はじめに アクセスログの解析を行う上でURLから一部だけ抽出する処理ががよくあるので、 その場合に利用できるHIVE、Prestoの関数と利用例をまとめてみました HIVEとPrestoそれぞれで使える関数 HIVEは、parse_url Prestoは、url_extract_*** が関数として用意されている HIVE parse_url(string urlString, string partToExtract [, string keyToExtract]) 第一引数にURL、第二引数に抽出したい箇所を入力する 第三引数は特定のクエリパラメータだけを抽出したいときに利用する 第二引数に指定できるのは、 HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO の8つ URL:http://user:password@example.com:8888/index.html?query1=aaa&query2=bbb#hash に対して実行した場合 hive_sample.sql SELECT t1.URL, parse_url(t1.URL,'HOST') as HOST, parse_url(t1.URL,'PATH') as PATH, parse_url(t1.URL,'QUERY') as QUERY, parse_url(t1.URL,'QUERY','query1') as QUERY1, parse_url(t1.URL,'REF') as REF, parse_url(t1.URL,'PROTOCOL') as PROTOCOL, parse_url(t1.URL,'AUTHORITY') as AUTHORITY, parse_url(t1.URL,'FILE') as FILE, parse_url(t1.URL,'USERINFO') as USERINFO FROM (SELECT 'http://user:password@example.com:8888/index.html?query1=aaa&query2=bbb#hash' as URL) t1 ↓ 実行結果 Column Value URL http://user:password@example.com:8888/index.html?query1=aaa&query2=bbb#hash HOST example.com PATH /index.html QUERY query1=aaa&query2=bbb QUERY1 aaa REF hash PROTCOL http AUTHORITY user:password@example.com:8888 FILE /index.html?query1=aaa&query2=bbb USERINFO user:password Presto url_extract_host(string urlString) url_extract_fragment(url) url_extract_path(url) url_extract_port(url) url_extract_protocol(url) url_extract_query(url) url_extract_parameter(url, name) 例えば サイト内検索クエリを抽出したい場合 ■HIVE parse_url('http://example.com/search?q=book&page=1','QUERY','q') → book ■Presto url_extract_parameter('http://example.com/search?q=book&page=1','q') → book 参考 LanguageManual UDF — Hive Operators and User-Defined Functions (UDFs) https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF 6.18. URL Functions — Presto 0.187 Documentation https://prestodb.io/docs/current/functions/url.html
アクセスログの解析を行う上でURLから一部だけ抽出する処理ががよくあるので、 その場合に利用できるHIVE、Prestoの関数と利用例をまとめてみました
HIVEは、parse_url Prestoは、url_extract_*** が関数として用意されている
parse_url
url_extract_***
parse_url(string urlString, string partToExtract [, string keyToExtract])
第一引数にURL、第二引数に抽出したい箇所を入力する 第三引数は特定のクエリパラメータだけを抽出したいときに利用する
第二引数に指定できるのは、 HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO の8つ
HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO
URL:http://user:password@example.com:8888/index.html?query1=aaa&query2=bbb#hash に対して実行した場合
