- 投稿日:2020-08-04T23:27:11+09:00
クラウドの実務未経験でもAWS SAAに1.5ヶ月で合格した話
AWSのSAAの合格体験記です。
これから取ろうとしている人の参考になればいいなと思い、記事投稿します。取ろうと思ったきっかけ
新しい技術に触れてみたかったから
オンプレでやってたことがポチポチやるだけで実装できちゃうなんて、近未来的で楽しくないですか?
自身のスキルアップのため
クラウドに触れたこともないエンジニアであることに危機感を感じました。
「じゃあクラウド使う現場に行けばいいじゃん」って思われるかもしれませんが、そういったところへ行くには大概クラウド技術の実務経験が必要です。
クラウドを使う業務に携わるためには、クラウド技術の業務経験が必須級なのです。鶏が先か、卵が先か。みたいな話ですね。。。
このジレンマを破るために武器として、資格を取得しておくという選択肢は、アリなんじゃないかと思います。
世の中には資格否定派の方もいらっしゃると思いますが、持っていないよりマシじゃないでしょうか?
また、インフラ界隈は資格肯定派が多いようにも感じます。
流行ってるから上記は半分冗談ですが半分本気です。
使われていない技術をいくら一生懸命勉強したところで、価値に繋がりにくいと思います。受験当時の私について
- インフラエンジニア歴2年(オンプレ。設計経験無、構築経験少。)
- 23歳
- LPICレベル1持ってる
といった感じで、あまり技術力は高くない方だと思います。
凡人でも取れる!って皆様の自信に繋がればいいなと思います。取得に向けてやったこと
計画
まずは計画を立てましょう。2ヶ月以内に取るぞ!でも何でもいいので。期日を決めておかないとズルズル引き伸ばしやすいですし、長引くと最初の方に覚えたことはどんどん忘れていきます。
目安としては1〜2ヶ月くらいでいいんじゃないでしょうか。
私は一ヶ月を目標にしました。勉強
計画を立てたらそれに間に合うように勉強しました。
まずはとりあえず本を買って勉強しました。
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
本は自分が読みやすければどれでもいいんじゃないかと思います。
また、本だけだとインプットだけになってしまい、定着しずらいため、qiitaにアウトプットしました。
ここで気をつけたことは、「記事のクオリティは気にしない」という点です。
自分のメモ書きレベルの物を公開するのはどうしても恥ずかしいため、完成度を上げようと考えてしまいがちですが、ここで投稿する意味は自分がどこまで理解できているかを把握する(理解が0%なのか80%なのか100%なのか、自分で文字起こししているうちに気づくことができる)
という点が一番大切なため、完璧じゃなくていいのでどんどん投稿しました。しかし、本だけだとアップデートに追いついていない場合が多いので、その後、問題集をやってひたすら頭に叩き込むといいと思います。私はUdemyの教材を使いました。
また、わからないことがあったらAWSの公式ドキュメントを読み込みました。実際に使えるものはハンズオンでやってみたりもしました。
模擬試験は個人的にはオススメしません。解説などがないため、どこでどう間違ったか、分かりづらいです。金銭的余裕がある人は本番の感覚がつかめるので受けてみるのもありかもしれません。どうなったか
2月頭から学習し、3月中旬にて無事合格できました。
点数は788でした。720で合格なので、まああまり余裕はなかったですが合格です。
一応、すべての分野で「十分な知識を有する」の評価でした。所感
周りではAWSは難しい難しい言われていたので、うわぁ、、、って思ってましたが、実際に勉強したり触ってみると、意外とそんなことありませんでした。先入観で入ると損します。
また、受けてみて、いろんな技術に触れていくうちにどんどん学習意欲が湧き出てきました。この後、Dockerを使ってEC2にアプリをデプロイしたりなどいろいろな技術に実際に触れていきました。
今はまだ技術力が未熟でも、磨いて、つよつよエンジニアになりたいと思いました。
そのための第一歩として大きく踏み出せたんじゃないでしょうか。余談:なんでAzureやGCPじゃないの?
一番シェアが高いから選びました。
プログラミングでよく言われる「1つ目の言語を習得した後の、2つ目の言語の習得は早い」と同じ理論です。
AzureやGCPも、名前は違うだけでAWSとほぼ同じサービスってのがたくさんあります。であれば、qiitaなどでも一番参考文献の多いAWSから取得するのがスムーズだと思います。
また、今の会社で資格手当出してくれるのが上記の中でAWSだけだったからってのもあります。以上となります。ご質問、ご指摘等ありましたらコメントいただけると幸いです。
- 投稿日:2020-08-04T22:46:26+09:00
API GatewayのマッピングテンプレートでBodyのJSONを書き換える
API GatewayにPOST/PUTされてきたJSONのBody(
$input)を、マッピングテンプレートで中身を少しだけ書き換えてバックエンドへProxyしたい時:#set($body = $input.path('$')) #set($body.url = "https://example.tld/thingy/$body.id") $input.json('$')これだけで
url属性が#setで指定したURLに置き換わった状態のJSON文字列が生成される。
#setでの属性置き換え後、最後にJSON文字列化する部分が$body.json('$')では ない 点に注意。.json('$')は$inputにしか定義されていない。すべて参照渡しでまぁJavaScriptみたいなもんだよと言われれば、この使い方も、そんな気もしなくもないが、それにしても、
わかりにくすぎない!?
たったこれだけのことをするのに1日潰れてしまった……。
ref:
- 投稿日:2020-08-04T19:01:27+09:00
AWS Systems Managerのパッチマネージャーを使ってパッチ適用を自動化する
はじめに
本記事はAWS Well-Architected Labs - Operational Excellence - 100 - INVENTORY AND PATCH MANAGEMENTのポイントやハンズオン手順をまとめたものになります。AWS Well-Architected Labsについて知りたい方はこちらをご覧ください。
パッチ適用
パッチ適用運用はやらないといけないけど、手動で行う場合は面倒臭い作業です。数台のサーバーならまだしも数が多いとさらに大変です。パッチ適用はトイルの代表格と言っても過言ではないでしょう。そんなパッチ適用をパッチマネージャーを使えば自動化することができます。
