- 投稿日:2019-07-28T22:50:10+09:00
[java]10進数→n進数 n進数→10進数
10進数→n進数
import java.io.*; class ファイル名 { public static void main(String[]args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); System.out.print("\n何進数にしますか?(max36):"); String str1 = br.readLine(); int n = Integer.parseInt(str1); System.out.print("n進数に変換したい10進数の数字を入力して下さい:"); String str2 = br.readLine(); int x = Integer.parseInt(str2); String A = Integer.toString(x,n); System.out.println(x+"は"+n+"進数で"+A); } }n進数→10進数
import java.io.*; class ファイル名 { public static void main(String[]args) throws IOException { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); System.out.print("何進数の数字を10進数に変換しますか?:"); String N = br.readLine(); int n=Integer.parseInt(N); System.out.print("\n10進数に変換したい"+n+"進数の数字を入力して下さい:"); String X = br.readLine(); int A=Integer.parseInt(X,n); System.out.print("\n10進数で:"+A); } }
- 投稿日:2019-07-28T21:59:32+09:00
【備忘録】未経験から半年で学習してきたこと(Java)(1)
※駆け出しのエンジニアです。将来開発の仕事をし、東京・大阪勤務を希望します。
指摘・助言などよろしくお願いします。Java
1.特徴
Javaの特徴としては2つあります。
1)オブジェクト指向型言語
1つのプログラムを「オブジェクト」として作成する考え方です。
考え方なので多くの学習者たちが悩まされます。
オブジェクト指向には3つの特徴があります。・継承
・カプセル化
・ポリモーフィズム上記3つの特徴を簡単に書きます。
「継承」とは特徴・性質を引き継ぐことです。「カプセル化」はデータや値を守ることです。「ポリモーフィズム」は1つの枠組みをもとに、ほかの人が少しずつ変えられるようにできる方法です。2)マルチプラットフォーム
Javaのプログラムでは「.java」というソースファイルから文法などをチェックしてくれる「コンパイル」作業を通してできる「.class」というクラスファイルがあります。このクラスファイルはJavaVM(Java仮想マシン)があればどこでも実行することができます。
なぜJavaVMがあればどこでも動けるのか?
理由は2つあって、1つめは「JavaVMがクラスファイルを実行するから」です。2つめは「OSが違っていてもJavaVMが違いを吸収する」からです。2.変数
「変数」とはデータをいれる箱のようなものです。
変数で学習してきたことは3つあります。1)static変数
static変数とは1つのメソッドと別のメソッドで共有して使える変数です。
method AとBがあったとします。それぞれ共有のstatic変数があったとします。
片方の変数の値を変えると、別の変数の値もかえないとコンパイルがとおりません。2)メンバ変数
メンバ変数とはクラスに定義される変数です。
class A{
int b = 10;
・・・
}
上記のint型の変数bのようなものです。
メンバ変数はクラス内に定義されていればどこのメソッドでも使えます。3)ローカル変数
ローカル変数とはメソッド内に定義される変数です。
class A {
int b = 10; //メンバ変数
public void methodc(){
int d = 20; //ローカル変数
}
public void methode(){
int f = 30; //ローカル変数
System.out.println(f); //表示される
}
}メンバ変数、ローカル変数で出力できるかできないかアクセスの範囲が異なります。このような範囲のことを「スコープ」といいます。
次回「配列」など書いていきます。
- 投稿日:2019-07-28T21:36:29+09:00
Thymeleaf Layoutでgroovyの警告が出る場合の対処法
概要
JDK9から仕様が変わったリフレクション関係の警告
groovyは3.0から対応するようです。参考
β版が出ているので、暫定的に対象ライブラリのgroovyのjarを入れ替えれば警告は出なくなります。環境
- OpenJDK 11
- Spring Boot 2.1.4
- Thymeleaf Layout Dialect 2.3.0
警告
WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.codehaus.groovy.vmplugin.v7.Java7$1 (file:.m2/repository/org/codehaus/groovy/groovy/2.5.6/groovy-2.5.6.jar) to constructor java.lang.invoke.MethodHandles$Lookup(java.lang.Class,int) WARNING: Please consider reporting this to the maintainers of org.codehaus.groovy.vmplugin.v7.Java7$1 WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release対策
対象ライブラリのgroovyを入れ替える
[pom.xml]<dependency> <groupId>nz.net.ultraq.thymeleaf</groupId> <artifactId>thymeleaf-layout-dialect</artifactId> <exclusions> <exclusion> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy</artifactId> </exclusion> </exclusions> </dependency> <!-- TODO 正式リリース待ち --> <dependency> <groupId>org.codehaus.groovy</groupId> <artifactId>groovy</artifactId> <version>3.0.0-beta-1</version> </dependency>警告だけなんで、単純に警告を出さないようにするのも手みたいですね。
Java 10でSpring Boot 2.0 アプリケーションを開発するときの初歩的な注意点まだβ版なんで本番環境へは正式リリースを待ちましょう!
参考
https://issues.apache.org/jira/browse/GROOVY-8339
https://qiita.com/rubytomato@github/items/3d9f657196c1e941699a
- 投稿日:2019-07-28T21:15:33+09:00
Spring boot メモ書き(2)
目的
業務効率化
DI(Dependency injection)コンテナとは
ひとことでいうと、「プログラムではなく外部よりインスタンスを注入すること」 = 「依存性の注入」として訳されます。
new演算子を使ってプログラム内でインスタンスを作るのではなく、外部機能でインスタンスを作成して使用することができる
SpringBootではDI(依存性注入)を用いた設計が採用されており、コードの依存性を少なくすることができます。
クラスのインスタンスであるBeanは、DIコンテナに保存されます。
SpringBootのクラス間の呼び出し等は、DIコンテナに登録されたBeanを取得することで実行されます。
標準的なBeanの登録方法は、以下方法があります。
@Beanをメソッドに付与する。メソッドの返り値に指定したクラスのシングルトンが、DIコンテナに登録される- Bean登録したいクラスに、
@Componentをクラスに付与する。そのクラスのシングルトンがDIコンテナに登録される- API宣言である
@RestControllerや 環境クラス宣言である@Configurationt等、付与するだけでそのクラスのBean登録がされる。SpringBootの起動時に、@ComponentScanで指定したパッケージ以下をDIコンテナの読み込み対象にします。
@SpringBootApplication /* demo.serviceとdemo.domain以下のうち、@componentやDI登録用アノテーションが 付与されているクラス/メソッドをDIコンテナにBean登録する。 */ @ComponentScan( scopedProxy = ScopedProxyMode.TARGET_CLASS, basePackages = {"demo.service","demo.domain"} ) public class SBDataBaseDemoApplication { public static void main(String[] args) { SpringApplication.run(SBDataBaseDemoApplication.class, args); } }DI対象となる主なアノテーション
@Controllerコントローラー層のクラスに使用する。
@RestControllerWebAPIのコントローラー層のクラスに使用する。@Controllerと@ResponseBodyを組み合わせたものです。
@Serviceサービス層のクラスに使用する。主にビジネスロジックを実行するクラスに使用する。
@Repositoryデータ層のクラスに使用する。主にDBアクセスするクラスに使用する。
@Component上記の他にDI対象とするクラスに使用する。
参考
Spring 主要ポイント
https://atuweb.net/201509_spring_framework_good_points/
Spring Bootで作るRESTful Web Service
https://www.slideshare.net/WataruOhno/spring-fest-2018-spring-bootrestful-web-service
https://terasolunaorg.github.io/guideline/5.0.1.RELEASE/ja/ArchitectureInDetail/REST.html

- 投稿日:2019-07-28T19:55:27+09:00
Eclipseのコード補完で「えっ?」となったとき ~部分一致型コード補完(substring code completion)でつまづいたら~
概要
- Eclipseのコード補完機能で、あるクラスのメソッド名を補完させるときに意図しない補完になってしまう!とおもった場合の対策です
(Eclipse NEONで追加された部分一致でのコード補完(Substring code completion)機能の副作用の抑え方です)環境
- Eclipse IDE 2019‑06
「意図しない補完」とは↓のような場合(見たほうが早い)
Arraysでドット(.)を打つと、コード補完がはしる続いてtostringと入力してエンターを押すとdeepToStringが選ばれてしまう現象発生。
コード補完するときの部分一致(substring)は便利だが
以下のようにstringだけ入力しても、メソッド名の一部にstringが含まれるものを候補としてあげてくれる
修正方法その1:メソッド名の部分一致をオフする
メソッド名の部分一致が悪さをしている面もあるので、この機能を設定からオフしてみる。
EclipseのメインウィンドウからWindow>Preference>Java>Editor>Content Assist の順で選択していくとShow substring matchesという項目
があるので、それをオフ
する
部分一致(substring)をオフでつかってみる
なかなか良い感じ。
さっきみたいに意図せずdeepToStringが選択されることはなくなった。
あたりまえだけど、部分一致(substring)がオフだと、部分一致で補完できない
ためしに、Arrays.の後にstringと打ってみると、候補が何もでてこなくなった。
修正方法その2
まず、さきほどと同じようにWindow>Preference>Java>Editor>Content Assistで設定画面ひらいて
はチェックを入れる。
これで部分一致をひとまず有効にする。
次に、Content Assistの[+]マークをおして設定を展開してAdvancedを選択する。
次に↓のようにJava Proposalsにチェックを入れる
これでOK
コード補完を試す
さて、この設定で再度、コード補完を試す。
意図した動作で動いている模様
部分一致でコード補完を試す
部分一致のほうもちゃんと動作している。
修正方法2のほうが、より意図した動作(部分一致もつかえて、コード補完も意図どおり)となるようだ。
まとめ
- Eclipseのコード補完で「意図しない補完になってしまう」と思ったときの現象と対策について説明しました
- 部分一致でのコード補完(Substring code completion)機能はEclipse NEONで追加された機能ですが、その副作用で意図しない補完になってしまう場合にsubstring code completionをオフにしたり、Java Proposalsを有効にする対策を打つことで副作用を抑えられることがわかりました。
- コード補完についてはIntellij IDEA(やAndroid Studio)のほうがだいぶ先行してsubstring code completionに対応しており、こうした副作用も無いよう予めチューニングされているようです。
(Eclipseで遭遇するまであたり前で気づかなかったが、こういうUI工夫・使用感のチューニングで生まれる微差が生産性や品質に影響を与えるんだよなぁ、っと。)












- 投稿日:2019-07-28T18:33:14+09:00
Java Graphics2D と各種ライブラリでベクターグラフィックス画像 (PDF,SVG,PPT,EPS,SWF) を出力する
概要
- Java 標準ライブラリの Graphics2D クラスと外部ライブラリを使用して、ベクターグラフィックス画像 (PDF,SVG,PPT,EPS,SWF) を出力する
- 具体的な描画処理は Graphics2D を使用して共通化する
- 各種ベクター形式画像フォーマットへの出力は外部ライブラリを使用する
- 今回のプログラムは Graphics2D を使って描画しているような振る舞いをするが、実際には各種フォーマットに対応した Graphics2D のサブクラスが処理をしている
- 確認用に PNG (Portable Network Graphics) 画像も出力する
使用ライブラリ
- PDF (Portable Document Format): Orson PDF
- SVG (Scalable Vector Graphics): Apache Batik
- PPT (PowerPoint): Apache POI
- EPS (Encapsulated PostScript): VectorGraphics2D
- SWF (Small Web Format / Shockwave Flash): FreeHEP VectorGraphics
今回の動作環境
- macOS Mojave
- OpenJDK 11.0.2
- Apache Maven 3.6.1
ソースコード
ソースコード一覧
- pom.xml: Maven のビルド用設定ファイル
- App.java: 各種フォーマットへ出力するプログラム
├── pom.xml └── src └── main └── java └── com └── example └── App.javapom.xml: Maven のビルド用設定ファイル
- 各種外部ライブラリを dependencies に追加している
- 依存ライブラリを含めた実行可能な JAR ファイルを生成するため Maven Assembly Plugin を導入している
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.example</groupId> <artifactId>my-app</artifactId> <version>1.0-SNAPSHOT</version> <name>my-app</name> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <dependencies> <!-- For PDF --> <!-- https://mvnrepository.com/artifact/com.orsonpdf/orsonpdf --> <dependency> <groupId>com.orsonpdf</groupId> <artifactId>orsonpdf</artifactId> <version>1.9</version> </dependency> <!-- For SVG --> <!-- https://mvnrepository.com/artifact/org.apache.xmlgraphics/batik-all --> <dependency> <groupId>org.apache.xmlgraphics</groupId> <artifactId>batik-all</artifactId> <version>1.11</version> <type>pom</type> </dependency> <!-- For PPT --> <!-- https://mvnrepository.com/artifact/org.apache.poi/poi-scratchpad --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-scratchpad</artifactId> <version>4.1.0</version> </dependency> <!-- For EPS --> <!-- https://mvnrepository.com/artifact/de.erichseifert.vectorgraphics2d/VectorGraphics2D --> <dependency> <groupId>de.erichseifert.vectorgraphics2d</groupId> <artifactId>VectorGraphics2D</artifactId> <version>0.13</version> </dependency> <!-- For SWF --> <!-- https://mvnrepository.com/artifact/org.freehep/freehep-graphicsio-swf --> <dependency> <groupId>org.freehep</groupId> <artifactId>freehep-graphicsio-swf</artifactId> <version>2.4</version> </dependency> </dependencies> <build> <plugins> <!-- http://maven.apache.org/plugins/maven-assembly-plugin/ --> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.example.App</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> </project>App.java: 各種フォーマットへ出力するプログラム
