- 投稿日:2019-05-03T17:41:45+09:00
KerasのRNN (LSTM) で return_sequences=True を試してみる
はじめに
Kerasを使うとRNN (LSTM) なども手軽に試せて楽しいです。フレームワークごとに性能差などもあるのでしょうが、まずは取っつきやすいものからと思っています(データと最低限の設定を準備すれば使い始められる)。Kerasなら何とかいけるかも?と思っています。
RNN系のレイヤー全体にいえることとして、「return_sequences」というパラメータが存在するのですが
return_sequences=True って何?
という疑問が浮かびました。
Recurrentレイヤー - Keras Documentation後で詳しく述べますが、時系列データに対する最終的な出力だけでなく、途中時点での出力を学習するための設定であるようです。
return_sequencesとは
return_sequences: 真理値.出力系列の最後の出力を返すか,完全な系列を返すか.
うん、分からん。
とはいえ、こちらのページを見るとなんとなく分かってきました。
言語モデルの性能が、実装により異なる件を解決する – programming-soda – Mediumバッチ型でシーケンシャル型と同じ内容を学習するなら、系列の長さ毎にデータを作る必要が出てきます。A,B,C,Dの4つがあったら、A, B, C=>Dだけでなく、A=>B、A,B=>Cも学習でテータに含まないといけないということです。このように対策しても精度が改善することは確認済みですが、この場合シーケンス分だけデータが増え学習に時間がかかります。隠れ層の計算を毎回最初からやっていることになり非効率的です。
そのため、各ステップの隠れ層の状態から予測する形にします。図にすると以下のような形です。これにより、隠れ層の再計算をすることなく、都度に予測する形の学習が可能になります。
return_sequences=Trueを指定すると、そのような学習ができるというのです。具体的な問題で考える
前回の記事で取り上げた「{0.0, 1.0}からなる列の総和を出力するモデル」を考えます。
例えば[1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0]が入力であれば、8.0が出力されるようにします。
(前回の記事:Kerasで基本的なRNN (LSTM) を試してみる - Qiita)前回の記事では、入力列に対して、全体の総和だけを正解ラベルとして与えていました。
ところが、これは学習データに存在する長さの列に対してはそれなりにもっともな予測を出しますが、それ以外のものに対しては(長くても短くても)うまく動かないことがあります。
いろいろな長さの列を学習データに含めればよいですが、長さのバリエーションをカバーするため、用意しなければならないデータの量が増えてしまうのが難点。
前回の記事の「可変長の系列を入力する場合 (1)」では、実際にいろいろな長さの列を準備して学習を行っていました。ここで、数列の総和だけでなく、先頭から途中までの和(部分和)もうまく学習に使えると、幸せになれるかもしれません。LSTMを含むRNNは時系列データを扱っていて、1つの値が入力されるごとに内部状態が変わっていきます。今までは、途中の内部状態については何も制御せず、最終的な内部状態だけを制御していた(最終的な出力さえ合っていれば計算過程はどうでもいい)のですが、普通に考えると、この内部状態は部分和(その時点までの総和)を表しているのが自然なはずです。そうなるように内部状態を制御すれば、学習データより短い数列に対しても、それなりにうまく総和を予測できるようになることが期待できます。
これまではラベルは総和を表す実数値1個だけだったのですが、今度はラベルは部分和となり、入力と同じ長さの数列になります。
具体例を見るほうが早いでしょう。Xを時系列の {0.0, 1.0} 列、tをラベルとすると、学習データは以下のように変わります。Before
総和の
8.0だけをラベルとして与えていました。
X t 1.0 1.0 1.0 1.0 0.0 1.0 1.0 1.0 0.0 1.0 8.0 After
総和の値だけでなく、Xの部分和(先頭からある要素までの総和)をラベルとして与えます。
X t 1.0 1.0 1.0 2.0 1.0 3.0 1.0 4.0 0.0 4.0 1.0 5.0 1.0 6.0 1.0 7.0 0.0 7.0 1.0 8.0 例えば、この系列を先頭から5つ取り出した
X t 1.0 1.0 1.0 2.0 1.0 3.0 1.0 4.0 0.0 4.0 も、長さ5の学習データとして意味のあるデータになります。大雑把に言えば、このような(先頭からある長さを取り出した)部分列も実質的に学習していることになる、と理解できそうです。
ここで面白いのは、LSTMレイヤーが元々持っている内部状態を制御するだけですので、LSTMレイヤーのモデルの複雑さ(パラメータ数)自体は変わらない点かと思います。学習データの件数やパラメータ数は増えていないのに、学習できる情報量が増えている?ような気がして、ちょっと戸惑ってしまいます。
プログラムで検証
同じ長さの列だけを学習データとして与えたときに、それより短い・長い列の総和をうまく予測できるかという課題にチャレンジします。
rnn_dynamic_before.pyは、前回の記事の「可変長の系列を入力する場合 (1)」で取り上げた方法と同じで、ラベルには総和だけを与え、学習データを固定長に変えています。rnn_dynamic_after.pyは、学習データのラベルを部分和に変更しています。Before
rnn_dynamic_before.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Masking from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 len_sequence = 10 # 学習データの時系列の長さ batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples, sequence_len): # 乱数で {0.0, 1.0} の列を生成する X = np.random.randint(0, 2, (nb_of_samples, sequence_len)).astype("float32") # 各行の総和を正解ラベルとする t = np.sum(X, axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 return X.reshape((nb_of_samples, sequence_len, 1)), t # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples, len_sequence) # モデル構築 model = Sequential() model.add(Masking( input_shape=(None, input_dim), mask_value=-1.0)) model.add(LSTM( num_hidden_units, return_sequences=False)) model.add(Dense(output_dim)) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # (サンプル, 時刻, 特徴量の次元) の3次元の入力を与える。 # 学習データと同じ長さのデータ(総和は8.0) test_10 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_10)) # [[7.7854743]] # 学習データより短いデータ(総和は4.0) test_05 = np.array([1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_05)) # [[3.0897331]] # 学習データより長いデータ(総和は12.0) test_15 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)) # [[10.465068]]学習データと同じ長さであれば、それなりに近い値?(一応四捨五入すると期待の結果になる)が予測されますが、短いデータや長いデータだと誤差が大きくなってしまいます。短い方に関しては「答えは合ってるけど途中の計算過程はめちゃくちゃ」といった感じでしょうか。
After
学習の作り方とモデルの作り方が少し変わります。また、ラベルを部分和にしたので予測結果も部分和の数列になります。以下のコードでは予測結果の最後の要素(=数列全体の総和)だけを出力していますが、結果を全部表示して観察してみると面白いかもしれません。
なお、
TimeDistributedラッパーは、時系列データのそれぞれに対してレイヤーを適用することを示しています。各時刻の内部状態に対して同じ変換 (Dense) を行い、その時点での出力を求めましょう、という意味になるわけですね。
レイヤーラッパー - Keras Documentation
Keras Recurrentレイヤーメモ:return_sequences, RepeatVector, TimeDistributed - Qiitarnn_dynamic_after.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Masking from keras.layers.recurrent import LSTM from keras.layers.wrappers import TimeDistributed from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 len_sequence = 10 # 学習データの時系列の長さ batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples, sequence_len): # 乱数で {0.0, 1.0} の列を生成する X = np.random.randint(0, 2, (nb_of_samples, sequence_len)).astype("float32") # 各行の累積和を正解ラベルとする t = np.cumsum(X, axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 # ラベルも時系列データになるので、同じ形状になる。 return X.reshape((nb_of_samples, sequence_len, 1)), t.reshape((nb_of_samples, sequence_len, 1)) # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples, len_sequence) # モデル構築 model = Sequential() model.add(Masking( input_shape=(None, input_dim), mask_value=-1.0)) model.add(LSTM( num_hidden_units, return_sequences=True)) model.add(TimeDistributed(Dense(output_dim))) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # (サンプル, 時刻, 特徴量の次元) の3次元の入力を与える。 # 学習データと同じ長さのデータ(総和は8.0) test_10 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_10)[:, -1, :]) # [[7.762647]] # 学習データより短いデータ(総和は4.0) test_05 = np.array([1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_05)[:, -1, :]) # [[4.1512775]] # 学習データより長いデータ(総和は12.0) test_15 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)[:, -1, :]) # [[9.912318]]学習データより短い例では、Beforeと比べて誤差が小さくなっています。一方、長いデータに対してはうまく予測できていません。最後の予測は
12.0に近い値を期待していますが、学習データの長さは10で、部分和が12.0になるような学習データが存在しませんので、無理もないでしょう。試しに総和が10未満になる長いデータを一つ試すと# 学習データより長いデータ(総和は7.0) test_15 = np.array([1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)[:, -1, :]) # [[6.985335]]といったように、近い値を予測できました。
学習データとして十分長い列を使用すれば、この点は解決されそうです。
(いろいろ試すと、総和が10に近づくにつれて誤差が大きくなっているような気がします。学習データの作り方の性質上、値が10に近づくと総和がその値になるようなサンプルが少なくなっていくからでしょうか)ちなみに、乱数シードを定数で初期化しているにもかかわらず、
rnn_dynamic_after.pyではなぜか毎回結果が少しずつ変わってしまうようでした。rnn_dynamic_before.pyだと大丈夫なのですが。まとめ
数列の途中までを入力した時点での結果(部分問題の結果 or 計算過程)に意味があるような問題設定であれば、
return_sequences=Trueを使ってみるとよいと思います。
- 投稿日:2019-05-03T15:43:27+09:00
Chainer と TensorFlow の Dropout 実装メモ
背景
- TensorFlow Lite など, 推論エンジンでは乱数が使えない場合が多い(もしくは IoT 系デバイスだと, メルセンヌツイスターなどの擬似乱数を処理させると重い)
- 既存の機械学習ライブラリで Dropout をどのように実装しているか調べ, 推論でどう扱うかの判断をしたい
Chainer(v5.4)
Chainer では CPU では numpy.random を使い, GPU では CUDA の random を使っています.
