<transition-grouptag="tbody"id="left"><!-- 1 to 25 --><trv-for="trend in upTo25":key="trend.name"v-cloak><th><%trend.rank%></th><td><a:href="trend.url"class="has-text-grey-darker"><%trend.name%></a></td><td><%trend.volume%></td></tr></transition-group>
<tbodyis="transition-group"id="left"><!-- 1 to 25 --><trv-for="trend in upTo25":key="trend.name"v-cloak><th><%trend.rank%></th><td><a:href="trend.url"class="has-text-grey-darker"><%trend.name%></a></td><td><%trend.volume%></td></tr></tbody>
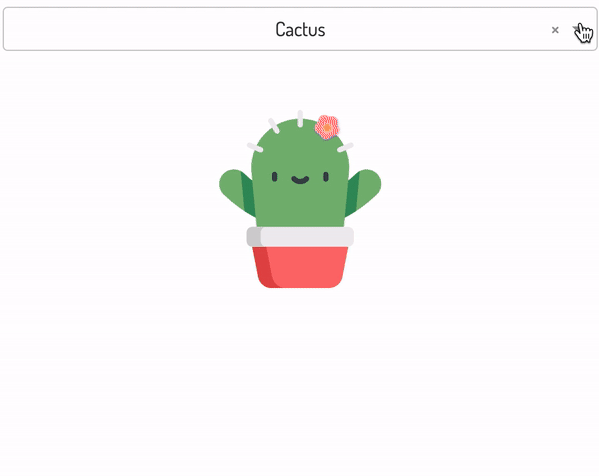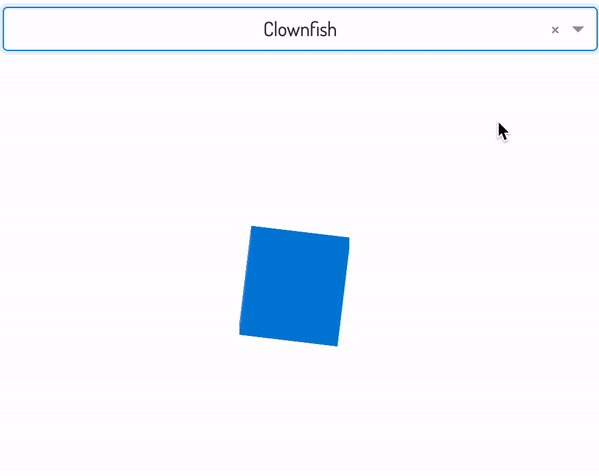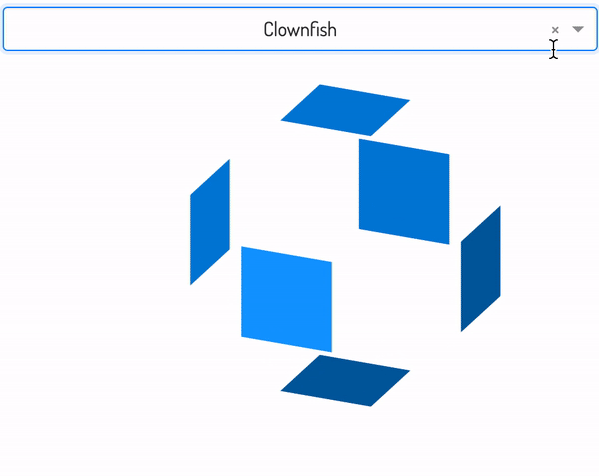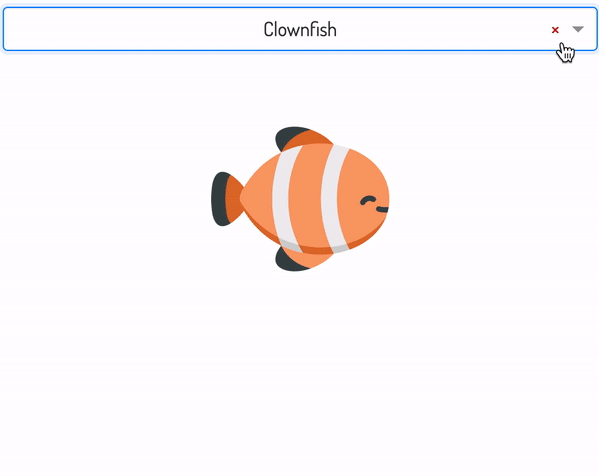
importdashimportdash_html_componentsashtmlimportdash_core_componentsasdccimporttimefromdash.dependenciesimportInput,Outputapp=dash.Dash(__name__)common_style={'position':'relative','width':'100%','font-family':'Dosis','text-align':'center'}app.layout=html.Div(children=[html.H1("Dash app with loading state",style={'margin-bottom':'10%'}),dcc.Dropdown(id='my-dropdown',options=[{'label':'Cactus','value':'https://image.flaticon.com/icons/svg/874/874979.svg'},{'label':'Clownfish','value':'https://image.flaticon.com/icons/svg/875/875011.svg'},{'label':'Crab','value':'https://image.flaticon.com/icons/svg/875/875010.svg'}],value='https://image.flaticon.com/icons/svg/874/874979.svg'),dcc.Loading(id="loading-1",children=[html.Div(id='output-container',)],style={"margin":"10%"},type="default"),],style=common_style)@app.callback(Output('output-container','children'),[Input('my-dropdown','value')])definput_triggers_spinner(value):time.sleep(2)returnhtml.Img(src=value,height="30%",width="30%",style={"margin":"10%"})if__name__=="__main__":app.run_server(debug=False)
Deprecated: Use API.media_upload() instead. Update the authenticated user’s status. Statuses that are duplicates or too long will be silently ignored.
