- 投稿日:2019-05-03T20:35:59+09:00
DatadogでAWS利用料金の推移を可視化する
背景
Excelにコピペするのは嫌でござる!LambdaもTerraformも書きとうない!Datadogならポチポチだけでできるはずだ!
準備が4つ必要です
ポチポチだけでイケた。AWSとDatadogすごい。神。
準備1: AWSでBudgetを作成する
AWS請求ダッシュボードにある「Budget」で、雑でも何でもいいので、「予算を作成」してください。もうあるなら、この準備は飛ばして大丈夫です。
作成が必要な理由は、Datadogは、Budget経由でBillingのデータを吸い出しているため、Budgetがとにかく存在してないと始まらないのです。
ちなみに予算を作ったところで、予算を超えると何も動かなくなるとか、予算の金額を毎月必ず請求されるとか、そんなことは一切ないです。AWSからの請求に対して、予算という枠組みで分析したり通知させるための仕組みです。
予算はこんな感じで作成しました。ちゃんと活用してる方からは石を投げられるんじゃなかろうか....
- 予算タイプは「コスト予算」
- 名前は「月別AWS予算」
- 間隔は「月別」
- 予算は、前月実績に+20%くらいの金額をテキトーに入れておきます
- 定期予算
- フィルタリングは無し。include all。
- 非ブレンドコスト
- 含められる関連コストは、すべてチェック
- アラートもテキトーに組む
準備2: AWSでIAM権限を付与する
IAM権限
budgets:ViewBudgetを、Datadogのロールに付与します。もう付与してあるなら、この準備は不要です。DatadogのAWSインテグレーションを、以下マニュアルの「All Permissions」で提示されるIAM権限で設定してれば含まれてますが、改めてご確認ください。準備3: DatadogでAWS Billingインテグレーションを有効化する
Datadogがマニュアルを用意してくれてます。
有効化後、これを書いてる今も Broken ですが、AWSからデータを取れてるので気にしなくていいです。
準備4: 一晩くらい待つ
請求関連のメトリクスは更新頻度が少なく、日に数回らしいです。ここまでの準備しても、Datadogでまとまった量のデータが最初に見えるようになるのは、一晩くらい経ってからです。焦らず待ちましょう。
Datadogで可視化する
これで可視化できます。AWSから吸い出してるメトリクスは4つですが、「by」で切り口にできる、何ていうんですかあれは、あれがあるので、めちゃめちゃ面倒くさい願望をぶつけなければ、大体なんとかなる気がします。
- aws.billing.budget_limit
- aws.billing.actual_spend
- aws.billing.forecasted_spend
- aws.billing.estimated_charges
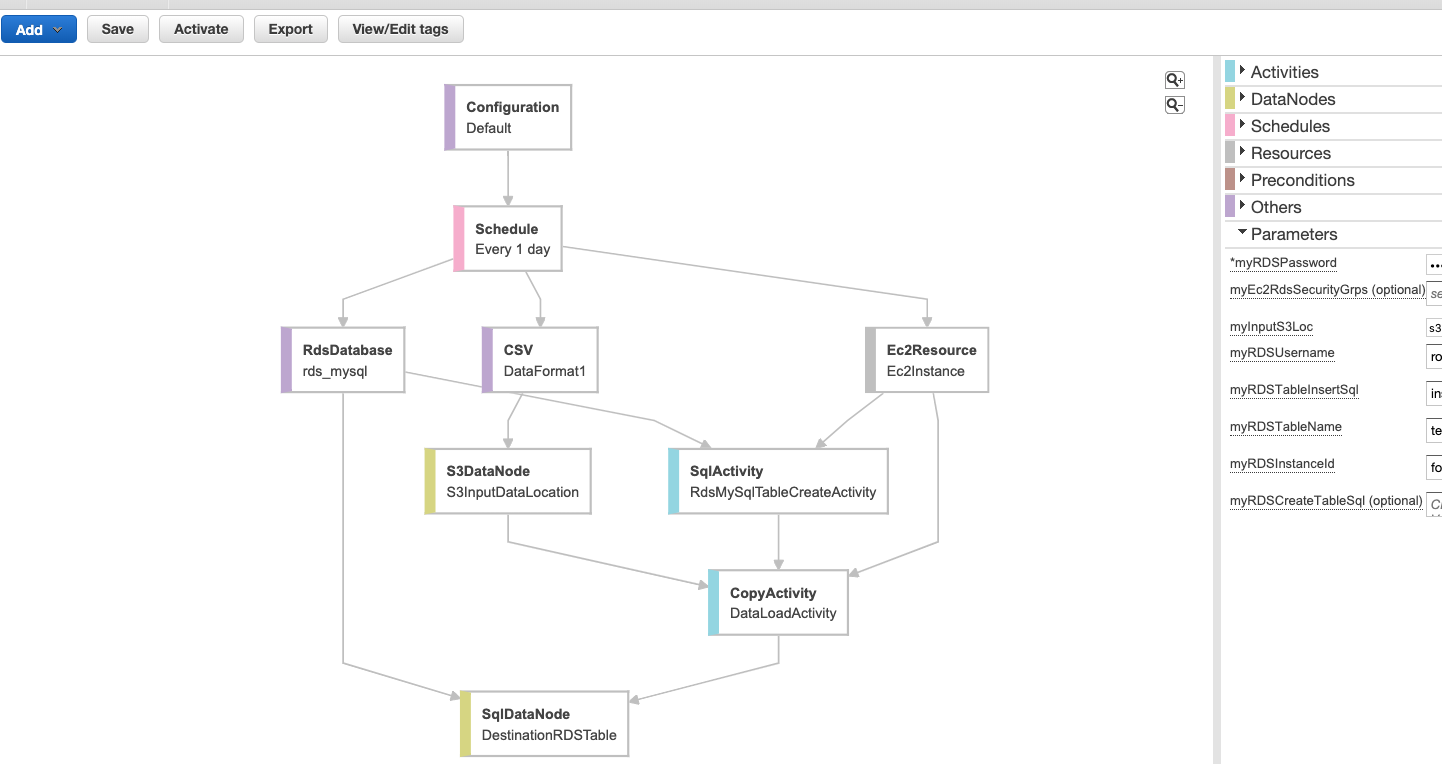
利用料金の推移のグラフ
こんなグラフが作れます。積み上がってるのは費目で、EC2, RDS, DataTransfer,,,毎に出ます。メトリクスの性質として、月末締めで一旦ゼロになります。
グラフのJSONはこのように。aws.billing.estimated_charges を servicename 毎にやるのがミソですね。ソートしてほしい。
{ "viz": "timeseries", "requests": [ { "q": "sum:aws.billing.budget_limit{*}", "type": "line", "style": { "palette": "dog_classic", "type": "dashed", "width": "normal" }, "aggregator": "avg", "conditional_formats": [] }, { "q": "sum:aws.billing.actual_spend{*}", "type": "line", "style": { "palette": "dog_classic", "type": "dashed", "width": "normal" } }, { "q": "sum:aws.billing.forecasted_spend{*}", "type": "line", "style": { "palette": "dog_classic", "type": "dashed", "width": "normal" } }, { "q": "sum:aws.billing.estimated_charges{*} by {servicename}", "type": "area", "style": { "palette": "cool", "type": "solid", "width": "normal" } } ], "autoscale": true }利用料金 Top 10
aws.billing.estimated_charges を servicename 毎に、こちらは利用料金の多い順にソートされてます。注意として、ダッシュボードの表示期間が月をまたいでる場合、先月と今月の金額が混ざります。select rangeでイイ感じに調整して見てください。
JSONはこのように。
{ "viz": "toplist", "requests": [ { "q": "top(sum:aws.billing.estimated_charges{*} by {servicename}, 10, 'mean', 'desc')", "type": null, "style": { "palette": "dog_classic", "type": "solid", "width": "normal" }, "conditional_formats": [] } ] }さらに凝った可視化をするには
AWS側の予算で分析軸を作れるのと、Datadog側のダッシュボードやグラフの仕組みで可視化できるので、物事に限度はありますが頑張れるのではないでしょうか。
Datadogで監視&通知する
ところでDatadogにメトリクスが来ているので、Datadogで監視&通知できます。AWS Budgetの仕組みでも監視と通知ができます。が、メトリクスの動きに対して、DatadogではAnomary Detectionなど凝った監視ができるので、活用するといい、はずだ!


