- 投稿日:2019-05-23T23:52:28+09:00
AWS Cloud9、踏み台経由設定でのハマりポイント
ブラウザ上で使えるクラウドIDE「aws cloud9」の実行環境を、ssh経由のサーバーで稼働させ、かつ踏み台経由で接続する設定の場合に一つハマったので、知見を共有しておきます。
開発環境が一通り入っているサーバーを外のネットワークに直に晒すのは気持ち悪いので、awsのpublic subnetにある踏み台とprivate subnetにある実働サーバーというよくある構成を考えます。
ここでsshの踏み台にするec2インスタンス(以下サーバーA)、Cloud9を実際にホストするec2インスタンス(以下サーバーB)とも、aws EC2の現時点でのデフォルトOSであるamazon linux2で仮想マシンを生成しておきます。
(awsのVPCやサブネットの構築などについてはすでに知っている前提とします)また、サーバーBにはCloud9が要求する開発ツール類を事前に一通り入れておきます。
sudo yum update -y
sudo yum groupinstall -y "Development Tools"
sudo yum install -y glibc-static
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.34.0/install.sh | bash
. .bashrc
nvm install v10
ここから、新規にCloud9の接続設定を作ります。
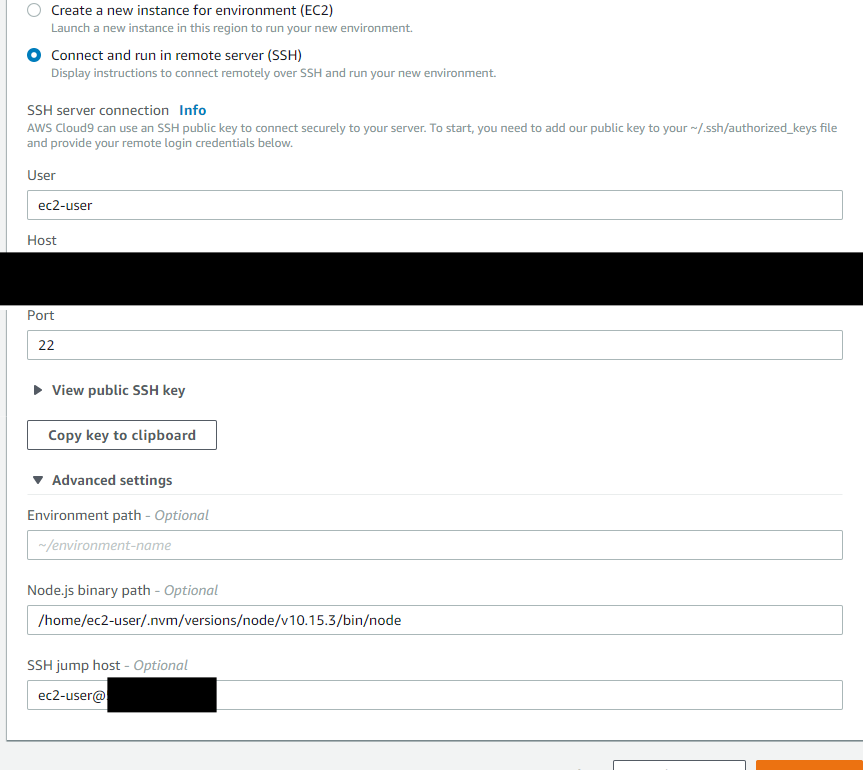
サービス一覧からCloud9を選択、"Create environment"で適当に環境名を指定して"Next step"をクリックして設定画面に移行。
今回はSSH接続にしたいのでEnvironment typeは「Connect and run in remote server (SSH)」を選択。ユーザー名、サーバーBのローカルIP、ポート番号を入力。
また、"Copy key to clipboard"でコピーした公開鍵を、この時点でサーバーA、サーバーBとも、
~/.ssh/authorized_keysに追加しておきます。
続いてAdvanced settingsを開き、"SSH jump host"の項目に
踏み台にするホストAのユーザー名とIPを設定します。
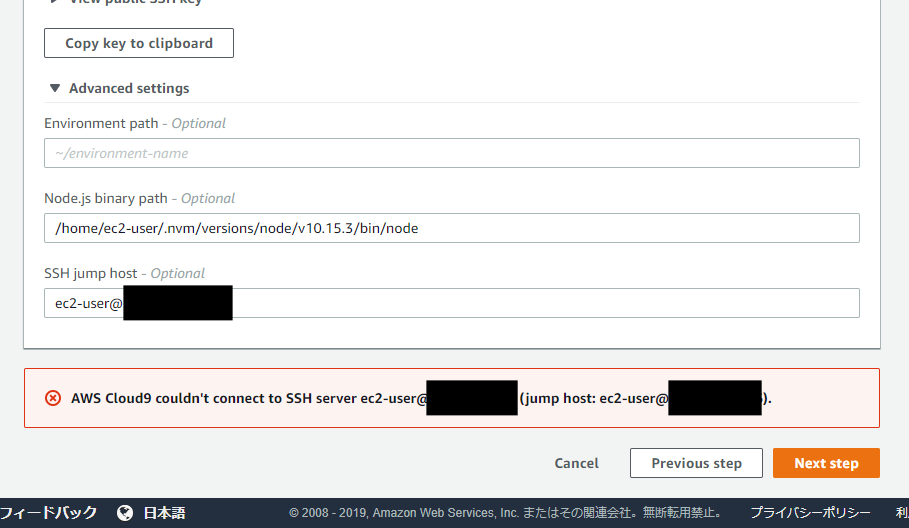
これで下の"Next step"ボタンをクリックすると(ちょっとスクリーンショットのキャプチャ範囲が見切れていますが)確認画面に進むはずが、なぜか「AWS Cloud9 couldn't connect to SSH server」と出て進めません。
ここから先に進めずにしばらく無駄に時間を費やしたのですが、AWSのディスカッションフォーラムに答えがありました。
https://forums.aws.amazon.com/thread.jspa?messageID=872411&tstart=0The Amazon Linux 2 AMI does not come pre-installed with one of the Cloud9 SSH required packages nc/netcat. I manually installed the nc package (sudo yum install nc -y) on the Jump Host instance which resolved the Cloud9 SSH connection issue. An alternative would be to use the Amazon Linux 1 AMI as my Jump Host instance.
amazon linux 2の初期状態では、nc(netcat)コマンドが入っていないために踏み台経由の初期化処理を実行できない、というのが原因でした。
そこでサーバーAで
sudo yum install -y ncを実行し、もう一度"Next step"をクリック。
今度は無事設定確認画面に進んだので、あとはクリックして進めていくだけでOK。
無事Cloud9が起動しました。
同じawsの中なのに、意外なところでハマるもんですね。

- 投稿日:2019-05-23T23:07:10+09:00
AWS CodeStarで後からgitリポジトリを変更する
DevOps環境を一発で用意してくれるCodeStar。詳細はここでは省略。
https://aws.amazon.com/jp/codestar/GitHubかCodeCommitにリポジトリも作成するけどこの時既存リポジトリは選択できない。
必ず新規に作成するしかない。
選択できても色々と設定ファイルがないとデプロイできないので仕方ない仕様。
先に設定ファイルを準備すれば変更はできる。既存リポジトリ側の準備
新規に作成したリポジトリから設定ファイルを持ってくる。
例えばLaravelのプロジェクトテンプレートで作るとこれが作成される。Laravel5.3なので古いけど普段見ない設定ファイルがあるのが分かる。
https://github.com/kawax/codestar-php-laravel
- appspec.yml : CodeDeploy用のファイル。
- scripts/ : appspec.ymlから実行してるスクリプト。
- buildspec.yml : CodeBuild用のファイル。template-configuration.jsonはここで必要。
- template.yml : CloudFormation用のファイル。
必要ならそれぞれ変更。
CodeStarの変更
実際にはCodePipelineの設定。
なお、設定変更するにはIAMの権限が必要。管理者以外でエラーが出た場合は権限の設定してもらうしかない。
CodeStar使おうとするとこれ以外にも色々権限が必要になる。
https://dev.classmethod.jp/cloud/aws/iam-pass-role/CodeStarダッシュボードからスタート
↓
「継続的デプロイメント」タイル
↓
「パイプラインの編集」
↓
CodePipeline。一番上「編集する:Source」部分の「ステージを編集する」
↓
えんぴつマーク?っぽい編集ボタン
↓
「GitHubに接続する」から既存リポジトリとブランチを選択。
↓
保存していって最終的に「変更をリリースする」。設定ファイルを間違えてなければデプロイされるはず。
変更してもCodeStarダッシュボード側には反映されない。
終わり
CodeStarは今調査してるので色々あるけど今回はこれだけ。
自分で見るならCodeStar使う必要はないけど
他社のAWSで自分がずっと見るわけでもなく詳しい人がいない状態の場合、CodeStarから始めるのがたぶん一番簡単。
ブラックボックスな独自AMIでPHPのバージョンアップもできないような状態ではどうにもならない。CodeStarから始めるとDevOps環境一式を全部用意してくれる。
AMIは素のAmazon Linux。PHPのインストールなどはスクリプトでやってるのでバージョンアップでもなんでもできる。
AWSリソースもCloudFormationで設定。
ほとんどのことをリポジトリに含める設定ファイルで管理できる。他社のAWSを一から調査するとどこで何を使ってるかが分かりにくいのでこれだけ見ればいいと言えると後で楽。
- 投稿日:2019-05-23T21:50:45+09:00
AWS認定Big Data勉強記 - 8.2: Kinesis Data Firehose
こんにちは、えいりんぐーです
今回は Amazon Kinesis Data Firehose についてまとめます。
参考資料
- Black Beltオンラインセミナー資料
- 公式ドキュメント
- ブログ
- YouTube
全般
- ストリーミングデータをデータストアや分析ツールにロードするサービス
- ストリーミングデータをキャプチャして変換し、Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、Splunk にロードする
- このプロセスを管理するのに、ハードウェアとソフトウェアのプロビジョニング、デプロイ、継続的なメンテナンスについて管理したり、その他のアプリケーションを記述する必要がない
- 同じ AWS リージョン内にある 3 つの拠点でデータが同期的に複製されるため、データ転送時の高い可用性と耐久性を提供する
- 各配信ストリームで、毎秒 2,000 件のトランザクション、毎秒 5,000 件および毎秒 5 MB のレコードの取り込みが可能
概念
- ソース
- ストリーミングデータが継続的に生成され、キャプチャされるところ
- Amazon EC2 インスタンスで実行中のロギングサーバー、モバイルデバイスで実行中のアプリケーション、IoT デバイスのセンサー、Kinesis のストリームなど
- 配信ストリーム
- Kinesis Data Firehose の基盤となるエンティティで、そこにデータを送信することにより、Firehose を利用できる
- レコード
- データ生成元からストリームに送信される処理対象のデータで、最大サイズは Base64 エンコーディング前で、1,000 KB
- デスティネーション
- データが配信されるデータストアで、現在サポートされているデスティネーションは、Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、Splunk
使い方
配信ストリーム
- Amazon S3 への配信前にデータを圧縮できる。GZIP、ZIP、SNAPPY の圧縮形式がサポートされている。さらにデータを Amazon Redshift にロードする場合は、GZIP のみがサポートされている。
- Amazon S3 バケットに送信されるデータを暗号化できる。配信ストリームを作成する際に、お客様が所有する AWS Key Management Service (KMS) キーによるデータの暗号化を選択できる。
- CloudWatch Logs のサブスクリプション機能を使用すると、CloudWatch Logs から Kinesis Data Firehose にデータをストリーミングできる。CloudWatch Logs のすべてのログイベントは、既に gzip 形式で圧縮されている。
- AWS Lambda 関数を呼び出すことで、受信データを変換してから送信先に送信することができる
- Lambda 関数によるデータ変換を使用する場合、Firehose では Lambda 呼び出しとデータ配信のすべてのエラーを Amazon CloudWatch Logs のログに記録できる。Lambda 呼び出しまたはデータ配信が失敗した場合、ユーザーは特定のエラーログをそこで確認できる
- ソースレコードバックアップ
- Lambda 関数によるデータ変換を使用する場合、ソースレコードバックアップを有効にすると、Amazon Kinesis Data Firehose で未変換の受信データは別の S3 バケットに送信される
- バッファサイズとバッファ間隔
- 受信ストリーミングデータを送信先に配信する前に、一定のサイズにバッファするか、一定の時間にバッファできる。バッファサイズとバッファ間隔は、配信ストリームの作成時に設定する
- バッファサイズは MB 単位で、送信先が S3 の場合は 1 MB~128 MB で、送信先が Elasticsearch Service である場合は 1 MB~100 MB
- バッファサイズはデータ圧縮前に適用される。
- バッファ間隔は、60 秒から 900 秒の間で 1 秒ごとに設定できる。送信先へのデータ配信が配信ストリームへのデータ書き込みより遅くなった場合、Firehose では、すべてのデータが送信先に配信されるように、バッファサイズを動的に拡大して遅れを取り戻す
- Redshift
- 送信先の Redshift クラスターが VPC 内にある場合は、VPC から Firehose の IP アドレスのブロックを解除して、Kinesis Data Firehose から Redshift クラスターにアクセスできるようにする必要がある
- Redshift を送信先として選択した場合、Kinesis Data Firehose ではまず S3 バケットにデータが送信される。その後 Redshift COPY コマンドが実行され、S3 バケットから Redshift クラスターにデータがロードされる
- Elasticsearch Service
- Kinesis Data Firehose では、Amazon Elasticsearch Service インデックスを一定の期間でローテーションさせることができる。
- なんのこっちゃ
- Amazon Elasticsearch Service にデータをロードする際に、すべてまたは配信に失敗したデータのみをバックアップでき、この機能を利用してデータの損失を防ぐために、バックアップ用の Amazon S3 バケットを用意する必要がある
データ準備と時間
- Lambda 関数で変換されたすべてのレコードは、以下の 3 つのパラメータと共に Firehose に戻す必要がある
- recordId: Lambda 関数の呼び出し中、recordId は各レコードと共に Firehose から Lambda 関数に渡される
- result: 各レコードの変換結果のステータス
- "Ok": レコードが期待どおり正しく変換された場合
- "Dropped": ユーザーの処理ロジックによりレコードが期待どおりドロップされた場合
- "ProcessingFailed": レコードを期待どおりに変換することができなかった場合
- data: based64 エンコード後の変換済みデータペイロード
- ユーザーがデータ変換用の Lambda 関数を作成するために使用できる設計図
- 一般的な Firehose 処理: 上記のデータ変換およびステータスモデルが含まれる。この設計図はあらゆるカスタム変換ロジックに使用
- Apache ログから JSON: Apache ログ行を解析して JSON オブジェクトに変換し、事前定義された JSON フィールド名を使用
- Apache ログから CSV: Apache ログ行を解析して CSV 形式に変換
- Syslog から JSON: Syslog 行を解析して JSON オブジェクトに変換し、事前定義された JSON フィールド名を使用
- Syslog から CSV: Syslog 行を解析して CSV 形式に変換
データの追加
- 配信ストリームにデータを追加するには、Amazon Kinesis Agent や Firehose の PutRecord オペレーションや PutRecordBatch オペレーションを使用
- Kinesis Agent
- データを収集して配信ストリームに送信する機能を実現する Java アプリケーション。Linux 上で動く
- AWS コンソールまたは Firehose API によって配信の作成や更新を行っている場合、Kinesis ストリームを配信ストリームのソースとして設定でき、設定が完了すると、Kinesis ストリームから Firehose によって自動的にデータが読み取られ、指定された送信先にロードされる
- Kinesis Data Firehose では、各 Kinesis シャードにつき毎秒 1 回 Kinesis Data Streams GetRecords() が呼び出される
- 配信ストリームのソースに Kinesis データストリームが設定されている場合、Kinesis Data Firehose では LATEST 位置からデータの読み取りを開始
- Kinesis Data Streams が Firehose 配信ストリームのソースに設定されると、Firehose の PutRecord オペレーションと PutRecordBatch オペレーションが無効になる
- CloudWatch Logs から Firehose 配信ストリームにデータを追加するには、配信ストリームにイベントを送信する CloudWatch Logs サブスクリプションフィルターを作成する
データ配信
- UTC 時間のプレフィックスを YYYY/MM/DD/HH 形式で追加してから、Amazon S3 にオブジェクトが送信される
- S3 オブジェクト名の命名規則は、DeliveryStreamName-DeliveryStreamVersion-YYYY-MM-DD-HH-MM-SS-RandomString で、DeliveryStreamVersion は 1 から始まり、配信ストリームの設定が変更されるたびに 1 ずつ増加
- 送信先が Redshift の場合、S3 オブジェクトを Redshift クラスターにまとめてロードするために、Kinesis Data Firehose にマニフェストファイルを作成
- 単一の配信ストリームがデータを配信できるのは単一の Amazon S3 バケットに対してのみ
- 単一の配信ストリームがデータを配信できるのは単一の Amazon Redshift クラスターまたはテーブルのみ
- 単一の配信ストリームがデータを配信できるのは単一の Amazon Elasticsearch Service ドメインおよびインデックスのみ
トラブルシュート
- S3 バケットへのデータ配信が失敗した場合、Amazon Kinesis Data Firehose では、最大 24 時間 5 秒ごとにデータの配信が再試行され、24 時間の保持期間が経過しても問題が継続する場合、データは破棄される
- Redshift クラスターへのデータ配信が失敗した場合、Amazon Kinesis Data Firehose では、最大 60 分間 5 分ごとにデータの配信が再試行される。スキップされたオブジェクトに関する情報はエラーフォルダ内のマニフェストファイルとして S3 バケットに送信されるため、手動によるバックフィルに使用できる
- 送信先が Amazon Elasticsearch Service である場合、デリバリーストリームの作成時に 0~7200 秒の間再試行期間を指定することができる。Amazon ES ドメインへのデータ配信が失敗した場合、Amazon Kinesis Data Firehose では、指定された期間にデータ配信が再試行される
- Lambda
- ネットワークのタイムアウトに到達して Lambda の呼び出し制限に達したなどの理由で関数の呼び出しが失敗する場合
- この失敗シナリオでは、Firehose はデフォルトで呼び出しを 3 回再試行し、そのあと問題のレコードのバッチをスキップします。スキップされたレコードは処理失敗レコードとして扱われる
- 呼び出しの再試行回数は、CreateDeliveryStream API および UpdateDeliveryStream API を使用して 0 から 300 の間で設定できる
- このタイプの失敗では、Firehose のエラーログ機能を使用して、呼び出しエラーを CloudWatch Logs に書き出すことができる
- レコードが Lambda 関数から返されるときにレコードの変換結果が "ProcessingFailed" に設定される場合
- これらのレコードは処理失敗レコードとして扱われる
- Lambda 関数のログ機能を使用して、エラーログを CloudWatch Logs に書き出すことができる
- どちらのタイプの失敗シナリオでも、処理失敗レコードは S3 バケットの processing_failed フォルダに送信される
- 投稿日:2019-05-23T21:35:09+09:00
Route53ResolverをCloudFormationで作ろう
概要
こんにちは、kuwana-kbです。業務でAWSの Route 53 Resolver を使用する機会がありました。
今回は簡単な解説とCloudFormationのテンプレートを紹介したいと思います。Route53Resolverとは
Route 53 Resolverは、AmazonVPCとオンプレ間の名前解決を簡単にしてくれるサービスです。AmazonVPCとオンプレという条件があるため、このサービスを利用するケースとしては、基本的にDirectConnectやVPNを利用しているのが前提になると思います。個人だとあまり使う機会がなさそうな印象ですね。
以下に、公式説明を引用します。Amazon VPC とオンプレミス両方のリソースを使用するワークロードを実行しているお客様は、オンプレミスでホストしているプライベート DNS レコードも解決する必要があります。同様に、これらのオンプレミスのリソース側で、AWS でホストしている名前を解決する必要がある場合もあります。そのようなお客様が、名前がホストされている場所に関係なく、Route 53 Resolver のルールとエンドポイントを使用して双方向のクエリ解決を実行できるようになりました。
引用元:ハイブリッドクラウドの DNS を簡素化する Amazon Route 53 Resolver を発表少しイメージしにくいかもしれないので、次に具体的なケースを挙げてみたいと思います。
解決したかった課題
今回解決したかった課題は以下になります。
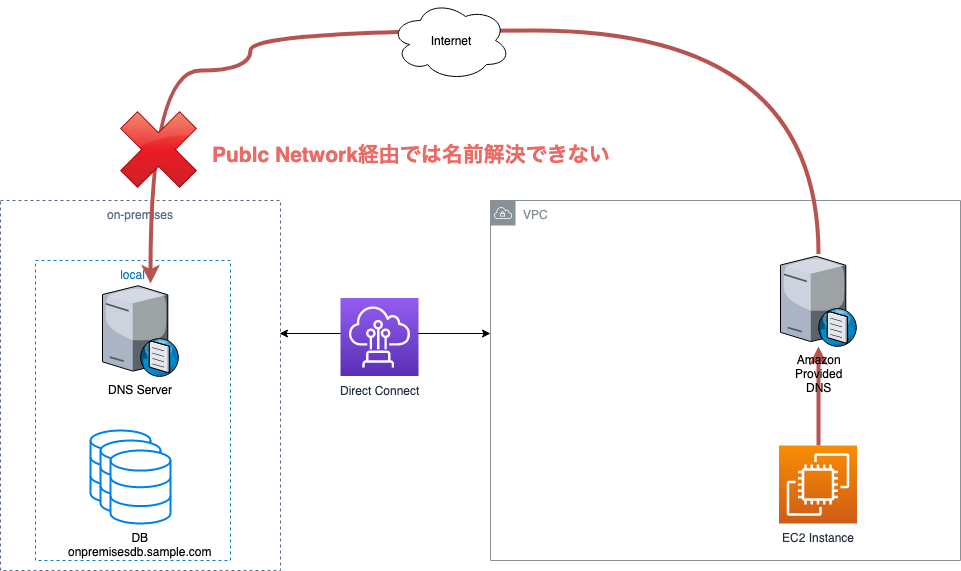
- オンプレのDBである
onpremisesdb.sample.comに対して、AWSのインスタンスからSQLを投げたい。- しかし、
onpremisesdb.sample.comのDNSレコードはオンプレ上の内部DNSにしか存在せず、Public Network経由では名前解決できない。 ※onpremisesdb.sample.comは架空のドメインです。サービスが「AWSとオンプレの2環境で運用している」や「オンプレからAWSへの移行途中である」といった背景があると、このような課題に直面するかもしれません。この課題を解決するために、Route53 Resolverを使用します。
解決方法
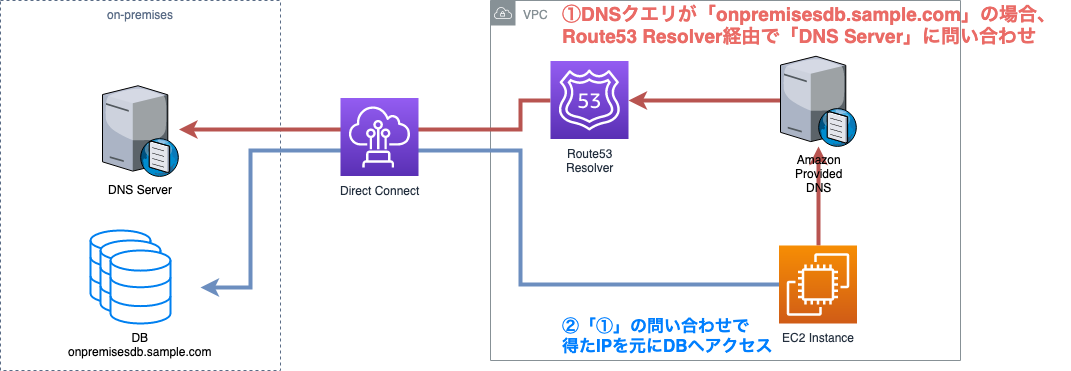
今回の解決方法は以下のような流れになっています。
1. VPC内のDNSクエリがonpremisesdb.sample.comの場合、Route53 Resolver経由でオンプレのDNS Serverに問い合わせる
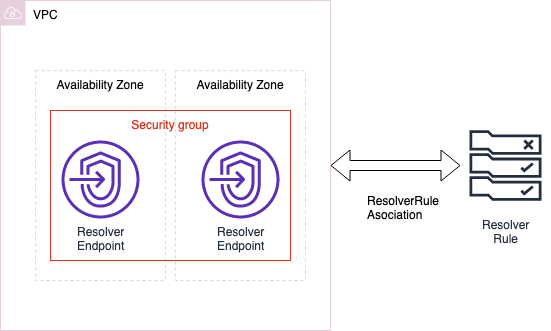
2. 「1」の問い合わせで得たIPを元にDBにSQLを投げる図にすると以下のような流れになります。
「1」の動作でRoute53 Resolverを使用しています。
CloudFormationでRoute53 Resolverを作ろう
では、実際にCloudFormationでRoute53 Resolverを作ってみましょう。
今回使用するテンプレートで、作成するリソースは以下の4つになります。
- ResolverEndpoint用のセキュリティグループ
- ResolverEndpoint
- ResolverRule
- ResolverRuleAssociation
図にすると以下のような形になります。(VPCとAZは作成されません)
各リソースの役割はおそらく以下のようになっています。(ちょっと自信ない)
- ResolverRuleで転送したいドメインと転送先DNSの判断をする
- ResolverEndpointがResolverのエンドポイントとなる
- ResolverRuleAssociationがResolverRuleとVPCを紐付ける(なぜ必要なのかはよくわからない…)
- セキュリティグループでResolverEndpointへのアクセスできる対象を絞る
具体的なパラメータについては、テンプレート内にコメントで記載しています。
CloudFormationテンプレート
Resolver.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Create Route53Resolver Resources: # ---------------------------------------------------------------------- # # リゾルバエンドポイント用のセキュリティグループ # 対象となるVPCからのDNSクエリ(port53)のみ受け付ける # ---------------------------------------------------------------------- # ResolverEndpointSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: resolver-endpoint-sg GroupDescription: Security group for resolver endpoint. This only allows DNS query from VPC. SecurityGroupIngress: - CidrIp: 172.0.0.0/16 #endpointへのアクセスを許可するIPを記載する。VPCに限定する場合はVPCのCIDRブロックを書く FromPort: 53 ToPort: 53 IpProtocol: tcp - CidrIp: 172.0.0.0/16 FromPort: 53 ToPort: 53 IpProtocol: udp SecurityGroupEgress: - IpProtocol: '-1' #アウトバウンドはすべての通信を許可 CidrIp: 0.0.0.0/0 Tags: - Key: Name Value: resolver-endpoint-sg VpcId: vpc-xxxxxxxx #sgと紐付けるVPCのIDを記載する # ---------------------------------------------------------------------- # # DNSリゾルバのエンドポイント # ---------------------------------------------------------------------- # ResolverEndpoint: Type: AWS::Route53Resolver::ResolverEndpoint Properties: Direction: OUTBOUND #AWS環境からオンプレ環境へDNSクエリを投げたいのでOUTBOUNDに設定 IpAddresses: - SubnetId: subnet-xxxxxxxx #endpointを設置するsubnetIDを記載する。 - SubnetId: subnet-yyyyyyyy #リゾルバーの信頼性を高めるため、別々のAZに設置された2つ以上のサブネットIDを指定すること Name: resolver-endpoint SecurityGroupIds: - !Ref ResolverEndpointSG # ---------------------------------------------------------------------- # # DNSリゾルバのルール # DB(onpremisesdb.sample.com)宛のDNSクエリだった場合に、オンプレのDNSにクエリを転送する # ---------------------------------------------------------------------- # ResolverRule: Type: AWS::Route53Resolver::ResolverRule Properties: DomainName: onpremisesdb.sample.com #転送したいドメイン名を記載する Name: test-resolver-rule ResolverEndpointId: !Ref ResolverEndpoint RuleType: "FORWARD" TargetIps: - Ip: 10.10.10.10 #オンプレのDNSのIPを記載する Port: 53 # ---------------------------------------------------------------------- # # リゾルバとVPCをつなぐためのリソース # マネジメントコンソールでは、このリソースは自動で作成される # ---------------------------------------------------------------------- # ResolverRuleAssociation: Type: AWS::Route53Resolver::ResolverRuleAssociation Properties: Name: resolver-rule-association ResolverRuleId: !Ref ResolverRule VPCId: vpc-xxxxxxxxRoute53 Resolverはマネジメントコンソールから手動で設定することも可能です。ただ、設定をコード化してバージョン管理した方が変更を追いやすく管理しやすいので、今回はCFn化しました。テンプレートについては、必要最小限の記述にとどめているため、適宜
ParametersやMappings等を使って最適化してください。Route53 Resolver以外の解決方法について
今回はRoute53 Resolverを用いた解決方法をご紹介しました。しかし、Route53のPrivate Hosted Zoneを用いることでも今回のケースに(一応)対応することができます。
どういう方法かというと、オンプレの内部DNSのレコードをAWSのPrivate Hosted Zoneでも保持するという方法です。しかし、この方法だとオンプレの内部DNSレコードに変更がある度にPrivate Hosted Zoneのレコードの修正が必要になります。Route53 Resolverを用いた方が運用コストがかからないので、Route53 Resolverを採用した次第です。
参考資料

- 投稿日:2019-05-23T19:27:49+09:00
【参加レポート】ワークショップで学ぶ、今日から始められる AWS セキュリティサービス
ここから始めるAWSセキュリティ 〜リスク可視化と分析による 継続的セキュリティ の実現〜
リスク可視化と分析による 継続的セキュリティ の実践
登壇者:桐山隼人さんセッションの目的
AWS環境におけるセキュリティ対策を
「まず、何から始めたらいいの?どこまでやったらいいの?」から脱出する。継続的セキュリティ Continuous security(CS)
Continuous security (CS) is itself a distinct pillar with standalone best practices that cross all of the other pillars.
