- 投稿日:2019-07-28T23:57:39+09:00
StepFunctions を Serverless フレームワークで実装したサンプル
概要
AWS公式の StepFunctions チュートリアル を Serverless フレームワークを使って実装したサンプル
プロジェクトの作成
作業するディレクトリを作成します。
serverless フレームワークもなければインストールしてください。npm install -g serverless npm install serverless-pseudo-parameters mkdir call-center-state-machineプロジェクトのルートフォルダは以下のような構成になります。
. ├── handlers │ ├── assign_case.rb │ ├── close_case.rb │ ├── escalate_case.rb │ ├── open_case.rb │ └── work_on_case.rb ├── package.json └── serverless.ymlステートマシンで実行される関数の作成
handlers/open_case.rbdef handler(event:, context:) my_case_id = event['inputCaseID'] my_message = "Case #{my_case_id} : opend..." { Case: my_case_id, Message: my_message } endhandlers/assign_case.rbdef handler(event:, context:) my_case_id = event['Case'] my_message = "#{event['Message']} assigned..." { Case: my_case_id, Message: my_message } endhandlers/work_on_case.rbdef handler(event:, context:) my_case_id = event['Case'] my_message = event['Message'] my_case_status = Random.rand.round my_message += if my_case_status == 1 'resolved...' else 'unresolved...' end { Case: my_case_id, Status: my_case_status, Message: my_message } endhandlers/close_case.rbdef handler(event:, context:) my_case_id = event['Case'] my_message = "#{event['Message']} closed." my_case_status = event['Status'] { Case: my_case_id, Status: my_case_status, Message: my_message } endhandlers/escalate_case.rbdef handler(event:, context:) my_case_id = event['Case'] my_message = "#{event['Message']} escalating." my_case_status = event['Status'] { Case: my_case_id, Status: my_case_status, Message: my_message } endIAMロールとステートマシンのワークフローの設定
serverless.ymlservice: call-center-state-machine provider: name: aws region: us-west-1 runtime: ruby2.5 plugins: - serverless-step-functions - serverless-pseudo-parameters functions: openCaseFunc: handler: handlers/open_case.handler assignCaseFunc: handler: handlers/assign_case.handler workOnCaseFunc: handler: handlers/work_on_case.handler closeCaseFunc: handler: handlers/close_case.handler escalateCaseFunc: handler: handlers/escalate_case.handler stepFunctions: stateMachines: callCenterStateMachine: definition: Comment: 'A simple AWS Step Functions state machine that automates a call center support session.' StartAt: OpenCase States: OpenCase: Type: Task Resource: "arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${self:stage, 'dev'}-openCaseFunc" Next: AssignCase AssignCase: Type: Task Resource: "arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${self:stage, 'dev'}-assignCaseFunc" Next: WorkOnCase WorkOnCase: Type: Task Resource: "arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${self:stage, 'dev'}-workOnCaseFunc" Next: IsCaseResolved IsCaseResolved: Type: Choice Choices: - Variable: '$.Status' NumericEquals: 1 Next: CloseCase - Variable: '$.Status' NumericEquals: 0 Next: EscalateCase CloseCase: Type: Task Resource: "arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${self:stage, 'dev'}-closeCaseFunc" End: true EscalateCase: Type: Task Resource: "arn:aws:lambda:#{AWS::Region}:#{AWS::AccountId}:function:${self:service}-${self:stage, 'dev'}-escalateCaseFunc" Next: Fail Fail: Type: Fail Cause: 'Engage Tier 2 Support.'デプロイ
sls deploy
- 投稿日:2019-07-28T23:06:53+09:00
スタートアップで働いて得られた開発tips
スタートアップに入り1年以上が経ちました。日々目まぐるしく環境が変化していく中でやってしまった失敗。
どんな失敗に遭遇し、どう対応したかを簡単にまとめてみました!ぜひ、参考になれば幸いです!
(もし、需要がありそうな項目があれば深掘りして再投稿してみます)【フロント・サーバーサイド】
ページのレスポンス速度向上
当初とにかく指摘されたのはサイトのレスポンス速度でした。
そこで、レスポンス速度向上に取り組み、
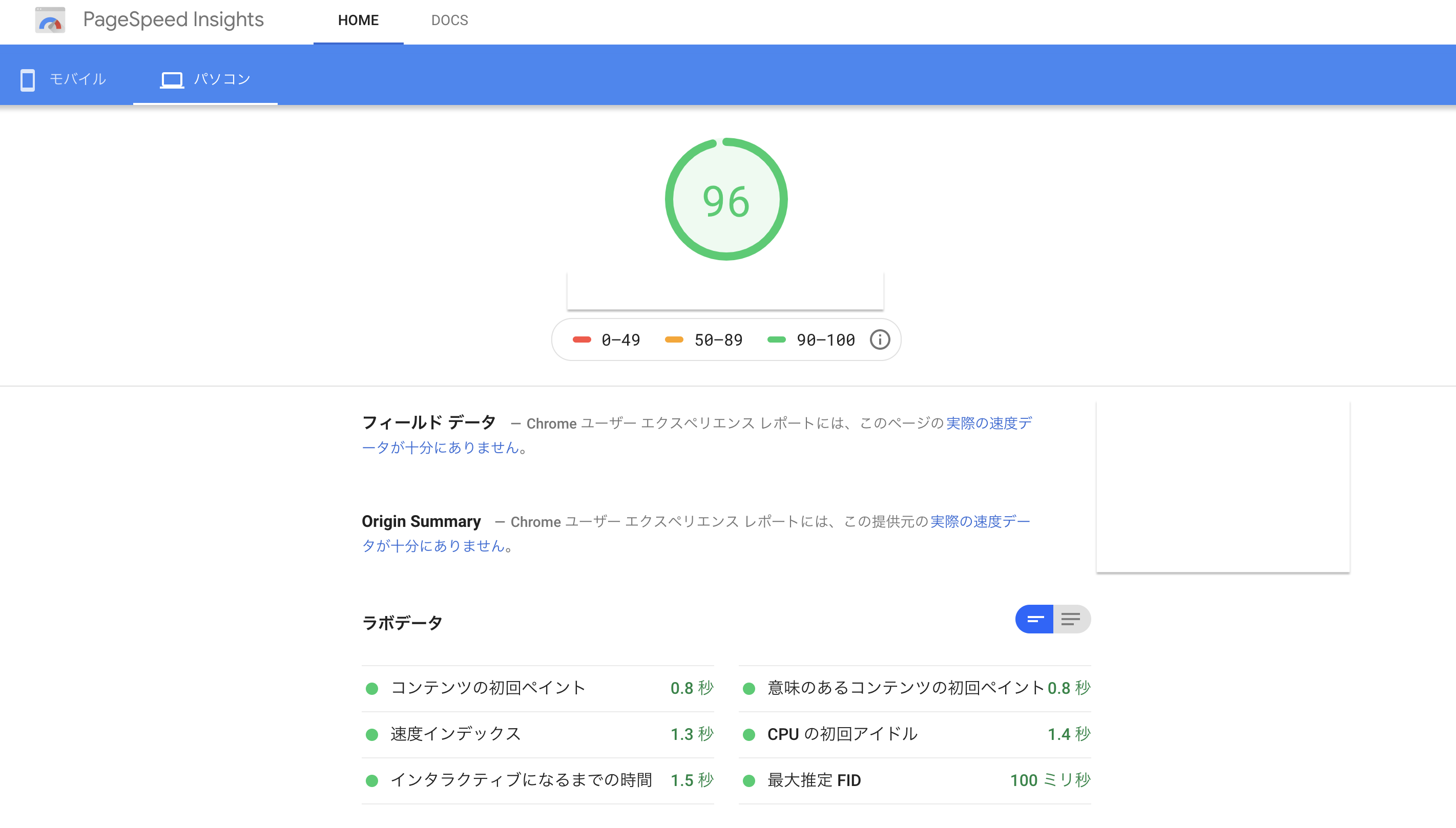
結果的にPCのトップページの評価が40点台→MAX96点にまで向上させることができました。
ちなみにモバイルは70点付近です(笑)
測定ツールはPageSpeed Insights(ページの読み込み時間の測定・改善策の提案をしてくれるサイト)です。【PCでは96点】
行った対策は以下です。
- N+1対策
- キャッシュの導入(一旦memocacheで対応)
- 画像の最適化
- JavaScriptとCSSにasync / defer
- クエリの修正(テーブルやカラムの追加)
- ページを開いた際に大量のデータを計算するなどの処理はレスポンスを遅くします!!
【インフラ系】
ElasticBeanstalkのインスタンスタイプはElasticBeanstalkから変更する
ElasticBeanstalkで環境を作成している場合、EC2からインスタンスタイプの変更しないようにしましょう。
依存関係などを崩してしまうため、うまく行きません。(僕はこれでサーバーを半日落しました(泣))
僕はこの時、環境の再構築をすることでサーバーの復活を果たすことができました。Elastic Beanstalk > ダッシュボード > アクション > 環境の再構築
エラーページは設定しておく
こちらはサーバーを落としてしまった際、またはメンテナンスの際に
503画面が表示されてしまうとユーザーの不信感につながりかねません。404や500はrails側で設定できますが503はサーバーが落ちてしまっているのでインフラの方で設定して置かなければなりません。CloudFrontのCustom Error Responseを利用して、S3上にあるSorryページを表示する
スロークエリの設定
クエリの重さは、目に見えているページだけでなくサーバーにも大きな負担をかけてしまいます。
その結果、バックグラウンドでも影響が出てしまうことがあります。(メールが大量に届くor届かなくなる、またはjobなど)常にチェックできるように設定しておきましょう!Amazon RDS for MySQLでスロークエリーログを出力させる手順
ヘルスが変化した際の通知
様々な要因がありますが、ヘルスが
Severeになって気づいたら数時間サーバーが止まってしまっていた。なんてことにならないようにヘルス変化は常に通知しておきましょう。Elastic Beanstalkで環境を構築している際はElastic Beanstalk > 設定 > 通知 > 通知したい先のアドレス設定 > 適用
で設定できます!
【その他】
ドキュメント管理で効率的に時間を活用する
僕の独自の共有に時間がかかるランキングは
1位 開発フローの把握
2位 システムの環境構築
3位 ユーザーからのお問い合わせ対応特に上位2つは出入りの激しい(笑)スタートアップの開発リソースを減らしてしまう深刻な問題だと思います。
一番対応の簡単な方法としてドキュメント管理に力を入れています。
もし、こんな質問がきたらこのマニュアルを渡すのようなパターンができていればいいドキュメント管理ができているなと思うようになりました。
(ドキュメントはGithubのwikiにまとめています)Githubのタグを使い、新加入のエンジニアのキャッチアップ迅速に
ドキュメント管理関連でもう一つ。
途中から参加したエンジニアさんはシステムの把握に時間がかかると思います。
システムの把握に時間をかけすぎてしまうのはもったいないのですが、かけなさすぎると思いがけないバグを生んでしまいます。これがデータ保存系・更新系だと対応が大変です。。そこで僕がよく使うのはGithubの
アサインとタグ付けです。
心がけていることは①自分が担当するissue・pullrequestには必ずself assignする ②ある程度シリーズ化したorしそうなissue・pullrequestにはタグづけをするこの2つを徹底すると以下のことがおきます。
→タグ一つ検索するだけで誰がどのタスクを担当し。どんなコードを書いたかがわかる
→上記がわかるとトラブルやバグ仕様の把握をしたいときに誰とコミュニケーションをとればいいかがすぐわかるこの流れが出来上がると、間に常勤のエンジニアが入ってコミュニケーションの橋渡しをせずに済み、
コミュニケーションコストが大幅に下がります!【イメージ】
rails本家のコードを使わせていただきました。本当はこんな開発者おりません。
【タグでソート】
【アサイン者でソート】
おまけ
副業案件お待ちしております。得意分野はRuby on Railsです!
職務経歴書
- 投稿日:2019-07-28T21:18:07+09:00
レストラン検索Bot作ってみた(店カテゴリー選択、リッチメニュー、英語対応)
はじめに
何番煎じかわからないですが、位置情報からレストランを検索できるLINEBotを開発しました。なるべくお金をかけずに開発する上で工夫した点についてまとめます。
開発したもの
友達登録QRコードです。良ければ動作をお試し下さい!
ぐるなびAPIは一時利用のため、2019/11/5まで利用可能です。
環境
- AWS Lambda(Node.js 10.x)
- Amazon API Gateway
- Messaging API
- ぐるなびAPI
- Google Translate API(v3.0)
工夫①:位置情報を含めた文脈
最初の会話で送ってもらった位置情報を次の会話で使用したい場合にどうするかです。
これは、MessagingAPIのpostbackを使用しました。位置情報のリクエストを受け取ると、そのリクエストをもとにpostbackの選択肢を作成します。
indexJa.jsasync function handleLocationMessage(payload, callback) { try { var latitude = payload.message.latitude; var longitude = payload.message.longitude; const replymessage = JSON.stringify({ replyToken: payload.replyToken, messages: [ { "type": "template", "altText": "店のカテゴリを選んでください。", "template": { "type": "buttons", "actions": [ { "type": "postback", "label": "和食", "displayText": "和食", "data": `category_l=RSFST01000&latitude=${latitude}&longitude=${longitude}` }, { "type": "postback", "label": "中華", "displayText": "中華", "data": `category_l=RSFST14000&latitude=${latitude}&longitude=${longitude}` }, { "type": "postback", "label": "洋食", "displayText": "洋食", "data": `category_l=RSFST13000&latitude=${latitude}&longitude=${longitude}` }, { "type": "postback", "label": "アジア・エスニック料理", "displayText": "アジア・エスニック料理", "data": `category_l=RSFST15000&latitude=${latitude}&longitude=${longitude}` } ], "title": "店のカテゴリ", "text": "店のカテゴリを選んでください" } } ] }); await Line.postMessage(replymessage); callback(null,""); } catch (error) { return callback(new Error(error.message)); } }工夫②:位置情報のURIアクション
リッチメニューから直接位置情報を送れるように、URIアクションを設定しました。
richmenu_ja.json{ "size": { "width": 2500, "height": 1686 }, "selected": true, "name": "レストラン検索", "chatBarText": "メニュー", "areas": [ { "bounds": { "x": 114, "y": 207, "width": 1118, "height": 1386 }, "action": { "type": "uri", "uri": "line://nv/location" } }, { "bounds": { "x": 1421, "y": 561, "width": 1033, "height": 421 }, "action": { "type": "message", "text": "日本語に設定して" } }, { "bounds": { "x": 1413, "y": 1004, "width": 1041, "height": 442 }, "action": { "type": "message", "text": "Please set to English" } } ] }ちなみにリッチメニューのJSONはLINE Bot Designerから簡単に作成することができました。
工夫③:言語設定
リッチメニューから言語設定をできるようにしました。
最初はDBやキャッシュを参照して...と考えましたが、「現在のリッチメニューのID」で言語の判断をしていいます。具体的なフローは
①リッチメニューからの言語設定のリクエストを受信
③言語によって各リッチメニューを動的にセット
③位置情報のリクエストを受信すると、現在のリッチメニューIDを取得
④リッチメニューIDによって、言語それぞれの処理を実行結構力技ですが、リッチメニューから言語設定を実現できました!