(非推奨:代わりにAPI.media_upload()を使用してください。 認証済みユーザーのステータスを更新します。 重複している、または長すぎる状況は黙って無視されます。)(Google翻訳)
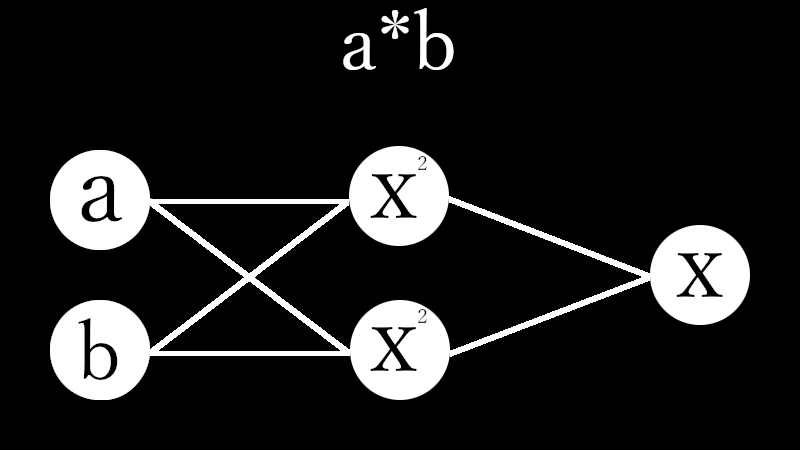
# d y / d h1dydh1=w2# d h1 / d u1dh1du1=h1*(1-h1)# d u_1 / d w1du1dw1=x# 上から du1 / dw1 の直前までを一旦計算dLdu1=dLdy*dydh1*dh1du1dLdu1=dLdu1[None]# du1dw1は (3,) というshapeなので、g_u1w1[None]として(1, 3)に変形du1dw1=du1dw1[None]# dL / dw_1: 求めたい勾配dLdw1=dLdu1.T.dot(du1dw1)print(dLdw1)
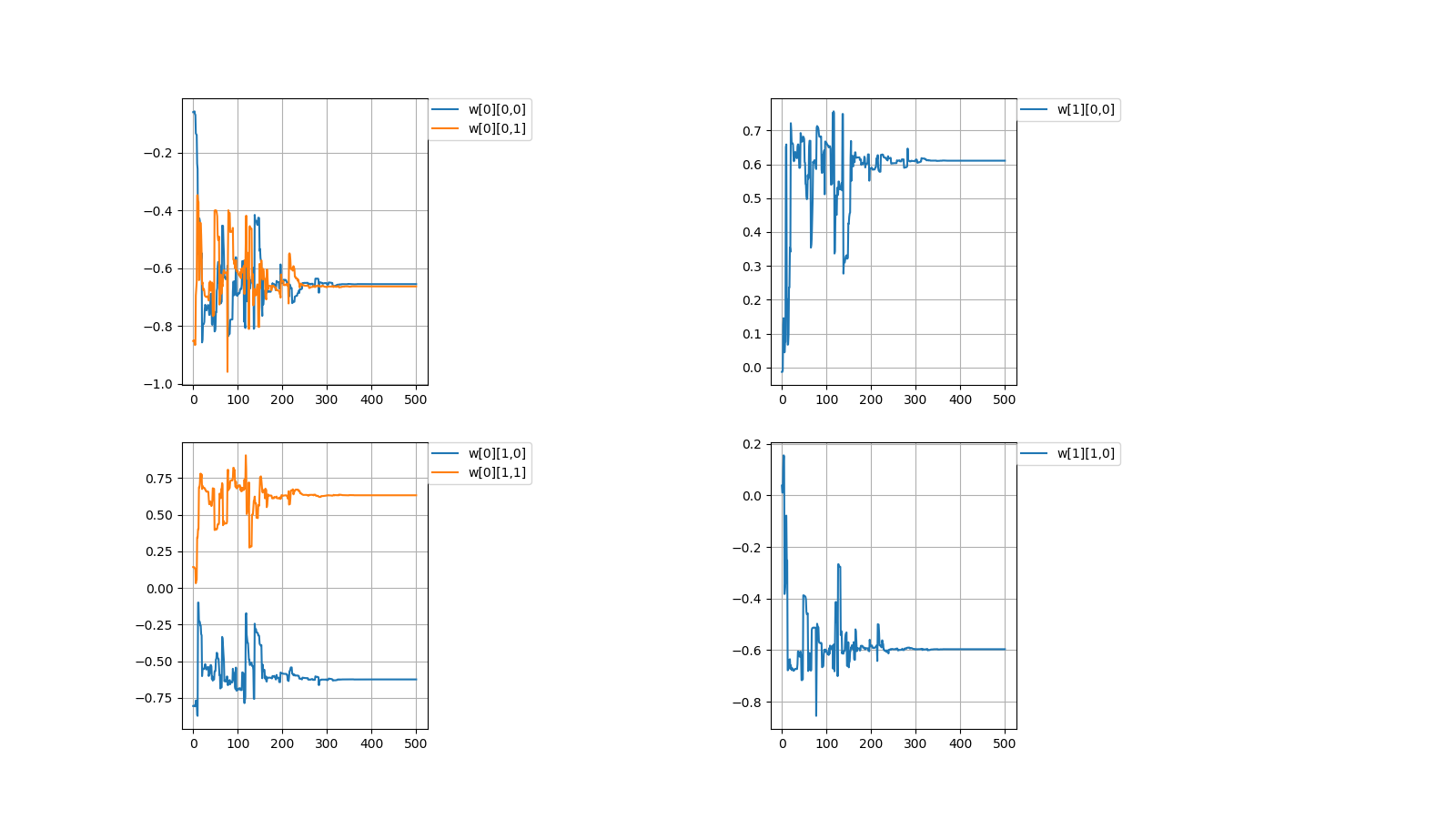
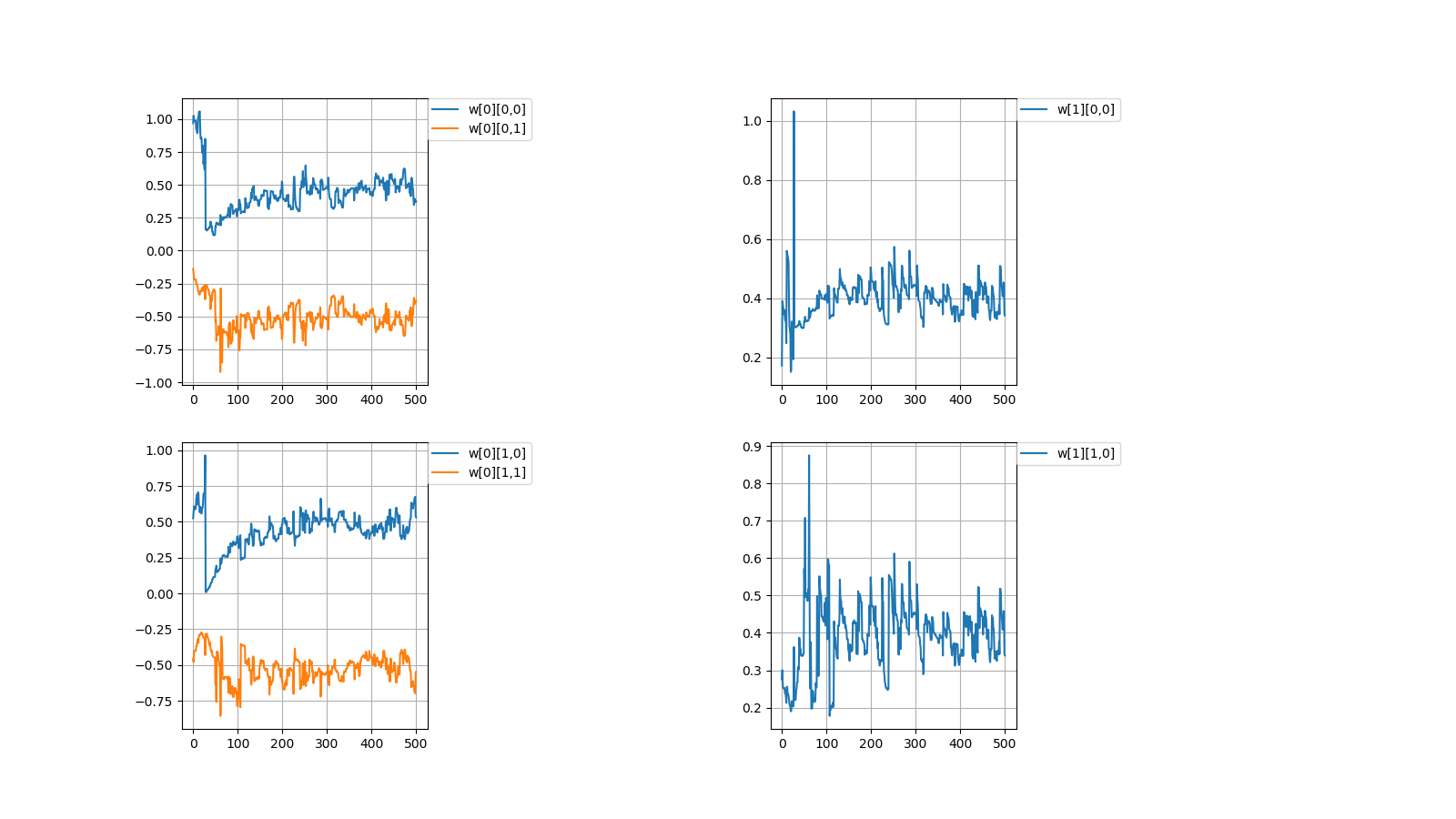
毎度恒例、初期値を乱数(-1.0~1.0)の間で決めてから学習を繰り返すと目標値に収束するか試してみました。
Every time, after deciding the initial value between random numbers (-1.0~1.0),
I tried to repeat the learning to converge to the target value.
上記のように値が収束しない場合がときたまあります。
本当はプログラムを組んで収束しない時の統計を出すべきなんでしょうが
そこまでの気力がありませんでした。
Occasionally, the values don't converge as described above.
Properly, it should be put out the statistics when doesn't converge by programming
I didn't have the energy to get it.
2,収束したらしたでいつも同じぐらいの値で収束する
どういう訳か、例えばw[0][0,0]=±0.6...ぐらいの値に落ち着く事がほとんどです。
2,It always converges with the similar value
For some reason, for example, it is almost always settled to the value of w [0][0,0] = ±0.6...
一見、簡単そうなパーセプトロンでも謎が多いです。
