジャーズ kddi 犯罪 htc ヒーロー uq Topic 18: 掲示板 批判 橋下 報じる 市長 有吉 韓国 相次ぐ 物議 ネット Topic 19: ゴルフ ゴルファー パター スイング シャフト クラブ スコア レッスン ラウンド 練習LDA
Topic 1: 選手 氏 試合 代表 戦 放送 番組 語る 監督 サッカー Topic 2: 韓国 ネット 位 iphone 語 ケータイアップデート ユーザー 氏 心 掲示板 Topic 3: 自転車 ゴルフ 車 チョコレート クルマ ネット クラブ 自動車 被災 小沢 Topic 4: 賞 アプリ 映画 写真 東京 アカデミー 撮影 iphone 受賞 作品 Topic 5: アプリ android max ドコモ スマート 利用 エスマックス フォン サービス 向け Topic 6: 写真 氏 テレビ ネット 売れ筋 作品 チェック iphone 展 ニュース Topic 7: 企業 年収 会社 結果 位 やる % 調査 氏 香川 Topic 8: 応募 プレゼント キャンペーン クリスマス 当選 くださる 東京 いただく 期間 限定 Topic 9: 転職 仕事 求人 livedoor 会社 悩み 営業 東京 考える 部屋 Topic 10: 映画 作品 監督 公開 本 声 観る ネット 演じる 役 Topic 11: 画面 表示 ソフトバンク アプリ 設定 知る iphone facebook 入力 クリック Topic 12: 肌 ケア 美 効果 美容 応募 当選 韓国 メイク 香り Topic 13: ゴルフ % デザイン ブランド 女子 アイテム ファッション 商品 ポイント 男性 Topic 14: ネット 番組 放送 女子 テレビ !」 akb 声 好き やる Topic 15: 更新 ソフトウェア くださる ダウンロード ビデオ 利用 アップデート データ 設定 表示 Topic 16: 結婚 男性 仕事 恋愛 独 相手 代 聞く 好き しれる Topic 17: 映画 公開 ドラマ 演じる 本 映像 作品 dvd 役 監督 Topic 18: 対応 スマート フォン 機能 搭載 android モデル max サービス 端末 Topic 19: 製品 バッテリー 搭載 対応 pc 撮影 カメラ 充電 容量 usb Topic 20: 映画 公開 孫 社長 作品 映像 本 シリーズ ジョン 韓国学習時間
計算コストはNTMの方が圧倒的に大きくなります。
- NTM
- (100 Epoch) ~ 15分 w/ GPU
- LDA
- (10 Passes) ~ 1分14秒 w/ CPU
まとめ
従来の確率生成モデルとしてのトピックモデルに対して、Neural Topic Modeling(NTM)の強みを説明しました。
- 確率生成モデルとしてのTopic Modelingでは、モデルの拡張や変更の際に推論が難しくなります。VAEとして構築することで、事後分布を直接推論でき、この困難さを解決できます。
PyTorchによってNTMの簡易な実装を行い、コードを公開しました。
- VAEをトピックモデルとして使用するときの工夫も説明しました。
従来手法としてLDAでTopic Modelingを行い、NTMとの比較を行いました。
- 計算コストとしては圧倒的にLDAの方が軽く、性能も安定します。
- Neuralに構築することで、細かなモデルの調整を行いやすくなります。
- たとえば、トピック単語の重複が起こりにくくなるよう調整したい場合、推論モデルの全見直しは必要なく、LossにSparsityについてのL1ペナルティ項を加えるだけで実現できます。


- 投稿日:2019-07-28T19:10:07+09:00
AIが三国志を読んだら、孔明が知力100、関羽が武力99、を求められるのか?をガチで考える物語(自然言語処理編)
背景
関羽「どれどれ、拙者たち英傑の活躍は後世では
どのように伝えられているのかな?」
孔明「なんとっ・・!!?扇からビーム出しとる?
そしてSDガンダムと融合しとる!?
あまつさえ、女体化して萌キャラなっとる!?」"この報告は孔明にとってはショックだった・・・"
劉禅「いや、オマイラは知力100だったり、
武力99だったりして優遇されとるだろ。
朕なんて101匹いても勝てないぞ」
魏延「オレ、ゲンシジン、ミタイ、ナッテル・・・」孔明「いや、わたしが知力100なのは当然でしょ」
司馬懿「まてぃ。最後に勝ったのはワシだよ?」
荀彧「違います。私こそが王佐の才・・・」甘寧「最強はこの鈴の甘寧」
張遼「張来々!最強はワタシだ!」
張飛「オレっちを忘れちゃいないかい!?」誰が一番、武力・知力が高いのか、
英傑たちの議論は白熱していった・・・。曹操「みなの衆、静まれいっ!!
ちかごろは、えーあいなるものがあると聞く。
わしは有能なものは泥棒でも使ってやるぞ。
えーあいに聞いてみようではないか!?」本投稿の趣旨
KOEIの武将ステータスに大きな敬意を払いつつ、
三国志の小説を 自然言語解析 & 機械学習 すると、
各武将のステータスはどのようになるのか?
の実験&研究を行う物語。まさに技術の無駄の無双乱舞。
(そして無駄に長い背景)Colaboratoryを使って、環境構築不要でブラウザだけで
誰でも本格的な「三国志分析」が出来るという、
誰得コダワリ技のご紹介。
(※ふつーの自然言語処理の技としても流用可)出来るだけ、コピペだけでお手元でも試していただけるように書く予定。
結論の一部を先に見てみよう
注:左から順に「武力、知力、政治、魅力」
武将名 本実験の推論結果 (参考)KOEI三国志5データ 曹操 95, 92, 87, 105 87, 96, 97, 98 劉備 89, 89, 84, 105 79', 77, 80,'99 諸葛亮 78, 98, 90, 104 60, 100, 96, 97 関羽 92, 75, 62, 82 99, 83, 64, 96 張飛 97, 61, 44, 77 99, 45, 17, 44 魏延 91, 65, 50, 68 94, 48, 37, 56 袁紹 70, 71, 66, 77 81, 77, 49, 92 吉川英治の「三国志」@青空文庫をINPUTとして、
「自然言語処理」と「機械学習」によって上記のように、
武力や知力などのパラメータを推論する。三国志小説の機械学習結果として、
1つの武将を50次元ベクトルに変換し、そのベクトルを、
全く同じ「式」に入れて出てきた値が、上記の表。このような方法:「小説(自然言語)」⇒「数値化」⇒「式」
によって、武力/知力を求めることが出来るか?
という実験&研究が今回のテーマ。他の成果としては、
以下のような武将名の「演算」が楽しめる。
(これも実際の出力結果より抜粋)
- 諸葛亮に近い人は誰?
- ⇒ 姜維、司馬懿、陸遜、周瑜、魏延、馬謖
- 劉備にとっての関羽は、曹操にとって誰?
- ⇒ 袁紹、張遼
- ※若いころの馴染み的な意味や対比が多いので袁紹?
- 孫権にとっての魯粛は、劉備にとって誰?
- ⇒ 司馬徽(水鏡先生)、徐庶
- ※賢者を紹介するポジションなのか?
精度の高い結果を得るためには、前提として、
三国志という特殊な小説を、
うまーく自然言語処理(の前処理)をすることが最重要。
草履売りから蜀漢皇帝になるように、処理の改善のたびに、
コードが三国志を征服していくような物語を楽しんでほしい。なお、機械学習の結果は面白いけれども、自然言語側から、
しかも1つの小説だけから作るのは精度に限度があるため、
本当にゲームのパラメータを決めたいならば、
INPUTとなる小説やテキストを大量に用意することが望ましい。
(このような手法が可能かどうか?を実験する目的であり、
実際にパラメータをコレで決めたいわけではない)天下三分の計 ~全体方針/目次~
曹操「えーあい?、えーあい?・・・」
楊修「おk、把握した。全軍退却!!」
劉備「待てぃ。話が終わってしまうw」
楊修「じゃあ劉備殿は えーあい が分かるのですかな?」
劉備「ぐっ! 孔明! 任せた、あとよろ!」
孔明「・・・。」
劉備「あとよろ! あとよろ!」
孔明「では天下三分の計の如く、
3つのステップで今回の計画をご説明しんぜよう」
劉備「(3回言わないとやってくれないんだもんな・・・)」■今回の進め方は以下3つのステップである。
① 吉川英治「三国志」@青空文庫を、
三国志の固有名称に気をつけて、
形態素解析し単語単位にバラす。② バラした結果をWord2Vecによって、ベクトル化する。
(Word2Vec:単語をN次元のベクトルで表現でき、
その足し算引き算等の演算が行える技術。
「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
https://qiita.com/youwht/items/f21325ff62603e8664e6
を先に見て頂くと良いかもしれない)③ それぞれの「武将」がベクトル化された状態になるため、
その中から「武力」や「知力」と相関が高いような
ベクトル(複数ベクトルの集合体)を見つければ、
何らかの数式によって、KOEI三国志のパラメータに
近いものが計算できるのではないか?一番最初にして最大の難関は、①の形態素解析、
三国志の世界を出来るだけ正しく認識すること。以下のような、三国志の世界独特の壁が立ちはだかる。
- 韓玄,劉度,趙範,金旋「我ら荊州四英傑をえーあいは分かるかな?」
- 玄徳=劉玄徳=劉備玄徳 ⇒ 「劉備」のこと
※いらすとやさんの劉備の画像(あるんですね!)ではさっそく①形態素解析から始めよう!
桃園の誓い ~環境準備~
"我ら生まれた時は違えども、死すべき時は同じと願わん!"
今回義兄弟の誓いをたてる最強のツールは以下3点。
- Colaboratory (ブラウザ上で無料で使えるPython実行環境)
- Janome (環境構築が超楽な形態素解析器)
- Word2Vec (自然言語を数値化/ベクトル化する仕組み)
まずは、ColaboratoryとJanomeで、
一番簡単な自然言語処理の仕組みを作ってみる。
(ブラウザだけでお手元で簡単に試せます)Colaboratoryの準備
Colaboratory (要Googleアカウント)
にアクセス。基本的な使い方はぐぐってくだされぃ。
環境構築不要でブラウザだけでプログラミングが出来る。「ファイル」⇒「Python3の新しいノートブック」を作成しよう。
GoogleDriveに今回使う様々なデータを保存したいので、
下記のコマンドでGoogleDriveをマウントしよう。GoogleDriveのマウント# これを実行すると、認証用URLが表示されて、キーを入力すると # 「drive/My Drive/」の中に、認証したアカウントのgoogle driveが入る from google.colab import drive drive.mount('/content/drive')日本語を区切って品詞判定などが出来る、
Janome をインストールする。
Colaboratoryでは、コマンドの冒頭に「!」を書くことで、
いわゆるシェルコマンドが実行できる。Janomeのインストール!pip install janomeさっそく、Janomeで名詞・動詞の抽出をしてみよう!
Janomeで形態素解析(名詞・動詞の抽出)#素状態のJanomeの性能を確認する # Janomeのロード from janome.tokenizer import Tokenizer # Tokenneizerインスタンスの生成 tokenizer = Tokenizer() # テキストを引数として、形態素解析の結果、名詞・動詞原型のみを配列で抽出する関数 def extract_words(text): tokens = tokenizer.tokenize(text) return [token.base_form for token in tokens if token.part_of_speech.split(',')[0] in['名詞', '動詞']] sampletext = u"文章の中から、名詞、動詞原型などを抽出して、リストにするよ" print(extract_words(sampletext)) sampletext = u"劉備と関羽と張飛の三人は桃園で義兄弟の契りを結んだ" print(extract_words(sampletext)) sampletext = u"悪来典韋はかえって、許褚のために愚弄されたので烈火の如く憤った" print(extract_words(sampletext))実行結果['文章', '中', '名詞', '動詞', '原型', '抽出', 'する', 'リスト', 'する'] ['劉', '備', '関', '羽', '張', '飛', '三', '人', '桃園', '義兄弟', '契り', '結ぶ'] ['典', '韋', '許', '褚', 'ため', '愚弄', 'する', 'れる', '烈火', '憤る']ここまででもう、最も簡単な自然言語処理をする環境が整った!!
