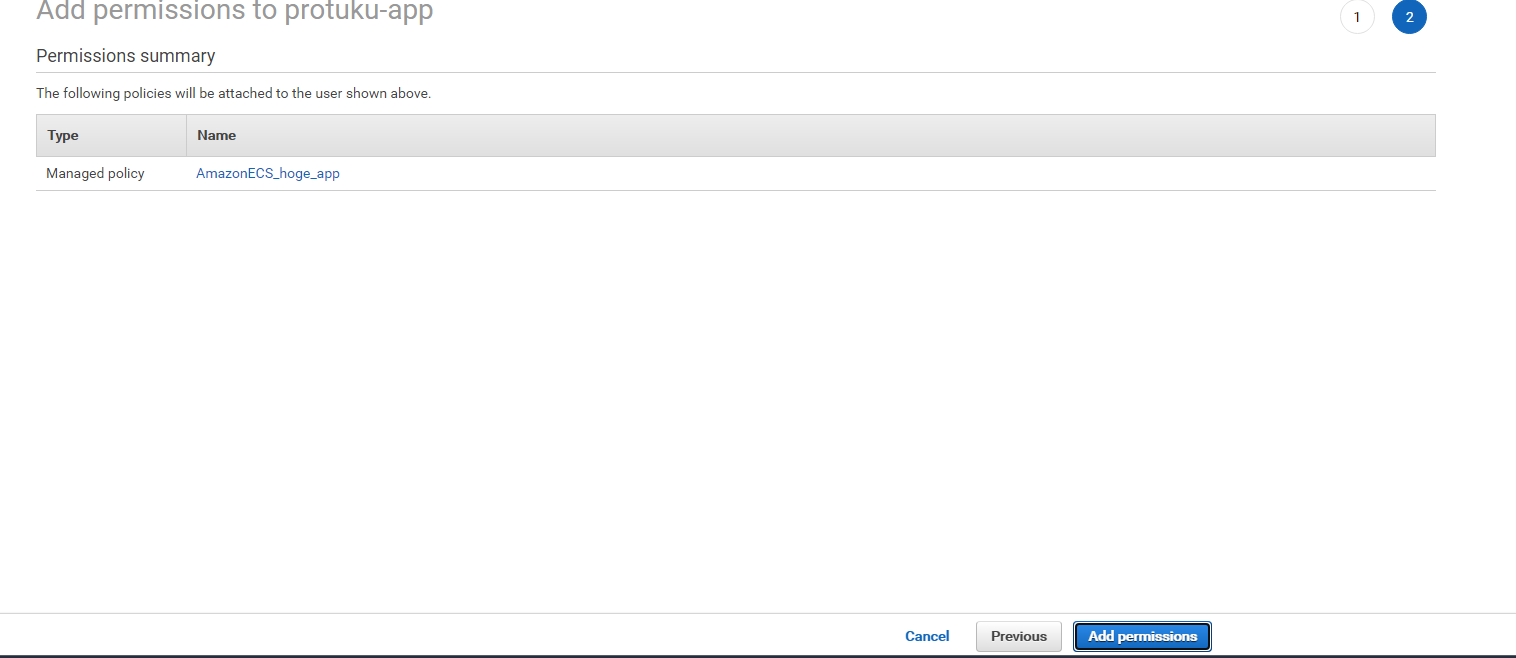
- 投稿日:2020-11-17T22:37:03+09:00
【初心者向け】Rails6で作られたWebアプリをCircleCIを使いAWS ECR・ECSへ自動デプロイする方法②-1 インフラ構築編【コンテナデプロイ】
記事の続きをご覧いただきありがとうございます。
前回の下準備編の続きになります。今回はインフラ構築編②-1です。
タイトル ① 下準備編 ②-1 インフラ構築編 ←今ここ! ②-2 インフラ構築編(執筆中) 自動デプロイ編(執筆中) 少し長いので覚悟してください!笑
それでは、早速やってきましょう!
インフラ構築編②-1
最初に流れを説明します。ここでやることは主に2つだけですが、色々と設定する項目があります。地道にやっていきましょう。
- クラスターの作成
- RDSの設置
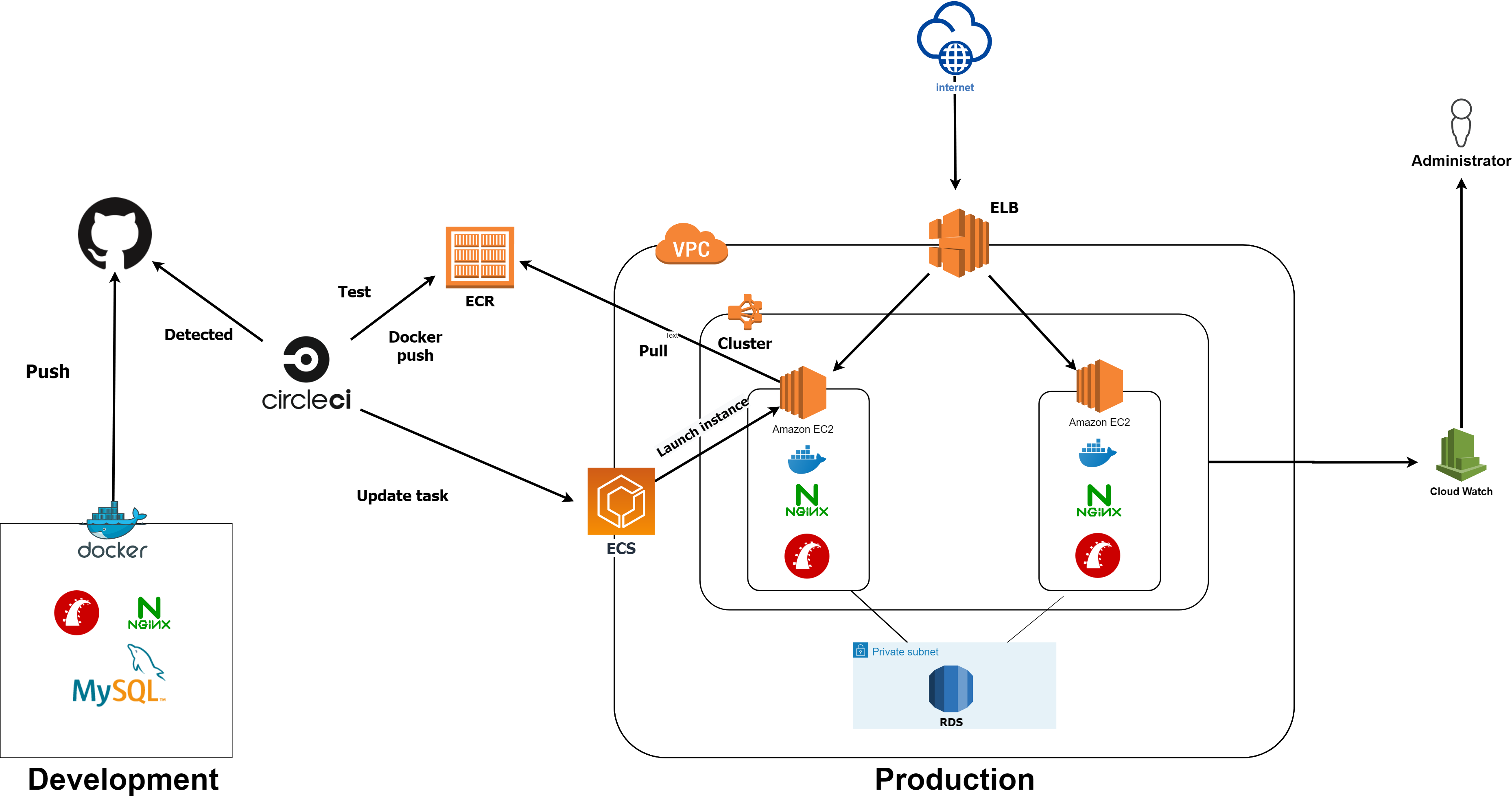
このような構成になってます。
クラスターの作成
クラスターの作成をawsコマンドを使って作成します。クラスターというのはコンテナインスタンスの集合体の名称です。
(クラスターという単語は、今年話題になったので日本語の意味からなんとなく察しが付いた方も多いと思います)ざっくりいうと、このクラスターの中にRailsとNginxのDockerコンテナ(このDockerコンテナの集まりをServiceと呼びます)が配置されるといった感じです。
以下のコマンドを順番に実行して作成していきます。
$ ecs-cli configure profile --profile-name 任意のプロフィール名 --access-key アクセスキー --secret-key シークレットアクセスキー $ ecs-cli configure --cluster 任意のクラスター名 --default-launch-type EC2 --config-name 任意の設定名 --region ap-northeast-1 $ ecs-cli up --keypair キーペア名 --capability-iam --size 2 --instance-type t2.small --cluster-config 任意の設定名 --ecs-profile 任意のプロフィール名私の場合は、アプリ名(protuku-app)を名前にしたので、
$ ecs-cli configure profile --profile-name protuku-app --access-key xxxxxxxxxxxxxxxx --secret-key xxxxxxxxxxxxxx $ ecs-cli configure --cluster protuku-app-cluster --default-launch-type EC2 --config-name protuku-app-cluster --region ap-northeast-1 $ ecs-cli up --keypair protuku-app --capability-iam --size 2 --instance-type t2.small --cluster-config protuku-app-cluster --ecs-profile protuku-appのような感じでコマンドを実行しました。
また、私の場合、最後のecs-cli upコマンドを実行したとき
time="2020-10-22T20:41:46+09:00" level=fatal msg="Error executing 'up': describe instance type offerings: AuthFailure: AWS was not able to validate the provided access credentials\n\tstatus code: 401, request id: xxxxxxxxxのようなエラーが出ました。もし、このようなエラーが起きたら、キーペアやアクセスキーの設定が間違っている可能性があります。私は、IAMの作成からやり直したらうまくいったのでこの辺の設定が間違っていた可能性があります。
また、ローカルのPCの時刻がずれていてもこのようなエラーが起きる可能性がありますので、PCの時刻がずれていないかどうか確認してください。
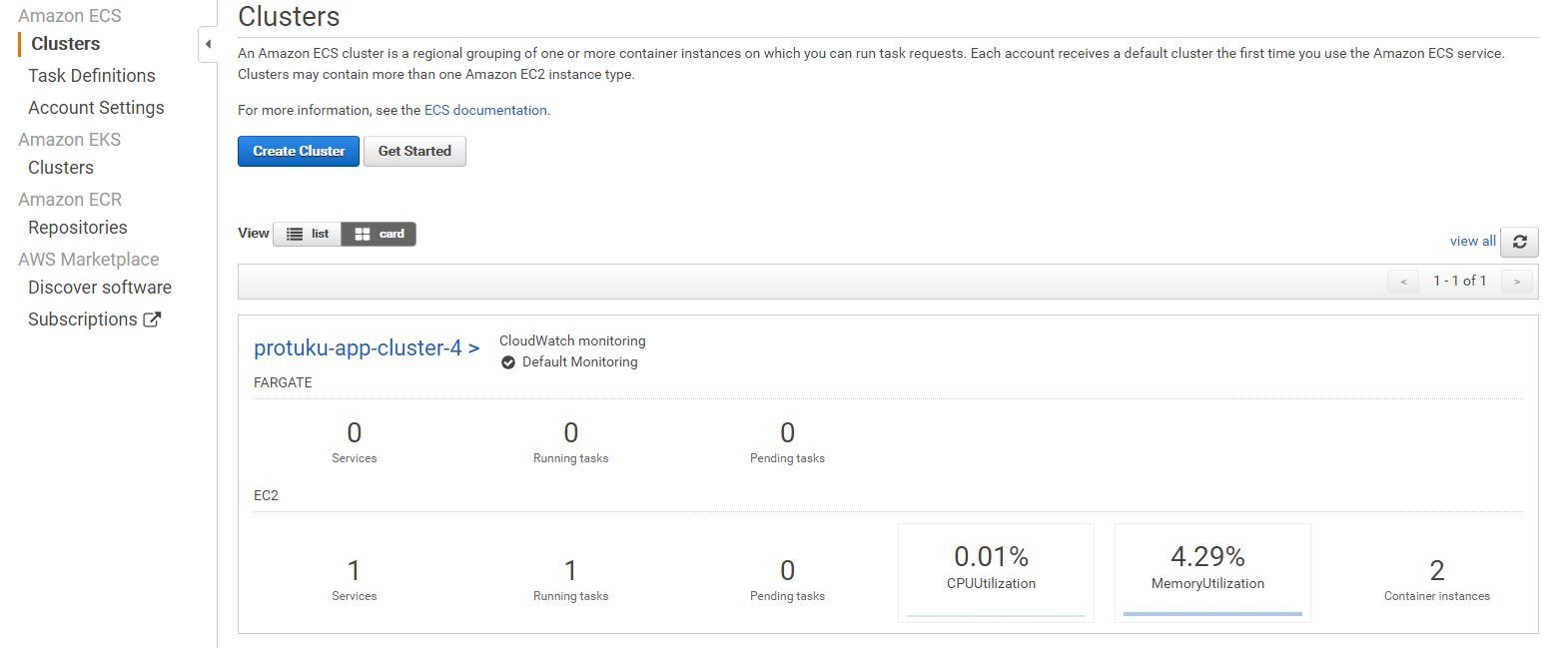
詳しくはこちらの記事を参考にしてみるといいかもしれません。最後のecs-cli upコマンドの実行に成功すると次のように、クラスター用のVPC、サブネット、セキュリティグループなどが作成されます!
$ ecs-cli up --keypair protuku-app --capability-iam --size 2 --instance-type t2.small --cluster-config protuku-app-cluster --ecs-profile protuku-app INFO[0000] Saved ECS CLI cluster configuration protuku-app-cluster-4 INFO[0000] Using recommended Amazon Linux 2 AMI with ECS Agent 1.46.0 and Docker version 19.03.6-ce INFO[0000] Created cluster cluster=protuku-app-cluster region=ap-northeast-1 INFO[0001] Waiting for your cluster resources to be created... INFO[0001] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0062] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0122] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: vpc-xxxxxxxxxxxxxxxxxx Security Group created: sg-xxxxxxxxxxxxxxxxxx Subnet created: subnet-xxxxxxxxxxxxxxxxxx Subnet created: subnet-xxxxxxxxxxxxxxxxxx Cluster creation succeeded.ServicesからElastic Container Service(ECS)を選択し、Clusterをクリックすると、以下のようにクラスターが生成されているのが確認できると思います。(こちらはデプロイ後の画面なのでService、Taskが1になってますが、実際はまだ作成していないので0になっているはずです。)
RDSの作成
次にRDSを作成していきます。DBサーバーにはMySQLを利用します。
RDSというのは、 AWSのフルマネージドなリレーショナルデータベースのサービスになります。バックアップ、DBのアップデート、スケーリングなどをAWSがすべて自動でやってくれるので、よりコアな開発に集中することができる!といったものです。RDSにはインターネット上からアクセスできないようにしたいのでプライベートサブネットに配置します。また、冗長化のために複数のアベイラビリティゾーンにRDSを設置していきます。
まず、事前準備として、RDS用のプライベートサブネットを2つ(リージョンが1aと1cのものでいいと思います)と、DBパラメータグループ、DBオプショングループを作成していきます。
RDS用のプライベートサブネットの作成
他記事で恐縮ですが、プライベートサブネットの作成に関してはこちらの記事が大変わかりやすいので、こちらを見て作成してみてください。VPCはすでにあるのでサブネットの作成だけでOKです。
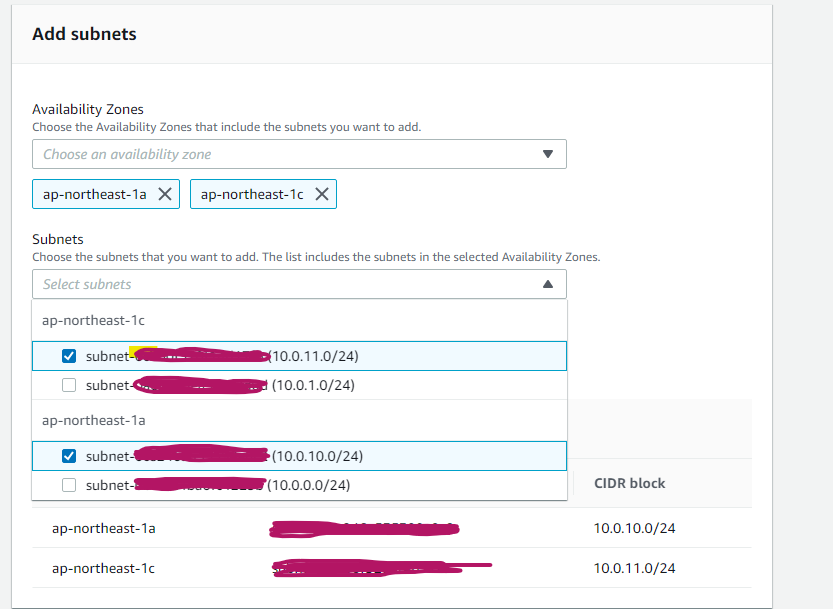
一番近い東京リージョンであるap-northeast-1aと1cのふたつのプライベートサブネットを作りこのサブネットにRDSを設置していきます。RDS用のサブネットグループを作成する
サブネットグループというのは、VPC内にあるサブネットを複数指定して、RDSインスタンスが起動するサブネットを指定した設定のことです。マルチAZを実現させるために、この設定をする必要があります。
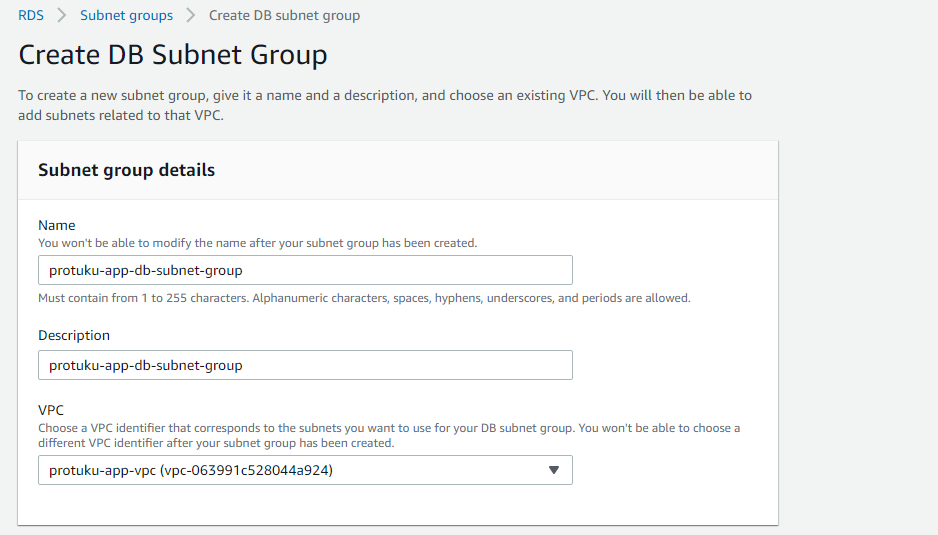
まず、ServicesからRDSのコンソールへいき、Subnet groupsを選択し、Create DB Subnet Groupをクリックします。
以下のように任意の名前を入れます。VPCには作成したVPCを選択します。
次に最初に作った2つのプライベートサブネットを追加していきます。
Avalilability Zonesは1aと1c選択し、作成したサブネットを2つ選択して、Createをクリックして作成完了です。
DBパラメータグループの作成
RDSではDBの設定ファイルを直接編集するといったことができないので、代わりにパラメータグループというのを使って設定値を編集することができます。
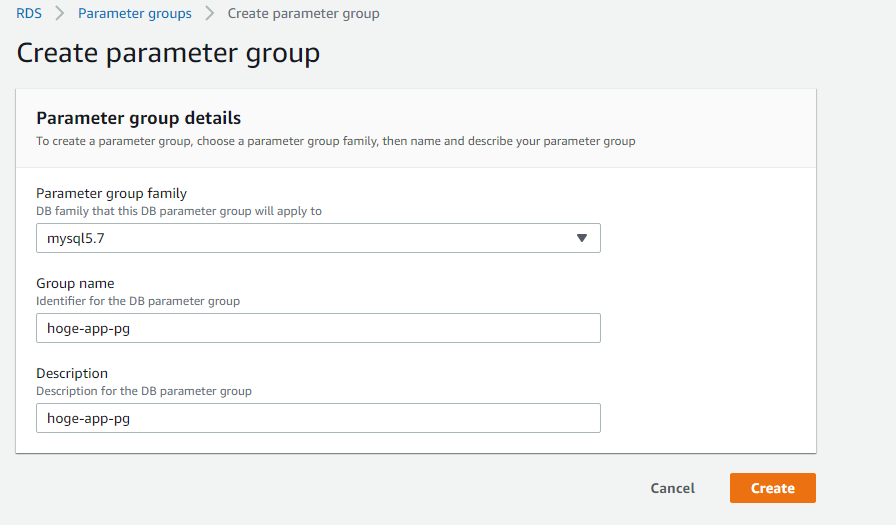
デフォルトでパラメータグループは作成されるのですが、こちらは設定値を変えることができないので、自分で作成する必要があります。RDSのコンソールからParameter groupsをクリックし、Create parameter groupをクリック
group familyにmysql5.7を選択し、任意の名前を入れてCreateして完了です。
DBオプショングループの作成
オプショングループはDBの機能的な部分を設定します。プラグインを導入したいとかそういったときに利用します。
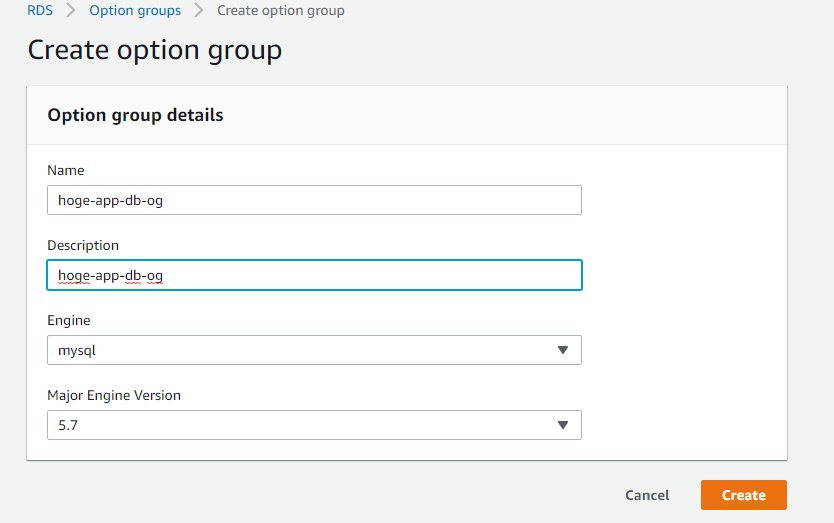
こちらもデフォルトで設定されるのですが、デフォルトのものを編集するのではなく、自分で作成したものを編集するのがセオリーのようです。後々変更したいといったときのために作成しておきます。RDSのコンソールからOption groupsを選択し、Create groupをクリック
こちらも任意の名前を入力して、mysqlの5.7を選択し、createをクリックして作成完了です。
RDSインスタンスの設置
さて、下準備が整ったのでやっとインスタンスを作成できます!
