- 投稿日:2019-05-23T14:35:50+09:00
なんで、SQLで「カラム名 = null」,「カラム名 <> null」は0件なのか
何故、NULL は = で比較したらあかんのか
新人さんたちは、不思議な値「NULL」でよく躓いてしまいます。
特に、教えていてアプローチに悩むのが、SQLの「IS NULL」という比較構文です。
私も、理解していない点が多くあったので、わからない点を纏めてみました。やさしい上級者の方は、恐れ入りますが間違いがあったらご指摘頂けますと幸いです…
経緯
教育を行っていた際、"where x = null"と記述した際、0件なのであれば、
逆となる条件の"where x <> null"はなぜ全件じゃないのか?と聞かれたことが発端でした。そこで、3値論理というワードを全く知らなかった自分のため、
また、NULLとは何ぞやといった点をわかりやすく教えるため、記述しました。~(おさらい)本題に行く前に、WHEREってなんだっけ~
SQLの概念と、SELECT,FROM,WHEREの概念を簡単に理解している前提で書きます。
WHEREはDBに保有しているデータに、条件と一致するデータか~と質問する為の構文です。
「あなたは15歳以上ですか?」と10人から確認したい場合、
10人に質問しなければいけませんよね。DBも同じで、10行(レコード)あった場合、1件づつ、合計10回問いかけを行っています。
いくつか、想定動作と結果をイメージしながら考えてみましょう。hogeテーブル
id name age 1001 たろう 10 1002 じろう 15 1003 NULL 20 例えば、hogeテーブルから、年齢が15歳以上のデータ(レコード)を取得したいとします。
SQL記述例:
SQL*Plus--※1のSQL例 SQL> SELECT * 1> FROM hoge 2> WHERE age >= 15;上記のSQLを記述した場合、各行で下記のような計算が行われます。
id name age 計算条件 結果 1001 たろう 10 10は15以上? 偽 1002 じろう 15 15は15以上? 真 1003 NULL 20 20は15以上? 真 DBは真の計算結果となるものを返すので、
1002,1003の2件を取得します。また、新人さんが混乱しやすい問題として、このようなSQLがあります。
SQL*Plus--※1のSQL例 SQL> SELECT * 1> FROM hoge 2> WHERE 1 = 1;よく、1=1ってなんだ?って身構えられるのですが、
単純に「1と1」を全レコードで比較しているだけです。
id name age 計算条件 結果 1001 たろう 10 1は1? 真 1002 じろう 15 1は1? 真 1003 NULL 20 1は1? 真 この場合、1001,1002,1003の3件が返却されます。
~(おさらい)WHEREでnullを=で比較するとどうなるんだっけ~
SQLで例えば、[カラム名] = NULLのように比較演算子を利用し、NULLと比較をした場合、
カラムにNULLが入っているレコードがあった場合でも、結果は0件です。SQL*Plus--※1のSQL例 SQL> SELECT * 1> FROM hoge 2> WHERE name is NULL; ID NAME ---- ----- 1003 NULL --※2のSQL例 SQL> SELECT * FROM hoge 2> WHERE name = NULL; レコードが選択されませんでした。また、BETWEENを利用した場合についても、同様の動作をします。
SQL*Plus--※SQL例 SQL> SELECT * FROM hoge 2> WHERE name BETWEEN 0 and NULL; --ANDに置き換えて記述した場合(上記と同等のSQL) SQL> SELECT * FROM hoge 2> WHERE name >= 0 and name <=NULL; レコードが選択されませんでした。(NOTをつけない)INの場合、ORでの探索条件となるので、
