- 投稿日:2020-09-13T23:39:13+09:00
これだけはおさえておきたいCypressコマンド集
はじめに
【初心者向けワークショップ】Cloud9+Docker Compose+CypressでE2Eテストを書いてみよう!の記事でCypressを使ったE2Eのテストを書くワークショップの記事を書きました。
この記事では、こういう検証をしたい場合Cypressではどう書くのかを記していきます。
コマンド集は公式ドキュメントにもあります。
本記事ではその中からよく使いそうなこれだけはおさえておきたいものをピックアップして、要素の操作と検証など実践に使いやすい形のサンプルを用意してみました。
また、CypressのテストコードだけでなくHTMLも合わせて載せておりますので参考にしていただけたらと思います。ページ遷移
以下、前提として baseUrlが
cypress.jsonに定義されているものとします。e2e/cypress.json{ "baseUrl": "http://localhost:8080", "reporter": "junit", "reporterOptions": { "mochaFile": "cypress/results/output.xml" } }cypress/integration/spec.jsit('open page', () => { // ページ遷移(パスを指定) cy.visit('/') // Qiitaのページを開く(URLを指定) cy.visit('https://qiita.com') }要素の取得、要素の値を取得
要素の取得
cy.get('[セレクタ]')で要素を取得できます。<div id='header'></div>it('Get element', () => { cy.visit('/') // 要素の取得 cy.get('#header') })親・子要素の取得
<ul class='parent'> <li class='active child'>list1</li> <li class='child'>list2</li> <li class='child'>list3</li> </ul>it('Get child and parent element', () => { cy.visit('/') // 子要素の取得 cy.get('ul').children('.active').should('have.text', 'list1') cy.get('ul').children().should('have.length', 3) cy.task('log', '== 子要素の取得 ==') cy.get('ul').children().each(($li, index, $list) => { cy.task('log', $li.text()) }) // 親要素の取得 cy.get('.child').parent().should('have.class', 'parent')※ ログの出力方法は、後述の ログの出力 をご覧ください。
コンソールログ(抜粋)apache | 172.20.0.3 - - [13/Sep/2020:05:05:16 +0000] "GET / HTTP/1.1" 200 254 cypress | == 子要素の取得 == cypress | list1 cypress | list2 cypress | list3 cypress | cypress | (Results) cypress |ページタイトルの取得
cy.title()でページタイトルを取得できます。
要素の取得でも説明した通り、cy.get('title')でも取得できます。<title>sample page title</title>it('Verify title', () => { cy.visit('/') // ページタイトルを取得して検証する cy.title().should('eq', 'sample page title') cy.get('title').should('have.text', 'sample page title') })要素の操作
クリック、チェック操作
チェックボックスにチェックを入れたり、ラジオボタンを選択したりボタンをクリックすることができます。
<form> <div> <input type='checkbox' name='check' value='check_1' checked='checked'> <input type='checkbox' name='check' value='check_2'> </div> <div> <input type='radio' name='feedback' value='good' checked='checked'>良い <input type='radio' name='feedback' value='bad'>悪い </div> </form> <button type=button onclick='alert("clicked button")'>Click here</button>it('Click or check an element', () => { cy.visit('/') // 要素をチェックする cy.get('[value="check_1"]').check() // チェックボックス cy.get('[type="radio"]').first().check() // ラジオボタンの1番目 // 要素をクリックする cy.get('[type="button"]').click() })入力操作
テキストボックスに文字の入力することができます。
また、入力されたテキスト内の文字を削除することもできます。<textarea>hoge</textarea>it('Delete text and type text', () => { cy.visit('/') // テキストエリアの文字列を検証(消去前) cy.get('textarea').should('have.value', 'hoge') // テキストエリアの文字を消去 cy.get('textarea').clear() // テキストエリアの文字列を検証(消去後) cy.get('textarea').should('have.value', '') // テキストエリアに文字を入力 cy.get('textarea').type('Hello, World') // テキストエリアの文字列を検証(入力後) cy.get('textarea').should('have.value', 'Hello, World') })検証
要素の値の検証
cy.get('[セレクタ]').should('have.id')などhave.xxxで指定します。
また、cy.get('[セレクタ]').should('have.attr', '[属性名]', '[値]')でも各属性の値は取得できます。<div class='title'> <div id='main_title'>Content title</div> <div class='sub_title'>Sub title</div> </div> <input type='number' name='numberbox' value='1'>it('Verify element values and attributes', () => { cy.visit('/') // 要素のテキストを検証する cy.get('#main_title').should('have.text', 'Content title') // 要素のid属性の値を検証する cy.get('.title div:first-child').should('have.id', 'main_title') // 要素のclass属性の値を検証する cy.get('.title div:last-child').should('have.class', 'sub_title') // 要素のvalue属性の値を検証する cy.get('[name="numberbox"]').should('have.value', '1') // 要素のtype属性の値を検証する cy.get('[name="numberbox"]').should('have.attr', 'type', 'number') // 要素のname属性の値を検証する cy.get('[type="number"]').should('have.attr', 'name', 'numberbox') })テキストの部分一致、完全一致の検証
<title>sample page title</title> <div class='title'> <div id='main_title'>Content title</div> <div class='sub_title'>Sub title</div> </div>it('Verify title', () => { cy.visit('/') // ページタイトルを取得して検証する // 完全一致 cy.title().should('eq', 'sample page title') cy.get('title').should('have.text', 'sample page title') // 部分一致 cy.title().should('include', 'sample') cy.get('title').contains('sample') // ページ内のどこかに文字列が存在することを検証する cy.contains('Sub') })要素が表示されている・いないことの検証
<div class='title'> <div id='main_title'>Content title</div> <input type='hidden' name='userid' value='12345'> </div>it('Verify element display', () => { cy.visit('/') // 要素が表示されていることを検証する cy.get('#main_title').should('be.visible') // 要素が表示されていないことを検証する cy.get('.title > input').should('not.be.visible') })ロケーションの取得
it('Get location', () => { cy.visit('https://qiita.com') // ロケーションの取得 cy.location().should((loc) => { expect(loc.href).to.eq('https://qiita.com/') expect(loc.hostname).to.eq('qiita.com') expect(loc.pathname).to.eq('/') expect(loc.port).to.eq('') expect(loc.protocol).to.eq('https:') }) })現在のページのURLの取得は
cy.url()でも可能です。it('Get current url', () => { cy.visit('https://qiita.com') // URLの取得その1 cy.location().should((loc) => { expect(loc.href).to.eq('https://qiita.com/') }) // URLの取得その2 cy.url().should('eq', 'https://qiita.com/') })ログの出力
cypress/plugins/index.jsを以下のように編集します。cypress/plugins/index.jsmodule.exports = (on, config) => { on('task', { log (message) { console.log(message) return null } }) }cypress/integration/spec.jsit('Log', () => { cy.visit('/') // ログの出力 cy.task('log', "*** ログ開始 ***") cy.task('log', "hoge") cy.task('log', "fuga") cy.task('log', "*** ログ終了 ***") })Cypressのコンソールログ(抜粋)cypress | Running: spec.js (1 of 1) apache | 172.20.0.3 - - [13/Sep/2020:02:41:17 +0000] "GET / HTTP/1.1" 200 152 cypress | *** ログ開始 *** cypress | hoge cypress | fuga cypress | *** ログ終了 *** cypress | cypress | (Results) cypress |
- 投稿日:2020-09-13T23:04:12+09:00
1年後の自分よ、WebVRやりたいときはこれを見ろ
1年後の自分へ
きっと君は、「うわあ一年前WebVR勉強したのに結局全然勉強してねえや最近」と嘆いていることだろう。
そんな君に、今僕がさくっと調べたWebVR関連のサイトをサクッと教えてやるぜ。これを見ろ
以前作った「かくれんぼ」の3D版を作るために色々調べた結果をここに示すぜ
「かくれんぼ」が何か思い出せないならこれを見ろ
https://qiita.com/canonno/items/00738c7d928c3ec655d5・WebVRを実装するライブラリ「A-frame」ドキュメント
https://aframe.io/docs/1.0.0/introduction/・缶から星を出しまくるもの。サクッとハンズオンできそう
https://qiita.com/name_yy/items/9144f612a8e15d14f9ff・A-frameの英語ドキュメントに沿って実装してくれている日本語Qiita。ハンズオン用。
https://qiita.com/thomi40/items/dfc4175efece38ab5747・p5jsとWebVRとを組み合わせたスーパーマン。実装には時間がかかりそう。
https://leoouyang.com/let-it-snow
※このスーパーマンの解読にはjavascriptのelementについて理解が必要だ。
この人は各オブジェクトを生成するロジックをあらかじめ書いておきElement単位で制御している。
・https://developer.mozilla.org/ja/docs/Web/API/Document/createElement
・https://developer.mozilla.org/ja/docs/Web/API/Node/appendChild
・https://techacademy.jp/magazine/22315
・https://qiita.com/KDE_SPACE/items/e21bb31dd4d9c162c4a6さいごに
Good Luck!
- 投稿日:2020-09-13T22:18:45+09:00
ES6〜ES10のIE11使用状況
業務上IE11の使用が避けられないためES6〜ES10の使用状況を備忘録的に残していきます。
ES2015(ES6)
ES2015(ES6)追加仕様 実行可否 コンソールエラーメッセージ クラス (class) NG 構文エラーです。 テンプレート文字列 ( Hello ${name})NG 文字が正しくありません。 モジュール (import, export) - (未確認) アロー関数 (=>) NG 構文エラーです。 デフォルト引数 (function(x=0, y=0)) NG ')' がありません。 可変長引数 (function(x, y, ...arg)) NG 識別子がありません。 定数 (const) OK - 局所変数 (let) OK - for of ループ (for item of items) NG ';' がありません。 Map オブジェクト OK - Set オブジェクト ラーは出ないがnew Setの中身を評価できなく実行できない - 配列関数 (from()) NG オブジェクトは 'from' プロパティまたはメソッドをサポートしていません。 配列関数 (of()) NG オブジェクトは 'of' プロパティまたはメソッドをサポートしていません。 分割代入 ([x, y] = [10, 20]) NG 構文エラーです。 スプレッド構文 (...args) NG 識別子がありません。 型付き配列 (Uint8Array, ...) - (未確認) シンボルオブジェクト (Symbol) NG 'Symbol' は定義されていません。 8進数(0o)と2進数(0b) NG ')' がありません。 言語依存フォーマット (NumberFormat()) OK - 非同期処理 (Promise) NG 構文エラーです。 ES2016(ES7)
ES2016(ES7)追加仕様 実行可否 コンソールエラーメッセージ array.includes() NG オブジェクトは 'includes' プロパティまたはメソッドをサポートしていません。 べき乗演算子(**) NG 構文エラーです。 ES2017(ES8)
ES2017(ES8)追加仕様 実行可否 コンソールエラーメッセージ オブジェクト参照 (object.values()) NG オブジェクトは 'values' プロパティまたはメソッドをサポートしていません オブジェクト参照 (object.entries()) NG オブジェクトは 'entries' プロパティまたはメソッドをサポートしていません。 パディング (string.padStart()) NG オブジェクトは 'padStart' プロパティまたはメソッドをサポートしていません。 パディング (string.padEnd()) NG オブジェクトは 'padEnd' プロパティまたはメソッドをサポートしていません。 プロパティ記述子参照 (object.getOwnPropertyDescriptors()) NG オブジェクトは 'getOwnPropertyDescriptors' プロパティまたはメソッドをサポートしていません。 関数末尾のカンマ (,) NG 識別子がありません。 非同期処理(async, await) NG 構文エラーです。 ES2018(ES9)
ES2018(ES9)追加仕様 実行可否 コンソールエラーメッセージ テンプレート文字列の強化(\uの扱い) NG 識別子がありません。 オブジェクトのスプレッド構文とレスト構文 (...obj) NG 識別子、文字列または数がありません。 正規表現のsフラグ (/.../s) NG 正規表現で構文エラーが発生しました。 正規表現の名前付きキャプチャグループ (?<...>) NG 文字の繰り返しを表す正規表現演算子が不正です。 正規表現の前方マッチ条件検索 ((?<=...), (?<!...)) - (未確認) 正規表現のUnicodeプロパティマッチ (\p{...}) - (未確認) Promiseのfinally構文 - (未確認) Promiseのfor await (... of ...)構文 - (未確認) ES2019(ES10)
ES2019(ES10)追加仕様 実行可否 コンソールエラーメッセージ catch引数の不要化 NG '(' がありません。 Symbol.description - (未確認) JSON superset NG 終了していない文字列型の定数です。 Well-formed JSON.stringify NG コンロソールエラーは出ないが未対応 function.toString() でコメントも文字列化 OK - Object.fromEntries() NG オブジェクトは 'fromEntries' プロパティまたはメソッドをサポートしていません。 string.trimStart() NG オブジェクトは 'trimStart' プロパティまたはメソッドをサポートしていません。 string.trimEnd() NG オブジェクトは 'trimEnd' プロパティまたはメソッドをサポートしていません。 array.flat() NG オブジェクトは 'flat' プロパティまたはメソッドをサポートしていません。 array.flatMap() NG 構文エラーです。
- 投稿日:2020-09-13T22:07:02+09:00
Node.jsでナイーブベイズ分類器を使った分類を行う
ナイーブベイズ分類器のBayesモジュールを使う
ナイーブベイズ分類器は、次のようなことができます。
- スパムメールの判定
- ニュース記事やブログ記事のカテゴリー判定
ごく簡単にいうと、学習に必要なのはカテゴリーに関連する単語をたくさん登録するだけです。カテゴリーのわかっている文章を単語に分解して登録します。判定するときには、カテゴリーに関わる単語の出現率で判定されます。
もちろん、もっと正しい理解をしたほうがいいですが、bayesモジュールを使うならこの程度のイメージを持っておくだけで使えて、なかなか有益な結果を得られます。詳しく知りたい方は末尾のリンク先を参照してください。1
使い方(イメージ)
// 学習 classifier.learn('カテゴリーAに関する長文・・・・・', 'カテゴリーA') classifier.learn('カテゴリーBに関する長文・・・・・', 'カテゴリーB') classifier.learn('カテゴリーCに関する長文・・・・・', 'カテゴリーC') // 判定 const category = classifier.categorize('カテゴリーを判定したい文章')準備(予備知識)
分かち書き
先に示したように、bayesモジュールのlearnメソッドを使ってカテゴリーのわかっている文章を学習させます。英語であれば自動で単語に分割して登録されるのですが、日本語の場合は単語への分割がうまくいきません。そこで、bayesが日本語の文章の単語への分割=分かち書きができるようにその機能を持ったメソッドを渡してあげます。分かち書きの機能を提供するtiny-segmenterモジュールを使って次のようにします。(イメージを掴むために、こちらのサイトでtiny-segmenterの動作を見ておくとよいです。)
const segmenter = new TinySegmenter() var classifier = bayes({ tokenizer: function (text) { return segmenter.segment(text); } });async/await
また、最初の使い方イメージでは省略しましたが、bayesのlearnメソッドとcategorizeメソッドはasyncで提供されているため、簡単に使用するにはawaitをつけて呼び出す必要があります。awaitはaysncメソッド内でしか使えません。そのため下記のサンプルコードではasyncが使われています。
データ準備
学習に使う文章はWikipediaからもってきましょう。以下のURLでアクセスするとXMLデータが得られます。2
https://ja.wikipedia.org/wiki/特別:データ書き出し/キーワード得られるデータにはちょっと無駄な情報が多いですが簡単に済ますために今回はこれをこのまま使いましょう。ブラウザで以下の3つのURLにアクセスして、それぞれyoritomo.txt、takauji.txt、ieyasu.txtとして保存してください。
yoritomo.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/源頼朝takauji.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/足利尊氏ieyasu.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/徳川家康これで準備は完了です。
インストール
bayesのインストールnpm install bayestiny-segmenterのインストールnpm install tiny-segmenterデモ・コード
実行結果は次の通りです。
実行結果$ node bayes-demo.js 判定=[源頼朝] -- 日本で最初に幕府を開いた人物で、妻は尼将軍としても有名な北条政子である。 判定=[源頼朝] -- 後鳥羽天皇によって征夷大将軍に任ぜられた。 判定=[源頼朝] -- 奥州を平定した。 判定=[足利尊氏] -- 室町幕府を開いた。 判定=[足利尊氏] -- 鎌倉幕府の滅亡後、鎮守府将軍・左兵衛督に任ぜられた。 判定=[足利尊氏] -- 歌人としても知られる。 判定=[徳川家康] -- 幼少時代を人質として過ごした。 判定=[徳川家康] -- 室町幕府最後の将軍足利義昭が信長包囲網を企てたとき、協力要請を受けたがこれを無視した。これがデモ・コードです。ぐだぐだ説明する必要もないと思います。シンプル。
bayes-demo.jsvar bayes = require('bayes'); const TinySegmenter = require('tiny-segmenter') const fs = require('fs') // 分かち書きの機能を使うため const segmenter = new TinySegmenter() // 学習用文章の読み込み var txt_yoritomo = fs.readFileSync('yoritomo.txt', 'utf-8') var txt_takauji = fs.readFileSync('takauji.txt', 'utf-8') var txt_ieyasu = fs.readFileSync('ieyasu.txt', 'utf-8') // 分かち書き機能の設定 var classifier = bayes({ tokenizer: function (text) { return segmenter.segment(text); } }); async function demo() { // 学習 await classifier.learn(txt_yoritomo, '源頼朝'); await classifier.learn(txt_takauji, '足利尊氏'); await classifier.learn(txt_ieyasu, '徳川家康'); // 判定して結果を表示 async function categorize(text) { // 判定 var r = await classifier.categorize(text); console.log("判定=[" + r + "] -- " + text); } // 文章のカテゴリーを判定する(分類する) categorize('日本で最初に幕府を開いた人物で、妻は尼将軍としても有名な北条政子である。'); categorize('後鳥羽天皇によって征夷大将軍に任ぜられた。'); categorize('奥州を平定した。'); categorize('室町幕府を開いた。'); categorize('鎌倉幕府の滅亡後、鎮守府将軍・左兵衛督に任ぜられた。'); categorize('歌人としても知られる。'); categorize('幼少時代を人質として過ごした。'); categorize('室町幕府最後の将軍足利義昭が信長包囲網を企てたとき、協力要請を受けたがこれを無視した。'); } demo()bayesモジュールのコードを読む(わずか271行!)
