- 投稿日:2019-05-24T23:18:24+09:00
Python個人的メモその2:データ構造編~あなたの目的に狙いを決めて~
はじめに
Python個人的メモその1:入力編~標準入力とファイルからの入力~では最も重要となる入力を扱いました.
では,その次に重要なものとは?
出力ですかね? いやいやデータ構造の方が重要でしょうが!!!!(出力は後にまとめます)ここでいうデータ構造とは,リストやdictなど,複数の値を一括で管理するようなものを指します.
リスト
最もオーソドックスなデータ構造と言えるでしょう.他の言語で言うと「要素数可変な配列」といったところです.
初期化は,[]かlist()です.どっちでもよいですがlist()の方がパッと見て分かりやすいようなそうでもないような気がします.
複数の値が連続して入っており,0からカウントを始め,頭からi番目の要素はリスト名[i]でアクセスします.
後ろに要素を追加したい時はリスト名.append(新要素)とします.要素数はlen(配列名)です.
ちなみに,一番後方に何か操作を加えるのは問題ないのですが,先頭に対してそれをやるのはあまりにも遅すぎるのでやらない方がいいです.list_samplel = [1,2,3,4] print(l[2]) #3 l.append(5) print(l) #[1,2,3,4,5] print(len(l)) #5deque
リストとほぼ同じ扱い方をしますが,こちらは先頭からの取り出し・削除を高速にできます.
つまり,両端から追加・削除が必要な場合に使います.
また,初期化時にmaxlenを用いると,保持する要素数を制限でき,新たに要素を追加し制限を超過した際,追加した側とは反対側の要素から順に勝手に削除してくれます.deque_samplefrom collections import deque d=deque(maxlen=2) #右側追加 d.append(3) #左側追加 d.appendleft(5) print(d) #deque([5,3]) d.append(7) print(d) #deque([3,7]) 右から入れたので左端が押し出されたheapq
ソート用の値「キー」と保存しておきたいデータをセットで入れておきます.
内部ではヒープ構造(今回は説明を省きます)によって常に最小のキーを持つデータが先頭に来るようになっているので,popでいつでも最小値を取り出せます.しかしそれ以外のデータの順序は不明なので注意が必要.heapq_sampleimport heapq hq = [] key = h(x) #キーはソートに用いるので整数がオーソドックスかと heapq.heappush(hq, (key, x)) min_key, y = heapq.heappop(hq)#キー,データの順defaultdict
アクセス用のキーと,それに対応するデータをセットで入れておける構造です.
例えば,人の名前をキー,その人の電話番号を値としてphone_numという名前で管理しておくと,
Aさんの電話番号を知りたいときphone_num["A"]でアクセスできるわけです.
ここまではdictという機能でもできますが,dictは都度キーに対して初期化が必要になります.存在しないキーに対するアクセスはエラーになります.つまり,Bさんの電話番号を登録していない(Bというキーが存在していない)のに
phone_num["B"]にアクセスしてはいけないのです.
defaultdictでは初期化処理を予め決めておくことで,これを防ぐことができます.
例えばデータの型をstrとしてdefaultdictを用いるのであればこのようになります.defaultdict_samplefrom collections import defaultdict dd=defaultdict(str) dd["aaa"] = "rrr" #とりあえず存在するキーに対してアクセス dd["aaa"] += "444" print(dd["aaa"]) #"rrr444" #存在しないキーにアクセス dd["eee"] += "111" print(dd["eee"]) # "111"ちなみにデータを入れた順序は保証されません.
set(集合)
set型という,集合を取り扱える型があります.
例えばA,Bという集合に対する和(AまたはBに属する),差(Aに属するがBに属さない),積(AにもBにも属する)や,
片方が片方の部分集合か,などの演算ができます.
また,リストとは異なり要素は重複しません.つまり,同じ要素が2つ以上存在する場合,1つを除いて勝手に削除します.
さらに,データを入れた順序は保証されません.
データは変更可能ですが変更不能のものがいい場合,frozensetという型もあります.set_samples={}#set()でも可 s.add(3) s.add(3) s.add(2) s.add(5) print(s) #{2,3,5} #積集合 print(s & {1,3}) #{3} #削除 s.remove(3) print(s) #{2,5} #すべて削除 s.clear()おわりに
よく使うPythonのデータ構造はこのあたりかな,という感じです.
あとは木構造とかグラフ構造がデフォルトであればなあと使ってて思います.
一応ライブラリはありますが,自分で実装しなければいけない場面は多々あると思うので省略します.
- 投稿日:2019-05-24T22:59:46+09:00
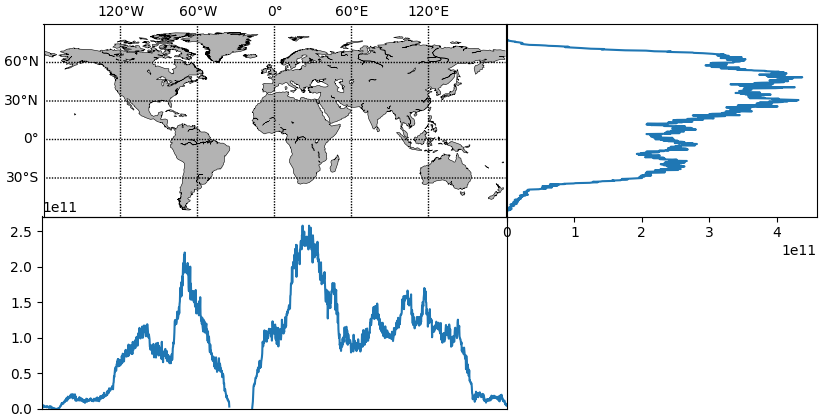
世界地図・その右と下にグラフを描く
論文用の画像を作るためのテンプレートのメモ.
真ん中:世界地図,右と下:緯度・経度ごとの陸地面積.
若干枠線がズレるのはなぜ?
map_right_bottom.pyimport numpy as np import matplotlib.pyplot as plt from matplotlib.gridspec import GridSpec from mpl_toolkits.basemap import Basemap north, south, dlat = 90.0, -60.0, 30.0 east , west , dlon = 180.0, -180.0, 60.0 def gen_axes(figWidth=10.0, rightWidth=4.0, bottomHeight=2.5): ''' center|right ------ bottom ''' centerWidth = figWidth - rightWidth centerHeight = centerWidth * (north - south) / (east - west) figHeight = centerHeight + bottomHeight fig = plt.figure(figsize=(figWidth, figHeight)) gs = GridSpec(2, 2, width_ratios=(centerWidth,rightWidth), height_ratios=(centerHeight,bottomHeight), wspace=0.0, hspace=0.0) return [plt.subplot(gs[0,0]), plt.subplot(gs[0,1]), plt.subplot(gs[1,0])] # center, right, bottom def center_map(ax): m = Basemap(llcrnrlon=west, llcrnrlat=south, urcrnrlon=east, urcrnrlat=north, ax=ax) m.drawcoastlines(linewidth=.4) m.fillcontinents(color='0.7') m.drawparallels(np.arange(south+dlat,north,dlat), labels=[1,0,0,0]) m.drawmeridians(np.arange(west +dlon,east ,dlon), labels=[0,0,1,0]) return def right_plot(ax, data): ax.plot(data, np.arange(len(data))[::-1]) left, right = ax.get_xlim() left = 0 ax.set_xlim(left=left, right=right) ax.hlines(y=range(120, 720, 120), xmin=left, xmax=right, linestyles=':', linewidth=1.0) ax.set_ylim(0, len(data)) ax.tick_params(left=False, right=False) ax.tick_params(labelleft=False, labelright=False) return def bottom_plot(ax, data): ax.plot(data) ax.set_xlim(0, len(data)) bottom, top = ax.get_ylim() bottom = 0 ax.set_ylim(top=top, bottom=bottom) ax.vlines(x=range(240, 1440, 240), ymin=bottom, ymax=top, linestyles=':', linewidth=1.0) ax.tick_params(top=False, bottom=False) ax.tick_params(labeltop=False, labelbottom=False) ax.set_facecolor((0.0, 0.0, 0.0, 0.0)) def main(*args): landMap = # グリッドごとの陸地面積マップ landMap = np.ma.masked_less_equal(landMap, 0.0) landLat = landMap.sum(axis=1) landLon = landMap.sum(axis=0) axs = gen_axes() center_map (axs[0]) right_plot (axs[1], landLat) bottom_plot(axs[2], landLon) plt.show()
- 投稿日:2019-05-24T22:57:16+09:00
結局Pythonのフレームワークは何を使えば良いの? [Flask vs Django]2019
はじめに
機械学習やら色々な新しい事を実践的に試すべく
エロサイトを開発中。モトダチ
開発実践用にオープンしているので広告は入っておりませんのでお気軽にどうぞ。
色々工夫したアプリケーションの作りになっているのでレスポンスは速いはず。自分への忘備録も含めてFlaskの知識をまとめてみたいと思います。
Flaskについて
最近はPythonが人気沸騰中だと思います。
Pythonの中でWEBフレームワークといえばDjangoとFlaskの2トップだと思います。
ほとんどの人がPythonでウェブアプリを構築する場合その2つのどちらかを選択するのかな、と。Flask VS Django問題
Pythonアプリを作りたいけどDjangoとFlaskのどっちが良いの?という疑問はよく起こります。
僕も最初は迷いました。
まぁ極端なことを言えば作りたいものに合わせて選択してね?ってことだと思うんだけどそれは酷ってもんですよね。
そこに回答はないんですよ。
・どのようなPythonアプリを作りたいか
・どのような規模のアプリケーションになるか
・どのような人がコーディングをするかこの記事では迷ってるんだよねって人への一助になればと思います。
Flaskについて
まずはじめにFlaskの特徴を。
Flaskはマイクロフレームワークで軽量で最小の機能しか備わってないということが最大の特徴です。(最小だったり最大だったりややこしいw)
機能があまり含まれていないので色々自由が効き、簡単に習得することができます。
もちろんライブラリを追加することで様々な機能を使うことができます。
Djangoについて
Djangoはデフォルトで必要な機能を持ち合わせたフレームワーク。
認証、管理画面、RSSフィードなどよく使われる機能があらかじめ含まれています。
既存機能をサクッと導入したい場合は速い反面、初心者やフレームワークに慣れてない人にとってはとっつきにくい面があります。
Flaskを使うと良いケース
・簡単なウェブアプリをサクッと開発したい
・REST APIを開発したい
・Pythonをつつき始めたばかりの初心者
・その他ウェブ言語でフレームワークを使用したことがない方
・HP+フォームなどのシンプルなページを実装したい方Djangoを使うと良いケース
・認証や管理画面があるようなガッツリとしたウェブアプリを作りたい方
・今までその他ウェブ言語でフレームワークを使用したことがある方
・MVCでの開発経験がある方最後に
最初に挙げたモトダチはFlaskで構築してます。
Pythonのウェブアプリケーションは初めてでしたがサクサクと進める事ができました。色々意見頂けると開発のモチベーションが上がります。
何かあればぜひコメント下さい。
- 投稿日:2019-05-24T22:39:30+09:00
覚えたての転移学習を使って上白石萌歌さんと上白石萌音さんを分類してみた話
はじめまして!!
つい1ヶ月ほど前から深層学習とPyTorchの勉強をはじめたidachiです!!
これから勉強したものをアウトプットするために記事を書いていこうと思うのでよろしくお願いします!!(不定期)
今回は転移学習について勉強し、PyTorchのチュートリアルや他の人の記事を参考に実装してみました。
転移学習とは
以下の記事を参考に勉強しました。
転移学習:機械学習の次のフロンティアへの招待
Kerasで学ぶ転移学習
ざっくり僕なりの言葉でまとめると、低次の特徴量(月だと丸いとか?)はいろんなところで使い回せるのでそれは学習してある重みを使えばよく、高次の特徴量(クレーターがあるとか?)はその物体特有の特徴量なのでそこだけ学習し直すことで、少ないデータ量で速く学習を終わらすことができるものが転移学習...なんですかね?今回やりたいこと
突然ですが、僕は上白石萌歌さんが大好きです!!本気で好きです!!
ということで、上白石萌歌さんと上白石萌音さんを分類できるようにしたい!となりました。(は?)やるべきことは大まかに以下の2つとなります。
1. 上白石萌歌さん(以下moka)と上白石萌音さん(以下mone)のデータセットを作成する(スクレイピング)
2. 転移学習をPyTorchで実装するこれからこの2つについて書いていきます。
データ収集
(以下のコードはjupyter notebook上で実行)
これが一番時間かかりました。かなり苦労しました。
とりあえず 上白石萌歌 画像 だったり 上白石萌音 画像 と調べたりして、使えそうな画像がたくさんあるサイトを探したりしたのですが、あまりいいサイトが見つからなかったので、結局Yahoo画像検索を使うことにしました。
スクレイピングのコードは以下。
(browser.get()のurlは適宜変えれば良い)from selenium import webdriver import io from urllib import request from PIL import Image browser = webdriver.Safari() browser.get("https://ord.yahoo.co.jp/o/image/RV=1/RU=aHR0cHM6Ly9zZWFyY2gueWFob28uY28uanAvd2ViL3NhdmVwcmVmP3ByZWZfZG9uZT1odHRwcyUzQSUyRiUyRnNlYXJjaC55YWhvby5jby5qcCUyRmltYWdlJTJGc2VhcmNoJTNGcCUzRCUyNUU0JTI1QjglMjU4QSUyNUU3JTI1OTklMjVCRCUyNUU3JTI1OUYlMjVCMyUyNUU4JTI1OTAlMjU4QyUyNUU5JTI1OUYlMjVCMyUyNnJrZiUzRDElMjZkaW0lM0QlMjZjdHlwZSUzRGZhY2UlMjZpbXclM0QwJTI2aW1oJTNEMCUyNmltYyUzRCUyNmVpJTNEVVRGLTgmaW1zcmNoX2RzPTE-;_ylt=A2RCL5i6xedc1B0AkAGU3uV7") elems = [] tbs = [] #一ページ目の処理 #一ページ目は 次へ しか表示されない tbs = browser.find_elements_by_class_name("tb") for tb in tbs: tb = tb.find_element_by_tag_name("img").get_attribute("src") elems.append(tb) ref = browser.find_element_by_id("Sp1") ref = ref.find_element_by_class_name("m") ref = ref.find_element_by_tag_name("a").get_attribute("href") browser.get(ref) #二ページ目のは 前へ と 次へ しか表示されない for i in range(1, 15): tbs = [] tbs = browser.find_elements_by_class_name("tb") for tb in tbs: tb = tb.find_element_by_tag_name("img").get_attribute("src") elems.append(tb) ref = browser.find_element_by_id("Sp1") ref = ref.find_elements_by_class_name("m") ref = ref[1].find_element_by_tag_name("a").get_attribute("href") browser.get(ref) fs = [] for elem in elems: try: fs.append(io.BytesIO(request.urlopen(elem).read())) except: continue for index, f in enumerate(fs): img = Image.open(f) try: img.save('Image/img{}.jpg'.format(index)) except: continueとりあえずここまでで画像の収集は完了。ここからは収集した画像から顔だけを切り抜いていく。
顔の切り抜きは、OpenCV2を使用した。
以下のサイトからコードをお借りしました。
大量の画像から顔の部分のみトリミングして保存する方法
コードは以下。
(カスケードファイルがどこにあるかわからない場合は
https://github.com/opencv/opencv/tree/master/data/haarcascades
からカスケードファイルをダウンロードして自分の置きたい場所に置けば良い)import cv2 import matplotlib.pyplot as plt import numpy as np import sys, os from PIL import Image %matplotlib inline #入力ファイルのパスを指定 in_jpg = "./mone/" out_jpg = "./mone_out/" #リストで結果を返す関数 def get_file(dir_path): filenames = os.listdir(dir_path) return filenames pic = get_file(in_jpg) for i in pic: # 画像の読み込み image_gs = cv2.imread(in_jpg + i) # 顔認識用特徴量ファイルを読み込む --- (カスケードファイルのパスを指定) cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt.xml") # 顔認識の実行 face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1)) # 顔だけ切り出して保存 no = 1; for rect in face_list: x = rect[0] y = rect[1] width = rect[2] height = rect[3] dst = image_gs[y:y + height, x:x + width] save_path = out_jpg + '/' + 'out_(' + str(i) +')' + str(no) + '.jpg' #認識結果の保存 a = cv2.imwrite(save_path, dst) plt.show(plt.imshow(np.asarray(Image.open(save_path)))) print(no) no += 1ここまででやっと顔面データセットが完成です!!
顔を見すぎて混乱してきました・・・転移学習させてみる
以下のサイトを参考にしました。
TRANSFER LEARNING TUTORIAL
PyTorch (9) Transfer Learning (Dogs vs Cats)
Google Colaboratoryで実行しました。
(https://colab.research.google.com/drive/1hhgzPhzFxUeKC-jFsEXCc0BDo261Xcv8)VGG16を使って転移学習をやってみた。
結果
epoch 0, loss: 0.7737 val_loss: 0.6472 val_acc: 0.5333 val_acc improved from 0.00000 to 0.53333! epoch 1, loss: 0.7488 val_loss: 0.5552 val_acc: 0.7333 val_acc improved from 0.53333 to 0.73333! epoch 2, loss: 0.6776 val_loss: 0.6033 val_acc: 0.6667 epoch 3, loss: 0.6643 val_loss: 0.4808 val_acc: 0.8000 val_acc improved from 0.73333 to 0.80000! epoch 4, loss: 0.6296 val_loss: 0.6594 val_acc: 0.6000 epoch 5, loss: 0.7010 val_loss: 0.4576 val_acc: 0.7333 epoch 6, loss: 0.5446 val_loss: 0.4440 val_acc: 0.7667 epoch 7, loss: 0.5787 val_loss: 0.4283 val_acc: 0.8333 val_acc improved from 0.80000 to 0.83333! epoch 8, loss: 0.5084 val_loss: 0.4287 val_acc: 0.9000 val_acc improved from 0.83333 to 0.90000! epoch 9, loss: 0.5290 val_loss: 0.5065 val_acc: 0.7333 epoch 10, loss: 0.5405 val_loss: 0.4559 val_acc: 0.8000 epoch 11, loss: 0.5156 val_loss: 0.4661 val_acc: 0.8000 epoch 12, loss: 0.5797 val_loss: 0.4679 val_acc: 0.7667 epoch 13, loss: 0.5404 val_loss: 0.4361 val_acc: 0.8667 epoch 14, loss: 0.5209 val_loss: 0.4413 val_acc: 0.8333 epoch 15, loss: 0.5192 val_loss: 0.4349 val_acc: 0.7667 epoch 16, loss: 0.5288 val_loss: 0.5070 val_acc: 0.7000 epoch 17, loss: 0.5752 val_loss: 0.4322 val_acc: 0.8000 epoch 18, loss: 0.5562 val_loss: 0.3914 val_acc: 0.8667 epoch 19, loss: 0.5750 val_loss: 0.3962 val_acc: 0.8667 epoch 20, loss: 0.5043 val_loss: 0.5074 val_acc: 0.7333 epoch 21, loss: 0.5454 val_loss: 0.3975 val_acc: 0.9000 epoch 22, loss: 0.4642 val_loss: 0.4125 val_acc: 0.8333 epoch 23, loss: 0.4313 val_loss: 0.3846 val_acc: 0.8333 epoch 24, loss: 0.4801 val_loss: 0.3881 val_acc: 0.8000 epoch 25, loss: 0.4927 val_loss: 0.4130 val_acc: 0.8000 epoch 26, loss: 0.4634 val_loss: 0.4261 val_acc: 0.8667 epoch 27, loss: 0.4777 val_loss: 0.4104 val_acc: 0.8667 epoch 28, loss: 0.5163 val_loss: 0.4168 val_acc: 0.8333 epoch 29, loss: 0.4600 val_loss: 0.4135 val_acc: 0.8667validationに対しての最高精度は90%となりました!!
データ数が少ない割には良い結果がでたのではないでしょうか。実際にテストしてみる
テストした画像達は以下。
実際にテストして、結果をmoneとmokaに分離して表示してみると、以下のようになった。
moneの方は割と良い結果なのではないでしょうか!
mokaの方は良い結果とはいえないですね...まとめ
今回は転移学習について勉強し、PyTorchでの実装までをやってみました。
結果に関してはまずまずといった感じなのでしょうか。
改善策としては、画像を増やす(前処理で左右反転とかしたら画像の水増しができそう)だったり、過学習気味かもしれないので他の重みを使うだったりが思いつきます。今回はこれで終わりです。
未熟なのでいろんなところにトンチンカンなことが書いてあるかもしれません。
見つけたら教えていただけると嬉しいです。次回やることはまだ未定ですが、どうにか続けていきたいです。それでは!
次回できました!!