function/link レベルでの seed の設定はありません.
https://docs.chainer.org/en/stable/reference/generated/chainer.functions.dropout.html
https://github.com/chainer/chainer/blob/v5/chainer/functions/noise/dropout.py
deterministic に評価する場合は forward(backward) 実行前に numpy で seed を設定すればいいのかしら?
Tensorflow r1.13
Tensorflow 自体には
Dropoutという builtin op はありません.
RandomUniform,Scale,Division(+Floor) に分解されます.https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/python/ops/nn_ops.py#L2983
TensorFlow では, graph レベルと op レベルで seed を設定することができます.
https://www.tensorflow.org/api_docs/python/tf/random/set_random_seed
TensorFlowで乱数シードを固定する
https://qiita.com/yuyakato/items/9a5d80e6c7c41e9a9d22これにより, deterministic な実行にさせることができる... はず.
TensorFlow Lite の場合,
RandomUniformbuiltin op はありません.
tocoの graph transformation でRandomUniformは定数のテンソルに変換されます(seedが設定されている場合.seedが設定されていないと純粋にランダムになり定数化できないので変換エラーになります)
このとき, 乱数には tf 側の乱数ルーチンを使って, 振る舞いを同一にしています.自作の tflite コンバーターを作る場合は, 乱数の生成をどうするか考える必要がありますね.
推論側での対応について
基本は deterministic にして事前計算ですが, 実行時に乱数生成することも考えてみます.
WebGL などの GPU 実行で, 本質的に乱数を生成するのが難しい環境では, ノイズテクスチャを作ったり, 近似の乱数生成関数や, シェーダで評価しやすい乱数生成関数を使うことができそうです.
CPU で組み込み系であれば, xorshift や pcg32 などがよいでしょうか.
推論の呼び出し回数などが, ランタイム側で取得できれば, 呼び出し回数を seed にして事前計算した乱数のテンソルを切り替えるという手もありそうです.
モンテカルロレイトレーシング業界からみた Dropout のふるまい
機械学習でいう Dropout は, モンテカルロレイトレーシング業界からみると russian roulette に似ていますね.