ソース


- 投稿日:2019-07-28T21:18:04+09:00
AWS認定SysOpsアドミニストレーター アソシエイトにギリギリ合格した話
概要
AWSのベンダー資格である、SysOpsアドミニストレータを受験し738点でギリギリ合格できたので、勉強方法を共有します。
受験前のAWSの経験・知識
- 2週間前にAWSアソシを受験し合格した
- LPIC level1、IPAの応用情報・DBスペシャリストを保有している
- 業務・趣味を合わせたAWS経験は半年ほど
- Gitlabサーバの構築・運用
- 開発環境・CICDパイプライン構築
- AWSで使用したことのあるサービス
- EC2,VPC,Route53,Cognito,Lamda,S3,RDS,DynamoDB,CodeBuild,CodeCommit,CodeDeploy,CodePipeline,IAM
勉強方法
2週間前にソーリュションアーキテクトアソシに合格しており、知識がまだ定着している状態から勉強を開始しました。
SysOps用の勉強は模試受験+WEB問題集(350問)1周です。
総勉強時間は10時間程度でしょうか。模試受験
最初に公式の模擬試験を受けて自分のレベルを確認しました。
ソリューションアーキテクト アソシだけの知識でも7割程度の正解率でした。今思うと上振れだったと思います。
一方でIAMの細かい話や請求レポートなどのソーリュションアーキテクトで学習しなかった分野についてはサッパリ分かりませんでした。
SysOpsアドミニストレーター固有の部分を抑えれば行けそうな感触を持ちました。WEB問題集
ソリューションアーキテクト受験時に、AWS WEB問題集で学習しようというAWS試験のWEB問題集サイトのダイヤモンドプランに登録していました。
この問題集は6000円程しますが、ソリューションアーキテクトのアソシとプロに両対応していて、かつ今回のSysOpsアドミニストレーターも対応しています。
SysOpsの問題は350問程用意されていたので、2日で1周しました。ソーリュションアーキテクトの範囲外の知らないサービス・使い方については解説を読み理解していきました。
理解したつもりになれたので、勢いで1周目完了時点で受験申込しました。
結果
738点でギリギリ合格しました。
720点が合格ラインなため、おそらく後1,2問間違えていれば不合格のはずです。WEB問題集をこなしていましたが、試験問題の6,7割ほどは初見の感覚を持ちました。
試験中に大雑把に自己採点した結果も7割ギリ程度だったので、落ちたかなと思いながら試験終了ボタンを押しましたが、合格していて良かったです。。どうすればより高い合格点を取れたかを振り返ってみると、
ソーリュションアーキテクトレベルの知識を持っているのであれば、ソーリュションアーキテクトの範囲外かつSysOpsアドミニストレーターの試験範囲の各サービスのホワイトペーパーや、運用者目線での各サービスの事例などのドキュメントがあればそれらを最初に読み込むと良かったと思いました。
SysOpsのWeb問題集を周回するのも大事ですが、ソーリュションアーキテクトと重複している部分も多いので効率的では無かったように思います。今後
まずはアソシ3冠を目指したいと思います。
そして、AWS WEB問題集で学習しようにはソリューションアーキテクトプロフェッショナル向けの問題も用意されているので、記憶が定着しているうちにプロフェッショナル向けの勉強を進めます。
- 投稿日:2019-07-28T21:00:50+09:00
Terraform getting-startedをやってみた
何番煎じかわかりませんがTerraformのgetting-startedをやってみました。
インストールからデストロイまでになります。インストール
2019/07/27
terraformの最新バージョンのURLを確認するには下記ダウンロードページからURLを調べる
consolemkdir ~/.terraform cd ~/.terraform wget URL unzip ダウンロードしたファイルPATH設定
terraformに対してPATHを通しておく
echo 'export $PATH:~/terraform'インストール確認
consoleterraform --version Terraform v0.12.3 + provider.aws v2.20.0 Your version of Terraform is out of date! The latest version is 0.12.5. You can update by downloading from www.terraform.io/downloads.htmlアクセスキーの設定
terraformは下記の優先順位アクセスキーの情報を取得して認証を行う。
1. tfファイル
2. 環境変数AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY
3.~/.credential今回はterraform用のIAMユーザを発行するのでtfファイルを使用する。
じゃあ、tfファイルにアクセスキーを記載しよう!と思うところだがtfファイルを公開することがあると
アクセスキーがバレてしまうので変数を使用してアクセスキーは別ファイルに外だししたほうが良い。
変数の外だしはtfvarsファイルを作成する。
デフォルトではterraform.tfvarsを自動で読み込む。別名にする場合はコマンド実行時に--var-fileで指定する必要がある。terraform.tfvarsmy_region = "リージョン" my_access_key = "アクセスキー" my_secret_key = "シークレットキー"変数は
"${変数名}"で指定する
.tfファイル側でも変数を宣言する必要がある。
宣言はvariable 変数名 {}variable my_region {} variable my_access_key {} variable my_secret_key {} provider "aws" { access_key = "${var.my_access_key}" secret_key = "${var.my_secret_key}" region = "${var.my_region}" }チュートリアルに記載されていたami-idは使えなかったのでAmazonLinux2のamiを適当に使う
resource "aws_instance" "example" { ami = "ami-0c3fd0f5d33134a76" instance_type = "t2.micro" }最終的には下記のようになった。
example.tfvariable my_region {} variable my_access_key {} variable my_secret_key {} provider "aws" { access_key = "${var.my_access_key}" secret_key = "${var.my_secret_key}" region = "${var.my_region}" } resource "aws_instance" "example" { ami = "ami-0c3fd0f5d33134a76" instance_type = "t2.micro" }初期化
下記コマンドで初期化を行う
terraform init実行
terraform applyを実行するとdiffのような形式で作成されるリソースが+付きで表示される。
Enter a value:に対してyesで応答する。consoleterraform apply An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.example will be created + resource "aws_instance" "example" { + ami = "ami-0c3fd0f5d33134a76" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) + cpu_threads_per_core = (known after apply) + get_password_data = false + host_id = (known after apply) + id = (known after apply) + instance_state = (known after apply) + instance_type = "t2.micro" + ipv6_address_count = (known after apply) + ipv6_addresses = (known after apply) + key_name = (known after apply) + network_interface_id = (known after apply) + password_data = (known after apply) + placement_group = (known after apply) + primary_network_interface_id = (known after apply) + private_dns = (known after apply) + private_ip = (known after apply) + public_dns = (known after apply) + public_ip = (known after apply) + security_groups = (known after apply) + source_dest_check = true + subnet_id = (known after apply) + tenancy = (known after apply) + volume_tags = (known after apply) + vpc_security_group_ids = (known after apply) + ebs_block_device { + delete_on_termination = (known after apply) + device_name = (known after apply) + encrypted = (known after apply) + iops = (known after apply) + snapshot_id = (known after apply) + volume_id = (known after apply) + volume_size = (known after apply) + volume_type = (known after apply) } + ephemeral_block_device { + device_name = (known after apply) + no_device = (known after apply) + virtual_name = (known after apply) } + network_interface { + delete_on_termination = (known after apply) + device_index = (known after apply) + network_interface_id = (known after apply) } + root_block_device { + delete_on_termination = (known after apply) + iops = (known after apply) + volume_id = (known after apply) + volume_size = (known after apply) + volume_type = (known after apply) } } Plan: 1 to add, 0 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes応答後、作成開始する。作成にかかった時間も表示される。
consoleaws_instance.example: Creating... aws_instance.example: Still creating... [10s elapsed] aws_instance.example: Still creating... [20s elapsed] aws_instance.example: Still creating... [30s elapsed] aws_instance.example: Creation complete after 32s [id=i-xxxxxxxxxxxxxxxxx] Apply complete! Resources: 1 added, 0 changed, 0 destroyed.状態確認
terraform showコマンドで現在の状態を確認することができる
consoleterraform show # aws_instance.example: resource "aws_instance" "example" { ami = "ami-0c3fd0f5d33134a76" arn = "arn:aws:ec2:ap-northeast-1:xxxxxxxxxxxx:instance/i-xxxxxxxxxxxxxxxxx" associate_public_ip_address = true availability_zone = "ap-northeast-1a" cpu_core_count = 1 cpu_threads_per_core = 1 disable_api_termination = false ebs_optimized = false get_password_data = false id = "i-xxxxxxxxxxxxxxxxx" instance_state = "running" instance_type = "t2.micro" ipv6_address_count = 0 ipv6_addresses = [] monitoring = false primary_network_interface_id = "eni-xxxxxxxxxxxxxxxxx" private_dns = "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" private_ip = "xxx.xxx.xxx.xxx" public_dns = "ec2-18-182-16-157.ap-northeast-1.compute.amazonaws.com" public_ip = "xxx.xxx.xxx.xxx" security_groups = [ "default", ] source_dest_check = true subnet_id = "subnet-xxxxxxx" tenancy = "default" volume_tags = {} vpc_security_group_ids = [ "sg-xxxxxxxx", ] credit_specification { cpu_credits = "standard" } root_block_device { delete_on_termination = true iops = 100 volume_id = "vol-xxxxxxxxxxxxxxxxx" volume_size = 8 volume_type = "gp2" } }リソースの変更
リソースの変更を行うにはまずtfファイルを編集する。
AmazonLinux2 から AmazonLinuxに変更する
#でコメントアウト可能example.tfresource "aws_instance" "example" { # ami = "ami-0c3fd0f5d33134a76" ami = "ami-04b2d1589ab1d972c" instance_type = "t2.micro" }変更後terraform applyを実行する。
consoleterraform apply aws_instance.example: Refreshing state... [id=i-xxxxxxxxxxxxxxxxx] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: -/+ destroy and then create replacement Terraform will perform the following actions: # aws_instance.example must be replaced -/+ resource "aws_instance" "example" { ~ ami = "ami-0c3fd0f5d33134a76" -> "ami-04b2d1589ab1d972c" # forces replacement ~ arn = "arn:aws:ec2:ap-northeast-1:xxxxxxxxxxxx:instance/i-xxxxxxxxxxxxxxxxx" -> (known after apply) ~ associate_public_ip_address = true -> (known after apply) ~ availability_zone = "ap-northeast-1a" -> (known after apply) ~ cpu_core_count = 1 -> (known after apply) ~ cpu_threads_per_core = 1 -> (known after apply) - disable_api_termination = false -> null - ebs_optimized = false -> null get_password_data = false + host_id = (known after apply) ~ id = "i-xxxxxxxxxxxxxxxxx" -> (known after apply) ~ instance_state = "running" -> (known after apply) instance_type = "t2.micro" ~ ipv6_address_count = 0 -> (known after apply) ~ ipv6_addresses = [] -> (known after apply) + key_name = (known after apply) - monitoring = false -> null + network_interface_id = (known after apply) + password_data = (known after apply) + placement_group = (known after apply) ~ primary_network_interface_id = "eni-xxxxxxxxxxxxxxxxx" -> (known after apply) ~ private_dns = "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" -> (known after apply) ~ private_ip = "xxx.xxx.xxx.xxx" -> (known after apply) ~ public_dns = "ec2-xxx-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com" -> (known after apply) ~ public_ip = "xxx.xxx.xxx.xxx" -> (known after apply) ~ security_groups = [ - "default", ] -> (known after apply) source_dest_check = true ~ subnet_id = "subnet-xxxxxxxx" -> (known after apply) - tags = {} -> null ~ tenancy = "default" -> (known after apply) ~ volume_tags = {} -> (known after apply) ~ vpc_security_group_ids = [ - "sg-xxxxxxxx", ] -> (known after apply) - credit_specification { - cpu_credits = "standard" -> null } + ebs_block_device { + delete_on_termination = (known after apply) + device_name = (known after apply) + encrypted = (known after apply) + iops = (known after apply) + snapshot_id = (known after apply) + volume_id = (known after apply) + volume_size = (known after apply) + volume_type = (known after apply) } + ephemeral_block_device { + device_name = (known after apply) + no_device = (known after apply) + virtual_name = (known after apply) } + network_interface { + delete_on_termination = (known after apply) + device_index = (known after apply) + network_interface_id = (known after apply) } ~ root_block_device { ~ delete_on_termination = true -> (known after apply) ~ iops = 100 -> (known after apply) ~ volume_id = "vol-xxxxxxxxxxxxxxxxx" -> (known after apply) ~ volume_size = 8 -> (known after apply) ~ volume_type = "gp2" -> (known after apply) } } Plan: 1 to add, 0 to change, 1 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value:リソースの破棄
リソースの破棄を行うには