- 投稿日:2019-05-24T22:12:54+09:00
PythonでGoogleCloudStorageへファイルをアップロード・ダウンロードする方法
まず最初に準備(サービスアカウント、バケット作成)
まずはこの記事を参考に以下のことをやります。
GoogleCloudStorageでPythonからファイルをやりとりする方法
- サービスアカウントの作成(API)
- クラウドストレージでバケットを作成サービスアカウント作成時に、役割が「ストレージ管理者」になっていますが自分はそれが選べなかったので、「オーナー」にしました。
全リソースへのアクセス権限があるみたいなので迷ったらこれでいいのではないでしょうか。
PythonでGoogleCloudStorageを操作
Googleクラウドのパッケージをインストールします。
sudo pip install --upgrade google-cloud以下のスクリプトでバケットにローカルファイルのアップロードと、バケットからのダウンロードが可能です。
import os from google.cloud import storage #クラウドストレージ(バケット)に接続 os.environ["GOOGLE_APPLICATION_CREDENTIALS"]='キーファイルパス(Json)' client = storage.Client() bucket = client.get_bucket('バケット名') #ファイルをアップロード blob = bucket.blob('保存ファイル名') blob.upload_from_filename(filename='ローカルファイルパス') #アップロードしたファイルをダウンロード blob2 = bucket.get_blob('取得ファイル名') print(blob2.download_as_string())以下のエラーが出た場合(No module named 'google.api_core.client_info')
自分の場合はここで以下のエラーが出て先に進めなかったのですが、
ModuleNotFoundError: No module named 'google.api_core.client_info'pythonの仮想環境を構築し、そこにライブラリをインストールすることで正常に動きました。
venv: Python 仮想環境管理$ python3 -m venv venv $ source venv/bin/activate $ venv/bin/pip install --upgrade google-cloud $ pip install google.cloud.storageこれらのコマンド打った後に、実行したら無事に操作できました。
次にやりたいこと
- pythonのウェブフレームワークを使用して、簡単な文字起こしサービスを作成
- まずはローカルからではなくwebからアップロードしたものをバケットに送れるようにする
- Cloud Speech-to-Text を使用
- 今回はテキストファイルを用いたが、課題は結構アップロードからダウンロードまで時間がかかったこと
- 長い音声ファイルを場合のレスポンス。。
- 投稿日:2019-05-24T21:36:40+09:00
Flaskで「Hello World」を出力させる
はじめに
未来電子テクノロジーでインターンをしている松井です。
*プログラミング初心者であるため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するのでどんどん指摘してください。Flaskのインストール
Flaskをpipでインストールします。
$pip install flask $python3 >>> import flask >>> flask.__version__ '1.0.2'プログラムを書く
server.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'Hello World' if __name__ == '__main__': app.debug = True app.run(host='0.0.0.0', port=8000)プログラムを実行する
$python3 server.pyをコンソールで実行します。
次にRunning on http://0.0.0.0:8000/を見つけて、http://0.0.0.0:8000/の部分をコピーします。
それをGoogleで接続すると、Hello Worldと出力されます。簡単でしたね。
returnの部分をいじると、HTMLファイルなども表示できます。
ぜひ、いろいろ調べてみてください。
- 投稿日:2019-05-24T21:07:47+09:00
Python + mysql-connector-python の使い方まとめ
最近、docker と python ばかり弄り回しているのですが、pythonの構文ってすごい気持ちいがいいですよね。
プログラム経験がそこまで高くないので、今までは、Typescriptが一番気持ちがいいプログラム言語だと思っていたのですが、Pythonの楽な構文と見通しの良さとipythonでその場で実行してプログラムを確認できる環境にとても幸せを感じています。笑
ちょっとMYSQLを触っていたので、mysqlとpythonを繋げるmysql-connector-pythonの使い方を忘れないようにするためのメモ書きです。
参考サイト
https://basicincome30.com/python3-mysql-connectorimport mysql.connector # コネクションの作成 conn = mysql.connector.connect( host='hostname', port='3306', user='username', password='password', database='dbname' )これだけで、mysqlと接続完了接続。楽!!!
dockerを使っているなら、hostnameは、mysqlの起動しているドッカーコンテナのコンテナ名にすればOK。# コネクションが切れた時に再接続してくれるよう設定 conn.ping(reconnect=True) # 接続できているかどうか確認 print(conn.is_connected())mysqlは一定時間接続がないと止まるみたいなので、pingを送って接続が途切れないようにしておく。
接続確認も簡単。テーブル作成
# DB操作用にカーソルを作成 cur = conn.cursor() # id, name, priceを持つテーブルを(すでにあればいったん消してから)作成 table = 'test_table' cur.execute("DROP TABLE IF EXISTS `%s`;", table) cur.execute( """ CREATE TABLE IF NOT EXISTS `%s` ( `id` int auto_increment primary key, `name` varchar(50) not null, `price` int(11) not null ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci """, table) )データ挿入(INSERT)
cur.execute("INSERT INTO test_table VALUES (1, 'BTC', 10200)") # プレースホルダを利用して挿入 cur.execute("INSERT INTO test_table VALUES (2, 'ETH', %s)", (5000, )) cur.execute("INSERT INTO test_table VALUES (%s, %s, %s)", (3 ,'XEM', 2500)) cur.execute("INSERT INTO test_table VALUES (%(id)s, %(name)s, %(price)s)", {'id': 4, 'name': 'XRP', 'price': 1000}) # executemanyで複数データを一度に挿入 records = [ (5, 'MONA', 3000), (6, 'XP', 1000), ] cur.executemany("INSERT INTO test_table VALUES (%s, %s, %s)", records)データ選択 (SELECT)
cur.execute("SELECT * FROM test_table ORDER BY id ASC") # 全てのデータを取得 rows = cur.fetchall() for row in rows: print(row) # 出力結果 """ (1, 'BTC', 10200) (2, 'ETH', 5000) (3 ,'XEM', 2500) (4, 'XRP', 1000) (5, 'MONA', 3000) (6, 'XP', 1000) """ # 1件取得 cur.execute("SELECT * FROM test_table WHERE name=%s", ('BTC', )) print(cur.rowcount) print(cur.fetchone()) # 出力結果 """ 1 (1, 'BTC', 10200) """データ更新 (UPDATE)・データ削除 (DELETE)
# UPDATE cur.execute('UPDATE test_table SET name=%s WHERE id=1', ('ビットコイン',)) cur.execute('UPDATE test_table SET name=%s WHERE id=%s', ('イーサリアム', 2)) # DELETE cur.execute('DELETE FROM test_table WHERE id = 3')コネクションを閉じる
# DB操作が終わったらカーソルとコネクションを閉じる cur.close() conn.close()mysql-connector-pythonのいいところは、commitしないくてもデータベースに反映されるところがいいね。
今後はPythonメインでプログラムを書いていきたいから、徹底的に覚えていこう。
- 投稿日:2019-05-24T21:01:17+09:00
Python 事始め 2019 for mac
令和になって人生で初めての負荷試験担当になりました(予定)。
今から死ぬことになるんだろうな、と戦々恐々としながら AWS の負荷試験入門の本(アフェリンクじゃないよ) 読んでます。どうせなら保守 & 保守が辛い jMeter よりも、保守しやすく柔軟性の高いと言われてる Locust を使うことを目標に python 始めました。
python (もとい自分の知らない言語)を始めるにあたり必要になるのは開発環境。
開発環境といえば docker ですよね。
大体下になりました。
- vscode -> ダウンロードする. python 拡張入れるで大体使える。
- docker -> 環境汚さない。バージョン切り替え用意。構築まで早い。好き。
docker は公式にあるものを使います。それが一番早い。
https://hub.docker.com/_/python$ docker pull python:3 $ docker run --rm python:3 python --version Python 3.7.3これで準備おわりです。便利な世の中。
次、作業環境を構築していきます。
Dockerfileの用意、これも公式をパクれば良いです。
若干書き換えてますが、今は気にしないのが大人です。FROM python:3 WORKDIR /usr/src/app COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD [ "pytest", "test.py" ]
Dockerfileで requirements.txt なるものをコピーしてるので用意してあげます。
簡単に調べてみると、これはパッケージ管理用のファイルみたいでした。requirements.txtpytestここまでを build してコンテナ作成します。
$ docker build -t test .よくあるこんにちは世界をやります。
hello/api.pydef hello(): return 'hello world !!' if __name__ == '__main__': print(hello())こんにちはできました!
$ docker run --rm test python hello/api.py hello world !!次、開発にとって大事なテスト導入します。
デフォルトのやつもあるみたいですが、さっきスルーしてもらった pytest がわりかしスマートで良さそうでした。テストするにあたってまず自作関数をモジュールとして読み込めるようにします。
__init__.pyってのを作って定義すればよしなに。hello/__init__.pyfrom .api import ( hello )次にテストファイル
test.pyimport pytest from hello import hello def test_hello(): assert 'hello orld' == hello()そしてテスト実行!
$ docker run --rm test ============================= test session starts ============================== platform linux -- Python 3.7.3, pytest-4.5.0, py-1.8.0, pluggy-0.11.0 rootdir: /usr/src/app collected 1 item test.py F [100%] =================================== FAILURES =================================== __________________________________ test_hello __________________________________ def test_hello(): > assert 'hello orld' == hello() E AssertionError: assert 'hello orld' == 'hello world !!' E - hello orld E + hello world !! E ? + +++ test.py:5: AssertionError =========================== 1 failed in 0.07 seconds ===========================Dockerfile はコマンドが省略されたとき CMD をデフォルトとして実行します。
今回はpytest test.pyですね。
そしてはい、こけます。
修正しましょう。import pytest from hello import hello def test_hello(): - assert 'hello orld' == hello() + assert 'hello world' == hello()あと毎回 build -> run って叩くのめんどいので Makefile 作りましょう。
python のランナーは探せば良いのあるかもしれないけど、今回のやつ程度なら Makefile でサクで良いです。(先頭タブじゃないとダメなのが面倒)# vim:set noexpandtab : build: @docker build -t csvql . test: build @docker run --rm csvql$ make test ... ============================= test session starts ============================== platform linux -- Python 3.7.3, pytest-4.5.0, py-1.8.0, pluggy-0.11.0 rootdir: /usr/src/app collected 1 item test.py . [100%] =========================== 1 passed in 0.04 seconds ===========================無事通りました

ここまで出来ればあとは開発へまとめ
- バージョン切り替えができる環境
- 環境に左右されない。汚さない。
- ユニットテストができるように
- モジュール化を覚えた
- vscode 使った?
- 投稿日:2019-05-24T18:15:17+09:00
matplotlibで対数グラフを描くときの目盛り設定
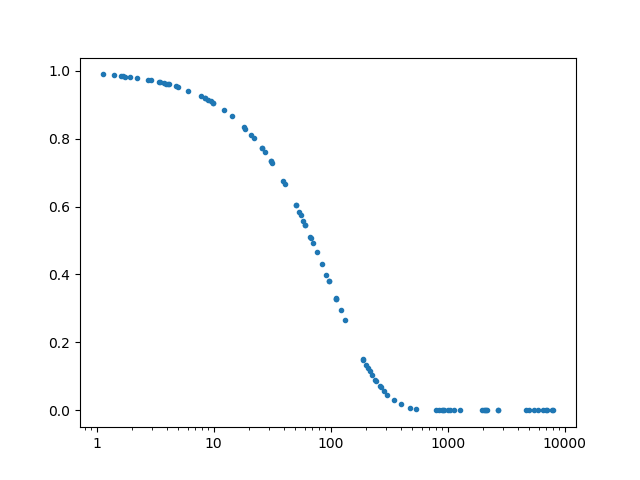
matplotlibで対数軸のグラフを描いているときに困ったことと解決策の記録です.
困ったこと
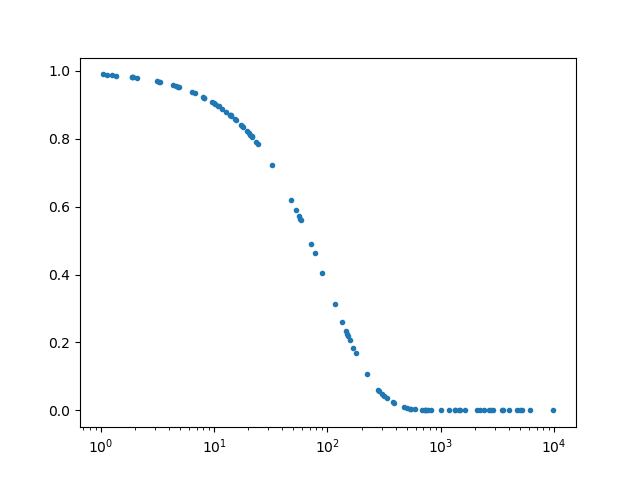
matplotlibで対数軸にプロットしたいときには,
ax.set_xscale('log')と書くと思います.次のコードを実行すると確かに対数軸でプロットされます(下図).ただし,これではデフォルトで対数軸が$10^n$のかたちで表示されてしまいます.時と場合によっては,1, 10, 100...の方が良いこともあるので困ります.どうしたら変更できるのか調べました.#coding: utf-8 import sys import random import math import matplotlib.pyplot as plt x = [] y = [] for i in range(100): x.append(10**random.uniform(0,4)) for i in range(len(x)): y.append(math.exp(-x[i]/10**2)) fig, ax = plt.subplots() ax.plot(x, y,'.') ax.set_xscale('log') plt.show()
解決策1
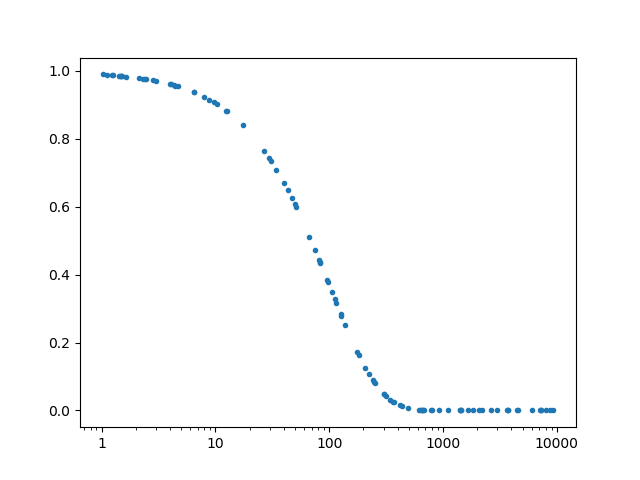
力技で解決してしまう方法です.目盛りの位置とそれに対応する目盛りの文字列を用意してあげます.面倒くさいですが,手っ取り早いとは思います.
#coding: utf-8 import sys import random import math import matplotlib.pyplot as plt x = [] y = [] for i in range(100): x.append(10**random.uniform(0,4)) for i in range(len(x)): y.append(math.exp(-x[i]/10**2)) fig, ax = plt.subplots() ax.plot(x, y,'.') ax.set_xscale('log') ############################################ pos = [1, 10, 100, 1000, 10000] ticks = ['1', '10', '100', '1000', '10000'] ax.set_xticks(pos) ax.set_xticklabels(ticks) ############################################ plt.show()
解決策2
なんかよく分からないおまじないを書いたら解決できるやつです.おまじないは2行です.2つ目の
ax.get_xaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())は,ax.set_xscale('log')の後に書かないと意味ないっぽいです.import matplotlib.tickerax.get_xaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())#coding: utf-8 import sys import random import math import matplotlib.pyplot as plt ########################################## import matplotlib.ticker ########################################## x = [] y = [] for i in range(100): x.append(10**random.uniform(0,4)) for i in range(len(x)): y.append(math.exp(-x[i]/10**2)) fig, ax = plt.subplots() ax.plot(x, y,'.') ax.set_xscale('log') ####################################################################### ax.get_xaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter()) ####################################################################### plt.show()
参考にさせていただいたページ
- 投稿日:2019-05-24T17:26:52+09:00
リモートのjupyter notebookをローカルで使用したい
環境
- macOS Mojave 10.14.4
- 適当なリモートサーバ
コマンド
リモートPC$jupyter notebook --no-browser --port=8890ローカルPC$ssh -N -f -L 8890:localhost:8890 User@ip-addressあとはローカルPCのブラウザでこちらにアクセス
補足
port番号は任意のもので構いません
deep learningの計算って時間かかりますよね。
- 投稿日:2019-05-24T16:25:44+09:00
Pythonで関数に複数の引数を渡す処理
未来電子テクノロジーでインターンをしている山田です。
Pythonについて学習のアウトプットとして投稿します。
プログラミング初心者であるため、内容に誤りがあるかもしれません。
もし、誤りがあれば修正するのでどんどん指摘してください。引数とは
引数とは、関数に渡す値のことです。
引数によって、関数の処理結果を変えることができます。
今回は関数に引数を渡す処理について、単数の場合と複数の場合に分けて説明していきます。単数の場合
まず関数を定義します。
その際、因数を引き受けるための仮引数を指定しておく必要があります。
その下に実行する処理を書きます。
さらに、関数に引数を渡すには、「関数名(引数)」という形にして、関数を呼び出します。
渡された引数は、関数の仮引数に代入されます。
こうすることで、その値を関数の処理の中で用いることができます。script.pydef today(weather): print('今日の天気は'+ weather +'です') today('晴れ') today('雨')複数の場合
引数は複数であっても、関数に渡すことができます。
その場合は、仮引数をコンマ(「,」)で区切って、定義しましょう。
下のように、単数の場合と同じですが、引数の順番は、対応する仮引数の順番と同じにしなければなりません。script.pydef today(weather,message): print('今日の天気は'+ weather +'なので'+message) today('雨','傘を持っていきましょう')注意点
変数には、その変数が使える範囲(スコープ)が存在するということに注意しましょう。
関数の中で定義した変数のスコープというのは関数の中に限られます。
関数の外で使った場合は、正常に処理されないということを押さえておきましょう。
- 投稿日:2019-05-24T16:18:58+09:00
【画像スタイル変換】Pytorchの画像スタイル変換を使って、画風変換動画を作る!
1 やりたいこと
画風変換とは、
DeepLeaningで、ある画像を、別の画像風にしてくれるものである。見た方が早い「2018年版 深層学習によるスタイル変換まとめ」
https://qiita.com/ta-ka/items/b59286cdf9b4d9f9ff14というような形で、スタイル画像をコンテンツ画像に合成させるようなイメージだ!
面白そう!そしてやってみると意外と簡単にできて、
元画像(自分)
夕焼け(スタイル)
合成画像
さて、やりたいのは動画にしてみようということだ
2 環境
割と重いので、GoogleColaboratryを利用することを強く推奨する。
基本的なコードはPytorch Tutorialのものを使い、実装していく。
利用するもの
Mac
--ffmpeg
--PIL
Colaboratry3 おおまかな手順
動画像編集
動画→画像
画像→スタイル変換
スタイル変換後→合成
4 動画編集
まず、動画を短くしよう。imovieなどを利用して、
5秒くらいにするといい。目安として、1秒の動画を作るのに、30分程度かかる
(1フレーム1分程度)
4秒の動画を作るのに2時間以上はかかった。5 動画→画像
ffmpeg -i input.mp4 -vcodec png image_%03d.pngにより、動画を連番画像にできる。
image_001.png
image_002.png
...
