- 投稿日:2019-05-23T23:42:52+09:00
Google Photos APIを使ってGoogleフォトからAmazon Photosへ自動コピーする
こんにちは。
私は普段、画像ストレージにはGoogleフォトを利用しています。しかし「Googleフォトの写真をAmazon Photosに全コピーしたい」案件が発生しました。
幸いAmazonプライム会員ですので保存容量は問題ありませんが1、その手法が問題になりました。
そこで今回、Google Photos APIを使ったGoogleフォトからAmazon Photosへの(なんちゃって)自動バックアップの仕組みを作ったのでそこで得られた知見をまとめます。
モチベーション
改めて今回の動機はこんな感じです。
- Amazon Fire TV StickのスクリーンセーバーにAmazon Photosの写真が使える!
- そのためにGoogleフォトのデータをAmazon Photosにコピーしたい
- 対象データはGoogleフォトの共有アルバムの全データ
- Googleフォトの共有アルバムには今後も画像が追加されていく
自分で撮ったスマホの写真だけならアプリでAmazon Photosに自動アップロードできますが2、Googleフォトの共有アルバムには家族や友人が撮影したデータも含まれるため、何かしらの仕組みが必要だと考えました。
問題点と妥協案
最初に考えたこと
全部手動でアップロードする
Googleフォトではアルバム単位で全画像のダウンロードが可能なので、ダウンロード→アップロードを手動でやる作戦です。
1回限りなら悪くありませんが、アルバムには随時画像が追加されていくため論外です。
API連携
次に考えたのがこんな感じのAPI連携です。
しかし次の問題により諦めました。
- Googleフォトの更新検知やWebhookする仕組みが無い(知らないだけ?)
- 現在Amazon Cloud Drive APIは使えない
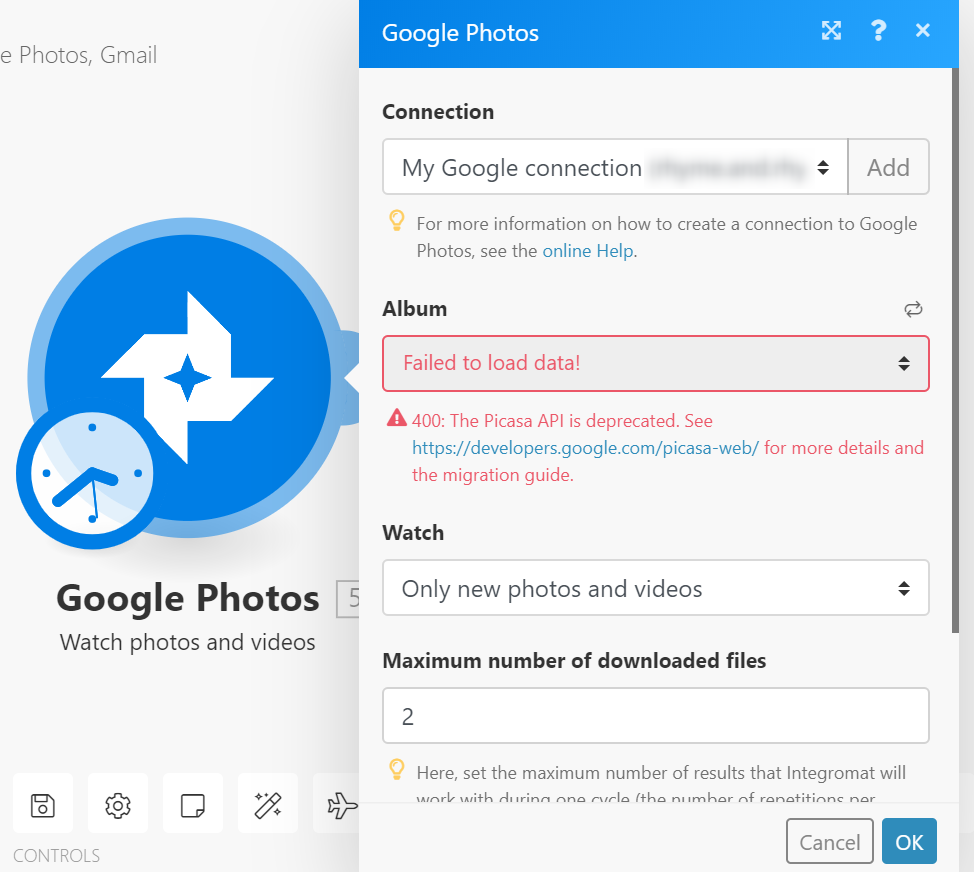
1点目についてはGoogle Photos APIでは提供されておらず、IFTTTやIntegromatなどのWeb連携サービスでも提供されていません。
Integromatには「Google Photosをトリガーで使えるぞ!」とあるのですが、実際に作ってみると内部がPicasa APIのままらしく、エラーが発生し設定ができません。
2点目について、Amazon Photosの実態はAmazon Driveというオンラインストレージに格納されたデータを切り出したものです。このためGoogleフォトから取得したデータをAmazonのAPIに乗っければイケるかと思いましたが、Amazon DriveのAPIは現在、新規利用を停止しています。
https://developer.amazon.com/ja/amazon-drive
なんちゃって自動化案
これらの問題を受けて、以下のような「なんちゃって自動化案」を考えました。
- 端末のタスクスケジューラに以下2.の処理を一定間隔で実行するように登録する。
- Google Photos APIで対象アルバムの全データを走査し、ローカル環境に存在しないデータをダウンロード。この時、Exif情報が失われているので可能な限り付加する。(後述)
- Amazon Photosのデスクトップアプリにて、上記1.でダウンロードしたディレクトリを自動アップロード対象に設定する。
……どうでしょうか。これは自動化なのでしょうか。
特に3.のデスクトップアプリの使用が必須であるため、ローカル端末が起動している間しか同期できません。(しかもリアルタイムじゃない)
ですが、これで一応は当初の要求を実現できそうです。
自動化の手順
ここからGoogle Photos APIを利用したプログラム部分です。
今回作成したプログラムはGitHub上にアップロードしています。
https://github.com/quotto/googlephoto-backup以降の説明部分ではコードを一部抜粋しています。
Google OAuth2.0による認可
Google Photos APIを利用するには、Google Developer Consoleからプロジェクトを作成し、それに対するAccessTokenの発行が必要です。
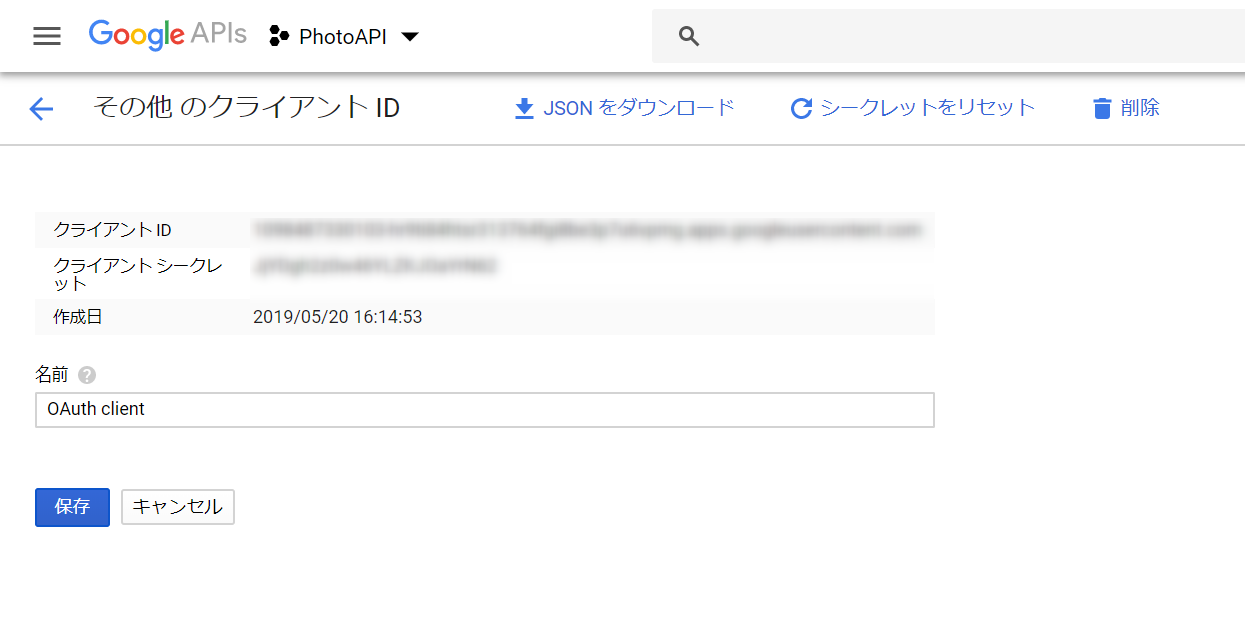
ClientIDとClientSecretの取得
Google Developer Consoleからプロジェクトを作成し、ClientIDとClientSecretを入手します。
この手順は公式ガイドの通りに進めれば問題なくできるはず。
AccessTokenの発行
続いてAPIを叩くのに必要なAccessTokenを発行します。
Webアプリであれば公式のサンプルがそのまま使えますが、今回はそんな立派なものは必要ないためサンプルをもとに簡易なプログラムを用意しました。
oauth.jsconst fs = require('fs'); const request = require('request-promise'); const config = require('./config'); const express = require('express') const bodyParser = require('body-parser'); const http = require('http') const app = express(); const server = http.Server(app); app.get('/auth/google/callback',(req,res)=>{ request.post(`${config.oauthEndpoint}/token`,{ headers:{'Content-Type': 'application/json'}, json: { code: req.query.code, client_id: config.oAuthClientID, client_secret: config.oAuthclientSecret, redirect_uri: config.oAuthCallbackUrl, grant_type: 'authorization_code' } }).then((data)=>{ res.send('Oauth process succeed.Please back to app console.'); res.end(); fs.open('credential','w',(err,fd)=>{ const authenticate_data = { token: data.access_token, refreshToken: data.refresh_token, expires: Date.now() + (data.expires_in * 1000) } fs.writeSync(fd,JSON.stringify(authenticate_data)) ; console.log('Oauth process succeed.'); console.log('Press Ctrl-C and run application.'); }); }) }) server.listen(config.port,()=>{ const scope = config.scopes.join('%20'); const oauth_url = `${config.oauthEndpoint}/auth?client_id=${config.oAuthClientID}&redirect_uri=${config.oAuthCallbackUrl}&response_type=code&scope=${scope}&access_type=offline` console.log('Please access this URL:'); console.log(oauth_url); })このプログラムを実行すると認証画面のURLが表示され、expressサーバを起動してAccessTokenの発行準備に入ります。