bayesモジュールのソースコードを見てみると、わずか271行しかない比較的簡単な内容となっている。読んで理解するにはさすがに少しナイーブベイズ分類器について理解を深めておいたほうがよい。ナイーブベイズ分類器の良い解説記事はたくさんあるので探して読んでください。1
leanメソッドが学習部分です。
naive_bayes.js抜粋/** * textがどのcategoryに対応しているか学習することで、ナイーブベイズ分類器を訓練する * * @param {String} text * @param {Promise<String>} class */ Naivebayes.prototype.learn = async function (text, category) { var self = this //はじめてのカテゴリの場合は、カテゴリのデータ構造を初期化する self.initializeCategory(category) //カテゴリにマップされたドキュメント数をカウントする self.docCount[category]++ //学習したドキュメントの総数をカウント self.totalDocuments++ //テキストを単語に分割して配列にする var tokens = await self.tokenizer(text)learnメソッドの後半では、各単語の出現回数をカウントしています。カウントしているのは、カテゴリ中の単語出現回数(wordFreqencyCount)と、カテゴリーの総単語数(wordCount)です。
naive_bayes.js抜粋//テキスト内の各トークンの頻度カウントを取得します。 //get a frequency count for each token in the text var frequencyTable = self.frequencyTable(tokens) /* このカテゴリの語彙数と単語数を更新します。 Update our vocabulary and our word frequency count for this category */ Object .keys(frequencyTable) .forEach(function (token) { //この単語がない場合は、私たちの語彙に追加します。 //add this word to our vocabulary if not already existing if (!self.vocabulary[token]) { self.vocabulary[token] = true self.vocabularySize++ } var frequencyInText = frequencyTable[token] //このカテゴリのこの単語の頻度情報を更新する //update the frequency information for this word in this category if (!self.wordFrequencyCount[category][token]) self.wordFrequencyCount[category][token] = frequencyInText else self.wordFrequencyCount[category][token] += frequencyInText //このカテゴリにマップされたすべての単語のカウントを更新します。 //update the count of all words we have seen mapped to this category self.wordCount[category] += frequencyInText }) return self }categorizeメソッドは与えられたテキストのカテゴリーを判定します。すべてのカテゴリーごとに可能性を調べて、最も高い可能性のカテゴリーを選択します。可能性の算出は、テキスト中の各単語について、各単語の確率を加算するという方法です。非常にシンプルですね。
naive_bayes.js抜粋/** * テキストがどのカテゴリに属するかを決定する * * @param {String} text * @return {Promise<string>} category */ Naivebayes.prototype.categorize = async function (text) { var self = this , maxProbability = -Infinity , chosenCategory = null var tokens = await self.tokenizer(text) var frequencyTable = self.frequencyTable(tokens) //カテゴリを反復処理して、最も確率の高いカテゴリを求める Object .keys(self.categories) .forEach(function (category) { // このカテゴリの全体的な確率を計算することから始める // => 学習したすべての文書のうち、このカテゴリのものはどれくらいあったか var categoryProbability = self.docCount[category] / self.totalDocuments //アンダーフロー対策に対数(log)を取る var logProbability = Math.log(categoryProbability) //テキスト中の各単語 `w` について P( w | c ) を決定する Object .keys(frequencyTable) .forEach(function (token) { var frequencyInText = frequencyTable[token] var tokenProbability = self.tokenProbability(token, category) // console.log('token: %s category: `%s` tokenProbability: %d', token, category, tokenProbability) //この単語のP( w | c )の対数(log)を求める logProbability += frequencyInText * Math.log(tokenProbability) }) if (logProbability > maxProbability) { maxProbability = logProbability chosenCategory = category } }) return chosenCategory }以上
- 投稿日:2020-09-13T21:45:21+09:00
npm install --save について
はじめに
本投稿は
npm installコマンドの--saveオプションについてですが、すでにnpmでパッケージをインストールする際、ネットを検索すると
--saveというオプションをよく見かける。
ex)axios をインストールする場合$ npm install axios --save
-gでグローバルにインストールする際には見ないのだが、何者なのか調べてみた。npm install --save オプションについて
package.jsonのdependenciesに登録してくれるようだ。何がうれしいのか
git にコミットする際、パッケージをインストールしているフォルダ
node_modulesは.gitignoreによって除外されます。
違う開発環境を git からクローンして構築する場合、package.jsonを元に復元します。
よって、同じパッケージ環境を簡単に構築することができます。結論:
--saveオプションは必要か現在の環境では
--saveオプションは不要です。
2017-05-30にリリースされたnpm5.0.0以降ではデフォルトで--saveがつくようになりました。
よって、現在では古い環境を除いて基本的に不要です。参考
https://yosuke-furukawa.hatenablog.com/entry/2017/05/30/090602
https://blog.npmjs.org/post/161081169345/v500
https://nodejs.org/ja/download/releases/
- 投稿日:2020-09-13T21:28:56+09:00
React Hooksで作るFlux入門
この記事について
モダンフロントエンドにおいて、Fluxというアプリケーションアーキテクチャが存在します。
従来、Fluxの思想に従って実装を行うためには、同名ライブラリ"Flux"やReduxが採用されるケースが多かったのですが、React16.8でのReact Hooksの登場により、ライブラリに頼ることなくFluxを実現できるようになりました。
本記事では、Fluxの概念・なぜそれが必要なのかについて説明した後、React Hooksを用いたFlux実装の一例を紹介します。使用する環境・バージョン
- OS: macOS Mojave 10.14.5
- Node.js: v12.13.0
- npm: 6.13.4
- React: 16.13.0
読者に要求する前提知識
JS, React, React Hooksが書けるだけの知識があること
Fluxとは?
Fluxとは、UIをもつwebアプリケーションを構築するときのデザインパターン/アーキテクチャです。
アプリケーションのデザインパターンといえば、他にはMVC(Model View Controller)パターンやMVVM(Model-View-ViewModel)などが存在します。
Fluxもそれらと同様に、「アプリケーションを作るときに、どういう構造にするべきなのか」という考え方の一つなのです。Fluxが誕生した背景
MVCやMVVMがある中で、なぜFluxという思想が新しく生まれたのでしょうか。その疑問に答えるためには、背景を見ていきます。
レガシーアプリケーションの画面描画の仕組み
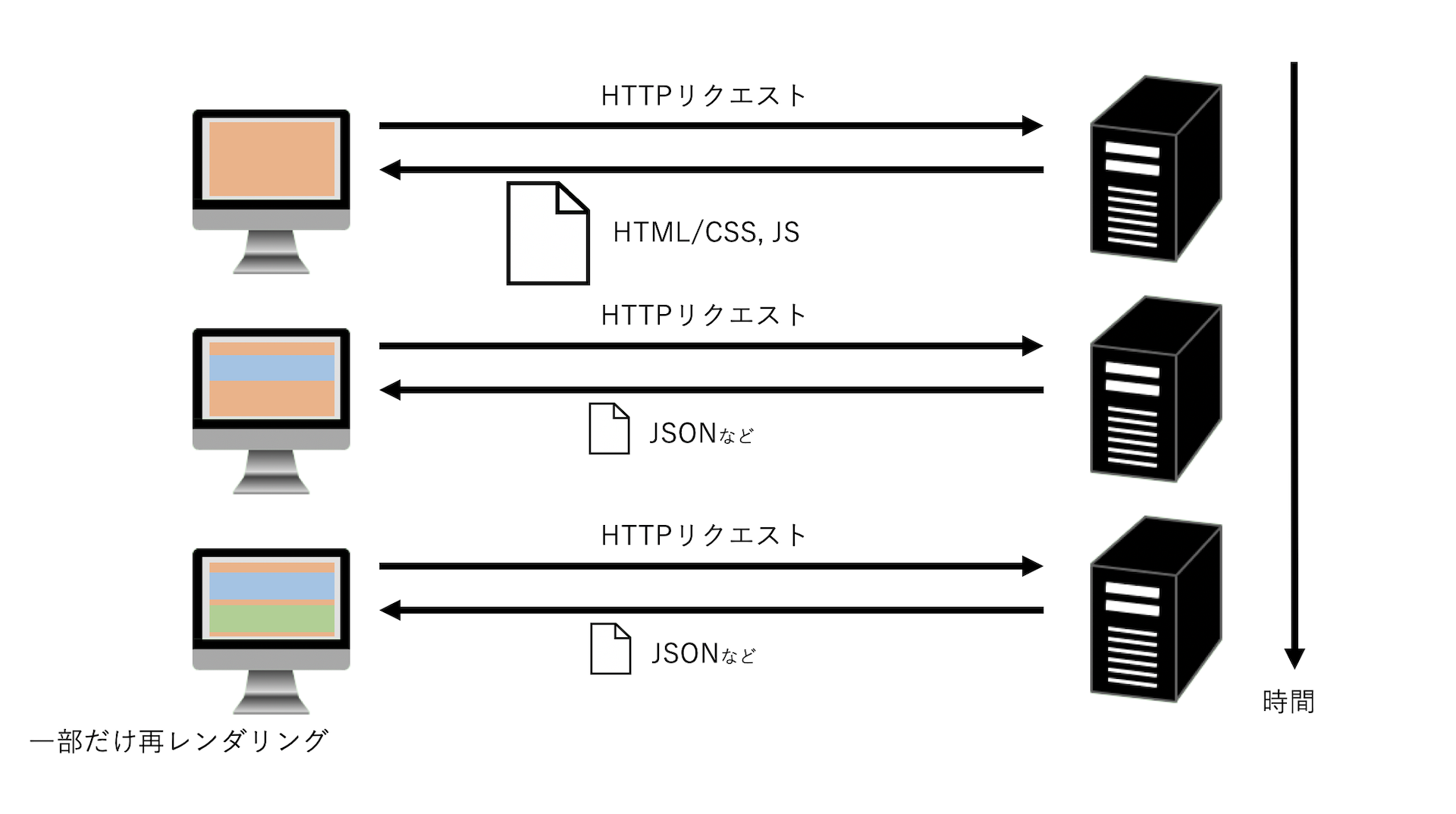
従来のレガシーなWebアプリケーションというのは、以下のようなスタイルでコンテンツを生成していました。
1. クライアントがHTTPリクエストを送信
2. サーバーサイドで、リクエストに応じたHTMLを生成→送信(必要ならばAPI・DBなどからのデータ取得を行う)
3. クライアントは、サーバーから受け取ったHTMLをそのまま表示このシステムでの特徴としては、「新しい画面・コンテンツの表示には、サーバーから新しく画面ファイルの取得→画面のリロードが必要」ということです。
しかし、これではちょっとした画面更新だけで、HTMLやCSS,JSファイルをいちいちやりとりしなければいけないので、応答速度が落ちるという欠点がありました。
SPA(Single-Page Application)の画面描画の仕組み
ここでSPA(Single-Page Application)というものが登場しました。これは、画面更新の際に
1. クライアントがサーバーに画面更新に必要なデータを要求
2. サーバーサイドは、画面のhtmlファイルではなく、要求されたデータのみをjson等で返す
3. クライアントは、サーバーから受け取ったデータをもとに画面の一部を再レンダリングという風にして、画面更新時のクライアントーサーバー間のやりとりを軽量にし、パフォーマンスを向上させています。
SPAの登場によって、フロントエンドの役割が大きく転換することになります。
レガシーアプリケーションでは、JSはサーバーサイドから受け取った画面のみを扱えばよかったのに対し、SPAでは画面更新時にどう正しく更新するかというところまでカバーしなくてはならないからです。(おまけ:ちなみに、ページ生成という仕事をフロント側に任せることができるようになったため、バックエンド側の役割も変化しています。フロントエンドがデータ取得に使うためだけのAPI・マイクロサービスが多く造られるようになり、それらがBFF(Backends For Frontends)と呼ばれるようになりました)
参考:今さら聞けない!シングルページアプリケーションとは
参考:SPAにおける状態管理: 関数型のアプローチも取り入れるフロントエンド系アーキテクチャの変遷SPAの再レンダリング時に、正しく画面を更新するために必要な考え方が「状態管理」です。
SPAの状態管理について
状態管理についてはこちらの記事が非常にわかりやすいため、これに沿って説明します。
参考:今から始めるReact入門 〜 flux編例えば、「未読1件」の表示を画面にしているときに、新たにサーバーサイドから追加の「未読2件」の通知がきたとします。
このときフロントエンド側では、「今ある未読1件と、新たに追加された未読2件を合わせて、合計3件の未読がある」という風に判断し、表示しなければいけません。このように、「今の状態(=未読)」をずっと保持し、正しく更新し続ける機能のことを状態管理といいます。
そのときに、状態管理がされていないと、サーバーサイドからきた未読「2件」という数字をそのまま表示することになってしまいます。Fluxで状態管理を行う流れ
Fluxはこの状態管理をReactでやりやすくしてくれます。
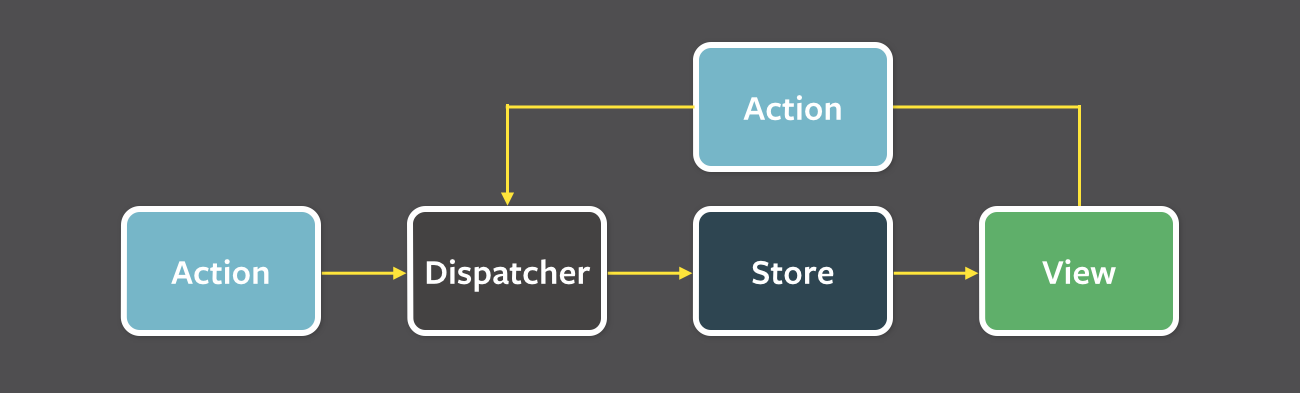
Fluxは以下の4つの要素で構成されています。
- View: フォームやボタンといった、アプリケーションの画面
- Action: アプリケーションの更新情報を得る為の内部API
- Dispatcher: Actionを受け取って、アプリケーションの更新作業を実際に行う関数
- Store: アプリケーションの状態の保持を行うデータストア
状態管理の流れとしては、
1. Viewで(クリック等の操作を行って)どんな更新をしたいのか、Actionに通知
2. ActionはViewからの通知を受け取って、dispatcherに渡す
3. dispatcherは実際に状態を更新してviewに反映
画像引用元:Flux公式Doc In-Depth Overviewこのように、「Storeを更新するときは、必ずDispatcherを通す」という単方向のデータフローにすることで、Storeで保持されている状態や、それに伴い発生する画面遷移の把握が容易になります。
参考:Fluxとはなんなのか実装
ここからは、Fluxに沿った状態管理・画面更新をReact Hooksで実装していきます。
今回は、「画面に複数個のボタンがあり、それぞれ押すとon/offが切り替わる&初期状態に戻すリセットボタンも別にある」というものを作ることを想定しています。
ディレクトリ構造
Reactアプリのフォルダは、
create-react-appコマンドで簡単に作成することができます。
そのsrcディレクトリ以下で、今回関係があるところのみを抜粋して表示します。src/ ├─ App.js ├─ components │ └─ Component.js ├─ contexts │ └─ Context.js ├─ actions │ └─ ActionCreater.js └─ reducers └─ Reducer.jsActionの実装
Actionの実態はJSオブジェクトです。Actionは後々Dispatcherに渡されるものなので、このJSオブジェクトがDispatcher関数の引数となります。