image_125.png次に、Pytorchのチュートリアルに突っ込める画像は正方形である必要がある。
(厳密にはおそらくスタイル画像と元画像のアスペクト比が同じ)PILなどで任意の領域にクロップしてしまおう
from PIL import Image #img file pic_start = 1 pic_finish = 125 for i in np.arange(pic_start,pic_finish+1): print("\r{:}".format(i),end = "") #open image im = Image.open("image_{:0=3}.png".format(i)) box = (0,200,0,200)#トリミング位置 im = im.crop(box) im.save("image2_{:0=3}.png".format(i))同様にスタイル画像も正方形にしておきます。(やったことにしておきます)
style.jpg6 画像→スタイル変換
さて、全てをcropというフォルダに突っ込み、
google driveにフォルダごとぶち込みます。google driveはcolaboratoryにデータをマウントするのが簡単だからです。
さて、google driveの新規の(その他の中の)colaboratoryを起動しましょう
そして
上のバーの「ランタイム」→「ランタイムのタイプの変更」→「None → GPU」に変更します。さて、コードは以下のページにあるものを基本的に利用していますが、for文を回すために順番を入れ替えて実装します。
https://pytorch.org/tutorials/advanced/neural_style_tutorial.htmlまず、google driveをcolaboratryにマウントしましょう。
一番上に付け足します。from google.colab import drive drive.mount('/content/drive') %cd drive/"My Drive"/crop次にクラスや関数の定義をまとめてやっちゃいます。
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from PIL import Image import matplotlib.pyplot as plt import torchvision.transforms as transforms import torchvision.models as models import copy device = torch.device("cuda" if torch.cuda.is_available() else "cpu") import numpy as npclass ContentLoss(nn.Module): def __init__(self, target,): super(ContentLoss, self).__init__() # we 'detach' the target content from the tree used # to dynamically compute the gradient: this is a stated value, # not a variable. Otherwise the forward method of the criterion # will throw an error. self.target = target.detach() def forward(self, input): self.loss = F.mse_loss(input, self.target) return input class StyleLoss(nn.Module): def __init__(self, target_feature): super(StyleLoss, self).__init__() self.target = gram_matrix(target_feature).detach() def forward(self, input): G = gram_matrix(input) self.loss = F.mse_loss(G, self.target) return input def gram_matrix(input): a, b, c, d = input.size() # a=batch size(=1) # b=number of feature maps # (c,d)=dimensions of a f. map (N=c*d) features = input.view(a * b, c * d) # resise F_XL into \hat F_XL G = torch.mm(features, features.t()) # compute the gram product # we 'normalize' the values of the gram matrix # by dividing by the number of element in each feature maps. return G.div(a * b * c * d) class Normalization(nn.Module): def __init__(self, mean, std): super(Normalization, self).__init__() # .view the mean and std to make them [C x 1 x 1] so that they can # directly work with image Tensor of shape [B x C x H x W]. # B is batch size. C is number of channels. H is height and W is width. self.mean = torch.tensor(mean).view(-1, 1, 1) self.std = torch.tensor(std).view(-1, 1, 1) def forward(self, img): # normalize img return (img - self.mean) / self.std次にfor文を使って全てのimageを順番に学習にかけていき保存していきます。
pic_start = 1 pic_finish = 125 for ite in np.arange(pic_start,pic_finish+1): # desired size of the output image imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu loader = transforms.Compose([ transforms.Resize(imsize), # scale imported image transforms.ToTensor()]) # transform it into a torch tensor def image_loader(image_name): image = Image.open(image_name) # fake batch dimension required to fit network's input dimensions image = loader(image).unsqueeze(0) return image.to(device, torch.float) content_img = image_loader("image_{:0=3}.png".format(ite)) style_img = image_loader("redsky_style.jpg") assert style_img.size() == content_img.size(), \ "we need to import style and content images of the same size" unloader = transforms.ToPILImage() # reconvert into PIL image plt.ion() def imshow(tensor, title=None): image = tensor.cpu().clone() # we clone the tensor to not do changes on it image = image.squeeze(0) # remove the fake batch dimension image = unloader(image) plt.imshow(image) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated plt.figure() imshow(style_img, title='Style Image') plt.figure() imshow(content_img, title='Content Image') cnn = models.vgg19(pretrained=True).features.to(device).eval() cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device) cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device) # desired depth layers to compute style/content losses : content_layers_default = ['conv_4'] style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5'] def get_style_model_and_losses(cnn, normalization_mean, normalization_std, style_img, content_img, content_layers=content_layers_default, style_layers=style_layers_default): cnn = copy.deepcopy(cnn) # normalization module normalization = Normalization(normalization_mean, normalization_std).to(device) # just in order to have an iterable access to or list of content/syle # losses content_losses = [] style_losses = [] # assuming that cnn is a nn.Sequential, so we make a new nn.Sequential # to put in modules that are supposed to be activated sequentially model = nn.Sequential(normalization) i = 0 # increment every time we see a conv for layer in cnn.children(): if isinstance(layer, nn.Conv2d): i += 1 name = 'conv_{}'.format(i) elif isinstance(layer, nn.ReLU): name = 'relu_{}'.format(i) # The in-place version doesn't play very nicely with the ContentLoss # and StyleLoss we insert below. So we replace with out-of-place # ones here. layer = nn.ReLU(inplace=False) elif isinstance(layer, nn.MaxPool2d): name = 'pool_{}'.format(i) elif isinstance(layer, nn.BatchNorm2d): name = 'bn_{}'.format(i) else: raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__)) model.add_module(name, layer) if name in content_layers: # add content loss: target = model(content_img).detach() content_loss = ContentLoss(target) model.add_module("content_loss_{}".format(i), content_loss) content_losses.append(content_loss) if name in style_layers: # add style loss: target_feature = model(style_img).detach() style_loss = StyleLoss(target_feature) model.add_module("style_loss_{}".format(i), style_loss) style_losses.append(style_loss) # now we trim off the layers after the last content and style losses for i in range(len(model) - 1, -1, -1): if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss): break model = model[:(i + 1)] return model, style_losses, content_losses input_img = content_img.clone() # if you want to use white noise instead uncomment the below line: # input_img = torch.randn(content_img.data.size(), device=device) # add the original input image to the figure: plt.figure() imshow(input_img, title='Input Image') def get_input_optimizer(input_img): # this line to show that input is a parameter that requires a gradient optimizer = optim.LBFGS([input_img.requires_grad_()]) return optimizer def run_style_transfer(cnn, normalization_mean, normalization_std, content_img, style_img, input_img, num_steps=300, style_weight=1000000, content_weight=1): """Run the style transfer.""" print('Building the style transfer model..') model, style_losses, content_losses = get_style_model_and_losses(cnn, normalization_mean, normalization_std, style_img, content_img) optimizer = get_input_optimizer(input_img) print('Optimizing..') run = [0] while run[0] <= num_steps: def closure(): # correct the values of updated input image input_img.data.clamp_(0, 1) optimizer.zero_grad() model(input_img) style_score = 0 content_score = 0 for sl in style_losses: style_score += sl.loss for cl in content_losses: content_score += cl.loss style_score *= style_weight content_score *= content_weight loss = style_score + content_score loss.backward() run[0] += 1 if run[0] % 50 == 0: print("run {}:".format(run)) print('Style Loss : {:4f} Content Loss: {:4f}'.format( style_score.item(), content_score.item())) print() return style_score + content_score optimizer.step(closure) # a last correction... input_img.data.clamp_(0, 1) return input_img output = run_style_transfer(cnn, cnn_normalization_mean, cnn_normalization_std, content_img, style_img, input_img) plt.figure() imshow(output, title='Output Image') # sphinx_gallery_thumbnail_number = 4 plt.ioff() plt.show() out = output.cpu() out = out.data.numpy() out = out.reshape(3,512,512) print(out.shape) np.max(out[0]) out[0] = out[0]*255 out[1] = out[1]*255 out[2] = out[2]*255 out = out.astype(np.uint8).transpose(1,2,0) from PIL import Image im = Image.fromarray(out) im.save("image2_{:0=3}.png".format(ite))長いので後から説明になりますが、
for ite in np.arange(): ... content_img = image_loader("image_{:0=3}.png".format(ite)) style_img = image_loader("style.jpg")ここで
順番に画像を読み出します。そして最後の部分はpytorchの出力をPILに渡して
image2_001.png
image2_002.png
...
image2_125.png
と連番で保存していきます。out = output.cpu() out = out.data.numpy() out = out.reshape(3,512,512) print(out.shape) np.max(out[0]) out[0] = out[0]*255 out[1] = out[1]*255 out[2] = out[2]*255 out = out.astype(np.uint8).transpose(1,2,0) im = Image.fromarray(out) im.save("image2_{:0=3}.png".format(ite))7 スタイル連番画像→動画
google driveに保存されたimage2の連番画像をローカルに落とし、(colabでやってもいい)以下のコマンド
ffmpeg -r 30 -i image2_%03d.png -vcodec libx264 -pix_fmt yuv420p -r 30 out.mp4によりout.mp4を出力できます。



- 投稿日:2019-05-24T15:47:58+09:00
MQTTでドローンにコマンドを送る
執筆中です
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
これまでの記事で,
ドローンの情報をMQTTで受け取って,地図上に表示する
事ができました.次は「MQTTでドローンから情報を受け取る」のではなくて,
「MQTTでドローンに操作コマンドを送る」をやってみたいと思います.最終的にはWebブラウザからフルコントロールできる様にしたいわけですが,
今回は,PythonのGUIプログラムで簡易的に操作できるようにしてみます.準備するもの
・これまで使用したLinux PC
dronekit-sitlも入っていて,Webサーバーも立っているPCです.
引き続き利用します.システム構成
ドローンを操作するGUIプログラム
コマンドラインでキー入力して動かすプログラムを作っても良いですが,
せっかくなのでGUIのプログラムを作ります.具体的にはPython用GUIライブラリのTkinterを使用してデザインします.
Tkinter以外にも,Kivy,PyQt,wxPythonもありますが,
今回はとりあえずTkinterです.Tkinterライブラリのインストール
aptでTkinterのパッケージをインストールする必要があります.
Tkinterライブラリのインストール$sudo apt install python-tkPythonプログラム本体
ここ を右クリック-[名前を付けて保存]するか,
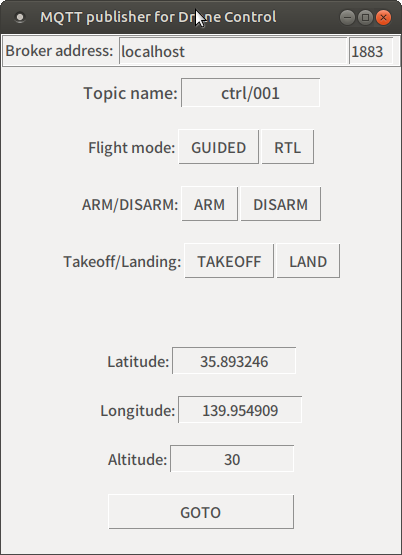