しかし結果をよ~く見てみると・・・。げぇっ!関羽! ~武将名識別①~
げぇっ!「関羽」
が認識されていない・・・関羽 ⇒ '関', '羽'
とバラバラになっている。「義兄弟」などの一般名詞と違い、
「劉備」「関羽」「張飛」などの三国志の武将名は、
普通に実行するだけでは認識されないのだ。桃園の義兄弟レベルの人名が認識されないなんて大したことないな。
いやいや、Janomeではmecab-ipadic-NEologdの辞書データを使える。Janomeの作者様 (@moco_beta 様) によって、
mecab-ipadic-NEologdを同梱したパッケージを公開していただいている。
(大感謝!温州蜜柑を差し上げたい)
以下のURLにアクセスして、自分のGoogleDriveにコピーしよう。https://drive.google.com/drive/folders/0BynvpNc_r0kSd2NOLU01TG5MWnc
(右クリックですぐにコピー、自分のGoogleDriveに持ってこれる)janome+neologdのインストール#結構時間がかかる(6分くらい) #Mydrive上の、先程のjanome+neologdのパスを指定する #最新版とファイル名が一致しているかどうかは各自で確認すること !pip install "drive/My Drive/Janome-0.3.9.neologd20190523.tar.gz" --no-compileインストールは成功した、かに見えるが、
最後に以下のような記載が出て、
「RESTART RUNTIME」のボタンが出る。インストール実行結果の末尾#WARNING: The following packages were previously imported in this runtime: # [janome] #You must restart the runtime in order to use newly installed versions.ColaboratoryのRUNTIMEを一度リセットしてね、
というお話なので、このボタンを押せばOKJanomeの作者様の公式の方法はローカル環境向けであるため、
python -c "from janome.tokenizer import Tokenizer; Tokenizer(mmap=True)"
↑このコマンドを実行することになっているようだが、
Colaboratoryでは、RUNTIMEリセットすればこのコマンドは不要。NEologd同梱版では、最初のTokenneizerインスタンスの生成コードだけ
ちょっと変える必要がある。
以下のコードで、NEologdの効果を見てみよう!NEologd入れた状態で形態素解析する# Janomeのロード from janome.tokenizer import Tokenizer # Tokenneizerインスタンスの生成 ★ここが異なる★ tokenizer = Tokenizer(mmap=True) # テキストを引数として、形態素解析の結果、名詞・動詞原型のみを配列で抽出する関数 def extract_words(text): tokens = tokenizer.tokenize(text) return [token.base_form for token in tokens if token.part_of_speech.split(',')[0] in['名詞', '動詞']] sampletext = u"劉備と関羽と張飛の三人は桃園で義兄弟の契りを結んだ" print(extract_words(sampletext)) sampletext = u"悪来典韋はかえって、許褚のために愚弄されたので烈火の如く憤った" print(extract_words(sampletext)) sampletext = u"田豊。沮授。許収。顔良。また――審配。郭図。文醜。などという錚々たる人材もあった。" print(extract_words(sampletext)) sampletext = u"第一鎮として後将軍南陽の太守袁術、字は公路を筆頭に、第二鎮、冀州の刺史韓馥、第三鎮、予州の刺史孔伷、第四鎮、兗州の刺史劉岱、第五鎮、河内郡の太守王匡、第六鎮、陳留の太守張邈、第七鎮、東郡の太守喬瑁" print(extract_words(sampletext))実行結果['劉備', '関羽', '張飛', '三', '人', '桃園', '義兄弟', '契り', '結ぶ'] ['悪来', '典韋', '許褚', 'ため', '愚弄', 'する', 'れる', '烈火', '憤る'] ['田豊', '沮授', '許', '収', '顔良', '審配', '郭図', '文醜', '錚々たる', '人材', 'ある'] ['鎮', '後将軍', '南陽', '太守', '袁術', '字', '公路', '筆頭', '二', '鎮', '冀州', '刺史', '韓', '馥', '三', '鎮', '予州', '刺史', '孔', '伷', '四', '鎮', '兗州', '刺史', '劉', '岱', '第五', '鎮', '河内郡', '太守', '王匡', '六', '鎮', '陳', '留', '太守', '張', '邈', '七', '鎮', '東郡', '太守', '喬', '瑁']劉備、関羽、張飛はもちろんのこと、
典韋、許褚、田豊'、沮授、などが認識出来ていることが分かる。
また、こうした有名武将の認識以外の面でも、
動詞や一般名詞の認識精度も上がるため、全体的に望ましい結果になる。だがこの結果をよーく見てみると・・・・。
反董卓連合の全滅 ~武将名識別②~
NEologdを導入することで「劉備」「関羽」などの
ステータスが90以上ありそうな人や、SSRになっていそうな人
は認識出来るようになったが、
三国志の世界にはまだまだ有名ではないコモン扱いの人々は沢山居る。先の結果では、裏切者の代名詞:「許収」が認識されていない。
また、タピオカ入り蜜水が大好きなニセ皇帝「袁術」さんは認識されたが、
韓馥、孔伷、劉岱、張邈、喬瑁、は全滅である。
これでは反董卓連合の激文を書くことができない。
さすがのNEologdでもここまではカバーしていなかったのだ。そこで、「三国志登場人物リスト」を作って、
「ユーザ辞書」としてJanomeに登録することにした。https://ja.wikipedia.org/wiki/三国志演義の人物の一覧
このページの人物一覧をもとに、単純に1行に1名ずつ書いたテキストを作る。
それをアップロードして、以下のように読み込んでみよう。人名リストの読み込み#人物の名前が列挙してあるテキストから、ワードリストを作成する import codecs def getKeyWordList(): input_file = codecs.open('drive/My Drive/Sangokusi/三国志_人名リスト.txt' , 'r', 'utf-8') lines = input_file.readlines() #読み込み result_list = [] for line in lines: tmp_line = line tmp_line = tmp_line.replace("\r","") tmp_line = tmp_line.replace("\n","") #ゴミデータ削除のため、2文字以上のデータを人名とみなす if len(tmp_line)>1: result_list.append(tmp_line) return result_list jinbutu_word_list = getKeyWordList() print(len(jinbutu_word_list)) print(jinbutu_word_list[10:15])実行結果1178 ['張楊', '張虎', '張闓', '張燕', '張遼']このように、1178名分の人物を入れた、単純なリストを得た。
なお、マニアックな調整点や考慮点として、
「馬忠」は同姓同名がいるため、その区別はあきらめたり、
「喬瑁」はwikiに居なかったので後で追加したり、
「張繍」「張繡」の微妙な字体の違いとか、
「祝融夫人」⇒「祝融」に変更したりなどの調整はしている。このリストをもとに、Janomeで利用可能な、
「ユーザ辞書形式」のCSVファイルを作成する。
設定できる箇所は多いのだが、今回は単純な人名リストであるため、
全部同じ登録内容で楽をする。Janomeのユーザ辞書csvの作成#作成したキーワードリストから、janomeのユーザ辞書形式となるCSVファイルを作成する keyword_list = jinbutu_word_list userdict_list = [] #janomeのユーザ辞書形式に変換をかける。コストや品詞の設定等 for keyword in keyword_list: #「表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音」 #参考:http://taku910.github.io/mecab/dic.html #コストは,その単語がどれだけ出現しやすいかを示しています. #小さいほど, 出現しやすいという意味になります. 似たような単語と 同じスコアを割り振り, その単位で切り出せない場合は, 徐々に小さくしていけばいい userdict_one_str = keyword + ",-1,-1,-5000,名詞,一般,*,*,*,*," + keyword + ",*,*" #固有名詞なので、かなりコストは低く(その単語で切れやすく)設定 userdict_one_list = userdict_one_str.split(',') userdict_list.append(userdict_one_list) print(userdict_list[0:5]) #作成したユーザ辞書形式をcsvでセーブしておく import csv with open("drive/My Drive/Sangokusi/三国志人名ユーザ辞書.csv", "w", encoding="utf8") as f: csvwriter = csv.writer(f, lineterminator="\n") #改行記号で行を区切る csvwriter.writerows(userdict_list)実行結果[['張譲', '-1', '-1', '-5000', '名詞', '一般', '*', '*', '*', '*', '張譲', '*', '*'], ['張角', '-1', '-1', '-5000', '名詞', '一般', '*', '*', '*', '*', '張角', '*', '*'], ['張宝', '-1', '-1', '-5000', '名詞', '一般', '*', '*', '*', '*', '張宝', '*', '*'], ['張梁', '-1', '-1', '-5000', '名詞', '一般', '*', '*', '*', '*', '張梁', '*', '*'], ['張飛', '-1', '-1', '-5000', '名詞', '一般', '*', '*', '*', '*', '張飛', '*', '*']]これで、有名(?)武将1000名以上が掲載されたユーザ辞書を得ることが出来た!
いよいよこの辞書を適用した結果を試してみよう。ユーザ辞書を使った場合# Janomeのロード from janome.tokenizer import Tokenizer #ユーザ辞書、NEologd 両方使う。★ここが変更点★ tokenizer_with_userdict = Tokenizer("drive/My Drive/Sangokusi/三国志人名ユーザ辞書.csv", udic_enc='utf8', mmap=True) # テキストを引数として、形態素解析の結果、名詞・動詞原型のみを配列で抽出する関数 def extract_words_with_userdict(text): tokens = tokenizer_with_userdict.tokenize(text) return [token.base_form for token in tokens #どの品詞を採用するかも重要な調整要素 if token.part_of_speech.split(',')[0] in['名詞', '動詞']] sampletext = u"劉備と関羽と張飛の三人は桃園で義兄弟の契りを結んだ" print(extract_words_with_userdict(sampletext)) sampletext = u"悪来典韋はかえって、許褚のために愚弄されたので烈火の如く憤った" print(extract_words_with_userdict(sampletext)) sampletext = u"田豊。沮授。許収。顔良。また――審配。郭図。文醜。などという錚々たる人材もあった。" print(extract_words_with_userdict(sampletext)) sampletext = u"第一鎮として後将軍南陽の太守袁術、字は公路を筆頭に、第二鎮、冀州の刺史韓馥、第三鎮、予州の刺史孔伷、第四鎮、兗州の刺史劉岱、第五鎮、河内郡の太守王匡、第六鎮、陳留の太守張邈、第七鎮、東郡の太守喬瑁" print(extract_words_with_userdict(sampletext))実行結果['劉備', '関羽', '張飛', 'の', '三', '人', '桃園', '義兄弟', '契り', '結ぶ'] ['悪来', '典韋', '許褚', 'ため', '愚弄', 'する', 'れる', '烈火', '憤る'] ['田豊', '沮授', '許', '収', '顔良', '審配', '郭図', '文醜', '錚々たる', '人材', 'ある'] ['鎮', '後将軍', '南陽', '太守', '袁術', '字', '公路', '筆頭', '二', '鎮', '冀州', '刺史', '韓馥', '三', '鎮', '予州', '刺史', '孔伷', '四', '鎮', '兗州', '刺史', '劉岱', '第五', '鎮', '河内郡', '太守', '王匡', '六', '鎮', '陳', '留', '太守', '張邈', '七', '鎮', '東郡', '太守', '喬瑁']「ウムッ!」
かなり三国志のコダワリを入れた結果が得られた!!
もちろん荊州四英傑のデータも入れているため、
弱小君主たちもそのファンも納得の分析が出来る。余談:
形態素解析を行う場合、まず出てくる候補はmecabであろう。
しかし、mecabは環境構築が結構難しく大変である。
Colaboratory上ですぐに使う方法も知られてはいるが、
じゃあ、neologd入れられる?ユーザ辞書自分で追加できる?
となると、なかなかWeb上だけではサクサク環境構築出来ないと思う。
その点でJanomeは環境構築ハードルを下げてくれるので超オススメ!
三国志などの独自世界に対応した超カスタマイズ自然言語処理環境を
作る方法としては、おそらく最も扱いやすい手順を得られたと思う。
作者様ありがとうございます☆温州蜜柑を差し上げたい。2つ目一見するともうこれで十分だろ、感があるが、
まだまだ敵は立ちはだかる。
いよいよ次は「孔明の罠」にハマる物語。その前に、ちょっと疲れてきたので休憩を兼ねて、
ここでスポンサーの曹操様から、
CM(イベントのご案内)を入れさせていただこう!突然ですが、CMです☆
「SEKIHEKIのたた会」イベント案内
日時 : 208年11月20日頃
(東南の風がふくまでご自由にご歓談ください)
場所 : 赤壁
参加者: 曹操・周瑜・諸葛亮など豪華ゲストが続々登壇!
LT : 黄蓋 「三代の功臣が若手に無茶振りされた話」
諸葛亮「10万本の矢を集めたノウハウを大公開」
蔡瑁 「転職直後に上司の信頼を得る方法」
龐統 「絶対に船酔いしない基盤構築を教えます」
曹操 「部下を生き生きと働かせるアジャイル風マネジメント」
その他: 懇親会あり。あの有名武将と人脈を作るチャンス☆
(寝返り目的の参加はご遠慮ください)ここまで読んでいる人(居るのか?)には垂涎のイベント。
ぜひみなさまお誘いあわせの上ご参加ください!!
曹操「赤壁の戦いでお会いしましょう!(※ただし関羽テメーはダメだ)」なお、ここまでで吉川英治三国志に興味を持った方は、
下記の速読アプリにも全巻無料で登録されていマス。
訓練不要で誰でも速読!日本一の速読アプリ「瞬間速読」の個人開発物語
残念ながらSEKIHEKIイベントにご参加できなかった方は、
こちらのアプリでイベントの様子を見ていただくことが出来ます。さあ、いよいよ次は孔明の罠の登場だ。
「孔明」の罠 ~字(あざな)識別~
やった、人名データを登録したからこれで解析が出来るぞ!