パッチ適用自動化を行う上でのAWSサービスやSystems Manager機能間の関係
パッチマネージャーを使ったパッチ適用を行う場合はいくつかのAWSサービスやSystems Manager機能を連携させる必要があります。最初利用した時は関係性が若干分かりにくかったため、まとめておきます。
マネージドインスタンス
まずはパッチ適用の自動化対象のサーバをSystems Managerの管理下にする必要があります。ちなみにSystems Manager管理下にあるサーバはマネージドインスタンスと呼ばれます。EC2だけでなく、オンプレミスのマシンもマネージドインスタンスにすることができます。マネージドインスタンスにする条件は公式ドキュメントを参照してください。
Systems Manager の前提条件パッチマネージャー
どのパッチをどのインスタンスに適用させるかをパッチマネージャーで設定することができます。
パッチベースライン
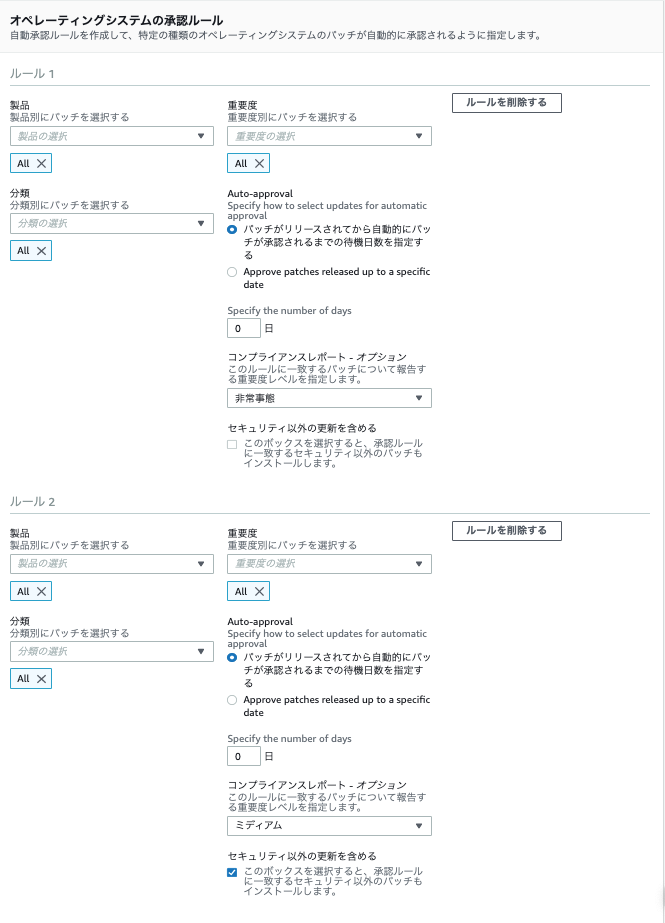
パッチ適用のルールを定義することができます。OS毎にデフォルトのベースラインが用意されており、それらは変更することはできませんが、ユーザの用途に合ったパッチベースラインをカスタムバッチベースラインとして作成することができます。具体的には以下のような設定を行います。
- Product (製品)
- 承認ルールが適用されるオペレーティングシステムのバージョン
- Classification (分類)
- 承認ルールが適用されるパッチのタイプ
- Severity (重要度)
- ルールが適用されるパッチの重要度の値
- Auto-approval (自動承認)
- 自動承認のためにパッチを選択する方法
- Compliance reporting (コンプライアンスレポート)
- ベースラインで承認されたパッチに割り当てる重要度
- Include non-security updates (セキュリティに関連しない更新を含める)
- セキュリティに関連するパッチに加えて、ソースリポジトリで使用可能なセキュリティに関連しない Linux オペレーティングシステムのパッチをインストールするには、このチェックボックスをオンにします
パッチグループ
パッチベースラインを適用するインスタンスをパッチグループとしてグループ化できます。パッチグループに所属させたいインスタンスには
key=Patch Groupのタグを付与する必要があります。パッチグループ作成時はkeyに対するvalueを指定して作成します。パッチグループはパッチベースラインに対して関連付けられます。SSMドキュメント AWS-RunPatchBaseline
パッチベースラインに設定されているパッチ適用を行うためにはRun Command経由でSSMドキュメントであるAWS-RunPatchBaselineを実行する必要があります。Run Commnandの実行はメンテナンスウィンドウ、AWS CLI,SDK等から行います。実行時の必須パラメータとして以下を指定します。
- Operation
- Scan
- 適用予定のパッチ一覧だけを確認し、インストールは行わない
- Install
- 適用対象のパッチをインストールします。
- RebootOption
- RebootIfNeeded
- 再起動が必要なパッチが合った場合はインスタンスを再起動する
- NoReboot
- インスタンスの再起動は行わない
SSM ドキュメント AWS-RunPatchBaseline について
また、どのインスタンスに対してRun Commandを実行するかターゲットを指定します。注意として、パッチ適用を行うインスタンスはパッチグループにも所属させ、Run Commandのターゲットしても指定してあげる必要があるということです。
ハンズオン手順
パッチマネージャーを使ったパッチ適用を試せるAWS Well-Architected Labs - Operational Excellence - 100 - INVENTORY AND PATCH MANAGEMENTのハンズオン手順を記載します。
セットアップ
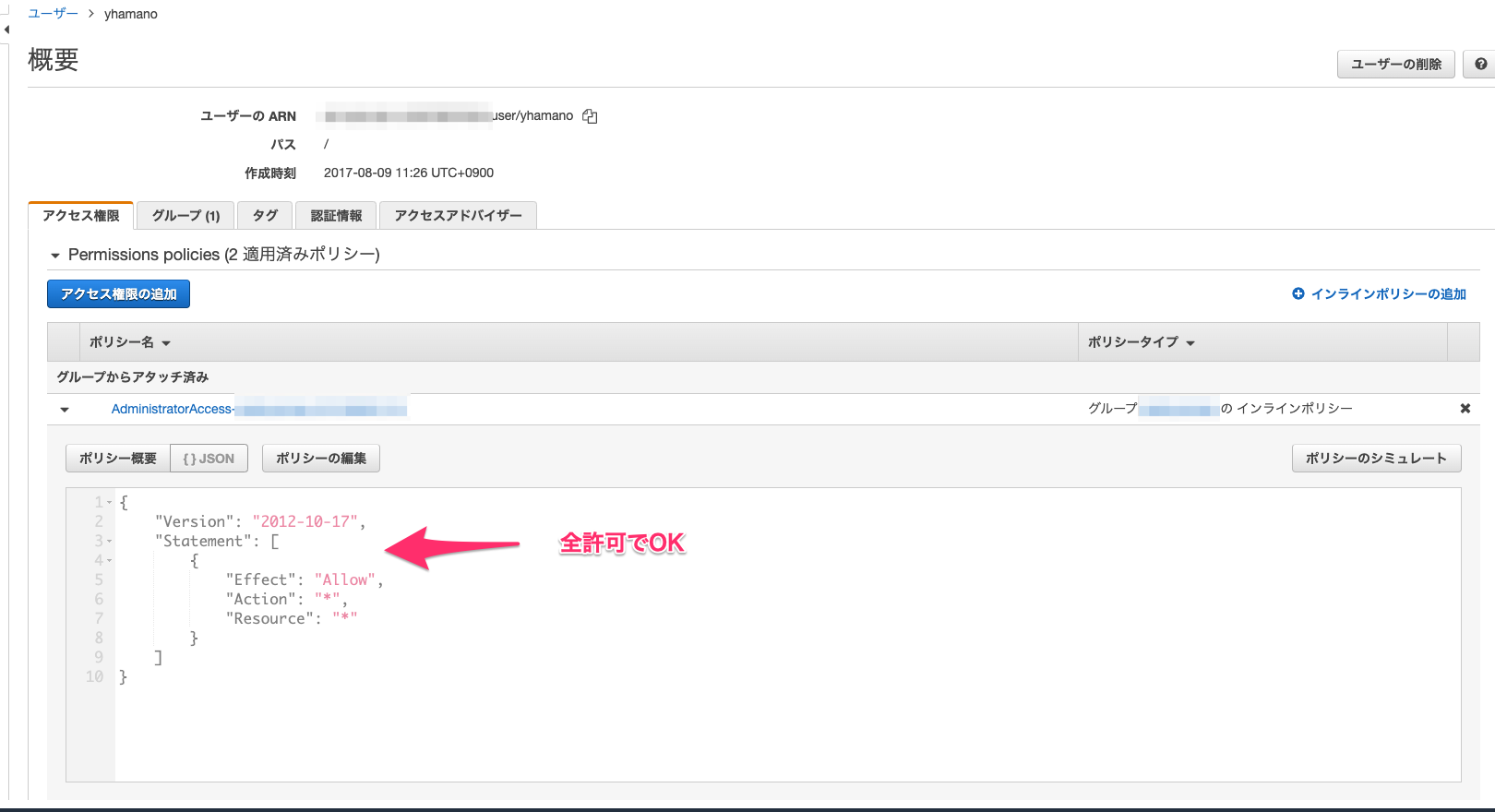
IAMユーザ作成
まずはAdministratorAccess相当のポリシーがアタッチされたIAMユーザを用意しましょう。以降はこのIAMユーザでAWSマネジメントコンソールにログインし、操作してください。
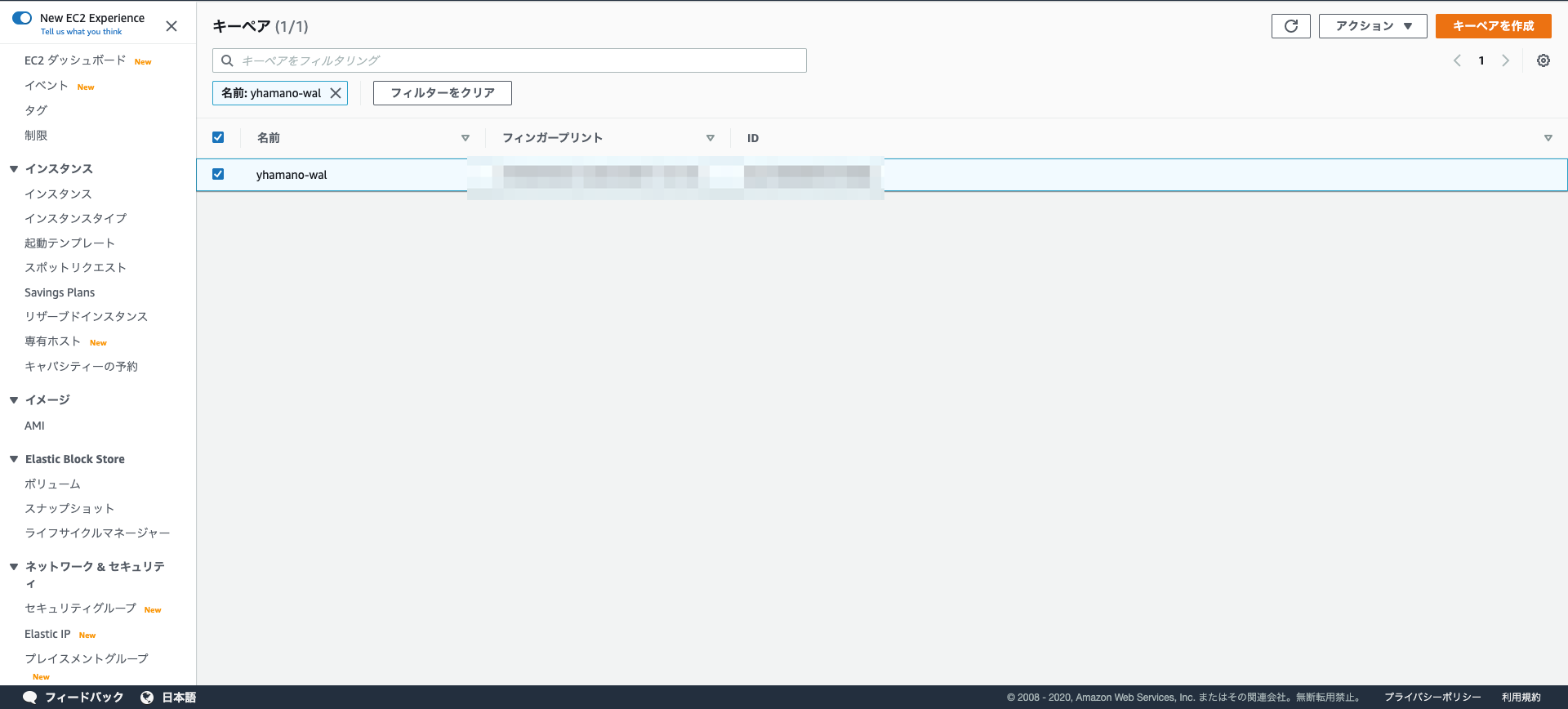
EC2キーペア作成
EC2のキーペアを適当な名前で作成します。今回は
yhamano-walという名前で作成します。ファイル形式はpemを選んでください。
CloudFormationでのデプロイ
テンプレートファイルのダウンロード
今回のハンズオン環境をCloudFormationを用いてデプロイします。
まず、こちらからCloudFormationテンプレートをローカルにダウンロードしてください。IAMロール作成
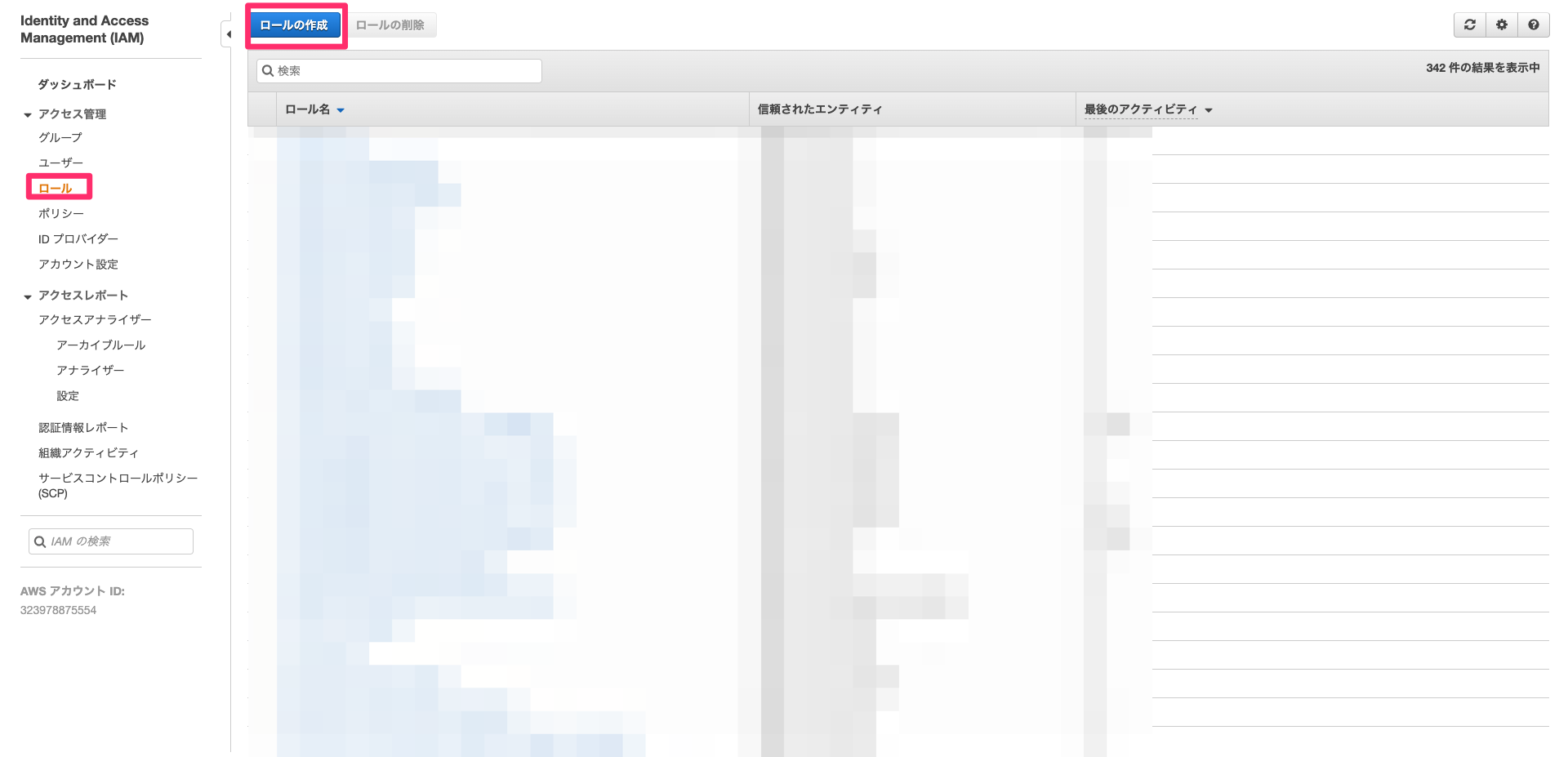
CloudFormationで作成するEC2にアタッチするIAMロールを事前に作成します。
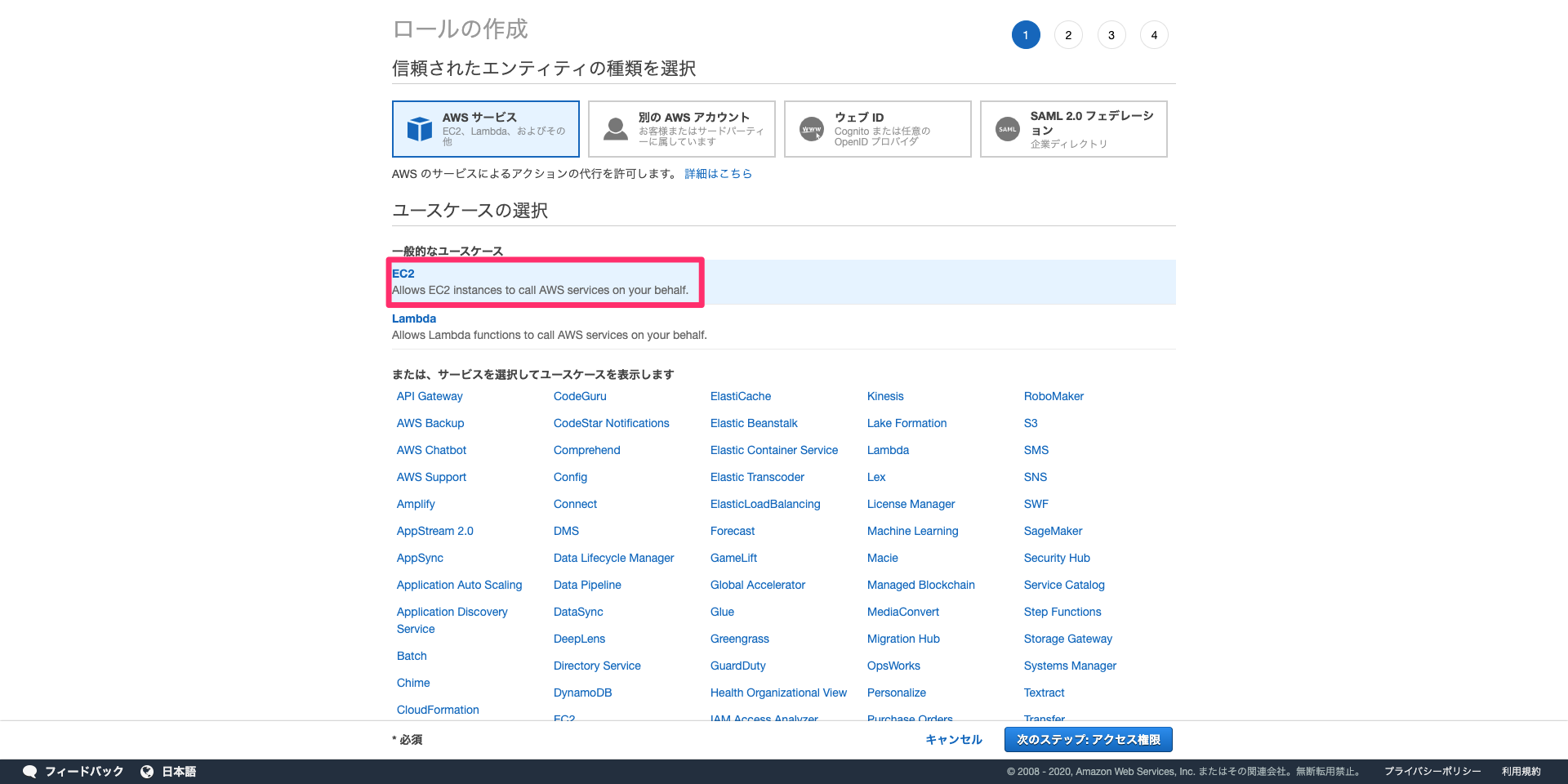
AWSマネジメントコンソールからIAM画面に遷移し、ロールの作成を選択します。
ユースケースの選択でEC2を選択します。
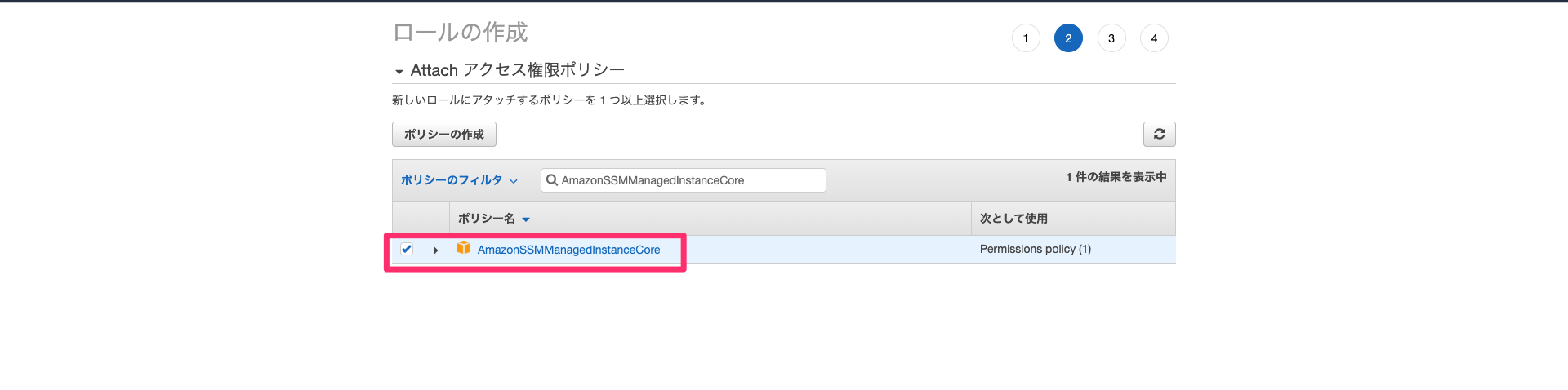
Attchアクセス権限ポリシーでAmazonSSMManagedInstanceCoreを選択します。元々の手順ではAmazonEC2RoleforSSMを選択するようになっていますが、権限が大きすぎることからこちらは非推奨となっています。詳しくはクラメソさんのブログを参照ください。
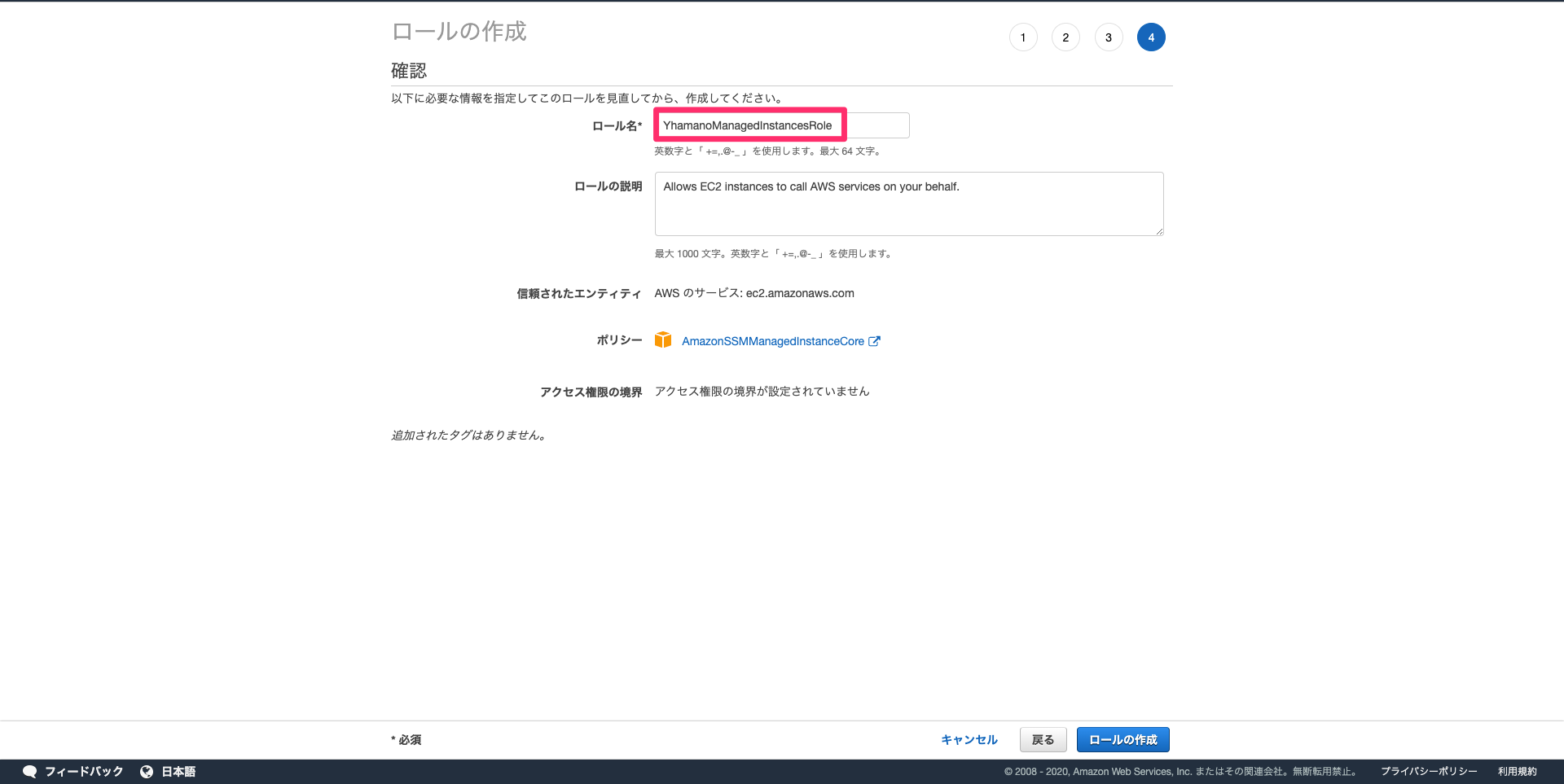
タグは何も指定せずに、ロール名を入力してロールの作成を行います。ロール名は適当でOKです。
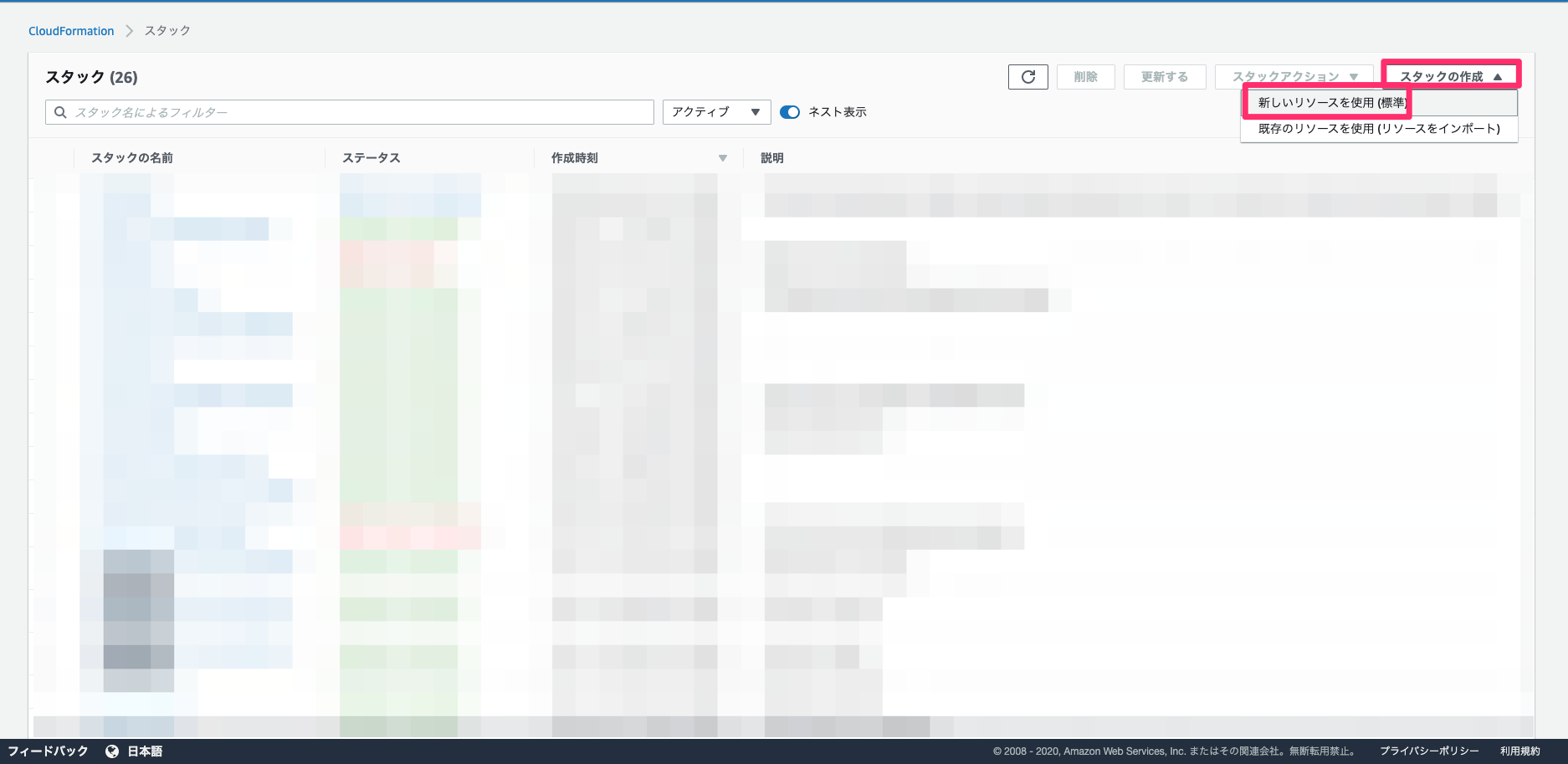
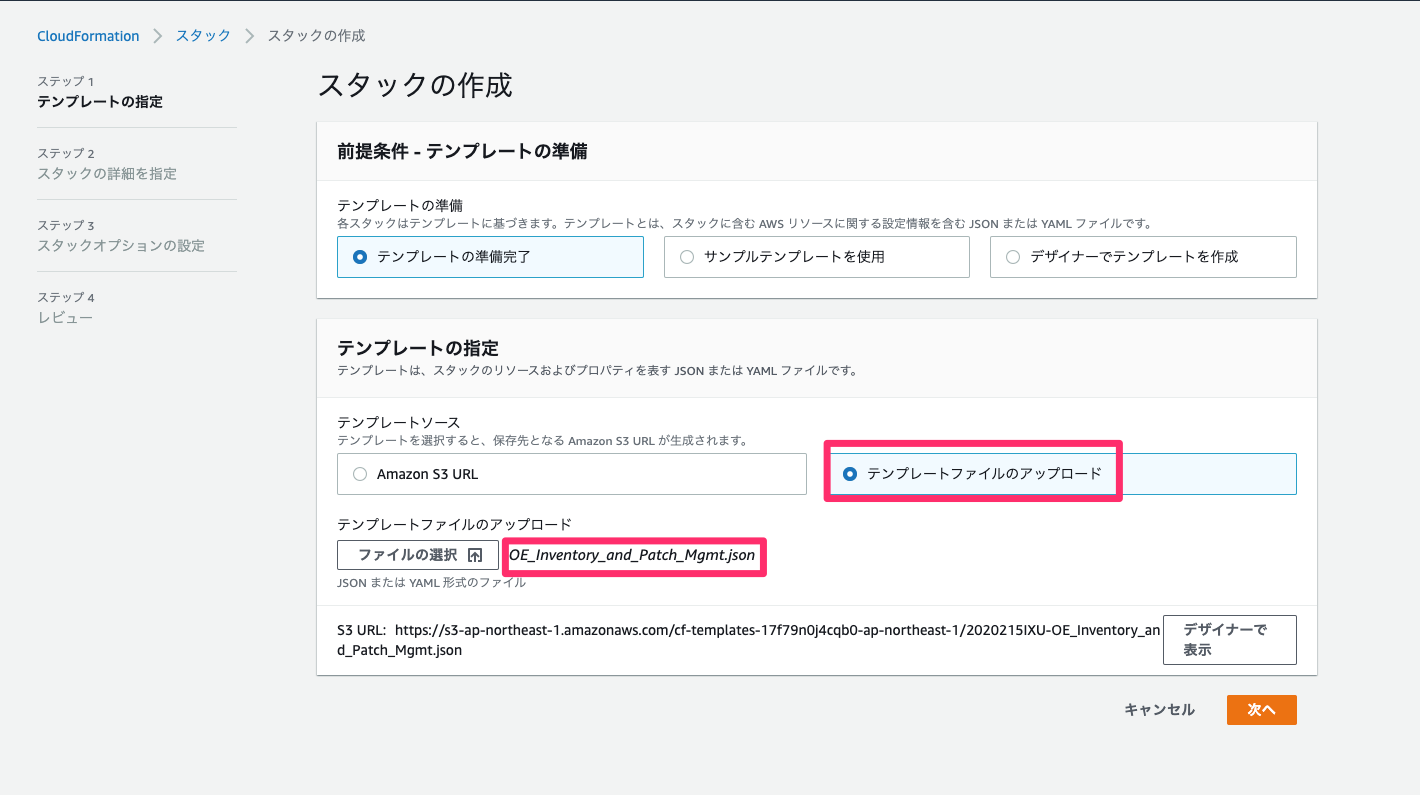
スタック作成
スタックの作成を行なっていきます。CloudFormationの画面に遷移し、新しいリソースを使用(標準)を選択します。
テンプレートファイルのアップロードから先ほどダウンロードしたCloudFormationテンプレートを選択します。
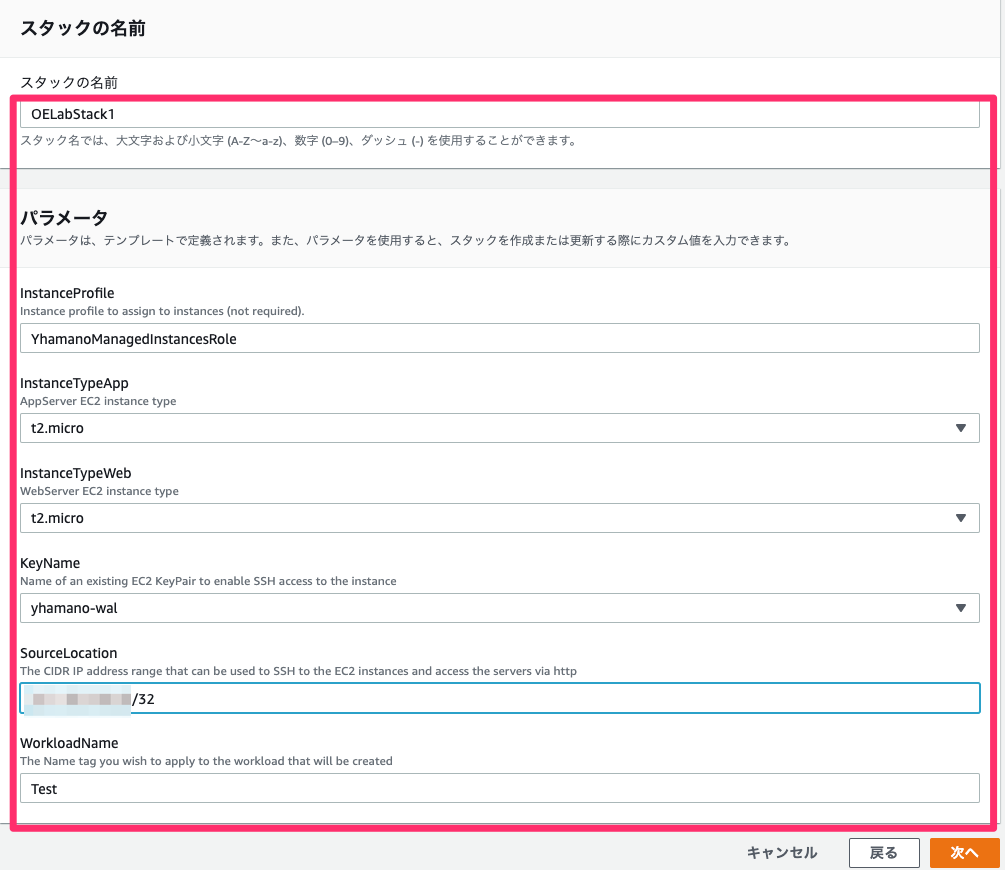
次に各種パラメータを入力します。
- スタックの名前
- OELabStack1