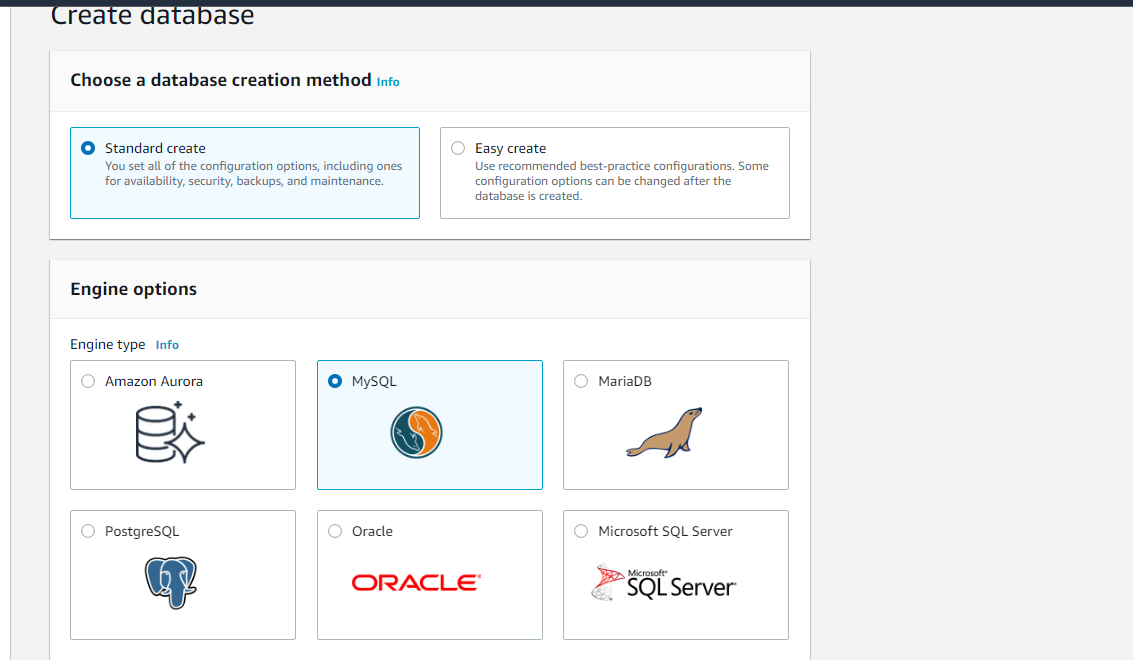
RDSのコンソールからDatabaseを選択し、Create databaseをクリック。
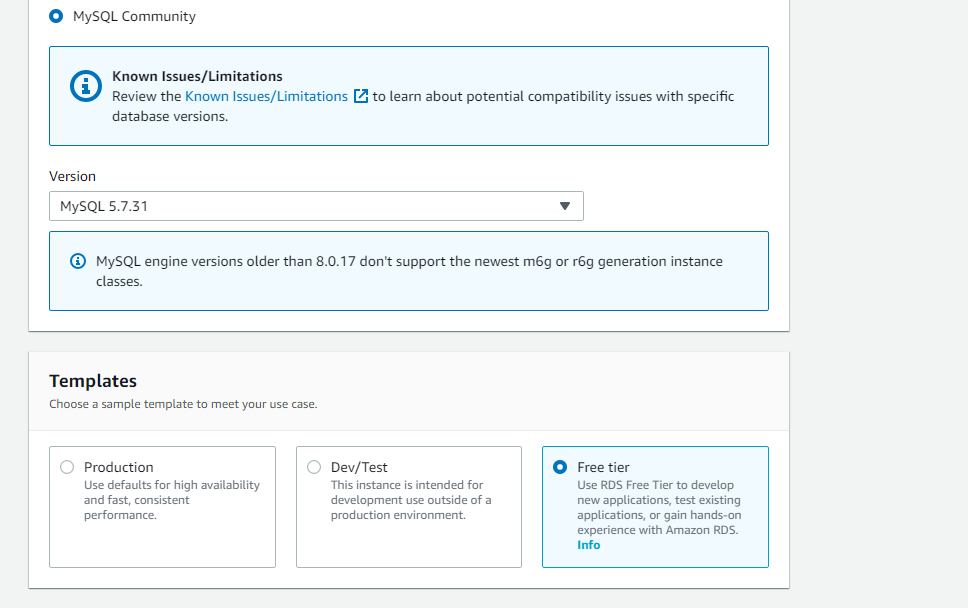
スタンダードを選択し、DBはMySQLを選択
今回は無料タイプを選択します。
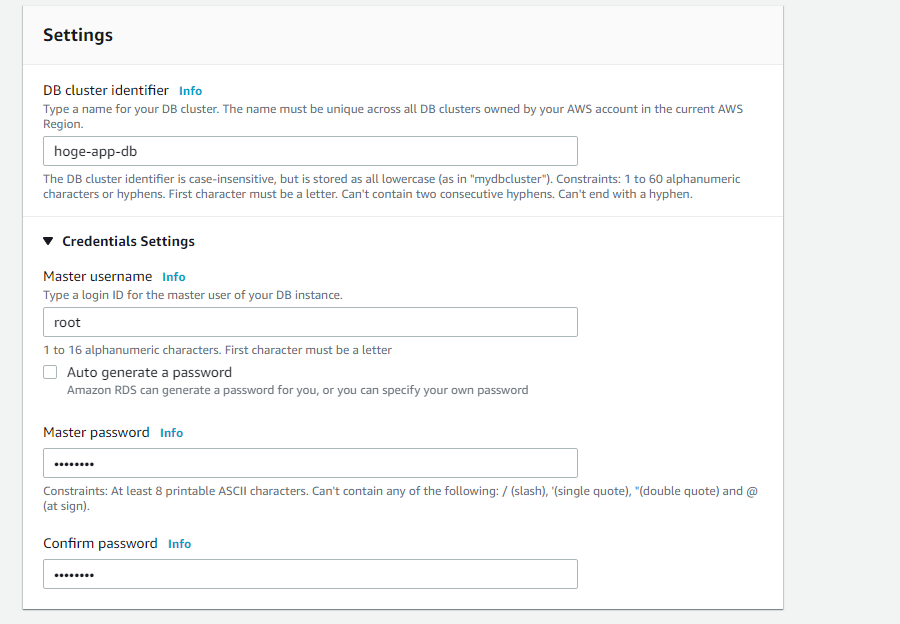
次に、任意のDBインスタンス名を入力します。Credentials Settingsをクリックし、DBに接続するときの任意のユーザー名とパスワードを設定します。
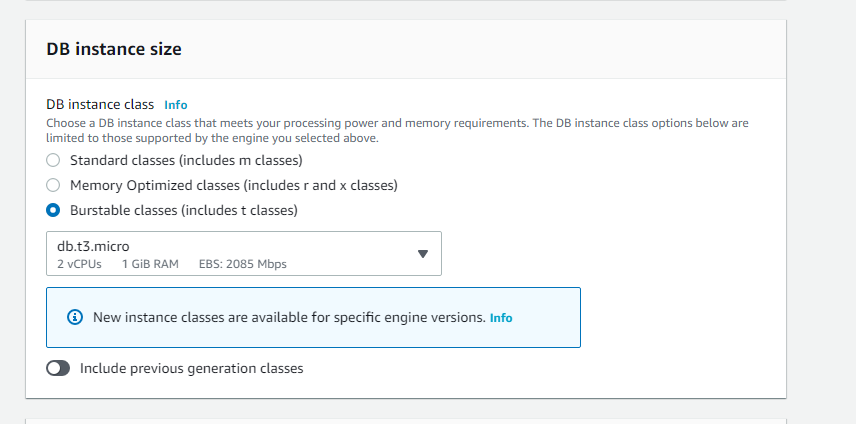
こちらはなるべく安く済ませたいので、バースト可能クラスを選び、t3.microを選択します。
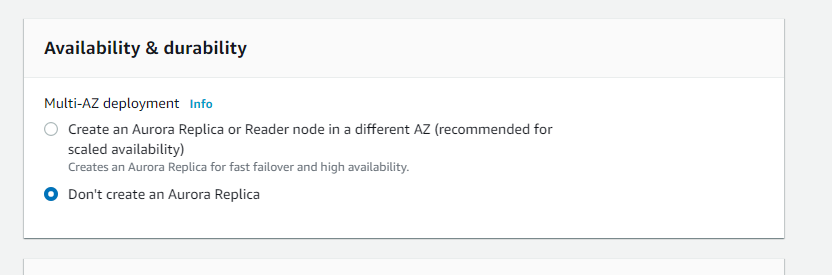
マルチAZの設定は今回は無しにします。作成すると自動でマルチAZにできるのですが、料金がかかってしまうため設定しません。デフォルトだと作成するにチェックが入っているので気を付けましょう。(英語版だけかも)
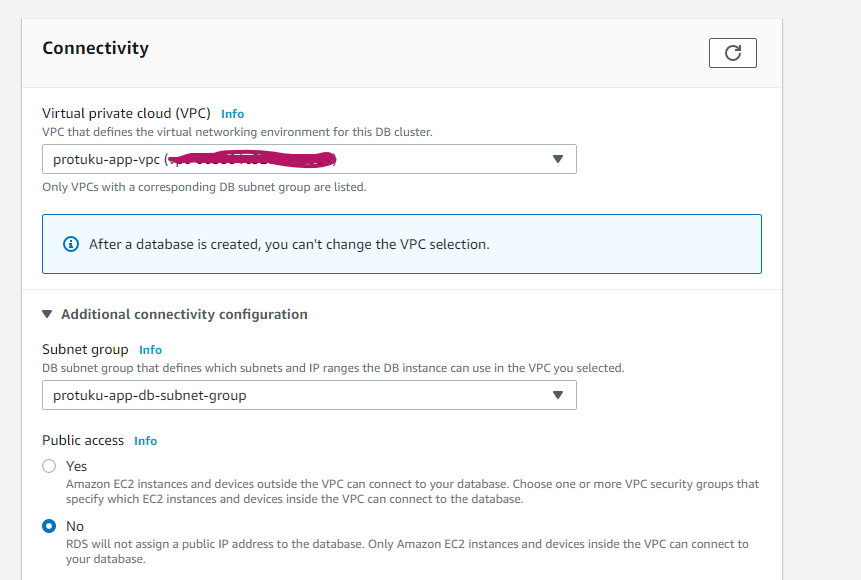
作成したVPCとサブネットグループを選択します。パブリックアクセスは無しを選択します。
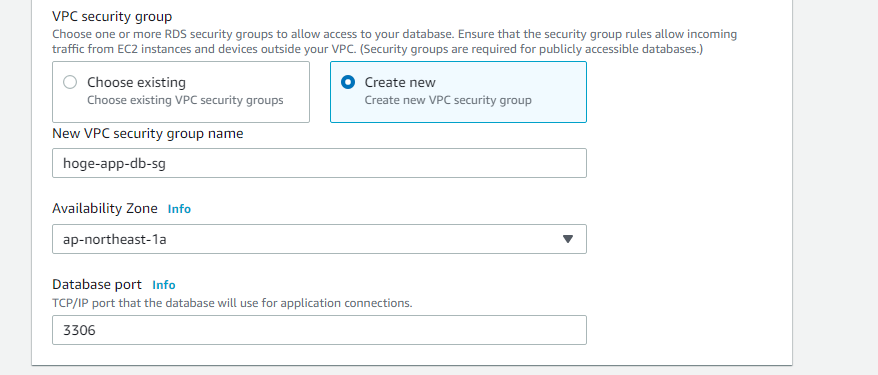
ここで新規にRDSのセキュリティグループを作成します。任意の名前を入力し、アベイラビリティゾーンは1aを選択します。
ポート番号はデフォルトの3306のままいきます。
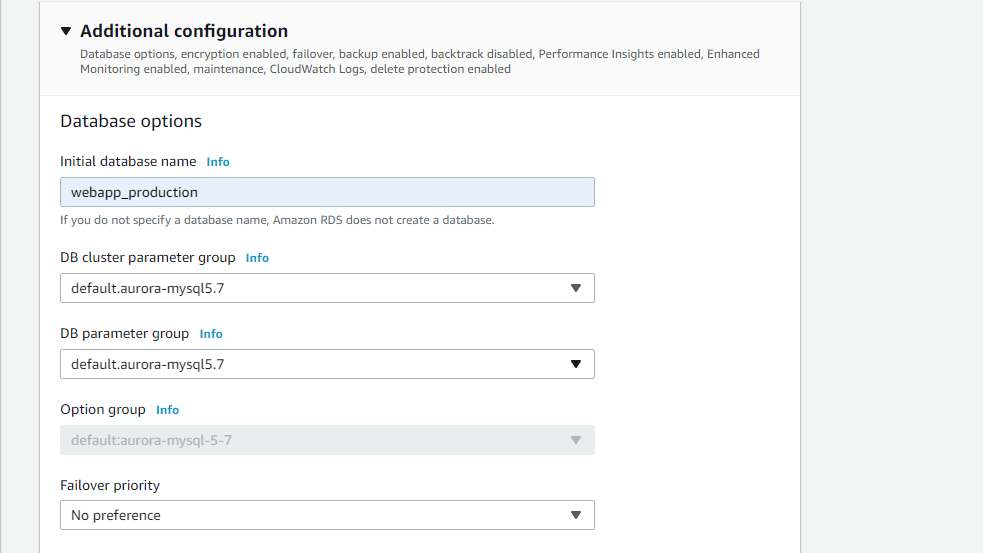
次に追加の接続設定を開き、database nameを入力します。
これは、Railsアプリのconfig/database.ymlのproduction:にあるdatabaseの名前と同じ名前を入力しましょう。
たとえば私の場合は、webapp_productionと入力しました。
その後、上記で作成したパラメータグループとオプショングループを選択します。(画像は諸事情によりデフォルトのままになってますので気をつけてください。)
その他色々設定がありますが、他はデフォルトのままでとりあえずはOKだと思います!
設定があっていることを確認してCreateDatabaseをクリックしてRDSの作成は完了です。
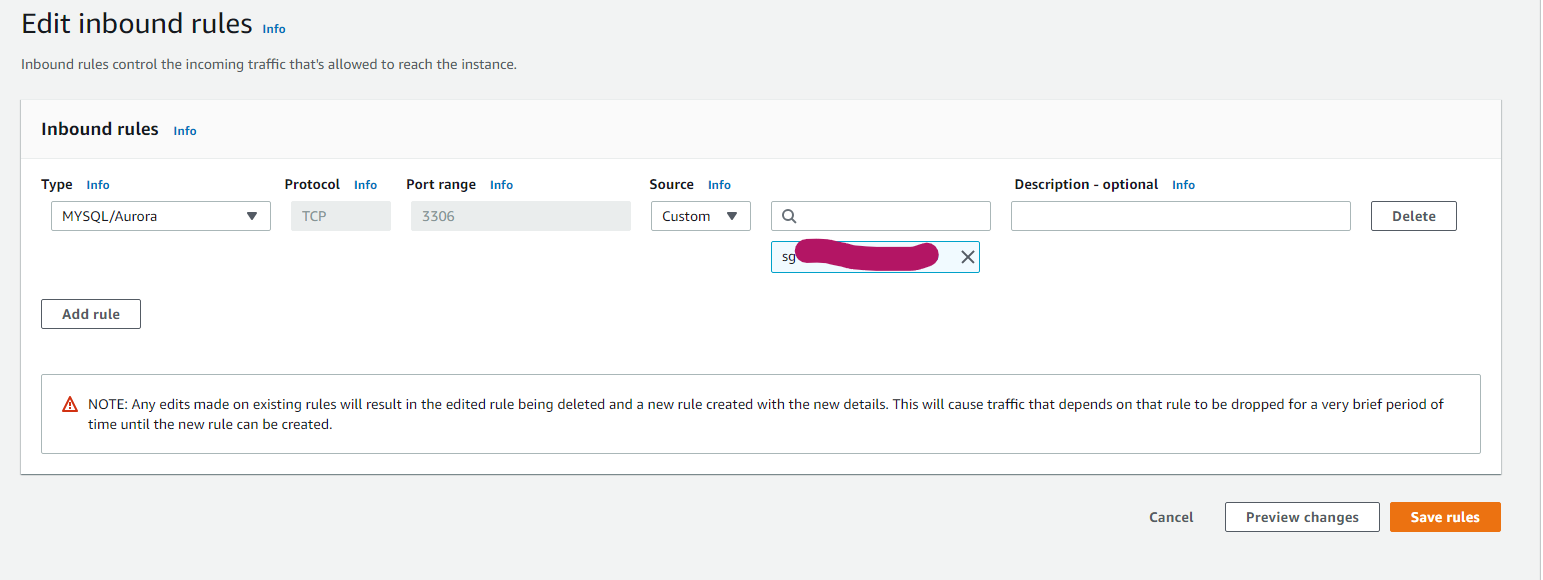
RDSのセキュリティグループを設定する
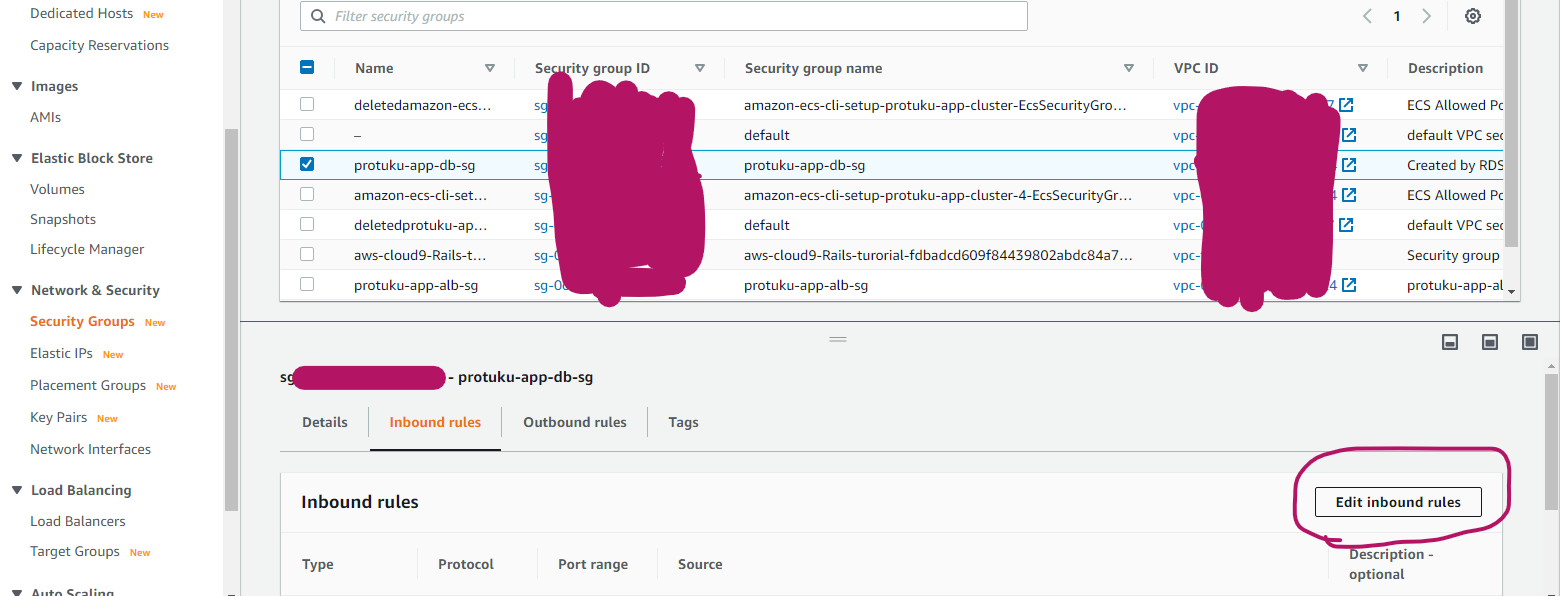
現状のままではセキュリティグループが設定されていないので、DBにすべてのトラフィックを許可してしまってる状態です。これではセキュリティー上よろしくないので、DBにはサーバーからのSSH接続のみ許可するように設定していきます。
EC2のコンソールへいき、Security Groupsを選択し、Edit inbound rulesを選択します。
設定は
- タイプ: MYSQL/Aurora
- プロトコル: SSH
- ポート: 3306
- ソース: クラスターのセキュリティグループ(最初にawsコマンドを実行したとき自動で作られてるはずです)
設定を入力したら、Createをクリックします。これでセキュリティグループの作成は完了です。
セキュリティグループの作成が完了したら、実際にDBに接続できるか確認してみましょう。
サーバーにSSHログインして、以下のコマンドを実行します。サーバーへのSSHログインの方法は割愛します。
windowsならRLoginやPuttyなどを使ってログインできるのでググってみてください。[ec2-user@ip-xxxxxxxx ~]$ mysql -u 設定したユーザー名 -h RDSのエンドポイント -p以下のような画面になったら成功です。(mysql not found とかでてきたらmysqlをインストールする必要があります。ref: https://hacknote.jp/archives/51267/)
最後まで読んでいただきありがとうございます!