> node oauth.js Please access this URL: https://accounts.google.com/o/oauth2/auth?client_id=作成したClientID&re direct_uri=http://127.0.0.1:9999/auth/google/callback&response_type=code&scope=https://www.googleapis.com/auth/photoslibrary.rea donly%20profile&access_type=offlineこの時の認証URLに設定するパラメータは以下のとおりです。
- client_id:前の手順で取得したClientIDを設定します。
- redirect_uri:Web画面から認証を終えた後のコールバックURLを指定します。
- response_type:固定で
codeを設定します。- scope:APIに許可する操作範囲を指定します。複数設定する場合は空白文字(%20)で区切ります。
- access_type:RefreshTokenを受け取る場合には
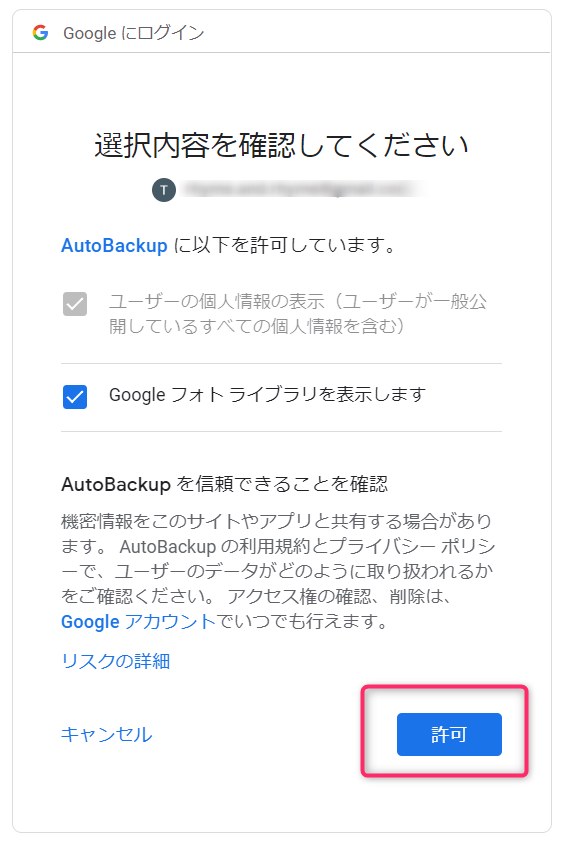
offlineを指定します。URLをコピーしてブラウザからアクセスして、アプリのAPI利用を許可します。
これでAccessTokenの発行は完了です。コンソールは
Ctrl-Cで終了します。プロジェクトルートに
credentialという名前のJSONファイルができています。このファイルはAccessTokenとRefreshToken、AccessTokenの期限時刻(ミリ秒)が格納されています。credential{ "token":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "refreshToken":"yyyyyyyyyyyyyyyyyyyyyyyyyyy", "expires":1558589917676 }Google Photos APIでローカル環境に画像をダウンロードする
準備が整ったので画像のダウンロード処理を実行します。大まかな流れとしては
「対象アルバムのデータ件数取得」→「1件ずつ画像データ読み込み」→「Exif情報を付けて保存」
となります。
アルバムのデータ件数取得
最初にGoogle Photos APIで対象アルバムのデータ件数を取得します。
app.jsconst album = await request.get(`${config.apiEndpoint}/v1/albums/${config.backupAlbumId}`,{ headers: {'Content-Type': 'application/json'}, json: true, auth: {'bearer':credential.token} }); const item_count = Number(album.mediaItemsCount);ここではalbumIdを固定で指定しています。なおalbumIdは
https://photoslibrary.googleapis.com/v1/albumsへのリクエストで確認できます。画像データの読み込み
アルバム内に保存されているデータの一覧は、1回のリクエストで最大100件取得できます。エンドポイント
https://photoslibrary.googleapis.com/v1/mediaItems:searchに対して、対象アルバムのIdをalbumIdに、最大取得件数をpageSizeに指定します。2回目以降に取得するデータ(例えば101件目、201件目……)は
MediaItems.nextPageTOkenにより識別されます。app.js// 対象アルバムの全画像を100件ずつ取得する const iterate = Math.ceil(item_count/config.searchPageSize); for(let i=0; i<iterate; i++) { ... const parameter = {albumId:config.backupAlbumId, pageSize:config.searchPageSize}; if(next_page_token) { parameter.pageToken = next_page_token; } const items = await request.post(`${config.apiEndpoint}/v1/mediaItems:search`,{ headers: {'Content-Type': 'application/json'}, json: parameter, auth: {'bearer':credential.token} }); if(items && items.mediaItems) { const downloadAsyncJob = []; items.mediaItems.forEach((media_item)=>{ // 対象のMIMETYPEに一致するメディアのみダウンロード処理実行 if(config.backupMimeType.indexOf(media_item.mimeType.toLowerCase()) >= 0) { downloadAsyncJob.push(downloadImage(media_item)); } }); // 1リクエスト最大100回の並列ダウンロードが終わるまで待機 await Promise.all(downloadAsyncJob); next_page_token = items.nextPageToken; } .... }続いてダウンロード処理の本体です。
