- 投稿日:2020-11-17T23:53:38+09:00
ハンドトラッキングを試してみろう!
今回、mediapipeの動き方を調査して、ハンドトラッキングの仕組みについて話させていただきます。
伝えたいこと
- mediapipeの概要
- ハンドトラッキングモデルの仕組み
mediapipeの概要
MediaPipeは、クロスプラットフォーム(デスクトップ、モバイル、ウェブ、Raspberryなどのマイコン)のマルチモーダル適用MLパイプラインを構築するためのフレームワークです。
コンセプト
https://google.github.io/mediapipe/framework_concepts/framework_concepts.html
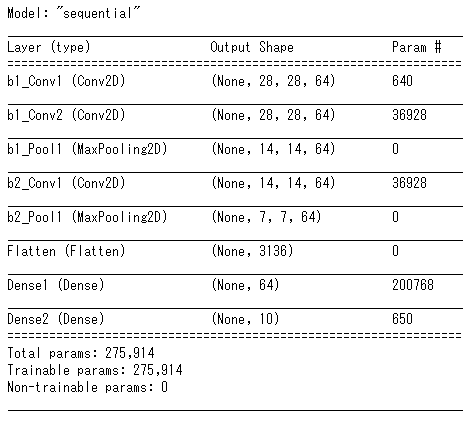
- グラフ(Graph):以上の画像のようなノードのネットワークを保持します
- パケット(Packet):基本データユニットです。パケットの中にはペイロード(テキストや画像データなど)とタイムスタンプがあります
- ノード(Nodes):インプットストリームのパケットを処理してアウトプットストリームに新しいパケットを抽出します
- ストリーム(Streams):一連のパケットを伝送する2つのノード間の接続です
- 側パケット(Side packets):タイムスタンプのない単一パケット(設定値とか、静的なワンタイムインプット)
ハンドトラッキンググラフ
試しのリンク:https://viz.mediapipe.dev/demo/hand_tracking
参考:https://webbigdata.jp/ai/post-3992仕組み
ハンドトラッキンググラフ:
インプットノード(input_frames_gpu):ウェブカメラからビデオデータ
- インプット動画を水平方向に反転する(ImageTransformation)
- 後ろのフローに1つ画像だけ権限をする(FlowLimiter)
- 画像全体を操作し、手のバウンディングボックスを返す手のひら検出器モデル(HandDetectionというノード)
- インプット:画像
- アウトプット:手のバウンディングボックス(NORM_RECT)
- 手のひら検出器によって定義されたトリミングされた画像領域で動作し、忠実度の高い3D手のキーポイントを返す手のランドマークモデル(HandLandmarkというノード)。
- インプットは
- 画像(IMAGE)
- 手があるバウンディングボックス(NORM_RECT)
- アウトプットは
- 手の21位置(LANDMARKS)
- 右手か左手か(HANDEDNESS)
- 現時点の手のバウンディングボックス(NORM_RECT)
- そのハウンディングボックスにある手があるかどうか(PRESENCE)
一旦今回ここまでです。次、ハンドトラッキンググラフのコードを編集してみて簡単なことをやりましょう!
- 投稿日:2020-11-17T22:37:38+09:00
YOLOv3-tf2 を使った物体検出 —独自データセットの用意からリアルタイム検出まで—
はじめに
はじめまして.私はアルバイトで深層学習を用いた分析などをしている大学生です.
物体検出を扱うことがあったのですが,調べることも多く手間取りました.
そこで,作業を進める中で得たことを自分なりにまとめてみました.方針
これから物体検出を試してみようとする人に向けての記事です.
Tensorflow2 を使いたいという条件で自前で画像を用意して学習させて,実際に動かしてみます.
精度の向上等を主にするものではありません.YOLOv3-tf2 とは
物体検出モデルの YOLOv3 の Tensorflow2 代替実装です.今回はこちらのリポジトリを利用します.
$ git clone https://github.com/zzh8829/yolov3-tf2.gitデータセットを作る
学習させるためのデータセットを作ります.
データセットは基本画像ファイルとアノテーションファイルの2つから成ります.
アノテーションとは対象となる物体の名前,座標や状態を記載しておくラベル付けのファイルのことです.実際に写真を撮って1枚ずつ labelImg 等のアノテーションツールを利用してラベル付けを行います.
このようにできることがベストですが,相応の手間と時間がかかってしまいます.
そこで今回は物体の透過画像を背景画像に貼って擬似的に画像を生成し,アノテーションを作ることにします.
対象の物体の画像に偏りができてしまうので注意が必要ですが,手間を減らして完璧な精度を持ったアノテーションと画像のセットを量産できるメリットがあります.画像
Python では Pillow(PIL) を使うことで画像の操作をすることができます.
背景はリアルな画像だけでなくランダムな単色画像を背景にする混ぜることで背景画像に依存しない学習が望めます.
物体も回転や明度変更を行うことで汎化性能の向上を図れます.
回転すると画像サイズが変わるため物体のギリギリになるようにアノテーションできるように処理する必要があります.
