- 投稿日:2020-11-17T23:58:30+09:00
missingintegers python 個人メモ
missingintegers
普通にやったらもちろんN**2で返ってくる。ので、おそらく普通のやり方らしいが、フラグを作ってそこを積算的に立てていく。と一周+最後の判別ですむ(サイズ(N)で住む)
def solution(A): A = sorted(A) B = [i for i in A if (0 < i) and (i <= len(A))] tester = [0] * len(A) for i in B: tester[i-1] +=1 try: return tester.index(0) + 1 except: return len(B)+1
- 投稿日:2020-11-17T23:41:22+09:00
スマートリモコン「NatureRemo」のAPIの使い方
Nature Remo
Nature RemoはNature Remo 3, Nature Remo miniなどのスマートリモコンを販売しています。
Nature Remo 3は1万円程度で「温度センサー」「湿度センサー」「照度センサー」「人感センサー」「Alexa」「Google Assistant」「Siri(ショートカット)」に対応しています。API
Nature Remoの商品はAPI「Nature Remo Cloud API」が公開されており「センサーの情報」「リモコン制御」などがプログラミングから可能です。
この記事でAPIの使い方はわかりやすく出ているので、具体的なコードを見なくてもいい人はリンク先からみてください。
自分はPythonを使ってやっていきます。https://developer.nature.global/
プログラミング
nature-remoというPythonのライブラリがあるためそちらを使うのが賢いですが、この後の「iOSのショートカット対応」への理解を深めるためにそちらのライブラリは使用しないでurllib,jsonのライブラリを使って進めていきます。
そちらの方法が見たい方は以下の記事を見てください。
https://qiita.com/morinokami/items/6eb2ac6bed48d2c7534b温度, 湿度, 照度、人感センサー情報取得
人感センサーは最後に動きを検出した日付を返してくれるが少し特殊
##実行結果## 温度 : 23度 湿度 : 54% 明るさは : 57度 最後に検知したのは2020-11-15T10:32:01Zです。from urllib.parse import urlencode from urllib.request import urlopen, Request from urllib.error import HTTPError from json import loads api_key = "jmgkkDkFTiMp55iRcVGCRiTU5OUg7FqaQfKYDOECUXI.LPVbfXhH9bqcJfzqsyZ-4" # APIアクセストークン url = "https://api.nature.global/1/devices/" headers = { "accept" :"application/json", "Authorization" :"Bearer " + api_key, } request = Request(url, headers=headers) try: with urlopen(request) as response: data_byte = response.read() data= loads(data_byte) except HTTPError as e: print(e) device_info = data[0]["newest_events"] print("温度 : " + str(device_info["te"]["val"]) + "度") print("湿度 : " + str(device_info["hu"]["val"]) + "%") print("明るさは : " + str(device_info["il"]["val"]) + "度") print("最後に検知したのは" + str(device_info["mo"]["created_at"]) + "です。")人感センサー日付 改良版
上のままでは人感センサーの日付がこのままではわかりずらいので、「〇〇分前」という処理をしたいと思います。
datetimeライブラリを使って日付の差分を出していきます。この処理をすることで2倍ほどのコード量になってしまっているので必要なければ上のを使ってください。
24時間以上検知がないと〇日前、1時間以上検知がないと〇時間前、60分内に収まっていれば〇分前になっています。##実行結果## 温度 : 22.9度 湿度 : 54% 明るさは : 67度 人感センサー :2日前from urllib.parse import urlencode from urllib.request import urlopen, Request from urllib.error import HTTPError from json import loads import datetime api_key = "jmgkkDkFTiMp55iRcVGCRiTU5OUg7FqaQfKYDOECUXI.LPVbfXhH9bqcJfzqsyZ-4" # APIアクセストークン url = "https://api.nature.global/1/devices/" headers = { "accept" :"application/json", "Authorization" :"Bearer " + api_key, } request = Request(url, headers=headers) try: with urlopen(request) as response: data_byte = response.read() data= loads(data_byte) except HTTPError as e: print(e) device_info = data[0]["newest_events"] print("温度 : " + str(device_info["te"]["val"]) + "度") print("湿度 : " + str(device_info["hu"]["val"]) + "%") print("明るさは : " + str(device_info["il"]["val"]) + "度") detect_date_str = str(device_info["mo"]["created_at"]).split("T")[0].split("-") detect_time_str = str(device_info["mo"]["created_at"]).split("T")[1].split("Z")[0].split(":") detect_date = [int(n) for n in detect_date_str] detect_time = [int(n) for n in detect_time_str] date = datetime.datetime(year=detect_date[0], month=detect_date[1], day=detect_date[2], hour=detect_time[0], minute=detect_time[1], second=detect_time[2]) now = datetime.datetime.now() difference_time = now - date if difference_time.days > 0: print("人感センサー :{}日前".format(difference_time.days)) elif difference_time.total_seconds > 3600: print("人感センサー : {}時間前".format(difference_time.total_seconds/3600)) else: print("人感センサー :{}分前".format(int(difference_time.total_seconds()/60)))テレビ/ライト操作
- テレビとライトは同じコードで書けるのでまとめています。(applianceを変えることでテレビ/ライトの切り替えが可能です。)
- テレビ/ライトの操作だけでなく、テレビ/ライトのIDの取得に1度アクセスしているので、先にID(device_id)をプログラム内に入力してしまうことでアクセス数を減らすことが可能です。
- ニックネーム(nickname)を指定することで2台同じ家電があっても大丈夫なようにしています。1台であればその処理はいりません。
必要なもの
appliance:家電を選択(テレビ:TV, ライト: LIGHT)
nickname:操作したい家電のニックネーム(例:Two-Storied-TV)
api_access_key: APIアクセストークン(APIアクセストークンは「https://home.nature.global/」で発行したもの)##出力結果(テレビ)## 操作するボタンを数字で選んでください。 0 : TV_power 1 : TV_source 2 : TV_schedule 3 : TV_mute 4 : TV_terrestrial ⌇ 47 : TV_subtitle 48 : TV_exit 49 : TV_rewind_10sec 50 : TV_forward_30sec 入力:48 成功です。##出力結果(ライト)## 操作するボタンを数字で選んでください。 0 : Light_on 1 : Light_off 2 : Light_all 3 : Light_night 4 : Light_bright 5 : Light_dark 入力:1 成功です。from urllib.parse import urlencode from urllib.request import urlopen, Request from urllib.error import HTTPError from json import loads appliance = "TV" #操作する家電の種類["TV", "LIGHT"] nickname = "Two-Storied-TV" #テレビ/ライトのニックネーム #nickname = "Atrium-light" #ライトのニックネーム api_access_key = "jmgkkDkFTiMp55iRcVGCRiTU5OUg7FqaQfKYDOECUXI.LPVbfXhH9bqcJfzqsyZ-4" # APIアクセストークン url = "https://api.nature.global" headers = { "Authorization" :"Bearer " + api_access_key, "accept" :"application/json", "Content-Type" :"application/x-www-form-urlencoded" } #全ての家電情報を取得 request = Request(url + "/1/appliances/", headers=headers) try: with urlopen(request) as response: data = response.read() devices = loads(data) except HTTPError as e: print(e) #デバイスID探索 device_id = "" for device in devices: if device["type"] == appliance and device["nickname"] == nickname: device_id = device["id"] buttons = device[appliance.lower()]["buttons"] #各ボタンの表示 print("操作するボタンを数字で選んでください。") num = 0 for button in buttons: if button["label"] != "":#空白のボタンがあるためif文で処理 print(str(num) + " :\t" + button["label"]) num += 1 selected_button = int(input("入力:")) signal = buttons[select_button]["name"] #データ送信 request = Request(url + "/1/appliances/" + device_id + "/" + appliance.lower(), headers=headers) data = { "button": signal } data = urlencode(data).encode("utf-8") try: urlopen(request, data) print("成功です。") except HTTPError as e: print(e)エアコン操作
- エアコンの操作だけでなく、エアコンのIDの取得に1度アクセスしているので、先にID(AirCon_device_id )をプログラム内に入力してしまうことでアクセス数を減らすことが可能です。
- ニックネーム(nickname)を指定することで2台エアコンがあっても大丈夫なようにしています。1台であればその処理はいりません。
from urllib.parse import urlencode from urllib.request import urlopen, Request from urllib.error import HTTPError from json import loads temperature = list(range(16, 31)) #温度 operation_mode = ["cool", "warm", "dry", "blow", "auto"] #モード air_volume = ["1", "2", "3", "4", "5", "auto"] #風量 air_direction = ["1", "2", "3", "4", "5", "auto"] #風向き button = ["", "power-off"] #電源 空白は電源オン nickname = "Two-Stroried-AirCon" #エアコンのニックネーム api_key = "jmgkkDkFTiMp55iRcVGCRiTU5OUg7FqaQfKYDOECUXI.LPVbfXhH9bqcJfzqsyZ-4" # APIアクセストークン url = "https://api.nature.global" headers = { "accept" :"application/json", "Authorization" :"Bearer " + api_key, "Content-Type" :"application/x-www-form-urlencoded" } req = Request(url + "/1/appliances/", headers=headers) try: with urlopen(req) as response: data = response.read() devices = loads(data) except HTTPError as e: print(e) AirCon_device_id = "" for device in devices: if device["type"] == "AC" and device["nickname"] == nickname: AirCon_device_id = device["id"] buttons = device["aircon"] request = Request(url + "/1/appliances/" + AirCon_device_id + "/aircon_settings", headers=headers) data = { "temperature": temperature[10], "operation_mode": operation_mode[3], "air_volume": air_volume[4], "air_direction": air_direction[2], "button": button[1], } data = urlencode(data).encode("utf-8") try: response = urlopen(request, data) print("成功です。") except HTTPError as e: print(e)
- 投稿日:2020-11-17T23:20:00+09:00
Powerpointの表をスクレイピング
政府CIOポータルのオープンデータのオープンデータ伝道師一覧のpptxの表をスクレイピング
wget https://cio.go.jp/sites/default/files/uploads/documents/opendata-dendoushi_ichiran.pptx -O ichiran.pptx pip install python-pptximport pptx import pandas as pd prs = pptx.Presentation("ichiran.pptx") dfs = [] for page in prs.slides: data = [[cell.text for cell in row.cells] for row in page.shapes[1].table.rows] dfs.append(pd.DataFrame(data[1:], columns=data[0])) df = pd.concat(dfs).set_index("No.") df["所属団体等"] = df["所属団体等"].str.replace("\n", "", regex=True) df1 = df.join( df["氏名"].str.split("\n", expand=True).rename(columns={0: "ふりがな", 1: "名前"}) ).drop("氏名", axis=1) df2 = df1.reindex(columns=["名前", "ふりがな", "主な活動エリア", "これまでの主な実績等", "所属団体等"]) df2.to_csv("ichiran.csv", encoding="utf_8_sig")
- 投稿日:2020-11-17T23:20:00+09:00
Powerpoint(pptx)の表をスクレイピング
政府CIOポータルのオープンデータのオープンデータ伝道師一覧のpptxの表をスクレイピング
wget https://cio.go.jp/sites/default/files/uploads/documents/opendata-dendoushi_ichiran.pptx -O ichiran.pptx pip install python-pptximport pptx import pandas as pd prs = pptx.Presentation("ichiran.pptx") dfs = [] for page in prs.slides: data = [[cell.text for cell in row.cells] for row in page.shapes[1].table.rows] dfs.append(pd.DataFrame(data[1:], columns=data[0])) df = pd.concat(dfs).set_index("No.") df["所属団体等"] = df["所属団体等"].str.replace("\n", "", regex=True) df1 = df.join( df["氏名"].str.split("\n", expand=True).rename(columns={0: "ふりがな", 1: "名前"}) ).drop("氏名", axis=1) df2 = df1.reindex(columns=["名前", "ふりがな", "主な活動エリア", "これまでの主な実績等", "所属団体等"]) df2.to_csv("ichiran.csv", encoding="utf_8_sig")
- 投稿日:2020-11-17T23:15:40+09:00
pythonでgbizinfoを介して法人番号を一気に取得
はじめに
こんなことはありませんか?
toBの企業情報は取得しているけどCRMには法人番号はない。
あるのは、法人名と設立年度などの基本情報。
こんな時に他のリストのデータセットと結合する際に、何を結合keyにすればいいのか?
悩むと思います。行政の定める法人番号さえあれば、あらゆる企業情報を結合し、1つの情報にすることができます。
例えば,以下のように、テーブルAとテーブルBを結合したい時がありうるとします。テーブルA(企業情報)
会社名 設立年 都道府県 hoge fuga 3 テーブルB(コンタクト情報)
会社名 見込み金額 受注状況 hoge 3000 初回接続 gbizinfoを使ってみる
sqlなどデータベース言語に触れることがある人ならわかると思います。
文字列同士の結合はDB負荷がかかるという事に。
法人番号さえあれば共通の結合Keyとして使用できます。
法人番号を取得する場合に、便利なのが、経産省のgbizinfoです
なんとこのサービスREST APIを備えているのです。
なので、とっても法人番号の取得が簡単です。
https://info.gbiz.go.jp/api/index.htmlのちにheadersの情報でX-hojinInfo-api-tokenが必要になるので
あらかじめAPIの利用申請が必要です。pythonで呼んでみる
サンプルデータ
以下のように、会社名と設立年度だけが入ったデータがあるとします。
このデータに法人番号を入れたいです。
リクエストの際のメソッドはGETです
会社名 設立年 楽天モバイル株式会社 2018 株式会社松屋フーズ 2018 リクエストしてみる
request.pyimport json import pandas as pd import requests class CorporateNumbers: def __init__(self): self.headers = { "Accept": "application/json", "X-hojinInfo-api-token": "###token###" } self.endpoint_url = 'https://info.gbiz.go.jp/hojin/v1/hojin' def _create_taeger_company_dataframe(self): df = pd.read_clipboard() return df def _get_corporate_number(self,df): #df = self._create_taeger_company_dataframe() name = df.name founded_year = df.founded results = [] for name,founded in zip(name,founded_year): data = { 'name':name, 'founded':founded } res = requests.get( url = self.endpoint_url, headers = self.headers, params = data ) json = res.json()['hojin-infos'] results.extend(json) df = pd.io.json.json_normalize(results) return df def _merge_dataframe(self): df1 = self._create_taeger_company_dataframe() df2 = self._get_corporate_number(df = df1) df3 = pd.merge(df1,df2,on='name',how='left') return df3結果

- 投稿日:2020-11-17T22:58:28+09:00
PythonのTkinterメモ(自分用)
ウィジェット
Frame
概要:ウィジェットを格納する枠組みを作る。Label
概要:文字列やイメージを表示する。Message
概要:複数行の文字列を表示する。Button
概要:ボタンを作る。Radiobutton
概要:ラジオボタンを作る。Listbox
概要:リストボックスを作る。Scrollbar
概要:スクールバーを作る。Scale
概要:スケールを作る。Entry
概要:1行の文字列を入力と編集。Menu
概要:メニューボタンを作る。Menubutton
概要:メニューボタンを作る。Bitmap
概要:ビットマップを作る。Canvas
概要:キャンバスを作る。Text
概要:テキストの入力と編集。LabelFrame
概要:ラベル付きフレーム。スピンボックス
概要:スピンボックスを作る。PanedWindow
概要:ペインウィンドウを作る。
ウィジェットのオプション
foreground (fg)
文字や線を描くのに使用する色を指定background (bg)
背景色の指定text
ウィジェット内に表示されるテキストtextvariable
テキストを格納するオブジェクトを指定image
ウィジェット内に表示されるイメージbitmap
ウィジェット内に表示されるビットマップborderwidth (bd)
ウィジェットの枠の幅relief
ウィジェットの枠のスタイルheight
ウィジェットの高さwidth
ウィジェットの幅anchor
ウィジェットや表示されるデータの位置を指定
- 投稿日:2020-11-17T22:43:33+09:00
ミルクボーイから学ぶ条件分岐
はじめに
「〜やないか」と「〜ちゃうやないか」が繰り返される点が、プログラミング言語の条件分岐に落とし込みやすいと閃いてしまったので(?)、書かずにいられませんでした。
コーンフレークネタを再現するならこんな感じでしょうか。
コード
class Breakfast: def is_sweet(self): return True def is_crunchy(self): return True def is_eaten_with_milk(self): return True def is_good_for_dinner(self): return True def is_eaten_by_monk(self): return True def exists_at_bottom_of_parfait(self): return True def is_chinese(self): return True class Mother: def good_for_the_last_supper(self, breakfast): return True def knows_why_pentagon_is_big(self, breakfast): return False def used_to_adored(self, breakfast): return True def knows_who_to_thank(self, breakfast): return False def corn_flakes(self, breakfast): return False class Father: def predict(self, breakfast, corn_flakes): if not corn_flakes: return "鯖の塩焼" mother = Mother() breakfast = Breakfast() corn_flakes = False if breakfast.is_sweet() and breakfast.is_crunchy() and breakfast.is_eaten_with_milk(): corn_flakes = True if mother.good_for_the_last_supper(breakfast): corn_flakes = False if not mother.knows_why_pentagon_is_big(breakfast): corn_flakes = True if breakfast.is_good_for_dinner(): corn_flakes = False if mother.used_to_adored(breakfast): corn_flakes = True if breakfast.is_eaten_by_monk(): corn_flakes = False if breakfast.exists_at_bottom_of_parfait(): corn_flakes = True if breakfast.is_chinese(): corn_flakes = False if not mother.knows_who_to_thank(breakfast): corn_flakes = True if not mother.corn_flakes(breakfast): corn_flakes = False father = Father() print(father.predict(breakfast, corn_flakes))実行結果
$ python milkboy.py 鯖の塩焼
- 投稿日:2020-11-17T22:06:45+09:00
PythonでCKAN APIをオープンデータとしてアップロード&Github Actionsで自動連携する
目次
概要
最近、Code for Africaという団体が運営しているopenAFRICAというアフリカのオープンデータのポータルサイトと、自身がルワンダの水道公社WASACと共同でメンテナンスしている水道ベクトルタイルデータの自動連携機能を、Pythonで実装した。
日本の自治体のオープンデータサイトでも多く使われていると思われるCKANというAPIを用いているので、自組織が持っているファイルなどのオープンデータをAPI経由で自動連携させたい場合に活用できると思うので、共有したいと思う。
前提条件
- CKAN APIを使っているオープンデータプラットフォームに自組織のアカウントを持っている
- Githubでオープンデータを管理している
この記事を通して、Githubに置いてあるオープンデータを更新したタイミングで、Github Actionを用いて、CKAN経由でプラットフォーム上のデータを自動連携させるようにします。
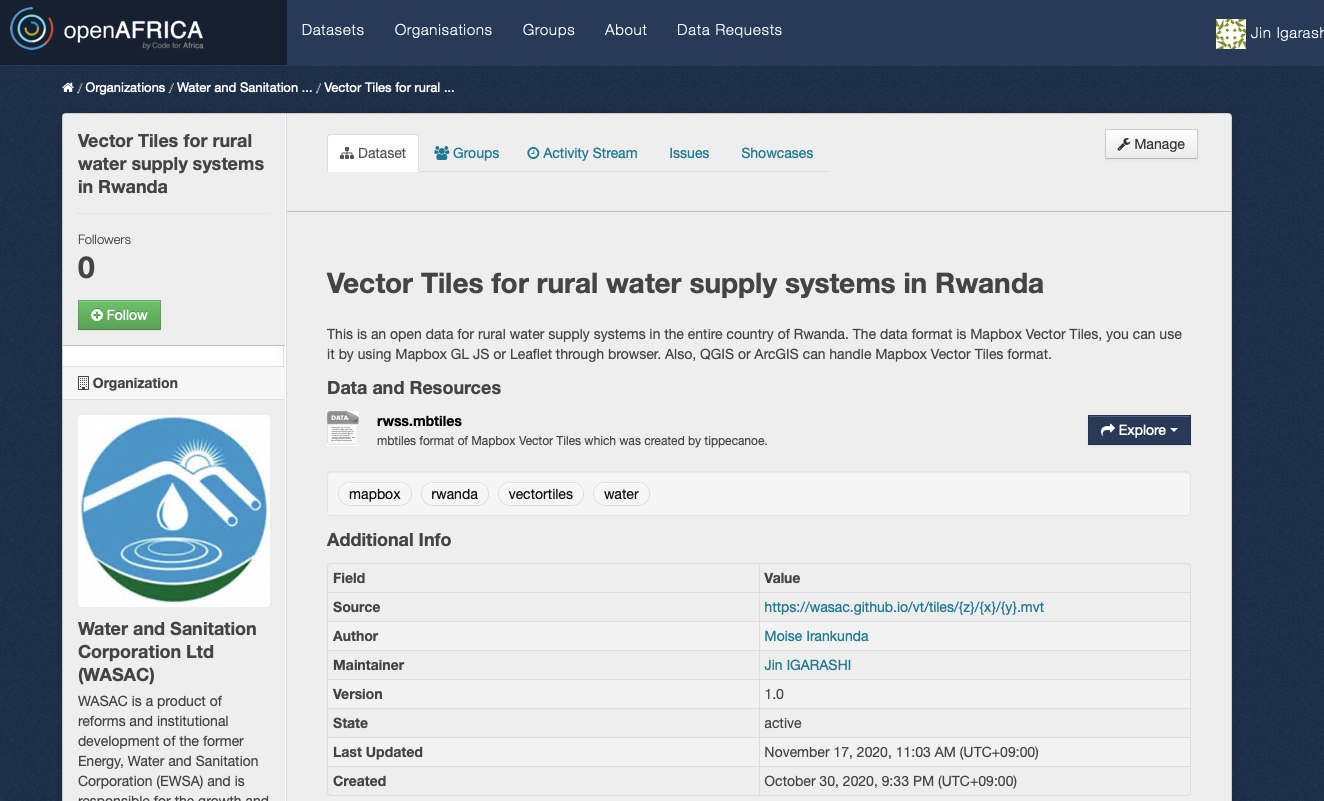
ちなみにルワンダの水道公社の水道ベクトルタイルのオープンデータのopenAFRICAのページは以下のリンクにあります。
https://open.africa/dataset/rw-water-vectortiles
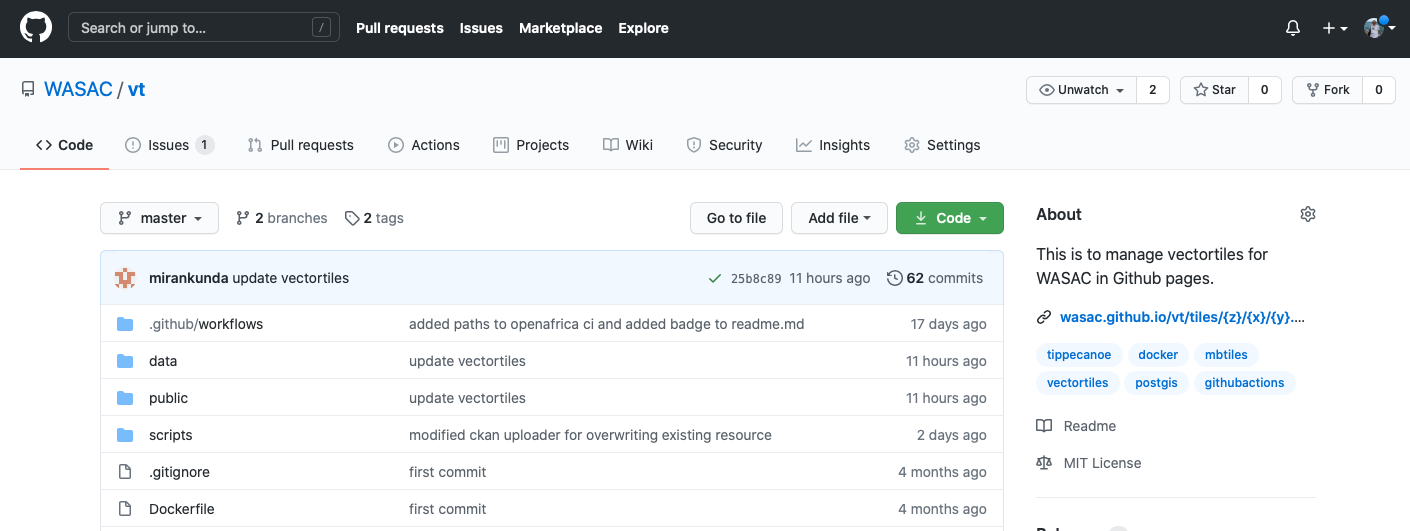
また水道ベクトルタイルのGithubリポジトリは以下のリンクにあり、毎週水道公社内のサーバーからGithubに自動更新されます。
https://github.com/WASAC/vt
データアップロードの仕組み
リポジトリのダウンロードとインストール
pipenvがインストールされていない場合は、まず設定を行ってください。
git clone https://github.com/watergis/open-africa-uploader cd open-africa-uploader pipenv install pipenv shellCKAN APIを用いたファイルのアップロードの仕組み
まずリポジトリ内の
OpenAfricaUploader.pyのソースコード全文を載せます。import os import ckanapi import requests class OpanAfricaUploader(object): def __init__(self, api_key): """Constructor Args: api_key (string): CKAN api key """ self.data_portal = 'https://africaopendata.org' self.APIKEY = api_key self.ckan = ckanapi.RemoteCKAN(self.data_portal, apikey=self.APIKEY) def create_package(self, url, title): """create new package if it does not exist yet. Args: url (str): the url of package eg. https://open.africa/dataset/{package url} title (str): the title of package """ package_name = url package_title = title try: print ('Creating "{package_title}" package'.format(**locals())) self.package = self.ckan.action.package_create(name=package_name, title=package_title, owner_org = 'water-and-sanitation-corporation-ltd-wasac') except (ckanapi.ValidationError) as e: if (e.error_dict['__type'] == 'Validation Error' and e.error_dict['name'] == ['That URL is already in use.']): print ('"{package_title}" package already exists'.format(**locals())) self.package = self.ckan.action.package_show(id=package_name) else: raise def resource_create(self, data, path, api="/api/action/resource_create"): """create new resource, or update existing resource Args: data (object): data for creating resource. data must contain package_id, name, format, description. If you overwrite existing resource, id also must be included. path (str): file path for uploading api (str, optional): API url for creating or updating. Defaults to "/api/action/resource_create". If you want to update, please specify url for "/api/action/resource_update" """ self.api_url = self.data_portal + api print ('Creating "{}"'.format(data['name'])) r = requests.post(self.api_url, data=data, headers={'Authorization': self.APIKEY}, files=[('upload', open(path, 'rb'))]) if r.status_code != 200: print ('Error while creating resource: {0}'.format(r.content)) else: print ('Uploaded "{}" successfully'.format(data['name'])) def resource_update(self, data, path): """update existing resource Args: data (object): data for creating resource. data must contain id, package_id, name, format, description. path (str): file path for uploading """ self.resource_create(data, path, "/api/action/resource_update") def upload_datasets(self, path, description): """upload datasets under the package Args: path (str): file path for uploading description (str): description for the dataset """ filename = os.path.basename(path) extension = os.path.splitext(filename)[1][1:].lower() data = { 'package_id': self.package['id'], 'name': filename, 'format': extension, 'description': description } resources = self.package['resources'] if len(resources) > 0: target_resource = None for resource in reversed(resources): if filename == resource['name']: target_resource = resource break if target_resource == None: self.resource_create(data, path) else: print ('Resource "{}" already exists, it will be overwritten'.format(target_resource['name'])) data['id'] = target_resource['id'] self.resource_update(data, path) else: self.resource_create(data, path)
OpenAfricaUploader.pyを呼び出してファイルをアップロードするソースコードは以下のような感じです。import os from OpenAfricaUploader import OpanAfricaUploader uploader = OpanAfricaUploader(args.key) uploader.create_package('rw-water-vectortiles','Vector Tiles for rural water supply systems in Rwanda') uploader.upload_datasets(os.path.abspath('../data/rwss.mbtiles'), 'mbtiles format of Mapbox Vector Tiles which was created by tippecanoe.')