TODO
- pytorch での実装を調べる(pytorch では dropout での乱数は, 一様分布ではなくベルヌーイ分布を利用している模様)
- xorshift とかの軽量乱数生成で学習させるとどうなるか調べる
- Halton 列などの準モンテカルロで学習させるとどうなるか調べる
- Deterministic(seed 固定)で学習させると, 学習の精度がどうなるか調べる
- 学習時は non-deterministic で, 推論時だけ deterministic にすると, 推論の精度がどうなるか調べる
- 投稿日:2019-05-03T13:42:27+09:00
【Lambda式】コード読むのに必須なんだけど。。。(><;
はっきり言って、コードを難解だと思わせている記述法にLambda式がある。
あと、K.。。。もだけど、こっちはそういうものだと想像できるが、Lambda式の効用はいまいち。
参考②と③のような一行サンプルはだいたい理解できる。
そういう書き方はコード短縮には便利かも。。位の理解だけど。。。
参考①のコードになるともう一つ理解ができない。
ということで、少し我慢して追求すれば理解できるかもということで、参考①の最初のコード例を納得行くまで動かしてみました。
【参考】
・①Python keras.layers.core.Lambda() Examples
・②18. Lambdas@PythonTips
・③Pythonの無名関数(ラムダ式、lambda)の使い方@note.nkmk.meコード例
from keras.layers.core import Lambda def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4))ここまでは、一行で書けることの確認。
以下が例のコード。。
これ動かしてみます。def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply])とりあえず、必要なLibをimportして、x1,x2を定義して関数動かしてみます。
from keras.layers.core import Lambda import keras.backend as K from keras.layers import concatenate def distance_layer(x1, x2): ... x1=[0,0,1] x2=[0,2,2] print(distance_layer(x1, x2))案の定、エラー
AttributeError: 'list' object has no attribute 'get_shape'
どうやらlistだからget_shapeが無いらしい。。
ということで、np.arrayにしてみます。import numpy as np ... def distance_layer(x1, x2): ... x1=np.array([0,0,1]) x2=np.array([0,2,2]) print(distance_layer(x1, x2))やはり、同じエラー
AttributeError: 'numpy.ndarray' object has no attribute 'get_shape'
じゃということで、get_shape使わずに直接shape入れようdistance = Lambda(_distance, output_shape=(x.shape[-1],))([x1, x2])そうだよなぁ~
TypeError: 'tuple' object is not callable
もう一度、ググってみます。。参考によれば以下のようにtensorsだそうです。
まあ、ここは質問がmodel.add(Lambda(lambda x: resz))なので当然か。。ですが、Should be model.add(Lambda(resz)), lambda is redundant. Also, input and output of Lambda should be tensors, numpy array is not allowed.【参考】
・AttributeError: 'function' object has no attribute 'get_shape'` #5987
ということで、たまたまかもですが、入力を以下のとおりに変更します。import numpy as np import tensorflow as tf ... def distance_layer(x1, x2): ... my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(may_tensor)これで動きました!
出力は。。。
Tensor("concatenate_1/concat:0", shape=(6,), dtype=int32)
Tensorの型とかいらないんだけど。。。でググりました「tensor to numpy」
【参考】
・How can I convert a tensor into a numpy array in TensorFlow?print(tf.Session().run(my_tensor))やっと、望みの結果が得られましたとさ。。。
[0 2 1 0 0 2]
この結果は、x1-x2とx1*x2の結合になっています。
ちなみに、以下もググると出てきます、。。やってみると。。print(my_tensor.eval(session=tf.Session()))[0 2 1 0 0 2]
同じ結果が得られました。なんか一周しすっきりしたので、この記事はここで終わります。
おまけにここまでの全コードを載せておきます。まとめ
・Lambdaについてちょっと関数を動かしてみた
・Lambda関数の入出力はTensorのようだ
・Tensorの具体的な値を求めるには、実際にRunしてやる必要がある・さて、Grad_camのコードを読もう。。。
おまけ
from keras.layers.core import Lambda import keras.backend as K import numpy as np import tensorflow as tf from keras.layers import concatenate def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4)) def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply]) x1=[0,0,1] x2=[0,2,2] my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(tf.Session().run(my_tensor)) print(my_tensor.eval(session=tf.Session()))
- 投稿日:2019-05-03T13:42:27+09:00
【Lambdaクラス】コード読むのに必須なんだけど。。。(><;
はっきり言って、コードを難解だと思わせている記述法にLambdaクラスがある。
あと、K.。。。もだけど、こっちはそういうものだと想像できるが、Lambdaクラスの効用はいまいち。
参考②と③のような一行サンプルはだいたい理解できる。
そういう書き方はコード短縮には便利かも。。位の理解だけど。。。
参考①のコードになるともう一つ理解ができない。
ということで、少し我慢して追求すれば理解できるかもということで、参考①の最初のコード例を納得行くまで動かしてみました。
【参考】
・①Python keras.layers.core.Lambda() Examples
・②18. Lambdas@PythonTips
・③Pythonの無名関数(ラムダ式、lambda)の使い方@note.nkmk.meコード例
from keras.layers.core import Lambda def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4))ここまでは、一行で書けることの確認。
以下が例のコード。。
これ動かしてみます。def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply])とりあえず、必要なLibをimportして、x1,x2を定義して関数動かしてみます。
from keras.layers.core import Lambda import keras.backend as K from keras.layers import concatenate def distance_layer(x1, x2): ... x1=[0,0,1] x2=[0,2,2] print(distance_layer(x1, x2))案の定、エラー
AttributeError: 'list' object has no attribute 'get_shape'
どうやらlistだからget_shapeが無いらしい。。
ということで、np.arrayにしてみます。import numpy as np ... def distance_layer(x1, x2): ... x1=np.array([0,0,1]) x2=np.array([0,2,2]) print(distance_layer(x1, x2))やはり、同じエラー
AttributeError: 'numpy.ndarray' object has no attribute 'get_shape'
じゃということで、get_shape使わずに直接shape入れようdistance = Lambda(_distance, output_shape=(x.shape[-1],))([x1, x2])そうだよなぁ~
TypeError: 'tuple' object is not callable
もう一度、ググってみます。。参考によれば以下のようにtensorsだそうです。
まあ、ここは質問がmodel.add(Lambda(lambda x: resz))なので当然か。。ですが、Should be model.add(Lambda(resz)), lambda is redundant. Also, input and output of Lambda should be tensors, numpy array is not allowed.【参考】
・AttributeError: 'function' object has no attribute 'get_shape'` #5987
ということで、たまたまかもですが、入力を以下のとおりに変更します。import numpy as np import tensorflow as tf ... def distance_layer(x1, x2): ... my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(may_tensor)これで動きました!