待てあわてるなこれは「孔明」の罠だ。
このまま解析しても良い結果は得られない。
次の例文を見ていただこう。「車上、白衣簪冠の人影こそ、まぎれなき諸葛亮孔明にちがいなかった。」
「これは予州の太守劉玄徳が義弟の関羽字は雲長なり」
「趙子龍は、白馬を飛ばして、馬上から一気に彼を槍で突き殺した。」
「趙雲子龍も、やがては、戦いつかれ、玄徳も進退きわまって、すでに自刃を覚悟した時だっ「孔明」とは字(あざな)であり、「諸葛亮」が本名である。
彼は通常「孔明」と表現されているが、
諸葛亮、や、諸葛亮孔明、と表現されていることもたびたびある。
また、
「劉備」の字(あざな)は「玄徳」
「関羽」の字(あざな)は「雲長」
「趙雲」の字(あざな)は「子龍」
であり、文中でも「玄徳は~~」「雲長は~~」などと
たびたび字(あざな)が登場する。このように、三国志の世界では、同じ人物に対して、
様々な呼び方が存在している。少なくとも以下の4パターンは同じ人物として扱わないと困る。
「趙雲」=「子龍」=「趙子龍」=「趙雲子龍」
「劉備」=「玄徳」=「劉玄徳」=「劉備玄徳」
江東の小覇王とか、劉皇叔とか、は一旦忘れる。これが、世に名高い「孔明(あざな)」の罠。
ハマると同じ人物が4分裂してしまう凶悪な罠だ。この罠を回避するために、まずは
字(あざな)と武将名のリストを作成し、
字をフルネームに変える置換処理を作る。さらに、単純に置換しただけでは、
「趙子龍」⇒「趙趙雲」
「趙雲子龍」⇒「趙雲趙雲」
となってしまうため、これらの重複防止措置を取る。なお、字(あざな)で書かれる場合が多いのは
かなり有名な武将に限定されているため、
今回用意した字リストは約130人分までだ。
このくらいまでなら、適宜三国志のファンサイトを参照して作成可能だ。
単純にカンマ区切りで、あざな&フルネームのCSVを作成し、読み込む。あざなCSVの読み込みimport csv csv_file = open("drive/My Drive/Sangokusi/三国志_あざな変換リスト.csv", "r", encoding="utf8", errors="", newline="" ) #リスト形式 azana_reader = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True) azana_list = [ e for e in azana_reader ] csv_file.close() print(len(azana_list)) print(azana_list[2]) #全員の字リストを作るのは難しかったが、 #['雲長', '関羽']のような132人の代表的な字とその対比表が入っている実行結果132 ['雲長', '関羽']このようにして作成した対比表を用いて、
テキストに対する字(あざな)の変換処理を作る。字(あざな)の変換処理の実装#これは、字(あざな)を置き換えるだけの単純な置換処理 def azana_henkan(input_text): result_text = input_text for azana_pair in azana_list: result_text = result_text.replace(azana_pair[0],azana_pair[1]) return result_text #単純に、字からの変換をかけるだけだと、 #趙雲子龍→趙雲趙雲などのようになる場合が多いため、 #同一の人物名で重複している場合は、一方を削除する。 #また、劉玄徳、趙子龍、などのような表現に対応するため、 #フルネームで2文字の場合はAAB→AB(劉玄徳→劉劉備→劉備) #フルネームで3文字の場合はAAB→AB(諸葛孔明→諸葛諸葛亮→諸葛亮) # となる名寄せを行う。 #(※名字1文字+名前二文字はあまり居ない気がするので無視) def jinmei_tyouhuku_sakujyo(input_text): jinbutu_word_list = getKeyWordList() result_text = input_text for jinbutumei in jinbutu_word_list: result_text = result_text.replace(jinbutumei+jinbutumei, jinbutumei) if len(jinbutumei) == 2: result_text = result_text.replace(jinbutumei[0]+jinbutumei, jinbutumei) if len(jinbutumei) == 3: result_text = result_text.replace(jinbutumei[0]+jinbutumei[1]+jinbutumei, jinbutumei) return result_text sampletext = u"これは予州の太守劉玄徳が義弟の関羽字は雲長なり" print(jinmei_tyouhuku_sakujyo(azana_henkan(sampletext))) sampletext = u"趙子龍は、白馬を飛ばして、馬上から一気に彼を槍で突き殺した。" print(jinmei_tyouhuku_sakujyo(azana_henkan(sampletext))) sampletext = u"趙雲子龍も、やがては、戦いつかれ、玄徳も進退きわまって、すでに自刃を覚悟した時だった。" print(jinmei_tyouhuku_sakujyo(azana_henkan(sampletext)))実行結果これは予州の太守劉備が義弟の関羽字は関羽なり 趙雲は、白馬を飛ばして、馬上から一気に彼を槍で突き殺した。 趙雲も、やがては、戦いつかれ、劉備も進退きわまって、すでに自刃を覚悟した時だった。「ウムッ!」
やっと、三国志の固有名詞と、孔明の罠に対応することが出来た!
いよいよ三国統一の最後のツメとして、
漢中攻略に向かおう
前処理としては最後の関門に向かう。鶏肋は死刑に ~ストップワード除去~
曹操「鶏肋、鶏肋・・・」
楊修「おk、把握した」「鶏肋」とは、食べるには身がないがダシが取れるので
そのまま捨てるには惜しいことから
「大して役に立たないが、捨てるには惜しいもの」のこと。「雲長は気の毒になって、彼の好きな酒を出して与えたが」
↑ここで言う「彼」はもちろん「張飛」のこと。
しかし別なシーンでは、「彼」は「曹操」や「劉備」かもしれない。この「彼」を除かずに分析を行うと、
「曹操」≒「彼」のような分析結果が出てしまう。
(単純に曹操が登場回数が多いこともあり)一見意味のありそうな「彼」だが、
実際解析する上では雑音にしかならない。
よって、楊修と同じように死刑にしてしまおう。曹操「何勝手に退却しているんだよw死刑!」
このような鶏肋ワードの一覧として、良く使われるのが、
SlothLib というサイトだ。ここに乗っている単語は全て死刑(削除)にするコードを書く。
まず、SlothLibにアクセスしてそのデータをリスト化する。
SlothLibからのデータの取得&リスト化#雑音になりやすい単語(「彼」など)はストップワードとして除外する #SlothLibのテキストを使う。 #どんな言葉が除外されるのかは、直接URLを見れば良い #参考: http://testpy.hatenablog.com/entry/2016/10/05/004949 import urllib slothlib_path = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt' #slothlib_file = urllib2.urlopen(slothlib_path) #←これはPython2のコード slothlib_file = urllib.request.urlopen(slothlib_path) slothlib_stopwords = [line.decode("utf-8").strip() for line in slothlib_file] slothlib_stopwords = [ss for ss in slothlib_stopwords if not ss==u''] #['彼','彼女',・・・]のようなリストになる print(len(slothlib_stopwords)) print(slothlib_stopwords[10:15])実行結果310 ['いま', 'いや', 'いろいろ', 'うち', 'おおまか']310個の鶏肋ワードを取得することが出来た。
このようにして出来たリストを使って、
名詞動詞の抽出後に、鶏肋リスト中の単語は除外する処理、を実装しよう。鶏肋ワードの除去機能を実装するsampletext = u"彼は予州の太守劉玄徳が義弟の関羽字は雲長。彼は劉備玄徳の義兄弟だ" tmp_word_list = extract_words_with_userdict(jinmei_tyouhuku_sakujyo(azana_henkan(sampletext))) print(tmp_word_list) #このようにして、単語リストからストップワードを除外する tmp_word_list = [word for word in tmp_word_list if word not in slothlib_stopwords] print(tmp_word_list)実行結果['彼', '予州', '太守', '劉備', '義弟', '関羽', '字', '関羽', 'なり', '彼', '劉備', 'の', '義兄弟'] ['予州', '太守', '劉備', '義弟', '関羽', '関羽', 'なり', '劉備', 'の', '義兄弟']上下の抽出結果を比べてみると、
「彼」という単語が消えているのが分かる。さあ、全ての準備が整った。
最後にこれらの成果を吉川英治の全文に適用してみよう。ジャーンジャーンジャーン(全文の形態素解析)
これまでの全ての成果を全文に適用する時が来た。
まず、「青空文庫」から吉川英治三国志の全文をダウンロードし、
全部の章を結合したテキストを作っておく。ここで注意しなければならないのは、
以下のような青空文庫の独自表記。公孫※[#「王+贊」、第3水準1-88-37]《こうそんさん》
⇒「公孫瓚」に置換しておく必要がある。
私は以下のような変換コードを1万行くらい書いてある、
独自のコードを以前から使っているが、もっといいやり方がある気がする。
self.resulttext=re.sub(r'※[#.*?1-88-37.*?]',"瓚",self.resulttext)既に本稿が長くなりすぎており、
これは三国志というか青空文庫ハッキングの話であるため、
本稿においては割愛させていただく。このような変換処理をかけた全文テキストデータを用意した所から話を続ける。
まず、字(あざな)の名寄せを行う。
全文テキストに対して、字(あざな)変換処理をかけるimport codecs def azana_henkan_from_file(input_file_path): input_file = codecs.open(input_file_path, 'r', 'utf-8') lines = input_file.readlines() #読み込み result_txt = "" for line in lines: result_txt += line result_txt = azana_henkan(result_txt) return result_txt #ファイル生成用関数定義 #mesのテキストを、filepathに、utf-8で書き込む def printFile(mes,filepath): file_utf = codecs.open(filepath, 'w', 'utf-8') file_utf.write(mes) file_utf.close() return "OK" azana_henkango_zenbun = azana_henkan_from_file('drive/My Drive/Sangokusi/三国志全文.txt') azana_henkango_zenbun = jinmei_tyouhuku_sakujyo(azana_henkango_zenbun) printFile(azana_henkango_zenbun,'drive/My Drive/Sangokusi/三国志全文_あざな変換済み.txt')これで生成された字(あざな)変換済みのテキストに対して、
NEologd、ユーザ辞書、を搭載したJanomeによる形態素解析を行おう。
出来たデータは、pickleを使ってGoogleDrive内に保存しておけば、
引き続き作業を行う時に楽になる。全文の形態素解析%%time #全文分解するのに10分ほどかかる import codecs # ['趙雲', '白馬', '飛ばす', '馬上', '彼', '槍', '突き', '殺す'] このようなリストのリスト(二次元リスト)になる def textfile2wordlist(input_file_path): input_file = codecs.open(input_file_path, 'r', 'utf-8') lines = input_file.readlines() #読み込み result_word_list_list = [] for line in lines: # 1行ずつ形態素解析によってリスト化し、結果格納用のリストに格納していく # Word2Vecでは、分かち書きされたリスト=1文ずつ、のリストを引数にしている tmp_word_list = extract_words_with_userdict(line) #別途準備しておいたstopワードリストを使って除外処理を行う tmp_word_list = [word for word in tmp_word_list if word not in slothlib_stopwords] result_word_list_list.append(tmp_word_list) return result_word_list_list Word_list_Sangokusi_AzanaOK_with_userdict_neologd = textfile2wordlist('drive/My Drive/Sangokusi/三国志全文_あざな変換済み.txt') #作成したワードリストは、pickleを使って、GoogleDriveに保存しておく(一回10分くらいかかるからね) import pickle with open('drive/My Drive/Sangokusi/Word_list_Sangokusi_AzanaOK_with_userdict_neologd_V4.pickle', 'wb') as f: pickle.dump(Word_list_Sangokusi_AzanaOK_with_userdict_neologd, f) #保存したpickleファイルは、以下のように復元する with open('drive/My Drive/Sangokusi/Word_list_Sangokusi_AzanaOK_with_userdict_neologd_V4.pickle', 'rb') as f: Word_list_Sangokusi_AzanaOK_with_userdict_neologd = pickle.load(f) print(len(Word_list_Sangokusi_AzanaOK_with_userdict_neologd)) print(Word_list_Sangokusi_AzanaOK_with_userdict_neologd[10:20])これでとうとう、
吉川英治三国志全文を解析し、
武将名をかなり正しく認識&名寄せした上で、
「名詞、動詞」のリストに変換することが出来た!次の作戦は、出来たリストを機械学習にかけ、
抽出された「武将名」の学習を行うことだ。
(次回へ続く・・・?)自然言語処理編の終わり
仲達「こんなに長い記事を書いているなんて、
フフフ、諸葛亮も長くはないぞ!」長くなりすぎた。
キリも良いので、作者と読者の健康のために一旦ここまでで切る。
CMとかやってるからだよ三国志の世界を機械学習するためには、
今回実施したようなコダワリの前加工処理が精度向上の鍵になる。関羽千里行なみに、各関門をなぎ倒していく物語はいかがだっただろうか?
また、Colaboratory + Janome + NEologd + ユーザ辞書、
まで全セットの使い方として、
自然言語処理の裾野開拓にお役に立つことがあれば幸いである。
(Web上で簡単に作れて、NEologd+ユーザ辞書、まで使えるノウハウは、
かなり調べても全て説明しているものは見当たらなかったため)以前より、プログラマ向けに対象を限定せず、
非プログラマ/非Qiitaユーザでも雰囲気は楽しめるレベル、を
イメージして記事を投稿してきたが、
今回については、「三国志」知らない人には意味不明であろう。
Qiitaにも「三国志」タグは無かった・・・(当たり前)「SEKIHEKIのたた会」イベントの参加者はQiita見て無さそうだし、
この投稿も「孔明の罠」って書きたかっただけだし、
「機械学習編」は書かないかもしれない。後半が気になる人や、三国志分析が面白かったという人、
横山光輝リスペクトの部分でニヤっとした人は、
ぜひ応援よろしくお願いします。
後半では各英傑たちの「主人公補正」が明らかになるかも!?長文おつきあいありがとうございました。
以上です。


- 投稿日:2019-07-28T19:04:11+09:00
Django Channels でチャットアプリ作成(Python)
はじめに
Djangoを使ったチャットアプリを作ってみました。
その中でChannelsと呼ばれるライブラリを使用したのですが、
まだまだ記事が少なく、構築が非常に大変だと感じました。今回は振り返りの意味も込めて、記事を残します。
不備や、間違った記載があればご指摘いただけると幸いです。また記事の最後に今回作成したものを
Githubに上げておりますので、参考にどうぞ!