- InstanceProfile
- 先ほど作成したIAMロール名を入力します。
- InstanceTypeApp,InstanceTypeWeb
- デフォルトで入力されているt2.microでOK
- KeyName
- 先ほど作成したEC2キーペアを選択
- SourceLocation
- アクセス元のグローバルIPを指定。こちらアクセスすると確認できる。入力時は/32を末尾に追記すること
- WorkloadName
- Test
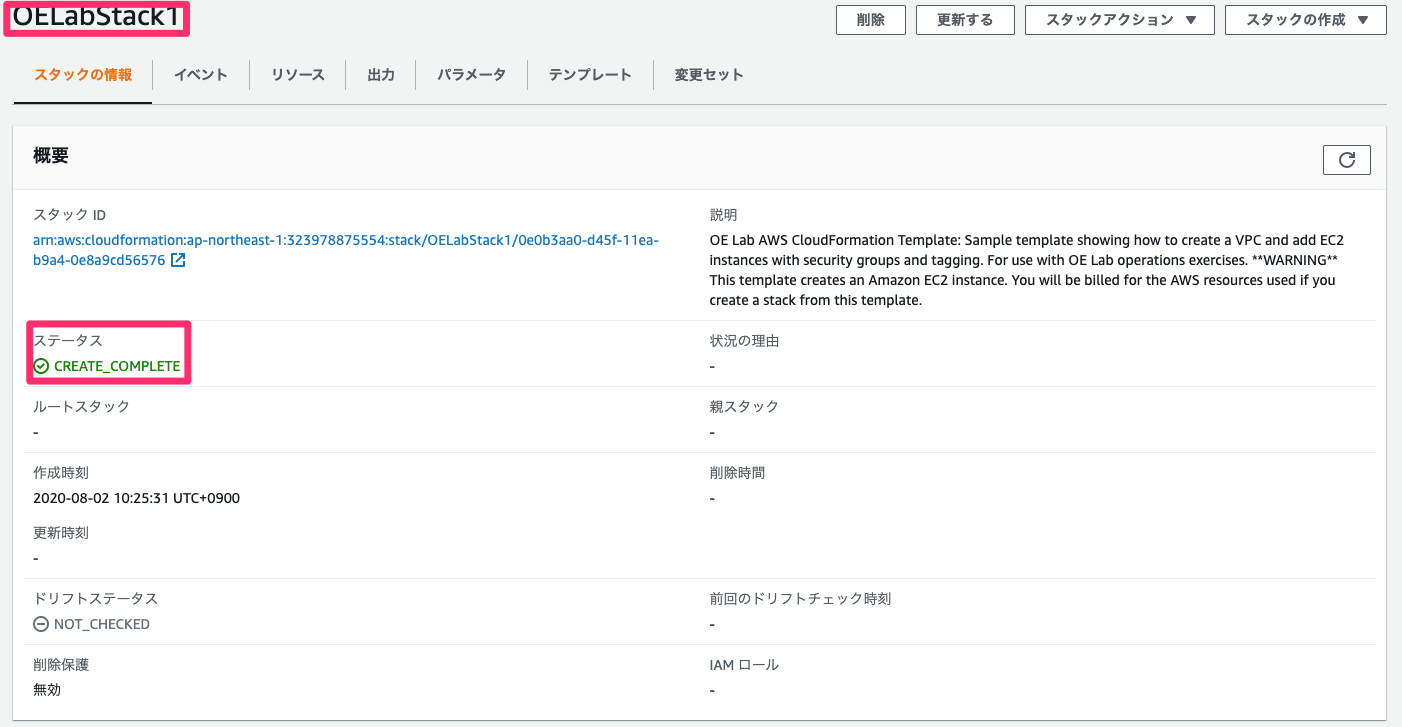
オプション設定は何も入力せずに、レビュー画面を確認し、問題無ければスタックの作成を行う。作成開始後はステータスがCREATE_COMPLETEになるまで待ちます。
再度同じCloudFormationの実行手順で別環境を作成します。
各種パラメータは以下です。
- スタックの名前
- OELabStack2
- InstanceProfile
- 先ほど作成したIAMロール名を入力します。
- InstanceTypeApp,InstanceTypeWeb
- デフォルトで入力されているt2.microでOK
- KeyName
- 先ほど作成したEC2キーペアを選択
- SourceLocation
- アクセス元のグローバルIPを指定。こちらアクセスすると確認できる。入力時は/32を末尾に追記すること
- WorkloadName
- Prod
Systems Managerを用いた状態管理
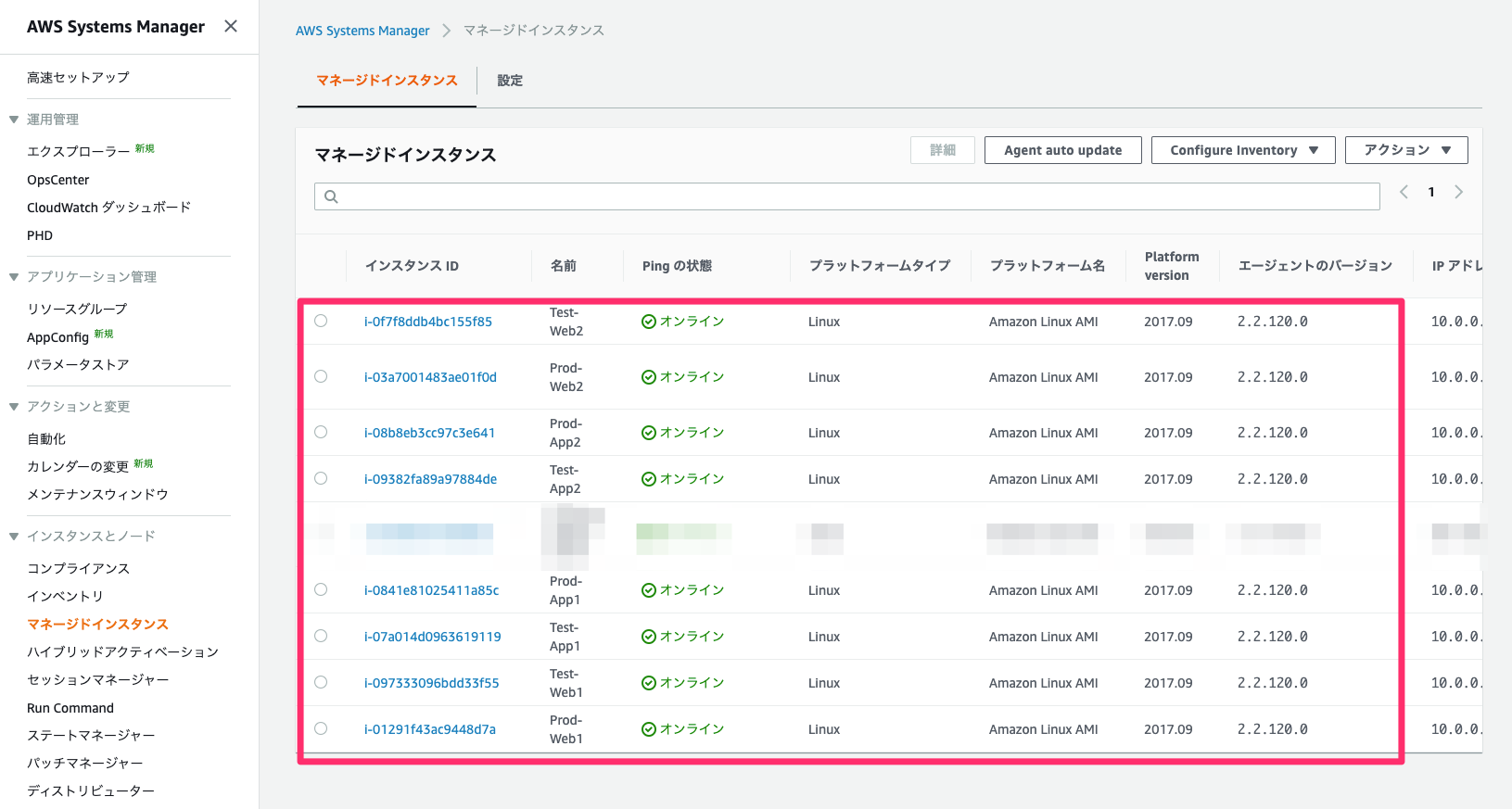
マネージドインスタンスへの登録確認
Systems Managerのマネージドインスタンス一覧に作成した8つのEC2インスタンスが表示されることを確認する。IAMロールをアタッチしてから一覧に表示されるまで数分かかる場合もあります。
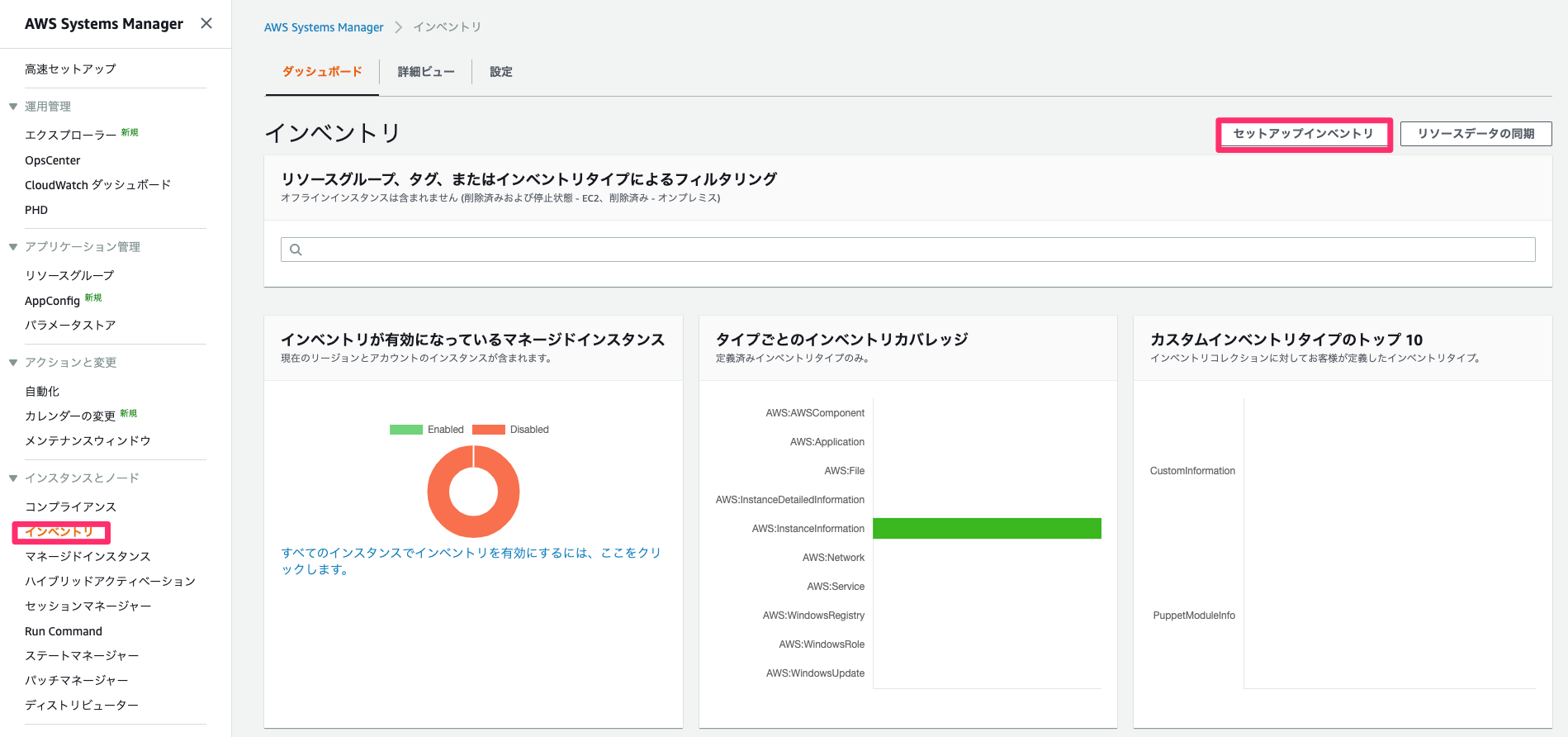
インベントリ設定
マネージドインスタンスをインベントリに設定します。なお、パッチマネージャーでのパッチ適用をする場合にインベントリ設定を行う必要はありません。インベントリ画面からセットアップインベントリを選択します。
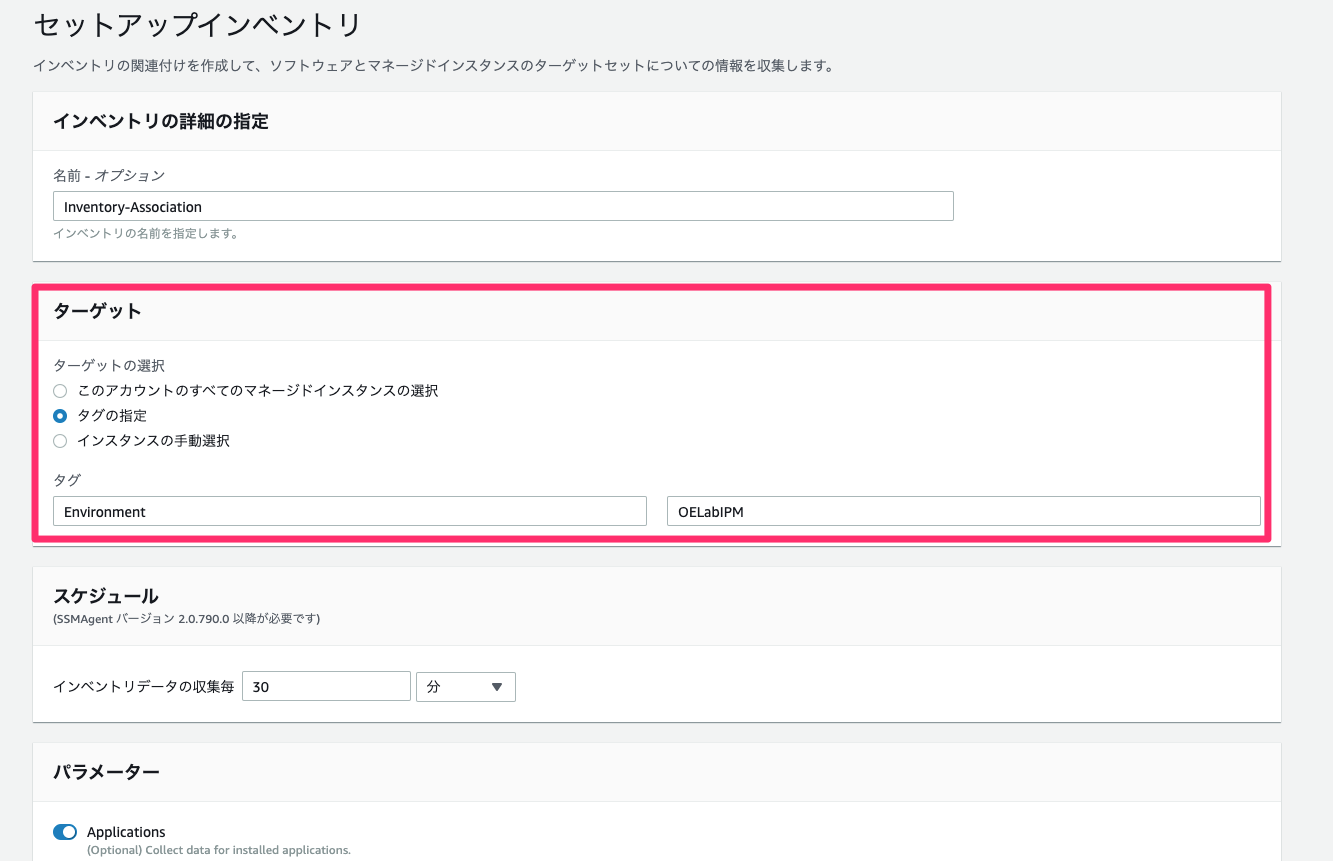
ターゲットでタグの指定を選択し、
key=Environment,value=OELabIPMを入力し、その他の設定はそのままでインベントリを作成する。
パッチ管理
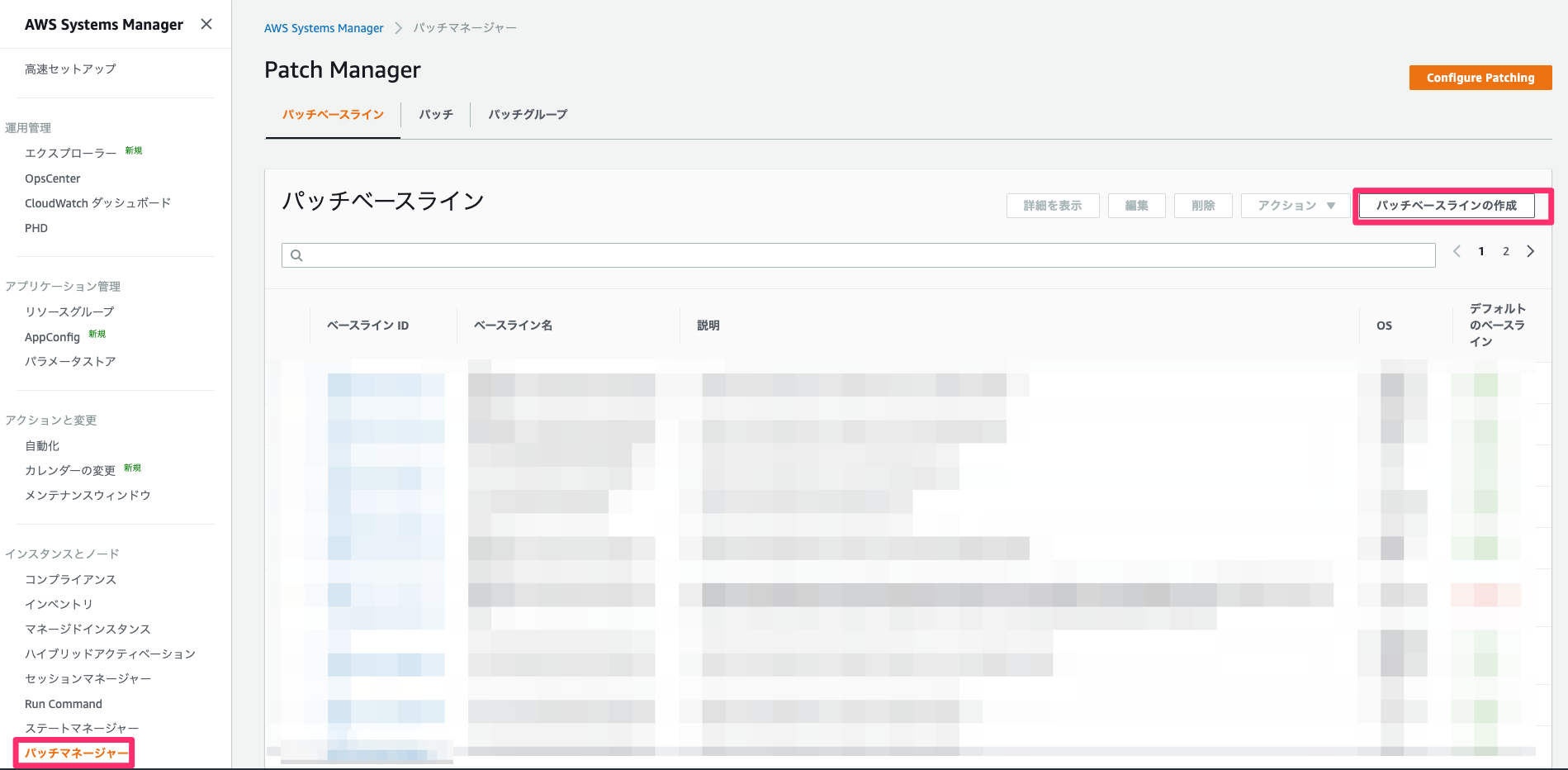
パッチベースライン作成
まずパッチベースラインの作成を行います。
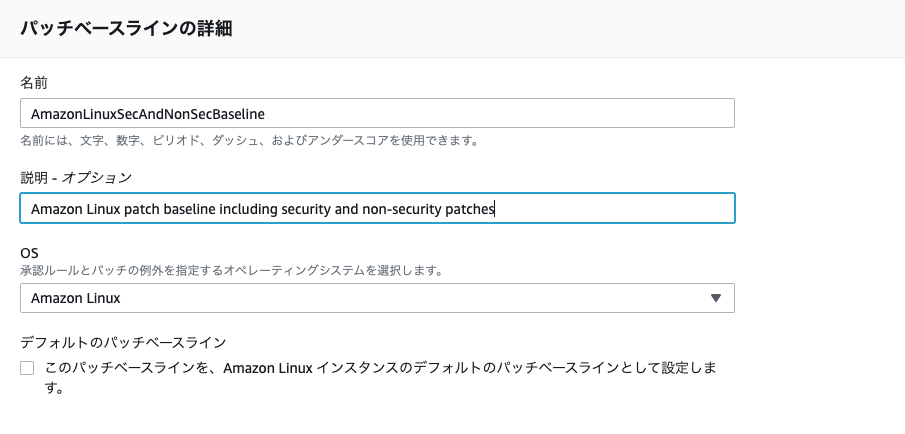
各種パラメータは以下です。記載されていないパラメータはデフォルト設定でOK
- パッチベースラインの詳細
- 名前
- AmazonLinuxSecAndNonSecBaseline
- 説明
- Amazon Linux patch baseline including security and non-security patches
- OS
- Amazon Linux
- オペレーティングシステムの承認ルール
- ルール1
- 製品
- ALL
- 分類
- ALL
- 重要度
- ALL
- コンプライアンスレポート オプション
- 非常事態
- ルール2
- 製品
- ALL
- 分類
- ALL
- 重要度
- ALL
- コンプライアンスレポート オプション
- ミディアム
- セキュリティ以外の更新を含める
- チェック
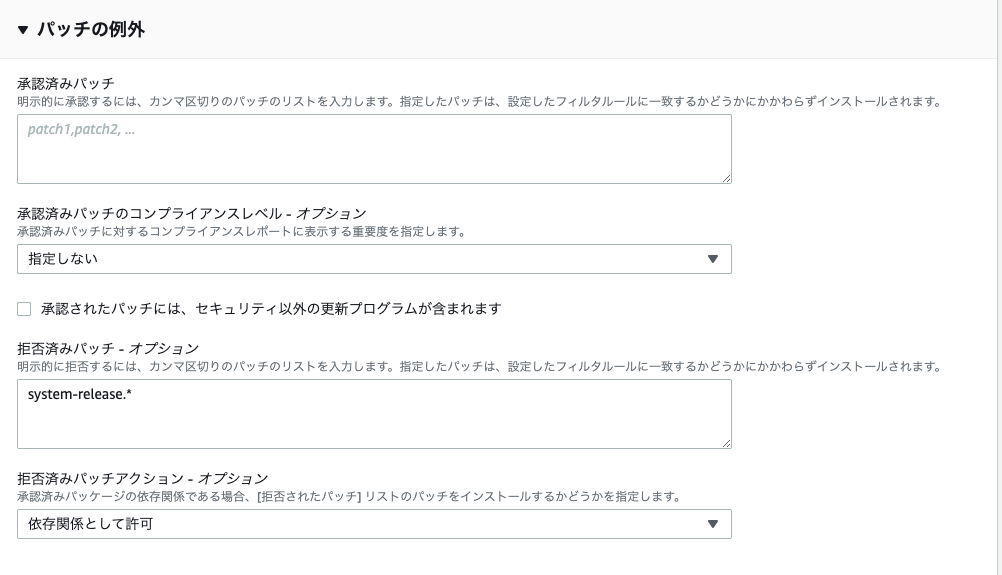
- パッチの例外
- 拒否済みパッチ オプション
- system-release.*
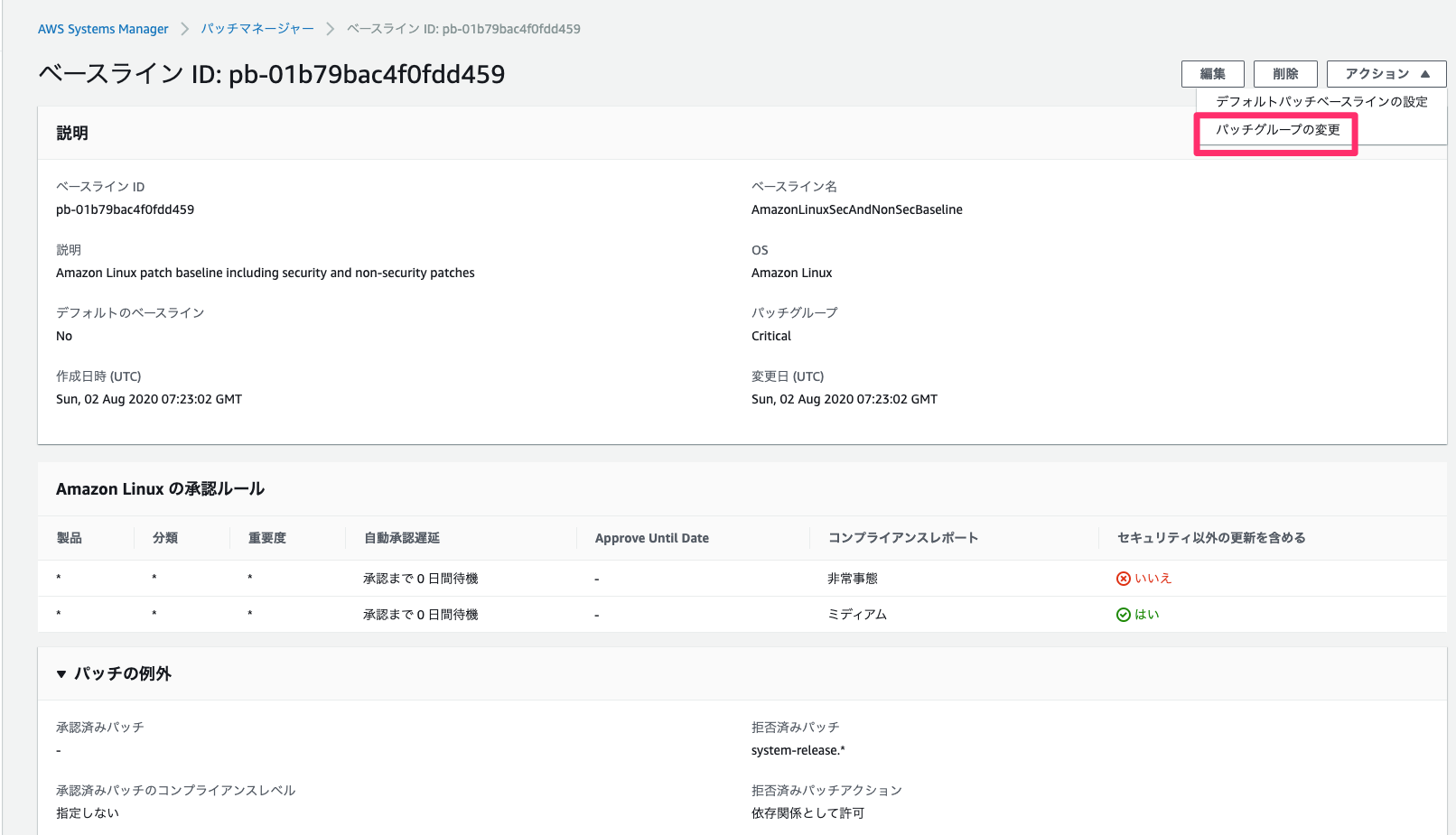
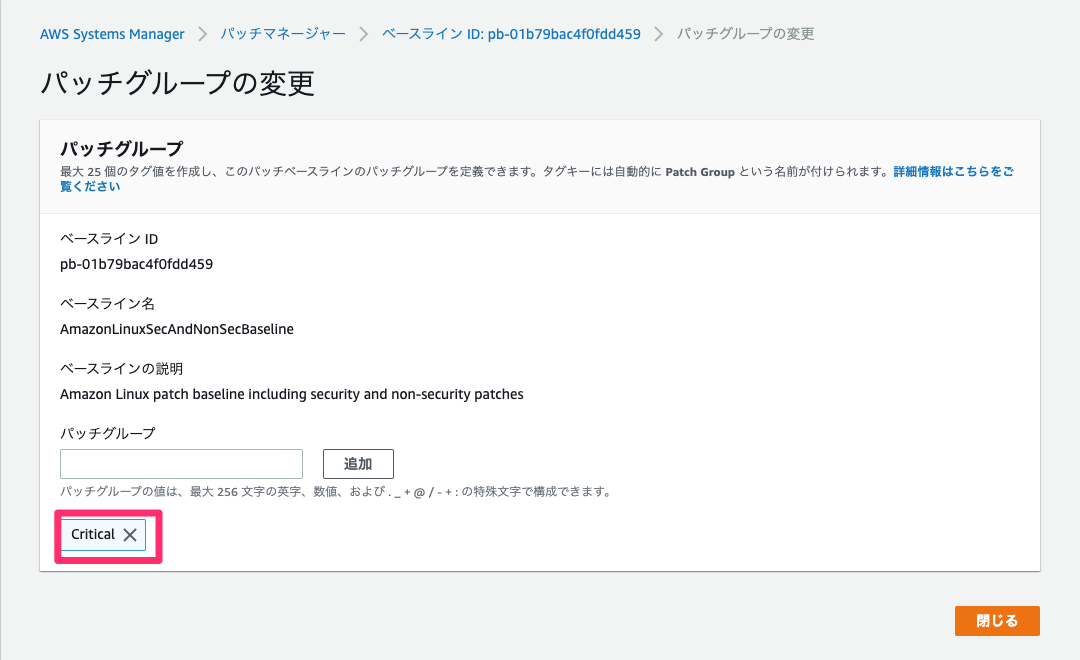
パッチグループの割り当て
EC2のタグに
key=Patch Groupが設定されていればパッチグループとして定義されますが、今回はタグkey=Patch Group,value=Criticalが最初から付与された状態で作成されているため、パッチグループの割り当てのみ行います。
作成したパッチベースライン詳細画面からパッチグループの変更を選択し、パッチグループにはCriticalを入力し、追加します。
Run Commandを介してAWS-RunPatchBaselineでインスタンスにパッチを適用する
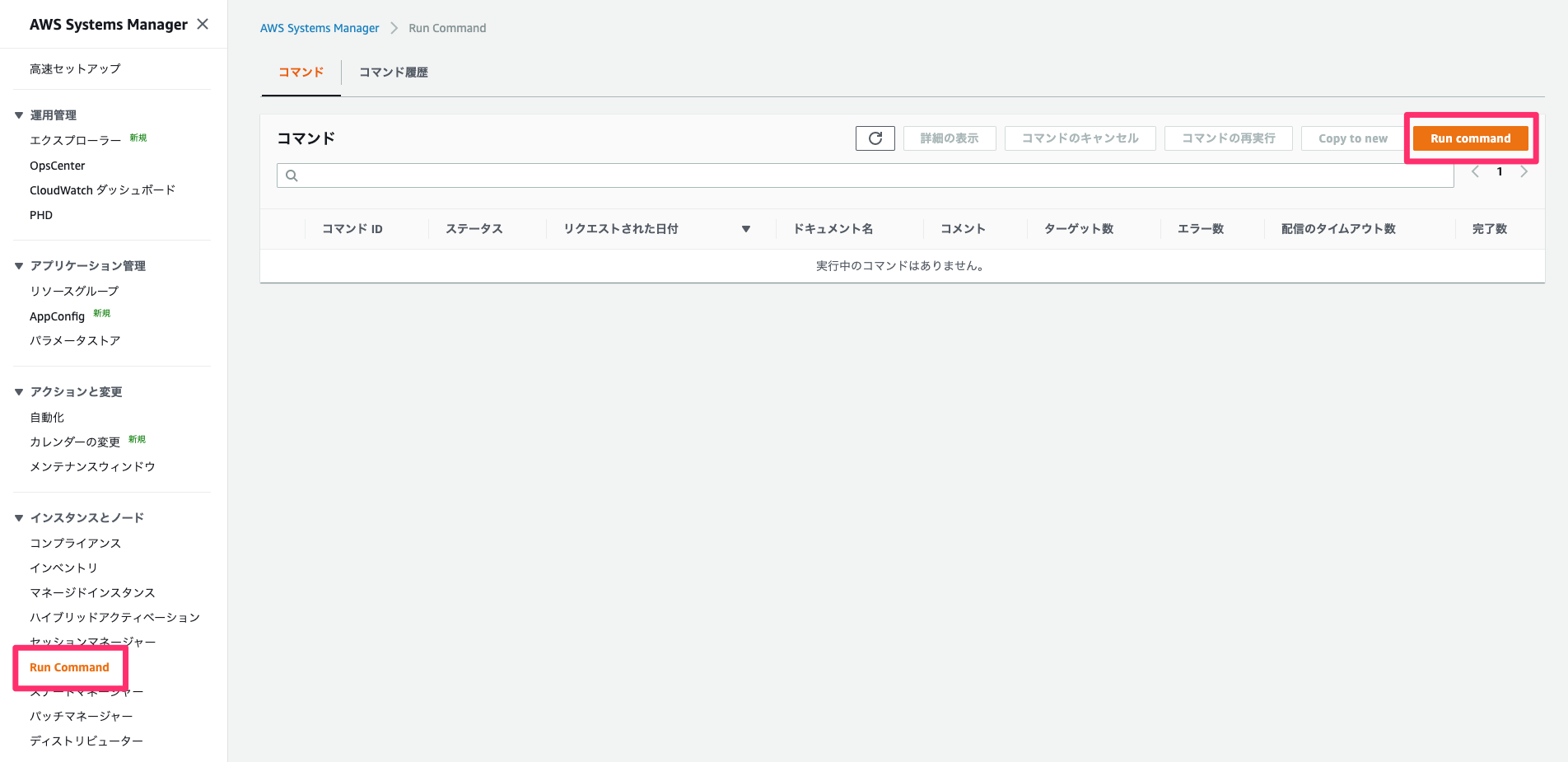
Run Command画面からRun Commandを選択します。
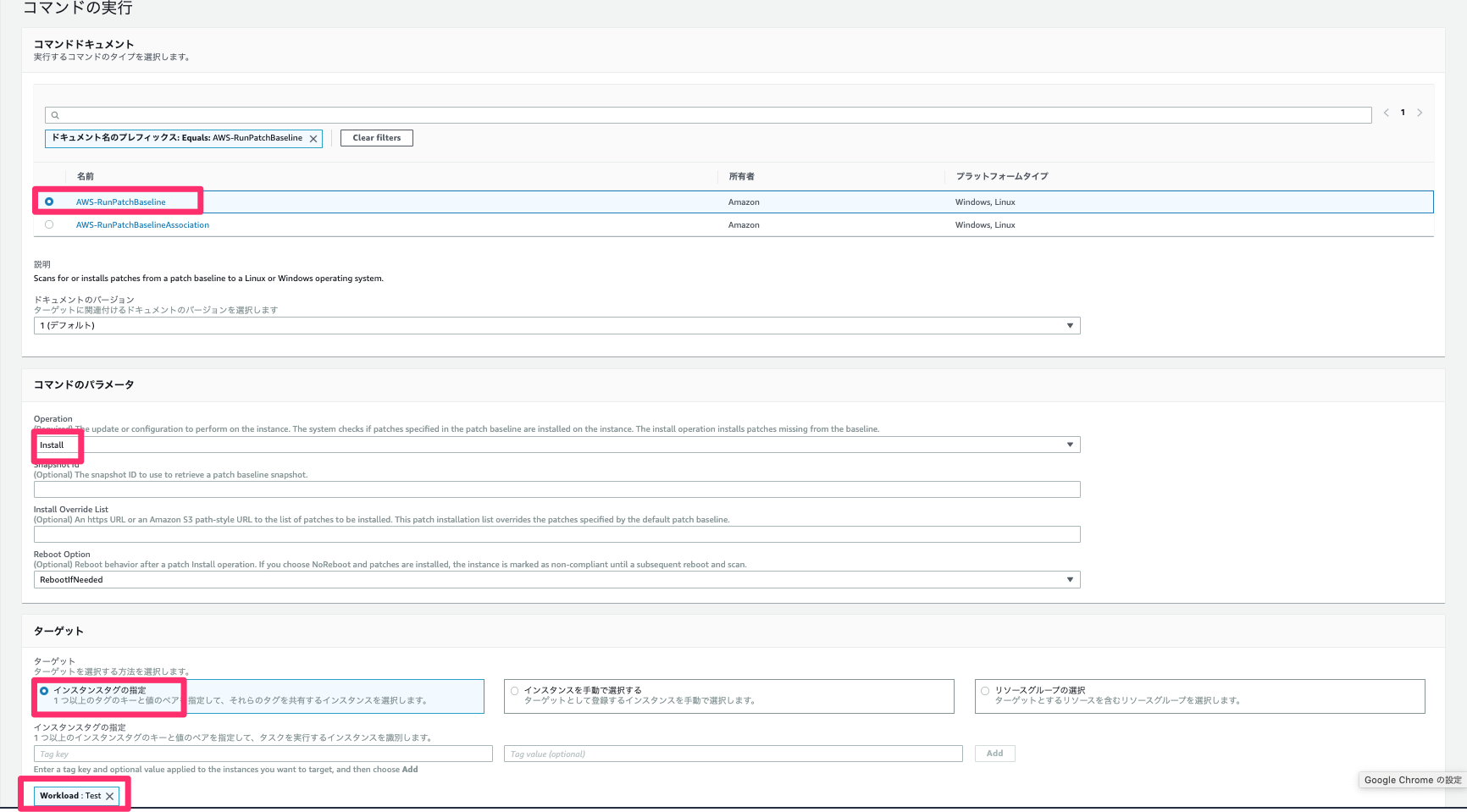
各種パラメータは以下を設定します。記載されていないパラメータはデフォルトの設定でOK
- コマンドドキュメント
- AWS-RunPatchBaseline
- コマンドのパラメータ
- Operation
- Install
- ターゲット
- インスタンスタグの指定
- key
- Workload
- value
- Test
対象インスタンス(タグが
key=Workload,value=Testの4つ)のRun Command処理が成功することを確認する。
メンテナンスウィンドウの作成と自動運用アクティビティのスケジュール
メンテナンスウィンドウ実行用のIAMリソース作成
Systems Managerがユーザーに代わってメンテナンスウィンドウでタスクを実行できるようにIAMリソースを作成します。
以下の設定のIAMロールを作成します。
- ロール名
- SSMMaintenanceWindowRole
- ロールの説明
- Role for Amazon SSMMaintenanceWindow
- アタッチポリシー
- AmazonSSMMaintenanceWindowRole
作成後に信頼関係を以下に変更する。
{ "Version":"2012-10-17", "Statement":[ { "Sid":"", "Effect":"Allow", "Principal":{ "Service":[ "ec2.amazonaws.com", "ssm.amazonaws.com", "sns.amazonaws.com" ] }, "Action":"sts:AssumeRole" } ] }メンテナンスウィンドウの作成
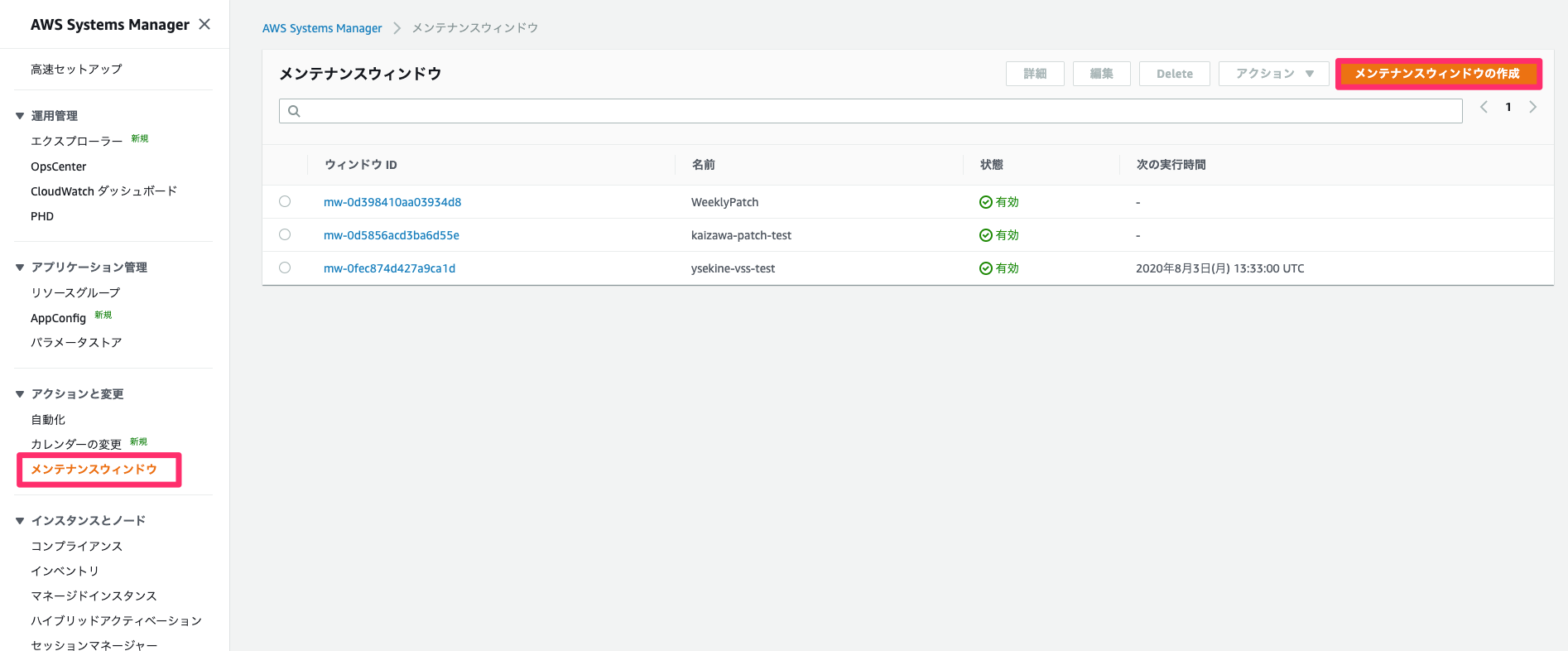
メンテナンスウィンドウ画面からメンテナンスウィンドウの作成を行う。
