- 投稿日:2019-05-03T23:13:14+09:00
aikoにとっての"あなた"と"あたし"は20年でどう変化したか -word2vecによる歌詞の分析-
分析に至った背景
以前から自然言語処理で何か面白いことをしたいと思ってはいたものの、手をつけないまま何か月も過ごしていました。しかし!!!今年のGWは奇跡の10連休です。思い切って何かに挑戦してみようと思い、自分の好きなアーティストであるaikoの歌詞を分析することにしました。
また、Qiita投稿などのアウトプットを怠っていることに最近危機感を覚えていたので、今回Qiitaに投稿してみます。
注意事項
- 筆者は機械学習や自然言語処理については初心者です。何かご意見・ご指摘ありましたらコメントをお願いします。
- 当記事では技術的に深い話はしていません。ご容赦ください。
この記事で言及すること
- MeCab・word2vecの使用例(ソースコード)
- 歌詞の分析結果
この記事で言及しないこと
- MeCab・word2vecの仕組み
- スクレイピングの手法や仕組みの詳細
著作物の収集と分析に関して
当記事で言及している歌詞データの収集および分析については著作権法47条の5に照らし合わせ、著作権法上問題ないものと判断します(同条2号の情報解析およびその結果の提供に該当と判断)。
問題定義
歌詞を分析するといってもどういう観点で分析すればいいのでしょうか。
いろいろと考えた結果、aikoの楽曲の歌詞に頻繁に出てくる"あなた"や"あたし"という言葉の意味を明らかにするというアイデアが思いつきました。次いで、曲を書くアーティストたちも年齢によって恋愛や愛に対する思いが変化し、その変化が歌詞に現れるのではないか、という仮説が思いつきました。
分析対象となるデータ量も少ないので毎年の変化を分析するのは現実的とは言えなさそうです。そこで今回は分析対象を以下の二つにしてみました。
①20代までのaikoの楽曲(104曲)
②30代以降のaikoの楽曲(94曲)今回の分析では、"あなた"や"あたし"という分析対象の語句に対して類似度の高い語句を算出することで、分析対象となった語句自体の意味を考察していこうと思います。
分析の大きな流れとしては以下の3ステップとなります。
具体的な手段としては、1はWebスクレイピング、2はMeCab、そして3はword2vecを使用します。
1. 歌詞データの収集
2. 歌詞データの前処理
3. 歌詞データの分析Scrapyによる歌詞データのスクレイピング
分析の下準備として、歌詞検索サイトからaikoの楽曲200曲をスクレイピングしました。
スクレイピングの対象は、インディーズ時代の楽曲からアルバム『May Dream』に含まれる楽曲までです。年でいうと1996年から2016年までですね。(ちなみに発表年は1曲1曲ネットで調べて手入力しました。。。)
前述の通りスクレイピングについて詳しく言及しませんが簡単にまとめると、Scrapyを使用してHTML内の歌詞を保持しているタグを指定(XPath)し、1曲ごとにスクレイピングするように実装しました。
Scrapy含めスクレイピングの基礎知識・手法については以下の書籍が非常に参考になりました。おすすめです。
Pythonクローリング&スクレイピング -データ収集・解析のための実践開発ガイド-
MeCabによる形態素解析・分かち書き
word2vecで歌詞を分析するにあたり、インプットとなるデータ(歌詞)を「分かち書き」された状態にする必要があります。今回、その実現のためにオープンソースの形態素解析エンジンであるMeCabを使用しました。
http://taku910.github.io/mecab/今回はMeCabで形態素解析を実行し、名詞・形容詞・副詞のみを抽出し、その語句をlistに格納してword2vecに渡しました。
寄り道 - 用語の確認
分かち書きとは
文を書く時、ある単位ごとに区切って、その間に空白を置くこと。また、その書き方。
コトバンク - 分かち書き形態素解析とは
形態素解析とは、言語学においてある言葉が変化・活用しない部分を最小単位の「素」と捉え、その素ごとに言葉を分解してゆく手法のことである。
weblio辞書 - 形態素解析形態素解析と分かち書きの具体例
形態素解析前の文章実践ドメイン駆動設計。エリック・エヴァンスが確立した理論を実際の設計に応用する。形態素解析の実行結果(略) ['エリック・エヴァンス', '名詞', '一般', '*', '*', '*', '*', '*'] ['が', '助詞', '格助詞', '一般', '*', '*', '*', 'が', 'ガ', 'ガ'] ['確立', '名詞', 'サ変接続', '*', '*', '*', '*', '確立', 'カクリツ', 'カクリツ'] ['し', '動詞', '自立', '*', '*', 'サ変・スル', '連用形', 'する', 'シ', 'シ'] ['た', '助動詞', '*', '*', '*', '特殊・タ', '基本形', 'た', 'タ', 'タ'] ['理論', '名詞', '一般', '*', '*', '*', '*', '理論', 'リロン', 'リロン'] ['を', '助詞', '格助詞', '一般', '*', '*', '*', 'を', 'ヲ', 'ヲ'] ['実際', '副詞', '助詞類接続', '*', '*', '*', '*', '実際', 'ジッサイ', 'ジッサイ'] ['の', '助詞', '連体化', '*', '*', '*', '*', 'の', 'ノ', 'ノ'] (略)分かち書き実践 ドメイン 駆動 設計 。 エリック・エヴァンス が 確立 し た 理論 を 実際 の 設計 に 応用する 。word2vecによる単語のベクトル化
word2vecとは、テキストデータを学習して単語の意味をベクトルとして表現するライブラリのことです。ある単語に類似した単語を算出したり、単語同士の加算・減算が可能です。
自分の言葉で説明しようとすると10時間くらいかかりそうなので以下のサイトを見て理解してみてください。
絵で理解するWord2vecの仕組み実際にやってみた
実際に動作させたソースコードを以下に示します(import~word2vecのモデル生成)。記録を残しつつ対話的に実行したかったこともあり、実際はJupyter Notebookで動かしました。
source# 必要なライブラリのインポート import sys import re import MeCab import psycopg2 import pandas as pd import matplotlib.pyplot as plt from gensim.models import word2vec # 楽曲テーブルへの接続 POSTGRESQL_URL = 'postgresql://postgres:(パスワード)localhost:5432/(スキーマ)' conn = psycopg2.connect(POSTGRESQL_URL) # 歌詞データの取得 COL_TITLE = 0 COL_LYRICS = 1 COL_YEAR = 2 song_list = [] sql_str = "SELECT title, lyrics, made_in FROM songs WHERE words_by IN ('aiko', 'AIKO')" curs = conn.cursor() curs.execute(sql_str, ) song_list = curs.fetchall() IDX_WORD = 0 IDX_POS = 1 TARGET_YEAR = 2005 TARGET_POS_LIST = ['名詞', '形容詞', '副詞'] EXCEPTIONAL_SONG_LIST = ['相合傘(汗かきMix)'] # 重複削除のため EXCEPTIONAL_LIST = ['・', 'さ', 'ん', 'の', 'ら', 'よ', '°', 'そう', 'よう', 'ない', 'それ', 'あれ', 'これ' , 'ここ', 'そこ', 'はず', '人', '何', '事', '様', '話', '日', '目', '度', '時', '今'] analyzed_young_list = [] analyzed_old_list = [] analyzed_list = [] # 形態素解析用のインスタンス生成 tagger = MeCab.Tagger() tagger.parse('') for song in song_list: # 重複する曲は除外 if song[COL_TITLE] in EXCEPTIONAL_SONG_LIST: continue # 形態素解析の実行 parsed_item = tagger.parse(song[COL_LYRICS]) # 1曲ごとにデータ整形 lines = parsed_item.split('\n') items = (re.split('[\t,]', line) for line in lines) for item in items: # 不要データは除外 if len(item) <= IDX_POS: continue # 対象品詞以外は除外 if not item[IDX_POS] in TARGET_POS_LIST: continue # 半角記号の除去 if re.match(r"[a-zA-z!-/:-@[-`{-~]", item[IDX_WORD]): continue # 不要語句の除去(記号など) if item[IDX_WORD] in EXCEPTIONAL_LIST: continue # 数値の除去 if item[IDX_WORD].isnumeric(): continue if song[COL_YEAR] <= TARGET_YEAR: analyzed_young_list.append(item[IDX_WORD]) else: analyzed_old_list.append(item[IDX_WORD]) analyzed_list.append(item[IDX_WORD]) # word2vecのモデルを定義 ~20代の歌詞 model_young = word2vec.Word2Vec([analyzed_young_list], size=500, min_count=2, window=7, iter=1000, seed=2019) # word2vecのモデルを定義 30代~の歌詞 model_old = word2vec.Word2Vec([analyzed_old_list], size=500, min_count=2, window=7, iter=1000, seed=2019) # word2vecのモデルを定義 all model = word2vec.Word2Vec([analyzed_list], size=500, min_count=2, window=7, iter=1000, seed=2019) # 定数定義 PDCOL_WORD = '語句' PDCOL_SIMILARITY = '類似度' HEADER_YOUNG = "[~20代]" HEADER_OLD = "[30代~]" # 以降で分析実行分析結果
さて... 分析結果を発表していきたいと思います。
ちなみに、分析結果と言っているのは分析対象の語句(ダブルクォーテーションで括っています)に類似した語句を類似度が高い順に示した表のことですので、その認識で確認してみてください。
20代以前と30代以降の比較結果
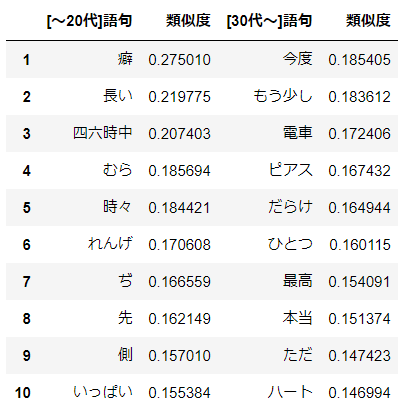
aikoにとっての"あなた"
分析処理
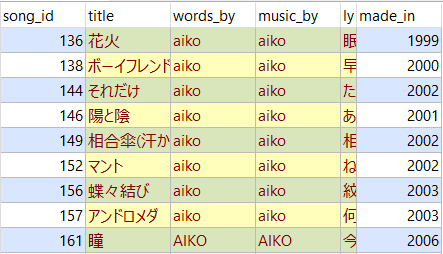
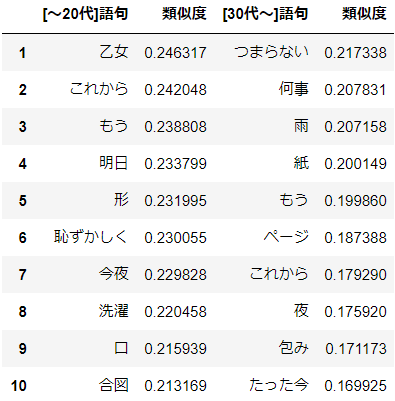
KEYWORD = 'あなた' result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10) df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY]) df_young.index = df_young.index + 1 result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10) df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY]) df_old.index = df_old.index + 1 display(pd.concat([df_young, df_old], axis=1))分析結果
おお!どうやらaikoにとって"あなた"とは"あたし"のことみたいです。20代以前と30代以降とで一貫していますね。20代以前では"心"や"気持ち"など内面を示す言葉が上位に登場している一方で、30代以降では2位に"声"がありますね。自らの心中ではなく実在する"あなた"の"声"を想って歌詞を書いたということでしょうか。
aikoにとっての"あたし"
分析処理
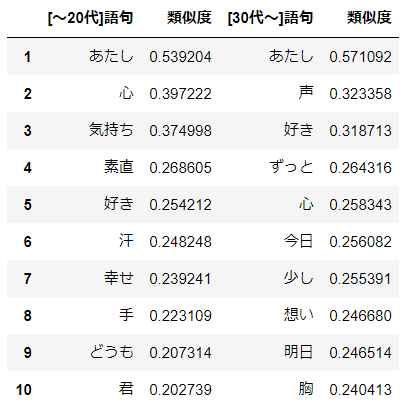
KEYWORD = 'あたし' result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10) df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY]) df_young.index = df_young.index + 1 result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10) df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY]) df_old.index = df_old.index + 1 display(pd.concat([df_young, df_old], axis=1))分析結果
"あなた"≒"あたし"なので"あたし"≒"あなた"も成り立ちます。20代以前では"好き"や"幸せ"などの直接的な表現が上位に多くありますが、30代以降ではあまり見られません。年齢を重ねるごとにそのような直接的な表現を避けるようになったということでしょうか。
aikoにとっての"好き"
分析処理
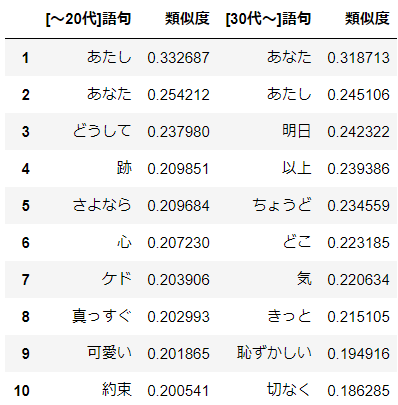
KEYWORD = '好き' result_young = model_young.wv.most_similar(positive=KEYWORD, topn=10) df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY]) df_young.index = df_young.index + 1 result_old = model_old.wv.most_similar(positive=KEYWORD, topn=10) df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY]) df_old.index = df_old.index + 1 display(pd.concat([df_young, df_old], axis=1))分析結果
おお!これは面白い結果になりました。"あなた"と"あたし"の順位が逆転しています。ただこれはどう捉えればよいのでしょう。。。
これまでの分析結果を踏まえると、"あたし"の心中で留まっていた"好き"という思いが、30代以降では"あなた"を意識して表現されているということでしょうかね。"あなた" + "あたし" = ???
分析処理
# "あなた" + "あたし" = ??? KEYWORD_1 = 'あなた' KEYWORD_2 = 'あたし' result_young = model_young.wv.most_similar(positive=[KEYWORD_1,KEYWORD_2], topn=10) df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY]) df_young.index = df_young.index + 1 result_old = model_old.wv.most_similar(positive=[KEYWORD_1,KEYWORD_2], topn=10) df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY]) df_old.index = df_old.index + 1 display(pd.concat([df_young, df_old], axis=1))分析結果
"あなた" + "あたし" = "心" だったのが
"あなた" + "あたし" = "声" に変わりました。
どういうことでしょうか。。。"あたし" - "あなた" = ???
分析処理
# "あたし" - "あなた" = ??? KEYWORD_1 = 'あたし' KEYWORD_2 = 'あなた' result_young = model_young.wv.most_similar(positive=[KEYWORD_1], negative=[KEYWORD_2], topn=10) df_young = pd.DataFrame(result_young, columns=[HEADER_YOUNG + PDCOL_WORD, PDCOL_SIMILARITY]) df_young.index = df_young.index + 1 result_old = model_old.wv.most_similar(positive=[KEYWORD_1], negative=[KEYWORD_2], topn=10) df_old = pd.DataFrame(result_old, columns=[HEADER_OLD + PDCOL_WORD, PDCOL_SIMILARITY]) df_old.index = df_old.index + 1 display(pd.concat([df_young, df_old], axis=1))分析結果
類似度も低く謎な感じになってきました。"あなた" + "癖" = "あたし"というのはわかるようなわからないような。。おまけ
あまり類似度が高くなかったのでおまけ扱いとしますが、結構おもしろい結果になってます。
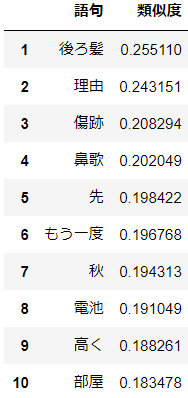
aikoにとっての"夏"(20年分)
分析結果
"後ろ髪"が1位(笑)。名残惜しいということでしょうか。aikoにとっての"冬"(20年分)
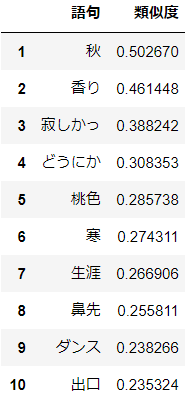
分析結果
aikoにとって"冬"は"秋"らしいです。おそらく季節を表す言葉が続けざま(秋→冬)に出たために類似度が高くなったのでしょう。"寂しかっ(た)"や"寒"が出てくるのはイメージとあっていますね。
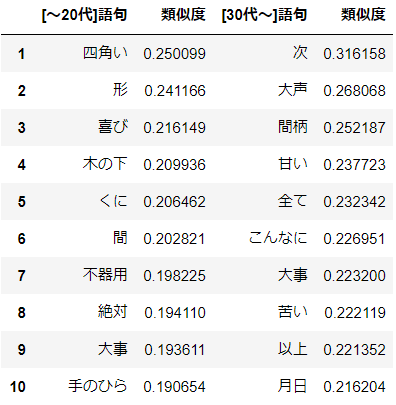
aikoにとっての"恋"
分析結果
次って(笑)aikoにとっての"愛"
分析結果
30代のaiko(笑)つまらない割には愛を歌っている気がします。20代以前の方は"これから"や"明日"など未来を感じる言葉があってよいですね。
最後に
先人の苦労によってこんなにも簡単に分析できてしまいました。感謝感謝。
とりあえず、疲れたけど楽しかったです(小学生)。参考資料
分析全般
・B'zの歌詞をPythonと機械学習で分析してみた 〜Word 2 Vec編〜word2vecについて
・絵で理解するWord2vecの仕組み
・models.word2vec – Word2vec embeddings著作権法について
・著作権法
・平成30年改正著作権法がビジネスに与える「衝撃」

- 投稿日:2019-05-03T22:49:09+09:00
Pythonコマンドラインアプリケーションのサンプルコード
目的
Pythonでコマンドラインインタフェースのアプリケーション、ツール類を作ったりする場合、すべてスクラッチでプログラムを書いていくのは面倒なものです。
開発現場でさっとコピーして適用しやすいように簡単なサンプルコードを作成しました。サンプルコードの実行
python2.7で実行して確認済み。
$ python cli.py --helpサンプルコードの実行結果
usage: cli.py [-h] [--id ID] [--amount AMOUNT] {create,show,update,delete} コマンドラインインターフェースのサンプルコード。 positional arguments: {create,show,update,delete} create: データを作成する | show: データを確認する | update: データを更新する | delete: データを削除する optional arguments: -h, --help show this help message and exit --id ID ID指定 $ python cli.py show --id 1 --amount AMOUNT 数量を指定する $ python cli.py create --id 1 --amount 100.0サンプルコード
本体はGithubに設置してあります。これを雛形にコマンドラインアプリケーションを作成すると便利です。特徴としては、具体的なビジネスロジックの実装をクラス定義して、コマンドライン引数の解析処理と分割管理している点です。
cli.py# -*- coding: UTF-8 -*- """ Command Line Interface Sample. """ import argparse from pprint import pprint class Command(object): """ """ def __init__(self, args): # Get argument parse options self.args = args def create(self): id = self.args.id amount = self.args.amount if id == 0: raise Exception("--id is required.") if amount == 0: raise Exception("--amount is required.") txt = 'create(id={}, amount={})'.format(id, amount) print(txt) def show(self): id = self.args.id if id == 0: raise Exception("--id is required.") txt = 'show(id={})'.format(id) print(txt) def update(self): id = self.args.id amount = self.args.amount if id == 0: raise Exception("--id is required.") if amount == 0: raise Exception("--amount is required.") txt = 'update(id={}, amount={})'.format(id, amount) print(txt) def delete(self): id = self.args.id if id == 0: raise Exception("--id is required.") txt = 'delete(id={})'.format(id) print(txt) def run(args): # クラスメソッドをコール try: c = Command(args) getattr(c, args.command)() except Exception as e: print(e) if __name__ == '__main__': parser = argparse.ArgumentParser(description='コマンドラインインターフェースのサンプルコード。') # 主要コマンド command_list = ['create', 'show', 'update', 'delete'] command_help = 'create: データを作成する' command_help += ' | show: データを確認する' command_help += ' | update: データを更新する' command_help += ' | delete: データを削除する' parser.add_argument('command', type=str, choices=command_list, help=command_help) # コマンドオプション指定 parser.add_argument('--id', type=int, help='ID指定 $ python cli.py show --id 1', default=0) parser.add_argument('--amount', type=float, help='数量を指定する $ python cli.py create --id 1 --amount 100.0', default=0) args = parser.parse_args() # Get start run(args)参考資料
- 投稿日:2019-05-03T22:11:17+09:00
『ディープラーニングの力で結月ゆかりの声になるリポジトリ』の性能アップ (音質+速度)
1.概要
『ディープラーニングの力で結月ゆかりの声になるリポジトリ』
https://github.com/Hiroshiba/become-yukarin
の性能をアップするための方法について解説します。前回(パラメータチューニング(第一段階編) )の続きになります。
性能アップについては当初、第二段階のみ書くつもりでしたが第一段階についても、合わせて記事にすることにしました。
本稿での性能アップとは、音質の改善と推定速度(音声変換時間)の短縮のことを指しています。
次の内容について解説していきます。
- 第ゼロ段階の実施
- 第一段階のパラメータ調整
- 第二段階の学習データ削減
- 第二段階を用いたノイズ学習
2.導入方法
前回に引き続き、同環境にて実施するため、導入方法は前回 を参照。
3.実行環境
こちらも前回に引き続き、同環境にて実施するため、前回 の実行環境を参照。
4.学習データ音声と検証方法
第一段階、第二段階の学習に使う音声はパラレルデータを用意します。
分かり易いよう二つの音声を一つにしたものが以下になります。
左側音声が筆者、右側音声が変換先です。←地声|変換先→
— ひろ (@Khirotake) 2019年5月3日
グラフ:1ms毎にスペクトログラムの値(0-1に正規化)を表示 pic.twitter.com/5n5RChyuqF本稿ではパラレルデータの地声の音声を音声変換し、どのように音質が改善したか検証します。
※実際に処理するときは学習データのパラレルデータを数百ファイル程度用意して処理します。5.第ゼロ段階の実施
この章は第一段階の学習の結果、大きなノイズが出てしまう場合に実施してください。
変換音声にノイズが乗る程度であれば、6章へ進めてください。前提:第一段階、第二段階の学習と推定(変換の実施)が終わっていること。
[動作環境]
become-yukarin
├dat
│ ├in_1st_my_wav ・・・ 地声の音声が格納されている
│ └in_1st_yukari_wav ・・・ 変換先の音声が格納されている
├test_data_sr ・・・ 第二段階の音声変換のためのインプットディレクトリ
└output
└yukari_2nd ・・・ 第二段階の変換後の音声が格納されるディレクトリ第二段階の処理を使い、学習データのデータクレンジングを行います。
なぜ、第二段階の処理を使っているかと言うと、データクレンジング処理を作るノウハウがないため暫定でしています。
第二段階の処理ではエンコード、デコード処理が入っておりノイズ除去に使われているオートエンコーダーと同等の処理を行うことができると考えます。