ローカル用に構築していく
構成
Docker Compose を使用して、開発環境を準備いたします。
今回は下記のような環境でローカルサーバーを立てていきたいと思います。
名称 内容 ポート番号 django アプリサーバー 8001, 3001 nginx Webサーバー 8000 mysql DBサーバー 3306 redis キャッシュサーバー 6379 環境構築
DockerFileをまずゴリゴリ書いていきます。
Djangoから、Dockerfile# Django FROM python:3.6 ENV PYTHONUNBUFFERED 1 WORKDIR /server ADD requirements.txt /server/ RUN pip install --upgrade pip RUN pip install -r requirements.txt ADD . /server/ライブラリインストール用のファイルも記載していきます。
requirements.txtchannels_redis==2.2.1 asgiref==2.3.0 channels==2.1.2 daphne==2.2.1 Django==2.1 PyMySQL==0.9.2 pytz==2018.5 redis==2.10.6Django の起動を自動で起動するためのシェルを書いていきます。
start-django.sh#!/bin/bash python manage.py makemigrations python manage.py migrate python manage.py collectstatic --noinput nohup uwsgi --socket :8001 --module chat_demo.wsgi & daphne -b 0.0.0.0 -p 3001 --ping-interval 10 --ping-timeout 120 chat_demo.asgi:applicationnginx用のDockerfileを書いていきます。
nginxはWebサーバーとして使用していきます。
設定ファイルの中身はGithubを参照のことDockerfileFROM nginx:1.11.7 RUN apt-get update # 設定ファイル nginx ADD nginx/nginx.conf /etc/nginx/nginx.conf ADD nginx/default.conf /etc/nginx/sites-available/default ADD nginx/default.conf /etc/nginx/sites-enabled/default ADD nginx/start-nginx.sh /etc/nginx/start-nginx.sh ADD nginx/uwsgi_params /etc/nginx/uwsgi_params ADD nginx/robots.txt /usr/share/nginx/robots.txtMysqlのDockerfileも作成していきます。
init.sql起点で作成、my.cnfは各自記載してもよし、記載しなくてもよしだと思います。DockerfileFROM mysql:5.7 ADD ./init.sql /docker-entrypoint-initdb.d/init.sql ADD ./my.cnf /etc/mysql/my.cnf RUN chmod 644 /etc/mysql/my.cnfDocker Compose を使って各種Dockerの構築していきます。
docker-compose.ymlversion: '3' services: nginx: build: context: ./ dockerfile: ./nginx/Dockerfile command: 'sh /etc/nginx/start-nginx.sh' environment: TZ: 'Asia/Tokyo' ports: - 8000:8000 volumes: - ./nginx/logs/nginx/:/var/log/nginx/ - ./nginx/uwsgi_params:/etc/nginx/uwsgi_params - ./django/static:/var/www/static/ depends_on: - django redis: image: redis:alpine expose: - "6379" mysql: image: mysql:5.7 ports: - 3306:3306 environment: - MYSQL_ROOT_PASSWORD=test # YOUR PASSWORD - MYSQL_ROOT_HOST=% volumes: - ./db/db-datadir:/var/lib/mysql - ./db:/docker-entrypoint-initdb.d - ./db/my.cnf:/etc/mysql/my.cnf django: build: context: ./django dockerfile: Dockerfile command: 'sh /server/start-django.sh' # command: 'python /server/manage.py runserver' expose: - "8001" - "3001" volumes: - ./django:/server/ depends_on: - mysql - redis最後に下記コマンドを実行して、
サーバーが正常に立ち上がるか確認します。Djangoの初期構築
Djangoの初期構築をしていきます。
$ docker-compose run django django-admin startproject chat_demoプロジェクトが生成されますので、確認します。
(chat_demoの中にchat_demoが作られるのが、、、という人は1階層上に上げても良いかもしれないです。)
生成された、settings.pyに今回入れるredis, channels, databaseの設定を追加していきます。
settings.py# 一部割愛:変更・追加点のみ INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'channels', # 追加 'chat' # 追加 ] # 〜〜〜 省略 WSGI_APPLICATION = 'chat_demo.wsgi.application' ASGI_APPLICATION = 'chat_demo.routing.application' # 追加 # 〜〜〜 省略 # Redisの設定 CHANNEL_LAYERS = { "default": { "BACKEND": "channels_redis.core.RedisChannelLayer", "CONFIG": { "hosts": [('redis', 6379)] } } } # 〜〜〜 省略 # databaseの設定 import pymysql pymysql.install_as_MySQLdb() DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'test', 'USER': 'test', 'PASSWORD': 'test', 'HOST': 'db', 'PORT': 3306, 'OPTIONS': {'charset': 'utf8mb4'} } }chat_demo/asgi.py# coding: utf-8 import os import django from channels.routing import get_default_application os.environ.setdefault("DJANGO_SETTINGS_MODULE", "chat_demo.settings") django.setup() application = get_default_application()チャットアプリケーションを作成:URL設定
チャットアプリケーションを作っていきます。
ついでにDBの接続確認がてらマイグレートもしておきます。docker-compose run django python /server/chat_demo/manage.py startapp chat docker-compose run django /server/manage.py migrate上記のコマンドを実行するとチャットアプリとなる骨組みを生成します。
画像のようなファイルが作成されていればOKです。
ルーティングを設定していきます。
今回は部屋ごとにルームがあり、そこから
チャットを展開していくようなアプリを作っていきたいと思います。urlイメージ# 表示用のルーティング設定 / ルート ルーム作成する所、既存のルーム一覧も表示される /chat/{ルーム名} ルーム内、チャットを表示していく所 /room/{ルーム名} ルームの作成処理 # Websocketで繋いでいくとこの設定 /ws/{ルーム名}/{個人ID} ルーム毎に個人IDを割り振っていきます。まず、大元のURLを設定していきます。
下記のような形でルーティングを設定していきます。
今後の機能追加も鑑みて大元のURLから
アプリケーション毎に辿れるような設計にします。chat_demo/urls.pyurlpatterns = [ path('', include('chat.urls', namespace='chat')), # 追加 path('admin/', admin.site.urls), ]chat/urls.pyfrom django.urls import include, path from .views import * app_name = 'chat' urlpatterns = [ path('', index, name='index'), path('chat/<str:room_name>', chat, name='chat_room'), path('room/', room, name='room'), ]chat_demo/routing.pyfrom django.urls import include, path from channels.routing import ProtocolTypeRouter, URLRouter from channels.auth import AuthMiddlewareStack from channels.sessions import SessionMiddlewareStack from django.urls import path from chat.consumers import * websocket_urlpatterns = [ path('<str:room_name>', ChatConsumer), ] application = ProtocolTypeRouter({ 'websocket': AuthMiddlewareStack( URLRouter( websocket_urlpatterns ) ), })チャットアプリケーションを作成:model作成
URLの設定が完了しましたら、DBに入れるテーブルを作成していきます。
Djangoではmodels.pyに作成した後、マイグレーションすることで、
mysqlに自動で紐づくような作りになっています。テーブル設計を簡単にしていきます。
今回はルームとそれに紐づくメッセージのみとします。Roomテーブル
名称 内容 型 id ユニークキー uuid name ルーム名 char created_at 作成日時 datetime Messageテーブル
名称 内容 型 id ユニークキー uuid room 外部キー(Roomテーブル) ForeignKey name 会話者 char centent 会話内容 text created_at 作成日時 datetime 実際にゴリゴリ実装していきます。
chat/models.pyimport uuid from django.db import models from django.utils import timezone class Room(models.Model): id = models.UUIDField(primary_key=True, default=uuid.uuid4) name = models.CharField(max_length=50) created_at = models.DateTimeField(default=timezone.now) class Message(models.Model): id = models.UUIDField(primary_key=True, default=uuid.uuid4) room = models.ForeignKey( Room, blank=True, null=True, related_name='room_meesages', on_delete=models.CASCADE ) name = models.CharField(max_length=50) content = models.TextField() created_at = models.DateTimeField(default=timezone.now)チャットアプリケーションを作成:View作成
Chatの見える部分(フロント部分)と、
ルーティングした際のサーバー側の動きを実装していきます。まずはフロントに当たるテンプレートのhtmlファイルに結びつける
モデルをいれていきます。chat/views.pyfrom .models import * from django.http import HttpResponseRedirect, HttpResponse from django.template import loader from django.shortcuts import redirect from django.urls import reverse def index(request): room_list = Room.objects.order_by('-created_at')[:5] template = loader.get_template('chat/index.html') context = { 'room_list': room_list, } return HttpResponse(template.render(context, request)) def chat(request, room_name): messages = Message.objects.filter(room__name=room_name).order_by('-created_at')[:50] room = Room.objects.filter(name=room_name)[0] template = loader.get_template('chat/chat_room.html') context = { 'messages': messages, 'room': room } return HttpResponse(template.render(context, request)) def room(request): name = request.POST.get("room_name") room = Room.objects.create(name=name) return HttpResponseRedirect(reverse('chat:chat_room', args=[name]))次にhtmlファイルとCSSファイルを作っていきます。
Javascriptは、送信するときのWebsocketサーバーに向き先を宛てて
実装していきます。chat/index.html{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'chat/style.css' %}"> <div class="header"> Django - チャットアプリデモ </div> <h2>ルームを新しく作成する<h2> <div class="create-room-box"> <form action="/room/" method="post"> {% csrf_token %} <input placeholder="ルーム名を入力" type="text" name="room_name" value=""> <input type="submit" class="send" name="button" value="作成"> </form> </div> <h2>ルーム一覧</h2> <ul class="select-room-box"> {% for room in room_list %} <a href="/chat/{{ room.name }}">{{ room.name }}</a> {% endfor %} </ul>chat/chat_room.html{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'chat/style.css' %}"> <div class="container"> <div class="header"> <a href="/" class="back"><戻る</a> Django - チャットアプリデモ - {{ room.name }} </div> <div class="chat-room-body"> {% for message in messages %} <div class="chat-box"> <div class="chat-header"> 名前:{{message.name}} </div> <div class="chat-body"> {{message.content}} </div> </div> {% endfor %} <div id="footer"></div> </div> <div class="chat-room-footer"> <div class="send-msg"> <input placeholder="名前を入力" id="name" value=""/> <input placeholder="メッセージを入力" id="msg" value=""/><button id="send">送信</button> </div> </div> </div> <script> const url = 'ws://localhost:8000/ws/' + '{{room.name}}' var ws = new WebSocket(url) document.getElementById("send").onclick = function sendMessage () { var sendData = { name: document.getElementById('name').value, message: document.getElementById('msg').value } ws.send(JSON.stringify(sendData)) } ws.onmessage = e => { var receiveData = JSON.parse(e.data) var messageBox = document.createElement('div') messageBox.className = 'chat-box' var header = '<div class="chat-header">名前:' + receiveData.name + '</div>' var body = '<div class="chat-body">' + receiveData.message + '</div>' document.getElementById('footer').insertAdjacentHTML('beforebegin', header + body) document.getElementById('footer').appendChild(messageBox) } </script>ここまで来ると、ある程度形ができてきているかと思います。
チャットアプリケーションを作成:WebSocketサーバー構築
最後にチャットアプリの肝となるWebSocketサーバー部分を作成していきます。
asgi.pyやnginx側では設定が完了しておりますが、
肝心の中身がまだなので、実装していきます。chat/consumer.pyfrom channels.generic.websocket import AsyncWebsocketConsumer from django.db import connection from django.db.utils import OperationalError from channels.db import database_sync_to_async from django.core import serializers from django.utils import timezone import json from .models import * from urllib.parse import urlparse import datetime import time class ChatConsumer(AsyncWebsocketConsumer): groups = ['broadcast'] async def connect(self): try: await self.accept() self.room_group_name = self.scope['url_route']['kwargs']['room_name'] await self.channel_layer.group_add( self.room_group_name, self.channel_name ) except Exception as e: raise async def disconnect(self, close_code): await self.channel_layer.group_discard( self.room_group_name, self.channel_name ) await self.close() async def receive(self, text_data): try: print(str(text_data)) text_data_json = json.loads(text_data) message = text_data_json['message'] name = text_data_json['name'] await self.createMessage(text_data_json) await self.channel_layer.group_send( self.room_group_name, { 'type': 'chat_message', 'message': message, 'name': name, } ) except Exception as e: raise async def chat_message(self, event): try: message = event['message'] name = event['name'] await self.send(text_data=json.dumps({ 'type': 'chat_message', 'message': message, 'name': name, })) except Exception as e: raise @database_sync_to_async def createMessage(self, event): try: room = Room.objects.get( name=self.room_group_name ) Message.objects.create( room=room, name=event['name'], content=event['message'] ) except Exception as e: raise完成
ここまで来ると完成となります。
Githubはこちらになります。
docker-compose up -dで起動できると思いますのでお試しください。




- 投稿日:2019-07-28T18:40:35+09:00
簡単!30行で書くGoogle画像検索のスクレイピング
やること
- 以前の記事でFlickr APIを使って画像データをダウンロードしましたが、
今回はGoogle画像検索を使い、画像データのダウンロードを実行したいと思います。- Selenium WebDriverを使ってChromeを起動し、Google画像検索画面で検索を実行する操作を自動化しています。
手順概要
- 1. ライブラリのインポート
- 2. Google画像検索の実行
- 3. 検索結果をスクレイピング
- 4. 画像データのダウンロード
動作環境
- macOS Catalina 10.15 beta
- google chrome 75.0.3770.142
- Python 3.6.8
- beautifulsoup4 4.8.0
- selenium 3.141.0
- python-chromedriver-binary 2.38.0
- lxml 4.3.4
- requests 2.21.0
1. ライブラリのインポート
- 下記のライブラリをインポートします
ライブラリimport requests import os, time, sys from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.common.keys import Keys2. Google画像検索の実行
- Chromeを起動し、Google画像検索の画面を開きます
- その後、検索フォームにキーワードを入力し、
- その後エンターキーを押下するように設定します(キーワードはプログラム実行時に指定)
- find_element_by_nameに"q"を指定します(検索フォームのname属性は以下の通り確認)
 2.Google画像検索の実行# launch chrome browser driver = webdriver.Chrome() # google image search driver.get('https://www.google.co.jp/imghp?hl=ja&tab=wi&ogbl') # execute search keyword = sys.argv[1] driver.find_element_by_name('q').send_keys(keyword, Keys.ENTER)
2.Google画像検索の実行# launch chrome browser driver = webdriver.Chrome() # google image search driver.get('https://www.google.co.jp/imghp?hl=ja&tab=wi&ogbl') # execute search keyword = sys.argv[1] driver.find_element_by_name('q').send_keys(keyword, Keys.ENTER)3. 検索結果をスクレイピング
- 検索結果画面のURLを指定し、htmlの情報を取得します
- BeautifulSoupを使って解析します。HTMLパーサーにはlxmlを指定しました
- 10個のimgタグを取得します
3.検索結果をスクレイピングcurrent_url = driver.current_url html = requests.get(current_url) bs = BeautifulSoup(html.text, 'lxml') images = bs.find_all('img', limit=10)
- imagesにはimgタグが以下のように格納されます
[<img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ1" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ2" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ3" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ4" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ5" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ6" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ7" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ8" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ9" width="XXX"/>, <img alt="「XXX」の画像検索結果" height="XXX" src="https://encrypted-tbn0.gstatic.com/images?q=tbn:XXXYYYZZZ10" width="XXX"/>]4. 画像データのダウンロード
- はじめに、保存するディレクトリを作成します
- ディレクトリの名前は検索キーワードになります
- 画像データを取得するため、imgタグ内のsrc属性を取得(3.でimagesの内容参照)
- requests.getで画像データを取得します
- with openで検索キーワードのディレクトリに連番(開始インデックスは1)で書き込む宣言をします
- f.writeでresponce(画像データ)を書き込みます
- 1ファイルをダウンロードした後は、サーバー側の負荷を抑えるためにリクエストの間隔を空けるために1秒空けます(time.sleepで1秒間停止)
- 終了したらブラウザを閉じます
4.画像データのダウンロードos.makedirs(keyword) WAIT_TIME = 1 for i, img in enumerate(images, 1): src = img.get('src') response = requests.get(src) with open(keyword + '/' + '{}.jpg'.format(i), 'wb') as f: f.write(response.content) time.sleep(WAIT_TIME) driver.quit()コードの実行
- 実行時に検索キーワードを指定する(XXXX部分)
コードの実行$ python py_scrayping.py XXXXソースコード全体
参考文献
- 投稿日:2019-07-28T18:25:59+09:00
【Python】ルーターやスイッチでshow ip int bを定期的にcsv出力する
はじめに
netmikoはネットワーク機器にSSH接続するためのPythonモジュールです。
netmikoのコマンド実行結果は非構造化データです。
TextFSMとntc-templatesを利用して、構造化データに変換できるのでcsvにきれいに保存できます。ntc-templatesは様々なネットワーク機器のshowコマンド解析結果を構造化データに変換するためのテンプレート集です。ntc-templatesのダウンロード
- ここからzipをダウンロードします
- ホームディレクトリ(Windowsならユーザーのディレクトリ)に展開します
- フォルダ名をntc-templates-masterからntc-templatesに変更
Netmikoが自動で~/ntc-templates/templates/indexを参照してくれます。
コード
netmikoなどのpip installはお忘れなく!