- 投稿日:2019-05-03T19:40:05+09:00
DynamoDB で、条件付き更新 と トランザクション を組み合わせて、UNIQUE 制約を実現する方法
はじめに
現状、DynamoDB では、 RDB で言うところの
UNIQUE制約がありません。つまり「UserテーブルでEmailを一意になるように制約をかける」といったことができません。正確に言うと、ハッシュキー属性にはUNIQUE制約があります。
この記事では、ハッシュキーにはUNIQUE制約があることを利用しつつ、条件付き更新とトランザクションを組み合わせて、任意の属性を対象とするUNIQUE制約を実現する方法を紹介しています。以下のようなDynamoDBの知識を前提としています。
- 項目 と 属性 がなにを指しているのか理解している
- hash-key(とrange-key) を理解している
- 基本的な CRUD 関連の操作方法を理解している
- 条件付き更新を理解している
- トランザクションを理解している
必要に応じて、以下の AWS のドキュメントを参照してください。
UNIQUE制約の実現方法
例えば、以下のような User エンティティがあるとします。
User エンティティをDynamoDBに新規作成する場合、以下の項目を作成する処理をトランザクションで実行します。
- User エンティティ自体を保存する項目(
エンティティ項目)- UserのEmail属性を UNIQUE属性にするための項目(
UNIQUE制約用項目)
エンティティ項目では、EmailやNameなどのエンティティ自体の情報を記録します。
UNIQUE制約用項目では、UNIQUE制約をかけたい項目をhash-keyとして設定し、条件付き更新で試みます。例として、Emailに対してUNIQUE制約をかけたい場合を考えます。このとき、
UNIQUE制約用項目を以下の手順で作成します。
- PK(hash-key) を
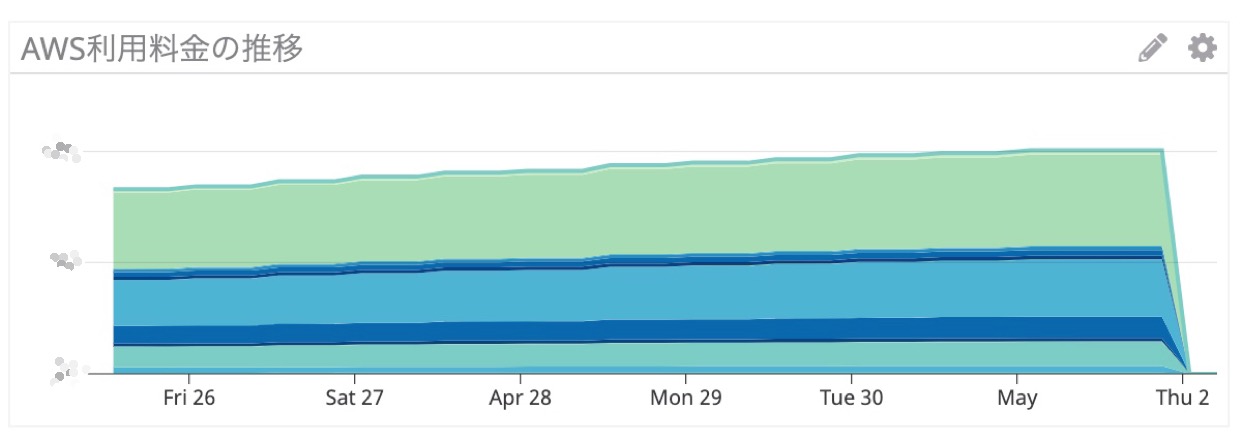
User#Email#test@example.comという値で設定。if attribute_not_exists(PK)で、書き込みを試みる。以下の図は、UNIQUE制約に引っかかってエラーが起こる場合を示しています。
Bob が
test@example.comで項目を作成した後に、Alice がtest@example.comで項目を作成しようとして失敗します。 Aliceが書き込むときにはif attribute_not_exists(PK)の条件が偽になるからです。トランザクションで実行された場合、ロールバックが実行され、Aliceの項目作成処理がキャンセルされます。
このようにして、UNIQUE制約を実現しています。
更新と削除の処理について
上記は、新規作成時の処理について解説しました。更新と削除のときにも注意が必要です。
それぞれ以下のような処理を行います。更新時
更新の場合は、Emailの値を変更する場合のみ UNIQUE制約について考慮する必要があります。
以下の更新処理をトランザクションで実行します。
エンティティ項目のEmail属性の値を更新する- 新しいEmailについて、
if attribute_not_exists(PK)という条件で書き込みを試みる- 古いEmailについて、
UNIQUE制約用項目を削除する削除時
削除の場合は、以下の処理をトランザクションで実行します。
エンティティ項目を削除するUNIQUE制約用項目を削除するまとめ
現状、DynamoDBでは任意の属性に対してUNIQUE制約をかけることができないので、条件付き更新 と トランザクションを組み合わせて擬似的に実現する方法を紹介しました。
「hash-key に設定できないけどUNIQUE制約を設定したい属性がある」といった場合に、有効な方法であると考えています。デメリットとしては、実装が少し複雑になってしまうところでしょうか。
DynamoDBは、アップデートされるごとに機能が増えたり、機能の制約が緩和されたりするので、将来的に UNIQUE制約を設定できる可能性もあるかもしれません。そうなった場合は、この方法は不要になるでしょう。

- 投稿日:2019-05-03T18:53:32+09:00
Using Amazon Elastic Container Registry (ECR) as soon as possible anyway.
Create an image you want.
$ mkdir docker-php && cd docker-php$ vim index.phpindex.php<?php echo "Hello, world."; ?>$ vim DockerfileDockerfileFROM php:7-apache COPY index.php /var/www/html/$ docker build -t php .$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE php latest cba780f28f8b 52 seconds ago 378MB php 7-apache 1dffbbe4a5d3 3 weeks ago 378MBInstall AWS CLI to use ECR.
$ curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" $ sudo python get-pip.py $ sudo pip install awscli $ rm -rf get-pip.py$ aws --version aws-cli/1.16.150 Python/2.7.13 Darwin/17.5.0 botocore/1.12.140Create IAM (If you don't have it.)