Python での実装(クリックして展開)
from PIL import Image, ImageEnhance, ImageDraw import os import random # 画像サイズ size = (4608, 3456) # 生成枚数 num_of_images = 100 dirs = ["watch", "ramune"] # dirs = os.listdir('./Photos') for i in range(num_of_images): # 物体情報を保持する obj_details = [] # 背景画像 red = random.randint(0, 255) green = random.randint(0, 255) blue = random.randint(0, 255) bg = Image.new('RGB', size, (red, green, blue)) # bg = Image.open('background.jpg') # 物が置けない場所を管理する # - 透過していると物が置ける(もっといい処理ありそう) # - 重なったり,実際に存在し得ない場所に配置されないようにする deployable_area = Image.new('RGBA', size, (0, 0, 0, 0)) for j in range(len(dirs)): photos = os.listdir("./Photos/" + dirs[j]) obj = Image.open("./Photos/" + dirs[j] + "/" + photos[i % len(photos)]) # 明度変更 obj = ImageEnhance.Brightness(obj).enhance(random.uniform(0.7, 1.3)) # 回転 obj = obj.rotate(angle=random.randint(0, 360), expand=True, fillcolor=(0, 0, 0, 0)) # 回転により生まれた余計な部分を削除する crop = obj.convert('RGB').getbbox() obj = obj.crop(crop) while True: obj_x = random.randint(0, bg.size[0] - obj.width) obj_y = random.randint(0, bg.size[1] - obj.height) # 配置可能か検証 for _x in range(obj_x, obj_x + obj.width): for _y in range(obj_y, obj_y + obj.height): if deployable_area.getpixel((_x, _y)) == (0, 0, 0, 255): break else: continue break else: break continue obj_details.append( { "xmin": obj_x, "xmax": obj_x + obj.width, "ymin": obj_y, "ymax": obj_y + obj.height, "name": dirs[j] } ) print(obj_x, obj_y, "に", dirs[j], "を配置") for _x in range(obj.width): for _y in range(obj.height): if obj.getpixel((_x, _y)) != (0, 0, 0, 0): deployable_area.putpixel((_x + obj_x, _y + obj_y), (0, 0, 0, 255)) bg.paste(obj, (obj_x, obj_y), obj.split()[3]) bg.save("./dataset/images/" + str(i).zfill(len(str(num_of_images))) + ".jpg")アノテーション
アノテーションは PascalVOC 形式で作ります.作るのは以下のような画像と同名の XML ファイルです.
001.xml<annotation> <filename>001.jpg</filename> <size> <width>4608</width> <height>3456</height> <depth>3</depth> </size> <object> <name>watch</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>928</xmin> <ymin>1162</ymin> <xmax>1533</xmax> <ymax>1861</ymax> </bndbox> </object> </annotation>記載されている内容は
- filename: 対象の画像名です.
- size
- width/height: 画像の縦横pxです.
- depth: 色の層です.
3は RGB の 3 色に対応します.白黒であれば1です.- object
- name: 物体の名前です.
- pose:
Left,Frontal,Right,Rearなど物体の向きを記述できます. 特に指定がなければUnspecifiedです.- truncated: オブジェクトの一部分に対応していることを示します.例えば人に対する上半身のみ,や画像で見切れている場合に
1を指定します.そうでなければ0です.- difficult: 認識が難しいオブジェクトを示します.例えば他の要素を含まないと認識できないものであるときは
1を指定します.そうでなければ0です.- bndbox: 物体の存在する範囲を指定します.左上座標をxmin/ymin, 右下座標を xmax/ymax に記述します.
PascalVOC 形式には他にも記述可能な項目がありますが,このリポジトリを利用する上で必要なことは以上です.
形式の詳細はこちら: The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Development Kit画像とアノテーションのフォルダは分けておきます.
XML は Python なら ElementTree ライブラリで作れます.
Python 実装例(クリックして展開)
import xml.etree.ElementTree as Et # from PIL import Image # bg = Image.new('RGB', size, (red, green, blue)) # obj_details = [{ # "xmin": 131, # "xmax": 176, # "ymin": 309, # "ymax": 403, # "name": "book" # }] root = Et.Element("annotation") filename = Et.SubElement(root, "filename") filename.text = str(i).zfill(len(str(num_of_images))) + ".jpg" size = Et.SubElement(root, "size") width = Et.SubElement(size, "width") width.text = str(bg.size[0]) height = Et.SubElement(size, "height") height.text = str(bg.size[1]) width = Et.SubElement(size, "depth") width.text = str(3) for obj_detail in obj_details: object = Et.SubElement(root, "object") name = Et.SubElement(object, "name") name.text = obj_detail["name"] pose = Et.SubElement(object, "pose") # Pose pose.text = "Unspecified" truncated = Et.SubElement(object, "truncated") # truncated truncated.text = str(0) difficult = Et.SubElement(object, "difficult") # difficult difficult.text = str(0) bndbox = Et.SubElement(object, "bndbox") xmin = Et.SubElement(bndbox, "xmin") xmin.text = str(obj_detail["xmin"]) xmin = Et.SubElement(bndbox, "xmax") xmin.text = str(obj_detail["xmax"]) ymin = Et.SubElement(bndbox, "ymin") ymin.text = str(obj_detail["ymin"]) ymax = Et.SubElement(bndbox, "ymax") ymax.text = str(obj_detail["ymax"]) xml = Et.ElementTree(root) xml.write("./dataset/xml/" + str(i).zfill(len(str(num_of_images))) + ".xml", encoding="utf-8")
学習の前に座標がずれていないか確認しておくと良いでしょう.TFRecord を作る
学習には画像とアノテーションをまとめた TFRecord 形式のファイルを生成する必要があります.