一個ずつ説明していきます。
コンストラクタ
このモジュールはあらかじめopenAFRICAにアップロードするためにベースとなるポータルサイトのURLをコンストラクタ内で設定しています。
self.data_portal = 'https://africaopendata.org'の部分のURLを自組織が利用しているCKAN APIのURLと置き換えてください。def __init__(self, api_key): """Constructor Args: api_key (string): CKAN api key """ self.data_portal = 'https://africaopendata.org' self.APIKEY = api_key self.ckan = ckanapi.RemoteCKAN(self.data_portal, apikey=self.APIKEY)コンストラクタの呼び出しは次のようになります。
args.keyにご自身のアカウントのCKAN APIキーを指定してください。uploader = OpanAfricaUploader(args.key)パッケージの作成
package_createというAPIを利用してパッケージを作成します。その際引数には以下を指定します。
- name=ここで指定した文字列がパッケージのURLになります
- title=パッケージのタイトルです
- owner_org=CKANのポータル上の対象組織のIDです
作成に成功すると、パッケージ情報が戻り値として返って来ます。既にある場合はエラーになるため、例外処理の中で既存のパッケージ情報を取得する処理を書いています。
def create_package(self, url, title): """create new package if it does not exist yet. Args: url (str): the url of package eg. https://open.africa/dataset/{package url} title (str): the title of package """ package_name = url package_title = title try: print ('Creating "{package_title}" package'.format(**locals())) self.package = self.ckan.action.package_create(name=package_name, title=package_title, owner_org = 'water-and-sanitation-corporation-ltd-wasac') except (ckanapi.ValidationError) as e: if (e.error_dict['__type'] == 'Validation Error' and e.error_dict['name'] == ['That URL is already in use.']): print ('"{package_title}" package already exists'.format(**locals())) self.package = self.ckan.action.package_show(id=package_name) else: raiseこの関数の呼び出し方は以下の通りになります
uploader.create_package('rw-water-vectortiles','Vector Tiles for rural water supply systems in Rwanda')リソースの作成及び更新
リソースの作成は
resource_createという関数で行っています。/api/action/resource_createというREST APIを使用して、アップロード対象のバイナリデータやファイル情報などもろもろを渡してあげれば良いです。def resource_create(self, data, path, api="/api/action/resource_create"): self.api_url = self.data_portal + api print ('Creating "{}"'.format(data['name'])) r = requests.post(self.api_url, data=data, headers={'Authorization': self.APIKEY}, files=[('upload', open(path, 'rb'))]) if r.status_code != 200: print ('Error while creating resource: {0}'.format(r.content)) else: print ('Uploaded "{}" successfully'.format(data['name']))但し、
resource_createだけだとリソースの追加だけしかできず、更新するたびにどんどん数が増えてしまいますので、/api/action/resource_updateというAPIを使って、既存のリソースがあったら更新してあげるようにします。
resource_updateの使い方は基本的にresource_createと同じで、違いはdataのなかにresource_idがあるかないかだけですdef resource_update(self, data, path): self.resource_create(data, path, "/api/action/resource_update")
resource_createとresource_updateをいい感じに組み合わせて、既存のリソースがあったら更新し、なかったら新規作成するという処理にしたのがupload_datasetsという関数です。def upload_datasets(self, path, description): # ファイル名を拡張子と分離します filename = os.path.basename(path) extension = os.path.splitext(filename)[1][1:].lower() # リソース作成用のデータを作ります data = { 'package_id': self.package['id'], #パッケージのID 'name': filename, #更新対象のファイル名 'format': extension, #フォーマット(ここでは拡張子にしています) 'description': description #ファイルの説明 } # 既にパッケージ内にリソースがあった場合はアップロード対象のファイル名と同じ名前のリソースがあるかないかチェックする。 resources = self.package['resources'] if len(resources) > 0: target_resource = None for resource in reversed(resources): if filename == resource['name']: target_resource = resource break if target_resource == None: # 同じ名前のリソースがない場合はresource_createを呼び出す self.resource_create(data, path) else: # リソースがある場合はdataにIDを設定してresource_updateを呼び出す print ('Resource "{}" already exists, it will be overwritten'.format(target_resource['name'])) data['id'] = target_resource['id'] self.resource_update(data, path) else: # リソースがない場合はresource_createを呼び出す self.resource_create(data, path)
upload_datasets関数の呼び出し方は以下のようになります。uploader.upload_datasets(os.path.abspath('../data/rwss.mbtiles'), 'mbtiles format of Mapbox Vector Tiles which was created by tippecanoe.')アップロードのソースをコマンドラインから呼べるようにする
upload2openafrica.pyでコマンドラインから呼べるようにしています。import os import argparse from OpenAfricaUploader import OpanAfricaUploader def get_args(): prog = "upload2openafrica.py" usage = "%(prog)s [options]" parser = argparse.ArgumentParser(prog=prog, usage=usage) parser.add_argument("--key", dest="key", help="Your CKAN api key", required=True) parser.add_argument("--pkg", dest="package", help="Target url of your package", required=True) parser.add_argument("--title", dest="title", help="Title of your package", required=True) parser.add_argument("--file", dest="file", help="Relative path of file which you would like to upload", required=True) parser.add_argument("--desc", dest="description", help="any description for your file", required=True) args = parser.parse_args() return args if __name__ == "__main__": args = get_args() uploader = OpanAfricaUploader(args.key) uploader.create_package(args.package,args.title) uploader.upload_datasets(os.path.abspath(args.file), args.description)実際に使う際は以下のような感じになります。
upload_mbtiles.shというシェルスクリプトを作っています。環境変数にCKAN_API_KEYを設定するようにしてください。#!/bin/bash pipenv run python upload2openafrica.py \ --key ${CKAN_API_KEY} \ --pkg rw-water-vectortiles \ --title "Vector Tiles for rural water supply systems in Rwanda" \ --file ../data/rwss.mbtiles \ --desc "mbtiles format of Mapbox Vector Tiles which was created by tippecanoe."これでCKAN APIを使ってオープンデータをアップロードできるようになりました。
データ連携の自動化
でも毎回手動でCKANと連携するのは面倒なので、Github Actionで自動化します。ワークフローファイルは以下のような感じです。
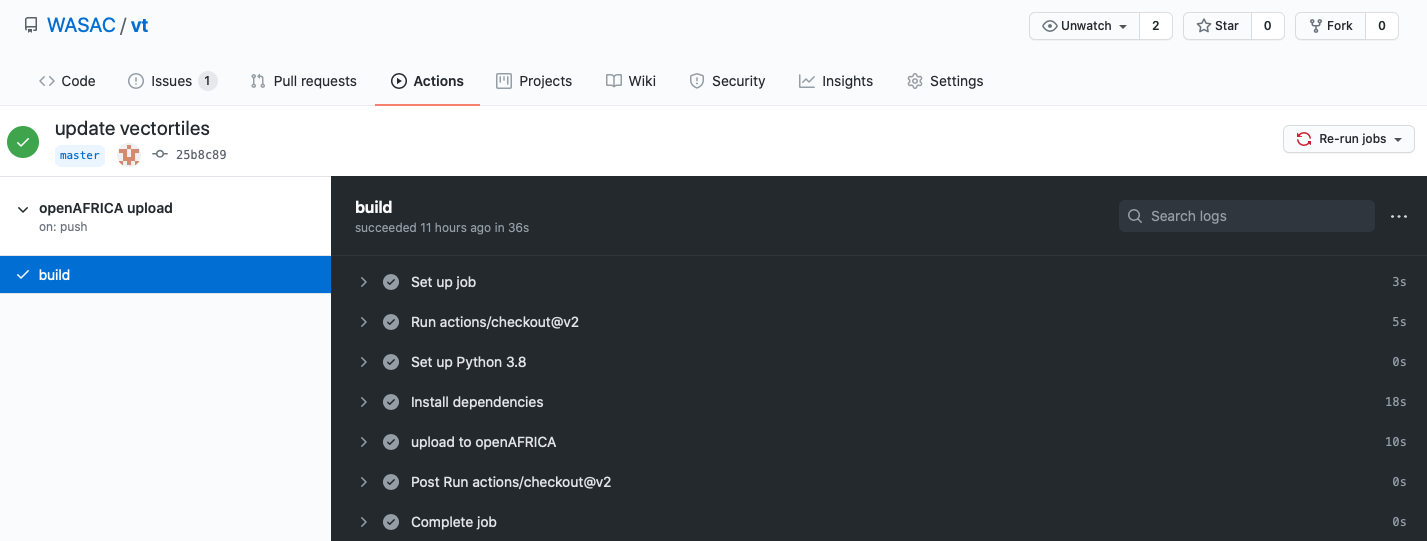
name: openAFRICA upload on: push: branches: [ master ] # ここではdataフォルダ以下が更新された場合にワークフローが走るようにしています paths: - "data/**" jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python 3.8 uses: actions/setup-python@v2 with: python-version: 3.8 - name: Install dependencies # ここでまずPipenvの初期設定をします run: | cd scripts pip install pipenv pipenv install - name: upload to openAFRICA # GithubのリポジトリのSettingsページのSecretsでCKAN_API_KEYという名前で登録しておけば次のようにして環境変数を使うことができます env: CKAN_API_KEY: ${{secrets.CKAN_API_KEY}} # その上で、シェルスクリプトを呼んであげるようにします run: | cd scripts ./upload_mbtiles.shこれだけでGithubにファイルがアップロードされたらオープンデータプラットフォームに自動連携できるようになりました。次の画像はルワンダの水道公社のGithub Acitonが実行された際の画面です。
まとめ
CKAN APIは国内外の様々なオープンソースプラットフォームで使用されています。そのCKAN APIはPythonを用いることで比較的簡単にデータ連携を実装することが可能です。またオープンデータを管理しているのがGithub上なら、Github Actionを用いてさらに容易に自動連携することができます。
今回openAFRICA向けに作成したモジュールが国内外の他のCKANを使ったオープンデータの利活用に役に立つことを願っています。
- 投稿日:2020-11-17T22:06:45+09:00
PythonでCKAN APIを使ってオープンデータとしてアップロード&Github Actionsで自動連携する
目次
概要
最近、Code for Africaという団体が運営しているopenAFRICAというアフリカのオープンデータのポータルサイトと、自身がルワンダの水道公社WASACと共同でメンテナンスしている水道ベクトルタイルデータの自動連携機能を、Pythonで実装した。
日本の自治体のオープンデータサイトでも多く使われていると思われるCKANというAPIを用いているので、自組織が持っているファイルなどのオープンデータをAPI経由で自動連携させたい場合に活用できると思うので、共有したいと思う。
前提条件
- CKAN APIを使っているオープンデータプラットフォームに自組織のアカウントを持っている
- Githubでオープンデータを管理している
この記事を通して、Githubに置いてあるオープンデータを更新したタイミングで、Github Actionを用いて、CKAN経由でプラットフォーム上のデータを自動連携させるようにします。
ちなみにルワンダの水道公社の水道ベクトルタイルのオープンデータのopenAFRICAのページは以下のリンクにあります。
https://open.africa/dataset/rw-water-vectortiles
また水道ベクトルタイルのGithubリポジトリは以下のリンクにあり、毎週水道公社内のサーバーからGithubに自動更新されます。
https://github.com/WASAC/vt
データアップロードの仕組み
リポジトリのダウンロードとインストール
pipenvがインストールされていない場合は、まず設定を行ってください。
git clone https://github.com/watergis/open-africa-uploader cd open-africa-uploader pipenv install pipenv shellCKAN APIを用いたファイルのアップロードの仕組み
まずリポジトリ内の
OpenAfricaUploader.pyのソースコード全文を載せます。import os import ckanapi import requests class OpanAfricaUploader(object): def __init__(self, api_key): """Constructor Args: api_key (string): CKAN api key """ self.data_portal = 'https://africaopendata.org' self.APIKEY = api_key self.ckan = ckanapi.RemoteCKAN(self.data_portal, apikey=self.APIKEY) def create_package(self, url, title): """create new package if it does not exist yet. Args: url (str): the url of package eg. https://open.africa/dataset/{package url} title (str): the title of package """ package_name = url package_title = title try: print ('Creating "{package_title}" package'.format(**locals())) self.package = self.ckan.action.package_create(name=package_name, title=package_title, owner_org = 'water-and-sanitation-corporation-ltd-wasac') except (ckanapi.ValidationError) as e: if (e.error_dict['__type'] == 'Validation Error' and e.error_dict['name'] == ['That URL is already in use.']): print ('"{package_title}" package already exists'.format(**locals())) self.package = self.ckan.action.package_show(id=package_name) else: raise def resource_create(self, data, path, api="/api/action/resource_create"): """create new resource, or update existing resource Args: data (object): data for creating resource. data must contain package_id, name, format, description. If you overwrite existing resource, id also must be included. path (str): file path for uploading api (str, optional): API url for creating or updating. Defaults to "/api/action/resource_create". If you want to update, please specify url for "/api/action/resource_update" """ self.api_url = self.data_portal + api print ('Creating "{}"'.format(data['name'])) r = requests.post(self.api_url, data=data, headers={'Authorization': self.APIKEY}, files=[('upload', open(path, 'rb'))]) if r.status_code != 200: print ('Error while creating resource: {0}'.format(r.content)) else: print ('Uploaded "{}" successfully'.format(data['name'])) def resource_update(self, data, path): """update existing resource Args: data (object): data for creating resource. data must contain id, package_id, name, format, description. path (str): file path for uploading """ self.resource_create(data, path, "/api/action/resource_update") def upload_datasets(self, path, description): """upload datasets under the package Args: path (str): file path for uploading description (str): description for the dataset """ filename = os.path.basename(path) extension = os.path.splitext(filename)[1][1:].lower() data = { 'package_id': self.package['id'], 'name': filename, 'format': extension, 'description': description } resources = self.package['resources'] if len(resources) > 0: target_resource = None for resource in reversed(resources): if filename == resource['name']: target_resource = resource break if target_resource == None: self.resource_create(data, path) else: print ('Resource "{}" already exists, it will be overwritten'.format(target_resource['name'])) data['id'] = target_resource['id'] self.resource_update(data, path) else: self.resource_create(data, path)
OpenAfricaUploader.pyを呼び出してファイルをアップロードするソースコードは以下のような感じです。import os from OpenAfricaUploader import OpanAfricaUploader uploader = OpanAfricaUploader(args.key) uploader.create_package('rw-water-vectortiles','Vector Tiles for rural water supply systems in Rwanda') uploader.upload_datasets(os.path.abspath('../data/rwss.mbtiles'), 'mbtiles format of Mapbox Vector Tiles which was created by tippecanoe.')
一個ずつ説明していきます。
コンストラクタ
このモジュールはあらかじめopenAFRICAにアップロードするためにベースとなるポータルサイトのURLをコンストラクタ内で設定しています。
self.data_portal = 'https://africaopendata.org'の部分のURLを自組織が利用しているCKAN APIのURLと置き換えてください。def __init__(self, api_key): """Constructor Args: api_key (string): CKAN api key """ self.data_portal = 'https://africaopendata.org' self.APIKEY = api_key self.ckan = ckanapi.RemoteCKAN(self.data_portal, apikey=self.APIKEY)コンストラクタの呼び出しは次のようになります。
args.keyにご自身のアカウントのCKAN APIキーを指定してください。uploader = OpanAfricaUploader(args.key)パッケージの作成
package_createというAPIを利用してパッケージを作成します。その際引数には以下を指定します。
- name=ここで指定した文字列がパッケージのURLになります
- title=パッケージのタイトルです
- owner_org=CKANのポータル上の対象組織のIDです
作成に成功すると、パッケージ情報が戻り値として返って来ます。既にある場合はエラーになるため、例外処理の中で既存のパッケージ情報を取得する処理を書いています。
def create_package(self, url, title): """create new package if it does not exist yet. Args: url (str): the url of package eg. https://open.africa/dataset/{package url} title (str): the title of package """ package_name = url package_title = title try: print ('Creating "{package_title}" package'.format(**locals())) self.package = self.ckan.action.package_create(name=package_name, title=package_title, owner_org = 'water-and-sanitation-corporation-ltd-wasac') except (ckanapi.ValidationError) as e: if (e.error_dict['__type'] == 'Validation Error' and e.error_dict['name'] == ['That URL is already in use.']): print ('"{package_title}" package already exists'.format(**locals())) self.package = self.ckan.action.package_show(id=package_name) else: raiseこの関数の呼び出し方は以下の通りになります
uploader.create_package('rw-water-vectortiles','Vector Tiles for rural water supply systems in Rwanda')リソースの作成及び更新
リソースの作成は
resource_createという関数で行っています。/api/action/resource_createというREST APIを使用して、アップロード対象のバイナリデータやファイル情報などもろもろを渡してあげれば良いです。def resource_create(self, data, path, api="/api/action/resource_create"): self.api_url = self.data_portal + api print ('Creating "{}"'.format(data['name'])) r = requests.post(self.api_url, data=data, headers={'Authorization': self.APIKEY}, files=[('upload', open(path, 'rb'))]) if r.status_code != 200: print ('Error while creating resource: {0}'.format(r.content)) else: print ('Uploaded "{}" successfully'.format(data['name']))但し、
resource_createだけだとリソースの追加だけしかできず、更新するたびにどんどん数が増えてしまいますので、/api/action/resource_updateというAPIを使って、既存のリソースがあったら更新してあげるようにします。
resource_updateの使い方は基本的にresource_createと同じで、違いはdataのなかにresource_idがあるかないかだけですdef resource_update(self, data, path): self.resource_create(data, path, "/api/action/resource_update")
resource_createとresource_updateをいい感じに組み合わせて、既存のリソースがあったら更新し、なかったら新規作成するという処理にしたのがupload_datasetsという関数です。def upload_datasets(self, path, description): # ファイル名を拡張子と分離します filename = os.path.basename(path) extension = os.path.splitext(filename)[1][1:].lower() # リソース作成用のデータを作ります data = { 'package_id': self.package['id'], #パッケージのID 'name': filename, #更新対象のファイル名 'format': extension, #フォーマット(ここでは拡張子にしています) 'description': description #ファイルの説明 } # 既にパッケージ内にリソースがあった場合はアップロード対象のファイル名と同じ名前のリソースがあるかないかチェックする。 resources = self.package['resources'] if len(resources) > 0: target_resource = None for resource in reversed(resources): if filename == resource['name']: target_resource = resource break if target_resource == None: # 同じ名前のリソースがない場合はresource_createを呼び出す self.resource_create(data, path) else: # リソースがある場合はdataにIDを設定してresource_updateを呼び出す print ('Resource "{}" already exists, it will be overwritten'.format(target_resource['name'])) data['id'] = target_resource['id'] self.resource_update(data, path) else: # リソースがない場合はresource_createを呼び出す self.resource_create(data, path)
upload_datasets関数の呼び出し方は以下のようになります。uploader.upload_datasets(os.path.abspath('../data/rwss.mbtiles'), 'mbtiles format of Mapbox Vector Tiles which was created by tippecanoe.')アップロードのソースをコマンドラインから呼べるようにする
upload2openafrica.pyでコマンドラインから呼べるようにしています。import os import argparse from OpenAfricaUploader import OpanAfricaUploader def get_args(): prog = "upload2openafrica.py" usage = "%(prog)s [options]" parser = argparse.ArgumentParser(prog=prog, usage=usage) parser.add_argument("--key", dest="key", help="Your CKAN api key", required=True) parser.add_argument("--pkg", dest="package", help="Target url of your package", required=True) parser.add_argument("--title", dest="title", help="Title of your package", required=True) parser.add_argument("--file", dest="file", help="Relative path of file which you would like to upload", required=True) parser.add_argument("--desc", dest="description", help="any description for your file", required=True) args = parser.parse_args() return args if __name__ == "__main__": args = get_args() uploader = OpanAfricaUploader(args.key) uploader.create_package(args.package,args.title) uploader.upload_datasets(os.path.abspath(args.file), args.description)実際に使う際は以下のような感じになります。
upload_mbtiles.shというシェルスクリプトを作っています。環境変数にCKAN_API_KEYを設定するようにしてください。#!/bin/bash pipenv run python upload2openafrica.py \ --key ${CKAN_API_KEY} \ --pkg rw-water-vectortiles \ --title "Vector Tiles for rural water supply systems in Rwanda" \ --file ../data/rwss.mbtiles \ --desc "mbtiles format of Mapbox Vector Tiles which was created by tippecanoe."これでCKAN APIを使ってオープンデータをアップロードできるようになりました。
データ連携の自動化
でも毎回手動でCKANと連携するのは面倒なので、Github Actionで自動化します。ワークフローファイルは以下のような感じです。
name: openAFRICA upload on: push: branches: [ master ] # ここではdataフォルダ以下が更新された場合にワークフローが走るようにしています paths: - "data/**" jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python 3.8 uses: actions/setup-python@v2 with: python-version: 3.8 - name: Install dependencies # ここでまずPipenvの初期設定をします run: | cd scripts pip install pipenv pipenv install - name: upload to openAFRICA # GithubのリポジトリのSettingsページのSecretsでCKAN_API_KEYという名前で登録しておけば次のようにして環境変数を使うことができます env: CKAN_API_KEY: ${{secrets.CKAN_API_KEY}} # その上で、シェルスクリプトを呼んであげるようにします run: | cd scripts ./upload_mbtiles.shこれだけでGithubにファイルがアップロードされたらオープンデータプラットフォームに自動連携できるようになりました。次の画像はルワンダの水道公社のGithub Acitonが実行された際の画面です。
まとめ
CKAN APIは国内外の様々なオープンソースプラットフォームで使用されています。そのCKAN APIはPythonを用いることで比較的簡単にデータ連携を実装することが可能です。またオープンデータを管理しているのがGithub上なら、Github Actionを用いてさらに容易に自動連携することができます。
今回openAFRICA向けに作成したモジュールが国内外の他のCKANを使ったオープンデータの利活用に役に立つことを願っています。
- 投稿日:2020-11-17T21:57:22+09:00
Anaconda で conda install したはずの パッケージが import できない
問題
Anaconda で install したはずの パッケージが使用できず 下記のようなエラーが発生しました.
ModuleNotFoundError: No module named 'selenium'今回はselenium をinstall したはずなのに 上記のようなエラーが出ました.
原因
anacondaプロンプトで python プログラム(****.py) を動作するときにpy.exeを使用していた.
対策
起動するときに 以下のように記述した.
前: py *********.py (エラーが出た)
後: python *********.py (動いた)
感想
pyrhon.exe と py.exe 2種は違うものだと知った(今までは同じだと思っていた)
py.exe とはいったい何なのか,新たな疑問が生まれた
解決してみれば非常に単純な問題だが,時間がかかった
単純なミス過ぎて,ネットで検索しても出てこなかった.この記事が誰かの役に立とうれしいです.解決までの道
自分に対するメモです
1.問題に気づく
2.py と python パッケージをどこからimportしているか調べるimport sys,pprint pprint.pprint(sys.path)結果が違うことに気づく!!(計 2時間程度)
3.解決 (力尽きて作業進まず)
- 投稿日:2020-11-17T21:31:07+09:00
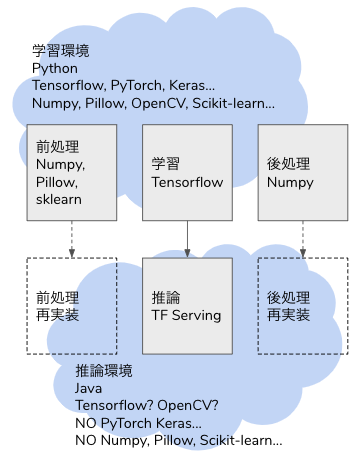
Tensorflow Serving を使い倒す
Tensorflow Serving を使い倒す
有望なディープラーニングのライブラリは Tensorflow と PyTorch で勢力が二分されている現状です。それぞれに強み弱みがあり、以下のような特徴があると思います。
- Tensorflow:Tensorflow Serving や Tensorflow Lite のような豊富な推論エンジン、Keras の便利な学習 API
- PyTorch:Define by Run による強力な学習、TorchVision による便利な画像処理
研究や学習では PyTorch が圧倒的になっていますが、推論器を動かすとなると Tensorflow のほうが有力な機能を提供していると思います。PyTorch は ONNX で推論することが可能ですが、モバイル向けや End-to-end なパイプラインサポートとなると、Tensorflow Lite や TFX 含めて Tensorflow が便利です。
本ブログでは Tensorflow Serving を用いた推論器とクライアントの作り方を説明します。Tensorflow Serving を動かすだけであれば多様な記事がありますが、本ブログではデータの入力から前処理、推論、後処理、出力まで、End-to-end で Tensorflow でカバーする方法を紹介します。
今回書いたコード:https://github.com/shibuiwilliam/e2e_tensorflow_serving
問題意識
ディープラーニングでモデルを学習した後、モデルは saved model や ONNX 形式で出力できても、前処理や出力が学習時の Python コードしかなく、推論へ移行するときに書き直すことになります。
学習も推論も Python で、Python コードをそのまま使い回せるなら良いですが(それでも間違うことが多々ありますが)、本番システムは Java や Golang、Node.js で Python を組み込む基盤や運用がないということがあります。Python 以外の言語で画像やテーブルデータの処理が Python ほど豊富であるとは限りませんし、Python で実行している前処理をそのまま動かすことができるとは限りません。
解決策のひとつは、機械学習の推論プロセスをサポートする推論器を作ることです。推論プロセスのすべてを Tensorflow の saved model に組み込んでしまい、Tensorflow Serving へ生データをリクエストすれば推論結果がレスポンスされる API を作れば、連携するバックエンドは REST クライアントや GRPC クライアントとして Tensorflow Serving にリクエストを送るだけで良くなります。
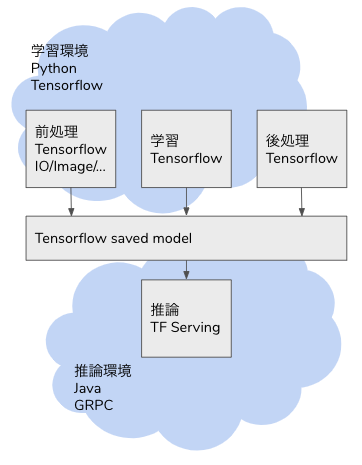
Tensorflow の Operator はニューラルネットワークだけでなく、画像のデコードやリサイズ、テーブルデータの One Hot 化等、機械学習に必須な処理が可能になっています。従来であれば Python の Pillow や Scikit-learn に依存していた処理が Tensorflow の計算グラフに組み込まれているため、推論のデータ入力から推論結果の出力まで、全工程を Tensorflow Serving でカバーすることができます。
本ブログでは Tensorflow Serving による画像分類、テキストの感情分析、テーブルデータの 2 値分類を使い、Tensorflow Serving の可能性を示していきたいと思います。
Tensorflow Serving
Tensorflow Serving は Tensorflow や Keras のモデルを推論器として稼働させるためのシステムです。Tensorflow の saved model を Web API(GRPC と REST API)として稼働させることができます。また単なる Web API だけでなく、バッチシステムとして動かすこともできます。複数バージョンのモデルを同一の Serving に組み込み、エンドポイントを分けることも可能です。Tensorflow Serving は Docker で起動させることが一般的です。
画像分類
ディープラーニングの重要な使い途の一つが画像処理です。今回はInception V3を使った画像分類を Tensorflow Serving で動かします。
画像分類のプロセスは以下になります。
- 生データの画像ファイルを入力データとして受け取る。
- 画像をデコードする。
- 画像をリサイズして Inception V3 の入力 Shape である(299,299,3)に変換する。
- Inception V3 で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Inception V3 が担うのは常勤お 4 のみで、1,2,3,5,6 は前処理や後処理として周辺システムでカバーする必要があります。学習時は Python で Pillow や OpenCV、Numpy 等々を使って書きますが、推論時に同様のライブラリを使えるとは限りません。特に Python 以外の言語で構築する場合、OpenCV を使うことはできるかもしれませんが、他の Pillow や Numpy は他のライブラリで代替するか、自作する必要があります。
しかし Tensorflow であれば、1,2,3,5,6 も Tensor Operation に組み込み、推論の全行程をカバーすることができます。そのためには tf.function に前処理(1,2,3)と後処理(5,6)の Operation を記述します。
以下のdef serfing_fnがその Operation になります。Pillow や Numpy でも同様の処理を書くことがあると思いますが、記述量も複雑さも大差ない実装が可能です。from typing import List import tensorflow as tf from tensorflow import keras class InceptionV3Model(tf.keras.Model): def __init__(self, model: tf.keras.Model, labels: List[str]): super().__init__(self) self.model = model # Inception V3 model self.labels = labels # ImageNet labels in list @tf.function( input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="image")] ) def serving_fn(self, input_img: str) -> tf.Tensor: def _base64_to_array(img): img = tf.io.decode_base64(img) img = tf.io.decode_jpeg(img) img = tf.image.convert_image_dtype(img, tf.float32) img = tf.image.resize(img, (299, 299)) img = tf.reshape(img, (299, 299, 3)) return img img = tf.map_fn(_base64_to_array, input_img, dtype=tf.float32) predictions = self.model(img) def _convert_to_label(candidates): max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(self.labels, idx)) return label return tf.map_fn(_convert_to_label, predictions, dtype=tf.string) def save(self, export_path="./saved_model/inception_v3/0/"): signatures = {"serving_default": self.serving_fn} tf.keras.backend.set_learning_phase(0) tf.saved_model.save(self, export_path, signatures=signatures)上記
