- 投稿日:2019-05-03T21:42:05+09:00
pythonで学習したDNNモデルをC++から利用する(PyTorch & libtorch版)
はじめに
みなさんDNNは活用しているでしょうか。最近は様々なDNNフレームワークがOSSとして公開されており、DNNを簡単に始めることができるようになりました。便利な世の中になったものです。
さてTensorflowやChainer、PyTorchといった最近よく使われているDNNフレームワーク、あるいはKerasのような抽象化APIは、だいたいPythonで書くことが多いと思います。しかし学習フェーズは良いとしても、学習済みのモデルを使って何らかの予測をする場合には、Pythonの応答性能が気になります。特にカメラ映像に対して連続的に予測をしたい場合には、リアルタイム性がかなり重要になってきます。
@yukiB さんの[Python]KerasをTensorFlowから,TensorFlowをc++から叩いて実行速度を上げるによれば、同じ学習済みモデルを使っていても、C++で実行すればPythonの2割〜6割程度の実行時間で処理ができるみたいです。これはC++によるDNNを試してみるしかないでしょう。
ということで、今回はPyTorchを用いてMNISTをCNNで学習させ、その学習済みモデルをC++から使ってみたいと思います。
環境
今回検証した環境は、以下になります。利用したUbuntu18.04は、実際にはParallels Desktop上の仮想環境です。
(iMacやMacbookでcudaが使えるようになってほしいなぁ・・・)
バージョン Host OS macOS Sierra 10.12.6 virtualization Parallels Desktop for Mac Pro 14.1.3 (45485)
バージョン Guest OS Ubuntu 18.04.2 LTS miniconda3 4.6.14 gcc 7.4.0 opencv 4.1.0 python 3.7.1 pytorch & libtorch 1.1.0 ソースコード
今回のソースコードは、githubのnmatsui/libtorch_pytorch_mnistにpushしてあります。もし興味がありましたら、forkして遊んでみてください。
準備
ライブラリのインストール
C++で利用できるように、まずはOpenCVとlibTorchをインストールします。なおcudaが使えないため、libtorchはCPUバージョンをインストールします。
パッケージのインストール
$ sudo apt install -y build-essential cmake unzip pkg-config wget $ sudo apt install -y qt5-default libvtk6-dev zlib1g-dev libwebp-dev \ libopenexr-dev libgdal-dev libjpeg-dev libpng-dev \ libtiff-dev libtiff5-dev libv4l-dev libavcodec-dev \ libavformat-dev libswscale-dev libxine2-dev \ libxvidcore-dev libx264-dev libdc1394-22-dev \ libtheora-dev libvorbis-dev libgtk-3-dev libtbb-dev \ libatlas-base-dev libopencore-amrnb-dev \ libopencore-amrwb-dev libeigen3-dev gfortran yasmOpenCV4のインストール
$ cd ${HOME} $ wget -O opencv-4.1.0.zip https://github.com/opencv/opencv/archive/4.1.0.zip $ unzip opencv-4.1.0.zip $ cd opencv-4.1.0 $ mkdir build && cd build $ cmake -DCMAKE_BUILD_TYPE=RELEASE \ -DCMAKE_INSTALL_PREFIX=/usr/local \ -DCMAKE_CXX_FLAGS=-D_GLIBCXX_USE_CXX11_ABI=0 \ -DWITH_QT=ON -DWITH_OPENGL=ON -DFORCE_VTK=ON -DWITH_TBB=ON -DWITH_GDAL=ON \ -DWITH_XINE=ON -DBUILD_EXAMPLES=ON -DENABLE_PRECOMPILED_HEADERS=OFF \ .. $ make -j4 $ sudo make install $ sudo ldconfig