Actionオブジェクトは、「Storeに対してどんな操作がしたいのか」というのをtypeオブジェクトに保持していることが多いです。Actionの生成過程においては、生成actionをdispatchに渡すところまで実装することが多く、ここまでのメソッドをActionCreaterと呼びます。
以下に、ActionCreaterの例を示します。
ActionCreater.js// buttonNoで指定された番号のボタンのon/offを切り替えるためのActionを発行→dispatcherに渡す export function toggleButton(dispatch, buttonNo) { const action = { type: "toggle", data: { button: buttonNo } }; dispatch(action); } // 全ボタンの状態を初期状態に戻すためのActionを発行→dispatcherに渡す export function resetAllButton(dispatch) { const action = { type: "reset", }; dispatch(action); }ここで利用している変数dispatchには、後述するdispatcher関数が格納されています。
Storeの実装
Storeの実装は、Hooksの一つである
useReducerの第一引数のstoreで行います。
後述するdispatcherと一緒に、Hooksの一つであるuseContextを使ってApp内のどこでも使えるように共有する形になります。まずはContextを作ります。
Context.jsimport { createContext } from 'react' export const AppContext = createContext({ state: { onState: Array(10).fill(false) }, dispatch: null });App内のどこでも呼び出せるようにしないといけないのが「StoreとDispatcher」なので、それぞれを保持するフィールド(
stateとdispatch)を用意しています。Contextを用意したら、今度はそれをApp全体で共有できるように
App.jsで設定を行います。App.jsimport React, { useReducer } from 'react'; import { AppContext } from './contexts/Context'; import { AppReducer } from './reducers/Reducer'; function App() { const initialState = { isState : Array(10).fill(false) }; // initialStateで、state(≒store)の初期値を設定する // ここで作ったdispatchには、state(≒store)を操作する関数が格納されている const [state, dispatch] = useReducer(AppReducer, initialState); return ( <div className="App"> // こうすることで、<AppContext>以下にある(略)部分のcomponentで // 変数stateとdispatchを呼び出せるようになる <AppContext.Provider value={{state, dispatch}}> (略) </AppContext.Provider> </div> ); } export default App;Dispatcherの実装
dispatcherはStoreの変更・更新を行うものです。
これの実態はuseReducerの第二返り値のdispatch関数です。これの実装は第一引数AppReducerの中で行います。
つまり、言い方を変えれば「useReducerの第一引数で渡された関数が、第二返り値のdispatchに格納される」のです。Reducerは、現在のStateと新たに生成されたActionを引数として受け取り、新しいStateを返り値として返す関数です。
(nowState, action) => newStatedispatcherの実装を担う
useReducerの第一引数「AppReducer」を、この条件に合うよう、引数を「現在のState, Action」、返り値を「新しいState」として作ります。Reducer.jsexport function AppReducer(state, action) { var NewonState = state.onState.slice(); // actionのtypeによって、newStateの生成処理を変える switch(action.type){ case 'toggle': var i = action.data.button; NewisPlayed[i] = !state.onState[i]; return {onState: NewonState} case 'reset': var filledfalse = Array(10).fill(false); return {onState: filledfalse} default: return state; } }ViewからのAction発行
ActionCreater, dispatcher, storeが用意できたら、いよいよViewからActionを発行してStoreを変更するロジックです。
Viewでやらなければいけないのは、以下2つです。
- ActionCreaterの呼び出し
- ActionCreaterに引数として渡すdispatcher関数の用意
例えば、「ボタンをクリックしたら、ActionCraterのtoggleButtonを呼ぶ」ためには以下のように記述します。
Component.jsimport React, { useContext } from 'react'; // ActionCreaterのインポート import { toggleButton } from '../actions/actionCreaters'; function MyButton(props) { // Contextにあるdispatcher関数を取得 const {dispatch} = useContext(AppContext); return ( // 使いたい場所でActionCreater関数を呼び出す <button onClick={() => toggleButton(dispatch, props.buttonno)}> {props.buttonno} </button> ); }ソースコードの参考文献

- 投稿日:2020-09-13T20:59:23+09:00
【JS】重複しないランダムな三桁の数字を作る
コード
sample.js// ランダムな三桁の数字 function three_random_number() { const three_digit_number = []; for (let i = 0; three_digit_number.length < 3; i++) { const number = Math.floor(Math.random() * 10) if(!three_digit_number.includes(number)){ three_digit_number.push(number); } } console.log(three_digit_number); } three_random_number()コードの説明
const three_digit_number = [];:カラの配列の作成
for (let i = 0; three_digit_number.length < 3; i++) {}:長さが3の配列が出来るまでループ
Math.floor(Math.random() * 10):0~9までのランダムな整数値の作成
if(!three_digit_number.includes(number)){ }:three_digit_numberが、numberで作られたランダムな整数値を持っていなければ、true(!は否定の論理演算子)・
three_digit_number.push(number)
:配列three_digit_numberにnumberの数字を追加
- 投稿日:2020-09-13T20:15:42+09:00
【ReactNative】SafeAreaの余白を設定する方法(Android, iOS両方)
SafeAreaとは?
スクリーンで言うとこの部分です。
上の画像は既にSafeAreaの余白を設定したあとのスクリーンショットなのですが、
Viewだけで構成すると、ステータスバーにコンテンツが重なってしまいます。対策
- SafeAreaViewを使う (iOS)
- StatusBar.currentHeightをpaddingTopに設定する (Android)
SafeAreaView
SafeAreaViewはiOSのノッチの部分の余白を取ってくれる、
react-nativeが提供するコンポーネントです。このコンポーネントを使えば、iOSでノッチやステータスバーとコンテンツがかぶることはありませんが、Androidのステータスバーの余白は設定されないため、以下のように別途対応が必要になります。StatusBar.currentHeight
StatusBarは、react-nativeが提供するコンポーネントで、StatusBar.currentHeightでステータスバーの高さを取ることができるので、paddingTop: Platform.OS === "android" ? StatusBar.currentHeight : 0のようにして、Androidの場合にpaddingTopで余白を取るようにすれば良いです。最終的には、以下のようなコードになりました。
App.tsximport { StatusBar as ExpoStatusBar } from "expo-status-bar"; import React, { useState, useCallback } from "react"; import { StyleSheet, Platform, StatusBar, Text, View, Button, SafeAreaView, } from "react-native"; export default function App() { const [count, setCount] = useState(0); const increment = useCallback(() => setCount(count + 1), [count]); return ( <SafeAreaView style={styles.container}> <ExpoStatusBar style="auto" /> <View> <Text>Open up App.tsx to start working on your app!</Text> <Text>Count = {count}</Text> <Button title="Count Up" onPress={increment} /> </View> </SafeAreaView> ); } const styles = StyleSheet.create({ container: { backgroundColor: "#fff", paddingTop: Platform.OS === "android" ? StatusBar.currentHeight : 0, }, });

- 投稿日:2020-09-13T19:17:10+09:00
ウソ穴 Ver 6 の作り方
はじめに
個人開発
ウソ穴の作り方を紹介します。ウソ穴とは
ウソ穴は、ライブ映像 or 動画とARを組み合わせて、壁に穴が空いた錯覚を作り出します。Webサイトなので、ユーザーはアプリのインストール無くウソ穴を使用できます。ウソ穴 Ver 6
今回は、Android端末でも動作実績のある Ver 6 を紹介します。
デモ映像
ウソ穴 Ver 6 Type B で顔に穴を開けてみました。
見た目の涼を演出しようと、顔に穴をあけたのですが、『涼しい』って感じにならなかった。シースルーより貫通の方が涼しく見えると思ったのですが、、#ウソ穴 #AR #protoout #なんか違う pic.twitter.com/jCjkVYfN1a
— j4amountain (@zsipparu) August 29, 2020ウソ穴 Ver 6 Type A で壁に穴を開け、外のベランダの様子を見ました。
今日も危険な暑さなので、ウソ穴で窓を開けずに外が見えるようにしました。 #ウソ穴 #AR #protoout pic.twitter.com/5NZXFrkk5a
— j4amountain (@zsipparu) August 30, 2020ウソ穴 Ver 6 Type A,B,C タイプ別の特徴
ウソ穴 Ver 6 は、TypeA,B,C の3種類あります。
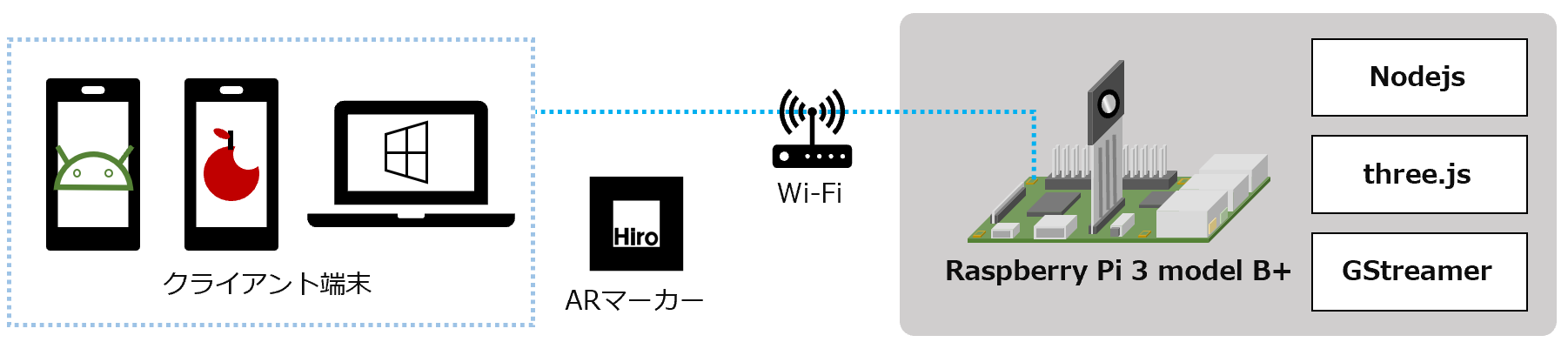
- ウソ穴 Type A / GStreamer
- ライブ配信と組み合わせたウソ穴
- ライブ配信はGStreamerを使用
- 映像遅延 : ライブ配信の遅延に依存
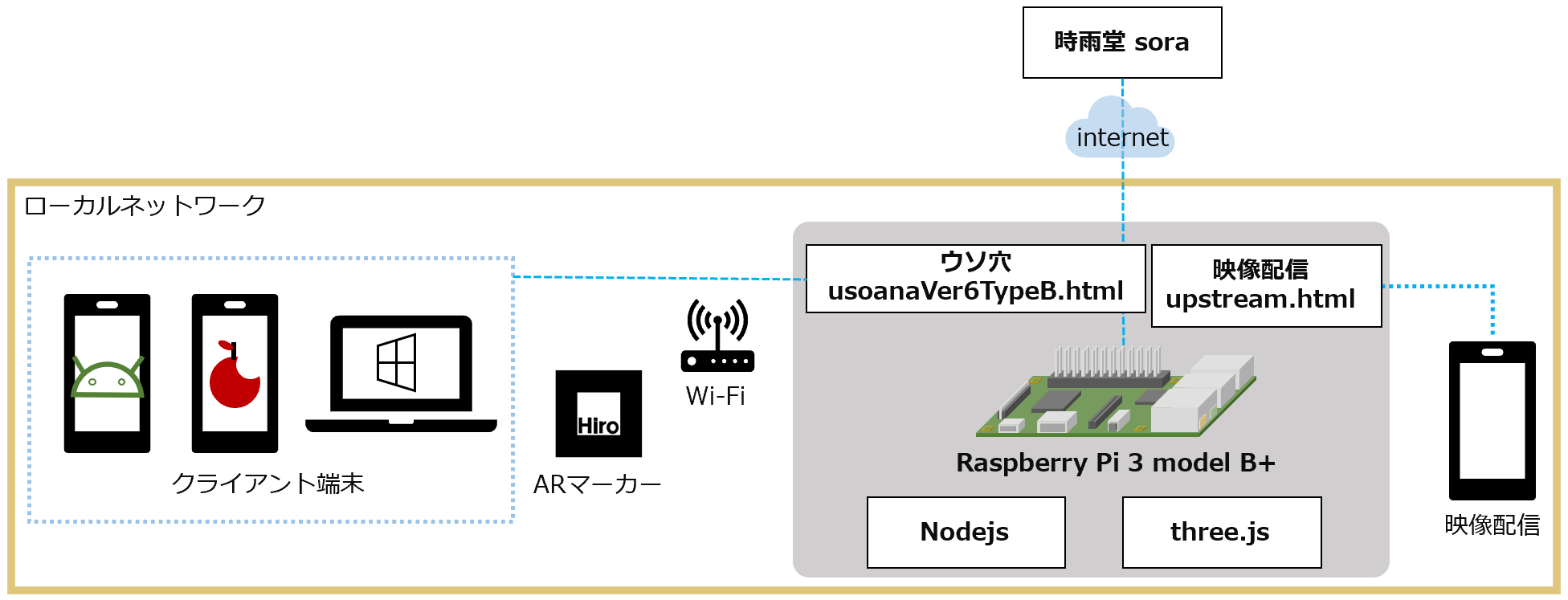
- ウソ穴 Type B / 時雨堂 sora
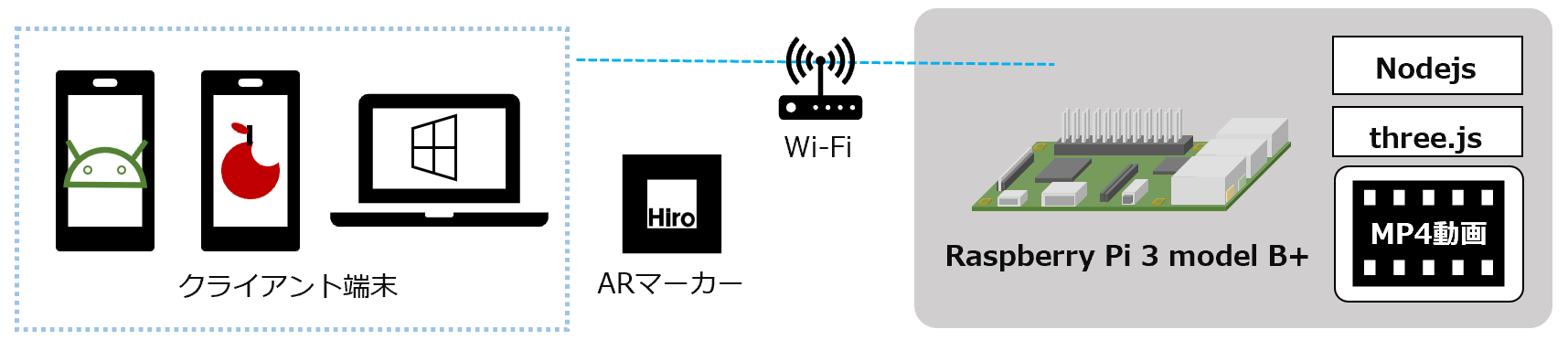
- ウソ穴 Type C / MP4動画
- 動画と組み合わせたウソ穴
- 映像遅延 : 動画ファイル読み込みの時間が必要
構成図
それぞれの構成図を紹介します。
ウソ穴 Ver 6 Type A / GStreamer
ウソ穴 Ver 6 Type B / 時雨堂 sora
ウソ穴 Ver 6 Type C / MP4動画
ソース
ソースは、githubに置きました。
作り方
作り方は、ウソ穴 Ver 5 と同じです。それぞれのリンクは以下です。
ウソ穴 Ver 6 Type A / GStreamer
作り方 -> ウソ穴 Ver 5 Type A / GStreamer
ウソ穴 Ver 6 Type B / 時雨堂 sora
作り方 -> ウソ穴 Ver 5 Type B / 時雨堂 Sora
ウソ穴 Ver 6 Type C / MP4動画
作り方 -> ウソ穴 Ver 5 Type C / MP4動画
ウソ穴の開発はつづく

- 投稿日:2020-09-13T18:53:44+09:00
TypeScript 基礎
TypeScriptとは
TypeScript はマイクロソフトによって開発され、メンテナンスされているフリーでオープンソースのプログラミング言語です。
大きな特徴として
- JavaScriptに対して、型定義などの機能を追加したもの。
- JavaScriptの最新仕様である、
ES2018の構文仕様が使え、JavaScript言語の完全なスーパーセットになっている。(JavaScriptの構文等がそのまま使うことができる。)- TypeScriptを書く際は、TypeScriptファイル(.ts) を 作成する必要があり、そのファイルをJavaScript ファイル(.js)にコンパイルししている。
なぜ型を追加する必要があるのか?