At first glance, even the seemingly easy perceptron has many mystery.
> jupyter notebook password
Enter password:
Verify password:
[NotebookPasswordApp] Wrote hashed password to C:\Users\masahiro\.jupyter\jupyter_notebook_config.json
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621225531.4895
Results logged to /tmp/python-build.20190621225531.4895.log
Last 10 log lines:
checking for --enable-universalsdk... no
checking for --with-universal-archs... no
checking MACHDEP... checking for --without-gcc... no
checking for --with-icc... no
checking for gcc... no
checking for cc... no
checking for cl.exe... no
configure: error: in `/tmp/python-build.20190621225531.4895/Python-3.7.2':
configure: error: no acceptable C compiler found in $PATH
See `config.log' for more details
gccをインストールすることで解決。
$ sudo apt-get install buid-essential
2. ZipImportError
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621230110.10841
Results logged to /tmp/python-build.20190621230110.10841.log
Last 10 log lines:
sys.exit(ensurepip._main())
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 204, in _main
default_pip=args.default_pip,
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 117, in _bootstrap
return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths)
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 27, in _run_pip
import pip._internal
zipimport.ZipImportError: can't decompress data; zlib not available
Makefile:1130: recipe for target 'install' failed
make: *** [install] Error 1
Zlibが無いということでインストールして解決。
$ sudo apt-get install zlib1g-dev
3. ModuleNotFoundError: No module named '_ctypes'
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621230630.24266
Results logged to /tmp/python-build.20190621230630.24266.log
Last 10 log lines:
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/commands/__init__.py", line 6, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/commands/completion.py", line 6, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/cli/base_command.py", line 18, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/download.py", line 38, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/utils/glibc.py", line 3, in <module>
File "/tmp/python-build.20190621230630.24266/Python-3.7.2/Lib/ctypes/__init__.py", line 7, in <module>
from _ctypes import Union, Structure, Array
ModuleNotFoundError: No module named '_ctypes'