各種パラメータは以下を設定します。記載されていないパラメータはデフォルト設定でOK
- メンテナンスウィンドウの詳細の入力
- 名前
- PatchTestWorkloadWebServers
- スケジュールを指定
- 期間
- 1時間
- タスクの開始を停止
- 0
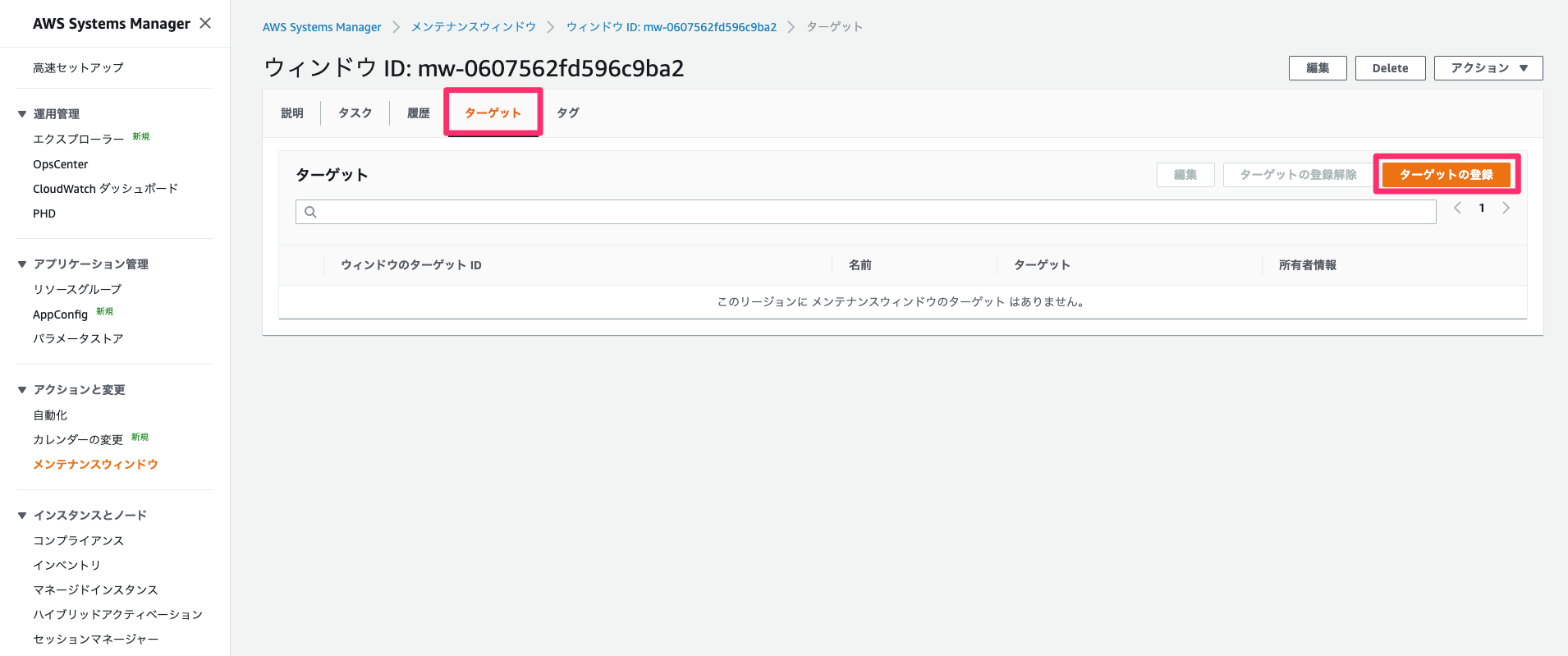
パッチメンテナンスウィンドウへのターゲットの割り当て
作成したメンテナンスウィンドウに対してターゲットの割り当てを行います。ウィンドウIDの詳細画面からターゲットの登録を選択します。
各種パラメータは以下を設定します。記載されていないパラメータはデフォルト設定でOK
- メンテナンスウィンドウのターゲットの詳細
- 名前
- TestWebServers
- ターゲット
- Target selection
key=Workload,value=Testkey=InstanceRole,value=WebServerパッチメンテナンスウィンドウへのタスクの割り当て
作成したメンテナンスウィンドウに対してタスクの割り当てを行います。ウィンドウIDの詳細画面からrun commandタスクの登録を選択します。
各種パラメータは以下を設定します。記載されていないパラメータはデフォルト設定でOK
- メンテナンスウィンドウのタスクの詳細
- 名前
- PatchTestWorkloadWebServers
- コマンドのドキュメント
- AWS-RunPatchBaseline
- ターゲット
- 登録済みターゲットグループの選択
- 先ほど登録したターゲットのID
- レート制御
- 並行性
- 1
- 誤差閾値
- 1
- IAMサービスロール
- カスタムサービスロールを使用する
- SSMMaintenanceWindowRole
- パラメーター
- Operation
- Install
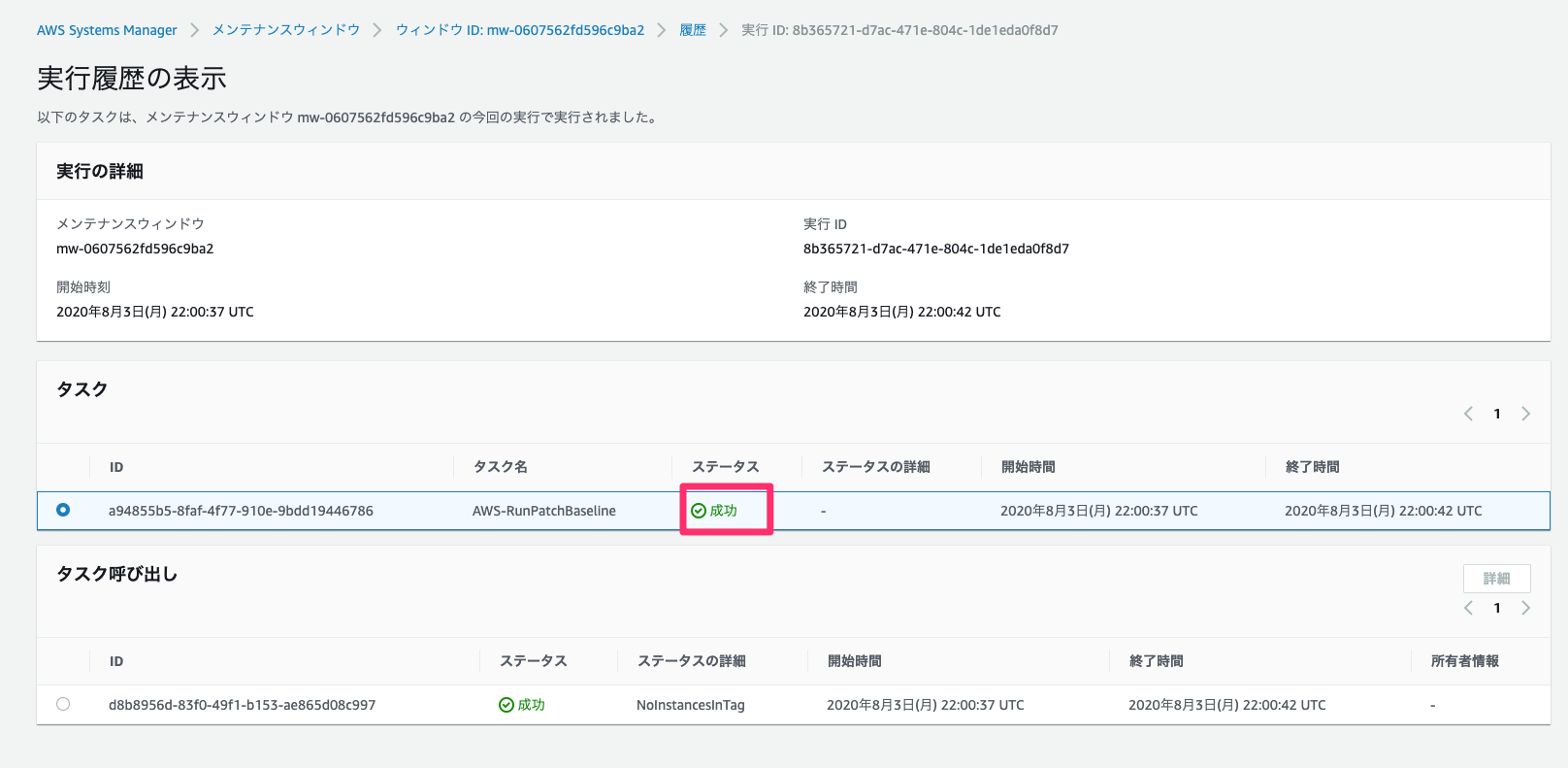
メンテナンスウィンドウの実行の確認
メンテナンスウィンドウの実行時間になったら、履歴から実行結果を確認し、ステータスが成功となっていることを確認する。
リソース削除
最後に作成したリソースを削除します。
- CloudFormationスタック
- OELabStack1
- OELabStack2
- インベントリ
- Inventory-Association
- メンテナンスウィンドウ
- PatchTestWorkloadWebServers
- パッチベースライン
- AmazonLinuxSecAndNonSecBaseline
おわりに
各サービスの関係性さえ理解すれば、比較的簡単にパッチマネージャーでパッチ適用を自動化することは可能ですが、パッチ適用フローを十分に精査する必要があると思います。実際のシステムに取り入れるのであれば、開発環境でまずは適用し、問題がなければ本番環境に適用するようなフローになると思います。また、どの分類のどの重要度までのパッチを適用すれば良いかも考慮する必要があります。ここら辺については従来通りエンジニア側で考える必要がありますが、パッチ適用作業自体を自動化できることを大きなメリットとなるため、機会があれば使っていきたいと思います。
参考


- 投稿日:2020-08-04T18:22:16+09:00
一時クレデンシャルを発行するローカルIMDSを作った
はじめに
AWSを使う上でクレデンシャルをEC2インスタンス上(~/.aws/credentials)に保存したり
プログラムの設定ファイルに指定することは、セキュリティ上の観点から推奨されません。
(というかアクセスキーを発行すること自体がセキュリティリスクになります)
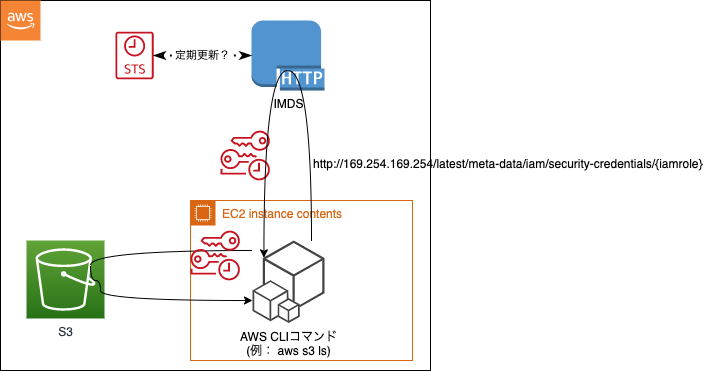
通常は、IAMロールをEC2に紐づけてIMDS(インスタンスメタデータサービス)から一時的な
クレデンシャルを取得してAWSリソースにアクセスにすると思います。この一時クレデンシャルを提供するのが、IMDS(後述)と呼ばれるサービスですが、
ローカルで動くIMDSもどきを作ってみたので、その紹介です。インスタンスメタデータサービス(IMDS)とは
このページを抜粋
インスタンスメタデータサービス(IMDS)は、一時的な認証情報へのアクセスを提供することで クラウドユーザーにとって大きなセキュリティ上の課題を解決し、手動またはプログラムによって インスタンスに機密認証情報をハードコードしたり、配布したりする必要をなくしました。 EC2 インスタンスにアタッチされた IMDS は、特別な「リンクローカル」の IP アドレス 169.254.169.254 で接続され、インスタンスで実行中のソフトウェアだけがアクセスできます。 アプリケーションは IMDS にアクセスして、インスタンス、ネットワーク、およびストレージに関する メタデータを利用できます。 また、IMDSは、インスタンスにアタッチされている IAM ロール による AWS 認証情報を使用 できるようにします。簡単に言うと、EC2上でaws sdkを使ったプログラムやaws cliコマンドを実行すると、
http://169.254.169.254/latest/meta-data/iam/security-credentials/{iamrole}
にリクエストを送信してクレデンシャルを取得し、その認証情報を使ってAWSリソースを操作します。処理イメージ
レスポンス例
一時セキュリティ認証情報{ "Code" : "Success", "LastUpdated" : "2020-08-04T06:34:37Z", "Type" : "AWS-HMAC", "AccessKeyId" : "ASIA4KYQ77T7MF27ET2B", "SecretAccessKey" : "Q8vJapXly4HA1~~", "Token" : "IQoJb3JpZ2lu~~", "Expiration" : "2020-08-04T12:38:26Z" }ローカルIMDSとは
有効期限が切れない間隔で定期的にsts.assumeRoleして一時クレデンシャルを取得して
それをリンクローカルアドレス(169.254.169.254)へのhttpリクエストの結果として返すDocker
コンテナです。使い方
前提)
・スイッチロール元アカウントID:111111111111 / ユーザ名:miyaz@sencorp
・スイッチロール先アカウントID:222222222222 / ロール名:Devスイッチロール先IAMロールの信頼関係に下記を指定