型があることにより、コードを書いている時点でエラーに気づくことができます。コンパイルをするときに、型の制約のチェックを行うことにより、すぐにエラーを修正可能。型を追加することによって効率的に開発を進めることが可能となっているのがメリットとして挙げられます。
numberで定義しているものにstring型のものを入れてしまった場合
let num: number = 1;let num: number = 'hoge'; // エラー: `string` を `number` に代入できませんこんな感じにエラーを出してくれます。
基本アノテーション
TypeScriptでは、変数、定数、関数、引数などの後ろに 「: 型名」を指定することで型を宣言することができます。
基本的な型定義
let num: number; let str: string; let bool: boolean; num = 1; num = '1'; // Error str = 'its'; str = 1; // Error bool = true; bool = 'true'; // Error配列の場合
let Array: string[]; Array = ['its', 'hoge']; Array[0] = 123; // Error Array = ['its', 123]; // Errorany型
any型はすべての型と互換性があります。
any型にはどんな方でも代入でき、その変数を何にでも代入できます。let hoge: any; hoge = 'name' hoge = 123 let num: number; hoge = num;これは問題なく動作します。
null undefindの扱い
nullとundefinedは、any型と同じ扱いをします。let num: number; let str: string; num = null; str = undefined;union型
union型は、プロパティを複数の型を定義して、そのどれかに当てはまると使用可能にできるものです。
type strOrNum = String | Number; strOrNum = 'hoge'; strOrNum = 123; strOrNum = true // Errorvoid
voidは関数に戻り値がない時に使います。function log(message): void { console.log(message); }インターフェース
インターフェースは、複数の型のアノテーションを一つにまとめることができます。
interface User { name: string; full_name: string; } let name:User; name = { name: 'hoge', full_name: 'hoge hoge'; }; name = { // Error : `full_name` is missing name: 'hoge', }; name = { // Error : `second` is the wrong type name: 'hoge', full_name: 123; };参考
wiki
https://ja.wikipedia.org/wiki/TypeScriptTypeScript の概要
https://qiita.com/EBIHARA_kenji/items/4de2a1ee6e2a541246f6TypeScript Deep Dive
https://typescript-jp.gitbook.io/deep-dive/
- 投稿日:2020-09-13T18:52:44+09:00
APIリクエストを並列に捌く【Promise.all】
複数のAPIリクエストを発行して、全部の返答が来るのを待って次の処理にうつる。
そのやり方です。※こちらの内容は、reduceでasyncする方法はこれ!で
@htsignさんにご指摘いただいたコメントをほとんどそのまま記事にさせていただいております。Promise.allを使え!
const itemCodeList = [ '000000001', '000000002', '000000003', ]; // キモはここ。 const itemList: Item[] = await Promise.all(itemCodeList.map(getItemFromCodeAPI)); // next func.. (有効なものだけに絞るとか) const validItemList = itemList.filter(item => item.status !== 404);解説
Promise.allを使うことで、並列に処理を捌くことができるようになります。
参考までに、APIを並列で捌かないよくない例として、私の愚コードを晒します。const itemCodeList = [ '000000001', '000000002', '000000003', ]; const itemList = await itemCodeList.reduce( async (accum: Promise<Item[]>, itemCode) => { const prev = await accum; // APIからの情報を待つ const item = await getItemFromCodeAPI(itemCode); item && prev.push(item); return Promise.resolve(prev); }, Promise.resolve([]));お分かりいただけますでしょうか?
ついさっきまでの自分はreduceの中でどうやってasync/awaitさせるかだけに執着してしまい、
APIリクエストを1つずつこなしていくめちゃくちゃ遅いコードを書いてしまっていたのです。。木を見て森を見ずってやつですかね、
恥ずかしすぎてまじぴえん。謝辞
@htsignさん、おかげさまで愚コードをリリースせずにすみました!
わかりやすいご指摘ありがとうございました!
- 投稿日:2020-09-13T18:38:40+09:00
javascriptで配列構造のデータからネスト構造のデータを作成
やりたいこと
配列構造
var datas = [ { id: 0, parent: null }, { id: 1, parent:0 }, { id: 2, parent:0 }, { id: 3, parent:1 }, { id: 4, parent: 1 }, { id: 5, parent: 2 } ]これをネスト構造に変換する
var tree = { id: 0, children: [ { id: 1, children: [ { id: 3, children:[] }, { id: 4, children: [] } ] },{ id: 2, children: [ { id: 5, children:[] } ] } ] }結論
実践
datasは順々に0番目からtreeに押し込まれていきます。
まずdatas[0]は、
{id:0,parent:null}は親がいませんからtreeにそのまま押し込まれます。(この処理だけ例外的なので、ここの処理は後から考えます)tree=[ {id:0, children:[] } ]ここからが再帰関数処理の考え所です。
datas[1]
{id:1,parent:0}は、treeの中から親となるid:0を探し出して、id:0のchildrenに自分自身を押し込みます。
datas[2]も同様に、treeの中から親となるid:0を探し出して、id:0のchildrenに自分自身を押し込みます。ここまでの動きを関数で示すと以下の通りです。
function createTree(){ return datas.reduce((acc,cur) => { var parent = tree.find(e=>e.id==cur.id) parent.children.push(cur) return acc },[]) }今のところ、treeは以下のように出来上がっているはずです。
var tree = [{ id: 0, children: [ { id: 1, children: [] },{ id: 2, children: [] } ] }]ここまでは良いのですが、datas[3]はparentがid:1のため、tree.findでは見つけるべき親を見つけられず、treeから親を見つけるためには以下のように記述する必要があります。
tree[0].children.find(e=>e.id==cur.id)このようにreduceのtree.findではネストの深部まで見つけられないため、深部まで探って見つけてくるような関数を実装してやります。
新たな関数名をdeepFindとしました。
ひとまずはfindと同じ機能となるよう実装します。function deepFind(tree,cur){ var result=tree.find(e=>e.id==cur.id) return result } //以下と同じ機能 result=tree.find(e=>e.id==cur.id)さて、deepFind関数を実装していくにあたり、datas[4]をどのように処理していくか考えましょう。
ひとまず、そのままではresultは何も返って来ないので、undefinedの時は次の層を探しにいくような処理に変えますfunction deepFind(tree,cur){ var result=tree.find(e=>e.id==cur.id) + if(result){ + return result + }else{ + result=tree[0].children.find(e=>e.id==cur.id) + return result + } }この状態でdatas[5]までは対応できます。
しかしdatas[6]の親はtree[0].childrenからは見つけれこれず、tree[1].childrenから見つけてくる必要があります。function deepFind(tree,cur){ var result=tree.find(e=>e.id==cur.id) if(result){ return result }else{ result=tree[0].children.find(e=>e.id==cur.id) + if(result){ + return result + }else{ + rusult=tree[1].children.find(e=>e.id==cur.id) + if(result){ + return result + }else{ + //以下同じように続いていく + } + } } }さて、ここまで書いていて気づくかもしれませんが、この関数は「resultがあればresultを返し、なければ探す範囲を変えて同じようにfindメソッドで検索していく」という流れです。
ということは、function deepFind(tree,cur)のtreeの部分さえ、次の探す範囲に書き換えてやればif文を無限に書く必要はなくなるわけです。
function deepFind(tree,cur){ var result=tree.find(e=>e.id==cur.id) if(result){ return result }else{ + return deepFind(*次の検索範囲*,cur) } }探す範囲がtreeなのは最初の一発だけなので、もっと一般的な意味あいで
targetという言葉に書き換えてやります。
ついでに探すキーワードをcurからsubjectに書き換えます。function deepFind(target,subject){ var result=target.find(e=>e.id==subject.id) if(result){ return result }else{ return deepFind(*次の検索範囲*,subject) } }さて、この次の検索範囲というのはどのように指定すれば良いのでしょうか。
data[1]とdata[2]ではtreeが、
datas[3]とdatas[4]ではtree[0].children、datas[5]ではtree[1].childrenが探す範囲でしたので、以下のようにすれば良さそうです。var idx=0; function deepFind(target,subject){ var result=target.find(e=>e.id==subject.id) if(result){ return result }else{ idx++ var nextTarget=tree[idx].children return deepFind(nextTarget,subject) } }ただこの記述だと、ネストが1階層は対応できますが、もっと深いネストになった時に対応できません。
treeのネストが深くなっていった時に、どうやったら抜け漏れなく親を探せるか考えます。
0①--1②--3③--5④ | | |-6④ | |-4③--7⑤ | |-8⑤ |-2②--9⑥ 検索範囲の指定方法 ①tree ②tree[0].children ③tree[0].children[0].children ④tree[0].children[0].children[0].children //これ以上深いネストはない ⑤tree[0].children[0].children[1].children //これより下に兄弟ネストはない ⑥tree[0].children[1]このように深いネストの時はtargetに[0].childrenを追加し、兄弟ネストに移る時は0にプラス1にすれば良いわけです。
したがってロジックとしては、
今探しているところに親が見つからない
→もう一段階深いネストがあれば、そこを検索
→それ以上深いネストがない時は、インデックスにプラス1して兄弟ネストを検索する
→兄弟ネストもない時は、一段階浅いネストに移動して兄弟ネストを検索する(その時インデックスは0に戻す)
という流れにすると良さそうです。function deepFind(target,subject){ var result=target.find(e=>e.id==subject.id) if(result){ return result }else{ //もう一段階深いネストがあれば、そこが次の検索ターゲット if(target[0].children.length){ var nextTarget=target[0].children } else { //深いネストがない場合は弟ネストを検索する。 if(idx+1<target.length){ //弟がいるか。idx+1がtarget.lengthと同じ値の時には弟はいない var nextTarget=target[idx+1].children } } else { //兄弟ネストもない時は、一段階浅いネストに移動してその弟ネストを検索する } return deepFind(nextTarget,subject) } }①tree
②tree[0].children
③tree[0].children[0].children
④tree[0].children[0].children[0].children //これ以上深いネストはない
⑤tree[0].children[0].children[1].children //これより下に兄弟ネストはない
⑥tree[0].children[1]var target=tree depth=0 brothers=[0] function deepFind(target,subject){ var result=target.find(e=>e.id==subject.id) if(result){ return result }else{ //もう一段階深いネストがあれば、そこが次の検索ターゲット if(target[idx].children.length){ var nextTarget=target[brothers[depth]].children depth++ brothers.push(0) } else { //深いネストがない場合は弟ネストを検索する。 if(idx+1<target.length){ //弟がいるか。idx+1がtarget.lengthと同じ値の時には弟はいない var nextTarget=target[brother[depth]].children } } else { //兄弟ネストもない時は、一段階浅いネストに移動してその弟ネストを検索する //ここの実装で行き詰まってしまっています } return deepFind(nextTarget,subject) } }