$ pip install netmiko $ pip install schedule以下ソースです。
ssib.pyimport netmiko import pprint import time import schedule import csv def SIIB(): device = {'device_type': 'cisco_ios', 'host': 'Cisco1', 'ip': 'ネットワーク機器のIP', 'username': '入力', 'password': '入力', 'secret': 'cisco'} print('Connecting...') conn = netmiko.ConnectHandler(**device) print('Enable...') conn.enable() print('Execute command...') # コマンド実行(TextFSMを有効にしてパース) result = conn.send_command('show ip interface brief', use_textfsm=True) print('SIIB done') header = result[0].keys() print('SIIB write') # DictWriterを使用してCSV形式で出力 with open('保存ファイル名', 'w', newline='') as f: writer = csv.DictWriter(f, fieldnames=header, lineterminator='\n') writer.writeheader() # ヘッダ出力 writer.writerows(result) # 結果出力 print('Disconnecting...') conn.disconnect() #以下はscheduleモジュールを使った定期実行部分。 #Ctrl Cで止められます #一分毎に実行 schedule.every(1).minutes.do(SIIB) while True: schedule.run_pending() time.sleep(1)作っていて困ったこと
- scheduleがちょっと特徴あるなと思いました
まとめ
netmikoは各ベンダーのコマンドをそのまま使えて便利ですね。
反面、各ベンダー毎にコードを書く手間が出てきそうです。
同じpythonモジュールのnapalmは異なるベンダー機器に対して共通のコマンドを使えるようです。便利そう。
- 投稿日:2019-07-28T18:23:19+09:00
深層学習とかでのPythonエラー「ImportError: cannot import name 'imread' from 'scipy.misc' 」への対処
目的
from scipy.misc import imreadで、
ImportError: cannot import name 'imread' from 'scipy.misc'というエラーが出る場合がある。
これは、シンプルで、
ぐぐると対策がわかるハズですが、
ちょっと、そういう活動が嫌ですね。簡単に答えがわかれば、いいという問題じゃない気もします。。。。エラーと対策
imread
のimportの仕方として、
>>> from scipy.misc import imread>>> from scipy.misc.pilutil import imread>>> from imageio import imreadがある。
選ばないとエラーになるのは、scipyの仕様が変わったためですが。。。。
version 1.1.0
なんでもOKになります。
>>> import scipy >>> scipy.__version__ '1.1.0' >>> from scipy.misc import imread >>> from scipy.misc.pilutil import imread >>> from imageio import imread >>>version 1.2.0
なんでもOKになります。version1.1.0に同じです。
>>> >>> import scipy >>> scipy.__version__ '1.2.0' >>> from scipy.misc import imread >>> from scipy.misc.pilutil import imread >>> from imageio import imread >>>version 1.3.0
このバージョンでは、エラーを出さないためには、
imageio import imread
が、解です。>>> import scipy >>> scipy.__version__ '1.3.0' >>> from scipy.misc import imread Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: cannot import name 'imread' from 'scipy.misc' (C:\Users\XYZZZ\AppData\Local\Programs\Python\Python37\lib\site-packages\scipy\misc\__init__.py) >>> from scipy.misc.pilutil import imread Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'scipy.misc.pilutil' >>> from imageio import imread >>> >>> >>>まとめ
エラーが出て、
ぐぐって、、、
そうするしかないですが、、、ちょっと、嫌です。関連(本人)
pythonをストレスなく使う!(generatorに詳しくなる。since1975らしい。)
pythonをストレスなく使う!(Pythonでは、すべてがオブジェクトとして実装されている)
pythonをストレスなく使う!(Pylintに寄り添う)
pythonをストレスなく使う!(ExpressionとStatement)
英語と日本語、両方使ってPythonを丁寧に学ぶ。今後
コメントなどあれば、お願いします。
勉強します、、、、
- 投稿日:2019-07-28T17:12:46+09:00
Python学習備忘録(自分用)
- 投稿日:2019-07-28T17:02:38+09:00
ローン返済のシミュレーションができるスクリプトを作った
1. はじめに
このスクリプトは一定期間で利子がつくローンの返済金額を計算することができます。
具体的には、借入額と返済回数と金利を入力することで、毎回の返済額・金利分・残額を出力することができます。
実際のローン返済の方法にもとづいて、元利均等返済と元金均等返済の両パターンに対応しています。インストールはこちらから。
https://github.com/shion-0412/Interest-calculation2. 開発環境
mac OS
ターミナル3. 用語説明
返済回数
返済を行う回数。返済が毎月ならば月数、毎年ならば年数のように数えてください。
返済期間が10年で毎月返済する場合、返済回数は120です。金利
残額に対して一定期間で乗算される比率のことです。
単利と複利の2つの方式がありますが、ローンの場合は金利込みの残額に対してさらに金利がかけられる、複利方式です。元利均等返済
毎回の返済額が、おしなべて同額となる返済方式です。
返済の目処が立てやすいですが、返済総額は増えます。元金均等返済
毎回の返済額のうち、元金の額が一定となる返済方式です。
初期の返済額が高額になりますが、利子分の返済額が少なく抑えられます。4. 使い方
元金均等返済##入力## python repayment.py gankin type the principal (yen): [借入額] type the number of repayment: [返済回数] type the interest rate (%): [一回あたりの金利] ##出力## time--repayment--interest--remains [回数]---[返済額]--[金利分]--[残額] Total repayment: [返済総額] yen. Total interest: [利子総額] yen.元利均等返済##入力## python repayment.py ganri type the principal (yen): [借入額] type the number of repayment: [返済回数] type the interest rate (%): [一回あたりの金利] ##出力## time--repayment--interest--remains [回数]---[返済額]--[金利分]--[残額] Every repayment: [毎回の返済額] yen. Total repayment: [返済総額] yen. Total interest: [利子総額] yen.5. 注意
ナニワ金融道を読んで思いつきで作りました。
ガチでローンの見積もりがしたい人は銀行に行ってください。
- 投稿日:2019-07-28T16:34:58+09:00
Python3+Flask Quick Start
はじめに
FlaskはPython用のマイクロWebフレームワークです。
必要最低限の機能で、動作も軽量なので、ちょっとした簡単なAPIを使えます。Flaskは公式ドキュメントがありますが、全てのソースコードが掲載されてるわけではないので、必要な部分だけ抽出してます。
実行環境
Ubuntu 19.04
python3.7参照ドキュメント
サイト URL 公式サイト http://flask.pocoo.org/ ドキュメント https://flask.palletsprojects.com/en/1.1.x/ Flaskのインストール(venv)
アプリごとに固有の環境を用意するため、Pythonをローカルでインストールするには?
環境を個別に用意するため、venvモジュールを使って仮想環境を用意し、flaskをインストールします。
Python 3.3 と 3.4 では、仮想環境の作成に推奨していたツールは pyvenv でしたが、Python 3.6では非推奨という情報があり、今回はvenvを使用することにいます。参考:
https://docs.python.org/ja/3/library/venv.html$ sudo apt-get install python3-venv $ python3.7 -m venv env $ source env/bin/activate $ pip3.7 install flaskFlask Quick Start
Flaskアプリケーションを動作させるには?
まずは https://flask.palletsprojects.com/en/1.1.x/quickstart/ を参考に簡単に Hello Worldを表示するアプリケーションを作成します。
hello.py#!/usr/bin/env python3 from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return "Hello World!" if __name__ == '__main__': app.run()@app.route はアクセスするディレクトリに応じた関数を呼び出すためのデコレータです。
ユーザがWebサーバへアクセスしたときに、リクエストのあったパスに応じた処理を行う機能を提供します。@app.route('/') def hello_world():Flaskアプリケーションの実行
アプリケーションを立ち上げる方法はいくつかありますが、ここでは flask run コマンドを実行してWebサーバを立ち上げます。
自分の使用しているPC( http://127.0.0.1:5000/ )に接続すると、「Hello World!」と表示されます。command$ export FLASK_ENV="development" $ export FLASK_APP="hello.py" $ flask run * Serving Flask app "hello.py" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active!この状態だとローカルのPCからしか接続できないので、以下のように--hostオプションを設定するとサーバ上でListenするIPアドレスを指定できます。0.0.0.0で指定すると、サーバが所持するすべてのネットワークインターフェースでListenすることができます。
command$ flask run --host=0.0.0.0Flaskの基本機能
ルーティング
アクセスされたパスに応じた処理を返すには?
リクエストを受けたときのルーティングを制御します。
デコレータのすぐ次の行にある関数が実行されます。routing.py#!/usr/bin/env python3 from flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'Index Page' @app.route('/hello') def hello(): return 'Hello, World' if __name__ == '__main__': app.run()デコレータに<変数>を含めると入力したURLを変数として受け取ることができます。
<converter:変数> のように変数を指定すると、型で文字列を受け取れます。
converter 説明 string テキスト状態として変数を受け取ります。デフォルトはこの動作を行います。 int 整数として受け取ります。 float 浮動小数点として受け取ります。 path パスとして受け取ります。 uuid UUIDとして受け取ります。 routing_variable.py#!/usr/bin/env python3 from flask import Flask, escape app = Flask(__name__) @app.route('/user/<username>') def show_user_profile(username): return 'User %s' % escape(username) @app.route('/post/<int:post_id>') def show_post(post_id): return 'Post %d' % post_id @app.route('/path/<path:subpath>') def show_subpath(subpath): return 'Subpath %s' % escape(subpath) if __name__ == '__main__': app.run()HTTPメソッド
HTTPメソッドに応じて処理を指定するには?
HTTPメソッドを指定して処理を行うことができます。
デフォルトでは、ルートはGET要求にのみ応答しますが、デコレータのmethods引数を使って、他のHTTPメソッドも処理できます。http_methods.py#!/usr/bin/env python3 from flask import Flask, request app = Flask(__name__) @app.route('/login', methods=['GET', 'POST']) def login(): if request.method == 'POST': return do_the_login() else: return show_the_login_form()レンダリングテンプレート
テンプレートを使ってWebページを表示するには?
テンプレートを使って、Web画面を表示することができますが、render_template() メソッドを使います。裏ではjinjaというテンプレートエンジンが動いています。
テンプレートエンジンにキーワード引数として渡す変数を指定するだけですrender_template.py#!/usr/bin/env python3 from flask import render_template app = Flask(__name__) @app.route('/hello/') @app.route('/hello/<name>') def hello(name=None): return render_template('hello.html', name=name)hello.html<!doctype html> <title>Hello from Flask</title> {% if name %} <h1>Hello {{ name }}!</h1> {% else %} <h1>Hello, World!</h1> {% endif %}リクエストオブジェクト
フォームデータを処理するには?
要求方法は、method属性を使用して利用できます。
フォームデータにアクセスするには、POSTを受け付けるようにします。form.py#!/usr/bin/env python3 from flask import Flask, request, render_template, redirect, url_for app = Flask(__name__) @app.route('/', methods=['POST', 'GET']) def index(): return redirect(url_for('login')) @app.route('/login', methods=['POST', 'GET']) def login(): error = "" if request.method == 'POST': if valid_login(request.form['username'], request.form['password']): return render_template('hello.html', user=request.form['username']) else: error = 'Invalid username/password' return render_template('login.html', error=error) def valid_login(user,password): if user == "test" and password == "pass": return True return Falselogin.html<html> <body> {{ error }} <form action = "/login" method = "POST"> <p>Name <input type = "text" name = "username" /></p> <p>Value <input type ="text" name = "password" /></p> <p><input type = "submit" value = "submit" /></p> </form> </body> </html>hello.html<html> <body> hello {{user}}! </body> </html>リダイレクトとエラー
リダイレクトするには?
