- 投稿日:2020-08-05T22:56:41+09:00
minikube使ってみて、Kubernetesに入門してみた気分になる
この記事は富士通システムズウェブテクノロジーの社内技術コミュニティで、「イノベーション推進コミュニティ」
略して「いのべこ」が企画する、いのべこ夏休みアドベントカレンダー 2020の11日目の記事です。
本記事の掲載内容は私自身の見解であり、所属する組織を代表するものではありません。
ここまでお約束
はじめに
この記事では、Dockerには触れたことがあって使うことはできるけど。
Kubernetes(通称K8s。どう発音するのだろう。けーはちえす?けーえいつ?)は難しそうだなーと思って
使ったことがない未経験者が、ふとminikubeなるものを見つけ、これなら簡単に使える気になれるのでは?!と思って思い立ったときに試した内容をシェアするための記事です。
以下の環境を想定して記事を作成しています。
- Windows10 2004 Update
- WSL2(ubuntu 20.04)
- docker(Docker Engine CE 19.03.12)
minikubeとは
公式リポジトリには、以下のような説明が書かれています。
minikube implements a local Kubernetes cluster on macOS, Linux, and Windows. minikube's primary goals are to be the best tool for local Kubernetes application development and to support all Kubernetes features that fit.
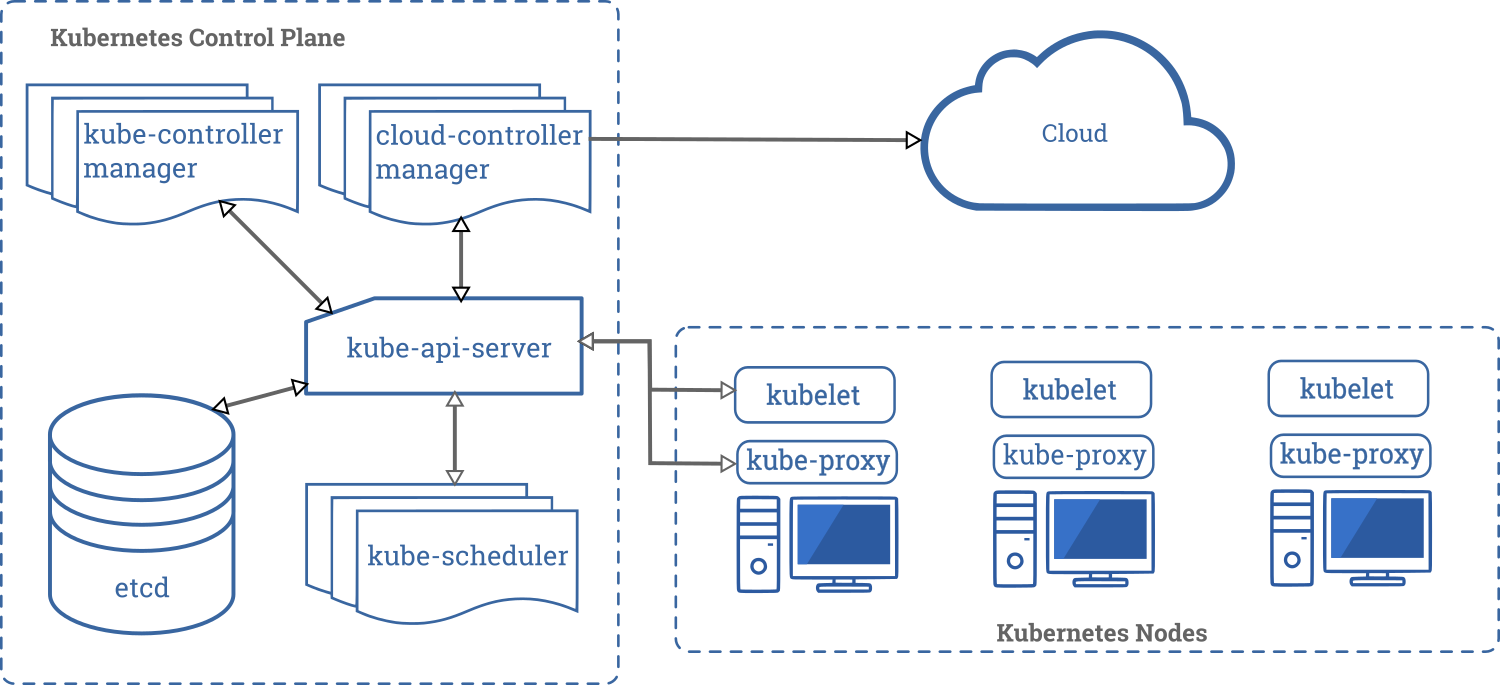
ローカルでK8sクラスタを構築し、
ローカルでのアプリケーション開発におけるK8sを利用しやすくしたもの。ととらえればいいのかな?K8sクラスタとは?
ローカルでクラスタを構築と言っているが、K8sにおけるクラスタはどういうものなのか。
公式ページから引用します。
Kubernetesのコンポーネントより
この図における、Kubernetes Nodesの部分を、ローカル環境で簡単に用意してくれるていうものらしい。
実際、Kubernetesクラスタを構築するにはいくつか方法があるようで・・・
- minikube
- kubeadm
- kops
- kubespray
などがあるようです。
公式ページでは、kubeadmを使用したプロダクション環境用のK8sクラスタ構築の手順が公開されていましたが、複雑でどれもローカル環境でのテスト用に準備するには手間がかかりそうです。K8sクラスタを構築するような記事がインターネット上にあったりしますが、マスターノードを構築して、
非マスターノードの構築して・・・とやたらと手順が複雑でめげてしまいそうです。。。
それに比べて、簡単にシングルノードのクラスタを構築できるものが、minikubeのようです。インストール方法
導入方法は、Kubernetesの公式ドキュメントに詳しく書かれています。
Minikubeのインストール
私の環境には、WSL2とdocker(docker desktop経由ではなく、CLIでインストールしました)がインストールされているため、
その状態からの抜粋でお送りします。# ローカル環境にkubectl/minikubeをインストールします # kubectlを取得します $ curl -Lo /usr/local/bin/kubectl https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 41.9M 100 41.9M 0 0 32.2M 0 0:00:01 0:00:01 --:--:-- 32.2M # kubectlに実行権限を付与します $ chmod +x /usr/local/bin/kubectl # minikubeのインストールを行います $ curl -Lo /usr/local/bin/minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 55.7M 100 55.7M 0 0 29.6M 0 0:00:01 0:00:01 --:--:-- 29.5M # 実行権限の付与 $ chmod +x /usr/local/bin/minikubeインストールができました。インストールしたツールが動作するか確認してみましょう。
$ docker version Client: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:45:44 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:44:15 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683 $ minikube version minikube version: v1.12.1 commit: 5664228288552de9f3a446ea4f51c6f29bbdd0e0-dirty $ kubectl version Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.6", GitCommit:"dff82dc0de47299ab66c83c626e08b245ab19037", GitTreeState:"clean", BuildDate:"2020-07-15T16:58:53Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}公式サンプルを試してみる
minikube/kubectlのインストールができたら、公式サンプルを試してみましょう。
公式のドキュメントに、サンプルのコマンドが載っていますので、
確認しながら実施してみたいと思います。minikubeを使用したローカルクラスタの構築
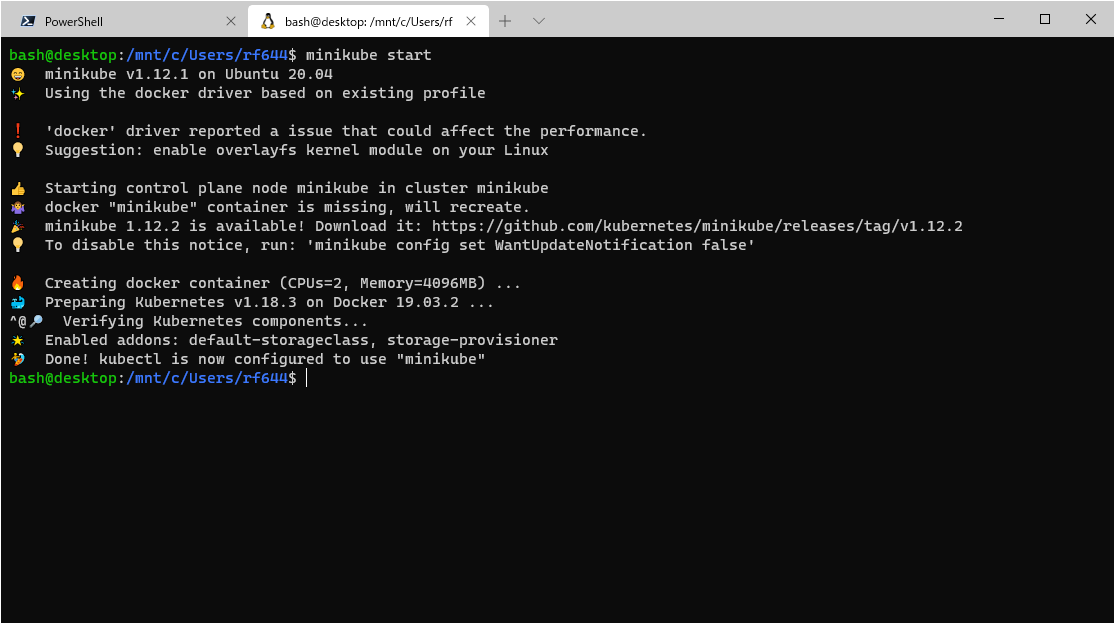
# minikubeを使用して、ローカル環境にKubernetesクラスタを構築します。 $ minikube start
上記のようになれば、起動成功です!Windows Terminalを使用していると、絵文字があって楽しいですね。
WSLのデフォルトコンソールだと、<?>のようになって何が何だかという感じ。デフォルト指定してminikubeでクラスタを起動した場合、
--vm-driverフラグにはnone
いわゆる、dockerドライバーが選択されます。(ローカル環境にDockerがインストールされている必要があります)また、ログを見る限りだと、
--cpusは2、--memoryは4gが割り当てられているようです。kubernetesのデプロイを実行します
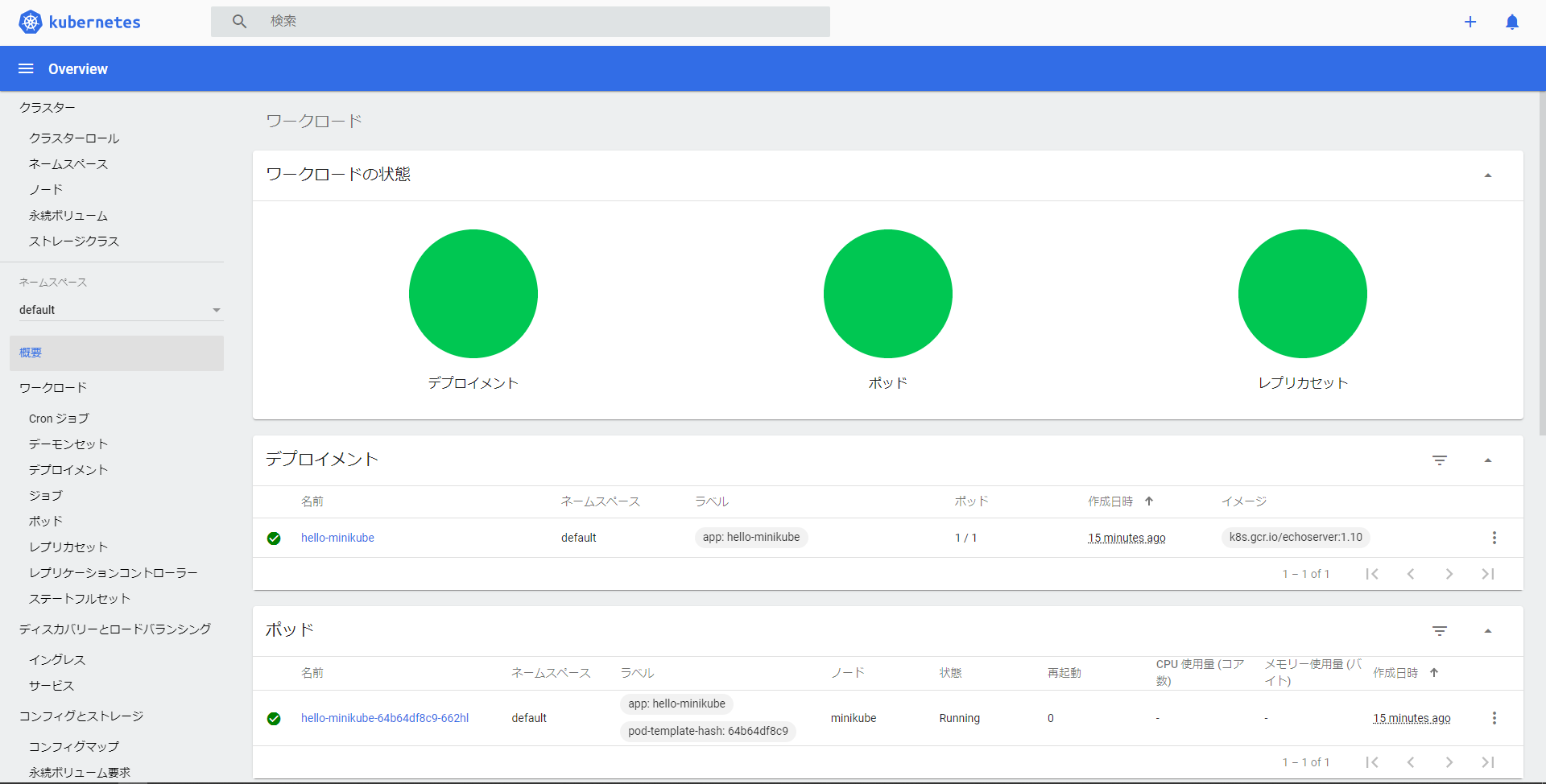
$ kubectl create deployment hello-minikube --image=k8s.gcr.io/echoserver:1.10 deployment.apps/hello-minikube created $ kubectl expose deployment hello-minikube --type=NodePort --port=8080 service/hello-minikube exposed以下のコマンドで、podが起動していることを確認できます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE hello-minikube-64b64df8c9-662hl 1/1 Running 0 90sデプロイされたコンテナの動作を確認する
公式ページでは
curl $(minikube service hello-minikube --url)で、
動作しているコンテナにアクセスできるようですが、WSL2の環境では、以下のようになり実行できません。$ minikube service hello-minikube --url ? Starting tunnel for service hello-minikube. |-----------|----------------|-------------|------------------------| | NAMESPACE | NAME | TARGET PORT | URL | |-----------|----------------|-------------|------------------------| | default | hello-minikube | | http://127.0.0.1:41527 | |-----------|----------------|-------------|------------------------| http://127.0.0.1:41527 ❗ Because you are using a Docker driver on linux, the terminal needs to be open to run it.ただ、上記でURLが出ている、