- All information security platforms that are in use expose full functionality via APIs.
- Immutable infrastructure mindsets are adopted to ensure production systems are locked down.
- Security controls are automated so as not to impede DevOps agility.
- Security tools are integrated into the CI/CD pipeline.
- Source code for key intellectual property on build or test machines are only accessible by trusted users with credentials. Build and test scripts do not contain credentials to any system that has intellectual property.
- External penetration tests (done out of band) are scheduled either periodically or on a regular cadence are used to perform deep-dive analysis.
- Telemetry from production security controls such as WAF and RASP are delivered back to development teams to inform application updates.
- Accurate inventory of all software packages and version information is documented via infrastructure as code. Automated detection is used to identify whether any of the packages have known CVEs associated and define specific remediation actions.
https://devops.com/9-pillars-of-continuous-security-best-practices/ より
継続的セキュリティをやる意義
- 環境変化適応
- セキュリティ対策は実施した瞬間から危殆化する
- 実施した瞬間から、少しずつ時代遅れになってくる
- スピード
- セキュリティ侵害は攻撃側の方が早い
- 攻撃側は金銭などにモチベーションが高いので手法を取り込んでくる
- コスト最適化
- リスクベースのアプローチで考える
- セキュリティ障害は経営の脅威になる
- 予算をどの程度つけるかは決裁者次第。予算を検討すると青天井になる。一方で何も起きなければ、「無駄」に思われてしまう。
- リスクが高いものほど、お金をかけていく。
セキュリティリスクの方程式
リスク = 脅威 x 脆弱性 x 情報資産
- 脅威
- 手法
- 標的型攻撃
- マルウェ
- サイバー攻撃
- 対策
- 異常検知
- 脅威インテリジェンス
- AWSのソリューション
- 脆弱性
- 要因
- セキュリティホール
- 設定ミス
- 心理的要素
- 対策
- 脆弱性診断
- ベンチマーク評価
- AWSのソリューション
- 情報資産
- 対象
- 機密情報
- 個人情報
- 知的財産
- 対策
- ユーザ振る舞い分析
- 情報漏洩防止
- AWSのソリューション
- 保護対象の特徴
- 変更が可能なもと不可能なもがある。
- 指紋や虹彩などの生体情報は変更不可能
- クレジットカード番号は変更可能
- 変更不可能な情報資産はupdateできない前提で考えなければならない。
AWSのソリューション
Amazon GuradDuty 継続的監視と脅威検知
- 機械学習を利用したクラウドネイティブな脅威検知
- 脅威の種類
- 悪意のあるポートスキャン
- 総当たり攻撃
- インスタンスへの脅威
- Command&Controlサーバとの通信
- EC2インスタンスに侵入されてしまい、第3者の攻撃に利用されている
- 入力ソース
- VPC Flow Logs(VPC内の通信元/先)
- DNS Logs(DNSサーバへの問い合わせ)
- CloudTrail
Amazon Inspector - プラットフォーム脆弱性分析
- EC2にエージェントをインストールして、インスタンスの脆弱性を診断する。
- CVEやCISベンチマークに基づいたリスク評価
- エクゼクティブサマリー含めた評価レポート
- Amazon Inspectorのルールパッケージ
- ホスト評価のルール
- CVEに基づく一般的な脆弱性
- CIS Operating System Security
- ネットワーク到達性
- 自分で意図したネットワーク設計になっているのか。
- PCI DSS
- インターネットに接してるかでセキュリティ対策の評価が変わってくる。
- 自動推論にる評価 - 「設定内容」 と 「ネットワークの設定内容のスナップショット」で評価する
- 実際にパケットを飛ばしている訳ではない。設定から推定する
Amazon Macie - 事業価値のあるデータを保護
- 継続的監視によるデータ漏洩のリスクを評価する
- 現在(2019年5月23日)は北バージニアとオレゴンのみ
Amazon Security Hub
- 現在(2019年5月23日)はプレビュー版
- 上の3つを一元的ににアクセスできるダッシュボードを提供する。
まずはここから
- 全リージョンで GuardDutyを有効化
- InspecorでEC2インスタンスを評価
- Macie で S3にある重要データの棚卸し
- Security Hub で可視化
- AWS Configで全リソースの設定変更記録を開始
- Securty Hub で Compliance Standardsを有効化する
- セキュリティ管理アカウントで組織全体を監視する
- Securitie HubのカスタムアクションでFindingsの追加
リスクベースアプローチで優先順付け
- 現時点のリスクの偏在を監視
- ベースラインアプローチ
- 企業のルール / 業界のルール からの逸脱を評価する
- AWS Config で管理する。 Security Hubからアクセスできる
- AWS Config
- 元々はAWSリソースの構成管理/変更記録のサービス
- ルールから逸脱した時に、過去の履歴がないと、「いつから」の問いに答えられない
- 逸脱した時に検知したことを通知してほしい
ガバナンス
- 監視と評価に基づく意思決定と指示
- AWS organizations を使う
最初のAWSアカウントは1つだけど、事業ごとに、サービスごとにアカウントが増えていく。それらを管理しなければならない。
- Landing Zone で管理する
マルチアカウント戦略
- 目的が違うアカウントは分ける。目的を分ける方が新技術を投入しやすい
- アカウントの種類
- マスターアカウント
- 支払い
- 共有サービスアカウント
- 事業に必要なサービスが稼働する
- ログ管理用アカウント
- 他のアカウントで出力されたログを集める
- 何もなければアクセスすることが少ない
- セキュリティアカウント
- セキュリティ管理者への通知
ワークショップ
- 資料
- https://scaling-threat-detection.awssecworkshops.jp
- 大事なこと
- セキュリティ障害の最大要因
- 人間こそが間違いを起こすのです。善意の人であっても人間です。騙されてしまうこともあります。同じクレデンシャルを複数の箇所で使用してしまったり、多要素認証のハードウェアトークを利用しないもの人間です。人為的な要因をできる限りデータから隔離する必要がります。
- データ侵入の検知
- 情報漏洩が発生する数分前から攻撃を受けている。一方で68%が情報漏洩後に1ヶ月以上経過してから気づく。
- 補足
- モジュール 1で 入力するeメールアドレス
- Amazon SNSの サブスクリプションに登録され、脅威を検知した時の通知先になる
- 検証メールが送信されるので、confirm しておく必要がある。
- 忘れるとモジュール2後に動き出す攻撃を検知した結果を受け取れない。そうすると、モジュール3の前提を満たせない。
- モジュール2のCloudFormationが失敗する
- リージョン us-west-2d はt2.microをサポートしないので失敗する。
- 作成するサブネットはランダムに選ばれるので、失敗したらやり直して、別のAZが対象になることを祈る。
東京リージョンと料金
GuradDuty 、Inspector 、Macie、Security Hubのうち、Macie だけ東京リージョンなし
料金 (2019年5月23日時点)
- GuradDuty
- VPC フローログと DNS ログ分析
- 最初の 500 GB/月 -> 1.18 USD/GB
- 次の 2000 GB/月 -> 0.59 USD/GB
- 2500 GB/月を超えた場合 -> 0.29 USD/GB
- AWS CloudTrail イベント分析
- 1,000,000 イベントあたり/月 -> 4.72 USD/1,000,000 イベント
- Inspector
- 最初の 250 回のインスタンス評価 -> 0.15 USD/回
- 次の 750 回のインスタンス評価 -> 0.13 USD/回
- 次の 4,000 回のインスタンス評価 -> 0.10 USD/回
- 次の 45,000 回のインスタンス評価 -> 0.07 USD/回
- これ以上のインスタンス評価 -> 0.04 USD/回
- Macie
- Security Hub
- プレビュー期間中なので追加料金なし
導入したとに気になること
- 検知した通知が届く頻度
- 投稿日:2019-05-23T18:50:48+09:00
AWS SSM でコピー&ペーストするときに遅くなる場合の解消法
現象
SSMでセッションマネージャーを利用する際、100文字以上のコピー&ペーストを行うと100文字以降からのペーストが遅くなる。
??かなーりおそい??解決方法
session-manager-pluginを1.1.17.0へアップデートする(現状バージョンの指定方法がわからないですが。。。)
アップデートはリファレンス( https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager-working-with-install-plugin.html )のインストール手順をそのまま行えばできます。(Ubuntuで確認済み)
session-manager-plugin --versionでバージョン確認できます。
ちなみに手元のUbuntu18.04LTSのでやったログは以下。$ session-manager-plugin --version 1.0.37.0 $ curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/ubuntu_64bit/session-manager-plugin.deb" -o "session-manager-plugin.deb" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 2918k 100 2918k 0 0 899k 0 0:00:03 0:00:03 --:--:-- 899k $ sudo dpkg -i session-manager-plugin.deb (データベースを読み込んでいます ... 現在 168528 個のファイルとディレクトリがインストールされています。) session-manager-plugin.deb を展開する準備をしています ... Stopping session-manager-plugin Removed /etc/systemd/system/network-online.target.wants/session-manager-plugin.service. Preparing for install session-manager-plugin (1.1.17.0-1) で (1.0.37.0-1 に) 上書き展開しています ... session-manager-plugin (1.1.17.0-1) を設定しています ... 新バージョンの設定ファイル /usr/local/sessionmanagerplugin/VERSION をインストールしています ... Starting session-manager-plugin Created symlink /etc/systemd/system/network-online.target.wants/session-manager-plugin.service → /lib/systemd/system/session-manager-plugin.service. rm: '/usr/local/bin/session-manager-plugin' を削除できません: そのようなファイルやディレクトリはありません ureadahead (0.100.0-21) のトリガを処理しています ... ureadahead will be reprofiled on next reboot $ session-manager-plugin --version 1.1.17.0参考資料
https://github.com/aws/amazon-ssm-agent/issues/149
↑ちょっと荒れててワロタ
- 投稿日:2019-05-23T14:12:05+09:00
AWS LambdaでBoxのWebhookを処理する
概要
BoxのフォルダにWebHookを設定し、AWS Lambdaに送信されたデータを取得/操作するまでの基本的な手順についてまとめています。
(2019年3月時点)参考
Lambda 実行ロールの作成
Lambda関数の実行時には、「AWSLambdaBasicExecutionRole」が付与されたIAM Roleが必要です。
以下の手順でIAM Roleを作成しておき、以後Lambda関数を作成する際に
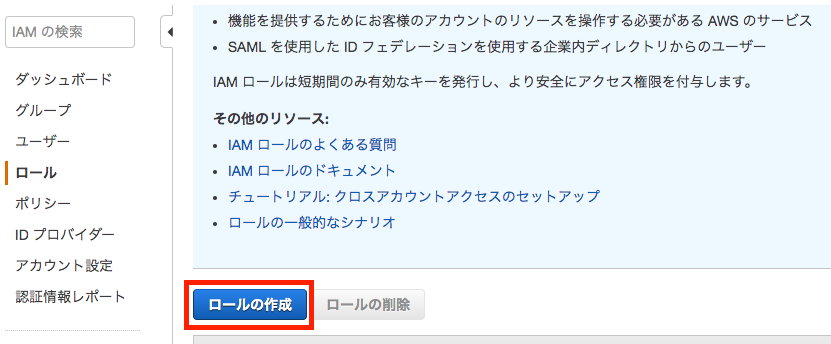
Roleを割り当てることとします。IAM > ロールの作成
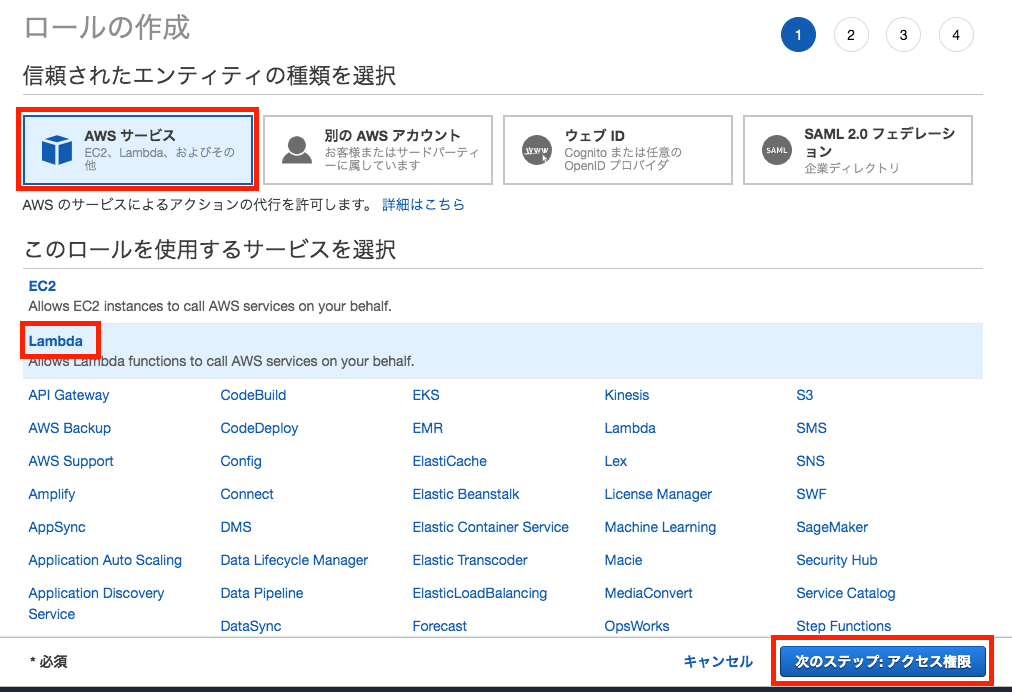
「AWSサービス」を選択し、次に「Lambda」を選択後、
「次のステップ:アクセス権限」をクリックします。
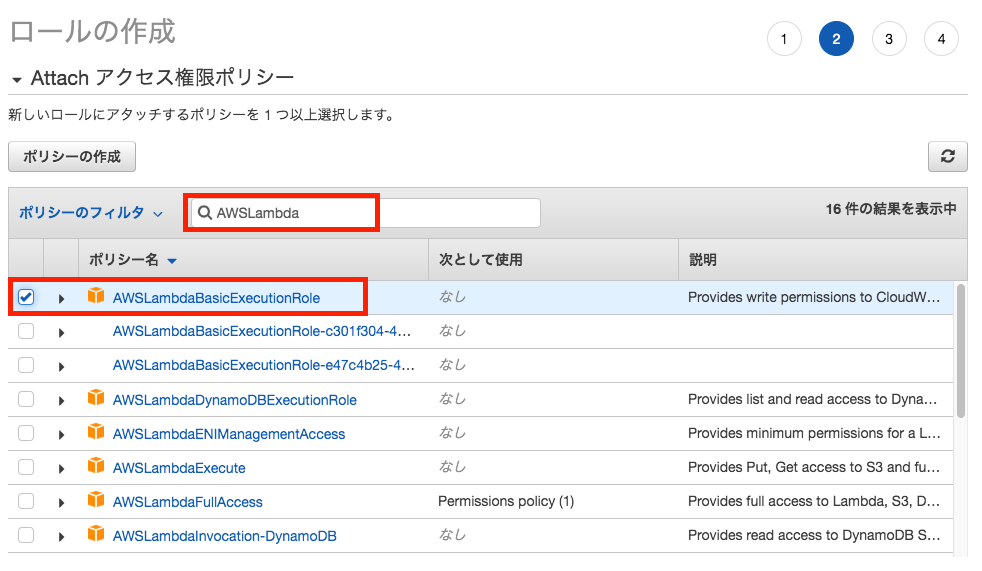
「ポリシーのフィルタ」欄に「AWSLambda」と入力し、候補表示の中から
「AWSLambdaBasicExecutionRole」にチェックして「次のステップ:タグ」をクリックします。
※Lambda関数を実行するだけなら、選択するポリシーは
「AWSLambdaBasicExecutionRole」だけとなりますが、その他に
- S3へのアクセス
- RDBへのアクセスなどもLambda関数から実行する場合には、この画面で適宜追加のポリシーも選択しておく必要があります。
タグの追加(オプション)画面で、このIAM Roleに割り当てるタグを指定できます。
たとえば、このRoleを所有しているユーザ名や、プロジェクト名、管理部署名など必要に応じ入力します。
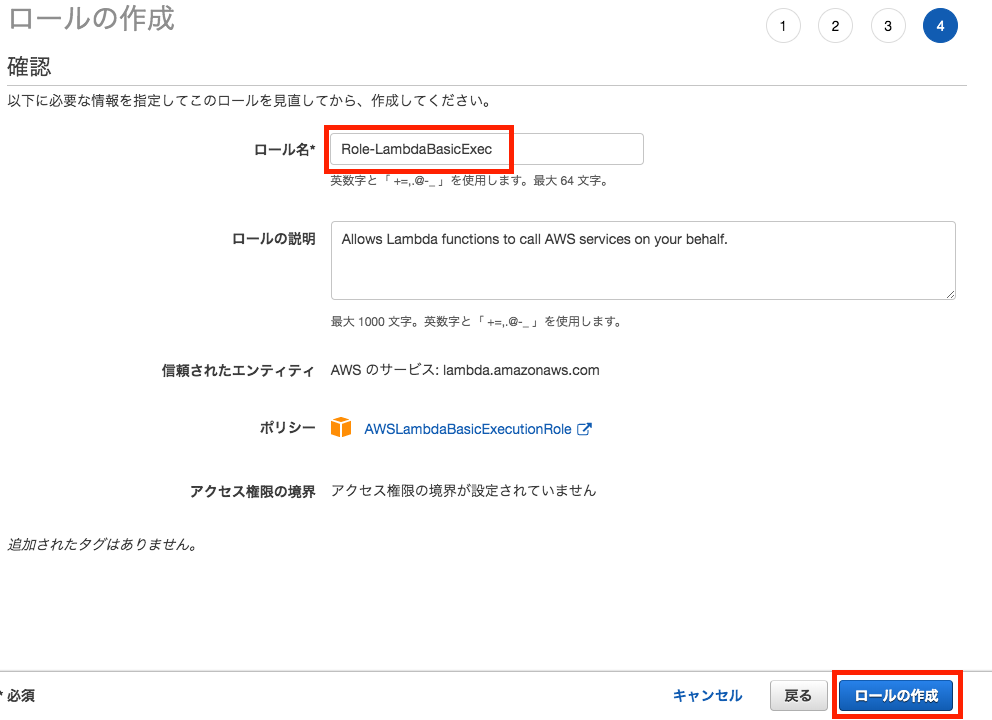
今回は空欄のまま「次のステップ:確認」をクリックして進めます。「ロール名」にロールの名称を指定し(本例では"Role-LambdaBasicExec")、
「ロールの作成」をクリックします。
ロールの一覧画面にて、今回作成したロールが表示されていることを確認します。
Lambda関数の作成
「関数の作成」画面から、「設計図の使用」
キーワードに「microservice-http」と入力し、候補から
「microservice-http-endpoint-python3」を選択します。
関数の作成に必要な情報を入力します。
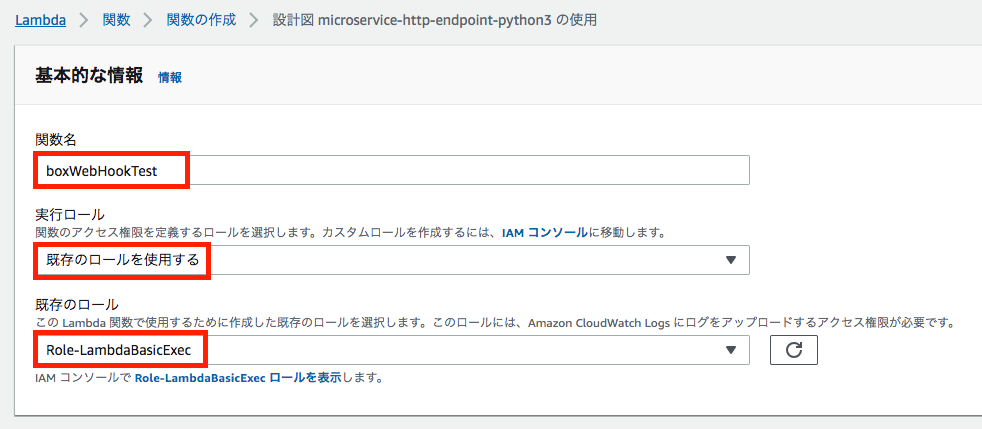
基本的な情報
関数名
本例では"boxWebHookTest"としました。実行ロール
「既存のロールを使用する」を選択し、プルダウンから前掲の手順で作成したIAM Roleを選択します。
(本例では「Role-LambdaBasicExec」)
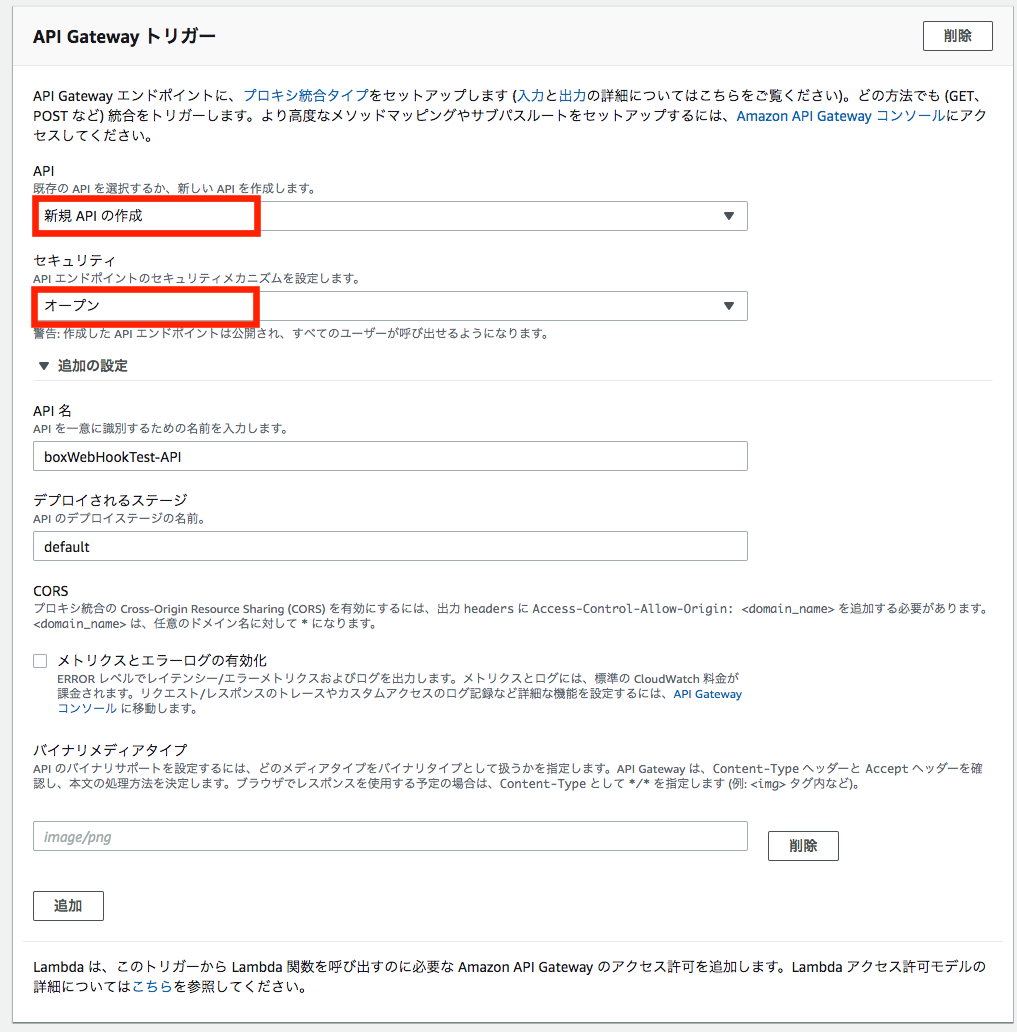
API Gatewayトリガー
API
新規APIの作成セキュリティ
今回は認証なしでAPI Gatewayを呼び出せるように、「オープン」を選択します。API名
APIの識別名を指定します。
デフォルトで
関数名-API
の命名規則で生成されますので、今回はそのまま
boxWebHookTest-API
としておきます。デプロイされるステージ
APIのデプロイ先を「ステージ」指定により切り替えることが可能ですが、defaultのままにしておきます。
関数のコード
デフォルトのPythonコードが表示されていますが、
そのままにしておきます。
「関数の作成」を実行します。
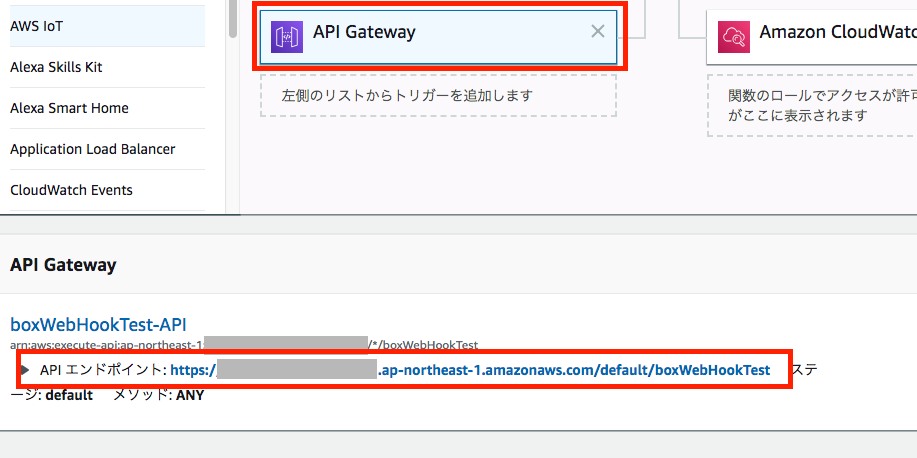
Lambda関数が作成された旨のメッセージが表示され、関数とAPI Gatewayの設定画面が表示されます。
Designer画面で「API Gateway」のパネルを選択すると、下の画面にAPI EndpointのURLが表示されます。
このURLは後でWebHookの飛ばし先として使いますので、メモ帳に貼り付けておきます
WebHookの作成
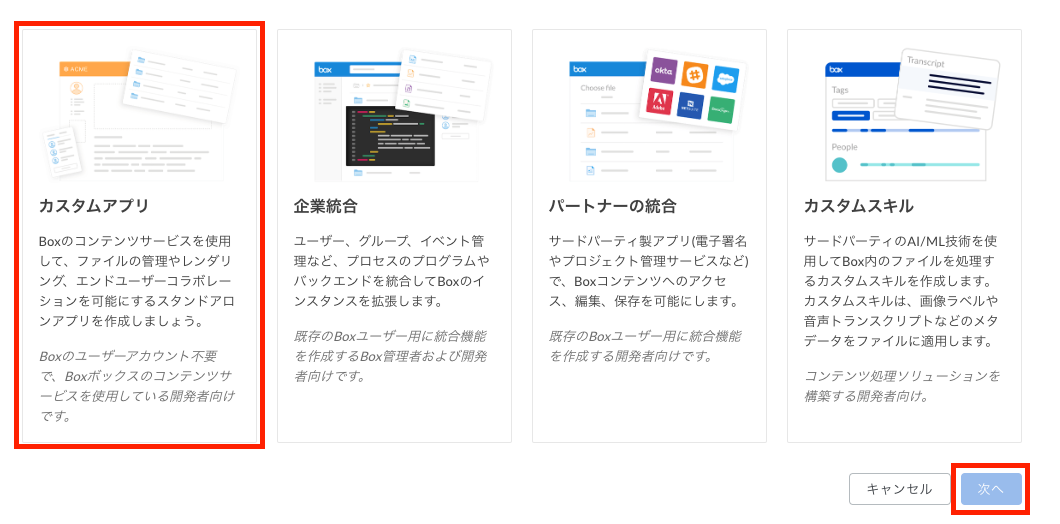
開発者コンソールにて、新規アプリケーションを作成します。
- カスタムアプリ
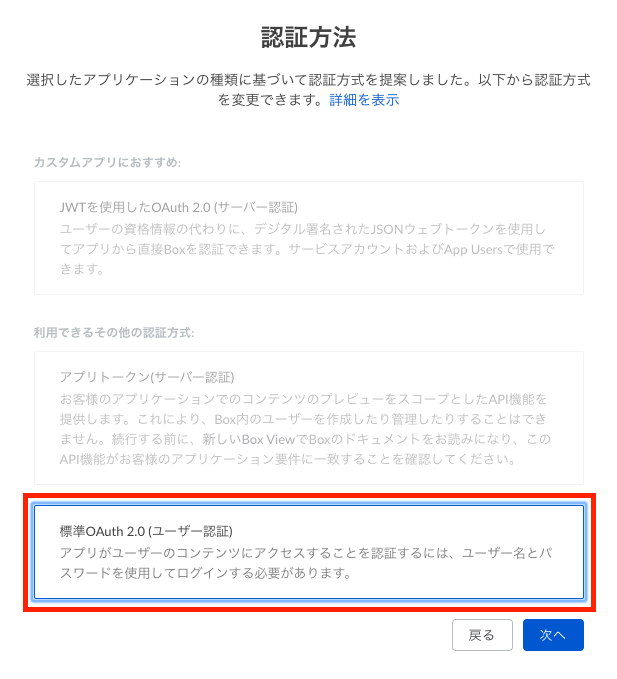
- 標準OAuth2.0(ユーザ認証)
アプリケーションスコープで「Webhookを管理」にチェックを入れて「変更を保存」します。
※このアプリのトークンを使って、Webhookを生成しますので、Webhook管理権限が必要です。
Webhookを登録する際に使用するトークンを生成します。
OAuthのサンプルコードをいずれか実行し、
アクセストークンを取得しておきます。このとき生成したアクセストークンは1時間だけ有効です。
後続のWebhook作成を1時間以内に完了できなかった場合は、
再度、アクセストークンを取り直して下さい。※DeveloperトークンでWebhookを作成すると、約1日経過後に当該のWebhookが正しく機能しなくなる事象が出ましたため、
OAuth 3legged認証を経て入手したアクセストークンを使う必要があります。
(事象については本記事下部の「翌日以降のWebhookのBody内容が不正(Anonymous User扱い)となる」参照)テスト用のフォルダをBox上に作成します。
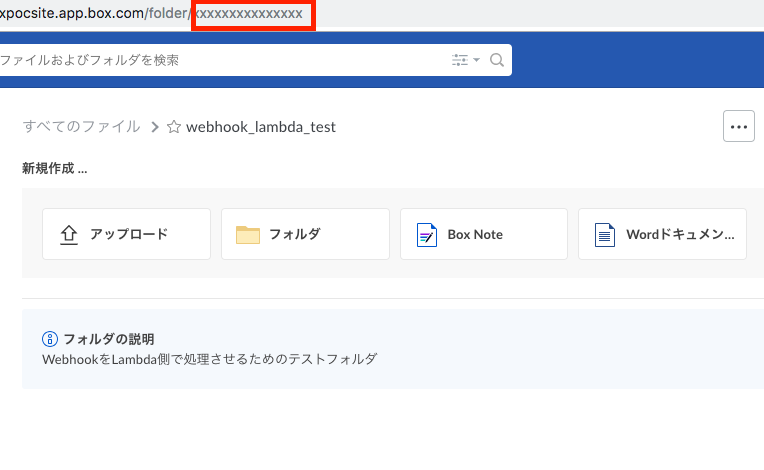
そのフォルダをBoxのWebUIで開き、フォルダIDをメモ帳に貼り付けておきます。
https://boxpocsite.app.box.com/folder/xxxxxxxxxxxxxxx
URLの末尾、/folder/の後に続く数値部分がフォルダIDです。
このフォルダにファイルがアップロードされたタイミングで実行されるWebhookを作成します。
ここまでの手順で、以下の情報が手元に揃っているはずです。
- Box上に作成した、テスト用のフォルダID
- AWS LambdaのAPI Endpoint URL
- BoxアプリのDeveloperトークン
上記の値を代入して、Webhook作成を行います。
Curlコマンドの場合は以下の構文になります。構文
```
$ curl https://api.box.com/2.0/webhooks \-H "Authorization: Bearer xxxx(Developerトークン)xxxx" \
-H "Content-Type: application/json" -X POST \
-d '{"target": {"id": "テスト用フォルダのID値", "type": "folder"}, "address": "AWS LambdaのAPI Endpoint URL", "triggers": ["トリガーのイベント"]}'
