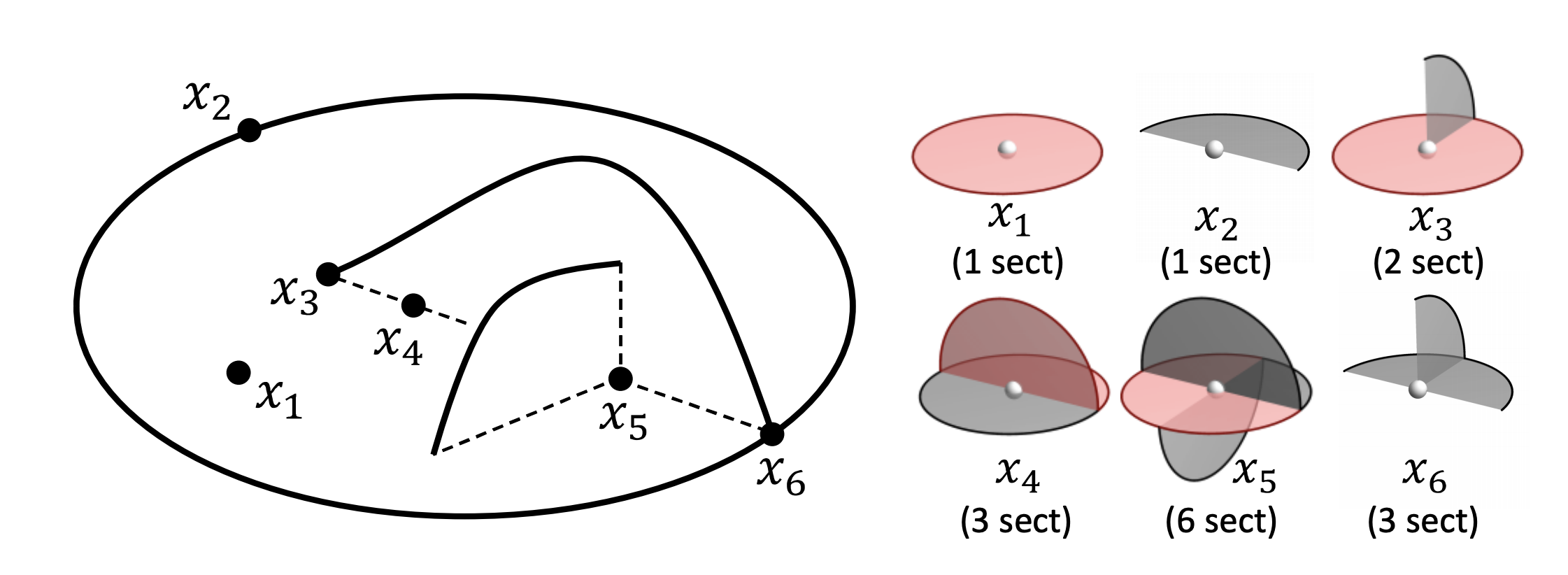
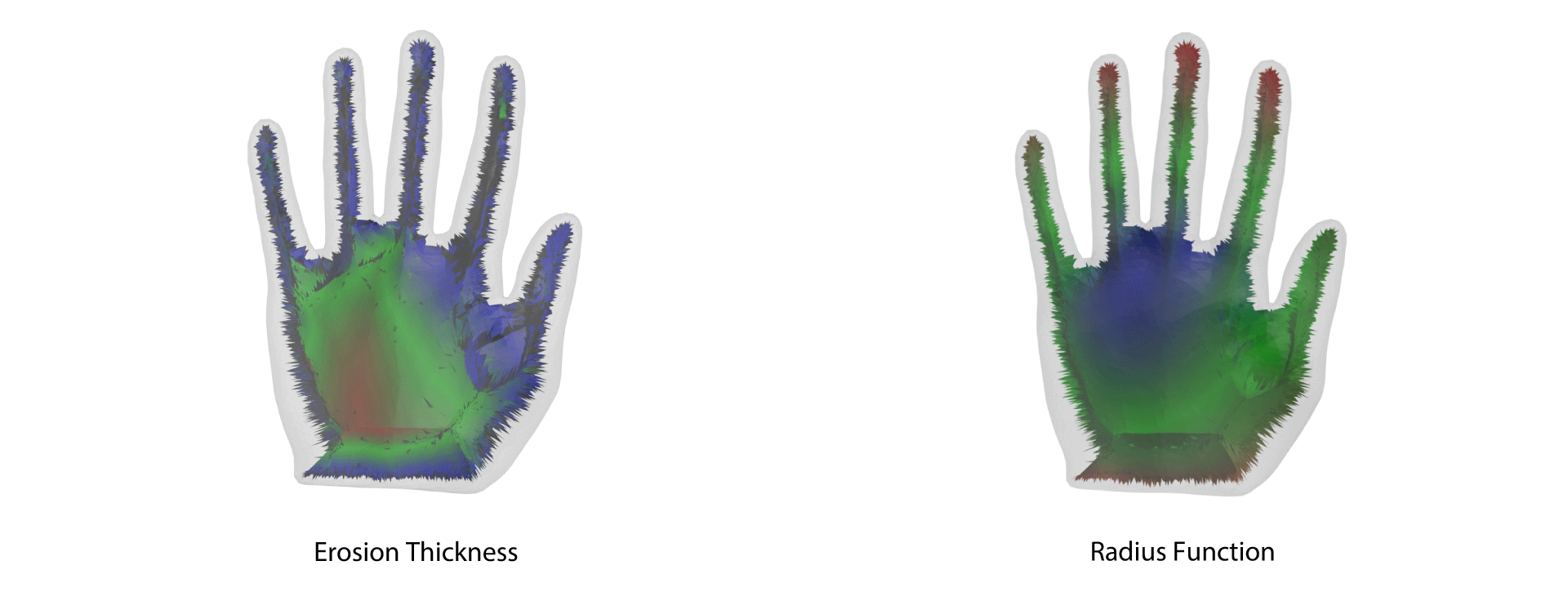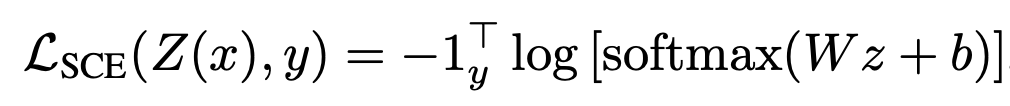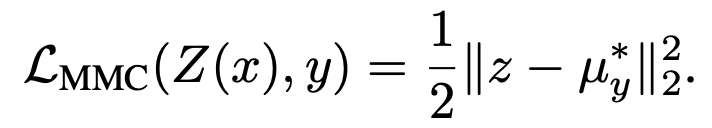Yajie Yan, Kyle Sykes Erin Chambers, David Letscher, Tao Ju. Erosion Thickness on Medial Axes of 3D Shapes. ACM Transactions on Graphics, SIGGRAPH 2016. DOI:https://doi.org/10.1145/2897824.2925938↩
Tamal K. Dey, Hyuckje Woo, and Wulue Zhao. 2003. Approximate medial axis for CAD models. In Proceedings of the eighth ACM symposium on Solid modeling and applications (SM ’03). DOI:https://doi.org/10.1145/781606.781652↩
Tamal K. Dey and Jian Sun. 2006. Defining and computing curve-skeletons with medial geodesic function. In Proceedings of the fourth Eurographics symposium on Geometry processing (SGP ’06). ↩
Lu Liu, Erinn W. Chambers, David Letscher, Tao Ju. 2011. Extended grassfire transform on medial axes of 2D shapes. Computer-Aided Design. DOI:https://doi.org/10.1016/j.cad.2011.09.002↩
fromitertoolsimportaccumulateimportmathm=10**5L=[xforxinrange(2,m+1)]#エラトステネスのふるいで素数を抽出
foryinrange(2,int(math.sqrt(m)+1)):L=[zforzinLif(z==yorz%y!=0)]#N+1/2も素数であるものを抽出
P=[]forwinL:if(w+1)/2inL:P.append(w)#累積和のために作成