MediaItemオブジェクトの配列がレスポンスとして格納されるので、1件ずつ処理を回して画像データを読み出します。app.js// 画像データのダウンロード処理 // media_item:MediaItemオブジェクト const downloadImage = (media_item)=>{ return new Promise((resolve,reject)=>{ // ファイル名はid+元々のファイルの拡張子とする const filename = media_item.id + media_item.filename.substring(media_item.filename.lastIndexOf('.')); const saveFile = path.join(config.backupDir,filename); fs.stat(saveFile,(err,stat)=>{ if(!stat) { //ファイルが存在しなければダウンロード処理を開始する const metadata = media_item.mediaMetadata; const rawdataUrl = `${media_item.baseUrl}=w${metadata.width}-h${metadata.height}` logger.info(`download:${filename} from ${rawdataUrl}`) request({url:rawdataUrl,encoding: null,method: 'GET'},(err,res,body)=>{ ... // rawdataからはExif情報が含まれないためJPEGであればAPIから取得したメタデータをよりExif情報を設定する const data = media_item.mimeType.toLowerCase() === 'image/jpeg' ? insertExif(metadata,body) : body; fs.writeFile(saveFile,data,{encoding:'buffer'},(err)=>{ ... resolve(); }); }); } else { //ファイルが既に存在すれば何もせず完了 resolve(); } }); }); }画像データをダウンロードするにあたっては次の点がポイントです。
- ローカル環境に保存するファイル名は
MediaItem.idを用います。オリジナルのファイル名も取得できますが、Googleフォトではオリジナルのファイル名が同じでも異なるデータとして管理されるためです。- 「同名ファイルがローカルディレクトリに存在しない」ものを更新(追加)データと判断してダウンロード対象とします。
- 画像データは
MediaItem.baseURLから取得できます。ただしこのURLから取得できるデータはExif情報が含まれていないので、別途設定する必要があります。(後述)差分のチェック方法が残念すぎますが、他に良い方法が思いつきませんでした……APIで「アップロード日の降順」とかで指定ができれば良かったのですが、それもできず苦肉の策で全件走査しています。
1,000件、2,000件程度であれば大丈夫だと思いますが、数万件になると処理時間的にもAPIの利用制限的にも厳しいと思います。
Exif情報の注入
前段で触れましたが今回のプログラムでは対象データがJPEG画像であった場合、Exif情報を注入してバイナリデータを作り直します。
普通にGoogleフォトからダウンロードした場合には問題ないのですが、API経由で取得したMediaItem.baseURLのデータからはExif情報が削除されているためです。
このためAPI経由で取得した
MediiaItem.metadataを基にExif情報を設定します。ただしAPIで取得できるExif情報は一部のみであり、いずれにしてもオリジナル画像からは大部分が削除されてしまいます。今回Exif情報の作成にはPiexifjsを利用させていただきました。
app.js// Exifデータの挿入 // metadata:Google Photos APIから取得したMediaItemのmedaData.Photo // jpeg_data: 対象画像のbufferデータ const insertExif = (metadata,jpeg_data) =>{ const zeroth = {}; const exif = {}; const gps = {}; if(metadata.photo.cameraMake) zeroth[piexif.ImageIFD.Make] = metadata.photo.cameraMake; if(metadata.photo.cameraModel) zeroth[piexif.ImageIFD.Model] = metadata.photo.cameraModel; if(metadata.width) zeroth[piexif.ImageIFD.ImageWidth] = Number(metadata.width); if(metadata.height) zeroth[piexif.ImageIFD.ImageLength] = Number(metadata.height); if(metadata.photo.focalLength) exif[piexif.ExifIFD.FocalLength] = metadata.photo.focalLength; if(metadata.photo.apertureFNumber) exif[piexif.ExifIFD.FNumber] = metadata.photo.apertureFNumber; if(metadata.photo.isoEquivalent) exif[piexif.ExifIFD.ISOSpeedRatings] = metadata.photo.isoEquivalent; if(metadata.photo.exposureTime) exif[piexif.ExifIFD.ExposureTime] = metadata.photo.exposureTime; const creationTime = new Date(metadata.creationTime); const year = creationTime.getFullYear(); const month = creationTime.getMonth() < 9 ? `0${creationTime.getMonth()+1}`:str(creationTime.getMonth()+1); const date = creationTime.getDate() < 10 ? `0${creationTime.getDate()}`:creationTime.getDate(); const hour = creationTime.getHours() < 10 ? `0${creationTime.getHours()}`:creationTime.getHours(); const minute = creationTime.getMinutes() < 10 ? `0${creationTime.getMinutes()}`:creationTime.getMinutes(); const second = creationTime.getSeconds() < 10 ? `0${creationTime.getSeconds()}`:creationTime.getSeconds(); exif[piexif.ExifIFD.DateTimeOriginal] = `${year}:${month}:${date} ${hour}:${minute}:${second}`; const exifObj = {"0th":zeroth,"Exif":exif}; const exifStr = piexif.dump(exifObj); return new Buffer(piexif.insert(exifStr,jpeg_data.toString('binary')), 'binary'); }Amazon Photosデスクトップアプリで自動アップロード
ここまででGoogleフォトからの画像データダウンロードが完了しました。最後にAmazon Photosへのデータアップロードのため、デスクトップアプリをインストール・設定します。
まずは公式サイトからインストーラーを入手して、インストールします。
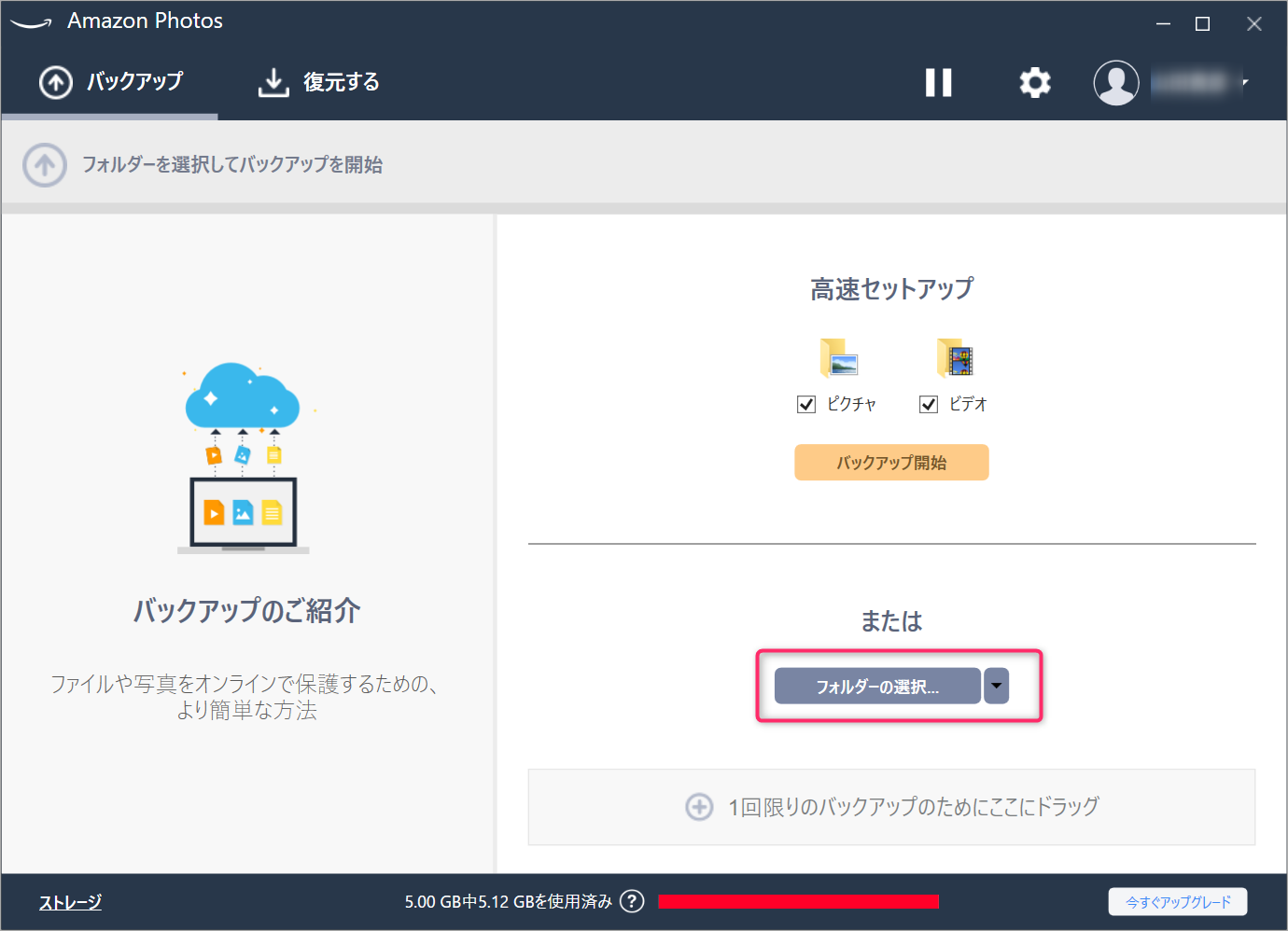
