- 投稿日:2020-09-13T23:54:22+09:00
CodeCommitとECRを連携してAWS Batchで実行結果の確認する方法
概要
前回の内容をCodeCommitからECRにプッシュしてAWS Batchで実行する形を作ります。
CodeCommitとの連携でいろいろ試行錯誤したのでその内容をメモしていこうかと。準備
Dockerファイルは前回のものをそのまま使います。
Commitするソースの準備
- ディレクトリは以下のようになっています。
- CodeCommitにコミットするため.gitignoreを設定しています。
.gitignore buildspec.yml dockerfile module\data module\data\signal-datas_1.csv module\src module\src\logger.py module\src\pandasTest.py
- pandasTest.py
- 今回は環境変数、引数に与えたものを出力できるように修正しています。
import pandas as pd from logger import LoggerObj import sys import os aws_region_name = os.getenv('DYNAMODB_REGION', 'ap-northeast-1') if __name__ == "__main__": args=sys.argv logObj=LoggerObj() log=logObj.createLog() log.info('処理開始') log.info(args) log.info(aws_region_name) test=pd.read_csv('data/signal-datas_1.csv') log.info(test.head()) log.info('処理終了')
- buildspec.yml
- CodeBuildを使うためbuildspec.ymlを作成します。
XXXXXXXXXXはAWSのアカウントIDpandastest2はECRのリポジトリを指定します。(事前に作成してください)- 公式のサンプルでは環境変数で設定していますが、今回はお試しなので固定値にしています。
version: 0.2 phases: install: runtime-versions: docker: 19 commands: - echo install step... pre_build: commands: - echo logging in to AWS ECR... - $(aws ecr get-login --no-include-email --region ap-northeast-1) build: commands: - echo build Docker image on `date` - echo Building the Docker image... - docker build -t pandastest:latest . - docker tag pandastest:latest XXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/pandastest2:latest post_build: commands: - echo build Docker image complete `date` - echo push latest Docker images to ECR... - docker push XXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/pandastest2:latestソースのコミットからビルド
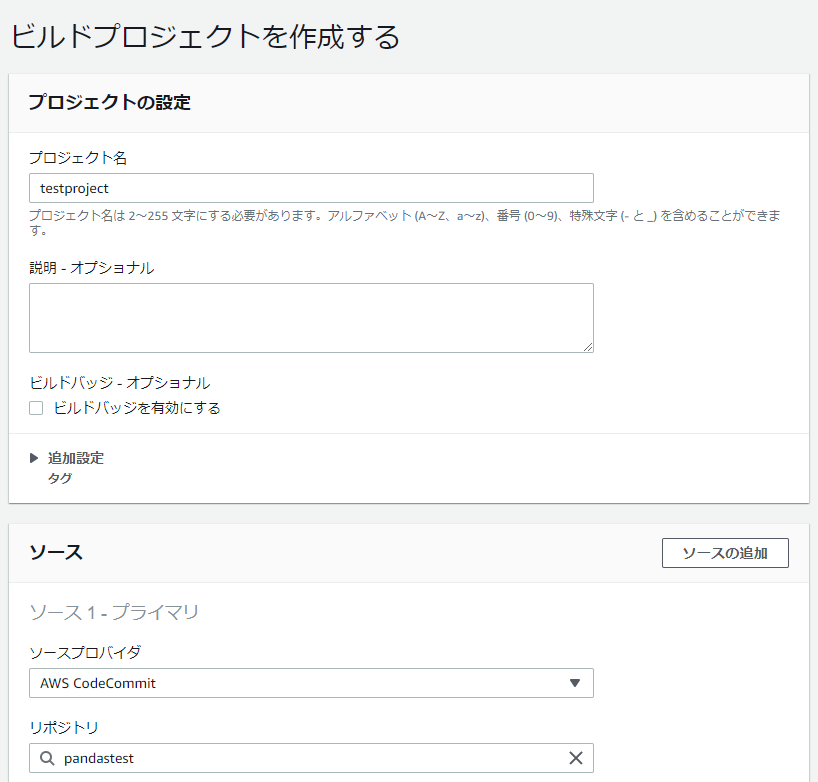
リポジトリにソースをコミットします。
- 事前にリポジトリを作成しソースをコミットします。認証の方法などは公式ページ参照
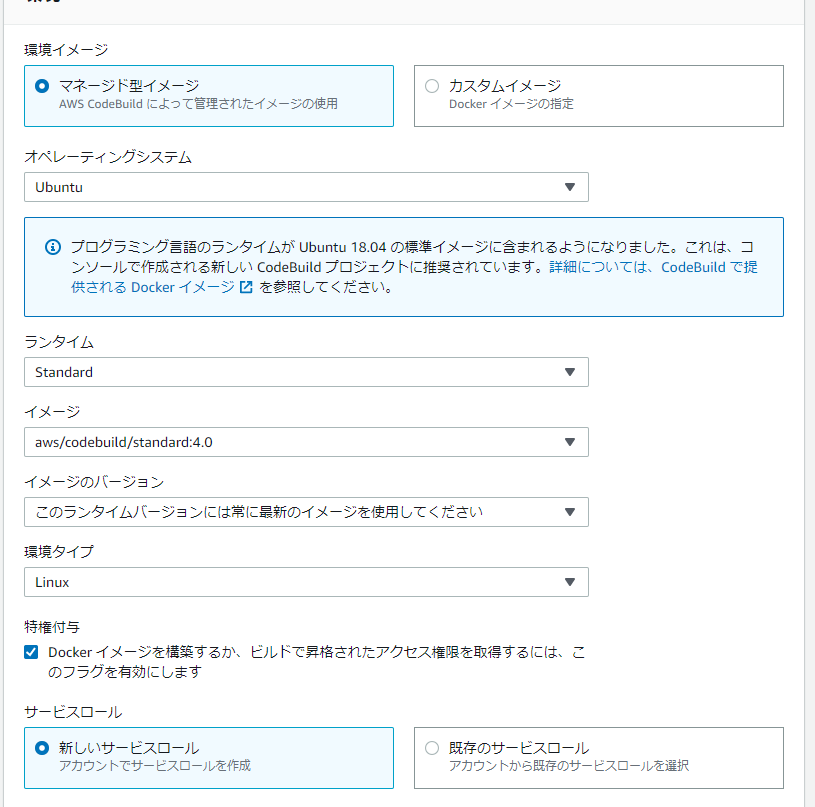
CodeBuildでビルドの実行を行います。
- オペレーティングシステムは
ubuntuにしないとDockerファイルのapt-getがエラーになってしまうようです。- 特権付与
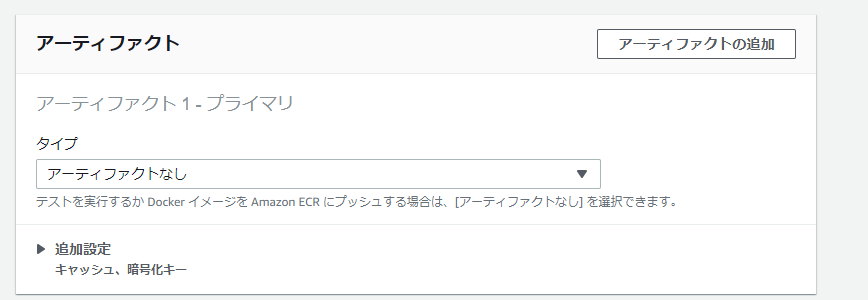
Docker イメージを構築するか、ビルドで昇格されたアクセス権限を取得するには、このフラグを有効にしますをチェックしないとイメージの作成で失敗します。- アーティファクトはECRにプッシュするのでなしです。
- ロールには権限が足りないのでこちらを参照して権限を追加します。以下の記述を追加します。
{ "Action": [ "ecr:BatchCheckLayerAvailability", "ecr:CompleteLayerUpload", "ecr:GetAuthorizationToken", "ecr:InitiateLayerUpload", "ecr:PutImage", "ecr:UploadLayerPart" ], "Resource": "*", "Effect": "Allow" },
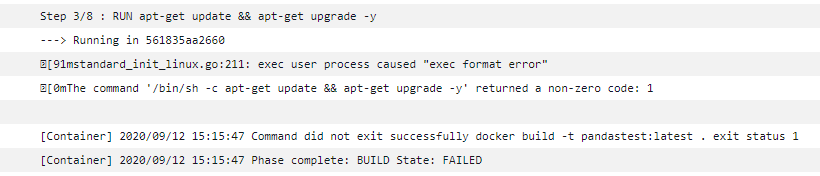
- ビルドを実行し終了することを確認します。
- 失敗した場合はcloudWatchLogを確認します。
ジョブ定義の作成から実行
- AWSコンソール上から
Batchを選択します。コンテナイメージにはECRに登録されているコンテナimageの
イメージの URIを設定します。
- 環境変数は以下のように設定します。
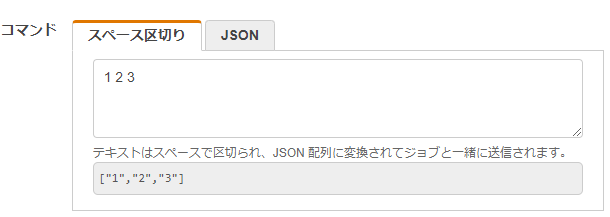
- 引数は以下のように設定します。
作成後
ジョブの送信から作成したジョブを選択して実行します。結果は CloudWatch Log で確認できます。
- 引数、環境変数が出力されていることを確認できます。


- 投稿日:2020-09-13T22:39:40+09:00
EC2作成直後の状態から最速でVue.js(CDN版)のWebサイトを立ち上げる
はじめに
超・初心者向けシリーズ。
とりあえずVue.js始めてみたいけどどんな感じでやってみたらいいの?な人向け。以下の通りに実行していけば、S3の静的Webサイトホスティング上でVue.jsのHello Worldが動く。
手順
1. yumのアップデート
$ sudo yum update2. Node.jsのインストール(npmがNode.jsに含まれる)
Vue.jsの静的解析はESLintという強力なlinterがあるので、それを動かすためにnpmを入れておく。
Node.jsについては、予め、rpm.nodesource.com でサポートバージョンを確認しておく。今回は、記事を書いたタイミングでサポートされている14をインストールする。
$ curl -sL https://rpm.nodesource.com/setup_14.x | sudo bash - $ sudo yum install -y nodejs3. ESLintのインストール
なんか色々インストールしているが、「とりあえずこれを静的解析に入れておけばかなり良い感じにチェックしてくれる」なものを入れている。