Makefile:1130: recipe for target 'install' failed
make: *** [install] Error 1
libffi-devをインストールすることで解決。
$ sudo apt-get install libffi-dev
4. Missing the bzip2 lib? Missing the bzip2 lib? OpenSSL lib?
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib?
WARNING: The Python readline extension was not compiled. Missing the GNU readline lib?
ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib?
Please consult to the Wiki page to fix the problem.
https://github.com/pyenv/pyenv/wiki/Common-build-problems
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621231127.5162
Results logged to /tmp/python-build.20190621231127.5162.log
Last 10 log lines:
install|*) ensurepip="" ;; \
esac; \
./python -E -m ensurepip \
$ensurepip --root=/ ; \
fi
Looking in links: /tmp/tmpid_vpfsb
Collecting setuptools
Collecting pip
Installing collected packages: setuptools, pip
Successfully installed pip-18.1 setuptools-40.6.2
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621225531.4895
Results logged to /tmp/python-build.20190621225531.4895.log
Last 10 log lines:
checking for --enable-universalsdk... no
checking for --with-universal-archs... no
checking MACHDEP... checking for --without-gcc... no
checking for --with-icc... no
checking for gcc... no
checking for cc... no
checking for cl.exe... no
configure: error: in `/tmp/python-build.20190621225531.4895/Python-3.7.2':
configure: error: no acceptable C compiler found in $PATH
See `config.log' for more details
gccをインストールすることで解決。
$ sudo apt-get install buid-essential
2. ZipImportError
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621230110.10841
Results logged to /tmp/python-build.20190621230110.10841.log
Last 10 log lines:
sys.exit(ensurepip._main())
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 204, in _main
default_pip=args.default_pip,
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 117, in _bootstrap
return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths)
File "/tmp/python-build.20190621230110.10841/Python-3.7.2/Lib/ensurepip/__init__.py", line 27, in _run_pip
import pip._internal
zipimport.ZipImportError: can't decompress data; zlib not available
Makefile:1130: recipe for target 'install' failed
make: *** [install] Error 1
Zlibが無いということでインストールして解決。
$ sudo apt-get install zlib1g-dev
3. ModuleNotFoundError: No module named '_ctypes'
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621230630.24266
Results logged to /tmp/python-build.20190621230630.24266.log
Last 10 log lines:
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/commands/__init__.py", line 6, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/commands/completion.py", line 6, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/cli/base_command.py", line 18, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/download.py", line 38, in <module>
File "/tmp/tmp9dawx9je/pip-18.1-py2.py3-none-any.whl/pip/_internal/utils/glibc.py", line 3, in <module>
File "/tmp/python-build.20190621230630.24266/Python-3.7.2/Lib/ctypes/__init__.py", line 7, in <module>
from _ctypes import Union, Structure, Array
ModuleNotFoundError: No module named '_ctypes'
Makefile:1130: recipe for target 'install' failed
make: *** [install] Error 1
libffi-devをインストールすることで解決。
$ sudo apt-get install libffi-dev
4. Missing the bzip2 lib? Missing the bzip2 lib? OpenSSL lib?
$ pyenv install 3.7.2
Downloading Python-3.7.2.tar.xz...
-> https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tar.xz
Installing Python-3.7.2...
WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib?
WARNING: The Python readline extension was not compiled. Missing the GNU readline lib?
ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib?
Please consult to the Wiki page to fix the problem.
https://github.com/pyenv/pyenv/wiki/Common-build-problems
BUILD FAILED (Ubuntu 16.04 using python-build 1.2.12-2-geb68ec9)
Inspect or clean up the working tree at /tmp/python-build.20190621231127.5162
Results logged to /tmp/python-build.20190621231127.5162.log
Last 10 log lines:
install|*) ensurepip="" ;; \
esac; \
./python -E -m ensurepip \
$ensurepip --root=/ ; \
fi
Looking in links: /tmp/tmpid_vpfsb
Collecting setuptools
Collecting pip
Installing collected packages: setuptools, pip
Successfully installed pip-18.1 setuptools-40.6.2