今回はここで一旦区切ります。次回はインフラ構築編②-2として、Webからのアクセスを負荷分散するために、ALB(アプリケーションロードバランサー)を作成する方法を書いていこうと思いますので、乞うご期待ください!
思い出しながら調べつつ記事を書いているので、ご指摘や、ご不明な点などあればコメントいただけますと嬉しいです!

- 投稿日:2020-11-17T22:15:48+09:00
SAAに合格したのでどんな感じだったか書いてみる
未経験からエンジニアになって2年目になるのですが、そろそろ何かしらの資格に挑戦してみようかなあと思い、SAAを受験してみました。
勉強期間、試験内容など、どんな感じだったかまとめていきたいと思います〜
SAAの試験の概要はこちら
勉強時間、勉強方法
勉強期間はトータルして大体5週間ちょっとぐらいです。9月下旬に勉強を始めて、11月16日に試験を受けたので、期間としては2ヶ月程ありますが、サボったり、仕事が忙しかったり、ドラマにはまってしまったりwと勉強してない期間も結構あったので、そこは省いた期間となります。
教材は、Udemyで、
- AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
- AWS認定ソリューションアーキテクト アソシエイト模擬試験問題集この2つを購入しました。
勉強方法としてはいたってシンプルで、
- 教材の動画をみて内容を理解
- 問題を解く。
- 解けるようになるまで繰り返す。
こんな感じでやりました。
正直、これやっとけば全然受かるやろと調子こいてましたが、蓋を開けてみたら、合格ラインが720/1000のところ、741点とめっちゃギリギリで合格してました。。ひえ。。
今になってから言えることですが、結構ちゃんと勉強しないと受からない試験なんじゃないかなと思います。。
自分の場合、ただひたすら解いて覚えることに集中してしまい、
内容を根本から理解する、仕組みを理解する
といったことがちょっと甘くなってました。
これが、あまり点数が取れなかった原因だと思ってます。
ただ、このudemyの教材で、試験直前に復習していた内容が、ほぼほぼそのまま出たりもしました。(逆にそれがなかったら落ちてたんじゃないかとw)
なので、この教材はすごいおすすめです。
一つ言うなら、ちょっと解説が分かりにくいというか、足りないことがちょこちょこあるので、そういったところは、随時調べて意味を理解する、、という作業が必要になるかと思います。
受験時の試験内容
試験内容としては、主に
- EBS, EFS, S3
- Auto Scaling, Ec2、CloudFrontあたりを使ったアーキテクチャ構成
この辺りの問題が結構出てきた印象でした。
試験を受けた後に、分野別にスコアと評価が見られるのですが、「高パフォーマンスアーキテクチャの設計」については、再学習した方が良いよーと書かれてました。やはり問題を解くだけでなく、特にアーキテクチャに関しては、自分で図を書いてみたり等、理解することに重点を置いた勉強も大事なのではないかと思いました。
受験後の感想
資格としては取得できたものの、
知識としては曖昧な部分も結構多く、決してドヤ顔はできません。実際に触ってなんぼ、なところもあるかなと思っているので、
改めて、色々アプリを動かしてみながらインフラを触っていくことでもっとできるようになれればと思います〜
- 投稿日:2020-11-17T20:09:25+09:00
zoom会議での話のウケ度を数値化してみた
はじめに
最近zoomでの会議や授業などが増えてきていますが、やはり対面じゃないとどのくらい話に関心を持ってくれているのかわからない…ということがあると感じ、数値化してみればいいんじゃないか?と思い立ち作ってみました。
初投稿なので拙い部分もありますが最後まで読んでいただければ幸いです
目的
zoom会議の画像または動画を取得し、写っている顔を認識、話への関心度を測定する。
実装
試しに
今回zoom会議に出席している人物の顔認識をするのにAmazon Rekognitionを使うことにしました。
使い方はこちらの記事を参考させていただきました。
https://qiita.com/G-awa/items/477f2324552cb908ecd0detect_face.pyimport cv2 import numpy as np import boto3 # スケールや色などの設定 scale_factor = .15 green = (0,255,0) red = (0,0,255) frame_thickness = 2 cap = cv2.VideoCapture(0) rekognition = boto3.client('rekognition') # フォントサイズ fontscale = 1.0 # フォント色 (B, G, R) color = (0, 120, 238) # フォント fontface = cv2.FONT_HERSHEY_DUPLEX # q を押すまでループします。 while(True): # フレームをキャプチャ取得 ret, frame = cap.read() height, width, channels = frame.shape # jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor))) ret, buf = cv2.imencode('.jpg', small) # Amazon RekognitionにAPIを投げる faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL']) # 顔の周りに箱を描画する for face in faces['FaceDetails']: smile = face['Smile']['Value'] cv2.rectangle(frame, (int(face['BoundingBox']['Left']*width), int(face['BoundingBox']['Top']*height)), (int((face['BoundingBox']['Left']+face['BoundingBox']['Width'])*width), int((face['BoundingBox']['Top']+face['BoundingBox']['Height'])*height)), green if smile else red, frame_thickness) emothions = face['Emotions'] i = 0 for emothion in emothions: cv2.putText(frame, str(emothion['Type']) + ": " + str(emothion['Confidence']), (25, 40 + (i * 25)), fontface, fontscale, color) i += 1 # 結果をディスプレイに表示 cv2.imshow('frame', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()とりあえずコードを試しに動かしてみると顔認識&感情分析ができた!、、、のですが動画取得だと重くて途中で止まってしまいました。
なので画像を読み込ませることにします。
(これは参考にした記事のコードです。)画面のキャプチャ
画像のキャプチャはこちらの記事を参考にさせていただきました。
https://qiita.com/koara-local/items/6a98298d793f22cf2e36PILを利用して画面のキャプチャを行いました。
capture.pyfrom PIL import ImageGrab ImageGrab.grab().save("./capture/PIL_capture.png")別にcaptureというフォルダを作りそのフォルダに保存するようにしました。
実装
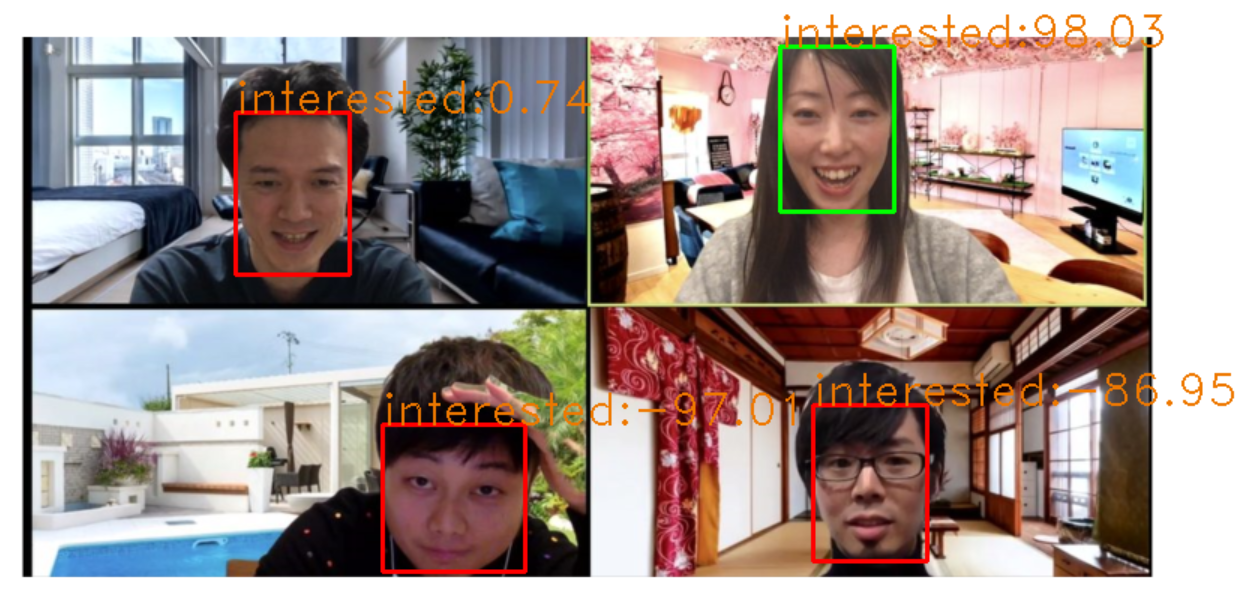
face_detect.pyimport cv2 import numpy as np import boto3 # スケールや色などの設定 scale_factor = .15 green = (0,255,0) red = (0,0,255) frame_thickness = 2 #cap = cv2.VideoCapture(0) rekognition = boto3.client('rekognition') # フォントサイズ fontscale = 1.0 # フォント色 (B, G, R) color = (0, 120, 238) # フォント fontface = cv2.FONT_HERSHEY_DUPLEX from PIL import ImageGrab ImageGrab.grab().save("./capture/PIL_capture.png") # フレームをキャプチャ取得 #ret, frame = cap.read() frame = cv2.imread("./capture/PIL_capture.png") height, width, channels = frame.shape frame = cv2.resize(frame,(int(width/2),int(height/2)),interpolation = cv2.INTER_AREA) # jpgに変換 画像ファイルをインターネットを介してAPIで送信するのでサイズを小さくしておく small = cv2.resize(frame, (int(width * scale_factor), int(height * scale_factor))) ret, buf = cv2.imencode('.jpg', small) # Amazon RekognitionにAPIを投げる faces = rekognition.detect_faces(Image={'Bytes':buf.tobytes()}, Attributes=['ALL']) # 顔の周りに箱を描画する for face in faces['FaceDetails']: smile = face['Smile']['Value'] cv2.rectangle(frame, (int(face['BoundingBox']['Left']*width/2), int(face['BoundingBox']['Top']*height/2)), (int((face['BoundingBox']['Left']/2+face['BoundingBox']['Width']/2)*width), int((face['BoundingBox']['Top']/2+face['BoundingBox']['Height']/2)*height)), green if smile else red, frame_thickness) emothions = face['Emotions'] i = 0 score = 0 for emothion in emothions: if emothion["Type"] == "HAPPY": score = score + emothion["Confidence"] elif emothion["Type"] == "DISGUSTED": score = score - emothion["Confidence"] elif emothion["Type"] == "SURPRISED": score = score + emothion["Confidence"] elif emothion["Type"] == "ANGRY": score = score - emothion["Confidence"] elif emothion["Type"] == "CONFUSED": score = score - emothion["Confidence"] elif emothion["Type"] == "CALM": score = score - emothion["Confidence"] elif emothion["Type"] == "SAD": score = score - emothion["Confidence"] i += 1 if i == 7: cv2.putText(frame, "interested" +":"+ str(round(score,2)), (int(face['BoundingBox']['Left']*width/2), int(face['BoundingBox']['Top']*height/2)), fontface, fontscale, color) # 結果をディスプレイに表示 cv2.imshow('frame', frame) cv2.waitKey(0) cv2.destroyAllWindows()画像の読み込み自体にはOpenCVを用いました。
Amazon RekognitionはHAPPY,DISGUSETED,SURPRISED,ANGRY,CONFUSED,CALM,SADの6つの感情が読み取れるのでHAPPYとSURPRISEDをプラスの感情(興味度高)、その他の感情をマイナスの感情(興味度低)として計算をしていき最終的に-100~100の範囲で興味度を認識した顔の上に表示するようにしました。
zoomで人を集められなかったため人の画像をお借りしています。
https://tanachannell.com/4869Amazon Rekognitionにはほかにも機能があるので是非興味のある方は見てみてください!
https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.html問題点
・zoomの参加人数が大人数の場合表示される文字同士が重なってしまいとても見づらくなってしまう。
・Zoom画面のキャプチャではないため実行してすぐにコマンドプロンプトを最小化しなければ画像にコマンドプロンプトが写ってしまう。最後に
せっかく作ったのだから人に見てもらいたい!という思いで書き始めましたが、書いてると自分が作っている間の追体験ができ、勉強になりました。
自分がこんな風に作ったものが世の中に浸透していったらとても楽しいかもしれませんね!
- 投稿日:2020-11-17T19:25:35+09:00
AWS BeanstalkでLaravelをデプロイするときにCloudwatch Logsにログを転送する
前提のBeanstalk環境
PHP 7.4 running on 64bit Amazon Linux 2/3.1.3
やること
- lavavel.logのパーミッション設定
- EC2にCloudwatch Logsのロググループ作成のためのサービスロールを追加
- 設定ファイル(.ebextensions)の作成
1. lavavel.logのパーミッション設定
$ chmod 0664 /var/www/html/storage/logs/laravel.log2. lavavel.logのパーミッション設定
- Beanstalk環境のIAM インスタンスプロフィールに設定されているIAMロールに、CloudWatchLogsFullAccessのポリシーを追加 (Codepipelineでデプロイしている場合は、そのロールにも同様にCloudWatchLogsFullAccessのポリシーを追加)
3. 設定ファイル(.ebextensions)の作成
- PHP Platformでデフォルトで追加されるログの設定
参考: https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/AWSHowTo.cloudwatchlogs.html
.ebextensions/4-eblog.configoption_settings: - namespace: aws:elasticbeanstalk:cloudwatch:logs option_name: StreamLogs value: true - namespace: aws:elasticbeanstalk:cloudwatch:logs option_name: DeleteOnTerminate value: false - namespace: aws:elasticbeanstalk:cloudwatch:logs option_name: RetentionInDays value: 7
- カスタムログでlaravel.logを設定する
.ebextensions/5-laravellog.configpackages: yum: awslogs: [] files: "/etc/awslogs/awscli.conf" : mode: "000600" owner: root group: root content: | [plugins] cwlogs = cwlogs [default] region = `{"Ref":"AWS::Region"}` "/etc/awslogs/awslogs.conf" : mode: "000600" owner: root group: root content: | [general] state_file = /var/lib/awslogs/agent-state "/etc/awslogs/config/logs.conf" : mode: "000600" owner: root group: root content: | [/var/www/html/storage/logs/laravel_log] log_group_name = `{"Fn::Join":["/", ["/aws/elasticbeanstalk", { "Ref":"AWSEBEnvironmentName" }, "var/www/html/storage/logs/laravel_log"]]}` log_stream_name = {instance_id} file = /var/www/html/storage/logs/laravel* commands: "01": command: systemctl enable awslogsd.service "02": command: systemctl restart awslogsd
- 投稿日:2020-11-17T17:34:32+09:00
TypeScript な サーバーレス Nuxt を API Gateway で動かす
TypeScript + Nuxt + API Gateway + AWS SAM
いちばん最後に構成図があります。(でかいので最後)
近頃では SSR よりも SSG という風潮ですが、公開速度が求められるケースでは SSG だと実現できないこともあるわけで。いまさらながら Nuxt.js を AWS Lambda + API Gateway で実行するまでのやり方を記録として残しておきます。
あと、この構成のメリットは、めちゃくちゃ安いことです。全体のコストとしては CloudFront の料金が支配的で、アクセス量によっては月額 1,000 円以内に収まります。
ぶっちゃけ、よほど Nuxt, TypeScript, AWS に自信がないかぎりやらない方がいいです。モジュール 1 つ追加するだけでも相当な Try & Error だし、切り分けがしんどいし、インフラコストに 1,000 円もかけられないんだ!という人以外には本当にオススメしません。自分は全部かなり自信がある人ですが、それでもめちゃくちゃしんどかったです。
序盤はおもにパッケージサイズとの戦いの記録です。中盤は Nuxt の API との戦い、終盤は AWS との戦いになります。
成果物はここ(記事と若干の乖離があるけど) => https://github.com/sonodar/nuxt-serverless-app
ちなみにまだ微妙に書き途中。
プロジェクト作成
プロジェクトを 1 から作る場合は
create-nuxt-appで作成するのが楽です。yarn create nuxt-app nuxt-serverless-app create-nuxt-app v3.4.0 ✨ Generating Nuxt.js project in nuxt-serverless-app ? Project name: nuxt-serverless-app ? Programming language: TypeScript ・・・(1) ? Package manager: Yarn ? UI framework: None ? Nuxt.js modules: ? Linting tools: ESLint, Prettier, Lint staged files ? Testing framework: None ? Rendering mode: Universal (SSR / SSG) ・・・(2) ? Deployment target: Server (Node.js hosting) ・・・(3) ? Development tools: (Press <space> to select, <a> to toggle all, <i> to invert selection) ? Continuous integration: None ? Version control system: Gitポイントは、
Programming languageで必ずTypeScriptを選択すること。これを選択しないで後からTypeScriptを追加するのは意外と面倒です。あとUniversal (SSR / SSG)とServer (Node.js hosting)も必須ですが, 間違えても簡単に直せます。他の選択肢は任意です。個人的には、既存のプロジェクトをマイグレーションする場合でも, 先に
create-nuxt-appで雛形を作成してから components などのファイルをコピーして適宜修正しています。足回りを実装し直すよりも楽なことが多いので。特に ESLint とかはバージョンによって全然変わるし辛い。すでに大規模なシステムではできないと思いますけど。srcDir 変更
サーバーサイドのソースコードは nuxt とは完全に分離する必要があるため,
srcDirを変更して nuxt 管理のソースをnuxt-src, Lambda で実行されるサーバーサイドをserverとします。mkdir nuxt-src mv assets components layouts middleware pages plugins static store nuxt-src/nuxt.config.jsexport default { + srcDir: './nuxt-src',tsconfig.json の
pathsも忘れずに変更します。
~をnuxt-srcに,~~をプロジェクトルートにマッピングします。
プロジェクトルートのマッピングはserverMiddlewareにパスを追加する際に絶対に必要です。ないと nuxt がserverMiddlewareを解決できません。tsconfig.json"paths": { "~/*": [ - "./*" + "./nuxt-src/*" ], - "@/*": [ + "~~/*": [ "./*" ] },最初からある
@は邪悪なので消します。scssでは~しか使えないので, 表記を統一するため@は毎回消しています。既存プロジェクトで、すでに利用している場合は~と同じ修正をします。jest.config.js がある場合は,
moduleNameMapperやcollectCoverageFromも忘れずに修正します。Lambda ハンドラーの作成
Lambda 関数も TypeScript で実装したいので