```例として、登録用の値が
- テスト用のフォルダID : 1234567890
- AWS LambdaのAPI Endpoint URL : https://xxx.amazonaws.com/default/boxWebHookTest
- BoxアプリのDeveloperトークン : zzzzzzzzzzzzzzzzzz
- トリガーのイベント : FILE.UPLOADED
の場合は、以下となります。
$ curl https://api.box.com/2.0/webhooks \ > -H "Authorization: Bearer zzzzzzzzzzzzzzzzzz" \ > -H "Content-Type: application/json" -X POST \ > -d '{"target": {"id": "1234567890", "type": "folder"}, "address": "https://xxx.amazonaws.com/default/boxWebHookTest", "triggers": ["FILE.UPLOADED"]}'Webhook作成のAPIコールが成功すると、以下の構文で戻り値が返ってきます。
{"id":"WebhookのID","type":"webhook","target":{"id":"フォルダID","type":"folder"},"created_by":{"type":"user","id":"Webhook作成を実行したユーザID","name":"ユーザ名","login":"ログイン用メールアドレス"},"created_at":"生成時刻(太平洋時間)","address":"Webhookの飛ばし先URL","triggers":["Webhookをトリガーするイベント"]}Webhookの到達確認
Webhookを実際にトリガーし、AWS LambdaのAPI Endpointまで到達するかを確認します。
Lambda関数のコンソールにて、Lambdaイベントの中身をそのままPrintするPythonコードを作成します。
import json def lambda_handler(event, context): print(json.dumps(event, indent=4)) # JSON形式の戻り値を設定する return { 'statusCode' : 200, 'headers' : { 'content-type' : 'text/html' }, 'body' : '<html><body>OK</body></html>' }コードの入力が完了したら、右上の「保存」をクリックします。
※AWS Lambdaコンソールでは、設定変更の都度「保存」が必要ですBoxのテストフォルダに何かファイルを1つアップロードします。
(どんなファイルでも構いません。)ファイルをアップロードすることでWebhookイベントが発生し、AWS LambdaのAPI Endpoint URLめがけてPOSTメソッドが実行されます。
ファイルのアップロード完了後、Lambda関数の設定画面から「モニタリング」を選択します。
続いて「CloudWatchのログを表示」をクリックします。
ログストリームが生成されているので、リンクをクリックして開きます。
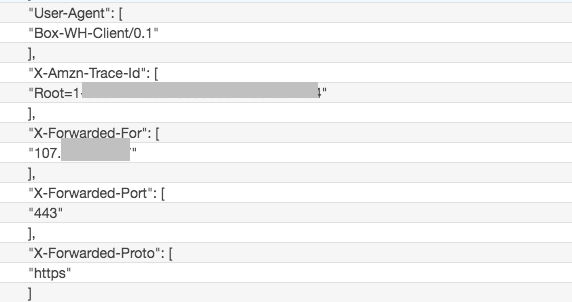
ログを上から見ていくと、Header情報などの管理情報に続いて、POSTのbody部分を確認できます。
この"body"部分にWebhookの本体が格納されています。
"body": "{\"type\":\"webhook_event\",\"id\":\"eb92204d-dcc6-4(省略)WebhookのBody内容
POSTされたWebhookのデータ部分は、以下のJSON形式となっています。
参考:
https://developer.box.com/reference#webhooks-v2{ "type":"webhook_event", "id":"webhookイベントのID", "created_at":"2019-03-18T01:34:02-07:00", "trigger":"FILE.UPLOADED", "webhook":{ "id":"WebhookのID(Box上での識別ID)", "type":"webhook" }, "created_by":{ "type":"user", "id":"BoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "source":{ "id":"Webhookをトリガーしたコンテンツ(ファイルなど)に付与されたID", "type":"コンテンツの種別(file or folderが入る)", "file_version":{ "type":"file_version", "id":"ファイルバージョンID", "sha1":"ファイルのSHA1ハッシュ値" }, "sequence_id":"0", "etag":"0", "sha1":"ファイルのSHA1ハッシュ値", "name":"ファイル/フォルダ名", "uniq":"486d66f9a8b64f8af37bfd2eff9d0d4e", "key_ref":null, "description":"", "size":0, "path_collection":{ "total_count":2, "entries":[ { "type":"folder", "id":"0", "sequence_id":null, "etag":null, "name":"最上位のフォルダ名" }, { "type":"folder", "id":"2階層目のフォルダID", "sequence_id":"1", "etag":"1", "name":"webhook_lambda_test" } ] }, "created_at":"2019-03-18T01:34:02-07:00", "modified_at":"2019-03-18T01:34:02-07:00", "trashed_at":null, "purged_at":null, "content_created_at":"2019-03-13T23:12:56-07:00", "content_modified_at":"2019-03-13T23:12:56-07:00", "created_by":{ "type":"user", "id":"コンテンツを作成したBoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "modified_by":{ "type":"user", "id":"コンテンツを最終更新したBoxのユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "owned_by":{ "type":"user", "id":"コンテンツ所有者のBoxユーザID", "name":"Boxのユーザ名", "login":"BoxユーザのログインMailアドレス" }, "shared_link":null, "parent":{ "type":"folder", "id":"Webhookをトリガーしたコンテンツを格納しているフォルダのID", "sequence_id":"1", "etag":"1", "name":"webhook_lambda_test" }, "item_status":"active" }, "additional_info":[ ] }補足
フォルダ名/ファイル名などが2バイト文字の場合、値としてUnicode変換したものが代入されます。
本例では、Boxの最上位のフォルダ名としてWebhookに入っていた値は
\u3059\u3079\u3066\u306e\u30d5\u30a1\u30a4\u30ebという文字列でした。
これを変換すると
文字列「すべてのファイル」になります。フォルダ名/ファイル名に2バイト文字が全く含まれていない場合は、オリジナルの名前がそのまま入ります(Unicode化されない)。
本例では、2階層目のフォルダ名はwebhook_lambda_testでしたので、
Bodyの中でも
"name":"webhook_lambda_test"
と、そのままの名前で記載されています。Webhookの有効期限
最後のWebhook実行(実行結果が成功)から、いちどもWebhookが使われていない状態で2週間が経過
「使われていない」とは、Webhookイベントが発火していない、ということ。最後の実行(実行結果がFail)から2週間が経過
上記、いずれかの条件を満たすと、そのWebhookは削除されます。
削除されたWebhookは再度作り直す必要があります。ハマった/やらかしました集
翌日以降のWebhookのBody内容が不正(Anonymous User扱い)となる
翌日、2個目のファイルを同じフォルダにアップロードしたところ、
Webhookは起動してPOSTが行われたが、BODY部を見ると
- trigger : NO_ACTIVE_SESSION
- ユーザID :2
- ユーザ名 : Anonymous User
となっていました。
1回目の成功したときと同じユーザーでBoxにログインし直しても、事象は改善せず。{ "type":"webhook_event", "id":"9c6f708d-1393-49c0-9b4a-96f93ead0b58", "created_at":"2019-03-19T03:01:47-07:00", "trigger":"NO_ACTIVE_SESSION", "webhook":{ "id":"151732426","type":"webhook" }, "created_by":{ "type":"user", "id":"2", "name":"Anonymous User", "login":"" }, "source":{ "id":"424148311576", "type":"file" }, "additional_info":[ ] }当該のWebhookの状態を確認すると、生きているように見えます。
{ "id":"151732426", "type":"webhook", "target":{ "id":"70394214504", "type":"folder" }, "created_by":{ "type":"user","id":"ユーザID", "name":"ユーザ名", "login":"ログインメールアドレス" }, "created_at":"2019-03-18T01:00:54-07:00", "address":"AWS LambdaのAPI Endpoint URL", "triggers":["FILE.UPLOADED"] }LambdaがWebhookサーバ側にStatus Codeを返していない可能性を考えましたが、
正しく200を返していることも確認できました。
(切り分け)アプリで生成したトークンで再度WebHook作成
開発者トークンでWebhookを作成したことが悪さしている可能性を考慮して、
OAuth認証アプリで生成したトークンを使い、Webhookを再作成トークン生成に使用したアプリケーション名称:
GLENN-OAUTH-SAMPLE-PYTHON作成時刻: 2019/03/27 13:46
作成したWebhook
{
"id": "153930739",
"type": "webhook",
"target": {
"id": "70394214504",
"type": "folder"
},
"created_by": {
"type": "user",
"id": "xxxx",
"name": "xxxx",
"login": "xxxx"
},
"created_at": "2019-03-26T21:46:22-07:00",
"address": "https://xxxxxx.ap-northeast-1.amazonaws.com/default/boxWebHookTest",
"triggers": [
"FILE.DOWNLOADED",
"FILE.UPLOADED"
]
}
2019/03/27 15:08
Webhookの作成から1時間以上経過後、ファイルを再度Upload
→正常なWebhookが返ることを確認切り分けから、DeveloperトークンでWebhookを作成したことが原因と考えられます。
自前のWebサーバ宛てのWebhookが失敗する
本ページはAWS LambdaをWebhookの宛先として使用していますが、
これより前に、自前でNginxのサーバを立てて、安いSSLサーバ証明書を買って
FlaskでWebhookを受け取る仕組みを作ろうとして、
無事失敗しました。発生事象
Webhbookは問題無くトリガーされたが、Webサーバ側のアクセスログには何も記録されない。
TCPDumpを取ったところ、SSL Handshakeの過程で、BoxのWebhook送信元サーバが
自発的にSSL Handshakeを切ってしまっていた。
Reason Codeは 「Unknown CA」。原因
自前で立てたWebサーバ側の設定漏れ。
サーバ証明書は入れていたが、中間証明書を入れ忘れていた。
そのため、BoxのWebhookサーバ側で信頼チェインの検証に失敗していた。上記のサイトに自前Webサーバのドメイン名を入れてテストしたところ、
Chainのエラーとなったことで気づくことができました。対応
サーバ証明書に中間証明書を追加。
Nginxなので、証明書ファイル1つの中に順に追記するだけでよいです。-----BEGIN CERTIFICATE----- サーバSSL証明書 -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- SSL中間証明書1 -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- SSL中間証明書2 -----END CERTIFICATE-----参考:
https://www.sslbox.jp/support/man/interca_coressl.php
https://tsunokawa.hatenablog.com/entry/2014/09/24/114014nginxをリスタート後、
- 上記のSSLチェックサイトのテスト結果良好
- Webhook受信時のSSL Handshakeが成功
- Webhookが受け取れた
を確認できました。









- 投稿日:2019-05-23T13:49:59+09:00
「【招待制】今日から始められる AWS セキュリティサービス」に参加してきたメモ
AWS セキュリティーワークショップ
- リスク可視化と分析による 継続的セキュリティ の実践
- 登壇者:桐山隼人さん
- 著書:すべてわかるセキュリティ大全, IoTビジネスとセキュリティを3段階と4要素で理解する
セッションの目的
AWS環境においてのセキュリティって。。。
- まず何からはじめたらいいのか
- どこまでやったらいいのか「継続的セキュリティ(CS)」
定義
- 人によって定義はまちまち
- DevOps.comより抜粋
- セキュリティにはプラットフォームが必要でAPIによって呼び出す
- 自動化で実施していくもの
- 統合インテグレーションと言われるものが必要
やる意味
- 環境変化適応
- セキュリティ対策は実施した瞬間から危殆化する
- スピード
- セキュリティ侵害は攻撃側のほうがはやい
- 攻撃は自動化してどんどん新しい攻撃手法を取り入れていく
- コスト最適化
- リスクベースのアプローチで考える
- 何が一番重要で守らなきゃいけない?を考える必要がある
- リスクは瞬間で変わっていく
セキュリティリスク
セキュリティリスクの方程式
- 驚異
- どういうリスクが企業にあるか?どういう企業はリスクが高いのかを考える
- 有名であればあるほど狙ってやろうという気持ちが高まる、など
- 脆弱性
- 企業の中に存在するもの
- セキュリティホールや設定ミスとか
- 心理的要素を突く攻撃もある(人事に対してや、プレッシャーかかってる人へのメールとか)
- 情報資産
- 企業が持ってるデータの情報資産の価値が高ければ高いほどやばい
- 企業によって持ってるデータが違うので重要度がぜんぜん違う
- 医療機関のほうが金融機関よりも重要、みたいな
分析と可視化
- リスク分析
- 驚異分析 (AWS GuardDuty)
- 脆弱性分析 (AWS Inspector)
- 情報資産分析 (AWS Macie) ↑をやることがセキュリティ対策
継続的監視と驚異検知
機械学習を用いたクラウドネイティブな驚異検知サービス
- 驚異を検知してくれる = GuardDuty
- 検知方法:クエリのログやネットワークログ、API操作ログを使って驚異を検知する
プラットフォーム脆弱性分析
- API連携によって開発運用プロセスにリスク評価を統合
- やってくれること:こういうセキュリティ設定したほうがいいですよ、とかも評価してくれる
- Inspectorのルールパッケージ
- ホスト評価のルール(CVEに基づく一般的な脆弱性、COS OSSCB, ベストプラクティス、とか4軸)
- ネットワーク到達可能性のルール ←NEW!!
- 自分で意図したネットワーク設計になっているか
- インターネット出てる?
- 意図したところだけ使われてる?
- PCI DSSの要件満たしてる?
- これを知るためにInspectorのルール評価が使える
- やってること
- 自動推論による評価
- Logic Specification + Network Snapshot + query = Result
- パケットレスポートスキャン↑をやっている
事業価値のある(重要データ)データを保護
- 認証情報、知的財産、個人情報とかを保護
- Macieがスキャンして、監視できる
一個一個の画面にはいるのめんどくない?
ー> Security Hub というサービスがあります!リスク分析ダッシュボード - Security Hub
- AWS環境のセキュリティコンプライアンス状態を可視化できる
- 一元的にみれるよ!
まずここからその1
- まずは始めるなら
- GurardDutyを全リージョンで有効化
- InspectorでEC2インスタンスを評価
- エージェントレスもありますよ
- MacieでS3にある重要データの棚卸し
- サポートリージョンは北バージニアとオレゴンのみ
- Securitie Hubでデータ集約して可視化
コンプライアンスルール
リスクベースアプローチによる優先順位づけ
- リスクベースアプローチを保管する考え方が大事
- ベースラインアプローチ
- 業界ルール
- などこれは守らないといけないよね、みたいなシステム外の観点のこと
- = コンプライアンスルール → 「Compliance Check + AWS Config」 で管理できる
※ AWS Config = 構成変更を記録してくれるサービス
まずここからその2
- Configで全リソースの設定変更履歴の管理を開始
- Security HubでCompliance Standardsを有効化する
ガバナンス
- AWS Organizations
マルチアカウント
- 増えていった時、一個一個どうやって管理すればいいのか
- Landing Zoneを使おう!
- ここに着地して貰えればいいよ、的なニュアンスを含めたもの
- アカウント統制をしたい時、こういうルールだけ守ってね、の枠を定義できるもの
- ベストプラクティスをまとめたまとめ集
- 目的が違うアカウントを分けておいたほうがいい
- ログ管理とセキュリティアカウント、など
- 日頃の振る舞いが違うやつ
- 混ぜるとノイズが入るので、新しい技術が入れづらい = 入れていいの?のリスクが発生する
- だからアカウントは分けておきましょう
- アカウントのセキュリティイベントを集めて通知する
- 通知はアカウントごとでSNSトピックを生成する
- 集約はSecurity Hubで
まずはここからその3
- セキュリティアカウントを作る
- Securitie Hub上で監視対象のメンバーアカウントを追加
- Securitie HubのカスタムアクションでFindingsの追加
次のステップ...
- わからない人はAWSのSAに相談してね!
- ワークショップや資料があるので勉強してね!
ワークショップ内容
- 投稿日:2019-05-23T13:17:35+09:00
誰も使っていないときだけ、マシンを自動停止させたい
これはなに?