以下のコードをコピー&ペーストしてファイルを作成してください.gui_mqtt_send.py#!/usr/bin/env python # -*- coding: utf-8 -*- import sys import Tkinter import paho.mqtt.client as mqtt import json # MQTTブローカーの情報,パブリッシュするトピック mqtt_server = 'localhost' mqtt_port = 1883 mqtt_topic = 'ctrl/001' # このトピック名を受信するドローンが動く # ドローンに投げるコマンドのベースになる辞書 drone_command = { "command":"None", "d_lat":"0", "d_lon":"0", "d_alt":"0" } # メイン関数 def main(args): # Tkinterのウィンドウを作る root = Tkinter.Tk() root.title(u'MQTT publisher for Drone Control') # ウィンドウタイトルバー root.geometry('400x520') # ウィンドウサイズ # フライトモード、ARM/DISARM用のコールバック関数 def Button_pushed(event): # コマンド(実際はボタン上のテキスト)を取得 drone_command["command"] = event.widget["text"] # MQTTのサーバー、ポート番号、トピック名を取る mqtt_server = EditBox_Host.get() mqtt_port = int(EditBox_Port.get() ) mqtt_topic = EditBox_topic.get() # ブローカーへ接続 client = mqtt.Client() client.connect( mqtt_server, mqtt_port, 60 ) client.loop_start() # データをJSONで作ってPub json_command = json.dumps( drone_command ) client.publish( mqtt_topic, json_command ) client.loop_stop() # GOTOコマンド用のコールバック関数 def Goto_pushed(event): # コマンドを作る drone_command["command"] = "GOTO" drone_command["d_lat"] = EditBox_lat.get() drone_command["d_lon"] = EditBox_lon.get() drone_command["d_alt"] = EditBox_alt.get() # MQTTのサーバー、ポート番号、トピック名を取る mqtt_server = EditBox_Host.get() mqtt_port = int(EditBox_Port.get() ) mqtt_topic = EditBox_topic.get() # ブローカーへ接続 client = mqtt.Client() client.connect( mqtt_server, mqtt_port, 60 ) client.loop_start() # データをJSONで作ってPub json_command = json.dumps( drone_command ) client.publish( mqtt_topic, json_command ) client.loop_stop() #-------------------------------------------- # 以降はウィンドウのデザインだけ # MQTTブローカーのアドレス、ポートを入力する部分 frame_top = Tkinter.Frame(root,bd=2,relief='ridge') frame_top.pack(fill="x") Static_Host = Tkinter.Label(frame_top,font=("",11),text=u'Broker address: ') Static_Host.pack(anchor='n',side='left') EditBox_Host = Tkinter.Entry(frame_top,font=("",11),width=28) EditBox_Host.insert(Tkinter.END,'localhost') EditBox_Host.pack(anchor='n',side='left') EditBox_Port = Tkinter.Entry(frame_top,font=("",11),width=5) EditBox_Port.insert(Tkinter.END,'1883') EditBox_Port.pack(anchor='n',side='left') # トピック名の入力部分 frame1 = Tkinter.Frame(root,pady=10) frame1.pack() Label_topic = Tkinter.Label(frame1,font=("",12),text="Topic name:") Label_topic.pack(side="left") EditBox_topic = Tkinter.Entry(frame1,font=("",12),justify="center",width=15) EditBox_topic.insert(Tkinter.END,'ctrl/001') EditBox_topic.pack(side="left") # フライトモード部分 frame2 = Tkinter.Frame(root,pady=10) frame2.pack() Label_mode = Tkinter.Label(frame2,font=("",11),text="Flight mode:") Label_mode.pack(side="left") Button_mode_guided = Tkinter.Button(frame2,font=("",11),text=u'GUIDED') Button_mode_guided.bind("<Button-1>",Button_pushed ) Button_mode_guided.pack(side="left") Button_mode_rtl = Tkinter.Button(frame2,font=("",11),text=u'RTL') Button_mode_rtl.bind("<Button-1>",Button_pushed ) Button_mode_rtl.pack(side="left") # ARM/DISARM部分 frame3 = Tkinter.Frame(root,pady=10) frame3.pack() Label_ada = Tkinter.Label(frame3,font=("",11),text="ARM/DISARM:") Label_ada.pack(side="left") Button_ada_arm = Tkinter.Button(frame3,font=("",11),text=u'ARM') Button_ada_arm.bind("<Button-1>",Button_pushed ) Button_ada_arm.pack(side="left") Button_ada_disarm = Tkinter.Button(frame3,font=("",11),text=u'DISARM') Button_ada_disarm.bind("<Button-1>",Button_pushed ) Button_ada_disarm.pack(side="left") # 離着陸部分 frame4 = Tkinter.Frame(root,pady=10) frame4.pack() Label_ada = Tkinter.Label(frame4,font=("",11),text="Takeoff/Landing:") Label_ada.pack(side="left") Button_Takeoff = Tkinter.Button(frame4,font=("",11),text=u'TAKEOFF') Button_Takeoff.bind("<Button-1>",Button_pushed ) Button_Takeoff.pack(side="left") Button_mode_land = Tkinter.Button(frame4,font=("",11),text=u'LAND') Button_mode_land.bind("<Button-1>",Button_pushed ) Button_mode_land.pack(side="left") #空白 Label_lat = Tkinter.Label(root,pady=10,font=("",12),text=" ") Label_lat.pack() # 緯度入力 frame5 = Tkinter.Frame(root,pady=10) frame5.pack() Label_lat = Tkinter.Label(frame5,font=("",11),text="Latitude:") Label_lat.pack(side="left") EditBox_lat = Tkinter.Entry(frame5,font=("",11),justify="center",width=15) EditBox_lat.insert(Tkinter.END,'35.893246') EditBox_lat.pack(side="left") # 経度入力 frame6 = Tkinter.Frame(root,pady=10) frame6.pack() Label_lon = Tkinter.Label(frame6,font=("",11),text="Longitude:") Label_lon.pack(side="left") EditBox_lon = Tkinter.Entry(frame6,font=("",11),justify="center",width=15) EditBox_lon.insert(Tkinter.END,'139.954909') EditBox_lon.pack(side="left") # 高度入力 frame7 = Tkinter.Frame(root,pady=10) frame7.pack() Label_alt = Tkinter.Label(frame7,font=("",11),text="Altitude:") Label_alt.pack(side="left") EditBox_alt = Tkinter.Entry(frame7,font=("",11),justify="center",width=15) EditBox_alt.insert(Tkinter.END,'30') EditBox_alt.pack(side="left") # GOTOボタン frame8 = Tkinter.Frame(root,pady=10) frame8.pack() Button_goto = Tkinter.Button(frame8,font=("",11),text=u'GOTO', width=20) Button_goto.bind("<Button-1>",Goto_pushed ) Button_goto.pack(side="left") # メインループ root.mainloop() return 0 if __name__ == '__main__': sys.exit(main(sys.argv))実行結果
コンソールから
bash
$python gui_mqtt_send.py
で起動すると,次のようなウィンドウが現れます.
ドローン側プログラム(dronekit-sitl版)
Pythonプログラム本体
実行結果
おわりに
- 投稿日:2019-05-24T15:39:34+09:00
関数型Python チートシート ~遅延と無限~
概要
Python ではイテレータを使うことで 必要に迫られるまで処理を後回しにすることが可能。組み込み関数の
map等でその恩恵を受けられるが、標準ライブラリのitertoolsを使うことで より豊かな表現力を持てる。さらに(海外では相当人気の)サードパーティ製モジュールmore-itertoolsを使うと より表現力が増す。本稿では python組み込み関数,
itertools,more-itertoolsを網羅的・コンパクトに概観する。表記:
itertoolsに含まれるものは接頭辞なしで言及する。例:itertools.countはcountmore-itertoolsに含まれるものは接頭辞Mで言及する。例:M.chunked- イテはイテレータの略
本文
イテ作成:
range,count,repeat,M.repeatfunc,M.iterate,M.tabulateで無からイテを作れる。cycle,M.ncycle,M.count_cycleは繰り返してカサ増し。teeはコピー。
イテ微調整:M.intersperseはセパレータ挿入。M.padded,M.padnoneは短い時に埋める。M.prependは先頭に追加。M.collapse,M.flattenは平坦化。M.consumeはイテを進めるだけ。
イテ結合:chain,from_iterableは直列的な結合。zip,zip_longest,M.zip_offsetは並列的な結合。M.interleave,M.interleave_longest,M.roundrobinは別な観点での並列的な結合。
イテ分割:M.partitionは述語で2つのイテに分割。M.bucketはキー関数で分割。M.divide,M.distributeはNつに分割。M.unzipはzipの逆。
要素→listOf要素:M.chunked,M.slicedは要素をN個組に。M.grouperはイテの要素数をNに。M.adjacentは述語の判定結果を付与。M.split_atは述語で集める(セパレータは消失)。M.split_before,M.split_afterではセパレータは消失しない。M.split_intoは不均一に集める。
要素→listOf要素(window的):M.windowedはWindow作成,M.pairwiseは幅2のWindow作成。M.staggerで変則的なWindowを作れる。
述語でフィルタ:filter,filterfalseが基本。takewhile,dropwhileは字義通り。M.strip,M.lstrip,M.rstripはイテの最初と最後の方にフォーカスしたフィルタ。M.locate,M.rlocateは述語を満たすインデックスを要素にもつイテを作成(注:フィルタでない)。
非述語でフィルタisliceが基本。M.islice_extendedは負のインデックスを指定可。M.take,M.tailは最初/最後のN個が欲しい時。M.first,M.first_true,M.last,M.nthはピンポイントで1個欲しい時。M.unique_everseen,M.unique_justseenは(努力的に)重複排除。M.compressはマスクでフィルタ。
イテに関する述語/関数:allは全数確認,anyは存在確認,M.all_equalは全部同じかを確認。M.ilenは長さ。M.oneは要素数1のアサーション兼要素取得。M.exactly_nは述語を満たす要素数をテスト。M.quantifyは述語を満たす要素数の数。
関数適用:map(注:zipWithとしても使える),starmapが簡便な時も。
集約系操作accumulateは累積和(和以外の任意の関数も使える)。M.differenceは階差。groupByはグループ化。M.groupby_transformはグループ化+map。M.map_reduceはグループ化してその各グループ中でmap + reduceを実行。
特殊操作:M.side_effectはタップ+α。M.replaceは置換。M.sort_togetherは超便利なソート。M.collateはソート済みなN個のイテをマージ。M.dotproductは内積。M.unique_to_eachは重複確認。M.run_length, 情報理論の圧縮技術で使うやつ。M.numeric_range, numpyでのlinspace。
イテ生成(組み合わせ論): 必要な時にドキュメントを読むべしcombinations,combinations_with_replacement,permutations,product,M.distinct_permutations,M.circular_shifts,M.partitions,M.powerset,M.random_product,M.random_permutation,M.random_combination,M.random_combination_with_replacement,M.nth_combination参考
- 公式ドキュメント
- more-itertools: 公式ドキュメント
- 投稿日:2019-05-24T15:39:32+09:00
Python3系でORB+RANSACでの画像間マッチングの実装
はじめに
今回は、二枚の画像に対してORB特徴量を抽出し,
二枚の画像で得た特徴点を元にマッチングを行う方法について説明します。
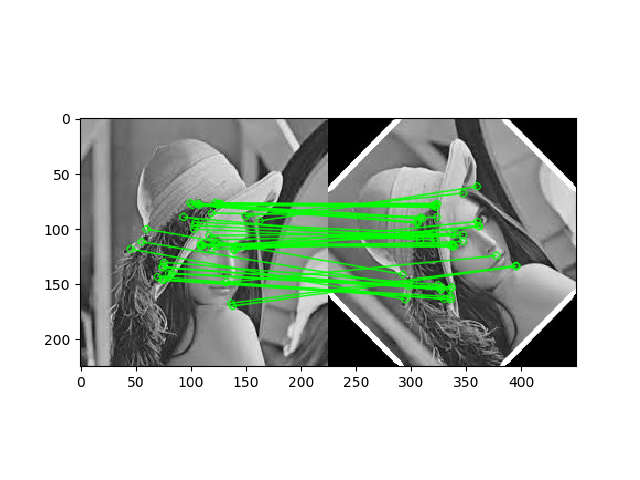
以下の画像のように二枚の画像それぞれ特徴点を抽出し、対応する特徴点を結びます。
ORB (Oriented FAST and Rotated BRIEF)
ORBは、特徴点、特徴量を抽出するアルゴリズムで、カメラの運動(移動、回転、ズーム)にロバスト(不変)なアルゴリズムで、ORBができた経緯としてもともとSIFTというアルゴリズムが、移動、回転に加えてズームにロバストなアルゴリズムであったが、SIFTは計算量が多く、低速だったため、速度を改良したSURFというアルゴリズムがでてきました。ただし、SIFTもSURFも特許で守られているため、使用するためには特許料を払う必要があります。
そこで、移動、回転、ズームに対してロバストであり、計算速度も速く、フリーで使うことができるORBというアルゴリズムが2011年に開発されました。RANSAC
今回のように、画像から特徴点を取るといった場合に、ノイズなどの原因で法則性から大きく外れた、外れ値がデータに含まれる場合があります。その外れ値をうまく無視して、法則性を推定する手法としてRANSACがあります。
ORB+RANSACのマッチング
今回のプログラムでは画像間のマッチングを行う際に、抽出したORB特徴量を用い、マッチングの信頼度を上げるために、RANSACを適用します。
また、今回のプログラムを動かすPythonの環境はPython3系とします。
手順は以下のようになります。
- 画像ファイルの読み込み
- ORBで特徴点&特徴量の抽出
- RANSAC
- 画像に特徴点を書き込み
- 結果の出力
import numpy as np import cv2 from matplotlib import pyplot as plt MIN_MATCH_COUNT = 10 good_match_rate = 0.15 #得られた特徴点のうち使用する点の割合 img1 = cv2.imread('./0203/vessel1-1b.png',0) # 一枚目 img2 = cv2.imread('./0203/vessel1-2b.png',0) # 二枚目 # Initiate ORB detector orb = cv2.ORB_create() # キーポイント検出,ORB記述 kp1, des1 = orb.detectAndCompute(img1,None) kp2, des2 = orb.detectAndCompute(img2,None) # create BFmatcher object bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True) #bf = cv2.BFMatcher(cv2.NORM_L1, crossCheck=False) # Match descriptors. matches = bf.match(des1,des2) matches = sorted(matches, key = lambda x:x.distance) good = matches[:int(len(matches) * good_match_rate)] #MIN_MATCH_COUNT以上なら出力,それ以下ならelseへ if len(good)>MIN_MATCH_COUNT: src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2) dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2) #RANSAC M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC,5.0) matchesMask = mask.ravel().tolist() h,w = img1.shape pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2) dst = cv2.perspectiveTransform(pts,M) img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA) else: print ("Not enough matches are found - %d/%d") % (len(good),MIN_MATCH_COUNT) matchesMask = None draw_params = dict(matchColor = (0,255,0), # draw matches in green color singlePointColor = None, matchesMask = matchesMask, # draw only inliers flags = 2) img3 = cv2.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params) #出力 plt.imshow(img3, 'gray'),plt.show()結果
結果は以下に示すように、はじめにで示した図と比べて、
精度の高いマッチングが行えていることがわかります。

- 投稿日:2019-05-24T15:05:11+09:00
Watson StudioのJupyter NotebookからICOSのファイルを使う
以前の記事
Watson StudioのJupyter NotebookからICOSへファイル出力をする
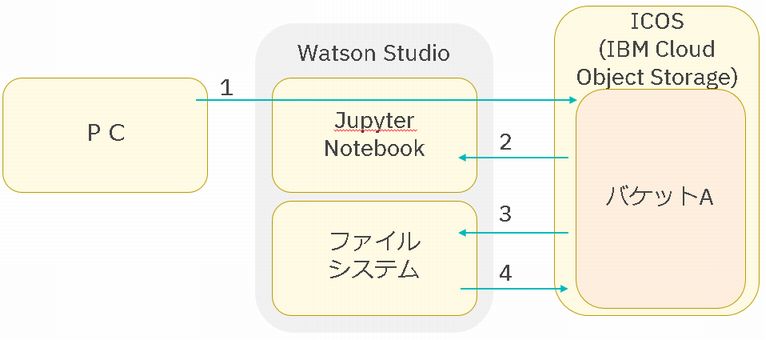
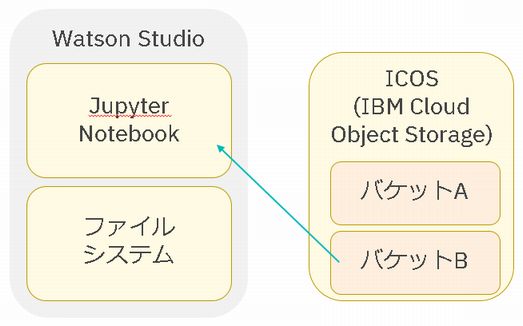
では、以下の1から4のようなファイル操作について記載しました。
Watson Studioでプロジェクトを作成すれば、自動的にICOSに一つバケット(上図の「バケットA」)が作成され、前回の記事はそのバケットのファイル操作を記載しました。
今回の記事は、Watson Studioのプロジェクトとは関係のないバケットへアクセスする方法を記載します。
(以下の絵の「バケットB」からのデータ取り込み)
0. 準備
IBM Cloudコンソールから、バケットを1つ作ります。
名前は、「qiita-bucket-b」としました。
csvファイルを1つアップロードしました。
このファイルをWatson StudioのJupyter notebookに取り込むことができれば、この記事は完成です。
1. APIキー作成
「qiita-bucket-b」へのアクセス権限を持ったAPIキーを作成し、Jupyter notebookからはそのキーを用いることで、「qiita-bucket-b」にアクセスできる、というのが基本的な動きです。
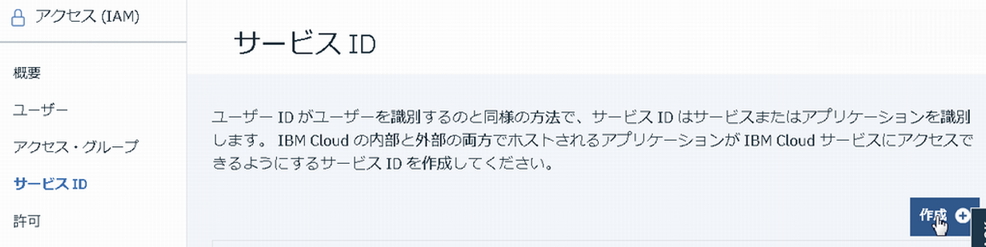
1.1 サービスID作成
このあたりちょっと分かりづらいのですが、アクセス権限は直接APIキーに付与されるのではなく、サービスIDに紐付くものです。そのため、以下のような手順となります。
1. サービスIDを作成
2. サービスIDに権限を付与
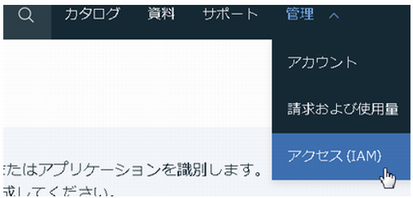
3. サービスIDに対応するAPIキーを作成IBM Cloudコンソールで、管理→アクセス(IAM)を開きます。
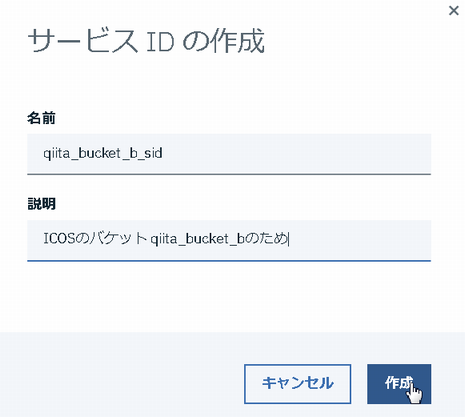
サービスIDを作成します。
名前や説明は任意です。
ここまででサービスIDが作成されました。
1.2 権限の付与
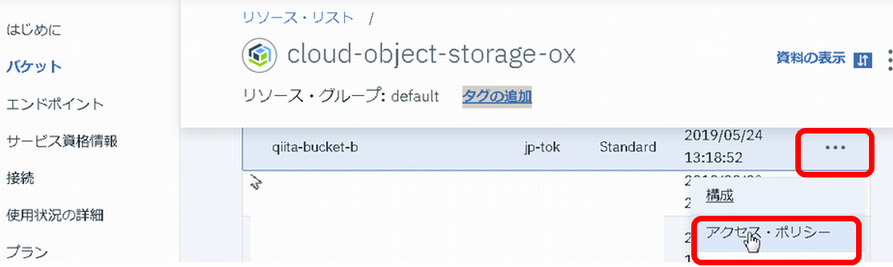
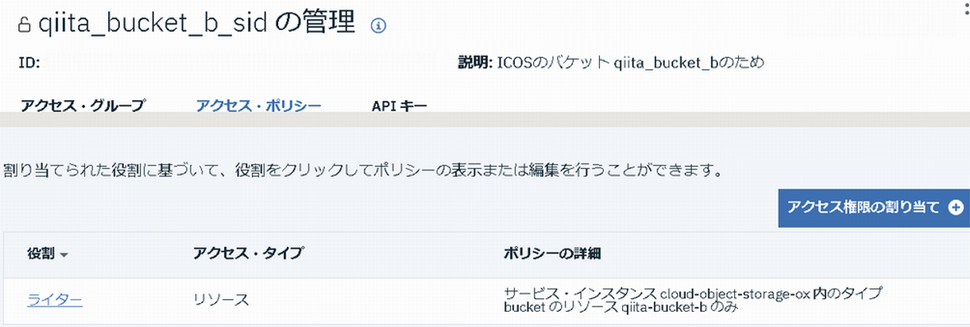
作成したサービスIDに対して、「qiita-bucket-b」へのアクセス権限を付与します。
IBM CloudコンソールのICOSの管理画面から、「qiita-bucket-b」を探し、下のようにアクセス・ポリシーをクリックしてください。
サービスIDとして、1.1で作成したサービスIDを選択し、「アクセス・ポリシーの作成」をクリックします。
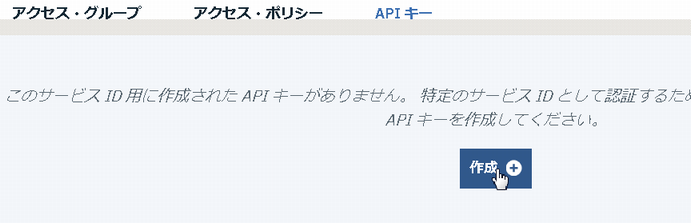
1.3 APIキー作成
再度、管理→アクセス(IAM)のサービスIDを開きます。
1.1で作成したサービスIDを探し、「アクセス・ポリシー」を見てみると、1.2で付与した権限が正しく設定されていることを確認できます。
(なお、1.2の手順ではなく、ここから「アクセス権限の割り当て」を行うことも可能ですが、1.2の手順のほうが簡単です)以下のようにAPIキーを作成します。
一応ダウンロードしておきます。
ダウンロードされたJSONを開くと、APIキーを確認できます。
このAPIキーがあれば、バケット「qiita-bucket-b」へアクセスできます!"apiKey": "xxxyyyzzz"2. Jupyter Notebookからアクセス
どこにどう上記のAPIキーを指定すればいいか、悩ましいところですが、最も簡単な方法は、以下のように、Assetに登録されている適当なファイルを「Insert to code」して下さい。
これを雛形として、書き換えるのが楽なためです。
そして、insertされたコードの以下の4箇所を書き換えてください。
2.1 ibm_api_key_id
1.3で作成したAPIキーに変更してください。
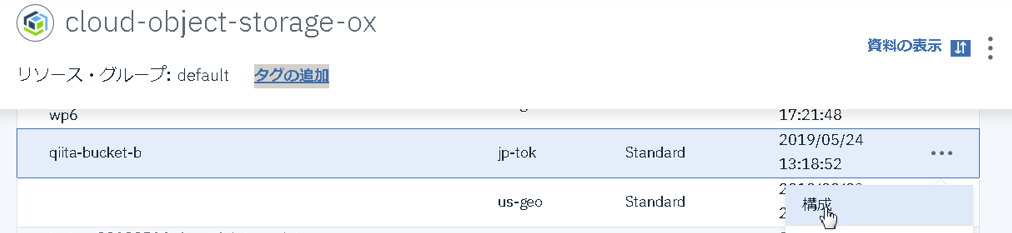
ibm_api_key_id='xxxyyyzzz'2.2 endpoint_url
エンドポイントは、バケットごとに異なるため、IBM CloudコンソールのICOSの管理画面から確認するのが無難です。以下のように「構成」のところから確認できます。
これをコピーして貼り付けます。
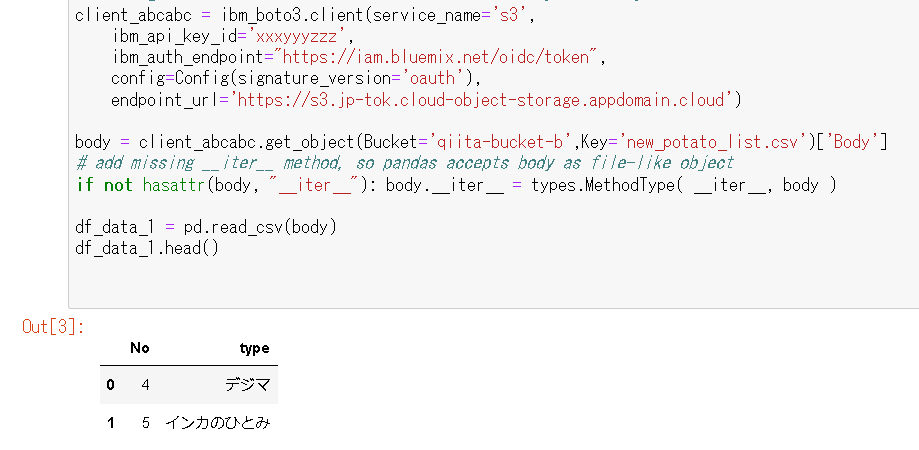
endpoint_url='https://s3.jp-tok.cloud-object-storage.appdomain.cloud')2.3 Bucket
以下の通りです。
Bucket='qiita-bucket-b'2.4 Key
バケットにある、アクセスしたいファイルを指定します。
Key='new_potato_list.csv'これで実行すると、ファイルの内容を確認できます。
本文は以上です。
補足1
このようなことを実現する方法は、他にもたくさんあると思います。
例えば、本来はWatson StudioのAssetでバケットへのconnectionを作るのがいいのかも知れません。
しかし、設定項目が多く何を入れればいいのか分かりづらいです。
そして、Jupyter notebookで上記のconnectionを「insert to code」しても、なぜかURLしか入ってくれません。(バグでしょうか。。)
補足2
2.2 endpoint_url では、わざわざバケットのエンドポイントを確認しました。
エンドポイントはさまざまありますが、これを間違えたときのエラーが分かりづらく、最初から正確に指定したいためです。存在しないエンドポイントを指定すると以下のエラーが出力されますが、これは分かりやすい例です。