terraform destroyを実行する。consoleterraform destroy aws_instance.example: Refreshing state... [id=i-xxxxxxxxxxxxxxxxx] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_instance.example will be destroyed - resource "aws_instance" "example" { - ami = "ami-xxxxxxxxxxxxxxxxx" -> null - arn = "arn:aws:ec2:ap-northeast-1:xxxxxxxxxxxx:instance/i-xxxxxxxxxxxxxxxxx" -> null - associate_public_ip_address = true -> null - availability_zone = "ap-northeast-1a" -> null - cpu_core_count = 1 -> null - cpu_threads_per_core = 1 -> null - disable_api_termination = false -> null - ebs_optimized = false -> null - get_password_data = false -> null - id = "i-xxxxxxxxxxxxxxxxx" -> null - instance_state = "running" -> null - instance_type = "t2.micro" -> null - ipv6_address_count = 0 -> null - ipv6_addresses = [] -> null - monitoring = false -> null - primary_network_interface_id = "eni-xxxxxxxxxxxxxxxxx" -> null - private_dns = "ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal" -> null - private_ip = "xxx.xxx.xxx.xxx" -> null - public_dns = "ec2-xxx-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com" -> null - public_ip = "xxx.xxx.xxx.xxx" -> null - security_groups = [ - "default", ] -> null - source_dest_check = true -> null - subnet_id = "subnet-xxxxxxxx" -> null - tags = {} -> null - tenancy = "default" -> null - volume_tags = {} -> null - vpc_security_group_ids = [ - "sg-xxxxxxxx", ] -> null - credit_specification { - cpu_credits = "standard" -> null } - root_block_device { - delete_on_termination = true -> null - iops = 100 -> null - volume_id = "vol-xxxxxxxxxxxxxxxxx" -> null - volume_size = 8 -> null - volume_type = "gp2" -> null } } Plan: 0 to add, 0 to change, 1 to destroy. Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes aws_instance.example: Destroying... [id=i-xxxxxxxxxxxxxxxxx] aws_instance.example: Still destroying... [id=i-xxxxxxxxxxxxxxxxx, 10s elapsed] aws_instance.example: Still destroying... [id=i-xxxxxxxxxxxxxxxxx, 20s elapsed] aws_instance.example: Still destroying... [id=i-xxxxxxxxxxxxxxxxx, 30s elapsed] aws_instance.example: Destruction complete after 35s Destroy complete! Resources: 1 destroyed.参考
https://dev.classmethod.jp/cloud/aws/terraform_getting-started/
https://qiita.com/kohey18/items/38400d8c498baa0a0ed8
- 投稿日:2019-07-28T19:39:09+09:00
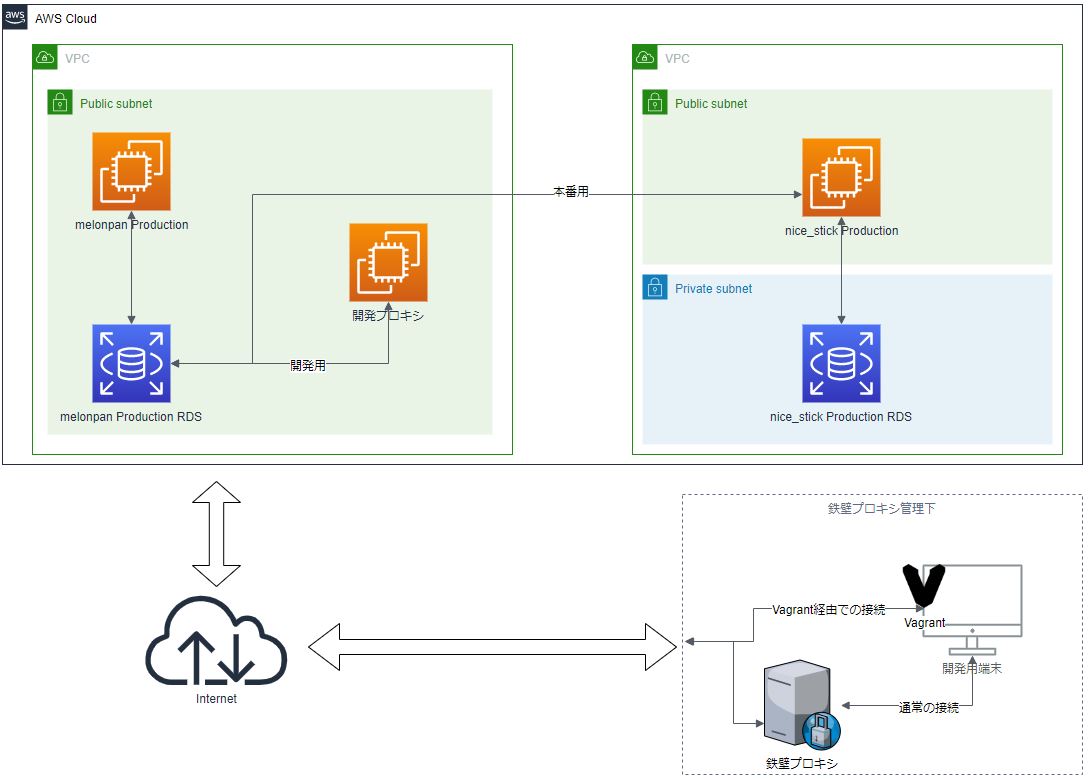
プロキシに阻まれたVagrantからRDSに接続する
プロキシに阻まれて何もできない・・・
- ホストマシン(以下「ホスト」)は、かなり堅い認証プロキシ(以下「鉄壁プロキシ」)経由でインターネットに接続されている(Vagrantの通信はことごとく407になる)
- 開発用に、ホスト上のVagrant環境からの通信だけを捌くプロキシサーバ(以下「開発プロキシ」)をEC2に構築する(許可は取ってる)
- EC2にsquidを入れ、Vagrantからの通信を受ける
- 別で動いているWEBアプリケーションのRDSに対して接続できるようにし、データを取得できるようにする
環境
- Windows 10 1803(ホスト)
- Vagrant 2.2.2
- VirtualBox 6.0.0
- CentOS 7.6.1810(ゲスト)
- Ruby 2.6.0
- Rails 5.2.2
- vagrant-vbguest 0.18.0
- vagrant-proxyconf 2.0.4
- dotenv 2.7.4
- mysql 5.7(RDS)
例として設定する項目と値
記事内での設定例については、ここに記す値を利用する
項目 設定値 ホストのグローバルIPアドレス 111.222.333.444 squid.conf内でのルール名 myrule1 開発プロキシのユーザ名 ec2-user 開発プロキシのsquid用ポート 60008 開発プロキシのElastic IP 55.555.5.555 開発プロキシのプライベートIP 172.16.11.11 開発プロキシのpemファイル nice_stick.pem RDSのエンドポイント xxxxxxxx.yyyyyyyy.ap-northeast-1.rds.amazonaws.com RDSのポート 3306 RDSのパブリックアクセシビリティ 有効 プロジェクト名 nice_stick .env DB_USERNAME nice_stick .env DB_PASSWORD melonpan
- RDSは、セキュリティグループで55.555.5.555からの3306番の接続を許可し、mysql側で、
nice_stick@55.555.5.555からのパスワード利用での接続を許可しておくmelonpanプロジェクトの本番DBに、nice_stickプロジェクトの開発環境からアクセスできるようにしていく
EC2(開発プロキシ側)の設定
- Amazon Linux 2でインスタンス作成、ElasticIPも割り当てておく
- セキュリティグループのインバウンドに、ホストのグローバルIPアドレスを設定する
- したがって、鉄壁プロキシ経由でホストのグローバルIPアドレスに対して22番ポートでの接続ができるようにしておく
今回は、下記の設定を行う
terminal(開発プロキシ側)sudo yum -y squid install sudo vi /etc/squid/squid.confsquid.conf(抜粋)(省略) acl localnet src fe80::/10 ← の下に acl myrule1 src 111.222.333.444/32 を追加 (中略) http_access allow localhost ← の下に http_access allow myrule1 を追加 (中略) # Squid normally listens to port 3128 ← の下に http_port 60008 を追加上記の編集を行って保存、
terminal(開発プロキシ側)sudo squid -k parse sudo systemctl restart squid.service sudo systemctl enable squid.serviceを行う。squid -k parse は、squid.confの構成のチェックをしているので、エラーがあれば修正する。
エラーがある状態でsystemctl restartしても、エラーが発生するので、きちんと直す。省略するが、ダイジェスト認証などの認証機能を導入しておくほうが(かなり)望ましい。
https://skkskynw.hateblo.jp/entry/2016/09/04/165725Vagrant側の設定
ホストへのVagrant/VirtualBoxのインストールは行われているものとする
Vagrantプラグインのインストール
プロジェクトルートで、下記コマンドを実行する
cmd.exevagrant plugin install vagrant-vbguest vagrant plugin install vagrant-proxyconf vagrant plugin install dotenvインストール後、
cmd.exevagrant plugin listを行い、上記3つのプラグインがインストールされていることを確認する
.envとVagrantfileの編集
.envPROXY_URL=http://55.555.5.555:60008Vagrantfile(抜粋)Dotenv.load Vagrant.configure("2") do |config| (中略) if Vagrant.has_plugin?("vagrant-proxyconf") config.proxy.enabled config.proxy.http = ENV['PROXY_URL'] config.proxy.https = ENV['PROXY_URL'] config.proxy.no_proxy = "localhost,127.0.0.1" end (中略) config.vm.synced_folder ".", "/vagrant", type: "virtualbox" end上記設定を行い、vagrant up する
Ruby、Rails、mysqlクライアントのインストール等はすませておく。
Railsプロジェクトも作成しておく(database.ymlを編集するので)SSHログインと開発プロキシの動作確認
vagrantの通信がプロキシサーバから出ているかを確認する
terminal(開発プロキシ側)[ec2-user@172.16.11.11 ] $ sudo tail -f /var/log/squid/access.logcmd.exe(vagrant側,sshログイン後)[vagrant@localhost] curl ifconfig.ioec2側ターミナルにアクセスログが記録され、vagrant側ターミナルに開発プロキシのElastic IPが返ってくればOK。
これで開発自体はできる。RDSに接続するために
ここからが本題。
上記の設定値のとおり、今回接続するRDSは本番用であり、接続はRDSのセキュリティグループ、mysqlのユーザ管理で制御されている。AWSとVagrant環境のイメージは下記のとおり。
図は https://www.draw.io/ を利用して作成
この状態で、database.ymlに下記のような設定をしても、接続できずにしばらくしたあと110エラーが返ってくる
database.ymlmelonpan_production_for_nice_stick_development: <<:default host: xxxxxxxx.yyyyyyyy.ap-northeast-1.rds.amazonaws.com database: melonpan_production username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %>鉄壁プロキシを使わないネットワークで、同じ構成の環境を作成して実験したところ、上記の記述でも接続できた。
また、開発プロキシにSSH接続してRDSへ接続しても、正常に接続できた。
したがって、vagrant内のプロジェクトでも、この状態では、RDSへの接続で利用される外部ネットワーク接続はVagrantを通じた「開発プロキシ」ではなく、ホストに通じている「鉄壁プロキシ」だということがわかる。これはmysqlコマンドでも同様だった。
mysqlの接続は、AWS内にすら届いておらず、鉄壁プロキシの段階ではじかれていたということ。
(これ自体を回避できる方法があったらコメントください)てっきり、ifconfigコマンドで開発プロキシのElasticIPが返ってきていたので、開発プロキシ経由で接続してくれると思っていた。
SSHポートフォワーディングの利用による解決
上記の図の通り、開発プロキシはRDSと同じサブネットにいるので、Vagrantから開発プロキシに対してSSHポートフォワードしてあげれば繋がるのではと考えた。
https://qiita.com/nishidataishi/items/40928debaddeb2e33d1d や、
https://cloudpack.media/9675 を参考に、プロジェクトルートに pemfiles ディレクトリを作成。
Vagrantfile.rbのsynced_folder部分を下記に書き換えて、開発プロキシのpemファイルをpemfilesディレクトリ配下にコピー。
(※ sshコマンドがpemファイルの権限でエラーを吐くので、600にする必要がある。ゲスト側でchmodしても変えられない。)この段階で、/pemfiles ディレクトリをgitignoreにしておく(超重要)
.gitignore/pemfiles ← を追加Vagrantfileconfig.vm.synced_folder ".", "/vagrant", type: "virtualbox", :mount_options => ['dmode=775', 'fmode=775'] config.vm.synced_folder "./pemfiles", "/vagrant/pemfiles", type: "virtualbox", :mount_options => ['dmode=600', 'fmode=600']cmd.exe(vagrant側,sshログイン後)[vagrant@localhost] sudo ssh -f -N -L 60008:xxxxxxxx.yyyyyyyy.ap-northeash-1.rds.amazonaws.com:3306 -i /vagrant/pemfiles/nice_stick.pem ec2-user@55.555.5.555を実行して、バックグラウンドでポートフォワーディングさせるように設定。
database.ymlを下記のように書き換え
database.ymlmelonpan_production_for_nice_stick_development: <<:default host: 127.0.0.1 port: 60008 database: melonpan_production username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %>これでRailsサーバを起動したところ、RDSに接続してデータを取得できた。
都度設定するのは面倒なので、後で.bashrcあたりにでも書き込んでおく。本番サーバでは不要な手続きなので、developmentとproduction/stagingでは、database.yml での記述を変える。
database.yml(本番記述例)melonpan_production_for_nice_stick_production: <<:default host: xxxxxxxx.yyyyyyyy.ap-northeash-1.rds.amazonaws.com database: melonpan_production username: <%= Rails.application.credentials.melonpan_production_database_user %> password: <%= Rails.application.credentials.melonpan_production_database_pass %>開発時のmelonpan_productionへの接続は、melonpan_production_for_nice_stick_developmentを、
本番はmelonpan_production_for_nice_stick_productionを使うようにする
(modelディレクトリ内で、melonpanモジュールを作っているのは、本体と別アプリのテーブルの名前空間を分けて名前衝突を防ぐため)app/model/melonpan/melonpan_db_connection.rb#frozen_string_literal: true module Melonpan class MelonpanDbConnection < ActiveRecord::Base self.abstract_class = true establish_connection: "melonpan_production_for_nice_stick_#{Rails.env}".to_sym end endあとは、実際に接続してデータを取得するクラスで、MelonpanDbConnectionを継承すればOK。
これで、開発環境はポートフォワーディング経由で、本番環境は直接接続というように切り分けられた。P.S.
この問題の解決に実働30時間も費やしたのがくやしいし認証プロキシつらい。
- 投稿日:2019-07-28T13:35:06+09:00
AWS Pinpoint とAWS iOS SDKでセグメントを指定したPush配信
AWS Pinpointとは
顧客にパーソナライズされ、タイミング良く、関連性の高いコミュニケーションを複数チャネルを通して送り、顧客理解とエンゲージメントを高めるためのサービスです。
公式ドキュメント https://aws.amazon.com/jp/pinpoint/
モバイルPush配信、Eメール、SMSなどの配信を、属性やイベントなど適切な条件に一致するユーザにのみ配信し、その動向を解析して可視化することができます。
私のこと
- サーバサイドエンジニア
- 普段は主にAWSのサービスを使ってAPIなどのサーバサイドのアプリケーションを開発している
- モバイルPush配信は、Amazon SNSなどを利用して配信側のシステム構築を行ったことがある
- iOSアプリ開発は、プログラミング学習サイトでおみくじアプリを作ってローカルで動かした程度
今回試したこと
- AWS SDKを使って、アプリケーションサーバを介さずにiOSアプリからAWS Pinpointへデータを送る。
- 送られたデータを元にiOS端末にモバイルPush配信を行う。
- カスタム属性を設定を設定してセグメント配信を行う。
環境構築
今回は、AWS Amplifyという便利な物を使ってAWS PinpointとiOSアプリを連携していきます。
用意するもの
- Mac
- Xcode
- Cocoapods
- AWSアカウント
- IAMユーザのアクセスキーとシークレットキー
- AWS Amplify CLI
- Apple Developers programアカウント (登録しても使えるようになるまでに数日かかるので注意
)
- iPhone(実機)
iOSアプリケーションを作る
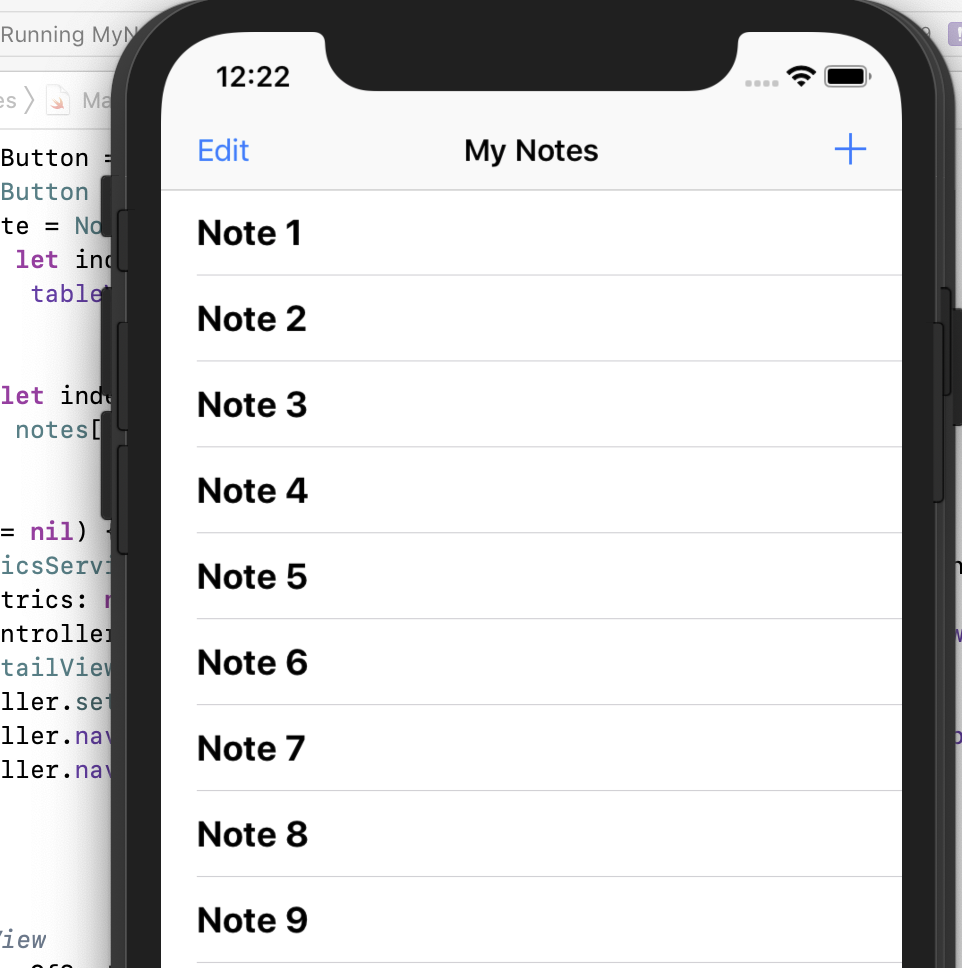
こちらのサンプルコードをダウンロードして使います。シンプルなノートアプリです。
https://github.com/aws-samples/aws-mobile-ios-notes-tutorial/Xcodeで開いて実行すると以下のようなアプリが起動します。
Amplify CLIインストールと設定
Amplify CLI はこちらを参考にしてインストールします。
https://aws-amplify.github.io/docs/$ npm install -g @aws-amplify/cli $ exec $SHELL -l $ amplify -v 1.8.2その後、以下を実行して、リージョン、ユーザ名、アクセスキー、シークレットキーを設定します。
$ amplify configureAmplify CLIを使って AWS PinpointプロジェクトとiOSの設定ファイルを作成する
AWS Pinpointプロジェクトは AWSコンソールなどから単体で作成することもできますが、今回は、Amplifyを使って関連リソースを一緒に作成します。
こちらを参考に Pinpointを設定します。
https://aws-amplify.github.io/docs/ios/analytics
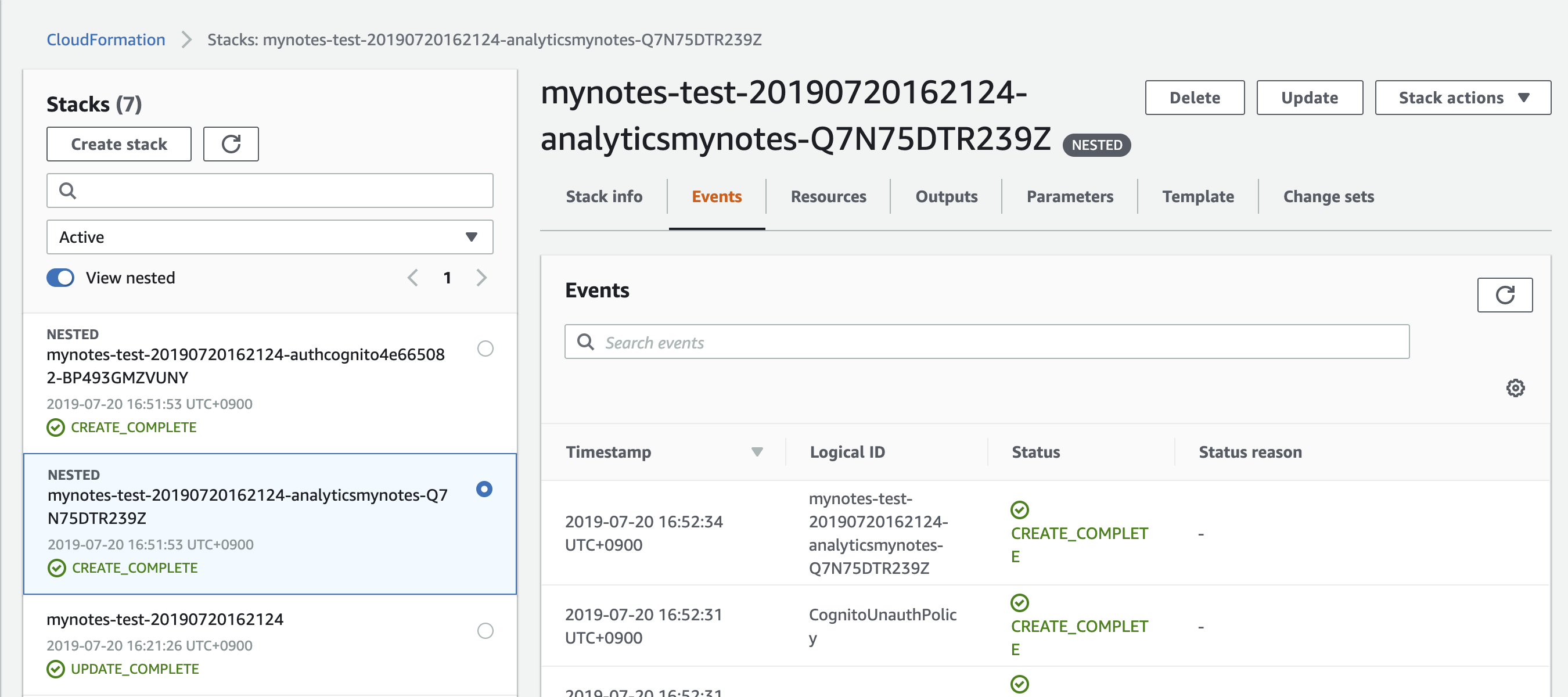
(pod install --repo-update まで実施していきます。)$ cd ./YOUR_PROJECT_FOLDER $ amplify add analytics $ amplify status | Category | Resource name | Operation | Provider plugin | | --------- | --------------- | --------- | ----------------- | | Auth | cognitoabcd0123 | Create | awscloudformation | | Analytics | yourprojectname | Create | awscloudformation | $ amplify pushamplify pushを実行すると Cloudformationが実行され、必要なAWSリソースが自動的に構築されます。Pinpointも作成されます。
どんなリソースが作成されているかは、Cloudformationを見るとわかります。
ここまでできたら、以下のようなjsonファイルが生成されています。
awsconfiguration.json{ "UserAgent": "aws-amplify/cli", "Version": "0.1.0", "IdentityManager": { "Default": {} }, "CredentialsProvider": { "CognitoIdentity": { "Default": { "PoolId": "リージョン:xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "Region": "リージョン" } } }, "PinpointAnalytics": { "Default": { "AppId": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "Region": "リージョン" } }, "PinpointTargeting": { "Default": { "Region": "リージョン" } } }このjsonファイルは、Xcodeを開いて、Info.plist があるディレクトリにimportしておきます。
Podfile には AWSPinpoint を追加します。
# Uncomment the next line to define a global platform for your project platform :ios, '11.0' target 'MyNotes' do # Comment the next line if you don't want to use dynamic frameworks use_frameworks! # Pods for MyNotes pod 'AWSPinpoint', '~> 2.10.0' endインストールを実行します。
pod install --repo-updatePush Notificationの配信準備(証明書の作成と登録)
雑に説明すると、
1. iOSのアプリ登録をして証明書作成、テスト端末登録、プロビジョニングファイルを作成する。
2. Push配信の証明書を作成してAWS Pinpointに登録する。
という手順です。注意する点は、iOSアプリケーションの証明書には 開発用(Development)と本番用(Distribution)がありますが、Push配信を確認するためには本番用が必要なので Distribution の方で作成する必要がある、ということです。
基本的にこちらの方法でやればできます。
Setting Up APNS for Push Notifications
、、が、iOSアプリ開発初心者にはわかりにくいかもしれません。iOSアプリ証明書とテスト端末登録、プロビジョニングファイル作成
iOSアプリケーションの証明書作成はこちらの記事[iPhone] iOS App IDs を登録する
がとてもわかりやすく、参考になりました。
(ありがとうございます!)
