- 投稿日:2020-11-17T22:35:38+09:00
UIPanGestureRecognizer(パン)とUISwipeGestureRecognizer(スワイプ)をいっしょに使う
同じviewにパンとスワイプを同時に与えると、パンしか効かなくなる。
素早くスワイプした時だけスワイプを発火してそれ以外の時はパンするコードがこちら。
基本PanGestureで、Pan速度が一定を超えた時だけSwipeになります。
スタックオーバーフローの記事の引用です。元記事には実際のジェスチャアニメーションの様子があります。let swipeVelocity: CGFloat = 500 @objc func didPan(_ sender: Any) { guard let panGesture = sender as? UIPanGestureRecognizer else { return } let gestureEnded = Bool(panGesture.state == UIGestureRecognizer.State.ended) let velocity = panGesture.velocity(in: self.view) if gestureEnded && abs(velocity.y) > swipeVelocity { handlePanAsSwipe(withVelocity: velocity.y) } else { handlePan(panGesture) } } func handlePan(_ recognizer: UIPanGestureRecognizer) { switch recognizer.state { // Panの操作を書く case .began: case .changed: default: break } } func handlePanAsSwipe(withVelocity velocity: CGFloat) { if velocity > 0 { print("down") // 下Swipeの操作を書く } else { print("up") // 上Swipeの操作を書く } }let panOrSwipe = UIPanGestureRecognizer(target: self, action: #selector(didPan(_:))) view.addGestureRecognizer(panOrSwipe)?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2020-11-17T21:33:16+09:00
Self-Sizing(Auto Layoutによる高さの自動調整)機能について
はじめに
この機能を知るきっかけとなったのは、セルのimageViewを誤って大きくしてしまったことでした。
オレンジが変更箇所になってます。この結果、チェックマークが表示された時にCellが縦に大きくなると言う現象が起きました。
この件を相談すると、Self-Sizingという機能が元々備わっていて、セルの表示に影響が出たと分かりました。
Self-Sizingとは
タイトルにもある通り、セルなどの高さを自動で調整してくれる機能です。
Xcode 9(iOS 11 SDK)でデフォルトになったみたいです。それ以前はコードで表示しなければいけなかったみたいです。
私はデフォルトになってからswiftの勉強を始めたので気にしたこともなかったです。最後に
今回の件は、
そりゃ、セルのimageViewの大きさ変えたら、表示するために高さ変わるやろ〜って感じですが、
チェックマークの表示を切り替えるたびにサイズが切り替わるのでめっちゃ焦りました(笑)
チェックマークのサイズを誤って変更したばっかりに、Self-Sizingの機能が働いてくれて、表示できる様に高さを変更してくれていたんですね〜参考サイト
https://dev.classmethod.jp/articles/xcode-9-uitableview-self-sizing-by-default/
- 投稿日:2020-11-17T19:39:50+09:00
ARKit+Vision+iOS14 で らくがき のジオメトリ化①
有名なARアプリ『らくがきAR』がやっている、"キャプチャ画像から輪郭を検出しそれをジオメトリにする" 、を試してみた。
この記事では、まず、輪郭検出の過程を説明します。(ジオメトリ化は次回)
<完成イメージ>

iOS14からVisonに新しく輪郭検出の機能 VNContour が追加されたのでこれを利用。
VNContour はWWDC2020のビデオ Explore Computer Vision APIs の11:32あたりから詳しく説明されている。VNContour からは 輪郭を画像ではなく、閉じたパス(CGPath)情報として取得できる ので、パス上の座標を使って3Dのジオメトリをつくれる(はず。次の記事を書くときに試す)。
輪郭検出の手順
①キャプチャ画像からスクリーンに表示されている範囲を切り出す
②輪郭検出の前に①の画像を加工し輪郭検出しやすくする
③輪郭を検出する
④画像にある輪郭は複数検出されるので、着目したい輪郭のみ選択する
⑤④を表示する以下、詳細を説明します。
①キャプチャ画像からスクリーンに表示されている範囲を切り出す
ARKitからキャプチャ画像を取得する場合、
ARSessionDelegateのsession(_:didUpdate:)のタイミングでARFrameのcapturedImageから取得するが、この画像はスクリーンサイズやデバイスの向きが全く考慮されていない。
そのため、輪郭検出機能に画像のどの部分を検出させるのか、検出結果として返されるCGPathをスクリーン座標にどう合わせれば良いのか、をキャプチャ画像からは判断できない。ARKitはキャプチャ画像をスクリーン表示サイズに変換する手段として
ARFrameのdisplayTransform(for:viewportSize:)をとおして変換行列を提供している。
が、このメソッドの活用は単純ではなく、stackoverflowの質問回答 の情報でなんとか変換することができた。具体的に何をやならければならないかというと、次のようにする。
1) キャプチャした画像全体(スクリーン外も含む)を 0.0〜1.0 の座標系に変換し、
2) ポートレートの場合、Y座標の上下、X座標の左右を反転し、
3) スクリーンで見えている向き・位置に座標を移動し、
4) 移動後、スクリーンサイズに戻し、
5) スクリーンサイズで画像を切り出すstackoverflowのまんまですがコードは次の通り。
// 1) キャプチャ画像を 0.0〜1.0 の座標に変換 let normalizeTransform = CGAffineTransform(scaleX: 1.0/imageSize.width, y: 1.0/imageSize.height) // 2) 「Flip the Y axis (for some mysterious reason this is only necessary in portrait mode)」とのことでポートレートの場合に座標変換。 // Y軸だけでなくX軸も反転が必要。 var flipTransform = CGAffineTransform.identity if interfaceOrientation.isPortrait { // X軸Y軸共に反転 flipTransform = CGAffineTransform(scaleX: -1, y: -1) // X軸Y軸共にマイナス側に移動してしまうのでプラス側に移動 flipTransform = flipTransform.concatenating(CGAffineTransform(translationX: 1, y: 1)) } // 3) キャプチャ画像上でのスクリーンの向き・位置に移動 // 参考 : https://developer.apple.com/documentation/arkit/arframe/2923543-displaytransform let displayTransform = frame.displayTransform(for: interfaceOrientation, viewportSize: viewPortSize) // 4) 0.0〜1.0 の座標系からスクリーンの座標系に変換 let toViewPortTransform = CGAffineTransform(scaleX: viewPortSize.width, y: viewPortSize.height) // 5) 1〜4までの変換を行い、変換後の画像をスクリーンサイズでクリップ let transformedImage = image.transformed(by: normalizeTransform.concatenating(flipTransform).concatenating(displayTransform).concatenating(toViewPortTransform)).cropped(to: self.scnView.bounds)②輪郭検出の前に①の画像を加工し輪郭検出しやすくする
VNContour で白紙に書いた絵を認識させたとき、明るい場所で、白紙も一様に「白」ならきれいに輪郭を検出してくれるが、白紙にすこし暗い場所があると、それを輪郭として認識してしまい扱いにくくなる現象にぶつかった。
そこで輪郭検出の前に次の処理を行うことで、白紙上の絵を認識させやすくすることができた。let blurFilter = CIFilter.morphologyMinimum() blurFilter.inputImage = screenImage blurFilter.radius = 5 guard let blurImage = blurFilter.outputImage else { return nil } // ペンの線を強調。RGB各々について閾値より明るい色は 1.0 にする。 let thresholdFilter = CIFilter.colorThreshold() thresholdFilter.inputImage = blurImage thresholdFilter.threshold = 0.1 guard let thresholdImage = thresholdFilter.outputImage else { return nil } // 検出範囲を画面の中心部分に限定する let screenImageSize = screenImage.extent // CIMorphologyMinimumフィルタにより画像サイズと位置が変わってしまうので、オリジナル画像のサイズ・位置を基準にする let croppedImage = thresholdImage.cropped(to: CGRect(x: screenImageSize.width/2 - detectSize/2, y: screenImageSize.height/2 - detectSize/2, width: detectSize, height: detectSize))1)
CIFilter.morphologyMinimum()で、暗い部分を広げる
これは、線が細い・薄いと輪郭が途切れてしまうことを回避し、輪郭検出を安定させるための加工。
ドキュメント : morphologyMinimumFilter
2)CIFilter.colorThreshold()で、特に色の暗い部分のみ抽出する
これはグラデーションのような陰影があっても、特に暗い部分(ペンで書いた線)だけ輪郭検出させるための加工。
ちなみにCIColorThresholdはiOS14から利用できるようになったフィルター。
3) CIImage の croppedメソッド を使ってスクリーンの中心部分を切り出す
輪郭検出を画面の中心部分(着目している部分)に限定するための加工。ポイントは 3) の切り出しの前に、1)、2)のフィルタをかけるところ。
1)や2)は画面全体に処理をするので負荷を考慮して 3) の画像切り出し後に実施したいが、画像切り出し後に実施すると、のちの輪郭検出処理で画像の縁が「輪郭」と検出されてしまう現象に悩まされることになる。特にCIFilter.morphologyMinimum()の処理画像は radius で指定したサイズ分だけ画像が拡張され四辺のいずれでも色情報が無い領域が追加さるので、思ったような輪郭検出ができない。以下、画像がどのように加工されていくのかの例示。
■元画像
■CIFilter.morphologyMinimum()で加工後。線が太くなっていることがわかる。欲しいのは絵の外側の輪郭だけなので詳細部分が潰れてしまっても問題ない。
■CIFilter.colorThreshold()で加工&画像中央だけクリップ後。線だけ抽出できている。
③輪郭を検出する
輪郭検出はシンプル。
処理対象の画像を引数としてVNDetectContoursRequestを作ってVNImageRequestHandlerに渡すだけ。let handler = VNImageRequestHandler(ciImage: preprocessedImage) let contourRequest = VNDetectContoursRequest.init() contourRequest.maximumImageDimension = Int(detectSize) // 検出画像サイズはクリップした画像と同じにする。デフォルトは512。 contourRequest.detectsDarkOnLight = true // 明るい背景で暗いオブジェクトを検出 try? handler.perform([contourRequest])
contourRequest.detectsDarkOnLight = trueとしているが、デフォルトが true なので指定しなくても良い。④画像にある輪郭は複数検出されるので、着目したい輪郭のみ選択する
輪郭検出を行うと、輪郭と思われるものは片っ端から検出される。
次の画像は検出された輪郭(赤線)のすべてを表示させた場合のもの。
隙間という隙間の輪郭が検出されていることがわかる(CIFilter.morphologyMinimum()で加工しなければぴったりとペンの線に沿ったパスの取得も可能)。
欲しいのは一番外側の輪郭なので、これを特定したい。
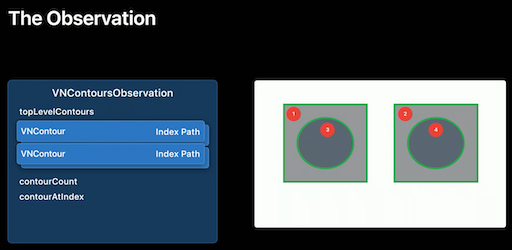
ここで、輪郭検出の結果VNContoursObservationの中の構造は次のようになっている。
検出された輪郭はネスト構造になっており、ネストの一番外側の輪郭は特定できるものの複数あり得ることを示している。となると、複数の輪郭があった場合、どうやって着目したいの輪郭を選び出すか?ここでは次のように単純に判定することにした。
『トップレベルの輪郭について、構成する座標数が一番多いもの』
トップレベルの輪郭は