G=[0]*(m+1)foriinP:G[i+1]=1#累積和
Q=list(accumulate(G))n=int(input())for_inrange(n):s,t=map(int,input().split())print(Q[t+1]-Q[s])'''
以下の素数判定は遅い。
上のようにエラトステネスの篩を使う
def isPrime(n):
if n == 1:
return False
if n % 2 == 0:
return False
for i in range(3, int(math.sqrt(n)+1), 2):
if n % i == 0:
return False
return True
'''
3.今回は、Freenomなので、Freenom上でNameServer(Mydomain>Managing domain>ManagementTools)よりNameServerをcloudflareに記載されているものに変更 今回の相違点
4.herokuに変更を適用させる。参考文献では、「Personal>'appName'>Setting>Domains and cerfificates 」とありましたが、私の方ではDomains and cerfificatesは確認できず、別個でした。
そのため、Personal>'appName'>Setting>Domains」から独自ドメインを適用しました。
Python + Seleniumで「Message: session not created」が発生した場合
PythonでSeleniumを動かしている時に「Message: session not created」が発生して、気づいたら数時間エラー解決に掛かっていました。
このエラーをググると大体「Chromeのバージョン」と「Chrome-driverのバージョン」違いで発生するという情報が出てきますが、今回自分が経験したパターンは異なっていたので、備忘録として残しておきたいと思います。
[root@v111-111-111-11 html]# python3 run.py
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/selenium/webdriver/chrome/webdriver.py", line 81, in __init__
desired_capabilities=desired_capabilities)
File "/usr/local/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 157, in __init__