上記記事と異なる点は、今回は自分のテスト用iPhoneにPush配信するのが目的なので、Provisioning Profile作成時に、「App Store」ではなく、「Ad Hoc」を選択して作成します。Push配信証明書をAWS Pinpointに登録する
Push配信のために必要なp12ファイルを用意します。
Setting Up APNS for Push Notificationsの、 Step 2: Create an APNs SSL Certificate の通りにして作成します。作成されたp12ファイルを AWS Pinpointに登録します。
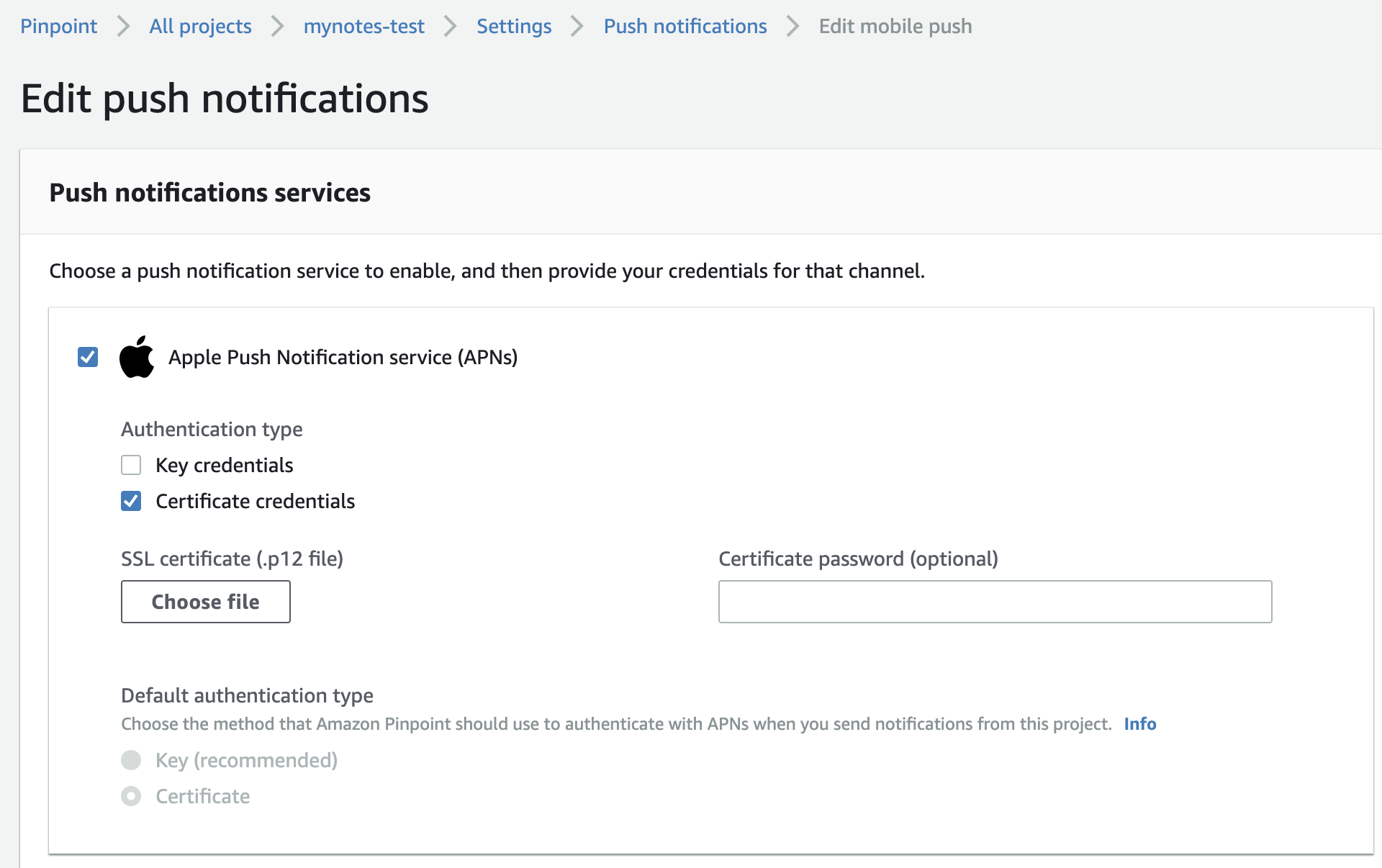
AWSマネージメントコンソール Pinpoint 左メニューの Push notificationをクリック
右に現れた画面のEditを押すと下記のような設定画面が現れるので、 Apple Push Notification service (APNs) を選択し、 SSL certificate (.p12 file) に、先ほどのp12ファイルを指定し、 Certificate password (optional) に、作成時に指定したパスワードを指定して保存すると完了です。
iOSアプリ修正とAWS Pinpointの配信設定
ここまでがとても大変ですが、ここから先はとても簡単です。
iOSアプリにAWS Pinpointへの登録処理を追加
GitHubのチュートリアルに習って、以下のクラスを新規Swiftファイルとして追加します。
AWSAnalyticsService.swiftimport Foundation import AWSCore import AWSPinpoint class AWSAnalyticsService : AnalyticsService { var pinpoint: AWSPinpoint? init() { let config = AWSPinpointConfiguration.defaultPinpointConfiguration(launchOptions: nil) pinpoint = AWSPinpoint(configuration: config) } func recordEvent(_ eventName: String, parameters: [String : String]?, metrics: [String : Double]?) { let event = pinpoint?.analyticsClient.createEvent(withEventType: eventName) if (parameters != nil) { for (key, value) in parameters! { event?.addAttribute(value, forKey: key) } } if (metrics != nil) { for (key, value) in metrics! { event?.addMetric(NSNumber(value: value), forKey: key) } } pinpoint?.analyticsClient.record(event!) pinpoint?.analyticsClient.submitEvents() } }これを AppDelegate から呼び出します。
チュートリアルのコードでは既に、 LocalAnalyticsService を使う記述があるのでそこを AWSAnalyticsService に変更します。AppDelegate.swiftimport UIKit import AWSPinpoint @UIApplicationMain class AppDelegate: UIResponder, UIApplicationDelegate, UISplitViewControllerDelegate { var window: UIWindow? var dataService: DataService? var analyticsService: AnalyticsService? func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool { : (省略) : // Initialize the analytics service //analyticsService = LocalAnalyticsService() analyticsService = AWSAnalyticsService() : (省略) : }こちらのクラスメソッドさんの記事 【2018年版】Amazon Pinpoint で iOS のサンプルアプリ(Swift)にセグメントプッシュを送る の ノートアプリの プッシュ 通知を有効にする に習って
- Push通知許諾
- デバイストークンをAWS Pinpointへ送信
を追加します。
クラスメソッドさんありがとうございます!セグメント配信
セグメント配信とは、ユーザ属性などを元に、一定条件のグループを作ってそのグループ対象に配信することです。
AWS Pinpointでは、事前にフィルター条件を指定してセグメント設定をしておき、Campaign という名称の配信条件設定を行い、Campaign の単位で配信していきます。
セグメント設定
左メニューのSegmentsを選ぶと右側にSegmentの画面が開きます。
属性を指定してセグメント配信
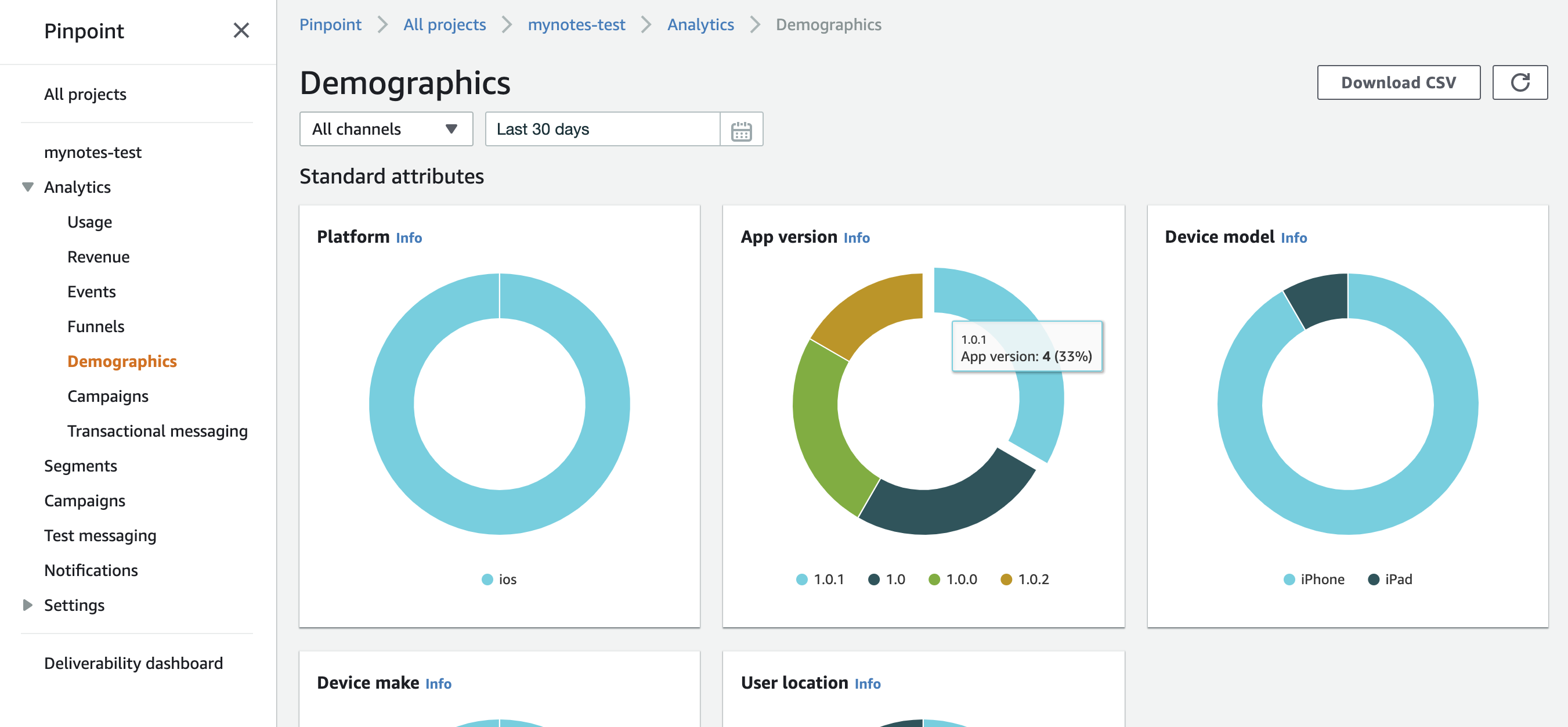
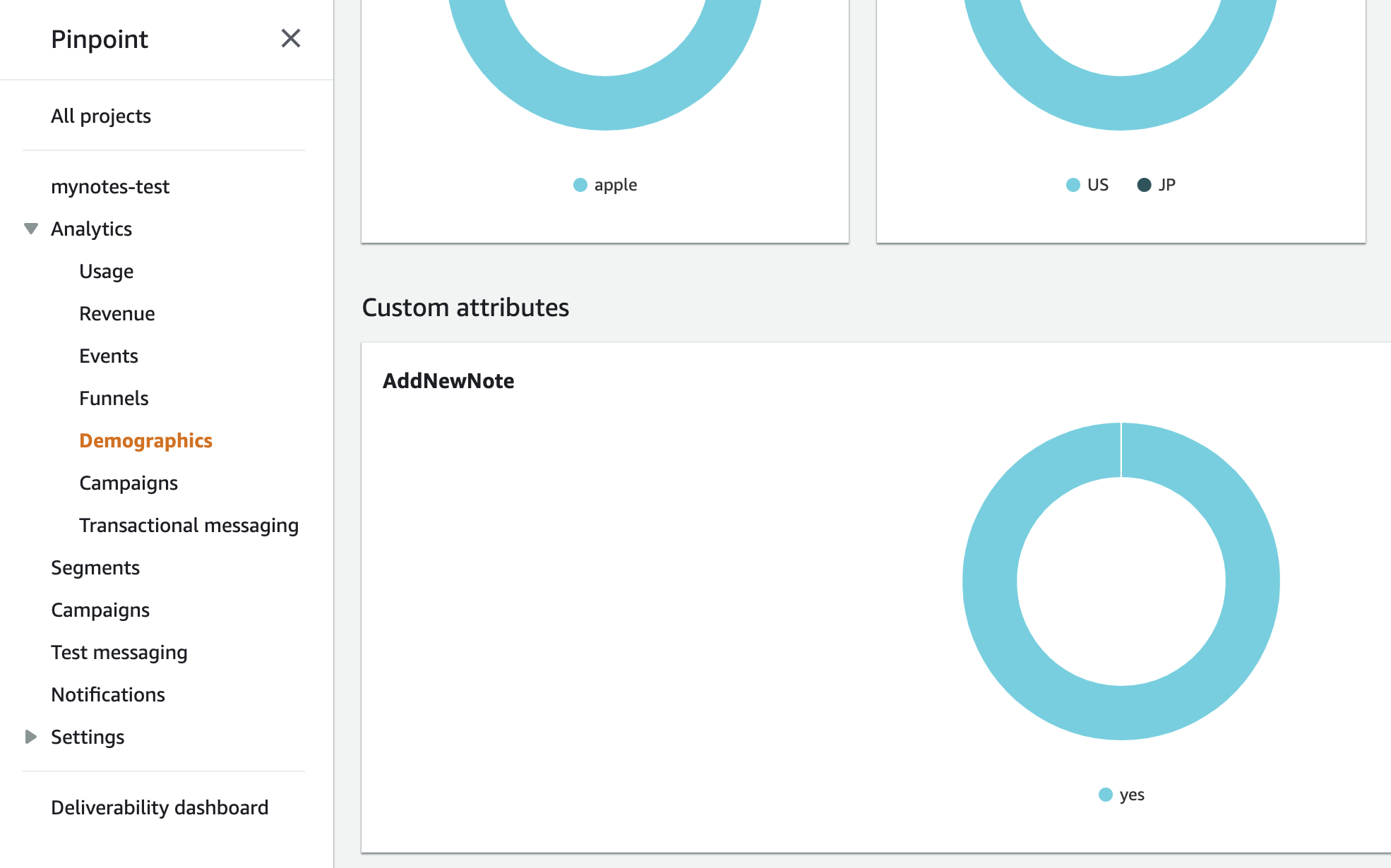
アプリのOSやバージョンなどは標準の属性として登録されるようになっています。
いくつかの端末やシミュレータでアプリを実行したあと、AWS Pinpointのコンソール画面を開き、AnalyticsのDemographicsを見ると、PlatformやAppVersion、Device modelなどがグラフで表示されています。
バージョン番号をアップしながら、いくつかの種類のシミュレータで実行したので複数のバージョンがグラフに表示されているのがわかります。
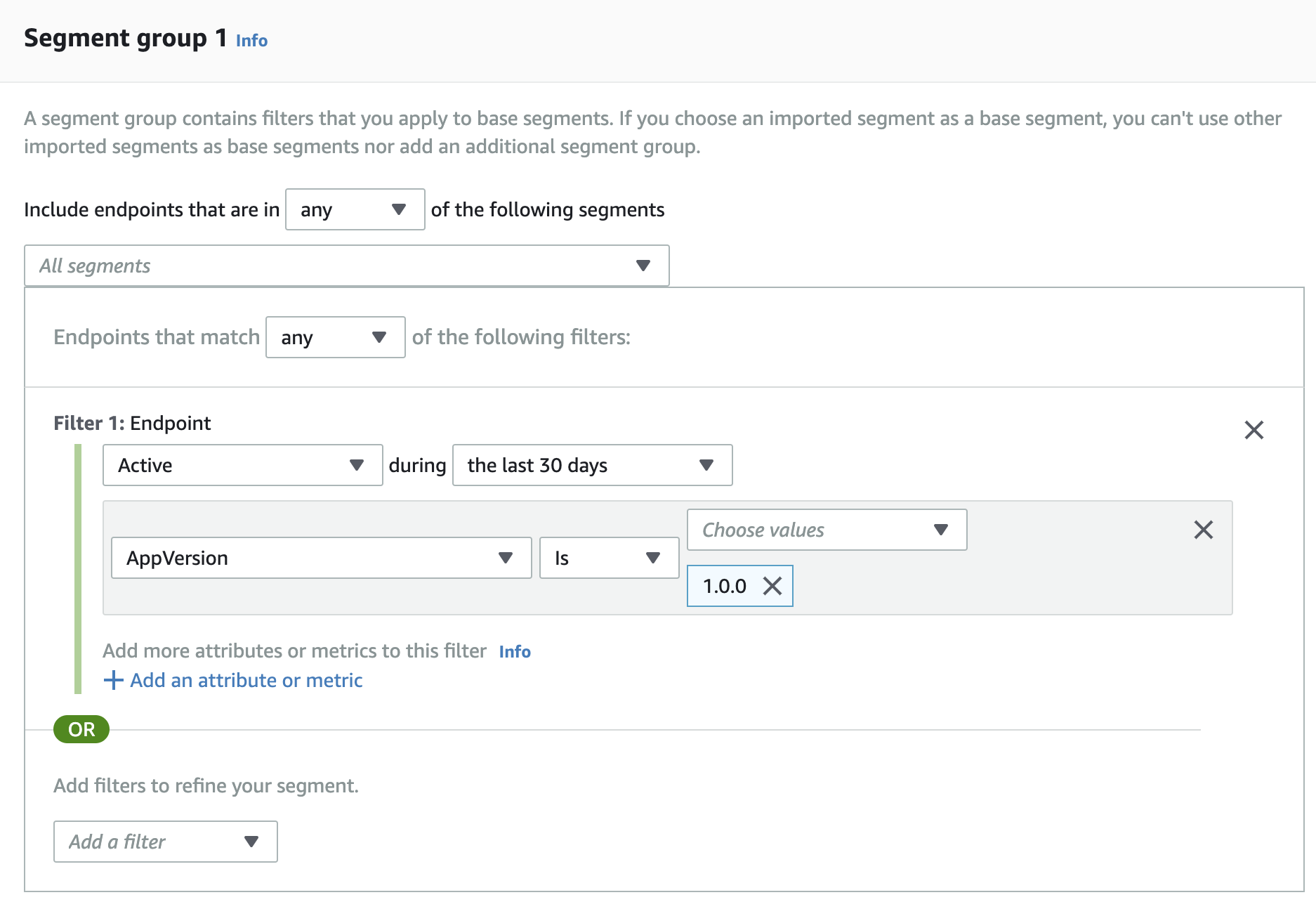
App version でセグメントを作成する場合のセグメント作成画面は以下のようにします。
このセグメントを以下のようなメッセージを配信することができます。
カスタム属性の登録
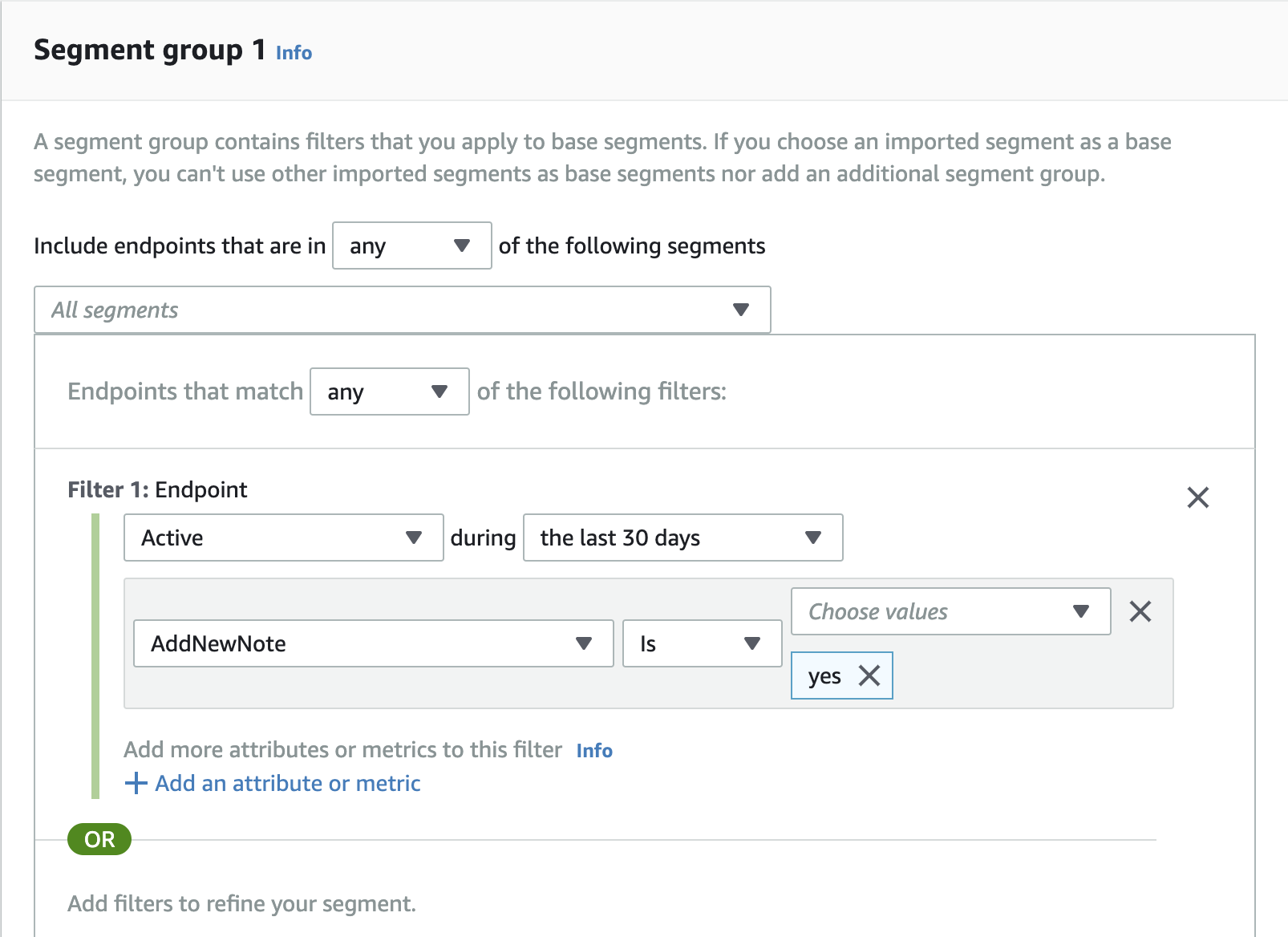
独自の属性を追加する場合は、以下のようにiOSアプリ側から属性を登録します。
事前にPinpoint側で設定などは不要です。func updateEndpointProfile(_ key: String, value: String) { let pinpointTargetingClient = pinpoint!.targetingClient pinpointTargetingClient.addAttribute([value], forKey: key) pinpointTargetingClient.updateEndpointProfile() }これを先ほど追加した AWSAnalyticsServiceクラスに追加し、ViewControllerのinsertNewObjectメソッドから呼び出してみます。
class MasterViewController: UITableViewController { : (省略) : @objc func insertNewObject(_ sender: Any) { analyticsService?.recordEvent("AddNewNote", parameters: nil, metrics: nil) // ★ここに追加。 行を追加したひとは AddNewNotes属性 を yes にする。 analyticsService?.updateEndpointProfile("AddNewNote", value: "yes") self.performSegue(withIdentifier: "showDetail", sender: sender) } : (省略) :これを実行し、アプリで+を押して行を追加した後、AWS Pinpointのコンソール画面のDemographicを見ると、Custom attributesとして AddNewNote が追加されています。
