- 投稿日:2020-08-05T17:52:05+09:00
tensorflow-gpuが動いたCUDA, cuDNNのバージョンのメモ
PyPIに置かれているtensorflow-gpuビルドが対応している
CUDA, cuDNNバージョンをメモするだけの記事です。新しいバージョンで動作を確認したらこの記事に追記していきます。
対応CUDA, cuDNN一覧
このページは個人が自分用メモとして作っていますので
tensorflow公式に記載がない場合のみ参考までにご覧ください。tensorflow公式
https://www.tensorflow.org/install/source#tested_build_configurationsWindwows10
tensorflow CUDA cuDNN 備考 2.3.0 10.1 7.6 手元環境で動作を確認 2.2.0 10.1 7.6 手元環境で動作を確認 2.1.0 10.1 7.6 Release Noteに記載あり 2.0.0 10.0 7.4 公式サイトに記載あり Ubuntu 18.04
tensorflow CUDA cuDNN 備考 2.3.0 10.1 2.2.0 10.1 7.6 手元環境で動作を確認 2.1.0 10.1 7.6 Release Noteに記載あり 2.0.0 10.0 7.4 公式サイトに記載あり バージョンについて
pip installでインストールされるtensorflow-gpuビルドは特定のバージョンのCUDAを参照するようになっているので、バージョンが違うCUDAを入れると動きません。
どのバージョンのtensorflow-gpuがどのバージョンのCUDAを使うようにビルドされているかは古いバージョンについてはこちらに一覧されているので問題ないんですが、2020年8月現在tensorflow 2.3.0までリリースされているのに一覧表には2.1.0までしか載ってません。
https://www.tensorflow.org/install/source#tested_build_configurationsじゃあRelease Notesに載ってるかというとtensorflow 2.1.0には対応CUDAバージョンが書かれているのにtensorflow 2.2以降のRelease Notesには載ってません。
https://github.com/tensorflow/tensorflow/releasesこれだと困るので新しいバージョンがちゃんと動いたらそのときのバージョンをメモしておこうというのがこの記事です。新しいバージョンについても新しい記事を書くんじゃなくてここに追記していきます。
自分で確認する方法
CUDAが入っていないかバージョンが適切でない場合、importした際に以下のようにエラーメッセージが出ます。その際に表示されるdllのファイル名でバージョンが分かります。以下ではcudart64_101.dllを読もうとしているのでおそらくCUDA10.1が必要なんだろうという感じです。
python>>> import tensorflow as tf 2020-08-05 00:33:55.037723: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'cudart64_101.dll'; dlerror: cudart64_101.dll not found 2020-08-05 00:33:55.037919: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.確認に使っている手元環境
Windows10
Anaconda3
Ryzen7-1700X
GTX-1080TiUbuntu18.04
Anaconda3
core i9-9900K
TitanV
- 投稿日:2020-08-05T12:45:47+09:00
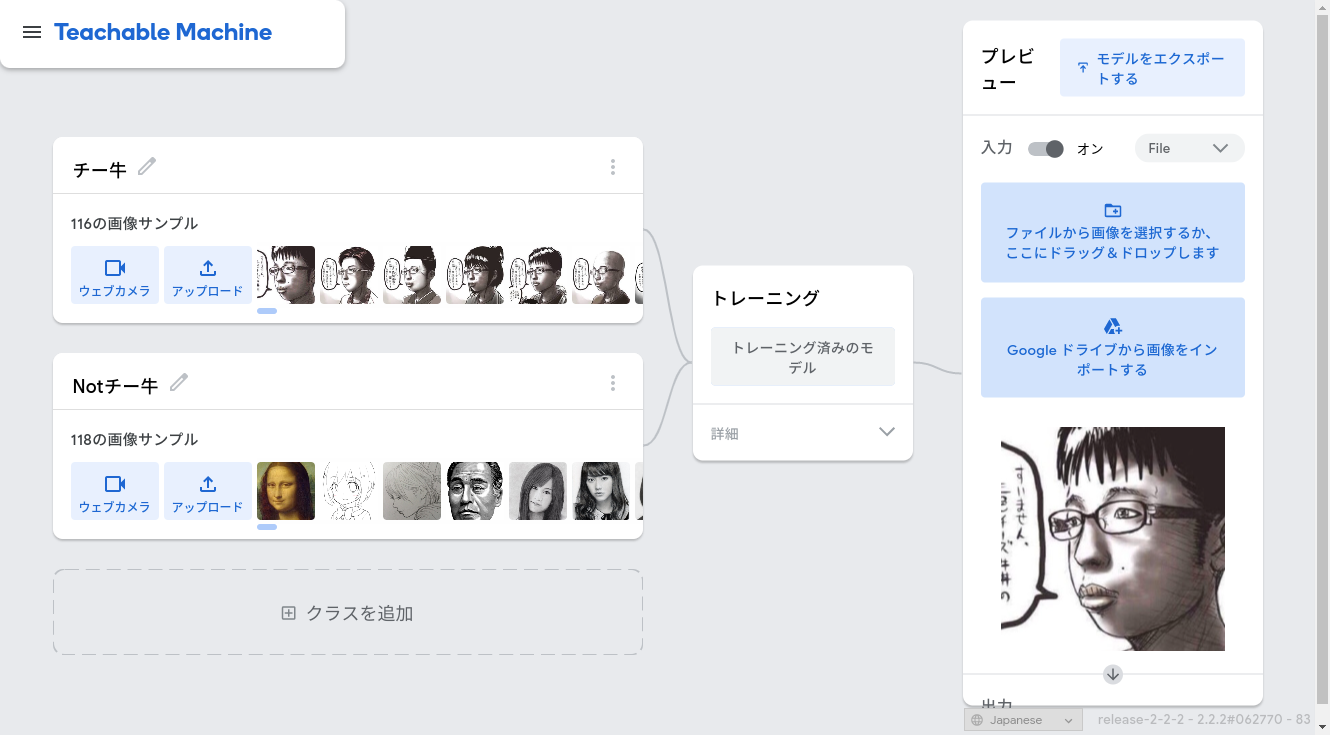