※実施する前は「in_1st_my_wav」、「in_1st_yukari_wav」をバックアップしておいてください。地声の音声のデータクレンジングを実施
1.「in_1st_my_wav」のファイルを「test_data_sr」にコピーする。
2. 第二段階の処理を実施する。
3.「output/yukari_2nd」のファイルを「in_1st_my_wav」に上書きする。変換先の音声のデータクレンジングを実施
1.「in_1st_yukari_wav」のファイルを「test_data_sr」にコピーする。
2. 第二段階の処理を実施する。
3.「output/yukari_2nd」のファイルを「in_1st_yukari_wav」に上書きする。データクレンジングが終わったら、第一段階の処理を実施し変換後の音声に大きなノイズがないこと確認する。
6.第一段階のパラメータ調整
音声を分解するときのパラメータを以下にします。詳細は前回 を参照。
frame_periodを10としているのはフレーム間隔が長くなっても第一段階の学習に影響しないためです。
orderを30としているのはメルケプストラムの次数(order)を上げると声質が含まれているデータのデータ量が単純に多くなるため音質が良くなります。
[動作環境]
become-yukarin
├become-yukarin
│ └param.py
└dat
└config.jsonparam.py(抜粋)class AcousticFeatureParam(NamedTuple): frame_period: int = 10 order: int = 30config.jsonのin_channelsとout_channelsをorder+2とする。
config.json(抜粋){ "model": { "in_channels": 32, "out_channels": 32 }第一段階の学習のパイパーパラメータをOptunaを使い自動調整して、音質改善を試みます。
Optunaはchainerを作った会社が提供しているフレームワークで、学習結果が良くなるまでハイパーパラメータの最適値を探してくれます。
ハイパーパラメータ自動最適化ツール「Optuna」公開Optunaをインストールします。
command(インストール)$ sudo pip install optuna第一段階のソースコード(train.py)にOptunaを組み込みます。
参考:賢いパラメータ探索: Optuna入門 with Chainer[動作環境]
become-yukarin
├train.py ・・・ 第一段階学習のソースコード
├train_optuna.py ・・・ 第一段階学習のソースコードにOputunaを組み込んだソースコード(新規作成)train_optuna.pyimport argparse from functools import partial from pathlib import Path from chainer import cuda from chainer import optimizers from chainer import training from chainer.dataset import convert from chainer.iterators import MultiprocessIterator from chainer.training import extensions from chainerui.utils import save_args from become_yukarin.config.config import create_from_json from become_yukarin.dataset import create as create_dataset from become_yukarin.model.model import create from become_yukarin.updater.updater import Updater import optuna from optuna.integration import ChainerPruningExtension parser = argparse.ArgumentParser() parser.add_argument('config_json_path', type=Path) parser.add_argument('output', type=Path) arguments = parser.parse_args() config = create_from_json(arguments.config_json_path) arguments.output.mkdir(exist_ok=True) config.save_as_json((arguments.output / 'config.json').absolute()) def objective(trial): # model if config.train.gpu >= 0: cuda.get_device_from_id(config.train.gpu).use() predictor, discriminator = create(config.model) models = { 'predictor': predictor, 'discriminator': discriminator, } # dataset dataset = create_dataset(config.dataset) batchsize = trial.suggest_int('batchsize', 1, 128) train_iter = MultiprocessIterator(dataset['train'], batchsize) test_iter = MultiprocessIterator(dataset['test'], batchsize, repeat=False, shuffle=False) train_eval_iter = MultiprocessIterator(dataset['train_eval'], batchsize, repeat=False, shuffle=False) # optimizer def create_optimizer(model): alpha = trial.suggest_loguniform('alpha', 1e-5, 1e-2) beta1 = trial.suggest_uniform('beta1', 0, 1) optimizer = optimizers.Adam(alpha, beta1, beta2=0.999) optimizer.setup(model) return optimizer opts = {key: create_optimizer(model) for key, model in models.items()} # updater converter = partial(convert.concat_examples, padding=0) updater = Updater( loss_config=config.loss, predictor=predictor, discriminator=discriminator, device=config.train.gpu, iterator=train_iter, optimizer=opts, converter=converter, ) # trainer trigger_log = (config.train.log_iteration, 'iteration') trigger_snapshot = (config.train.snapshot_iteration, 'iteration') trainer = training.Trainer(updater, out=arguments.output) ext = extensions.Evaluator(test_iter, models, converter, device=config.train.gpu, eval_func=updater.forward) trainer.extend(ext, name='test', trigger=trigger_log) ext = extensions.Evaluator(train_eval_iter, models, converter, device=config.train.gpu, eval_func=updater.forward) trainer.extend(ext, name='train', trigger=trigger_log) trainer.extend(extensions.dump_graph('predictor/loss')) ext = extensions.snapshot_object(predictor, filename='predictor_{.updater.iteration}.npz') trainer.extend(ext, trigger=trigger_snapshot) trainer.extend(extensions.LogReport(trigger=trigger_log)) trainer.extend(ChainerPruningExtension(trial, 'validation/main/loss', (1, 'iteration'))) save_args(arguments, arguments.output) trainer.run() if __name__ == '__main__': study = optuna.study.create_study() study.optimize(objective, n_trials=100)
- 実行例
command$ python train_optuna.py dat/config.json dat/model/yukari_1st
- 結果
第一段階パラメータ調整後の音声
— ひろ (@Khirotake) 2019年5月3日
グラフ:1ms毎にスペクトログラムの値(0-1に正規化)を表示 pic.twitter.com/BRyDlLLnOs
- パラメータ調整前の音声
第一段階パラメータ調整前の音声
— ひろ (@Khirotake) 2019年5月3日
グラフ:1ms毎にスペクトログラムの値(0-1に正規化)を表示 pic.twitter.com/h3wUOiMO8n聞き比べてもらうと、第一段階の音質が改善したことがわかると思います。
7.第二段階の学習データ削減
第二段階の学習では、学習データとして変換先のスペクトログラムのみを使用して学習しています。
6章の結果のグラフは音声のスペクトログラムを表示しています。
筆者は音声分野の研究をしている訳ではないので理由はわかりませんが、人の声の特徴はスペクトログラムの低次元側に集まっているらしいです。
このため、学習するスペクトログラムは下記、spectrogram(2次元配列)の2次元目にある513個のうち前半部分を使用します。[動作環境]
become-yukarin
└become-yukarin
├dateset
│ └dataset.py ・・・ データ加工処理
└super_resolution.py ・・・ 第二段階の変換処理dataset.py(抜粋)・・・ class AcousticFeatureProcess(BaseDataProcess): ・・・ spectrogram = pyworld.cheaptrick(x, f0, t, fs)第二段階の学習データを加工している処理のspectrogramを前1/4に削る。
dataset.py(抜粋)・・・ class AcousticFeatureProcess(BaseDataProcess):def create_sr(config: SRDatasetConfig): data_process_base = ChainProcess([ LowHighSpectrogramFeatureLoadProcess(validate=True), SplitProcess(dict( #input=LambdaProcess(lambda d, test: numpy.log(d.low[:, :-1])), #target=LambdaProcess(lambda d, test: numpy.log(d.high[:, :-1])), # add 1/4 input=LambdaProcess(lambda d, test: numpy.log(d.low[:, :(int)((d.low.shape[1])/4)])), target=LambdaProcess(lambda d, test: numpy.log(d.high[:, :(int)((d.high.shape[1])/4)])), )), ]) ・・・第二段階の変換処理をしている箇所で、インプットデータの前1/4に学習を適応して反映する。
super_resolution.py(抜粋)・・・ def convert(self, input: numpy.ndarray) -> numpy.ndarray: # add 1/4 inputを変更 input = input[:, :(int)(input.shape[1]/4)+1] ・・・ def convert_to_audio( self, input: numpy.ndarray, acoustic_feature: AcousticFeature, sampling_rate: int, ): acoustic_feature = acoustic_feature.astype_only_float(numpy.float64) # add 1/4 spectrogramを変更 spectrogram = acoustic_feature.spectrogram spectrogram[:, :(int)(input.shape[1]/4)+1] = input[:, :(int)(input.shape[1]/4)+1] out = pyworld.synthesize( f0=acoustic_feature.f0.ravel(), #spectrogram=input.astype(numpy.float64), spectrogram=spectrogram.astype(numpy.float64), aperiodicity=acoustic_feature.aperiodicity, fs=sampling_rate, frame_period=self._param.acoustic_feature_param.frame_period, )学習時と変換時のスペクトログラムを前1/4にすることで、データ量を1/4にすることができます。
これにより、第二段階でネックとなっていた音声変換時の速度が4倍となリます。8.第二段階を用いたノイズ学習
第二段階の学習はスペクトログラムに対して行なっていますが、高音質化のキモはノイズを学習させているところにあります。
第二段階の学習に使う中間データを作成しているコードを見ていきます。[動作環境]
become-yukarin
├become-yukarin
│ └param.py ・・・ 第二段階の中間データ作成用にパラメータを変更する
├scripts
│ ├extract_spectrogram_pair.py ・・・ 第二段階の中間データ作成
│ └extract_spectrogram_pair_noise.py ・・・ 第二段階の中間データ作成(新規作成)
├test_data_sr ・・・ 第二段階の音声変換のためのインプットディレクトリ
└output
└yukari_2nd ・・・ 第二段階の変換後の音声が格納されるディレクトリextract_spectrogram_pair.py(抜粋)・・・ def generate_file(path): ・・・ feature = acoustic_feature_process(wave, test=True).astype_only_float(numpy.float32) high_spectrogram = feature.spectrogram fftlen = pyworld.get_cheaptrick_fft_size(arguments.sample_rate) low_spectrogram = pysptk.mc2sp( feature.mfcc, alpha=arguments.alpha, fftlen=fftlen, )第二段階の中間データ作成(extract_spectrogram_pair.py)では、変換先の音声からスペクトログラムを取り出したものをhigh_spectrogramとし、変換先の音声のmfccをスペクトログラムに変換したものをlow_spectrogramとしています。
この二つのスペクトログラムを学習データとして第二段階で処理します。端的に第二段階でしていることを言えば、音声に合成するときの『mfccからスペクトログラムへの変換誤差のノイズ』をディープラーニングで補正しています。
mfccは第一段階で処理する学習データ(の一部)となっており、第二段階では第一段階の誤りを補正していると言えます。実際に第二段階を試した人は分かると思いますが、上記の誤差補正は大幅に音質が良くなるものではないようです。
そこで、low_spectrogram側に大きなノイズを入れた音声と差し替えて、ノイズを学習させることにします。low_spectrogramを10~15のorderで作成したスペクトログラムに差し替えます。
extract_spectrogram_pair_noise.py""" extract low and high quality spectrogram data. """ import argparse import multiprocessing from pathlib import Path from pprint import pprint import numpy import pysptk import pyworld from tqdm import tqdm from become_yukarin.dataset.dataset import AcousticFeatureProcess from become_yukarin.dataset.dataset import WaveFileLoadProcess from become_yukarin.param import AcousticFeatureParam from become_yukarin.param import VoiceParam import random base_voice_param = VoiceParam() base_acoustic_feature_param = AcousticFeatureParam() parser = argparse.ArgumentParser() parser.add_argument('--input_directory', '-i', type=Path) parser.add_argument('--output_directory', '-o', type=Path) parser.add_argument('--sample_rate', type=int, default=base_voice_param.sample_rate) parser.add_argument('--top_db', type=float, default=base_voice_param.top_db) parser.add_argument('--pad_second', type=float, default=base_voice_param.pad_second) parser.add_argument('--frame_period', type=int, default=base_acoustic_feature_param.frame_period) parser.add_argument('--order', type=int, default=base_acoustic_feature_param.order) parser.add_argument('--alpha', type=float, default=base_acoustic_feature_param.alpha) parser.add_argument('--f0_estimating_method', default=base_acoustic_feature_param.f0_estimating_method) parser.add_argument('--enable_overwrite', action='store_true') arguments = parser.parse_args() pprint(dir(arguments)) def generate_file(path): out = Path(arguments.output_directory, path.stem + '.npy') if out.exists() and not arguments.enable_overwrite: return # load wave and padding wave_file_load_process = WaveFileLoadProcess( sample_rate=arguments.sample_rate, top_db=arguments.top_db, pad_second=arguments.pad_second, ) wave = wave_file_load_process(path, test=True) # make acoustic feature acoustic_feature_process = AcousticFeatureProcess( frame_period=arguments.frame_period, order=arguments.order, alpha=arguments.alpha, f0_estimating_method=arguments.f0_estimating_method, ) # make acoustic feature acoustic_feature_process_noise = AcousticFeatureProcess( frame_period=arguments.frame_period, order=random.randint(10, 15), alpha=arguments.alpha, f0_estimating_method=arguments.f0_estimating_method, ) feature = acoustic_feature_process(wave, test=True).astype_only_float(numpy.float32) high_spectrogram = feature.spectrogram feature_noise = acoustic_feature_process_noise(wave, test=True).astype_only_float(numpy.float32) low_spectrogram = feature_noise.spectrogram # save numpy.save(out.absolute(), { 'low': low_spectrogram, 'high': high_spectrogram, }) def main(): paths = list(sorted(arguments.input_directory.glob('*'))) arguments.output_directory.mkdir(exist_ok=True) pool = multiprocessing.Pool() list(tqdm(pool.imap(generate_file, paths), total=len(paths))) if __name__ == '__main__': main()第二段階の中間データを作成するときのパラメータを以下にします。
param.py(抜粋)class AcousticFeatureParam(NamedTuple): frame_period: int = 1 order: int = 30第二段階の中間データ作成時にはフレーム間隔を1msにすることで学習データを増やしています。
- 実行例
command$ python scripts/extract_spectrogram_pair_noise.py -i dat/in_2nd_yukari_many_wav -o dat/out_2nd_yukari_many_npy $ python train_sr.py dat/config_sr.json dat/model/yukari_2nd第二段階の音声変換時には以下のパラメータに戻します。
param.py(抜粋)class AcousticFeatureParam(NamedTuple): frame_period: int = 10 order: int = 30第二段階の変換元の音声には、第一段階のパラメータ調整前で作成した音声を使用しました。
第一段階のパラメータ調整後ではノイズがあまりないため、検証のためノイズが大きい音声を使用しています。「test_data_sr」ディレクトリに第一段階のパラメータ調整前で作成した音声を格納し、以下を実行する。
- 実行例
command$ python scripts/super_resolution_test.py yukari_2nd -md dat/model -iwd dat/in_2nd_yukari_many_wav -it 10000
- 第二段階の中間データ変更後の音声(extract_spectrogram_pair_noise.py)
第二段階変更後の音声
— ひろ (@Khirotake) 2019年5月3日
グラフ:1ms毎にスペクトログラムの値(0-1に正規化)を表示 pic.twitter.com/6TrTJhwlMc
- 第二段階の中間データ変更前の音声(extract_spectrogram_pair.py)
第二段階変更前の音声
— ひろ (@Khirotake) 2019年5月3日
グラフ:1ms毎にスペクトログラムの値(0-1に正規化)を表示 pic.twitter.com/4f5i2uoslU9.まとめ
『ディープラーニングの力で結月ゆかりの声になるリポジトリ』の性能アップということで、実際に試して効果があった方法を解説してきました。
第一段階では大きく音質を改善することができましたが、第二段階ではノイズが低減したことが分からなかったと思います。
第二段階のインプット音声に消せるノイズがあまりなく、第二段階の効果が出なかったと思われます。実際に第二段階を試していたときは、データクレンジングする前で大きなノイズがある状態でしていましたので、大きなはノイズは除去できていました。
ただし、速度面では第二段階の変換時のデータ量を1/4にし、パラメータのframe_periodを5から10にすることでデータ量を1/8(速度8倍)にできました。
第一段階で音質が改善できたと言ってもまだ、音声の輪郭がぼやけている感じがしますので、
今後は、より人の声になるような第二段階の処理に改善する必要があると思います。最後に、素晴らしいコードを公開してくださった作者のヒホ氏に感謝します。
間違いなどありましたらコメントで教えてもらえると幸いです。
- 投稿日:2019-05-03T21:47:47+09:00
テーブル作成支援ツールのPython移植 #6
はじめに
[#5]までで作成したC++の処理をPythonへ移植する。
本記事では基本中の基本となる「文字列の分割」を実験する。実装
文字列をタブ区切りで分割str = "index number\titem name\tdata" print( str ) #->index number item name data strSplit = str.split('\t') print( strSplit ) #->['index number', 'item name', 'data']結果
文字列の分割は簡単にできた。
知っていれば何のことはないが、未知の言語では
- 関数名は正しいのか?
- 拡張機能なのか?
- 分割後の型はどうなるのか?