この属性を使ってセグメントを作成してみます。
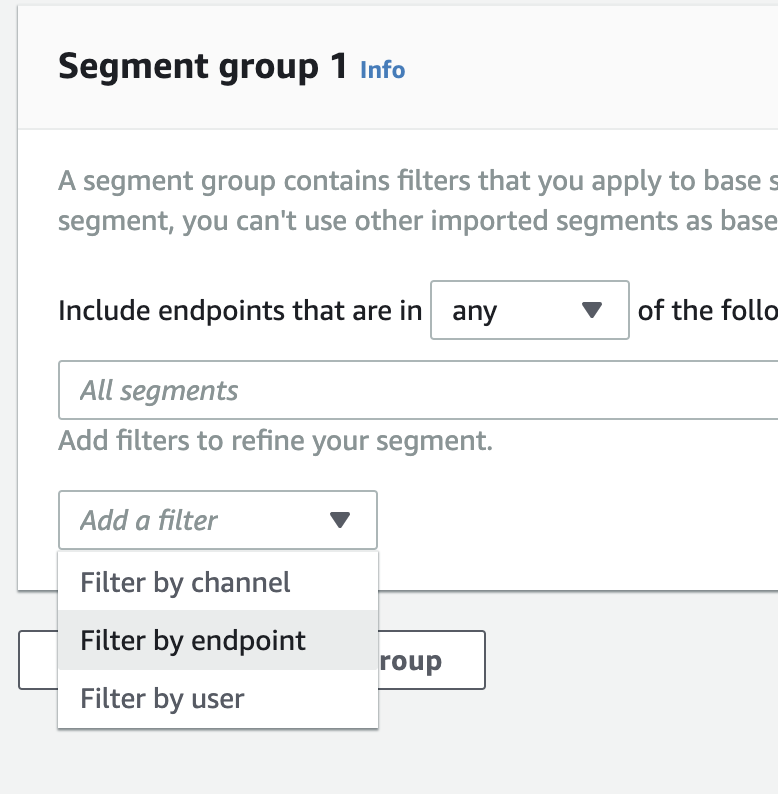
セグメント作成画面で Filter by endpoint 選択します。
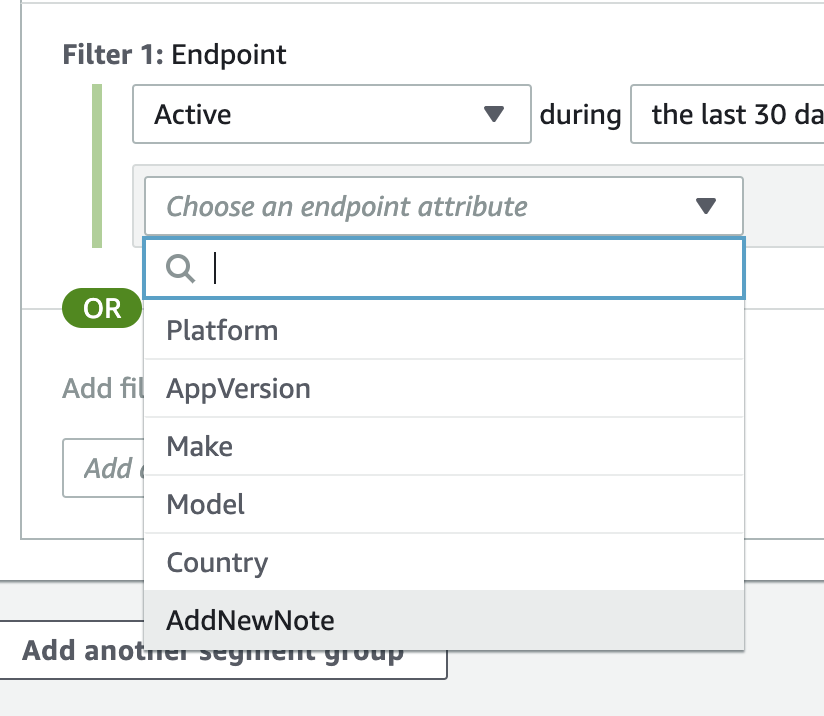
Chose an endpoint attribute に先ほどの AddNewNote が追加されています。
これを利用すれば、特定の機能を使ったユーザや、アプリ内の設定値の状況などをアプリケーションサーバを介することなく確認したり、その属性に対してPush通知を送ることができそうです。
イベント
今回のサンプルコードには既にイベントの登録が含まれています。
追加した AWSAnalyticsServiceクラスの recordEvent です。
実際にイベントを送信している場所は、 ViewController の各処理に実装されています。MasterViewController.swift: (省略) : @objc func insertNewObject(_ sender: Any) { // ここでイベントをAWS Pinpointに送信している analyticsService?.recordEvent("AddNewNote", parameters: nil, metrics: nil) self.performSegue(withIdentifier: "showDetail", sender: sender) } : (省略) :AWS Pinpointのコンソール画面の Eventを開くと利用状況がグラフで表示されます。
イベントからも何かできるはずですがまだ勉強不足です・・
感想
AWS Pinpointにはもっと多くの機能があります。
また、Pinpointから配信したデータをディープラーニングのサービスへデータ連携させたりすることも可能です。
今回は、ここまででのアウトプットですが、もっと、使いこなせるように色々ためしていきたいともいます。参考にさせていただいた記事
[iPhone] iOSアプリを登録、申請して公開するまで
【2018年版】Amazon Pinpoint で iOS のサンプルアプリ(Swift)にセグメントプッシュを送る
個人開発だと適当になりがちなiOSの証明書とアカウントを理解する
iOSアプリのプロビジョニング周りを図にしてみる

- 投稿日:2019-07-28T05:47:42+09:00
ターゲットトラッキングを使った Sidekiq のスケーリング
はじめに
キュー内のメッセージ数に応じて Sidekiq を実行する EC2 インスタンスをスケールする方法を紹介します。
といっても、基本的なスケーリングポリシーの設計は参考資料[1]に書いてあることほぼそのままです。
参考資料では SQS を例に書いてますが、一般的な非同期メッセージングサービスであれば同様の考え方でスケーリングポリシーを設計することができます。準備
Sidekiq のプロセスを実行するEC2インスタンスをオートスケールするにあたって、いくつか準備することがあります。
- スケールインのときに Sidekiq をグレースフルシャットダウンさせる
- Sidekiq のメトリクスを監視する
スケールインのときに Sidekiq をグレースフルシャットダウンさせる
Sidekiq がジョブの実行中にシャットダウンしてしまわないようにするために、インスタンス停止時のライフサイクルフックをトリガーにして、Sidekiq のプロセスをグレースフルにシャットダウンさせます。
詳細な設定方法は参考資料[3]に譲ります。Sidekiq をメトリクス監視する
Sidekiq の稼働中の状態を正確に知るために、基本的なメトリクスを観測できるようにします。
後に出てくるシステムのパラメータを決定する上でも役立ちます。
参考資料[4]に詳細な手順が紹介されています。メトリクスの例
- キュー長
- キューに登録されてから、Sidekiq で処理されるまでの最大待ち時間
- Busy なプロセスの数
スケーリングポリシーの設計
参考資料[2]によると、ターゲット追跡に使用できるメトリクスには以下の制約があります:
すべてのメトリクスがターゲット追跡に使用できるわけではありません。これは、カスタマイズされたメトリクスを指定する場合に重要になる場合があります。メトリクスは有効な使用率メトリクスであり、インスタンスの使用頻度を指定する必要があります。メトリクス値は Auto Scaling グループのインスタンス数に比例して増減する必要があります。それにより、メトリクスデータを使用して比例的にインスタンス数をスケールアウトまたはスケールインできます。
例えば、以下のようなものです。
- AutoScaling Group あたりのCPU使用率の平均値
- 稼働中のプロセス数の合計
キューイングシステムの場合は以下が候補になります(参考資料[1]参照)。
- 1インスタンス(or 1プロセス)あたりのキュー長
共通しているのは、 システムの負荷が同じ場合、インスタンス数に反比例して増減する量であるということです。
つまり、インスタンス数を$I$、ターゲット追跡対象のメトリクスを$M_T$とすると、以下の式で表せます:
$$M_T\propto I^{-1}$$
例として、$M_T$が「CPU使用率の平均値」の場合、各インスタンスのCPU使用率を$c_i$とすると、 $IM_T=\sum{c_i}=\text{const.}$と表せるので、たしかに反比例の関係にあります。
また、$M_T$が「1インスタンスあたりのキュー長」の場合、キュー長を$N$とすると、$IM_T=N=\text{const.}$と書け、やはり反比例の関係にあります。
システム全体で処理する負荷を表す量として、Webサービスでは「インスタンスのCPU使用率の平均値」を採用するのに対して、キューイングシステムでは「キュー長」を採用していることになります。
1. システムのパラメータの設計
参考資料[1]にしたがって、以下のパラメータを決定します。
- 1インスタンスあたりの許容できるキューの長さ: $N_I^{\ast}$
- 1メッセージあたりの許容できる最大遅延時間: $L^{\ast}$
- 1インスタンスあたりのメッセージ処理時間: $T_I$
例として、 $T_I=0.56\text{s}, L^{*}=60\text{s}$ とすると、$N_I^{\ast}=L^{\ast}/T_I=107.14$ と計算できます。
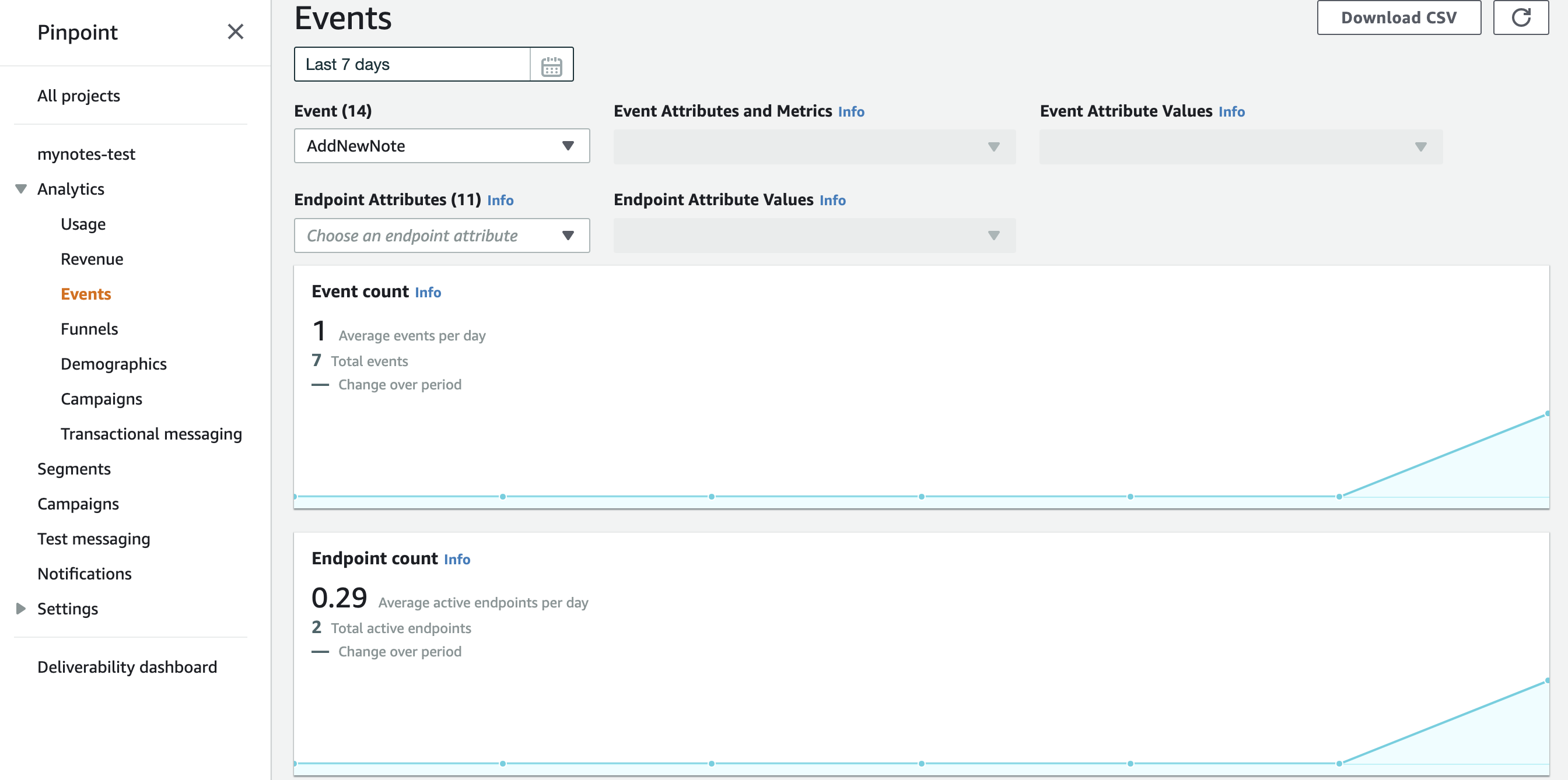
$L^{\ast}$はサービスの要件から決めることができますが、$T_L$は不明なので、システムのメトリクスの観測値などから推定する必要があります。キューのサイズとレイテンシーの関係がわかっていれば、$T_I$を推定できます。例えば、以下のようなグラフが得られている場合、ピーク時のキュー長が 750 に対してレイテンシーが 7 min なので、$T_I\approx7*60/750=0.56\text{s}$ くらいだとわかります。
キューの長さ
レイテンシー
今回の例では $M_T^{\ast}=N_I^{\ast}=100$とします。
なお、$M_T^{\ast}$ はターゲット追跡ポリシーにおける、メトリクスの目標値です。2. ターゲット追跡ポリシーに指定するカスタムメトリクスを監視する
1インスタンスあたりのキュー長をカスタムメトリクスとして観測する必要があります。
キュー長を$N$, インスタンス数を$I$とすると、$N_I=N/I$を計算してカスタムメトリクスとして push します。例えば、1分ごとにCloudWatch Event を生成し、 Lambda Function でメトリクスを push することで実現できます。メトリクス名は
QueueSizePerInstanceとします。3. ターゲット追跡ポリシーの作成
あとは、2で設定したカスタムメトリクスをもとにターゲット追跡ポリシーを作成するだけです。
詳細は参考資料[1]に譲るとして、ターゲット追跡ポリシーの設定は以下のようにします。conf.json{ "TargetValue":100.0, "CustomizedMetricSpecification":{ "MetricName":"QueueSizePerInstance", "Namespace":"Sidekiq", "Dimensions":[ { "Name":"Stage", "Value":"prd" } ], "Statistic":"Average", "Unit":"Count" } }まとめ