http://127.0.0.1:41527にアクセスすれば、動作は確認できますので、curlなどで覗いてみましょう。$ curl curl http://172.17.0.3:30971 Hostname: hello-minikube-64b64df8c9-662hl Pod Information: -no pod information available- Server values: server_version=nginx: 1.13.3 - lua: 10008 Request Information: client_address=172.19.0.1 method=GET real path=/ query= request_version=1.1 request_scheme=http request_uri=http://172.17.0.3:8080/ Request Headers: accept=*/* host=172.17.0.3:30971 user-agent=curl/7.68.0 Request Body: -no body in request-無事、動作確認できたのではないでしょうか。
最後に、作成したサービスとminikubeで作成したクラスタを削除し、動作確認は終了です。$ kubectl delete services hello-minikube service "hello-minikube" deleted $ kubectl delete deployment hello-minikube deployment.apps "hello-minikube" deleted $ minikube service list # "hello-minikube"のサービスがなくなっています。 |----------------------|---------------------------|--------------|-----| | NAMESPACE | NAME | TARGET PORT | URL | |----------------------|---------------------------|--------------|-----| | default | kubernetes | No node port | | kube-system | kube-dns | No node port | | kubernetes-dashboard | dashboard-metrics-scraper | No node port | | kubernetes-dashboard | kubernetes-dashboard | No node port | |----------------------|---------------------------|--------------|-----| $ minikube stop # ローカルクラスタの停止 ✋ Stopping "minikube" in docker ... ? Powering off "minikube" via SSH ... ? Node "minikube" stopped. $ minikube delete # ローカルクラスタの削除 ? Deleting "minikube" in docker ... ? Deleting container "minikube" ... ? Removing /home/bash/.minikube/machines/minikube ... ? Removed all traces of the "minikube" cluster.minikubeを使ってできること
minikubeのコマンドラインには、kubernetesを使用するにあたり様々なものが用意されています。
helpの内容を見てみましょう。minikube --help minikube provisions and manages local Kubernetes clusters optimized for development workflows. Basic Commands: start Starts a local Kubernetes cluster status Gets the status of a local Kubernetes cluster stop Stops a running local Kubernetes cluster delete Deletes a local Kubernetes cluster dashboard Access the Kubernetes dashboard running within the minikube cluster pause pause Kubernetes unpause unpause Kubernetes Images Commands: docker-env Configure environment to use minikube's Docker daemon podman-env Configure environment to use minikube's Podman service cache Add, delete, or push a local image into minikube Configuration and Management Commands: addons Enable or disable a minikube addon config Modify persistent configuration values profile Get or list the the current profiles (clusters) update-context Update kubeconfig in case of an IP or port change Networking and Connectivity Commands: service Returns a URL to connect to a service tunnel Connect to LoadBalancer services Advanced Commands: mount Mounts the specified directory into minikube ssh Log into the minikube environment (for debugging) kubectl Run a kubectl binary matching the cluster version node Add, remove, or list additional nodes Troubleshooting Commands: ssh-key Retrieve the ssh identity key path of the specified cluster ip Retrieves the IP address of the running cluster logs Returns logs to debug a local Kubernetes cluster update-check Print current and latest version number version Print the version of minikube Other Commands: completion Generate command completion for a shell Use "minikube <command> --help" for more information about a given command.以下では、便利そうだなーと思ったコマンドを紹介します。
dashboard
minikube dashboardで起動します。
起動するとコンソールに、
? Opening http://127.0.0.1:42011/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ in your default browser...