など、心配事は尽きない。。。
早く自身の中での「当たり前」まで昇華させたいものだ。
- 投稿日:2019-05-03T20:53:04+09:00
SQLiteのインメモリモードとファイルモードの性能を比較してみた
- 簡単なベンチマークプログラムを用いてインメモリモードとファイルモードのCRUDの性能を比較
概要
ふと「SQLiteってインメモリモードとファイルモードでどれくらい性能差があるのか?」という疑問が浮かんだので、なるべく時間をかけずにベンチマークコードを書いて試してみた。せっかくなので結果を共有する。
結果
単位は秒。10回実施した平均値を示す。
Mac/SSD
機種ID: MacBookPro10,2 プロセッサ名: Intel Core i5 プロセッサ速度: 2.5 GHz メモリ: 8 GB
# 操作 ファイルモード インメモリモード 1 100万行のbulk-insert 6.290 5.835 2 1行をinsert 0.247 0.225 3 文字列カラムでソート 0.221 0.195 4 数値カラムでソート 0.238 0.175 5 文字列・数値でフィルタ 0.008 0.007 6 更新 0.130 0.086 7 削除 0.186 0.127 Windows/HDD
プロセッサ: Intel Core i7-7700 プロセッサ速度: 3.6 GHz メモリ: 32 GB
# 操作 ファイルモード インメモリモード 1 100万行のbulk-insert 4.655 3.417 2 1行をinsert 0.285 0.132 3 文字列カラムでソート 0.209 0.185 4 数値カラムでソート 0.242 0.220 5 文字列・数値でフィルタ 0.009 0.007 6 更新 0.556 0.105 7 削除 0.781 0.127 ベンチマークコード
Githubで公開している。
- SQLite Benchmark
以下は抜粋。
db.create_all() sw = StopWatch() sw.start() entities = [dict( text1=random_text(3), text2=random_text(3), number1=random(), number2=random(), ) for i in range(args.records)] sw.wrap('generate {0} records'.format(args.records)) db.session.execute(ItemMapper.__table__.insert(), entities) db.session.commit() sw.wrap('bulk insert {0} records'.format(args.records)) del entities item = ItemMapper() item.text1 = 'aaa' item.text2 = 'bbb' item.number1 = 0.1 item.number2 = 0.2 db.session.add(item) db.session.commit() sw.wrap('insert 1 records') result1 = ItemMapper.query.order_by(ItemMapper.text1, ItemMapper.text2).offset(1000).limit(20).all() sw.wrap('select order by text1, text2 offset 1000 limit 20') result2 = ItemMapper.query.order_by(ItemMapper.number1, ItemMapper.number2).offset(1000).limit(20).all() sw.wrap('select order by number1, number2 offset 1000 limit 20') result3 = ItemMapper.query.filter(ItemMapper.text1.startswith('a')) \ .filter(ItemMapper.number1 > 0.5).offset(1000).limit(20).all() sw.wrap('select where text1 like a* and number1 > 0.5 offset 1000 limit 20') ItemMapper.query.filter(ItemMapper.text1 == 'aaa').update(dict(text1='bbb')) db.session.commit() sw.wrap('update text1 bbb where text1==aaa') ItemMapper.query.filter(ItemMapper.text1 == 'bbb').delete() db.session.commit() sw.wrap('delete where text1 == bbb') sw.describe() reports.append(sw.get_report()) db.drop_all()
- 投稿日:2019-05-03T20:45:33+09:00
Django入門編を終えた感想
はじめに
以下のページを参考に、PaizaCloud上で簡単なWebアプリケーションを作成してみました。
https://paiza.hatenablog.com/entry/2018/02/28/paizacloud_django今回は実際にDjangoを利用してみて驚いた点を紹介します。
モデルファイルを元にテーブルが作成される
Djangoでアプリケーションディレクトリ上で作成した「models.py」の定義データを元にテーブルが作成されます。
要するにアプリケーションで使用するテーブルを作成するためのDDL実行などが一切不要ということです。
手順は以下のようになります。【1】modelファイル作成(models.py)
from django.db import models # テーブル名は「アプリケーション名 + "_" + メソッド名」の形式で作成されます # 1メソッド:1テーブル class Post(models.Model): # カラム名 = models.作成するカラムの種類に該当するメソッド(定義情報) body = models.CharField(max_length=200)【2】マイグレーションファイル作成
models.py を元に、以下コマンドによりマイグレーションファイル(※1)を作成する。
(※1)テーブルを作成するための定義ファイル。「models.py」を元に作成される。$ python manage.py makemigrations アプリケーション名★実際には上記コマンドを実行したことによりアプリケーションディレクトリに「migrations」というディレクトリが作成されました。「migrations」の中にはテーブルの定義情報、スクリプトが格納されているようです。
【3】DB反映
以下コマンドを実行し、【2】で作成したマイグレーションファイルの情報をDBへ反映する。
(【2】で一緒に作成された「migrations」ディレクトリ内のスクリプトが実行される模様)$ python manage.py migrate【4】テーブル定義情報を確認する
【1】でmodels.pyに定義したテーブル情報が実際にDBに定義されていることを確認する。# インストールしているDBシェルを呼び出し(入門編ではmysqlを使用) $ python manage.py dbshell # 定義されているテーブル一覧参照 # todo_postテーブルが作成されていることを確認(アプリケーション名は「todo」) mysql> show tables; +----------------------------+ | Tables_in_mydb | +----------------------------+ | auth_group | | auth_group_permissions | | auth_permission | | auth_user | | auth_user_groups | | auth_user_user_permissions | | django_admin_log | | django_content_type | | django_migrations | | django_session | | todo_post | +----------------------------+ 11 rows in set (0.00 sec) # todo_postテーブルのカラム情報を参照 # bodyカラムが定義されていること # ※なお、PrimaryKeyが定義されていない場合は自動でidカラムがPrimaryKeyとして定義される模様 mysql> describe todo_post; +-------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | body | varchar(200) | NO | | NULL | | +-------+--------------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)上記の仕様により、models.pyファイルの共有のみで各環境ごとに同じテーブル定義を容易に利用できるようです。テーブル定義情報を別途持ちまわる必要がないため、非常に開発効率が良いように思えます。
FW標準のDB管理画面が用意されている
管理者ユーザを作成(コマンド:python3 manage.py createsuperuser)し、「admin.py」ファイルを作成することにより、ブラウザ経由でDB管理画面を表示することができる。
以下が管理画面へのログイン画面。
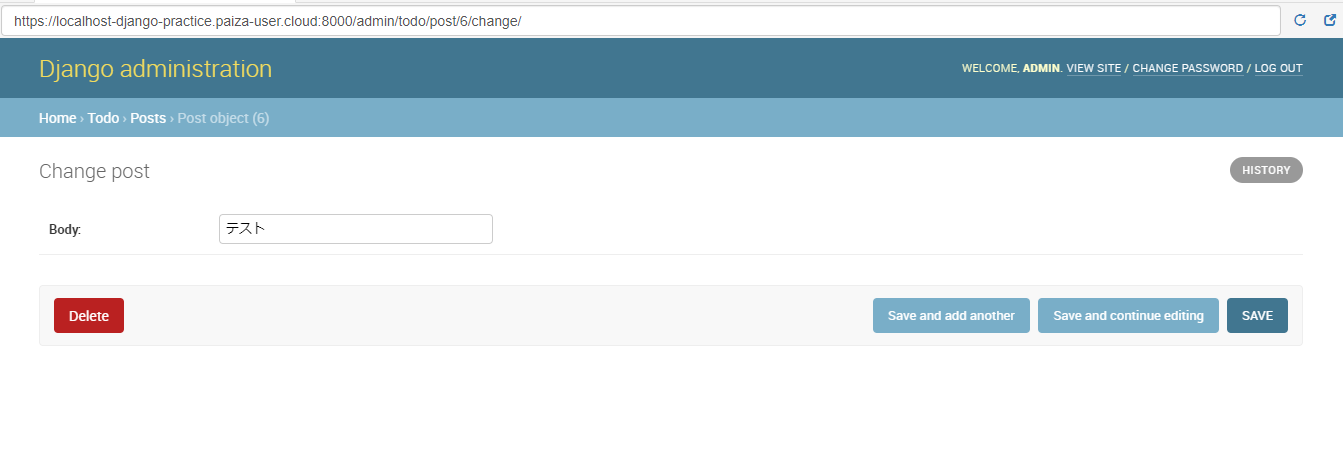
(標準でログイン画面まで利用できる。すごい・・)
これが実際の管理画面です。(現在bodyカラムが「テスト」というレコードが登録されてます。)
データの追加/削除等が可能な模様。
管理画面に関してはカスタマイズが可能なようです。
詳細は今後勉強していきます。Next
入門編を終えたため、今後は簡単なWebアプリケーションを作成する予定です。
Djangoの他標準機能を試運転できるような開発ができればと考えてます。
(案探し中。。)
- 投稿日:2019-05-03T20:20:29+09:00
Flaskでクエリストリングを獲得する際に、思った値が取れない時の原因と対策
はじめに
Flaskを使っているときにGETやPOSTで想定通りのパラメータを取得することができず1時間くらい右往左往したため、忘記録として記述しておく。
問題が起きたプログラム
問題となったのは、パラメータlで受け取ったURLにリダイレクトするだけの以下のAPI。
なお粗末なプログラムですが、GitHubで公開しているので興味のある方はどうぞ。import string from flask import Flask, request HTML = '''\ <!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>redirect</title> <meta http-equiv="refresh" content="0; URL='${link}'" /> </head> <body> このページは自動的に転送されます。<br> 転送されない場合は<a href="${link}">こちら</a>をクリックしてください </body> </html> ''' app = Flask(__name__) @app.route('/') def index(): link = request.args.get('l', '') assert link, 'Cannot get l parameter querystring' return string.Template(HTML).substitute({'link': link})上記のWebアプリを
html://hoge.com/r/に配置して、パラメータlに適当なURLを与えてやる。たとえば、次のような感じで使うことを想定している。http://hoge.com/r/?l=http:fuga.com/問題と原因
パラメータlに色々なURLを放り込んでみるが、クエリを持つURLを与えると思った通りのリダイレクトをしてくれない。たとえば、以下のような感じ。
html://hoge.com/r/?l=http:fuga.com/?q=1&date=20190501問題は明らかで、与えたl内に?や&が入っていること。解決するにはなんとかこれを消してやればよい。
replaceなどの力技も可能だが、極力スマートにやりたい。(あとAPI側をいじりたくない解決策
リダイレクト先のURLを作ったあとに
urllib.parse.quoteをかけてやることで解決する。import urllib target = 'http:fuga.com/?q=1&date=20190501' return 'html://hoge.com/r/?l=' + urllib.parse.quote(target)これでlで指定したURL(パラメータ付き)に正しくアクセスできる。
あとAPI側での修正は必要ない。よしなにデコードしてくれるようだ。おまけ
実はこの
urllib.parse.quoteは非常に便利で、たとえば、クロールしてきたWebページを保存するときに、そのURLをエンコードしてやることでファイル名として扱えたりできる。
- 投稿日:2019-05-03T20:20:29+09:00
Flaskでクエリストリングを獲得する際に、思った値が取れない原因と対策
はじめに
Flaskを使っているときにGETやPOSTで想定通りのパラメータを取得することができず1時間くらい右往左往したため、忘記録として記述しておく。
問題が起きたプログラム
問題となったのは、パラメータlで受け取ったURLにリダイレクトするだけの以下のAPI。
なお粗末なプログラムですが、GitHubで公開しているので興味のある方はどうぞ。import string from flask import Flask, request HTML = '''\ <!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>redirect</title> <meta http-equiv="refresh" content="0; URL='${link}'" /> </head> <body> このページは自動的に転送されます。<br> 転送されない場合は<a href="${link}">こちら</a>をクリックしてください </body> </html> ''' app = Flask(__name__) @app.route('/') def index(): link = request.args.get('l', '') assert link, 'Cannot get l parameter querystring' return string.Template(HTML).substitute({'link': link})上記のWebアプリを
html://hoge.com/r/に配置して、パラメータlに適当なURLを与えてやる。たとえば、次のような感じで使うことを想定している。http://hoge.com/r/?l=http:fuga.com/問題と原因
パラメータlに色々なURLを放り込んでみるが、クエリを持つURLを与えると思った通りのリダイレクトをしてくれない。たとえば、以下のような感じ。
html://hoge.com/r/?l=http:fuga.com/?q=1&date=20190501問題は明らかで、与えたl内に?や&が入っていること。解決するにはなんとかこれを消してやればよい。
replaceなどの力技も可能だが、極力スマートにやりたい。(あとAPI側をいじりたくない解決策
リダイレクト先のURLを作ったあとに
urllib.parse.quoteをかけてやることで解決する。import urllib target = 'http:fuga.com/?q=1&date=20190501' return 'html://hoge.com/r/?l=' + urllib.parse.quote(target)これでlで指定したURL(パラメータ付き)に正しくアクセスできる。
あとAPI側での修正は必要ない。よしなにデコードしてくれるようだ。おまけ
実はこの
urllib.parse.quoteは非常に便利で、たとえば、クロールしてきたWebページを保存するときに、そのURLをエンコードしてやることでファイル名として扱えたりできる。
- 投稿日:2019-05-03T18:31:16+09:00
NLP(自然言語処理)ライブラリGiNZAとJanomeを比較してみた。
はじめに
つい先日GiNZAというNLPライブラリが公開されたので、既存のライブラリと性能を比較してみました。
比較対象はJanome。
サンプルテキスト
比較に用いた文字列はWikipediaにある原子力発電のページ
https://ja.wikipedia.org/wiki/原子力発電
上記のページでページ全体を選択してコピペして利用しました。
Janome
https://mocobeta.github.io/janome/
インストールは以下のコマンドを実行。
pip install janomeテストコードは以下のとおり。
from time import time txt = """ 原子力発電 出典: フリー百科事典『ウィキペディア(Wikipedia)』 ナビゲーションに移動検索に移動 〜中略〜 最終更新 2019年4月30日 (火) 14:38 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスの下で利用可能です。追加の条件が適用される場合があります。詳細は利用規約を参照してください。 プライバシー・ポリシーウィキペディアについて免責事項開発者Cookieに関する声明モバイルビュー Wikimedia Foundation Powered by MediaWiki """ t1 = time() from janome.tokenizer import Tokenizer t2 = time() t = Tokenizer() tokens = t.tokenize(txt.replace(' ',' ')) t_janome = "" i = 0 for token in tokens: if token.surface != "\n": t_janome += " " + token.surface i += 1 print(i, time() - t1, time() - t2)実行結果は以下のとおり。
27935, 3.574777126312256, 3.574641227722168検出した形態素は27,935個で、経過時間は3.57秒。
GiNZA
https://megagonlabs.github.io/ginza/
インストールは以下のコマンドを実行。
pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz"テストコードは以下のとおり。
from time import time txt = """ 原子力発電 出典: フリー百科事典『ウィキペディア(Wikipedia)』 ナビゲーションに移動検索に移動 〜中略〜 最終更新 2019年4月30日 (火) 14:38 (日時は個人設定で未設定ならばUTC)。 テキストはクリエイティブ・コモンズ 表示-継承ライセンスの下で利用可能です。追加の条件が適用される場合があります。詳細は利用規約を参照してください。 プライバシー・ポリシーウィキペディアについて免責事項開発者Cookieに関する声明モバイルビュー Wikimedia Foundation Powered by MediaWiki """ t1 = time() import spacy nlp = spacy.load('ja_ginza_nopn') t2 = time() doc = nlp(txt) t_ginza = "" i = 0 for sent in doc.sents: for token in sent: if token.orth_ != "\n": t_ginza += " " + token.orth_ i += 1 print(i, time() - t1, time() - t2)実行結果は以下のとおり。
25665, 18.349574089050293, 17.297925233840942検出した形態素は25,665個で、経過時間は18.34秒。
考察
圧倒的にJanomeが早いです。
ただ、単語の分析はGiNZAの方が良いような印象をうけました。例えば、「経済産業省」という単語をJanomeは「経済 産業 省」と分けましたが、GiNZAは「経済産業省」という一つの単語として認識していました。
文章に依存する話ではありますが、目的に応じて使い分けると良いかなと感じます。
ということで、次は何するかな(^-^)
- 投稿日:2019-05-03T17:42:12+09:00
【初心者向け】JavaGoldが解説するPythonの基礎 パート2
概要
パート1に引き続きPythonの基礎的内容をシェアできればと思います!
ご覧になっていない方は、まずはパート1を^^アジェンダ
・if文
・for文
・関数
・例外処理
・pass文
・スコープ
・クラス
・クロージャ
・引数
・終わりにif文
Javaのswitch~case構文は存在しないが、「in」と言うキーワードを使うことで同じような実装が可能。「elif」は、「else if」の略。
・if文
val1 = 1 val2 = 2 if val1 == val2: print('test1') elif val1 > val2: print('test2') else: print('test3') # test3・「in」キーワードを使用した、switch文ライクな書き方
val3 = 3 if val3 == 1: print('test1') elif val3 in(2,3): print('test2') # test2 elif val3 in(3,4): print('test3') else: print('test4')for文
for文は、Javaのforeach文に相当。range関数と組み合わせて使うことが多い。
while文はあるが、do-while文は存在しない。・for文とrange関数
for i in range(3): print(i) # 0、1、2と順に表示・for文と文字列(リストや辞書なども使用可能)
for c in 'test': print(c) # t, e, s, tと順に表示関数
関数の定義には「def」を使用。※引数は全て参照渡し。
def fnc(a, b=1): # bはデフォルト値付きの引数 return a + b # 戻り値 # 関数呼び出し print(fnc(10)) # 11・関数を呼び出す際に、引数名を指定することで定義順を無視することが可能。
def fnc(a, b, c): print(a, b, c) # 関数呼び出し fnc(c=3, a=1, b=2)# 1 2 3■ 関数とメソッドの違い
ほとんど一緒の様なものと思って良いです!関数:特定のクラスには縛られないもの。モジュール内にdefで定義されたもの。
書き方: 関数( 引数 )メソッド:特定のクラス(またはそのクラスのインスタンス)専用のもの。クラス内にdefで定義されたもの。
書き方: 値.メソッド( 引数 )例えば len("文 字 列") は "文 字 列" の長さを取得する関数なのに、 "文 字 列".split() は文字を空白文字で分割する メソッド (オブジェクト.関数) ですね。
基本的にはメソッドの場合は、そのオブジェクト固有の処理が多いです。
例えば "文字列".split や "文字列".startswith などです。これは文字列固有です。
ですが len は文字列にも、リストにも使えます。 len("文字列") len([0, 1, 2]) なのです。こういった場合は、Pythonでは関数で用意されています。・Pythonの関数(オブジェクト) と オブジェクト.関数() の違いは何ですか?
http://blog.pyq.jp/entry/2017/09/14/100000※関数の全ての引数は参照渡しされるが、渡されたオブジェクトの型(mutable型とimmutable型)で挙動が異なる!
変更可能(mutable)な型では元の値は変更される。一方、変更不可(immutable)な型では元の値は変更されない。
変更不可(immutable)な型をもつオブジェクトが渡されたときは値渡しのように振る舞うが値渡しというわけではない。■変更不可(immutable)な型
・int, float, complexといった数値型
・文字列型(string)
・タプル型(tuple)
・bytes
・Frozen Set型■変更可能(mutable)な型
・リスト型(list)
・バイト配列(bytearray)
・集合型(set)
・辞書型(dictionary)例外処理
「try~except~else~finally」という構文で処理。
exceptがJavaで言うcatch文で”例外が発生した時に実行する文、elseはexceptに補足されなかった処理を記述する。try: x = 10 / 0 except Exception as e: print(e) # division by zero # 例外が発生しなかった場合に行う処理 else: print('test1') # 例外発生有無に関係なく必ず走る処理 finally: print('test2')# test2・明示的に例外を発生させるには「raise」を使用する。(Javaではthrow文)
try: raise Exception('test3') except Exception as e: print(e) # test3pass文
「何もしない」ことを明示するための構文。Javaにはない。
例えば、以下の様な時に使用する。
・条件分岐のときに何も実行しない
・例外が発生したときに何もしない
・関数やクラスの実装が明確でない# 偶数のみ出力 for i in range(10): if(i % 2) == 0: print(i) else: passスコープ
スコープの種類は以下の4種類。頭文字を取ってLEGB と言われている。
①ローカルスコープ(Local scope)
→関数内のみ。ローカルスコープからはビルトインスコープやモジュールスコープの変数や関数を参照することはできるが、変数に値を代入(上書き)することは不可。②エンクロージング(Enclosing (function's) scope)
→関数の中で関数が定義されている、そんな場合に初めて意識するスコープで、端的にいうと関数の外側のローカルスコープ。③グローバルスコープ(Global Scope)
→モジュール(ファイル全体)内全体。④ビルトインスコープ(Built-in scope)
→組み込み変数(None)や組み込み関数(print関数)のスコープで、どこからでも参照可能。スコープの詳細についてこちらの記事を参考にさせて頂きました。
詳細が記載されていますので、時間がある方はご覧下さい。クラス
コンストラクタは「init」と言う名前にし、第一引数には必ず「self」を定義する。
selfは自身のインスタンスを表すオブジェクト。Name.classclass Name: # クラス変数 LANG = 'JP' # コンストラクタ def __init__(self): self.name = '' # getter def getName(self): return self.name # setter def setName(self, name): self.name = name taro = Name() taro.setName('イチロー') print(taro.getName()) # イチロー print(Member.LANG) # JPクロージャ
関数のローカル変数を参照するような関数。
関数呼び出しが終わってもローカル変数を参照し続けられる。
Javascriptのクロージャとほぼ同等。クロージャの詳細についてはこちらの記事に載っています。
引数
引数の種類は以下の4種類。
①通常の引数
②デフォルト値付きの引数
→関数呼び出しの際に省略された場合に採用するデフォルト値を定義した引数のこと。#②デフォルト値付きの引数 def fnc(a, b = 1): return a + b # 戻り値③可変長の引数
→1つ以上の値を受け取る引数のこと。引数名の前にアスタリスク(*)を付ければこの引数になる。関数側では受け取った可変長引数はタプルとして扱う。#③可変長の引数 def fnc(a, b, *args): print(a, b, args) fnc('a','b','c','d','e') # a b ('c','d','e')④キーワード付きの可変長の引数
→引数を指定する際に、キーワードを付ける必要がある可変長の引数。
引数名の前にアスタリスク(*)を二つ付ければこの引数になる。なお、関数側では受け取った可変長引数は、定義時に付けた名前を持つ辞書型のデータとして扱う。#④キーワード付きの可変長の引数 def fnc(a, b, **args): print(a, b, args) fnc('a','b',arg1 = 'c',arg2 = 'd',arg3 = 'e')# a b {'arg1': 'c', 'arg3': 'e', 'arg2': 'd'} #fnc('a','b','c','d','e') ←キーワード指定しないとエラーになる終わりに
パート1 & 2でおおよそのPythonの基礎を説明しました。
PythonにはWEBフレームワークや、機械学習ライブラリが豊富にあるのでこの基礎と組み合わせればやりたいことは実現できる?はず!!
自分はこれからPythonを使ったWebAPIを作りたいと思います参考文献
・Pythonの関数(オブジェクト) と オブジェクト.関数() の違いは何ですか?
http://blog.pyq.jp/entry/2017/09/14/100000・Pythonのスコープについて
http://note.crohaco.net/2017/python-scope/・【Python】クロージャ(関数閉方)とは
https://qiita.com/naomi7325/items/57d141f2e56d644bdf5f・Pythonにおける値渡しと参照渡し
https://crimnut.hateblo.jp/entry/2018/09/05/070000・AmadaShirou. Programing Keikensya No Tameno Python Saisoku Nyumon (Japanese Edition) Kindle 版
- 投稿日:2019-05-03T17:41:45+09:00
KerasのRNN (LSTM) で return_sequences=True を試してみる
はじめに
Kerasを使うとRNN (LSTM) なども手軽に試せて楽しいです。フレームワークごとに性能差などもあるのでしょうが、まずは取っつきやすいものからと思っています(データと最低限の設定を準備すれば使い始められる)。Kerasなら何とかいけるかも?と思っています。
RNN系のレイヤー全体にいえることとして、「return_sequences」というパラメータが存在するのですが
return_sequences=True って何?
という疑問が浮かびました。
Recurrentレイヤー - Keras Documentation後で詳しく述べますが、時系列データに対する最終的な出力だけでなく、途中時点での出力を学習するための設定であるようです。
return_sequencesとは
return_sequences: 真理値.出力系列の最後の出力を返すか,完全な系列を返すか.