誰もログインしていないときだけ
halt(shutdown) を実行するスクリプトです。AWS(Amazon Web Service) の EC2(Elastic Compute Cloud) インスタンスを自動停止させるために作りました。
EC2のインスタンスは起動している時間で課金されるので、たとえば開発用などで誰も使わない夜中には停止させて経費を浮かせたい、ということがしばしばあります。こういった自動停止は
AWS Lambdaを使う例がよく紹介されていますが、それだと問答無用で落としてしまいます。残業して開発している人がキレないよう、あえてcronでやることにしました。使い方
- 以下のスクリプトを適当なところに置き、実行権限を付与する
root権限のcrontabで自動実行を設定する私が扱っているインスタンスでは以下のようにしています。
crontab0,30 20-23 * * * /usr/local/sbin/condhalt※ 20:00~23:30 まで30分毎。細かな書式はQiitaの記事「cronの設定方法」が分かりやすかったです
注意
halt(shutdown)の実行には root 権限が必要なので、このスクリプトも root 権限が必要です
root のcrontabに設定すると問題が少ないと思いますwとhaltコマンドの位置を確認する
OS、ディストリビューションによってはこれらのコマンドが置かれているパスが違う可能性があるので、適宜書き換えてくださいスクリプト本体
condhalt.pl#!/usr/bin/perl use strict; use warnings; my $user = 0; open(PCMD, '/usr/bin/w |'); while ( <PCMD> ) { $user++ if ( m| pts/[0-9]+ | ); } close(PCMD); if ( $user == 0 ) { system('/usr/sbin/halt'); }今後
この方法はお手軽なので対象インスタンスが1台2台ならいいんですが、数が増えるとスクリプトを置いたり
crontabの設定をするのは面倒です。AWS Lambdaでなんとかしたいところなので、暇を見つけて作りたいと思っています。
- 投稿日:2019-05-23T10:56:50+09:00
【Ruby + AWS】Amazon EC2インスタンスでLINE Bot Server構築してみた
はじめに
こんにちは。ここ最近ですが、仕事でLINE Botを作ることになりましたので、必要な設定を共有できればと思います。
なお、この記事ではあくまで概念とLINE Bot Serverを構築するまでの準備のレベルを書こうと思うので、あえてBot Server部分のコードは省略します(というか、書き始めたばかりなので新規に埋め込んだコードがほとんどない)。追記
よくよく考えたら、概念図のポンチ絵、左部分おかしいですね、、、
LINEのネイティブ・WebアプリケーションがあってそこにユーザとBotがいるので、本来は入れ子にするべきでしたね。後日、修正します。LINE Botの概念図
手書きのポンチ絵なのて、字が下手な部分はご愛嬌...
なお、このポンチ絵は以下の3つの資料を参考に書きました。https://developers.line.biz/ja/docs/messaging-api/overview/
https://developers.line.biz/ja/docs/messaging-api/getting-started/
https://developers.line.biz/ja/docs/messaging-api/building-bot/
当初、弊社のWebアプリケーション用のサーバとは別にLINE PFがアクセスするエンドポイント用のサーバを用意する必要があったので、スクリプト言語で書く必要もないかなと考えGoでやろうかと言っていましたが、それほど大規模なアクセスを想定していないこと、既存のアプリケーションと一旦統合するような設計を採る事にしたため、RubyでBot Serverを作る事にしました。
環境の確認
- OS: Amazon Linux AMI release 2018.03
- Nginx: 1.14.1
- Ruby: 2.4.6
Route 53でコールバック用に使うレコード名を登録 || セキュリティグループの設定
上記のLINE PF(プラットフォーム)がコールバック用のエンドポイントとなるURLにアクセスできるようにレコード名を登録してあげます。また、グローバルにアクセスできるようにSecurity Groupの設定も行って下さい。
EC2インスタンス上でLINE Bot Serverを設定
Bot Server検証用の環境を構築しようとした矢先に気づいたのですが、LINE Botではコールバック用のURLは
HTTP over SSLしか対応していない事が発覚し、検証環境でもSSL証明書を導入する必要が出てきました。そのため、EC2インスタンス単体で証明書をインポートする機構が必要だったため、今回はLet's Encryptで導入する形を採りました。SSL証明書の導入(Let's Encrypt)
基本的には、下記の部分のコマンドの引用です。
https://certbot.eff.org/lets-encrypt/centosrhel6-nginx
- certbot-autoの導入
% wget https://dl.eff.org/certbot-auto % sudo mv certbot-auto /usr/local/bin/certbot-auto % sudo chown root /usr/local/bin/certbot-auto % sudo chmod 0755 /usr/local/bin/certbot-auto
- 証明書の発行
% sudo /usr/local/bin/certbot-auto --nginx certonly --debug
- NGINXをリバースプロキシとして設定し、SSL証明書をインポート
server { listen 80; server_name ***.***.***; location / { root /var/www/html; index index.html index.htm; } } server { listen 443; ssl on; server_name ***.***.***; ssl_certificate /etc/letsencrypt/live/***.***.***/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/***.***.***/privkey.pem; location / { proxy_set_header X-Real-IP $remote_addr; proxy_pass http://127.0.0.1:3000; } }% sudo service nginx restartRubyによるBot Serverの構築
LINEリポジトリから公式に提供されているhttps://github.com/line/line-bot-sdk-rubyというRuby用のBot Kitをインストールします。
なお、Bot Kitは、他にも多くの言語をサポートしている模様ですので、基本的なLINE Botの作り方は採用する言語に合わせてBot Kitを用意すればOKです。echo botによる動作確認
各Bot Kitリポジトリのexamplesディレクトリ配下にサンプルコードが用意されています。今回は、echobotでユーザメッセージをそのまま鸚鵡返しするBot Serverを採用し、動作確認を行います。
https://github.com/line/line-bot-sdk-ruby/tree/master/examples/echobot
echo Botによる動作確認が取れました。
まとめ
これまた、設定部分の所しかかけていませんが、これからどんどんコードを書いていこうと思います。
因みに、line-bot-sdkの事を、Bot Kitって言っているのは、プラモデルを作るのと同じように、「部品が用意されていて、それを組み合わせて静的なモデルを完成させる」感覚になっているので、ライブラリというよりツールキット(Bot用だからBot Kit)という言い方しています。
まぁ、そんな与太話はどうでもいいと思うので、中身を詳細に書き次第、改めて記事を書いていきます。
それではまた。参考文献


- 投稿日:2019-05-23T10:53:47+09:00
EC2のIPアドレスを調べる方法(超初心者向け)
はじめに
既にサービス稼働中のAWS EC2にSSH等でアクセスする際、AWSに触れたことの無い方がIPアドレスを知りたいケースがあるかと思い、AWSの詳細になるべく踏み込まず確認する手順をまとめました。
※前提として、AWSマネジメントコンソールでEC2を参照でき、ファイアウォール(セキュリティグループやネットワークACL)が適切に設定され、各インスタンスに対象ユーザーの公開鍵が配布済みであるとします。
※VPCのピアリング接続等を含めると、話がややこしくなるのですが、基本これで行けるハズです。確認方法(準備)
- AWSマネジメントコンソールにログインする。
- ログイン後、トップメニューのサービスより「EC2」を選択する。
- EC2ダッシュボードが表示されるので、EC2のメニューにより「インスタンス」を選択する。
- トップメニューの右側に表示されている地名が対象リージョンとなっているか確認する。
(異なるリージョンを選択していないと場合によってはインスタンス数がゼロと表示されちょっと焦ります)- 作成済みのインスタンス一覧が表示されるので、一覧の上部右側にある歯車アイコンをクリックし、列に表示する項目を選択する。
- チェックする項目は、「Name」「インスタンスの状態」「IPv4パブリックIP」「VPC ID」です。それ以外の項目にチェックがあっても構いません。
確認方法
- AWS外部からアクセスできるインスタンスは「IPv4パブリックIP」にIPアドレスの値が入っています。
- 「IPv4パブリックIP」の値がハイフンのものは、外部からアクセスすることはできないため、外部からアクセスできるインスタンスを経由することになります。
- 内部からアクセスする際のIPアドレスは、インスタンス一覧にチェックを入れると「説明」が表示され、「プライベートIP」で確認することができます。
- 「VPC ID」が同一のインスタンス内で原則アクセスすることができます。(VPCの設定次第では例外もある)
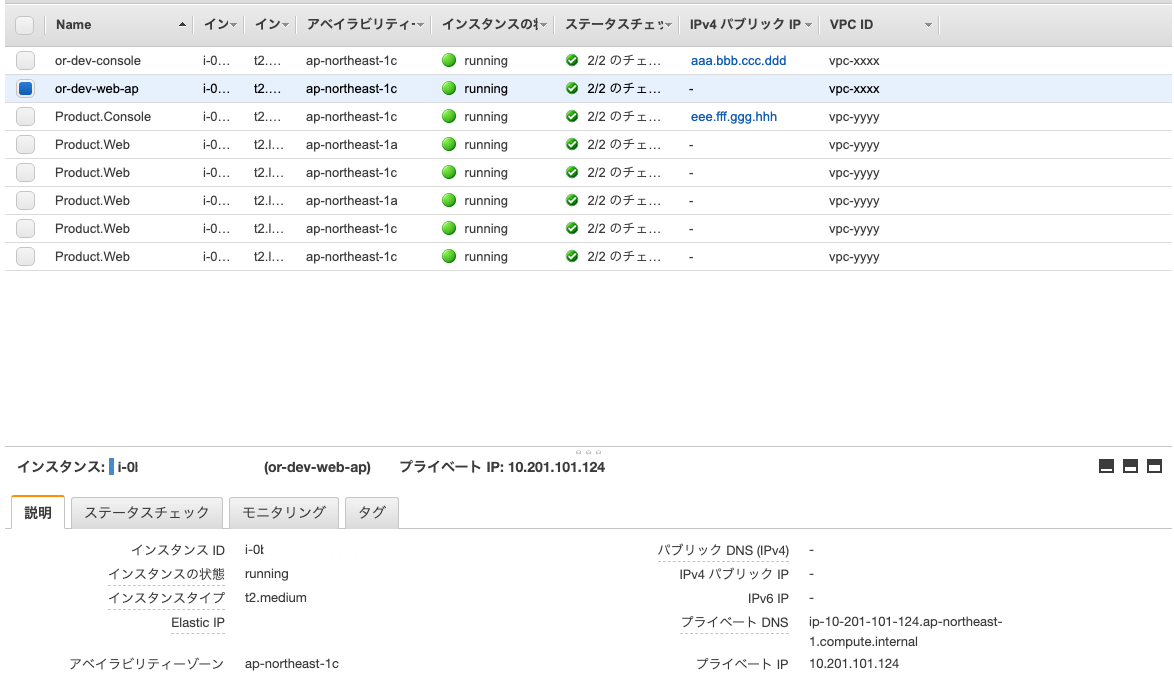
以下、インスタンス一覧のイメージ図です(パブリックIPアドレス等はマスキングしています)
- 例えば、選択中の
or-dev-web-apにアクセスするには同じVPC ID(vpc-xxxx)でIPv4パブリックIPが割りてられているor-dev-consoleを踏み台にします(IPアドレスaaa.bbb.ccc.dddにアクセスします)。or-dev-consoleからor-dev-web-apにアクセスする際は、プライベートIPアドレス10.201.101.124を指定します。- VPC ID
vpc-yyyyのパブリックIPアドレスが割り振られていないインスタンスにアクセスする際も同様です。- IPv4パブリックIPは固定のIPアドレスを取得していない場合、インスタンスの再起動で変更されます。ただし、IPv4パブリックIPにリンクが貼られていれば、固定IPが割り振られて(Elastic IPがアタッチされて)いますので、再起動によって変更されることはありません。
- プライベートIPもインスタンスの再起動によって変更されます。(こちらも固定する方法はあるのですが、再起動でIPアドレスが変わる認識の方が良いかと)
おわりに
なるべく詳細に触れないようご紹介しましたが、何らかの要因でどうしてもアクセスできない場合もあるかと思います。その際は有識者に聞いてもらうのが早いのですが、その機には是非AWSについて学習して頂ければ幸いです。
- 投稿日:2019-05-23T09:29:15+09:00
AWS認定Big Data勉強記 - 8.1: Kinesis Data Streams
こんにちは、えいりんぐーです
今回は Amazon Kinesis Data Streams についてまとめます。
参考資料
- Black Beltオンラインセミナー資料
- 公式ドキュメント
- ブログ
- YouTube
- その他
- [AWS]kinesisまとめ
- こちらの記事も良くまとまっています。
全般
Kinesis Data Streams とは
- 特定のニーズに合わせてストリーミングデータを処理、分析するカスタムアプリケーションを構築するためのサービス。
- データプロデューサーからすばやくデータを移動して、連続的にデータを処理し、データストアに送る前にデータを変換したり、メトリクスや分析をリアルタイムで実行したり、他の処理のためにさらに複雑なデータストリームを取得したりできる。
- データスループットのレベルでデータをストリーミングするために必要なインフラストラクチャ、ストレージ、ネットワーキング、設定を管理するため、ハードウェア、ソフトウェア、その他のサービスのプロビジョニング、デプロイ、継続的なメンテナンスを心配する必要がない。
- 3 つのアベイラビリティーゾーンでデータが同期的にレプリケートされるため、可用性とデータ耐久性が高い。
SQSとの違い
Kinesis Data Streams
Amazon Kinesis Data Streams では、ビッグデータのストリーミングをリアルタイムで処理できる。レコードを並べ替えることができ、複数の Amazon Kinesis アプリケーションに対して同じ順序でレコードを読み取ったり再生したりできる。Amazon Kinesis クライアントライブラリは特定のパーティションキーに対するすべてのレコードを同じレコードプロセッサに提供し、同じ Amazon Kinesis データストリームから読み取る複数のアプリケーションの構築を容易にする。使用する状況
- 関連する複数のレコードを同じ処理系に回す時
- 複数のアプリケーションが同じストリームを同時に使用する時
- レコードを数時間後に同じ順序で使用する時
Amazon SQS
Amazon SQS は、コンピュータ間でやり取りされるメッセージを格納するための、信頼性のある、拡張性の高い、ホスティングされたキューを提供する。Amazon SQS を使用すると、分散したアプリケーションコンポーネント間でデータを簡単に移動でき、自動化されたワークフローのようなメッセージレベルでの確認/失敗セマンティクスを備えたメッセージを独立して処理するアプリケーションを構築できる。使用する状況
- メッセージングセマンティクス (メッセージレベルの確認/失敗など) および可視性タイムアウト、例えば、作業項目のキューがあり、各項目の正常な完了を個別に追跡する時
- ジョブキューがあり、遅延のある個別のジョブをスケジュールする必要がある時
- 例えば、負荷の一時的な上昇や事業の自然な成長の結果として、バッファ要求や負荷が変化するような場合
概念
- シャード
- スループットの単位で、データレコードが保存されるところ。
- 1シャードは、1MB/秒のデータ入力と、2MB/秒のデータ出力をサポート。
- また、各シャードは1秒あたり最大1,000件のPUTレコードをサポート。
- 1 秒あたり最大 5 件の読み取りトランザクションをサポート。
- 読み込みトランザクションは最大 10,000 レコードを提供でき、トランザクションあたり 10 MB の上限がある。
- GetRecords では、1 つのシャードから最大 10 MB のデータを取得でき、呼び出しごとに最大 10,000 レコードを取得できる。
- デフォルトでストリームに追加された時点から24時間アクセス可能。
- 最大7日間まで上げることができる。
- レコード
- データストリームに保存されるデータの単位。
- シーケンス番号、パーティションキー、データ BLOB で構成される。
- データBLOBの最大サイズは1MB。
- パーティションキー
- レコードを分離してデータストリームの異なるシャードにルーティングするために使用する。
- シーケンス番号
- 各レコードの一意の識別子。
- データを Amazon Kinesis データストリームに追加すると、Amazon Kinesis によってシーケンス番号が割り当てられる。
- シャード間では増加しない。
データの書き込み
- PutRecord, PutRecords, KPL, Kinesis Agentを使ってストリームにデータを追加する。
- Kinesis Producer Library (KPL)
- Kinesis データストリームにデータを格納するのに便利な、高度な設定が可能なライブラリ。非同期処理。
- PutRecordなどは同期処理。
- Kinesis Agent
- データの収集および Amazon Kinesis データストリームへのデータの送信を容易にする、ビルド済みの Java アプリケーション。Linux ベースのサーバー環境にインストールして利用する。
- ストリームの容量制限を超えている間、PUT データの呼び出しは
ProvisionedThroughputExceeded例外で拒否される。拡張ファンアウト (Enhanced fan-out)
コンシューマーとシャード間に論理的な 2 MB/秒スループットパイプを提供する Kinesis Data Streams コンシューマーのオプション機能。普通に複数のコンシューマーを設計すると、Kinesis Data Streams の性能制限を超えてしまう場合や、200ms以下のデータ提供速度を求める場合に利用する。
- コンシューマーはまず、コンシューマー自体を Kinesis Data Streams サービスに登録する必要がある。
- KCL を使用している場合、KCL version 2.x はコンシューマーの登録を自動で行う。
- 登録されると、すべての登録されたコンシューマーはプロビジョニングされた独自の論理的な拡張ファンアウトスループットを持つようになる。
- 次に、コンシューマーは HTTP/2 SubscribeToShard API を使用して、そのスループットパイプ内のデータを取得する。
データの読み取り
- Kinesis アプリケーション
- Kinesis Data Streams からのデータを読み取って処理するデータコンシューマー。
- Kinesis Data Analytics, Kinesis API, KCLを使用する。
- Kinesis Client Library (KCL)
- データコンシューマー。
- データストリームボリュームの変化への適応、ストリーミングデータの負荷分散、分散サービスの調整、データ処理の耐障害性などの複雑な問題に対応。
- KCLは、各 Amazon Kinesis アプリケーションの Amazon DynamoDB テーブルを自動的に作成し、リシャーディングイベントやシーケンス番号チェックポイントなどの状態情報を追跡および管理する。
- Kinesis アプリケーションをオートスケールグループの一部であるEC2インスタンス上で実行することで、アプリケーションの処理能力を自動的にスケールできる。
- Kinesis Connector Library
- KCLとは言わない。
- Amazon Kinesis Data Streams を AWS の他のサービスやサードパーティ製ツールと簡単に統合できるようになる。
- Amazon DynamoDB、Amazon Redshift、Amazon S3、Elasticsearch に対するコネクタを利用できる。
- Kinesis Storm Spout
- Amazon Kinesis Data Streams と Apache Storm を統合するライブラリ。
- Kinesis Data Streamsからデータをフェッチし、そのデータをタプルとして送出する。
ApproximateArrivalTimestamp
- レコードが Amazon Kinesis によって正常に受信および保存された時に設定される。
- 容量制限を超えている間、READ データの呼び出しは
ProvisionedThroughputExceeded例外で拒否されるData Streams の管理
- リシャーディング
- シャードの分割や結合を使用してデータストリームをスケールするために使用するプロセス。
- シャードの分割では、1 つのシャードが 2 つのシャードに分割されて、データストリームのスループットが上がる。
- シャードの結合では、2 つのシャードが 1 つのシャードに結合されて、データストリームのスループットが下がる。
- 一度に実行できるリシャーディングオペレーションは 1 つだけ。
セキュリティ
- アカウントとデータストリームの所有者のみが、自分が作成した Kinesis リソースにアクセスできる。
- HTTPS プロトコルを使用して SSL エンドポイント経由で、Kinesis からのデータの格納と取得を安全に行うことができる。
- AWS KMS マスターキーでサーバー側の暗号化を使用して、データストリームに保存されているデータを暗号化できる。
- Kinesis Data Streams のサーバー側の暗号化は、ユーザーが指定した AWS KMS マスターキー (CMK) を使用して自動的にデータを暗号化してから、データストリームストレージレイヤーに書き出し、ストレージから取得した後でデータを復号化する。
- 独自の暗号化ライブラリを使用して、データを Kinesis に格納する前にクライアント側のデータを暗号化できる。
- VPC エンドポイントを作成すると、Amazon Virtual Private Cloud (VPC) から Kinesis Data Streams API にパブリックIPを使わずにプライベートでアクセスできる。
- 投稿日:2019-05-23T09:07:17+09:00
ECS vs Fargate【きのこたけのこ戦争?だがFargateが圧勝しました!】
こんにちは。朝から晩までAWS検証中の黒川です。
ECSとFargateの違い分かりますか?
私は昔、コンテナをEC2タイプかFargateタイプが選べると知り、「どっちがどう違うんじゃい?」と出鼻をくじかれました。
また、複雑なマイクロサービスに向いているのはどっち?など双方のメリットとデメリットが理解できていないと感じたので改めて整理しようと思います。
☑️本記事のテーマ
ECSとFargateはどちらを使うべきか迷っている方の為の記事です
☑️結論
Fargateが圧勝
☑️理由
Fargateは料金安いし運用難易度が低い、一方コンテナインスタンスはスケーリング難易度が高いため
Fargateとは?これってECSのサービスの1つですよね?
ECSサービスの定義
「イケてる設計」を目指すエンジニアは、(何故か)コンテナサービスをクラウドで動かすことを選択しますよね。設計が複雑だったり、環境変化のスピードに対応するマイクロサービス型のビジネスに向いていたり。。
さて、ここでECSサービスをちょっくら分解してみることにしてみましょう。
・コンテナを実行するサービスである
・タスクを管理するサービスである
タスクとは、コンテナの定義を定めたDockerfileのようなもので、複数のコンテナを定義することが多いです。例えば、nginxのコンテナとphp-fpmのコンテナをひとつのタスクにまとめる、とか。
ECSはコンテナを実行するわけではなく、タスクを管理するコントロールプレーンを用意してくれるという点に注意。
それじゃあ、一体コンテナを実行しているのは誰だ?
コンテナを実行しよう
コンテナを実行したいのなら、次の2つのオプションが用意されているので選択しましょう。
・ECSコンテナインスタンスを使用する
・Fargateを使用する
次の図は両者の違いを示したものです。
あれ?「ECS」のサービスに「EC2」と「Fargate」っていうスタイルがあるんだっけ?そう、つまり「コンテナインスタンス vs Fargate」という記事のタイトルであるべきでしたね。
きのこたけのこ言ってる場合じゃないよ、全く。。
ECSコンテナインスタンスは「ECSコンテナのエージェントを持っているEC2インスタンス」ってこと以外は普通のEC2と何ら変わりないですね。
他のEC2インスタンスと同様に「インスタンス」画面に並んで動いているし。
上司 「ってことで、もちろんEC2インスタンスの監視、パッチ、セキュリティ面の配慮は君の仕事だから、後はよろしく頼んだよ。」
部下 「(えー。。。サーバー管理は骨が折れるから好きじゃ無いけど、、)」
コンテナインスタンスとはつまりそういうこと。
EC2の管理が面倒なんですよね。
あと、インスタンスタイプ(t2.microとか)を適切に選ぶって結構ハードル高いですよね。
Fargateの料金とEC2インスタンスタイプの弱点
上述の管理面と同様に、EC2インスタンスタイプは弱点がいくつかあります。コンテナインスタンスのクラスターは通常、オートスケーリンググループ内で実行することかと思いますが、スケーリングは簡単じゃ無いですね。
なぜなら
・タスクの配置がよろしく無く、キャパシティ関連の問題でエラーとなった場合でもスケールをする明確なメトリックの基準がない
・Cloudformationでクラスターをスケールアップする際、オートスケーリングやECSって連動して認識しない
・長時間実行しているタスクをkillしないでスケールダウンってめちゃくちゃ難しい
AWS公式ドキュメントでさえ、クラスターをオートスケーリングする件については記載がないですし。
Fargateの圧勝です
Fargateはタスクの実行を管理してくれるもので、EC2インスタンスを管理する必要は一切無いです。お金はvCPUとメモリーの量で決まり、タスクの実行時間で決まるから凄く簡単そうに聞こえる。
Fargateで実行するタスクは、専用のプライベートIPアドレスを持ったENIで動いています。
同一タスク上のコンテナ同士はlocalhostを通じてお互いに通信することができるし、ENIを通して外とインバウンド、アウトバウンドの通信がとれるってこと。
もちろん、パブリックIPアドレスについても同様です。
ECS Fargate 料金 高い 安い 運用難易度 高い 低い EFSとの統合 難しいが可能 無理 EBSとの統合 難しいが可能 無理 NWオプション 複数選択可能 ENI
まとめ

ECSかFargateかどっちが良いの?っていうのは適切な質問ではないですね。
ECSは両方含んでいるので、正しくは「コンテナインスタンスとFargateどっちが良い?」っていうことです。
確かに、EC2インスタンスを手中で管理したいって企業も多いと思うが、マイクロサービスをするのなら圧倒的にFargateに軍配が上がります。
コンテナインスタンスをスケーリングすることは難しいので、Fargateをオススメします。
Fargateは運用するのが楽なので、もし可能なら試してみて下さい。





- 投稿日:2019-05-23T07:10:52+09:00
数時間で完全理解!わりとゴツいKubernetesハンズオン!!
社内でKubernetesハンズオンをやってみたのでおすそ分け。
参加者6人からバンバン出てくる質問に答えながらやって、所要時間4時間ほどでした。SpeakerDeckにも資料を上げています。
https://speakerdeck.com/ktam1219/yaruze-kuberneteshanzuonハンズオンの目標
- Kubernetesとお友達になる
- イメージを掴む
- 触ってみる(ローカル・EKS・ちょっとGKE)
- 構築・運用ができるような気分になる
- 巷にあふれるKubernetesの記事・スライドが理解できるようになる
EKSがメインになっているのは、会社の業務でAWSを使うことが多いからです。
純粋にKubernetesを勉強したいだけならGKEのほうがオススメ。
とはいえ、大部分はKubernetesの一般的なお話なので、この記事を読む分にはどちらでもいいかと思います。前提知識・準備
- Docker / Docker Composeは前提知識として扱います。
- 以下が用意されている前提で進めます
- Docker for Desktop
- kubectl
- AWS CLI(IAMユーザー作ってprofile設定済み)
- aws-iam-authenticator
- eksctl
$ docker -v Docker version 18.09.2, build 6247962 $ kubectl version --short --client Client Version: v1.13.4 $ aws --version aws-cli/1.16.125 Python/2.7.14 Darwin/18.2.0 botocore/1.12.115 $ aws-iam-authenticator help (省略) $ eksctl version [ℹ] version.Info{BuiltAt:"", GitCommit:"", GitTag:"0.1.31"}Kubernetesとは
一言でいえば、
コンテナオーケストレーションシステム
- たくさんのサーバーに
- たくさんのコンテナを置いて
- 連携させるようなアプリケーションを
- デプロイ・管理・スケールとかさせるやーつ
の、デファクトスタンダード
2014年にGoogleがOSSとして公開しました。Googleの長きにわたるコンテナ運用の知見が詰まっているらしい。
現在はCNCF(Cloud Native Computing Foundation : クラウドネイティブなOSS技術の推進を行う団体)が管理。
Dockerも公式にサポート(Docker Swarmあるのに!?)CNCF、錚々たるメンバーが錚々たるOSSを管理しています。
動作環境としては、GCPだけでなくオンプレや他のクラウドでも動きます。
各種パブリッククラウドでは、自力で構築しなくてもマネージドサービスが出ています。
- GCP: GKE
- AWS: EKS (ECSあるのに!?)