observation.topLevelContoursで取得できるので、この中から選び出す。let outSideContour = observation.topLevelContours.max(by: { $0.normalizedPoints.count < $1.normalizedPoints.count })
VNContourにはnormalizedPointsという輪郭を構成する点座標の配列を持っている。
この配列の要素数が多ければノイズのような小さなものではなく、複雑な輪郭を持ったものであり、おそらくそれが着目したいものの輪郭であろう、という判定方法である。
単純な判定ではあるが試した限り、自分の認識と異なるような輪郭を捉えることはなかった。⑤④を表示する
検出された輪郭のCGPathは左下が(0, 0)、右上が(1, 1) という座標系になっているので、UIKitの座標系である 左上が(0 ,0)の座標系に変換する必要がある。
CGPathの座標変換はCGAffineTransformを使い、次のように行う。var transform = CGAffineTransform(scaleX: detectSize, y: -detectSize) transform = transform.concatenating(CGAffineTransform(translationX: 0, y: detectSize)) let transPath = path.copy(using: &transform)まず、
CGAffineTransform(scaleX: detectSize, y: -detectSize)でスクリーン上のサイズに拡大すると同時に上下を反転する変換行列を作る。このままでは上下反転によりパス全体がY座標のマイナス側に移動してしまうため、CGAffineTransform(translationX: 0, y: detectSize)で左上が (0, 0) になるようにパスを移動する行列を作り、これを乗算する。あとは、変換行列を CGPath のcopy(using:)に与えて座標変換されたCGPathを作成し、これをCAShapeLayerのpathに与えて描画する。let pathLayer = CAShapeLayer() (略) pathLayer.path = transPath pathLayer.strokeColor = UIColor.blue.cgColor pathLayer.lineWidth = 10 pathLayer.fillColor = UIColor.clear.cgColor self.view.layer.addSublayer(pathLayer)説明は以上です。
次回は、取得したCGPathからSceneKitで扱えるジオメトリ の生成に挑戦。全体ソースコード
ViewController.swiftimport ARKit import Vision import CoreImage.CIFilterBuiltins class ViewController: UIViewController, ARSessionDelegate { @IBOutlet weak var scnView: ARSCNView! private let device = MTLCreateSystemDefaultDevice()! private var contourPathLayer: CAShapeLayer? // キャプチャ画像上の輪郭検出範囲 private let detectSize: CGFloat = 320.0 override func viewDidLoad() { super.viewDidLoad() // AR Session 開始 self.scnView.session.delegate = self let configuration = ARWorldTrackingConfiguration() configuration.planeDetection = [.horizontal] self.scnView.session.run(configuration, options: [.removeExistingAnchors, .resetTracking]) } // ARフレームが更新された func session(_ session: ARSession, didUpdate frame: ARFrame) { // 一番外側の輪郭を取得 guard let contour = getFirstOutsideContour(frame: frame) else { return } DispatchQueue.main.async { // 輪郭を描画 self.drawContourPath(contour: contour) } } private func getFirstOutsideContour(frame: ARFrame) -> VNContour? { // キャプチャ画像をスクリーンで見える範囲に切り抜く let screenImage = cropScreenImageFromCapturedImage(frame: frame) // 輪郭検出しやすいように画像処理を行う guard let preprocessedImage = preprocessForDetectContour(screenImage: screenImage) else { return nil } // 輪郭検出 let handler = VNImageRequestHandler(ciImage: preprocessedImage) let contourRequest = VNDetectContoursRequest.init() contourRequest.maximumImageDimension = Int(detectSize) // 検出画像サイズはクリップした画像と同じにする。デフォルトは512。 contourRequest.detectsDarkOnLight = true // 明るい背景で暗いオブジェクトを検出 try? handler.perform([contourRequest]) // 検出結果取得 guard let observation = contourRequest.results?.first as? VNContoursObservation else { return nil } // トップレベルの輪郭のうち、輪郭の座標数が一番多いパスを見つける let outSideContour = observation.topLevelContours.max(by: { $0.normalizedPoints.count < $1.normalizedPoints.count }) if let contour = outSideContour { return contour } else { return nil } } private func cropScreenImageFromCapturedImage(frame: ARFrame) -> CIImage { let imageBuffer = frame.capturedImage // カメラキャプチャ画像をスクリーンサイズに変換 // 参考 : https://stackoverflow.com/questions/58809070/transforming-arframecapturedimage-to-view-size let imageSize = CGSize(width: CVPixelBufferGetWidth(imageBuffer), height: CVPixelBufferGetHeight(imageBuffer)) let viewPortSize = self.scnView.bounds.size let interfaceOrientation = self.scnView.window!.windowScene!.interfaceOrientation let image = CIImage(cvImageBuffer: imageBuffer) // 1) キャプチャ画像を 0.0〜1.0 の座標に変換 let normalizeTransform = CGAffineTransform(scaleX: 1.0/imageSize.width, y: 1.0/imageSize.height) // 2) 「Flip the Y axis (for some mysterious reason this is only necessary in portrait mode)」とのことでポートレートの場合に座標変換。 // Y軸だけでなくX軸も反転が必要。 var flipTransform = CGAffineTransform.identity if interfaceOrientation.isPortrait { // X軸Y軸共に反転 flipTransform = CGAffineTransform(scaleX: -1, y: -1) // X軸Y軸共にマイナス側に移動してしまうのでプラス側に移動 flipTransform = flipTransform.concatenating(CGAffineTransform(translationX: 1, y: 1)) } // 3) キャプチャ画像上でのスクリーンの向き・位置に移動 // 参考 : https://developer.apple.com/documentation/arkit/arframe/2923543-displaytransform let displayTransform = frame.displayTransform(for: interfaceOrientation, viewportSize: viewPortSize) // 4) 0.0〜1.0 の座標系からスクリーンの座標系に変換 let toViewPortTransform = CGAffineTransform(scaleX: viewPortSize.width, y: viewPortSize.height) // 5) 1〜4までの変換を行い、変換後の画像をスクリーンサイズでクリップ let transformedImage = image.transformed(by: normalizeTransform.concatenating(flipTransform).concatenating(displayTransform).concatenating(toViewPortTransform)).cropped(to: self.scnView.bounds) return transformedImage } private func preprocessForDetectContour(screenImage: CIImage) -> CIImage? { // 画像の暗い部分を広げて細い線を太くする。 // WWDC2020(https://developer.apple.com/videos/play/wwdc2020/10673/) // 04:06あたりで紹介されているCIMorphologyMinimumを利用。 let blurFilter = CIFilter.morphologyMinimum() blurFilter.inputImage = screenImage blurFilter.radius = 5 guard let blurImage = blurFilter.outputImage else { return nil } // ペンの線を強調。RGB各々について閾値より明るい色は 1.0 にする。 let thresholdFilter = CIFilter.colorThreshold() thresholdFilter.inputImage = blurImage thresholdFilter.threshold = 0.1 guard let thresholdImage = thresholdFilter.outputImage else { return nil } // 検出範囲を画面の中心部分に限定する let screenImageSize = screenImage.extent // CIMorphologyMinimumフィルタにより画像サイズと位置が変わってしまうので、オリジナル画像のサイズ・位置を基準にする let croppedImage = thresholdImage.cropped(to: CGRect(x: screenImageSize.width/2 - detectSize/2, y: screenImageSize.height/2 - detectSize/2, width: detectSize, height: detectSize)) return croppedImage } private func drawContourPath(contour: VNContour) { // UIKitで使うため、クリップしたときのサイズに拡大し、上下の座標を反転後、左上が (0,0)になるようにする let path = contour.normalizedPath var transform = CGAffineTransform(scaleX: detectSize, y: -detectSize) transform = transform.concatenating(CGAffineTransform(translationX: 0, y: detectSize)) let transPath = path.copy(using: &transform) // 表示中のパスは消す if let layer = self.contourPathLayer { layer.removeFromSuperlayer() self.contourPathLayer = nil } // 輪郭を描画 let pathLayer = CAShapeLayer() var frame = self.view.bounds frame.origin.x = frame.width/2 - detectSize/2 frame.origin.y = frame.height/2 - detectSize/2 frame.size.width = detectSize frame.size.height = detectSize pathLayer.frame = frame pathLayer.path = transPath pathLayer.strokeColor = UIColor.blue.cgColor pathLayer.lineWidth = 10 pathLayer.fillColor = UIColor.clear.cgColor self.view.layer.addSublayer(pathLayer) self.contourPathLayer = pathLayer } }





- 投稿日:2020-11-17T19:26:13+09:00