package com.example; import java.awt.Color; import java.awt.Dimension; import java.awt.BasicStroke; import java.awt.Graphics2D; import java.awt.geom.Ellipse2D; import java.awt.geom.Line2D; import java.awt.geom.Rectangle2D; import java.awt.image.BufferedImage; import java.io.IOException; import java.io.File; import java.io.FileOutputStream; import javax.imageio.ImageIO; import org.w3c.dom.DOMImplementation; // PDF import com.orsonpdf.Page; import com.orsonpdf.PDFDocument; import com.orsonpdf.PDFGraphics2D; // SVG import org.apache.batik.anim.dom.SVGDOMImplementation; import org.apache.batik.svggen.SVGGraphics2D; // PPT import org.apache.poi.hslf.model.PPGraphics2D; import org.apache.poi.hslf.usermodel.HSLFGroupShape; import org.apache.poi.hslf.usermodel.HSLFSlide; import org.apache.poi.hslf.usermodel.HSLFSlideShow; // EPS import de.erichseifert.vectorgraphics2d.Document; import de.erichseifert.vectorgraphics2d.Processor; import de.erichseifert.vectorgraphics2d.Processors; import de.erichseifert.vectorgraphics2d.VectorGraphics2D; import de.erichseifert.vectorgraphics2d.intermediate.CommandSequence; import de.erichseifert.vectorgraphics2d.util.PageSize; // SWF import org.freehep.graphicsio.swf.SWFGraphics2D; public class App { public static void main(String[] args) throws Exception { createPNG(); createPDF(); createSVG(); createPPT(); createEPS(); createSWF(); } /** * 描画します。 * * @param g Graphics2D オブジェクト * @param w 描画範囲の横幅 * @param h 描画範囲の縦幅 */ private static void draw(Graphics2D g, double w, double h) { // 線の太さ g.setStroke(new BasicStroke((float) (w + h) / 20.0f)); // 背景 g.setPaint(Color.LIGHT_GRAY); g.fill(new Rectangle2D.Double(0, 0, w, h)); // 枠線 g.setPaint(Color.BLUE); g.draw(new Rectangle2D.Double(0, 0, w, h)); // 円 g.setPaint(Color.RED); g.fill(new Ellipse2D.Double(w / 4, h / 4, w / 2, h / 2)); // 線 g.setPaint(new Color(255, 255, 0, 100)); Line2D line = new Line2D.Double(w / 8, h / 8, w / 2, h / 2); g.draw(line); } /** * PNG (Portable Network Graphics) ファイルを出力します。 */ private static void createPNG() throws IOException { int w = 297 * 2; int h = 210 * 2; BufferedImage image = new BufferedImage(w, h, BufferedImage.TYPE_INT_ARGB); Graphics2D g = image.createGraphics(); draw(g, w, h); ImageIO.write(image, "png", new File("png.png")); } /** * PDF (Portable Document Format) ファイルを出力します。 */ private static void createPDF() throws Exception { // 1 inch = 25.4mm = 72pt double w = 297 * 72 / 25.4; double h = 210 * 72 / 25.4; PDFDocument pdfDoc = new PDFDocument(); Page page = pdfDoc.createPage(new Rectangle2D.Double(0, 0, w, h)); PDFGraphics2D g = page.getGraphics2D(); draw(g, w, h); pdfDoc.writeToFile(new File("pdf.pdf")); } /** * SVG (Scalable Vector Graphics) ファイルを出力します。 */ private static void createSVG() throws IOException { int w = 297 * 2; int h = 210 * 2; DOMImplementation domImpl = SVGDOMImplementation.getDOMImplementation(); String svgNS = SVGDOMImplementation.SVG_NAMESPACE_URI; org.w3c.dom.Document doc = domImpl.createDocument(svgNS, "svg", null); SVGGraphics2D g = new SVGGraphics2D(doc); g.setSVGCanvasSize(new Dimension(w, h)); draw(g, w, h); g.stream("svg.svg"); } /** * PPT (PowerPoint) ファイルを出力します。 */ private static void createPPT() throws IOException { HSLFSlideShow ppt = new HSLFSlideShow(); Dimension pageSize = ppt.getPageSize(); double w = 297; double h = 210; double coef = Math.min(pageSize.getWidth() / w, pageSize.getHeight() / h); w = w * coef; h = h * coef; HSLFSlide slide = ppt.createSlide(); HSLFGroupShape group = slide.createGroup(); Rectangle2D bounds = group.getAnchor(); bounds.setRect(0, 0, w, h); PPGraphics2D g = new PPGraphics2D(group); draw(g, w, h); try (FileOutputStream out = new FileOutputStream("ppt.ppt")) { ppt.write(out); } } /** * EPS (Encapsulated PostScript) ファイルを出力します。 */ private static void createEPS() throws IOException { int w = 297 * 2; int h = 210 * 2; VectorGraphics2D g = new VectorGraphics2D(); draw(g, w, h); CommandSequence commands = g.getCommands(); Processor processor = Processors.get("eps"); PageSize size = new PageSize(w, h); Document doc = processor.getDocument(commands, size); doc.writeTo(new FileOutputStream("eps.eps")); } /** * SWF (Small Web Format / Shockwave Flash) ファイルを出力します。 */ private static void createSWF() throws IOException { int w = 297 * 2; int h = 210 * 2; SWFGraphics2D g = new SWFGraphics2D(new File("swf.swf"), new Dimension(w, h)); g.writeHeader(); g.startExport(); draw(g, w, h); g.endExport(); g.dispose(); } }プログラムをビルドして実行
Maven で実行可能な JAR ファイルを生成する。
$ mvn packagejava コマンドで JAR ファイルを指定して実行する。
$ java -jar target/my-app-1.0-SNAPSHOT-jar-with-dependencies.jarこれで PNG, PDF, SVG, PPT, EPS, SWF の6種類のファイルが出力できる。
出力された各種ベクターグラフィックス画像ファイル
PNG (Portable Network Graphics)
PNG はベクター形式の画像フォーマットではないが比較用に載せておく。
PNG ファイルの情報をコマンドで確認する。
$ file png.png png.png: PNG image data, 594 x 420, 8-bit/color RGBA, non-interlaced $ pngcheck png.png OK: png.png (594x420, 32-bit RGB+alpha, non-interlaced, 99.3%).画像は macOS Mojave のプレビューアプリで閲覧したもの。
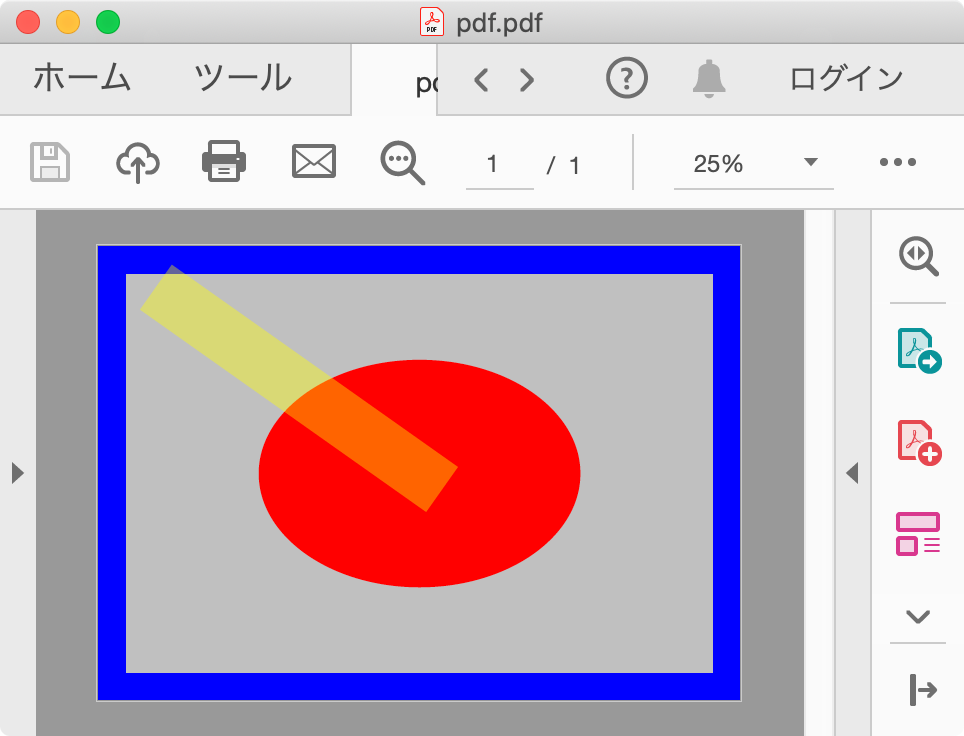
PDF (Portable Document Format)
PDF ファイルの情報をコマンドで確認する。
$ file pdf.pdf pdf.pdf: PDF document, version 1.4 $ pdfinfo pdf.pdf Producer: OrsonPDF 1.7 CreationDate: Sun Jul 28 15:24:27 2019 ModDate: Sun Jul 28 15:24:27 2019 Tagged: no Form: none Pages: 1 Encrypted: no Page size: 841.89 x 595.276 pts (A4) (rotated 0 degrees) File size: 1138 bytes Optimized: no PDF version: 1.4画像は Adobe Acrobat Reader DC で閲覧したもの。
SVG (Scalable Vector Graphics)
SVG ファイルの情報をコマンドで確認する。
$ file svg.svg svg.svg: SVG Scalable Vector Graphics image $ identify svg.svg svg.svg SVG 594x420 594x420+0+0 16-bit sRGB 1379B 0.000u 0:00.012画像は Inkscape で閲覧したもの。ベクターデータのオブジェクトが確認できる。
SVG は XML 文書なので中身がテキストデータになっており確認しやすい。生成された SVG ファイルの中身をここに載せておく。
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE svg PUBLIC '-//W3C//DTD SVG 1.0//EN' 'http://www.w3.org/TR/2001/REC-SVG-20010904/DTD/svg10.dtd'> <svg stroke-dasharray="none" shape-rendering="auto" xmlns="http://www.w3.org/2000/svg" font-family="'Dialog'" width="594" text-rendering="auto" fill-opacity="1" contentScriptType="text/ecmascript" color-interpolation="auto" color-rendering="auto" preserveAspectRatio="xMidYMid meet" font-size="12px" fill="black" xmlns:xlink="http://www.w3.org/1999/xlink" stroke="black" image-rendering="auto" stroke-miterlimit="10" zoomAndPan="magnify" version="1.0" stroke-linecap="square" stroke-linejoin="miter" contentStyleType="text/css" font-style="normal" height="420" stroke-width="1" stroke-dashoffset="0" font-weight="normal" stroke-opacity="1" ><!--Generated by the Batik Graphics2D SVG Generator--><defs id="genericDefs" /><g ><g fill="silver" stroke-width="50.7" stroke="silver" ><rect x="0" width="594" height="420" y="0" stroke="none" /><rect fill="none" x="0" width="594" height="420" y="0" stroke="blue" /><ellipse rx="148.5" fill="red" ry="105" cx="297" cy="210" stroke="none" /></g ><g fill="rgb(255,255,0)" fill-opacity="0.3922" stroke-width="50.7" stroke-opacity="0.3922" stroke="rgb(255,255,0)" ><line y2="210" fill="none" x1="74.25" x2="297" y1="52.5" /></g ></g ></svg >PPT (PowerPoint)
PPT ファイルの情報をコマンドで確認する。
$ file ppt.ppt ppt.ppt: Composite Document File V2 Document, Little Endian, Os: Windows, Version 5.1, Code page: 1252, Title: PowerPoint Presentation, Revision Number: 0, Name of Creating Application: Microsoft PowerPoint, Last Saved Time/Date: Mon Apr 7 20:47:14 2003, Number of Words: 0画像は Keynote で閲覧したもの。ベクターデータのオブジェクトが確認できる。
EPS (Encapsulated PostScript)
EPS ファイルの情報をコマンドで確認する。
$ file eps.eps eps.eps: PostScript document text conforming DSC level 3.0, type EPS, Level 3画像は macOS Mojave のプレビューアプリで閲覧したもの。ベクターデータのオブジェクトが確認できる。
SWF (Small Web Format / Shockwave Flash)
SWF ファイルの情報をコマンドで確認する。
$ file swf.swf swf.swf: Macromedia Flash data (compressed), version 8画像は Elmedia Video Player で閲覧したもの。
参考資料
OrsonPDF
- Orson PDF
- GitHub - jfree/orsonpdf: A fast, lightweight PDF generator for the Java platform
- Overview (OrsonPDF version 1.7)
Apache Batik
- Apache(tm) Batik SVG Toolkit - a Java-based toolkit for applications or applets that want to use images in the Scalable Vector Graphics (SVG)
- SVG Generator: SVGGraphics2D
- Overview (Apache Batik Javadoc)
Apache POI
- POI-HSLF and and POI-XLSF - Java API To Access Microsoft Powerpoint Format Files
- Busy Developers' Guide to HSLF drawing layer
- Overview (POI API Documentation)
VectorGraphics2D
- VectorGraphics2D
- GitHub - eseifert/vectorgraphics2d: Graphics2D implementations to export various vector file formats
- vectorgraphics2d/VectorGraphics2D.java at master · eseifert/vectorgraphics2d · GitHub
FreeHEP VectorGraphics





- 投稿日:2019-07-28T14:18:54+09:00
Javaパフォーマンス関連覚書
Javaの主にパフォーマンスに関連するオプションとツールの覚書。
前提
- Java 1.8
- Java HotSpot(TM) 64-Bit Server VM
コマンドラインオプション
GCアルゴリズムとヒープサイズ
シリアルGC
-XX:+UseSerialGC単一スレッドのGCを使う。いわゆるサーバマシンでJavaEE基盤となるJVMに対して使う利点はほぼなさそうだが、ヒープサイズが100 MB程度以下で済むようなマイクロなJVMを複数起動するような場合ではアリかもしれない。