のように表示されるので、ブラウザなどでアクセスしてみてください。
すると、kubernetesクラスタの状態を確認するためのダッシュボードにアクセスすることができます。
dashboardは素のK8sの場合デプロイされておらず、kubectlを使用してデプロイ~プロキシコマンドを実行することによって、ダッシュボードにアクセスできるようになります。それがワンコマンドで・複雑(?)なオプションなしで実行できるのは少し便利なのかな?と思います。
service
稼働しているserviceの一覧を表示します。
$ minikube service list |----------------------|---------------------------|--------------|-------------------------| | NAMESPACE | NAME | TARGET PORT | URL | |----------------------|---------------------------|--------------|-------------------------| | default | hello-minikube | 8080 | http://172.17.0.3:30971 | | default | kubernetes | No node port | | kube-system | kube-dns | No node port | | kubernetes-dashboard | dashboard-metrics-scraper | No node port | | kubernetes-dashboard | kubernetes-dashboard | No node port | |----------------------|---------------------------|--------------|-------------------------|困りごと
minikube startしてstop>deleteした後、またminikube startしてローカルクラスタを構築しようとするとエラーになります。minikube start ? minikube v1.12.1 on Ubuntu 20.04 ✨ Automatically selected the docker driver ❗ 'docker' driver reported a issue that could affect the performance. ? Suggestion: enable overlayfs kernel module on your Linux ? Starting control plane node minikube in cluster minikube ? Creating docker container (CPUs=2, Memory=2200MB) ... ? StartHost failed, but will try again: creating host: create: creating: create kic node: create container: docker run -d -t --privileged --security-opt seccomp=unconfined --tmpfs /tmp --tmpfs /run -v /lib/modules:/lib/modules:ro --hostname minikube --name minikube --label created_by.minikube.sigs.k8s.io=true --label name.minikube.sigs.k8s.io=minikube --label role.minikube.sigs.k8s.io= --label mode.minikube.sigs.k8s.io=minikube --volume minikube:/var --security-opt apparmor=unconfined --cpus=2 --memory=2200mb -e container=docker --expose 8443 --publish=127.0.0.1::8443 --publish=127.0.0.1::22 --publish=127.0.0.1::2376 --publish=127.0.0.1::5000 gcr.io/k8s-minikube/kicbase:v0.0.10@sha256:f58e0c4662bac8a9b5dda7984b185bad8502ade5d9fa364bf2755d636ab51438: exit status 125 stdout: 8df93322265580c4510cb0a0e9d59bd4cc3f306aaadf73a1681e6d4c605a7dd5 stderr: docker: Error response from daemon: cgroups: cannot find cgroup mount destination: unknown. ^@? docker "minikube" container is missing, will recreate.???
docker runも同様の理由でできなくなります。
docker: Error response from daemon: cgroups: cannot find cgroup mount destination: unknown.一応、WSL2の再起動(shutdownからのWSLの起動)で治ります。
また、以下のコマンドでも治ります。(応急処置です)
sudo mkdir /sys/fs/cgroup/systemd sudo mount -t cgroup -o none,name=systemd cgroup /sys/fs/cgroup/systemd原因は深くは追及してないので、わかりましたらここに残したいと思います。
感想
公式チュートリアルをなぞっただけですが、minikubeでローカルクラスタを構築することができました。
Kubernetesに入門する・Kubernetes環境をローカルマシンにもって動作確認環境にできるのはとても便利そうです。
これをきっかけに、皆さんも1人1Kubernetesクラスタを持って開発に勤しみましょう(?)
- 投稿日:2020-08-05T18:43:27+09:00
Linux学習用に、データ永続化したDebianのDockerコンテナを用意する
実現したいこと
- Linux環境(Debian)であること
- コンテナを削除してもデータが消えず、再作成した際にそのままデータが残っていること
(ただしホームディレクトリ以下のみを対象とする)ディレクトリ構成
Dockerfileとdataディレクトリをホストマシンに用意しておきます。$ tree . . ├── Dockerfile └── data 1 directory, 1 fileDockerfile
Dockerfileの内容は以下の通りです。
ARG UID=501の「501」は、ホストマシンでidコマンドを打って確認した値ですので、ご自身で試される場合は適宜書き換える必要があります。
y_tsubasaの部分は任意のユーザ名を使用します。今回は、ホストマシンのユーザ名と合わせました。
useraddコマンドで一般ユーザを追加しますが、-mオプションを付与することで、ホームディレクトリも合わせて作成します。FROM debian ARG UID=501 RUN useradd -m -u ${UID} y_tsubasa USER ${UID}コマンド
以下のコマンドを使用します。
イメージ構築
$ docker build -t linux-training .コンテナ作成&起動
-vオプションで、ホストマシンのディレクトリをマウントしています。
つまり、ホストマシンのdataディレクトリとコンテナ内のホームディレクトリ/home/y_tsubasaでデータを共有するようになります。
-wオプションで、ログイン時のカレントディレクトリを指定しています。
(付与しない場合は、ルートディレクトリとなります)$ docker run -v ~/repo-private/linux-training/data:/home/y_tsubasa \ -w /home/y_tsubasa \ --name linux-training \ -it linux-trainingコンテナ再起動
$ docker start -ai linux-training実際に動かしてみる
コンテナを作成&起動します。
$ docker run -v ~/repo-private/linux-training/data:/home/y_tsubasa \ -w /home/y_tsubasa \ --name linux-training \ -it linux-training y_tsubasa@c04b4bbfb4c9:~$ファイルを作成し、
exitします。y_tsubasa@c04b4bbfb4c9:~$ ls y_tsubasa@c04b4bbfb4c9:~$ touch test y_tsubasa@c04b4bbfb4c9:~$ ls test y_tsubasa@c04b4bbfb4c9:~$ exit(一応)再起動して、ファイルが残っていることを確認します。