その前に train として使う画像のリスト,val として使う画像のリスト,学習させる物体が書かれたリストが書かれたファイルを作ります.
改行してファイル名を記述していきます.拡張子は不要で,train に利用したい画像が 001.jpg から 100.jpg ならtrain.txt000 001 002 ... (略) ... 100と順に記述して適当に train.txt のように名前をつけて保存しておきます.val.txt も同様に行います.
物体が書かれたリストも同じように改行して記述していきます.
dataset.namesapple orange ... (略) ... banana適当に dataset.names のように名前をつけて保存します.
ここまでで以下のようにな構造になっているといい感じです.
dataset |--images | |--000.jpg | |--001.jpg | |--... |--xml | |--000.xml | |--001.xml | |--... |--train.txt |--val.txt |--dataset.namesリポジトリのコードは VOC2012 データセットに対応しているので,リポジトリのコードを適宜変更します.変更箇所は以下の3つです.
yolov3-tf2/tools/voc2012.py# 20-21行目: 画像を読み込めるように img_path = os.path.join(FLAGS.data_dir, 'images', annotation['filename']) # 95-96行目: train.txt / val.txt を読み込めるように image_list = open(os.path.join(FLAGS.data_dir, '%s.txt' % FLAGS.split)).read().splitlines() # 99-100行目: XML を読み込めるように annotation_xml = os.path.join(FLAGS.data_dir, 'xml', name + '.xml')ここまで来たら準備完了です.TFRecord を生成するには以下を実行します.
$ python tools/voc2012.py \ --data_dir './dataset' \ --split train \ --output_file ./dataset/dataset_train.tfrecord $ python tools/voc2012.py \ --data_dir './dataset' \ --split val \ --output_file ./dataset/dataset_val.tfrecord学習させる
転移学習をさせるための元の重みデータをダウンロードしてくる必要があります.
$ wget https://pjreddie.com/media/files/yolov3.weights -O data/yolov3.weightまた,重みデータを変換するために,以下を実行します.
$ python convert.py適宜引数を変えて以下を実行します.
$ python train.py \ --dataset ./dataset/dataset_train.tfrecord \ --val_dataset ./dataset/dataset_val.tfrecord \ --classes ./dataset/dataset.names \ --num_classes 20 \ --mode fit --transfer darknet \ --batch_size 16 \ --epochs 50 \ --weights ./checkpoints/yolov3.tf \ --weights_num_classes 80./checkpoint/ に記録されていきます.
学習が停滞したら EarlyStopping が効きます.検出させてみる
Webカメラからの入力を受け付けているので試してみます.
実際にラムネ(2枚)と時計(5枚)の画像を貼り付けた画像を100枚ほど生成して学習させてみました.python detect_video.py --video 0 --weight ./checkpoint/yolov3_train_42.tf --num_classes 2 --classes ./dataset/dataset.names精度は怪しいですが用意する手間を考えたらかなりよくできたのではないでしょうか.(映像が汚くて申し訳ない)
これから
このリポジトリには性能評価指標である mAP が実装されていません.
要望は多いようで最近の Issue にもあります.yolov3-tf2/issues/125 は古いながらも参考になりそうです.
時間があれば試してみます.



- 投稿日:2020-11-17T21:31:07+09:00
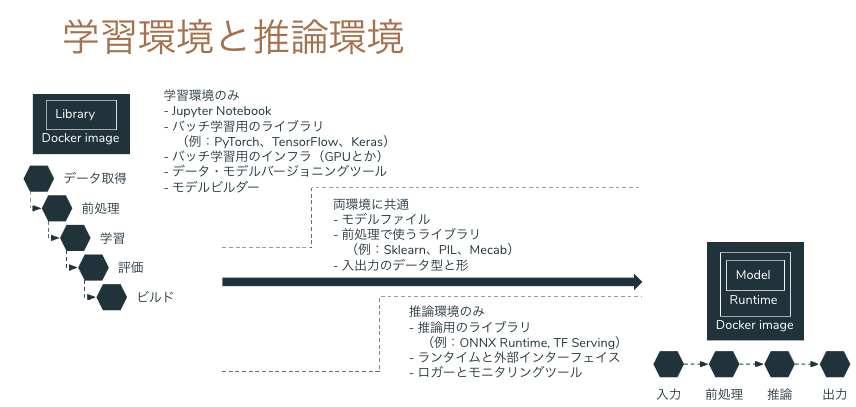
Tensorflow Serving を使い倒す
Tensorflow Serving を使い倒す
有望なディープラーニングのライブラリは Tensorflow と PyTorch で勢力が二分されている現状です。それぞれに強み弱みがあり、以下のような特徴があると思います。
- Tensorflow:Tensorflow Serving や Tensorflow Lite のような豊富な推論エンジン、Keras の便利な学習 API
- PyTorch:Define by Run による強力な学習、TorchVision による便利な画像処理
研究や学習では PyTorch が圧倒的になっていますが、推論器を動かすとなると Tensorflow のほうが有力な機能を提供していると思います。PyTorch は ONNX で推論することが可能ですが、モバイル向けや End-to-end なパイプラインサポートとなると、Tensorflow Lite や TFX 含めて Tensorflow が便利です。
本ブログでは Tensorflow Serving を用いた推論器とクライアントの作り方を説明します。Tensorflow Serving を動かすだけであれば多様な記事がありますが、本ブログではデータの入力から前処理、推論、後処理、出力まで、End-to-end で Tensorflow でカバーする方法を紹介します。
今回書いたコード:https://github.com/shibuiwilliam/e2e_tensorflow_serving
問題意識
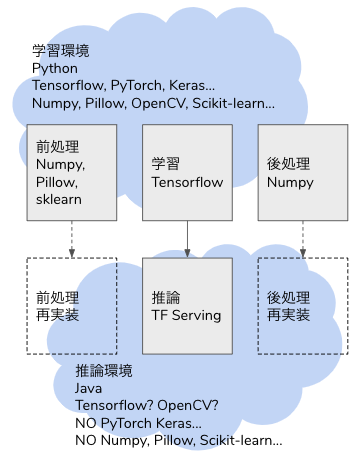
ディープラーニングでモデルを学習した後、モデルは saved model や ONNX 形式で出力できても、前処理や出力が学習時の Python コードしかなく、推論へ移行するときに書き直すことになります。
学習も推論も Python で、Python コードをそのまま使い回せるなら良いですが(それでも間違うことが多々ありますが)、本番システムは Java や Golang、Node.js で Python を組み込む基盤や運用がないということがあります。Python 以外の言語で画像やテーブルデータの処理が Python ほど豊富であるとは限りませんし、Python で実行している前処理をそのまま動かすことができるとは限りません。
解決策のひとつは、機械学習の推論プロセスをサポートする推論器を作ることです。推論プロセスのすべてを Tensorflow の saved model に組み込んでしまい、Tensorflow Serving へ生データをリクエストすれば推論結果がレスポンスされる API を作れば、連携するバックエンドは REST クライアントや GRPC クライアントとして Tensorflow Serving にリクエストを送るだけで良くなります。
Tensorflow の Operator はニューラルネットワークだけでなく、画像のデコードやリサイズ、テーブルデータの One Hot 化等、機械学習に必須な処理が可能になっています。従来であれば Python の Pillow や Scikit-learn に依存していた処理が Tensorflow の計算グラフに組み込まれているため、推論のデータ入力から推論結果の出力まで、全工程を Tensorflow Serving でカバーすることができます。
本ブログでは Tensorflow Serving による画像分類、テキストの感情分析、テーブルデータの 2 値分類を使い、Tensorflow Serving の可能性を示していきたいと思います。
Tensorflow Serving
Tensorflow Serving は Tensorflow や Keras のモデルを推論器として稼働させるためのシステムです。Tensorflow の saved model を Web API(GRPC と REST API)として稼働させることができます。また単なる Web API だけでなく、バッチシステムとして動かすこともできます。複数バージョンのモデルを同一の Serving に組み込み、エンドポイントを分けることも可能です。Tensorflow Serving は Docker で起動させることが一般的です。