$ npm init -y $ npm install --save-dev eslint eslint-config-standard eslint-plugin-standard eslint-plugin-import eslint-plugin-node eslint-plugin-promise eslint-plugin-vue4. ESLintの設定ファイル(.eslintrc.yml)の作成
rulesの
no-undef: warnは今回の記事では不要だが、CDN版でaxiosを動かそうとするとエラーが出てしまうので…….eslintrc.ymlextends: - 'plugin:vue/recommended' - 'plugin:vue/essential' - 'standard' env: browser: true rules: no-undef: warn globals: Vue: true5. ESLint実行の設定
ESLintの実行はそのままだと面倒なので、
npm run lintで実行できるようにしておく。
npm init -yした時に作成される package.json の以下の部分を書き加えるpackage.json(前略) "scripts": { "test": "echo \"Error: no test specified\" && exit 1" ★この行を消して "lint": "eslint contents/*.js contents/*.html" ★この行を書き加える }, (以下略)6. おためしコンテンツを作成
contents/index.html<html> <head> <meta charset="utf-8"> <title>Vue TEST</title> </head> <body> <div id="app"> {{ message }} </div> <script src="https://cdn.jsdelivr.net/npm/vue"></script> <script src="/app.js"></script> </body> </html>contents/app.jsconst app = new Vue({ el: '#app', data: { message: 'Hello World!!' } }) app.$mount('#app')7. S3バケットを作成
…の前にコンフィグ設定
$ aws configure AWS Access Key ID [None]: xxxxxxxxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]: json今度こそバケットを作成
$ aws s3 mb s3://neruneruo-vuejs-test-bucket $ aws s3 ls静的Webサイトホスティングの設定
$ aws s3 website s3://neruneruo-vuejs-test-bucket --index-document index.htmlファイルをアップロード
$ aws s3 cp contents/index.html s3://neruneruo-vuejs-test-bucket/index.html --acl public-read $ aws s3 cp contents/app.js s3://neruneruo-vuejs-test-bucket/app.js --acl public-readこれで、静的WebサイトホスティングのURLにアクセスしたら「Hello World!!」が表示されたはずだ。
あとは、ガンガン
npm run lintしながら Vue.js の世界を堪能しよう!
- 投稿日:2020-09-13T19:51:26+09:00
【初心者向け】AWS学習前の知っておくべきネットワーク用語について
はじめに
ポートフォリオをAWSにデプロイするために、AWSサーバー構築を勉強し始めましたが、基本的なネットワーク知識が必要だと感じたので、ネットワーク用語についてまとめました。
参考にしました→キタミ式基本情報
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版用語解説
プロトコル
ネットワークを通じてコンピューター同士がやり取りするための約束事のこと。プロトコルには様々な種類があり、情報を送り出す端末の選定、データの形式、パケットの構成、エラーの対処などを取り決めた通信、などが決まっている。それらを7階層に分けたOSI(Open Systems Interconnection)基本参照モデルというモデルがある。
OSI参照モデル
階層 階層名 役割 第7層 アプリケーション層 具体的にどんなサービスを提供するか 第6層 プレゼンテーション層 データはどんな形式にするか 第5層 セッション層 通信の開始から終了までどう管理するか 第4層 トランスポート層 通信の信頼性はどう確保するか 第3層 ネットワーク層 ネットワークとネットワークをどう中継するか 第2層 データリンク層 同一のネットワーク内でどう通信するか 第1層 物理層 物理的にどうつなぐか(例えばLANケーブル) ゲートウェイ
トランスポート層(第4層)以上が異なるネットワーク間で、プロトコル変換による中継機能を提供する装置。ネットワーク双方で使っているプロトコルの差をこの装置が変換、吸収することで、お互いの接続を可能にしている。
IP(Internet Protocol)
ネットワーク層のプロトコル。経路制御を行いネットワークからネットワークへとパケットを運んで相手に送り届ける。IPによって構成されるネットワークは、コンピュータやネットワーク機器などを識別するためにIPアドレス(後述)という番号を割り当てて管理する。
TCP(Transmission Control Protocol)
トランスポート層のプロトコル。通信相手とのコネクションを確立してから、データを送受信するコネクション型の通信プロトコル。パケットの順序や送信エラー時の再送などを制御して、送受信するデータの信頼性を保証する。
UDP(User Datagram Protocol)
トランスポート層のプロトコル。事前に送信相手と接続確認を取ったりせず、一方的にパケットを送りつけるコネクションレス型の通信プロトコル。パケットの再制御などを一切行わないため信頼性に欠けますが、その分高速になる。
IPアドレス
ネットワーク上で互いに重複しない唯一無二の番号で、いわゆる「住所」のようなもの。1998年10月に米国で設立された民間の非営利法人ICANNで一括管理している。IPアドレスは、32ビットで構成されており、「192.168.1.3」のように、8ビットずつ10進法に変換したものを「.」(ピリオド)で区切って表記する。つまりIPアドレスは「0.0.0.0」〜「255.255.255.255」までとなる。
IPアドレスには「パブリックIPアドレス」と「プライベートIPアドレス」の2種類が存在する。・パブリックIPアドレス
インターネットに接続する際に用いるIPアドレスのこと。プロバイダーやサーバー事業者から貸し出される。
・プライベートIPアドレス
インターネットで使われないIPアドレス。主な用途として社内LANを構築するときや、ネットワークの実験をする際に用いる。
IPアドレスの範囲が決まっている。
IPアドレス範囲 10.0.0.0〜10.255.255.255 172.16.0.0〜172.31.255.255 192.168.0.0〜192.168.255.255
また、IPアドレスは「ネットワーク部」と「ホスト部」に分かれている・ネットワーク部
どのネットワークかを示すアドレス。
