- 投稿日:2019-06-22T14:43:42+09:00
TensorFlow の入り口(1)/グラフ・セッションの基本とデバッグ方法、変数の基本と再利用方法
TensorFlow の入り口(1)/グラフ・セッションの基本とデバッグ方法、変数の基本と再利用方法
はじめに
本記事は、TensorFlow の基礎知識を説明するものです。
大まかには TensorFlow 初心者の方を読み手として想定しています。正直なところ、TensorFlow は使い始める際のハードルが高いです。
初めて使う人にとっては、かなりの苦戦を強いられるライブラリでしょう。TensorFlow を使うには、独特の概念を理解する必要があります。
そして、そこを乗り越えたとしても、そもそも覚えるべきこと(関数など)が多いです。ただし高水準のAPI(後述)を使えば、ある程度は楽になるかもしれません。
例えば、ひたすら「深層学習を手軽に試してみたい」という目的の場合は、そちらの方がおすすめです。
(※ そもそも、その目的であれば、Keras が特に適していると思います)TensorFlow 最初のハードル
TensorFlow の最初のハードルとして、次を挙げたいと思います。
- グラフとセッション
- 変数の扱い方
これらは独特の仕組みであり、最初は必ず戸惑う部分でしょう。
本記事は、上記2点に焦点を当てています。これら2点をおさえておけば、「コーディングして(数値の)ログを出し、デバッグする」という最も基本的な開発のサイクルに入ることができます。
※ 裏を返せば、「知識がないと、この基本サイクルにすら入れない」ということです。。少しつらいですね。これが、ハードルの高さの所以です。
一旦そのサイクルに入ってしまえば、あとはその他のライブラリと概ね同じ要領で学習を進めることができるでしょう。各種の関数の知識を地道に増やしていけば大丈夫かと思います。
高水準APIの存在
最初に断っておくと、TensorFlow を使ったコードを書くにあたり、グラフとセッションそのものの操作を回避する方法があります(笑)。
高水準のAPI(tf.estimator.Estimatorやtf.kerasなど)です。この記事の冒頭で、「深層学習を手軽に試してみたいという目的なら Keras が適している」と書きました。
それと同じようなことで、高水準のAPIを使えば、グラフやセッションの操作は隠蔽されるため、プログラマはその問題に直面しなくて済みます。しかし、後々細かい操作が必要になったときに、グラフやセッションの知識は重要になる(だろう)と個人的には思っています。
高水準APIの存在を知ってなお「グラフやセッションなどの低水準のAPIを学んでおきたい!」と思う方は、このまま先の項目に進んでください。
バージョン
私が使っている環境のバージョン情報です。
OS: Windows 7(64 bit)
Python: 3.6.6
TensorFlow: 1.11.0(今なお発展中で色々と変化しているライブラリであるため、バージョンの情報は重要ですね)
なお私の場合、TensorFlow は、
pip install tensorflowでインストールしています。
この場合 tensorflow とともに、tensorboard が一緒にインストールされ、パス指定なしで tensorboard コマンドが直接使用できるようになります。グラフとセッション
TensorFlow といえば Define-and-Run 。
コード内に記述した計算手順に沿って「計算グラフ」を最初に構築しておき、その後で計算処理を実行する仕組みです。(※ ただし現在の TensorFlow では、Eager Execution という Define-and-Run でなく Define-by-Run によるAPIが用意されています。興味のある方は調べてみてください)
TensorFlow の最初の一歩としては、まず、
tf.Graphとtf.Sessionの2つを覚えることになるかと思います。これらが、「グラフ」と「セッション」です。
tf.Graphは、計算処理の内容を保持するものです。これ単体では計算処理を実行できません。
tf.Sessionが、計算処理の実行を司る機構です。(補足: TensorFlow では、計算グラフはデータフロー・グラフ(dataflow graph)と呼ばれています)
◇ グラフの構築
後で実際のコード例とともに説明しますが、
tf.add(加算)やtf.matmul(行列の積)等のtf.Operationを、次のtf.Operationの引数として渡すという手順を繰り返すことにより、グラフが構築できます。
tf.Operationとは、演算そのものです。これについては、後の項目で説明します。
(演算の種類は、四則演算や行列計算をはじめとして、もちろん無数にあります)◇ セッションによる計算処理の実行
tf.Sessionの生成時には "graph" という引数でtf.Graphを指定します。計算を実行する際には、
tf.Session.runという関数を実行します。
引数としてはtf.Operation(後述)をとります。これにより、指定した演算を実行します。
そうすると、戻り値としてtf.Tensorの中身の値が得られます。
つまり、tf.Sessionを run することで初めて、計算結果の数値が(Python 側で)受け取れるということです。
tf.Session.closeを呼び出すと、セッションが閉じます。◇ 実践(3次元空間における距離の計算)
では、さっそくグラフとセッションの操作を実践してみましょう。
次のような計算を考えます。
- 3つの数値をそれぞれ2乗する
- 得られた3つの値をすべて加算する
- 加算して得られた値のルート(平方根)を計算する
3次元空間における、点 (a, b, c) の原点からの距離の計算です。