バグの原因を効率的に特定する方法
最近バグ調査をすることが多く、手元にバグ調査をするためのメモが溜まってきたので公開します。
なお、これは「ハマった」状態になったときに使うためのメモです。サクッと調べてすぐに解決できるならそれが一番です。
ただ、ハマったときには視野狭窄がおきるので、堂々巡りしたり、1つの場所にこだわりすぎて、結局解決が長引いてしまうことがあります。また、手当たり次第に調べるのも非効率です。効率的に調べるには戦略が必要です。
このメモではその戦略を示したいともいます。
1つ1つの手順は必ずしも守る必要はなく、過去の経験からあたりが付くならいきなりそこを調べても良いです。ただ、頭の中では戦略を意識し、いつでも戻れるようにしておくと、ハマったときには強い味方になります。
バグの原因を探索問題と捉える
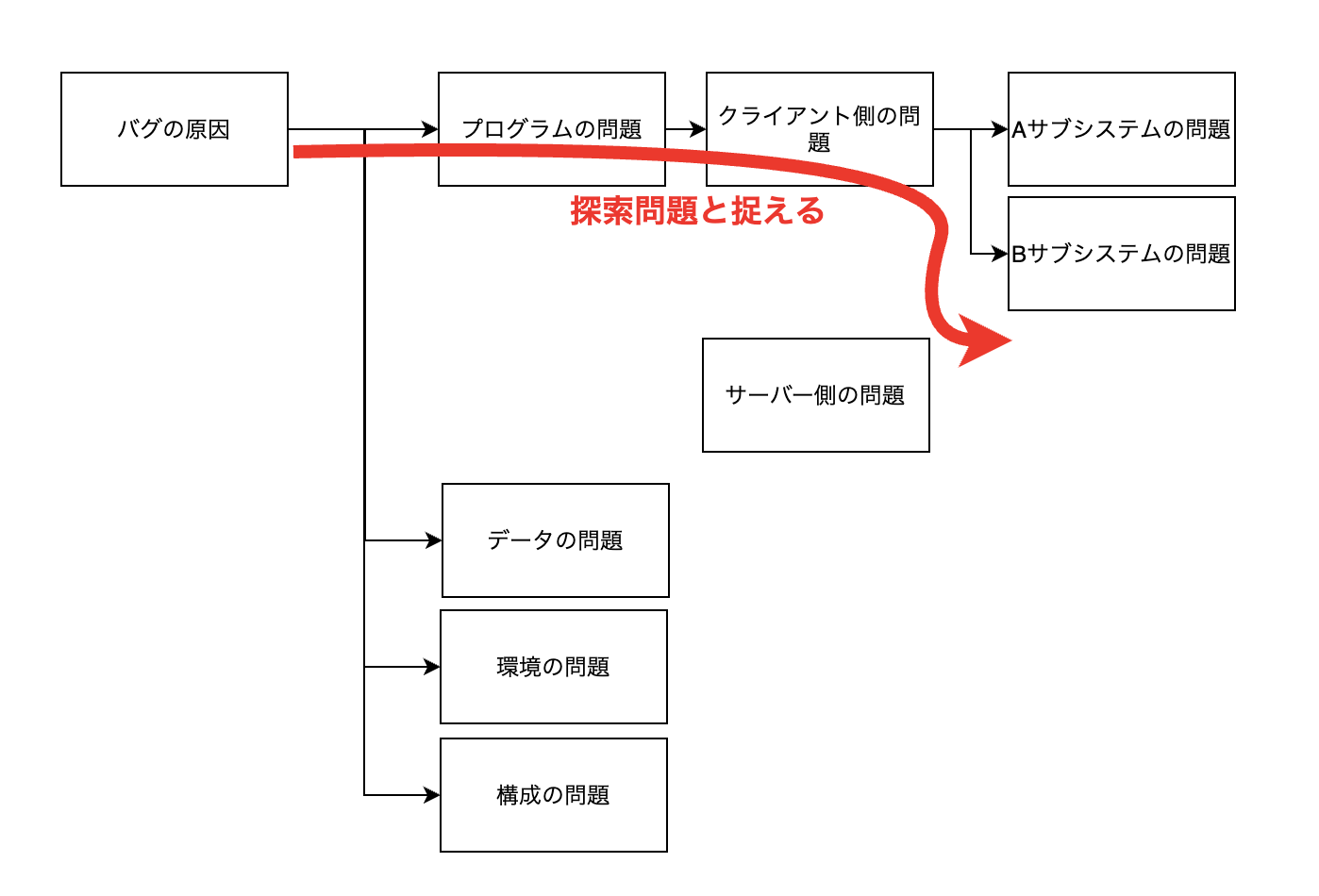
バグ調査を、原因をMECEに分類した探索木と捉えるところから始まります。
探索木にするためには、調査の過程をツリー状にメモを書き出していきます。こうすれば自然とMECEを意識するようになります。
最初から全部を書き出す必要はありませんが、プログラム、データ、環境、構成のように原因の大分類だけでも洗い出しておくと、思い込みの防止に繋がります。
また、探索問題なので、深さ優先なのか、幅優先なのか、ヒューリスティクスを用いるのか、トップダウンなのかボトムアップなのかなどを意識しながら進めることになります。
私はたいてい、ヒューリスティクスを用いて深さ優先で探した後、一定期間で解決しない場合は幅優先探索に切り替えるようにしています。
Notionなどのツールを使えばコードや画像も貼り付けられるし、履歴がそのまま残るので、後日別のバグを調査するときにも役立ちます。
調査の手順は、1.バグの再現⇒2.発生するコードの特定⇒3.原因調査の順に進める
バグの原因調査の出発点は、まずバグを再現することです。バグに再現性がない場合、どの条件で発生するのかわかりません。
次に、バグが発生するコードを特定します。
例えばこのような感じです。
擬似コードvar x = 0; print(x); // ?ここで発生していた! var y = x + 1;発生する場所=原因の場所とは限りません。ですが、この作業によって調査の出発点を得ることができます。
なお、サーバーの起動時に発生する場合など、必ずしもコードを特定できない場合もあると思います。その場合は「発生する瞬間」を特定するようにします。
発生場所がわかったら原因調査に入ります。
バグの発生箇所は二分探索で効率的に調べることができる
バグが発生する状況/しない状況は、二分探索を使って効率的に調べることができます。
例えば、ある関数の一部をコメントアウトしてバグが発生しなくなるかどうかを調べるとしたら、1つ1つの処理をコメントアウトするのではなく、全体を半分ずつコメントアウトしていきます。
(例)
1.関数の後半半分をコメントアウトする擬似コードfunc test() { 処理1 処理2 // 処理3 // 処理4 }2.後半のうち、さらに後半だけをコメントアウトする
擬似コードfunc test() { 処理1 処理2 処理3 // 処理4 }このような絞り込み方をすることで効率的に発生箇所を調べることができます。
バグが発生する状況/しない状況を用意し、その差を縮めていくように調査する
バグが発生する状況と、バグの発生しない状況を用意します。その差を縮めていくことで、最後にはバグの原因を突き止めることができます。
(例)
・ このマシンでは起きるが、このマシンでは起きない
・ このコードを実行すると起きるが、このコードをコメントアウトすると起きない
・ この画面では起きるが、この画面では起きない用意するのが難しい場合は、ほとんど何も処理のないシンプルなプログラムを作ることもあります。
例えば、新しくプロジェクト作成して何も処理を入れていないアプリなどです。そこにバグが発生するプログラムが利用しているライブラリを加えたらどうなるかなど、少しずつバグが発生する状況に近づけていきます。
また、MECEに分類した探索木を使って二分探索で調べることもできます。
例えば、最初の図であれば次のように2つに分けます。
- プログラムと構成
- 環境とデータ
まず環境とデータを以前のバージョンに戻し、バグが再現したら今度は環境だけを戻す、といった方法で探索することができます。
この考え方を応用すれば、実験計画法なども活用できそうですが、私は試したことはありません。
それでも発生しない状況を作るのが難しい/手間がかかりすぎる場合もあると思います。その場合は頭の中で「こういう状況なら必ずバグがでない」という想定だけは持っておきます。
バグが発生する状況/しない状況が用意できたら、両者を近づけていき、差が出るポイントを見つけます。
ログや内部情報のスナップショットを取得する。取得できない場合は取得できるようにする
ログや内部情報のスナップショット(デバッグ出力など)は、バグ調査全体を通じて利用しますが、バグの発生する状況/しない状況の差を縮めていくと、どうしても差が縮まないポイントがでてきます。
例えば、マシンAとマシンBでは全く同じコード、データ、環境なのに、マシンAだけバグが発生する、といった状況です。
その時は、より詳細な情報を出力できるようにします。
例えば、発生する状況/しない状況それぞれについて
- 問題が発生する箇所の前後で、問題に関係する変数の値をログに残し、差を確認する
- 差異がない場合は、その変数の元となるAPIのレスポンス値をログに残し、差を確認する
- 差異がない場合は、APIのレスポンスの元になったデータベースの値をログに残し、差を確認する
(もちろんログではなくデバッガで値を確認しても良いです)
という流れで進めます。
どれだけ調べても一見差が無いように見える場合もありますが、思い込みの可能性もあるので、diffをとると良いでしょう。
それでも解決しない場合に備える
それでも解決しないことはあります。
その場合は根本的な原因調査を諦めて回避策を取る、などのプロジェクト的な判断を伴うことがあります。つまり、バグ調査というタスクの上位のタスクに戻ることになります。
バグ調査にハマってしまい、上位のタスクに戻るまでに時間がかかりすぎることも問題です。
これを避けるために、1つ1つの調査に時間的な区切りを入れます。
私はポモドーロ・テクニックを用いて、25分のターンで区切って作業をしています。
次のようなステップで進めています。
1.ターンの前にターンのゴールを明確にする(例:環境の問題か否かを見極める)
2.作業を実施する
3.ターンが終わったら、振り返り、次に何をするのかを考えるときには、何ターンも同じ場所を調査することもありますが、ターンで区切っておくと「いくらなんでも時間がかかり過ぎだな」という反省をするきっかけを得ることができます。
- 投稿日:2020-11-17T19:18:49+09:00
[Swift] 数値を漢数字に変換する
NumberFormatterを使えばいいです。が、いくつか注意点があります。//漢数字 let formatter = NumberFormatter() formatter.numberStyle = .spellOut formatter.locale = .init(identifier: "ja-JP") let number = 123456789012345678 if let string = formatter.string(from: NSNumber(value: number)){ print(string) //十二京三千四百五十六兆七千八百九十億千二百三十四万五千六百七十八 }まずロケールを指定しないと
.spellOutに設定しても英語になります。数値が負だった場合はしっかり「マイナス」と付けてくれるので安心です。
ただ、数値が「百京」を超えると変換してくれず、代わりに三桁区切りの数字が返ってくるようになります。let numberA = Int(1E18) let numberB = Int(1E18) - 1 if let string = formatter.string(from: NSNumber(value: numberA)){ print(string) //1,000,000,000,000,000,000 } if let string = formatter.string(from: NSNumber(value: numberB)){ print(string) //九十九京九千九百九十九兆九千九百九十九億九千九百九十九万九千九百九十九 }
Intのみを対象とするなら、実用的にはこのような関数を作っておく必要があると思います。func toKansuji(from number: Int) -> String? { if number >= Int(1E18){ return nil } if number <= -Int(1E18){ return nil } return formatter.string(from: NSNumber(value: number)) }
- 投稿日:2020-11-17T18:27:34+09:00
[Swift] Swiftでポインタを使って処理を高速化してみる
前書き
Swiftのような高級言語(高水準言語)を書いている人にとって、普段はポインタを意識することはないでしょう。
今回はそんな世界へと一歩踏み入れてみましょう!
ポインタを使った高速化
簡単な例を使って見ていきましょう。
Example1
1. コード例
0~1000の数字を合計するだけの処理を考えた時、以下のようになります。
func runLoopNumbers() { var sum = 0 for i in (0...1000) { sum += i } }これをポインタを用いた場合は、以下のように書けます。
func runLoopPointerNumbers() { var sum = 0 let sumPointer = UnsafeMutablePointer<Int>(&sum) for i in (0...1000) { sumPointer.pointee += i } }この
UnsafeMutablePointerというのを用いることでポインタを表しています。
(表すための方法がいくつかあり、参考文献の方に詳しく載せているのでそちらをご覧ください)2. 比較結果
それぞれ10回ずつ実行した結果とその平均時間を取ると
回数 ポインタなし ポインタあり 1回目 2.10E-02 7.37E-04 2回目 9.09E-03 7.12E-04 3回目 9.41E-03 7.10E-04 4回目 9.87E-03 7.16E-04 5回目 9.72E-03 7.19E-04 6回目 9.12E-03 7.25E-04 7回目 1.01E-02 7.26E-04 8回目 9.05E-03 7.28E-04 9回目 9.14E-03 7.30E-04 10回目 8.93E-03 7.15E-04 Average 1.05E-02 7.22E-04 = 0.010539 = 0.000722 実行時間が1秒にも満たないので、一見たいしたことはないかもしれませんが...
実行速度に15倍程の差がついていることがわかります。※ DateのtimeIntervalSinceで計測
※ E-01 = 10^-1 = 1/10Example2
海外の競技プログラミングでお馴染みLeetCodeの「1. Two Sum」という問題を例にとってみましょう。
0. 前提
問題は以下のようになっています。
Given an array of integers, return indices of the two numbers such that they add up to a specific target. You may assume that each input would have exactly one solution, and you may not use the same element twice.つまり
「与えられた配列(nums)から2つを選択し、指定した値(target)を作れるかどうか」
ということになります。その最初の例として、以下が与えられます。
Given nums = [2, 7, 1, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1].1. コード例
愚直に
forやwhileを使って解けば、このようになるでしょう。(あくまで一例として)func twoSum(_ nums: [Int], _ target: Int) -> [Int] { for i in 0 ..< nums.count { var j = i+1 while j < nums.count { if nums[i] + nums[j] == target { return [i, j] } j += 1 } } return [] }シンプルに配列を2回調査する線形探索をしています。
これをポインタを用いた場合は、以下のように書けます。
func twoSum(_ nums: [Int], _ target: Int) -> [Int] { var newNums = nums let pointer = UnsafeMutablePointer<Int>(&newNums) for i in 0 ..< nums.count { var j = i+1 while j < nums.count { if pointer[i] + pointer[j] == target { return [i, j] } j += 1 } } return [] }
var newNums = numsとしているのが冗長ですが、ポインタを使うために仕方なく置く必要があります。2. 比較結果
ポインタなし ポインタあり 24ms 8ms 実行速度が3倍早くなっていることがわかります。
処理が重たいものであればもっと顕著な差が出せるでしょう。3. 余談
ちなみにポインタを使わなくても、この問題は高速にできるので載せておきます。(あくまで一例として)
func twoSum(_ nums: [Int], _ target: Int) -> [Int] { var keyValue = [Int: Int]() for (i, num) in nums.enumerated() { if let index = keyValue[target-num] { return [i, index] } keyValue[num] = i } return [] }数字をkeyとして値をキャッシュしておき検索する(ハッシュテーブルを使う)方法です。
これであれば、O(n)で済むのでかなり高速です。実行時間は8msでポインタを使った時と同じ速度を出すことができました。
終わりに
実務で使うというのはなかなか難しいかもしれません。
競技プログラミングのようなロジックだけを考える、といった部分的な使い方であればとても入りやすいでしょう。ただ、余談でも紹介しましたが...