-XX:+AggressiveHeap大きなヒープを単一のJVMに割り当てられる状況で有利に動くようにオプションが割り当てられる、なかば投げやりなオプション。
AggressiveHeap,PringFlagsFinalbool AggressiveHeap := true {product} uintx BaseFootPrintEstimate := 4236855296 {product} bool BindGCTaskThreadsToCPUs := true {product} intx CICompilerCount := 18 {product} uintx InitialHeapSize := 4238344192 {product} uintx MaxHeapSize := 4238344192 {product} uintx MaxNewSize := 4272947200 {product} uintx MinHeapDeltaBytes := 524288 {product} uintx NewSize := 4272947200 {product} uintx OldPLABSize := 8192 {product} uintx OldSize := 4260364288 {product} bool PrintFlagsFinal := true {product} bool PrintGCDetails := true {manageable} bool ResizeTLAB := false {pd product} bool ScavengeBeforeFullGC := false {product} uintx TLABSize := 262144 {product} uintx ThresholdTolerance := 100 {product} bool UseLargePagesIndividualAllocation := false {pd product} bool UseParallelGC := true {product} uintx YoungPLABSize := 262144 {product}パラレルGC(スループット型)
-XX:+UseParallelOldGCOld領域のGCに複数スレッドを使う。
-XX:+UseParallelGCYoung領域(とOld領域)のGCに複数スレッドを使う(
-XX:-UseParallelOldGCと明示的にOFFにしなければ-XX:+UseParallelOldGCも有効になる)。コンカレントGC(CMS)
-XX:+UseConcMarkSweepGCOld領域のGCをバックグラウンドで処理する(Young領域は複数スレッドで処理する)。
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGCするといっしょに有効になり、Young領域のGCに複数スレッドを使う。-XX:+UseConcMarkSweep -XX:-UseParNewGC(Young領域のGCに複数スレッド使用を無効化)の組み合わせは非推奨。
-XX:CMSInitiatingOccupancyFraction=NOld領域のスキャンを開始するタイミングを使用率で指定。Concurrent Mode Failure(ヒープのスキャンとオブジェクトの解放が追い付かずにヒープがいっぱいになってしまい、フルGCを誘発)が多発したらこの値を減らして早いうちにOld領域を処理させる。
-XX:+UseCMSInitiatingOccupancyOnlyCMSInitiatingOccupancyFractionの値を優先してスキャンのタイミングを決定する。
-XX:ConcGCThreads=Nスキャンのスレッド数を指定する。
G1GC
-XX:+UseG1GCYoung領域のGCを複数スレッドで処理し、Old領域はバックグラウンドで処理する。大きなヒープサイズ(目安として6 GB以上)のときに、CMSと比べて有利(処理の複雑さゆえに小さなヒープサイズでは逆に非効率)。
-XX:InitiatingHeapOccupancyPercent=NコンカレントGCのCMSInitiatingOccupancyFractionと同様。
-XX:G1MixedGCCountTarget=NOld領域リージョンの混合GC回数目標を指定する。Concurrent Mode Failureが多発したら減らし、混合GCに時間がかかりすぎている場合は増やす。
-XX:G1HeapRegionSize=Nリージョンサイズを指定する。ヒープに割り当てるオブジェクトサイズが大きい場合は、リージョンサイズも大きくすると効率的。通常はヒープサイズに応じて、リージョン数が2048個以内になるよう1~32 MBの範囲で自動調整。
巨大な(リージョンサイズの半分以上)オブジェクトは、Old扱いとなる。オブジェクトサイズがリージョンサイズの倍数より少しだけ大きいと、未使用領域によってリージョンの断片化が発生する可能性がある。このようなケースでも大きなオブジェクトが、リージョンの半分以下のサイズとなるように調整すれば、通常のオブジェクトとしてEden相当のリージョンで割当てが行われるようになる。チューニング目標指定
-XX:MaxGCPauseMillis=N(最大停止時間目標)最大停止時間の目標値を指定して、ヒープサイズを動的に変更する。
-XX:GCTimeRatio=N(スループット目標)GCにかけてよい時間の割合を指定して、ヒープサイズを動的に変更する(スループット目標)。GC時間のアプリケーション時間に対する比率が、$\frac{1}{(1 + N)}$となるように動的に変更する。
-XX:GCTimeRatio=19ならGC時間が全体の$\frac{1}{20}$つまり5%になるようにする。優先度は、「最大停止時間目標」 > 「スループット目標」で、これらが満たされていれば必要に応じて最小限のヒープ領域となるようサイズを縮小する。
サイズ指定
-XmsNヒープの初期サイズをNで指定する。
-XmxNヒープの最大サイズをNで指定する。
-XmnN(-XX:NewSize=N)Young領域の初期サイズを指定する。G1GCでは指定しないことが推奨(最大一時停止目標時間がオーバーライドされる)。
-XX:NewRatio=NYoung領域に対するOld領域の割合(サイズ比)を指定する。
NewRatio=1Heap PSYoungGen total 458752K, used 23593K [0x00000000e0000000, 0x0000000100000000, 0x0000000100000000) eden space 393216K, 6% used [0x00000000e0000000,0x00000000e170a560,0x00000000f8000000) from space 65536K, 0% used [0x00000000fc000000,0x00000000fc000000,0x0000000100000000) to space 65536K, 0% used [0x00000000f8000000,0x00000000f8000000,0x00000000fc000000) ParOldGen total 524288K, used 0K [0x00000000c0000000, 0x00000000e0000000, 0x00000000e0000000) object space 524288K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000e0000000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576KNewRatio=5Heap PSYoungGen total 153088K, used 7895K [0x00000000f5580000, 0x0000000100000000, 0x0000000100000000) eden space 131584K, 6% used [0x00000000f5580000,0x00000000f5d35dc8,0x00000000fd600000) from space 21504K, 0% used [0x00000000feb00000,0x00000000feb00000,0x0000000100000000) to space 21504K, 0% used [0x00000000fd600000,0x00000000fd600000,0x00000000feb00000) ParOldGen total 873984K, used 0K [0x00000000c0000000, 0x00000000f5580000, 0x00000000f5580000) object space 873984K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000f5580000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576K
-XX:MaxNewSize=NYoung領域の最大サイズを指定する。
NewSize=500M,MaxNewSize=500MHeap PSYoungGen total 448000K, used 23040K [0x00000000e0c00000, 0x0000000100000000, 0x0000000100000000) eden space 384000K, 6% used [0x00000000e0c00000,0x00000000e22801a0,0x00000000f8300000) from space 64000K, 0% used [0x00000000fc180000,0x00000000fc180000,0x0000000100000000) to space 64000K, 0% used [0x00000000f8300000,0x00000000f8300000,0x00000000fc180000) ParOldGen total 536576K, used 0K [0x00000000c0000000, 0x00000000e0c00000, 0x00000000e0c00000) object space 536576K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000e0c00000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576K
-XX:MetaspaceSize=Nメタスペースの初期サイズを指定する。
-XX:MaxMetaspaceSize=Nメタスペースの最大サイズを指定する(デフォルト無制限)。
MetaspaceSize=100M,MaxMetaspaceSize=100MHeap PSYoungGen total 448000K, used 23040K [0x00000000e0c00000, 0x0000000100000000, 0x0000000100000000) eden space 384000K, 6% used [0x00000000e0c00000,0x00000000e22801a0,0x00000000f8300000) from space 64000K, 0% used [0x00000000fc180000,0x00000000fc180000,0x0000000100000000) to space 64000K, 0% used [0x00000000f8300000,0x00000000f8300000,0x00000000fc180000) ParOldGen total 536576K, used 0K [0x00000000c0000000, 0x00000000e0c00000, 0x00000000e0c00000) object space 536576K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000e0c00000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576K
-XX:InitialSurvivorRatio=NYoun領域中のSurvivor領域の初期値比率を指定する。短命オブジェクトがOldへ昇格していることがわかっており、それを抑制したい場合に大きな値を指定する。
InitialSurvivorRatio=1Heap PSYoungGen total 232960K, used 7004K [0x00000000eab00000, 0x0000000100000000, 0x0000000100000000) eden space 116736K, 6% used [0x00000000eab00000,0x00000000eb1d7240,0x00000000f1d00000) from space 116224K, 0% used [0x00000000f8e80000,0x00000000f8e80000,0x0000000100000000) to space 116224K, 0% used [0x00000000f1d00000,0x00000000f1d00000,0x00000000f8e80000) ParOldGen total 699392K, used 0K [0x00000000c0000000, 0x00000000eab00000, 0x00000000eab00000) object space 699392K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000eab00000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576KInitialSurvivorRatio=5Heap PSYoungGen total 279552K, used 12595K [0x00000000eab00000, 0x0000000100000000, 0x0000000100000000) eden space 209920K, 6% used [0x00000000eab00000,0x00000000eb74ce68,0x00000000f7800000) from space 69632K, 0% used [0x00000000fbc00000,0x00000000fbc00000,0x0000000100000000) to space 69632K, 0% used [0x00000000f7800000,0x00000000f7800000,0x00000000fbc00000) ParOldGen total 699392K, used 0K [0x00000000c0000000, 0x00000000eab00000, 0x00000000eab00000) object space 699392K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000eab00000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576KInitialSurvivorRatio=10Heap PSYoungGen total 314368K, used 16773K [0x00000000eab00000, 0x0000000100000000, 0x0000000100000000) eden space 279552K, 6% used [0x00000000eab00000,0x00000000ebb61618,0x00000000fbc00000) from space 34816K, 0% used [0x00000000fde00000,0x00000000fde00000,0x0000000100000000) to space 34816K, 0% used [0x00000000fbc00000,0x00000000fbc00000,0x00000000fde00000) ParOldGen total 699392K, used 0K [0x00000000c0000000, 0x00000000eab00000, 0x00000000eab00000) object space 699392K, 0% used [0x00000000c0000000,0x00000000c0000000,0x00000000eab00000) Metaspace used 2293K, capacity 4480K, committed 4480K, reserved 1056768K class space used 254K, capacity 384K, committed 384K, reserved 1048576K値を増やすと、Youngに占めるEdenの割合が増え、Survivor(FROM/TO)の割合が減る。
$Survivor領域初期サイズ = \frac{Young領域サイズ}{InitialSurvivorRatio + 2}$
デフォルトは"8"でYoung領域の10%がSurvivor領域になる。
$Survivor領域最大サイズ = \frac{Young領域最大サイズ}{MinSurvivorRatio + 2}$
デフォルトは"3"で、Survivor領域の最大は最大Youngの20%になる。
-XX:MinSurvivorRatio=N/-XX:TargetSurvivorRatioそれぞれSurvivor領域のサイズ、空けておきたいサイズを割合指定する。
-XX:InitialTenuringThreshold=N/-XX:MaxTenuringThreshold=NSurvivor領域に保持しておく期間(GCの回数)の初期値、最大値を指定する。言い換えるとこれを超えるGC回数よりも長命なオブジェクトはOld領域(Tenured)へ昇格する。
-XX:-UseAdaptiveSizePolicyヒープの各領域サイズの調整機能を無効化する。各領域サイズをカチッとキメているときに使用する。
-XX:ParallelGCTreads=NGCのスレッド数を指定する。デフォルトでは8コアまでコア数と同じ。9コア以降で残りコア数の5/8倍スレッド追加される、というややこしい値になる。CPUコア数がN(>8)のとき、$8 + \frac{5(N - 8)}{8}$となる。
複数JVMを起動するような環境ではデフォルトは多すぎる可能性があるので、適宜減らしたりする。効果があるのは以下の処理。
- UseParallelGCでのYoung領域(と副作用としてのUseParallelOldGCでのOld領域)
- UseParNewGCでのYoung領域
- UseParGCでのYoung領域
- CMSおよびG1でのSTWP処理
GC情報出力設定
後述する解析ツールで事後分析するのに使う。
-verbose:gc(-XX:+PrintGC)GCに関する最低限の情報(ヒープ全体のGC前後におけるサイズと所要時間)を出力する。
[GC (System.gc()) 10496K->1549K(2010112K), 0.0016090 secs] [Full GC (System.gc()) 1549K->463K(2010112K), 0.0058750 secs]1行目は以下のように読み取る。
- マイナーGCが(
System.gc()によって)発生- GC前後でヒープサイズが10,496 KBから1,549 KBになった
- JVM全体のヒープ予約サイズは2,010,112 KBである
- このGCに0.0016090秒かかった
-XX:+PrintGCDetails全てのGCで詳細情報(各GCアルゴリズムに応じた詳細内容、例えばYoung世代がどうなったとか)を出力する。
[GC (System.gc()) [PSYoungGen: 10496K->1557K(611840K)] 10496K->1565K(2010112K), 0.0017862 secs] [Times: user=0.11 sys=0.00, real=0.00 secs] [Full GC (System.gc()) [PSYoungGen: 1557K->0K(611840K)] [ParOldGen: 8K->463K(1398272K)] 1565K->463K(2010112K), [Metaspace: 2609K->2609K(1056768K)], 0.0080374 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]1行目は以下のように読み取る。