出力は。。。
Tensor("concatenate_1/concat:0", shape=(6,), dtype=int32)
Tensorの型とかいらないんだけど。。。でググりました「tensor to numpy」
【参考】
・How can I convert a tensor into a numpy array in TensorFlow?print(tf.Session().run(my_tensor))やっと、望みの結果が得られましたとさ。。。
[0 2 1 0 0 2]
この結果は、x1-x2とx1*x2の結合になっています。
ちなみに、以下もググると出てきます、。。やってみると。。print(my_tensor.eval(session=tf.Session()))[0 2 1 0 0 2]
同じ結果が得られました。なんか一周しすっきりしたので、この記事はここで終わります。
おまけにここまでの全コードを載せておきます。因みに、Lambdaコメントアウトして、まんま
return concatenate([distance, multiply])だと、入力をTensorにしろと怒られます。
この関数は、入力Tensor,出力Tensorの関数なんですね。。。
※え~??まとめ
・Lambdaについてちょっと関数を動かしてみた
・Lambda関数の入出力はTensorのようだ
・Tensorの具体的な値を求めるには、実際にRunしてやる必要がある・さて、Grad_camのコードを読もう。。。
おまけ
from keras.layers.core import Lambda import keras.backend as K import numpy as np import tensorflow as tf from keras.layers import concatenate def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4)) def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply]) x1=[0,0,1] x2=[0,2,2] my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(tf.Session().run(my_tensor)) print(my_tensor.eval(session=tf.Session()))
- 投稿日:2019-05-03T04:57:59+09:00
GUIでDeep Learning用のDockerコンテナを作って学習する話(portainer)
はじめに
この記事はDockerでDeep LearningやってみたいけどCUIはめんどくさいという人向けの記事です。
Docker と nvidia-dockerのインストール方法等はもっとわかりやすい記事があるので、そちらをご覧ください。
Docker入門 ~Tensorflowも超簡単に!!~
https://qiita.com/yakigac/items/f14f12f182a564c091d0今回の最終目標はDockerコンテナでTensorflow-gpuを動かすことです。
動作環境
- Ubuntu 18.04.2 LTS
- Docker 18.09.5
- nvidia-docker 2.0.3
- portainer 1.20.2
portainarインストール
以下のコマンドを順に実行
docker volume create portainer_datadocker run -d -p 9000:9000 --name portainer --restart always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainerブラウザから
http://localhost:9000で接続できるます。ポートを変えたいときはコマンド内の
9000の部分を置き換えればいいです。Deployment — Portainer 1.20.2 documentation
https://portainer.readthedocs.io/en/stable/deployment.htmlportainerの初期設定
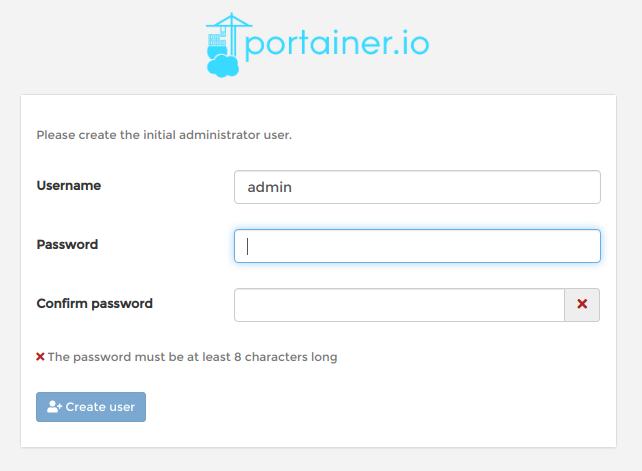
下の画面が表示されるので、ユーザー登録をします。
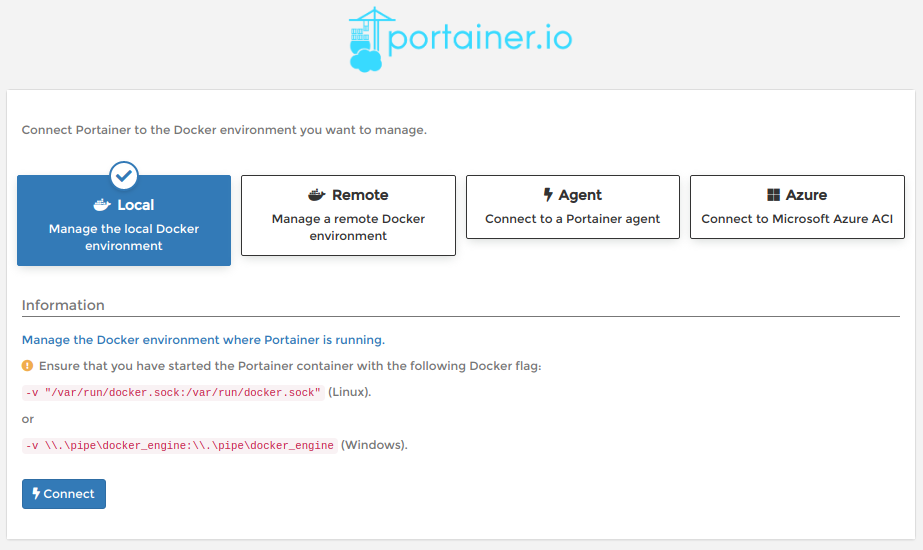
続いて、どこのDockerに接続するか聞かれるので
localを選択。
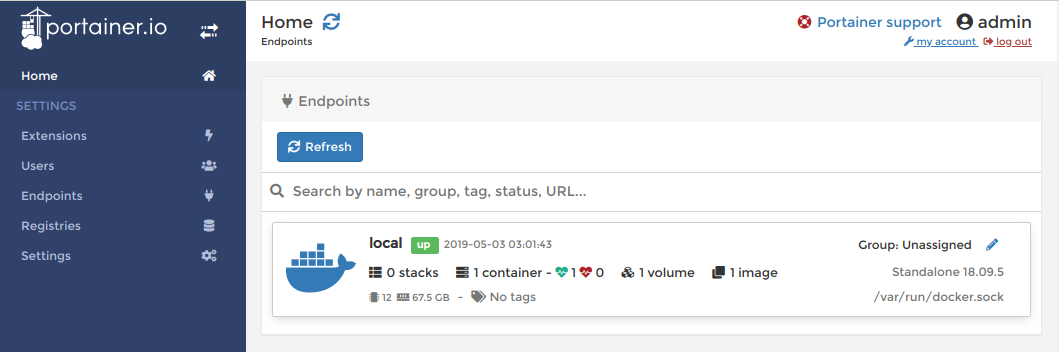
Homeに移動できるので、Endpointsの中のlocalをクリックするとDashboardに移動できます。
基本的にportainerは
Dashboardから操作します。次回からはログインをするとHomeを開けます。コンテナを作る
今回はTensorflow公式のイメージを使用します(公式ページ)。
使用するイメージは
tensorflow/tensorflow:latest-gpu-py3としました。
(tensolflowの最新バージョンのGPU版でpython3系のイメージ)コンテナの一覧を開く
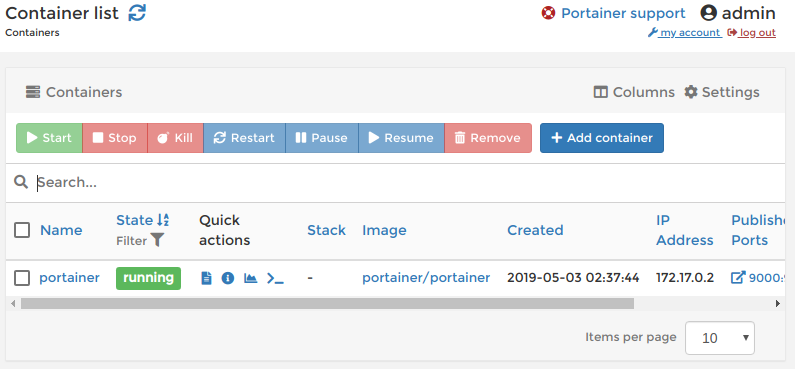
DashboardのContainersを選択すると, 以下のように現在のコンテナ一覧が表示されます(起動していないものも含む)。
コンテナの新規作成画面を開く
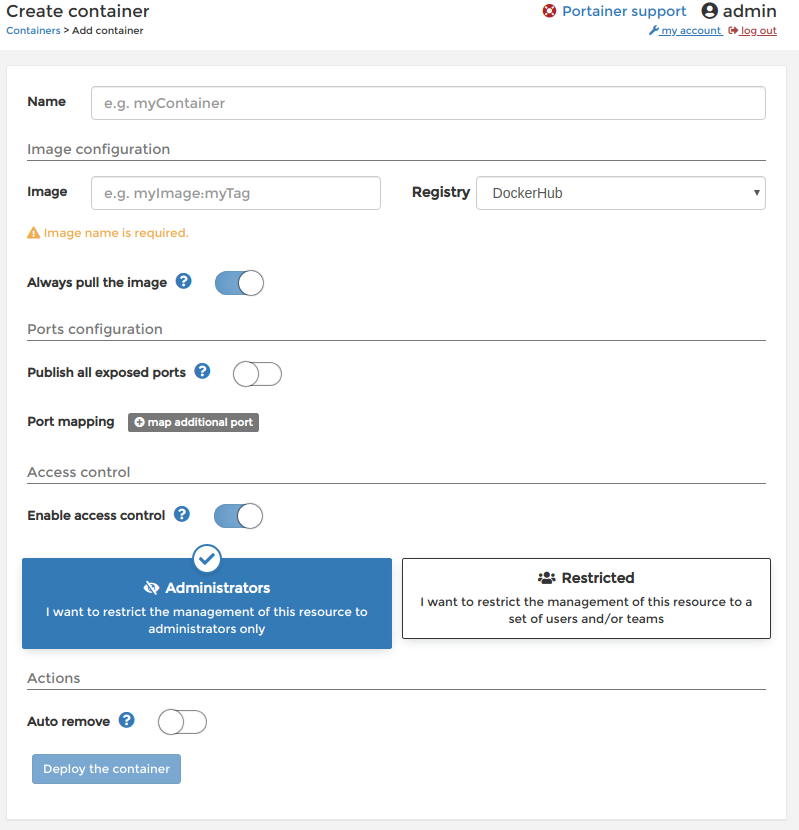
Container listのAdd containerをクリックするとCreate container画面が開きます。
コンテナ名とイメージ名を入力
Nameにコンテナ名を入力する。今回はコンテナ名をTensorflowとしました。
先ほどのイメージ名を入力。このイメージはDockerHubにあるのでRegistryはDockerHubでいいです。
Interactive & TTYを有効にする
Docker内のコンソールに接続できるように
Interactive & TTYを有効にします。
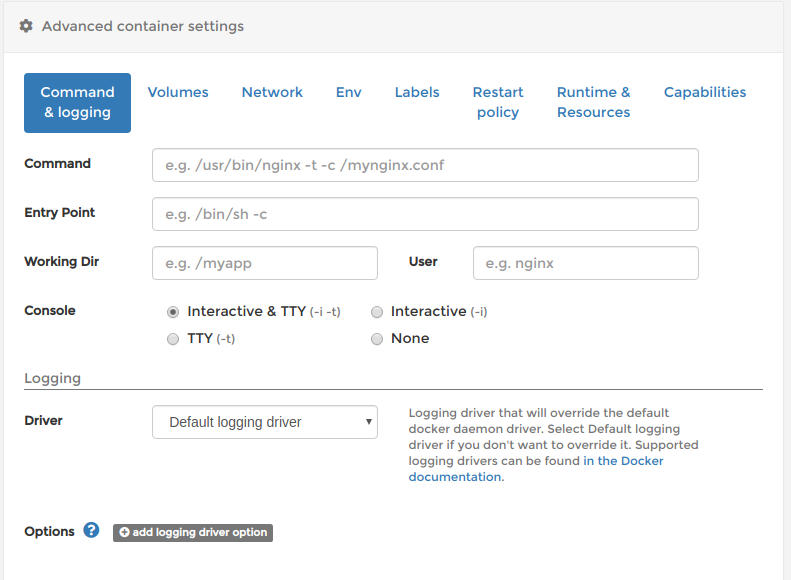
docker runのコマンドのオプションで言うと-itです。変更する場所は、
Create container画面の下側のAdvanced container settings内のCommand & loggingです。
ConsoleのInteractive & TTYのチェックします。
ランタイムの変更
GPUを使用するコンテナを作成するときは、nvidia-dockerを使用することを明示しなければなりません。
docker runのオプションで言うと--runtime=nvidiaの部分です。変更する場所は、
Create container画面の下側のAdvanced container settings内のRuntime & Resourcesです。
Runtimeをnvidiaに変更してください。
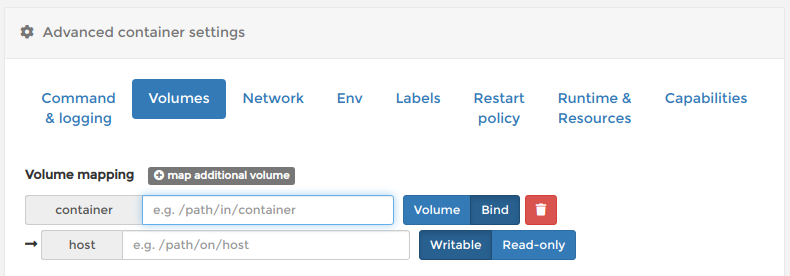
共有フォルダの作成
ホスト側とコンテナ内に共有フォルダを作成します。必須ではありませんが