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:root" }, "Action": "sts:AssumeRole", "Condition": { "StringLike": { "sts:RoleSessionName": "${aws:username}" } } } ] }スイッチロール元アカウントのクレデンシャルをローカルの ~/.aws/credentialsにセット
[default] aws_access_key_id=~~~ aws_secret_access_key=~~~docker-compose.ymlを作成
docker-compose.ymlversion: '3.8' services: app: image: centos:7 tty: true ## 既存のdocker-compose.ymlで使いたい場合はここ以降をコピペでOK(RoleArnは書き換え要) imds: image: miyaz/local-imds:latest volumes: - ~/.aws:/root/.aws environment: IMDS_ROLE_ARN: "arn:aws:iam::222222222222:role/Dev" networks: default: ipv4_address: 169.254.169.254 networks: default: ipam: config: - subnet: 169.254.169.0/24実行する
以下の例では、centos7にawscliを入れて
aws s3 lsを実行する手順です。
ちなみにimdsはエラーメッセージ以外は何もログ出力しません(念の為)docker-compose up -d docker-compose exec app bash yum -y install awscli aws s3 ls解説
imdsコンテナがIMDSの役割を持っています。
~/.awsをボリューム共有するので、スイッチロール可能なクレデンシャルが指定され
ている必要があります。環境変数[IMDS_ROLE_ARN]に権限を引き受けるロールを指定します。
IMDS_ROLE_ARN: "arn:aws:iam::{AccountId}:role/{IamRole}"スイッチロール元クレデンシャルのプロファイル名が
defaultでなければ、
環境変数[IMDS_SOURCE_PROFILE]で指定できます。imdsが169.254.169.254というIPで動くので、そこからクレデンシャルを取得する
appコンテナが169.254.169.0/24のIPを持っていればOK。
ymlファイルに記載のdefaultのコメントアウトを外すと通常はdefaultネットワークを
使いつつ、クレデンシャル取得時のみ169.254.169.0/24ネットワークを使います。ちなみに、この設定は入れた方がいいと思ったので、roleSessionNameに自動的に
スイッチロール元のIAMユーザ名が入るようにしています。ローカルIMDSのコードはこちら
どこで使えるか?
うーん、あまり有用な使い道は思いつかないですが、、強いて言えばということで。
AWSパートナー経由で契約している場合などOrganizationsが使えない場合はスイッチ
ロール運用している会社が多いと思います。
その場合にはログイン専用アカウントのみにIAMユーザを作成し、ログイン後スイッチロール
して他のアカウントのマネジメントコンソールにアクセスしていると思います。で、開発しているアプリ(gitリポジトリ)とAWSアカウントが紐づいている場合、新たに
参加した開発者にはスイッチロール用クレデンシャルを伝えて .aws/configに追記してもらうと思います。~/.aws/configに追記する例[profile hoge-dev] region=ap-northeast-1 role_arn=arn:aws:iam::222222222222:role/Dev source_profile=default role_session_name=miyaz@sencorpアプリのコードベースにあるdocker-compose.ymlに予めRole名が記載されて
いれば、これを伝達する必要がなくなって手間削減!!(無理やりwまとめ
思いついたので試してみたら動いた!!
て感じで、あまり運用上有用な使い方はなさそうですが、仕組みの理解は進みました\(^o^)/
- 投稿日:2020-08-04T16:55:52+09:00
SageMakerを使って機械学習に入門してみる
はじめに
AWS公式のAmazon SageMaker の開始方法の手順に沿って、機械学習モデルを構築してデプロイするまでの流れを実践してみる事にしました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
機械学習とは
ここでは割愛。概要を把握するには以下を参照。
SageMakerの概要
詳しくはAWS公式のAmazon SageMaker のドキュメントを参照。
Amazon SageMaker は、完全マネージド型の機械学習サービスです。Amazon SageMaker では、データサイエンティストと開発者が素早く簡単に機械学習モデルの構築と研修を行うことができ、稼働準備が整ったホスト型環境に直接デプロイできます。統合された Jupyter オーサリングノートブックインスタンスから、調査および分析用のデータソースに簡単にアクセスできるため、サーバーを管理する必要がありません。また、一般的な機械学習アルゴリズムも使用できます。そうしたアルゴリズムは、分散環境できわめて大容量のデータに対しても効率良く実行できるよう最適化されています。自前のアルゴリズムやフレームワークもネイティブでサポートされているため、Amazon SageMaker ではお客様固有のワークフローに合わせて調整できる柔軟性の高い分散型トレーニングも行えます。Amazon SageMaker Studio または Amazon SageMaker コンソールからクリック 1 つで起動して、安全でスケーラブルな環境にモデルをデプロイします。トレーニングとホスティングは、分ごとの使用量で課金されます。最低料金や前払いの義務はありません。
(https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html より引用)
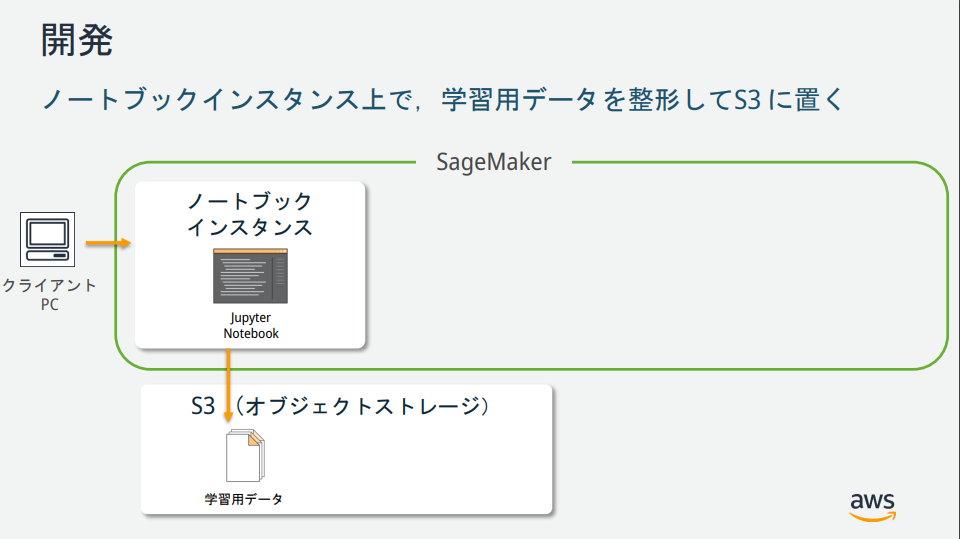
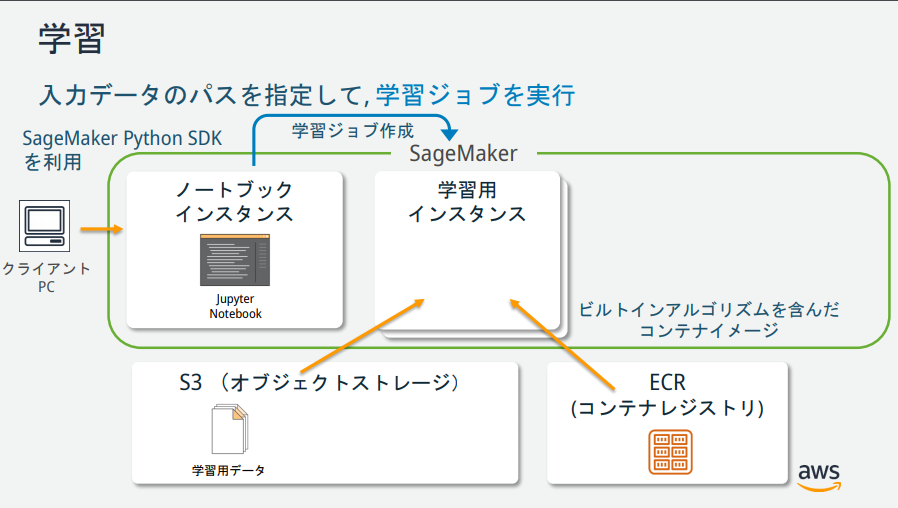
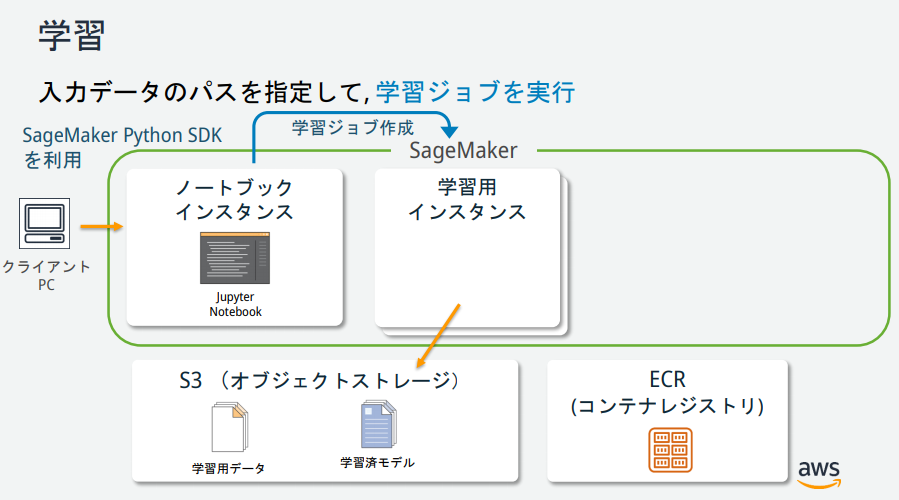
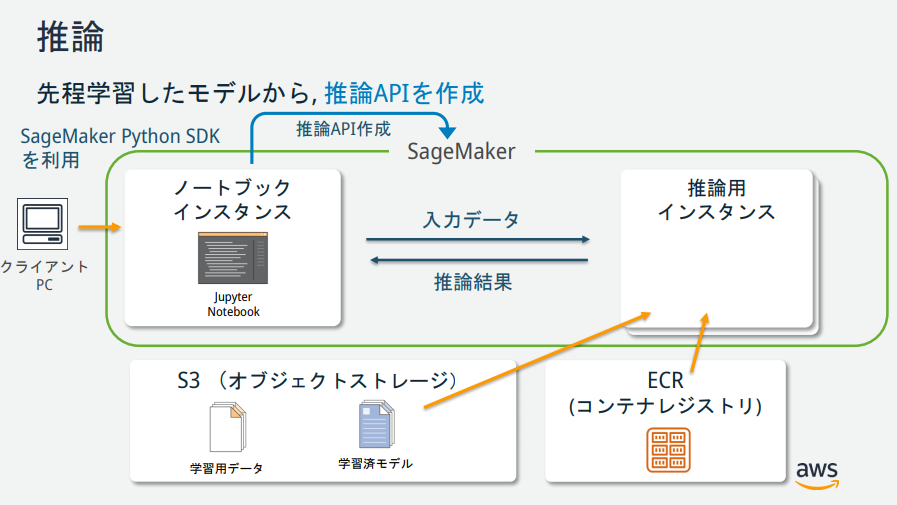
SageMakerの説明図を見る限りいくつかインスタンスが存在するが、それぞれどのような役割なのか?