EndpointConnectionError: Could not connect to the endpoint URL: "https://s3.jp-tok.cloud-object-storage.appdomain.clou/qiita-bucket-b/new_potato_list.csv"しかし、存在するが間違ったエンドポイントを指定すると以下のようなエラーが出力されます。
バケット名やファイル名が違うときも同じエラーが出力されるため、何が間違ってるのかが分かりません。NoSuchKey: An error occurred (NoSuchKey) when calling the GetObject operation: The specified key does not exist.








- 投稿日:2019-05-24T15:00:52+09:00
勤怠管理Webアプリケーションを作ってみた
はじめに
現在アルバイトしているバーではタイムカードを表計算ソフトで管理しているのですが、これをもうちょっと楽にできないかなと思い、勤怠管理Webアプリケーションを作ってみました。
まだまだ改善の余地があり、追加したい機能などもありますが、行き詰まりまして...
大枠は完成したので、一度ここでアウトプットして整理してみます。ご指摘がありましたら、コメントしていただけると嬉しいです。
環境など
OS macOS Mojave 使用言語 Python 3.6.7(Anaconda) フレームワーク Django 2.2 バージョン管理 Git 確認用ブラウザ Google Chrome 制作期間 約2週間 実際の作業1(大枠を作成)
最初の準備
conda仮想環境構築
Anacondaで仮想環境を作成して、そこで動かしていくので作成します。
詳しくはこちらの方が記事で書いておられますので読んでみてください。→【初心者向け】Anacondaで仮想環境を作ってみる
conda create -n(または--name) 環境名 python(=バージョン指定)
でpythonのバージョンを指定して仮想環境を作成できます。
また、conda activate 指定した環境名で作成した環境をアクティベートできます。conda create -n py36 python=3.6.7 conda activate py36Djangoのインストール
この仮想環境を立ち上げた状態でインストールします。
(py36) TaronoMacBook-Pro:clock taro$ conda install djangoこれで環境構築できました。
今後はここで作業していくので、以降シェルコマンドはこの環境上で動かしているとみなしてください。
実際に環境構築で一番手間取ったかもしれません。最終的に動いているのはこの状態なのですが、ここまで来るのに右往左往してしまいました。Djangoでの最初の作業
startproject
プロジェクトのディレクトリを保存したい場所でターミナルを開き、以下のコマンドを入力。
clockは勝手につけた名前。django-admin startproject clock次のような構造のディレクトリができます。
clock ├── clock │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-36.pyc │ │ ├── settings.cpython-36.pyc │ │ ├── urls.cpython-36.pyc │ │ └── wsgi.cpython-36.pyc │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── manage.py外側のclockディレクトリはただの入れ物なのでリネーム可能。
startapp
以下のコマンドを入力し、外側のディレクトリ内(このプロジェクトのルートディレクトリ)でattendanceという名前のアプリの入れ物を作ります。
python manage.py startapp attendance次のようにattendanceディレクトリができます。
clock ├── attendance │ ├── __init__.py │ ├── __pycache__ │ ├── admin.py │ ├── apps.py │ ├── migrations │ ├── models.py │ ├── tests.py │ └── views.py ├── clock └── manage.pyよく使うDjangoコマンド
- Djangoのデータベースをマイグレーションコマンドで作成。
python manage.py makemigrations python manage.py migrate2段階のコマンドで、一度マイグレーションする物のリストを作ってから、実際にマイグレーションしています。(git add から git commit の流れに似ています)
- サーバーを動かす。
python manage.py runserverDjangoの全体像
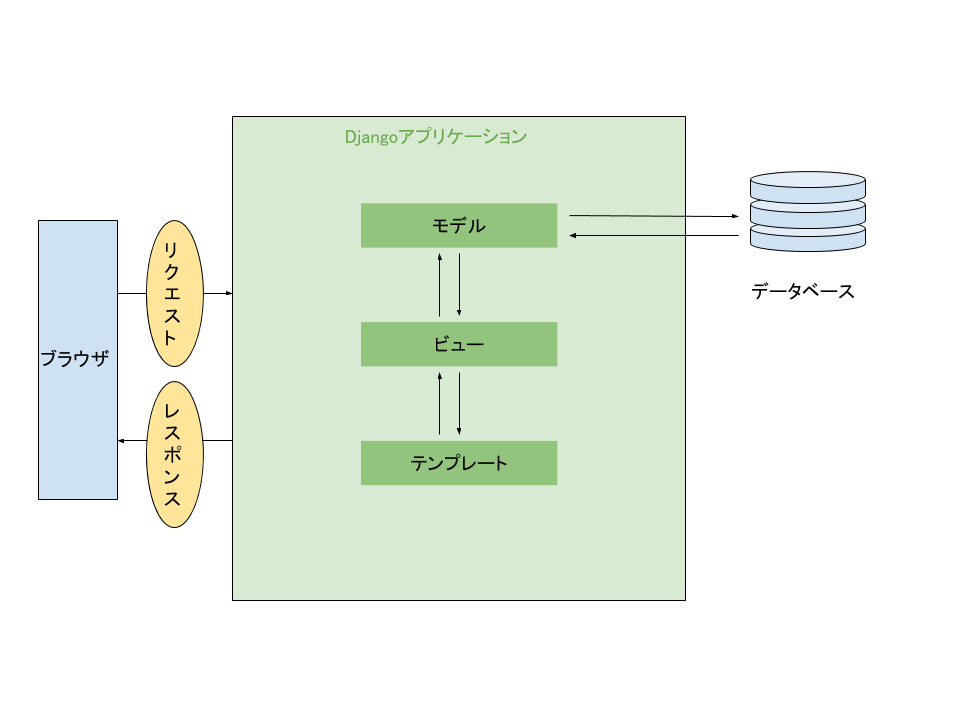
超ざっくりした絵ですみません笑
とっても簡略化すると、
1.ブラウザからリクエストされたURLをDjangoのURLディスパッチャなるコアモジュールが受ける
2.そのディスパッチャが、urls.pyに記述したURLconf(URLのパターンとそれぞれのパターンに対するリクエストの送り先を示した地図のようなもの)に従って、ビューにリクエストを送る
3.ビューがモデルオブジェクトを取得してビジネスロジックを実行する(状況に応じてmodel.pyの内容とデータベースが同期される)
4.最終的にビューが情報をテンプレートにレンダリングしてレスポンスを作成する
5.作成されたレスポンスをディスパッチャがブラウザに送るという流れです。
主にコードを書いていくのはmodels.pyとviews.pyになります。あとテンプレートファイルとしてのHTMLファイルですね。setting.pyの編集
Djangoの設定ファイルを編集します。
setting.pyINSTALLED_APPS = [ 'attendance.apps.AttendanceConfig', # djangoにattendanceアプリの存在を知らせる #... ] #... LANGUAGE_CODE = 'ja' # 言語を日本語に TIME_ZONE = 'Asia/Tokyo' # タイムゾーンを日本時間にURLconfの編集
urls.pyを編集します。
ルートのURLconfにコードがたくさん書かれるのを防ぐために、アプリケーションごとにURLconfを用意し、ルートには各アプリのURLconfへの道を教えてあげます。↓ルート
clock/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('', include('attendance.urls')), path('admin/', admin.site.urls), ]↓attendanceアプリ(新しくurls.pyファイルを作成してください)
attendance/urls.pyfrom django.urls import path from . import views # ←これ忘れないようにする!! app_name = 'attendance' urlpatterns = [ path('', views.index, name='index'), path('result/', views.result, name='result'), ]他の場所からの呼び出しが簡単になるように、app_name変数を定義してください。
まだviews.pyには何もありません。これから記述していきます。モデルの作成
勤怠時間の打刻モデルということで、SubmitAttendanceクラスを作成し、モデルとします。
attendance/models.pyfrom django.db import models from django.contrib.auth import get_user_model # Create your models here. class SubmitAttendance(models.Model): class Meta: db_table = 'attendance' PLACES = ( (1, 'Bar Foo'), (2, 'Bar Baz'), (3, 'Bar Qux'), (4, 'Bar Quux'), (5, 'Bar Corge'), (6, 'Bar Grault'), ) IN_OUT = ( (1, 'IN'), (0, 'OUT'), ) staff = models.ForeignKey(get_user_model(), verbose_name="スタッフ", on_delete=models.CASCADE, default=None) place = models.IntegerField(verbose_name='出勤場所名', choices=PLACES, default=None) in_out = models.IntegerField(verbose_name='IN/OUT', choices=IN_OUT, default=None) time = models.TimeField(verbose_name="打刻時間") date = models.DateField(verbose_name='打刻日')
- models.Modelを継承したクラスを定義します。
- データベースに格納された時のメタデータとして、テーブル名を与えています。
- バーの店舗と、出勤or退勤の選択肢を作るために、ここでタプルに格納しています。(もちろん店舗名は架空の名前に置き換えています。笑)
- 変数は以下の通り↓
- staff:ログイン中のユーザー名
- place:PLACESタプルから選ぶ
- in_out:IN_OUTタプルから選ぶ
- time:打刻した時間
- date:打刻した日付
- verbose_nameはデータベースのcolumnの名前
フォームの作成
最初のページで、バーの店舗名と出勤か退勤かを選択させるフォームを作ります。
コードはforms.pyを作り、そこに記述します。attendance/forms.pyfrom django import forms from .models import SubmitAttendance class SubmitAttendanceForm(forms.ModelForm): class Meta: model = SubmitAttendance fields = ('place', 'in_out')indexビューの作成
最初の画面を出すためのIndexViewと、結果画面を出すためのResultViewに分けています。
attendance/views.pyfrom django.shortcuts import render, redirect from django.views import View from django.contrib.auth.mixins import LoginRequiredMixin from .models import SubmitAttendance from .forms import SubmitAttendanceForm from datetime import datetime from django.utils import timezone # Create your views here. class IndexView(LoginRequiredMixin, View): def get(self, request): form = SubmitAttendanceForm context = { 'form': form, "user": request.user, } return render(request, 'attendance/index.html', context) index = IndexView.as_view()※ログインに関する記述がありますが、これは後ほど記述します。
クラスベースのビューを記述しています。
先ほど作成したフォームを、オブジェクトとして変数formに代入。
ログイン中のユーザーを変数userに代入。
context辞書に、テンプレートへ送る変数をまとめて、render関数をつかってリクエストをテンプレートへ送ります。
最後にこのクラスをas_view()を用いて、ビューとしてインスタンス化します。indexテンプレートの作成
まずはテンプレートファイルを保存するディレクトリを作ります。
attendance/template/attendanceとなるようにディレクトリを新たに2つ追加し、内側のattendanceの中に、base.htmlとindex.htmlを作ります。
templatesディレクトリの中にattendanceディレクトリをもう一度作っていますが、これは「お約束」みたいなものです。テンプレートの継承
全てのhtmlファイルに共通な部分を、テンプレートファイルを作るごとに何回も何回も書いていたら大変なので、そういった部分はbase.htmlに書いて、index.htmlで継承するという手続きを踏みます。
base.html{% load static %} <html> <head> <meta charset='utf-8'> <link rel="stylesheet" type="text/css" href="{% static 'attendance/css/style.css' %}"> <title>勤怠打刻ページ</title> </head> <body> {% block content %} {% endblock %} </body> </html>冒頭で
{% extends 継承元 %}と記述することで継承元のファイルを継承し、{% block content %}と{% endblock %}の中に内容を記述します。
static(静的)ファイルに関する記述があります。Bootstrapのstyle.cssをstaticディレクトリの中に保存して使っています。index.html{% extends "attendance/base.html" %} {% block content %} {% if user.is_authenticated %} <div class="container"> <form method="post" action="{% url 'attendance:result' %}"> {% csrf_token %} <h1>{{ user }} さん</h1> <h2 id="time"></h2> <script> time(); function time(){ var now = new Date(); document.getElementById("time").innerHTML = now.toLocaleString(); } setInterval('time()',1000); </script> <p>出勤場所:<input type="hidden" name="place">{{ form.place }}</p> <p>IN/OUT:<input type="hidden" name="in_out">{{ form.in_out }}</p> <p><input class="btn btn-primary" type="submit" value="Submit"></p> </form> <a href="../accounts/logout">ログアウト</a> </div> {% endif %} {% endblock %}
- {%%}はテンプレートタグ。HTML上にPythonのようなコードを書くことができるタグです。
- scriptタグで囲まれた部分は、現在時刻を表示しています。
- {{ }}で囲まれた部分には、先ほどビューから送った変数です。
- formタグ内で入力された値はview.resultに送られるようaction属性を指定します。
{% csrf_token %}はこのページのように入力データを送るときに記述しなければならない、セキュリティのお約束のようなものです。resultビューの作成
attendance/views.py#... class ResultView(View): def post(self, request): form = SubmitAttendanceForm(request.POST) now = datetime.now() month = now.month day = now.day hour = now.hour minute = now.minute obj = form.save(commit=False) obj.place = request.POST["place"] obj.in_out = request.POST["in_out"] obj.staff = request.user obj.date = datetime.now().date() obj.time = datetime.now().time() obj.save() if request.POST["in_out"] == '1': comment = str(month) + "月" + str(day) +"日" + str(hour) + "時" + str(minute) + "分\n" + "出勤確認しました。今日も頑張りましょう!" else: comment = str(month) + "月" + str(day) +"日" + str(hour) + "時" + str(minute) + "分\n" + "退勤確認しました。お疲れ様でした(^-^)!" context = { 'place': SubmitAttendance.PLACES[int(obj.place)-1][1], 'comment': comment, } return render(request, 'attendance/result.html', context) result = ResultView.as_view()
- 入力値とともに送られてきたPOSTメソッドのリクエストをformに代入。
- objが並んでいるところは入力値をモデルの変数に代入し、データベースに保存しています。
- 出勤か退勤かで変数commentに代入する文字列を変えて、result.htmlに送ります。
resultテンプレートの作成
result.html{% extends 'attendance/base.html' %} {% block content %} <p>出勤場所:{{ place }}</p> <p>{{ comment }}</p> <a href="../accounts/logout">ログアウト</a> {% endblock %}実際の作業2(ログインページの作成)
こちらのサイトを参考にしました↓↓
Django2 でユーザー認証(ログイン認証)を実装するチュートリアル -2- サインアップとログイン・ログアウト設定とURLconf
accountsアプリを作り、setting.pyのINSTALLED_APPに、
accounts.app.AccountsConfigを記述してaccountsアプリの存在を示してあげます。
また、accountsアプリとルートのURLconfも編集します。clock/urls.py#... #以下を追加 path('accounts/', include('django.contrib.auth.urls')), #...accounts/urls.pyfrom django.urls import path from . import views app_name = 'accounts' urlpatterns = [ path('login/', views.login, name='login'), path('logout/', views.logout, name='logout') ]Djangoが用意してくれているログインフォームがあるので、ビューの編集はしません。
テンプレート
Djangoではログインページのテンプレートファイルは、
accounts/templates/registration/login.htmlというところに書くと決まっていますので、素直にこの構造を作ります。accounts/templates/registration/login.html{% extends 'admin/base.html' %} {% block content %} {% if form.errors %} <p>ユーザー名とパスワードが一致しません。</p> {% endif %} {% if next %} {% if user.is_authenticated %} <p>アクセス権のあるアカウントでログインしてください。</p> {% else %} <p>ログインしてください。</p> {% endif %} {% endif %} <form method="post" action="{% url 'login' %}"> {% csrf_token %} <table class="container"> <tr> <td>{{ form.username.label_tag }}</td> <td>{{ form.username }}</td> </tr> <tr> <td>{{ form.password.label_tag }}</td> <td>{{ form.password }}</td> </tr> </table> <input type="submit" value="login" /> <input type="hidden" name="next" value="{{ next }}" /> </form> {% endblock %}これで、以下のようなテンプレートが作成されます。
ここまでで、先ほどつくったindex.htmlやresult.htmlは動くと思います。
ただ、ユーザーが登録されていないので、登録します。
実際の作業3(管理者アカウントの作成と管理者ページ)
admin.pyの編集
モデルをDjango管理画面で管理できるようにするには、アプリのディレクトリ内のadmin.pyを次のように編集します。
attendance/admin.pyfrom django.contrib import admin from .models import SubmitAttendance # Register your models here. admin.site.register(SubmitAttendance)管理者アカウントの作成
ターミナルで
python manage.py createsuperuserと入力すると、管理者ユーザーの登録内容を求められるので好きな値を入力してください。管理者ページ
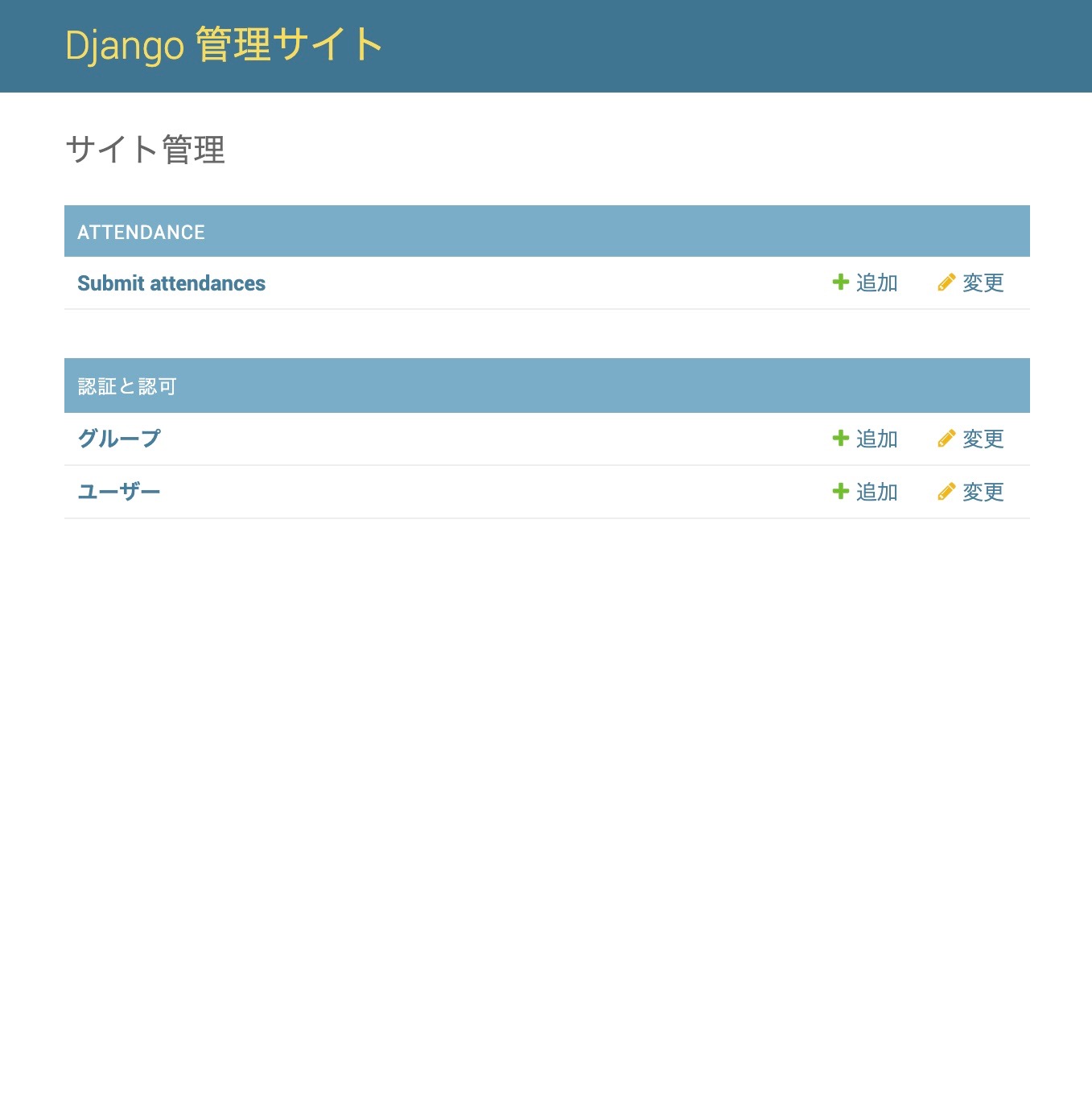
http://127.0.0.1:8000/admin
にアクセスして、先ほど入力したIDとパスワードを入力します。管理者ページは次のような感じになっています。
認証と認可のところのユーザーをクリックすると、ユーザーの登録・削除ができます。
実際の作業4(デモ)
ここまでで作ったものを表示してみます。
http://127.0.0.1:8000
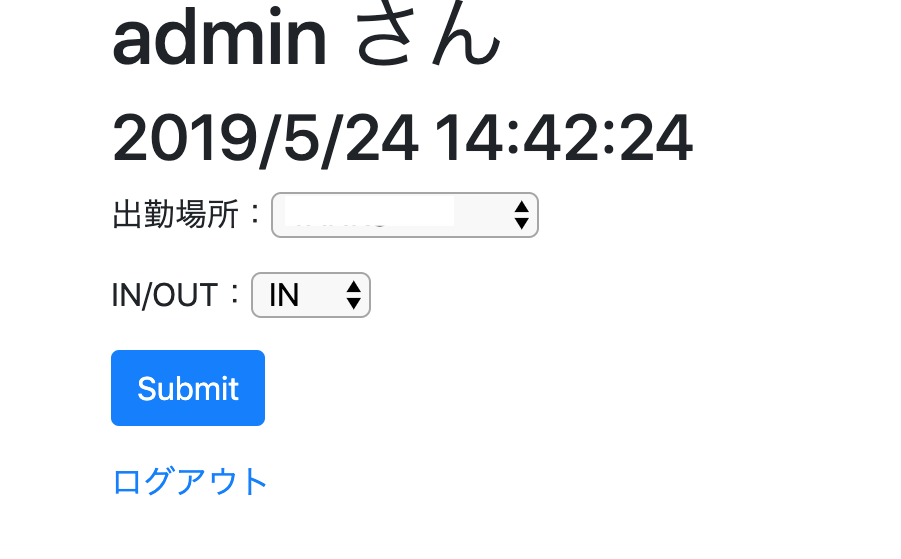
へアクセスし、先ほど登録したユーザーでログインしてみましょう。
以下のような画面が表示されるはずです。
出勤場所と、IN/OUTを選択してSubmitすると...
こんな感じになります!(hogehogeのところには設定した店舗名が表示されます。)
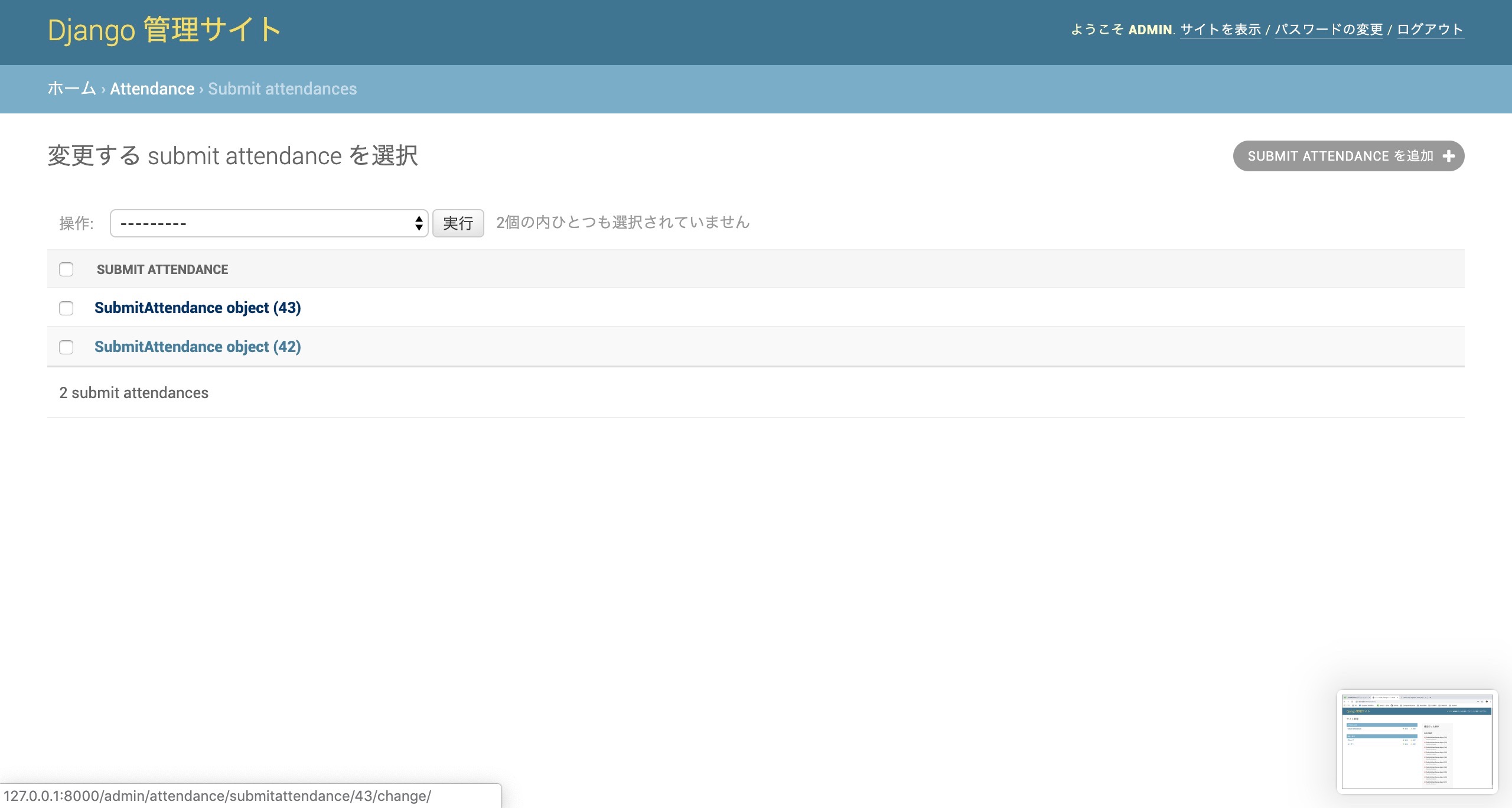
管理者ページで見てみる
先ほどの管理者ページ内にあったSubmitAttendanceをクリックすると、登録されたオブジェクトが見れます。
index.htmlで値が入力されて生成されたオブジェクトもしっかりあります。
1つクリックしてみると...
はい、こんな感じです。
これではみにくいので、同時生成されるデータベースファイルdb.sqlite3をのぞいてみます。
いい感じです。
最後に
長々とまとまりのない文章だったかもしれませんが、最後まで読んでいただいた方、ありがとうございます。
これから
- 上にあるデータベースファイルから「ユーザー」ごとの「勤務時間」を計算し、お給料を計算するモデルを作成中です。←ここで詰まりました...
- 出勤場所からしかアクセスできないように、アクセス可能なIPアドレスを制限する。(不正打刻防止のために、これは必須)
参考にしたWebサイトや本
未経験からやってみたのでおそらく累計30~50個(もっとかな?)ほどのwebサイトを参考にさせていただいたと思うのですが、流石に覚えていないので、よく拝見したものを掲載しておきます。



- 投稿日:2019-05-24T15:00:52+09:00
Djangoで勤怠管理Webアプリケーションを作ってみた
はじめに
現在アルバイトしているバーではタイムカードを表計算ソフトで管理しているのですが、これをもうちょっと楽にできないかなと思い、勤怠管理Webアプリケーションを作ってみました。
まだまだ改善の余地があり、追加したい機能などもありますが、行き詰まりまして...