InceptionV3Modelクラスのインスタンスを saved model として保存し、Tensorflow Serving として起動することができます。起動した Tensorflow Serving は GRPC として 8500 ポート、REST API として 8501 ポートが開放されます。docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name inception_v3 \ -v $(pwd)/saved_model/inception_v3:/models/inception_v3 \ -e MODEL_NAME=inception_v3 \ tensorflow/serving:2.3.0エンドポイントの定義は以下のようになっています。
inputs以下が入力定義で、outputs以下が出力定義です。inputsではimageタグのデータを取ります。Shape が-1となっていますが、これは画像の base64 エンコードされたデータを入力とするためです。この時点で Tensorflow Serving への入力は(299,299,3)次元の配列ではなく、画像データそのものとなっています。
curl localhost:8501/v1/models/inception_v3/versions/0/metadata$ curl localhost:8501/v1/models/inception_v3/versions/0/metadata { "model_spec":{ "name": "inception_v3", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "image": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_image:0" } }, "outputs": { "output_0": { "dtype": "DT_STRING", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "StatefulPartitionedCall:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }リクエストは以下のように実行することができます。GRPC と REST API の例を書いていますが、どちらも画像をバイナリデータとして読み込み、base64 エンコードして Tensorflow Serving のエンドポイントにリクエストします。クライアントは前処理することなく Tensorflow Serving にデータをリクエストします。
注意点は Tensorflow のtf.io.decode_base64がbase64.urlsafe_b64encodeされたデータでないとデコードできないという点です。def read_image(image_file: str = "./a.jpg") -> bytes: with open(image_file, "rb") as f: raw_image = f.read() return raw_image # GRPC def request_grpc( image: bytes, model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) base64_image = base64.urlsafe_b64encode(image) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name request.inputs["image"].CopyFrom(tf.make_tensor_proto([base64_image])) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_0"].string_val[0].decode("utf-8") return prediction #REST def request_rest( image: bytes, model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} base64_image = base64.urlsafe_b64encode(image).decode("ascii") request_dict = {"inputs": {"image": [base64_image]}} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0]推論結果は以下のようになります。
# GRPC $ python request_inceptionv3.py -f GRPC Siamese cat # REST API $ python request_inceptionv3.py -f REST Siamese catテキストの感情分析
続いてテキスト分類です。テキスト処理も画像と同様で、入力、前処理、後処理、出力になる箇所を
Tensorflow でカバーします。今回はサンプルデータとしてKaggle にある感情分析の NLP データを使用します。感情分析の英文データで、[anger, fear, joy, love, sadness, surprise]の 6 クラス分類となっています。
- anger: i felt anger when at the end of a telephone call
- fear: i pay attention it deepens into a feeling of being invaded and helpless
- joy: i am feeling totally relaxed and comfy
- love: i want each of you to feel my gentle embrace
- sadness: i realized my mistake and i m really feeling terrible and thinking that i shouldn't do that
- surprise: i feel shocked and sad at the fact that there are so many sick people
Tensorflow のテキスト処理で使えるライブラリは複数あります。
- Tensorflow Text
- Tensorflow Transform
- Tensorflow Keras Preprocessing
- Tensorflow Keras Layers Preprocessing
今回はTensorflow Keras Layers Preprocessingを使います。これを選んだのは API が使いやすいという理由です。
テキスト分類では以下の手順をたどります。前処理はテキストや目的次第ですが、今回は簡単のために tfidf を使います。
- 生データのテキストを入力データとして受け取る。
- テキストを前処理してベクターにする。
- ニューラルネットワーク で推論し、Softmax を得る。
- 各ラベルに Softmax の確率をマッピングする。
- 最も確率の高いラベルを出力する。
Tensorflow Keras Layers PreprocessingではTextVectorizationで テキストデータの tfidf のベクター化が可能です。
以下は TextVectorization を使用したサンプルコードです。TextVectorization.adaptでテキストデータに対して変換マップを作ることができます。adapt した TextVectorization はtf.keras.layerとして Keras Model の 1 レイヤーに組み込むことができます。今回は入力レイヤーに使います。def make_text_vectorizer( data: np.ndarray, ) -> tf.keras.layers.experimental.preprocessing.TextVectorization: text_vectorizer = tf.keras.layers.experimental.preprocessing.TextVectorization( output_mode="tf-idf", ngrams=2 ) text_vectorizer.adapt(data) return text_vectorizer def define_model( text_vectorizer: tf.keras.layers.experimental.preprocessing.TextVectorization, optimizer: str = "adam", loss: str = "categorical_crossentropy", metrics: List[str] = ["accuracy"], ) -> tf.keras.Model: inputs = keras.Input(shape=(1,), dtype="string") x = text_vectorizer(inputs) x = layers.Dense(1)(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(256, activation="relu")(x) outputs = layers.Dense(6, activation="softmax")(x) model = keras.Model(inputs, outputs) model.compile(optimizer=optimizer, loss=loss, metrics=metrics) return modelfit したモデルを使って saved model を作成します。今回は TextVectorization が入力データの前処理を担うため、後処理(手順 4,5)の分類部分のみ追加実装しています。
class TextModel(tf.keras.Model): def __init__(self, model: tf.keras.Model, labels: List[str]): super().__init__(self) self.model = model self.labels = labels @tf.function( input_signature=[tf.TensorSpec(shape=[None], dtype=tf.string, name="text")] ) def serving_fn(self, text: str) -> tf.Tensor: predictions = self.model(text) def _convert_to_label(candidates): max_prob = tf.math.reduce_max(candidates) idx = tf.where(tf.equal(candidates, max_prob)) label = tf.squeeze(tf.gather(self.labels, idx)) return label return tf.map_fn(_convert_to_label, predictions, dtype=tf.string) def save(self, export_path="./saved_model/text/"): signatures = {"serving_default": self.serving_fn} tf.keras.backend.set_learning_phase(0) tf.saved_model.save(self, export_path, signatures=signatures)保存した saved model で Tensorflow Serving を起動します。
docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name text \ -v $(pwd)/saved_model/text:/models/text \ -e MODEL_NAME=text \ tensorflow/serving:2.3.0Tensorflow Serving のメタデータは以下のとおりになっています。入力として
textフィールドにテキストデータを入れてリクエストします。出力はoutout_0に推論結果のラベルがレスポンスされます。
curl localhost:8501/v1/models/text/versions/0/metadata$ curl localhost:8501/v1/models/text/versions/0/metadata { "model_spec":{ "name": "text", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "text": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_text:0" } }, "outputs": { "output_0": { "dtype": "DT_STRING", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "StatefulPartitionedCall:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }今回も GRPC と REST のリクエスト例を示します。テキストデータをそのままリクエストに入れることができます。事前に前処理する必要はありません。
def read_text(text_file: str = "./text.txt") -> str: with open(text_file, "r") as f: text = f.read() return text # GRPC def request_grpc( text: str, model_spec_name: str = "text", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name request.inputs["text"].CopyFrom(tf.make_tensor_proto([text])) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_0"].string_val[0].decode("utf-8") return prediction # REST API def request_rest( text: str, model_spec_name: str = "text", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} request_dict = {"inputs": {"text": [text]}} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0]テーブルデータ 2 値分類
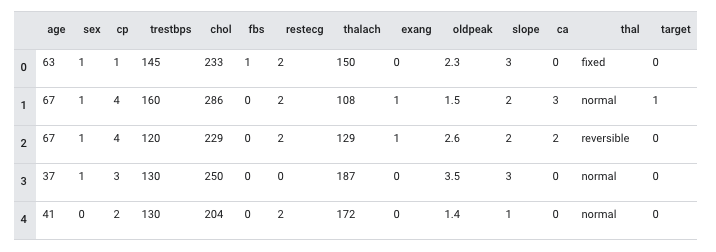
最後にテーブルデータです。
モデル自体は Tensorflow のサンプルで公開されているClassify structured data with feature columnsを使用します。以下のようなデータ構成になっています。
テーブルデータの前処理は tensorflow.feature_columnで各種データの変換をサポートしています。tensorflow.feature_columnを使用した推論の流れは以下のようになります。
- データを入力データとして受け取る。
- データをカラムに応じて前処理する。
- ニューラルネットワーク で推論し、Sigmoid を得る。
- 陽性の確率を出力する。
前処理含めて学習時にカラムの前処理を定義することができます。使い方はシンプルで、データの特徴に応じて変換方法を適用するだけで使えます。
from tensorflow import feature_column from tensorflow.keras import layers feature_columns = [] for header in ["age", "trestbps", "chol", "thalach", "oldpeak", "slope", "ca"]: feature_columns.append(feature_column.numeric_column(header)) age = feature_column.numeric_column("age") age_buckets = feature_column.bucketized_column( age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65] ) feature_columns.append(age_buckets) thal = feature_column.categorical_column_with_vocabulary_list( "thal", ["fixed", "normal", "reversible"] ) thal_one_hot = feature_column.indicator_column(thal) feature_columns.append(thal_one_hot) thal_embedding = feature_column.embedding_column(thal, dimension=8) feature_columns.append(thal_embedding) crossed_feature = feature_column.crossed_column( [age_buckets, thal], hash_bucket_size=1000 ) crossed_feature = feature_column.indicator_column(crossed_feature) feature_columns.append(crossed_feature)
feature_columnで定義したデータの前処理をモデルの入力レイヤーとして活用することが可能です。def define_model( feature_columns: List[Any], optimizer: str = "adam", loss: str = "binary_crossentropy", metrics: List[str] = ["accuracy"], ) -> tf.keras.Model: feature_layer = tf.keras.layers.DenseFeatures(feature_columns) model = tf.keras.Sequential( [ feature_layer, layers.Dense(128, activation="relu"), layers.Dense(128, activation="relu"), layers.Dense(1, activation="sigmoid"), ] ) model.compile(optimizer=optimizer, loss=loss, metrics=metrics) return modelこれでモデルは完成です。モデルを保存して saved model とし、Tensorflow Serving として起動することができます。
docker run -t -d --rm \ -p 8501:8501 \ -p 8500:8500 \ --name table_data \ -v $(pwd)/saved_model/table_data:/models/table_data \ -e MODEL_NAME=table_data \ tensorflow/serving:2.3.0Tensorflow Serving への入力データはカラム毎にフィールドを指定する形式になります。metadata を取ると以下のようになっています。長くなっていますが、各カラムで入力フィールドを定義しており、受け付けるデータ型や Shape が明示されています。
curl localhost:8501/v1/models/table_data/versions/0/metadata$ curl localhost:8501/v1/models/table_data/versions/0/metadata { "model_spec":{ "name": "table_data", "signature_name": "", "version": "0" } , "metadata": {"signature_def": { "signature_def": { "serving_default": { "inputs": { "oldpeak": { "dtype": "DT_DOUBLE", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_oldpeak:0" }, "restecg": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_restecg:0" }, "trestbps": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_trestbps:0" }, "slope": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_slope:0" }, "sex": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_sex:0" }, "ca": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_ca:0" }, "exang": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_exang:0" }, "fbs": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_fbs:0" }, "chol": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_chol:0" }, "thalach": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_thalach:0" }, "thal": { "dtype": "DT_STRING", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_thal:0" }, "cp": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_cp:0" }, "age": { "dtype": "DT_INT64", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "serving_default_age:0" } }, "outputs": { "output_1": { "dtype": "DT_FLOAT", "tensor_shape": { "dim": [ { "size": "-1", "name": "" }, { "size": "1", "name": "" } ], "unknown_rank": false }, "name": "StatefulPartitionedCall_1:0" } }, "method_name": "tensorflow/serving/predict" }, "__saved_model_init_op": { "inputs": {}, "outputs": { "__saved_model_init_op": { "dtype": "DT_INVALID", "tensor_shape": { "dim": [], "unknown_rank": true }, "name": "NoOp" } }, "method_name": "" } } } } }たとえば json でリクエストする場合、以下のようなデータでリクエストすることができます。
{ "age": [[71]], "sex": [[0]], "cp": [[4]], "trestbps": [[112]], "chol": [[149]], "fbs": [[0]], "restecg": [[0]], "thalach": [[125]], "exang": [[0]], "oldpeak": [[1.6]], "slope": [[2]], "ca": [[0]], "thal": [["normal"]] }PythonでGRPC、RESTでリクエストする場合は以下になります。
def request_grpc( data: Dict[str, Any], model_spec_name: str = "inception_v3", signature_name: str = "serving_default", address: str = "localhost", port: int = 8500, timeout_second: int = 5, ) -> str: serving_address = f"{address}:{port}" channel = grpc.insecure_channel(serving_address) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) request = predict_pb2.PredictRequest() request.model_spec.name = model_spec_name request.model_spec.signature_name = signature_name age = np.array(data["age"], dtype=np.int64) sex = np.array(data["sex"], dtype=np.int64) cp = np.array(data["cp"], dtype=np.int64) trestbps = np.array(data["trestbps"], dtype=np.int64) chol = np.array(data["chol"], dtype=np.int64) fbs = np.array(data["fbs"], dtype=np.int64) restecg = np.array(data["restecg"], dtype=np.int64) thalach = np.array(data["thalach"], dtype=np.int64) exang = np.array(data["exang"], dtype=np.int64) oldpeak = np.array(data["oldpeak"], dtype=np.float64) slope = np.array(data["slope"], dtype=np.int64) ca = np.array(data["ca"], dtype=np.int64) thal = np.array(data["thal"], dtype=str) request.inputs["age"].CopyFrom(tf.make_tensor_proto(age)) request.inputs["sex"].CopyFrom(tf.make_tensor_proto(sex)) request.inputs["cp"].CopyFrom(tf.make_tensor_proto(cp)) request.inputs["trestbps"].CopyFrom(tf.make_tensor_proto(trestbps)) request.inputs["chol"].CopyFrom(tf.make_tensor_proto(chol)) request.inputs["fbs"].CopyFrom(tf.make_tensor_proto(fbs)) request.inputs["restecg"].CopyFrom(tf.make_tensor_proto(restecg)) request.inputs["thalach"].CopyFrom(tf.make_tensor_proto(thalach)) request.inputs["exang"].CopyFrom(tf.make_tensor_proto(exang)) request.inputs["oldpeak"].CopyFrom(tf.make_tensor_proto(oldpeak)) request.inputs["slope"].CopyFrom(tf.make_tensor_proto(slope)) request.inputs["ca"].CopyFrom(tf.make_tensor_proto(ca)) request.inputs["thal"].CopyFrom(tf.make_tensor_proto(thal)) response = stub.Predict(request, timeout_second) prediction = response.outputs["output_1"].float_val[0] return prediction def request_rest( data: Dict[str, Any], model_spec_name: str = "table_data", signature_name: str = "serving_default", address: str = "localhost", port: int = 8501, timeout_second: int = 5, ): serving_address = f"http://{address}:{port}/v1/models/{model_spec_name}:predict" headers = {"Content-Type": "application/json"} request_dict = {"inputs": data} response = requests.post( serving_address, json.dumps(request_dict), headers=headers, ) return dict(response.json())["outputs"][0][0]まとめ
Tensorflow の Operation を活用すれば、ディープラーニングのモデルだけでなく、データ入力から前処理、後処理までを計算グラフに組み込むことができます。学習から推論器へとシステムを移管する際、コードの書き換えが発生して非効率なシステム開発や設計になることがあります。End-to-end でテンソル演算に組み込んで Tensorflow Serving で推論することで、機械学習の学習時と同様の推論 API を構築することできます。

- 投稿日:2020-11-17T20:48:04+09:00
【Python】table[key][0] += 1 でやっていることがわからない
table[key][0] += 1 でやっていることがわからない。
Kaggleで他の人のノートブックをみている際に以下のような記述を見つけた。
import random import string import collections action_seq = [2,1] action_seq, table = [], collections.defaultdict(lambda: [0, 0, 0]) key = ''.join([str(a) for a in action_seq[:-1]]) table[key][0] += 1 print(table[key][0])上記の実行結果は以下のようになる。
1正直何がどうなって「1」という結果になるのかさっぱりわからなかった。
collections.defaultdict()の処理内容や、lambdaについても確認したがそれでもよくわからない。
そもそも配列に対して「+= 1」を行う行為がどのような結果になるのか想像がつかなかった。どのようにして理解をしたか
以下のようなデバックを行うことで動き方を理解することができた。
import random import string import collections action_seq, table = [], collections.defaultdict(lambda: [0, 0, 0]) action_seq = [2,1] key = ''.join([str(a) for a in action_seq[:-1]]) print(table) table[key][0] += 1 print(table) table[key][1] += 1 print(table) table[key][2] += 1 print(table)結果は以下のようになる。
defaultdict(<function <lambda> at 0x7fd38dfa43b0>, {}) defaultdict(<function <lambda> at 0x7fd38dfa43b0>, {'2': [1, 0, 0]}) defaultdict(<function <lambda> at 0x7fd38dfa43b0>, {'2': [1, 1, 0]}) defaultdict(<function <lambda> at 0x7fd38dfa43b0>, {'2': [1, 1, 1]})この結果からわかることは、「table[key][0] += 1」では以下のような構成で処理される。
table[key]...テーブルのキーを「2」に設定 [0]...デフォルトで設定した[0,0,0]の1番目の列を指定 += 1...テーブルキー2の配列の1番目の列の値に1を加算あくまで[key]の後に指定している[0]は列指定であることがわかりました。
※二次元配列なのか?とか余計なことを考えていたので混乱しました。。結構この処理内容を理解するのに時間が掛かったので参考になれば嬉しいです。
- 投稿日:2020-11-17T20:45:46+09:00
macOSでのnumbaインストール時のエラー解決
- 2020年11月時点
- OS: macOS Big Sur 11.0.1
- CPU: Intelの方
- Python: 3.9
前提
HomebrewでLLVMのインストールをしている。
numbaインストール時エラー一覧
llvm-configのパス
RuntimeError: llvm-config failed executing, please point LLVM_CONFIG to the path for llvm-configエラー概要: llvm-configの実行に失敗。LLVM_CONFIGにパスを設定してください。
LLVMインストール時「llvm-config」という実行ファイルがインストールされているのでそのパスを環境変数LLVM_CONFIGに設定すればOK。
pip3などでnumbaをインストールする前に下記コマンドで環境変数を設定する。(各々のllvm-configのパスをLLVM_CONFIGに設定してください)export LLVM_CONFIG=/usr/local/Cellar/llvm@9/9.0.1_2/bin/llvm-config私のllvm-configは下記パスだった。
/usr/local/Cellar/llvm@9/9.0.1_2/bin/llvm-configパスが不明の場合
brewでLLVMをインストールした場合、
usr/local/opt/にエイリアスが作成されているので、そこからたどる(Finder > 移動 > コンピュータでルートディレクトリを見れる。隠しフォルダの表示の仕方は各自調べてください)。目的のものが見つかれば、右クリックしてoptionキーを押せば「"llvm-config"のパス名をコピー」という項目が出るのでそれをクリックしてコピーできる。
LLVMのバージョン違い
RuntimeError: Building llvmlite requires LLVM 10.0.x or 9.0.x, got '11.0.0'. Be sure to set LLVM_CONFIG to the right executable path. Read the documentation at http://llvmlite.pydata.org/ for more information about building llvmlite.エラー概要: llvmliteのビルドは LLVM 10.0.x か LLVM 9.0.x を要求しているが11.0.0が見つかった。LLVM_CONFIGに正しい実行できるパスを設定してください。
brewでLLVMをインストールする際
brew install llvmとすると、最新バージョンがインストールされる。2020年11月時点ではLLVM 11.0.0がインストールされていた。brewでパッケージをインストールする際は@(アットマーク)でバージョンを指定できるのでbrew install llvm@9でバージョン9のLLVMをインストールする。(2020年11月時点ではなぜかllvm@10は無い)
- 投稿日:2020-11-17T20:09:25+09:00
zoom会議での話のウケ度を数値化してみた
はじめに
最近zoomでの会議や授業などが増えてきていますが、やはり対面じゃないとどのくらい話に関心を持ってくれているのかわからない…ということがあると感じ、数値化してみればいいんじゃないか?と思い立ち作ってみました。
初投稿なので拙い部分もありますが最後まで読んでいただければ幸いです
目的
zoom会議の画像または動画を取得し、写っている顔を認識、話への関心度を測定する。
実装
試しに
今回zoom会議に出席している人物の顔認識をするのにAmazon Rekognitionを使うことにしました。
使い方はこちらの記事を参考させていただきました。
https://qiita.com/G-awa/items/477f2324552cb908ecd0detect_face.pyimport cv2 import numpy as np import boto3 # スケールや色などの設定 scale_factor = .15 green = (0,255,0) red = (0,0,255) frame_thickness = 2 cap = cv2.VideoCapture(0) rekognition = boto3.client('rekognition') # フォントサイズ fontscale = 1.0 # フォント色 (B, G, R) color = (0, 120, 238) # フォント fontface = cv2.FONT_HERSHEY_DUPLEX # q を押すまでループします。 while(True): # フレームをキャプチャ取得 ret, frame = cap.read() height, width, channels = frame.shape # jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor))) ret, buf = cv2.imencode('.jpg', small) # Amazon RekognitionにAPIを投げる faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL']) # 顔の周りに箱を描画する for face in faces['FaceDetails']: smile = face['Smile']['Value'] cv2.rectangle(frame, (int(face['BoundingBox']['Left']*width), int(face['BoundingBox']['Top']*height)), (int((face['BoundingBox']['Left']+face['BoundingBox']['Width'])*width), int((face['BoundingBox']['Top']+face['BoundingBox']['Height'])*height)), green if smile else red, frame_thickness) emothions = face['Emotions'] i = 0 for emothion in emothions: cv2.putText(frame, str(emothion['Type']) + ": " + str(emothion['Confidence']), (25, 40 + (i * 25)), fontface, fontscale, color) i += 1 # 結果をディスプレイに表示 cv2.imshow('frame', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()とりあえずコードを試しに動かしてみると顔認識&感情分析ができた!、、、のですが動画取得だと重くて途中で止まってしまいました。
なので画像を読み込ませることにします。
(これは参考にした記事のコードです。)画面のキャプチャ
画像のキャプチャはこちらの記事を参考にさせていただきました。
https://qiita.com/koara-local/items/6a98298d793f22cf2e36PILを利用して画面のキャプチャを行いました。
capture.pyfrom PIL import ImageGrab ImageGrab.grab().save("./capture/PIL_capture.png")別にcaptureというフォルダを作りそのフォルダに保存するようにしました。
実装
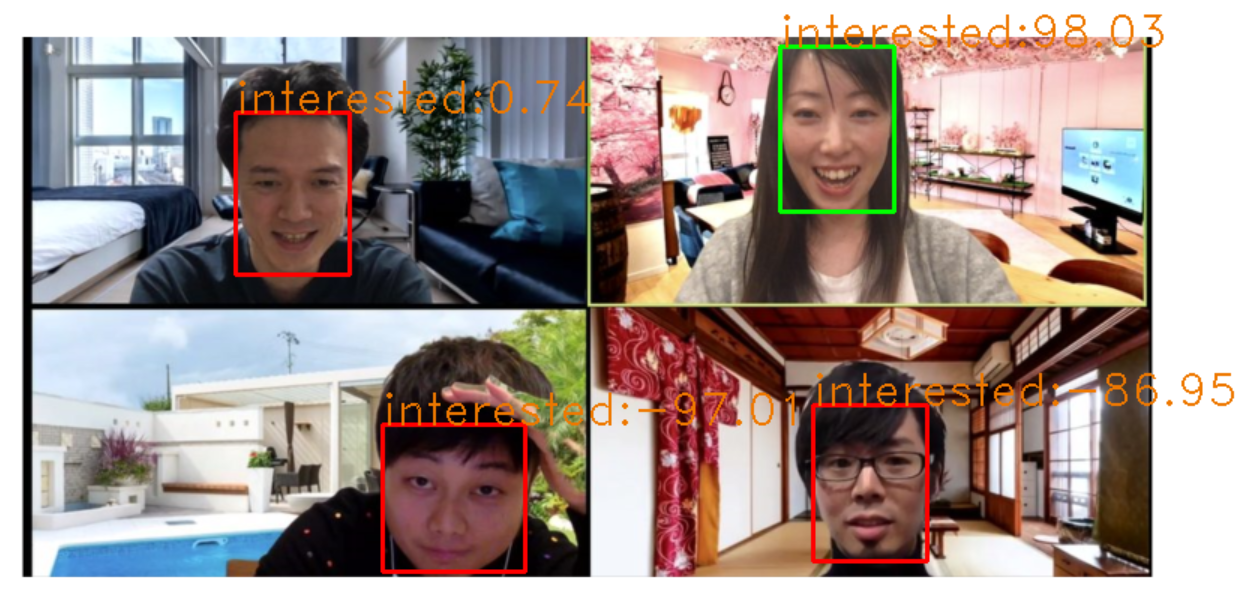
face_detect.pyimport cv2 import numpy as np import boto3 # スケールや色などの設定 scale_factor = .15 green = (0,255,0) red = (0,0,255) frame_thickness = 2 #cap = cv2.VideoCapture(0) rekognition = boto3.client('rekognition') # フォントサイズ fontscale = 1.0 # フォント色 (B, G, R) color = (0, 120, 238) # フォント fontface = cv2.FONT_HERSHEY_DUPLEX from PIL import ImageGrab ImageGrab.grab().save("./capture/PIL_capture.png") # フレームをキャプチャ取得 #ret, frame = cap.read() frame = cv2.imread("./capture/PIL_capture.png") height, width, channels = frame.shape frame = cv2.resize(frame,(int(width/2),int(height/2)),interpolation = cv2.INTER_AREA) # jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor))) ret, buf = cv2.imencode('.jpg', small) # Amazon RekognitionにAPIを投げる faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL']) # 顔の周りに箱を描画する for face in faces['FaceDetails']: smile = face['Smile']['Value'] cv2.rectangle(frame, (int(face['BoundingBox']['Left']*width/2), int(face['BoundingBox']['Top']*height/2)), (int((face['BoundingBox']['Left']/2+face['BoundingBox']['Width']/2)*width), int((face['BoundingBox']['Top']/2+face['BoundingBox']['Height']/2)*height)), green if smile else red, frame_thickness) emothions = face['Emotions'] i = 0 score = 0 for emothion in emothions: if emothion["Type"] == "HAPPY": score = score + emothion["Confidence"] elif emothion["Type"] == "DISGUSTED": score = score - emothion["Confidence"] elif emothion["Type"] == "SURPRISED": score = score + emothion["Confidence"] elif emothion["Type"] == "ANGRY": score = score - emothion["Confidence"] elif emothion["Type"] == "CONFUSED": score = score - emothion["Confidence"] elif emothion["Type"] == "CALM": score = score - emothion["Confidence"] elif emothion["Type"] == "SAD": score = score - emothion["Confidence"] i += 1 if i == 7: cv2.putText(frame, "interested" +":"+ str(round(score,2)), (int(face['BoundingBox']['Left']*width/2), int(face['BoundingBox']['Top']*height/2)), fontface, fontscale, color) # 結果をディスプレイに表示 cv2.imshow('frame', frame) cv2.waitKey(0) cv2.destroyAllWindows()画像の読み込み自体にはOpenCVを用いました。
Amazon RekognitionはHAPPY,DISGUSETED,SURPRISED,ANGRY,CONFUSED,CALM,SADの6つの感情が読み取れるのでHAPPYとSURPRISEDをプラスの感情(興味度高)、その他の感情をマイナスの感情(興味度低)として計算をしていき最終的に-100~100の範囲で興味度を認識した顔の上に表示するようにしました。
zoomで人を集められなかったため人の画像をお借りしています。
https://tanachannell.com/4869Amazon Rekognitionにはほかにも機能があるので是非興味のある方は見てみてください!
https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.html問題点
・zoomの参加人数が大人数の場合表示される文字同士が重なってしまいとても見づらくなってしまう。
・Zoom画面のキャプチャではないため実行してすぐにコマンドプロンプトを最小化しなければ画像にコマンドプロンプトが写ってしまう。最後に
せっかく作ったのだから人に見てもらいたい!という思いで書き始めましたが、書いてると自分が作っている間の追体験ができ、勉強になりました。
自分がこんな風に作ったものが世の中に浸透していったらとても楽しいかもしれませんね!
