- 投稿日:2019-05-23T23:58:12+09:00
PythonのStatsmodelsを使用してGLMに入門する
はじめに
あるデータを回帰分析したいとします。極単純なデータであれば線形回帰で十分ですが、データが線形に並んでいなかったり、誤差が正規分布に従っていない場合は、線形回帰では予測誤差が大きくなってしまいます(線形回帰を最小二乗法で実施する場合は誤差が正規分布であることを仮定しています。)。
そこで、自身で回帰曲線を与えたり、誤差構造を与えたりできるモデルとして一般化線形モデル(以下、GLM)を使用します。参考
環境
- macOS Majave 10.14.3
- statsmodels==0.9.0
手順
GLMの基本
GLMは線形予測子、リンク関数、誤差構造という3つの要素によって成り立っています。ぞれぞれ意味を説明します。
目的変数を$y$、説明変数を$x_i$とします。リンク関数を$\psi$としたとき、説明変数と誤差を含まないな目的変数の間に、次の関係が成り立つとします。
\psi(\hat y) = \sum_{i=0}^{M}w_i \phi_i(x)この右辺の式を線形予測子といいます。
具体的なリンク関数と線形予測子を与えて、意味を見てみましょう。
説明変数は1変数とします。リンク関数$\psi(\hat y)$を$\log \hat y$として、線形予測子を$ \phi_i(x)=x^i$、$M=1$とします。すると上の式は次のようになります。\log \hat y = w_0 + w_1 xこれを少し書き換えて$y=$の形にしてやります。すると次のようになります。
\hat y = e^{w_0 + w_1 x}これは回帰モデルが$e$の肩に乗った式になっています。したがって、このモデルによる予測値は指数関数の曲線のような値になります。線形回帰モデルでは直線の予測しかできなかったのに対し、このモデルでは曲線の予測ができるようになっています。
このように、リンク関数は予測曲線の構造を決め、線形予測子は説明変数$x_i$が予測にどのように効くのかを決定します。誤差構造はyが従う分布のことです。上の例で考えた式$y(x)$に対し、ある$x$を固定したときの$y(x)$の分布を決定します。
例えば誤差構造を平均$\lambda$のポアソン分布としてみましょう。このポアソン分布は、入力$x$に対する $\hat y(x)=e^{w_0 + w_1 x}$の値を平均値とした$y$の分布なので、$\lambda = e^{w_0 + w_1 x}$となります。最終的に$y$の分布は次のように書けます。y \sim p(y|\lambda) \\ p(y|\lambda) = \frac{\lambda^y e^{-\lambda}}{y!} \\ \lambda = e^{w_0 + w_1 x}これでモデルが出来ました。あとは最尤推定法でデータ$x_n, t_n$に対し、尤度$L = \prod_n p(t_n|\lambda(x_n, w))$を最大化するような$w$を求めれば良いことになります。
求めた$w$を代入した$\hat y = e^{w_0 + w_1 x}$が予測式になります。細かい話
もう少しちゃんとした話をします。
一般化線形モデルは本来、目的変数$y$を指数型分布族で捉えようとするモデルです。指数型分布族は次のように表せる確率密度関数です。
p(y|\theta, \varphi) = \exp\left[\frac{y \theta -a(\theta)}{\varphi} + c(y, \varphi)\right]この分布の平均値は$\mu = a'(\theta)$、分散は$V = \varphi a''(\theta)$です。この時点では入力$\mathbf{x}$は登場していません。
入力$\mathbf{x}$と$y$を結びつけるには、$y$の平均値を$\mathbf{x}$の式でモデリングしてやれば良いです。そこで、$y$の平均値$\mu = a'(\theta)$が$\theta$に依存することを考慮し、$\theta$と$\mathbf{x}$を結びつけるための、逆関数を持つ単調関数$g(\theta) = \mathbf{w^\top \phi(x)}$を考えます。こうして与えられた$\left(p(y|\theta, \varphi), g(\theta), w^\top \phi(x)\right)$の3要素を持ったモデルのことを一般化線形モデルと呼びます。
これによって、$y$の平均値は$\mu = a'(g^{-1}(\mathbf{w^\top \phi(x)}))$で与えられます。$\psi^{-1} = a'g^{-1}$と書いたときの$\psi$をリンク関数と呼びます。$g$を選ぶことで、予測曲線を決定します。特に$g$を恒等関数に取ったリンク関数を正準リンク関数と呼びます。ポアソン分布のときは、指数型分布族の定義式とポアソン分布の密度関数を比べることで下記の対応がすぐに分かります。
\begin{align} \varphi &= 1 \\ \theta &= \log \lambda \\ a(\theta) &= e^\theta \\ c(y) &= -\log y! \end{align}これから正準リンク関数が$\psi(\theta) = \log\theta$であることがわかります。
statsmodelを使ったモデル作成
ボストン市の住宅価格データ(https://pythondatascience.plavox.info/scikit-learn/scikit-learn%E3%81%AB%E4%BB%98%E5%B1%9E%E3%81%97%E3%81%A6%E3%81%84%E3%82%8B%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88)を用いてGLMを試してみます。
ただし、以下では使い方を確認するにとどめ、チューニングなどは行いません。(GLM用に良いデータが有ればちゃんとやってみます)statsmodelで使用できる誤差構造とリンク関数の組み合わせは下記のとおりです。
誤差構造 リンク関数 使えると書いてないけどエラーにならないリンク関数 Poisson identity, log, sqrt Binomial identity, log, cauchy, logit, probit, cloglog Gamma identity, log, inverse_power Gaussian identity, log, inverse_power InverseGaussian identity, log, inverse_power, inverse_squared NegativeBinomial identity, log, cloglog, nbinom, Power sqrt, inverse_power, inverse_squared Tweedie identity, log, Power sqrt, inverse_power, inverse_squared まずはデータを読み込みトレーニングとテストに分けます。
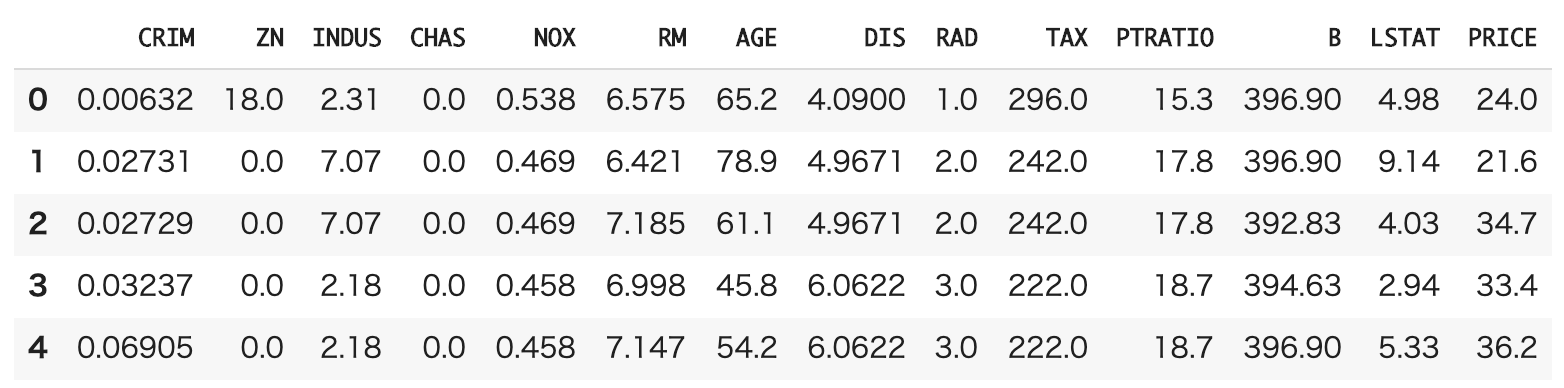
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl import seaborn as sns from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split boston = load_boston() df = pd.DataFrame(boston.data, columns=boston.feature_names) df['PRICE'] = boston.target X = df.drop('PRICE', axis=1) y = df['PRICE'] # テータ分割 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size =0.8)ちなみにデータはこんな感じです。
statsmodels.apiでリンク関数と誤差関数を、statsmodels.formula.apiでGLMモデルを使用します。import statsmodels.api as sm import statsmodels.formula.api as smf # 説明変数と目的変数を一つの行列にする必要あり data = pd.concat([X_train, y_train], axis=1) # 線形予測子を定義 formula = "PRICE ~ 1 + INDUS + CHAS + RM + RAD" # リンク関数を選択 link = sm.genmod.families.links.log # 誤差構造を選択 family = sm.families.Poisson(link=link) mod = smf.glm(formula=formula, data=data, family=family ) result = mod.fit() print(result.summary())モデルの評価方法はいくつかあると思いますが、AICはすぐに計算できて便利です。
# AIC result.aic予測は
predictメソッドを使用します。y_pred = result.predict(X_test)おわりに
今回は一般化線形モデルについて見てきました。一般化線形モデルは統計モデルなので、予測モデルがよく当てはまった場合、その誤差構造などから現象に潜むミクロな構造がわかるかもしれません。モデルを通して、なぜ変数がこのようなモデルによって説明できるのか考えるのが楽しくなると思います。
- 投稿日:2019-05-23T23:40:42+09:00
Python 2次元配列(数値)の数値を半角空白で区切ってprintする
はじめに
競プロやブラウザでのプログラミング問題を解く場合、
演算結果をprintで出力することが多いと思います。2次元配列の数値のリストを
空白区切りで出力をする必要が出た時に、
混乱したのでメモしておきます。戒め。
やりたいこと
以下のような2次元配列を用意する。
2の出力を行います。sample_list = [] for i in range(4): sub = [] for j in range(5): sub.append((i*10)+j) sample_list.append(sub)# 1. print(sample_list)の場合 [[0, 1, 2, 3, 4], [10, 11, 12, 13, 14], [20, 21, 22, 23, 24], [30, 31, 32, 33, 34]] # 2. やりたい出力 0 1 2 3 4 10 11 12 13 14 20 21 22 23 24 30 31 32 33 34実現方法
mapメソッドでリスト内の要素を文字に変換します。
それを再度listに入れ、
空白で区切って文字列にするためにjoinメソッドを使用します。for i in range(H): print(' '.join(list(map(str,sample_list[i])))) """ 出力 0 1 2 3 4 10 11 12 13 14 20 21 22 23 24 30 31 32 33 34 """おまけ
2次元配列をそのままmapで変換できないかと思い、試してみたのですが、
一つ下の次元に対してstrメソッドが適応されるようでした。この仕様を初めて知ったので問題を解いている時に混乱してしまいました。
冷静に考えるとすぐ上記に記載した方法でできますね。S = list(map(str,sample_list)) print(S) print(' '.join(S[0])) """ ['[0, 1, 2, 3, 4]', '[10, 11, 12, 13, 14]', '[20, 21, 22, 23, 24]', '[30, 31, 32, 33, 34]'] [ 0 , 1 , 2 , 3 , 4 ] """おわりに
最終的に1次元ずつ変換することに落ち着いたのですが、
何次元あったとしても一気に変換する方法ないのでしょうか...?
- 投稿日:2019-05-23T23:39:31+09:00
pythonのインデントはタブ派?スペース派?
1.背景
私はデータ分析を行う際にpythonを使っています。これまでは、特に深く考えず、pythonを書く時のインデントは「タブキー」を押していました。
Jupyter notebookではタブキーをおしても半角スペース4つとして扱われるので問題がなかったのですが、他のエディタを使ったときに半角スペースとタブが混在して「IndentationError」が頻発しました。
そこで、今後は明確にどちらかに統一していこうと考えたことから、「半角スペースかタブのどちらが良いのか?」という疑問が生まれました。
2.Twitterでのアンケート調査 -タブ派多数!
周りの人がどのようにしているのか知ろうと思い、Twitterでアンケートを取ってみました。結果は「タブ」と「スペース4個」がいい勝負で、タブ派の勝利。ただ、この設問だと「タブキーで半角4個」のパターンの人が「タブ」を選択している可能性があるため、設問が悪かったなぁと思いました。
python使っている方に質問です。インデントのつけ方を教えてください。
— はぁこ?ビール女子麦子開発中 (@paco_itengineer) May 22, 20193.PEP8を確認 -スペース4つ!
PEP8-jaのインデントの章を見てみると以下のように書かれています。
1レベルインデントするごとに、スペースを4つ使いましょう。
はい。明確に描かれていますね?「スペース4つ」だそうです。
4.今後の方針
これより、今後、私はpythonのインデントには「スペース4つ」を使うことにしました。ただし、「タブキー」を押す習慣は今さら変えられないので、エディタ側で「タブキーを押すとスペース4つを入力する」という設定を徹底しようと思います。
(ちなみに、普段使っているJupyterNotebookは、タブキーを押すとスペース4つ入力されるようになっていました。)
本件は私個人が調べて判断した結果ですので、他の考え方やご意見があれば、コメントいただけると幸いです。
- 投稿日:2019-05-23T23:04:38+09:00
windows10にPythonをインストールしてDjangoを動かすまで
MinicondaでPythonをインストール
- Miniconda — Conda documentation
- インストール先を
C:\Miniconda3に変更- まあ別にどこでもいいけどパスは短いほうが楽だと思った
- それ以外はデフォルト
環境変数を設定
- ユーザー環境変数に追加
C:\Miniconda3C:\Miniconda3\ScriptsC:\Miniconda3\Library\binC:\>python -V Python 3.7.3 C:\>conda -V conda 4.6.14仮想環境を作成
C:\>conda create -n myenv python=3.7.3
実行ログ
Collecting package metadata: done Solving environment: done ## Package Plan ## environment location: C:\Miniconda3\envs\myenv added / updated specs: - python=3.7.3 The following packages will be downloaded: package | build ---------------------------|----------------- pip-19.1.1 | py37_0 1.8 MB python-3.7.3 | h8c8aaf0_1 17.8 MB setuptools-41.0.1 | py37_0 680 KB sqlite-3.28.0 | he774522_0 945 KB vs2015_runtime-14.15.26706 | h3a45250_4 2.4 MB wheel-0.33.4 | py37_0 57 KB ------------------------------------------------------------ Total: 23.6 MB The following NEW packages will be INSTALLED: ca-certificates pkgs/main/win-64::ca-certificates-2019.1.23-0 certifi pkgs/main/win-64::certifi-2019.3.9-py37_0 openssl pkgs/main/win-64::openssl-1.1.1b-he774522_1 pip pkgs/main/win-64::pip-19.1.1-py37_0 python pkgs/main/win-64::python-3.7.3-h8c8aaf0_1 setuptools pkgs/main/win-64::setuptools-41.0.1-py37_0 sqlite pkgs/main/win-64::sqlite-3.28.0-he774522_0 vc pkgs/main/win-64::vc-14.1-h0510ff6_4 vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.15.26706-h3a45250_4 wheel pkgs/main/win-64::wheel-0.33.4-py37_0 wincertstore pkgs/main/win-64::wincertstore-0.2-py37_0 Proceed ([y]/n)? y Downloading and Extracting Packages setuptools-41.0.1 | 680 KB | ############################################################# | 100% python-3.7.3 | 17.8 MB | ############################################################# | 100% pip-19.1.1 | 1.8 MB | ############################################################# | 100% sqlite-3.28.0 | 945 KB | ############################################################# | 100% wheel-0.33.4 | 57 KB | ############################################################# | 100% vs2015_runtime-14.15 | 2.4 MB | ############################################################# | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use: # > activate myenv # # To deactivate an active environment, use: # > deactivate # # * for power-users using bash, you must source #仮想環境を起動
C:\>activate myenv (myenv) C:\>毎回コマンドを叩くのは面倒なのでバッチを作る
プロジェクトを作りたいディレクトリにバッチを置いて叩くC:\Projects\activate-myenv.bat@echo off cmd /k "activate myenv"叩くとこうなる(myenv) C:\Projects>Djangoをインストール
(myenv) C:\Projects>pip install django==2.2.1
実行ログ
Collecting django==2.2.1 Downloading https://files.pythonhosted.org/packages/b1/1d/2476110614367adfb079a9bc718621f9fc8351e9214e1750cae1832d4090/Django-2.2.1-py3-none-any.whl (7.4MB) |████████████████████████████████| 7.5MB 544kB/s Collecting pytz (from django==2.2.1) Downloading https://files.pythonhosted.org/packages/3d/73/fe30c2daaaa0713420d0382b16fbb761409f532c56bdcc514bf7b6262bb6/pytz-2019.1-py2.py3-none-any.whl (510kB) |████████████████████████████████| 512kB 467kB/s Collecting sqlparse (from django==2.2.1) Downloading https://files.pythonhosted.org/packages/ef/53/900f7d2a54557c6a37886585a91336520e5539e3ae2423ff1102daf4f3a7/sqlparse-0.3.0-py2.py3-none-any.whl Installing collected packages: pytz, sqlparse, django Successfully installed django-2.2.1 pytz-2019.1 sqlparse-0.3.0プロジェクトを作成
(myenv) C:\Projects>django-admin startproject myproj開発サーバを起動
プロジェクト内に移動(myenv) C:\Projects>cd myproj開発サーバを起動(myenv) C:\Projects\myproj>python manage.py runserver localhost:8080
実行ログ
Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. May 23, 2019 - 22:51:39 Django version 2.2.1, using settings 'myproj.settings' Starting development server at http://localhost:8080/ Quit the server with CTRL-BREAK.毎回コマンドを叩くのは面倒なのでバッチを作る
プロジェクト内にバッチを置いて叩くC:\Projects\myproj\runserver.bat@echo off cmd /k "activate myenv & python manage.py runserver localhost:8080"ウェブサイトを開く
http://localhost:8080/にアクセスする
- ロケットが表示されてればOK
The install worked successfully! Congratulations!