うん、分からん。
とはいえ、こちらのページを見るとなんとなく分かってきました。
言語モデルの性能が、実装により異なる件を解決する – programming-soda – Mediumバッチ型でシーケンシャル型と同じ内容を学習するなら、系列の長さ毎にデータを作る必要が出てきます。A,B,C,Dの4つがあったら、A, B, C=>Dだけでなく、A=>B、A,B=>Cも学習でテータに含まないといけないということです。このように対策しても精度が改善することは確認済みですが、この場合シーケンス分だけデータが増え学習に時間がかかります。隠れ層の計算を毎回最初からやっていることになり非効率的です。
そのため、各ステップの隠れ層の状態から予測する形にします。図にすると以下のような形です。これにより、隠れ層の再計算をすることなく、都度に予測する形の学習が可能になります。
return_sequences=Trueを指定すると、そのような学習ができるというのです。具体的な問題で考える
前回の記事で取り上げた「{0.0, 1.0}からなる列の総和を出力するモデル」を考えます。
例えば[1.0, 1.0, 1.0, 1.0, 0.0, 1.0, 1.0, 1.0, 0.0, 1.0]が入力であれば、8.0が出力されるようにします。
(前回の記事:Kerasで基本的なRNN (LSTM) を試してみる - Qiita)前回の記事では、入力列に対して、全体の総和だけを正解ラベルとして与えていました。
ところが、これは学習データに存在する長さの列に対してはそれなりにもっともな予測を出しますが、それ以外のものに対しては(長くても短くても)うまく動かないことがあります。
いろいろな長さの列を学習データに含めればよいですが、長さのバリエーションをカバーするため、用意しなければならないデータの量が増えてしまうのが難点。
前回の記事の「可変長の系列を入力する場合 (1)」では、実際にいろいろな長さの列を準備して学習を行っていました。ここで、数列の総和だけでなく、先頭から途中までの和(部分和)もうまく学習に使えると、幸せになれるかもしれません。LSTMを含むRNNは時系列データを扱っていて、1つの値が入力されるごとに内部状態が変わっていきます。今までは、途中の内部状態については何も制御せず、最終的な内部状態だけを制御していた(最終的な出力さえ合っていれば計算過程はどうでもいい)のですが、普通に考えると、この内部状態は部分和(その時点までの総和)を表しているのが自然なはずです。そうなるように内部状態を制御すれば、学習データより短い数列に対しても、それなりにうまく総和を予測できるようになることが期待できます。
これまではラベルは総和を表す実数値1個だけだったのですが、今度はラベルは部分和となり、入力と同じ長さの数列になります。
具体例を見るほうが早いでしょう。Xを時系列の {0.0, 1.0} 列、tをラベルとすると、学習データは以下のように変わります。Before
総和の
8.0だけをラベルとして与えていました。
X t 1.0 1.0 1.0 1.0 0.0 1.0 1.0 1.0 0.0 1.0 8.0 After
総和の値だけでなく、Xの部分和(先頭からある要素までの総和)をラベルとして与えます。
X t 1.0 1.0 1.0 2.0 1.0 3.0 1.0 4.0 0.0 4.0 1.0 5.0 1.0 6.0 1.0 7.0 0.0 7.0 1.0 8.0 例えば、この系列を先頭から5つ取り出した
X t 1.0 1.0 1.0 2.0 1.0 3.0 1.0 4.0 0.0 4.0 も、長さ5の学習データとして意味のあるデータになります。大雑把に言えば、このような(先頭からある長さを取り出した)部分列も実質的に学習していることになる、と理解できそうです。
ここで面白いのは、LSTMレイヤーが元々持っている内部状態を制御するだけですので、LSTMレイヤーのモデルの複雑さ(パラメータ数)自体は変わらない点かと思います。学習データの件数やパラメータ数は増えていないのに、学習できる情報量が増えている?ような気がして、ちょっと戸惑ってしまいます。
プログラムで検証
同じ長さの列だけを学習データとして与えたときに、それより短い・長い列の総和をうまく予測できるかという課題にチャレンジします。
rnn_dynamic_before.pyは、前回の記事の「可変長の系列を入力する場合 (1)」で取り上げた方法と同じで、ラベルには総和だけを与え、学習データを固定長に変えています。rnn_dynamic_after.pyは、学習データのラベルを部分和に変更しています。Before
rnn_dynamic_before.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Masking from keras.layers.recurrent import LSTM from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 len_sequence = 10 # 学習データの時系列の長さ batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples, sequence_len): # 乱数で {0.0, 1.0} の列を生成する X = np.random.randint(0, 2, (nb_of_samples, sequence_len)).astype("float32") # 各行の総和を正解ラベルとする t = np.sum(X, axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 return X.reshape((nb_of_samples, sequence_len, 1)), t # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples, len_sequence) # モデル構築 model = Sequential() model.add(Masking( input_shape=(None, input_dim), mask_value=-1.0)) model.add(LSTM( num_hidden_units, return_sequences=False)) model.add(Dense(output_dim)) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # (サンプル, 時刻, 特徴量の次元) の3次元の入力を与える。 # 学習データと同じ長さのデータ(総和は8.0) test_10 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_10)) # [[7.7854743]] # 学習データより短いデータ(総和は4.0) test_05 = np.array([1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_05)) # [[3.0897331]] # 学習データより長いデータ(総和は12.0) test_15 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)) # [[10.465068]]学習データと同じ長さであれば、それなりに近い値?(一応四捨五入すると期待の結果になる)が予測されますが、短いデータや長いデータだと誤差が大きくなってしまいます。短い方に関しては「答えは合ってるけど途中の計算過程はめちゃくちゃ」といった感じでしょうか。
After
学習の作り方とモデルの作り方が少し変わります。また、ラベルを部分和にしたので予測結果も部分和の数列になります。以下のコードでは予測結果の最後の要素(=数列全体の総和)だけを出力していますが、結果を全部表示して観察してみると面白いかもしれません。
なお、
TimeDistributedラッパーは、時系列データのそれぞれに対してレイヤーを適用することを示しています。各時刻の内部状態に対して同じ変換 (Dense) を行い、その時点での出力を求めましょう、という意味になるわけですね。
レイヤーラッパー - Keras Documentation
Keras Recurrentレイヤーメモ:return_sequences, RepeatVector, TimeDistributed - Qiitarnn_dynamic_after.py#!/usr/bin/env python3 import tensorflow as tf from keras.models import Sequential from keras.layers import Dense, Masking from keras.layers.recurrent import LSTM from keras.layers.wrappers import TimeDistributed from keras.optimizers import Adam import numpy as np import random input_dim = 1 # 入力データの次元数:実数値1個なので1を指定 output_dim = 1 # 出力データの次元数:同上 num_hidden_units = 128 # 隠れ層のユニット数 len_sequence = 10 # 学習データの時系列の長さ batch_size = 300 # ミニバッチサイズ num_of_training_epochs = 100 # 学習エポック数 learning_rate = 0.001 # 学習率 num_training_samples = 1000 # 学習データのサンプル数 # データを作成 def create_data(nb_of_samples, sequence_len): # 乱数で {0.0, 1.0} の列を生成する X = np.random.randint(0, 2, (nb_of_samples, sequence_len)).astype("float32") # 各行の累積和を正解ラベルとする t = np.cumsum(X, axis=1) # LSTMに与える入力は (サンプル, 時刻, 特徴量の次元) の3次元になる。 # ラベルも時系列データになるので、同じ形状になる。 return X.reshape((nb_of_samples, sequence_len, 1)), t.reshape((nb_of_samples, sequence_len, 1)) # 乱数シードを固定値で初期化 random.seed(0) np.random.seed(0) tf.set_random_seed(0) X, t = create_data(num_training_samples, len_sequence) # モデル構築 model = Sequential() model.add(Masking( input_shape=(None, input_dim), mask_value=-1.0)) model.add(LSTM( num_hidden_units, return_sequences=True)) model.add(TimeDistributed(Dense(output_dim))) model.compile(loss="mean_squared_error", optimizer=Adam(lr=learning_rate)) model.summary() # 学習 model.fit( X, t, batch_size=batch_size, epochs=num_of_training_epochs, validation_split=0.1 ) # 予測 # (サンプル, 時刻, 特徴量の次元) の3次元の入力を与える。 # 学習データと同じ長さのデータ(総和は8.0) test_10 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_10)[:, -1, :]) # [[7.762647]] # 学習データより短いデータ(総和は4.0) test_05 = np.array([1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_05)[:, -1, :]) # [[4.1512775]] # 学習データより長いデータ(総和は12.0) test_15 = np.array([1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)[:, -1, :]) # [[9.912318]]学習データより短い例では、Beforeと比べて誤差が小さくなっています。一方、長いデータに対してはうまく予測できていません。最後の予測は
12.0に近い値を期待していますが、学習データの長さは10で、部分和が12.0になるような学習データが存在しませんので、無理もないでしょう。試しに総和が10未満になる長いデータを一つ試すと# 学習データより長いデータ(総和は7.0) test_15 = np.array([1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1], dtype="float32").reshape((1, -1, 1)) print(model.predict(test_15)[:, -1, :]) # [[6.985335]]といったように、近い値を予測できました。
学習データとして十分長い列を使用すれば、この点は解決されそうです。
(いろいろ試すと、総和が10に近づくにつれて誤差が大きくなっているような気がします。学習データの作り方の性質上、値が10に近づくと総和がその値になるようなサンプルが少なくなっていくからでしょうか)ちなみに、乱数シードを定数で初期化しているにもかかわらず、
rnn_dynamic_after.pyではなぜか毎回結果が少しずつ変わってしまうようでした。rnn_dynamic_before.pyだと大丈夫なのですが。まとめ
数列の途中までを入力した時点での結果(部分問題の結果 or 計算過程)に意味があるような問題設定であれば、
return_sequences=Trueを使ってみるとよいと思います。
- 投稿日:2019-05-03T17:41:30+09:00
PyTorchのTensorBoardサポートを試してみる
PyTorchがv1.1.0にアップデートされ、オフィシャルのTensorBoardサポート機能が追加されました。
torch.utils.tensorboardにあるSummaryWriterを使ってTensorBoard用に学習ログなどを書き出すことができます。この記事では、このSummaryWriterを使ってみた結果を紹介したいと思います。
(まだexperimental状態なので、すぐに古い情報になってしまうかもしれません。)実行環境:
- Ubuntu 18.04 (Windows10のWSLで)
- python==3.6.8
- pytorch==1.1.0
- tensorboard==1.14.0a20190502 (tb-nightly)準備編
PyTorch
PyTorchは公式ページ(https://pytorch.org/get-started/locally/) を参考に、環境に合わせてインストールしてください。
TensorBoardサポートはv1.1.0からなので、お間違いなく。TensorBoard
TensorBoardについてはv1.14が必要です。PyPIにある最新のものはv1.13なのでnightlyバージョンをインストール必要があります。v1.14でも古めのやつだと上手くいかなかったので、最新のものをとってくることをおすすめします。
インストールは
pip install tb-nightlyで出来ます。
その他
環境によっては、他にも追加でインストールが必要かもしれません。
僕の環境ではpastがないよって怒られました。pastはpip install futureでインストールできます。(pastなのにfuture!?ってなった)
SummaryWriterの使い方
さて、SummaryWriterの使い方を紹介していきたいと思います。
公式には説明や使用例がちょっとしかありませんが、tensorboardXというパッケージのドキュメントや使用例が参考になりそうです。tensorboardXは、TensorBoardをPyTorchなどから利用するためのパッケージです。こちらにもSummaryWriterというクラスがあるのですが、ぱっと見、使い方はほぼ同じに見えます。(ちなみに以下のコードはtensorboardXのSummaryWriterでも動きます。)
PyTorchのgithubレポジトリを覗いてみると、tensorboardXの作者によるプルリクTensorBoard support within PyTorch #16196から、公式でのTensorBoardサポートにつながっていったみたいですね。
参考ページ:
ドキュメント
tensorboardXに関する記事
基本の使用例
まずは超基本的な使用例として、適当に作ったnumpy配列のプロットをTensorBoardで表示してみましょう。
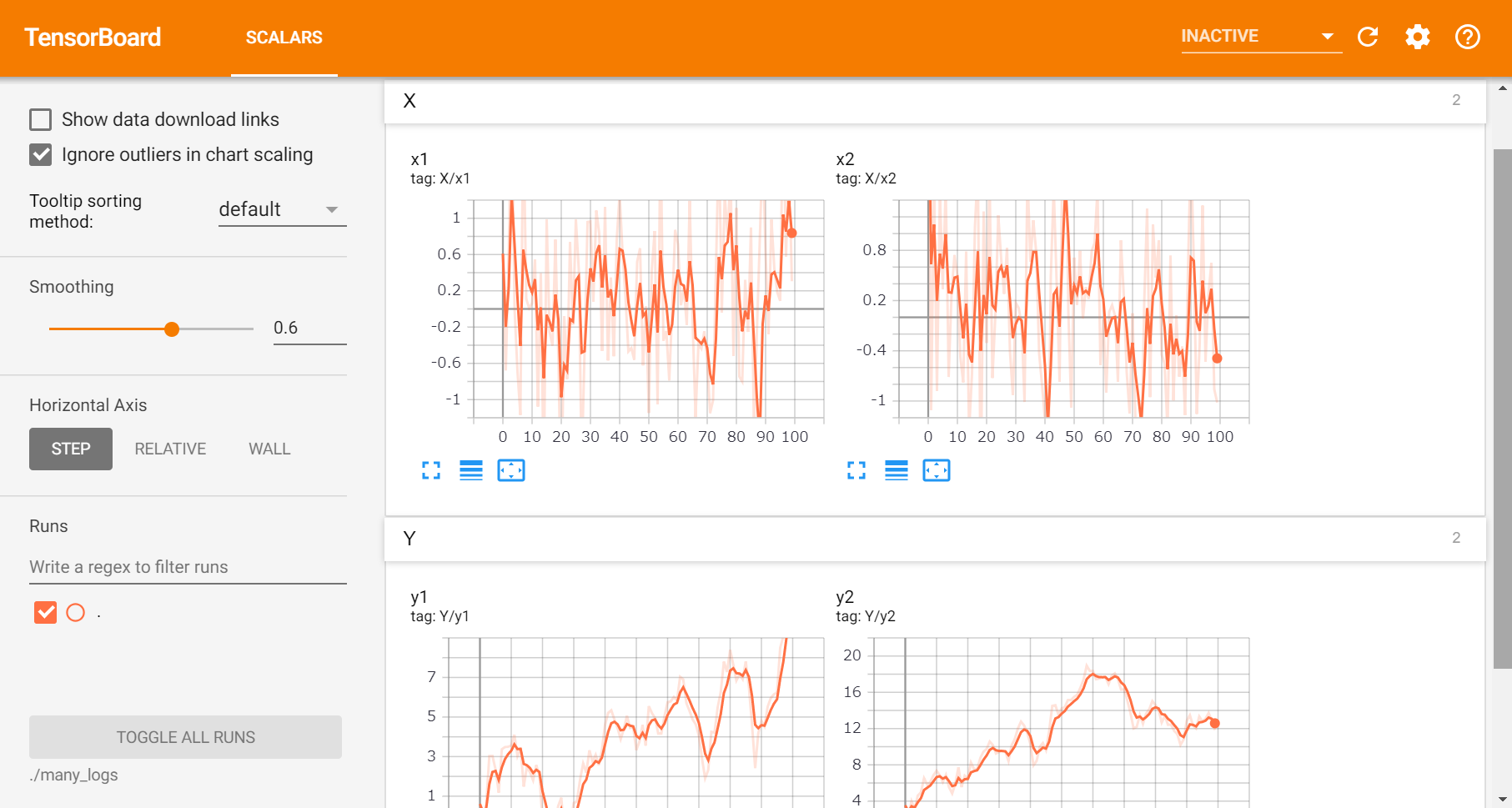
import numpy as np from torch.utils.tensorboard import SummaryWriter x = np.random.randn(100) y = x.cumsum() # xの累積和 # log_dirでlogのディレクトリを指定 writer = SummaryWriter(log_dir="logs") # xとyの値を記録していく for i in range(100): writer.add_scalar("x", x[i], i) writer.add_scalar("y", y[i], i) # writerを閉じる writer.close()add_scalarの引数は
add_scalar(tag, scalar_value, global_step=None, walltime=None)のようになっています。
- tag
- 何のデータかを指定するための名前
- scalar_value
- 記録したい値
- global_step
- 何番目の値かを指定
- 現在のepoch数などを想定していただければ。
walltimeはどういう時にいじるのかよく分からなかったので省略。
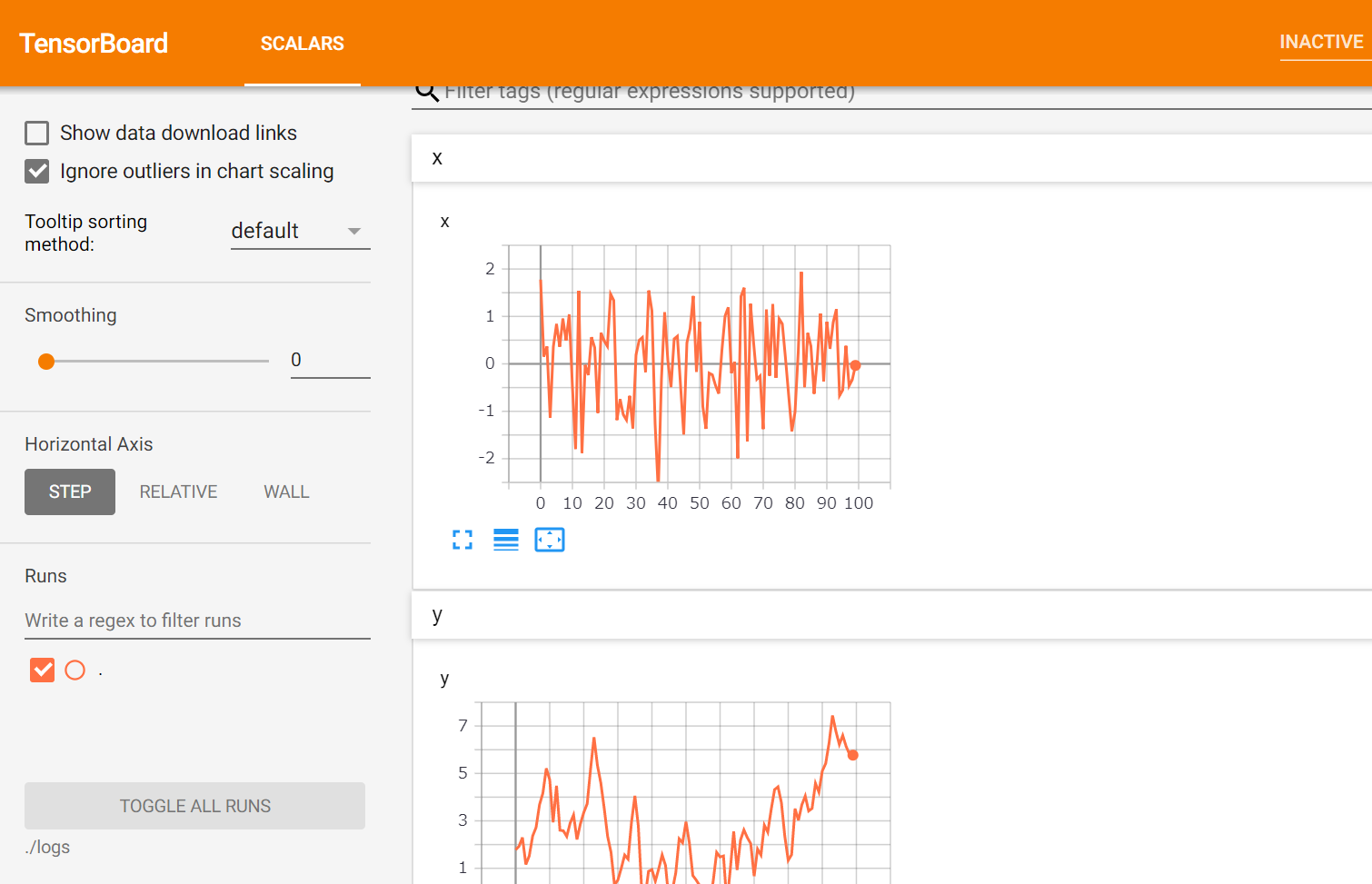
さて、上のやつを実行後に
tensorboard --logdir="logsのパス"とすると、こんな感じになります。(デフォルトだとlocalhost:6006でアクセスできるはず)
楽ちんですね。
もう一工夫
さて、上の例ではtagに安直な名前を指定していました。しかし、ログをとる対象が多い時に上のように別枠で表示されると見にくいです。
例えば、ニューラルネットの学習を記録する時だと、lossやaccuracyなどの評価指標、それらのtrain/validation dataでの値と監視対象多いですよね。
実は、tagの指定の仕方でプロットをグルーピングできます。
具体的には、tag="group_name/value_name"のようにすることで、group_nameの部分が同じものは並べてプロットしてくれます。今回もとっても単純な例で試してみましょう。
import numpy as np from torch.utils.tensorboard import SummaryWriter # ログをとる対象を増やしてみる x1 = np.random.randn(100) y1 = x1.cumsum() x2 = np.random.randn(100) y2 = x2.cumsum() writer = SummaryWriter(log_dir="many_logs") # tagの書き方に注目! for i in range(100): writer.add_scalar("X/x1", x1[i], i) writer.add_scalar("Y/y1", y1[i], i) writer.add_scalar("X/x2", x2[i], i) writer.add_scalar("Y/y2", y2[i], i) writer.close()TensorBoardで見てみるとこんな感じになります。
実践的な使用例
気が向いたら追記します。
まとめ
以上、PyTorchのSummaryWriterの簡単な紹介でした。
add_scalarについてしか書きませんでしたが、画像やヒストグラムなどをTensorBoardに書き出すこともできます。プロットって案外時間をとられがちなとこなので、こういうとこが便利になっていくのはうれしいですね。
- 投稿日:2019-05-03T17:07:54+09:00
Djangoインストール時に、ModuleNotFoundErrorが起きる時の対処法
はじめに
Djangoインストール時にModuleNotFoundErrorが起きた時に考えられる原因と対処法を説明します。
開発環境
OS:macOS Mojave(10.14.4)
Django==2.1.7ModuleNotFoundErrorが起きた時に考えられる原因はpythonが参照できるディレクトリにDjangoが存在しないことです。
まずは、以下の対話的コマンドでpython(ここではpython3)が参照可能なディレクトリを確認します。
$ python3 Python 3.7.2 (default, Mar 18 2019, 17:25:47) [Clang 10.0.0 (clang-1000.10.44.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> print(sys.path) ['', '/Users/user/.pyenv/versions/3.7.2/lib/python37.zip', '/Users/user/.pyenv/versions/3.7.2/lib/python3.7', '/Users/user/.pyenv/versions/3.7.2/lib/python3.7/lib-dynload', '/Users/user/hoge/Django/hoge/fuga_venv/lib/python3.7/site-packages']次に、以下のコマンドでDjangoがあるディレクトリを確認します。
$ pip3 show django Name: Django Version: 2.2.1 Summary: A high-level Python Web framework that encourages rapid development and clean, pragmatic design. Home-page: https://www.djangoproject.com/ Author: Django Software Foundation Author-email: foundation@djangoproject.com License: BSD Location: /Users/user/hoge/Django/hoge/fuga_venv/lib/python3.7/site-packages Requires: pytz, sqlparse Required-by:ここでDjangoのパスをpython3が参照可能でなければ、(今回の事例では参照可能になっています。)パスを変更するなりの対処をします。インストール先のpythonのバージョンが異なるとかもありえますので、その時は適切なバージョンのpythonに切り替えてからDjangoを再度インストールしてあげましょう。
パスの設定に関してはこちらの記事が参考になります。
MacでPATHを通すpythonのバージョン切り替えに関してはこちらの記事を参考ください。
pyenvにより、pythonのバージョンを変更する
- 投稿日:2019-05-03T16:41:33+09:00
メルペイのGWポイント還元で最大限得する方法(遊び)
メルペイとそのGWキャンペーン
皆さん、メルペイはご存知でしょうか。
メルペイとは、メルカリのスマホ決済サービスのことです。
このGW中(4/26(金)~5/6(月))に、メルペイでは、「ニッポンのゴールデンウィークまるっと半額ポイント還元!キャンペーン」を行っています。
このキャンペーンでは、メルペイ加盟店でメルペイを利用して決済すると、
支払いの翌日に支払額の50%相当(セブン-イレブン店頭での支払いの場合は70%相当)がポイント還元されます。
ただし、キャンペーン期間を通じて計P2,500が上限となっています。ここで気づくべきところは、ポイント還元で得たポイントをさらにメルペイの決済に回せるというところです。つまり、(50%なら)5000円分投入しなくても、P2500がゲットできるのです。
如何に最大限の効率でP2500を回収するか、言い換えれば、如何に投入額を抑えて、P2500を得ることができるかを考えてみます。
それには、初日以外は、ポイント還元で得られたポイントで、決済を進めるのが良さそうです。ポイント還元で得られたポイントで決済を進める⇒等比級数モデル
初日投入金額を$a_0$として還元率をPとしたとき、M+1日目には$a_0 p^M$のバックが得られます(セブンと他の加盟店を混ぜないことで簡単な話にしました)。
この形、もちろん見覚えありますよね?