画像分類
ディープラーニングの重要な使い途の一つが画像処理です。今回はInception V3を使った画像分類を Tensorflow Serving で動かします。
画像分類のプロセスは以下になります。
- 生データの画像ファイルを入力データとして受け取る。
- 画像をデコードする。
- 画像をリサイズして Inception V3 の入力 Shape である(299,299,3)に変換する。
- Inception V3 で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Inception V3 が担うのは常勤お 4 のみで、1,2,3,5,6 は前処理や後処理として周辺システムでカバーする必要があります。学習時は Python で Pillow や OpenCV、Numpy 等々を使って書きますが、推論時に同様のライブラリを使えるとは限りません。特に Python 以外の言語で構築する場合、OpenCV を使うことはできるかもしれませんが、他の Pillow や Numpy は他のライブラリで代替するか、自作する必要があります。
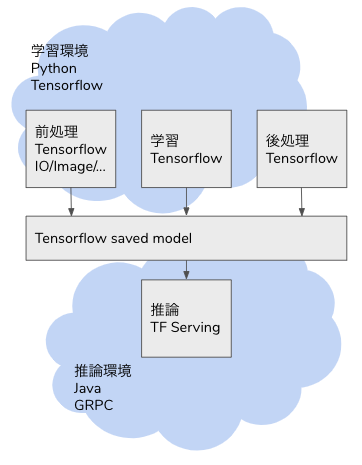
しかし Tensorflow であれば、1,2,3,5,6 も Tensor Operation に組み込み、推論の全行程をカバーすることができます。そのためには tf.function に前処理(1,2,3)と後処理(5,6)の Operation を記述します。
以下のdef serfing_fnがその Operation になります。Pillow や Numpy でも同様の処理を書くことがあると思いますが、記述量も複雑さも大差ない実装が可能です。from typing import List import tensorflow as tf from tensorflow import keras class InceptionV3Model(tf.keras.Model): def __init__(self, model: tf.keras.Model, labels: List[str]): super().__init__(self) self.model = model # Inception V3 model self.labels = labels # ImageNet labels in list @tf.function( input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="image")] ) def serving_fn(self, input_img: str) -> tf.Tensor: def _base64_to_array(img): img = tf.io.decode_base64(img) img = tf.io.decode_jpeg(img) img = tf.image.convert_image_dtype(img, tf.float32) img = tf.image.resize(img, (299, 299)) img = tf.reshape(img, (299, 299, 3)) return img img = tf.map_fn(_base64_to_array, input_img, dtype=tf.float32) predictions = self.model(img) def _convert_to_label(candidates): max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(self.labels, idx)) return label return tf.map_fn(_convert_to_label, predictions, dtype=tf.string) def save(self, export_path="./saved_model/inception_v3/0/"): signatures = {"serving_default": self.serving_fn} tf.keras.backend.set_learning_phase(0) tf.saved_model.save(self, export_path, signatures=signatures)上記
InceptionV3Modelクラスのインスタンスを saved model として保存し、Tensorflow Serving として起動することができます。起動した Tensorflow Serving は GRPC として 8500 ポート、REST API として 8501 ポートが開放されます。docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name inception_v3 \ -v $(pwd)/saved_model/inception_v3:/models/inception_v3 \ -e MODEL_NAME=inception_v3 \ tensorflow/serving:2.3.0エンドポイントの定義は以下のようになっています。
inputs以下が入力定義で、outputs以下が出力定義です。inputsではimageタグのデータを取ります。Shape が-1となっていますが、これは画像の base64 エンコードされたデータを入力とするためです。この時点で Tensorflow Serving への入力は(299,299,3)次元の配列ではなく、画像データそのものとなっています。
curl localhost:8501/v1/models/inception_v3/versions/0/metadata$ curl localhost:8501/v1/models/inception_v3/versions/0/metadata { "model_spec":{ "name": "inception_v3", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "image": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_image:0" } }, "outputs": { "output_0": { "dtype": "DT_STRING", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "StatefulPartitionedCall:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }リクエストは以下のように実行することができます。GRPC と REST API の例を書いていますが、どちらも画像をバイナリデータとして読み込み、base64 エンコードして Tensorflow Serving のエンドポイントにリクエストします。クライアントは前処理することなく Tensorflow Serving にデータをリクエストします。
注意点は Tensorflow のtf.io.decode_base64がbase64.urlsafe_b64encodeされたデータでないとデコードできないという点です。def read_image(image_file: str = "./a.jpg") -> bytes: with open(image_file, "rb") as f: raw_image = f.read() return raw_image # GRPC def request_grpc( image: bytes, model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) base64_image = base64.urlsafe_b64encode(image) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name request.inputs["image"].CopyFrom(tf.make_tensor_proto([base64_image])) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_0"].string_val[0].decode("utf-8") return prediction #REST def request_rest( image: bytes, model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} base64_image = base64.urlsafe_b64encode(image).decode("ascii") request_dict = {"inputs": {"image": [base64_image]}} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0]推論結果は以下のようになります。