公式ドキュメント
- Python 3.7.3 ドキュメント
- 12. 仮想環境とパッケージ
- ホントは仮想環境にこっち使おうと思ったけどめんどくさそうだからやめた
- Django 2.2 ドキュメント
- 投稿日:2019-05-23T22:29:48+09:00
[自分用メモ]Djangoで初Webアプリ開発に挑戦 Part7
前回
[自分用メモ]Djangoで初Webアプリ開発に挑戦 Part6
クラスベースビュー
今まではビューをメソッドとして書いてきました。
クラスベースビューとはビューをクラスとして書いたビューで、メソッドベースに比べてコードがすっきりしています。views.pyを編集してみます。
polls/views.pyfrom django.http import HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Choice, Question class IndexView(generic.ListView): template_name = 'polls/index.html' context_object_name = 'latest_question_list' def get_queryset(self): """Return the last five published questions.""" return Question.objects.order_by('-pub_date')[:5] index = IndexView.as_view() class DetailView(generic.DetailView): model = Question template_name = 'polls/detail.html' detail = DetailView.as_view() class ResultsView(generic.DetailView): model = Question template_name = 'polls/results.html' results = ResultsView.as_view() ...それぞれ、urls.pyを編集しなくてもいいように
as_view()をつかってインスタンス化しています。静的ファイルの追加
HTMLで書かれたウェブページの見た目を綺麗にするために、CSSなどの静的(static)ファイルが用いられます。Djangoでもテンプレートの見た目を綺麗にするために、静的ファイルを利用できます。
ディレクトリの作成
pollsディレクトリ下にstaticディレクトリを作り、その中にtemplates同様pollsディレクトリを作り、その中にstyle.cssというファイルを作ります。
テンプレートファイルの冒頭を編集
全てのbase.htmlを継承しているテンプレートにCSSを適用する前提で、base.htmlの冒頭にテンプレートタグを用いて
{% load static %}を追加し、ヘッダーにスタイルシートの場所を教えてあげます。base.html{% load static %} <html> <head> <link rel="stylesheet" type="text/css" href="{% static 'polls/style.css' %}"> </head> <body> {% block content %} {% endblock %} </body> </html>これでOKです。
最後に
今回のシリーズはここで終わりです。メインと思われるところをさらっと自分用のメモとして書きました。
読んでくれた方、ありがとうございました。
- 投稿日:2019-05-23T20:56:56+09:00
pyenvの使い方
pyenv で困った時
使うコマンドたち
pyenv install --list
pyenv install 0.0.0
pyenv local
pyenv globalエラー
Mojaveのせいでエラーが出る場合がある。その時はこれを参照。
- 投稿日:2019-05-23T20:56:56+09:00
pyenvとpipenv
pyenv で困った時
使うコマンドたち
pyenv install --list
pyenv install 0.0.0
pyenv local
pyenv globalエラー
Mojaveのせいでエラーが出る場合がある。その時はこれを参照。
- 投稿日:2019-05-23T20:48:28+09:00
LINE Notifyを使ってLINEへメッセージを送信するpythonプログラムを作ってみる
目的
LINE上で動くプログラムを作成するにはLINEでの手続きとサーバーが必要だったり、初心者には煩わしい。
LINEへメッセージ送信を行うプログラムを作成したいだけなんでLINE Notifyを使ってみる。参考にしたサイト
たったの2ステップでLINEにメッセージを通知する方法【python】
LINE側 設定手順
1.LINE Notifyにログインする。マイページを開く
https://notify-bot.line.me/ja/2.アクセストークンを発行する
アクセストークンの発行(開発者向け)で「トークンを発行する」をクリック
- トークン名:任意の文字列を入力
- トークルーム:「1:1でLINE Notifyからの通知を受ける」にチェック
他はグループトークから選択するみたい3.作成したアクセストークンをコピーしておく→プログラム内で定義する
実際にやってみた
コーディング1回目
sendmessege.pyline_notify_token = "<ここにアクセストークンを定義する>" line_notify_api = 'https://notify-api.line.me/api/notify' def main(): print("LINEへ送信するメッセージを入力してください。") message = input("送信メッセージ:") print('送信メッセージ:' + message) payload = {'message': message} headers = {'Authorization': 'Bearer ' + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) if __name__== '__main__': main()気付き・感想
- メッセージ送信だけならこんなに簡単だと思わなかった。
- 自分のLINEへメッセージ送信できたが、ここから利用価値をつけくわえたい
- requestsモジュールは事前に"pip install"しておく
コマンド:pip install requests- アクセストークンをソースにハードコーディングしないといけない←Java屋さんだから設定情報をDIできないの嫌だな。
コーディング2回目
変更内容
- DI対応:configparserを使って外出ししたアクセストークンを読み込むsendmessege.py# -*- coding: utf-8 -*- import requests import configparser # 設定ファイル情報 config = "" line_notify_token = "" line_notify_api = "" # iniファイルを読み込み def iniread(): global config global line_notify_token global line_notify_api config = configparser.ConfigParser() config.read('setting.ini') line_notify_token = config['LINENotify']['line_notify_token'] line_notify_api = config['LINENotify']['line_notify_api'] def main(): # 設定ファイル読み込み iniread() print("LINEへ送信するメッセージを入力してください。") message = input("送信メッセージ:") print('送信メッセージ:' + message) payload = {'message': message} headers = {'Authorization': 'Bearer ' + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) if __name__== '__main__': main()気付き・感想
- 今回はiniファイルにしたが、定義内容をディクショナリでアクセスできる。configparserモジュールいい感じ。
- もう少しオブジェクト指向で関心を区別しながらクラスをちゃんと設計せねば。
- configparser用のテストがデバッグ用になっている。ユニットテスト用のライブラリ使わねば。
- 投稿日:2019-05-23T20:48:15+09:00
線形SVCとハイパーパラメータの最適化
はじめに
乳癌の腫瘍が良性であるか悪性であるかを判定するためのウィスコンシン州の乳癌データセットについて、線形SVCとハイパーパラメータのチューニングにより予測器を作成する。
シリーズ
- 線形重回帰による決定係数の算出とモデルの選択
- 線形重回帰による決定係数の算出とモデルの選択 part_2
- 単回帰分析による寄与率の算出
- 線形回帰と特徴量の絞り込み
- ロジスティック回帰とハイパーパラメータのチューニング
- 線形SVCとハイパーパラメータのチューニング
線形SVCのハイパーパラメータ
詳細は以下を参照されたい。
sklearn.svm.LinearSVC
ハイパーパラメータ 選択肢 default penalty l1,l2 l2 loss hinge、squared_hinge squared_hinge dual boolt型 True tol float型 0.0001 C float型 1 multi_class ovr、crammer_singer ovr fit_intercept bool型 True intercept_scaling float型 1 class_weight 辞書型、balanced 1(全クラス) verbose int型 0 random_state int型 None max_iter int型 1000 手順
- 乳癌データの読み込み
- 条件設定
- トレーニングデータ、テストデータの分離
- グリッドサーチ
- ランダムサーチ
- ハイパーパラメータを中忍ぐしない場合との比較 # pythonによる実装
%%time import scipy.stats from sklearn.datasets import load_breast_cancer from sklearn.svm import LinearSVC from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score #乳癌データの読み込み cancer_data = load_breast_cancer() #条件設定 max_score = 0 SearchMethod = 0 LSVC_grid = {LinearSVC(): {"C": [10 ** i for i in range(-5, 6)], "multi_class": ["ovr", "crammer_singer"], "class_weight": ["balanced"], "random_state": [i for i in range(0, 101)]}} LSVC_random = {LinearSVC(): {"C": scipy.stats.uniform(0.00001, 1000), "multi_class": ["ovr", "crammer_singer"], "class_weight": ["balanced"], "random_state": scipy.stats.randint(0, 100)}} #トレーニングデータ、テストデータの分離 train_X, test_X, train_y, test_y = train_test_split(cancer_data.data, cancer_data.target, random_state=0) #グリッドサーチ for model, param in LSVC_grid.items(): clf = GridSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: max_score = score best_param = clf.best_params_ best_model = model.__class__.__name__ #ランダムサーチ for model, param in LSVC_random.items(): clf =RandomizedSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: SearchMethod = 1 max_score = score best_param = clf.best_params_ best_model = model.__class__.__name__ if SearchMethod == 0: print("サーチ方法:グリッドサーチ") else: print("サーチ方法:ランダムサーチ") print("ベストスコア:{}".format(max_score)) print("ベストモデル:{}".format(best_model)) print("パラメーター:{}".format(best_param)) #ハイパーパラメータを調整しない場合との比較 model = LinearSVC() model.fit(train_X, train_y) score = model.score(test_X, test_y) print("") print("デフォルトスコア:", score)結果
サーチ方法:グリッドサーチ ベストスコア:0.972027972027972 ベストモデル:LinearSVC パラメーター:{'C': 1, 'class_weight': 'balanced', 'multi_class': 'crammer_singer', 'random_state': 58} デフォルトスコア: 0.937062937063 Wall time: 1h 2min 31sおわりに
線形SVCでもデフォルトよりも高い正解率を得ることができた。
- 投稿日:2019-05-23T20:20:25+09:00
vs code insiders のクイックスタートを色々な言語で試してみた。
vs code insidersにIDEの未来の姿を見たので、勉強を兼ねて構築手順をまとめてみました。
クイックスタートの言語毎で若干差異があるようで、かじった事のある言語を試してみました。
vs code insidersそのものの詳しい説明については他のわかりやすい記事を参照してください。
簡単に言うと、今までは開発環境と実際の動く環境は別々で、トラブルが起こりやすい状況でのプログラミングが普通だったんですが、実際の動く環境でプログラミングができる。を提供するのがvs code insidersです。2019-05-23時点では以下の言語のクイックスタート(以下チュートリアル)があります。
https://code.visualstudio.com/docs/remote/containers
- node
- python
- go
- java
- dotnetcore
- php
- rust
- cpp
この中でnode、python、go、phpを今回試していきます。
事前準備
チュートリアルを始める前に、git や vs code insiders&extention(remote development)、docker等をインストールしてください。
dockerはshared driveの設定も忘れずに。チュートリアル ダウンロード
任意のディレクトリで以下のコマンドを実行
shgit clone https://github.com/Microsoft/vscode-remote-try-node git clone https://github.com/Microsoft/vscode-remote-try-python git clone https://github.com/Microsoft/vscode-remote-try-go git clone https://github.com/Microsoft/vscode-remote-try-phpチュートリアルの順番について
説明しやすさの観点から go → node → php → python の順番で進めます。
go
- vs code insidersを立ち上げて任意のディレクトリにダウンロードした
vscode-remote-try-goを開く- 右下に「Folder contains〜」というポップアップが出るので「Reopen in Container」のボタンを押す
- 「Installing Dev Container [details]〜」に切り替わる
- しばらく待ち ※進捗状況は[detail]から
- 左下の緑の枠が「Dev Container: GO」になったら環境構築終了
- メニューの表示→ターミナルを開いて、
go run server.goを実行Server listening on port 9000が出力されればwebサーバ立ち上げ完了- http://localhost:9000/ にアクセス
出力文字を変えたい場合は
server.goの"Hello remote world!"を任意の文字列に変更し、ターミナルからCTRL+c で停止した後、再度go run server.goを実行してページをリロードすると反映されていると思います。node
環境構築はディレクトリ
vscode-remote-try-nodeを開いた後はgoと途中まで一緒(上記4まで)なので割愛します。
5. 左下の緑の枠が「Dev Container: Node.js Sample」になったら環境構築終了
6. 表示→ターミナルを開いて、node server.jsを実行
7.Running on http://0.0.0.0:3000が出力されればwebサーバ立ち上げ完了
8. http://localhost:3000/ にアクセス出力文字を変えたい場合は server.js の対象箇所を変更できます。
goと同様に停止後→再実行で反映されます。PHP
1〜5 まで割愛
6. 表示→ターミナルを開いて、php -S localhost:8000を実行
7. F1ボタンを押してRemote-Containers: Forward Port from Container〜を選択後、「Forward 8000」をクリック
8. http://localhost:8000/ にアクセスphpはgo、node の手順+ポート転送の手順が必要となります。
出力文字を変えたい場合は index.phpを変更します。
また、変更にサーバの再起動は必要なく、ページのリロードのみで反映されます。python
1〜5まで割愛
6 以降では、デフォルトの設定では動かなかった&ポート番号(9000)がgoとカブるので以下の変更をします。.devcontainer/devcontainer.json"appPort": 9000, ↓ "appPort": 5000,.vscode/devcontainer.json"appPort": 9000, ↓ "appPort": 5000,app.py#以下をファイル末尾に追加 if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=5000)表示→ターミナルを開いて、
python app.pyを実行出力文字を変えたい場合は static/index.htmlを変更します。
また、変更にサーバの再起動は必要なく、ページのリロードのみで反映されます。
※goとnodeも別ファイルとしてindex.htmlを読み込むように変更すればサーバ再起動は必要ありません。
- 投稿日:2019-05-23T19:44:33+09:00
{Python} ブランド古着転売勢に捧げるガチ勢のためのオンラインストア スクレイピング
毎日4店舗以上のブランド古着オンラインサイトでポチポチして
お目当のブランドの新着商品を調べているブランド古着転売ガチ勢A君。A君「おりゃーー、トレファク、カインド、セカンドストリート、ラグタグ ぽちぽちぽちぽち」