example_01.pyimport tensorflow as tf # <Step 1> まずグラフを構築 g = tf.Graph() with g.as_default(): a = tf.Variable(2, name="a", dtype=tf.int32) b = tf.Variable(3, name="b", dtype=tf.int32) c = tf.Variable(6, name="c", dtype=tf.int32) sum = tf.add_n([tf.square(a), tf.square(b), tf.square(c)], name="squared_distance") # 加算 output = tf.sqrt(tf.cast(sum, dtype=tf.float32), name="distance") # ルート計算 init_op = tf.global_variables_initializer() # <Step 2> tf.Session.run を呼び出し、計算処理を実行 sess = tf.Session(graph=g) sess.run(init_op) # 計算を実行する前に、変数(tf.Variable)を初期化しておく # init_op.run(session=sess) # 初期化方法はこちらでもよい print('-- print(output) --') print(output) # ただ print() しても計算結果の値は得られない print('-- sess.run(output) --') print(sess.run(output)) sess.close() # summary_writer = tf.summary.FileWriter('logs', sess.graph) # 計算グラフのファイルへの保存。説明は後述 # summary_writer.close()実は TensorFlow の変数は
tf.Variable()で生成しただけでは使用できず、別途初期化の処理が必要なので注意が必要です。その初期化処理というのがtf.global_variables_initializerです。上記プログラムでは、最初に
tf.global_variables_initializerを sess.run(init_op) で実行することで、すべての変数を一挙に初期化しています。次の点には注意してください:
- 初期化せずに sess.run(output) を実行しようとすると、
Attempting to use uninitialized valueというエラーが出ます。- sess.close() を実行した後に sess.run(output) などを呼び出すとエラーとなり、
Attempted to use a closed Session.という文言が出ます。- 上記プログラムではルートをとる処理
tf.sqrtの直前でtf.castの処理を入れていますが、これはtf.sqrtに入力する数値の型(dtype)がtf.int32のままではエラーになるためです。ここでは、型をtf.float32に変換して対処しています。なお、tf.Session を生成する部分は、引数なしで tf.Session() としてもよいです(後述【補足1】参照)。
また、上記プログラムでは変数の初期化を sess.run(init_op) として実行する代わりに、
init_op.run(session=sess) として実行することも可能です。◇ 実行結果
上記プログラムの実行結果を示します。
-- print(output) -- Tensor("distance:0", shape=(), dtype=float32) -- sess.run(output) -- 7.0print(output) と書いても、計算結果の値は得られないことが確認できます。
sess.run(output) と書くことではじめて計算処理が実行され、結果の値 7.0 が得られます。ここで出てくる Tensor とは、
tf.Tensor(テンソル)のオブジェクトです。
テンソルについては後で説明します。[参考URL]グラフとセッションについての公式の情報はここにあります。
TensorFlow ドキュメント "Graphs and Sessions"さて、グラフとセッションの基本部分の大枠は、ここまでの説明で押さえられるかと思います。
※ 以下は補足情報です。初見では一旦飛ばして先に進むのが良いかと思います。
【補足1】暗黙のデフォルトグラフ
上のサンプルコード(example_01.py)では律儀に
tf.Graph()を記述しています。
しかし実は、簡単な計算を実行するだけであればtf.Graph()をまったく記述しなくても良いです。TensorFlow の入門的な情報を調べて回っていると、tf.Graph の生成が記述されていないサンプルコードによく出会うことがあります。
このような場合、暗黙のグラフがデフォルトグラフとして生成されるようになっています。
セッションを引数なしで、tf.Session()と記述して生成すると、そのデフォルトグラフが利用されます。【補足2】コンテキストマネージャと閉じられるセッション
セッションは最終的には
tf.Session.closeによって閉じるべきです。
しかし、with 句を利用した場合、with 句の範囲を抜けるとセッションは自動的に閉じられます。※ コンテキストマネージャとは TensorFlow の概念ではなく、Python がもつ概念です。
詳細については、例えば次の Qiita記事をご覧ください。
with 文と @contextlib.contextmanager が便利【補足3】Define-and-Run とパフォーマンスの恩恵
Define-and-Run の仕組みはクセがあり、コーディングの際やや面倒なのは確かです。
その分、計算処理を実行前にコンパイルする機構により、処理のパフォーマンスを高めています。トレードオフですね。上記URL(TensorFlow 公式ドキュメント "Graphs and Sessions")の説明によると、グラフをあらかじめ用意しておくことで、XLAコンパイラという機構が実行時の効率を高めてくれるようです。
【補足4】リモートホストの TensorFlow の制御
tf.Sessionは、計算処理の実行を司る「窓口」あるいは「受付」のような存在です。