webpackをインストールします。webpack や rollup のようなバンドラーを利用しないと Lambda 関数のデプロイパッケージがあっという間に上限の 50 MB を超えるためバンドラーは必須です。nuxt に webpack は含まれているので, cli と loader のみを追加します。
yarn add -D webpack-cli ts-loaderaws-serverless-express を利用した Lambda 関数を実装するために必要なファイルを揃えます。
expressなどはwebpackでバンドルするので, 依存はすべてdevDependenciesに入れます。yarn add -D express @types/express cors @types/cors yarn add -D aws-serverless-express @types/aws-serverless-express @types/aws-lambda # 以下は必要に応じて yarn add -D cookie-parser @types/cookie-parserまた、
nuxtパッケージそのものは babel などに依存があり, パッケージサイズが肥大化するため,nuxt-startを別途インストールして node_modules の容量を削減します。まず、
package.jsonのdependenciesをすべてdevDependenciesに移動します。package.json- "dependencies": { - "@nuxt/typescript-runtime": "^2.0.0", - "core-js": "^3.6.5", - "nuxt": "^2.14.6" - }, + "dependencies": {}, "devDependencies": { "@nuxt/types": "^2.14.6", "@nuxt/typescript-build": "^2.0.3", + "@nuxt/typescript-runtime": "^2.0.0", "@nuxtjs/eslint-config": "^3.1.0", "@nuxtjs/eslint-config-typescript": "^3.0.0", "@nuxtjs/eslint-module": "^2.0.0", @@ -35,6 +31,7 @@ "@types/express": "^4.17.8", "aws-serverless-express": "^3.3.8", "babel-eslint": "^10.1.0", + "core-js": "^3.6.5", "eslint": "^7.10.0", "eslint-config-prettier": "^6.12.0", "eslint-plugin-nuxt": "^1.0.0", @@ -42,6 +39,7 @@ "express": "^4.17.1", "husky": "^4.3.0", "lint-staged": "^10.4.0", + "nuxt": "^2.14.6",yarn add nuxt-start@2.14.7 # バージョンは nuxt に合わせる
@nuxtjs/axiosなど, nuxt の module や plugin も dependencies に含める必要があります。Lambda やサーバーサイドのソース用に
serverディレクトリを作成します。mkdir serverLambda 関数のハンドラーを実装します。プログラマティックに Nuxt を扱う方法は公式サイトにありますが, 現時点では TypeScript の型定義はないので自前で用意します。
また, 公式サイトにあるようなnuxtではなくnuxt-startを利用します。server/nuxt-start.d.tsdeclare module 'nuxt-start' { const loadNuxt: (command: string) => Promise<any> }express のインスタンス生成は別ファイルでやります。このファイルは、後に
serverMiddlewareとしても利用可能なように, express のインスタンスを default export します。(必ず default で export します)server/index.tsimport express from 'express' import cors from 'cors' const app = express() app.use(express.json()) app.use(express.urlencoded({ extended: true })) // express の動作確認用に API のエンドポイントを追加しておきます const apiRouter = express.Router() apiRouter.use(cors()) apiRouter.post('/echo', (req, res) => res.json(req.body)) app.use('/api', apiRouter) export default appこれにより、ローカル開発では通常の express アプリケーションとして
serverMiddlewareで扱うことができ, 開発効率が大幅に向上します。server/lambda.tsimport http from 'http' import { APIGatewayProxyHandler } from 'aws-lambda' import awsServerlessExpress from 'aws-serverless-express' import awsServerlessExpressMiddleware from 'aws-serverless-express/middleware' import { loadNuxt } from 'nuxt-start' import app from './index' const binaryMimeTypes = [ 'application/javascript', // 'application/json', 'application/octet-stream', 'application/xml', 'font/eot', 'font/opentype', 'font/otf', 'image/jpeg', 'image/png', 'image/svg+xml', 'text/comma-separated-values', 'text/css', 'text/html', 'text/javascript', 'text/plain', 'text/text', 'text/xml', ] let server: http.Server async function createServer(): Promise<http.Server> { const nuxt = await loadNuxt('start') app.use(awsServerlessExpressMiddleware.eventContext()) app.use(nuxt.render) server = awsServerlessExpress.createServer(app, undefined, binaryMimeTypes) return server } // ここでは async function 不可 export const handler: APIGatewayProxyHandler = (event, context) => { createServer().then((server) => awsServerlessExpress.proxy(server, event, context) ) }Lambda 関数の TypeScript トランスパイル用に webpack.config.js を作成します。
ポイントは, 出力先を.nuxt/distディレクトリにすることと,externalsにnuxt-startを含めることです。webpack.config.jsconst path = require('path') module.exports = { mode: 'production', entry: { lambda: path.resolve(__dirname, './server/lambda.ts'), }, output: { path: path.resolve(__dirname, './.nuxt/dist'), filename: '[name].js', libraryTarget: 'commonjs', }, target: 'node', externals: ['nuxt-start'], module: { rules: [ { test: /\.ts$/, use: 'ts-loader', exclude: /node_modules/, }, ], }, resolve: { extensions: ['.ts', '.js'], }, }nuxt build 後に webpack が走るように postbuild を package.json に追加します。
package.json"scripts": { "dev": "nuxt-ts", "build": "nuxt-ts build", + "postbuild": "webpack", "start": "nuxt-ts start",試しに build してみます。
yarn buildこのままだと以下のように
Error: TypeScript emitted no outputというエラーが出ます。ERROR in ./server/lambda.ts Module build failed (from ./node_modules/ts-loader/index.js): Error: TypeScript emitted no output for /Users/ryohei-sonoda/git/nuxt-serverless-app/server/lambda.ts. at makeSourceMapAndFinish (/Users/ryohei-sonoda/git/nuxt-serverless-app/node_modules/ts-loader/dist/index.js:53:18) at successLoader (/Users/ryohei-sonoda/git/nuxt-serverless-app/node_modules/ts-loader/dist/index.js:40:5) at Object.loader (/Users/ryohei-sonoda/git/nuxt-serverless-app/node_modules/ts-loader/dist/index.js:23:5) error Command failed with exit code 1. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.tsconfig.json で
noEmitをfalseにします。tsconfig.json"strict": true, - "noEmit": true, + "noEmit": false, "experimentalDecorators": true,これでビルドが通ります。
最後に, nuxt.config.js で
serverMiddlewareを追加します。nuxt.config.js// Build Configuration (https://go.nuxtjs.dev/config-build) build: {}, + + serverMiddleware: ['~~/server/index.ts'], }まず、ローカルで express が動作するか確認します。
yarn dev127.0.0.1:3000 で LISTEN されるので, 先程生やした動作確認用のエンドポイントに POST してみます。
curl -v -H "Content-Type: application/json" localhost:3000/api/echo -d '{"message":"hoge"}'* Trying 127.0.0.1... * TCP_NODELAY set * Connected to localhost (127.0.0.1) port 3000 (#0) > POST /api/echo HTTP/1.1 > Host: localhost:3000 > User-Agent: curl/7.54.0 > Accept: */* > Content-Type: application/json > Content-Length: 18 > * upload completely sent off: 18 out of 18 bytes < HTTP/1.1 200 OK < X-Powered-By: Express < Content-Type: application/json; charset=utf-8 < Content-Length: 18 < ETag: W/"12-HG8TY3NadWW3zeWB3QbSQHxbAxc" < Date: Thu, 05 Nov 2020 14:16:51 GMT < Connection: keep-alive < * Connection #0 to host localhost left intact {"message":"hoge"}ローカルではちゃんと nuxt の
serverMiddlewareとして機能しています。Lambda アップロードパッケージ作成
続いて, パッケージ作成処理です。
ビルドしたファイルのうち、含めるのは以下のみです。
- .nuxt/dist/server/
- .nuxt/dist/client/
- .nuxt/dist/lambda.js
- node_modules/
assets を CloudFront で配信するので,
.nuxt/dist/clientは実質不要になる。手順の便宜上ここでは含める。# devDependencies のパッケージを node_modules から削除 yarn install --production zip -rq upload.zip .nuxt/dist node_modulesだいたい 8 MB くらいのサイズになります。なお,
nuxt-startではなくnuxtをそのまま使うと 31 MB にもなります。なお, 自分の場合, 毎回 devDependencies を削除していたら開発スピードが落ちるので, パッケージの作成は docker コンテナ上で実施しています。利用している docker イメージは
lambci/lambda:build-nodejs12.xです。sam テンプレート作成
sam のテンプレートを作成します。ここでは 2 ファイルのみなので
sam initコマンドは使いません。template.ymlAWSTemplateFormatVersion: 2010-09-09 Description: Serverless Nuxt App Transform: - AWS::Serverless-2016-10-31 Resources: NuxtApi: Type: AWS::Serverless::Api Properties: Name: serverless-nuxt-app StageName: v1 NuxtFunction: Type: AWS::Serverless::Function Properties: FunctionName: serverless-nuxt-app CodeUri: ./upload.zip Handler: .nuxt/dist/lambda.handler Runtime: nodejs12.x MemorySize: 512 Timeout: 10 Description: Serverless Nuxt App Environment: Variables: NODE_ENV: production Events: Root: Type: Api Properties: Path: "/" Method: any RestApiId: !Ref NuxtApi Nuxt: Type: Api Properties: Path: "/{proxy+}" Method: any RestApiId: !Ref NuxtApi # Lambda 関数用の CloudWatch LogGroup # あらかじめ作成してログ保持日数が指定しておく NuxtFunctionLog: Type: AWS::Logs::LogGroup Properties: LogGroupName: /aws/lambda/serverless-nuxt-app RetentionInDays: 7 Outputs: ApiEndpoint: Description: "API Gateway endpoint URL" Value: !Sub "https://${NuxtApi}.execute-api.${AWS::Region}.amazonaws.com/v1/"この状態でローカル実行してみます。
sam local start-api127.0.0.1:3000 で起動したというメッセージが出てきます。
Mounting NuxtFunction at http://127.0.0.1:3000/{proxy+} [DELETE, GET, HEAD, OPTIONS, PATCH, POST, PUT] Mounting NuxtFunction at http://127.0.0.1:3000/ [DELETE, GET, HEAD, OPTIONS, PATCH, POST, PUT] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-11-05 23:27:53 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)で、ブラウザで http://127.0.0.1:3000 にアクセスすると、しばらくたって以下の様な 200 OK のログが出ます。
Invoking .nuxt/dist/lambda.handler (nodejs12.x) Decompressing /Users/ryohei-sonoda/git/nuxt-serverless-app/upload.zip Failed to download a new amazon/aws-sam-cli-emulation-image-nodejs12.x:rapid-1.1.0 image. Invoking with the already downloaded image. Mounting /private/var/folders/x2/_5zc52s57jv5vsjrg3hxnwqr0000gp/T/tmp597u_xzy as /var/task:ro,delegated inside runtime container START RequestId: 674bfa66-7dee-1b63-3f58-afbc633de810 Version: $LATEST END RequestId: 674bfa66-7dee-1b63-3f58-afbc633de810 REPORT RequestId: 674bfa66-7dee-1b63-3f58-afbc633de810 Init Duration: 937.57 ms Duration: 3220.72 ms Billed Duration: 3300 ms Memory Size: 512 MB Max Memory Used: 98 MB 2020-11-05 23:28:15 127.0.0.1 - - [05/Nov/2020 23:28:15] "GET / HTTP/1.1" 200 -でもブラウザは真っ白もしくはエラー画面です。
curl で確認してみると Base64 にエンコードされた HTML が返り, ブラウザではデコードできずにエラーになっています。* Rebuilt URL to: localhost:3000/ * Trying 127.0.0.1... * TCP_NODELAY set * Connected to localhost (127.0.0.1) port 3000 (#0) > GET / HTTP/1.1 > Host: localhost:3000 > User-Agent: curl/7.54.0 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < x-powered-by: Express < etag: "e93-aSp1uNPhobCrmddhNg5VzLYfihY" < content-type: text/html; charset=utf-8 < accept-ranges: none < content-length: 3731 < vary: Accept-Encoding < date: Thu, 05 Nov 2020 14:46:43 GMT < connection: close < Server: Werkzeug/1.0.1 Python/3.7.8 < * Closing connection 0 PCFkb2N0eXBlIGh0bWw+CjxodG1sIGRhdGEtbi1oZWFkLXNz...現状はおとなしく
sam local start-apiでのブラウザ確認を諦めるしかありません。最初から deflate 圧縮しちゃえばバイナリ扱いになってイケるかな?と思って
compressionパッケージを試しましたが, compression された後に Base64 エンコードされるので結局ダメでした。デプロイの設定を samconfig.toml に書きます。
samconfig.tomlversion = 0.1 [default] [default.deploy] [default.deploy.parameters] stack_name = "serverless-nuxt-app" s3_bucket = "your-bucket-name" s3_prefix = "sam-src/serverless-nuxt-app" region = "ap-northeast-1" capabilities = "CAPABILITY_IAM"デプロイします。
cd sam export AWS_ACCESS_KEY_ID=your-aws-access-key-id export AWS_SECRET_ACCESS_KEY=your-aws-secret-access-key sam deployCloudFormation outputs from deployed stack ---------------------------------------------------------------------------------------------------------------------------------------------- Outputs ---------------------------------------------------------------------------------------------------------------------------------------------- Key ApiEndpoint Description API Gateway endpoint URL Value https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1/ ---------------------------------------------------------------------------------------------------------------------------------------------- Successfully created/updated stack - serverless-nuxt-app in ap-northeast-1出力された ApiEndpoint にブラウザでアクセスすると, 無事に nuxt の画面が表示されました。