$ docker start -ai linux-training y_tsubasa@c04b4bbfb4c9:~$ ls test y_tsubasa@c04b4bbfb4c9:~$ exitコンテナを削除します。
$ docker ps -a | grep linux c04b4bbfb4c9 linux-training "bash" About a minute ago Exited (0) 14 seconds ago linux-training $ docker rm c04b4bbfb4c9 c04b4bbfb4c9コンテナを新しく作成&起動し、ファイルがあることを確認します。
$ docker run -v ~/repo-private/linux-training/data:/home/y_tsubasa \ -w /home/y_tsubasa \ --name linux-training \ -it linux-training y_tsubasa@e58a1f1bfcca:~$ ls testホストマシンからも、ファイルを確認できます。
$ ls data test参考
- 投稿日:2020-08-05T17:35:59+09:00
pythonでプリンタのインク残量を調査
はじめに
aloha !
さて、今回は普段使っているプリンタのインクの残量を確認する方法を調べてみました。
エプソンの場合は、ブラウザからHTTPでアクセスするグラフで表示してくれます。http://[PRINTER_IP_ADDR]/PRESENTATION/HTML/TOP/PRTINFO.HTMLただ、今回はデータとして取得したいのでpythonで取得してみます。
環境
・EPSONプリンタ(EP-881ANを使いました)
・docker image(ubuntu)
・python3
・pip3
・vim※私の場合は、Jetson Nanoにdockerを入れて使ってます。
方針
プリンタの値を取得する方法として、SNMP(Simple Network Management Protocol)を使ってみたのですが、インク残量がよくわからず、IPP(Internet Printing Protocol)を使うことにしました。
SNMPを使うとどのカートリッジの型番(KAM-〜とか)を使うべきかの情報は取れます。手順
pyippの導入
# pip3 install pyippプリンタのIPアドレスの確認
プリンタのIPアドレスを確認するためにnmapを使ってIPPが開いているデバイスを探します。
もし、nmapが未導入であれば、つぎのコマンドで導入します。nmapの導入
# apt install nmapnmapを使って、IPPのポート番号である631番がopenになっているマシンを探します。
プリンタと同一のネットワークセグメントにあることを前提に以下のコマンドを使います。
[SUBNET MASK]は、16とか24とかサブネットマスクを入れてください。
例)192.168.10.0/24# nmap -sS -p631 [NETWORK]/[SUBNET MASK] -openつぎのようにプリンタのIPアドレス[PRINTER_IP_ADDR]が見つかりました。
Starting Nmap 7.70 ( https://nmap.org ) at 2020-08-01 07:20 UTC Nmap scan report for [PRINTER_IP_ADDR] Host is up (0.031s latency). PORT STATE SERVICE 631/tcp open ipp Nmap done: 256 IP addresses (14 hosts up) scanned in 60.89 secondsサンプルコード
pyippの公式サンプルコードを参考にファイルを作成します
# vi printer.py[PRINTER_IP_ADDR]にはnmapで見つかったプリンタのIPアドレスを記入します。
printer.pyimport asyncio from pyipp import IPP, Printer async def main(): """Show example of connecting to your IPP print server.""" async with IPP("ipps://[PRINTER_IP_ADDR]:631/ipp/print") as ipp: printer: Printer = await ipp.printer() print(printer) if __name__ == "__main__": loop = asyncio.get_event_loop() loop.run_until_complete(main())実行結果
Printer(info=Info(name='EPSON EP-881A Series', printer_name='ipp/print', printer_uri_supported=['ipps://[PRINTER_IP_ADDR]:631/ipp/print', 'ipp://[PRINTER_IP_ADDR]:631/ipp/print'], uptime=7283, command_set='ESCPL2,BDC,D4,D4PX,ESCPR7,END4,GENEP,URF', location='', manufacturer='EPSON', model='EP-881A Series', printer_info='EPSON EP-881A Series', serial='******************', uuid='********-****-****-****-************', version='01.70.AN30K1'), markers=[ Marker(marker_id=0, marker_type='ink-cartridge', name='Black ink', color='#000000', level=51, low_level=15, high_level=100), Marker(marker_id=1, marker_type='ink-cartridge', name='Cyan ink', color='#00FFFF', level=45, low_level=15, high_level=100), Marker(marker_id=4, marker_type='ink-cartridge', name='Light Cyan ink', color='#7FFFFF', level=53, low_level=15, high_level=100), Marker(marker_id=5, marker_type='ink-cartridge', name='Light Magenta ink', color='#FF7FFF', level=56, low_level=15, high_level=100), Marker(marker_id=2, marker_type='ink-cartridge', name='Magenta ink', color='#FF00FF', level=61, low_level=15, high_level=100), Marker(marker_id=3, marker_type='ink-cartridge', name='Yellow ink', color='#FFFF00', level=62, low_level=15, high_level=100)], state=State(printer_state='idle', reasons=None, message=None), uris=[Uri(uri='ipps://[PRINTER_IP_ADDR]/ipp/print', authentication=None, security='tls'), Uri(uri='ipp://[PRINTER_IP_ADDR]:631/ipp/print', authentication=None, security=None)])まとめ
IPPを使うと簡単にプリンタのインク残量が取得できました。
黒が51%、シアンが45%、ライトシアンが53%、ライトマゼンタが56%、マゼンタが61%、黄色が62%という結果になりました。mahalo
- 投稿日:2020-08-05T11:07:13+09:00
Windows10にVMwareで仮想サーバを構築し、Dockerを使ってみる
概要
Dockerを使用したときの備忘録も兼ねて、手順を残しておきたいと思います。
仮想環境:VMware Workstation 14 Player
OS:CentOS8VMware Workstationインストール
インストール手順について記載された記事が多数あるため、
私のほうでは、記載はしません。以下手順を参考にしてみてください。
Windows10にVMware Workstation PlayerをインストールCentOS8環境構築
インストール手順について記載された記事が多数あるため、
私のほうでは、記載はしません。以下手順を参考にしてみてください。
CentOS8をVMwareWorkstationにインストールDockerインストール