・ホスト部
どのパソコンかを示すアドレス。
まとめ
まだまだ知らなければいけない知識はありそうですが、この辺で。学習する上で必要だと思う用語が出てきたら随時更新していきます。
ネットワークについて、理解しづらい部分が多いですね。ネットワークを理解せずにAWSに取り掛かると、「この通信ってなんの通信だっけ?」となって、応用がきかなくなりそうです。あとインターネットに接続する際、セキュリティの知識も必要になると感じました。


- 投稿日:2020-09-13T19:25:17+09:00
AWS Elastic Beanstalkとは
AWS Elastic Beanstalk についてよく分からなかったので理解を深めるためにまとめます。
Elastic Beanstalkとは
Amazon Web Services (AWS) はめっちゃたくさんの機能があって逆に使いこなせんという初心者の方がすごい多いと思います。実際僕もそうです。
公式のドキュメントによると、、、よくわからん。。笑
要するにAWSにはインフラ系のたくさんの機能があるけど(容量のプロビジョニング、負荷分散、拡張、およびアプリケーションの状態のモニタリング等、、、)こういうのってせっかく早くアプリをリリースしたいのに、ここらへんで問題起きちゃうと大変だし、インフラの深い知識も必要になるからまるっと管理できる機能がほしいよ−って事ででてきたのがElastic Beanstalkという訳だと思います。また、一連の Amazon EC2 インスタンスのサイズの変更、アプリケーションのモニタリングなど、ほとんどのデプロイタスクを Elastic Beanstalk ウェブインターフェイス (コンソール) から直接実行できるみたい。。すごいですね。
Elastic Beanstalk を使用するには、アプリケーションを作成し、アプリケーションソースバンドル (Java .war ファイルなど) の形式でアプリケーションバージョンを Elastic Beanstalk にアップロードした後、アプリケーションに関する情報を提供します。Elastic Beanstalk によって自動的に環境が起動され、コードの実行に必要な AWS リソースが作成および構成されます。環境が起動した後は、環境を管理し、新しいアプリケーションバージョンをデプロイできます。
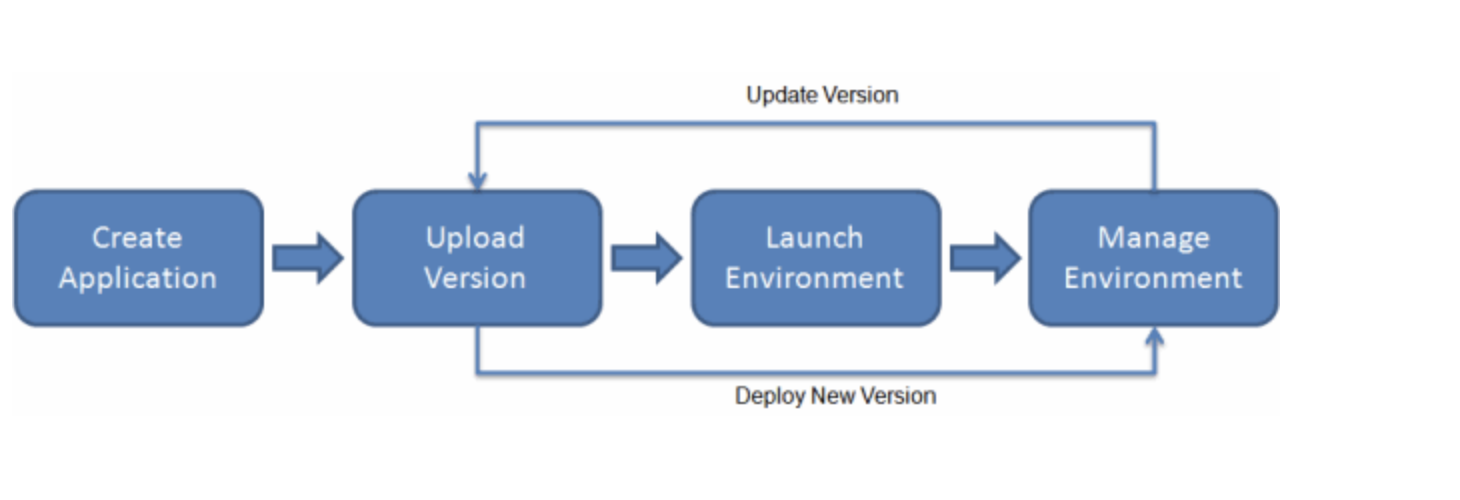
Elastic Beanstalk のワークフロー
どうやって利用するのか、、、。
アプリケーションを作成してデプロイした後、アプリケーションに関する情報をElastic Beanstalk コンソール、API、コマンドラインインターフェイス(統合された AWS CLI など)を介して利用できるみたい。
しかもElastic Beanstalk使用量自体は無料!!アプリケーションが使用する基になる AWS リソースに対してのみ支払うだけらしい。
概念
AWS Elastic Beanstalk では、アプリケーションを環境として実行するリソースをすべて管理できますとのこと。Elastic Beanstalk の主要な概念はこれらです。
アプリケーション
Elastic Beanstalk アプリケーションは概念的にはフォルダと似ています。この中に環境、バージョン、環境設定等の部品が入っているということですね。
アプリケーションバージョン
アプリケーションバージョンとは要するに、設計・開発・テスト・改善の一連の工程を短期間で繰り返す、イテレーションというアジャイルの開発サイクルの中で、デプロイ可能のコードをS3データとしてまとめたもの。アプリケーションバージョンはアプリケーションの一部であり、多数のバージョンを持つことができる、また各アプリケーションバージョンは一意です。
実行中の環境では、アプリケーションに既にアップロードしてあるアプリケーションバージョンをデプロイしたり、新しいアプリケーションバージョンをアップロードしてすぐにデプロイしたりできます。複数のアプリケーションバージョンをアップロードして、ウェブアプリケーションのバージョン間の違いをテストすることもできます。環境
環境は、アプリケーションバージョンを実行する AWS リソースのコレクションです。各環境が実行するのは一度に 1 つのアプリケーションバージョンだけですが、同じアプリケーションバージョンや複数の異なるアプリケーションバージョンを多数の環境で同時に実行できます。環境を作成するときは、指定したアプリケーションバージョンを実行するために必要なリソースを Elastic Beanstalk がプロビジョニングします。これはすごい。。
環境枠
Elastic Beanstalk 環境を起動したら、まず環境枠を選択します。環境枠は環境で実行するアプリケーションのタイプを指定し、それをサポートするために Elastic Beanstalk でプロビジョニングするリソースを決定します。HTTP リクエストを処理するアプリケーションは、ウェブサーバー環境枠で実行されます。Amazon Simple Queue Service (Amazon SQS) キューからタスクを引き出す環境は、ワーカー環境枠で実行されます。
環境設定
環境設定は、環境とその環境に関連付けられているリソースの動作を定義するパラメータと設定のコレクションを識別します。環境の設定を更新すると、変更の種類に応じて、Elastic Beanstalk は自動的に既存のリソースに変更を適用するか、既存のリソースを削除して新しいリソースをデプロイします。
保存された設定
保存された設定 は、一意の環境設定を作成するための開始点として使用できるテンプレートです。設定を作成するか、保存された設定を変更し、Elastic Beanstalk コンソール、EB CLI、AWS CLI、または API を使用して環境に適用できます。API および AWS CLIは、保存された設定を 設定テンプレートとして参照します。
プラットフォーム
プラットフォームは、オペレーティングシステム、プログラミング言語ランタイム、ウェブサーバー、アプリケーションサーバー、および Elastic Beanstalk コンポーネントの組み合わせです。ウェブアプリケーションはプラットフォームを対象にして設計します。Elastic Beanstalk には、アプリケーションを構築できるさまざまなプラットフォームが用意されています。
- 投稿日:2020-09-13T17:51:38+09:00
AWS基礎 7つのベストプラクティスとVPC・サブネットについて
自分用のメモです。
AWS基礎
7つのベストプラクティス
①「故障に備えた設計で障害を回避」
障害時でもシステムが停止しないように、システムの機能を分散する。②「コンポーネント間を疎結合で柔軟に」
_コンポーネント(構成要素)を緩やかに結び付けて柔軟に
管理しやすいように分ける。③「伸縮自在性を実装」
_使いたい分だけ、追加したり減らしたりする事ができる。④「すべての層でセキュリティを強化」
_ネットワークからアプリケーションまでOSI参照モデルの全ての層でセキュリティを意識することが大切。⑤「制約を恐れない」
_クラウドの利点を活用してシステム構築および運用する。⑥「処理の並列化を考慮」
_別の処理を同時進行させ効率的な処理をする。⑦「さまざまなストレージの選択肢を活用」
_優れた設計のシステムでは、複数のストレージソリューションを使用し、さまざまな機能を有効にしてパフォーマンスとリソースの使用効率を高めています。◆VPCとは?