axios モジュールを試す
せっかく動作確認用の API があるので, axios モジュールをインストールして
asyncDataで実行してみます。yarn add @nuxtjs/axiosnuxt.config.js// Modules (https://go.nuxtjs.dev/config-modules) - modules: [], + modules: ['@nuxtjs/axios'],これだけだと
$axiosが認識されないので, tsconfig.json に追記。tsconfig.json}, "types": [ "@types/node", - "@nuxt/types" + "@nuxt/types", + "@nuxtjs/axios" ] },トップページで echo API を実行してレスポンスを画面表示する処理を追記。
nuxt-src/pages/index.vue<div> <Logo /> <h1 class="title">nuxt-serverless-app</h1> + <pre>{{ data }}</pre> <div class="links"> <a href="https://nuxtjs.org/" @@ -27,8 +28,14 @@ <script lang="ts"> import Vue from 'vue' +import { Context } from '@nuxt/types' -export default Vue.extend({}) +export default Vue.extend({ + async asyncData(ctx: Context) { + const { data } = await ctx.$axios.post('/api/echo', { message: 'hoge' }) + return { data: JSON.stringify(data) } + }, +}) </script> <style>ローカルで実行(
yarn dev)してみます。ちゃんと{"message":"hoge"}が表示されます。
デプロイしてみる。
rm -rf .nuxt upload.zip yarn build yarn install --production zip -rq upload.zip .nuxt/dist node_modules sam deployダメでした。Internal Server Error になります。Lambda のログを確認。
{ "errorType": "Runtime.UnhandledPromiseRejection", "errorMessage": "Error: connect ECONNREFUSED 127.0.0.1:3000", "reason": { "message": "connect ECONNREFUSED 127.0.0.1:3000", "name": "Error", "stack": "Error: connect ECONNREFUSED 127.0.0.1:3000\n at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1141:16)", "config": { ...axios で
127.0.0.1:3000に繋ぎにいってる。Lambda では LISTEN プロセスがいるわけではないので, 当然これだとエラーになる。なので
baseURLを指定してあげればいい。環境変数から渡すようにしよう。nuxt.config.js// Modules (https://go.nuxtjs.dev/config-modules) modules: ['@nuxtjs/axios'], + + axios: { + baseURL: process.env.BASE_URL || 'http://localhost:3000', + }, + // Build Configuration (https://go.nuxtjs.dev/config-build) - build: {}, + build: { + publicPath: (process.env.BASE_URL || '') + '/_nuxt/', + }, + + router: { + base: (process.env.BASE_PATH || '') + '/', + },ついでに忘れてた
publicPathとrouter.baseも修正。API Gateway の場合, 必ずステージ名が URL の末尾にパスとして追加されるので, これをしないと相対パスが解決できずに画像や js が読み込めなくなる。例えば
/_nuxt/assets/hoge.imgの場合
https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1/_nuxt/assets/hoge.img
が正解なのに
https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/_nuxt/assets/hoge.img
になっちゃう。API Gateway みたいに baseURL がサブディレクトリで終わらなければ無問題。template.ymlEnvironment: Variables: NODE_ENV: production + BASE_PATH: /v1/ + BASE_URL: !Sub "https://${NuxtApi}.execute-api.${AWS::Region}.amazonaws.com/v1/"rm -rf .nuxt upload.zip yarn build yarn install --production zip -rq upload.zip .nuxt/dist node_modules sam deploysam のエラー。循環参照になってるからダメだよって。
Error: Failed to create changeset for the stack: sonoda-nuxt-api-test, ex: Waiter ChangeSetCreateComplete failed: Waiter encountered a terminal failure state Status: FAILED. Reason: Circular dependency between resources: [NuxtFunctionRootPermissionv1, NuxtFunction, NuxtApiDeploymentb5e0e7a20a, NuxtFunctionNuxtPermissionv1, NuxtApi, NuxtApiv1Stage]仕方ないので, ベタ書き。どうせ後でドメインを割り当てるんだから, いったんはこれで行く。
template.ymlEnvironment: Variables: NODE_ENV: production BASE_PATH: /v1/ - BASE_URL: !Sub "https://${NuxtApi}.execute-api.${AWS::Region}.amazonaws.com/v1/" + BASE_URL: https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1で, デプロイして動作確認すると・・・, 同じエラー
connect ECONNREFUSED 127.0.0.1:3000どうやら
nuxt.config.jsでのprocess.envはビルド時の環境変数を参照して, 出力されたファイルに埋め込まれるようだ。なので、ビルド時に指定する。template.yml は戻しておく。
template.ymlEnvironment: Variables: NODE_ENV: production - BASE_PATH: /v1/ - BASE_URL: https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1rm -rf .nuxt upload.zip # ビルドの前に指定 export BASE_PATH=/v1/ export BASE_URL=https://xxxxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/v1 yarn build yarn install --production zip -rq upload.zip .nuxt/dist node_modules sam deploy今度はうまくいきました。
TODO 以下、書きかけ
CloudFront 経由にする場合、axios モジュールは via ヘッダを削除する
https://qiita.com/ykunimoto/items/9509aad5f024cb547fb1
https://qiita.com/kubotak/items/fc1a877f99a569fc54bbyarn add axios する
@nuxtjs/axiosだけだと dependencies に含まれているはずなのにaxiosが認識されない。(未調査)参考リンク
- https://qiita.com/hiroyky/items/298e8a475dcd6dc70727
- https://github.com/sketchnotes/nuxt-express-ts
- https://github.com/tonyfromundefined/nuxt-serverless
実際の構成図
- Directus という OSS の Headless CMS を利用しています。ここは Contentful や microCMS でも問題ないです。
- 実際の構成では CMS が VPC にいるので、Lambda も VPC に入れています。
- 1 つの CloudFront でパスを分けて 3 つのオリジンを構成しています。
- キャッシュクリアにキューを使っている主な目的はバッファリングのためです。



- 投稿日:2020-11-17T16:53:21+09:00
ELBのポートを考える
はじめに
ELBでやたらにポート番号が聞かれて少し混乱してしまったので、備忘録的にまとめておきます。
また、今回はこちらの記事を参考にまとめさせてもらいました。
間違えて解釈していることが十分にあるので、随時ご指摘いただけたら非常に嬉しいです!対象読者
- AWSアカウントを持っている方。
- ELBの使い方があやふやな人。
ELB
前回書いた記事に構築の仕方は書いているので、今回は、それぞれがどの様な設定を行っているかをまとめられたらと思っています。
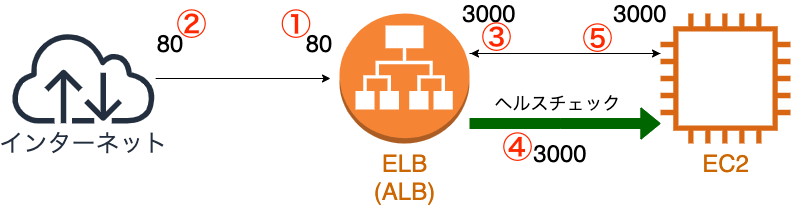
ELBの仕事
ELBの主な仕事は、以下のチャートで表すことができます。
今回は簡単のため、行先のインスタンスはEC2を1つだけとして考えます。
上のチャートの様に基本的に決めなければいけないポートは
- ELBの外部向けのポート
- 外部からの通信に用いるポート
- ELBの内部向けのポート
- ヘルスチェック時に見るポート
- ターゲットグループが開いているポート
になります。
実際に、 ELBを構築しながら確認していきます。
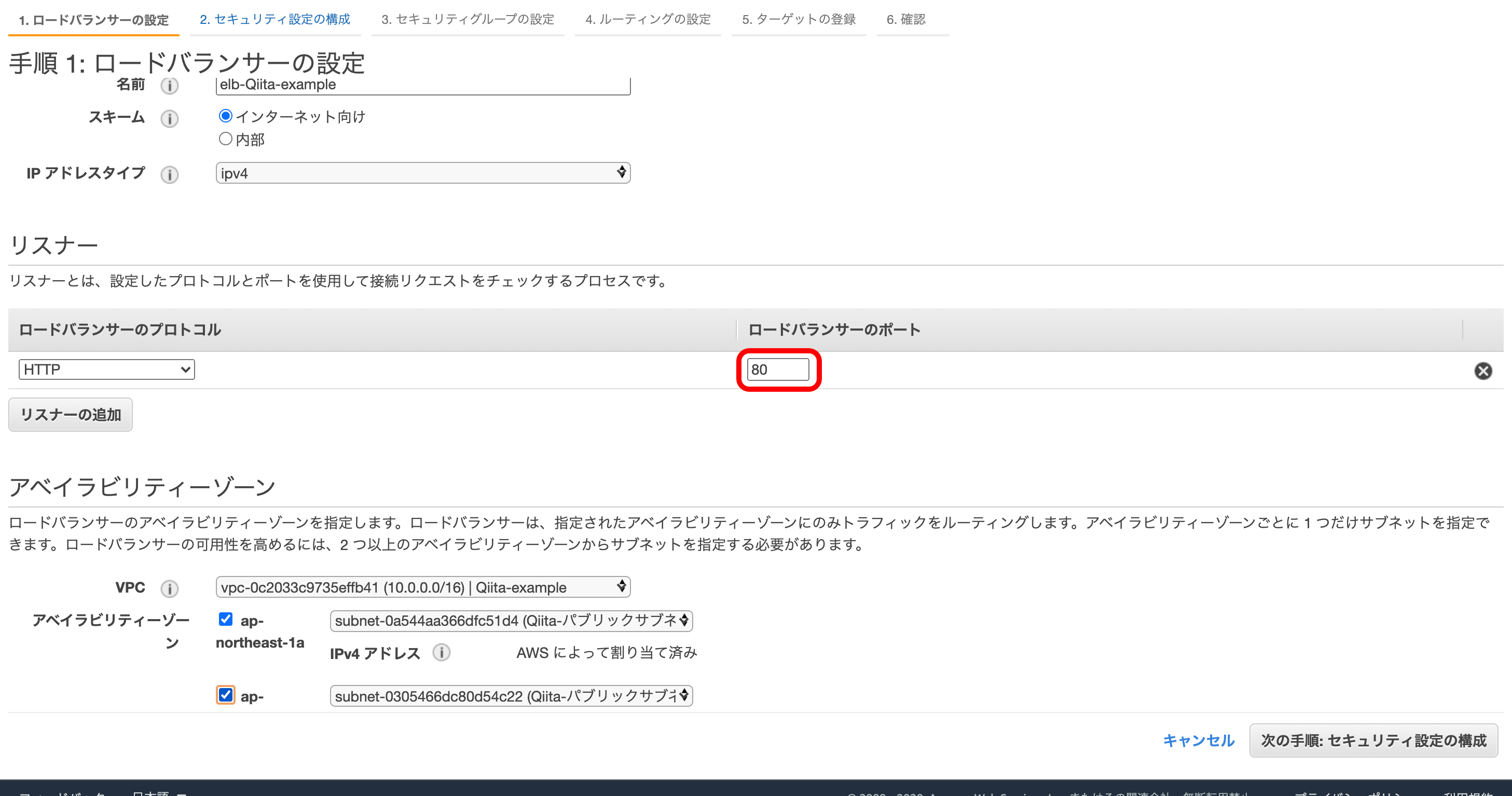
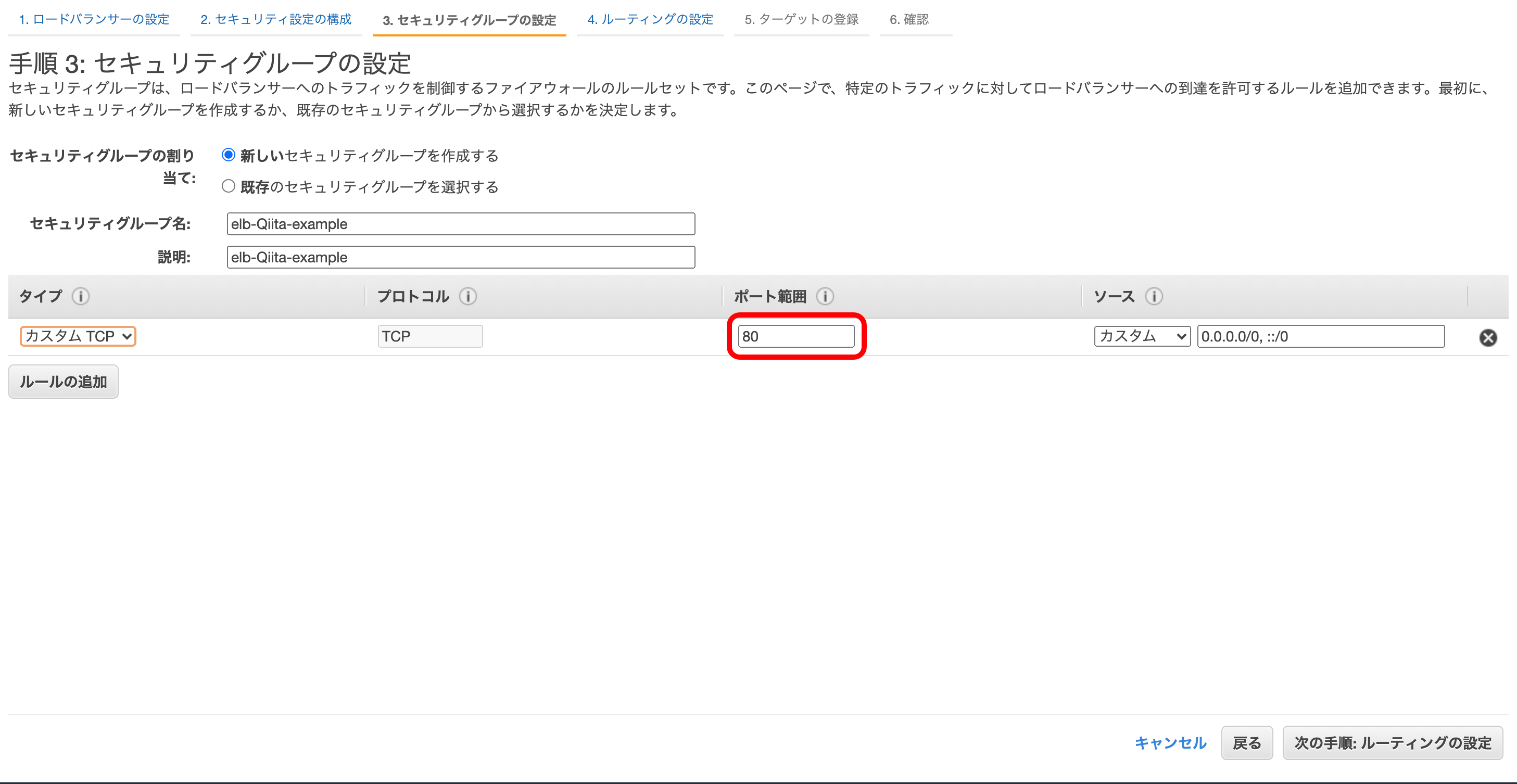
今回はALBとして考えていきます。① ELBの外部向けのポート
ここで、ELBの外部に向けポートを決めます。
リスナーとは『データを送信してくる相手』という意味です。
httpは慣例的に80番を使うので、今回もそれに倣って『HTTP』『80』にしておきます。
② 外部からの通信に用いるポート
ここで、『どこからの通信に対して許可をするのか』を決めます。
先ほど行った通り、http通信は慣例的に80番を使うので『カスタムTCP』『80』にしておきます。
※補足
上の様に、そのインスタンスに対するアクセスを規制するセキュリティグループをインバウンドルールといいます。
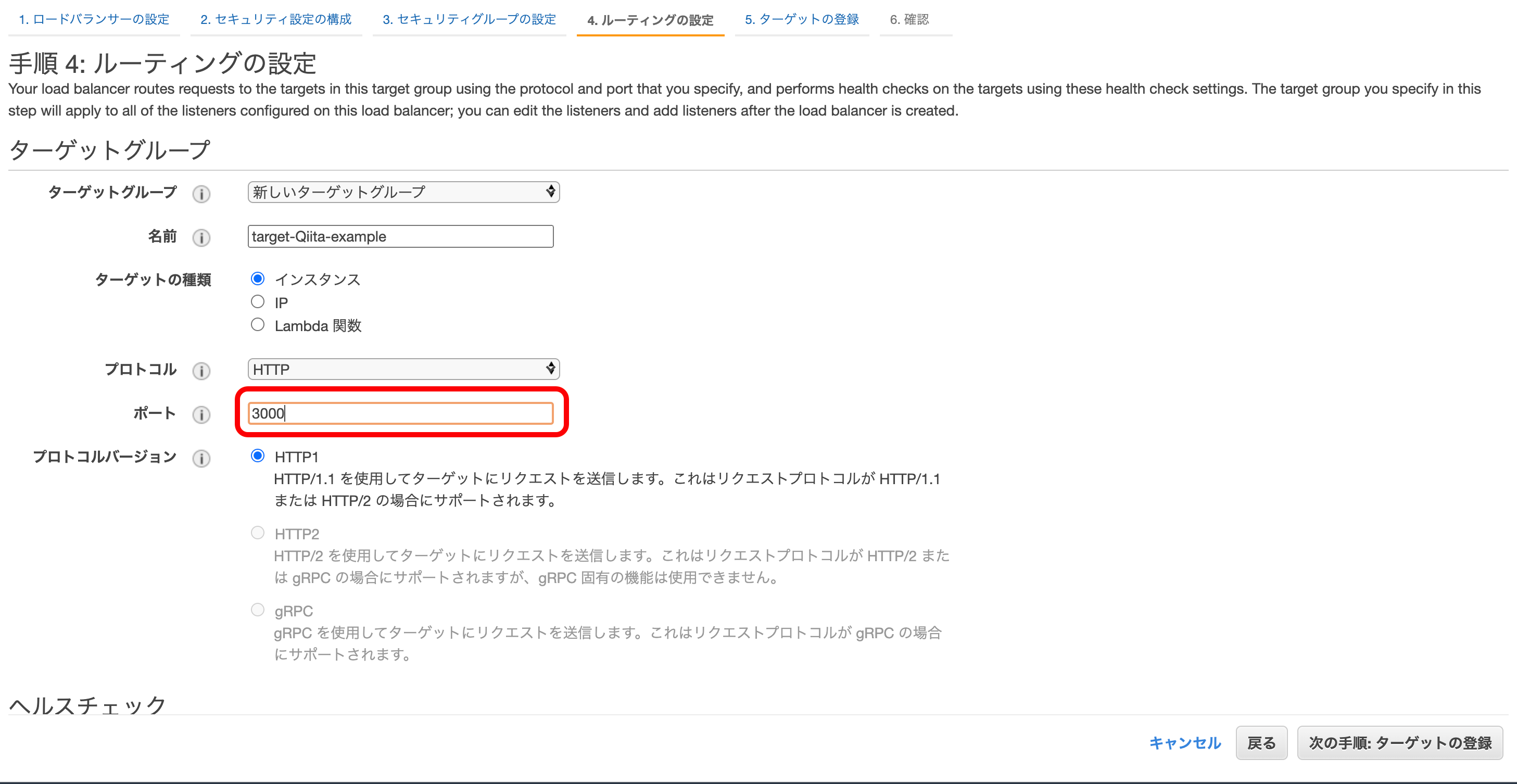
その逆に、そのインスタンスのデータ送信を規制することセキュリティグループをアウトバウンドルールといいます。③ ELBの内部向けのポート
ターゲットグループとはデータを送信する相手のことです。
今回、ターゲットグループであるEC2は3000を開けているとしているので、こちらも『3000』を開けます。
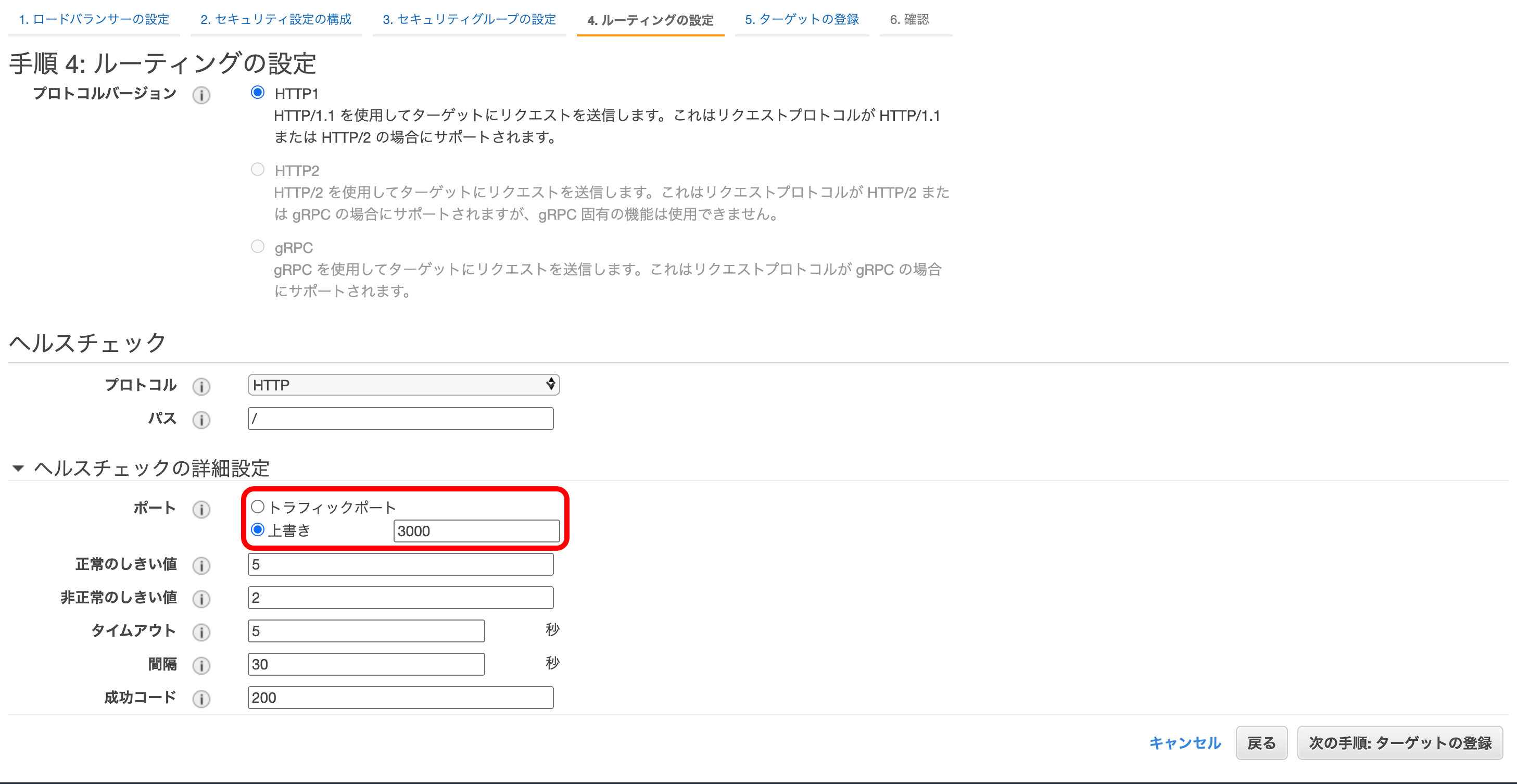
④ ヘルスチェック時に見るポート
ヘルスチェックとは、インスタンスが正常に機能しているかどうかを調べるシステムです。
デフォルトでは、③で決めたポートと同じ行先を見るのですが、今回はわざと明示的に設定します。
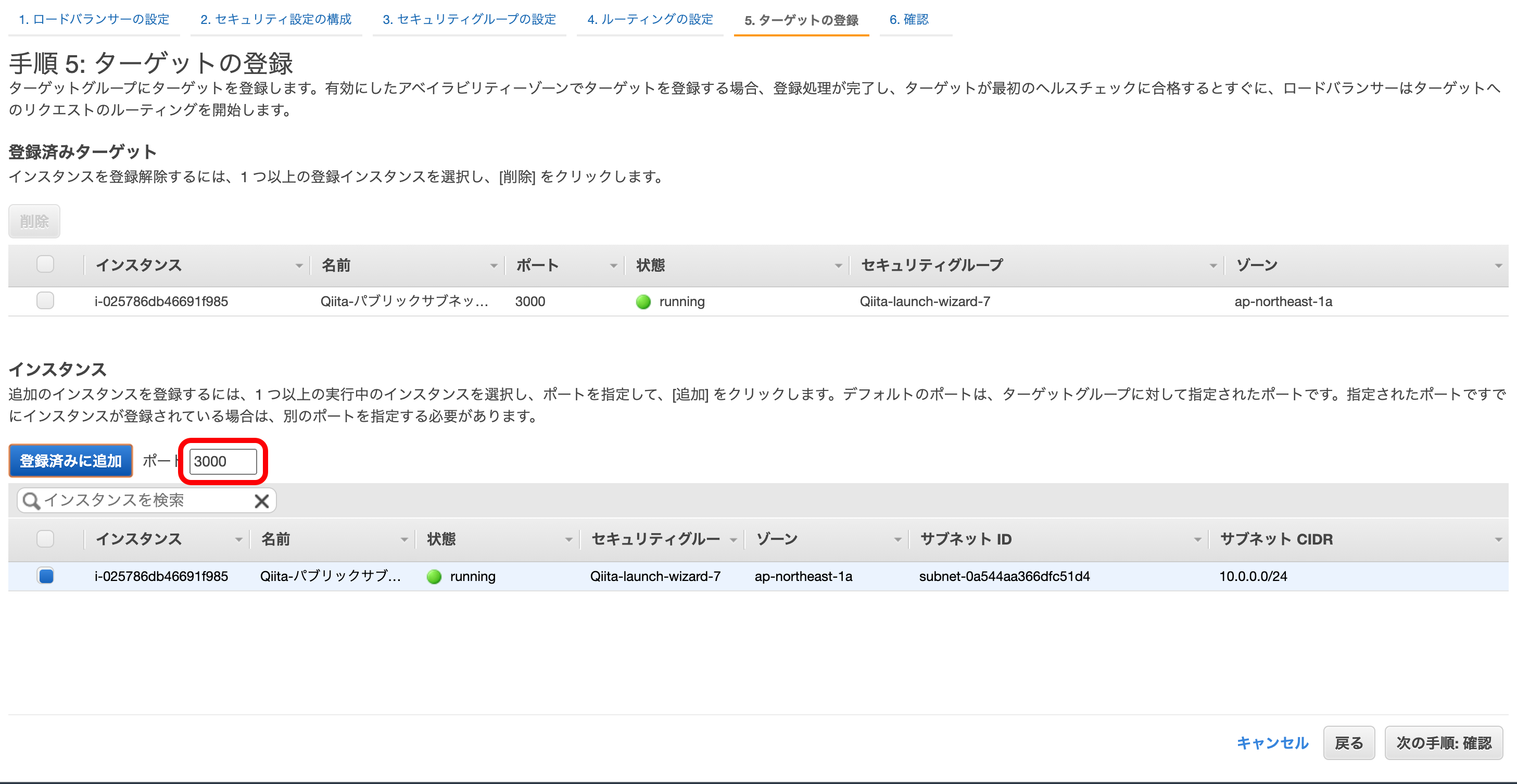
⑤ ターゲットグループが開いているポート
ターゲットグループが開いているポートをここで設定します。
デフォルトでは、④と同じポート番号になっています。
まとめ
httpsの時の挙動も今後調べていこうと思います。
- 投稿日:2020-11-17T15:58:39+09:00
Manajro Linuxにaws-session-manager-pluginをインストールする方法
yay aws-session-manager-plugin
- 投稿日:2020-11-17T14:42:00+09:00
[AWS CloudFormation] S3イベント通知先にLambdaを設定(循環依存回避)
循環依存の発生
以下のようにS3バケットに通知設定を行い、
オブジェクトが生成されたことをトリガにLambdaを実行しようとした場合、
互いのリソースを参照しており循環依存でデプロイエラーとなる# S3バケット testBucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub ${RootStackName}-test-bucket NotificationConfiguration: # 通知設定 LambdaConfigurations: - Event: 's3:ObjectCreated:*' # ** Lambda関数ARN参照 ** Function: !Sub 'arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:function:${RootStackName}-OnDetectFunction' # S3にオブジェクトが生成されたことをトリガに実行されるLambda OnDetectFunction: Type: AWS::Serverless::Function Properties: CodeUri: handlers FunctionName: !Sub ${RootStackName}-OnDetectFunction Policies: - S3ReadPolicy: BucketName: !Ref testBucket # ** S3バケット名を参照 ** # Lambda実行権限をS3に追加 TriggerLambdaPermission: Type: 'AWS::Lambda::Permission' Properties: Action: 'lambda:InvokeFunction' FunctionName: !GetAtt OnDetectFunction.Arn Principal: 's3.amazonaws.com'循環依存の回避
このAWSの回答を参考にする
方法としては、一旦依存関係のない状態(通知設定をしていない状態)でS3バケットを定義し、
カスタムリソースを使用して、LambdaでS3バケットに通知設定を行う
以下が実際に記述したもの# S3バケット testBucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub ${RootStackName}-test-bucket # NotificationConfiguration削除 # S3にオブジェクトが生成されたことをトリガに実行されるLambda OnDetectFunction: Type: AWS::Serverless::Function Properties: CodeUri: handlers FunctionName: !Sub ${RootStackName}-OnDetectFunction Policies: - S3ReadPolicy: BucketName: !Ref testBucket # Lambda実行権限をS3に追加 TriggerLambdaPermission: Type: 'AWS::Lambda::Permission' Properties: Action: 'lambda:InvokeFunction' FunctionName: !GetAtt OnDetectFunction.Arn Principal: 's3.amazonaws.com' # S3バケットにイベント通知設定を追加するためのロール ApplyNotificationFunctionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: lambda.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole Path: / Policies: - PolicyName: S3BucketNotificationPolicy PolicyDocument: Version: '2012-10-17' Statement: - Sid: AllowBucketNotification Effect: Allow Action: s3:PutBucketNotification Resource: - !Sub 'arn:aws:s3:::${testBucket}' - !Sub 'arn:aws:s3:::${testBucket}/*' # カスタムリソース生成時に実行するLambda ApplyBucketNotificationFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${RootStackName}-ApplyBucketNotificationFunction Role: !GetAtt 'ApplyNotificationFunctionRole.Arn' InlineCode: | const AWS = require('aws-sdk'); const S3 = new AWS.S3(); const cfnResponse = require('cfn-response'); exports.handler = async (event, context) => { try { if (event.RequestType !== 'Create') { return await cfnResponse.send(event, context, cfnResponse.SUCCESS); } const params = { Bucket: event.ResourceProperties.S3Bucket, NotificationConfiguration: { LambdaFunctionConfigurations: [ { Events: ['s3:ObjectCreated:*'], LambdaFunctionArn: event.ResourceProperties.FunctionARN }, ], }, }; await S3.putBucketNotificationConfiguration(params).promise(); return await cfnResponse.send(event, context, cfnResponse.SUCCESS, {}, event.PhysicalResourceId); } catch (err) { return await cfnResponse.send(event, context, cfnResponse.FAILED, {}); } }; # カスタムリソース ApplyNotification: Type: Custom::ApplyNotification Properties: ServiceToken: !GetAtt 'ApplyBucketNotificationFunction.Arn' # カスタムリソース生成時に実行するLambda # 以下はカスタムリソース生成時に実行するLambdaに渡すパラメータ S3Bucket: !Ref testBucket # イベント通知設定を追加するS3バケット名 FunctionARN: !GetAtt OnDetectFunction.Arn # イベント通知送信先Lambda注意事項
- CloudFormationに応答を返すためのcfn-responseモジュールは、インライン実装にしか対応していない
cfnResponse.sendで送信しているカスタムリソースの応答オブジェクトが正しくCloudFormationに届かない場合、リソース生成中の状態でハングアップしてしまう(応答を返さないパスがないことを確認する、cfnResponse.sendをawaitで待たない場合もアウト)- リソース生成中の状態でハングアップしてしまったリソースの削除にも1時間程度かかる
- 投稿日:2020-11-17T14:33:18+09:00
AWSの各サービスをかわいらしく紹介するCM動画があったので、再生リストにまとめました。
AWSのサービスを調べている中で、
公式から配信されている、とってもかわいらしいCM動画を見つけました。例: EC2
小難しいイメージがある各サービスを、端的にわかりやすく解説してくれている動画なのですが、
特定のチャンネルにまとめられておらず、網羅的に観るのが難しかったので、再生リストにまとめてみました。まだまだあるよ!という方は、ぜひコメントにて教えていただければと思います。
よろしくお願いいたします。
- 投稿日:2020-11-17T13:22:53+09:00
IT未経験でAWS Solution Architect Associateに合格できた話
Quiitaは初投稿となります。
よろしくお願いいたします。筆者は現在、IT会社に勤めて2年目になります。
去年の2月にAWS SAAに合格したので、
記録もかねて勉強法や当時の技術レベルなどを交えて、記載していきたいと思います。感覚ベースの話が多いと思いますので、概要をざっくり知りたいなどの、
これから受けようと思っている方や、
最近勉強し始めたけど、何となく不安だなと感じている方にはおススメかもしれません。まずは勉強を開始するときの技術レベルです。
▼技術レベル
・AWSの知識
Amazonが関わっているクラウドのサービス?