ポインタを使う前にアルゴリズムをちゃんと用いることで高速化できることが多いです。とはいえ、触ってみてるのは楽しいので、是非みなさんも使ってみてください!
参考文献
Swiftのポインタ関連
ポインタ関連
- 投稿日:2020-11-17T18:10:32+09:00
正規化ラグランジュ補間【Swift, Python】
何ヶ月か前Swiftを勉強してた時に、やるべきことを放棄してこういうものを作ったりしてました。その時は堕落していて、思い出すだけでマジで何やってんだよバカだなーと思います。
「こまけえこたぁいいからさっさと触らせろ」という方は下記の
Usageをご覧ください。ラグランジュ補間とは
統計学とかにも確か使われる、グラフ上の複数の点と点を繋ぐ曲線の方程式を導出するやつです。
例えば、
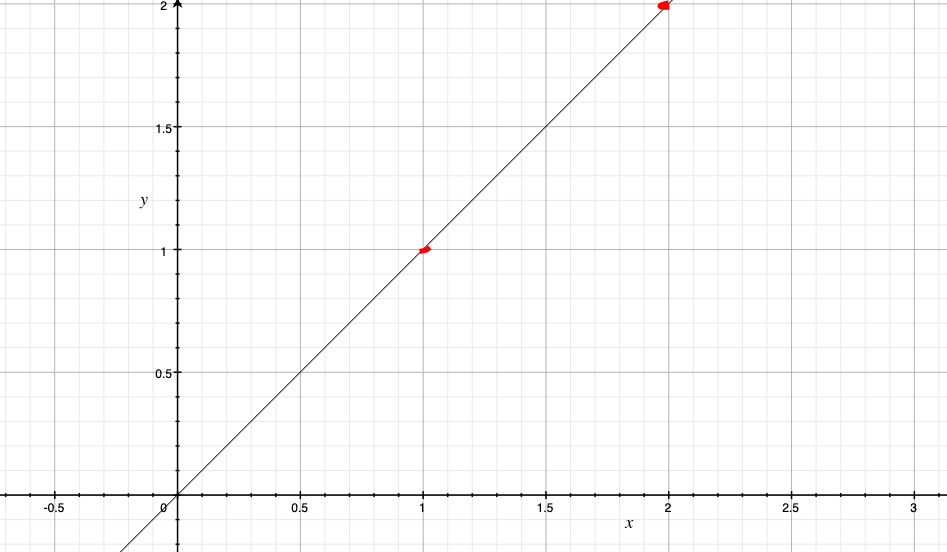
(1, 1), (2, 2)というxy平面上の2つの点があったとします。するとこの二つを結ぶ直線はy = xです。
そうではなく
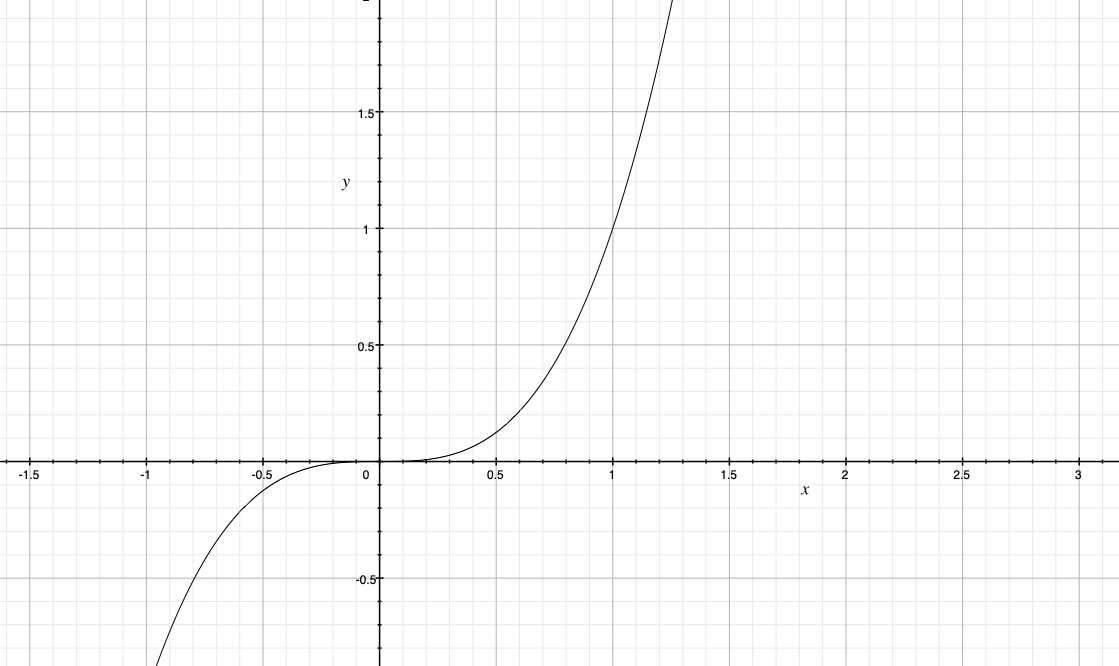
(1, 1), (2, 8), (3, 27)という3点があったとすると、それらを結ぶ曲線はy = x^3です。
なんで正規化なのか
計算量を大幅に削減するためです。図の拡大縮小を行うだけで、(確か)
O(n^3)オーダーがO(n^2)になります。定義式はこうです(Wikipedia)。
これを簡単にすると定数
ajでy = a_0 + a_1x + ... + a_{n-1}x^nと表せます。これはつまり、ラグランジュ補間を計算するとは多項式の積を計算することに他ならないということです(ヴァンデルモンド行列というものを用いた計算方法もありますが、それは計算量が多いです)。
多項式の係数を計算するならば、例えば画像の例ではもし分母の
xjが全てjだったら計算が早くなりそうだなーという事がわかります。仮におっぱい関数をラグランジュ補間で描画したいとします。その時の改善に至る道はこうです。
0:おっぱいの境界線からいくつかの点を選びxy座標で表現する。
1:指定した座標は現実的に考えれば無理数であろうが、それを有理数に近似する
2:有理数ということは、かければ必ず全ての座標のxが整数になる倍率が存在する
3:その倍率でおっぱいの図を拡大する
4:座標は(3, 28.5), (7, 22.2), (8, 53.1)...のようになるが、この3, 7, 8は結局バラバラで、Wikipediaの画像でいう分母計算が大変。計算量を減らすためにはさらに測り直して(3, 28.5), (4, 26.4), (5, 23.2)...と、x要素が1ずつ上がってゆくようにする。
5:さらにxを1から始めれば、わざわざ選んだ点群ごとに始点を変えなくて済むので(1, 2.3), (2, 3.3), (3, 28.5)...のように測る。これは結局、
・
(1, *), (2, *), (3, *)...と順順に測ってゆくに集約されます。こうすれば計算量を改善できます。
Usage
使用する場合は
Codeをコピペして下さい。
座標群が(1, y0), (2, y2) ..., (n, yn-1)と表された時print(LagrangeInterplation([y0, y1, ..., yn-1]))とすれば、配列が返ってきます。その配列を
[a0, a1, ...an-1]とすると、座標群の通る曲線の方程式はy = a_0 + a_1x + ... a_{n-1}x^nであるということを表します。これでおっぱい関数でもなんでも描画できるはずです。しかし実際にはクネクネしてしまうので、おっぱい関数を作る場合にはより良い方法を採択する事が望ましいかと思われます。今思い出しましたが、私はおっぱい関数を楽して作るためにこのメソッドを作りました。
Code
for Python
import math # Normalize-Lagrange Interplation(Python) def LagrangeInterplation(A): n = len(A) p = float(math.factorial(n-1)) z = A[-1] / p Q, R = [1.0], [-1.0 * (n-1) * z, z] for i in reversed(range(2, n, 1)): z *= -1.0 * i / (n-i) * A[i-1] / A[i] Q = PolynomialExpansion([-1.0 * (i+1), 1.0], Q) S = [] for j in range(0, len(Q)): S.append(z * Q[j] + R[j]) R = PolynomialExpansion([-1.0 * (i-1), 1.0], S) p1= p if n % 2 == 1 else -1 * p z1 = float(A[0]) / p1 Q1 = PolynomialExpansion([-2.0, 1.0], Q) for j in range(0, n): R[j] += z1 * Q1[j] if R[-1] == 0.0: while R[-1] == 0.0: del R[-1] return R # PolynomialExpansion def PolynomialExpansion (A, B): C = [] m, n = len(A), len(B) for i in range(0, m+n-1): c = 0 for k in range(0, i+1): if i-k < m and k < n: c += A[i-k] * B[k] C.append(c) return C # Tlanslate hand to number def translate1 (str): A = list(str) for i in range(len(A)): if A[i].isdigit() or A[i] == '/': del A[i] return Afor Swift
//MARK:- Lagrange補間 //階乗の演算子 postfix operator <!> postfix func <!> (n:Int) -> Int { var v = [Int]() if n == 0 {v.append(1)} else if n == 1 {v.append(1)} else if n == 2 {v.append(2)} else { for i in 2...n {v.append(i)} repeat { var u = [Int]() let t = v.count for i in 0..<t / 2 { u.append(v[2*i] * v[2*i + 1]) } if t % 2 == 1 {u.append(v.last!)} v = u } while v.count > 1 } return v[0] } //多項式の乗算 func PolynomialExpansion (_ A:[Int], _ B:[Int]) -> [Int] { var C = [Int]() let m = A.count, n = B.count for i in 0..<m+n-1 { var c = 0 for k in 0...i { if i-k < m, k < n { c += A[i-k] * B[k] } } C.append(c) } return C } func PolynomialExpansion (_ A:[Double], _ B:[Double]) -> [Double] { var C = [Double]() let m = A.count, n = B.count for i in 0..<m+n-1 { var c = 0.0 for k in 0...i { if i-k < m, k < n { c += A[i-k] * B[k] } } C.append(c) } return C } //Double関数 func D(_ a:Int) -> Double { return Double(a) } //数列を予測するためのラグランジュ補間 func LaglangeInterplation(_ A:[Int]) -> [Double] { let n = A.count, p = D((n-1)<!>) var z = D(A.last!) / p, Q = [1.0], R = [-1.0 * D(n-1) * z, z] for i in (2..<n).reversed() { z *= -1.0 * D(i) / D(n - i) * D(A[i-1]) / D(A[i]) Q = PolynomialExpansion([-1.0 * D(i+1), 1.0], Q) var S = [Double]() for j in 0..<Q.count { S.append(z * Q[j] + R[j]) } R = PolynomialExpansion([-1.0 * D(i-1), 1.0], S) } let p1 = n % 2 == 1 ? p : -1.0 * p, z1 = Double(A[0]) / p1, Q1 = PolynomialExpansion([-2.0, 1.0], Q) for j in 0..<n { R[j] += z1 * Q1[j] } if R.last! == 0.0 { repeat { R.remove(at: R.count - 1) } while R.last! == 0.0 } return R }まとめ
作ったのが昔すぎて、関数の中で何をしているのか忘れてしまいました。失敬。

- 投稿日:2020-11-17T18:05:52+09:00
【Swift】RxSwiftでDelegateを卒業する
Delegateについての図解がこちら
https://qiita.com/Sossiii/items/a64c78640d5747fc5126Delegateで代理的な処理を行う時、最低でも15行〜ほど必要になりますが、
RxSwiftを使うと4行〜から実装することができます。「ポップのOKボタンを押した時の処理」
をDelegateとRxSwiftDelegateパターン
//ポップアップ側 protocol PopupViewDelegate: class { func okButton() } class PopupView: UIView { ... weak var delegate: PopupViewDelegate? ... @IBAction func okButtonTapped(_ sender: UIButton) { delegate?.okButton() } } //呼び出し側 class ViewController: UIViewController { ... let popupView = PopupView() popupView.delegate = self ... } extension ViewController: PopupViewDelegate { func okButton() { //タップされた時の処理 } }RxSwiftパターン
//ポップアップ側 class PopupView: UIView { ... @IBOutlet var okButton: UIButton! ... } //呼び出し側 import RxSwift class ViewController: UIViewController { ... let popupView = PopupView() let _ = popupView.okButton.rx.tap .subscribe({ _ in //タップされた時の処理 }) ... }おわりに
いかがでしたでしょうか?