- Ubuntu 18.04のgcc 7.4.0でOpenCV4を普通にビルドすると、 新型のバイナリインターフェース(GNU 5.x ABI)で共有ライブラリがビルドされるようです。libTorchは旧型のバイナリインタフェース(GNU 4.x ABI)でビルドされているらしいので、OpenCVとlibTorchを同時にlinkするとldがこけます。
- そのため、OpenCVのMakefile生成時に
-DCMAKE_CXX_FLAGS=-D_GLIBCXX_USE_CXX11_ABI=0を指定して、GNU 4.x ABI互換でOpenCV4をビルドします。
- これに気づくまで1日かかりました。。。
libTorchのインストール
$ cd ${HOME} $ wget -O libtorch-1.1.zip https://download.pytorch.org/libtorch/cpu/libtorch-shared-with-deps-latest.zip $ unzip libtorch-1.1.zip $ sudo cp -r libtorch/include/* /usr/local/include/ $ sudo cp -r libtorch/lib/* /usr/local/lib/ $ sudo cp -r libtorch/share/* /usr/local/share/ $ sudo ldconfig
- pytorchのリポジトリに含まれる
tools/build_libtorch.pyを使ってlibtorchをソースコードからビルドすることもできます。C++プログラムのビルド
ソースコードのダウンロード
$ cd ${HOME} $ git clone https://github.com/nmatsui/libtorch_pytorch_mnist.gitC++プログラムのビルド
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ mkdir build && cd build $ cmake .. $ make $ cp pimage/predict_image .. $ cp pcamera/predict_camera ..
- この段階で
makeに失敗した場合、おそらくOpenCVとlibtorchの共有ライブラリが上手くリンクできないのだと思われます。もし古いOpenCVなどがインストールされているならば、削除してみると上手くいくかもしれません。MNISTの学習(Python)
ライブラリのインストールが成功したら、MNISTの教師データを用いて学習させます。学習部分はPythonで書いています。
condaを用いてPython仮想環境を準備$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ conda env create --file conda-linux.yaml $ conda activate pytorch_mnist学習を行う
$ ./train.py --epochs 12 ../models/mnist_py.pt ../data
- 1つ目の引数は学習済みモデルを保存するファイル名、2つ目の引数はダウンロードしてきたMNISTの学習データとテストデータを格納するルートディレクトリです。
- オプションでepochを12回に指定しています。学習時に指定できるその他のオプションは、
./train.py --helpで確認してください。Test set: Average loss: 0.050700, Accuracy: 9847/10000 (98.47%)
- 学習が終わると、↑のようにテストデータを評価した際のAverage lossとAccuracyが表示されます。
今回使用したモデルは、次のようになります。