案件でVPC・EC2・RDSという名称は見るけど、よくわかってない。・インフラの知識
Web三層構成は研修でやったなぁ。
難しくて一人じゃできない。・勉強方法の知識
一夜漬け is 最強 と思っている。当時は、大げさでもなく本当にこのような状態でした。
計画を立てるのはできても、その通りに実行できた試しがなく、自信なんて微塵もありませんでした。▼勉強した期間
・半年実務で4ヶ月くらい何んとなくAWSサービスを触れていって、
本腰入れて詰め込んだのは2か月ほどでした。
一日に約100問ほどをWEB問題集で解いていき、参考書はほとんど使いませんでした。
1日2時間は意地でも守り、土日は絶対に勉強しないというルールを作っていました。▼勉強方法
・WEB問題集をひたすら解くただそれだけをひたすらにやりました。
通勤と退勤の電車の中では携帯でとにかく解いていました。
問題の数をこなしてくると、だんだん後ろから忘れてくるので、新規の問題をこなすのに並行して、
最初から問題を解くことを心掛けました。例)新しい範囲としてNo.10~20まで解いて、その日に前にやったNo.1~5までを解く
*この勉強を進めて1か月後
▼2000円の模擬試験に挑戦
・確か650点くらい目標として、本腰入れて勉強してから1か月半くらいで取ろうとしていたので、
当時かなり焦りました。
間違えた問題をどの分野か項目分けして、弱点を洗い出し、1週間弱点補修の時期にあてました。
弱点補修のやり方も、WEB問題集の解説を読み、
選択肢中で、なぜこれが不正解なのかという観点で勉強を進めました。ちなみに模擬試験は自分のPCで受けれるので、場所はどこでもOKです。
▼WEB問題集の学習状況
・No.125くらいある項目の中で、大体どこをランダムで解いても7割8割くらい正解できるそれは問題を覚えてきたから、と分かりきっているのですが、
高い正答率を見てモチベーションを保っていました。▼2回の試験日変更
・同期のUdemyの問題が難しすぎて焦ったUdemyの問題は比較的難易度が高いとされていますが、あまりにもこたえられなく不安になり、
二回の試験日変更を行いました。※AWSの試験は試験日の変更が"2回"しかできません。
私はそれを知らず、そのうちの1回を、
次の日に試験日をずらすというもったいない使い方をしていました。*試験当日
▼試験時間までに行っていたこと
・問題を解くのをやめ、参考書を本のように読むこの、参考書を本のように読むという行為は、個人的にはかなり効果もあり、
モチベーションが上がりました。
読書として読み進めることで、備えてきた知識の再確認をすることができ、
安心感が高まり、落ち着いて試験に臨めました。試験は申し込んだ会場での試験になります。
私が行った会場は人数が少なく、おじ様と二人で受けました。▼試験結果
・804点で無事合格試験会場は絶対に静かにしなければならないのですが、
絶対に一発で受かりたかったので、さすがに震えました。
最高に嬉しかった記憶があります。WEB問題集の効果ですが、私はこの問題集のみを使用して学習を続けていたため、
効果はかなりあったと思います。
クイズ形式で、回答に簡単な解説が出るタイプがお好きな方はおススメです。
簡単な解説なので、わからない部分はAWS各サービスのブラックベルトなどを見て補いました。▼まとめ
正直あまりお勧めできる勉強方法ではありませんが、
意外と自分に合うと思う方はいらっしゃるのではないか、
と思います。
(学生時代一夜漬けばかりしていた人とか)意識していて正解だったことは、
選択肢の中から不正解のものに対して、
なぜこれは適切ではないのか
というところです。不正解の選択肢を、なぜ不正解なのか自分で導けることによって、
一か八かの選択をしてしまう問題が大いに減りました。
同時にAWS試験を攻略するコツでもあると思いました。文中で私は、絶対に一発で受かりたかったと記しているのですが、
なぜかというと、
AWSの試験料はものすごく高いと思っていたからです。(SAAは¥15000)私は試験料の明細を携帯の壁紙にしていました。効果は個人的にはありました☆
是非お試しください。また、別の資格を取得した際などで、記事を書こうと思います。
最後まで閲覧いただき、ありがとうございました。▼参考URL
・WEB問題集 (SAA対策以外の問題もあります)
https://aws.koiwaclub.com/exam/・AWS模擬試験 (希望のレベルをクリックすると模擬試験の欄があります)
https://aws.amazon.com/jp/certification/certification-prep/・ブラックベルト
(AWSの方がサービスの概要や注意点を、わかりやすくスライドでまとめている資料です)
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
- 投稿日:2020-11-17T12:49:20+09:00
Amazon RDS for PostgreSQLの監査ログをCloudWatch Logsに出力する
はじめに
Amazon RDS for PostgreSQLの監査ログをCloudWatch Logsに出力します。
パラメータグループに設定を変更後、DBにログインしてSQLコマンドを実行します。パラメータグループの変更項目
項目 値 pgaudit.role rds_pgaudit shared_preload_libraries pgaudit pgaudit.log_level log pgaudit.log 'all, -misc' SQL
SQLSHOW shared_preload_libraries; SHOW pgaudit.role; CREATE EXTENSION pgaudit;手順
1. RDSのパラメータグループを作成するCloudFormationのテンプレートの一部
テンプレート.ymlType: AWS::RDS::DBParameterGroup Properties: Parameters: timezone: Asia/Tokyo pgaudit.role: rds_pgaudit shared_preload_libraries: pgaudit pgaudit.log_level: log pgaudit.log: 'all, -misc'このパラメータグループをRDSにアタッチします。
2. SQLのシェルスクリプト
スクリプトSSH_HOST=[踏み台サーバーのIPアドレス] BASTION_SSHKEY=[踏み台サーバーの秘密鍵のパス] BASTION_SSHUSER=[踏み台サーバーのユーザー] DB_HOST=[DBのエンドポイント] DB_NAME=[DB名] DB_USER=[DBのユーザー名] DB_PASSWORD=[DBのパスワード] DBRESULT=`ssh -T -l ${BASTION_SSHUSER} -i ${BASTION_SSHKEY} ${SSH_HOST} <<EOC export PGPASSWORD=${DB_PASSWORD} psql -U ${DB_USER} -d ${DB_NAME} -h ${DB_HOST} << EOF SHOW shared_preload_libraries; SHOW pgaudit.role; CREATE EXTENSION pgaudit; EOF exit $? EOC ` echo ${DBRESULT}
- 投稿日:2020-11-17T12:43:25+09:00
AWSを勉強する - VPC
Virtual Private Cloud(VPC)
AWSクラウド内に論理的に分離されたセクションを作り、ユーザーが定義した仮想ネットワークを構築するサービス
- 任意のIPアドレス範囲の選択して仮想ネットワークを構築
- サブネットの作成、ルートテーブルやネットワークゲートウェイの設定など仮想ネットワーキング環境を完全に制御可能
- 必要に応じてクラウド内外のネットワーク同士を接続することも可能
- 複数の接続オプションが利用可能
- インターネット経由
- VPN/専用線
単一のVPCを構築すると単一のAZの範囲に設定される。
同一リージョン内では、VPCは複数のAZにリソースを含めることができる。
VPCとサブネットの組み合わせでネットワーク空間を構築する。VPCはサブネットとのセットが必須。
- CIDR方式でアドレスレンジを選択
- AZのサブネットを選択
- インターネット経路を選択
- VPCへのトラフィック許可の設定
CIDR
VPC内ではサブネット数は200までが最大とされている
既に利用されていて設定できないアドレス
ホストアドレス 用途 .0 ネットワークアドレス .1 VPCルーター .2 Amazonが提供するDNSサービス .3 AWSで予約されているアドレス .255 ブロードキャストアドレス サブネット