- Sign in or create an account on AWS.
- Create IAM user
- Choose "User" at left side.
- Enter name that you like and check "access via program".
- Attache "AmazonEC2ContainerRegistryFullAccess"
- Skip tagging.
- Confirm your information.
- Done
Apply your information using AWS CLI.
$ aws configure AWS Access Key ID [None]: ****************** [Enter you Access Key ID] AWS Secret Access Key [None]: ****************** [Enter your Secret Access Key] Default region name [None]: ap-northeast-1 Default output format [None]: jsonYou can check your info this command.
$ aws configure listCreate repository on ECR
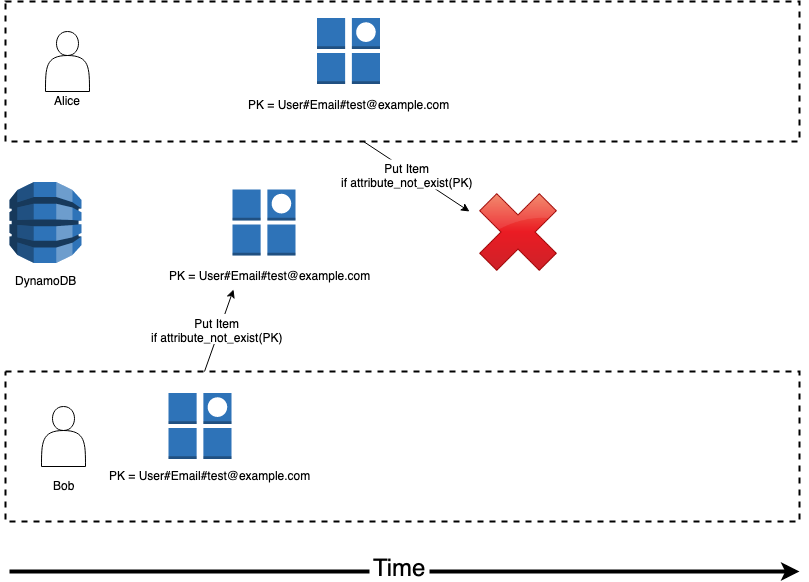
Access to ECR -> Amazon ECR -> Repositories.
Enter "php" (in here) as repository name.
Done.
Push to ECR from local image.
Log in to AWS
$ (aws ecr get-login --no-include-email --region ap-northeast-1) docker login -u AWS -p ....$ docker login -u AWS -p .... ... Login Succeededpush to your ECR repository.
Use your id instead of ************.
$ docker tag php:latest ************.dkr.ecr.ap-northeast-1.amazonaws.com/php:latest $ docker push ************.dkr.ecr.ap-northeast-1.amazonaws.com/php:latestIf you'd like to update your image, tagging and push again as same tag.

- 投稿日:2019-05-03T15:40:13+09:00
SORACOM Air, data communication service for IoT devices
Beating drum for IoT
The term IoT is everywhere in the mainstream media these days. Companies are looking for, and also being asked to implement IoT solutions. Furthermore, the Japanese government introduced so-called "IoT tax exemption" from June 2018 to 2021 fiscal year, in order to promote IoT solution to companies, expecting to promote efficiency to industries to prepare for upcoming population decline. 1 No matter what is the motivations, the driving force to introduce IoT solutions to the existing workflow is growing day by day for every industry. However, Implementing a whole IoT solution requires a wide knowledge of infrastructure, from the physical layer to the application layer. AWS surely offers AWS IoT Core and Greengrass service to simplify implementation which would take responsibility of message broker part; getting traffic to cloud then analyze the data from connected devices. On the other hand, the task left for AWS users side is to collect information. AWS IoT users need to implement a network from on-premise to AWS, shown in the right in the diagram below. Connectivity is the first challenge for systems newly introducing IoT.
Challenge of a network for IoT Devices
Wireless network interface and routers are easily used by IoT devices to connect to the network to cloud in the initial mock-up. The existence of a router adds one more device to hop and additional battery power. This potentially adds a point of network failure. Usage of one more device could be a problem if the information needed to collect resides outside of the building, such as agricultural fields.
What SORACOM did
SORACOM alleviated these challenges for users implementing IoT using cloud solutions in the back end. In 2015, SORACOM introduced SORACOM Air service offering 3G network to sensor devices that typically require a wireless connection. The service is in the form of a SIM card that is ready to connect to sensor devices to 3G network. Furthermore, since SORACOM service heavily uses AWS service in the back end2, their management console is similar to AWS management console, thus preexisting AWS customers would feel familiar with their online management tools and reporting capability. SORACOM Air asks only 5 to 10 yen (several cents) for the initial fee, and there is no mandatory period of the contract. The cost of the SORACOM Air SIM card is as minimum as a couple of yen per a day, depending on the speed class of the network, which users can configure anytime via their management console.
If the device finished testing for the day, for example, users can set the SIM state inactive to save the cost. This flexibility of cost per SIM card would provide cost efficiency for any companies which has to execute proof of concept before stepping into the production of IoT devices. The SIM itself is sold 1,240 yen (approx. 10 USD).
What is under their hood of SORACOM Air
Soracom Air is basically a MVNO (Mobile Virtual Network Operator) service. What separates SORACOM from the other MVNO vendor is they provide the service without owning actual hardware in the data center. SORACOM utilize Layer 2 connection to telecom vendor, such as NTT Docomo and KDDI etc. However, most of their administrative tasks, such as packet exchange and bandwidth administration are accomplished in their own application developed in house. These applications are running in AWS. Therefore their architecture is quite scalable. This initial cost strategy saved initial cost for the service start-up, and ultimately the cost for their users. Users can now enjoy as low as 300 yen (a couple of USD) per a month for one SORACOM Air SIM, without costing initial commitment on their budget.3
The latest involvement of SORACOM into AWS IoT service.
After launching SORACOM Air in 2015, they expanded their service line-ups which serve for connecting the on-premise system to the cloud, such as SORACOM Canal4 connect to AWS VPC. SORACOM also participated on the Secure element vendors of AWS IoT Greengrass5, and SORACOM Funnel directly connect to various cloud services including AWS IoT and Kinesis families. The latest release of their product, SORACOM LTE-M Button powered by AWS, directly connect to AWS IoT 1-Click service. Surprisingly, batteries of this button can be exchanged and the button could be re-usable after battery power is exhausted. This feature of the exchangeable battery was lacking in the previously existing AWS IoT button sold by Amazon. One could expect SORACOM to keep providing pleasant surprise to AWS users, expanding network service for connectivity to AWS and keep providing benefit for all AWS customers.
