- 投稿日:2020-08-04T23:37:44+09:00
【機械学習】カーネル密度推定を使った教師あり学習 その3
カーネル密度推定を使った教師あり学習
この記事は機械学習の初心者が書いています。
予めご了承ください。この記事では、着想の背景を数式を用いて説明します。
確率密度と確率
カーネル密度推定はカーネル関数で確率密度関数を推定することでした。
それでは確率密度関数とは、一体なんだったでしょうか?確率密度関数は出やすさの分布を表しています。
事象Aについて、値xで確率密度が高いとは事象Aが起きたとき、そのときの値がxである確率が相対的に高いということです。
「事象A」を「ラベル0」と置き換えてみましょう。
「値xでは、ラベル0である確率密度が高い」とは「あるデータがラベル0だったとき、そのデータが値xである確率が相対的に高い」という意味になります。ここで、確率密度≠確率であることに注意しなければいけません。
確率密度は「特定の事象に対する相対的な出やすさ」であり、他の事象の確率密度と比較できる保障はありません。
そもそも連続データにおいて、特定の値が出る確率は定義されていません。
ある程度の幅がないと確率は計算できないのです。P(X=x)=0 \\ P(X \leqq x)=p確率密度関数を積分すると、その区間(2次元以上なら領域)における確率を求めることができます。
つまり特定の値「の近く」の確率は計算できるわけです、おそらく。
値xの確率密度が高ければ値x「の近く」が出る確率は高く、値xの確率密度が低ければ値x「の近く」が出る確率も低くなります。一つ例をあげて考えてみたいと思います。
値xでは、ラベル0の確率密度よりラベル1の確率密度のほうが高いです。
このとき、
- ラベルが0のときに値x「の近く」が出る確率
- ラベルが1のときに値x「の近く」が出る確率
どちらが高いでしょうか?
厳密ではありませんが、直感的に後者のほうが高いと思われます(雑)。
今後この直感が正しいものとして議論を進めます。「ラベルが0」を「y=0」、「ラベルが1」を「y=1」と書き直しましょう。
すると、ここまでの話は値xにおけるラベル0の確率密度 \leqq 値xにおけるラベル1の確率密度 \\ \Rightarrow y=0のときに値xが出る確率 \leqq y=1のときに値xが出る確率 \\ \Rightarrow P(x|y=0) \leqq P(x|y=1)とまとめられます。
ただし、正確には値x「の近く」です。条件付き確率とベイズの定理
値xについて、
P(y=0|x) \leqq P(y=1|x)が成り立てば、ラベル0ではなくラベル1を割り当てるのが妥当だと言えます。
したがって「値xを取り出す」という条件のもとで「ラベル0 or ラベル1である」確率、条件付き確率を求めることができたら優勝です。この不等式をベイズの定理を用いて書き直してみます。
P(y=0|x) \leqq P(y=1|x) \\ \Leftrightarrow \frac{P(x|y=0)P(y=0)}{P(x)} \leqq \frac{P(x|y=1)P(y=1)}{P(x)}分母のP(x)は共通していて、0以上です。
結局、P(x|y=0)P(y=0) \leqq P(x|y=1)P(y=1)を示すことができれば
P(y=0|x) \leqq P(y=1|x)が成り立つことが言えます。
いまカーネル密度推定を使ってP(x|y=0) \leqq P(x|y=1)であることがわかっています。
したがってP(y=0)とP(y=1)の値を知ることができれば決着がつきます。ラベル比の推定
P(y=0)は「あるデータを選んだところ、それがラベル0である確率」と解釈できます。
母集団のP(y=0)とP(y=1)を求めることは容易ではありません。
そこで、教師データのラベルの構成比をP(y=0)とP(y=1)の推定値にします。
100件の教師データのうち、40件がラベル0、60件がラベル1ならP(y=0)=0.4\\ P(y=1)=0.6と推定します。
実は、私が過去の記事で実装した分類器ではP(y=0)とP(y=1)の影響を無視していました。
「各ラベルの比が等しい」という強い仮定を置いていたのです。再実装
これまでの説明をもとに、もう一度オブジェクト指向の分類器を実装します。
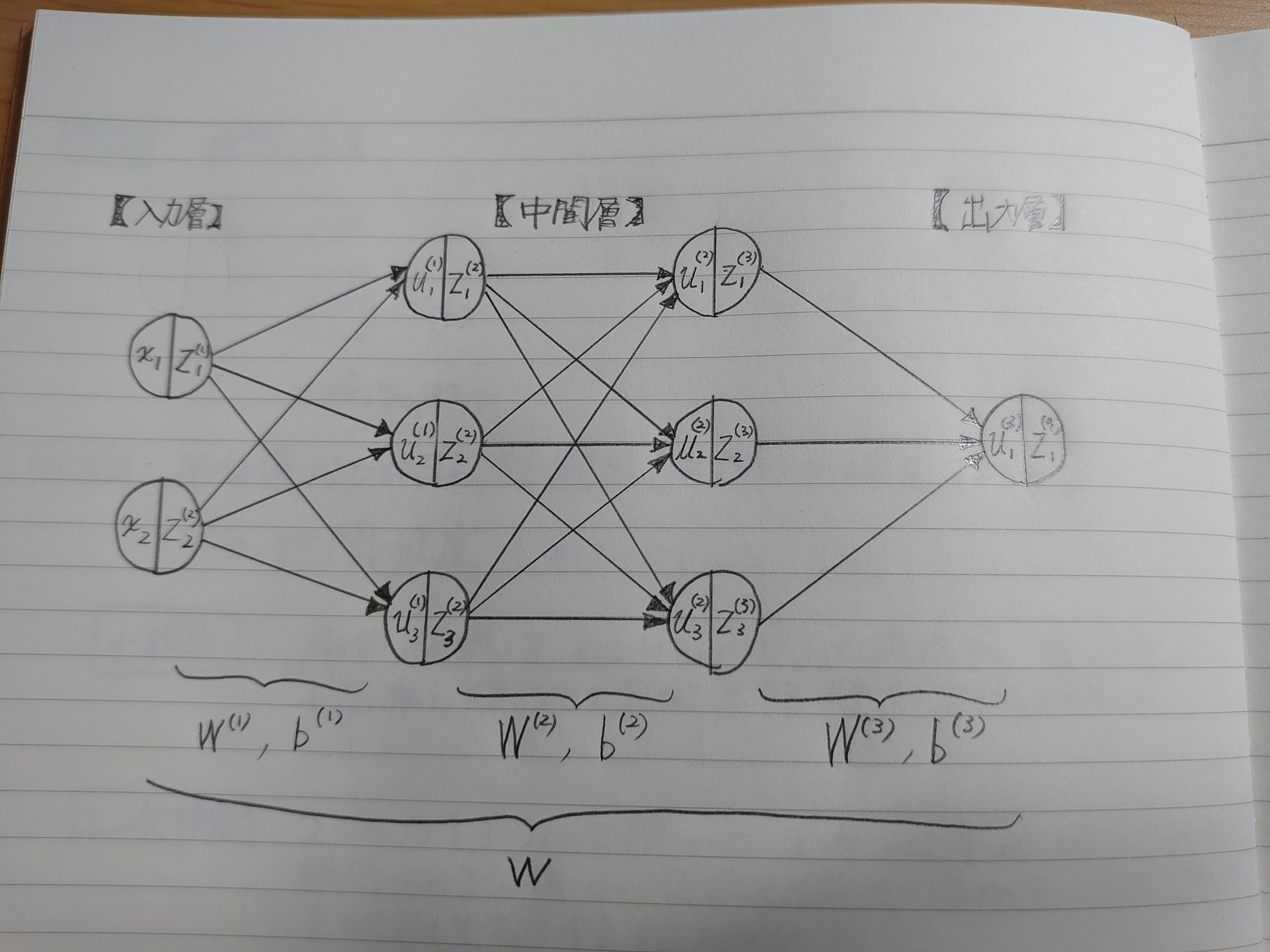
import numpy as np class GKDEClassifier(object): def __init__(self, bw_method="scotts_factor", weights="None"): # カーネルのバンド幅 self.bw_method = bw_method # カーネルのウェイト self.weights = weights def fit(self, X, y): # yのラベル数 self.y_num = len(np.unique(y)) # ラベル比の計算 self.label, y_count = np.unique(y, return_counts=True) self.y_rate = y_count/y_count.sum() # 推定した確率密度関数を格納するリスト self.kernel_ = [] # 確率密度関数を格納 for i in range(self.y_num): kernel = gaussian_kde(X[y==self.label[i]].T) self.kernel_.append(kernel) return self def predict(self, X): # 予測ラベルを格納するリスト pred = [] # テストデータのラベル別確率を格納するndarray self.p_ = np.empty([self.y_num, len(X)]) # ラベル別確率を格納 for i in range(self.y_num): self.p_[i] = self.kernel_[i].evaluate(X.T) # ラベル比をかける for j in range(self.y_num): self.p_[j] = self.p_[j] * self.y_rate[j] # 予測ラベルの割り振り for k in range(len(X)): pred.append(self.label[np.argmax(self.p_.T[k])]) return pred以下、追加した箇所と修正した箇所について説明します。
ラベル比の計算
self.label, y_count = np.unique(y, return_counts=True) self.y_rate = y_count/y_count.sum()fitメソッドに教師データのラベル比を計算する部分を追加しました。
ラベルごとの登場回数y_countを合計値で割ることで、y_rateの合計値を1にしています。
合計値で割らずにy_countをそのまま利用しても、結果は変わりません。さらにラベルの内訳(0や1、あるいは文字列)をリストlabelとして出力します。(重要)
確率密度関数の計算
新しいコードがこちら。
種々のラベルに合致するよう修正しました。for i in range(self.y_num): kernel = gaussian_kde(X[y==self.label[i]].T) self.kernel_.append(kernel)これが今までのコードです↓↓
kernel = gaussian_kde(X[y==i].T)もともとは「ラベルがiのデータ」を指定していましたが、新たに「i種類目のラベルのデータ」を指定するように変更しました。
出力したlabelから指定することで、非負整数ではないラベル(文字列など)に対応させます。ラベル比を反映
for j in range(self.y_num): self.p_[j] = self.p_[j] * self.y_rate[j]predictメソッドに確率密度にラベル比をかけ合わせる部分を追加しました。
予測ラベルの割り振り
新しいコードがこちら。
for k in range(len(X)): pred.append(self.label[np.argmax(self.p_.T[k])])リストlabelから割り当てラベルを指定することで、非負整数以外のラベルにも対応させました。
その他
predictメソッド内のごちゃごちゃしていた部分をnumpyを使って書き直しました。
先にndarrayを作成してから結果を代入することで、可読性と計算スピードの向上を図っています。最後に
自分の脳内をなんとか最後まで書き終えることができました。
お付き合いいただき、ありがとうございました。
記事を読んだ方に少しでも面白さを感じていただければ幸いです。(2020/8/5 修正)
- 投稿日:2020-08-04T23:37:37+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 020 解説
Youtube
動画解説もしています。
問題
P-020: レシート明細データフレーム(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭10件を抽出せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合でも別順位を付与すること。
解答
コードdf_amount_rank = pd.concat([df_receipt[['customer_id', 'amount']] \ ,df_receipt['amount'].rank(method='first', ascending=False)], axis=1) df_amount_rank.columns = ['customer_id', 'amount', 'amount_ranking'] df_amount_rank.sort_values('amount_ranking', ascending=True).head(10)出力customer_id amount amount_ranking 1202 CS011415000006 10925 1.0 62317 ZZ000000000000 6800 2.0 54095 CS028605000002 5780 3.0 4632 CS015515000034 5480 4.0 10320 ZZ000000000000 5480 5.0 72747 ZZ000000000000 5480 6.0 28304 ZZ000000000000 5440 7.0 97294 CS021515000089 5440 8.0 596 CS015515000083 5280 9.0 11275 CS017414000114 5280 10.0解説
・PandasのDataFrame/Seriesにて、ランク列を新たに作成し、列を連結して、データを順位付けする方法です。
・数字情報をランキング形式で見たい時に使用します。
・'concat('<列名A>','<列名B>','<列名C>')'は、指定した列を連結する関数です。'axis=1'は、列を連結することを指します。(※'axis=0'は行方向、'axis=1'は列方向を指します)
・'rank(method(average/min/max/first),'ascending=True/False')'は、指定した列のランキングを表示する関数です。
・averageは平均値、minは低い方に揃える、maxは高い方に揃える、firstは出てきた順にランクを付与します。
・今回の場合、amount のランキングを rank で表示し、指定された列と連結するために concat を使用しています。
・'columns('<列名A>','<列名B>','<列名C>')'は、列名を再指定する関数です。
・P-017,018で使用した sort_values を用いて、ランキング順に並び直して表示しています。※rankの参考記事はこちら
- 投稿日:2020-08-04T23:22:25+09:00
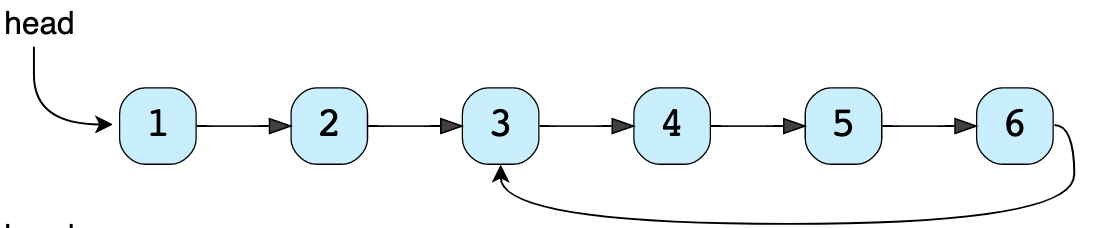
アルゴリズム 体操21 LinkedList Cycle
LinkedList Cycle
上の画像のように、LinkedListが、サイクルであるかどうかを判別する関数を記述します。
Solution
LinkedListを走査するためのslowおよびfastポインターを利用します。 各反復で、slowポインターは1ステップ移動し、fastポインターは2ステップ移動します。
サイクルがない場合は、2つの結果が得られます。
- LinkedListにサイクルがない場合、fastポインターはslowポインターの前にLinkedListの末尾に到達し、LinkedListにサイクルがないことを示します。
- LinkedListにサイクルがない場合、slowポインターはfastポインターに追いつくことができません。
LinkedListにサイクルがある場合、fastポインターが最初にサイクルに入り、その後にslowポインターが続きます。この後、両方のポインタがサイクルを無限に動き続けます。 いずれかの段階でこれらのポインターの両方が出会った場合、LinkedListにサイクルがあると結論付けることができます。
2つのポインターが出会う可能性があるかどうかを分析しましょう。 fastポインターが背後からslowポインターに近づくと、2つの可能性があります。
- fastポインターは、slowポインターの1つ後ろに位置します。
- fastポインターは、slowポインターの2つ後ろに位置します。
fastポインターとslowポインターの間の他のすべての距離は、これら2つの可能性のいずれかに帰着します。
fastポインタが常に最初に動くことを考慮して、これらのシナリオを分析しましょう。
- fastポインターがslowポインターの1つ後ろにある場合:fastポインターは2ステップ移動し、slowポインターは1ステップ移動し、両方が出会います。
- fastポインターがslowポインターの2ステップ後ろにある場合:fastポインターは2ステップ移動し、slowポインターは1ステップ移動します。 移動後、fastポインタはslowポインタの1つ後ろになり、このシナリオは最初のシナリオに帰着します。
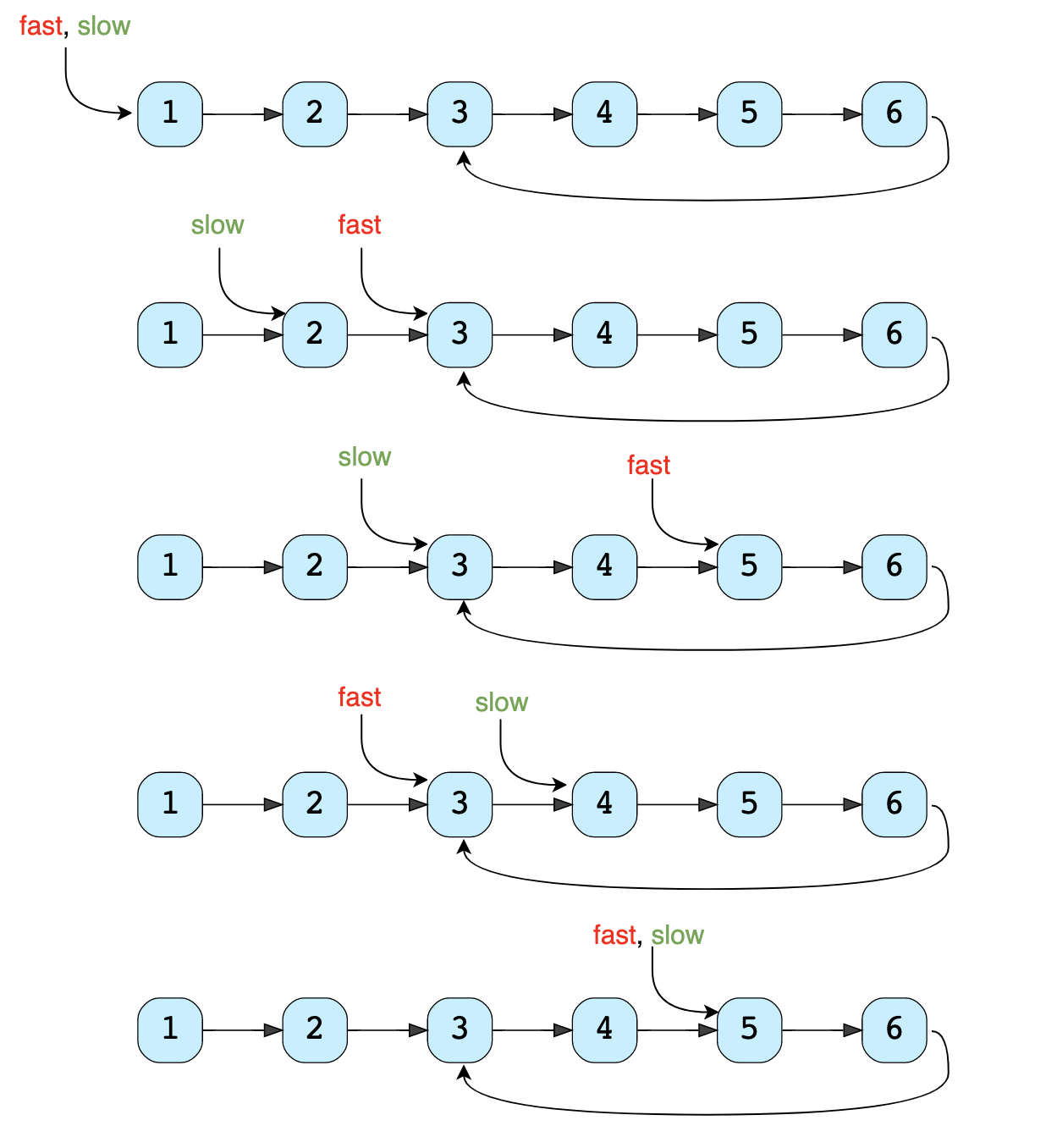
デモ
実装
class Node: def __init__(self, value, next=None): self.value = value self.next = next def has_cycle(head): # time complexity O(n) # space complexity O(1) fast, slow = head, head while fast is not None and slow is not None: fast = fast.next.next slow = slow.next if fast == slow: return True return False def main(): head = Node(1) head.next = Node(2) head.next.next = Node(3) head.next.next.next = Node(4) head.next.next.next.next = Node(5) head.next.next.next.next.next = Node(6) print("LinkedList has cycle: " + str(has_cycle(head))) head.next.next.next.next.next.next = head.next.next print("LinkedList has cycle: " + str(has_cycle(head))) head.next.next.next.next.next.next = head.next.next.next print("LinkedList has cycle: " + str(has_cycle(head))) main()
- 投稿日:2020-08-04T22:03:29+09:00
女子プロゴルファーの顔診断AIを作ってみた③
1. はじめに
前回学習モデルの作成まで行いました。
今回は、学習モデルを用いて実際のWebアプリケーションを作成してデプロイまで行います。
完成イメージはこんな感じ
2. Flaskを用いて作成
main.py# モジュールをインポートする import cv2 import os from flask import Flask, request, redirect, url_for, render_template, flash from werkzeug.utils import secure_filename from keras.models import Sequential, load_model from keras.preprocessing import image from PIL import Image import tensorflow as tf import numpy as np from datetime import datetime import face_recognition # 選手名 classes = ['渋野日向子', '小祝さくら', '原英莉花'] num_classes = len(classes) image_size = 64 # アップロードされた画像を保存するファイル UPLOAD_FOLDER = "uploads/" # アップロードを許可する拡張子を指定 ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif']) # Flaskクラスのインスタンスを設定 app = Flask(__name__) # アップロードされたファイルの拡張子をチェックする関数を定義 def allowed_file(filename): # 1つ目の条件:変数filenameに'.'という文字が含まれているか。 # 2つ目の条件:変数filenameの.より後ろの文字列がALLOWED_EXTENSIONSのどれに該当するかどうか # rsplitは区切る順序が文字列の最後から’1’回区切る。lowerは文字列を小文字に変換 return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS # 顔を検出する(haarcascade) def detect_face(img_path): image = face_recognition.load_image_file(img_path) faces = face_recognition.face_locations(image) if len(faces)>0: face_max = [(abs(faces[i][0]-faces[i][2])) * (abs(faces[i][1]-faces[i][3])) for i in range(len(faces))] top, right, bottom, left = faces[face_max.index(max(face_max))]#1人しか写っていなのでこれで問題ない faceImage = image[top:bottom, left:right] final = Image.fromarray(faceImage) final = np.asarray(final.resize((image_size,image_size))) final = Image.fromarray(final) basename = datetime.now().strftime("%Y%m%d-%H%M%S") filepath = UPLOAD_FOLDER + basename+".png" final.save(filepath) return final else: return "顔画像を入力してください" #学習済みモデルをロードする model = load_model('./golfer.h5', compile=False) graph = tf.get_default_graph() # app.route()で関数に指定したURLを対応づける。/ http://127.0.0.1:5000/以降のURLを指定 @app.route('/', methods=['GET', 'POST']) def upload_file(): global graph # as_default()で対象となるグラフを指定 with graph.as_default(): # HTTPメソッドがPOSTであれば if request.method == 'POST': # POSTリクエストにファイルデータが含まれているか if 'file' not in request.files: flash('ファイルがありません') # redirectは引数のURLに移動する関数 return redirect(request.url) file = request.files['file'] if file.filename == '': flash('ファイルがありません') return redirect(request.url) # ファイルがあって許可された形式であれば if file and allowed_file(file.filename): # ファイル名に危険な文字列がある場合、無効化する。 filename = secure_filename(file.filename) # uploadsフォルダーに保存する file.save(os.path.join(UPLOAD_FOLDER, filename)) # ファイルパスを作成する filepath = os.path.join(UPLOAD_FOLDER, filename) # #受け取った画像を読み込み、np形式に変換 img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size)) # 顔部分を検出する img = detect_face(filepath) if type(img)!=str: img = image.img_to_array(img) data = np.array([img]) #変換したデータをモデルに渡して予測する result = model.predict(data)[0] predicted = result.argmax() pred_answer = "この女子プロは " + str(classes[predicted]) + " です" return render_template("index.html",answer=pred_answer) else: return render_template("index.html",answer=img) return render_template("index.html",answer="") # FlaskでWebアプリ開発中にCSSが反映されない問題を解決する @app.context_processor def override_url_for(): return dict(url_for=dated_url_for) def dated_url_for(endpoint, **values): if endpoint == 'static': filename = values.get('filename', None) if filename: file_path = os.path.join(app.root_path, endpoint, filename) values['q'] = int(os.stat(file_path).st_mtime) return url_for(endpoint, **values) if __name__ == "__main__": port = int(os.environ.get('PORT', 8080)) app.run(host ='0.0.0.0',port = port)3. index.htmlとstylesheet
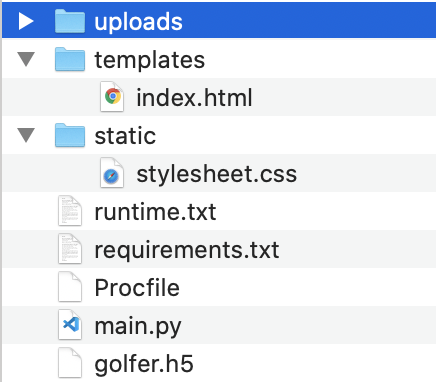
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>女子プロゴルファー判定</title> <!-- <link rel="stylesheet" href="./static/stylesheet.css"> --> <link rel= "stylesheet" type= "text/css" href= "{{ url_for('static',filename='stylesheet.css') }}"> </head> <body> <header> <a class="header-logo" href="#">女子プロゴルファー判定</a> </header> <div class="main"> <h2>画像の顔を識別します</h2> <p>画像を送信してください</p> <form method="POST" enctype="multipart/form-data"> <input class="file_choose" type="file" name="file"> <input class="btn" value="submit!" type="submit"> </form> <div class="answer">{{answer}}</div> </div> <footer> </footer> </body> </html>stylesheet.cssheader { background-color: rgb(100, 81, 255); height: 100px; margin: -8px; display: flex; flex-direction: row-reverse; justify-content: space-between; } .header-logo { color: #fff; font-size: 30px; margin: auto; } .header_img { height: 25px; margin: 15px 25px; } .main { height: 370px; } h2 { color: #444444; margin: 90px 0px; text-align: center; } p { color: #444444; margin: 70px 0px 30px 0px; text-align: center; } .answer { margin: 70px 0px 30px 0px; text-align: center; font-size: 30px; color: blue; font-weight: bold; } form { text-align: center; } h2 { color: #444444; text-align: center; } footer { background-color: #F7F7F7; height: 110px; margin: -8px; position: relative; } .footer_img { height: 25px; margin: 15px 25px; } small { margin: 15px 25px; position: absolute; left: 0; bottom: 0; }4. ファイルの構成
ファイルの構成は以下のようにする
templatesフォルダ内にindex.html
staticフォルダ内にstylesheet.css残りのファイルはこちらの記事を参考にしてください
【完全版】Flaskで作ったAPIをHerokuにデプロイする手順(備忘録)5. herokuへデプロイする
5-1. Herokuへ会員登録する
Herokuこちらより登録する
5-2. Herokuへログイン
$ heroku login5-3. 設定
Create New App ⇨ App nameを入力し、国をUnited Statesで登録。
アプリのページに遷移しSetteingsに移動、Add buildpackをクリックしてPythonを追加。5-4. 以下をターミナルより実行
git init※ 最初の1回だけ。2回やるとうまくデプロイできなくなります。
heroku git:remote -a (アプリ名)git add .git commit -m “(何を変更したかメッセージを書く)”git push heroku master以上でデプロイは完了です
6. webアプリの確認
下記コードにて確認する
heroku open以上で3回に渡った画像アプリの投稿を終了する。

- 投稿日:2020-08-04T20:42:04+09:00
Subprocessに標準入力できない...