# GRPC $ python request_inceptionv3.py -f GRPC Siamese cat # REST API $ python request_inceptionv3.py -f REST Siamese catテキストの感情分析
続いてテキスト分類です。テキスト処理も画像と同様で、入力、前処理、後処理、出力になる箇所を
Tensorflow でカバーします。今回はサンプルデータとしてKaggle にある感情分析の NLP データを使用します。感情分析の英文データで、[anger, fear, joy, love, sadness, surprise]の 6 クラス分類となっています。
- anger: i felt anger when at the end of a telephone call
- fear: i pay attention it deepens into a feeling of being invaded and helpless
- joy: i am feeling totally relaxed and comfy
- love: i want each of you to feel my gentle embrace
- sadness: i realized my mistake and i m really feeling terrible and thinking that i shouldn't do that
- surprise: i feel shocked and sad at the fact that there are so many sick people
Tensorflow のテキスト処理で使えるライブラリは複数あります。
- Tensorflow Text
- Tensorflow Transform
- Tensorflow Keras Preprocessing
- Tensorflow Keras Layers Preprocessing
今回はTensorflow Keras Layers Preprocessingを使います。これを選んだのは API が使いやすいという理由です。
テキスト分類では以下の手順をたどります。前処理はテキストや目的次第ですが、今回は簡単のために tfidf を使います。
- 生データのテキストを入力データとして受け取る。
- テキストを前処理してベクターにする。
- ニューラルネットワーク で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Tensorflow Keras Layers PreprocessingではTextVectorizationで テキストデータの tfidf のベクター化が可能です。
以下は TextVectorization を使用したサンプルコードです。TextVectorization.adaptでテキストデータに対して変換マップを作ることができます。adapt した TextVectorization はtf.keras.layerとして Keras Model の 1 レイヤーに組み込むことができます。今回は入力レイヤーに使います。def make_text_vectorizer( data: np.ndarray, ) -> tf.keras.layers.experimental.preprocessing.TextVectorization: text_vectorizer = tf.keras.layers.experimental.preprocessing.TextVectorization( output_mode="tf-idf", ngrams=2 ) text_vectorizer.adapt(data) return text_vectorizer def define_model( text_vectorizer: tf.keras.layers.experimental.preprocessing.TextVectorization, optimizer: str = "adam", loss: str = "categorical_crossentropy", metrics: List[str] = ["accuracy"], ) -> tf.keras.Model: inputs = keras.Input(shape=(1,), dtype="string") x = text_vectorizer(inputs) x = layers.Dense(1)(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(256, activation="relu")(x) outputs = layers.Dense(6, activation="softmax")(x) model = keras.Model(inputs, outputs) model.compile(optimizer=optimizer, loss=loss, metrics=metrics) return modelfit したモデルを使って saved model を作成します。今回は TextVectorization が入力データの前処理を担うため、後処理(手順 4,5)の分類部分のみ追加実装しています。
class TextModel(tf.keras.Model): def __init__(self, model: tf.keras.Model, labels: List[str]): super().__init__(self) self.model = model self.labels = labels @tf.function( input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="text")] ) def serving_fn(self, text: str) -> tf.Tensor: predictions = self.model(text) def _convert_to_label(candidates): max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(self.labels, idx)) return label return tf.map_fn(_convert_to_label, predictions, dtype=tf.string) def save(self, export_path="./saved_model/text/"): signatures = {"serving_default": self.serving_fn} tf.keras.backend.set_learning_phase(0) tf.saved_model.save(self, export_path, signatures=signatures)保存した saved model で Tensorflow Serving を起動します。
docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name text \ -v $(pwd)/saved_model/text:/models/text \ -e MODEL_NAME=text \ tensorflow/serving:2.3.0Tensorflow Serving のメタデータは以下のとおりになっています。入力として
textフィールドにテキストデータを入れてリクエストします。出力はoutout_0に推論結果のラベルがレスポンスされます。
curl localhost:8501/v1/models/text/versions/0/metadata$ curl localhost:8501/v1/models/text/versions/0/metadata { "model_spec":{ "name": "text", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "text": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_text:0" } }, "outputs": { "output_0": { "dtype": "DT_STRING", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "StatefulPartitionedCall:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }今回も GRPC と REST のリクエスト例を示します。テキストデータをそのままリクエストに入れることができます。事前に前処理する必要はありません。