class MnistCNNModel(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 32, 3) self.conv2 = nn.Conv2d(32, 64, 3) self.pool = nn.MaxPool2d(2, 2) self.dropout1 = nn.Dropout2d() self.fc1 = nn.Linear(12 * 12 * 64, 128) self.dropout2 = nn.Dropout2d() self.fc2 = nn.Linear(128, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = self.pool(F.relu(self.conv2(x))) x = self.dropout1(x) x = x.view(-1, 12 * 12 * 64) x = F.relu(self.fc1(x)) x = self.dropout2(x) x = self.fc2(x) return F.log_softmax(x, dim=1)基本的に「KerasサンプルのMNIST CNNモデル keras/examples/mnist_cnn.py」をそのまま持ってきてますが、最適化関数はPyTorchのサンプル(pytorch/examples/mnist/main.py)をそのまま持ってきたため、AdaDeltaではなくてMomentum SDGになってます(train.py)。
学習済みモデルを使った手書き数字の認識(Python)
lossとAccuracyは悪くないので、それなりにうまく学習できているはずです。
ではこの学習済みモデルが上手く機能するかどうか、Pythonで書いた手書き数字画像の認識プログラムを動かしてみます。適当に作ったテスト用の画像をdigit_imagesディレクトリに入れておきましたので、それを認識してみましょう。
手書き数字の画像を認識する(Python)
$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ ./predict.py ../models/mnist_py.pt ../digit_images/2.png label: 2 (prob: 0.998020)
- 1つ目の引数は学習済みモデルのファイル名、2つ目の引数は予測する手書き数字の画像ファイル名です。
PyTorchに予測させた画像は、↑です。ちゃんと「2」と認識しました。
学習済みモデルを使った手書き数字の認識(C++)
学習したモデルはきちんと動作しそうなので、次はC++で手書き文字認識をしてみましょう。
学習済みモデルの変換(Python)
PyTorchのマニュアル LOADING A PYTORCH MODEL IN C++ を見ると、Python(PyTorch)で学習したモデルをC++で読むための公式の手順が書かれています。PyTorch素晴らしい。
PyTorchのモデルをTorch Scriptへ変換する
$ cd ${HOME}/libtorch_pytorch_mnist/pytorch $ ./convert_model.py ../models/mnist_py.pt ../models/mnist_cpp.pt
- 1つ目の引数は学習済みモデルのファイル名、2つ目の引数は変換するC++用のモデルファイル名です。
変換済みモデルを使った手書き数字の認識(C++)
では、ビルドしておいたC++プログラムを使って、先ほどと同じ手書き数字画像を認識してみます。
手書き数字の画像を認識する(C++)
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ ./predict_image ../models/mnist_cpp.pt ../digit_images/2.png label: 2 (prob: 0.993486)
- 1つ目の引数はC++用に変換済みモデルのファイル名、2つ目の引数は予測する手書き数字の画像ファイル名です。
さくっと認識できました。C++の方はOSネイティブの実行ファイルのため、Pythonよりも心持ち早いと思います。が、1画像の認識程度では違いはあまりわかりません(笑
PyTorchのPython APIとlibtorchのC++ APIは、ほぼ同じようなシグネチャで作られています。Pythonの実装とほとんど同じような記述でC++の実装が書けるのは、よくできていると思います(OpenCVの画像を扱うあたりは若干異なりますが)。
USBカメラ映像の各フレームで手書き数字を連続的に認識する(C++)