今回以下の記事を参考にさせていただきました。
Docker入門Dockerインストール後から記載していきます。
Dockerfile作成
- Tomcat用
/root/tomcat配下#Tomcatファイル格納ディレクトリ・ログ用ディレクトリ作成 cd /root/tomcat mkdir files mkdir logs ls -l →files・logsディレクトリが作成されていること #Tomcatモジュールダウンロード cd files wget http://ftp.jaist.ac.jp/pub/apache/tomcat/tomcat-9/v9.0.37/bin/apache-tomcat-9.0.37.tar.gz #ダウンロード確認 ls -ltr →ダウンロードしたファイルが存在すること #Dokcerfile作成 vim Dockerfile #以下を追記 FROM centos:8 RUN yum install -y java ADD files/apache-tomcat-9.0.37.tar.gz /opt/ CMD [ "/opt/apache-tomcat-9.0.37/bin/catalina.sh", "run" ]
- Nginx用
/root/nginx配下#設定ファイル格納ディレクトリ・ログ用ディレクトリ作成 cd /root/nginx mkdir files mkdir logs ls -l →files・logsディレクトリが作成されていること #Nginx設定ファイル作成 #default.confは、「location /tomcat/」の記載以外は、コンテナ作成時の初期ファイルです。 #今回は事前に取得しております。 cd files vim default.conf server { listen 80; listen [::]:80; server_name localhost; #charset koi8-r; #access_log /var/log/nginx/host.access.log main; location / { root /usr/share/nginx/html; index index.html index.htm; } location /tomcat/ { proxy_pass http://tomcat-1:8080/; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # location ~ /\.ht { deny all; } } #Dokcerfile作成 vim Dockerfile FROM nginx:latest RUN mv /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf_org COPY ./files/default.conf /etc/nginx/conf.d/イメージ作成
Dockerfileをもとに、イメージを作成する
コンソール#Tomcatイメージ作成 cd /root/tomcat docker build -t tomcat:1 . #Nginxイメージ作成 cd /root/nginx docker build -t nginx-tomcat:1 .Dockerネットワーク作成
コンテナ間の通信を可能にするために、作成する
コンソールdocker network create tomcat-networkコンテナ作成
作成したイメージをもとに、コンテナを作成
コンソール#Tomcatコンテナ docker run --name tomcat-1 --network tomcat-network -v /root/tomcat/logs:/share/logs -d tomcat:1 #Nginxコンテナ docker run --name nginx-tomcat-1 --network tomcat-network -p 10080:80 -v /root/nginx/logs:/share/logs -d nginx-tomcat:1アクセス確認
VMにログインして、Firefoxを開き、以下にアクセス
http://localhost:10080/
→Nginxのページが開くことhttp://localhost:10080/tomcat/
→Tomcat画面が表示されることまとめ
Dockerを使用することで、環境構築がより簡素化できるため、
積極的に活用していきたい。
- 投稿日:2020-08-05T11:07:03+09:00
Java画像を最小化する方法
この記事では、Spring BootベースのJavaアプリケーションを例に、Javaイメージを最小化するための一般的なコツをいくつか紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
コンテナ技術の普及に伴い、コンテナベースのアプリケーションが増えています。コンテナは頻繁に使用されていますが、ほとんどのコンテナユーザーは、コンテナイメージのサイズという単純だが重要な問題を無視しているかもしれません。この記事では、コンテナイメージを簡素化する必要性について簡単に説明し、Spring Boot ベースの Java アプリケーションを例に、Java イメージを最小化するための一般的なトリックをいくつか紹介します。
コンテナイメージを簡素化する必要性
コンテナイメージの簡素化は非常に必要です。これについては、セキュリティとアジリティの両面から説明します。
セキュリティについて
イメージから不要なコンポーネントを削除することで、攻撃面やセキュリティリスクを減らすことができます。Dockerでは、Seccompを使ってコンテナ内の操作を制限したり、AppArmorを使ってコンテナのセキュリティポリシーを設定したりすることができます。ただし、これらを利用するにはセキュリティ分野での十分な習熟度が必要です。
敏捷性
コンテナイメージを簡略化することで、コンテナのデプロイ速度を向上させることができます。アクセス トラフィックが突然バーストしたと仮定して、突然増加した圧力に対処するためにコンテナの数を増やす必要があるとします。一部のホストにターゲットイメージが含まれていない場合は、まずイメージを引っ張ってからコンテナを起動する必要があります。この場合、イメージを小さくすることで処理を高速化し、スケールアップの期間を短縮することができます。また、小さい画像の方がより早く構築でき、ストレージや伝送コストを節約することができます。
よくあるコツ
Java アプリケーションをコンテナ化するには、以下の手順を実行します。
1、Java ソース・コードをコンパイルし、JAR パッケージを生成します。
2、JAR パッケージとサードパーティ製 JAR 依存関係を適切な位置に移動します。
このセクションで使用する例は、Spring Boot ベースの Java アプリケーションである spring-boot-docker です。この例で使用した最適化されていないdockerfileは以下の通りです。FROM maven:3.5-jdk-8 COPY src /usr/src/app/src COPY pom.xml /usr/src/app RUN mvn -f /usr/src/app/pom.xml clean package ENTRYPOINT ["java","-jar","/usr/src/app/target/spring-boot-docker-1.0.0.jar"]アプリケーションはMavenを使って作成したもので、dockerfileのベースイメージにはmaven:3.5.5-jdk-8を指定しています。このイメージのサイズは635MBです。この方法で作成した最終的なイメージのサイズは719MBとかなり大きいです。理由は、ベースイメージが大きいことと、最終イメージをビルドするためにMavenが多くのJARパッケージをダウンロードするためです。
マルチステージビルド
Javaアプリケーションを実行するには、Javaランタイム環境(JRE)だけが必要です。MavenやJava Development Kit (JDK)のコンパイル、デバッグ、実行ツールは必要ありません。したがって、簡単な最適化方法は、Javaソースコードをコンパイルして作成するイメージと、Javaアプリケーションを実行するイメージを分離することです。そのためには、Docker 17.05のリリース前に2つのdockerfileファイルを維持する必要があり、イメージ構築の複雑さが増します。Docker 17.05からは、マルチステージビルド機能により、1つのdockerfile内で複数のFROM文を使用できるようになりました。それぞれのFROM文で異なるベースイメージを指定し、全く新しいイメージ構築プロセスを開始することができます。前のイメージ構築ステージの製品を別のステージにコピーし、必要な内容だけを最終イメージに残すように選択することができます。最適化されたdockerfileは以下のようになります。