- 投稿日:2020-11-17T18:10:32+09:00
正規化ラグランジュ補間【Swift, Python】
何ヶ月か前Swiftを勉強してた時に、やるべきことを放棄してこういうものを作ったりしてました。その時は堕落していて、思い出すだけでマジで何やってんだよバカだなーと思います。
「こまけえこたぁいいからさっさと触らせろ」という方は下記の
Usageをご覧ください。ラグランジュ補間とは
統計学とかにも確か使われる、グラフ上の複数の点と点を繋ぐ曲線の方程式を導出するやつです。
例えば、
(1, 1), (2, 2)というxy平面上の2つの点があったとします。するとこの二つを結ぶ直線はy = xです。
そうではなく
(1, 1), (2, 8), (3, 27)という3点があったとすると、それらを結ぶ曲線はy = x^3です。
なんで正規化なのか
計算量を大幅に削減するためです。図の拡大縮小を行うだけで、(確か)
O(n^3)オーダーがO(n^2)になります。定義式はこうです(Wikipedia)。
これを簡単にすると定数
ajでy = a_0 + a_1x + ... + a_{n-1}x^nと表せます。これはつまり、ラグランジュ補間を計算するとは多項式の積を計算することに他ならないということです(ヴァンデルモンド行列というものを用いた計算方法もありますが、それは計算量が多いです)。
多項式の係数を計算するならば、例えば画像の例ではもし分母の
xjが全てjだったら計算が早くなりそうだなーという事がわかります。仮におっぱい関数をラグランジュ補間で描画したいとします。その時の改善に至る道はこうです。
0:おっぱいの境界線からいくつかの点を選びxy座標で表現する。
1:指定した座標は現実的に考えれば無理数であろうが、それを有理数に近似する
2:有理数ということは、かければ必ず全ての座標のxが整数になる倍率が存在する
3:その倍率でおっぱいの図を拡大する
4:座標は(3, 28.5), (7, 22.2), (8, 53.1)...のようになるが、この3, 7, 8は結局バラバラで、Wikipediaの画像でいう分母計算が大変。計算量を減らすためにはさらに測り直して(3, 28.5), (4, 26.4), (5, 23.2)...と、x要素が1ずつ上がってゆくようにする。
5:さらにxを1から始めれば、わざわざ選んだ点群ごとに始点を変えなくて済むので(1, 2.3), (2, 3.3), (3, 28.5)...のように測る。これは結局、
・
(1, *), (2, *), (3, *)...と順順に測ってゆくに集約されます。こうすれば計算量を改善できます。
Usage
使用する場合は
Codeをコピペして下さい。
座標群が(1, y0), (2, y2) ..., (n, yn-1)と表された時print(LagrangeInterplation([y0, y1, ..., yn-1]))とすれば、配列が返ってきます。その配列を
[a0, a1, ...an-1]とすると、座標群の通る曲線の方程式はy = a_0 + a_1x + ... a_{n-1}x^nであるということを表します。これでおっぱい関数でもなんでも描画できるはずです。しかし実際にはクネクネしてしまうので、おっぱい関数を作る場合にはより良い方法を採択する事が望ましいかと思われます。今思い出しましたが、私はおっぱい関数を楽して作るためにこのメソッドを作りました。
Code
for Python
import math # Normalize-Lagrange Interplation(Python) def LagrangeInterplation(A): n = len(A) p = float(math.factorial(n-1)) z = A[-1] / p Q, R = [1.0], [-1.0 * (n-1) * z, z] for i in reversed(range(2, n, 1)): z *= -1.0 * i / (n-i) * A[i-1] / A[i] Q = PolynomialExpansion([-1.0 * (i+1), 1.0], Q) S = [] for j in range(0, len(Q)): S.append(z * Q[j] + R[j]) R = PolynomialExpansion([-1.0 * (i-1), 1.0], S) p1= p if n % 2 == 1 else -1 * p z1 = float(A[0]) / p1 Q1 = PolynomialExpansion([-2.0, 1.0], Q) for j in range(0, n): R[j] += z1 * Q1[j] if R[-1] == 0.0: while R[-1] == 0.0: del R[-1] return R # PolynomialExpansion def PolynomialExpansion (A, B): C = [] m, n = len(A), len(B) for i in range(0, m+n-1): c = 0 for k in range(0, i+1): if i-k < m and k < n: c += A[i-k] * B[k] C.append(c) return C # Tlanslate hand to number def translate1 (str): A = list(str) for i in range(len(A)): if A[i].isdigit() or A[i] == '/': del A[i] return Afor Swift
//MARK:- Lagrange補間 //階乗の演算子 postfix operator <!> postfix func <!> (n:Int) -> Int { var v = [Int]() if n == 0 {v.append(1)} else if n == 1 {v.append(1)} else if n == 2 {v.append(2)} else { for i in 2...n {v.append(i)} repeat { var u = [Int]() let t = v.count for i in 0..<t / 2 { u.append(v[2*i] * v[2*i + 1]) } if t % 2 == 1 {u.append(v.last!)} v = u } while v.count > 1 } return v[0] } //多項式の乗算 func PolynomialExpansion (_ A:[Int], _ B:[Int]) -> [Int] { var C = [Int]() let m = A.count, n = B.count for i in 0..<m+n-1 { var c = 0 for k in 0...i { if i-k < m, k < n { c += A[i-k] * B[k] } } C.append(c) } return C } func PolynomialExpansion (_ A:[Double], _ B:[Double]) -> [Double] { var C = [Double]() let m = A.count, n = B.count for i in 0..<m+n-1 { var c = 0.0 for k in 0...i { if i-k < m, k < n { c += A[i-k] * B[k] } } C.append(c) } return C } //Double関数 func D(_ a:Int) -> Double { return Double(a) } //数列を予測するためのラグランジュ補間 func LaglangeInterplation(_ A:[Int]) -> [Double] { let n = A.count, p = D((n-1)<!>) var z = D(A.last!) / p, Q = [1.0], R = [-1.0 * D(n-1) * z, z] for i in (2..<n).reversed() { z *= -1.0 * D(i) / D(n - i) * D(A[i-1]) / D(A[i]) Q = PolynomialExpansion([-1.0 * D(i+1), 1.0], Q) var S = [Double]() for j in 0..<Q.count { S.append(z * Q[j] + R[j]) } R = PolynomialExpansion([-1.0 * D(i-1), 1.0], S) } let p1 = n % 2 == 1 ? p : -1.0 * p, z1 = Double(A[0]) / p1, Q1 = PolynomialExpansion([-2.0, 1.0], Q) for j in 0..<n { R[j] += z1 * Q1[j] } if R.last! == 0.0 { repeat { R.remove(at: R.count - 1) } while R.last! == 0.0 } return R }まとめ
作ったのが昔すぎて、関数の中で何をしているのか忘れてしまいました。失敬。

- 投稿日:2020-11-17T17:38:08+09:00
割当問題に対するハンガリー法と汎用ソルバーの比較
これなに
「割り当て問題とハンガリー法と整数計画問題と」で汎用ソルバーが遅いという記事がありました。
この記事では、コードを少し直して「数理モデルを作成して汎用ソルバーで解く」方が高速であることを紹介します。Pythonのコード
コードは以下になります。実行には
pip install numpy pulp munkresが必要です。import random import time import numpy as np from munkres import Munkres from pulp import PULP_CBC_CMD, LpProblem, LpVariable, lpDot, lpSum, value class AssigmentProblem: def __init__(self, size, seed=0): self.size = size random.seed(seed) rng = range(self.size) self.weight = np.array([[random.randint(1, 100) for i in rng] for j in rng]) def solve_hungarian(self): start_tm = time.time() m = Munkres() result = m.compute(self.weight.tolist()) val = sum([self.weight[i, j] for i, j in result]) tm = time.time() - start_tm print(f"hungarian {tm = :.2f} {val = }") def solve_pulp(self): m = LpProblem("AssignmentProblem") rng = range(self.size) x = np.array(LpVariable.matrix('x', (rng, rng), cat='Binary')) m += lpDot(self.weight.flatten(), x.flatten()) start_tm = time.time() for i in rng: m += lpSum(x[i]) == 1 m += lpSum(x[:, i]) == 1 m.solve(PULP_CBC_CMD(mip=False, msg=False)) val = value(m.objective) tm = time.time() - start_tm print(f"pulp {tm = :.2f} {val = }") if __name__ == "__main__": p1 = AssigmentProblem(300) p1.solve_hungarian() p1.solve_pulp()実行結果
※
tm:計算時間(秒)、val:目的関数値
※ 上段がハンガリー法、下段が汎用ソルバーhungarian tm = 2.43 val = 352 pulp tm = 1.94 val = 352.0このように、汎用ソルバーの方が速くなりました。
※ 上記の下段の時間は、数理モデル作成と汎用ソルバー実行の両方を含んでいます。
※ 数理モデル作成はPuLPというモデラーを使い、汎用ソルバー実行はcbcというソルバーを使っています。主な修正ポイント
- 元の記事で時間がかかっていたのは数理モデルの作成でした。理由は
lpSumを使わずにsumを使っていたからです。sumは無駄なメモリを作成し遅くなります。
- 「数理モデルにおける変数の和」も参考にしてください。
- 数理モデルの変数は0-1のバイナリ変数ですが、連続変数として解いています。割当問題の隣接行列が全ユニモジュラなので、線形緩和しても整数解が得られるからです。
余談
- 今回使用した汎用ソルバーは、cbcという無料ソルバーです。有料ソルバーを使うともっと高速になるでしょう。
- 実務では近似解で十分なことが多いです。近似解法のソルバーを使えば、解の精度とトレードオフですが、さらに高速になるでしょう。
- 今回のデータは完全2部グラフですが、実務ではデータが疎なことが多いです。その場合、変数が減るのでさらに高速になるでしょう。
- NetworkXでも割当問題を解けるのですが、比較にならないほど遅かったです。
- 投稿日:2020-11-17T17:24:40+09:00
djangoでよくやってしまうエラー その1 template.exceptions.TemplateDoesNotExistについて(備忘録)
template.exceptions.TemplateDoesNotExist
djangoを勉強していたらよく遭遇するエラーでした!
意味としてはずばり【テンプレートがありません!】というシンプルなエラー原因としては
・テンプレートがそもそもない
・URLが間違っている
・単純な記載ミス
などが挙げられます。テンプレートがそもそもない
表示したいテンプレートがフォルダの中にあるかしっかり確認しましょう。
URLが間違っている
全体のurls.py、アプリごとのurls.pyをそれぞれ確認とsettings.pyでしっかりアプリがインストールされているか確認
単純な記載ミス
スペルはちゃんとあっているか、階層構造は表示しているかなど、、、、
- 投稿日:2020-11-17T16:53:29+09:00
Ubunts環境構築からpythonファイルをexe化する手順
はじめに
Ubuntsは使用したことがなく、Hyper-Vとはなんぞやって部分から入りました。
そこから、pythonをexe化する機会は世間的にあまり多くないのか様々な情報に当たりましたがexe化することができたのでまとめます。
環境
windows10 64bit
ubunts 20.04
python 3.7.7
pip 20.2.4
pyenv version 2020.11.15
pyinstaller 4.0
Hyper-vとは
windows 社が無償で提供する仮想化技術の一つ。
windows8~やwindows serverに標準搭載している機能。
サーバマネージャーから機能をONすることで使用可能となる。詳細はこちらHyper-Vとは?
- Windows10のHyper-V上でUbuntuを動かす -ubuntsの構築はこの方の記事を見て構築すれば問題ないと思います。 ネットワークの設定は後程、Hyper-Vマネージャーの作成した仮想マシンの設定にて、’ネットワークアダプター’を新しい仮想スイッチに設定する必要があります。
ubuntsの最新のパッケージ情報を取得
sudo apt updateubuntsのパッケージ情報を更新
sudo apt upgradepyenvを使用するためにもろもろインストール
sudo apt install -y build-essential # c++コンパイラ sudo apt install -y libffi-dev sudo apt install -y libssl-dev # openssl sudo apt install -y zlib1g-dev sudo apt install -y liblzma-dev sudo apt install -y libbz2-dev libreadline-dev libsqlite3-dev # bz2, readline, sqlite3 sudo apt install -y gitpyenvのパッケージのインストール
git clone https://github.com/pyenv/pyenv.git ~/.pyenv.bashrcの更新
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc echo 'eval "$(pyenv init -)"' >> ~/.bashrc source ~/.bashrcpythonのインストール
pyenv install 3.7.7デフォルトだと3.8.5を使用していたので今回の3.7.7をデフォルトで使用したいため
echo "3.7.7" > .python-versionpipenvのインストール
pip install pipenvWARNING: You are using pip version 19.2.3, however version 20.2.4 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.こいつが出てくるとおもうので
pip install --upgrade pippipenvを初期設定
pipenv install
Pythonで開発するときに,プロジェクト毎のパッケージ管理や仮想環境の構築を簡単に自動で行ってくれるツール。パッケージのインストールならpip,仮想環境の構築ならvirtualenv(venv)を使えば対応できますが,pipenvはそれらをまとめてより簡単に扱えるようにサポートしてくれます.
Using /usr/bin/python3.8 to create virtualenv・・・
×Failed creating virtual enviroment
私の場合は上記のエラーが出てきました。
Pythonのバージョンが違うみたいなのでpipenv --python 3.7これで使用するPythonのversionを指定しました。
activateする
pipenv shell
仮想環境にこれで入れましたパッケージが必要な場合は導入する
pipenv install argparse pipenv install argparse==1.4.*Pipfileに入っていることを確認
cat Pipfilepyinstallerの導入
pip install pyinstallerpipenvにてpyinstallerを導入
pipenv install pyinstallerexe化したいファイルが存在しているディレクトリに移動し、
exe実行
LD_LIBRARY_PATH=/home/namae/.pyenv/bin/pyenv pyinstaller test.pyこれでエラーが吐かれました。
OSError: Python library not found: libpython3.7m.so.1.0 libpython3.7mu.so.1.0 libpython3.7.so.1.0 libpython3.7m.so This would mean your Python installation doesn't come with proper library files. This usually happens by missing development package, or unsuitable build parameters of Python installation. * On Debian/Ubuntu, you would need to install Python development packages * apt-get install python3-dev * apt-get install python-dev * If you're building Python by yourself, please rebuild your Python with `--enable-shared` (or, `--enable-framework` on Darwin)環境変数PYTHON_CONFIGURE_OPTSに、--enable-sharedオプションをセットせずにpyenv installしていると発生します。
LD_LIBRARY_PATH=/home/namae/.pyenv/versions/3.7.7 pyenv install LD_LIBRARY_PATH=/home/namae/.pyenv/versions/3.7.7 pyinstaller test.py --onefile Building EXE from EXE-00.toc completes successfully.exeができました!!
動作確認
cd dist ./test hello起動してます、OKです!
フォルダ大きい問題がありますが
私がexe化したいファイルだとそこまで大きく(約12MBくらいはありましたが)
できました。
参考にした記事
- 投稿日:2020-11-17T16:28:43+09:00
[Python]サポートベクトルマシンの理論と実装を徹底解説してみた
はじめに
今回は機械学習のアルゴリズムの一つであるサポートベクトルマシンについての理論をまとめていきます。
お付き合い頂ければ幸いです。
サポートベクトルマシンの理論
それでは最初にサポートベクトルマシンの理論についてまとめていきます。
ハードマージンとソフトマージン
サポートベクトルマシン(svm)は汎化性能や応用分野の広さから、データ分析の現場でよく用いられる機械学習のアルゴリズムの一つです。
マージン最大化と呼ばれる考えに基づき、主に2値分類問題に用いられます。多クラス分類や回帰問題への応用も可能です。
計算コストが他の機械学習のアルゴリズムと比較して大きいため、大規模なデータセットには向かないという弱点があります。
線形分離可能(一つの直線で二つに分けられる)なデータを前提としたマージンを
ハードマージン、線形分離不可能なデータを前提として、誤判別を許容するマージンをソフトマージンと呼びます。線形分離可能を
一つの直線で二つに分けられると書きましたが、これは2次元のデータにおいてのみであるので、線形分離可能の概念を一般化してn次元空間上の集合をn-1次元の超平面で分離できることを線形分離可能と定義します。二次元の平面上のデータを一次元の線で分類できるとき、それは線形分離可能であるといえます。また、三次元の空間上のデータを二次元の平面で分類できるときも、線形分離可能であるといえます。
このように、n次元のデータを分類するn-1次元の平面(厳密には平面ではない)を
分離超平面と呼び、また分離超平面とその分離超平面に最も近いデータとの距離をマージンと呼び、このマージンを最大化することがこのアルゴリズムの目標になります。また、
分離超平面に最も近いでデータのことをサポートベクトルと呼びます。以下に図解します。
図に示す
マージンを最大化するような超平面を作成することで精度を上昇させることができるのは、直感的に明らかですよね。図示するために今回は二次元でデータを表現しましたが、n次元空間上のデータをn-1次元の超平面で分割していると考えてください。
二次元の数ベクトル空間上においては、上の図のように二つのデータを分割する直線を$ax + by + c = 0$と表すことができ、パラメータ$a, b, c$を調整することで全ての直線を表すことができます。
n次元数ベクトル空間の超平面の式
今回はn次元数ベクトル空間上の超平面を想定しているので、その超平面の式を以下数式で与えられます。今、全部でN個のデータが存在する場合を考えます。
$$W^TX_i + b = 0 \quad (i = 1, 2, 3, ...N)$$
それではこの超平面の式を用いて、ハードマージン(線形分離可能な問題)の最適化に用いる式を導出しましょう。
ハードマージン最適化の式を導出
$W^TX_i+b=0$の部分を計算すると、$w_1x_1 + w_2x_2 + ...w_nx_n+b=0$となり、これは二次元における直線の式である$ax + by + c = 0$をn次元に拡張した超平面の式であることが感覚的に理解できると思います。
図の三角のデータは$K_1$の集合に属していて、図の星のデータは$K_2$の集合に属していると考えると、以下の式を満たすことが分かります。
W^TX_i + b > 0 \quad (X_i \in K_1)\\ W^TX_i + b < 0 \quad (X_i \in K_2)この式をまとめて表すためにラベル変数tを導入します。
i番目のデータ$x_i$がクラス1に属するときに$t_i=1$、クラス2に属するときに$t_i=-1$とします。
t_i = \left\{ \begin{array}{ll} 1 & (X_i \in K_1) \\ -1 & (X_i \in K_2) \end{array} \right.このように定義した$t_i$を用いると、条件式を以下のように表すことができます。
$$t_i(W^TX_i + b) > 0 \quad (i = 1, 2, 3, ...N)$$
このように、条件式を一行で表すことができました。
マージンはn次元空間上の点と超平面との距離になるので、点と直線の距離について復習しましょう。二次元の点と直線の距離は、点を$A(x0,y0)$ 、直線を$l:ax+by+c=0$とすると以下の式で表されましたね。
d = \frac{|ax_0 + by_0 + c|}{\sqrt{a^2+b^2}}n次元空間上の1点と超平面との距離は以下の式で表されます。
d = \frac{|w_1x_1 + w_2x_2... + w_nx_n + b|}{\sqrt{w_1^2+w_2^2...+w_n^2}} = \frac{|W^TX_i + b|}{||w||}よって、ここまでの式からマージンMを最大化するという条件は以下の式で表されます。
max_{w, b}M, \quad \frac{t_i(W^TX_i + b)}{||W||} \geq M \quad (i = 1, 2, 3, ...N)ちょっとよく分からないと思うので、解説します。
あるデータ$X_a$を選んだときの、$X_a$と超平面$W^TX + b=0$との距離は、$ \frac{t_i(W^TX_a + b)}{||W||}$と表されますね。
$|W^TX_a + b|$をラベル変数tを用いて$t_i(W^TX_a + b)$と表しています。
また、$max_{w, b}M$は変数$w, b$のもとでMを最大化するという意味であり、$\frac{t_i(W^TX_i + b)}{||W||} \geq M $という条件は、超平面と全てのデータとの距離をマージンMよりも大きくするということを表しています。
よって、この数式を満たすMを求めるということが、サポートベクトルマシンを最適化するということになります。
ここで、$\frac{t_i(W^TX_i + b)}{||W||} \geq M $の両辺をMで割り、以下の条件を導入します。
\frac{W}{M||W||} = \tilde{W}\\ \frac{b}{M||W||} = \tilde{b}すると、最適化問題の条件式は以下のように表されます。
t_i(\tilde{W^T}X_i + \tilde{b}) \geq 1全てのデータに対して上の式は成り立ちますが、等号が成り立つときの$X_i$が最も近いデータの$X_i$になります。
つまり、マージンMを簡略化した $\tilde{M}$は以下の式で表されます。
\tilde{M} = \frac{t_i(\tilde{W^T}X_i + \tilde{b})}{||\tilde{W}||} = \frac{1}{||\tilde{W}||}この式変形により、最適化問題は以下のようになります。
max_{\tilde{W}, \tilde{b}}\frac{1}{||\tilde{W}||}, \quad t_i(\tilde{W^T}X_i + \tilde{b}) \geq 1 \quad (i = 1, 2, 3, ...N)結構難しくなってきましたね。頑張っていきましょう。
途中の式変形でチルダがついてしまいましたが、簡単のために取っ払いましょう。そして、$\frac{1}{||\tilde{W}||}$の部分については、ノルムの逆数を最大化するという意味ですので、簡単のためにノルムを二乗を最小化する問題に変換しましょう。ここの部分の式変形は少しごり押しです。後の計算を簡単にするために$\frac{1}{2}$をつけます。
min_{W, b}\frac{1}{2}||W||^2, \quad t_i(W^TX_i + b)\geq 1 \quad (i = 1, 2, 3, ...N)上記の式を解くこと、つまり$t_i(W^TX_i + b)\geq 1$という条件の下で$\frac{1}{2}||W||^2$を最小化することによりマージンを最大化することができます。これが線形分離可能な場合の最適化問題の式になります。
しかし、この条件では線形分離可能な問題しか解くことができません。つまり、ハードマージンにしか適用できません。
この式をソフトマージンにも適用できるように、制約条件を緩めましょう。
ソフトマージンの最適化の式を導出
上記の式の制約条件$t_i(W^TX_i + b)\geq 1$を緩めることで、線形分離不可能な問題(ソフトマージン)にも対応できるようにしましょう。
以下に図解します。
この図のように線形分離不可能な問題を考えます。図の赤矢印で示すように、マージンの内側にデータが入り込んでしまっています。
$W^TX_i + b = 1$を満たす超平面上にサポートベクトル(超平面に最も近いデータ)が存在するのはここまでの話から考えると当然ですね。
図の赤矢印で示すデータは$ t_i(W^TX_i + b)\geq 1$を満たしていませんが、$ t_i(W^TX_i + b)\geq 0.5$という条件なら満たすかもしれません。
よって、スラッグ変数$\xi$を導入することで制約条件を緩めることにしましょう。以下のように定義します。
t_i(W^TX_i + b)\geq 1 - \xi_i \\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}以上の式より、データがマージンの内側にある場合にのみ、制約を緩めることにします。
よって、このスラッグ変数を導入することにより、マージン最適化問題は以下のようになります。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad 制約条件\quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nマージンを最大化しようとする、つまり$\frac{1}{2}||W||^2$を最小化すると当然マージンの中に入ってくるデータが増えるため、$C\sum_{i=1}^{N} \xi_i$が増加します。よって、この最適化問題は相反する二つの項のバランスを取りながら最小化をはかることになります。
Cハイパーパラメーターであり、私たちが調節しながらモデルを構築することになります。
ここまでの復習
ここまでで、ハードマージンとソフトマージンにおける最適化問題の式を導出しました。以下にまとめます。
ハードマージンのとき
min_{W, b}\frac{1}{2}||W||^2, \quad t_i(W^TX_i + b)\geq 1 \quad (i = 1, 2, 3, ...N)ソフトマージンのとき
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad \quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nソフトマージンは線形分離不可能な問題のときに用いるもので、ハードマージンは線形分離可能な問題のときに用いるものでしたね。
最適化問題を解く
それでは最適化問題を解いていくことを考えていきましょう。
この最適化問題を解くときに、上記の式を直接解くことはほとんどありません。
上記のような式を最適化問題の
主問題といいますが、多くの場合この主問題を直接解くのではなく、この主問題を双対問題と呼ばれる別の形の数式に変換して、その数式を解くことで最適化問題を解いていきます。今回、この最適化問題を解くためにラグランジュの未定乗数法を用いましょう。
ラグランジュの未定乗数法についてはこちらの記事を参考にしてください。
自分も完全に理解している訳ではないので、一部厳密性に欠ける部分があると思いますがご了承ください。簡単に解説します。
ラグランジュの未定乗数法について
ラグランジュの未定乗数法は制約付き最適化問題の代表的な手法です。
目的関数$f(X)$をn個の不等式制約$g(X)_i \leqq0, i = 1, 2, 3, ...n$の条件の下で最小にするときを考えます。
まず、以下のラグランジュ関数を定義します。
L(X, α) = f(X) + \sum_{i=1}^{n}α_ig_i(X)この不等式制約付き最適化問題は、ラグランジュ関数について以下の四つの条件を満たす$(\tilde{X}, \tilde{α})$を求める問題に帰結します。
\frac{\partial L(X, α)}{\partial X}=0\\ \frac{\partial L(X, α)}{\partial α_i} = g_i(X)\leqq 0, \quad (i=1, 2,... n)\\ 0 \leqq α, \quad (i = 1,2, ...n)\\ α_ig_i(X) = 0, \quad (i = 1, 2,...n)このように、最適化問題を直接解くのではなく、ラグランジュの未定乗数法を用いることで別の式を用いて最適化問題を解くことができます。この別の式を
双対問題と呼ぶのでしたね。最適化問題に適用
それでは、サポートベクトルマシンのソフトマージンの式にラグランジュの未定乗数法を適用してみましょう。
目的関数は以下です。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\}不等式制約は以下です。
t_i(W^TX_i + b)\geq 1 - \xi_i \quad \xi_i \geq 0 \quad i = 1, 2,...N今回はn個のデータ全てに不等式制約が二個ずつあるため、ラグランジュ乗数をα、βとすると、ラグランジュ関数は以下のようになります。
L(W,b,\xi,α,β)=\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i-\sum_{i=1}^{N}α_i\bigl\{t_i(W^TX_i+b)-1+\xi_i\bigl\}-\sum_{i=1}^{N}β_i\xi_i最適化問題を解くとき、次の条件を満たします。
\frac{\partial L(W,b,\xi,α,β)}{\partial W}= W - \sum_{i=1}^{N}α_it_iX_i=0\\ \frac{\partial L(W,b,\xi,α,β)}{\partial b}= -\sum_{i=1}^{N}α_it_i = 0\\ \frac{\partial L(W,b,\xi,α,β)}{\partial W} = C - α_i -β_i = 0これら三つの式を整理すると以下のようになります。
W =\sum_{i=1}^{N}α_it_iX_i\\ \sum_{i=1}^{N}α_it_i = 0\\ C = α_i + β_iこの三つの式をラグランジュ関数に代入して頑張って計算すると以下のように変数αのみの式になります。
\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_jまた、αは0以上であるため、双対問題は以下の条件を満たすαを求めることになります、
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...Nこのように、ソフトマージンにおけるサポートベクトルマシンの双対問題の式を導出することができました。
それではこれから、この双対問題を簡単に解くための手法の一つであるカーネル法についてまとめていきます。
カーネル法について
それではカーネル法について解説していきます。
ここで、Wikipediaからの引用を見ていきましょう。
カーネル法(カーネルほう、英: kernel method)はパターン認識において使われる手法の一つで、 判別などのアルゴリズムに組み合わせて利用するものである。よく知られているのは、サポートベクターマシンと組み合わせて利用する方法である。
パターン認識の目的は、一般に、 データの構造(例えばクラスタ、ランキング、主成分、相関、分類)を見つけだし、研究することにある。この目的を達成するために、 カーネル法ではデータを高次元の特徴空間上へ写像する。特徴空間の各座標はデータ要素の一つの特徴に対応し、特徴空間への写像(特徴写像)によりデータの集合はユークリッド空間中の点の集合に変換される。特徴空間におけるデータの構造の分析に際しては、様々な方法がカーネル法と組み合わせて用いられる。特徴写像としては多様な写像を使うことができ(一般に非線形写像が使われる)、それに対応してデータの多様な構造を見いだすことができる。カーネル法とは、低次元のデータを高次元に写像して分離する方法だと考えてよいと思います。
厳密には違うのですが、まあここはざっくりとした理解で良いでしょう。
それでは、なぜサポートベクトルマシンでカーネル法が用いられるのかを解説します。
なぜサポートベクトルマシンでカーネル法が用いられているのか
以下の二種類のデータを分類する場合を考えてください。
このような二次元のデータの場合、一次元の直線で二つの種類のデータを分離することができませんね。