docker cpとかしなくていいので楽です。
Create container画面の下側のAdvanced container settings内のVolumesから設定できます。
Volume mappingのmap additional volumeをクリックしてボリュームを追加します。
BindとWritableを選択します。
container側にコンテナ側の共有フォルダのパス、host側にホスト側の共有フォルダのパスを入力します。
コンテナを作成
最後に
Deploy the containerをクリックすればコンテナが作成されます。
共有フォルダの権限変更
今のままでは共有フォルダの権限のせいでホスト側から書き込めません。
なので、コンテナ内から権限を付与する必要があります(もっといい方法あれば教えてください…)。
Container listの作成したコンテナのQuick actionsの>_をクリックすると、Container console画面が開くので、Connectをクリック。
するとコンソールが開くので、次のコマンドを入力。
chmod a+rwx <共有フォルダのパス>これでTensorflowが動くコンテナ完成です。
動作確認
コンテナ内のコンソールで以下を実行してください。
python -c "from tensorflow.python.client import device_lib;device_lib.list_local_devices()"実行結果
2019-05-02 19:53:24.463116: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2FMA 2019-05-02 19:53:24.601321: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2019-05-02 19:53:24.610259: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2019-05-02 19:53:24.610914: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x4cbebd0 executing computations on platform CUDA. Devices: 2019-05-02 19:53:24.610929: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): GeForce GTX 1080 Ti, Compute Capability 6.1 2019-05-02 19:53:24.610934: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (1): GeForce GTX 1080 Ti, Compute Capability 6.1 2019-05-02 19:53:24.630432: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3192000000 Hz 2019-05-02 19:53:24.631122: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x4d305d0 executing computations on platform Host. Devices: 2019-05-02 19:53:24.631140: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined> 