NULL値は出ませんが、他の比較値(下記例だと1001のこと)は正しく取得出来ます。SQL*Plus--このSQLは1003のNULLさんは対象外となる SQL> SELECT * FROM hoge 2> WHERE name IN (NULL,1001); ID NAME ---- ----- 1003 NULL --INで記載されている内容と同等のSQL SQL> SELECT * FROM hoge 2> WHERE name = NULL -- NULL値を=で比較するため、こちらの比較結果は0件 3> OR name = "たろう"; -- 「たろう」に合致するレコードはあるので、1件返却される ID NAME ---- ----- 1001 たろう問題提起(なんで「カラム名 <> null」は0件なのか)
新人さんが、この結果はおかしい、バグってる!と騒いでいました。
SQL*PlusSQL> SELECT * FROM hoge 2> WHERE NOT(name = NULL); レコードが選択されませんでした。主張としては、[カラム名] = NULLが0件なのであれば、
その否定は全件なのではないかといったお話でした。
私もこの主張は正しいな…と感じてしまったので調べました。
どうやら、3値論理という概念が深く関係しており、まず3値論理を理解しなければわからないようです。3値論理とは
3値論理とは真偽値をTRUE,FALSEの2つに加えて、UNKNOWN(不明)という3つの値で管理する方法です。1
ここでいう、UNKNOWNとはどういったデータかというと、おおまかに下記の2種類に分類されます。
①「家の総移動距離」 や 「モグラの飛行時間」のような、論理的に存在できない値
※ハウルの動く城とか、タイヤの付いた家、飛ぶモグラ等の
前提になると話がすごくややこしくなるので、一般的な概念で考えて下さい…②「タモリの目の色」 や 「星の数」 や 「一部アイドルの実年齢」のような、わからない(観測できない)値
※こちらも、「タモリ サングラス 外す」等で検索すると画像が出てきますが、2
そんな画像はない前提でお願いします…NULL値は、TRUEでもなく、FALSEでもなく、このUNKNOWNという第3値に分類されます。
UNKNOWNを比較してみよう
上記が理解できると、なんとなく分かる人もいるかもしれませんが、
WHERE 星の数 = 100000000000000のような荒唐無稽な質問は
もしかしたらTRUEかもしれませんし、FALSEかもしれませんが、わかりません!!というのが最適解になってしまいます。
星の数 計算条件 結果 NULL null は100000000000000? UNKNOWN したがって、結果がTRUEではないため、返却されません。
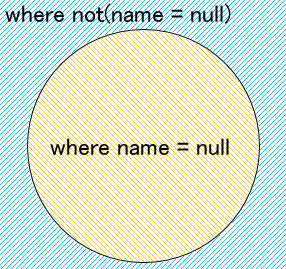
逆にWHERE not(星の数 = 100000000000000)であってもこの結果はUNKNOWNです。
星の数 計算条件 結果 NULL null は100000000000000ではない? UNKNOWN だってわからないんですもん。
おまけ
少し応用的な話になってしまいますが、NOT INの挙動を聞くと、
1回目は大体まちがって認識されているのですが、上記らへんを押さえていれば、実は簡単に解けます。SQL*PlusSQL> SELECT * FROM hoge 2> WHERE name NOT IN(NULL,1001); --同等のSQL SQL> SELECT * FROM hoge 2> WHERE name <> NULL 3> AND name <> 1001;not in はその名の通り、羅列した要素のいずれとも合致していないという条件のため、
AND と<>で構成されることになります。このとき、<> NULLは0件で、AND演算なので、必ず0件になります。
タモリの目の色は何色なのか、画像から解析できませんでした。 ↩
- 投稿日:2019-05-23T14:35:50+09:00
何故、NULL は=で比較したらあかんのか
何故、NULL は = で比較したらあかんのか
新人さんたちは、不思議な値「NULL」でよく躓いてしまいます。
特に、教えていてアプローチに悩むのが、SQLの「IS NULL」という比較構文です。
私も、理解していない点が多くあったので、わからない点を纏めてみました。やさしい上級者の方は、恐れ入りますが間違いがあったらご指摘頂けますと幸いです…
また、この記事は、無職やめ太郎さんインスパイアです。経緯