CIDR範囲で分割したネットワークセグメント
インターネットアクセス範囲を定義するために利用数パブリックサブネット
トラフィックがインターネットゲートウェイにルーティングされるサブネット
インターネットと接続が必要なリソースを揃える
パブリックサブネットからインターネットに接続するにはインターネットゲートウェイが必要プライベートサブネット
インターネットゲートウェイへのルートがないサブネット
インターネットから隔離することでセキュリティを高める
プライベートサブネットからインターネットに接続するにはNATゲートウェイがパブリックサブネットに必要(NATゲートウェイに接続してからインターネットに接続する)VPC外部接続
VPCの外側にあるリソースとの通信にはパブリックのAWSネットワークかエンドポイントを利用する。
例)S3を使う時、エンドポイントを利用してVPC外にあるS3とつなげるインターネット経路を設定
ルートテーブルとCIDRアドレスでルーティングを設定する
- ルートテーブルでパケットの行き先を設定
- VPC作成時にデフォルトで1つルートテーブルを作成
- VPC内はCIDRアドレスでルーティング
VPCトラフィック設定
セキュリティグループ
インスタンス単位の通信制御に利用する。
インバウンド(内向き、外部からVPCへ)とアウトバウンド(外向き、内部から外部へ)の両方の制御が可能。制御項目
- プロトコル
- ポート範囲
- 送受信先のCIDRかセキュリティグループ
セキュリティグループは、デフォルトでアクセスを拒否されていて、設定された項目のみにアクセスを許可する。
応答トラフィックはルールに関係なく通信が許可される。ネットワークACL
サブネットごとの通信制御に利用する。
インバウンド(内向き、外部からVPCへ)とアウトバウンド(外向き、内部から外部へ)の両方の制御が可能。ネットワークACLは、デフォルトでアクセスが許可されている。
応答トラフィックであろうと明示的に許可設定しないと通信遮断される。用語まとめ
ゲートウェイ
VPCの内部と外部との通信をやり取りする出入り口。
インターネットゲートウェイ
VPCとインターネットとを接続するためにゲートウェイ。
各VPCに1つだけアタッチすることができる。仮想プライベートゲートウェイ
VPCがVPNやDirect Connectと接続するためのゲートウェイ。
各VPCに1つだけアタッチすることができる。VPCエンドポイント
S3やDynamoDBと接続する際に利用するゲートウェイエンドポイントと
それ以外の大多数のサービスで利用するインターフェイスエンドポイントがある。ゲートウェイエンドポイント
ルーティングを利用したサービス。
S3、DynamoDBへの通信は、エンドポイントを通じて行われる。ピアリング接続
2つのVPC間でプライベートな接続をするための機能。
AWSアカウントをまたがっての接続も可能。VPCピアリングでの通信相手は、VPC内のEC2インスタンス。
VPCフローログ
VPC内の通信の解析に利用。
ENI(Elastic Network Interface)単位で記録される。
送信元・送信先アドレス、ポート、プロトコル番号、データ量、許可/拒否が記録される。参考
- 投稿日:2020-11-17T11:26:43+09:00
AWS Lambda を使ってFizzBuzzしたった
Backgroud
AWS Lambdaを使ったサーバレスアプリケーションについての話を聞く機会が増えたので試しに作ってみた。
Preparetion
↓
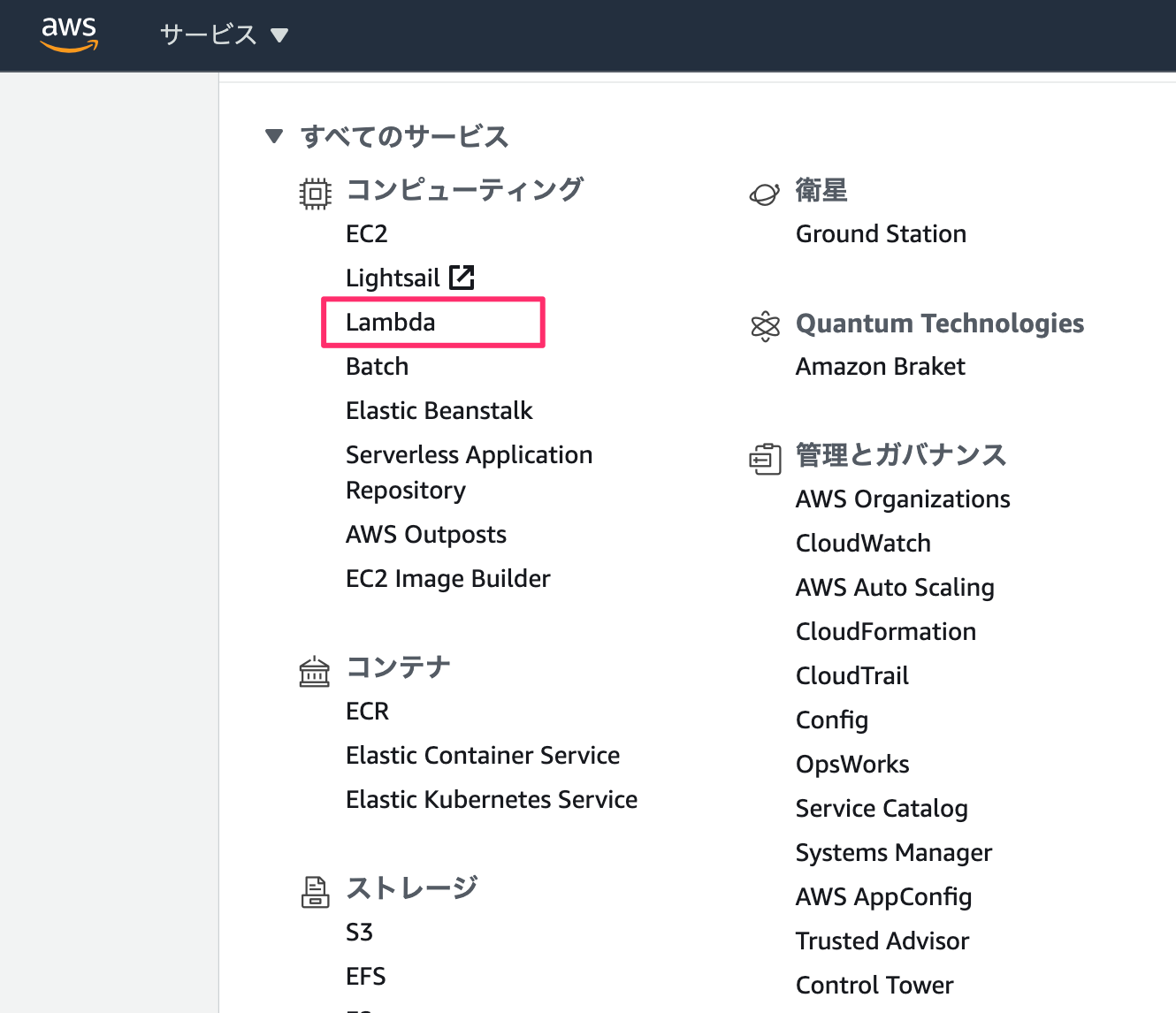
↓
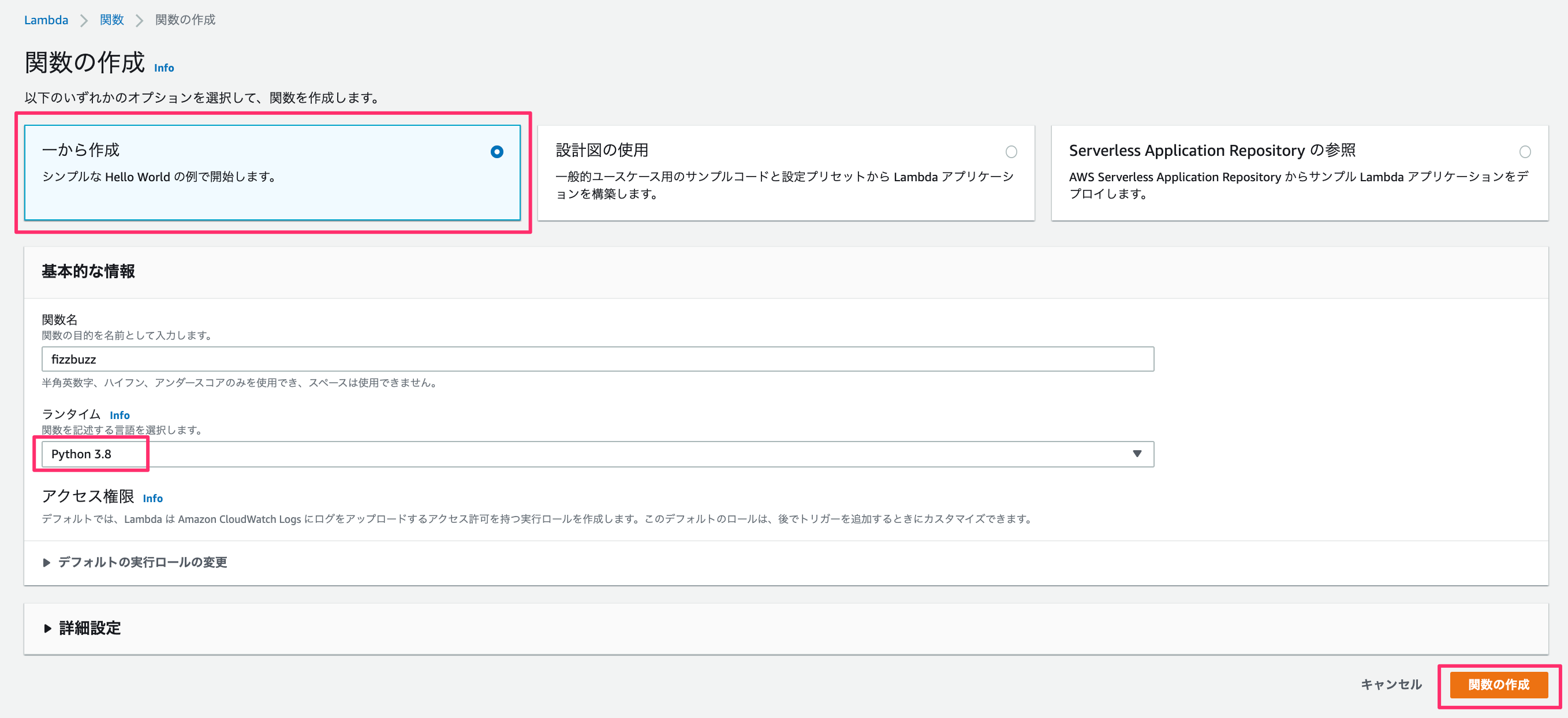
Development (lambdaのみ)
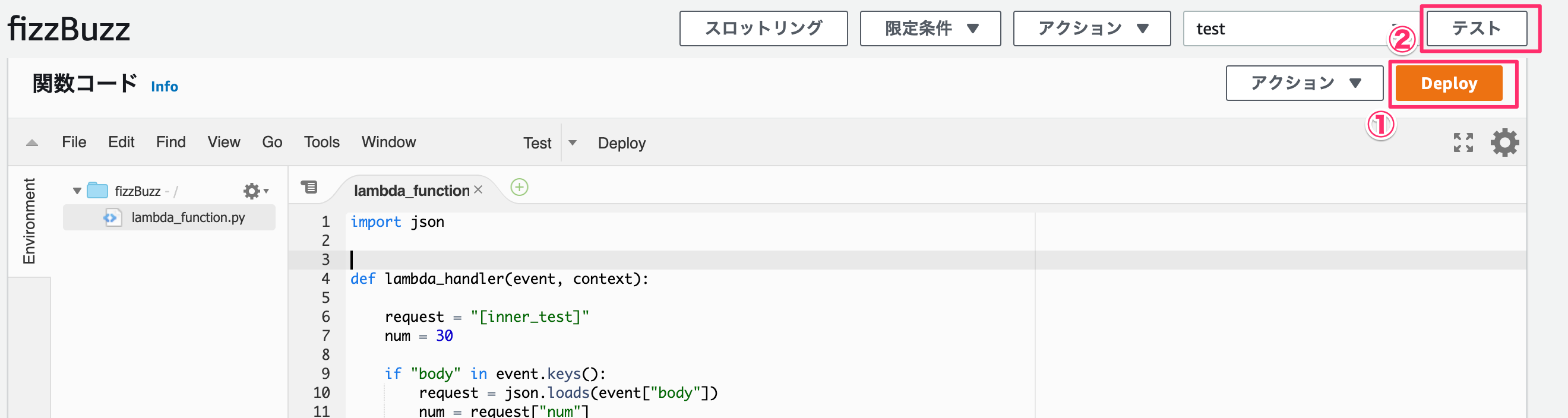
import json def lambda_handler(event, context): request = "[inner_test]" num = 30 doc = { "message":'Hello from Lambda!', "request":process(num) } # TODO implement return { 'statusCode': 200, 'body': json.dumps(doc) } def process(src): if src % 15 == 0: return "FizzBuzz" elif src % 5 == 0: return "Buzz" elif src % 3 == 0: return "Fizz" else : return srcと書いたのちに、「Deploy」 -> 「テスト」 を押す。
そうすると、、、
実行結果がログで出力される。
Development (with API Gateway)
先ほどの構成はlambdaのみだったが、ここではAPI Gatewayを使って外部からリクエストをかけてみる。
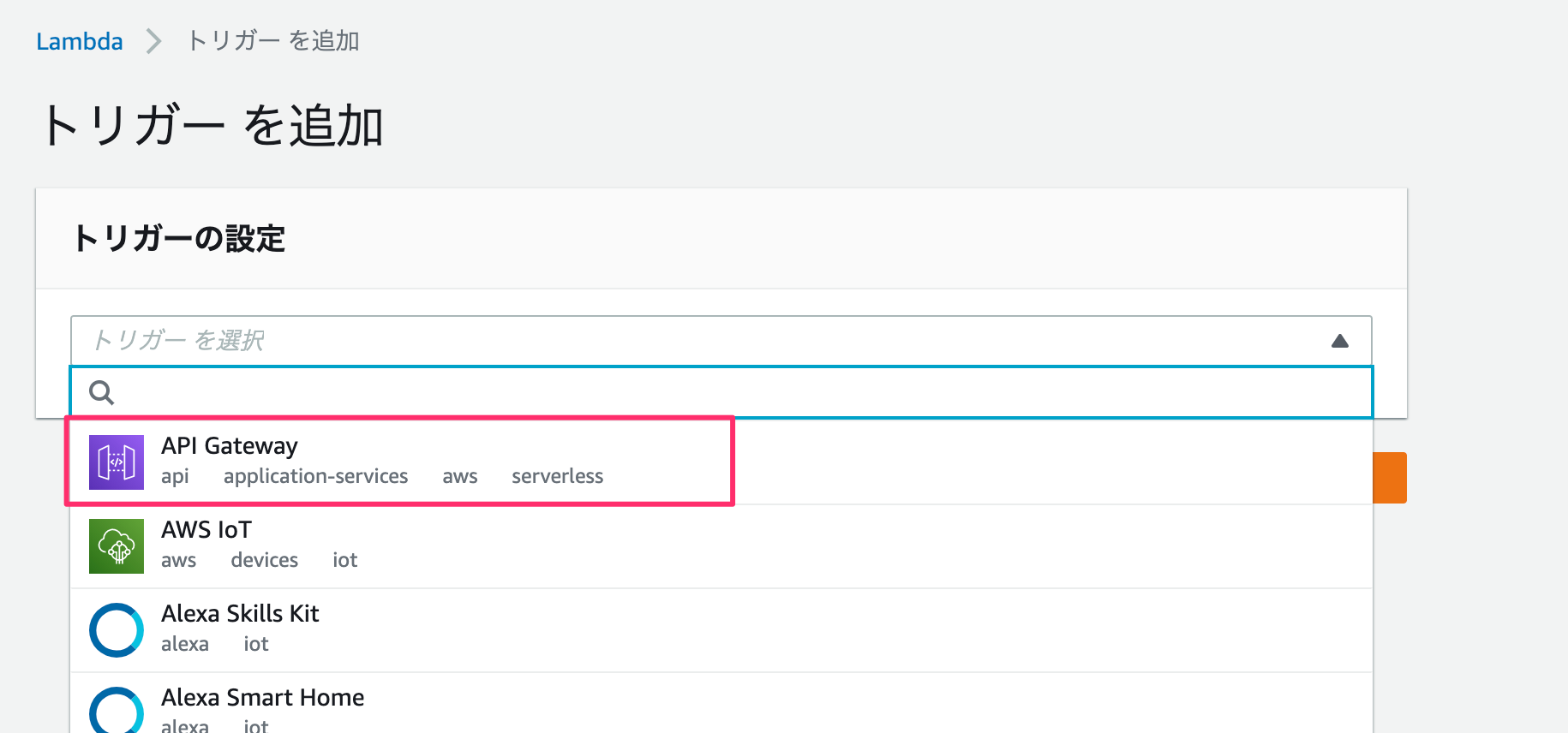
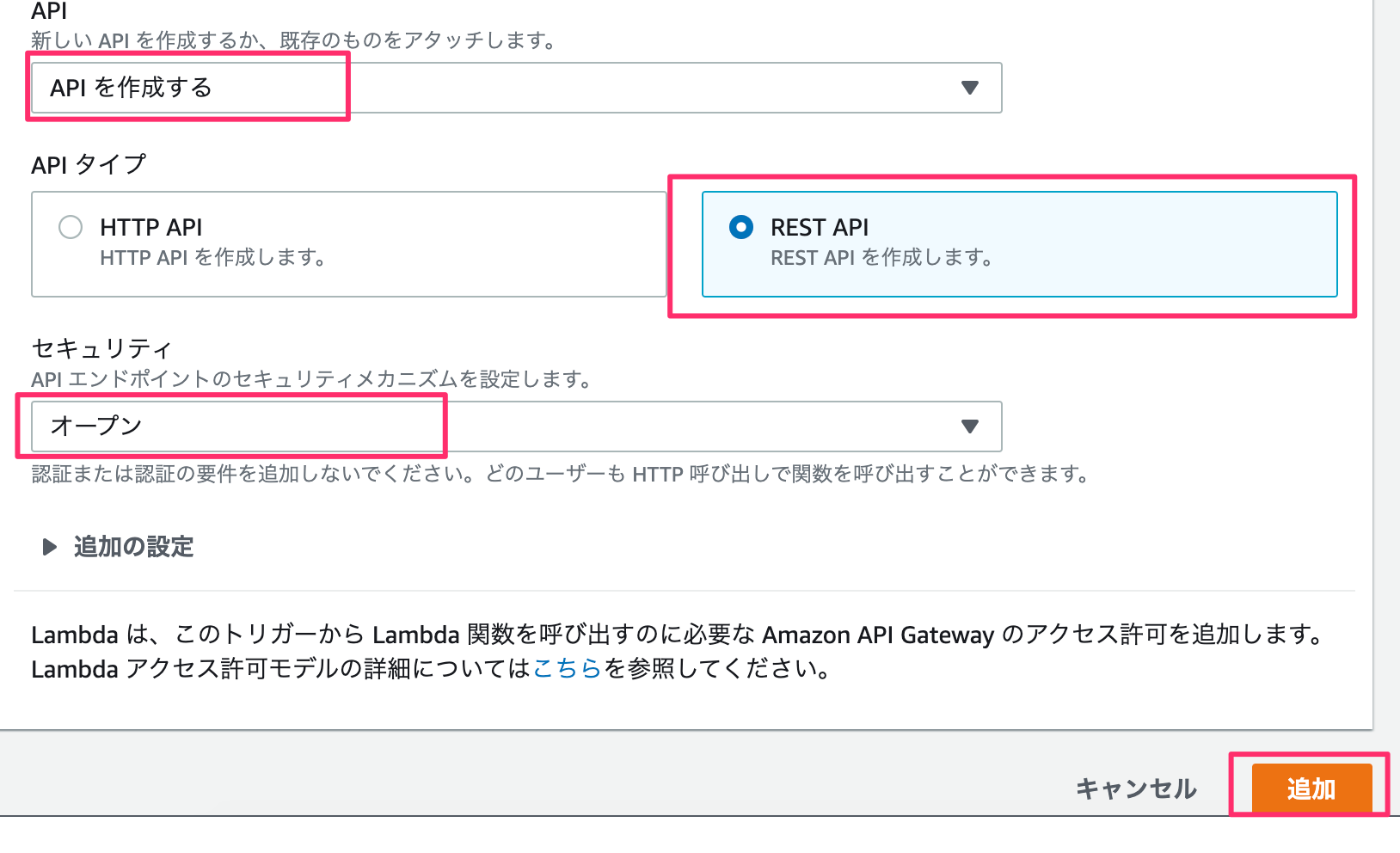
まず、トリガーからAPI Gatewayを選ぶ。
セキュリティはお好みで。
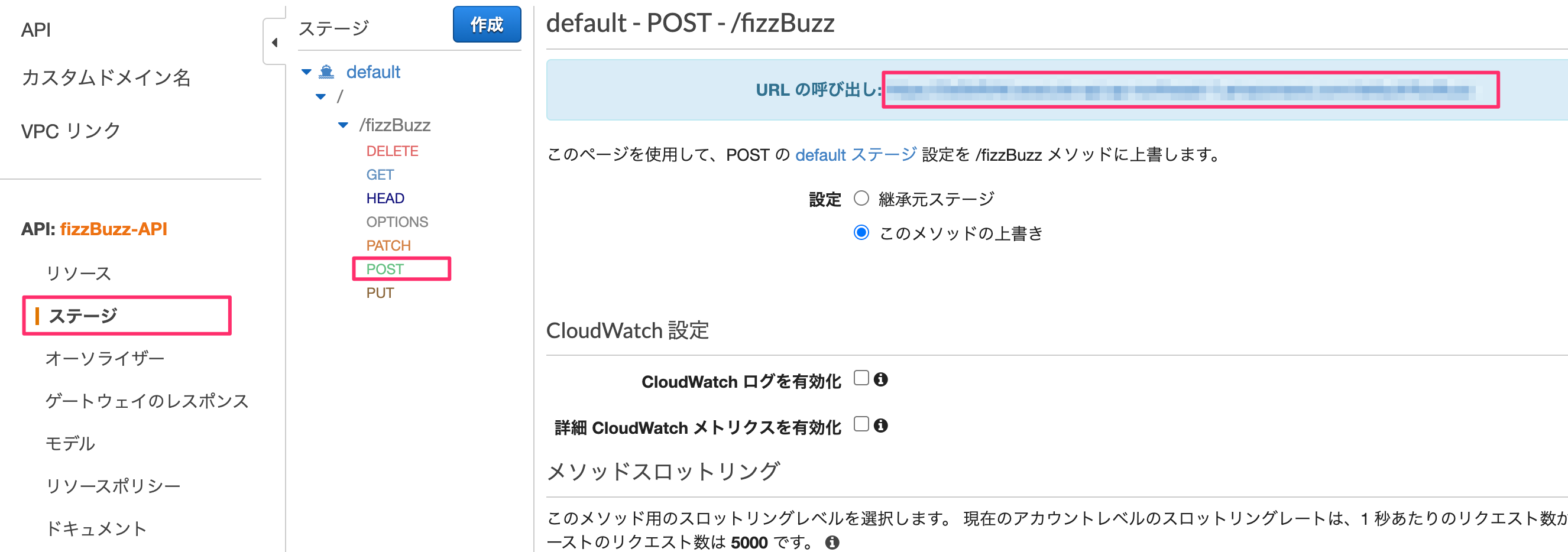
「ステージ」→「POST」を選び、URLを取得する。
URL自体の構成はhttps://{restapi_id}.execute-api.{region}.amazonaws.com/{stage_name}/
それで、lambdaにてリクエストされた値を取得し、FizzBuzzする。コードベースで話すと
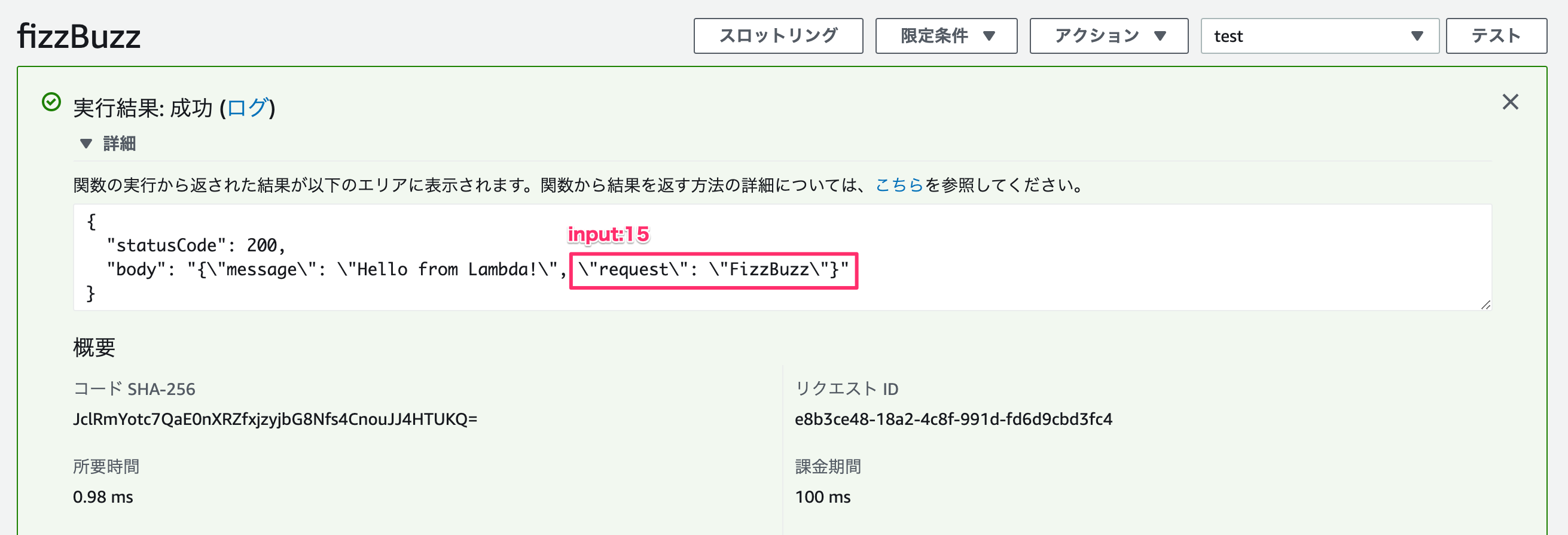
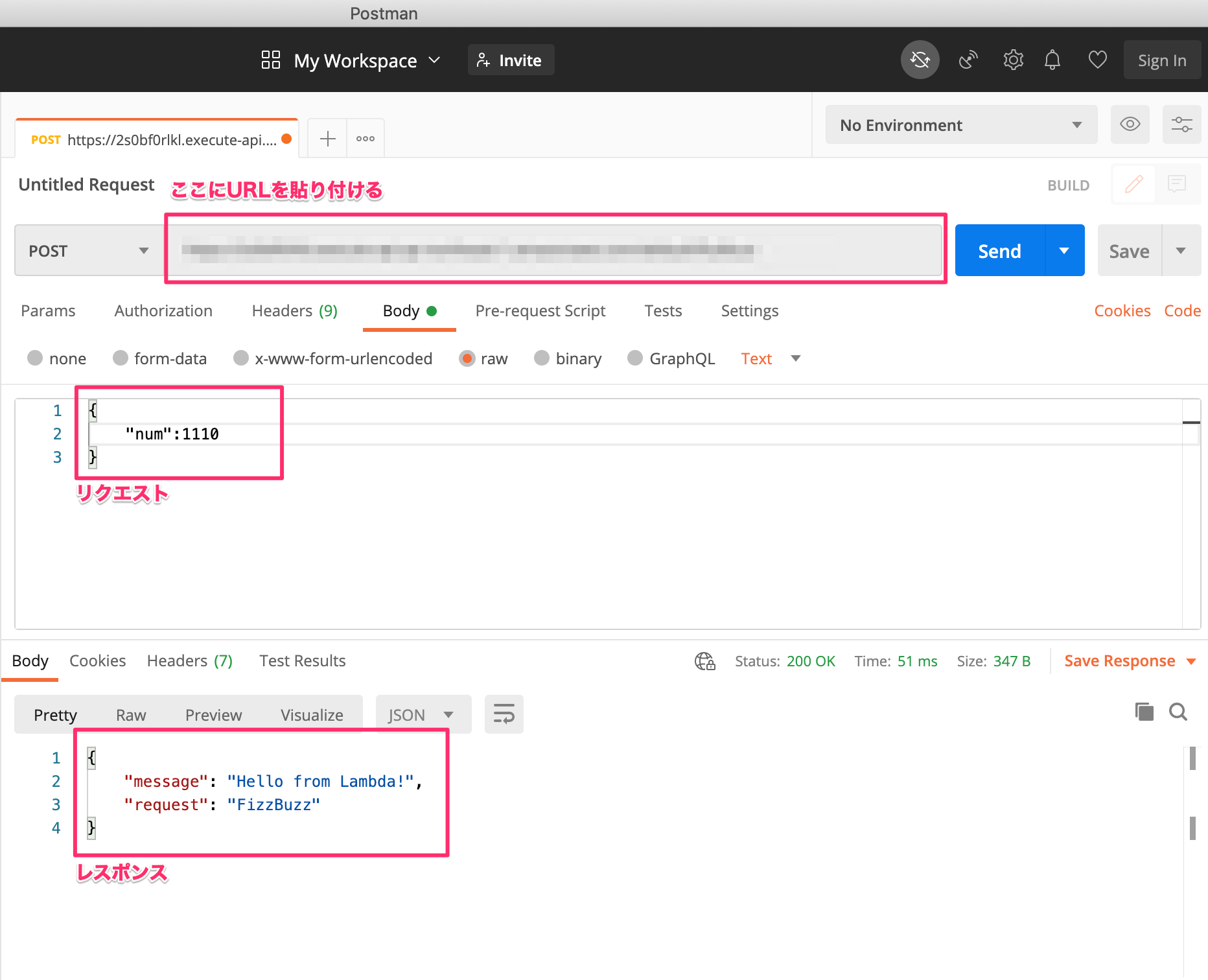
event["body"]をjsonでパースして入力値を取得する。import json def lambda_handler(event, context): request = "[inner_test]" num = 30 #API Gatewayに対応 #ここでリクエストの値を取得 if "body" in event.keys(): request = json.loads(event["body"]) num = request["num"] doc = { "message":'Hello from Lambda!', "request":process(num) } # TODO implement return { 'statusCode': 200, 'body': json.dumps(doc) } def process(src): if src % 15 == 0: return "FizzBuzz" elif src % 5 == 0: return "Buzz" elif src % 3 == 0: return "Fizz" else : return src実際にfizzbuzzの値が返ってくるか、Postmanを使ってAPIを叩いてみてみる。
numの値を変えると、FizzBuzzFizzBuzz、数字のいずれかが返ってきます。
これでできた。
Future
サーバレス言わずに最小のVPS使って必要なパッケージ落とせばいいと思っていたのですが時間かけずにできた。
lambda処理後にS3とリンクすればデータは残せそうです。Reference

- 投稿日:2020-11-17T07:13:55+09:00
AWS運用日記 初心者が『AWS』触ってみた
AWSを登録して初期設定をするところまで。
以下の3つを設定し終えたら記事書きますmm
❶CloudWatchで料金アラートを設定:使いすぎを防止
❷IAMで作業ユーザーを作成:セキュリティ対策
❸CloudTrailで操作ログを記録:ユーザーの行動ログを収集では、また後程。この記事に追加していきます(´ω`
- 投稿日:2020-11-17T01:05:02+09:00
【AWS】Rails6で作られたWebアプリをCircleCIを使いECR・ECSへ自動デプロイする方法①下準備編【コンテナデプロイ】
今回個人開発で制作したRailsアプリをCircleCIを使いコンテナデプロイさせることに成功したので、備忘録としてこちらに記載させていただきます。(またReadmeなど整い次第、実際のアプリも別記事で紹介させていただきます。)
こちらですが、長くなってしまったので記事を分けて書いていってます。
タイトル ① 下準備編 ←今ここ! ②-1 インフラ構築編 ②-2 インフラ構築編(執筆中) 自動デプロイ編(執筆中) また、現在私はwindows10を利用しており、macの方は適時置き換えて進めていってください。