このように線形分離不可能な問題に対応するために、このデータを多次元のデータに拡張しましょう。
具体的には、二次元のデータ$X = (x_1, x_2)$を五次元に拡張する場合には以下のような関数を通して写像します。
$$ψ(X) = (x^2_1, x^2_2, x_1x_2, x_1, x_2)$$
このように、データの次元をより高次元に拡張したものを
高次元特徴空間と呼び、それに対して最初の入力データの空間を入力空間と呼びます。上の式をより一般化しましょう。n次元の入力空間のデータを、より高次元のr次元特徴空間に写像する関数を以下のように定義します。
ψ(X) = (φ_1(X), φ_2(X), φ_3(X), ...φ_r(X))$φ_1(X)$などの関数は、元の関数のデータを組み合わせて変化を加えるという関数です。
このような関数を用いて高次元特徴空間にデータを拡張していくと、ある段階で分離超平面により分離可能なデータになります。というか、究極的には一つ一つのデータを全て別の次元、データがn個あればn次元まで拡張すれば、必ずn-1次元の分離超平面で分離することができます。
つまり、線形分離可能なデータに変化するのです。
後はこの分離超平面を逆写像して元のデータの分離超平面に変換することで、入力空間においてデータを分離する曲線(厳密には入力空間よりも一つ次元が小さな次元に曲線を拡張したもの)を得ることができます。
それでは、高次元特徴空間における最適化問題の式を考えていきましょう。
高次元特徴空間の最適化問題の式を考える前に、入力空間の最適化問題の復習です。
入力空間の最適化問題の復習
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...N高次元特徴空間のデータは入力空間のデータ$X_i^T$,$X_j$1を関数$ψ(X)$を用いて写像したものであるので、高次元特徴空間の最適化問題は以下のようになります。
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{ψ(X)_i}^Tψ(X)_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...N高次元特徴空間において、この最適化問題をといていけばよいことが分かりますね。
カーネル法を用いる
ここで問題になるのは以下の項です。
{ψ(X)_i}^Tψ(X)_j特徴空間が高次元になればなるほど、この項の計算量がとんでもないことになりますよね。
この部分の計算を簡単にする方法がカーネルトリックと呼ばれる方法です。
以下のように
カーネル関数を定義します。K(X_i, X_j) = {ψ(X)_i}^Tψ(X)_j少しごまかしますが、このカーネル関数を用いると$ψ(X)$を直接計算せずに内積を計算することができます。
このように、$ψ(X)$を直接計算せずに内積を計算するためにはある条件を満たす必要があるのですが、
なんだかよく分からない説明するのが大変なので参考となるサイトだけ貼っておきます。双対問題において$ψ(X)$は内積の形でしか出てこないため、この方法は非常に有用です。
以下のような三つのカーネル関数が用いられます。
ガウスカーネルK(X_i, X_j) = exp\bigl\{-\frac{||X_i -X_j||^2}{2σ^2}\bigl\}
多項式カーネルK(X_i, X_j) = (X_i^TX_j + c)^d
シグモイドカーネルK(X_i, X_j) = tanh(bX_i^TX_j + c)それでは、実際に多項式カーネルにより内積が簡単に計算できる具体例をみていきましょう。
カーネル法の具体例
以下のような二次元入力空間を三次元特徴空間に写像する関数を考えます。
ψ(X) = ψ(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2)この関数を用いると、二つの二次元ベクトルX, Yは以下のようになります。
ψ(X) = ψ(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2)\\ ψ(Y) = ψ(y_1, y_2) = (y_1^2, \sqrt{2}y_1y_2, y_2^2)それではこれらの内積を考えていきましょう。
\begin{align} ψ(X)^Tψ(Y) & = (x_1^2, \sqrt{2}x_1x_2, x_2^2)^T(y_1^2, \sqrt{2}y_1y_2, y_2^2)\\ &=x_1^2y_1^2 + 2x_1y_1x_2y_2 + x_2^2y_2^2\\ &= (x_1y_1 + x_2y_2)^2\\ &=((x_1,x_2)^T(y_1,y_2))^2\\ &=(X^TY)^2 \end{align}このように、$ψ(X)^Tψ(Y)$を直接計算せずに、元のベクトルの内積を二乗することで、$ψ(X)^Tψ(Y)$を計算することができます。
カーネル法についてもう少し詳しく知りたい方はこちらの記事を参考にしてください。
それではこれから、サポートベクトルマシンの実装についてまとめていきます。
サポートベクトルマシンの実装
分類問題:ハードマージン
線形分離可能なデータを分離するsvmを実装していきます。
用いるデータはiris(アヤメ)データセットです。
iris(アヤメ)データセットについて
irisデータは、アヤメという花の品種のデータです。
アヤメの品種である
Setosa、Virginica、Virginicaの3品種に関するデータが50個ずつ、全部で150個のデータです。実際に中身を見ていきましょう。
from sklearn.datasets import load_iris import pandas as pd iris = load_iris() iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) print(iris_df.head())sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
iris.feature_namesに各々のカラム名が格納されているので、それをpandasのDataframeの引数に渡すことで上のようなデータを出力できます。
Sepal Lengthはがく弁の長さが、Sepal Widthにはがく弁の幅が、Petal lengthには花びらの長さが、Petal Widthには花びらの幅のデータが格納されています。以下のようにすれ正解ラベルを表示できます。
print(iris.target)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]このように、アヤメの品種である
setosa、versicolor、virginicaをそれぞれ0, 1, 2としています。アヤメのデータについての説明はここまでです。
実装
以下のコードでデータセットを作成しましょう。
import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC from sklearn.datasets import load_iris import mglearn iris = load_iris() X = iris.data[:100, 2:] Y = iris.target[:100] print(X.shape) print(Y.shape)(100, 2)
(100,)今回は
setosa、versicolorのpetal lengthとpetal widthのデータを用いて分類を行います。以下のコードでデータの描画を行います。
mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.legend(['setosa', 'versicolor'], loc='best') plt.show()
mglearn.discrete_scatter(X[:, 0], X[:, 1], Y)のコードは第一引数をX軸、第二引数にY軸、第三引数に正解ラベルをとって、scatterプロットを行います。
loc='best'により、凡例がグラフの邪魔にならない位置にくるように調整しています。上のデータから、明らかに直線で分離できることが分かりますね。むしろ簡単すぎるくらいです。
次のコードでモデルを作成しましょう。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) svm = LinearSVC() svm.fit(X_train, Y_train)モデルの作成自体はこのコードで終わりです。簡単ですね。
以下のコードでモデルがどのような形になったのかを図示しましょう。
plt.figure(figsize=(10, 6)) mglearn.plots.plot_2d_separator(svm, X) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.xlabel('petal length') plt.ylabel('petal width') plt.legend(['setosa', 'versicolor'], loc='best') plt.show()
しっかりとデータを分ける境界線が作成されていることが確認できますね。
mglearn.plots.plot_2d_separator(svm, X)の部分は少し分かりにくいと思うので解説します。定義となるコードを確認しましょう。plot_2d_separator(classifier, X, fill=False, ax=None, eps=None, alpha=1,cm=cm2, linewidth=None, threshold=None,linestyle="solid"):
第一引数に分類モデルを渡して、第二引数に元のデータを渡すと境界線を引いてくれる関数ですね。
ここまでで、線形分離可能な問題におけるsvmのモデルの実装は終了です。
分類問題: ソフトマージン
今回はソフトマージンの問題について取り扱います。
import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC from sklearn.datasets import load_iris import mglearn iris = load_iris() X = iris.data[50:, 2:] Y = iris.target[50:] - 1 mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.legend(['versicolor', 'virginica'], loc='best') plt.show()
今度は
versicolorとverginicaのpetal lengthとpetal widthについてのデータをプロットしています。完全に線形分離することは不可能な問題ですね。
ここでソフトマージンの式を復習です。導出はこちらの記事を参考にしてください。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad \quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nデータがマージンの内側に入り込んでしまうので、$ C\sum_{i=1}^{N} \xi_i$の項により制限を緩めているのでしたね。
このCの値は
skleaarnにおいて、デフォルトで1.0になっています。この数値を変化させて、図がどう変わるのか確認してみましょう。以下のコードで、引数に与えたモデルの境界線をプロットする関数を定義します。def make_separate(model): mglearn.plots.plot_2d_separator(svm, X) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.xlabel('petal length') plt.ylabel('petal width') plt.legend(['setosa', 'versicolor'], loc='best') plt.show()以下のコードで図を描画しましょう。
C=0.1とします。X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) svm = LinearSVC(C=0.1) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))0.96
次は
C=1.0です。svm = LinearSVC(C=1.0) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))1.0
次は
C=100です。svm = LinearSVC(C=100) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))1.0
適切なCを設定するのが大切ですね。色々変えながら様子を見ていくのがよさそうです。
ここまででソフトマージンの実装は終了です。
それではこれから、カーネル法を用いたときの実装と用いなかったときの実装についてまとめていきます。
カーネル法を用いずに実装
今回は線形分離不可能な問題をカーネル法を用いずに分類していきます。
ここでは、カーネル関数を使わない方法を、カーネル法を使わないと定義しています。
以下のコードでデータを準備して、図示しましょう。
import mglearn import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.svm import LinearSVC from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline from sklearn.svm import SVC moons = make_moons(n_samples=300, noise=0.2, random_state=0) X = moons[0] Y = moons[1] plt.figure(figsize=(12, 8)) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.plot() plt.show()
make_moonsは、二次元の月のような形をしたデータを作成する関数です。サンプル数とノイズを設定することができます。
図を見て頂ければ分かりますが、明らかに線形分離不可能ですよね。
この線形分離不可能なデータを線形分離可能なデータに変形するために、この入力空間のデータを高次元特徴空間のデータに写像しましょう。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) poly = PolynomialFeatures(degree=2) X_train_poly = poly.fit_transform(X_train) X_test_poly = poly.fit_transform(X_test)これで、入力空間のデータを高次元特徴空間に写像することができました。
どのようなデータに写像されたか確認しましょう。
print(poly.get_feature_names()) print(X_train_poly.shape)['1', 'x0', 'x1', 'x0^2', 'x0 x1', 'x1^2']
(225, 6)このような形で、二次元入力空間が六次元特徴空間に拡張されています。
次のコードでデータを標準化します。
scaler = StandardScaler() X_train_poly_scaled = scaler.fit_transform(X_train_poly) X_test_poly_scaled = scaler.fit_transform(X_test_poly)データの標準化とは、全てのデータに対して平均を引いた後に標準偏差で割ることで、データの平均を0、分散を1にすることです。
こちらの記事に分かりやすく書いていたので、参考にしてください。
それでは、次のコードでモデルを実装して評価します。
lin_svm = LinearSVC() lin_svm.fit(X_train_poly_scaled, Y_train) print(lin_svm.score(X_test_poly_scaled, Y_test))0.84
ちょっと低いですね。もう少し高次元に写像しましょう。
しかし、高次元に写像して標準化するという処理が面倒くさいので、
Pipelineというものを使用しましょう。poly_scaler_svm = Pipeline([ ('poly', PolynomialFeatures(degree=3)), ('scaler', StandardScaler()), ('svm', LinearSVC()) ]) poly_scaler_svm.fit(X_train, Y_train) print(poly_scaler_svm.score(X_test, Y_test))0.9733333333333334
このように、
Pipelineを用いると、データを高次元に写像して、標準化して、svmモデルに入れるという作業を簡略化して書くことができます。degree=3にすることで、より高次元の特徴空間に写像しています。精度はかなり良いですね。高次元に写像するとかなり効果的です。
次は、この図を描画してみましょう。以下のコードです。
_x0 = np.linspace(-1.5, 2.7, 100) _x1 = np.linspace(-1.5, 1.5, 100) x0, x1 = np.meshgrid(_x0, _x1) X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1))) y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3) plt.figure(figsize=(12, 8)) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.show()
なかなかきれいな線が引けていることが確認できましたね。それではコードを解説します。
_x0 = np.linspace(-1.5, 2.7, 100) _x1 = np.linspace(-1.5, 1.5, 100) x0, x1 = np.meshgrid(_x0, _x1)ここの部分のコードで格子点を作成しています。こちらの記事に分かりやすく書いてあるので、参考にしてください。
np.linspaceは第一引数に始点、第二引数に終点、第三引数に点の数を指定して、numpyのarrayを作成します。それをnp.meshgridに渡すことで、100×100の格子点を作成しています。X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1)))
(x0.ravel()により、100×100のarrayを一次元配列に変換した後、reshape(-1, 1)により二次元の10000×1の行列に変換し、np.hstackによりaxis=1の水平方向に対して結合しています。つまり、Xは10000×2の行列になっています。y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3)
model.decision_function(X)により10000個の格子点と分離超平面との距離を求めて、それを100×100のデータに変換しています。
plt.contourfは等高線を図示する関数で、levelsにどの部分で色を変化させるかを指定できます。以上でカーネル法を使わない実装は終了です。
カーネル法を用いた実装
それではカーネル法を用いて実装を行っていきます。
データを準備しましょう。ここまでは同じです。
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.svm import SVC moons = make_moons(n_samples=300, noise=0.2, random_state=0) X = moons[0] Y = moons[1] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0)次のコードでモデルを実装しましょう。
karnel_svm = Pipeline([ ('scaler', StandardScaler()), ('svm', SVC(kernel='poly', degree=3, coef0=1)) ]) karnel_svm.fitX_train, Y_train()
SVCのkarnel引数にpolyを指定することで、多項式カーネルを指定し、degree=3を指定することで三次元までの写像を考えることができます。これでモデルの作成ができました。次は、このモデルを図示してみましょう。また同じことをするんですが、面倒くさいので関数にします。
def plot_decision_function(model): _x0 = np.linspace(-1.7, 2.7, 100) _x1 = np.linspace(-1.5, 1.7, 100) x0, x1 = np.meshgrid(_x0, _x1) X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1))) y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3) def plot_dataset(x, y): plt.plot(x[:, 0][y == 0], x[:, 1][y == 0], 'bo', ms=15) plt.plot(x[:, 0][y == 1], x[:, 1][y == 1], 'r^', ms=15) plt.xlabel('$x_1$', fontsize=20) plt.ylabel('$x_2$', fontsize=20, rotation=0) plt.figure(figsize=(12, 8)) plot_decision_function(karnel_svm) plot_dataset(X, Y) plt.show()
mglearnでプロットしても良かったのですが、今回はplt.plotでプロットしました。Y=0となるものを青色の丸で、Y=1となるものを赤色の三角で描画しています。図から分かるように、カーネル法を使っても使わなくても同じ結果が返ってきます。しかし、カーネル法を用いた方が内部的に計算がかなり簡単になっているので、できるだけカーネル法を使った方が良い気がします。
どのように簡単になるのかはこちらの記事を参考にしてください。
終わりに
ここまでお付き合い頂きありがとうございました。
非常に長い記事になりました。ここまで読んで下さり本当にありがとうございます。
お疲れさまでした。
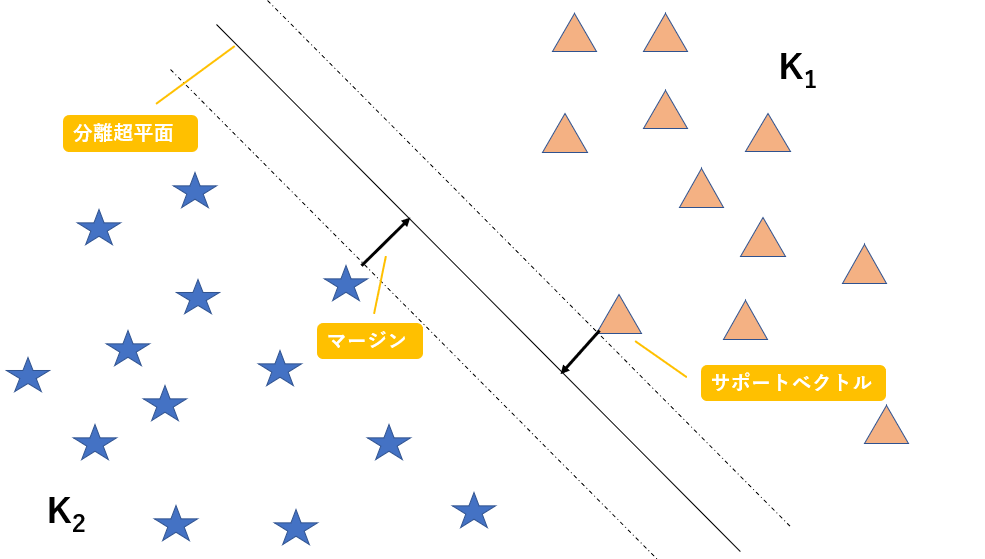
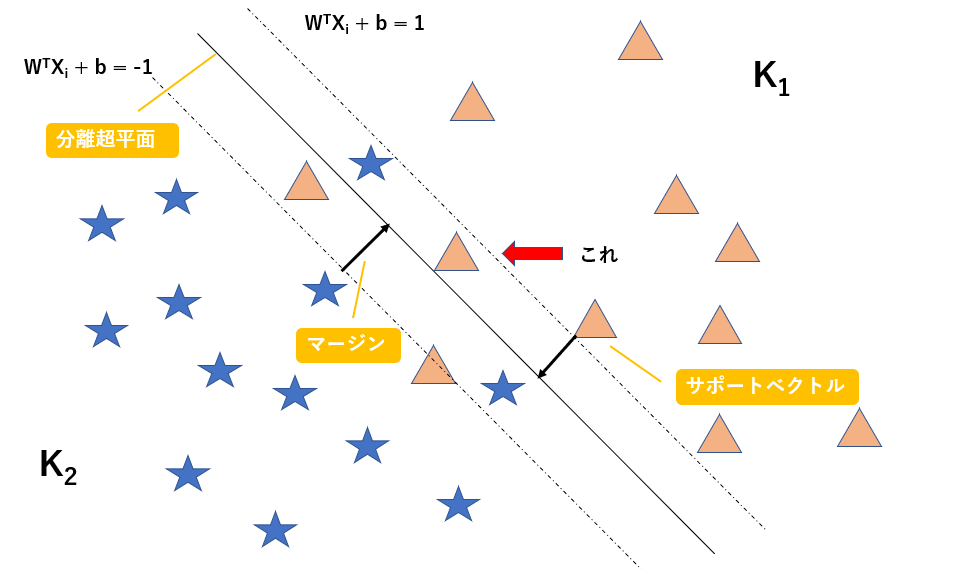

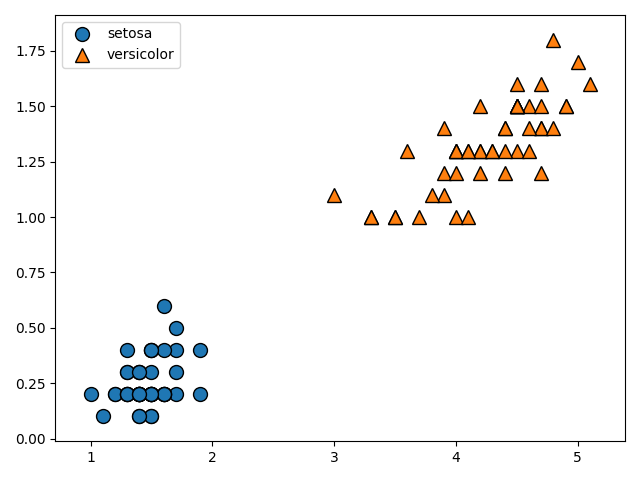
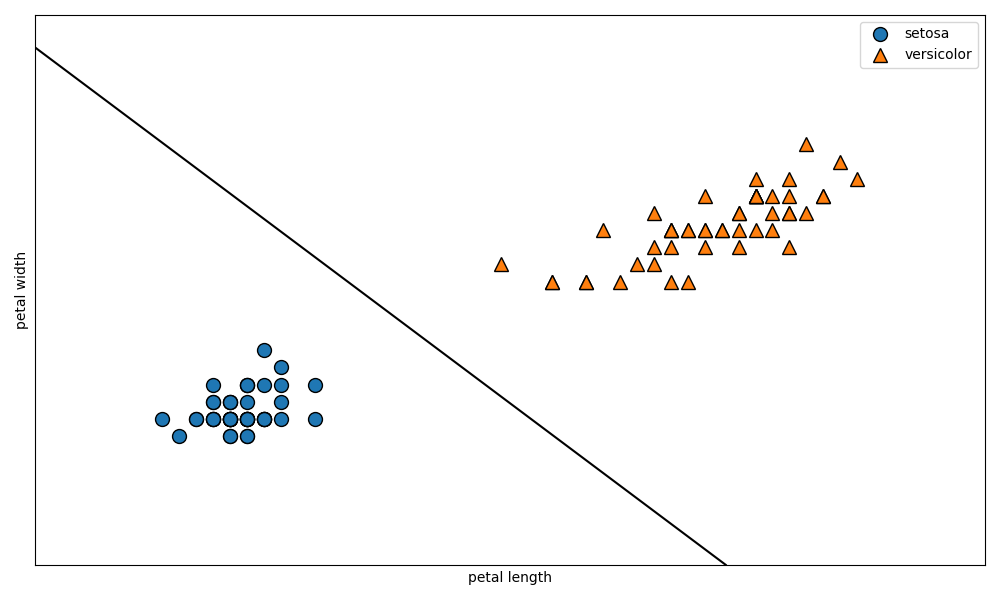
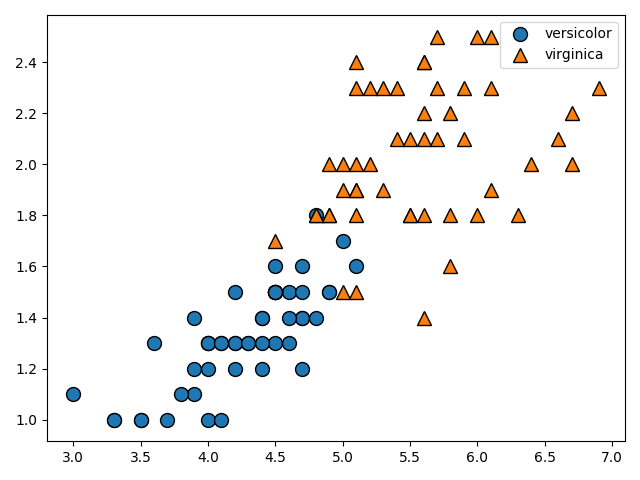
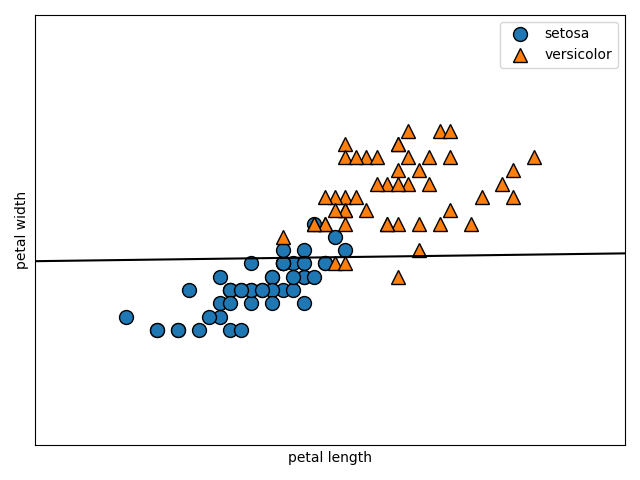
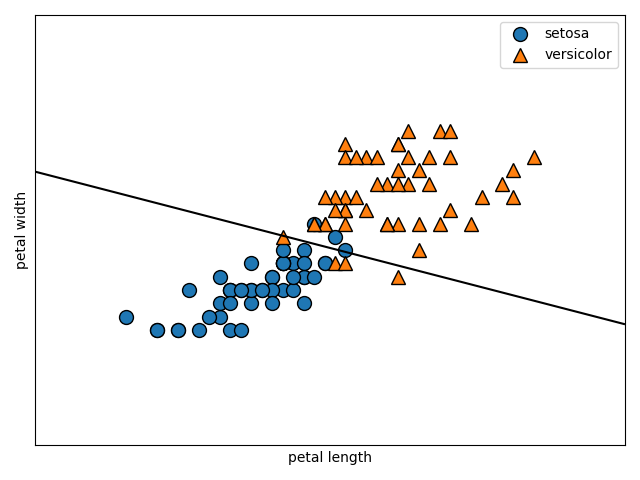
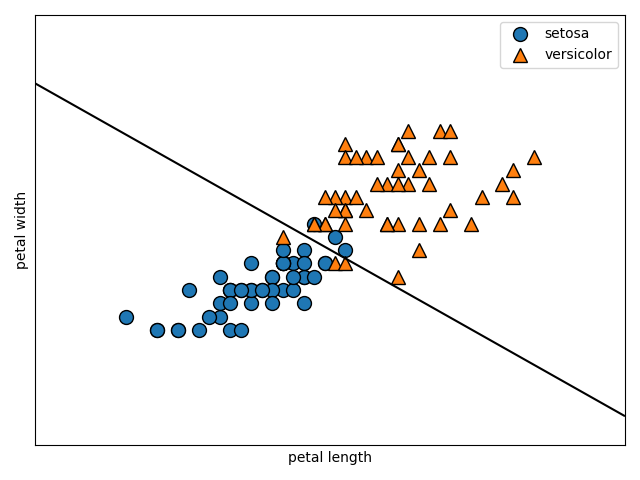
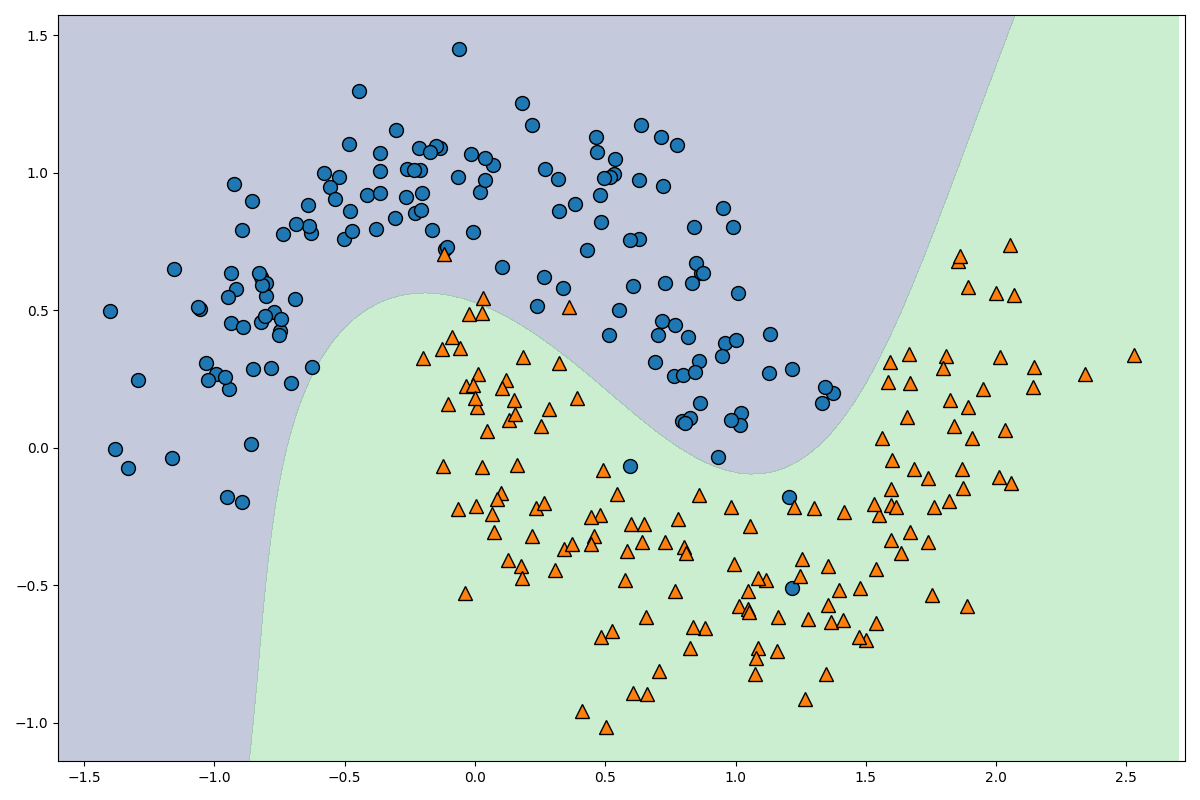
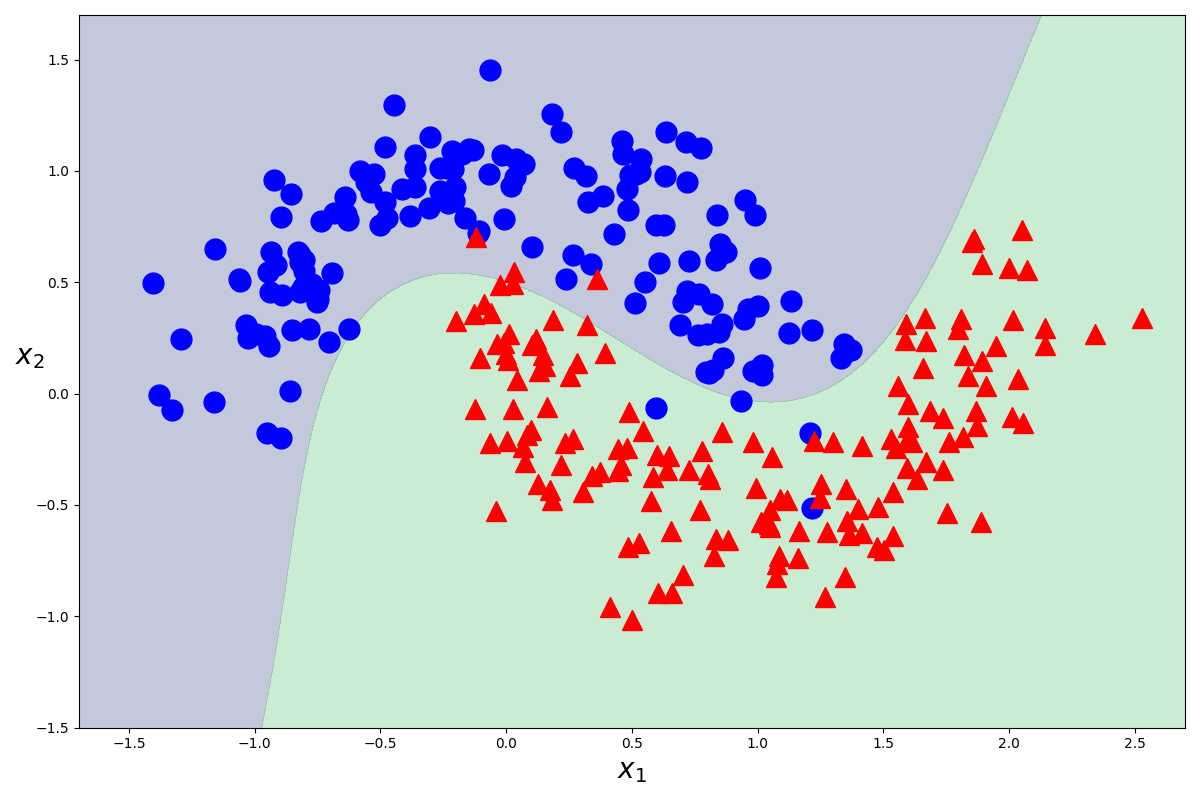
- 投稿日:2020-11-17T16:28:43+09:00
[Python]サポートベクトルマシン(SVM)の理論と実装を徹底解説してみた
はじめに
今回は機械学習のアルゴリズムの一つであるサポートベクトルマシンについての理論をまとめていきます。
お付き合い頂ければ幸いです。
サポートベクトルマシンの理論
それでは最初にサポートベクトルマシンの理論についてまとめていきます。
ハードマージンとソフトマージン
サポートベクトルマシン(svm)は汎化性能や応用分野の広さから、データ分析の現場でよく用いられる機械学習のアルゴリズムの一つです。
マージン最大化と呼ばれる考えに基づき、主に2値分類問題に用いられます。多クラス分類や回帰問題への応用も可能です。
計算コストが他の機械学習のアルゴリズムと比較して大きいため、大規模なデータセットには向かないという弱点があります。
線形分離可能(一つの直線で二つに分けられる)なデータを前提としたマージンを
ハードマージン、線形分離不可能なデータを前提として、誤判別を許容するマージンをソフトマージンと呼びます。線形分離可能を
一つの直線で二つに分けられると書きましたが、これは2次元のデータにおいてのみであるので、線形分離可能の概念を一般化してn次元空間上の集合をn-1次元の超平面で分離できることを線形分離可能と定義します。二次元の平面上のデータを一次元の線で分類できるとき、それは線形分離可能であるといえます。また、三次元の空間上のデータを二次元の平面で分類できるときも、線形分離可能であるといえます。
このように、n次元のデータを分類するn-1次元の平面(厳密には平面ではない)を
分離超平面と呼び、また分離超平面とその分離超平面に最も近いデータとの距離をマージンと呼び、このマージンを最大化することがこのアルゴリズムの目標になります。また、
分離超平面に最も近いでデータのことをサポートベクトルと呼びます。以下に図解します。
図に示す
マージンを最大化するような超平面を作成することで精度を上昇させることができるのは、直感的に明らかですよね。図示するために今回は二次元でデータを表現しましたが、n次元空間上のデータをn-1次元の超平面で分割していると考えてください。
二次元の数ベクトル空間上においては、上の図のように二つのデータを分割する直線を$ax + by + c = 0$と表すことができ、パラメータ$a, b, c$を調整することで全ての直線を表すことができます。
n次元数ベクトル空間の超平面の式
今回はn次元数ベクトル空間上の超平面を想定しているので、その超平面の式を以下数式で与えられます。今、全部でN個のデータが存在する場合を考えます。
$$W^TX_i + b = 0 \quad (i = 1, 2, 3, ...N)$$
それではこの超平面の式を用いて、ハードマージン(線形分離可能な問題)の最適化に用いる式を導出しましょう。
ハードマージン最適化の式を導出
$W^TX_i+b=0$の部分を計算すると、$w_1x_1 + w_2x_2 + ...w_nx_n+b=0$となり、これは二次元における直線の式である$ax + by + c = 0$をn次元に拡張した超平面の式であることが感覚的に理解できると思います。
図の三角のデータは$K_1$の集合に属していて、図の星のデータは$K_2$の集合に属していると考えると、以下の式を満たすことが分かります。
W^TX_i + b > 0 \quad (X_i \in K_1)\\ W^TX_i + b < 0 \quad (X_i \in K_2)この式をまとめて表すためにラベル変数tを導入します。
i番目のデータ$x_i$がクラス1に属するときに$t_i=1$、クラス2に属するときに$t_i=-1$とします。
t_i = \left\{ \begin{array}{ll} 1 & (X_i \in K_1) \\ -1 & (X_i \in K_2) \end{array} \right.このように定義した$t_i$を用いると、条件式を以下のように表すことができます。
$$t_i(W^TX_i + b) > 0 \quad (i = 1, 2, 3, ...N)$$
このように、条件式を一行で表すことができました。
マージンはn次元空間上の点と超平面との距離になるので、点と直線の距離について復習しましょう。二次元の点と直線の距離は、点を$A(x0,y0)$ 、直線を$l:ax+by+c=0$とすると以下の式で表されましたね。
d = \frac{|ax_0 + by_0 + c|}{\sqrt{a^2+b^2}}n次元空間上の1点と超平面との距離は以下の式で表されます。
d = \frac{|w_1x_1 + w_2x_2... + w_nx_n + b|}{\sqrt{w_1^2+w_2^2...+w_n^2}} = \frac{|W^TX_i + b|}{||w||}よって、ここまでの式からマージンMを最大化するという条件は以下の式で表されます。
max_{w, b}M, \quad \frac{t_i(W^TX_i + b)}{||W||} \geq M \quad (i = 1, 2, 3, ...N)ちょっとよく分からないと思うので、解説します。
あるデータ$X_a$を選んだときの、$X_a$と超平面$W^TX + b=0$との距離は、$ \frac{t_i(W^TX_a + b)}{||W||}$と表されますね。
$|W^TX_a + b|$をラベル変数tを用いて$t_i(W^TX_a + b)$と表しています。
また、$max_{w, b}M$は変数$w, b$のもとでMを最大化するという意味であり、$\frac{t_i(W^TX_i + b)}{||W||} \geq M $という条件は、超平面と全てのデータとの距離をマージンMよりも大きくするということを表しています。
よって、この数式を満たすMを求めるということが、サポートベクトルマシンを最適化するということになります。
ここで、$\frac{t_i(W^TX_i + b)}{||W||} \geq M $の両辺をMで割り、以下の条件を導入します。
\frac{W}{M||W||} = \tilde{W}\\ \frac{b}{M||W||} = \tilde{b}すると、最適化問題の条件式は以下のように表されます。
t_i(\tilde{W^T}X_i + \tilde{b}) \geq 1全てのデータに対して上の式は成り立ちますが、等号が成り立つときの$X_i$が最も近いデータの$X_i$になります。
つまり、マージンMを簡略化した $\tilde{M}$は以下の式で表されます。
\tilde{M} = \frac{t_i(\tilde{W^T}X_i + \tilde{b})}{||\tilde{W}||} = \frac{1}{||\tilde{W}||}この式変形により、最適化問題は以下のようになります。
max_{\tilde{W}, \tilde{b}}\frac{1}{||\tilde{W}||}, \quad t_i(\tilde{W^T}X_i + \tilde{b}) \geq 1 \quad (i = 1, 2, 3, ...N)結構難しくなってきましたね。頑張っていきましょう。
途中の式変形でチルダがついてしまいましたが、簡単のために取っ払いましょう。そして、$\frac{1}{||\tilde{W}||}$の部分については、ノルムの逆数を最大化するという意味ですので、簡単のためにノルムを二乗を最小化する問題に変換しましょう。ここの部分の式変形は少しごり押しです。後の計算を簡単にするために$\frac{1}{2}$をつけます。
min_{W, b}\frac{1}{2}||W||^2, \quad t_i(W^TX_i + b)\geq 1 \quad (i = 1, 2, 3, ...N)上記の式を解くこと、つまり$t_i(W^TX_i + b)\geq 1$という条件の下で$\frac{1}{2}||W||^2$を最小化することによりマージンを最大化することができます。これが線形分離可能な場合の最適化問題の式になります。
しかし、この条件では線形分離可能な問題しか解くことができません。つまり、ハードマージンにしか適用できません。
この式をソフトマージンにも適用できるように、制約条件を緩めましょう。
ソフトマージンの最適化の式を導出
上記の式の制約条件$t_i(W^TX_i + b)\geq 1$を緩めることで、線形分離不可能な問題(ソフトマージン)にも対応できるようにしましょう。
以下に図解します。
この図のように線形分離不可能な問題を考えます。図の赤矢印で示すように、マージンの内側にデータが入り込んでしまっています。
$W^TX_i + b = 1$を満たす超平面上にサポートベクトル(超平面に最も近いデータ)が存在するのはここまでの話から考えると当然ですね。
図の赤矢印で示すデータは$ t_i(W^TX_i + b)\geq 1$を満たしていませんが、$ t_i(W^TX_i + b)\geq 0.5$という条件なら満たすかもしれません。
よって、スラッグ変数$\xi$を導入することで制約条件を緩めることにしましょう。以下のように定義します。
t_i(W^TX_i + b)\geq 1 - \xi_i \\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}以上の式より、データがマージンの内側にある場合にのみ、制約を緩めることにします。
よって、このスラッグ変数を導入することにより、マージン最適化問題は以下のようになります。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad 制約条件\quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nマージンを最大化しようとする、つまり$\frac{1}{2}||W||^2$を最小化すると当然マージンの中に入ってくるデータが増えるため、$C\sum_{i=1}^{N} \xi_i$が増加します。よって、この最適化問題は相反する二つの項のバランスを取りながら最小化をはかることになります。
Cハイパーパラメーターであり、私たちが調節しながらモデルを構築することになります。
ここまでの復習
ここまでで、ハードマージンとソフトマージンにおける最適化問題の式を導出しました。以下にまとめます。
ハードマージンのとき
min_{W, b}\frac{1}{2}||W||^2, \quad t_i(W^TX_i + b)\geq 1 \quad (i = 1, 2, 3, ...N)ソフトマージンのとき
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad \quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nソフトマージンは線形分離不可能な問題のときに用いるもので、ハードマージンは線形分離可能な問題のときに用いるものでしたね。
最適化問題を解く
それでは最適化問題を解いていくことを考えていきましょう。
この最適化問題を解くときに、上記の式を直接解くことはほとんどありません。
上記のような式を最適化問題の
主問題といいますが、多くの場合この主問題を直接解くのではなく、この主問題を双対問題と呼ばれる別の形の数式に変換して、その数式を解くことで最適化問題を解いていきます。今回、この最適化問題を解くためにラグランジュの未定乗数法を用いましょう。
ラグランジュの未定乗数法についてはこちらの記事を参考にしてください。
自分も完全に理解している訳ではないので、一部厳密性に欠ける部分があると思いますがご了承ください。簡単に解説します。
ラグランジュの未定乗数法について
ラグランジュの未定乗数法は制約付き最適化問題の代表的な手法です。
目的関数$f(X)$をn個の不等式制約$g(X)_i \leqq0, i = 1, 2, 3, ...n$の条件の下で最小にするときを考えます。
まず、以下のラグランジュ関数を定義します。
L(X, α) = f(X) + \sum_{i=1}^{n}α_ig_i(X)この不等式制約付き最適化問題は、ラグランジュ関数について以下の四つの条件を満たす$(\tilde{X}, \tilde{α})$を求める問題に帰結します。
\frac{\partial L(X, α)}{\partial X}=0\\ \frac{\partial L(X, α)}{\partial α_i} = g_i(X)\leqq 0, \quad (i=1, 2,... n)\\ 0 \leqq α, \quad (i = 1,2, ...n)\\ α_ig_i(X) = 0, \quad (i = 1, 2,...n)このように、最適化問題を直接解くのではなく、ラグランジュの未定乗数法を用いることで別の式を用いて最適化問題を解くことができます。この別の式を
双対問題と呼ぶのでしたね。最適化問題に適用
それでは、サポートベクトルマシンのソフトマージンの式にラグランジュの未定乗数法を適用してみましょう。
目的関数は以下です。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\}不等式制約は以下です。
t_i(W^TX_i + b)\geq 1 - \xi_i \quad \xi_i \geq 0 \quad i = 1, 2,...N今回はn個のデータ全てに不等式制約が二個ずつあるため、ラグランジュ乗数をα、βとすると、ラグランジュ関数は以下のようになります。
L(W,b,\xi,α,β)=\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i-\sum_{i=1}^{N}α_i\bigl\{t_i(W^TX_i+b)-1+\xi_i\bigl\}-\sum_{i=1}^{N}β_i\xi_i最適化問題を解くとき、次の条件を満たします。
\frac{\partial L(W,b,\xi,α,β)}{\partial W}= W - \sum_{i=1}^{N}α_it_iX_i=0\\ \frac{\partial L(W,b,\xi,α,β)}{\partial b}= -\sum_{i=1}^{N}α_it_i = 0\\ \frac{\partial L(W,b,\xi,α,β)}{\partial W} = C - α_i -β_i = 0これら三つの式を整理すると以下のようになります。