そうです、等比級数の一般項です。
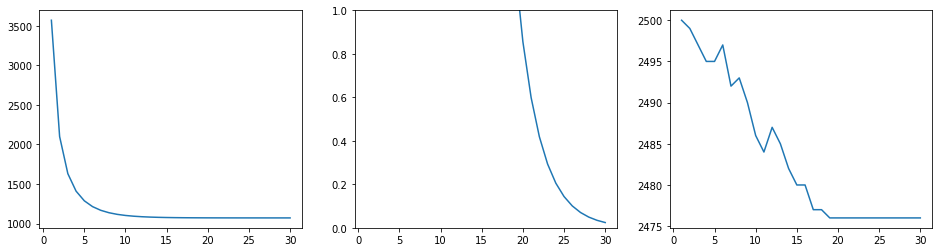
この等比級数の初項(初日投入金額)以外のM+1日目までの和が2500円になると考え、初日投入金額を求める式を導くと、$$a_0 = 2500 \times \frac{1-p}{p} \times \frac{1}{1-p^M}$$
となります。
$a_0$はPとMの関数であることが見て取れますが、Pは0.5 or 0.7であるので、結局Mのみの関数であることがわかります。このMを、以降、回収期間と呼ぶことにします。じゃあ、回収期間Mを決めて、つまり、どれぐらいの日数でポイントを回収したいかを決めて、初回投入金額を求めれば終わりじゃん~。
ということには、実はなりません。
初出の事実になりますが、還元されるポイントは、決済額に還元率をかけたものの小数点以下を切り捨てることで決まり、1円以下のバックは0円になるためです。これを0円還元とでも呼びましょう。そこで、一番小額なM+1日目の還元額が、次の式を満たすかどうかをチェックする必要がでてきます。
$$ a_0 p^M > 1$$
$a_0$を回収期間Mで表して、Mについてこの不等式を解いても良いのですが、$a_0 p^M$の値をプロットした方が楽だしわかりやすいと思ったので、pythonで計算・プロットしていこうと思います。
等比級数モデルと課すべき条件についてpythonを用いて調べる
import numpy as np import matplotlib.pyplot as plt %matplotlib inline p=0.7; Mx=30 c = 2500*(1-p)/p M = np.arange(1,Mx+1) a_0 = c/(1-p**M) #初回投入金額 bp = a_0*(p**M) #M+1日目の還元金額(back point) bpt = np.array([]) #総還元額 for mx in range(1,Mx+1): s=0; a = c/(1-p**mx) for n in range(1,mx+1): a=a*p if a>=1: a=int(a) #還元時の切り捨て s=s+a else:# P1を切る場合 print(mx) break bpt = np.append(bpt,s) plt.figure(figsize=(16,4)) plt.subplot(1,3,1) plt.plot(M,a_0) plt.subplot(1,3,2) plt.plot(M,bp) plt.ylim(0,1) plt.subplot(1,3,3) plt.plot(M,bpt) # plt.ylim(2499,2501)
(キャプション・軸名等は時間がある時に加えます。)このコード・実行結果は、70%還元(セブン)の場合に、回収期間Mを変化させたものとなっています。
左の画像は、回収期間Mに対する$a_0$のプロットです。双曲線を描き、Mが大きくなるほど1000円に漸近していきます。P2500を得るのに、単に0.7で2500を割った値を投入しなくてもよく、Mが長ければ、1000円程度の投入で十分なのです。
中央の画像は、気になっていた$a_0 p^M$のプロットです。回収期間Mが長くなると、還元額が1円を切ってしまっています。M=20を超えると、途中からポイント還元がなされず、P2500に達しないことになります。
この2つから、1円以下の還元額のみ切り捨て処理を考慮した場合、M=19(計20日)で初日だけ1073円のお金を払えば、最大効率でP2500が手に入ると言えます。
ここでわざわざ強調した理由は、毎度毎度行われている切り捨て処理に関して、上2つの結果は考慮していないからです。そこで、初項を求めるときを除いて切り捨て処理を考慮した際に、想定している回収期間M中での総還元額を求めた結果を右の画像に示します。
M=1以外はP2500に到達せず、M=18以降からは一定値を取っています。段々と総還元額が減っていくのは、初回投入金額$a_0$を決める際に、切り捨て処理を考慮せず、等比級数の和から求めていることに起因します。切り捨て処理をしているので、M+1日間(1日目除く)の等比級数の和より小さく求まるのは当たり前です。また、M=18以降で一定値を取るのは、途中から0円還元が始まるからです。
この結果からわかることは、初回投入金額$a_0$の大きさで回収期間中に0円還元が始まるかどうかが決まり、もし0円還元が始まると一定値2475円を取るということです。一定値を取っていないところは、回収期間Mを超えてポイント還元を楽しめば、合計でP2500回収できるかもしれません。まとめ・更なる解析
まとめ
ポイント還元で得られたポイントで決済を繰り返し行っていく等比級数モデルを立て、課すべき条件を考え、pythonで解析を行いました。
0円還元以外の切り捨て処理を考慮せず、回収期間Mを設定することで、最小初日投入金額$a_0$を求めると、M=19で$a_0$=1073 円となりました。
毎度毎度の切り捨て処理を考慮すると、回収期間Mから見積もった$a_0$では、M=1以外は回収期間中にP2500に到達できないことも(当たり前のことだが)図示できました。更なる解析
この記事を書きながら考えたので実行してはいませんが、最大効率でP2500を得るための初回投入金額を正確に決定する方法には、次のものがあると思います。
初期投入金額を振りながら(for文)、切り捨て処理をしたうえで(intへのキャスト)、P2500に到達するまで回収していく(while文)とかでプログラムを書いて求める方法です。ただし、0円還元の際にwhile文をちゃんと抜け出せるよう注意が必要だと思います笑
興味がある方は、やってみてください。
読んでいただきありがとうございました。以上
- 投稿日:2019-05-03T16:09:13+09:00
畳み込み積分とは?(定義、イメージ、意味など)
畳み込み積分、あらゆる分野で出てきますよね。
私は信号処理の分野で出会っているのですが、初めて見たときはその意味が全く分かりませんでした。おそらくそんな方は結構多いと思いますので、私が身に着けた畳み込み積分のイメージについて共有したいと思います。
いつも通り数学的な厳密性は不問としておいてください。定義
たたみ込み積分は
s(t) = \int_{-\infty}^{\infty}f(\tau)g(t-\tau)d\tauという積分で定義されます。定義に関してはいくらでもコマゴマと書いている書籍、ウェブサイトがございますので、そちらをご覧ください。
本稿では、あくまでフワーッと畳み込み積分のイメージをとらえて頂くことを目標にしたいと思います。正弦波とデルタ関数の畳み込み積分
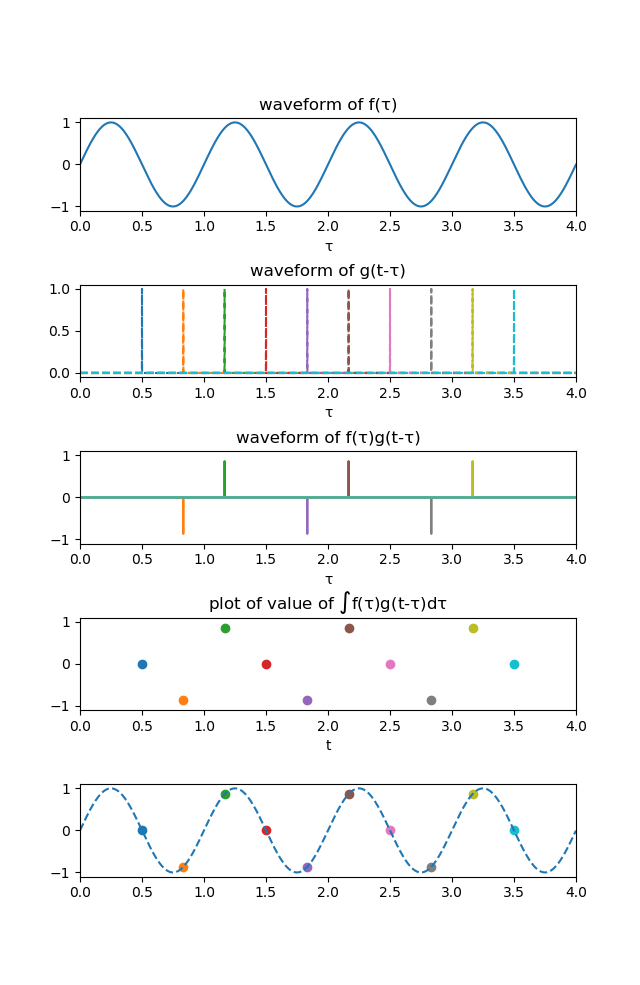
まずは、$f(\tau)$を正弦波、$g(t-\tau)$をデルタ関数としたときの畳み込み積分の様子を図で以下に示します。
大前提として、ある関数$f(t)$とデルタ関数の畳み込み積分の結果は$f(t)$になります。これもいろいろな教科書に書いてあるので、導出は省略します。
いくつかの$t$に注目して解説していきます。
(1) たとえば$t=0.5$のとき、デルタ関数が0ではない値を持つのは$\tau=0.5$ですので、2枚目のグラフの一番左の青い点線がこれに対応します。
しかし、1枚目のグラフを見てわかる通り、今回のシミュレーションでは正弦波の周期を1としているので、正弦波の値は$\tau=0,0.5,1,...$で0になります。よって、$f(0.5)g(0.5-0.5)=0$となり、(見えませんが)3枚目のグラフの$\tau=0.5$の点では値は0となっています。(2) 次に、$t=0.8$に注目します。
デルタ関数はこのとき$\tau=0.8$で0以外の値を持ちます。2枚目のグラフのオレンジ色の点線です。
そして、この場合は先ほどと違い、正弦波も0ではない値を持ちます。よって、これらの積は3枚目で下向きに伸びているオレンジの線のように$f(0.8)g(0.8-0.8)=f(0.8)={\rm sin}(2\pi\times 0.8)$という値を持つことになります。上記(1)、(2)のようにいろいろな$t$についてこの過程を繰り返してやると、4枚目のような点たちをプロットすることができます。
ある程度たくさんプロットして、これらを曲線でフィッティングすると、5枚目のようにもとの正弦波を復元することができます。
この例が畳み込み積分の最も簡単な例になります、
というのも、$g(t)$がデルタ関数だと3枚目のグラフ上で(一つの$t$に対して)0ではないの値を持つ箇所が1か所しかなく、積分(総和)を考えずともその値をそのまま4枚目にプロットすれば良いからです。
たとえば、(1)の場合では3枚目も4枚目も0、(2)の場合では3枚目も4枚目も${\rm sin}(2\pi\times 0.8)$にプロットすればよかったですよね。これが、$g(t)$がデルタ関数ではないときにはそう簡単にはいかなくなるのです。
次の章ではデルタ関数ではなく矩形関数の場合の畳み込み積分についてみていきます。正弦波と矩形関数の畳み込み積分
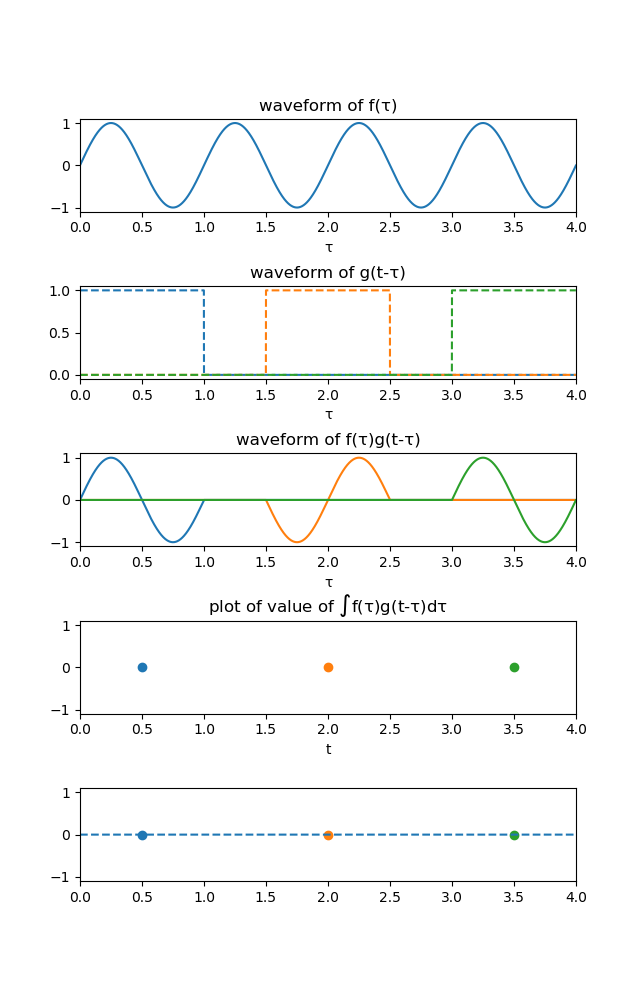
次に、まずは、$f(\tau)$を正弦波、$g(t-\tau)$を矩形関数としたときの畳み込み積分の様子を図で以下に示します。
これも大前提ですが、矩形関数の矩形幅が正弦波の周期と一致するとき、その畳み込み積分の結果はすべての$t$について0になります。
先ほどの同じように、いくつかの$t$に注目していきましょう。
(1) たとえば$t=0.5$のとき、本稿で扱う矩形関数が0ではない値を持つのは$0 < \tau < 1$ですので、2枚目のグラフの一番左の青い点線のハコがこれに対応します。
ちょうどこのハコを窓にして$f(\tau)$を覗くように、3枚目のグラフでは$0 < \tau < 1$に青線で描かれている$f(\tau)$が現れ、それ以外の部分は0になります。そしてここからがポイントなのですが、この青線を$\tau$の全区間にわたって足し合わせた(積分した)ものが4枚目にプロットするべき値となります。
すなわち、$s(0.5)$を求めるためには$\int_{-\infty}^{\infty}f(\tau)g(0.5-\tau)d\tau$を計算しなければならないのです。これがデルタ関数の場合とチョット違うところです。(デルタ関数でも本来同じ過程を踏むのですが、$g(t)$がデルタ関数だとしたら上記の積分は一瞬で解けるため、事実上積分の必要は無いということです。)
今回の場合は、3枚目のように矩形関数によって正弦波がちょうど1周期分取り出されているので、その総和は当然0になります。
よって、4枚目では$t=0.5$で0にプロットすればいいわけです。(2) ほかにも、$t=2$のときでは矩形関数は$1.5 < \tau < 2.5$で1となるので、2枚目のオレンジ線のハコが書けます。
先ほどの全く同様に、これを窓として$f(\tau)$を覗くと3枚目のグラフでは$1.5 < \tau < 2.5$にオレンジ線で描かれている$f(\tau)$が現れ、それ以外の部分は0になります。
このオレンジ線の総和もやはり0なので、4枚目の$t=2$にも0にプロットしたらいいとわかります。矩形関数の矩形幅が正弦波の周期と同じ長さのとき、ハコはどこにあったとしてもそこから見える$f(\tau)$は1周期分になるはずなので、4枚目、5枚目は常に0という結果になるはずです。
ちょっと一般化して考える
ここまでで、なんとなく畳み込み積分のイメージをつかんでもらえたのではないかと思いますので、ちょっと一般化して何をしているのかをまとめます。
便宜上、$f(\tau)$を「基準関数」、$g(t-\tau)$を「中心$t$のズラし関数」と呼ぶことにしましょう。畳み込み積分は、
- $t=t'$における畳み込み積分の結果$s(t')$を求めるために、まずは基準関数と中心$t'$のズラし関数を掛け合わせる
- 掛け合わせた結果の関数を、全区間にわたって積分したものが求めたい$s(t')$
- $t'=t'+\Delta$としてズラし関数をちょっとだけズラし、1.に戻る
という操作によって実行されます。
畳み込み積分の物理的な意味
1章では畳み込み積分の定義について述べ、2章3章ではデルタ関数・矩形関数との畳み込み積分の結果を視覚的にとらえてきました。
4章では2章3章で行った操作を、「基準関数」「ズラし関数」という言葉を使ってちょっと一般化しました。
本章では、畳み込み積分の物理的な意味についてご紹介いたします。ただ、物理的意味はもしかしたら畳み込み積分が使われる分野や場面に応じて変わる可能性があるので、あくまでもone of theイメージであると思っていただけるといいかなと思います。「ズラし関数」「畳み込み積分の結果」「基準関数」の関係についてですが、ひとことで言うと
ズラし関数は「時刻$t'$における畳み込み積分の結果を計算するにあたって、基準関数の時刻$t'$付近の影響をどの程度受けるか」を表しています。たとえば、2章ではズラし関数としてデルタ関数を扱いましたよね。
デルタ関数は時刻$t'$という特定の時刻でのみ1となり、それ以外の時刻では常に0です。これは「畳み込み積分の結果は、時刻$t'$における基準関数の値以外の影響を全く受けない」と捉えなおすことができます。だからこそ3枚目のグラフから4枚目のグラフにかけて、全く値が変わらなかったわけです。さらに、3章ではズラし関数として矩形関数を扱いました。
矩形関数は時刻$t'-0.5$から時刻$t'+0.5$でのみ1となり、それ以外の時刻では常に0です。これは「畳み込み積分の結果は、時刻$t'-0.5$から時刻$t'+0.5$における基準関数の値の影響を等しく受ける」と捉えなおすことができます。こうなると、3枚目のグラフでは波が現れますが、4枚目にプロットするべき点としては波のすべての成分が互いに打ち消しあった「0」となる、という感じです。ほかにも、たとえばズラし関数がsinc関数だった場合(信号処理分野では頻出)にはどうでしょうか。
sinc関数の形は以下のような感じです。
sinc関数は真ん中で1をとるので基準関数の時刻$t'$の成分はかなり強く表れますが、同時に外側でも波打っており常に0というわけではないので、これに付随して基準関数の時刻$t'$の周りの影響も色濃く受ける、と予想されますよね。
実際その通りで、信号処理の分野では受信信号が元の波形とsinc関数の畳み込み積分として得られ、元の波形を復元するためにsinc関数の影響を取り除かなければならないなんてこともあります。まとめ
本稿では2章・3章で畳み込み積分のイメージをつかめるように、図で一連の流れを示しました。
最後の5章では「基準関数」「ズラし関数」「畳み込み積分の結果」の間にどのような関連性があるのかについて述べました。
理解の一助になれたとしたら幸いです。参考にしたらいいと思う資料
東北工業大学 中川朋子先生
http://www.ice.tohtech.ac.jp/~nakagawa/laplacetrans/convolution1.htm
ズラし関数を「忘却の度合い」と表現されていらっしゃいます。
この見方で言うと、デルタ関数は「一瞬で忘れるような忘れ方」、矩形関数は「しばらくはメッチャ覚えてるけどある日ふと忘れてしまうような忘れ方」と言えます。付録
例のごとくクソコードですが貼っておきます。
一番上のresolutionとか関数の種類を指定するところをいじるとグラフをちょっと変えられます。#%% これらの値を変更すると出力されるグラフが変わる resolution = 3 g_function = 'rect' #rectまたはdelta #%% 諸々の設定と関数の定義(さわらなくてもOK) import numpy as np import matplotlib.pyplot as plt def rect(center_index, full_length, sampling): temp = np.zeros(full_length) temp[center_index-int(sampling/2): center_index+int(sampling/2)] = 1 return temp def delta(center_index, full_length): temp = np.zeros(full_length) temp[center_index] = 1 return temp #%% 畳み込み積分の計算 iteration = 4 sampling = 1000 N = iteration * sampling center_index = int(N/2) time_index = np.arange(N)/sampling f_signal = np.sin(2*np.pi*time_index) conv_signal = np.zeros(N) for i in range(int(sampling/2), N-int(sampling/2)): if g_function == 'rect': g_signal = rect(i, len(f_signal), sampling) elif g_function == 'delta': g_signal = delta(i, N) else: print('すみません、gの関数は矩形関数かデルタ関数にのみ対応しています') conv_signal[i] = np.sum(f_signal * g_signal) #%% グラフの出力 plt.subplots_adjust(wspace=0.4, hspace=0.8) fig = plt.figure(1) f_plt = fig.add_subplot(511) f_plt.set_title('waveform of f(τ)') f_plt.set_xlabel('τ') f_plt.set_xlim([0, 4]) f_plt.set_ylim([-1.1, 1.1]) g_plt = fig.add_subplot(512) g_plt.set_title('waveform of g(t-τ)') g_plt.set_xlabel('τ') g_plt.set_xlim([0, 4]) fg_plt = fig.add_subplot(513) fg_plt.set_title('waveform of f(τ)g(t-τ)') fg_plt.set_xlabel('τ') fg_plt.set_xlim([0, 4]) fg_plt.set_ylim([-1.1, 1.1]) conv_plt = fig.add_subplot(514) conv_plt.set_title('plot of value of $\int$f(τ)g(t-τ)dτ') conv_plt.set_xlabel('t') conv_plt.set_xlim([0, 4]) conv_plt.set_ylim([-1.1, 1.1]) lay_plt = fig.add_subplot(515) lay_plt.set_xlim([0, 4]) lay_plt.set_ylim([-1.1, 1.1]) f_plt.plot(time_index, f_signal) if g_function == 'rect': lay_plt.plot(time_index, conv_signal, linestyle='--') elif g_function == 'delta': lay_plt.plot(time_index, f_signal, linestyle='--') #res_sample = np.arange(int(sampling/2),N-int(sampling/2), int(1000/resolution)) res_sample = np.linspace(500,len(f_signal)-500,resolution) res_sample = [int(n) for n in res_sample] for i in res_sample: if g_function == 'rect': g_signal = rect(i, len(f_signal), sampling) elif g_function == 'delta': g_signal = delta(i, N) g_plt.plot(time_index, g_signal, linestyle = '--') fg_signal = f_signal * g_signal fg_plt.plot(time_index, fg_signal) conv_plt.scatter(time_index[i], conv_signal[i]) lay_plt.scatter(time_index[i], conv_signal[i])
- 投稿日:2019-05-03T16:08:03+09:00
スクレイピング
- 投稿日:2019-05-03T15:59:12+09:00
Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite Part.2
MobileNetV2-PoseEstimation
Tensorflow-bin
1.Introduction
前回記事 Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite Part.1 により、
Openposeのトレーニング実施とOpenVINO/Tensorflow Liteモデルを生成しました。
今回は作成した学習済みファイルとPythonでOpenVINOとTensorflow Liteのリアルタイム骨格検出を行います。
Tensorflow-GPU および CUDA を使用せず、PythonとOpenVINOで、CPUのみによる推論と描画を行います。何故私がここまでCPU推論にこだわっているかというと、電気を大食いして高熱を発するGPUや、設置スペースを無駄に消費する外付けデバイス、インタフェースの性能が低いことに引きずられて十分なパフォーマンスが得られないデバイス、などは実戦投入するときに扱いづらいと考えているからです。 扱いやすさとは裏腹に、 連続稼働数時間で停止してしまうようなインフラはとても良くない です。
余談はさておき、GPUを使用せずにどれほどの性能が得られるでしょうか。
前回記事投稿時のスピードは下図のとおり、超遅いです。【前回】 Tensorflow-CPU's Test Core i7, FP32 (disabled OpenVINO/Tensorflow Lite) - 4 FPS
Youtube: https://youtu.be/nEKc7VIm42A
では、いつもどおりいきなり結果に行きます。 前回と同じモデルを使用し、OpenVINO対応しただけです。
前回・今回ともにGPUを使用していません。 今回は精度とスピードのバランスを計るため、2種類のモデルを生成して動作検証しました。
今回はCPU推論にも関わらずフレームレートが10倍ほど向上しています。
動画はUSBカメラの撮影レートを30FPSに制限していますが、高速なフレームレートで撮影すると40FPSまで速度が向上します。
ちなみに、 Core i7 でも Core m3 でも結果は同じです。【今回】 Boost Mode, OpenVINO Test Core i7 CPU only (disabled GPU), Sync - FP32 - 40 FPS++
Youtube: https://youtu.be/J-a2kHS4nTc
【今回】 Boost Mode, OpenVINO Test NCS2 x1, Async - FP16 - 25 FPS
Youtube: https://youtu.be/CUAojvJYRLE
【今回】 Normal Mode, OpenVINO Test Core i7 CPU only, Sync - FP32 (enabled OpenVINO) - 15-19 FPS
Youtube: https://youtu.be/t66bnWwZ7rE
【今回】 Normal Mode, OpenVINO Test NCS2 x1, Async - FP16 - 8-10 FPS
Youtube: https://youtu.be/hFFUectGQ2A
2.Environment
- Ubuntu 16.04 x86_64
- OpenVINO 2019 R1.0.1
- Tensorflow v1.12.0 + Tensorflow Lite
- USB Camera
- Python 3.5
- NCS2 x1
3.Procedure
手順もなにも無く、この記事の一番上にあるニコちゃんマークのリンク先のリポジトリをクローンして実行するだけです。
一応、作成したロジック群を全て下記に転記しておきます。 みなさんのご参考になれば幸いです。
非同期モードのプログラムは NCS2 の複数本挿しによるブーストにも対応しています。
なお、Tensorflow Lite版は遅すぎて使い物になりませんでしたので、ロジックのご紹介だけにとどめておきます。openvino-usbcamera-cpu-ncs2-sync.py_同期推論モードimport sys import os import numpy as np import cv2 from os import system import io import time from os.path import isfile from os.path import join import re import argparse import platform try: from armv7l.openvino.inference_engine import IENetwork, IEPlugin except: from openvino.inference_engine import IENetwork, IEPlugin def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints fps = "" detectfps = "" framecount = 0 time1 = 0 camera_width = 320 camera_height = 240 keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 30) cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) parser = argparse.ArgumentParser() parser.add_argument("-d", "--device", help="Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable. (Default=CPU)", default="CPU", type=str) parser.add_argument("-b", "--boost", help="Setting it to True will make it run faster instead of sacrificing accuracy. (Default=False)", default=False, type=bool) args = parser.parse_args() plugin = IEPlugin(device=args.device) if "CPU" == args.device: if platform.processor() == "x86_64": plugin.add_cpu_extension("lib/libcpu_extension.so") if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP32/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP32/frozen-model.xml" elif "GPU" == args.device or "MYRIAD" == args.device: if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" else: print("Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable.") sys.exit(0) model_bin = os.path.splitext(model_xml)[0] + ".bin" net = IENetwork(model=model_xml, weights=model_bin) input_blob = next(iter(net.inputs)) exec_net = plugin.load(network=net) inputs = net.inputs["image"] h = inputs.shape[2] #368 w = inputs.shape[3] #432 threshold = 0.1 nPoints = 18 try: while True: t1 = time.perf_counter() ret, color_image = cap.read() if not ret: break colw = color_image.shape[1] colh = color_image.shape[0] new_w = int(colw * min(w/colw, h/colh)) new_h = int(colh * min(w/colw, h/colh)) resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h - new_h)//2:(h - new_h)//2 + new_h,(w - new_w)//2:(w - new_w)//2 + new_w, :] = resized_image prepimg = canvas prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW, (1, 3, 368, 432) outputs = exec_net.infer(inputs={input_blob: prepimg})["Openpose/concat_stage7"] detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 for part in range(nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (canvas.shape[1], canvas.shape[0])) # (432, 368) keypoints = getKeypoints(probMap, threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) frameClone = np.uint8(canvas.copy()) for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.namedWindow("USB Camera", cv2.WINDOW_AUTOSIZE) cv2.imshow("USB Camera" , frameClone) if cv2.waitKey(1)&0xFF == ord('q'): break # FPS calculation framecount += 1 if framecount >= 15: fps = "(Playback) {:.1f} FPS".format(time1/15) framecount = 0 time1 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime except: import traceback traceback.print_exc() finally: print("\n\nFinished\n\n")openvino-usbcamera-cpu-ncs2-async.py_非同期推論モードimport sys import os import numpy as np import cv2 from os import system import io import time from os.path import isfile from os.path import join import re import argparse import platform try: from armv7l.openvino.inference_engine import IENetwork, IEPlugin except: from openvino.inference_engine import IENetwork, IEPlugin import multiprocessing as mp from time import sleep import threading import heapq def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(detected_keypoints, outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints processes = [] fps = "" detectfps = "" framecount = 0 detectframecount = 0 time1 = 0 time2 = 0 lastresults = None keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] def image_preprocessing(color_image, w, h, new_w, new_h): resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h-new_h)//2:(h-new_h)//2 + new_h,(w-new_w)//2:(w-new_w)//2 + new_w, :] = resized_image return canvas def camThread(results, frameBuffer, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h): global fps global detectfps global lastresults global framecount global detectframecount global time1 global time2 global cam global window_name cam = cv2.VideoCapture(0) if cam.isOpened() != True: print("USB Camera Open Error!!!") sys.exit(0) cam.set(cv2.CAP_PROP_FPS, vidfps) cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) window_name = "USB Camera" wait_key_time = 1 cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE) while True: t1 = time.perf_counter() # USB Camera Stream Read s, color_image = cam.read() if not s: continue if frameBuffer.full(): frameBuffer.get() color_image = image_preprocessing(color_image.copy(), w, h, new_w, new_h) frameClone = np.uint8(color_image.copy()) frameBuffer.put(color_image) if not results.empty(): detected_keypoints, outputs, keypoints_list = results.get(False) detectframecount += 1 for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(detected_keypoints, outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) lastresults = [detected_keypoints, outputs, keypoints_list] else: if not isinstance(lastresults, type(None)): detected_keypoints, outputs, keypoints_list = lastresults for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(detected_keypoints, outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.putText(frameClone, detectfps, (w-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.imshow(window_name, frameClone) if cv2.waitKey(wait_key_time)&0xFF == ord('q'): sys.exit(0) ## Print FPS framecount += 1 if framecount >= 15: fps = "(Playback) {:.1f} FPS".format(time1/15) detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2) framecount = 0 detectframecount = 0 time1 = 0 time2 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime time2 += elapsedTime # l = Search list # x = Search target value def searchlist(l, x, notfoundvalue=-1): if x in l: return l.index(x) else: return notfoundvalue def async_infer(ncsworker): #ncsworker.skip_frame_measurement() while True: ncsworker.predict_async() class NcsWorker(object): def __init__(self, devid, device, model_xml, frameBuffer, results, camera_width, camera_height, number_of_ncs, vidfps, nPoints, w, h, new_w, new_h): self.devid = devid self.frameBuffer = frameBuffer self.model_xml = model_xml self.model_bin = os.path.splitext(model_xml)[0] + ".bin" self.camera_width = camera_width self.camera_height = camera_height self.threshold = 0.1 self.nPoints = nPoints self.num_requests = 4 self.inferred_request = [0] * self.num_requests self.heap_request = [] self.inferred_cnt = 0 self.plugin = IEPlugin(device=device) if "CPU" == device: if platform.processor() == "x86_64": self.plugin.add_cpu_extension("lib/libcpu_extension.so") self.net = IENetwork(model=self.model_xml, weights=self.model_bin) self.input_blob = next(iter(self.net.inputs)) self.exec_net = self.plugin.load(network=self.net, num_requests=self.num_requests) self.results = results self.number_of_ncs = number_of_ncs self.predict_async_time = 250 self.skip_frame = 0 self.roop_frame = 0 self.vidfps = vidfps self.w = w #432 self.h = h #368 self.new_w = new_w self.new_h = new_h def skip_frame_measurement(self): surplustime_per_second = (1000 - self.predict_async_time) if surplustime_per_second > 0.0: frame_per_millisecond = (1000 / self.vidfps) total_skip_frame = surplustime_per_second / frame_per_millisecond self.skip_frame = int(total_skip_frame / self.num_requests) else: self.skip_frame = 0 def predict_async(self): try: if self.frameBuffer.empty(): return self.roop_frame += 1 if self.roop_frame <= self.skip_frame: self.frameBuffer.get() return self.roop_frame = 0 prepimg = self.frameBuffer.get() reqnum = searchlist(self.inferred_request, 0) if reqnum > -1: prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW, (1, 3, 368, 432) self.exec_net.start_async(request_id=reqnum, inputs={self.input_blob: prepimg}) self.inferred_request[reqnum] = 1 self.inferred_cnt += 1 if self.inferred_cnt == sys.maxsize: self.inferred_request = [0] * self.num_requests self.heap_request = [] self.inferred_cnt = 0 heapq.heappush(self.heap_request, (self.inferred_cnt, reqnum)) try: cnt, dev = heapq.heappop(self.heap_request) except: return if self.exec_net.requests[dev].wait(0) == 0: self.exec_net.requests[dev].wait(-1) detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 outputs = self.exec_net.requests[dev].outputs["Openpose/concat_stage7"] for part in range(self.nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (self.w, self.h)) # (432, 368) keypoints = getKeypoints(probMap, self.threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) self.results.put([detected_keypoints, outputs, keypoints_list]) self.inferred_request[dev] = 0 else: heapq.heappush(self.heap_request, (cnt, dev)) except: import traceback traceback.print_exc() def inferencer(device, model_xml, results, frameBuffer, number_of_ncs, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h): # Init infer threads threads = [] for devid in range(number_of_ncs): thworker = threading.Thread(target=async_infer, args=(NcsWorker(devid, device, model_xml, frameBuffer, results, camera_width, camera_height, number_of_ncs, vidfps, nPoints, w, h, new_w, new_h),)) thworker.start() threads.append(thworker) for th in threads: th.join() if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("-d", "--device", help="Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable. (Default=CPU)", default="CPU", type=str) parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)') parser.add_argument("-b", "--boost", help="Setting it to True will make it run faster instead of sacrificing accuracy. (Default=False)", default=False, type=bool) args = parser.parse_args() device = args.device if "CPU" == device: number_of_ncs = 1 if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP32/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP32/frozen-model.xml" elif "MYRIAD" == device: number_of_ncs = args.number_of_ncs if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" elif "GPU" == device: number_of_ncs = 1 if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" else: print("Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable.") sys.exit(0) camera_width = 320 camera_height = 240 vidfps = 30 nPoints = 18 w = 432 # Network size (Width) h = 368 # Network size (Height) new_w = int(camera_width * min(w/camera_width, h/camera_height)) new_h = int(camera_height * min(w/camera_width, h/camera_height)) try: mp.set_start_method('forkserver') frameBuffer = mp.Queue(4) results = mp.Queue() # Start detection MultiStick # Activation of inferencer p = mp.Process(target=inferencer, args=(device, model_xml, results, frameBuffer, number_of_ncs, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h), daemon=True) p.start() processes.append(p) if device == "MYRIAD": sleep(number_of_ncs * 7) # Start streaming p = mp.Process(target=camThread, args=(results, frameBuffer, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h), daemon=True) p.start() processes.append(p) while True: sleep(1) except: import traceback traceback.print_exc() finally: for p in range(len(processes)): processes[p].terminate() print("\n\nFinished\n\n")tflite_usbcamera_cpu-sync.py_TensorflowLite版import cv2, sys, time import numpy as np import tensorflow as tf from PIL import Image def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints width = 320 height = 240 fps = "" framecount = 0 time1 = 0 elapsedTime = 0 index_void = 2 num_threads = 4 keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 30) cap.set(cv2.CAP_PROP_FRAME_WIDTH, width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height) #input_details = [{'shape': array([ 1, 368, 432, 3], dtype=int32), 'quantization': (0.0078125, 128), 'index': 493, 'dtype': <class 'numpy.uint8'>, 'name': 'image'}] #output_details = [{'shape': array([ 1, 46, 54, 57], dtype=int32), 'quantization': (0.0235294122248888, 0), 'index': 490, 'dtype': <class 'numpy.uint8'>, 'name': 'Openpose/concat_stage7'}] try: # Tensorflow v1.13.0+ #interpreter = tf.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_1.4_224/output_tflite_graph.tflite") interpreter = tf.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_0.5_224/output_tflite_graph.tflite") except: # Tensorflow v1.12.0- #interpreter = tf.contrib.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_1.4_224/output_tflite_graph.tflite") interpreter = tf.contrib.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_0.5_224/output_tflite_graph.tflite") interpreter.allocate_tensors() interpreter.set_num_threads(int(num_threads)) input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() input_shape = input_details[0]['shape'] h = input_details[0]['shape'][1] #368 w = input_details[0]['shape'][2] #432 threshold = 0.1 nPoints = 18 while True: t1 = time.perf_counter() ret, color_image = cap.read() if not ret: break # Resize image colw = color_image.shape[1] colh = color_image.shape[0] new_w = int(colw * min(w/colw, h/colh)) new_h = int(colh * min(w/colw, h/colh)) resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h - new_h)//2:(h - new_h)//2 + new_h,(w - new_w)//2:(w - new_w)//2 + new_w, :] = resized_image prepimg = canvas prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add # Estimation interpreter.set_tensor(input_details[0]['index'], np.array(prepimg, dtype=np.uint8)) interpreter.invoke() outputs = interpreter.get_tensor(output_details[0]['index']) #(1, 46, 54, 57) outputs = outputs.transpose((0, 3, 1, 2)) #(1, 57, 46, 54) # View detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 for part in range(nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (canvas.shape[1], canvas.shape[0])) # (432, 368) keypoints = getKeypoints(probMap, threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) frameClone = np.uint8(canvas.copy()) for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.namedWindow("USB Camera", cv2.WINDOW_AUTOSIZE) cv2.imshow("USB Camera" , frameClone) if cv2.waitKey(1)&0xFF == ord('q'): break # FPS calculation framecount += 1 if framecount >= 5: fps = "(Playback) {:.1f} FPS".format(time1/15) framecount = 0 time1 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime cap.release() cv2.destroyAllWindows()4.Finally
GPD Pocket2というモバイルPCを所有していますが、正直に言うと、こういう小型PCをライン側などにそっと置いておくだけで色々できそうな気がしています。 この小型PCは Core m3 を搭載しています。 デフォルトWindows10 ですが、 Ubuntu化が可能です。
当然ながら、突き抜けた高精度を求める場合は、GPU あるいは クラウドパワーで巨大なモデルをブンブンする必要があります。
http://gpdjapan.com/gpd_pocket_info/
トレーニング用のスクリプト、Tensorflowのチェックポイント、推論用スクリプト、カスタマイズ済みTensorflow、の全てはGithubのリポジトリにコミット済みですので、 使えそうな機会があればご自由にご利用ください。
次は、Jetson Nano か TPU を使用した Pose Estimation にチャレンジしてみたいと思います。最近、マシンパワーにものを言わせてGPUでブイブイするのがどれほど現実的な話なのか疑問に感じていたり。。。ボソッ








- 投稿日:2019-05-03T15:59:12+09:00
Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite (Inference by OpenVINO/NCS2) Part.2
MobileNetV2-PoseEstimation
Tensorflow-bin
1.Introduction
前回記事 Learn "Openpose" from scratch with MobileNetv2 + MS-COCO and deploy it to OpenVINO/TensorflowLite Part.1 により、
Openposeのトレーニング実施とOpenVINO/Tensorflow Liteモデルを生成しました。
今回は作成した学習済みファイルとPythonでOpenVINOとTensorflow Liteのリアルタイム骨格検出を行います。
Tensorflow-GPU および CUDA を使用せず、PythonとOpenVINOで、CPUのみによる推論と描画を行います。何故私がここまでCPU推論にこだわっているかというと、電気を大食いして高熱を発するGPUや、設置スペースを無駄に消費する外付けデバイス、インタフェースの性能が低いことに引きずられて十分なパフォーマンスが得られないデバイス、などは実戦投入するときに扱いづらいと考えているからです。 また、手軽さとは裏腹に、 連続稼働数時間で停止してしまうような不安定なインフラはとても良くない です。
余談はさておき、GPUを使用せずにどれほどの性能が得られるでしょうか。
前回記事投稿時のスピードは下図のとおり、超遅いです。【前回】 Tensorflow-CPU's Test Core i7, FP32 (disabled OpenVINO/Tensorflow Lite) - 4 FPS
Youtube: https://youtu.be/nEKc7VIm42A
では、いつもどおりいきなり結果に行きます。 前回と同じモデルを使用し、OpenVINO対応しただけです。
前回・今回ともにGPUを使用していません。 今回は精度とスピードのバランスを計るため、2種類のモデルを生成して動作検証しました。
今回はCPU推論にも関わらずフレームレートが10倍ほど向上しています。
動画はUSBカメラの撮影レートを30FPSに制限していますが、高速なフレームレートで撮影すると40FPSまで速度が向上します。 (つまり、30FPSのUSBカメラの撮影スピードより推論スピードのほうが速いという結果です。)
ちなみに、 Core i7 でも Core m3 でも結果は同じです。【今回】 Boost Mode, OpenVINO Test Core i7 CPU only (disabled GPU), Sync - FP32 - 40 FPS++
Youtube: https://youtu.be/J-a2kHS4nTc
【今回】 Boost Mode, OpenVINO Test NCS2 x1, Async - FP16 - 25 FPS
Youtube: https://youtu.be/CUAojvJYRLE
【今回】 Normal Mode, OpenVINO Test Core i7 CPU only, Sync - FP32 (enabled OpenVINO) - 15-19 FPS
Youtube: https://youtu.be/t66bnWwZ7rE
【今回】 Normal Mode, OpenVINO Test NCS2 x1, Async - FP16 - 8-10 FPS
Youtube: https://youtu.be/hFFUectGQ2A
2.Environment
- Ubuntu 16.04 x86_64
- OpenVINO 2019 R1.0.1
- Tensorflow v1.12.0 + Tensorflow Lite
- USB Camera
- Python 3.5
- NCS2 x1
3.Procedure
手順もなにも無く、この記事の一番上にあるニコちゃんマークのリンク先のリポジトリをクローンして実行するだけです。
一応、作成したロジック群を全て下記に転記しておきます。 みなさんのご参考になれば幸いです。
非同期モードのプログラムは NCS2 の複数本挿しによるブーストにも対応しています。
なお、Tensorflow Lite版は遅すぎて使い物になりませんでしたので、ロジックのご紹介だけにとどめておきます。openvino-usbcamera-cpu-ncs2-sync.py_同期推論モードimport sys import os import numpy as np import cv2 from os import system import io import time from os.path import isfile from os.path import join import re import argparse import platform try: from armv7l.openvino.inference_engine import IENetwork, IEPlugin except: from openvino.inference_engine import IENetwork, IEPlugin def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints fps = "" detectfps = "" framecount = 0 time1 = 0 camera_width = 320 camera_height = 240 keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 30) cap.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) parser = argparse.ArgumentParser() parser.add_argument("-d", "--device", help="Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable. (Default=CPU)", default="CPU", type=str) parser.add_argument("-b", "--boost", help="Setting it to True will make it run faster instead of sacrificing accuracy. (Default=False)", default=False, type=bool) args = parser.parse_args() plugin = IEPlugin(device=args.device) if "CPU" == args.device: if platform.processor() == "x86_64": plugin.add_cpu_extension("lib/libcpu_extension.so") if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP32/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP32/frozen-model.xml" elif "GPU" == args.device or "MYRIAD" == args.device: if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" else: print("Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable.") sys.exit(0) model_bin = os.path.splitext(model_xml)[0] + ".bin" net = IENetwork(model=model_xml, weights=model_bin) input_blob = next(iter(net.inputs)) exec_net = plugin.load(network=net) inputs = net.inputs["image"] h = inputs.shape[2] #368 w = inputs.shape[3] #432 threshold = 0.1 nPoints = 18 try: while True: t1 = time.perf_counter() ret, color_image = cap.read() if not ret: break colw = color_image.shape[1] colh = color_image.shape[0] new_w = int(colw * min(w/colw, h/colh)) new_h = int(colh * min(w/colw, h/colh)) resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h - new_h)//2:(h - new_h)//2 + new_h,(w - new_w)//2:(w - new_w)//2 + new_w, :] = resized_image prepimg = canvas prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW, (1, 3, 368, 432) outputs = exec_net.infer(inputs={input_blob: prepimg})["Openpose/concat_stage7"] detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 for part in range(nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (canvas.shape[1], canvas.shape[0])) # (432, 368) keypoints = getKeypoints(probMap, threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) frameClone = np.uint8(canvas.copy()) for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.namedWindow("USB Camera", cv2.WINDOW_AUTOSIZE) cv2.imshow("USB Camera" , frameClone) if cv2.waitKey(1)&0xFF == ord('q'): break # FPS calculation framecount += 1 if framecount >= 15: fps = "(Playback) {:.1f} FPS".format(time1/15) framecount = 0 time1 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime except: import traceback traceback.print_exc() finally: print("\n\nFinished\n\n")openvino-usbcamera-cpu-ncs2-async.py_非同期推論モードimport sys import os import numpy as np import cv2 from os import system import io import time from os.path import isfile from os.path import join import re import argparse import platform try: from armv7l.openvino.inference_engine import IENetwork, IEPlugin except: from openvino.inference_engine import IENetwork, IEPlugin import multiprocessing as mp from time import sleep import threading import heapq def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(detected_keypoints, outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints processes = [] fps = "" detectfps = "" framecount = 0 detectframecount = 0 time1 = 0 time2 = 0 lastresults = None keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] def image_preprocessing(color_image, w, h, new_w, new_h): resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h-new_h)//2:(h-new_h)//2 + new_h,(w-new_w)//2:(w-new_w)//2 + new_w, :] = resized_image return canvas def camThread(results, frameBuffer, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h): global fps global detectfps global lastresults global framecount global detectframecount global time1 global time2 global cam global window_name cam = cv2.VideoCapture(0) if cam.isOpened() != True: print("USB Camera Open Error!!!") sys.exit(0) cam.set(cv2.CAP_PROP_FPS, vidfps) cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width) cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height) window_name = "USB Camera" wait_key_time = 1 cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE) while True: t1 = time.perf_counter() # USB Camera Stream Read s, color_image = cam.read() if not s: continue if frameBuffer.full(): frameBuffer.get() color_image = image_preprocessing(color_image.copy(), w, h, new_w, new_h) frameClone = np.uint8(color_image.copy()) frameBuffer.put(color_image) if not results.empty(): detected_keypoints, outputs, keypoints_list = results.get(False) detectframecount += 1 for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(detected_keypoints, outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) lastresults = [detected_keypoints, outputs, keypoints_list] else: if not isinstance(lastresults, type(None)): detected_keypoints, outputs, keypoints_list = lastresults for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(detected_keypoints, outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs, keypoints_list) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.putText(frameClone, detectfps, (w-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.imshow(window_name, frameClone) if cv2.waitKey(wait_key_time)&0xFF == ord('q'): sys.exit(0) ## Print FPS framecount += 1 if framecount >= 15: fps = "(Playback) {:.1f} FPS".format(time1/15) detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2) framecount = 0 detectframecount = 0 time1 = 0 time2 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime time2 += elapsedTime # l = Search list # x = Search target value def searchlist(l, x, notfoundvalue=-1): if x in l: return l.index(x) else: return notfoundvalue def async_infer(ncsworker): #ncsworker.skip_frame_measurement() while True: ncsworker.predict_async() class NcsWorker(object): def __init__(self, devid, device, model_xml, frameBuffer, results, camera_width, camera_height, number_of_ncs, vidfps, nPoints, w, h, new_w, new_h): self.devid = devid self.frameBuffer = frameBuffer self.model_xml = model_xml self.model_bin = os.path.splitext(model_xml)[0] + ".bin" self.camera_width = camera_width self.camera_height = camera_height self.threshold = 0.1 self.nPoints = nPoints self.num_requests = 4 self.inferred_request = [0] * self.num_requests self.heap_request = [] self.inferred_cnt = 0 self.plugin = IEPlugin(device=device) if "CPU" == device: if platform.processor() == "x86_64": self.plugin.add_cpu_extension("lib/libcpu_extension.so") self.net = IENetwork(model=self.model_xml, weights=self.model_bin) self.input_blob = next(iter(self.net.inputs)) self.exec_net = self.plugin.load(network=self.net, num_requests=self.num_requests) self.results = results self.number_of_ncs = number_of_ncs self.predict_async_time = 250 self.skip_frame = 0 self.roop_frame = 0 self.vidfps = vidfps self.w = w #432 self.h = h #368 self.new_w = new_w self.new_h = new_h def skip_frame_measurement(self): surplustime_per_second = (1000 - self.predict_async_time) if surplustime_per_second > 0.0: frame_per_millisecond = (1000 / self.vidfps) total_skip_frame = surplustime_per_second / frame_per_millisecond self.skip_frame = int(total_skip_frame / self.num_requests) else: self.skip_frame = 0 def predict_async(self): try: if self.frameBuffer.empty(): return self.roop_frame += 1 if self.roop_frame <= self.skip_frame: self.frameBuffer.get() return self.roop_frame = 0 prepimg = self.frameBuffer.get() reqnum = searchlist(self.inferred_request, 0) if reqnum > -1: prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW, (1, 3, 368, 432) self.exec_net.start_async(request_id=reqnum, inputs={self.input_blob: prepimg}) self.inferred_request[reqnum] = 1 self.inferred_cnt += 1 if self.inferred_cnt == sys.maxsize: self.inferred_request = [0] * self.num_requests self.heap_request = [] self.inferred_cnt = 0 heapq.heappush(self.heap_request, (self.inferred_cnt, reqnum)) try: cnt, dev = heapq.heappop(self.heap_request) except: return if self.exec_net.requests[dev].wait(0) == 0: self.exec_net.requests[dev].wait(-1) detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 outputs = self.exec_net.requests[dev].outputs["Openpose/concat_stage7"] for part in range(self.nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (self.w, self.h)) # (432, 368) keypoints = getKeypoints(probMap, self.threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) self.results.put([detected_keypoints, outputs, keypoints_list]) self.inferred_request[dev] = 0 else: heapq.heappush(self.heap_request, (cnt, dev)) except: import traceback traceback.print_exc() def inferencer(device, model_xml, results, frameBuffer, number_of_ncs, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h): # Init infer threads threads = [] for devid in range(number_of_ncs): thworker = threading.Thread(target=async_infer, args=(NcsWorker(devid, device, model_xml, frameBuffer, results, camera_width, camera_height, number_of_ncs, vidfps, nPoints, w, h, new_w, new_h),)) thworker.start() threads.append(thworker) for