def read_text(text_file: str = "./text.txt") -> str: with open(text_file, "r") as f: text = f.read() return text # GRPC def request_grpc( text: str, model_spec_name: str = "text", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name request.inputs["text"].CopyFrom(tf.make_tensor_proto([text])) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_0"].string_val[0].decode("utf-8") return prediction # REST API def request_rest( text: str, model_spec_name: str = "text", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} request_dict = {"inputs": {"text": [text]}} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0]テーブルデータ 2 値分類
最後にテーブルデータです。
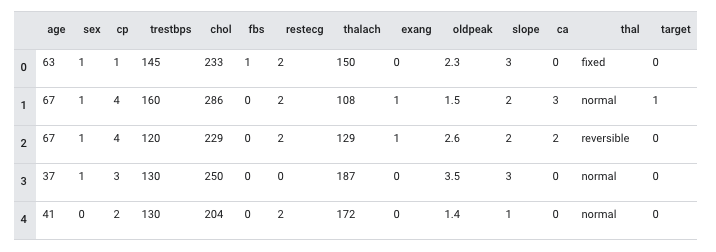
モデル自体は Tensorflow のサンプルで公開されているClassify structured data with feature columnsを使用します。以下のようなデータ構成になっています。
テーブルデータの前処理は tensorflow.feature_columnで各種データの変換をサポートしています。tensorflow.feature_columnを使用した推論の流れは以下のようになります。
- データを入力データとして受け取る。
- データをカラムに応じて前処理する。
- ニューラルネットワーク で推論し、Sigmoid を得る。
- 陽性の確率を出力する。
前処理含めて学習時にカラムの前処理を定義することができます。使い方はシンプルで、データの特徴に応じて変換方法を適用するだけで使えます。
from tensorflow import feature_column from tensorflow.keras import layers feature_columns = [] for header in ["age", "trestbps", "chol", "thalach", "oldpeak", "slope", "ca"]: feature_columns.append(feature_column.numeric_column(header)) age = feature_column.numeric_column("age") age_buckets = feature_column.bucketized_column( age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65] ) feature_columns.append(age_buckets) thal = feature_column.categorical_column_with_vocabulary_list( "thal", ["fixed", "normal", "reversible"] ) thal_one_hot = feature_column.indicator_column(thal) feature_columns.append(thal_one_hot) thal_embedding = feature_column.embedding_column(thal, dimension=8) feature_columns.append(thal_embedding) crossed_feature = feature_column.crossed_column( [age_buckets, thal], hash_bucket_size=1000 ) crossed_feature = feature_column.indicator_column(crossed_feature) feature_columns.append(crossed_feature)
feature_columnで定義したデータの前処理をモデルの入力レイヤーとして活用することが可能です。def define_model( feature_columns: List[Any], optimizer: str = "adam", loss: str = "binary_crossentropy", metrics: List[str] = ["accuracy"], ) -> tf.keras.Model: feature_layer = tf.keras.layers.DenseFeatures(feature_columns) model = tf.keras.Sequential( [ feature_layer, layers.Dense(128, activation="relu"), layers.Dense(128, activation="relu"), layers.Dense(1, activation="sigmoid"), ] ) model.compile(optimizer=optimizer, loss=loss, metrics=metrics) return modelこれでモデルは完成です。モデルを保存して saved model とし、Tensorflow Serving として起動することができます。
docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name table_data \ -v $(pwd)/saved_model/table_data:/models/table_data \ -e MODEL_NAME=table_data \ tensorflow/serving:2.3.0Tensorflow Serving への入力データはカラム毎にフィールドを指定する形式になります。metadata を取ると以下のようになっています。長くなっていますが、各カラムで入力フィールドを定義しており、受け付けるデータ型や Shape が明示されています。
curl localhost:8501/v1/models/table_data/versions/0/metadata$ curl localhost:8501/v1/models/table_data/versions/0/metadata { "model_spec":{ "name": "table_data", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "oldpeak": { "dtype": "DT_DOUBLE", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_oldpeak:0" }, "restecg": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_restecg:0" }, "trestbps": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_trestbps:0" }, "slope": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_slope:0" }, "sex": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_sex:0" }, "ca": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_ca:0" }, "exang": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_exang:0" }, "fbs": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_fbs:0" }, "chol": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_chol:0" }, "thalach": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_thalach:0" }, "thal": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_thal:0" }, "cp": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_cp:0" }, "age": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_age:0" } }, "outputs": { "output_1": { "dtype": "DT_FLOAT", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "StatefulPartitionedCall_1:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }たとえば json でリクエストする場合、以下のようなデータでリクエストすることができます。