→AWS公式が公開している資料が分かりやすかったので、以下に記載。
(https://pages.awscloud.com/event_JAPAN_hands-on-ml_ondemand_confirmation.html より引用)
チュートリアル
AWS公式のチュートリアルを実施。
Amazon S3 バケットを作成する
機械学習に使用するデータ、および、学習結果(モデル)を格納するための場所(バケット)を作成。
Amazon SageMaker ノートブックインスタンスの作成
Amazon SageMakerノートブックインスタンスとは、Jupyter Notebookがインストールされたフルマネージドな機械学習EC2コンピューティングインスタンス。
Jupyter ノートブックを作成する
Jupyter ノートブックとは
プログラムの作成、実行結果、グラフ、作業メモや関連するドキュメントなどを、ノートブックと呼ばれるファイル形式にまとめて、一元的に管理することを目的としたオープンソースツール。
データ分析作業などで、対話的にプログラムを実行してその結果を参照しながら次の作業を行う場合や、出力された結果を保存し、メモとともに作業記録のように残したい場合などに特に有益である。(https://www.seplus.jp/dokushuzemi/blog/2020/04/tech_words_jupyter_notebook.html より引用)
「New」から「conda_python3」を選択。新しいノートブックが作成される。
S3とロールを指定するコードを記述。
from sagemaker import get_execution_role role = get_execution_role() bucket='0803-sagemaker-sample'データをダウンロード、調査、および変換する
MNIST データセットをダウンロードする
MNISTデータとは
MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセットです。さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセットです。
(https://udemy.benesse.co.jp/ai/mnist.html より引用)
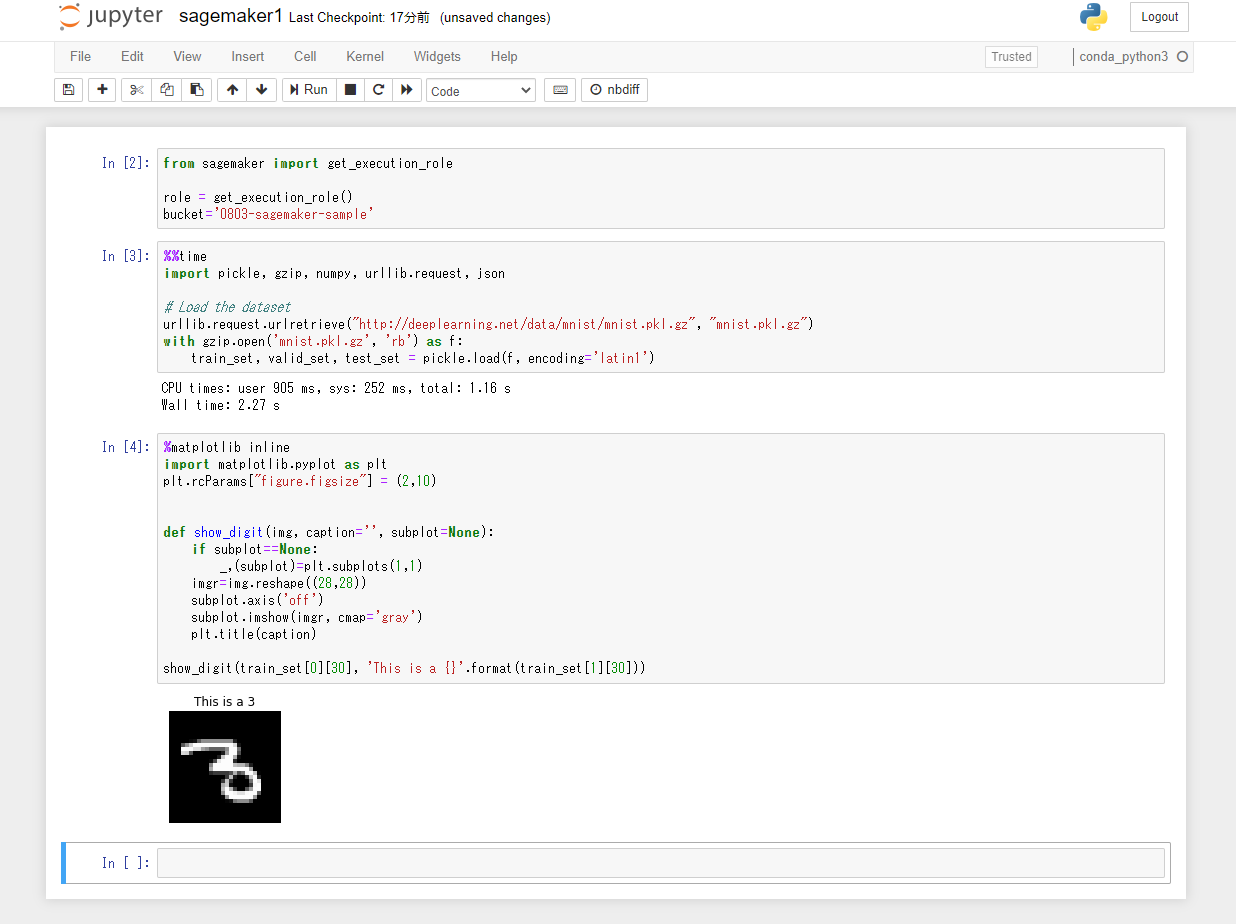
MNISTデータセットのダウンロードを行うコードを記述。
%%time import pickle, gzip, numpy, urllib.request, json # Load the dataset urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz") with gzip.open('mnist.pkl.gz', 'rb') as f: train_set, valid_set, test_set = pickle.load(f, encoding='latin1')トレーニングデータセットを調べる
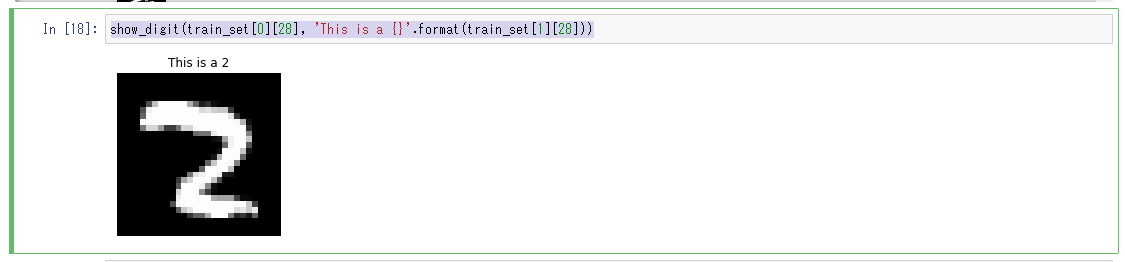
以下のPythonコードを3つ目のセルにペーストして、「Run」ボタンをクリック。MNISTデータセットの31枚目の画像データがラベルの内容と共に表示される。
%matplotlib inline import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (2,10) def show_digit(img, caption='', subplot=None): if subplot==None: _,(subplot)=plt.subplots(1,1) imgr=img.reshape((28,28)) subplot.axis('off') subplot.imshow(imgr, cmap='gray') plt.title(caption) show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))
モデルをトレーニングする
トレーニングアルゴリズムを選択する
機械学習では、通常モデルに適したアルゴリズムをみつけるための評価プロセスが必要になる。
今回は SageMaker の組み込みアルゴリズムの1つである k-means を使うことが決まっているため、評価プロセスはスキップする。k-meansとは
K-means 法はクラスタリングを行うための定番のアルゴリズムの1つ。ここでは詳細は割愛。
トレーニングジョブの作成
以下のPythonコードを4つ目のセルにペーストして、「Run」ボタンをクリック。
from sagemaker import KMeans data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket) output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training data will be uploaded to: {}'.format(data_location)) print('training artifacts will be uploaded to: {}'.format(output_location)) kmeans = KMeans(role=role, train_instance_count=2, train_instance_type='ml.c4.8xlarge', output_path=output_location, k=10, data_location=data_location)トレーニングの実行
モデルのトレーニングを実行。以下のPythonコードを5つ目のセルにペーストして、「Run」ボタンをクリック。トレーニングの所要時間は約10分。
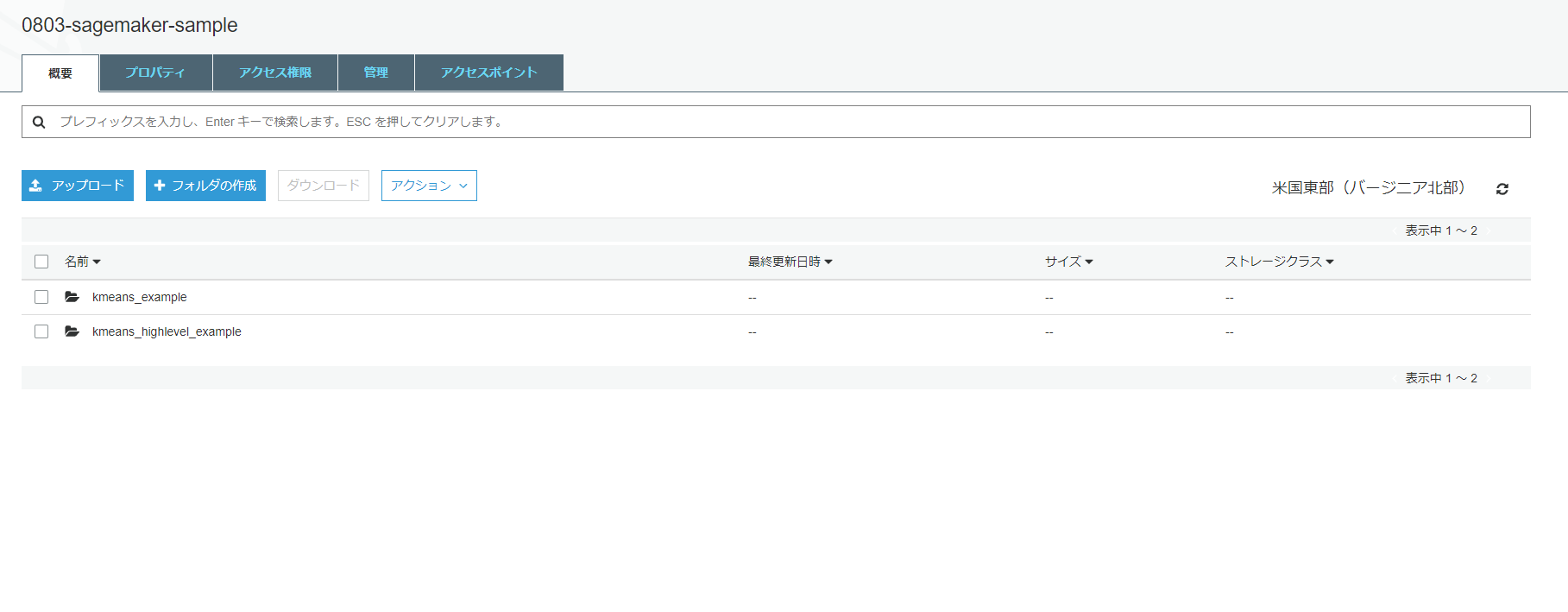
%%time kmeans.fit(kmeans.record_set(train_set[0]))モデルのトレーニング完了後にS3を確認すると、モデルのトレーニングデータとモデルのトレーニング中に生成されるモデルアーティファクトが格納されている。
モデルを Amazon SageMaker にデプロイする
SageMaker にモデルをデプロイするためには、以下の3ステップの手順を実施する必要がある。
- SageMaker上でモデルを作成
- エンドポイントの設定の作成
- エンドポイントの作成
deployというメソッド一つでこれらの作業を行うことができる。以下のPythonコードを6つ目のセルにペーストして、「Run」ボタンをクリック。
%%time kmeans_predictor = kmeans.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')モデルを検証する
モデルがデプロイされた為、検証を行う。以下のPythonコードを7つ目のセルにペーストして、「Run」ボタンをクリック。
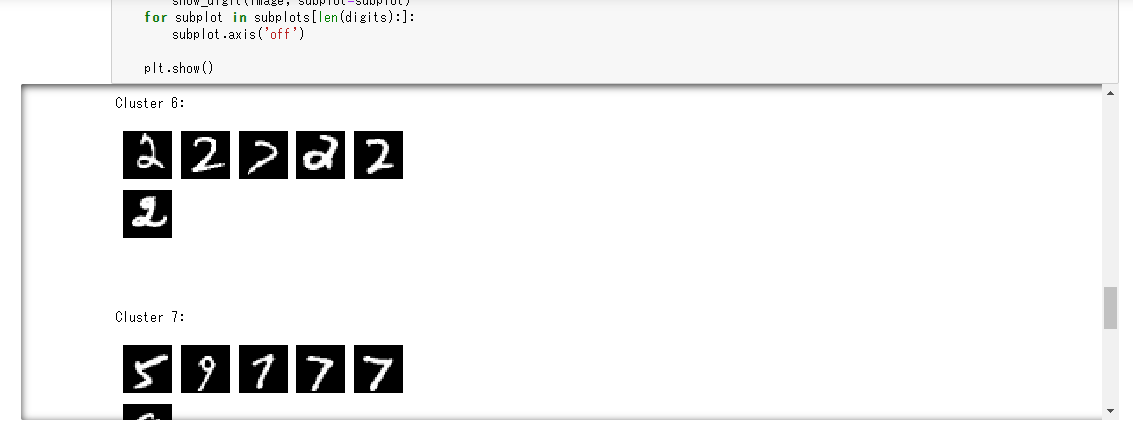
result = kmeans_predictor.predict(valid_set[0][28:29]) print(result)valid_setデータセットの30番目の画像に対する推論結果が得られる。valid_setの28番目のデータは、クラスター6に属していることがわかる。
[label { key: "closest_cluster" value { float32_tensor { values: 6.0 } } } label { key: "distance_to_cluster" value { float32_tensor { values: 6.878328800201416 } } } ]続いて、valid_setデータセットの先頭から100個分の推論結果を取得する。以下のPythonコードを8つ目のセルと9つ目のセルにペーストして、順番に「Run」ボタンをクリック。
%%time result = kmeans_predictor.predict(valid_set[0][0:100]) clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]for cluster in range(10): print('\n\n\nCluster {}:'.format(int(cluster))) digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ] height = ((len(digits)-1)//5) + 1 width = 5 plt.rcParams["figure.figsize"] = (width,height) _, subplots = plt.subplots(height, width) subplots = numpy.ndarray.flatten(subplots) for subplot, image in zip(subplots, digits): show_digit(image, subplot=subplot) for subplot in subplots[len(digits):]: subplot.axis('off') plt.show()
「トレーニングデータセットの調査」で使用したshow_digitメソッドを利用しvalid_setデータセットの28番目を表示。
クラスター4に含まれている画像である事が分かる。show_digit(train_set[0][28], 'This is a {}'.format(train_set[1][28]))
モデルがデプロイされて、動作していることも検証できた為完了。
作成した AWS リソースの削除
粛々と削除。特筆すべき事はなし。
おわりに
今回はSagrMakerを利用し、初めての機械学習に挑戦してみた。
機械学習、というと何となく障壁が高いイメージだったが、想像以上に簡単に使う事ができた。各パブリッククラウドの最近の発表を見ていると、機械学習への敷居を下げようとしている印象を受ける。
(レベルが高い分析を行う場合は専門の機械学習エンジニアのスキルが必要となると思うが、)一定レベルの機械学習については、機械学習を専門とするエンジニア以外でもマネージドサービスを使ってスピード感を持って構築するスキルが求められていくのではないかと考えるので、機械学習についても学習を進めていきたい。参考資料
Amazon SageMaker の開始方法
【初心者向け】Amazon SageMakerではじめる機械学習 #SageMaker
Amazon SageMaker 機械学習エンジニア向け体験ハンズオン

- 投稿日:2020-08-04T16:38:45+09:00
本番環境とcredentials.yml.enc
この記事で伝えたいこと
production環境の秘匿情報をcredentialsで扱う前にしっかり調べましょう。
ただのコピペダメ絶対。基礎知識 暗号化と復号について
〜開発環境〜
$ rails newした時config/master.keyと共にcredentials.yml.encは作成されるようです。
そしてこのmaster.keyを使用して暗号化、復号します。
(master.keyは大切に保管しましょう)秘匿情報の編集には以下のコマンドを実行します。
$ rails credentials:edit #master.keyが存在しない時実行すると新たに作成する〜本番環境〜
暗号化と復号にはsecret_key_baseも必要になります。
ローカルで$ rails secretコマンドを実行し作成します。
事前にローカルのmaster.keyをサーバーにも配置しておくこと。本番環境で気をつけること
credentials.yml.encの暗号化、復号にはmaster.keyを使用すると先ほど書きました。このmaster.key、デフォルトでgitignoreに登録されているためGitの管理対象外となっています。
ここからが大切です。
EC2でgitのリポジトリをクローンしてもこのmaster.keyは当然サーバー上にやってきません。
その事を忘れて本番環境の秘匿情報を追加しようと思い$ rails credentials:editコマンドを実行すると...サーバー上にはmaster.keyが無いので新たに生成されてしまいます。この時点ではローカルのmaster.keyとサーバーのmaster.keyが異なりcredentials.yml.encの復号ができなくなります。あら大変。
Couldn't decrypt config/credentials.yml.enc. Perhaps you passed the wrong key?こんなエラーや、
ActiveSupport::MessageEncryptor::InvalidMessageこんなエラーが発生します。
もう一度credentialsの復号がしたい
ローカルのmaster.keyをサーバーに置いてあげれば良いです。
master.keyを紛失した場合は、config/credentials.yml.encを削除してから以下のコマンドで
新たなものを生成してくれるようです。
ただしcredentialsの中身は全て吹き飛びますのでご注意を。$ sudo EDITOR=vim rails credentials:editRails6以降とcredentilas.yml.enc
6以降は環境ごとに秘匿情報を分けられるようになりました。(祝)
本番環境で情報を追加したい時以下コマンドを実行します。
環境に応じてenvironment以降を変化させます。$ rails credentials:edit --environment productionこのコマンドはconfig/credentials/production.yml.encと、config/credentials/production.keyを作成します。ファイル名とキーの名前にそれぞれ該当する環境が記載されます。
サーバーにはproduction.keyのみを上げれば良い。この場合でもmaster.keyやsecret_key_baseの扱いには注意。
参考
Rails 5.2 で ActiveSupport::MessageEncryptor::InvalidMessage
Rails5.2から追加された credentials.yml.enc のキホン
Rails5.2の新機能credentials等でパスワード等を管理する
【Ruby/Rails】デプロイ作業をCapistranoで自動化する
- 投稿日:2020-08-04T15:01:34+09:00
AWS KMSを理解する
AWS KMSはマネージドでは暗号化に使う鍵を管理してくれるサービスです。
が、、ややこしい暗号化の方法
- サーバーサイド暗号化
- クライアントサイド暗号化
の二種類あります。そしてAWS KMSの特徴であるEnvelop Encryptionはクライアントサイド暗号化で使用できます。サーバーサイド暗号化ではCMK(Customer Managed Key)を使用した通常の暗号化が可能です。AWS KMSのEnvelop EncryptionではデータをCDK(Customer Data Key)で暗号化し、CDKをCMKで暗号化し、CMKをAWS内で管理・保管してくれます。
AWS Key Management Service Developer GuideここからはAWS CLIから実際に、サーバーサイド暗号化とクライアントサイド暗号化を試してみます。
前提条件
CMKの作成がされていて、CLIで使用するIAM UserにCMKを使用する権限が与えられているということを前提とします。また、暗号化するファイルは以下とします
sample.txtHello KMSクライアントサイド暗号化(復号も)
- AWS CLIからAWS KMSのAPIを使ってCMKからCDKを生成
- Opensslを使用して、CDKを鍵としてAES256でデータを暗号化
- 暗号化されたCDKをCMKで復号
- 復号された平文のCDKでデータを復号
という流れになります
aws kms generate-data-key \ --key-id {作成したcmkのAlias or Key ID} \ --key-spec AES_256 \ --output json > cdk.json出力にはKeyIdにCMKのKey IDが含まれます。これはCDKのKey IDではないので注意です。 KMSではCDKを暗号化・復号するためのアルゴリズムのみを保持しているため、CDK自体は保持しません。
cdk.json{ "CiphertextBlob": "暗号化されたCDK", "Plaintext": "平文のCDK", "KeyId": "CMKのKEY ID" }CiphertextBlob、Plaintextはbase64でエンコードされた状態で帰ってくるので、暗号化する前にデコードする必要があります。
jq -r '.Plaintext' cdk.json | base64 --decode | xxd -pこの平文のCDKを使用して、データを暗号化します。ちなみに
aws kms encryptというAPIがありますが、これはこの後、説明するサーバーサイド暗号化をするためのAPIです。Envelop Encryptionをするためには自身でOpensslなどを使用して暗号化の処理をする必要があります。openssl enc -aes256 -in sample.txt -out encrypted_sample.txt enter aes-256-cbc encryption password: base64でデコードしたCDK Verifying - enter aes-256-cbc encryption password:確認用これで暗号化完了なので、CDKのPlaintextは用済みになります。CDKはCMKで暗号化されますが、この時点では暗号化されたものと、Plaintextがどちらもローカルに存在することになるので、Plaintextは早急に削除しなくてはなりません。一方で暗号化されたCDKは復号する際に必要になるため、自身で保管する必要があります。
jq -r '.CiphertextBlob' cdk.json | base64 --decode >> encrypted_cdk.txt // 暗号化されたCDKを保存 rm cdk.json // CDKのPlaintextを削除次に保存した暗号化されたCDKを使用してデータを復号します。
aws kms decrypt \ --ciphertext-blob fileb://encrypted_cdk.txt \ --key-id {CDKの暗号化に使用したCMKのalias or KEY ID} > decrypted_cdk.jsonレスポンスはこんな感じ
{ "KeyId": "復号に使用したCMKのKey ID", "Plaintext": "CMKで複合された平文のCDK", "EncryptionAlgorithm": "SYMMETRIC_DEFAULT" }こちらもまたbase64でエンコードされてるので
jq -r '.Plaintext' decrypted_cdk.json | base64 --decode | xxd -p最後にOpensslで上記のhexに変換した結果を使って復号します
openssl enc -aes256 -d -in encrypted_sample.txt -out decrypted_sample.txt enter aes-256-cbc decryption password: 上記のhexに変換した結果サーバーサイド暗号化(復号も)