仮想ネットワークサービスの事。
AWS内のネットワーク環境(セキュリティ面の設定も含まれる)VPCはAZを跨げるが、リージョンは跨げない(国をまたいで作れないって感じ)
・リージョン=国、利用できる地域
・AZ=(アベイラビリティーゾーン)データセンターAZを1つのリージョンに複数作成することで、壊れても他のデータセンターが稼働できる。
◆サブネット
大きなネットワークを複数の小さなネットワークに分割管理しセキュリティレベルを高めるという考え方。
サブネットはAZを跨ぐことが出来ない、つまり一つのAZを選択して作成する。VPCやサブネットにはIPアドレスの範囲を割り当てて使用。
◆CIDR表記とサブネットマスク表記
「192.168.1.0〜192.168.1.255」や「192.168.0.0〜192.168.255.255」といった表現は長いため、通常IPアドレス範囲を示す時には、「CIDR表記(サイダー)」もしくは「サブネットマスク表記」のいずれかの表記を用いる。IPアドレスの最大表記
0.0.0.0/0 → 全てのIPアドレス
10.21.59.223/32 → 10.21.59.223 (1つのみ)
10.21.59.223/24 → 10.21.59.* (256個)
10.21.59.223/16 → 10.21. *. * (65536個)/24で割り切れるIPの数は256個 /1減る毎に割り切れるIPは倍になっていく/23は512個 /22は1024個…
※VPCのアドレスレンジ帯は/16〜/28の範囲で作る
範囲を超えるとエラーになる。◆パブリックIPアドレス
インターネットに接続する際に用いるIPアドレスのこと。 パブリックIPアドレスは、プロバイダーやサーバー事業者から貸し出しされる。◆プライベートIPアドレス
インターネットで使われないIPアドレス。 プライベートIPアドレスは、誰にも申請することなく自由に使える。社内LANを構築するようなときなど、このIPアドレスを用いるようにする。基礎_2
AWSチャンネル参照
- 投稿日:2020-09-13T17:31:21+09:00
【AWS】リザーブドインスタンスの見積りに失敗した件
はじめに
クラウドインフラについて勉強中です。
Amazon EC2の見積りを作成していたところ、リザーブドインスタンスの理解を正しくできておらず誤った算出をしてしまったので、備忘の意味も込めて内容を記しておきます。※初投稿です。
今後クラウドインフラについてアウトプットを増やしていきたいと思っています。
気になる部分があれば何でもご指摘いただけると喜びます!失敗した内容
失敗した内容としては、「1年契約する」ことで、「利用した時間×利用費」に対して割引が適用されると理解してしまってました。
例えば、月々500時間稼働した場合、リザーブド料金×500=月々の利用費用となるというイメージでした。正しい理解
正しくは、「1年契約する」ことで、対象のインスタンスを「1年間フル稼働」した場合にかかる費用から大幅に割引される、というものでした。
つまり、月々500時間の稼働であったとしても、フル稼働分の744時間分の費用がかかる。
ただし、掛ける対象がオンデマンド料金より格段に安いリザーブド料金となる。
なので、対象のサーバが契約期間内で6,7割の時間で稼働し続けるなら、リザーブドインスタンスを適用したほうがお得ですよ、という話。参考情報
>リザーブドインスタンス では、実際の使用に関係なく、全期間の料金をお支払いいただきます。
参考:課金の仕組み
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/concepts-reserved-instances-application.html
- 投稿日:2020-09-13T15:03:43+09:00
create_dynamic_frame_from_optionsでデータベーステーブルの特定列のみを取得したい
AWS Glueで、create_dynamic_frame_from_optionsを使ってAurora(MySQL互換)の各テーブルのDynamicFrameを作成し、write_dynamic_frame_from_optionsでパーティション分割したParquetフォーマットのファイルとしてS3に吐き出すだけの簡単なJobを動かしていたんですが、ある大きめなテーブル(数百万行、かつ、TEXT型フィールドが複数含まれる)だけで2時間以上かかったり、メモリ不足で処理が完了しなくなってました。
おそらく、不要なTEXT型フィールドを取り除いてしまえば必要とするメモリも少なくてすみ、処理も早くなるだろうと思ったんですが、オプションを眺めても取得するカラムを指定できそうなものがない。そこで、必要なカラムのみを指定したVIEWをAuroraのDBに作成し、GlueのJobはテーブルの代わりにVIEWを使用してDynamicFrameを作成、ファイルに出力することで数分で終わるようになりました。
ということで、同じようなケースで困っている方はVIEW作るのおすすめです。
ただ、push_down_predicateで取得する行はフィルタリングできるので、なにか別の方法でもっと簡単にできるのではないかという気もしています。
- 投稿日:2020-09-13T10:41:25+09:00
DynamoDBテーブルを少なくするためにテーブルを統合する設計方法
はじめに
こんにちは!
最近仕事でDynamoDBの設計について議論をしているとき、「DynamoDBのテーブルは一つだけにすることがベストプラクティス」というのが少し盛り上がりました。スキーマレスなDynamoDBならではの議論で面白いですね。実は私が前職で開発をしていた時にこれに近いことを実践していて、なるべくDynamoDBのテーブルは少なくなるような設計を行っていました。この記事はその手法を共有したいと思います。
本記事の対象読者
- DynamoDBを使ったことがある方
- ハッシュキー、レンジキー、LSI、GSIがどういうものか何となく理解できている方
なぜDynamoDBのテーブルは少ないほうが良いのか?
ひと昔前はAWSのDynamoDB開発者ガイドに
DynamoDB アプリケーションではできるだけ少ないテーブルを維持する必要があります。設計が優れたアプリケーションでは、必要なテーブルは 1 つのみです。
と書かれていました。必要なテーブルは 1 つのみ、というのはなかなか衝撃的な言葉です。
しかし、最新のものを見ると記述が少し変わり、一般的なルールとして、DynamoDB アプリケーションはできるだけ少ないテーブルを維持する必要があります。
となっています。テーブルはなるべく少なくすべきだという表現に緩められています。
なぜテーブルは少ないほうが良いのでしょうか?
調べて分かったことや個人的な意見を加えると、以下がメリットとして挙げられると思います。
- キャパシティ管理の効率化
- テーブルがたくさんあると、キャパシティのチューニングもテーブルの数だけ行うことになり、管理が大変
- テーブルを少なくすることで、キャパシティを合計で考えることができ、シンプルになる
- テーブル数の上限超過の抑制
- 大規模なシステムになると上限を超えてしまう恐れがある
- たとえば一つのアカウントで複数のサービスを運用している場合
では、テーブルを少なくすることによるデメリットはあるのでしょうか?
個人的にあまりないと考えますが、挙げるとすれば以下になると思います。
- テーブルのインデックス設計などがテンプレート見ただけだとわかりづらいため、別途補助的なドキュメントが必要
- アクセスが集中する
デメリットを挙げてはみましたが、ドキュメントは結局のところテーブルの数に関係なく用意すべきだと思いますし、アクセスが集中する件はパーティションキーをちゃんと設計すれば回避できることなので大きな問題ではないと感じます。
ということで、テーブルの数は少ないほうがメリットがありそうです。
もちろんシステムの特性によってはそうではない場合もあると思いますので、絶対ではありません。テーブルを統合する設計方法
テーブルを少なくするためには、複数のテーブルを一つに統合していくというアプローチが一般的だと思います。今回はこの設計手法を説明します。
具体的な話に入る前に、複数のテーブルを一つに統合した後に最低限満たされていないといけない要件をまずは書き出してみます。以下の二つになるかと思います。
- クエリ結果に、複数の統合前テーブルのデータが混在しないこと
- 例えば、AとBというテーブルを統合したテーブルでAのデータを取得する目的でクエリを実行したときに、必ずAの情報のみが取得されること
- あとから別の物理テーブルを簡単に統合できること