RxSwiftを使うことでプロトコルの実装や継承がなく、
uiコンポーネントがあれば実装することができます。
だいぶ実装が楽になりますね。
- 投稿日:2020-11-17T15:56:51+09:00
Swift Lambda Runtime で、Lambda 関数から DynamoDB Local に接続する
前回 Swift Lambda Runtime を使用して Lambda 関数を作成・実行しましたが、
今回はその続きで、AWS サービスの一つでデータベースの DynamoDB Local に接続する Lambda 関数を作成します。
私は DynamoDB に触るのはこれが初めてですので、誤りがあれば指摘して頂けたらありがたいです。
0. DynamoDB とは
今回作成する関数に必要な知識として、Amazon DynamoDB の特徴をあげます。
- キーバリュー型 & スキーマレスな、いわゆる NoSQL データベース
「リージョン( Region )」・「アクセスキー( Access Key )」という概念があり、データベースはそれ毎に作成される
リージョン:AWS で予め定められた各地域
例:日本なら『東京』、アメリカなら『カルフォルニア』、『オレゴン』など
アクセスキー:DynamoDB にアクセスするユーザーに割り振られたキー。
RDB( MySQL, ... ) でいう「 テーブル 」があり、レコードの事を「 Items 」、フィールド(カラム)の事を「 Attributes 」と呼ぶ。
データベースに対する操作は HTTP ( S ) でする(ステートレス)
データ型は大きく3つある。
- スカラー型 ・・・ 文字、数値、バイナリ、ブール、Null 型
- ドキュメント型 ・・・ リスト(要素の型が自由な配列)、マップ(辞書)型
- 集合型 ・・・ 数値、文字列、バイナリの集合(集合内要素の型は同一)
1. 作成する Lambda 関数
簡単なメッセージを出力する関数です。
Lambda 関数へ送信するリクエストに、パラメータとして「名前( name )」を入れる
リクエストを受け取った Lambda 関数が、 DynamoDB に名前を保存する
保存した名前をメッセージとして出力する
2. DynamoDB Local のインストール
Docker を使用して、ローカルPCに DynamoDB ( DynamoDB Local )をインストールします。
ここで注意ですが、上で述べたように、DynamoDB のデータベースは「リージョン」と「アクセスキー」に対して自動で割り振られ、
MySQL や PostgreSQL のように「 データベースの作成 」コマンドのようなものはありません。
これを念頭に置いて、ターミナルを開いて下記のコマンドを入力して下さい。
DynamoDB を使用するためのイメージとコンテナが作成されます。
ターミナル$ docker run --name dynamodb -p 8000:8000 -d amazon/dynamodb-local -jar DynamoDBLocal.jar -sharedDb
コマンドの意味を確認します。(ドキュメント)
--name [文字列]:コンテナ名の指定
- --name dynamodb:コンテナ名を「dynamodb」で指定
-p:ポートフォワードの設定。(ホスト側ポート):(Docker コンテナ側ポート)です。
- -p 8000:8000:Docker側(右側)の8000番ポートをホストPC側(左側)8000番ポートに対応させる
-d:コンテナをデタッチド・モードで実行。(コンテナを終了させない)
- コンテナを、端末から切り離してバックグラウンドで実行します。
amazon/dynamodb-local:イメージ名の指定
-jar DynamoDBLocal.jar -sharedDb:コンテナが起動するときに実行するコマンド
最後の「 -jar DynamoDBLocal.jar -sharedDb 」ですが、私自身がすぐに理解出来なかったのでもう少し詳しく見ていきます?
docker history を使って、上記コマンドでこのイメージがどのように作成されたのかを見てみます。
ターミナル$ docker history amazon/dynamodb-local IMAGE CREATED CREATED BY SIZE COMMENT aa787d0973f2 5 weeks ago /bin/sh -c #(nop) CMD ["-jar" "DynamoDBLoca… 0B <missing> 5 weeks ago /bin/sh -c #(nop) ENTRYPOINT ["java"] 0B <missing> 5 weeks ago /bin/sh -c #(nop) EXPOSE 8000 0B ・・・(略)
「 CREATED BY 」列の二行目に注目です。
docker run コマンドで「イメージ名」の次に記述するのは「コンテナが起動するときに実行するコマンド」ですが、
ENTRYPOINT を指定した場合、この ENTRYPOINT で指定したコマンドへの引数となります。(ドキュメントの「CMD」「ENTRYPOINT」)
ですので今回の場合、
$ java -jar DynamoDBLocal.jar -sharedDbという java コマンドをコンテナ起動時に実行している事になります。
私は Java は全く分からないのですが、
- java [ オプション ] -jar [ ファイル名 ] [ 引数 ]:指定した Java ファイルを引数を与えて起動する
らしいので、そういう事なんだと思います??
ただ今回重要なのは引数で、「 -sharedDb 」オプションにより、データベースを共有化しています。(ドキュメント)
つまり、「リージョン」「アクセスキー」に関係無く、同一のデータベースが使用されます。
ローカル環境でデバッグなどをする時には、この設定をすると簡単に始められます。
3. DynamoDB GUI クライアントのインストール
DynamoDB データを視覚的に確認するため、AWS 公式の NoSQL Workbench for DynamoDB GUI Client をインストールします。
ターミナル// Homebrew をインストールしていない場合 $ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)" // Homebrew で NoSQL Workbench for DynamoDB GUI Client をインストール brew install nosql-workbench-for-amazon-dynamodb
インストール出来たらアプリを起動してメニュー画面を開きます。
開いたら、まず接続設定・確認をします。
これで接続できたと思います。戻ったメニュー画面で接続名( Connection Name )が表示されていればOKです。
ついでに、同じ画面で「アクセスキー」「シークレットアクセスキー」を確認出来ます。
(今回は「 -sharedDb 」により共有化しているので関係ありません)
まだ説明していませんでしたが、データベースの接続には「シークレットアクセスキー」も必要になります。
これが RDB でいう「接続ユーザーのパスワード」に相当するかと思います。
4. DynamoDB Table の作成
そのまま GUI クライアントの左サイドバーの項目を順番に操作してテーブルを作成します。
それぞれの意味としては、だいたい次のようになります。
「 Data modeler 」:テーブル定義
「 Visualizer 」:1で作成したテーブルの詳細確認。確認してOKなら DynamoDB へコミットする
「 Operation Builder 」:テーブルデータの操作。2でコミットすると、ここに作成されたテーブルが表示される。
「 Data modeler 」「 Visualizer 」にはサンプルもいくつかあるので見ると参考になります。
ではテーブルを作成していきます。
このクライアント GUI でテーブルを作成する場合は、まず「 Data Model 」を作成します。
ここには、これから作成するテーブルの説明や作成者を記述します。モデル名は「 Local 」としていますが、何でも良いです。
モデルができたらテーブルの作成です。
「 Add table 」をクリックしてテーブル名「 test_table 」と入力しています。
続いて RDB のようにフィールドを定義するのですが、DynamoDB は「主キー」のみの定義で十分です。
他のカラムは特に定義の必要無しで自由に保存・(あれば)読込みできます。
「 Primary key attributes 」で主キーの定義をします。
すぐ下に「Add sort key」というチェックボックスがありますが、これは複数主キーの定義です。
今回は無視して進めます。
作成できたと思いますので、左サイドバーの「 Visualizer 」画面でこのテーブル追加をコミット(確定)します。
コミット画面で、先ほど作成した接続を選択してコミットです。
「 Operation Builder 」画面を開いて、テーブルが作成されたか確認します。
「 Open 」ボタンを押して、
テーブル名が表示されているので OK です。
これで準備は完了ですので、ソースコードを書いていきます‼️
5. DynamoDB との接続
では、ソースコードを記述していきます。
今回は DynamoDB へのドライバーとして、Soto というライブラリを使わせて頂きます。
全ての AWS サービスへのアクセスを提供する Soto ライブラリ
他のドライバーとして、Amazon の公式ドライバーもあります。
前回の続きから Package.swift、main.swift を修正・追加していきます。
Package.swift
まず、Package.swift に Soto ライブラリを読み込むための記述をします。「 dependencies 」に次のように追加します。
Package.swiftの一部dependencies: [ .package(url: "https://github.com/swift-server/swift-aws-lambda-runtime.git", .upToNextMajor(from:"0.3.0")), .package(url: "https://github.com/soto-project/soto.git", from: "5.0.0-beta"), ],そして「 targets 」項目の「 dependencies 」にも追記します。
Package.swiftの一部dependencies: [ .product(name: "AWSLambdaRuntime", package: "swift-aws-lambda-runtime"), .product(name: "SotoDynamoDB", package: "soto"), ]main.swift
次に main.swift ですが、短いので全て記載します。
main.swiftimport AWSLambdaRuntime import SotoDynamoDB import AsyncHTTPClient struct Input: Codable { let name: String } struct Output: Codable { let message: String } struct Handler: EventLoopLambdaHandler { typealias In = Input typealias Out = Output let db: SotoDynamoDB.DynamoDB let tableName: String = "test_table" init(context: Lambda.InitializationContext) { let httpClient: AsyncHTTPClient.HTTPClient = .init(eventLoopGroupProvider: .createNew) let db: SotoDynamoDB.DynamoDB = .init( client: .init( credentialProvider: .static( accessKeyId: "dummyAccessKeyId", secretAccessKey: "dummySecretAccessKey" ), httpClientProvider: .shared(httpClient) ), endpoint: "http://localhost:8000" ) self.db = db } func handle(context: Lambda.Context, event: Input) -> EventLoopFuture<Output> { db .putItem( .init(item: ["name": event.name], tableName: tableName) ) .flatMap { _ in db.getItem( .init(key: ["name": .s(event.name)], tableName: tableName) ) } .map { output in guard case let .s(name) = output.item?["name"] else { return .init(message: "正しく保存できていません") } return .init(message: "ようこそ, \(name)さん!") } } } Lambda.run(Handler.init)
上から順に説明します。
まず一番上の import 文ですが、これで Soto ライブラリを 使えるようにしています。
もう一つの「 AsyncHTTPClient 」は、DynamoDB への操作に必要な HTTP クライアントとして使用します。
Soto ライブラリ内でも、デフォルトの HTTP クライアントを作成するときにこれを使用しています。
main.swiftの一部import SotoDynamoDB import AsyncHTTPClient
次に、作成する Lambda 関数へ渡す入力用、Lambda 関数実行後の出力用構造体の定義をしています。
main.swiftの一部struct Input: Codable { let name: String } struct Output: Codable { let message: String }
そして「 EventLoopLambdaHandler 」protocol に準拠した 「 Handler 」構造体を定義しています。
Lambda との接続関数 Lambda.run の引数に使うためにですが、前回のように直接クロージャを引数にしても大丈夫です。
今回はコードを見やすくするために構造体を使用しています。
では DynamoDB 接続用クライアントを用意します。必要な情報は下記になります。
accessKeyId(アクセスキー)、secretAccessKey(シークレットキー):今回は何でも良いです。
region:省略出来るので記述していません。
endpoint:localhost と、さらに上記 docker run コマンドの p オプションのホスト側のポートを指定します。
main.swiftの一部init(context: Lambda.InitializationContext) { let httpClient: AsyncHTTPClient.HTTPClient = .init(eventLoopGroupProvider: .createNew) let db: SotoDynamoDB.DynamoDB = .init( client: .init( credentialProvider: .static( accessKeyId: "dummyAccessKeyId", secretAccessKey: "dummySecretAccessKey" ), httpClientProvider: .shared(httpClient) ), endpoint: "http://localhost:8000" ) self.db = db }
最後に Lambda 関数のメインとなるコードを記述します。
func handle(context: Lambda.Context, event: Input) -> EventLoopFuture<Output> { db .putItem( .init(item: ["name": event.name], tableName: tableName) ) .flatMap { _ in db.getItem( .init(key: ["name": .s(event.name)], tableName: tableName) ) } .map { output in guard case let .s(name) = output.item?["name"] else { return .init(message: "正しく保存できていません") } return .init(message: "ようこそ, \(name)さん!") } }引数 event により、受け取った値を入力値として関数内で使用できます。
putItem で保存して、保存した(はずの)データを getItem で読み込み、最後にそれをメッセージとして出力しています。
getItem 内に 「 "name": .s(event.name) 」とありますが、これは指定したキー「 name 」の値を、スカラー型の文字型としてSwift 側へデコードする事を表しています。
6. 作成した関数を実行
Xcode でプロジェクトを実行してから、ターミナルを開き
ターミナル$ curl --header "Content-Type: application/json" --request POST --data '{"name": "山田"}' http://localhost:7000/invokeとして
ターミナル{"message":"ようこそ, 山田さん!"}と出力されれば完成です❗️
念のため確認してみます。
データが確認できました‼️???