SELECT t1.URL, parse_url(t1.URL,'HOST') as HOST, parse_url(t1.URL,'PATH') as PATH, parse_url(t1.URL,'QUERY') as QUERY, parse_url(t1.URL,'QUERY','query1') as QUERY1, parse_url(t1.URL,'REF') as REF, parse_url(t1.URL,'PROTOCOL') as PROTOCOL, parse_url(t1.URL,'AUTHORITY') as AUTHORITY, parse_url(t1.URL,'FILE') as FILE, parse_url(t1.URL,'USERINFO') as USERINFO FROM (SELECT 'http://user:password@example.com:8888/index.html?query1=aaa&query2=bbb#hash' as URL) t1
↓ 実行結果
url_extract_host(string urlString) url_extract_fragment(url) url_extract_path(url) url_extract_port(url) url_extract_protocol(url) url_extract_query(url) url_extract_parameter(url, name)
url_extract_host(string urlString)
url_extract_fragment(url)
url_extract_path(url)
url_extract_port(url)
url_extract_protocol(url)
url_extract_query(url)
url_extract_parameter(url, name)
■HIVE parse_url('http://example.com/search?q=book&page=1','QUERY','q') → book ■Presto url_extract_parameter('http://example.com/search?q=book&page=1','q') → book
parse_url('http://example.com/search?q=book&page=1','QUERY','q')
url_extract_parameter('http://example.com/search?q=book&page=1','q')
LanguageManual UDF — Hive Operators and User-Defined Functions (UDFs) https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
6.18. URL Functions — Presto 0.187 Documentation https://prestodb.io/docs/current/functions/url.html
カラムを追加するべきか別テーブルとして切り出すべきかの指針をまとめる。 カラムを追加する メリット 運用が楽(SQLでJOINする必要がない) 用意に1対1の関係性が担保できる デメリット カラム数が増えて分かりづらくなる 別テーブルをつくる メリット 1対Nの関係をとれる 既存のテーブルを使った処理に影響を与えない デメリット 運用が大変(SQLでJOINする必要がある) 指針 以下の場合は別テーブルとして分けた方が良い。逆にそれ以外の場合はカラム追加で大丈夫。 - 1対Nの関係になるとき - 履歴を管理したいとき - 追加カラム数が多いとき
カラムを追加するべきか別テーブルとして切り出すべきかの指針をまとめる。
以下の場合は別テーブルとして分けた方が良い。逆にそれ以外の場合はカラム追加で大丈夫。 - 1対Nの関係になるとき - 履歴を管理したいとき - 追加カラム数が多いとき
この記事はざっくりと正規化を説明する記事です。情報の不足は多々ありますが、正規化を理解する導入になれば幸いです。 正規化とは? データの重複を無くすことです。 例:社員テーブル これは各社員のデータを保存する「社員テーブル」です。 この社員テーブルには重複するデータ、「所属部署」の列が存在します。正規化のためには、この列を改変する必要があります。 データの重複を解消するために、別テーブルの「部署テーブル」を用意しました。 部署テーブル側では各部署名に「部署ID」を設定します。 社員テーブル側では各社員に「部署ID」を与えます。 これで部署名の重複が解消されました。これが正規化です。 なぜ正規化が必要? さきほどの例をもとに、正規化しなかった場合と正規化していた場合とを比較します。 正規化しなかった場合 仮に「コールセンター課」を「カスタマーサービス課」に改名するとした場合どうでしょうか? 各社員の行にある「コールセンター課」を、すべて「カスタマーサービス課」に変えなければなりません。 つまり、社員全員分の部署名を確認→改変することになります。 正規化した場合 正規化していた場合は簡単です。 「部署テーブル」にある「コールセンター課」を「カスタマーサービス課」に改名するだけです。 まとめ 正規化しなかった場合は社員テーブルの全行を検索・更新する必要があります。 対して正規化していた場合は、ほんの数行の部署テーブルを検索して、たった一行を更新するだけで済みます。 どちらが負荷の軽い処理であるかは明らかです。 リレーショナルデータベースを使うときは正規化しましょう! おまけ:NoSQLって? リレーショナルデータベースと正規化は万能ですが、全能ではありません。 例えば、超高速な動作が欲しい、あるいはデータ構造の自由度が欲しい場合、リレーショナルデータベースはベストな選択ではない場合があります。 そういった要求のために、あえて正規化やリレーションを捨て、特定の事柄に特化したデータベースが存在します。それがNoSQLです。 数多の種類と、それぞれに特化した能力があるため一口では言えません。 もしリレーショナルデータベースに不足を感じたら、調べてみてはいかがでしょうか?