- 投稿日:2020-09-13T17:57:34+09:00
弊学最大の課題を解決するユーザースクリプト【LiveCampusのブラウザバック】
まえがき
記事について
記事中にLiveCampusと書きましたが、この記事は全く架空のシステムに関するものであり株式会社NTTデータ九州による大学に特化した学務支援ソリューションLiveCampusシリーズとは一切無関係(察してください)です。
ユーザースクリプトの導入について
ユーザースクリプトと言えば聞こえはいいですが要は人様のサイトを改変するわけであり、事務の根幹に関わるシステムでそういったことを認めている大学は無いでしょう。導入は自己責任でお願いします。
概要
総合ポータルシステム LiveCampusという架空のシステムでブラウザの「戻る」ボタンが使えるようにするユーザースクリプトを作りました。
GreasyForkで公開中です。はじめに
日本全国津々浦々様々な大学に導入されている、ある基幹システムがあります。
このシステムは主には事務の効率化のために存在するようですが、利用するのは事務の人たちばかりではありません。
例えば教員はこのシステムを通じてレポートを課したり授業連絡を行いますし、学生も同様に履修登録からレポートの提出まで行います。このシステムを導入している大学は全国で37校1に登ります。大学に在学している限り頻繁に利用するシステムですから、認知度は高いでしょう。
(↑筆者がTwitterとSlackで独自に集計。調査としての妥当性はない)しかし一方でこのシステムは別の側面からも広く知られています。それは尽く直感に反する極めて独特な操作性という側面です。
むやみに子ウィンドウが開く、時刻のフォーマットが悪く0:00が実際のところいつを指しているのかわからない、ナビゲーションが滅茶苦茶で求める機能にどこからアクセスするのかわからない、「一時保存」で落ちる、大事な時に限って極端に重い、たまにNullPointerExceptionを出す…その操作性の独特さはビジネス計画の講義となれば毎年必ずと言っていいほど学生から代替システムの企画を作られ、ユーザビリティの講義となれば教員からも悪い例として取り上げられるほど広範かつ多岐に渡るものですが、
不正な操作が行われました。
システムエラーにより利用を継続することができなくなりました。処理を続ける場合はログインしなおして下さい。中でも最も大きいのはブラウザの「戻る」ボタンを押すと「不正な操作が行われました」として即座にエラー落ちする動作でしょう。
以降ブラウザの「戻る」ボタンを押すことをブラウザバックと言うことにしますが、一般的に人間がブラウザバックを使うときには前のページに戻るという動作を期待します。エラー落ちではありません。
しかしエラーで落ちるとわかっていても戻りたいときにブラウザバックという癖は抜けないのです。これによって弊学では一体どれだけの時間的資源が失われてきたでしょうか。もはや一刻の猶予もありません。せめてこの点だけでもなんとか改善できないでしょうか。手法
Tampermonkey/Greasemonkeyで利用できるユーザースクリプトとして実装します。その流れとしては以下のとおりです。
- 規定のブラウザバックの動作を無効化する
- ブラウザバックの際にページ内にある「戻る」ボタン(ブラウザの「戻る」ボタンとは別)を探してクリックするようにする
わざわざページ内の「戻る」ボタンを探してクリックする処理は回りくどいようですが、Window.locationなどを使った通常のページ遷移では即座にエラー落ちするのでこの方法を使わざるを得ません。
またページ内に「戻る」ボタンが無いこともありますから、そういう場合にはトップページに戻ることにします。ブラウザバックに期待される動作ではないですがエラー落ちよりはマシでしょう。実装
1. 規定のブラウザバックの動作の無効化
JavaScriptで規定の動作の無効化といえばEvent.preventDefault()ですが、これはブラウザバックの際などに起こるWindowEventHandlers.onpopstateイベントでは使えないようです。
しかし偉大なる先駆者2345678によればHistory.pushState()で適当に1つ履歴を追加する=ブラウザバックしたときに戻る先のページが現在のページを指し示すようにすることで規定のブラウザバックを無効化できるとのこと。
「同じページに戻る」わけなので再読み込みなども発生しないようです。したがってこの実装はたった1行で成ります。空の履歴を追加しているだけです。
// 通常のブラウザバックを無効化する history.pushState(null, null, null);2. ブラウザバック時にページ内の戻るボタンを探してクリック
規定のブラウザバックの動作は無効化できたので、次にWindowEventHandlers.onpopstateイベント時にページ内の「戻る」ボタンを探してクリックする処理を作ります。
これは単純にDocument.querySelector()で「戻る」ボタンの要素を検索し、HTMLElement.click()でその要素にクリックイベントを起こせば良いでしょう。
検索の際、「戻る」ボタンに振られている属性は一貫しないのでそれぞれに対応した複数のCSSセレクタを用います。
それでも「戻る」ボタンが1つも見つからないような場合にはヘッダメニューにあるLiveCampusのロゴをクリックしてトップページに戻ることにします。またさらに、そのロゴも見つからないような場合にはLiveCampusにログインしていない(例えばログイン前のトップページにいる)と考えられます。そういう場合には普通にブラウザバックできるはずですから、History.back()を使って先ほど無効化した規定のブラウザバックの動作を蘇らせましょう。
実装は次のようになりました。
window.onpopstate = () => { // DOM中の「戻る」ボタンを探す const buttons = [ document.querySelector(".icon-back"), document.querySelector("img[alt='戻る']"), document.querySelector("img[src$='modoru.gif']"), document.querySelector("h1 a") ].filter(button => button); // ボタンが見つかればクリック、見つからなければ通常のブラウザバックを行う if (buttons.length) { buttons[0].click(); } else { history.back(); } }最終的に出来上がったコード
GithubとGreasyForkでも公開中です。
// ==UserScript== // @name fix livecampus browser back // @description 総合ポータルシステム LiveCampusでブラウザバックを使えるようにする // @author fukuchan // @license GPL-3.0-or-later; https://www.gnu.org/licenses/gpl-3.0.txt // @match *://a-portal.aichi-u.ac.jp/* // @match *://access.sit.ac.jp/* // @match *://campus.kyushu-ns.ac.jp/* // @match *://gakujo.shizuoka.ac.jp/* // @match *://idp.idm.kyutech.ac.jp/* // @match *://jlc.jumonji-u.ac.jp/* // @match *://ksuweb.kyusan-u.ac.jp/* // @match *://lc-nue.naruto-u.ac.jp/* // @match *://lc.brs.nihon-u.ac.jp/* // @match *://lc.nagoya-cu.ac.jp/* // @match *://lc.okiu.ac.jp/* // @match *://lc.s.kaiyodai.ac.jp/* // @match *://lc.sgk.ac.jp/* // @match *://lc.sun.ac.jp/* // @match *://livecampus.adb.fukushima-u.ac.jp/* // @match *://portal.bgu.ac.jp/* // @match *://siweb.iuk.ac.jp/* // @match *://tgulc.u-gakugei.ac.jp/* // @match *://vos-lc-web01.nagaokaut.ac.jp/* // @match *://www.lc.nishogakusha-u.ac.jp/* // ==/UserScript== // 通常のブラウザバックを無効化する history.pushState(null, null, null); window.onpopstate = () => { // DOM中の「戻る」ボタンを探す const buttons = [ document.querySelector(".icon-back"), document.querySelector("img[alt='戻る']"), document.querySelector("img[src$='modoru.gif']"), document.querySelector("h1 a") ].filter(button => button); // ボタンが見つかればクリック、見つからなければ通常のブラウザバックを行う if (buttons.length) { buttons[0].click(); } else { history.back(); } }あとがき
このシステムで「戻る」ボタンを使えたほうが良いということは誰もが認識していることだとは思いますが、機能の追加には莫大な予算が必要とされているようです(追加する機能の内容に依ると思うが、参考として年9000万円程度9)。そのほうが良いからと言ってそれだけの予算を組むのも厳しいものがあるのでしょう。
もちろんだからといってユーザースクリプトで対処するというのもまえがきに書いたような理由できっと褒められたものではありません。しかし利用者側で出来る場当たり的対処としてはこのようなユーザースクリプトの導入も選択肢に入るかもしれない…なんだかんだ言っても便利だし…そう思ってこの記事を書きました。便利だよ。
つまり何が言いたいかって各大学は9000万円の1/10でいいから私にくれてもいいのよ♡参考
- 投稿日:2020-09-13T17:52:58+09:00
A-Frameで3Dモデルを使用するときのメモ
ローカルで動かすのに苦戦したのでメモ
A-Frameで3Dモデル
gltfモデルのサンプルを落としてきた。scene.gltf scene.bin index.htmlindex.html<!doctype html> <html> <head> <!-- A-Frameの導入 --> <script src="https://aframe.io/releases/1.0.4/aframe.min.js"></script> <title>A-Frame</title> </head> <body> <a-scene> <!-- gltfファイル --> <a-assets> <a-asset-items id="bird" src="scene.gltf" ></a-asset-items> </a-assets> <a-entity gltf-model="#bird" scale="0.01 0.01 0.01"></a-entity> </a-scene> </body> </html>index.htmlをそのままクリックしても開かない。
VScodeのliveserverか、Netlifyにデプロイして実行。
- 投稿日:2020-09-13T17:49:45+09:00
存在感の薄い「凝集度」に光を当てる - LCOMでクラスを凝集度を測定しよう
存在感の薄い「凝集度」
品質の高いソフトウェアにするために「結合度が低く、凝集度が高い」設計がよいとされています。ソフトウェアのコンポーネント(関数、クラス、モジュール etc)をどう分割するか、またどうやって互いに関連付けるかに関する設計方針ですね。この「結合度」、「凝集度」の意味は一言で言うと以下のようになります。
- 結合度 - コンポーネント間の依存の多さ、また依存の度合い(低いほど良い)
- 凝集度 - 関連する操作が一つのコンポーネント内にまとまっている度合い(高いほど良い)
結合度と凝集度は表裏一体の概念です。コンポーネントを上手に分割できれいれば、だいたい結合度は低くなるし凝集度は高くなります。関連する操作が一つのコンポーネント内にぎゅっと押し込められていれば、関連の薄い操作は別コンポーネントにあって互いに依存しないようになっているし、逆にコンポーネント間の依存が少なければ、各コンポーネントの責務が明確で互いに関連する操作がコンポーネントで完結している、みたいな感じですね。
「結合度」はよく話題になりますし、コンポーネント間を疎結合に保つためのテクニックもいろいろ知られています。DI(依存性注入)とか依存関係逆転の原則とかAPIファーストとかですね。
でも、「凝集度」のほうは存在感薄くないですか?結合度の片割れのわりには全然話題にならないし、凝集度を高く保つためのテクニックもあまり知られていません。
Qiitaの記事数で比べると人気の差は歴然としています。キーワード検索の検索結果は「結合度」が3807件ですが、「凝集度」は234件しかありません(2020年9月調べ)。10分の1以下。凝集度ちゃん人気なくてカワイソウ。
で、そもそも凝集度という概念がわかりにくいと思うんですよね。関連する操作を一つのコンポーネントにまとめるとか、コンポーネントの責務を明確にして一つのコンポーネントが一つの責任に集中するように設計するとか、言っていることはわかるような気がしますが、具体的にどうすればいいかピンと来ませんよね。
そこで次の節では、凝集度を測るメトリック LCOM を題材に、凝集度をより具体的に理解していきたいと思います。
凝集度のメトリック LCOM
クラスの凝集度を測るメトリックに LCOM (Lack of Cohesion of Methods)というものがあります。直訳すると「メソッドの凝集度の不足度」です。その名のとおり、凝集度が足りないと値が大きくなります。LCOM にはいくつかのバリエーションがありますが、今回紹介するのはいわゆる LCOM4 と呼ばれているものです。
高凝集なクラスは、クラス内のメソッドが互いに関連しているはずです。この「互いに関連している」を定量的に評価しようとするのが LCOM というメトリックです。
LCOM はメソッド内で参照しているインスタンス変数(と他のメソッド)に着目します。直感的には、2つのメソッドが互いに関連しているならば、きっと同じインスタンス変数を参照しているはずです。LCOM ではそういう互いに関連する(=同じインスタンス変数を直接的・間接的に参照している)メソッドでグループ分けして、そのグループの数を数えます。
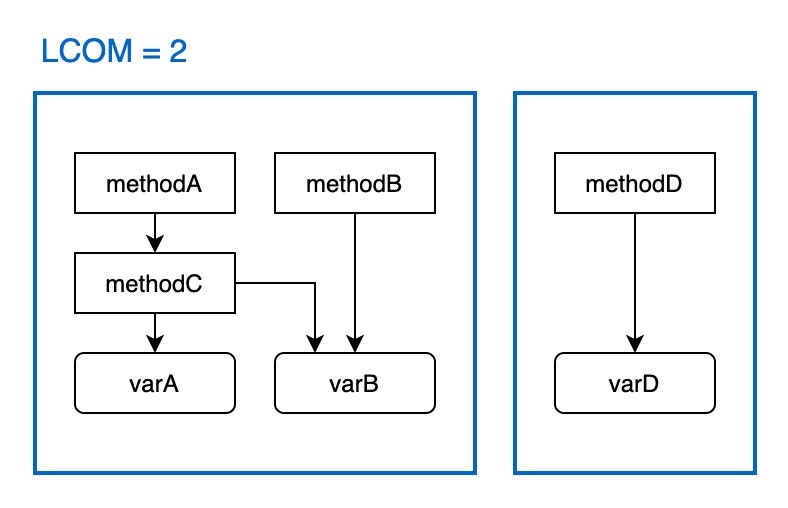
図で表すとわかりやすいです。あるクラス内のメソッドが次のような構造になっているとします。
このクラスには4つのメソッドと3つのインスタンス変数があります。methodA は methodC を呼び出し、methodC は varA と varB を参照していて...のように、矢印は参照関係を表しています。矢印でつながっているメソッド同士を一つのグループにまとめると、青い枠で囲まれたグループが2つあります。グループ数がそのまま LCOM の値になります。このクラスの LCOM は 2 です。
LCOM4 の意味は明快で、次のようなものです。
- LCOM = 1 なら凝集度が高いクラス。これで OK
- LCOM > 1 なら凝集度が低いクラス。クラスを分割するようリファクタリングを検討すべき
上記のクラスについて言えば、LCOM = 2 なのでこれは凝集度が低いクラスで、methodD を別クラスにできるか検討しようということになります。