self.start_session(capabilities, browser_profile)
File "/usr/local/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 252, in start_session
response = self.execute(Command.NEW_SESSION, parameters)
File "/usr/local/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute
self.error_handler.check_response(response)
File "/usr/local/lib/python3.7/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.SessionNotCreatedException: Message: session not created
from disconnected: Unable to receive message from renderer
(Session info: headless chrome=80.0.3987.122)
for i in range(len(hoge)):の場合、iはhogeがどんなものであろうとただのインデックスでしかない。しかし、for i in hoge:と書くと、iはhogeの各要素が入ることになる。
例えば、hoge = schoolsという2次元配列があり、その要素を全て出力するコードを以下の2通りで書いてみる。
hogeがもしイテレータだったとしたらTypeError: object of type 'generator' has no len()のようなエラーが生じるため、lenは使えない。よって、for i in hoge:と書かなければならない。ここで、イテレータではないlistやstrなどの場合もfor i in hoge:と書くとコードに一貫性が生じる。
そもそも、Pythonのfor文はイテレータであってもイテレータでなくても、内部的にはiter(hoge)でinの後ろに置いたイテラブルオブジェクトはイテレータ化され、next(hoge)を繰り返すという動作は全く同じである。そのため、listやstrなどの場合もあたかもイテレータであるかのように実装する方が自然に感じる。
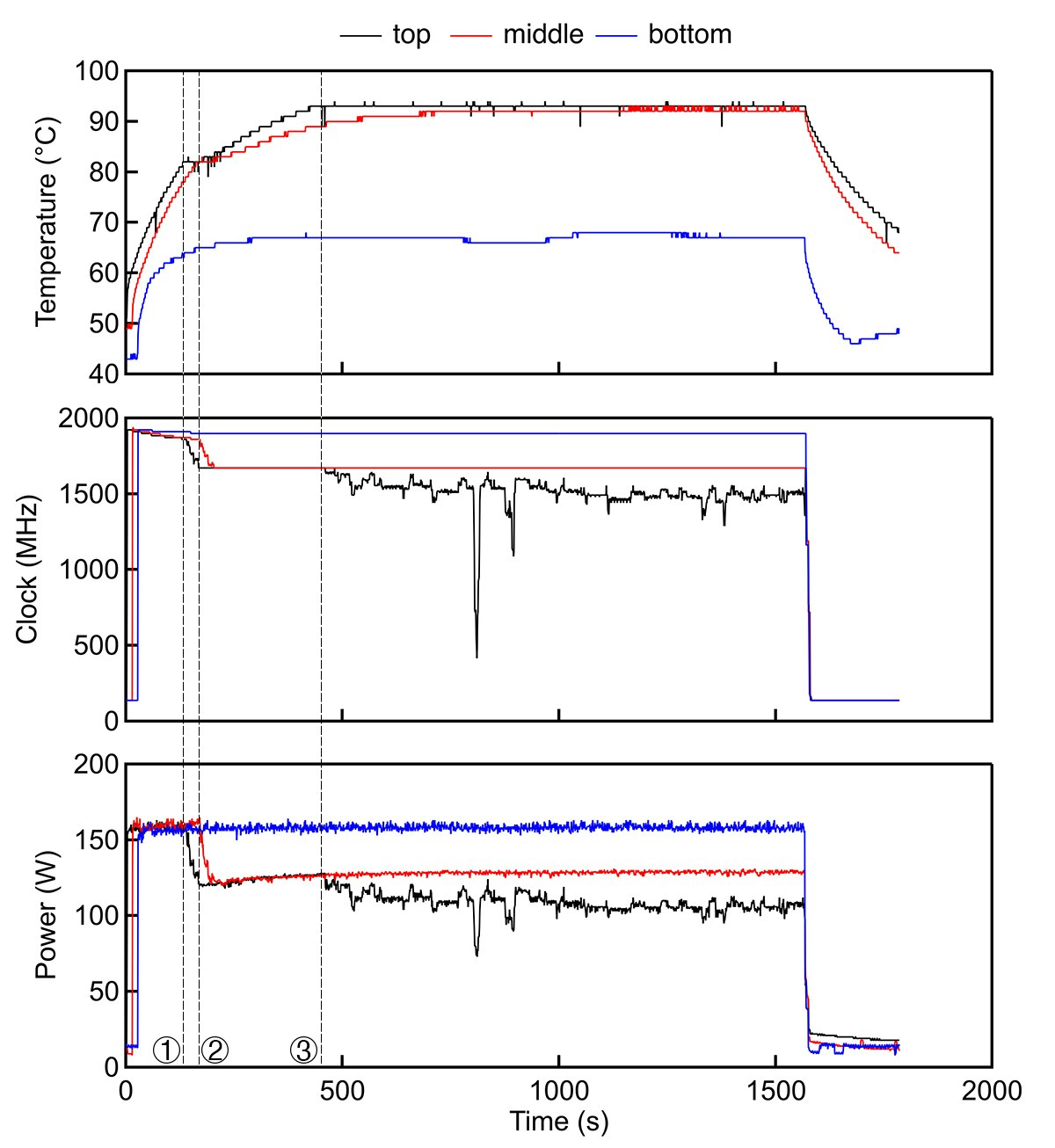
とりあえず最初に自作したGPUマシンがこちら(以下、"空冷マシン")。