Incentives based on the Act on Special Measures for Productivity Improvement](https://www.jetro.go.jp/en/invest/incentive_programs/) ↩
SORACOM, INC (2019), 公式ガイドブック SORACOMプラットフォーム 日経BPブックナビ. Page. 26 ↩
AWS IoT Greengrass now enables simplified deployments, enhanced security, and greater flexibility ↩




- 投稿日:2019-05-03T13:46:22+09:00
Alexaスキルの多言語対応
Alexaスキルの多言語対応
概要
本ページは、Alexaスキルの多言語がにあたって参考となる情報、および注意するべき事項を整理するものです。公式ドキュメントにだいたい書いてあるのですが、具体的な意味が分かりづらかったり、追加の参考情報があったほうが分かりやすいものなどある気がしました。
以下の環境を前提とします。
- SDK、ランタイム:ASK SDK v2 for Node.js
- バックエンド:AWS Lambda
参考情報
- 公式ドキュメント:多言語に対応するスキルを開発する
- 基本的な流れや注意事項はこちらに記載されています。
注意事項
1つのLambdaファンクションの対応するべき言語
公式ドキュメントに以下の記載があります。
”カスタムスキル用に作成したクラウドベースのサービスは、サポートされているすべての言語からのリクエストを処理できる必要があります”
バックエンドに何がくるかわからないので公式マニュアルでは抽象的な言い方になっていますが、Lambdaファンクションの場合は、 バックエンドのLambdaファンクション一つで対応したい言語の全てを正常に処理できるようにする(言語別にファンクションを分割できない) という意図になります。
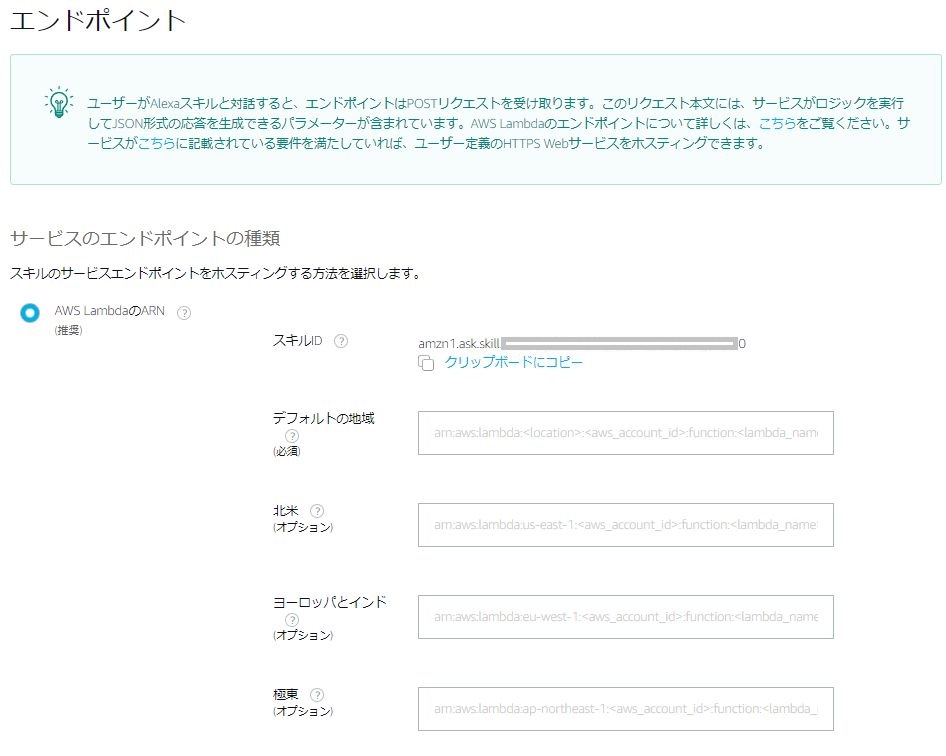
下図のように、スキルには複数のエンドポイント(Lambdaファンクションの場合は複数のARN)を指定することができますが、あくまで性能面(レイテンシ)改善のための機能であり、言語別に呼び分けるものではありません。つまり、"北米から呼ばれるLambdaファンクションは英語だけ処理するロジック"、などではNGであり、"同一のコードで複数の言語の処理を行う"必要があります。
公式ドキュメントのヒントにも以下の記載があります。
ヒント: レイテンシーを低減するには、コードを複数のエンドポイントにデプロイすることをお勧めします。フォーラムでも以下のやり取りがありました。参考まで。
Alexa Skills Kit (ASK) (日本語) Question: エンドポイントの同一コードの意味#最初は”もしかして呼び分け可能?”と勘違いしそうになったので念の為記載。
Lambdaファンクションの複数言語対応
ユーザの言語の判別
- request オブジェクトのlocaleプロパティを利用します。
- localeプロパティの種別
サンプルコード(skill-sample-nodejs-howto)
その他
記載中。
- 投稿日:2019-05-03T13:34:27+09:00
AWS, Azure, GCP and IBM Cloud サービスの対応比較の自習メモ
マルチクラウドやハイブリッドクラウドを考える上で、3大クラウドのサービス内容を勉強する機会がありました。そこで、整理のために、対応表を作成してみました。各社のすべてのサービスを網羅しているわけではないですが、仮想サーバーやオブジェクトストレージなどのコアとなるサービスを中心として表にしました。 そして、各社の中で、何処が優れ、どれが劣っているとかの比較をするものではありません。 主要なサービス名の言葉の対応を目的としたものです。
最近1ヶ月くらいで勉強したことを、外観的に整理したものなので、間違いも含まれると思います。 気づいた方は、コメントを頂けると幸いです。
比較項目 AWS Azure GCP IBM Cloud クラウド利用の親ID アカウント アカウント アカウント アカウント アカウントの分割管理 ディレクトリ プロジェクト 識別とアクセス管理 IAM Azure Active Directory IAM IAM 仮想ネットワークとアクセス管理 VPC 仮想ネットワーク VPC ネットワーク Security Group for VPC (Beta) 仮想サーバー EC2 Virtual Machines Compute Engine Virtual Server オブジェクト・ストレージ・サービス S3 BLOB Storage Cloud Object Storage (ICOS) 稼働監視と警報 CloudWatch モニター Stackdriver IBM Cloud Monitoring with Sysdig ログ管理 CloudTrail モニター Stackdriver IBM Cloud Log Analysis with LogDNA メッセージ通知 SNS モニター Stackdriver Alert Notification ロードバランサー ELB ロードバランサー 負荷分散 Load Balancers オートスケーリング Auto Scaling Virtual Machine Scale Sets インスタンスグループ Auto-Scaling DNSサービス Route53 DNS zones Cloud DNS Internet Services - DNS キャッシング(CDN) CloudFront CDNのプロファイル Cloud CDN Internet Services - CDN 自動プロビジョニング CloudFormation Azure Resource Manager Google Cloud Deployment Manager SQLデータベース・サービス MZ対応 RDS(Amazon Aurora, MySQL, MariaDB,PostgreSQL, Oracle, MS SQL Server) CosmosDB SQL Cloud SQL (MySQL, PostgreSQL),Spanner Databases for PostgreSQL SQLデータベース・サービス HA on SZ RDSでは同一ゾーン、他ゾーンの選択可 MySQL,PostgreSQL,MariaDB,MS SQL Server Compose for MySQL, Db2, Db2 Warehouse NoSQLデータベース・サービス MZ対応 DynamoDB Azure Cosmos DB for MongoDB API Cloud Datastore,Cloud Firestore,Cloud Bigtable Cloudant,Databases for MongoDB キャッシング(KVS) ElastiCache (memcache, Redis) Redis Cloud Memory Store (Redis) Databases for Redis メッセージング・サービス Amazon MQ Service Bus Cloud Pub/Sub MQ,Messages for RabbitMQ アプリ・ランタイム Elastic Beanstalk App Service App Engine Cloud Foundry サーバーレス Lambda Function App Google Cloud Functions IBM Cloud Functions Kubernetesサービス Elastic Container Service for Kubernetes (EKS) Azure Kubernetes Service (AKS) Kubernetes Engine (GKE) Kubernetes Service (IKS) Container Registry Amazon Elastic Container Registry Container registries Container Registry Container Registry OpenShift セットアップガイド https://aws.amazon.com/jp/quickstart/architecture/openshift/ マーケットプレイス Red Hat OpenShift Container Platform Self-Managed ソリューションガイド https://cloud.google.com/solutions/partners/openshift-on-gcp 予定 参考資料