この記事はざっくりと正規化を説明する記事です。情報の不足は多々ありますが、正規化を理解する導入になれば幸いです。
データの重複を無くすことです。
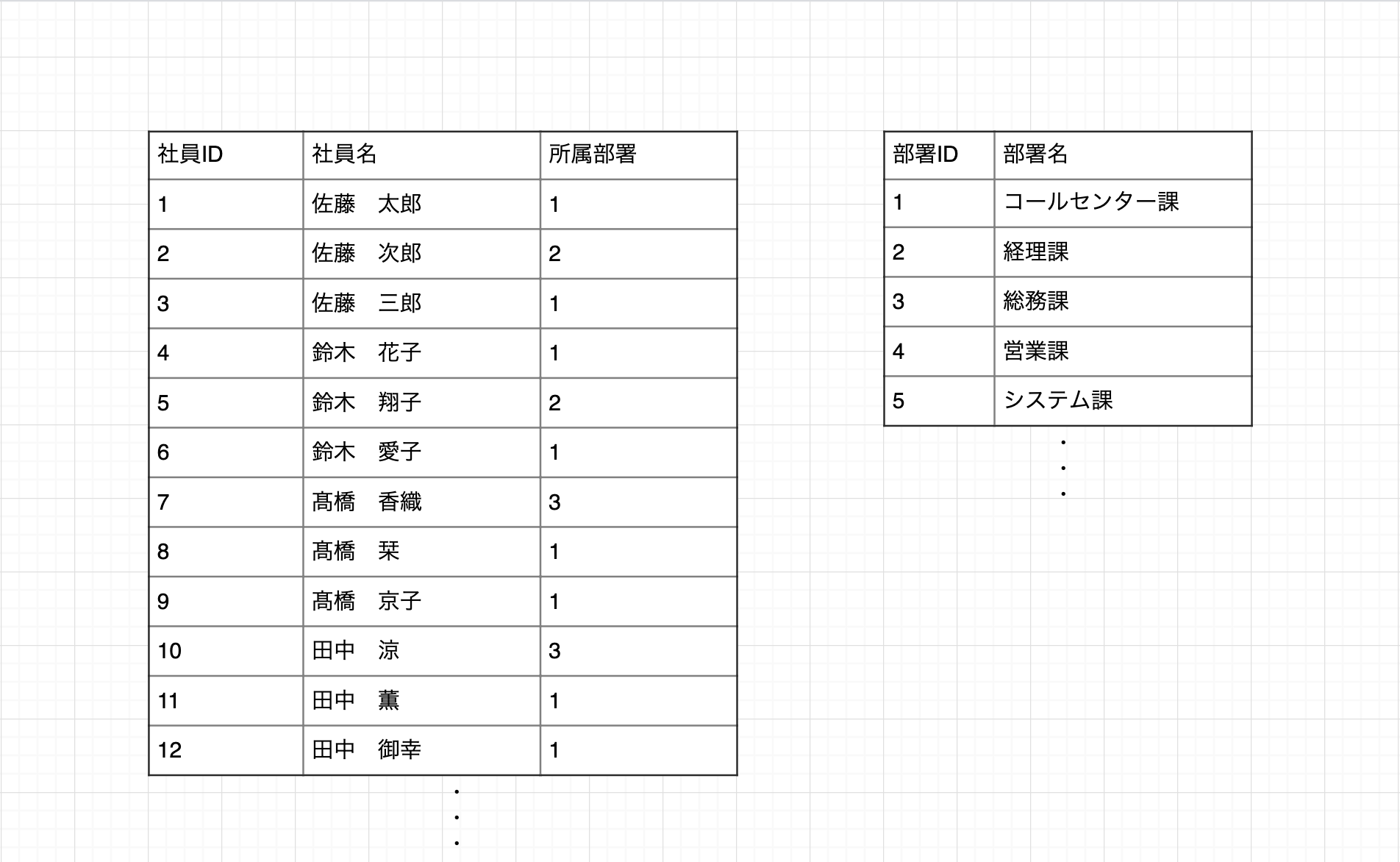
例:社員テーブル これは各社員のデータを保存する「社員テーブル」です。 この社員テーブルには重複するデータ、「所属部署」の列が存在します。正規化のためには、この列を改変する必要があります。
データの重複を解消するために、別テーブルの「部署テーブル」を用意しました。 部署テーブル側では各部署名に「部署ID」を設定します。 社員テーブル側では各社員に「部署ID」を与えます。 これで部署名の重複が解消されました。これが正規化です。