INBED君「ね!A君、毎日4店舗以上も検索しにいくの疲れない? A君しかも調べてるブランド1つとかじゃないでしょ?各ウェブサイトで5個も6個も調べてると日が暮れるんじゃない?」
A君「これが僕の生きる道です。おりゃーー ポチポチポチ」
INBED君 「A君さ、スクレイピングって知ってる?」
A君 「は?? いいえ、そんなブランドは知りませんね。僕はハイブランド狙いなんで!! ドメスティックブランドですか? ケッ!」
INBED君 「違うよ。スクレイピングとはね、ウェブサイトから特定の情報を抽出するこのできるコンピューターソフトウェア技術のことだよ。」
A君「なんですかそれは。。 それで一体何ができるんですか?」
INBED君 「今、A君がやってる作業を数分以内に終わらすことができるよ。」
A君 「教えてください。(素直)」
読者対象:
スクレイピングをやってみたい方
A君のような転売屋の方ブランド古着オンラインストア スクレイピング
本記事ではBeautifulSoupを使ってオンラインストアから特定ブランドの新着をスクレイピング
する方法を書いてみました。
* cvcへの保存、特定のwebsiteを作成して閲覧等は割愛させて頂きました。環境:
Mac OS High Sierra ver 10.13.6
Python 3.6.5 (anaconda)環境構築 :
Terminalでpip install beautifulsoup4 pip listbeautifulsoup4 がlistに表示されていればOK。
コード
以下、
セカンドストリートオンラインストア
&
カインドオルオンラインストア
をスクレイピングする完成コードを記載。セカンドストリートオンラインストア
import requests from bs4 import BeautifulSoup base_url = "https://www.2ndstreet.jp" brands = [ "vainl archive", #←好きなブランド名に変更可能 "好きなブランド" ] for brand in brands: url = f"{base_url}/search?keyword={brand}&sortBy=arrival" resp = requests.get(url) soup = BeautifulSoup(resp.text, 'html.parser') lis = soup.find_all("li", {"class": "new"}) for li in lis: link = base_url + li.find("a").attrs["href"] price = li.find("p", {"class": "price"}).contents[0] img = base_url + li.find("img").attrs["src"] print(f"{link} \n Image: {img} \n Price: {price}\n")コード カインドオルオンラインストア
import requests from bs4 import BeautifulSoup base_url = "https://shop.kind.co.jp" brands = [ "vainl archive" ] for brand in brands: print(brand + "\n") url = f"{base_url}/item_list/?kw={brand}" resp = requests.get(url) soup = BeautifulSoup(resp.text, 'html.parser') divs = soup.find_all("div", {"class": "item"}) for div in divs: if div.find("p", {"class": "icn"}).find("img"): link = base_url + div.find("p", {"class": "pn"}).find("a").attrs["href"] price = div.find("p", {"class": "sp"}).contents[0].strip()[:-10] + "円" img = "https:" + div.find('p', {"class": "img"}).find('img').attrs["src"] print(f"{link} \n Image: {img} \n Price: {price}\n")解説 (セカンドストリートオンラインストア)
今回は、セカンドストリートオンラインさんを例に使用して解説します。
目標は、購入先のリンク、画像のURL、プライスを出力することです。
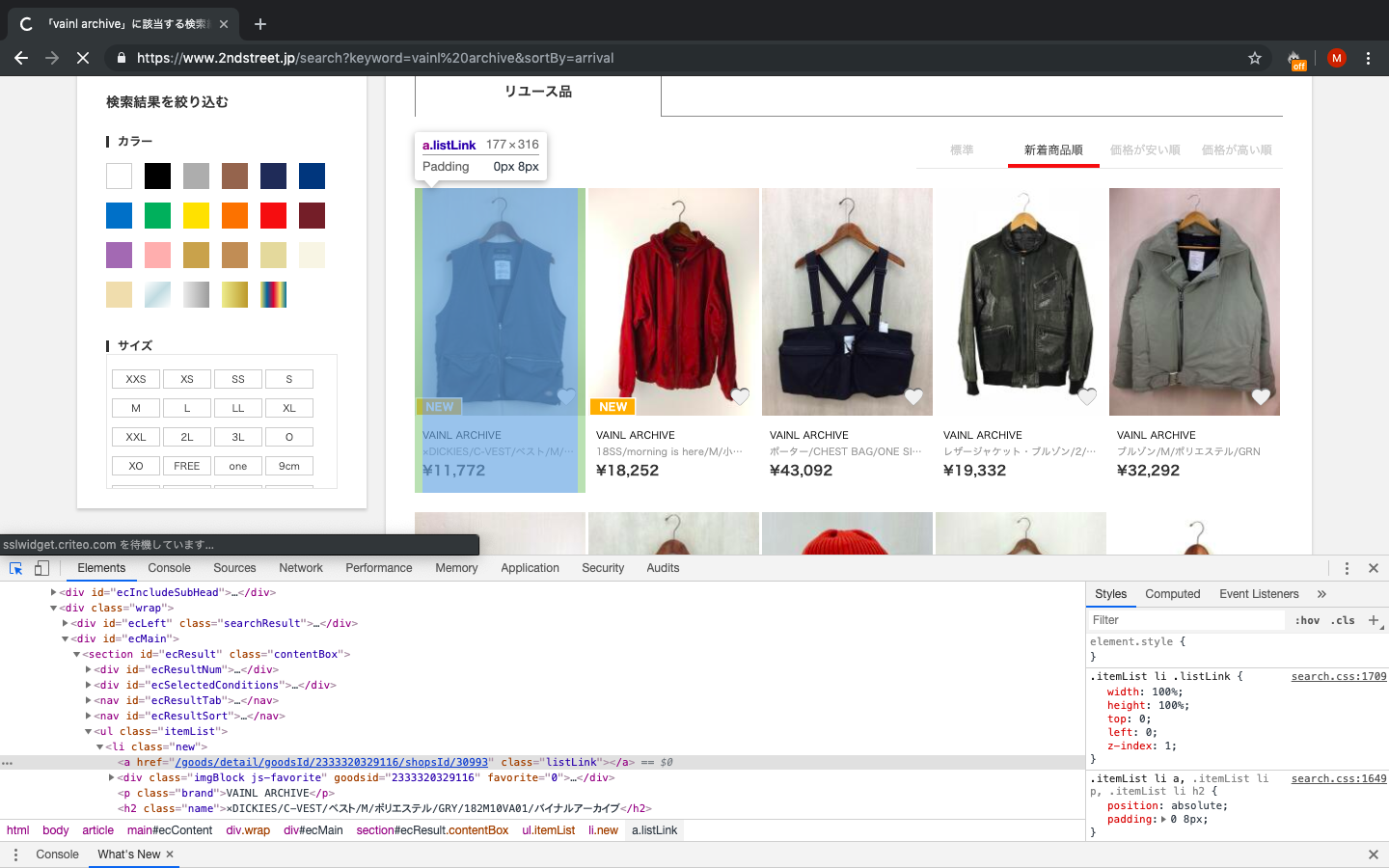
では、やってみましょう!新着商品をスクレイピングするため、NEW(新着タグ)ありとなしのコードにどのような差があるのかを確認するのが第一段階です。
下記の画像の青くなっている部分のコードを確認してみます。
こちらの黒のベストには黄色のNEW(新着のタグ)が付いていることがわかります。
黒ベスト with 新着タグ
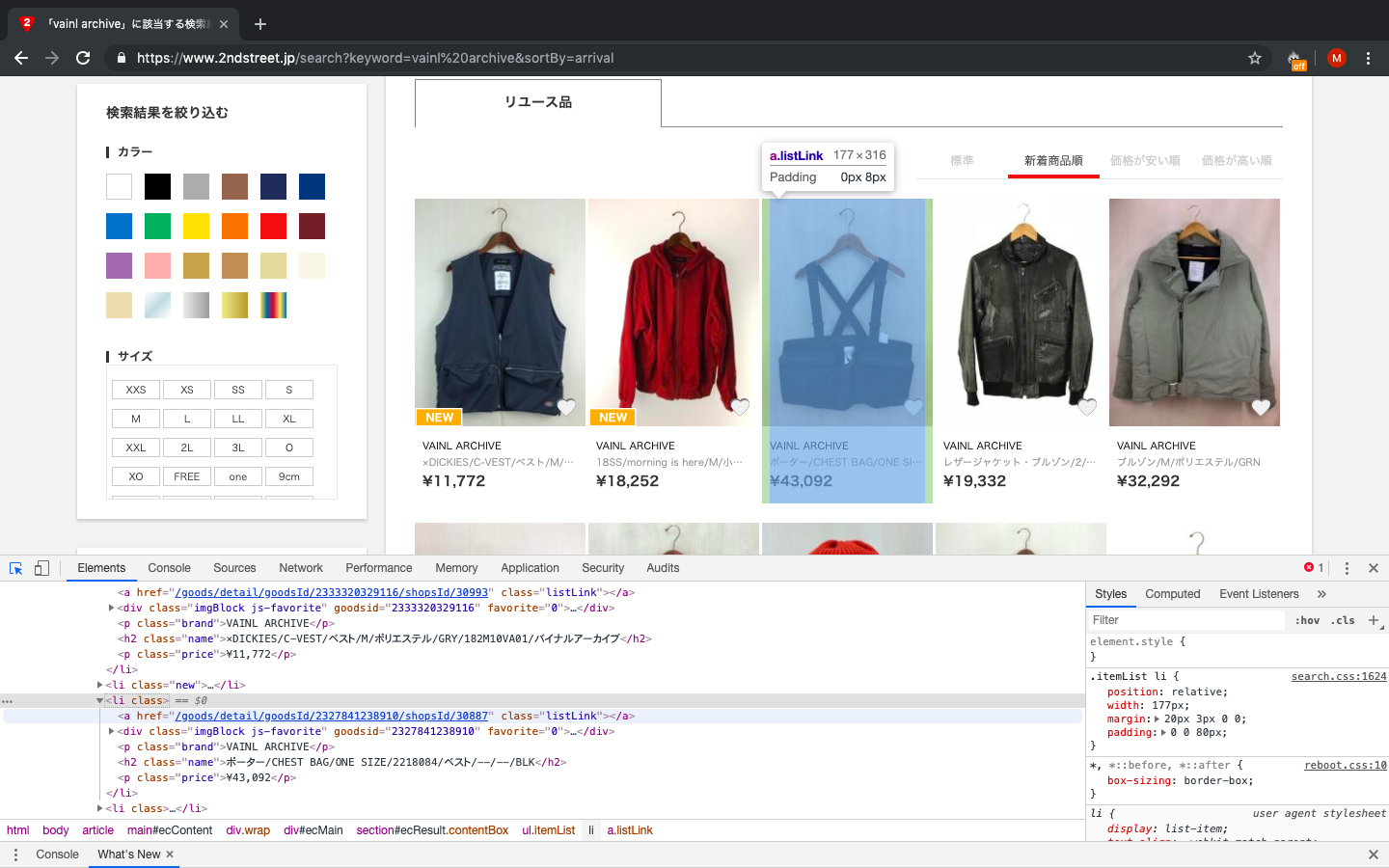
<li class="new"> # with tag <a href="/goods/detail/goodsId/2333320329116/shopsId/30993" class="listLink"> </a> <div class="imgBlock js-favorite" goodsid="2333320329116" favorite="0"> <img src="/img/pc/goods/233332/03/29116/1_tn.jpg" style="width: 100%"> <a href="/user/login" class="favorite"></a> </div> <p class="brand">VAINL ARCHIVE</p> <h2 class="name">×DICKIES/C-VEST/ベスト/M/ポリエステル/GRY/182M10VA01/バイナルアーカイブ </h2> <p class="price">¥11,772</p> </li>NEW タグが付いていないPorter とVAINLのコラボのベストも確認してみます。
<li class=""> # without tag <a href="/goods/detail/goodsId/2327841238910/shopsId/30887" class="listLink> </a> <div class="imgBlock js-favorite" goodsid="2327841238910" favorite="0"> <img src="/img/pc/goods/232784/12/38910/1_tn.jpg" style="width: 100%"> <a href="/user/login" class="favorite"></a> </div> <p class="brand">VAINL ARCHIVE</p> <h2 class="name">ポーター/CHEST BAG/ONE SIZE/2218084/ベスト/--/--/BLK</h2> <p class="price">¥43,092</p> </li>この二つを見比べるとli classに"new"があるか空白かの違いが読み取れます。
この場合、"new"をclassに持つ全てのli タグをsoup.find_allで見つけ出します。
そうすれば、NEW タグのついているものだけを取り出すことが可能です。lis = soup.find_all("li", {"class": "new"})次に for文を用い、link, price, imgの変数にli要素を一つずつ代入し、出力します。
for li in lis: link = base_url + li.find("a").attrs["href"] price = li.find("p", {"class": "price"}).contents[0] img = base_url + li.find("img").attrs["src"] print(f"{link} \n Image: {img} \n Price: {price}\n")RUNすれば、画像のURL、商品URL、プライスが返ってきます。
Running] python -u "/Desktop/scraping/2ndstreet.py" https://www.2ndstreet.jp/goods/detail/goodsId/2333320329116/shopsId/30993 Image: https://www.2ndstreet.jp/img/pc/goods/233332/03/29116/1_tn.jpg Price: ¥11,772 https://www.2ndstreet.jp/goods/detail/goodsId/2332840352406/shopsId/30972 Image: https://www.2ndstreet.jp/img/pc/goods/233284/03/52406/1_tn.jpg Price: ¥18,252以上です。
- cvcへの保存、特定のwebsiteを作成して閲覧等は今度やります。
- 投稿日:2019-05-23T18:52:26+09:00
setのいろいろ python
add(), update() セット型の集合に要素を追加
>>> myset = set(['a', 'b']) # セットを作成 #add() >>> myset.add('c') >>> myset {'a', 'c', 'b'} >>> myset.add('a') #'a'はすでにmysetの中に含まれているので、何も起こらない >>> myset.add((5, 4)) >>> myset {'a', 'c', 'b', (5, 4)} #update() >>> myset.update([1, 2, 3, 4]) # update()は、イテラブルなオブジェクトに対してのみ使える >>> myset {'a', 1, 'c', 'b', 4, 2, (5, 4), 3} >>> myset.update({1, 7, 8}) >>> myset {'a', 1, 'c', 'b', 4, 7, 8, 2, (5, 4), 3} >>> myset.update({1, 6}, [5, 13]) >>> myset {'a', 1, 'c', 'b', 4, 5, 6, 7, 8, 2, (5, 4), 13, 3}remove(), discard(), pop()セット型の集合から要素を削除
remove(x)
このメソッドは、集合から要素xを削除する。
もし、集合の中にxがなければ、KeyErrorとなる>>> s = set([1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> s.remove(5) >>> print s set([1, 2, 3, 4, 6, 7, 8, 9]) >>> print s.remove(4) None >>> print s set([1, 2, 3, 6, 7, 8, 9]) >>> s.remove(0) KeyError: 0discard(x)
このメソッドも、集合から要素xを削除する。
もし、集合の中にxがなくても、KeyErrorとはならない。>>> s = set([1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> s.discard(5) >>> print s set([1, 2, 3, 4, 6, 7, 8, 9]) >>> print s.discard(4) None >>> print s set([1, 2, 3, 6, 7, 8, 9]) >>> s.discard(0) >>> print s set([1, 2, 3, 6, 7, 8, 9])pop()
このメソッドは、集合の中から任意の要素を削除し、その値を返す。
空集合に対して、pop()メソッドを適用すると、KeyErrorとなる>>> s = set([1]) >>> print s.pop() 1 >>> print s set([]) >>> print s.pop() KeyError: pop from an empty set
- 投稿日:2019-05-23T17:29:46+09:00
【MNIST】【Pytorch】CNNをPyTorchのSequentialを使って実装する
PytorchのチュートリアルにはSequential Modelというものがあり、Kerasのように層を作るだけでネットワークを構成できる。
https://qiita.com/daikiclimate/items/80309935d66f44f0c572
にて全結合層のみのネットワークを作った
今回はCNN(Conv層のある)を作ろうと思ったが、
torch.nnにはFlattenのような関数がなくConv->Linerにネットワークがつながらないそのため、Flattenというクラスをnn.moduleに継承させて無理やり追加させる。
import torch import torchvision import torchvision.transforms as transforms import numpy as np import torch.optim as optim import torch.nn as nn import numpy as np batch_size = 128 class Flatten(nn.Module): def forward(self, input): return input.view(input.size(0), -1) #トレインデータ、テストデータのロード transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, ), (0.5, ))]) trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False) #モデルの定義 model = torch.nn.Sequential( nn.Conv2d(1, 8, 5), # 28 * 28 * 16-> 24 * 24 * 16 nn.ReLU(), nn.MaxPool2d(2), #24 * 24 *16 -> 12 * 12 * 16 nn.Conv2d(8, 16, 5), # 12* 12 * 16 -> 8* 8 * 32 nn.ReLU(), nn.Dropout2d(), Flatten(), nn.Linear(8 * 8 * 16, 128), nn.Linear(128, 10) ) #勾配法 optimizer = optim.SGD(model.parameters(), lr=0.01) #誤差関数 criterion = nn.CrossEntropyLoss() training_loss = [] #モデルの学習 model.train() for i in range(10): runnning_loss = 0.0 for j, data in enumerate(trainloader): inputs, teacher_labels = data model.zero_grad() outputs = model(inputs) #lossの計算逆伝搬 loss = criterion(outputs,teacher_labels) loss.backward() optimizer.step() runnning_loss += loss.data.item() #途中結果の表示 #バッチサイズに合わせて変更する必要あり if j % 100 == 99: print("[{:d}, {:d} loss : {:.3f}]".format(i, j+1, runnning_loss/2000)) runnning_loss = 0.0 training_loss.append(loss) count_when_correct = 0 total = 0 for data in testloader: #テストデータのロード test_data, test_labels = data #テストデータの推論 outputs = model(test_data) _, predicted = torch.max(outputs.data, 1) #正答率の算出 total += test_labels.size(0) count_when_correct += (predicted == test_labels).sum() print('正解率:%d / %d => %.1f'% (count_when_correct, total, int(count_when_correct)/int(total)*100 ),"%")
- 投稿日:2019-05-23T17:21:22+09:00
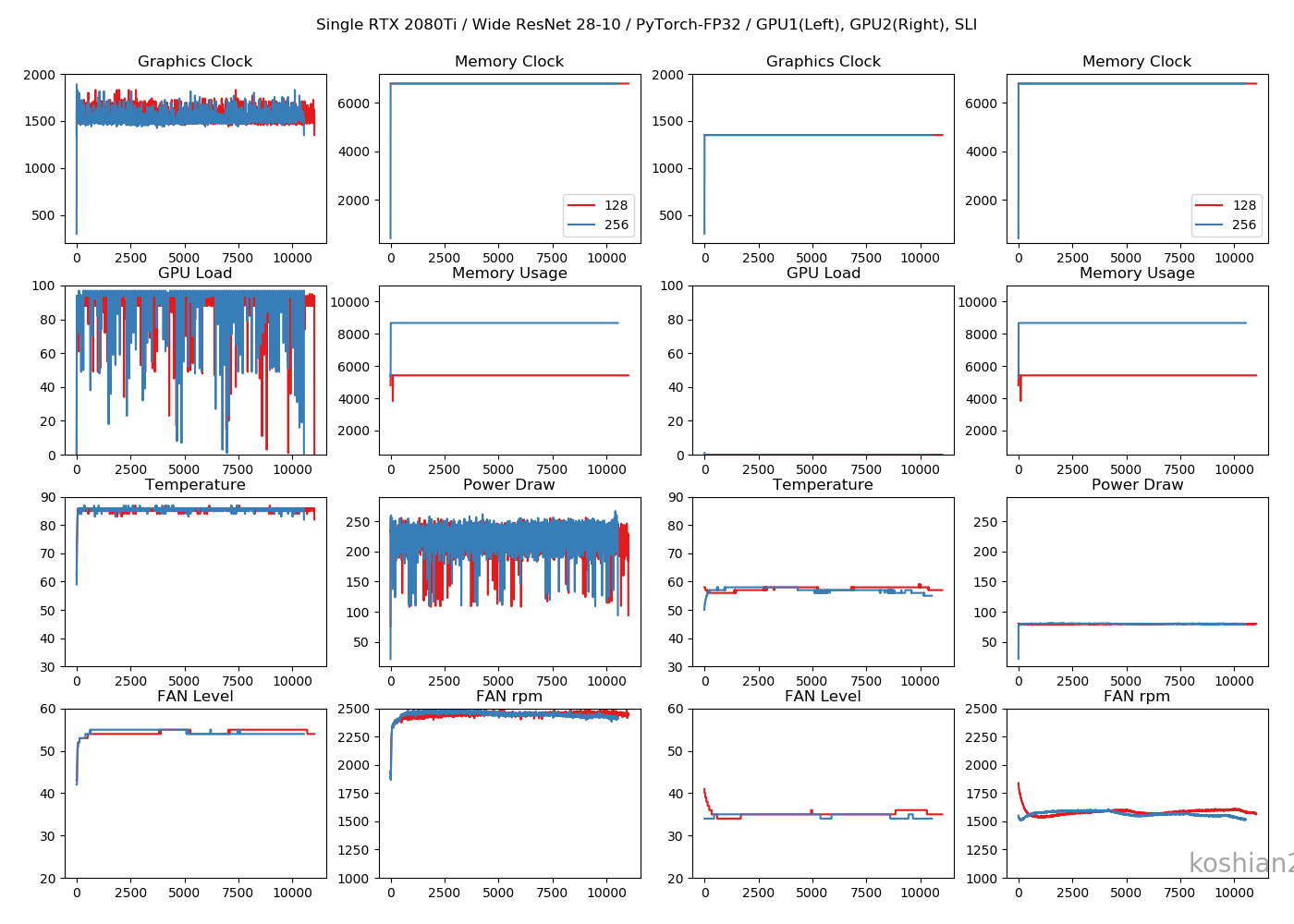
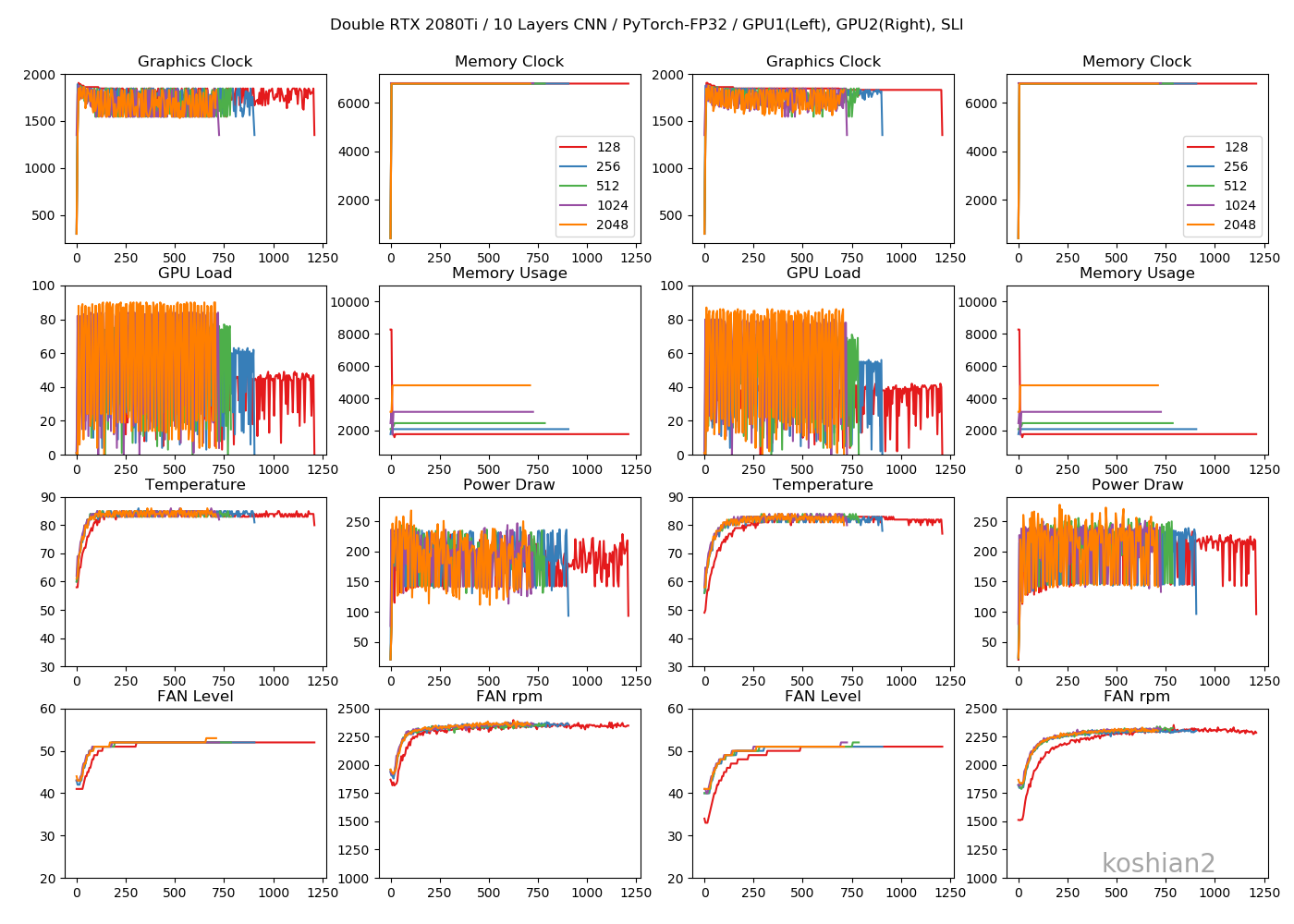
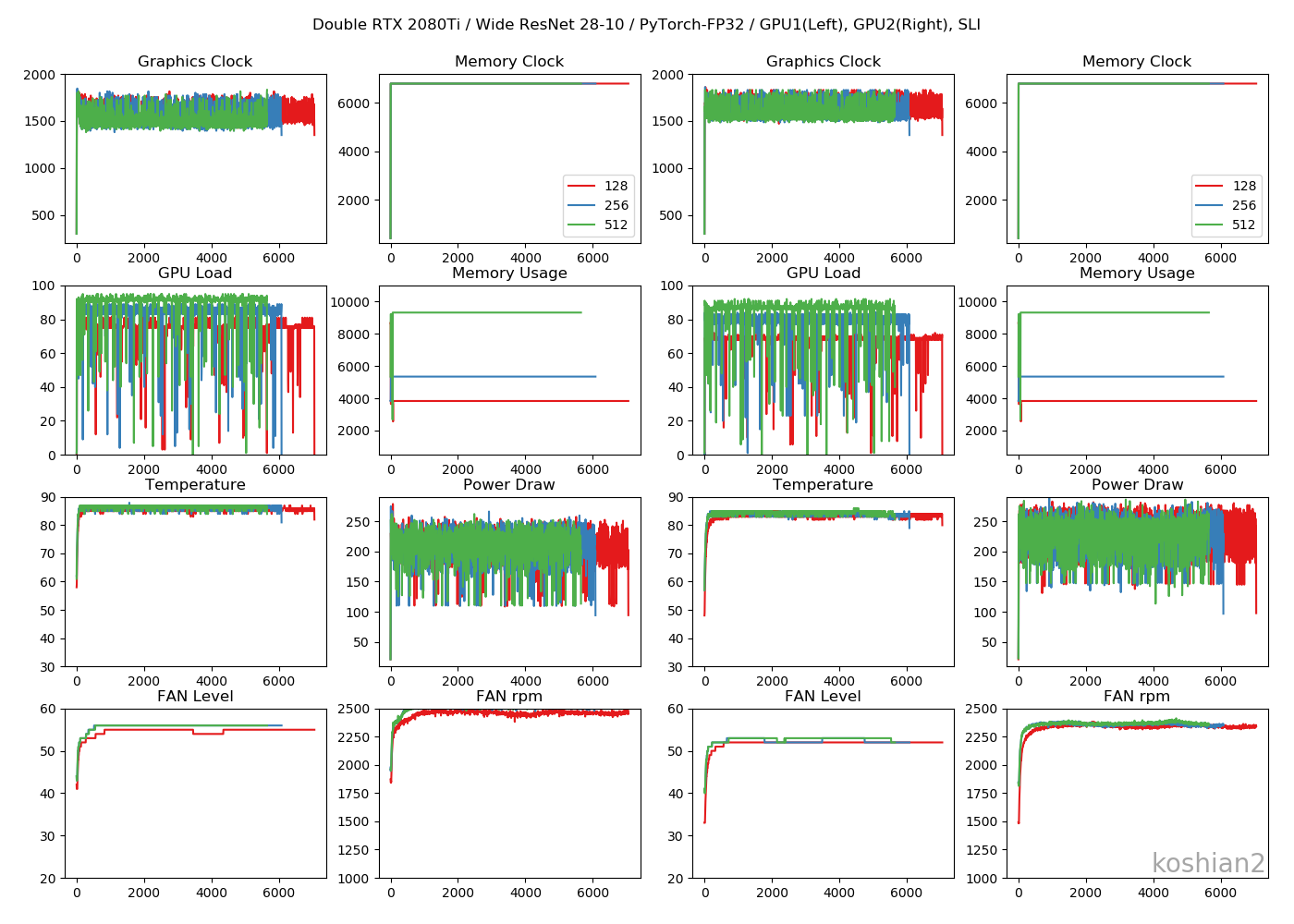
対決!RTX 2080Ti SLI vs Google Colab TPU ~PyTorch編~
RTX 2080Tiを2枚使って頑張ってGPUの訓練を高速化する記事の続きです。TensorFlowでは複数GPU時に訓練が高速化しないという現象がありましたが、PyTorchを使うとRTX 2080Tiでもちゃんと高速化できることを確認できました。これにより、2GPU時はTensorFlowよりも大幅に高速化できることがわかりました。
前回までの記事
ハードウェアスペック
- GPU : RTX 2080Ti 11GB Manli製×2 SLI構成
- CPU : Core i9-9900K
- メモリ : DDR4-2666 64GB
- CUDA : 10.0
- cuDNN : 7.5.1
- PyTorch : 1.1.0
- Torchvision : 0.2.2
前回と同じです。「ELSA GPU Monitor」を使って、GPUのロードや消費電力をモニタリングします(5秒ごとCSV出力)。
結果
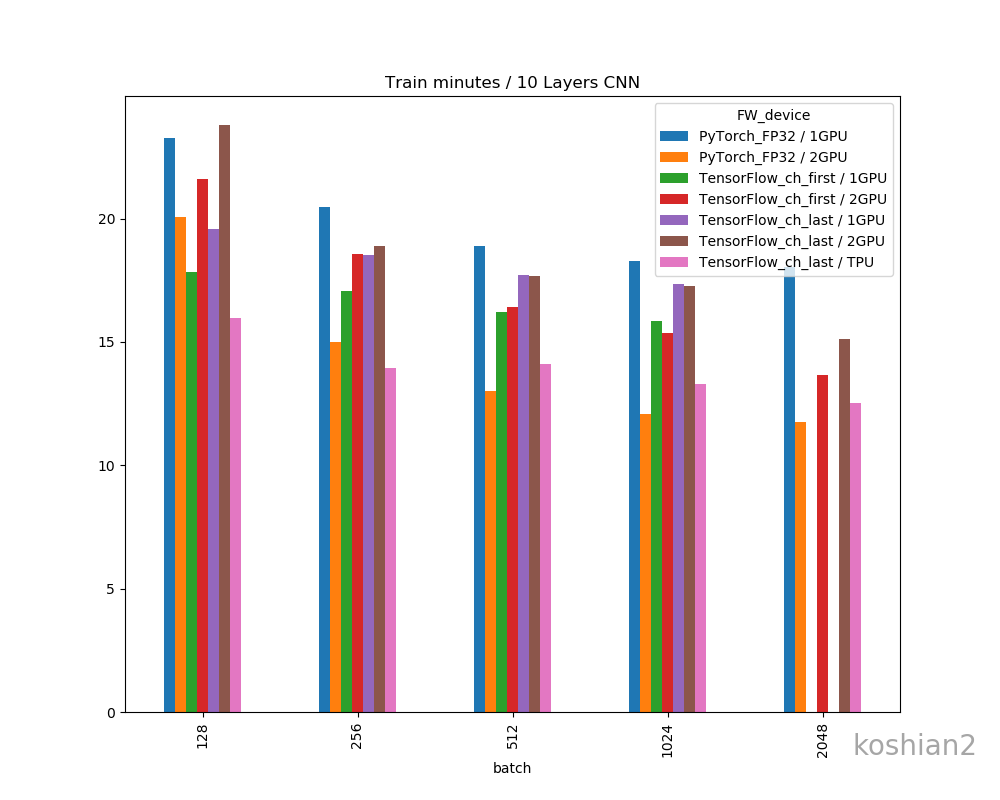
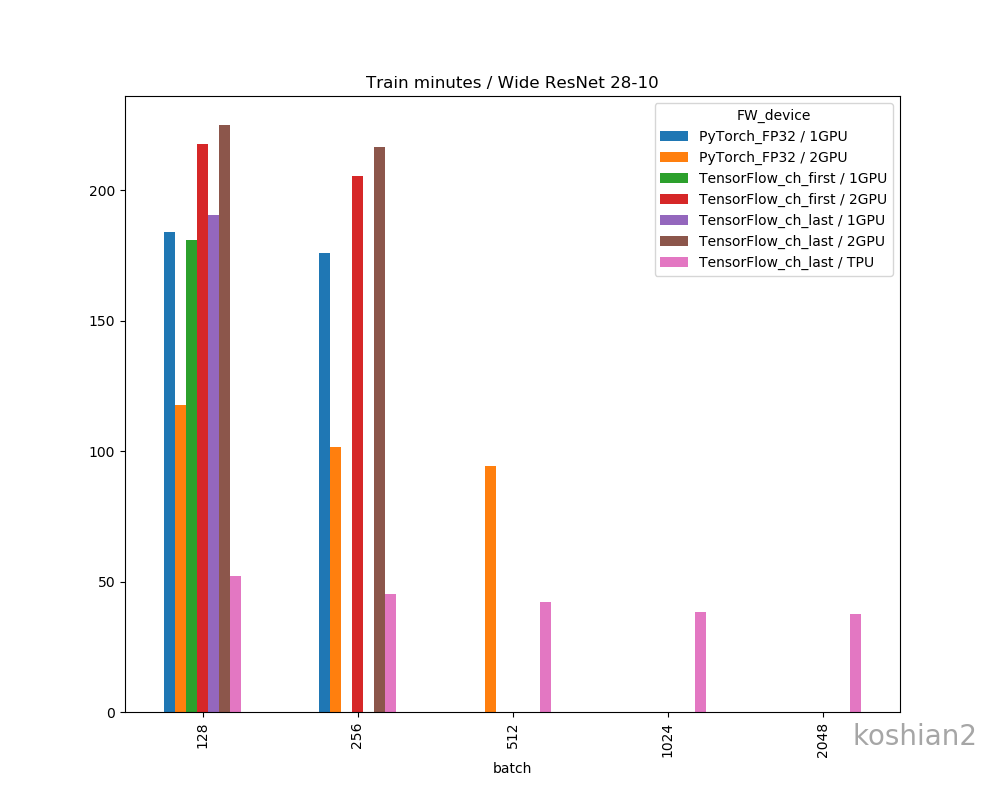
10層CNN
10層CNNの詳細は初回の記事を参照してください。縦軸に訓練時間、横軸にバッチサイズを取ったものです。
「TensorFlow_ch_first」はこちらで書いたTensorFlowかつchannels_firstとしたケースです。「TensorFlow_ch_last」はchannels_lastのケースで、TensorFlow/Kerasのデフォルトの設定はchannels_lastになります。
「1GPU, 2GPU」はRTX2080Tiの数で、2GPUの場合は、TensorFlowは
multi_gpu_modelを使い、データパラレルとして並列化させています。PyTorchの場合は、if use_device == "multigpu": model = torch.nn.DataParallel(model)このように同じくデータパラレルで並列化させています。大きいバッチでデータのないところは、OOMになってしまうため測っていない場所です。
このグラフから以下のことがわかります。
- 小さいCNNかつ1GPUでは、必ずしもPyTorchが最速とは限らない。むしろTensorFlow、特にchannels_firstにしたTensorFlowのほうが速いことがある。
- TensorFlowとPyTorchの差は、小さいCNNではバッチサイズを大きくすると縮まっていく。
- ただし、PyTorchでは2GPUにしたときは明らかにTensorFlowよりも速くなる。バッチサイズ512以降では、Colab TPUよりもFP32で既に速い。
- PyTorchのほうが大きいバッチサイズを出しやすい。TensorFlowの場合は、1GPUではバッチサイズが2048のケースがOOMで訓練できなかったが、PyTorchの場合は1GPUでバッチサイズ2048を訓練できる。
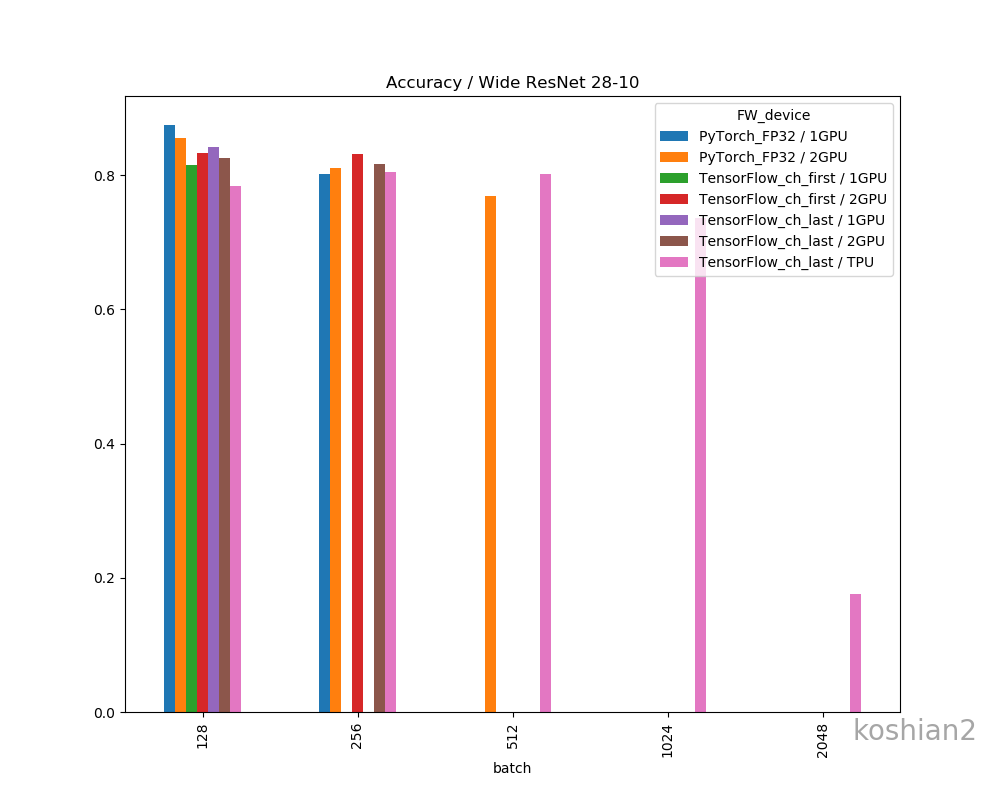
Wide ResNet 28-10
こちらはWide ResNet 28-10の訓練時間を比較したものです。