最後に、USBカメラ映像の各フレームで、リアルタイムに手書き数字の認識をしてみましょう。
本来であれば、各フレームをキューにバッファリングしてCPUコアごとに分散処理させ、間に合わない場合にはイイカンジに間引くような仕組みを作り込むべきですが、今回はシンプルに全てシングルスレッド上でDNNを回しています。
USBカメラのキャプチャを開始する
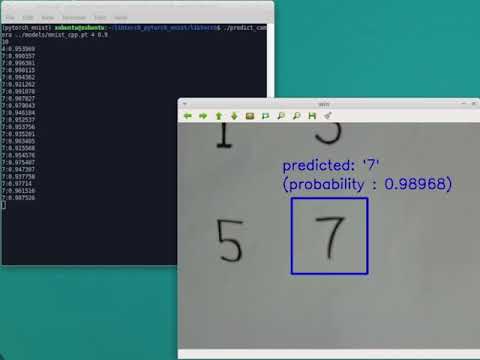
$ cd ${HOME}/libtorch_pytorch_mnist/libtorch $ ./predict_camera ../models/mnist_cpp.pt 4 0.9
- 1つ目の引数はC++用に変換済みモデルのファイル名、2つ目の引数はUSBカメラのデバイスIDです。
- 3つ目の引数は「認識できた」と判定するためのしきい値です。上記の場合、0.9以上の確率で分類された際に「認識できた」とみなします。
USBカメラの映像で、指定された位置の手書き文字を認識する。
(youtubeで動画が再生されます)今回のUSBカメラは10~15FPSぐらいで動作させていますが、ほぼ遅延無く手書き数字認識ができているようです。
まとめ
ということで、pythonで学習したPyTorchのDNNモデルをC++から利用することができました。今後はちゃんとGPUも使い、より複雑なモデルをC++で動作させてみたいところです。
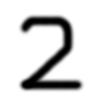
- 投稿日:2019-05-03T15:07:08+09:00
Ubuntu16.04にCaffe2をインストールする
はじめに
この記事では、ubuntu16.04にディープラーニングフレームワーク「Caffe2」をインストールする手順を記載します。
環境
・Ubuntu16.04(Windows10上のVirtualBoxにインストール)
・Python2.7
・CPU Onlyインストール手順
※Ubuntu16.04はインストール直後の状態です。
※権限が足りない場合は適宜付与してください。1.事前に必要ないくつかのパッケージをインストール
$ sudo apt-get update $ sudo apt-get install -y --no-install-recommends \ build-essential \ git \ libgoogle-glog-dev \ libgtest-dev \ libiomp-dev \ libleveldb-dev \ liblmdb-dev \ libopencv-dev \ libopenmpi-dev \ libsnappy-dev \ libprotobuf-dev \ openmpi-bin \ openmpi-doc \ protobuf-compiler \ python-dev \ python-pip $ pip install --upgrade pip $ sudo apt-get install python-setuptools $ pip install --user \ future \ numpy \ protobuf \ typing \ hypothesis $ sudo apt-get install -y --no-install-recommends \ libgflags-dev \ cmake $ sudo apt-get install -y --no-install-recommends \ libgflags-dev \ cmake2.Pytorch(Caffe2)本体をインストール&ビルド(私の環境だと1時間がかかった)
$ git clone https://github.com/pytorch/pytorch.git && cd pytorch $ git submodule update --init --recursive $ sudo apt-get install python-yaml $ python setup.py install3.Caffe2のインストール確認
$ cd ~ && python -c 'from caffe2.python import core' 2>/dev/null && echo "Success" || echo "Failure" Successリンク
AIエンジニアを目指してみる
Ubuntu16.04にCaffeをインストールする参考