問題
pythonの標準ライブラリであるsubprocessなるものが存在する。
これは、複数の実行ファイルを同時に実行できる代物だが、今回は実行ファイルへの標準入力で詰まった。例えば以下のようなC++のファイルを作成し、exeにしたとする。
sample.cppinclude <iostream> using namespace std; int main(){ while(true){ int a; cout << "input" cin >>a; cout << a * 2; return 0; } }まぁ、数字を受け取ってそれを2倍した数を表示するだけなのだが、これを常にwhileで実行し続けいちいち起動せずにpythonから実行したい。
これをするときにどうしたらいいかわからなかった...。
解決策
先ほどのコードをsample.exeとして実行形式にした。
その後、以下のコードでうまくいった。import subprocess # byteでのやり取りが面倒くさいため、universal_newlineをtrue sample = subprocess.Popen("sample.exe", stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True) if sample.stdout.readline() == "input:\n": # 読み取る文章は改行まで含める必要がある。 sample.stdin.write("20\n") # 入力にも改行が必要になる sample.stdin.flush() # 入力がバッファにたまった状態になっているので、ここで初めて入力となる。これでうまくいく。
重要な部分はコード上に書いておいたため、一緒に確認すべし。
てか、めっちゃむずいね。subprocess
- 投稿日:2020-08-04T19:04:49+09:00
【Python】Pythonスクリプトで(自分が)よく使うフレーズのメモ
今回の内容
Pythonスクリプトで(自分が)よく使うフレーズのメモです。
スクリプト先頭の記述
#!/usr/bin/env python3Unix系の環境で直接実行できる。
[追記訂正]
#coding: utf-8文字コードの指定は必要ないらしい。引数をリストとして取得
import sys argv_list = [sys.argv[i] for i in range(1,len(sys.argv))]スクリプトとして実行したときのみ実行
if __name__ == '__main__':拡張子なしのファイル名を取得
import os basename_without_ext = os.path.splitext(os.path.basename(filepath))[0]
- 投稿日:2020-08-04T18:44:23+09:00
論文Deep Self-Learning From Noisy Labelsを読んで
記事の概要
ここでは,論文Deep Self-Learning From Noisy Labels[1]を紹介します.この論文はICCV2019にて採択されているものです.また,Pytorchによる実装をGitHubで公開しています.ただ,精度はそれほど出ておらず,この原因の考察はこの記事の最後に述べています.
論文の内容
概要
本論文で取り組んでいるのは,深層学習による画像クラス分類のタスクにおける,ノイズの含まれるデータセットを用いた学習の精度の向上です.ここでの「ノイズを含む」というのは,データセットのクラスラベルが誤って付加されているという状況を示すものです.深層学習ではモデルの学習のために一般に大きなデータセットが必要とされますが,ラベルの整備された巨大なデータセットを準備するのはかなり面倒です.加えて,厳密なデータセットを作るときには人間が手動でアノテーションを行うのが一般的ですが,その際にミスが起こることも考えられます.一方で,Webからクローリングしてきたデータをそのまま用いれば簡便にラベル付き巨大データセットを揃えることができますが,この場合には一般により多くのラベルのミスが含まれています.このような現状から,ある程度ノイズを含んだデータセットを用いて正しく学習を行える深層学習モデルは現実世界において有用だと考えられ,本論文はその実現を目指すための論文になります.
本論文の新規性
ノイズの含まれるデータセットを用いた深層学習の既存の研究は多くあります.そのなかには,ラベルの誤り率を示すための遷移行列を導入したり,ノイズに強い損失関数を設定したりというものがあります.しかしそれらの手法では,ラベルの間違いがランダムであるという仮定を暗黙のうちに置いています.一方で現実的には,ラベルのノイズは入力に依存することが多くあります.例えばどのクラスに属するか紛らわしい画像では,誤ったラベルがつけられる可能性が高くなります.本論文では,そのような現実世界におけるラベルのノイズに即した学習を提案しています.
また,もう一つのこの論文の特長として,ノイズのないデータセットなどの付加情報を用いる必要がないということが挙げられます.既存の研究では,手動でノイズを除いたデータセットを用いている手法も多くあります.しかし既に述べたように手動でのラベル付加は限られた数であっても負担となります.本手法では,ノイズの含まれたデータセットのみを用いて,いわゆるself-learningの形式でモデルの学習を行っています.
手法の概要
提案手法のモデルの学習では,学習フェーズとラベル訂正フェーズという二つのフェーズが存在します.これらのフェーズは,1エポックごとに交互に行われます.
学習フェーズ
学習フェーズでは,画像分類のためのモデルFを学習させます.このフェーズは,一般的に行われる深層学習のトレーニングとほとんど同じだと思ってください.ただ一点だけ,損失関数が少し異なり,下の式の$L_{TOTAL}$のように表されます.
$$
L_{TOTAL} = (1 - \alpha) L_{CCE}(F(\theta, x), y) + \alpha L_{CCE}(F(\theta, x), \hat{y})
$$
ここで,$L_{CCE}$はクロスエントロピー損失関数です.また,$y$はデータに付けられたラベル,$\hat{y}$は訂正されたラベルです.この$\hat{y}$は,後で説明するラベル訂正フェーズで得るものです.$\alpha$はハイパーパラメータで,この二つの損失関数のバランスをとるためのものです.なお,最初のエポックではラベル訂正フェーズはまだ行われておらず訂正ラベルは得られないので,$\alpha = 0$とします.ラベル訂正フェーズ
続いてラベル訂正フェーズについて説明します.このフェーズの目標は,上手く訂正したラベル$\hat{y}$を手に入れて,学習フェーズで使えるようにすることです.また,そのために,以下のステップを踏みます.
1. 各クラスの訓練データからランダムにそれぞれ$m$個のサンプルをとる.
2. 各クラスの$m$個のサンプルから代表となるプロトタイプ$p$個を決める.
3. 全部のデータに対して各クラスのプロトタイプとの類似度から訂正ラベルを決定する.順番に説明していく前に,ここで用いるデータごとの「類似度」について定義しておきます.まず,深層学習モデル$F$を,$F = f \circ G$と定義します.ここで,$G$は特徴量抽出層,$f$は分類のための全結合層です.これを用いて,入力$x_1$,$x_2$に対して,類似度を$G(x_1)$と$G(x_2)$のコサイン類似度とします.すなわち,
$$
\frac{G(x_1)^\mathsf{T}G(x_2)}{||G(x_1)|| ~ ||G(x_2)||}
$$
のように表します.以下では「類似度」という記述はすべてこの「特徴量ベクトルのコサイン類似度」と捉えてください.サンプリング
まず各クラスから$m$個のデータをランダムにサンプリングします.これは,以降の計算にデータ数$n$に対して$O(n^2)$の計算量がかかるので,それを削減するためのものです.
プロトタイプの決定
続いて各クラスごとに,先ほど選んだ$m$個のデータのなかから$p$個のプロトタイプを決定します.このプロトタイプに求める条件は,各クラスの特徴量を上手く表してくれているということです.より具体的には,以下の二つの条件を上手く備えたものをプロトタイプとします.
・自身と似ている特徴量が多く存在する.
・他のプロトタイプとはなるべく似ていない.
つまり理想的には,クラス内の特徴量に$p$個のクラスタがあれば,$p$個のプロトタイプがそれぞれのクラスタ内の代表点としたいわけです.以下に具体的な手法を書きます.第一に,$m$個の特徴量の類似度を調べます.行列$S$を,$S_{ij}$が$i$番目のサンプルと$j$番目のサンプルの類似度となるように定義します.
第二に,各サンプルの密度$\rho$を定義します.これは,そのサンプルの周りにどれくらい点が密集しているかを示しています.
$$
\rho_i = \sum_{j = 1}^m sign(S_{ij} - S_c).
$$
ここで,$sign$は,正の値に対して$1$を,負の値に対して$-1$を,$0$に対して$0$を返す関数です,また,$S_c$は適当な基準値で,ここでは$S$の中で上位40%に当たる数値としています.これにより,自分と似ているサンプルの数が多いものほど$\rho$の値も大きくなります.第三に,各サンプルのプロトタイプ決定用の類似度$\eta$を定義します.
\eta_i = \max_{j, \rho_j > \rho_i} S_{ij} ~~(\rho_i < \rho_{max}), \\ \eta_i = \min_{j} S_{ij} ~~(\rho_i = \rho_{max})すなわち,密度$\rho$が最大のものはなるべく小さい類似度をとり,それ以外のものは,自分より密度$\rho$が大きいサンプルの中から最大の類似度をとります.これにより,$\eta$が小さいものほど,プロトタイプに相応しい性質を兼ね備えていると言えることになります.
そして最後に,$\rho$と$\eta$を用いてプロトタイプの決定を行います.$\rho$は小さい方が良く,$\eta$は小さい方がいいことに留意してください.ここでは,$\eta < 0.95$を満たす中から$\rho$が大きい上位$p$個のサンプルを取得します.これをそのクラスのプロトタイプとします.
訂正ラベルの生成
各クラスのプロトタイプが求まったので,すべてのデータについて訂正ラベルを求めます.単純に,プロトタイプ群によく似ているクラスに振り分けるだけです.各データに対して,それぞれのクラスのプロトタイプとの類似度の平均を算出し,その値が最も大きかったクラスのラベルを訂正ラベル$\hat{y}$とします.
論文の実装
ここからは論文の実装について記していきます.ソースコードはGitHubを確認してください.ただし,既に書いたように論文で記されている精度は確認されていません.この原因の考察は最後に記します.
実装概要
論文と同様に,Clothing1M[2]データセットとFoodLog-101N[3]データセットを用いて実験を行いました.また,FoodLog-101NデータセットはFoodLog-101[4]データセットをテストデータに用いることを想定されているようなので,それに従います.モデルやハイパーパラメータなども論文中に書かれている内容をそのまま用いています.
主な実行環境の詳細を記しておきます.
・Python : 3.5.2
・CUDA : 10.2
・Pytorch : 0.4.1
・torchvision : 0.2.1
・Numpy : 1.17.2結果
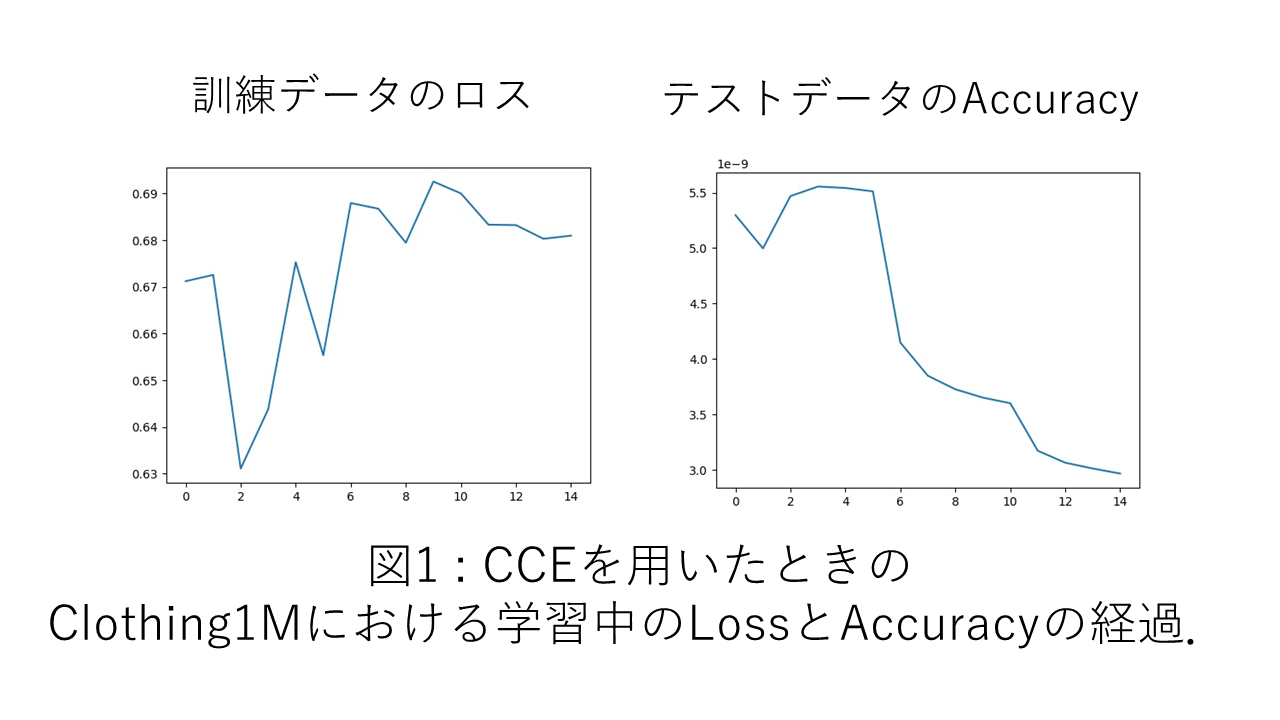
論文中に書かれているAccuracyは下の表のようになっています.CCEは単純にクロスエントロピーを用いて最適化を行ったときの精度です.
CCE 提案手法 Clothing1M 69.54 74.45 Food-101N 84.51 85.11 一方で,再現実装におけるAccuracyは下の表のようになっています.提案手法の精度で曖昧な雰囲気にしているのは,かなり乱数による誤差が大きかったためです.後に述べますが,この原因について様々な確認をしていたこともあり,このブレの程度に関する定量的な評価はできていません.ただ,提案手法がCCEを有意に超えるような現象は見受けられません.
CCE 提案手法 Clothing1M 68.10 64前後 Food-101N 85.05 80前後 精度低下の考えられる原因
実装が間違っている可能性
ここは本実装が間違っていない保証をただ述べる項ですので,興味のない方は読み飛ばしてください.
本実装に間違いがあるとした場合,クロスエントロピーを用いたときの精度は論文とそこまで変わらないので,問題があるのはラベル訂正に関わる部分かと思います.これを,訂正ラベルを生成する部分,訂正ラベルを利用する部分の二つに切り分けて確認しています.
第一に,訂正ラベルを生成する部分の確認についてです.まず,そこに関係ある関数は想定通りの挙動をしていることを個別に確認しました.次に,訂正後ラベルと元のノイジーラベルはある程度一致しており,ある程度ノイジーラベルに沿ったラベル訂正が行われていることも確認しています.さらに,ラベル訂正の挙動の正確性についての定量的な確認も行いました.Clothing1Mについては,データセットの一部にクリーンなラベルが付けられているので,ラベル訂正の精度を確認することができます.ここではラベル訂正の精度にスポットを当てるため,学習済みモデルと訓練データにより生成したラベル訂正モジュールを用いてテストデータにラベルを振り,訓練データ全体のラベルの正解率と訂正後のテストラベルの正解率を比較しました.このときの結果は下の表のようになっています(論文中では訓練データのラベル正解率が61.74となっていますが,Clothing1Mの元論文では61.54となっているため,そちらを信用します).これを見ると,元の訓練データのノイズを含むラベルのAccuracyは上回っていることは分かります.
訓練データのラベル テストデータの訂正ラベル 61.54 69.92 このようなことから分かる通り,全体としてのラベル訂正の挙動は合っていると考えられます.以上によりラベル訂正モジュールは正しいことが確認できるかと思います.
第二に,訂正ラベルを利用する部分の確認です.これについては,ソースコードの訂正後のラベルを受け渡す箇所を,訂正前のラベルを受け渡すように書き換えた上で実験したところ,元のCCEと同程度の精度が出ました.したがって,訂正ラベルを用いた最適化を行う部分にも間違いはないと考えられます.以上二つの理由から,実装バグの観点はクリアしていると考えています.
実行環境の違い
今回用いたハイパーパラメータは,論文中のものをそのまま用いており,例えばClothing1Mでは計15エポックで5エポックごとに学習率を減衰させています.しかし図1を見ると分かるように,最初の5エポックは学習率が大きすぎて不要なようにも見えます.このようなことが起こる原因として,一つ大きく考えられるのは,実行時に用いたライブラリやバージョンの違いかと思います.
ラベル訂正フェーズを開始するタイミングについて
ラベル訂正フェーズは,ニューラルネットワークがある程度適切な特徴量を抽出できるようになってからでないと,逆に精度を悪くする可能性があると考えられます.元論文でも最初はラベル訂正フェーズを挿入しないことを暗に示すような記述があるのですが,その具体的な設定については述べられていません.本実装においては,1エポック目終了直後からラベル訂正フェーズを始めたときの結果を示しています.論文を読む限り1エポック目終了後からラベル訂正が始まるようにも見えるのですが,完全にそうではないと言い切れないような書き方がされているようにも思われます.
実際に実験してみると,最初の方のエポックでラベル訂正を入れたことによりAccuracyが序盤で30%付近まで落ちる現象も場合によっては確認されました.そこで,ラベル訂正フェーズを開始するエポックをいくつか変えたところ,Accuracyがガクリと下がる現象は消えても,最終的な精度はそこまで変わりませんでした.より長いエポック数で途中からラベル訂正を入れるようにすれば結果は変わるかもしれませんが,これについては疑問が残るままです.
乱数
結果の分散の定量的な評価はできていないのですが,学習の波の激しさや数回試した雰囲気から,乱数の影響は無視できないかと思います.元論文についても,少なくともFood-101Nについては,この手法による精度の向上は乱数による影響の範囲を抜け出していないように感じます.ちなみに,Food-101Nの実験に関しては元論文もそこまで詳しく解析していません.
おまけの考察
Food-101Nにおいては元論文でもそこまで精度の向上が見られず,乱数で説明がついてしまう可能性についても述べましたが,この原因は手法そのものにあるかと思います.14クラスの分類であるClothing1Mは訂正ラベルは十分高い確率で元ラベルと同じラベルとなっていますが,101クラスの分類であるFood-101Nでは,訂正ラベルが元ラベルと同じラベルになる確率はClothing1Mに比べて全体的に低いことが確認されました.Food-101Nはクリーンなラベルがついていないので訂正ラベルの正確性は分かりませんが,Clothing1Mよりは低い値になっていることはほぼ間違いないと思います.そして,101クラスの分類を少数のプロトタイプを用いて行うことの難しさを考えれば,不思議ではない結果であるように思います.そのためFood-101Nのような多クラスでの分類の場合にこの手法を適用する場合には,決定的にクラスを割り振らないようソフトラベルを用いたり,訂正ラベルを用いた学習の重みを減らしたりする工夫が必要になってくるかと思います.
参考文献
[1] Jiangfan Han, Ping Luo, and Xiaogang Wang. Deep Self-Learning From Noisy Labels. In International Conference on Computer Vision, 2019.
[2] Tong Xiao, Tian Xia, Yi Yang, Chang Huang, and Xiaogang Wang. Learning from Massive Noisy Labeled Data for Image Classification. In Computer Vision and Pattern Recognition, 2015.
[3] Kuang-Huei Lee, Xiaodong He, Lei Zhang, and Linjun Yang. CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise. In Computer Vision and Pattern Recognition, 2018.
[4] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – Mining Discriminative Components with Random Forests. In European Conference on Computer Vision, 2014.
- 投稿日:2020-08-04T17:30:04+09:00
KerasでGAN作ってみたので学習過程を動画にしてみた。
はじめに
以前の記事でGanによる手書き文字認識をKerasで実装しました。
その際にGanの学習過程がどのようになっているのか気になったので動画にしてみました。今回は比較も行いたかったため、GanとCGanの二つで行いました。
動画を見てみると、Ganがどのように手書き文字の特徴を捉えているのかが動画内で確認できます。
二つの動画を見比べてみるとGGanとGanでは学習の様子が全く違い、CGanは畳み込み層による特徴がしっかりとででいることがわかるかと思います
動画はYoutube上にアップしてあります。GAN : https://www.youtube.com/watch?v=ORVZVZqYYqU
CGAN : https://www.youtube.com/watch?v=ByicWghi-iwGanとCGanの違い
二つの違いはネットワークに用いている層の種類の違いだけです。
Ganは全結合層、CGanは畳み込み層でネットワークが構築されています。動画では層による学習の違いがよくみて取れます。
終わりに
ネットワークの学習過程を覗いてみるのもおもしろいなと感じました!