- マイナーGCが(
System.gc()によって)発生- GC前後でYoung領域サイズが10,496 KBから1,557 KBになった
- Young領域の予約サイズは611,840 KBである
- GC前後でヒープ全体のサイズが10,496 KBから1,565 KBになった
- JVM全体のヒープ予約サイズは2,010,112 KBである
- このGCに0.0017862秒かかった
2行目は以下のように読み取る。
- フルGCが(
System.gc()によって)発生- GC前後でYoung領域サイズが1,557 KBから0 KBになった
- Young領域の予約サイズは611,840 KBである
- GC前後でOld領域サイズが8 KBから463 KBになった
- Old領域の予約サイズは1,398,272 KBである
- GC前後でヒープ全体のサイズが1,565 KBから463 KBになった
- JVM全体のヒープ予約サイズは2,010,112 KBである
- GC前後でMetaspace領域が2,609 KBから2,609 Kになった(変わっていない)
- このGCに0.0080374秒かかった
-XX:+PrintGCApplicationConcurrentTime最後の停止からの経過時間を出力する。
Application time: 0.0069325 seconds
-XX:+PrintGCApplicationStoppedTime停止時間を出力する。
Total time for which application threads were stopped: 0.0093222 seconds, Stopping threads took: 0.0000362 seconds
-XX:+PrintGCTimeStamps/-XX:+PrintGCDateStampsGC情報出力時にタイムスタンプを付与する。
+PrintGCTimeStampsはJVM起動からの経過秒、+PrintGCDateStampsでは日付と時刻にフォーマットされる(ロケール処理等もあるので他の一般的なタイムスタンプ付与処理と同様、後者のが理屈の上ではオーバーヘッドが大きい)。PrintGCTimeStamps+PrintGC0.113: [GC (System.gc()) 10496K->1501K(2010112K), 0.0013196 secs] 0.114: [Full GC (System.gc()) 1501K->463K(2010112K), 0.0068458 secs]PrintGCDateStamps+PrintGC2019-07-25T19:23:34.716+0900: [GC (System.gc()) 10496K->1149K(2010112K), 0.0016237 secs] 2019-07-25T19:23:34.718+0900: [Full GC (System.gc()) 1149K->463K(2010112K), 0.0073745 secs]あまり意味はないが両方出力させることもできる。
PrintGCDateStamps+PintGCTimeStamps+PrintGC2019-07-25T19:23:34.716+0900: 0.106: [GC (System.gc()) 10496K->1149K(2010112K), 0.0016237 secs] 2019-07-25T19:23:34.718+0900: 0.108: [Full GC (System.gc()) 1149K->463K(2010112K), 0.0073745 secs]
-XX:+PrintReferenceGCソフト参照と弱い参照に対して処理された内容を出力する。GCへの影響度を調べたいときに使う。
+PrintGCDetails,+PrintReferenceGC[GC (System.gc()) [SoftReference, 0 refs, 0.0000099 secs][WeakReference, 11 refs, 0.0000229 secs][FinalReference, 7 refs, 0.0000123 secs][PhantomReference, 0 refs, 0 refs, 0.0000198 secs][JNI Weak Reference, 0.0000075 secs][PSYoungGen: 20992K->811K(611840K)] 20992K->819K(2010112K), 0.0018664 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [Full GC (System.gc()) [SoftReference, 0 refs, 0.0000082 secs][WeakReference, 3 refs, 0.0000188 secs][FinalReference, 0 refs, 0.0000044 secs][PhantomReference, 0 refs, 0 refs, 0.0000068 secs][JNI Weak Reference, 0.0000236 secs][PSYoungGen: 811K->0K(611840K)] [ParOldGen: 8K->466K(1398272K)] 819K->466K(2010112K), [Metaspace: 2555K->2555K(1056768K)], 0.0056317 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
-Xloggc:/path/to/gclogGC情報をファイル出力する(事後分析用)。
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=N -XX:GCLogFileSize=sizeGCログのローテーション設定。
Nは保持世代数、sizeには10Mという風にサイズを指定する。ただし、これだと起動・停止を繰返した場合に期待通りに世代管理できない。あくまでも起動中に指定サイズ×面数のファイルを作ってくれるだけ。なので
-Xloggc:/path/to/gclog%tというようにタイムスタンプをファイル名に付与して、logrotateあたりでコントロールするほうが融通が利く(ついでに%pでPIDを付与することもできる)。GCログが大きくなりすぎてディスクフルになるような事態を絶対に避けるということであれば、ログの内容を失うというリスクと引換に世代数とファイルサイズでコントロールすることになる。/path/to/gclogYYYY-mm-dd_HH-MM-SSJava HotSpot(TM) 64-Bit Server VM (25.211-b12) for linux-amd64 JRE (1.8.0_211-b12), built on Apr 1 2019 20:39:34 by "java_re" with gcc 7.3.0 Memory: 4k page, physical 7895296k(7172276k free), swap 8257532k(8257532k free) CommandLine flags: -XX:InitialHeapSize=126324736 -XX:MaxHeapSize=2021195776 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC 0.064: [GC (System.gc()) 1249K->328K(119808K), 0.0012307 secs] 0.065: [Full GC (System.gc()) 328K->254K(119808K), 0.0034913 secs]ログ出力中の"CommandLine flags: "行にあるように、
-Xloggcを付与すると-XX:+PrintGC -XX:+PrintGCTimStampsで動作する。
出力ファイルは後述の解析ツールで事後分析可能。Heap Dump出力
-XX:+HeapDumpONOutOfMemoryErrorOOME時にHeap Dumpを出力する。OOMEはGCに時間がかかりすぎている場合(具体的にはGC時間98%以上、かつヒープ回収率が2%未満のとき)に起きる。
-XX:-UseGCOverheadLimitでこの動作を変更可能。
-XX:HeapDumpPath=/path/to/heapdumpHeap Dump出力先を指定する。出力ファイルは後述の解析ツールで事後分析可能。
その他メモリ関連
-XX:SoftRefLRUPolicyMSPerMB=Nソフト参照の存続期間を指定する。より早く解放したいなら値を小さくする。
-XX:MaxDirectMemorySize=Nネイティブバイトバッファのメモリ使用量を指定する。
-XX:+UseLargePagesOSのLarge Pageを使用してメモリを割り当てる。
-XX:+LargePageSizeInBytes=NLarge Pageのサイズを指定する(Solaris only)。
-XX:+StringTableSize=N
intern()で格納するネイティブメモリ上のHashTableサイズを指定する。デフォルトは1009または60013。
-XX:+UseCompressedOopsオブジェクト参照に35bitのポインタを使用する。ヒープサイズが32 GB未満ではデフォルト有効。
-XX:PrintTLABGCログ中にTLAB(Thread Local Allocation Buffer。Edenの一部)情報を出力する。
*TLABはTranslation Lookaside Bufferではないので注意(こちらは通常TLBと略される)TLAB: gc thread: 0x0000000061a68000 [id: 225212] desired_size: 10496KB slow allocs: 0 refill waste: 167936B alloc: 1.00000 20992KB refills: 1 waste 100.0% gc: 10747880B slow: 0B fast: 0B TLAB: gc thread: 0x00000000029ae000 [id: 209860] desired_size: 10496KB slow allocs: 0 refill waste: 167936B alloc: 1.00000 20992KB refills: 1 waste 94.0% gc: 10104240B slow: 0B fast: 0B TLAB totals: thrds: 2 refills: 2 max: 1 slow allocs: 0 max 0 waste: 97.0% gc: 20852120B max: 10747880B slow: 0B max: 0B fast: 0B max: 0B
-XX:TLABSize=NTLABサイズを指定する。
-XX:-ResizeTLABTLABのサイズ変更を無効にする。
-XX:TLABSIZE=N指定時は常に無効。JITコンパイラ関連
-XX:+TieredCompilation階層的なJITコンパイルを有効化する。クライアントコンパイラとサーバコンパイラ併用モード。ネイティブメモリを余裕をもって確保できる場合に有効。
-XX:ReservedCodeCacheSize=NN MB単位で指定。コンパイルされたコードを格納する領域の予約サイズ。64bit Java 8でのデフォルトは240MB(TierdCompilationの場合)。必要な領域サイズを見積もることは事実上不可能なので、足りなくなったら(枯渇したというメッセージを出力したら)倍々で増やしていく。
-XX:CompileThreshold=NJITコンパイルの閾値。この値を超えて実行されたコードはコンパイルする。サーバコンパイラではデフォルト10000。この値を小さくするとJITによるコンパイルが早く始まるので、ウォームアップ時間が短く済むが、その間のCPU使用率は上がる。裏では呼出しカウンタ(メソッドをコールするたびに増加)とバックエッジカウンタ(ループから戻るたびに増加)の和で判定する。
もうちょっとでコンパイルされて効率化されるはずなのに、というコードがあるとわかっているのであれば値を小さく設定することも有効かもしれない。
-XX:+PrintCompilationJITコンパイラのログを出力する。
84 1 3 java.lang.String::hashCode (55 bytes) 84 2 3 java.lang.String::equals (81 bytes) 85 3 3 java.lang.String::<init> (82 bytes) 85 4 3 java.util.Arrays::copyOfRange (63 bytes) 85 6 3 java.lang.Character::toLowerCase (9 bytes) 86 9 3 java.lang.CharacterDataLatin1::getProperties (11 bytes) 86 8 3 java.lang.CharacterDataLatin1::toLowerCase (39 bytes) 86 7 3 java.lang.CharacterData::of (120 bytes)1行目は、JVM起動から84 m秒後にコンパイルID=1として、クライアントコンパイラが完全モード(3)でStringクラスのhashCodeメソッド(Javaバイトコードで55 byteのサイズ)をコンパイルした、となる。
コンパイルのモードは以下の通り。
- 0: インタプリタ実行
- 1: クライアントコンパイラがシンプルモードでコンパイル
- 2: クライアントコンパイラが制限モードでコンパイル
- 3: クライアントコンパイラが完全モードでコンパイル
- 4: サーバコンパイラがコンパイル
階層的コンパイラを有効化しておくと、下のような出力もある。
98 23 s 3 java.lang.StringBuffer::append (13 bytes)"s"は
synchronizedメソッドであることを表す。ほかには"%"がOSR(On Stack Replacement)コンパイル(つまりループ等実行中に当該コードをコンパイルコードに入れ替える)を、"!"は例外ハンドラを含むメソッドであることを、"n"はネイティブメソッドのラッパーであることを表す。
-XX:CICompilerCount=NJITコンパイラが使用するスレッド数を指定する。JITコンパイラがCPUを使用しすぎているとわかっているときに減らすのに使える。デフォルトではCPUコア数とコンパイラ種別(サーバ、クライアント)に応じて変わる。
JFR関連
-XX:+FlightRecorder-XX:+UnlockCommercialFeaturesJFRを使えるようにする。
ツール
JVM情報取得
起動しているJavaプロセスの情報を取得する
jps jcmd -ljps205220 Main 205560 Jpsjcmd205220 org/netbeans/Main --branding visualvm --cachedir /path/to/cachedir 213948 sun.tools.jcmd.JCmdjcmdの"-l"は省略可。
JVMの起動時間を取得する
jcmd $pid VM.uptime205220: 98108.749 sJVMのシステムプロパティを取得する
jcmd $pid VM.system_properties205220: #Sat Jul 27 01:01:10 GMT+09:00 2019 java.vendor=Oracle Corporation ~略~JVMバージョンを取得する
jcmd $pid VM.version205220: Java HotSpot(TM) 64-Bit Server VM version 25.192-b12 JDK 8.0_192JVMのコマンドラインを取得する
jcmd $pid VM.command_line205220: VM Arguments: jvm_args: -Xms24m -Xmx256m -Dsun.jvmstat.perdata.syncWaitMs=10000 -Dsun.java2d.noddraw=true -Dsun.java2d.d3d=false -Dnetbeans.keyring.no.master=true -Dplugin.manager.install.global=false --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=jdk.jvmstat/sun.jvmstat.monitor.event=ALL-UNNAMED --add-exports=jdk.jvmstat/sun.jvmstat.monitor=ALL-UNNAMED --add-exports=java.desktop/sun.swing=ALL-UNNAMED --add-exports=jdk.attach/sun.tools.attach=ALL-UNNAMED --add-modules=java.activation -XX:+HeapDumpOnOutOfMemoryError~中略~ java_command: org/netbeans/Main --branding visualvm --cachedir /path/to/cachedir java_class_path (initial): C:\pleiades\java\8\lib\visualvm\platform\lib\boot.jar;~中略~ Launcher Type: SUN_STANDARDコマンドフラグを取得する
jcmd $pid VM.flags -all-allなし205220: -XX:CICompilerCount=18 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=~省略~-all指定(抜粋)bool NeedsDeoptSuspend = false {pd product} bool NeverActAsServerClassMachine = false {pd product} bool NeverTenure = false {product} uintx NewRatio = 2 {product} uintx NewSize := 8388608 {product} uintx NewSizeThreadIncrease = 5320 {pd product}