もし無ければ、更新ボタンを押してみて下さい。
7. 最後に
簡単に DynamoDB に接続出来て個人的には感動です?
この後ですが、DynamoDB Stream を使って自動で Lambda を起動するものが欲しいので、それを作っていきたいと思います。
Swift の Server Side は出来る事がドンドン増えてきてすごく楽しいので、是非色々やってみてください✌️











- 投稿日:2020-11-17T11:26:11+09:00
[Swift] テキストから顔文字を抽出する
誰にだってテキストから顔文字を抽出したいことがあると思います(要出典)。
手法
2016年のこちらの論文の第2節で提案されているものを用います。
風間 一洋, 水木 栄, 榊 剛史『Twitterにおける顔文字を用いた感情分析の検討』
https://www.jstage.jst.go.jp/article/pjsai/JSAI2016/0/JSAI2016_3H3OS17a4/_article/-char/ja「顔文字抽出」とは
一口に「顔文字抽出」と言っても指すところは曖昧です。例えば「(・∀・)モウヤメレ!!」という顔文字はテキストを含みますが、この部分は顔文字として扱われるべきでしょうか。抽出されるべきは「(・∀・)」なのか、それとも「(・∀・)モウヤメレ!!」なのか。あるいは「(・∀・)モウヤメレ」を一区切りとする考え方もありそうです。
この論文で言われている顔文字は「基本形」と呼ばれるもので、1つの顔として認識され、かつテキストを含まない「(・∀・)」の部分のようです。実装
構文的に意味を取りにくい部分があったので、適宜実験的に補完しながら実装しました。また意味的な読みやすさのため、場合分けや条件文をかなり冗長に書いています。
方針
顔文字をそうでない部分と区別する「顔文字主要文字」を中心として、その周辺を探索し、それらしき範囲を確定させていきます。
顔文字主要文字
ここでいきなりかなり迷いました。顔文字判定の核となる概念である顔文字主要文字の定義がイマイチわからなかったのです。
Unicode文字プロパティの一般カテゴリが表1に示す値を持つ記号類か,表2に示す日本語の文字以外の文字を,顔文字主要文字とする.
とあるのですが、構文上
Unicode文字プロパティの一般カテゴリが表1に示す値を持つ記号類or表2に示す日本語の文字以外の文字Unicode文字プロパティの一般カテゴリが表1に示す値を持つ記号類 and 表2に示す日本語の文字以外の文字のどちらを指すのかわからず。実験的にはどうやら前者のようだったので、そちらで実装します。
func isKaomojiMain(_ unicodeScalar: UnicodeScalar) -> Bool { if CharacterSet.punctuationCharacters.contains(unicodeScalar){ return true } if CharacterSet.symbols.contains(unicodeScalar){ return true } return !inJapaneseBlock(unicodeScalar) } func inJapaneseBlock(_ unicodeScalar: UnicodeScalar) -> Bool { let value = unicodeScalar.value if 0x0000...0x007F ~= value{ return true } if 0xFF61...0xFF9F ~= value{ return true } if 0x4E00...0x9FFF ~= value{ return true } if 0x3041...0x309F ~= value{ return true } if 0x30A0...0x30FF ~= value{ return true } if 0xFF01...0xFF60 ~= value{ return true } return false }これで顔文字主要文字の判定ができました。
顔文字探索
STEP1とされている顔文字探索を実装します。この手法では文字列をUnicode文字列として扱う必要があるため、変換します。
func search(from text: String, G: Int, L: Int) -> [String] { let unicodeScalars = Array(text.unicodeScalars) var results: [String] = [] var i = 0 while true{ if unicodeScalars.endIndex == i{ break } if isKaomojiMain(unicodeScalars[i]){ extract(from: unicodeScalars, center: i, G: G) } i += 1 } }
extract関数は後々実装するとして、ひとまずSTEP1は完了です。forループではなくwhileを用いているのは後々のためです。領域拡張
STEP2を実装します。
extract関数の内部に突っ込むのがいいでしょう。まだSTEP2の実装なので返り値は指定していません。
引数に与えられるcenterはSTEP1で発見した顔文字主要文字のindexです。
顔文字主要文字同士の間に最大G文字を許容しながら領域を拡張するということは、端点からG文字以内に顔文字主要文字があればそこまで領域を拡張する、ということを繰り返せばいいことになります。func extract(from scalars: [UnicodeScalar], center: Int, G: Int){ var result = scalars[center...center] #領域拡張 while true{ var changed = false if let i = (max(0, result.startIndex - G) ..< result.startIndex).first{isKaomojiMain(scalars[$0])}{ if result.startIndex != i{ changed = true } result = scalars[i..<result.endIndex] } if let i = (result.endIndex ..< min(scalars.endIndex, result.endIndex + G)).last{isKaomojiMain(scalars[$0])}{ if result.endIndex != i+1{ changed = true } result = scalars[result.startIndex..<i+1] } if !changed{ break } } }
maxとかminとかが入り混じって少し読みにくいですが、この部分のお気持ちは「領域外(index<0とか)に飛び出さないように」に尽きるので、適当に読んでいただければ大丈夫です。領域縮小
STEP3の領域縮小もやります。これも
extractに書いていけば良さそうです。
ただ、論文には顔文字は文末に使われる傾向があるために「(^^)『」や「。(^^)」のような前後の括弧や句読点と隣接することが多いので,領域の前後でそれぞれ一部括弧類の向きが異なる38文字を削除する.
としか書いておらず、その38文字が具体的になんなのかがわかりません。仕方がないのでこの部分では実験的に誤検出されることが多かった数文字を削除することにしました。
補助として次の二つを定義します。
func shouldBeDroppedLeft(_ unicodeScalar: UnicodeScalar) -> Bool { let charcterSet = CharacterSet(charactersIn: "))」』]】}〉〕。、,.!?!?…→") if charcterSet.contains(unicodeScalar){ return true } return false } func shouldBeDroppedRight(_ unicodeScalar: UnicodeScalar) -> Bool { let charcterSet = CharacterSet(charactersIn: "((「『[【{〈〔。、,.!?!?…←") if charcterSet.contains(unicodeScalar){ return true } return false }これらを用いて実装していきます。
//領域縮小 while result.count != 0 && shouldBeDroppedLeft(result[result.startIndex]){ result = scalars[result.startIndex + 1 ..< result.endIndex] } while result.count != 0 && shouldBeDroppedRight(result[result.endIndex - 1]){ result = scalars[result.startIndex ..< result.endIndex - 1] }領域補完
STEP4です。これが難しい。
iOSでサポートされている137文字の顔文字リストを,顔文字の前後に対して,3の処理を施した後で,顔文字と判定されなかった部分を隣接する1文字と共に抽出して,拡張用の部分文字列として使用する.例えば「m(_ _)m」からは左側の「m(」と右側の「)m」が抽出される.