インストールしたアプリを起動して、「フォルダを追加」でGoogleフォトから画像をダウンロードしたフォルダを指定します。
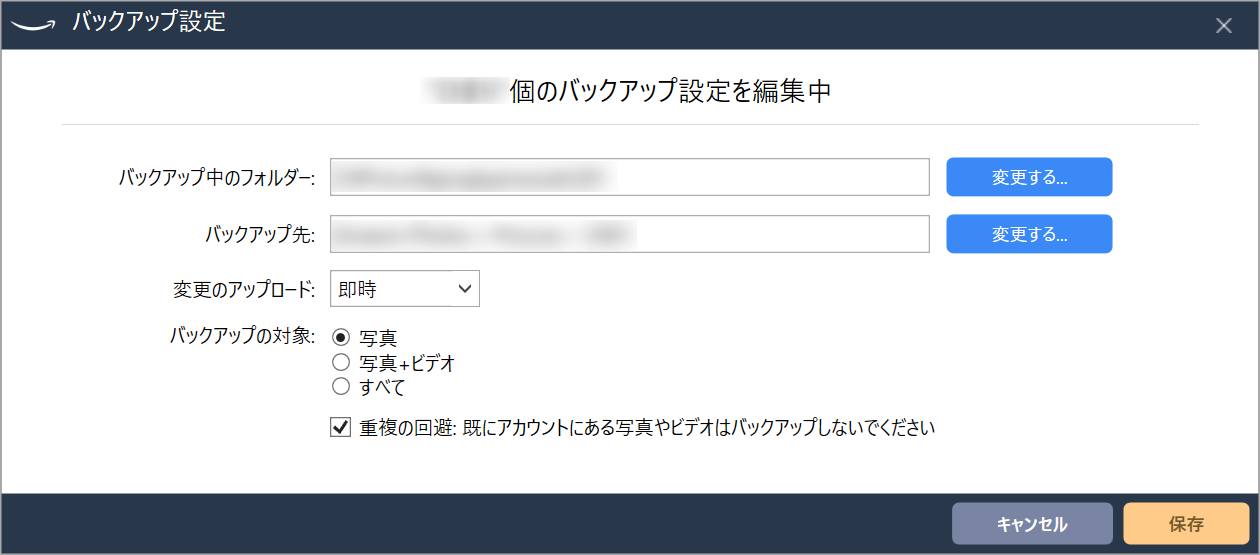
するとこのような画面が表示されるため、設定を保存します。
- バックアップ先:Amazon Cloud Drive上のアップロード先のディレクトリ
- 変更のアップロード:即時
- バックアップの対象:写真のみ
- 「重複の回避」にチェック
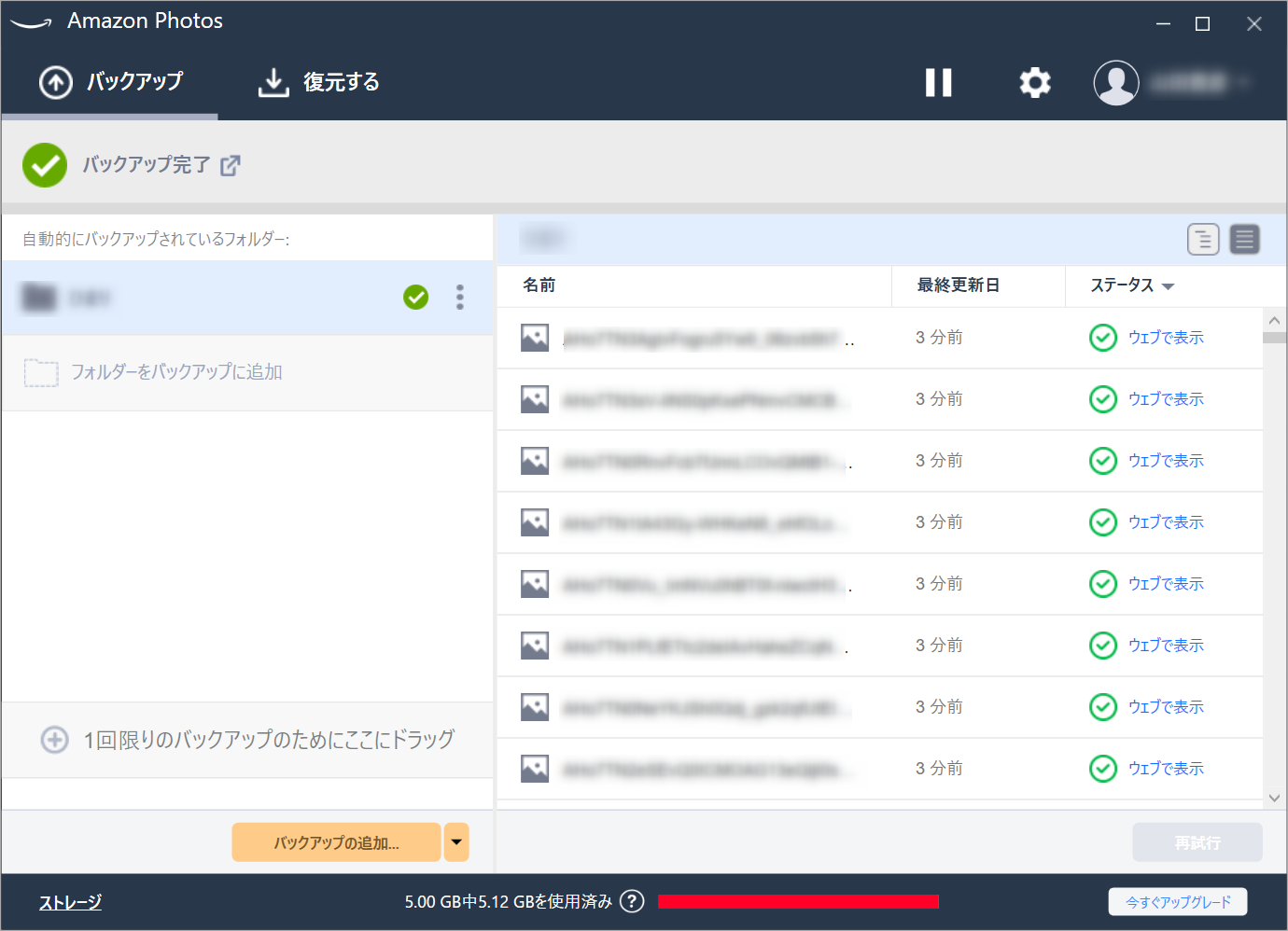
あとはアプリがローカルディレクトリ自動でを検知してAmazon Photosにアップロードしてくれます!
タスクのスケジュール化
最後にGoogleフォトからのダウンロード処理を定期実行させます。
私の環境はWindowsのため以下のようなbatファイルをプロジェクト直下に作成し、タスクスケジューラに設定しました。
autobackup.bat@echo off cd %~dp0 node app.jsGoogle Photos APIについてまとめ
Google Photos APIを使ってみた感想ですが、
- 更新を検知する機能は無いので差分チェックが辛い
- 「アップロード日」という項目は無いので、やっぱり差分チェックが辛い
- アプリからダウンロードしない場合(MediaItem.baseURLから読み込んだ場合)JPEGのExif情報は削除されている
こうやって見るとAPIを使った処理は制約がけっこう多いですね。もうちょっと使い勝手がよくなればいいな、と思います。
- 投稿日:2019-05-23T20:55:56+09:00
Selenium Grid をSynology NASのDockerで動かしてみる
はじめに1
わたしはSynologyのNASがすきです
自宅でDiskStation 216jを使い始め、
いまはDiskStation 218+との2台体制です。
会社ではDiskStationの導入を推進しました。
(6ページ目まで飛ばしていいのよ)
はじめに2
SynologyのNASはパッケージという仕組みで
アプリをインストール、サービスの拡張が可能です。
DiskStationは使い勝手の良いUIを用意しており、
追加できるサービスにも独自のUIを用意しているものがあります。
きっかけ1
NASのさらなる活用方法を考えているなかで、
Seleniumの勉強を始めるとともに、
DiskStation上で動作するDockerを利用し、
Selenium Gridの運用を行ってみることにしました
(Dockerはintel CPU搭載モデルでのみ利用可能)
きっかけ2
しかし、そもそもDockerについて知らず、
Synologyが用意するUIで、Docker コンテナ、
Seleniumの設定をおこなおうとしたため、
Qiitaからコピペして試すことができず
「どこに何を書いたらええんや!!?」と
なってしまいました
やっとはじめ
ありきたりなSelenium hubとnodeの設定ですが、
SynologyのNASのUIを紹介しながら、
設定した箇所のみピックアップして記載します。
環境
- PC :MacBook Pro 2014 macOS Mojave
- NAS :Synology DiskStation 218+
RAM:10GB(2GB+8GB)
HDD:4TB + 3TB
アプリのインストール
- パッケージセンターからDockerをインストールする
- DockerのレジストリでSelenium関連(HubとNode)をダウンロードする
- DockerのパッケージでSelenium関連(HubとNode)をコンテナ化する
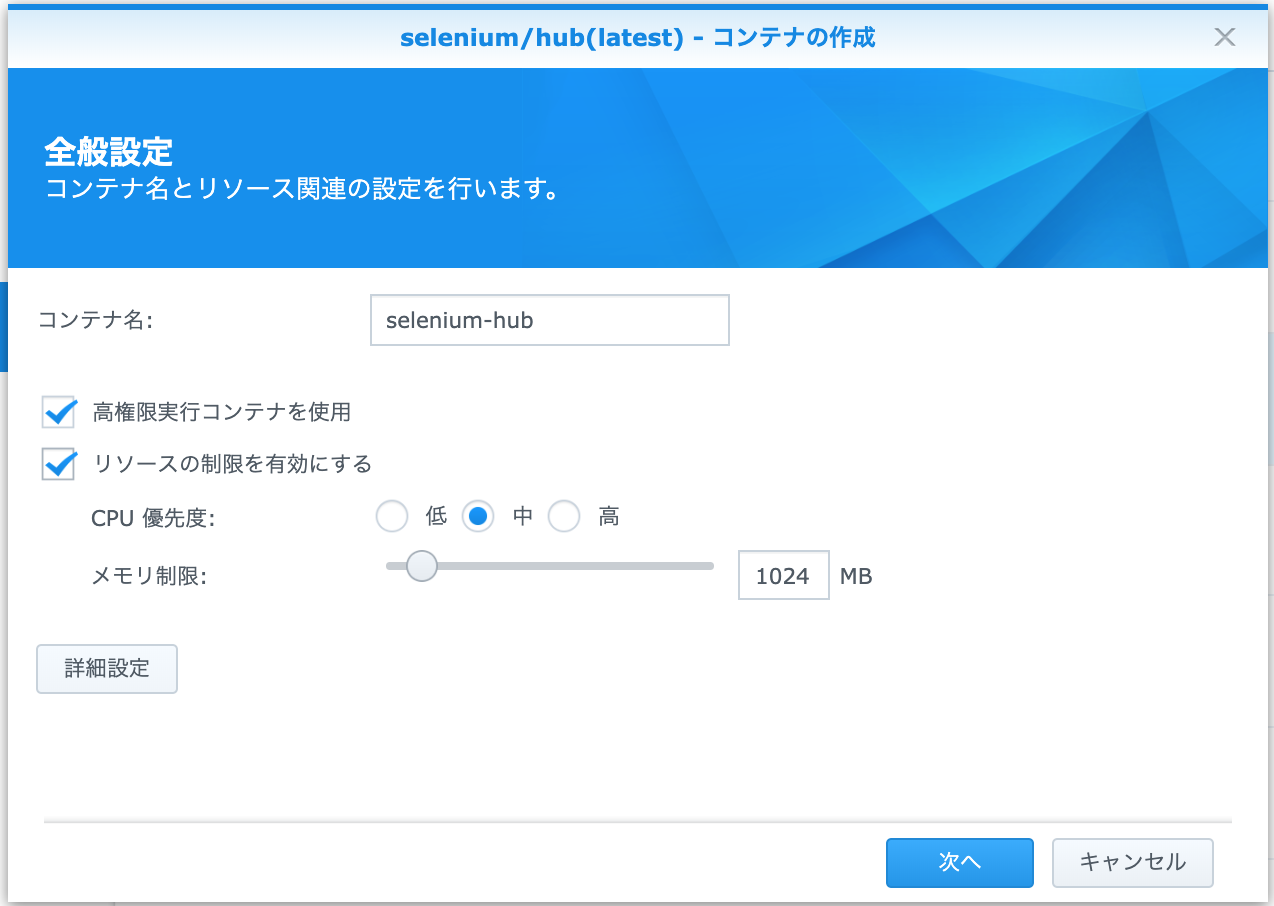
Selenium-Hub設定(全般設定)
- コンテナ名を指定
- 高権限実行コンテナを使用(お好みで)ON
- リソースの制限を有効にする(お好みで)ON

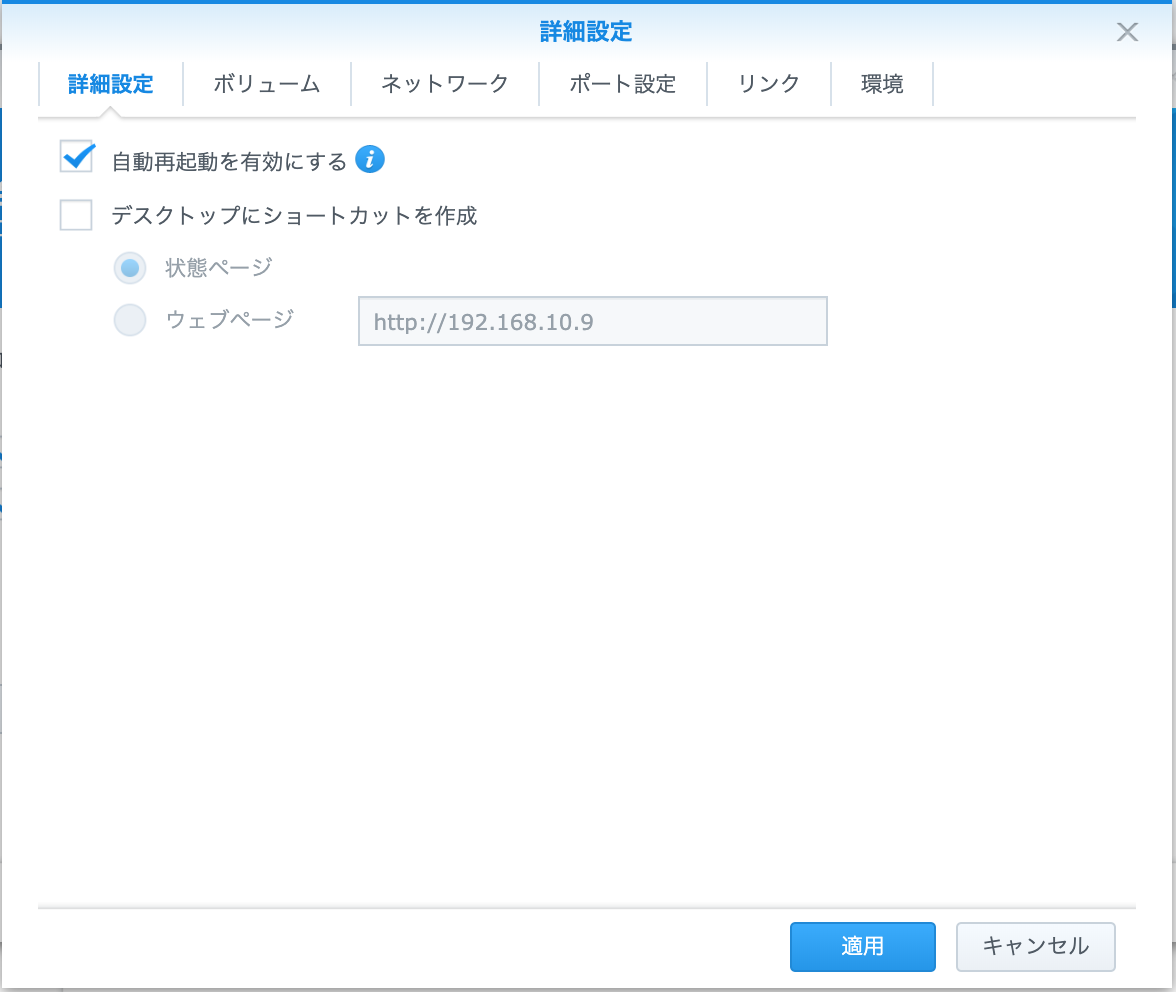
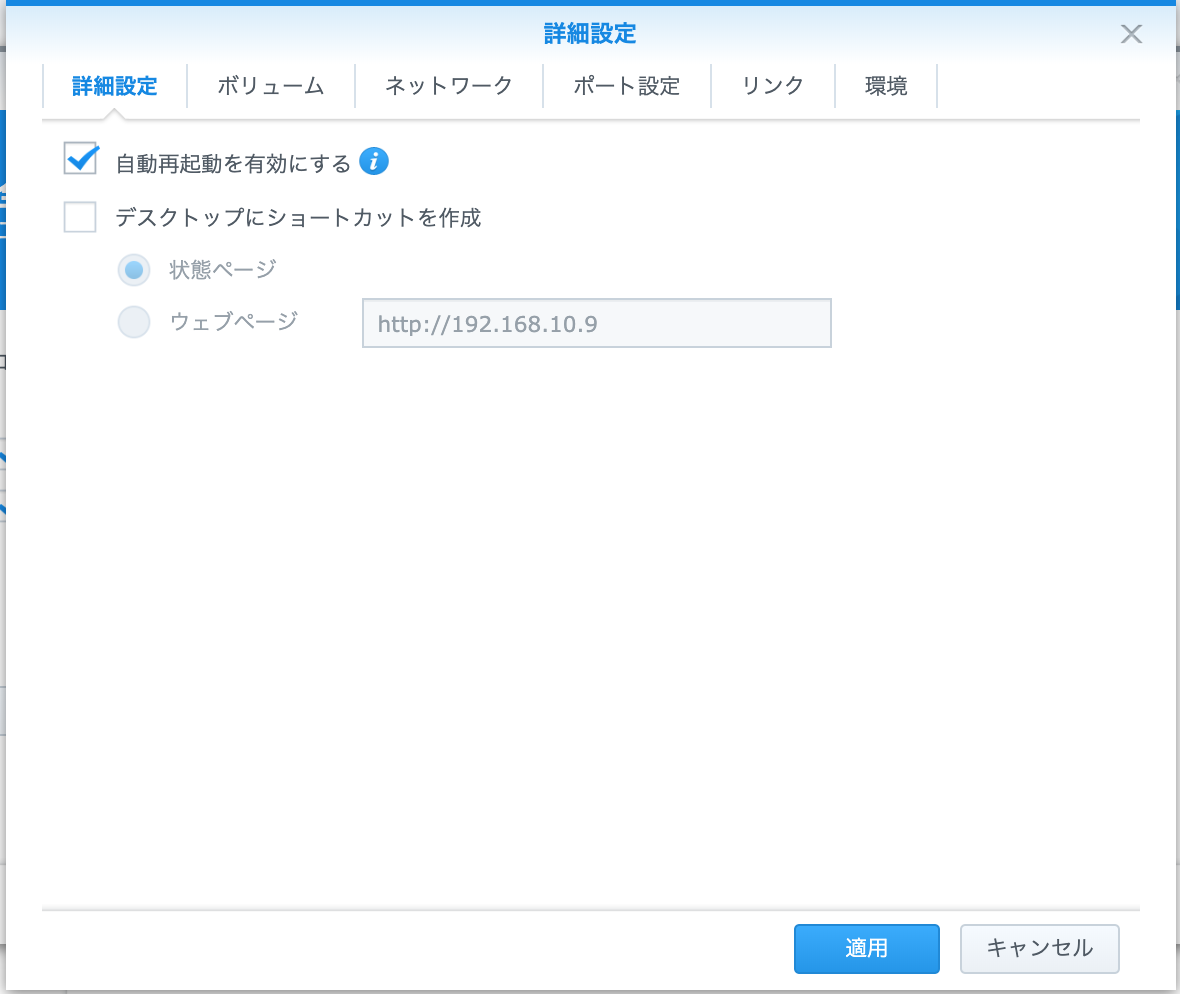
Selenium-Hub設定(Hubの詳細設定)
- 自動再起動を有効にするをON
(夜はNASを電源OFFする方おすすめ)

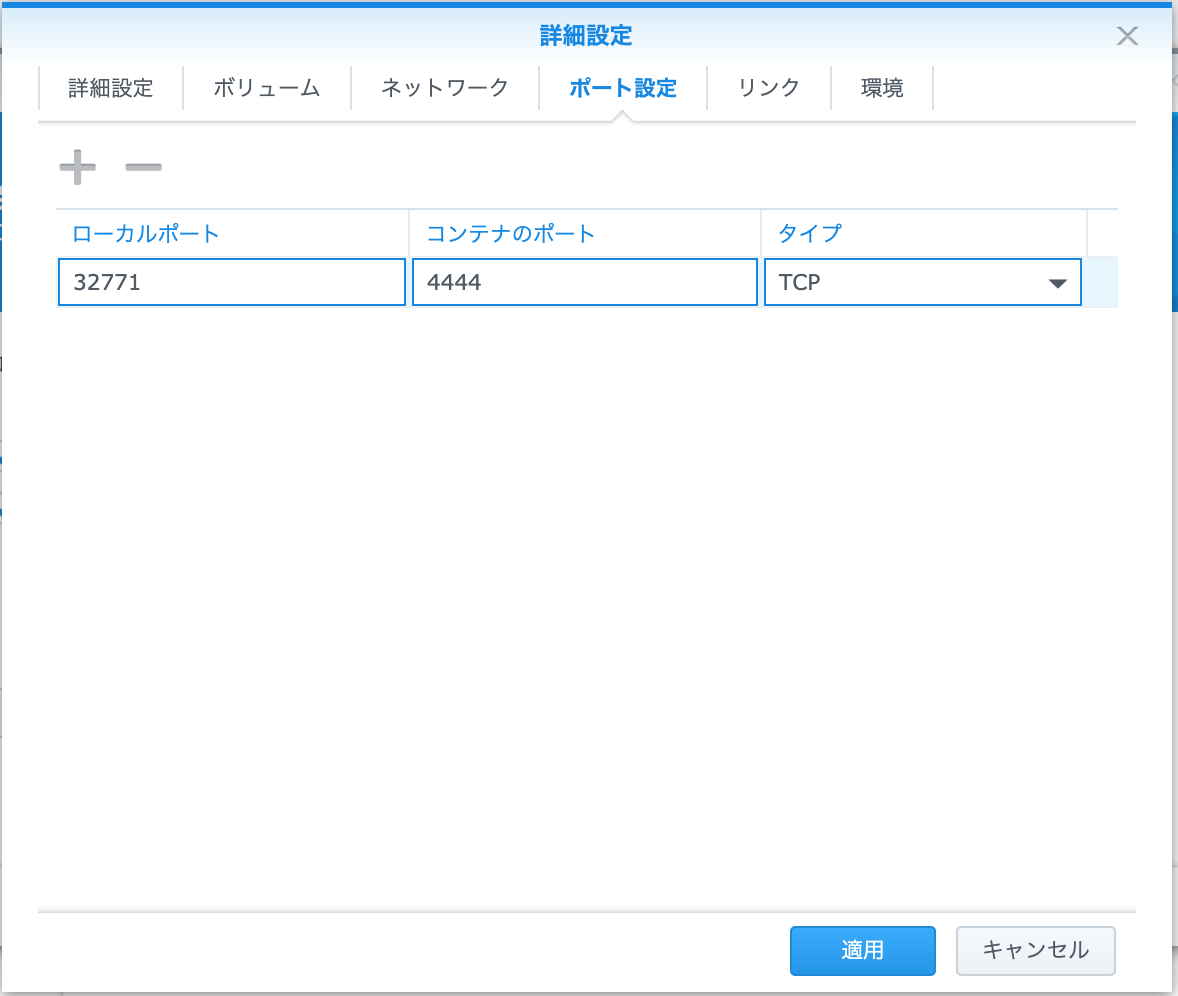
Selenium-Hub設定(ポート設定)
- ローカルポート:環境に合わせて
- コンテナポート:4444

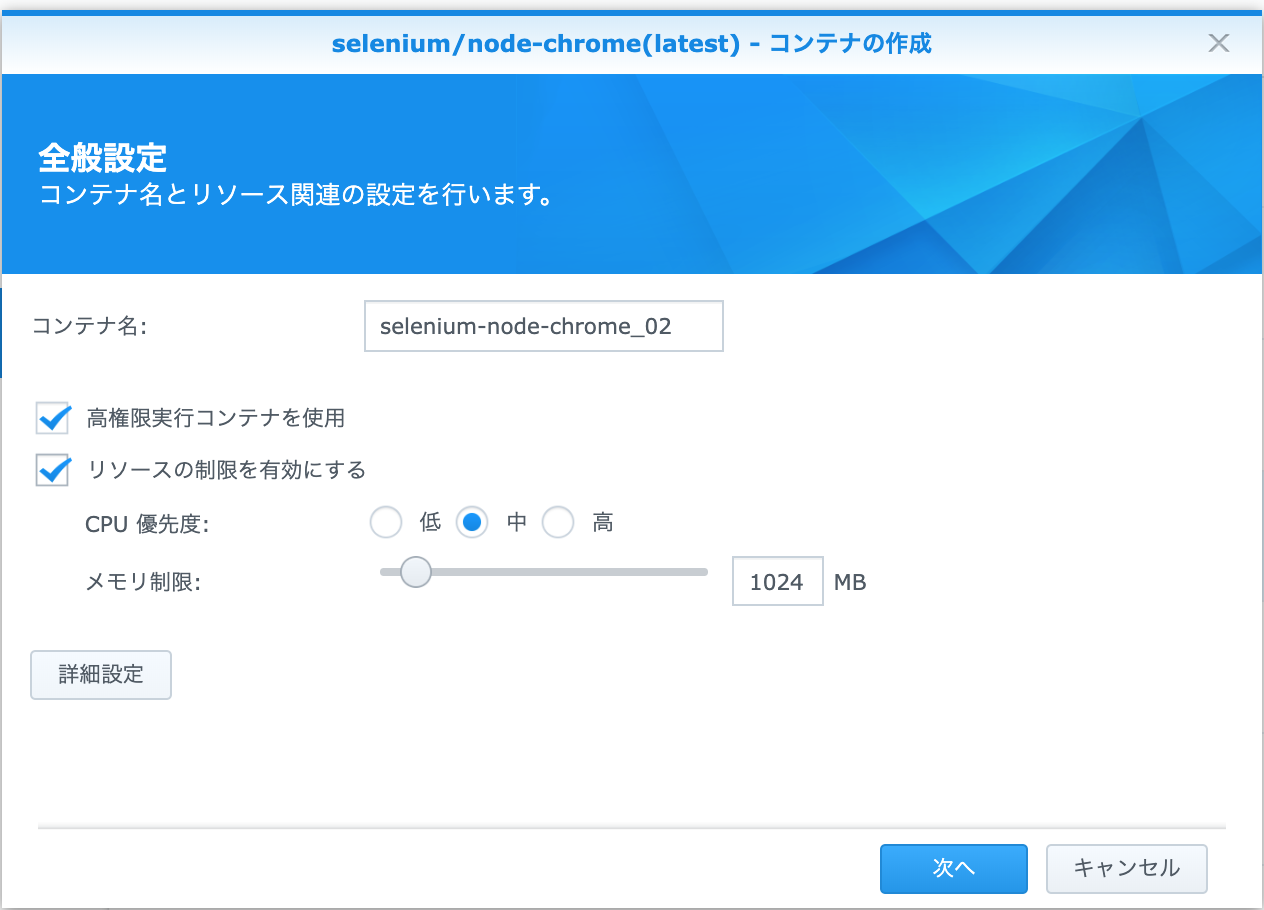
Selenium-node設定(全般設定)
- コンテナ名を指定
- 高権限実行コンテナを使用(お好みで)ON
- リソースの制限を有効にする(お好みで)ON

Selenium-node設定(nodeの詳細設定)
- 自動再起動を有効にする
(夜はNASを電源OFFする方おすすめ)

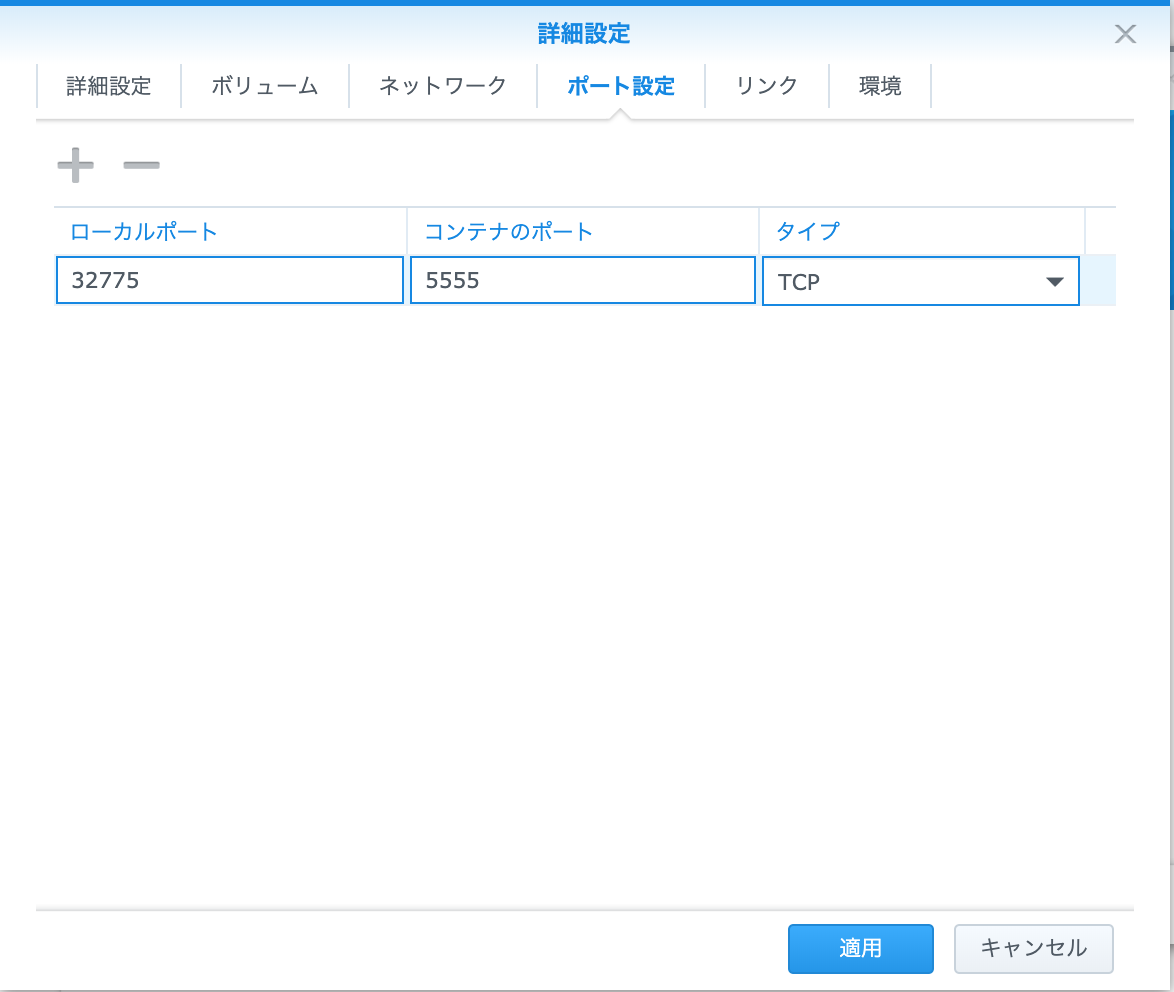
Selenium-node設定(ポート設定)
- ローカルポート:環境に合わせて
- コンテナポート:5555

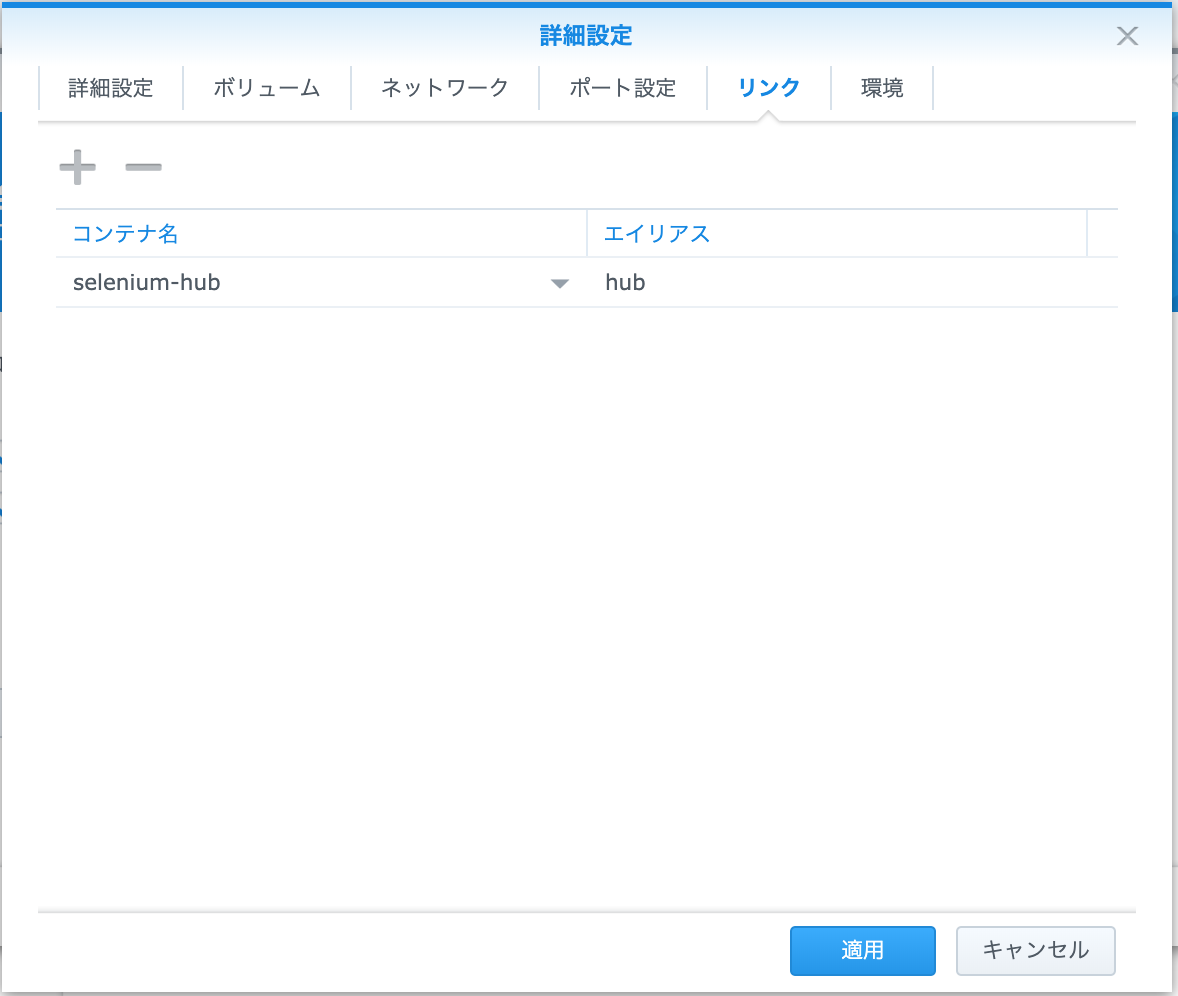
Selenium-node設定(リンク)
- コンテナ名:selenium-hubを指定
- エイリアス:お好みで

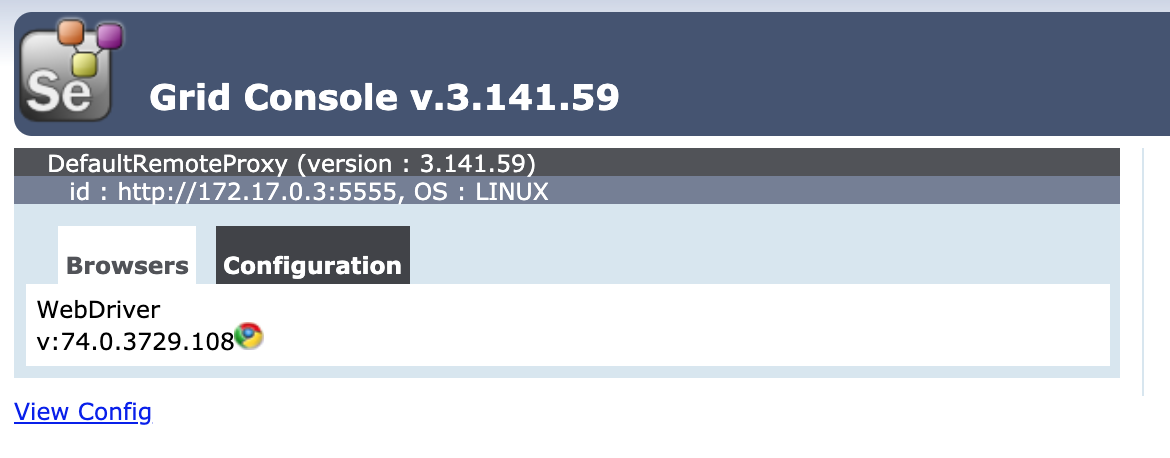
確認
ブラウザでNASのIPに対し、Selenium-hubの「ローカルポート」を指定。以下のように
Selenium-nodeが表示されれば成功
あとは、一般に書かれてる「WebDriver.Remote」でSelenium-hubに接続すればOK
さいごに
それではすばらしいNAS Lifeをお過ごしください:)
- 投稿日:2019-05-23T20:20:25+09:00
vs code insiders のクイックスタートを色々な言語で試してみた。
vs code insidersにIDEの未来の姿を見たので、勉強を兼ねて構築手順をまとめてみました。
クイックスタートの言語毎で若干差異があるようで、かじった事のある言語を試してみました。
vs code insidersそのものの詳しい説明については他のわかりやすい記事を参照してください。
簡単に言うと、今までは開発環境と実際の動く環境は別々で、トラブルが起こりやすい状況でのプログラミングが普通だったんですが、実際の動く環境でプログラミングができる。を提供するのがvs code insidersです。2019-05-23時点では以下の言語のクイックスタート(以下チュートリアル)があります。
https://code.visualstudio.com/docs/remote/containers
- node
- python
- go
- java
- dotnetcore
- php
- rust
- cpp
この中でnode、python、go、phpを今回試していきます。
事前準備
チュートリアルを始める前に、git や vs code insiders&extention(remote development)、docker等をインストールしてください。
dockerはshared driveの設定も忘れずに。チュートリアル ダウンロード
任意のディレクトリで以下のコマンドを実行