- 大きいCNNかつ1GPUでは、PyTorchとTensorFlowの訓練時間の差はほとんどない。特にTensorFlowでChannels firstにすればPyTorchかそれ以上の速さは出せる。
- しかし、複数GPUになると、明らかにPyTorchのほうが速くなる。TensorFlowのGPU並列化が何かおかしい。
- ただし、WRNのような大きなCNNのでは、PyTorch+2GPU+FP32ではまだColab TPUに勝てなかった
- PyTorchの場合、TensorFlowのできなかった1GPUでのバッチサイズ256、2GPUのバッチサイズ512を訓練することができた。なぜかPyTorchのほうが訓練できるバッチサイズが大きい。
PyTorch個別の結果
今回やったPyTorchだけの結果を表します
1GPU・10層CNN
バッチ 1エポック[s] 2~中央値[s] 訓練時間 精度 128 15.86 13.90 0:23:15 0.8915 256 12.72 12.29 0:20:28 0.8900 512 13.60 11.33 0:18:53 0.8837 1024 16.52 10.93 0:18:17 0.8860 2048 15.50 10.80 0:18:03 0.8639 1GPU・WRN
バッチ 1エポック[s] 2~中央値[s] 訓練時間 精度 128 111.89 110.42 3:03:57 0.8743 256 105.71 105.47 2:55:48 0.8011 2GPU・10層CNN
バッチ 1エポック[s] 2~中央値[s] 訓練時間 精度 128 16.07 11.92 0:20:04 0.8896 256 8.96 9.00 0:15:00 0.8912 512 8.74 7.80 0:13:01 0.8816 1024 9.52 7.24 0:12:05 0.8814 2048 8.34 7.05 0:11:45 0.8688 2GPU・WRN
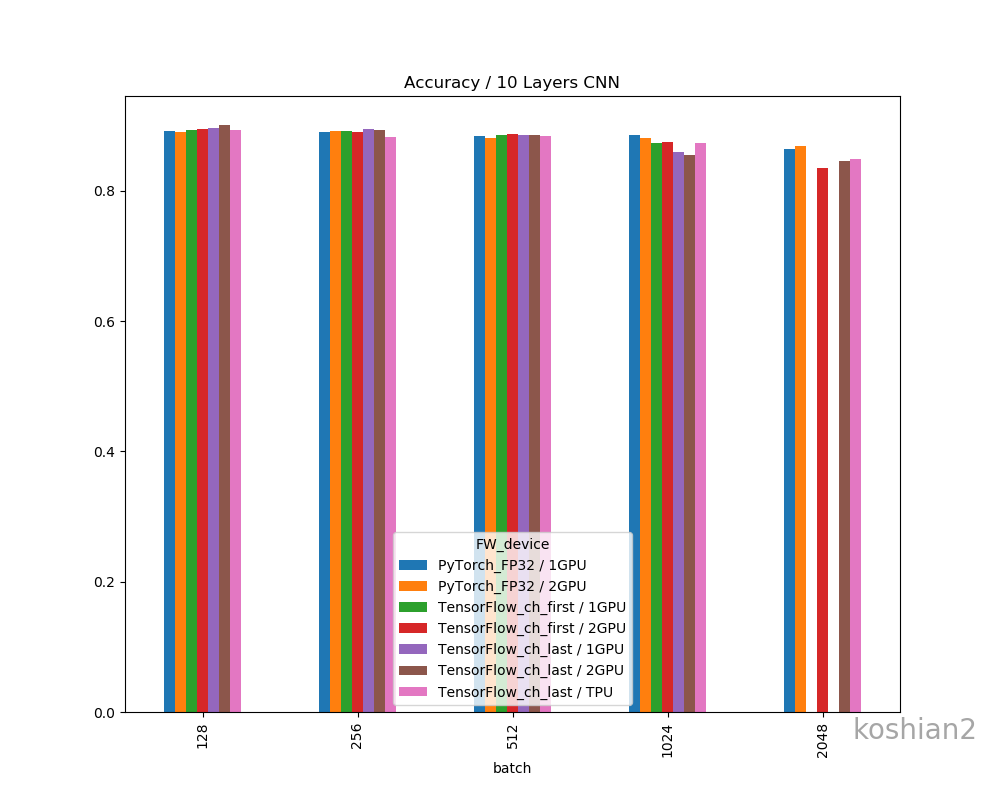
バッチ 1エポック[s] 2~中央値[s] 訓練時間 精度 128 72.75 70.58 1:57:38 0.8559 256 58.43 60.83 1:41:22 0.8109 512 59.01 56.49 1:34:14 0.7695 精度比較
一応、フレームワークやデバイス間で精度の差があるか確認しておきましょう。
精度の明確な差はこのデータだけではなさそうに思えます。明確に議論するならケースごとにもう少し試行回数を増やして精査しないといけません。
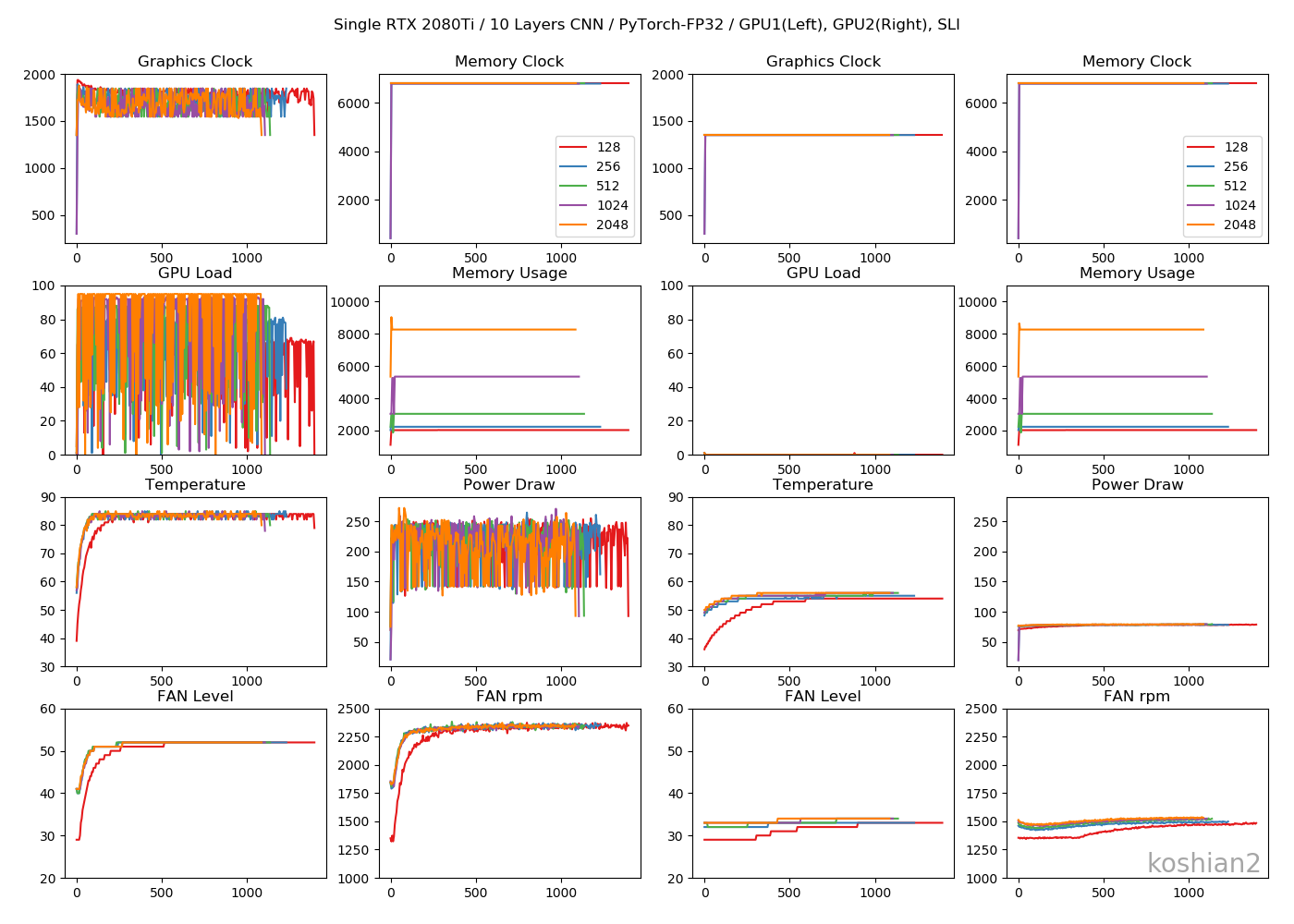
GPUログ
1GPU・10層CNN
目につくのは「Memory Usage」です。TensorFlowのケースではモデルが大きかろうが小さかろうが、確保できるだけめいいっぱいメモリ確保しているのに対し、PyTorchではモデルに見合ったサイズしかメモリ確保していません。TensorFlowのGPU最適化やっぱりおかしいんじゃ。1GPU・WRN
TensorFlowのケースよりGPUロードの振れ幅が大きくなっていますが、これはエポックの終わりで一瞬だけ計算しない時間があるからです。訓練ループを書いているせいもあるかもしれません。2GPU・10層CNN
2GPUの場合は、GPUごとに同じ動きになっていてわかりやすいです。2GPU・WRN
TensorFlowのときにあった、GPUロードの1枚目と2枚目の不均一性は解消されました。これなら自然ですし、速度も出るはずです。まとめ
RTX 2080Ti SLI環境の場合、次のことがわかりました。
- FP32の精度では、1GPUの場合、TensorFlowとPyTorchの速さはあまり変わらない。TensorFlowでchannels_firstにするとPyTorchの速度を上回ることもある。
- ただし、2GPUにするとPyTorchの完勝になる。TensorFlowでは逆に遅くなってしまう。
- 10層CNNのような小さいモデルでは、2GPUのPyTorchにすると、FP32の精度を保ちながらColab TPUより高速化できる。
- ハードウェアが同一なのに、PyTorchのほうが大きなバッチサイズを訓練できることがある。
- PyTorchはモデルの大きさに応じてGPUメモリを専有する。TensorFlow/Kerasは大きいモデルだろうが小さいモデルだろうが、デフォルトでは確保できるだけ確保していて、GPUの最適化がおかしい。
PyTorch with テンソルコアでどれだけ速くなるかは次回に書きたいと思います。
コード
https://gist.github.com/koshian2/f54fe6a4a71f3ba3d68cc2d90c0a3d6d
お知らせ
技術書典6で頒布したモザイク本の通販を下記URLで行っています。会場にこられなかったけど欲しいという方は、ぜひご利用ください。
『DeepCreamPyで学ぶモザイク除去』通販
https://note.mu/koshian2/n/naa60d5c9ebbaディープラーニングや機械学習における画像処理の基本や応用を学びながら、モザイク除去技術DeepCreamPyを使いこなし、自分で実装するまでを目指す解説書です(TPUの実装中心に書いています)。
- 投稿日:2019-05-23T17:20:26+09:00
機械学習によるサザエさんじゃんけんの予測(GoogleColaboratory対応)Sckit-learn編
はじめに
今回は国民的アニメ「サザエさん」のエンディングのじゃんけんの予測に挑戦しました。
使用したツール
・GoogleColaboratory
・Googleスプレッドシート
・メモ帳(アプリケーション)手順
1-1 データの入手
まずはここからサザエさんのじゃんけんの過去のデータを入手します。ここには1991年の最初の回以降の全ての放送回のじゃんけんのデータが公開されています。
本来は1年分ずつメモ帳にコピペして検索と置換を使ってカンマ区切りファイル(csvファイル)を作っていくのですが、30分くらいかかってしまうのでこの記事を書いている今日(2019年5月23日)時点までの過去のじゃんけんのデータをここに公開しておきます。(この記事ではこのデータを共有用スプレッドシートと呼びます)スプレッドシート形式なのでマイドライブに新規スプレッドシートを作成し、コピペして使ってください。1-2 データの加工
データの加工と言っても大したことはしません。みなさんがこの記事を読んでいるときには、先程コピペしたスプレッドシートのデータはもう最新ではないので、新たにデータを追加してもらいます。
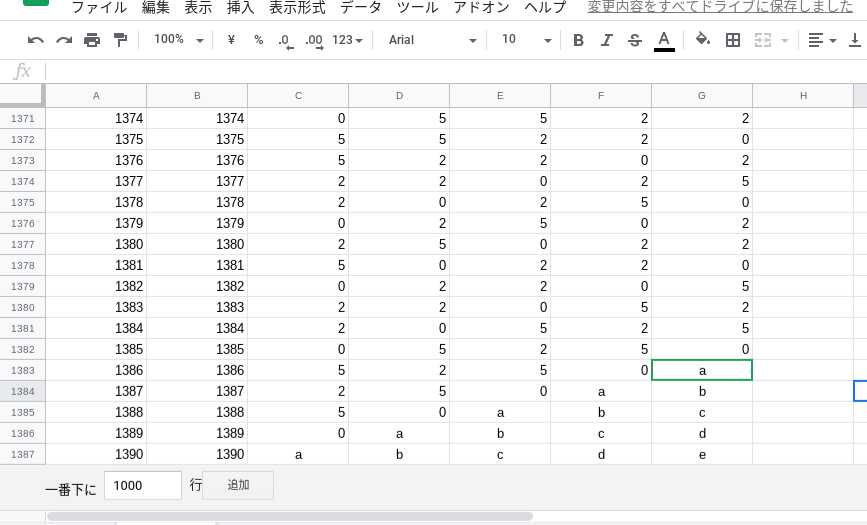
大体は共有用スプレッドシートのデータの形式を見ていただければわかりますが、一応それぞれの列の意味を説明します。A列、B列
その放送が何回目かを表します。(1386回から最新回の番号になるまで放送回の番号を入れていってください。最新回が何回目かはここの一番最新の年を選択し、一番下の第☓☓☓☓回 ☓☓年☓月☓☓日の部分を見ていただければわかります)
G列
その回にサザエさんがどの手を出したかを表します。(この記事ではグーを0、チョキを2、パーを5として扱います)
F列
その回の1回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、1つ上の行のG列と同じ数値なのがわかると思います)
E列
その回の2回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、2つ上の行のG列と同じ数値なのがわかると思います)
D列
その回の3回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、3つ上の行のG列と同じ数値なのがわかると思います)
C列
その回の4回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、4つ上の行のG列と同じ数値なのがわかると思います)
例
1390回が最新回の場合は、このように加工することになります。この記事を書いている時点でまだ不明なデータはアルファベットで書いてあります。
before
after
1-3 ダウンロード
完成したら「ファイル」→「形式を指定してダウンロード」→「カンマ区切りの値(csv,現在のシート)」
でダウンロードして、「サザエさん予測データ」というファイル名に名前を変更しておいてください。2 コーディング
ここまで来たらソースコードを書いていきます。
まずはGoogleColaboratoryにアクセスし、「ファイル」→「Python3の新しいノートブック」を選択し、新規ipynbファイルを作成します。
作成したら、右上にある「接続」ボタンをクリックし緑の✔マークになるまで待ちます。
続いて、左上の「>」ボタン(?)をクリックし、「ファイル」→「アップロード」を押すとファイル選択ダイアログが出ると思うので、先程ダウンロードした「サザエさん予測.csv」を選択しアップロードします。これでコードを書く準備が整いました。「挿入」→「コードセル」から新規コードセルを追加して、以下のソースコードをそのセルの中に入力します。サザエさん予測.py#import文。今回は必要ないものも入っています。 import pandas as pd import numpy as np import warnings from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.utils.testing import all_estimators from sklearn.externals import joblib #pandasのread_csv()で事前にアップロードしたcsvを読み込む。 csv = pd.read_csv("サザエさん予測.csv",encoding="utf-8",dtype={'4回前':np.float64, '3回前':np.float64, '2回前':np.float64, '1回前':np.float64, '今回':np.float64}) y = csv.loc[:,"今回"] x = csv.loc[:,["4回前","3回前","2回前","1回前"]] #結果を保存する配列を定義 predicted = [] warnings.filterwarnings('ignore') #じゃんけんの予測はランダム性が高いので100回予測して最も予測された回数が高かったものを答えとします。 for i in range (100): #学習用データとテスト用データに分ける x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1,train_size=0.9,shuffle=True) clf = RandomForestClassifier() #学習 clf.fit(x_train,y_train) y_pred = clf.predict(x_test) #この下に予測する回の過去4回の結果を打ち込みます。小数点1ケタまでなので注意 real = [5.0,2.0,5.0,0.0] real = np.reshape(real,(1,4)) #予測 real_pre = clf.predict(real) predicted.append(real_pre[0]) #それぞれの手が予測された回数をカウント rock = 0 tyoki = 0 paper = 0 for i in range(100): if predicted[i] == 0: rock = rock + 1 if predicted[i] == 2: tyoki = tyoki + 1 if predicted[i] == 5: paper = paper + 1 print("サザエさんが出す手を予測します") print("確率はグーが",rock,"%,チョキが",tyoki,"%,パーが",paper,"%です")書き終わったらそのセルの左上にある再生ボタンのようなものをクリックして実行してみてください。
サザエさんが出すであろう手の確率が表示されるはずです。
出力例
サザエさんが出す手を予測します
確率はグーが 23 %,チョキが 56 %,パーが 21 %です
train_test_split()を使用しているため毎回結果は変わりますが、だいたい50%で出す手が的中し、この結果をもとに出す手を考えると勝率は70~90%程度になり、負けはほぼ無くなるはずです。(もちろん出す人の運にもよりますが)まとめ
今回はsckit-learnの
RandomForestClassifier()を使ってサザエさんのじゃんけんを予測してみました。確率論で考えるとじゃんけんで勝てる確率は33%なので、今回の結果には僕はまあまあ満足しています。
- 投稿日:2019-05-23T17:20:26+09:00
Sckit-learnによるサザエさんじゃんけんの予測
はじめに
今回は国民的アニメ「サザエさん」のエンディングのじゃんけんの予測に挑戦しました。僕はまだ趣味でプログラミングを数年しただけなので、分かり辛いところもあると思いますがよろしくお願いします。
使用したツール
・GoogleColaboratory
・Googleスプレッドシート
・メモ帳(アプリケーション)予測方法
サザエさんのじゃんけんの手は過去2回に関係があるという情報があったので今回は過去4回のデータから次の手の予測を試みます。回帰分析や深層学習については別の記事で行う予定です。
手順
1-1 データの入手
まずはここからサザエさんのじゃんけんの過去のデータを入手します。ここには1991年の最初の回以降の全ての放送回のじゃんけんのデータが公開されています。
本来は1年分ずつメモ帳にコピペして検索と置換を使ってカンマ区切りファイル(csvファイル)を作っていくのですが、30分くらいかかってしまうのでこの記事を書いている今日(2019年5月23日)時点までの過去のじゃんけんのデータをここに公開しておきます。(この記事ではこのデータを共有用スプレッドシートと呼びます)スプレッドシート形式なのでマイドライブに新規スプレッドシートを作成し、コピペして使ってください。1-2 データの加工
データの加工と言っても大したことはしません。みなさんがこの記事を読んでいるときには、先程コピペしたスプレッドシートのデータはもう最新ではないので、新たにデータを追加してもらいます。
大体は共有用スプレッドシートのデータの形式を見ていただければわかりますが、一応それぞれの列の意味を説明します。A列、B列
その放送が何回目かを表します。(1386回から最新回の番号になるまで放送回の番号を入れていってください。最新回が何回目かはここの一番最新の年を選択し、一番下の第☓☓☓☓回 ☓☓年☓月☓☓日の部分を見ていただければわかります)
G列
その回にサザエさんがどの手を出したかを表します。(この記事ではグーを0、チョキを2、パーを5として扱います)
F列
その回の1回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、1つ上の行のG列と同じ数値なのがわかると思います)
E列
その回の2回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、2つ上の行のG列と同じ数値なのがわかると思います)
D列
その回の3回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、3つ上の行のG列と同じ数値なのがわかると思います)
C列
その回の4回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、4つ上の行のG列と同じ数値なのがわかると思います)
例
1390回が最新回の場合は、このように加工することになります。この記事を書いている時点でまだ不明なデータはアルファベットで書いてあります。
before
after
1-3 ダウンロード
完成したら「ファイル」→「形式を指定してダウンロード」→「カンマ区切りの値(csv,現在のシート)」
でダウンロードして、「サザエさん予測データ」というファイル名に名前を変更しておいてください。2 コーディング
ここまで来たらソースコードを書いていきます。
まずはGoogleColaboratoryにアクセスし、「ファイル」→「Python3の新しいノートブック」を選択し、新規ipynbファイルを作成します。
作成したら、右上にある「接続」ボタンをクリックし緑の✔マークになるまで待ちます。
続いて、左上の「>」ボタン(?)をクリックし、「ファイル」→「アップロード」を押すとファイル選択ダイアログが出ると思うので、先程ダウンロードした「サザエさん予測.csv」を選択しアップロードします。これでコードを書く準備が整いました。「挿入」→「コードセル」から新規コードセルを追加して、以下のソースコードをそのセルの中に入力します。サザエさん予測.py#import文。今回は必要ないものも入っています。 import pandas as pd import numpy as np import warnings from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.utils.testing import all_estimators from sklearn.externals import joblib #pandasのread_csv()で事前にアップロードしたcsvを読み込む。 csv = pd.read_csv("サザエさん予測.csv",encoding="utf-8",dtype={'4回前':np.float64, '3回前':np.float64, '2回前':np.float64, '1回前':np.float64, '今回':np.float64}) y = csv.loc[:,"今回"] x = csv.loc[:,["4回前","3回前","2回前","1回前"]] #結果を保存する配列を定義 predicted = [] warnings.filterwarnings('ignore') #じゃんけんの予測はランダム性が高いので100回予測して最も予測された回数が高かったものを答えとします。 for i in range (100): #学習用データとテスト用データに分ける x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1,train_size=0.9,shuffle=True) clf = RandomForestClassifier() #学習 clf.fit(x_train,y_train) y_pred = clf.predict(x_test) #この下に予測する回の過去4回の結果を打ち込みます。小数点1ケタまでなので注意 real = [5.0,2.0,5.0,0.0] real = np.reshape(real,(1,4)) #予測 real_pre = clf.predict(real) predicted.append(real_pre[0]) #それぞれの手が予測された回数をカウント rock = 0 tyoki = 0 paper = 0 for i in range(100): if predicted[i] == 0: rock = rock + 1 if predicted[i] == 2: tyoki = tyoki + 1 if predicted[i] == 5: paper = paper + 1 print("サザエさんが出す手を予測します") print("確率はグーが",rock,"%,チョキが",tyoki,"%,パーが",paper,"%です")書き終わったらそのセルの左上にある再生ボタンのようなものをクリックして実行してみてください。
サザエさんが出すであろう手の確率が表示されるはずです。
出力例
サザエさんが出す手を予測します
確率はグーが 23 %,チョキが 56 %,パーが 21 %です
train_test_split()を使用しているため毎回結果は変わりますが、だいたい50%で出す手が的中し、この結果をもとに出す手を考えると勝率は70~90%程度になり、負けはほぼ無くなるはずです。(もちろん出す人の運にもよりますが)まとめ
今回はsckit-learnの
RandomForestClassifier()を使ってサザエさんのじゃんけんを予測してみました。確率論で考えるとじゃんけんで勝てる確率は33%なので、今回の結果には僕はまあまあ満足しています。参考にしたサイト
- 投稿日:2019-05-23T17:20:26+09:00
【Python】Sckit-learnによるサザエさんじゃんけんの予測(GoogleColaboratory対応!)