2019-05-02 19:53:24.631495: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433]Found device 0 with properties: name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.6325 pciBusID: 0000:01:00.0 totalMemory: 10.91GiB freeMemory: 10.68GiB 2019-05-02 19:53:24.631743: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433]Found device 1 with properties: name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.6325 pciBusID: 0000:02:00.0 totalMemory: 10.92GiB freeMemory: 10.77GiB 2019-05-02 19:53:24.632553: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512]Adding visible gpu devices: 0, 1 2019-05-02 19:53:24.633699: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-05-02 19:53:24.633719: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 1 2019-05-02 19:53:24.633727: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003]0: N Y 2019-05-02 19:53:24.633733: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003]1: Y N 2019-05-02 19:53:24.634226: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115]Created TensorFlow device (/device:GPU:0 with 10389 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1) 2019-05-02 19:53:24.634577: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115]Created TensorFlow device (/device:GPU:1 with 10479 MB memory) -> physical GPU (device: 1, name: GeForce GTX 1080 Ti, pci bus id: 0000:02:00.0, compute capability: 6.1)GPUが認識できているのがわかります。
最後に
コンテナがGUIで全部使えるのほんとに楽でいいです。portainerすごい。
Deep LearningをちゃんとやっていくにはDockerは必須なんじゃないかなぁと個人的には思うので、もっと勉強しなきゃと思う次第です。
portainerには、まだよくわかってない機能がたくさんありそうなのでもっと使いこなしていきたい所存。
時間があったら、portainerでimageビルドする記事も書きます。