HTTPアクセスをリダイレクトするには、redirect() を使用します。
redirect.py#!/usr/bin/env python3 from flask import Flask, redirect, url_for app = Flask(__name__) @app.route('/') def index(): return redirect(url_for('redirect')) @app.route('/redirect') def redirect(): return "Hello"エラーページを表示するには?
errorhandlerのデコレータでエラーが発生した場合のページを設定できます。
404でアクセス先のリソースがない場合、page_not_found()で指定された関数を実行します。error.py#!/usr/bin/env python3 from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template("hello.html") @app.errorhandler(404) def page_not_found(error): return render_template('page_not_found.html'), 404page_not_found.html404 File not found.APIs with JSON
JSONを扱うには?
FlaskでREST APIを扱う場合は、json形式でデータを受け渡しする必要があります。
JSONデータを扱うには jsonify() を使います。#!/usr/bin/env python3 from flask import Flask, jsonify app = Flask(__name__) @app.route("/" methods=['GET']) def output_data(): return jsonify({'message': 'Hello, world!}) @app.route("/", methods=['POST']") def accept_data(): data = request.get_json() return jsonify(data)commandline$ curl localhost:5000 { "message": "Hello World!" } $ curl -X POST -H 'Accept:application/json' -H 'Content-Type:application/json' -d '{"Hello":"World"}' http://localhost:5000/ { "Hello": "World" }セッション
Flaskでセッションを管理するには?
Webアクセスに使うHTTPプロトコルは状態を保持できないので、ログイン状態を保持することができません。そのため、一度ログインした情報を保持するためには他の手段が必要です。
Flaskでは、session()関数で、クッキーを用いてセッション管理を行います。
session.py#!/usr/bin/env python3 from flask import Flask, session, redirect, url_for, escape, request app = Flask(__name__) app.secret_key = 'app key' @app.route('/') def index(): if 'username' in session: return 'Logged in as %s' % escape(session['username']) return 'You are not logged in' @app.route('/login', methods=['GET', 'POST']) def login(): if request.method == 'POST': session['username'] = request.form['username'] return redirect(url_for('index')) return ''' <form action="" method="post"> <p><input type=text name=username> <p><input type=submit value=Login> </form> ''' @app.route('/logout') def logout(): # remove the username from the session if its there session.pop('username', None) return redirect(url_for('index'))
- 投稿日:2019-07-28T16:16:31+09:00
Jupyterでよく使うもの
Data analysis
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set('talk', 'whitegrid', 'bright', font_scale=1.0, rc={"lines.linewidth": 2, 'grid.linestyle': '--', "xtick.major.size": 6, "ytick.major.size": 6})Ref. https://note.nkmk.me/python-matplotlib-seaborn-basic/
import plotly # only used in jupyter notebook plotly.offline.init_notebook_mode(connected=False)File operation
import glob import re import osFont check
import matplotlib.font_manager matplotlib.font_manager.findSystemFonts(fontpaths=None, fontext='ttf') import matplotlib as mpl mpl.matplotlib_fname()Figure
fig = plt.figure(figsize=(6,4), dpi=80) fig.subplots_adjust(left=0.2, wspace=0.6, bottom=0.15, hspace = 0.6) fig.suptitle("") ax1 = fig.add_subplot(1,1,1) ax1.plot(df["xxx"], df["yyy"], "o-", color='black', linestyle='solid', linewidth=2) ax1.axis('tight') ax1.set_xlabel("x_label") ax1.set_ylabel("y_label") ax1.grid(True)
- 投稿日:2019-07-28T16:06:00+09:00
Pythonプログラミング 安産祈願マークをつくるよ
日本で一番有名なマークである
安産祈願マークを
プログラムで作ってみましょう!!!動画はこちら
https://www.youtube.com/embed/5We7M65se3cさて
作り方は
numpyとmatplotlibを用いて
マークを描いていきます。widgetも用いて
うねうね変形できるようにもします。ソースはこちら
import numpy as np import matplotlib.pyplot as plt from ipywidgets import interact, FloatSlider, IntSlider,Select %matplotlib inline r = IntSlider(min=1, max=8, step=1, value=5) t = FloatSlider(min=1.0, max=1.5, step=0.1, value=1.0) c = Select(options=['black', 'red', 'blue','green'], value='black',description='coler : ',disabled=False) @interact(r=r,t=t,c=c) def plot_man(r,t,c): plt.figure(figsize=(10,9)) plt.axes().set_aspect('equal', 'datalim') # circle 1 x = [np.sin(np.radians(_x))*r for _x in np.linspace(-180,180,721)] y = [np.cos(np.radians(_y))*r*t for _y in np.linspace(-180,180,721)] plt.plot(x, y, c) # circle 2 x2 = [i*0.7 for i in x] y2 = [i*0.7 for i in y] plt.plot(x2, y2, c) # line x3 = [0,0] y3 = [min(y)*1.25,max(y)*1.25] plt.plot(x3, y3, c) # lines x4 = [i*1.2 for i in x] y4 = [i*1.2 for i in y] for i in range(16): x5 = [x[i*45],x4[i*45]] y5 = [y[i*45],y4[i*45]] plt.plot(x5, y5, c) plt.xlim([-20,20]) plt.ylim([-20,20]) plt.show()jupyter notebookで
動かすことができます。結果はこうなります。
rで円の半径を変更
tで楕円の倍率を変更
colorで色を変更です。楕円は
円の縦横方向を n 倍にすることで実現しています。なので
縦方向であれば
xの値はそのままに
yの値の倍率を変えてあげると
縦方向の楕円になります。今回のやり方では
まず半径を決めて円を用意します。
内側の円は1つめの円の倍率を変えただけです。縦棒はxの値が0でyの値を変化させることで
実現させ、外側の棒たちは大きな円を用意し
1つめの円から外側の円に向かう値で
描いています。一応16本になるみたいなので
22.5度の角度になるような計算で
座標を求めています。全部足すと
安産マークになります!!!!!!!せっかくなので
GIFも作ってみましょうmatplotlibではアニメーション機能で
mp4やgifも作れますが
環境によっては動かないこともあり今回は
画像をたくさん生成して
無理くりGIFに落とし込みます。ソースはこちら
from PIL import Image, ImageDraw, ImageFont import numpy as np import matplotlib.pyplot as plt from ipywidgets import interact, FloatSlider, IntSlider,Select import os data_dir = 'anzan_data/' if not os.path.exists(data_dir): os.makedirs(data_dir) for a in range(30): plt.figure(figsize=(3,3)) plt.axes().set_aspect('equal', 'datalim') plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) plt.tick_params(bottom=False, left=False, right=False, top=False) plt.xlim([-20,20]) plt.ylim([-20,20]) c ='black' n = (np.abs(np.sin(a))+1) # circle 1 x = [np.sin(np.radians(_x))*8 for _x in np.linspace(-180,180,721)] y = [np.cos(np.radians(_y))*8*n for _y in np.linspace(-180,180,721)] plt.plot(x, y, c) # circle 2 x2 = [i*0.7 for i in x] y2 = [i*0.7 for i in y] plt.plot(x2, y2, c) # line x3 = [0,0] y3 = [min(y)*1.25,max(y)*1.25] plt.plot(x3, y3, c) # lines x4 = [i*1.2 for i in x] y4 = [i*1.2 for i in y] for i in range(16): x5 = [x[i*45],x4[i*45]] y5 = [y[i*45],y4[i*45]] plt.plot(x5, y5, c) file_name = data_dir + 'tmp_{0:02}.png'.format(a) plt.savefig(file_name) images = [] for a in range(30): file_name = data_dir + 'tmp_{0:02}.png'.format(a) img = Image.open(file_name) images.append(img) gif_name = 'anzan.gif' images[0].save(gif_name,save_all=True, append_images=images[1:], optimize=False, duration=2, loop=0)jupyter notebookで実行すると
安産祈願マークがnotebookの在るディレクトリに
作成されます。結果は
はい
ビロンビロンして
気持ちのいいGIFが生成されます。是非興味のある方は
試してみてください。それでは
- 投稿日:2019-07-28T15:53:58+09:00
WindowsのPython embeddable版でTensorFlowを使う
【内容】
WindowsのPython embeddable版でTensorFlowを使おうとして少しハマったので、解決方法を共有します。
【前提条件】
WindowsのPython embeddable版 + pip がインストールされていることが前提です。
embeddable版のインストール方法は下記の記事を参照してください。
【Windowsで環境を極力汚さずにPythonを動かす方法 (Python embeddable版)】また、TensorFlowをWindowsで動かすためには「Microsoft Visual C++ 2015 再頒布可能パッケージ Update 3」が必要になります。
Python embeddable版を動かすためにも必要ですので、すでにインストールされているはずです。最後に2019年07月28日現在、Windows環境でTensorFlowが対応しているのはPython3.5/3.6/3.7の64bit版のみになります。
なお、本記事で検証したバージョンは以下になります。
- Python 3.5.4 embeddable 64bit
- Python 3.6.7rc2 embeddable 64bit
- Python 3.7.3 embeddable 64bit
- Python 3.7.4 embeddable 64bit
- TensorFlow 1.11.0, 1.13.0, 1.13.1, 1.14.0
【pipを用いたTensorFlowのインストール方法】
Python3.5/3.6/3.7の64bit版では下記のコマンドを実行することでTensorFlowをインストールすることが可能です。
(pythonのインストールフォルダ)\Scripts\pip install tensorflow または (pythonのインストールフォルダ)\Scripts\pip install tensorflow-gpuただし、embeddable版ではエラーが発生して失敗します。
バージョンによって原因と解決方法が異なりますので、それぞれについて解説します。先に投稿した【Windowsで環境を極力汚さずにPythonを動かす方法 (Python embeddable版)】の手順を踏んでいる場合はエラーなくインストールできるはずですので、これ以降読む必要はありません。
【Python 3.5.4 embeddableの場合】
embeddable版はpython本体をzipファイルの中に収めていますが、ある特定モジュールのインストールスクリプトが、このzipファイルの中を参照できないようです。
よって、以下の手順でzipファイルを解凍して、その中身をzipファイルと同じ名前のフォルダに保存することで、問題を回避できます。【対応方法】
- pythonをインストールしたフォルダ内に「python35.zip」というZIPファイルが存在します。 このファイルの名前を「__python35.zip」に変更します。
- pythonをインストールしたフォルダ内に新規フォルダを作成し、名前を「python35.zip」とします。
- 先ほど名前を変更したZIPファイル「__python35.zip」の中身を「python35.zip」フォルダ内に解凍します。
- 最後に
(pythonのインストールフォルダ)\Scripts\pipコマンドを実行して、TensorFlowをインストールします。【Python 3.6.7rc2 embeddableの場合】(3.7.2、3.7.3、3.7.4でも確認済み)
通常Pythonはカレントディレクトリに存在するPythonファイルをimportできるのですが、embeddable版ではパスが通らずアクセスできない状態になっています。
このため、特定のモジュールのインストールスクリプトが自身のモジュールを参照できずにエラーになってしまいます。
そこで、下記の方法でカレントディレクトリにパスを通すことで、問題を回避します。【対応方法】
- pythonをインストールしたフォルダ内に「current.pth」というファイルを作成します。 (ファイル名は何でも良いですが、拡張子を「.pth」としてください)
- 「current.pth」をメモ帳などで開いて
import sys; sys.path.append('')と記載して保存します。- 最後に
(pythonのインストールフォルダ)\Scripts\pipコマンドを実行して、TensorFlowをインストールします。【動作確認】
下記のコマンドを実行して、TensorFlowのバージョンが表示されるか確認します。
(pythonをインストールしたフォルダ)\python -c "import tensorflow as tf; print(tf.__version__)"【結果】
1.14.0【動作確認2】
TensorFlowのチュートリアル(手書き数字識別)を実行します。
mnist_test.pyimport tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) print(model.evaluate(x_test, y_test))【実行】
(pythonをインストールしたフォルダ)\python mnist_test.py【結果 TF_1.11.0 CPU版】
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 1s 0us/step Epoch 1/5 2018-10-19 11:11:41.986927: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 60000/60000 [==============================] - 14s 228us/step - loss: 0.1996 - acc: 0.9413 Epoch 2/5 60000/60000 [==============================] - 13s 221us/step - loss: 0.0797 - acc: 0.9752 Epoch 3/5 60000/60000 [==============================] - 13s 219us/step - loss: 0.0524 - acc: 0.9834 Epoch 4/5 60000/60000 [==============================] - 13s 218us/step - loss: 0.0371 - acc: 0.9880 Epoch 5/5 60000/60000 [==============================] - 13s 219us/step - loss: 0.0266 - acc: 0.9915 10000/10000 [==============================] - 0s 46us/step [0.08852570028939517, 0.9753]【結果 TF_1.14.0 GPU版】