{ "age": [[71]], "sex": [[0]], "cp": [[4]], "trestbps": [[112]], "chol": [[149]], "fbs": [[0]], "restecg": [[0]], "thalach": [[125]], "exang": [[0]], "oldpeak": [[1.6]], "slope": [[2]], "ca": [[0]], "thal": [["normal"]] }PythonでGRPC、RESTでリクエストする場合は以下になります。
def request_grpc( data: Dict[str, Any], model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name age = np.array(data["age"], dtype=np.int64) sex = np.array(data["sex"], dtype=np.int64) cp = np.array(data["cp"], dtype=np.int64) trestbps = np.array(data["trestbps"], dtype=np.int64) chol = np.array(data["chol"], dtype=np.int64) fbs = np.array(data["fbs"], dtype=np.int64) restecg = np.array(data["restecg"], dtype=np.int64) thalach = np.array(data["thalach"], dtype=np.int64) exang = np.array(data["exang"], dtype=np.int64) oldpeak = np.array(data["oldpeak"], dtype=np.float64) slope = np.array(data["slope"], dtype=np.int64) ca = np.array(data["ca"], dtype=np.int64) thal = np.array(data["thal"], dtype=str) request.inputs["age"].CopyFrom(tf.make_tensor_proto(age)) request.inputs["sex"].CopyFrom(tf.make_tensor_proto(sex)) request.inputs["cp"].CopyFrom(tf.make_tensor_proto(cp)) request.inputs["trestbps"].CopyFrom(tf.make_tensor_proto(trestbps)) request.inputs["chol"].CopyFrom(tf.make_tensor_proto(chol)) request.inputs["fbs"].CopyFrom(tf.make_tensor_proto(fbs)) request.inputs["restecg"].CopyFrom(tf.make_tensor_proto(restecg)) request.inputs["thalach"].CopyFrom(tf.make_tensor_proto(thalach)) request.inputs["exang"].CopyFrom(tf.make_tensor_proto(exang)) request.inputs["oldpeak"].CopyFrom(tf.make_tensor_proto(oldpeak)) request.inputs["slope"].CopyFrom(tf.make_tensor_proto(slope)) request.inputs["ca"].CopyFrom(tf.make_tensor_proto(ca)) request.inputs["thal"].CopyFrom(tf.make_tensor_proto(thal)) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_1"].float_val[0] return prediction def request_rest( data: Dict[str, Any], model_spec_name: str = "table_data", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} request_dict = {"inputs": data} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0][0]まとめ
Tensorflow の Operation を活用すれば、ディープラーニングのモデルだけでなく、データ入力から前処理、後処理までを計算グラフに組み込むことができます。学習から推論器へとシステムを移管する際、コードの書き換えが発生して非効率なシステム開発や設計になることがあります。End-to-end でテンソル演算に組み込んで Tensorflow Serving で推論することで、機械学習の学習時と同様の推論 API を構築することできます。

- 投稿日:2020-11-17T09:00:40+09:00
KerasによるCNNモデル構築
本記事について
「TensorFlow開発入門」を読んで学んだことをアウトプットするための記事です。
追記:限定記事として公開してあったので、一般記事に変更しました。
環境
基本的な環境は以下の通り
- anaconda 3
- jupyter notebook
- python 3.6.10
参考にした書籍が2018年4月に出版されたものなので、書籍のままのversionだとエラーが出ます。
したがってversionを以下のように指定します。tensorflowとtensorflow-gpuについてはどちらかをインストールしてください。
CUDAとcuDNNはtensorflow-gpuをインストールした場合に導入してください。
- tensorflow 1.14.0
- tensorflow-gpu 1.14.0
- CUDA 10.0
- cuDNN 7.4
- keras 2.3.1
- opencv 4.4.0
- numpy 1.18.5
- scipy 1.5.0
- matplotlib 3.2.2
- pillow 7.2.0
- h5py 2.10.0
ローカルマシンで行ったので、PCの詳細も載せておきます。
- windows 10 home 64bit
- CPU : Ryzen 7 2700x
- メモリ : 16GB
- GPU : RTX 2060
行うこと
おなじみmnistの手書き数字の分類をCNNで行います。
手順
大まかに以下のような手順で行います。
- データの読み込みと整形
- 畳み込み層と全結合層によるネットワークの構築
- 学習と評価
コードに関して
jupyter notebook に書いたものをコピペして貼り付けていきます。
本題
データの読み込みと確認
from tensorflow.python.keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() print('shape of x_train:', x_train.shape) print('shape of y_train:', y_train.shape) print('shape of x_test:', x_test.shape) print('shape of y_test:', y_test.shape) # shape of x_train: (60000, 28, 28) # shape of y_train: (60000,) # shape of x_test: (10000, 28, 28) # shape of y_test: (10000,)ここで注意すべきなのは、手書き文字のデータが「チャネル」の情報を保持していないことである。
データの整形
学習データはチャネルを持つ必要がある.