shgit clone https://github.com/Microsoft/vscode-remote-try-node git clone https://github.com/Microsoft/vscode-remote-try-python git clone https://github.com/Microsoft/vscode-remote-try-go git clone https://github.com/Microsoft/vscode-remote-try-phpチュートリアルの順番について
説明しやすさの観点から go → node → php → python の順番で進めます。
go
- vs code insidersを立ち上げて任意のディレクトリにダウンロードした
vscode-remote-try-goを開く- 右下に「Folder contains〜」というポップアップが出るので「Reopen in Container」のボタンを押す
- 「Installing Dev Container [details]〜」に切り替わる
- しばらく待ち ※進捗状況は[detail]から
- 左下の緑の枠が「Dev Container: GO」になったら環境構築終了
- メニューの表示→ターミナルを開いて、
go run server.goを実行Server listening on port 9000が出力されればwebサーバ立ち上げ完了- http://localhost:9000/ にアクセス
出力文字を変えたい場合は
server.goの"Hello remote world!"を任意の文字列に変更し、ターミナルからCTRL+c で停止した後、再度go run server.goを実行してページをリロードすると反映されていると思います。node
環境構築はディレクトリ
vscode-remote-try-nodeを開いた後はgoと途中まで一緒(上記4まで)なので割愛します。
5. 左下の緑の枠が「Dev Container: Node.js Sample」になったら環境構築終了
6. 表示→ターミナルを開いて、node server.jsを実行
7.Running on http://0.0.0.0:3000が出力されればwebサーバ立ち上げ完了
8. http://localhost:3000/ にアクセス出力文字を変えたい場合は server.js の対象箇所を変更できます。
goと同様に停止後→再実行で反映されます。PHP
1〜5 まで割愛
6. 表示→ターミナルを開いて、php -S localhost:8000を実行
7. F1ボタンを押してRemote-Containers: Forward Port from Container〜を選択後、「Forward 8000」をクリック
8. http://localhost:8000/ にアクセスphpはgo、node の手順+ポート転送の手順が必要となります。
出力文字を変えたい場合は index.phpを変更します。
また、変更にサーバの再起動は必要なく、ページのリロードのみで反映されます。python
1〜5まで割愛
6 以降では、デフォルトの設定では動かなかった&ポート番号(9000)がgoとカブるので以下の変更をします。.devcontainer/devcontainer.json"appPort": 9000, ↓ "appPort": 5000,.vscode/devcontainer.json"appPort": 9000, ↓ "appPort": 5000,app.py#以下をファイル末尾に追加 if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=5000)表示→ターミナルを開いて、
python app.pyを実行出力文字を変えたい場合は static/index.htmlを変更します。
また、変更にサーバの再起動は必要なく、ページのリロードのみで反映されます。
※goとnodeも別ファイルとしてindex.htmlを読み込むように変更すればサーバ再起動は必要ありません。
- 投稿日:2019-05-23T19:39:27+09:00
【Heroku】ルートに無いディレクトリ上で、デプロイ時にビルドを実行する
問題
Herokuはデプロイ時にルートにcomposer.jsonやpackage.jsonがあった場合、
jsonファイルを元に依存パッケージのインストールやアップデート、ビルド等行ってくれますが、ルートから外れたものは行ってくれません。例えばこんな構成だと、package.json は無視されますしビルドは行われません。
ディレクトリ構成. ├── react │ ├── package.json ← 対象外 ・・・ └── composer.json ← 対象こういったルートから外れたjsonを対象にしたい場合、下記のように記述すればOK。
解決策
ルートにpackage.jsonのシンボリックリンクを作成
ディレクトリ構成. ├── react │ ├── package.json ・・・ ├── package.json(react/package.jsonのシンボリックリンク) └── composer.jsonpackage.jsonに追記。
react/package.json// package.jsonのscriptsに下記スクリプトを追加 "scripts": { ・・・ "heroku-postbuild": "cd ./ビルド対象のディレクトリ名 && npm run build" },scripts内でshell打てるんだから、対象ディレクトリに移動してビルドすればいいじゃない、
と答え見た時は愕然としました。
こういうのは頭柔らかくしないといけませんね。参考:
https://github.com/heroku/heroku-buildpack-nodejs/issues/323
- 投稿日:2019-05-23T12:17:14+09:00
ReactプロジェクトがWindowsだけ動かない場合の処方箋
React Static プロジェクトを Windows でビルドしようとすると、大変不可解なクラッシュが発生しました。
$ react-static build Bundling application for Production... Cleaning dist... [✓] Dist cleaned Cleaning artifacts... : : (中略) : [✓] Site Data Downloaded Fetching Route Data... [==========================================================] 104/104 100% 11556/s 0.0s [✓] Route Data Downloaded (0.3s) Exporting HTML across 4 threads... Error: Invariant Violation: Failed exporting HTML for URL / (../src/pages/index.tsx): Minified React error #130; visit https://reactjs.org/docs/error-decoder.html?invariant =130&args[]=undefined&args[]= for the full message or use the non-minified