- Azure: AKS
- IBM Cloud(旧Bluemix): IKS
- Alibaba: Container Service for Kubernetes
今はまだ導入の知見がもてはやされるような段階ですが、
もうしばらくすると当たり前の技術になっているかもしれません。Kubernetesって何がうれしいの?
Dockerって便利だよね
-> 本番環境で使いたいよね
-> でもDockerって基本的に1コンテナ1機能だよね
-> 複雑なアプリケーションを構築しようとすると複数種のコンテナが必要だよね
-> さて、どうやって構築しよう…?ためしにDockerComposeでの構築を考えてみると…
- コンテナが1台のサーバーに収まらないだろうから、どのコンテナがどのサーバーにあるか管理しなくちゃ
- コンテナが死んだときに気づけるようにしないと。回復方法も用意せねば
- サーバーを跨いだコンテナ間通信って結構めんどくさい
- コンテナを更新するとき、コンテナ間の依存関係とかデプロイ順序とか考えなくちゃ
- 複数サーバーにコンテナがあるんなら、ロードバランシングも考えなくちゃ
- サーバーのスケーリングをしないといけないこともあるよね…
- 各コンテナからログが出てくるけど、ちゃんと管理しておかないと運用辛いよね
- etc...
人類には高度すぎますね。。
でも、できるんです。
そう、Kubernetesならね。Kubernetesのイメージを掴む
ベースとなるアイデア
コンテナの管理をいい感じにやってくれるシステムがあればいいじゃん。というのがベースとなる考え方です。
このいい感じのシステムに「こんな感じでシステムを運用して」と注文書を投げつけてよしなにやってくれると最高。
そしてそれをやってくれるのがKubernetesです。
- いい感じに場所を判断してコンテナを配置
- コンテナが死んだら自動回復
- サーバー間ネットワークもいい感じに
- ローリングアップデート / Blue/Greenデプロイメントもお手の物
- ロードバランシングもやってくれる
- サーバーのオートスケーリングも(クラウドなら)設定可能
- ログ収集もカンタンに
Kubernetes用語に変換してみよう
先ほどの図の要素を一旦Kubernetes用語に変換しておきます。
- いい感じのシステム: Master(ControlPlaneとも)
- コンテナが配置されるサーバー: Node
- Nodeの集合: DataPlane
- MasterとDataPlaneを合わせて: Cluster
- Masterに投げる注文書: マニフェストファイル
- Masterに注文書を投げつけるやつ: kubectl
- CLIツール
- 注文書を投げつけるだけでなくいろんな操作ができる
となります。
マニフェストファイル
Kubernetesにおけるマニフェストファイルの考え方が特徴的なので取り上げておきます。
マニフェストファイルは、システムのあるべき姿を書いているファイルで、yaml(もしくはjson)で記述されます。
「宣言的設定」 ( <-> 「命令的設定」)が特徴です。例えるなら、命令的設定は普通のそば屋さん。
ざるそば1つ注文してそばを受け取ったら、そば屋さんはその後のことには関与しません。
追加注文したいとなると、またお店の人を呼んで注文する必要があります。
Ansible、Terraform、CloudFormationといったものはコレですね。宣言的設定はわんこそば。
わんこそばでは、お椀にそばがある状態があるべき姿で、そば屋さんはお椀を常に監視しています。
そして、そばを食べてお椀からそばがなくなると、自動で追加してくれます。
Kubernetesでは、コンテナの自動回復等、マニフェストファイルを適用したあともその内容を維持するよう動いてくれます。つまりまとめると
- 宣言的に書いたマニフェストを
- kubectlを使ってmasterに渡すと
- 各nodeにコンテナをデプロイしたりしてくれて
- その後はいい感じに監視・維持をしてくれるやーつ
Kubernetesをローカルで試してみよう
さて、ここからハンズオンです。とりあえずやってみましょう。
Docker for DesktopのKubernetesを有効化
Preference画面を開いて、以下のように設定しましょう。
初回は有効になるまで5分ほどかかります。
以前使ったことがある人は、Resetしておいたほうが躓かないかもしれません。
kubectlのconfig設定
kubectlで操作するKubernetesクラスターをdocker-for-desktopに
$ kubectl config use-context docker-for-desktopちゃんと設定されているか確認してみます。
$ kubectl config current-context docker-for-desktop動作確認
なんかいろいろ動いてる
$ kubectl get pods --namespace=kube-system NAMESPACE NAME READY STATUS RESTARTS AGE kube-system etcd-docker-for-desktop 1/1 Running 0 1m kube-system kube-apiserver-docker-for-desktop 1/1 Running 0 1m kube-system kube-controller-manager-docker-for-desktop 1/1 Running 0 1m kube-system kube-dns-86f4d74b45-xb4qh 3/3 Running 0 2m kube-system kube-proxy-8r45p 1/1 Running 0 2m kube-system kube-scheduler-docker-for-desktop 1/1 Running 0 1m下準備
docker-for-desktopでingress(後述)が使えるよう下準備。ローカルだけの操作なのであまり気にしなくてOK。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/mandatory.yaml $ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/provider/cloud-generic.yamlサンプルアプリをデプロイ
サンプルアプリケーションのマニフェストファイルを取ってきます。
$ git clone git@github.com:kubernetes/examples.gitDocker for DesktopのKubernetesはかなり負荷が大きいので、立てるコンテナの数を調整します。
$ vi examples/guestbook/frontend-deployment.yaml 10行目 replicas: 3 <- これを1に変更 $ vi examples/guestbook/redis-slave-deployment.yaml 11行目 replicas: 2 <- これを1に変更デプロイ!
examples/guestbook以下のマニフェストファイルをすべてデプロイします。$ kubectl apply -f examples/guestbook/これでサンプルアプリケーション自体は動き出しましたが、外部からアクセスするためにもうひと手間。
$ cat << 'EOT' >./guestbook-ingress.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: guestbook-ingress spec: rules: - http: paths: - path: / backend: serviceName: frontend servicePort: 80 EOTこれもデプロイします。
$ kubectl apply -f guestbook-ingress.yamlADDRESSがlocalhostになるまで待機します。
$ kubectl get ingress NAME HOSTS ADDRESS PORTS AGE guestbook-ingress * localhost 80 24m
http://localhostにアクセスするとサンプルアプリケーションの画面が出てきます。
ポートが80なんで、PCの状況によってはうまくアクセスできなかったりするかも。
http://127.0.0.1だとうまくいく場合もあるとか…。
何が起きたの?
図で表すとこんなのができています。
が、落ち着いてください。
要点を抜き出してみると、フロントエンドとRedisだけの単純なアプリです。
まずはこの図が理解できるようになりましょう。
Pod
- Kubernetesの最小デプロイ単位
- 1つ以上のコンテナとストレージボリュームの集まり
- 同一Pod内のコンテナは同一Nodeに配置される
- 「同一Nodeで動作する必要があるか?」がPod構成の一つの基準
- 1つのPod内のコンテナは同じIPアドレスとポートを使用する
- Pod内のコンテナ間の通信はプロセス間通信として行う
ReplicaSet
- 同じ仕様のPodが指定した数だけ存在するよう生成・管理する
- Podが死んだときも指定した数になるよう自動回復してくれる
- PodとReplicaSetは疎結合
- "Label"というメタデータを使って都度検索している
- 手動でPodのLabelを書き換えれば、 ReplicaSetから切り離してデバッグするといったことも可能
Deployment
- 新しいバージョンのリリースを管理するための仕組み
- ReplicaSetの変更を安全に反映させる / 世代管理する
- Podのスケール、コンテナの更新、ロールバックetc...
- 2つのDeployment戦略
- Recreate
- RollingUpdate
- ReplicaSetとDeploymentも疎結合
DeploymentのマニフェストファイルにReplicaSetとPodの情報も入れます。
(ReplicaSetやPod単体のマニフェストファイルも書けるけど、あまりやらない)試しにサンプルアプリケーションの
frontend-deployment.yamlを見てみましょう。
redis-master-deployment.yaml,redis-slave-deployment.yamlもだいたい同じです。apiVersion: apps/v1 # apply時に使用するAPIの種別。リソース(kind)によって決まる kind: Deployment # Deploymentのマニフェスト metadata: name: frontend # Deploymentリソースの名前。「metadata.name + ランダム文字列」の名前でReplicaSetが生成される spec: selector: matchLabels: # ReplicaSetがPodを検索するときのLabel app: guestbook tier: frontend replicas: 1 # ReplicaSetが生成・管理するPodの数 template: # ---ここからPodの定義-------------------------------------------- metadata: labels: # PodのLabel。ReplicaSetが管理下のPodを検索するときに使う app: guestbook tier: frontend spec: containers: - name: php-redis # コンテナ名 image: gcr.io/google-samples/gb-frontend:v4 # コンテナイメージ resources: # 使用するCPU, Memoryの指定 requests: cpu: 100m memory: 100Mi env: # 環境変数 - name: GET_HOSTS_FROM value: dns ports: # EXPOSEするポートの指定 - containerPort: 80Service
- Podの集合(主にReplicaSet)に対する経路やサービスディスカバリを提供
- クラスタ内DNSで、
<Service名>.<Namespace名>で名前解決可能に- 同じNamespace内なら
<Service名>だけでOK- ここでもLabelによって対象のPodが検索される
- 対象のPodが動的に入れ替わったりしても、Labelさえついていれば一貫した名前でアクセスできる
Serviceのマニフェストファイルはこんな感じです。
frontend-service.yamlはフロントエンド用、redis-*-service.yamlはバックエンド用なので、Serviceのtypeが違います。apiVersion: v1 kind: Service # Serviceのマニフェスト metadata: name: frontend # Serviceリソースの名前 labels: # ServiceにつけるLabel app: guestbook tier: frontend spec: type: NodePort # Serviceの種別。NodePortはクラスタ外からアクセスできるやつ ports: - port: 80 # アクセスを受け付けるポート selector: # 対象のPodを検索するときのLabel app: guestbook tier: frontendapiVersion: v1 kind: Service metadata: name: redis-master labels: app: redis role: master tier: backend spec: # 省略されているけどtypeはデフォルトの"ClusterIP"。クラスタ上の内部IPアドレスにServiceを公開 ports: - port: 6379 targetPort: 6379 selector: app: redis role: master tier: backendIngress
- Serviceをクラスタ外に公開
- NodePortタイプのServiceと違い、パスベースで転送先のServiceを切り替えるといったことも可能
- Service(NodePort) : L4層レベルでの制御
- Ingress : L7層レベルでの制御
クラウド上でやる場合は、Serviceのtypeに
Loadbalancerを指定して各クラウドのロードバランサーを使うので、
あんまり出番が無いかも。とりあえず先ほど使った
guestbook-ingress.yamlはこんな感じです。apiVersion: extensions/v1beta1 kind: Ingress # Ingressのマニフェスト metadata: name: guestbook-ingress # Ingressリソースの名前 spec: rules: # ルーティングのルールの配列 - http: paths: - path: / backend: # "frontend"Serviceの80番ポートにアクセス serviceName: frontend servicePort: 80中を覗いてみよう
構成がわかったところで、次は中がどうなっているのか覗いてみましょう。
kubectl get [リソースタイプ]で一覧、kubectl describe [リソースタイプ] [リソース名]で詳細が確認できます。Deployment
Deoloyment一覧 ("-o wide"は詳細を見るためのオプション)
$ kubectl get deploy -o wide NAME (略) SELECTOR frontend ... app=guestbook,tier=frontend redis-master ... app=redis,role=master,tier=backend redis-slave ... app=redis,role=slave,tier=backend
SELECTORの項目に出ているのは、ReplicaSetを検索するためのセレクタです。
DeploymentとReplicaSetは疎結合だと先ほど書きましたが、こういうことです。手元で検索する場合は以下のようにします。
$ kubectl get rs -l app=guestbook,tier=frontendDeployment詳細 (長いので手元で見て!)
$ kubectl describe deploy frontendReplicaSet
ReplicaSet一覧
$ kubectl get rs -o wide NAME (略) SELECTOR frontend-5c548f4769 ... app=guestbook,pod-template-hash=1710490325,tier=frontend redis-master-55db5f7567 ... app=redis,pod-template-hash=1186193123,role=master,tier=backend redis-slave-584c66c5b5 ... app=redis,pod-template-hash=1407227161,role=slave,tier=backend名前が
Deployment名 + ランダム文字列になっていますね。
また、SELECTORにpod-template-hashというものが入っています。RollingUpdateなどで同じtemplateのPodを管理するReplicaSetが複数混在しても大丈夫なように固有値のLabelをKubernetesが自動で入れています。ReplicaSet詳細 (長いので手元で見て!)
$ kubectl describe rs frontend-5c548f4769Pod
Pod一覧
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE frontend-5c548f4769-xhpxz 1/1 Running 0 1d 10.1.1.65 docker-for-desktop redis-master-55db5f7567-2n4qp 1/1 Running 0 1d 10.1.1.67 docker-for-desktop redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d 10.1.1.66 docker-for-desktop今度は名前が
ReplicaSet名 + ランダム文字列になっていますね。Pod詳細 (長いので手元で見て!)
設定や起動日時、状態、イベント等確認できます$ kubectl describe pod frontend-5c548f4769-xhpxzPodはログも見れます(長いので手元で見て!)
$ kubectl logs frontend-5c548f4769-xhpxzService
Service一覧
$ kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR frontend NodePort 10.102.204.76 <none> 80:30590/TCP 1d app=guestbook,tier=frontend kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d <none> redis-master ClusterIP 10.98.133.213 <none> 6379/TCP 1d app=redis,role=master,tier=backend redis-slave ClusterIP 10.107.141.173 <none> 6379/TCP 1d app=redis,role=slave,tier=backendfrontendだけtypeが
NodePortなので、外部にポートが開かれています。
先ほどはIngressを立ててアクセスしましたが、実はlocalhost:30590(ポート番号は都度変わります)でもアクセスできます。
ただし、ServiceなのでL4制御です。Service詳細 (長いので手元で見て!)
$ kubectl describe svc frontendIngress
Ingress一覧
$ kubectl get ing NAME HOSTS ADDRESS PORTS AGE guestbook-ingress * localhost 80 1dIngress詳細 (長いので手元で見て!)
$ kubectl describe ing guestbook-ingressスケールさせてみよう
frontendのPodを2つに増やしてみます。
$ vi examples/guestbook/frontend-deployment.yaml 10行目 replicas: 1 <- これを2に変更デプロイ
$ kubectl apply -f examples/guestbook/frontend-deployment.yaml増えてる!
$ kubectl get pod NAME READY STATUS RESTARTS AGE frontend-5c548f4769-vltkv 1/1 Running 0 15s frontend-5c548f4769-xhpxz 1/1 Running 0 1d redis-master-55db5f7567-2n4qp 1/1 Running 0 1d redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d自動回復させてみよう
意図的にPodを削除してみます。
先ほど増えた2つめのPodを削除してみましょう。$ kubectl delete pod frontend-5c548f4769-vltkvしばらくすると新しいpodができています!
$ kubectl get pod NAME READY STATUS RESTARTS AGE frontend-5c548f4769-ns5q2 1/1 Running 0 8s frontend-5c548f4769-xhpxz 1/1 Running 0 1d redis-master-55db5f7567-2n4qp 1/1 Running 0 1d redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1dDeploymentのデプロイ管理っぷりを見てみよう
Podの変更が起こらないと履歴が記録されない(スケールじゃダメ)ので、試しに使用メモリを変えてみます。
$ examples/guestbook/frontend-deployment.yaml 23行目 memory: 100Mi <- これを120Miに変更デプロイ
$ kubectl apply -f examples/guestbook/frontend-deployment.yaml徐々に切り替わっていきます。
# 徐々に切り替わっている! $ kubectl get pod NAME READY STATUS RESTARTS AGE frontend-5c548f4769-ns5q2 1/1 Running 0 11m frontend-5c548f4769-xhpxz 1/1 Running 0 1d frontend-68dd74b969-ztcdw 0/1 ContainerCreating 0 5s redis-master-55db5f7567-2n4qp 1/1 Running 0 1d redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d $ kubectl get pod NAME READY STATUS RESTARTS AGE frontend-5c548f4769-xhpxz 1/1 Running 0 1d frontend-68dd74b969-6shhj 0/1 ContainerCreating 0 6s frontend-68dd74b969-ztcdw 1/1 Running 0 21s redis-master-55db5f7567-2n4qp 1/1 Running 0 1d redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d $ kubectl get pod NAME READY STATUS RESTARTS AGE frontend-68dd74b969-6shhj 1/1 Running 0 26s frontend-68dd74b969-ztcdw 1/1 Running 0 41s redis-master-55db5f7567-2n4qp 1/1 Running 0 1d redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1dDeploymentで管理している履歴を見てみましょう。
$ kubectl rollout history deployments frontend deployment.extensions/frontend REVISION CHANGE-CAUSE 1 <none> 2 <none>REVISIONの数値が大きいほうが新しいものです。
CHANGE-CAUSEはマニフェストファイルに"Annotation"と呼ばれる情報を付け加えると出てきますが、今回は気にしないことにします。REVISION=2の詳細を見てみます(長いので手元で見て!)
$ kubectl rollout history deployments frontend --revision=2リビジョンを戻してみましょう。
今回リビジョンを指定していますが、1つ前に戻るときは"--to-revision"は省略できます。$ kubectl rollout undo deployments frontend --to-revision=1もう一度履歴を見ると、REVISION=1が消えています。
ロールバックでもリビジョンは積まれますが、同内容のリビジョンは履歴から消えます。$ kubectl rollout history deployments frontend deployment.extensions/frontend REVISION CHANGE-CAUSE 2 <none> 3 <none>ところでMasterって何やってるの?
Masterも結局Podの集まりです。
kube-systemのnamespaceの中にMasterに属するPodが。$ kubectl get pods --namespace=kube-system NAMESPACE NAME READY STATUS RESTARTS AGE kube-system etcd-docker-for-desktop 1/1 Running 0 1m kube-system kube-apiserver-docker-for-desktop 1/1 Running 0 1m kube-system kube-controller-manager-docker-for-desktop 1/1 Running 0 1m kube-system kube-dns-86f4d74b45-xb4qh 3/3 Running 0 2m kube-system kube-proxy-8r45p 1/1 Running 0 2m kube-system kube-scheduler-docker-for-desktop 1/1 Running 0 1metcd
- クラスタ内のさまざまなデータを保存している一貫性のある高可用性のKVS
kube-apiserver
- クラスタに対する全ての操作を司るAPIサーバー
- 認証や認可の処理なども行う
kube-scheduler
- PodのNodeへの割り当てを行うスケジューラー
- Podを配置するNodeの選択も行う
kube-controller-manager
- 各種Kubernetesオブジェクトのコントローラーを起動し管理するマネージャー
NodeにもMasterと連携するものが入っています。
kubelet
- Nodeのメイン処理であるPodの起動・管理を行うエージェント
kube-proxy
- Serviceが持つ仮想的なIPアドレス(ClusterIP)へのアクセスをルーティングする
図に表すとこんな感じになります。
お片付け
guestbookアプリケーションを削除
$ kubectl delete -f examples/guestbook/しばらくすると削除される
$ kubectl get pod No resources found.Docker for DesktopのKubernetesを無効化
EKSでクラスタを作ってみよう
EKSとは
- 複数AZでmasterを冗長構成して実行
- masterの監視・自動回復
- 自動アップグレード・パッチ適用
- 他のAWSサービスとの統合
- DataPlane(EC2)は自前で用意する必要がある
- ざっくり費用感 : $144/月 (2019/04現在・東京リージョン : EC2費用は別途)
クラスタを作ってみよう!
…とは言いつつ今回は手順を確認するだけでよいかと思います。
本来どんな手順が必要なのかは知っておくといいけど、もっといいやり方があるので実際にやるのは時間がもったいないので。
スライドには手順も書いているので、やってみたい方はそちらを参照。もっといいやり方
eksctl
- 非公式・デファクトスタンダード
- https://eksctl.io/
- コマンド一つでクラスタ構築
クイックスタート
- 公式・最近出た
- https://aws.amazon.com/jp/quickstart/architecture/amazon-eks/
- https://dev.classmethod.jp/cloud/aws/eks-quickstart/
- Cfnを使ってクラスタ構築
- ベストプラクティスに従っているので結構豪華な構成
eksctlを使ってみよう
eksctlとは
- コマンド一つでEKSのClusterができちゃうツール
- CloudFormationのテンプレートを自動生成して構築してる
- nodeのオートスケーリングなど、便利な機能も
- とはいえまだ発展途上
- ロゴを見てみると分かると思いますが、goでできています
やってみよう!
コマンド1つでクラスタができます!
$ eksctl create cluster \ --name eksctl-handson \ --region ap-northeast-1 \ --nodes 3 \ --nodes-min 3 \ --nodes-max 3 \ --node-type t2.medium \ --ssh-public-key <キーペア名>ただし構築完了まで15分ぐらいかかります…
ap-northeast-1bが選択できる古いAWSアカウントはAZ指定も必要です。その他のオプションはヘルプを参照してください。
$ eksctl create cluster -h構築が完了すると、以下のような感じになります。
とりあえずデプロイしよう
git cloneしてきた内容をもとに戻します。
$ cd examples $ git reset --hard $ cd ../frontend-serviceのタイプをLoadBalancerに変更します。
クラウドのロードバランサー(ここではELB)と連携するタイプです。$ vi examples/guestbook/frontend-service.yaml 9-13行目 # comment or delete the following line if you want to use a LoadBalancer type: NodePort <- ここをコメントアウト # if your cluster supports it, uncomment the following to automatically create # an external load-balanced IP for the frontend service. # type: LoadBalancer <- ここをアンコメントapply!