Gan動画
https://www.youtube.com/watch?v=ORVZVZqYYqU
CGan動画
- 投稿日:2020-08-04T16:55:52+09:00
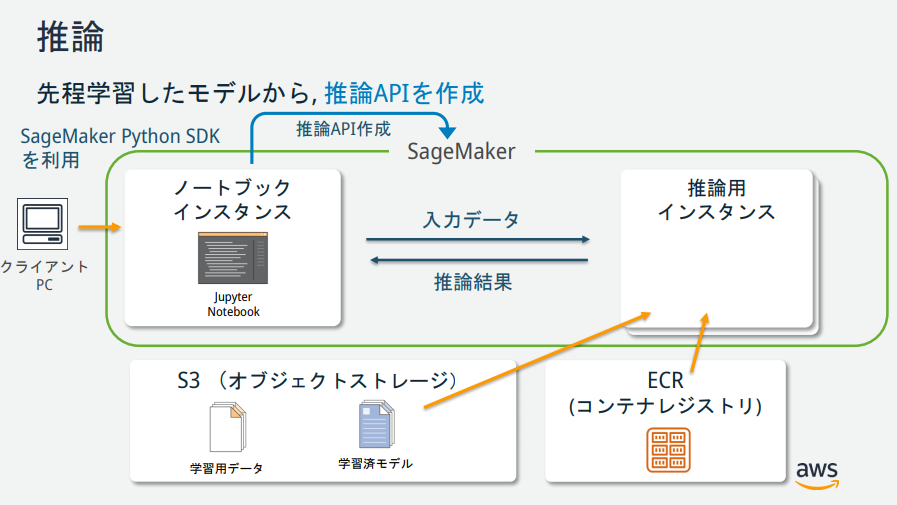
SageMakerを使って機械学習に入門してみる
はじめに
AWS公式のAmazon SageMaker の開始方法の手順に沿って、機械学習モデルを構築してデプロイするまでの流れを実践してみる事にしました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
機械学習とは
ここでは割愛。概要を把握するには以下を参照。
SageMakerの概要
詳しくはAWS公式のAmazon SageMaker のドキュメントを参照。
Amazon SageMaker は、完全マネージド型の機械学習サービスです。Amazon SageMaker では、データサイエンティストと開発者が素早く簡単に機械学習モデルの構築と研修を行うことができ、稼働準備が整ったホスト型環境に直接デプロイできます。統合された Jupyter オーサリングノートブックインスタンスから、調査および分析用のデータソースに簡単にアクセスできるため、サーバーを管理する必要がありません。また、一般的な機械学習アルゴリズムも使用できます。そうしたアルゴリズムは、分散環境できわめて大容量のデータに対しても効率良く実行できるよう最適化されています。自前のアルゴリズムやフレームワークもネイティブでサポートされているため、Amazon SageMaker ではお客様固有のワークフローに合わせて調整できる柔軟性の高い分散型トレーニングも行えます。Amazon SageMaker Studio または Amazon SageMaker コンソールからクリック 1 つで起動して、安全でスケーラブルな環境にモデルをデプロイします。トレーニングとホスティングは、分ごとの使用量で課金されます。最低料金や前払いの義務はありません。
(https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html より引用)
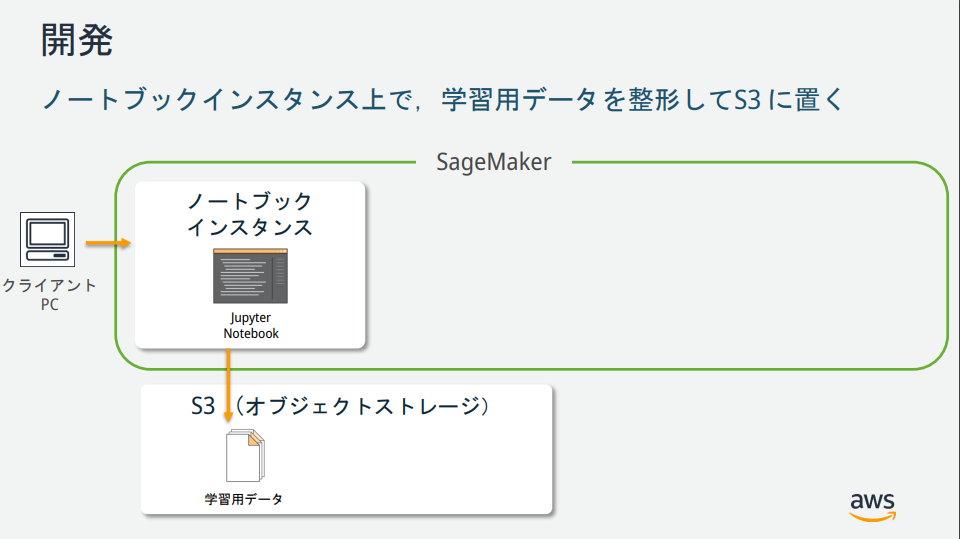
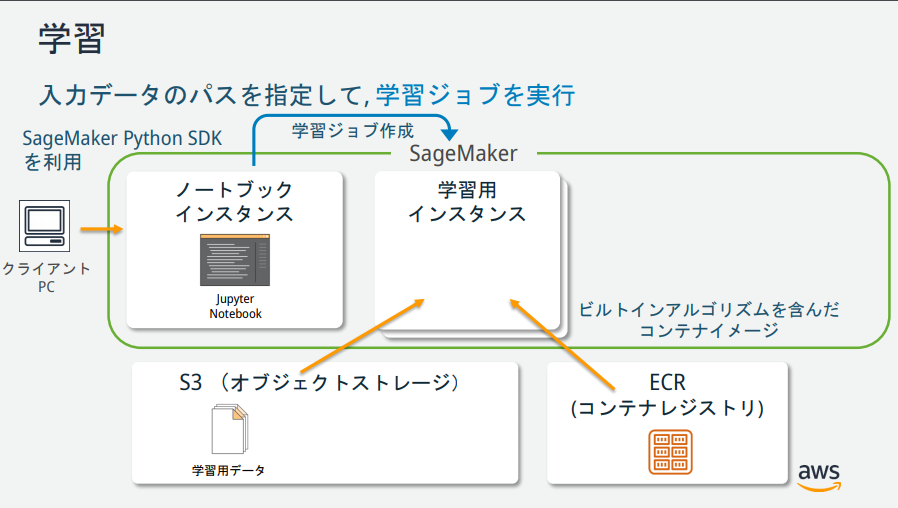
SageMakerの説明図を見る限りいくつかインスタンスが存在するが、それぞれどのような役割なのか?
→AWS公式が公開している資料が分かりやすかったので、以下に記載。
(https://pages.awscloud.com/event_JAPAN_hands-on-ml_ondemand_confirmation.html より引用)
チュートリアル
AWS公式のチュートリアルを実施。
Amazon S3 バケットを作成する
機械学習に使用するデータ、および、学習結果(モデル)を格納するための場所(バケット)を作成。
Amazon SageMaker ノートブックインスタンスの作成
Amazon SageMakerノートブックインスタンスとは、Jupyter Notebookがインストールされたフルマネージドな機械学習EC2コンピューティングインスタンス。
Jupyter ノートブックを作成する
Jupyter ノートブックとは
プログラムの作成、実行結果、グラフ、作業メモや関連するドキュメントなどを、ノートブックと呼ばれるファイル形式にまとめて、一元的に管理することを目的としたオープンソースツール。
データ分析作業などで、対話的にプログラムを実行してその結果を参照しながら次の作業を行う場合や、出力された結果を保存し、メモとともに作業記録のように残したい場合などに特に有益である。(https://www.seplus.jp/dokushuzemi/blog/2020/04/tech_words_jupyter_notebook.html より引用)
「New」から「conda_python3」を選択。新しいノートブックが作成される。
S3とロールを指定するコードを記述。
from sagemaker import get_execution_role role = get_execution_role() bucket='0803-sagemaker-sample'データをダウンロード、調査、および変換する
MNIST データセットをダウンロードする
MNISTデータとは
MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセットです。さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセットです。
(https://udemy.benesse.co.jp/ai/mnist.html より引用)
MNISTデータセットのダウンロードを行うコードを記述。
%%time import pickle, gzip, numpy, urllib.request, json # Load the dataset urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz") with gzip.open('mnist.pkl.gz', 'rb') as f: train_set, valid_set, test_set = pickle.load(f, encoding='latin1')トレーニングデータセットを調べる
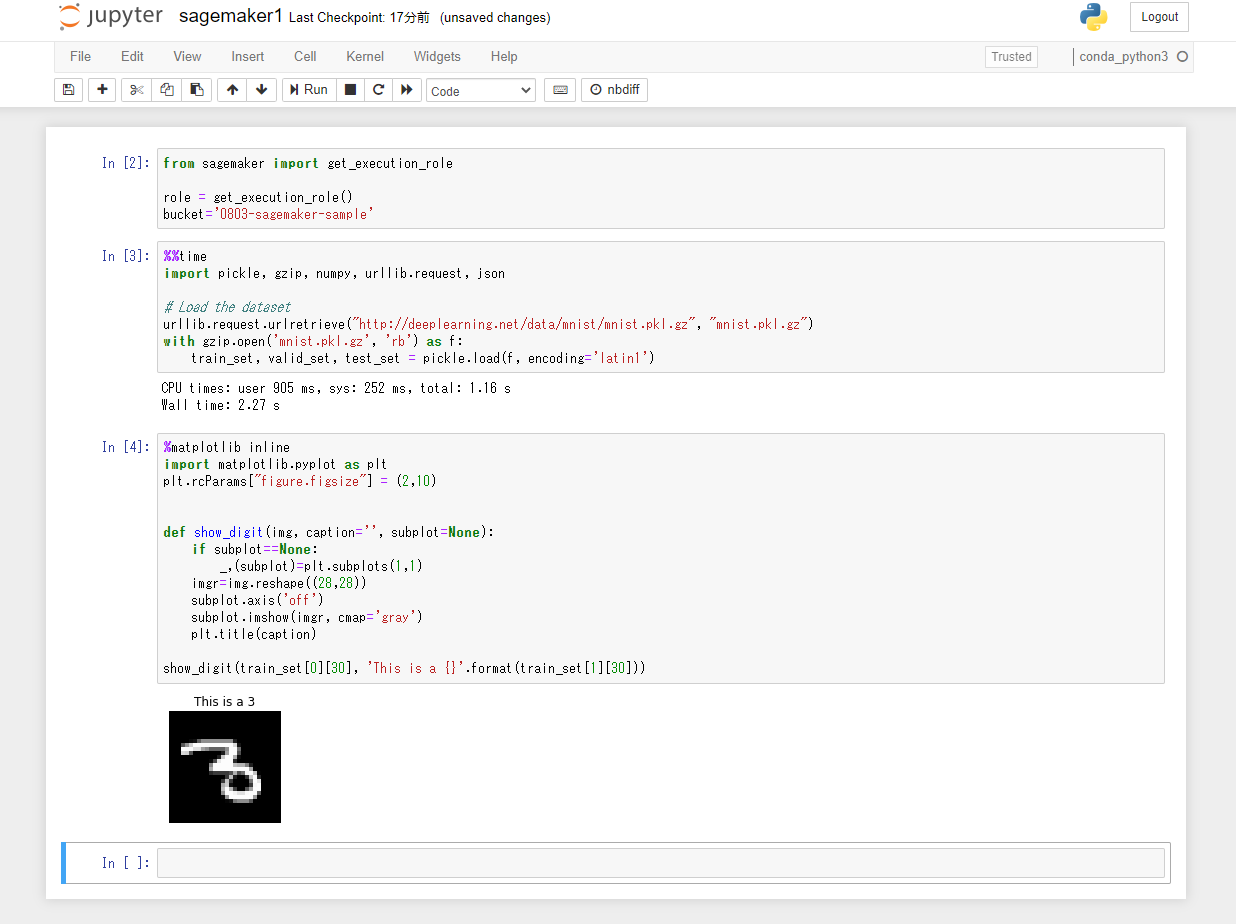
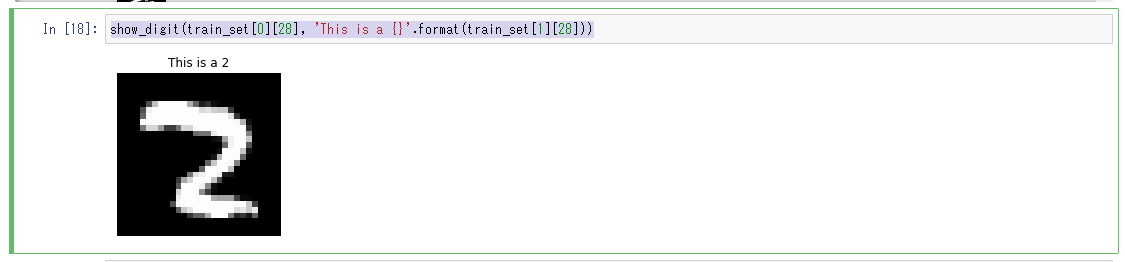
以下のPythonコードを3つ目のセルにペーストして、「Run」ボタンをクリック。MNISTデータセットの31枚目の画像データがラベルの内容と共に表示される。
%matplotlib inline import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (2,10) def show_digit(img, caption='', subplot=None): if subplot==None: _,(subplot)=plt.subplots(1,1) imgr=img.reshape((28,28)) subplot.axis('off') subplot.imshow(imgr, cmap='gray') plt.title(caption) show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))
モデルをトレーニングする
トレーニングアルゴリズムを選択する
機械学習では、通常モデルに適したアルゴリズムをみつけるための評価プロセスが必要になる。
今回は SageMaker の組み込みアルゴリズムの1つである k-means を使うことが決まっているため、評価プロセスはスキップする。k-meansとは
K-means 法はクラスタリングを行うための定番のアルゴリズムの1つ。ここでは詳細は割愛。
トレーニングジョブの作成
以下のPythonコードを4つ目のセルにペーストして、「Run」ボタンをクリック。
from sagemaker import KMeans data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket) output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training data will be uploaded to: {}'.format(data_location)) print('training artifacts will be uploaded to: {}'.format(output_location)) kmeans = KMeans(role=role, train_instance_count=2, train_instance_type='ml.c4.8xlarge', output_path=output_location, k=10, data_location=data_location)トレーニングの実行
モデルのトレーニングを実行。以下のPythonコードを5つ目のセルにペーストして、「Run」ボタンをクリック。トレーニングの所要時間は約10分。
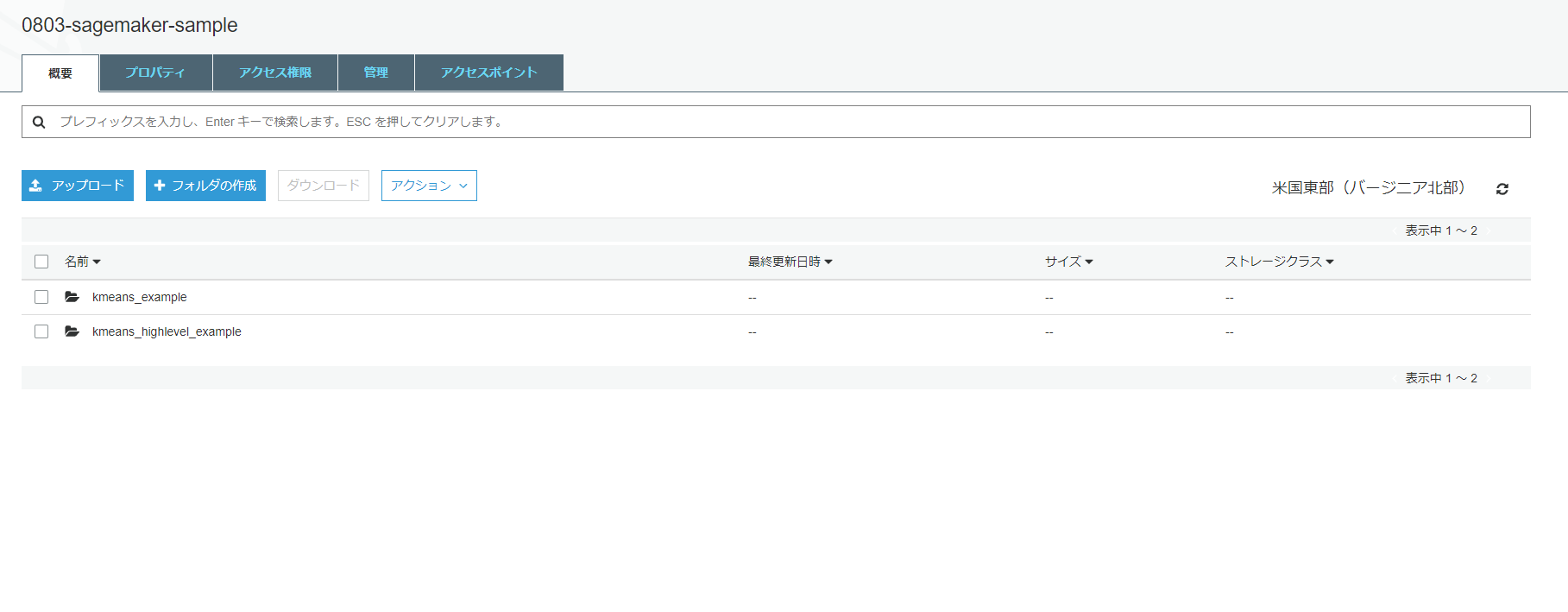
%%time kmeans.fit(kmeans.record_set(train_set[0]))モデルのトレーニング完了後にS3を確認すると、モデルのトレーニングデータとモデルのトレーニング中に生成されるモデルアーティファクトが格納されている。
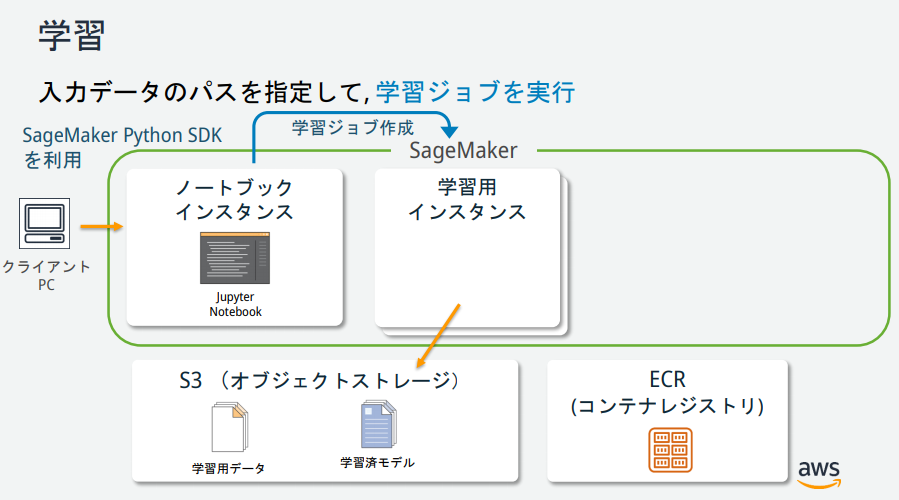
モデルを Amazon SageMaker にデプロイする
SageMaker にモデルをデプロイするためには、以下の3ステップの手順を実施する必要がある。
- SageMaker上でモデルを作成
- エンドポイントの設定の作成
- エンドポイントの作成
deployというメソッド一つでこれらの作業を行うことができる。以下のPythonコードを6つ目のセルにペーストして、「Run」ボタンをクリック。
%%time kmeans_predictor = kmeans.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')モデルを検証する
モデルがデプロイされた為、検証を行う。以下のPythonコードを7つ目のセルにペーストして、「Run」ボタンをクリック。
result = kmeans_predictor.predict(valid_set[0][28:29]) print(result)valid_setデータセットの30番目の画像に対する推論結果が得られる。valid_setの28番目のデータは、クラスター6に属していることがわかる。
[label { key: "closest_cluster" value { float32_tensor { values: 6.0 } } } label { key: "distance_to_cluster" value { float32_tensor { values: 6.878328800201416 } } } ]続いて、valid_setデータセットの先頭から100個分の推論結果を取得する。以下のPythonコードを8つ目のセルと9つ目のセルにペーストして、順番に「Run」ボタンをクリック。
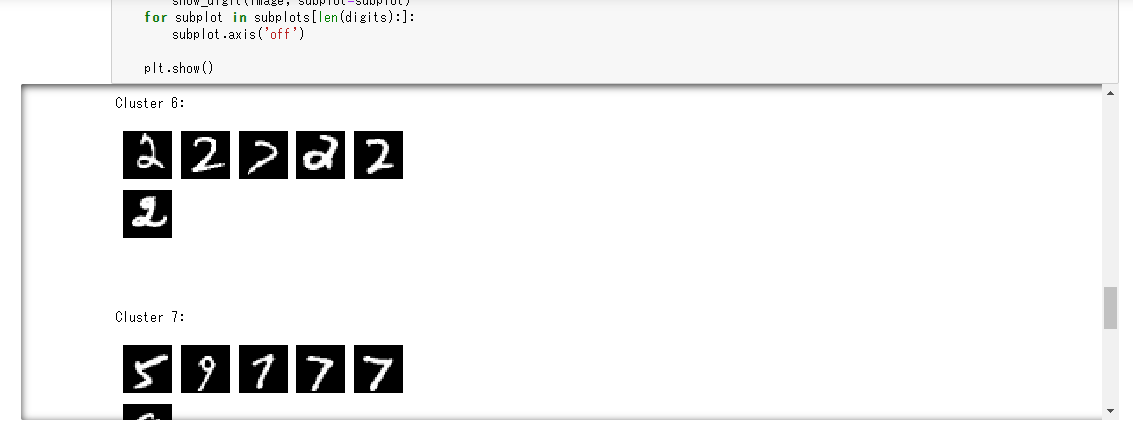
%%time result = kmeans_predictor.predict(valid_set[0][0:100]) clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]for cluster in range(10): print('\n\n\nCluster {}:'.format(int(cluster))) digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ] height = ((len(digits)-1)//5) + 1 width = 5 plt.rcParams["figure.figsize"] = (width,height) _, subplots = plt.subplots(height, width) subplots = numpy.ndarray.flatten(subplots) for subplot, image in zip(subplots, digits): show_digit(image, subplot=subplot) for subplot in subplots[len(digits):]: subplot.axis('off') plt.show()
「トレーニングデータセットの調査」で使用したshow_digitメソッドを利用しvalid_setデータセットの28番目を表示。
クラスター4に含まれている画像である事が分かる。show_digit(train_set[0][28], 'This is a {}'.format(train_set[1][28]))
モデルがデプロイされて、動作していることも検証できた為完了。
作成した AWS リソースの削除
粛々と削除。特筆すべき事はなし。
おわりに
今回はSagrMakerを利用し、初めての機械学習に挑戦してみた。
機械学習、というと何となく障壁が高いイメージだったが、想像以上に簡単に使う事ができた。各パブリッククラウドの最近の発表を見ていると、機械学習への敷居を下げようとしている印象を受ける。
(レベルが高い分析を行う場合は専門の機械学習エンジニアのスキルが必要となると思うが、)一定レベルの機械学習については、機械学習を専門とするエンジニア以外でもマネージドサービスを使ってスピード感を持って構築するスキルが求められていくのではないかと考えるので、機械学習についても学習を進めていきたい。参考資料
Amazon SageMaker の開始方法
【初心者向け】Amazon SageMakerではじめる機械学習 #SageMaker
Amazon SageMaker 機械学習エンジニア向け体験ハンズオン

- 投稿日:2020-08-04T16:38:32+09:00
【TitanCraft】マインクラフトに巨人を召喚するためのツール作った
TitanCraft is 何?
スマホなどで撮影した1枚の全身画像から、3Dオブジェクトを経由してしてマインクラフトの
.schematicファイルを生成します。
生成された.schematicファイルをWorldEditなどのmodを使ってマイクラのワールドに読み込ませると巨人を召喚できます。ソースコードはここで公開しています
こんなことができます
その日 人類は思い出した
ヤツらに支配されていた恐怖を…
鳥籠の中に囚われていた屈辱を…
処理の流れ
以下の画像を使って処理の流れを追ってみます。(画像はここから取得しました
)
1. 入力画像から前景を抜き出す
私が作成したremove_bgというリポジトリを使って前景を抜き出します。
その際、次の工程のPIFuでマスク画像が必要なので、それも一緒に作成します。
remove_bgでは、まず入力画像に対してSemantic Segmentationを適用して対象のオブジェクトを抽出します。その後、trimapという3値画像を生成し、入力画像とあわせてFBA_Mattingに入力して前景の抽出を行っています。[処理結果]
サンプルの画像に背景がほとんど無いのであまり適切では無いですが、うまく人物が切り出せていることがわかります。(股のや首の近くなど少し背景が残ってしまっているところもありますね)
remove.bgのAPIを使えばもっと高精度になると思いましたが、有料だったので今回は使っていません。2.