特別必要がなければ使いませんが、実はtf.Sessionは生成時に "target" という引数が指定可能になっています。この仕組みを使うと、リモートホストにある TensorFlow ベースの処理を動かすことができるようです。例えば、gRPC というRPCフレームワークを用い、分散深層学習を行なうことが可能なようです。
(※ 詳細については十分調査できていない為、本記事では割愛します)【補足5】tf.initialize_all_variables
今でも、TensorFlow 関連の情報を調べていると、
2015~2016年あたりの(例えば Qiita の)Web記事が出てきて、TensorFlow の変数を
tf.initialize_all_variablesという関数で初期化するプログラムが載っていたりします。
しかし、これは 2017年時点ですでに非推奨となっています。【補足6】TensorFlow によるプログラムを常駐させる場合
TensorFlow を常駐プロセスにしておき、随時リクエストを受け付けて、深層学習の推定処理を
実行するためには、おそらくセッションを閉じずにずっと保持しておくという形をとることになると思います。必要になった時にセッションを毎回生成する方法もあるでしょうが、ニューラルネットワークの構造が巨大な場合、モデルファイルの読み込みにかなり時間がかかる問題が発生します。
モデルファイルの読み込みは最初の1回だけにしておき、あとはセッションを保持して使い回せば、推定の際の処理時間が短縮され、この問題は解消されます。巨大なモデルに対し
tf.estimator.Estimatorを使った場合、この問題に直面することになるでしょう。注意が必要です。Tensor と Operation
TensorFlow における「グラフ」という言葉は、「グラフ理論」のグラフだと考えておけばよいと思います。
この「グラフ」は、ノード(節点)とエッジ(辺)から構成されます。
イメージとしては、節点が線で結ばれているネットワークです。TensorFlow の概念では、ノードが演算(オペレーション)、エッジがデータ(テンソル)に対応しています。プログラム上で、それぞれに対応するものは
tf.Operationとtf.Tensorです。tf.add や tf.multiply のような四則演算は tf.Operation に属します。
深層学習における活性化関数のひとつtf.nn.reluや、損失関数の最小化の処理(tf.train.Optimizer.minimize)もtf.Operationです。下図を見れば、グラフとノードのイメージがつかめるかと思います。
これは、「グラフとセッション」の項のサンプルコード(example_01.py)における計算グラフを TensorBoard で可視化したものです。
(右上に見える "init" が、変数の初期化処理のオペレーションです)
【補足】計算グラフの保存(
tf.summaryの利用)計算グラフ(
tf.Graph)の保存は、tf.summary.FileWriterで行なうことができます。
サンプルコードの末尾に 2行分コメントアウトされた部分がありましたが、その部分が計算グラフの保存処理にあたります。summary_writer = tf.summary.FileWriter('logs', sess.graph)第一引数は、ログを保存するディレクトリを指定します。上記の例では、"logs" というディレクトリにファイルを保存する形になります。
第二引数では、保存対象のtf.Graphを指定します。
tf.Sessionは "graph" というプロパティを持っているので、sess.graph としてtf.Graphを取得することが可能です。ここで得た summary_writer に対し、add_summary() という関数を呼ぶことで、スカラー量をはじめとした諸々の値の記録を行ない、後で TensorBoard で数値のグラフ(折れ線グラフ)を確認することができます。
(これは、深層学習において損失関数などの値の変化の可視化に使えます。つまり、パラメータチューニングで役立ちます)ただし、
tf.summaryと TensorBoard の使用方法の詳細については本記事の範囲を超えるため、今回はこれ以上踏み込みません。※ かつては
tf.train.SummaryWriterというものがあったようですが、すでに廃止されたようです。「今後はtf.summray.FileWriterを使いましょう」ということでよいと思います。変数と定数とプレースホルダ
TensorFlow では、変数(
tf.Variable)の扱い方に注意が必要です。
- 変数は tf.Variable 等で生成しただけでは使用できず、別途初期化の処理が必要。
- 変数に新たに値を格納したい場合は、所定のAPI
tf.assignを使用することが必要。1点目については、例としては既に見た
tf.global_variables_initializerが初期化の処理です。(実は変数を個別に初期化する方法もありますが、わざわざ使うメリットは特にないかと思います)変数の生成方法は、
tf.Variableの他にtf.get_variableがあります。
こちらは、既存の変数を再利用する(共有変数)際に必須となる関数です。後の項目で説明します。◇ 定数とプレースホルダ
TensorFlow で数値を用意するとき、すでに何度も紹介している変数(
tf.Variable)の他に、次のものを使用することができます。
- 定数(
tf.constant)- プレースホルダ(
tf.placeholder)定数は、特に説明は不要かと思います。
通常のプログラミングと同じような感覚で定数を設定できます。また、tf.Variableのような初期化も必要ありません。
なお、tf.constant()はtf.Tensorを返します。プレースホルダは、
tf.Variable等と違い、最初の時点で入力値を決めなくてよい仕組みです。入力値はtf.Session.runする際、引数として渡します。プレースホルダの仕組みは、計算グラフの構築の時点ではデータの内容や数量を決められない場合に役立ちます。
特に、深層学習において訓練の際にミニバッチを入力する処理では、プレースホルダは必須といってよいと思います。◇ tensor-like objects