ではテーブルを一つに統合していくには実際にどうしたらよいかを例を交えながら説明したいと思います。
ここからはDynamoDBで作成するテーブルを物理テーブルと呼びます。以下の二つの物理テーブルがあるとします。
UserTableがシステムに登録しているユーザの情報、そのシステムでユーザが登録した何かしらの計画情報がPlanTableだと考えてください。UserTable
キータイプ 属性名 Hash userId Range birthDate GSIweight Hash status GSIweight Range createdAt
属性名 型 userId string birthDate string userName string weight string height string status string createdAt string PlanTable
キータイプ/インデックス名 属性名 Hash planId Range startDate LSI Range createdAt GSIStatus Hash status GSIStatus Range endDate GSIUser Hash userId GSIUser Range startDate
属性名 型 planId string startDate string endDate string planName string createdAt string description string status string userId string これらの物理テーブルを一つの物理テーブル
DynamoMonoTableに統合します。これを実現する方法を言葉で先に述べてしまうと、もともと物理テーブルとして存在した
UserTableとPlanTableをDynamoMonoTable内で論理的に分割された論理テーブルとして登録します。論理的に分割されているというのは、キーやインデックスでクエリをかけたときに複数の論理テーブルの情報が混在せず取得できるようになっていることを指します。
これが達成できれば前述の統合後のテーブル要件の1がクリアできます。また受け皿となる
DynamoMonoTableがどんな論理テーブルも登録できるように汎用的な設計にします。
これが達成できれば前述の統合後のテーブル要件の2がクリアできます。以降、統合されるテーブルを統合元テーブル、受け皿となるテーブルを統合先テーブルと呼びます。
統合先テーブルの各キー・インデックスに設定する属性名を汎用的な名前にする
統合先テーブル(
DynamoMonoTable)の各キー・インデックスに設定する属性名を汎用的な名前にしていきます。
インデックスに設定する属性名を汎用的な名前にしたのが以下です。DynamoMonoTable
キー名・インデックス名 属性名 Hash HASH Range RANGE LSI RANGE LSIRANGE GSI0 HASH GSI0HASH GSI0 RANGE GSI0RANGE GSI1 HASH GSI1HASH GSI1 RANGE GSI1RANGE GSI2 HASH GSI2HASH GSI2 RANGE GSI2RANGE GSIの名前は0からインクリメントしています。判別できればなんでもよいと思います。
LSIのHashキーはテーブルのHashキーを設定する制約があるため、記載を省いています。CloudFormationのテンプレートにしたのが以下になります。
dynamodb.ymlResources: DynamoMonoTable: Type: AWS::DynamoDB::Table Properties: TableName: DynamoMonoTable-${self:provider.stage} AttributeDefinitions: - AttributeName: HASH AttributeType: S - AttributeName: RANGE AttributeType: S - AttributeName: LSIRANGE AttributeType: S - AttributeName: GSI0HASH AttributeType: S - AttributeName: GSI0RANGE AttributeType: S - AttributeName: GSI1HASH AttributeType: S - AttributeName: GSI1RANGE AttributeType: S - AttributeName: GSI2HASH AttributeType: S - AttributeName: GSI2RANGE AttributeType: S KeySchema: - AttributeName: HASH KeyType: HASH - AttributeName: RANGE KeyType: RANGE LocalSecondaryIndexes: - IndexName: LSI KeySchema: - AttributeName: HASH KeyType: HASH - AttributeName: LSIRANGE KeyType: RANGE Projection: ProjectionType: ALL GlobalSecondaryIndexes: - IndexName: GSI0 KeySchema: - AttributeName: GSI0HASH KeyType: HASH - AttributeName: GSI0RANGE KeyType: RANGE Projection: ProjectionType: ALL - IndexName: GSI1 KeySchema: - AttributeName: GSI1HASH KeyType: HASH - AttributeName: GSI1RANGE KeyType: RANGE Projection: ProjectionType: ALL - IndexName: GSI2 KeySchema: - AttributeName: GSI2HASH KeyType: HASH - AttributeName: GSI2RANGE KeyType: RANGE Projection: ProjectionType: ALL BillingMode: PAY_PER_REQUESTこのようにキー名・インデックス名を汎用的にしておけば、どんな値が入ってきても対応できます。つまり、あとから別のテーブルを統合しようとしても簡単に統合することができます。これで前述の統合後のテーブル要件の2がクリアできました。
ここで試しにこのテーブル定義に先ほどの
UserTable、PlanTableを当てはめてみたいと思います。
当てはめてみると例えば以下のような中身になると思います。UserTableSample{ "HASH": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9",//userId "RANGE": "2000-01-01",//birthDate "GSI0HASH": "expired",//status "GSI0RANGE": "2020-08-01",//createdAt "userId": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9", "birthDate": "2000-01-01", "userName": "taro", "weight": "70", "height": "180", "status": "expired", "createdAt": "2020-08-01" } { "HASH": "67b09448-64e9-4ec0-be71-226f95022d28",//userId "RANGE": "2000-02-01",//birthDate "GSI0HASH": "active",//status "GSI0RANGE": "2019-07-11",//createdAt "userId": "67b09448-64e9-4ec0-be71-226f95022d28", "birthDate": "2000-02-01", "userName": "jiro", "weight": "80", "height": "170", "status": "active", "createdAt": "2019-07-11" }PlanTableSample{ "HASH": "9def6275-3903-4382-99cd-3bad452e13e9",//planId "RANGE": "2000-01-01",//startDate "LSIRANGE": "1999-12-24",//createdAt "GSI0HASH": "complete",//status "GSI0RANGE": "2020-02-01",//endDate "GSI1HASH": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9",//userId "GSI1RANGE": "2000-01-01",//startDate "planId": "9def6275-3903-4382-99cd-3bad452e13e9", "startDate": "2000-01-01", "endDate": "2020-02-01", "planName": "birthDay", "createdAt": "1999-12-24", "description": "birthDay plan", "status": "complete", "userId": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9" } { "HASH": "0579e467-930f-4872-9b7d-92313b71231d",//planId "RANGE": "2020-01-01",//startDate "LSIRANGE": "2019-12-24",//createdAt "GSI0HASH": "active",//status "GSI0RANGE": "2020-12-01",//endDate "GSI1HASH": "67b09448-64e9-4ec0-be71-226f95022d28",//userId "GSI1RANGE": "2020-01-01",//startDate "planId": "0579e467-930f-4872-9b7d-92313b71231d", "startDate": "2020-01-01", "endDate": "2020-02-01", "planName": "xxproject", "createdAt": "2019-12-24", "description": "xxproject plan", "status": "active", "userId": "67b09448-64e9-4ec0-be71-226f95022d28" }上記のレコードを
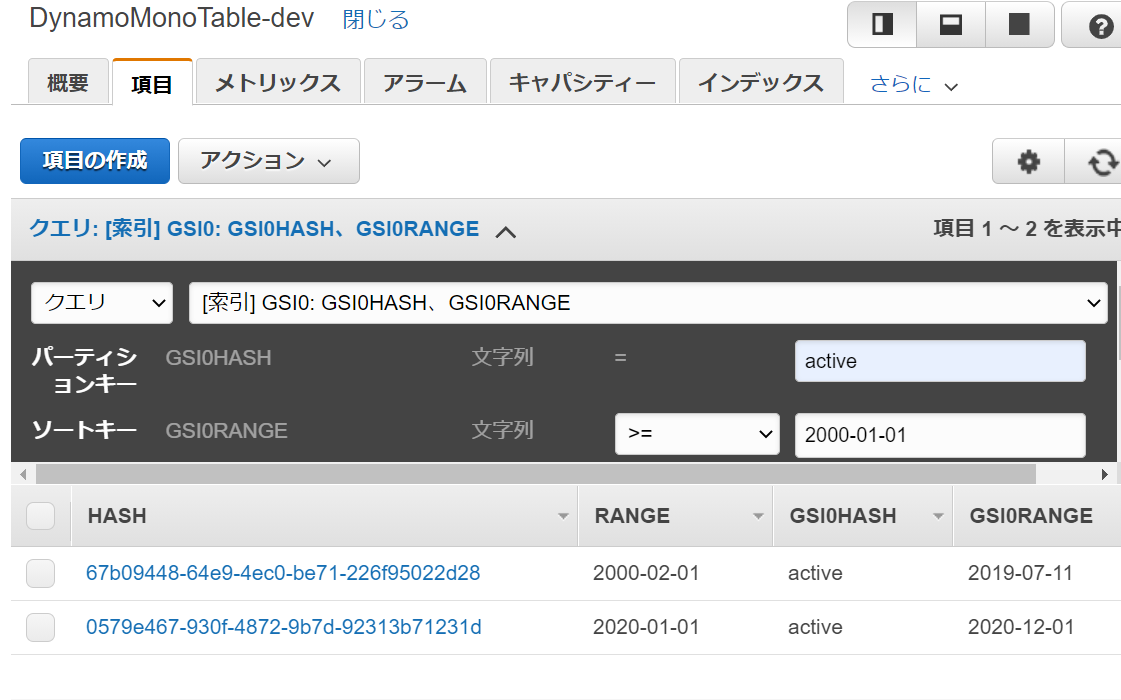
DynamoMonoTableに登録して、PlanTableにあるデータを取得しようとGSI0 HASH = active、GSI0 Range >= 2000-01-01の条件でクエリをかけてみました。
このように
UserTableのレコードも混じって取得されてしまいました。
このケースではPlanTableのGSI0とGSI1を入れ替えれば解決しますが、さらに別のテーブルを統合しようと思ったときにいちいち細かい調整をしていてはいつか首が回らなくなります。そもそもGSIは一つのテーブルに5つしか設定できないので、どう考えても限界があります。
この状態では前述の統合後のテーブル要件の1がクリアできているとは言えません。それでは肝となる論理テーブルへの分割をしていきます。
論理テーブル名を決める
統合元物理テーブル(
UserTable、PlanTable)の論理テーブル名を決めます。
識別できればなんでもいいのですが、ここではそれぞれの頭文字をとって、UserTableをUST、PlanTableをPLTとしたいと思います。各キー・インデックスを論理テーブル名と連結したものに変更する
論理テーブル単位でデータをとってくるために、統合元物理テーブルの各キー・インデックスを論理テーブル名と連結したものに変更していきます。
ポイントは以下の二つです。
- 他の論理テーブルと区別できるようにしたいキーやインデックスに論理テーブル名を連結する
- 必ず論理テーブル単位で全取得するインデックスを用意する
例えばHASHのuserIdやplanIdはuuidなので一意であることは確率的に保証されています。こういう場合は論理テーブル名を連結しなくてOKです(念のために連結しても問題ありません)。逆に先ほどのGSI0のケースではGSI0HASHで一意に定まらなかったので論理テーブル名を連結する必要があります。
論理テーブ単位で全取得するインデックスがなぜ必要かというと、テーブルを全取得して削除なりバッチ処理をする際に必要だからです。設計当初にそういった要件がなくても、あとあと必要になることが多いので、作っておいたほうが無難です。以上のポイントを踏まえ、先ほどjson形式でお見せしたデータ例を変更したのが以下になります。
LogicalUserTableSample{ "HASH": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9",//userId "RANGE": "2000-01-01",//birthDate "GSI0HASH": "UST",//全取得用。Rangeは不要 "GSI1HASH": "UST|expired",//論理テーブル名とstatusを連結 "GSI1RANGE": "2020-08-01",//createdAt "userId": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9", "birthDate": "2000-01-01", "userName": "taro", "weight": "70", "height": "180", "status": "expired", "createdAt": "2020-08-01" } { "HASH": "67b09448-64e9-4ec0-be71-226f95022d28",//userId "RANGE": "2000-02-01",//birthDate "GSI0HASH": "UST",//全取得用。Rangeは不要 "GSI1HASH": "UST|active",//論理テーブル名とstatusを連結 "GSI1RANGE": "2019-07-11",//createdAt "userId": "67b09448-64e9-4ec0-be71-226f95022d28", "birthDate": "2000-02-01", "userName": "jiro", "weight": "80", "height": "170", "status": "active", "createdAt": "2019-07-11" }LogicalPlanTableSample{ "HASH": "9def6275-3903-4382-99cd-3bad452e13e9",//planId "RANGE": "2000-01-01",//startDate "LSIRANGE": "1999-12-24",//createdAt "GSI0HASH": "PLT",//全取得用。Rangeは不要 "GSI1HASH": "PLT|complete",//論理テーブル名とstatusを連結 "GSI1RANGE": "2020-02-01",//endDate "GSI2HASH": "PLT|cb823d42-28c8-4a3a-81c9-4513b8cdaeb9",//論理テーブル名とuserIdを連結 "GSI2RANGE": "2000-01-01",//startDate "planId": "9def6275-3903-4382-99cd-3bad452e13e9", "startDate": "2000-01-01", "endDate": "2020-02-01", "planName": "birthDay", "createdAt": "1999-12-24", "description": "birthDay plan", "status": "complete", "userId": "cb823d42-28c8-4a3a-81c9-4513b8cdaeb9" } { "HASH": "0579e467-930f-4872-9b7d-92313b71231d",//planId "RANGE": "2020-01-01",//startDate "LSIRANGE": "2019-12-24",//createdAt "GSI0HASH": "PLT",//全取得用。Rangeは不要 "GSI1HASH": "PLT|active",//論理テーブル名とstatusを連結 "GSI1RANGE": "2020-12-01",//endDate "GSI2HASH": "PLT|67b09448-64e9-4ec0-be71-226f95022d28",//論理テーブル名とuserIdを連結 "GSI2RANGE": "2020-01-01",//startDate "planId": "0579e467-930f-4872-9b7d-92313b71231d", "startDate": "2020-01-01", "endDate": "2020-02-01", "planName": "xxproject", "createdAt": "2019-12-24", "description": "xxproject plan", "status": "active", "userId": "67b09448-64e9-4ec0-be71-226f95022d28" }これを