とあるのですが、現在のiOSの顔文字リストは137どころではなく、自動抽出する方法も見当たらず、手作業で200ほど集めたところ(約半分)で気力が尽きました。集まったところまでで許してください。
まず補助関数として次の二つを定義します。
func isPermittedLeftSequence(_ unicodeScalars: [UnicodeScalar]) -> Bool { let list: [[UnicodeScalar]] = [ ["m","("], ["(","("], ["ヽ","("], ["ヾ","("], ["o","("], [".","°"], ["。","・"], ["ヾ","ノ"], [" ","ノ"], ] return list.contains(unicodeScalars) } func isPermittedRightSequence(_ unicodeScalars: [UnicodeScalar]) -> Bool { let list: [[UnicodeScalar]] = [ [")",")"], [")","m"], [")","ノ"], [")","ノ"], ["`","A"], [";",")"], [")","o"], ["°","."], ["・","。"], ["=","3"], ] return list.contains(unicodeScalars) }よく見るシリーズです。
領域補完もextractに追加しましょう。この部分はあんまりうまい実装が浮かばなかったので、ベタ書きです。//領域補完 let leftside = Array(scalars[max(0, result.startIndex - 1)..<min(result.startIndex+1, result.endIndex)]) if isPermittedLeftSequence(leftside){ result = scalars[max(0, result.startIndex - 1) ..< result.endIndex] } let rightside = Array(scalars[max(result.startIndex, result.endIndex-1)..<min(scalars.endIndex, result.endIndex + 1)]) if isPermittedRightSequence(rightside){ result = scalars[result.startIndex ..< min(scalars.endIndex, result.endIndex + 1)] }以上で
extractが完成します。この関数はresultのstartIndexとendIndexを返すことにしましょう。func extract(from scalars: [UnicodeScalar], center: Int, G: Int) -> (start: Int, end: Int) { var result = scalars[center...center] //領域拡張 //コード省略 //領域縮小 //コード省略 //領域補完 //コード省略 return (result.startIndex, result.endIndex) }顔文字判定
顔文字判定は
judgeとして別の関数に書きましょう。searchを次のようにします。var results: [String] = [] while true{ if unicodeScalars.endIndex == i{ break } if isKaomojiMain(unicodeScalars[i]){ let (start, end) = extract(from: unicodeScalars, center: i, G: G) if end <= i || start == end{ i += 1 continue } if judge(Array(unicodeScalars[start..<end]), L: L){ let kaomoji = unicodeScalars[start..<end].map{String($0)}.joined() results.append(kaomoji) i = end continue } } i += 1 }少し早いですが、
i=endの部分で先にSTEP6を実装してしまいました。顔文字だった部分を飛ばしてそのさきを調べるだけで大したことではないので気にしなくて大丈夫です。さて、
judgeの中身ですが、次のようにします。「文字数」がUnicodeScalarsのcountとしてなのか、Stringのcountとしてなのか定かでなかったため、とりあえずUnicodeScalarsの方で実装しました。func judge(_ unicodeScalars: [UnicodeScalar], L: Int) -> Bool { if unicodeScalars.count < L{ return false } if Set(unicodeScalars).count <= 1{ return false } let first = unicodeScalars.first! let last = unicodeScalars.last! if first == "「" && last == "」"{ return false } if first == "『" && last == "』"{ return false } if first == "”" && last == "”"{ return false } if first == "”" && last == "”"{ return false } if first == "\"" && last == "\""{ return false } if first == "(" && last == ")"{ let middle = unicodeScalars.dropLast().dropFirst() //数値 if middle.allSatisfy({0x0030...0x0039 ~= $0.value}){ return false } //漢字 if middle.allSatisfy({0x4E00...0x9FFF ~= $0.value}){ return false } } let filtered = unicodeScalars.filter{scalar in let category = scalar.properties.generalCategory return [.decimalNumber, .letterNumber, .uppercaseLetter, .lowercaseLetter, .otherLetter, .titlecaseLetter, .modifierLetter, .otherNumber].contains(category) } if Double(filtered.count) / Double(unicodeScalars.count) > 0.5{ return false } return true }完成
STEP6はもう実装してあるので、これで完成です。全体のコードは折りたたんでおくので見たい人が見てください。
全体のコード
func search(from text: String, G: Int, L: Int) -> [String] { let unicodeScalars = Array(text.unicodeScalars) var results: [String] = [] var i = 0 while true{ if unicodeScalars.endIndex == i{ break } if isKaomojiMain(unicodeScalars[i]){ let (start, end) = extract(from: unicodeScalars, center: i, G: G) if end <= i || start == end{ i += 1 continue } if judge(Array(unicodeScalars[start..<end]), L: L){ let kaomoji = unicodeScalars[start..<end].map{String($0)}.joined() results.append(kaomoji) i = end continue } } i += 1 } return results } func extract(from scalars: [UnicodeScalar], center: Int, G: Int){ var result = scalars[center...center] #領域拡張 while true{ var changed = false if let i = (max(0, result.startIndex - G) ..< result.startIndex).first{isKaomojiMain(scalars[$0])}{ if result.startIndex != i{ changed = true } result = scalars[i..<result.endIndex] } if let i = (result.endIndex ..< min(scalars.endIndex, result.endIndex + G)).last{isKaomojiMain(scalars[$0])}{ if result.endIndex != i+1{ changed = true } result = scalars[result.startIndex..<i+1] } if !changed{ break } } //領域縮小 while result.count != 0 && shouldBeDroppedLeft(result[result.startIndex]){ result = scalars[result.startIndex + 1 ..< result.endIndex] } while result.count != 0 && shouldBeDroppedRight(result[result.endIndex - 1]){ result = scalars[result.startIndex ..< result.endIndex - 1] } //領域補完 let leftside = Array(scalars[max(0, result.startIndex - 1)..<min(result.startIndex+1, result.endIndex)]) if isPermittedLeftSequence(leftside){ result = scalars[max(0, result.startIndex - 1) ..< result.endIndex] } let rightside = Array(scalars[max(result.startIndex, result.endIndex-1)..<min(scalars.endIndex, result.endIndex + 1)]) if isPermittedRightSequence(rightside){ result = scalars[result.startIndex ..< min(scalars.endIndex, result.endIndex + 1)] } return (result.startIndex, result.endIndex) } func judge(_ unicodeScalars: [UnicodeScalar], L: Int) -> Bool { if unicodeScalars.count < L{ return false } if Set(unicodeScalars).count <= 1{ return false } let first = unicodeScalars.first! let last = unicodeScalars.last! if first == "「" && last == "」"{ return false } if first == "『" && last == "』"{ return false } if first == "”" && last == "”"{ return false } if first == "”" && last == "”"{ return false } if first == "\"" && last == "\""{ return false } if first == "(" && last == ")"{ let middle = unicodeScalars.dropLast().dropFirst() //数値 if middle.allSatisfy({0x0030...0x0039 ~= $0.value}){ return false } //漢字 if middle.allSatisfy({0x4E00...0x9FFF ~= $0.value}){ return false } } let filtered = unicodeScalars.filter{scalar in let category = scalar.properties.generalCategory return [.decimalNumber, .letterNumber, .uppercaseLetter, .lowercaseLetter, .otherLetter, .titlecaseLetter, .modifierLetter, .otherNumber].contains(category) } if Double(filtered.count) / Double(unicodeScalars.count) > 0.5{ return false } return true } func isKaomojiMain(_ unicodeScalar: UnicodeScalar) -> Bool { if CharacterSet.punctuationCharacters.contains(unicodeScalar){ return true } if CharacterSet.symbols.contains(unicodeScalar){ return true } return !inJapaneseBlock(unicodeScalar) } func inJapaneseBlock(_ unicodeScalar: UnicodeScalar) -> Bool { let value = unicodeScalar.value if 0x0000...0x007F ~= value{ return true } if 0xFF61...0xFF9F ~= value{ return true } if 0x4E00...0x9FFF ~= value{ return true } if 0x3041...0x309F ~= value{ return true } if 0x30A0...0x30FF ~= value{ return true } if 0xFF01...0xFF60 ~= value{ return true } return false } func shouldBeDroppedLeft(_ unicodeScalar: UnicodeScalar) -> Bool { let charcterSet = CharacterSet(charactersIn: "))」』]】}〉〕。、,.!?!?…→") if charcterSet.contains(unicodeScalar){ return true } return false } func shouldBeDroppedRight(_ unicodeScalar: UnicodeScalar) -> Bool { let charcterSet = CharacterSet(charactersIn: "((「『[【{〈〔。、,.!?!?…←") if charcterSet.contains(unicodeScalar){ return true } return false } func isPermittedLeftSequence(_ unicodeScalars: [UnicodeScalar]) -> Bool { let list: [[UnicodeScalar]] = [ ["m","("], ["(","("], ["ヽ","("], ["ヾ","("], ["o","("], [".","°"], ["。","・"], ["ヾ","ノ"], [" ","ノ"], ["キ","タ"], ["イ","エ"], ] return list.contains(unicodeScalars) } func isPermittedRightSequence(_ unicodeScalars: [UnicodeScalar]) -> Bool { let list: [[UnicodeScalar]] = [ [")",")"], [")","m"], [")","ノ"], [")","ノ"], ["`","A"], [";",")"], [")","o"], ["°","."], ["・","。"], ["=","3"], ] return list.contains(unicodeScalars) }
使ってみましょう。print(search(from: "嬉しいです(≧▽≦)", G: 3, L: 3)) //["(≧▽≦)"] print(search(from: "嫌い(`ε´) 絶交しよ(  ̄っ ̄)", G: 3, L: 3)) //["(`ε´) ", "(  ̄っ ̄)"]もう少し長い文章でもいけるでしょうか。
地震だ!┗(^o^;)┓震度どのくらいかな??wwWwwWWw┏(;^o^)┛ニュースになってるかな??wWWWwwww(´・`:) こ…これ…これは…………僕の貧乏揺すりだあああああ ┗(^o^)┛WwwwWW┏(^o^)┓ドコドコドコドコwwwwwwww
— ドコドコbot (@dokodoko_bot) November 10, 2020//["┗(^o^;)┓", "┏(;^o^)┛", "(´・`:) こ…これ", "┗(^o^)┛", "┏(^o^)┓"] print(search(from: "地震だ!┗(^o^;)┓震度どのくらいかな??wwWwwWWw┏(;^o^)┛ニュースになってるかな??wWWWwwww(´・`:) こ…これ…これは…………僕の貧乏揺すりだあああああ ┗(^o^)┛WwwwWW┏(^o^)┓ドコドコドコドコwwwwwwww", G: 3, L: 3))若干誤検出していますが、しっかり抜き出せていますね。
所感
しばらく使用してみているのですが、「キタ━━━(゚∀゚)━━━!!!」などの顔文字がとても間抜けな結果になります。
print(search(from: "キタ━━━(゚∀゚)━━━!!!", G: 3, L: 3)) //["━━━(゚∀゚)━━━"]私の用途ではこの種の顔文字ではテキストも抜き出せたほうがいいので、多少エスケープ処理を足す必要がありそうです。
また、シンプルな構成の顔文字が検出されにくいという問題があります。「(ー ー;)」「(..)」「(ToT)」など標準的な記号のみで表現された顔文字が引っかからないため、この辺りも調整が必要かと思われます。当初流行りの深層学習で……など考えていましたが、どうなんでしょう。系列データとして扱う場合は合成文字の処理が辛そうですから、画像認識系のタスクになるんでしょうか。どなたかやってみて欲しいところです。
- 投稿日:2020-11-17T11:05:50+09:00
firebase loginができなくて困ったことまとめ
fastlaneで
Firebase App Distributionにアプリをあげようとした際にfirebase loginでつまずいたことをまとめました。問題① Error: @grpc/grpc-js only works on Node ^8.13.0 || >=10.10.0
これはnodeのバージョンが
8.13.0または10.10.0以上でないために起こるエラーです。
nodeのバージョンを切り替える必要があります。入っているnodeのバージョンを確認
$ nodebrew ls v9.11.2 v12.4.0使っているnodeのバージョンを確認
$ node -v v9.11.2バージョンを切り替える
$ nodebrew use v12.4.0 use v12.4.0 $ node -v v12.4.0これで切り替え完了です!
その後切り替えたnodeを元にfirebaseを入れ直す必要があります。
$ npm uninstall firebase-cli $ npm uninstall firebase-tools $ npm install -g firebase-tools --force問題② -bash: firebase: command not found
これはPATHが通っていないことでコマンドが機能していないために起こるエラーです。
npmのPATHの確認と設定が必要になります。PATHの確認
$ npm bin -g /Users/ユーザー/.nodebrew/node/v12.4.0/bin (not in PATH env variable)
not in PATH env variableが表示されているということはnpmのPATHが通っていません。PATHを通す
$ export PATH=$PATH:`npm bin -g` $ npm bin -g /Users/mu/.nodebrew/node/v12.4.0/binこれで完了です!