[1] AWSドキュメント、https://docs.aws.amazon.com/index.html#lang/ja_jp
[2] Azureドキュメント、https://docs.microsoft.com/ja-jp/azure/
[3] GCPドキュメント、https://cloud.google.com/docs/?hl=ja
[4] IBM Cloud ドキュメント、https://cloud.ibm.com/docs
- 投稿日:2019-05-03T12:02:11+09:00
メモ ECS AWSコンソールからクラスタ、タスク、サービス作成
やること
- ECSリソース操作に関してはAWSコンソール上で行う
- ECSクラスタを作成
- ECSタスクを作成 (自前ビルドしたイメージを起動)
- ECSサービスを作成
- 起動したコンテナのログを確認 CloudWatchLogs
- 終了したコンテナの再起動確認
- タスクのイメージを更新
ECSの概念についてはこちらの記事で Amazon EC2 Container Service(ECS)の概念整理
環境
- AWSコンソールにログインできる (今回使うリソースの作成権限があるユーザで)
- ECRに標準出力するイメージを持つリポジトリがある ここで作ったechoalpine使う
作業
ECSクラスタを作成する
何はともあれクラスタを作ってみる
コンソールの検索バーからECSと検索してECS画面に遷移
クラスタを選択して、クラスタの作成クラスタのテンプレート選択
- ネットワークのみ (AWS Fargeteを使用)を選択して次のステップ
クラスタの設定
CIDRブロックは余ってるのを使う
- クラスタ名:
ecs-cluster-echoalpine- VPC作成:
チェックする- CIDRブロック:
11.0.0.0/16- サブネット1:
11.0.0.0/24- サブネット2:
11.0.1.0/24作成
ECSタスクを作成
AWSコンソールからタスク定義のページへ遷移 -> 新しいタスク定義の作成
起動タイプの互換性の選択
- Fargate
タスクとコンテナの定義の設定
- タスク名:
echoalpine-task- タスクロール:
ecsTaskExecutionRoleネットワークモード:
awsvpcタスクメモリ:
2GBタスクCPU:
1 vCPUコンテナの追加から
- コンテナ名:echoalpine
- イメージ:AWSアカウントID.dkr.ecr.イメージのあるECRリージョン.amazonaws.com/echoalpine:1.0.0
- メモリ制限:128
- 環境変数追加:MY_ENV_VALVALUE"This is my env val !!"指定箇所以外はデフォルトの指定
作成タスクを作成するとCloudWatchロググループも作成される
今回のロググループ名は/ecs/echoalpine-taskだったサービスの作成
クラスタ一覧から作成したクラスタを選択して遷移するとサービスというタブが開いていると思うのでサービスの新規作成を行う
作成するサービスで先ほど作成したタスクを利用する
※記述していない箇所はデフォルトの設定サービスの設定
起動タイプ: Fargate
タスク定義(Family):
echoalpine-taskタスク定義(Revision):
1(latest)プラットフォームのバージョン:
LATESTクラスタ:
ecs-cluster-echoalpineサービス名:
echoalpine-serviceタスクの数:
1ネットワーク構成
- クラスタVPC: クラスタ作成時に作成したVPC ここではCIRDブロック11.0.0.0のもの
- サブネット: クラスタ作成時に作成した2つのサブネットを指定
サービスを作成するとAWS Cloud Mapにリソースが作成されるのでサービス削除時にそれも削除するようにする
Auto Scalingオプション
- Service Auto Scaling: サービスの必要数を直接変更しない
入力項目が確認できたらサービスの作成
起動したコンテナのログを確認 CloudWatchLogs
サービスを作成したことで指定タスクのコンテナが立ち上がり、動作している状態になっていると思うのでCloudWatchLogsでコンテナで動かしているシェルの標準出力を確認してみる
CloudWatchページでタスク作成時に生成された
/ecs/echoalpine-taskを選択しログを確認する
起動させているコンテナは10秒毎にmy echoalpine container!! 1.0.0と出力し、10回出力するとkiss of death...と言い残し一生を終えるドラマチックなセミみたいなコンテナ恐らくCloudWatchでその出力が確認できる (タスク定義でイメージをechoalpineにしていれば)
タスク定義で環境変数MY_ENV_VALを指定したので、このシェルがecho my echoalpine container!! 1.0.1 $MY_ENV_VALとなれば出力は
my echoalpine container!! 1.0.1 This is my env val !!となる終了したコンテナの再起動確認
セミコンテナは10回echoすると死んでしまうので、ECSのサービスがよしなに復活させてくれているか確認する
特に行う操作は無く、コンテナが再起動されると新しいログストリームが作成されるのでその中で再び同じ動作をしているか確認する
DockerイメージのCMDで指定しているプロセスが終わったらしっかりと再起動されているので嬉しくなった
動作させる新しいDockerイメージが用意できたのでタスクの新しいリビジョンを作成し、サービスで新しいリビジョンのタスクを使うように変更
(web)サービス等を運用していると動作可能な新しいイメージが出来ると思うので、それの適用を行う
新しいイメージの指定はタスク定義のechoalpine-taskの中に入って最新のリビジョンを選択してから新しいリビジョンの作成を行う変更する部分はコンテナの中身
登録されているechoalpineを選択しイメージを新しいバージョンにする# before xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/echoalpine:1.0.0 # after xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/echoalpine:1.0.11.0.0を1.0.1にした
コードは書かないが、echo.shのecho "my echoalpine container!! 1.0.0"をecho "my echoalpine container!! 1.0.1 $MY_ENV_VAL"に変更した
echoalpineの記事イメージのみを更新したら作成
そうすると1つだったリビジョンが2つに増えているここまでがタスクの更新だが、これだけでは動いているコンテナの動作は変わらない
1.0.1を動かすためにはサービスの更新を行う
クラスタecs-cluster-echoalpine-> サービスechoalpine-serviceを選択右上の更新ボタンを押すと、サービスの作成で行った画面に登録した情報が入っている状態になっている
タスク定義(Family)は
echoalpine-taskのまま
タスク定義(Revision)を2(latest)に設定それ以外は何も変更せずにサービスの更新を行う
少し待っていると新しいCloudWatchのログストリームが生成され
my echoalpine container!! 1.0.1 This is my env val !!