FROM maven:3.5-jdk-8 AS build COPY src /usr/src/app/src COPY pom.xml /usr/src/app RUN mvn -f /usr/src/app/pom.xml clean package FROM openjdk:8-jre ARG DEPENDENCY=/usr/src/app/target/dependency COPY --from=build ${DEPENDENCY}/BOOT-INF/lib /app/lib COPY --from=build ${DEPENDENCY}/META-INF /app/META-INF COPY --from=build ${DEPENDENCY}/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","hello.Application"]dockerfileでは、最初のステージのビルドイメージとして
maven:3.5-jdk-8を使用し、Javaアプリケーションを実行するベースイメージとしてopenjdk:8-jreを使用しています。第一段階でコンパイルした.classファイルのみを、サードパーティのJARの依存関係とともに最終イメージにコピーしています。最適化の結果、イメージのサイズは459MBに縮小されました。ベースイメージとしてディストロレスイメージを使用する
多段ビルドによって最終イメージのサイズは小さくなっていますが、それでも459MBは大きすぎます。総合的に分析した結果,ベースとなる
openjdk:8-jreのサイズは443MBと大きすぎることがわかりました.そこで,次の最適化のステップとして,ベース画像のサイズを小さくすることにしました.この問題を解決するために開発されたのが、GoogleのオープンソースプロジェクトであるDistrolessです。Distrolessイメージは、アプリケーションとその実行時の依存関係だけを含んでいます。これらのイメージには、パッケージマネージャ、シェル、その他標準的なLinuxディストリビューションに含まれると思われるプログラムは含まれていません。現在、Distroless は Java、Python、Node.js、.NET などの環境で動作するアプリケーション用のベースイメージを提供しています。
Distrolessイメージを使用したdockerfileファイルは以下のようになります。
FROM maven:3.5-jdk-8 AS build COPY src /usr/src/app/src COPY pom.xml /usr/src/app RUN mvn -f /usr/src/app/pom.xml clean package FROM gcr.io/distroless/java ARG DEPENDENCY=/usr/src/app/target/dependency COPY --from=build ${DEPENDENCY}/BOOT-INF/lib /app/lib COPY --from=build ${DEPENDENCY}/META-INF /app/META-INF COPY --from=build ${DEPENDENCY}/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","hello.Application"]この dockerfile と以前のものとの唯一の違いは、アプリケーションを実行するためのベースイメージが
openjdk:8-jre(443 MB) からgcr.io/distroless/java(119 MB) に変更されたことです。その結果、最終的なイメージのサイズは135MBになります。ディストロレスイメージを使うことの唯一の不便な点は、イメージにシェルが含まれていないことです。docker attachを使ってアプリケーションの標準入力、標準出力、標準エラー(またはこれら3つの組み合わせ)を実行中のコンテナにアタッチしてデバッグすることはできません。 distrolessのdebugイメージはbusyboxシェルを提供します。しかし、このイメージをリパッケージしてコンテナをデプロイしなければならず、非デバッグイメージに基づいてデプロイされたコンテナには役に立ちません。セキュリティの観点から見ると、攻撃者はシェルを介して攻撃できないので、これは利点になるかもしれません。
アルパインイメージをベースイメージとして使用する
docker attach を使用する必要があり、画像サイズを最小限に抑えたい場合は、ベース画像としてアルプスの画像を使用することができます。アルパイン画像は信じられないほど小さいのが特徴で、ベース画像のサイズは4MB程度しかありません。
アルペン画像を使用したdockerfileは以下のようになります。
FROM maven:3.5-jdk-8 AS build COPY src /usr/src/app/src COPY pom.xml /usr/src/app RUN mvn -f /usr/src/app/pom.xml clean package FROM openjdk:8-jre-alpine ARG DEPENDENCY=/usr/src/app/target/dependency COPY --from=build ${DEPENDENCY}/BOOT-INF/lib /app/lib COPY --from=build ${DEPENDENCY}/META-INF /app/META-INF COPY --from=build ${DEPENDENCY}/BOOT-INF/classes /app ENTRYPOINT ["java","-cp","app:app/lib/*","hello.Application"]
openjdk:8-jre-alpineはalpineをベースに構築されたもので、Javaランタイムを含んでいます。この dockerfile でビルドされたイメージのサイズは 99.2 MB で、 distroless イメージをベースにビルドされたイメージよりも小さくなっています。実行中のコンテナにアタッチするには、
docker exec -ti <container_id> shコマンドを実行してください。Distroless と Alpine の比較
Distroless と Alpineはどちらも非常に小さなベース画像を提供することができます。本番環境ではどちらを使うべきでしょうか?セキュリティを第一に考えるのであれば、パッケージ化されたアプリケーションが実行できるのはバイナリファイルだけなので、distroless をお勧めします。イメージのサイズを重視するのであれば、alpine をお勧めします。
その他のコツ
前述のコツに加えて、以下のような操作を行うことで、さらにイメージサイズをシンプルにすることができます。
1、dockerfile内の複数の命令を1つにまとめます。これにより、画像のレイヤー数が減り、画像サイズが小さくなります。
2、安定した大きなコンテンツをイメージの下層に配置し、頻繁に変化する小さなコンテンツを上層に配置します。この方法では、直接画像サイズを小さくすることはできません。しかし、イメージキャッシュの仕組みをフルに活用して、イメージの構築とコンテナのデプロイを高速化します。
Dockerfilesを最適化するためのヒントについては、Dockerfilesを書くためのベストプラクティスを参照してください。概要
1、一連の最適化により、Javaアプリケーションの画像サイズは719MBから約100MBに縮小されました。アプリケーションが他の環境で動作する場合も、同様の原理で最適化することができます。
2、Javaイメージの場合、Googleが提供する別のツールであるjibは、複雑なイメージ構築プロセスを自動的に処理し、簡略化されたJavaイメージを提供することができます。これを使えば、dockerfileを書く必要はなく、Dockerをインストールする必要すらありません。
3、デバッグに不便なdistro-lessなどのコンテナについては、そのログを一元的に保存しておけば、問題のトレースやトラブルシューティングが容易になります。詳しくは、コンテナのログ処理のための技術的なベストプラクティスの記事を参照してください。アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-08-05T10:31:52+09:00
コンテナログ処理の技術的なベストプラクティス:Dockerを例に挙げる
この記事では、Dockerを例に、コンテナログ処理の一般的な方法やベストプラクティスをいくつか紹介しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
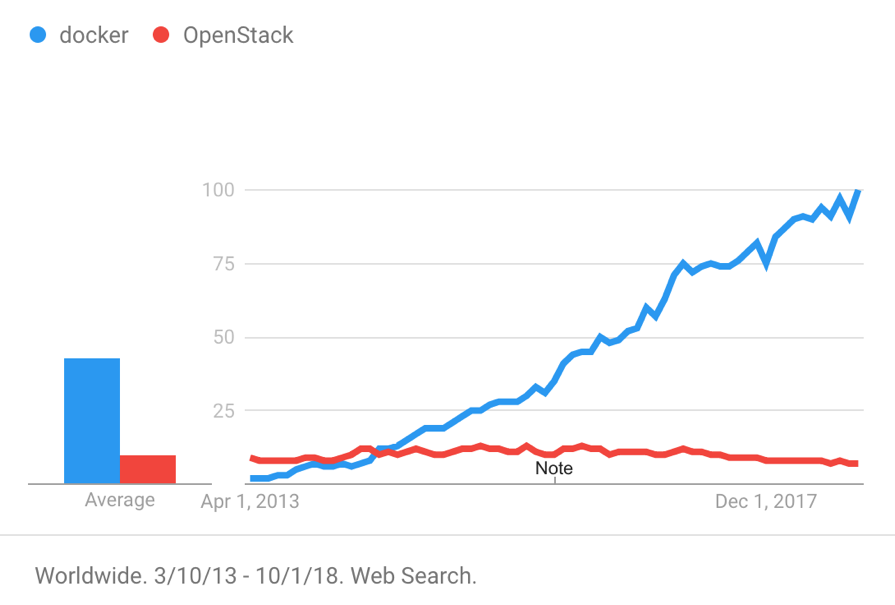
Docker, Inc. 旧社名:dotCloud, Inc)は、2013年にDockerをオープンソースプロジェクトとしてリリースしました。その後、Dockerに代表されるコンテナ製品は、分離性能の良さ、移植性の高さ、リソース消費の少なさ、起動の早さなど複数の特徴から、瞬く間に世界中で人気を博しました。下図は2013年からのDockerとOpenStackの検索傾向を示しています。
コンテナ技術は、アプリケーションの展開や配信など、多くの便利さをもたらします。また、以下のようなログ処理のための多くの課題ももたらします。
1、コンテナの中にログを保存した場合、コンテナが取り外されるとログは消えてしまいます。コンテナは頻繁に作成・削除されるため、コンテナのライフサイクルは仮想マシンよりもはるかに短いです。そのため、ログを永続的に保存する方法を見つける必要があります。