$ kubectl apply -f examples/guestbook/しばらくすると構築が完了します。
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/frontend-56f7975f44-2vtbr 1/1 Running 0 8s pod/frontend-56f7975f44-j25zn 1/1 Running 0 8s pod/frontend-56f7975f44-mss7q 1/1 Running 0 8s pod/redis-master-6b464554c8-wrjrp 1/1 Running 0 8s pod/redis-slave-b58dc4644-ft2fd 1/1 Running 0 7s pod/redis-slave-b58dc4644-p59fk 1/1 Running 0 7s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/frontend LoadBalancer 10.100.61.11 xxxxxx.ap-northeast-1.elb.amazonaws.com 80:31673/TCP 8s service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 23m service/redis-master ClusterIP 10.100.137.217 <none> 6379/TCP 7s service/redis-slave ClusterIP 10.100.217.57 <none> 6379/TCP 7s NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/frontend 3 3 3 3 8s deployment.apps/redis-master 1 1 1 1 8s deployment.apps/redis-slave 2 2 2 2 7s NAME DESIRED CURRENT READY AGE replicaset.apps/frontend-56f7975f44 3 3 3 8s replicaset.apps/redis-master-6b464554c8 1 1 1 8s replicaset.apps/redis-slave-b58dc4644 2 2 2 7s
service/frontendのEXTERNAL-IPにELBのドメインがついているので、そこにアクセスしてみましょう。ダッシュボードを入れてみよう
ダッシュボード用のPodをapply
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yamlダッシュボードにログインするためのトークンを取得
$ aws-iam-authenticator token -i eksctl-handson | jq -r '.status.token'プロキシ経由でダッシュボードにアクセス
$ kubectl proxy --port=8000 --address='0.0.0.0' --disable-filter=true
http://localhost:8000/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/にアクセスすると、ダッシュボードのログイン画面になります。トークンを入力してログインしましょう。
ログを収集してみよう
KubernetesのログをCloudWatchLogsに入れてみます。
CloudWatch Container Insights
が、ハンズオン実施後に「CloudWatch Container Insights」が発表されました。
ログやメトリクスを取得してくれるマネージドサービスです。
まだパブリックプレビューですが、AWSを使う場合はコレがスタンダードになると思われます。
https://dev.classmethod.jp/cloud/aws/cloudwatch-container-insights/とりあえずここでは
DaemonSetの概念が出てくるので従来の手順を書いておきます。Dockerコンテナのログ
Dockerコンテナでは、標準出力がログとして扱われます。ログはデフォルトでjson型式のファイルになります。
今回は各NodeにfluentdのPodを置き、Node内のPodが出力したログファイルを収集してCloudWatchに送ります。
DaemonSet
さて、ReplicaSetでPodを配置するときは、Nodeの選択はできませんでした。Kubernetesがよしなにやってくれます。
今回のように各Nodeに1つずつPodを起きたいときは、DaemonSetを使います。
ということでやってみましょう。
デプロイ
NodeのEC2に紐付いているIAM Roleの名前を取得
$ INSTANCE_PROFILE_NAME=$(aws iam list-instance-profiles | jq -r '.InstanceProfiles[].InstanceProfileName' | grep nodegroup) $ ROLE_NAME=$(aws iam get-instance-profile --instance-profile-name $INSTANCE_PROFILE_NAME | jq -r '.InstanceProfile.Roles[] | .RoleName')IAM Roleにログ収集用のインラインポリシーを追加
$ cat << "EoF" > ./k8s-logs-policy.json { "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] } EoF $ aws iam put-role-policy --role-name $ROLE_NAME --policy-name Logs-Policy-For-Worker --policy-document file://k8s-logs-policy.jsonfluentdのマニフェストファイルを取得
$ wget https://eksworkshop.com/logging/deploy.files/fluentd.ymlクラスタ名を変更
$ vi fluentd.yml 197行目 value: us-east-1 <- ap-northeast-1 に変更 199行目 value: eksworkshop-eksctl <- eksctl-handson に変更fluentdをデプロイ
$ kubectl apply -f fluentd.ymlしばらくするとCloudWatchにログが上がってきます。
マニフェストファイルを見てみる
fluentd.yamlを見てみると、DaemonSetが設定されているのが分かりますね。(略) --- apiVersion: extensions/v1beta1 kind: DaemonSet # DaemonSetのマニフェスト metadata: name: fluentd-cloudwatch namespace: kube-system labels: k8s-app: fluentd-cloudwatch spec: template: # ---ここからPodの定義-------------------------------------------- metadata: labels: k8s-app: fluentd-cloudwatch spec: serviceAccountName: fluentd terminationGracePeriodSeconds: 30 # Because the image's entrypoint requires to write on /fluentd/etc but we mount configmap there which is read-only, # this initContainers workaround or other is needed. # See https://github.com/fluent/fluentd-kubernetes-daemonset/issues/90 initContainers: - name: copy-fluentd-config image: busybox command: ['sh', '-c', 'cp /config-volume/..data/* /fluentd/etc'] volumeMounts: - name: config-volume mountPath: /config-volume - name: fluentdconf mountPath: /fluentd/etc (略)Helmを使ってみよう
Helmとは
- Kubernetes用のパッケージ管理ツール
- パッケージは"Chart"と呼ばれ、マニフェストファイルのテンプレートが含まれる
- "Tiller"と呼ばれるサーバーアプリケーション(これもPod)を介してクラスタ内にパッケージをインストール
- ちなみに"helm"は兜ではなく船の舵、"chart"は海図、"tiller"は舵柄の意味
Role-Based Access Control (RBAC)
- Kubernetesの権限制御の仕組み
- Kubernetesのリソースへのアクセスをロールによって制御
- ユーザーとロールをBindingによって紐付けることによって機能する
- ユーザー種別
- 認証ユーザー・グループ : クラスタ外からKubernetes APIを操作するためのユーザー
- ServiceAccount : PodがKubernetes APIを操作するためのユーザー
- ロール種別
- Role : 指定のnamespace内でのみ有効
- ClusterRole : クラスタ全体で有効
- HelmにもRBACを有効にできるChartが多く管理されている
Helmのインストール
- https://helm.sh/docs/using_helm/#installing-helm
- Macの場合
brew install kubernetes-helmTiller用のサービスアカウントのマニフェストファイルを作成
"cluster-admin"はデフォルトで存在するClusterRole$ cat <<EoF > tiller_rbac.yaml --- apiVersion: v1 kind: ServiceAccount metadata: name: tiller namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: tiller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: tiller namespace: kube-system EoFTiller用のサービスアカウントを作成
$ kubectl apply -f tiller_rbac.yamlTillerのサービスアカウントを指定してクラスタにHelmを導入
これでTillerのPodがkube-systemネームスペースにデプロイされる$ helm init --service-account tillerJenkinsをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/jenkins" で確認$ cat <<EoF > jenkins.yaml rbac: create: true master: service_port: 8080 persistence: size: 1Gi EoFJenkinsをインストール
$ helm install -f jenkins.yaml --name jenkins stable/jenkinsしばらくするとデプロイ完了(2-3分ぐらい)