dev environ ment for full errors and additional helpful warnings. - react-dom-server.node.production.min.js:10 ba [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:10:312 - react-dom-server.node.production.min.js:11 r [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:11:166 - react-dom-server.node.production.min.js:44 a.render [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:44:191 : : (中略) : Error: Error: Invariant Violation: Failed exporting HTML for URL about (../src/pages/about.ts x): Minified React error #130; visit https://reactjs.org/docs/error-decoder.html?invar iant=130&args[]=undefined&args[]= for the full message or use the non-minified dev env ironment for full errors and additional helpful warnings. - react-dom-server.node.production.min.js:10 ba [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:10:312 - react-dom-server.node.production.min.js:11 r [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:11:166 - react-dom-server.node.production.min.js:44 a.render [e-sea]/[react-dom]/cjs/react-dom-server.node.production.min.js:44:191 : : (後略) :他の環境で動かしてみたところ、下記のような状態でした。
- macOS: 問題なし
- (VirtualBox) Windows: 問題なし
- Windows PC: クラッシュ❗️
nodeJS のバージョンがバラバラでしたので、一時的に v12.2.0 に合わせてみましたが、やはり再現します。
OS 周りの環境依存問題でしょうか?解決策
プロジェクトルートまでのパスから シンボリックリンク を除外します。
これだけで嘘のように現象が改善しました。
その他、解決策候補
今回は複数環境の実験から、早々に OS 周りの環境依存の問題と目星をつけていたので除外していましたが、ググっている最中に出てきた解決策です。
react-domとreactとの間で、バージョン不整合が起きている可能性
- React Hooks の絡みで、特に 16.7.x ▶︎ 16.8.x 移行時とかに起きやすいそうです。
export defaultしているのに、import { Hoge } from形式でインポートしてしまっている所感
Windows におけるシンボリックリンクとかジャンクションとかその辺り、不遇すぎませんか、、??
- 投稿日:2019-05-23T11:07:26+09:00
SlackでOAuth認証してみた
SlackのOAuth2を利用することになり、作業前は細かい動作がピンとこなかったので手順をまとめておきます。
Slackのユーザ情報を取得する実際のコードも載せています。SlackのOAuth2.0については以下を参考にしました。
SlackでOAuth2を利用したときのメモ
Using OAuth 2.0 | Slack手順概要
ざっくり以下の流れが必要になります。
- Slackアプリに登録する
- Slackアプリの権限設定などを行う
- 認可コードを受け取るコールバックサーバを立てる
- Webブラウザで認可リクエスト投げる
- コールバックサーバで認可コードを受け取り、そのコードを含めたリクエストを投げる
Slackアプリの登録
まず、Slackアプリを登録します
Slack API: Applications | Slack を開いて、
Create New Appを選択して、任意のアプリ名とチームを選択してください。ClientIDの取得
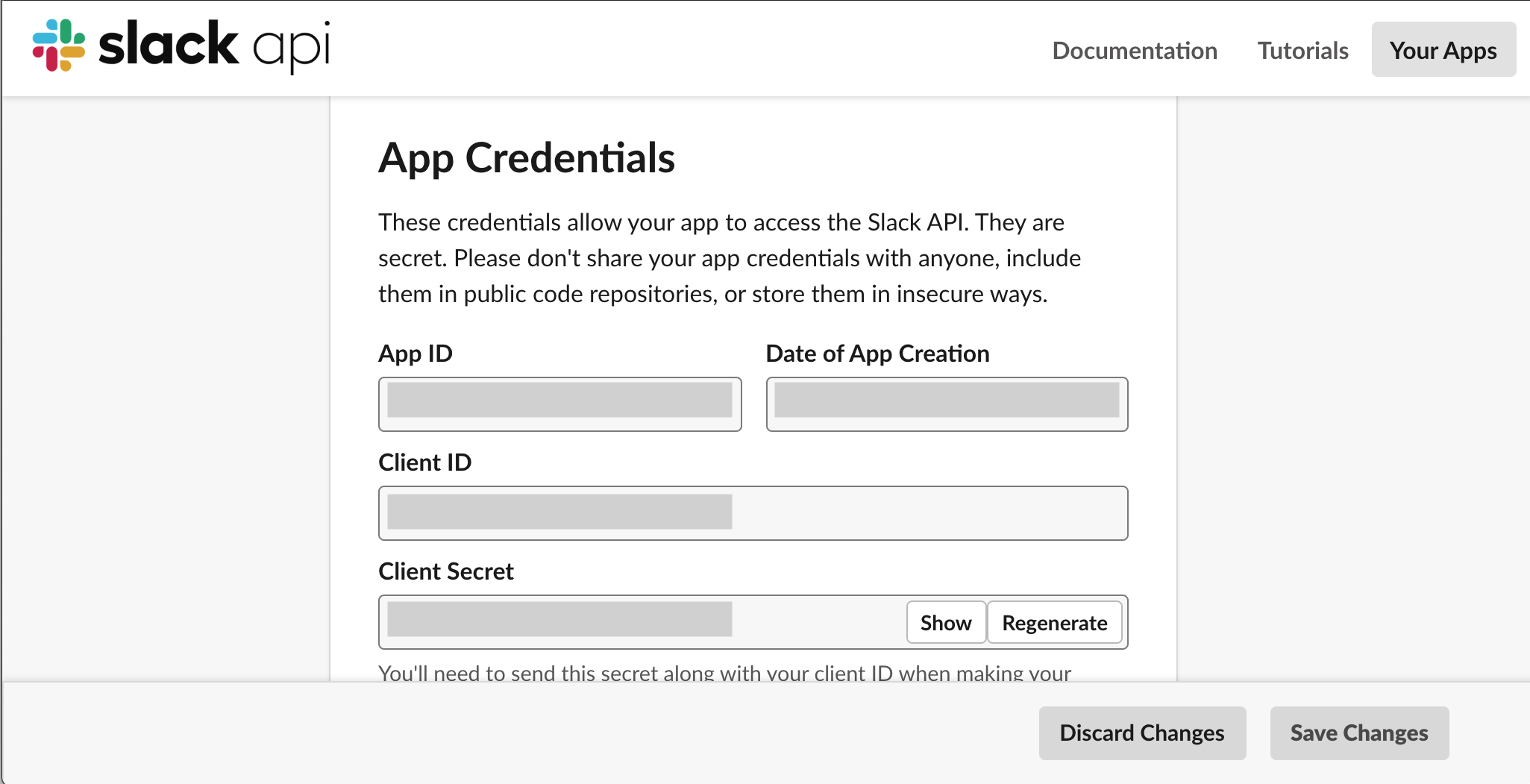
Basic Informationのページの画面中央のApp CredentialsにIDが書いてあります
Client IDとClient Secretが必要になるので控えておいてください。(漏洩しないよう注意)ただ、いつでも見えるので後でも良いです。
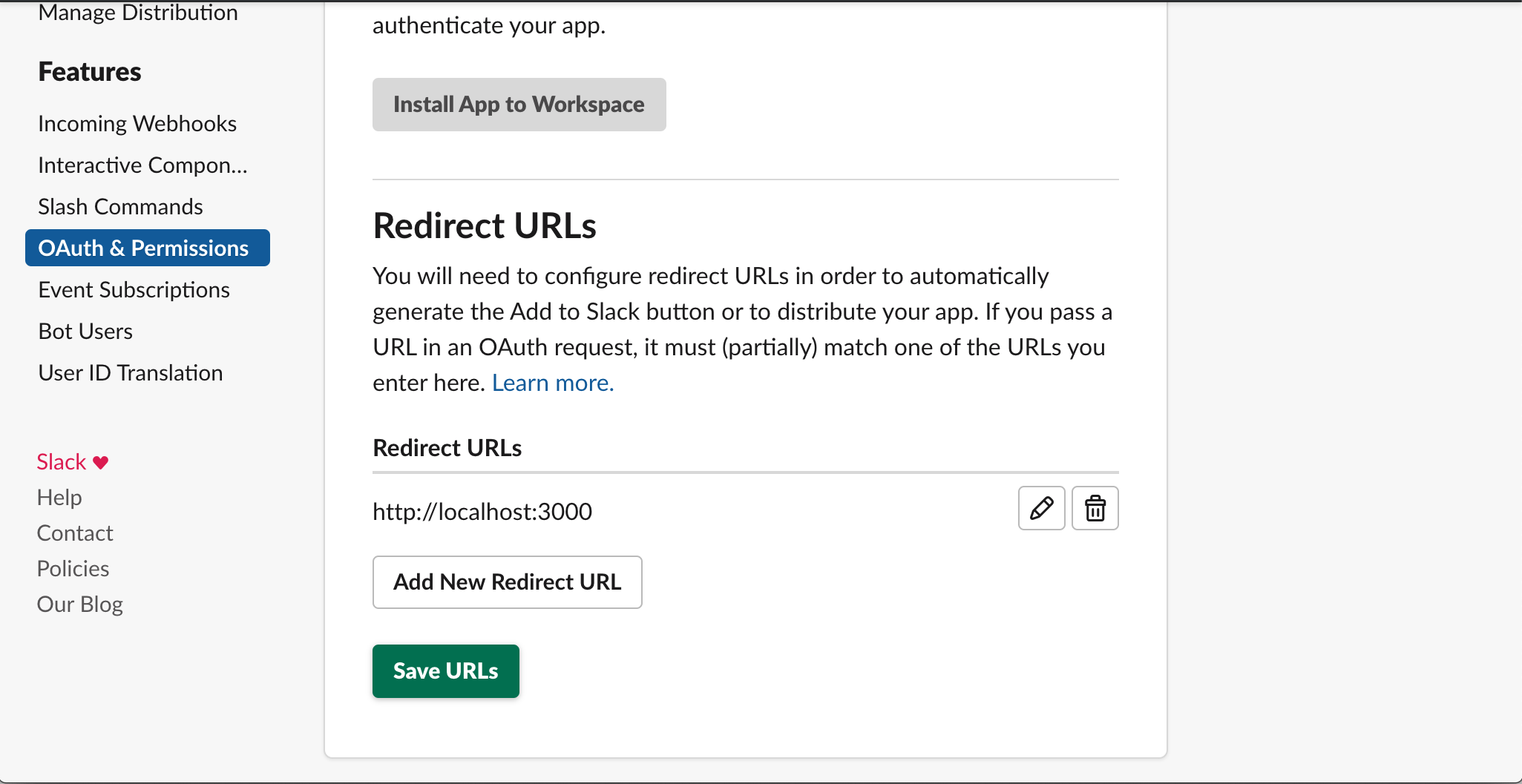
Recirect URLsの設定
左メニューより、
OAuth & Permissionsを選択します。
Redirect URLsの項目からコールバックを受けるサーバのURLを追加します。今回はローカルサーバに立てるので、
http://localhost:3000を登録します。
Scopeの設定
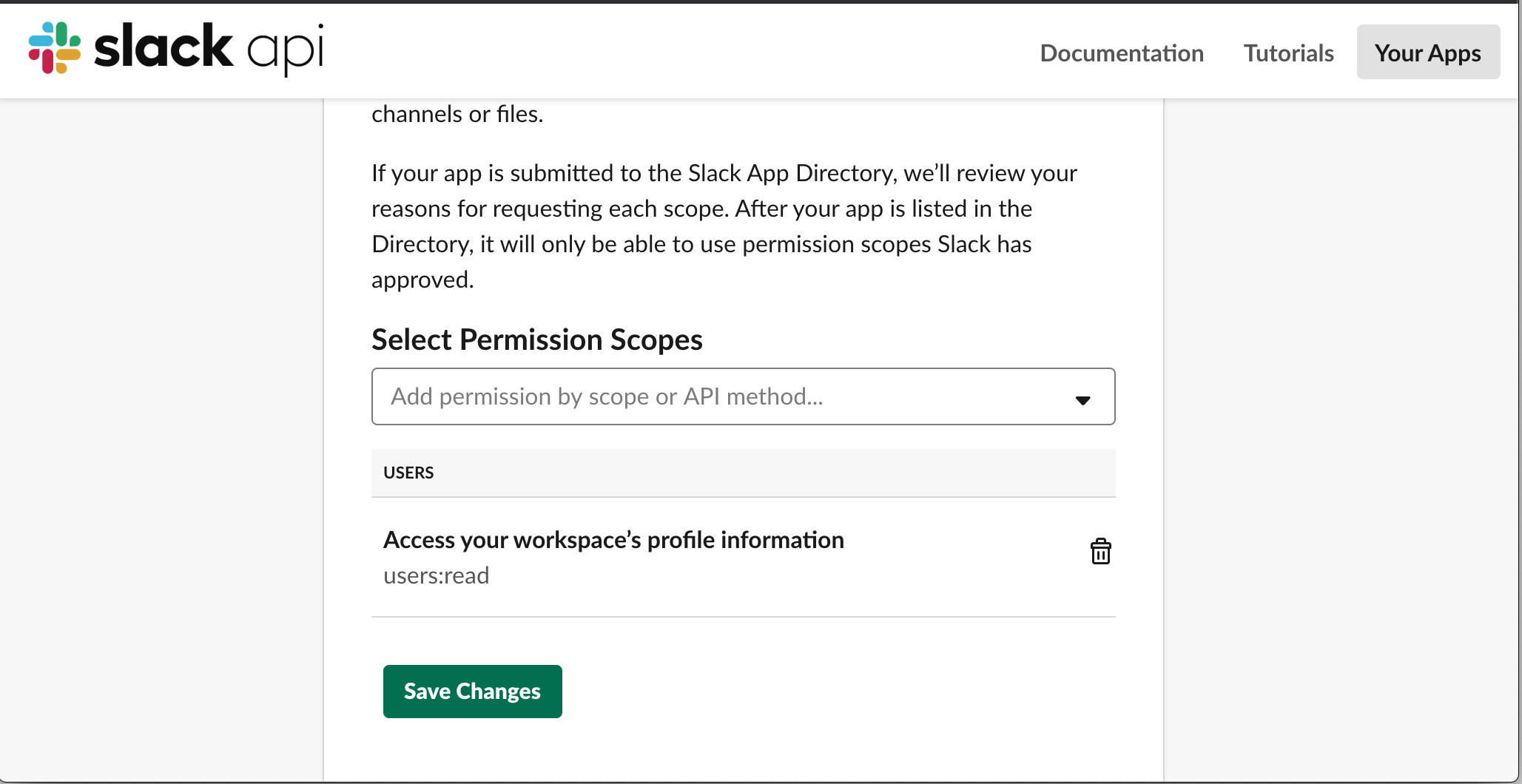
画面下部の
Scopes中のSelect Permission Scopesからusers:readを選択します
認可のみであれば
identity.basicでも良いのですが、サンプルコードではユーザ情報まで取得しているため、これを選択しますここまででSlack側の設定は完了です
OAuth認証を行うためにはコールバックを受け取るためのサーバが必要になります。
実際のアプリの場合はグローバルなサーバとなりますが、今回は確認なのでローカルホストにサーバを起動します。サンプルコードは dbgso/slack-oauth2.0-client にあげています。
内容はコードの中身をみてくださいコードの取得
git clone https://github.com/dbgso/slack-oauth2.0-client.git cd slack-oauth2.0-client yarn # or npm installクライアントIDの設定
任意のエディタで
app.jsを編集して、SlackのクライアントIDを設定してください。
IDはClientの取得で控えておいたものです。// Slack App の Client ID - const slack_client_id = ''; + const slack_client_id = '実際のclient_id'; // Slack App の Client Secret - const slack_client_secret = '' + const slack_client_secret = '実際のclient_secret'起動
node app.jsこれで
http://localhost:3000にSlackからのコールバックを受け取るサーバが立ち上がります。Webブラウザから認可リクエスト