-allでは-XX:+PrintFlagsFinalを指定したときと同じ出力が得られる。"="はデフォルト値を使っていて、":="はデフォルト以外の値を使っていることを表す(つまりオプション指定あり、またはエルゴノミクスによる自動調整)。"{product}"とあるのは、プラットフォーム共通の値で、"{pd product}"となっていたらプラットフォーム固有の値。"{manageable}"となっていたら実行中に変更可能であることを表す。jinfo -flags $pidAttaching to process ID 205220, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.192-b12 Non-default VM flags: -XX:CICompilerCount=18 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=null -XX:+IgnoreUnrecognizedVMOptions -XX:InitialHeapSize=25165824 -XX:MaxHeapSize=268435456 -XX:MaxNewSize=89128960 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=8388608 -XX:OldSize=16777216 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC Command line: -Xms24m -Xmx256m -Dsun.jvmstat.perdata.syncWaitMs=10000 -Dsun.java2d.noddraw=true -Dsun.java2d.d3d=false -Dnetbeans.keyring.no.master=true -Dplugin.manager.install.global=false --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=jdk.jvmstat/sun.jvmstat.monitor.event=ALL-UNNAMED --add-exports=jdk.jvmstat/sun.jvmstat.monitor=ALL-UNNAMED --add-exports=java.desktop/sun.swing=ALL-UNNAMED --add-exports=jdk.attach/sun.tools.attach=ALL-UNNAMED --add-modules=java.activation -XX:+IgnoreUnrecognizedVMOptions ~省略~jinfo -flag HeapDumpOnOutOfMemoryError $pid-XX:+HeapDumpOnOutOfMemoryErrorコマンドフラグを動的に変更する
jinfo -flag +PrintGC $pidスレッド情報(Thread Dump、javacore)
Thread Dumpを取得する
アプリケーションがスケールしないようなときに見る。これも後述する解析ツールで事後分析するのに使う。
jstack $pid jcmd $pid Tread.printjstack/jcmdFull thread dump Java HotSpot(TM) 64-Bit Server VM (25.192-b12 mixed mode): "RequestProcessor queue manager" #97 daemon prio=1 os_prio=-2 tid=0x0000000023fb0000 nid=0x356f4 in Object.wait() [0x00000000318af000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(Native Method) at org.openide.util.RequestProcessor$TickTac.obtainFirst(RequestProcessor.java:2217) - locked <0x00000000f01753c8> (a java.lang.Class for org.openide.util.RequestProcessor$TickTac) at org.openide.util.RequestProcessor$TickTac.run(RequestProcessor.java:2193) ~中略~ "Service Thread" #24 daemon prio=9 os_prio=0 tid=0x000000001c9af800 nid=0x30d50 runnable [0x0000000000000000] java.lang.Thread.State: RUNNABLE ~中略~ "Finalizer" #3 daemon prio=8 os_prio=1 tid=0x000000001a72b800 nid=0x32e08 in Object.wait() [0x000000002078f000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144) - locked <0x00000000f03a7018> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:216) ~省略~java.lang.Thread.Stateが"BLOCKED"なら、何らかの理由(例えばsynchronizedでロック待ち状態)でブロックされていることがわかる。
jstack -lでロックに関する情報を出力できる(ハングして応答しないようなら"-F"で強制出力も可)。
またはkill -3 $pidでも出力可能。クラス情報
クラスのロードに関する情報を取得する
jstat -class $pidLoaded Bytes Unloaded Bytes Time 7654 16421.5 65 94.3 2.48GC(メモリ)関連
Heap Dumpを取得して解析する
jcmd $pid GC.heap_dump /path/to/heap.hprof jmap -dump:format=b,file=/path/to/heap.hprof $pid jhat /path/to/heap.hprof
jhatでWEBサーバが起動し、"http://localhost:7000" をブラウザ等で開くとこのような形で解析結果を参照可能(ポートは-portで指定可能)。
こちらも後述する解析ツールで事後分析するのに使う。
Heapをヒストグラム表示する
jcmd $pid GC.class_histgram jmap -histo $pid jmap -histo:live $pid # FullGCしてから情報取得num #instances #bytes class name ---------------------------------------------- 1: 2743 3243448 [I 2: 10371 820992 [C 3: 920 633184 [D 4: 1418 512408 [B 5: 2797 319688 java.lang.Class 6: 5282 248672 [Ljava.lang.Object; 7: 10144 243456 java.lang.String 8: 5886 188352 java.util.HashMap$Node 9: 87 156848 [J ~省略~
intの配列("[I")がヒープの3 MB程度を占めていることがわかる。Javaの内部クラスは"<"と"%gt;"で囲まれて表示される。ランタイム分析ツール
主にJMX(Java Management eXtensions)を使用し、起動中のJVMから情報を取得するツール類。
リモートから接続を許可するには、診断対象のJVM起動時に以下のシステムプロパティを設定する。
-Dcom.sun.management.jmxremote=true-Dcom.sun.management.jmxremote.port=$port-Dcom.sun.management.jmxremote.authenticate=true|false-Dcom.sun.management.jmxremote.ssl=true|false既に起動中のJVMであれば、以下のようにして設定する。
jcmd $pid ManagementAgent.start jmxremote.port=7091 jmxremote.authenticate=false jmxremote.ssl=falsejstat
実行中のJVMの各種統計情報を取得する。
vmstatやiostatのJava版と思えばよい。間隔と回数を指定でき、秒単位で指定する場合は"1s"のように指定する。"s"をつけないとms単位になるので注意。最初のオプションに続いて"-t"をつけるとタイムスタンプ(JVM起動からの経過秒)をつけてくれる。jstat -options # 使用可能なオプションを表示 jstat -option [-t] $pid [Ns|N] countメモリ・GC関連
GC情報の取得
jstat -gc $pidS0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT 512.0 512.0 0.0 0.0 3072.0 2801.4 8192.0 8143.8 26240.0 25255.1 3456.0 2994.5 431 0.841 227 8.809 9.650
項目 意味 S0C Survivor0(From/To)領域のサイズ S1C Survivor1(From/To)領域のサイズ S0U Survivor0(From/To)領域の使用サイズ S1U Survivor1(From/To)領域の使用サイズ EC Eden領域のサイズ EU Eden領域の使用サイズ OC Old領域のサイズ OU Old領域の使用サイズ MC Metaspaceのサイズ MU Metaspaceの使用サイズ CCSC 圧縮クラス領域のサイズ CCSU 圧縮クラス領域の使用サイズ YGC Young世代のGC回数 YGCT Young世代のGC時間 FGC フルGC回数 FGCT フルGC時間 GCT 総GC時間 サイズはKB単位でGC回数や時間は累計。
各領域の容量
jstat -gccapacity $pidNGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC 4096.0 4096.0 4096.0 512.0 512.0 3072.0 8192.0 8192.0 8192.0 8192.0 0.0 1073152.0 26496.0 0.0 1048576.0 3456.0 431 19306GCサマリと発生理由
jstat -gccause $pidS0 S1 E O M CCS YGC YGCT FGC FGCT GCT LGCC GCC 0.00 0.00 100.00 99.95 94.91 86.17 431 0.841 25345 952.938 953.779 Allocation Failure Ergonomicsこちらは使用率(%)。LGCC(Last GC Cause)は直前のGC理由で、GCCは今まさに実行中のGC理由。"-gccause"を"-gcutil"に変えるとLGCCとGCCが表示されない。
New領域の統計
jstat -gcnew $pidS0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT 512.0 512.0 0.0 0.0 15 15 512.0 3072.0 3072.0 431 0.841
項目 意味 TT 殿堂入り(Old昇格)閾値(Tenuring Threshold) MTT 殿堂入り(Old昇格)最大閾値(Max Tenuring Threshold) DSS 適切なSurvivor領域サイズ(KB) "-gcnewcapacity"とするとNew領域のサイズに関する統計を取得する。
Old領域の統計
jstat -gcold $pidMC MU CCSC CCSU OC OU YGC FGC FGCT GCT 26496.0 25148.6 3456.0 2978.0 8192.0 8191.9 431 37158 1394.167 1395.008同様に"-gcoldcapacity"とするとOld領域のサイズに関する統計を取得する。
なお、ヒープ情報は
jcmdでも確認可能。jcmd $pid GC.heap_infoPSYoungGen total 3584K, used 2597K [0x00000000ffc00000, 0x0000000100000000, 0x0000000100000000) eden space 3072K, 84% used [0x00000000ffc00000,0x00000000ffe894a0,0x00000000fff00000) from space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000) to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000) ParOldGen total 8192K, used 8143K [0x00000000ff400000, 0x00000000ffc00000, 0x00000000ffc00000) object space 8192K, 99% used [0x00000000ff400000,0x00000000ffbf3f18,0x00000000ffc00000) Metaspace used 25255K, capacity 25956K, committed 26240K, reserved 1073152K class space used 2994K, capacity 3312K, committed 3456K, reserved 1048576Kクラスロード統計
jstat -class $pidLoaded Bytes Unloaded Bytes Time 4622 8810.3 399 608.7 2.58JITコンパイル統計
jstat -compile $pidLoaded Bytes Unloaded Bytes Time 4622 8810.3 399 608.7 2.58jstat -printcompilation $pidCompiled Size Type Method 5485 734 1 sun/management/GcInfoCompositeData$2 runTypeは"-XX:+PrintCompilation"で出力するコンパイルモード。
Jconsole
基本的な機能を持ったJMXクライアントツール。
JVisualvm
より高機能なJMXクライアントツール。Pluginを導入することで、Jconsole自体も統合できる。
サンプリングでスレッドごとのCPU使用率を確認したり、プロファイリングでメソッドごとの呼出し回数や処理時間を確認できる。
Heap DumpやThread Dumpファイルを開くこともできる。
OSが出力したcoreファイルを開いて、Heap DumpやThread Dumpを取得することもできる。
JMC
商用本番環境でJFRを使用するには商用ライセンスが必要。それ以外でJMCを使用する分には商用ライセンス不要。
JMXクライアントツールとして以外にアラート設定により、例えばCPU使用が閾値を超えた場合やデッドロック検出時にアクションをトリガーできる。
そして何よりも、JFR(Java Flight Recorder)による低コスト(CPUオーバーヘッドは3%程度と謳われている)なアプリケーションのプロファイリングが可能。
JFRは
jcmdからも操作できる。また、JVM起動時に商用機能を有効化していない場合は、ここで有効化もできる。jcmd $pid VM.unlock_commercial_features jcmd $pid VM.check_commercial_features jcmd $pid JFR.start name=hoge duration=1m filename=~/hoge.jfr jcmd $pid JFR.check非純正事後解析ツール
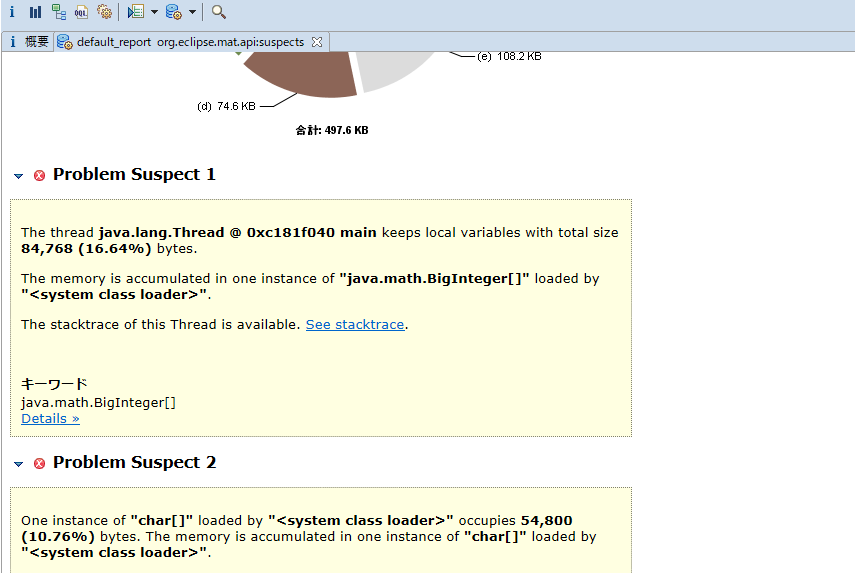
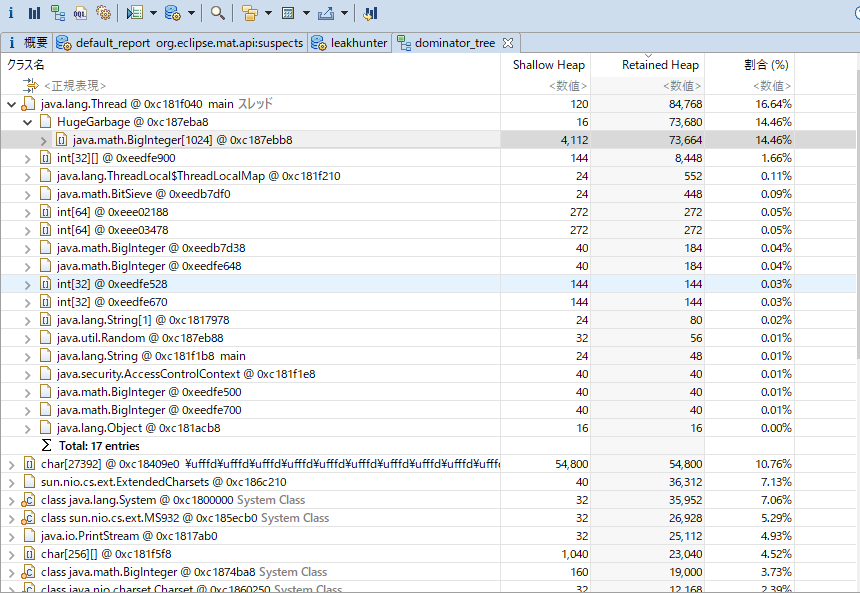
Heap Dump解析
Eclipse Memory Analyzer(MAT)が有名。パフォーマンス上よろしくないと思われる点も指摘してくれる。オブジェクトの階層等も追いかけやすい。
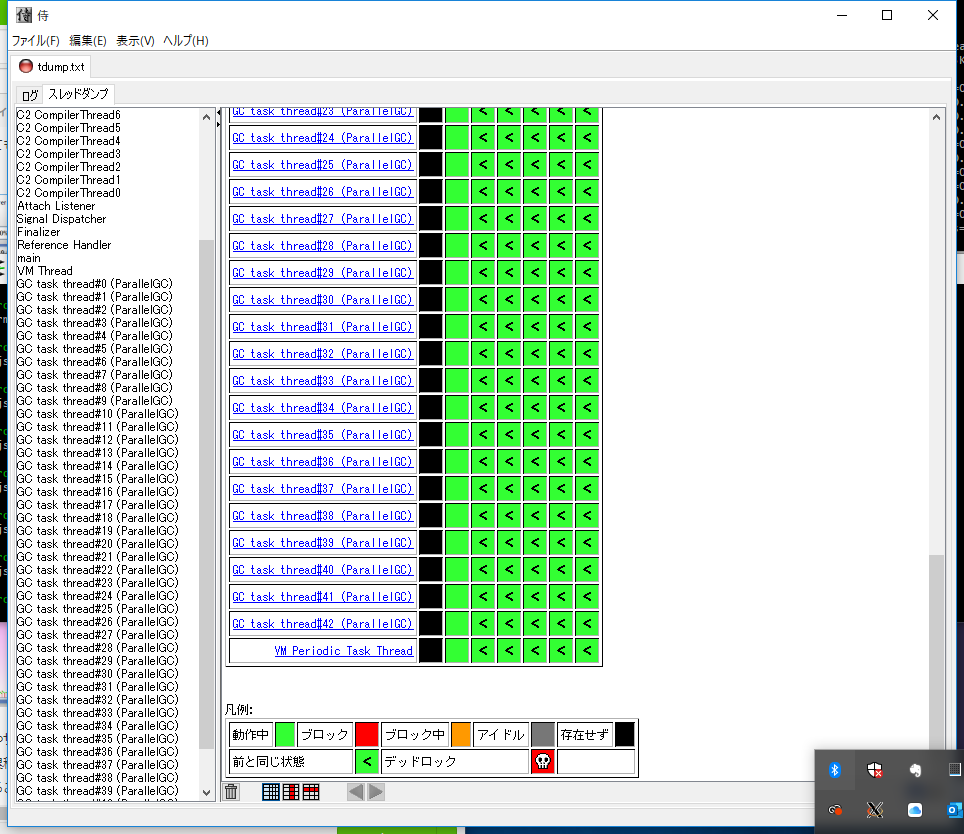
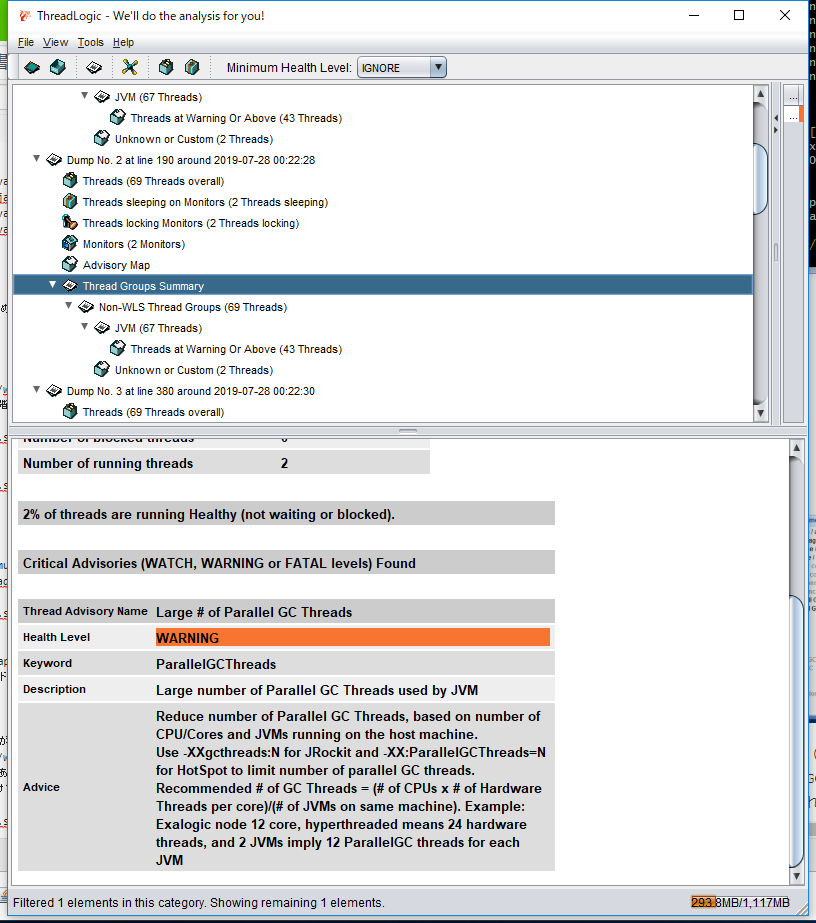
Thread Dump解析
samuraiやThreadLogicが有名。
samuraiはこのようにテーブル表示させると、Heap Dump取得時点のスレッド状態遷移をグラフィカルに確認できる。ブロックされていたり(赤表示)デッドロックになっていたり(赤地に骸骨マーク)するので見つけやすい。
ThreadLogicはこのようにアドバイスも表示してくれる。Oracle(Weblogic)開発者の知見が詰まっている。GCログ解析
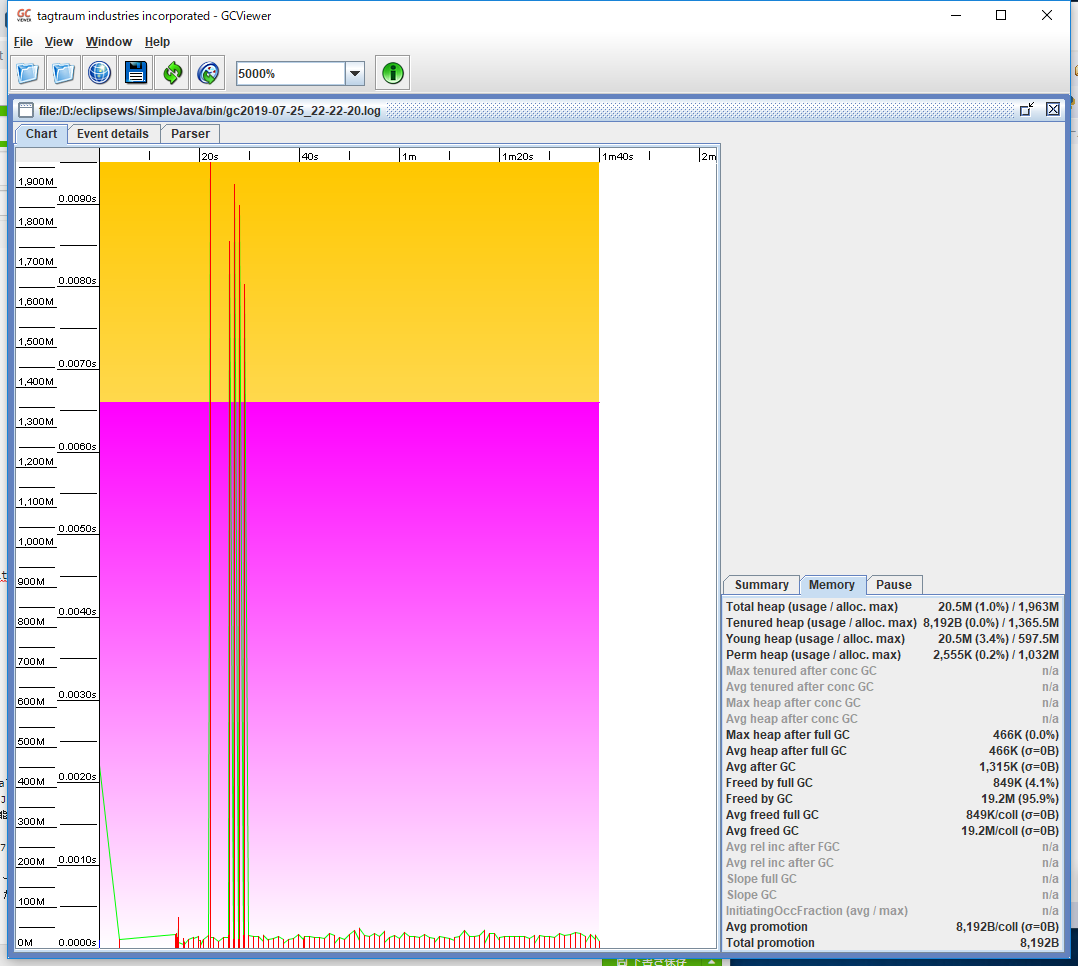
GCViewerが有名。Oracle HotSpotだけでなくIBM JavaやOpenJDKにも対応している。さらにはGUIで操作できるだけでなく、コマンドラインツールとしても使用可能。
このようにグラフ描画やサマリーレポートなども出力される。スループット(ここではアプリケーションの動作時間から累積停止時間を引いた割合)やヒープの健全性としてGC後にどれくらいヒープが解放されたかも見ることができる。付録
GCチューニングの基本
ガベージ・コレクション・チューニング・ガイド 2.エルゴノミクスを参照。
- (明らかに大容量メモリが必要となるとわかっている場合を除き)最大ヒープサイズは変更せず、必要なスループット目標を設定する
- ヒープが最大まで使われてもなおスループット目標が満たされない場合は最大ヒープサイズを大きくする
- スループット目標は達成されるが、停止時間が長すぎるなら停止の目標時間を設定する。
ヒープサイズの一般的なガイドライン
ガベージ・コレクション・チューニング・ガイド 4.世代のサイズ設定を参照。
- 一時停止時間が問題になっていなければできるだけ多くのメモリをJVMに割当てる
- 適切に選択された"-Xms"と"-Xmx"を同じ値に設定することで、JVMがサイズ調整をする負荷を軽減させる
- 割当ては並列化可能なため、CPUコア数を増やすのに伴ってメモリサイズも増加させる
- まずは物理的に割当て可能な最大(スワップしない程度)のメモリをJVMが使えるようにする("-Xms"と"-Xmx")
- Young領域に適切なサイズを実測する
コレクタ選択のガイドライン
ガベージ・コレクション・チューニング・ガイド 5.使用可能なコレクタを参照。
- ヒープが100 MB程度未満、またはシングルプロセッサ環境での実行→
-XX:+UseSerialGC- ピーク時のスループットを優先し、1秒以上の停止時間を許容できる→
-XX:+UseParallelGC- レスポンス時間を優先し、1秒以上の停止時間を許容できない→
-XX:+UseConcMarkSweepGCor-XX:+UseG1GC(ヒープサイズが6 GB以上)- G1の選択基準は以下のいずれか
- ヒープの50%以上が生きている
- オブジェクトの割当て率または昇格率の変動が大きい
参考情報

- 投稿日:2019-07-28T13:23:40+09:00
Python, Java, C++の速度比較
Python, Java, C++の速度比較
はじめに
私はもともとPythonをメインに勉強してきたのですが、今週からJavaとC++の勉強を始めたので、実行速度の比較をしてみることにしました。
AtCoderから計算量の多いDPの問題を選んで、ほぼ同一のアルゴリズムで提出してみました。
問題1
Educational DP Contest / DP まとめコンテスト L問題 - Deque
Python
DP.pyn = int(input()) a = list(map(int, input().split())) dp = [[0] * n for _ in range(n)] for i in range(n): dp[i][i] = a[i] for i in range(n - 2, -1, -1): for j in range(i + 1, n): dp[i][j] = max(a[i] - dp[i + 1][j], a[j] - dp[i][j - 1]) print(dp[0][n - 1])実行速度:TLE
シンプルに解けていますがPythonではなんと制限時間オーバーで間に合わず、ACになりません。
PyPy
DP.pyn = int(input()) a = list(map(int, input().split())) dp = [[0] * n for _ in range(n)] for i in range(n): dp[i][i] = a[i] for i in range(n - 2, -1, -1): for j in range(i + 1, n): dp[i][j] = max(a[i] - dp[i + 1][j], a[j] - dp[i][j - 1]) print(dp[0][n - 1])実行速度:324ms