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/jenkins-f65b9477-89s69 1/1 Running 0 33m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/jenkins LoadBalancer 10.100.22.208 xxxxxx.ap-northeast-1.elb.amazonaws.com 8081:30196/TCP 33m service/jenkins-agent ClusterIP 10.100.58.26 <none> 50000/TCP 33m service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 2h NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE deployment.apps/jenkins 1 1 1 1 33m NAME DESIRED CURRENT READY AGE replicaset.apps/jenkins-f65b9477 1 1 1 33mパスワード取得(インストール時のログに取得方法が書いているやつ)
$ printf $(kubectl get secret --namespace default jenkins -o jsonpath="{.data.jenkins-admin-password}" | base64 --decode);echo XXXXXXXXログインURL取得(インストール時のログに取得方法が書いているやつ)
$ export SERVICE_IP=$(kubectl get svc --namespace default jenkins --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}") $ echo http://$SERVICE_IP:8080/login http://xxxxxx.ap-northeast-1.elb.amazonaws.com:8080/loginアクセスしてログインすると以下のような画面になります。
username : admin
password : コマンドで取得したやつ
Jenkinsをアンインストール
--purgeはオプション。付けない場合、リビジョンの記録が残り、ロールバックができる$ helm delete --purge jenkins監視できるようにしてみよう
これも「CloudWatch Container Insights」に置き換わるのではないかと思いますが、一応書いておきます。
今回はPrometheus/Grafanaを利用します。
- Prometheus
- OSSのリソース監視ツール
- 導入がカンタン、いい感じに通知くれる、高性能などで人気が高い
- ただ、データの可視化が本業ではないので力不足
- Grafana
- OSSのログ・データ可視化ツール
- Prometheusが収集したデータをかっこよく表示できる
Prometheusをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/prometheus" で確認$ cat <<EoF > prometheus.yaml alertmanager: persistentVolume: size: 1Gi storageClass: "gp2" server: persistentVolume: size: 1Gi storageClass: "gp2" retention: "12h" pushgateway: enabled: false EoFPrometheusをインストール
$ kubectl create namespace prometheus $ helm install -f prometheus.yaml --name prometheus --namespace prometheus stable/prometheusデプロイが完了したらアクセスしてみる(立ち上がるまで数分かかる)
以下はインストール時のログに出てくるやつ$ export POD_NAME=$(kubectl get pods --namespace prometheus -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}") $ kubectl --namespace prometheus port-forward $POD_NAME 9090
http://localhost:9090/targetsにアクセスすると、Prometheusの画面が確認できます。
Grafanaをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/grafana" で確認$ cat <<EoF > grafana.yaml persistence: storageClassName: gp2 adminPassword: password datasources: datasources.yaml: apiVersion: 1 datasources: - name: Prometheus type: prometheus url: "http://prometheus-server.prometheus.svc.cluster.local" access: proxy isDefault: true service: type: LoadBalancer EoFGrafanaをインストール
$ kubectl create namespace grafana $ helm install -f grafana.yaml --name grafana --namespace grafana stable/grafanaデプロイが完了したらアクセスしてみる(立ち上がるまで数分かかる)
以下はインストール時のログに出てくるやつ$ export ELB=$(kubectl get svc -n grafana grafana -o jsonpath='{.status.loadBalancer.ingress[0].hostname}') $ echo "http://$ELB" http://xxxxxx.ap-northeast-1.elb.amazonaws.comアクセスしてログインすると以下の画面になります。
- username : admin
- password : password (grafana.yamlに書いた)
ダッシュボードを作る
今回はImport画面から、公開されているテンプレートを導入してみましょう。
テンプレート番号は
3131です。
なんだかそれっぽいのが出ました。
3146ならこんな感じになります。
お片付け
クラスタ内をお片付けしないと、eksctlでクラスタを削除するときにCloudFormationで怒られてしまうのでご注意。
PrometheusとGrafanaを削除
$ helm delete --purge prometheus $ helm delete --purge grafanafluentdを削除
$ kubectl delete -f fluentd.ymlダッシュボードを削除
$ kubectl delete -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yamlguestbookアプリを削除
$ kubectl delete -f examples/guestbook/ログ収集用にIAM RoleにくっつけたPolicyを外す
$ INSTANCE_PROFILE_NAME=$(aws iam list-instance-profiles | jq -r '.InstanceProfiles[].InstanceProfileName' | grep nodegroup) $ ROLE_NAME=$(aws iam get-instance-profile --instance-profile-name $INSTANCE_PROFILE_NAME | jq -r '.InstanceProfile.Roles[] | .RoleName') $ aws iam delete-role-policy --role-name $ROLE_NAME --policy-name Logs-Policy-For-Workereksctlでクラスタを削除
途中までしか見てくれないので、AWSコンソールで本当に削除されたか確認したほうがいいです。$ eksctl delete cluster --name eksctl-handson(おまけ)GKEでクラスタを作ってみよう
やっぱり本家も見ておかないと、ということでちょっとだけ。
CLIやGCPプロジェクトの設定は終わっている前提です。やってみよう
コマンド1つでNodeも含めてクラスタを作ってくれます。
なんと3分半ぐらいでできる!!$ gcloud container clusters create gke-handson --cluster-version=1.12.7-gke.10 --machine-type=n1-standard-1 --num-nodes=3
kubectlのconfigもちゃんと変わってる!
$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE docker-for-desktop docker-for-desktop-cluster docker-for-desktop * xxxxxx_asia-northeast1-a_gke-handson xxxxxx_asia-northeast1-a_gke-handson xxxxxx_asia-northeast1-a_gke-handsonデフォルトでfluentdやprometheusが入ってる!
$ kubectl get pods --namespace=kube-system NAME READY STATUS RESTARTS AGE event-exporter-v0.2.3-f9c896d75-52nkr 2/2 Running 0 2m5s fluentd-gcp-scaler-69d79984cb-zm56b 1/1 Running 0 113s fluentd-gcp-v3.2.0-5mncb 2/2 Running 0 63s fluentd-gcp-v3.2.0-9sdg7 2/2 Running 0 74s fluentd-gcp-v3.2.0-t59sr 2/2 Running 0 54s heapster-v1.6.0-beta.1-6fc8df6cb8-54qrk 3/3 Running 0 85s kube-dns-autoscaler-76fcd5f658-22l8j 1/1 Running 0 104s kube-dns-b46cc9485-5kspm 4/4 Running 0 92s kube-dns-b46cc9485-j8fmn 4/4 Running 0 2m5s kube-proxy-gke-gke-handson-default-pool-d757b1ec-9ld7 1/1 Running 0 108s kube-proxy-gke-gke-handson-default-pool-d757b1ec-lcl8 1/1 Running 0 110s kube-proxy-gke-gke-handson-default-pool-d757b1ec-z2m6 1/1 Running 0 110s l7-default-backend-6f8697844f-s8lgv 1/1 Running 0 2m6s metrics-server-v0.3.1-5b4d6d8d98-tn8cw 2/2 Running 0 87s prometheus-to-sd-4v26j 1/1 Running 0 111s prometheus-to-sd-k4jj7 1/1 Running 0 110s prometheus-to-sd-mhs8h 1/1 Running 0 110sこれで3Nodeのクラスタができました。
もちろん今まで使ってきたマニフェストファイルが使えるのでデプロイしてみましょう。
$ kubectl apply -f examples/guestbook/お片付け
削除も3分半ぐらいで終わります!!
$ gcloud container clusters delete gke-handsonkubectlのconfigもちゃんと消えています。