はじめに
今回は国民的アニメ「サザエさん」のエンディングのじゃんけんの予測に挑戦しました。僕はまだ趣味でプログラミングを数年しただけなので、分かり辛いところもあると思いますがよろしくお願いします。
使用したツール
・GoogleColaboratory
・Googleスプレッドシート
・メモ帳(アプリケーション)予測方法
サザエさんのじゃんけんの手は過去2回に関係があるという情報があったので今回は過去4回のデータから次の手の予測を試みます。回帰分析や深層学習については別の記事で行う予定です。
手順
1-1 データの入手
まずはここからサザエさんのじゃんけんの過去のデータを入手します。ここには1991年の最初の回以降の全ての放送回のじゃんけんのデータが公開されています。
本来は1年分ずつメモ帳にコピペして検索と置換を使ってカンマ区切りファイル(csvファイル)を作っていくのですが、30分くらいかかってしまうのでこの記事を書いている今日(2019年5月23日)時点までの過去のじゃんけんのデータをここに公開しておきます。(この記事ではこのデータを共有用スプレッドシートと呼びます)スプレッドシート形式なのでマイドライブに新規スプレッドシートを作成し、コピペして使ってください。1-2 データの加工
データの加工と言っても大したことはしません。みなさんがこの記事を読んでいるときには、先程コピペしたスプレッドシートのデータはもう最新ではないので、新たにデータを追加してもらいます。
大体は共有用スプレッドシートのデータの形式を見ていただければわかりますが、一応それぞれの列の意味を説明します。A列、B列
その放送が何回目かを表します。(1386回から最新回の番号になるまで放送回の番号を入れていってください。最新回が何回目かはここの一番最新の年を選択し、一番下の第☓☓☓☓回 ☓☓年☓月☓☓日の部分を見ていただければわかります)
G列
その回にサザエさんがどの手を出したかを表します。(この記事ではグーを0、チョキを2、パーを5として扱います)
F列
その回の1回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、1つ上の行のG列と同じ数値なのがわかると思います)
E列
その回の2回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、2つ上の行のG列と同じ数値なのがわかると思います)
D列
その回の3回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、3つ上の行のG列と同じ数値なのがわかると思います)
C列
その回の4回前にサザエさんが何を出したかを表します。(スプレッドシートを見ると、4つ上の行のG列と同じ数値なのがわかると思います)
例
1390回が最新回の場合は、このように加工することになります。この記事を書いている時点でまだ不明なデータはアルファベットで書いてあります。
before
after
1-3 ダウンロード
完成したら「ファイル」→「形式を指定してダウンロード」→「カンマ区切りの値(csv,現在のシート)」
でダウンロードして、「サザエさん予測データ」というファイル名に名前を変更しておいてください。2 コーディング
ここまで来たらソースコードを書いていきます。
まずはGoogleColaboratoryにアクセスし、「ファイル」→「Python3の新しいノートブック」を選択し、新規ipynbファイルを作成します。
作成したら、右上にある「接続」ボタンをクリックし緑の✔マークになるまで待ちます。
続いて、左上の「>」ボタン(?)をクリックし、「ファイル」→「アップロード」を押すとファイル選択ダイアログが出ると思うので、先程ダウンロードした「サザエさん予測.csv」を選択しアップロードします。これでコードを書く準備が整いました。「挿入」→「コードセル」から新規コードセルを追加して、以下のソースコードをそのセルの中に入力します。サザエさん予測.py#import文。今回は必要ないものも入っています。 import pandas as pd import numpy as np import warnings from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.utils.testing import all_estimators from sklearn.externals import joblib #pandasのread_csv()で事前にアップロードしたcsvを読み込む。 csv = pd.read_csv("サザエさん予測.csv",encoding="utf-8",dtype={'4回前':np.float64, '3回前':np.float64, '2回前':np.float64, '1回前':np.float64, '今回':np.float64}) y = csv.loc[:,"今回"] x = csv.loc[:,["4回前","3回前","2回前","1回前"]] #結果を保存する配列を定義 predicted = [] warnings.filterwarnings('ignore') #じゃんけんの予測はランダム性が高いので100回予測して最も予測された回数が高かったものを答えとします。 for i in range (100): #学習用データとテスト用データに分ける x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.1,train_size=0.9,shuffle=True) clf = RandomForestClassifier() #学習 clf.fit(x_train,y_train) y_pred = clf.predict(x_test) #この下に予測する回の過去4回の結果を打ち込みます。小数点1ケタまでなので注意 real = [5.0,2.0,5.0,0.0] real = np.reshape(real,(1,4)) #予測 real_pre = clf.predict(real) predicted.append(real_pre[0]) #それぞれの手が予測された回数をカウント rock = 0 tyoki = 0 paper = 0 for i in range(100): if predicted[i] == 0: rock = rock + 1 if predicted[i] == 2: tyoki = tyoki + 1 if predicted[i] == 5: paper = paper + 1 print("サザエさんが出す手を予測します") print("確率はグーが",rock,"%,チョキが",tyoki,"%,パーが",paper,"%です")書き終わったらそのセルの左上にある再生ボタンのようなものをクリックして実行してみてください。
サザエさんが出すであろう手の確率が表示されるはずです。
出力例
サザエさんが出す手を予測します
確率はグーが 23 %,チョキが 56 %,パーが 21 %です
train_test_split()を使用しているため毎回結果は変わりますが、だいたい50%で出す手が的中し、この結果をもとに出す手を考えると勝率は70~90%程度になり、負けはほぼ無くなるはずです。(もちろん出す人の運にもよりますが)まとめ
今回はsckit-learnの
RandomForestClassifier()を使ってサザエさんのじゃんけんを予測してみました。確率論で考えるとじゃんけんで勝てる確率は33%なので、今回の結果には僕はまあまあ満足しています。参考にしたサイト
- 投稿日:2019-05-23T16:30:59+09:00
pandas CSVファイル・バッファの読み書き
pandasでCSVファイルの読み込み
pandasのread_csv関数のパラメタがfilepath_or_bufferとなっていたので、
CSVファイルではなくbufferを利用する方法をメモしておく。ファイルを利用する
よく事例が転がっているタイプ。
CSVファイルからDataFrameに読み込む
import pandas as pd df = pd.read_csv("in.csv")DataFrameをCSV形式でファイルに書き込む
df.to_csv("out.csv")バッファを利用する
バッファを活用するパターンは事例がすぐにみつからない。
バッファからDataFrameに読み込む
import io import pandas as pd data = 'AAA,BBB\n1,2\n3,4' df = pd.read_csv(io.StringIO(data))DataFrameをCSV形式でバッファに書き込む
buffer = io.StringIO() df.to_csv(buffer, index=False) # indexを指定しないと行番号が出力される print(buffer.getvalue()) # バッファの参照実行結果AAA,BBB 1,2 3,4参考
pandas 0.24.2 documentation » API Reference » Input/Output » read_csv
- 投稿日:2019-05-23T16:11:10+09:00
【自然言語処理】Pythonを使って簡単なチャットボット を作ってみた。
はじめに
会社でチャットボットを導入するということで勉強がてらプログラミング初心者が簡単なルールベースチャットボットを作ってみたのでこの記事はそのアウトプットです。
ひとまず今回はアプリとしてではなくnote book形式で動かすことを目標にやっています。(最終的にはLINE Botにしたい...)
参考記事
全体の流れ
今回の記事の流れとしてはこんな感じです。
ラベリングするためのモデルを作る
↓
実際にラベリングしてみる
↓
ラベリングしたデータをPythonでチャットボットっぽくしてみる動作環境
- Python3.6
- MacOS
使ったモジュール
モジュールについての説明は省きます。
from itertools import chain import pycrfsuite import sklearn from sklearn.metrics import classification_report from sklearn.preprocessing import LabelBinarizer import codecs from janome.tokenizer import Tokenizer固有表現抽出をする
取り敢えず文章から単語を取得してラベリングする必要があるので機械学習でモデルを作っていきます。
まずは機械学習するためのデータセットです。
今回はチャットボット作成の参考にさせていただいた@Hironsanさんのデータセットを使わせていただきました。
こちらからダウンロードできます。
@Hironsan様ありがとうございます、深く感謝しております。
ただこのデータセットだけだと面白みがないので学習後のモデルを使ってスクレイピングした文章をラベリングしてそれをデータセットに加えて再学習というのを何度か繰り返してみました。
それについては気が向いたらまとめてみようと思うので今回は飛ばして先に進みます。
(学習後のモデルはGitHubに置いておきます。)ダウンロードしたデータセットを読み込んでトレーニングデータを作ります。
本来はテストデータとトレーニングデータを分けて検証などしますが、今回は取り敢えず動かすというのとデータセットもそこまで多くないので全てトレーニング用にブチ込みます。
class CorpusReader(object): def __init__(self, path): with codecs.open(path, encoding='utf-8') as f: sent = [] sents = [] for line in f: if line == '\n': sents.append(sent) sent = [] continue morph_info = line.strip().split('\t') sent.append(morph_info) train_num = int(len(sents)) self.train_sents = sents[:train_num]早速データセットをを見込んでみます。
c = CorpusReader('corpus.txt') # データセットの名前変えてます。 train_sents = c.train_sents print(c.train_sents[0][0]) =>['2005', '名詞', '数', '*', '*', '*', '*', '*', 'B-DAT']データセットから取り出した内容はこんな感じ。
今回は形態素解析された文章を突っ込まれるとそれをラベリングするというものを作ります。
ではこのデータセットを学習させるための準備をしていきます。
文字種の判定
def is_hiragana(ch): return 0x3040 <= ord(ch) <= 0x309F def is_katakana(ch): return 0x30A0 <= ord(ch) <= 0x30FF def get_character_type(ch): if ch.isspace(): return 'ZSPACE' elif ch.isdigit(): return 'ZDIGIT' elif ch.islower(): return 'ZLLET' elif ch.isupper(): return 'ZULET' elif is_hiragana(ch): return 'HIRAG' elif is_katakana(ch): return 'KATAK' else: return 'OTHER' def get_character_types(string): character_types = map(get_character_type, string) character_type_str = '-'.join(sorted(set(character_types))) return character_type_str学習前の準備
素性抽出やラベル抽出をするための処理を書きます。
def extract_pos_with_subtype(morph): idx = morph.index('*') return '-'.join(morph[1:idx]) def word2features(sent, i): word = sent[i][0] chtype = get_character_types(sent[i][0]) postag = extract_pos_with_subtype(sent[i]) features = [ 'bias', 'word=' + word, 'type=' + chtype, 'postag=' + postag, ] if i >= 2: word2 = sent[i-2][0] chtype2 = get_character_types(sent[i-2][0]) postag2 = extract_pos_with_subtype(sent[i-2]) iobtag2 = sent[i-2][-1] features.extend([ '-2:word=' + word2, '-2:type=' + chtype2, '-2:postag=' + postag2, '-2:iobtag=' + iobtag2, ]) else: features.append('BOS') if i >= 1: word1 = sent[i-1][0] chtype1 = get_character_types(sent[i-1][0]) postag1 = extract_pos_with_subtype(sent[i-1]) iobtag1 = sent[i-1][-1] features.extend([ '-1:word=' + word1, '-1:type=' + chtype1, '-1:postag=' + postag1, '-1:iobtag=' + iobtag1, ]) else: features.append('BOS') if i < len(sent)-1: word1 = sent[i+1][0] chtype1 = get_character_types(sent[i+1][0]) postag1 = extract_pos_with_subtype(sent[i+1]) features.extend([ '+1:word=' + word1, '+1:type=' + chtype1, '+1:postag=' + postag1, ]) else: features.append('EOS') if i < len(sent)-2: word2 = sent[i+2][0] chtype2 = get_character_types(sent[i+2][0]) postag2 = extract_pos_with_subtype(sent[i+2]) features.extend([ '+2:word=' + word2, '+2:type=' + chtype2, '+2:postag=' + postag2, ]) else: features.append('EOS') return features def sent2features(sent): return [word2features(sent, i) for i in range(len(sent))] def sent2labels(sent): return [morph[-1] for morph in sent] def sent2tokens(sent): return [morph[0] for morph in sent]これで素性とラベルを抽出できるようになったのでトレーニング用に素性とラベルに分けます。
X_train = [sent2features(s) for s in train_sents] y_train = [sent2labels(s) for s in train_sents]分けたデータを入れてパラメーターをセットして学習させます。
trainer = pycrfsuite.Trainer(verbose=False) for xseq, yseq in zip(X_train, y_train): trainer.append(xseq, yseq) trainer.set_params({ 'c1': 1.0, # coefficient for L1 penalty 'c2': 1e-3, # coefficient for L2 penalty 'max_iterations': 50, # stop earlier # include transitions that are possible, but not observed 'feature.possible_transitions': True }) trainer.train('model.crfsuite')これでカレントディレクトリに学習済のモデルが生成されるのでそれを使ってラベリングしてみようと思います。
取り敢えず今回使ったモデルを使ってラベリングする為にjanomeを使って渡した文章を形態素解析してリストにしてくれる関数を準備
def dump_morph(word): t = Tokenizer() name_type_list = [] for i in t.tokenize(word): name_type = str(i).replace('\t', ',') name_type_list.append(name_type.split(',')) return name_type_listこれを使うとこんな感じの出力が得られます。
words=dump_morph('私の名前は田中です。') for word in words: print(word)['私', '名詞', '代名詞', '一般', '*', '*', '*', '私', 'ワタシ', 'ワタシ'] ['の', '助詞', '連体化', '*', '*', '*', '*', 'の', 'ノ', 'ノ'] ['名前', '名詞', '一般', '*', '*', '*', '*', '名前', 'ナマエ', 'ナマエ'] ['は', '助詞', '係助詞', '*', '*', '*', '*', 'は', 'ハ', 'ワ'] ['田中', '名詞', '固有名詞', '人名', '姓', '*', '*', '田中', 'タナカ', 'タナカ'] ['です', '助動詞', '*', '*', '*', '特殊・デス', '基本形', 'です', 'デス', 'デス'] ['。', '記号', '句点', '*', '*', '*', '*', '。', '。', '。']ではこれを先ほど学習させたモデルに突っ込んで元の文章と並べてみましょう。
t = Tokenizer() words=dump_morph('私の名前は田中です。') print(t.tokenize('私の名前は田中です。', wakati=True)) print(tagger.tag(sent2features(words)))['私', 'の', '名前', 'は', '田中', 'です', '。'] ['O', 'O', 'O', 'O', 'B-PSN', 'O', 'O']人名であろう田中にB-PSNとラベルが振られています。
これで系列ラベリングする為のモデルは完成です。
特定のラベルでラベリングされた単語を取得する
ではここまで作ってきたプログラムを使ってチャットボットっぽいことができるプログラムを作ってみます。
def classifying(type_list, kind): tag = tagger.tag(sent2features(type_list)) for i in range(len(tag)): type_list[i].append(tag[i]) for l in type_list: if l[-1] == kind: return l[0] def free_word_bot(text_set): target_list = [] for i in text_set: text = i[0] label = i[1] print(text) ans = input('あなた: ') target = classifying(dump_morph(ans), label) target_list.append(target) print(target_list)質問とその質問が答えとして欲しいラベルを2次元配列で渡してあげるとその質問を投げてユーザーから入力された内容をレベリングしてそのラベルの中から予め渡しているラベルと一致する単語をリストとして保持して最終的にそのリストの内容をprintしてくれる関数を作ってみました。
ではこの関数を使って実際に欲しい単語を抽出してみましょう。
こんな感じで文章から必要としているラベルを見つけてリストに格納することができました。
これを発展させてばウェブサイトとかにあるチャットボットとかも作れるのかな?と思たりしています。
まとめ
今回はとりあえずチャットボット作ってみようという所から、qiitaに記事を投稿してアウトプットしてみたいということでこの記事を書いてみました。
超ド新米エンジニア(もはやエンジニアとは呼べない)なので色々アレなところもあると思いますので何かあったらコメントを頂けると幸いです。
次回はこれを元に今作っているLINE Botができたらそれも書いてみようと思っているのですがデプロイするのでつまずいているので一度おうむ返しのLINE Botを作ってデプロイしてみることにしたので先にその記事を書いてみようと思います。
それでは!!!
GitHubにはまだpushしていないのであげたら追記します!