さきほどの例をもとに、正規化しなかった場合と正規化していた場合とを比較します。
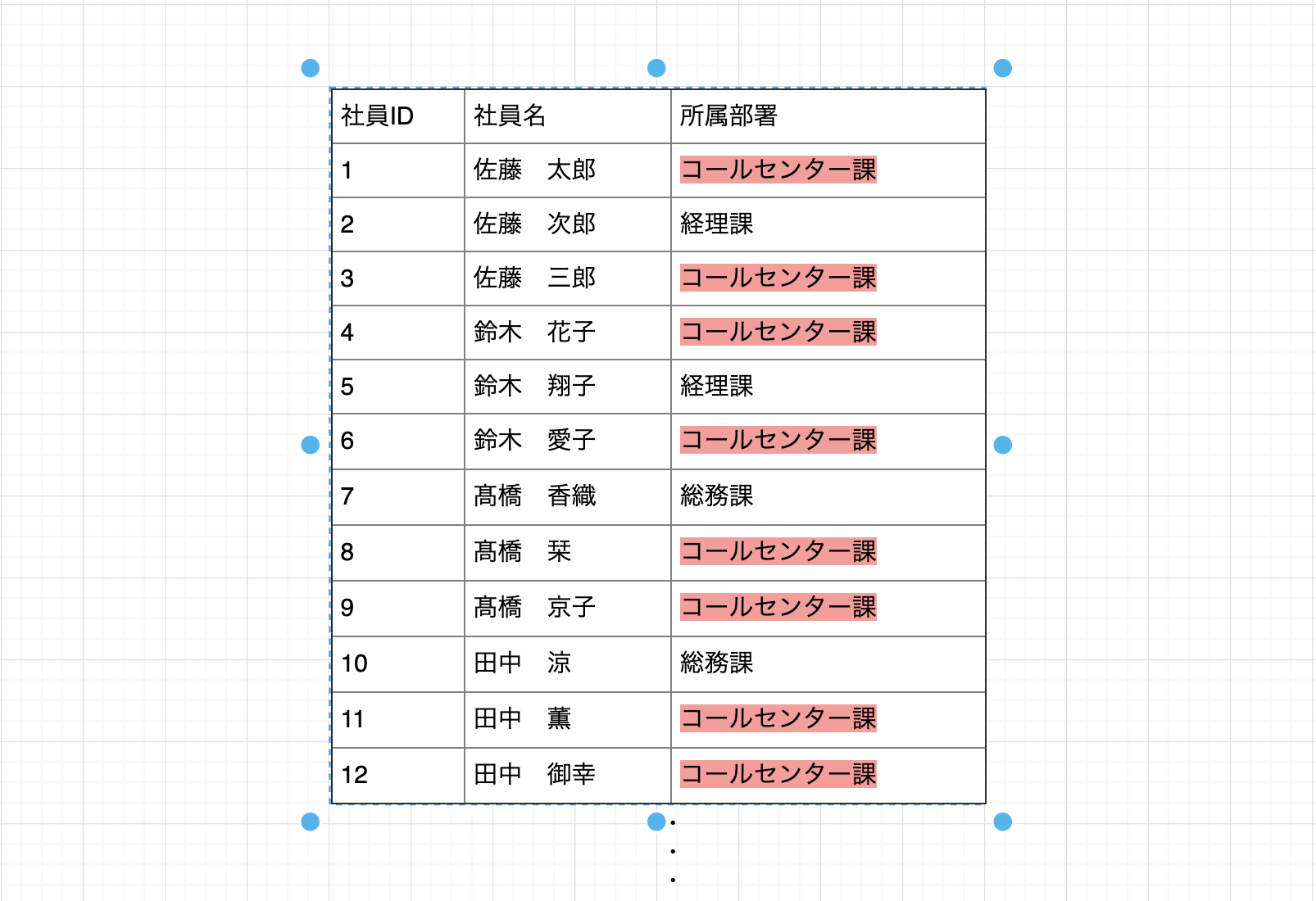
正規化しなかった場合 仮に「コールセンター課」を「カスタマーサービス課」に改名するとした場合どうでしょうか? 各社員の行にある「コールセンター課」を、すべて「カスタマーサービス課」に変えなければなりません。 つまり、社員全員分の部署名を確認→改変することになります。
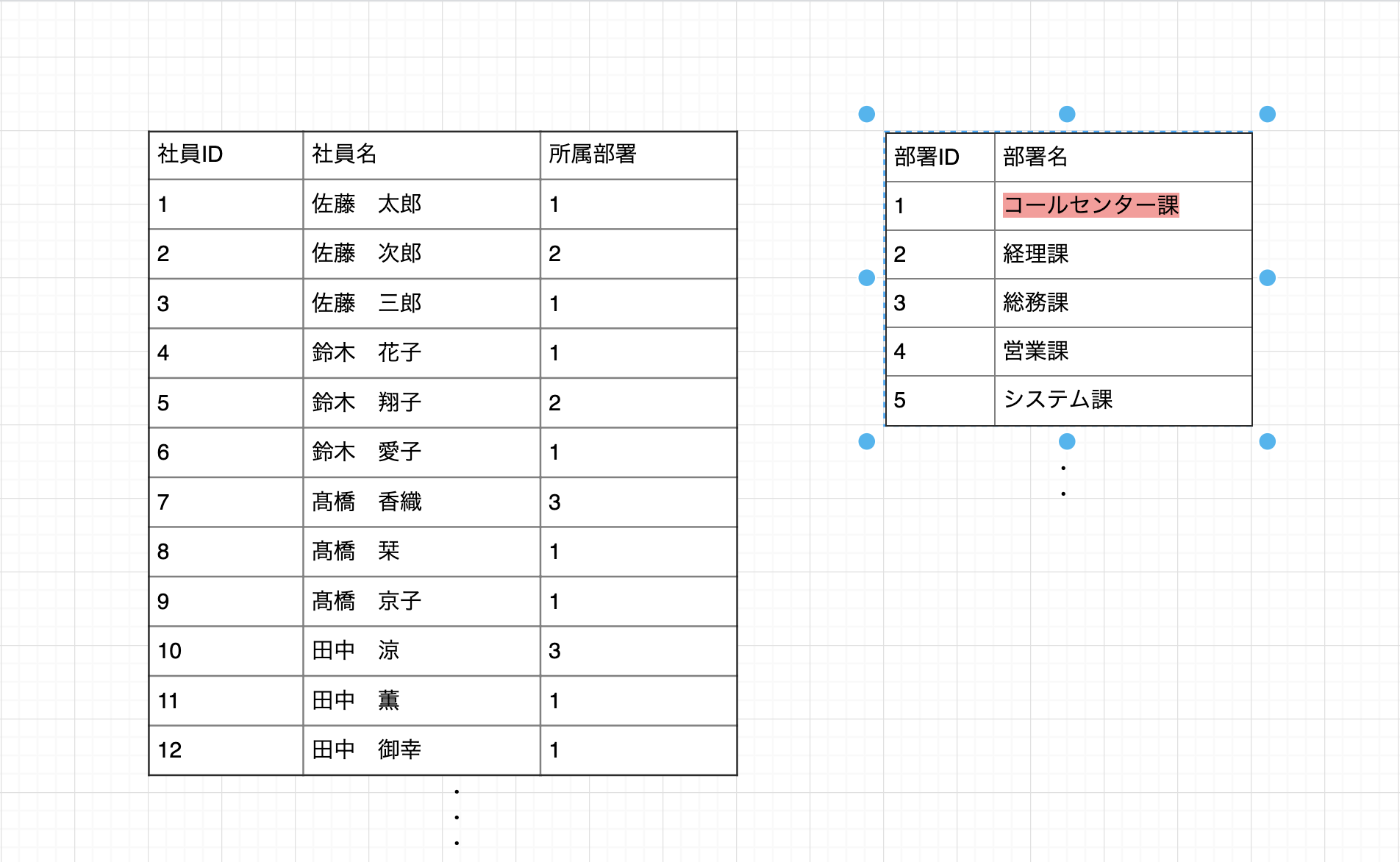
正規化した場合 正規化していた場合は簡単です。 「部署テーブル」にある「コールセンター課」を「カスタマーサービス課」に改名するだけです。
正規化しなかった場合は社員テーブルの全行を検索・更新する必要があります。 対して正規化していた場合は、ほんの数行の部署テーブルを検索して、たった一行を更新するだけで済みます。 どちらが負荷の軽い処理であるかは明らかです。
リレーショナルデータベースを使うときは正規化しましょう!
リレーショナルデータベースと正規化は万能ですが、全能ではありません。 例えば、超高速な動作が欲しい、あるいはデータ構造の自由度が欲しい場合、リレーショナルデータベースはベストな選択ではない場合があります。 そういった要求のために、あえて正規化やリレーションを捨て、特定の事柄に特化したデータベースが存在します。それがNoSQLです。 数多の種類と、それぞれに特化した能力があるため一口では言えません。 もしリレーショナルデータベースに不足を感じたら、調べてみてはいかがでしょうか?