クライアントサイドでの暗号化とはことなり、サーバーサイド暗号化はEnvelop Encryptionをしません。そのため、クライアントからAWSにPlaintextを送信し、AWSの中で暗号化され、暗号化されたデータが帰ってくるということになります。そのため、転送中のデータに関しても暗号が求められる場合はクライアントサイドでの暗号化を選択する必要があります。
aws kms encrypt \ --key-id 暗号化に使用するCMKのalias or Key ID \ --plaintext fileb://sample.txt \ --query CiphertextBlob \ --output text | base64 --decode > serverside_encrypted.txtaws kms decrypt \ --ciphertext-blob fileb://serverside_encrypted.txt \ --key-id データの暗号化に使用したCMKのalias or Key ID \ --output json > serverside_decrypted.json複合したデータはbase64でエンコードされているので、
jq -r '.Plaintext' serverside_decrypted.json | base64 --decodeこのようにCMKで直接、データを暗号化することもできますが、暗号化できるデータのサイズは4KBまでとなっているため注意が必要です。
さいごに
最後に、KMSで注意が必要なのはCMKへのアクセス権限です。KMSにはキーポリシーやGrant APIなどを使用して、柔軟にアクセス権限をコントロールすることができますが、CMKはリージョン間をまたいで共有できないことに注意してください(クロスアカウントはできます)

- 投稿日:2020-08-04T14:09:50+09:00
Amplifyで、STSの認証を直接行う
Amazon CognitoのIDプールを使って外部プロバイダーがウェブベースの認証を提供する場合に、Cognitoが発行する認証の有効期限を伸ばすことがそのままでは難しかったので、その調査の記録を書いておきます。
そもそもの認証フロー
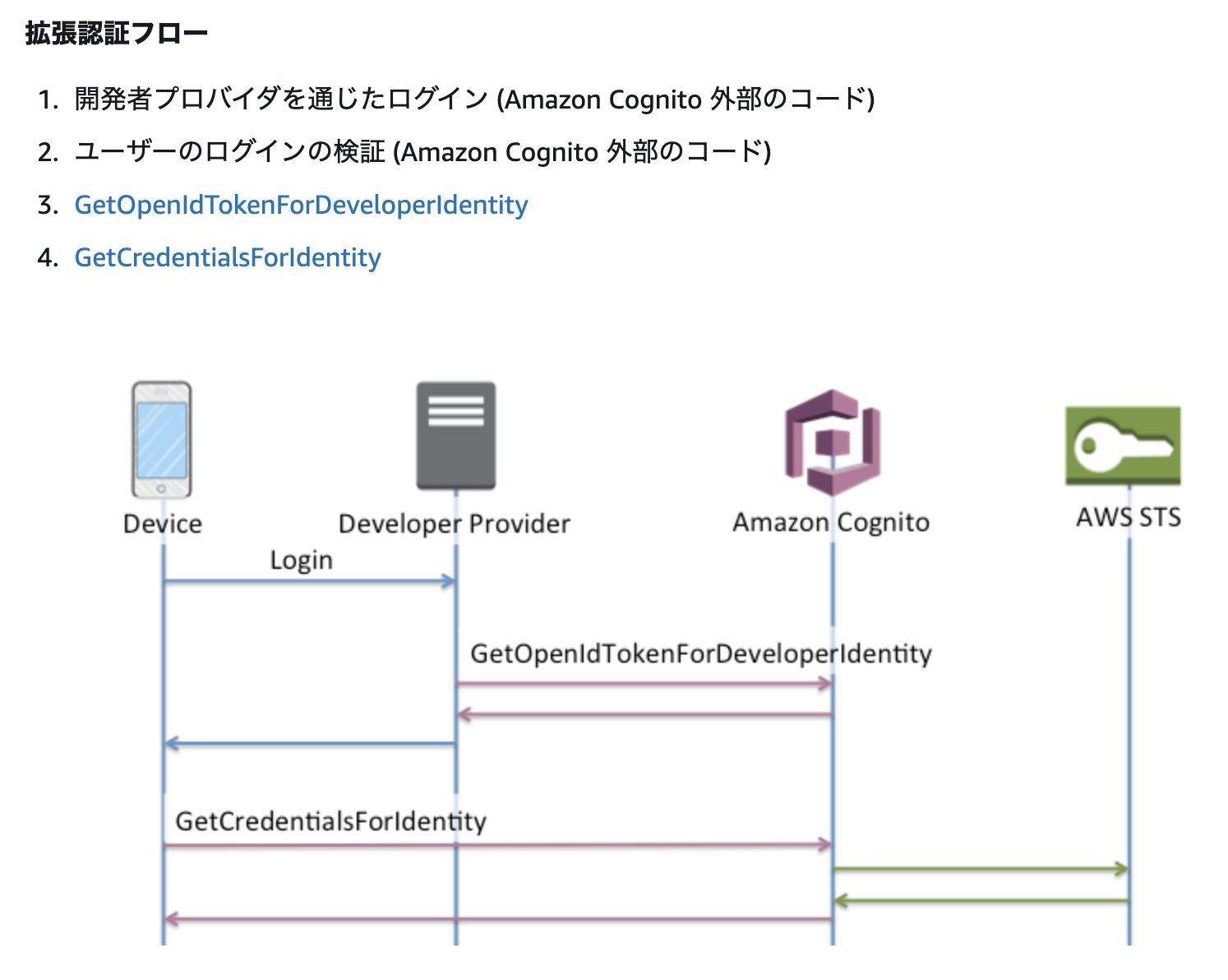
開発者認証or外部プロバイダーどちらを使ったとしても、Amplifyの認証を素直に使うと下の拡張認証フローになります。
引用元:
https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/authentication-flow.htmlこの図を見てもらうとわかるのですが、最終的な認証情報はAWS STSから渡ってきます。そして、AWS STSでは認証情報を発行する際にその有効期限を指定することができます。しかし、拡張認証フローだとAmazon CognitoがAWS STSとやり取りしてしまうため、有効期限を指定することが出来ず、デフォルトの有効期限(
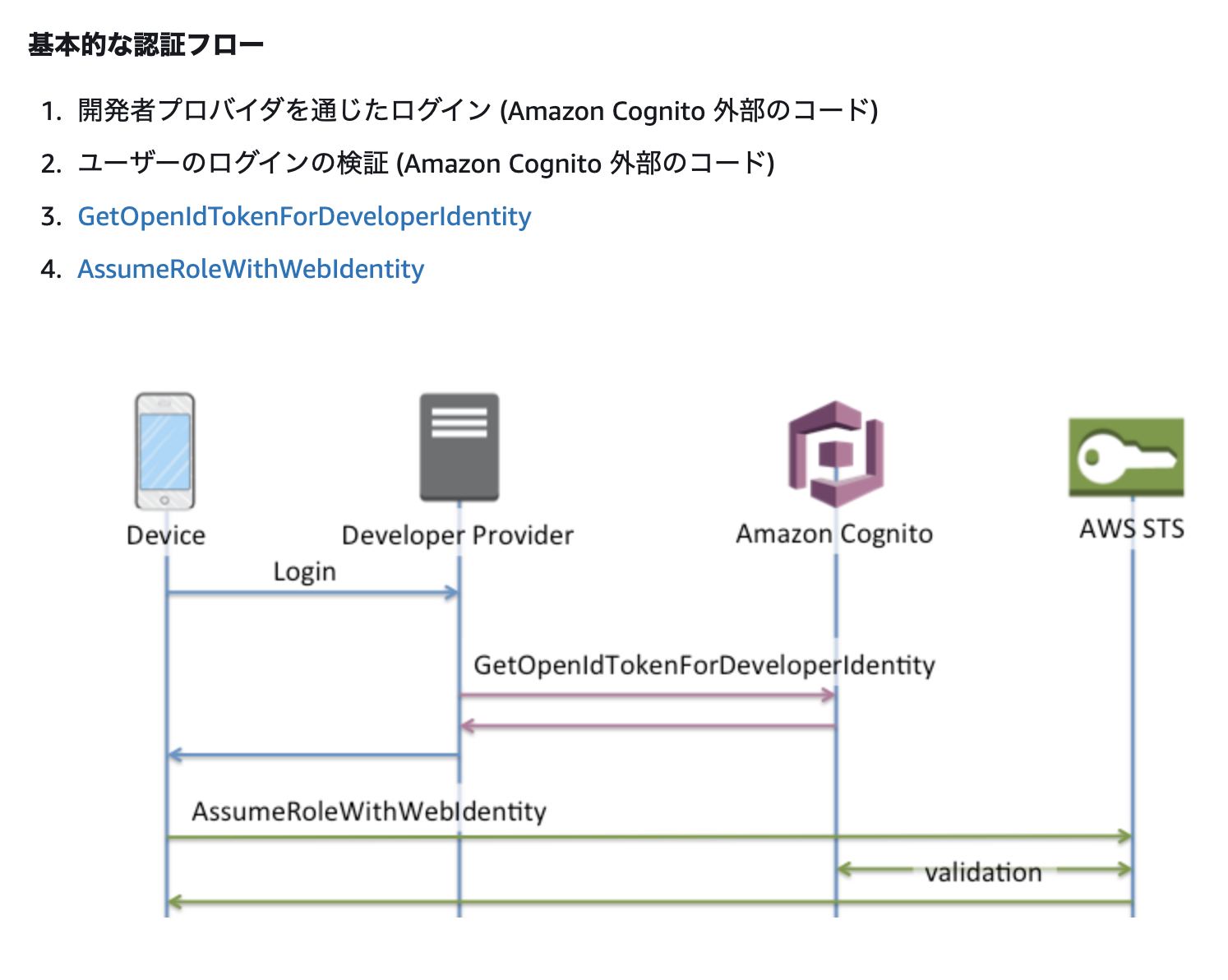
3600秒)が指定されてします。そこで、先程のページに有る、基本的な認証フローを使うことになります。
引用元: https://docs.aws.amazon.com/ja_jp/cognito/latest/developerguide/authentication-flow.html
見ての通り、AWS STSへ直接アクセスすることが出来ます。
実際のやり方
AmplifyでのCognito認証はすでに済んでいるものとし、AWS STSの認証に必要な下記のパラメータはすべて準備出来ているものとします。
- (A)
sts:AssumeRoleWithWebIdentityアクションが実行可能なIAM Role(そしてそのARN)- (B) 64字以下のセッション名として使う任意の文字列
- (C)
GetOpenIdToken...で発行されたトークン上記がそろえば、あとはさっくりAWS SDKのAPIを叩くだけです。
const stsParams = { DurationSeconds: 900, // 最小900秒(15分)〜最大43200秒(12時間)まで設定することが出来ます。 RoleArn: `(A)の値`, RoleSessionName: `(B)の値`, WebIdentityToken: `(C)の値`, }; const sts = new AWS.STS(); const stsResponse = await sts.assumeRoleWithWebIdentity(stsParams).promise(); AWS.config.update({ credentials: new AWS.Credentials({ accessKeyId: stsResponse.Credentials.AccessKeyId, secretAccessKey: stsResponse.Credentials.SecretAccessKey, sessionToken: stsResponse.Credentials.SessionToken, }), });Amplifyの認証設定はいっさいやらないんかい!って感じですが、Amplifyのコードを見る限り、Credentialsクラスなどから認証情報を設定する方法はなさそうです。AWSのグローバルの認証情報を更新しておくと、Amplifyのもろもろはそれを見て勝手に認証してくれるようなので、この書き方に落ち着きました。
- ※ Amplifyのバージョンによって、aws-sdkのバージョンが違ってくるので、この書き方はできない場合があります。
- ※ この書き方はaws-sdk v2系を想定しています。
- ※サーバー側のAPIを用意できるなら、CognitoのEPをそのままモックしてしまうほうが良いです。
- 投稿日:2020-08-04T11:33:17+09:00
terraform: AWS provider や s3 backend の設定に role の arn をハードコードせずに switch role や MFA 環境で実行する方法
概要
terraform を MFA 認証有の IAM ユーザ権限で switch role しつつ実行するのに手間どったので、対応方法を記載しておきます。
実行時に使用する switch role 先の arn を aws provider や s3 backend 設定にハードコードすると簡単にできるらしいのですが、role は環境(開発/テスト/本番)依存するものなので、ハードコードしたくないですよね。同じようなことで困っている人は世の中にそこそこいて、関連する issue がいくつか挙がっています。
その中で、terraform の開発者っぽい人が、"terraform は自動実行を意識しているので、MFA の one time password を interactive に入力するとか対応しねーんだよ!" と言っているコメントがあったので、それをヒントに workaround を調査しました。MFA および switch role 環境の場合
事前の設定
~/.aws/config, credentials ファイルは通常通り設定済みとします。# mfa の記述をしないのがポイント
ポイントは以下です。
- source profile のアカウントへのログインには MFA が必要
- target profile のとこに MFA の設定は記述しない
~/.aws/config[profile source] output = json region = ap-northeast-1 [profile target] role_arn = <arn of role to switch> source_profile = source region = ap-northeast-1 # mfa の設定は記述しない~/.aws/credentials[source] aws_access_key_id = <your access key id> aws_secret_access_key = <your secret key>jq コマンドをダウンロードして、path を通しておきます。
terraform 実行前に実行すること
ポイントは IAM 認証時に発行される session token を事前に取得して設定しておくことです。
コマンド# 環境変数をクリアする。環境変数に認証情報が残っていると aws cli, sdk に(意図せずに)参照されてしまう。 unset AWS_SHARED_CREDENTIALS_FILE unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN # token を取得する export AWS_PROFILE=source # changeme aws sts get-session-token --serial-number <your mfa device serial number> --token-code <one time code> > tmp.token aws_access_key_id=`cat tmp.token| jq -r ".Credentials.AccessKeyId"` aws_secret_access_key=`cat tmp.token| jq -r ".Credentials.SecretAccessKey"` aws_session_token=`cat tmp.token| jq -r ".Credentials.SessionToken"` # .aws/credentials ファイルとは別に credentials ファイルを作成し、terraform 実行時に参照する。 export AWS_SHARED_CREDENTIALS_FILE=tmp.credentials # 参照する credentials ファイルを変更する。 cat << EOF > $AWS_SHARED_CREDENTIALS_FILE [source] aws_session_token=$aws_session_token aws_secret_access_key=$aws_secret_access_key aws_access_key_id=$aws_access_key_id EOF export AWS_SDK_LOAD_CONFIG=1 export AWS_PROFILE=target # changeme後は、通常通り terraform を実行できます。
AWS_SHARED_CREDENTIALS_FILE=tmp.credentials にて、session token が記載された credential ファイルを参照するようにしています。MFA のない switch role 環境の場合
事前の設定
~/.aws/config, credentials ファイルは通常通り設定済みとします。
terraform 実行前に実行すること
コマンドexport AWS_SDK_LOAD_CONFIG=1 export AWS_PROFILE=target # changeme後は、通常通り terraform を実行できます。
参考: 私が上記設定を試した terraform の構成
backend には s3 を用いています。
terraform.tfterraform { required_version = ">= 0.12.26" backend "s3" {} } # Configure the AWS Provider provider "aws" { version = ">= 2.62.0" region = "ap-northeast-1" }backend.hcl は環境別に用意しています。
env/dev/backend.hclbucket = <dev 用の bucket 名> key = "sample_terraform.tfstate" region = "ap-northeast-1" encrypt = trueterraform 実行コマンドは以下です。
terraform実行コマンドENV="dev" export TF_DATA_DIR=./.terraform/$ENV terraform init -backend-config=env/${ENV}/backend.hcl terraform apply -var="env=${ENV}"まとめ
こういうどーでもいいことで時間を使いたくないものですよね。
誰かのお役に立てばと思います。もっと elegant な方法をご存知の方は教えてください。
- 投稿日:2020-08-04T09:29:38+09:00
ECS+EC2の環境で、ディスク使用量のメトリクスを収集してみる
はじめに
ECSには、Container Insightsという、CloudWatchにメトリクスデータを流す機能があり、コンテナのメトリクスを収集する機能があります。
ところが、ここではディスク使用量について収集することができません(収集可能なメトリクスは後述)。
そこで、さくっとContainer Insightsを使わずにディスク使用量を収集する方法について書き残しておきます。メトリクスの収集
まず、EC2でもそうですが、デフォルトのままでは、インスタンスの中のメトリクスを収集することができません。
メトリクスを収集するためには、CloudWatch Agentをインスタンス内にインストール、起動するなどが必要です。
ECSの場合は、「はじめに」でも触れましたが、Container Insightsという機能があり、これをクラスターに適用すると、クラスター内のコンテナについてのメトリクスが収集できるようになります。Container Insightsで収集可能なメトリクス
では、Container Insightsで収集可能な標準的なメトリクスについて、まとめてみましょう。
メトリクス名 内容 ContainerInstanceCount 実行中EC2インスタンスの数 CpuUtilized CPUユニット数 CpuReserved 予約されているCPUユニット数 DeploymentCount デプロイ数 DesiredTaskCount 必要なタスク数 MemoryUtilized タスクで使用中のメモリサイズ MemoryReserved タスクにより予約されているメモリサイズ NetworkRxBytes ネットワーク受信バイト数 NetworkTxBytes ネットワーク送信バイト数 PendingTaskCount PENDING状態のタスク数 RunningTaskCount RUNNING状態のタスク数 ServiceCount サービス数 StorageReadBytes ストレージのReadバイト数 StorageWriteBytes ストレージのWriteバイト数 TaskCount タスク数 TaskSetCount タスクセット数 クラスターのディスク使用量を収集してみよう
方法としては、CloudWatch Agentのコンテナをサイドカーとしてタスク化する、というイメージになります。
前提
- ECSクラスターは既に作成済みの前提とします
- aws cliを事前にローカル環境にダウンロードして、使えるようにしておいてください
手順
IAMロールを作成する
まず、2つのIAMロールを作成します。
ECSタスク用ロール
名称は任意です。以下のPolicyを適用してください。
- CloudWatchAgentServerPolicy
ECSタスク実行用ロール
名称は任意です。以下のPolicyを適用してください。
- AmazonSSMReadOnlyAccess
- AmazonECSTaskExecutionRolePolicy
- CloudWatchAgentServerPolicy
System Manager
パラメータストアにで、収集するメトリクスの情報を記述しておきます。
内容については、CloudWatch Agentの定義にしたがってください。CloudWatch エージェント設定ファイルを手動で作成または編集する
- 名前:任意
- 種類:String
- 値 ディスク使用量だけを収集する簡単な定義例
{ "metrics": { "metrics_collected": { "disk":{ "resources":[ "/", "/tmp" ], "measurement":[ "total", "used" ] }, "append_dimensions":{ "stackName":"Prod" } } }, "logs": { "metrics_collected": { "emf": {} } } }タスクを定義する
続いては、クラスター内で実行するタスク定義の追加です。
このタスクは、CLoudWatch Agentとして動作するサイドカーになります。以下、サンプルですが、下記定義を、ローカルにファイル保存してください。
{ "family": "ecs-cwagent-ec2", "taskRoleArn": "ECSタスク用ロールのARN", "executionRoleArn": "ECSタスク実行用ロールのARN", "networkMode": "bridge", "containerDefinitions": [ { "name": "cloudwatch-agent", "image": "amazon/cloudwatch-agent:latest", "secrets": [ { "name": "CW_CONFIG_CONTENT", "valueFrom": "[System Managerパラメータストア名]" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-create-group": "True", "awslogs-group": "/ecs/ecs-cwagent-ec2", "awslogs-region": "[リージョン]", "awslogs-stream-prefix": "ecs" } } } ], "requiresCompatibilities": [ "EC2" ], "cpu": "256", "memory": "256" }ECSタスク用ロールのARN、ECSタスク実行用ロールのARN、System Managerパラメータストア名は、上記で作成した各IAMロール、パラメメータストアの名前に従って設定してください。
リージョンは、クラスターを作成済みのリージョンにしてください。
あと、CPU/Memoryサイズは適当に変更して大丈夫です。ファイルを保存したら、タスク定義を追加します。
aws ecs register-task-definition --cli-input-json file://タスク定義ファイル名 --region リージョン名例
aws ecs register-task-definition --cli-input-json file://./ecs.txt --region ap-northeast-1タスクを実行する
ここまできたら、最後にタスクを実行します。
aws ecs run-task --cluster ECSクラスタ名 --task-definition タスク定義名 --region リージョン --launch-type EC2これで、しばらくたつと、CloudWatchにメトリクスが収集されだします。
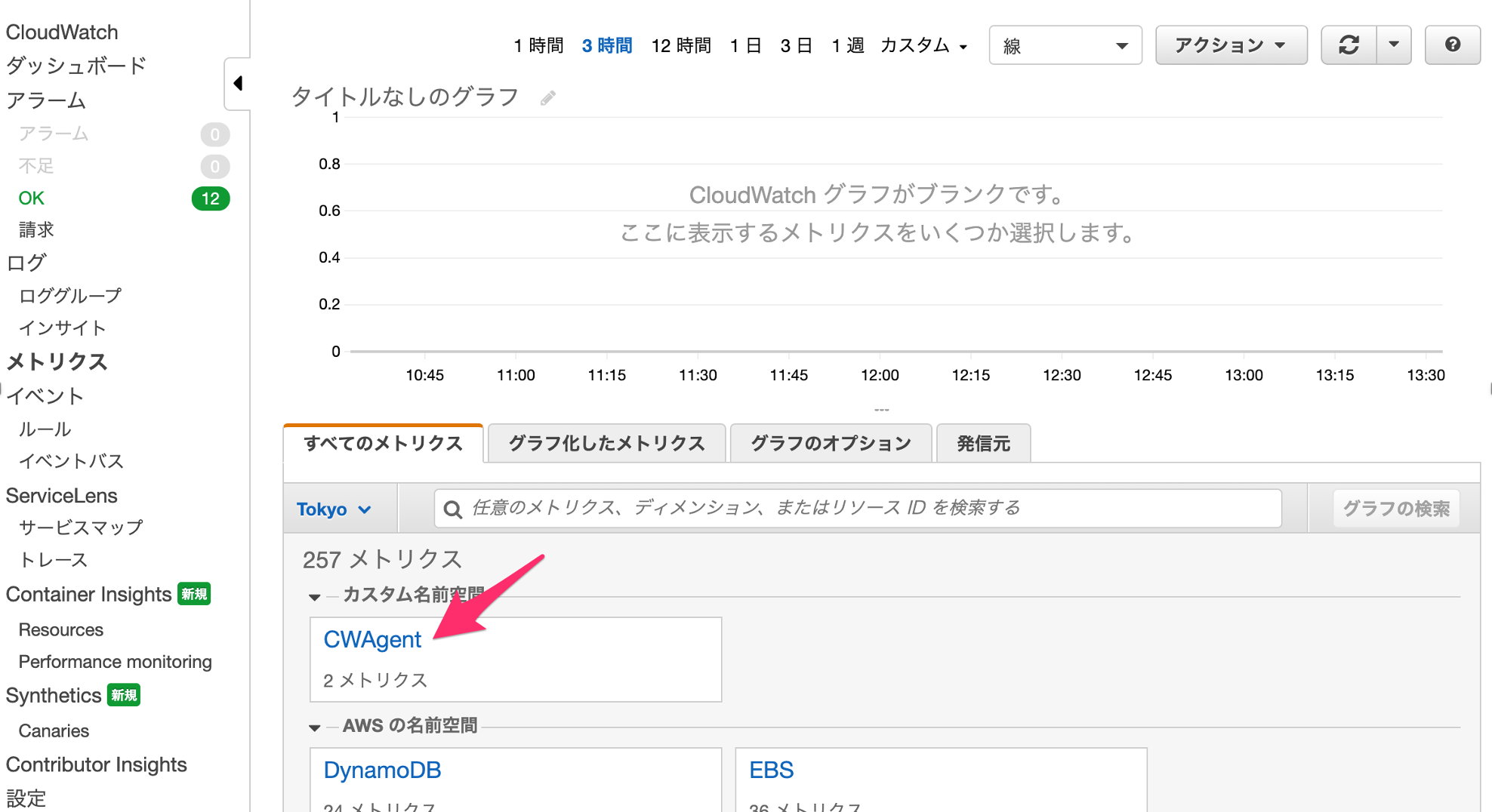
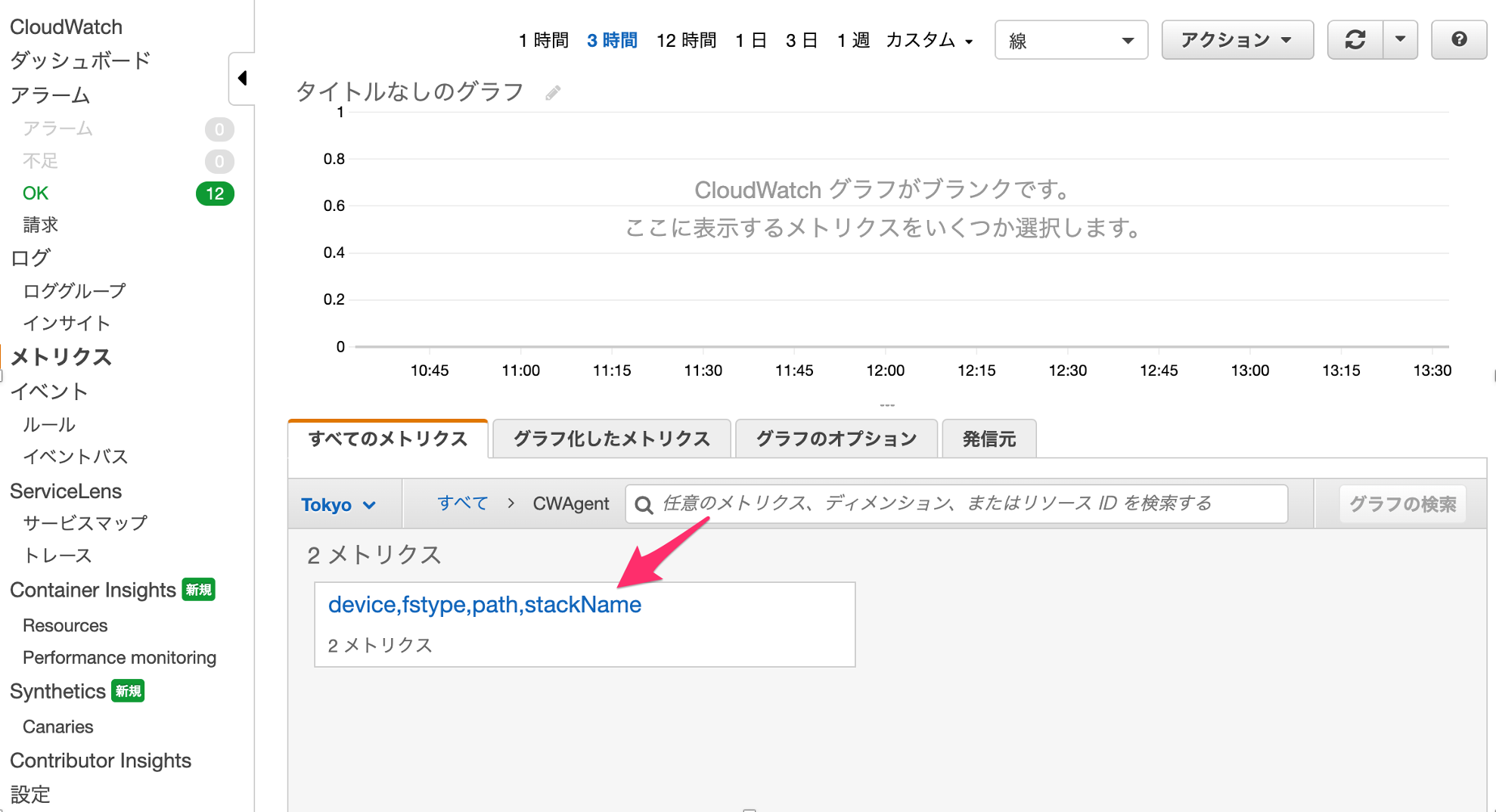
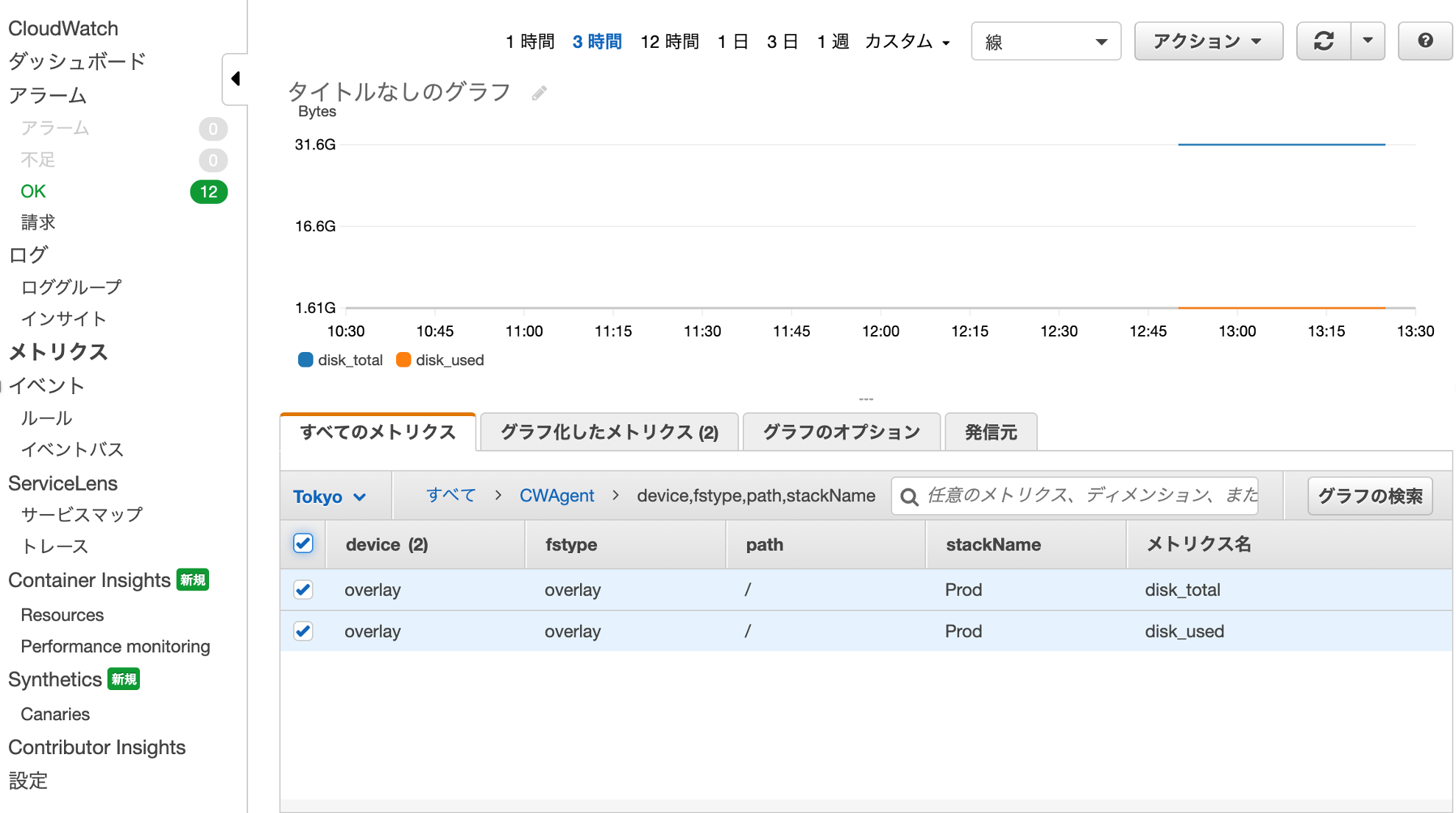
CloudWatch
メトリクスができてます!