- 投稿日:2019-05-23T15:54:05+09:00
PythonとTwitterAPIでTwitterクライアント的なのを作ったお話【びよりったー】
ヽ(廿Δ廿 )にゃんぱすー。情報系の学生をしております、なっぢです。
Qiitaの記事を書いてみたいと思ったので、PythonでTwitterクライアントを作った話をします。事の経緯
(ここは別に大事じゃないので読みたくなけりゃ飛ばしてもらって大丈夫です)
via芸のために愛用していた非公式クライアントが自分の引継ぎミスで使えなくなったのがきっかけです。
Twitterはやめたくないし、新しいクライアントを探すのも面倒なので、
Pythonの勉強も兼ねて自分で作ってみよう。という発想に至りました(?)。
以前、アプリケーションの登録をしていた。っていうのも大きかったです。開発環境
Python 3.7.3
コマンド一覧
実装したコマンドの一覧です。一応隠しコマンドもあります。
置換コマンド
Example>> おなかが減った-onfind関数を用いて文章中の置換コマンドを検索し、replace関数で置換します。
置換コマンドごとに検索を行うので、複数の置換コマンドにも対応しています。subコマンド
Example>> おなかが減った-on >> sub任意の文章を入力後に実行するとツイートされます。このときのツイートがこちら。
mtlコマンド
Example>> mtl自分のツイートを表示するコマンドです。まともなツイートをしていないので実行結果は控えます。
-mtlコマンド
Example>> -mtl >> 100mtlコマンドとは違って、表示する数を指定できます(APIの仕様上、200件までですが)。
こちらも、まともなツイートをしていないので実行結果は控えます。srcコマンド
Example>> src >> にゃんぱす検索コマンドです。リツイートとリプライは省いて表示します。
img:コマンド
Example>> img:XXXXXXX.png知り合いが追加してくれたコマンドです。感謝。
Twitterでサポートしている一般的な画像ファイルであれば大丈夫(とのこと)です。
この記事の投稿時には複数画像をツイートする機能はありません。exitコマンド
Example>> exitプログラムを終了するコマンドです。
今後の展望
- タイムラインの表示機能を追加
TwitterなのにTLが見れないのはどうなの。って感じなので早々に実装したいです。
リプライとかリツイート(仕様上可能なのかは知らない)も実装したいと考えています。- 現在ある機能のアップデート
検索機能にオプション(Twitterでいうfrom)を追加したり、複数画像に対応させたいです。- Webアプリケーション化
おわりに
今まではPythonを避けていたのですが、今回の開発でなかなか面白い言語だなぁ。って思ったので
全く毛色の違うプログラムも書きたいと思います。また、少しではありますが共同開発というものも体験でき、いい経験になりました。
拙い文章ではありましたがお読みいただきありがとうございました。


- 投稿日:2019-05-23T14:12:05+09:00
AWS LambdaでBoxのWebhookを処理する
概要
BoxのフォルダにWebHookを設定し、AWS Lambdaに送信されたデータを取得/操作するまでの基本的な手順についてまとめています。
(2019年3月時点)参考
Lambda 実行ロールの作成
Lambda関数の実行時には、「AWSLambdaBasicExecutionRole」が付与されたIAM Roleが必要です。
以下の手順でIAM Roleを作成しておき、以後Lambda関数を作成する際に
Roleを割り当てることとします。IAM > ロールの作成
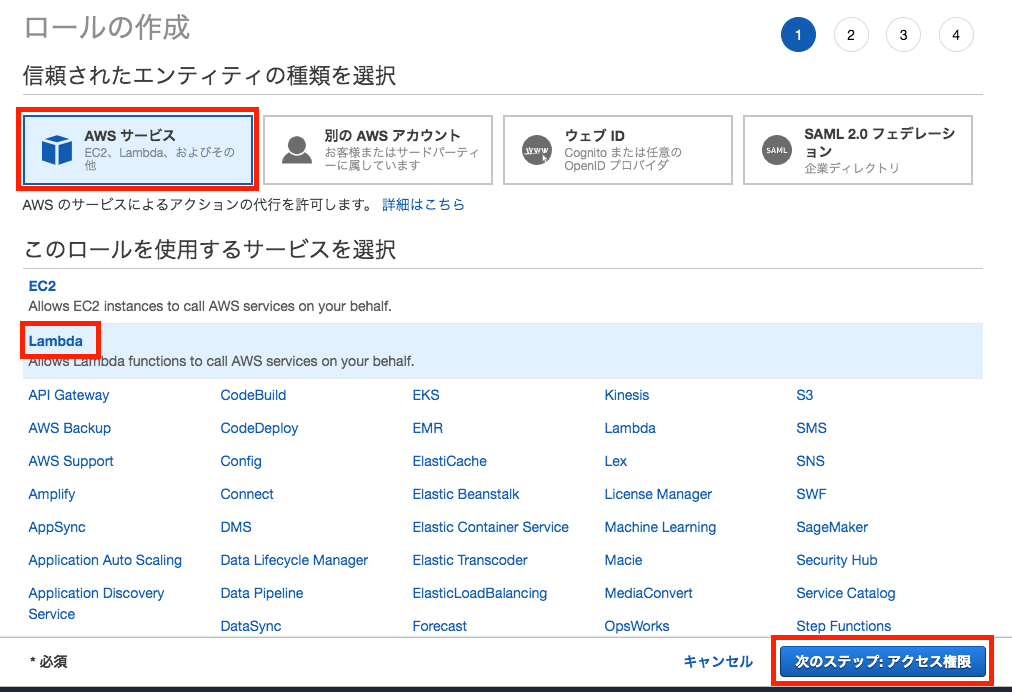
「AWSサービス」を選択し、次に「Lambda」を選択後、
「次のステップ:アクセス権限」をクリックします。
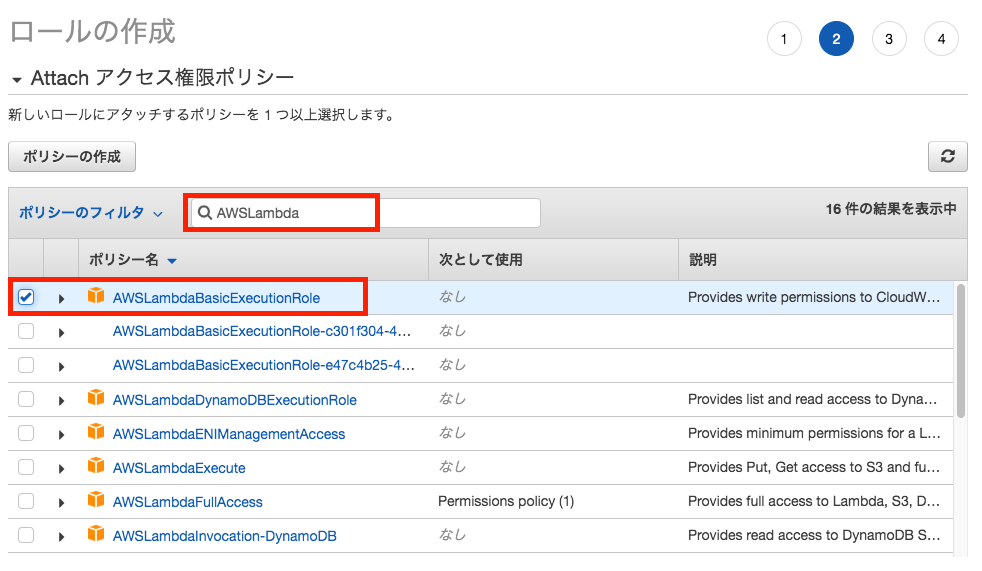
「ポリシーのフィルタ」欄に「AWSLambda」と入力し、候補表示の中から
「AWSLambdaBasicExecutionRole」にチェックして「次のステップ:タグ」をクリックします。
※Lambda関数を実行するだけなら、選択するポリシーは
「AWSLambdaBasicExecutionRole」だけとなりますが、その他に
- S3へのアクセス
- RDBへのアクセスなどもLambda関数から実行する場合には、この画面で適宜追加のポリシーも選択しておく必要があります。
タグの追加(オプション)画面で、このIAM Roleに割り当てるタグを指定できます。
たとえば、このRoleを所有しているユーザ名や、プロジェクト名、管理部署名など必要に応じ入力します。
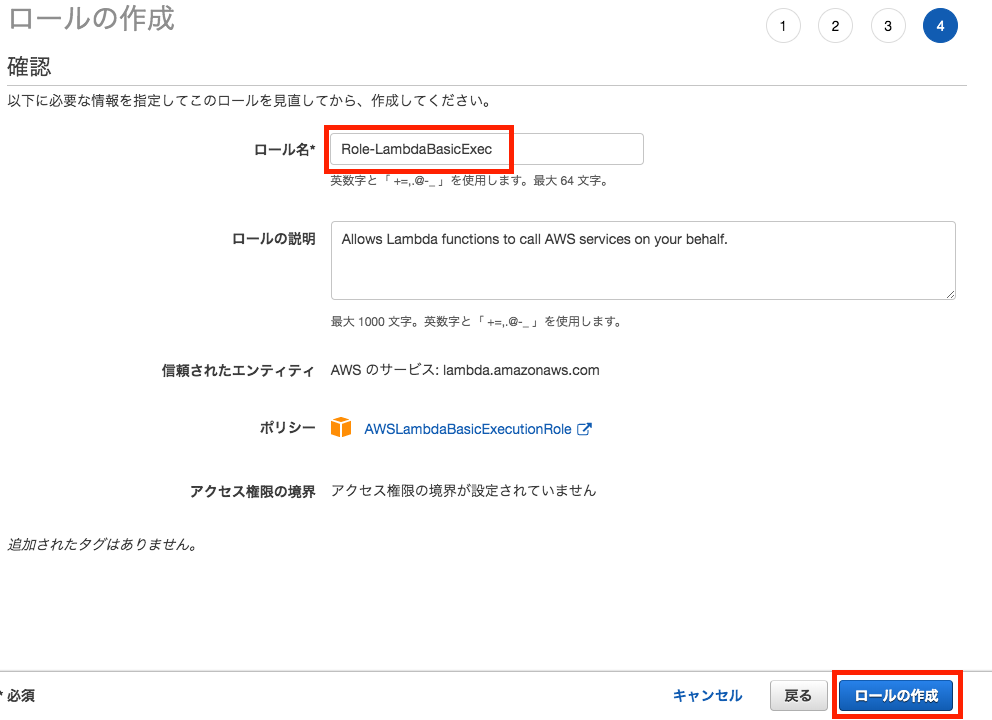
今回は空欄のまま「次のステップ:確認」をクリックして進めます。「ロール名」にロールの名称を指定し(本例では"Role-LambdaBasicExec")、
「ロールの作成」をクリックします。
ロールの一覧画面にて、今回作成したロールが表示されていることを確認します。
Lambda関数の作成
「関数の作成」画面から、「設計図の使用」
キーワードに「microservice-http」と入力し、候補から
「microservice-http-endpoint-python3」を選択します。
関数の作成に必要な情報を入力します。
基本的な情報
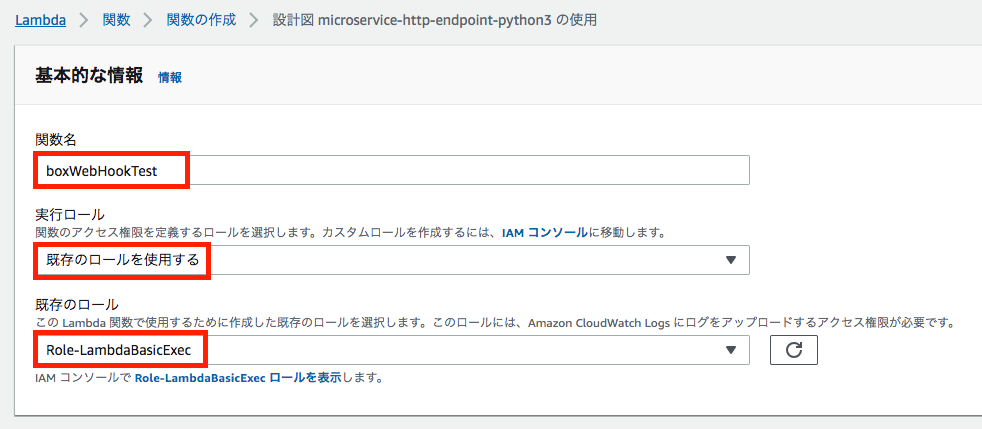
関数名
本例では"boxWebHookTest"としました。実行ロール
「既存のロールを使用する」を選択し、プルダウンから前掲の手順で作成したIAM Roleを選択します。
(本例では「Role-LambdaBasicExec」)
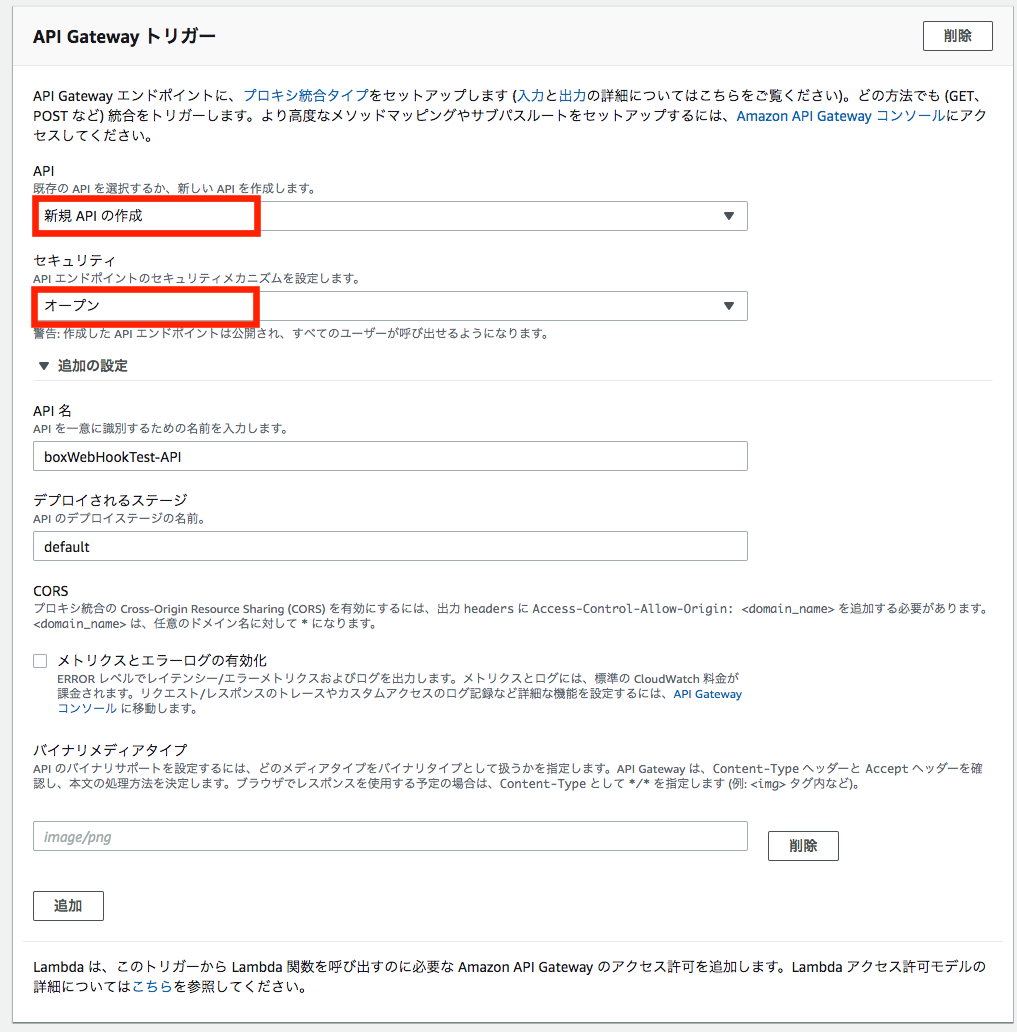
API Gatewayトリガー
API
新規APIの作成セキュリティ
今回は認証なしでAPI Gatewayを呼び出せるように、「オープン」を選択します。API名
APIの識別名を指定します。
デフォルトで
関数名-API
の命名規則で生成されますので、今回はそのまま
boxWebHookTest-API
としておきます。デプロイされるステージ
APIのデプロイ先を「ステージ」指定により切り替えることが可能ですが、defaultのままにしておきます。
関数のコード
デフォルトのPythonコードが表示されていますが、
そのままにしておきます。
「関数の作成」を実行します。
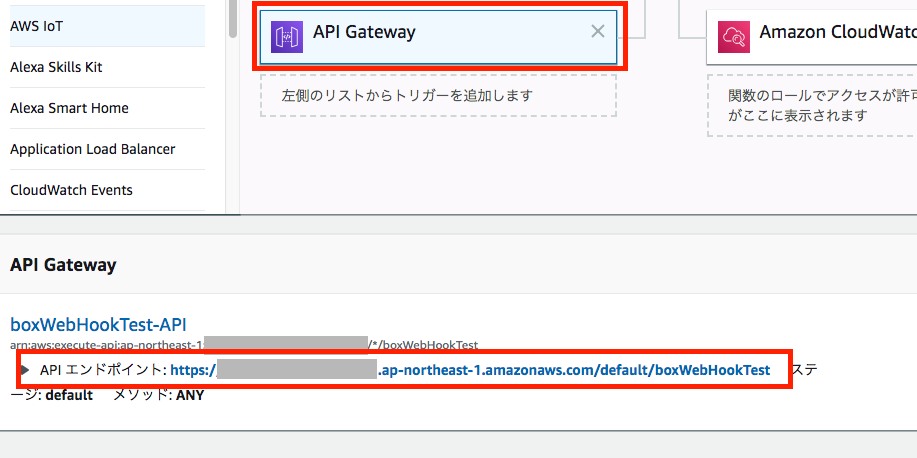
Lambda関数が作成された旨のメッセージが表示され、関数とAPI Gatewayの設定画面が表示されます。
Designer画面で「API Gateway」のパネルを選択すると、下の画面にAPI EndpointのURLが表示されます。
このURLは後でWebHookの飛ばし先として使いますので、メモ帳に貼り付けておきます
WebHookの作成
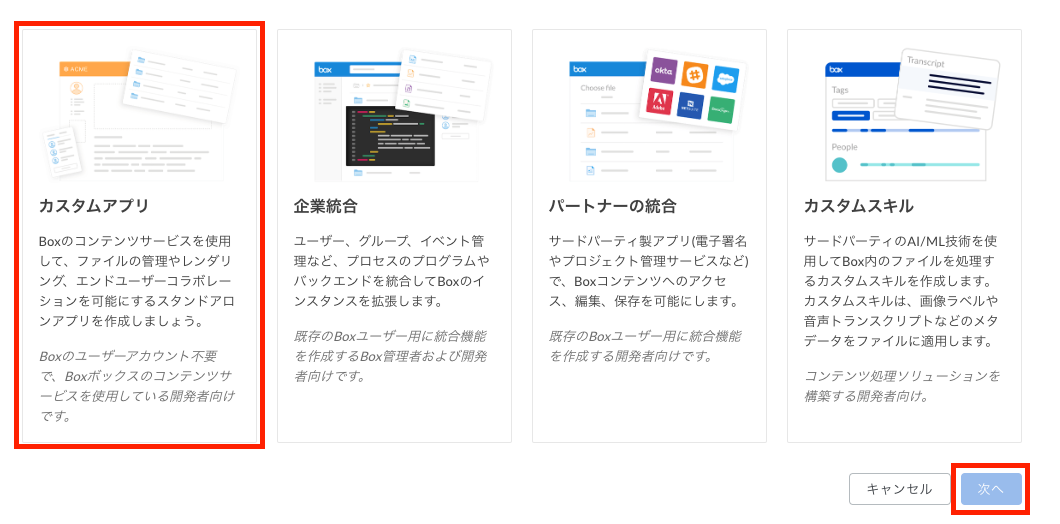
開発者コンソールにて、新規アプリケーションを作成します。
- カスタムアプリ
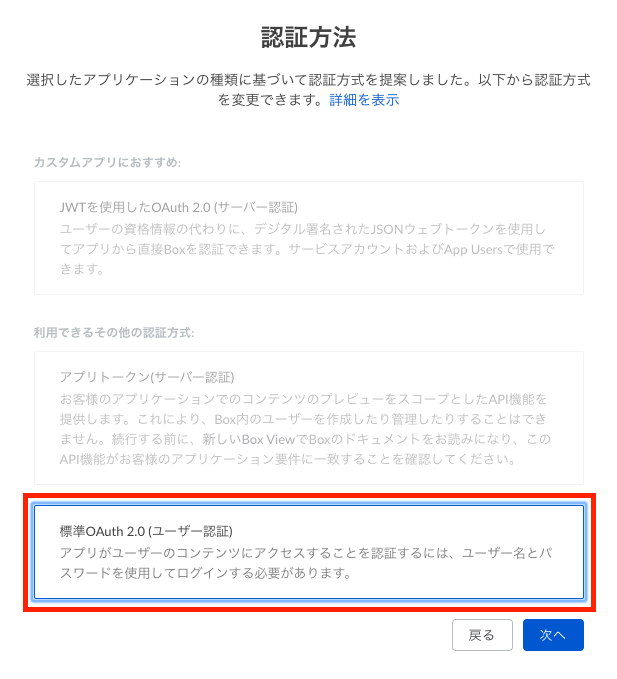
- 標準OAuth2.0(ユーザ認証)
アプリケーションスコープで「Webhookを管理」にチェックを入れて「変更を保存」します。
※このアプリのトークンを使って、Webhookを生成しますので、Webhook管理権限が必要です。
Webhookを登録する際に使用するトークンを生成します。
OAuthのサンプルコードをいずれか実行し、
アクセストークンを取得しておきます。このとき生成したアクセストークンは1時間だけ有効です。
後続のWebhook作成を1時間以内に完了できなかった場合は、
再度、アクセストークンを取り直して下さい。※DeveloperトークンでWebhookを作成すると、約1日経過後に当該のWebhookが正しく機能しなくなる事象が出ましたため、
OAuth 3legged認証を経て入手したアクセストークンを使う必要があります。
(事象については本記事下部の「翌日以降のWebhookのBody内容が不正(Anonymous User扱い)となる」参照)テスト用のフォルダをBox上に作成します。
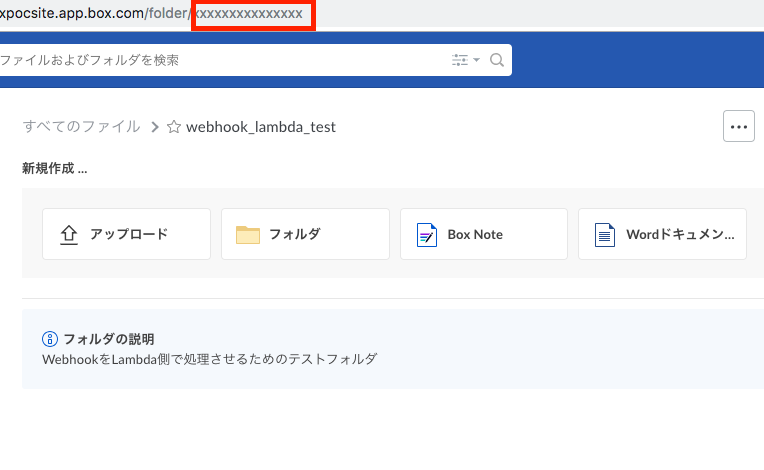
そのフォルダをBoxのWebUIで開き、フォルダIDをメモ帳に貼り付けておきます。
https://boxpocsite.app.box.com/folder/xxxxxxxxxxxxxxx
URLの末尾、/folder/の後に続く数値部分がフォルダIDです。
このフォルダにファイルがアップロードされたタイミングで実行されるWebhookを作成します。
ここまでの手順で、以下の情報が手元に揃っているはずです。
- Box上に作成した、テスト用のフォルダID
- AWS LambdaのAPI Endpoint URL
- BoxアプリのDeveloperトークン
上記の値を代入して、Webhook作成を行います。
Curlコマンドの場合は以下の構文になります。構文
```
$ curl https://api.box.com/2.0/webhooks \-H "Authorization: Bearer xxxx(Developerトークン)xxxx" \
-H "Content-Type: application/json" -X POST \
-d '{"target": {"id": "テスト用フォルダのID値", "type": "folder"}, "address": "AWS LambdaのAPI Endpoint URL", "triggers": ["トリガーのイベント"]}'
```例として、登録用の値が
- テスト用のフォルダID : 1234567890
- AWS LambdaのAPI Endpoint URL : https://xxx.amazonaws.com/default/boxWebHookTest
- BoxアプリのDeveloperトークン : zzzzzzzzzzzzzzzzzz
- トリガーのイベント : FILE.UPLOADED
の場合は、以下となります。
$ curl https://api.box.com/2.0/webhooks \ > -H "Authorization: Bearer zzzzzzzzzzzzzzzzzz" \ > -H "Content-Type: application/json" -X POST \ > -d '{"target": {"id": "1234567890", "type": "folder"}, "address": "https://xxx.amazonaws.com/default/boxWebHookTest", "triggers": ["FILE.UPLOADED"]}'Webhook作成のAPIコールが成功すると、以下の構文で戻り値が返ってきます。
{"id":"WebhookのID","type":"webhook","target":{"id":"フォルダID","type":"folder"},"created_by":{"type":"user","id":"Webhook作成を実行したユーザID","name":"ユーザ名","login":"ログイン用メールアドレス"},"created_at":"生成時刻(太平洋時間)","address":"Webhookの飛ばし先URL","triggers":["Webhookをトリガーするイベント"]}Webhookの到達確認
Webhookを実際にトリガーし、AWS LambdaのAPI Endpointまで到達するかを確認します。
Lambda関数のコンソールにて、Lambdaイベントの中身をそのままPrintするPythonコードを作成します。
import json def lambda_handler(event, context): print(json.dumps(event, indent=4)) # JSON形式の戻り値を設定する return { 'statusCode' : 200, 'headers' : { 'content-type' : 'text/html' }, 'body' : '<html><body>OK</body></html>' }コードの入力が完了したら、右上の「保存」をクリックします。
※AWS Lambdaコンソールでは、設定変更の都度「保存」が必要ですBoxのテストフォルダに何かファイルを1つアップロードします。
(どんなファイルでも構いません。)ファイルをアップロードすることでWebhookイベントが発生し、AWS LambdaのAPI Endpoint URLめがけてPOSTメソッドが実行されます。
ファイルのアップロード完了後、Lambda関数の設定画面から「モニタリング」を選択します。
続いて「CloudWatchのログを表示」をクリックします。
ログストリームが生成されているので、リンクをクリックして開きます。
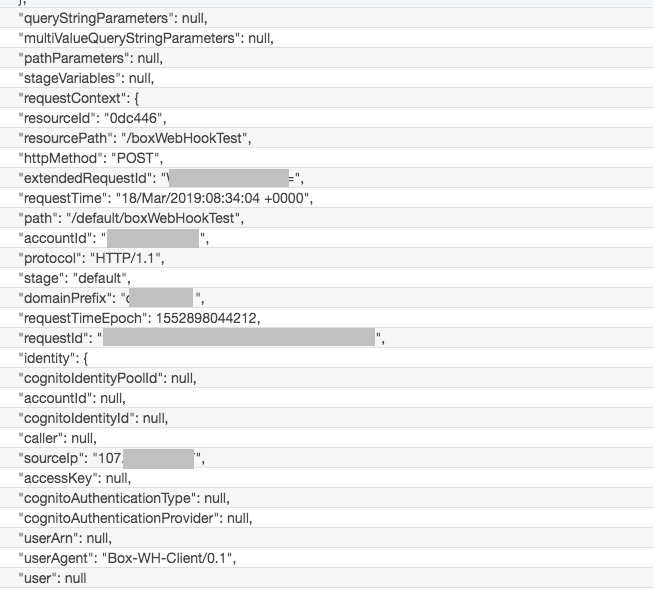
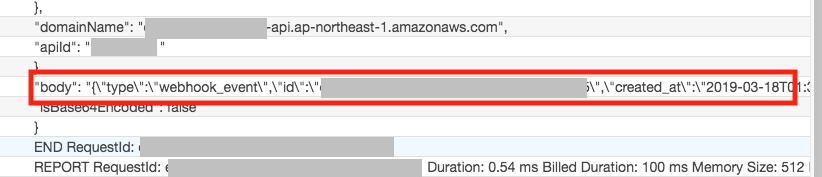
ログを上から見ていくと、Header情報などの管理情報に続いて、POSTのbody部分を確認できます。
この"body"部分にWebhookの本体が格納されています。
"body": "{\"type\":\"webhook_event\",\"id\":\"eb92204d-dcc6-4(省略)WebhookのBody内容
POSTされたWebhookのデータ部分は、以下のJSON形式となっています。
参考:
https://developer.box.com/reference#webhooks-v2{ "type":"webhook_event", "id":"webhookイベントのID", "created_at":"2019-03-18T01:34:02-07:00", "trigger":"FILE.UPLOADED", "webhook":{ "id":"WebhookのID(Box上での識別ID)", "type":"webhook" }, "created_by":{ "type":"user", "id":"BoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "source":{ "id":"Webhookをトリガーしたコンテンツ(ファイルなど)に付与されたID", "type":"コンテンツの種別(file or folderが入る)", "file_version":{ "type":"file_version", "id":"ファイルバージョンID", "sha1":"ファイルのSHA1ハッシュ値" }, "sequence_id":"0", "etag":"0", "sha1":"ファイルのSHA1ハッシュ値", "name":"ファイル/フォルダ名", "uniq":"486d66f9a8b64f8af37bfd2eff9d0d4e", "key_ref":null, "description":"", "size":0, "path_collection":{ "total_count":2, "entries":[ { "type":"folder", "id":"0", "sequence_id":null, "etag":null, "name":"最上位のフォルダ名" }, { "type":"folder", "id":"2階層目のフォルダID", "sequence_id":"1", "etag":"1", "name":"webhook_lambda_test" } ] }, "created_at":"2019-03-18T01:34:02-07:00", "modified_at":"2019-03-18T01:34:02-07:00", "trashed_at":null, "purged_at":null, "content_created_at":"2019-03-13T23:12:56-07:00", "content_modified_at":"2019-03-13T23:12:56-07:00", "created_by":{ "type":"user", "id":"コンテンツを作成したBoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "modified_by":{ "type":"user", "id":"コンテンツを最終更新したBoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "owned_by":{ "type":"user", "id":"コンテンツ所有者のBoxユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "shared_link":null, "parent":{ "type":"folder", "id":"Webhookをトリガーしたコンテンツを格納しているフォルダのID", "sequence_id":"1", "etag":"1", "name":"webhook_lambda_test" }, "item_status":"active" }, "additional_info":[ ] }補足