大枠は完成したので、一度ここでアウトプットして整理してみます。ご指摘がありましたら、コメントしていただけると嬉しいです。
環境など
OS macOS Mojave 使用言語 Python 3.6.7(Anaconda) フレームワーク Django 2.2 バージョン管理 Git 確認用ブラウザ Google Chrome 制作期間 約2週間 実際の作業1(大枠を作成)
最初の準備
conda仮想環境構築
Anacondaで仮想環境を作成して、そこで動かしていくので作成します。
詳しくはこちらの方が記事で書いておられますので読んでみてください。→【初心者向け】Anacondaで仮想環境を作ってみる
conda create -n(または--name) 環境名 python(=バージョン指定)
でpythonのバージョンを指定して仮想環境を作成できます。
また、conda activate 指定した環境名で作成した環境をアクティベートできます。conda create -n py36 python=3.6.7 conda activate py36Djangoのインストール
この仮想環境を立ち上げた状態でインストールします。
(py36) TaronoMacBook-Pro:clock taro$ conda install djangoこれで環境構築できました。
今後はここで作業していくので、以降シェルコマンドはこの環境上で動かしているとみなしてください。
実際に環境構築で一番手間取ったかもしれません。最終的に動いているのはこの状態なのですが、ここまで来るのに右往左往してしまいました。Djangoでの最初の作業
startproject
プロジェクトのディレクトリを保存したい場所でターミナルを開き、以下のコマンドを入力。
clockは勝手につけた名前。django-admin startproject clock次のような構造のディレクトリができます。
clock ├── clock │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-36.pyc │ │ ├── settings.cpython-36.pyc │ │ ├── urls.cpython-36.pyc │ │ └── wsgi.cpython-36.pyc │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── manage.py外側のclockディレクトリはただの入れ物なのでリネーム可能。
startapp
以下のコマンドを入力し、外側のディレクトリ内(このプロジェクトのルートディレクトリ)でattendanceという名前のアプリの入れ物を作ります。
python manage.py startapp attendance次のようにattendanceディレクトリができます。
clock ├── attendance │ ├── __init__.py │ ├── __pycache__ │ ├── admin.py │ ├── apps.py │ ├── migrations │ ├── models.py │ ├── tests.py │ └── views.py ├── clock └── manage.pyよく使うDjangoコマンド
- Djangoのデータベースをマイグレーションコマンドで作成。
python manage.py makemigrations python manage.py migrate2段階のコマンドで、一度マイグレーションする物のリストを作ってから、実際にマイグレーションしています。(git add から git commit の流れに似ています)
- サーバーを動かす。
python manage.py runserverDjangoの全体像
超ざっくりした絵ですみません笑
とっても簡略化すると、
1.ブラウザからリクエストされたURLをDjangoのURLディスパッチャなるコアモジュールが受ける
2.そのディスパッチャが、urls.pyに記述したURLconf(URLのパターンとそれぞれのパターンに対するリクエストの送り先を示した地図のようなもの)に従って、ビューにリクエストを送る
3.ビューがモデルオブジェクトを取得してビジネスロジックを実行する(状況に応じてmodel.pyの内容とデータベースが同期される)
4.最終的にビューが情報をテンプレートにレンダリングしてレスポンスを作成する
5.作成されたレスポンスをディスパッチャがブラウザに送るという流れです。
主にコードを書いていくのはmodels.pyとviews.pyになります。あとテンプレートファイルとしてのHTMLファイルですね。setting.pyの編集
Djangoの設定ファイルを編集します。
setting.pyINSTALLED_APPS = [ 'attendance.apps.AttendanceConfig', # djangoにattendanceアプリの存在を知らせる #... ] #... LANGUAGE_CODE = 'ja' # 言語を日本語に TIME_ZONE = 'Asia/Tokyo' # タイムゾーンを日本時間にURLconfの編集
urls.pyを編集します。
ルートのURLconfにコードがたくさん書かれるのを防ぐために、アプリケーションごとにURLconfを用意し、ルートには各アプリのURLconfへの道を教えてあげます。↓ルート
clock/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('', include('attendance.urls')), path('admin/', admin.site.urls), ]↓attendanceアプリ(新しくurls.pyファイルを作成してください)
attendance/urls.pyfrom django.urls import path from . import views # ←これ忘れないようにする!! app_name = 'attendance' urlpatterns = [ path('', views.index, name='index'), path('result/', views.result, name='result'), ]他の場所からの呼び出しが簡単になるように、app_name変数を定義してください。
まだviews.pyには何もありません。これから記述していきます。モデルの作成
勤怠時間の打刻モデルということで、SubmitAttendanceクラスを作成し、モデルとします。
attendance/models.pyfrom django.db import models from django.contrib.auth import get_user_model # Create your models here. class SubmitAttendance(models.Model): class Meta: db_table = 'attendance' PLACES = ( (1, 'Bar Foo'), (2, 'Bar Baz'), (3, 'Bar Qux'), (4, 'Bar Quux'), (5, 'Bar Corge'), (6, 'Bar Grault'), ) IN_OUT = ( (1, 'IN'), (0, 'OUT'), ) staff = models.ForeignKey(get_user_model(), verbose_name="スタッフ", on_delete=models.CASCADE, default=None) place = models.IntegerField(verbose_name='出勤場所名', choices=PLACES, default=None) in_out = models.IntegerField(verbose_name='IN/OUT', choices=IN_OUT, default=None) time = models.TimeField(verbose_name="打刻時間") date = models.DateField(verbose_name='打刻日')
- models.Modelを継承したクラスを定義します。
- データベースに格納された時のメタデータとして、テーブル名を与えています。
- バーの店舗と、出勤or退勤の選択肢を作るために、ここでタプルに格納しています。(もちろん店舗名は架空の名前に置き換えています。笑)
- 変数は以下の通り↓
- staff:ログイン中のユーザー名
- place:PLACESタプルから選ぶ
- in_out:IN_OUTタプルから選ぶ
- time:打刻した時間
- date:打刻した日付
- verbose_nameはデータベースのcolumnの名前
フォームの作成
最初のページで、バーの店舗名と出勤か退勤かを選択させるフォームを作ります。
コードはforms.pyを作り、そこに記述します。attendance/forms.pyfrom django import forms from .models import SubmitAttendance class SubmitAttendanceForm(forms.ModelForm): class Meta: model = SubmitAttendance fields = ('place', 'in_out')indexビューの作成
最初の画面を出すためのIndexViewと、結果画面を出すためのResultViewに分けています。
attendance/views.pyfrom django.shortcuts import render, redirect from django.views import View from django.contrib.auth.mixins import LoginRequiredMixin from .models import SubmitAttendance from .forms import SubmitAttendanceForm from datetime import datetime from django.utils import timezone # Create your views here. class IndexView(LoginRequiredMixin, View): def get(self, request): form = SubmitAttendanceForm context = { 'form': form, "user": request.user, } return render(request, 'attendance/index.html', context) index = IndexView.as_view()※ログインに関する記述がありますが、これは後ほど記述します。
クラスベースのビューを記述しています。
先ほど作成したフォームを、オブジェクトとして変数formに代入。
ログイン中のユーザーを変数userに代入。
context辞書に、テンプレートへ送る変数をまとめて、render関数をつかってリクエストをテンプレートへ送ります。
最後にこのクラスをas_view()を用いて、ビューとしてインスタンス化します。indexテンプレートの作成
まずはテンプレートファイルを保存するディレクトリを作ります。
attendance/template/attendanceとなるようにディレクトリを新たに2つ追加し、内側のattendanceの中に、base.htmlとindex.htmlを作ります。
templatesディレクトリの中にattendanceディレクトリをもう一度作っていますが、これは「お約束」みたいなものです。テンプレートの継承
全てのhtmlファイルに共通な部分を、テンプレートファイルを作るごとに何回も何回も書いていたら大変なので、そういった部分はbase.htmlに書いて、index.htmlで継承するという手続きを踏みます。
base.html{% load static %} <html> <head> <meta charset='utf-8'> <link rel="stylesheet" type="text/css" href="{% static 'attendance/css/style.css' %}"> <title>勤怠打刻ページ</title> </head> <body> {% block content %} {% endblock %} </body> </html>冒頭で
{% extends 継承元 %}と記述することで継承元のファイルを継承し、{% block content %}と{% endblock %}の中に内容を記述します。
static(静的)ファイルに関する記述があります。Bootstrapのstyle.cssをstaticディレクトリの中に保存して使っています。index.html{% extends "attendance/base.html" %} {% block content %} {% if user.is_authenticated %} <div class="container"> <form method="post" action="{% url 'attendance:result' %}"> {% csrf_token %} <h1>{{ user }} さん</h1> <h2 id="time"></h2> <script> time(); function time(){ var now = new Date(); document.getElementById("time").innerHTML = now.toLocaleString(); } setInterval('time()',1000); </script> <p>出勤場所:<input type="hidden" name="place">{{ form.place }}</p> <p>IN/OUT:<input type="hidden" name="in_out">{{ form.in_out }}</p> <p><input class="btn btn-primary" type="submit" value="Submit"></p> </form> <a href="../accounts/logout">ログアウト</a> </div> {% endif %} {% endblock %}
- {%%}はテンプレートタグ。HTML上にPythonのようなコードを書くことができるタグです。
- scriptタグで囲まれた部分は、現在時刻を表示しています。
- {{ }}で囲まれた部分には、先ほどビューから送った変数です。
- formタグ内で入力された値はview.resultに送られるようaction属性を指定します。
{% csrf_token %}はこのページのように入力データを送るときに記述しなければならない、セキュリティのお約束のようなものです。resultビューの作成
attendance/views.py#... class ResultView(View): def post(self, request): form = SubmitAttendanceForm(request.POST) now = datetime.now() month = now.month day = now.day hour = now.hour minute = now.minute obj = form.save(commit=False) obj.place = request.POST["place"] obj.in_out = request.POST["in_out"] obj.staff = request.user obj.date = datetime.now().date() obj.time = datetime.now().time() obj.save() if request.POST["in_out"] == '1': comment = str(month) + "月" + str(day) +"日" + str(hour) + "時" + str(minute) + "分\n" + "出勤確認しました。今日も頑張りましょう!" else: comment = str(month) + "月" + str(day) +"日" + str(hour) + "時" + str(minute) + "分\n" + "退勤確認しました。お疲れ様でした(^-^)!" context = { 'place': SubmitAttendance.PLACES[int(obj.place)-1][1], 'comment': comment, } return render(request, 'attendance/result.html', context) result = ResultView.as_view()
- 入力値とともに送られてきたPOSTメソッドのリクエストをformに代入。
- objが並んでいるところは入力値をモデルの変数に代入し、データベースに保存しています。
- 出勤か退勤かで変数commentに代入する文字列を変えて、result.htmlに送ります。
resultテンプレートの作成
result.html{% extends 'attendance/base.html' %} {% block content %} <p>出勤場所:{{ place }}</p> <p>{{ comment }}</p> <a href="../accounts/logout">ログアウト</a> {% endblock %}実際の作業2(ログインページの作成)
こちらのサイトを参考にしました↓↓
Django2 でユーザー認証(ログイン認証)を実装するチュートリアル -2- サインアップとログイン・ログアウト設定とURLconf
accountsアプリを作り、setting.pyのINSTALLED_APPに、
accounts.app.AccountsConfigを記述してaccountsアプリの存在を示してあげます。
また、accountsアプリとルートのURLconfも編集します。clock/urls.py#... #以下を追加 path('accounts/', include('django.contrib.auth.urls')), #...accounts/urls.pyfrom django.urls import path from . import views app_name = 'accounts' urlpatterns = [ path('login/', views.login, name='login'), path('logout/', views.logout, name='logout') ]Djangoが用意してくれているログインフォームがあるので、ビューの編集はしません。
テンプレート
Djangoではログインページのテンプレートファイルは、
accounts/templates/registration/login.htmlというところに書くと決まっていますので、素直にこの構造を作ります。accounts/templates/registration/login.html{% extends 'admin/base.html' %} {% block content %} {% if form.errors %} <p>ユーザー名とパスワードが一致しません。</p> {% endif %} {% if next %} {% if user.is_authenticated %} <p>アクセス権のあるアカウントでログインしてください。</p> {% else %} <p>ログインしてください。</p> {% endif %} {% endif %} <form method="post" action="{% url 'login' %}"> {% csrf_token %} <table class="container"> <tr> <td>{{ form.username.label_tag }}</td> <td>{{ form.username }}</td> </tr> <tr> <td>{{ form.password.label_tag }}</td> <td>{{ form.password }}</td> </tr> </table> <input type="submit" value="login" /> <input type="hidden" name="next" value="{{ next }}" /> </form> {% endblock %}これで、以下のようなテンプレートが作成されます。
ここまでで、先ほどつくったindex.htmlやresult.htmlは動くと思います。
ただ、ユーザーが登録されていないので、登録します。
実際の作業3(管理者アカウントの作成と管理者ページ)
admin.pyの編集
モデルをDjango管理画面で管理できるようにするには、アプリのディレクトリ内のadmin.pyを次のように編集します。
attendance/admin.pyfrom django.contrib import admin from .models import SubmitAttendance # Register your models here. admin.site.register(SubmitAttendance)管理者アカウントの作成
ターミナルで
python manage.py createsuperuserと入力すると、管理者ユーザーの登録内容を求められるので好きな値を入力してください。管理者ページ
http://127.0.0.1:8000/admin
にアクセスして、先ほど入力したIDとパスワードを入力します。管理者ページは次のような感じになっています。
認証と認可のところのユーザーをクリックすると、ユーザーの登録・削除ができます。
実際の作業4(デモ)
ここまでで作ったものを表示してみます。
http://127.0.0.1:8000
へアクセスし、先ほど登録したユーザーでログインしてみましょう。
以下のような画面が表示されるはずです。
出勤場所と、IN/OUTを選択してSubmitすると...
こんな感じになります!(hogehogeのところには設定した店舗名が表示されます。)
管理者ページで見てみる
先ほどの管理者ページ内にあったSubmitAttendanceをクリックすると、登録されたオブジェクトが見れます。
index.htmlで値が入力されて生成されたオブジェクトもしっかりあります。
1つクリックしてみると...
はい、こんな感じです。
これではみにくいので、同時生成されるデータベースファイルdb.sqlite3をのぞいてみます。
見やすいとは言えないですが、何がどこにあるかはわかります。
最後に
長々とまとまりのない文章だったかもしれませんが、最後まで読んでいただいた方、ありがとうございます。
これから
- 上にあるデータベースファイルから「ユーザー」ごとの「勤務時間」を計算し、お給料を計算するモデルを作成中です。←ここで詰まりました...
- 出勤場所からしかアクセスできないように、アクセス可能なIPアドレスを制限する。(不正打刻防止のために、これは必須)
参考にしたWebサイトや本
未経験からやってみたのでおそらく累計30~50個(もっとかな?)ほどのwebサイトを参考にさせていただいたと思うのですが、流石に覚えていないので、よく拝見したものを掲載しておきます。
- 投稿日:2019-05-24T13:56:03+09:00
【Django】renderとreverse_lazyの使い分けについて
概要
Djangoでアプリ作成のときに、
renderとreverse_lazyの違いがわからなかったので、備忘録として書きます。TemplateView or Function
結論からいうと、
reverse_lazyはTemplateViewで使い、renderはfunctionで実装する場合に使用します。下記にて、投稿サイトをイメージした例になります。
PostClassとlistfunctionに注目してくださいmyapp/models.pyfrom django.db import models class PostModel(models.Model): title = models.CharField(max_length=50) memo = models.TextField()myapp/views.pyfrom django.views.generic import CreateView from django.urls import reverse_lazy from .models import PostModel class PostClass(CreateView): template_name = 'post.html' model = PostModel fields = ('title','memo') success_url = reverse_lazy('list') def listfunction(request): object_list = PostModel.objects.all() return render(request, 'list.html')myapp/urls.pyfrom django.urls import path from .views import PostClass, listfunction urlpatterns = [ path('post/', PostClass.as_view(), name='post'), path('list/', listfunction, name='list'), ]post.html<form action="" method="POST"> {% csrf_token %} <p>タイトル:<input type="text" name="title"></p> <p>メモ:<input type="text" name="memo"></p> <input type="submit" value="投稿する"> </form>list.html<div class="container"> {% for post in object_list %} <div class="post"> <p>タイトル:{{ post.title }}</p> <p>メモ:{{ post.memo }}</p> </div> {% endfor %} </div>まとめ
上記でも書いたように
reverse_lazyはTemplateViewの場合renderはfunctionの場合になります参照:
https://docs.djangoproject.com/ja/2.2/ref/urlresolvers/
https://teratail.com/questions/103080
https://teratail.com/questions/50683以上
- 投稿日:2019-05-24T12:01:50+09:00
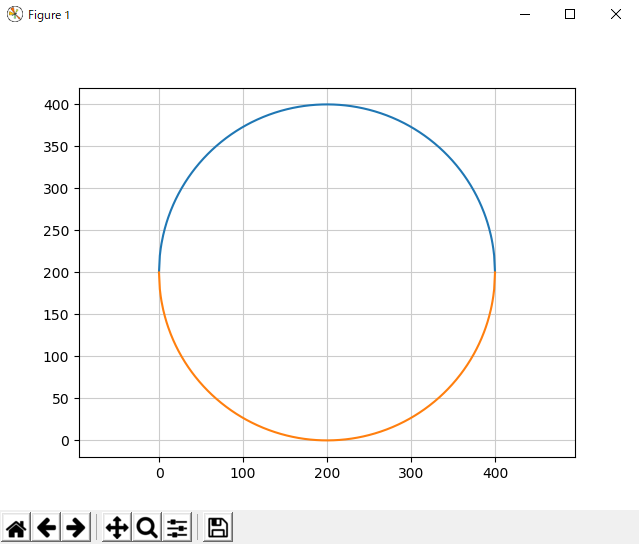
【Python】高校の数学で習った「円の方程式」を使って、円を描いてみた^^
はじめに
高校の数学で習った円の方程式は覚えてますでしょうか?
(x-a)^2+(y-b)^2 = r^2こちらが「円の方程式」です!
どんな場合でも「中心の座標(a,b)」と「半径r」の2つが分かれば、円の方程式を使って円を描くことができます。この記事では以下の3つの方法で、円の方程式とPythonを使って円を描いていきます。
1. 円の中心と円周上の1点を指定する方法 2. 正方形の対角を2点指定する方法 3. 円周上の3点を指定する方法環境
- Windows 10 home
- Python 3.7.1
matplotlib,numpy,sympyのライブラリを使うので以下のコマンドでそれぞれインストールしておきましょう。
> pip install matplotlib > pip install numpy > pip install sympy1. 円の中心と円周上の1点を指定する方法
1-1. 手順
① : 与えられた2点間の距離を求める。(半径)
② : 1点目を円の中心、①で求めた値を半径とする円を描画する。1-2. ソースコード
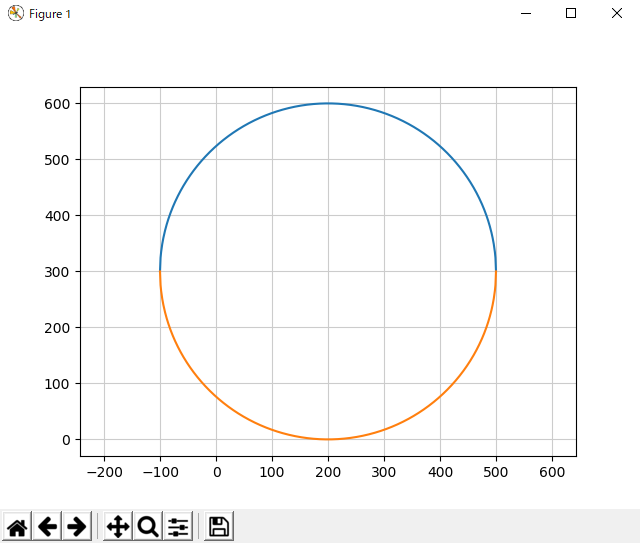
Circle1.pyimport matplotlib.pyplot as plt import numpy as np # 円周上の1点 x1 = 500 y1 = 300 # 円の中心 a = 200 b = 300 # 1: 与えられた2点間の距離を求める。(半径) r = np.sqrt((a-x1)**2 + (b-y1)**2) # 2: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示1-3. 実行結果
このようになれば、成功です。
2. 正方形の対角を2点指定する方法
2-1. 手順
① : 与えられた2点の中点を求める。(円の中心)
② : ①で求めた点と、2点目を通ってy軸と平行な直線との距離を求める。(半径)
③ : ①で求めた点を円の中心、②で求めた値を半径とする円を描画する。2-2. ソースコード
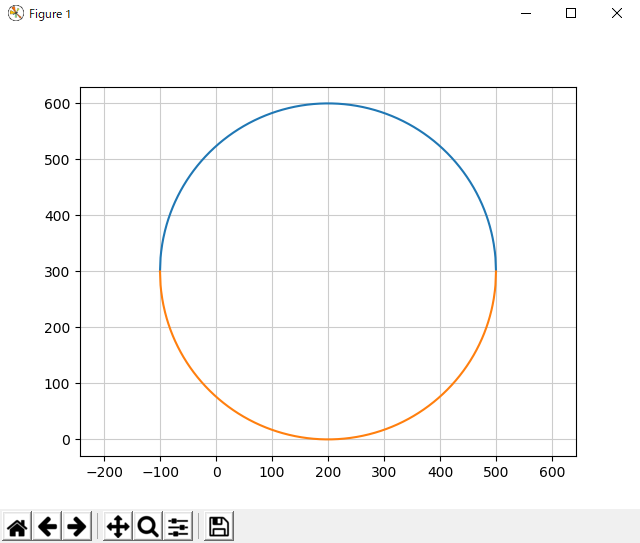
Circle2.pyimport matplotlib.pyplot as plt import numpy as np # 円周上の2点 x1 = -100 y1 = 300 x2 = 500 y2 = 300 # 1: 与えられた2点の中点を求める。(円の中心) a = (x2-x1)/2 b = (y2-y1)/2 # 2: 1で求めた点と、2点目を通ってy軸と平行な直線との距離を求める。(半径) r = x2-a # 3: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示2-3. 実行結果
このようになれば、成功です。
3. 円周上の3点を指定する方法
3-1. 手順
① : 与えられた3点から、各辺の式を求める。
② : 各辺の垂直二等分線の式を求める。
③ : 垂直二等分線の交点を求める。(円の中心)
④ : ③で求めた点と、与えられた1つの点との距離を求める。(半径)
⑤ : ③で求めた点を円の中心、④で求めた値を半径とする円を描画する。3-2. ソースコード
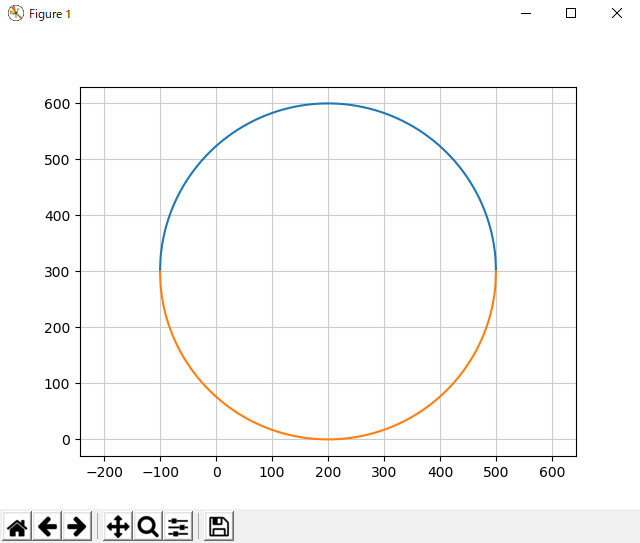
Circle3.pyimport matplotlib.pyplot as plt import numpy as np from sympy import Symbol, solve # 円周上の3点 x1 = -100 y1 = 300 x2 = 500 y2 = 300 x3 = 200 y3 = 600 # 1: 与えられた3点から、各辺の式を求める。 aa = Symbol("aa") bb = Symbol("bb") ex1 = x1*aa+bb-y1 ex2 = x3*aa+bb-y3 result1 = solve([ex1,ex2],[aa,bb])#x1,y1とx3,y3の2点からなる直線の式 ex1 = x2*aa+bb-y2 result2 = solve([ex1,ex2],[aa,bb])#x2,y2とx3,y3の2点からなる直線の式 # 2: 各辺の垂直二等分線の式を求める。 ex1 = (-1/result1[aa])*((x3+x1)/2)+bb-((y3+y1)/2) result3 = solve(ex1,bb)#result1の辺の垂直二等分線 ex2 = (-1/result2[aa])*((x3+x2)/2)+bb-((y3+y2)/2) result4 = solve(ex2,bb)#result2の辺の垂直二等分線 # 3: 垂直二等分線の交点を求める。(円の中心) ex1 = (-1/result1[aa])*aa+result3[0]-bb ex2 = (-1/result2[aa])*aa+result4[0]-bb result5 = solve([ex1,ex2],[aa,bb]) a = round(result5[aa])#円の中心のx座標 b = round(result5[bb])#円の中心のy座標 # 4: 3で求めた点と、与えられた1つの点との距離を求める。(半径) r = np.sqrt(((a-x1)**2)+((b-y1)**2))#円の半径の計算 # 5: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # 6: グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示3-3. 実行結果
このようになれば、成功です。
終わりに
ここまで読んでいただき、ありがとうございました。
高校数学の記事をあげたのですが、急にどうした!?って感じです。というのも、数学を勉強し直そうと思い、谷尻かおりさんの「Pythonで学び直す高校数学」という本を手に取った次第であります。
今回、取り上げた記事の内容はその本の第3章にある「方程式で図形を描く」という部分の最後のコラムのチャレンジ問題になります。その問題の解答がなかった?ので、自分なりに挑戦してみて、それを記事にしました。参考になったら嬉しいです。
- 投稿日:2019-05-24T12:01:50+09:00
【Python】高校の数学で習った「円の方程式」を使って、円を描いてみた
はじめに
高校の数学で習った円の方程式は覚えてますでしょうか?