- Webサービスだけでなく、キューイングシステムのようなワークロードの場合でもターゲット追跡ポリシーを指定することができる
- SQSだけでなく、Sidekiqの場合も考え方は同じ(ただし、安全にスケールするための準備が必要)
参考資料

- 投稿日:2019-07-28T05:47:42+09:00
ターゲット追跡ポリシーを使った Sidekiq のスケーリング
はじめに
キュー内のメッセージ数に応じて Sidekiq を実行する EC2 インスタンスをスケールする方法を紹介します。
といっても、基本的なスケーリングポリシーの設計は参考資料[1]に書いてあることほぼそのままです。
参考資料では SQS を例に書いてますが、一般的な非同期メッセージングサービスであれば同様の考え方でスケーリングポリシーを設計することができます。準備
Sidekiq のプロセスを実行するEC2インスタンスをオートスケールするにあたって、いくつか準備することがあります。
- スケールインのときに Sidekiq をグレースフルシャットダウンさせる
- Sidekiq のメトリクスを監視する
スケールインのときに Sidekiq をグレースフルシャットダウンさせる
Sidekiq がジョブの実行中にシャットダウンしてしまわないようにするために、インスタンス停止時のライフサイクルフックをトリガーにして、Sidekiq のプロセスをグレースフルにシャットダウンさせます。
詳細な設定方法は参考資料[3]に譲ります。Sidekiq をメトリクス監視する
Sidekiq の稼働中の状態を正確に知るために、基本的なメトリクスを観測できるようにします。
後に出てくるシステムのパラメータを決定する上でも役立ちます。
参考資料[4]に詳細な手順が紹介されています。メトリクスの例
- キュー長
- キューに登録されてから、Sidekiq で処理されるまでの最大待ち時間
- Busy なプロセスの数
スケーリングポリシーの設計
参考資料[2]によると、ターゲット追跡に使用できるメトリクスには以下の制約があります:
すべてのメトリクスがターゲット追跡に使用できるわけではありません。これは、カスタマイズされたメトリクスを指定する場合に重要になる場合があります。メトリクスは有効な使用率メトリクスであり、インスタンスの使用頻度を指定する必要があります。メトリクス値は Auto Scaling グループのインスタンス数に比例して増減する必要があります。それにより、メトリクスデータを使用して比例的にインスタンス数をスケールアウトまたはスケールインできます。
例えば、以下のようなものです。
- AutoScaling Group あたりのCPU使用率の平均値
- 稼働中のプロセス数の合計
キューイングシステムの場合は以下が候補になります(参考資料[1]参照)。
- 1インスタンス(or 1プロセス)あたりのキュー長
共通しているのは、 システムの負荷が同じ場合、インスタンス数に反比例して増減する量であるということです。
つまり、インスタンス数を$I$、ターゲット追跡対象のメトリクスを$M_T$とすると、以下の式で表せます:
$$M_T\propto I^{-1}$$
例として、$M_T$が「CPU使用率の平均値」の場合、各インスタンスのCPU使用率を$c_i$とすると、 $IM_T=\sum{c_i}=\text{const.}$と表せるので、たしかに反比例の関係にあります。
また、$M_T$が「1インスタンスあたりのキュー長」の場合、キュー長を$N$とすると、$IM_T=N=\text{const.}$と書け、やはり反比例の関係にあります。
システム全体で処理する負荷を表す量として、Webサービスでは「インスタンスのCPU使用率の平均値」を採用するのに対して、キューイングシステムでは「キュー長」を採用していることになります。
1. システムのパラメータの設計
参考資料[1]にしたがって、以下のパラメータを決定します。
- 1インスタンスあたりの許容できるキューの長さ: $N_I^{\ast}$
- 1メッセージあたりの許容できる最大遅延時間: $L^{\ast}$
- 1インスタンスあたりのメッセージ処理時間: $T_I$
例として、 $T_I=4.48\text{s}, L^{*}=60\text{s}$ とすると、$N_I^{\ast}=L^{\ast}/T_I=13.39$ と計算できます。
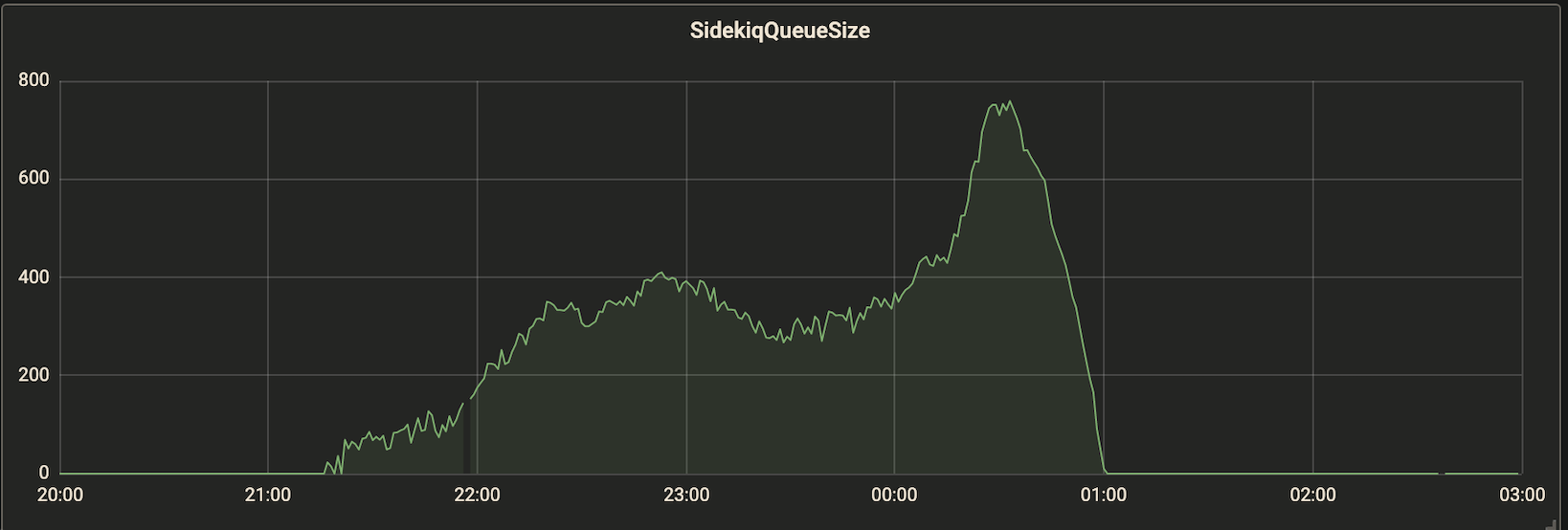
$L^{\ast}$はサービスの要件から決めることができますが、$T_L$は不明なので、システムのメトリクスの観測値などから推定する必要があります。キューのサイズとレイテンシーの関係がわかっていれば、$T_I$を推定できます。例えば、図1,2 のようなグラフが得られているとします。常時 8 インスタンス稼働しているとすると、ピーク時の1インスタンスあたりのキュー長が 750/8=93.75 に対してレイテンシーが 7 min なので、$T_I\approx7*60/93.75=4.48\text{s}$ くらいだとわかります。
図1. キューの長さ
図2. レイテンシー
今回の例では $M_T^{\ast}=N_I^{\ast}=10$とします。
なお、$M_T^{\ast}$ はターゲット追跡ポリシーにおける、メトリクスの目標値です。2. ターゲット追跡ポリシーに指定するカスタムメトリクスを生成する
1インスタンスあたりのキュー長をカスタムメトリクスとして観測する必要があります。
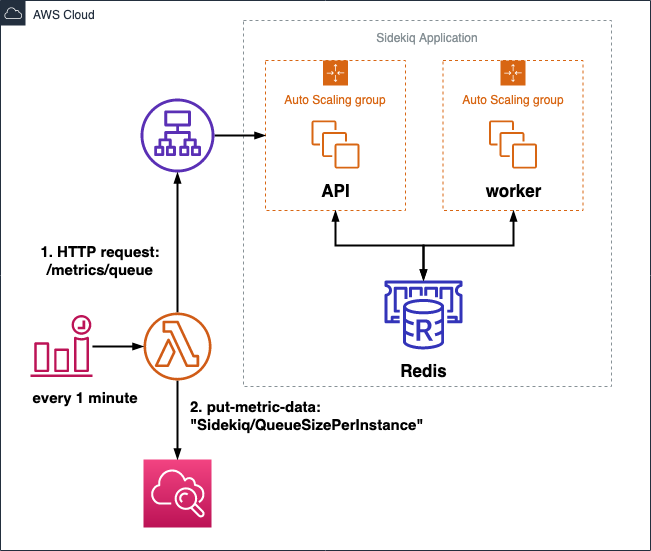
キュー長を$N$, インスタンス数を$I$とすると、$N_I=N/I$ を計算してカスタムメトリクスとして発行します。例えば、図3のように、1分ごとにCloudWatch Event を生成し、 Lambda Function でメトリクスを発行します。メトリクス名は
QueueSizePerInstanceとします。図3. ターゲットメトリクスを発行するための構成例
3. ターゲット追跡ポリシーの作成
あとは、2で設定したカスタムメトリクスをもとにターゲット追跡ポリシーを作成するだけです。
詳細は参考資料[1]に譲るとして、ターゲット追跡ポリシーの設定は以下のようにします。conf.json{ "TargetValue":10.0, "CustomizedMetricSpecification":{ "MetricName":"QueueSizePerInstance", "Namespace":"Sidekiq", "Dimensions":[ { "Name":"Stage", "Value":"prd" } ], "Statistic":"Average", "Unit":"Count" } }まとめ
- Webサービスだけでなく、キューイングシステムのようなワークロードの場合でもターゲット追跡ポリシーを指定することができる
- SQSだけでなく、Sidekiqの場合も考え方は同じ(ただし、安全にスケールするための準備が必要)
参考資料
- 投稿日:2019-07-28T03:23:52+09:00
AWS 認定ソリューションアーキテクト – アソシエイトに合格しました
まえがき
さっきAWS 認定ソリューションアーキテクト – アソシエイト(以下AWS SAA)に合格しました。
https://aws.amazon.com/jp/certification/certified-solutions-architect-associate/
まだメールが届いていないので正式ではないかもしれませんが
試験終了時の合否判定に「合格」って書いてあったので見間違いでない限りは合格です。試験を受けながら思ったことや、合格した喜びが冷めないうちに
文章を書いた方がいいな、と思ってこうして当日中にQiita初投稿をしようとしています。
「Rust楽しい」っていう下書きをしてましたが、そんなもんそっちのけです。あとがき
思うがまま、合格した喜びに任せて文章を書いたら全くまとまらなくなってしまいました。
ただ、他のAWS SAAに合格した人の記事で散々語り尽くされている内容はあまり書かないようにしてます。
(もちろん被ってる内容もあると思いますが、それは被らせるくらい本当に重要だと思った内容のはずです)
なのでAWS SAAに合格した人の記事を漁っていて既に他の人の記事を読み尽くしているときに初めて読んで意味がある記事かもしれません。