PIFuで画像から3Dオブジェクト生成PIFuという手法を使って画像から3Dオブジェクトを生成します。
この処理によって、3D形状だけでなく画像に写っていない部分の服や髪型などのテクスチャも推論してくれます。
PLFuの詳細については私はあまり理解できていないですが、この記事などにもう少し詳しく載っています。[処理結果]
(meshlabで可視化)入力画像には全く写っていない背中やお尻の部分もよく再現されています。すごいですね。
現状では、このまま3Dオブジェクトとして使うのは少し厳しいかもしれませんが、今後技術がさらに進展すれば1枚の画像からキレイな3Dオブジェクトが生成できる日も遠くなさそうですね3. 3Dオブジェクトからマインクラフト用の
.schematicファイル生成私が作成したobj2schematicというリポジトリを使って、2.で生成した
.objファイルからマインクラフト用の.schematicファイルを作ります。
PIFuが生成する.objファイルを読み込み、中身を解析してマイクラのブロックに変換しています。
生成された.schematicファイルをWorldEditなどのmodでワールドに読み込ませることで巨人を召喚できます![処理結果]
どうでしょうか⁉
まぁまぁよく出来てると思います以下、召喚した巨人のギャラリーです。
そびえ立つ巨人と見守る村人たち
夕焼けの巨人
丑三つ刻の巨人
巨人の肩の上に立つ
中身は空洞です
オマエヲミテルゾまとめ
1枚の画像からマインクラフト内に巨人を召喚するツールを作りました。
Google Colabで実行できるようにしておいたので是非使ってみてください。
ローカルで実行する場合は、pythonの環境が必要ですが、そこさえクリアできればすぐに使えると思います。
GPU無しの私の環境(MacBook Pro(2019))でも1画像(512x512)あたり2~3分で処理することが出来ます。「すげー!」と息子に言ってもらいたくて作りましたが、想像通りにできて満足です
今回は全身画像から3Dオブジェクトを作りましたが、使用するモデルを切り替えることで他にも色々できるんじゃないかと考えています。
何かアイデアがある方はコメントなどで教えていただけると対応するかもしれませんまた、
PIFuやFBA_Mattingなどの公開されているモデルを使用させてもらっていますが、各手法の詳細について理解していなくても使えるような状態になっていることはすごいことだと改めて感じました。












- 投稿日:2020-08-04T16:17:18+09:00
PythonとSeleniumとChromedriverでスクレイピング
やりたいこと
Science DirectのあるJournalに掲載されているすべての論文の書誌情報+アブストラクトを収集したい。
まずはスクレイピングの基礎を学ぶ
(参考:https://codezine.jp/article/detail/12230)
requestsパッケージとBeautifulSoup4パッケージを使ってやるのが基本らしい。
ということで、まずはこいつらをインストールpip install requests, beautifulsoup4んで、こんなことをしてみた。
import request from bs4 import BeautifulSoup # スクレイピング対象の URL にリクエストを送り HTML を取得する res = requests.get('https://www.ymori.com/books/python2nen/test1.html') # レスポンスの HTML から BeautifulSoup オブジェクトを作る soup = BeautifulSoup(res.text, 'html.parser') print(soup)とりあえず、htmlをテキストで取得はできたわけだが、例えばチェックボックスをOnにしたり、ボタンをクリックしたりとかってどうやってやるんだ??
SeleniumとChromedriver
調べていくと、Javascriptを駆使して動的に色々と表示内容を変えるようなページはBeautifulSoupではできないらしい。
どうしようと調べていくとSeleniumというパッケージにたどり着いた。
(参考:https://qiita.com/Fujimon_fn/items/16adbd86fad609d993e8)
どうやら、RPAのようなことをやれるらしい。つまり、Webブラウザを人に見えるような形で順に操作していく。
ただ、これだけだとダメで使っているブラウザに合わせたドライバが必要。
(参考:https://kurozumi.github.io/selenium-python/installation.html#drivers)インストール
Seleniumとchromedriverをインストールする。
インストールするにあたり、ChromeDriverのページで、自分のChromeとバージョンが一致するドライバのバージョンを確認しておく(確認したら84.0.4147.30だった)。
(参考:https://qiita.com/hanzawak/items/2ab4d2a333d6be6ac760)pip install selenium, chromedriver-binary==84.0.4147.30これでインストールすると、パスの設定が要らなくなる(ただし、
import chromedriverを入れる必要がある)
ただ、別にChromeDriverから直接、ダウンロードしてきたExeファイルを、例えばc:\workとかにおいて、明示的にパスを渡すというのでもできる。こちらの場合、パッケージのインポートは不要。とりあえず起動させてみる
以下は
import chromedriverではなく、明示的にパス渡しした例。OpenBrowser.pyimport requests from selenium import webdriver # import chromedriver_binary load_url = "https://www.sciencedirect.com/journal/reliability-engineering-and-system-safety/vol/204/suppl/C" driver = webdriver.Chrome(executable_path='c:/work/chromedriver.exe') # driver = webdriver.Chrome() driver.get(load_url)すると、ブラウザが勝手に立ち上がって、指定したアドレスのページにとんだ。
完全にRPAやな。ページの操作
やりたいのは、Jounralのページにアクセスしたら、
- まずは左上にある「Select All」をクリックして、表示されているPaperのチェックボックスをすべてOnにする
- Export Citations をクリックして文献情報をDLするためのダイアログを表示させる
- 文献情報をDLするためのダイアログで「Export citation and abstract to text」をクリック。→するとテキストファイルだDLされる。
- テキストファイルのDLが済んだら、ページの上のほうにある「Previous Vol/Issue」をクリックして、一つまえの巻号のページに進む。
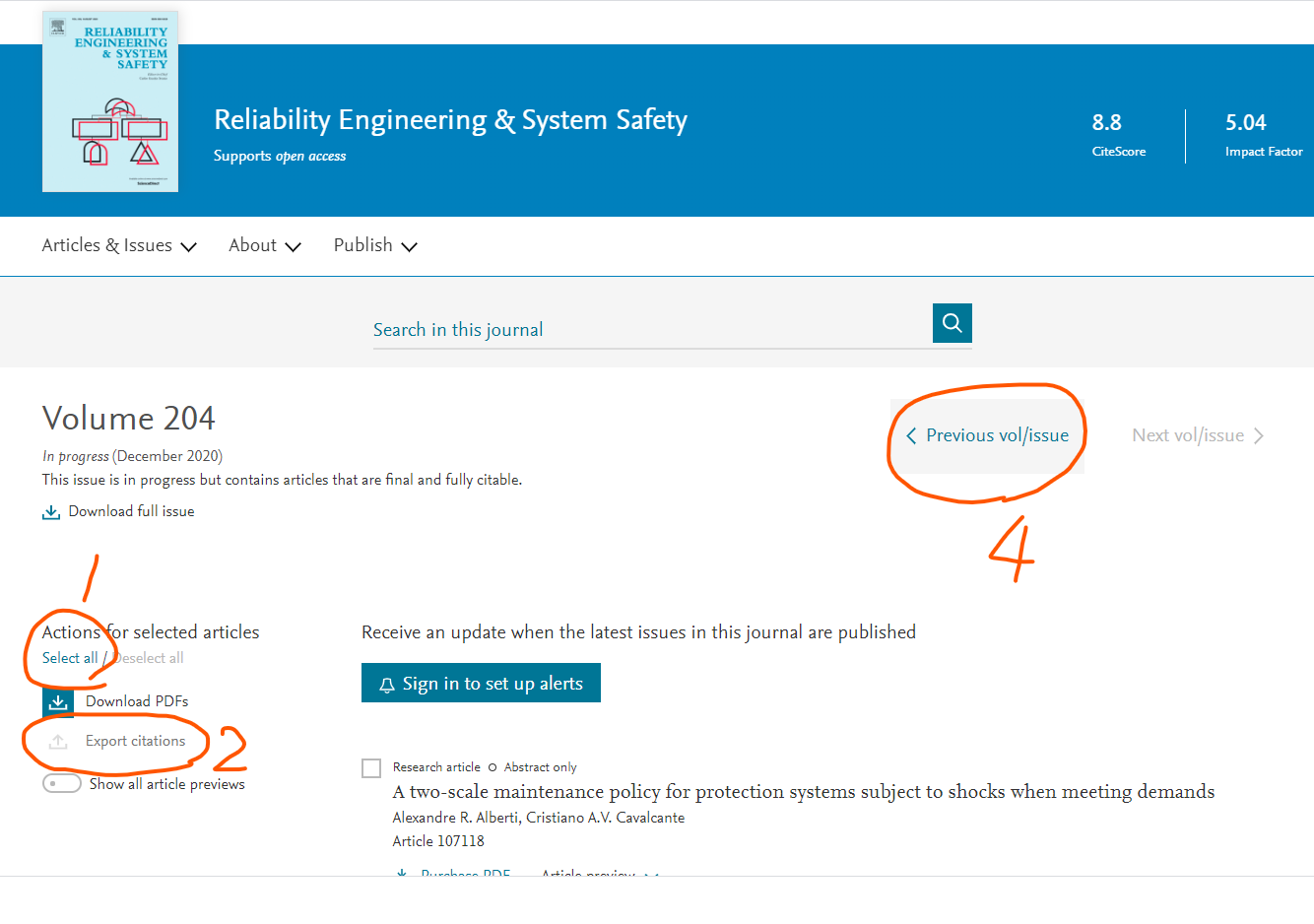
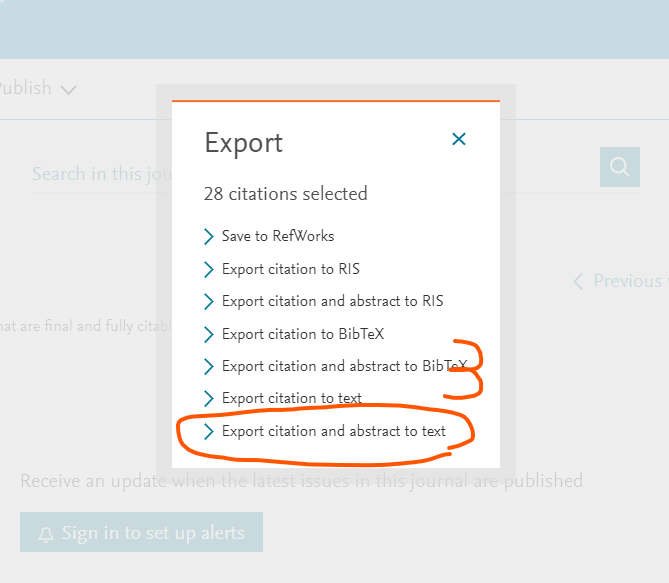
っていう処理。これをループ処理すればすべての文献の情報がGetできる。
ってことで、「Select All」と「Export Citations」と「Export citation and abstract to text」をクリックする方法を調べる。基本的は、driverが読み込んだページから、操作したい対象をIDやらclass名やらName属性やら見つけ出して、.click()を送ればよい。
ってことで、まずは「Select_All」を探してみる。
クロームで当該ページにいきF12キーでDeveloper画面を出す。
んで、Ctrl+Fで検索ボックスを出して「Select All」と入力して検索。すると、Select Allが記載されているところが見つかる。
実はbuttonタグで作られてたんやね。まあ、そりゃそうか。ただ、ぱっと見はボタンには見えないので、ちょっと意外だった。
とりあえず、このbuttonタグの個所で右クリック⇒Copy⇒ Copy selectorを選択して、CSS Selectorを取得しておく。
で、ソースコードの方に戻って、
先ほどのcss selectorをペースト。ただ、必要なのは、後ろほうの「button.」以下のみ。ってことでbutton = driver.find_element_by_css_selector("button.button-link.button-link-secondary.js-select-all") button.click()要素のアクセス可能になるまでの待機処理
なんだけど、いきなりOpenBrowser.pyに上記を書き加えて実行しても失敗する。というのは、ChromeにURLを渡したら、すぐにアクセス可能になるのではなく、実際にURLからHTMLを取ってきて、それをブラウザが解析して、要素にアクセスできるようになるまでの間にタイムラグがあるから。
なので、しばらく待たないといけない。
このページではtimeパッケージからtime.sleep()を取ってきて使ってる。ただ、この方法はこのマニュアルにも書いてある通り、スマートではない。ってことでWebDriverに付属しているWait機能を使う。ってことで以下のようなソース。
(参考:https://qiita.com/uguisuheiankyo/items/cec03891a86dfda12c9a)
(参考:https://www.selenium.dev/selenium/docs/api/py/webdriver_support/selenium.webdriver.support.expected_conditions.html)
なお、マニュアルでは、IDで要素を指定する方法しかのってなかったのだが、css selectorの場合はCSS_SELECTORというのを使う。(参考:https://selenium-python.readthedocs.io/locating-elements.html)・・・と実際に使って試したんだけど、Waitではうまくいかなかった。どうしてもタイミングのずれが生じてしまうみたいで、エラーになる。
なので、結局time.sleep()も含めることにした。WaitAndOperation.pyimport requests from selenium import webdriver # import chromedriver_binary from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC load_url = "https://www.sciencedirect.com/journal/reliability-engineering-and-system-safety/vol/204/suppl/C" driver = webdriver.Chrome(executable_path='c:/work/chromedriver.exe') # driver = webdriver.Chrome() driver.get(load_url) #WebDriverWait(driver, 10).until(EC.visibility_of_all_elements_located) time.sleep(5) #WebDriverWait(driver, 20).until( # EC.element_to_be_clickable((By.CSS_SELECTOR, "button.button-link.button-link-secondary.js-select-all")) #) button = driver.find_element_by_css_selector("button.button-link.button-link-secondary.js-select-all") button.click()他の要素についても同様に・・・
ということで、他の「Export Citations」やら「Export citation and abstract to text」につてもCSS Selectorを取得して、クリックする処理を書き加えていく。
一方、「Previous Vol/Issue」はボタンではなくリンクだった。リンクについても同じようにcss selectorで指定できたりするが、リンクのテキストでも要素にアクセスできる。ってことでテキストでアクセスしてみた。
final.pyimport time import requests #from bs4 import BeautifulSoup # import chromedriver_binary from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC load_url = "https://www.sciencedirect.com/journal/reliability-engineering-and-system-safety/vol/204/suppl/C" Last_url = "https://www.sciencedirect.com/journal/reliability-engineering-and-system-safety/vol/20/issue/1" driver = webdriver.Chrome(executable_path='c:/work/chromedriver.exe') driver.get(load_url) while 1: time.sleep(5) button = driver.find_element_by_css_selector("button.button-link.button-link-secondary.js-select-all") button.click() time.sleep(2) button2 = driver.find_element_by_css_selector("button.button-alternative.text-s.u-margin-xs-top.u-display-block.js-export-citations-button.button-alternative-primary") button2.click() time.sleep(2) button3 = driver.find_element_by_css_selector("button.button-link.button-link-primary.u-margin-xs-bottom.text-s.u-display-block.js-citation-type-textabs") button3.click() time.sleep(3) #現在のURLを取得する Purl = driver.current_url #PurlとCurlが同じならBreak if Purl== Last_url: break link = driver.find_element_by_link_text('Previous vol/issue') link.click()
- 投稿日:2020-08-04T16:04:47+09:00
WindowsでPIP Install するとSSLエラーになるのを解消する。
発生したエラー
(ptoe) D:\MyFile\arc\pyenv\ptoe>pip install pprint WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))': /simple/pprint/ WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))': /simple/pprint/ WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))': /simple/pprint/ WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))': /simple/pprint/ WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))': /simple/pprint/ Could not fetch URL https://pypi.org/simple/pprint/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pprint/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))) - skipping ERROR: Could not find a version that satisfies the requirement pprint (from versions: none) ERROR: No matching distribution found for pprint Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)'))) - skippingSSL認証でエラーになっている。接続先が信用できないということだが原因が何かはわからない。
社用PCなのであまりネットワーク設定をいじるのも怖い。解決方法
ググったところ、pipのオプションで接続先を信頼済みとすればOKらしい。
(MACの例ばかりでWindowsの例が少ないのが不安だけど。)「--trusted-host」オプションでインストール時のみ接続先のサイトを認証OKにする。
必要なのは下記3つ。足りないと上記同様のエラーとなる。--trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org実践
1.PIPを更新する。
(ptoe) D:\MyFile\arc\pyenv\ptoe>python -m pip install --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org --upgrade pip Collecting pip Downloading https://files.pythonhosted.org/packages/36/74/38c2410d688ac7b48afa07d413674afc1f903c1c1f854de51dc8eb2367a5/pip-20.2-py2.py3-none-any.whl (1.5MB) |████████████████████████████████| 1.5MB 3.3MB/s Installing collected packages: pip Found existing installation: pip 19.2.3 Uninstalling pip-19.2.3: Successfully uninstalled pip-19.2.3 Successfully installed pip-20.2PIPのアップグレードが通った!!(´ω`)
2.エラーになっていたライブラリのインストール
(ptoe) D:\MyFile\arc\pyenv\ptoe>python -m pip install --trusted-host pypi.python.org --trusted-host files.pythonhosted.org --trusted-host pypi.org pip pprint Requirement already satisfied: pip in  d:\myfile\arc\pyenv\ptoe\lib\site-packages (20.2) Collecting pprint Downloading pprint-0.1.tar.gz (860 bytes) Using legacy 'setup.py install' for pprint, since package 'wheel' is not installed. Installing collected packages: pprint Running setup.py install for pprint ... done Successfully installed pprint-0.1ライブラリも正常にインストールできた。
永続化
毎回「--trusted-host」を3つも書いてインストールするのはちょっと...
という場合は、pip.iniを作成して書いとけば以降は--trusted-hostオプションを指定する必要はなくなる。[global] trusted-host = pypi.python.org pypi.org files.pythonhosted.orgWindowsの場合にpip.iniをどこに置けばいいか全然わからなかったけど、
pipの公式ドキュメントに書いてあった。#ユーザーローカルの場合 %APPDATA%\pip\pip.ini #グローバルの場合 C:\ProgramData\pip\pip.ini #仮想環境(venv)の場合 %VIRTUAL_ENV%\pip.ini仮想環境の格納イメージ
参考
https://github.com/pypa/pip/issues/5448
https://pip.pypa.io/en/stable/user_guide/#configuration
- 投稿日:2020-08-04T15:37:53+09:00
IBM Cloudのメール配信サービス(SendGrid)を使ってNode.js、Pythonからメール配信してみた!