MobileNetでチー牛診断
- 投稿日:2020-08-05T09:26:21+09:00
Image Style Transferを実装した
本記事について
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)でGatysらによって発表された画像スタイル変換の論文「Image Style Transfer Using Convolutional Neural Networks」について内容の要約と実装(tensorflow2.1)を行った。
ソースコードはhttps://github.com/FaunieMuskie/ImageStyleTransfer にも。論文概要
本論文はニューラルネットワークによる画像スタイル変換の草分け的存在である。
本論文以前にも画像スタイルの変換、すなわち画像のテクスチャのみを転送する問題については考えられていたが、既存の手法はターゲット画像から低次元の画像特徴量を抽出するものであり、ターゲット画像の持つ意味的なコンテンツ(オブジェクトや風景)を抽出することができないという限界があった(例えばターゲット画像の粗いスケールを維持しながら高周波のテクスチャ情報を変換するアプローチ等が存在した)。
本論文は、高レベルの画像の意味抽出を行えるCNNを用いて、画像のコンテンツとスタイルを分けてモデル化した画像スタイル変換を初めて行ったものである。
手法と実装
この論文の主旨を簡単にまとめると、学習済みのVGG19を画像の特徴量抽出に用いて、入力画像のコンテンツ特徴量・スタイル特徴量が、それぞれ変換元コンテンツ画像のコンテンツ特徴量と、変換先スタイル画像のスタイル特徴量の両方に近づくように入力画像を学習することで、元のコンテンツ画像のコンテンツを保ったまま変換先スタイル画像のスタイルを持った画像を生成する、ということである。
アーキテクチャ
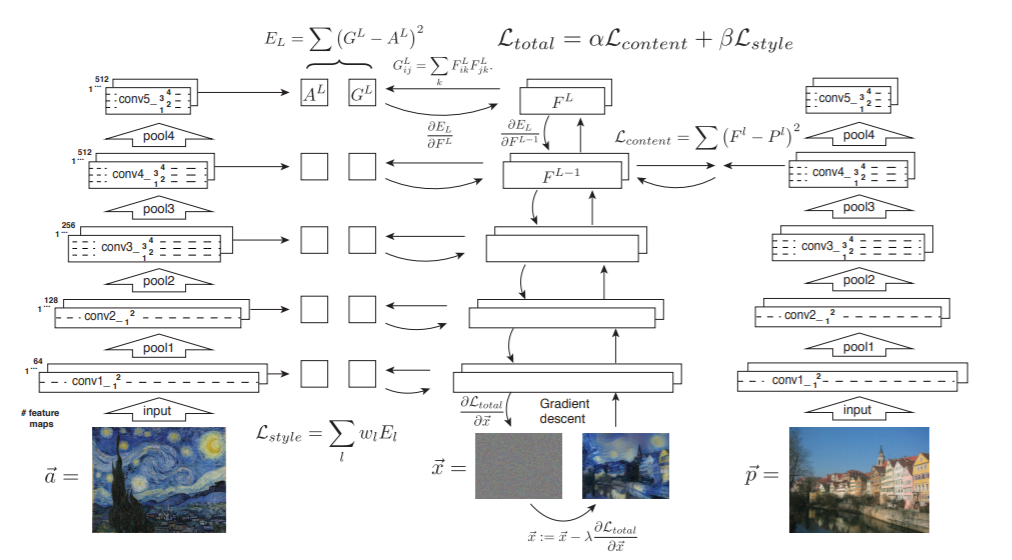
モデルのアーキテクチャは以下のようになる。
左の列はスタイル画像がVGG19に入力され各層($l=1..L$)でスタイル特徴量$A^l$が抽出される様子を表している。また、右の列はコンテンツ画像がVGG19に入力されある1層でコンテンツ特徴量$P^l$が抽出される様子を表している。そして、中央の列は入力画像がVGG19に入力されある層でコンテンツ特徴量$F^l$と各層でスタイル特徴量$G^l$が抽出され、コンテンツ画像のコンテンツ特徴量との2乗誤差と、スタイル画像のスタイル特徴量との2乗誤差を損失関数として、誤差逆伝搬法により入力画像が更新される様子を表している。import tensorflow as tf from tensorflow import keras from tensorflow.keras.applications.vgg19 import VGG19 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.vgg19 import preprocess_input from tensorflow.keras.models import Model from tensorflow.keras import losses import numpy as np import matplotlib.pyplot as plt model = VGG19(weights='imagenet', include_top=False)特徴量抽出
$l$層のコンテンツ特徴量$F^l$は、単純に入力に対する$l$層の出力から得られる。ただ、$l$層の出力は(特徴マップの高さ$H$)×(特徴マップの幅$W$)×(フィルタの数$N^l$)で出力されるので、(フィルタの数$N^l$)×(特徴マップのサイズ$M^l(=H・W)$)の2次元にしたものが$F^l$である。
一方、スタイル特徴量$G^l$は$F^L$のグラム行列で得られる。
$$ G^l_{ij} = \sum_{k} F^l_{ik} F^l_{jk}$$