計算グラフを組む際、各ノードに対し引数として入力できるオブジェクトは、テンソルである必要があります。
しかし、必ずしもtf.Tensorそのものでなければならないわけではなく、Python のリストなどを渡すことも許容されます。
(その場合、TensorFlow 内部では、tf.Tensorへの変換が行なわれるようです)TensorFlow 公式ドキュメント(Graphs and Sessions)では、それらの「テンソルとみなされるもの」は、"tensor-like objects" と呼ばれています。以下のものが、"tensor-like objects" です。
tf.Tensortf.Variable- numpy.ndarray (Numpy の配列)
- Python のリスト(あるいは tensor-like object のリスト)
- Python のスカラー値(int や float 等)
テンソル(Tensor)とは何かというと、ベクトルや行列を包含する上位概念であり、プログラミングの世界でいえば、多次元配列だと思っておけばよいと思います。
ベクトルは1方向に数値が並び、行列は2方向に数値が展開していきます。
ベクトル、行列はそれぞれ1階のテンソル、2階のテンソルです。
行列を重箱のように重ねていけば、3階のテンソルとなります。
なお、スカラーは0階のテンソルです。本記事のテーマを逸脱するので割愛しますが、画像認識では「チャネル(チャンネル)」という概念が出てくるため、3階のテンソルがごく普通のものとして出てきます。
しかし3階のテンソルは行列を並べただけのものです。特に何ら身構えることはないと思います。【雑談】テンソルという概念の難しさ
数学で出てくる「テンソル」の真の姿は、多次元配列ではありません。
ベクトルの場合、同じベクトルであっても、基底のとり方によって座標は変わります。しかし、基底のとり方を変えても、違うベクトルになるわけではありません。(※ 線型代数で説明される内容です)
テンソルについても、これと同様の話が出てきます。多次元配列(座標など)はあくまで表面上のもの、いわば「仮面のようなもの」です。
真の姿はその後ろにいて、それそのもの自体は一意です。数学におけるテンソルの定義などをみると、独特の用語や抽象性の高さのため、
到底、読んですらすらと理解できるようなものではない気がします。しかし、TensorFlow のプログラミングを行う上では、そういった難しい話は忘れてしまってほぼ問題ないでしょう。ひとまず、上記の「多次元配列」ぐらいの簡単な理解で、特別困ることはありません。
◇ 実践(行列の乗算)
プレースホルダに、
Tensor-like objectsのひとつ、Numpy 配列(ndarray)を入力するサンプルプログラムを示します。
処理内容としては、単に行列の掛け算をするだけです。example_02.pyimport tensorflow as tf import numpy as np # 2行2列の行列を2つ生成(ndarray) np_a = np.arange(0, 4).reshape(2, 2) np_b = np.arange(4, 8).reshape(2, 2) g = tf.Graph() with g.as_default(): with tf.name_scope("input"): # 名前空間 a = tf.placeholder(tf.int32, shape=(2, 2), name="a") b = tf.placeholder(tf.int32, shape=(2, 2), name="b") with tf.name_scope("output"): # 名前空間 output = tf.matmul(a, b, name="product") # 行列の乗算 sess = tf.Session(graph=g) tf.global_variables_initializer().run(session=sess) print(a) print(b) print('--') print(a.name) # tf.Tensor の名前を参照 print(b.name) print(output.name) print() print('-- matrix a --') print(a.eval(feed_dict={a: np_a}, session=sess)) print() print('-- matrix b --') print(b.eval(feed_dict={b: np_b}, session=sess)) print() print('-- output --') print(sess.run(output, feed_dict={a: np_a, b: np_b})) sess.close()
tf.placeholderへの入力値は、feed_dict という Python 辞書に格納して渡します。なお、
tf.Tensorに対して "eval" というメソッドを呼んでいますが、これは sess.run と同じ処理を行うものです。sess.run なのか eval なのかについては、その場その場で書きやすい方を使えばよいかと思います。◇ 実行結果
Tensor("input/a:0", shape=(2, 2), dtype=int32) Tensor("input/b:0", shape=(2, 2), dtype=int32) -- input/a:0 input/b:0 output/product:0 -- matrix a -- [[0 1] [2 3]] -- matrix b -- [[4 5] [6 7]] -- output -- [[ 6 7] [26 31]]行列 a と b の積が出力されているのが確認できます。
またこの結果からは、tf.placeholderはtf.Tensorを返すことも分かります。なお
tf.Tensorは "name" (名前)というプロパティを持っています。
上記コードのように、a.name などとして名前を参照できます。
"name" の先頭には、名前空間の情報が付加されます(上記の例では "input"、"output")。名前空間