背景
現在私が担当している案件で一般ユーザー向けのサービスを提供する予定で、ユーザー登録をした際などにメールをユーザーに送信する必要があるとのことで、メール送信サーバーをどうやって調達するかが課題となった。
お客様の方で用意できるメール送信サーバーで使えるものはないということだったので、IBM Cloud内で使用可能なサービスがないのかを調査した結果以下のサービスが利用できそうなので、実際に使えるのかどうか、利用方法はどんな感じかを実際にサービス登録して使ってみたのでこの記事にまとめました。
https://cloud.ibm.com/docs/email-delivery?locale=jaE メール配信について
SendGrid の IBM Cloud E メール配信サービスは、メール・リレー・サービスです。このサービスにより、スマート・ホストを使用してアウトバウンド・メール・サービスのリレーが可能になります。スマート・ホストは、SMTP サーバー、メール・クライアント、または SMTP を処理可能な任意のサービスまたはプログラム言語からの SMTP トラフィックをリレーします。 また、このサービスでは、メトリックの生成、E メール・リストの追跡、E メール・アクティビティー (E メールのバウンス、クリック、ドロップ、オープンなど) の追跡も行います。 このサービスには、ニュースレター支援や認証などの他の機能も用意されています。※なお、マニュアルには何が出来るかほとんど記載されていませんが、サポートに問い合わせたところ、IBM Cloud経由でSendGridに作成されたアカウントで選択したアカウント・タイプで使用可能なSendGridの機能はそのまま利用できるとのことです。
登録方法
https://cloud.ibm.com/classic/services/emaildelivery にアクセスし、Order Email Delivery Serviceのボタンをクリックする
Account Typeを選択し、Email Address、Username、Passwordを設定し、Continueボタンをクリックする
※UsernameとPasswordはSendGridアカウントのユーザー名、パスワードとして使用される。
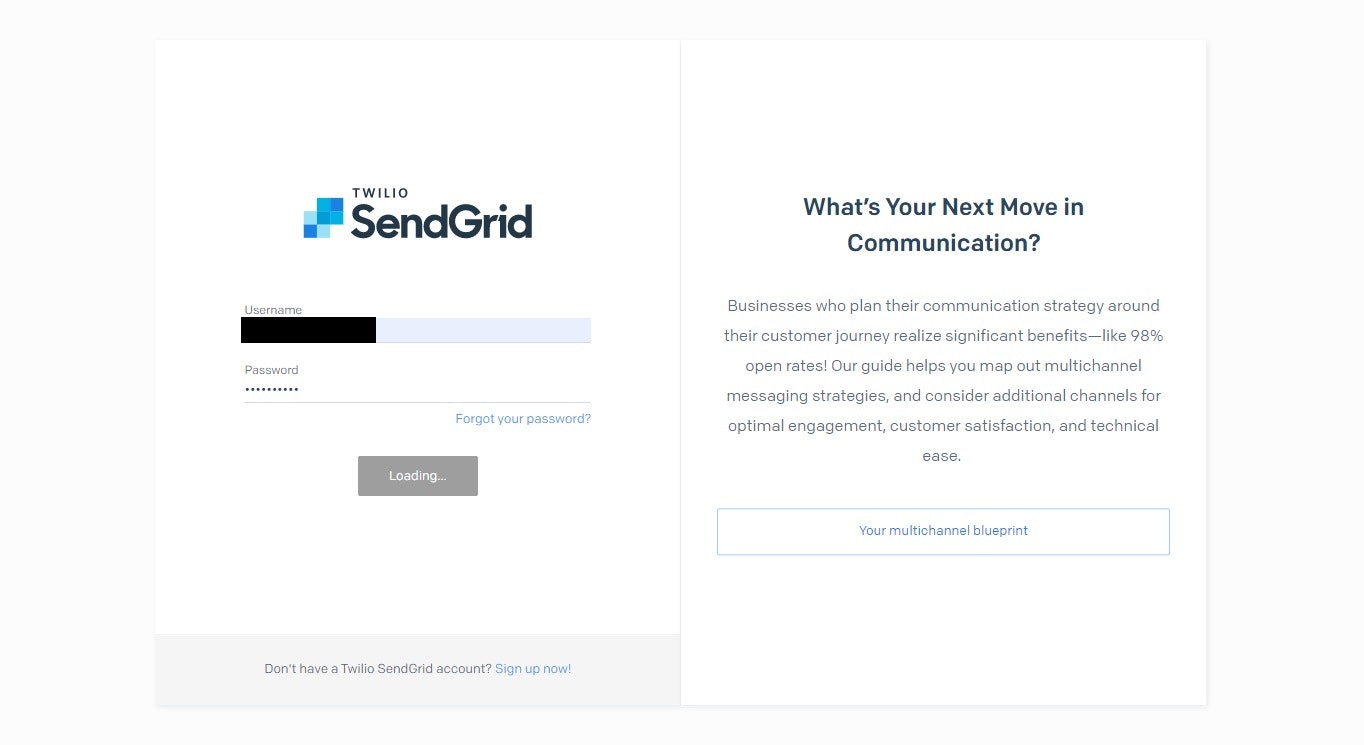
登録が完了し一覧に表示されたら、ActionsよりAccess Vendor Portalを選択し、Send Gridのポータルにアクセスする
手順3で設定したUsernameとPasswordでログイン出来ることを確認する。
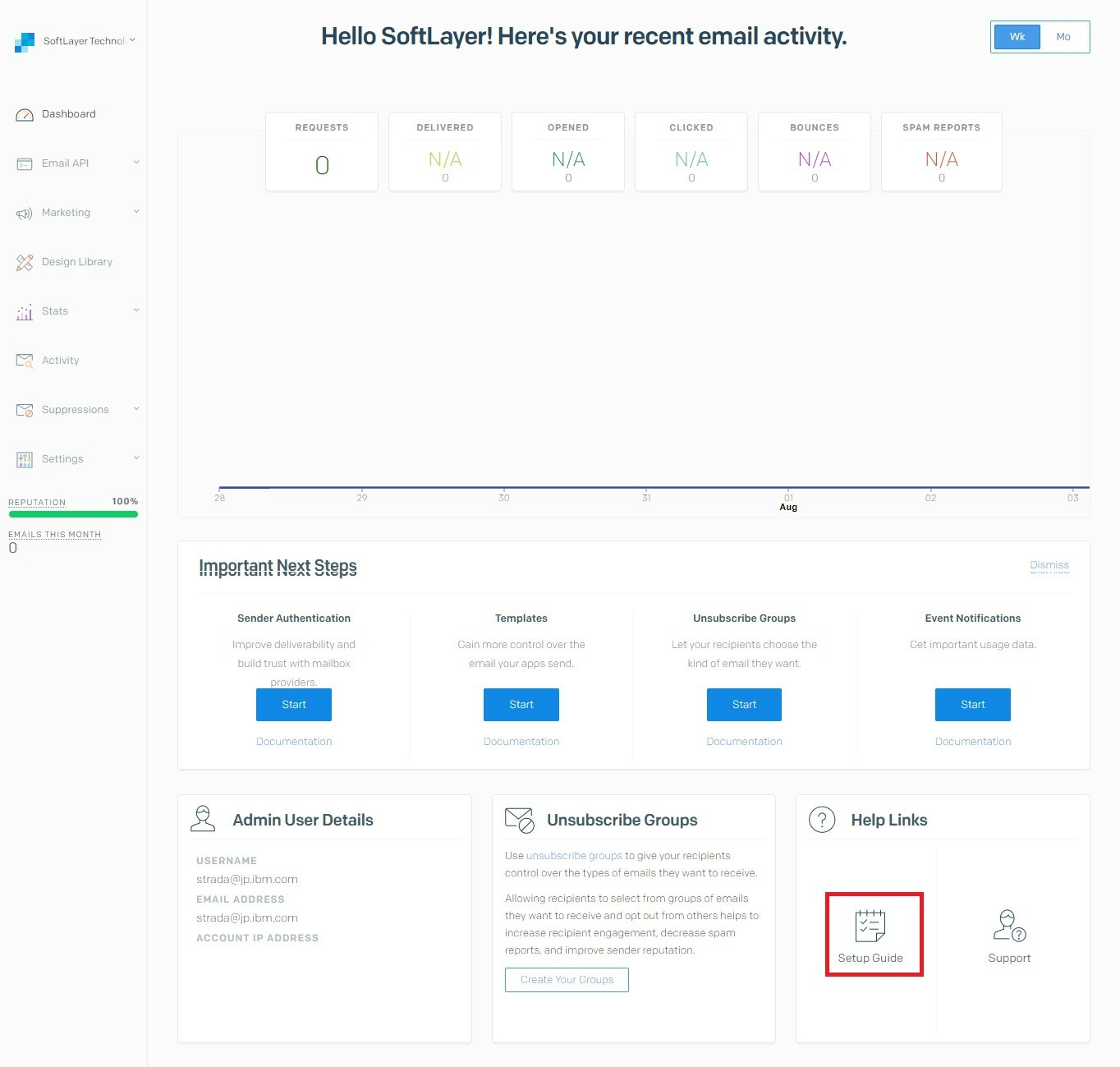
使い方
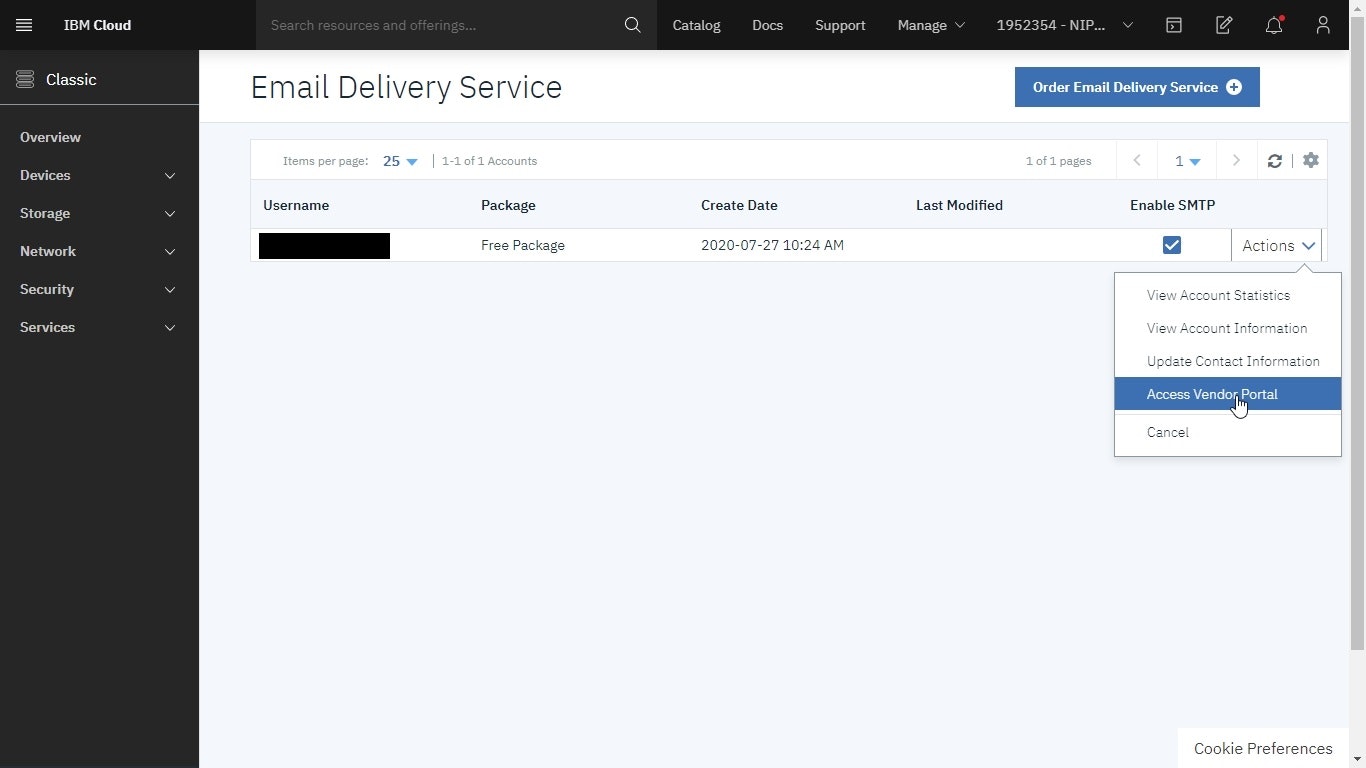
SendGridのポータルからSetup Guideを開く
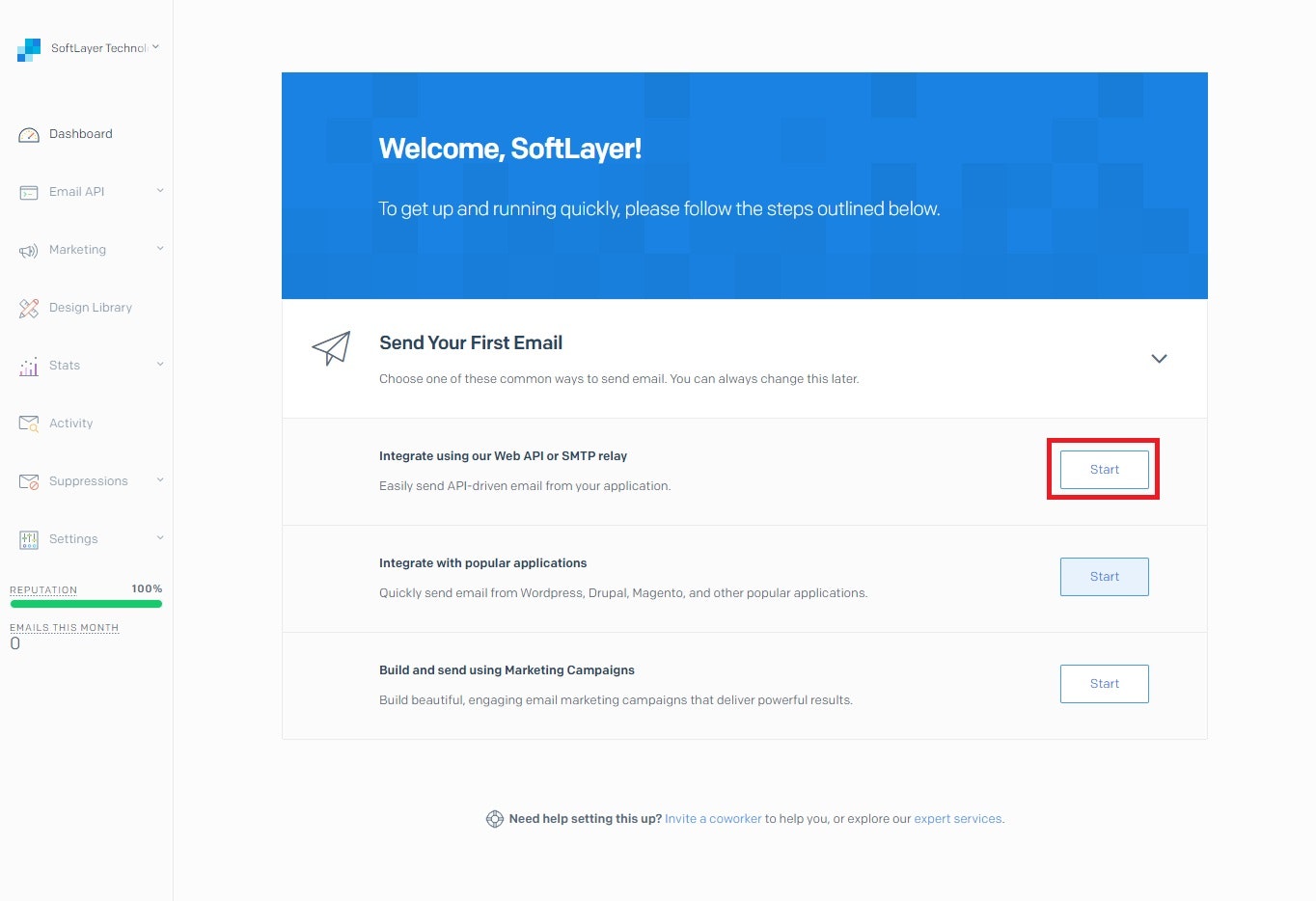
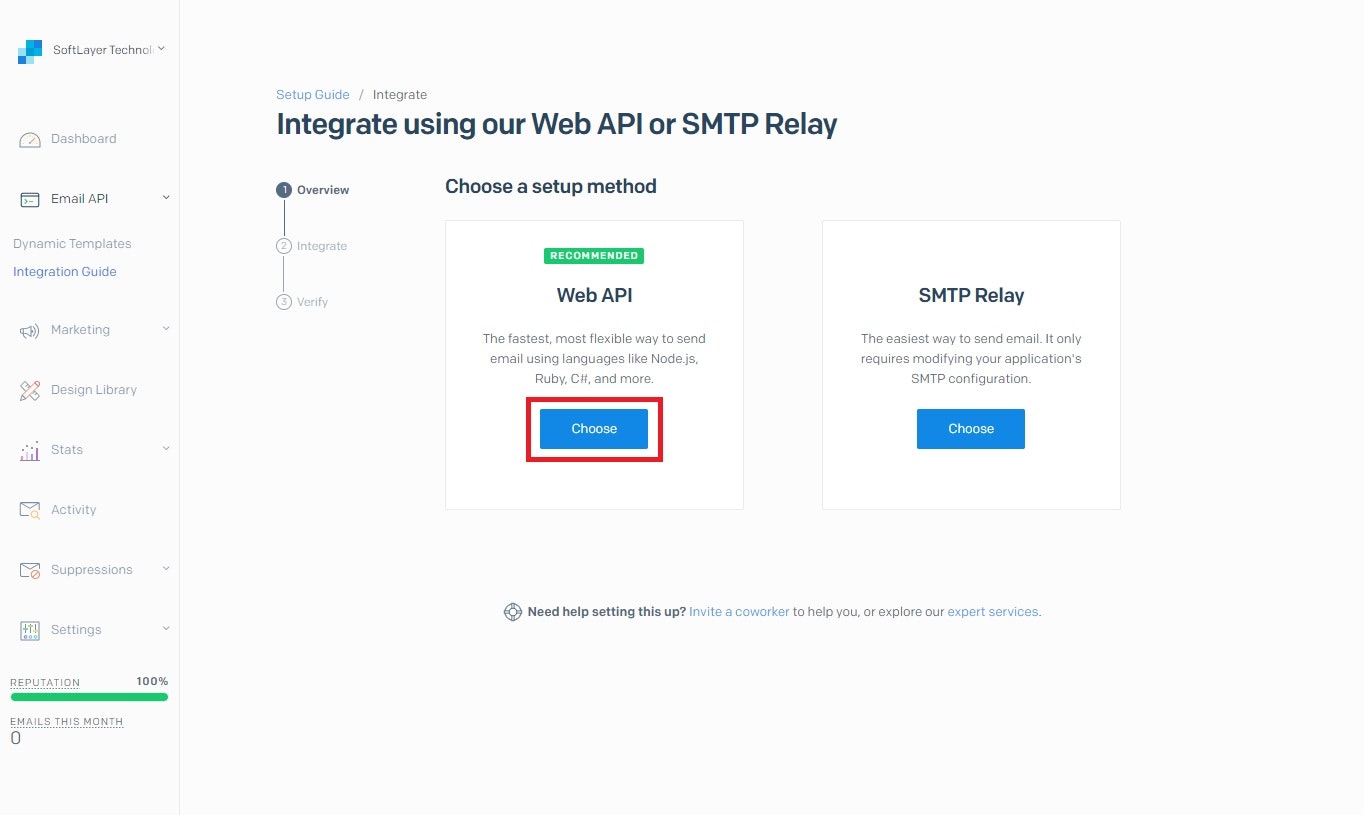
Integrate using our Web API or SMTP Relay横のStartを選択する
Web API以下のChooseを選択する
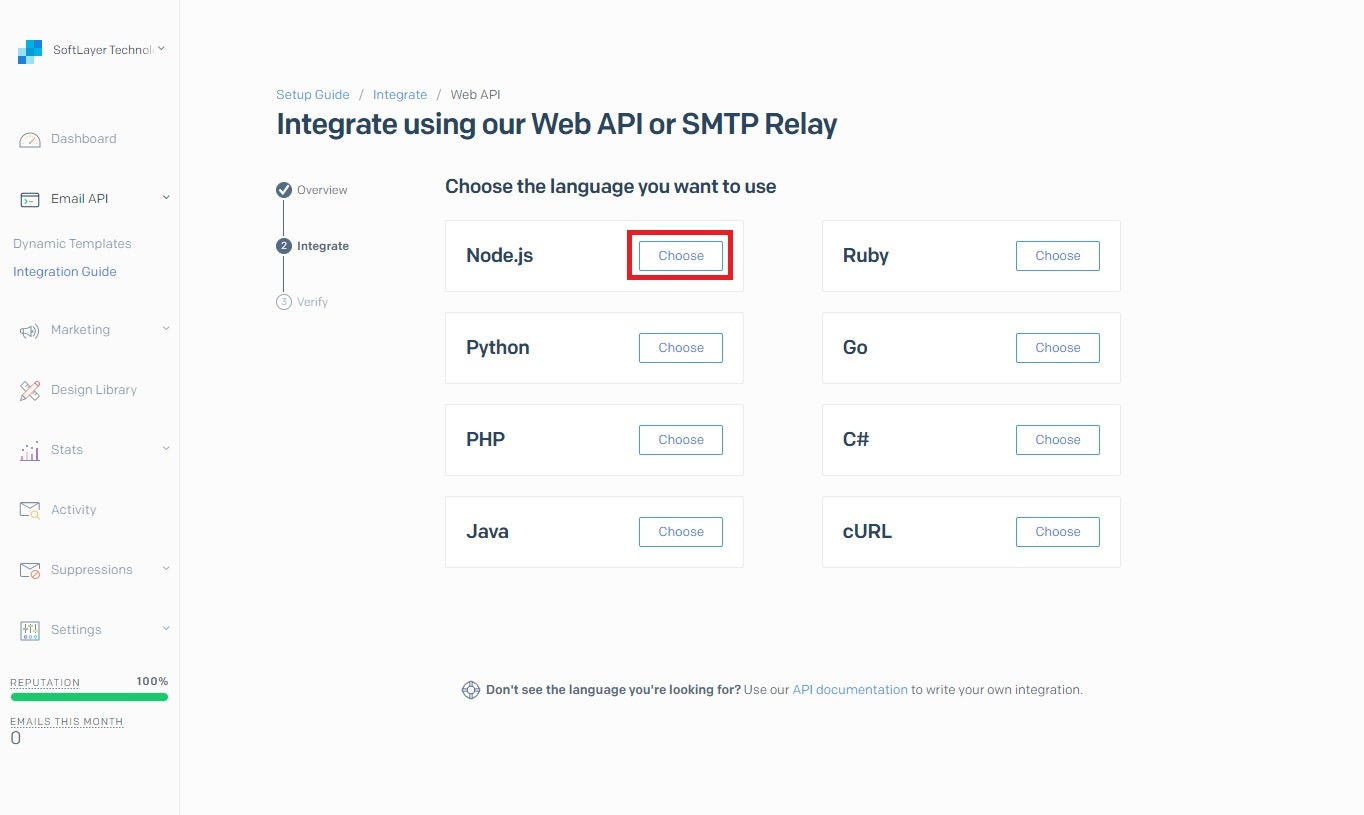
使用した言語横のChooseを選択する
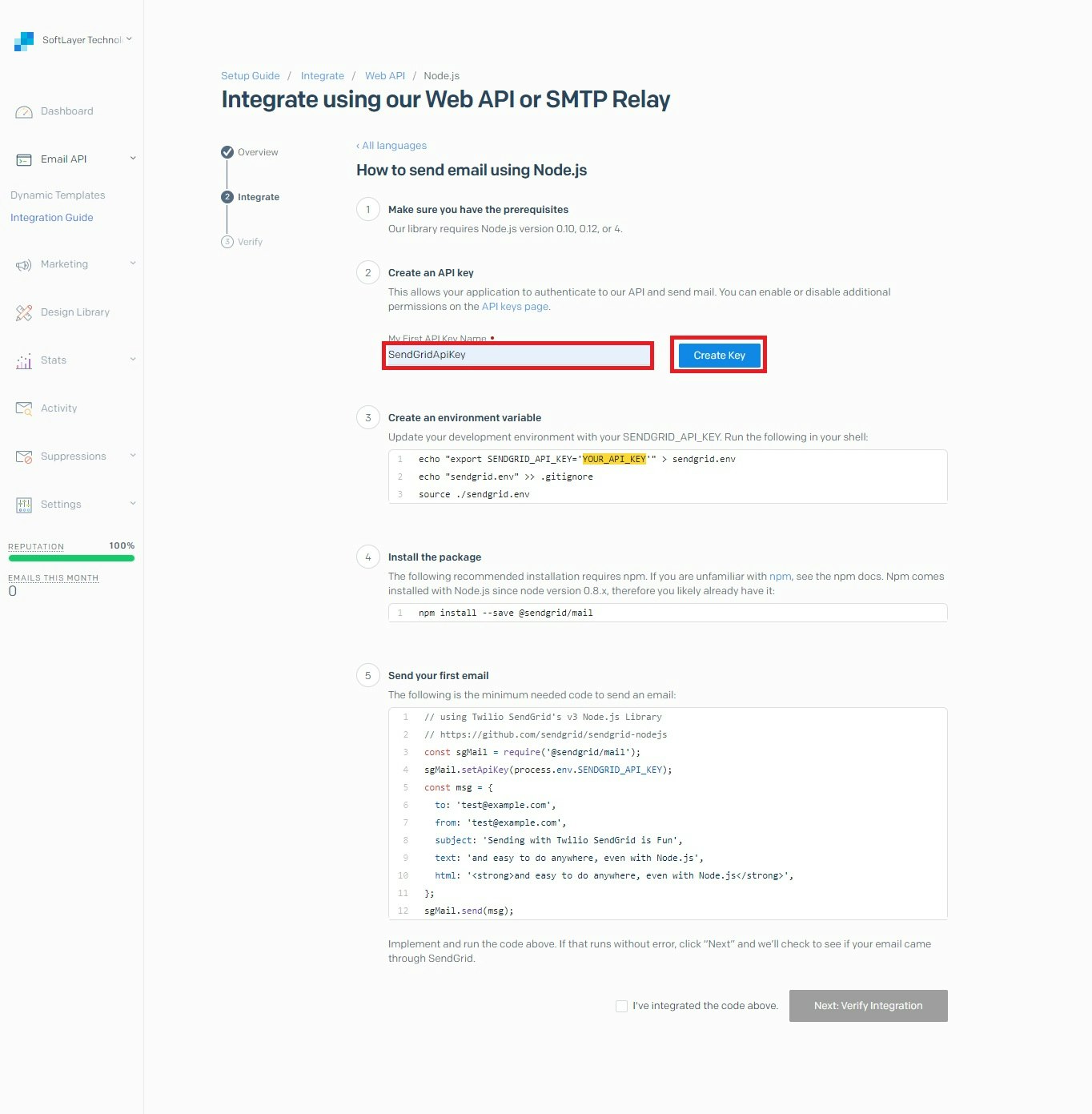
My First API Key Name配下にAPIキー名を入力した上で、Create Keyボタンをクリックする
後は画面に表示された手順に乗っ取り該当のコードを実装し、実行すればメールが送信される

- 投稿日:2020-08-04T13:59:05+09:00
初心者に捧ぐ!極力お金をかけずにプログラミングを学ぶ方法
はじめに
初心者対象!と銘打っていながら、私も初心者です。ただ自分でプログラミングを学んでいるだけの学生です。
1年半くらい前にかる~~くPythonを触ってその後熱が冷めて今年の4月くらいからまた勉強をはじめました。
自分用のメモとして4ヶ月経った今感じる良かったなと思う学習法や気づきなどを書き留めていきたいと思います。専門的な横文字などをできるだけ簡単に書いていくように努めていますので、冗長になってしまう部分もあるかとは思いますが、どうか許してください。現状プログラミング学習で使用したお金は、Udemyでの講座料として一万円程です。早くメイクマネーしてMacBookが欲しいです。
Who I am
私は文系の大学生です。ですが独学で勉強し、来年よりエンジニアとして就職が決まっております。
留学中、英単語を調べるのがめんどくさくてプログラミングを学習し始めたのがきっかけです。
一番好きな言語はPythonで、アルバイトでPHPをたまに触ります。
後述するサイトで学習し、ある程度基本的な動作は理解している(つもり)なものは
Python、Go、TypeScript(JavaScript)、PHP、HTML+CSSです。最近はReactを勉強しています。プログラミングとは?