DynamoMonoTableに登録し、先ほどと同じくPlanTableのデータを取るべくGSI1でクエリをかけてみます。
GSI1 HASHが
PLT|activeとなるので、必ずPlanTableのデータだけを取得できるようになります。論理テーブルに分割することができました。
これで前述の統合後のテーブル要件の1がクリアできました。本設計手法を適用するときに気を付けること
今回ご紹介した設計手法を適用するにあたって気を付けるべき点を述べます。
テンプレートを見ただけではキー・インデックスの属性名がわからなくなる
テーブルを統合する前はDynamoDBのテンプレートを見ればどのキー・インデックスにどの属性を指定しているか一目でわかりましたが、統合した場合はテーブルのテンプレートを見てもどんな属性が入るかがわかりません。別途論理テーブルのスキーマをまとめたドキュメントが必要になります。
アクセスが一つのテーブルに集中する
この設計手法固有の問題ではありませんが、テーブルを統合したことによりアクセスが一つのテーブルに集中します。しっかり分散するように、より気を付けてHASHキーを選定する必要があります。
アプリ側のロジックが少し複雑になる
DynamoDBへのCRUDを行うときに論理テーブル名を連結する必要があります。逆にパースする場面もあるかもしれません。そういった処理を行うutility関数の実装が必要になると思います。
おわりに
今回はDynamoDBのテーブルはなるべく少ないほうが良い、という考えのもと、複数のテーブルを一つに統合していく手法を説明しました。
この方法はいくつかある手段の一つに過ぎないと思います。またシステムによってはマッチしない設計手法だとも思います。
ですが比較的広く適用できる設計手法だと思いますので、少しでも皆様の参考になれば幸いです。今回お見せしたテンプレートやサンプルデータは以下のGithubに置いておきましたので、よろしければ参考にしてください。

- 投稿日:2020-09-13T10:10:12+09:00
AWS EC2 EC2 Instance (Amazon Linux AMI)の作成
はじめに
今回は、AWS EC2を使用して、無料でできる範囲のLinuxサーバーを建ててみようと思います。
無料でできる範囲で実施しようと思いましたが、私の場合AWSアカウントを持って1年以上経過しているため、無理なようです。
ですので、実施したことをメモとして残します。今回実施する内容
AWS EC2を使用して、Amazon Linux AMI2を使用したLinuxサーバーを建てます。
参考
Tutorial: Getting started with Amazon EC2 Linux instances
AmazonのEC2 Linuxのインスタンス作成に関する説明です。
これに従いながら実施します。「Amazon EC2 インスタンスタイプ」
インスタンスタイプの説明です。用語
AWS EC2とは
AWSの説明
AmazonのEC2のページによれば、以下のことが最初に記載されています。
Amazon Elastic Compute Cloud (Amazon EC2) は、安全でサイズ変更可能なコンピューティング性能をクラウド内で提供するウェブサービスです。ウェブスケールのクラウドコンピューティングを開発者が簡単に利用できるよう設計されています。Amazon EC2 のシンプルなウェブサービスインターフェイスによって、手間をかけず、必要な機能を取得および設定できます。お客様のコンピューティングリソースに対して、高機能なコントロールが提供され、Amazon の実績あるインフラストラクチャ上で実行できます。
何のことかよくわからないですが、仮想サーバーなのかなと思います。
AWS EC2の料金
料金については、AWSのページに説明がありますが、なかなかわかりづらいですね。色々とネットに情報がありますし、それでもわからない。
で、オンデマンドの時のAWS EC2の料金は、ざっと以下のようなものかと思います。
- Instance起動時間
- DLデータ転送量
Elastic IPアドレスを使うなら、
- Elastic IPアドレス使用時間(Instance未起動時のみ)
Instance起動時間は、初期は1分間の課金がかかった後、その後、時間、もしくは秒単位でかかります。
DLデータ転送料金は、t2.microで0.0136USD/時間くらいです。リージョンが東京の場合です。
DLデータ転送量は、1GBまでは無料で、それ以降9.999TBまでは0.114 USD/月かかります。さらにそれ以降はもう少し安くなりますが、設定はされています。Elastic IPアドレスは、IPアドレスを固定するためのもので、これを使用しないとInstanceを停止でIPアドレスは解放され、開始すると別のIPアドレスに変わります。
0.005USD/時間です。なかなかわかりづらい料金体系です。
Instanceを一日起動:0.0136USD×24=0.3264USD
1か月(31日):0.3264USD×31=10.1184USD
データ転送量はどれだけ使うかに依存するため難しいですね。
Elastic IPアドレスは、Instance停止時にかかるため、上記のように起動しっぱなしであればかからない。
起動中のコストが0.0136USDで、停止中が0.005USDドルなため、停止できるのであれば停止しておいたほうが安いのは間違いありません。AWS EC2の概要
AWS EC2 Instanceの作成
それでは、Tutorial: Getting started with Amazon EC2 Linux instancesに従って、順にInstanceの作成を行います。
1. AWS EC2画面へ
まずは、AWSへログインします。それからサービスでEC2を選びます。
ここまでは基本なので、説明しません。
EC2の画面上で、左のメニューの「インスタンス」を押下すると以下のような画面になるため、ここで、「Instanceの作成」ボタンを押します。
2. Amazon AMIの選択
続いてAmazon AMI(Amazon Machine Image)の選択です。
40個くらいのAMIが用意されているようです。
要するに、どういうOSを選択するかということだと思いますが、今回は無料で実施したいため、左側の「無料利用枠のみ」を選択すると、18個に絞られました。
「Amazon Linux AMI2」、「Amazon Linux AMI」、「Microsoft Windows Server 2019 Base」、「Red Hat」など色々あるようですが、今回は、「Amazon Linux AMI2」を使用します。
どれがいいかは用途によるのでしょうが、「Amazon Linux AMI」については、サポートが2020/12/31でいったん切れるようですので、「Amazon Linux AMI」を使おうと思うならば、「Amazon Linux AMI2」にしておいたほうが無難かと思います。
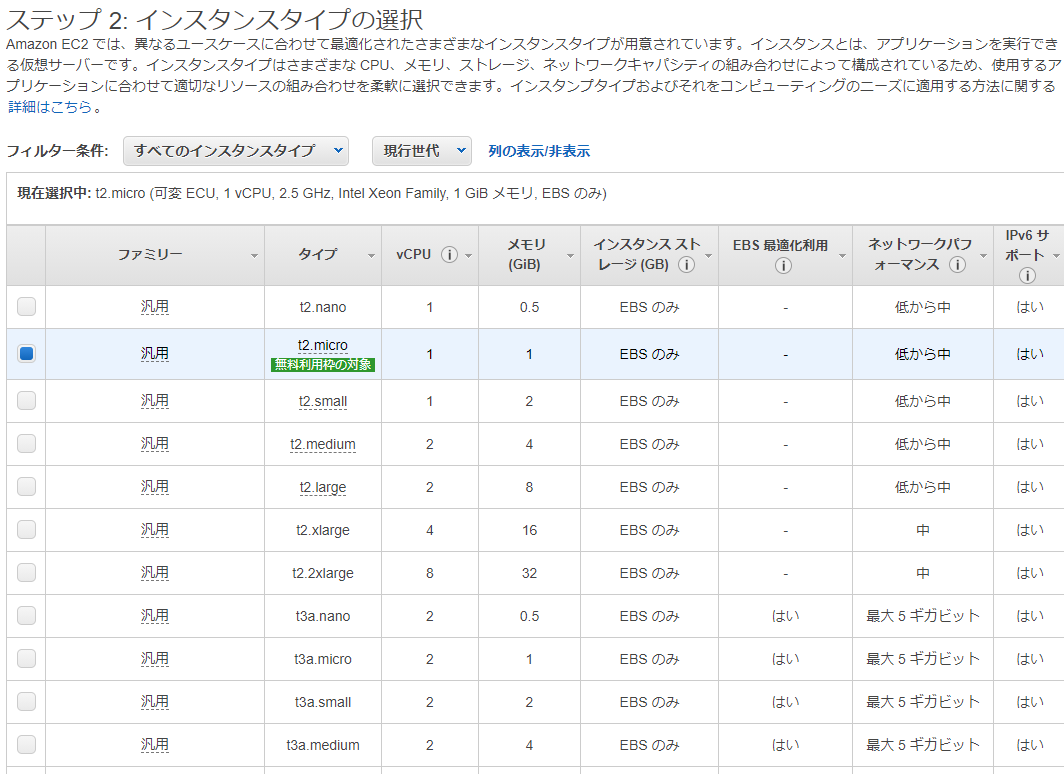
CPUは、64ビット(X86)を使用します。Armもあるようですが、どうなのかよくわかりません。3. インスタンスタイプの選択
無料で利用できるのは、タイプが「t2.micro」なのでこれを選びます。
タイプをみてよくわからなかったので、少しググってみて理解できたことを示します。「t2.micro」は、
タイプ:t2
サイズ:micro
であり、タイプの「t」で分類を示し、「2」は2世代目ということ。
「Amazon EC2 インスタンスタイプ」によれば、タイプは、色々あるようです。インスタンスのグループは、大きく、「汎用」、「コンピュータ最適化」、「メモリ最適化」、「高速コンピューティング」、「ストレージ最適化」にわかれます。
さて色々説明は書いてはあるのですが、この時点ですでにどれ選んだらいいのかわからなくなりました。