その中がこれ!
展開すると、パラメータストアに定義したディスク総サイズと使用量が取得されています。
補足
メトリクス間隔の調整
メトリクスの収集間隔は、デフォルトで60秒です。
この間隔を変更するには、System Managerのパラメータストアに設定した定義に"agent": { "metrics_collection_interval": 10 }のように、
metrics_collection_intervalの定義を追加すればOKです。
- 投稿日:2020-08-04T09:29:38+09:00
ECSの環境で、ディスク使用量のメトリクスを収集してみる
はじめに
ECSには、Container Insightsという、CloudWatchにメトリクスデータを流す機能があり、コンテナのメトリクスを収集する機能があります。
ところが、ここではディスク使用量について収集することができません(収集可能なメトリクスは後述)。
そこで、さくっとContainer Insightsを使わずにディスク使用量を収集する方法について書き残しておきます。メトリクスの収集
まず、EC2でもそうですが、デフォルトのままでは、インスタンスの中のメトリクスを収集することができません。
メトリクスを収集するためには、CloudWatch Agentをインスタンス内にインストール、起動するなどが必要です。
ECSの場合は、「はじめに」でも触れましたが、Container Insightsという機能があり、これをクラスターに適用すると、クラスター内のコンテナについてのメトリクスが収集できるようになります。Container Insightsで収集可能なメトリクス
では、Container Insightsで収集可能な標準的なメトリクスについて、まとめてみましょう。
メトリクス名 内容 ContainerInstanceCount 実行中EC2インスタンスの数 CpuUtilized CPUユニット数 CpuReserved 予約されているCPUユニット数 DeploymentCount デプロイ数 DesiredTaskCount 必要なタスク数 MemoryUtilized タスクで使用中のメモリサイズ MemoryReserved タスクにより予約されているメモリサイズ NetworkRxBytes ネットワーク受信バイト数 NetworkTxBytes ネットワーク送信バイト数 PendingTaskCount PENDING状態のタスク数 RunningTaskCount RUNNING状態のタスク数 ServiceCount サービス数 StorageReadBytes ストレージのReadバイト数 StorageWriteBytes ストレージのWriteバイト数 TaskCount タスク数 TaskSetCount タスクセット数 クラスターのディスク使用量を収集してみよう
方法としては、CloudWatch Agentのコンテナをサイドカーとしてタスク化する、というイメージになります。
前提
- ECSクラスターは既に作成済みの前提とします
- aws cliを事前にローカル環境にダウンロードして、使えるようにしておいてください
手順
IAMロールを作成する
まず、2つのIAMロールを作成します。
ECSタスク用ロール
名称は任意です。以下のPolicyを適用してください。
- CloudWatchAgentServerPolicy
ECSタスク実行用ロール
名称は任意です。以下のPolicyを適用してください。
- AmazonSSMReadOnlyAccess
- AmazonECSTaskExecutionRolePolicy
- CloudWatchAgentServerPolicy
System Manager
パラメータストアにで、収集するメトリクスの情報を記述しておきます。
内容については、CloudWatch Agentの定義にしたがってください。CloudWatch エージェント設定ファイルを手動で作成または編集する
- 名前:任意
- 種類:String
- 値 ディスク使用量だけを収集する簡単な定義例
{ "metrics": { "metrics_collected": { "disk":{ "resources":[ "/", "/tmp" ], "measurement":[ "total", "used" ] }, "append_dimensions":{ "stackName":"Prod" } } }, "logs": { "metrics_collected": { "emf": {} } } }タスクを定義する
続いては、クラスター内で実行するタスク定義の追加です。
このタスクは、CLoudWatch Agentとして動作するサイドカーになります。以下、サンプルですが、下記定義を、ローカルにファイル保存してください。
{ "family": "ecs-cwagent-ec2", "taskRoleArn": "ECSタスク用ロールのARN", "executionRoleArn": "ECSタスク実行用ロールのARN", "networkMode": "bridge", "containerDefinitions": [ { "name": "cloudwatch-agent", "image": "amazon/cloudwatch-agent:latest", "secrets": [ { "name": "CW_CONFIG_CONTENT", "valueFrom": "[System Managerパラメータストア名]" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-create-group": "True", "awslogs-group": "/ecs/ecs-cwagent-ec2", "awslogs-region": "[リージョン]", "awslogs-stream-prefix": "ecs" } } } ], "requiresCompatibilities": [ "EC2" ], "cpu": "256", "memory": "256" }ECSタスク用ロールのARN、ECSタスク実行用ロールのARN、System Managerパラメータストア名は、上記で作成した各IAMロール、パラメメータストアの名前に従って設定してください。
リージョンは、クラスターを作成済みのリージョンにしてください。
あと、CPU/Memoryサイズは適当に変更して大丈夫です。ファイルを保存したら、タスク定義を追加します。
aws ecs register-task-definition --cli-input-json file://タスク定義ファイル名 --region リージョン名例
aws ecs register-task-definition --cli-input-json file://./ecs.txt --region ap-northeast-1タスクを実行する
ここまできたら、最後にタスクを実行します。
aws ecs run-task --cluster ECSクラスタ名 --task-definition タスク定義名 --region リージョン --launch-type EC2これで、しばらくたつと、CloudWatchにメトリクスが収集されだします。
CloudWatch
メトリクスができてます!
その中がこれ!
展開すると、パラメータストアに定義したディスク総サイズと使用量が取得されています。
補足
メトリクス間隔の調整
メトリクスの収集間隔は、デフォルトで60秒です。
この間隔を変更するには、System Managerのパラメータストアに設定した定義に"agent": { "metrics_collection_interval": 10 }のように、
metrics_collection_intervalの定義を追加すればOKです。
- 投稿日:2020-08-04T09:29:38+09:00
[AWS] ECSの環境で、ディスク使用量のメトリクスを収集してみる
はじめに
ECSには、Container Insightsという、CloudWatchにメトリクスデータを流す機能があり、コンテナのメトリクスを収集する機能があります。
ところが、ここではディスク使用量について収集することができません(収集可能なメトリクスは後述)。
そこで、さくっとContainer Insightsを使わずにディスク使用量を収集する方法について書き残しておきます。メトリクスの収集
まず、EC2でもそうですが、デフォルトのままでは、インスタンスの中のメトリクスを収集することができません。
メトリクスを収集するためには、CloudWatch Agentをインスタンス内にインストール、起動するなどが必要です。
ECSの場合は、「はじめに」でも触れましたが、Container Insightsという機能があり、これをクラスターに適用すると、クラスター内のコンテナについてのメトリクスが収集できるようになります。Container Insightsで収集可能なメトリクス
では、Container Insightsで収集可能な標準的なメトリクスについて、まとめてみましょう。
メトリクス名 内容 ContainerInstanceCount 実行中EC2インスタンスの数 CpuUtilized CPUユニット数 CpuReserved 予約されているCPUユニット数 DeploymentCount デプロイ数 DesiredTaskCount 必要なタスク数 MemoryUtilized タスクで使用中のメモリサイズ MemoryReserved タスクにより予約されているメモリサイズ NetworkRxBytes ネットワーク受信バイト数 NetworkTxBytes ネットワーク送信バイト数 PendingTaskCount PENDING状態のタスク数 RunningTaskCount RUNNING状態のタスク数 ServiceCount サービス数 StorageReadBytes ストレージのReadバイト数 StorageWriteBytes ストレージのWriteバイト数 TaskCount タスク数 TaskSetCount タスクセット数 クラスターのディスク使用量を収集してみよう
方法としては、CloudWatch Agentのコンテナをサイドカーとしてタスク化する、というイメージになります。
前提
- ECSクラスターは既に作成済みの前提とします
- aws cliを事前にローカル環境にダウンロードして、使えるようにしておいてください
手順
IAMロールを作成する
まず、2つのIAMロールを作成します。
ECSタスク用ロール
名称は任意です。以下のPolicyを適用してください。
- CloudWatchAgentServerPolicy
ECSタスク実行用ロール
名称は任意です。以下のPolicyを適用してください。
- AmazonSSMReadOnlyAccess
- AmazonECSTaskExecutionRolePolicy
- CloudWatchAgentServerPolicy
System Manager
パラメータストアにで、収集するメトリクスの情報を記述しておきます。
内容については、CloudWatch Agentの定義にしたがってください。CloudWatch エージェント設定ファイルを手動で作成または編集する
- 名前:任意
- 種類:String
- 値 ディスク使用量だけを収集する簡単な定義例
{ "metrics": { "metrics_collected": { "disk": { "resources":[ "/", "/tmp" ], "measurement":[ "total", "used" ], "append_dimensions":{ "stackName":"Prod" } } } }, "logs": { "metrics_collected": { "emf": {} } } }タスクを定義する
続いては、クラスター内で実行するタスク定義の追加です。
このタスクは、CLoudWatch Agentとして動作するサイドカーになります。以下、サンプルですが、下記定義を、ローカルにファイル保存してください。
{ "family": "ecs-cwagent-ec2", "taskRoleArn": "ECSタスク用ロールのARN", "executionRoleArn": "ECSタスク実行用ロールのARN", "networkMode": "bridge", "containerDefinitions": [ { "name": "cloudwatch-agent", "image": "amazon/cloudwatch-agent:latest", "secrets": [ { "name": "CW_CONFIG_CONTENT", "valueFrom": "[System Managerパラメータストア名]" } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-create-group": "True", "awslogs-group": "/ecs/ecs-cwagent-ec2", "awslogs-region": "[リージョン]", "awslogs-stream-prefix": "ecs" } } } ], "requiresCompatibilities": [ "EC2" ], "cpu": "256", "memory": "256" }ECSタスク用ロールのARN、ECSタスク実行用ロールのARN、System Managerパラメータストア名は、上記で作成した各IAMロール、パラメメータストアの名前に従って設定してください。
リージョンは、クラスターを作成済みのリージョンにしてください。
あと、CPU/Memoryサイズは適当に変更して大丈夫です。ファイルを保存したら、タスク定義を追加します。
aws ecs register-task-definition --cli-input-json file://タスク定義ファイル名 --region リージョン名例
aws ecs register-task-definition --cli-input-json file://./ecs.txt --region ap-northeast-1タスクを実行する
ここまできたら、最後にタスクを実行します。
aws ecs run-task --cluster ECSクラスタ名 --task-definition タスク定義名 --region リージョン --launch-type EC2これで、しばらくたつと、CloudWatchにメトリクスが収集されだします。
CloudWatch
メトリクスができてます!
その中がこれ!
展開すると、パラメータストアに定義したディスク総サイズと使用量が取得されています。
補足
メトリクス間隔の調整
メトリクスの収集間隔は、デフォルトで60秒です。
この間隔を変更するには、System Managerのパラメータストアに設定した定義に"disk": { "resources":[ "/", "/tmp" ], "measurement":[ "total", "used" ], "append_dimensions":{ "stackName":"Prod" }, "metrics_collection_interval": 10 }のように、
metrics_collection_intervalの定義を追加すればOKです。
- 投稿日:2020-08-04T08:22:44+09:00
AWSから請求書が届いた
先月からAmazonWebServiceを利用し始めました。
サーバーとかすぐに構築できて便利だなーって思いながら使っていました。
先日、請求書がきたので確認して見たら料金が2000円を超えていた。
内訳がきになるので明細書を見て見る。
どうやらNATゲートウェイに対して請求がきていたようです。
料金について調べてみる。
以下AWS公式サイトから抜粋
https://aws.amazon.com/jp/vpc/pricing/===========================================
NAT ゲートウェイ料金VPC 内に NAT ゲートウェイを作成することを選択した場合は、NAT ゲートウェイがプロビジョニングされ利用可能であった "NAT ゲートウェイ時間" に対して料金が請求されます。データ処理料金は、トラフィックの送信元か送信先にかかわらず、NAT ゲートウェイで処理されたギガバイト単位で適用されます。1 時間未満の NAT ゲートウェイ時間は、1 時間分として請求されます。また、NAT ゲートウェイを介して転送されるすべてのデータに対して標準的な AWS データ転送料金が発生します。NAT ゲートウェイへの課金を止めたい場合は、AWS マネジメントコンソール、コマンドラインインターフェイス、API を使用して NAT ゲートウェイを削除します。
===========================================AWSのサービスは従量課金制と聞いてはいたが、時間当たりで計算されるのですね。
とりあえず、使用していなかったNAT ゲートウェイを削除。
これで来月請求はないはず。
NATゲートウェイに限らず使用していないものは削除しておいた方が良いみたいですね。
- 投稿日:2020-08-04T06:33:05+09:00
Java で Amazon SES SMTP を使用してメールを送信する
会員がログインパスワードを忘れたとき、登録してあるメールアドレスにメールを送信してその中のリンクを押すとパスワードがリセットされる、というのをやりたかったので、AWS 上のWebアプリにメール送信機能を実装。
メール送信機能は jar ファイルにして部品化。
プログラミングより AWS の設定が面倒臭い気がしました。
1.環境
VS Code
Java Extension Pack
Spring Boot Extension Pack2.SMTP認証情報の習得
以下の URL の内容の通り、AWS のコンソールにログインして「Amazon SES コンソールを使用して Amazon SES SMTP 認証情報を取得する」の1~6を実施してSMTPユーザー名とSMTPパスワードを取得します。
取得するとメールサーバー名とポート番号も表示されます。
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/smtp-credentials.html
3.Gradle Project の作成
VS Code のコマンドパレットで「Spring Initializr: Generate a Gradle Project」 → 「Java」 → 「任意のGroupId」 → 「任意のArtifactId」 → 「任意のバージョン」 → 「dependenceies は空白」を選択して Gradle Project を作成します。
(別に Spring Boot じゃなくてもいいですけど…)4.依存関係の追加とか
Amazon SES SMTP を使用してメールを送信するために必要な javax.mail.jar を取得するため、build.gradle ファイルに依存関係を追加します。
build.gradledependencies { implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'com.sun.mail:javax.mail:1.6.2' //←追加★ testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } } //↓ついでに追加★ bootJar { enabled = false } jar { enabled = true baseName = 'aws-ses-send' version = '' from configurations.compileClasspath.collect { it.isDirectory() ? it : zipTree(it) } }5.実装
AWSのサイトのコードをほぼそのまま使います。
AmazonSES.javapackage com.xxx.aws; import java.util.Properties; import javax.mail.Message; import javax.mail.Session; import javax.mail.Transport; import javax.mail.internet.InternetAddress; import javax.mail.internet.MimeMessage; public class AmazonSES { // Replace sender@example.com with your "From" address. // This address must be verified. static final String FROM = "送信元メールアドレス"; static final String FROMNAME = "送信元名"; // Replace recipient@example.com with a "To" address. If your account // is still in the sandbox, this address must be verified. // static final String TO = "recipient@example.com"; // Replace smtp_username with your Amazon SES SMTP user name. static final String SMTP_USERNAME = "SMTPユーザー名"; // Replace smtp_password with your Amazon SES SMTP password. static final String SMTP_PASSWORD = "SMTPパスワード"; // The name of the Configuration Set to use for this message. // If you comment out or remove this variable, you will also need to // comment out or remove the header below. // static final String CONFIGSET = "ConfigSet"; //←不要ならコメントアウト★ // Amazon SES SMTP host name. This example uses the 米国西部 (オレゴン) region. // See https://docs.aws.amazon.com/ses/latest/DeveloperGuide/regions.html#region-endpoints // for more information. static final String HOST = "メールサーバー名"; // The port you will connect to on the Amazon SES SMTP endpoint. static final int PORT = ポート番号; // static final String SUBJECT = "Amazon SES test (SMTP interface accessed using Java)"; // static final String BODY = String.join( // System.getProperty("line.separator"), // "<h1>Amazon SES SMTP Email Test</h1>", // "<p>This email was sent with Amazon SES using the ", // "<a href='https://github.com/javaee/javamail'>Javamail Package</a>", // " for <a href='https://www.java.com'>Java</a>." // ); public void send(String to, String subject, String body) throws Exception { // Create a Properties object to contain connection configuration information. Properties props = System.getProperties(); props.put("mail.transport.protocol", "smtp"); props.put("mail.smtp.port", PORT); props.put("mail.smtp.starttls.enable", "true"); props.put("mail.smtp.auth", "true"); // Create a Session object to represent a mail session with the specified properties. Session session = Session.getDefaultInstance(props); // Create a message with the specified information. MimeMessage msg = new MimeMessage(session); msg.setFrom(new InternetAddress(FROM,FROMNAME)); msg.setRecipient(Message.RecipientType.TO, new InternetAddress(to)); msg.setSubject(subject); msg.setContent(body,"text/html"); // Add a configuration set header. Comment or delete the // next line if you are not using a configuration set // msg.setHeader("X-SES-CONFIGURATION-SET", CONFIGSET);//←不要ならコメントアウト★ // Create a transport. Transport transport = session.getTransport(); // Send the message. try { System.out.println("Sending..."); // Connect to Amazon SES using the SMTP username and password you specified above. transport.connect(HOST, SMTP_USERNAME, SMTP_PASSWORD); // Send the email. transport.sendMessage(msg, msg.getAllRecipients()); System.out.println("Email sent!"); } catch (Exception ex) { System.out.println("The email was not sent."); System.out.println("Error message: " + ex.getMessage()); } finally { // Close and terminate the connection. transport.close(); } } }https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/send-using-smtp-java.html
6.送信元として有効なメールアドレスをAWSに登録する
以下の URL の内容の通り、AWS のコンソールにログインして「Amazon SES コンソールを使用して E メールアドレスを検証する」の1~7を実施して、送信元として有効なメールアドレスを登録します。
この手順が終わったメールアドレスのみ送信元メールアドレスとして使えます。
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/verify-email-addresses-procedure.html
7.送信先の制限を外す
この状態だと、送信先を自由に選択してメールを送ることはできません。
送信先のメールアドレスも送信元同様、送信先としてメールを送信できるか事前に検証してOKになってないる必要があります。
「サンドボックスの中にいる」という状況です。
送信先を自由に選択してメールを送るには「サンドボックスの外に出る」必要があります。
以下の URL の内容の通り、AWS のコンソールにログインして「Amazon SES サンドボックス外への移動」の1~9を実施して、サポートセンターから許可をもらいます。
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/request-production-access.html
許可がもらえれば送信先の事前検証は不要になります。
8.実行
VS Code のターミナルから以下のコマンドを実装して、jar ファイルを作成します。
.\gradlew build作成した jar ファイルを呼び出し元のプロジェクトに配置して、実装した send メソッドを呼べばメール送信できます。
以上です。
- 投稿日:2020-08-04T02:02:35+09:00
Template error: Fn::Select cannot select nonexistent value at index 1
問題
以下のCloudFormationテンプレートでサブネットを東京リージョンに構築しようとしたところ、表題のエラーを吐きました。
Resources: PrivateSubnet2: Type: AWS::EC2::Subnet Properties: CidrBlock: 10.0.2.0/24 VpcId: !Ref CFnVPC AvailabilityZone: !Select [ 1, !GetAZs ] MapPublicIpOnLaunch: true Tags: - Key: Name Value: PrivateSubnet2
原因
Fn::GetAZsはアカウントのデフォルトサブネットのAZを配列で返却します。
私のアカウントではデフォルトサブネットのAZを1つしか登録していませんでした。
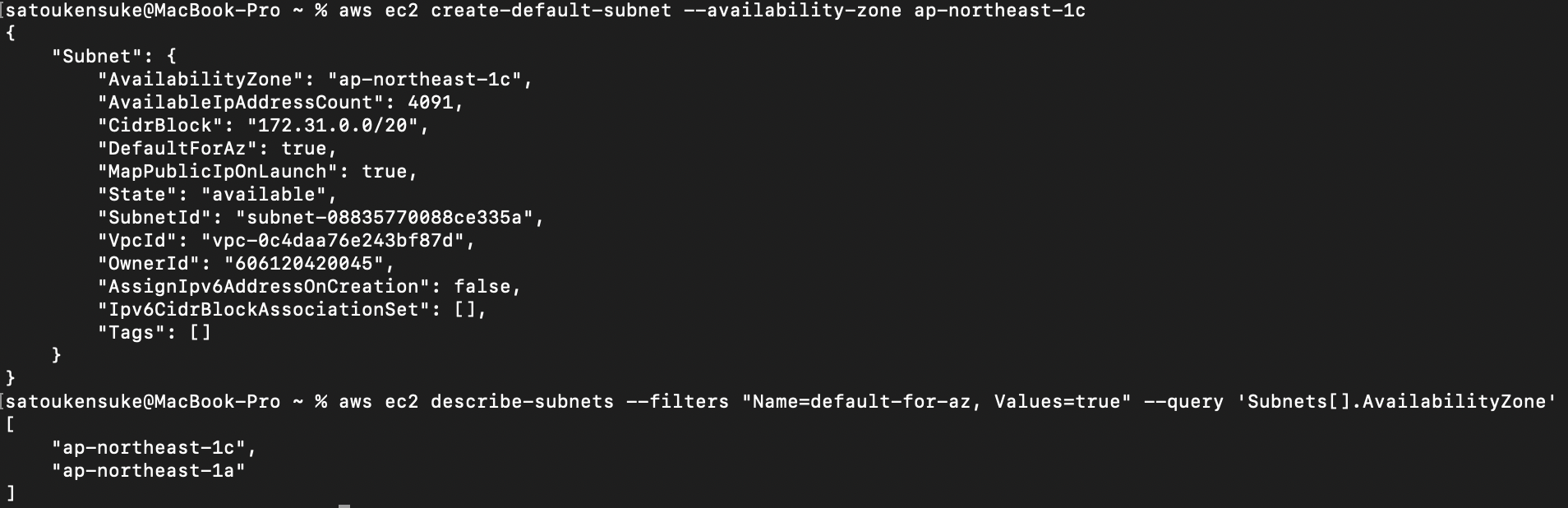
問題のCloudFormationテンプレートで、Fn::GetAZsで取得したAZ配列の2番目を参照しますが、存在しないためエラーとなりました。対処方法
デフォルトサブネットを作成し、AZを増やします。
東京リージョンにはap-northeast-1a,ap-northeast-1c,ap-northeast-1dの3つのAZが存在します。(実際はap-northeast-1bもありますが、使用できるアカウントが制限されているため除外します)アカウントが使用できるAZの確認
aws ec2 describe-availability-zones --query 'AvailabilityZones[].ZoneName'
デフォルトサブネットのAZを確認(
Fn::GetAZsが返す値)aws ec2 describe-subnets --filters "Name=default-for-az, Values=true" --query 'Subnets[].AvailabilityZone'
デフォルトサブネットをAZに作成
aws ec2 create-default-subnet --availability-zone ap-northeast-1c
確認
再度、CloudFormationテンプレートでスタック作成してみます。
エラーなくサブネットを作成することができました。
参考