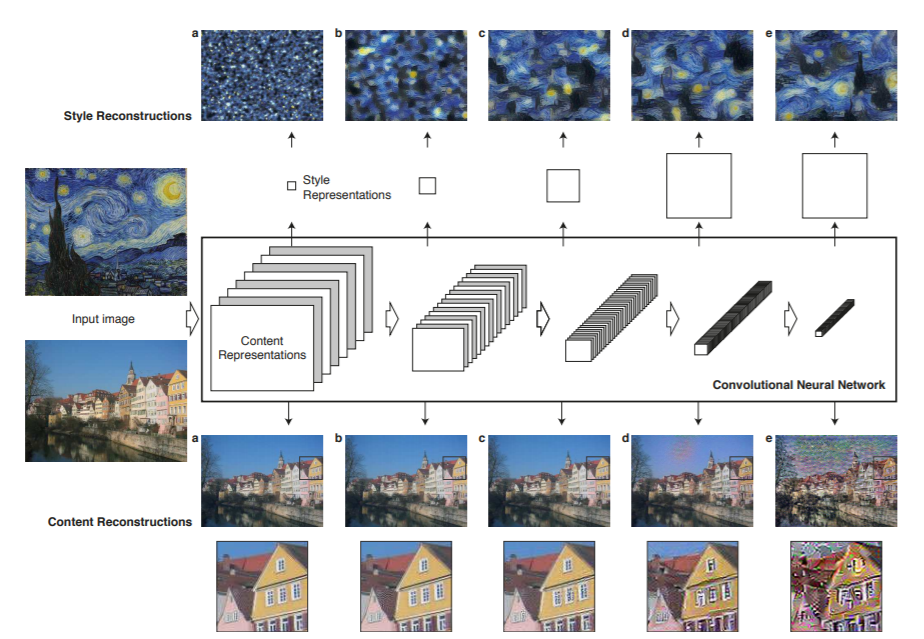
実際にこれらの特徴量の表現がどのようなものかを表したものが以下の図であり、コンテンツの特徴が高いレイヤーでも表現されていることや、層の深さによってスタイルの異なる特徴が表現されていることが分かる。
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers]) feature_extractor = Model(inputs=model.inputs, outputs=outputs_dict) def reshape_f(x): x=tf.reshape(x,[tf.shape(x)[0]*tf.shape(x)[1],tf.shape(x)[2]]) x=tf.transpose(x) return x def make_con_feature(tef,layer): con_feature=feature_extractor(tef)[layer][0,:,:,:] con_feature=reshape_f(con_feature) return con_feature def make_st_feature(tef,layer): matrix=make_con_feature(tef,layer) st_feature = tf.matmul(matrix, matrix, transpose_b=True) return st_feature損失関数
コンテンツの損失関数$L_{content}$は
$$ L_{content} = \frac{1}{2} \sum_{i,j} (F^l_{ij}-P^l_{ij})$$
スタイルの損失関数$L_{style}$は、あるレイヤーでの損失
$$ E_l = \frac{1}{4N^2_lM^2_l} \sum_{i,j} (G^l_{ij}-A^l_{ij})$$
を重み$w_l$で足し合わせて
$$ L_{style} = \sum^L_{l=0} w_l E_l $$
とする。
トータルでの損失関数はそれぞれに係数$\alpha,\beta$をかけて足した、
$$ L_{total} = \alpha L_{content} + \beta L_{style}$$
とする。def con_loss(con_feature,gen_con_feature): nu = tf.reduce_sum(tf.square(con_feature - gen_con_feature)) de = tf.constant(2.0) return tf.divide(nu,de) def single_style_loss(st_feature,gen_st_feature,M): nu=tf.reduce_sum(tf.square(st_feature - gen_st_feature)) de= tf.constant(4.0) * tf.cast(tf.square(tf.shape(st_feature)[0]),tf.float32) * tf.cast(M,tf.float32) # tf.cast(tf.square(M),tf.float32)にするとMが大きいとき動かないのでMを2回に分けて割った return tf.divide(tf.divide(nu,de),tf.cast(M,tf.float32)) def style_loss(st_tf,gen_tf): st_loss=tf.zeros(shape=()) for layer in st_layers: st_feature=make_st_feature(st_tf,layer) gen_st_feature=make_st_feature(gen_tf,layer) M=tf.shape(make_con_feature(st_tf,layer))[1] st_loss=st_loss+single_style_loss(st_feature,gen_st_feature,M)/len(st_layers) return