本当に「その温度感であれば読んでください」ぐらいの駄文長文なので興味がない人は読まなくていいです、時間の無駄になると思います。...とはいえこんな駄文長文を本当に投稿していいのか、と悩んでいたところ日付が変わってしまいました。
メールはまだ届いていません。ホントウニゴウカクシタンダロウカ
せっかく3500文字近く書いたのに投稿しないのも勿体ない気がしてきたので投稿しちゃいます、えい!何をこの記事に書くか
- 試験を実際に受けて感じた「これから受ける人に伝えたいこと」
- どんな人が受かったかの参考になるか分からないけれど「自己紹介」
これから受ける人に伝えたいこと
AWSコンソールをたくさん触ろう
まず前提としてAWS SAAは問題文があって、それに対して選択肢から回答を選びます。
そしてこの回答、比率としては少ないのですが「AWSにはできないこと」が書かれていることがあります。
中途半端な知識でこの選択肢を読んでしまうと「え、そんなことできるの? それが一番ベストだよね?」みたいになるのですが
実は「AWSにはできないこと」だからそれを選んではいけなかった、みたいなことがあります。
なので普段からAWSコンソールに触れて何ができるのか、何はできないのか実感として知っておいた方がかなり安心して回答を選べると思います。
僕はS3の暗号化をほとんどしたことがなかったので、「バケットに対してデフォルト暗号化という機能があるのか」「バケットポリシーに暗号化について記載するのか」分からず回答できませんでした。
一応、本番では多分前者だろうと思って選んだのですが合ってそうですね。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/bucket-policy-encryption-s3/英語は読んだ方がいい
「自分は英語苦手だし・・・」とか思って読まないつもりでいたのですが
意外と日本語が読みにくいので "Englishボタン" を押す心算でいた方がいいです。
例えば「ネットワークファイルシステム」みたいなカタカナが大量に出てくるのですが
「Network File System」のことだと気付くのに時間がかかるんですよね、カタカナだと。ただの直訳なのに。
でも英語で読めば「あー、NFSか」ってなってすぐに回答の選択肢に入っているAWS EFSが答えだと分かったりするので
日本語の意味が捉えにくいな、と思ったらすぐに英語を一度読んでみることをオススメします。フラグ大事
(僕が一番伝えたいことはこれなのですが、小手先のテクニックなので重要ではないです)
問題にフラグを付けることができるのですが、後から「フラグが付いている問題だけを読み直す機能」があります。
ここら辺は模試で一度使い方に慣れておいた方がいいと思います。そしてフラグの何が一番大事かというと「どういう問題にフラグを立てるか」という作戦を用意しておいた方がいいです。
僕の場合、問題には三種類ありました。
- 即答できる問題(10%)
- 前提知識不足で全く分からない問題(10%)
- 考えれば分かるけど自信がない問題(80%)
「後から見直す問題にフラグを立てる」という方針でフラグを立てていった結果、90%の問題にフラグが立ってしまいました。
まぁその90%をもう一度見直して合格したので結果的には正解だったのかもしれませんが、
もう少し効率のいいやり方があったのかなぁ、とは思います。
なので「絶対に分からない問題にはフラグを立てない」とか「ある程度自信がある問題はフラグを立てない」とか
各々自分にあったフラグの立て方の作戦を用意した方がいいんじゃないかな、と思います。自己紹介
AWS SAAに合格した自分のスペックについて書きます。
スペック
- 大学院卒
- 社会人経験5年目
- Atcoder青色(メイン言語はJava)
- 資格0(囲碁は初段、ピアノも資格あり、Web/情報系の資格はAWS SAAが初)
- 最近の業務はshell芸がメイン、残り90%はディレクションやクライアントとの折衝、社内基盤の整備
- 趣味で一時期Vueを触ってた(着せ替えゲームを作った)
ってところでしょうか。資格をとるお金や時間が勿体無い人間だったので説明できるスペックが全然ないです。
ちょっと長くなりますが、どれくらいの能力があるのかの指標としてスペックの代わりに経歴を書いてみます。経歴
大学/大学院は情報科学系の学科に通学していました。
一応、授業で基礎的なところはさらえるはずなのですが
身についたのは数学的な知識とC言語少しと研究室でガリガリ書いたMatlabぐらいだと思います。
就職するまではWeb系はからっきしでしたしサーバすら立てれない、linuxコマンドもmvやcdなどのファイル操作しか分からない感じでした。
Javaも授業で軽く知っただけなのでほとんど入社してから覚えました。入社1年目で先輩に教えてもらいながらEC2をAMIから立てたりELB作ったり、
あとは「Jmeterによる負荷試験の環境をCloud Formationから構築して別VPCの検証環境とVPCピアリングして〜」みたいなことを
インターン生がやっているところを横から見ていた りはしました。入社2年目になると案件が変わってオンプレミスになったのでAWSに触るのは開発環境ぐらいでしたが
相変わらずEC2をAMIから立てたりセキュリティグループを変更したりはしていました(むしろ1年目より内容は減った)。入社3年目になって案件をかけ持ちすることになってがっつりAWSで動いている案件に入って
CloudFront触ったりWAF触ったりS3触ったりとやることはだいぶ増えたのですが
この3年間に共通して言えるのが 既に誰かが構築した環境をいじるだけ で
なんだかAWSコンソールは触っているけれどAWSについてはあまり理解できてないなぁ・・・という感じでした。4年目になって新しい要件にも触れるようになって
Athena 使ってみたりWAFのルールをAWS APIで動的に変更したりとちょっとトリッキーなことをやり始めたのですが
相変わらず「VPC? サブネット? ACL? 可用性?」って感じで一番知っておくべきというか
基礎的で重要な部分についてはあまりちゃんと理解しないままでした。ちなみに入社5年目になりましたが、いまだに自分で環境を1から構築したことはないです。
今ならやろうと思えばできる気がしますが耳年増(使い方が間違ってる?)になっている感じ。つい先月か2ヶ月前に会社の方針でAWSの資格保有者を増やそう、という話になって
自分が立候補したので3日間で行われるAWS SAA試験対策講座を受けてきました。
今までなんとなく人から聞いていた話が体系立てられて話されるので「ほーんそういうことかー」みたいな感じでした。
新しく得られた知識はほとんどなかったのですが
「こういう観点でサービスを選択した方がいい」とか知識をどう扱うかの部分について学べたのがよかったです。で、試験を無料で受けれるバウチャーをもらったので早速今日受けてみて合格した、というのがここまでの経歴です。
おわりに
とりあえず伝えたかったのは「こんな人でもトレーニングを受けたらあまり勉強せずに受かったよ」ということです。
「資格取るぞー!」って意気込んでるけどAWSほとんど触ったことない、って人にはあまり役に立たない記事かもしれませんが
「業務ではAWS使ったことあるけど、資格なんてまだ自分には早いかも・・・」と思ってる人にはそんなことないよ、って言いたいです。
特に弊社は資格に無頓着な人が多くてAWS SAAの資格を持ってるのは僕が二人目になると思うのですが
本当は10人20人くらいほとんど勉強しなくても取れる人がいるはず・・・!いかがでしたでしょうか。何かお役に立てる情報はあったでしょうか。ではでは。
- 投稿日:2019-07-28T01:51:37+09:00
AWS Chatbot(Beta)を試してみた
AWS Chatbot(Beta)を試してみました。
どんなもの?
SlackとAmazon Chimeに通知するサービスです。
データソースは以下のAWSサービスが選択できます。(2019-07-28時点)
- AWS Billing and Cost Management
- AWS CloudFormation
- Amazon CloudWatch
- Amazon GuardDuty
- AWS Health
- AWS Security Hub
1. Slackを選択
AWS Chatbotから[Configure new client]を選択後、Slackを選択する。
2. Slack側設定
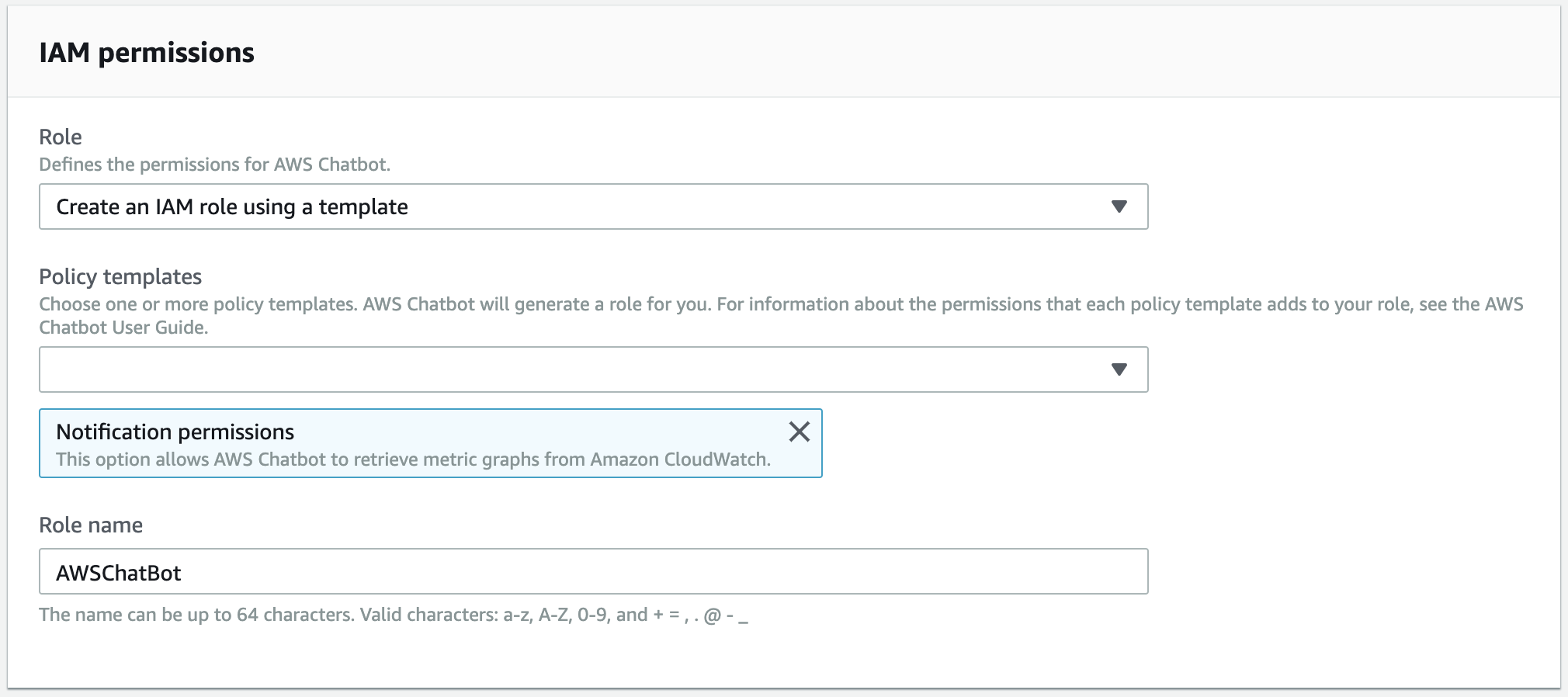