th in threads: th.join() if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("-d", "--device", help="Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable. (Default=CPU)", default="CPU", type=str) parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)') parser.add_argument("-b", "--boost", help="Setting it to True will make it run faster instead of sacrificing accuracy. (Default=False)", default=False, type=bool) args = parser.parse_args() device = args.device if "CPU" == device: number_of_ncs = 1 if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP32/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP32/frozen-model.xml" elif "MYRIAD" == device: number_of_ncs = args.number_of_ncs if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" elif "GPU" == device: number_of_ncs = 1 if args.boost == False: model_xml = "models/train/test/openvino/mobilenet_v2_1.4_224/FP16/frozen-model.xml" else: model_xml = "models/train/test/openvino/mobilenet_v2_0.5_224/FP16/frozen-model.xml" else: print("Specify the target device to infer on; CPU, GPU, MYRIAD is acceptable.") sys.exit(0) camera_width = 320 camera_height = 240 vidfps = 30 nPoints = 18 w = 432 # Network size (Width) h = 368 # Network size (Height) new_w = int(camera_width * min(w/camera_width, h/camera_height)) new_h = int(camera_height * min(w/camera_width, h/camera_height)) try: mp.set_start_method('forkserver') frameBuffer = mp.Queue(4) results = mp.Queue() # Start detection MultiStick # Activation of inferencer p = mp.Process(target=inferencer, args=(device, model_xml, results, frameBuffer, number_of_ncs, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h), daemon=True) p.start() processes.append(p) if device == "MYRIAD": sleep(number_of_ncs * 7) # Start streaming p = mp.Process(target=camThread, args=(results, frameBuffer, camera_width, camera_height, vidfps, nPoints, w, h, new_w, new_h), daemon=True) p.start() processes.append(p) while True: sleep(1) except: import traceback traceback.print_exc() finally: for p in range(len(processes)): processes[p].terminate() print("\n\nFinished\n\n")tflite_usbcamera_cpu-sync.py_TensorflowLite版import cv2, sys, time import numpy as np import tensorflow as tf from PIL import Image def getKeypoints(probMap, threshold=0.1): mapSmooth = cv2.GaussianBlur(probMap, (3, 3), 0, 0) mapMask = np.uint8(mapSmooth>threshold) keypoints = [] contours = None try: #OpenCV4.x contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) except: #OpenCV3.x _, contours, _ = cv2.findContours(mapMask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) for cnt in contours: blobMask = np.zeros(mapMask.shape) blobMask = cv2.fillConvexPoly(blobMask, cnt, 1) maskedProbMap = mapSmooth * blobMask _, maxVal, _, maxLoc = cv2.minMaxLoc(maskedProbMap) keypoints.append(maxLoc + (probMap[maxLoc[1], maxLoc[0]],)) return keypoints def getValidPairs(outputs, w, h): valid_pairs = [] invalid_pairs = [] n_interp_samples = 10 paf_score_th = 0.1 conf_th = 0.7 for k in range(len(mapIdx)): pafA = outputs[0, mapIdx[k][0], :, :] pafB = outputs[0, mapIdx[k][1], :, :] pafA = cv2.resize(pafA, (w, h)) pafB = cv2.resize(pafB, (w, h)) candA = detected_keypoints[POSE_PAIRS[k][0]] candB = detected_keypoints[POSE_PAIRS[k][1]] nA = len(candA) nB = len(candB) if( nA != 0 and nB != 0): valid_pair = np.zeros((0,3)) for i in range(nA): max_j=-1 maxScore = -1 found = 0 for j in range(nB): d_ij = np.subtract(candB[j][:2], candA[i][:2]) norm = np.linalg.norm(d_ij) if norm: d_ij = d_ij / norm else: continue interp_coord = list(zip(np.linspace(candA[i][0], candB[j][0], num=n_interp_samples), np.linspace(candA[i][1], candB[j][1], num=n_interp_samples))) paf_interp = [] for k in range(len(interp_coord)): paf_interp.append([pafA[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))], pafB[int(round(interp_coord[k][1])), int(round(interp_coord[k][0]))] ]) paf_scores = np.dot(paf_interp, d_ij) avg_paf_score = sum(paf_scores)/len(paf_scores) if ( len(np.where(paf_scores > paf_score_th)[0]) / n_interp_samples ) > conf_th : if avg_paf_score > maxScore: max_j = j maxScore = avg_paf_score found = 1 if found: valid_pair = np.append(valid_pair, [[candA[i][3], candB[max_j][3], maxScore]], axis=0) valid_pairs.append(valid_pair) else: invalid_pairs.append(k) valid_pairs.append([]) return valid_pairs, invalid_pairs def getPersonwiseKeypoints(valid_pairs, invalid_pairs): personwiseKeypoints = -1 * np.ones((0, 19)) for k in range(len(mapIdx)): if k not in invalid_pairs: partAs = valid_pairs[k][:,0] partBs = valid_pairs[k][:,1] indexA, indexB = np.array(POSE_PAIRS[k]) for i in range(len(valid_pairs[k])): found = 0 person_idx = -1 for j in range(len(personwiseKeypoints)): if personwiseKeypoints[j][indexA] == partAs[i]: person_idx = j found = 1 break if found: personwiseKeypoints[person_idx][indexB] = partBs[i] personwiseKeypoints[person_idx][-1] += keypoints_list[partBs[i].astype(int), 2] + valid_pairs[k][i][2] elif not found and k < 17: row = -1 * np.ones(19) row[indexA] = partAs[i] row[indexB] = partBs[i] row[-1] = sum(keypoints_list[valid_pairs[k][i,:2].astype(int), 2]) + valid_pairs[k][i][2] personwiseKeypoints = np.vstack([personwiseKeypoints, row]) return personwiseKeypoints width = 320 height = 240 fps = "" framecount = 0 time1 = 0 elapsedTime = 0 index_void = 2 num_threads = 4 keypointsMapping = ['Nose', 'Neck', 'R-Sho', 'R-Elb', 'R-Wr', 'L-Sho', 'L-Elb', 'L-Wr', 'R-Hip', 'R-Knee', 'R-Ank', 'L-Hip', 'L-Knee', 'L-Ank', 'R-Eye', 'L-Eye', 'R-Ear', 'L-Ear'] POSE_PAIRS = [[1,2], [1,5], [2,3], [3,4], [5,6], [6,7], [1,8], [8,9], [9,10], [1,11], [11,12], [12,13], [1,0], [0,14], [14,16], [0,15], [15,17], [2,17], [5,16]] mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], [23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], [55,56], [37,38], [45,46]] colors = [[0,100,255], [0,100,255], [0,255,255], [0,100,255], [0,255,255], [0,100,255], [0,255,0], [255,200,100], [255,0,255], [0,255,0], [255,200,100], [255,0,255], [0,0,255], [255,0,0], [200,200,0], [255,0,0], [200,200,0], [0,0,0]] cap = cv2.VideoCapture(0) cap.set(cv2.CAP_PROP_FPS, 30) cap.set(cv2.CAP_PROP_FRAME_WIDTH, width) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height) #input_details = [{'shape': array([ 1, 368, 432, 3], dtype=int32), 'quantization': (0.0078125, 128), 'index': 493, 'dtype': <class 'numpy.uint8'>, 'name': 'image'}] #output_details = [{'shape': array([ 1, 46, 54, 57], dtype=int32), 'quantization': (0.0235294122248888, 0), 'index': 490, 'dtype': <class 'numpy.uint8'>, 'name': 'Openpose/concat_stage7'}] try: # Tensorflow v1.13.0+ #interpreter = tf.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_1.4_224/output_tflite_graph.tflite") interpreter = tf.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_0.5_224/output_tflite_graph.tflite") except: # Tensorflow v1.12.0- #interpreter = tf.contrib.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_1.4_224/output_tflite_graph.tflite") interpreter = tf.contrib.lite.Interpreter(model_path="models/train/test/tflite/mobilenet_v2_0.5_224/output_tflite_graph.tflite") interpreter.allocate_tensors() interpreter.set_num_threads(int(num_threads)) input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() input_shape = input_details[0]['shape'] h = input_details[0]['shape'][1] #368 w = input_details[0]['shape'][2] #432 threshold = 0.1 nPoints = 18 while True: t1 = time.perf_counter() ret, color_image = cap.read() if not ret: break # Resize image colw = color_image.shape[1] colh = color_image.shape[0] new_w = int(colw * min(w/colw, h/colh)) new_h = int(colh * min(w/colw, h/colh)) resized_image = cv2.resize(color_image, (new_w, new_h), interpolation = cv2.INTER_CUBIC) canvas = np.full((h, w, 3), 128) canvas[(h - new_h)//2:(h - new_h)//2 + new_h,(w - new_w)//2:(w - new_w)//2 + new_w, :] = resized_image prepimg = canvas prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add # Estimation interpreter.set_tensor(input_details[0]['index'], np.array(prepimg, dtype=np.uint8)) interpreter.invoke() outputs = interpreter.get_tensor(output_details[0]['index']) #(1, 46, 54, 57) outputs = outputs.transpose((0, 3, 1, 2)) #(1, 57, 46, 54) # View detected_keypoints = [] keypoints_list = np.zeros((0, 3)) keypoint_id = 0 for part in range(nPoints): probMap = outputs[0, part, :, :] probMap = cv2.resize(probMap, (canvas.shape[1], canvas.shape[0])) # (432, 368) keypoints = getKeypoints(probMap, threshold) keypoints_with_id = [] for i in range(len(keypoints)): keypoints_with_id.append(keypoints[i] + (keypoint_id,)) keypoints_list = np.vstack([keypoints_list, keypoints[i]]) keypoint_id += 1 detected_keypoints.append(keypoints_with_id) frameClone = np.uint8(canvas.copy()) for i in range(nPoints): for j in range(len(detected_keypoints[i])): cv2.circle(frameClone, detected_keypoints[i][j][0:2], 5, colors[i], -1, cv2.LINE_AA) valid_pairs, invalid_pairs = getValidPairs(outputs, w, h) personwiseKeypoints = getPersonwiseKeypoints(valid_pairs, invalid_pairs) for i in range(17): for n in range(len(personwiseKeypoints)): index = personwiseKeypoints[n][np.array(POSE_PAIRS[i])] if -1 in index: continue B = np.int32(keypoints_list[index.astype(int), 0]) A = np.int32(keypoints_list[index.astype(int), 1]) cv2.line(frameClone, (B[0], A[0]), (B[1], A[1]), colors[i], 3, cv2.LINE_AA) cv2.putText(frameClone, fps, (w-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA) cv2.namedWindow("USB Camera", cv2.WINDOW_AUTOSIZE) cv2.imshow("USB Camera" , frameClone) if cv2.waitKey(1)&0xFF == ord('q'): break # FPS calculation framecount += 1 if framecount >= 5: fps = "(Playback) {:.1f} FPS".format(time1/15) framecount = 0 time1 = 0 t2 = time.perf_counter() elapsedTime = t2-t1 time1 += 1/elapsedTime cap.release() cv2.destroyAllWindows()4.Finally
GPD Pocket2というモバイルPCを所有していますが、正直に言うと、こういう小型PCをライン側などにそっと置いておくだけで色々できそうな気がしています。 この小型PCは Core m3 を搭載しています。 デフォルトWindows10 ですが、 Ubuntu化が可能です。
当然ながら、突き抜けた高精度を求める場合は、GPU あるいは クラウドパワーで巨大なモデルをブンブンする必要があります。
http://gpdjapan.com/gpd_pocket_info/
トレーニング用のスクリプト、Tensorflowのチェックポイント、推論用スクリプト、カスタマイズ済みTensorflow、の全てはGithubのリポジトリにコミット済みですので、 使えそうな機会があればご自由にご利用ください。
次は、Jetson Nano か TPU を使用した Pose Estimation にチャレンジしてみたいと思います。最近、マシンパワーにものを言わせてGPUでブイブイするのがどれほど現実的な話なのか疑問に感じていたり。。。ボソッ
5.Appendix
7月に名古屋で
ディープラーニングガジェット品評会を開催いたします。 ご興味が有る方は こちらの記事 をご覧ください。
只今、発表者の事前予約を受付中です。
- 投稿日:2019-05-03T15:07:08+09:00
Ubuntu16.04にCaffe2をインストールする
はじめに
この記事では、ubuntu16.04にディープラーニングフレームワーク「Caffe2」をインストールする手順を記載します。
環境
・Ubuntu16.04(Windows10上のVirtualBoxにインストール)
・Python2.7
・CPU Onlyインストール手順
※Ubuntu16.04はインストール直後の状態です。
※権限が足りない場合は適宜付与してください。1.事前に必要ないくつかのパッケージをインストール
$ sudo apt-get update $ sudo apt-get install -y --no-install-recommends \ build-essential \ git \ libgoogle-glog-dev \ libgtest-dev \ libiomp-dev \ libleveldb-dev \ liblmdb-dev \ libopencv-dev \ libopenmpi-dev \ libsnappy-dev \ libprotobuf-dev \ openmpi-bin \ openmpi-doc \ protobuf-compiler \ python-dev \ python-pip $ pip install --upgrade pip $ sudo apt-get install python-setuptools $ pip install --user \ future \ numpy \ protobuf \ typing \ hypothesis $ sudo apt-get install -y --no-install-recommends \ libgflags-dev \ cmake $ sudo apt-get install -y --no-install-recommends \ libgflags-dev \ cmake2.Pytorch(Caffe2)本体をインストール&ビルド(私の環境だと1時間がかかった)
$ git clone https://github.com/pytorch/pytorch.git && cd pytorch $ git submodule update --init --recursive $ sudo apt-get install python-yaml $ python setup.py install3.Caffe2のインストール確認
$ cd ~ && python -c 'from caffe2.python import core' 2>/dev/null && echo "Success" || echo "Failure" Successリンク
AIエンジニアを目指してみる
Ubuntu16.04にCaffeをインストールする参考
- 投稿日:2019-05-03T13:42:27+09:00
【Lambda式】コード読むのに必須なんだけど。。。(><;
はっきり言って、コードを難解だと思わせている記述法にLambda式がある。
あと、K.。。。もだけど、こっちはそういうものだと想像できるが、Lambda式の効用はいまいち。
参考②と③のような一行サンプルはだいたい理解できる。
そういう書き方はコード短縮には便利かも。。位の理解だけど。。。
参考①のコードになるともう一つ理解ができない。
ということで、少し我慢して追求すれば理解できるかもということで、参考①の最初のコード例を納得行くまで動かしてみました。
【参考】
・①Python keras.layers.core.Lambda() Examples
・②18. Lambdas@PythonTips
・③Pythonの無名関数(ラムダ式、lambda)の使い方@note.nkmk.meコード例
from keras.layers.core import Lambda def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4))ここまでは、一行で書けることの確認。
以下が例のコード。。
これ動かしてみます。def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply])とりあえず、必要なLibをimportして、x1,x2を定義して関数動かしてみます。
from keras.layers.core import Lambda import keras.backend as K from keras.layers import concatenate def distance_layer(x1, x2): ... x1=[0,0,1] x2=[0,2,2] print(distance_layer(x1, x2))案の定、エラー
AttributeError: 'list' object has no attribute 'get_shape'
どうやらlistだからget_shapeが無いらしい。。
ということで、np.arrayにしてみます。import numpy as np ... def distance_layer(x1, x2): ... x1=np.array([0,0,1]) x2=np.array([0,2,2]) print(distance_layer(x1, x2))やはり、同じエラー
AttributeError: 'numpy.ndarray' object has no attribute 'get_shape'
じゃということで、get_shape使わずに直接shape入れようdistance = Lambda(_distance, output_shape=(x.shape[-1],))([x1, x2])そうだよなぁ~
TypeError: 'tuple' object is not callable
もう一度、ググってみます。。参考によれば以下のようにtensorsだそうです。
まあ、ここは質問がmodel.add(Lambda(lambda x: resz))なので当然か。。ですが、Should be model.add(Lambda(resz)), lambda is redundant. Also, input and output of Lambda should be tensors, numpy array is not allowed.【参考】
・AttributeError: 'function' object has no attribute 'get_shape'` #5987
ということで、たまたまかもですが、入力を以下のとおりに変更します。import numpy as np import tensorflow as tf ... def distance_layer(x1, x2): ... my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(may_tensor)これで動きました!
出力は。。。
Tensor("concatenate_1/concat:0", shape=(6,), dtype=int32)
Tensorの型とかいらないんだけど。。。でググりました「tensor to numpy」
【参考】
・How can I convert a tensor into a numpy array in TensorFlow?print(tf.Session().run(my_tensor))やっと、望みの結果が得られましたとさ。。。
[0 2 1 0 0 2]
この結果は、x1-x2とx1*x2の結合になっています。
ちなみに、以下もググると出てきます、。。やってみると。。print(my_tensor.eval(session=tf.Session()))[0 2 1 0 0 2]
同じ結果が得られました。なんか一周しすっきりしたので、この記事はここで終わります。
おまけにここまでの全コードを載せておきます。まとめ
・Lambdaについてちょっと関数を動かしてみた
・Lambda関数の入出力はTensorのようだ
・Tensorの具体的な値を求めるには、実際にRunしてやる必要がある・さて、Grad_camのコードを読もう。。。
おまけ
from keras.layers.core import Lambda import keras.backend as K import numpy as np import tensorflow as tf from keras.layers import concatenate def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4)) def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply]) x1=[0,0,1] x2=[0,2,2] my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(tf.Session().run(my_tensor)) print(my_tensor.eval(session=tf.Session()))
- 投稿日:2019-05-03T13:42:27+09:00
【Lambdaクラス】コード読むのに必須なんだけど。。。(><;
はっきり言って、コードを難解だと思わせている記述法にLambdaクラスがある。
あと、K.。。。もだけど、こっちはそういうものだと想像できるが、Lambdaクラスの効用はいまいち。
参考②と③のような一行サンプルはだいたい理解できる。
そういう書き方はコード短縮には便利かも。。位の理解だけど。。。
参考①のコードになるともう一つ理解ができない。
ということで、少し我慢して追求すれば理解できるかもということで、参考①の最初のコード例を納得行くまで動かしてみました。
【参考】
・①Python keras.layers.core.Lambda() Examples
・②18. Lambdas@PythonTips
・③Pythonの無名関数(ラムダ式、lambda)の使い方@note.nkmk.meコード例
from keras.layers.core import Lambda def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4))ここまでは、一行で書けることの確認。
以下が例のコード。。
これ動かしてみます。def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply])とりあえず、必要なLibをimportして、x1,x2を定義して関数動かしてみます。
from keras.layers.core import Lambda import keras.backend as K from keras.layers import concatenate def distance_layer(x1, x2): ... x1=[0,0,1] x2=[0,2,2] print(distance_layer(x1, x2))案の定、エラー
AttributeError: 'list' object has no attribute 'get_shape'
どうやらlistだからget_shapeが無いらしい。。
ということで、np.arrayにしてみます。import numpy as np ... def distance_layer(x1, x2): ... x1=np.array([0,0,1]) x2=np.array([0,2,2]) print(distance_layer(x1, x2))やはり、同じエラー
AttributeError: 'numpy.ndarray' object has no attribute 'get_shape'
じゃということで、get_shape使わずに直接shape入れようdistance = Lambda(_distance, output_shape=(x.shape[-1],))([x1, x2])そうだよなぁ~
TypeError: 'tuple' object is not callable
もう一度、ググってみます。。参考によれば以下のようにtensorsだそうです。
まあ、ここは質問がmodel.add(Lambda(lambda x: resz))なので当然か。。ですが、Should be model.add(Lambda(resz)), lambda is redundant. Also, input and output of Lambda should be tensors, numpy array is not allowed.【参考】
・AttributeError: 'function' object has no attribute 'get_shape'` #5987
ということで、たまたまかもですが、入力を以下のとおりに変更します。import numpy as np import tensorflow as tf ... def distance_layer(x1, x2): ... my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(may_tensor)これで動きました!
出力は。。。
Tensor("concatenate_1/concat:0", shape=(6,), dtype=int32)
Tensorの型とかいらないんだけど。。。でググりました「tensor to numpy」
【参考】
・How can I convert a tensor into a numpy array in TensorFlow?print(tf.Session().run(my_tensor))やっと、望みの結果が得られましたとさ。。。
[0 2 1 0 0 2]
この結果は、x1-x2とx1*x2の結合になっています。
ちなみに、以下もググると出てきます、。。やってみると。。print(my_tensor.eval(session=tf.Session()))[0 2 1 0 0 2]
同じ結果が得られました。なんか一周しすっきりしたので、この記事はここで終わります。
おまけにここまでの全コードを載せておきます。因みに、Lambdaコメントアウトして、まんま
return concatenate([distance, multiply])だと、入力をTensorにしろと怒られます。
この関数は、入力Tensor,出力Tensorの関数なんですね。。。
※え~??まとめ
・Lambdaについてちょっと関数を動かしてみた
・Lambda関数の入出力はTensorのようだ
・Tensorの具体的な値を求めるには、実際にRunしてやる必要がある・さて、Grad_camのコードを読もう。。。
おまけ
from keras.layers.core import Lambda import keras.backend as K import numpy as np import tensorflow as tf from keras.layers import concatenate def add_def(a, b=1): return a + b add_lambda = lambda a, b=1: a + b print(add_def(3, 4)) print(add_lambda(3, 4)) def distance_layer(x1, x2): """Distance and angle of two inputs. Compute the concatenation of element-wise subtraction and multiplication of two inputs. """ def _distance(args): x1 = args[0] x2 = args[1] x = K.abs(x1 - x2) return x def _multiply(args): x1 = args[0] x2 = args[1] return x1 * x2 distance = Lambda(_distance, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) multiply = Lambda(_multiply, output_shape=(K.int_shape(x1)[-1],))([x1, x2]) return concatenate([distance, multiply]) x1=[0,0,1] x2=[0,2,2] my_tensor=distance_layer(tf.convert_to_tensor(x1),tf.convert_to_tensor(x2)) print(tf.Session().run(my_tensor)) print(my_tensor.eval(session=tf.Session()))
- 投稿日:2019-05-03T13:26:55+09:00
バレンタインのネタ系サービスを作った
概要
令和になってしまいましたが、2ヶ月以上前のイベントである、バレンタインのネタ系サービスを開発していたので、今更ながら記事を書きます。
また、今回紹介するサービスはすでにクローズしているので、githubに公開しています。
https://github.com/kouryou/ValentineGacha経緯
弊社では数ヶ月に1回のペースで、エンジニア全体でのLT大会が行われます。ちょうどそのLT大会がバレンタインの時期だったので、バレンタインに関するデモアプリケーションを作って登壇しました。
その後サーバーサイドのソースコードを公開しようと思い、リファクタリングをしていたのですが、他にもやるべきことをやっていたら、気がついたらこんなに時間が経ってしまいました。キング・クリムゾンのせいですね。メンバー
今回は(当時)新卒3人で以下のような構成でチームを組んで開発を行いました。
- サーバーサイドエンジニア
- フロントエンドエンジニア
- デザイナー
僕はサーバーサイドの開発を担当したため、今回はサーバーサイドで使った技術のお話をしようと思います。
作ったもの
「バレンタインガチャ」というサービスを開発しました。
↑デザイナーさんが作ってくれたロゴですこのサービスは、「チョコが欲しい人」と「チョコが余ってる人」をつなぐサービスです。
バレンタインにおける格差を是正するために開発しました。これで、チョコをもらえないバレンタインは二度と来ないでしょう。
え?「チョコをもらえないバレンタインなんてなかった」だって?