教育を行っていた際、"where x = null"と記述した際、0件なのであれば、
"where x <> null"はなぜ全件じゃないの?と聞かれたことが発端でした。そこで、3値論理というワードを全く知らなかった自分のため、説明できるように噛み砕いた記事です。
また、NULLとは何ぞやといった点にアプローチ出来るためにこれからの新人さんたちに教えるために記述致しました。おはなし
むかしむかし(約2日前)、あるところにプログラム未経験の新入社員さんと、
講師の私がいました。新入社員さんは社内でSQL(Oracle Database SQL)のお勉強に日々勤しんでおり、
私はSQLの書き方を教えていました。ある日、where文でのNULL値の比較方法について教えていたときのことです。
~where文でのNULL値の比較方法を教えていた時~
私「NULLを比較したいときはis NULLを使うんやで」(※1)
新人「じゃあ、NULLを等価演算子(=)やIN,between等で比較したらエラーになるの?」
私「NULLを=,>,<等で比較したら、SQLは動くけど、結果は0件やで(なんでかわからんけど)」(※2)hogeテーブル
id name 1001 たろう 1002 じろう 1003 NULL SQL*Plus--※1のSQL例 SQL> SELECT * 1> FROM hoge 2> WHERE name is NULL; ID NAME ---- ----- 1003 NULL --※2のSQL例 SQL> SELECT * FROM hoge 2> WHERE name = NULL; レコードが選択されませんでした。
私「勿論、betweenも一緒で、0~NULLとかNULL~0のような比較の場合も0件やで」SQL*Plus--※SQL例 SQL> SELECT * FROM hoge 2> WHERE name between 0 and NULL; レコードが選択されませんでした。新人「じゃあ、INの中にNULLが入っている場合も0件になるの?」
私「INに関しては、NULLが入っていても、0件になるとは限らんで」
私「NULLであるレコードは取得出来ないけど、それ以外の指定された値は正常に取れるで」私「IN句でやってることをORで書き換えるとわかりやすいかな、書いてみるわ」
SQL*Plus--このSQLは1003のNULLさんは対象外となる SQL> SELECT * FROM hoge 2> WHERE name IN (NULL,1001); ID NAME ---- ----- 1003 NULL --INで記載されている内容と同等のSQL SQL> SELECT * FROM hoge 2> WHERE name = NULL -- NULL値を=で比較するため、こちらの比較結果は0件 3> OR name = "たろう"; -- 「たろう」に合致するレコードはあるので、1件返却される ID NAME ---- ----- 1001 たろう私「INの中に記載されたもの全てを、OR条件で比較するからこういったSQLと同等になるはず」
私「但し、= NULLのデータは存在しないので、1003番さんは帰ってこないんや」新人「なんとなく全容が解りました。多分、きっと、恐らく理解しました!」
私「うい。(なんやその自信のなさは…)」後日
新人「先生、実際に動かしてみて、何故か想定と違う動きをするんですが…」
私「ちょっと画面見せて?」SQL*PlusSQL> SELECT * FROM hoge 2> WHERE NOT(name = NULL); レコードが選択されませんでした。新人「name = NULLは全件、条件に対してfalseなんですよね?」
新人「その否定なので、trueになりませんか?」
新人「つまり、name <> NULLとかNOT(name = NULL)は全件取得になりませんか?」私「お、おう、せやったっけな…?(俺もそう思うんやけど、やばい、わからん)」
私「ちょっとお腹痛いからトイレ行ってくるわ、その後で説明するわ(とっとと調べよ)」3値論理を理解する
私「新人さんの言ってる通りや、なんで全件帰ってこないんや?」
私「そもそもそういえばなんで、NULLはis NULLで比較せなあかんのや…?」