と出力されるようになっている動作させているコンテナを停止させる
サービスの
タスクの数を0にして更新するとコンテナの動作は止まるまとめ
確かめたかったことは自前ビルドしたDockerイメージを使ってみること、プロセスが終了したときの再起動処理、標準出力へのログ確認、イメージ新バージョンになった時の更新、コンテナに環境変数渡せるか
この記事ではやってないけどALBから指定ポートへのルーティングも出来ていたのでとりあえず良さそう懺悔
AWSコンソールを操作しているのに画像が1枚もないのは甘え
参考
- 投稿日:2019-05-03T10:05:52+09:00
メモ ECR ローカルMacからAWS CLIコマンドでリポジトリ作成/イメージpush/リポジトリ削除まで
やること
- ローカルのMacからAWS CLIでECRにリポジトリを作成し、ビルドしたdocker imageをpush
- AWSマネジメントコンソールでpushされたイメージ確認
- AWS CLIでイメージの削除、リポジトリの削除
基本的にやってることはAmazon ECRにおけるdockerの基本と同じ
DockerHubとGoogleCloud Container Registryにしかイメージ上げたことなかったのでECRにも上げてみる環境
- Mac
- Dockerインストール済み
- aws cli使える(configureまで済ませてある)
- AWSマネジメントコンソールにログインできる
作業
AWSマネジメントコンソールにログイン
まずはAWSコンソールにログインしてECSと検索する
左側にAmazon ECR リポジトリという項目があるので遷移
作ったリポジトリ一覧が表示されるか空の状態になってるローカルからAWS CLIでリポジトリを作成する
おもむろにコマンドをキメる
aws ecr create-repository --region リージョン --repository-name リポジトリ名リージョンが東京でいいなら
ap-notrheast-1にする今回は10秒毎にechoを繰り返すalpineイメージをpushするのでリポジトリ名は
echoalpineとしたaws ecr create-repository --region ap-notrheast-1 --repository-name echoalpineAWSコンソールから確認してリポジトリが作成されていればOK
ECRにpushするdockerイメージのビルド (ただpullしたのでもok)
ここはわざわざビルドしなくても
docker pull alpineとかで取得したイメージをpushしてもいいけれどechoalpineという名前なのでビルドする適当にechoalpine イメージ用のディレクトリを作成してその中に
Dockerfileとecho.shというファイルを作成するmkdir echoalpine cd echoalpine touch Dockerfile touch echo.shDockerfileFROM alpine:3.9.3 ADD ./echo.sh /tmp/echo.sh CMD /tmp/echo.shecho.sh#!/bin/ash count=0 while true do echo "my echoalpine container!! 1.0.0" sleep 10 count=$(expr $count + 1) if [ $count -ge 10 ]; then echo "kiss of death..." exit fi doneビルドする
docker build -t echoalpine ./動作確認(10回echoして終了、後のECS再起動確認のため)
docker run --rm -it --name echoalpine echoalpineECRにpushするイメージのタグ付け
先程作成したイメージもしくはpullしたイメージをECRのリポジトリにpushするためにtag付けする
形式は以下docker tag ターゲットイメージ:タグ AWSアカウントID.dkr.ecr.ECRのリージョン.amazonaws.com/ECRリポジトリ名:ECRリポジトリに登録するタグechoalpineをタグ付けしたコマンドはこれ
AWSアカウントIDは適宜変更docker tag echoalpine:latest xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/echoalpine:1.0.0タグ付けしたイメージをリポジトリにpush
まずはECRへのpush権限をdockerに与えるためにawsコマンドを実行
aws ecr get-login --region リージョン --no-include-emailaws ecr get-login --region ap-northeast-1 --no-include-email > docker login -u AWS -p zzzzzzz== https://xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.comdockerログイン用コマンドが出力されるのでそれを実行するとECRのリポジトリにpush出来るようになる
権限の有効期限は12時間らしい先程タグ付けしたイメージをpushする
docker push xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/echoalpine:1.0.0AWSコンソールの作成したリポジトリを選択してイメージを確認すると
1.0.0のイメージが上がっているはずpullも出来る
docker pull xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/echoalpine:1.0.0作成したイメージとリポジトリの削除
ECRのリポジトリはAWS CLIからだと--forceオプションを付けないと削除できない
イメージを削除してからリポジトリを削除してみる(--forceで削除しないのは誤ってリポジトリを削除しないように使わないようにしている)イメージの削除はAWS CLIから削除できる
aws ecr batch-delete-image --region リージョン --repository-name リポジトリ名 --image-ids imageTag=バージョン(タグ)aws ecr batch-delete-image --region ap-northeast-1 --repository-name echoalpine --image-ids imageTag=1.0.0イメージが消えたのをコンソールから確認したらリポジトリを削除する
aws ecr delete-repository --region リージョン --repository-name リポジトリ名 (--force)aws ecr delete-repository --region ap-northeast-1 --repository-name echoalpineリポジトリが消えたのを確認する
まとめ
aws ecr get-loginでECR用の権限を得る以外いつものdockerとあまり変わらない
ECSとかCodeBuildとかで使っていきたい参考
- 投稿日:2019-05-03T09:45:00+09:00
AWS上でPrometheus構築(2)
結構時間たっちゃったけど続き
systemd回りとかは前回の記事で書いてるので今回は最初から詳しいことは省きますやること
cpu/memの使用率が一定超えたらアラート(node_exporter)
fluentdのプロセス数が想定より低くなってたらアラート
crondが死んだらアラート(普通やらんと思うけど個人的トラウマにより)
通知先はslackのみ監視される側
fluent-plugin-prometheus なるものがあるようですが、今回はそこまでちゃんとチェックしたいわけではないので
process-exporterを利用することに。
prometheus的に主流なのは各アプリごとの専用exporterを使うことらしいですが、
まあ一応今回利用するexporterも https://prometheus.io/docs/instrumenting/exporters/ ここに載ってるので良いでしょうきっとprocess-exporterの設置
cd /opt/prometheus wget https://github.com/ncabatoff/process-exporter/releases/download/v0.5.0/process-exporter-0.5.0.linux-amd64.tar.gz tar -zxf process-exporter-0.5.0.linux-amd64.tar.gz mv process-exporter-0.5.0.linux-amd64/ ./process-exporter rm -f process-exporter-0.5.0.linux-amd64.tar.gzprocess-exorterの設定ファイル
mkdir -p /opt/prometheus/process-exporter/config/ vi /opt/prometheus/process-exporter/config/process-exporter.yml/opt/prometheus/process-exporter/config/process-exporter.ymlprocess_names: - name: "{{.Comm}}" comm: - fluentd - name: "{{.Comm}}" comm: - crondhttps://github.com/ncabatoff/process-exporter
制作元のusageで大体なんとか基本はcommで用が足りるかと思います。
commでどうもならんようなアプリプロセスの場合にexeを持ち出したり、実行時引数によって同じアプリでも監視対象にしたりしなかったりしたいような場合cmdlineも持ち出す感じかと。