フォルダ名/ファイル名などが2バイト文字の場合、値としてUnicode変換したものが代入されます。
本例では、Boxの最上位のフォルダ名としてWebhookに入っていた値は
\u3059\u3079\u3066\u306e\u30d5\u30a1\u30a4\u30ebという文字列でした。
これを変換すると
文字列「すべてのファイル」になります。フォルダ名/ファイル名に2バイト文字が全く含まれていない場合は、オリジナルの名前がそのまま入ります(Unicode化されない)。
本例では、2階層目のフォルダ名はwebhook_lambda_testでしたので、
Bodyの中でも
"name":"webhook_lambda_test"
と、そのままの名前で記載されています。Webhookの有効期限
最後のWebhook実行(実行結果が成功)から、いちどもWebhookが使われていない状態で2週間が経過
「使われていない」とは、Webhookイベントが発火していない、ということ。最後の実行(実行結果がFail)から2週間が経過
上記、いずれかの条件を満たすと、そのWebhookは削除されます。
削除されたWebhookは再度作り直す必要があります。ハマった/やらかしました集
翌日以降のWebhookのBody内容が不正(Anonymous User扱い)となる
翌日、2個目のファイルを同じフォルダにアップロードしたところ、
Webhookは起動してPOSTが行われたが、BODY部を見ると
- trigger : NO_ACTIVE_SESSION
- ユーザID :2
- ユーザ名 : Anonymous User
となっていました。
1回目の成功したときと同じユーザーでBoxにログインし直しても、事象は改善せず。{ "type":"webhook_event", "id":"9c6f708d-1393-49c0-9b4a-96f93ead0b58", "created_at":"2019-03-19T03:01:47-07:00", "trigger":"NO_ACTIVE_SESSION", "webhook":{ "id":"151732426","type":"webhook" }, "created_by":{ "type":"user", "id":"2", "name":"Anonymous User", "login":"" }, "source":{ "id":"424148311576", "type":"file" }, "additional_info":[ ] }当該のWebhookの状態を確認すると、生きているように見えます。
{ "id":"151732426", "type":"webhook", "target":{ "id":"70394214504", "type":"folder" }, "created_by":{ "type":"user","id":"ユーザID", "name":"ユーザ名", "login":"ログインメールアドレス" }, "created_at":"2019-03-18T01:00:54-07:00", "address":"AWS LambdaのAPI Endpoint URL", "triggers":["FILE.UPLOADED"] }LambdaがWebhookサーバ側にStatus Codeを返していない可能性を考えましたが、
正しく200を返していることも確認できました。
(切り分け)アプリで生成したトークンで再度WebHook作成
開発者トークンでWebhookを作成したことが悪さしている可能性を考慮して、
OAuth認証アプリで生成したトークンを使い、Webhookを再作成トークン生成に使用したアプリケーション名称:
GLENN-OAUTH-SAMPLE-PYTHON作成時刻: 2019/03/27 13:46
作成したWebhook
{
"id": "153930739",
"type": "webhook",
"target": {
"id": "70394214504",
"type": "folder"
},
"created_by": {
"type": "user",
"id": "xxxx",
"name": "xxxx",
"login": "xxxx"
},
"created_at": "2019-03-26T21:46:22-07:00",
"address": "https://xxxxxx.ap-northeast-1.amazonaws.com/default/boxWebHookTest",
"triggers": [
"FILE.DOWNLOADED",
"FILE.UPLOADED"
]
}
2019/03/27 15:08
Webhookの作成から1時間以上経過後、ファイルを再度Upload
→正常なWebhookが返ることを確認切り分けから、DeveloperトークンでWebhookを作成したことが原因と考えられます。
自前のWebサーバ宛てのWebhookが失敗する
本ページはAWS LambdaをWebhookの宛先として使用していますが、
これより前に、自前でNginxのサーバを立てて、安いSSLサーバ証明書を買って
FlaskでWebhookを受け取る仕組みを作ろうとして、
無事失敗しました。発生事象
Webhbookは問題無くトリガーされたが、Webサーバ側のアクセスログには何も記録されない。
TCPDumpを取ったところ、SSL Handshakeの過程で、BoxのWebhook送信元サーバが
自発的にSSL Handshakeを切ってしまっていた。
Reason Codeは 「Unknown CA」。原因
自前で立てたWebサーバ側の設定漏れ。
サーバ証明書は入れていたが、中間証明書を入れ忘れていた。
そのため、BoxのWebhookサーバ側で信頼チェインの検証に失敗していた。上記のサイトに自前Webサーバのドメイン名を入れてテストしたところ、
Chainのエラーとなったことで気づくことができました。対応
サーバ証明書に中間証明書を追加。
Nginxなので、証明書ファイル1つの中に順に追記するだけでよいです。-----BEGIN CERTIFICATE----- サーバSSL証明書 -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- SSL中間証明書1 -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- SSL中間証明書2 -----END CERTIFICATE-----参考:
https://www.sslbox.jp/support/man/interca_coressl.php
https://tsunokawa.hatenablog.com/entry/2014/09/24/114014nginxをリスタート後、
- 上記のSSLチェックサイトのテスト結果良好
- Webhook受信時のSSL Handshakeが成功
- Webhookが受け取れた
を確認できました。









- 投稿日:2019-05-23T11:58:51+09:00
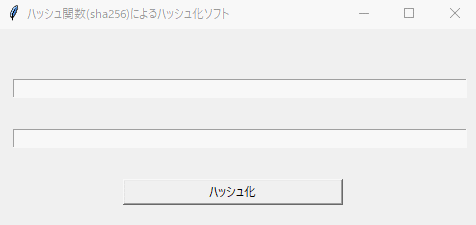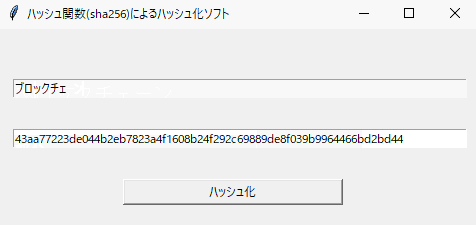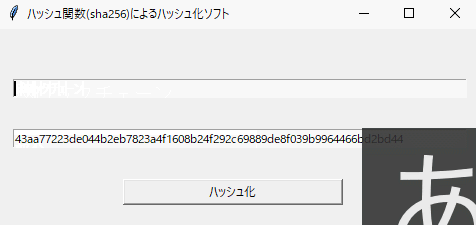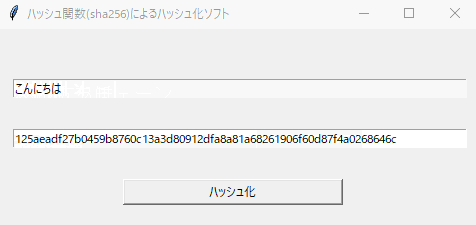
【Python】Tkinterによる40行で作るGUIアプリ「ハッシュ化ソフト」
はじめに
私の研究分野であるブロックチェーン技術において、ハッシュ関数はめっちゃ大事な技術の一つです。今回はそのハッシュ関数の一種であるSHA256を使って、簡単にハッシュ値を生成できるものを作っていきましょう!コマンドプロンプトに出すだけだと面白くないので、Tkinterを使ってGUIアプリを作成していきます。
ハッシュ関数の具体的な内容に関しては、ブロックチェーン技術及び関連技術の記事にありますので、興味があれば、ぜひこちらをご参照ください。→ ハッシュ関数の詳細(ブロックチェーン技術及び関連技術)
完成するとこんな感じに動きます!
環境
- Windows 10 home
- Python 3.7.1
ハッシュ関数(SHA256)によるハッシュ化ソフトの制作
インポート
使うライブラリは以下の2つです。
hashlibをインポートすることで、ハッシュ関数SHA256を使うことができるようになります。import tkinter as tk import hashlib as hashウィンドウの作成
import tkinter as tk class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() master.geometry("480x200") master.title("ハッシュ関数(SHA256)によるハッシュ化ソフト") def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()このプログラムでウィンドウを作っていきます。
サイズは480×200です。タイトル名はハッシュ関数(SHA256)によるハッシュ化ソフトです。
詳しくはPythonによるTkinterを使った雛形(クラス化手法)の記事をご参照ください。完成したプログラム
こちらが完成したプログラムになります。
hash.pyimport tkinter as tk import hashlib as hash class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() master.geometry("480x200") master.title("ハッシュ関数(SHA256)によるハッシュ化ソフト") self.setGUI() def setGUI(self): self.txt1 = tk.Entry(width=75) self.txt1.place(x=15,y=50) self.txt2 = tk.Entry(width=75) self.txt2.place(x=15,y=100) self.btn = tk.Button(text="ハッシュ化",command = self.btn_click,width=30) self.btn.place(x=125, y=150) def btn_click(self): if self.txt1.get() == "": self.txt2.delete(0, tk.END) self.txt2.insert(0,"") else: self.txt2.delete(0, tk.END) self.txt2.insert(0,hash.sha256(self.txt1.get().encode()).hexdigest()) def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()setGUI関数でテキストボックスやボタンを配置していきます。
btn_click関数でボタンを押した時の処理を行います。ここで、上部のテキストボックスの内容をハッシュ関数に入れ、そのハッシュ値を下部のテキストボックスで表示します。以上でハッシュ関数(SHA256)によるハッシュ化ソフトは完成になります。
ここまで読んでいただき、ありがとうございました。
- 投稿日:2019-05-23T11:36:57+09:00
基礎知識の補填 Python (タプル)
今回は、タプルについてリストとの違いが曖昧だったので勉強し直してみた。
タプルとは
タプルは、リストとよく似ているデータ型である。
基本的にリストと同じようにインデックスを使って要素を管理することができる。
また、インデックス指定で要素を取り出したり、スライスを使用して複数要素を取り出すことができる。タプルがリストと異なるところ
タプルはリストと違って要素を書き換えることができない。
インデックス指定した要素へ代入して要素を書き換えるということができない。
一度、作ったタプルは、要素を追加したり削除したりして長さを変更することができないようになっている。タプルの定義
タプルは、丸括弧()で要素を囲み、要素同士はカンマ(,)で区切る。
タプル = (要素1, 要素2, ・・・)
使用例
>>> t = (1, 2, 3, 4) >>> t (1, 2, 3, 4) # 出力結果スライス使用例
>>> t[0] 1 >>> t[1:3] (2, 3)書き換えることができない
>>> t[0] = 'five' # ←文字列で更新しようとすると怒られる Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment足し算(連結)することが可能
要素の書き換えや削除等はできないが、新たな要素と足し合わせて(連結)別な変数に入れ込むことが可能。
>>> t2 = t + (10, 20, 30) >>> t2 (1, 2, 3, 4, 10, 20, 30)タプルを使用するときの注意点
値が1つしかないタプルを作りたい場合は注意が必要。
値が1つしか入ってなくなくても、カンマを付けとかないとタプルとして認識されない。t3 = (1, )
- 投稿日:2019-05-23T08:00:14+09:00
AWS SDK for Python(boto3)でAmazon Managed Blockchainのブロックチェーンネットワークを作成してみた
Amazon Managed Blockchainでブロックチェーンネットワークを構築するのにAWS CloudFormationを利用したいなぁとドキュメントを読んでみたらリソースがありませんでした。oh...
AWS CloudFormationのカスタムリソースを利用すれば管理できるので、まずはAWS SDKでAmazon Managed Blockchainが取り扱えるのか確認してみました。AWS CloudFormationのカスタムリソースについては下記が参考になります。
カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources.htmlCloudFormationで提供されていない処理をカスタムリソースで作ってみた。 | DevelopersIO
https://dev.classmethod.jp/cloud/aws/cfn-api-custom/AWS CloudFormationでCognitoユーザープールをMFAのTOTPを有効にして作成する - Qiita
https://qiita.com/kai_kou/items/f56bb13a5d47ee05d766Amazon Managed Blockchainってなんぞ?