私「とりあえず、isで比較する理由を調べたらそのうちわかるやろ(スマホで検索~)」siri「お前、5年生のくせに3値論理を正しく理解してないやろ」
siri「SQLの論理体系は3値論理に基づいてるんやで」1
私「なんや3値論理て」siri「そもそも、NULLってのは、①男性の出産回数とかみたいな適用出来ない値、」
siri「②タモリの目の色、みたいな確認できない未知の情報のときに使う印(≠値)なんやで」
私「それはわかる、人間テーブルで例えると、①前者は宇宙人の出身国~、②後者は一部アイドルの実年齢~みたいな感じとかやな?」siri「そこまで理解してるなら、よく考えたらわかるやろがい」
iPhone「NULLってのは値じゃないし、よくわからない不思議な印なんやで」
iPhone「よくわからない情報と比較する=よくわからない結果やで」私「確かに、タモリの目の色は黒?って聞かれたらわからんって答えるし、」
私「タモリの目の色は黒ではない色?って聞かれたらわからんって答えるな」2
私「そもそも、値として使っちゃ駄目という前提の地点で、上の例は破綻してるけど…」
私「つまり、true = falseはfalseやけど、true = nullはnullが帰ってくるわけやな」その後
私「かくかくしかじか、タモリが云々ってことで、NOT(name = NULL);も、name = NULLも0件やで」
新人「はい、理解しました(こいつ調べてきたな)」応用的な問題
私「ちゅうわけで、ちょっと応用になるけど、このSQLを実行した時の結果はどう出るかわかる?」
SQL*PlusSQL> SELECT * FROM hoge 2> WHERE name NOT IN(NULL,1001);新人「えと、要約するとINの中に入っていないデータを全部取得するんですよね?」
新人「つまり、書き換えると、こういう意味になる、といった認識であってますか…?」SQL*PlusSQL> SELECT * FROM hoge 2> WHERE name <> NULL 3> AND name <> 1001;私「せやな、いずれにも合致しないデータになるから、ANDで≠になるで」
新人「で、name <> NULLは結果として合致するデータはなくて、」
新人「AND演算子だからこれは0件になりますか?」私「正解、その解法であってるで」
かくして…
新人さんたちはSQLのNULLの比較方法を理解し、
その後のJavaで"is null"と記述し、コンパイルエラーになるのでした。
おしまい。
タモリの目の色は何色なのか、画像から解析できませんでした。 ↩
- 投稿日:2019-05-23T11:37:59+09:00
レガシープロジェクトを引き継いだ時、最初にするべき7つのこと
営業一課で使っている PHPアプリを保守してくれないかな?
○○さんが1人で作ってメンテしてたやつなんだけど皆さんは上司からこんな仕事を振られたことはないでしょうか?私は過去に何度か経験した1のですが、こういった仕事はなぜか:
- 正確な仕様を知っている人はいない(知ってた人は辞めた)
- テスト計画書・デプロイ手順書・仕様書といったドキュメントは無い
- ソースコードはもちろんスパゲッティ
- でも、業務ではガッツリ使われているので廃止できない
というレガシープロジェクトばかりでした。この記事では、レガシープロジェクトを引き継いでしまった時に、最初に何をするべきか書いていきたいと思います。
なお、ここで最悪なのは「とりあえず、緊急の不具合から直してしまおう」と、いきなりコードの修正にかかることです。
※なお、「レガシー」には様々な定義がありますが、この記事では「プログラマー1人 + 他数名が兼務で保守」「社員25人が使う社内アプリ」程度の規模のメンテ不良のプロジェクトを「レガシープロジェクト」と呼んでいます。なので「40年物の基幹COBOLシステム」とかは考慮していません。
なぜ、いきなりコードを修正してはいけないのか?
いきなりコードを修正すると誤った修正をしてしまう可能性が大です。
プロジェクトを担当して日が浅いあなたは、まだ正確な仕様を理解できていません。あなたが修正しようとしている「不具合」は本当に不具合なのでしょうか?また、ユーザーから「こういう不具合があるので直してください」と依頼される事がありますが、レガシープロジェクトはUIが難解だったりロクなマニュアルがなかったりするため、ユーザーは往往にして、