Webブラウザで以下のURLを開きます
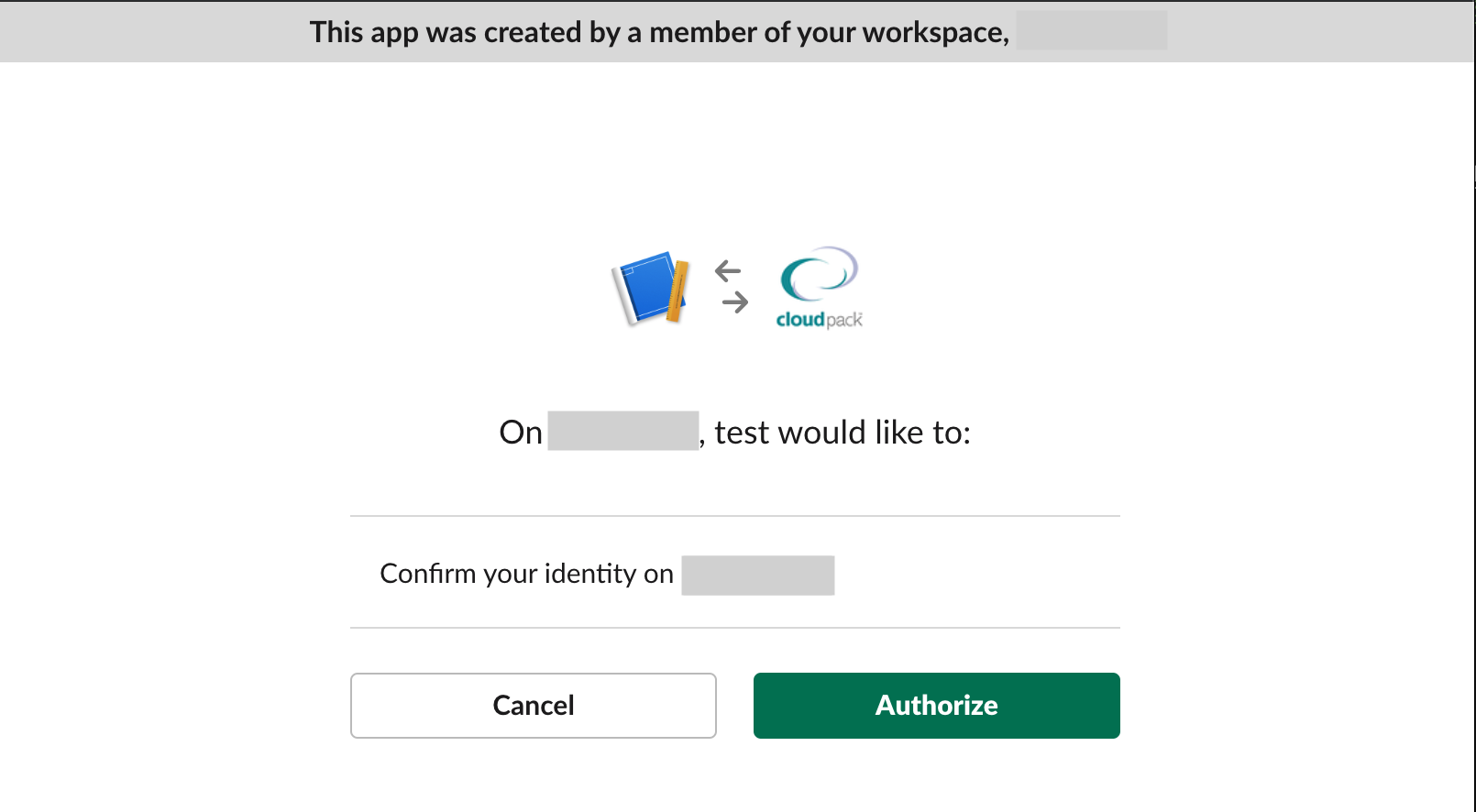
SLACK_CLIENT_IDの部分は実際のclient_idに合わせてください。それ以外は変更なしで大丈夫ですhttps://slack.com/oauth/authorize?client_id=<SLACK_CLIENT_ID>&scope=identify&redirect_uri=http://localhost:3000/以下のような画面が表示されるはずです。
ここでAuthorizeボタンを押すとredirect_uriで指定したhttp://localhost:3000に対してリクエストが送られます。
実行結果
Slackのユーザ情報を取得するまでの流れは以下のようになっています。
認可するのみであれば6.のユーザ情報取得までは必要ありません。
- Authorizedボタンを押下する
http://localhost:3000にHTTPリクエストが飛ぶ- HTTPリクエストのクエリ中に
認可コードが含まれているので取得認可コードを使ってhttps://slack.com/api/oauth.accessにリクエストしてアクセストークンを取得アクセストークンを使ってhttps://slack.com/api/auth.testにリクエストしてuser_idを取得user_idを使ってhttps://slack.com/api/users.infoにリクエストして、Slack上のユーザ情報を取得するうまく行けば以下のようなログがコンソール上に流れるはずです。
アクセストークン取得
https://slack.com/api/oauth.accessからのレスポンス{ ok: true, access_token: '****-**********-************-************-********************************', scope: 'read,identify', user_id: '*********', team_name: '******', team_id: '*********' }user_id取得
https://slack.com/api/auth.testからのレスポンス{ ok: true, url: 'https://******.slack.com/', team: '******', user: '*****', team_id: '*********', user_id: '*********' }Slackユーザ情報取得
https://slack.com/api/users.infoからのレスポンス自身のSlackユーザ情報が表示されます。この情報は別にいらない、ということであれば
https://slack.com/api/users.infoへのリクエスト処理は不要です。{ "ok": true, "user": { "id": "**********", "team_id": "**********", "name": "**********", "deleted": false, "color": "d58247", "real_name": "**********", "tz": "Asia/Tokyo", "tz_label": "Japan Standard Time", "tz_offset": 32400, "profile": { "title": "", "phone": "", "skype": "", "real_name": "**********", "real_name_normalized": "**********", "display_name": "**********", "display_name_normalized": "**********", "status_text": "", "status_emoji": "", "status_expiration": 0, "avatar_hash": "**********", "image_original": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_original.jpg", "email": "**********", "first_name": "***", "last_name": "***", "image_24": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_24.jpg", "image_32": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_32.jpg", "image_48": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_48.jpg", "image_72": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_72.jpg", "image_192": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_192.jpg", "image_512": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_512.jpg", "image_1024": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_1024.jpg", "status_text_canonical": "", "team": "**********", "is_custom_image": true }, "is_admin": false, "is_owner": false, "is_primary_owner": false, "is_restricted": false, "is_ultra_restricted": false, "is_bot": false, "is_app_user": false, "updated": 1557212637, "has_2fa": false } }失敗時ログ
こんなログが流れている場合は認可が失敗しています。
client_idが正しいか、Redirect URLsやPermissionsの設定を見直してみてください。{ ok: false, error: 'invalid_code' } { ok: false, error: 'not_authed' }認可のみであれば
identity.basicでも良いのですが、サンプルコードではユーザ情報まで取得しているため、これを選択しますちなみに、こう書きましたが、
identity.basicを選んだ状態で、ユーザ情報を取得しようとすると以下のようなエラーがでます。{"ok":false,"error":"missing_scope","needed":"users:read","provided":"identify"}コードの中身
- Node.js v10.15.3
- express 4.17
- request 2.88
でコールバックサーバを立てました。
リクエスト処理の度にネストが深くなってしまってみづらいですが、50行程度なので逆に小細工するよりこっちの方がみやすいかなと思ってます。requestをPromiseにしてくれ...