複雑な計算グラフを組む際には、整理のために名前空間を使うと良いでしょう。
名前空間を用いるメリットは2つあります。
- ソースコードの見通しが良くなる。
- 計算グラフの各ノードに付ける名前("name")の衝突が避けられる。
- TensorBoard で計算グラフを可視化した際、ノードが名前空間で括られ見通しが良くなる。
TensorFlow を設計した人は、C++ の思想を意識していたのでしょうか。。
C++ には名前空間の概念があり、名前の衝突を過度に警戒する必要がありません。
毎回必ずしも変数や定数に気の利いた名前を付けられるわけではないので、ありがたい仕組みです。名前空間の使い方ですが、2つの方法があります。
tf.name_scopetf.variable_scope
tf.name_scopeは、tf.get_variableを使う場合に無視されてしまうので注意が必要です。
tf.get_variableを使う際には、tf.variable_scopeの方を用いるようにした方が良いでしょう。
tf.variable_scopeは名前に "variable" が入っていますが、tf.Variable以外のノード(tf.Tensor等)に対しても有効であり、無視されたりはしないので不安視することはありません。変数の再利用
行ないたい計算処理の内容によっては、同じ変数(
tf.Variable)を何度も繰り返し使いたい場合があります。例えば、再帰ニューラルネットワーク(ベーシックなRNN、LSTM、GRU)を組む場合、隠れ層を構成する変数を、何度も利用することになります。
(再帰ニューラルネットワークについては本記事の範囲を超えるので、詳細は割愛します)
tf.get_variableとtf.variable_scopeを組み合わせて使い、特定の制御方法を使うことで、変数を再利用できます。
tf.Variable()で生成した変数の場合は再利用できないので、注意が必要です。
(再利用しようとすると、エラーになります)他にも、注意すべき点はいくつかあります。
- セッションを閉じずに保持しておくことが前提(閉じた後も再利用可能というものではない)
tf.get_variableで変数を再利用する際には tf.variable_scope が必要になる。tf.get_variableは、tf.variable_scopeの reuse オプションで再利用を可能にする設定をしていない場合、既存変数と重複する名前("name")を指定して変数を生成しようとするとエラーになる。
tf.Variable()(関数)を呼び出して生成した変数は、tf.get_variable で再利用することができない。
変数の再利用は、
tf.variable_scopeの "reuse" という引数を使って制御します。
あるいは、tf.get_variable_scope().reuse_variables() でもよいです。# reuse=True で再利用 with tf.variable_scope("test", reuse=True): # ここに各種変数の処理を記述 # あるいは下記のようにします with tf.variable_scope("test"): tf.get_variable_scope().reuse_variables()突き詰めていくと説明の分量がそれなりに多くなってしまうため、
これ以上の詳細な部分については別の方が書かれている記事を参考情報として記載するに留めます。「基礎から実践 TensorFlow 重み共有」
https://qiita.com/halhorn/items/6805b1fd3f8ff74840df「TensorFlow の名前空間を理解して共有変数を使いこなす」
https://qiita.com/TomokIshii/items/ffe999b3e1a506c396c8◇ 実践 3項間漸化式
変数の再利用を実践するコード例を示します。
example_03.pyimport tensorflow as tf def get_next_term(term_1, term_2): # 次の項の値の計算 coef_1 = tf.get_variable("coef_1", shape=(), dtype=tf.int32) coef_2 = tf.get_variable("coef_2", shape=(), dtype=tf.int32) return coef_1 * term_1 + coef_2 * term_2 def main(): # 隣接3項間漸化式に従い、10番目までの項を得る # 初期値(初項) init_val_1 = 1 init_val_2 = 1 g = tf.Graph() with g.as_default(): tf_init_val_1 = tf.Variable(init_val_1) #dtype=tf.int32 tf_init_val_2 = tf.Variable(init_val_2) #dtype=tf.int32 sess = tf.Session(graph=g) output_list = [] # 便宜上、2つの初期値(初項)を追加しておく output_list.extend([tf_init_val_1, tf_init_val_2]) with tf.variable_scope("recurrence") as scope: # 再利用(共有)する2つの変数。漸化式の係数の役割。 coef_1 = tf.get_variable(name="coef_1", shape=(), dtype=tf.int32 , initializer=tf.constant_initializer(2)) coef_2 = tf.get_variable(name="coef_2", shape=(), dtype=tf.int32 , initializer=tf.constant_initializer(1)) print(coef_1.name) print(coef_2.name) for i in range(8): # 2つの初項 + 8項で、合計10個の項を得る scope.reuse_variables() # 変数の再利用 output = get_next_term(output_list[i], output_list[i+1]) output_list.append(output) init_op = tf.global_variables_initializer() # 初期化 sess = tf.Session() init_op.run(session=sess) print("-- output --") print(sess.run(output_list)) sess.close() if __name__=='__main__': main()名前空間 "tf.variable_scope" は、get_next_term 関数の外側で問題なく使用できます。