まったく同じコードですが、PyPyで提出すれば通ります。競技プログラミングでPythonで戦うにはPyPyやNumPyをうまく使う必要があります。
Java
Main.javaimport java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); long[] a = new long[n]; for (int i=0; i<n; i++) { a[i] = sc.nextInt(); } long[][] dp = new long[n][n]; for (int i=0; i<n; i++) { dp[i][i] = a[i]; } for (int i = n - 2; i > -1; i--) { for (int j = i + 1; j < n; j++) { dp[i][j] = Math.max(a[i] - dp[i + 1][j], a[j] - dp[i][j - 1]); } } System.out.println(dp[0][n - 1]); } }実行速度:258ms
やっていることは同じですが、Pythonよりもコードがずいぶん長くなりますね。速度はPyPyと同じくらいでしょうか。
C++
main.cpp#include <bits/stdc++.h> using namespace std; #define rep(i, n) for (int i = 0; i < n; ++i) int main() { int n; cin >> n; vector<long long> a(n); rep(i, n) cin >> a[i]; long long dp[n][n]; rep(i, n) dp[i][i] = a[i]; for (int i = n - 2; i > -1; --i) { for (int j = i + 1; j < n; ++j) { dp[i][j] = max(a[i] - dp[i + 1][j], a[j] - dp[i][j - 1]); } } cout << dp[0][n - 1] << endl; }実行速度:31ms
なにこの速度おかしくないですか…
問題2
Educational DP Contest / DP まとめコンテスト B問題 - Frog2
Python
DP.pyn, k = [int(i) for i in input().split()] h = [int(i) for i in input().split()] dp = [float('inf')] * n dp[0] = 0 for i in range(1, n): for j in range(max(i - k, 0), i): dp[i] = min(dp[i], dp[j] + abs(h[i] - h[j])) print(dp[n - 1])実行速度:TLE
Pythonはコードが短くていいですね。と思いきや、またもTLEです。
PyPy
DP.pyn, k = [int(i) for i in input().split()] h = [int(i) for i in input().split()] dp = [float('inf')] * n dp[0] = 0 for i in range(1, n): for j in range(max(i - k, 0), i): dp[i] = min(dp[i], dp[j] + abs(h[i] - h[j])) print(dp[n - 1])実行速度:408ms
PyPyで同一のコードを提出してACになりました。
Java
Main.javaimport java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); int k = sc.nextInt(); int[] heights = new int[n]; for (int i = 0; i < n; i++) { heights[i] = sc.nextInt(); } int[] dp = new int[n]; for (int i = 0; i < n; i++) { dp[i] = Integer.MAX_VALUE; } dp[0] = 0; for (int i = 1; i < n; i++) { for (int j=Math.max(i - k, 0); j < i; j++) { dp[i] = Math.min(dp[i], dp[j] + Math.abs(heights[i] - heights[j])); } } System.out.println(dp[n - 1]); } }実行速度:449ms
問題1はJavaの方が早かったですが、問題2ではPyPyの方が早い結果になりました。やはり速度はほぼ同等でしょうか。
C++
main.cpp#include <bits/stdc++.h> using namespace std; #define rep(i, n) for (int i = 0; i < n; ++i) int main() { int n, k; cin >> n >> k; vector<int> h(n), dp(n); rep(i, n) cin >> h[i]; rep(i, n) dp[i] = 999999999; dp[0] = 0; for (int i = 1; i < n; ++i) { for (int j = max(i - k, 0); j < i; ++j) { dp[i] = min(dp[i], dp[j] + abs(h[i] - h[j])); } } cout << dp[n - 1] << endl; }実行速度:56ms
尋常ではない実行速度です。他より10倍くらい高速ですね。
まとめ
問題1
問題2
Pythonは遅いけどPyPyやNumPyを使えば戦えると思います。
JavaはPyPyと同じくらいの速度のようです。
C++の速度は異常。


- 投稿日:2019-07-28T08:48:35+09:00
Swiftの代入演算子ってタプルを返すんだなって話
代入演算子の動きが違うんだなあ的なちょっとしたメモ
Swiftは5 (Windowsしかないのでひとまずオンライン環境)Swiftの勉強中、「Javaの代入演算子的な使い方ってSwiftだとできるんだろうか」と思い立った。
Test1.javatry { final File file = new File("src\\test.txt"); try (final BufferedReader reader = new BufferedReader(new FileReader(file))) { String str; while((str = reader.readLine()) != null) { System.out.println(str); } } } catch (IOException e) { e.printStackTrace(); }
(str = reader.readLine()) != nullの部分で、1行読み取った結果をstrに代入する。
代入演算子はその代入した値を返すので、つまりは1行読み取った結果の文字列とnullを比較することになる。もっと単純なのだと、
Test2.javaint a = 1; int b = a = 2;これはaに2を代入した後で、a = 2は代入した値を返す。つまり、bには2が入るということ。
というわけで、Swiftでもやってみた。
test1.swiftvar a = 10 var b = a = 10 print(a) print(b)すると。
10 ()bがタプルになった。
これ、ほんとにタプルか?ときになったので・・・test1.swiftvar a = 10 var b = a = 10 print(b == ())すると。
True本当にタプルだった。
(何でタプルを返すんだろう、って思ったけど気にしないことにした)
知らずにやってたらやらかしてたかも・・・と思ったのでメモ。
- 投稿日:2019-07-28T08:38:42+09:00
SpringでInterceptorを使う
Springでinterceptorについて勉強しましたので記事を書いてみます。
Interceptorの概要
SpringにおけるInterceptorクラスは、例えば「コントローラが呼ばれる前に何か共通の処理を行うクラスを実装したい」といった際に使うクラスです。
例えばリクエストをマッピングする前にアクセスしてきたユーザを認証する処理を行いたいときなどに使います。実装クラス
実装したクラスをざっと説明します。
Interceptorクラス
TestInterceptor.javaimport java.lang.reflect.Method; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.servlet.http.HttpSession; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.core.annotation.AnnotationUtils; import org.springframework.web.method.HandlerMethod; import org.springframework.web.servlet.handler.HandlerInterceptorAdapter; import com.example.annotation.NonAuth; import com.example.models.TestUser; import com.example.service.UserPermissionService; public class TestInterceptor extends HandlerInterceptorAdapter{ @Autowired UserPermissionService service; @Override public boolean preHandle( HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // リクエストがマッピングできていない場合はfalse if( handler instanceof HandlerMethod ) { // @NonAuthが付与されているかどうかをチェックする HandlerMethod hm = (HandlerMethod) handler; Method method = hm.getMethod(); NonAuth annotation = AnnotationUtils.findAnnotation(method, NonAuth.class); if (annotation != null) { return true; } // ユーザ認証 HttpSession session = request.getSession(false); try { TestUser user = (TestUser)session.getAttribute("user"); if(!service.checkPermission(user)) { response.sendRedirect("/error"); return false; } }catch(NullPointerException e){ response.sendRedirect("/error"); return false; } return true; } response.sendRedirect("/error"); return false; } }・InterceptorクラスではHandlerInterceptorAdaptorを継承しなければなりません。
・preHandle()はコントローラの処理が呼ばれる前に呼ばれるメソッド。他にもコントローラの処理が終わった後に呼ばれるpostHandle()や一連のリクエスト処理が終わった後に呼ばれるafterCompletion()などをOverrideすることができます。
・そもそもNonAuthアノテーションが付与されているメソッドにリクエストをしている場合はtrueを返します(後述)
・上記クラスではUserPermission.checkPermission()でユーザ認証を行い、チェックに弾かれた場合はエラー画面にリダイレクトします(後述)
・そもそも渡されているHandlerがHandlerMethodのインスタンスでない場合はエラー画面にリダイレクトします(後述)Configurationクラス
BeanConfiguration.javaimport org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.HandlerInterceptor; import com.example.interceptor.TestInterceptor; import com.example.service.TestService; @Configuration public class BeanConfiguration { @Bean public HandlerInterceptor testInterceptor() throws Exception{ return new TestInterceptor(); } }・Interceptorクラスをbean定義します。
WebMvcConfigクラス
WebMvcConfig.javaimport org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Configuration; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.config.annotation.InterceptorRegistry; import org.springframework.web.servlet.config.annotation.WebMvcConfigurer; @Configuration public class WebMvcConfig implements WebMvcConfigurer { @Autowired HandlerInterceptor testInterceptor; @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(testInterceptor); } }・InterceptorはWebMvcConfigurerを継承したクラスでaddInterceptors()によってSpringに認識させてあげる必要があります。
・InterceptorクラスはAutowiredで呼び出します。Controllerクラス
TestInterceptorController.javaimport javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpSession; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import com.example.annotation.NonAuth; import com.example.models.TestUser; @Controller @RequestMapping("/interceptor") public class TestInterceptorController { @RequestMapping(value="/index",method = RequestMethod.GET) @NonAuth public String index(Model model, HttpServletRequest request) { TestUser user = new TestUser(); user.setName("Tanaka"); HttpSession session = request.getSession(false); if (session == null){ session = request.getSession(true); session.setAttribute("user", user); }else { session.setAttribute("user", user); } return "test/index"; } @RequestMapping(value="/test", method=RequestMethod.GET) public String test(Model model) { model.addAttribute("msg", "HelloWorld!"); return "test/test"; } }・まずindexにアクセスするとセッションにユーザが登録されます。
・indexではNonAuthアノテーションがついているので問答無用で認証を通過します。
・testにアクセスする場合は認証をクリアしなければなりません。大まかな実装クラスは以上になります。
補足
特定のメソッドはpreHandle()内で必ずtrueを返却したい場合
・前述しましたが、例えばアノテーションを使用する方法があります。
・アノテーションは自分で定義します。
・InterceptorクラスのpreHandle()に入るとで定義したアノテーションが付与されたメソッドであるかどうかを調べています。
・付与されている場合は問答無用でtrueを返却するようにしています。
・以下のサイトを参考にさせていただきました。
https://qiita.com/dmnlk/items/cce551ce18973f013b36認証に失敗した際にエラー画面に遷移させたい場合
・Springでエラーハンドリングをしたい場合は、ErrorController(Springで用意されているクラス)を継承したクラスを定義します。
ErrorControllerimport org.springframework.boot.web.servlet.error.ErrorController; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import com.example.annotation.NonAuth; @Controller public class ErrController implements ErrorController { private static final String PATH = "/error"; @RequestMapping("/404") @NonAuth String notFoundError() { return "test/error"; } @RequestMapping(PATH) @NonAuth String home() { return "test/error"; } @Override @NonAuth public String getErrorPath() { return PATH; } }・定義しているメソッドでは認証処理を行わないため、NonAuthアノテーションを付与します。
・Interceptorクラスの中でエラー画面をdispatchした後にreturn falseは必ずしないといけないようです。なぜなら、return falseを書かないと、エラー画面への遷移が行われたとしても、handlermethod(マッピングされたcontrollerのメソッド)は起動されてしまうからです。以下のサイトを参考にしました。
https://stackoverflow.com/questions/44740332/redirect-using-spring-boot-interceptor
上記のサイト中に書かれていることをgoogle翻訳してみます。Returns: true if the execution chain should proceed with the next interceptor or the handler itself. Else, DispatcherServlet assumes that this interceptor has already dealt with the response itself.