- 投稿日:2020-11-17T09:36:01+09:00
Swift4で同期通信をする
今回は、Swift4で同期HTTP通信を実現します。
使いどきはあまりイメージできておりませんが、書き換えチャレンジです。参考にしたSwift2のコード
まず、Swift4で同期HTTP通信をするためにこちらのサイトを参考にしました。
サイトに掲載されていたSwift2のコードも、勉強のため載せておきます。public class HttpClientImpl { private let session: NSURLSession public init(config: NSURLSessionConfiguration? = nil) { self.session = config.map { NSURLSession(configuration: $0) } ?? NSURLSession.sharedSession() } public func execute(request: NSURLRequest) -> (NSData?, NSURLResponse?, NSError?) { var d: NSData? = nil var r: NSURLResponse? = nil var e: NSError? = nil let semaphore = dispatch_semaphore_create(0) session .dataTaskWithRequest(request) { (data, response, error) -> Void in d = data r = response e = error dispatch_semaphore_signal(semaphore) } .resume() dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER) return (d, r, e) } }Swift2からSwift4へ変換する
この状態で、Compiler Errorが6つ出ていました。
基本的には、Fixボタンをクリックしていったら良いんですが、、
dispatch_semaphore_waitだけ、Fixボタンでは消えてくれませんでした。?この問題については、AppleのDeveloperページを参考にします。
ときどき、こういったFixボタンで変換できないのが面倒ですね。。https://developer.apple.com/documentation/dispatch/dispatchsemaphore
結果、次のようになりました。
完成したコード
全て変換し終えたコードがこちらです。
public class HttpClientImpl { private let session: URLSession public init(config: URLSessionConfiguration? = nil) { self.session = config.map { URLSession(configuration: $0) } ?? URLSession.shared } public func execute(request: URLRequest) -> (NSData?, URLResponse?, NSError?) { var d: NSData? = nil var r: URLResponse? = nil var e: NSError? = nil let semaphore = DispatchSemaphore(value: 0) session .dataTask(with: request) { (data, response, error) -> Void in d = data as NSData? r = response e = error as NSError? semaphore.signal() } .resume() _ = semaphore.wait(timeout: DispatchTime.distantFuture) return (d, r, e) } }また、使うときはこんな感じです。
// 通信先のURLを生成. let myUrl:URL = URL(string: "https://www.example.com/xxx")! let req = NSMutableURLRequest(url: myUrl) let postText = "key1=value1&key2=value2" let postData = postText.data(using: String.Encoding.utf8) req.httpMethod = "POST" req.httpBody = postData let myHttpSession = HttpClientImpl() let (data, _, _) = myHttpSession.execute(request: req as URLRequest) if data != nil { // 受け取ったデータに対する処理 }
- 投稿日:2020-11-17T08:31:06+09:00
UIToolBarに上下ボタンや完了ボタンをつけるExtension
はじめに
ある入力フォームで、キーボードの上に、上下ボタンや完了ボタンがついているのをよく見かけます。そういう気遣いほんとありがたい
今回は、一文追加するだけで、それらを実装してくれるExtensionを作ってみたのでそれを紹介します。実装後イメージ
完了ボタンのみ
上下ボタンと完了ボタン
使い方
完了ボタンのみ
override func viewDidLoad() { super.viewDidLoad() // 対象のテキストフィールドがアクティブなとき、キーボードのツールバーに、完了ボタンを設定する。 addPreviousNextableDoneButtonOnKeyboard(textFields: [textField1], previousNextable: false) }上下ボタンと完了ボタン
override func viewDidLoad() { super.viewDidLoad() // 対象のテキストフィールドがアクティブなとき、キーボードのツールバーに、前後ボタンや完了ボタンを設定する。 addPreviousNextableDoneButtonOnKeyboard(textFields: [textField2, textField3], previousNextable: true) }Extension
// // ViewController+ToolBar.swift // KeyboardUpDownSample // // Created by Miharu Naruse on 2020/11/15. // // 参考元サイト // - URL:: https://stackoverflow.com/questions/14148276/toolbar-with-previous-and-next-for-keyboard-inputaccessoryview import Foundation import UIKit extension UIViewController { /// 対象のテキストフィールドがアクティブなとき、キーボードのツールバーに、前後ボタンや完了ボタンを設定する処理。 /// - Parameters: /// - textFields: 設定したいテキストフィールドの配列 /// - previousNextable: 前後ボタンを有効にするか否か /// /// 使い方 /// ============================================= /// // テキストフィールドのキーボードのツールバーの設定 /// addPreviousNextableDoneButtonOnKeyboard(textFields: [textField1], previousNextable: false) /// addPreviousNextableDoneButtonOnKeyboard(textFields: [textField2, textField3], previousNextable: true) /// func addPreviousNextableDoneButtonOnKeyboard(textFields: [UITextField], previousNextable: Bool = false) { for (index, textField) in textFields.enumerated() { // テキストフィールドごとにループ処理を行う。 let toolBar = UIToolbar(frame: CGRect(x: 0, y: 0, width: UIScreen.main.bounds.width, height: 50)) toolBar.barStyle = .default /// バーボタンアイテム var items = [UIBarButtonItem]() // MARK: 前後ボタンの設定 if previousNextable { // 前後ボタンが有効な場合 /// 上矢印ボタン let previousButton = UIBarButtonItem(image: UIImage(systemName: "chevron.up"), style: .plain, target: self, action: nil) if textField == textFields.first { // 設定したいテキストフィールドの配列のうち、一番上のテキストフィールドの場合、不活性化させる。 previousButton.isEnabled = false } else { // 上記以外の場合 // 1つ前のテキストフィールドをターゲットに設定する。 previousButton.target = textFields[index - 1] // ターゲットにフォーカスを当てる。 previousButton.action = #selector(UITextField.becomeFirstResponder) } /// 固定スペース let fixedSpace = UIBarButtonItem(barButtonSystemItem: UIBarButtonItem.SystemItem.fixedSpace, target: self, action: nil) fixedSpace.width = 8 /// 下矢印ボタン let nextButton = UIBarButtonItem(image: UIImage(systemName: "chevron.down"), style: .plain, target: self, action: nil) if textField == textFields.last { // 設定したいテキストフィールドの配列のうち、一番下のテキストフィールドの場合、不活性化させる。 nextButton.isEnabled = false } else { // 上記以外の場合 // 1つ後のテキストフィールドをターゲットに設定する。 nextButton.target = textFields[index + 1] // ターゲットにフォーカスを当てる。 nextButton.action = #selector(UITextField.becomeFirstResponder) } // バーボタンアイテムに前後ボタンを追加する。 items.append(contentsOf: [previousButton, fixedSpace, nextButton]) } // MARK: 完了ボタンの設定 let flexSpace = UIBarButtonItem(barButtonSystemItem: .flexibleSpace, target: nil, action: nil) let doneButton = UIBarButtonItem(title: "完了", style: .done, target: view, action: #selector(UIView.endEditing)) // バーボタンアイテムに完了ボタンを追加する。 items.append(contentsOf: [flexSpace, doneButton]) toolBar.setItems(items, animated: false) toolBar.sizeToFit() textField.inputAccessoryView = toolBar } } }参考元サイト

- 投稿日:2020-11-17T07:31:59+09:00
[Swift5]配列と配列の差集合を取得する方法
方法
(array1 - array2 を実行する場合を考えます。)
- array1とarray2を結合してSetに変換
- 1の結果からarray2の要素を取り除く
コード
let array1 = ["a", "b", "c", "d", "e"] let array2 = ["a", "c", "e"] let unionSet = Set(array1 + array2) let diffArray = Array(unionSet.subtracting(array2)) print(diffArray) // ["b", "d"]自作した構造体に対しても同じように実行できます。
struct Food: Hashable { //Hashableのプロトコルメソッド static func == (lhs: Food, rhs: Food) -> Bool { return (lhs.name == rhs.name) && (lhs.price == rhs.price) } let name: String let price: Int } let food1 = Food(name: "ラーメン", price: 800) let food2 = Food(name: "うどん", price: 700) let food3 = Food(name: "そば", price: 600) let myFavoriteFood = [food1, food2, food3] let yourFavoriteFood = [food1] let unionSet = Set(myFavoriteFood + yourFavoriteFood) let diffArray = Array(unionSet.subtracting(yourFavoriteFood)) print(diffArray[0], diffArray[1]) // Food(name: "うどん", price: 700) Food(name: "そば", price: 600)
- 投稿日:2020-11-17T06:10:37+09:00
TableViewのCell再利用について
はじめに
TableViewはスクロールするたびに新しいCellを作っているわけではないみたいです。
勉強始めたてのころはCellが新しく作られているのか、それとも再利用されているのかという疑問も持たないかもしれません。(私がそうでした)
しかし、実際に使っていく中で、この辺りを理解しておいた方がいいと思い知らされたので記事を書いてみます。なぜ再利用するか
パフォーマンスが低下するから!みたいです。
新しいCellを作成していたら、スクロールすればするほどCellが作成されるのでよくないみたいです!(100個も200個も作ってられない)
再利用の場合、画面の外に行ったCellを使うことで必要なCellの数が抑えられるからです。セルの登録
カスタムセルをコードで書く場合は
register(_:forCellReuseIdentifier:)
をviewDidLoadなどで呼んで登録しておく必要があるみたいです。
Storyboard上でカスタムセルを定義している場合はいらないらしいですよ。
この登録はreuseIdentifierにIDを入力してIDで管理することができます。
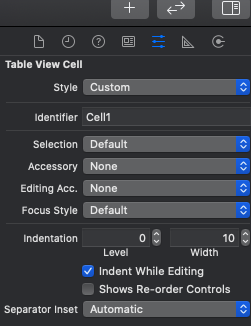
(画像のIdentifier)
セルを再利用する
ここからが本題です。
実際にセルを再利用する時は、スクロールして画面表示外からセルが現れる時です。
ですので、セルを生成するための処理の中に再利用のコードを書く必要があるわけです。
セルが作成されるのは
tableView(_:cellForRowAt:)
の中です。
この中にセルを再利用するコード
dequeueReusableCell(withIdentifier:for:)
を書いて、セルを生成する時に再利用できるセルがあれば再利用してください?♂️っていう指示を書きます。
この時の再利用可能なセルはreuseIdentifierで紐付けしたものになります。画面外に行った再利用待ちのセルはどこへ?
Reuse QueueというものをtableViewは持っていて、これはreuseIdentifierごとに存在しています。
上の画像で言うと、IdentifierがCell1なのでCell1用のReuse Queueが存在しています。
再利用できるものをID別で入れておく在庫置き場の様なものですね。
画面外に行くと、セルは自分のIDのReuse Queueの中に入り、同じIDのセルが必要になった時に取り出されます。セルは再利用したいけど、セルの内容に変更の処理を行いたい時
セルの見た目が変更されたままReuse Queueの中に入り、変更が残ったまま再利用されることがあります。
そこで使用するのが
prepareForReuse()
です。
ここにセルの変更内容を初期状態に戻す処理を書くことで、初期状態のセルを再利用することができます。最後に
セルの再利用についての記事を書きました。
tableViewは頻繁に使うので仕組みも理解していた方が良いそうです。
今回初めてQiitaで記事を書いてみたので良いアウトプットになりました。
間違っている箇所などありましたらご指摘ください。
わかりやすいコード例とかができましたらまた載せていきます。参考記事