2、コンテナ時代に入ってからは、仮想マシンや物理マシンよりも管理すべきオブジェクトが増えます。対象となるコンテナにログオンして問題をトラブルシューティングすると、問題が複雑化し、コストが増大します。
3、コンテナ技術を使えば、マイクロサービスをより簡単に実装することができます。それはシステムをデカップリングすると、より多くのコンポーネントをもたらします。システムの稼働状況を総合的に把握し、問題を素早く見つけ、コンテキストを正確に復元するための技術が必要です。ログ処理
この記事では、Dockerを例に、コンテナログ処理の一般的な方法とベストプラクティスをいくつか紹介します。Alibaba Cloud Log Serviceチームが長年のログ処理分野でのハードワークを経て結論付けたこれらの方法とベストプラクティスは以下の通りです。
1、コンテナログのリアルタイム収集
2、クエリ分析と可視化
3、ログのコンテキスト分析
4、LiveTail - LiveTail - クラウド上のtail-fコンテナログのリアルタイム収集
コンテナのログタイプ
ログを収集するには、まずログがどこに保存されているかを把握する必要があります。この記事では、NGINXとTomcatコンテナのログを収集する方法を紹介します。
NGINXで生成されるログファイルはaccess.logとerror.logです。NGINXのDockerfileはaccess.logとerror.logをそれぞれSTDOUTとSTDERRにリダイレクトします。
Tomcat は catalina.log、access.log、manager.log、host-manager.log など複数のログファイルを生成しますが、tomcat Dockerfile はこれらのログを標準出力にリダイレクトしません。その代わりに、コンテナ内に保存されます。
ほとんどのコンテナログはNGINXやTomcatのコンテナログに似ています。コンテナログを2つのタイプに分類することができます。
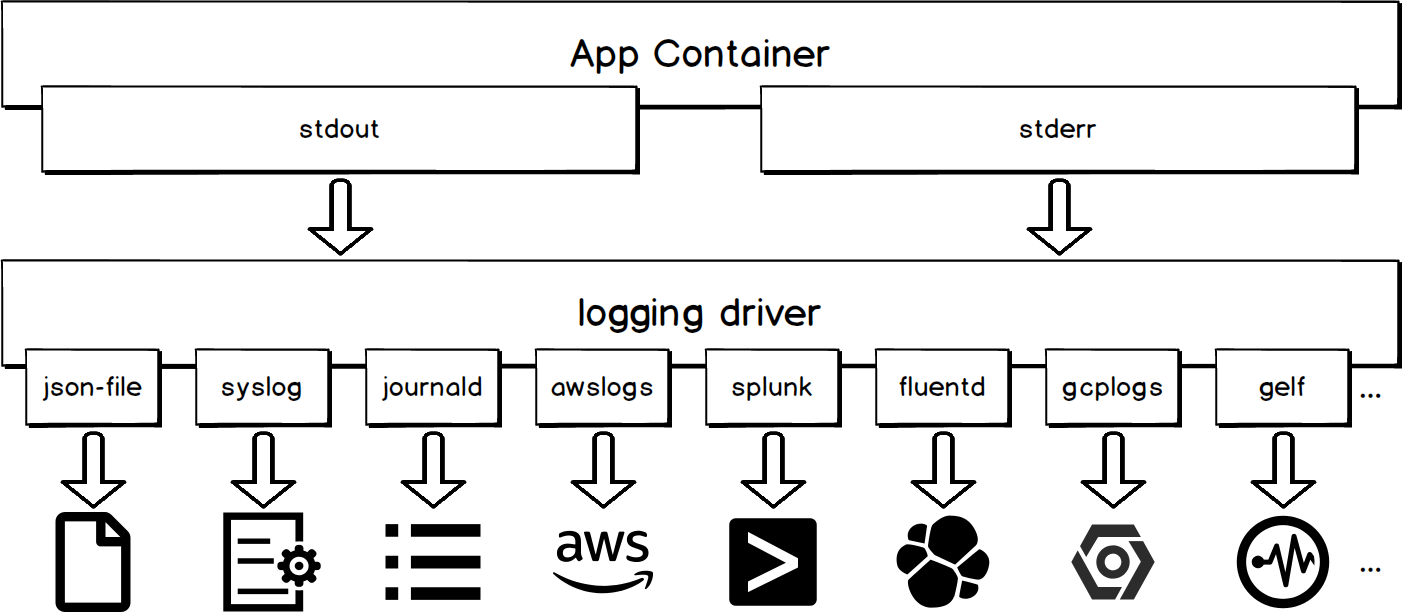
Container log types Description Standard output Information output through STDOUT and STDERR, including text files redirected to the standard output. Text log Logs that are stored inside the containers and are not redirected to the standard output. 標準出力
Logging Drivers
コンテナの標準出力は、Logging Driverの統一処理の対象となります。次の図に示すように、異なるロギングドライバは、異なる宛先に標準出力を書き込みます。
コンテナログの標準出力を集めるのは、使い勝手が良いのがメリットです。
# You can use the following command to configure a syslog logging driver for all containers at the level of docker daemon. dockerd -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111 # You can use the following command to configure a syslog logging driver for the current container docker run -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111 alpine echo hello world欠点
json-fileやjournald以外のロギングドライバを使用すると、docker logs APIが利用できなくなります。ホスト上のコンテナの管理に portainer を使用し、コンテナログの収集に json-file と journald 以外のロギングドライバを使用したとします。コンテナログの標準出力をユーザーインターフェイスから見ることができなくなります。Docker Logs API
デフォルトでロギングドライバーを使用しているコンテナの場合、docker logsコマンドをdockerデーモンに送信することで、コンテナログの標準出力を取得することができます。この方法を使用するログ収集ツールには、logspout や sematext-agent-docker などがあります。
2018-01-01T15:00:00から始まる最新の5つのコンテナログを取得するには、以下のコマンドを使用します。docker logs --since "2018-01-01T15:00:00" --tail 5 <container-id>欠点
ログが多いときにこの方法を適用すると、docker デーモンにかなりの負担がかかります。その結果、dockerデーモンはコンテナの作成や削除のためのコマンドに迅速に対応できなくなります。jsonファイルのファイル
ロギングドライバはデフォルトでコンテナログをJson形式で
/var/lib/docker/containers/<container-id>/<container-id>-json.logにあるホストファイルに書き出します。これにより、ホストファイルを直接収集することで、コンテナログの標準出力を取得することができます。コンテナログは、JSONファイルを収集して収集することをお勧めします。これにより、docker logs APIが利用できなくなったり、dockerデーモンに影響が出たりすることはありません。また、多くのツールがホストファイルを収集するためのネイティブサポートを提供しています。Filebeat と Logtail はこれらのツールの代表的なものです。
テキストログ
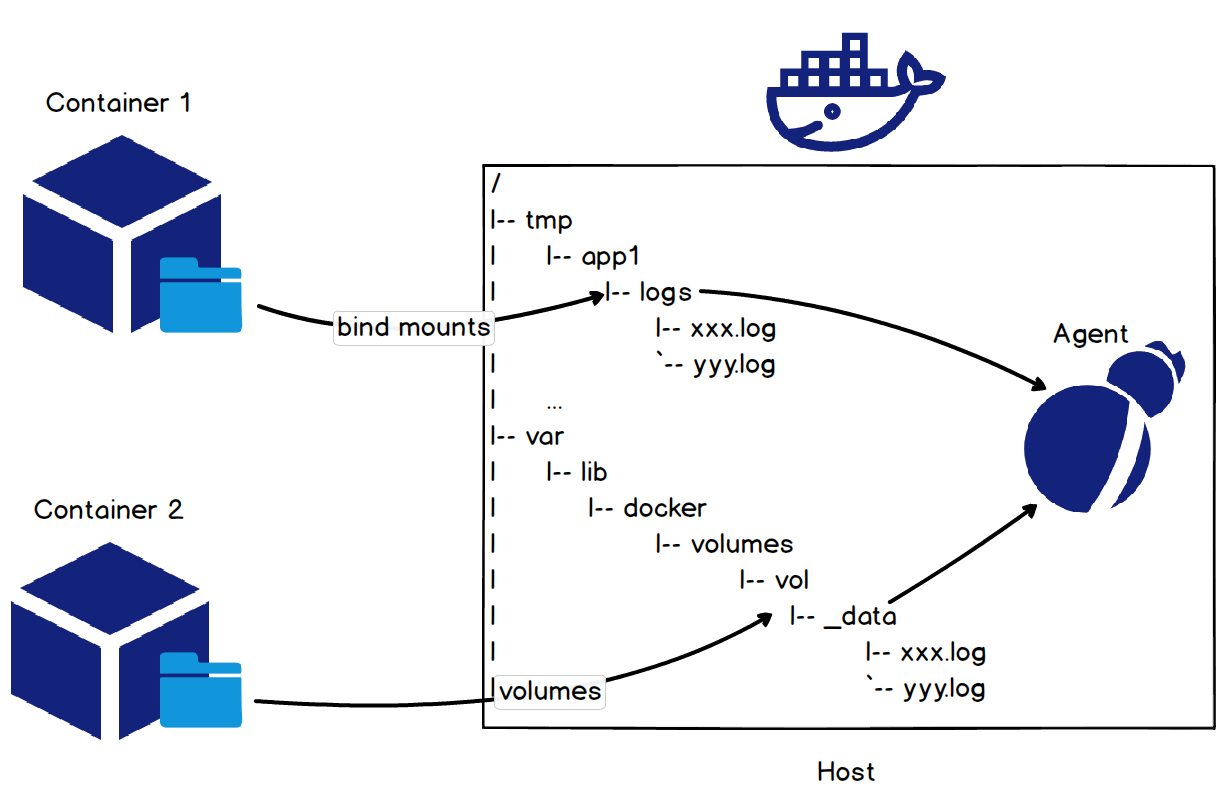
ホストファイルディレクトリのマウント
コンテナでテキストログファイルを収集する最も簡単な方法は、ホストファイルのディレクトリをコンテナのログのディレクトリにマウントすることです。これは、次の図のようにコンテナを起動したときにバインドマウントまたはボリュームメソッドを使用することで行うことができます。
Tomcatコンテナのアクセスログについては、
docker run -it -v /tmp/app/vol1:/usr/local/tomcat/logs tomcatというコマンドで、ホストファイルディレクトリ/tmp/app/vol1をコンテナのアクセスログディレクトリ/usr/local/tomcat/logsにマウントします。これにより、ホストファイルディレクトリ/tmp/app/vol1の下にログを収集することで、Tomcatコンテナのアクセスログを収集することができます。コンテナのマウントポイントを計算する Rootfs
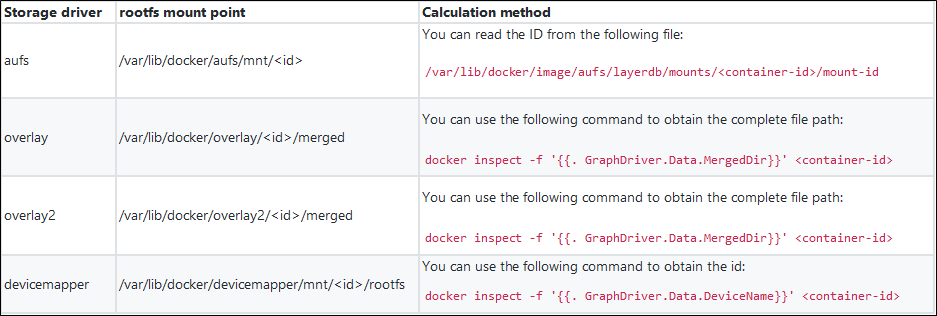
ホストファイルディレクトリをマウントしてコンテナのログを収集するのは、コンテナの起動時にマウントコマンドを実行する必要があるため、アプリケーションにとっては少し押し付けがましいです。ログ収集プロセスがユーザから透過的であれば、それは完璧です。実際、これはコンテナのrootfsのマウントポイントを計算することで実現できます。
ストレージドライバは、コンテナrootfsのマウントポイントと密接に関係する概念です。実際に使用する際には、Linuxのバージョンやファイルシステムの種類、コンテナのI/Oなど様々な要素を考慮して、最適なストレージドライバを選択することになります。ストレージドライバの種類からコンテナrootfsのマウントポイントを算出し、コンテナ内のログを収集することができます。以下の表に、いくつかのストレージドライバのrootfsのマウントポイントと計算方法を示します。
ログテールソリューション
ログサービスチームは、様々なコンテナログの収集方法を総合的に比較し、ユーザーの声や訴えをまとめて整理した上で、コンテナログを処理するためのオールインワンソリューションを開発しています。
特徴
Logtailソリューションには以下のような機能があります。
1、ホスト上のホストファイルとコンテナログの収集をサポートします(標準出力とログファイルを含む)。
2、コンテナの自動検出をサポートします。つまり、収集対象のログを設定した後、条件を満たすコンテナが作成されると、そのコンテナのターゲットログが自動的に収集されます。
3、Dockerラベルや環境変数のフィルタリングによるコンテナの指定に対応しています。ホワイトリスト、ブラックリストの仕組みをサポートしています。
4、データの自動タグ付けに対応しています。つまり、収集したログにコンテナ名、コンテナIPアドレス、ファイルパスなどのデータソース識別情報を付加します。
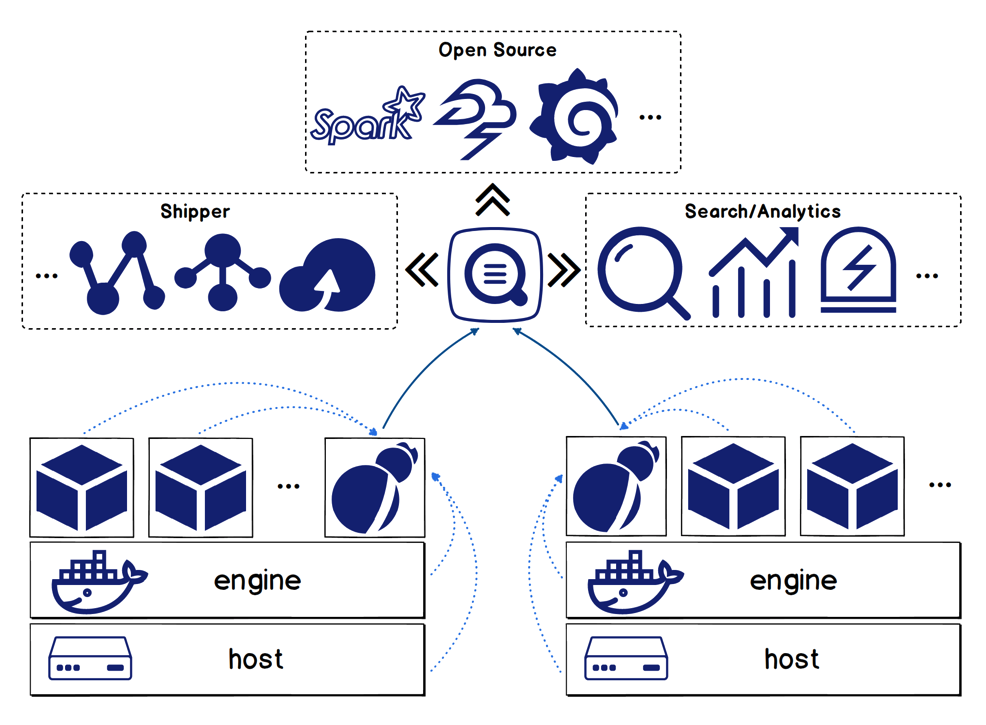
5、K8sコンテナログの収集に対応しています。コア競争力
1、チェックポイント機構を使用し、追加の監視プロセスを展開することで、アットリーストワンスのセマンティクスを確実にします。