2019-07-28 15:35:49.126687: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2019-07-28 15:35:49.135333: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library nvcuda.dll 2019-07-28 15:35:49.851931: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties: name: GeForce MX150 major: 6 minor: 1 memoryClockRate(GHz): 1.5315 pciBusID: 0000:01:00.0 2019-07-28 15:35:49.860067: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check. 2019-07-28 15:35:49.868413: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1763] Adding visible gpu devices: 0 2019-07-28 15:35:50.629424: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-07-28 15:35:50.633160: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1187] 0 2019-07-28 15:35:50.635637: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1200] 0: N 2019-07-28 15:35:50.639866: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1326] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1360 MB memory) -> physical GPU (device: 0, name: GeForce MX150, pci bus id: 0000:01:00.0, compute capability: 6.1) Epoch 1/5 60000/60000 [==============================] - 6s 98us/sample - loss: 0.2195 - acc: 0.9353 Epoch 2/5 60000/60000 [==============================] - 5s 82us/sample - loss: 0.0955 - acc: 0.9705 Epoch 3/5 60000/60000 [==============================] - 5s 81us/sample - loss: 0.0684 - acc: 0.9787 Epoch 4/5 60000/60000 [==============================] - 5s 82us/sample - loss: 0.0524 - acc: 0.9828 Epoch 5/5 60000/60000 [==============================] - 5s 82us/sample - loss: 0.0449 - acc: 0.9851 10000/10000 [==============================] - 0s 48us/sample - loss: 0.0768 - acc: 0.9751 [0.07682957069921541, 0.9751]
- 投稿日:2019-07-28T15:46:34+09:00
Pythonで文の日本語判定を行う
100文字程度の短い文が日本語かどうかを判定したい場合があります。
単純な方法として、ひらがな、もしくは、カタカナが含まれているかどうかを見ることで、近似的に判定することができます。import re def is_japanese(str) return True if re.search(r'[ぁ-んァ-ン]') else False厳密にはこの方法では不十分です。
漢字だけの日本語文もあれば、英文中に顔文字としてカタカナが使われたりすることもあります。
それでも、これだけで必要十分な篩い分けができるので重宝している方法です。
対象とする文書群や問題によっては有効であるかと思います。
- 投稿日:2019-07-28T15:38:02+09:00
Pythonのrequests_futureの実行方法による速度比較
Pythonの
requests_futuresの実行方法によって速度が変わる。
requests_futureを使うときは、sessionを一度にまとめて作って、後から評価するようにしないと並列で動かない。多分テストコード
from concurrent.futures import ThreadPoolExecutor from requests_futures.sessions import FuturesSession import requests import time session = FuturesSession(executor=ThreadPoolExecutor(max_workers=30)) num_links = 100 links = [f"http://example.com/{_}" for _ in range(1,num_links)] fs = [] print(f"requesting to {num_links} links") t1 = time.time() for l in links: f = session.get(l) fs.append(f) t2 = time.time() print(f"push to pool w/ requests_future: {t2-t1} sec") for f in fs: f.result().status_code == 200 t3 =time.time() print(f"eval in pool w/ requests_future: {t3-t2} sec") for l in links: f = session.get(l) f.result().status_code == 200 t4 = time.time() print(f"eval everytime w/ requests_future: {t4-t3} sec") for l in links: r = requests.get(l) r.status_code == 200 t5 = time.time() print(f"eval everytime w/ requests: {t5-t5} sec")実行結果
requesting to 100 links push to pool w/ requests_future: 0.08985710144042969 sec eval in pool w/ requests_future: 0.9865047931671143 sec eval everytime w/ requests_future: 24.10741138458252 sec eval everytime w/ requests: 44.42911386489868 sec
- 投稿日:2019-07-28T15:19:44+09:00
python 内包表記 使えるテンプレート
自分のPCのipアドレスの取得
nicのアドレスを取得ifconfig.pyimport netifaces as n ipcmp=lambda x:(int(x.split(".")[0]),int(x.split(".")[1]),int(x.split(".")[2]),int(x.split(".")[3])) nn=sorted([n.ifaddresses(i)[n.AF_INET][0]['addr'] for i in n.interfaces() if n.AF_INET in n.ifaddresses(i)],key=ipcmp) print(nn)ラムダ式は、アドレスをソートするためにstringからintに変換している
result.txt['127.0.0.1', '192.168.1.10']よく使う内包表記
自分のいるネットワークの一覧表
無料wifiでやらないでください。
myNet.pyfrom kamene.all import * import requests,json mac=lambda m:(requests.get('http://macvendors.co/api/%s'% m).json()['result'])['company'] ipcmp=lambda x:(int(x[0].split(".")[0]),int(x[0].split(".")[1]),int(x[0].split(".")[2]),int(x[0].split(".")[3])) net=sorted([(x[1][ARP].psrc,x[1][ARP].hwsrc) for x in arping('192.168.1.*', timeout=1, verbose=0)[0]],key=ipcmp) for x in net: print("%-16s %-20s %-20s"%(x[0],x[1],mac(x[1])))result.txt192.168.1.1 xx:xx:xx:3f:8a:21 Mitsubishi Electric Corporation 192.168.1.11 xx:xx:bc:2d:e4:77 PEGATRON CORPORATION 192.168.1.90 xx:xx:92:10:3c:f6 SEIKO EPSON CORPORATION 192.168.1.108 xx:xx:eb:97:47:1a Raspberry Pi Foundation 192.168.1.111 xx:x:xeb:97:47:1a Raspberry Pi Foundation 192.168.1.119 xx:xx:2d:68:24:3d Espressif Inc. 192.168.1.151 xx:xx:77:17:5d:70 HangZhou Gubei Electronics Technology Co.,Ltd 192.168.1.155 xx:xx:8e:a7:d8:3a Espressif Inc. 192.168.1.160 xx:xx:42:75:18:71 HangZhou Gubei Electronics Technology Co.,Ltd 192.168.1.161 xx:xx:42:63:0d:93 HangZhou Gubei Electronics Technology Co.,Ltd 192.168.1.199 xx:xx:xx:21:11:fd SNOM Technology AG
- 投稿日:2019-07-28T15:18:26+09:00
Python ✖︎ Flask ✖︎ Webアプリ(4)DBに接続して操作してみよう
目的
- Flask で Postgresql に接続
- DB にレコードを登録できること
- DB からレコードを取得できること
本編
環境準備
python のパッケージを追加
requirements.txtflask sqlalchemy psycopg2上記を
pip install -r requirements.txtでインストールポイント
sqlalchemyは python の ORM ライブラリ(簡単に言うとDB 操作は sqlalchemy が担当するよ)
psycopg2は flask と postgresql を繋いでくれる役割
インストールしたパッケージを一括でアンインストールする(必要があれば)
- pip でインストールしたパッケージの一覧を取得
$ pip freeze > piplist.txt
- 一括でアンインストール
$ pip uninstall -y -r piplist.txt前回まで
Python ✖︎ Flask ✖︎ Webアプリ(3)Docker登場 DBの準備
Python ✖︎ Flask ✖︎ Webアプリ(2)HTMLの表示とメソッドとパラメータの受け取りかた
Python ✖︎ Flask ✖︎ Webアプリ(1)こんにちは世界フォルダ構成
. ├── README.md ├── docker-compose.yml ├── form.html ├── postgresql │ └── init │ ├── 1_create_db.sql │ └── 2_create_table.sh ├── requirements.txt ├── src │ ├── UserModel.py │ ├── main.py │ ├── setting.py │ └── templates │ └── hello.html └── test.httpDB接続の準備
setting.pyfrom sqlalchemy import * from sqlalchemy.orm import * from sqlalchemy.ext.declarative import declarative_base import psycopg2 # postgresqlのDBの設定 DATABASE = "postgresql://postgres:@192.168.1.19:5432/flask_tutorial" # Engineの作成 ENGINE = create_engine( DATABASE, encoding="utf-8", # TrueにするとSQLが実行される度に出力される echo=True ) # Sessionの作成 session = scoped_session( # ORM実行時の設定。自動コミットするか、自動反映するなど。 sessionmaker( autocommit=False, autoflush=False, bind=ENGINE ) ) # modelで使用する Base = declarative_base() Base.query = session.query_property()ポイント
DB の接続先情報
DATABASE = "postgresql://postgres:@192.168.1.19:5432/flask_tutorial
DATABASE = "postgresql://{DBのユーザ}:{DBのパスワード}@{url}:{ポート番号}/{DB名}
今回のDBは前回用意したDBをそのまま利用
{url}は自分のPCのIPを入力Engine 作成
ENGINE = create_engine( DATABASE, encoding="utf-8", # TrueにするとSQLが実行される度に出力される echo=True )Engine はDBにアクセスするための土台なんだと覚えとけば、とりあえずOK
- Session作成
session = scoped_session( # ORM実行時の設定。自動コミットするか、自動反映するなど。 sessionmaker( autocommit=False, autoflush=False, bind=ENGINE ) )SessionはflaskとDBとのやり取りを全て担当してくれるもの
データを挿入するテーブルを準備
2_create_table.sh#!/bin/bash psql -U postgres -d flask_tutorial << "EOSQL" CREATE TABLE users ( id SERIAL NOT NULL, name VARCHAR(200), created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL, updated_at TIMESTAMP WITHOUT TIME ZONE NOT NULL, PRIMARY KEY (id) ); EOSQLUserModel.pyfrom datetime import datetime from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime from setting import Base from setting import ENGINE class User(Base): """ UserModel """ __tablename__ = 'users' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(200)) created_at = Column(DateTime, default=datetime.now, nullable=False) updated_at = Column(DateTime, default=datetime.now, nullable=False) def __init__(self, name): self.name = name if __name__ == "__main__": Base.metadata.create_all(bind=ENGINE)ポイント
- DBのDockerコンテナを初めて起動した際に、
2_create_table.shでUserテーブルを作成する
※ DBが一度作成されている場合は、/Users/${USER}/Volumes/flask_tutorial/postgresを削除する- flask側にDB上に、どんなテーブルがあるのかをsqlarchemyを使用して定義してあげる
DB 確認
- コンテナを起動
$ docker-compose up -d Creating network "flask-tutorial_default" with the default driver Creating flask_tutorial_postgresql ... done Creating flask_tutorial_pgadmin4 ... done
- pgadminでUserテーブルが作成されていることを確認
DB操作準備
main.pyfrom flask import Flask, request, render_template from UserModel import User from setting import session from sqlalchemy import * from sqlalchemy.orm import * # appという名前でFlaskのインスタンスを作成 app = Flask(__name__) # 登録処理 @app.route('/', methods=["POST"]) def register_record(): name = request.form['name'] session.add(User(name)) session.commit() return render_template("hello.html", name=name, message="登録完了しました!") # 取得処理 @app.route('/', methods=["GET"]) def fetch_record(): name = request.args.get('name') db_user = session.query(User.name).\ filter(User.name == name).\ all() if len(db_user) == 0: message = "登録されていません。" else: message = "登録されています。" return render_template("hello.html", name=name, message=message) if __name__ == '__main__': app.run()ポイント
操作に必要なものをインポート
- 操作対象のテーブル
- DBの操作を行うのでsessionが必要
from UserModel import User from setting import session from sqlalchemy import * from sqlalchemy.orm import *
- 登録処理
# 登録処理 @app.route('/', methods=["POST"]) def register_record(): name = request.form['name'] session.add(User(name)) session.commit() return render_template("hello.html", name=name, message="登録完了しました!")実際に登録している箇所は以下
session.add(User(name)) session.commit()
session.addでINSERT文を実行
session.commit()コミットしてる
- 取得処理
# 取得処理 @app.route('/', methods=["GET"]) def fetch_record(): name = request.args.get('name') db_user = session.query(User.name).\ filter(User.name == name).\ all() if len(db_user) == 0: message = "登録されていません。" else: message = "登録されています。" return render_template("hello.html", name=name, message=message)取得処理は、以下
db_user = session.query(User.name).\ filter(User.name == name).\ all()
session.query(User.name)で取得したいテーブル.列名
filter(User.name == name)はWHERE句
all()でクエリを実行※ 今回は単純なSELECT文のみ、テーブル結合などもできるので必要に応じて適宜調べてください。
DB操作確認
- コンテナを起動
$ docker-compose up -d Creating network "flask-tutorial_default" with the default driver Creating flask_tutorial_postgresql ... done Creating flask_tutorial_pgadmin4 ... done
- flaskを起動
$ python src/main.py * Serving Flask app "main" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
- form.htmlで確認
次回
- nginxのdockerコンテナを用意して、静的なページをflaskから切り離す
- 投稿日:2019-07-28T15:18:26+09:00
Python ✖︎ Flask ✖︎ Webアプリ(4)DBに接続
目的
- Flask で Postgresql に接続
- DB にレコードを登録できること
- DB からレコードを取得できること
本編
環境準備
python のパッケージを追加
requirements.txtflask sqlalchemy psycopg2上記を
pip install -r requirements.txtでインストールポイント