W =\sum_{i=1}^{N}α_it_iX_i\\ \sum_{i=1}^{N}α_it_i = 0\\ C = α_i + β_iこの三つの式をラグランジュ関数に代入して頑張って計算すると以下のように変数αのみの式になります。
\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_jまた、αは0以上であるため、双対問題は以下の条件を満たすαを求めることになります、
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...Nこのように、ソフトマージンにおけるサポートベクトルマシンの双対問題の式を導出することができました。
それではこれから、この双対問題を簡単に解くための手法の一つであるカーネル法についてまとめていきます。
カーネル法について
それではカーネル法について解説していきます。
ここで、Wikipediaからの引用を見ていきましょう。
カーネル法(カーネルほう、英: kernel method)はパターン認識において使われる手法の一つで、 判別などのアルゴリズムに組み合わせて利用するものである。よく知られているのは、サポートベクターマシンと組み合わせて利用する方法である。
パターン認識の目的は、一般に、 データの構造(例えばクラスタ、ランキング、主成分、相関、分類)を見つけだし、研究することにある。この目的を達成するために、 カーネル法ではデータを高次元の特徴空間上へ写像する。特徴空間の各座標はデータ要素の一つの特徴に対応し、特徴空間への写像(特徴写像)によりデータの集合はユークリッド空間中の点の集合に変換される。特徴空間におけるデータの構造の分析に際しては、様々な方法がカーネル法と組み合わせて用いられる。特徴写像としては多様な写像を使うことができ(一般に非線形写像が使われる)、それに対応してデータの多様な構造を見いだすことができる。カーネル法とは、低次元のデータを高次元に写像して分離する方法だと考えてよいと思います。
厳密には違うのですが、まあここはざっくりとした理解で良いでしょう。
それでは、なぜサポートベクトルマシンでカーネル法が用いられるのかを解説します。
なぜサポートベクトルマシンでカーネル法が用いられているのか
以下の二種類のデータを分類する場合を考えてください。
このような二次元のデータの場合、一次元の直線で二つの種類のデータを分離することができませんね。
このように線形分離不可能な問題に対応するために、このデータを多次元のデータに拡張しましょう。
具体的には、二次元のデータ$X = (x_1, x_2)$を五次元に拡張する場合には以下のような関数を通して写像します。
$$ψ(X) = (x^2_1, x^2_2, x_1x_2, x_1, x_2)$$
このように、データの次元をより高次元に拡張したものを
高次元特徴空間と呼び、それに対して最初の入力データの空間を入力空間と呼びます。上の式をより一般化しましょう。n次元の入力空間のデータを、より高次元のr次元特徴空間に写像する関数を以下のように定義します。
ψ(X) = (φ_1(X), φ_2(X), φ_3(X), ...φ_r(X))$φ_1(X)$などの関数は、元の関数のデータを組み合わせて変化を加えるという関数です。
このような関数を用いて高次元特徴空間にデータを拡張していくと、ある段階で分離超平面により分離可能なデータになります。というか、究極的には一つ一つのデータを全て別の次元、データがn個あればn次元まで拡張すれば、必ずn-1次元の分離超平面で分離することができます。
つまり、線形分離可能なデータに変化するのです。
後はこの分離超平面を逆写像して元のデータの分離超平面に変換することで、入力空間においてデータを分離する曲線(厳密には入力空間よりも一つ次元が小さな次元に曲線を拡張したもの)を得ることができます。
それでは、高次元特徴空間における最適化問題の式を考えていきましょう。
高次元特徴空間の最適化問題の式を考える前に、入力空間の最適化問題の復習です。
入力空間の最適化問題の復習
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{X_i}^TX_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...N高次元特徴空間のデータは入力空間のデータ$X_i^T$,$X_j$1を関数$ψ(X)$を用いて写像したものであるので、高次元特徴空間の最適化問題は以下のようになります。
max\Bigl\{{\tilde{L}(α) = \sum_{i=1}^{N}α_i - \frac{1}{2}\sum_{i=1}^{N}\sum_{i=j}^{N}α_iα_jt_it_j{ψ(X)_i}^Tψ(X)_j\Bigr\}}\\ \sum_{i=1}^{N}α_it_i = 0, \quad 0 \leqq α_i \leqq C, i = 1,2,...N高次元特徴空間において、この最適化問題をといていけばよいことが分かりますね。
カーネル法を用いる
ここで問題になるのは以下の項です。
{ψ(X)_i}^Tψ(X)_j特徴空間が高次元になればなるほど、この項の計算量がとんでもないことになりますよね。
この部分の計算を簡単にする方法がカーネルトリックと呼ばれる方法です。
以下のように
カーネル関数を定義します。K(X_i, X_j) = {ψ(X)_i}^Tψ(X)_j少しごまかしますが、このカーネル関数を用いると$ψ(X)$を直接計算せずに内積を計算することができます。
このように、$ψ(X)$を直接計算せずに内積を計算するためにはある条件を満たす必要があるのですが、
なんだかよく分からない説明するのが大変なので参考となるサイトだけ貼っておきます。双対問題において$ψ(X)$は内積の形でしか出てこないため、この方法は非常に有用です。
以下のような三つのカーネル関数が用いられます。
ガウスカーネルK(X_i, X_j) = exp\bigl\{-\frac{||X_i -X_j||^2}{2σ^2}\bigl\}
多項式カーネルK(X_i, X_j) = (X_i^TX_j + c)^d
シグモイドカーネルK(X_i, X_j) = tanh(bX_i^TX_j + c)それでは、実際に多項式カーネルにより内積が簡単に計算できる具体例をみていきましょう。
カーネル法の具体例
以下のような二次元入力空間を三次元特徴空間に写像する関数を考えます。
ψ(X) = ψ(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2)この関数を用いると、二つの二次元ベクトルX, Yは以下のようになります。
ψ(X) = ψ(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2)\\ ψ(Y) = ψ(y_1, y_2) = (y_1^2, \sqrt{2}y_1y_2, y_2^2)それではこれらの内積を考えていきましょう。
\begin{align} ψ(X)^Tψ(Y) & = (x_1^2, \sqrt{2}x_1x_2, x_2^2)^T(y_1^2, \sqrt{2}y_1y_2, y_2^2)\\ &=x_1^2y_1^2 + 2x_1y_1x_2y_2 + x_2^2y_2^2\\ &= (x_1y_1 + x_2y_2)^2\\ &=((x_1,x_2)^T(y_1,y_2))^2\\ &=(X^TY)^2 \end{align}このように、$ψ(X)^Tψ(Y)$を直接計算せずに、元のベクトルの内積を二乗することで、$ψ(X)^Tψ(Y)$を計算することができます。
カーネル法についてもう少し詳しく知りたい方はこちらの記事を参考にしてください。
それではこれから、サポートベクトルマシンの実装についてまとめていきます。
サポートベクトルマシンの実装
分類問題:ハードマージン
線形分離可能なデータを分離するsvmを実装していきます。
用いるデータはiris(アヤメ)データセットです。
iris(アヤメ)データセットについて
irisデータは、アヤメという花の品種のデータです。
アヤメの品種である
Setosa、Virginica、Virginicaの3品種に関するデータが50個ずつ、全部で150個のデータです。実際に中身を見ていきましょう。
from sklearn.datasets import load_iris import pandas as pd iris = load_iris() iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) print(iris_df.head())sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
iris.feature_namesに各々のカラム名が格納されているので、それをpandasのDataframeの引数に渡すことで上のようなデータを出力できます。
Sepal Lengthはがく弁の長さが、Sepal Widthにはがく弁の幅が、Petal lengthには花びらの長さが、Petal Widthには花びらの幅のデータが格納されています。以下のようにすれ正解ラベルを表示できます。
print(iris.target)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]このように、アヤメの品種である
setosa、versicolor、virginicaをそれぞれ0, 1, 2としています。アヤメのデータについての説明はここまでです。
実装
以下のコードでデータセットを作成しましょう。
import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC from sklearn.datasets import load_iris import mglearn iris = load_iris() X = iris.data[:100, 2:] Y = iris.target[:100] print(X.shape) print(Y.shape)(100, 2)
(100,)今回は
setosa、versicolorのpetal lengthとpetal widthのデータを用いて分類を行います。以下のコードでデータの描画を行います。
mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.legend(['setosa', 'versicolor'], loc='best') plt.show()
mglearn.discrete_scatter(X[:, 0], X[:, 1], Y)のコードは第一引数をX軸、第二引数にY軸、第三引数に正解ラベルをとって、scatterプロットを行います。
loc='best'により、凡例がグラフの邪魔にならない位置にくるように調整しています。上のデータから、明らかに直線で分離できることが分かりますね。むしろ簡単すぎるくらいです。
次のコードでモデルを作成しましょう。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) svm = LinearSVC() svm.fit(X_train, Y_train)モデルの作成自体はこのコードで終わりです。簡単ですね。
以下のコードでモデルがどのような形になったのかを図示しましょう。
plt.figure(figsize=(10, 6)) mglearn.plots.plot_2d_separator(svm, X) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.xlabel('petal length') plt.ylabel('petal width') plt.legend(['setosa', 'versicolor'], loc='best') plt.show()
しっかりとデータを分ける境界線が作成されていることが確認できますね。
mglearn.plots.plot_2d_separator(svm, X)の部分は少し分かりにくいと思うので解説します。定義となるコードを確認しましょう。plot_2d_separator(classifier, X, fill=False, ax=None, eps=None, alpha=1,cm=cm2, linewidth=None, threshold=None,linestyle="solid"):
第一引数に分類モデルを渡して、第二引数に元のデータを渡すと境界線を引いてくれる関数ですね。
ここまでで、線形分離可能な問題におけるsvmのモデルの実装は終了です。
分類問題: ソフトマージン
今回はソフトマージンの問題について取り扱います。
import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC from sklearn.datasets import load_iris import mglearn iris = load_iris() X = iris.data[50:, 2:] Y = iris.target[50:] - 1 mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.legend(['versicolor', 'virginica'], loc='best') plt.show()
今度は
versicolorとverginicaのpetal lengthとpetal widthについてのデータをプロットしています。完全に線形分離することは不可能な問題ですね。
ここでソフトマージンの式を復習です。導出はこちらの記事を参考にしてください。
min_{W, \xi}\Bigl\{\frac{1}{2}||W||^2 + C\sum_{i=1}^{N} \xi_i\Bigr\} \quad \quad t_i(W^TX_i + b)\geq 1 - \xi_i\\ \xi_i = max\Bigl\{0, M - \frac{t_i(W^TX_i + b)}{||W||}\Bigr\}\\ i = 1, 2, 3, ... Nデータがマージンの内側に入り込んでしまうので、$ C\sum_{i=1}^{N} \xi_i$の項により制限を緩めているのでしたね。
このCの値は
skleaarnにおいて、デフォルトで1.0になっています。この数値を変化させて、図がどう変わるのか確認してみましょう。以下のコードで、引数に与えたモデルの境界線をプロットする関数を定義します。def make_separate(model): mglearn.plots.plot_2d_separator(svm, X) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.xlabel('petal length') plt.ylabel('petal width') plt.legend(['setosa', 'versicolor'], loc='best') plt.show()以下のコードで図を描画しましょう。
C=0.1とします。X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) svm = LinearSVC(C=0.1) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))0.96
次は
C=1.0です。svm = LinearSVC(C=1.0) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))1.0
次は
C=100です。svm = LinearSVC(C=100) svm.fit(X_train, Y_train) make_separate(svm) print(svm.score(X_test, Y_test))1.0
適切なCを設定するのが大切ですね。色々変えながら様子を見ていくのがよさそうです。
ここまででソフトマージンの実装は終了です。
それではこれから、カーネル法を用いたときの実装と用いなかったときの実装についてまとめていきます。
カーネル法を用いずに実装
今回は線形分離不可能な問題をカーネル法を用いずに分類していきます。
ここでは、カーネル関数を使わない方法を、カーネル法を使わないと定義しています。
以下のコードでデータを準備して、図示しましょう。
import mglearn import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.svm import LinearSVC from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline from sklearn.svm import SVC moons = make_moons(n_samples=300, noise=0.2, random_state=0) X = moons[0] Y = moons[1] plt.figure(figsize=(12, 8)) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.plot() plt.show()
make_moonsは、二次元の月のような形をしたデータを作成する関数です。サンプル数とノイズを設定することができます。
図を見て頂ければ分かりますが、明らかに線形分離不可能ですよね。
この線形分離不可能なデータを線形分離可能なデータに変形するために、この入力空間のデータを高次元特徴空間のデータに写像しましょう。
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0) poly = PolynomialFeatures(degree=2) X_train_poly = poly.fit_transform(X_train) X_test_poly = poly.fit_transform(X_test)これで、入力空間のデータを高次元特徴空間に写像することができました。
どのようなデータに写像されたか確認しましょう。
print(poly.get_feature_names()) print(X_train_poly.shape)['1', 'x0', 'x1', 'x0^2', 'x0 x1', 'x1^2']
(225, 6)このような形で、二次元入力空間が六次元特徴空間に拡張されています。
次のコードでデータを標準化します。
scaler = StandardScaler() X_train_poly_scaled = scaler.fit_transform(X_train_poly) X_test_poly_scaled = scaler.fit_transform(X_test_poly)データの標準化とは、全てのデータに対して平均を引いた後に標準偏差で割ることで、データの平均を0、分散を1にすることです。
こちらの記事に分かりやすく書いていたので、参考にしてください。
それでは、次のコードでモデルを実装して評価します。
lin_svm = LinearSVC() lin_svm.fit(X_train_poly_scaled, Y_train) print(lin_svm.score(X_test_poly_scaled, Y_test))0.84
ちょっと低いですね。もう少し高次元に写像しましょう。
しかし、高次元に写像して標準化するという処理が面倒くさいので、
Pipelineというものを使用しましょう。poly_scaler_svm = Pipeline([ ('poly', PolynomialFeatures(degree=3)), ('scaler', StandardScaler()), ('svm', LinearSVC()) ]) poly_scaler_svm.fit(X_train, Y_train) print(poly_scaler_svm.score(X_test, Y_test))0.9733333333333334
このように、
Pipelineを用いると、データを高次元に写像して、標準化して、svmモデルに入れるという作業を簡略化して書くことができます。degree=3にすることで、より高次元の特徴空間に写像しています。精度はかなり良いですね。高次元に写像するとかなり効果的です。
次は、この図を描画してみましょう。以下のコードです。
_x0 = np.linspace(-1.5, 2.7, 100) _x1 = np.linspace(-1.5, 1.5, 100) x0, x1 = np.meshgrid(_x0, _x1) X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1))) y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3) plt.figure(figsize=(12, 8)) mglearn.discrete_scatter(X[:, 0], X[:, 1], Y) plt.show()
なかなかきれいな線が引けていることが確認できましたね。それではコードを解説します。
_x0 = np.linspace(-1.5, 2.7, 100) _x1 = np.linspace(-1.5, 1.5, 100) x0, x1 = np.meshgrid(_x0, _x1)ここの部分のコードで格子点を作成しています。こちらの記事に分かりやすく書いてあるので、参考にしてください。
np.linspaceは第一引数に始点、第二引数に終点、第三引数に点の数を指定して、numpyのarrayを作成します。それをnp.meshgridに渡すことで、100×100の格子点を作成しています。X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1)))
(x0.ravel()により、100×100のarrayを一次元配列に変換した後、reshape(-1, 1)により二次元の10000×1の行列に変換し、np.hstackによりaxis=1の水平方向に対して結合しています。つまり、Xは10000×2の行列になっています。y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3)
model.decision_function(X)により10000個の格子点と分離超平面との距離を求めて、それを100×100のデータに変換しています。
plt.contourfは等高線を図示する関数で、levelsにどの部分で色を変化させるかを指定できます。以上でカーネル法を使わない実装は終了です。
カーネル法を用いた実装
それではカーネル法を用いて実装を行っていきます。
データを準備しましょう。ここまでは同じです。
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipeline from sklearn.svm import SVC moons = make_moons(n_samples=300, noise=0.2, random_state=0) X = moons[0] Y = moons[1] X_train, X_test, Y_train, Y_test = train_test_split(X, Y, stratify=Y, random_state=0)次のコードでモデルを実装しましょう。
karnel_svm = Pipeline([ ('scaler', StandardScaler()), ('svm', SVC(kernel='poly', degree=3, coef0=1)) ]) karnel_svm.fitX_train, Y_train()
SVCのkarnel引数にpolyを指定することで、多項式カーネルを指定し、degree=3を指定することで三次元までの写像を考えることができます。これでモデルの作成ができました。次は、このモデルを図示してみましょう。また同じことをするんですが、面倒くさいので関数にします。
def plot_decision_function(model): _x0 = np.linspace(-1.7, 2.7, 100) _x1 = np.linspace(-1.5, 1.7, 100) x0, x1 = np.meshgrid(_x0, _x1) X = np.hstack((x0.ravel().reshape(-1, 1), x1.ravel().reshape(-1, 1))) y_decision = model.decision_function(X).reshape(x0.shape) plt.contourf(x0, x1, y_decision, levels=[y_decision.min(), 0, y_decision.max()], alpha=0.3) def plot_dataset(x, y): plt.plot(x[:, 0][y == 0], x[:, 1][y == 0], 'bo', ms=15) plt.plot(x[:, 0][y == 1], x[:, 1][y == 1], 'r^', ms=15) plt.xlabel('$x_1$', fontsize=20) plt.ylabel('$x_2$', fontsize=20, rotation=0) plt.figure(figsize=(12, 8)) plot_decision_function(karnel_svm) plot_dataset(X, Y) plt.show()
mglearnでプロットしても良かったのですが、今回はplt.plotでプロットしました。Y=0となるものを青色の丸で、Y=1となるものを赤色の三角で描画しています。図から分かるように、カーネル法を使っても使わなくても同じ結果が返ってきます。しかし、カーネル法を用いた方が内部的に計算がかなり簡単になっているので、できるだけカーネル法を使った方が良い気がします。
どのように簡単になるのかはこちらの記事を参考にしてください。
終わりに
ここまでお付き合い頂きありがとうございました。
非常に長い記事になりました。ここまで読んで下さり本当にありがとうございます。
お疲れさまでした。
- 投稿日:2020-11-17T16:12:21+09:00
Python3エンジニア認定基礎試験~模擬試験を解いてみた〜
この記事について
Python 3 エンジニア認定基礎試験の勉強した内容を記事にしました。
試験概要
試験名:Python 3 エンジニア認定基礎試験
問題数:40問
出題形式:選択式
試験方式:コンピューター上で実施するCBT(Computer Based Testing)形式
試験時間:60分
合格基準: 7割正解
受験料:一般価格 11,000円(税込)
学割価格:5,500円(税込)出題範囲
出題範囲は主教材であるオライリー・ジャパン「Pythonチュートリアル 第3版」より以下の比率で出題します。詳細はこちら
https://cbt.odyssey-com.co.jp/pythonic-exam.html模擬試験の問題
問1 以下のプログラムを実行した際の出力結果を選びなさい。
terminalimport json x = {'name':'yamada','data':[2,3,4]} print(json.dumps(x))JSON(JavaScript Object Notation)は、軽量のデータ交換フォーマットです。
人間にとって読み書きが容易で、マシンにとっても簡単にパースや生成を行なえる形式です。json.dumps()は、PythonオブジェクトをJSON形式にエンコードすることのできる関数です。
実行結果は以下のようになります。
terminal{"name": "yamada", "data": [2, 3, 4]}参考
json --- JSON エンコーダおよびデコーダ
https://docs.python.org/ja/3/library/json.html?highlight=json問2
プログラムを実行し、下記の実行結果を得たい。terminal2017-09-11下記のプログラムの(A)及び(B)に記述すべきコードの組み合わせを選択肢から選びなさい。
terminalfrom (A) import (B) now = date.today() print(now)正解: (A)datetime (B)date
参考
datetime --- 基本的な日付型および時間型
https://docs.python.org/ja/3/library/datetime.html問3 以下のプログラムを実行した際の出力結果として正しいものを選択しなさい。
terminaldic = 'diveintocode' print(dic[1:10:2])文字列が入っている変数dicの 1番目の要素から10番目の要素まで(iveintocod)から1つ飛ばしで出力。
実行結果は以下のようになります。
terminalienoo問4 ビルドイン関数dir()についての適切なものを選びなさい。
dir()関数とは、定義されている関数や属性などの一覧を調べることができる組み込み関数です。
terminaldir()terminal['In', 'Out', '_', '_5', '_6', '_7', '_8', '__', '___', '__builtin__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', '_dh', '_i', '_i1', '_i10', '_i2', '_i3', '_i4', '_i5', '_i6', '_i7', '_i8', '_i9', '_ih', '_ii', '_iii', '_oh', '_sh', 'dic', 'exit', 'get_ipython', 'json', 'quit', 'sample_no', 'sample_txt', 'x']正解: モジュールが定義している名前を確認することができる。
問5 以下のプログラムをインタープリタで実行した出力結果として正しいものを選びなさい
sys(システムパラメータ)モジュールのargvを使用することで、
Pythonのプログラム実行時に引数を渡すことができます。test.pyimport sys print(sys.argv)下記コマンドで実行します。
terminal$ python test.py test実行結果は以下のようになります。
terminal['test.py', 'test']参考
sys --- システムパラメータと関数
https://docs.python.org/ja/3/library/sys.html#sys.argv問6 以下のプログラムを実行した際の出力結果を選びなさい。
terminald = 'dive\ninto\ncode\t' print(len(d))Pythonオブジェクトの長さ (要素の数) を返します。
実行結果は以下のようになります。
terminal15問7 対話環境のでヒストリ情報が保存されているファイルを選択肢の中から選びなさい。
正解: .python_history
問8 以下のプログラムを実行した際の出力結果を選びなさい。
terminala = 2 b = 5 c = 3.0 + b, 5 * a print(c)タプルの要素は任意の Python オブジェクトです。
二つ以上の要素からなるタプルは、個々の要素を表現する式をカンマで区切って構成します。実行結果は以下のようになります。
terminal(8.0, 10)問9
以下のプログラムを実行した際の出力結果として正しいものを選択しなさい。terminald = 'xxxxDIVExxxxDIVExxxxDIVE' print(d.replace('DIVE', 'CODE', 1))文字列をコピーし、現れる部分文字列 old 全てを new に置換して返します。オプション引数 count が与えられている場合、先頭から count 個の old だけを置換します。
terminalxxxxCODExxxxDIVExxxxDIVE問10
以下のプログラムを実行した際の出力結果を選びなさい。terminalprint(range(5))start に指定した数値から順に step に指定した数値だけ足していき、 stop に指定した数値を超えない範囲までの連続した数値を要素として持つオブジェクトを作成します。
実行結果は以下のようになります。
terminalrange(0, 5)問11
pythonインタープリタにてterminalD:\home\name\pythonと出力させるための入力として正しいものを選びなさい。
正解: print(r'D:\home\name\python')
参考
Pythonでエスケープシーケンスを無視(無効化)するraw文字列
https://note.nkmk.me/python-raw-string-escape/問12
terminal(1,3,5) < (1,2,3,4)terminalFALSEまとめ
- 投稿日:2020-11-17T16:05:12+09:00
「伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門」を更新しました
本を更新しました
チャプター「「動的に生成したHTML」を返せるようになる」 を更新しました。
続きを読みたい方は、ぜひBookの「いいね」か「筆者フォロー」をお願いします ;-)
以下、書籍の内容の抜粋です。
「静的ファイル配信」と「動的なHTMLの生成」
さて、ここまでで「適切なヘッダーの生成」(
Dateとか、Content-Typeとか)ができるようになり、「並列処理」もできるようになり、HTTPのルールに従ってレスポンスを返す基盤の部分はかなり整ってきました。これで 「Webサーバー (=HTTPサーバー) として最低限の機能を揃えていく」 というステップは、ほぼ終わりです。
次のステップとして、 「レスポンスボディとして何を返すか?」 についてもう少し詳しく見ていきましょう。
既に実装済みである「HTMLファイルや画像ファイルの内容をレスポンスボディとしてそのまま返す」という機能は、一般的には 「静的ファイル配信」 と呼びます。
この機能さえあれば、例えば IETFによるRFCのWebページ などは十分に作成可能です。
内容をHTMLファイルに書いて保存しておけば良いだけですから。しかし、皆さんの見慣れたホームページを作成するにはまだまだ機能不足です。
例えば 前橋先生のホームページ ^[本書を書くきっかけを与えて頂いた「Webサーバを作りながら学ぶ 基礎からのWebアプリケーション開発入門」の著者です。詳しくはこちら] のような比較的簡素な^[前橋先生、すいません。]ホームページですら、まだ作れません。
何が作れないかと言うと、下記のようないわゆる「アクセスカウンター」の部分です。
アクセスカウンターの数字は、ページを読み込むごとに数字が増えていきます。
この機能を、皆さんの今のWebサーバーで実現するにはどうすればいいでしょうか?アクセスカウンターの数字が変わるということは、レスポンスボディの内容が変わるということです。
現在のWebサーバーから返却されるレスポンスボディはHTMLファイルの内容そのままですので、レスポンスボディの内容を変えようと思うとHTMLファイルを編集する必要があります。つまり、この機能を提供しようと思うと、HTTPリクエストが来る度に毎回HTMLファイルを自動で(もしくは手動で)編集して保存するような機能が必要になってしまいます。
これは(実現可能ですが)あまりに非効率そうですし、面倒くさそうです。そうなってくると、
「レスポンスボディをファイルから取得するのではなく、Pythonの文字列として生成すれば毎回違うレスポンスボディを生成するのは簡単なのでは?」
という発想になるのは自然なことでしょう。これを 「動的なHTMLの生成」(あるいは 「動的なレスポンスの生成」)と呼びます。
コラム: 「静的」と「動的」
「静的」という言葉はなかなか厄介です。また、対義語である「動的」という言葉も同様に厄介です。
「静的」とは「変化しないもの」、「動的」は「変化するもの」を意味するわけですが、「何に対して何が静的なのか」「何に対して何が動的なのか」を常に意識する必要があります。
例えば「
静的ファイル配信」は「変化しないファイルの配信」を意味しています。
これは、何に対して何が変化しないファイルなのでしょうか?HTMLファイルそのものは、常に変化しえます。ファイルをエディタで編集するだけです。
Webサーバーの機能として見た時も、HTMLファイルを編集してしまうとレスポンスボディも変化してしまうでしょう。「静的ファイル配信」のことを「"いつも"同じレスポンスが返ってくるWebサービス」と表現する方もいらっしゃいますが、このことを考えると正確ではないことが分かります。
HTMLファイルを編集すればレスポンスも変化するのですから。答えは、「リクエストに対して内容が変化しないファイルの配信」です。
「リクエストに応じて内容を変化させないファイルの配信」と言ったほうが分かりやすいかもしれません。ですので、ファイルを編集したときは、内容が変化してもよいのです。
私がジュニアエンジニアだったころは、
「でもHTMLファイルを編集したらレスポンスは変わるんでしょ?いつも同じって嘘じゃない?」
と思って混乱していました。
また他にも、Javascriptを説明する際に「Web上で動的なコンテンツを提供するためのプログラミング言語」と説明されることがあります。
この説明における「動的なコンテンツ」というのは、「時間の経過あるいはユーザーの操作に対して、配信済みのHTMLが変化するコンテンツ」のことです^[正確にはJavascriptが変化させるのはDOMであってHTMLではありませんが、そこはご愛嬌。]。ブラウザに表示させるHTMLは一度レスポンスとしてブラウザへ送ってしまうと、サーバー側のプログラムから変更させることは基本的にはできません。
CSSなどは確かにコンテンツの表示内容を変化(文字の色を赤くしたり)させますが、配信済みのHTMLの内容を変化させているわけではありません。ただし、HTMLと一緒にプログラムをブラウザに送りつけておけば、ブラウザがそのプログラムを後から実行することで配信済みのHTMLを変更させることができます。
それがJavascriptなのです。単に「動的なコンテンツ」を「Webページを変化させる」とだけ理解してしまうと、