プログラミングとはその名の通りプログラムを組むことでコンピューターに様々な指示が与えられるもので、プログラミング言語というのがコンピューターが理解できる言語だと思えばいいと思います。(厳密にはマシン語がどうとかスクリプト言語はどうとか色々ありますけど)
最近良く目にするプログラミング言語といえばPythonかなという風に思っています。理由は機械学習などのデータサイエンスの分野からWebアプリケーションまで応用が効くのにもかかわらず学習コストが低いからだと思います。もっと細かく
人工知能のエンジニアもいれば、データベースのエンジニア、サーバ等を構築・管理するインフラエンジニア、WEBアプリケーションを開発するWEBエンジニア、などなどプログラマーと言っても多岐にわたります。ですので、ざっくり自分は何をするためにプログラミングを学びたいかを明確にしてから言語を選ぶことが賢いのかなという風に思っています。
私自身、好奇心旺盛なのでなんでも関心を持つタイプなのですが、「面白さとかどうでもいいので稼げるスキルを身に着けたい!!」という場合はとりあえずJavaScript(TypeScript)はどんな分野でも使いそうな気がします。プログラミングスクールでは、Rubyという言語とRuby on railsというRubyのためのWEBアプリケーション開発フレームワークを学習するそうです。ただRubyの需要は下降傾向にあると思っていて、今から独学で始める際にはPythonやGoを推したいですね。ですのでPythonを学ぶ体でこの記事を進めさせていただきます。
しかし一つの言語に慣れ、プログラミングを行っていれば別の言語も似通っている部分が多いですし、データ構造やアルゴリズムといったようなものは一度理解してしまえば転用できるため無駄にはならないと思いますので、なんとな~~くプログラミングやってみたいなという方は引き続き読み勧めていただきたいです。Python(パイソン)でなにができるの?
ほとんどなんでもできる、が正解だと思います。汎用業務アプリ開発などでなければ、基本的にあなた自身のアイデアに依存すると思っています。
私が作成したもので言えば、
-英単語を複数入力し一括で結果をCSVファイル(Excel等でも開けるように)に出力するプログラム
-Tinder自動スワイププログラム(はずかしい)
-バーコードを読み取って対応する書籍の情報を取得するプログラム
-FX自動売買プログラム(こちらの方は後述します)こちらのページでPythonカテゴリ内の人気記事を簡単に閲覧できます。
【Python】 Qiita殿堂入り記事私としては、プログラムは、「こうなればいいのにな」という課題を解決するための単なる道具であると思っています。(ぜんぜん違うよ!という方居られましたらすいません、、、)
動画で学習❗①Paiza
私はまずPaizaというサイトでPythonを学習しました。こちらのサイトはPythonの講義でしたら完全無料で受けられ、動画視聴→演習というステップで理解度を確認できるため使いやすかったです。Pythonについてサラッと学ぶ感じなのでこの時点ではまだまだ実用的ではないという風に思っています。私自身この段階では「クラスって何??文法とかはわかるけどこれでなにをするの??」という感じでした。
Paizaで一通りPythonを学習したら、自分で一度プログラムを組んでみることをおすすめします。何か少し調べればできそうな範囲で、汚いコードでもいいので書いてみてください。そこからまた学びがあると思います。
動画で学習❗②Udemy
Udmeyについてご紹介させてもらいます。簡単に言えば受験サプリです。好きなときにPC・スマホから視聴でき、期間無制限です。自分が見たい講座を購入し受講するという流れです。質問があれば相談できますし、レビューなどで事前に受講者の評価も確認できます。何万人も受講しているような講座を受ければある程度確実にしっかりとしたものを学べると思います。あとはセール以外のときに講座買うのは絶対ダメです。通常価格24000円!となっていたりするのですが、結構な頻度でセールが行われ、1200~1680円くらいでだいたい買えるのでそのときに買いましょう。
酒井潤さんという現役シリコンバレーエンジニアの方の講座は無駄がなく実用的なものばかりで個人的には一番おすすめです。
こちらが内容も面白く、実りが合ったという風に感じています。
現役シリコンバレーエンジニアが教えるPythonでFXのシストレFintechアプリの開発
PaizaでPythonの基礎をある程度身につけたら酒井先生のPython入門講座を受講することをお勧めします。他にも英語で開講されている講義だと、母数が多い分競争も激しいため検索上位に出てくる講義はこの価格でこんなクオリティ受けてもいいの?と思うような内容も多いという風に感じています。殆どの場合英語字幕をつけられると思うので、臆することなく英語での受講もおすすめします。英語に慣れることはプログラミングで躓いた際に必ず役に立つと思います。(Stackoverflowなどの質問サイトでは英語で解決策が載っていたり、公式ドキュメントも英語のものが多いため)
私は現在で7個ほど講座を終えましたがUdemyを使う前と現在では全く別人のように思えます。
動画で学習❗③Coursera
Courseraは海外の大学の授業を受けられるサイトで、特にデータサイエンスの分野で注目を浴びています。
タイムリーな良記事があったためご紹介させていただきます。
【動画でも】タダで学べる有名大学レベルのデータサイエンス【そう、courseraならね。】私自身データサイエンスの分野は勉強している途中のため、割愛させていただきます。
他にも東大の松尾研究所の教材も高いクオリティかつ無料のため人気です。動画で学習❗④YouTube
YouTubeは本当にピンキリという感じがします。中でも、しょう先生という方のチャンネルは初心者にも優しいと思います。他にもその都度必要な知識があればサクッと見れるのが利点ではあるかなという風に思っています。
私は「CSS Animation」等で検索し、良さそうなデザインを学んだりするときに使っています。技術面以外での内容は見ないようにしています。商材屋とかサロン勧誘屋みたいな人多そうなので、、、
最後に
プログラミングの難しいところは、システムの理解に対して単純にプログラミング言語だけの知識だけでは対応できない点や、単純に処理の内容だけでなく、他の点で躓くところが多い部分にあると感じています。
実際現場で開発するとなるとDockerやKuberneatsを使ったりCircleCI等を用いたりAWSでインフラを構築したり・・・。?なんですかそれは???私自身エンジニアとしてまだしっかり働いているわけではないためわからないことが多いです。みんなやる前では何もわかりません。分かる人や賢い人からうまく技術を盗み自分のものにしていきましょう。自身の経験として、「そのシステムが何をするか」だけでなく「どういう経緯で生まれたか」も学ぶと、自然に理解できるかなという風に思います。Qiitaで面白そうな記事を読みまくる、インプットだけでなく得た知見はQiita等でアウトプットする(限定公開でも)、動画学習サイトで何かを習った際はその技術を用いて自分独自のものを1から築いてみる、なにかに躓いたときは別の視点からアプローチしてみる、をただひたすらに繰り返すことで段々と理解できてきているように感じています。
そのため今後も一週間に一度はQiitaで学習で得た知見を言語化して行きたいと思っています。上記で上げた動画サイトの他にも基本情報技術者試験の本を通読してコンピュータについての基礎知識を入れておくとなお捗ると思います。今後IT系で働くつもりなら受験の有無に関わらず、ぜひさらっと勉強することをおすすめします。私は秋の受験に向けて勉強中です
オンライン授業で実りがないなぁという風に感じている大学生の方も、上で挙げたようなサイトを利用してプログラミングのスキルを得てみませんか?
皆さんそれぞれ学習する意図は異なるとは思いますが、プログラミングのスキルを得て人生がより良いものになることを祈っています。初心者プログラマーの方はともに頑張りましょう!
- 投稿日:2020-08-04T12:16:01+09:00
PythonのSliceにモヤっとした話 がスッキリした話
slice処理の違和感
前記事です:PythonのSliceにモヤっとした話
殆どのプログラマはおそらく、配列からある要素を抜き出したい場合添字にIndexを指定するというのが意識に刷り込まれているのではないでしょうか。
Index+++++++++++++++++++++++++++++++++++++ element + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + +++++++++++++++++++++++++++++++++++++ index + 0 + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 +ある配列の7個目の要素を抜き出したい場合、以下の様なコードと結果になる事に違和感を覚えるプログラマはまずいないでしょう。
l=[1,2,3,4,5,6,7,8,9] print(l[6]) #7そのため、配列に対してslice操作を行う場合も、当然のようにIndexで範囲を指定しようとします。
l=[1,2,3,4,5,6,7,8,9] print(l[6:7]) #[7]oh… 私はIndexの6~7を指定したつもりだったので、予想した結果は
#[7,8]なのですが、現実は非情でした。
違和感の正体
結論から言えばsliceの処理で配列の添字とするべきは、IndexでなくLengthでした。
Length+++++++++++++++++++++++++++++++++++++ element + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + +++++++++++++++++++++++++++++++++++++ length 0___1___2___3___4___5___6___7___8___9l=[1,2,3,4,5,6,7,8,9] print(l[6:7]) #[7]Lengthの図表と処理を見比べ、添字がIndexではなくLengthなんだと脳内で置き換えてみると、長さ6~7の間にある要素を取得する処理となるため、出力結果にも違和感がなくなりました、ああスッキリ。
でもなんでLength?
判りません。
range関数のようにLengthを指定してIndexの範囲を取得する処理はたしかに直感的で便利ですが、だからといってIndex基準が主流の配列の添字に対してまでLength基準での添字記法を態々混在させる程のどんな素晴らしい理由があるのか、結局判りませんでした。実はわかりやすい(?)Lengthを使った配列操作
上では配列の添字にLengthを使うことに対し否定的でしたが、実は誰しもLengthを添字にしようとしたことがあるはずなんです(多分)、私はあります。
あれは幼い頃、お年玉をはたいて近所のLaoxでDelphi2.0とはじめてのDelphiみたいな参考書を購入し(何故Delphiを選んだのかは判りません、多分GUIプログラミング言語の中で一番安かったとかそんな理由です)、意気揚々とプログラムの勉強を始めた時です。
参考書のサンプルを見ながらコードを組んではエラーと修正を繰り返しつつ、配列のページに差し掛かりました。参考書「配列の最初の要素を取得するには、添字に0を指定します。」
僕「なんで?」当時、周囲にその疑問に答えられる人は誰もおらず、渋々最初の要素を取りたいときは0、次の要素を取りたいときは1、と呪いのように意識に刷り込みました。
なので今回私が抱いた違和感も、実は全くプログラミングを知らない人ならそもそも違和感すら感じず受け入れるのかもしれません。
仮にすべての配列操作がLength基準によって行われる言語が主流になったなら、参考書「配列の最初の要素を取得するには、添字に1を指定します。」
僕「なるほど」こんな世界もあり得るのかもしれません。
というわけで
結論としては、納得は行かないが理解はした、という感じです、あんまりスッキリしませんでしたね。
とはいえ、今更Length基準で配列操作を行うのが世界の主流になられても困ってしまいますし、配列の添字はこれからもできる限りIndex基準で統一して欲しい、と言う希望を述べつつ終わりとさせていただきます。
- 投稿日:2020-08-04T10:12:54+09:00
gensimじゃなくてtomotopy使おうよ
tomotopyって?
tomotopyは、TOpic MOdeling TOol の略で、主にLDA(Latent Dirichlet Allocation)とその派生のアルゴリズムを扱えるPythonライブラリです。
同様の機能を持つライブラリgensimと比べて簡単に扱え、C++で組まれているので計算も速いです。
導入方法
pipで入れるだけです。
pip install tomotopy使い方
例として、gensimチュートリアルにある次のデータセットを使います。
Human machine interface for lab abc computer applications A survey of user opinion of computer system response time The EPS user interface management system System and human system engineering testing of EPS Relation of user perceived response time to error measurement The generation of random binary unordered trees The intersection graph of paths in trees Graph minors IV Widths of trees and well quasi ordering Graph minors A surveytomotopyでLDAを利用する場合は、次のようになります。
データセットは、前処理後のものを使います(前処理はこれと同じ)。
import tomotopy as tp from pprint import pprint texts = [ ['human', 'interface', 'computer'], ['survey', 'user', 'computer', 'system', 'response', 'time'], ['eps', 'user', 'interface', 'system'], ['system', 'human', 'system', 'eps'], ['user', 'response', 'time'], ['trees'], ['graph', 'trees'], ['graph', 'minors', 'trees'], ['graph', 'minors', 'survey'] ] # モデルの初期化 model = tp.LDAModel(k=2, seed=1) # kはトピック数 # コーパスの作成 for text in texts: model.add_doc(text) # 学習 model.train(iter=100) # トピックの単語分布の取り出し for k in range(model.k): print(f"Topic {k}") pprint(model.get_topic_words(k, top_n=5)) """output Topic 0 [('system', 0.20972803235054016), ('user', 0.15742677450180054), ('human', 0.10512551665306091), ('interface', 0.10512551665306091), ('computer', 0.10512551665306091)] Topic 1 [('trees', 0.2974308431148529), ('graph', 0.2974308431148529), ('survey', 0.1986166089773178), ('minors', 0.1986166089773178), ('system', 0.0009881423320621252)] """tomtopyの特徴
良いところ
- 扱いやすい。
LDAを利用したいときにやりたいほとんどのことが、モデルの初期化や学習関数の引数を設定することにより簡単にできます。
(並列化、TF-IDF、単語頻度や文書頻度の上限下限の設定など)
- 学習アルゴリズムがサンプリング(崩壊型ギブスサンプリング)である。
gensimでは変分推論が用いられいますが、サンプリングの方が精度が良いと言われています。
サンプリングのデメリットとして、時間がかかることが挙げられますが、
tomotopyはC++で組まれており、並列化も簡単にできるので、MALLETとかと比べるとすごく速いです。
- LDAの派生が利用できる。
次のものが利用できます。
- Labeled LDA (
LLDAModel)- Partially Labeled LDA (
PLDAModel)- Supervised LDA (
SLDAModel)- Dirichlet Multinomial Regression (
DMRModel)- Generalized Dirichlet Multinomial Regression (
GDMRModel)- Hierarchical Dirichlet Process (
HDPModel)- Hierarchical LDA (
HLDAModel)- Multi Grain LDA (
MGLDAModel)- Pachinko Allocation (
PAModel)- Hierarchical PA (
HPAModel)- Correlated Topic Model (
CTModel)- Dynamic Topic Model (
DTModel)悪いところ
- かゆいところに手が届かない場合がある。
tomotopyは扱いやすさに特化しているためか、「えっ、これできないの?」ってときがたまにあります。
例えば、
- 処理後のコーパスを再利用できない(学習する都度コーパスを作らなければならない)。
- RAMを節約する方法がない。
(まぁどちらもウン千万件のデータセットでもなければそこまで気にならないです。)
まとめ
tomotopyを利用すると、非常に簡単に、LDA系のモデルを、サンプリングにより、学習できます。
正直もうgensimには戻れません。
- 投稿日:2020-08-04T10:00:08+09:00
WSL上で実行したPythonがAbortedになる現象への対処法
概要
WSL上でPython(Jupyter notebook)を実行した際にエラーが発生し正常に実行できない現象への対処方法。
起動直後ではなく、起動後かなり時間が経過した後に発生する傾向。環境
- Windows10
- WSL (Ubuntu 18.04.2 LTS)
エラー内容
Fatal Python error: _Py_InitializeMainInterpreter: can't initialize time OverflowError: timestamp too large to convert to C _PyTime_t Current thread 0x00007f0232c21080 (most recent call first): Aborted (core dumped)原因
uptimeがオーバーフローして負の範囲になってしまっている。
issue$ uptime 11:23:19 up -24855 days, -3:-14, 0 users, load average: 0.52, 0.58, 0.59対処方法
PC自体を再起動する。
もしくはPowershellを管理者モードで起動し、以下のコマンドを実行。WSLを再起動する。PS XXXXXX> Get-Service LxssManager | Restart-ServiceLxssManagerとは
Windows Subsystem for Linux 関連。Linuxでよく使用されるバイナリのフォーマットである ELF を Windows で動作させる機能に関するサービス。
- 投稿日:2020-08-04T10:00:08+09:00
WSL上で実行したPython(Jupyter notebook)がAbortedになる現象への対処法
概要
WSL上でPython(Jupyter notebook)を実行した際にエラーが発生し正常に実行できない現象への対処方法。
起動直後ではなく、起動後かなり時間が経過した後に発生する傾向。環境
- Windows10
- WSL (Ubuntu 18.04.2 LTS)
エラー内容
Fatal Python error: _Py_InitializeMainInterpreter: can't initialize time OverflowError: timestamp too large to convert to C _PyTime_t Current thread 0x00007f0232c21080 (most recent call first): Aborted (core dumped)原因
uptimeがオーバーフローして負の範囲になってしまっている。
issue$ uptime 11:23:19 up -24855 days, -3:-14, 0 users, load average: 0.52, 0.58, 0.59対処方法
PC自体を再起動する。
もしくはPowershellを管理者モードで起動し、以下のコマンドを実行。WSLを再起動する。PS XXXXXX> Get-Service LxssManager | Restart-ServiceLxssManagerとは
Windows Subsystem for Linux 関連。Linuxでよく使用されるバイナリのフォーマットである ELF を Windows で動作させる機能に関するサービス。
- 投稿日:2020-08-04T09:40:43+09:00
pythonのsubprocess君、なぜかstdoutしてくれない。
問題
例えば、C++でこういう中身のexeファイルを作ったとする。
#include <iostream> using namespace std; int main(){ int A,B; cout << "Aを入力してください" cin >> A; cout << "Bを入力してください" cin >> B; cout << A+B; }至ってシンプルな入力された二つの数字を足し合わせるプログラムである。
これをpythonのsubprocessで実行すると以下のような動きをする。
??????
何も表示されない...
なんだこれは...そこで、何も表示されていないが、10と20を入力してみる。
すると,$ 10 $ 20 $ Aを入力してくださいBを入力してください30うっわ。
なんか一番最後に表示してほしかったものが表示されてら。解決策
これはC++の方で解決してあげなければならない。
標準出力の各行には必ず改行が必要となる。
そうしないとsubprocess君は出力を認識できないのだ。なので、
#include <iostream> using namespace std; int main(){ int A,B; cout << "Aを入力してください\n" cin >> A; cout << "Bを入力してください\n" cin >> B; cout << A+B << "\n"; }これで解決である。
- 投稿日:2020-08-04T09:11:22+09:00
M-SOLUTIONS プロコンオープン 2020 復習
今回の成績
感想
背水の陣ですね…。Highest更新!と思っていたのですが…。
Dの場合分けがうまくいかず、Fに移って解けそうな感じがしていたのですが、問題を勘違いしていました。
15分前に思いついた解法が合っていてコンテスト後に自力で解くことができたので、コンテスト中に死ぬ気で集中して取り組まなければと思いました。
具体的には、バチャコンを再開する(ABCは結構解いてしまったのでCodeforcesのdiv2,3)or水青黄diffの問題を30分~1時間で制限時間をつけて解くというのが良いかと思いました。復習記事投稿するのが一週間も遅れてしまいました。以後気を付けたいです…。
最近全く奮わないですがいつか伸びると信じてやるしかないです。地力はついてきてるはずなので。A問題
1問目から若干面倒な問題でした。
しかし、比較する値を配列に入れておけばループを回すだけで考えることができます。A.pyx=int(input()) h=[1800,1600,1400,1200,1000,800,600,400] for i in range(8): if x>=h[i]: print(i+1) breakB問題
$a<b<c$にするのに必要な回数を考え、それが$k$回を超えるか考えます。$a<b$→$b<c$の順で等号が成り立つようにそれぞれ$b,c$を2倍にしていけば良いです。
B.pya,b,c=map(int,input().split()) k=int(input()) ans=0 while a>=b: ans+=1 b*=2 while b>=c: ans+=1 c*=2 print("Yes" if ans<=k else "No")C問題
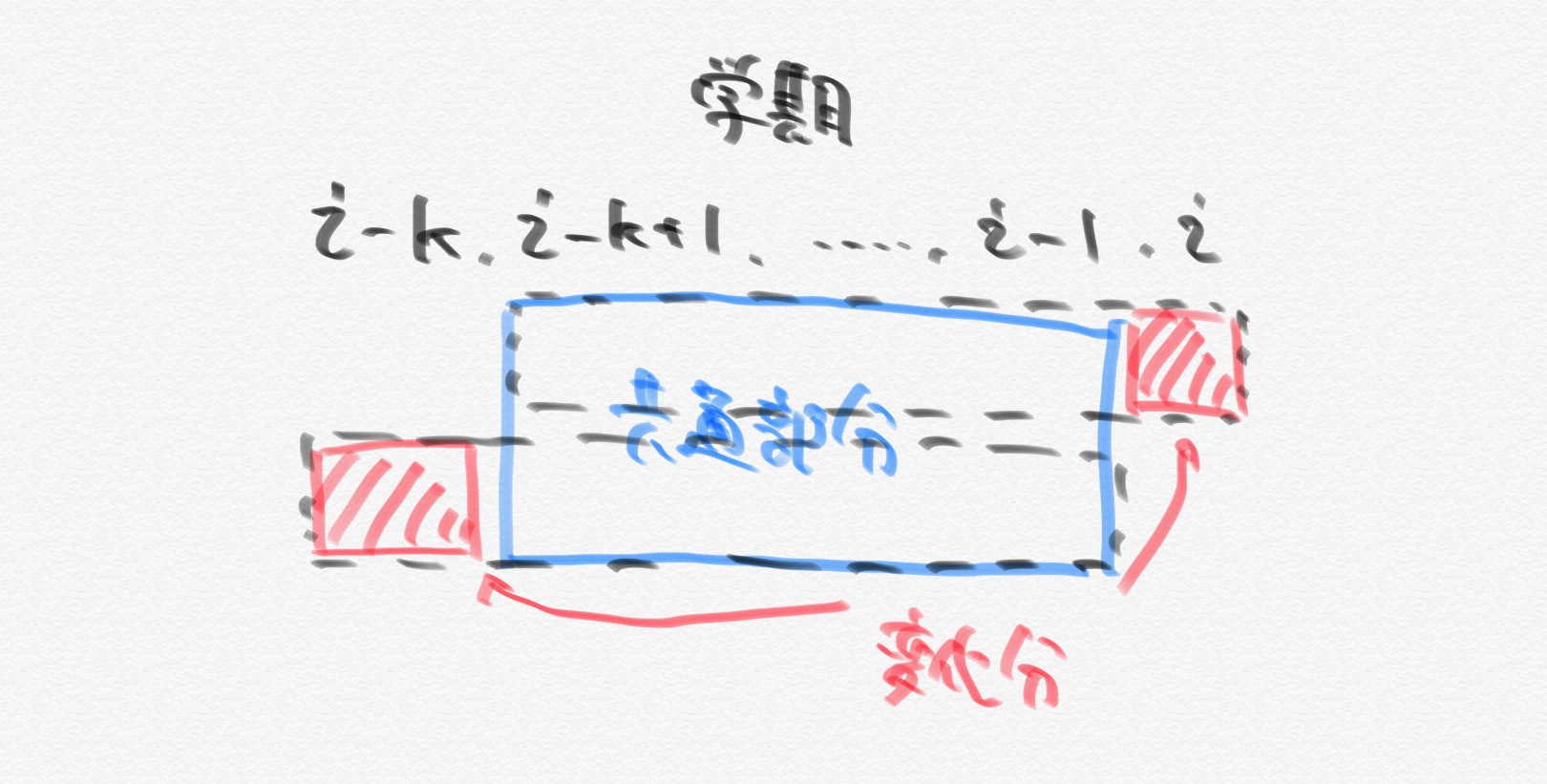
数を全てかけると計算に時間がかかるので省略することを考えます。評点として直近$K$学期のぶんが必要で、前後の学期で評点は1学期分しかずれないので、そのズレを考えます。
このズレは上記の赤色の部分であるので、$i$学期の評定が$i-1$学期の評定より高い時、$i$学期の期末テストの点数が$i-k$学期の期末テストの点数より高ければ良いです。
C.pyn,k=map(int,input().split()) a=list(map(int,input().split())) ans=[0]*(n-k) for i in range(k,n): ans[i-k]=(a[i]>a[i-k]) for i in range(0,n-k): print("Yes" if ans[i] else "No")D問題
実装が合わず時間がかかりそうだったのでDを捨ててFを解いていました。実装を一発で合わせられなかったので全然ダメですね。雑な方針で解いてしまったのが原因です。
まず、DPで状態を保存しようと思いましたが状態の持ち方が思い付きませんでした。今思うと、持っているお金の状態は制限されるので実装を考えるとDPの方が良いかもですね…。詳しくは解説を参照してください。
一株あたりの金額の動きが掴みにくかったので折れ線グラフを考えたのですが、これは良い手だったと思います。(困ったら、図示!実験!)