「〇〇さんにこうしろと言われたって、▲▲▲さんに聞きました」
「わかりません。私は前任者から引き継いだだけなんです」
「とにかく業務が回らないんです。ここを直せばいいだけなんですから」・・・なんて、仕様を理解せずに使っていたり、目先のトラブルを解決したいがためにアドホックな修正を提案してきたりします2。しかし、誤った修正をして後々矛盾に苦しむのはあなたです。
そして、コードの修正方法を判断できたとしても、普通の作業に(信じられないような)危険が伴うことが、レガシープロジェクトではありえます。私が過去に遭遇した例としては:
- 事例: 開発環境を作ろうと
rails db:setup3を実行したら、全エンジニアで共有している開発DBが初期化された- 事例: デバッグ中の開発版をテスト環境にデプロイしたら、利用者から大クレームが来た。実はテスト環境を業務で使っていた。
- 事例: デプロイしたら依存ライブラリのビルドが始まったが、なぜかビルドに失敗し、サービス停止5分の予定が結局30分間サービス停止した。
ただでさえ不具合山積みなのに、追加でトラブルを起こしては目も当てられません。また、このような環境では気が散ってコーディングのミスを犯す可能性も高まります。まず安全を確保することを優先してください。
最初にするべき7つのこと
とにかく、普通のことを普通にできる体制を整えましょう。
1. 協力者を確保する
プロジェクトを引き継いだら、まずプロジェクトに協力する人を確保してください。例えば以下のような人たちです:
- 前任者(まだ退職していなければ)
- コードレビュワー
- テストエンジニア
- インフラエンジニア
- ユーザーの代表者
- アプリの仕様を知っている人(ベテランユーザーなど)
この人たちとは、プロジェクトを回す上で遅かれ早かれ協力を仰ぐことになりますから、早いうちに抱き込んでおきましょう(Slackチャンネルを作るなど)。また、上司やユーザーと交渉をする時(「サーバー増設したい」「この機能を廃止したい」)に、1人より5人の方が何かとスムーズにいくでしょう。
2. 仕様をドキュメント化する
ユーザーに聞いたり、コードを読んだりして、アプリの仕様をドキュメントに書き出しましょう。
ここでは完璧な仕様書を目指す必要はありません。正確性・網羅性よりも、ともかくドキュメントを作ってしまうことが大事です。というのも、ドキュメントが無い状態では、用語が通じなかったり、事実ではなく想像に基づいて物を言ったりして、議論が迷走しがちになるからです。
ユーザー 「カレンダー通知を直してくれないか?急いでるんだ」
プログラマー「『カレンダー通知』って何ですか?僕の担当の『予定管理システム』関係ですか?」
ユーザー 「予約前日にユーザーにプッシュ通知するやつさ」
プログラマー「ああ、『前日メッセージ』ですね。あれを送信してるのは、予定管理システムじゃなくて、メッセージ画面ですよ?」
ユーザー 「えっ?メッセージ画面ってなに?」
プログラマー「あなたのチームのシステムです。そちらの、プログラマーに聞いてください」なんて。
目に見えるドキュメントがあれば「ここを変えましょう」と具体的で生産的な議論ができるようになります。
また、引き継ぎ直後の理解が浅い段階ではドキュメントに間違った記述をしてしまうこともあるでしょう。
しかし、ドキュメントならば、少なくとも誤りを見つけて訂正することはできます。ドキュメントが無い状態で(各々の頭の中の)誤解に気づいて訂正するのは、たいてい不可能です。3. テストやデプロイの手順書を作る
テストやデプロイは開発サイクル中に繰り返し行うものなので、ドキュメントに書き起こして安全・確実に実施できるようにすべきです。テストやデプロイは最終的には自動化するのが望ましいところですが、レガシープロジェクトでは手動でのテスト・デプロイすらおろそかになりがちです。まず手動での手順を整備しましょう。
テストならTestRailなどで管理するのがベターですが、無ければExcelでも構いません。とにかく、「管理されている状態」に持っていくことが大事です。
仕様と同様に、ドキュメント化されていることで、
- この機能のテストが足りていない
- このテストケースは重複している
- このテストケースは誤りだ
- このデプロイ手順はキャッシュを使って高速化できる
- この手順は簡単に自動化できるのではないか?