「文字の色を変化させるCSSも動的コンテンツを提供しているのでは?」
「HTMLのformタグもボタンを押すかどうかでページの挙動が変わるわけだから、動的なのでは?」
などと混乱してしまいます。
(私は混乱していました。)
このように「静的」「動的」という言葉はよく出てくるわりに理解が難しいので、何に対して何が変化する/しないのか、常に注意しておきましょう。
現在時刻を表示するページを作成する
少し回りくどい説明をしてしまいましたが、やりたいことはソースコードを見てもらったほうが早いかもしれません。
実際に「動的なHTMLの生成」を行い、リクエストする度に結果が変わるようなページを作成してみましょう。
アクセスカウンターをいきなり実装するには過去のアクセス数を保存しておくデータベースのようなものが必要になり少し面倒ですので、まずは簡単のため
/nowというpathにアクセスすると現在時刻を表示するだけのページを作成してみましょう。(アクセスカウンターの実装はもう少し後で取り組みます。)
ソースコード
現在時刻を表示するページを追加するために、
workerthread.pyを変更したソースコードがこちらです。
study/workerthread.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter14/workerthread.py解説
42-59行目
response_body: bytes response_line: str # pathが/nowのときは、現在時刻を表示するHTMLを生成する if path == "/now": html = f"""\ <html> <body> <h1>Now: {datetime.now()}</h1> </body> </html> """ response_body = textwrap.dedent(html).encode() # レスポンスラインを生成 response_line = "HTTP/1.1 200 OK\r\n" # pathがそれ以外のときは、静的ファイルからレスポンスを生成する else: # ...追加したのはこの部分です。
やっていることは、
「pathが/nowだったら、pythonで現在時刻を表示するHTMLを生成し、レスポンスボディとする」
ということです。
ソースコードについていくつか補足しておきます。
response_body: bytes response_line: str
response_bodyやresponse_lineを代入する箇所が複数に分かれてしまっていますので、事前に型注釈をしておくことにしました。変数の型注釈は、エディタ等に「この変数はこの型の値を代入することを想定していますよ」とヒントを伝える意味があります。
このように記載しておくと、間違って「あっちではstrを代入、こっちではbytesを代入」などとしてしまった際にエディタが事前に警告してくれるようになります。html = f"""\ <html> <body> <h1>Now: {datetime.now()}</h1> </body> </html> """ response_body = textwrap.dedent(html).encode()
ヒアドキュメント+dedent()を使っています。
単に普通のhtmlを書きたいだけなのですが、インデントとか改行とかがpythonでは意味を持ってしまいますので、工夫しています。
それほど難しくはないので、「python ヒアドキュメント」「python dedent」などで調べてみてください。動かしてみる
それでは早速動かしてみましょう。
いつもどおりサーバーを起動した後、Chromeで
http://localhost:8080/nowへアクセスしてみてください。
質素ではありますが、上記のようなページが表示されたでしょうか?
表示されたら、何度かページをリロードしてみてください。
毎回、表示される内容が変わっているでしょうか?
これで動的なHTMLの生成の完了です。
簡単でしたね。改めて振り返っておくと、今回やったことの大事なポイントは、
「サーバ起動後、ソースコードもHTMLファイルも全く編集していないのに毎回違う結果がブラウザに表示されている」
ということです。単にファイルの内容をそのままレスポンスボディとして出力しているだけでは実現できなかった機能です。
HTTPリクエストの内容を表示するページを作成する
せっかくなので、もう1つぐらい動的なHTMLのページを作ってみましょう。
次は、送られてきたHTTPリクエストの内容をそのままHTMLで表示する
/show_requestというページを追加してみます。
続きはBookで!

- 投稿日:2020-11-17T15:45:41+09:00
chromedriver_binaryのバージョンをそろえる
WindowsのChrome86が入った環境で
ドライバの.exeをいちいち入れるのが何となく嫌で
自動でドライバを選んでくれる?らしいimport chromedriver_binaryを使おうと思い
pip install import chromedriver_binaryを実行して
pythonのseleniumを使ったコードを実行したら
あんたのChromeとバージョンが違う、というエラーが出た。どうやら現時点最新の Chrome87用がインストールされたらしい。
では自分のChrome86のバージョンを確認してpip install import chromedriver_binary==86.04240.193そのまま実行すると
ERROR: Could not find a version that satisfies the requirement chromedriver_binary==86.04240.193 (from versions: 2.29.1, 2.31.1, 2.33.1, 2.34.0, 2.35.0, 2.35.1, 2.36.0, 2.37.0, 2.38.0, 2.39.0, 2.40.1, 2.41.0, 2.42.0, 2.43.0, 2.44.0, 2.45.0, 2.46.0, 70.0.3538.16.0, 70.0.3538.67.0, 70.0.3538.97.0, 71.0.3578.30.0, 71.0.3578.33.0, 71.0.3578.80.0, 71.0.3578.137.0, 72.0.3626.7.0, 72.0.3626.69.0, 73.0.3683.20.0, 73.0.3683.68.0, 74.0.3729.6.0, 75.0.3770.8.0, 75.0.3770.90.0, 75.0.3770.140.0, 76.0.3809.12.0, 76.0.3809.25.0, 76.0.3809.68.0, 76.0.3809.126.0, 77.0.3865.10.0, 77.0.3865.40.0, 78.0.3904.11.0, 78.0.3904.70.0, 78.0.3904.105.0, 79.0.3945.16.0, 79.0.3945.36.0, 80.0.3987.16.0, 80.0.3987.106.0, 81.0.4044.20.0, 81.0.4044.69.0, 81.0.4044.138.0, 83.0.4103.14.0, 83.0.4103.39.0, 84.0.4147.30.0, 85.0.4183.38.0, 85.0.4183.83.0, 85.0.4183.87.0, 86.0.4240.22.0, 87.0.4280.20.0) ERROR: No matching distribution found for chromedriver_binary==86.04240.193見つからない、この一覧しか無いぞ?とのこと。
完全一致のバージョンが無いが、同じ86だったら大丈夫だろうか?pip install import chromedriver_binary==86.0.4240.22.0すると、動いた。
めでたしめでたし。
- 投稿日:2020-11-17T15:45:05+09:00
[Kaggle]大腸癌を分類[fine tuning]
はじめに
つくりながら学ぶ!PyTorchによる発展ディープラーニングという本の1-5のファインチューニングで細胞の分類をしてみました。(筆者GitHubで全てのコードが見られます)
データはKaggleのColorectal Histology MNISTを使いました。開発環境
- Google Colaboratory
やったこと
Kather_texture_2016_image_tiles_5000フォルダ内に8種類に画像が分類されているのでそれを見分けます。
実行結果
使用デバイス: cuda:0 0%| | 0/47 [00:00<?, ?it/s]Epoch 1/100 ------------- 100%|██████████| 47/47 [07:26<00:00, 9.49s/it] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 2.1278 Acc: 0.1060 Epoch 2/100 ------------- 100%|██████████| 110/110 [17:17<00:00, 9.43s/it] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.8146 Acc: 0.7206 100%|██████████| 47/47 [00:12<00:00, 3.76it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.4196 Acc: 0.8547 Epoch 3/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.3953 Acc: 0.8597 100%|██████████| 47/47 [00:12<00:00, 3.79it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.3262 Acc: 0.8853 Epoch 4/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.3165 Acc: 0.8894 100%|██████████| 47/47 [00:12<00:00, 3.84it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2910 Acc: 0.8973 Epoch 5/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.2828 Acc: 0.8971 100%|██████████| 47/47 [00:12<00:00, 3.81it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2194 Acc: 0.9247 Epoch 6/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.2596 Acc: 0.9097 100%|██████████| 47/47 [00:12<00:00, 3.83it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2573 Acc: 0.9087 Epoch 7/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.2405 Acc: 0.9171 100%|██████████| 47/47 [00:12<00:00, 3.84it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2294 Acc: 0.9240 Epoch 8/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.2199 Acc: 0.9223 100%|██████████| 47/47 [00:12<00:00, 3.88it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2053 Acc: 0.9267 Epoch 9/100 ------------- 100%|██████████| 110/110 [01:04<00:00, 1.71it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.1993 Acc: 0.9309 100%|██████████| 47/47 [00:12<00:00, 3.85it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2009 Acc: 0.9293 Epoch 10/100 ------------- 100%|██████████| 110/110 [01:03<00:00, 1.72it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.2097 Acc: 0.9280 100%|██████████| 47/47 [00:12<00:00, 3.85it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.1770 Acc: 0.9400 Epoch 11/100 ------------- 100%|██████████| 110/110 [01:03<00:00, 1.72it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.1860 Acc: 0.9363 100%|██████████| 47/47 [00:12<00:00, 3.90it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.1753 Acc: 0.9400 Epoch 12/100 ------------- 100%|██████████| 110/110 [01:03<00:00, 1.74it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.1751 Acc: 0.9429 100%|██████████| 47/47 [00:11<00:00, 3.95it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2092 Acc: 0.9260 Epoch 13/100 ------------- 100%|██████████| 110/110 [01:03<00:00, 1.73it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.1595 Acc: 0.9466 100%|██████████| 47/47 [00:11<00:00, 3.92it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.2082 Acc: 0.9307 Epoch 14/100 ------------- 100%|██████████| 110/110 [01:03<00:00, 1.73it/s] 0%| | 0/47 [00:00<?, ?it/s]train Loss: 0.1653 Acc: 0.9431 100%|██████████| 47/47 [00:11<00:00, 3.94it/s] 0%| | 0/110 [00:00<?, ?it/s]val Loss: 0.1639 Acc: 0.9500大体この辺でval lossが定常状態に達したので載せるのはここまでにしておきます。
精度95%はすごくないですか。考察・終わりに
病理組織画像も見分けられるというのは驚き桃の木山椒の木。
- 投稿日:2020-11-17T14:35:58+09:00
A4のPDFを2ページごとのA3に変換する
A4のPDFを2ページごとに左右に割付けてA3にしたいなぁという欲望にかられていたら、
「A4のPDFをA3に2面付(2in1)する -- Python(PyPDF2)」
https://qiita.com/miko/items/054b982700c6219c7fceを見つけたので、少しアレンジしてみる。
とどのつまり、例えばA4の10ページ分のPDFがあったとしたら、2in1でA3の5ページ分のPDFに変換するということです。
そして総ページ数が奇数の場合、最後のページの右側は真っ白にして、とにかく全ページをA3に変換する。pdf_A3.pyimport PyPDF2 A3_width = 1190.5511811024 A3_height = 841.8897637795 #元になるA4ファイルの読み込み pdf_file = open('***.pdf','rb') pdf_reader = PyPDF2.PdfFileReader(pdf_file) #元になるA4ファイルのページ数の把握 page_num = pdf_reader.getNumPages() cnt = 1 for start_page in range(0, page_num, 2): A3_page = PyPDF2.pdf.PageObject.createBlankPage(width=A3_width, height=A3_height) end_page = start_page + 1 #左に奇数ページを配置 page_left = pdf_reader.getPage(start_page) A3_page.mergePage(page_left) #右に偶数ページを配置するが、総ページ数が奇数のとき最後のA3ページの右側は白紙にする if start_page + 1 < page_num: page_right = pdf_reader.getPage(end_page) A3_page.mergeRotatedScaledTranslatedPage(page_right, 0, 1, A3_width / 2, 0, expand=False) else: pass pdf_writer = PyPDF2.PdfFileWriter() pdf_writer.addPage(A3_page) #生成するファイル名の後にゼロ埋め4桁の数字を付すためのおまじない file_num = str(cnt).zfill(4) file_name = 'test_A3_' + file_num + '.pdf' output_file = open(file_name,'wb') pdf_writer.write(output_file) output_file.close() cnt += 1 pdf_file.close() print ('終了!')なんの需要があるのか分からないプログラムだが、パソコンの画面って横長だからさ、A4のPDFを横並びにしてA3にして表示したら見やすいだろ、と言い張りたいが、Acrobat Readerなりのビューアーの設定で表示を「見開きページ」にすればいいだけの話です。
- 投稿日:2020-11-17T13:52:54+09:00
FaissをCentOS7にインストール
概要:
Anacondaを導入していない CentOS7 環境に、faissをインストールする方法のメモ。
Anacondaなら CentOS7 にも問題なくインストールできるかは、私は分かってはいないが… pipではスムーズにインストールできなかったので、インストール可能な手順を記録。背景:
CentOS7環境になぜかインストールできない!
世界的に見ると、同様の問題にぶち当たっている人は何名かはいるようなのですが、明確に"コレだぜ!"といった解決策を見出している情報もなく… 半日以上を費やしてしまった。
複数の CentOS7 環境で、同様にインストールができないことは確認しているので、CentOS7固有の問題かと思われ、手順を確立しておきたかった。
最初は順調でした…
FaissというFacebook社が公開している、類似性検索(およびクラスタリング)のための高速アルゴリズムを実装したライブラリです。
今、SentenceBERTでベクトル化した値から、SemanticSearchする仕組みを構築しようとしているのですが…
当初は単純に検索したいベクトルと、全検索対象のベクトルのCos類似度を算出・Sortして一番類似性の高いベクトルを取得するような実装でした。
しかしこのSemanticSearchの検索対象が大量になった場合に、算出コストがヤバいことになりそうな気配を感じていました。ちょっと調べると、この問題に対し、ベクトルをIndex化して(?)低コスト(短時間で)で算出することができる「Faiss」というライブラリが見つかりました。
早速、Google Colab上で試してみました!!pip3 install faiss-cpu import numpy as np import faiss d = max([len(v) for v in sentence_vectors]) index = faiss.IndexFlatL2(d) index.add(np.array(sentence_vectors).astype('float32')) closest_n = 1 D, I = index.search(np.array(query_embeddings).astype('float32'), closest_n)楽勝〜!!
まだ検索対象のベクトルが少数(100以下)のテストなので、劇的な変化は感じませんが…
実際に検索時間は短縮し、類似性検索もCos類似度での抽出結果とも差はないので、実際の仕組みに組み込んでみようと取り組み始めました。
さて… 本題のCentOS7のサーバーにインストールしましょう!! 当然楽勝でしょう?!
Colabと同様に pip でインストール。
Faiss は Anaconda でのインストールが主流のようですが、私は Anaconda は使っていないので pip です。
pip の場合は faiss-cpu / faiss-gpu というモジュール名を指定するようですよね… cpu・gpuを切り替える場合は、uninstallして再度どちらかでインストールし直すみたいです。https://pypi.org/project/faiss-cpu/
https://pypi.org/project/faiss-gpu/しか〜し! エラーが出てる! なぜ?!
$ sudo pip3 install faiss-cpu Collecting faiss-cpu Downloading https://files.pythonhosted.org/packages/8b/3e/d64ff22504a70fb15457de8fb2f5fd84e35448fdcd9958880ae8d0438a82/faiss-cpu-1.6.4.post2.tar.gz Building wheels for collected packages: faiss-cpu Running setup.py bdist_wheel for faiss-cpu ... error Complete output from command /usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-i9sic395/faiss-cpu/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" bdist_wheel -d /tmp/tmp2c2gltlxpip-wheel- --python-tag cp36: running bdist_wheel running build running build_py running build_ext building 'faiss._swigfaiss' extension swigging faiss/faiss/python/swigfaiss.i to faiss/faiss/python/swigfaiss_wrap.cpp swig -python -c++ -Doverride= -I/usr/local/include -Ifaiss -DSWIGWORDSIZE64 -o faiss/faiss/python/swigfaiss_wrap.cpp faiss/faiss/python/swigfaiss.i unable to execute 'swig': No such file or directory error: command 'swig' failed with exit status 1 ---------------------------------------- Failed building wheel for faiss-cpu Running setup.py clean for faiss-cpu Failed to build faiss-cpu Installing collected packages: faiss-cpu Running setup.py install for faiss-cpu ... error Complete output from command /usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-i9sic395/faiss-cpu/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-q0l4dufw-record/install-record.txt --single-version-externally-managed --compile: running install running build running build_py running build_ext building 'faiss._swigfaiss' extension swigging faiss/faiss/python/swigfaiss.i to faiss/faiss/python/swigfaiss_wrap.cpp swig -python -c++ -Doverride= -I/usr/local/include -Ifaiss -DSWIGWORDSIZE64 -o faiss/faiss/python/swigfaiss_wrap.cpp faiss/faiss/python/swigfaiss.i unable to execute 'swig': No such file or directory error: command 'swig' failed with exit status 1 ---------------------------------------- Command "/usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-i9sic395/faiss-cpu/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-q0l4dufw-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-build-i9sic395/faiss-cpu/ちなみに、ローカルの Mac で試してみました。Colabだけでうまく行く方法だったのかも?!
いえいえ、ローカルのMacでも何の問題もなく faiss-cpu でインストールが完了します… これはヤバイ匂いがする!迷宮に迷い込みました…
いろいろWeb上で調べてみたのですが、決定打となる対策は見当たりません…
その中でも、faiss-centos という私の現在の悩み事のタネのワードが組み合わされた代物が見つかりました。
これはイケるでしょ!!https://pypi.org/project/faiss-centos/
ここは気合で! ほれ!!
$ sudo pip3 install faiss-centos WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead. Collecting faiss-centos Could not find a version that satisfies the requirement faiss-centos (from versions: ) No matching distribution found for faiss-centosが〜ん…
さらにいろいろWebを彷徨うものの、以下のように解決したんだかどうだか… いまいちわからん。
https://github.com/facebookresearch/faiss/issues/866その後も、いろいろやりました!
その中でも、faiss-centos は wheel ではなくて egg なので、pip のバージョンを8に落として試すとか…
egg ファイルを unzip で伸張してみるとか…
openblas-serial や gmp-devel をインストールしてみるとか…しかしこちらの苦悩などお構いなしに、_swigfaiss が見つからんとか、何かが足りん!だとか無理難題を言ってきます。 疲れたぁ…
ちょっと一休み… というか別のことをして気を紛らわせたり、お茶を飲んだり、ボーっとしたり…
あれ〜!?
さて、一休みもしたし、脳みその疲れも取れたし、もうすっかり夜になってるし!
再度 CentOS7 のサーバーにログインして…$ python3 Python 3.6.8 (default, Apr 2 2020, 13:34:55) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import faiss >>>エラーが出てない!!
休憩前は、エラーだったのに… とうとう私の元にも7人のコビトさん達がやってきてくれたのかぁ??
だって… pipでインストールされた形跡もない!? どゆこと??
$ pip3 freeze | grep faiss $なので目的のフォルダーに移動し、もう一度… エラーだ。
またルートに戻って、もう一度… イケる! 何の違い??なにやら、「 https://pypi.org/project/faiss-centos/ 」からダウンロードした、faiss_centos-1.5.2-py3.6.egg をunzip した、faiss/ フォルダを直下にして、import するとOKのようなのです。
一筋の光が…だとしたら… この faiss/ フォルダを、site-packages/ にコピーしたら???
結論
その後、追加でインストールが必要なライブラリなどを特定し、CentOS7でも faiss をインストールできる手順を特定しました。
分かってしまえば、コレだけでしたぁ…
$ wget https://files.pythonhosted.org/packages/f6/8b/ab69a201ea1b8be759ba16f172f92d1fb935a8f4a94f02fe52c7d8ec579f/faiss_centos-1.5.2-py3.6.egg $ unzip faiss_centos-1.5.2-py3.6.egg $ sudo cp -r ./faiss /usr/local/lib/python3.6/site-packages (もしくは… $ sudo cp -r ./faiss /usr/lib/python3.6/site-packages 環境に合わせて…) $ sudo yum install openblas-serial $ sudo yum install gmp gmp-devel $ python3 Python 3.6.8 (default, Apr 2 2020, 13:34:55) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import faiss >>>もし、同じような問題にぶち当たっている人がいたら、参考にしてもらえると嬉しいですね。
- 投稿日:2020-11-17T13:18:38+09:00
【画像処理】PythonとOpenCVを用いたエッジ検出でぷーさんを丸裸に!
はじめに
はじめまして!大学で機械学習や深層学習を専門に勉強しているヨシキと申します!
今回はPythonとOpenCVを用いたエッジ検出ついて解説していきたいと思います。(自分の理解を深めるためでもあります笑)
とりあえずPythonとかって何ができんねんと思っている方にも楽しんで理解していただけるよう尽力します!そもそもエッジ検出って何?
画像処理の世界でエッジというのは、画像内で明るさが急激に変化する箇所という意味合いがありますが、いまいちピンときませんよね。普段皆さんがエッジと聞いてどういう意味を思い浮かべるでしょうか?
縁とか輪郭とか思い浮かべた人は正解です!
つまりエッジ検出とは画像処理をしやすくするため、輪郭という特徴のみを抽出する技術なんです!環境
今回は、皆さんにも実際に手を動かしてプログラムを動かしてほしいと思ったので、ローカルではなくGoogleドライブとGoogle Colaboratoryを使用して実装していきたいと思います。
メリットとしては、pipなどでライブラリをインストールすることなく使用できるといった点で利便性が高いので選択しました。環境作り
1.まずはgoogleアカウントを作成しましょう!(すでに持っている方はそれを使用しても構いません)できましたらgoogleドライブにアクセスしてログインしましょう。
2.アクセス出来たら左上の新規のボタンからフォルダという項目を選択しましょう。
クリックすると名前入力欄が出てくると思います。なんでもいいですが、私はEdgeというフォルダ名にしました!3.そうすると、マイドライブ内にフォルダができたと思います。そうしたら、そこにアクセスして、もう一度、新規ボタンからImagesとSrcというフォルダを作成しましょう。Imagesには、エッジ検出したい画像をアップしたり、エッジ検出後の画像をアップしたりします。
Srcにはソースコードを書いていきます。4.さて、そろそろ最後です!Imagesには、エッジ検出したい画像を入れておきましょう!新規ボタンのファイルのアップロードからできます。
Srcでは、新規から一番下のその他を選んでGoogle Colaboratoryを選択しましょう。(もしなければアプリを追加から検索してインストールしましょう!)選択したら、エディタの画面に遷移するはずです。5.最後に、Google Colaboratoryの仕様についてです。
・Google Colaboratoryは30分程度で接続が切れてしまい、切れてしまうと再接続しなくてはならないので注意です。(ソースコードが消えるとかはないです笑)
・接続するときに以下のようにコードを求められるので、URLにアクセスしてコードを取得しましょう!
・わかりやすさのため名前はUntitled.ipynbから変更しておきましょう。
・保存はファイルの欄からできます。こまめにしておきましょう!ソースコード
全体的にオブジェクト指向的な設計を意識しました。
基本的なコード解説はコメントアウトに残しておきました。import cv2 #------------Setting------------# #Setting for using google drive from google import colab colab.drive.mount('/content/gdrive') #Directory setting b_dir='gdrive/My Drive/Edge/' #Setting working directory #Experiment setting (Parameter setting for canny operator) min_val=100 max_val=150 #Imput file setting t_dir=b_dir+'Images/' data='ぷーさん' ext='.JPG' org_name=t_dir+data+ext #Output file setting canny_name=t_dir+data+'_Canny _'+str(min_val)+'_'+str(max_val)+ext #------------Image processing------------# #Image read org=cv2.imread(org_name) if org is None: print('\n**********************************************************\n') print(org_name+' cannot be read\n') print('************************************************************\n') else: #Grayscale image generation gray=cv2.cvtColor(org,cv2.COLOR_BGR2GRAY) #Apply image operator canny=cv2.Canny(gray,min_val,max_val) #Save image cv2.imwrite(canny_name,canny)解説(注意事項)
まず、以下では、OpenCVのインポートとディレクトリの設定をしています。
ここで1つ注意点があります。
最終行のEdgeというところです。ここは、各自最初に設定していただいたフォルダの名前を参照しているので、皆さんが最初に作成したフォルダの名前に書き換えておきましょう。
import cv2 #------------Setting------------# #Setting for using google drive from google import colab colab.drive.mount('/content/gdrive') #Directory setting b_dir='gdrive/My Drive/Edge/' #Setting working directory次に以下では、パラメータ設定と画像ファイルの設定、あと出力画像のファイルの設定をしています。
ここに関しては、2つ注意点があります!