(x-a)^2+(y-b)^2 = r^2こちらが「円の方程式」です!
どんな場合でも「中心の座標(a,b)」と「半径r」の2つが分かれば、円の方程式を使って円を描くことができます。この記事では以下の3つの方法で、円の方程式とPythonを使って円を描いていきます。
1. 円の中心と円周上の1点を指定する方法 2. 正方形の対角を2点指定する方法 3. 円周上の3点を指定する方法環境
- Windows 10 home
- Python 3.7.1
matplotlib,numpy,sympyのライブラリを使うので以下のコマンドでそれぞれインストールしておきましょう。
> pip install matplotlib > pip install numpy > pip install sympy1. 円の中心と円周上の1点を指定する方法
1-1. 手順
① : 与えられた2点間の距離を求める。(半径)
- 2点間の距離の求め方は以下の公式になります。
AB = \sqrt{(x2 - x1)^2 + (y2 - y1)^2}② : 1点目を円の中心、①で求めた値を半径とする円を描画する。
1-2. ソースコード
Circle1.pyimport matplotlib.pyplot as plt import numpy as np # 円周上の1点 x1 = 500 y1 = 300 # 円の中心 a = 200 b = 300 # 1: 与えられた2点間の距離を求める。(半径) r = np.sqrt((a-x1)**2 + (b-y1)**2) # 2: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示1-3. 実行結果
このようになれば、成功です。
2. 正方形の対角を2点指定する方法
2-1. 手順
① : 与えられた2点の中点を求める。(円の中心)
- 線分の中点を求める方程式は以下の通りです。
x = \frac{x1 + x2}{2} \hspace{20pt} y = \frac{y1 + y2}{2}② : ①で求めた点と、2点目を通ってy軸と平行な直線との距離を求める。(半径)
③ : ①で求めた点を円の中心、②で求めた値を半径とする円を描画する。2-2. ソースコード
Circle2.pyimport matplotlib.pyplot as plt import numpy as np # 円周上の2点 x1 = 0 y1 = 400 x2 = 400 y2 = 0 # 1: 与えられた2点の中点を求める。(円の中心) a = (x2+x1)/2 b = (y2+y1)/2 # 2: 1で求めた点と、2点目を通ってy軸と平行な直線との距離を求める。(半径) r = x2-a # 3: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示2-3. 実行結果
このようになれば、成功です。
3. 円周上の3点を指定する方法
3-1. 手順
① : 与えられた3点から、各辺の式を求める。
② : 各辺の垂直二等分線の式を求める。
③ : 垂直二等分線の交点を求める。(円の中心)
④ : ③で求めた点と、与えられた1つの点との距離を求める。(半径)
⑤ : ③で求めた点を円の中心、④で求めた値を半径とする円を描画する。3-2. ソースコード
Circle3.pyimport matplotlib.pyplot as plt import numpy as np from sympy import Symbol, solve # 円周上の3点 x1 = -100 y1 = 300 x2 = 500 y2 = 300 x3 = 200 y3 = 600 # 1: 与えられた3点から、各辺の式を求める。 aa = Symbol("aa") bb = Symbol("bb") ex1 = x1*aa+bb-y1 ex2 = x3*aa+bb-y3 result1 = solve([ex1,ex2],[aa,bb])#x1,y1とx3,y3の2点からなる直線の式 ex1 = x2*aa+bb-y2 result2 = solve([ex1,ex2],[aa,bb])#x2,y2とx3,y3の2点からなる直線の式 # 2: 各辺の垂直二等分線の式を求める。 ex1 = (-1/result1[aa])*((x3+x1)/2)+bb-((y3+y1)/2) result3 = solve(ex1,bb)#result1の辺の垂直二等分線 ex2 = (-1/result2[aa])*((x3+x2)/2)+bb-((y3+y2)/2) result4 = solve(ex2,bb)#result2の辺の垂直二等分線 # 3: 垂直二等分線の交点を求める。(円の中心) ex1 = (-1/result1[aa])*aa+result3[0]-bb ex2 = (-1/result2[aa])*aa+result4[0]-bb result5 = solve([ex1,ex2],[aa,bb]) a = round(result5[aa])#円の中心のx座標 b = round(result5[bb])#円の中心のy座標 # 4: 3で求めた点と、与えられた1つの点との距離を求める。(半径) r = np.sqrt(((a-x1)**2)+((b-y1)**2))#円の半径の計算 # 5: 円の方程式 x = np.arange(a-r, a+r+1) y = np.sqrt(r**2 - (x-a)**2) + b yy = -y + 2*b # 6: グラフを描画 plt.plot(x, y) plt.plot(x, yy) plt.axis("equal") plt.grid(color="0.8") plt.show() # 画面に表示3-3. 実行結果
このようになれば、成功です。
終わりに
ここまで読んでいただき、ありがとうございました。
高校数学の記事をあげたのですが、急にどうした!?って感じです。というのも、数学を勉強し直そうと思い、谷尻かおりさんの「Pythonで学び直す高校数学」という本を手に取った次第であります。
今回、取り上げた記事の内容はその本の第3章にある「方程式で図形を描く」という部分の最後のコラムのチャレンジ問題になります。その問題の解答がなかった?ので、自分なりに挑戦してみて、それを記事にしました。参考になったら嬉しいです。
- 投稿日:2019-05-24T11:41:13+09:00
LINE Notify API 調査とpythonを用いたサンプルプログラム(画像・スタンプ)
LINE Notify APIに関する調査(公式ドキュメンとを参考)
☆公式ドキュメント
https://notify-bot.line.me/doc/ja/LINE Notify APIには大きく分けて認証系、通知系。
今回は通知系についてまとめて行く。LINE Notifyの通知系を使うと、
①LINE Notifyの公式アカウントから通知が届くようになる。
②LINEでのグールプに対してトークンを発行し、該当グループに対して通知を送信する。トークンの発行は、下記リンクから
https://notify-bot.line.me/ja/
①ログイン
②右上部のユーザー名をクリックし、マイページに移動。画面下部のアクセストークンを発行から、トークンを発行。LINE NotifyでPOSTできるパラメーター
パラメーター名 簡単な説明 message メッセージ 最大1000文字まで送信可能 imageThumnail イメージサムネイル。最大240×240pxのJPEGのみ imageFullsize 最大1024×1024pxのJPEGのみ stickerPackageId スタンプのパッケージ識別子 stickId スタンプの識別子 といった感じ。
パラメータの詳細については、公式ドキュメントを参考にしてください。
※画像を送るパラメータは3つあるけれども、画像ファイルを指定して送信できるのはimageFileのみなので注意。サンプルプログラム(python)
imageFileを用いて画像を送信するサンプル
※imageFileはPNGを使用できます。
import requests #imageFileでの画像送信 def LineNotify(): # トークンと通知の設定 line_notify_api = 'https://notify-api.line.me/api/notify' # このAPIにアクセスする line_notify_token = '*********************' # 発行されたトークンを記載 headers = {'Authorization': 'Bearer ' + line_notify_token} # メッセージ msg = 'LINEで通知だよ!!!!!画像添付あり' payload = {'message': msg} # 画像 image = './sample.png' files = {"imageFile": open(image, "rb")} #バイナリーデーターで画像を開く # POSTメソッド requests.post(line_notify_api, data=payload, headers=headers, files=files) if __name__=='__main__': LineNotify()スタンプを送信するサンプルプログラム
※'stickerPackageId'と 'stickerId'はLINE Notify公式ドキュメントで確認できます。
下記リンク
https://devdocs.line.me/files/sticker_list.pdfdef LineNotify(): # トークンと通知の設定 line_notify_api = 'https://notify-api.line.me/api/notify' # このAPIにアクセスする line_notify_token = '*********************' # 発行されたトークンを記載 headers = {'Authorization': 'Bearer ' + line_notify_token} # メッセージ msg = 'LINEで通知だよ!!!!!画像添付あり' payload = {'message': msg,'stickerPackageId': 2, 'stickerId': 28} #送信したいスタンプの識別子を記載 # POSTメソッド requests.post(line_notify_api, data=payload, headers=headers) if __name__=='__main__': LineNotify()その他参考文献
pythonのプログラムに関して参考にしました。
https://qiita.com/tadaken3/items/0998c18df11d4a1c7427
- 投稿日:2019-05-24T11:21:15+09:00
Pythonにおけるクラスとインスタンスの関係
ProgateでPythonの基礎的なコードの学習を修了したので、個人的にややこしいと感じた部分を復習を兼ねてまとめます。
クラスからインスタンスを生成
menu.pyclass MenuItem: pass menu_item1 = MenuItem() menu_item.name = 'メロンパン' menu_item.price = 150「クラス名()」でインスタンスが生成されます。
また、「インスタンス名.インスタンス変数」で情報を追加することができます。
ここでは「name」がメロンパンであるという情報と、「price」が150であるという情報を追加しました。インスタンスメソッド
menu.pyclass MenuItem: def info(self): print('こちらがメニューです。') print(self.name + ':' + str(self.price) + '円') menu_item1 = MenuItem() menu_item1.name = 'メロンパン' menu_item1.price = 150 menu_item1.info()クラス内で定義したメソッドは、「インスタンス名.メソッド名」でインスタンスに対して呼び出せます。
(インスタンス自体を代入させるため引数selfは必須)実行結果は以下のようになります。
こちらがメニューです。
メロンパン:150円
initメソッド
menu.pyclass MenuItem: def __init__(self): print("こちらがメニューです。") menu_item1 = MenuItem()このメソッドは、インスタンスを生成すると自動で呼び出されるようになっています。
そのためここでは、インスタンスを生成しただけで「こちらがメニューです」が表示されます。まとめ
クラスからインスタンスを生成、インスタンス、initに関してまとめてみました。
ここがPythonで最初につまづいたポイントだった人も多いのではないでしょうか。
私もまだまだアウトプットを完璧にするには練習が必要なので、修行を積んでいきます。
- 投稿日:2019-05-24T11:11:38+09:00
tensorflow2.0の学習を、gradient tapeで書くと遅い
結論はタイトルの通りです。
公式のコードを動かすだけで結果を比較できます。
今後の高速化に期待ですかね。。。Kerasのfitで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/beginner
gradient tapeで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/advanced速度結果
- kerasのfitの方が、約25倍速い。
Kerasのfit
CPU times: user 38.7 s, sys: 2.61 s, total: 41.3 s Wall time: 30.8 sgradient tape
CPU times: user 24min 29s, sys: 21.2 s, total: 24min 50s Wall time: 12min 40sその他の結果
Kerasのfit
- code
model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)
- 精度
... Epoch 5/5 60000/60000 [==============================] - 6s 100us/sample - loss: 0.0254 - accuracy: 0.9912 10000/10000 [==============================] - 0s 44us/sample - loss: 0.0842 - accuracy: 0.9812gradient tape
- code
@tf.function def train_step(images, labels): with tf.GradientTape() as tape: predictions = model(images) loss = loss_object(labels, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss(loss) train_accuracy(labels, predictions) @tf.function def test_step(images, labels): predictions = model(images) t_loss = loss_object(labels, predictions) test_loss(t_loss) test_accuracy(labels, predictions) EPOCHS = 5 for epoch in range(EPOCHS): for images, labels in train_ds: train_step(images, labels) for test_images, test_labels in test_ds: test_step(test_images, test_labels) template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}' print (template.format(epoch+1, train_loss.result(), train_accuracy.result()*100, test_loss.result(), test_accuracy.result()*100))
- 精度
Epoch 5, Loss: 0.02371377870440483, Accuracy: 99.28133392333984, Test Loss: 0.07314498722553253, Test Accuracy: 98.22599792480469考察
- Q: お手本のモデルの定義がいけないのではないか?: https://github.com/tensorflow/tensorflow/issues/23014
- A: お手本のモデルはkerasのlayerを使っているので、そこが問題では無いと考えられる。
- 投稿日:2019-05-24T11:11:38+09:00
tensorflow2.0の学習を、gradient tapeで書くと遅い?
結論はタイトルの通りです。
公式のコードを動かすだけで結果を比較できます。
今後の高速化に期待ですかね。。。Kerasのfitで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/beginner
gradient tapeで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/advanced速度結果
- kerasのfitの方が、約25倍速い。
Kerasのfit
CPU times: user 38.7 s, sys: 2.61 s, total: 41.3 s Wall time: 30.8 sgradient tape
CPU times: user 24min 29s, sys: 21.2 s, total: 24min 50s Wall time: 12min 40sその他の結果
Kerasのfit
- code
model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)
- 精度
... Epoch 5/5 60000/60000 [==============================] - 6s 100us/sample - loss: 0.0254 - accuracy: 0.9912 10000/10000 [==============================] - 0s 44us/sample - loss: 0.0842 - accuracy: 0.9812gradient tape
- code
@tf.function def train_step(images, labels): with tf.GradientTape() as tape: predictions = model(images) loss = loss_object(labels, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss(loss) train_accuracy(labels, predictions) @tf.function def test_step(images, labels): predictions = model(images) t_loss = loss_object(labels, predictions) test_loss(t_loss) test_accuracy(labels, predictions) EPOCHS = 5 for epoch in range(EPOCHS): for images, labels in train_ds: train_step(images, labels) for test_images, test_labels in test_ds: test_step(test_images, test_labels) template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}' print (template.format(epoch+1, train_loss.result(), train_accuracy.result()*100, test_loss.result(), test_accuracy.result()*100))
- 精度
Epoch 5, Loss: 0.02371377870440483, Accuracy: 99.28133392333984, Test Loss: 0.07314498722553253, Test Accuracy: 98.22599792480469考察
- Q: お手本のモデルの定義がいけないのではないか?: https://github.com/tensorflow/tensorflow/issues/23014
A: お手本のモデルはkerasのlayerを使っているので、そこが問題では無いと考えられる。
以下のissueのコードを実行すると、異なった結果がでる。(gradient_clipの方が速い)
https://github.com/tensorflow/tensorflow/issues/28714Start of epoch 0 Start of epoch 1 Start of epoch 2 Start of epoch 0 Start of epoch 1 Start of epoch 2 train 6.240314280999883 Epoch 1/3 782/782 [==============================] - 3s 4ms/step - loss: 0.3294 - sparse_categorical_accuracy: 0.9058 Epoch 2/3 782/782 [==============================] - 3s 4ms/step - loss: 0.1495 - sparse_categorical_accuracy: 0.9556 Epoch 3/3 782/782 [==============================] - 3s 3ms/step - loss: 0.1093 - sparse_categorical_accuracy: 0.9672 fit 9.801731540999754
- 投稿日:2019-05-24T11:11:38+09:00
tensorflow2.0の学習を、gradient tapeで書くと遅いと思ったがそんなことはなかった
公式のコードを動かすだけで結果を比較してしまったが故に、gradient tapeが遅いと思いましたが、そんなことはありませんでした。ほとんど同じ速度です。
Kerasのfitで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/beginner
gradient tapeで学習したMNIST: https://www.tensorflow.org/alpha/tutorials/quickstart/advanced結果
ほとんど同じでした。
Kerasのfit
Epoch 5/5 train: 60000/60000 [==============================] - 135s 2ms/sample - loss: 0.0032 - accuracy: 0.9990 test: 10000/10000 [==============================] - 6s 609us/sample - loss: 0.0890 - accuracy: 0.9823 CPU times: user 10min 35s, sys: 14.7 s, total: 10min 50s Wall time: 11min 27sgradient tape
Epoch 5, Loss: 0.025853322818875313, Accuracy: 99.20600128173828, Test Loss: 0.06388840824365616, Test Accuracy: 98.29166412353516 CPU times: user 22min 22s, sys: 31.7 s, total: 22min 54s Wall time: 11min 47s間違えた理由
- 学習しているモデルとデータが微妙に違いました。
- モデルとデータを揃えた結果、上記のようにほとんど同じ結果になりました。
参考:誤った結果(当初の間違え)
公式速度結果
- kerasのfitの方が、約25倍速い。
Kerasのfit
CPU times: user 38.7 s, sys: 2.61 s, total: 41.3 s Wall time: 30.8 sgradient tape
CPU times: user 24min 29s, sys: 21.2 s, total: 24min 50s Wall time: 12min 40sその他の結果
Kerasのfit
- code
model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)
- 精度
... Epoch 5/5 60000/60000 [==============================] - 6s 100us/sample - loss: 0.0254 - accuracy: 0.9912 10000/10000 [==============================] - 0s 44us/sample - loss: 0.0842 - accuracy: 0.9812gradient tape
- code
@tf.function def train_step(images, labels): with tf.GradientTape() as tape: predictions = model(images) loss = loss_object(labels, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss(loss) train_accuracy(labels, predictions) @tf.function def test_step(images, labels): predictions = model(images) t_loss = loss_object(labels, predictions) test_loss(t_loss) test_accuracy(labels, predictions) EPOCHS = 5 for epoch in range(EPOCHS): for images, labels in train_ds: train_step(images, labels) for test_images, test_labels in test_ds: test_step(test_images, test_labels) template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}' print (template.format(epoch+1, train_loss.result(), train_accuracy.result()*100, test_loss.result(), test_accuracy.result()*100))
- 精度
Epoch 5, Loss: 0.02371377870440483, Accuracy: 99.28133392333984, Test Loss: 0.07314498722553253, Test Accuracy: 98.22599792480469その他メモ
- Q: お手本のモデルの定義がいけないのではないか?: https://github.com/tensorflow/tensorflow/issues/23014
A: お手本のモデルはkerasのlayerを使っているので、そこが問題では無いと考えられる。
以下のissueのコードを実行すると、異なった結果がでる。(gradient_clipの方が速い)
https://github.com/tensorflow/tensorflow/issues/28714Start of epoch 0 Start of epoch 1 Start of epoch 2 Start of epoch 0 Start of epoch 1 Start of epoch 2 train 6.240314280999883 Epoch 1/3 782/782 [==============================] - 3s 4ms/step - loss: 0.3294 - sparse_categorical_accuracy: 0.9058 Epoch 2/3 782/782 [==============================] - 3s 4ms/step - loss: 0.1495 - sparse_categorical_accuracy: 0.9556 Epoch 3/3 782/782 [==============================] - 3s 3ms/step - loss: 0.1093 - sparse_categorical_accuracy: 0.9672 fit 9.801731540999754
- 投稿日:2019-05-24T10:26:15+09:00
【画像生成】AutoencoderとVAEと。。。遊んでみた♬AEとその潜在空間は???