st_loss def total_loss(gen_tf,a,b): con_feature=make_con_feature(con_tf,con_layer) gen_con_feature=make_con_feature(gen_tf,con_layer) cl=con_loss(con_feature,gen_con_feature) sl=style_loss(st_tf,gen_tf) return a*cl+b*sl勾配計算
通常の機械学習と異なり、重みではなく入力に対する損失関数の勾配を求める。
@tf.function def grad_and_loss(gen_tf): with tf.GradientTape() as tape: loss=total_loss(gen_tf,con_weight,st_weight) grad = tape.gradient(loss, gen_tf) return grad,loss実装結果
アーキテクチャの図では初期入力画像がホワイトノイズ画像にしているが、収束を早くするためにコンテンツ画像を初期入力に用いた。また、元論文ではmax_poolingではなくaverage_poolingを推奨し、最適化の手法はSGDではなくL-BFGSを推奨していた。
元画像


変換後
若干絵ぽくはなったが、イテレーションが足りなかったり、重みの係数の値が微妙なのかもしれない。con_input_path = 'elephant.jpg' st_input_path='gogh.jpg'con_input = image.load_img(con_input_path, target_size=(224, 224)) keras.preprocessing.image.save_img('content.png', con_input) con_input = image.img_to_array(con_input) con_input = np.expand_dims(con_input, axis=0) con_input = preprocess_input(con_input) st_input = image.load_img(st_input_path, target_size=(224, 224)) plt.imshow(st_input) keras.preprocessing.image.save_img('style.png', st_input) st_input = image.img_to_array(st_input) st_input = np.expand_dims(st_input, axis=0) st_input = preprocess_input(st_input)gen_tf=tf.Variable(gen_input) con_tf=tf.Variable(con_input) st_tf=tf.Variable(st_input) con_layer='block4_conv2' st_layers=['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1'] con_weight=1e-9 st_weight=1e-6 iterations = 1000optimizer = keras.optimizers.SGD( keras.optimizers.schedules.ExponentialDecay( initial_learning_rate=100.0, decay_steps=100, decay_rate=0.96 ) ) for i in range(1, iterations + 1): grad,loss = grad_and_loss(gen_tf) optimizer.apply_gradients([(grad, gen_tf)]) if i% 100 == 0: print("Iteration %d: loss=%.2f" % (i, loss)) result = gen_tf[0,:,:,:].numpy() keras.preprocessing.image.save_img('result.png', result)まとめ