上図のように増加分と減少分を全て利益として獲得する場合が最大の株式の利益を受け取る方法です(これ以上の利益受け取ることができないことは変化量の絶対値の合計を考えればわかります。)。したがって、底の値と天井の値のみを保存してその底で買って天井で売れば良いので、変化の正負が入れ替わる値を保存すれば良いです。また、$N$日目の時点では全ての株を売る必要があるので、$N$日目で株価が上昇している場合は$N$日目に株を全て売り、逆に上昇していない場合はすでに全ての株を売り切ってるので$N$日目は株の売買をする必要はありません。
以上を実装すれば以下のようになります。かなり見にくいコードで申し訳ないです。
D.py#bottomかtopか n=int(input()) a=list(map(int,input().split())) an=[] for i in range(1,n): if a[i]>a[i-1]: an.append(a[i-1]) if i==n-1: an.append(a[i]) break pm=0 for j in range(i+1,n): if pm==0: if a[j]>=a[j-1]: if j==n-1: an.append(a[j]) continue else: an.append(a[j-1]) pm=1 else: if a[j]<=a[j-1]: continue else: an.append(a[j-1]) pm=0 if j==n-1: an.append(a[j]) ans=1000 k=0 for i in range(len(an)): if i%2==0: k=ans//an[i] ans-=k*an[i] else: ans+=k*an[i] k=0 print(ans)E問題
今回は解きません。
F問題
コンテスト中一時間かけても解けませんでしたが、きちんと情報を整理できていれば解けていたと感じる問題でした。また、自分の実装コードはかなり汚いので、他の方のコードを参照してください。
以下のU,D,R,Lはそれぞれ飛行機の進む方向であり問題文の表記と一緒です。
まず、真逆を向いている飛行機は衝突するような組としてありそうです。すなわち、$x$座標が同じで進む方向がU-Dとなる組み合わせと$y$座標が同じで進む方向がR-Lとなる組み合わせの二つです。また、前者の場合はUの座標がDの座標よりも小さいことが必要で、後者の場合はRの座標がLの座標よりも小さいことが必要です。
また、それぞれの飛行機の初期位置が最も近い組を求めたいので、Uの飛行機が組になるDとして最適なのは$x$座標が同じで$y$座標がUの$y$座標以上であり、飛行機の初期位置を$x$座標ごとにあり得る$y$座標を昇順で保存すれば
bisect_leftを使って探すことができます。同様に、R-Lも$y$座標ごとに保存しておくことで探すことができます。そして、最も近い初期位置の飛行機の組が求まり、この値を5倍したものが求める秒数になります。実は衝突しうる飛行機としては他のパターンもあります(コンテスト終了前15分程度で思いついたので実装を諦めました)。具体的には、U-R,U-L,D-R,D-Lのパターンです。しかし、先ほどと違って$x$座標または$y$座標を管理する方法では難しいです。そこで、衝突する位置が初期位置からどれだけ離れているかを$t(\geqq 0)$,U(or R)に含まれる飛行機の初期位置を$(x_1,y_1)$,D(or L)に含まれる飛行機の初期位置を$(x_2,y_2)$として、衝突する飛行機の組の初期位置の条件を考えました(一般化!)。すると、以下のようになりました。
(1)U-Rの時
$(x_1,y_1+t)=(x_2+t,y_2)$
$\rightarrow x_1-x_2=y_2-y_1$
$\leftrightarrow x_1+y_1=x_2+y_2$(2)U-Lの時
$(x_1,y_1+t)=(x_2-t,y_2)$
$\rightarrow x_2-x_1=y_2-y_1$
$\leftrightarrow x_1-y_1=x_2-y_2$(3)D-Rの時
$(x_1,y_1-t)=(x_2+t,y_2)$
$\rightarrow x_1-x_2=y_1-y_2$
$\leftrightarrow x_1-y_1=x_2-y_2$(4)D-Lの時
$(x_1,y_1-t)=(x_2-t,y_2)$
$\rightarrow x_2-x_1=y_1-y_2$
$\leftrightarrow x_1+y_1=x_2+y_2$したがって、それぞれの場合について、初期位置のx座標とy座標の足し算または引き算が等しいような初期位置ごとに分けて保存すれば良いです。また、(1),(3)の時は$x1>x2$,(2),(4)の時は$x1<x2$を満たす中で最も初期位置の距離の小さい組を求めたいので、初期位置ごとに分ける際に$x$座標のみを昇順で保存すれば最も近い初期位置の組は
bisect_left,bisect_rightを用いて求めることができます。そして、求めるのは初期位置の$x$座標の差であり$t$に相当するので、この値を10倍したものが答えの候補となります。F.py#十字で合流する場合 #if文の位置を間違えていた n=int(input()) ud=[[[],[]] for i in range(200001)] rl=[[[],[]] for i in range(200001)] from bisect import * cross=[[dict(),dict()] for i in range(4)] for i in range(n): x,y,u=input().split() x,y=int(x),int(y) if u=="U": ud[x][0].append(y) if x+y in cross[0][1]: cross[0][1][x+y].append(x) else: cross[0][1][x+y]=[x] if x-y in cross[1][1]: cross[1][1][x-y].append(x) else: cross[1][1][x-y]=[x] elif u=="D": ud[x][1].append(y) if x+y in cross[3][1]: cross[3][1][x+y].append(x) else: cross[3][1][x+y]=[x] if x-y in cross[2][1]: cross[2][1][x-y].append(x) else: cross[2][1][x-y]=[x] elif u=="R": rl[y][0].append(x) if x+y in cross[0][0]: cross[0][0][x+y].append(x) else: cross[0][0][x+y]=[x] if x-y in cross[2][0]: cross[2][0][x-y].append(x) else: cross[2][0][x-y]=[x] else: rl[y][1].append(x) if x+y in cross[3][0]: cross[3][0][x+y].append(x) else: cross[3][0][x+y]=[x] if x-y in cross[1][0]: cross[1][0][x-y].append(x) else: cross[1][0][x-y]=[x] for i in range(200001): ud[i][0].sort() ud[i][1].sort() rl[i][0].sort() rl[i][1].sort() ans=[] for i in range(200001): l1,l2=len(ud[i][0]),len(ud[i][1]) if l1 and l2: for j in ud[i][0]: b=bisect_left(ud[i][1],j) if b!=l2: ans.append(ud[i][1][b]-j) l1,l2=len(rl[i][0]),len(rl[i][1]) if l1 and l2: for j in rl[i][0]: b=bisect_left(rl[i][1],j) if b!=l2: ans.append(rl[i][1][b]-j) for i in range(4): for j in range(2): for k in cross[i][j]: cross[i][j][k].sort() for i in range(4): for j in cross[i][1]: if j in cross[i][0]: l=len(cross[i][0][j]) if i%2==1: for k in cross[i][1][j]: b=bisect_left(cross[i][0][j],k) if b!=l: ans.append(2*cross[i][0][j][b]-2*k) else: for k in cross[i][1][j]: b=bisect_right(cross[i][0][j],k)-1 if b!=-1: ans.append(2*k-2*cross[i][0][j][b]) if len(ans): print(min(ans)*5) else: print("SAFE")

- 投稿日:2020-08-04T09:05:03+09:00
AtCoder ABC 174 Python
総括
A,BのみACでした。
もう少しでC,Dも解けそうなきがするものの、なかなか解けない・・・。問題
https://atcoder.jp/contests/abc174/tasks
A. Air Conditioner
回答
X = int(input()) if X >= 30: print('Yes') else: print('No')これは書くだけ。
B. Distance
回答
N, D = map(int, input().split()) count = 0 for _ in range(N): x, y = map(int, input().split()) distance = (x ** 2 + y ** 2)**0.5 if distance <= D: count += 1 print(count)これも問題文通り書くだけですが、ルートで距離をだして判定するよりも、距離の2乗どうしを比較したほうがよさそうです。
C. Repsept
回答(コンテスト時)
K = int(input()) answer = -1 target = 0 for i in range(K): target += 7 * 10**i if target % K == 0: answer = i + 1 print(answer) break print(answer)問題文通り実装すると当然通りません。
入力例3の999983が問題の最大値となりますが、これを解こうとすると10の999983乗を計算しなければならず明らかに無理です。回答(後日)
K = int(input()) count = 1 mod = 7 answer = -1 for _ in range(K): if mod % K == 0: answer = count break count += 1 mod = (mod * 10 + 7) % K print(answer)10の累乗を減らすことを考えます。
問題は
7,777,777....の数字を割り切れる最初の数がわかればよいので7,777,777....を保持しておく必要はなく、あまり(mod)を保持しておけば解けそうです。言い換えると、
target += 7 * 10**iではなくmod = (mod * 10 + 7) % KをK回繰り返せばよさそうなことがわかります。ここまでくれば後は書くだけです。
D. Alter Altar
回答(コンテスト時)
N = int(input()) stones = input() count_R = stones.count('R') if N == count_R: answer = 0 elif N - count_R > count_R: answer = count_R else: if 'R' in list(stones)[:N//2]: answer = count_R - 1 else: answer = count_R print(answer)これでは解けません。
難しく考えすぎ、条件分岐がぐちゃぐちゃになってしまいました。
この方針でいくと、条件分岐が足りていないです。回答(後日)
N = int(input()) stones = input() total_count_R = stones.count('R') left_count_R = stones[:total_count_R].count('R') answer = total_count_R - left_count_R print(answer)後日、すっきりした頭で考えるとシンプルにとけることがわかりました。
WRという並びがなくなるように操作を行えばよいので、結局、すべてのRが左側に集まるように操作を行えばよいことがわかります。すべての
Rが左側に集まるような操作の回数は、何通りか実験してみると下記であることがわかります。
- すべてのRの個数であるtotal_count_Rから
- 左からtotal_count_Rまでに含まれているRの個数であるleft_count_Rを引くここまでわかれば、コードはかなりシンプルに書くことができます。
E. Logs
回答(コンテスト時)
import heapq N, K = map(int, input().split()) K_copy = K A = list(map(int, input().split())) A = list(map(lambda x: x*-1, A)) heapq.heapify(A) while K: max1 = heapq.heappop(A) max2 = heapq.heappop(A) for i in range(2, K_copy+1): temp = max1 / i if temp > max2: heapq.heappush(A, temp) heapq.heappush(A, max2) K -= 1 break print(A)これでは通りません。
「一番長い丸太を半分に切り続ける」という方針ですが、これだと、例えば同じ丸太を2回切ることとなった場合に、本来であれば3等分に切るべきところ、中途半端な切り方になってしまいます。また、少し改良して、「一番長い丸太を見つけて、最適な切り方で切りなおす」という方法も考えられますが、これは実装が難しそうですし、たぶん
TLEになるだろうということで断念しました。回答(後日)
N, K = map(int, input().split()) A = list(map(int, input().split())) def check(l): count = 0 for L in A: count += L // l if L % l != 0: count += 1 count -= 1 return count <= K bottom, top = 0, max(A) while top - bottom > 1: mid = (top + bottom) // 2 if check(mid): top = mid else: bottom = mid print(top)「丸太をK回切って最小にする」を逆から考えます。
「丸太を特定の長さ(最小)にするためにK回以内で行えるか?」です。2分探索で「丸太の長さを最小にするちょうどよい場所」を探しにいき、
その際の「K回以内で行えるか」の判定をdef check()でを行っていきます。E問題については、かつっぱさんのYouTubeを参考にさせていただきました。
https://youtu.be/0jwtdtinPiE





- 投稿日:2020-08-04T08:28:32+09:00
アルゴリズム 体操20 Remove Duplicates
Remove Duplicates
ソートされた数値の配列が引数として渡されて、そこからすべての重複を削除します。新たなデータ構造は使用せず
In-place で重複を削除した後、配列の新しい長さを返します。例
Input: [2, 3, 3, 3, 6, 9, 9]
Output: 4 ([2, 3, 6, 9])Input: [2, 2, 2, 11]
Output: 2 ([2, 11])Solution
# The time complexity: O(N) # Space Complexity: O(1) def remove_duplicates(arr): # index of the next non-duplicate element next_non_duplicate = 1 i = 1 while(i < len(arr)): if arr[next_non_duplicate - 1] != arr[i]: arr[next_non_duplicate] = arr[i] next_non_duplicate += 1 i += 1 return next_non_duplicate類題
並べ替えられていない数値の配列とターゲットの「キー」を指定して、「キー」と一致する要素全て削除し、配列の新しい長さを返します。
例
Input: [3, 2, 3, 6, 3, 10, 9, 3], Key=3
Output: 4 ([2, 6, 10, 9])Input: [2, 11, 2, 2, 1], Key=2
Output: 2 ([11, 1])実装
# The time complexity: O(N) # Space Complexity: O(1) def remove_element(arr, key): nextElement = 0 # index of the next element which is not 'key' for i in range(len(arr)): if arr[i] != key: arr[nextElement] = arr[i] nextElement += 1 return nextElement
- 投稿日:2020-08-04T08:07:45+09:00
MS Forms/Google Formsにアップロードされた画像ファイルをPDFに一括変換する
MS Forms/Google Formsに提出された画像ファイルをPDFに一括変換する
MS Formsにアップロードされた画像ファイル形式
- MS Formsを通してアップロードされるファイルは以下のようになる.
- ファイル名_学生の姓名.拡張子.という形式になっている.人によっては名姓になっていることもあるので注意
- 0FBABF78-CCCB-4958-A17B-61BC43EF27D3_工大 太郎.jpeg
- 0FBABF78-CCCB-4958-A17B-61BC43EF27D3_工大 太郎 1.jpeg
- フォームで提出するフォーマットとして画像を指定していれば,jpg,png,pdfなどが存在する.ファイル名部分は学生に依存するので,仮に同名のファイルが提出されていた場合,名前 1.jpegのように通し番号がつくっぽい
- test_工大 花子.png
- これを以下のように学生番号_通し番号.pdfなファイルに変換したい
- X0111_1.pdf
- X0111_2.pdf
- X0123_1.pdf
Google Formsにアップロードされる画像ファイルの形式
- Google Formsを通してアップロードされるファイルは以下のようになる.
- ファイル名 - 学生の姓名.拡張子.という形式になっている.学生によっては名姓になっていることもあるので注意
- 0FBABF78-CCCB-4958-A17B-61BC43EF27D3 - 工大太郎.jpeg
- 0FBABF78-CCCB-4958-A17B-61BC43EF27D3 - 工大太郎(1).jpeg
- 同名のファイルを同じ学生がアップロードすると2つ目から(1)などが後ろにつく
- test_工大花子.png
- これを以下のように学生番号_通し番号.pdfなファイルに変換したい
- X0111_1.pdf
- X0111_2.pdf
- X0123_1.pdf
できることとできないこと
- MS FormsやGoogle Formsのファイルアップロード機能を利用して提出された画像ファイルを名簿情報に基づいて学生番号_通し番号.pdfのようなPDFに個別に変換することができる
- 画像ファイル以外のPDF変換はできない
- 画像ファイルで対応しているのはjpg,pngだけ.heicなどその他のフォーマットには未対応
- docx,pptx,htmlなどはren_*file2sid.pyでファイル名を変換してからAcrobatで一括変換を想定
- Acrobat起動->ファイル->作成->複数のPDFファイルを作成
できなかったけどできるようになったこと
- 元のファイルで姓名がひっくり返っていた
- 姓名と名姓の両パターンで検索を実施するように修正
- 同名のファイルを同じ学生が一度にアップロードしている場合があった
- ファイル名末尾に" 1.jpg"や"(1).jpg"みたいに通し番号がつくっぽいのでファイル名から姓名を取り出すときに数字を正規表現を利用して削除した
- Value errorなどで変換に失敗することがある->プログラムを再実行すると変換に成功する(今の所ほぼ100%再実行で成功している.原因不明).
- ○に4のような機種依存文字がファイル名に含まれているとcsv出力時にcp932だと失敗する
- 出力時の文字コードをutf8に変更
準備
- 以下のようなフォーマットのcsvファイルを作成する
- 姓名の間に空白が含まれている必要がある
- ファイルはExcelからcsv出力されたcp932の文字コードであること
- このプログラムでは変換したファイル名を管理するためのcsvを出力するが,そちらはutf8で出力する(機種依存文字がファイル名に使われていることがあるため)
sid name B88000 工大 太郎 B87999 工大 花子
- アップロードされた画像ファイルを特定のフォルダにまとめてほりこむ
MS Formsに提出された画像ファイルのPDF変換
ファイル名の変更(ren_msfile2sid.py)
- https://github.com/igaki/renconpdf/blob/master/ren_msfile2sid.py
- 準備で作成した番号と氏名が書かれたcsvファイル名,画像ファイルがあるフォルダ名を指定してプログラムを実行する
python ren_msfile2sid.py cpu2020.csv examaのように実行する- 第1引数が名簿のcsvファイル名,第2引数が画像等のファイルが格納されたディレクトリ名
- 画像ファイルがあるフォルダにあるファイルが指定したフォルダ/output に移動される
- 画像ファイルがあるフォルダ名.csvファイルに,どの学生がどのファイルを提出し,どうリネームされたかが記述される
PDFファイルへの変更(con_sid2pdf.py)
- https://github.com/igaki/renconpdf/blob/master/con_sid2pdf.py
- ren_....pyで指定した第2引数(画像フォルダ名)と同じものを第1引数に指定して実行する 例
python consid2pdf.py cpuexamaを実行する画像フォルダ名/outputにある学生番号_通し番号.jpgなどの画像データがcompleteに移動され,同時にpdf化されたファイルがpdfフォルダに作成される- 変換に失敗した画像データがある場合はoutputに残る.その場合,con_sid2pdf.pyを再実行すると正しく変換されることが有る.
Google Formsに提出された画像ファイルのPDF変換
ファイル名の変更(ren_gfile2sid.py)
- https://github.com/igaki/renconpdf/blob/master/ren_gfile2sid.py
- 準備で作成した学生番号と学生氏名が書かれたcsvファイル名,画像ファイルがあるフォルダ名を指定してプログラムを実行する
python ren_gfile2sid.py se2_2020.csv examaのように実行する- 第1引数が学生名簿のcsvファイル名,第2引数が画像等のファイルが格納されたディレクトリ名
- 画像ファイルがあるフォルダにあるファイルが指定したフォルダ/output に移動される
- 画像ファイルがあるフォルダ名.csvファイルに,どの学生がどのファイルを提出し,どうリネームされたかが記述される
PDFファイルへの変更(con_sid2pdf.py)
- MS Forms側で利用したものと同じ
- 投稿日:2020-08-04T07:29:22+09:00
アルゴリズム 体操19 Pair with Target Sum
Pair with Target Sum
並べ替えられた数値の配列と対象の合計を指定して、合計が指定された対象と等しい配列のペアを見つけます。
2つの数値のインデックス(つまり、ペア)を返す関数を作ります。ペアが存在しなければ、インデックス -1を返します。例題
Input: [1, 2, 3, 4, 6], target=6
Output: [1, 3]Input: [2, 5, 9, 11], target=11
Output: [0, 2]Solution
ダブルポインターのアプローチを利用できます。 まず、配列の先頭を指すポインタと最後を指すポインタから始めます。 すべてのステップで、2つのポインターが指す数が合計してターゲットの合計になるかどうかを確認します。 もしそうなら、ペアを見つけたことになります。それ以外の場合は、次の2つのいずれかを行います。
- 2つのポインターが指す2つの数値の合計がターゲットの合計より大きい場合、これは、合計が小さいペアが必要であることを意味します。 したがって、エンドポインターをデクリメントできます。
- 2つのポインターが指す2つの数値の合計がターゲットの合計よりも小さい場合は、より大きな合計のペアが必要であることを意味します。 したがって、開始ポインターを増分できます。
実装
def pair_with_targetsum(arr, target_sum): left_pointer = 0 right_pointer = len(arr) - 1 while left_pointer < right_pointer: sum = arr[left_pointer] + arr[right_pointer] if sum == target_sum: return [left_pointer, right_pointer] if sum > target_sum: right_pointer -= 1 else: left_pointer += 1 return [-1, -1]
- 投稿日:2020-08-04T07:29:22+09:00
アルゴリズム 体操20 Pair with Target Sum
Pair with Target Sum
並べ替えられた数値の配列と対象の合計を指定して、合計が指定された対象と等しい配列のペアを見つけます。
2つの数値のインデックス(つまり、ペア)を返す関数を作ります。ペアが存在しなければ、インデックス -1を返します。例題
Input: [1, 2, 3, 4, 6], target=6
Output: [1, 3]Input: [2, 5, 9, 11], target=11
Output: [0, 2]Solution
ダブルポインターのアプローチを利用できます。 まず、配列の先頭を指すポインタと最後を指すポインタから始めます。 すべてのステップで、2つのポインターが指す数が合計してターゲットの合計になるかどうかを確認します。 もしそうなら、ペアを見つけたことになります。それ以外の場合は、次の2つのいずれかを行います。
- 2つのポインターが指す2つの数値の合計がターゲットの合計より大きい場合、これは、合計が小さいペアが必要であることを意味します。 したがって、エンドポインターをデクリメントできます。
- 2つのポインターが指す2つの数値の合計がターゲットの合計よりも小さい場合は、より大きな合計のペアが必要であることを意味します。 したがって、開始ポインターを増分できます。
実装
def pair_with_targetsum(arr, target_sum): left_pointer = 0 right_pointer = len(arr) - 1 while left_pointer < right_pointer: sum = arr[left_pointer] + arr[right_pointer] if sum == target_sum: return [left_pointer, right_pointer] if sum > target_sum: right_pointer -= 1 else: left_pointer += 1 return [-1, -1]
- 投稿日:2020-08-04T06:57:22+09:00
1を並べるだけで見える数の神秘~レピュニット数と不思議な性質~
はじめに
$1$ をひたすら並べてみましょう.
1, 11, 111, 1111, 11111, 111111, 11111111, 111111111, 1111111111, …
このように $1$ を $n$ 個並べてできる自然数 $R_n$ は Repunit 数 (レピュニット数) と呼ばれています.1
つまり,
$R_1 = 1$,
$R_2 = 11$,
$R_3 = 111$,
$R_4 = 1111$,
$R_5 = 11111$,
………
といった具合です.
とてもシンプルな定義の Repunit 数ですが, 実はいくつかの不思議な性質を持っています.
本記事ではその性質達について紐解いていきましょう.高校数学レベルで理解できる内容ですので, 是非肩の力を抜いてお楽しみください!
Repunit数の一般項
数列を与えられるとその一般項を求めたくなるのが全人類の悲しき性です.
なので, まずはRepunit数の一般項を求めていきましょう.
$n$ 番目の Repunit 数を $R_n = \underbrace{1111 \dots 11}_{\text{$n$ 桁}}$ と書くことにします.
このとき $R_n$ は次のように見れば等比数列の和とみなせます.\begin{align} R_n &= \underbrace{1111 \dots 11}_{\text{$n$ 桁}} \\ &= 1 + 10 + 100 + \dotsb + \underbrace{1000…00}_{\text{$n$ 桁}} = \sum_{k = 0}^{n - 1}10^k \end{align}従って等比数列の和の公式から,
\begin{align} R_n = \frac{10^n - 1}{9} \end{align}となり, 一般項を求めることができました.
Repunit数にまつわる美しい定理
筆者が本記事で一番書きたかった内容です.
Repunit 数について以下に述べる定理が成り立ちます2.$n$ を $2, 5$ を素因数に持たない自然数とする.
このとき, $n$ で割り切れる Repunit 数が必ず存在する.例えば…
$n$ として $3$ をとると, $3$ で割り切れる Repunit 数として $R_3 = 111$ がとれます.