- 投稿日:2019-05-03T10:31:31+09:00
InceptionV3で胸部X線画像の方向分類
環境
- Ubuntu 18.04
- Anaconda 1.9.6
- Tensorflow-gpu 1.12.0
- Keras-gpu 2.2.4
- GeForce GTX 1050 Ti(totalMemory: 3.95GiB freeMemory: 3.89GiB) + AkiTiONODE
※GPUを使いましたが、CPUでもできます。(確かめてませんが、、)
必要なもの
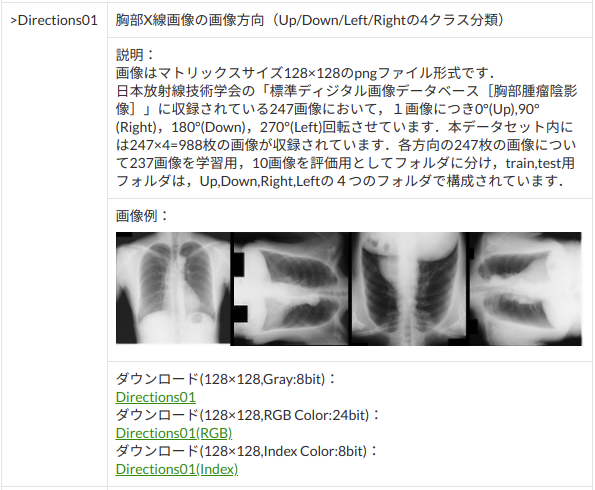
日本放射線技術学会「標準ディジタル画像データベース[胸部腫瘤陰影像]」Direction01
http://imgcom.jsrt.or.jp/minijsrtdb/
画像サイズ 128*128、色深度 Gray 8 bitのデータを選択してダウンロード。
ダウンロードしたら解凍。ここではわかりやすくデスクトップへ。
Direction01.zipをデスクトップに移動して、右クリックから「ここで展開」を実行。
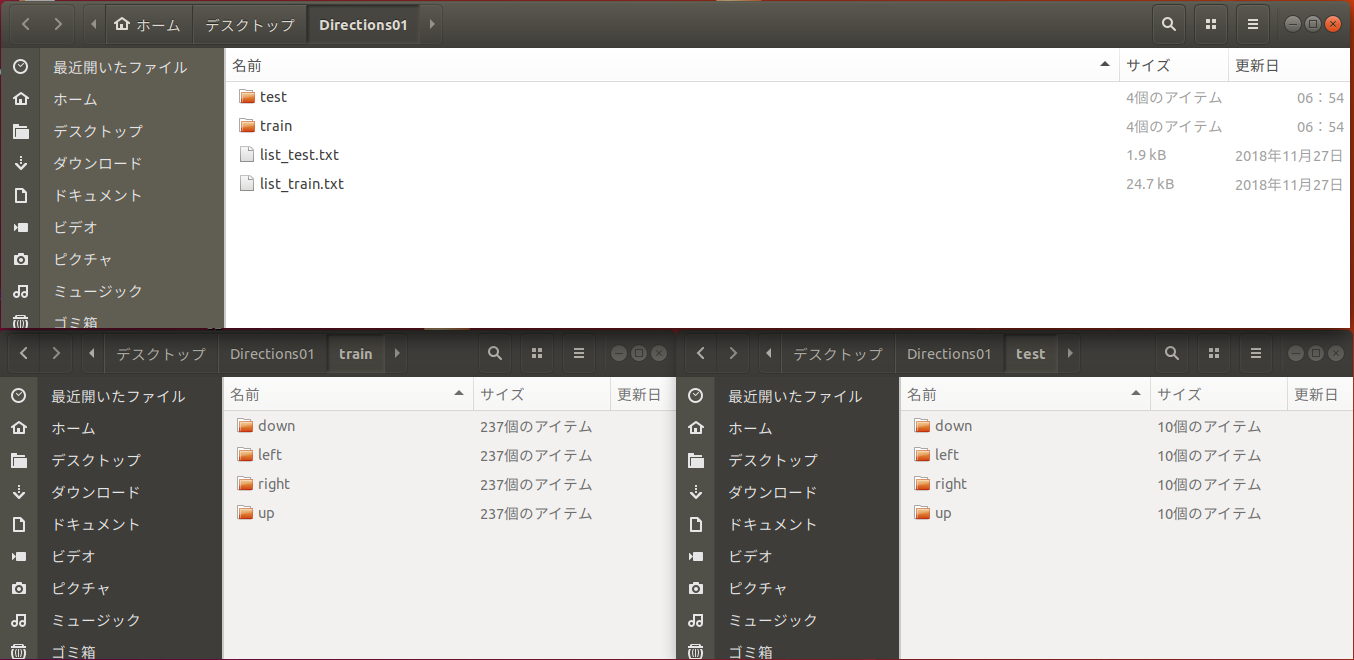
Direction01フォルダの中身は、とても親切に、トレーニングとテストデータが分かれており、かつ、それぞれのフォルダの中身も、Right, Left, down, upに整理されている。作成・提供者に感謝。
コード
さっそく、モデルをトレーニングしていく。
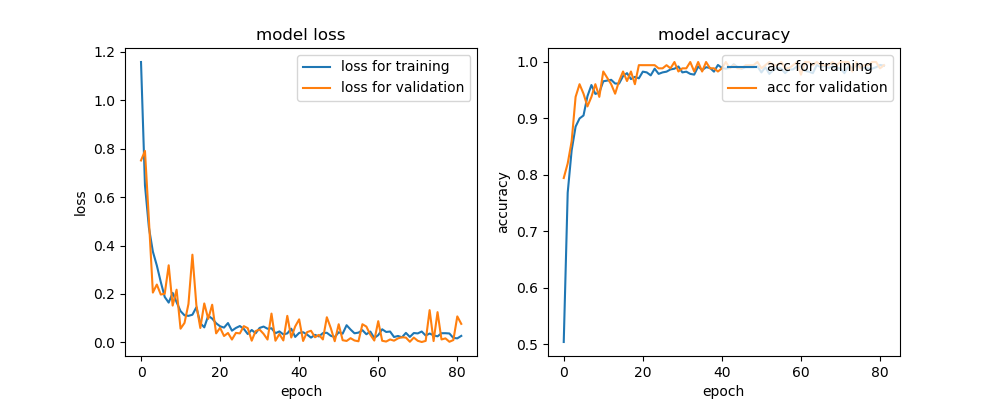
以下のような感じで試してみた。''' Created on 2019/05/03 @author: tatsunidas ''' ''' 必要なもの Directions01のtrainとtestまでの絶対パス(フォルダの場所) データジェネレータ(データを水増しする) モデル(InceptionV3) コールバック トレーニング(categorical_crossentropy, Nadam, acc) グラフ化 モデルとグラフの保存 テスト ''' from keras.preprocessing.image import ImageDataGenerator import keras from keras.applications.inception_v3 import InceptionV3 from keras.layers import Dense, Flatten, BatchNormalization from keras.models import Model from keras.optimizers import Nadam import matplotlib.pyplot as plt #Directions01のtrainとtestまでの絶対パス(フォルダの場所) ''' ここでは例を載せています。自分の環境に合わせて下さい。 例えば、Win10の方は、'C:\Users\あなたのユーザ名\Desktop'などになります。 ''' trainDir = '/home/tatsunidas/デスクトップ/Directions01/train' testDir = '/home/tatsunidas/デスクトップ/Directions01/test' #モデルの保存先と名前:ここでは例を載せています。自分の環境に合わせて下さい。 model_save_to = '/home/tatsunidas/デスクトップ/' model_filename = 'model_best_directions01.h5' plot_capture_to = '/home/tatsunidas/デスクトップ/result_plot.png' # データのア(オ)ーギュメンテーション(水増し)の準備 datagen=ImageDataGenerator( rescale = 1./255, validation_split=0.2,#自動でバリデーションデータを分割させる rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, fill_mode='nearest', horizontal_flip=False,#今回はローテーション画像の判定なのでFalseのままにしておく vertical_flip=False#今回はローテーション画像の判定なのでFalseのままにしておく ) #画像処理しながらトレーニングデータの水増しをしてくれるように設定 train_generator = datagen.flow_from_directory( trainDir, target_size=(299, 299), color_mode = "grayscale", class_mode='categorical', batch_size=10, shuffle=True, subset='training' ) #画像処理しながらバリデーションデータを入力してくれるように設定 val_generator = datagen.flow_from_directory( trainDir, target_size=(299, 299), color_mode = "grayscale", class_mode='categorical', batch_size=10, shuffle=True, subset='validation' ) # callback """ トレーニング中に学習をさせているにも関わらず損失値が下がらなくなったら途中で終了させる設定。 ただし、単に中断するのではなく、何回か継続させてみて、それでも改善が見られない場合に中断するようにしている。 """ callbacks_list = [ #損失が一番小さいとき、モデルの重みを保存(あくまでも「重み」であることに注意) keras.callbacks.ModelCheckpoint( filepath=model_save_to+model_filename, monitor = 'val_loss', save_best_only=True ), # 損失が改善しなくなったら、継続して学習を10回チャンレンジさせる keras.callbacks.EarlyStopping( monitor='val_loss', patience=10#もっと小さくてよい ), # 損失が改善しなくなったら、7回目で学習率を0.1下げてみる keras.callbacks.ReduceLROnPlateau( monitor='val_loss', factor=0.1, patience=7#もっと小さくてよい ), # tensorboardという学習過程をブラウザで可視化するための設定。 # keras.callbacks.TensorBoard( # log_dir=tflogDir, # histogram_freq=1, # embeddings_freq=1 # ) ] #modelの構築 #インセプションV3をランダム初期化。特徴抽出部分に使う。 base_model_v3 = InceptionV3(include_top=False, weights=None ,input_shape=(299,299,1)) #分類部分を追加 x = base_model_v3.output x = Flatten()(x) x = BatchNormalization()(x) x = Dense(256, activation='relu')(x) x = Dense(128, activation='relu')(x) x = Dense(64, activation='relu')(x) preds = Dense(4, activation='sigmoid')(x)# 今回は4クラスの分類なので model = Model(inputs=base_model_v3.input, outputs=preds) #モデルの構造を確認 model.summary() #モデルを固定 #多クラス分類・シングルラベルなので、loss="categorical_crossentropy",metrics=['accuracy'] model.compile(optimizer=Nadam(lr=2e-5),loss="categorical_crossentropy",metrics=['accuracy']) #計算量を分散するためにエポック内でステップを分割 STEP_SIZE_TRAIN=train_generator.samples//train_generator.batch_size STEP_SIZE_VALID=val_generator.samples//val_generator.batch_size #モデルのトレーニング history = model.fit_generator(generator=train_generator, steps_per_epoch=STEP_SIZE_TRAIN, validation_data = val_generator, validation_steps = STEP_SIZE_VALID, callbacks=callbacks_list, epochs=100#例えば最大100回学習の場合 ) #最後のモデルの保存 model.save(filepath=model_save_to+'model_last.h5', overwrite=False, include_optimizer=True) #トレーニング過程をグラフ化 fig, (axL, axR) = plt.subplots(ncols=2, figsize=(10,4)) # loss def plot_history_loss(fit): # Plot the loss in the history axL.plot(fit.history['loss'],label="loss for training") axL.plot(fit.history['val_loss'],label="loss for validation") axL.set_title('model loss') axL.set_xlabel('epoch') axL.set_ylabel('loss') axL.legend(loc='upper right') # acc def plot_history_acc(fit): # Plot the loss in the history axR.plot(fit.history['acc'],label="acc for training") axR.plot(fit.history['val_acc'],label="acc for validation") axR.set_title('model accuracy') axR.set_xlabel('epoch') axR.set_ylabel('accuracy') axR.legend(loc='upper right') plot_history_loss(history) plot_history_acc(history) fig.savefig(plot_capture_to) plt.close() ''' 最後にテストデータをモデルに予測させて精度を確かめる ''' test_datagen = ImageDataGenerator( rescale = 1./255 ) test_generator = test_datagen.flow_from_directory( testDir, target_size=(299, 299), color_mode = "grayscale", class_mode='categorical', batch_size=5, shuffle=False ) STEP_SIZE_TEST=test_generator.samples//test_generator.batch_size test_gen=model.predict_generator( test_generator, steps=STEP_SIZE_TEST, verbose=1 ) #精度を出力 print(model.evaluate_generator(generator=test_generator, steps=STEP_SIZE_TEST, verbose = 1))結果
学習が終了すると、テストが自動で処理され、コンソールにテスト結果が出力される。
[0.0001470107831664791, 1.0]
左が損失値、右が精度。このデータセットに対しては、ほぼ完璧なモデルになった。作成される成果物
コード内で指定した場所に以下のファイルが作成される。
今回の学習の過程は、result_plot.pngを見れば確認できる。
過学習をすれすれでコラえながら学習していることがわかる。
この記事を書いたモチベーション
備忘録として見返すと楽しそうと思ったから。
その他
コメント歓迎です。誤りなどもご指摘いただけましたら、時間のあるときに修正させていただきます。
参考URL
JSRT画像部会「MINIJSRT_DATABASE」:http://imgcom.jsrt.or.jp/minijsrtdb/
グラフ部分:https://qiita.com/hiroyuki827/items/213146d551a6e2227810