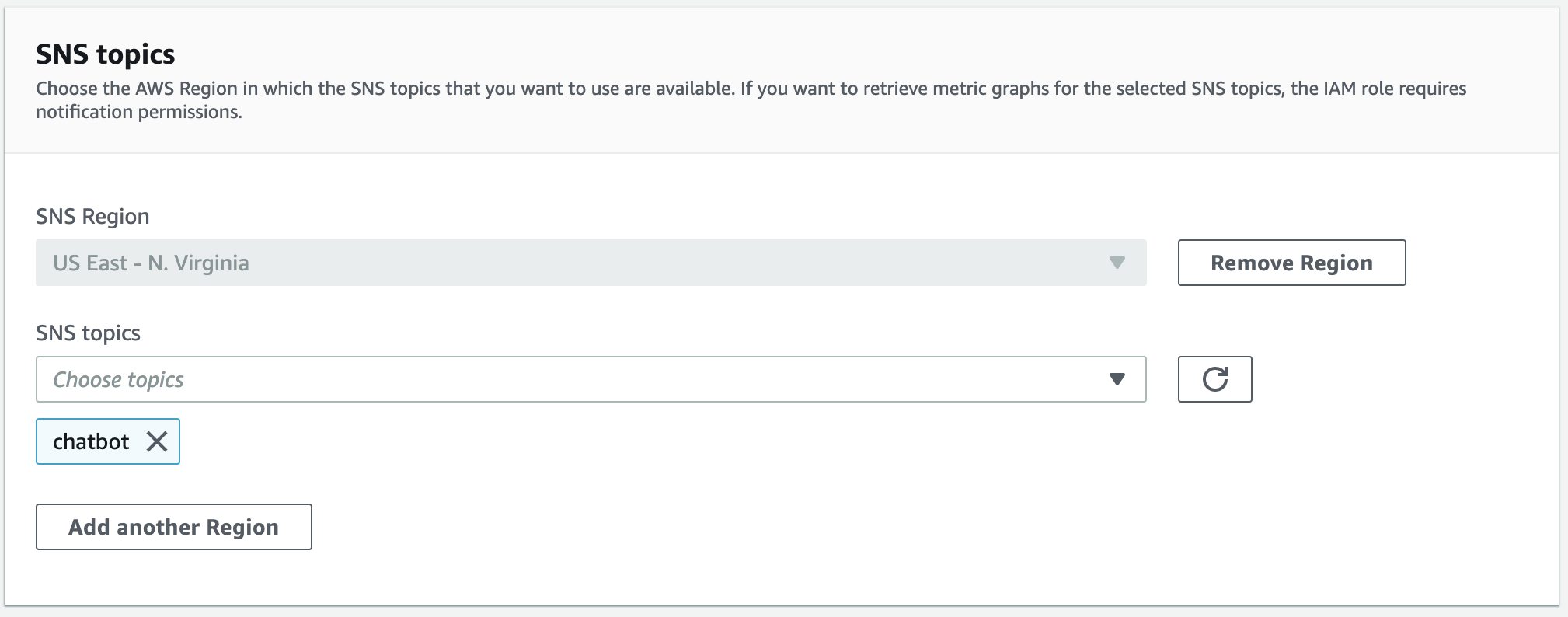
3. AWS Chatbot側設定
Slackチャネル、Role、SNSトピックを指定する。
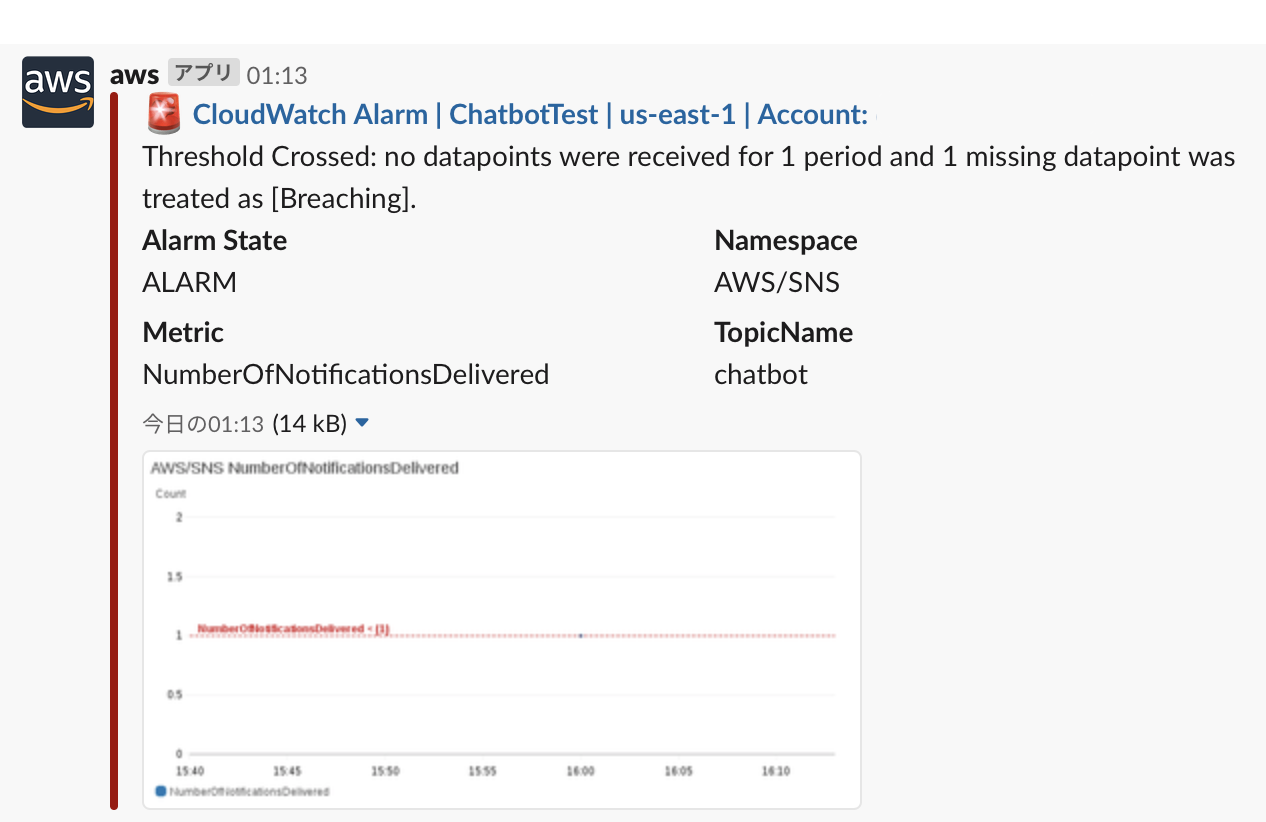
CloudwatchアラームをSlackに通知した例
上記で指定したSNSトピックをCloudwatchAlarmの通知先に設定後、アラームを発生させる。
雑感
現在の機能は通知だけでちょっと寂しいので、HubotのようにSlackからデプロイ等ができるようにならなかなぁ。


- 投稿日:2019-07-28T00:44:42+09:00
【AWS】CloudFormationでLambdaの環境変数が暗号化できない
顛末
CloudFormationでスタックを作成するにあたり、Lambdaが利用する外部APIのアクセストークンを環境変数内でKMS暗号化して保管したい。さらに希望としては関数のコンソールを開いただけでは環境変数の値は暗号化されて見えなくなっていてほしい。
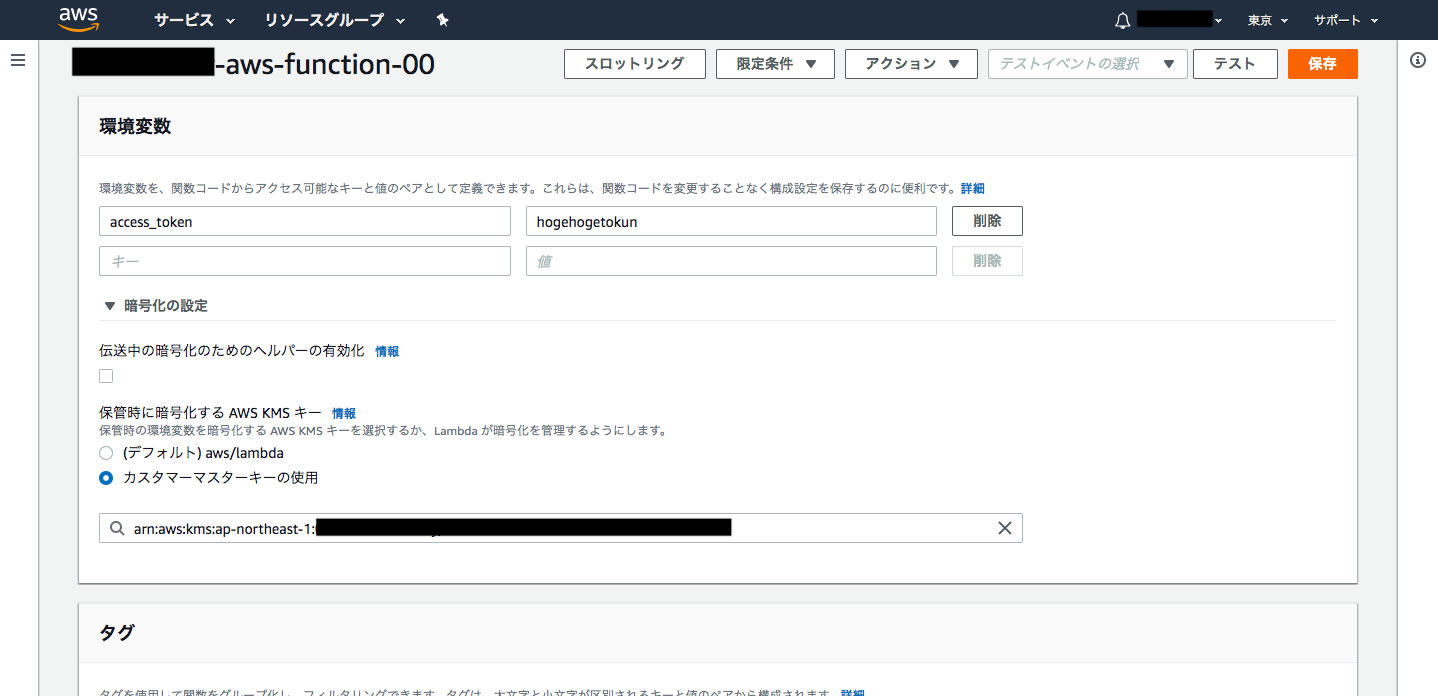
そこで以下のようなスタックテンプレートを作成してスタックを作成してみた。stack-template.ymlParameters: AccessToken: Type: String (中略) Key00: Type: AWS::KMS::Key Properties: KeyPolicy: Version: "2012-10-17" Id: !Sub ${appName}-aws-apikey-00-keypolicy Statement: - Sid: "Allow administration of the key" Effect: "Allow" Principal: AWS: !Sub arn:aws:iam::${AWS::AccountId}:root Action: "*" Resource: "*" - Sid: "Allow use of the key" Effect: "Allow" Principal: AWS: !GetAtt Role00.Arn Action: - "kms:Encrypt" - "kms:Decrypt" - "kms:ReEncrypt*" - "kms:GenerateDataKey*" - "kms:DescribeKey" Resource: "*" Function00: Type: AWS::Lambda::Function Properties: Environment: Variables: access_token: hogehogetokun KmsKeyArn: !GetAtt Key00.Arn (中略)しかし、CloudFormationにより作成されたLambda関数のコンソールを見てみると、
保管時に暗号化する AWS KMS キーは指定されているが、伝送中の暗号化のためのヘルパーの有効化は無効のままのため、環境変数は暗号化されず丸見えである。
調べてみるとクラスメソッドの下記の記事でも、同箇所でCloudFormationで環境変数を暗号化までする方法が見つからず、関数のコンソールから設定している。
https://dev.classmethod.jp/cloud/aws/lambda-slack-cloudwatch-cloudformation/
仕方がないのでコンソールから手動で
伝送中の暗号化のためのヘルパーの有効化を有効化してKMSキーを指定し、環境変数を暗号化した。やはり見えないほうが落ち着く。
早くCloudFormationでここまで設定きるようになってほしい。
以上
- 投稿日:2019-07-28T00:44:42+09:00
【AWS】Lambdaで環境変数のKMS暗号化を行う際のトラブルシューティング
はじめに
本記事では、AWS Key Management Serviceを利用してAWS Lambdaに設定する環境変数をKMS暗号化して利用しようとした際に必要となったトラブルシューティングを記載していく。
トラブルシューティング
CloudFormationで「伝送中の暗号化のためのヘルパーの有効化」を設定できない
CloudFormationでKMSキーの作成からLambda関数の環境変数への適用までを行いたい。
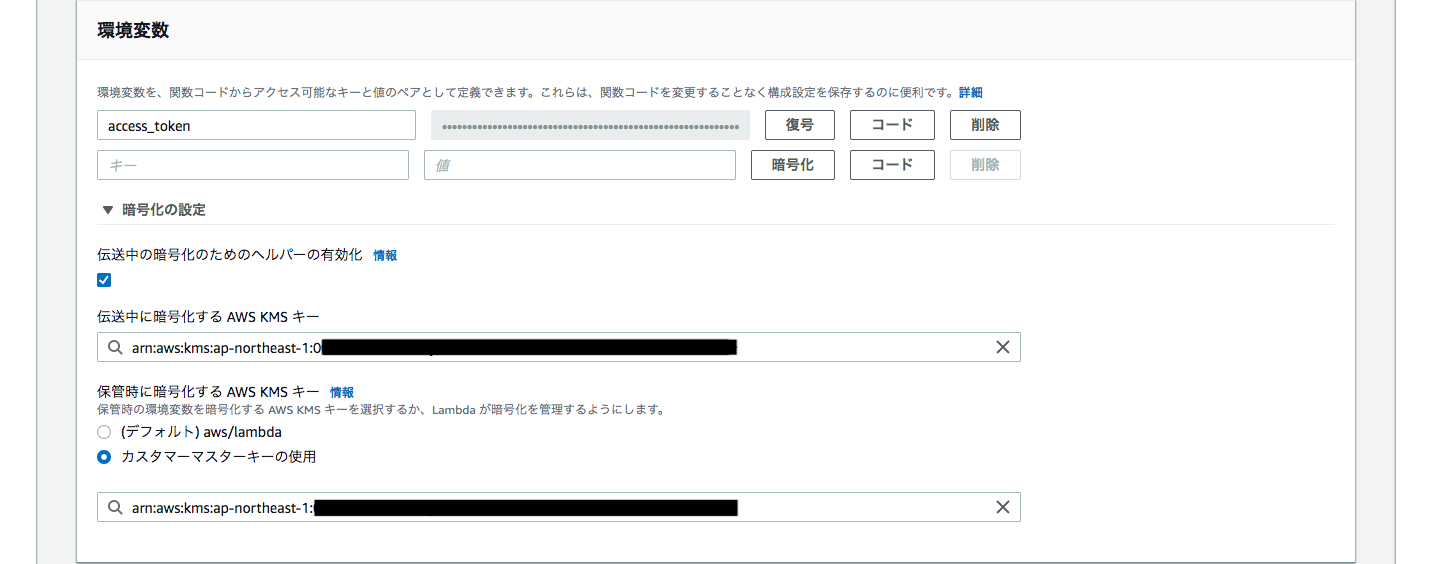
そこで以下のようなスタックテンプレートを作成してスタックを作成してみた。stack-template.ymlParameters: AccessToken: Type: String (中略) Key00: Type: AWS::KMS::Key Properties: KeyPolicy: Version: "2012-10-17" Id: !Sub ${appName}-aws-apikey-00-keypolicy Statement: - Sid: "Allow administration of the key" Effect: "Allow" Principal: AWS: !Sub arn:aws:iam::${AWS::AccountId}:root Action: "*" Resource: "*" - Sid: "Allow use of the key" Effect: "Allow" Principal: AWS: !GetAtt Role00.Arn Action: - "kms:Encrypt" - "kms:Decrypt" - "kms:ReEncrypt*" - "kms:GenerateDataKey*" - "kms:DescribeKey" Resource: "*" Function00: Type: AWS::Lambda::Function Properties: Environment: Variables: access_token: hogehogetokun KmsKeyArn: !GetAtt Key00.Arn (中略)しかし、CloudFormationにより作成されたLambda関数のコンソールを見てみると、
保管時に暗号化する AWS KMS キーは指定されているが、伝送中の暗号化のためのヘルパーの有効化は無効のままのため、環境変数は暗号化されず平文が丸見えである。
調べてみるとクラスメソッドの下記の記事でも、同箇所でCloudFormationで環境変数を暗号化までする方法が見つからなかったようで、本箇所のみ関数のコンソールから設定している。
https://dev.classmethod.jp/cloud/aws/lambda-slack-cloudwatch-cloudformation/
仕方がないのでわたしもコンソールから手動で
伝送中の暗号化のためのヘルパーの有効化を有効化してKMSキーを指定し、環境変数を平文で表示されないようにした。
環境変数の復号結果がbytes型になる
KMS暗号化された環境変数をコード内で復号すると既定でbytes型の文字列になる。
文字列として扱いたい場合はdecode('utf-8')などでバイト列から文字列にデコードする必要がある。lambda_function.pyimport boto3,os from base64 import b64decode def lambda_handler(event, context): ENCRYPTED = os.environ['access_token'] DECRYPTED = boto3.client('kms').decrypt(CiphertextBlob=b64decode(ENCRYPTED))['Plaintext'] print(DECRYPTED) print(DECRYPTED.decode('utf-8'))# 実行結果 b'hogehogetokun' hogehogetokun環境変数を暗号化した際に「コード」ボタンで表示できる「シークレットスニペットの復号」のコード内では特にutf-8デコードはされていなかったので、DECRYPTEDが後続の処理にうまくわたせずにハマった。
参考
https://qiita.com/seisyu1985/items/880c5e49e8c8677bc9e3
https://qiita.com/FGtatsuro/items/f45c349e06d6df95839b
https://python.civic-apps.com/python3-bytes-str-convert/以上