$n$ として $21$ をとると, $21$ で割り切れる Repunit 数として $R_6 = 111111$ がとれます.
$n$ として $877$ をとると, $877$ で割り切れる Repunit 数として $R_{438} = \underbrace{1111…11}_{\text{438桁}}$ がとれます.いやあ美しい.
あのシンプルな定義からは想像もできないほどうっとりする定理です.本章ではこの定理を証明しましょう.
高校数学の美しい物語さんでは Fermat の小定理を用いた証明が掲載されていますが, ここでは別のアプローチを採用してみます.鳩舎論法
ここでは鳩舎論法について説明します.
主張はとても簡単です.今, $M$ 羽の鳩がいて $N (< M)$ 個の鳥小屋があるとします.
そして, 鳩達を各鳥小屋に入れていきます.
このとき少なくとも $2$ 羽以上の鳩が入っている鳥小屋が存在する, というのがステートメントです.
当たり前に感じますが実はとても強力で, 数学の様々な分野でその効果を発揮します.
本記事でもこの鳩舎論法を用いて上述した定理を証明します.
証明
$n$ を $2, 5$ を素因数に持たない自然数とする.
ここで $n + 1$ 個の Repunit 数 $R_1, R_2, …, R_{n}, R_{n + 1}$ を考える.
鳩舎論法より $R_j \equiv R_i\ \ \ (\mathrm{mod}. n)$ となる $1 \leq i < j \leq n + 1$ が存在する.
つまり,R_j - R_i \equiv 0 \ \ \ (\mathrm{mod}. n)である.
このとき,\begin{align} R_j - R_i &= \frac{10^j - 1}{9} - \frac{10^i - 1}{9} \\ &= \frac{10^j - 10^i}{9} \\ &= 10^i \cdot \frac{10^{j - i} - 1}{9} \\ &= 10^i R_{j - i} \end{align}と計算できるので,
10^i R_{j - i} \equiv 0 \ \ \ (\mathrm{mod}. n)となる.
今, $n$ は $2, 5$ を素因数に持たないので $10$ と互いに素だから,R_{j - i} \equiv 0 \ \ \ (\mathrm{mod}. n)とできる.
従って, $n$ で割り切ることができる Repunit 数 を得ることができた.(おまけ)コード
コマンドライン引数に数値を渡したときに, その数値で割り切ることができる最小の Repunit 数 を求めるコードを記載しておきます.3
get_repunit_length.pyimport sys def get_repunit_length(number): if (number <= 0): return -1 elif ((number % 2 == 0) or (number % 5 == 0)): return 0 else: repunit = 1 length = 0 while(True): length += 1 if (repunit % number == 0): return length else: repunit = repunit + 10 ** length if __name__ == "__main__": args = sys.argv input = int(args[1]) result = get_repunit_length(input) if (result == -1): print("自然数を入力してください。") elif (result == 0): print(f'{input} で割り切れるRepunit数は存在しません。') else: print(f'{input} で割り切れる最小のRepunit数は R_{result} です。')Repunit素数
ここからはおまけです.
Repunit 数でありかつ素数であるものを Repunit 素数 といいます.
例えば $R_2 = 11$ は Repunit 素数 です.
また $R_{19} = 1111111111111111111$ も Repunit 素数です.
他に Repunit 素数 にはどのようなものがあるでしょうか?
Wikipediaには以下の表が掲載されています.
ここで, $n$ というのは $n$ 番目の Repunit 数 を意味しています.
$n$ 発見年 発見者 $2$ - - $19$ - - $23$ - - $317$ 1978 Williams $1031$ 1986 Williams, Dubner $49081$ 1999 Dubner $86453$ 2000 Baxter $109297$ 2007 Dubner $270343$ 2007 Voznyy 現在分かっている Repunit 素数 はこの $9$ つだけです.
Repunit 素数が無数にあるかどうかは未解決問題となっています.いつ Repunit 数が素数になるかはわかっていませんが, 部分的に調べることもできます.
例えば, $n$ が合成数のときは $R_n$ も合成数となります.4
これは, Repunit 数に関する次の性質から直ちに分かります.自然数 $n, m$ に対して, $m$ が $n$ を割り切るのであれば $R_m$ は $R_n$ を割り切る.
上記性質の証明は是非皆さんも考えてみてください.
一応ここにも書いておきますので, 答え合わせにどうぞ.
証明
$m$ は $n$ を割り切るので, ある自然数 $k$ を用いて $n = km$ とかける.
このとき,\begin{align} R_{n} &= \frac{10^n - 1}{9} \\ &= \frac{10^{km} - 1}{9} \\ &= \frac{(10^m)^k - 1}{9} \\ &= \frac{(10^m - 1)(10^{m(k - 1)} + 10^{m(k - 2)} + \cdots + 1)}{9} \\ &= (10^{m(k - 1)} + 10^{m(k - 2)} + \cdots + 1)R_{m} \end{align}となり, $(10^{m(k - 1)} + 10^{m(k - 2)} + \cdots + 1)$ は自然数だから $R_m$ は $R_n$ を割り切る.
おわりに
数学って本当に面白いんですよ.
もちろんゴリゴリの解析学や代数学, 位相数学を駆使して挑むような分野であったり, 問題設定自体がかなり高度なものがほとんどです.
けどそれだけじゃない.
例えば今回みたいに適当に数を並べたり, 数を入れ替えたりしてみるだけでもそこには華々しい珠玉の数学達が眠っています.5
これってすごいことだと思うんです.
たまには数遊びでもしてみて, あなただけの数学と戯れてみるのもいいのではないでしょうか。
もし面白そうなテーマや発見があったら是非教えてください!
Repunitという名前の由来は「Repeated(繰り返す)」 + 「Unit(1)」からきています ↩
AtCoder ABC174 C.Repsept ではこの定理が背景にある問題が出題されています
問題名は Repsept で, これは「Repeated(繰り返す)」 + 「sept(7)」からきているようですね ↩このコードを $777…77$ 用に修正してもAtCoder ABC174 C.Repseptでは LTE となり通りません
もう一工夫が必要となります ↩$n$ が素数のときに $R_n$ が素数になるとは主張していないので注意してください ↩
三角関数に隠された組み合わせの秘密でも数をジグザグ並べただけでしたよね (宣伝) ↩
- 投稿日:2020-08-04T02:52:07+09:00
ラズパイにNumPyをインストールする方法
ラズパイでNumpyをpipでインストールしたのですが、それだと以下のエラーが出てしまいました。
エラー内に記述されているトラブルシューティングのURLを確認します。
https://numpy.org/devdocs/user/troubleshooting-importerror.htmlTraceback (most recent call last): File "/home/pi/.local/lib/python3.5/site-packages/numpy/core/__init__.py", line 24, in <module> from . import multiarray File "/home/pi/.local/lib/python3.5/site-packages/numpy/core/multiarray.py", line 14, in <module> from . import overrides File "/home/pi/.local/lib/python3.5/site-packages/numpy/core/overrides.py", line 7, in <module> from numpy.core._multiarray_umath import ( ImportError: libf77blas.so.3: cannot open shared object file: No such file or directory During handling of the above exception, another exception occurred: Traceback (most recent call last): File "test.py", line 1, in <module> import numpy as np File "/home/pi/.local/lib/python3.5/site-packages/numpy/__init__.py", line 142, in <module> from . import core File "/home/pi/.local/lib/python3.5/site-packages/numpy/core/__init__.py", line 50, in <module> raise ImportError(msg) ImportError: IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE! Importing the numpy C-extensions failed. This error can happen for many reasons, often due to issues with your setup or how NumPy was installed. We have compiled some common reasons and troubleshooting tips at: https://numpy.org/devdocs/user/troubleshooting-importerror.html Please note and check the following: * The Python version is: Python3.5 from "/usr/bin/python3" * The NumPy version is: "1.18.5" and make sure that they are the versions you expect. Please carefully study the documentation linked above for further help. Original error was: libf77blas.so.3: cannot open shared object file: No such file or directoryラズパイへNumPyのインストール方法は別に存在した
トラブルシューティングを確認するとpipでインストールすると駄目っぽい事が書かれています。
There are sometimes issues reported on Raspberry Pi setups when installing using pip3 install (or pip install). These will typically mention:
指示に従い、以下のコマンドを実行します
$ sudo apt-get install libatlas-base-dev $ pip3 uninstall numpy # remove previously installed version $ apt install python3-numpyこの手順を踏むとNumPyがラズパイで使用できるようになりました。
- 投稿日:2020-08-04T02:29:12+09:00
StyleGAN2で未知のポケモンを生み出す[前編]
今回やること
何番煎じだという感じですが,ポケモンの自動生成モデルの学習をしようと思います.調べてみると最新のモデルのStyleGAN2ベースですでに試している方がいます.しかし実際のコードやデータセット,実装までは公開されていなかったのでこのへんを記事にまとめておきたいなと思っています.
StyleGAN2とは
StyleGAN2はNVIDIAが発表した画像生成モデルです.スタイル変換を用いることが特徴的な生成モデルで,現状では複数のタスクにおいてSOTAとなっている強力なモデルです.
データセット
何か良いデータセットはないものかと調べていると,事前にデータを15000件収集して公開してくれている方がいたのでこちらを使わせていただきました.
MonsterGANほかにもKaggleのPokemon-Image-DatasetやOne-Shot-Pokemon-Imagesなども候補に挙がります.One-Shot-Pokemon-Imagesにはポケモンカードのデータセットが含まれていて,そちらが非常にデータ量が多いためポケモンカード生成タスクに応用されているようです.
※コチラより引用先行事例
Michael Frieseという方が熱心にStyleGAN・StyleGAN2を用いたポケモン生成に挑戦していらっしゃるようです.
StyleGANでは既にかなりいい感じに結果を残されているようです.
※ コチラより引用猫や馬などの学習済みモデルから転移学習を行うと,学習自体がうまくいく上に生成画像に転移前のドメインの雰囲気が反映されるらしい.
すごくエモい.馬から転移
※ コチラから引用猫から転移
※ コチラから引用車から転移
※ コチラから引用StyleGAN2を用いた生成結果は途中までしか公開されていませんでした.540kimgまで学習した結果です.学習途中なので品質は置いておいて,かなりバリエーションが多く感じます.
※ コチラから引用自前で行った学習結果
まだ学習途中なのですが,StyleGAN2を使った学習の経過をお見せします.RTX1070で学習を行っているため,むちゃなモデルはメモリサイズの関係で不可能です.今回はデータセットをすべて64x64にリサイズして利用しました.
モデルの概要
G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/Normalize - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 10, 512) - G_mapping/dlatents_out - (?, 10, 512) - Truncation/Lerp - (?, 10, 512) - G_synthesis/dlatents_in - (?, 10, 512) - G_synthesis/4x4/Const 8192 (?, 512, 4, 4) (1, 512, 4, 4) G_synthesis/4x4/Conv 2622465 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/4x4/ToRGB 264195 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2622465 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2622465 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Upsample - (?, 3, 8, 8) - G_synthesis/8x8/ToRGB 264195 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/16x16/Conv0_up 2622465 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2622465 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Upsample - (?, 3, 16, 16) - G_synthesis/16x16/ToRGB 264195 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/32x32/Conv0_up 2622465 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2622465 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Upsample - (?, 3, 32, 32) - G_synthesis/32x32/ToRGB 264195 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/64x64/Conv0_up 2622465 (?, 512, 64, 64) (3, 3, 512, 512) G_synthesis/64x64/Conv1 2622465 (?, 512, 64, 64) (3, 3, 512, 512) G_synthesis/64x64/Upsample - (?, 3, 64, 64) - G_synthesis/64x64/ToRGB 264195 (?, 3, 64, 64) (1, 1, 512, 3) G_synthesis/images_out - (?, 3, 64, 64) - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 8, 8) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 16, 16) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 32, 32) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 64, 64) - G_synthesis/noise8 - (1, 1, 64, 64) - images_out - (?, 3, 64, 64) - --- --- --- --- Total 27032600 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 64, 64) - labels_in - (?, 0) - 64x64/FromRGB 2048 (?, 512, 64, 64) (1, 1, 3, 512) 64x64/Conv0 2359808 (?, 512, 64, 64) (3, 3, 512, 512) 64x64/Conv1_down 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 64x64/Skip 262144 (?, 512, 32, 32) (1, 1, 512, 512) 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 32x32/Skip 262144 (?, 512, 16, 16) (1, 1, 512, 512) 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 16x16/Skip 262144 (?, 512, 8, 8) (1, 1, 512, 512) 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) 8x8/Skip 262144 (?, 512, 4, 4) (1, 1, 512, 512) 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) Output 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 26488833snapshotのグリッドの設定の変更を忘れていてめちゃくちゃ画像みにくくすみません...学習が大変なのでやり直しはまだです.
データセットの例(reals.png)
生成結果(288kimg: 19時間)
徐々に輪郭が形成されてきて,人型や動物型にも見えるポケモンの概形できてきました.学習がしっかり進んでいるかどうかFrechet Inception Distance(FID)を出力して監視しています.今のところ順調に進んでいます.公式のページにはFIDは一桁だと載っているのですが,さすがにそこまで学習するのにコストが高すぎるので自分の目視で生成画像がいい感じになったら学習を止めるつもりです.
network-snapshot- time 19m 34s fid50k 278.0748 network-snapshot- time 19m 34s fid50k 382.7474 network-snapshot- time 19m 34s fid50k 338.3625 network-snapshot- time 19m 24s fid50k 378.2344 network-snapshot- time 19m 33s fid50k 306.3552 network-snapshot- time 19m 33s fid50k 173.8370 network-snapshot- time 19m 30s fid50k 112.3612 network-snapshot- time 19m 31s fid50k 99.9480 network-snapshot- time 19m 35s fid50k 90.2591 network-snapshot- time 19m 38s fid50k 75.5776 network-snapshot- time 19m 39s fid50k 67.8876 network-snapshot- time 19m 39s fid50k 66.0221 network-snapshot- time 19m 46s fid50k 63.2856 network-snapshot- time 19m 40s fid50k 64.6719 network-snapshot- time 19m 31s fid50k 64.2135 network-snapshot- time 19m 39s fid50k 63.6304 network-snapshot- time 19m 42s fid50k 60.5562 network-snapshot- time 19m 36s fid50k 59.4038 network-snapshot- time 19m 36s fid50k 57.2236まとめ
今回はデータセットと先行事例を調査して,実際に学習を進めてみたところまでを書いてみました.
自分の環境で動いたコードやもっと学習が進んだ後の生成結果などは後日の後編の記事としてまとめます.後半→学習がある程度すすんだら








- 投稿日:2020-08-04T02:04:27+09:00
StyleGAN2で未知のポケモンを生み出す[前編]
今回やること
何番煎じだという感じですが,ポケモンの自動生成モデルの学習をしようと思います.調べてみると最新のモデルのStyleGAN2ベースですでに試している方がいます.しかし実際のコードやデータセット,実装までは公開されていなかったのでこのへんを記事にまとめておきたいなと思っています.
StyleGAN2とは
StyleGAN2はNVIDIAが発表した画像生成モデルです.スタイル変換を用いることが特徴的な生成モデルで,現状では複数のタスクにおいてSOTAとなっている強力なモデルです.
データセット
何か良いデータセットはないものかと調べていると,事前にデータを15000件収集して公開してくれている方がいたのでこちらを使わせていただきました.
MonsterGANほかにもKaggleのPokemon-Image-DatasetやOne-Shot-Pokemon-Imagesなども候補に挙がります.One-Shot-Pokemon-Imagesにはポケモンカードのデータセットが含まれていて,そちらが非常にデータ量が多いためポケモンカード生成タスクに応用されているようです.
※コチラより引用先行事例
Michael Frieseという方が熱心にStyleGAN・StyleGAN2を用いたポケモン生成に挑戦していらっしゃるようです.
StyleGANでは既にかなりいい感じに結果を残されているようです.
※ コチラより引用猫や馬などの学習済みモデルから転移学習を行うと,学習自体がうまく上に生成画像に転移前のドメインの雰囲気が反映されるらしい.
すごくエモい.馬から転移
※ コチラから引用猫から転移
※ コチラから引用車から転移
※ コチラから引用StyleGAN2を用いた生成結果は途中までしか公開されていませんでした.540kimgまで学習した結果です.学習途中なので品質は置いておいて,かなりバリエーションが多く感じます.
※ コチラから引用自前で行った学習結果
まだ学習途中なのですが,StyleGAN2を使った学習の経過をお見せします.RTX1070で学習を行っているため,むちゃなモデルはメモリサイズの関係で不可能です.今回はデータセットをすべて64x64にリサイズして利用しました.
モデルの概要
G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/Normalize - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 10, 512) - G_mapping/dlatents_out - (?, 10, 512) - Truncation/Lerp - (?, 10, 512) - G_synthesis/dlatents_in - (?, 10, 512) - G_synthesis/4x4/Const 8192 (?, 512, 4, 4) (1, 512, 4, 4) G_synthesis/4x4/Conv 2622465 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/4x4/ToRGB 264195 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2622465 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2622465 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Upsample - (?, 3, 8, 8) - G_synthesis/8x8/ToRGB 264195 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/16x16/Conv0_up 2622465 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2622465 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Upsample - (?, 3, 16, 16) - G_synthesis/16x16/ToRGB 264195 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/32x32/Conv0_up 2622465 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2622465 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Upsample - (?, 3, 32, 32) - G_synthesis/32x32/ToRGB 264195 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/64x64/Conv0_up 2622465 (?, 512, 64, 64) (3, 3, 512, 512) G_synthesis/64x64/Conv1 2622465 (?, 512, 64, 64) (3, 3, 512, 512) G_synthesis/64x64/Upsample - (?, 3, 64, 64) - G_synthesis/64x64/ToRGB 264195 (?, 3, 64, 64) (1, 1, 512, 3) G_synthesis/images_out - (?, 3, 64, 64) - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 8, 8) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 16, 16) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 32, 32) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 64, 64) - G_synthesis/noise8 - (1, 1, 64, 64) - images_out - (?, 3, 64, 64) - --- --- --- --- Total 27032600 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 64, 64) - labels_in - (?, 0) - 64x64/FromRGB 2048 (?, 512, 64, 64) (1, 1, 3, 512) 64x64/Conv0 2359808 (?, 512, 64, 64) (3, 3, 512, 512) 64x64/Conv1_down 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 64x64/Skip 262144 (?, 512, 32, 32) (1, 1, 512, 512) 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 32x32/Skip 262144 (?, 512, 16, 16) (1, 1, 512, 512) 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 16x16/Skip 262144 (?, 512, 8, 8) (1, 1, 512, 512) 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) 8x8/Skip 262144 (?, 512, 4, 4) (1, 1, 512, 512) 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) Output 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 26488833snapshotのグリッドの設定の変更を忘れていてめちゃくちゃ画像みにくくすみません...学習が大変なのでやり直しはまだです.
データセットの例(reals.png)
生成結果(288kimg: 19時間)
徐々に輪郭が形成されてきて,人型や動物型にも見えるポケモンのが概形できてきました.学習がしっかり進んでいるかどうかFrechet Inception Distance(FID)を出力して監視しています.今のところ順調に進んでいます.公式のページにはFIDは一桁だと載っているのですが,さすがにそこまで学習するのにコストが高すぎるので自分の目視で生成画像がいい感じになったら学習を止めるつもりです.
network-snapshot- time 19m 34s fid50k 278.0748 network-snapshot- time 19m 34s fid50k 382.7474 network-snapshot- time 19m 34s fid50k 338.3625 network-snapshot- time 19m 24s fid50k 378.2344 network-snapshot- time 19m 33s fid50k 306.3552 network-snapshot- time 19m 33s fid50k 173.8370 network-snapshot- time 19m 30s fid50k 112.3612 network-snapshot- time 19m 31s fid50k 99.9480 network-snapshot- time 19m 35s fid50k 90.2591 network-snapshot- time 19m 38s fid50k 75.5776 network-snapshot- time 19m 39s fid50k 67.8876 network-snapshot- time 19m 39s fid50k 66.0221 network-snapshot- time 19m 46s fid50k 63.2856 network-snapshot- time 19m 40s fid50k 64.6719 network-snapshot- time 19m 31s fid50k 64.2135 network-snapshot- time 19m 39s fid50k 63.6304 network-snapshot- time 19m 42s fid50k 60.5562 network-snapshot- time 19m 36s fid50k 59.4038 network-snapshot- time 19m 36s fid50k 57.2236まとめ
今回はデータセットと先行事例を調査して,実際に学習を進めてみたところまでを書いてみました.
自分の環境で動いたコードやもっと学習が進んだ後の生成結果などは後日の後編の記事としてまとめます.後半→学習がある程度すすんだら
- 投稿日:2020-08-04T01:00:25+09:00
DeepRunning ~Level5~
Level5.深層学習 DAY1
5-1.ニューラルネットワークの全体像
●クライアントの人からすれば、インプットで何を使って、アウトプットで何が出るかしか気にしない。
エンジニアは特に中間層を意識する必要がある。☆確認テスト1☆
5-1-1 ディープラーニングは、結局何をやろうとしているか2行以内で述べよ。
また、次の中のどの値の最適化が最終目的か。①入力値[X] ②出力値[Y] ③重み[W] ④バイアス[b]
⑤総入力[u] ⑥中間層入力[z] ⑦学習率[ρ](確認テストって前に勉強してからその確認なのじゃないだろうかと思いつつ・・・)
⇒予測値と正解の値からパラメータを更新し、人間の頭脳のように学習させること。
最適化する値は、③重み[W]と④バイアス[b]【解答】誤差を最小化するパラメータを発見すること。
③重み[W]、④バイアス[b]☆確認テスト2☆
5-1-2 次のネットワークを紙にかけ。
入力層:2ノード1層
中間層:3ノード2層
出力層:1ノード1層ノートに手書きで書いてみました。
5-2.ニューラルネットワーク(NN)でできること
【回帰】
●結果予測 ・・・ 売上予想、株価予想
●ランキング・・・ 競馬順位予想、人気順位予想【分類】
●猫写真の判別
●手書き文字認識
●花の種類分類※Amazonの売上データなどは、入力にして売上予想をしているのだろうな。
ちょっとした回帰予測はやってみたい。
また、顔の判別はスタンダードであるが、やってみたい。
ラズベリーパイと組み合わせて、動作する機能を作りたい。5-3.回帰
●連続する実数値を取る関数の近似
・線形回帰
・回帰木
・ランダムフォレスト
・ニューラルネットワーク(NN)5-4.分類
●性別(男女)や動物の種類など離散的な結果を予想するための分析
・ベイズ分類
・ロジスティック回帰
・決定木
・ランダムフォレスト
・ニューラルネットワーク(NN)※複雑な入り組んだ情報から予想するための分析。
5-5.深層学習の実用例
●自動売買(トレード)
良いモデルがあってもあまりオープンにならない。
情報はあるので、自分なりのアルゴリズムに収束させる。●チャットボット
コールセンターの自動化など、現在のニーズに合うもの。
FAQシステムも人件費の削減になる。●翻訳
Google翻訳等がある。
精度を上げるのに重要度を用いたり、アテンションメカニズム等がある。●音声解釈
AmazonEchoやGoogleHomeのようなスピーカー。
ドラゴンスピーチ(音声解釈の分野で発達している)
AIを使う部分と使わない部分がある。
自分でプロダクトを作ろうとした時に、精度を上げるために必要な音声のデータが必要。
莫大なデータを集めることになるが、それに見合った精度が出せるか分からない。
制度を上げるのに音声の圧縮など、試行錯誤による努力も必要。●囲碁・将棋AI
AlphaGo(囲碁)、Ponanza(将棋)など
⇒ディープラーニングの技術が密接に繋がっている。
強化学習とCNNのハイブリッドなど
※毎日、新聞に載るようなことが多く、
翌日から記事はちゃんと読もうと思った。(笑)