Amazon Managed Blockchainってなんぞ?という方は下記をご参考ください。
Amazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた - Qiita
https://qiita.com/kai_kou/items/5a968f42c5f96296f6fe前提
今回はAmazon Managed Blockchainのネットワーク、メンバー、ノードがAWS SDKで作成できるかの確認のみとなります。セキュリティグループ、インタフェースVPCエンドポイントやHyperledger Fabricの設定などは行いません。
- AWSアカウントがある
- AWSアカウントに以下の作成権限がある
- Managed Blockchainネットワーク
- AWS CLIの
aws configureコマンドでアカウント設定済みネットワーク構築して動作確認するまでの手順は下記が参考になります。
Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた - Qiita
https://qiita.com/kai_kou/items/e02e34dd9abb26219a7eAWS SDK for Python(boto3)でAmazon Managed BlockchainのAPIが提供されてる
ドキュメントを確認してみたらAWS SDKでAmazon Managed BlockchainのAPIが提供されていました。
boto/boto3: AWS SDK for Python
https://github.com/boto/boto3ManagedBlockchain — Boto 3 Docs 1.9.152 documentation
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.htmlPython環境の用意
Pipenvを利用したことがなかったので、ついでに初利用します(趣味)。
仮想環境じゃなくてもOKです。Pipenvを使ったPython開発まとめ - Qiita
https://qiita.com/y-tsutsu/items/54c10e0b2c6b565c887a# pipenvがインストールされてなかったら > pip install pipenv (略) Installing collected packages: virtualenv, virtualenv-clone, pipenv Successfully installed pipenv-2018.11.26 virtualenv-16.6.0 virtualenv-clone-0.5.3 # 仮想環境の作成 > pipenv --python 3.7 Creating a virtualenv for this project… Pipfile: /Users/xxx/dev/aws/managed-blockchain-use-sdk/Pipfile Using /Users/xxx/.anyenv/envs/pyenv/versions/3.7.0/bin/python3 (3.7.0) to create virtualenv… ⠴ Creating virtual environment... (略) ✔ Successfully created virtual environment! Virtualenv location: /Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz Creating a Pipfile for this project… # boto3のインストール > pipenv install boto3 Installing boto3… ⠴ Installing... (略) # 仮想環境へ入る > pipenv shell Launching subshell in virtual environment… Welcome to fish, the friendly interactive shellAWS SDK for Python(boto3)を利用して実装
ドキュメントを参考にネットワークなどを作成、取得できるか確認します。
ManagedBlockchain — Boto 3 Docs 1.9.152 documentation
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.htmlネットワークとメンバーの作成
create_networkでネットワーク作成できます。パラメータはAWS CLIとほぼ同じなので下記が参考になります。
AWS CLIと同じく最初のメンバーも合わせて作成する必要があります。Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた - Qiita
https://qiita.com/kai_kou/items/e02e34dd9abb26219a7e#%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%A8%E3%83%A1%E3%83%B3%E3%83%90%E3%83%BC%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8Bcreate_network.pyimport boto3 client = boto3.client("managedblockchain") def create_network(): new_network = client.create_network( ClientRequestToken="string", Name="TestNetwork", Description="TestNetworkDescription", Framework="HYPERLEDGER_FABRIC", FrameworkVersion="1.2", FrameworkConfiguration={ "Fabric": { "Edition": "STARTER" } }, VotingPolicy={ "ApprovalThresholdPolicy": { "ThresholdPercentage": 50, "ProposalDurationInHours": 24, "ThresholdComparator": "GREATER_THAN" } }, MemberConfiguration={ "Name": "org1", "Description": "Org1 first member of network", "FrameworkConfiguration": { "Fabric": { "AdminUsername": "AdminUser", "AdminPassword": "Password123" } } } ) print(new_network)実行するとネットワークとメンバーの作成が開始されて
NetworkIdとMemberIdが得られます。> python create_network.py {'ResponseMetadata': {'RequestId': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Tue, 21 May 2019 03:24:32 GMT', 'content-type': 'application/json', 'content-length': '86', 'connection': 'keep-alive', 'x-amzn-requestid': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'x-amz-apigw-id': 'xxxxxxxxxxxxxxx=', 'x-amzn-trace-id': 'Root=1-xxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx; Sampled=0'}, 'RetryAttempts': 0}, 'NetworkId': 'n-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'MemberId': 'm-XXXXXXXXXXXXXXXXXXXXXXXXXX'}ネットワーク情報の取得
list_networksでネットワーク情報が取得できます。
パラメータ指定することで検索もできるみたいです。list_network.pyimport boto3 client = boto3.client("managedblockchain") def list_network(): networks = client.list_networks( # Name="Test" # Name="string", # Framework="HYPERLEDGER_FABRIC", # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED", # MaxResults=123, # NextToken="string" ) print(networks) list_networks()> python list_network.py [{'Id': 'n-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Name': 'TestNetwork', 'Description': 'TestNetworkDescription', 'Framework': 'HYPERLEDGER_FABRIC', 'FrameworkVersion': '1.2', 'Status': 'CREATING', 'CreationDate': datetime.datetime(2019, 5, 21, 3, 24, 31, 929000, tzinfo=tzutc())}]ノードの作成
create_nodeでノード作成ができます。ClientRequestTokenに関しては指定しない場合自動生成してくれるとのことでした。手動での生成方法は未調査です。create_node.pyimport boto3 client = boto3.client("managedblockchain") def create_node(): new_node = client.create_node( # ClientRequestToken='string', NetworkId='n-5QBOS5ULTVEZZG6EMIPLPRSSQA', MemberId='m-OMLBOQIAMJDDPJV3FVGIAVUGBE', NodeConfiguration={ 'InstanceType': 'bc.t3.small', 'AvailabilityZone': 'us-east-1a' } ) print(new_node) create_node()> python create_node.py {'ResponseMetadata': {'RequestId': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Tue, 21 May 2019 04:04:44 GMT', 'content-type': 'application/json', 'content-length': '42', 'connection': 'keep-alive', 'x-amzn-requestid': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'x-amz-apigw-id': 'xxxxxxxxxxxxxxx=', 'x-amzn-trace-id': 'Root=1-xxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx;Sampled=0'}, 'RetryAttempts': 0}, 'NodeId': 'nd-XXXXXXXXXXXXXXXXXXXXXXXXXX'}ネットワーク、メンバーが作成中(
StatusがCREATING)の場合は作成できませんでした。ネットワーク、メンバー作成中に実行> python create_node.py Traceback (most recent call last): File "main.py", line 43, in <module> 'AvailabilityZone': 'us-east-1a' File "/Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz/lib/python3.7/site-packages/botocore/client.py", line 357, in _api_call return self._make_api_call(operation_name, kwargs) File "/Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz/lib/python3.7/site-packages/botocore/client.py", line 661, in _make_api_call raise error_class(parsed_response, operation_name) botocore.errorfactory.ResourceNotReadyException: An error occurred (ResourceNotReadyException) when calling the CreateNode operation: Member m-XXXXXXXXXXXXXXXXXXXXXXXXXX is in CREATING. you cannot create nodes at this time..メンバー情報の取得
list_membersでメンバーが取得できます。NetworkIdが必須となります。list_members.pyimport boto3 client = boto3.client("managedblockchain") def list_members(): members = client.list_members( NetworkId="n-XXXXXXXXXXXXXXXXXXXXXXXXXX" # Name="string", # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED", # IsOwned=True|False, # MaxResults=123, # NextToken="string" ) print(members["Members"]) list_members()> pyhton list_members.py [{'Id': 'm-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Name': 'demo', 'Description': 'demo member', 'Status': 'AVAILABLE', 'CreationDate': datetime.datetime(2019, 5, 21, 3, 24, 32, 271000, tzinfo=tzutc()), 'IsOwned': True}]ノード情報の取得
list_nodesでノードが取得できます。NetworkId、MemberIdが必須となります。list_nodes.pyimport boto3 client = boto3.client("managedblockchain") def list_nodes(): nodes = client.list_nodes( NetworkId="n-XXXXXXXXXXXXXXXXXXXXXXXXXX", MemberId="m-XXXXXXXXXXXXXXXXXXXXXXXXXX" # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED"|"FAILED", # MaxResults=123, # NextToken="string" ) print(nodes["Nodes"]) list_nodes()> pyhton list_nodes.py [{'Id': 'nd-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Status': 'AVAILABLE', 'CreationDate': datetime.datetime(2019, 5, 21, 4, 4, 44, 468000, tzinfo=tzutc()), 'AvailabilityZone': 'us-east-1a', 'InstanceType': 'bc.t3.small'}]特にハマることもなくboto3を利用してネットワーク、メンバー、ノードを作成することができました。
これで、AWS CloudFormationのカスタムリソースを利用してリソース管理することができそうです。
ただ、ネットワークとメンバー作成に20分程度かかるので、その待受処理などがAWS CloudFormationで実現できるのか、ちょっと心配です。(未調査)参考
カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources.htmlCloudFormationで提供されていない処理をカスタムリソースで作ってみた。 | DevelopersIO
https://dev.classmethod.jp/cloud/aws/cfn-api-custom/AWS CloudFormationでCognitoユーザープールをMFAのTOTPを有効にして作成する - Qiita
https://qiita.com/kai_kou/items/f56bb13a5d47ee05d766boto/boto3: AWS SDK for Python
https://github.com/boto/boto3ManagedBlockchain — Boto 3 Docs 1.9.152 documentation
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.htmlAmazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた - Qiita
https://qiita.com/kai_kou/items/5a968f42c5f96296f6feAmazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた - Qiita
https://qiita.com/kai_kou/items/e02e34dd9abb26219a7ePipenvを使ったPython開発まとめ - Qiita
https://qiita.com/y-tsutsu/items/54c10e0b2c6b565c887aAmazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた - Qiita
https://qiita.com/kai_kou/items/e02e34dd9abb26219a7e#%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%A8%E3%83%A1%E3%83%B3%E3%83%90%E3%83%BC%E3%82%92%E4%BD%9C%E6%88%90%E3%81%99%E3%82%8B
- 投稿日:2019-05-23T04:23:02+09:00
python入門[import] "from" relative_module "import" identifier とか
目的
import文に関して
import モジュール
という構文の意識が強くて、
from AA import BBBB
という構文で、BBBBがモジュールでないのが、どうにも、気持ち悪かった。。。
納得を求めて、調査したが、
結局、以下の記載が一番すっきりしていたので、メモ。https://docs.python.org/ja/3/reference/simple_stmts.html#grammar-token-import-stmt
import statement
import statementの説明は、以下。
import moduleは、ほんの一例に過ぎないと読める。
各々のケースの処理内容も説明されているので、更に、納得。(出典:https://docs.python.org/ja/3/reference/simple_stmts.html#grammar-token-import-stmt)
import_stmt ::= "import" module ["as" identifier] ("," module ["as" identifier])* | "from" relative_module "import" identifier ["as" identifier] ("," identifier ["as" identifier])* | "from" relative_module "import" "(" identifier ["as" identifier] ("," identifier ["as" identifier])* [","] ")" | "from" module "import" "*" module ::= (identifier ".")* identifier relative_module ::= "."* module | "."+
まとめ
「docs.python.org/ja/3/reference」が、一番いいときもあると感じた。
関連(本人)
今後
何かあれば、追記します。
コメントなどあれば、お願いします

- 投稿日:2019-05-23T04:23:02+09:00
python入門[import] 「from relative_module import identifier」 とか
目的
import文に関して
import モジュール
という構文の意識が強くて、
from AA import BBBB
という構文で、BBBBがモジュールでないのが、どうにも、気持ち悪かった。。。
納得を求めて、調査したが、
結局、以下の記載が一番すっきりしていたので、メモ。https://docs.python.org/ja/3/reference/simple_stmts.html#grammar-token-import-stmt
import statement
import statementの説明は、以下。
import moduleは、ほんの一例に過ぎないと読める。
各々のケースの処理内容も説明されているので、更に、納得。(出典:https://docs.python.org/ja/3/reference/simple_stmts.html#grammar-token-import-stmt)
import_stmt ::= "import" module ["as" identifier] ("," module ["as" identifier])* | "from" relative_module "import" identifier ["as" identifier] ("," identifier ["as" identifier])* | "from" relative_module "import" "(" identifier ["as" identifier] ("," identifier ["as" identifier])* [","] ")" | "from" module "import" "*" module ::= (identifier ".")* identifier relative_module ::= "."* module | "."+
まとめ
「docs.python.org/ja/3/reference」が、一番いいときもあると感じた。
関連(本人)
今後
何かあれば、追記します。
コメントなどあれば、お願いします
- 投稿日:2019-05-23T02:03:11+09:00
ロジスティック回帰とハイパーパラメータのチューニング
はじめに
乳癌の腫瘍が良性であるか悪性であるかを判定するためのウィスコンシン州の乳癌データセットについて、ロジスティック回帰とハイパーパラメータのチューニングにより予測器を作成する。
シリーズ
- 線形重回帰による決定係数の算出とモデルの選択
- 線形重回帰による決定係数の算出とモデルの選択 part_2
- 単回帰分析による寄与率の算出
- 線形回帰と特徴量の絞り込み
- ロジスティック回帰とハイパーパラメータのチューニング
ロジスティック回帰のハイパーパラメータ
詳細は以下を参照されたい。
sklearn.linear_model.LogisticRegression
ハイパーパラメータ 選択肢 default penalty l1,l2 l2 dual bool型 False tol float型 0.0001 C float型 1 fit_intercept bool型 True intercept_scaling float型 1 class_weight 辞書型、balanced 1(全クラス) random_state int型 None solver newton-cg、lbfgs、liblinear、sag、saga liblinear max_iter int型 100 multi_class ovr、multinomial、auto ovr verbose int型 0 warm_start bool型 False n_jobs int型、None None l1_ratio float、None None 手順
- 乳癌データの読み込み
- 条件設定
- トレーニングデータ、テストデータの分離
- グリッドサーチ
- ランダムサーチ
- ハイパーパラメータを中忍ぐしない場合との比較 # pythonによる実装
%%time import scipy.stats from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score #乳癌データの読み込み cancer_data = load_breast_cancer() #条件設定 max_score = 0 SearchMethod = 0 LR_grid = {LogisticRegression(): {"C": [10 ** i for i in range(-5, 6)], "random_state": [i for i in range(0, 101)]}} LR_random = {LogisticRegression(): {"C": scipy.stats.uniform(0.00001, 1000), "random_state": scipy.stats.randint(0, 100)}} #トレーニングデータ、テストデータの分離 train_X, test_X, train_y, test_y = train_test_split(cancer_data.data, cancer_data.target, random_state=0) #グリッドサーチ for model, param in LR_grid.items(): clf = GridSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: max_score = score best_param = clf.best_params_ best_model = model.__class__.__name__ #ランダムサーチ for model, param in LR_random.items(): clf =RandomizedSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: SearchMethod = 1 max_score = score best_param = clf.best_params_ best_model = model.__class__.__name__ if SearchMethod == 0: print("サーチ方法:グリッドサーチ") else: print("サーチ方法:ランダムサーチ") print("ベストスコア:{}".format(max_score)) print("ベストモデル:{}".format(best_model)) print("パラメーター:{}".format(best_param)) #ハイパーパラメータを調整しない場合との比較 model = LogisticRegression() model.fit(train_X, train_y) score = model.score(test_X, test_y) print("") print("デフォルトスコア:", score)結果
サーチ方法:ランダムサーチ
サーチ方法:ランダムサーチ ベストスコア:0.965034965034965 ベストモデル:LogisticRegression パラメーター:{'C': 866.92427079018307, 'random_state': 56} デフォルトスコア: 0.958041958042 Wall time: 11.5 sおわりに
ロジスティック回帰により約97%という高い正解率を得ることができた。計算時間が膨大になるため選択したパラメータは少なかったものの、ランダムサーチによりdefaultのハイパーパラメータによる値を上回ることができた。
- 投稿日:2019-05-23T00:32:04+09:00
【画像生成】AutoencoderとVAEと。。。遊んでみた♬
画像生成の基本ということで、MNISTのAutoencoderをやってみました。
一年ちょっと前、参考にあるように中間のLatent_dimの大きさが大きければ得られる画像は入力画像のそれとそん色無いというところまでやりました。
今回は、その先へ。。。今日はVAEとちょっとプラスアルファまでやってみようと思います。
どうやらこの先には大きな宝物が埋まっているかもというところにたどり着いたので、あとの楽しみにしてください。
え??そんなの知っていますという方は、以下は読み飛ばしてください。
【参考】
・CapsNetで遊んでみた♬~Autoencoderと比較すると~やったこと
・MNISTのAutoencoder
・MNISTのVAE
・異常検知について・MNISTのAutoencoder
ここは、いろいろなコードが考えられ、またMNISTには大仰ですが、以下を採用します。
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same',name='encoded')(x) encoder=Model(input_img, encoded) encoder.summary() x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') autoencoder.summary()ということで結果は以下のとおりになります。
ちなみに変化が見やすいように1000データで10epoch学習して10000個のTestデータで検証しています。
※今回は精度は問いません
コード全体は以下のとおりです。
VAE/AE_mnist_conv2d.py・MNISTのVAE
ここは参考の①②を参考にしています。特に参考①③についてはコードをほぼまんま参考にさせていただきました。また、参考②には詳細な説明があって、VAEとはということが理解できます。
【参考】
①KerasでAutoEncoderその2
②Variational Autoencoder徹底解説
③Example of VAE on MNIST dataset using MLP@KerasDocumentation
こうなると、このあたりやる意味あるのかというですが、ウワン的には上記のAEとこのVAEの差分がどうしても知りたいという欲求にかられました。
ということで、おさらいです。
コードの主要な部分は以下のとおりです。
encoderの最初の部分は通常のencoderと同じです。inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(16, (3, 3), activation='relu', padding='same')(inputs) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same',name='encoded')(x)以下で最後のTensorの引数を読込み、shapeに格納します。
そして、latent空間でdecoderの出力を制御したいので、以下のようにFlatten()してから、z_meanとz_log_varという分布の平均値と分散の対数に当たる変数を定義します。
この部分がVAEの主な考え方です。
※つまり、ある分布関数(以下で見るように、z=z_mean + K.exp(0.5 * z_log_var) * epsilonという関数)の変数にlatent空間でとる値を制限して制御する
そして例のLambdaクラスを利用して関数定義することにより、Tensorを引き渡す手法を取っています。
こうして、encoderは入力inputs=input_imgに対して、[z_mean, z_log_var]を出力とするモデルとなります。shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # instantiate encoder model encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder') encoder.summary()一方、decoderは入力は上記のLambdaの出力である[z_mean, z_log_var]の二次元の要素を持ったもので、上記のAutoencoderと同様なモデルです。
# build decoder model # decoder latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) outputs = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) # instantiate decoder model decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() # instantiate VAE model outputs = decoder(encoder(inputs)[2]) vae = Model(inputs, outputs, name='vae_mlp')一方、Lambdaが定義していた関数samplingは以下のようなもので、これこそがVAEの肝となるものです。
※参考②のReparameterization Trickあたりを見てください
また、参考③のKerasDocumentationにはこの関数に対して以下のコメントがあります"""Reparameterization trick by sampling for an isotropic unit Gaussian. # Arguments args (tensor): mean and log of variance of Q(z|X) # Returns z (tensor): sampled latent vector """ちなみにGauss分布との関係(すなわちパラメータ変換)については以下が参考になります。
【参考】
Reparameterization Trick for Gaussian Distribution「Assume we have a normal distribution q that is parameterized by θ, specifically $q_θ(x)=N(θ,1)$. We want to solve the below problem
min_θ E_q[x^2]We want to understand how the reparameterization trick helps in calculating the gradient of this objective $E_q[x^2]$.
One way to calculate $∇_θE_q[x^2]$ is as follows
∇_θE_q[x^2]=∇_θ∫q_θ(x)x^2dx=∫x^2∇_θq_θ(x)\frac{q_θ(x)}{q_θ(x)}dx=∫q_θ(x)∇_θ\log q_θ(x)x^2dx =E_q[x^2∇_θ\log q_θ(x)]For our example where qθ(x)=N(θ,1), this method gives
∇_θE_q[x2]=E_q[x^2(x−θ)]Reparameterization trick is a way to rewrite the expectation so that the distribution with respect to which we take the expectation is independent of parameter θ. To achieve this, we need to make the stochastic element in q independent of θ. Hence, we write x as
x=θ+ϵ,ϵ∼N(0,1)Then, we can write
E_q[x^2]=E_p[(θ+ϵ)^2]where p is the distribution of ϵ, i.e., N(0,1). Now we can write the derivative of $E_q[x^2]$ as follows
∇_θE_q[x^2]=∇_θE_p[(θ+ϵ)^2]=E_p[2(θ+ϵ)]share cite improve this answer」
def sampling(args): z_mean, z_log_var = args batch = K.shape(z_mean)[0] dim = K.int_shape(z_mean)[1] # by default, random_normal has mean=0 and std=1.0 epsilon = K.random_normal(shape=(batch, dim)) return z_mean + K.exp(0.5 * z_log_var) * epsilon最後にVAEのloss関数は以下のとおりです。
# Compute VAE loss reconstruction_loss = binary_crossentropy(K.flatten(inputs), K.flatten(outputs)) reconstruction_loss *= image_size * image_size kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var) kl_loss = K.sum(kl_loss, axis=-1) kl_loss *= -0.5 vae_loss = K.mean(reconstruction_loss + kl_loss)そして結果は100epochのとき、以下のとおり得られました。
コード全体は以下のとおりです。
VAE/keras_vae_conv2d.py異常検知について
そして参考①で議論されている異常検知、すなわち以下のコードのように学習を7のみに限定して学習すると、そのz空間での様子を見ると以下のようにほぼ全領域で7のような形状になっています。
# 学習に使うデータを限定する x_train1 = x_train[y_train==7] x_test1 = x_test[y_test==7] vae.fit(x_train1, epochs=epochs, batch_size=batch_size, validation_data=(x_test1, None))
そして異常検知の図は以下のとおりになります。
実はここから面白いのですが、この7を学習したモデルでさらに一つずつ文字を学習するとどうなるでしょうか??
DLの記憶って、どうなるか興味がわいたのでやってみましたが、今夜は遅くなったので明日の記事にしたいと思います。まとめ
・Autoencoderをやってみた
・VAEをやってみた
・異常検知についてやってみた・DLの記憶ってあるのかどうか明日書きます


![z_sample_t_No.7_100_50z0=[-0.7,-3]z7=[-0.7,2].gif](https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/233744/67942ae9-0958-7a7f-0386-2a874211bea4.gif)

- 投稿日:2019-05-23T00:32:04+09:00
【画像識別】AutoencoderとVAEと。。。遊んでみた♬
画像識別の基本ということで、MNISTのAutoencoderをやってみました。
一年ちょっと前、参考にあるように中間のLatent_dimの大きさが大きければ得られる画像は入力画像のそれとそん色無いというところまでやりました。
今回は、その先へ。。。今日はVAEとちょっとプラスアルファまでやってみようと思います。
どうやらこの先には大きな宝物が埋まっているかもというところにたどり着いたので、あとの楽しみにしてください。
え??そんなの知っていますという方は、以下は読み飛ばしてください。
【参考】
・CapsNetで遊んでみた♬~Autoencoderと比較すると~やったこと
・MNISTのAutoencoder
・MNISTのVAE
・予兆検知について・MNISTのAutoencoder
ここは、いろいろなコードが考えられ、またMNISTには大仰ですが、以下を採用します。
input_img = Input(shape=(28, 28, 1)) # adapt this if using `channels_first` image data format x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same',name='encoded')(x) encoder=Model(input_img, encoded) encoder.summary() x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_img, decoded) autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy') autoencoder.summary()ということで結果は以下のとおりになります。
ちなみに変化が見やすいように1000データで10epoch学習して10000個のTestデータで検証しています。
※今回は精度は問いません
コード全体は以下のとおりです。
VAE/AE_mnist_conv2d.py・MNISTのVAE
ここは参考の①②を参考にしています。特に参考①③についてはコードをほぼまんま参考にさせていただきました。また、参考②には詳細な説明があって、VAEとはということが理解できます。
【参考】
①KerasでAutoEncoderその2
②Variational Autoencoder徹底解説
③Example of VAE on MNIST dataset using MLP@KerasDocumentation
こうなると、このあたりやる意味あるのかというですが、ウワン的には上記のAEとこのVAEの差分がどうしても知りたいという欲求にかられました。
ということで、おさらいです。
コードの主要な部分は以下のとおりです。
encoderの最初の部分は通常のencoderと同じです。inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(16, (3, 3), activation='relu', padding='same')(inputs) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same',name='encoded')(x)以下で最後のTensorの引数を読込み、shapeに格納します。
そして、latent空間でdecoderの出力を制御したいので、以下のようにFlatten()してから、z_meanとz_log_varという分布の平均値と分散の対数に当たる変数を定義します。
この部分がVAEの主な考え方です。
※つまり、ある分布関数(以下で見るように、z=z_mean + K.exp(0.5 * z_log_var) * epsilonという関数)の変数にlatent空間でとる値を制限して制御する
そして例のLambdaクラスを利用して関数定義することにより、Tensorを引き渡す手法を取っています。
こうして、encoderは入力inputs=input_imgに対して、[z_mean, z_log_var]を出力とするモデルとなります。shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # instantiate encoder model encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder') encoder.summary()一方、decoderは入力は上記のLambdaの出力である[z_mean, z_log_var]の二次元の要素を持ったもので、上記のAutoencoderと同様なモデルです。
# build decoder model # decoder latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) outputs = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) # instantiate decoder model decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() # instantiate VAE model outputs = decoder(encoder(inputs)[2]) vae = Model(inputs, outputs, name='vae_mlp')一方、Lambdaが定義していた関数samplingは以下のようなもので、これこそがVAEの肝となるものです。
※参考②のReparameterization Trickあたりを見てください
また、参考③のKerasDocumentationにはこの関数に対して以下のコメントがあります"""Reparameterization trick by sampling for an isotropic unit Gaussian. # Arguments args (tensor): mean and log of variance of Q(z|X) # Returns z (tensor): sampled latent vector """ちなみにGauss分布との関係(すなわちパラメータ変換)については以下が参考になります。
【参考】
Reparameterization Trick for Gaussian Distribution「Assume we have a normal distribution q that is parameterized by θ, specifically $q_θ(x)=N(θ,1)$. We want to solve the below problem
min_θ E_q[x^2]We want to understand how the reparameterization trick helps in calculating the gradient of this objective $E_q[x^2]$.
One way to calculate $∇_θE_q[x^2]$ is as follows
∇_θE_q[x^2]=∇_θ∫q_θ(x)x^2dx=∫x^2∇_θq_θ(x)\frac{q_θ(x)}{q_θ(x)}dx=∫q_θ(x)∇_θ\log q_θ(x)x^2dx =E_q[x^2∇_θ\log q_θ(x)]For our example where qθ(x)=N(θ,1), this method gives
∇_θE_q[x2]=E_q[x^2(x−θ)]Reparameterization trick is a way to rewrite the expectation so that the distribution with respect to which we take the expectation is independent of parameter θ. To achieve this, we need to make the stochastic element in q independent of θ. Hence, we write x as
x=θ+ϵ,ϵ∼N(0,1)Then, we can write
E_q[x^2]=E_p[(θ+ϵ)^2]where p is the distribution of ϵ, i.e., N(0,1). Now we can write the derivative of $E_q[x^2]$ as follows
∇_θE_q[x^2]=∇_θE_p[(θ+ϵ)^2]=E_p[2(θ+ϵ)]share cite improve this answer」
def sampling(args): z_mean, z_log_var = args batch = K.shape(z_mean)[0] dim = K.int_shape(z_mean)[1] # by default, random_normal has mean=0 and std=1.0 epsilon = K.random_normal(shape=(batch, dim)) return z_mean + K.exp(0.5 * z_log_var) * epsilon最後にVAEのloss関数は以下のとおりです。
# Compute VAE loss reconstruction_loss = binary_crossentropy(K.flatten(inputs), K.flatten(outputs)) reconstruction_loss *= image_size * image_size kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var) kl_loss = K.sum(kl_loss, axis=-1) kl_loss *= -0.5 vae_loss = K.mean(reconstruction_loss + kl_loss)そして結果は100epochのとき、以下のとおり得られました。
コード全体は以下のとおりです。
VAE/keras_vae_conv2d.py異常検知について
そして参考①で議論されている異常検知、すなわち以下のコードのように学習を7のみに限定して学習すると、そのz空間での様子を見ると以下のようにほぼ全領域で7のような形状になっています。
# 学習に使うデータを限定する x_train1 = x_train[y_train==7] x_test1 = x_test[y_test==7] vae.fit(x_train1, epochs=epochs, batch_size=batch_size, validation_data=(x_test1, None))
そして異常検知の図は以下のとおりになります。
実はここから面白いのですが、この7を学習したモデルでさらに一つずつ文字を学習するとどうなるでしょうか??
DLの記憶って、どうなるか興味がわいたのでやってみましたが、今夜は遅くなったので明日の記事にしたいと思います。まとめ
・Autoencoderをやってみた
・VAEをやってみた
・異常検知についてやってみた・DLの記憶ってあるのかどうか明日書きます