fluentの場合は1起動設定につき引数ascii-8bitあり/なしで2つプロセスが起動するようなので、(例えばmulti-proc利用で親・子で合計3つ起動設定がある場合、6プロセス起動する)
どっちかが監視対象から外れるように書いてあげるとモアベターではありましょうが今回は面倒くさかったので放置起動オプションファイルの作成と設置、反映と起動
このあたりは前回やったことと99%一緒なので省略します
終わったらprometheusサーバにする予定のインスタンスから
curl http://[[インスタンスIP]]:[[設定したport]]/metrics
叩いて、なんかすごい量の文字列が返ってきたらok
ラベルnamedprocess_namegroup_num_procsが割とメインなのでこれで絞っても良いかと思います監視する側
process-exporter
scrape_configsにprocess-exporter用の設定を突っ込みます。
vi /opt/prometheus/prometheusserver/prometheus.yml/opt/prometheus/prometheusserver/prometheus.yml#### 途中省略 #### - job_name: 'process_test' ec2_sd_configs: - region: '監視したいインスタンスがいるリージョン' port: xxxx # process-exporterのlistenポート relabel_configs: - source_labels: [__meta_ec2_tag_Service] regex: prom_test action: keep - source_labels: [__meta_ec2_tag_Name] target_label: instancealert managerの設置
cd /opt/prometheus wget https://github.com/prometheus/alertmanager/releases/download/v0.16.2/alertmanager-0.16.2.linux-amd64.tar.gz tar -zxf alertmanager-0.16.2.linux-amd64.tar.gz mv alertmanager-0.16.2.linux-amd64 alertmanager rm -f alertmanager-0.16.2.linux-amd64.tar.gzalert ruleの設定ファイル
前回記事で後回しにした設定部分
/opt/prometheus/prometheusserver/prometheus.ymlrule_files: - /opt/prometheus/prometheusserver/alert_rules.yml/opt/prometheus/prometheusserver/alert_rules.ymlgroups: - name: node_exporter # 任意のグループ名 rules: - alert: cpu_exceed # 任意のアラート名 # 各インスタンスごとの各コアごとCPU idleの使用率を合計してコア数で割ったものが80%を超えていれば expr: sum(100 * (1 - rate(node_cpu_seconds_total{job='ec2-test',mode='idle'}[5m]))) by (instance) / count(node_cpu_seconds_total{job='ec2-test',mode='idle'}) by (instance) > 80 # 80%を超えた状態がこの時間継続すれば。なお省略可能、省略すると即時になるようです。 # 解除時はここの値は影響しないようです。即座にfiringが解除される模様。 for: 5m labels: severity: critical annotations: summary: "cpu of [{{ $labels.instance }}] has been used over 80% for more than 5 minutes." - alert: memory_exceed expr: 100 * (1 - node_memory_MemFree_bytes{job='ec2-test'} / node_memory_MemTotal_bytes{job='ec2-test'}) > 90 for: 5m labels: severity: critical annotations: summary: "memory of [{{ $labels.instance }}] has been used over 90% for more than 5 minutes." - name: process_exporter rules: - alert: crond expr: namedprocess_namegroup_num_procs{job='process_test',groupname='crond'} < 1 for: 1m labels: severity: critical annotations: summary: "[{{ $labels.instance }}] The number of crond process is less than 1 for 1 minutes." - alert: fluentd expr: namedprocess_namegroup_num_procs{job='process_test',groupname='fluentd'} < 6 for: 1m labels: severity: critical annotations: summary: "[{{ $labels.instance }}] The number of fluentd process is less than 6 for 1 minutes."公式のこの辺から演算子・クエリ周りの情報を追って、あとはprometheusのgraph画面でクエリ投げながらどんな値なのか確認しながらやればそれほど困らないと思います。
node_exporterのrateとかその辺はここで。
labels/annotationsはここの説明にもお世話になりました。
(ちなみにprocessのほうでわざわざ1分継続にしてる理由は、即時だとプロセスの再起動でも引っかかってうざそうだから)alert managerの設定ファイル
mkdir -p /opt/prometheus/alertmanager/config/ vi /opt/prometheus/alertmanager/config/alertmanager.yml/opt/prometheus/alertmanager/config/alertmanager.ymlglobal: slack_api_url: [[slackのwebhook url]] route: receiver: 'slack' group_by: ['alertname', 'instance'] group_wait: 30s group_interval: 1m repeat_interval: 10m receivers: - name: 'slack' slack_configs: - channel: '#通知先チャンネル' title: '{{ if eq .Status "firing" }}[FIRING]{{else}}[RESOLVED]{{end}} {{ .GroupLabels.alertname }}' text: '{{ .CommonAnnotations.summary }}' title_link: "http://[[prometheus本体サーバのipなりなんなり]]:[[listen port]]/alerts" send_resolved: trueslack回りの設定は公式の情報で困らないと思うので特に言うことはないですが、wait/interval回りは後述します
(ソース追ってまで何とかするほど困ることでも無いと思うのと、挙動の謎さに首をかしげ続けるのに疲れたので途中で調査打ち切りましたが)
titleを出し分けしているのは、発生時/回復時でメッセージ本体の左側の帯の色しか変わらないのでせめてもの抵抗alert managerの起動設定とか起動
今までと全く同じ流れなので割愛
あとは試しにcrond止めてみたりすれば確認できるかなと。
謎のgroup_interval
自分が意味を勘違いしている可能性は多々あるのですが
# 通知発生から実際に通知するまで待つ時間 group_wait: 2m # 2つ目以降の通知が発生し、それが同一グループである場合に通知するまで追加で待つ時間 # alert_rule上で言うとnameは同じだがalertが違う group_interval: 4m # 一度通知したアラートの条件が満たされ続けている時、次に通知するまで追加で待つ時間 # alert_rule上で言うとname/alert共に同じ repeat_interval: 8m大したことではないけど、例えばwaitと各intervalは合計されるのかとか気になったんで上記条件でちょっと試したら
08:34 プロセス1 stop 08:34 プロセス2 stop 08:36 プロセス1 アラート通知 08:36 プロセス2 アラート通知 しばらく放置 08:48 プロセス1 アラート通知 08:48 プロセス2 アラート通知 08:54 プロセス1 start 08:54 プロセス2 start 08:56 プロセス1 resolve通知 08:56 プロセス2 resolve通知group_waitとrepeat_intervalは合算されてそうだが…
group_intervalは一体?09:02 プロセス1 stop 09:04 プロセス1 アラート通知 09:04 プロセス2 stop 09:06 プロセス2 アラート通知 09:16 プロセス1 アラート通知リピート 09:18 プロセス2 アラート通知リピート 09:27 プロセス1 start 09:27 プロセス2 start 09:29 プロセス1 resolve通知 09:30 プロセス2 resolve通知group_intervalとは一体?