→ 3次元テンソルから4次元テンソルに変更x_train = x_train.reshape(60000, 28, 28, 1) x_test = x_test.reshape(10000, 28, 28, 1)学習データは1ピクセルに 0~255 の値を保持している.
→ 標準化(0~1の範囲にまとめる)x_train = x_train / 255. x_test = x_test / 255.正解データは0~9の数字として記録されている.
→ one-hot表現 に変更from tensorflow.python.keras.utils import to_categorical y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10)画像を表示してみる
画像データは数値の配列として入っているので、画像データに変換してみます。
from tensorflow.python.keras.preprocessing.image import array_to_img from IPython.display import display_png display_png(array_to_img(x_train[0]))
このような手書きの数字を分類していきます。ネットワークの構築
keras の Sequential API では 各層を「レイヤー」と呼び、レイヤーを追加することでネットワークを構築する.
よく使用されるレイヤーの引数を記述しておく.
引数 詳細 filters 生成する特徴量マップの数=生成するカーネル(フィルタ)の数 kernel_size カーネルのサイズ activation 使用する活性化関数 padding 入力画像に対してパディングを行うかの設定('same'で入出力のサイズが同じになる) input_shape 入力データのサイズを指定する(最初の層のみ指定) 畳み込み層への理解を深める
畳み込みは「畳み込み層」「プーリング層」の2つから構成される.
畳み込み層
入力からウィンドウを切り出し、ウィンドウとフィルタの内積を求める.
求めた内積は特徴量マップへ代入される.
特徴量マップは次の層への入力になる.
kerasでは Conv2D で層を追加できる.プーリング層
プーリング層は入力された画像を区分けし、区分けされた小行列ごとに最大値や平均を求める処理を行う.
基本的に出力されるのは、入力よりもサイズが小さいデータである.
最大値を求める場合のプーリング層は MaxPool2D で追加できる.from tensorflow.python.keras.models import Sequential from tensorflow.python.keras.layers import Conv2D, MaxPool2D, Flatten, Dense model = Sequential() model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same', input_shape=(28, 28, 1), name='b1_Conv1')) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same', name='b1_Conv2')) model.add(MaxPool2D(name='b1_Pool1')) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same', name='b2_Conv1')) model.add(MaxPool2D(name='b2_Pool1')) model.add(Flatten(name='Flatten'))全結合層
我らがディープラーニングの基本形.
kerasでは Dense で層を追加できる. (DenDse は「濃い」や「密集」等を表す)model.add(Dense(units=64, activation='relu', name='Dense1')) model.add(Dense(units=10, activation='softmax', name='Dense2'))構築したネットワークは次のコードで確認できる。
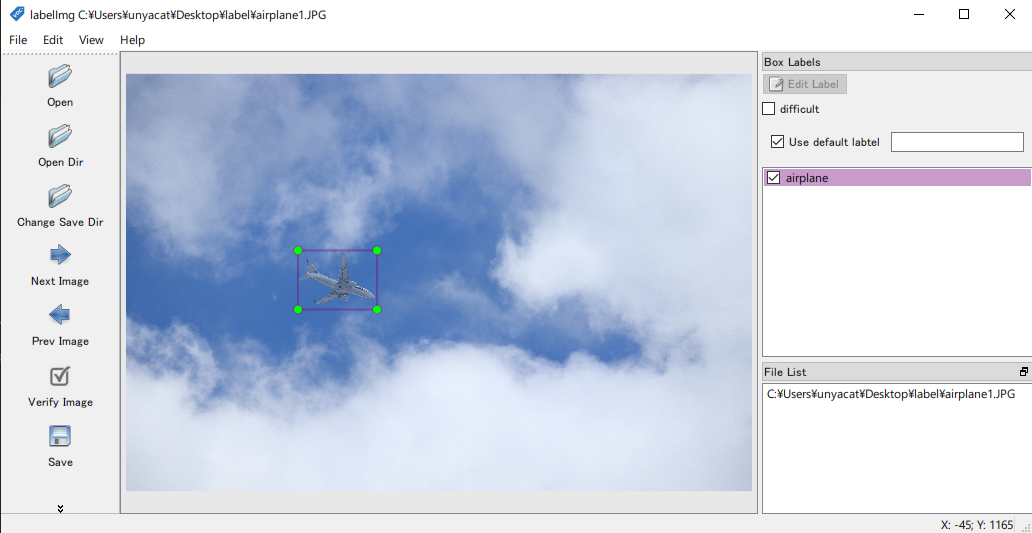
model.summary()
学習と評価
学習
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=32, epochs=8, validation_split=0.2)評価
今回は単純に正答率を出します
import numpy as np pred = model.predict(x_test) count = 0 for i in range(x_test.shape[0]): if np.argmax(pred[i]) == np.argmax(y_test[i]): count += 1 acc = count / x_test.shape[0] print("accuracy = ", acc) # accuracy = 0.9906最後に
transformerなどの手法が出てきたので、それも取り入れてみたいですね。(小並感)