と思ったらあるんですね。試しておきます
request-promiseを使ったHTTPクライアントを作る - Qiitaapp.js//@ts-check const request = require('request') const express = require('express'); const app = express(); // SSL関連でエラーが出るので、応急処置 SlackのAPIにリクエストするときに死んでいる模様。おそらく社内ネットワークのせい process.env["NODE_TLS_REJECT_UNAUTHORIZED"] = "0"; // Slack App の Client ID const slack_client_id = ''; // Slack App の Client Secret const slack_client_secret = '' app.get('/', (req, res) => { // 認可コードの取得 const code = req.query["code"]; // 認可コードを使って、アクセストークンをリクエストする request({ url: "https://slack.com/api/oauth.access", method: "POST", form: { client_id: slack_client_id, client_secret: slack_client_secret, code: code, redirect_uri: "http://localhost:3000/" } }, (error, response, body) => { // レスポンスからアクセストークンを取得する const param = JSON.parse(body); console.log(param); const access_token = param['access_token']; // アクセストークン // ユーザIDを取得するためのリクエスト request("https://slack.com/api/auth.test",{ method: "POST", form: { token: access_token } },(error, response, body) => { console.log(JSON.parse(body)); // アクセストークンを使ってユーザ情報をリクエスト // 認可のみが目的の場合はここはなくても良い request("https://slack.com/api/users.info ", { method: 'POST', form: { token: access_token, user: param['user_id'] } }, (error, response, body) => { res.send(JSON.parse(body)); }) }) }) }) app.listen(3000, () =>{ console.log('HTTP Server(3000) is running.'); });おわりに
OAuth認証はほぼ初めてだったので、実際にコード書くと流れがわかってよかったです。
あと、認証と認可って言葉難しいですよね。使い方間違ってたら教えてください。。。
参考
AWS CognitoにGoogleとYahooとLINEアカウントを連携させる - Qiita
SlackでOAuthを利用して BOT投稿 するための アクセストークン を取得する方法 - UTALI
SlackでOAuth2を利用したときのメモ - Qiita
オウム返し slack bot をぱっとつくる - Qiita
Ignore invalid self-signed ssl certificate in node.js with https.request? - Stack Overflow
- 投稿日:2019-05-23T11:07:26+09:00
SlackのOAuth認証を使ってユーザ情報を取得してみた
SlackのOAuth2を利用することになり、作業前は細かい動作がピンとこなかったので手順をまとめておきます。
Slackのユーザ情報を取得する実際のコードも載せています。SlackのOAuth2.0については以下を参考にしました。
SlackでOAuth2を利用したときのメモ
Using OAuth 2.0 | Slack手順概要
ざっくり以下の流れが必要になります。
- Slackアプリに登録する
- Slackアプリの権限設定などを行う
- 認可コードを受け取るコールバックサーバを立てる
- Webブラウザで認可リクエスト投げる
- コールバックサーバで認可コードを受け取り、そのコードを含めたリクエストを投げる
Slackアプリの登録
まず、Slackアプリを登録します
Slack API: Applications | Slack を開いて、
Create New Appを選択して、任意のアプリ名とチームを選択してください。ClientIDの取得
Basic Informationのページの画面中央のApp CredentialsにIDが書いてあります
Client IDとClient Secretが必要になるので控えておいてください。(漏洩しないよう注意)ただ、いつでも見えるので後でも良いです。
Recirect URLsの設定
左メニューより、
OAuth & Permissionsを選択します。
Redirect URLsの項目からコールバックを受けるサーバのURLを追加します。今回はローカルサーバに立てるので、
http://localhost:3000を登録します。
Scopeの設定
画面下部の
Scopes中のSelect Permission Scopesからusers:readを選択します
認可のみであれば
identity.basicでも良いのですが、サンプルコードではユーザ情報まで取得しているため、これを選択しますここまででSlack側の設定は完了です
OAuth認証を行うためにはコールバックを受け取るためのサーバが必要になります。
実際のアプリの場合はグローバルなサーバとなりますが、今回は確認なのでローカルホストにサーバを起動します。サンプルコードは dbgso/slack-oauth2.0-client にあげています。
内容はコードの中身をみてくださいコードの取得
git clone https://github.com/dbgso/slack-oauth2.0-client.git cd slack-oauth2.0-client yarn # or npm installクライアントIDの設定
任意のエディタで
app.jsを編集して、SlackのクライアントIDを設定してください。
IDはClientの取得で控えておいたものです。// Slack App の Client ID - const slack_client_id = ''; + const slack_client_id = '実際のclient_id'; // Slack App の Client Secret - const slack_client_secret = '' + const slack_client_secret = '実際のclient_secret'起動
node app.jsこれで
http://localhost:3000にSlackからのコールバックを受け取るサーバが立ち上がります。Webブラウザから認可リクエスト
Webブラウザで以下のURLを開きます
SLACK_CLIENT_IDの部分は実際のclient_idに合わせてください。それ以外は変更なしで大丈夫ですhttps://slack.com/oauth/authorize?client_id=<SLACK_CLIENT_ID>&scope=identify&redirect_uri=http://localhost:3000/以下のような画面が表示されるはずです。
ここでAuthorizeボタンを押すとredirect_uriで指定したhttp://localhost:3000に対してリクエストが送られます。
実行結果
Slackのユーザ情報を取得するまでの流れは以下のようになっています。
認可するのみであれば6.のユーザ情報取得までは必要ありません。
- Authorizedボタンを押下する
http://localhost:3000にHTTPリクエストが飛ぶ- HTTPリクエストのクエリ中に
認可コードが含まれているので取得認可コードを使ってhttps://slack.com/api/oauth.accessにリクエストしてアクセストークンを取得アクセストークンを使ってhttps://slack.com/api/auth.testにリクエストしてuser_idを取得user_idを使ってhttps://slack.com/api/users.infoにリクエストして、Slack上のユーザ情報を取得するうまく行けば以下のようなログがコンソール上に流れるはずです。
アクセストークン取得
https://slack.com/api/oauth.accessからのレスポンス{ ok: true, access_token: '****-**********-************-************-********************************', scope: 'read,identify', user_id: '*********', team_name: '******', team_id: '*********' }user_id取得
https://slack.com/api/auth.testからのレスポンス{ ok: true, url: 'https://******.slack.com/', team: '******', user: '*****', team_id: '*********', user_id: '*********' }Slackユーザ情報取得
https://slack.com/api/users.infoからのレスポンス自身のSlackユーザ情報が表示されます。この情報は別にいらない、ということであれば
https://slack.com/api/users.infoへのリクエスト処理は不要です。{ "ok": true, "user": { "id": "**********", "team_id": "**********", "name": "**********", "deleted": false, "color": "d58247", "real_name": "**********", "tz": "Asia/Tokyo", "tz_label": "Japan Standard Time", "tz_offset": 32400, "profile": { "title": "", "phone": "", "skype": "", "real_name": "**********", "real_name_normalized": "**********", "display_name": "**********", "display_name_normalized": "**********", "status_text": "", "status_emoji": "", "status_expiration": 0, "avatar_hash": "**********", "image_original": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_original.jpg", "email": "**********", "first_name": "***", "last_name": "***", "image_24": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_24.jpg", "image_32": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_32.jpg", "image_48": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_48.jpg", "image_72": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_72.jpg", "image_192": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_192.jpg", "image_512": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_512.jpg", "image_1024": "https://avatars.slack-edge.com/xxxx-xx-xx/****************_1024.jpg", "status_text_canonical": "", "team": "**********", "is_custom_image": true }, "is_admin": false, "is_owner": false, "is_primary_owner": false, "is_restricted": false, "is_ultra_restricted": false, "is_bot": false, "is_app_user": false, "updated": 1557212637, "has_2fa": false } }失敗時ログ
こんなログが流れている場合は認可が失敗しています。
client_idが正しいか、Redirect URLsやPermissionsの設定を見直してみてください。{ ok: false, error: 'invalid_code' } { ok: false, error: 'not_authed' }認可のみであれば
identity.basicでも良いのですが、サンプルコードではユーザ情報まで取得しているため、これを選択しますちなみに、こう書きましたが、
identity.basicを選んだ状態で、ユーザ情報を取得しようとすると以下のようなエラーがでます。{"ok":false,"error":"missing_scope","needed":"users:read","provided":"identify"}コードの中身
- Node.js v10.15.3
- express 4.17
- request 2.88
でコールバックサーバを立てました。
リクエスト処理の度にネストが深くなってしまってみづらいですが、50行程度なので逆に小細工するよりこっちの方がみやすいかなと思ってます。requestをPromiseにしてくれ...
と思ったらあるんですね。試しておきます
request-promiseを使ったHTTPクライアントを作る - Qiitaapp.js//@ts-check const request = require('request') const express = require('express'); const app = express(); // SSL関連でエラーが出るので、応急処置 SlackのAPIにリクエストするときに死んでいる模様。おそらく社内ネットワークのせい process.env["NODE_TLS_REJECT_UNAUTHORIZED"] = "0"; // Slack App の Client ID const slack_client_id = ''; // Slack App の Client Secret const slack_client_secret = '' app.get('/', (req, res) => { // 認可コードの取得 const code = req.query["code"]; // 認可コードを使って、アクセストークンをリクエストする request({ url: "https://slack.com/api/oauth.access", method: "POST", form: { client_id: slack_client_id, client_secret: slack_client_secret, code: code, redirect_uri: "http://localhost:3000/" } }, (error, response, body) => { // レスポンスからアクセストークンを取得する const param = JSON.parse(body); console.log(param); const access_token = param['access_token']; // アクセストークン // ユーザIDを取得するためのリクエスト request("https://slack.com/api/auth.test",{ method: "POST", form: { token: access_token } },(error, response, body) => { console.log(JSON.parse(body)); // アクセストークンを使ってユーザ情報をリクエスト // 認可のみが目的の場合はここはなくても良い request("https://slack.com/api/users.info ", { method: 'POST', form: { token: access_token, user: param['user_id'] } }, (error, response, body) => { res.send(JSON.parse(body)); }) }) }) }) app.listen(3000, () =>{ console.log('HTTP Server(3000) is running.'); });おわりに
OAuth認証はほぼ初めてだったので、実際にコード書くと流れがわかってよかったです。
あと、認証と認可って言葉難しいですよね。使い方間違ってたら教えてください。。。
参考
AWS CognitoにGoogleとYahooとLINEアカウントを連携させる - Qiita
SlackでOAuthを利用して BOT投稿 するための アクセストークン を取得する方法 - UTALI
SlackでOAuth2を利用したときのメモ - Qiita
オウム返し slack bot をぱっとつくる - Qiita
Ignore invalid self-signed ssl certificate in node.js with https.request? - Stack Overflow
- 投稿日:2019-05-23T02:09:41+09:00
【2分でイメージをつかむ】fsオブジェクト
なんでこれを書いたか
- Node.jsでサーバーを立てた後、やることはこれ
- ファイル読み込みをどうやってやるかのイメージをつかみたかったから
fsオブジェクトとは
- file system オブジェクト
- ファイルを扱うオブジェクトでHTMLファイルなど読み込める!
使い方
男は黙って、変数に読み込む
var fs = require('fs');まずはこれだけ使えるようになればOK
fs.readFile( './hello.html', 'UTF-8', コールバック関数 );
- 第1引数にファイルパスを指定(例えば・・'./hello.html')
- 第2引数には'UTF-8'を指定(一旦はこういうもんだと思っておけばOK)
- 第3引数には、読み込み完了後の処理を行うコールバック関数をかく
コールバック関数
- コールバック関数は、このファイルの読み込みが完了したら、発動します!
- 仮にこのファイルが、読み込みに1時間を要する超膨大ファイルだったとしましょう
- 1時間後、コールバック関数が発動し、そのあとに書いてるソースコードはようやく読まれるようになります
例えるなら、お会計をしている人が財布を探していて、なかなか列が進まない・・
しかし
- そんなことしてたら、ずーっと待ちっぱなしで列に並ぶ気が失せる
- というか財布探すのに1時間もかけて、店員もずっと待ってるって・・・店としてどうなんだ!
というご意見がありましたので、、
お財布探している間、次の方どうぞ〜
- に変更しました
- お財布が見つかり次第、お会計(コールバック関数)に移らせていただきます。
- 探している間は、次のお客様(readFile以降の処理)からお会計させていただきます。
簡単なコード例
function doRequest(req, res) { //hello.htmlを読み込もう! fs.readFile('./hello.html', 'UTF-8', // 読み込みが完了したら、コールバック関数が発動 function(err, data) { res.writeHead(200, {'Content-Type': 'text/html'}); // 読み込んだファイル(data)を書き込む res.write(data); res.end(); }); console.log('readFileのファイル読み込みが完了するまで、お待ちください'); console.log('おや、このログを見ているということは、まだファイルの読み込みが完了していないようですね'); }
- hello.htmlのファイル読み込みがおそーーかった場合、コールバック関数は発動せずに、readFile関数の下にある、console.logが呼び出される
- ファイル読み込みが完了した時点で、コールバック関数が発動する
こっから脱線
- コールバック関数は、「非同期処理」になります
- つまり、割り込みができるということです!
- 財布見つかった時点で、最後尾に列びなおさなくても、お会計に割り込めるというイメージです
じゃあ、それって並列処理なんですか?
- 違います
- 並列処理は、複数の作業を同時に実施します。
- レジいっぱいあるから財布探している人が割り込んでくる心配はない。同時にお会計ができるということです
参考