といった、品質についての議論や、
- 1日でテストを15件実施できたから、残り40件は3日で完了するはずだ
- A案は影響範囲が大きくてテストを50件実施する必要があるが、B案なら8件で済む
- Railsをアップデートすると、全テストに○人日かかるが、それだけの価値はある4
- デプロイに1回30分もかかるのは問題だ。機能追加より先に、デプロイ高速化に取り組もう
といった、工数配分についての議論ができるようになります。
また、テスト手順がドキュメント化されていれば、必要に応じてテスターを増員して短期間でテストできるようになります。
4. 不具合・機能をチケット管理する
レガシープロジェクトでは、不具合も足りない機能も山盛りになっているはずです。それらはRedmineなどのチケット管理ツールで、目に見える形で管理するようにします。チケットにすれば、
- 優先度を決める
- 大きな課題を、細かいチケットに分割する
- 全チケットが完了するまでのスケジュールを見積もる
といったことがしやすくなるし、タスクを忘れることも無くなります。
また、全体像が見えない状態だと、
「これは重要なんだ!今すぐやってくれ!」
と言われたとき、反論できず困ったことになります(言ってくる方も自身の職務上の責任があるわけですし)。一方、チケットが一覧されていれば、
「すみません。優先度:高のチケットが○件あるので、その後になります」
「〇〇さんの〇〇〇〇案件を後回しにすることになりますけど、交渉してきてもらえますか?」といった妥協をしやすくなります。
なお、チケット管理をExcelで行うことも可能ではありますが、専用のチケット管理ツールを使用することをお勧めします。Excelでチケット管理するのは、チケット番号を手動で振らなければならなかったり、チケットにコメントを付けにくかったり、更新時に関係者に共有する手間があったりして、不便が多いからです。
5. まともなテスト環境を用意する(できれば複数)
そのレガシープロジェクトにテスト環境はあるでしょうか?まれによくあることですが、
- 「テスト環境」と称する環境はあるが、本番環境とサーバー構成や設定が違ってしまっている(ので、不具合をテスト環境で見つけられない)
- テスト環境が無く、開発者のマシンで適当にテストした後いきなり本番適用するフローになっている(そしてバグる)
といった状況ではないでしょうか?ともかく「テスト環境が無い」では話にならないので、本番環境とできるだけ同じ設定のテスト環境を作りましょう。
なお、テスト環境を作る際には、サーバーを手動変更するのではなく、Ansibleなどの設定ツールを使うことをお勧めします。後々、複数案件を同時にテストしたり、自動テストを並列実行したりするのに、テスト環境が複数必要になることがあるからです。
6.CIツールを導入する(JenkinsやGitlab-CI)
レガシープロジェクトでは常に時間が足りなくなります。ボタン1個で、ビルド、ユニットテスト、リリース、コーディング規約チェックなどの定形作業をできるようにしてください。また、CIの形にしておくと、プロジェクトに新メンバーが参加したときの説明もしやすくなります(説明が「Jenkinsでビルドして」で済む)。
なお、Jenkinsは好きな場所に単独で建てることができる上、シェルスクリプトをコピペするだけでジョブが作れるので、おすすめです。
7. コーディングを楽にする
さて、ようやくコーディングに集中できる環境が整ってきました。しかし、レガシープロジェクトではソースコードが汚かったり、当たり前のツールが導入されていないことが多いです。人間の注意力は限られているので、本質的でない所で苦労していると、つまらないミスを犯す可能性が上がります。可能な限りのツールを導入しましょう:
- コーディング規約を自動チェックする(rubocop など)
- 脆弱性につながりうる書き方を自動チェックする(brakeman など)
- シンタックスシュガー言語を導入する(TypeScript, SCSS など)
- パッケージ管理する(bundler など)
- viではなくIntelliJなどのIDEを使う
- Dockerで開発用のDBを個人ごとに作れるようにする
- etc...
なお、ツールを導入するときは、
既存コードを変更せずに使えるか?(既存コードの問題点を無視できるか)
に注意してください。既存のコードを変更してしまうと、それによってエンバグしていないかテストが必要(大抵は全機能のテストが必要)になるからです。例えば、rubocop では
.rubocop_todo.ymlというファイルを生成すると、既存コードの問題点については一旦無視し、新規コードにのみチェックを行うようにできます。
今の職場がレガシープロジェクトだらけと言うわけではありません。最近はルールを整備したり、プログラマのレベルを上げたりしたおかげで、遭遇することは無くなっています。 ↩
ユーザーが仕様を理解しないことや、仕様の無矛盾性を考えないのは、普通のプロジェクトでもよくあります。そもそもユーザーにはそんな責任はありません(仕様に責任を持つのはプログラマーやマネージャの仕事)。ですが、レガシープロジェクトでは、基本機能の名前すら通じないレベルのケースもままあります。 ↩
rails db:setupはRailsの開発用のコマンドで、普通はローカルマシンにSQLite3のファイルを作成します。 ↩これがテストが管理されていないと、「全機能テストなんて何日かかるか分からない!Railsをアップデートより、それより目先の機能だ!!」となりがちです。 ↩
- 投稿日:2019-05-23T01:43:44+09:00
「プログラミング言語」について知っておいてほしいこと
「プログラム言語」に関しては、おすすめ、人気、学ぶべきもの、どれがイケているかの順位付け議論が盛んに行われていて、新人プログラマはどの言語を学べばいいか、迷ってしまい、結局モチベーションが上がらないことも多いと思います。
どのプログラミング言語を勉強するかを順位づけする前に、そもそもプログラミング言語とは何かを考えるのはどうでしょうか?