・Image Style Transferについて論文を読み実装した。
・「Image Style Transfer Using Convolutional Neural Networks」は画像スタイル変換について初めてニューラルネットワークによるアプローチを用い、良い結果をだした。
・本論文を実装する際は、損失関数を自作し入力に対する勾配を求める必要がある。
・結果は微妙だったので、ハイパーパラメータの調節が必要かもしれない。また時間があればVGGのデフォルト入力より大きい画像に対応させたい。期限内に記事を書いて出すため、以上。


- 投稿日:2020-08-05T02:43:04+09:00
StyleGAN2で未知のポケモンを生み出す[後編]
前回は概要や生成結果を示しました.今回は実際にGTX1070で動かすためにStyleGAN2の公式実装から変更した点などを紹介します.
諸事情で学習済みモデルが吹っ飛んだので,その辺の注意も含めてかいておきます!
公式実装の変更点
実際にいじったのは主にrun_training.pyとtraining/dataset.pyです.
モデルのデータはだいたい300MBくらいあってかなり重いので,保存頻度を考えないと容量が尽きて学習が終わります.僕の場合,途中で学習が止まった上にモデルを上書きする設定にしていたため空上書きされて二日分の学習済みモデルが吹っ飛びました.定期的に複数のモデルで保存することをお勧めします.
run_training.pydef run(...): ... # 生成サンプルはtickごとに出力・ネットワークは5tickに一回 train.image_snapshot_ticks = 1 train.network_snapshot_ticks = 5 # 今回は画像サイズ64でモデルを作成 dataset_args = EasyDict(tfrecord_dir=dataset, resolution = 64)こちらで紹介されていたメモリエラーの解消のための修正
training/dataset.pyclass TFRecordDataset: def __init__(...): ... # Load labels. assert max_label_size == 'full' or max_label_size >= 0 #self._np_labels = np.zeros([1<<30, 0], dtype=np.float32) self._np_labels = np.zeros([1<<20, 0], dtype=np.float32)また,GPUの処理が長くなりすぎると学習タスクがキルされてしまいます.僕もこれにやられました.対策としてはDWORD値の設定でタイムアウトを切ればいいみたいです.(http://www.field-and-network.jp/rihei/20121028223437.php)
学習前に設定しておくことをお勧めします.モデルの評価指標・学習の様子の監視
GANの定量的評価は難しい課題の一つですが,多くの研究ではFID(Frechet Inception Distance)と呼ばれる手法で生成画像の品質を評価しています.データセットの画像と生成画像を特徴量抽出モデルに入力して,その特徴量の分布間のFrechet距離を計算する手法です.
扱う多変量正規分布の次元数の関係でデータセットを最低でも4000枚程度はデータセットと生成画像から画像を用意する必要があり,特にデータセットの読み込みに時間がかかります.この処理を抜くと指標がなくなるので学習をいつ止めていいかもわからないので消せませんが,高速化できないものでしょうか...