LCOM4 の形式的定義
LCOM4 のざっくりとした説明は前節のとおりですが、一応形式的な定義も見ておきましょう。
【LCOM4 の定義】
あるクラスにおいて、
Mをメソッドの集合、Iをインスタンス変数の集合とします。次のような無向グラフGを考えます。
- 頂点の集合は
M- 辺の集合は
{ <m, n>∈MxM | (mがiにアクセスし、nがiにアクセスするようなi∈Iが存在する)or(mがnを呼び出す)or(nがmを呼び出す) }このとき、LCOM の値はグラフ
Gの連結成分の個数です。ちなみにですが、先に述べたように LCOM にはいくつかバリエーションがあります。凝集度 - Qiita に LCOM1 〜 3 までの定義がありますので、参考までに。
JavaScript の実装例
せっかくなので、JavaScript のクラスで実装例を見ておきましょう。
意味のあるクラスではありませんが、次のクラスは LCOM = 1 の例です。
// LCOM = 1 (高凝集) class A { methodA() { return this.var1 } methodB() { return this.var1 } }次の例も LCOM = 1 です。
// LCOM = 1 class A { methodA() {} methodB() {} methodC() { this.methodA() this.methodB() } }次のクラスは LCOM = 2 です。
// LCOM4 = 2 (低凝集) class A { methodA() { return this.var1 } methodB() { return this.var2 } methodC() { return this.methodB() } }ESLint のルールを実装してみた
勉強がてら ESLint プラグインを作ってみました。JavaScript クラスの LCOM4 の値を計測して 2 以上だったら警告を出してくれます。
実用的ではないと思いますが、参考までに。
まとめ
今回は「結合度」と比べて影の薄い「凝集度」にスポットを当てて説明してみました。
クラスの凝集度を測定するメトリック LCOM の紹介をしましたが、実際には凝集度はクラスに限定した概念ではなくもっと幅広いものです。結合度は関数、クラス、モジュール、マイクロサービスなど至るところに現れますが、同様に、凝集度もさまざまなレベルで考えることができます。
凝集度のメトリックもさまざまなものが考案されています。興味があれば調べてみるのをおすすめします。
参考
- 投稿日:2020-09-13T17:29:19+09:00
Nuxt.jsでURL直叩きの時はページが表示されるのに、nuxt-linkやブラウザバックでAn error occurredになる
事象
ググった時にもっと引っかかっても良いのになーと思いつつ、全然記事がヒットしなかったのでメモ。
Nuxt.jsでaxiosを使いAPIからデータを取得。
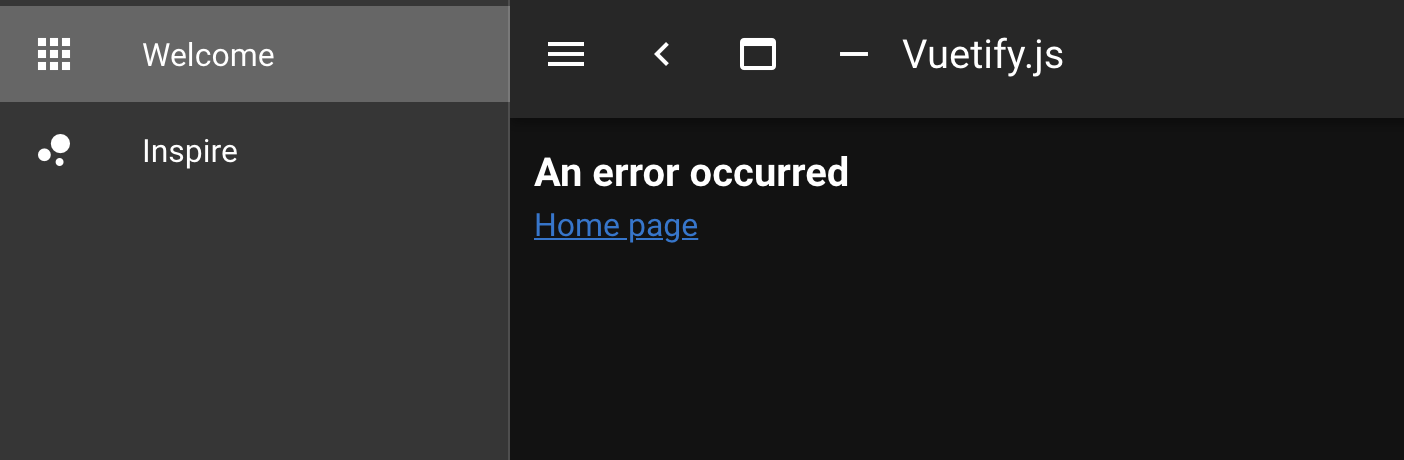
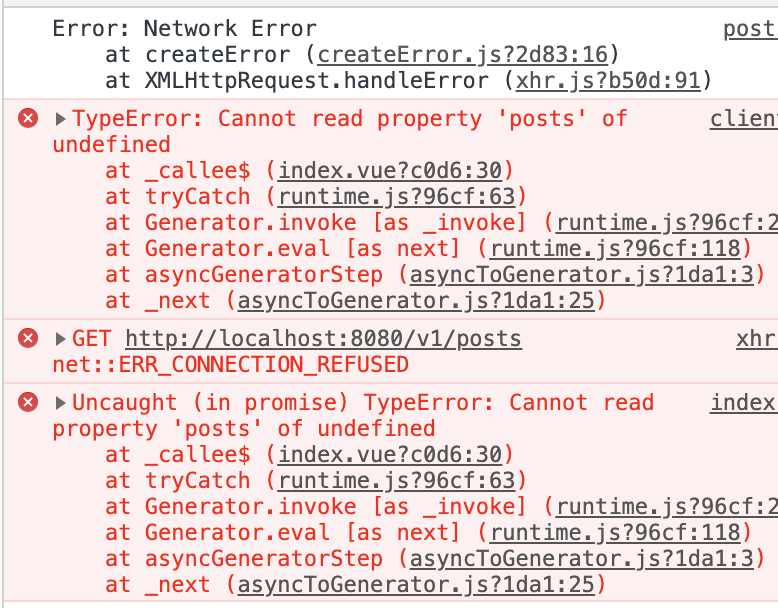
そのデータを元にページを表示している場合、URLを直接叩くと正常に表示されるが、nuxt-linkで遷移したりブラウザバックで移動するとAn error occurredというエラーが出る。参考:Chrome開発者ツール開いた時のエラー
結論
nuxt.config.jsで、axiosのproxyを設定しましょう。
理由
CORS(オリジン間リソース共有)が原因。
- URLを直接開いた時=SSR(サーバサイドレンダリング)が実行される。その名の通りサーバサイドで実行される。
- ブラウザバックやページ遷移=CSR(クライアントサイドレンダリング)が実行される。つまりクライアントのjsで実行されるので、CORSが関係してくる。
URL叩いた時に表示されるのであれば、APIのパスが誤っていたり処理がおかしいのではない。
サーバサイドとクライアントサイド、どちらで実行されているか気付けるかが鍵。
筆者は1時間以上悩みましたたとえ同じサーバ上で動いていても、バックエンドとフロントエンド(Nuxt)が違うportで動いていたら、CORSの対策が必要。
対処法
nuxt.config.js** Nuxt.js modules */ modules: [ - "@nuxtjs/axios" + "@nuxtjs/axios", + "@nuxtjs/proxy" ], + axios: { + proxy: true + }, + proxy: { + '/v1/': { + target: "https://example.com:8080/" + } + },参考(API呼び出し):pages/posts/_id.vue<script> export default { validate({ params }) { return /^\d+$/.test(params.id) }, async asyncData({ $axios, params }) { const response = await $axios.$get(`/v1/posts/${params.id}`) return { post: response.post } } } </script>
@nuxtjs/proxyはaxiosにセットで入っているので、yarn add不要です- /v1/の部分はお使いのAPIのパスに応じて変えてください。多くの場合、/api/になるはずです
- targetの部分はAPIのrootパスになるよう(必要だったらport番号も)適宜置き換えてください。
- 投稿日:2020-09-13T17:14:54+09:00
JavaScript 現在の日付の取得
2020/09/13 に実行した場合
example.jsvar today = new Date();//現在のdateオブジェクト var year = today.getFullYear();//2020 var month = today.getMonth() + 1;//09 (getMonth()は1月を0とした値を返す) var day = today.getDate();//13
- 投稿日:2020-09-13T17:05:34+09:00
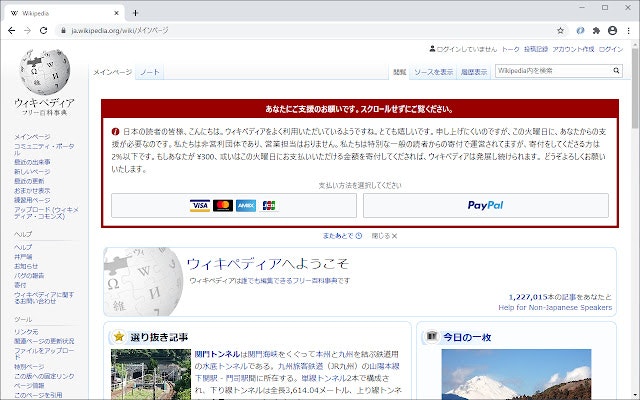
Wikipediaの寄付依頼をブロックするアドオンの作り方
成果物概要
WiKifuKiller(Wi寄付キラー)
Wikipediaのページを開いたときに表示される、寄付依頼を非表示にするブラウザ用アドオンです。
インストールするだけで難しい設定は必要ありません。
ぷれりり様に掲載して頂きました。画面イメージ
Before
After
インストール
各ブラウザのアドオン配布ページよりインストール可能です。
Firefox版:https://addons.mozilla.org/ja/firefox/addon/wikifukiller/
Chrome版:https://chrome.google.com/webstore/detail/wikifukiller/bkdigjebalbifmdhlklififbdibhmlmo?hl=ja
Edge版:https://microsoftedge.microsoft.com/addons/detail/wikifukiller/gjkedgecldjilmcbilahaicpfphndkem?hl=ja-JP制作理由
寄付を募ること自体は良いことだと考えていますが、文言がきつくなっている点や画面上の占める面積が大きくなってきたと感じたため。
Yahoo!ニュースでも「圧が凄い」「怖い」と言ったコメントが目についたため。
ガジェット通信のAdSense利用案に賛同したため。アフィリエイトやクリック報酬型広告はどうなのだろうか。
既存のアフィリエイトやクリック報酬型広告サービス(アマゾンやGoogle Adsenseなど)では審査が通らないわけではないだろう。
法人契約という方法もある。ガジェット通信より引用
開発環境
Visual Studio Code
(サクラエディタ等のテキストエディタでも可)
各種ウェブブラウザ動作確認済みの環境(2020/09/13時点)
Mozilla Firefox 80.0.1
Google Chrome 85.0.4183.102
Microsoft Edge(Chromium版) 85.0.564.51開発~リリースの流れ
- Firefoxアドオン開発のチュートリアルを実施
- 開発者ツールを使用し「寄付依頼」のタグ(適応されているid)を調査
- チュートリアルと同じ要領でWikipediaの寄付依頼タグを削除する処理を記述
- 各ブラウザで動作確認
- 各ストアにてリリースの手続き
コード解説
manifest.json
manifest.json{ "manifest_version": 2, "name": "WiKifuKiller", "version": "1.0.0", "description": "Wikipediaの寄付依頼をブロックします。", "icons": { "48": "icons/wikifukiller-48.png", "96": "icons/wikifukiller-96.png" }, "content_scripts": [ { "matches": ["*://*.wikipedia.org/*"], "js": ["wikifukiller.js"] } ] }最初の 3 つのキー manifest_version、name、version は必須であり、拡張機能の基本的なメタデータを指定します。
description は省略可能ですが、設定しておくことをお勧めします。この値はアドオンマネージャーに表示されます。
icons は省略可能ですが、設定しておくことをお勧めします。この値は拡張機能のアイコンを指定するものであり、アイコンはアドオンマネージャーに表示されます。manifest_version:「2」固定?
name:自分のアドオン名を記述
version:自分のアドオンのバージョンを記述
description:自分のアドオンの説明
icons:アイコン画像の相対パス
matches:適用先のURLを設定するため、WikipediaのURLを記述
js:読み込むJSファイル名を記述wikifukiller.js
wikifukiller.jsif(document.getElementById('siteNotice') != null) { document.getElementById('siteNotice').remove(); } if(document.getElementById('frb-inline') != null) { document.getElementById('frb-inline').remove(); }「寄付依頼」タグに振られているidがある場合に削除するという処理を記述。
Firefoxの場合はタグの存在チェックを行わなくてもエラーとなりませんでした。
Chromeの場合はタグの存在チェックを行わないとエラーとなっていました。
Edgeは未調査です。リリース
Firefox版
こちらに記載されている通りにリリース作業を実施しました。
手続き後、待ちが41/42となっていたものの約3時間ほどで公開されました。Chrome版
こちらに記載されている通りにリリース作業を実施しました。
手続き後、約3時間ほどで公開されました。Edge版
こちらに記載されている通りにリリース作業を実施しました。
手続き後、約10時間ほどで公開されました。スペシャルサンクス
命名:はるうさぎ
アイコン:みなみ急な思いつきで命名やアイコン作成をお願いしたにもかかわらず、すぐに対応して頂き本当に助かりました!
お二方ともTwitterにてアイコンやヘッダ画像作成等のお仕事を募集されていますので、何かあれば是非依頼してみてください。
みなみ様は私が窓口となっていますので、私のTwitterまでご連絡を頂ければ取り次ぎます。感想
以前Firefoxアドオンを作ろうと思い立ったときは、XULという独自言語で実装しなければならないなどハードルが高めの印象でした。
今はWebExtensionsに変わり、Firefox用に作成した物をそのままChrome、Edge向けにもリリースができ非常に楽でした。Wikipediaには繁栄して欲しいとは思うもののAdsense利用など、もう少しやり方があるのではないかと思います。
何かご質問やご意見等がありましたらTwitterにご連絡を頂ければと思います。宣伝
メイドカフェマップ for Android
元メイドさんと一緒に作った~メイドカフェマップ for Androidを公開しています。
インストールして頂いて評価やコメントを頂けると喜びます
メイドカフェマップ アプリ内からツイートできる機能がありますので、そちらをして頂くとさらに喜びます


- 投稿日:2020-09-13T16:35:20+09:00
vue/composition-api@1.0.0-beta7で入ったBREAKING CHANGESについて解説する
vue/composition-api@ 1.0.0-beta7で入ったBREAKING CHANGESについて解説します。
その変更はこちらのURLに記載されています。
https://github.com/vuejs/composition-api/releases/tag/v1.0.0-beta.7
<template>内でRef型の変数がUnwrapされるのは、setup()で返したオブジェクトのroot levelに限るという内容です。どういうことか
composition apiのsetup()では、
<template>内で扱いたいリアクティブな値をオブジェクトにまとめてreturnします。return { loading: ref(true), hogeState: { loading: ref(true) } }この場合、
vue/composition-api@1.0.0-beta7以前では、以下のように<template>を書くことが出来ました。<span>{{ loading }}</span> <span>{{ hogeState.loading }}</span>
Ref<T>であれば、本来は値を取り出すために.valueしなければいけないのですが、<template>内であればUnwrapされてT型の値が取り出せるのでスマートに書けるということでした。これが、
vue/composition-api@1.0.0-beta7以降では、root levelしかUnwrapされなくなるので以下のように書かないといけません。<span>{{ loading }}</span> <span>{{ hogeState.loading.value }}</span>…明らかに書きたくない書き方になりましたね。
所感と対策
個人的にはこの変更はポジティブだと思っています。
そもそもネストした箇所に
Ref<T>があるということは、setup()内に複数のreactiveなStateがあるなどで、root levelにまとめることが難しかったりややこしいという状況だと思います。// あり得るとしたら、複数のhooksを使っているなどの理由で、同じ名前のRefが生えてしまって仕方なくネストしているとかでしょうか return { hogeState: { loading: ref(true) }, fugaState: { loading: ref(true) } }その場合、コンポーネントのサイズが大きすぎるでしょうから分割したり、それが難しければ以下のように名前を変更してstateを扱えば済むので、そのように工夫する方が設計的には嬉しいように思います。
const { loading: hogeLoading } = useHoge() const { loading: fugaLoading } = useFuga() return { hogeLoading, fugaLoading }個人的には1コンポーネント1Stateで済むように、useHogeのサイズ感を適宜インフラ層を用意するなどして工夫することが大事だと考えます。
まとめ
composition-apiを既に使っている方で、ネストしたオブジェクトにRef型の変数を入れていそうだなと思う方はなるべく早くアップデートして要チェックです。
そうでない方は、頭の片隅にでも入れておいていただければと思います!