はじめに(参考記事)
おすすめのプログラミング言語を紹介する記事
人気のプログラミング言語を紹介する記事
学ぶべきプログラミング言語を紹介する記事
どれがイケてるかに関するポエム記事
プログラミング言語とは
「プログラミング言語」を、プログラミング言語で書かれたコードと混同していませんか?
wikipediaには
コンピュータプログラムを記述するための形式言語である
と記載されていますが、
コンピュータ・プログラミング言語の設計は「言語仕様」として示され、実装は「言語処理系」と呼ばれる。
とも記載されています。
狭義のプログラミング言語と広義のプログラミング言語を混同していると、プログラミング言語の違いが分かりにくくなります。「プログラミング言語」が示すものは、範囲によって、次の4段階に分かれると思います。
level1: 言語仕様
level2: 言語仕様 + 言語処理系
level3: 言語仕様 + 言語処理系 + ライブラリ管理/ライブラリ
level4: 言語仕様 + 言語処理系 + ライブラリ管理/ライブラリ + 開発環境/開発コミュニティwikipediaでは、level2までを「プログラミング言語」としていますが、紹介した記事では、level1~level4が混じっていることに注意しましょう。「プログラミング言語」でlevel1のみを想像した人は、上記の記事を読んでも消化不良になると思います。
各範囲を意識すると順位付けはどうなるのか?
おすすめ、人気、学ぶべきもの、どれがイケているかではなく、プログラム言語を評価する目的からlevel1~level4のどの観点を重視して評価すべきかをまず決めましょう。
ざっくりと、下記のような感じになると思います。
人気(シェア) ⇒ level4
人気(学術的な議論) ⇒ level1
業務(チーム開発)で使用する ⇒ level4
特化したものが必要 ⇒ level3みたいになると思います。(もちろん、一意に決まるわけではないですが)
なお、初学者の目的(プログラミングを理解する)はlevel1~level4のどの観点でを重視して評価すべきでしょうか?
私の個人の意見では、すでに作成物までを具体的に見据えてプログラミングを勉強する場合を除けば、level2が妥当だと思います。(level3以降の理解は1年程度の学習が必要だと考えます)
その際に最初に紹介した記事の内容が参考になりますか?学習曲線について
文科省のPythonはPythonじゃねぇの参照記事に下記の記載がありました。
プログラミング言語は「Python」を採用しているが、多くの学校現場で使われている「JavaScript」や「VBA」「Swift」「ドリトル」などの言語で記述した場合の資料も順次公表する。
上記の記載で違和感があったのは、これらのプログラミング言語の違いは、level2以降の観点で顕著になると思うのですが、level1の観点の教育で複数のプログラム言語の書き方の違いだけをピックアップして、意味があるのでしょうか?
個人的には、教育では導入時にlevel1からlevel4までの観点の違いがあることを明記したうえでプログラミング言語の違いを説明してほしいのですが、あまりそのような議論を見たことがありません。
なお、level3以降の観点でプログラミング言語を理解している人にとっては、「プログラマーは新しい言語を毎年1つは習得するべきだ」というのが腑に落ちるのだと思います。
プログラミング言語の議論について
プログラミング言語を説明する際には、下記のようなものはどうでしょうか?
・チーム開発で使用したいか?(Level4)
・今ある特定の目的のものが達成できるか?(Level3)
・50年前の過去に持ち帰って広めたい言語は何か?(Level2)
・300年後にタイムトラベルで送り出す人に薦めたい言語は何か?(Level1)いかがでしたか?
私は、50年前には「go」を持ち帰り、300年後にトラベルするために「ruby」を勉強したい凡人です。
※本記事は「タグ説明」タグを付与した記事です。
https://qiita.com/j5c8k6m8/items/2359627ff8c3778d95f6