上記のコードは、漸化式の係数の部分には定数
tf.constantを使えばよいのに変数を使っているのがいかにも不自然ですが、あくまでtf.get_variableによる変数再利用方法を説明するため便宜的にそうしているだけです。。なお、shape=() とすることで、0階のテンソル(=スカラー)を指定することができます。
これは知らないとどうしようもなさそうですね。
(shape=[1] とすると、スカラーでなくなってしまうので注意が必要です。
shape=0 や shape=None はエラーになります)もっとも、TensorFlow のテンソルのAPIは多分に Numpy に倣っているので、
Numpy についてよく知っている方にとっては特に問題ないかもしれません。
スカラーの指定の仕方が shape=() なのは、実は Numpy と同様です。なお上記コード(example_03.py)ではさりげなく sess.run(output_list) と書いていますが、
tf.Session.runは複数のオペレーションをリストとして渡してやると、それらのオペレーションを一挙に実行し、その計算結果をリストとして返してくれます。◇ 実行結果
上記プログラムの実行結果を示します。
recurrence/coef_1:0 recurrence/coef_2:0 -- output -- [1, 1, 3, 5, 11, 21, 43, 85, 171, 341]メリットは何なのか
上記の
tf.get_variableによる変数再利用の方法について、「わざわざこんなことをしなくても、tf.Variable()で生成した変数を持ち回れば、それで済むのでは」と思う方もいるかと思います。その実装方法でよい場合も多いかもしれません。これは少々難しい問いでした。
考え、調査するのに少し時間を要しました。結果として私がたどり着いた答えは以下の通りです。「
tf.get_variableによる再利用のほうがコードが簡潔に書ける」。基本的には、
tf.Variable()で生成した変数を持ち回る方法でも十分実装できます。
しかし TensorFlow の計算グラフの構築処理をいくつかの補助関数に分割して行なう場合、tf.Variableを渡さねばならない分、関数の引数が増えてしまいます。また、同じ補助関数で変数の生成と再利用を兼ねることができません。その点、
tf.get_variableのみで実装した補助関数であれば、tf.variable_scopeの "reuse" 引数で制御してやるだけで、生成と再利用の両方に用いることができるのです。
これにより、コードがより簡潔に、見通しよく書けるようになります。最後に
本記事では深層学習の実装は取り上げませんでしたが、いきなり深層学習に取り組むよりも、TensorFlow そのものの概念や仕組みを事前に押さえておいたほうが、いざ深層学習の実装に入ったときに楽かなという気がします。
次に TensorFlow の記事を書くことがあれば、その時は、多層パーセプトロン(MLP)の実装例を載せつつ、モデルファイルの保存や読み出しの処理について説明してみたいと思っています。
なお、本記事は TensorFlow 1.x を想定した内容になっています。
一方、最近 TensorFlow 2.0 (beta)が出たと話題になっていますが、
TensorFlow 2.0 ではデフォルトが Eager Execution になるようです。
TensorFlow、なかなか変化が激しいですね。今後 Eager Execution が広く使われるようになったとしても、Define-and-Run には一定の優位性があるので、しばらくは、その知識が役に立たなくなることはないかと思います。
さて。今回は、色々詰め込んだ結果、記事の分量が膨れ上がってしまいました。。

- 投稿日:2019-06-22T14:26:37+09:00
#CentOS 6.6(x86_64)にCUDA10.1とCUDNN7.6.0を入れる方法
事前にダウンロード
cuda-repo-rhel6-10-1-local-10.1.168-418.67-1.0-1.x86_64.rpm
libcudnn7-7.6.0.64-1.cuda10.1.x86_64.rpmscript
yum install epel-release sed -i "s/mirrorlist=https/mirrorlist=http/" /etc/yum.repos.d/epel.repo rpm -i cuda-repo-rhel6-10-1-local-10.1.168-418.67-1.0-1.x86_64.rpm yum clean all yum install cuda rpm -ivh libcudnn7-7.6.0.64-1.cuda10.1.x86_64.rpm
- 投稿日:2019-06-22T08:56:23+09:00
GraphPipeが意外と使えそう
だいぶ時間が経ってしまいましたが、こちらで初めて名前を聞き、そこで紹介されたこちらでさらに説明を聞いてきたので、早速試してみました。
GraphPipeとは
Oracleが開発した、学習済みモデルを使って、簡単に推論してくれる仕組みです。
細かい話はここを見ていただくのが一番です。
また、日本語の情報としては、ABeam Consultingの澤田様がここで情報発信しています。どう簡単なの?