実行チェーンが次のインターセプタまたはハンドラ自体に進む必要がある場合はtrueです。そうでない場合、DispatcherServletはこのインターセプターが既に応答自体を処理したと見なします。「そうでない場合...」のところで言っていることがよくわかりませんが、多分DispatcherServletはpreHandleでreturn falesされるとすでにresponseが返されたとみなすのだと思います(return falseしない場合はコントローラのメソッドが起動されてしまうわけですから、「そうでない場合」は「falseの場合」ということでしょうか? )。何はともあれ、コントローラのメソッドを起動させたくない場合はreturn falseを書けということらしいです。
preHandle()に渡ってくるHandlerはHandlerMethodとは限らない
・Interceptorクラスの中でhandlerがHandlerMethodかどうかを検証していますが、これはhandlerは必ずしもHandlerMethodではないからです。
・例えばマッピングを想定していないアドレスにリクエストを送ろうとすると、ResourceHttpRequestHandlerが渡ってきます。
・以下のサイトを参考にさせていただきました。
https://qiita.com/tukiyo320/items/d51ea698c848414b5874参考:
springbootでインターセプターを設定する
Interceptorでコントローラメソッドの前後に処理を入れる
SpringBootの特定のAnnotationが付与されたControllerのメソッドに対して事前処理を行う
Spring Boot 2.0 (Spring 5) の WebMvcConfigurer覚書
Springbootでエラー画面を表示する
SpringBoot(1.2くらい)を使っていてハマった事[随時更新]
Redirect using Spring boot interceptor
preHandleに来るmethodがHandlerMethodとは限らない
- 投稿日:2019-07-28T06:50:48+09:00
ぼく 「Javaでリストのループ中に自身(リスト)を増やし続ける処理を書いてなごみたいなあ(仕事中)」
ぼく 「やってみるか」
List<String> list = new ArrayList<>(Arrays.asList("foo", "hoo", "hoge")); for (String str : list) { list.add(str); } System.out.println(list); // 例外発生 // Exception in thread "main" java.util.ConcurrentModificationException // at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1042) // at java.base/java.util.ArrayList$Itr.next(ArrayList.java:996)ぼく 「ConcurrentModificationException?」
ぼく 「お前は誰だ」
ぼく 「forEachでやってみるか、」list.stream().forEach(list::add); System.out.println(list); // Exception in thread "main" java.util.ConcurrentModificationException // at java.base/java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1660) // at java.base/java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:658)ぼく 「だめだ、、」
ぼく 「こんなんじゃ、ただでさえ眠いお昼あとの時間をシエスタにしてしまうじゃないか、、」
ぼく 「ああ、、」
チームリーダー 「sigくん」
チームリーダー 「午前中に頼んでた調査の件だけど、何かわかった?」
ぼく 「リーダー、、!」
ぼく 「(やってないです)」
ぼく 「(とりあえずなにかしらの作業やってます感だすために、今の画面見せたろ)」
ぼく 「こんな感じです」
チームリーダー 「ほう、、」
チームリーダー 「このConcurrentModificationExceptionっていう例外、【繰り返し処理中に、繰り返し元のリストの要素数に変更があった時】に発生するんだよね」
チームリーダー 「Javaのイテレータは自身の構造を変更した回数を内部でmodCountという変数名で記録していて、その変更回数に繰り返し処理中ズレが見つかると、例外を投げるようになっているんだ」例:ArrayListの実装// addでmodCount(変更回数)が更新される public boolean add(E e) { modCount++; add(e, elementData, size); return true; } // modCount(変更回数)のチェック => ズレがあったら例外を投げる final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } // 次のループに向かう度に変更回数のチェックを行う public E next() { checkForComodification(); // modCount(変更回数)チェックが実行される int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }ぼく 「おお」
ぼく 「なんでわざわざこんなことを」
チームリーダー 「Javaの多くのコレクションはフェイルファストを採用してるからな」
ぼく 「フェイルファスト?」
チームリーダー 「転ばぬ先の杖だ。失敗するより先に、危険を察知した時点で例外を投げているんだよ」
チームリーダー 「Javaは基本的にマルチスレッドでのコレクションの構造の書き換えを保証しないって言っているからな」
チームリーダー 「今回はシングルスレッドだったが、万が一マルチスレッドでの動作だったとしても大丈夫なように、とりあえず先に例外を投げるようにしているんだ」
ぼく 「なるほど」
ぼく 「用心深いやつですね、、」
チームリーダー 「ちなみに、イテレータの外部から構造を変更するとアウトだが、イテレータの内部からならいける」イテレータの内部からaddList<String> list = new ArrayList<>(Arrays.asList("foo", "hoo", "hoge")); for (ListIterator<String> itr = list.listIterator(); itr.hasNext();) { String str = itr.next(); itr.add(str + "_itr"); } System.out.println(list); // [foo, foo_itr, hoo, hoo_itr, hoge, hoge_itr]ぼく 「リーダー、無限ループしていないのですが」
ぼく 「(定時まで無限に増え続ける配列を眺めて遊びたいのに、、)」
チームリーダー 「ListIterator.addで追加した要素はイテレータのnextの直前に挿し込まれるからな」
チームリーダー 「以降のhasNext()やnext()に影響を及ぼさない」
ぼく 「(まじか)」
チームリーダー 「というかそろそろ言いたいんだが」
チームリーダー 「これ仕事と関係ないよな」
チームリーダー 「お願いしてた調査、やってくれたんだよな?」
ぼく 「(やってません)」
チームリーダー 「よくわかった」
チームリーダー 「仕事なら無限にあるからな、とりあえず暇そうなsigくんには今週中にあれとこれと、、」
ぼく 「リーダー!」
チームリーダー 「なんだ」
ぼく 「危険を察知したので早退します」
ぼく 「フェイルファスト帰宅」
チームリーダー 「いいから仕事しろ」ざっくりとしたまとめ: ConcurrentModificationExceptionとは
- 反復処理中に、反復元のコレクションの構造に変化があると投げられる例外
- Javaのコレクションは反復処理中のリストの構造書き換えを保証していないので、これを良しとしないコレクションはフェイルファストでこの例外を投げる(保証しないけどまあいいよね、と許可するクラスもある)
- 「臆病だからシングルスレッドだろうがなんだろうが、とりあえず先に例外投げとくよ!」的スタンス
- 投稿日:2019-07-28T02:56:47+09:00
ProcessingをIntelliJ+Kotlin+Gradleで開発する
Processingのエディタ使いにくいし、Javaもどきが微妙に気持ち悪いし、
どうせならKotlinで書きたいし、Gradleで管理したいよねって趣旨。Java8をインストールする
ProcessingがJava9以上だと動かないため
https://github.com/processing/processing/wiki/Supported-Platforms#user-content-java-versions$ brew cask reinstall caskroom/versions/zulu8$ /usr/libexec/java_home -V Matching Java Virtual Machines (2): 10.0.2, x86_64: "Java SE 10.0.2" /Library/Java/JavaVirtualMachines/jdk-10.0.2.jdk/Contents/Home 1.8.0_222-zulu-8.40.0.25, x86_64: "Zulu 8" /Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home新しいプロジェクトを作成
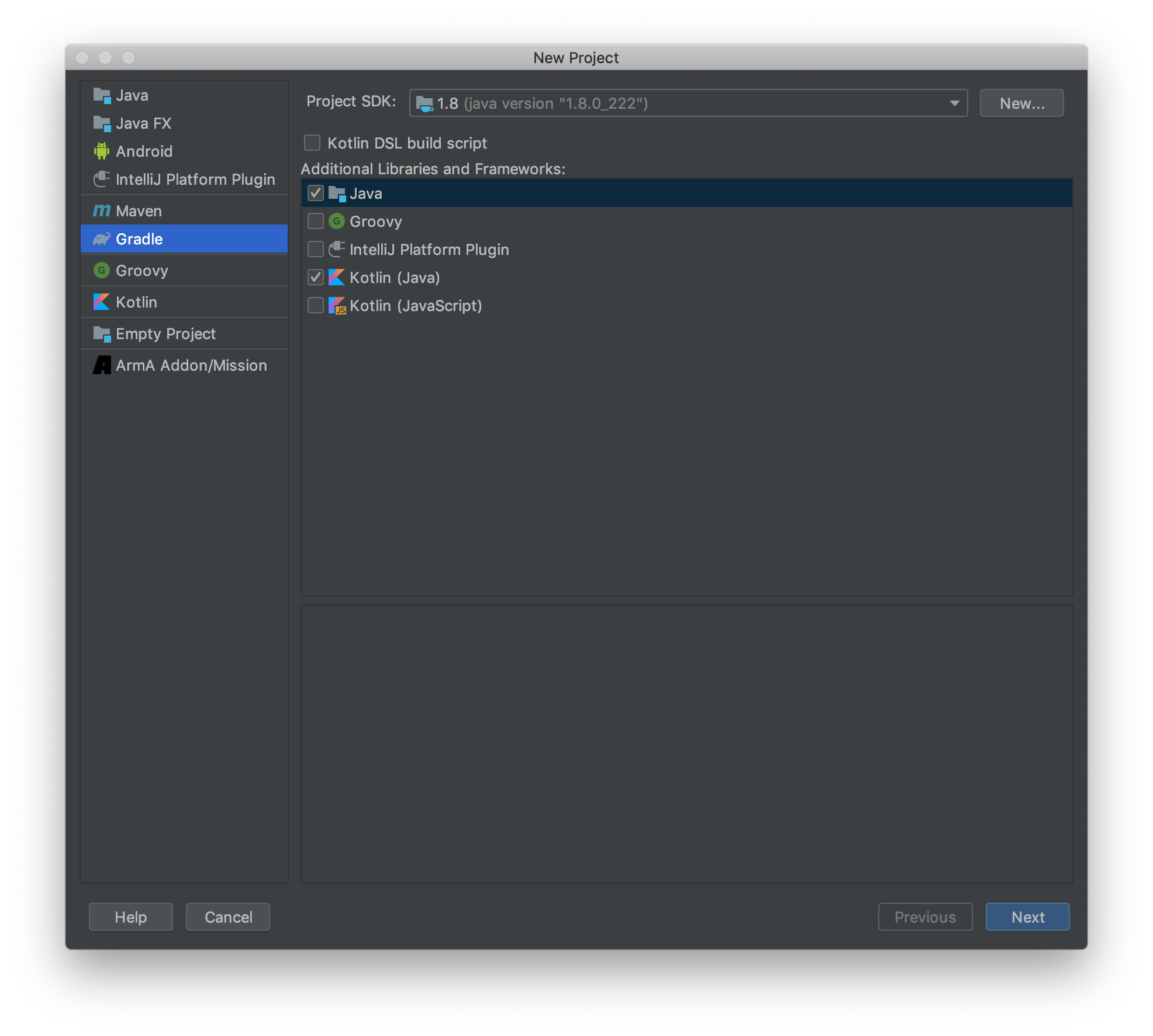
Gradle を選択し、 Java と Kotlin にチェックを付けます。
Project SDKはさっきインストールした1.8を指定してください。あとは道なりに
GradleにProcessingを追加
build.gradledependencies { compile group: 'org.processing', name: 'core', version: '3.3.7' }
build.gradleを開き
dependenciesの中にprocessingを追加します。するとダウンロードが開始されます。
ダウンロードが完了したら、External Librariesにorg.processing:coreが追加されていればOKです。プログラムを作成
src/main/kotlinに新しいKotlinファイルを作成します。
ファイル名は
Main.tkにしました。src/main/kotlin/Main.tkimport processing.core.* class Main : PApplet () { fun run() { return PApplet.main(Main::class.java.simpleName) } } fun main() : Unit = Main().run()Processing実行に必要な部分のみを記述した超シンプルな状態です。
実行してみる
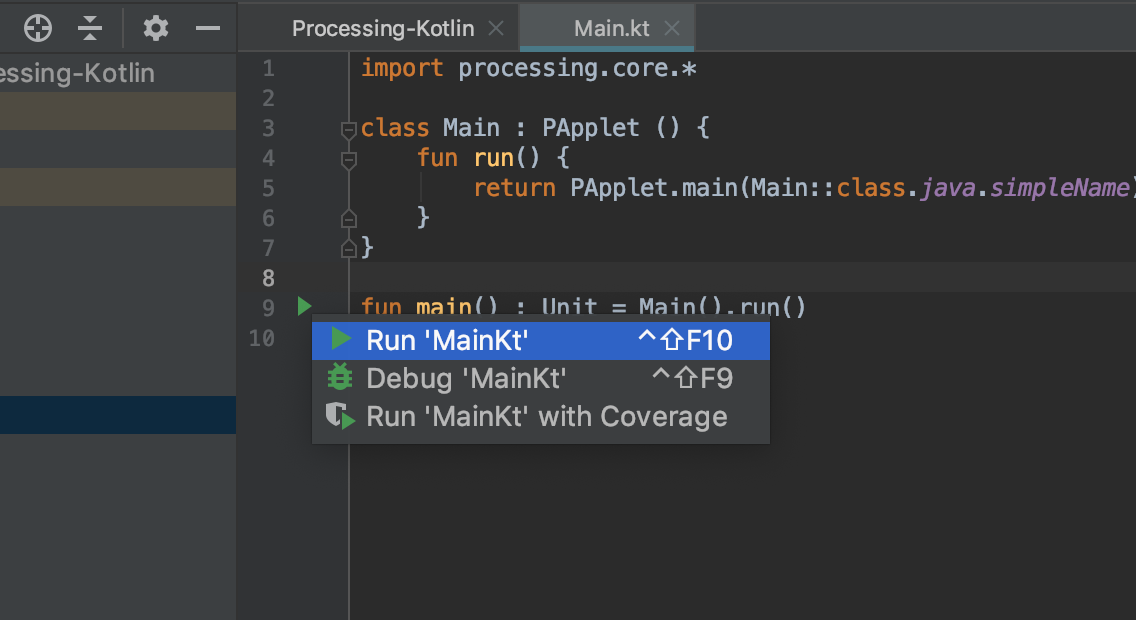
fun main()の隣に表示される三角形からRun MainKtを実行してください。
実行されると、
空のProcessingアプリが実行されました。
Kotlinで実装してみる
Processing公式の中にあるExamplesのFollow 3を試しにKotlinで実装してみます。
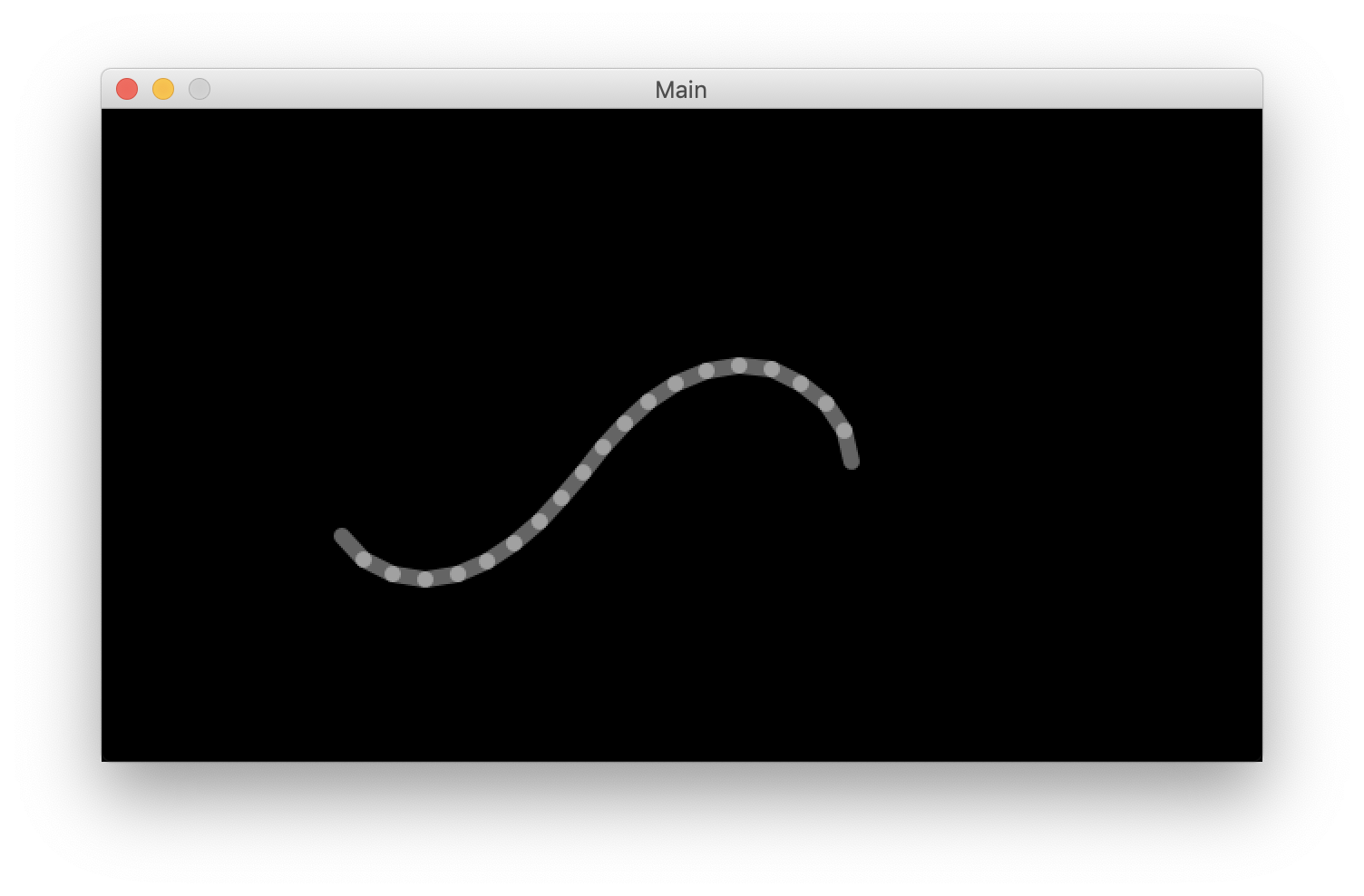
https://processing.org/examples/follow3.htmlsrc/main/kotlin/Main.tkimport processing.core.* class Main : PApplet () { var x = FloatArray(20) var y = FloatArray(20) var segLength = 18 override fun settings() { size(640, 360) } override fun setup() { strokeWeight(9F) stroke(255F, 100F) } override fun draw() { background(0f) dragSegment(0, mouseX.toFloat(), mouseY.toFloat()) for (i in 0 until x.size - 1) { dragSegment(i + 1, x[i], y[i]) } } private fun dragSegment(i: Int, xin: Float, yin: Float) { val dx = xin - x[i] val dy = yin - y[i] val angle = PApplet.atan2(dy, dx) x[i] = xin - PApplet.cos(angle) * segLength y[i] = yin - PApplet.sin(angle) * segLength segment(x[i], y[i], angle) } private fun segment(x: Float, y: Float, a: Float) { pushMatrix() translate(x, y) rotate(a) line(0F, 0F, segLength.toFloat(), 0F) popMatrix() } fun run() { return PApplet.main(Main::class.java.simpleName) } } fun main() : Unit = Main().run()これを実行すると
Processingが無事に動作しているのが確認できます。
ライブラリーを追加する
gradleに記述すると
build.gradlerepositories { mavenCentral() maven { url "https://clojars.org/repo" } } dependencies { implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk8" testCompile group: 'junit', name: 'junit', version: '4.12' compile group: 'org.processing', name: 'core', version: '3.3.7' compile group: 'ddf.minim', name: 'ddf.minim', version: '2.2.0' compile group: 'controlp5', name: 'controlp5', version: '2.2.4' compile group: 'de.sojamo', name: 'oscp5', version: '0.9.8' }mavenCentral には