よろしければTwitterのフォローお願いします!
https://twitter.com/Meijin_garden

- 投稿日:2020-09-13T16:25:00+09:00
【JavaScript】Arrayオブジェクト(配列)のメソッド一覧
配列のメソッド一覧
個人的に実務で使用頻度が高いと思うメソッドには *(アスタリスク)を付与しています。こちらを参考に優先度をつけて学習するのがオススメです。
基本メソッド
isArray(obj)
指定したobjが配列であるかどうかをBooleanで返す
isArrayconst ary = ['a', 'b', 'c']; console.log(Array.isArray(ary)); // trueincludes(el)*
elが配列に含まれているかどうかをBooleanで返す
includesconst ary = ['a', 'b', 'c']; console.log(ary.includes('c')); // trueindexOf(el, [index])
引数に指定した要素と合致する最初の要素のキーを取得する(indexは検索の開始位置、省略可能)
indexOfconst ary = ['a', 'b', 'c']; console.log(ary.indexOf('b')); // 1toString()
配列を文字列に変換する
toStringconst ary = ['a', 'b', 'c']; console.log(ary.toString()); // a, b, c要素追加メソッド
push(el)
配列の末尾に要素を追加する
pushconst ary = ['a', 'b', 'c']; console.log(ary.push('d')); // ['a', 'b', 'c', 'd']unshift(el)
配列の先頭に要素を追加する
const ary = ['b', 'c', 'd']; console.log(ary.unshift('a')); // ['a', 'b', 'c', 'd']要素削除メソッド
pop()
配列の末尾の要素を削除する
const ary = ['a', 'b', 'c']; console.log(ary.pop()); // ['a', 'b']shift()
配列の先頭の要素を削除する
const ary = ['a', 'b', 'c']; console.log(ary.shift()); // ['b', 'c']配列加工メソッド
concat(Array)
引数に指定した配列を後方に連結する
concatconst ary1 = ['a', 'b', 'c']; const ary2 = ['d', 'e', 'f']; console.log(ary1.concat(ary2)); // ['a', 'b', 'c', 'd', 'e', 'f']slice(start, [end])
start+1番目からend番目までの要素を取り出す(endは省略可能、省略した場合は末尾まで)
sliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.slice(2)); // ['c', 'd', 'e'] console.log(ary.slice(1, 3)); // ['b', 'c']splice(start, end, [el, ...])
start+1番目からstart+end番目までの要素をelで置き換える
spliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.splice(1, 2, 'x', 'y')); // ['a', 'x', 'y', 'd', 'e'];endの値を0にするとstartで指定した位置にelを挿入する
spliceconst ary = ['a', 'b', 'c']; console.log(ary.splice(1, 0, 'x')); // ['a', 'x', 'b', 'c'];elを指定しないとstart+1番目からstart+end番目までの要素を削除する
spliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.splice(1, 3)); // ['a', 'e'];fill(el, [start, end])
start+1番目からend番目までの要素をelで置き換える
fillconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.fill('x', 1, 3)); // ['a', 'x', 'x', 'd', 'e']要素並べ替えメソッド
sort()
要素を昇順に並び替える
sortconst ary = ['c', 'b', 'a']; console.log(ary.sort()); // x['a', 'b', 'c']reverse()
要素を逆順に並び替える
reverseconst ary = ['a', 'b', 'c']; console.log(ary.reverse()); // ['c', 'b', 'a']コールバック系メソッド
コールバック関数では共通して引数を3つまで取ることが可能です。
- 第1引数value=要素の値
- 第2引数index=要素のインデックス
- 第3引数array=元の配列
もちろん使用しない引数は省略して問題ありません。
forEach(callback)*
配列の要素をcallbackで順に処理する(返り値ナシ)
forEachconst ary = [1, 2, 3]; ary.forEach((value) => { console.log(value + value); // 2, 4, 6 });map(callback)*
配列の要素をcallbackで順に処理する(返り値アリ)
mapconst ary = [1, 2, 3]; const result = ary.map((value) => { return value + value; }); console.log(result); // 2, 4, 6filter(callback)*
条件callbackに合致した要素で新しく配列を生成する
filterconst ary = [3, 4, 5, 6]; const result = ary.filter((value) => { return value % 3 === 0; }); console.log(result); // [3, 6]find(callback)*
関数callbackが初めてtrueを返した要素を取得する
findconst ary = [3, 4, 5, 6]; const result = ary.find((value) => { return value > 5; }); console.log(result); // 6every(callback)*
配列のすべての要素が条件callbackに一致するかをBooleanで返す
everyconst ary = [3, 6, 9]; const result = ary.every((value) => { return value % 3 === 0; }); console.log(result); // truesome(callback)*
配列のいづれかの要素が条件callbackに一致するかをBooleanで返す
someconst ary = [1, 3, 5, 7]; const result = ary.some((value) => { return value % 2 === 0; }); console.log(result); // falseまとめ
すべてのメソッドを網羅しているわけではないのであしからず。やはり使用頻度が高いメソッドはコールバック系のメソッドですね。もし頻出なメソッドが抜けていたら教えていただけるとありがたいです。
Twitterアカウント
Twitterも更新していますので、よかったらフォローお願いします!
Twitterアカウントはこちら
- 投稿日:2020-09-13T16:25:00+09:00
Arrayオブジェクト(配列)のメソッド一覧
配列のメソッド一覧
個人的に実務で使用頻度が高いと思うメソッドには *(アスタリスク)を付与しています。こちらを参考に優先度をつけて学習するのがオススメです。
基本メソッド
isArray(obj)
指定したobjが配列であるかどうかをBooleanで返す
isArrayconst ary = ['a', 'b', 'c']; console.log(Array.isArray(ary)); // trueincludes(el)*
elが配列に含まれているかどうかをBooleanで返す
includesconst ary = ['a', 'b', 'c']; console.log(ary.includes('c')); // trueindexOf(el, [index])
引数に指定した要素と合致する最初の要素のキーを取得する(indexは検索の開始位置、省略可能)
indexOfconst ary = ['a', 'b', 'c']; console.log(ary.indexOf('b')); // 1toString()
配列を文字列に変換する
toStringconst ary = ['a', 'b', 'c']; console.log(ary.toString()); // a, b, c要素追加メソッド
push(el)
配列の末尾に要素を追加する
pushconst ary = ['a', 'b', 'c']; console.log(ary.push('d')); // ['a', 'b', 'c', 'd']unshift(el)
配列の先頭に要素を追加する
const ary = ['b', 'c', 'd']; console.log(ary.unshift('a')); // ['a', 'b', 'c', 'd']要素削除メソッド
pop()
配列の末尾の要素を削除する
const ary = ['a', 'b', 'c']; console.log(ary.pop()); // ['a', 'b']shift()
配列の先頭の要素を削除する
const ary = ['a', 'b', 'c']; console.log(ary.shift()); // ['b', 'c']配列加工メソッド
concat(Array)
引数に指定した配列を後方に連結する
concatconst ary1 = ['a', 'b', 'c']; const ary2 = ['d', 'e', 'f']; console.log(ary1.concat(ary2)); // ['a', 'b', 'c', 'd', 'e', 'f']slice(start, [end])
start+1番目からend番目までの要素を取り出す(endは省略可能、省略した場合は末尾まで)
sliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.slice(2)); // ['c', 'd', 'e'] console.log(ary.slice(1, 3)); // ['b', 'c']splice(start, end, [el, ...])
start+1番目からstart+end番目までの要素をelで置き換える
spliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.splice(1, 2, 'x', 'y')); // ['a', 'x', 'y', 'd', 'e'];endの値を0にするとstartで指定した位置にelを挿入する
spliceconst ary = ['a', 'b', 'c']; console.log(ary.splice(1, 0, 'x')); // ['a', 'x', 'b', 'c'];elを指定しないとstart+1番目からstart+end番目までの要素を削除する
spliceconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.splice(1, 3)); // ['a', 'e'];fill(el, [start, end])
start+1番目からend番目までの要素をelで置き換える
fillconst ary = ['a', 'b', 'c', 'd', 'e']; console.log(ary.fill('x', 1, 3)); // ['a', 'x', 'x', 'd', 'e']要素並べ替えメソッド
sort()
要素を昇順に並び替える
sortconst ary = ['c', 'b', 'a']; console.log(ary.sort()); // x['a', 'b', 'c']reverse()
要素を逆順に並び替える
reverseconst ary = ['a', 'b', 'c']; console.log(ary.reverse()); // ['c', 'b', 'a']コールバック系メソッド
コールバック関数では共通して引数を3つまで取ることが可能です。
- 第1引数value=要素の値
- 第2引数index=要素のインデックス
- 第3引数array=元の配列
もちろん使用しない引数は省略して問題ありません。
forEach(callback)*
配列の要素をcallbackで順に処理する(返り値ナシ)
forEachconst ary = [1, 2, 3]; ary.forEach((value) => { console.log(value + value); // 2, 4, 6 });map(callback)*
配列の要素をcallbackで順に処理する(返り値アリ)
mapconst ary = [1, 2, 3]; const result = ary.map((value) => { return value + value; }); console.log(result); // 2, 4, 6filter(callback)*
条件callbackに合致した要素で新しく配列を生成する
filterconst ary = [3, 4, 5, 6]; const result = ary.filter((value) => { return value % 3 === 0; }); console.log(result); // [3, 6]find(callback)*
関数callbackが初めてtrueを返した要素を取得する
findconst ary = [3, 4, 5, 6]; const result = ary.find((value) => { return value > 5; }); console.log(result); // 6every(callback)*
配列のすべての要素が条件callbackに一致するかをBooleanで返す
everyconst ary = [3, 6, 9]; const result = ary.every((value) => { return value % 3 === 0; }); console.log(result); // truesome(callback)*
配列のいづれかの要素が条件callbackに一致するかをBooleanで返す
someconst ary = [1, 3, 5, 7]; const result = ary.some((value) => { return value % 2 === 0; }); console.log(result); // falseまとめ
すべてのメソッドを網羅しているわけではないのであしからず。やはり使用頻度が高いメソッドはコールバック系のメソッドですね。もし頻出なメソッドが抜けていたら教えていただけるとありがたいです。
Twitterアカウント
Twitterも更新していますので、よかったらフォローお願いします!
Twitterアカウントはこちら
- 投稿日:2020-09-13T16:02:32+09:00
Uncaught DOMException: Failed to construct ~ cannot be accessed from origin 'null'.が出た時の対処(自分用メモ)
JavaScript本格入門 山田祥寛著
の第7章のラスト、7.6を進めていました。今回は-Web Worker-の基礎を理解するため、メインのJavaScriptコードを用意して、そこからワーカーを呼び出してみようといった流れでした。
いざ、ワーカーを呼び出してみるとうまくいきません。エラー箇所
コードには特に問題はなさそうなので、
ブラウザ(今回はGoogleChrome)で確認してみると以下のようなエラーが発生していました。
Uncaught DOMException: Failed to construct 'Worker': Script at '指定したJSファイル' cannot be accessed from origin 'null'. at HTMLInputElement.<anonymous> (エラー行)原因
そこで「Uncaught DOMException: Failed to construct」で検索してみると
と言う似た事例の記事がヒットしました。
ここでの回答から、作業ファイルをローカルに置いていたことが原因だということがわかりました。
それらのファイルをサーバーに配置したところ、無事問題は解決しました。
なんでサーバーに置かなければいけないのかと言うことまでは、今回はわかりませんでした...。
- 投稿日:2020-09-13T15:54:52+09:00
Jestとpuppetterで繰り返しテストをarrayにまとめたサンプル
Jestとpuppeteerでe2eテストを書いています。大量のページに対してページのtitleをチェックしています。配列に対象ページのURLとtitleをまとめると、すっきり書けたのでメモしておきます。
配列
検査したい要素、titleとurlをまとめて指定しています。
const pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ];テスト
testを配列のループで囲んでいます。ページを取得してtitleを照合しています。
for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); }コード全体
loop.test.jsconst pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ]; describe('LOOP', () => { beforeAll(async () => { await page.setDefaultNavigationTimeout(0); }); for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); } });実行結果
% jest loop.test.js PASS ./loop.test.js LOOP ✓ should be titled "はじめに - Bootstrap 4.5 - 日本語リファレンス" (696 ms) ✓ should be titled "ダウンロード - Bootstrap 4.5 - 日本語リファレンス" (331 ms) ✓ should be titled "ファイル構成 - Bootstrap 4.5 - 日本語リファレンス" (515 ms) Test Suites: 1 passed, 1 total Tests: 3 passed, 3 total Snapshots: 0 total Time: 2.251 s, estimated 9 s Ran all test suites matching /loop.test.js/i.