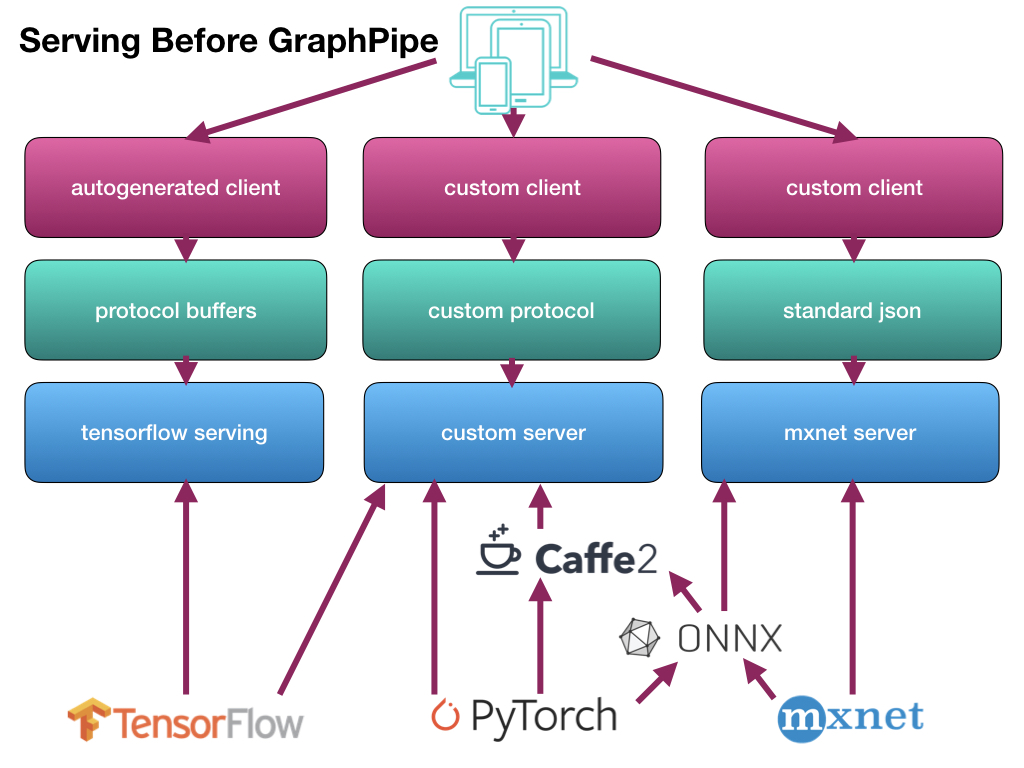
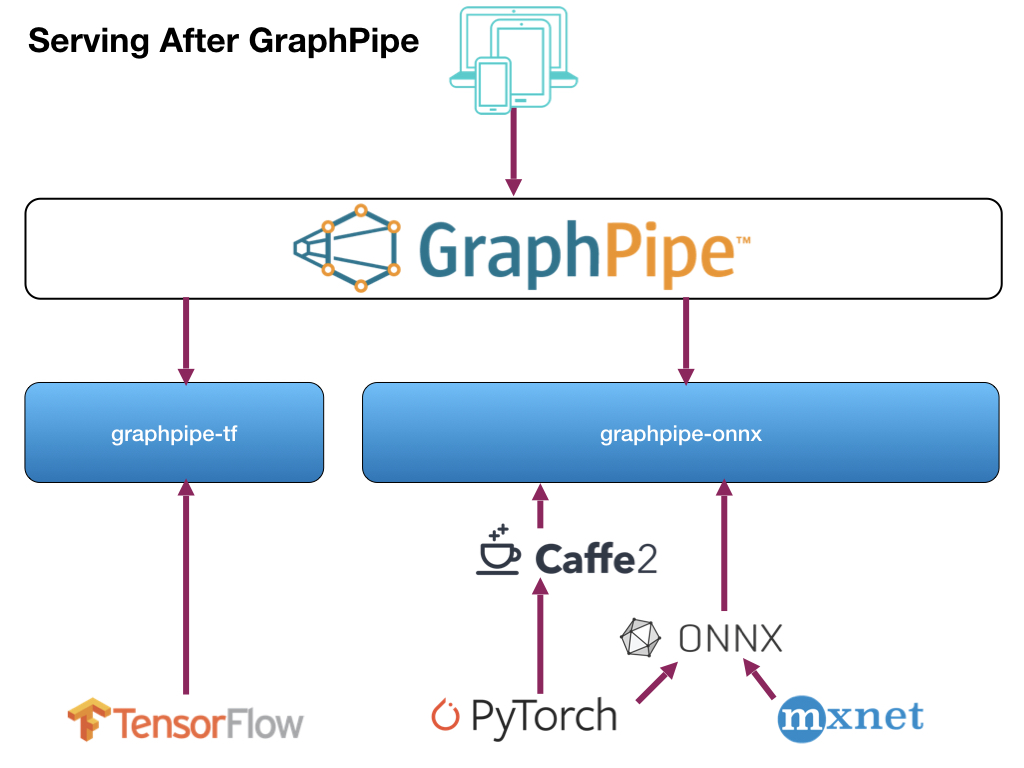
従来までの推論の流れは、それぞれのフレームワークで作成した学習済みモデルごとにサーバ側の仕組みを作成し、さらにクライアント側も合わせた形で作成していました。
それを、サーバ側/クライアント側とも一本化(サーバ側は2つ)して、らくしましょうという仕組みです。
使い方
サーバ側/クライアント側、それぞれの使い方を見ていきます。
サーバ側
Dockerでサーバアプリを起動します。
> docker run -it --rm \ -e https_proxy=${https_proxy} \ -p 9000:9000 \ sleepsonthefloor/graphpipe-tf:cpu \ --model=https://oracle.github.io/graphpipe/models/squeezenet.pb \ --listen=0.0.0.0:9000実行するイメージは、Docker Hubから取得します。
現在、以下の6種類が用意されています。
- CPU版
- TensorFlow
- sleepsonthefloor/graphpipe-tf:cpu
- ONNX/Caffee2
- sleepsonthefloor/graphpipe-onnx:cpu
- TensorFlow+Oracle Linux
- sleepsonthefloor/graphpipe-tf:oraclelinux-cpu
- ONNX/Caffe2+Oracle Linux
- sleepsonthefloor/graphpipe-onnx:oraclelinux-cpu
- GPU版
- TensorFlow
- sleepsonthefloor/graphpipe-tf:gpu
- ONNX/Caffee2
- sleepsonthefloor/graphpipe-onnx:gpu
これらを実行するサーバ環境に合わせて選択します。
使用する学習済みモデルは、「--model」で指定します。
「--listen」でポートを指定します。クライアント側
クライアント側はPython、または、Go言語で開発ができます。
ここではPythonの場合の説明をします。準備
まずモジュールをインストールします。
> pip install grapepipeソースコードの作成
サーバとやり取りするコードを作成します。
ここでは、画像(mug227.png)を渡し、識別結果を受け取るサンプルを作成します。pred.pyfrom io import BytesIO from PIL import Image, ImageOps import numpy as np import requests from graphpipe import remote data = np.array(Image.open("mug227.png")) data = data.reshape([1] + list(data.shape)) data = np.rollaxis(data, 3, 1).astype(np.float32) # channels first print(data.shape) pred = remote.execute("http://127.0.0.1:9000", data) print(“Expected 504 (Coffee mug), got: %s” % np.argmax(pred, axis=1))実行