といってもaws-ecs-cliのインストール方法が異なるぐらいで他は同じだと思います。(windowsだとインストールするのに少し手間がかかりました。)それと、筆者はAWSのコンソールの言語はあえて英語で設定しているので、英語で設定していただいた方が本記事は進めやすいと思います。
(AWS CLIのコマンドの名前とコンソールの英語表記が一致するので、お勧めです。)対象となる人
- AWSのアカウントを持っている人
- すでにDocker化されたRailsアプリがあり、インフラにAWSや、CI/CDツールを取り入れることにチャレンジしたい人
- 就活のポートフォリオとして上記の技術を取り入れたい人
- AWSに興味がある人
- macばっかでwindowsの記事がなくて困っている人
前提知識
- VPC、サブネットなどインフラに関する基礎知識
- CircleCI、Dockerの基礎知識
本記事で目指す構成
上記のような構成を目指します。
実際の流れを言葉で説明すると、
①Githubにpush(masterブランチ以外のときは自動テストとRubocopだけ実行される。)
②CircleCIがpushを検知して、ビルドを開始する。
③RSpecとRubocopをパスしたら、dockerイメージがビルドされ、ECRへpushされる。
④最新のDockerイメージを使い、ECSのタスク定義(ほぼdockerコンテナの起動方法を定義したもの、docker-compose.ymlみたいなものです)を更新する。
⑤EC2インスタンスが起動され、デプロイ完了。また、実際作成した個人開発アプリではRoute53とACMを用いたSSL化ももちろん行っており、こちらでかなり苦労したので別記事としてまた書こうと思います。SSL化は実運用する上では必須なので必ずやりましょう。
環境
- windows10 Pro
- Rails: 6.0.3.2
- ruby: 2.7.1p83 (2020-03-31 revision a0c7c23c9c) [x86_64-linux]
- Docker for windows
- MySQL 5.7
- nginx:1.15.8
- puma:4.3.5
下準備
下準備編では、主に4つのことをやります。
- ツールのインストール
- IAMユーザーを作成し、実行権限(ポリシーといいます)の付与
- aws configureの設定
- キーペアの作成
ツールをインストールする
以下の2つをインストールします。
- awscli
- aws-ecs-cli
windowsの方はこちらの記事を参考に進めていけばインストールできると思います。私はこの通りにやってインストールできました。
これらのツールを使うことによってターミナルからVPC、サブネット、クラスターの作成、ECRへのpush、タスクの再定義などがいちいちコンソールをぽちぽちしなくても出来るようになります。
IAMを作成する
コンソールにログインして、service を選択し、IAMと検索しクリック。
Usersをクリックし、Add user をクリック
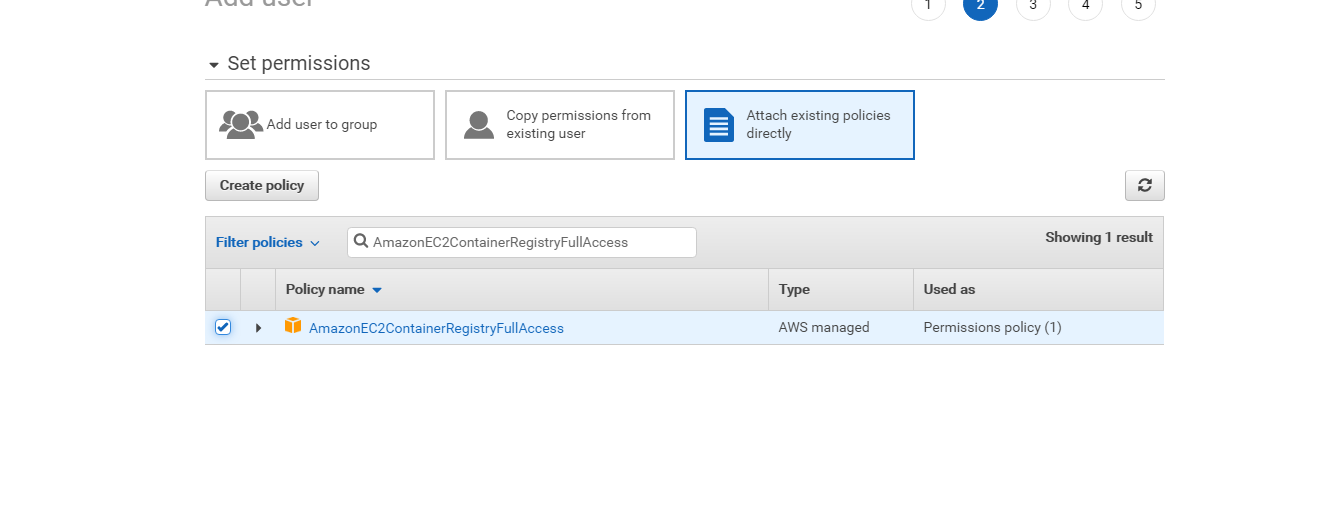
一番右のAttach existing policiesをクリックし、以下の2つのポリシーをアタッチする。
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
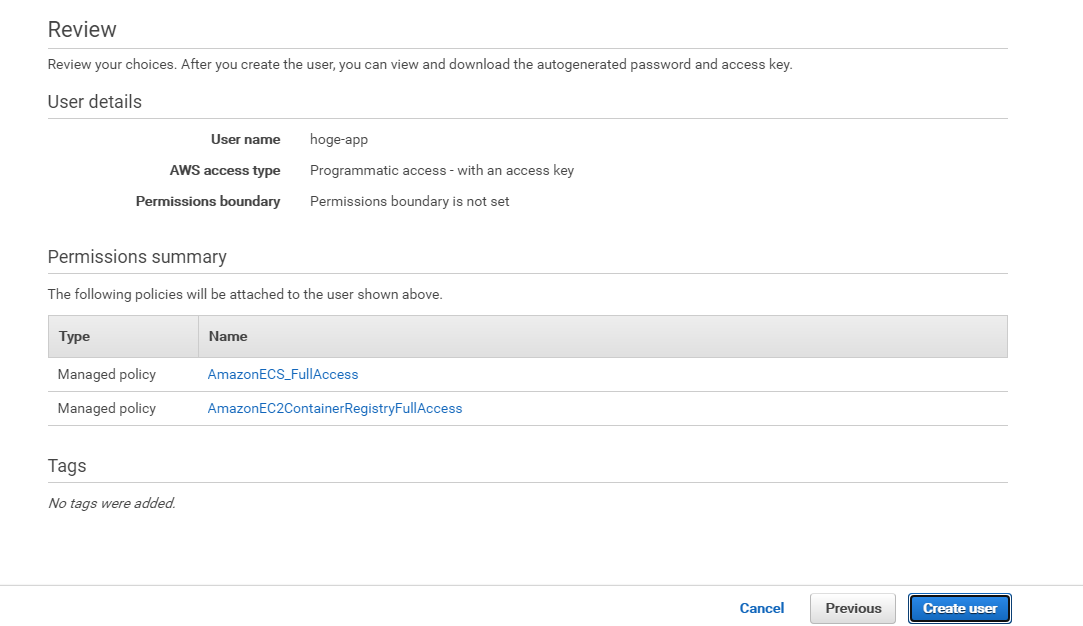
確認画面で設定した通りにアタッチできているのが確認出来たら、Create userをクリック
すると、次画面でアクセスキーとシークレットキーが作成されます。csvでダウンロードみたいなボタンが表示されると思うので、それをクリックするなどして、情報を保存します。シークレットアクセスキーを誤ってgitにpushしてしまい、何百万もの請求がAmazonから来た例もあるようなので、取り扱いには十分気を付けましょう。
ポリシーを追加する(権限付与)
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
さきほど、こちらのポリシーを付与しましたが、これだけではecs-cliのコマンドを実行するときに権限周りでエラーが発生してしまうので、別途追加していきます。
IAMのコンソールから、Policiesを選択し、Create Policiesを選択します。
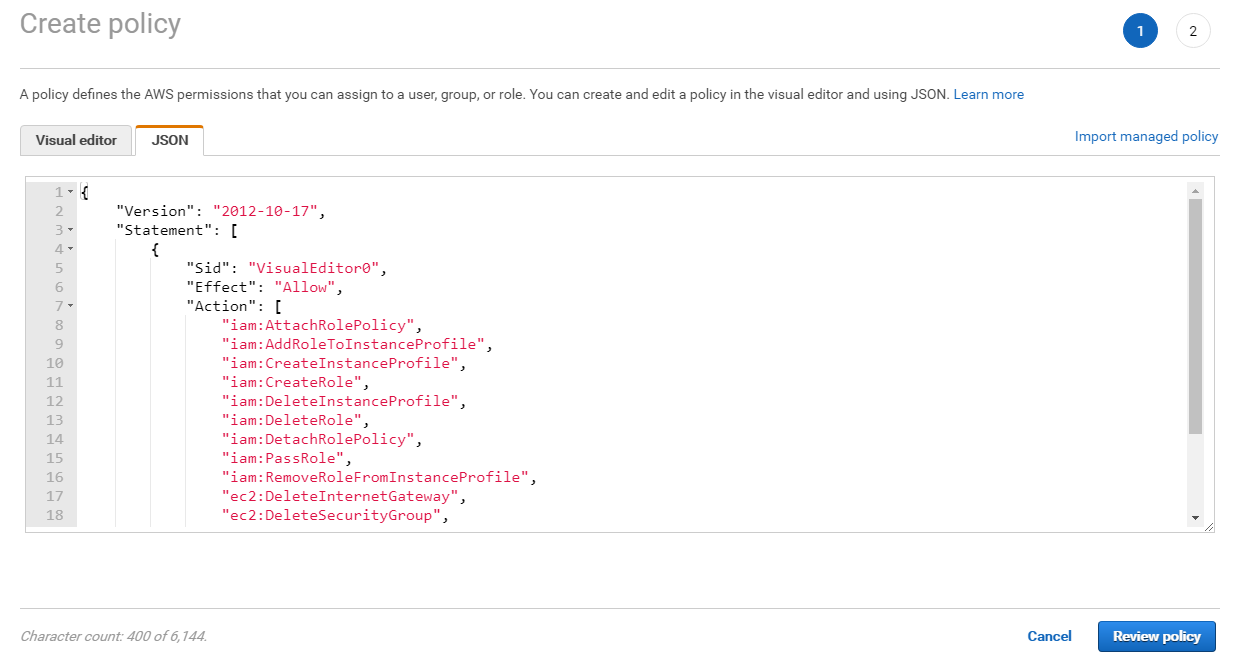
画面にあるJsonタブをクリックし、以下のコードを入力してください。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateInstanceProfile", "iam:CreateRole", "iam:DeleteInstanceProfile", "iam:DeleteRole", "iam:DetachRolePolicy", "iam:PassRole", "iam:RemoveRoleFromInstanceProfile", "ec2:DeleteInternetGateway", "ec2:DeleteSecurityGroup", "ec2:DeleteRouteTable" ], "Resource": "*" } ] }入力したら、Review policyをクリックします。
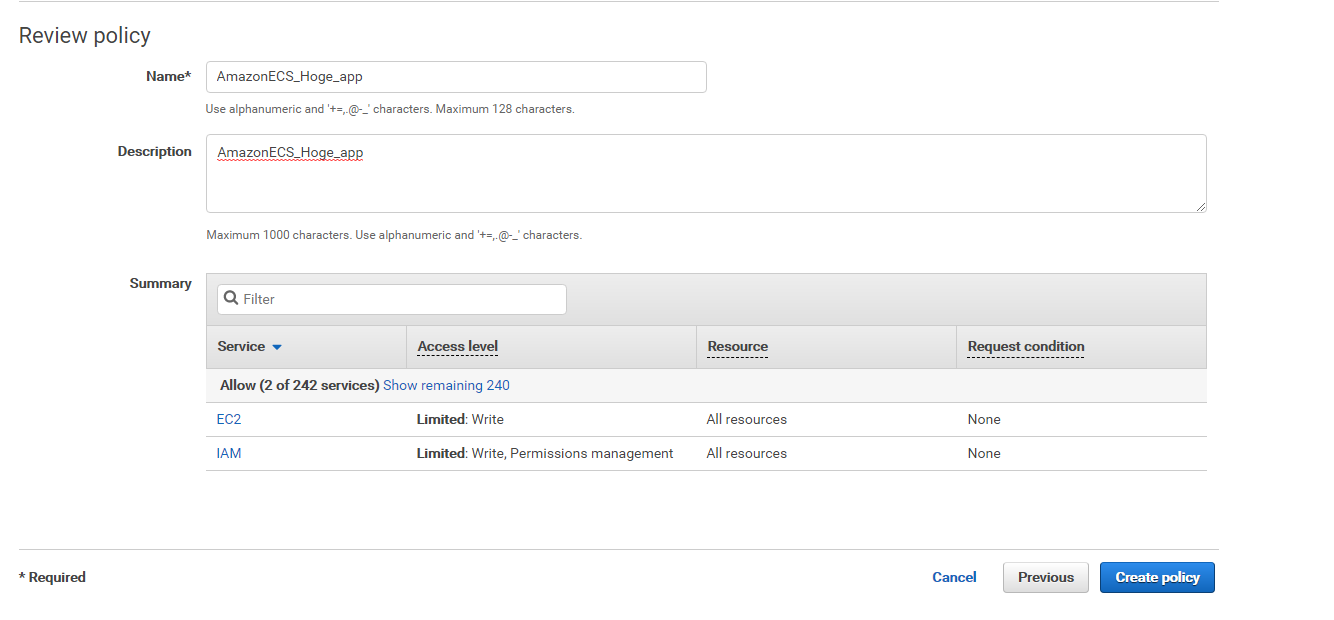
任意の名前と説明を入れ、Create policyをクリックします。
次に、作成したIAMユーザーに↑で新しく作成したポリシーを付与します。
Usersをクリックし、Add permissionsをクリック
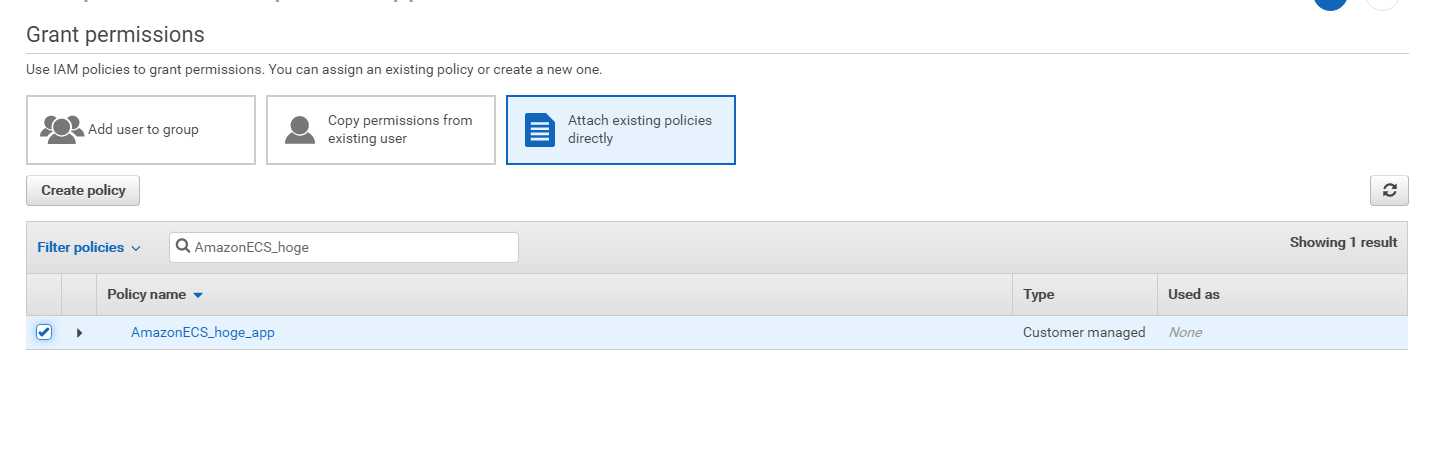
Attach existing policies directlyをクリックし、先ほど作成したポリシーを選択
確認画面で、正しいポリシーが選択できていたらAdd permissionsをクリックします。
ターミナルで「aws configure」を実行する
aws configureを--profileオプションを付けてターミナルで実行します。
実行すると対話形式で聞いてきますのでひとつずつ正確に入力しましょう。$ aws configure --profile 作成したユーザー名 AWS Access Key ID # 作成したときのアクセスキー AWS Secret Access Key # 作成したときのシークレットアクセスキー Default region name # ap-northeast-1 Default output format # jsonaws configure を実行するとホームディレクトリ配下に.awsディレクトリが自動生成され、そこにアクセスキーなどの情報が以下のような感じで保管されますので、確認してみてください。(完全に一緒にはならないかも)
~/.aws/credentials[ユーザー名] aws_access_key_id=AKIAIOSFODNN7AJDIFK aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/gkjkAKJDKJ [default] aws_access_key_id=AKIAIOSFODNN7EXAMPLE aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY~/.aws/config[profile ユーザー名] region = ap-northeast-1 output = json [default] region = ap-northeast-1 output = jsonキーペアの作成
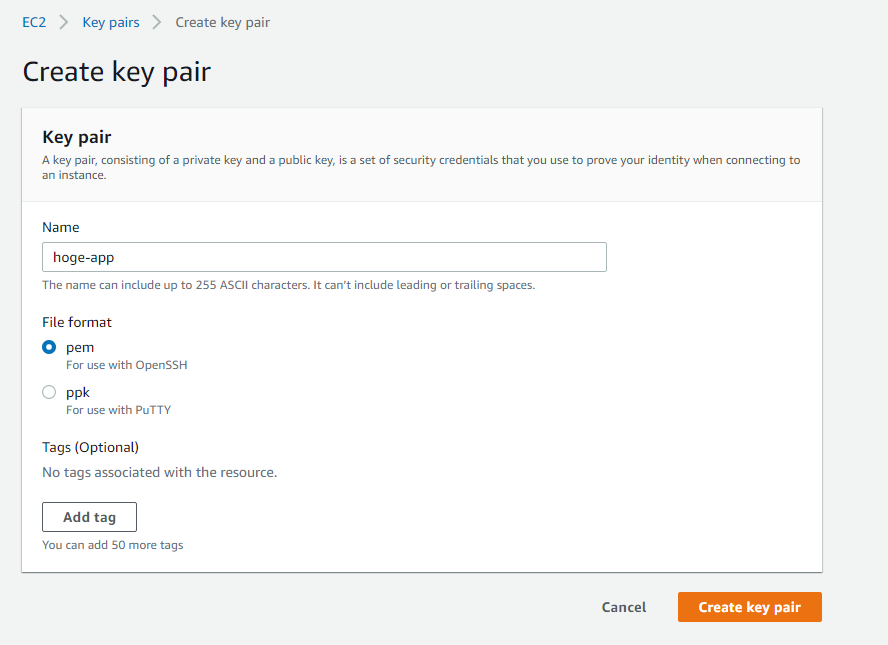
続いてキーペアの作成を行っていきます。
Service→EC2コンソール→key pair→Create key pairを選択し、適当なキーペア名を入力します。
ファイルの拡張子は.pemを選択し、Create key pairをクリックします。
完了すると.pemファイルが自動でダウンロードされるので、以下のコマンドを実行し、「.ssh」ディレクトリに移動して権限を変更します。
$ mv Downloads/sample-app.pem .ssh/ $ chmod 600 ~/.ssh/sample-app.pem以上で下準備編は完了です!お疲れ様でした!
続きはインフラ構築編②-1へお進みください!最後まで読んでいただきありがとうございます!
かなり長い記事になってしまったので、記載ミス等、何かご指摘などあればコメントいただけますと幸いです。