まあでも、waitとrepeatが直感的に動いてそうなら別に困らないかと思ったので調査終了。
何か知っている方がいればそっと教えてください。
- 投稿日:2019-05-03T08:37:25+09:00
ETLにAWS使う場合の選択肢
この記事は ただの集団 AdventCalendar PtW.2019 の7日目の記事です。
昨日はtakatorixさんのGo言語でフレーズ検索を実装してみるでした。はじめに
ETLネタで被っておりました。
機転を利かせて昨年末のAWS re:Invent 2018で出てきたGlueの上位版のようなAWS Lake Formationのプレビュー申請して内容を変更したりできれば良かったのですが、力量不足だったので気にせず記載します。
せめてGlueを避けて、今更ですがDataPipeline中心の内容で、選択に迷った時の一助になれば幸いです。AWS Data Pipeline
AWS Data Pipeline とは
ずばりETL(抽出、変換、ロード)を行うAWSのサービスです。
所感ですが、コンポーネントを繋いでいくだけで直感的にわかりやすく、公式のドキュメントを読むだけで大体のことは書いてあるので、使うためのハードルは低いです。基礎知識
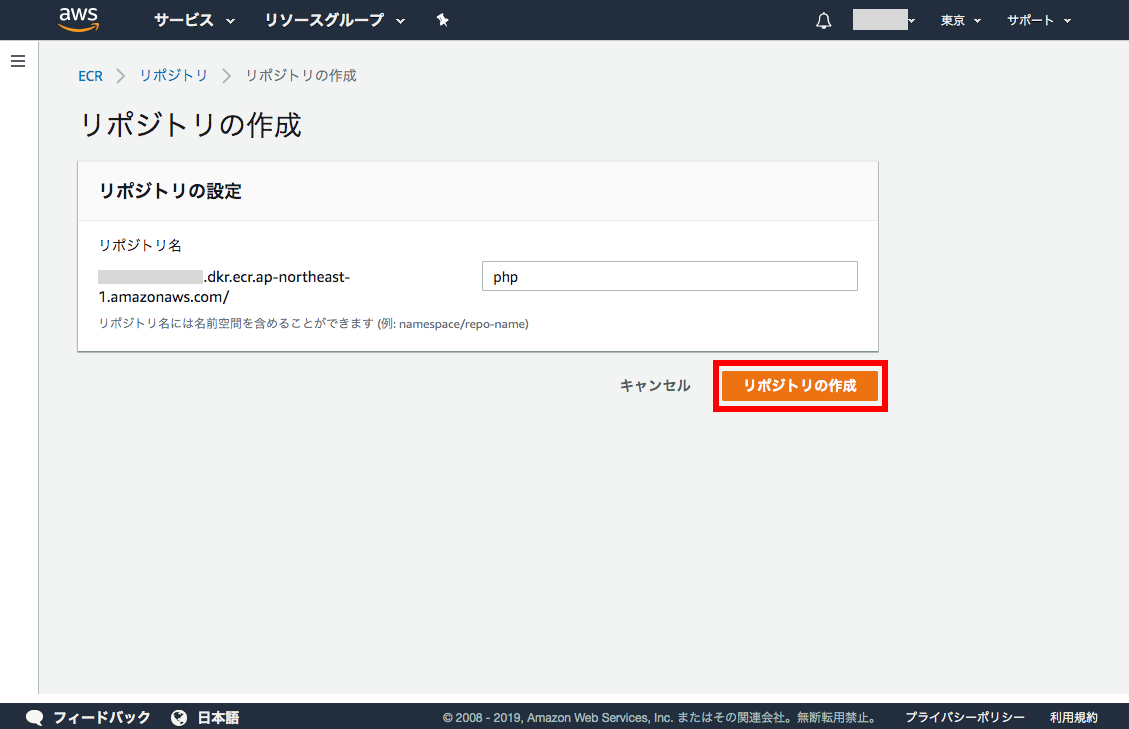
作成されたパイプラインのイメージです。上述はテンプレート(後述)を使って作成したものです。
以下のコンポーネントを定義して構成します。Activities
データ処理の内容を定義するコンポーネントです。
後述するDataNodesやResoucesを使って実行します。
- ShellCommandActivity
- シェルコマンドを実行する時に使います。実行するシェルを直接書いたり、S3に置いたシェルスクリプトファイルを実行したりします。
- SqlActivity
- SQLクエリを実行します。シェルと同様クエリを定義したり、S3にあるクエリファイルを読み込んで実行したりできます。
- RedshiftCopyActivity
- DynamoDBやS3からAmazonRedshiftにデータをコピーする時に使います。
- 他色々
Data Nodes
入出力で使用するデータの場所やタイプの定義です。
- DynamoDBDataNode
- SqlDataNode
- RedshiftDataNode
- S3DataNode
Schedules
実行スケジュール定義です。特にスケジュールを定義せずにオンデマンドに実行することも可能です。
Resouces
ActivitiesやPreconditionsを実行するコンピューティングリソースで、EC2かEMRクラスターを選択します。
PreConditions
アクティビティを実行するための事前条件を定義できます。
ファイルがある場合に実行するようにしたり、データの存在を確認したりできます。
- DynamoDBDataExists
- S3KeyExists
- ShellCommandPrecondition
- 他
使い方
- 基本的に上述のコンポーネント(他にもあります)を定義して、繋げていくと作成できます。 例えば、S3からRDSにデータを移動させるのであれば、S3とRDSのデータノードを作成して(付随する情報の定義も適宜作成される)、コピーするアクティビティと実行するリソースを作成して繋げると完成。
- ある程度の構成は、用途毎にあらかじめテンプレートとして用意されているので、ベースをテンプレートで作成しておいて編集していくやり方が簡単な気がします。
- テンプレート種類
- Load S3 data into RDS MySQL table (前述のイメージのもの)
- Export DynamoDB table to S3
- Run AWS CLI command
- etc
補足
- RDSでAuroraを使っているのであれば、AuroraはS3のファイルを直接ロードすることができるので、SqlDataNodeなどを作成せずに、SqlActivityにLOAD DATA FROM S3~のクエリを定義して実行することでも同じことができたりします。
- Transformは基本的にシェルスクリプトを書くことになるので、複雑な処理が必要であれば、PySparkやScalaを使えるGlueを使うのが良いです。
まとめ
- Glueとの違いはなんなのかなど、各サービスとの使い分けは公式に記載があります。
- https://aws.amazon.com/jp/glue/faqs/#AWS_Product_Integrations
- ここを見ればこの記事いらない気がするのですが、Apache Spark使うのであればGlueでいいと思います。あとは、定義したリソースのEC2やEMRクラスターに直接アクセスできたり、DataPipelineの方が責任分界点が利用者寄りな感じなので、より自分で制御したい場合はDataPipelineの選択肢もありかなというところでしょうか。
- Glueの場合、RDSをロード先にすると同じパプリックサブネットにする必要があるので、基本的にプライベートに置くであろうRDSにアクセスするためGlueから踏み台サーバーを見れるようにする必要があったりして多少嵌ったことがあったり、他ちょいちょい嵌りどころがある気が。
- ETLという観点から外れますが、GlueのデータカタログはAmazon Athenaでそのまま使えるので、何もしなくてもAthenaのコンソールでGlueのデータベースを選択して参照できて、それだけでも使う価値がありGlueにはプラスアルファな用途もあったりします。
- あとは少量のデータを扱うだけで実行時間が短ければ、制限が15分に拡大したLambdaを使うのも良い気がします。
なんだかまとまりがなくなってしまいましたが、ハードルの低さから、気軽に(料金は気にしない)ETLを試してみたいのであれば、DataPipelineという選択肢を考えるのもありなのかなと思います。
参考
- https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-2015-aws-data-pipeline-52837923
- https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-aws-glue
- https://aws.amazon.com/jp/glue/faqs/#AWS_Product_Integrations
- https://docs.aws.amazon.com/ja_jp/datapipeline/latest/DeveloperGuide/what-is-datapipeline.html
- https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Integrating.LoadFromS3.html
- https://www.qoosky.io/techs/0964aa9fdc