作成したコードを実行します。
> python pred.pyすると、すぐに結果が表示されます。
(1, 3, 227, 227) Expected 504 (Coffe mug), got: [504]これは、最初が送った画像のフォーマット、2行目が「正解は504で識別結果も504でした」という意味になります。
なお、実行時にはサーバ側にも実行ログが表示されます。
INFO[0491] Request for / took 195.09784msこれは、サーバ側での識別にかかった時間が195msですという意味になります。
学習済みモデルの種類
使用できる学習済みモデルは、以下のようになっています。
- TensorFlow
- SavedModel形式
- GraphDef(.pb)形式
- ONNX/Caffe2/PyTorch
- ONNX (.onnx) + value_inputs.json
- Caffe2 NetDef + value_inputs.json
Kerasの出力形式「.h5」からTensorFlowのGraphDef(.pb)への変換は、すでに用意されています。
> curl https://oracle.github.io/graphpipe/models/squeezenet.h5 > squeezenet.h5 > docker run -v $PWD:/tmp/ sleepsonthefloor/graphpipe-h5topb:latest \ squeezenet.h5 converted_squeezenet.pbまた、Caffe2/PyTorchの場合は、それぞれONNXに変換する必要があります。
参考:GraphDef(.pb)ファイルの保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util # グラフを構築する関数 # 学習時とも共通で使える def build_graph(): ... y = tf.nn.softmax(..., name=‘output’) # 出力層の名前 with tf.Graph().as_default() as graph: build_graph() with tf.Session() as sess: saver = tf.train.Saver() saver.restore(sess, ‘checkpoint.ckpt’) # 学習済みのグラフを読み込み graph_def = graph_util.convert_variables_to_constants( sess, graph.as_graph_def(), [‘output’]) # 出力層の名前を指定 # プロトコルバッファ出力 tf.train.write_graph(graph_def, '.', 'graph.pb', as_text=False)感想
作ったモデルが簡単に検証でき、また、他の人が作ったモデルもすぐに確認できるので、非常に便利です。
データサイエンティストとアプリケーションエンジニアがお互いを意識しないで作業できるのが嬉しいです。