sqlalchemyは python の ORM ライブラリ(簡単に言うとDB 操作は sqlalchemy が担当するよ)
psycopg2は flask と postgresql を繋いでくれる役割
インストールしたパッケージを一括でアンインストールする(必要があれば)
- pip でインストールしたパッケージの一覧を取得
$ pip freeze > piplist.txt
- 一括でアンインストール
$ pip uninstall -y -r piplist.txt前回まで
Python ✖︎ Flask ✖︎ Webアプリ(3)Docker登場 DBの準備
Python ✖︎ Flask ✖︎ Webアプリ(2)HTMLの表示とメソッドとパラメータの受け取りかた
Python ✖︎ Flask ✖︎ Webアプリ(1)こんにちは世界フォルダ構成
. ├── README.md ├── docker-compose.yml ├── form.html ├── postgresql │ └── init │ ├── 1_create_db.sql │ └── 2_create_table.sh ├── requirements.txt ├── src │ ├── UserModel.py │ ├── main.py │ ├── setting.py │ └── templates │ └── hello.html └── test.httpDB接続の準備
setting.pyfrom sqlalchemy import * from sqlalchemy.orm import * from sqlalchemy.ext.declarative import declarative_base import psycopg2 # postgresqlのDBの設定 DATABASE = "postgresql://postgres:@192.168.1.19:5432/flask_tutorial" # Engineの作成 ENGINE = create_engine( DATABASE, encoding="utf-8", # TrueにするとSQLが実行される度に出力される echo=True ) # Sessionの作成 session = scoped_session( # ORM実行時の設定。自動コミットするか、自動反映するなど。 sessionmaker( autocommit=False, autoflush=False, bind=ENGINE ) ) # modelで使用する Base = declarative_base() Base.query = session.query_property()ポイント
DB の接続先情報
DATABASE = "postgresql://postgres:@192.168.1.19:5432/flask_tutorial
DATABASE = "postgresql://{DBのユーザ}:{DBのパスワード}@{url}:{ポート番号}/{DB名}
今回のDBは前回用意したDBをそのまま利用
{url}は自分のPCのIPを入力Engine 作成
ENGINE = create_engine( DATABASE, encoding="utf-8", # TrueにするとSQLが実行される度に出力される echo=True )Engine はDBにアクセスするための土台なんだと覚えとけば、とりあえずOK
- Session作成
session = scoped_session( # ORM実行時の設定。自動コミットするか、自動反映するなど。 sessionmaker( autocommit=False, autoflush=False, bind=ENGINE ) )SessionはflaskとDBとのやり取りを全て担当してくれるもの
データを挿入するテーブルを準備
2_create_table.sh#!/bin/bash psql -U postgres -d flask_tutorial << "EOSQL" CREATE TABLE users ( id SERIAL NOT NULL, name VARCHAR(200), created_at TIMESTAMP WITHOUT TIME ZONE NOT NULL, updated_at TIMESTAMP WITHOUT TIME ZONE NOT NULL, PRIMARY KEY (id) ); EOSQLUserModel.pyfrom datetime import datetime from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, DateTime from setting import Base from setting import ENGINE class User(Base): """ UserModel """ __tablename__ = 'users' id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(200)) created_at = Column(DateTime, default=datetime.now, nullable=False) updated_at = Column(DateTime, default=datetime.now, nullable=False) def __init__(self, name): self.name = name if __name__ == "__main__": Base.metadata.create_all(bind=ENGINE)ポイント
- DBのDockerコンテナを初めて起動した際に、
2_create_table.shでUserテーブルを作成する
※ DBが一度作成されている場合は、/Users/${USER}/Volumes/flask_tutorial/postgresを削除する- flask側にDB上に、どんなテーブルがあるのかをsqlarchemyを使用して定義してあげる
DB 確認
- コンテナを起動
$ docker-compose up -d Creating network "flask-tutorial_default" with the default driver Creating flask_tutorial_postgresql ... done Creating flask_tutorial_pgadmin4 ... done
- pgadminでUserテーブルが作成されていることを確認
DB操作準備
main.pyfrom flask import Flask, request, render_template from UserModel import User from setting import session from sqlalchemy import * from sqlalchemy.orm import * # appという名前でFlaskのインスタンスを作成 app = Flask(__name__) # 登録処理 @app.route('/', methods=["POST"]) def register_record(): name = request.form['name'] session.add(User(name)) session.commit() return render_template("hello.html", name=name, message="登録完了しました!") # 取得処理 @app.route('/', methods=["GET"]) def fetch_record(): name = request.args.get('name') db_user = session.query(User.name).\ filter(User.name == name).\ all() if len(db_user) == 0: message = "登録されていません。" else: message = "登録されています。" return render_template("hello.html", name=name, message=message) if __name__ == '__main__': app.run()ポイント
操作に必要なものをインポート
- 操作対象のテーブル
- DBの操作を行うのでsessionが必要
from UserModel import User from setting import session from sqlalchemy import * from sqlalchemy.orm import *
- 登録処理
# 登録処理 @app.route('/', methods=["POST"]) def register_record(): name = request.form['name'] session.add(User(name)) session.commit() return render_template("hello.html", name=name, message="登録完了しました!")実際に登録している箇所は以下
session.add(User(name)) session.commit()
session.addでINSERT文を実行
session.commit()コミットしてる
- 取得処理
# 取得処理 @app.route('/', methods=["GET"]) def fetch_record(): name = request.args.get('name') db_user = session.query(User.name).\ filter(User.name == name).\ all() if len(db_user) == 0: message = "登録されていません。" else: message = "登録されています。" return render_template("hello.html", name=name, message=message)取得処理は、以下
db_user = session.query(User.name).\ filter(User.name == name).\ all()
session.query(User.name)で取得したいテーブル.列名
filter(User.name == name)はWHERE句
all()でクエリを実行※ 今回は単純なSELECT文のみ、テーブル結合などもできるので必要に応じて適宜調べてください。
DB操作確認
- コンテナを起動
$ docker-compose up -d Creating network "flask-tutorial_default" with the default driver Creating flask_tutorial_postgresql ... done Creating flask_tutorial_pgadmin4 ... done
- flaskを起動
$ python src/main.py * Serving Flask app "main" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
- form.htmlで確認
次回
- nginxのdockerコンテナを用意して、静的なページをflaskから切り離す
- 投稿日:2019-07-28T15:17:25+09:00
固有値、固有ベクトルの応用例(主成分分析)
はじめに
この記事は古川研究室 Workout_calendar 13日目の記事です。
本記事は古川研究室の学生が学習の一環として書いたものです。内容が曖昧であったり表現が多少異なったりする場合があります。また、この記事は全3部作となっており、この記事はいわば後編となっています。
前編:固有値と固有ベクトルの性質
中編:固有値と固有ベクトルの応用例(二次形式)
後編:固有値と固有ベクトルの応用例(主成分分析)←今こここの記事では前編の記事で軽く触れた固有値問題の例として、機械学習で用いられる次元削減法の1つである主成分分析について記していこうと思います。
主成分分析
主成分分析は、次元削減の手法の一つで多次元データを可視化する際などに使われます。
主成分分析で鍵となるのは以下に示す共分散行列です。S = \frac{1}{N}\sum_{n=1}^N(\mathbf{x}_n-\mathbf{\bar x})(\mathbf{x}_n-\mathbf{\bar x})^T式中の$\mathbf x_n$はD次元の各データ,$\mathbf{\bar x}$は全データの平均を示しています。
D次元データ$\mathbf x_n$を1次元空間に射影することを考えます。
また、主成分分析では、射影後のデータの分散がなるべく大きくなるように次元を削減します。
その方がデータの情報が多く残っていると判断しているわけですね。
データを射影するためにD次元のベクトルである$\mathbf{u}$を導入し、$\mathbf{u}$と$\mathbf{x}_n$の行列積を取ります。
また、$\mathbf{u}$を単位ベクトルと仮定します。つまり$\mathbf{u}^T\mathbf{u}=1$です。
射影後のデータの分散は$$
\frac{1}{N}\sum_{n=1}^N{\mathbf{u}^T\mathbf{x}_n-\mathbf{u}\mathbf{\bar x}}^2
$$となります。さらに式を展開していくと
\frac{1}{N}\sum_{n=1}^N(\mathbf{\mathbf{u}^T\mathbf{x}_n-u\mathbf{\bar x})(\mathbf{u}^T\mathbf{x}_n-\mathbf{u}\mathbf{\bar x})}^T\frac{1}{N}\sum_{n=1}^N\{(\mathbf{u}^T\mathbf{x}_n)(\mathbf{u}^T\mathbf{x}_n)^T-(\mathbf{u}^T\mathbf{x}_n)(\mathbf{u}^T\mathbf{\bar x})^T-(\mathbf{u}^T\mathbf{\bar x})(\mathbf{u}^T\mathbf{x}_n)^T+(\mathbf{u}^T\mathbf{\bar x})(\mathbf{u}^T\mathbf{\bar x})^T\}$\mathbf{(A^TB)^T=B^TA}$を各項に当てはめて整理すると
\frac{1}{N}\sum_{n=1}^N(\mathbf{u}^T\mathbf{x}_n^2\mathbf{u}-2\mathbf{u}^T\mathbf{\bar x} \mathbf{x}_n\mathbf{u}+\mathbf{u}^T\mathbf{\bar x}^2\mathbf{u})$\mathbf{u^T,u}$を括りだして
\frac{1}{N}\sum_{n=1}^N\mathbf{u}^T(\mathbf{x}_n^2-2\mathbf{\bar x}_n \mathbf{x}_n+ \mathbf{\bar x}_n^2)\mathbf{u}\\ =\mathbf{u^T}\left \{\frac{1}{N}\sum_{n=1}^N{(\mathbf{x}_n-\mathbf{\bar x})(\mathbf{x}_n-\mathbf{\bar x})}^T\right \}\mathbf{u} =\mathbf{u}^T\mathbf{Su}となります。こうして得られた分散$\mathbf{u}^T\mathbf{Su}$を最大化します。$\mathbf{S}$はデータによって定まる共分散行列なので$\mathbf{u}$に対して最大化します。
$\mathbf{u}$を最大化しようとすると「∞にすれば最大じゃんアハハ」と抜かす不届き者が後を絶たないので、制約項を追加します。
\mathbf{u}^TS\mathbf{u}+\lambda (1-\mathbf{u}^T\mathbf{u})$\lambda$は係数(ラグランジュ乗数)です。この式を$\mathbf{u}$について偏微分して、0となる場所を探します。
S\mathbf{u}-\lambda \mathbf{u}=0\\ S\mathbf{u}=\lambda \mathbf{u}なんとこの形はこの記事のいっちばん上で記した固有値問題の式$A\mathbf{x}=\lambda \mathbf{x}$と一致しています。つまり$\lambda$は固有値となるわけです。おおんすごいん
$S\mathbf{u}=\lambda \mathbf{u}$ に左から$\mathbf{u}^T$をかけると
$$
\mathbf{u}^TS\mathbf{u}=\lambda \mathbf{u}^T\mathbf{u}
$$$\mathbf{u}^T\mathbf{u}=1$なので
$$
\mathbf{u}^TS\mathbf{u}=\lambda
$$となり、分散が最大となるには、共分散行列の固有値から一番大きいものを選び、それに対応する固有ベクトルで射影すればよいということがわかりました。また、2次元、3次元へと射影するためには共分散行列の固有値の大きいものから順にそれに対応する固有ベクトルを選んでいけば良いです。固有値問題すげえ。
例えばデータが4次元の場合だと固有値は4つ出てきます。2次元に可視化するためには固有値が大きい順から二つを主成分とし、その固有値に対応した固有ベクトルによってデータを射影するのです。
実際に体感するために、具体的な実装例を以下に載せます。
print(__doc__) #PCA:主成分分析 # Code source: Gaël Varoquaux # License: BSD 3 clause import numpy as np#numpyをインストール import matplotlib.pyplot as plt#グラフを書くやつ from mpl_toolkits.mplot3d import Axes3D#3次元plotを行うためのツール from sklearn import decomposition#PCAのライブラリ from sklearn import datasets#datasetsを取ってくる n_component=2 np.set_printoptions(suppress=True) fig = plt.figure(2, figsize=(14, 6)) iris = datasets.load_iris() X = iris.data y = iris.target for i in range(4):#各データの平均を元のデータから引いている mean = np.mean(X[:,i]) X[:,i]=(X[:,i]-mean) X_cov=np.dot(X.T,X)#共分散行列を生成 w,v=np.linalg.eig(X_cov)#共分散行列の固有値、固有ベクトルを算出(固有値は既に大きさ順に並べられている) for i in range(n_component):#固有値の大きい順に固有ベクトルを取り出す Xpc[i]=v[:,i] Xpc=np.array(Xpc) Xafter=np.dot(X,Xpc.T)#取り出した固有ベクトルでデータを線形写像する pca = decomposition.PCA(n_components=2) pca.fit(X) Xlib = pca.transform(X) ax1 = fig.add_subplot(121) for label in np.unique(y): ax1.scatter(Xlib[y == label, 0], Xlib[y == label, 1]) ax1.set_title('library pca') ax1.set_xlabel("X_axis") ax1.set_ylabel("Y_axis") ax2 = fig.add_subplot(122) for label in np.unique(y): ax2.scatter(Xafter[y == label, 0], Xafter[y == label, 1]) ax2.set_title('original pca') ax2.set_xlabel("X_axis") ax2.set_ylabel("Y_axis") plt.show()
今回はScikit-learnに公開されているIrisデータセットという4次元のデータを2次元まで次元削減して可視化しています。
左はscikit-learnで公開されている主成分分析用のライブラリを使った結果、右は数式を実際に再現して主成分分析をした結果を示しています。
右と左で結果が違ってしまっているのは、scikit-learnのライブラリの仕様によるものです。普通固有ベクトルは一意に定まらない(向きが変わる)のですが、scikit-learnでは第1主成分とした固有ベクトルの第1要素が正となるように固有ベクトルを定めているため、結果が反転したりします。
Irisデータセットはアヤメの品種のデータセットです。セトナ、バーシクル、 バージニカという3種類のアヤメのがく片長,がく片幅,花びら長,花びら幅から構成されています。
Irisデータセットをそのまま図示しようとしても各アヤメのデータは4つあるため、2次元や3次元には図示できません。
そこで次元削減を行うのですが、出来るだけ情報を残して次元を落としたいものです。
主成分分析をした結果を見てみると、セトナ、バーシクル、 バージニカの3種類のデータが綺麗に分けられているように見えます。
これが分散の大きい軸を選ぶ利点です。分散の大きい軸を選ぶことで、データの情報を残したまま次元削減しているのです。
そしてそれを可能にしているのが固有値、固有ベクトルという要素なのです。まとめ
本記事では固有値問題の一例として主成分分析を実装しました。
それにより、固有値、固有ベクトルが機械学習においても大事な要素であることがわかりました。3本の記事に渡って固有値、固有ベクトルについて記述しましたが、3本通して読むことで固有値、固有ベクトルとは何か、どのように使われているのかを理解していただければ幸いです。
前編:固有値と固有ベクトルの性質
中編:固有値と固有ベクトルの応用例(二次形式)
後編:固有値と固有ベクトルの応用例(主成分分析)←今ここ参考文献:ゼロから学ぶ線形代数、機械学習のエッセンス、パターン認識と機械学習(下巻)