ASUS STRIX-GTX1080-A8G-GAMING(コアクロック: Base 1,670MHz /Boost 1,809MHz)を3枚積んで、無駄にでかいCPUクーラーまで積んでます。この時点で、外排気のGPUにしろよと言われそうですが、そんなことは買ったときは知らなかったのです。内排気のGPUを3枚も隙間なく重ねたことによって今回の熱問題が発生してしまっていることは否めないでしょう。ってことでGPUを複数枚ケース内に収めようと思っている人は、少なくとも外排気のGPUを購入したほうがよいでしょう。
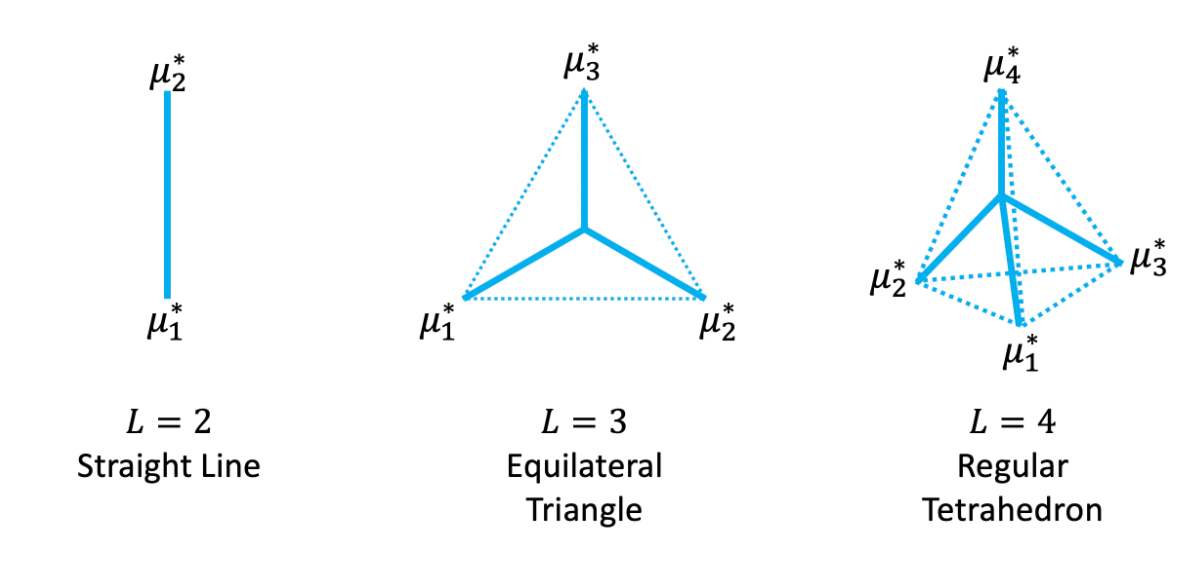
"Rethinking Softmax Cross-Entropy Loss for Adversarial Robustness (ICLR2020)"の解説とPytorchによる実装
ICLR2020においてposter発表された、"Rethinking Softmax Cross-Entropy Loss for Adversarial Robustness" 1の解説と実装を行っていきたいと思います!
この論文は、著者の前の論文"Max-Mahalanobis linear discriminant analysis networks"(ICML2018) 2の進化版となっています。
defgenerate_opt_means(C,p,L):"""
input
C = constant value
p = dimention of feature vector
L = class number
output
MMD (shape=(L,p))
"""opt_means=np.zeros((L,p))opt_means[0][0]=1foriinrange(1,L):forjinrange(i):opt_means[i][j]=-(1/(L-1)+np.dot(opt_means[i],opt_means[j]))/opt_means[j][j]opt_means[i][i]=np.sqrt(1-np.linalg.norm(opt_means[i])**2)forkinrange(L):opt_means[k]=C*opt_means[k]returnopt_means
classdot_loss(nn.Module):def__init__(self):super(dot_loss,self).__init__()defforward(self,y_pred,y_true):y_true=F.one_hot(y_true,num_classes=y_pred.size(1)).double()loss=-torch.sum(y_pred*y_true,dim=1)#batch_size X 1
returnloss.mean()