1点目はパラメータについてです。今回はエッジ検出の方法にキャニー法というものを使用しています。(この記事ではキャニー法に関しての説明は割愛します。)このパラメータは、私がこの値でうまくエッジをとってこれるだろうと設定した値なので、皆さんのほうで自由に変更してもらって構いません。
2点目は画像ファイルの設定についてです。こちらは、皆さんのほうでImagesフォルダに画像をアップロードしていただいたと思うので、その画像の拡張子より前をdataに、拡張子をextに格納するようにしてください。#Experiment setting (Parameter setting for canny operator) min_val=100 max_val=150 #Imput file setting t_dir=b_dir+'Images/' data='ぷーさん' ext='.JPG' org_name=t_dir+data+ext #Output file setting canny_name=t_dir+data+'_Canny _'+str(min_val)+'_'+str(max_val)+ext出力結果
Mounted at /content/gdrive
このように出力されれば成功です!
マイドライブのImagesを確認してみてください。エッジ検出された画像が出力されているはずです。
ではタイトルにもある通り私は、プロフィール画像のぷーさんをエッジ検出しましたので、結果をご覧ください。元画像ぷーさん
エッジ検出ぷーさん
し、しぶいぜ、、、
最後に
お疲れ様です!
ここまで付き合ってくださった方がいればうれしい限りです笑
また、この記事がきっかけでPythonってこんなことできるのかと興味を持っていただけたら幸いです。初投稿なのでなるべく丁寧にやったつもりですが、なにか至らぬ点や疑問点、ミスがありましたらコメントください。これからも機械学習などの記事をたくさん書いていくつもりなので良かったらフォローお願いします!



- 投稿日:2020-11-17T12:31:05+09:00
pandasでシュッと祝日データをデータフレームにする
TL;DR
from io import StringIO import urllib.request import pandas as pd req = urllib.request.Request('https://holidays-jp.github.io/api/v1/date.csv') with urllib.request.urlopen(req) as res: df_holiday = pd.read_csv(StringIO(res.read().decode()), header=None)コード解説
祝日データを取得できる場所へgetリクエストを投げる
req = urllib.request.Request('https://holidays-jp.github.io/api/v1/date.csv')シンプル いず ベスト
取得リクエストからデータを抽出する
with urllib.request.urlopen(req) as res: df_holiday = pd.read_csv(StringIO(res.read().decode()), header=None)リクエストデータはバイナリデータなのでdecode関数でstringへ変換し、その入力をStringIOを使ってread_csv関数に流しています。
まとめ
シンプルに作るならこの方法。より詳細に祝日データが欲しい場合は
jpholidayライブラリを使うと幸せになれるかも。参考記事
- 投稿日:2020-11-17T11:26:43+09:00
AWS Lambda を使ってFizzBuzzしたった
Backgroud
AWS Lambdaを使ったサーバレスアプリケーションについての話を聞く機会が増えたので試しに作ってみた。
Preparetion
↓
↓
Development (lambdaのみ)
import json def lambda_handler(event, context): request = "[inner_test]" num = 30 doc = { "message":'Hello from Lambda!', "request":process(num) } # TODO implement return { 'statusCode': 200, 'body': json.dumps(doc) } def process(src): if src % 15 == 0: return "FizzBuzz" elif src % 5 == 0: return "Buzz" elif src % 3 == 0: return "Fizz" else : return srcと書いたのちに、「Deploy」 -> 「テスト」 を押す。
そうすると、、、
実行結果がログで出力される。
Development (with API Gateway)
先ほどの構成はlambdaのみだったが、ここではAPI Gatewayを使って外部からリクエストをかけてみる。
まず、トリガーからAPI Gatewayを選ぶ。
セキュリティはお好みで。
「ステージ」→「POST」を選び、URLを取得する。
URL自体の構成はhttps://{restapi_id}.execute-api.{region}.amazonaws.com/{stage_name}/
それで、lambdaにてリクエストされた値を取得し、FizzBuzzする。コードベースで話すと
event["body"]をjsonでパースして入力値を取得する。import json def lambda_handler(event, context): request = "[inner_test]" num = 30 #API Gatewayに対応 #ここでリクエストの値を取得 if "body" in event.keys(): request = json.loads(event["body"]) num = request["num"] doc = { "message":'Hello from Lambda!', "request":process(num) } # TODO implement return { 'statusCode': 200, 'body': json.dumps(doc) } def process(src): if src % 15 == 0: return "FizzBuzz" elif src % 5 == 0: return "Buzz" elif src % 3 == 0: return "Fizz" else : return src実際にfizzbuzzの値が返ってくるか、Postmanを使ってAPIを叩いてみてみる。
numの値を変えると、FizzBuzzFizzBuzz、数字のいずれかが返ってきます。
これでできた。
Future
サーバレス言わずに最小のVPS使って必要なパッケージ落とせばいいと思っていたのですが時間かけずにできた。
lambda処理後にS3とリンクすればデータは残せそうです。Reference

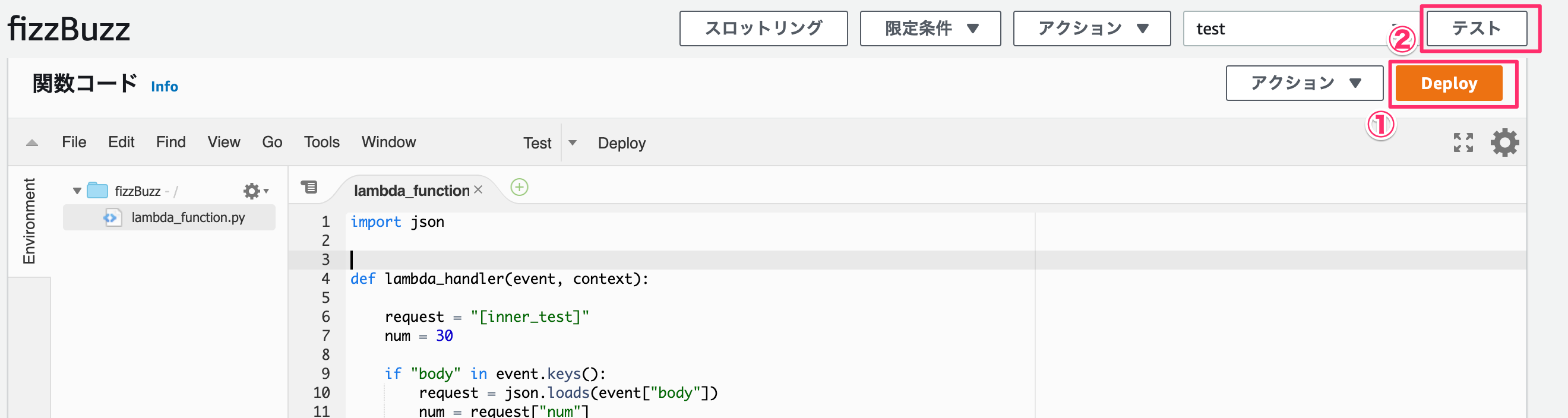
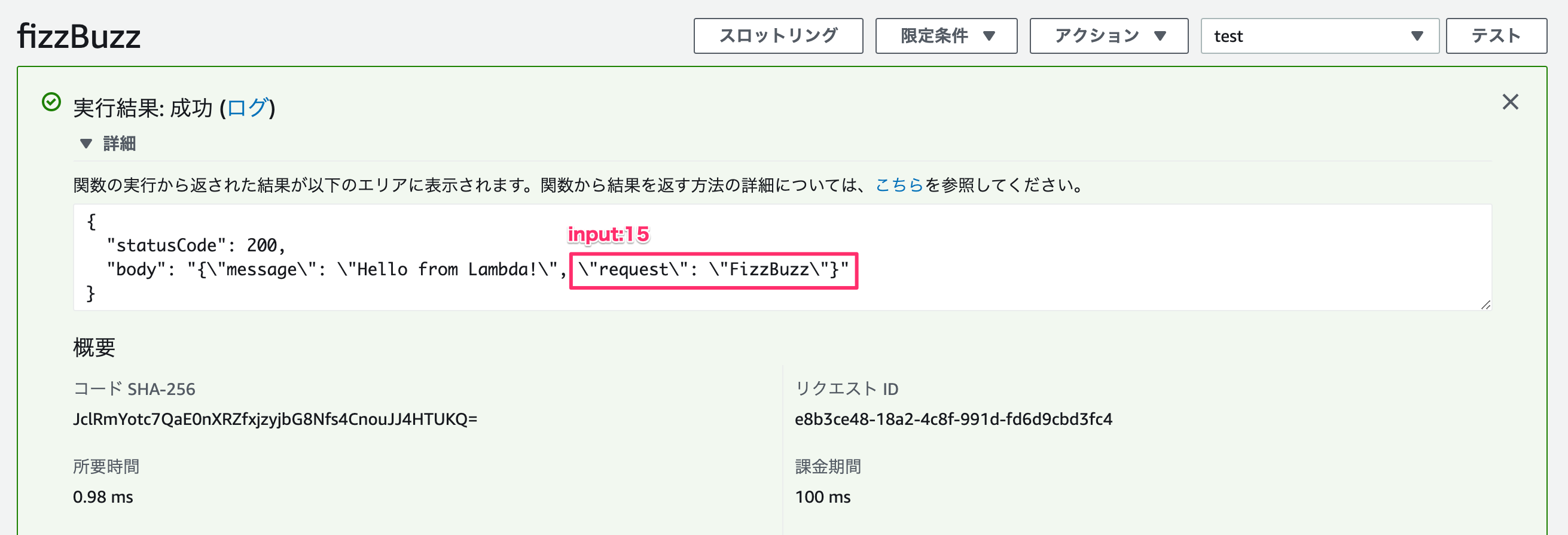
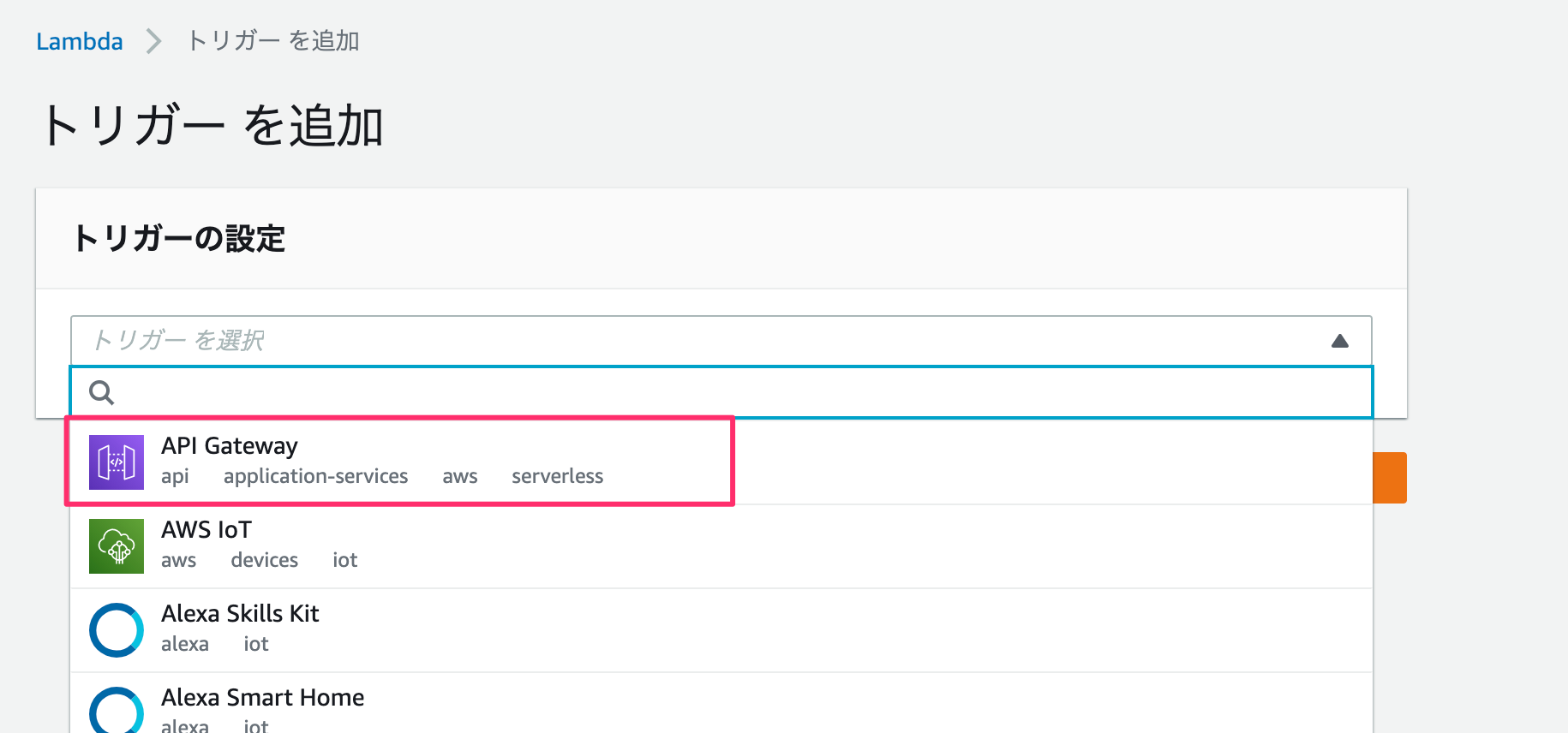
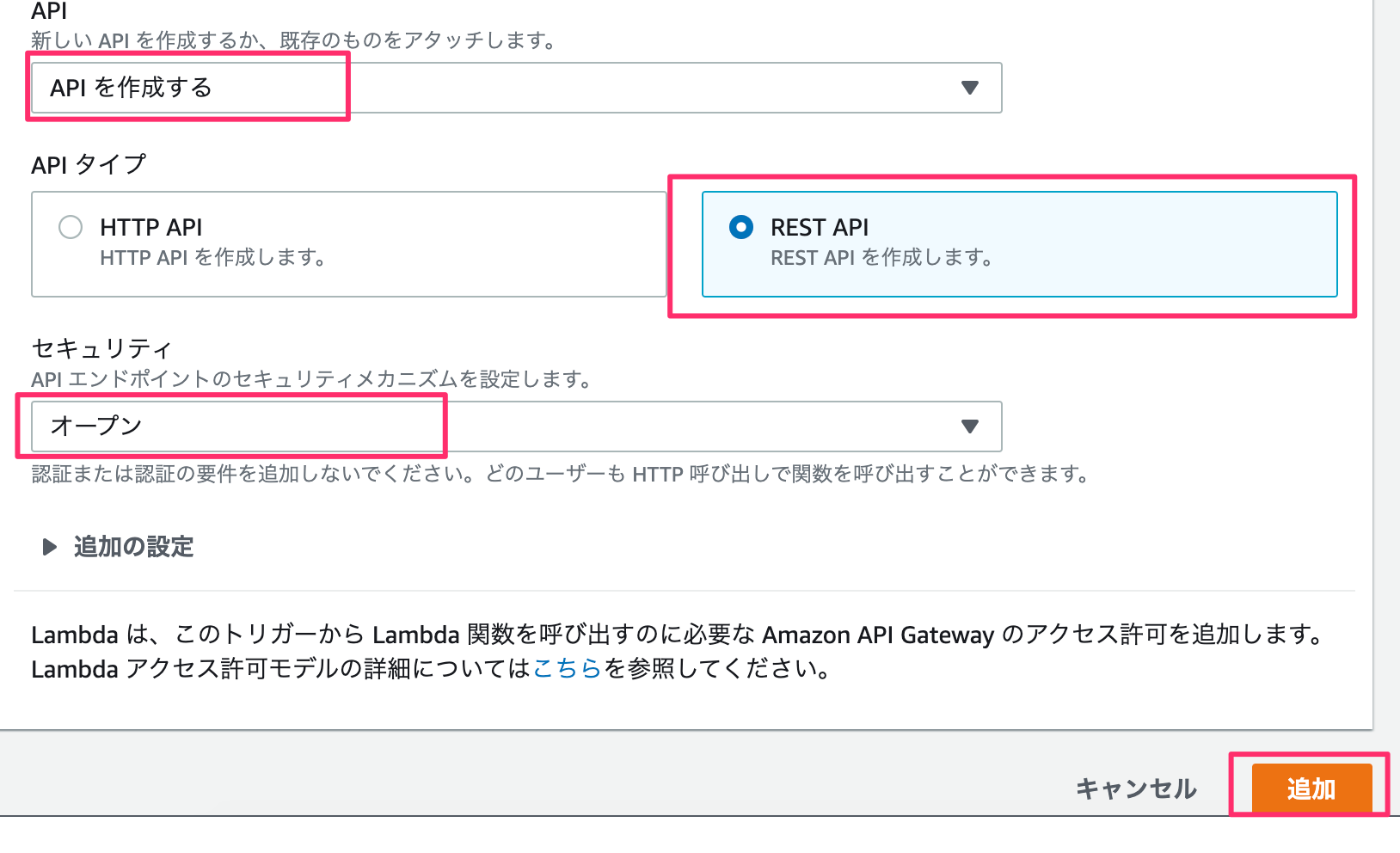
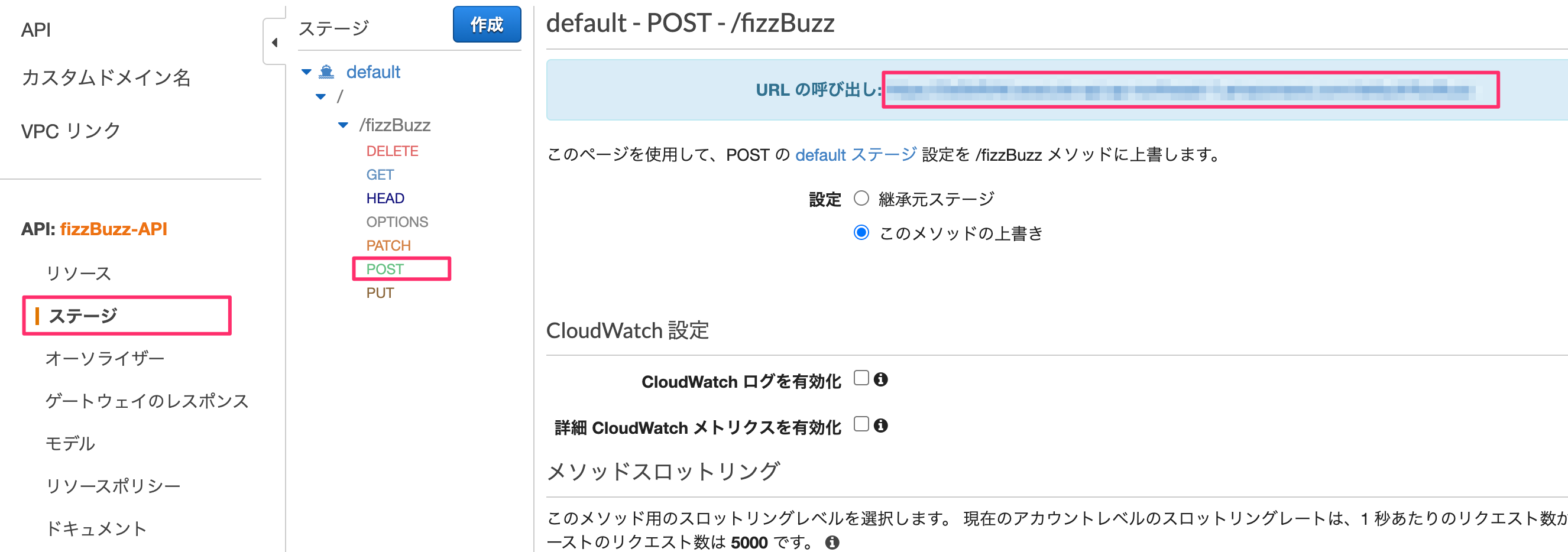
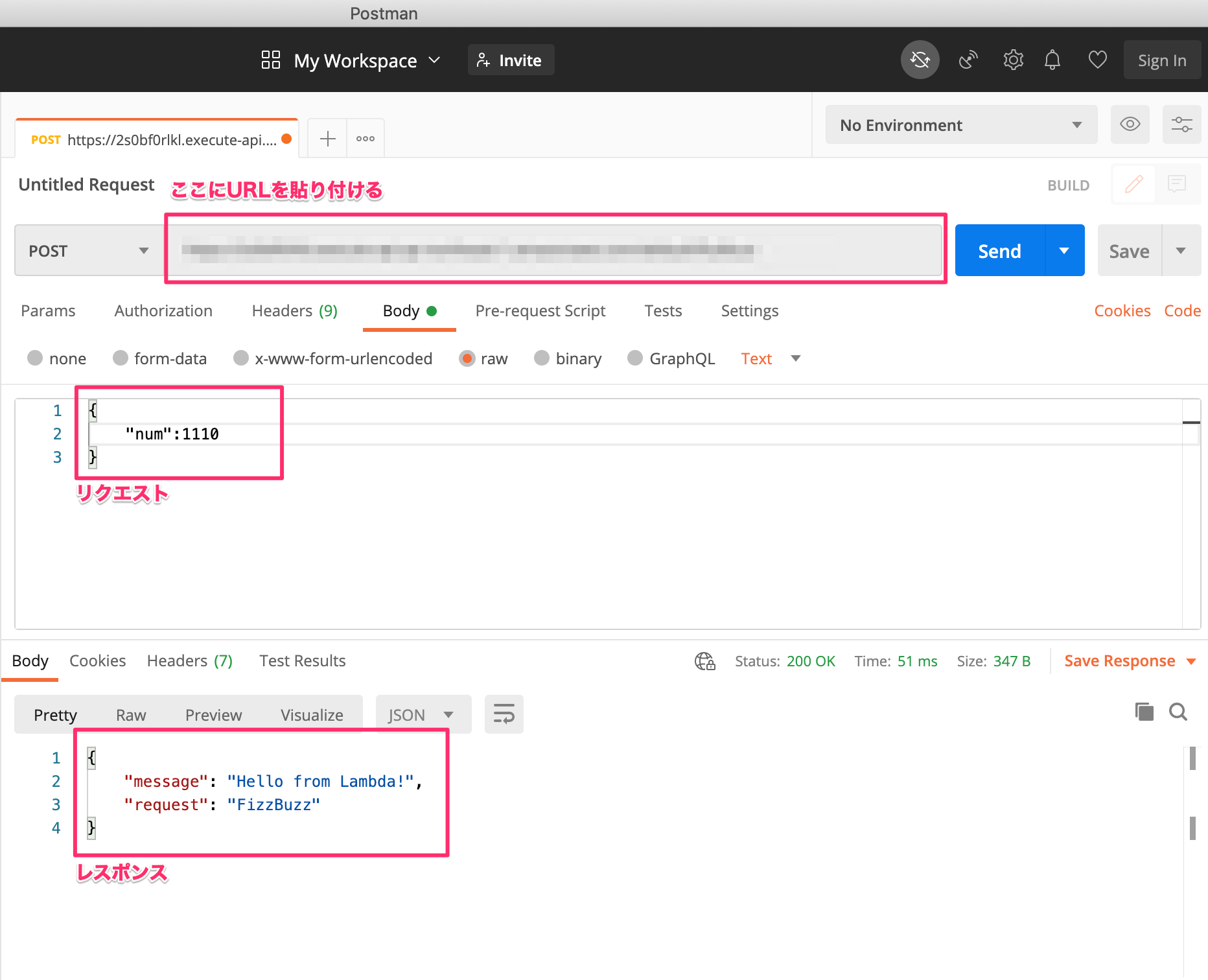
- 投稿日:2020-11-17T10:17:49+09:00
公的空間のイベント混雑状況をレーザー距離計で可視化する
概要
- 公的空間で行われるマルシェの混雑状況を2日間に渡りカウントし可視化する実験を試みた
- 通行量、滞在人数、滞在時間を計測するには入り口、出口を絞る必要がある。今回は会場のあるポイントの人の通過量を混雑度と見なす
- イベントでの入場者数は貴重なデータである。無人でカウントがどこまでできるのかを試してみる
- 広島駅北口エリアのエリアマネジメントを行う、エキキタまちづくり会議 (https://ekikita.jp) にご協力頂いた。
【参考】
エリアマネジメントについて(国土交通省)
https://www.mlit.go.jp/common/001059393.pdf
地方創生 まちづくり - エリアマネジメント - (内閣官房まち・ひと・しごと創生本部事務局)
https://www.kantei.go.jp/jp/singi/sousei/about/areamanagement/areamanagement_panf.pdf用意するもの
- Raspberry Pi3 Model B (4でもおそらく大丈夫)
- Raspberry Pi用のケース
- Raspberry Pi用のヒートシンク、ファン
- Raspberry Pi3 Model B B+ 対応 電源セット(5V 3.0A)
- vl53l1x 超音波距離センサー (最大計測範囲 4m)
- LED,330Ωの抵抗
- 100円ショップの三脚
- 100円ショップで購入したAirPodsのケース (センサーのカバーとして使用)
準備
- RaspberryPiのセットアップをしWifi接続できるようにしておく。
https://www.raspberrypi.org/downloads/- Ambient(IoTの可視化サービス)のライブラリが使用できるようにしておく。
- Ambientにてダッシュボードを作成し、チャネルIDとライトキーを取得しておく。
https://ambidata.io/refs/python/- vl53l1xのPython用ライブラリを使用できるようにしておく
https://github.com/pimoroni/vl53l1x-python組み立て
- Raspberry Piとレーザー距離センサー、LEDを以下のように接続する
プログラミング
- 汎用のライブラリを使うためPython3を使いプログラミング
- git cloneしたライブラリのexamplesフォルダにあるdistance.pyを改変して使用
- レーザー距離センサーの値をloopして読み取り、しきい値を下回った数を通過数としてカウント
- カウントする毎にGPIOピンに接続したLEDを点灯/消灯させる
- 5分毎のカウント数をAmbientに送信し可視化する
distance.py#!/usr/bin/env python import time import sys import signal import VL53L1X import ambient import datetime import RPi.GPIO as GPIO GPIO.setmode(GPIO.BCM) GPIO.setup(25, GPIO.OUT) #LED点滅用 from time import sleep print("""distance.py Display the distance read from the sensor. Uses the "Short Range" timing budget by default. Press Ctrl+C to exit. """) ambi = ambient.Ambient(xxxxx, 'xxxxxxxxxxxxxxxx') # ←ambientのチャネルIDとライトキー count = 0 sndcnt = 0 # Open and start the VL53L1X sensor. # If you've previously used change-address.py then you # should use the new i2c address here. # If you're using a software i2c bus (ie: HyperPixel4) then # you should `ls /dev/i2c-*` and use the relevant bus number. tof = VL53L1X.VL53L1X(i2c_bus=1, i2c_address=0x29) tof.open() # Optionally set an explicit timing budget # These values are measurement time in microseconds, # and inter-measurement time in milliseconds. # If you uncomment the line below to set a budget you # should use `tof.start_ranging(0)` tof.set_timing(66000, 70) tof.start_ranging(0) # Start ranging # 0 = Unchanged # 1 = Short Range # 2 = Medium Range # 3 = Long Range running = True def exit_handler(signal, frame): global running running = False tof.stop_ranging() print() sys.exit(0) # Attach a signal handler to catch SIGINT (Ctrl+C) and exit gracefully signal.signal(signal.SIGINT, exit_handler) while running: distance_in_mm = tof.get_distance() print("Distance: {}mm".format(distance_in_mm)) now = datetime.datetime.now() minute = '{0:%M}'.format(now) second = '{0:%S}'.format(now) print(minute) print(second) if distance_in_mm < 1300: # カウントするか否かのしきい値(mm) count += 1 GPIO.output(25, GPIO.HIGH) # LED点滅 sleep(0.5) GPIO.output(25, GPIO.LOW) sleep(0.5) if int(minute) % 5 == 0 and int(second) == 0: if sndcnt < 1: r = ambi.send({'d1': count}) if r.status_code != 200: continue print(count) print("***sended***\n") count = 0 sndcnt += 1 else: sndcnt = 0 time.sleep(0.1)現地に設置した様子
結果
- イベントの開催時間を通して正常なカウントをすることはできなかった。
- 調整設置場所、しきい値の変更など現地で調整したが、安定したカウントはできなかった。
赤背景:データ取得されていた部分
青背景:調整中
グレー背景:イベント開催時間外
不具合内容
- レーザー距離計の値が安定しない。対象物の素材(石、木、紙)や表面の凸凹により安定度が変わってしまう。
- 1人の通過で2〜3人分とカウントされてしまう。(検知した場合のwaitを入れてある程度改善した)
- 明るさ、日光が当たらない場合と当たらない場合での安定度の違いが大きい模様。
- 数時間に一度、ambientのapi URLに対して、HTTP MaxRetryErrorが出る。
自宅Wifiでは10時間以上稼働していたため、現地でお借りしたWifi設備による可能性が高い。今後に向けて
- コロナ渦で屋内イベントの開催が難しい状況であるが、まずは屋内で確実にカウントできるように調整を続ける
- 屋外でカウントが難しい問題は、他の種類のセンサーを検討することも考える
- ToFタイプの距離計を使う場合は安定して反射できる対象物を用意する
- 現地のWifi環境で予め長時間接続に問題がないかテストが必要