$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE docker-for-desktop docker-for-desktop-cluster docker-for-desktop念のため残っているリソースが無いかコンソールで確認しておくと吉。
EKSとGKE
- 柔軟性
- EKSはユーザーによるカスタマイズの幅が大きい
- でもやっぱり面倒なのでeksctlとかが誕生していたりする…
- GKEはいい感じにしてくれる
- 立ち上がりの速さ
- EKSは(eksctl利用で)15分ぐらい
- GKEは3分半ぐらい
- 費用
- EKSはmasterに費用がかかる(東京リージョンで$144/月ぐらい)
- GKEはmasterに費用がかからない!
- どっちを選ぼう?
- 純粋にKubernetesを使いたいだけなら圧倒的にGKE
- AWSのもろもろのサービスと合わせて使いたいならEKS
その他もろもろ
紹介しなかったリソースたち
ハンズオン中に出てこなかった主要なリソースを紹介します。
Job
- 単発の処理を管理
- 指定した数だけPodを作成して処理を実行
apiVersion: batch/v1 kind: Job # Jobのマニフェスト metadata: name: example_job labels: app: example spec: parallelism: 3 # 同時に実行するPodの数 template: # ---ここからPodの定義-------------------------------------------- metadata: labels: app: example spec: (略)CronJob
- 定期実行する処理を管理
- スケジュールに沿ってPodを作成して処理を実行
- コンテナ内でCronを設定しなくてよくなるので便利!
apiVersion: batch/v1beta1 kind: CronJob # CronJobのマニフェスト metadata: name: example_job labels: app: example spec: schedule: "*/1 * * * *" # 起動スケジュールをcronと同じ型式で定義 jobTemplate: spec: template: # ---ここからPodの定義-------------------------------------------- metadata: labels: app: example spec: (略)ConfigMap
- アプリケーションの設定情報を定義してPodに提供
- 環境変数として提供
- Volumeとして提供
apiVersion: v1 kind: ConfigMap metadata: name: cm-example data: # key-value型式で設定情報を書いていく EXAMPLE: this_is_example example.txt: | this is example# Podの定義中 (略) env: # 環境変数として提供 - name: EXAMPLE valueFrom: configMapKeyRef: name: cm-example key: EXAMPLE (略) containers: # Volumeとして提供。これで /config/example.txt が扱えるようになる - image: alpine (略) volumeMounts: ## コンテナ内でのVolumeのマウント設定 - name: cm-volume mountPath: /config volumes: ## Volumeの定義 - name: cm-volume configMap: name: cm-example (略)Secret
- アプリケーションの機密情報を定義してPodに提供
- 環境変数として提供
- Volumeとして提供
- ConfigMapとの違い
- 文字列をBase64エンコードした状態で扱う(バイナリデータを扱えるように)
- もちろん暗号化目的じゃないので、そのままGithubに上げたりしたらダメ
- (設定によって)etcd上に暗号化した状態で保存される
- NodeではPodのtmpfs(要するにメモリ)上に保存される
- Nodeは割り当てられたPodが参照するSecret以外はアクセスできない
- いくつかTypeがある
- Opaque: ConfigMapと同じ構造化されてないKey/Value形式
- kubernetes.io/tls: TLSの秘密鍵と公開鍵を格納
- kubernetes.io/service-account-token: Kubernetesのサービスアカウントのクレデンシャル
apiVersion: v1 kind: Secret metadata: name: secret-example stringData: password: xxxxxxxxxxxx # Base64エンコードされた文字列 credential.txt: | xxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxx# Podの定義中 (略) env: # 環境変数として提供 - name: PASSWORD valueFrom: secretKeyRef: name: secret-example key: password (略) containers: # Volumeとして提供。これで /secrets/credential.txt が扱えるようになる - image: alpine (略) volumeMounts: ## コンテナ内でのVolumeのマウント設定 - name: secret-volume mountPath: /secrets volumes: ## Volumeの定義 - name: secret-volume secret: secretName: secret-data (略)ストレージ関連もろもろ
- PersistentVolume
- ストレージの実体
- AWSならNodeのEC2が持つEBS
- PersistentVolumeClaim
- ストレージを論理的に抽象化したリソース
- PersistentVolumeに対して必要な容量を動的に確保
- StorageClass
- PersistentVolumeが確保するストレージの種類を定義
- AWSなら io1/ gp2/sc1/st1
- StatefulSet
- 継続的にデータを永続化するステートフルなアプリケーションの管理に向いたリソース
- 管理下のPodには連番の識別子が付与され、再作成されても同じ識別子であれば同じストレージを参照する
クラウドでKubernetesを使うなら基本的にマネージドのDBサービス等を使うので、自分から使う機会はあまりないかも。
外部から持ってきたマニフェストファイルに書かれていたりするので、存在は知っておいてもらいたい、というぐらいです。マニフェストファイルのフォーマットを調べる
Kubernetesの情報を本なりWebなりで見ていると、マニフェストファイルの例はたくさん出てきます。
でもパラメーターが多すぎて全部説明してくれるのはマニュアルぐらいなのでその調べ方をば。
https://qiita.com/Kta-M/items/039cee72e82590a0c4f4運用時の基本構成イメージ
と言いつつ運用はしたことないんですが、こんな感じの構成になるはず。
まとめ
ハンズオンの目標(再掲)
- Kubernetesとお友達になる
- イメージを掴む
- 触ってみる(ローカル・EKS・ちょっとGKE)
- 構築・運用ができるような気分になる
- 巷にあふれるKubernetesの記事・スライドが理解できるようになる
とはいえ…
Kubernetesは大規模で複雑なシステムで真価を発揮するものです。
単純なものならFargateとかECSとかのほうが良かったりもします。。
場合によってはEC2を使ったレガシーな構成でも事足りるはず。でも、数年後には
当たり前の技術になっている可能性が高いのではないかと思います。
そしてもっとカンタンに使えるようになっている可能性も十分にある!
たとえばEKSのFargate対応もあるとかないとか…。いずれにせよ、現時点でも自分の選択肢が増えるのはいいことだよね!
というわけで
とりあえず目標が達成できていたなら幸いです?
が、Kubernetes沼の入り口に立ったばかり。今回紹介しきれなかった用語、エコシステムなどまだ膨大に…。
俺たちの戦いはこれからだ!

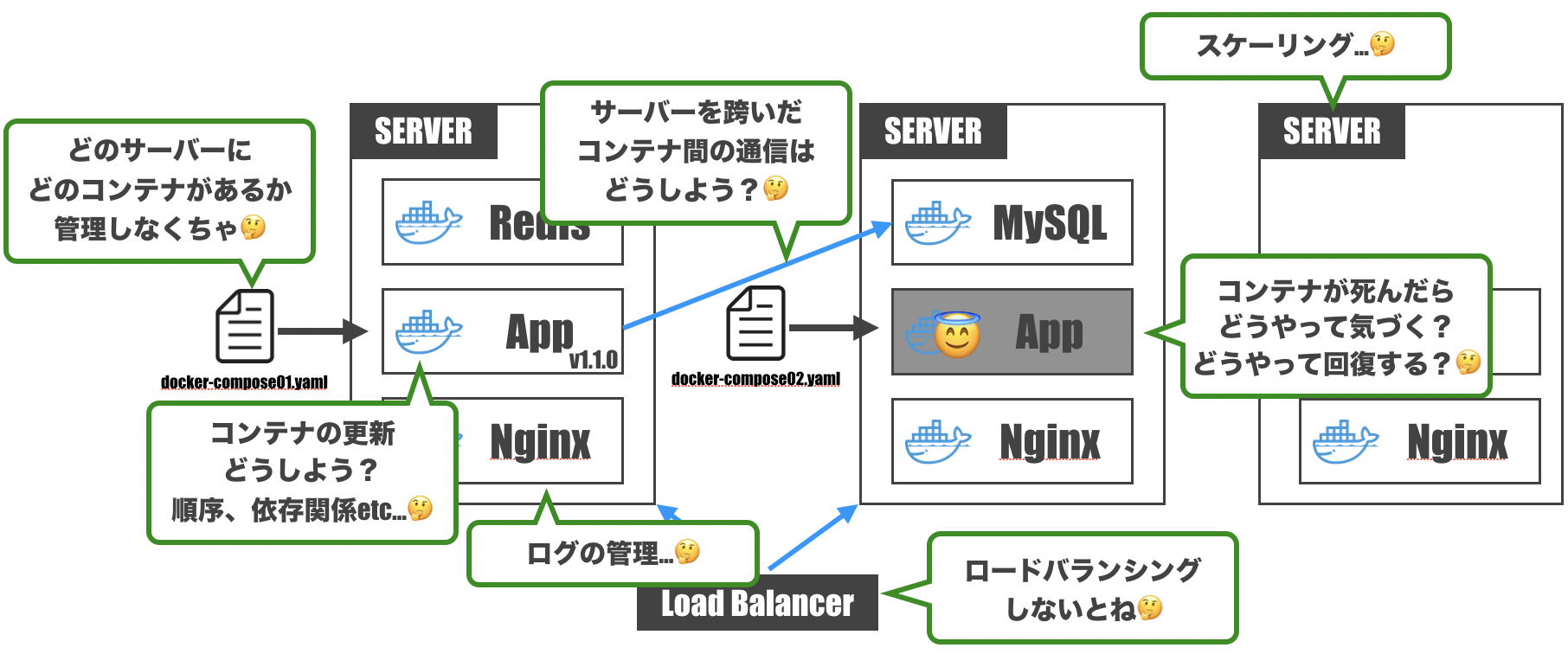
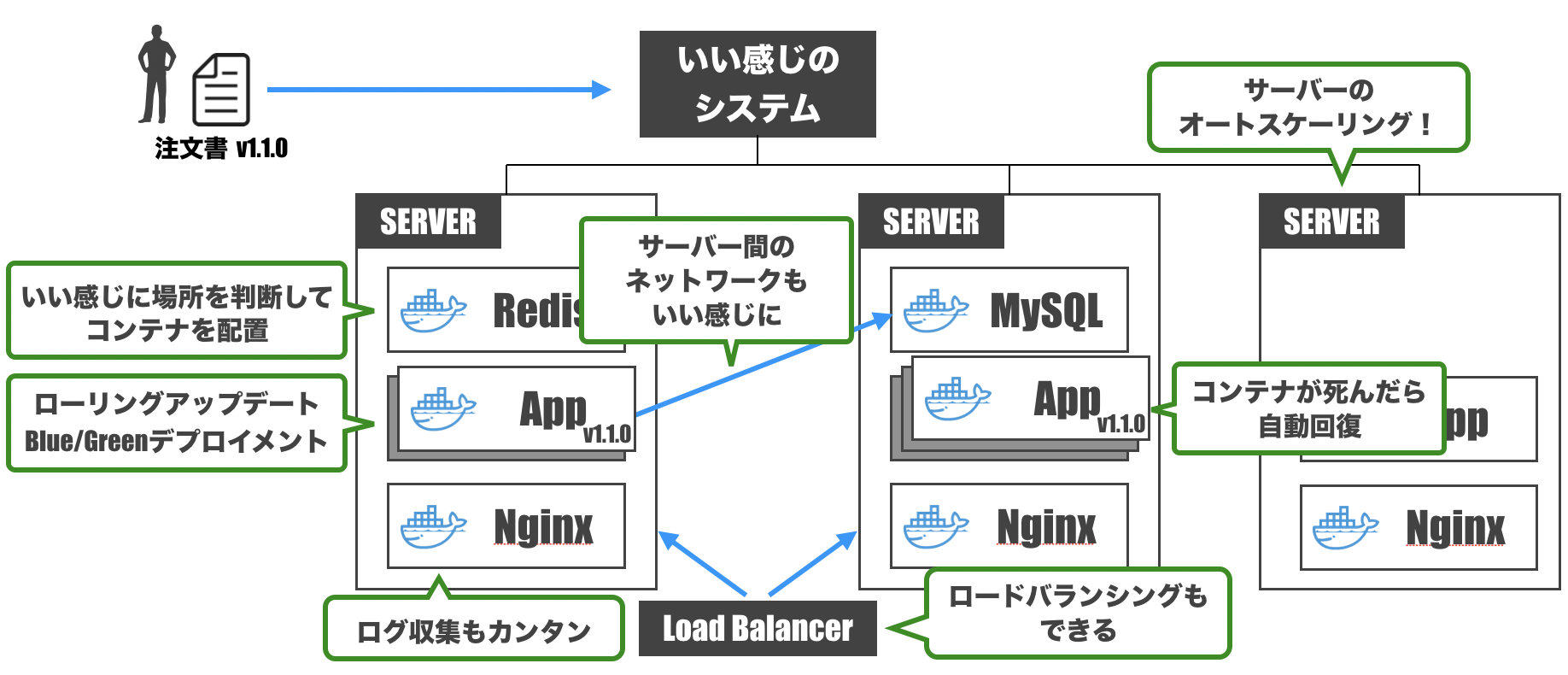
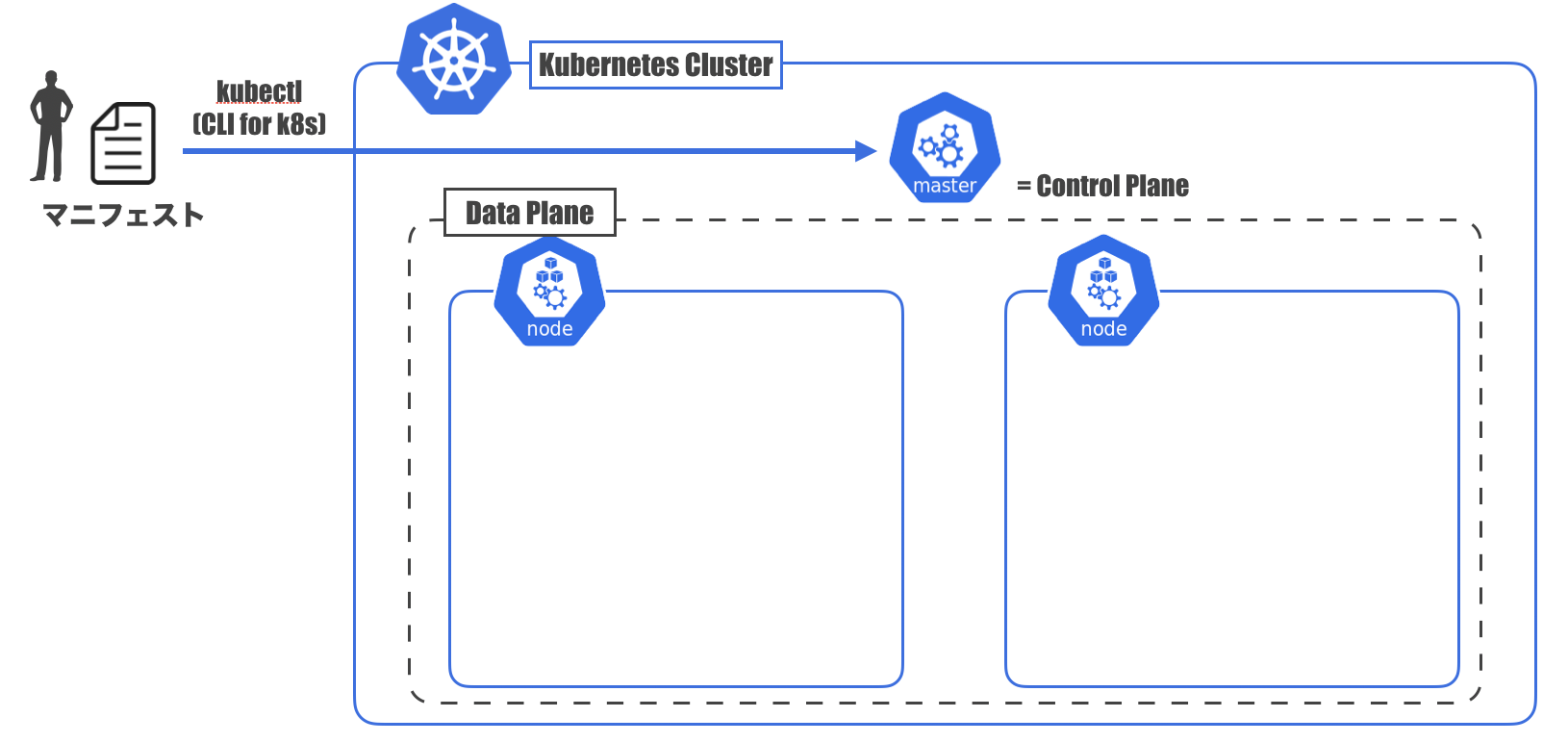
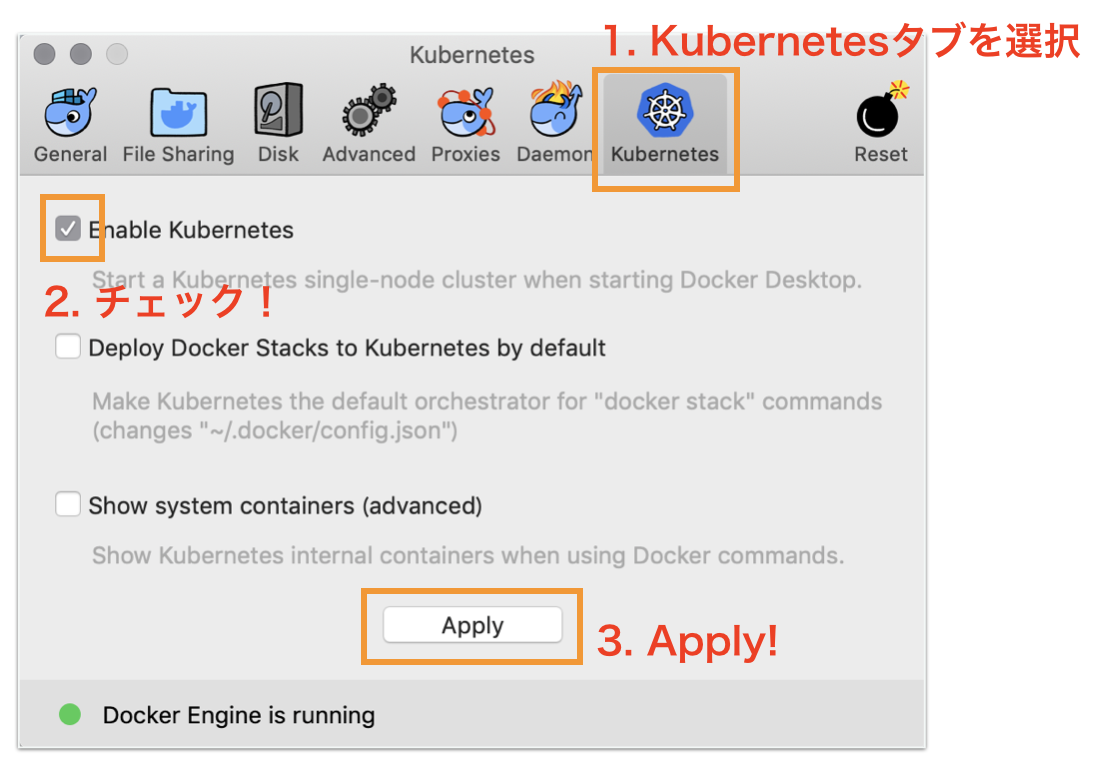

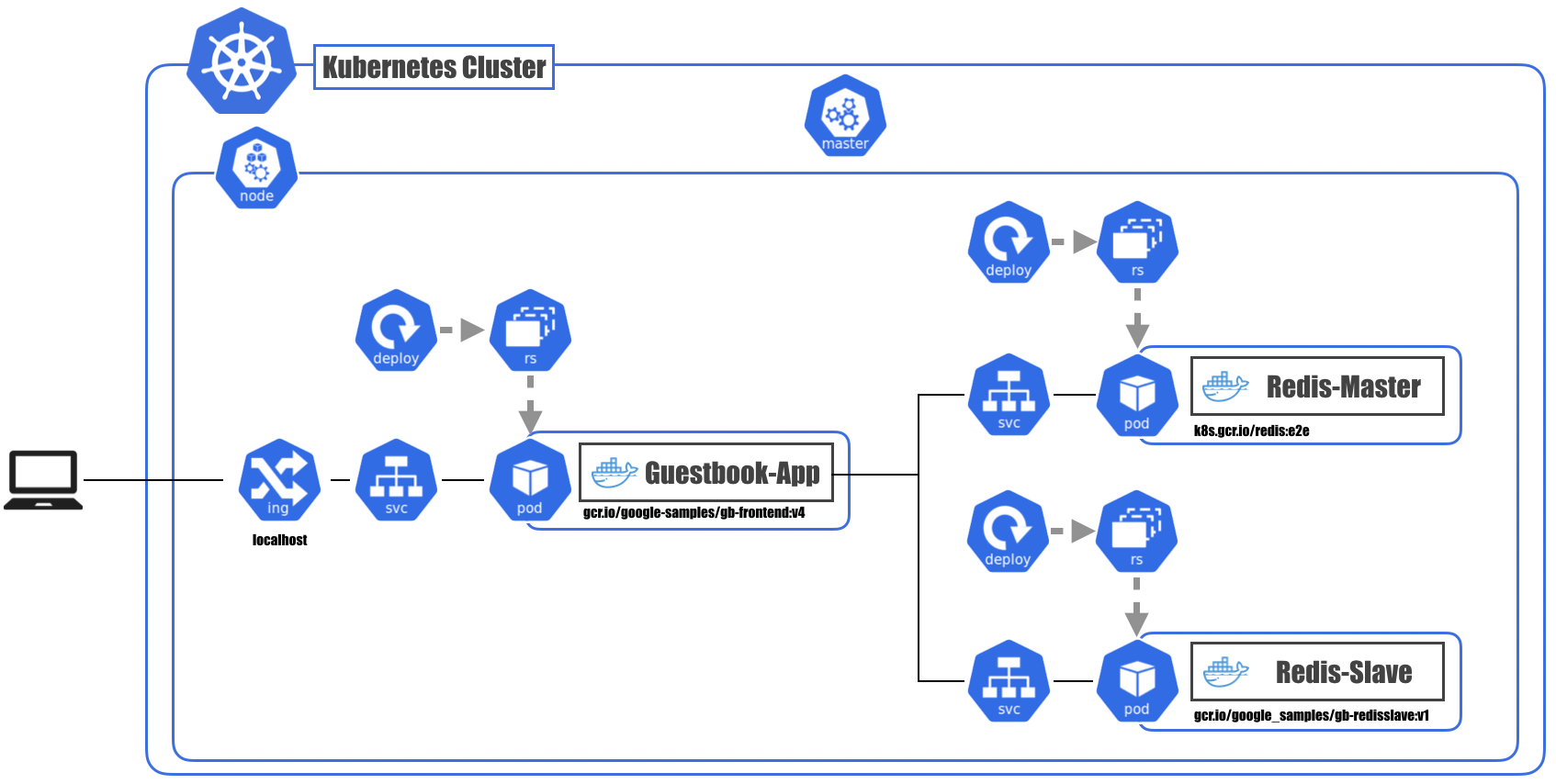
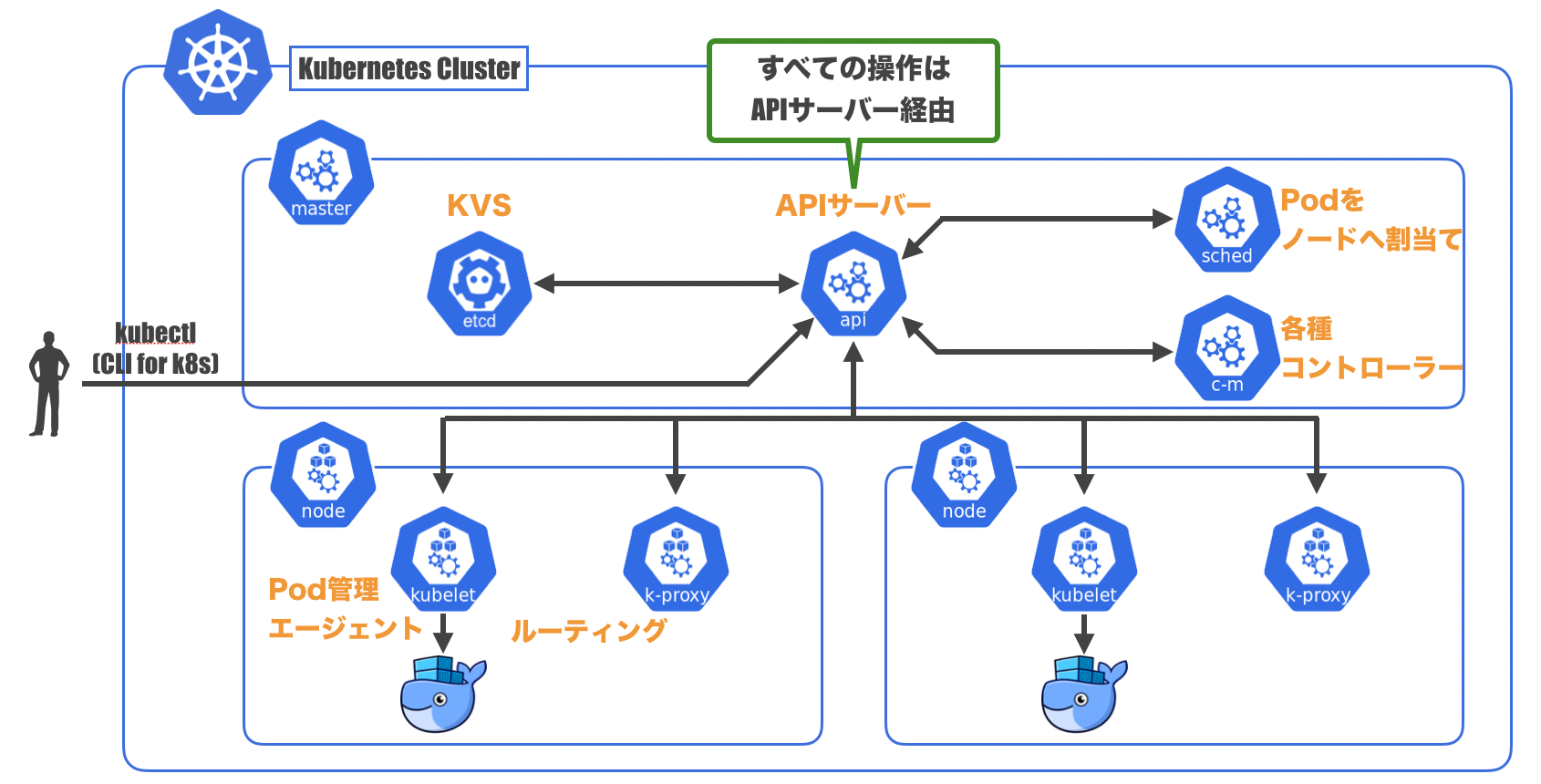
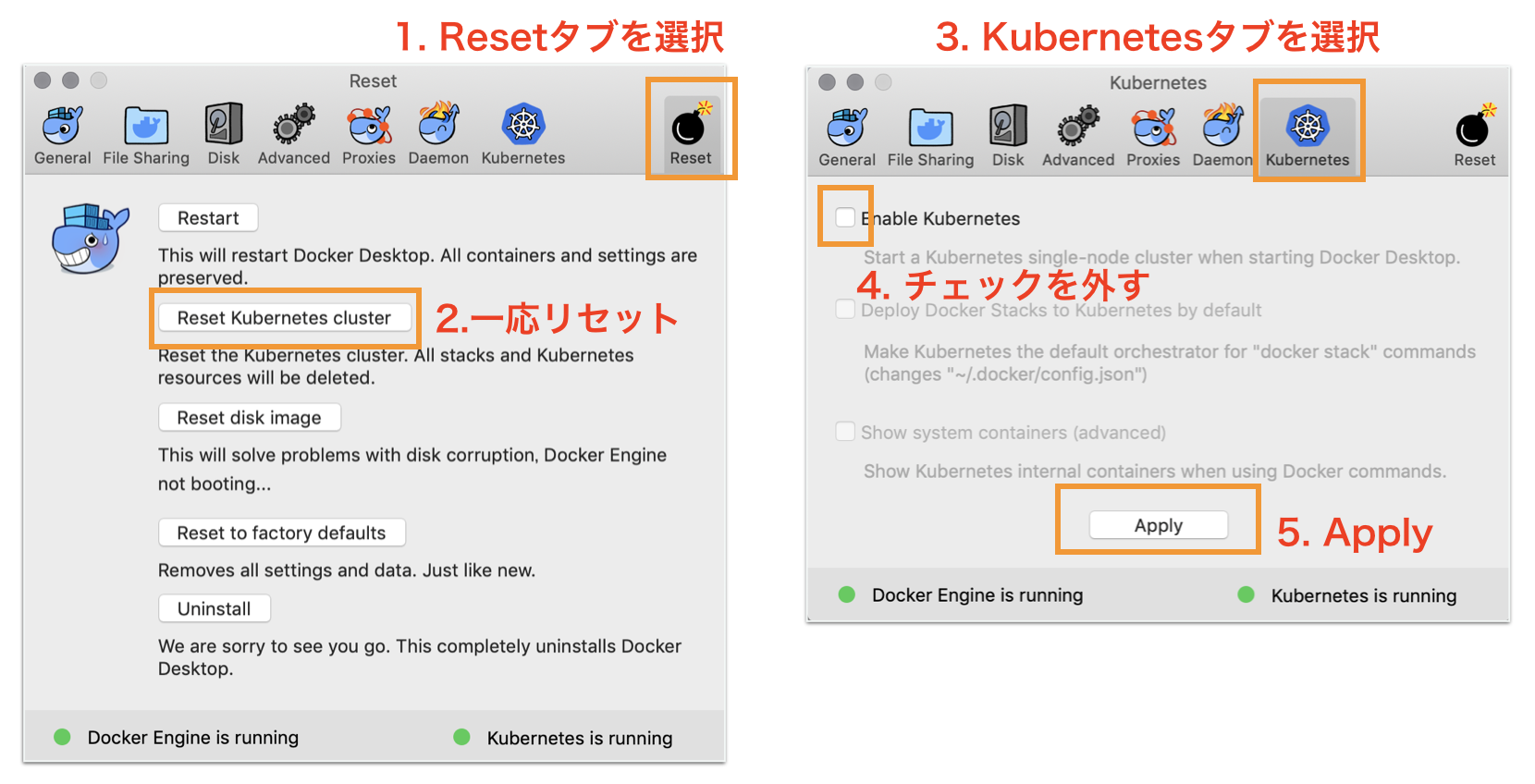
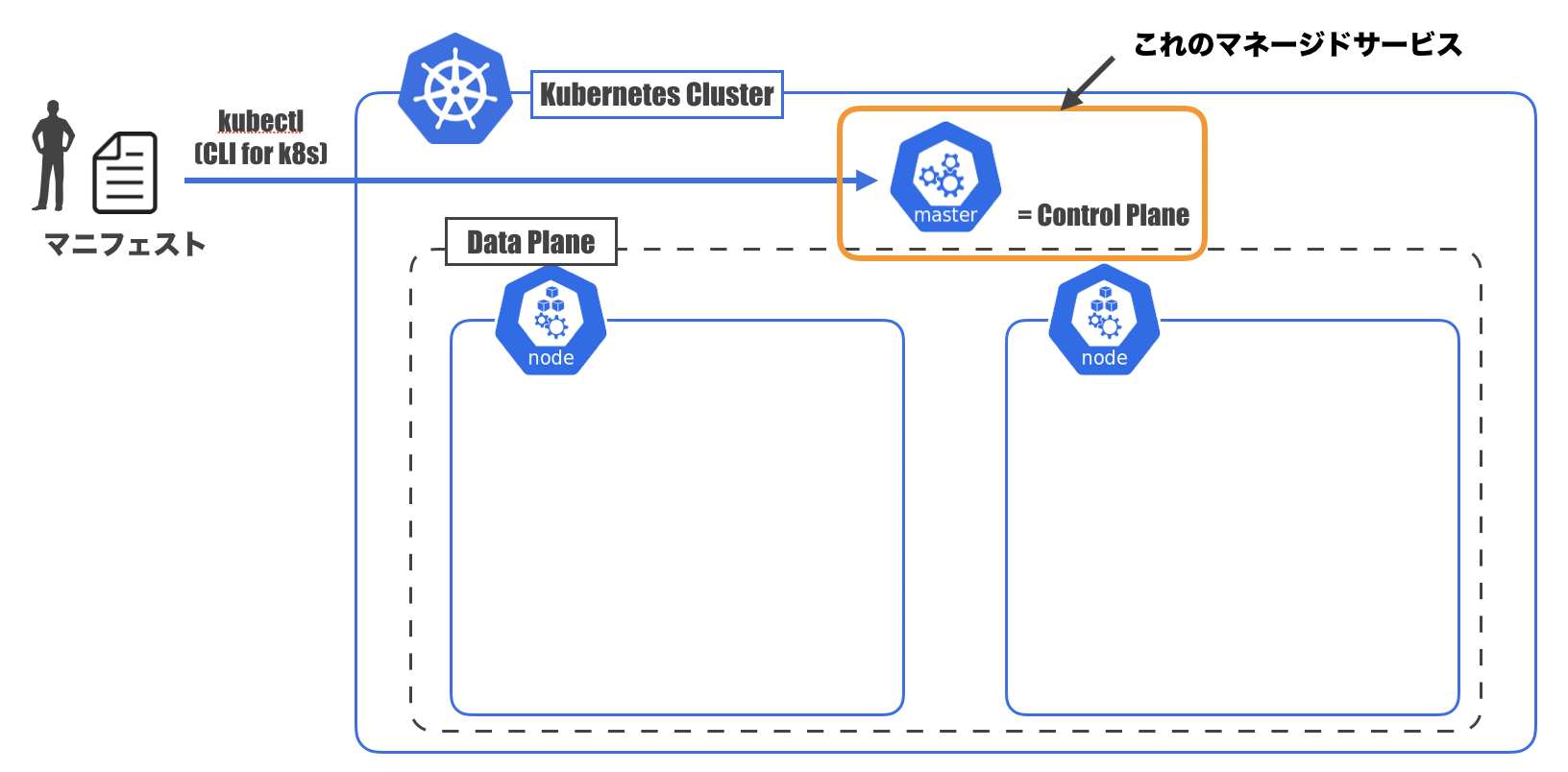

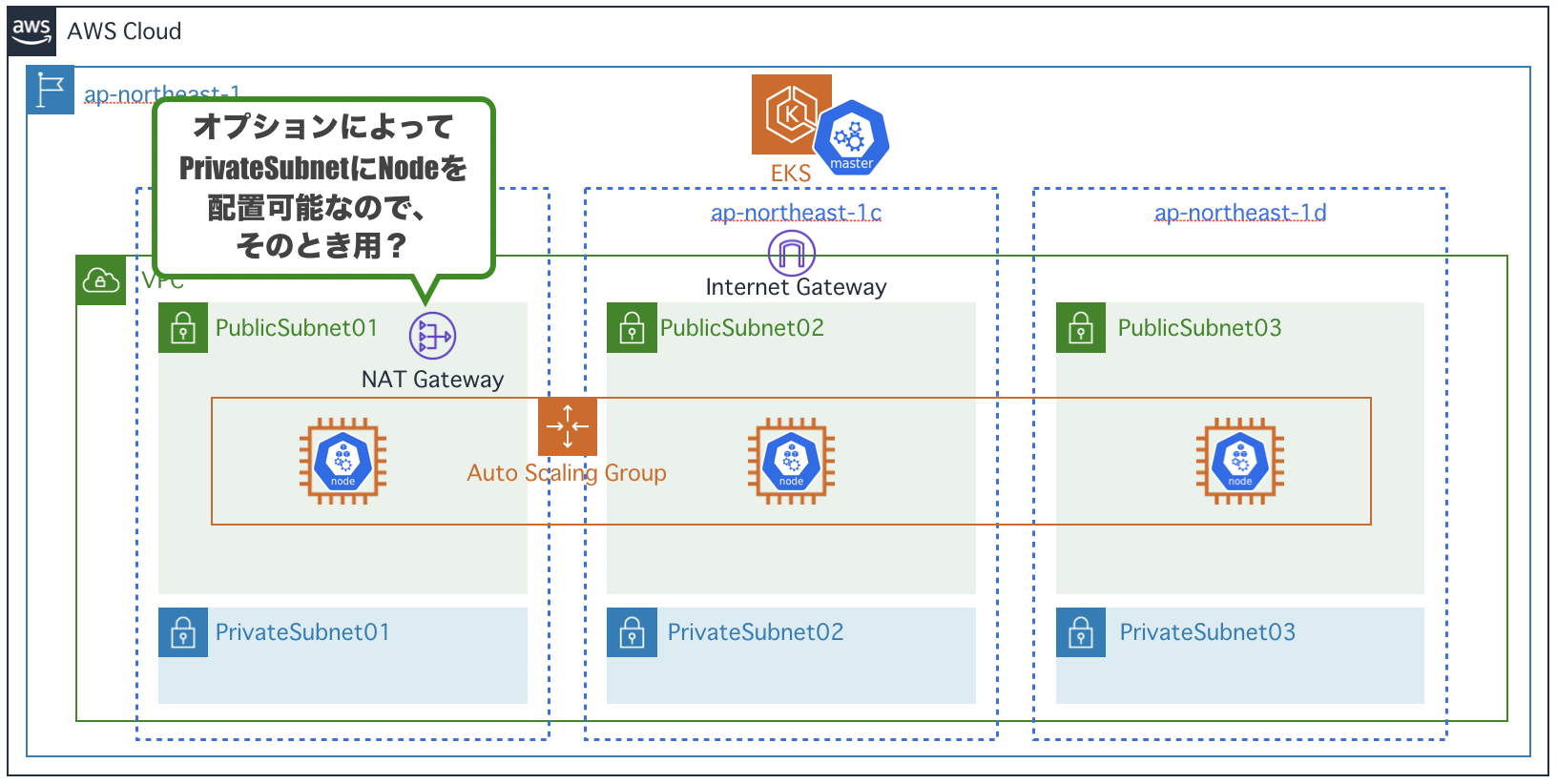
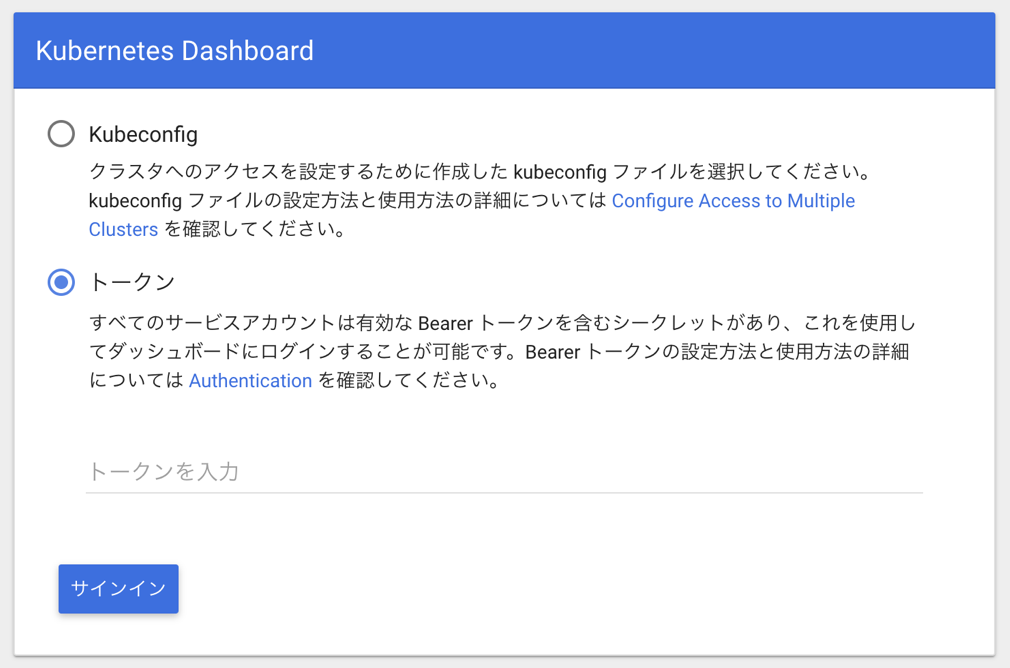
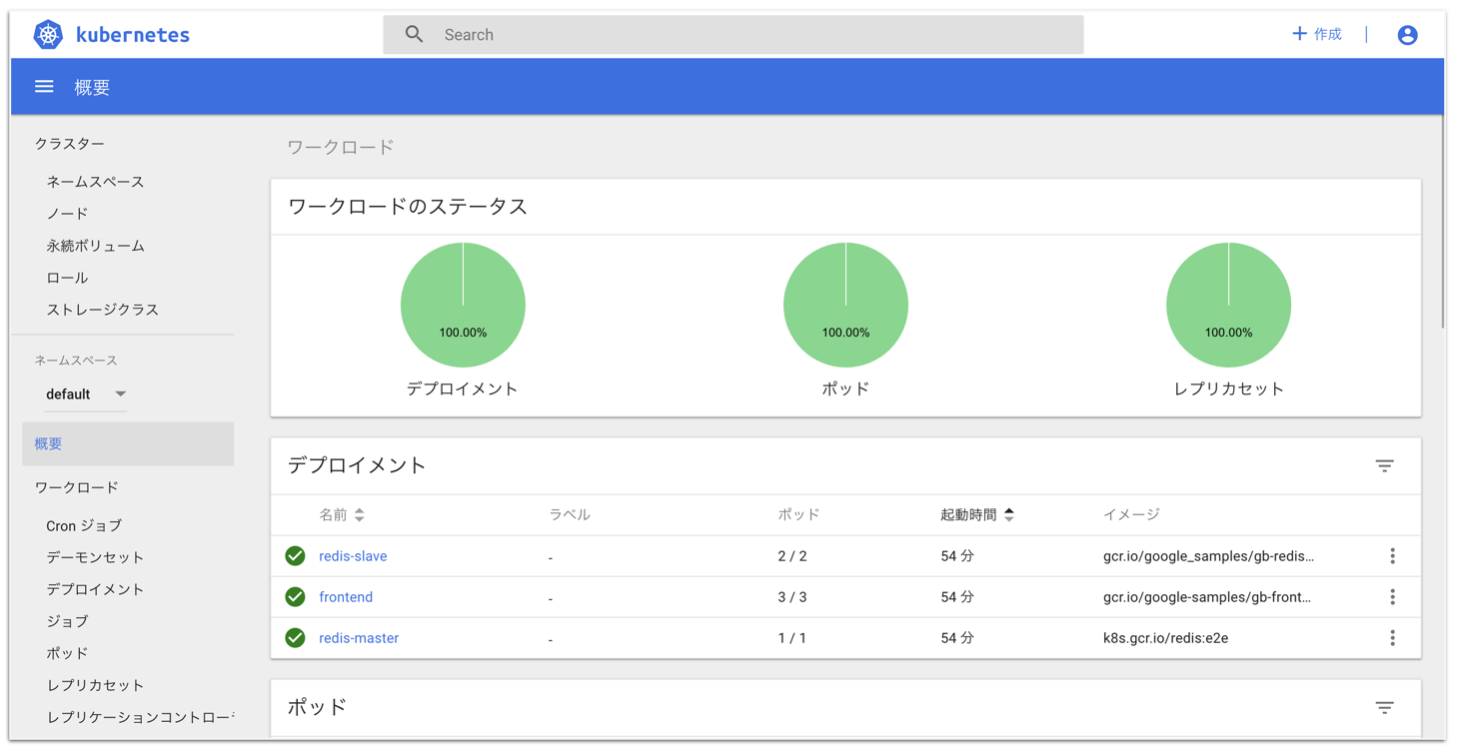
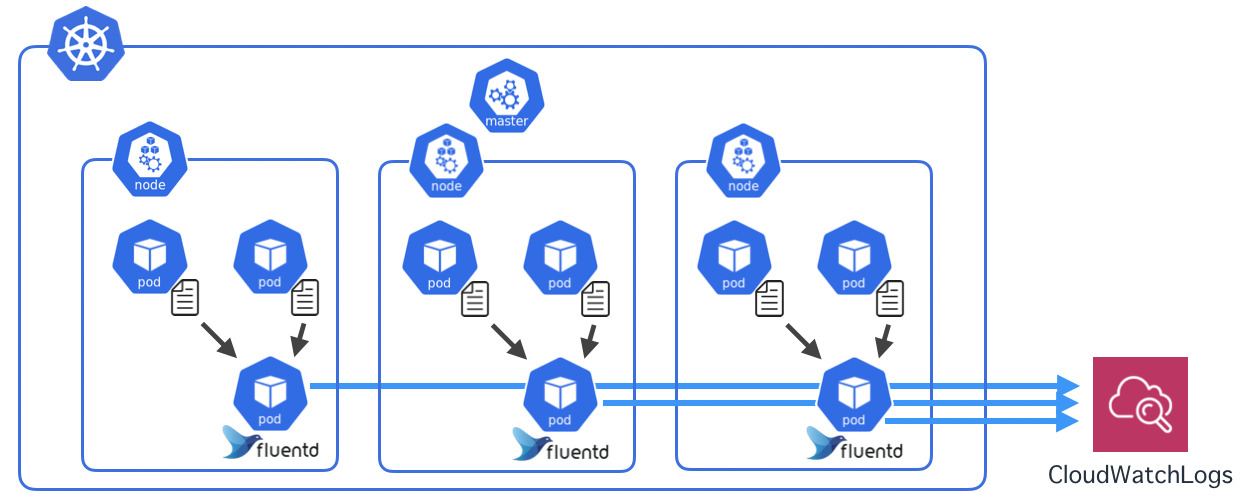
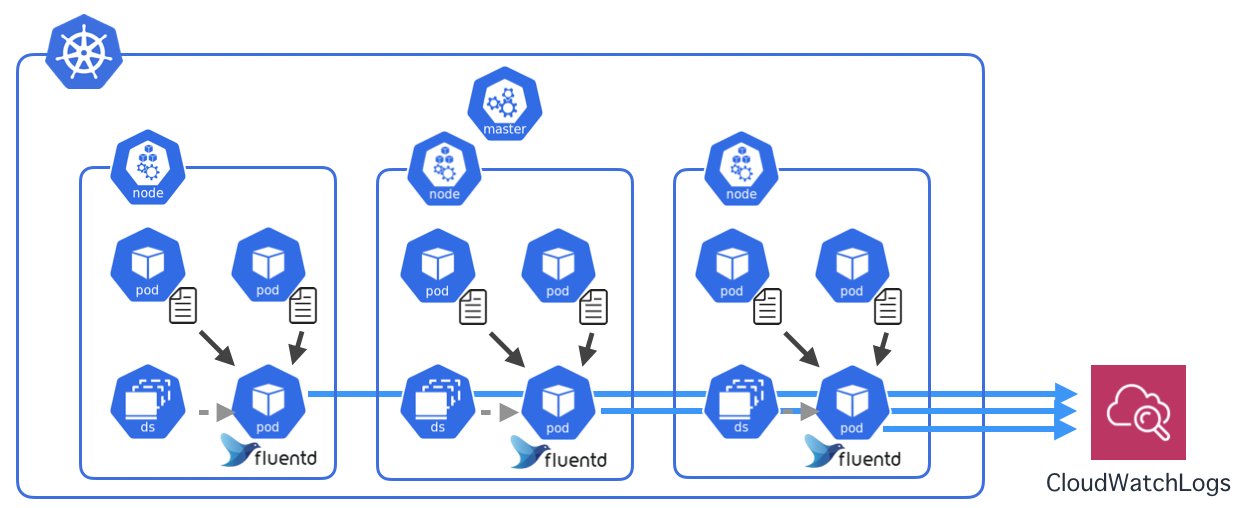
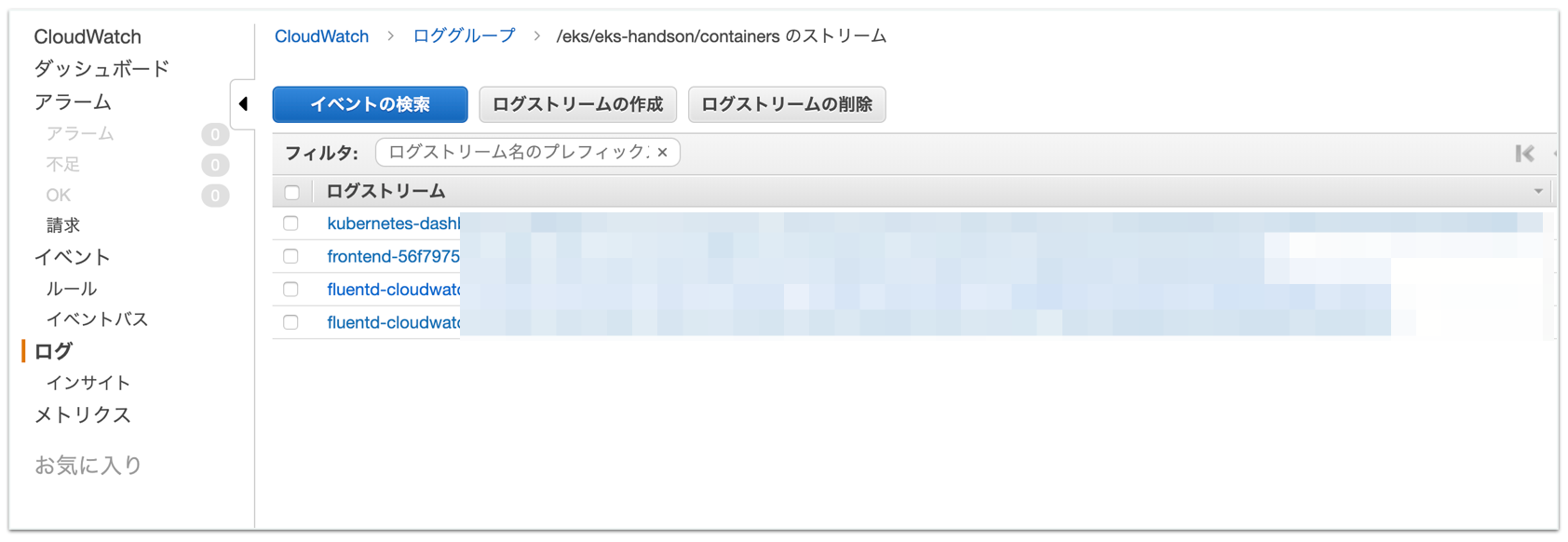
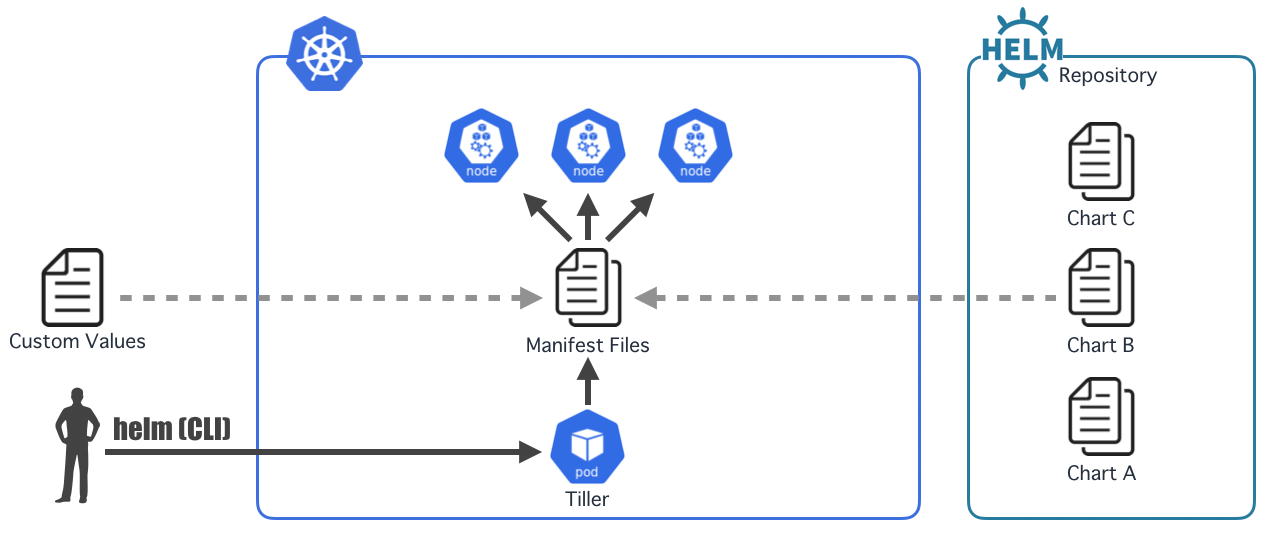

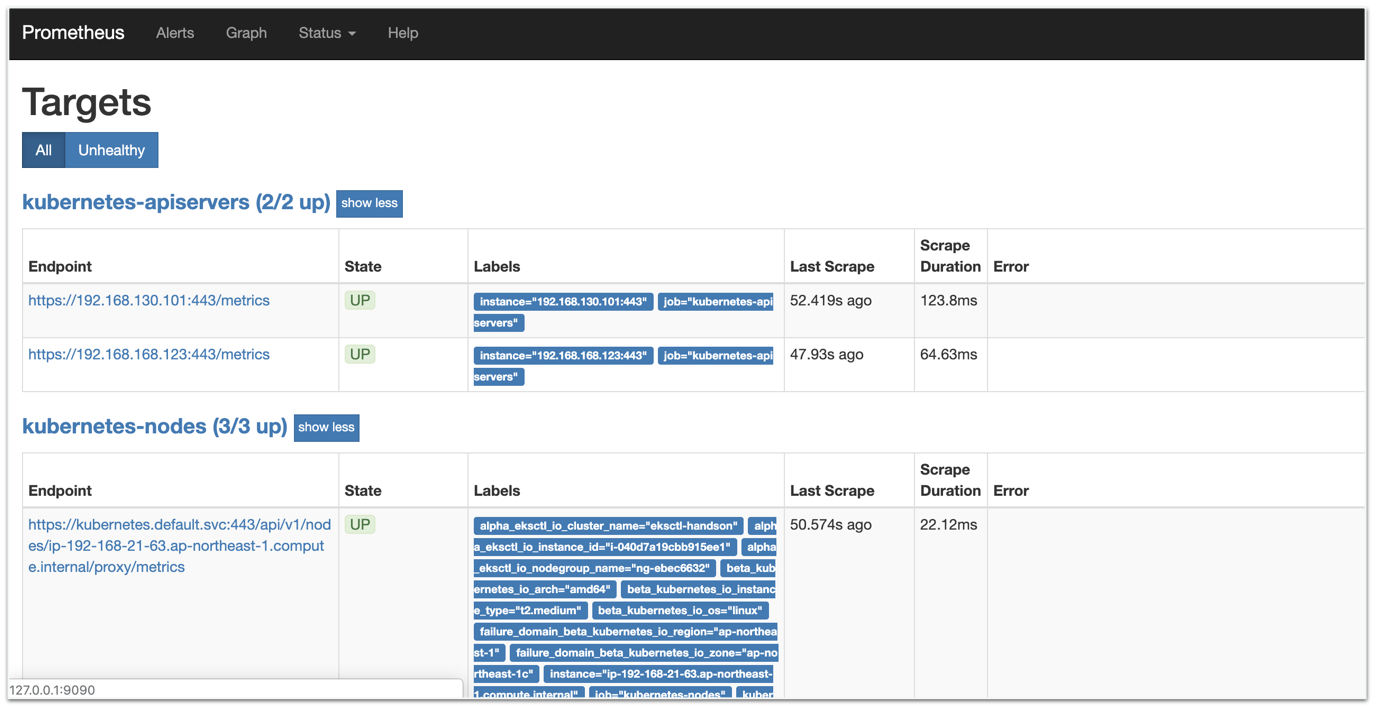
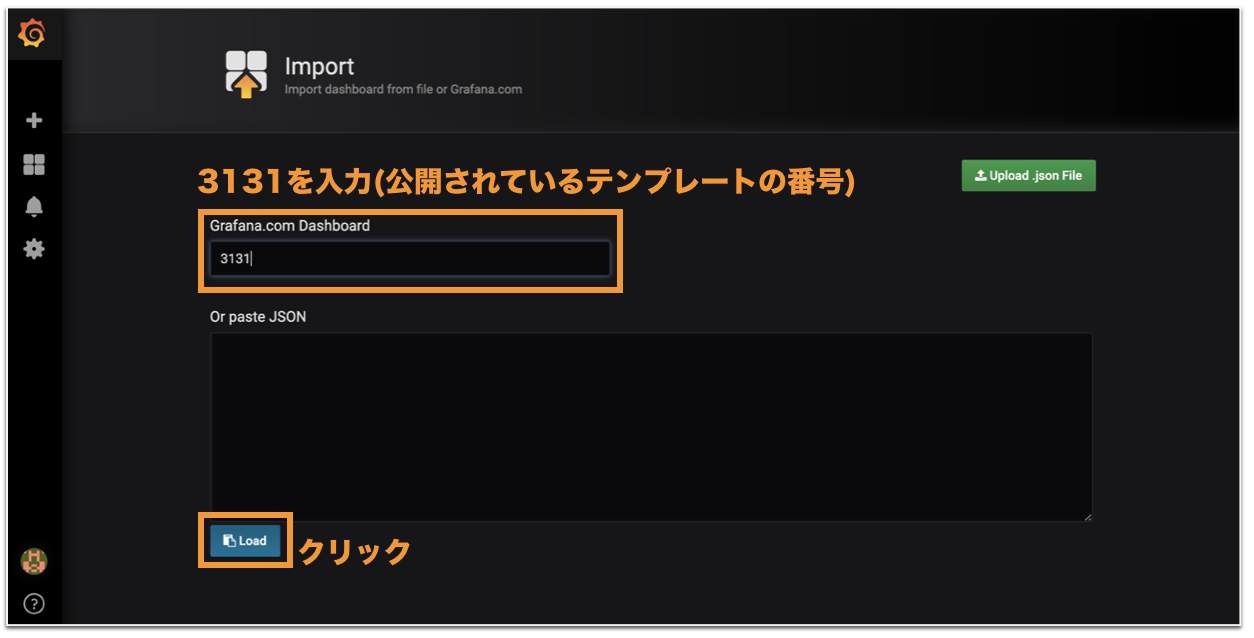
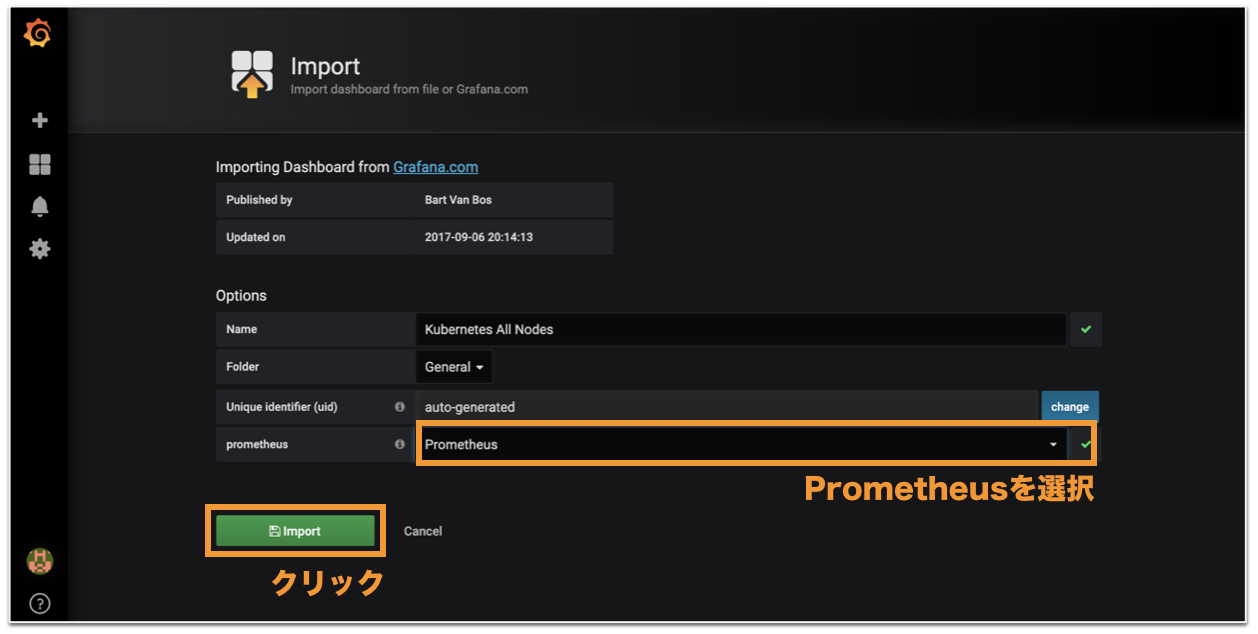
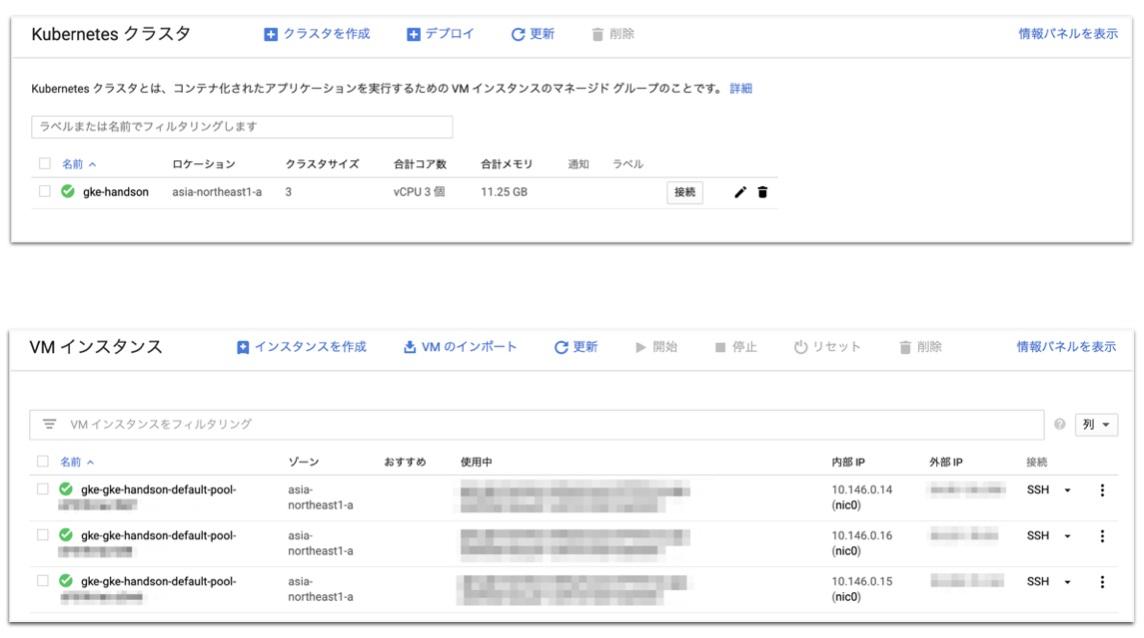
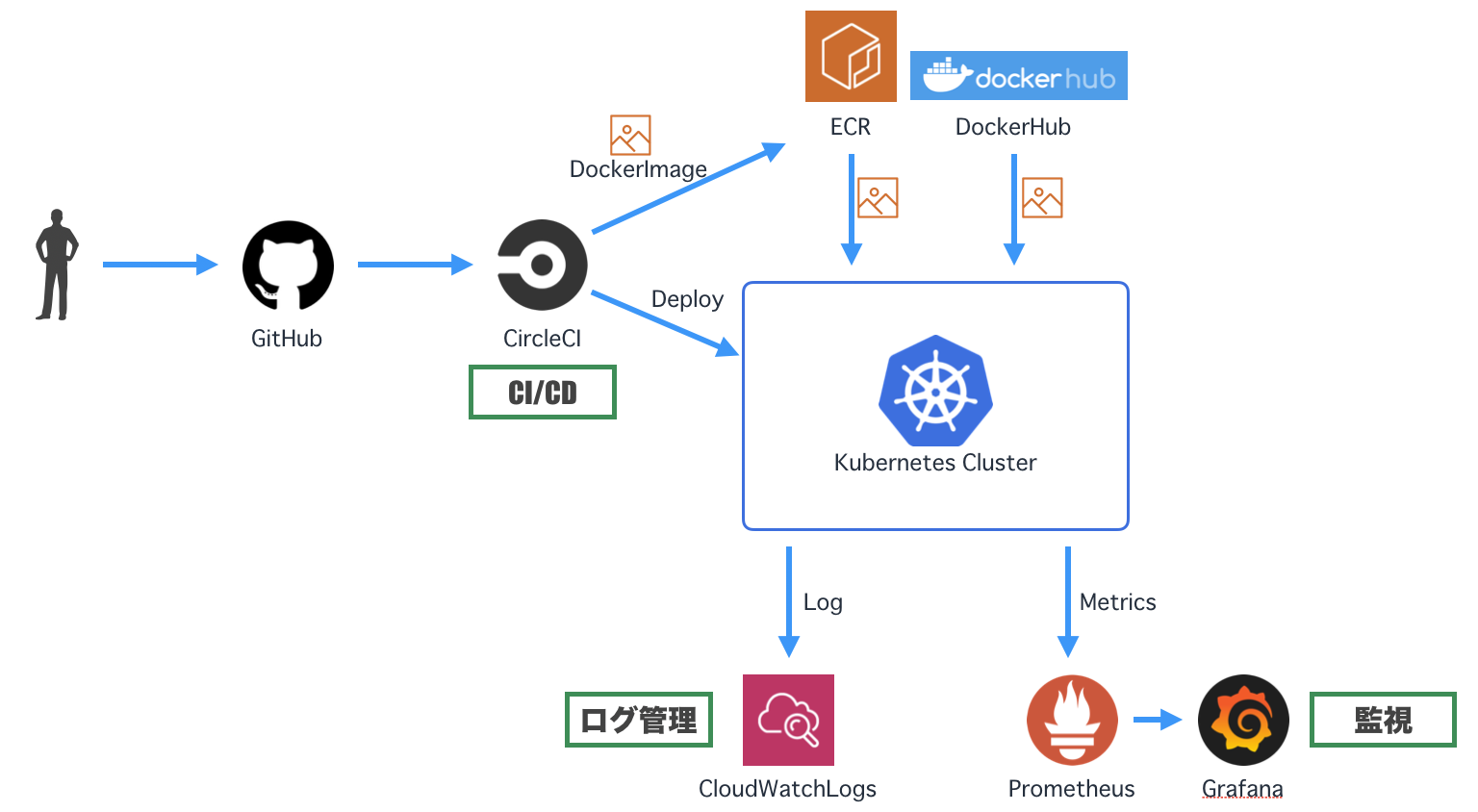
- 投稿日:2019-05-23T00:40:05+09:00
AWS CLIの初め方
この記事の対象開発環境
- macOS Mojave
- AWSコンソール(CLIインストールは飛ばして良い)
CLIインストール
$ python --version $ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-$bundle.zip" # unzipの-oは自動で上書きする。yum -yな感じ $ unzip -o awscli-bundle.zip $ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws $ aws ###説明文が出てきたらインストール完了設定
この設定でどのIAMユーザーでawsコマンドを使うかを定義する。
# IAM->ユーザー->認証情報->アクセスキーの作成でアクセスキーを発行。 # パスワードが見れるのとアクセスキーがダウンロードできるのは作成時の一回だけなのでダウンロードしよう AWS Access Key ID: AWS Secret Access Key: # awsにログインしている時のurlから取得する。 # urlパラメータのregionに割り当てられている値を入力(東京だとap-northeast-1) Default region name: # 特にこだわりが無ければjsonと入力 Default output format:AWS CLIのユーザー変更
先程の設定だけだとユーザーを変えるのにidとパスワードを変更する必要があるように見えますが、きちんとawsコマンドにはユーザーを複数登録する機能があります。
# 表示名の部分はなるべくIAMユーザー名にすること aws configure --profile 表示名これで上の設定と同じようにすればいいです。