グループ 説明 汎用 CPU、メモリなどバランスがとれており、汎用的に使えるもので、特にないならこれを選ぶのがいいかと思います。 コンピュータ最適化 CPU性能が高いということですね。処理が多いのに適用するんですね。 メモリ最適化 メモリが最適化ということですが、よくわかりませんでした。 高速コンピューティング コプロセッサが別にあるんですね。GPUとか別途追加されるんですね。まだに用途によって違うんですね。 ストレージ最適化 NVMeSSDとかHDDとかあるようです。 まずグループを選ぶのでしょうか?わからないと汎用になりそうですね。
これはなかなか選ぶのが難しそうです。企業で選ぶにしても、用途を明確にしないといけないですが、まずどれがどれってのもわからないし、そういわれても全部入りでと思ってしまいます。
となると無難な汎用になるのかなとは思いました。分類が決まったらタイプを選んで、そのあとサイズを選ぶのかなと思います。
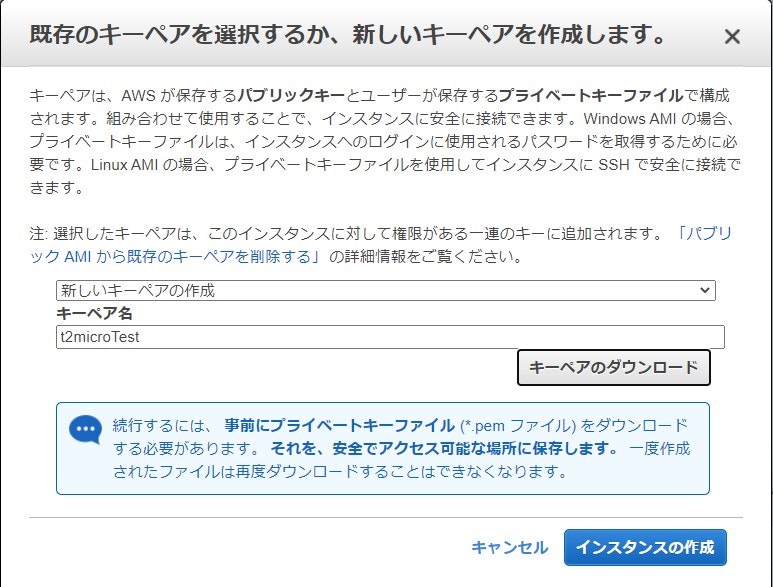
で選ぶと、次にキーペアの選択がでます。
初めての場合は新しいキーペアの作成として、ーを生成します。
このキーは今後Instanceへアクセスする場合に使用するため、非常に大事なものですので、保存して保管する必要があります。
これで選択すると、もうあとは初期化して、Instanceが生成されます。
思った以上に簡単でした。あとは、Instanceを開始して、SSH接続すればいいだけかなと思います。
私の場合だと、Tera Termで接続します。
IPアドレスは、Instance開始すると表示されるため、そこへ接続します。
初期値は、ユーザー名は、「ec2user」で、パスワードはなしです。
キーの設定が必要になるため、上記でDLしたキーを設定すればよいです。おわりに
とりあえずInstanceの作成はしてみましたが、この後料金を確認したところ、0.2USDくらいの課金がかかっていました。
続けようかどうしようか考えましたが、特に用途がないのでいったん中止することにしました。
また、必要になったら考えます。
- 投稿日:2020-09-13T02:16:59+09:00
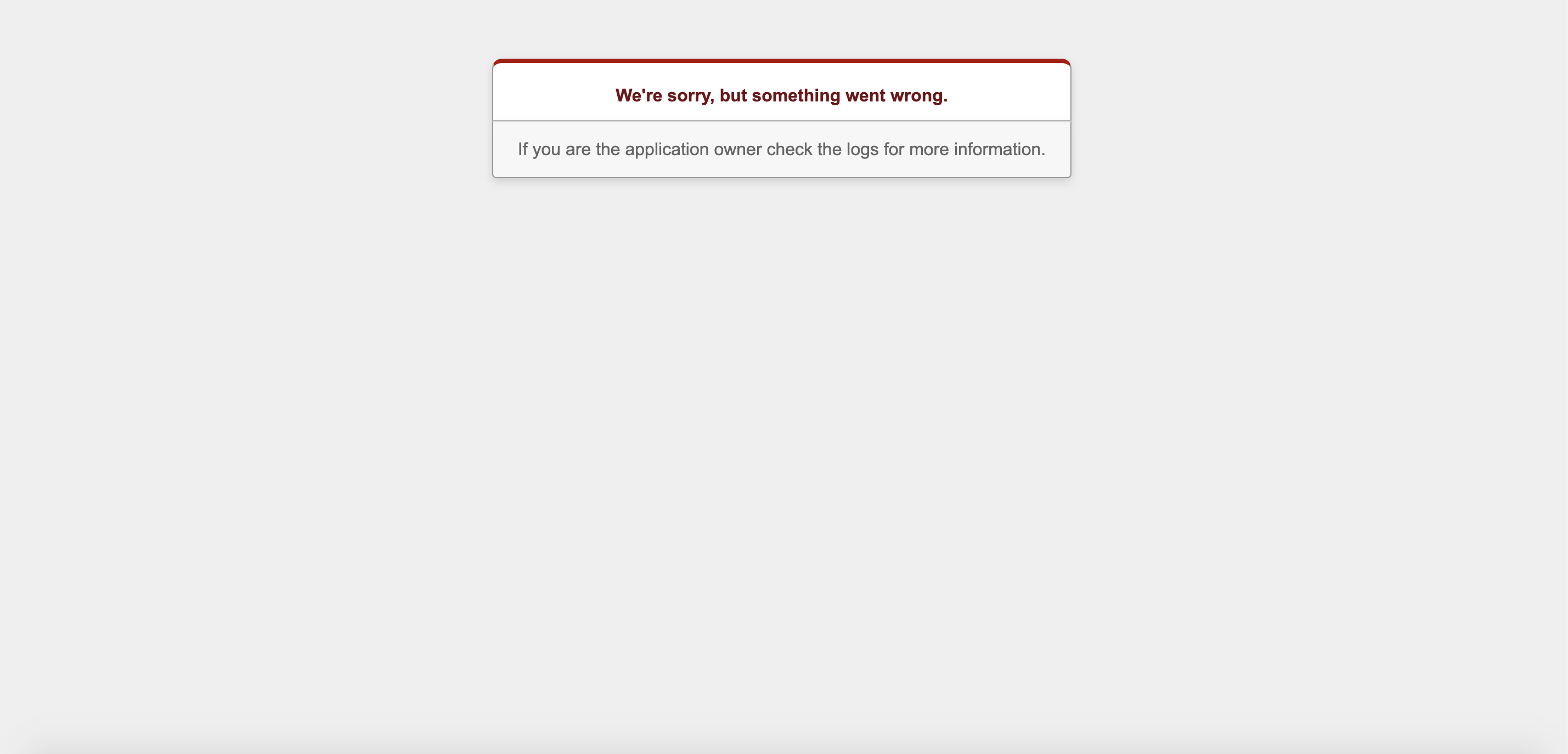
Rails本番環境に自動デプロイしたらwe're sorry, but something went wrong.
恐怖のwe're sorry, but something went wrong.
個人アプリを開発したぞ!
そして、追加実装したから設定済みの自動デプロイで本番環境のアプリを更新!
さぁ、本番環境への反映をチェックと......。we're sorry, but something went wrong.
何.....だと....! ?´д` ;
本番環境でアプリが開かない!? :(;゙゚'ω゚'):そのエラーに見事にハマった。
という事で、エラー解決に至るまでの死闘を描く。herokuへデプロイした際の同じエラー解決記事は結構見つかったものの、意外にMySQLでの解決策は見つからなかった。
今回はMySQLでの対処法だが、we're sorry, but something went wrong.エラーの全てが今回の内容で解決する訳ではないので、あくまで参考に留めて欲しい。
特に追加実装などでGemを増やした人は特に注意して欲しい
開発環境
- Ruby on Rails6
- DBはMySQL
- AWSにEC2インスタンスを使用してデプロイ済み
- Capistranoで自動デプロイ設定済み
というのが前提です。
事件の始まり(自動デプロイ直後)
ふと思い立って追加実装する為にGemを追加した。
記述を終えてローカル環境での動作を確認したので、私はコミットしてマージを終えた.....。本番環境へ反映させる為に、以下のコマンドをターミナルのローカルディレクトリで入力。
$ bundle exec cap production deploy無事にデプロイが完了したメッセージがターミナルに表示されたので、本番環境でのチェックをしたところ、上記画像のようにアプリが開かなくなってしまった.....。
何故だ!?((((;゚Д゚)))))))
ローカルでは問題なくても、いざ本番環境となるとエラーが起きてしまうパターンはある。
エラー文はググれば何となく分かっても、肝心の解決策が浮かばない。となると、エラーが起きている箇所のログをチェックする必要がある。
容疑者Logの捜査(本番環境のlogを追え!)
ローカル環境でLogをチェックする場合は、log/development.rbをチェックする。
ここで自身のLogが追えるので、ファイルを下にスクロールしていけば最新のLogへとたどり着ける。しかし今回の問題は本番環境なので、本番環境のログをチェックしないといけない。
その為にはEC2へログインする事になる。しかし、久しぶりでコマンドがうろ覚え.....。
以下を順にローカルのターミナルに入力していく。 ①mkdir ~/.ssh ②cd .ssh/ ③lsコマンドで、EC2で作成済みの<鍵名>.pemが表示される。 ④chmod 600 <鍵名>.pem ⑤ssh -i <鍵名>.pem ec2-user@<EC2で発行したElastic IP> すると、 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| と、上記の表示が出てEC2へのログインが完了。次がいよいよ本番環境のlogのチェック ①$ cd /var/www/<リポジトリ名> アプリのディレクトリへ移動 ②ls 再びlsコマンドを入力。 ③cd current 複数のファイルの中にcurrentがあるので移動。 ④cd log ⑤ls laコマンドを入力すると、production.log unicorn.stderr.log unicorn.stdout.log これらのlogファイルが表示される。 ⑥[ec2-user@****** log]$ cat 'production.log' 今回は本番環境のエラー内容を知りたいので、上記を入力する事で本番環境のlogが追える。 その中で表示されるエラー内容をチェックしましょう!終わらぬ事件(失敗する自動デプロイ)
エラー内容を見つけ、修正したら改めてmasterへコミット。
そして自動デプロイ!これがそのまま成功すればエラー解決となるが、そうは問屋がおろさなかった。
困ったことに自動デプロイが失敗するようになってしまった。何故だ!?((((;゚Д゚)))))))
ふと、ここで思った。
事件(エラー)が発生するようになったのは、Gemを増やしてから。ならば、bundle installしてみよう。
ただし、ローカルと本番環境の両方で。その結果、
本番環境 Bundle complete! 34 Gemfile dependencies, 115 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed. ローカル Bundle complete! 36 Gemfile dependencies, 126 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed.ローカル環境でのGemが36個に対し、本番環境は34個と反映されていなかった。
bundle installしても更新されない。どうすればいい?((((;゚Д゚)))))))
そこで参考になったのがこの記事。平和な日常(EC2インスタンスやデータベースの再起動)
つまりは自動デプロイも繰り返すと本番環境に反映しなくなってしまうという事が分かった。
【対処法】
①AWSのマネージメントコンソールにログインEC2 → インスタンス → 該当のインスタンスをクリック → アクションのインスタンスの状態 → 再起動 を行います。
②ターミナルからEC2にログイン後、以下のコマンドを実行してnginxとMySQLを再起動しよう。
EC2サーバーで入力 $ sudo service nginx start $ sudo service mysqld startもしも、MySQLではなく、mariaDBを使っていたら下記でデータベースを再起動しよう。
EC2サーバーで入力 $ sudo systemctl restart mariadbこれらのコマンドで、データベースやAWSインスタンスを再起動すれば自動デプロイが成功し、Gemのbundle installも反映されました。
今回はGemを起因としたエラーだったので、同じエラーでも全く解決策が違う可能性もあり得ます。
あくまで一つの手段として、インスタンスやデータベースの再起動をした上で、再度デプロイする事でサーバーが開かないエラーからは逃れることが出来る事もあるでしょう。
以上です。