昨夜のお約束の「DLの記憶」について書く準備として、AEと潜在空間について記事にしておこうと思います。
※DLの記憶はこの次の記事にしますやったこと
・通常のAEでVAEと同様な絵を作成する
・潜在空間内の画像生成
・潜在空間を移動させて画像生成する・通常のAEでVAEと同様な絵を作成する
通常のAEを以下のように改変してVAEと同じようなことができるか試してみました。
それは、どうしてもあのLatent_dimのところでGauss関数に押し込む必要性が合点できないからです。
すなわち、あの関数はどんなものでもよく(たぶん、BackPropagationできる程度に滑らかなら)、全体のAEとしての機能は変わらないだろうと考察されるからです。逆に言えば、自然に発生する分布(関数と呼んでいいかは別として)を利用しても同じように制御できる可能性があるということで、やってみました。
これはよく説明に「AEは入力を再現するだけ、VAEは自由に画像生成することができる。」すなわち「AEは自由に画像生成できない」というのは誤解だということが元々のモチベーションですコードは以下のとおりです。
変更点は、z_log_varを止めて、z_meanだけにしようということだけです。
この選択により、sampling関数は不要になります。
※分布は野となれ山となれということになります
すなわち、つなぎの部分が全結合になっていますが、通常のAEです。inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(32, (3, 3), activation='relu', strides=2, padding='same')(inputs) x = Conv2D(64, (3, 3), activation='relu', strides=2, padding='same')(x) shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) # instantiate encoder model encoder = Model(inputs, z_mean, name='encoder') encoder.summary()decoderも通常のまんまです。
# build decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2DTranspose(64, (3, 3), activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32, (3, 3), activation='relu', strides=2, padding='same')(x) outputs = Conv2DTranspose(1, (3, 3), activation='sigmoid', padding='same')(x) # instantiate decoder model decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() # instantiate VAE model outputs = decoder(encoder(inputs)) vae = Model(inputs, outputs, name='vae_mlp')異なるのは、この後に描画関数(おまけに掲載)をVAEと同じものを使います。
結果として以下のような図が得られます。
以下で示す図も含め、これらの図はほぼsampling関数を利用したものと変わりません。
・潜在空間内の画像生成
画像生成の制御もある意味簡単にできることが分かります。
以下は、おまけに掲載したコードで生成した潜在空間内で生成された画像です。
この絵を見ると、母関数としてガウス分布を仮定しなくとも、画像はバラバラに生成されているわけではなく、分類・適度に分散されながら生成されていることが分かります。
※この部分が実はあとあと面白い解釈ができるのですが、次回の議論とします
・潜在空間を移動させて画像生成する
そして、上記の潜在空間内を連続的に移動しながら画像生成します。
下記のように問題なく画像生成できます。
つまり、上に示した画像の潜在空間内の分布はガウス分布などの母関数を仮定しなくとも、画像生成は連続する変化となっており、途中の変化がなめらかになっているところがミソです。
以下のパラメータ変換で、潜在空間内の点を移動させながらdecoderで画像生成しています。
【参考】以下を参考にしています
Variational Autoencoder徹底解説z : s*z_0 + (1-t)*z_1def plot_results2(models, data, batch_size=128, model_name="vae_mnist"): z0=np.array([0.4,-2.3]) z1=np.array([0.4,2.7]) for t in range(50): s=t/50 z_sample=np.array([s*z0+(1-s)*z1]) x_decoded = decoder.predict(z_sample) plt.imshow(x_decoded.reshape(28, 28)) plt.title("z_sample="+str(z_sample)) plt.savefig('./mnist1000/z_sample_t{}'.format(t)) plt.pause(0.1) plt.close()※上記は50分割にしていますが、これはアップの都合でそうしているだけで、性能的には10倍くらいにしても問題なく動きます
以下のように円上を360度動かして、小さいサイズ(2.5MB位)にしたけど、やはりアップできないので、出来るようになったらアップすることとします。
円上を動かすコードは以下のとおりdef plot_results2(models, data, batch_size=128, model_name="vae_mnist"): for t in range(360): s=t/360 z_sample=np.array([[2*np.cos(2*s*np.pi),2*np.sin(2*s*np.pi)]]) x_decoded = decoder.predict(z_sample) plt.imshow(x_decoded.reshape(28, 28)) plt.title("z_sample="+str(t)) plt.savefig('./mnist1000/360/z_sample_t{}'.format(t)) plt.pause(0.01) plt.close()【参考】z0=np.array([0.4,-2.3])などとしている理由は以下の参考のとおりです
・Why do I get TypeError: can't multiply sequence by non-int of type 'float'?まとめ
・AEで潜在空間のパラメータを動かして画像生成できた
・潜在空間内でパラメータを自由に動かしたとき滑らかに画像生成できることが分かった・潜在空間内での画像生成と元の学習データの関係についてはDLの記憶とともに次回記事にします
おまけ
def plot_results(models, data, batch_size=32, model_name="vae_mnist"): """Plots labels and MNIST digits as function of 2-dim latent vector # Arguments models (tuple): encoder and decoder models data (tuple): test data and label batch_size (int): prediction batch size model_name (string): which model is using this function """ encoder, decoder = models x_test, y_test = data os.makedirs(model_name, exist_ok=True) filename1 = "./mnist1000/vae_mean100L2_3" # display a 2D plot of the digit classes in the latent space z_mean = encoder.predict(x_test, batch_size=batch_size) plt.figure(figsize=(12, 10)) plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test) plt.colorbar() plt.xlabel("z[0]") plt.ylabel("z[1]") plt.savefig(filename1+"z0z1.png") plt.pause(1) plt.close() filename2 = "./mnist1000/digits_over_latent100L2_3" # display a 30x30 2D manifold of digits n = 30 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) # linearly spaced coordinates corresponding to the 2D plot # of digit classes in the latent space grid_x = np.linspace(-4, 4, n) grid_y = np.linspace(-4, 4, n)[::-1] for i, yi in enumerate(grid_y): for j, xi in enumerate(grid_x): z_sample = np.array([[xi, yi]]) x_decoded = decoder.predict(z_sample) digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) start_range = digit_size // 2 end_range = n * digit_size + start_range + 1 pixel_range = np.arange(start_range, end_range, digit_size) sample_range_x = np.round(grid_x, 1) sample_range_y = np.round(grid_y, 1) plt.xticks(pixel_range, sample_range_x) plt.yticks(pixel_range, sample_range_y) plt.xlabel("z[0]") plt.ylabel("z[1]") plt.imshow(figure, cmap='Greys_r') plt.savefig(filename2+".png") plt.pause(1) plt.close()


![z_sample_t_NoSamplingz0=[0.4,-2.3]z7=[0.4,2.7].gif](https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/233744/064b5a51-2e0d-4c46-cdfb-0a4d61cf39d9.gif)
- 投稿日:2019-05-24T08:58:52+09:00
Pythonでmarkdownをhtmlにコンバートする
マークダウンをhtmlにコンバートする方法を探していた。pipで入れられるmarkdownがよさそうなので少し試してみる。
pyenvで入れた環境
$ python --version Python 3.6.5 $ pip --version pip 19.1.1 from /Users/ito_masakuni/.pyenv/versions/3.6.5/lib/python3.6/site-packages/pip (python 3.6)インストール
$ pip install markdown Collecting markdown Downloading https://files.pythonhosted.org/packages/c0/4e/fd492e91abdc2d2fcb70ef453064d980688762079397f779758e055f6575/Markdown-3.1.1-py2.py3-none-any.whl (87kB) 100% |████████████████████████████████| 92kB 5.8MB/s Requirement already satisfied: setuptools>=36 in /Users/ito_masakuni/.pyenv/versions/3.6.5/lib/python3.6/site-packages (from markdown) (39.0.1) Installing collected packages: markdown Successfully installed markdown-3.1.1下記のスクリプトを書いた。
import markdown sample_text = ''' # h1の文字が出てくると嬉しい --- ## h2の文字はでてくるだろう * リスト1 * リスト2 * リスト3 > 引用してくれ 本文で **太字にもなるし**、*斜体にもなるはず* 。 ``` まさかコードも入れられるんですか? if (!lie) { return true; } ``` | header1 | header2 | header3 | |:-----------|------------:|:------------:| | 左寄せ | 右寄せ | 中央寄せ | すごい! ''' md = markdown.Markdown() print(md.convert(sample_text))で、アウトプットはこうなった。
$ python md.py <h1>h1の文字が出てくると嬉しい</h1> <hr /> <h2>h2の文字はでてくるだろう</h2> <ul> <li>リスト1</li> <li>リスト2</li> <li>リスト3</li> </ul> <blockquote> <p>引用してくれ</p> </blockquote> <p>本文で <strong>太字にもなるし</strong>、<em>斜体にもなるはず</em> 。</p> <p><code>まさかコードも入れられるんですか? if (!lie) { return true; }</code></p> <p>| header1 | header2 | header3 | |:-----------|------------:|:------------:| | 左寄せ | 右寄せ | 中央寄せ |</p> <p>すごい!</p>テーブルが変換されていないので少し調べる。どうやらエクステンション指定して実行しないとならないみたい。オフィシャルでサポートされているエクステンションは、実行時に指定するだけでコンバートしてくれるみたい。テーブルはオフィシャルに含まれている。その他サードパーティもたくさんある模様。
呼び出しのところにエクステンションを持たせる。
md = markdown.Markdown(extensions=['tables']) print(md.convert(sample_text))実行する。
<h1>h1の文字が出てくると嬉しい</h1> <hr /> <h2>h2の文字はでてくるだろう</h2> <ul> <li>リスト1</li> <li>リスト2</li> <li>リスト3</li> </ul> <blockquote> <p>引用してくれ</p> </blockquote> <p>本文で <strong>太字にもなるし</strong>、<em>斜体にもなるはず</em> 。</p> <p><code>まさかコードも入れられるんですか? if (!lie) { return true; }</code></p> <table> <thead> <tr> <th align="left">header1</th> <th align="right">header2</th> <th align="center">header3</th> </tr> </thead> <tbody> <tr> <td align="left">左寄せ</td> <td align="right">右寄せ</td> <td align="center">中央寄せ</td> </tr> </tbody> </table> <p>すごい!</p>すごい!
- 投稿日:2019-05-24T03:06:58+09:00
PythonのStatsModelsで重回帰分析
はじめに
PythonのライブラリStatsModelsを使用して重回帰分析をやってみます。Rと違って少々不便です。
環境
- Google Colaboratory
- statsmodels==0.9.0
参考
手順
データの読み込み
ボストン市の住宅価格データを使用します。ボストン市の住宅価格を目的変数、NOxの濃度や部屋数などを説明変数として持っているデータです。
scipyが1.3だとstatsmodelsの0.9.0が使用できないのでダウングレード後、ランタイムを再起動します。!pip install scipy==1.2データを読み込み、プロットして確認してみます。
# 必須のモジュール import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklearn.datasets import load_boston # データを読み込み boston = load_boston() # 目的変数と説明変数の関係を確認 fig, ax = plt.subplots(5, 3, figsize=(15, 15)) xlabels = boston.feature_names for i in range(5): for j in range(3): if 3*i+j >= 13: break ax[i, j].scatter(boston.data[:, 3*i+j], boston.target, marker='.') ax[i, j].set_xlabel(xlabels[3*i+j]) ax[i, j].set_ylabel("price") plt.tight_layout() plt.show()
相関係数を算出
重回帰分析をする上では変数間の相関が、多重共線性として問題になります。そこで変数間の相関を確認しておきます。
# 目的変数と説明変数を一つのデータフレームにまとめる df = pd.DataFrame(boston.data, columns=boston.feature_names) df['PRICE'] = boston.target # 相関を計算 corr = df.corr() # データフレームに色をつける corr.style.format("{:.2}").background_gradient(cmap=plt.get_cmap('coolwarm'), axis=1)
seabornでも同様のヒートマップを作成できます。
fig, ax = plt.subplots(figsize=(10, 8)) sns.heatmap(corr, vmax=1, vmin=-1, center=0, annot=True, cbar=True, cmap='coolwarm', square=True, fmt='.2f', ax=ax)
変数減少法で重回帰分析
変数減少法を使用して分析してみます。
まずデータを準備します。
from sklearn.model_selection import train_test_split X = df.drop('PRICE', axis=1) y = df['PRICE'] # テータ分割 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size =0.8, random_state=0)全変数を使用して重回帰分析をしてみます。
import statsmodels.api as sm # 回帰モデル作成 mod = sm.OLS(y_train, sm.add_constant(X_train)) # 訓練 result = mod.fit() # 統計サマリを表示 print(result.summary()) OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.773 Model: OLS Adj. R-squared: 0.765 Method: Least Squares F-statistic: 102.2 Date: Thu, 23 May 2019 Prob (F-statistic): 9.64e-117 Time: 17:39:57 Log-Likelihood: -1171.5 No. Observations: 404 AIC: 2371. Df Residuals: 390 BIC: 2427. Df Model: 13 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 38.0917 5.522 6.898 0.000 27.234 48.949 CRIM -0.1194 0.037 -3.257 0.001 -0.192 -0.047 ZN 0.0448 0.014 3.102 0.002 0.016 0.073 INDUS 0.0055 0.063 0.087 0.931 -0.119 0.130 CHAS 2.3408 0.902 2.595 0.010 0.567 4.115 NOX -16.1236 4.212 -3.828 0.000 -24.404 -7.843 RM 3.7087 0.458 8.106 0.000 2.809 4.608 AGE -0.0031 0.014 -0.218 0.828 -0.031 0.025 DIS -1.3864 0.214 -6.480 0.000 -1.807 -0.966 RAD 0.2442 0.070 3.481 0.001 0.106 0.382 TAX -0.0110 0.004 -2.819 0.005 -0.019 -0.003 PTRATIO -1.0459 0.137 -7.636 0.000 -1.315 -0.777 B 0.0081 0.003 2.749 0.006 0.002 0.014 LSTAT -0.4928 0.054 -9.086 0.000 -0.599 -0.386 ============================================================================== Omnibus: 141.494 Durbin-Watson: 1.996 Prob(Omnibus): 0.000 Jarque-Bera (JB): 629.882 Skew: 1.470 Prob(JB): 1.67e-137 Kurtosis: 8.365 Cond. No. 1.55e+04 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 1.55e+04. This might indicate that there are strong multicollinearity or other numerical problems.多重共線性の疑いのある変数を探します。
最初にそれぞれの説明変数と目的変数の相関係数を計算しました。もし変数が独立であれば、回帰係数も相関係数と同じ符号になるはずです。しかし多重共線性があると、回帰係数が一意に決まらず不安定になり、相関係数と異なる符号になる場合があります。これを確認してみます。# constを除くために1から始める np.sign(result.params[1:]) # 目的変数を除くために-1までとする np.sign(corr['PRICE'][:-1]) # 0でない変数が相関している可能性あり np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1]) CRIM 0.0 ZN 0.0 INDUS 2.0 CHAS 0.0 NOX 0.0 RM 0.0 AGE 0.0 DIS -2.0 RAD 2.0 TAX 0.0 PTRATIO 0.0 B 0.0 LSTAT 0.0 dtype: float64INDUS、DIS、RADを取り除いて回帰分析してみます。
# 回帰モデル作成 d = ['INDUS', 'DIS', 'RAD'] mod = sm.OLS(y_train, sm.add_constant(X_train.drop(d, axis=1))) # 訓練 result = mod.fit() # 統計サマリを表示 print(result.summary()) OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.742 Model: OLS Adj. R-squared: 0.735 Method: Least Squares F-statistic: 112.9 Date: Thu, 23 May 2019 Prob (F-statistic): 5.42e-109 Time: 17:42:50 Log-Likelihood: -1197.5 No. Observations: 404 AIC: 2417. Df Residuals: 393 BIC: 2461. Df Model: 10 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 19.6164 5.196 3.776 0.000 9.402 29.831 CRIM -0.0603 0.037 -1.632 0.104 -0.133 0.012 ZN 0.0022 0.014 0.158 0.874 -0.025 0.029 CHAS 2.9510 0.949 3.111 0.002 1.086 4.816 NOX -5.3578 4.024 -1.331 0.184 -13.269 2.554 RM 4.4060 0.471 9.359 0.000 3.480 5.332 AGE 0.0202 0.015 1.393 0.164 -0.008 0.049 TAX -0.0003 0.002 -0.122 0.903 -0.005 0.004 PTRATIO -1.0610 0.141 -7.516 0.000 -1.339 -0.783 B 0.0076 0.003 2.457 0.014 0.002 0.014 LSTAT -0.4918 0.057 -8.562 0.000 -0.605 -0.379 ============================================================================== Omnibus: 166.959 Durbin-Watson: 1.995 Prob(Omnibus): 0.000 Jarque-Bera (JB): 885.215 Skew: 1.706 Prob(JB): 6.00e-193 Kurtosis: 9.399 Cond. No. 1.35e+04 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 1.35e+04. This might indicate that there are strong multicollinearity or other numerical problems.もう一度確認。
(np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1])).dropna() AGE 2.0 B 0.0 CHAS 0.0 CRIM 0.0 LSTAT 0.0 NOX 0.0 PTRATIO 0.0 RM 0.0 TAX 0.0 ZN 0.0 dtype: float64今度はAGEを落としてみる。
OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.741 Model: OLS Adj. R-squared: 0.735 Method: Least Squares F-statistic: 125.0 Date: Thu, 23 May 2019 Prob (F-statistic): 1.23e-109 Time: 17:47:01 Log-Likelihood: -1198.5 No. Observations: 404 AIC: 2417. Df Residuals: 394 BIC: 2457. Df Model: 9 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 18.1151 5.089 3.560 0.000 8.111 28.120 CRIM -0.0622 0.037 -1.682 0.093 -0.135 0.011 ZN -0.0037 0.013 -0.284 0.777 -0.030 0.022 CHAS 2.9959 0.949 3.156 0.002 1.130 4.862 NOX -2.8646 3.609 -0.794 0.428 -9.959 4.230 RM 4.5634 0.458 9.973 0.000 3.664 5.463 TAX -0.0004 0.002 -0.165 0.869 -0.005 0.004 PTRATIO -1.0582 0.141 -7.488 0.000 -1.336 -0.780 B 0.0082 0.003 2.656 0.008 0.002 0.014 LSTAT -0.4617 0.053 -8.664 0.000 -0.566 -0.357 ============================================================================== Omnibus: 176.632 Durbin-Watson: 1.980 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1038.791 Skew: 1.782 Prob(JB): 2.69e-226 Kurtosis: 10.001 Cond. No. 1.27e+04 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 1.27e+04. This might indicate that there are strong multicollinearity or other numerical problems.(np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1])).dropna() B 0.0 CHAS 0.0 CRIM 0.0 LSTAT 0.0 NOX 0.0 PTRATIO 0.0 RM 0.0 TAX 0.0 ZN -2.0 dtype: float64今度はZNを落としてみる。
OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.741 Model: OLS Adj. R-squared: 0.735 Method: Least Squares F-statistic: 140.9 Date: Thu, 23 May 2019 Prob (F-statistic): 1.04e-110 Time: 17:48:32 Log-Likelihood: -1198.5 No. Observations: 404 AIC: 2415. Df Residuals: 395 BIC: 2451. Df Model: 8 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 17.6474 4.809 3.670 0.000 8.193 27.102 CRIM -0.0625 0.037 -1.695 0.091 -0.135 0.010 CHAS 3.0095 0.947 3.178 0.002 1.148 4.871 NOX -2.3888 3.192 -0.748 0.455 -8.664 3.887 RM 4.5523 0.455 9.997 0.000 3.657 5.448 TAX -0.0005 0.002 -0.232 0.817 -0.005 0.004 PTRATIO -1.0433 0.131 -7.961 0.000 -1.301 -0.786 B 0.0082 0.003 2.666 0.008 0.002 0.014 LSTAT -0.4611 0.053 -8.670 0.000 -0.566 -0.357 ============================================================================== Omnibus: 176.890 Durbin-Watson: 1.980 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1043.397 Skew: 1.784 Prob(JB): 2.69e-227 Kurtosis: 10.018 Cond. No. 1.17e+04 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 1.17e+04. This might indicate that there are strong multicollinearity or other numerical problems.(np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1])).dropna() B 0.0 CHAS 0.0 CRIM 0.0 LSTAT 0.0 NOX 0.0 PTRATIO 0.0 RM 0.0 TAX 0.0 dtype: float64$t^2<2$の変数があるので更に変数を落とす。絶対値が一番小さいTAXを落とす。
OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.740 Model: OLS Adj. R-squared: 0.736 Method: Least Squares F-statistic: 161.4 Date: Thu, 23 May 2019 Prob (F-statistic): 8.14e-112 Time: 17:50:47 Log-Likelihood: -1198.5 No. Observations: 404 AIC: 2413. Df Residuals: 396 BIC: 2445. Df Model: 7 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 17.8533 4.721 3.782 0.000 8.572 27.134 CRIM -0.0654 0.035 -1.888 0.060 -0.134 0.003 CHAS 3.0146 0.945 3.188 0.002 1.156 4.873 NOX -2.7882 2.684 -1.039 0.300 -8.065 2.489 RM 4.5483 0.454 10.007 0.000 3.655 5.442 PTRATIO -1.0551 0.121 -8.736 0.000 -1.292 -0.818 B 0.0084 0.003 2.756 0.006 0.002 0.014 LSTAT -0.4611 0.053 -8.680 0.000 -0.566 -0.357 ============================================================================== Omnibus: 175.198 Durbin-Watson: 1.981 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1019.678 Skew: 1.768 Prob(JB): 3.80e-222 Kurtosis: 9.933 Cond. No. 7.56e+03 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 7.56e+03. This might indicate that there are(np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1])).dropna() B 0.0 CHAS 0.0 CRIM 0.0 LSTAT 0.0 NOX 0.0 PTRATIO 0.0 RM 0.0 dtype: float64今度はNOXを落とす。
# 回帰モデル作成 d = ['INDUS', 'DIS', 'RAD', 'AGE', 'ZN', 'TAX', 'NOX'] mod = sm.OLS(y_train, sm.add_constant(X_train.drop(d, axis=1))) # 訓練 result = mod.fit() # 統計サマリを表示 print(result.summary()) OLS Regression Results ============================================================================== Dep. Variable: PRICE R-squared: 0.740 Model: OLS Adj. R-squared: 0.736 Method: Least Squares F-statistic: 188.1 Date: Thu, 23 May 2019 Prob (F-statistic): 9.72e-113 Time: 17:53:56 Log-Likelihood: -1199.1 No. Observations: 404 AIC: 2412. Df Residuals: 397 BIC: 2440. Df Model: 6 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 16.4182 4.515 3.637 0.000 7.543 25.294 CRIM -0.0726 0.034 -2.138 0.033 -0.139 -0.006 CHAS 2.9178 0.941 3.101 0.002 1.068 4.768 RM 4.5315 0.454 9.976 0.000 3.638 5.425 PTRATIO -1.0490 0.121 -8.695 0.000 -1.286 -0.812 B 0.0089 0.003 2.970 0.003 0.003 0.015 LSTAT -0.4830 0.049 -9.903 0.000 -0.579 -0.387 ============================================================================== Omnibus: 168.794 Durbin-Watson: 1.973 Prob(Omnibus): 0.000 Jarque-Bera (JB): 933.196 Skew: 1.711 Prob(JB): 2.29e-203 Kurtosis: 9.613 Cond. No. 7.10e+03 ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The condition number is large, 7.1e+03. This might indicate that there are strong multicollinearity or other numerical problems.(np.sign(result.params[1:]) - np.sign(corr['PRICE'][:-1])).dropna() B 0.0 CHAS 0.0 CRIM 0.0 LSTAT 0.0 PTRATIO 0.0 RM 0.0 dtype: float64$t^2<2$の変数はないので、これで終了。決定係数は0.740、自由度調整済み決定係数は0.736となりました。
参考指標としてテストデータの決定係数を計算。
y_pred = result.predict(sm.add_constant(X_test.drop(d, axis=1))) se = np.sum(np.square(y_test-y_pred)) st = np.sum(np.square(y_test-np.mean(y_test))) R2 = 1-se/st print('決定係数:', R2) 決定係数: 0.5009870040610696おわりに
他にステップワイズ法などあるようで、Rだとこれらの作業を自動でやってくれるようですがpythonには無いようです。統計に関する計算はRでやったほうが良さそうです。

- 投稿日:2019-05-24T02:32:41+09:00