oscp5とcontrolp5がなかったため、clojars.orgを repositories に追加しました。おわり
これで戦える。


- 投稿日:2019-07-28T02:43:41+09:00
【Programming News】Qiitaまとめ記事 July 27, 2019 Vol.13
筆者が2019/7/27(土)に気になったQiitaの記事をまとめました。昨日のまとめ記事はこちら。
2019/7/15(月)~2019/7/20(土)のWeeklyのまとめのまとめ記事もこちらで公開しております。
Java
- Spring Boot
Python
- Tips
- Tools
Ruby
Rails
- Beginner
- Tips
- RSpec
JavaScript
Node.js
- Tips
Vue.js
- Tips
Android
Swift
PHP
- Tips
A-Frame
- Beginner
Line
MySQL
Azure
AWS
- EC2
- AWS Chatbot
Firebase
- Beginner
TypeScript
Google Apps Script
Go言語
Rust
- Beginner
Julia
ShellScript
Unity
Docker
Develop
- Tips
- Tools
- Apps
Raspberry
- Tips
Heroku
OAuth2.0
Visual Studio Code
IntelliJ IDEA
更新情報
Kotlin
- Kotlin入門
Android
Java
IDE
- 投稿日:2019-07-28T01:38:02+09:00
【Programming News】Qiitaまとめ記事 July 26, 2019 Vol.12
遅くなりましたが筆者が2019/7/26(金)に気になったQiitaの記事をまとめました。昨日のまとめ記事はこちら。
2019/7/15(月)~2019/7/20(土)のWeeklyのまとめのまとめ記事もこちらで公開しております。
Python
- Beginner
- Tips
- Apps
JavaScript
Ruby
- RSpec
Android
Swift
Kotlin
Rails
- Beginner
- Tips
React
Nuxt.js
Laravel
Sass
PHP
- Tips
MySQL
Oracle
AWS
- AWS Lambda
- AWS CodeStar
- AWS IoT
- Beginner
Docker
Visual Studio
- Beginner
IBM Cloud
Unity
- Tips
TypeScript
- Tips
- Tools
Raspberry
- Tips
- Apps
Julia
Git
- Tips
Vim
VirtualBox
更新情報
Kotlin
- Kotlin入門
Android
Java
IDE
- 投稿日:2019-07-28T00:56:32+09:00
【Apache Spark】SparseVector(疎ベクトル)とDenseVector(密ベクトル)
概要
- Apache SparkのSparseVector(疎ベクトル)とDenseVector(密ベクトル)についての整理
環境
- Apache Spark 2.4.3
- 機械学習パッケージ spark.ml
SparseVector(疎ベクトル)とは
Sparse(スパース)とは「スカスカしてる」という意味。
あるベクトルの要素に0がたくさん含まれるような場合
たとえば
[0.1,0.0,0.0,0.0,0.3]というベクトルがあったとき、
このベクトルを表現するには
「最初の要素の値が0.1、最後の要素の値が0.3であり要素数が5である」
という情報だけで十分だよね、という考え方にもとづく。(その他の要素の値は0.0とする)
こうやって、情報量を抑えられるのでメモリも節約できるというのがご利益。
スパースベクトル的なものは、たいていの機械学習ライブラリで実装されてる。
SparkでSparceVector
さて、Sparkでスパースベクトルを作る方法は簡単。
spark.mlパッケージのorg.apache.spark.ml.linalg.SparseVectorを使う。
SparseVectorクラスはインデックスの配列(indices)と値の配列(values)を指定して初期化する
[0.1,0.0,0.0,0.0,0.3]を作りたいときはインデクスの配列(indices)new int[] { 0, 2 }と値の配列(values)new double[] { 0.1, 0.5 }で初期化すればOK
SparseVector// SparseVector(疎ベクトル) int size = 3;//ベクトルの要素サイズ int[] indices = new int[] { 0, 4 }; double[] svalues = new double[] { 0.1, 0.5 }; Vector svec = new SparseVector(size, indices, svalues); System.out.println("SparseVector=" + Arrays.toString(svec.toArray()));実行結果SparseVector=[0.1, 0.0, 0.0, 0.0, 0.5]
Vector#toArrayで配列化できるが、必要ない場合はもちろん消費されるメモリはindices(添え字の配列)とvalues(値の配列)のみ保持されるのでメモリが節約される。DenseVector(密ベクトル)とは
スパースベクトルと対をなす。一般的な配列と同じようにベクトルの要素の値をすべて保持してる。
[0.1,0.0,0.0,0.0,0.3]SparkでDenseVector
DenseVecotrは値の配列(values)を指定して初期化する
[0.1,0.0,0.0,0.0,0.3]を作りたいときは、その要素数の配列new double[] { 0.1, 0.0, 0.0, 0.0, 0.5 }を渡して作るのがDenseVector(密ベクトル)
DenseVector// DenseVector(密ベクトル) double[] dvalues = new double[] { 0.1, 0.0, 0.0, 0.0, 0.5 }; Vector dvec = new DenseVector(dvalues); System.out.println("DenseVector=" + Arrays.toString(dvec.toArray()));実行結果DenseVector=[0.1, 0.0, 0.0, 0.0, 0.5]フルソースコード(Java)
Apache SparkをJavaから使う
SparkVectorExamples.javapackage org.riversun.spark; import java.util.Arrays; import org.apache.spark.ml.linalg.DenseVector; import org.apache.spark.ml.linalg.SparseVector; import org.apache.spark.ml.linalg.Vector; public class SparkVectorExamples { public static void main(String[] args) { // DenseVector(密ベクトル) double[] dvalues = new double[] { 0.1, 0.0, 0.0, 0.0, 0.5 }; Vector dvec = new DenseVector(dvalues); System.out.println("DenseVector=" + Arrays.toString(dvec.toArray())); // SparseVector(疎ベクトル) int size = 5;// ベクトルの要素サイズ int[] indices = new int[] { 0, 4 }; double[] svalues = new double[] { 0.1, 0.5 }; Vector svec = new SparseVector(size, indices, svalues); System.out.println("SparseVector=" + Arrays.toString(svec.toArray())); } }実行結果DenseVector=[0.1, 0.0, 0.0, 0.0, 0.5] SparseVector=[0.1, 0.0, 0.0, 0.0, 0.5]


- 投稿日:2019-07-28T00:27:24+09:00
[Apache Tomcat] Apache OpenWebBeansをつかってCDIを使えるようにした話
概要
Apache TomcatでCDIを使用できるようにするのは、pom.xmlを書いたり設定を行ったりしてめんどくさい。そこで今回はApache OpenWebBeansを使用して簡単にCDIを使用できるようにしていこうと思う。
前提条件
- javaコマンドが使用できること
- Gitが使用できること
- eclipseが使用できること(できたら)
全体構成
/作業先/ ├ Tomcat/ │ ├ apache-tomcat-9.0.22/ │ │ ├ bin/ │ │ │ ├ startup.bat │ │ │ └ startup.sh │ │ └ conf/ │ │ ├ Catalina/ │ │ │ └ localhost │ │ │ └ Sample.xml │ │ ├ context.xml │ │ └ logging.properties │ ├ current -> (/作業先/Tomcat/apache-tomcat-9.0.22/) │ ├ openwebbeans-distribution-2.0.9 │ │ ├ install_owb_tomcat7.bat │ │ └ install_owb_tomcat7.sh │ ├ apache-tomcat-9.0.22 │ └ openwebbeans-distribution-2.0.9-binary.zip └ quita └ cdi-sample └ WebContent └ WEB-INF └ beanse.xml作業手順
今回作業を行うディレクトリを作成する。(以下、作業先)
作業先にTomcatディレクトリを作成する。
Apache TomcatをTomcatディレクトリにダウンロードし、解凍する。
バージョン変更時を考えcurrentリンクを作成する。
# Windowsの場合 mklink /j current apache-tomcat-9.0.22 # linuxの場合 ln -s apache-tomcat-9.0.22 ./current【Windowsの場合実施】コンソールが文字化けしないようにするため、Apache Tomcat内にあるconf/logging.propertiesを変更する
logging.properties# 51行目付近 # 変更前 java.util.logging.ConsoleHandler.encoding = UTF-8 # 変更後 java.util.logging.ConsoleHandler.encoding = SJISApache OpenWebBeansをTomcatディレクリにダウンロードし、解凍する。
Apache OpenWebBeans内にあるinstall_owb_tomcat7を実行する
# Windowsの場合 install_owb_tomcat7.bat ..\current # linuxの場合 install_owb_tomcat7.sh ../current【Windowsの場合実施】Apache Tomcat内にあるconf/context.xmlの""タグ内にタグを追加し、以下のようにする
context.xml<Context> <!-- Default set of monitored resources. If one of these changes, the --> <!-- web application will be reloaded. --> <WatchedResource>WEB-INF/web.xml</WatchedResource> <WatchedResource>WEB-INF/tomcat-web.xml</WatchedResource> <WatchedResource>${catalina.base}/conf/web.xml</WatchedResource> <!-- ↓追加したタグ --> <Listener className="org.apache.webbeans.web.tomcat7.ContextLifecycleListener"/> <!-- Uncomment this to disable session persistence across Tomcat restarts --> <!-- <Manager pathname="" /> --> </Context>作業先に以下のGitをクローンする
以下の内容のxmlをApache Tomcat内にあるconf/Catalina/localhostに作成する。
Sample.xml<Context path="/Sample" reloadable="true" docBase="/作業先/quita/cdi-sample/WebContent"> </Context>Apache Tomcatのbin内にあるstartupを実行する
# Windowsの場合 startup.bat # linuxの場合 startup.shlocalhost:8080/Sample/SampleServlet にアクセスし、「Served at: 」と出力されることを確認する。
感想・まとめ
今回Apache OpenWebBeansを使用してApache TomcatでCDIを使用できるようにしてきた。Windowsの場合手作業が入るため少しめんどくさいがbat/shを実行すれば簡単にCDIを使用できるようになるのかなと思った。今回使用したソースはeclipseで作成してあるので、できる方はいろいろいじくってみるのもよいかもしれない。(eclipseで使用する場合は、ウィンドウ -> 設定 -> サーバー -> ランタイム環境 -> Tomcat9(Java11) -> 編集からTomcatインストールディレクトリを/作業先/Tomcat/currentに変更する)
間違い・問題等あったらコメントしてください。