そういう人と友達になってはいけませんとお母さんに言われました。ちなみに、「チョコが余ってる人なんているのか?」って意見が聞こえてきそうですが、そこはご安心を。足りないと困るという理由で、割と女性陣はチョコを多めに用意するらしく(チームメンバーの女性意見)、余るケースがよくあるとのことです。
もし余らなかったらコンビニにチョコを買いに行きましょう。前提
前提として、 Slack APIを利用したアプリケーションになっているため、事前に「チョコが欲しい人」と「チョコが余ってる人」は、指定されたSlackのワークスペースに入ってもらいます。
機能
- ガチャ機能
「チョコが余ってる人」がチョコをあげたい人数を決めて、ガチャを回すことができます。 ガチャを回すと、「チョコが欲しい人」の中から指定した人数の当選者が選ばれます。(特に確率操作はしておらず、完全にランダムです)通知機能
当選者に通知するため、以下のように当選通知のSlackが送ることができます。
かわいい子からチョコもらえる感じがあって最高です。この例では福沢諭吉にチョコが当選しました。(ホワイトデーのお返しが楽しみですね)
チャンネル作成機能
当選者とチョコをあげる人が、その後のコミュニケーションを取りやすいように、専用のプライベートチャンネルを作成する機能もあります。
この機能を利用すると、以下のようにチャンネルが作成されます。
技術
僕の担当したサーバーサイドの技術のみ紹介します。
今回は以下のようなサーバレスアーキテクチャで構成しました。
利用した技術は主に以下です。
- Serverless Framework
- Python
- Slack API
ちなみに全て初めて利用しました。
それぞれについて説明していきます。Serverless Framework
https://serverless.com
Serverless Frameworkはサーバレスアプリケーションを簡単にビルド&デプロイできるCLIツールです。名前で勘違いしやすいですが、フレームワークというよりはツールに近いと思います。サーバレスアプリケーション全体を
serverlss.ymlにまとめて記述できるので、AWSの画面をぽちぽちする必要がないのでいいですね。また、慣れてくると非常に早くアプリケーションを構築できるので、素早くプロトタイプを構築したい時にも良い選択肢になると思いました。
日本の個人開発だとFirebaseが盛り上がってますが、サーバレスはAWSが進んでいるため、AWS上で構築可能なServerless Frameworkも有力な選択肢だと思います。Python
Pythonに関しては正直この記事で特筆する内容は少ないですが、後述するSlack APIをPythonでどう叩くかは悩んだので、ここに記したいと思います。
今回はpython-slackclientというライブラリを使用しました。
以下は使用例で、あるチャンネルにメッセージを送るAPIを使用しています。from slackclient import SlackClient sc = SlackClient("SLACK_API_TOKEN") sc.api_call( "chat.postMessage", #API名 channel="C0XXXXXX", text="Hello from Python! :tada:" )使い方はシンプルで、第一引数に利用したいAPI名を、以降の引数に各APIにおいて必要なパラメータを渡してあげるだけです。
呼び出し方が統一されてるのでシンプルで使いやすかったです。Slack API
今回使用したSlackのAPIを用途ベースで紹介しようと思います。
ワークスペースに入っているユーザ全員の情報を入手する
users.listというAPIを用いました。
このAPIのレスポンスを元に、その中からランダムで当選者を選ぶということをしました。画像付きの通知をする
files.uploadというAPIを用いました。
他にもテキストベースのメッセージにattachmentsを使用するという方法もありますが、URLを送信した時のような見た目になるので今回は使用しませんでした。指定した人とのプライベートチェンネルを作成する
1つのAPIで行う方法が見つからなかったので、今回は以下のように3つのAPIを使用して対応しました。
チャンネルを作成して、作成したチャンネルに招待し、最後に退会するという流れです。
ちなみに退会する理由は、これらのAPIはbotユーザに権限がないため、管理者ユーザが行うことになるためです。
作成と招待だけでは、新しいチャンネルの作成者として、管理者ユーザがチャンネルに入った状態になってしまいます。
今回はチョコをあげる人と当選者のみのチャンネルにしたかったので、管理者ユーザには退会してもらうようにしました。これで目標としていたチョコをあげる人と当選者のチャンネルが作成できました。
最後に
新卒でチーム組んで開発したのは凄く良かったです。
LTで登壇するというのはハードルが高いように感じますが、このように新卒でチーム組んで登壇すると、ハードルが下がるのでおすすめです。
また、チーム開発をしている中で、同期から技術的に学ぶこともあります。
さらに一人で開発するよりもモチベーションが上がるのでサボりにくくなります。至れり尽くせりですね。4月から新卒になったエンジニアの皆さんも同期に声をかけて始めてみてはいかがでしょうか。


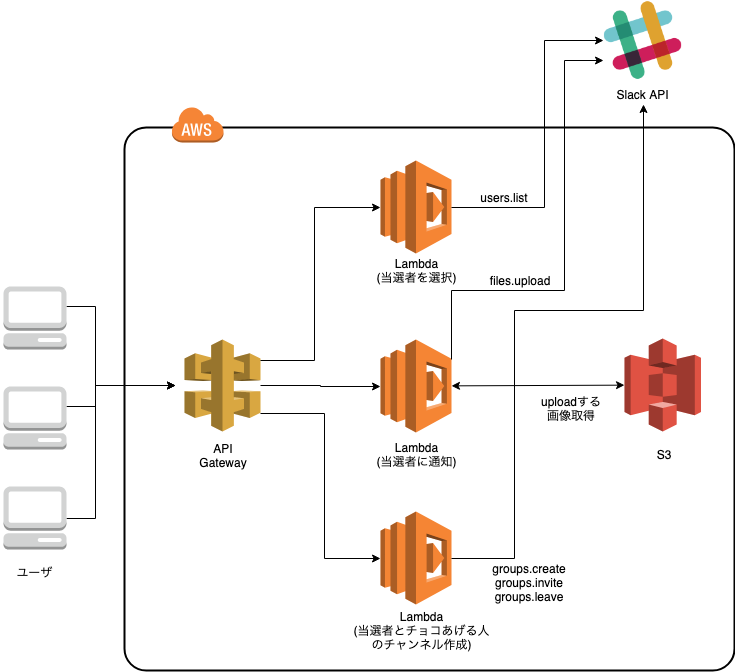
- 投稿日:2019-05-03T12:01:33+09:00
Pythonコード補完ソフトKite、ついにLinuxサポート追加
Kiteは、数週間前@KeisukeToyotaさんもこの記事で話していた、Pythonのスマートコード補完や参考書検索ができるツールです。もともとWindows、macOSにてPyCharm、VS Code、Vim、Sublime、Atomなどのエディタで使えますが、今日持ってLinuxサポートも追加したようです。
具体的な情報は公式サイトの発表記事まで。Ubuntu、Fedora、Arch Linux、Linux Mint、openSUSEなど、色々なLinuxで使えると言っています。デスクトップはKDE、XFCE、Gnome 2・3どれでもオーケーのようです。
数年前からLinuxサポートを約束していたので、ついに発表されて嬉しいです。
Kiteのダウンロードは公式サイトから。上の@KeisukeToyotaの記事にインストール手順が書いてあります。是非試して見ましょう。

- 投稿日:2019-05-03T09:43:18+09:00
テスト投稿
自己紹介
データサイエンスに関する研究(理論と応用)をしている学生です.
これまでR言語しか使ってきませんでしたが,最近Pythonの学習を始めました.
RとPythonで全然違うなあと思った点や,使い分ける上で注意すべき点をまとめていきます.たとえば
test.Rlis1 = list(1,2) lis2 = lis1 lis1[[1]] = 100 print(lis2) # 出力 [[1]] [1] 1 [[2]] [1] 2Pythonだと,全然違う結果になる.
参照渡しが行われている.test.pylis1 = [1,2] lis2 = lis1 lis1[0] = 100 print(lis2) # 出力 [100, 2]
- 投稿日:2019-05-03T09:43:18+09:00
はじめての投稿
自己紹介
データサイエンスに関する研究(理論と応用)をしている学生です.
これまでR言語しか使ってきませんでしたが,最近Pythonの学習を始めました.
RとPythonで全然違うなあと思った点や,使い分ける上で注意すべき点をまとめていきます.
今後,ご指摘やアドバイスなど,よろしくお願いいたします.たとえば
test.Rlis1 = list(1,2) lis2 = lis1 lis1[[1]] = 100 print(lis2) # 出力 [[1]] [1] 1 [[2]] [1] 2Pythonだと,全然違う結果になる.
参照渡しが行われている.test.pylis1 = [1,2] lis2 = lis1 lis1[0] = 100 print(lis2) # 出力 [100, 2]Rっぽく扱う(値渡し)をするためには,copyモジュールとやらを使えばよさそう.
- 投稿日:2019-05-03T09:43:18+09:00
リストオブジェクトの共有
自己紹介
データサイエンスに関する研究(理論と応用)をしている学生です.
これまでR言語しか使ってきませんでしたが,最近Pythonの学習を始めました.
RとPythonで全然違うなあと思った点や,使い分ける上で注意すべき点をまとめていきます.
今後,ご指摘やアドバイスなど,よろしくお願いいたします.たとえば
test.Rlis1 = list(1,2) lis2 = lis1 lis1[[1]] = 100 print(lis2) # 出力 [[1]] [1] 1 [[2]] [1] 2Pythonだと,全然違う結果になる.
参照渡しが行われている.test.pylis1 = [1,2] lis2 = lis1 lis1[0] = 100 print(lis2) # 出力 [100, 2]Rっぽく扱う(
値渡し)をするためには,copyモジュールとやらを使えばよさそう.
- 投稿日:2019-05-03T09:27:13+09:00
Windows+gVim+pipenvでPython開発ことはじめ
はじめに
Windows+gVim+pipenv環境ではじめてPythonを開発するので、その時に行ったことをまとめました。
gvim上でオムニ補完と静的コード解析ができるまでがゴールです。ChocolateyGetインストール
管理者権限のpowershellで下記実行
Set-ExecutionPolicy RemoteSigned install-packageprovider ChocolateyGetgitインストール
管理者権限のpowershellで下記実行
install-package git -providerName ChocolateyGetPythonインストール
管理者権限のpowershellで下記実行
install-package python -providerName ChocolateyGetpipenvのインストール
pip install --upgrade pip pip install pipenvgvimインストール
kaoriya本家からgvimをダウンロードし解凍する。
https://www.kaoriya.net/software/vim/$VIM(gvim.exeのあるフォルダ)をPATHに追加する
管理者権限で下記powershell実行(例)kaoriya-vimをCドライブ直下に解凍した場合 $SystemPath = [System.Environment]::GetEnvironmentVariable("Path", "Machine") $SystemPath += ";c:\vim81-kaoriya-win64" [System.Environment]::SetEnvironmentVariable("Path", $SystemPath, "Machine")gvimプラグインのインストール
下記プラグインを導入する。
https://github.com/davidhalter/jedi-vim
https://github.com/w0rp/ale※$VIMはgvim.exeのあるフォルダ
※プラグインマネージャを利用している場合はそっちで導入cd $VIM/plugins git clone --recursive https://github.com/davidhalter/jedi-vim.git git clone https://github.com/w0rp/ale.gitpythonファイルを開いたときのオムニ補完をjediに設定するようvimrcに追記
autocmd FileType python setlocal omnifunc=jedi#completionsgvim用のpipenvを作成し、flake8をインストールする
※$VIMはgvim.exeのあるフォルダパス
cd $VIM mkdir gvim_pipenv cd gvim_pipenv $env:PIPENV_VENV_IN_PROJECT = 1 pipenv --three pipenv install flake8gvim用のpipenvをgvimから使えるようvimrcに追記する
let $PATH = $PATH . ";" . $VIM . "\\gvim_pipenv\\.venv\\Scripts"プロジェクト作成
mkdir newproject cd newproject pipenv --threeプロジェクトに必要なライブラリをインストール
pipenv install hogehoge(必要なライブラリ)pipenvの仮想環境に入る
pipenv shell(以後の操作はこの仮想環境内で行う)
gvim起動
※pipenv仮想環境内で実行
gvim main.py実行
※pipenv仮想環境内で実行
python main.py豆知識
WindowsはPythonにPATHを通さなくてもPythonランチャーからPythonやモジュールの実行が可能。しかし、pipenvをpythonランチャーから起動すると何故かエラーがでるのでPATHを通してpipenvを実行する必要がある。ChocolateyGetからインストールすると自動でPATHが通る。
補完をするモジュールjediはjedi-vimの中にサブモジュールとして含まれているので別途インストールする必要はない
python-language-serverとvim-lspを用いても補完が可能だが、jedi-vimと違いpython-language-serverをシステムにインストールする必要があり、プロジェクトにインストールしたライブラリに対しての補完が効かない(なにかやり方はあるかもしれない)
pythonファイルをgvimで開いたときにそのpythonファイルが含まれるpipenv仮想環境に自動で入ってくれるプラグインvim-pipenvがあるが、Windowsには未対応である模様
- 投稿日:2019-05-03T08:54:01+09:00
Donkey Carに6DoFを追加する
やりたいこと Raspberry Piで自己位置推定
部屋の中ではDonkey Carがブイブイ回せたので、もうちょっと高度なことがしたい
CPU負荷の大きいことをやろうとしたけど、JETSON-nanoがまだ届かない
自己位置推定はインテルのトラッキングカメラは全部中でやってくれるのでCPU負荷は低い
自己位置推定をトラッキングカメラ任せにして、同じ場所を強化学習しながら走り続ける車が作れないか?
とりあえず、自己位置推定のサンプルをRaspberryPiで回してみよう。
CPU負荷の低いことをしよう
あんなに苦労したトラッキングを簡単にやってしまうT265なるトラッキングカメラをIntelが発売していた。
カメラで重い処理を全部やってくれるので、ラズパイ3でも余裕で動くよね?同じことをやってる先達はいっぱいいるので、参考にさせて頂きます。
走行させるのはいつものTT-02Bではなく、最近出番の少ないCC-01。
今回は後から何載せるのかわからないので、安定感のあるボディを採用。「フィードバックしてね」
と、やっていたら、英文メッセージ着信。(英訳はGoogle先生に頼りっぱなし)
いつもSlackでお世話になっている人からメッセージ。使わせていただくのだから、フィードバックはすべき。
けど、英語もまともに読めない私の感想が役に立つのかどうか?
そして今、日本は平成最後のゴールデンウィークで大混乱してる最中で、しばらくコワーキングスペースも使えない。まずは、あなたのブログをよく読んでみる。 そして、1つ問題がある。 日本は明々後日、皇帝の退位と新皇帝の即位があり、平成から令和にeraがChangeするので、 10日間、パーツショップも工房も休みだ。(だから回答は遅くなる)と返答。意味は通じたはず。通じるといいな・・・。
ブログをよく読んでみよう
https://markku.ai/post/realsense-t265/
T265をDonkeyで動かすブログはこちら。
まずは読んでみよう。結論 素晴らしい
・・・早えーよ一言で言えば、それが機能するときそれは本当に素晴らしいと正確です。それは時々それがその弱い瞬間を持っていてそれが混乱するのです。そして位置追跡はインクリメンタルなので、わずかなエラーでもその後のすべてに影響しますなるほど。
一度おかしくなったら、どうやって復旧するかが問題だな。また、位置データの原点が常にカメラが起動された場所にあることもかなりの制限です。これはカメラ自体の問題ではありませんが、これを使用して何かを実装するときにはまだ考慮すべき点があります周辺の映像やGPSの情報をもとに、原点復帰ができるといいんだけどな。
Donkeycarコミュニティのメンバーが、彼のユニットがRaspbianに取り組んでいると伝えました。彼は彼の魔術を分かち合うのに十分に素晴らしく、そして私たちはRaspbian上でrealsense SDKをコンパイルしました。 私はリポジトリの中にRealsenseとRaspbianのための公式の指示があるというヒントを得ました。あなたはそれらをここで見つけることができます。これらはOpenCVのようなもので、ヘッドレスのラズビアンランニングロボットには必要ありません。そのため、それらが機能する限り、私たちのより簡単な指示に従うこともできます。https://github.com/IntelRealSense/librealsense/blob/master/doc/installation_raspbian.md
ずいぶん見つけにくいところに、RealSenseのD435用のRaspbian(RaspberryPi3) Installationが置いてあるものだ。
とりあえず、指示に沿ってRaspberryPiのセットアップをしてみよう。
Donkey Carに環境をインストール
適当なバージョンで動くDonkey CarのROMを用意して、スワップファイルを拡張します。
コンパイルには必要です。Blogの内容に沿って設定して、コンパイルの準備。
# Toggle swap off sudo dphys-swapfile swapoff # Edit the config file and increase the swap size to 2048 # by editing variable CONF_SWAPSIZE=2048 sudo nano /etc/dphys-swapfile # Toggle swap back on sudo dphys-swapfile swapon # Reboot your raspberry sudo reboot # After reboot, check that swap size changed free # Should show something like Swap: 2097148ファイル/etc/dphys-swapfileのCONF_SWAPSIZEを2048に変更する。
/etc/dphys-swapfile]CONF_SWAPSIZE=2048ここから後は、原文通りにインストールできるのだが、最後に詰まったのはここ。
#ファイルを消去する指示は、初回は無視。 #コンパイルに失敗した時は、buildディレクトリごと消去したほうがいいので私は使わなかった xarg sudo rm < install_manifest.txt rm CMakeCache.txt export CC=/usr/bin/gcc-6 export CXX=/usr/bin/g++-6 cmake -D CMAKE_BUILD_TYPE="Release"\ -D FORCE_LIBUVC=ON \ -D BUILD_PYTHON_BINDINGS=ON \ -D BUILD_EXAMPLES=OFF .. #問題はここのmake -j4 私の環境では失敗する make -j4 sudo make install sudo ldconfig-j4オプション禁止
コンパイルをかけると、途中で止まってしまいます。
一晩ほっといても70%程度で先に進まなくなる。
先方にも連絡してみたのですが、彼の環境では正常動作したが、他の環境では再現したらしい。
ということで、色々聞いて回ったところ、どうやら-j4オプションで全部のコアを使ってコンパイルをすると、メモリを使い果たして止まってしまうらしい。そこで、
makeオプションなし。
これで一晩放置することとした。寝る前に放っておいたら、正常にコンパイルが終わっていた。
インストールもすんなり完了。サンプル実行
https://markku.ai/post/realsense-t265/
のサンプルプログラムをそのままコピーして動かしてみたところ、そのままで何の問題もなく動作。
さらに、RealSenseのサンプルプログラムも、~/test にコピーして動かすと、問題なく動作した。
画像が出てくるわけではなく、6DoFの座標がどんどん出てくるだけなので、面白みは全然ないが、T265を動かしたら、数値が追従するのでほぼ正常に動いているようだ。
次の目標
とりあえず、RaspberryPi3B+でRealSenseT265を動かすことはできた。
次はDonkeyCarのソフトに組み込んで、自己位置推定させながら動作させてみたい。
ハードウェアはもう出来上がっているんだけど、なかなかソフトが追いつかないです。
謝辞
いつもSlackで助言をして頂き、今回も協力して頂いた、Mikko Pohja氏に感謝します。
Mikko Pohja氏のBlogはこちら。
https://markku.ai/post/realsense-t265/



- 投稿日:2019-05-03T02:12:10+09:00
TweepyでTwitterに投稿する
はじめに
tweepyモジュールをインストールしておきましょう.
pip install twwepy でインストールできます.Twitter Application Management へアクセスして必要な情報をゲットします.
- 使用するアカウントと電話番号を紐付けしておきます.
- Create an app をクリックして新しいアプリケーションを作成します.アプリ名の登録など諸々を進めます.
- Keys and tokensタブでConsumer API keysとAccess token & access token secretについての情報をゲットします.
以上で準備完了です.
簡単にツイート
先ほど獲得した各種キーを下記コードに当てはめて実行すれば簡単なツイートはできます.
import tweepy # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) # 好きな言葉をツイート api.update_status("Pythonから投稿!")実際に投稿できていました!
同じ内容を何度も投稿すると, エラーになるので注意してください. 僕も下のようなエラーになりました.
raise TweepError(error_msg, resp, api_code=api_error_code) tweepy.error.TweepError: [{'code': 187, 'message': 'Status is a duplicate.'}]画像付きツイート
ほぼ先ほどと一緒です.
最後の一文のfilenameで画像ファイルを指定してください.import tweepy # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) #画像付きツイート api.update_with_media(status = '画像付きツイートテスト', filename = '')画像付きツイートも成功していました.
参考サイト

- 投稿日:2019-05-03T02:12:10+09:00
TweepyでTwitterにつぶやく
はじめに
tweepyモジュールをインストールしておきましょう.
pip install twwepy でインストールできます.Twitter Application Management へアクセスして必要な情報をゲットします.
- 使用するアカウントと電話番号を紐付けしておきます.
- Create an app をクリックして新しいアプリケーションを作成します.アプリ名の登録など諸々を進めます.
- Keys and tokensタブでConsumer API keysとAccess token & access token secretについての情報をゲットします.
以上で準備完了です.
簡単につぶやく
先ほど獲得した各種キーを下記コードに当てはめて実行すれば簡単なツイートはできます.
import tweepy # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) # 好きな言葉をツイート api.update_status("Pythonから投稿!")実際に投稿できていました!
同じ内容を何度も投稿すると, エラーになるので注意してください. 僕も下のようなエラーになりました.
raise TweepError(error_msg, resp, api_code=api_error_code) tweepy.error.TweepError: [{'code': 187, 'message': 'Status is a duplicate.'}]画像付きツイートをする
ほぼ先ほどと一緒です.
最後の一文のfilenameで画像ファイルを指定してください.import tweepy # 先ほど取得した各種キーを代入する CK="Consumer Key" CS="Consumer Secret" AT="Access Token" AS="Access Token Secret" # Twitterオブジェクトの生成 auth = tweepy.OAuthHandler(CK, CS) auth.set_access_token(AT, AS) api = tweepy.API(auth) #画像付きツイート api.update_with_media(status = '画像付きツイートテスト', filename = '')画像付きツイートも成功していました.
参考サイト