2、Logtailは、複数のダブル11とダブル12のショッピングフェスティバルに耐え、アリババグループ内の100万以上のクライアントに導入されています。安定性とパフォーマンスが保証されています。K8sコンテナログ集
LogtailはK8sのエコシステムと深く連携しており、K8sのコンテナログを便利に収集することができます。これもLogtailの特徴です。
コレクション構成管理:
1、Webコンソールを介したコレクション構成管理をサポートします。
2、CustomResourceDefinition(CRD)によるコレクション構成管理をサポートします。この方法は、K8sのデプロイ・公開手順と容易に統合することができます。コレクションモード:
1、DaemonSetモードを利用したK8のコンテナログの収集をサポートします。このモードでは、すべてのノードが収集クライアントLogtailを実行します。このモードは単一機能クラスタに適しています。
2、SidecarモードによるK8sコンテナのログ収集をサポートします。このモードでは、各ノードの各コンテナがコレクションクライアントLogtailを実行します。このモードは、大規模、ハイブリッド、PaaSクラスタに適しています。
Logtailソリューションの詳細については、https://www.alibabacloud.com/help/doc-detail/44259.htm を参照してください。クエリ分析と可視化
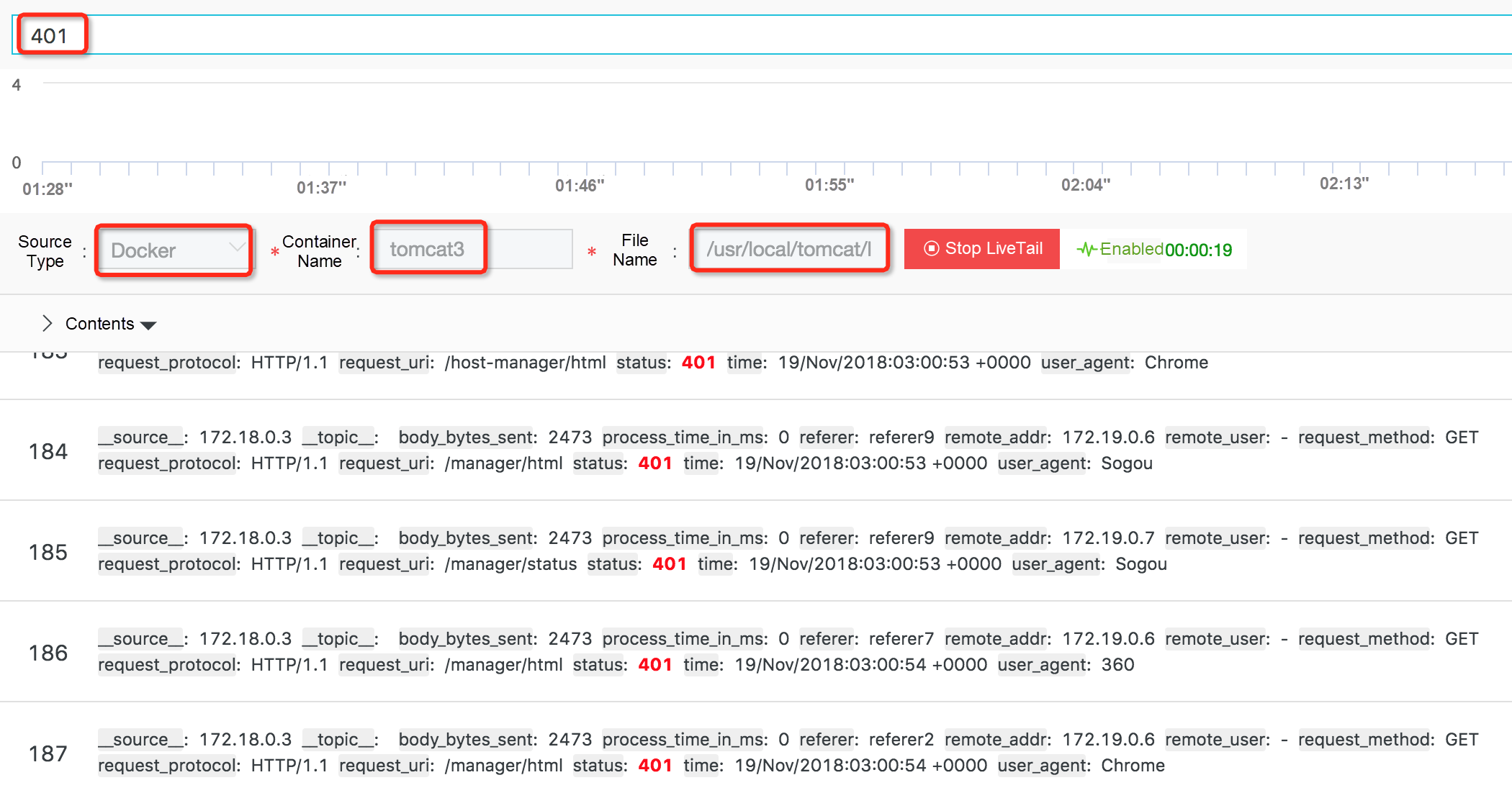
ログを収集した後は、これらのログに対してクエリ分析や可視化を行う必要があります。ここではTomcatコンテナのログを例に、Log Serviceが提供する強力なクエリ、分析、可視化機能について説明します。
保存された検索
コンテナログが収集されると、コンテナ名、コンテナIP、ターゲットファイルディレクトリなどのログ識別情報がこれらのログに添付されます。これにより、クエリを実行する際に、この情報に基づいてターゲット コンテナとファイルをすばやく見つけることができます。クエリ機能の詳細については、「クエリの構文」を参照してください。
リアルタイム分析
ログサービスのリアルタイム分析機能は、SQL構文に対応しており、200以上の集計機能を提供しています。SQL文の書き方を知っていれば、ビジネスニーズに合った分析文を簡単に書くことができます。例えば、以下のようになります。
1、以下のステートメントを使用して、アクセス回数の多いリクエストURIの上位10件をクエリすることができます。
* | SELECT request_uri, COUNT(*) as c GROUP by request_uri ORDER by c DESC LIMIT 10
- 以下のステートメントを使用して、最後の15分と最後の1時間の間のネットワークトラフィックの違いをクエリすることができます。
* | SELECT diff[1] AS c1, diff[2] AS c2, round(diff[1] * 100.0 / diff[2] - 100.0, 2) AS c3 FROM (select compare( flow, 3600) AS diff from (select sum(body_bytes_sent) as flow from log))本明細書では、対前年比較関数と対期間比較関数を用いて、異なる期間のデータ量を計算しています。
可視化
データを可視化するには、Log Serviceの複数の内蔵チャートを使用して、SQLの計算結果を視覚的に表示したり、複数のチャートを組み合わせてダッシュボードにしたりすることができます。
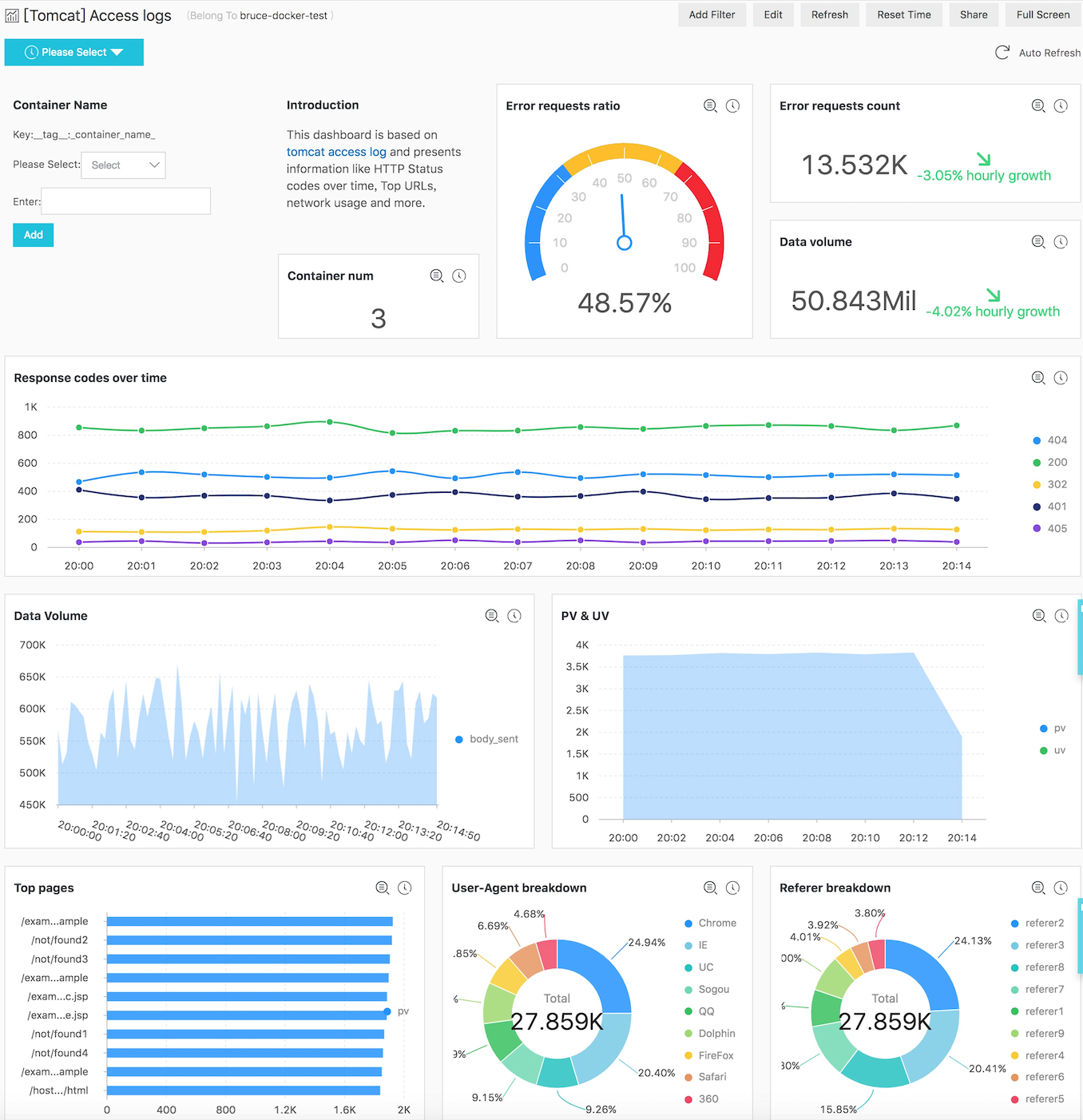
次の図は、Tomcatのアクセスログのダッシュボードです。このダッシュボードからは、エラーリクエストの割合やデータ量、レスポンスコードの経時変化など、様々な情報を見ることができます。このダッシュボードでは、複数のTomcatコンテナのデータを集計した結果を表示しています。また、ダッシュボードのフィルタ機能を利用してコンテナ名を指定することで、個別のコンテナのデータを表示することもできます。
ログの文脈分析
クエリ分析やダッシュボードなどの機能は、グローバルな情報を表示し、システム全体の運用状況を把握するのに役立ちます。しかし、特定の問題を特定するためには、通常、ログからコンテキスト情報が必要になります。
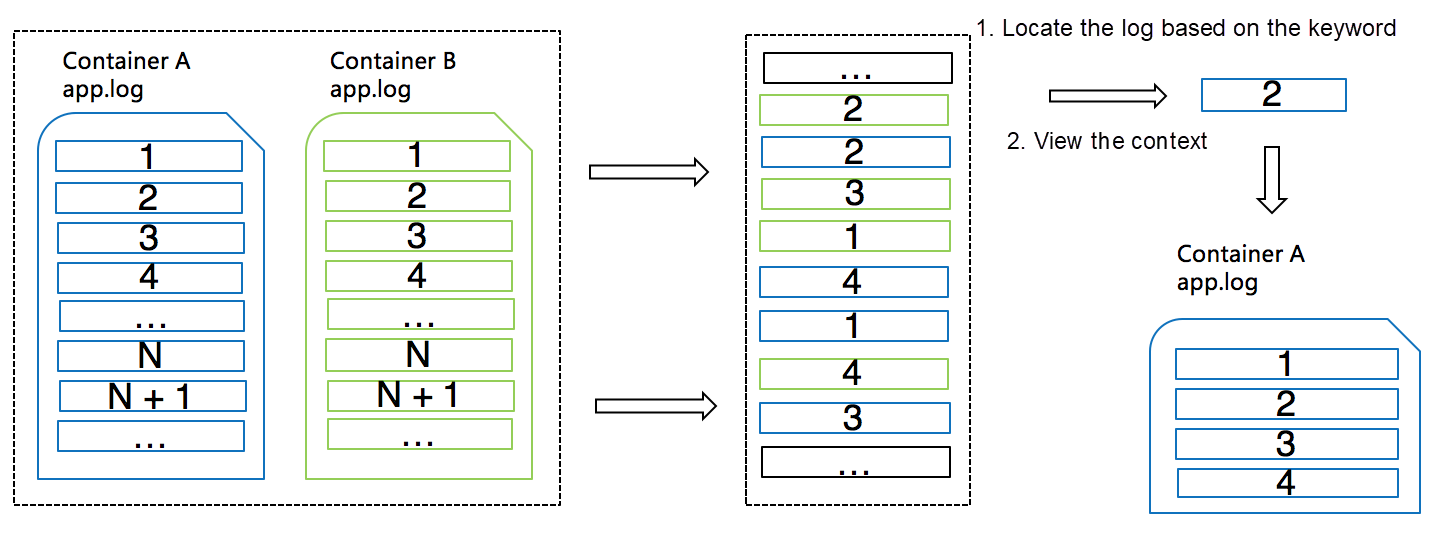
コンテキストの定義
コンテキストとは、ログのエラーの前後の情報など、問題の手がかりとなるものを指します。コンテキストには2つの要素が含まれます。
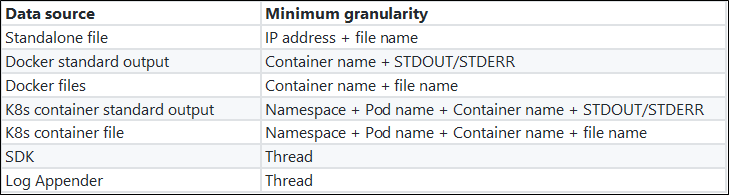
- 微分化の最小粒度:同じスレッドや同じファイルなど、コンテキストを区別するために使用される最小単位。この最小微分粒度は、調査中に集中できるため、問題の所在を特定する上で非常に重要です。
- オーダーの保証:同じ最小微分粒度であれば、毎秒何万もの操作が行われていても、情報は厳密な順序で提示されなければなりません。 次の表は、異なるデータソースの最小微分粒度を示しています。
コンテキストクエリの課題
ログの集中保管の背景には、ログ収集端末もサーバも元のログの順番を保つことができません。
1、クライアントレベルでは、同一ホスト上で複数のコンテナが稼働しており、各コンテナには収集対象のログファイルが複数存在します。ログ収集ソフトは、ログの解析や前処理に複数の CPU コアを使用しなければなりません。また、ネットワークデータを送信する際の遅いI/O問題に対処するために、マルチスレッド同時実行またはシングルスレッド非同期コールバックモードを使用しなければなりません。その結果、ログデータは、マシン上のイベント生成シーケンスに従ってサーバに到着することができません。
2、サーバ上では、水平拡張マルチノード負荷分散アーキテクチャのため、同じクライアントマシン上のログが複数のストレージノードに分散されてしまいます。複数のストレージノードに分散したログを元のシーケンスに戻すことは困難です。仕組み
ログ サービスは、各ログ レコードに追加情報を追加したり、サーバーのキーワード クエリ機能を使用したりすることで、これらの課題を効果的に解決します。次の図は、ログサービスがこれらの問題にどのように対処しているかを示しています。
1、ログレコードが収集されると、ログサービスは自動的にログのソース情報(前述の最小粒度)をsource_idとして追加します。コンテナの場合、そのような情報はコンテナ名とファイルパスになります。
2、ログサービスのログ収集クライアントは通常、ログパッケージとして複数のログを一度にアップロードします。クライアントは、これらのログパッケージのそれぞれに単調に増加するpackage_idを書き込み、ログパッケージの各ログレコードはパッケージベースのオフセットを持つ。
3、サーバは、source_id、package_id、オフセットをフィールドに結合し、このフィールドのインデックスを作成します。これにより、異なるタイプのログが混在してサーバーに保存されている場合でも、source_id、package_id、オフセットに基づいて正確にログエントリを見つけることができます。LiveTail - クラウド上のtail-f
ログコンテキストを見ることとは別に、コンテナの出力を継続的に監視したい場合もあります。
従来の方法
以下の表は、従来の方法でコンテナのログをリアルタイムに監視する方法を示しています。
問題点
コンテナのログを監視するために従来の方法を使用すると、以下のような問題点があります。
1、多数のコンテナの中から目的のコンテナを探すのは時間がかかる。
2、異なる種類のコンテナログを表示するために異なる観測方法を使用しなければならず、コストが増加する。
3、キー情報のクエリ結果の表示がシンプルで直感的ではない。新機能と仕組み
これらの問題を解決するために、ログサービスはLiveTail機能を提供しています。従来の方法と比較して、LiveTailには次のような利点があります。
1、1つのログエントリに基づいて、またはログサービスのクエリ分析機能を使用して、ターゲットコンテナを迅速に見つけることができます。
2、統一された方法を使用して、ターゲットコンテナに飛び込むことなく、異なるタイプのコンテナログを表示することができます。
3、キーワードベースのフィルタリングに対応しています。
4、キーカラムの設定をサポートしています。
LiveTailは、前のセクションで述べたようにコンテキストクエリのメカニズムを使用して、ターゲットコンテナとターゲットファイルを素早く見つけることができます。そして、クライアントは定期的にサーバーにリクエストを送り、最新のデータを引き出します。
参考文献
- https://www.alibabacloud.com/blog/trends-and-challenges-of-kubernetes-log-processing-for-serverless-kubernetes_593961
- https://www.alibabacloud.com/help/doc-detail/44259.htm
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