FIDはresults/.../metrix-fid50k.txtに出力されていくので,順調に学習が進んでいるか定期的に確認していくことになります.
metrix-fid50k.txtnetwork-snapshot- time 19m 34s fid50k 278.0748 network-snapshot- time 19m 34s fid50k 382.7474 network-snapshot- time 19m 34s fid50k 338.3625 network-snapshot- time 19m 24s fid50k 378.2344 network-snapshot- time 19m 33s fid50k 306.3552 network-snapshot- time 19m 33s fid50k 173.8370 network-snapshot- time 19m 30s fid50k 112.3612 network-snapshot- time 19m 31s fid50k 99.9480 network-snapshot- time 19m 35s fid50k 90.2591 network-snapshot- time 19m 38s fid50k 75.5776 network-snapshot- time 19m 39s fid50k 67.8876 network-snapshot- time 19m 39s fid50k 66.0221 network-snapshot- time 19m 46s fid50k 63.2856 network-snapshot- time 19m 40s fid50k 64.6719 network-snapshot- time 19m 31s fid50k 64.2135 network-snapshot- time 19m 39s fid50k 63.6304 network-snapshot- time 19m 42s fid50k 60.5562 network-snapshot- time 19m 36s fid50k 59.4038 network-snapshot- time 19m 36s fid50k 57.2236 network-snapshot- time 19m 40s fid50k 56.9055 network-snapshot- time 19m 47s fid50k 56.5965 network-snapshot- time 19m 34s fid50k 56.5844 network-snapshot- time 19m 38s fid50k 56.4158 network-snapshot- time 19m 34s fid50k 54.0568 network-snapshot- time 19m 32s fid50k 54.0307 network-snapshot- time 19m 40s fid50k 54.0492 network-snapshot- time 19m 32s fid50k 54.1482 network-snapshot- time 19m 38s fid50k 53.3513 network-snapshot- time 19m 32s fid50k 53.8889 network-snapshot- time 19m 39s fid50k 53.5233 network-snapshot- time 19m 40s fid50k 53.9403 network-snapshot- time 19m 43s fid50k 53.1017 network-snapshot- time 19m 39s fid50k 53.3370 network-snapshot- time 19m 36s fid50k 53.0706 network-snapshot- time 19m 43s fid50k 52.6289 network-snapshot- time 19m 39s fid50k 51.8526 network-snapshot- time 19m 35s fid50k 52.3760 network-snapshot- time 19m 42s fid50k 52.7780 network-snapshot- time 19m 36s fid50k 52.3064 network-snapshot- time 19m 42s fid50k 52.4976もし学習が途中で止まってしまったら
僕のように何らかのエラーで学習が止まってしまった場合,results以下に保存されているnetwork-snapshot-*.pklのモデルを読み込むことでそこから学習をやり直すことができます.
必要な記述は以下の通り.run_training.pydef run(...): ... train.resume_pkl = "./results/00000-stylegan2-tf_images-1gpu-config-f/network-snapshot-00640.pkl" train.resume_kimg = 640 train.resume_time = 150960train.resume_timeはlog.txtなどからモデルが保存されたときに出力されている計算時間をsecに直して入力すれば大丈夫です.
多分転移学習も同様に手法で,学習済モデルを指定してあげればできると思います.重みの固定化とか細かいことはモデルを読み込んでから手動で設定する必要があります.今回みたいなタスクで転移させる場合には全部再学習してしまってもいい気がしてますが...
log.txtdnnlib: Running training.training_loop.training_loop() on localhost... ... tick 40 kimg 640.1 lod 0.00 minibatch 32 time 1d 17h 56m sec/tick 2588.1 sec/kimg 161.76 maintenance 1203.1 gpumem 5.1僕が学習できたところまでの結果
640kimgでストレージ不足で落ちました(泣)
いい感じにFIDが下がっていたので悲しすぎます.
結構輪郭もはっきりしてきて,体の形だけじゃなくて顔みたいなものも再現され始めてますね.
早くこの先の学習結果が見たいのですが,学習し直しているので当分先になりそうです.学習が進み次第結果を追記します.
本家の実装からの変更点をすべて紹介しきれているか不安なので,コードを以下に挙げておきました.使い方もGitHubに書いてあるのでどうぞ.
https://github.com/Takuya-Shuto-engineer/PokemonGAN
参考文献
- https://qiita.com/MuAuan/items/477f72872fd33cce7949
- http://blog.livedoor.jp/tak_tak0/archives/52424358.html
- http://www.field-and-network.jp/rihei/20121028223437.php
- https://github.com/NVlabs/stylegan2
- https://blog.narumium.net/2020/07/16/windows10%E3%81%A7stylegan2%E3%82%92%E4%BD%BF%E3%81%A3%E3%81%9F%E7%94%BB%E5%83%8F%E7%94%9F%E6%88%90%EF%BC%88%E5%AE%9F%E8%B7%B5%E7%B7%A8%EF%BC%92%EF%BC%89/