- 投稿日:2020-09-13T15:45:10+09:00
【JS学習その①】JavaScriptとECMAScript
JS学習シリーズの目的
このシリーズは、私ジャックが学んだJavaScriptのメカニズムについてアウトプットも兼ねて、
皆さんと知識や理解を共有するためのものです。
(理解に間違いがあればご指摘いただけると幸いです)ECMAScriptとは
「JavaScript言語のコアの部分をECMAScriptとして仕様策定したもの」
1990年代(インターネット黎明期)に当時はブラウザとして大きなシェアを持っていた
"Netscape Navigator"(以降NNと略す)が皆さんご存じ"Internet Explore"(以降IEと略す)という
(当時は大きな)ライバルに勝つためにJavaScriptを生み出しました。
IEもこのJavaSciriptを使いたかったが、ライセンスなどの問題で使えなかったので新たに"JScript"を生み出しました。
しかし、この2つの言語には互換性がなかったため、ブラウザ間での仕様を統一するためにECMAScriptが作られました。
これにより、開発者がサイトなどの開発がしやすくなりハッピーになったというわけです。JavaScriptは実行環境によって使える機能が変わる
ECMAScriptについては前述した通りですが、あくまでJavaScriptの一部がECMAScriptです。
ブラウザ環境で動くのがECMAScript(他にもWeb APIsがある)ですが、PC内のNode.jsで動くときは
"ECMAScript"に加えて"CommonJS"が使われます。ここで重要なのは、「見出しの通りJavaScriptは実行環境によって使える機能が変わる」ということです。
まとめ
JavaScriptとは
・ECMAScriptの仕様に基づいて実装されているプログラミング言語
・環境によって使える機能が変わってくるおまけ
現在のECMAScriptの仕様策定は"Living Standard"といって、
「機能毎に使用を策定し、仕様が決まったものから最新版の仕様書に順次追加していく」
というプロセスを採用しています。
仕様策定プロセスはStage0~Stage4まで存在し、それぞれ
Stage0--アイデアレベル(Strawman)
Stage1--機能提案・検討(Proposal)
Stage2--暫定的に仕様決定(Draft)
Stage3--テスト・実装(Candidate)
Stage4--仕様決定(Finished)基本的にStage2(Draft)の段階からES最新版に取り込みします。
- 投稿日:2020-09-13T15:35:35+09:00
Next.jsの特徴
プログラミング勉強日記
2020年9月13日
JSには色々なフレームワークがあって、開発の用途によって使用するフレームワークが違うと思うので、まとめてみようと思う。ReactについてとAngularについて、Vue.jsまとめたので、今回はNext.jsについてまとめる。Next.jsとは
Reactの特徴の記事でも述べているが、Reactはフレームワークではなくライブラリである。Next.js(読み方「ネクストジェイエス」)はZEIT社が開発したJSのフレームワーク。
Reactと組み合わせてWebアプリ開発を強化するフレームワークで、ReactのアプリのJSで行う画面の書き換えの処理をサーバー側で実行させて待機時間を短くするサーバーサイドレンダリングを可能にする。サーバーサイドレンダリング(SSR)を実現する
上でも述べたように、JSは基本的にページのレンダリング(表示)時に実行される。なので、ページの大部分をJSに頼っていた李、ReactなどでSPA(Single Page Application)のような状態になっていると、初めてページを開くときに時間がかかってしまう。また、GoogleのクローラはJSを読み込んで結果を評価することもできるが、それもすべてではない。
こういったSEO(検索エンジン最適化)やパフォーマンスの観点からページをレンダリングする前にJSの処理をサーバー側で行うことでユーザの待機時間を短くできる。参考文献
Next.jsとは?JavaScriptフレームワークについて解説
Next.jsの環境構築【これからはじめるNext.js】
- 投稿日:2020-09-13T15:30:46+09:00
【JSメモ】ハンバーガーのトグルアクション
はじめに
ここでのトグルアクションは、
開くときは、ハンバーガーボタンで開く。
閉じるときは、画面のどこを押しても閉じるで実装したいと思います。
コード
sample.js// SP用:ハンバーガーのトグルアクション $(document).on('click', function(e) { if($(e.target).is('#hamburger')) { $('.c-header__nav').toggleClass('c-header__is-active'); } else if($(e.target).is('*')) { $('.c-header__nav').removeClass('c-header__is-active'); } });
- 投稿日:2020-09-13T14:37:10+09:00
Vueでカラムが選択可能なテーブルを作る
作るもの
こんな感じのカラムを選択できるようなテーブルを作ります。
<template> <table> <thead> <th> <label class="form-checkbox"> <input type="checkbox" v-model="isSelectAll" @click="select"> </label> </th> <th>ID</th> <th>ユーザー名</th> <th>画像</th> <th>作成日</th> </thead> <tbody> <tr v-for="user of users" :key="user.id"> <th> <input type="checkbox" :value="user" v-model="selected"> </th> <td>{{ user.id }}</td> <td>{{ user.name }}</td> <td>{{ user.image }}</td> <td>{{ user.date}}</td> </tr> </tbody> </table> </template> <script> export default { data() { return { users: [ { id: 1, name: 'jhin', image: 'https://image.test.com', date: '2020/09/10' }, { id: 2, name: 'ahri', image: 'https://image.test.com', date: '2020/09/11' }, { id: 3, name: 'yasuo', image: 'https://image.test.com', date: '2020/09/12' }, ], selected: [], isSelectAll: false, }; }, methods: { select() { this.selected = []; if (!this.isSelectedAll) { for(let i in this.item) { this.selected.push(this.items[i].id); } } } }, }; </script>チェックボックスの
v-modelに配列を指定することがポイント。チェックが入ると
:valueで指定したuserオブジェクトが配列のselectedに挿入されます。console.log(this.selected) /* チェックされたカラムの情報が配列に挿入される [ { id: 1, name: 'jhin', image: 'https://image.test.com', date: '2020/09/10' }, ], */非常に簡単。

- 投稿日:2020-09-13T14:37:10+09:00
Vueで行が選択可能なテーブルを作る
作るもの
こんな感じのカラムを選択できるようなテーブルを作ります。
<template> <table> <thead> <th> <label class="form-checkbox"> <input type="checkbox" v-model="isSelectAll" @click="select"> </label> </th> <th>ID</th> <th>ユーザー名</th> <th>画像</th> <th>作成日</th> </thead> <tbody> <tr v-for="user of users" :key="user.id"> <th> <input type="checkbox" :value="user" v-model="selected"> </th> <td>{{ user.id }}</td> <td>{{ user.name }}</td> <td>{{ user.image }}</td> <td>{{ user.date}}</td> </tr> </tbody> </table> </template> <script> export default { data() { return { users: [ { id: 1, name: 'jhin', image: 'https://image.test.com', date: '2020/09/10' }, { id: 2, name: 'ahri', image: 'https://image.test.com', date: '2020/09/11' }, { id: 3, name: 'yasuo', image: 'https://image.test.com', date: '2020/09/12' }, ], selected: [], isSelectAll: false, }; }, methods: { select() { this.selected = []; if (!this.isSelectedAll) { for(let i in this.item) { this.selected.push(this.items[i].id); } } } }, }; </script>チェックボックスの
v-modelに配列を指定することがポイント。チェックが入ると
:valueで指定したuserオブジェクトが配列のselectedに挿入されます。console.log(this.selected) /* チェックされたカラムの情報が配列に挿入される [ { id: 1, name: 'jhin', image: 'https://image.test.com', date: '2020/09/10' }, ], */非常に簡単。
- 投稿日:2020-09-13T13:35:59+09:00
【厳選8個】フロントエンド開発でちょっとした時に役立つCSS Tips集
Webアプリのフロントエンド開発をしているときによくあるケースのCSSのTips集です。
私はWebエンジニアをしていてCSSもたまに書くのですがたまにしかないため、「こういう時どうやってCSSを書けばいいんだっけ?」となることが多く、都度、調べています。
自分の備忘録的な目的でまとめていますが、もし同じような問題に遭遇してやり方がわからないという方のお役に立てれば幸いです。
環境
以下の環境で確認をしています。(2020年9月時点で最新版の環境です。)
- macOS Catalina :10.15.6
- Chrome:85.0.4183.102
1. 一行に収まらない長さのテキストの場合は「...」で切る
やりたいこと
解決策
テキストのスタイルに
overflow-x: hidden;、text-overflow: ellipsis;、white-space: nowrap;を指定するHTML
<div class="cut-long-text"> 一行に収まらない長さのテキストの場合は、途中でテキストを切って「...」で表示する </div>CSS
.cut-long-text{ overflow-x: hidden; /* はみ出る部分は非表示 */ text-overflow: ellipsis; /* はみ出る部分を...で表示 */ white-space: nowrap; /* 行の折り返しをしない */ }参考:APIリファレンス
2. タグ内の最後のスペースを表示する
やりたいこと
<div>I agree to </div><a>Terms of Service</a>のように、テキストの後ろにaタグのリンクテキストをつなげる場合。
この場合、toの後ろにスペースを入れたい。
(よくあるケースとしては下にある図のように、利用規約部分だけをリンクにしたい。)
解決策
white-space: pre;を指定するHTML
<div> <div class="text-show-space">I agree to </div><a>Terms of Service</a> </div>CSS
.text-show-space { white-space: pre; }参考:APIリファレンス
3. 文字とアイコンの位置を揃える
やりたいこと
テキストとSVGアイコンを同じ行に表示するときに、テキストとアイコンの上下方向の位置を揃えたい
解決策
アイコンの
line-heightをテキストと同じ高さに指定し、vertical-align: middle;を指定するHTML
<div class="text-with-icon">新規作成</div> <div class="icon-wrapper-alignment"> <div class="icon"> <svg width="16px" height="16px" aria-hidden="true" > ... </svg> </div> </div>CSS
.text-with-icon { line-height: 30px; } .icon-wrapper-alignment { line-height: 30px; /* テキストと同じline-heightにする */ } .icon { vertical-align: middle; /* 上下中央に配置する */ }参考:APIリファレンス
4. SVGアイコンの色をCSSから指定する
やりたいこと
SVGアイコンの色をCSSで指定したい
(テキストの色が状態によって変わるのでそれに合わせてアイコンの色も変えたい場合など)
解決策
svgアイコンのfillやstrokeの値に
fill="currentColor"を指定するHTML
<div class="text-info-color">新規作成</div> <div class="icon-wrapper"> <div class="icon text-info-color"> <svg width="16px" height="16px" aria-hidden="true" focusable="false" data-prefix="fas" data-icon="plus-circle" class="svg-inline--fa fa-plus-circle fa-w-16" role="img" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 512 512"> <path fill="currentColor" d="..."> </path> </svg> </div> </div>CSS
.text-info-color { color: turquoise; }参考:APIリファレンス
5. 両端にボタンを配置する
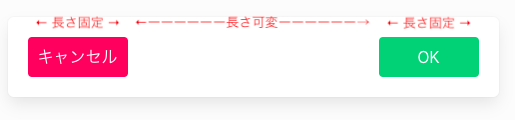
やりたいこと
Flexboxを使ってボタンを両端に配置したい
解決策
ボタンを囲む親要素に
justify-content: space-betweenを指定するHTML
<div class="flex-container"> <button>キャンセル</button> <button>OK</button> </div>CSS
.flex-container { display: flex; justify-content: space-between; width: 100%; }参考:APIリファレンス
6. ポップアップメニューを表示する
やりたいこと
ボタンを押したらそのすぐ横にポップアップメニューを表示したい。そのような場合のpositionの指定方法。
解決策
getBoundingClientRectでボタンの位置を取得して、ポップアップメニューの位置をabsoluteにする
HTML
<button class="button" id="button-menu">メニュー</button> <div class="box menu" id="menu"> <div class="menu-item">新規作成</div> <hr> <div class="menu-item">削除</div> <hr> <div class="menu-item">設定</div> </div>CSS
.menu { visibility: hidden; position: absolute; } .menu-item { line-height: 40px; }JavaScript
const buttonMenu = document.getElementById('button-menu') const menu = document.getElementById('menu') buttonMenu.addEventListener('click', () => { // ボタンの座標を取得する const buttonPosition = buttonMenu.getBoundingClientRect() // メニューの座標を設定する const style = menu.style; style.visibility = 'visible' style.top = `${buttonPosition.top + window.scrollY}px` style.left = `${buttonPosition.right + 20}px` })参考:APIリファレンス
7. 画像の縦横比を変えずに表示する
やりたいこと
画像を縦横比を変えずに表示させたい。
解決策
object-fitを利用する
HTML
<!-- 縦横比が変わってしまう --> <img class="img-fill" src="images/hot-air-balloon-5390487_1920.jpg"> <!-- 縦横比を維持 --> <img class="img-contain" src="images/hot-air-balloon-5390487_1920.jpg"> <!-- 縦横比を維持(はみ出る部分はトリミング) --> <img class="img-cover" src="images/hot-air-balloon-5390487_1920.jpg">CSS
.img-fill{ object-fit: fill; /* 縦横比が変わる */ width: 300px; height: 300px; } .img-contain{ object-fit: contain; /* 縦横比を維持 */ width: 300px; height: 300px; } .img-cover{ object-fit: cover; /* 縦横比を維持(はみ出る部分はトリミング) */ width: 300px; height: 300px; }参考:APIリファレンス
8. 画面全体を半透過でオーバーレイする
やりたいこと
ローディングやモーダルダイアログなどを出したいときに、背景となる画面全体を半透過でオーバーレイする
解決策
疑似要素(::before)を使用する
HTML
<div class="overlay"></div>CSS
.overlay { position: fixed; top: 0; left: 0; background-color: rgba(0, 0, 0, 0.6); } .overlay::before { content: ""; display: inline-block; height: 100vh; width: 100vw; }参考:APIリファレンス










- 投稿日:2020-09-13T13:19:51+09:00
Chart.js 値が正か負か判定し、グラフ色を変える
デモ
https://codepen.io/kakuta_yu/pen/RwayOxj
※CodePenに遷移します全コード
HTML
<canvas id="myChart"></canvas>JavaScript
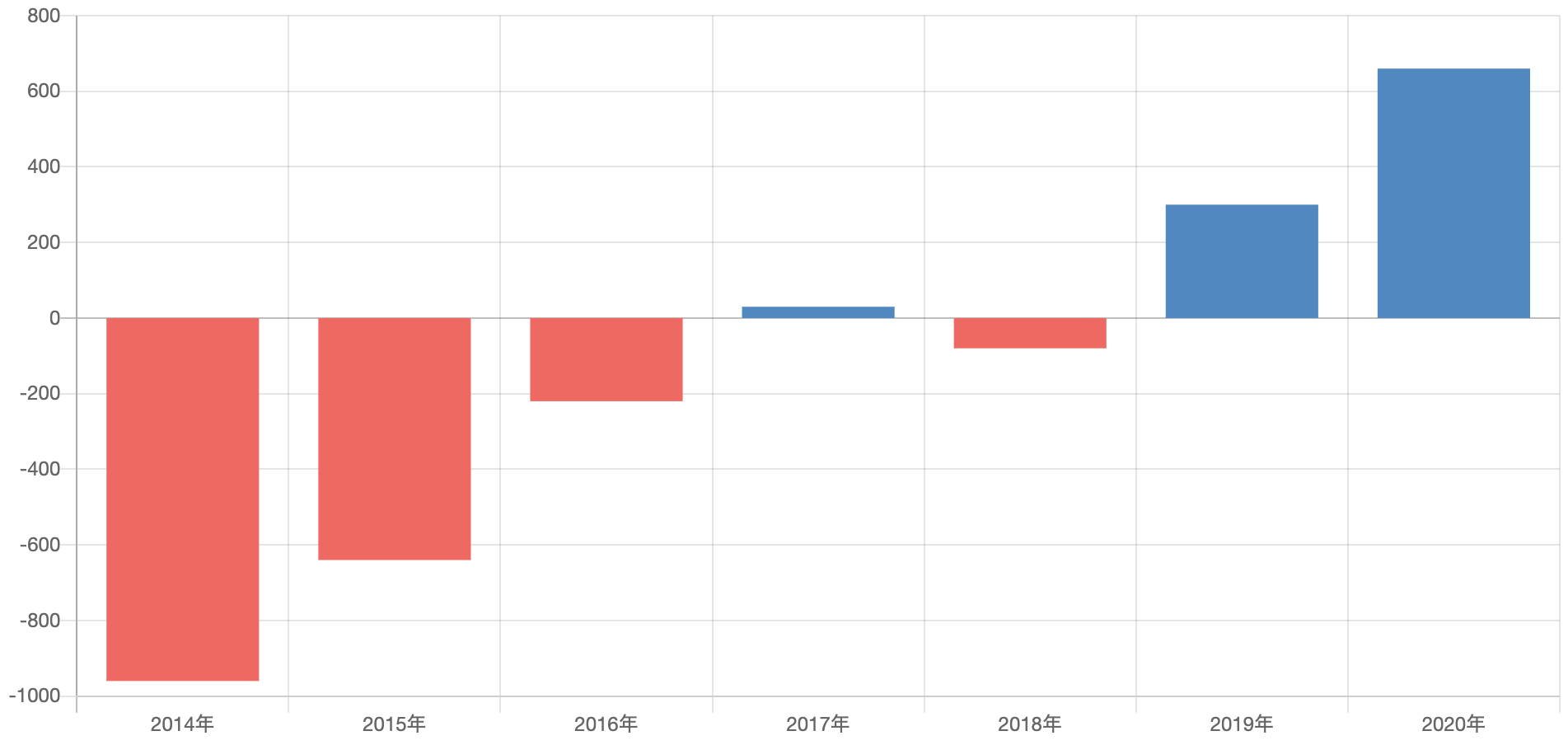
// 値を設定 var datasets = [ { label: '利益額', data: [-960, -640, -220, 30, -80, 300, 660], backgroundColor: ['#3F88C5'] // 配列にしておく必要がある } ] // 各棒グラフの値が正か負かによって色分け for (var i = 0; i < datasets[0].data.length; i++) { if (datasets[0].data[i] > 0) { datasets[0].backgroundColor[i] = '#3F88C5' // 値が正の場合は青 } else { datasets[0].backgroundColor[i] = '#FF5E5B' // 値が負の場合は赤 } } /* ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー グラフ描画 ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー */ var ctx = document.getElementById("myChart"); var myChart = new Chart(ctx, { type: 'bar', data: { labels: ['2014年', '2015年', '2016年', '2017年', '2018年', '2019年', '2020年'], datasets: datasets }, });解説
値を設定
描画する値を変数に入れます。
この時、backgroundColorを配列の形にしておくことを忘れないでください。
あとで値を判定してbackgroundColorに青と赤のカラーコードを入れていきますが、配列にしておかないとうまく入ってくれません。// 値を設定 var datasets = [ { label: '利益額', data: [-960, -640, -220, 30, -80, 300, 660], backgroundColor: ['#3F88C5'] // 配列にしておく必要がある } ]値の判定と色の設定
値の数だけループを回して色を設定します。
例えば3つ目の値が負だった時、backgroundColor[2]に赤のカラーコードを入れます。// 各棒グラフの値が正か負かによって色分け for (var i = 0; i < datasets[0].data.length; i++) { if (datasets[0].data[i] > 0) { datasets[0].backgroundColor[i] = '#3F88C5' // 値が正の場合は青 } else { datasets[0].backgroundColor[i] = '#FF5E5B' // 値が負の場合は赤 } }グラフの描画
上記で設定したdatasetsをグラフ描画コードへ入れます。
今回は最低限のコードしか記述していないため、デモでは凡例の色が赤になっていますが、このあたりはoptionで凡例を非表示にといった処理が必要です。/* ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー グラフ描画 ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー */ var ctx = document.getElementById("myChart"); var myChart = new Chart(ctx, { type: 'bar', data: { labels: ['2014年', '2015年', '2016年', '2017年', '2018年', '2019年', '2020年'], datasets: datasets }, });